Архитектура оборудования GP100 в глубину
Содержание
- Архитектура оборудования GP100 в глубину
- Исключительные производительность и энергоэффективность
- Потоковый мультипроцессор Pascal
- Разработан для высокопроизводительных вычислений с двойной точностью
- Поддержка арифметики FP16 ускоряет глубинное обучение
- Лучшая атомарность
- Изменения кэша L1/L2 в GP100
- Расширения GPUDirect
- Вычислительная совместимость
- Tesla P100: Первое в мире GPU с HBM2
- Архитектура Tesla P100
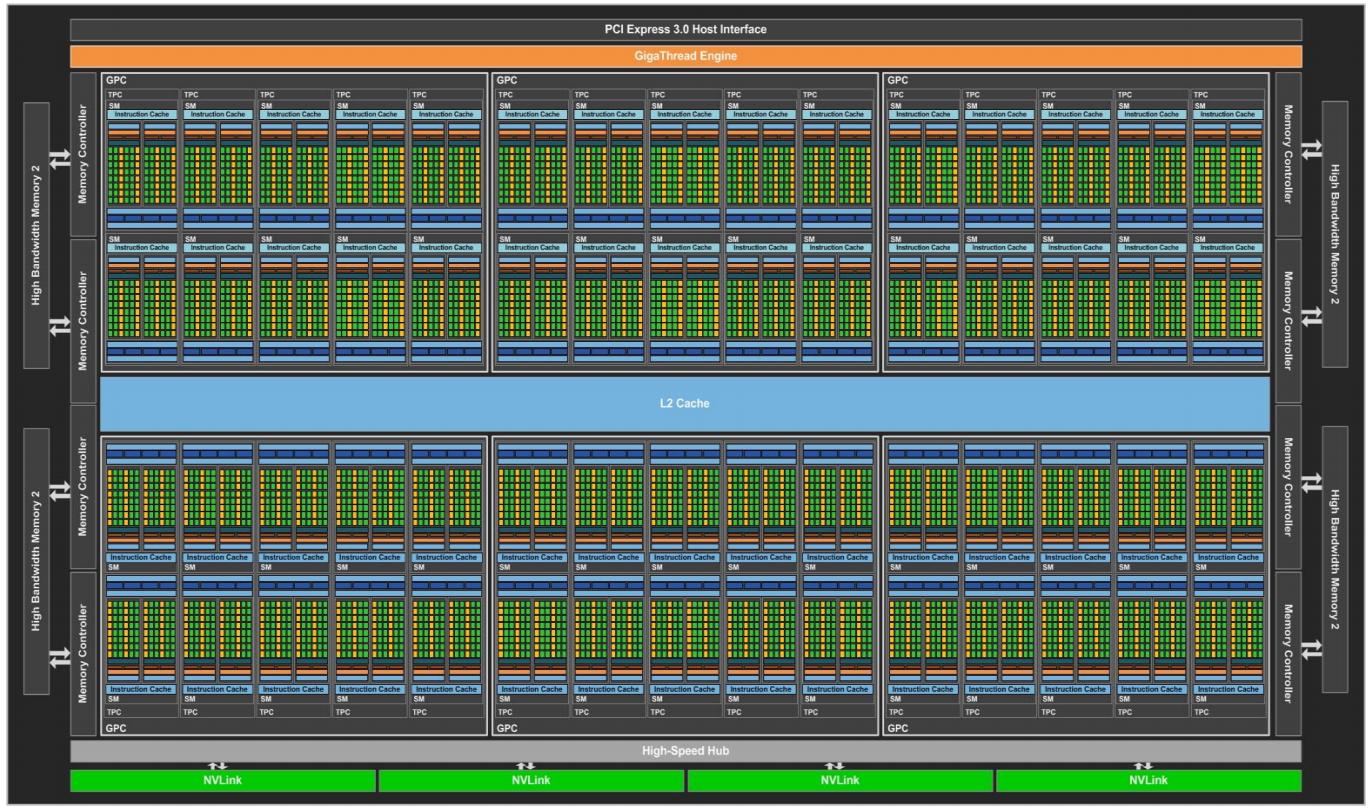
GP100 был разработан для того чтобы стать самым высокопроизводительным процессором для параллельных вычислений в мире для решения потребностей ускорения GPU компьютерных рыков, обслуживаемых нашей платформой ускорения Tesla P100. Как и предыдущие GPU уровня Tesla, GP100 составленииз массива кластеров графической обработки (GPC, Graphics Processing Clusters), кластеров обработки текстур (TPC, Texture Processing Clusters), потоковых микропроцессоров (SM, Streaming Multiprocessors) и контроллеров памяти. Полный GP100 состоит из шести GPC, 60 Pascal SM, 30 TPC (каждый содержит два SM) и восьми 512-битных контроллеров памяти (итого 4096 бит).
