Глава 5. Построение кластера сервера SQL
Содержание
Как уже объяснялось в Главе 4, Построение отказоустойчивого кластера, WSFC имеет возможность определения аппаратных или программных отказов и автоматически перемещать управление с отказавшего сервера (узла) на некий жизнеспособный узел. Построение кластера сервера SQL реализует эластичность на уровне экземпляров сервера SQL, которая строится поверх этого центрального фундаментального свойства кластеризации.
Как уже отмечалось ранее, сервер SQL является полностью осведомлённым о кластере приложением. Такой имеющийся отказоустойчивый кластер совместно использует общий набор ресурсов кластера, такие как размещённые в кластере (совместно используемые) дисковые устройства, сетевые средства, и, да, сам сервер SQL.
Сервер SQL позволяет делает возможным для вас отрабатывать отказ и в случае сбоя уходить на- другой узел (или с другого узла) в некотором кластере. При настройке активный/ пассивный некий экземпляр активно обслуживает запросы базы данных в одном из узлов некоторого кластера (активный узел). Другой узел находится в ожидании пока, по какой- то причине, не произойдёт отказ. В случае варианта с восстановлением после отказа, имеющийся второй узел (пассивный узел) берёт все ресурсы SQL (базы данных) даже без того чтобы конечный пользователь узнал что произошла некая отработка сбоя. Сам конечный пользователь может испытать некий вид кратковременного прерывания транзакции, так как сервер SQL не может принимать на лету полномочия транзакций. Однако этот конечный пользователь всё ещё подключён к некому отдельному серверу SQL и на самом деле не знает какой из узлов исполняет запросы. Такой тип прозрачности приложения является чрезвычайно желательным свойством, которое, которое сделало очень популярным построение SQL кластеров в последние 15 лет.
При некоторой настройке активный/ активный сервер SQL одновременно исполняет множество серверов с различными базами данных, позволяя организациям с более ограниченными аппаратными требованиями (то есть, не спроектировавшими вторичные системы) сделать возможным отрабатывать сбои с- или на- любой узел без установки в стороне (простаивающего) оборудования. Могут также иметься кластеры со множеством площадок в различных центрах обработки данных (площадках), что ещё более повышает Высокую доступность, которую может выполнять кластеризация сервера SQL.
{Прим. пер.: Обращаем ваше внимание на тот факт, что SQL Server 2017 привнёс собой новые методики организации HADR при помощи контейнеров и Kubernetes, подробнее в нашем переводе Главы 11. SQL Server и контейнеры из вышедшей в октябре 2018 в издательстве Apress книги Боба Вордса "Профессиональный SQL Server поверх Linux"}
Для построения кластера сервера SQL вам необходимо установить новый экземпляр сервера SQL внутри, как минимум, кластера из двух узлов. Вам не следует перемещать некий экземпляр сервера SQL из конфигурации без кластера в некую кластерную конфигурацию. Если у вас уже имеется некий установленный в среде без кластеризации сервер SQL, вам вначале требуется выполнить все необходимые резервные копии (или отключить базы данных) и затем убрать установку такого экземпляра сервера SQL без кластеризации. Для предыдущих версий сервера SQL и Windows Server возможно понадобится некое обновление путей и путей миграции. Вы также обязаны определить тот же самый ключ продукта на всех своих узлах, которые вы подготовили для одного и того же отказоустойчивого кластера. Также вам следует убедиться что вы применяете один и тот же идентификатор экземпляра сервера SQL для всех тех узлов, которые вы подготовили для своего отказоустойчивого кластера.
Имея запущенными и в состоянии исполнения все ресурсы WSFC, вы выполняете программу установки сервера
SQL 2014 на работающем узле (например, PROD-DB01). Вы получите запрос
на установку всех компонентов, требуемых для установки инсталлированного ранее сервера SQL (.NET Framework 3.5
или 4.0, Microsoft SQL Native Client и файлы поддержки установки Microsoft SQL Server 2016). Убедитесь что у
вас имеются надлежащие полномочия для выполнения установки сервера SQL!
С каждой новой версией сервера SQL становится всё проще и проще устанавливать и настраивать кластеризацию сервера SQL. Установка отказоустойчивого кластера сервера SQL состоит из следующих этапов:
-
Установите некий новый отказоустойчивый кластер сервера SQL - Создайте и настройте некий первоначальный экземпляр отказоустойчивого кластера сервера SQL, который будет применяться в вашем отказоустойчивом кластере сервера SQL.
-
Добавьте некий узел в отказоустойчивый кластер сервера SQL - Добавьте некий узел в отказоустойчивый кластер сервера SQL и выполните настройку свуоей высокой доступности.
Почти вся установка и настройка SQL со множеством узлов теперь может выполняться из вашего первичного (активного) узла. Рисунок 5.1 отображает построение конфигурации кластера с двумя узлами сервера SQL, который вы будете устанавливать в данной главе.
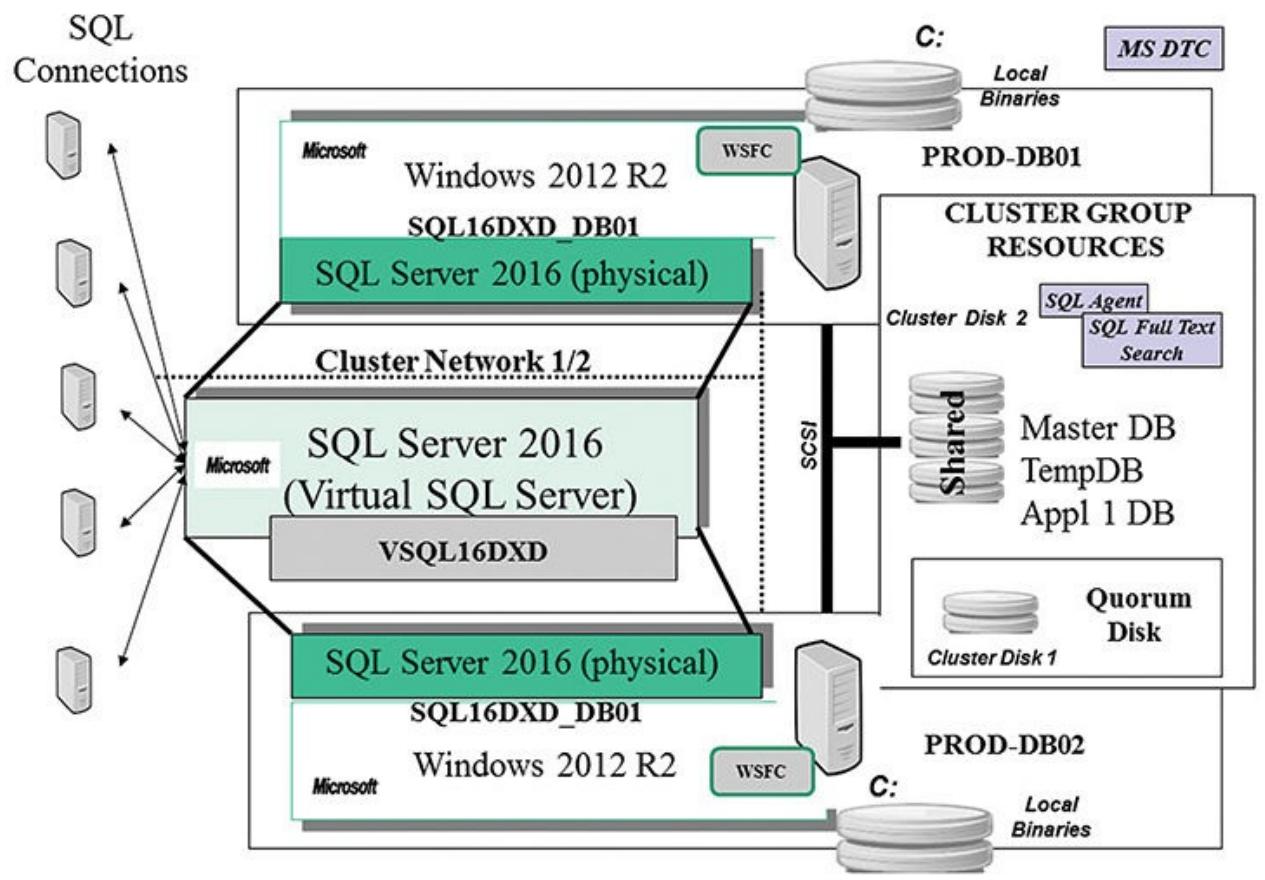
Мы начнём с выбора установки нового отказоустойчивого кластера сервера SQL из своего Центра установки
сервера SQL для узла PROD-DB01 (см. Рисунок 5.2).
