Глава 4. Построение отказоустойчивого кластера
Содержание
В сегодняшних быстро меняющихся бизнес средах корпоративные вычисления требуют чтобы весь имеющийся набор технологий, применяемых для разработки, развёртывания и управления критически важными бизнес приложениями был высоко надёжным, масштабируемым и эластичным. Сфера данной технологии включает имеющиеся сетевую среду, полный аппаратный или облачный стек, все операционные системы на их серверах, те приложения, которые вы развёртываете, системы управления базой данных, а также всё между ними.
Корпорации сегодня должны иметь возможность предоставлять некое завершённое решение в отношении следующего:
-
Масштабируемость - Поскольку организация растёт, имеется потребность в росте вычислительной мощности. Все имеющиеся в расположении системы должны позволять некоторой организации усиливать имеющееся оборудование, а также быстро и легко добавлять вычислительную мощность при возникновении потребности.
-
Доступность - Поскольку организация всё больше полагается на информацию, критически важно чтобы эта информация была доступно постоянно и при любых обстоятельствах. Простои не приемлимы. Перемещение к пяти девяткам надёжности (то есть 99.999% времени в рабочем состоянии) является необходимым, причём это не мечта.
-
Возможность взаимодействия - раз организация растёт и развивается, то же самое делают и её информационные системы. Будет непрактично полагать, что некая организация не имеет много разнообразных источников информации. Для приложений становится всё более важным получать всю имеющуюся информацию вне зависимости от её расположения.
-
Надёжность - Некая организация настолько хороша, насколько таковыми являются её данные и информация. Критически важным является чтобы все предоставляющие эту информацию системы были пуленепробиваемыми.
Предполагается, что вы уже применяете или запросили какой- то определённый уровень основательных возможностей в отношении надёжности сетевой среды, оборудования и операционной системы. Однако имеются некоторые дальнейшие серьёзные компоненты операционной системы, которые могут быть включены для ещё большего увеличения вашей полосы Высокой доступности. Центром многих свойств HA в серверах WIndows является WSFC (Windows Server Failover Clustering, Отказоустойчивый кластер севера Windows). Так было повсюду на протяжении некоторого времени и, как вы увидите в нескольких последующих главах, он применяется на основном фундаментальном уровне для выстраивания более расширенных и интегрированных свойств для сервера SQL и Высокой доступности (HA). Испытанным решением HA применяющим WSFC является построение кластера SQL, которое создаёт избыточные экземпляры сервера SQL (для устойчивости к сбоям) и совместно используемое хранилище между всеми серверами. Такое совместно применяемое хранилище обычно является зеркалируемой тем или иным способом системой хранения (для надёжности). Вы можете применять кластер SQL для устойчивости экземпляра локального сервера, а затем включить его в более крупную топологию при помощи групп доступности AlwaysOn поверх некоторых узлов.
Для построения кластера SQL создаётся некий экземпляр отказоустойчивого кластера (FCI, failover cluster instance); существенно важным является, чтобы экземпляр сервера SQL устанавливался именно по узлам WSFC и, возможно, по множеству подсетей. В данной сетевой среде некий FCI является экземпляром сервера SQL, исполняющимся на каком- то отдельном компьютере; однако, имеющийся FCI предоставляет восстановление после отказа с одного узла WSFC на другой если данный текущий (активный) узел становится недоступным. Вы можете достичь многих из своих корпоративных запросов Высокой доступности просто и без особых затрат применяя WSFC, балансировку сетевой нагрузки (NLB, network load balancing), отказоустойчивый кластер сервера SQL и группы доступности AlwaysOn (или их комбинации).
{Прим. пер.: Обращаем ваше внимание на тот факт, что SQL Server 2017 привнёс собой новые методики организации HADR при помощи контейнеров и Kubernetes, подробнее в нашем переводе Главы 11. SQL Server и контейнеры из вышедшей в октябре 2018 в издательстве Apress книги Боба Вордса "Профессиональный SQL Server поверх Linux"}
WSFC предоставляет основное ядро функциональности кластера для построения кластера сервера SQL (описываемое в Главе 5, Построение кластера сервера SQL). WSFC упрощает предоставление надёжности уровня экземпляра SQL и также является некоторой важной частью вариантов имеющейся Высокой доступности FCI AlwaysOn и групп доступности AlwaysOn (при одновременном включении отказоустойчивости уровня базы данных). Главе 6, Группы доступности AlwaysOn сервера SQL охватывает основное ядро свойства групп доступности AlwaysOn. Прочими элементами, стоящими того, чтобы быть включёнными, являются:
-
Отказоустойчивое построение кластеров с множеством площадок - С помощью Windows Server 2008 и более поздних версий вы можете создавать некую конфигурацию отказоустойчивого кластера со множеством площадок (Multisite failover clustering), которая содержит узлы, распределённые по множеству физических площадок или центров обработки данных (ЦОД). Отказоустойчивые кластеры со множеством площадок также имеют название географически распределённых отказоустойчивых кластеров, эластичных (stretch) клстеров или кластеров со множеством подсетей. Отказоустойчивые кластеры со множеством площадок позволяют вам создавать некий отказоустойчивый кластер сервера SQL со множестовм площадок.
-
Требования WSFC для кластера SQL и AlwaysOn - Когда вы желаете настроить отказоустойчивый кластер SQL (без AlwaysOn), FCI AlwaysOn, и группы доступности AlwaysOn, вы должны вначале создать некий кластер WSFC, который использует эти серверы. Хорошей новостью является то, что это проще, чем это было раньше, благодаря имеющемуся Мастеру создания кластера (Create Cluster Wizard) в Диспетчере отказоустойчивого кластера.
-
Уменьшение имеющихся ограничений аппаратных средств и комплектующих - Раньше вам приходилось знать какие ограничения на оборудование и программные средства вы должны иметь при настройке конфигураций кластера SQL. При использовании WSFC и сервера SQL 2016, многие из этих ограничений были исключены, например, такие как узлы больше не обязаны быть в точности теми же самыми. Вам всё ещё придётся проверять имеющийся список совместимости, но этот список теперь на самом деле короткий.
-
Нет необходимости иметь выделенную сетевую карту (NIC) между узлами - Благодаря улучшениям WSFC больше не требуется некое выделенное сетевое соединение между имеющимися в кластере узлами. Вам всего лишь необходимо иметь какой- то верный путь из каждого узла, который приеняется для мониторинга всех узлов в данном кластере; он не обязан быть выделенным, тем самым упрощается всё необходимое оборудование и сам процесс настройки. Вы всё ещё можете применять некое выделенное соединение для чего- то с названием сигнала подтверждения жизнеспособности (heartbeat).
-
Более простая установка кластера SQL - некоторые небольшие изменения были выполнены в самой установке SQL и имеющихся вариантах установки SQL для более простого решения установки кластера SQL и выполнения этапов. Например, вы можете вначале настроить установку кластера SQL для каждого узла, а потом применить Расширенный мастер для выполнения необходимого конфигурирования кластера SQL.
Эти свойства и улучшения скомбинированы чтобы сделать некое простое предложение Высокой доступности установки отказоустойчивого кластера сервера SQL и групп доступности AlwaysOn. Они выводят большую часть риска реализации за пределы данного уравнения и делают данный тип установки доступным для более широкой установочной базы.
Проще говоря, кластер позволяет вам представлять себе два или более сервера как одно устройство вычислений, которое обладает надёжностью Высокой доступности множества узлов. Кластеризация является чрезвычайно мощным инструментом для достижения виртуально прозрачной Высокой доступности какую только вы можете поместить в свой кластер.
Имеются два подхода для реализации отказоустойчивого кластера: режимы активный/ пассивный и активный/ активный. В некоторой конфигурации активный/ пассивный один из узлов в имеющемся отказоустойчивом кластере является активным узлом. Другой узел бездействует пока, по какой- то причине, не случится отработка отказа (на имеющийся пассивный узел). При некоторой ситуации восстановления после отказа второй узел (пассивный узел) получает контроль над всеми управляемыми узлами, причём сам конечный пользователь даже не знает что произошло некое восстановление после отказа. Единственным исключением для этого состоит в том, что этот конечный пользователь (например, клиент SQL) может испытывать некое краткосрочное прерывание транзакции, поскольку отказоустойчивый кластер не может принимать на лету полномочия транзакций. Однако этот конечный пользователь (клиент) даже не должен беспокоиться об этих различных узлах. Рисунок 4.1 показывает типичную конфигурацию отказоустойчивого кластера с двумя узлами в неком режиме активный/ пассивный, в которой Node 2 является бездействующим (то есть пассивным). Данный тип настроек идеален для создания необходимых кластеров на основании сервера SQL и прочих конфигураций кластера. Помните, что сервер SQL это всего лишь некоторое приложение, которое будет работать внутри данного типа кластерной конфигурации и является осведомлённым о кластере. Другими словами, сервер SQL становится "ресурсом" внутри отказоустойчивого кластера, который может получать преимущества от такой нодёжности отказоустойчивого кластера.
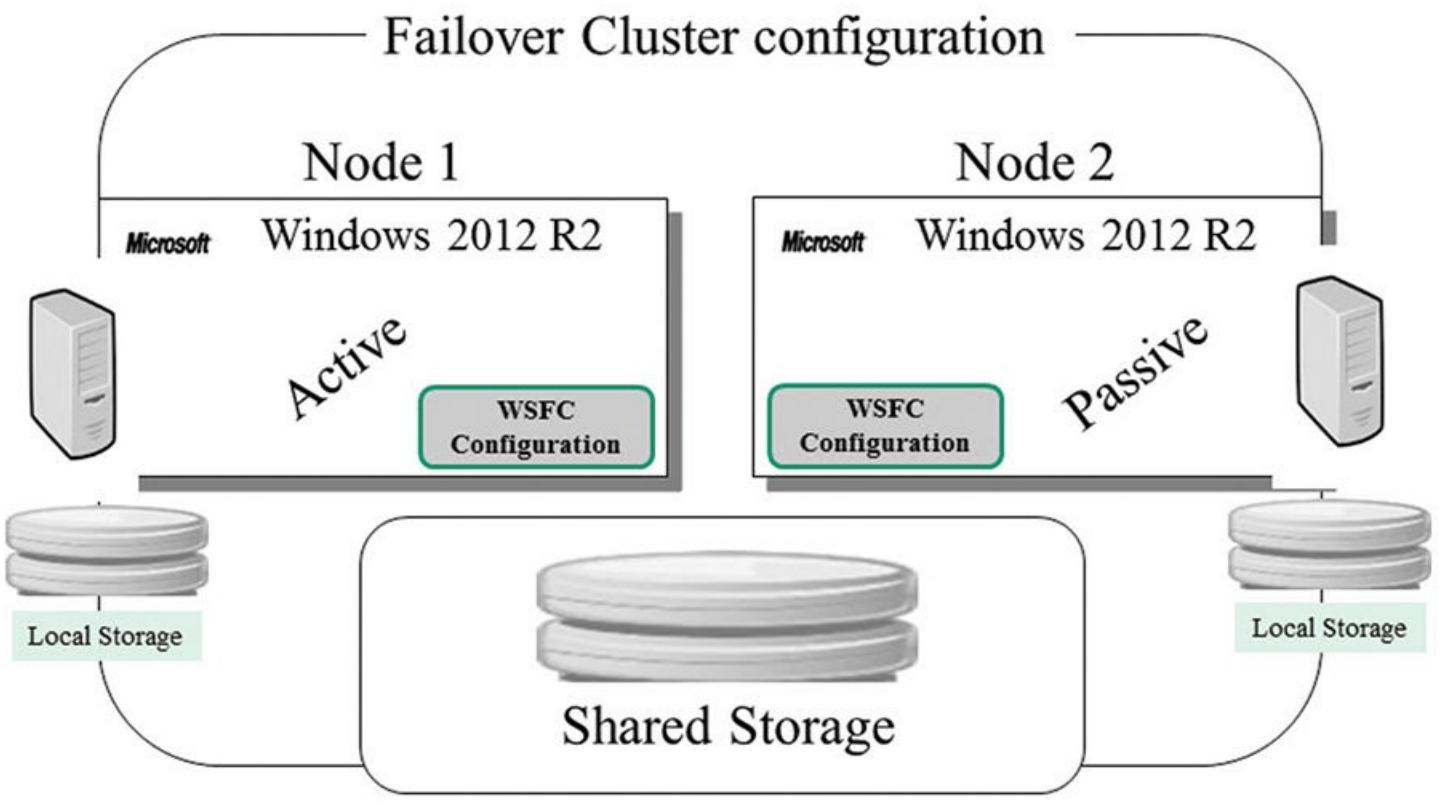
При некоторой конфигурации активный/ активный вы можете иметь активными оба узла в одно и то же время и размещая отдельные, исполняющие различные задания, экземпляры сервера SQL на каждом. В действительности это не является истинной совместимостью с RAC- подобным Oracle; вместо этого она просто применяет оба узла для мощности обработки различных рабочих нагрузок. Это даёт организациям с более ограниченными возможностями оборудования некую возможность использования кластерной конфигурации, которая может отрабатывать отказ на- или с- любого узла без необходимости устанавливать на площадке простаивающее оборудование, однако это вносит некую проблему нагрузки на каждый узел в случае возникновения отработки отказа. Поэтому будьте аккуратными с этим подходом.