Каждый GPC внутри GPC имеет десять SM. Каждый SM имеет 64 ядра CUDA и четыре блока текстур. Имея 60 SM, GP100 имеет в сумме 3840 ядер CUDA с одиночной точностью и 240 блоков текстур. Каждый контроллер памяти подключён к L2 кэшу с 512кБ, а каждый стек DRAM HBM2 управляется парой контроллеров памяти. Весь GPU содержит 4096кБ кэша L2.
Рисунок 7 отображает полный GP100 GPU c 60 блоками SM (различные продукты могут использовать различные конфигурации GP100). Ускоритель Telsa P100 использует 56 блоков SM.
Двумя ключевыми целями новых архитектур GPU являются предоставление высокой производительности и улучшение энергетической эффективности. Ряд изменений внесённых в SM в архитектуре Maxwell улучшили его эффективность в сравнении с Kepler. Pascal был построен на этой основе и присоединил дополнительные улучшения, которые позволили улучшить производительность рассчитываемую на Ватт ещё далее по отношению к Maxwell. Хотя 16нм FinFET процесс производства TSMC играет важную роль, многие изменения архитектуры GPU также были реализованы для дальнейшего понижения потребления энергии при сохранении высокой производительности.
| Продукт Tesla | Tesla K40 | Tesla M80 | Tesla P100 |
|---|---|---|---|
|
GK110 (Kepler) |
GM200 (Maxwell) |
GP100 (Pascal) |
|
15 |
24 |
56 |
|
15 |
24 |
28 |
|
192 |
128 |
64 |
|
2880 |
3072 |
3584 |
|
64 |
4 |
32 |
|
960 |
96 |
1792 |
|
745 МГц |
948 МГц |
1328 МГц |
|
810/875 МГц |
1114 МГц |
1480 МГц |
|
5040 |
6840 |
10600 |
|
1680 |
210 |
5300 |
|
240 |
192 |
224 |
|
384-битный GDDR5 |
384-битный GDDR5 |
4096-битный HBM2 |
|
До 12 ГБ |
До 24 ГБ |
До 16 ГБ |
|
1536 кБ |
3072 кБ |
4096 кБ |
|
256 кБ |
256 кБ |
256 кБ |
|
3840 кБ |
6144 кБ |
14336 кБ |
|
235 Вт |
250 Вт |
300 Вт |
|
7.1 млрд. |
8 млрд. |
15.3 млрд. |
|
551 мм2 |
601 мм2 |
610 мм2 |
|
28 нм |
28 нм |
16 нм FinFet |
1 Расчёт GPU в данной таблице приведён на основе разгонной тактовой частоты GPU. |
|||
Шестое поколение архитектуры SM GP100 улучшает использование ядра CUDA и энергоэффективность, что имеет результатом значительное общее улучшение производительности, а также делает возможными более высокие тактовые частоты ядра в сравнении с предыдущими GPU.
SM GP100 включает 64 ядра CUDA с одинарной точностью (FP32). Напротив, SM Maxwell и Kepler имели 128 и 192 FP32 ядер CUDA соответственно. SM GP100 разделяются на два блока обработки, причём оба имеют по 32 ядра CUDA одинарной точности, буфер инструкций, планировщик групп потоков (warp) и два блока диспетчеризации. Хотя GP100 и имеет половину от общего числа ядер CUDA Maxwell SM, от сопровождает тот же самый размер файла регистров и поддерживает аналогичное занятие групп потоков (warp) и блоков потоков (thread block). SM GP100 имеет то же число регистров что SM GM200 Maxwell и GK110 Kepler, однако весь GPU GP100 имеет намного больше SM и, таким образом, больше регистров в целом. Это означает, что потоки в GPU имеют доступ к большему числу регистров, а GP100 поддерживает больше потоков (thread), групп потоков (warp) и блоков потоков (thread block) на лету в сравнении с предыдущими поколениями GPU.