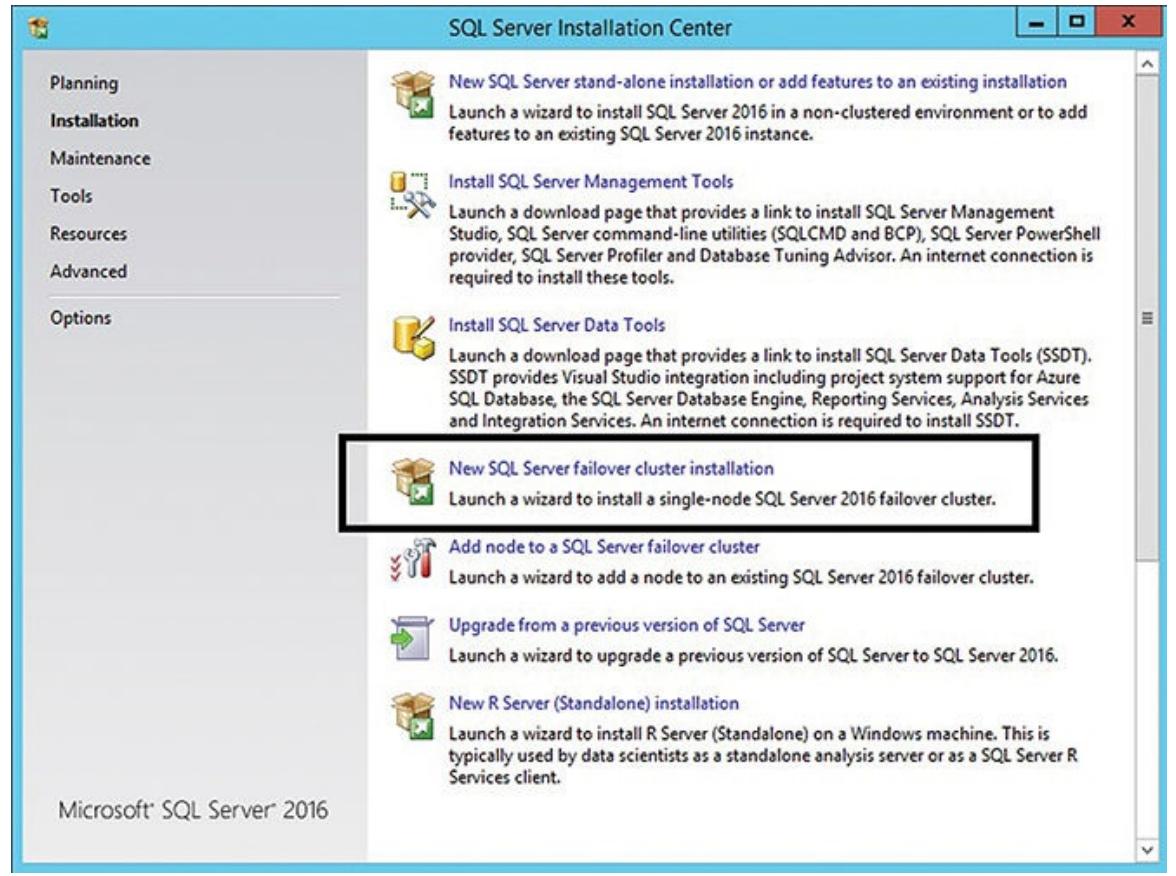
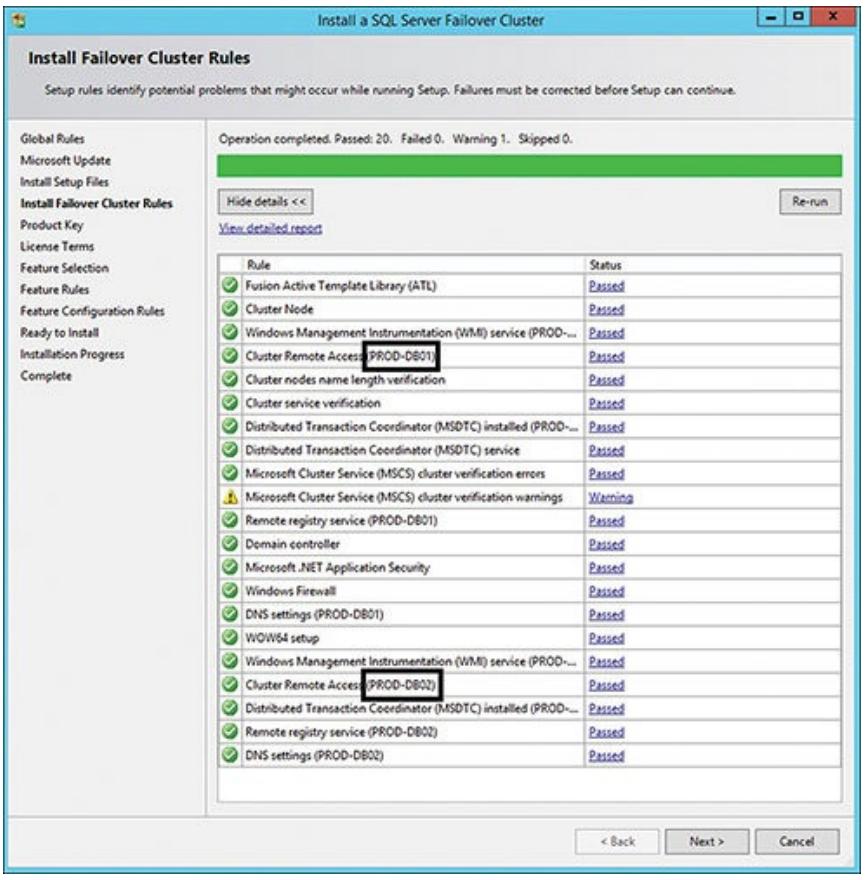
Откройте мастер установки отказоустойчивого кластера сервера SQL и начните с проверки правил своего узла
в данном кластере (PROD-DB01).
Рисунок 5.3 отображает диалог Установки правил
отказоустойчивого кластера и все результаты успешной начальной проверки отказоустойчивого кластера для вашего
узла PROD-DB01. Так как WSFC уже установлен, данный мастер также проверяет
на другом доступном узле, PROD-DB02, многие из тех же самых требований
установки (DTC, установки DNS, Удалённый доступ к кластеру и тому подобное).
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Построение отказоустойчивого кластера доступно в Стандартной редакции, Корпоративной редакции и Редакции разработки сервера SQL 2016. Однако, Стандартная редакция поддерживает только кластер с двумя узлами. Если вы желаете настроить кластер из более чем двух узлов, вам необходимо выполнить обновление до Корпоративной редакции сервера SQL 2016, которая не имеет ограничений на общее число узлов кластера. |
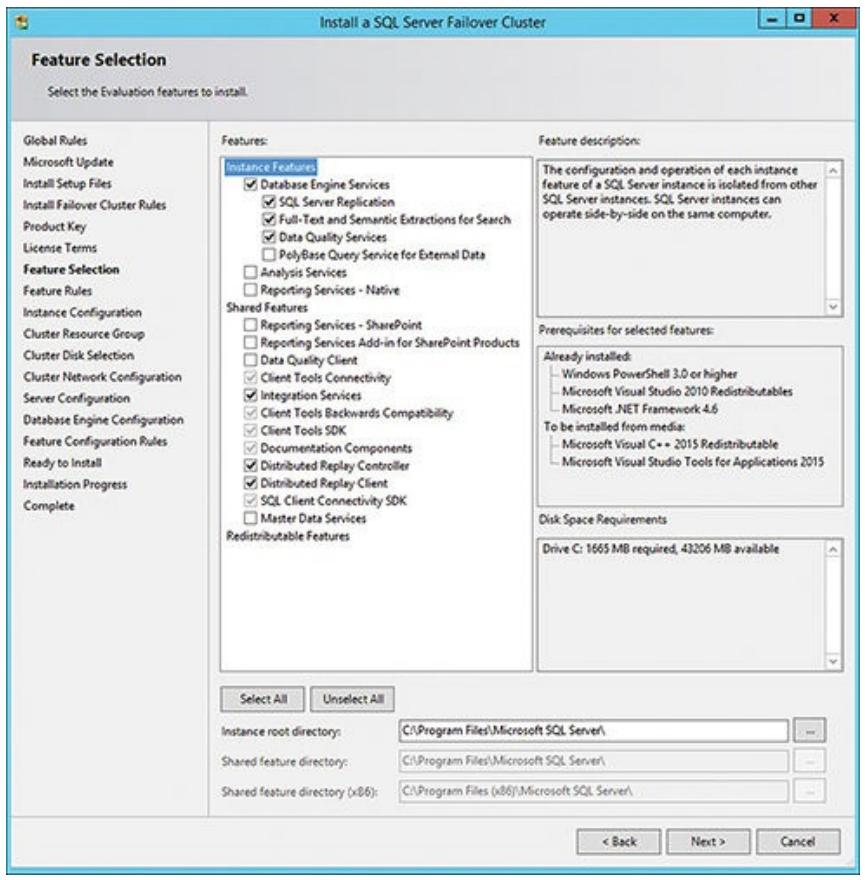
Если данная проверка завершится неудачно, вам потребуется перед продолжением разрешить все полученные предупреждения. После завершения диалога ключа продукта и терминов лицензирования загружаются необходимые файлы установки.
Затем вы получите приглашение для выполнения дальнейшей установки порции настроек своего сервера SQL в диалоге Дальнейшего выбора, показанного на Рисунке 5.4. Далее должен быть пройден некий набор проверок подтверждения последующих правил для таких моментов как поддержка кластера для вещей, подобных тому что кластер поддерживает данную редакцию и совместимость обновления данного языка продукта.
Далее вам необходимо определить сетевое имя данного сервера SQL (само имя нового отказоустойчивого кластера,
по существу, имя виртуального сервера SQL). Вам также требуется определить некоторое имя экземпляра для самого
физического сервера SQL (в данном примере SQL16DXD_DB01) на узле
PROD-DB01 (как это показано на
Рисунке 5.5).
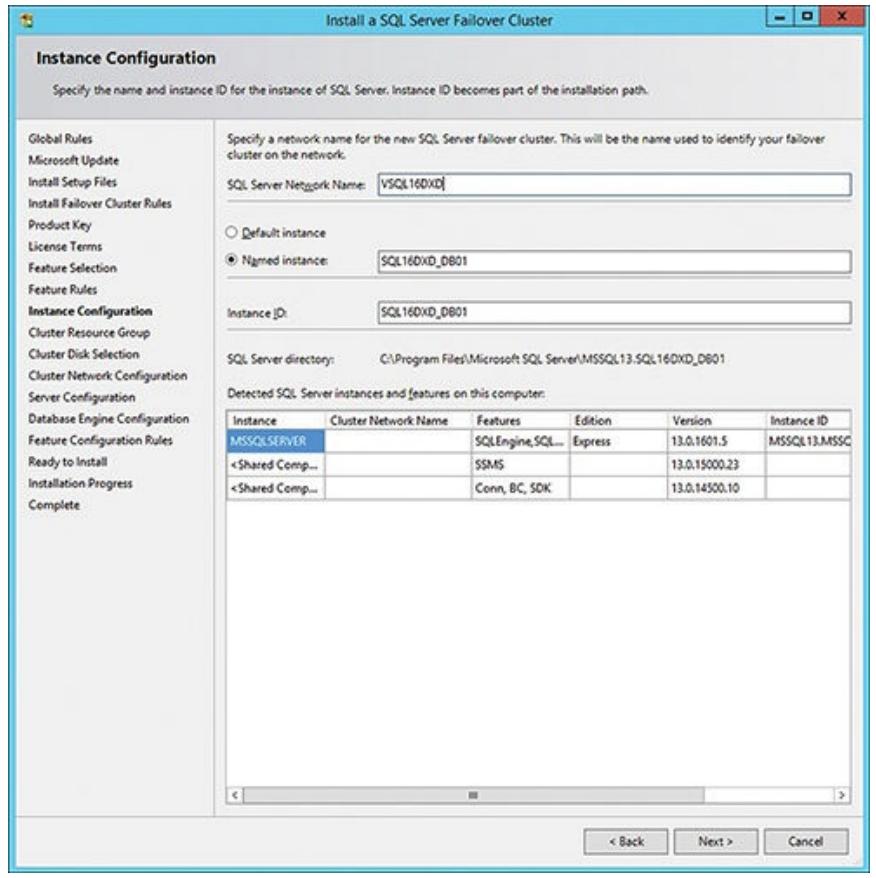
Когда некоторое приложение пытается подключиться к какому- то экземпляру сервера SQL 2016, который исполняется
в отказоустйчивом кластере, такое приложение обязано определить и имеющееся имя виртуального сервера, и само
имя экземпляра (если было применено некое имя экземпляра), например
VSQL16DXD\SQL16DXD_DB01 (имя виртуального сервера\ название экземпляра
сервера SQL, отличающееся от определяемого по умолчанию) или VSQL16DXD
(просто имя виртуального сервера без определённого по умолчанию имени экземпляра сервера SQL). Данное имя виртуального
сервера должно быть уникальном в своей сетевой среде.
