Глава 6. Группы доступности AlwaysOn сервера SQL
Содержание
- Глава 6. Группы доступности AlwaysOn сервера SQL
- Варианты применения AlwaysOn и групп доступности
- Построение конфигурации AlwaysOn со множеством узлов
- Проверка экземпляров сервера SQL
- Установка отказоустойчивой кластеризации
- Подготовка базы данных
- Включение HA AlwaysOn
- Резервное копирование базы данных
- Создание группы доступности
- Выбор баз данных для группы доступности
- Идентификация первичной и вторичной реплик
- Синхронизация данных
- Установка перехватчика
- Соединение с помощью перехватчика
- Отработка отказа на вторичных
- Панель управления и мониторинг
- Сценарий 3: Управление портфелем инвестиций с помощью AlwaysOn и групп доступности
- Выводы
Microsoft продолжает перемещать планку высокой доступности и производительности всё выше и выше
Обширные опции Высокой доступности, такие как группы доступности AlwaysOn и экземпляры кластера отказоустойчивости AlwaysOn (FCI, failover cluster instances) напару с разнообразием прочих улучшений семейства Windows Sever снабжают практически всех неоторой возможностью достижения мифических пяти девяток (то есть, 99.999% времени работоспособности). Micrsoft вложился в этот подход для большинства опций HA сервера SQL следующего поколения. Однако вы можете заметить, что некоторые из концепций и основных подходов в группах доступности AlawysOn слегка напоминают кластер сервера SQL и зеркалирование базы данных - и это потому, что так оно и есть! Оба этих свойства мостят некий путь к тому, что мы называем группами доступности AlwaysOn. Также важно запомнить, что эти и прочие опции Высокой доступности строятся поверх Отказоустойчивого кластера Windows Server (WSFC, Windows Server Failover Clustering).
{Прим. пер.: Обращаем ваше внимание на тот факт, что SQL Server 2017 привнёс собой новые методики организации HADR при помощи контейнеров и Kubernetes, подробнее в нашем переводе Главы 11. SQL Server и контейнеры из вышедшей в октябре 2018 в издательстве Apress книги Боба Вордса "Профессиональный SQL Server поверх Linux"}
Типичные варианты применения групп доступности AlwaysOn включают в себя:
-
Вам требуется высокая доступность около пяти девяток (доступность 99.999%). Это означает, что ваш уровень базы данных должен быть супернадёжным к отказам и почти не иметь потери данных в случае отказа.
-
Для восстановления при чрезвычайных ситуациях (DR, disaster recovery) вам необходимо реплицировать данные на другую площадку (возможно, в другой части страны или планеты), но вы можете терпеть небольшие потери данных (и задержки данных).
-
У вас имеется потребность производительности в разгрузке некоторых рабочих функций, таких как резервные копирования баз данных подальше от первичной базы данных. Такие резервные копии должны быть полностью точными и иметь самую высокую целостность для целей восстановления.
-
У вас имеется потребность производительности и доступности в разгрузке обработки/ доступа только по чтению вне пределов вашей первичной базы данных транзакций и вы можете выносить какие- то небольшие задержки. Даже когда ваша первичная база данных отключена, вы всё ещё можете выполнять доступ для своих приложений.
Все эти случаи применения могут быть разрешены свойствами групп доступности AlwaysOn, причёмэто проще сделать, чем вы полагаете. К концу данной главы вы увидите, что данных подход, соответствует сценариям ваших приложений Высокой доступности и оправдывает полную стоимость и обстоятельствам вашего выбора данного варианта когда ваши потребности требуют данного подхода.
Как уже упоминалось в этой книге, WSFC рассматривается как существенная часть имеющегося ядра компонентов основы HA. Однако, всё ещё возможно построить некую системы с Высокой доступностью без него (например, некая система, которая применяет ряд избыточных аппаратных средств и зеркалирование или RAID для своих дисковых подсистем). Однако Microsoft сделал WSFC краеугольным камнем своих возможностей построения кластера и именно WSFC применяется приложениями со включённым кластером (или осведомлённых о кластере). Самым первым примером технологии с включённым кластером является сам Microsoft сервер SQL 2016 (и большая часть его компонентов). Глава 4, Построение отказоустойчивого кластера описывает все существенные элементы WSFC, а Глава 5, Построение кластера сервера SQL описывает самые первые возможности сервера SQL, доставляемые применением отказоустойчивого кластера: построение кластера сервера SQL. Данная глава обсуждает другие возможности сервера SQL, доставляемые применением отказоустойчивого кластера: группы доступности AlwaysOn.
Быть "всегда включённым" достаточно сильное утверждение и обязательство. Теперь по болшей чсасти это достижимо для инфраструктуры, экземпляра, базы данной и уровня связности клиента Высокой доступности. Строящиеся на основе WSFC конфигурациии сервера SQL AlwaysOn усиливают WSFC для предоставленияя впечатляющего решения Высокой доступности, которое может быть построено с применением общедоступного обороудования и/ или основных конфигураций IaaS.
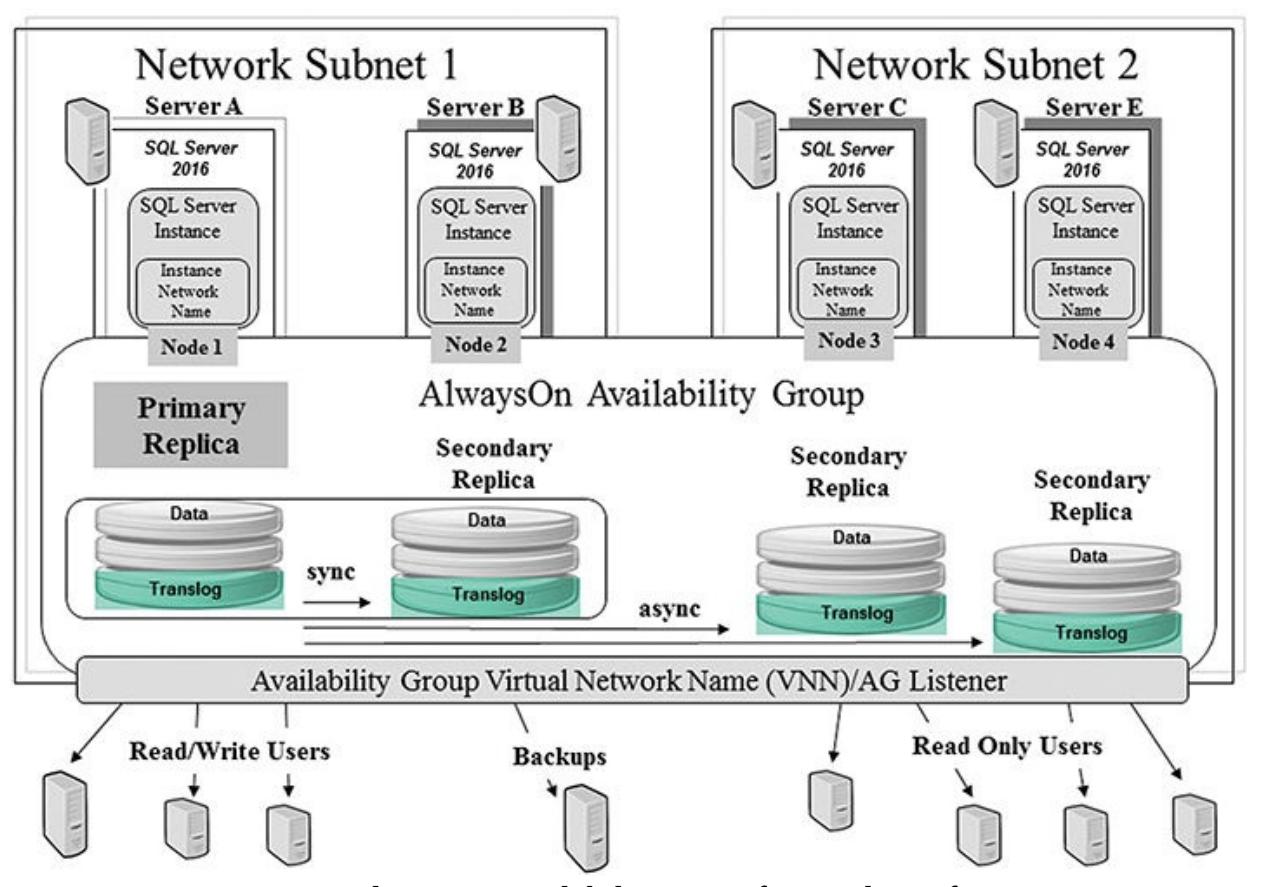
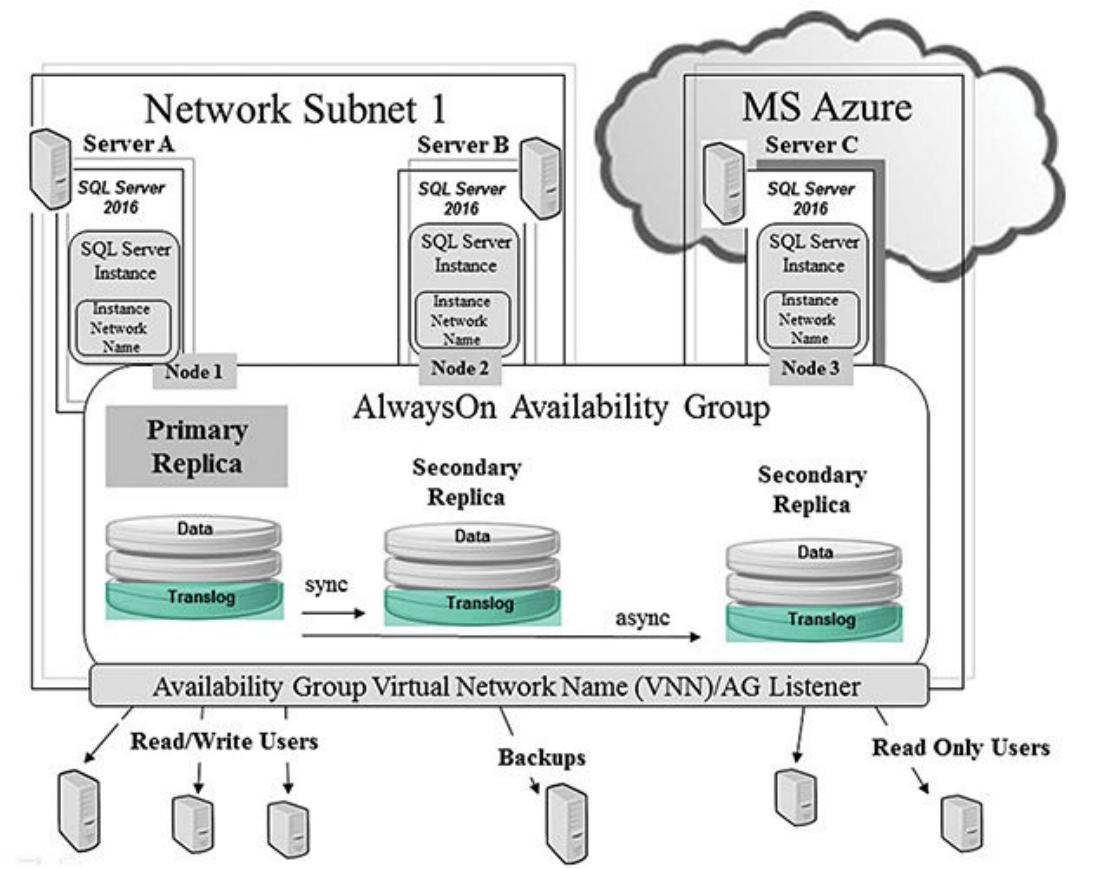
Рисунок 6.1 отображает достаточно базовое окружение с четырьмя узлами (то есть с четырьмя серверами) распределёнными в двух подсетях. Каждая из подсетей представляет некое изолированное множество мощности обработки (стоек) внутри некторого крупного центра обработки данных или различные подсети внутри некоторого предоставляемого отпечатка IaaS. Каждый сервер настроен с помощью WFSC и имеет некий экземпляр сервера SQL, установленный в нём для применения с данной конфигурацией группы доступности AlwaysOn.
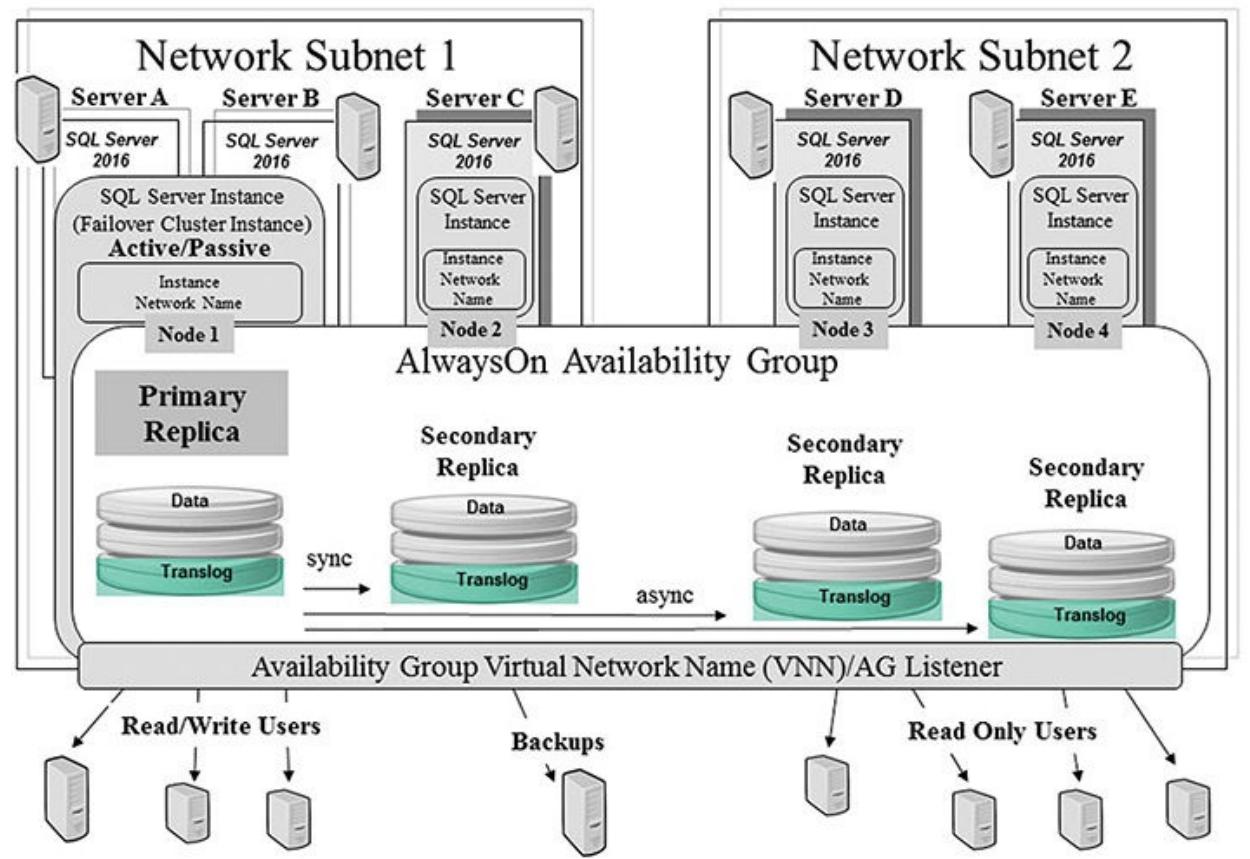
Вскорости я объясню все прочие возможности настройки групп доступности AlwaysOn. Однако, чтобы выделить
имеющуюся способность к взаимодействию со всеми базовыми строительными блоками, я бы хотел привлечь ваше
внимание к Рисунку 6.2, который отображает и
некий экземпляр Высокой доступности для Node 1 и какую- то
настройку группы доступности AlwaysOn. Этот первый набор двух серверов (A
и B) формирует некий отказоустойчивый узл экземпляра кластера с
полной надёжностью сервеа SQL уровня экземпляра. Такой высоко надёжный узел также применяется в общей
конфигурации группы доступности для предоставления самого первичного (самого приложения базы данных, которое
применяет данное приложение) наивысшего уровня надёжности из возможных, а также для предоставления
дополнительного уровня надёжности для одной или более вторичных реплик. Вам не придётся предоставлять
доступность самого первичного уровня экземпляра SQL, однако данный пример показывает, что вы можете
выполнить более чем всего лишь простую настройку AlwaysOn. Данный экземпляр кластера SQL совместно
использует эту базу данных как часть собственной настройка кластера для данного экземпляра. Сервер
A и сервер B формируют
данный кластер SQL и настроены как некий кластер активный/ пассивный. Весь данный кластер SQL является
Node 1 в общей настройке группы доступности.