Общая совместно используемая по всему GPU память также увеличивается благодаря увеличению числа SM и собираемая полоса пропускания совместно используемой памяти эффективнее более чем вдвое. Более высокое соотношение совместно используемой памяти, регистров и групп потоков (warp) на один SM в GP100 позволяет SM более эффективно выполнять код. Присутствует больше групп потоков (warp) для планировщика инструкций из которых существует возможность выбирать, больше нагрузок для инициализации и больше пропускной способности на один поток для совместного использования памяти.
Рисунок 8 отображает итоговую блок- схему SM GP100.
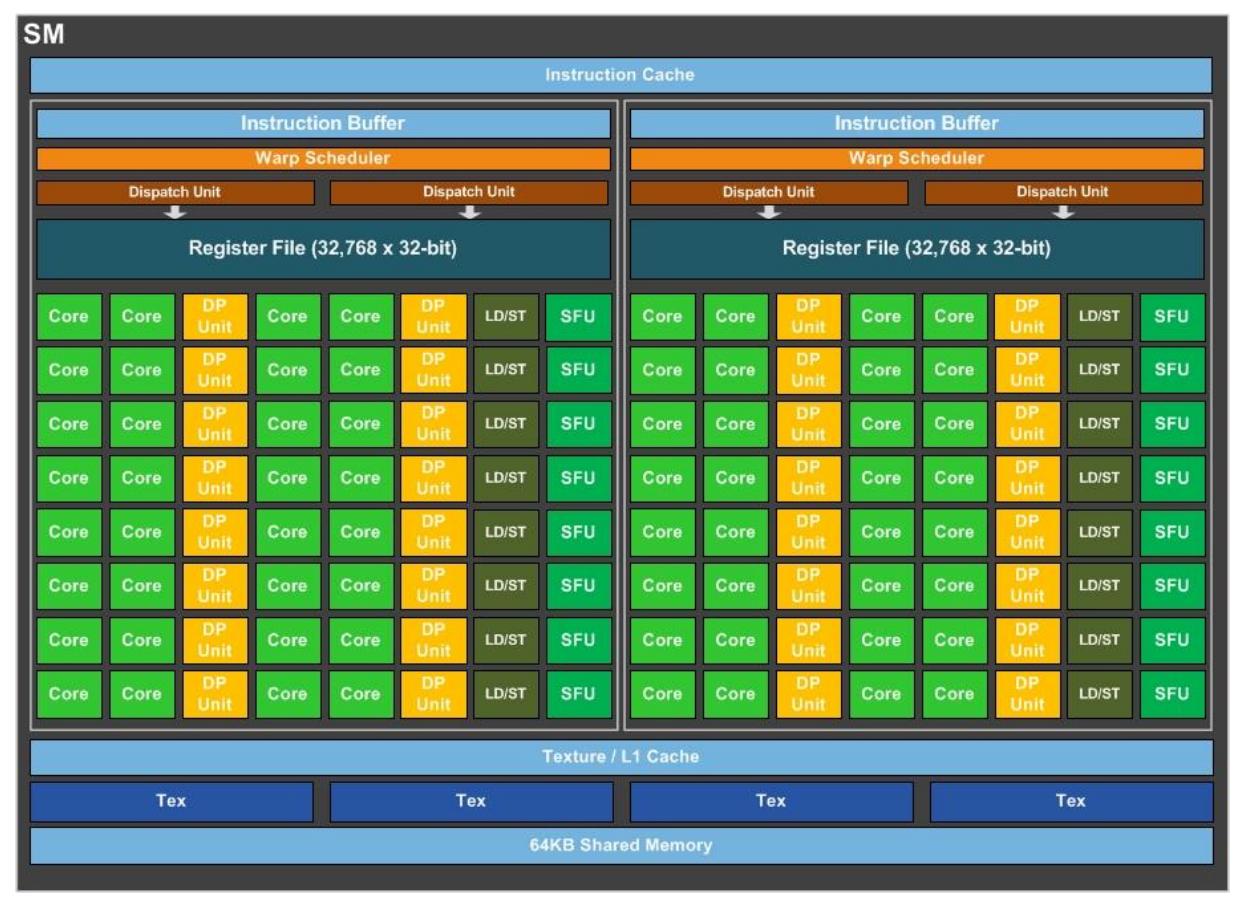
По сравнению с Kepler, SM Pascal предоставляет более простую организацию путей данных, которая требует меньшей площади на кристалле и меньше энергии для управления пересылкой данных в пределах SM. Pascal также предоставляет более качественное планирование и перекрывающиеся инструкции загрузки/ сохранения (load/store) для увеличения использования операций с плавающей точкой. Новая архитектура планировщика SM в GP100 совершенствует преимущества планировщика Maxwell даже является более интеллектуальной, предоставляя увеличенную производительность и уменьшая потребление мощности. Каждый планировщик группы потоков (warp, один на блок обработки) способен оперативно управлять двумя инструкциями группы потоков (warp) за такт.