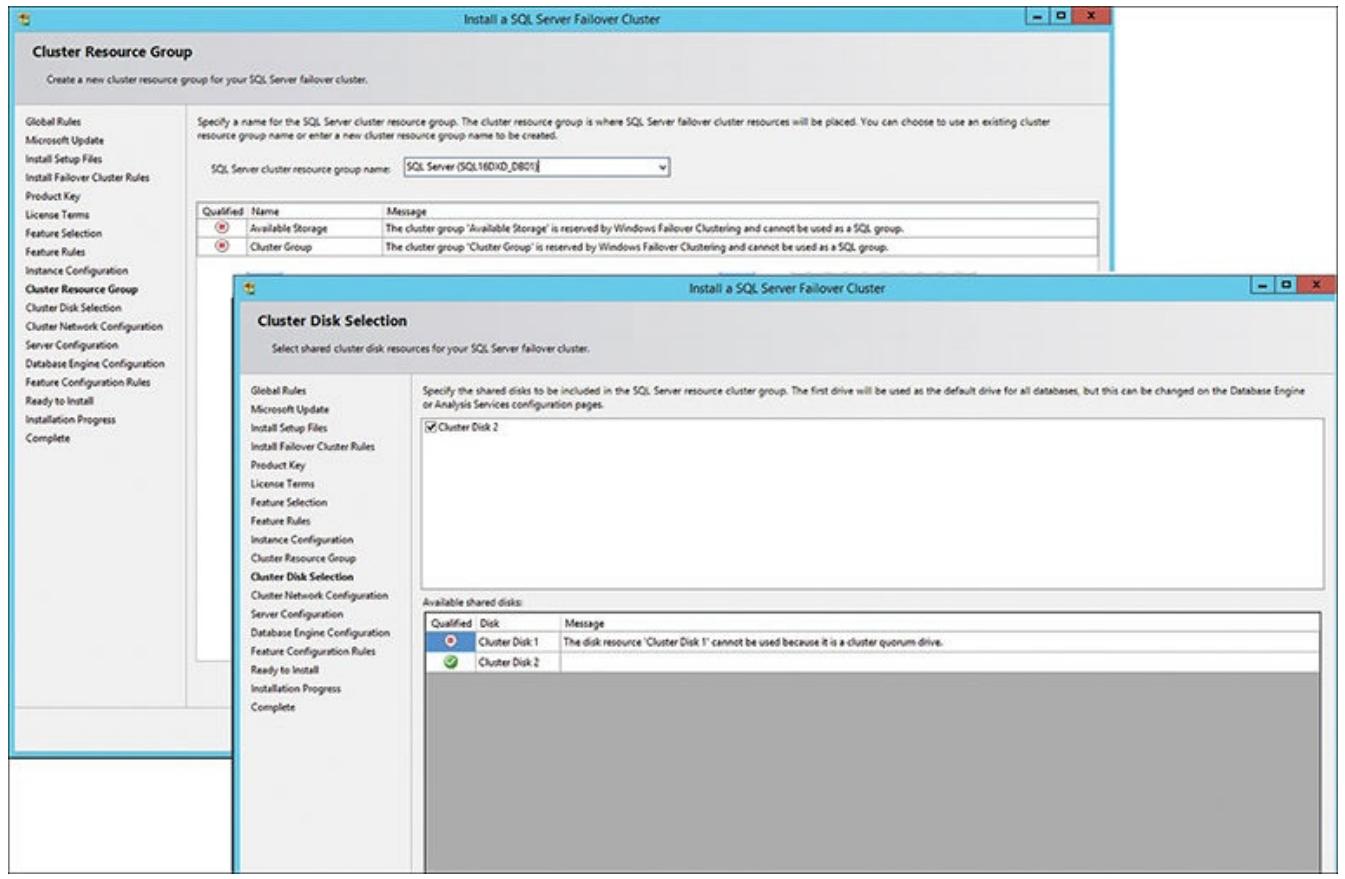
Далее следует определение группы ресурсов данного кластера для вашего кластера SQL, после чего следует ваш выбор
определённых дисков для создания кластера. Именно здесь ресурсы сервера SQL помещаются внутри WSFC. Для данного
примера вы можете применить имеющееся название группы ресурсов сервера SQL (SQL16DXD_DB01)
и кликнуть Next (см. Рисунок 5.6). После того как вы
назначите данную группу ресурса, вам необходимо определить какие диски кластера должны применяться в вашем
диалоге Выбора дисков кластера, также отображённом на Рисунке
5.6. Он содержит некий вариант диска Cluster Disk 2 (который был вашим совместно применяемым томом диска) и
вариант Cluster Disk 1 (который был размещением вашего устройства кворума). Вы просто выбираете все свой доступный
диск (диски), где вы желаете разместить свои файлы базы данных SQL (в данном примере вариант дискового устройства
Cluster Disk 2). Как вы можете видеть, единственным "квалифицированным диском" является устройство
Cluster Disk 2. Если вы выбрали в свою группу кластера ресурс кворума, появится сообщение предупреждения, которое
проинформирует вас об этом факте. Высеченным на камне правилом является изоляция вашего ресурса кворума в некую
отдельную группу кластера.
Следующим моментом, который вам следует сделать для определения этого нового виртуального сервера это
определить некий IP адрес и какую сетевую среду следует применять. Как вы можете увидеть из диалога Настройки
сетевой среды кластера, отображаемого на Рисунке 5.7,
вы просто набираете необходимый IP адрес (в нашем примере 20.0.0.222),
который должен быть IP адресом для данного виртуального сервера SQL во всех доступных виртуальных средах, известных
данной конфигурации кластера ( внашем примере для сетевой среды Cluster Network 1). Если этот определённый вами
IP адрес уже применяется, возникнет некая ошибка.
|
| Замечание |
|---|---|
|
Имейте в виду, что вы применяете некий отдельный IP адрес для своего отказоустойчивого кластера сервера SQL, который полностью отличается от всех IP адресов самого кластера. При некоторой установке сервера SQL без кластера, к данному серверу можно обращаться с применением IP адресов своих машин. При некоторой настройке с кластером вы не применяете имеющиеся IP адреса их физических серверов; вместо этого вы используете эти отдельно назначаемые адреса IP для своего "виртуального" сервера SQL. |
Затем вам необходимо определить учётные записи настроек сервера службы для своего Агента сервера SQL, Механизма базы данных и тому подобного. Они должны быть одними и теми же для для обоих узлов, которые вы включаете в свои настройки кластера сервера SQL (как вы можете видеть на Рисунке 5.8, имя учётной записи Агента сервера SQL и имя учётной записи Механизма базы данных).
Рисунок 5.7
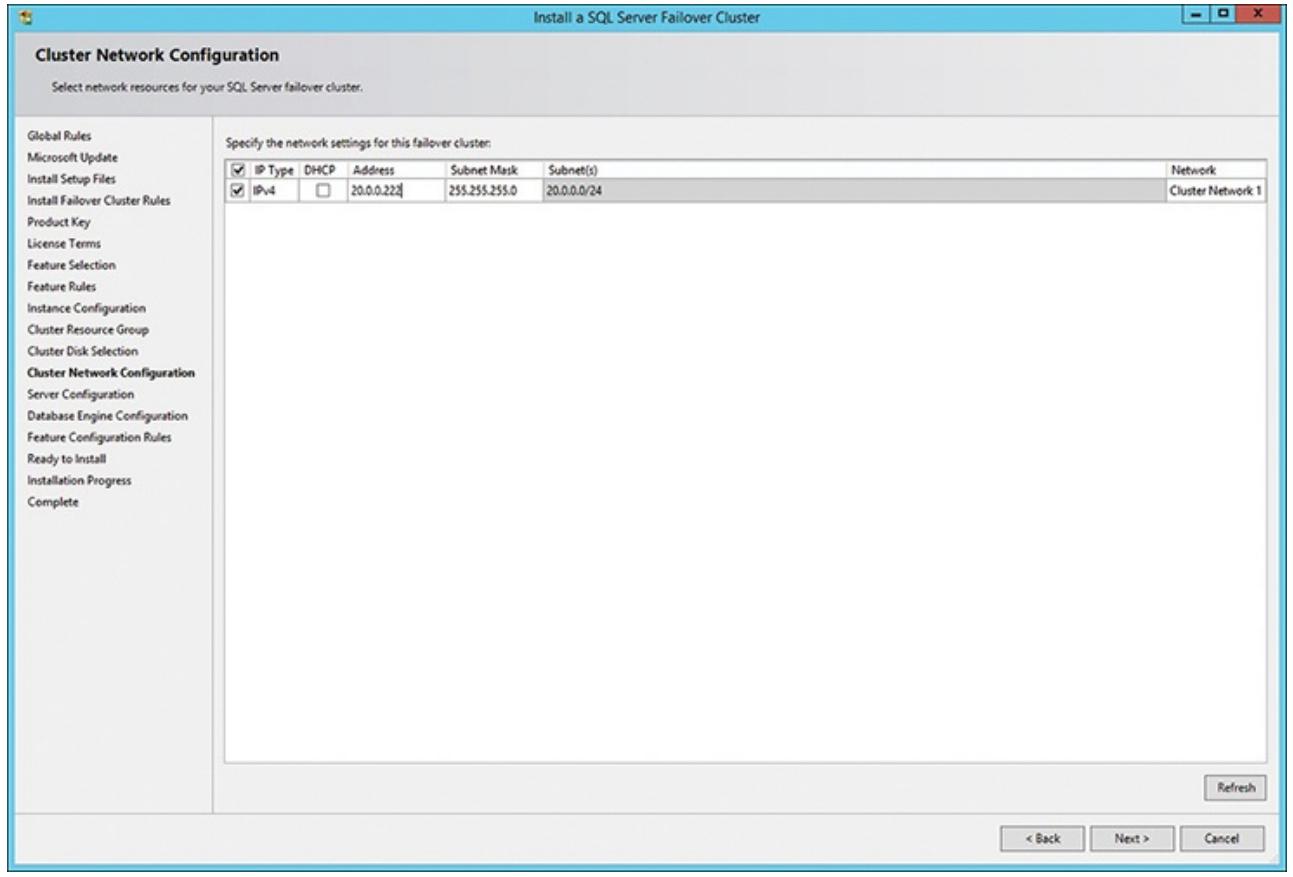
Определение конкретного IP адреса виртуального сервера SQL и того, какую сетевую среду применять
Рисунок 5.8
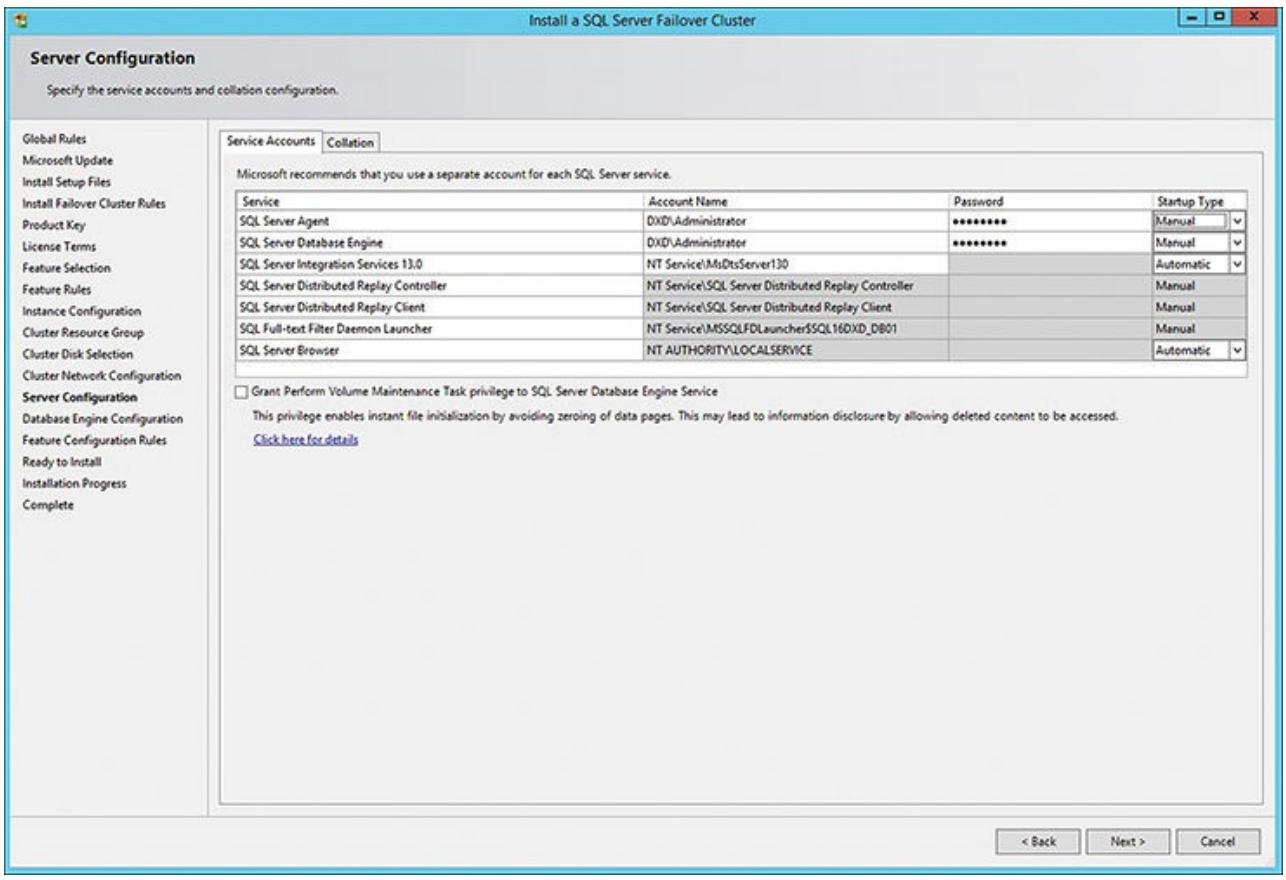
Определение учётных записей и пароля службы сервера SQL для нашего отказоустойчивого кластера
Затем вы видите диалог настройки Механизма базы данных со всеми обычными вещами, которые вы обычно должны определять: режим аутентификации, каталоги данных, TempDB, а также опции файловых потоков. В данный момент вы должны перенести свою работу обратно к далнейшей проверке правил настройки чтобы определить всё ли до данного момента определено правильно. Ваш следующий диалог отобразит общие сведения о том что должно быть сделано в данной инсталляции, а также расположение вашего файла настройки (и путь), который должен позже применяться если вы делаете установки из командной строки своих новых узлов в данном кластере (см. Рисунок 5.9).