Как уже упоминалось ранее, отказоустойчивый кластер SQL в действительносьти создаётся внутри (поверх) WSFC. WSFC, а не сервер SQL, способен обнаруживать отказы оборудования или программного обеспечения и автоматически смещать контроль над управляемыми ресурсами в некий жизнеспособный узел. Сервер SQL 2016 применяет отказоустойчивый кластер, основывающийся на имеющихся свойствах кдастера WFSC. Как уже отмечалось ранее, сервер SQL является полностью осведомлённом о кластере приложении и становится неким набором ресурсов, управляемых WSFC. Данный отказоустойчивый кластер совместно применяет некий общий набор ресурсов кластера, таких как хранилище кластера (то есть совместно писпользуемая система хранения).
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Вы можете установить сервер SQL на столько серверов, на сколько вы пожелаете; общее число ограничивается только самой лицензией операционной системы и редакцией сервера SQL, которые вы приобрели. Однако вам не стоит перегружать WSFC более чем 10 или около того серверами SQL для управления, если вы хотите помочь ему. |
Некий отказоустойчивый кластер сервера является группой двух или более отдельных серверов исполняющих WSFC и работающих совместно как какая- то отдельная система. Такой отказоустойчивый кластер, в совю очередь, предоставляет высокую доступность, масштабируемость, а также управление ресурсами и приложениями. Другими словами, некая группа серверов физически соединена посредством оборудования коммуникации (сетевой средой), совместно используемое хранилище (через соединения SCSI или Fibre Channel {Прим. пер.: а с применением современных распределённых систем хранения, таких как Starage Spaces, Ceph, ZFS и тому подобных и обычного сетевого интерконнекта с примененеием сетей TCP/IP или протокола сокетов, в том числе с использованием RDMA, а именно, Ethernet, Infiniband, OmniPath, Ангара и т.п.}), а также применяет WSFC для связывания всех их воедино в у правляемые ресурсы.
Отказоустойчивые кластеры сервера могут консервировать доступ клиента к приложениям и ресурсов в процессе отказов и планируемых отключений. Они предоставляют отказоустойчивость уровня экземпляра сервера. Если один из серверов в некотором кластере является недоступным из- за отказа или работ по сопровождению, ресурсы и приложения перемещаются (отрабатывают отказ) на другой доступный узел кластера.
Кластеры применяют особый алгоритм для определения некоторого отказа, а также применяют политики отработки отказа для определения того, как отрабатывать исполнение с какого- то отказавшего сервера. Эти политики также определяют как некий сервер должен применяться для востановления в данном кластере когда он станет доступным вновь.
Хотя кластер и не гарантирует непрерывность работы, он в действительности предоставляет достаточную доступность для большинства критически важных приложений и является неким строительным блоком большого числа решений с Высокой доступностью. WSFC может отслеживать приложения и ресурсы и автоматически распознавать и выполнять восстановления из большинства учловий отказа. Такая возможность предоставляет большую гибкость для управления рабочей нагрузкой внутри некоторого кластера и улучшает общую доступность всей системы. Осведомлённые о кластере технологии - такие как сервер SQL, Очереди сообщений Microsoft (MSMQ, Microsoft Message Queuing), Распределённый координатор транзакций (DTC, Distributed Transaction Coordinator), а также совместное применение файлов - уже были запрограммированы для работы внутри WSFC.
WSFC всё же имеет некоторую аппаратную и программную совместимость, о которой стоит беспокоиться, однако встроенный Мастер проверки правильности кластера позволяет вам определить будет ли ваша конфигурация работать. Кроме того, FCI сервера SQL не поддерживаются там, где имеющиеся узлы кластера также являются контроллерами домена.
Давайте рассмотрим немного более близко конфигурацию кластера активный/ пассивный с двумя узлами. Через определённые интервалы, имеющие название временных срезов (time slices), узлы нашего отказоустойчивого кластера выполняют определение являются ли они всё ещё жизнеспособными. Если определяется отказ имеющегося активного узла (он не работает), инициируется некая отработка отказа и другой узел принимает на себя работу отказавшего узла. Каждый физический сервер (узел) применяет отдельные сетевые адаптеры для своего собственного сетевого соединения. (Тем самым, всегда имеется по крайней мере одна возможность рабочего сетевого соединения для данного кластера на протяжении всего времени, как это показано на Рисунке 4.2).
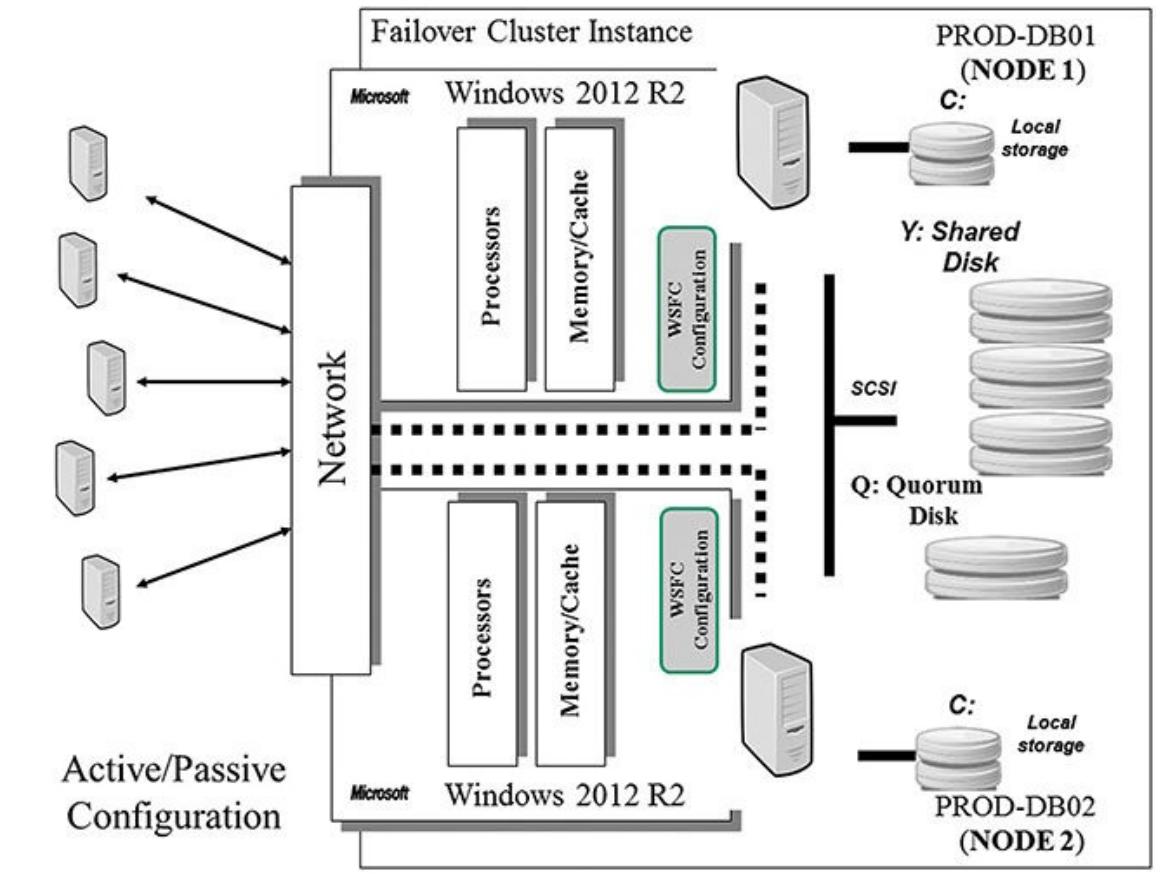
Совместно используемый дисковый массив является некоторой коллекцией физических дисков (SCSI RAID или соединённые Fibre Channel диски {Прим. пер.: а также диски, объединяемые при помощи технологии Storage Spaces или ей подобной- Ceph, ZFS и т.д}), к которым осуществляет доступ имеющийся кластер и управляется в качестве ресурса. WSFC поддерживает не разделяющие ничего (shared nothing) дисковые массивы, в которых только один узел может владеть заданным ресурсом в определённый момент времени. Всем прочим узлам запрещён доступ пока они не владеют этим ресурсом. Это защищает имеющиеся данные от перезаписи в случае, когда два компьютера имеют доступ к одному и тому же диску одновременно.
Определённый диск кворума является неким логическим диском, спроектированном в совместно используемом дисковом массиве для WSFC. Этот непрерывно обновляемый диск содержит информацию о текущем состоянии кластера. Если этот диск становится испорченным или разрушается, вся установка кластера также становится испорченной или разрушенной.
|
| Замечание |
|---|---|
|
Обычно (и как часть настройки диска Высокой доступности) данный диск квроума должен быть изолирован на некий диск полностью и должен быть снабжён зеркалом чтобы гарантировать что он доступен кластеру постоянно. Без него кластер не поднимется совсем и вы не сможете получить доступ к базам данных SQL. |
Архитектура WSFC требует некоего отдельного ресурса кворума в своём кластере, который применяется как определённая схема разрешения кофликтов во избежание сценариев расщепления сознания. Некий сценарий расщепления сознания (split-brain scenario) происходит когда все имеющиеся коммуникационные соединения между двумя или более узлами кластера отказывают. В этом случае ваш кластер может разделиться на два или более разделов, которые не могут взаимодействовать друг с другом. WSFC гарантирует, что даже при этих обстоятельствах некий ресурс доставляется в Интернет только на одном узле. Если бы все различные разделы данного кластера предоставляли бы все некий заданный ресурс в сеть, это бы нарушало гарантии кластера и было бы потенциальным источником разрушения целостности данных. Когда определённый кластер разделён на части, в качестве некоторого арбитра применяется имеющийся кворум. Именно тому разделу, который владеет ресурсом кворума, разрешается продолжать работу. Все остальные разделы данного кластера сообщают о получении "утраты кворума" и WSFC, а также все размещённые на этих узлах ресурсы, которые не являются частью раздела, обладающего кворумом, завершают работу.