Запомните, что группы доступности сосредоточены на отказоустойчивости и доступности уровня базы данных, применяя некий подход избыточности данных. Опять же, произрастая из практики зеркалирования имеющейся базы данных (и лежащих в основе технологий), некая транзакционно согласованная вторичная реплика сделана для того чтобы применяться как для доступа только по чтению (активно для применения на протяжении всего времени), так и для того, чтобы применяться для восстановления в случае если по какой- либо причине откажет её первичная база данных (первичная реплика). Взглянув вновь на Рисунок 6.1, вы можете отметить, что некая группа доступности AlwaysOn применяется как для Высокой доступности, так и для распределения нагрузки по чтению прочь от имеющегося первичного экземпляра сервера SQL на его вторую реплику. Вы можете иметь вплоть до восьми вторичных реплик в некоторой группе доступности, причём самая первая вторичная реплика применяется для автоматического восстановления посл отказа (с использованием установленного режима синхронной фиксации), а все прочие реплики доступны для распределения нагрузки и применения в качестве ручного восстановления после оказа. Помните, что это является избыточным хранением данных и вы можете быстро сжечь всё имеющееся пространство хранения. Находясь в режиме синхронной фиксации, вторичная реплика может также применяться для создания резервных копий базы данных, так как она полностью согласованна со своей первичной репликой. Замечательно!
Режимы
Как и в случае с зеркалированием базы данных, для перемещения данных между имеющимися журналами транзакций от основной первичной реплики к её вторичной реплике имеются два первичных режима репликации: синхронный режим и асинхронный режим.
Синхронный режим означает, что все записи данных любых изменений базы данных должны выполняться не только в самой первичной реплике, но также и в её вторичной реплика, как некоторая часть одной фиксируемой логической транзакции.
Рисунок 6.1 отображает некий окружающий блок
вокруг этих первичной и вторичной баз данных, которые применяются для такого синхронного режима репликации.
Это может быть затратным с точки зрения дублирования таких записей, поэтому имеющееся соединение между
этими первичной и вторичной базами должно быть быстрым и близко расположенным (внутри одной и той же подсети).
Однако, по той же самой причине, данные первичная и вторичная реплики находятся всё время в состоянии некоторой
транзакционной согласованности, что делает восстановление в случае отказа почти мгновенным. Синхронный режим
применяется для автоматического восстановления в случае отказов между основной первичной репликой и её вторичной
репликой. Вы можете иметь до трёх узлов в синхронном режиме (естественно, два вторичных и один первичный в один
и тот же момент времени). Рисунок 6.1 отображает, что
Node 1 и Node 2 настроены на
применение режима автоматического восстановления после отказа (синхронного). И, как уже ранее отмечалось,
благодаря имеющейся согласованности транзакций, также имеется возможность выполнять резервное копирование
базы данных для имеющейся второй реплики со 100% точностью и целостностью.
Асинхронный режим не имеет тех требований фиксированности транзакций, которые имеет синхронный режим и он достаточно легковесен (с точки зрения производительности и накладных расходов). Даже в асинхронном режиме в большинстве случаев транзакции могут выполнять её во вторичные реплики достаточно быстро (в пределах нескольких секунд). Сетевой обмен и общее число транзакций определяют итоговую скорость. Асинхронный режим также может применяться практически повсеместно где он вам необходим в пределах некоторой стабильной сетевой среды (в пределах всей страны или даже с другим континентом если у вас имеется приличная сетевая скорость).
Данное свойство групп доступности AlwaysOn также принимает преимущества сжатия записи транзакции, каковое сжатие всех имеющихся записей журнала транзакций применяется в зеркалировании базы данных и настройках AlwaysOn для увеличения общей скорости обмена для всех зеркалирований и репликаций. Это одновременно увеличивает общее число транзакций журнала, которые вы можете выстрелить в свой вторичный сервер, а также делает общий размер самого обмена намного меньшим, поэтому все записи журнала достигают своего назначения намного быстрее.
Кроме того, также как и в случае с зеркалированием базы данных, в процессе репликации данных определённой транзакции, если определяются ошибки страниц данных, такие страницы данных на этой вторичной реплике восстанавливаются как часть общих записей транзакций в эту реплику и повышают общую стабильность базы данных ещё больше (в сопоставлении со случаем если вы не делаете репликации). Это некое приятное свойство.
Доступные только для чтения реплики
Как вы можете видеть из Рисунка 6.1, вы можете создавать больше вторичных реплик (до восьми). Однако они обязаны быть асинхронными репликами. Вы легко можете добавлять эти реплики в свою группу доступности и предоставлять распределение рабочей нагрузки и значительную миграцию для своей производительности. Рисунок 6.1 и Рисунок 6.2 отображают две дополнительные вторичные реиплики, применяемые для обработки всего имеющегося доступа к данным в режиме только для чтения, который обычно ударял бы по самой первичной базе данных. Такие реплики, доступные только для чтения имеют данные близкие к режиму реального времени и могут быть почти во всех местах, где вы пожелаете (при наличии некоторой сетевой стабильности).
Восстановление при чрезвычайных ситуациях
Рисунок 6.3 отображает некие типичные настройки
групп доступности AlwaysOn для DR (Восстановление при чрезвычайных ситуациях). Они имеют некую первичную реплику
в Data Center 1 а её вторичная реплика располагается в
Data Center 2. Вы бы применяли асинхронный режим здесь из за имеющегося
расстояния и сетевых скоростей.
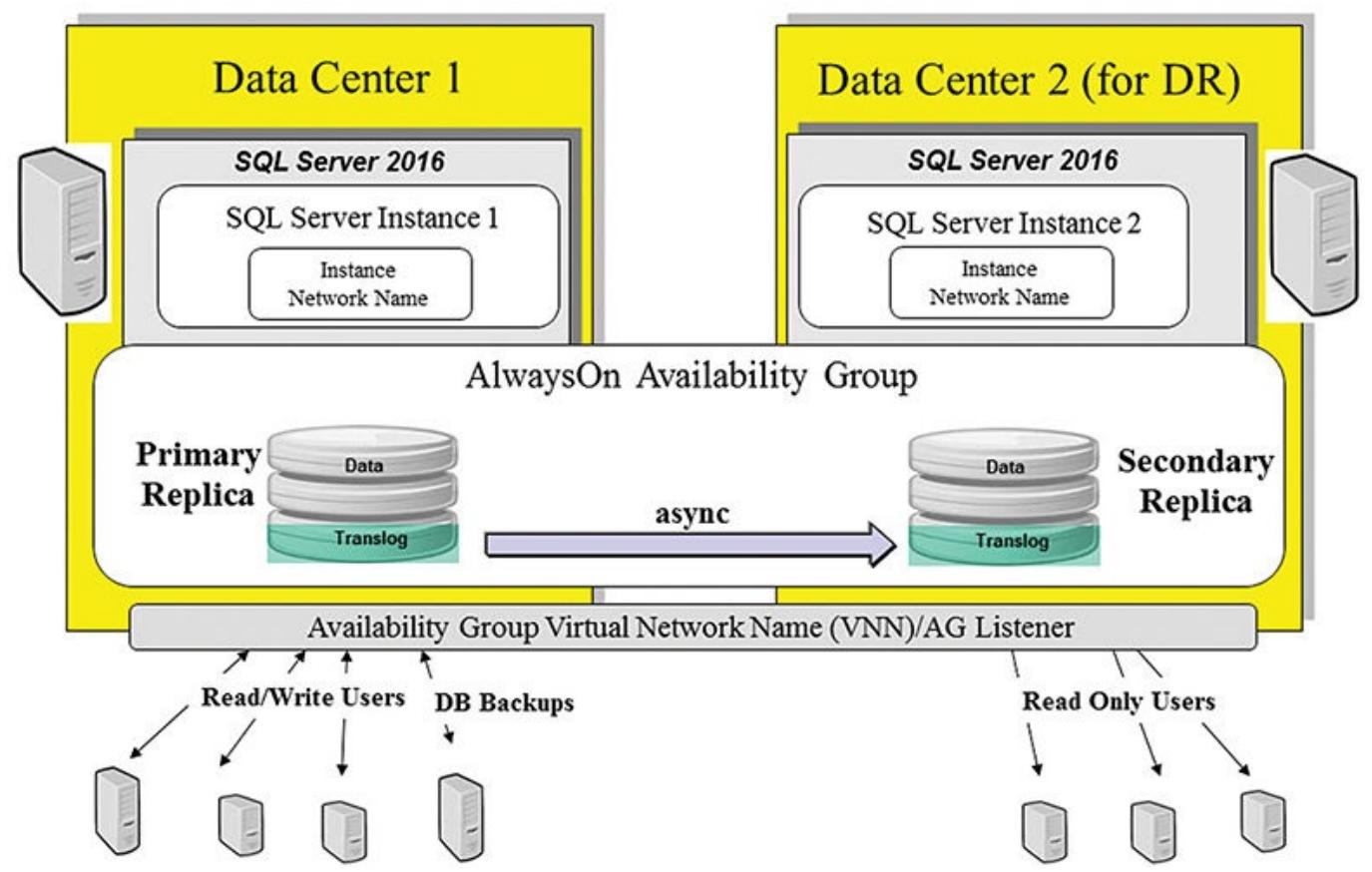
Это означает, что все вторичные реплики на такой площадке DR настолько хороши, насколько была асинхронно записана самая последняя транзакция. В данном режиме может происходить некоторая утрата данных, однако это без труда соответствует имеющимся требованиям DR и необходимым уровням обслуживания. В качестве некоторого преимущества, такая площадка DR (вторичная реплика) может также применяться для доступа к данным только для чтения, что отображено наРисунке 6.3. Вы существенно усиливаете некую копию своей первичной базы данных, которая обычно не рассматривается доступной если применялись прочие технологии DR. Большинство решений зеркалирования базы данных или прочих производителей пребывают в режиме непрерывного обновления и вовсе не поддерживают режимы доступа только для чтения.
Процессы ожидания групп доступности
Если вы взглянете опять на Рисунок 6.1, вы можете увидеть, что вспе виртуальные сетевые имена (VNN, virtual network names), которые были созданы для данного WFSC применяются при создании некоторой группы доступности. В частности, некоторая группа доступности должна знать все VNN (которые ссылаются на все персональные экземпляры) всех узлов в данной группе доступности. Они могут применяться напрямую для ссылок к таким первичным или вторичным репликами. Однако для большей стабильности (и согласованности) вы можете созавать некий процесс отслеживания (listener) как часть такой группы доступности который абстрагирует эти VNN от тех приложений, которые должны применять такие базы данных. Таким образом, данное приложение наблюдает постоянно только одно имя соединения, а лежащее в основе базовое состояние восстановления после отказа полностью изолировано от данного приложения, что с точки зрения приложения даёт ещё большие согласованность и доступность.
Конечные точки
Группы доступности также усиливают имеющуюся концепцию конечной точки для всех взаимодействий (и видимости) с одного узла к другому в некоторой конфигурации группы доступности. Такие конечные точки также выставляют пункты, применяемые самими группами доступности между узлами. Это также имеет место в случае с зеркалированием базы данных. Конечные точки групп доступности создаются как некая часть каждой конфигурации узла группы доступности (для каждой реплики).
Сервер SQL 2016 продвигает комбинации вариантов для достижения уровней Высокой доступности. Выстраивание некоторой конфигурации FCI AlwaysOn совместно с группами доступности AlwaysOn по две или более реплики каждая запускает вас в масштабирование распределённых рабочих нагрузок и максимальную Высокую доступность.
Данный раздел показывает как построить некую конфигурацию AlwaysOn со множеством узлов, создать определённую настройку кластера, определить конкретную группу доступности, описать все роли базы данных, реплицировать имеющиеся базы данных, и получить свои процессы отслеживания (listener) групп доступности запущенными и исполняющимися. Это самые основные шаги, которые подробнее описываются в следующих разделах:
Рисунок 6.4 отображает ту основную конфигурацию,
которую вы построите в последующих разделах. Имеется три узла для работы с ними, однако вы сосредоточитесь на
получении необходимого первичного и одного вторичного запущенными и исполняемыми в данном примере. Сам отказоустойчивый
кластер будет называться DXD_Cluster, его группа доступности будет
именоваться DXD-AG, а процесс отслеживания будет иметь название
DXD-Listener (и пременять IP адрес
20.0.0.243). Вы будете применять предоставляемую Microsoft базу данных
AdventureWorks. Последний третий узел может быть использован для создания другой вторичной реплики с доступностью
только для чтения если вы пожелаете или для целей DR (восстановления после чрезвычайных обстоятельств - Disaster
Recovery). В данном случае вы предназначаете её в качестве узла DR (вторичная реплика).
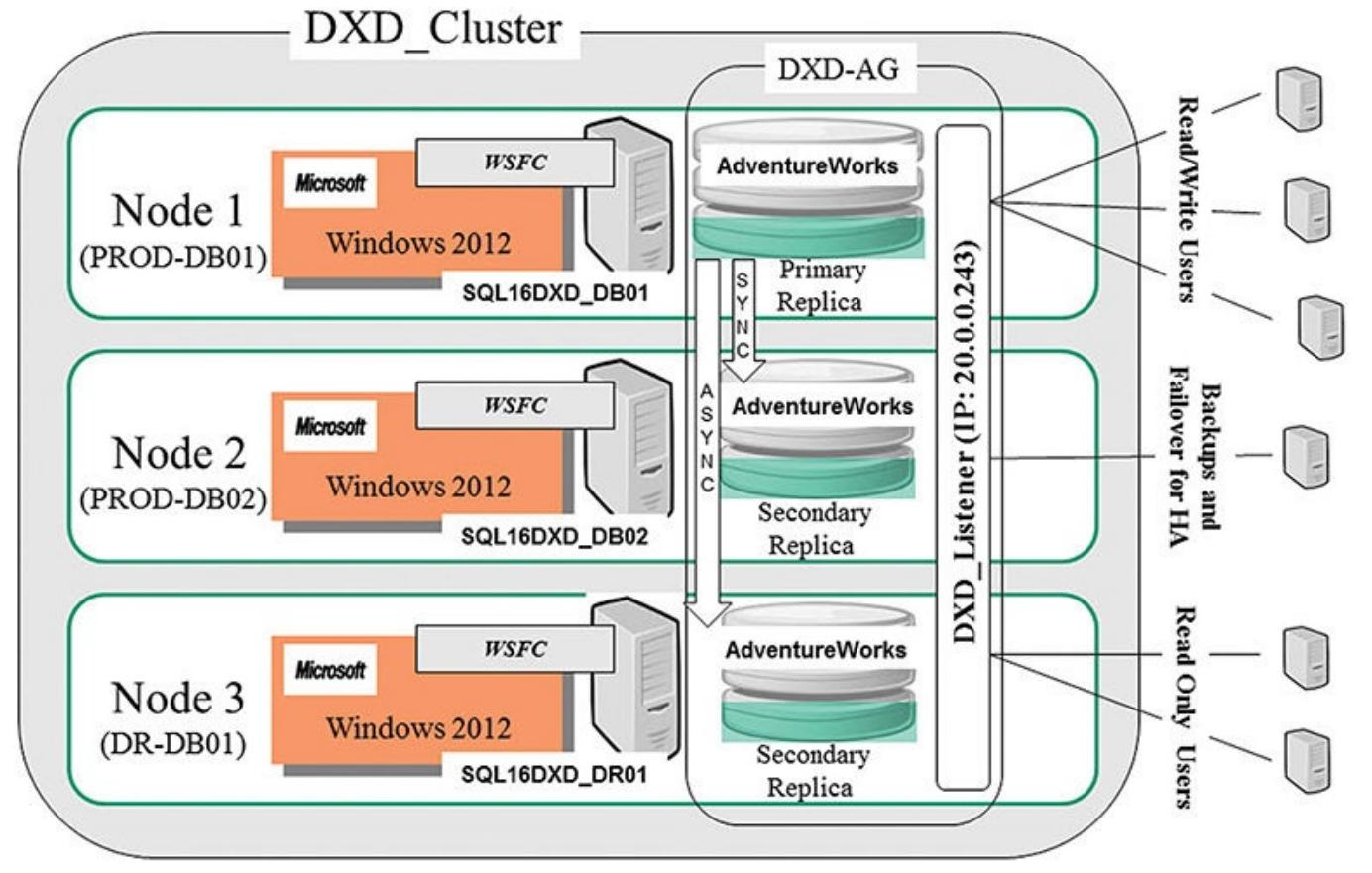
Данная группа доступности будет применяться следующим образом: первичная (Node 1)
для операций чтения/ записи, а вторичная (Node 2) для резервного копирования
и восстановления после отказов. Другая вторичная реплика (Node 3, если
вы добавите её) может применяться для доступа только по чтению.
