Глава 11. SQL Server и контейнеры
Содержание
Понятие виртуальных машин была известна уже достаточно давно, но в Microsoft я в действительности не видел чтобы клиенты начали применять SQL Server в качестве платформы базы данных в виртуальных машинах примерно до временного периода 2006 - 2007. Даже когда среды виртуальных машин, такие как Hyper-V и VMware приобрели популярность, я скептически относился к тому, что SQL Server будет хорошо работать в гостевой виртуальной машине. Сегодня, скорее всего, SQL Server развёрнут в виртуальных машинах в гораздо большем количестве нежели на голом железе.
В качестве новых виртуальных машин я вижу контейнеры. Но азарт и принятие контейнеров с платформами приложений и баз данных, таких как SQL Server растут быстрее чем я когда- либо наблюдал с виртуальными машинами.
В данной главе я намерен снабдить вас неким введением в контейнеры, а затем достаточно глубокое обсуждение набора примеров того как использовать контейнеры с SQL Server. Затем я завершу эту главу забавным примером применения SQL Server в macOS (пользователи Mac могли подумать что я проигнорирую их в этой книге) и некое обсуждение того как применять SQL Server в платформе контейнеров с названием Kubernetes. Мне кажется, что эта глава вам понравится. Это была одна из самых моих любимых глав в этой книге.
В то время как виртуальные машины лучше всего определяются как виртуализация оборудования, контейнеры (или заключение в контейнеры: containers или containerization) определяются как виртуализация операционной системы. Некая виртуальная машина состоит из полной операционной системы (гостевой), запущенной в какой- то машине хоста (поверх оборудования голого железа). Следовательно для машины хоста характерно размещение определённого числа виртуальных машин. Всякая виртуальная машина способна работать под управлением иной гостевой операционной системы.
Контейнеры опираются на единственную операционную систему хоста(которая может в свою очередь представлять какую- то виртуальную машину), совместно используя ресурсы ядра. Это делает контейнеры более легковесными нежели виртуальные машины. Даже хотя контейнеры и разделяют некое единственное ядро операционной системы, контейнеры изолированы друг от друга. Я обожаю следующую схему визуализации, которая отображена на Рисунке 11-1, который я нашёл в https://i.stack.imgur.com/exIhw.png для отображения отличий между контейнерами и виртуальными машинами.
Рисунок 11-1
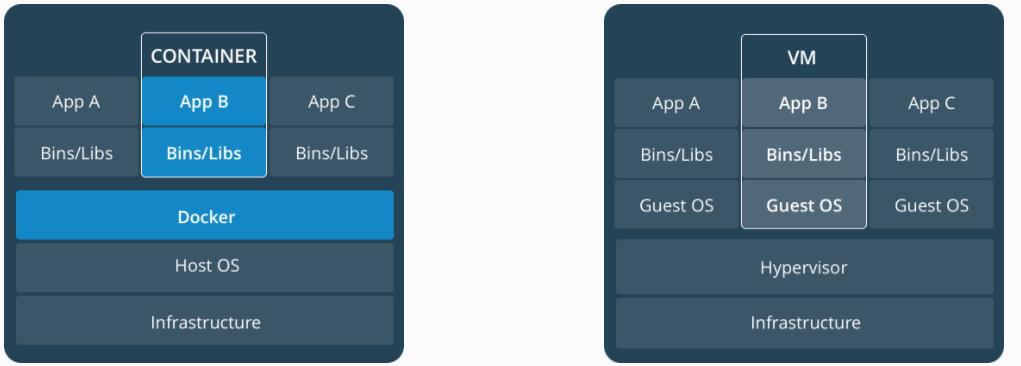
| Контейнеры | Виртуальные машины |
|---|---|
Контейнеры являются абстракцией на уровне прикладного приложения, которые пакуют сообща код и зависимости. Множество контейнеров может исполняться в одной и той же машине и совместно с прочими контейнерами применять ядро ОС хоста, причём каждый исполняется как изолированный процесс в пространстве пользователя. Контейнеры требуют меньше места нежели ВМ (образы контейнеров обычно в размере представлены десятками МБ) и запускаются почти моментально. |
Виртуальные машины (ВМ) представляют некий уровень абстракции физического оборудования, который превращает один сервер во множество серверов. Имеющийся гипервизор позволяет множеству ВМ запускаться в отдельной машине. Всякая ВМ содержит какую- то полную копию некоторой операционной системы, одно или более приложений, необходимые двоичные файлы и библиотеки, требуя десятки ГБ. ВМ к тому же могут быть не шустрыми при загрузке. |
Кроме того, данный пост stackoverflow.com является отличным описанием имеющихся отличий между виртуальными машинами и контейнерами. Только один комментарий относительно этого поста: автор описывает Union File System (UnionFS) с названием AuFS. UnionFS является важным понятием для контейнеров Docker поскольку поддерживает некую многоуровневкю файловую систему. Текущие выпуски Docker всё ещё применяют UnionFS, но в настоящее время применяется система с названием OverlayFS. Вы можете узнать дополнительные подробности OverlayFS в https://docs.docker.com/storage/storagedriver/overlayfs-driver/.
Контейнеры Docker создаются с помощью образов, которые определяют необходимое содержимое самой файловой системы и того что запускается в этом контейнере. Некий контейнер затем выступает каким- то экземпляром образа. Вы можете запускать множество контейнеров на основе одного и того же образа. Само содержимое этого образа Docker определяется неким Dockerfile. Docker предоставляет функциональнсоть построения какого- то образа Docker из некого описания Dockerfile. Кроме того, Docker поддерживает функциональность для построения приложений множества контейнеров с названием компоновки (compose). В своём следующем разделе я более подробно продемонстрирую образы, файлы и компоновку Docker применяя в качестве примера SQL Server.
Контейнеры Docker обладают следующими характеристиками:
-
Переносимость: Любой построенный вами образ Docker может быть исполнен везде гле поддерживаются контейнеры Docker, включая множество операционных систем, а также общедоступные и частные облачные решения. Я запускал контейнеры Docker в Windows, Linux, macOS и Azure.
-
Малый вес: Как я уже указывал, контейнеры Docker не содержат операционную систему целиком, как это происходит в случае виртуальных машин. Контейнеры Docker разделяют ресурсы ядра и тем самым обладают намного более меньшим весом нежели виртуальные машины.
-
Согласованность: Образы контейнера позволяют вам развёртывать некую согласованную версию вашего приложения или системы базы данных, аналогичной SQL Server. Я дополнительно обсужу позднее в этой главе как именно это предоставляет преимущества SQL Server.
-
Действенность: Контейнеры Docker предоставляют некий механизм для более быстрого развёртывания, меньшего времени простоя и более простых обновлений. В своём следующем разделе я поясню преимущества этого для SQL Server.
В помощь для управления вами контейнерами Docker, он предоставляет два основных компонента:
-
Клиент Docker: это программа с названием docker, которую вы применяете с определёнными параметрами для построения образов, а также для их активной доставки (pull), исполнения, запуска, останова и общего управления. Вы ознакомитесь с этими понятиями на примерах в данной главе.
-
Демон Docker: Сам клиент Docker взаимодействует с имеющейся программой демона, которая выполняет всю работу, на необходимость которой указывает сам клиент выстраиваемого образа, а также управляет контейнерами и исполняет их.
Контейнеры Docker применяют некую концепцию с названием пространства имён (namespaces) для изоляции одного контейнера от прочих (вы можете дополнительно ознакомиться с этим в https://docs.docker.com/engine/docker-overview/#the-underlying-technology {Прим. пер.: также обращаем внимание на наш перевод Контейнеризация при помощи LXC. Константина Иванова, где подробно обсуждается роль пространства имён в контейнеризации}). Даже несмотря на то, что контейнеры изолированы, они всё ещё способны взаимодействовать друг с другом (например, поверх TCP/IP {Прим. пер.: или RDMA}) Для своей полной документации по Docker воспользуйтесь полной справочной информацией. Для своего образования, пожалуйста, воспользуйтесь также дополнительными великолепными ресурсами относительно контейнеров, которые я обнаружил: Docker CheatSheet for Beginners With Examples и What exactly is a base image in Docker?.
Давайте погрузимся непосредственно в выяснение того как вы можете применять контейнеры для SQL Server и приложений баз данных.
В этом разделе данной книги я намерен показать вам практические примеры фундаментальных понятий контейнеров, которые я представил в своём открывающем разделе. Я покажу вам как развернуть некий простой контейнер с SQL Server, применить контейнеры чтобы показать как минимизировать время простоя для обновлений, построить и развернуть некий образ при помощи Dockerfile, и наконец реализовать развёртывание со множеством контейнеров с SQL Server и неким приложением.
Один момент, который следует помнить при чтении данного раздела: SQL Server поверх Linux не поддерживает множество экземпляров (которые в Windows называются именованными экземплярами) в одном и том же сервере, следовательно контейнеры являются тем методом, который следует применять когда вы желаете исполнения множества экземпляров SQL Server в одном и том же сервере Linux.
Пока я писал эту книгу, мой коллега Вин Ю вместе со мной построил последовательность лабораторных занятий для свободного доступа и самостоятельного обучения контейнерам Docker в SQL Server поверх Linux в https://github.com/Microsoft/sqllinuxlabs. Вин построил построил лабораторию для исследования контейнеров (которую можно найти на https://github.com/Microsoft/sqllinuxlabs/tree/master/containers). Я буду применять эти фрагменты лабораторных занятий в этом разделе чтобы показать как применять SQL Server с контейнерами. (Я добавил в качестве примеров для этой книги несколько сценариев, которые вы можете применять с этим лабораторным практикумом.) Я могу не придерживаться точного порядка лабораторных занятий Вина, а также я поясню ещё ряд подробностей команд, которые вы будете запускать чтобы посмотреть на контейнеры SQL в работе.
Для демонстрации этих примеров я создал некую новую Виртуальную машину Azure под управлением RHEL 7.5 (размер моей ВМ это стандарт D16s v3 [16 vcpu, 64 ГБ памяти], но вы можете делать и в в ВМ меньшего размера, просто постарайтесь иметь по крайней мере 4vcpu и 16 ГБ оперативной памяти). Затем я исполнил следующие команды из оболочки bash для обновления своей VM, установки пакета git и затем клонирования репозитория Github для получения сценариев и инструкций:
sudo yum -y update
sudo yum install git
git clone https://github.com/Microsoft/sqllinuxlabs.git
Теперь давайте установим механизм Docker с тем чтобы мы могли следовать за своими примерами на протяжении оставшейся части данной главы, выполнив следующие команды из своей оболочки bash:
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install http://mirror.centos.org/centos/7/extras/x86_64/Packages/pigz-2.3.3-1.el7.centos.x86_64.rpm
sudo yum install docker-ce
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Стандартный пакет Docker для RHEL является платной версией с названием Docker Enterprise Edition (вы можете ознакомиться с подробностями в https://docs.docker.com/install/linux/docker-ee/rhel). Для целей обсуждаемых лабораторных занятий и примеров из данной книги я намерен применять Docker Community Edition, которая построена для CentOS но совместима и для работы в RHEL. Дополнительно ознакомиться с подробностями относительно редакции Docker сообщества вы можете на https://docs.docker.com/install/. |
Теперь запустим сам механизм Docker при помощи следующей команды из своей оболочки bash:
sudo systemctl start docker
Также для того чтобы иметь Docker запущенным после какой- то перезагрузки, вы можете воспользоваться такой командой:
sudo systemctl enable docker
Теперь я готов показать вам как развёртывать SQL Server в контейнере.
В этом разделе я покажу вам основы развёртывания контейнеров с SQL Server и то как обновлять SQL Server при помощи контейнеров.
Основы контейнера Docker SQL Server
Давайте вначале ознакомимся с основами развёртывания некого контейнера с SQL Server и взаимодействию с ним. Контейнеры являются экземплярами некого образа. Microsoft опубликовал некую последовательность образов в Docker Hub на https://hub.docker.com/r/microsoft/mssql-server-linux/. {Прим. пер.: реестр теперь перемещён на сайт Microsoft https://hub.docker.com/_/microsoft-mssql-server, более того, предварительный просмотр контейнеров SQL Server 2019 доступен только там.} Образы Docker могут храниться в неком частном реестре или в каком- то общедоступном домене, таком как Docker Hub. Вы даже можете применять имеющееся облачное решение для частного реестра контейнеров, такое как Реест контейнеров Azure, о котором можно дополнительно прочесть на https://azure.microsoft.com/services/container-registry.