Такой ресурс кворума является ресурсом класса хранения и, помимо того, что он является основным арбитром в сценарии расщепления сознания, он применяется для хранения окончательной версии данной конфигурации кластера. Чтобы обеспечивать то, что этот кластер имеет всегда самую последнюю информацию о настройках кластера, вы обязаны развернуть дааный ресурс кворума в некоторой конфигурации дисков с Высокой доступностью (применяя зеркало, тройное зеркало или RAID 10, по крайней мере) {Прим. пер.: подробнее, см. Кворум кластера}.
Представление о кворуме как о некотором отдельном совместно используемом дисковом ресурсе означает, что имеющаяся подсистема хранения обязана взаимодествовать с присутствующей инфраструктурой кластера для предоставления определённой иллюзии какого- то отдельного дискового хранилища с очень ограниченной семантикой. Хотя такой диск кворума сам по себе может быть сделан обладающим Высокой доступностью при помощи RAID или зеркалирования, имеющийся порт контролера может быть единой точкой отказа. Кроме того, если некое приложение ненамеренно разрушает имеющийся диск кворума, или некий оператор изымает данный диск кворума, весь кластер становится недоступным.
Данная ситуация может быть разрешена при помощи некоторого набора опций большинства узлов как какого- то отдельного ресурса кворума с точки зрения WSFC. В данном наборе имеющийся журнал кластера и информация о настройках сохраняются на множестве дисков по всему кластеру. Некий новый ресурс набора большинства узлов гарантирует, что имеющиеся данные настройки кластер, хранимые на таком множестве большинства узлов остаётся согласованным по всем имеющимся различным дискам.
Все диски, которые выстраивают облако множества большинства узлов, в принципе, могут быть локальными дисками, физически подключёнными к самим узлам, или дисками в некоторой общей стуктуре хранения (то есть некоторая коллекция совместно используемых устройств SAN, storage area network - сети хранения данных, подключаемых коомутирующей структурой или арбитражной логикой Fibre- Channel петли SAN). Именно в реализации множества большинства узлов, предоставляемом как часть WSFC в Windows Server 2008 и более поздних версиях, каждый узел в имеющемся кластере применяет некий каталог в своей собственной локальной дисковой системе для хранения таких данных кворума, как это показано Рисунке 4.3.
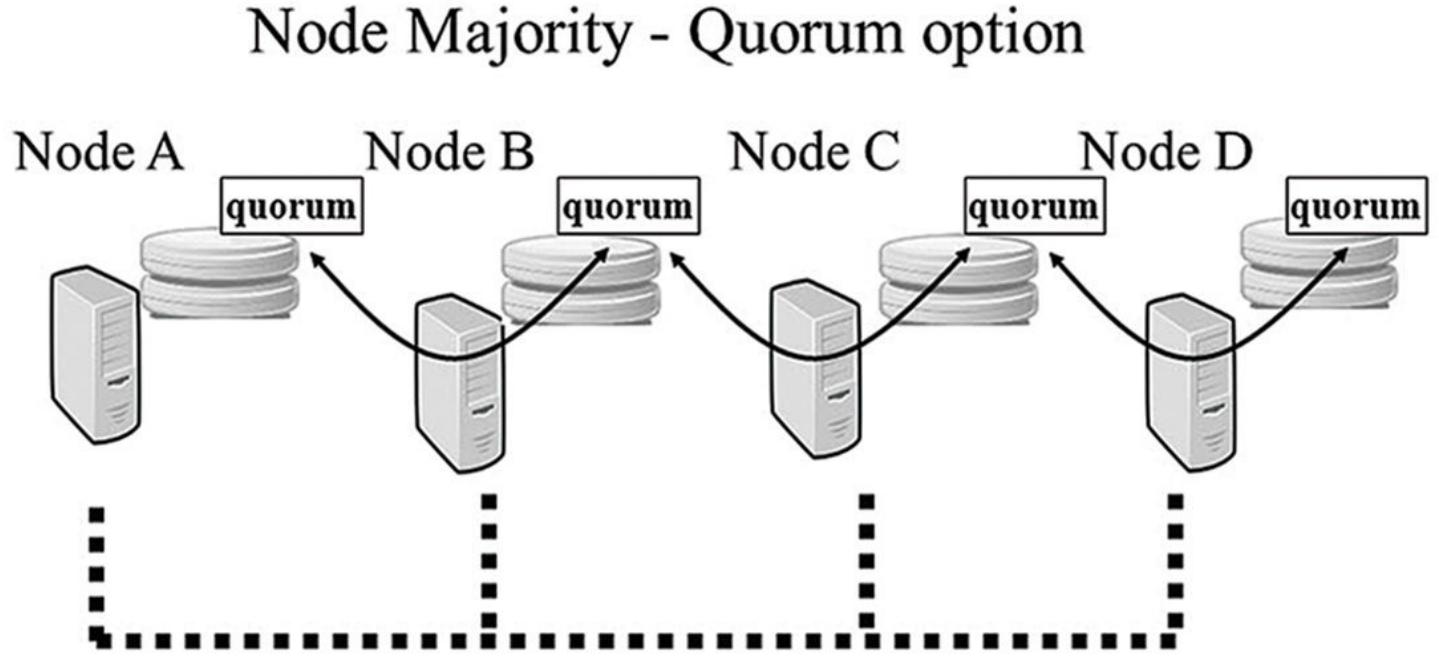
Если имеющаяся конфигурация определённого сервера изменяется, все изменения отражаются по всем различным дискам. Такое изменение рассматривается как принятое (то есть сделанное постоянным) только если это изменение сделано для некоторого большинства имеющихся узлов (то есть, [Общее число настроенных в кластере узлов]/2 +1). Таким образом, некоторое большинство из всех узлов имеет какую- то актуальную копию данного кворума данных. WSFC сам по себе запускакется только если некоторое большинство имеющихся в настоящее время узлов, настроенных как часть данного кластера, запущены и работают.
Если имеется меньшее число узлов, данный кластер сообщает что он не имеет кворума и, таким образом, WSFC ожидает (пытается повторно запуститься) пока дополнительные узлы не попытаются присоединиться. Тем самым, из- за того что актуальная конфигурация записана на большинстве имеющихся узлов, вне зависимости от отказавших узлов, данный кластер всегда гарантирует что он запустится с большей частью актуальных настроек.
В Windows 2008 и более поздних версиях, возможны некоторые дополнительные конфигурации диска кворума, которые решают различные стратегии голосования и также поддерживают географически разделённые кластерные узлы и они таковы:
-
Большинство узлов - Согласно данной конфигурации более половины изи всех голосующих узлов в данном кластере должны голосовать утвердительно для жизнеспособности этого кластера.
-
Большинство узлов и совместных файлов - Данная конфигурация аналогична конфигурации Большинства узлов с тем отличием, что некий совместный файл также настроен как свидетельствующий голос, причём связь с любого узла с этим совместным ресурсом также исчисляется как утвердительный голос. Для жизнеспособности данного кластера более половины из всех возможных голосов должна быть утвердительной.
-
Большинство узлов и диска - Данная конфигурация аналогична конфигурации Большинства узлов с тем отличием, что некий совместный дисковый ресурс кластера также настроен как свидетельствующий голос, причём связь с любого узла с этим совместным ресурсом также исчисляется как утвердительный голос.
-
Только диск - При использовании данной конфигурации некий совместный дисковый ресурс кластера спроектирован как некий свидетель, причём связь любого узла с этим совместным диском исчисляется как некий утвердительный голос.
Вы можете применять некую решающую технологию, имеющую название балансировки сетевой нагрузки (NLB, network load balancing), чтобы гарантировать что некий сервер всегда в состоянии обрабатывать запросы. NLB работает посредством разделения входящих кли ентских запросов по некоторому числу подключённых совместно серверов для поддержки некоторого определённого приложения. Некоторым типовым примером является применение NLB для обслуживания приходящих на ваш вебсайт посетителей. По мере того как всё больше посетителей приходит на ваш сайт, вы можете инкрементально увеличивать ёмкость добавляя серверы. Такой тип расширения часто именуется как программное масштабирование или горизонтальное масштабирование. это показано Рисунок 4.4 иллюстрирует данную архитектуру расширения кластера с помощью NLB.
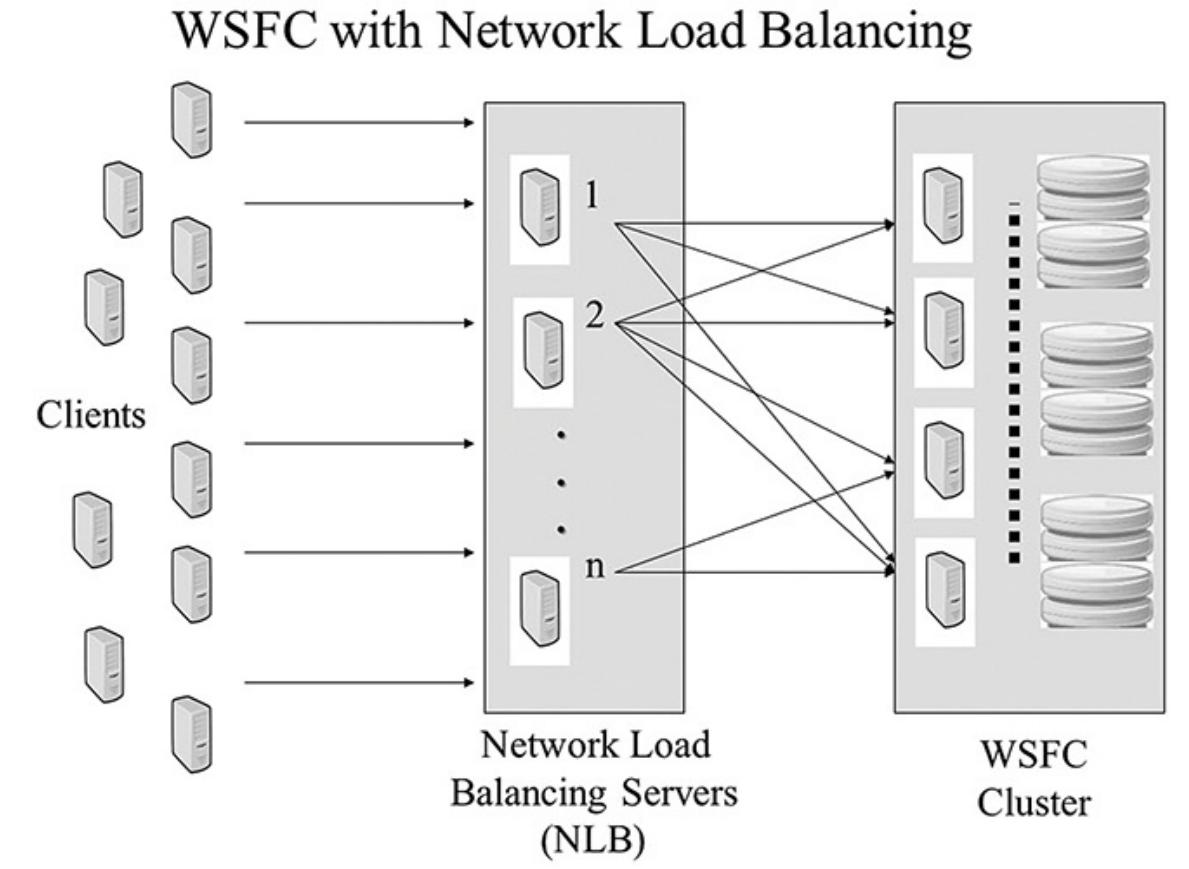
Применяя совместно технологии построения кластера WSFC и NLB вы можете создавать некую инфраструктуру с n- уровнями. Например, вы можете создать некое приложение электронной коммерции с n- уровнями развернув NLB по всей ферме серверов интерфейса и применяете кластер WSFC в основе для вашего приложения сферы деятельности, например, собранные в кластер ваши базы данных сервера SQL. Такой подход даёт вам основные преимущества с почти линейным масштабированием без единой точки отказа в сервере или приложении. Всё это, собранное со всеми наилучшими практиками стандартов отрасли для разработки сетевых инфраструктур с Высокой доступностью, может гарантировать, что ваш основанный на Windows с включённым доступом через Интернет бизнес будет в рабочем состоянии всё время и сможет быстро масштабироваться в ответ на запрос. В данную топологию могут добавляться другие уровни, такие как некий уровень центра приложения, который применяет балансировку нагрузки компонентов. Это в последующем расширяет имеющиеся кластер и масштабирование богатсвом кандидатов приложений которые могут получить преимущества от данного типа архитектуры.