Предположим что вы имеете установленными и исполняемыми по крайней мере два экземпляра сервера SQL на отдельных узлах, которые могут применяться в составе кластера для данной конфигурации. Им не требуется выполнять зеркалирование образов друг на друга, это просто жизнеспособные экземпляры сервера SQL, которые могут быть включены для AlwaysOn (в редакции Enterprise или Developer). Убедитесь, что эти экземпляры сервера SQL жизнеспособны и работают нормально.
Для каждого из ваших серверов (узлов) вам требуется настроить WSFC. Глава 4, Построение отказоустойчивого кластера учит как это выполнить применяя Диспетчер сервера в каждом из узлов. Эта глава не охватывает данную тему, но показывает вам что настроенные свойства должны выглядеть как это было раньше, когда вы начали настраивать свою конфигурацию групп доступности AlwaysOn. Как вы можете увидеть на Рисунок 6.5, свойство Отказоустойчивого кластера (Failover Clustering) должно быть установлено на всех узлах.
Рисунок 6.5
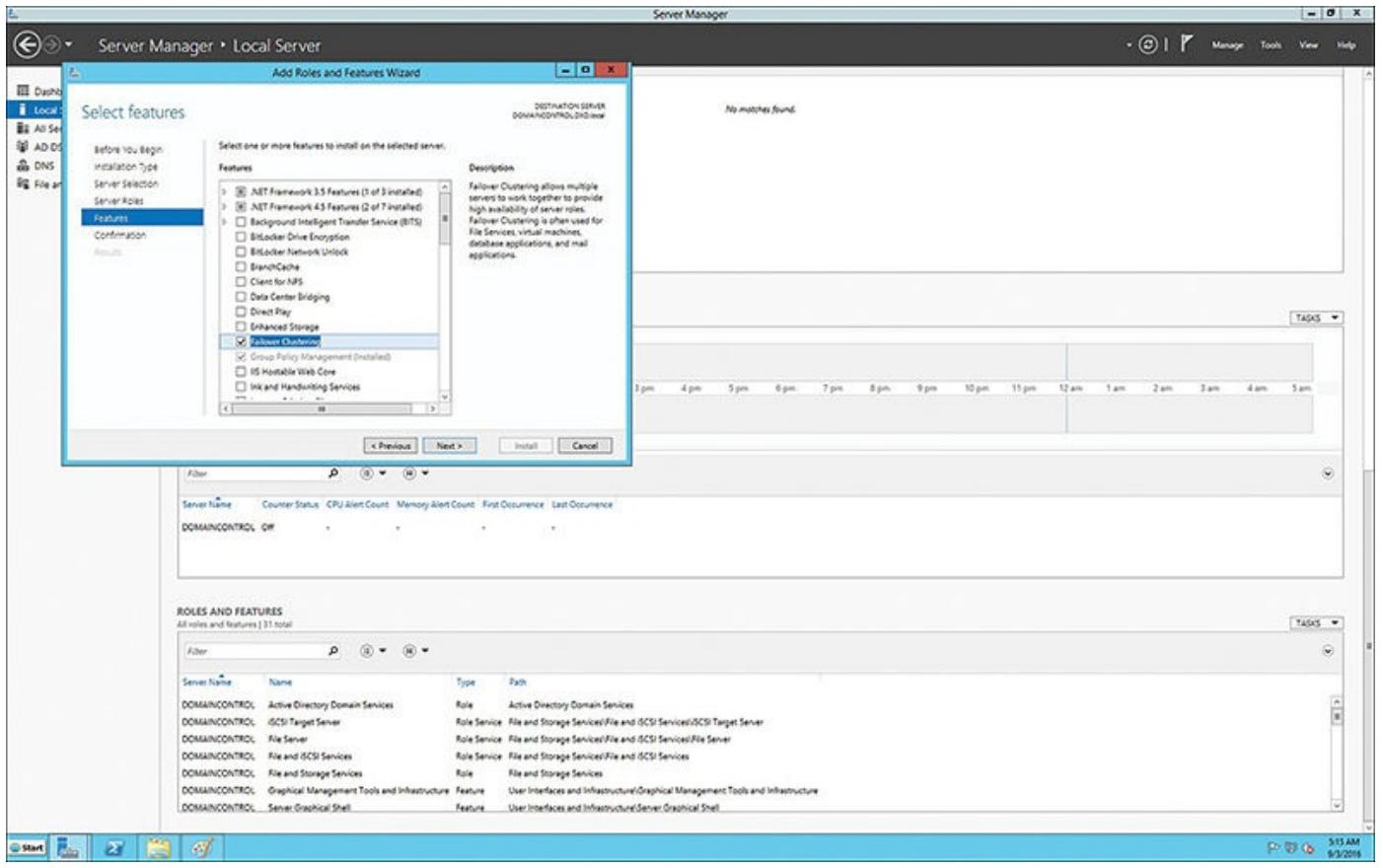
Отображение установленных свойств отказоустойчивого кластера из имеющегося Диспетчера сервера
Скорее всего вам также придётся выполнить некую валидацию всех настроек кластера.
Какое- то количество интенсивных тестов выполняются на каждом узле в том кластере, который вы настраиваете. Эти тесты требуют некоторого времени, поэтому запаситесь кофе или чаем, а впоследствии убедитесь что вы просмотрели все итоговые отчёты на предмет неких реальных ошибок. Скорее всего вы обнаружите ряд предупреждений, которые относятся к элементам, котрые не являются существенными для данных настроек (обычно какие- то моменты TCP/IP или прочих относящихся к сетевым ресурсам вещам). Когда всё это готово, вы готовы запустить свой AlwaysOn в дело.
Рисунок 6.6 отображает как вы создаёте точку доступа
группы своего кластера (с названием DXD_Cluster) в Диспетчере
отказоустойчивого кластера. Установленным IP адресом для этой точки доступа является
20.0.0.242.
Рисунок 6.6
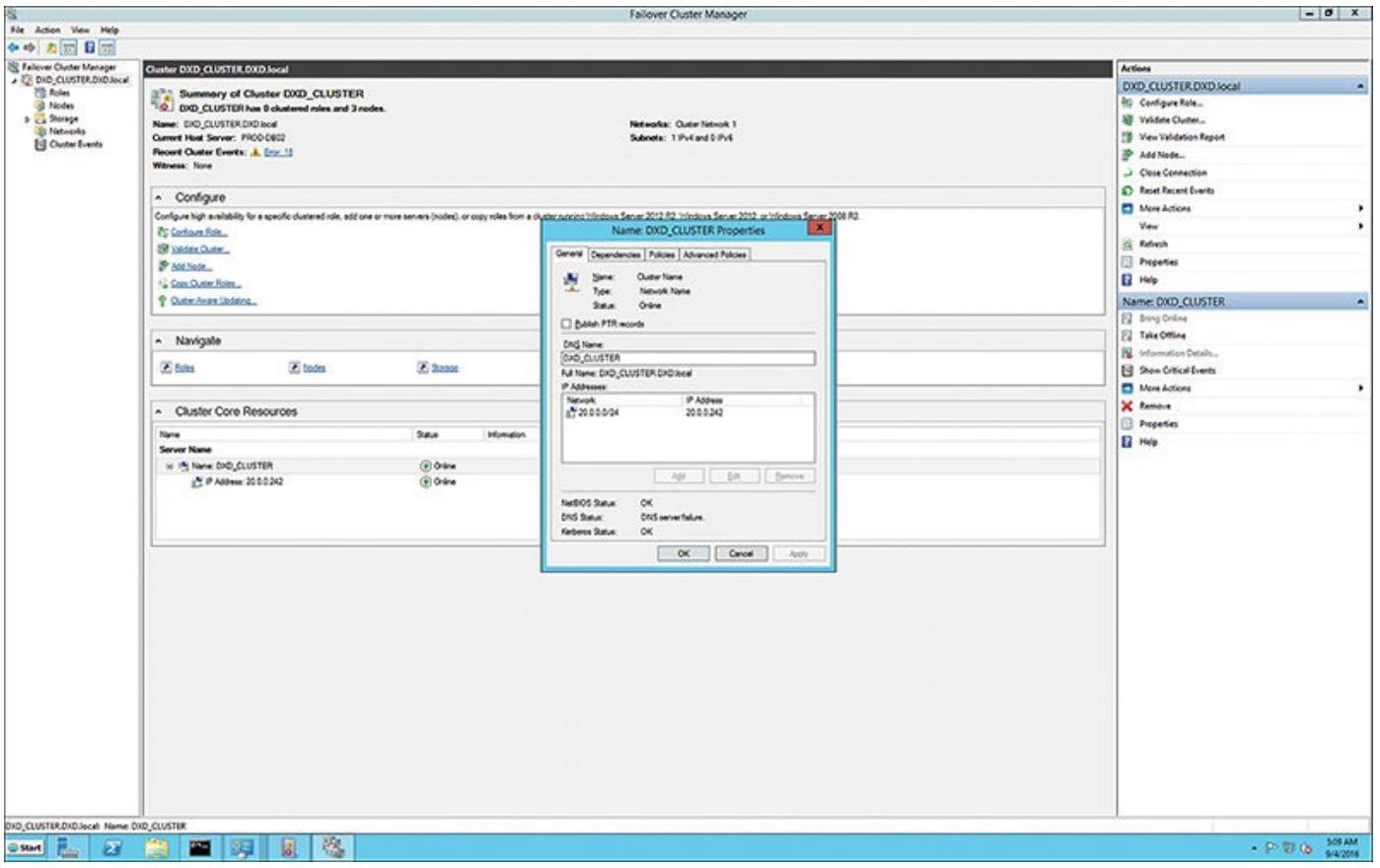
Применение Диспетчера отказоустойчивого кластера для создания некоторой точки доступа с целью администрирования самим кластером и названием кластера
Данный кластер должен содержать три узла, PROD-DB01,
PROD-DB02 и DR-DB01, как это
отображается в вашем Диспетчере отказоустойчивого кластера на
Рисунке 6.7.
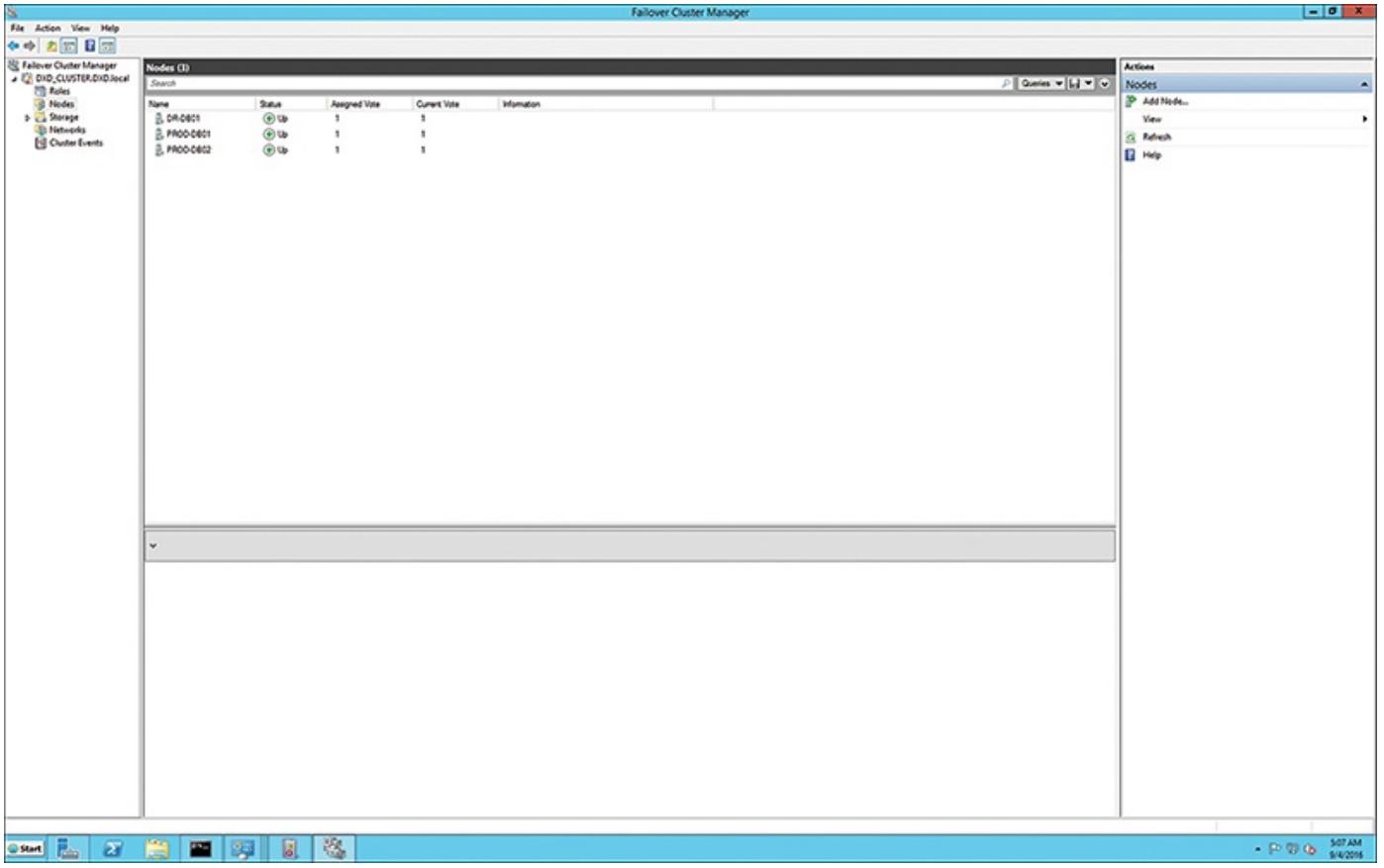
Теперь самое время запустить вашу конфигурацию AlwaysOn на другой стороне данного уравнения.
Вам необходимо удостовериться, что у вас имеется некая первичная база данных которая может быть применена в
данном примере. Я рекомендую использовать для данной цели ту базу данных AdventureWorks, которая поставляется
Microsoft в качестве примера базы данных с тем, чтобы вы могли её реплицировать. Если у вас пока нет её в
вашем экземпляре сервера SQL, а вы будете применять её в качестве своей первичной реплики (в данной
демонстрации это экземпляр вашего сервера SQL PROD-DB01/SQL16DXD_DB01),
будьте любезны скачать его с Microsoft и установите его. Если у вас уже имеется некая другая база данных,
которую вы желаете применять, пройдите далее и воспользуйтесь ею. Просто убедитесь что Модель восстановления
после чрезвычайных происшествий (DR) установлена в значение Full. Для репликации группы доступности
применяют журналы транзакций, и поэтому должна быть применена данная модель восстановления.