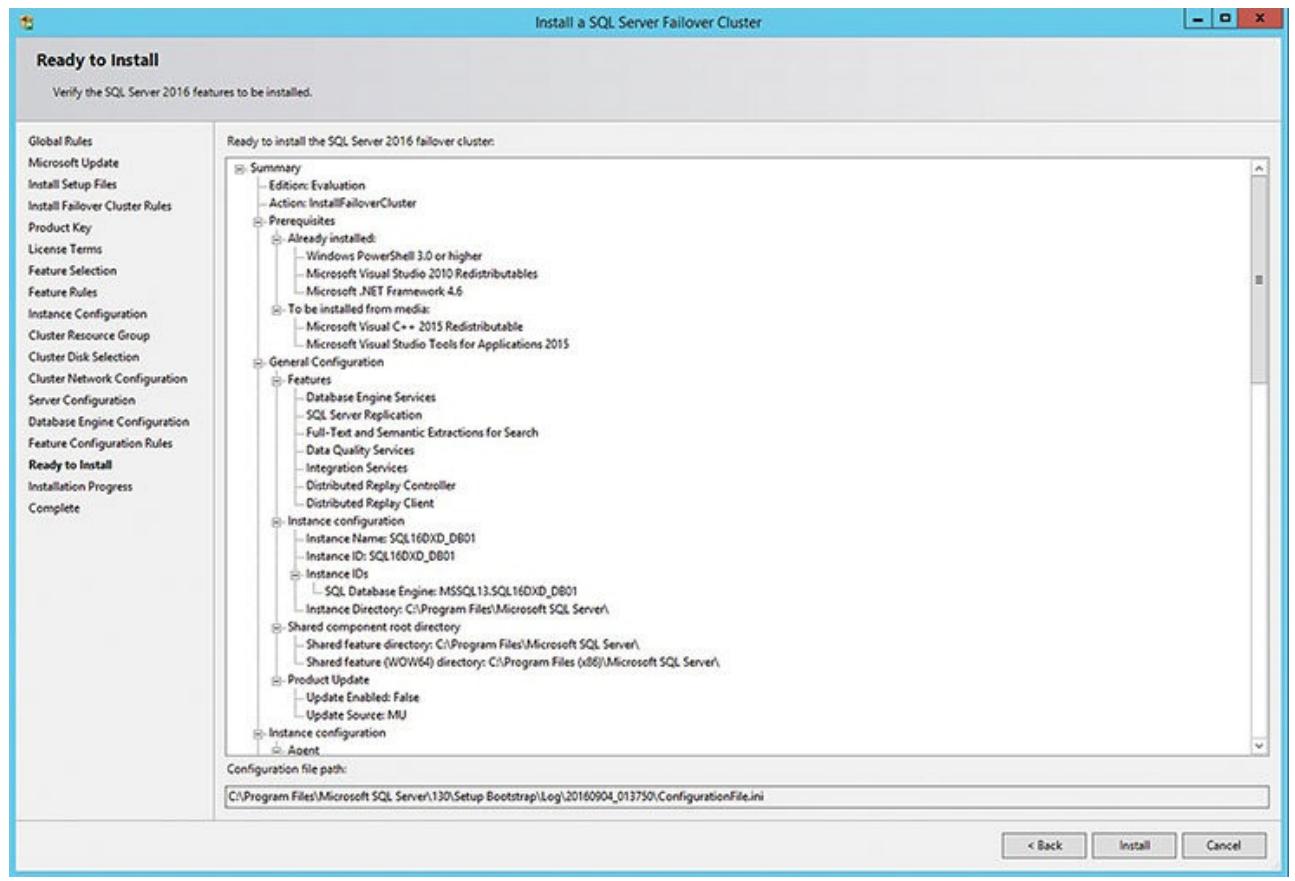
Рисунок 5.10 отображает завершённую установку сервера SQL для данного узла.
Прежде чем переместиться к следующей части устновки узла отказоустойчивого кластера вашего сервера SQL,
вы можете бросить быстрый взгляд на то что Диспетчер отказоустойчивого кластера установил к данному моменту
ткрыв свой узел Ролей в данном отказоустойчивом кластере. Рисунок 5.11 показывает поднятый и работающий экземпляр сервера SQL внутри своего
отказоустойчивого кластера, имя вашего сервера (VSQL16DXD), а также
прочие ресурсы, включая ваш экземпляр сервера SQL и необходимого агента сервера SQL для этого экземпляра.
Все они теперь в рабочем состоянии и управляются вашим отказоустойчивым кластером. Однако пока ещё нет
никакого второго узла. Если этот экземпляр сервера SQL откажет прямо сейчас, он не будет имень ничего для
отработки этого отказа.
Рисунок 5.10
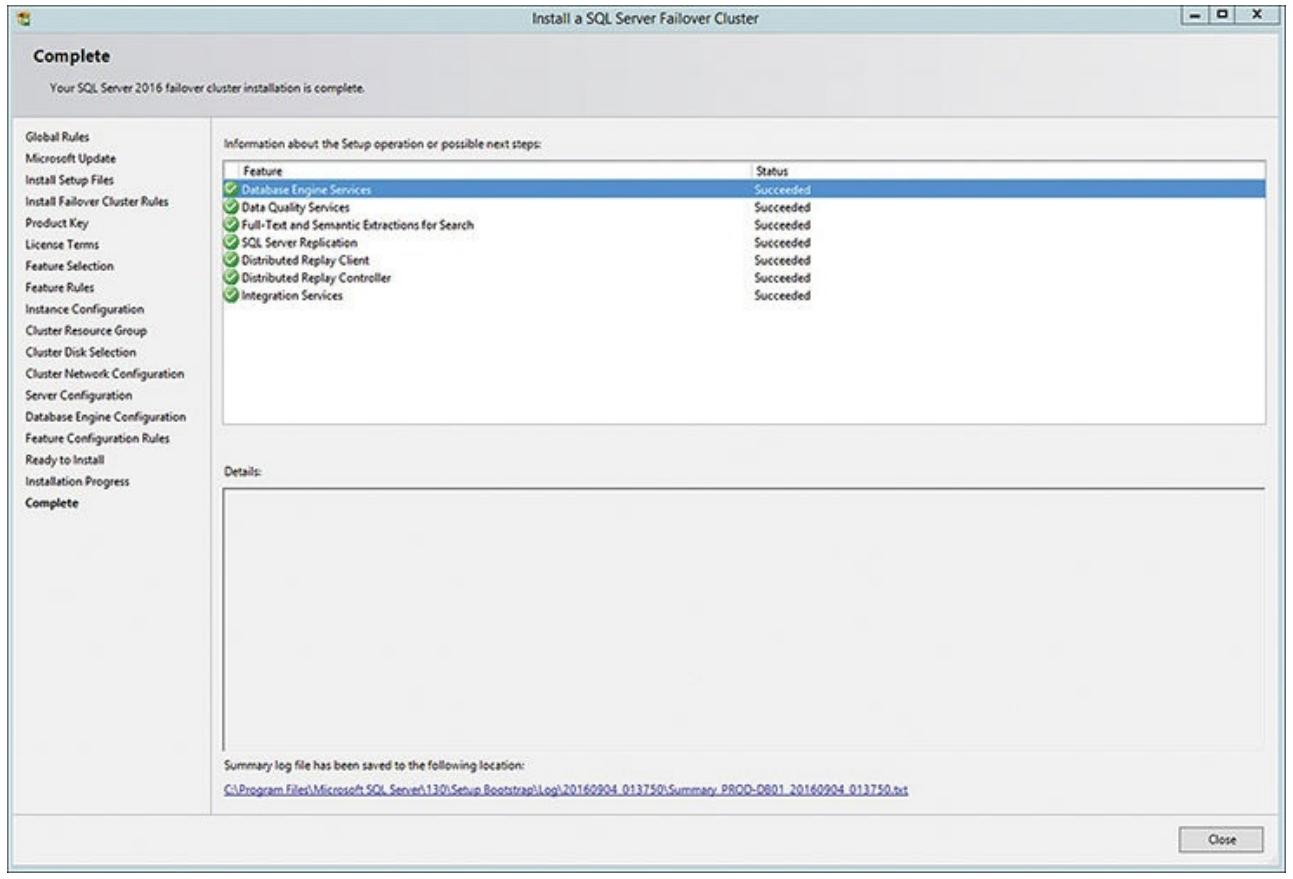
Для данного узла подготовка и установка отказоустойчивого кластера сервера SQL 2016 завершена
Рисунок 5.11
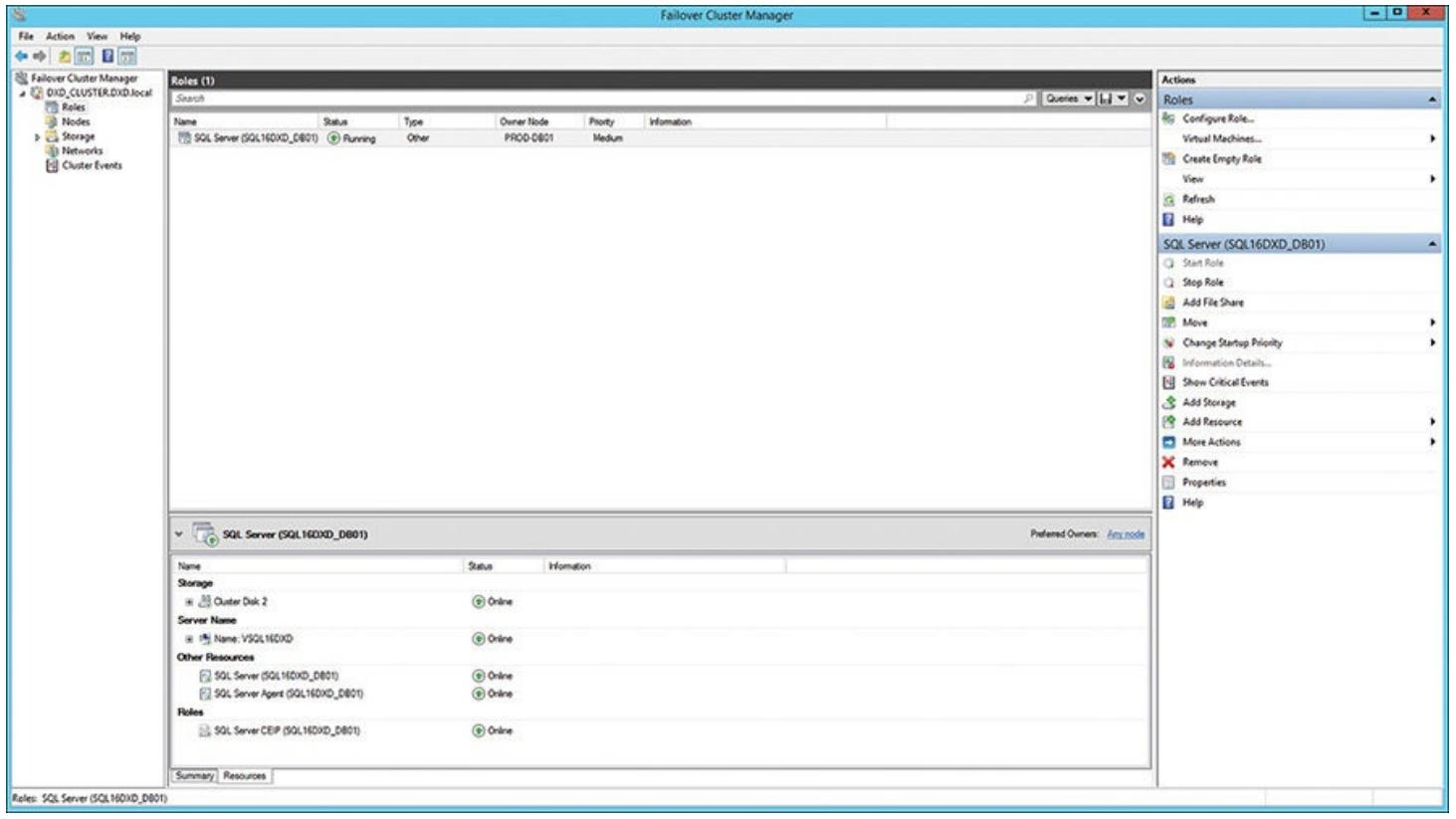