Верная практика установки включает в себя документирование всех необходимых адресов протокола Интернета (IP), сетевых имён, определений домена, а также ссылок серверов SQL для установки некоторой конфигурации отказоустойчивого кластера сервера SQL с двумя узлами (настроенного в режиме активный/ пассивный) или некоторой конфигурации групп доступности AlwaysOn прежде чем вы установите свои настройки кластера.
Вначале вы указываете сами серверы (узлы), например, PROD-DB01 (в
качестве своего первого узла) и PROD-DB02 (как свой второй узел), а
также определённое имя группы кластера, DXD_Cluster.
Сам кластер управляет следующими ресурсами:
-
Физическими дисками (
Cluster Disk 1предназначен для необходимого диска кворума,Cluster Disk 2предназначается для совместно используемых дисков и так далее) -
IP адрес кластера (например,
20.0.0.242) -
Имя кластера (сетевое имя, например,
DXD_Cluster) -
DTC (не обязательно)
-
название домена (например,
DXD.local)
Для документирования кластера SQL вам потребуется следующее:
-
Виртуальный IP адрес самого сервера SQL (например,
192.168.1.211) -
Виртуальное имя (сетевое имя) этого сервера SQL (например
VSQL16DXD) -
Экземпляр сервера SQL (например,
SQL16DXD_DB01) -
Агенты сервера SQL
-
Службы SSIS сервера SQL (если они требуются)
-
Экземпляры службы полнотекстового поиска сервера SQL (если они нужны)
Для документирования групп доступности AlwaysOn вам потребуется следующее:
-
IP адрес имеющегося перехватчика группы доступности (например,
20.0.0.243) -
Имя перехватчика группы доступности (например
DXD_LISTENER) -
Имя группы доступности (например,
DXD_AG) -
Экземплярs сервера SQL (например,
SQL16DXD_DB01,SQL16DXD_DB02,SQL16DXD_DR01) -
Агенты сервера SQL
-
Службы SSIS сервера SQL (если они требуются)
-
Экземпляры службы полнотекстового поиска сервера SQL (если они нужны)
После того, как вы успешно устанеовите, настроите и проверите свой отказоустойчивый кластер (в WSFC), вы можете добавить необходимые компоненты сервера SQL в качестве ресурсов, которые будут управляться WSFC. Вы можете узнать об установке кластера SQL и групп доступности AlwaysOn в Главе 5, Построение кластера сервера SQL и Главе 6, Группы доступности AlwaysOn сервера SQL.
В своём Windows 2012 R2 сервере или более поздней версии, вам необходимо высветить Диспетчер сервера Windows и установить имеющуюся функциональность отказоустойчивого кластера во свех подлежащих применению экземплярах. Пройдите следующие шаги:
-
В своём диспетчере сервера Windows выберите Добавление ролей и свойств из ниспадающих Задач в нижнем правом углу (см.Рисунок 4.5).
Рисунок 4.5
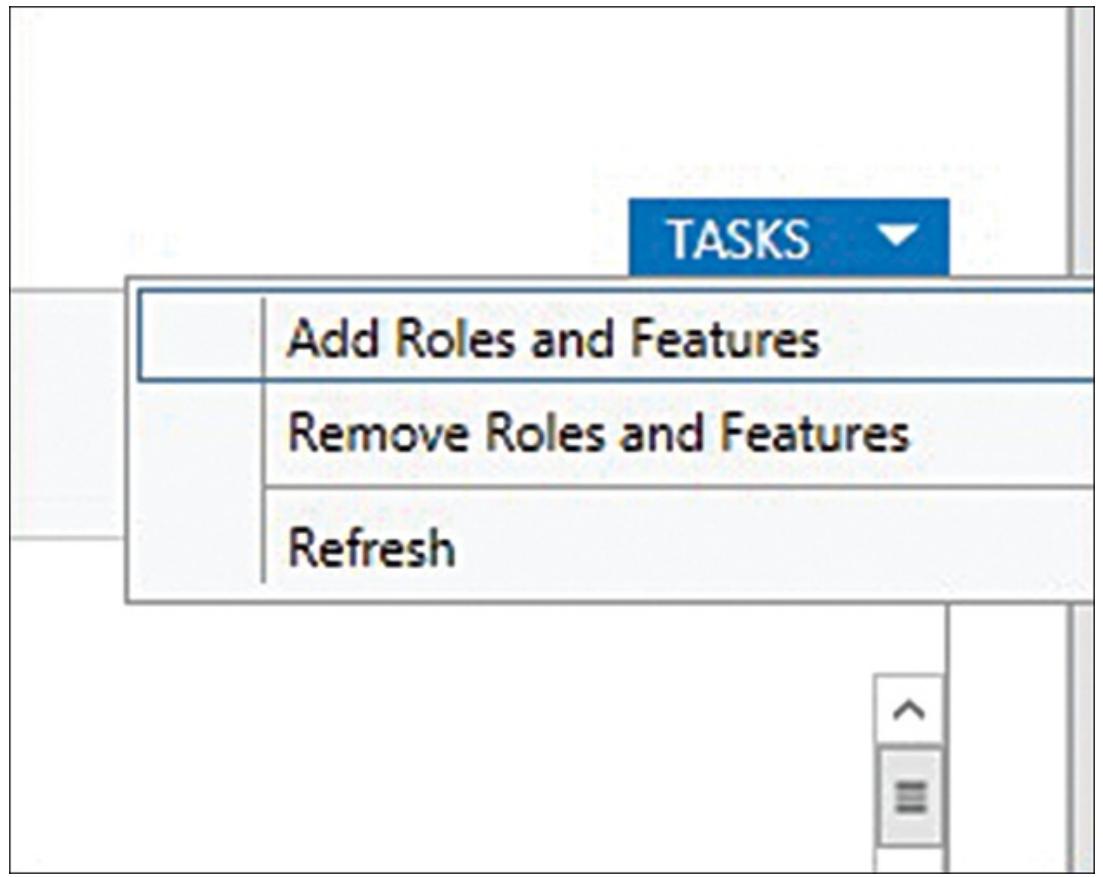
Применение диспетчера сервера Windows 2012 R2 для добавления отказоустойчивого кластера в некий локальный сервер
-
В своём следующем блоке диалога в мастере Добавления Ролей и свойств выберите в качестве установки либо установку на основе ролей, либо установку на основе свойств. Вам не требуется удалённая установка. Когда вы выполните выбор (обычно на основании свойств), кликните Далее.
-
Выберите верный целевой сервер (получатель) и затем кликните Далее.
-
В появившемся диалоге прокруыиайте вниз пока не отыщите опции Отказоустойчивого кластера, проверьте их, как это показано на Рисунке 4.6.
Рисунок 4.6
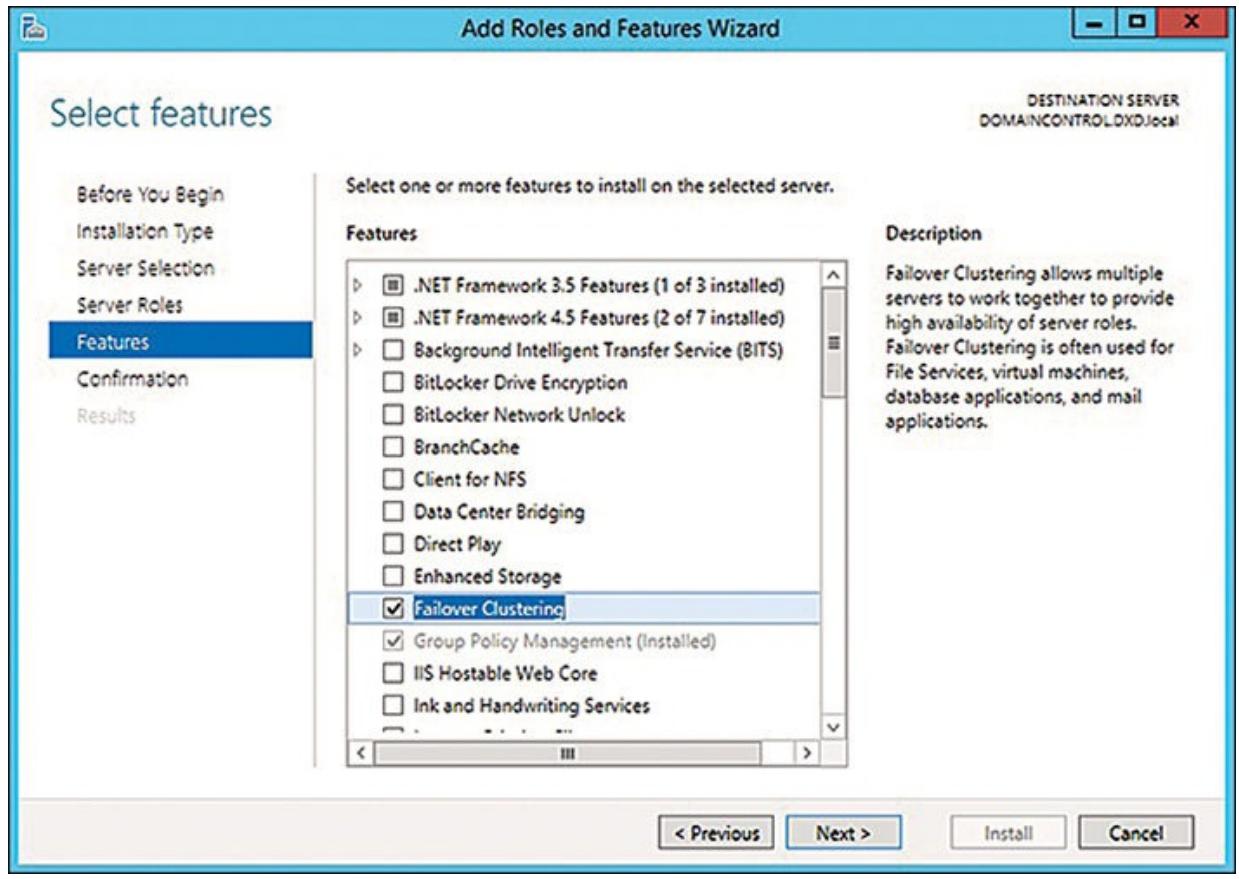
Применение диспетчера сервера Windows 2012 R2 для добавления отказоустойчивого кластера в некий локальный сервер
Рисунок Рисунок 4.7 показывает блок окончательного диалога подтверждения установки, который появится перед тем как функция включится. Когда она установится, вам необходимо проделать то же самое на всех остальных узлах (серверах), которые будут частью вашего кластера. Когда вы завершите это, вы сможете высветить свой Диспетчер отказоустойчивого кластера и запустить настройку кластера с этии двумя узлами.