Для каждого из имеющихся экземпляров сервера SQL, которые вы желаете включить в свои настройки AlwaysOn, вам
необходимо разрешить их экземпляры для AlwaysOn; они по умолчанию отключены. Из каждого узла запустите его
Диспетчер настроек сервера SQL и выберите необходимый узел служб сервера SQL в панели Служб. Кликните правой
кнопкой по необходимому экземпляру сервера SQL для данного узла (в данном примере имеющем название
SQL16DXD_DB01) и выберите Свойства (Properties).
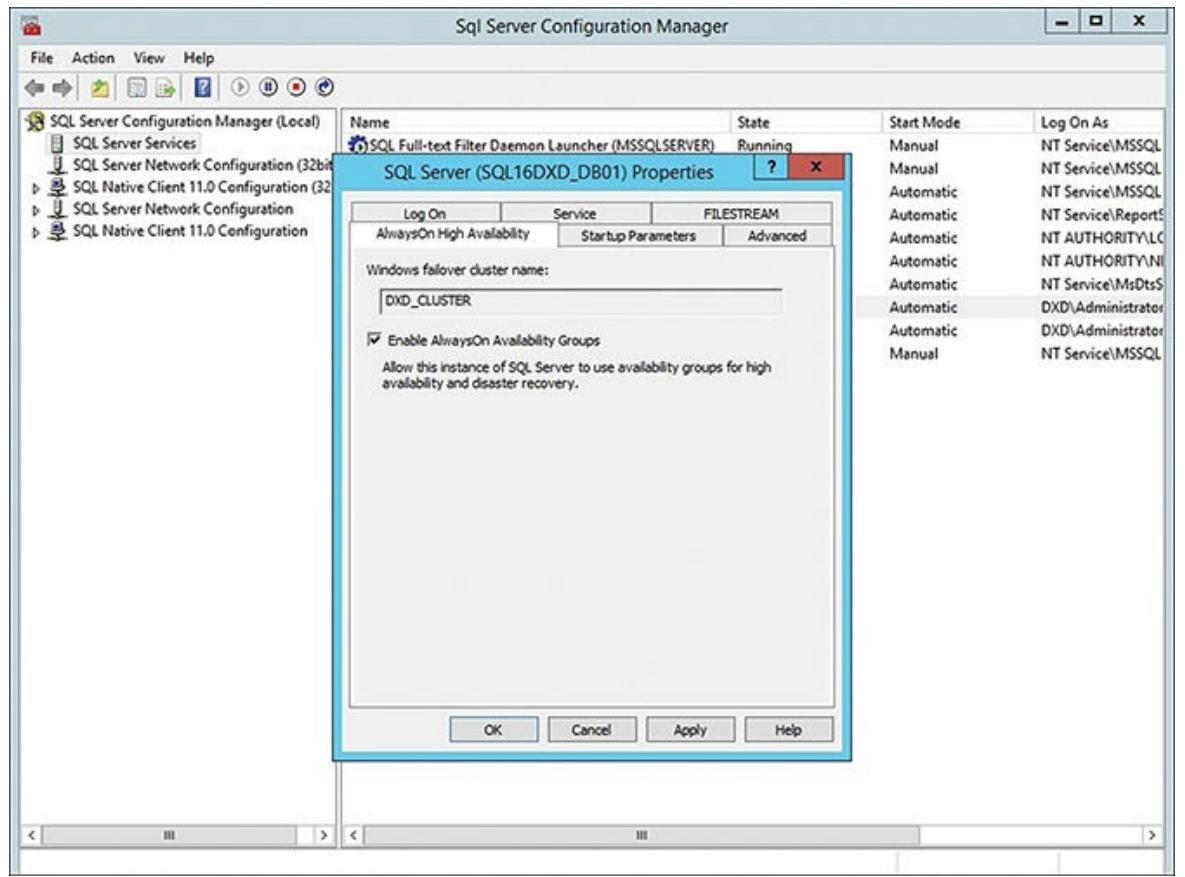
Рисунок 6.8 отображает все свойства данного
экземпляра сервера SQL. Кликните по закладке Высокой доступности AlwaysOn и проверьте группы доступности
AlwaysOn. (Отметим, что вданном блоке диалога появляются необходимое название кластера, так как данный сервер
уже определён в данном кластере на предыдущем этапе.) Кликните OK (или Применить, Apply) и вы увидите некое
замечание относительно потребности повторного запуска данной службы для применения этих параметров. Псоле
того как вы закроете данный диалог Свойств, пройдите вперёд и кликните правой кнопкой по необходимому
экземпляру сервера SQL вновь, однако на этот раз выберите вариант Перезапуска (Restart) для включения
свойства Высокой доступности AlwaysOn. Для всех оставшихся узлов (в нашем примере это
SQL16DXD_DB02 и SQL16DXD_DR01)
выполните то же самое для настройки сервера SQL и соответствующего экземпляра сервера SQL, подлежащих
включению в данную конфигурацию AlwaysOn.
Вы также можете выполнить это с помощью PowerShell. В приглашении командной строки Windows просто наберите
SQLPS и нажмите Enter.
Затем введите следующее:
Enable -SqlAlwaysOn –ServerInstance SQL16DXD_DB01 -FORCE
Данная комнда даже перезапустит вам имеющуюся службу сервера SQL.
Прежде чем вы пуститесь во все тяжкие создания требующейся группы доступности, вам следует выполнить
полное резервное копирование своей первичной базы данных (на Node 1:
SQL16DXD_DB01). Данная резервная копия будет применена для создания
всех баз данных в ваших вторичных репликах. С данного узла базы данных своей первичной базы данных
(в Студии управления сервером SQL - SQL Server Management Studio [SSMS]), выберите для исполнения полное
резервное копирование необходимой базы данных, кликнув правой кнопкой по этой базе данных, выберите Задачи
(Tasks), а затем кликните по Резервному копированию (Back Up).
Рисунок 6.9 отображает появляющийся диалог
резервного копирования базы данных. В нём кликните OK для осуществления полного необходимого резервного
копирования.
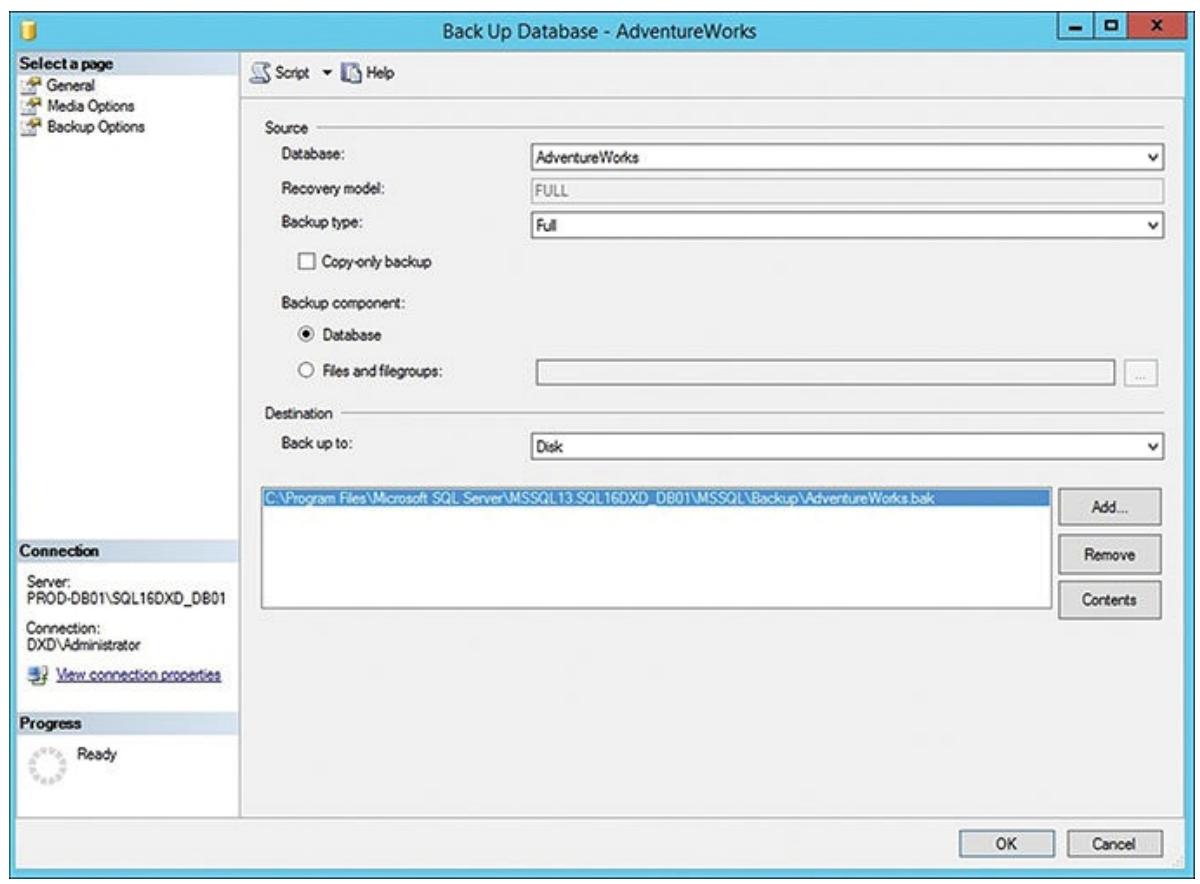
В этом месте я обычно предпочитаю скопировать такую полную резервную копию во все вторичные экземпляры и восстановить её, чтобы гарантировать что у меня имеется в точности те же самые вещи на всех узлах, прежде чем начать необходимую синхронизацию. После выполнения данного восстановления проверьте что определили Восстановление (Restore) с опцией (No Recovery). Когда вы покончите со всем этим, вы можете перейти к созданию необходимой группы доступности.
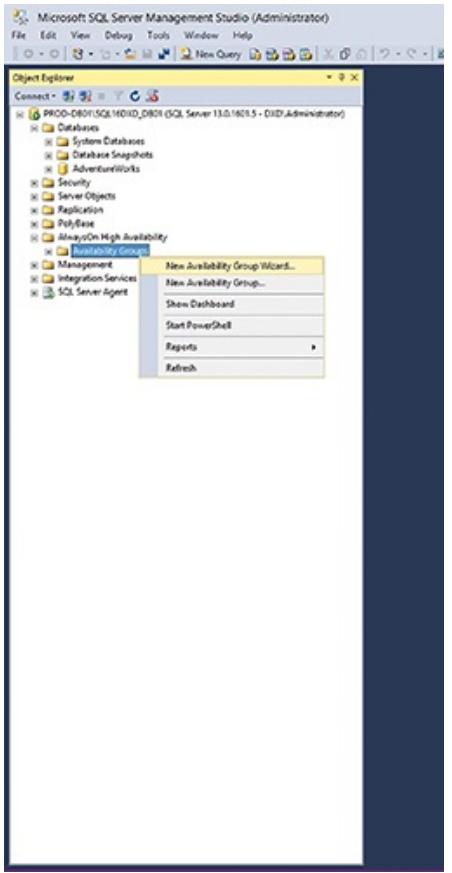
На Node 1 (в данном примере
SQL16DXD_DB01) раскройте свой узел Высокой доступности AlwaysOn для
данного экземпляра сервера SQL (в SSMS). Как отображено на
Рисунке 6.10, вы можете кликнуть правой кнопкой
по своему узлу Группы доступности и выбрать создание некоторой новой группы доступности (через имеющийся
мастер). Именно здесь будут осуществлены все действия по созданию всей необходимой группы доступности.
В данном мастере Новой группы доступности вы можете определить необходимое имя группы доступности, выбрать
те базы данных, которые подлежат репликации, определить все реплики, выбрать необходимую синхронизацию данных,
а также затем провести проверку. Первоначально появляется страница всплеска для данного мастера, в которой вы просто
кликаете Далее (Next). Это переносит вас в диалог Определения названия группы доступности.
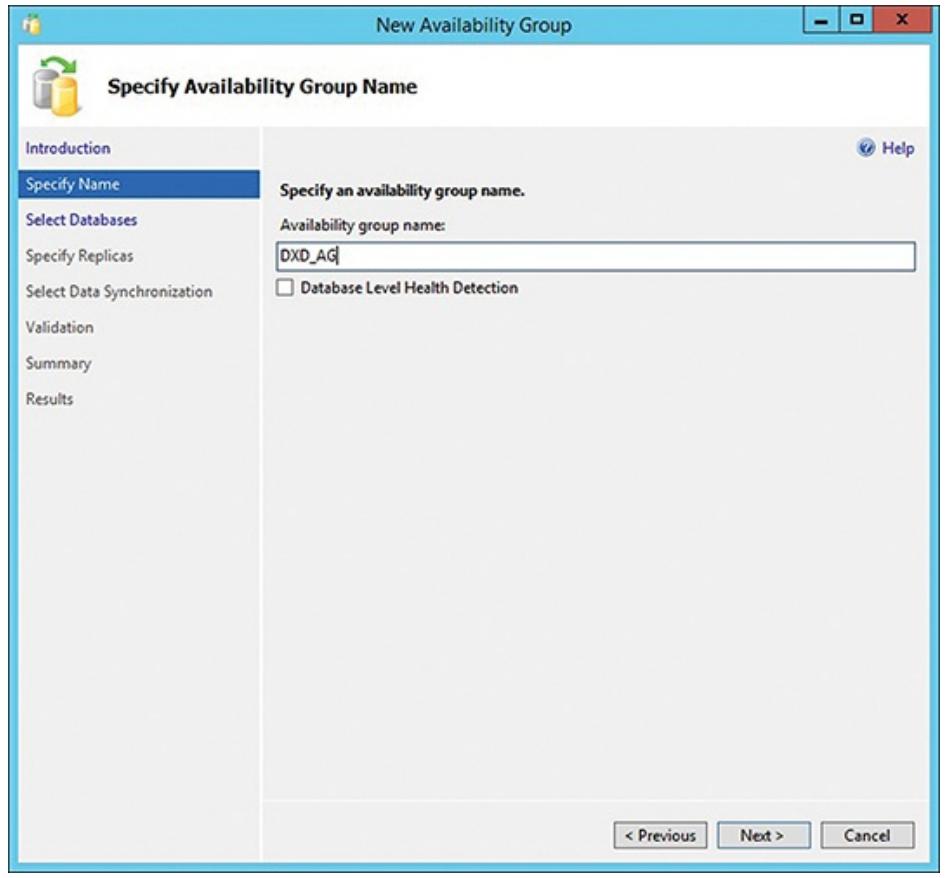
Рисунок 6.11 отображает данный диалог с определённым
названием вашей группы доступности в качестве DXD-AG. Кликните
Далее (Next).