Диспетчер отказоустойчивого кластера, отображающий вновь созданный экземпляр сервера SQL и прочие ресурсы кластера
Теперь вы должны позаботиться о своём вотором узле, который должен иметься внутри вашего кластера сервера
SQL (в данном примере PROD-DB02). Вы можете добавлять в свой кластер
сервера SQL столько узлов, сколько вам требуется, но здесь вы будете связаны с двумя для вашей настройки
активный/ пассивный. Для своего второго узла вам следует выбрать Добавление узла в некоторый отказоустойчивый
кластер сервера SQL, как это отбражено на Рисунке
5.12.
Рисунок 5.12
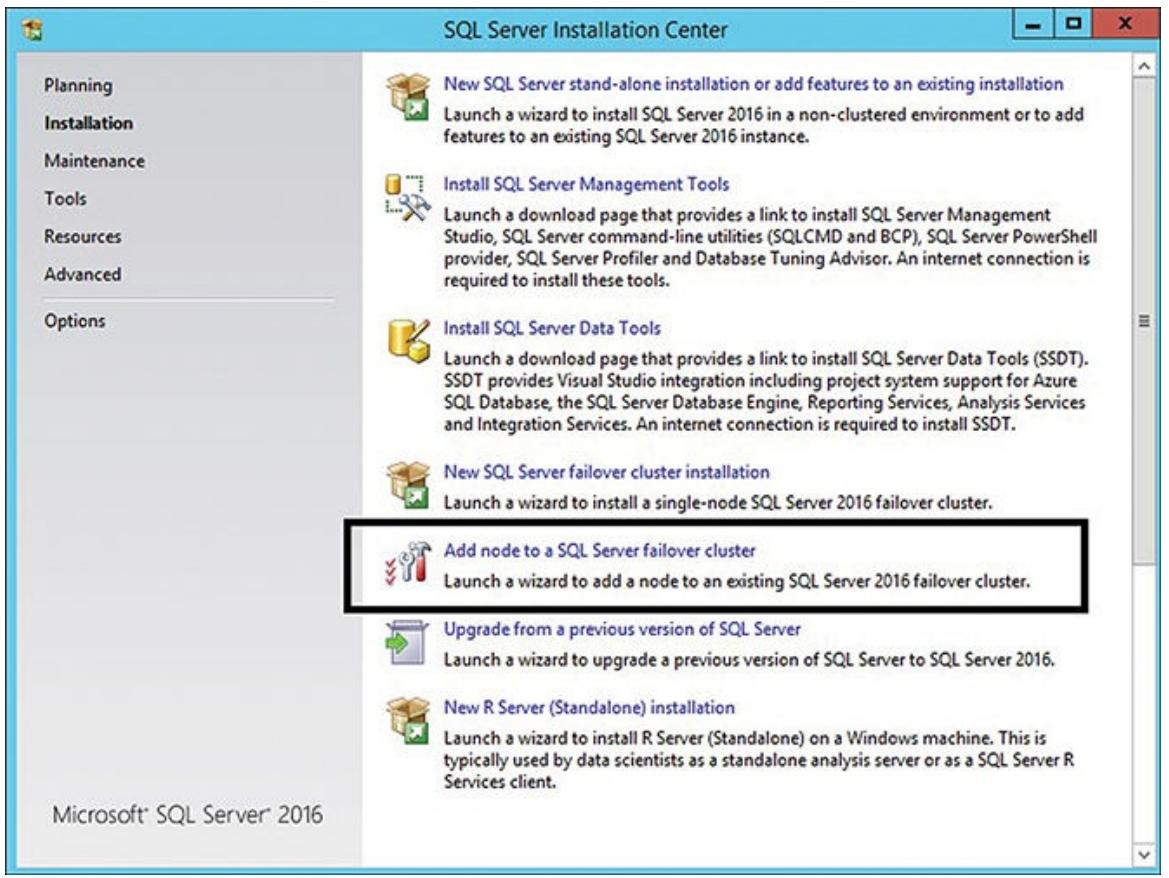
Добавления узла в варианте отказоустойчивого кластера сервера SQL в центре установки сервера SQL
Мастер добавления узла отказоустойчивого кластера вначале выполняет краткую проверку глобальных правил и отыскивает все критически важные обновления продуктов Microsoft Windows и сервера SQL, которые могут понадобиться для данной установки. Всегда будет хорошей мыслью установить самый современный код из возможных. На Рисунке 5.13 вы можете увидеть, что были обнаружены некие критически важные обновления для сервера SQL.