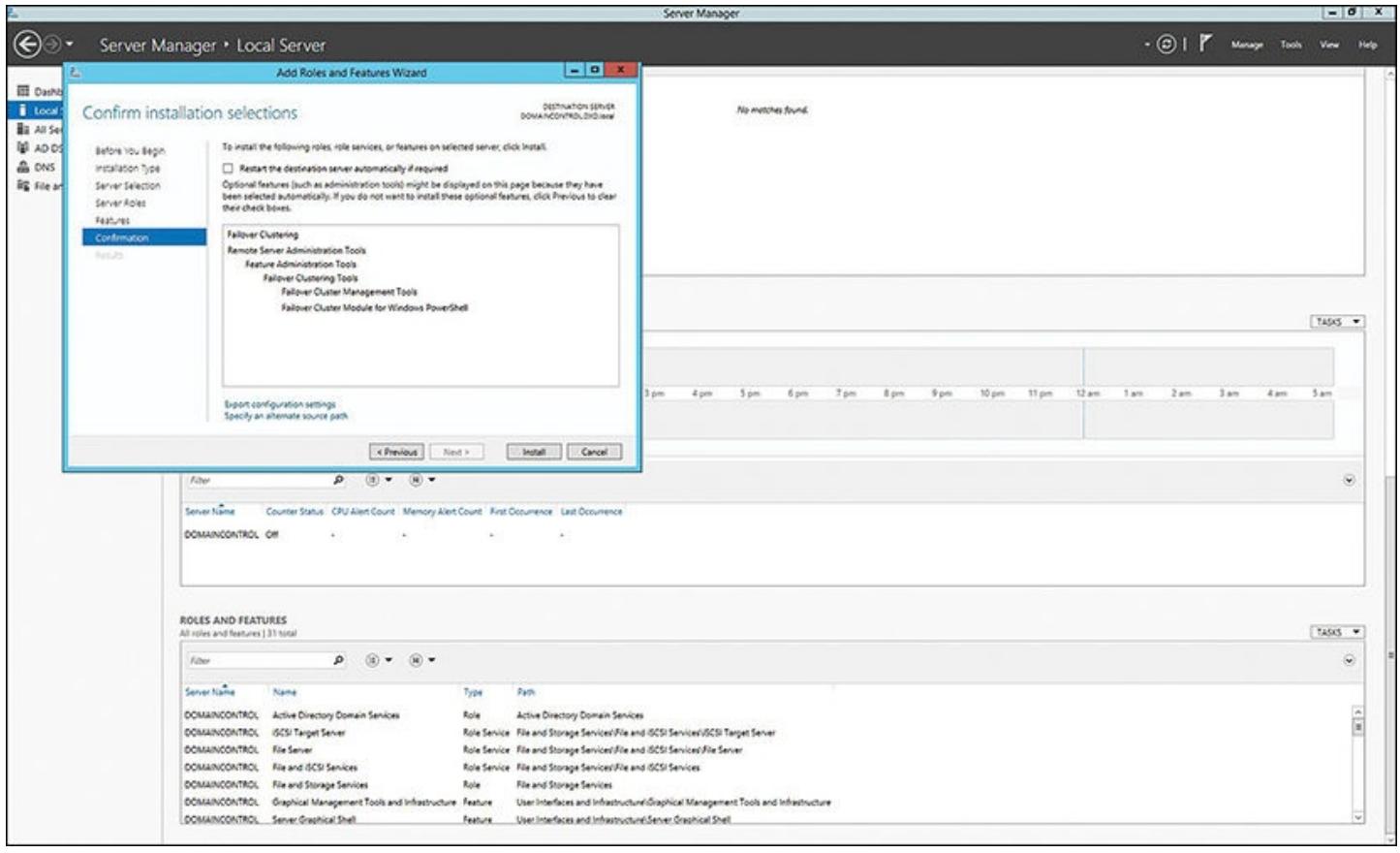
Имея установленным свойство Отказоустойчиого кластера на своём сервере, вы готовы воспользоваться Мастером проверки правильности настроек (см. Рисунок 4.8) чтобы определить все необходимые узлы, которые будут частью вашего кластера из двух узлов и проверить что они верно настроены для применения.
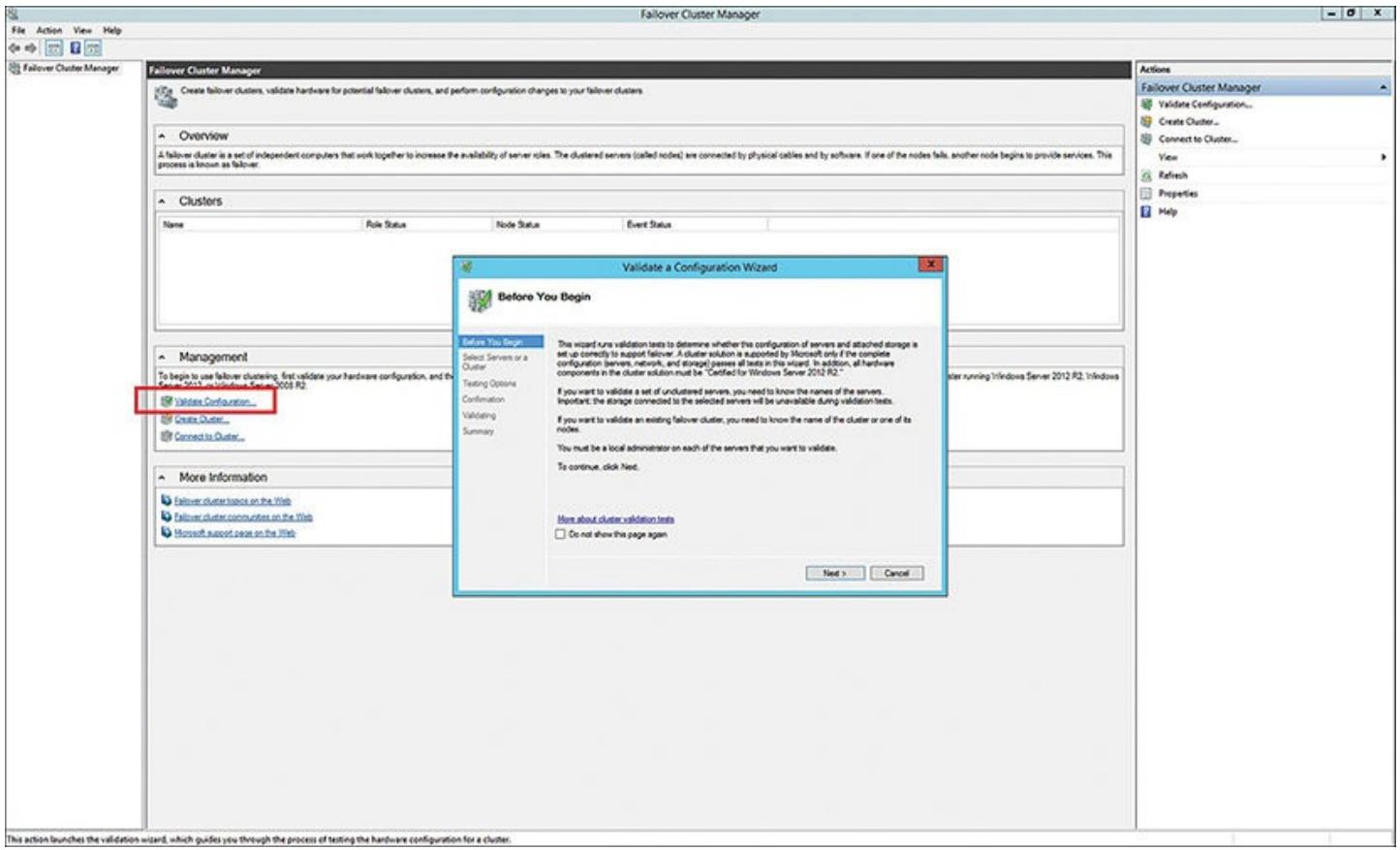
Данный кластер должен пройти все проверки. Когда его валидация завершится, вы можете создать свой кластер, присвоить ему название, и привести все узлы и ресурсы в рабочее состояние в данном кластере. Исполните следующие шаги:
-
В самом первом диалоге в своём мастере определите все серверы, применяемые в данном кластере. Для этого кликните кнопку Прсомотр справа от блока Введите имя и определите два нужных вам сервера:
PROD-DB01иPROD-DB02(см. Рисунок 4.9). Затем кликните OK.
-
В появившемся окне диалога задайте проведение всех тестов проверки для того чтобы убедиться что вы не упустили какие- либо проблемы в данном критически важном процессе валидации. Рисунок 4.10 отображает успешное завершение проверки отказоустойчивого кластера для конфигурации с двумя узлами. Все отмечено как "Validated".
Рисунок 4.10
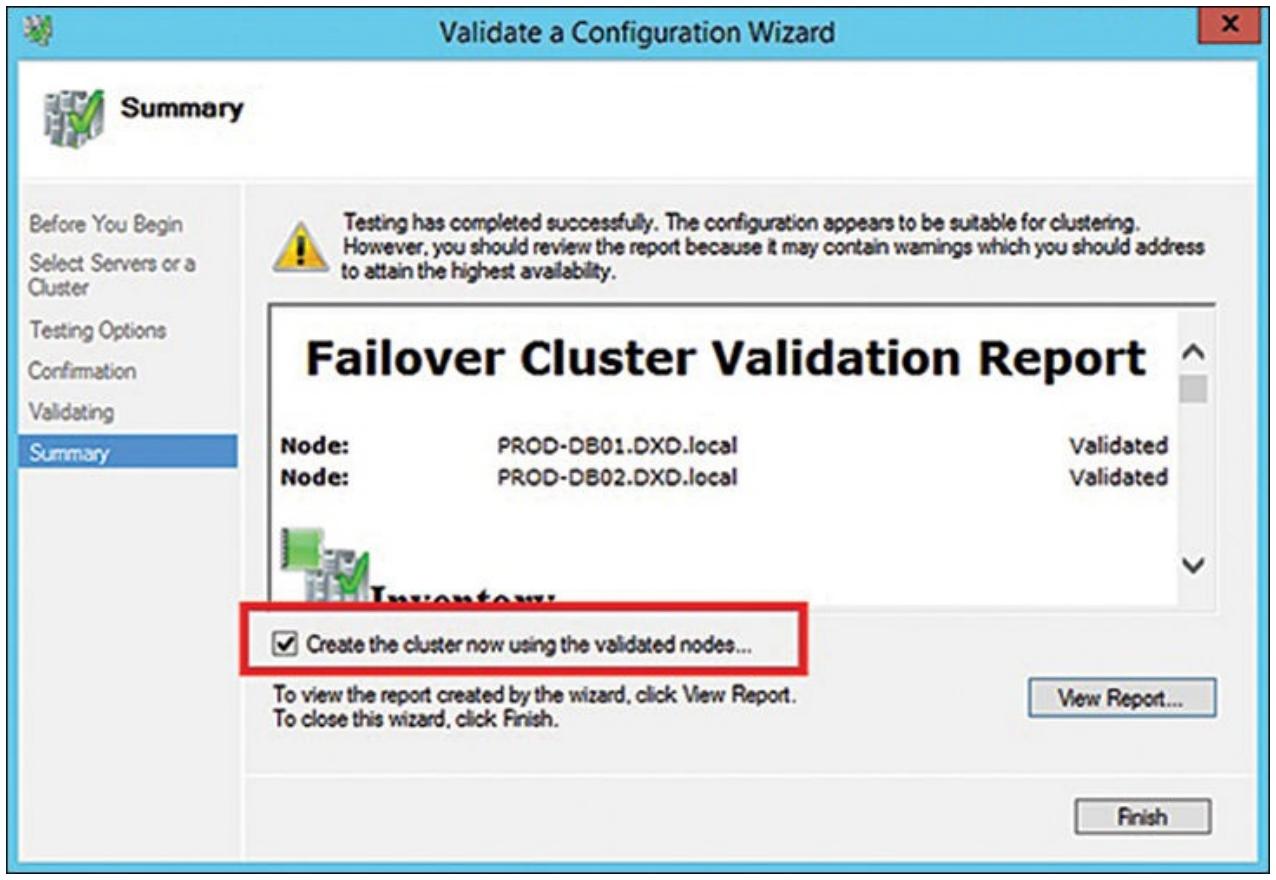
Итог проверки правильности отказоустойчивого кластера в Диспетчере отказоустойчивого кластера
-
Как это отображено на Рисунке 4.10, отметьте блок Создайте теперь кластер с применением удостоверенных узлов и кликните Завершить. Теперь появится мастер Создания кластера (да, другой мастер!). Этот мастер соберёт все точки доступа для администрирования данного кластера, подтвердит все компоненты этого кластера и создаст сам кластер с тем именем, которое вы определили.