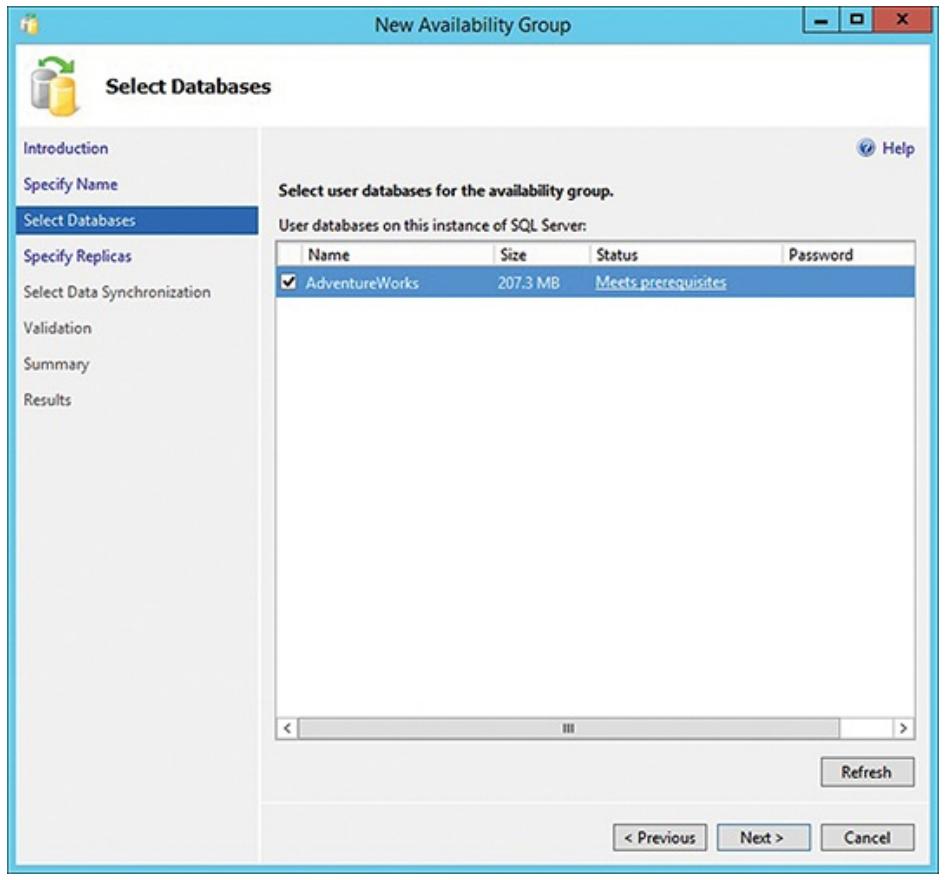
Затем вы получаете запрос на определение того, какие прикладные базы данных вы желаете включить в свою группу доступности. Рисунок 6.12 отображает такой перечень баз данных с выбранной AdventureWorks. Кликните Далее (Next).
Нашим следующим шагом является определение самих реплик и того, как они будут применяться. Первоначально
имеется только один экземпляр сервера (он же- первичный). Кликните кнопку Добавить реплики (Add Replicas)
в левом нижнем углу (под списком всех имеющихся экземпляров сервера) и выберите тот экземпляр вторичной реплики,
который пожелаете (в данном примере SQL16DXD_DB02 -
Node 2). Теперь в общем списке должны быть перечислены и первичный, и
вторичный экземпляры. Вы также хотите определить, что каждый из них должен применять автоматическое восстановление
при сбое (вплоть до трёх вторичных), пометив соответствующие блоки указания. Вам также нужен вариант синхронной
фиксации (вплоть до трёх) для обоих чтобы получить требуемую Высокую доступность.
Вам также следует включить свой третий узел (SQL16DXD_DR01), однако не
помечать его блоки Автоматического восстановления после сбоев (Automatic Failover) или Синхронной фиксации
(Synchronous commit). Вы хотите чтобы он был в режиме асинхронной репликации. Однако вы желаете разрешить этому
третьему узлу быть вторичным при доступе на чтение (выбрав Yes).
Рисунок 6.13 отображает все определённые для
каждого экземпляра сервера варианты восстановления после отказа и фиксации.
Рисунок 6.13
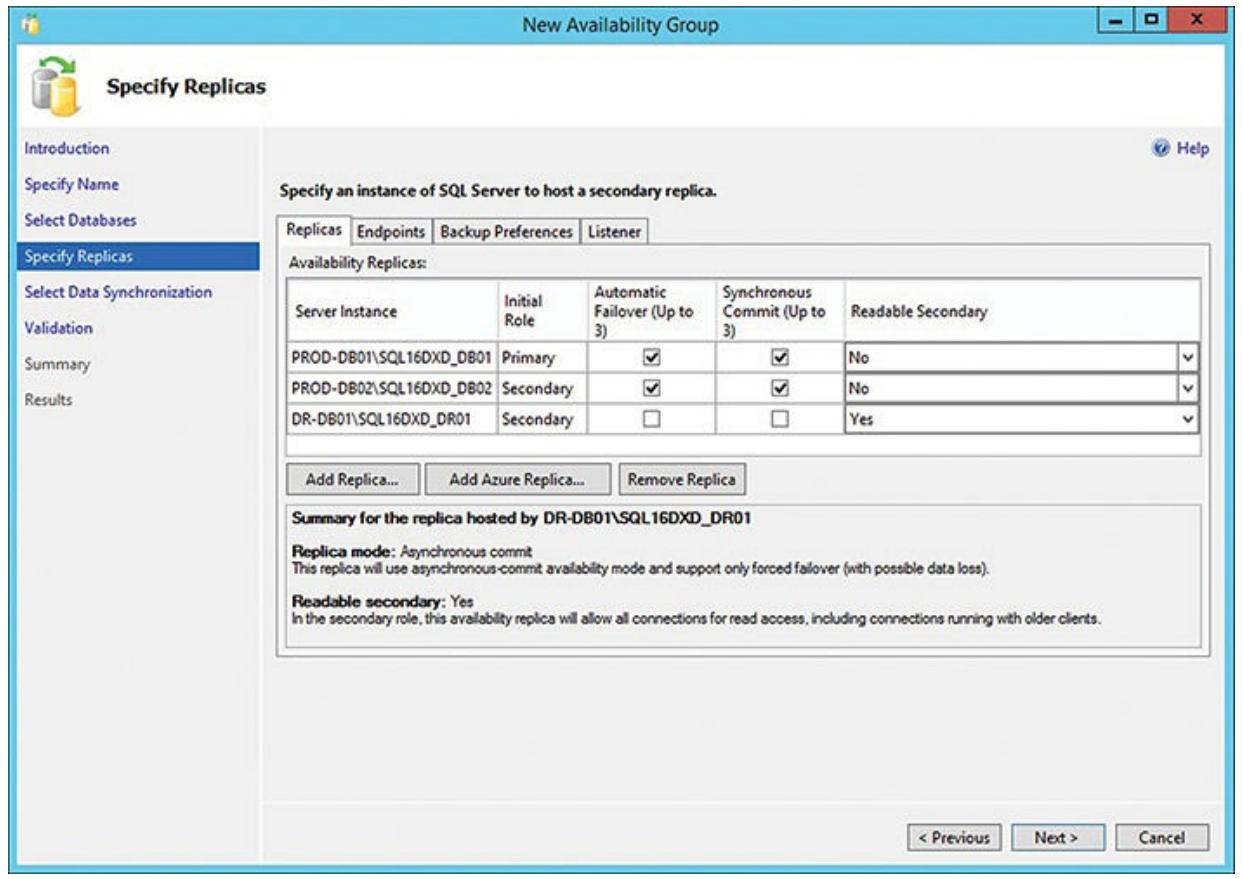
Опеределение конкретного экземпляра сервера SQL для размещения некоторой вторичной реплики и параметров восстановления после отказа данного экземпляра сервера
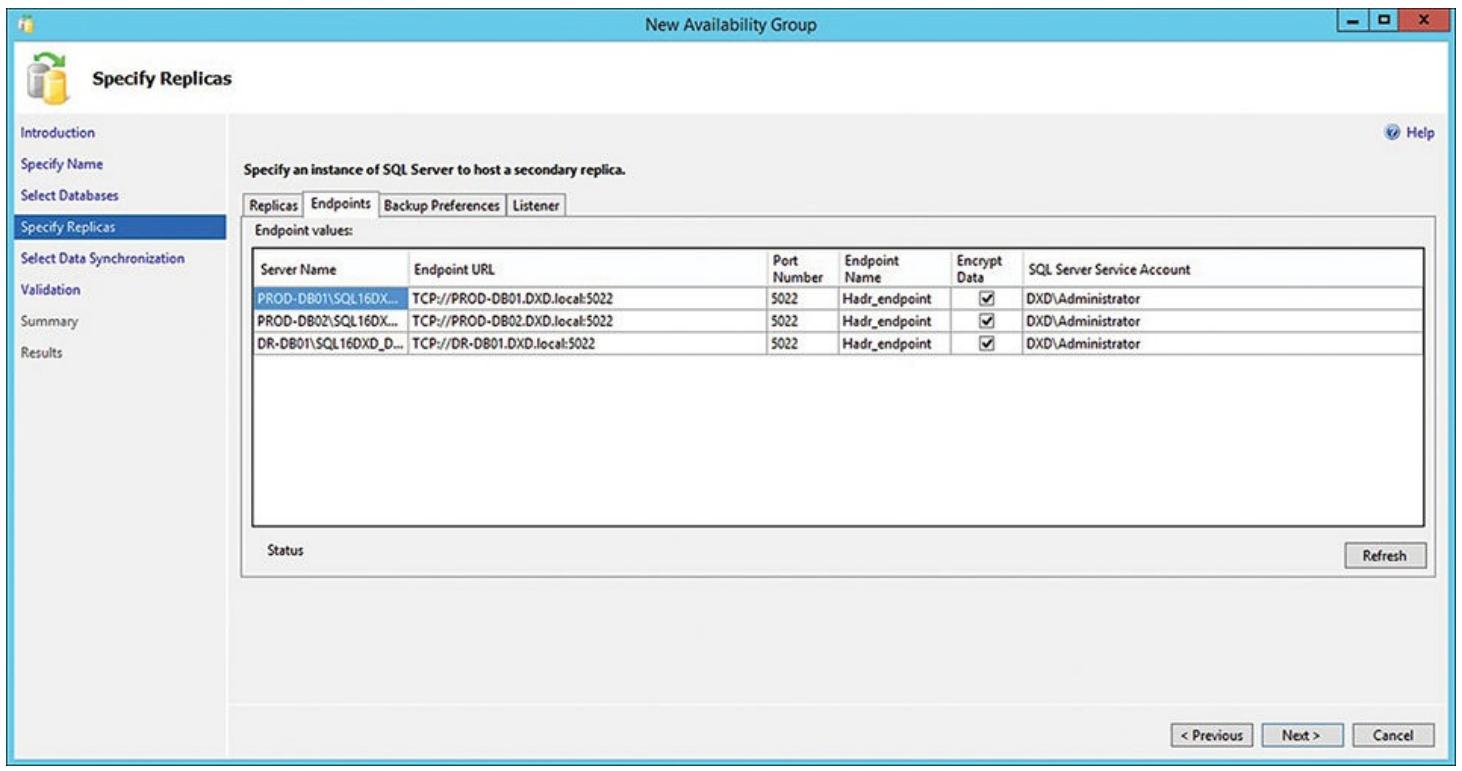
Тепперь, если вы кликните по закладке Конечных точек (Endpoints), вы увидите все конечные точки, которые
были созданы для применения этими экземплярами для взаимодействия друг с другом
(hadr_endpoint для каждого экземпляра сервера SQL). Здесь вам не
требуется вносить изменения, поэтому примем полученные по умолчанию значения, как это отображено на
Рисунке 6.14.
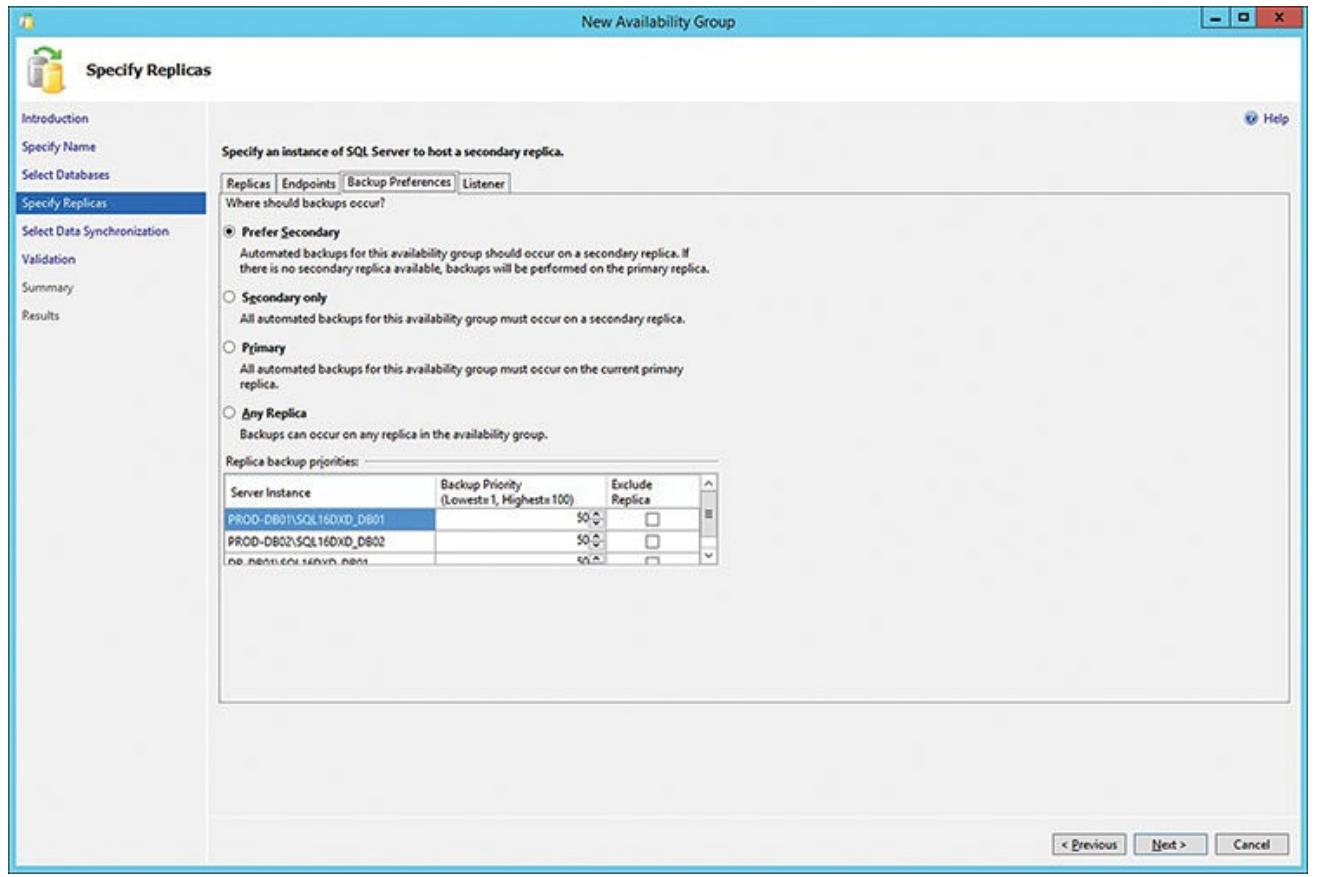
Если вы кликните по закладке Предпочтений резервного копирования (Backup Preferences), вы можете указать как (и где) вы желаете выполнять резервное копирование базы данных когда данная группа доступности будет оформлена и все реплики станут активными. Как вы можете увидеть из Рисунка 6.15, вы можете выбрать вариант Предпочесть вторичную (Prefer Secondary) для осуществления резервного копирования базы данных, тем самым разгружая свою первичную реплику от данной интенсивной задачи. Когда вы выберите этот вариант, если ваша вторичная реплика не будет доступная для выполнения необходимого резервного копирования, будет применена первичная.
Если вы кликните по заладке Процесса ожидания (Listener), вы можете увидеть что здесь у вас имеются две опции: не устанавливать такой процесс отслеживания группы доступности или создать его. На самом деле вы сделаете это чуть позже, поэтому в данный момент пропустите её (определив Не создавать сейчас процесс ожидания группы доступности - Do Not Create an Availability Group Listener Now) и кликните Далее (Next).