Опубликованные Microsoft образы для SQL Server на Docker Hub содержат образы для SQL Server 2017 от RTM вплоть до самых последних обновлений CU и GDR. Эти образы основаны на образе Linux Ubuntu 16.04 с редакцией Разработчика SQL Server. Это не означает что вы обязаны развёртывать данные образы исключительно в сервере Linux Ubuntu. Данный образ Docker, который мы построили с помощью Ubuntu может исполняться в любой платформе, поддерживающей Docker, поскольку само основное ядро Linux одно и то же во всех дистрибутивах Linux. Справедливости ради, если вам требуется полагаться на особую функциональность некого дистрибутива Linux, наш образ на основе Ubuntu может и не подойти для вас. В этом случае вам может потребоваться создать образ при помощи Dockerfile. Кроме того, если вы желаете использовать образ Docker с иным выпуском SQL Server, ознакомьтесь с нашей документацией.
|
| Замечание |
|---|---|
|
Вы можете построить свой собственный образ контейнера Docker для SQL Server с RHEL в качестве базового образа при помощи dockerfile. Обратитесь к нашему примеру. Microsoft работает над публикацией в будущем образов Docker, которые содержат такие дистрибутивы как RHEL. |
В этой главе я запускаю все команды Docker в качестве root при помощи sudo. Вы можете настроить Docker с тем, чтобы вы могли применять команды Docker не являясь пользователем root. Ознакомьтесь с этой документацией относительно подробностей.
Методом для развёртывания образа контейнера Docker Hub SQL Server является один из следующих двух:
-
Воспользуйтесь программой клиента Docker с параметром
pullкак это сделано в следующей команде из оболочки bash:sudo docker pull microsoft/mssql-server-linux:2017-latest{Прим. пер.: с учётом переезда репозитория на сайт Microsoft и наличием версий для просмотра SQL Server 2019, можно воспользоваться одной из следующих команд:}
sudo docker pull mcr.microsoft.com/mssql/server:2017-latest-ubuntu или sudo docker pull mcr.microsoft.com/mssql/server:2019-CTP2.2-ubuntu -
Запустите некий контейнер Docker определённый в одном из тех образов SQL Server, который если его ещё не было, вначале вытащит такой образ, а затем запустит соответствующий контейнер.
sudo docker run -e 'ACCEPT_EULA=Y' -e \ 'SA_PASSWORD=YourStrong!Passw0rd' \ -p 1500:1433 --name sql1 \ -d microsoft/mssql-server-linux:2017-latest{Прим. пер.: с учётом переезда репозитория на сайт Microsoft и наличием версий для просмотра SQL Server 2019, можно заменить microsoft/mssql-server-linux:2017-latest на:}
mcr.microsoft.com/mssql/server:2017-latest-ubuntu или mcr.microsoft.com/mssql/server:2019-CTP2.2-ubuntu
Если вы вначале вытащили этот образ, ваш второй вариант исполнения имеющегося контейнера запустит тот образ контейнера, который вы уже вытянули. Оба этих метода требуют некого подключения к Интернету с вашего сервера Linux.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Следующий пост в stackexchange.com имеет великолепное описание опыта для развёртывания контейнера в отключённом от Интернет режиме. Docker предоставляет возможность вытащить некий образ в подключённой к Интернету машине, сохранить этот образ в неком файле tar, скопировать полученный tar файл в ваш сервер Linux и затем воспользоваться загрузкой Docker для импорта имеющегося файла tar в неикц образ, который вы можете применять для запуска контейнера. |
Давайте для запуска своего контейнера применим второй метод, который автоматически вытащит необходимый образ Docker для SQL Server с самым последним обновлением CU. Я желаю поместить свой пароль sa, поэтому взял предыдущую команду в редактор nanо, изменил её строку на свой пароль sa и затем поместил полученный результат в свою оболочку bash в качестве такой команды:
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Sql2017isfast' \
-p 1500:1433 --name sql1 \
-d microsoft/mssql-server-linux:2017-latest
Если эта команда выполнилась успешно, вы обнаружите результат подобный приводимому ниже (если это самый первый раз, когда вы пробуете запустить некий образ контейнера SQL Server). Вы можете обнаружить, что ваш образ Docker не может быть найден локально, поэтому он вначале вытаскивается с Docker Hub, поэтому непосредственно выполняется docker pull.
Unable to find image 'microsoft/mssql-server-linux:2017-latest' locally
2017-latest: Pulling from microsoft/mssql-server-linux
f6fa9a861b90: Pull complete
da7318603015: Pull complete
6a8bd10c9278: Pull complete
d5a40291440f: Pull complete
bbdd8a83c0f1: Pull complete
3a52205d40a6: Pull complete
6192691706e8: Pull complete
1a658a9035fb: Pull complete
344203922c4b: Pull complete
5975df51ff07: Pull complete
Digest: sha256:97d2a9cd87ecfab641f24be254e03a45b8d551355e21516c0460da7daf8b526e
Status: Downloaded newer image for microsoft/mssql-server-linux:2017-latest 66e7e043e41683af4e1f419df41417e7fb3c19f8013b2d9d3e5c69a5d03ec3f8
Наилучшим способом узнать что ваш контейнер успешно запущен будет исполнение в вашей оболочке bash:
sudo docker ps
В своём сервере Linux полученный мной результат выглядит так:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a01c1c991cec microsoft/mssql-server-linux:2017-latest "/opt/mssql/bin/sqls..." About a minute ago Up About a minute 0.0.0.0:1500->1433/tcp sql1
Давайте разберём те параметры команды docker, которыми я воспользовался.
Параметр -e применялся для переменных среды, которые необходимы для запуска
SQL Server (аналогично тем, которые мы определяли при запуске вами соответствующего сценария mssql-conf как части
развёртывания SQL Server поверх Linux), включая приём EULA и определение некого пароля sa. (Обратим внимание,
что эти параметры передаются в саму программу sqlservr.)
Параметр -p применяется для установки соответствия
портов. SQL Server выполняет ожидание по порту 1433, однако применение этого порта для вашего контейнера может
вызвать конфликт с портом 1433 в сервере Linux вашего хоста или с иными контейнерами Docker для SQL Server, следовательно
данный параметр устанавливает соответствие порта 1500 порту 1433 в вашем контейнере. Я покажу как применять такой
переназначенный порт при подключении к SQL Server в вашем контейнере.
Параметр –name позволяет ввам определить некое дружественное пользователю название
для взаимодействия с данным контейнером в прочих командах Docker.
Параметр -d предписывает запуск вашего контейнера в фоновом режиме (т.е. с
отключением) с тем, чтобы ваша команда docker run вернула обратно в вашей оболочке bash курсор приглашения, но
при этом запускает сам контейнер в фоновом режиме.
Самый последний параметр это название вашего образа Docker, которым в данном случае является microsoft/mssql-server-linux:2017-latest. {Прим. пер.: позволим себе повториться: с учётом переезда репозитория на сайт Microsoft и наличием версий для просмотра SQL Server 2019, можно заменить microsoft/mssql-server-linux:2017-latest на: mcr.microsoft.com/mssql/server:2017-latest-ubuntu или mcr.microsoft.com/mssql/server:2019-CTP2.2-ubuntu.} Docker попытается отыскать этот образ локально в вашем сервере Linux. Если он не существует, он для начала попробует вытащить этот образ с имеющегося Docker Hub, как вы это видите из полученной ранее команды docker run.
Для того чтобы убедиться что ваш образ Docker для SQL Server теперь хранится локально, вы можете запустить такую команду:
sudo docker images
В своём сервере Linux я получил следующее:
REPOSITORY TAG IMAGE ID CREATED SIZE
microsoft/mssql-server-linux 2017-latest c90c3ab55158 13 days ago 1.44GB
Теперь, когда ваш контейнер Docker запущен, вы захотите подключиться к SQL Server. Давайте воспользуемся следующими двумя методами:
-
Вы можете взаимодействовать со своим контейнером при помощи команды Docker, исполняемой в оболочке bash следующим вызовом:
sudo docker exec -it sql1 bashВы должны получить некое приглашение оболочки, которое будет выглядеть как- то так:
root@66e7e043e416:/#В этом примере
66e7e043e416это идентификатор нашего контейнера, который становится названием нашего сервера, которое можно отыскать в соответствующем операторе T-SQL@@SERVERNAME.Именно эта оболочка bash позволяет вам запускать команды внутри самого контейнера (круто, не правда ли?). Для того чтобы воспользоваться sqlcmd выполните приводимую ниже команду (все образы SQL Server содержат инструментарий sqlcmd) внутри своего контейнера для подключения к SQL Server: (впишите свой пароль sa):
/opt/mssql-tools/bin/sqlcmd -U SA -P 'Sql2017isfast'Замечание Хотя интересно напрямую взаимодействовать с контейнером при помощи оболочки bash, большинство взаимодействий, которые вы будете иметь с контейнером, будут выполняться при помощи программ вне контейнера. Будьте осторожны, внося любые изменения внутри самого контейнера, если только вы не вносите изменения в данные или файлы на постоянном томе (который я опишу позднее в этой главе). Любые изменения в контейнере, не хранящемся в постоянном хранилище, будут утрачены когда вы удалите контейнер. В следующих примерах вы увидите, как запускать sqlcmd как внутри контейнера, так и за его пределами. Но в этих примерах я делаю изменения в базе данных SQL Server, которая находится на постоянном томе хранилища.
Наберите exit в sqlcmd и наберите exit чтобы покинуть данную оболочку.
-
Второй метод состоит в использовании инструмента SQL Server вне данного контейнера для подключения к этому SQL Server внутри данного контейнера. В своей ВМ Azure я установил инструменты SQL Server в соответствии с документацией, поэтому я могу воспользоваться
sqlcmdдля подключения к своему SQL Server в контейнере. Поскольку мой контейнер переназначен на порт 1500, а я выполняю подключение со своего локального сервера Linux, я могу выполнить некую команду в его оболочке bash подобным образом:sqlcmd -S localhost,1500 -Usa -PSql2017isfastЗамечание Вы можете подключаться к SQL Server в вашем контейнере с другого компьютера, который может выполнить доступ к вашему хосту сервера Linux при помощи IP адреса этого хоста сервера со значением порта 1500 в соответствующем параметре
-S. Этот порт должен быть открыт в имеющемся межсетевом экране.Теперь в приглашении sqlcmd выполните следующий оператор T-SQL:
SELECT @@version GOВаш результат будет выглядеть как это показано ниже, что отображает тот факт, что SQL Server полагает что он запущен в Ubuntu, но его хостом в действительности является RHEL:
--------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- Microsoft SQL Server 2017 (RTM-CU9-GDR) (KB4293805) - 14.0.3035.2 (X64) Jul 6 2018 18:24:36 Copyright (C) 2017 Microsoft Corporation Developer Edition (64-bit) on Linux (Ubuntu 16.04.5 LTS)Чтобы покинуть sqlcmd наберите exit.
Вы можете остановить свой контейнер при помощи такой команды из соответствующей оболочки bash
sudo docker stop sql1
Чтобы увидеть все контейнеры, даже те, которые не исполняются, вы можете воспользоваться следующей командой из надлежащей оболочки bash:
sudo docker ps -a
Ваши результаты будут выглядеть как- то так:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
66e7e043e416 microsoft/mssql-server-linux:2017-latest "/opt/mssql/bin/sqls..." About an hour ago Exited (0) 2 minutes ago sql1
Контейнеры Docker содержат все файлы или данные, которые вам приходится создавать или изменять при исполнении этого контейнера. Вы можете запускать и останавливать соответствующий контейнер, а те данные которые вы создали будут присутствовать только на время жизни данного контейнера. Однако, если вы удаляете свой контейнер, все данные в этом контейнере будут утрачены. Тем не менее имеется метод постоянного хранения (удержания, persist) любых данных в вашем контейнере таким образом, что все данные остаются в сохранности даже после удаления этого контейнера. Давайте взглянем на некий пример, который может подтвердить полезность обновления SQL Server для минимизации времени простоя. Прежде чем мы продолжим, удалите наш предыдущий контейнер и тот образ, который мы применяли при помощи следующей команды из надлежащей оболочки bash:
sudo docker rm sql1
sudo docker rmi microsoft/mssql-server-linux:2017-latest
Обновление SQL Server при помощи контейнеров
Для обновления SQL Server поверх Linux неким новым накопленным изменением в RHEL обычно вы запускаете некую команду
подобную sudo yum update mssql-server. Эта команда вытащит все самые последние
накопленные изменения, остановит SQl Server, применит новые двоичные файлы и затем запустит SQL Server. Если эти обновления
исполняются плавно, это не должно потребовать значительного количества времени, однако контейнеры предлагают иной метод.