-
Как показано на Рисунке 4.11, введите
DXD_CLUSTERв качестве имени данного кластера. Для данного кластера назначается IP адрес по умолчанию, но вы можете изменить его позже на тот IP адрес, который вы предпочтёте применять. Помните, что данный мастер знает об имеющихся двух узлах, которые вы только что проверили и он автоматически включит их в данный кластер. Как вы можете увидеть из Рисунка 4.12, в данный кластер включены оба узла.
-
Запросите чтобы все подходящие диски хранения были добавлены пометив блоке данного кластера Добавить все подходящие хранилища.
-
В появившемся итоговом диалоге просмотрите что было сделано, в том числе что подходящие диски будут включены. Пройдите далее и кликните Завершить. Рисунок 4.13 отображает выполненную настройку кластера для вашего кластера из двух узлов, включая имеющуюся сетевую среду, хранилище кластера и сами два узла (
PROD-DB01иPROD-DB02).
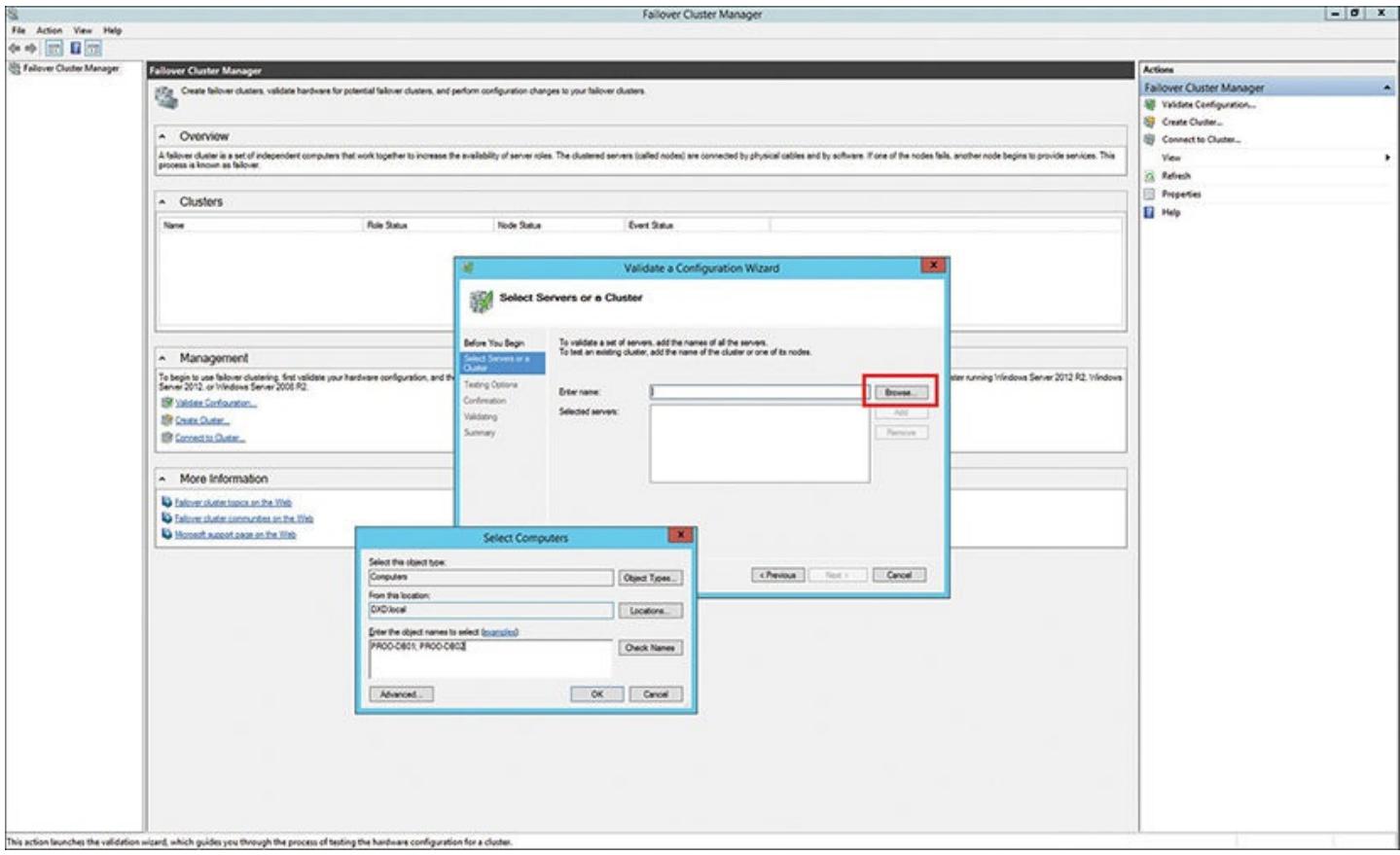
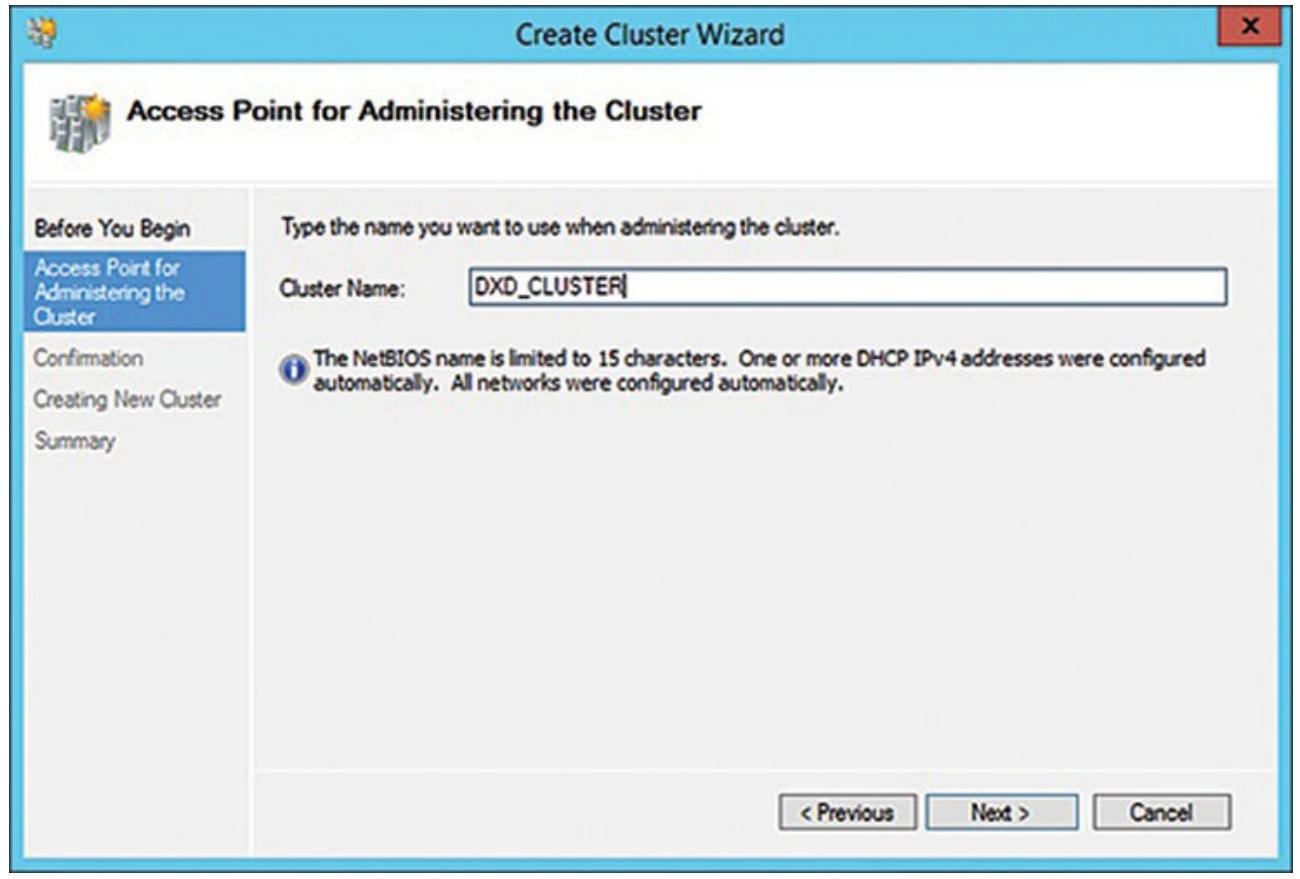
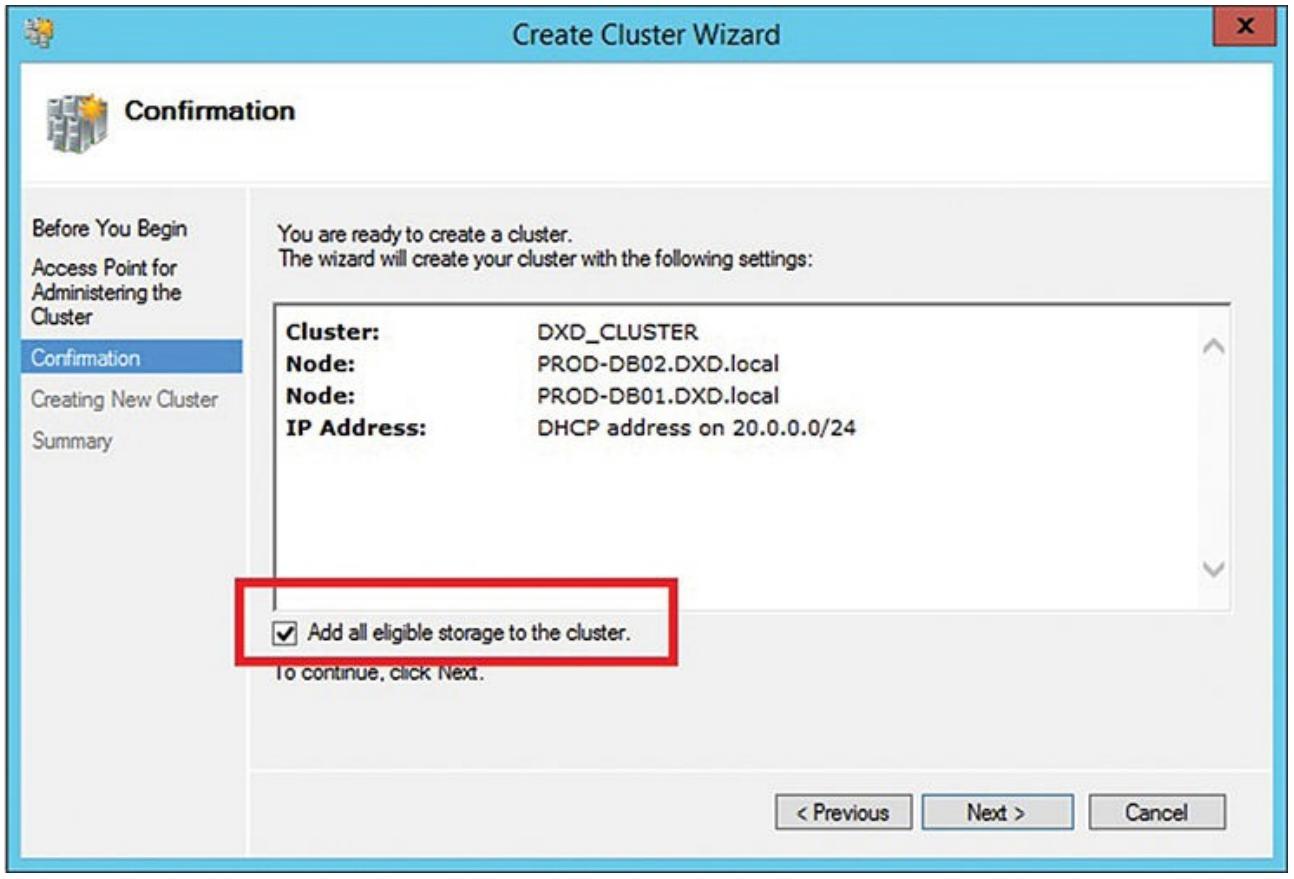