Самый последний момент, который вам необходимо выполнить перед шагом проверки, состоит в определении ваших предпочтений по синхронизации данных. Рисунок 6.16 показывает имеющиеся различные варианты. Если вы примените опцию Полностью (Full), вы получите полные резервные копии базы данных и журнала для каждой из выбранных баз данных. Затем эти базы данных восстанавливаются для всех вторичных реплик и подключаются к данной группе доступности. имеющаяся опция Только присоединиться (Join Only) запускает синхронизацию данных когда вы уже восстановите некие резервные копии базы данных и журнала (другими словами, когда вы уже восстановили некую базу данных в качестве вторичной реплики и вы просто желаете иметь эту вторичную реплику присоединённой к данной группе доступности). Вариант Пропустить начальную синхронизацию данных (Skip Initial Data Synchronization) просто означает, что вы самостоятельно выполните полное резервное копирование своих первичных баз данных и восстановите их когда будете готовы. Поскольку вы уже выполнили действия резервного копирования, вы можете здесь просто выбрать вариант Join Only и кликнуть Далее (Next).
Рисунок 6.16
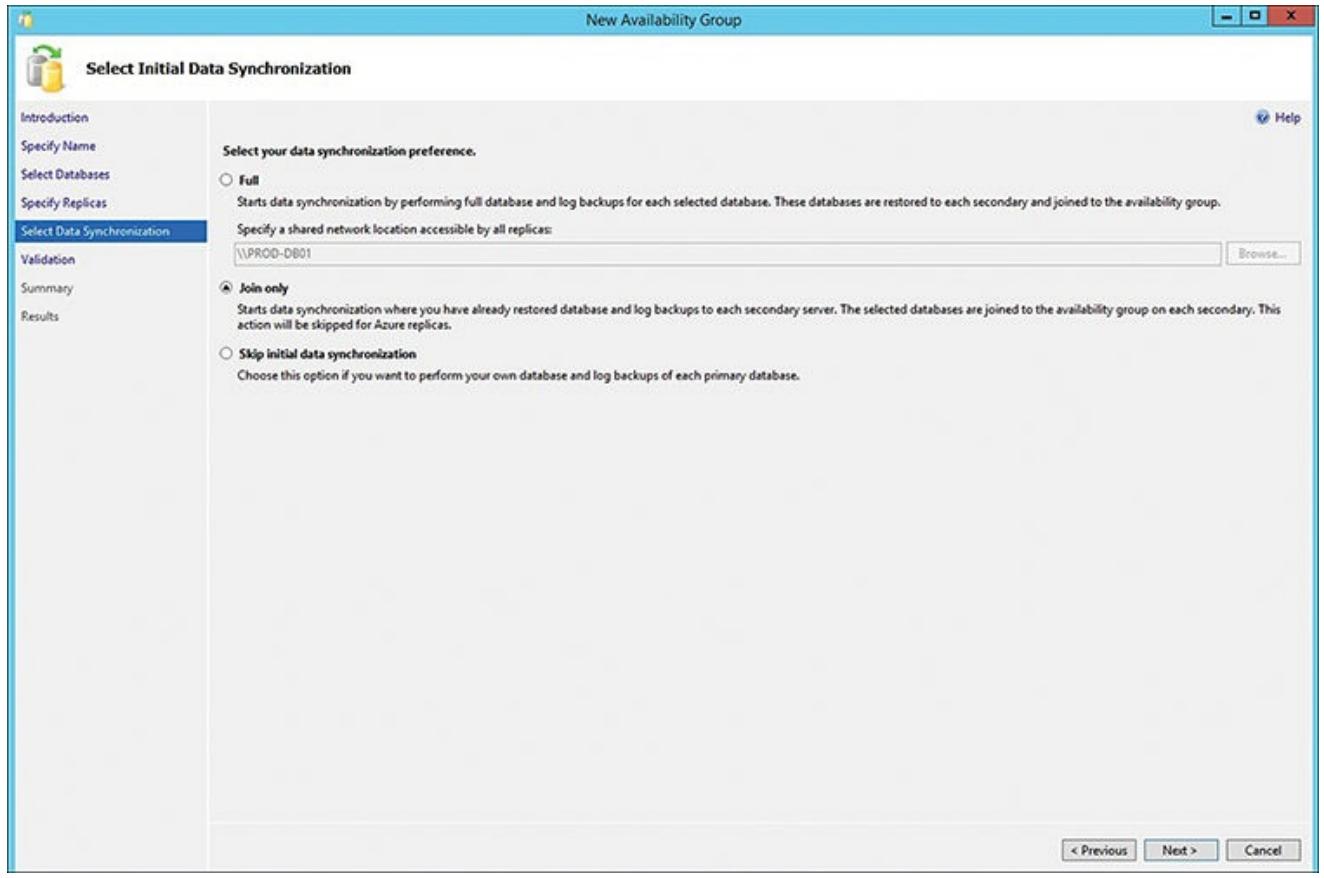
Определение необходимых вариантов начальной синхронизации данных для всех реплик в данной группе доступности
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Если вы выберете вариант Full, важно чтобы данное совместно используемое сетевое местоположение имело полную доступность для всех учётных записей служб из всех узлов в данной группе доступности (те учётные записи служб, которые применяются для запускаемых на каждом из узлов служб сервера SQL). |
Как вы можете увидеть на Рисунке 6.17, появится определённый диалог проверки, отображающий все успехи, отказы, предупреждения или проущенные этапы в данном процессе создания на основе всех определённых вами опций. На Рисунке 6.17 вы также можете увидеть диалог всех итогов выполненной работы и вы получите одну из последних возможностей убедиться что все необходимые задания были исполнены. Для завершения данного процесса просто кликните Далее (Next).
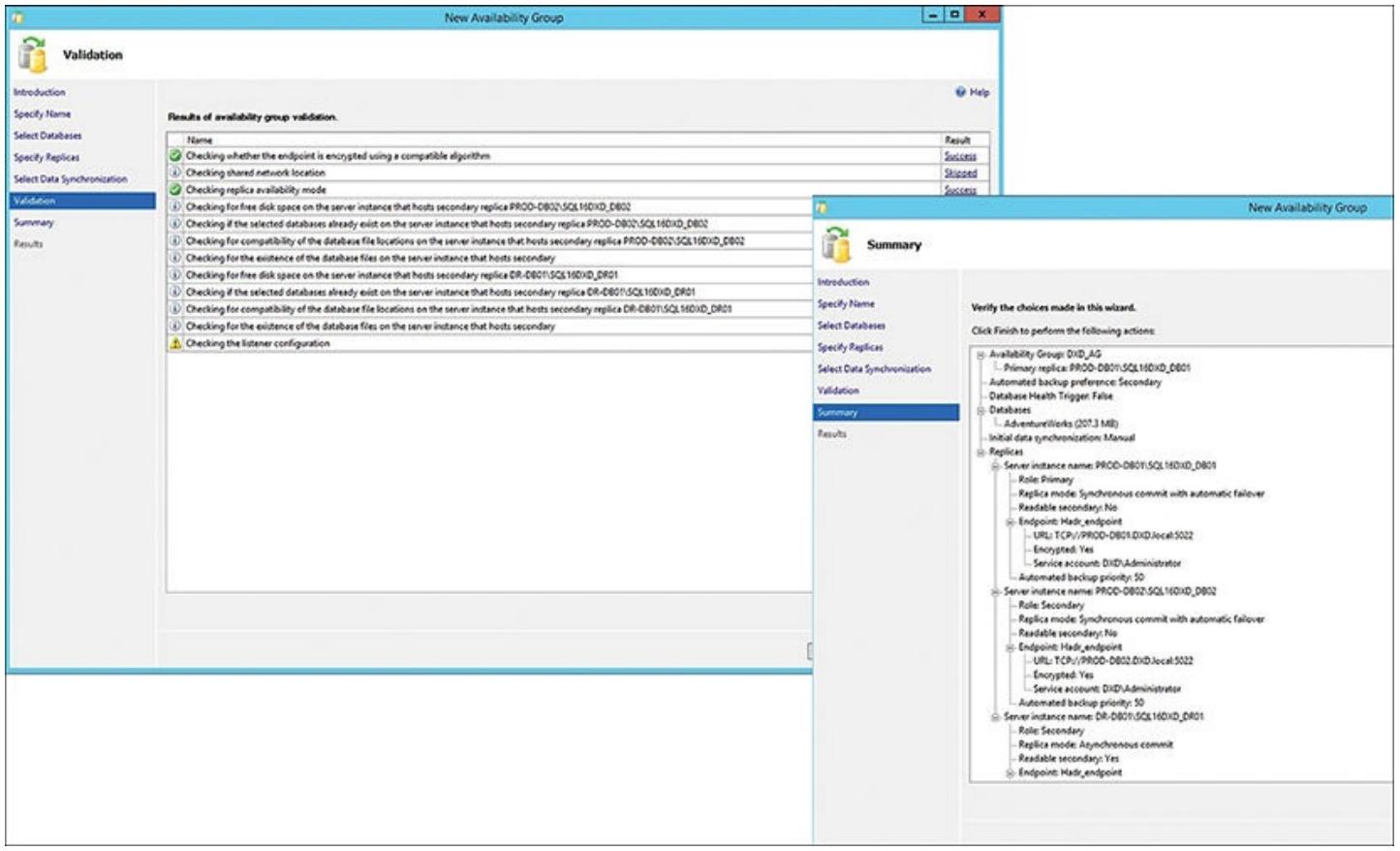
Как отображено на Рисунке 6.18, теперь вы видите все результаты этапов создания своей группы доступности. Вы можете видеть, что все вторичные реплики были присоединены к данной группе доступности (что указывается имеющимися на Рисунке 6.18 стрелками), и вы можете видеть, что данный узел группы доступности будет содержаться в SMSS для только что оформленной группы доступности. Вы можете видеть свои первичную и вторичные реплики, сами базы данных внутри данной группы доступности, а также некое указание на тот уровень узла базы данных с которым будет синхронизироваться эта база данных.
Рисунок 6.18
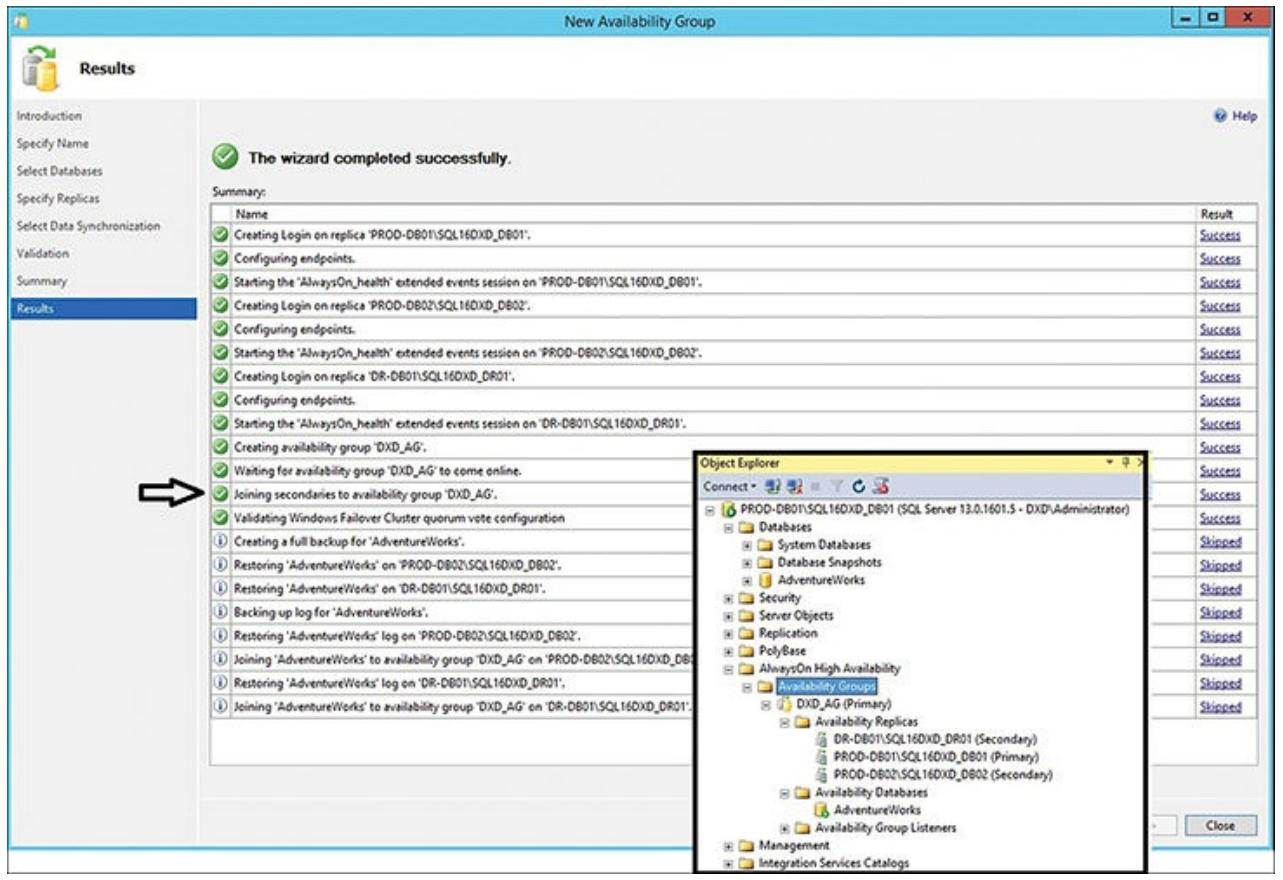
Диалог результатов Новой группы доступности совместно с результатами плученных групп доступности и всех присоединённых реплик вашего Проводника объекта SSMS
Когда имеющееся состояние этой базы данных изменится на "синхронизировано", вы в деле. Однако, чтобы завершить своё абстрагирование от имён экземпляров в ваших приложениях, вам необходимо создать процесс ожидания необходимой группы доступности (listener - перехватчик) для завершения данной настройки.
В данном процессе все VNN кластера связываются с названием процесса ожидания имеющейся группы доступности (перехватчиком - listener). Именно оно также является тем именем, которое выставляется для всех приложений чтобы подключаться к данной группе доступности. Пока в данной группе доступности будет работать хотя бы один узел, все приложения никогда не узнают ни о каких отказах узлов. Кликните правой кнопкой по созданной вами группе доступности и выберите Добавить перехватчик (Add Listener), как это отображено на Рисунке 6.19.