Позвольте мне показать как это происходит на некотором примере. Для данного раздела я буду применять образец базы данных
WideWorldImporters, поэтому в своей новой ВМ Azure я вначале выполню такие команды из своей соответствующей оболочки bash
для вытаскивания резервной копии этого образца:
wget https://github.com/Microsoft/sql-server-samples/releases/download/wide-world-importers-v1.0/WideWorldImporters-Full.bak
Самый первый шаг состоит в запуске некого контейнера (который и вытащит необходимый образ) на основе SQL Server 2017
поверх Linux CU8 со следующей командой из вашей оболочки bash (которую можно найти в образце сценария
dockerruncu8.sh) с лёгким отклонением от
нашего предыдущего раздела:
sudo docker run -e 'ACCEPT_EULA=Y' -e 'MSSQL_SA_PASSWORD=Sql2017isfast' -p 1401:1433 -v sqlvolume:/var/opt/mssql --name sql1 -d microsoft/mssql-server-linux:2017-CU8
Имеются три отличия в том как я запускаю этот контейнер Docker в сравнении с нашим предыдущим разделом:
-
Я применяю параметр
-vдля установки соответствия некоторого тома в имеющемся хосте Linux своему каталогу/var/opt/mssqlвнутри самого контейнера. Это означает, что все данные, хранимые в/var/opt/mssqlвнутри данного контейнера будут удерживаться в самом сервере Linux.Совет Для того чтобы отыскать реальный каталог в вашем сервере хоста Linux, в котором хранятся эти данные, исполните следующую команду:
sudo docker inspect volume sqlvolume -
Я применяю различные образы для SQL Server: в данном случае SQL Server 2017 CU8 (который на тот момент когда и пишу эту главу не является самым последним обновлением SQL Server).
-
Я применяю порт 1401 вместо 1500 для подключения к данному серверу.
Теперь давайте восстановим резервную копию WideWorldImporters в своём новом контейнере. Самый первый этап состоит в
переносе этой резервной копии из моего домашнего каталога в сам хост сервера Liux вовнутрь
своего контейнера. Я выполню это исполнив следующую команду из надлежащей оболочки bash
(который также можно отыскать в образце сценария
dockercopy.sh):
sudo docker cp WideWorldImporters-Full.bak sql1:/var/opt/mssql
Для восстановления этой базы данных я воспользуюсь командой docker exec для исполнения sqlcmd внутри самого
контейнера при помощи оператора T-SQL. В соотвествующей оболочке bash исполните следующую команду, которую можно
обнаружить в образце сценария docker_restorewwi.sh:
sudo docker exec -it sql1 /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P 'Sql2017isfast' -Q 'RESTORE DATABASE WideWorldImporters FROM DISK = "/var/opt/mssql/WideWorldImporters-Full.bak" WITH MOVE "WWI_Primary" TO "/var/opt/mssql/data/WideWorldImporters.mdf", MOVE "WWI_UserData" TO "/var/opt/mssql/data/WideWorldImporters_userdata.ndf", MOVE "WWI_Log" TO "/var/opt/mssql/data/WideWorldImporters.ldf", MOVE "WWI_InMemory_Data_1" TO "/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1"'
Теперь давайте запустим некий запрос чтобы убедиться что мы можем выполнять доступ к данным внутри этой базы данных.
На этот раз я применяю sqlcmd из своего хоста Linux (я показываю вам оба способа доступа к SQL Server внутри вашего
контейнера). Из соответствующей оболочки bash примените следующую команду, которую можно найти в образце сценария
dockerquery.sh:
sqlcmd -Usa -Slocalhost,1401 -Q'USE WideWorldImporters;SELECT * FROM [Application].[People];'
Если всё пройдёт нормально, ваш экран должен прокрутить строки из имеющейся таблицы People.
Теперь давайте предположим что вы желаете обновить SQL Server на самое последнее накопленное обновление. В случае данного контейнера вы не применяете инструменты навроде apt-get, но это нормально, так как я уже ранее в этой главе сказал что существует лучший способ обновления SQL Server.
Давайте запустим некий новый контейнер Docker с названием sql2, однако на этот
раз с самыми последними накопленными обновлениями. Я также хочу указать этому контейнеру тот же самый
sqlvolume для доступа ко всем базам данных, которые мы сохранили в своём контейнере
sql1. Чтобы минимизировать время простоя, я намерен вытащить самый последний образ
SQL Server вручную вместо того чтобы вытягивать его при использовании docker run. Из надлежащей оболочки bash исполните
такую команду:
sudo docker pull microsoft/mssql-server-linux:2017-latest
Теперь давайте остановим свой контейнер sql1 при помощи такой команды в соответствующей
оболочке bash:
sudo docker stop sql1
Она осуществит чистый останов SQL Server. Теперь давайте запустим некий новый контейнер с названием
sql2 с в точности теми же самыми параметрами что и ранее, включая соответствие
порта и название тома. Из надлежащей оболочки bash исполните приводимую ниже команду, которую можно найти в соответствующем
пример сценария docker_restorewwi.sh:
sudo docker run -e 'ACCEPT_EULA=Y' -e 'MSSQL_SA_PASSWORD=Sql2017isfast' -p 1401:1433 -v sqlvolume:/var/opt/mssql --name sql2 -d microsoft/mssql-server-linux:2017-latest
Так как я применяю тот же самый номер порта, что и для контейнера sql1, я могу
запустить ту же самую команду что и ранее для исполнения запроса к базе данных , который можно отыскать в
dockerquery.sh:
sqlcmd -Usa -Slocalhost,1401 -Q'USE WideWorldImporters;SELECT * FROM [Application].[People];'
И это сейчас достаточно клёво. У меня имелась возможность переключиться в некий
контейнер, исполняющий самые последние накопленные обновления, и при этом минимизировать время простоя вместо внесения
исправлений в имеющийся SQL Server. Здесь представлено то, во что вы должны влюбиться на самом деле. Так как я не удалил
свой контейнер sql1, я могу просто остановить свой контейнер
sql2. Бум! Теперь я выполняю свой предыдущий CU.
Это великолепный сценарий чтобы продемонстрировать обновления в SQL Server и удерживаемой базе данных даже если этот
контейнер удалён. В нашем следующем разделе я намерен показать вам как построить ваш собственный образ Docker чтобы включить
в него SQL Server и некую предварительно определённую базу данных. Для подтверждения того что я могу запустить оба
контейнера SQL Server за раз (но не для одного и того же тома), давайте остановим свой контейнер sql1
если у вас имелся запущенным sql1, но оставим sql2
исполняемым при помощи такой команды:
sudo docker stop sql1
Пока что я показал вам, как взаимодействовать и добавлять данные в контейнер Docker из образа SQL Server на сайте Docker Hub. Контейнеры Docker с SQL Server также могут помогать вам в некотором другим интересном сценарии. Допустим, у вас есть несколько разработчиков, работающих над приложением с SQL Server. Обычно вы настраиваете сервер разработки и позволяете разработчикам получить доступ к серверу. Одной из проблем такой конфигурации является настройка среды с тем, чтобы разработчики имели согласованную базу данных с согласованной версией SQL Server для всех разработчиков.
Контейнеры привносят некую новую стратегию в подобный сценарий. Вы можете построить некий образ Docker на основе соответствующего образа SQL Server и включим в этот образ некую резервную копию вашей стандартной базы данных, которую, как вы бы хотели, применяли все разработчики. Затем каждый разработчик может вытаскивать этот образ Docker и запускать контейнер (подобно наличию некой собственной песочницы). Кроме того, одним из великолепных свойств образов Docker является возможность его повторного использования. Вы можете выстраивать уровни образов путём создания образов на основе прочих образов.
Давайте в точности воспользуемся шагами из лабораторного практикума самообучения чтобы продемонстрировать некий пример этого. (Я предполагаю, что вы выполнили все команды из нашей предыдущей главы для клонирования нужного нам репозитория GitHub для данного лабораторного занятия.)
-
В своём сервере Linux измените каталог на папку
mssql-custom-image-exampleисполнив в соответствующей оболочке bash следующую команду:cd sqllinuxlabs/containers/mssql-custom-image-example -
Создайте некий Dockerfile, который имеет приводимое ниже содержимое (я предоставил в примерах для этой книги соответствующий файл
Dockerfleчтобы вы могли сравнить) набрав соответствующие команды в своей оболочке bash (Обратите внимание, что когда вы запускаете команду cat, вы получите некое приглашение > для набора всего остального):cat <<EOF>> Dockerfile > FROM microsoft/mssql-server-linux:latest > COPY ./SampleDB.bak /var/opt/mssql/data/SampleDB.bak > CMD ["/opt/mssql/bin/sqlservr"] > EOFКогда вы выполняете построение своего образа Docker при помощи соответствующей команды
docker build, Docker будет по умолчанию разыскивать некий файл с названием Dockerfile. Давайте расшифруем то что все эти команды сообщают в данном файле:FROM microsoft/mssql-server-linux:latest:Эта команда сообщает о необходимости вытаскивания самого последнего образа Docker SQL Server (который основывается на базовом образе Ubuntu) для подлежащего созданию вашего собственного нового образа. Возможно вы пожелаете чтобы все разработчики выполняли проверку и созидание в некой известной сборке, поэтому вы можете указать определённый CU, как это я уже показывал в своём предыдущем разделе. Отметим, что для SQL Server 2017, microsoft/mssql-server-linux:latest и Microsoft/mssql-server-linux:2017-latest являются одним и тем же, но мы производим два различных образа для кажого из названий.
COPY ./SampleDB.bak /var/opt/mssql/data/SampleDB.bak:Данная команда сообщает о необходимости копирования файла SampleDB.bak из текущего каталога в имеющийся образ контейнера Docker.
CMD [“/opt/mssql/bin/sqlservr”]:Эта команда вызывает исполнение нашей программы sqlservr из соответствующего каталога /opt/mssql/bin. Именно таким образом SQL Server запускает контейнер.
-
Теперь для построение нового образа Docker запустите следующую команду в своей оболочке bash:
sudo docker build . -t mssql-with-backup-exampleЗначение "
." является путём (PATH) для команды docker build, что в данном случае означает все файлы в нашем текущем каталоге. Параметр-tприменяется для установки тега данного образа с названием mssql-with-backup-example. Это название тега может применяться для ссылки когда вы запускаете некий контейнер из данного образа. В моём сервере Linux полученные результаты выглядят так:Sending build context to Docker daemon 3.263MB Step 1/3 : FROM microsoft/mssql-server-linux:latest latest: Pulling from microsoft/mssql-server-linux f6fa9a861b90: Already exists da7318603015: Already exists 6a8bd10c9278: Already exists d5a40291440f: Already exists bbdd8a83c0f1: Already exists 3a52205d40a6: Already exists 6192691706e8: Already exists 1a658a9035fb: Already exists 344203922c4b: Already exists 5975df51ff07: Already exists Digest: sha256:4f769a0b6603f9de2496e3ee455ce6b8b44db642714b50ed89b033e03e6e1e91 Status: Downloaded newer image for microsoft/mssql-server-linux:latest ---> 812f44c37fc8 Step 2/3 : COPY ./SampleDB.bak /var/opt/mssql/data/SampleDB.bak ---> a85e222cc553 Step 3/3 : CMD ["/opt/mssql/bin/sqlservr"] ---> Running in 91b10bc07736 Removing intermediate container 91b10bc07736 ---> 973ca0ed39a0 Successfully built 973ca0ed39a0 Successfully tagged mssql-with-backup-example:latest -
Выполнив следующую команду в нашей оболочке bash давайте подтвердим факт создания своего образа:
sudo docker imagesВаш образ должен появиться в результатах подобно следующему:
REPOSITORY TAG IMAGE ID CREATED SIZE mssql-with-backup-example latest 973ca0ed39a0 2 minutes ago 1.44GB microsoft/mssql-server-linux 2017-latest c90c3ab55158 2 weeks ago 1.44GB microsoft/mssql-server-linux latest 812f44c37fc8 2 weeks ago 1.44GB microsoft/mssql-server-linux 2017-CU8 229d30f7b467 2 months ago 1.43GB -
Теперь давайте запустим контейнер при помощи построенного нами нового образа выполнив следующую команду в оболочке bash (чтобы поместить ваш пароль sa скопируйте всё это в некий редактор, измените пароль на свой и затем вставьте всё обратно в свою оболочку). Обратите внимание: в этом примере я использую
sql3, так как у меня уже имеется некий запущенный контейнер с названиемsql2.sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Sql2017isfast' \ -p 1500:1433 --name sql3 \ -d mssql-with-backup-example -
Теперь посмотрите какие контейнеры запущены выполнив в своей оболочке bash такую команду:
sudo docker psВаши результаты должны выглядеть как- то так:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c4740bfdafa9 mssql-with-backup-example "/opt/mssql/bin/sqls…" 3 seconds ago Up 2 seconds 0.0.0.0:1500->1433/tcp sql3 38850dc61aa6 microsoft/mssql-server-linux:2017-latest "/opt/mssql/bin/sqls…" 6 hours ago Up 6 hours 0.0.0.0:1401->1433/tcp sql2Это хороший пример двух экземпляров SQL Server запущенных в одном и том же сервере хоста при помощи контейнеров (ибо сам SQL Server поверх Linux не поддерживает именованные экземпляры).