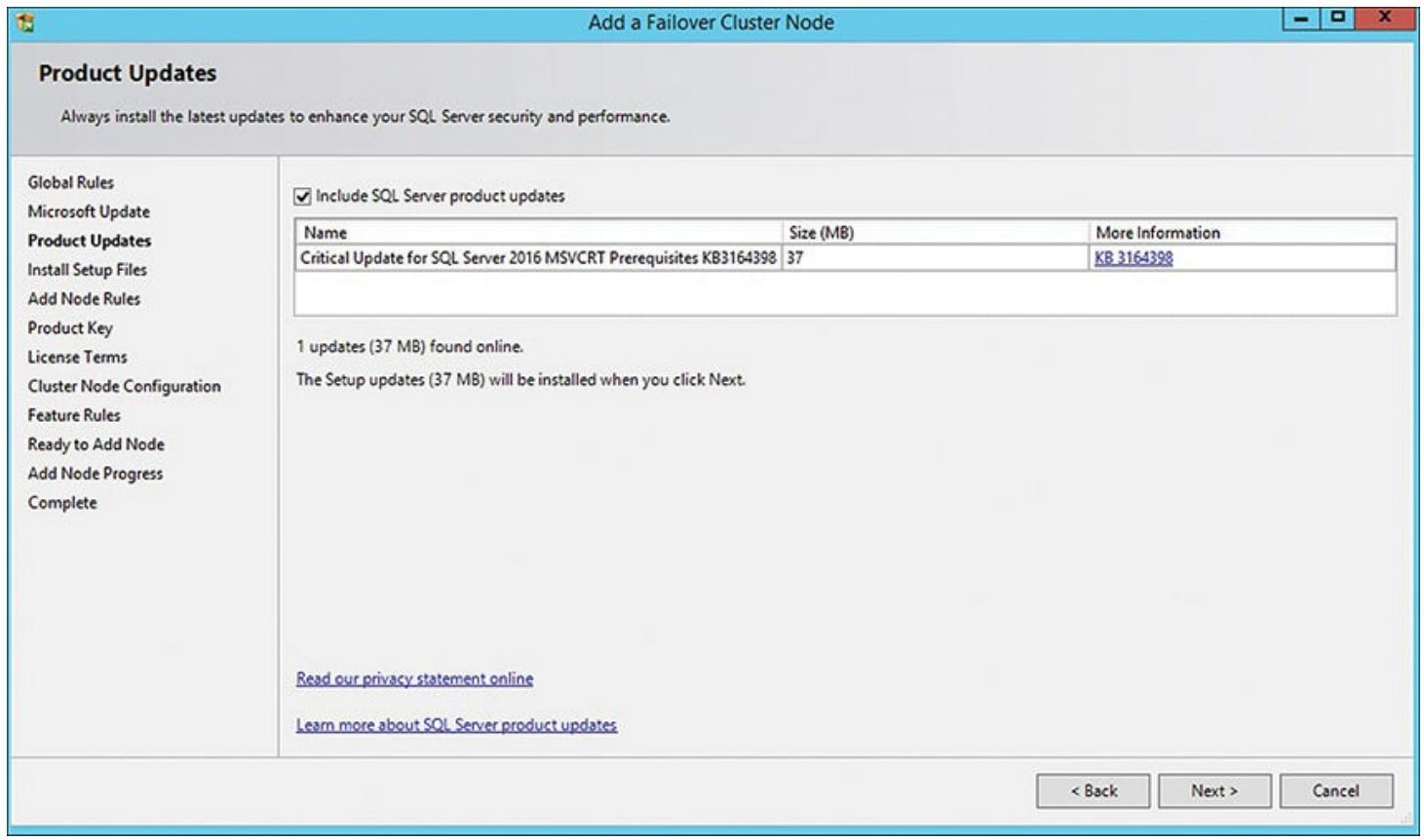
Все файлы обновления продукта и установки добавлены для данной инсталляции. Следующим этапом в вашем мастере
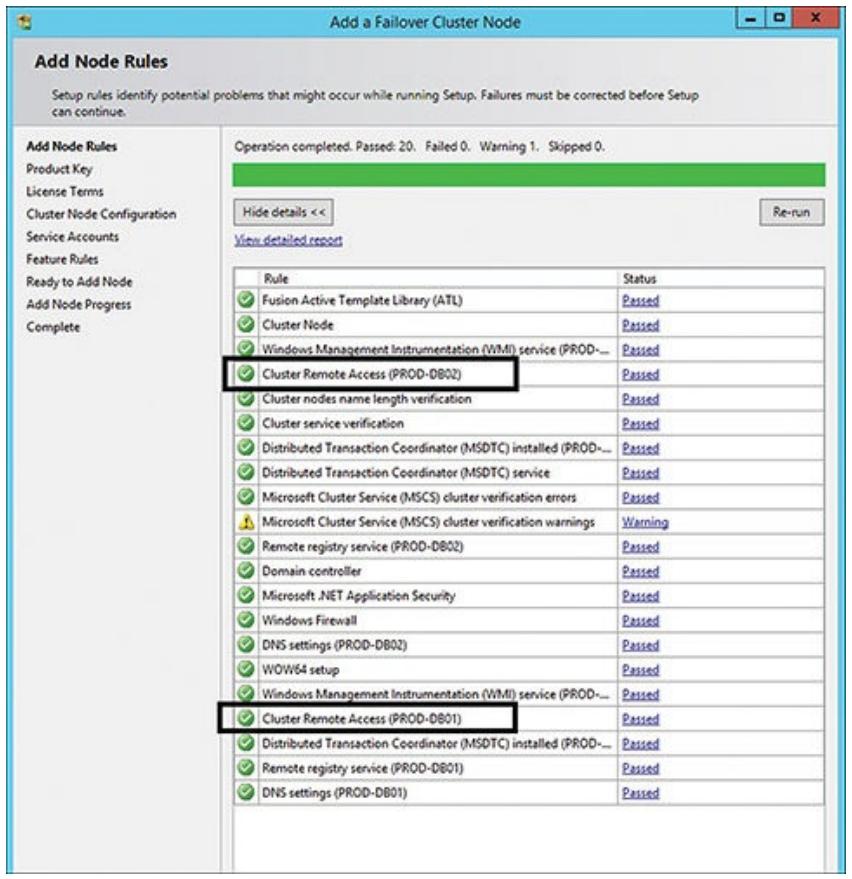
является диалог Добавления Правил узла, который исполнит проверку неких предварительных правил, перехват ключа
вашего продукта и лицензионных соглашений, пройдёт настройку вашего узла кластера, обработает установку
учётных записей этой службы и затем добавит полученный узел в ваш кластер. Это некая разновидность тех же
самых шагов, которые вы проделали для своего первоначального узла, но с точки зрения вашего второго узла
(как вы можете увидеть на Рисунке 5.14). Они также
включают в себя верификацию всех имеющихся служб отказоустойчивого кластера на данном втором узле, удостоверение
DTC, удалённый доступ к кластеру (для PROD-DB02), а также установки
DNS (и для PROD-DB01, и для
PROD-DB02).
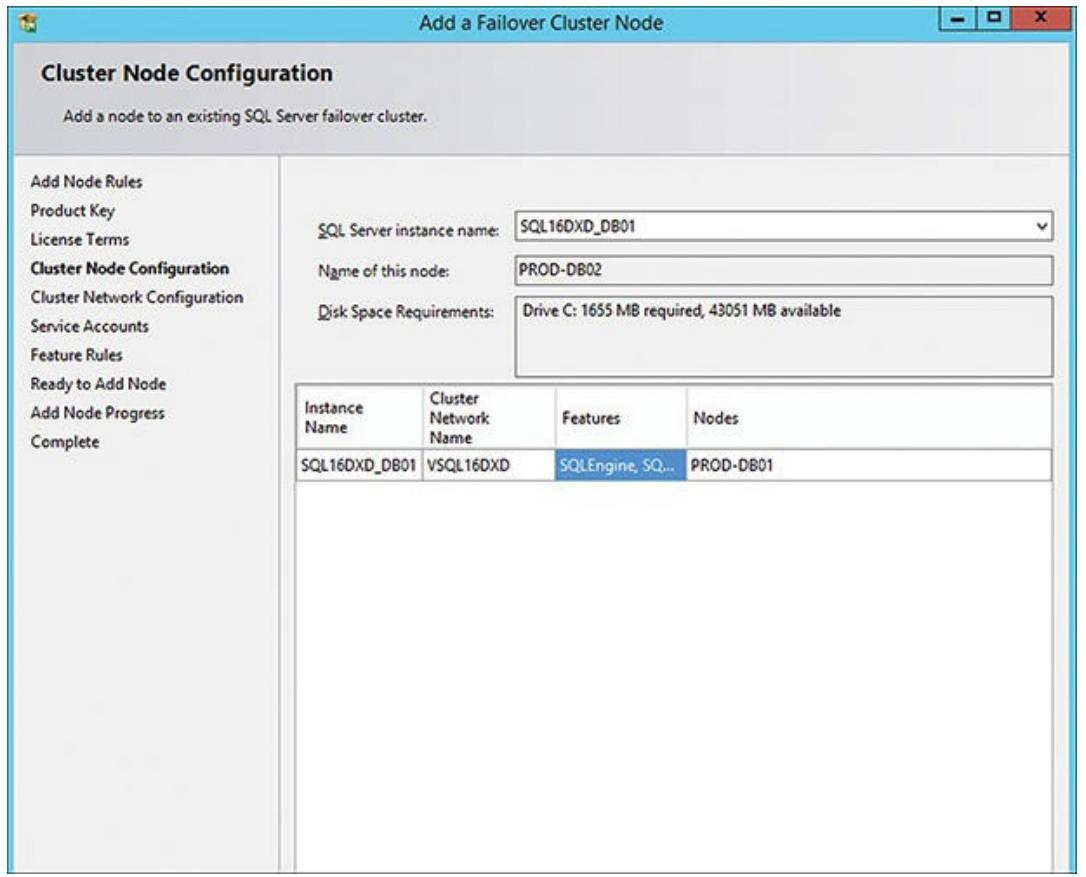
Затем следует настройка вашего узла кластера, в которой вы указываете имя экземпляра своего сервера SQL,
удостоверяете имеющееся название данного узла (в данном примере PROD-DB02)
и проверяете имеющееся сетевое имя кластера, применяемое для настроек данного узла кластера.
Рисунок 5.15 показывает настройки данного узла и
то, что данный экземпляр кластера SQL (PSQL16DXD_DB01) уже
настроен со своим узлом PROD-DB01.
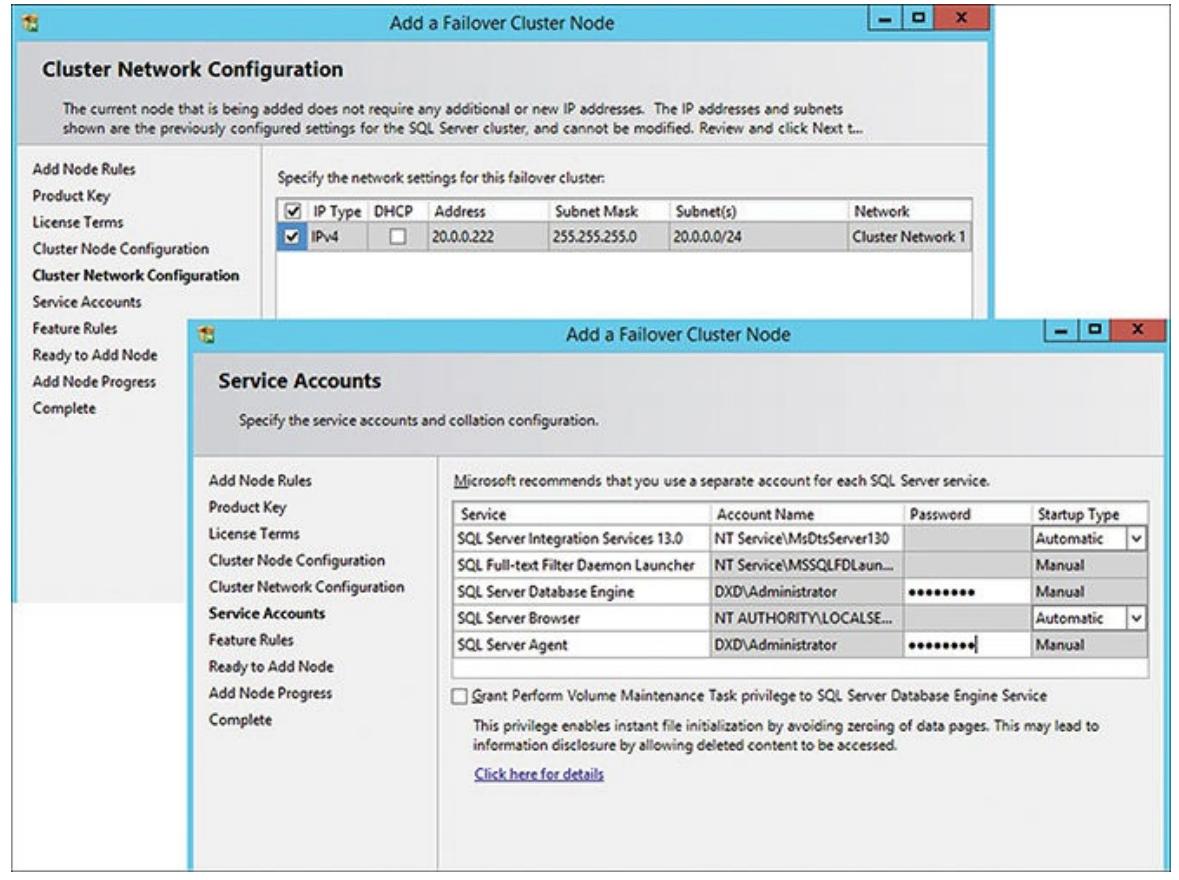
Вслед за этим идентифицируется (удостоверяется) настройка сетевой среды данного кластера. Текущий добавленный узел уже был связан с данным кластером, поэтому вам не придётся здесь добавлять или изменять некий IP адрес (только если вы не осущетсвляете настройку со множеством площадок). Далее следует определение вами учётных записей вашей службы, которые необходимы данному узлу для сервера SQL. Определения и сетевой среды, и учйтных записей данной службы отображаются на Рисунке 5.16.
Теперь вы завершили настройку своего второго узла и можете просто пересмотреть то, что было сделано данным процессом установки и завершить эту установку. Когда она завершена, вам может потребоваться повторный запуск данного сервера. Когда установки всех узлов окончены, вы должны получить полностью рабочую конфигурацию собранного в кластер сервера SQL.