Рисунок 6.19
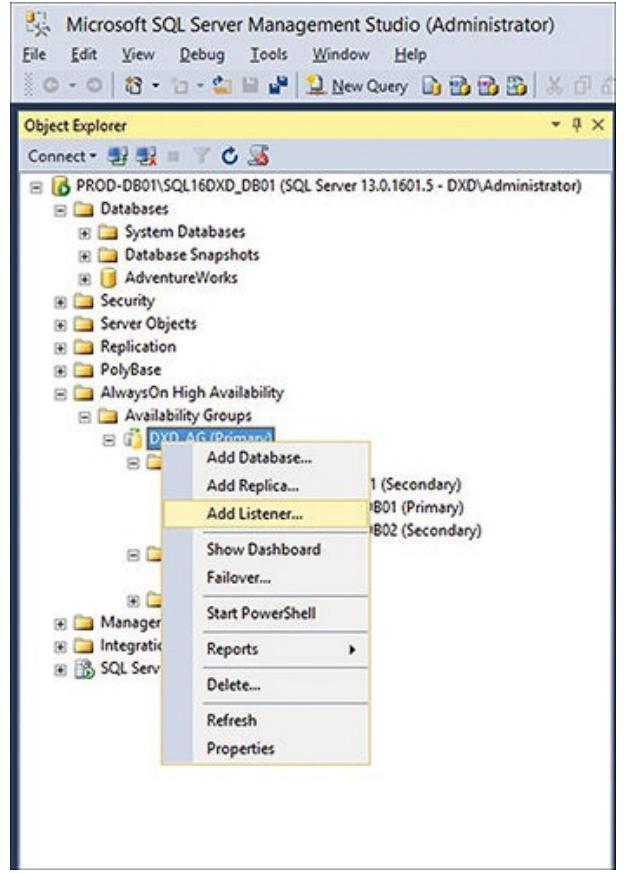
Определение необходимого нового процесса отслеживания групп доступности для данной новой группы доступности
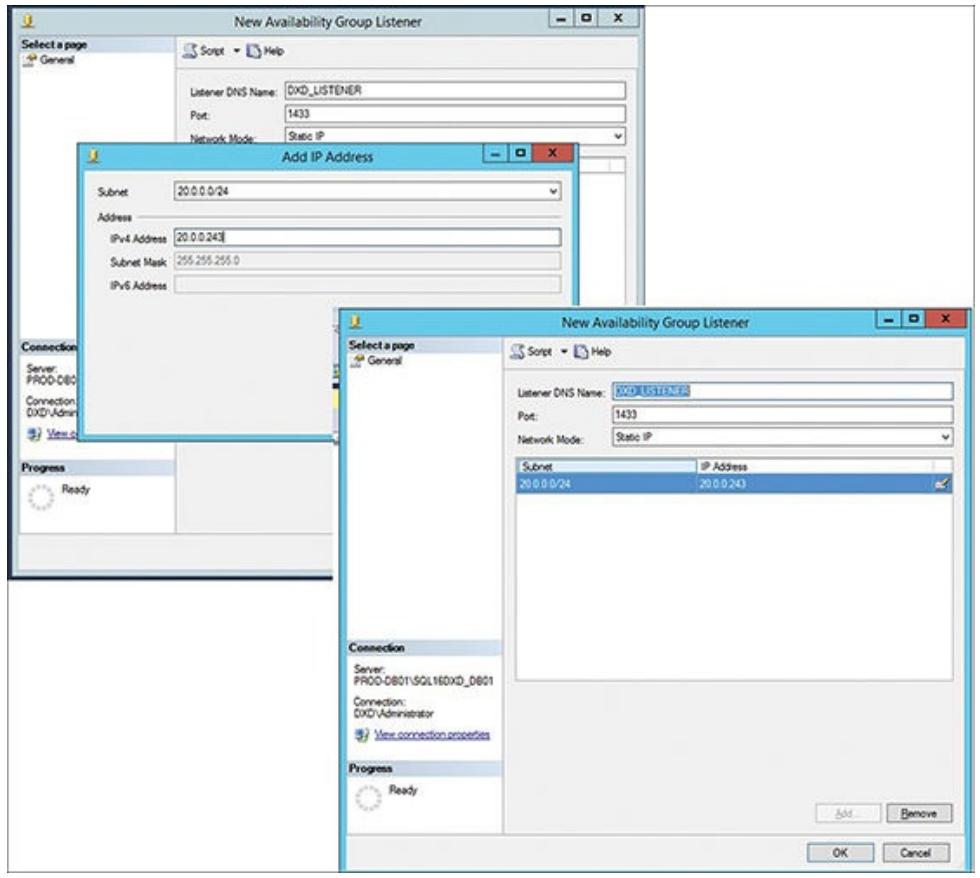
Теперь вы можете определить DNS имя данного перехватчика (в данном примере
DXD_LISTENER) и его порт (1433)
и вы можете указать применение некоторого статического адреса IP для данного процесса отслеживания.
Появится некий небольшой диалог (как показано на
Рисунке 6.20), который указывает установленный
IPv4 адрес для этого перехватчика (в данном примере 20.0.0.243).
Кликните OK. Рисунок 6.20 отображает имеющуюся
группу доступности и определённый созданный перехватчик группы доступности, который вы только что настроили.
(Между прочим, ваше приложение может применять данное имя перехватчика или его IP адрес для соединения с
имеющимся экземпляром SQL. Я покажу чуть позже как это сделать.)
Это всё. Вы должны быть запущенными и исполняющимися в режиме Высокой доступности и иметь перехватчик для применения в любом приложении. Если база данных не присоединилась надлежащим образом, или если Проводник объекта (Object Explorer) не отображает необходимое состояние синхронизации для вашей вторичной реплики, вы можете кликнуть правой кнопкой по соответствующей базе данных в необходимом узле Доступности баз данных (Availability Databases) для данной группы доступности и явным образом присоединить необходимую базу данных к этой группе доступности (как это показано на Рисунок 6.21).
Рисунок 6.21
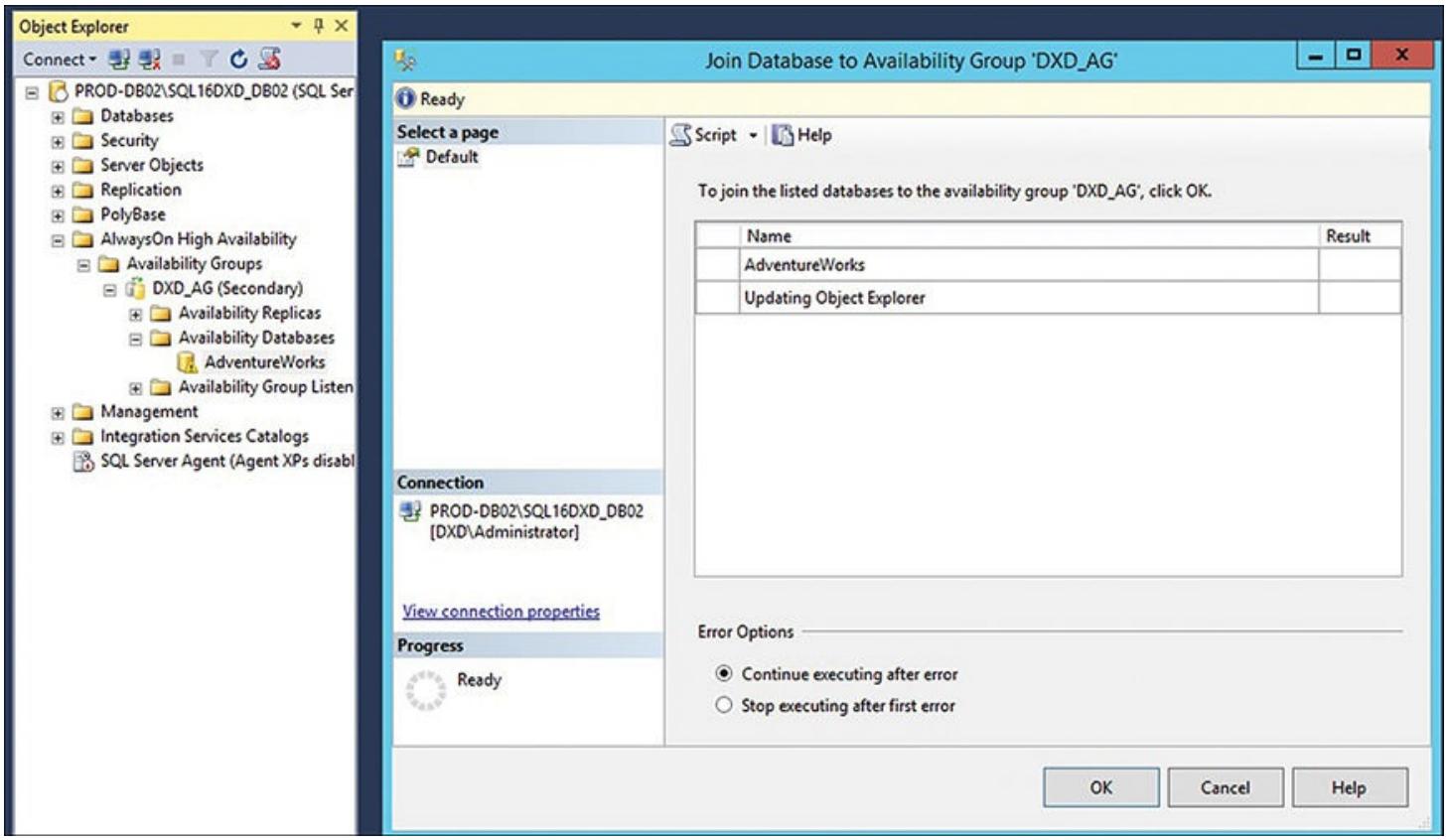
Явное присоединение определённой базы данных к вторичной реплике данной группы доступности
У вас теперь имеется полностью рабочеспособная группа доступности и перехватчик и, как вы можете
увидеть из просмотра Ролей диспетчера отказоустойчивого кластера (Failover Cluster Manager Roles, см.
Рисунок 6.22), данная группа доступности
DXD_AG исполняется и текущим узлом владельцем является
PROD-DB01. Вы также можете увидеть в нижней половине этого
просмотра текущее состояние ресурса данной группы доступности и имеющегося ресурса перехватчика.
Все демонстрируют работоспособность и отображают "Online".
Рисунок 6.22
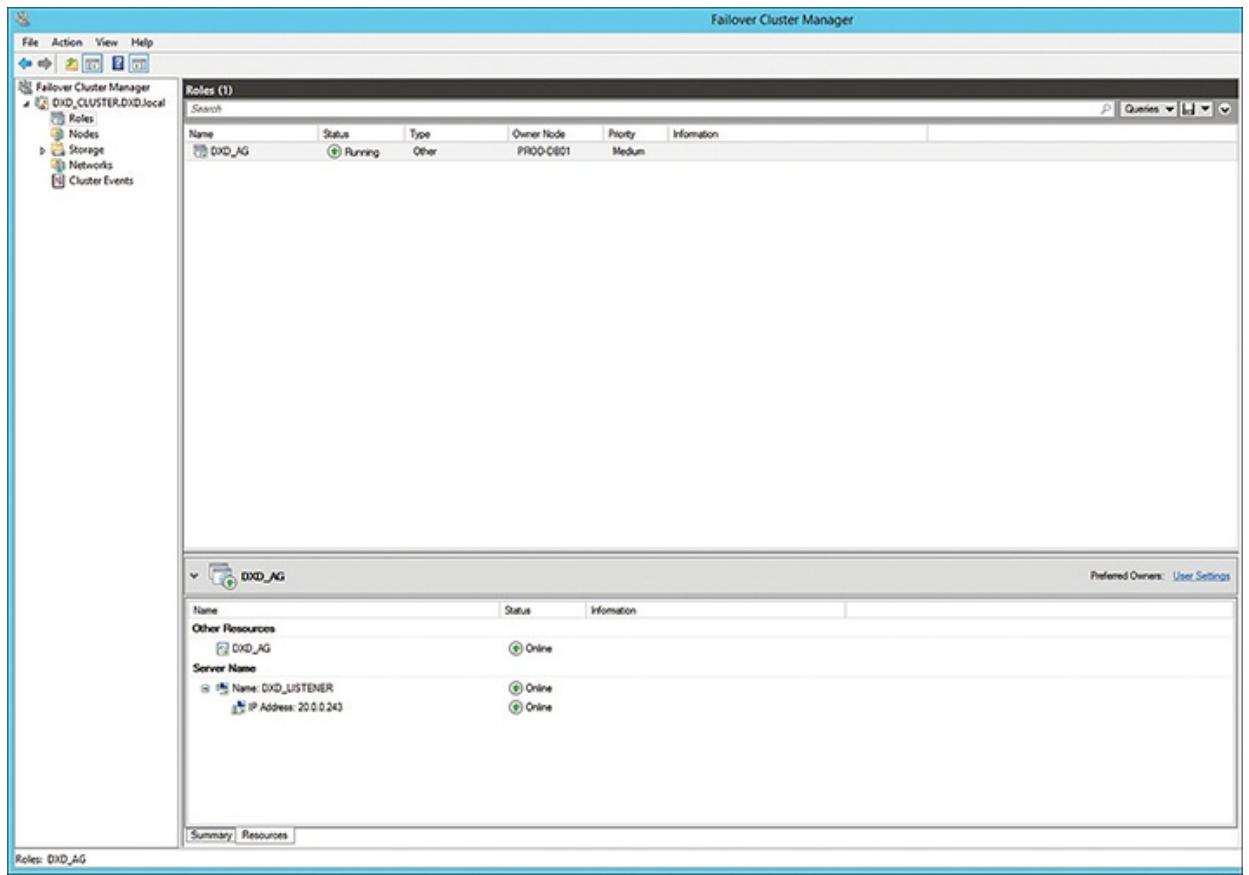
Просмотр отработанной вновь добавленной группы доступности и процесса отслеживания в Диспетчере отказоустойчивого кластера
Вы можете проделать некое быстрое тестирование при помощи SMSS на предмет соединения со своим новым
перехватчиком группы доступности как если бы он был сам собственно экземпляром сервера SQL. Как это отображено
на Рисунке 6.23, вы запускаете некий новый диалог
соединения, который определяет IP адрес перехватчика требуемой группы доступности
(20.0.0.243 с портом 1433). Вы
также можете определить необходимое имя перехватчика (DXD_LISTENER).
Пройдём далее и выполним соединение с применением любого из этих методов.
Рисунок 6.23
Подключение с применением имеющегося процесса отслеживания группы доступности (адрес IP
20.0.0.243, порт 1433)
После соединения вы можете открыть некое новое окно запроса (что также отображено на
Рисунке 6.23) и выбрать самые верхние 1000 строк
из таблицы CountryRegion в своеё схеме Person из установленной базы
данных AdventureWorks. Вы можете видеть, что эта база данных находится в некотором синхронном состоянии
и полностью работоспособна внутри данной конфигурации группы доступности. Вы в деле! Далее вы можете
проверить свойю отработку отказа Высокой доступности с первичной реплики на вторичную.
Вы можете отработать отказ изнутри сервера SQL кликнув правой кнопкой свою первичную реплику имеющегося
узла Группы доступности и выбрав Отработку отказа (Failover). Либо вы можете выполнить это из Диспетчера
отказоустойчивого кластера (Failover Cluster Manager). Отскочем назад в свой Диспетчер отказоустойчивого
кластера для узла PROD-DB01 и рассмотрим как вещи выглядят в нём.
Рисунок 6.24 показывает что
PROD-DB01 всё ещё является узлом владельцем для данной группы
доступности и когда вы кликаете правой кнопкой по этой группе доступности, вы можете выбрать перемещение
данной роли кластера (как это также отображено на
Рисунке 6.24. Перемещение данной роли кластера
на другой узел это всего лишь иной способ сообщения отработки отказа на иной узел.) Вы можете видеть все
остальные узлы в данной группе доступности, но в данном случае вы желаете отработать отказ на узел
PROD-DB02, так как это ваша вторичная реплика для отработки отказа.
Помните, что при отработке вами отказа соединение клиента разрывается и заетм устанавливается повторно к
имеющемуся новому узлу, и все находящиеся в полёте транзакции, которые не завершены в процессе данной
отработки отказа, вероятно придётся выполнить повторно. Кроме того, на
Рисунке 6.24 (внизу справа), вы можете видеть
текущее состояние роли с изменением её узла владельца на PROD-DB02
(вторичная реплика). Теперь вам необходимо проверить этот запрос SQL вновь.