-
Теперь давайте восстановим свою базу данных в полученном нами образе контейнера выполнив в своей оболочке bash следующую команду (не забудьте заменить sa на свой пароль). Всё это достаточно длинно, поэтому я включил этот пример сценария с названием
dockerrunmyimage.sh.sudo docker exec -it sql3 /opt/mssql-tools/bin/sqlcmd \ -S localhost -U SA -P Sql2017isfast \ -Q 'RESTORE DATABASE ProductCatalog FROM DISK = "/var/opt/mssql/data/SampleDB.bak" WITH MOVE "ProductCatalog" TO "/var/opt/mssql/data/ProductCatalog.mdf", MOVE "ProductCatalog_log" TO "/var/opt/mssql/data/ProductCatalog.ldf"' -
Теперь я применяю sqlcmd в своём сервере хоста Linux для подключения к своему новому контейнеру и исполните некий запрос к своей базе данных, содержащейся в этом образе. Выполните в своей оболочке bash такую команду:
sqlcmd -Slocalhost,1500 -Usa -
Теперь из приглашения sqlcmd выполните следующий оператор T-SQL:
SELECT COUNT(*) FROM ProductCatalog.dbo.Product GOВы должны получить счётчик 14 строк.
Давайте остановим оба контейнера, и sql2, и sql3, исполнив в вашей оболочке bash следующую команду (и да, вы можете управлять более чем одним контейнером одновременно) и вернувшись обратно в свой домашний каталог:
sudo docker stop sql2 sql3
cd ~
В своём следующем разделе я покажу вам как строить некое приложение со множеством приложений, которое содержит SQL Server при помощи концепции с названием компоновка (compose).
Построение некого образа контейнера Docker с применением Dockerfile является великолепной концепцией для построения отдельного контейнера. Однако во многих ситуациях некое приложение будет применять множество контейнеров с зависимостями между ними, например, какими- то веб приложением и базой данных. По этой причине Docker предоставляет некую возможность с названием компоновка (compose), которая позволяет вам строить т запускать некий набор контейнеров включая ссылки на Dockerfiles и зависимости. Вы можете ознакомиться с полной справочной информацией относительно компоновки docker.
И вновь давайте воспользуемся примером из лабораторного практикума чтобы продемонстрировать вам некий образец (Обратите внимание: этот пример аналогичен примеру из документации Docker). Для данного примера у меня имеются два контейнера, которые мне нужны в моём приложении:
-
Некий контейнер SQL Server, который содержит базу данных с названием
ProductCatalog. В данном случае у меня имеется некий сценарий, который я бы хотел исполнит чтобы создать нужную мне базу данных, регистрации, пользователей, объекты и наполнение данными. -
Некий контейнер, который содержит какое- то приложение
ASP.NETна основе Core .NET, которое будет выполнять доступ к базе данныхProductCatalogподключаясь к соответствующему контейнеру SQL Server и выполняя в нём запросы. Вы обнаружите что применение обсуждаемого процесса компоновки в Docker позволит соответствующему приложению подключаться к некому логическому имени, которому поставлен в соответствие необходимый контейнер SQL Server.
Давайте проследуем процессом компоновки своего приложения при помощи Docker, а затем я дам пояснения некоторых подробностей относительно того как работают эти контейнеры:
-
Прежде всего нам требуется установить пакет
docker-composeпри помощи следующих команд из вашей оболочки bash:sudo curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose -
Измените свой каталог на тот, в котором расположены все файлы, выполнив из оболочки bash такую команду:
cd sqllinuxlabs/containers/mssql-aspcore-example -
отредактируйте свой файл
docker-compose.ymlи поместите в него свой пароль на место значения переменной окруженияSA_PASSWORD(я пользуюсь редактором нано {Прим. пер.: а я File Commander Брайана Хэйварда}). Файлdocker-compose.ymlявляется неким файлом YAML (YAML является сокращением для YAML Ain’t Markup Language - "дружественного" формата упорядочения данных), который применяется для определения образов контейнеров, служб и зависимостей. Далее я лам пояснения относительно того как работают эти файлы. Представляйте себе этот файл как необходимый пункт запуска для построения образов Docker и запуска контейнеров. -
Измените свой файл
./mssql-aspcore-example-db/db-init.shи поместите надлежащий пароль sa для необходимого параметра-P, который применяется для sqlcmd. -
Для компоновки своего приложения выполните приводимую ниже команду из надлежащей оболочки bash, которая построит соответствующие образы Docker и запустит требующиеся контейнеры:
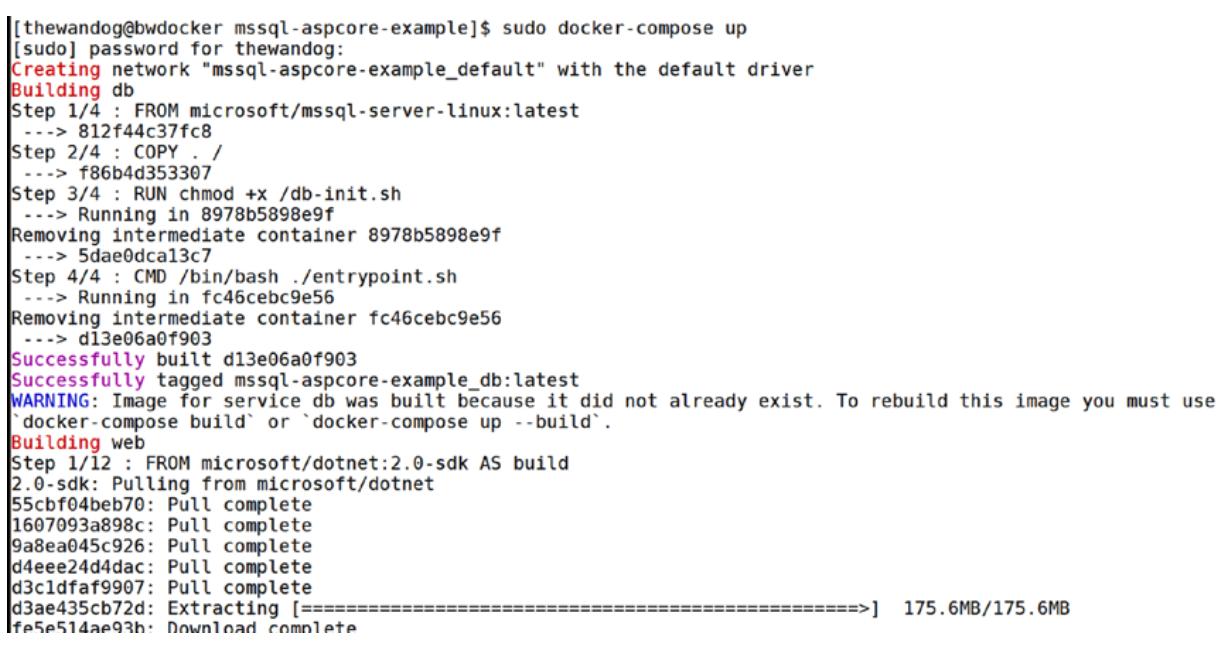
sudo docker-compose upЗа время этого исполнения будет прокручено много информации. Рисунок 11-2 показывает процесс исполнения компоновки docker в моём сеансе Linux.
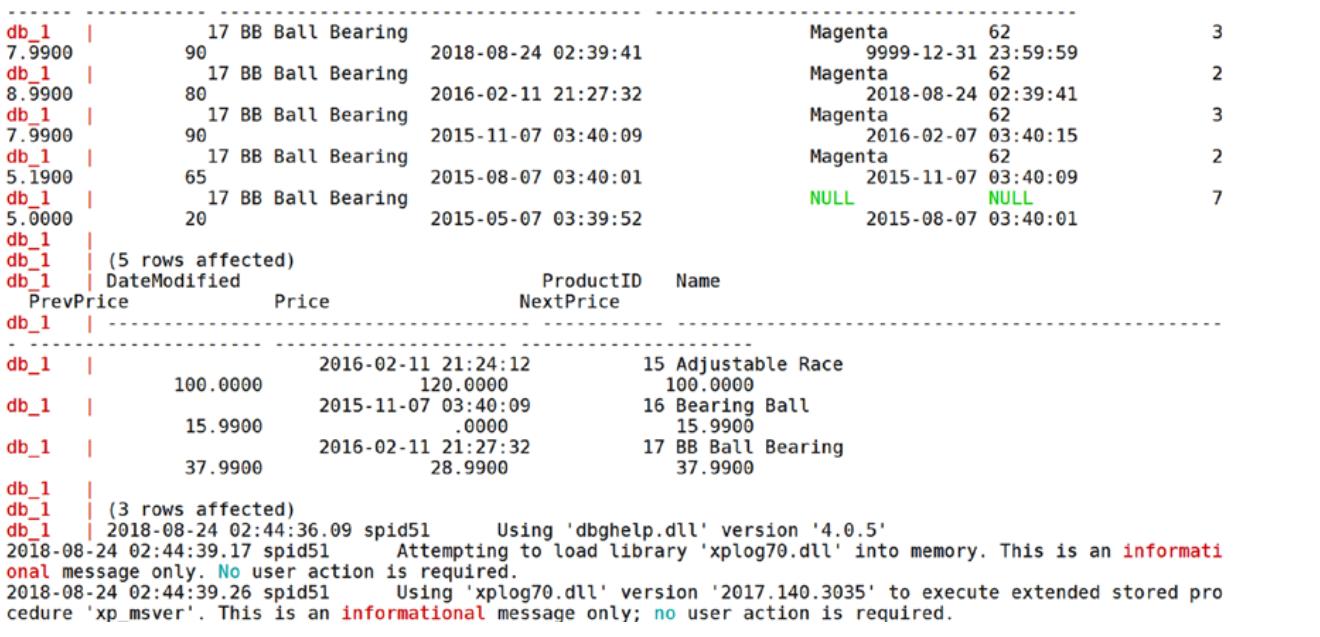
Эти контейнеры не запущены в фоновом режиме, поэтому когда данная компоновка завершится, ваш экран будет выглядеть подобно Рисунку 11-3.
-
Для запуска своего приложения мне необходимо открыть некий порт в своей виртуальной машине Azure. Моё приложение ASP.NET выполняет ожидание по порту 5000. Для открытия порта 5000 ознакомьтесь с соответствующими инструкциями.
-
Теперь в своём браузере перейдите на необходимый URL:
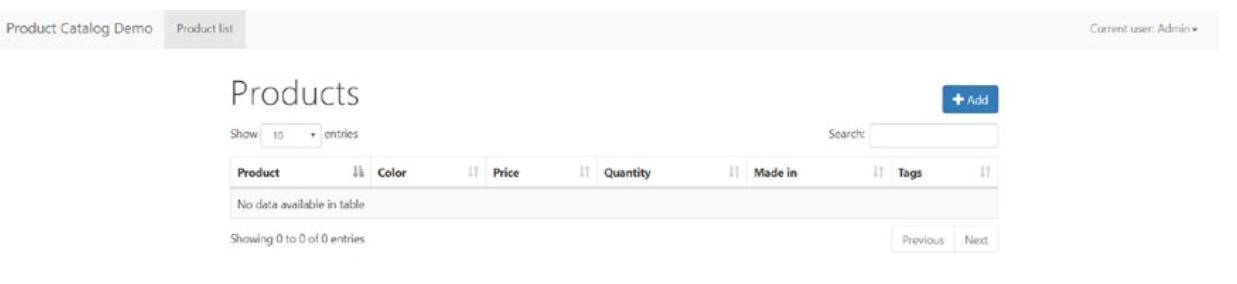
New-VM -Name VM01 -Generation 2http:<общедоступный IP адрес>:5000После построения вебстраницы вашего приложения вы должны обнаружить некую страницу, подобную Рисунку 11-4.
В верхней левой части данной страницы в своём экране кликните по Product Catalog Demo и ваш экран должен выглядеть подобно Рисунку 11-5.