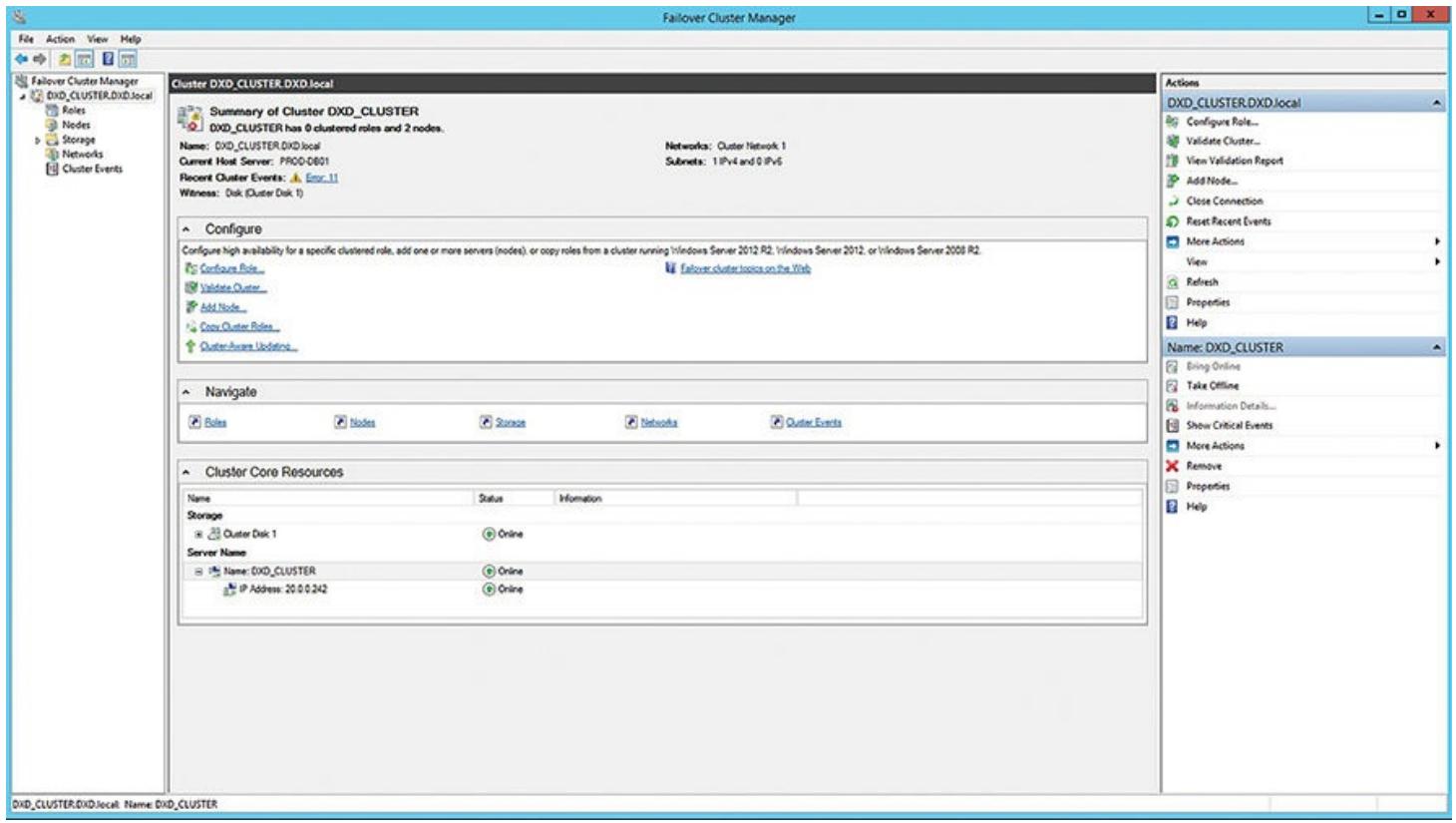
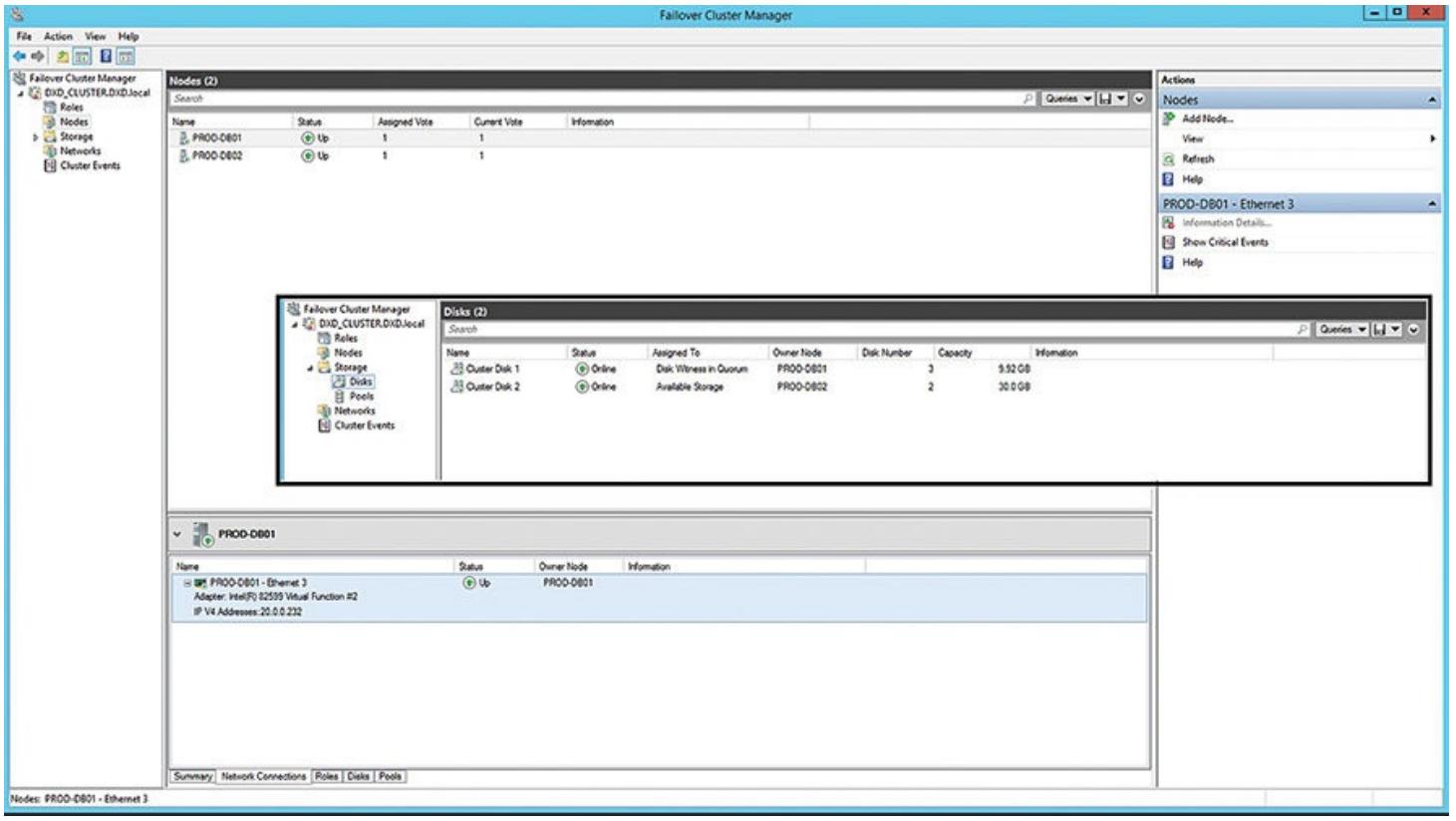
Рисунок 4.14 отображает вам обзор самих узлов данного кластера. Как вы можете видеть, оба узла стартовали и работают. Рисунок 4.14 таже все имеющиеся в данном кластере диски. Один диск применяется в качестве необходимого диска кворума (для решений кластера), а все остальные являются главными доступными дисками хранения, которые будут применяться для баз данных и тому подобного. Не забудьте определить (через имеющиеся свойства данных дисков кластера) оба узла как возможных владельцев для этих дисков. Это существенно, так как все диски разделяются между данными двумя узлами.
Теперь у вас имеется полностью функционирующий отказоустойчивый кластер с совместными дисками, готовый для применения таких вещей как кластер SQL. Определённая правильная практика состоит в документировании всех необходимых IP адресов, сетевых имён, определений домена, а также ссылок сервера SQL для установки некоторого отказоустойчивого кластера из двух узлов.