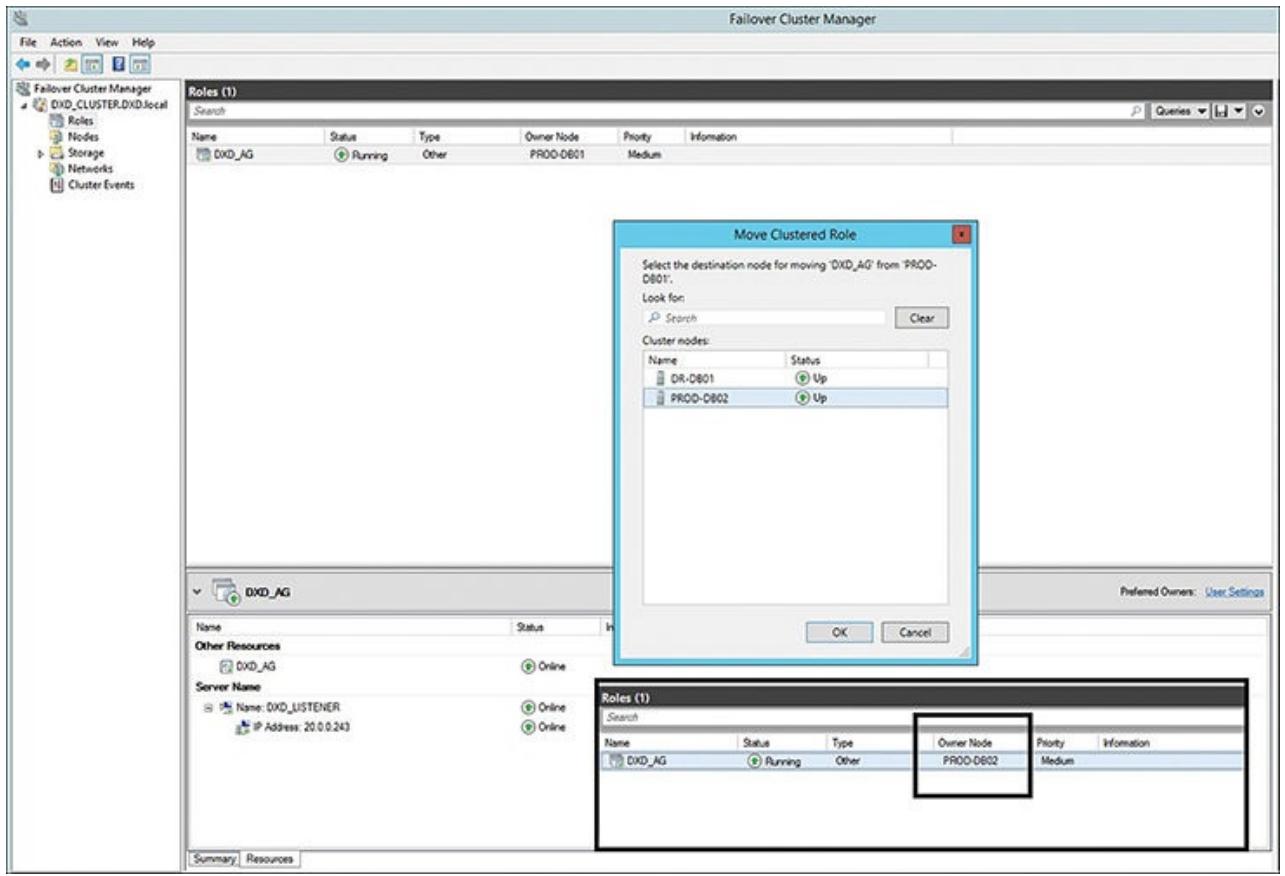
Рисунок 6.25 отображает новое исполнение того же самого запроса (через имеющийся перехватчик), что подтверждает успешность данного подключения клиента. Именно это является Высокой доступностью в работе!
Рисунок 6.25
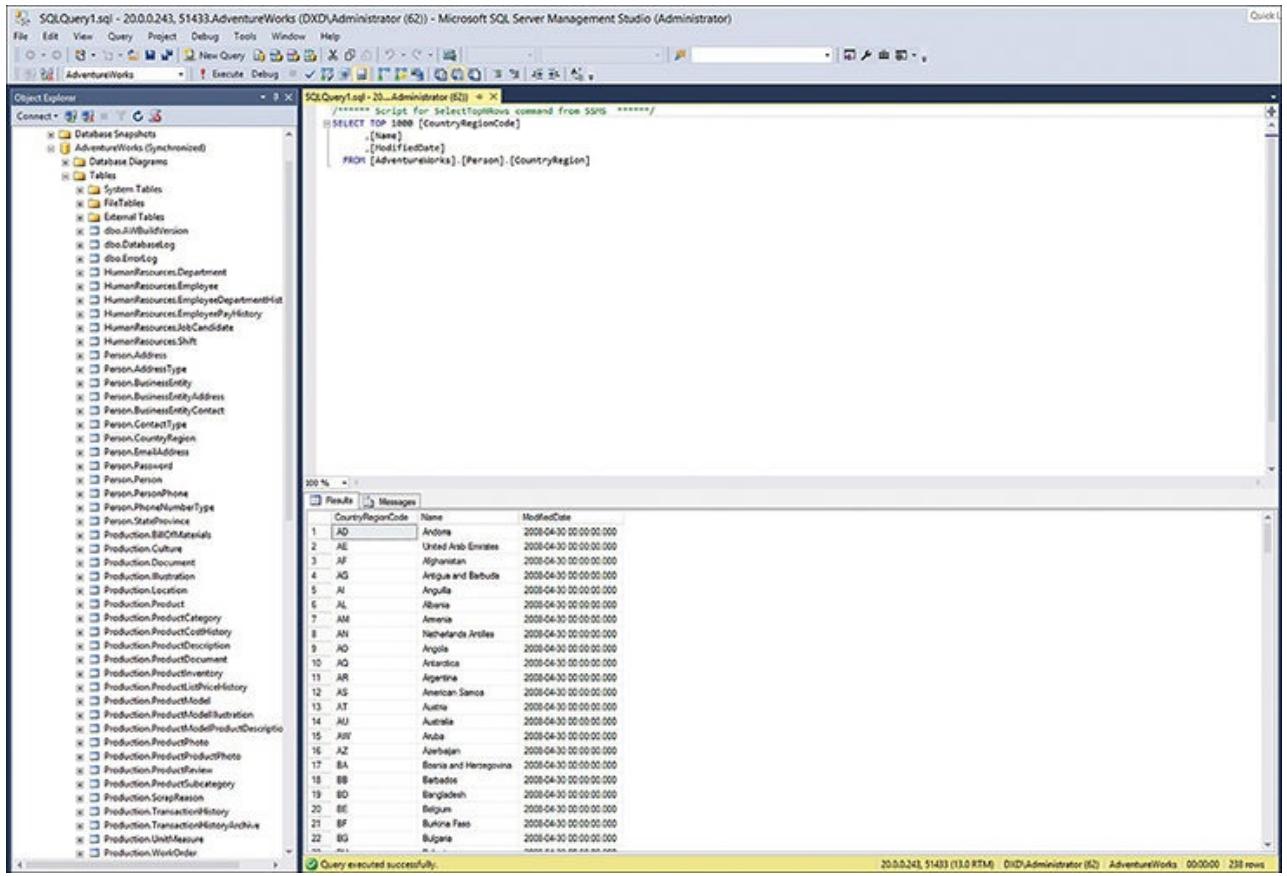
Успешное исполнение определённого запроса SQL с имеющегося процесса отслеживания, демонстрирующее Высокую доступность с точки зрения некоторого приложения
Для мониторинга (и отладки) в имеющуюся функциональность групп доступности AlwaysOn был добавлен целый ряд различных обзоров системы, некая панель управления, а также обзоры динамического управления. Вы можете открыть свою панель управления AlwaysOn кликнув правой кнопкой по нужной вам группе доступности и выбрав Отобразить панель управления (Show Dashboard). Вы можете применять эту панель управления для получения обзора одим взглядом текущего состояния жизнеспособности некоторой группы доступности AlwaysOn, её реплик доступности, а также баз данных. Вы можете применять эту панель управления для выполнения:
-
Выбора некоторой реплики для отработки отказа вручную.
-
Оценки утраты данных в случае, если вы принудительно выполните восстановление отказа.
-
Вычисления производительности синхронизации данных.
-
Вычисление воздействия на производительность синхронной фиксации вторичной реплики.
Данная панель управления также предоставляет ключевые состояния группы доступности и индикаторы производительности, включающие в себя:
-
Состояние раскрутки реплики
-
Режим и состояние синхронизации
-
Оценку утрваты данных
-
Оценку времени восстановления (подхват повторного исполнения)
-
Подробности реплики базы данных
-
Режим и состояние синхронизации
-
Время на восстановление журнала
Сервер SQL 2016 имеет обзоры динамического управления для групп доступности AlwaysOn, включая:
-
sys.dm_hadr_auto_page_repair -
sys.dm_hadr_cluster_networks -
sys.dm_hadr_availability_group_states -
sys.dm_hadr_database_replica_cluster_states -
sys.dm_hadr_availability_replica_cluster_nodes -
sys.dm_hadr_database_replica_states -
sys.dm_hadr_availability_replica_cluster_states -
sys.dm_hadr_instance_node_map -
sys.dm_hadr_availability_replica_states -
sys.dm_hadr_name_id_map -
sys.dm_hadr_cluster -
sys.dm_hadr_listener_states -
sys.dm_hadr_cluster_members
Наконец, каталог обзоров групп доступности AlwaysOn сервера SQL делает более простым просмотр ключевых компонентов всей настройки. Они включают в себя:
-
sys.availability_databases_cluster -
sys.availability_groups_cluster -
sys.availability_group_listener_ip_addresses -
sys.availability_read_only_routing_lists -
sys.availability_group_listeners -
sys.availability_replicas -
sys.availability_groups
|
| Замечание |
|---|---|
|
Для групп доступности является хорошим практическим приёмом снижение или удаление общего числа голосов кворума (веса) всех ваших вторичных асинхронных реплик (в особенности тех, которые вы применяете для восстановления при чрезвычайных ситуациях - DR, Disaster Recovery). Это может быть достаточно просто выполнено с помощью некоторого сценария PowerShell, который выглядит следующим образом: Вам также может понадобиться применить исправление ошибок для WSFC, если вы работаете со старой версией Windows server (Windows 2012 R2). Вы всегда можете быстро взглянуть через некий системный просмотр SELECT чтобы определить значения имеющихся кворума и голосов: |
Напомним из Главы 3, Выбор высокой доступности, что сценарий управления портфелем инвестиционного бизнеса (Сценарий 3) извлекает Высокую доступность выбирая избыточное хранение, WSFC и группы доступности AlwaysOn. Данное приложение управлени портфелем инвестиций в настоящее время располагается на некоторой основной ферме серверов в в сердце мирового финансового центра: в Нью- Йорке. Обслуживая только потребителей Северной Америки, это приложен ие предоставляет полную возможность выполнения всей торговле на биржах и возможности на всех финансовых рынках (Соединённых Штатов и международных), причём совместно с полныим портфелем отчислений по вкладам, истории операций и оценки авуаров. Первичными пользователями являются управляющие инвестициями для своих крупных потребителей. Покапка и продажа на бирже сотсавляет 90% дневной активности, помимо массовых авуаров, истории операций и оценочного отчёта, производимого после закрытия рынка. Три основных всплеска происходят в каждый день недели, которые производятся тремя основными торговыми рынками (Соединённые Штаты, Европа и Дальний Восток). На протяжении выходных дней данное приложение применяется для выработки отчётов долговременного планирования, а также переноса нагрузки бирж на предстоящую неделю.
Данная компания выбирает на каждом из серверов подход с избыточностью оборудования/ дисков, а также некую группу доступности Always со вторичной асинхронной репликой для восстановления в случае отказов, разгрузки резервного копирования базы данных и нагрузок составления отчётов как на имеющейся локально вторично реплике, так и во вторичной реплике Microsoft Azure. На самом деле, большая часть отчётов со временем перенаправляется на вторичную реплику Microsoft Azure; в среднем, данные отстают всего лишь на 10 секунд от своей первичной реплики. При данной технике построения теперь имеется множество вариантов смягчения рисков, а также нет сложности в сопровождении (см. Рисунок 6.26).
Когда данное решение Высокой доступности собрано воедино, оно превосходит цели задач Высокой доступности на регулярной основе. Также в результате получается великолепная производительность за счёт расчленения необходимых OLTP от составления отчётов; это очень часто встречающийся подход проектирования.
В данном сценарии доход на инвестированный капитал (ROI) может быть вычислен путём добавления необходимых инкрементальных стоимостей (или оценок) требуемых новых решений HA и их сопоставления с полной стоимостью простоя за некоторый период времени (в данном примере 1 год).
Общая инкрементальная стоимость обновления на данное решение Высокой доступности групп доступности AlwaysOn составляет приблизительно $222 000.
Теперь давайте пройдём полное вычисление ROI с такими инкрементальными стоимостями через общую стоимость времени простоя:
-
Стоимость сопровождения (на протяжении периода в 1 год):
-
$15k (оценка) - Ежегодная стоимость персонала системных администраторов (дополнительное время обучения такого персонала)
-
$50k (оценка) - Стоимость возобновления лицензий программного обеспечения (дополнительных компонентов HA; [3] ОС + [3] SQL сервер 2016)
-
-
Стоимость аппаратных средств:
-
$100k стоимость оборудования - Общая стоимость всех дополнительных технических средств в данном новом решении HA
-
$12k стоимость IaaS - То есть 12 x $1000/ месяц затрат на Microsoft Azur IaaS
-
-
-
$35k стоимость развёртывания - Общая стоимость развёртывания, тестирования, гарантии качества (QA), а также реализауции продуктов решения
-
$15k стоимость экспертизы HA
-
-
Стоимость времени простоя (на протяжении периода в 1 год):
-
Если вы выполняли отслеживание записей времени простоя на протяжении последнего года, воспользуйтесь этими данными; в противном случае произведите для данного вычисления некую оценку планируемого и внепланогвого времени простоя. Для данного сценария наша оценочная стоимость времени простоя за час составляет $150k/ час для данной компании финансового обслуживания. Ух ты, это громадная сумма!
-
Планируемое время простоя (стоимость потери выручки) = Планируемые часы простоя x стоимость часа простоя данной компании:
-
0.25% (оценка процентного соотношения планируемого простоя за 1 год) x 8760 часов в году = 21.9 часа запланированного простоя
-
21.9 часа (планируемого времени простоя) x $150k/ час (почасовая стоимость простоя) = $3 285 000/ год стоимость запланированного простоя. Однако, поскольку это было запланировано, не должно было никакого финансового планирования или торговли на бирже на протяжении этого времени, таким образом, смещаем его в значение около $0.
-
Не планируемое время простоя (стоимость потери выручки) = Не планируемые часы простоя x стоимость часа простоя данной компании:
-
0.15% (оценка процентного соотношения не планируемого простоя за 1 год) x 8760 часов в году = 13.14 часа не запланированного простоя
-
13.14 часа (не планируемого времени простоя) x $150k/ час (почасовая стоимость простоя) = $1 971 000/ год стоимость не запланированного простоя. Ух!
-
-
-
Итоговый доход на инвестиции (ROI):
-
Общая стоимость для получения данного решения Высокой доступности = $222 000 (за один год - слегка выше чем было установлено непосредственными инкрементальными стоимостями)
-
Общая стоимость времени простоя = $2 000 000 округлённо (за один год)
Данная инкрементальная стоимость составляет 13% от времени простоя за 1 год. Другими словами, общие инвестиции данного решения Высокой доступности окупят себя приблизительно за 1.2 месяца. С точки зрения бюджета, данная компания имеет заложенной в смету $900 000 на всю стоимость HA. Поэтому такое решение Высокой доступности в тренде снижения бюджета и далеко превосходит цели HA!
Что касается сервера SQL 2016, это всё о функциональности AlwaqysOn. Приспособление самого AlwaysOn и групп доступности было ошеломительным. Более старые, более сложные решения HA порваны вклочья данным ясным, высоко масштабируемым методом достижения пяти девяток и высокой производительности. Это в действительности следующее поколение Высокой доступности и масштабирования для имеющихся и новых уровней баз данных любого вида. Microsoft открыто предлагает всем своим потребителям, которые имеют реализованными доставку журналов, зеркалирования баз данных и даже построенные кластеры SQL, а также приглашает пользователей достичь групп доступности AlwaysOn в некоторый момент. Что касается Сценария 3, такие чрезвычайно требования доступности очень хорошо соответствуют тому, что приносят на стол группы доступности: короткие времена восстановления после отказов и очень ограниченная потеря данных. Что ещё более важно, производительность транзакций может сопровождаться разгрузкой от отчётов и резервного копирования на вторичные реплики.
{Прим. пер.: Обращаем ваше внимание на тот факт, что SQL Server 2017 привнёс собой новые методики организации HADR при помощи контейнеров и Kubernetes, подробнее в нашем переводе Главы 11. SQL Server и контейнеры из вышедшей в октябре 2018 в издательстве Apress книги Боба Вордса "Профессиональный SQL Server поверх Linux"}