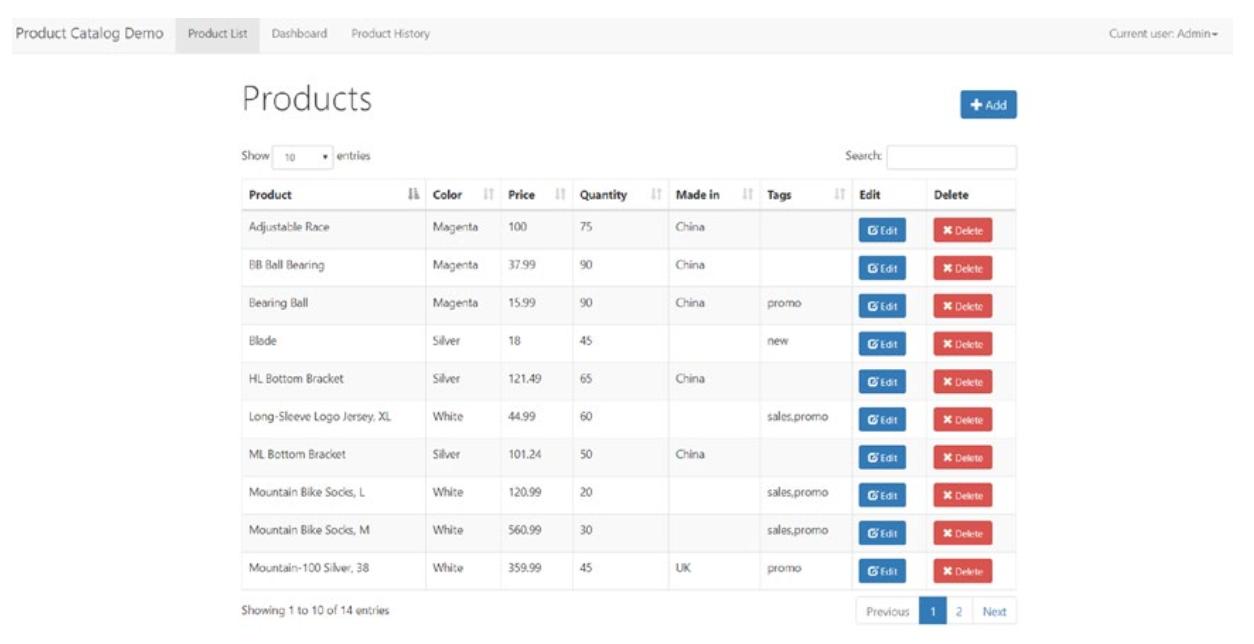
Давайте пошуруем за этими экранами относительно того как работают docker compose и эти контейнеры.
Из некого отдельного сеанса ssh (вы не можете использовать текущий сеанс ssh, так как эти контейнеры не запущены
в фоновом режиме. Если вы нажмёте ctrl+c вы прекратите работу этих
контейнеров), исполните следующую команду из оболочки bash чтобы посмотреть какие контейнеры запущены.
У вас также есть возможность принудить свои контейнеры перейти в фоновый режим при помощи
ctrl+z:
sudo docker ps --no-trunc
Вы должны обнаружить результаты, подобные таким:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
22b900fd8f3ea03ca7a9d923441291a507dc4b3eb07fb3189fea6b3c8a6e0935 mssql-aspcore-example_web "dotnet belgrade-product-catalog-demo.dll" 16 minutes ago Up 16 minutes 0.0.0.0:5000->5000/tcp mssql-aspcore-example_web_1
549d476ec793d96049a0193aeec78c6f32dc1661d79370c8855d7e50cc9797aa mssql-aspcore-example_db "/bin/sh -c '/bin/bash ./entrypoint.sh'" 16 minutes ago Up 16 minutes 0.0.0.0:1500->1433/tcp mssql-aspcore-example_db_1
Вы можете видеть, что имеются запущенными два контейнера. Для первого когтейнера соответствующей командой запуска
в этом контейнере была применена програма dotnet,
которая используется для исполнения некого ASP.NET приложения, в данном случае реализуемом посредством
belgrade-product-catalog-demo.dll (который встраивается при создании своего
образа Docker). Я не буду слишком углубляться в подробности всех механизмов приложения ASP.NET за исключением того
как работает необходимое подключение к SQL Server. Вы можете заглянуть в свой Dockerfile и обнаружить все имеющиеся
исходные файлы в каталоге qllinuxlabs/containers/mssql-aspcore-example/mssql-aspcore-example-app.
Во втором контейнере имеется следующая команда:
/bin/sh -c '/bin/bash ./entrypoint.sh'
Именно этот контейнер предназначен для образа SQL Server, поэтому давайте поясним как прмиеняется
entrypoint.sh для запуска SQL Server.
-
Перейдём в указанный ниже каталог, выполнив следующую команду:
cd ~/sqllinuxlabs/containers/mssql-aspcore-example/mssql-aspcore-example-db -
Для начала давайте просмотрим файл с названием Dockerfle выполнив команду
cat Dockerfle. Её резуьтаты должны выглядеть следующим образом:FROM microsoft/mssql-server-linux:latest COPY . / RUN chmod +x /db-init.sh CMD /bin/bash ./entrypoint.shИтак, мы знаем, что образ Docker из этого каталога будет построен из самого последнего образа SQL Server, причём все файлы из данного каталога будут скопированы в создаваемый контейнер, а затем будет изменён наш сценарий
db-init.shс тем, чтобы он мог выполниться. Наконец, той командой, которая запусти данный контейнер является наш сценарийentrypoint.sh. -
Мы знаем, что для запуска данного контейнера применяется
entrypoint.sh, поэтому давайте рассмотрим этот файл исполнивcat entrypoint.sh. Результаты должны выглядеть так (из вывода я удалил комментарии):/db-init.sh & /opt/mssql/bin/sqlservrЭта команда выполнит в фоновом режиме
db-init.sh, а затем запустит в приоритетном режиме (foreground)sqlservr. -
Теперь давайте рассмотрим
db-init.sh, запустивcat db-init.sh. Ваши результаты должны выглядеть так:#wait for the SQL Server to come up sleep 15s #run the setup script to create the DB and the schema in the DB /opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P Sql2017isfast -d master -i db-init.sqlИменно тут кроется лёгкая магия. Этот сценарий выполняет ожидание 15 секунд, чтобы позволить SQL Server выполнить запуск и затем исполняет необходимый сценарий
db-init.shприменяяsqlcmdв его контейнере. Я позволю посмотреть вамdb-init.shи далее, но в основном он сводится к созданию базы данных ProductCatalog, выработке регистраций и объектов, а также в наполнении некоторыми данными созданной базы данных. -
Теперь вы видете те механизмы, при помощи которых вы можете стартовать некий контейнер SQL Server и запускать какой- то сценарий T-SQL по созданию своей базы данных, объектов и данных.
Давайте взглянем на файл docker-compose.yml,
чтобы увидеть как компоновка docker узнаёт как выстраивать каждый контейнер.
-
Перейдите в первоначальный каталог гле расположен
docker-compose.ymlвыполнив в своей оболочке bash следующую команду:cd ~/sqllinuxlabs/containers/mssql-aspcore-example/ -
Теперь выведите содержимое своего файла
docker-compose.ymlисполнивcat docker-compose.yml. Ваши результаты выглядят так:version: "3" services: web: build: ./mssql-aspcore-example-app ports: - "5000:5000" depends_on: - db db: build: ./mssql-aspcore-example-db environment: SA_PASSWORD: "Sql2017isfast" ACCEPT_EULA: "Y" ports: - "1500:1433"
Наш тег services: позволяет вам определять конкретные контейнеры, которые
будут запускаться как часть вашего приложеия. Для каждой службы вы можете определить соответствующее местоположение
необходимого Dockerfile для построения её образа, значение порта для применения при запуске этого контейнера,
в том числе установку соответствия порта, а также зависит ли одна из служб от другой. В нашем случае служба
web зависит от службы
db. Это означает, что
служба db будет создана и запущена
прежде чем контейнер, требующийся для службы
web.
Вы также можете определять любые переменные среды необходимые вашим контейнерам, каковыми в нашем примере
является соответствующий аргумент EULA и пароль
sa для создаваемого контейнера SQl Server. А что касается контейнера
службы db, там устанавливается соответствие
порта 1500 порту SQL Server 1433.
Итак, чтобы просуммировать, когда на исполнение поднимается docker-compose,
docker вначале применяет файл docker-compose
docker-compose.yml для построения контейнера службы
db используя файл
Dockerfile из каталога ./mssql-aspcore-example-db.
Затем он запускает этот контейнер на основе полученного образа при помощи определённых переменных среды, причём
получаемая служба SQL Server доступна по порту хоста 1500.
Затем мы запускаем необходимый контейнер для своей службы web,
который создаёт требуемый образ Docker в каталоге ./mssql-aspcore-example-app
и запускает некий основанный на этом образе контейнер с использованием порта
5000
Одно важное окончательное соображение: Когда я впервые просматривал эти контейнеры, я не мого сообразить как моё
приложение ASP.NET узнаёт что требуется подключаться к порту 1500 для имеющегося
контейнера SQL Server. Необходимым ключом к разгадке выступает определение службы в файле
docker-compose.yml . Сама служба с названием
db по существу поставлена в соответствие
локальному хосту, 1500. Тем самым, наше приложение ASP/NET может воспользоваться
именем сервера db в соответствующей строке
для подключения к SQL Server в том контейнере, который ассоциируется со службой
db.
Я знаю, что это слегка сложно, но только потому, что я углубляюсь в подробности за сценой чтобы описать как работает скомпонованное из множества контейнеров приложение. Теперь давайте позабавимся. Перейдите к следующему разделу, чтобы увидеть, как я принимаю вызов SQL Mac!
В феврале 2018 я выступал на одном из своих самых любимых мероприятий, SQLBits в Лондоне. Одна из моих презентаций была посвящена SQL Server поверх Linux. Я использовал свой проверенный ноутбук HP Zbook Studio под управлением Windows 10 для проведения представлений и демонстраций. Кто- то из собравшейся аудитории поднял руку и сказад: "Боб, мне нравится что Microsoft приспосабливается под Linux, но я пользователь MacBook. Вы здесь применяете PC для этих демонстраций. Но я не вижу приверженности Microsoft сообществу MacBook."
Даже хотя я и не изучал этот вопрос, я был уверен в своём ответе. "Сейчас мы обладаем такими программным обеспечением и инструментами, с которыми вы имеете возможность запускать SQL Server и взаимодействовать с ним без виртуализации и без инструментов Windows в своём MacBook. И я полагаю, что вы сможете получать это установленным, а также поднятым и запущенным за пять минут. Я назвал это "Прими вызов SQL Mac." Один из присутствовавших сказал, что они готовы принять это пари (вы можете увидеть результаты этого вызова в его твите).
На самом деле я в действительности не знал, прав ли я на 100%, сказав это (в особенности относительно отсутствия виртуализации и части в пять минут), но я знал два момента чтобы сделать это смелое утверждение: (1) Я знал что наш образ контейнера docker был переносимым и легко будет работать на MacBook, так как я знал что Docker существует для MacOs; а также (2)наш инструментарий SQL Operations Studio является кроссплатформенным, поэтому он изначально работает на macOS.
Когда я вернулся назад в Техас, я сделал то, что я полагал никогда не сделаю, работая в Microsoft. Я спросил своего управляющего, Асада Хана, могу ли я приобрести MacBook. Он ответил, что принимая во внимание всю ту работу, которую я проделал в отношении Linux и контейнеров, это имеет смысл. Получив MacBook я решил принять вызов SQL Mac (ну, вы понимаете что такое положить на кон деньги за свои слова). И здесь я должен подтвердить что я был не прав. Я был не прав в том смысле, что мне потребовалось четыре минуты, а не пять, чтобы получить установленным такое программное обеспечение.
Давайте пройдёмся по этому эксперименту с тем, чтобы все кто читеат эту книгу и кто является пользователем MacBook смог попробовать это самостоятельно.
-
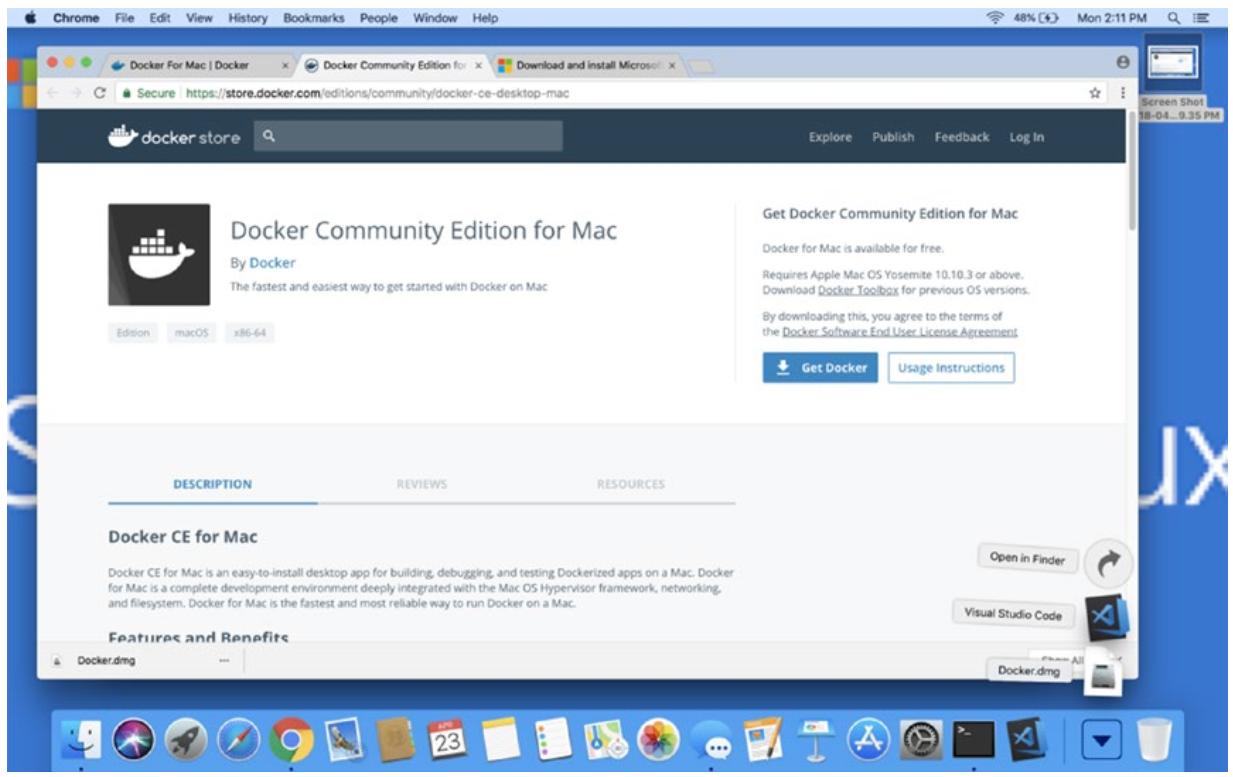
Первой вещью которую я сделал, это была установка и выгрузка Docker for Mac (Community Edition) в соответствии с описанием. (Я воспользовался каналом Stable). Рисунок 11-6 показывает этот опыт после выгрузки.