Вам следует осуществить быструю проверку, чтобы убедиться, что вы получаете доступ к этой базе данных через
его сетевое имя виртуального кластера сервера SQLи что все старые добрые базы данных peek подключены
к этой конфигурации кластера сервера SQL. Вы также можете убедиться, что все восстановления узла после отказа
отрабатываются как надо и позволяют вам получать свои данные вне зависимости от того, какой из узлов является
активным. Вы можете сделать это тестирование с помощью подхода грубой силы. Вначале подключитесь к имени виртуального
кластера сервера SQL (в данном примере VSQL16DXD\SQL16DXD_DB),
осуществите некий быстрый SELECT для таблицы Person, остановите свой сервер
PROD-DB01 а затем попробуйте выполнит то же самое предложение
SELECT снова, и вы достигните успеха - своих результирующих строк из
имеющейся таблицы Person. Данная последовательность проверки отображена на
Рисунке 5.17. Его левая сторона отображает имеющееся
соединение с имеющимся имененм виртуального кластера сервера SQL, а справа от него находится соединение, отказавшее
после того, как вы остановили свой узел PROD-DB01. Затем внизу справа
находится успешно выполненный для таблицы Person SELECT с ожидаемыми
строками результата.
|
| Замечание |
|---|---|
|
В качестве альтернативы вы также можете осуществить ту же самую нстройку кластера сервера SQL воспользовавшись имеющимся вариантом Расширенной установки сервера SQL. Работает любой из процессов установки. |
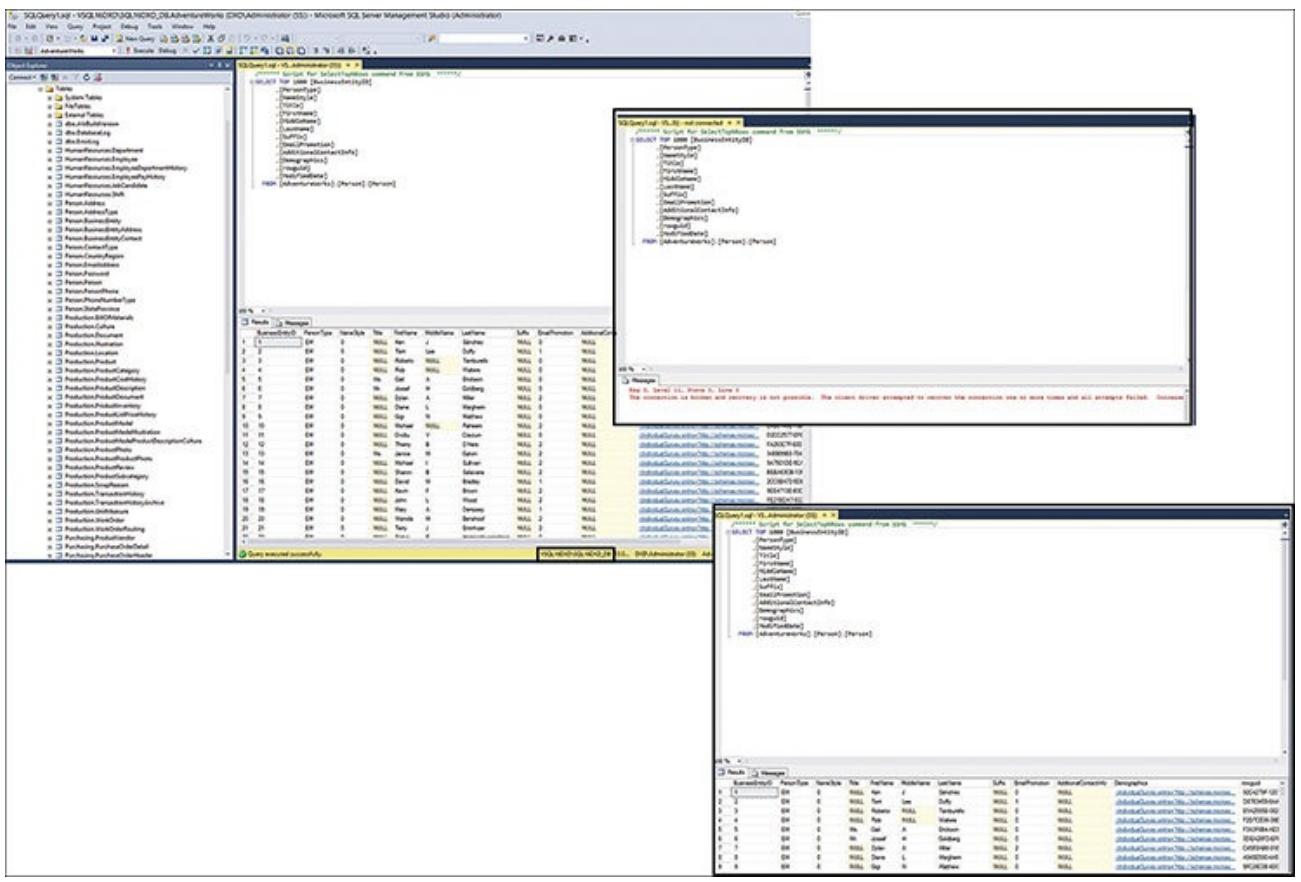
Наши поздравления! Вы находитесь в режиме Высокой доступности для своего уровня экземпляров сервера SQL!
В процессе установки и настройки кластера сервера SQL может возникнуть множество потенциальных проблем. Уделите внимание следующему:
-
Учётный записи и пароли службы сервера SQL должны сохраняться одними и теми же для всех узлов, или же некий узел будет не в состоянии повторно запустить какую- то службу сервера SQL. Вы можете применять учётную запись
administratorили некую спроектированную (например,ClusterилиClusterAdmin, которая имеет права администратора внутри данного домена, причём для каждого сервера. -
Дисковые устройств для всех дисков кластера должны быть одними и теми же на всех узлах (серверах). В противном случае вы можете быть не способным выполнить доступ к некому диску кластера.
-
Вам может понадобиться создание некоторого альтернативного метода подключения к серверу SQL если данное сетевое имя отключено и вы не можете соединиться при помощи TCP/IP. Вы можете применить именованные конвейеры, определяемые как
\\.\pipe\$$\SQLA\sql\query. -
При установке отказоустойчивого кластера вы можете столкнуться с проблеммами, относящимися к необходимости добавления записей домена. Если у вас отсутствуют правильные полномочия для данной доменной записи, откажет весь процесс. Вам может понадобиться общение сос своим народом системных администраторов для вовлечения их в решение данной проблемы.
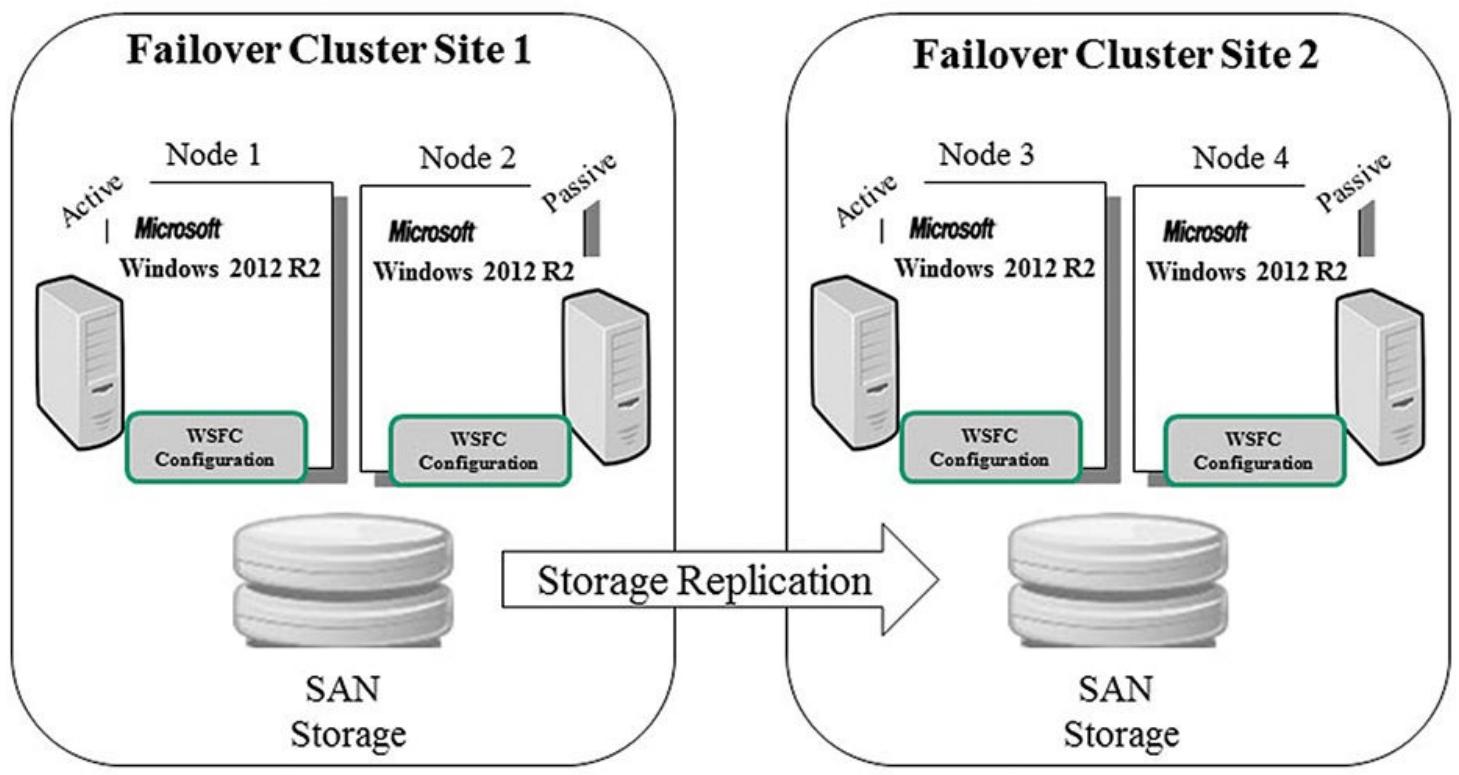
Многие бизнесы работают со своими центрами обработки данных (ЦОД) со множественным расположением или имеют вторичные ЦОД для предоставления устойчивости, распределяя их по площадкам в качестве некоторого механизма восстановления после чрезвычайных ситуаций. Первичной причиной осуществления этого является защита от отказа площадки в случае чрезвычайного происшествия с сетевой средой, электроснабжением, инфраструктурой или прочими обстоятельствами. Многие решения имеют реализацию отказоустойчивого кластера Windows Server и сервера SQL с такой моделью множества площадок. Отказоустойчивый кластер со множеством площадок содержит узлы, которые распределены по множеству физических площадок или ЦОД, с целью предоставления оступности по имеющимся ЦОД в случае некоторого чрезвычайного происшествия на некоторой площадке. Иногда отказоустойчивые кластеры со множеством площадок именуются как географически распределённые кластеры, эластичные кластеры или кластеры со множеством подсетей. На Рисунке 5.18 вы можете видеть некую конфигурацию кластера SQL со множеством площадок, которая также полагается на репликации уровня хранения (обычно доступные через возможности репликации блочного или битового уровня от производителей SAN или NAS).