Ещё одна возможность, которая была добавлена в ядра CUDA FP32 GP100 состоит в возможности и 16-битные и 32-битные инструкции и данные, как это объясняется позже в данной статье. Пропускная способность операции FP16 составляет до двойной от пропускной способности операции FP32.
Арифметика с двойной точностью является сердцем многих приложений HPC, таких как линейная алгебра, численное моделирование и квантовая химия. По этой причине одна из ключевых целей проектирования для GP100 состояла в значительном улучшении доставки производительности для дааных вариантов применения.
Каждый SM в GP100 снабжён 32 ядрами CUDA с двойной точностью (FP64), что составляет половину от числа ядер CUDA с одинарной точностью FP32. Полный GPU GP100 имеет 1920 ядер CUDA FP64. Такое соотношение 2:1 блоков с одинарной точностью (SP) к блокам с двойной точностью (DP) лучше выравнивается в новой конфигурации пути данных GP100, делая возможной более эффективную обработку рабочей нагрузки DP для GPU. Как и в предыдущих архитектурах GPU. GP100 поддерживает полную совместимость с арифметикой IEEE 754-2008 одинарной и двойной точности, включая поддержку для операций FMA (fused multiply add, смешанного с умножением сложения) и поддержку полной скорости для денормализованных чисел.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Kepler GK110 имел соотношение блоков SP к DP равным 3:1. |
Глубинное обучение является одной из самых быстрорастущих отраслей вычислений. Они являются китической составляющей во многих важных приложениях, включая перевод с языков в реальном масштабе времени, очень точное распознавание образов, автоматический захват изображений, распознавание автономных перемещающихся объектов, вычисление оптимального пути, избежание столкновений и тому подобных. Глубинное обучение является двухэтапным процессом.
-
Вначале нейронная сеть должна пройти обучение.
-
Затем эта сеть разворачивается в вашей области для выполнения вычислений умозаключений, при которых она применяет результаты предыдущего обучения для классификации, распознавания и общей обработки неизвестных входных данных.
В сравнении с ЦПУ, GPU может предоставлять гигантское ускорение производительности для тренировки Глубинного обучения и выполнения умозаключений.
В отличие от прочих приложений технических вычислений, кторым требуется более высокая точность вычислений с плавающей точкой, архитектуры глубинных нейронных сетей имеют врождённую эластичность к ошибкам благодаря алгоритмам обратной передачи ошибки обучения (backpropagation) применяемым при их обучении. Действительно, чтобы избежать переобучения сети на обучающем наборе данных, подходы аналогичные выбыванию (dropout) направлены на обеспечение хороших обобщений обучаемой сети и не сильную зависимость от точности (или ошибок) в вычислениях любого заданного блока.
Хранение данных P16 в сравнении с более высоким точностями FP32 и FP64 уменьшает потребление памяти нейронными сетями и тем самым делает возможным обучение и развёртывание больших сетей. Применение вычислений FP16 улучшает производительность в два раза по сравнению с арифметикой FP32 и аналогично обмен данными требует меньше времени чем обмен для FP32 и FP64.
|
| Замечание |
|---|---|
|
В GP100 две операции FP16 могут быть выполнены с применением одной спаренной инструкции. |
Архитектурные улучшения в GP100, объединённые с поддержкой типов данных FP16 позволяют значительно уменьшить времена обработки Глубинного обучения в сравнении с тем, что было достигнуто в последние годы.