Замечание при всей прозрачности, присутствует некая виртуализация под macOS для Docker, но она намного лучше чем была прежде. Применяемый Docker для Mac требует virtualBox, но теперь macOS имеет встроенную инфраструктуру гипервизора с малым весом, поэтому более точно будет сказать, что Docker для Mac не требует отдельной тяжёлой среды виртуализации. Вы можете ознакомиться с подробностями среду Docker для Mac.
-
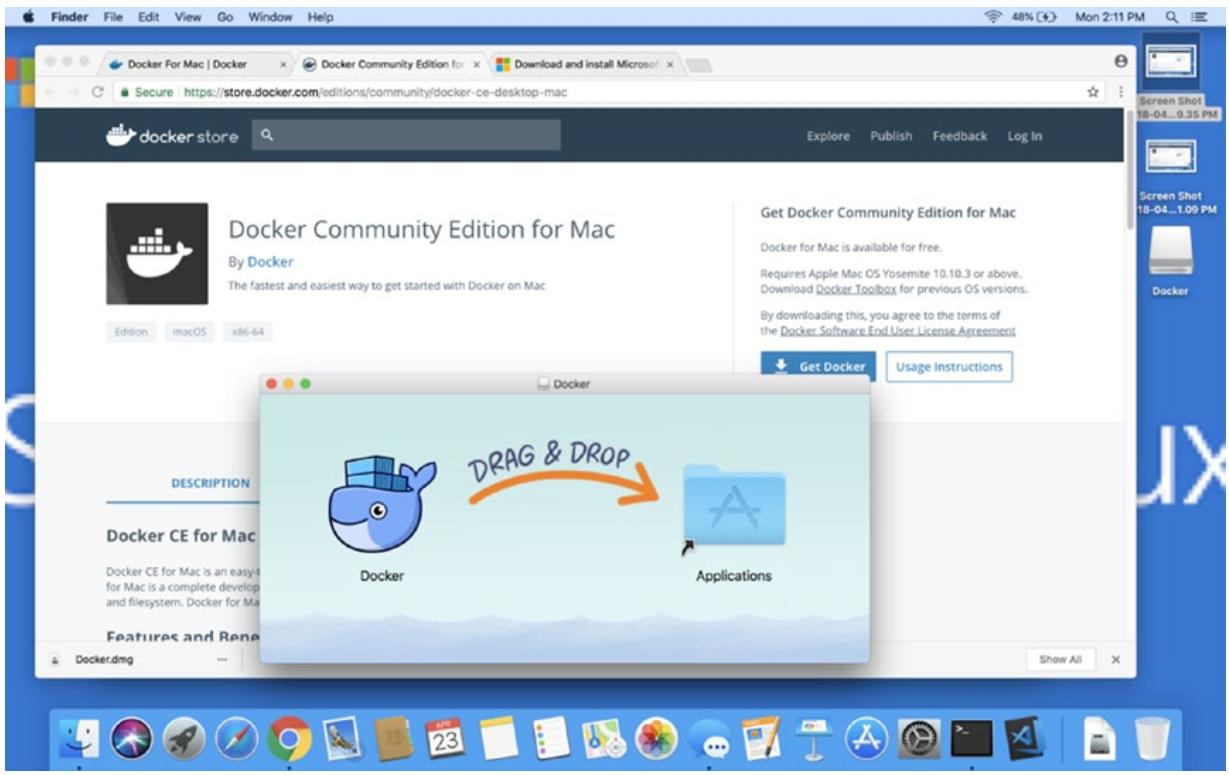
После выделения выгруженного Docker for Mac, всплывает новое окно для установки вами приложения Docker for Mac путём простого перетаскивания, как это показано на Рисунке 11-7.
-
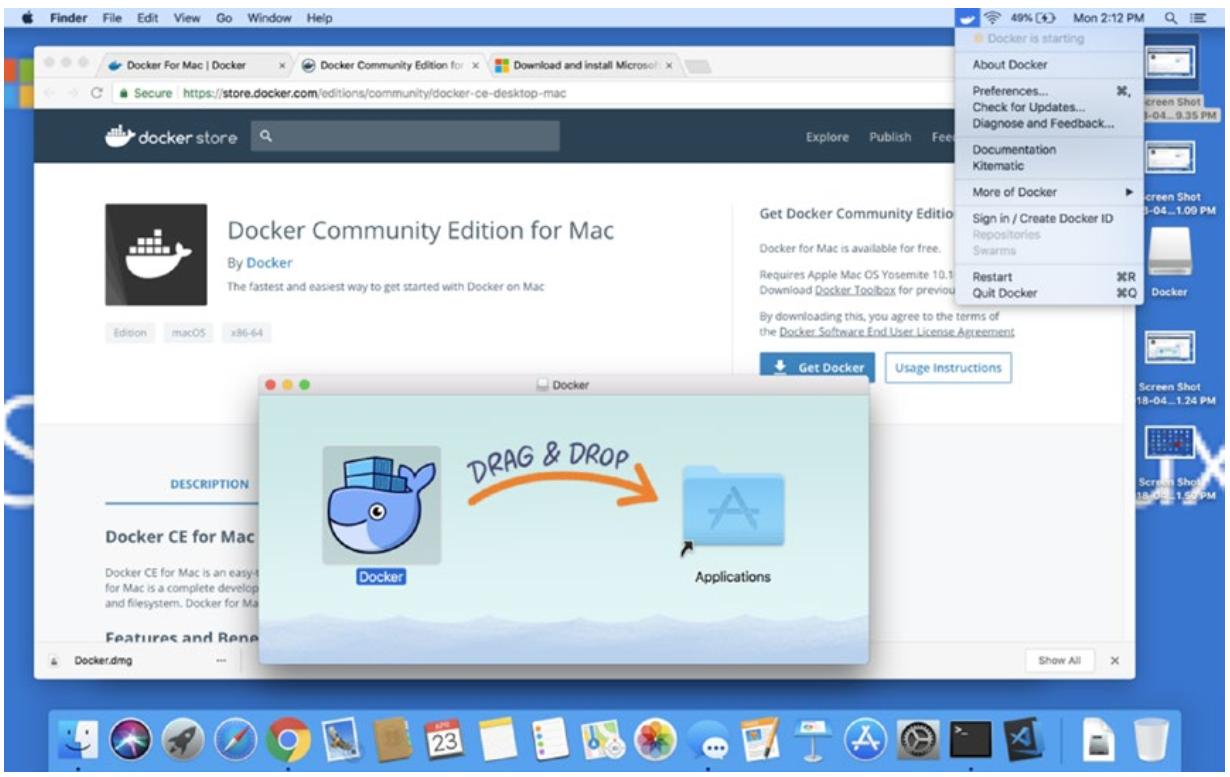
Теперь, когда Docker установлен в виде некого приложения, я запустил его из Панели запуска приложений в своём MacBook. Теперь в верхней части своего экрана я получил некую иконку для Docker и я могу наблюдать его запущенным, как это отражено на Рисунке 11-8.
-
Теперь я бы хотел многозадачности, поэтому пока запускался Docker, я выгрузил SQL Operations Studio for MacOS.
-
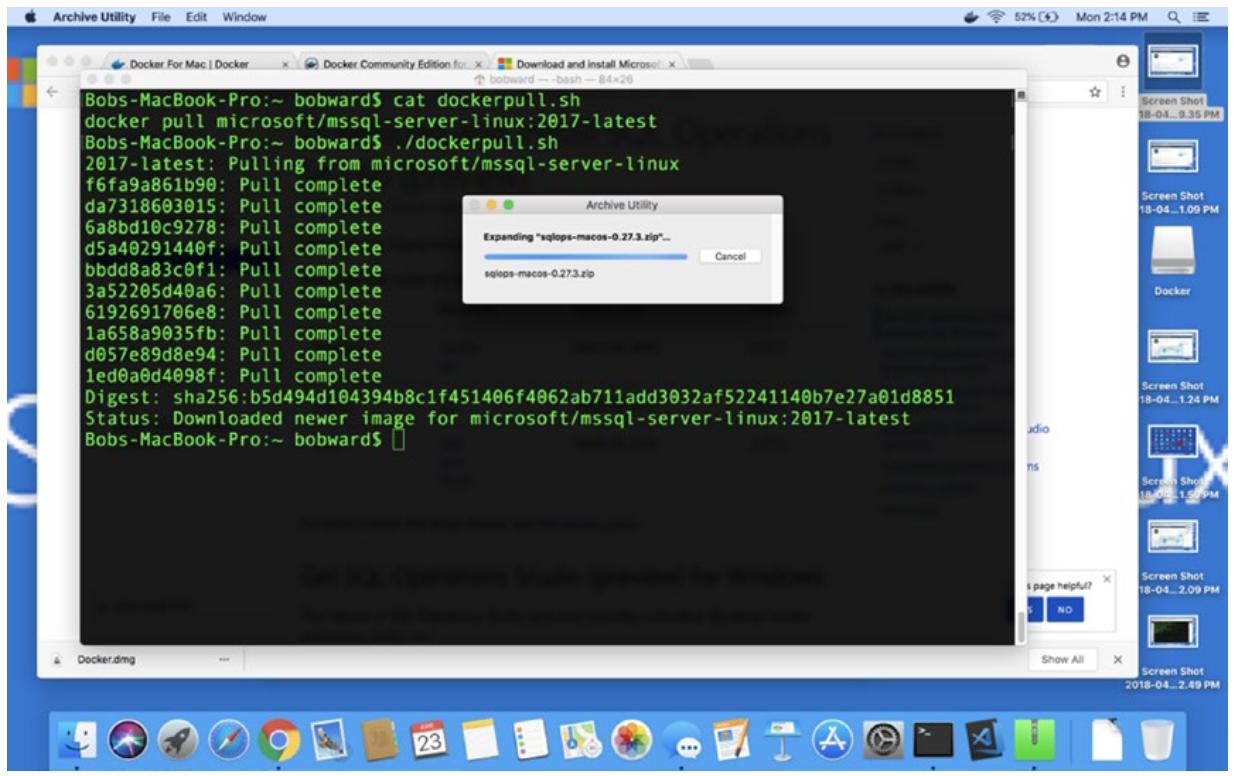
Пока продолжалась выгрузка, запустился Docker. Поэтому я вытащил необходимый образ SQL Server в своём Терминале macOS, который в действительности представляет оболочку bash. Я выполнил такую команду:
docker pull microsoft/mssql-server-linux:2017-latest -
Пока исполнялось это вытаскивание, я далее выделил свою выгруженную SQL Operations Studio. Это раскрытие выглядит как Рисунок 11-9.