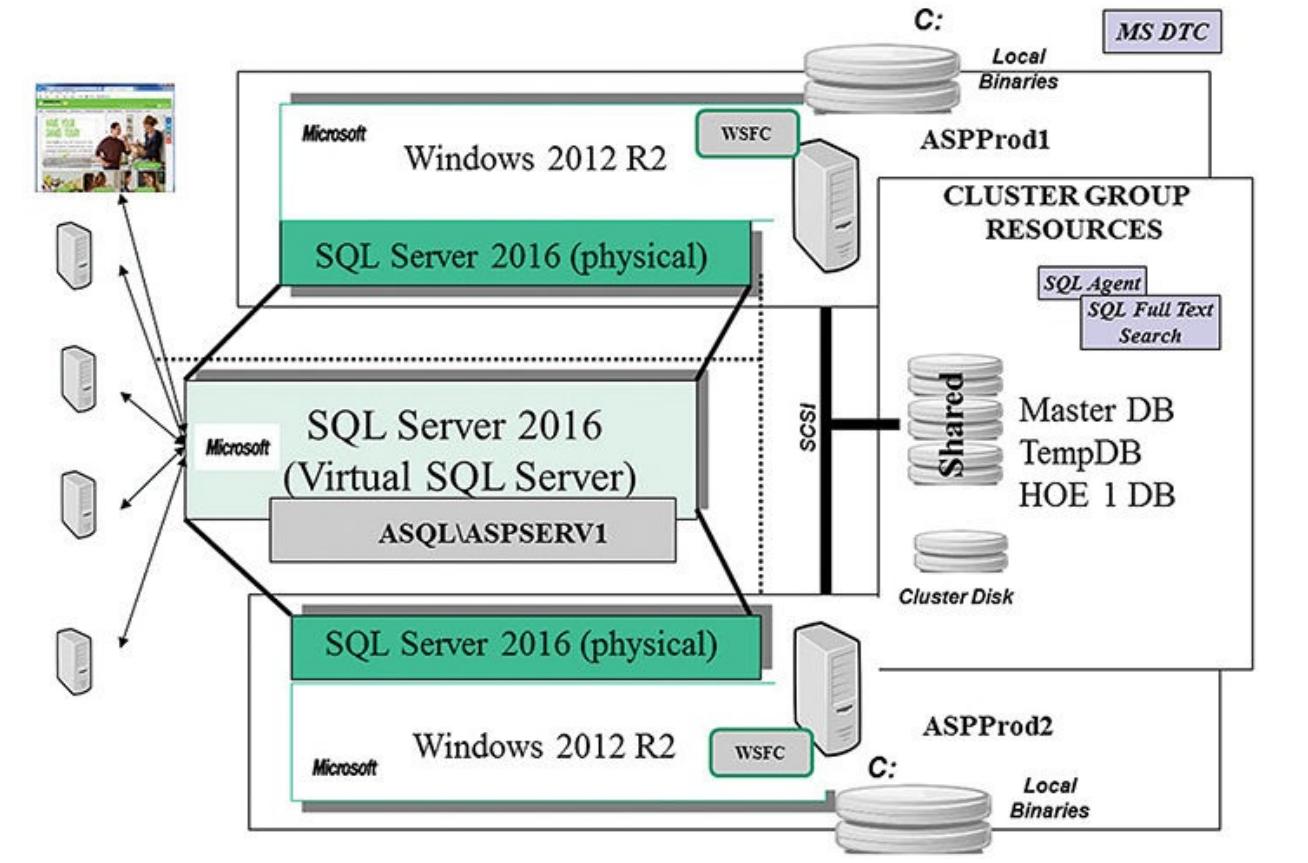
Возвращаясь к Главе 3, Выбор высокой доступности, которая сценарием бинеса Поставщика прикладных услуг (ASP, application service provider - Сценарий 1) достигает некоторой высокой доступности выбирая аппаратную отказоустойчивость, совместно используемые дисковые массивы RAID, WSFC и построение кластера SQL. Совместное наличие всех этих четырёх вариантов очевидно соответствует всем требовагниям времени в рабочем состоянии, устойчивости, производительности и стоимости. Соответсвие имеющегося уровня обслуживания ASP для его потребителей также делает возможными краткосрочность времени простоя, обусловленного обновлениями ОС или внесением исправлений, заменой оборудования, а также обновлением приложений. Имеющийся бюджет ASP был достаточно крупным для применения дополнительной избыточности оборудования.
Имеющийся ASP спланировал и реализовал три раздельных кластера для поддержки восьми пользовательских приложений, которые применяют сервер SQL. Каждый кластер сервера SQL был настроен с двумя узлами кластера в режиме активный/ пассивный. Пользователи ASP желают быть уверенными, что даже в случае возникновения некоторого отказа узла это не повлияет на производительность. Одним из способов такой гарантии является применения режима активный/ пассивный. Другими словами, там должен располагаться некий незанятый узлел, ожидающий вступления в дело в случае отказа. Когда пассивный узел приступает к обработке, он должен заработать на полную мощность почти моментально. Как это иллюстрируется Рисунком 5.19, каждый кластер SQL с двумя узлами может поддерживать от одного до трёх отдельных пользовательских приложений. Имеющийся ASP устанавливает руководство никогда не исполнять три приложения на кластер SQL в помощь риску всеобщей миграции; все имеющиеся потребители ASP согласились с таким подходом минимизации риска. Имеющееся первичное пользовательское приложение, показанное на Рисунке 5.19, является онлайновыми (Интернет) продуктами записей заказов жизнеспособности (HOE, health products order entry) и распределённая система. Имеющаяся база данных HOE является базой данных основных элементов заказов с приблизительным числом соединений SQL от 50 до 150. Когда данное ASP в иные дни достигает десятков основных пользовательских приложений, оно будет просто создавать некий новый кластер с двумя узлами. Именно это подтверждает возможность чрезвычайно масштабируемой, высоко производительной, смягчающей риски и эффективной в стоимостном отношении архитектуры для данного ASP.
В данном случае ROI может быть вычислен путём инкрементального добавления стоимости (или оценок) всех новых решений HA и их сопоставления с полной стоимостью времени простоя в течении некоторого периода времени (в данном примере 1 год).
Первоначально все стоимости приращения были оценены как находящиеся в диапазоне от $100k до $250k, что содержит следующие оценки:
-
Пять новых четырёхголовых сервера (с 64ГБ ОЗУ, локальной дисковой системой SCSI RAID 10, двумя NIC Ethernet, дополнительными контроллерами SCSI [для совместно используемых дисков]) по $30k на сервер.
-
Пять лицензий Microsoft Windows 2000 Advanced Server ≈ по $3k на сервер (Windows 2003 Enterprise Edition, $4k на сервер).
-
Восемнадцать дисковых систем SCSI с RAID 10 (с минимумом в 6 устройств на дисковую систему SCSI, 4 совместно используемые дисковые системы на кластер - всего 72 диска) ≈ $55k.
-
Стоимость пятидневного дополнительного обучения для персонала системных администраторов ≈ $15k.
-
Две новых лицензии сервера SQL (SQL Server 2016, Enterprise Edition) по $5k на сервер.
Общая стоимость инкрементальных расходов для обновления на такое построение решения кластера с высокой доступностью составляет приблизительно $245 000 (примерно по $81 600 на кластер с двумя узлами).
Давайте пройдём всё вычисление ROI с такими инкрементальными стоимостями применяя стоимость времени простоя:
-
Стоимость сопровождения (на протяжении периода в 1 год):
-
$15k (оценка): Стоимость персонала ежегодного администрирования (дополнительное время для обучения этого персонала)
-
$25k (оценка): Стоимость возобновления лицензий програмного обеспечения (для дополнительных компонентов HA: [5] ОС + [2] SQL сервер 2016)
-
-
Стоимость оборудования:
-
$205k стоимости аппаратных средств: Общая стоимость оборудования для необходимого нового решения HA
-
-
Стоимость развёртывания/ аттестации:
-
$20k стоимость развёртывания: Общая стоимость развёртывания, тестирования, QA, а также промышленной реализации данного решения
-
$10k стоимость аттестации HA
-
-
Стоимость времени простоя на протяжении периода в 1 год:
-
Если вы отслеживаете записи простоя на протяжении последнего года, воспользуйтесь этим значением; в противном случае сделайте некую оценку планируемого и не планируемого времени простоя для данной калькуляции. Для данного сценария оценочная стоимость часа простоя составляет $15k/час для данного ASP
-
Стоимость планируемого времени протсоя (Стоимость потери выручки) = Часы планируемого времени простоя x стоимость часа простоя организации
-
0.25% (оценка планируемого времени простоя в процентах за 1 год) x 8 760 часов в году = 21.9 часа планируемого времени простоя
-
21.9 часов (планируемого времеи простоя) x $15k/ час (стоимость одного часа простоя) = $328 500/ год стоимость планируемеого времени простоя
-
-
Стоимость не планируемого времени протсоя (Стоимость потери выручки) = Часы не планируемого времени простоя x стоимость часа простоя организации
-
0.25% (оценка не планируемого времени простоя в процентах за 1 год) x 8 760 часов в году = 21.9 часа планируемого времени простоя
-
21.9 часов (планируемого времеи простоя) x $15k/ час (стоимость одного часа простоя) = $328 500/ год стоимость не планируемеого времени простоя
-
-
Итоговое ROI:
-
Общая стоимость приобретения данного решения HA = $285 000 (на год - слегка выше чем установленная напрямую инкрементальная стоимость)
-
Общая стоимость времени простоя = $657 000 (за данный год)
Полученная инкрементальная стоимость составляет 43% от общей стоимости времени простоя за один год. Другими словами, все инвестиции в данное решение HA окупят себя за 0.43 года, или приблизительно за 5 месяцев! Вы можете понять почему этот ASP моргает глазами и вкладывается в это решение настолько быстро, насколько может.
Построение инфраструктуры вашей компании с кластерными технологиями в её сердцевине является гигантским шагом в сторону надёжности с пятью девятками. Если вы сделаете это, все ваши приложения, системные компоненты и разворачиваемые вами базы данных в такой архитектуре получат этот дополнительный элемент надёжности. WSFC и отказоустойчивый кластер SQL являются подходами высокой доступности на уровне экземпляра. Во многих случаях все необходимые изменения приложения или компонентов системы для получения преимуществ от данных кластерных технологий совершенно прозрачны. Применение комбинации NLB и WSFC делает возможным для вас не только восстановление после отказа приложений, но также и масштабирование для роста сетевой ёмкости. Многие организации повсеместно применяют такой подход активный/ пассивный c двумя узлами кластера сервера SQL на протяжении последних 10 или 15 лет.
Как вы увидите в следующей главе, применение свойства AlwaysOn расширяет такую эластичность на имеющийся уровень базы данных даже добавляя больше высокой доступности и масштабируемости в ваши реализации, если требуются более высокие требования высокой доступности.
{Прим. пер.: Обращаем ваше внимание на тот факт, что SQL Server 2017 привнёс собой новые методики организации HADR при помощи контейнеров и Kubernetes, подробнее в нашем переводе Главы 11. SQL Server и контейнеры из вышедшей в октябре 2018 в издательстве Apress книги Боба Вордса "Профессиональный SQL Server поверх Linux"}