Операции атомарности памяти важны в параллельном программировании, позволяя параллельным потокам правильно выполнять операции чтения-изменения-записи в совместно используемых структурах.
Kepler был снабжён операциями атомичности памяти в том же виде, что и Fermi. Обе архитектуры реализовывали атомичность совместно используемой памяти применяя шаблон lock/update/unlock (блокировка/изменение/снятие блокировки), который может быть затратным в случае при высокой конкуренции на обновления в определённых местоположениях в совместно используемой памяти.
Maxwell улучшил операции атомарности реализовав встроенную аппаратную поддержку для операций атомарности совместно используемой памяти для 32-битных целых и встроенную совместно используемую память 32-бит и 64-бит CAS (compare-and-swap), которая может быть использована для реализации других функций атомарности с уменьшенными накладными расходами (по сравнению с методами Fermi и Kepler, которые были реализованы программно).
GP100 строится поверх Maxwell но также улучшает операции атомарности с применением новых свойств
унифицированной памяти (Unified Memory) и NVLink (которые объясняются в следующих параграфах). Дополнительные
операции атомарности в глобальной памяти были расширены и включили данные FP64. Функция
atomicAdd() в CUDA теперь применима к 32 и 64-битным целым данным и данным
с плавающей точкой. Режим выравнивания для плавающей точки теперь
выравнивание-к-ближайшему-целому (round-to-nearest-even)
для всех атомарных операций сложения с плавающей точкой (ранее атомарные сложения FP32 применяли
выравнивание-к-нулю, round-to-zero).
Хотя GPU Fermi и Kepler были оснащены 64 кБ настраиваемой совместной памятью и кэшем L1, который мог разделять выделение памяти между L1 и функциями совместно используемой памяти в зависимости от рабочей нагрузки, начиная с Maxwell иерархия кэширования была изменена. SM GP100 имеет свой собственный выделенный пул совместно используемой памяти (64кБ/SM) и отдельный L1 кэш, который также может обслуживать кэш текстур в зависимости от рабочей нагрузки. Унифицированный кэш L1/текстур работает как образующий единое целое буфер для доступа к памяти, обирающий вместе все данные запрашиваемые потоками (thread) группы потоков (warp) прежде чем доставить эти данные в эту группу потоков (warp).
|
| Замечание |
|---|---|
|
Блок потоков (Thread Block) CUDA не может выделить 64 кБ совместно используемой памяти самостоятельно, однако два блока потоков могут использовать по 32 кБ каждый, и т.д.. |
Выделенная на каждый SM совместно используемая память означает, что приложения больше не нуждаются в
Выделенная на каждый SM совместно используемая память означает, что приложения больше не нуждаются в выборе предпочтений разделения L1/ совместная память для оптимальной производительности - все 64 кБ на SM всегда доступны для совместно используемой памяти.
GP100 снабжён унифицированным кэшем L2 4096 кБ, который предоставляет эффективное, высокоскоростное совместное использование данных между GPU. Для сравнения: в GK110 L2 кэш составлял 1536 кБ, в то время как GM200 снабжался L2 кэшем 3072 кБ. При большем кэше размещаемом на кристалле требуется меньшее число запросов к DRAM GPU, что уменьшает общее потребление мощности, уменьшает потребность в пропускной способности памяти и улучшает производительность.
Вне зависимости от того работаете ли вы в горах с геологическими данными, или исследуете решение сложной научной проблемы, вам необходима вычислительная платформа, которая предоставит наивысшую пропускную способность данных и наинизшую латентность из возможных. GPUDirect является возможностью, которая делает доступным GPU внутри отдельного компьютера или GPU в различных серверах размещённых в сетевой среде для прямого обмена данными без необходимости их перемещения в ЦПУ/оперативную память системы.