-
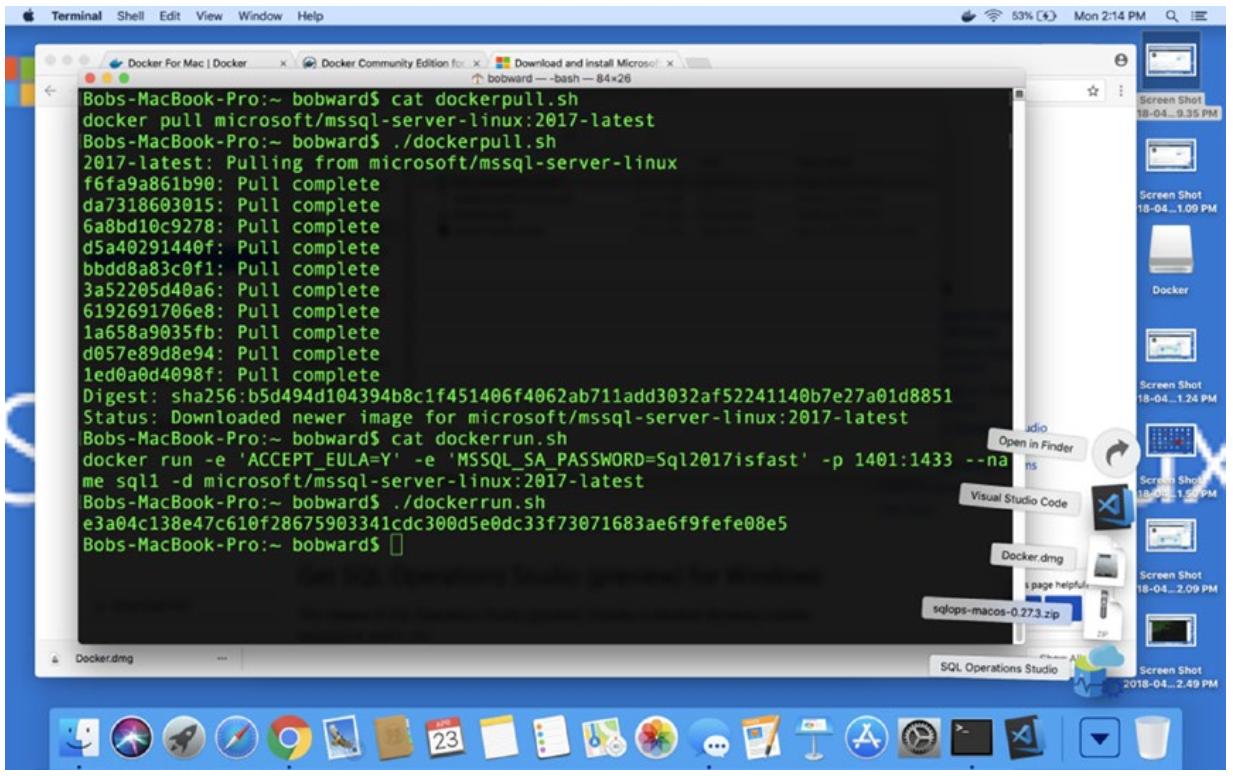
Пока выполнялось это выделение, docker выполнил для меня вытаскивание, поэтому я теперь могу запустить свой контейнер при помощи следующей команды из своего терминала macOS:
docker run -e 'ACCEPT_EULA=Y' -e 'MSSQL_SA_PASSWORD=Sql2017isfast' -p 1401:1433 --name sql1 -d microsoft/mssql-server-linux:2017-latest -
Выделение SQL Operations Studio завершено, поэтому я могу выбрать его для установки, как это видн на Рисунке 11-10.
-
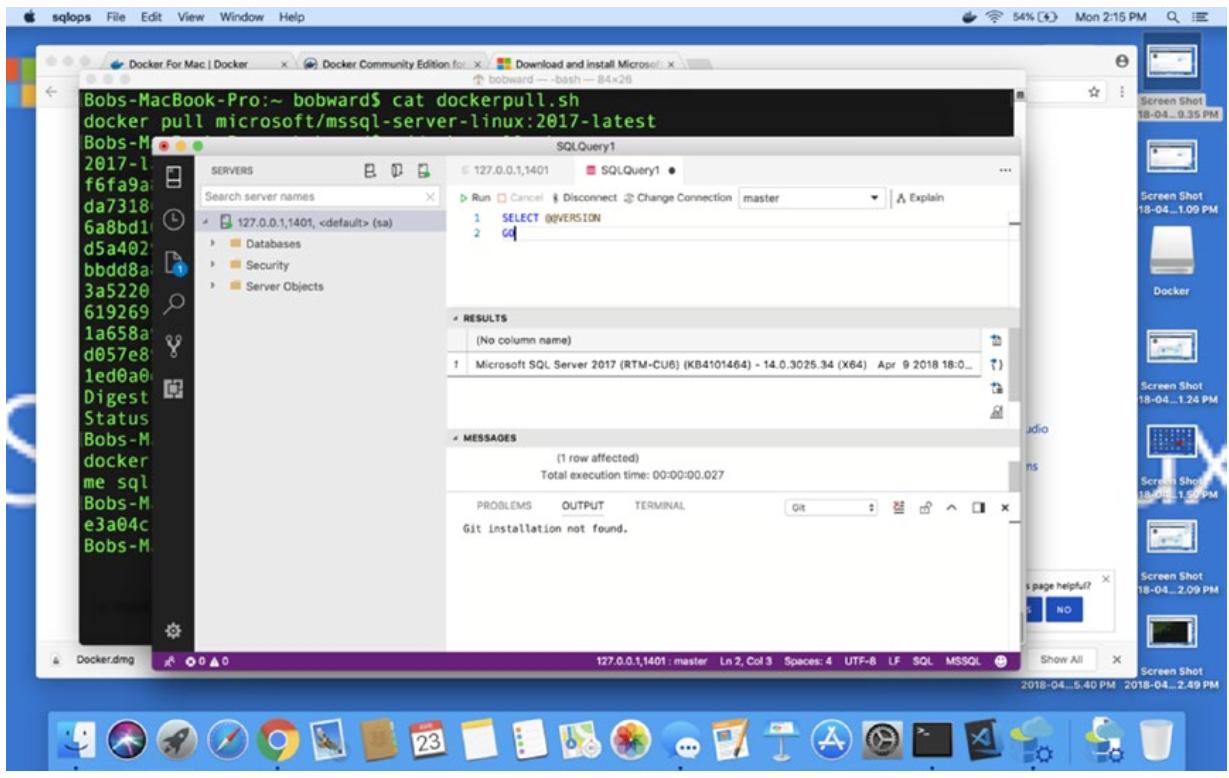
Теперь я могу запустить из Панели запуска SQL Operations Studio, подключиться к локальному хосту по порту
1401и выполнять запросы к своему контейнеру с SQL Server, как это показано на Рисунке 11-11.
И это всё. Если вы просто проследуете приведённым мною шагам безо всех моих комментариев и вас имеется разумное подключение Интернет, вы можете сделать всё это менее чем за пять минут. И вы после этого официально примите вызов SQL Mac. Давайте завершим данную главу рассмотрением уникального способа запуска контейнеров с SQL Server в промышленное применение при помощи среды с названием Kubernetes.
Kubernetes, как определяется на его вебсайте, является &qout;системой с открытым исходным кодом для авматизации развёртывания, масштабирования и управления контейнезированными приложениями&qout; - что также имеет название оркестрации контейнеров. В своей сердцевине, Kubernetes является некоторой системой для развёртывания и управления промышленным набором контейнеров. Одно дело запускать приложение со множеством контейнеров в вашем мервере Linux, но что если вы пожелаете развёртывать сотни контейнеров. Как вы это всё развернте и будете управлять неким эффективным образом? Более того, как вы можете настроить некую систему HADR (с высокой доступностью и восстановлением после сбоев) для своих контейнеров SQL Server? Всё это предоставляет Kubernetes.
Согласно Wikipedia, Kubernetes был основан инженерами в Google в 2015. Kubernetes означает по- гречески "управитель" или "капитан". Когда я впервые приступил к работе с Kubernetes, я вспомнил, что видел электронное письмо от своего коллеги Трэйвиса Райта с сокращением k8s для обозначения Kubernetes. Поэтому я проверил себя и убедился в достаточной степени что k8s означает сокращение для замены 8 букв между "k" и "s" в самом слове Kubernetes (подробнее...). Итак, я буду применять k8s на протяжении оставшейся части главы чтобы обозначать Kubernetes.
Одной из самых отличных стороно k8s является то, что он теперь исполняется на многих платформах: на машинах с голым железом, в виртуальных машинах, а также в облачных решениях. Например, вы можете установить в своём ноутбуке Minikube чтобы ознакомиться с основами k8s в действии с контейнерами Docker. Или же вы можете воспользоваться неким облачным решением навроде Openshift RedHat или AKS (Microsoft Azure Kubernetes Service).
Взгляните на полный набор известных решений для k8s. Для дальнейших ссылок вы также можете поместить себе в закладки основную страницу документации k8s. {Прим. пер.: а также наш перевод 2 издания Полного руководства Kubernetes Джиджи Сэйфана.}
Имеется множество сторон k8s, которые вы можете изучить для разработки приложений в контейнерах или для операций с системой k8s в целом. Для целей SQL Server c k8s, я полагаю вам важно ознакомится с такими терминами:
-
Кластер
Некий кластер k8s представляет собой развёртывание контейнеров по множеству узлов и подов, которые я определяю ниже.
-
Под
Некий под в k8s является группой из одного или более контейнеров, которые способны совместно использовать хранилище, сетевую среду и некое определение того как запускать контейнеры.
-
Узел
Я влюблён в описание узла из Главе 2,документации k8s. "Узел это рабочая машина в Kubernetes, ранее имевшая название minion. Некий узел может быть ВМ или физической машиной." На самом деле представляйте себе узлы как некий хост для набора из одного или более подов.
-
Набор реплик
Набор реплик определяет сколько экземпляров определённого пода следует запускать в любой момент времени и помогает определять высокую доступность подов. Наборы реплик важны для того чтобы позволять Kubernetes автоматически запускать новые поды в случае отказа какого- то пода.
-
Развёртывание
Некое развёртывание представляет собой какой- то декларативный метод определения подов и наборов реплик. Рекомендуется применять развёртывания для настройки подов и наборов реплик под высокую доступность. Именно этот метод мы и будем применять чтобы показать как задать и настроить HADR для SQL Server при помощи k8s.
-
Требование удерживаемого тома
K8s поддерживает основную концепцию хранения, которая может применяться подами через некий PersistentVolume (удерживаемый, постоянный том). Такое хранилище может совместно использоваться подами (что очень хорошо укладывается в решение совместного хранилища HADR для SQL Server). Требование (claim) удерживаемого тома является запросом от некого пользователя на какое- то хранилище PersistentVolume.
-
Служба
Некая служба являет собой какой- то логический набор подов и может быть абстракцией. Одним из типов службы является служба балансировки нагрузки одновременной обработки. Вы можете определить некий IP адрес для подобной службы балансировки нагрузки. Всякий под имеет некий уникальный IP адресЮ но именно балансировщик нагрузки является известным IP адресом. Представляйте себе это как имеющееся понятие виртуального IP адреса, применяемого Экземпляром отказоустойчивого кластера (Failover Cluster Instance) или как адрес ожидания (listener) для Групп доступности (AG, Availability Groups). Это будет снабжать SQL Server неким абстрактным IP адресом даже при выполнении k8s "восстановления после отказа".
Вы можете ознакомится с более полным описанием компонентов и архитектуры k8s {Прим. пер.: также напоминаем о своём переводе 2 издания Полного руководства Kubernetes Джиджи Сэйфана.} Вооружившись знанием об этих понятиях давайте рассмотрим всё это в действии посредством развёртывания контейнера SQL Server в k8x с помощью AKS.
Как я уже упоминал в изложении основ k8s, вы возможно обратили внимание на то что k8s предоставляет некую платформу, которая поддерживает HADR для контейнеров. SQL Server может воспользоваться преимуществами таких встроенных возможностей HADR, снабжая вас структурой вашего развёртывания и вашей службы правильным образом. Я опишу как HADR работает в k8s и затем поговорю об очень хорошем руководстве, которое вы можете применять при процессе развёртывания SQL Server при помощи k8s.
Как HADR работает с k8s
Я уже представил основные термины узлов, подов и служб. Позвольте мне некую визуализацию чтобы показать как HADR работает с подами, данной концепцией узлов и служб. Настройка SQL Server с подами и заявками удерживаемых томов является неким решением HADR с совместным хранилищем и предоставляет функциональность, аналогичную Экземпляру отказоустойчивого кластера Always On {Прим. пер.: например, ознакомьтесь с нашим переводом Главы 6. Группы доступности AlwaysOn сервера SQL из книги Полz Бертуччи "SQL Server 2016 с высокой доступностью. Выпущенный на волю."}.