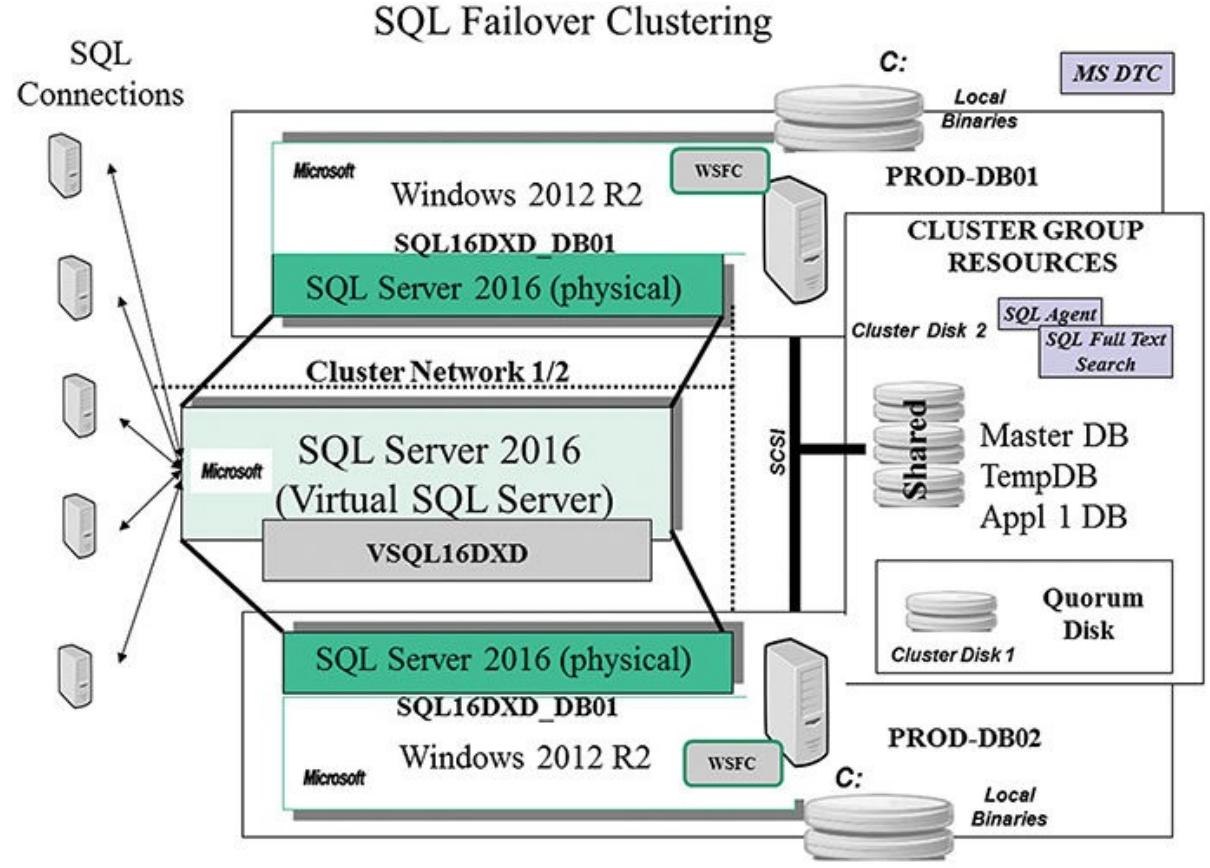
Установка кластера SQL продолжает становиться всё проще и проще. Её основная часть сейчас может выполняться
с одного узла. Рисунок 4.15 показывает некую конфигурацию
кластера из двух узлов, аналогичную той, что описывалась на
Рисунке 4.1, но в этот раз со всеми указанными
имеющимися серверами SQL и компонентами WSFC. Данные виртуальные серверы SQL являются единственной вещью, которую
способен видеть конечный пользователь. Как вы можете понять из
Рисунка 4.15, имя данного виртуального сервера
VSQL16DXD, а имя экземпляра данного сервера SQL
SQL16DXD_DB01. Данный рисунок также отображает все прочие ресурсы группы
кластера которые будут частью конфигурации кластера SQL: DTC (теперь необязателен), Агент SQL, Полнотекстовый
поиск сервера SQL, а также все совместные диски, где будут располагаться все базы данных и необходимый
кворум.
Агент сервера SQL устанавливается как часть данного процесса установки сервера SQL и он связан с тем экземпляром сервера SQL, который устанавливается. То же самое верно и для полнотекстового поиска сервера SQL; он связан с тем конкретным экземпляром сервера SQL, который устанавливается для работы с ним. Данный процесс установки сенрвера SQL полностью устанавливает всё программное обеспечение на все назначенные вами узлы (см. Главу 5, Построение кластера сервера SQL).
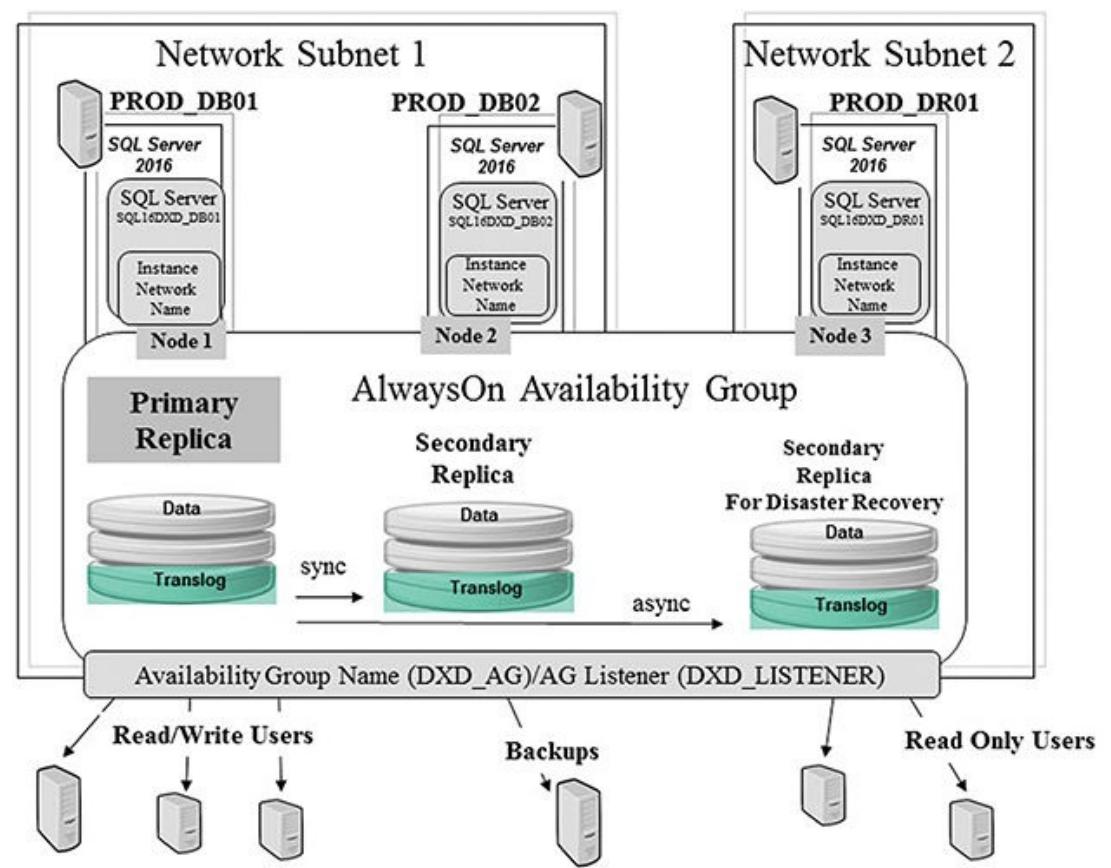
Создание групп доступности AlwaysOn сильно отличается от создания конфигурации кластера, но она всё ещё начинается из данной основы отказоустойчивого кластера. Однако обычно здесь нет совместно применяемого хранилища, и при этом отдельные экземпляры сервера SQL устанавливаются на каждый узел. Рисунок 4.16 отображает некую конфигурацию, которая включает какой- то первичный сервер SQL (на самом первом узле), вторичную реплику сервера SQL для восстановления после отказа (н имеющемся втором узле) и другую вторичную реплику сервера SQL (на некотором третьем узле), которая будет неким узлом восстановления при чрезвычайных происшествиях. Имеющиеся первичная и вторичная реплики имеют ссылки посредством созданной группы доступности, тем самым изолируя имеющегося конечного пользователя от установленного имени экземпляра физического сервера SQL (см.) Главу 6, Группы доступности AlwaysOn сервера SQL).
Прежде чем продвигаться далее, нам следует обсудить как вам необходимо расположить некую реализацию сервера SQL на совместно используемых дисках, управляемых данным отказоустойчивым кластером. Общая цель применения определённого экземпляра сервера SQL диктует как вы можете настроить общий доступ к диску и как его лучше всего приспособить под масштабируемость и доступность.
Обычно RAID 0 великолепен для хранилища, которое не нуждается в устойчивости к отказам; RAID 1 или RAID 10 прекрасен для хранилищ, которым требуется устойчивость к отказам, но они не готовы жертвовать слишком сильно производительностью (как это имеет место для большинства систем с обработкой транзакций в реальном времени, OLTP - online transaction processing); а RAID 5 отлично подходит для хранилищ, которым требуется отказоустойчивость, но в которых данные не изменяются слишком интенсивно (то есть низко непостоянство данных, как это имеет место в большинстве систем поддержки принятия решения, DSS - decision support systems/ систем доступных только для чтения).
Всегда имеется время и место для применения каждой из имеющихся различных конфигураций отказоустойчивых дисков. Таблица 4.1 предоставляет рекомендации, которым стоит следовать при выборе того, какой тип файла базы данных сервера SQL должен быть размещён на каком из уровней RAID дисковой конфигурации. Если вы применяете NAS или SAN {Прим. пер.: или SDN, программно определяемые хранилища: Storage Spaces, Ceph, ZFS и т.п.}, у вас автоматически будут иметься различные уровни надёжности, встроенные в эти устройства. Тем не менее, разделение на отдельные LUN приветствуется, так как вы сможете лучше управлять вещами на имеющихся уровнях канала.
Таблица 4.1| Устройство | Описание | Отказоустойчивость |
|---|---|---|
Диск кворума |
Диск кворума, применяемый в WSFC, должен быть изолирован на некий диск сам по себе (часто также и снабжён зеркалом для максимальной доступности) |
|
OLTP файлы базы данных сервера SQL |
Для систем OLTP все файлы дааных/ индекса определённой базы данных должны размещаться в некоторой дисковой системе RAID 10 |
|
DSS файлы базы данных сервера SQL |
Для систем DSS, которые в первую очередь применяются только для чтения, все файлы дааных/ индекса определённой базы данных следует размещать в некоторой дисковой системе RAID 5. |
|
tempdb |
Это очень интенсивно изменяемая форма дискового ввода/ вывода (когда нет возможности выполнять всё это в имеющемся кэше). |
|
Файлы журнала транзакций сервера SQL |
Файлы журнала транзакций сервера SQL должны находиться на своих собственных томах с зеркалом как по причинам производительности, так и для защиты базы данных. (Для систем DSS это также может быть RAID 5). |
|
Построение отказоустойчивого кластера является краеугольным камнем конфигураций с высокой доступностью как для кластера сервера SQL, так и для групп доступности AlwaysOn. Как описано в данной главе, должны иметься совместные ресурсы, такие как хранилище, узлы и даже серверы SQL. Именно эти ресурсы поддержки кластера встроены в общее качество способности управления внутри некоторого кластера так, как если бы они были одним работающим устройством. Даже если один из этих центральных ресурсов (например, узел) отказывает, данный кластер способен отработать этот отказ на другой имеющийся узел, тем самым достигая Высокую доступность на уровне самого сервера (узла). В Главе 5, Построение кластера сервера SQL вы увидите как отказоустойчивый кластер получает отказоустойчивость уровня экземпляра сервера SQL применяя совместное хранилище. Затем, в Главе 6, Группы доступности AlwaysOn сервера SQL, вы увидите как группы доступности AlwaysOn могут предоставить вам высокую доступность экземпляра сервера SQL и базы данных посредством избыточности как самого сервера SQL, так и имеющихся баз данных.
{Прим. пер.: Обращаем ваше внимание на тот факт, что SQL Server 2017 привнёс собой новые методики организации HADR при помощи контейнеров и Kubernetes, подробнее в нашем переводе Главы 11. SQL Server и контейнеры из вышедшей в октябре 2018 в издательстве Apress книги Боба Вордса "Профессиональный SQL Server поверх Linux"}