Функциональность RDMA в GPUDirect была предложена в Kepler GK110, позволяя устройствам сторонних производителей, таких как адаптеры InfiniBand (IB), платы сетевого интерфейса (NIC) и SSD {Прим. пер.: в особенности NVMe} напрямую осуществлять доступ к оперативной памяти на множестве GPU в пределах той же системы, предотвращая ненужные копии в памяти, драматично снижая накладные расходы ЦПУ и значительно понижая латентность отсылки и приёма сообщений MPI к/от памяти GPU. Она также снижает запросы на пропускную способность системной оперативной памяти и освобождает механизм DMA GPU для применения под прочие задачи CUDA.
GP100 удваивает предоставляемую пропускную способность чтения данных RDMA из памяти GPU источника и запись в память NIC получателя поверх PCIe. Удвоение полосы пропускания GPUDirect очень важно для многих вариантов применения, в особенности, для Глубинного обучения. Действительно, машины Глубинного обучения имеют высокое соотношение GPU к ЦПУ (в некоторых случаях 8 GPU на один ЦПУ), поэтому очень важно для такого GPU быстро взаимодействовать с вводом/ выводом без обратного обращения к ЦПУ для передачи данных.
GPU GP100 поддерживает новую вычислительную совместимость 6.0. Таблица 2 сопоставляет параметры различных вычислительных совместимостей для архитектур GPU NVIDIA.
| GPU | Kepler GK110 | Maxwell GM200 | Pascal GP100 |
|---|---|---|---|
|
3.5 |
5.2 |
6.0 |
|
32 |
32 |
32 |
|
64 |
64 |
64 |
|
2048 |
2048 |
2048 |
|
16 |
32 |
32 |
|
65536 |
65536 |
65536 |
|
65536 |
32768 |
65536 |
|
255 |
255 |
255 |
|
1024 |
1024 |
1024 |
|
16 KB/32 KB/48 KB |
96 KB |
64 KB |
Поскольку применение GPU для ускорения вычислений в приложениях сильно выросло в последние годы, многие из этих приложений имеют аппетит к данным. Чем большие задачи решают GPU, тем большая потребность в наборах данных и выше запрос к полосе пропускания DRAM. Для решения такого запроса в более высокой полосе пропускания, Tesla P100 стала первым ускорителем GPU применяющим HBM2 (High Bandwidth Memory 2 ).
HBM2 делает возможным значительное расширение полосы пропускания DRAM фундаментально меняя способ, которым DRAM упаковывается и присоединяется к GPU.
Вместо того, чтобы требовать множества дискретных чипов памяти вокруг GPU как это присутствует в традиционных конструкциях плат GPU c GDDR5, HBM2 включает в себя один или несколько вертикальных стеков множества кристаллов памяти. Кристаллы памяти связаны с применением микроскопических проводов, которые создаются сквозными путями через кремний и микронеровностями. Один 8Гб кристалл HBM2 содержит 5000 путевых отверстий в кремнии. Пассивная кремниевая переходная плата затем применяется для соединения стека памяти и кристалла GPU. Комбинация стека HBM2, кристалла GPU и кремниевой переходной платы упаковываются в единый пакет BGA размерами 55мм x 55мм. Обратите внимание на Рисунок 9 для иллюстрации GP100 и двух стеков HBM2 и Рисунок 10 с фотомикрографией реального P100 с GPU и памятью.
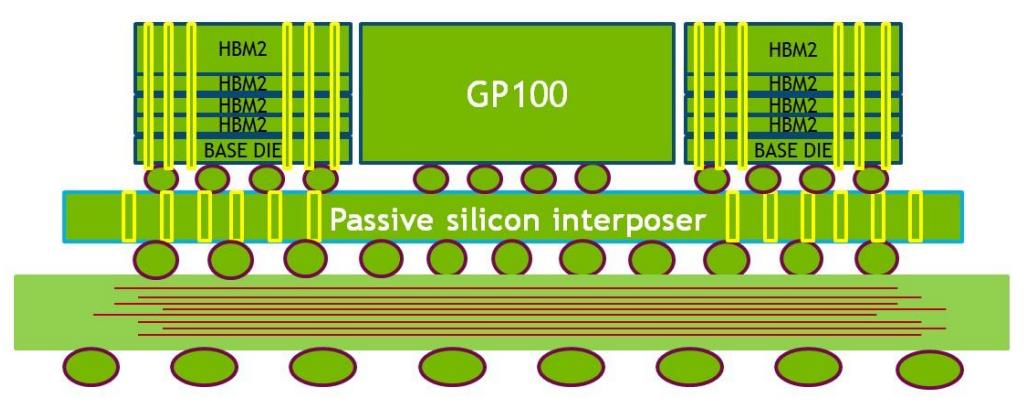

Фотомикрография на Рисунке 10 отображает поперечное сечение стека HBM2 Tesla P100 и GPU GP100. Стек HBM2 слева вверху построен из пяти кристаллов - лежащего в основе кристалла и 4 кристаллов поверх него. Кристалл памяти самого верхнего уровня очень тонкий. При сборке верхний кристалл и GPU выравниваются на одну высоту для предоставления лежащей в одной плоскости поверхности для теплоотвода.