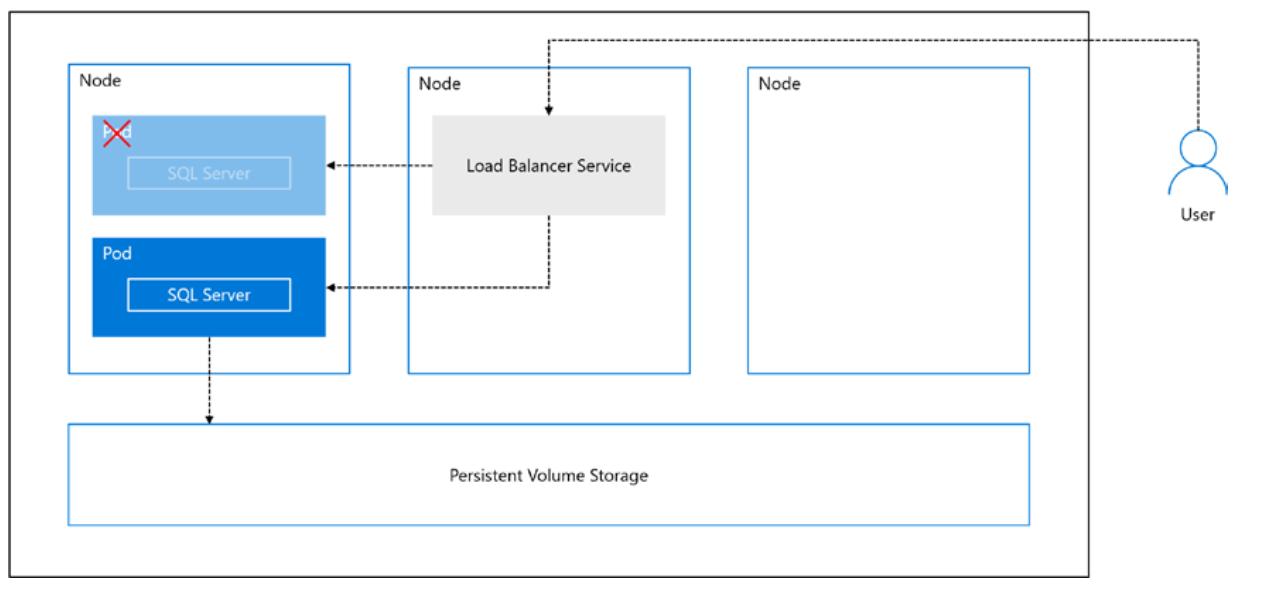
Прежде всего, если k8s определяет поды с имеющимися проблемами или уже отказавшие, k8s автоматически создаст некий новый под в том же самом узле в котором исполняется данный под, что запустит все контейнеры этого пода. Более того, есди данный под применяет некое Требование удерживаемого тома, соответствующий контейнер в созданном новом поде будет способен осуществить доступ к тем же самым данным, хранимым в таком удерживаемом томе. Кроме того, если вы настроите некую службу балансировки нагрузки, ассоциированную с этим подом (который имеет некий уникальный IP адрес), пользователи смогут подключаться к этой службе балансировки нагрузки, которая имеет некий фиксированный IP адрес чтобы избегать необходимости знать подробности IP . ресации конкретного пода Рисунок 11-12 отображает основное понятие отказа пода.
K8s также поддерживает восстановление после сбоя если отказывает по какой- либо причине некий узел. Будет запущен некий новый под в каом- то новом узле и имеющаяся служба балансировки нагрузки будет перенаправлена в этот новый под в таком новом узле. Так как k8s поддерживает отказы узлов, всякий промышленный кластер k8s для SQL Server должен иметь по крайней мере для поддержки восстановления после отказа три узла, причём не тлько для самого SQL Server, но также и для службы балансировки нагрузки. Рисунок 11-13 отображает такой сценарий.
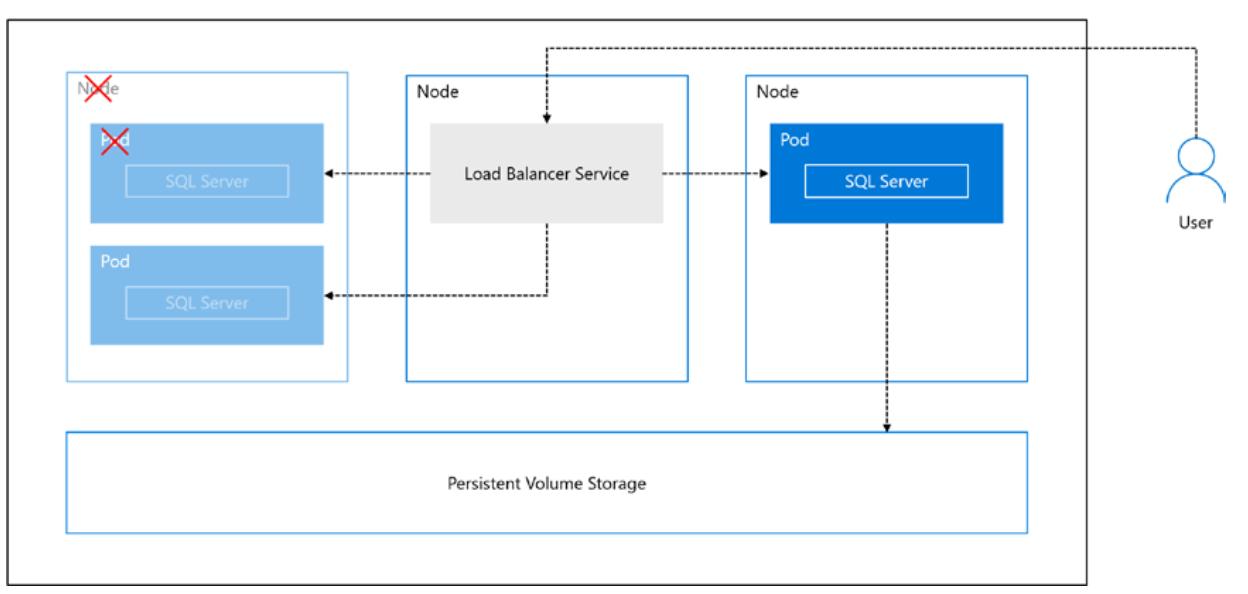
Один замечательный момент k8s и восстановления после отказа не отражён в этих визуализациях в том случае когда SQL Server падает или останавливается в неком контейнере. В такой ситуации k8s запустит некий новый контейнер в том же самом поде на том же самом узде.
|
| Замечание |
|---|---|
|
Когда k8s должен запускать соответствующий контейнер SQL Server в неком новом поде или в каком- то новом узле, этот контейнер может потребовать большей продолжительности для запуска, так как необходимый образ SQL Server может ботсутствовать в кэше в этом новом узле и ему потребуется вытаскивать его с Docker Hub. После того как этот образ вытащен, он будет кэширован для данного узла и последующие запуски будут происходить быстрее. |
Давайте рассмотрим k8s, SQL Server и встроенные HADR в действии проглядывая некое рководство, поддерживаемое в документации Microsoft.
Использование SQL Server со службой Kubernetes Azure
Одна из моих коллег, чрезвычайно талантливая Микаэла Бленди, потратила своё время на построение очень замечательного руководства относительно того как настраивать SQL Server для k6s с применением AKS. Я позволю вам воспользоваться вашей подпиской Azure чтобы пройтись по этому руководству. Я уже ознакомился с этим руководством, поэтому позвольте мне поделиться рядом наблюдений:
|
| Совет |
|---|---|
|
Если вы желаете пройтись по этому руководству без применения CLI Azure в своей локальной машине, рассмотрите возможность применения нового CloudShell Azure через его портал. Вы получите некую оболочку bash (или какой- то PowerShell) с тем чтобы такие инструменты как sqlcmd или редактор nano были установлены по умолчанию. Это невероятно круто! Вы можете дополнительно ознакомится с Azure CloudShell. |
-
Предварительные требования в данном руководстве указывают на эту страницу для создания вначале некого кластера AKS. Я просто использовал этот портал для создания службы Kubernetes и применил большинство значений по умолчанию для создания своего кластера. Однако мне пришлось подключиться к созданному мной вначале кластеру AKS, выполнив приводимые далее шаги в: этой части документации. Моя служба Kubernetes (а короче кластер k8s) именуется
bwsqlk8sв группе ресурсовbwk8s. Поэтому для подключения к своей службе AKS я воспользовался такой командой CloudShell Azure:az aks get-credentials --resource-group bwk8s --name bwsqlk8sЗатем для проверки своих узлов из своего Cloud Shell Azure я выполнил такую команду:
kubectl get nodesЯ построил кластер из трйх узлов, поэтому мои результаты выглядели так:
NAME STATUS ROLES AGE VERSION aks-agentpool-38442334-0 Ready agent 21m v1.11.2 aks-agentpool-38442334-1 Ready agent 21m v1.11.2 aks-agentpool-38442334-2 Ready agent 21m v1.11.2По завершению я могу двинуться дальше в соответствии с рассматриваемым руководством.
-
Чтобы убедиться в том что ваш под с необходимым контейнером SQL Server исполняется, воспользуйтесь такой командой:
kubectl get podsДля моего пода понадобилось около пяти минут чтобы отобразить состояние Running. Вы должны обнаружить что- то похожее на
NAME READY STATUS RESTARTS AGE mssql-deployment-3813464711-h312s 1/1 Running 0 17m -
sqlcmd (Да!) встроен в имеющийся CloudShell Azure, поэтому у меня была возможность подключения к своему новом развёртыванию SQL Server при помощи внешнего IP адреса установленной службы балансировки нагрузки.
-
Если вы пройдётесь по упражнениям удаления некого пода чтобы увидеть как работает HADR, это может потребовать до четырёх минут или около того чтобы запустился ваш новый под. Именно это, к сожалению, одна из оплошностей применения SQL Server с k8s. Четыре минут может быть слишком долго для простоя SQL Server. Чтобы сделать это более быстрым и лучшим мы работаем над привнесением прочих инноваций в функциональность SQL Server и k8s.
-
Чтобы увидеть в каком узле запущен ваш под воспользуйтесь такой командой kubectl:
kubectl get pods -o wide -
K8s даже поддерживает перезапуск вашего контейнера с исполняемым SQL Server в случае его падения или если SQL Server выполняет отсанов. Попробуйте сами. Подключитесь к своему контейнеру SQL Server через имеющийся внешний адрес своего балансировщика нагрузки и выполните команду T-SQL
SHUTDOWN. Если вы затем выполнитеkubectl get pods, вы вскорости обнаружите значениеSTATUSError и CrashLoopBackOff, но затем внутри того же самого пода оно вернётся обратно в Running. -
Вот один более продвинутый тест. Попробуйте осушить (draining) тот узел, где запущен ваш под с контейнером SQL Server. Осушение узла является неким способом имитации отказа узла. Команда
kubectl get pods -o wideпоказывает установленное для исполняемого пода название узла. Воспользовавшись этим именем выполните такую команду:kubectl drain <node name> --ignore-daemonsetsТеперь примените Команда
kubectl get pods -o wideчтобы посмотреть все контейнеры SQL Server, стартовавшие с новым подом в новом узле. Чтобы разрешить этому узлу применения вами осушения снова, выполните такую команду:kubectl uncordon <node name>
Вы можете видеть мощность встроенных HADR в k8s. Не требуется никакое программное обеспечение экземпляра отказоустойчивого кластера, да и SQL Server, честно говоря, даже не знает что работает в такой среде HADR. Как и в любой промышленной среде SQL Server, всегда включайте в решение надёжную стратегию резервного копирования.
Я должен признать, что это была одна из наиболее забавных глав для написания, ибо я считаю, что контейнеры и k8s являются впечатляющими новыми технологиями, которые становятся всё более и более популярными для размещения приложений и систем баз данных подобных SQL Server. В этой главе я сделал для вас введение в основы контейнеров, показал вам как развёртывать и применять контейнеры с SQL Server и даже вызовы со стороны пользователей MacBook для применения SQL Server "без Windows". Затем я завершил данную главу неким взглядом на тот новый способ размещения SQL Server и контейнеров под названием Kubernetes (k8s).
И данной главой я завершаю всю книгу, одну из самых приятных и при этом самых трудных вещей, которую я предпринимал за свою 25- летнюю карьеру в Microsoft. Я взял вас с собой в приключение начиная с истории, стоящей за SQL Server поверх Linux и процесса его развёртывания и подробностей. Затем я показал вам как строить ваши собственные базу данных и приложение. Затем я подробно описал все впечатляющие инструменты и встроенные свойства SQL Server, предоставляемые под все ваши потребности. После этого вы получили возможность рассмотреть насколько на самом деле надёжен SQL Server рассмотрев имеющиеся возможности производительности, безопасности и HADR. Далее я снабдил вас инсайдерской информацией относительно мощных возможностей управления и мониторинга для SQL Server поверх Linux. В Главе 10 я показал вам технологии миграции, включая сопоставление SQL Server с PostgreSQL. И затем вы только что завершили чтение данной главы по технологиям контейнеров , привносящих новый набор сценариев в развёртывание и исполнение SQL Server. Я надеюсь, что вы получили удовольствие от прочтения данной книги и будете иметь возможность применять ей в качестве справочных материалов в будущем для своего путешествия с SQL Server поверх Linux и контейнеров.