В сравнении с предыдущим поколением HBM1, HBM2 предоставляет более высокую плотность памяти и полосу пропускания памяти. HBM2 поддерживает четыре или восемь кристаллов DRAM в стеке, в то время как HBM1 поддерживает только четыре кристалла DRAM на стек. HBM2 поддерживает до 8 Гб на кристалл DRAM, в то время как HBM1 поддерживает только 2 Гб на кристалл. В то время как HBM1 был ограничен 128 ГБ/с пропускной способности на стек, P100 поддерживает 180 ГБ/с на стек с HBM2.
Как показано на блок схеме полного чипа GP100 (Рисунок 7), GPU GP100 соединяется с четырьмя стеками DRAM HBM2. Два 512-битных контроллера памяти соединяются с каждым стеком HBM2 для эффективного 4096-битного интерфейса памяти HBM2. Первоначально ускорители Tesla P100 будут поставляться с четырьмя 4-кристальными стеками HBM2, с общей памятью HBM2 16 ГБ.
Другим преимуществом памяти HBM2 является естественная поддержка функциональности кодирования исправления ошибок (ECC, error correcting code). ECC предоставляет более высокую надёжность для вычислительных приложений, что существенно при порче данных. Это в особенности важно для вычислительных сред с крупномасштабными кластерами, в которых GPU обрабатывают очень большие наборы данных и/или выполняют приложения продолжительное время.
Технология ECC обнаруживает и исправляет однобитные временные ошибки до того как они повлияют на систему. Для сравнения, GDDR5 не обеспечивает внутренней защиты ECC содержимого памяти и ограничивает обнаружение ошибок только шиной GDDR5. Ошибки в контроллере памяти или в самой DRAM не обнаруживаются.
GPU GK110 Kepler предлагает защиту ECC для GDDR5 выделяя часть доступной памяти для хранения ECC в явном виде. 6.25% от всей GDDR5 резервируется под биты ECC. В случае с Tesla K40 с 12 ГБ (в качестве примера), 750 МБ её общей памяти резервируется под операции ECC, имея результатом 11.25 ГБ (из 12 ГБ) доступной памяти с ECC возвращаемых в Tesla K40. Помимо этого, доступ к битам ECC вызывает уменьшение в полосе пропускания памяти на 12-15% при типичных рабочих нагрузках по сравнению с вариантом использования без ECC. Так как HBM2 внутренне поддерживает ECC, Tesla P100 не страдает от накладных расходов ёмкости, а ECC может быть активным всё время без штрафов по полосе пропускания. Как и для GPU GK110, файлы регистров, совместно используемая память, кэш L1, кэш L2 GPU GP100, а также DRAM HBM2 ускорителя Tesla P100 защищены ECC кодом коррекции единичной ошибки и обнаружения двойной ошибки (SECDED, Single Error Correct Double‐Error Detect).
Одной из наиболее волнующих новых функциональностей архитектуры системы Tesla P100 является новая конструкция, которая размещает GPU GP100 и стеки памяти HBM2, а также предоставляет связности NVLink и PCIe. Один или более ускорителей P100 могут применяться в рабочих станциях, серверах и вычислительных системах большого масштаба. Ускоритель P100 имеет размеры 140мм x 78мм и содержит высокоэффективные регуляторы напряжения, которые обеспечивают GPU различными необходимыми напряжениями. P100 ограничивает потребление 300 Вт.
Рисунок 11 показывает переднюю часть Tesla P100, а Рисунок 12 заднюю.

