Глава 1. Что такое Prometheus?
Содержание
Prometheus является основывающейся на измерениях системой мониторинга с открытым исходным кодом. Естественно, Prometheus далеко не единственный, кто делает это, итак, что делает его столь заметным?
Prometheus делает одну вещь, причём делает её хорошо. Он имеет простую, но очень мощную модель данных и язык запросов,который делает возможным для вас анализ того как исполняются ваши приложения и инфраструктуры. Он не пытается решать проблемы за пределами пространства измерений, оставляя их более приспособленным для этого инструментам.
С момента своего появления при участии нескольких разработчиков, работающих в SoundCloud в 2012 году, вокруг Prometheus выросли сообщество и экосистемы. Prometheus в основном написан на Go и лицензирован в соответствии с лицензией Apache 2.0. Есть сотни людей, которые внесли свой вклад в сам проект, который не контролируется ни одной компанией. Всегда сложно определить, сколько пользователей имеет некий проект с открытым исходным кодом, но я полагаю, что начиная с 2018 года десятки тысяч организаций применяют в промышленном применении Prometheus. В 2016 году проект Prometheus стал вторым 1 участником Фонда естественных облачных вычислений (CNCF, Cloud Native Computing Foundation).
Для инструментальной оснастки вашего собственного кода имеются клиентские библиотеки во всех популярных языках и средах исполнения, включая Go, Java/JVM, C#/.Net, Python, Ruby, Node.js, Haskell, Erlang и Rust. Подобное Kubernetes и Docker программное обеспечение уже вооружено инструментарием клиентских библиотек Prometheus. Имеются сотни интеграций программного обеспечения сторонних производителей, которые выставляют параметры в формате не Prometheus. Существуют такие именуемые экспортёрами продукты, которые включают в себя HAProxy, MySQL, PostgreSQL, Redis, JMX, SNMP, Consul и Kafka. Мой приятель также добавил поддержку для мониторинга серверов Minecraft, так как он серьёзно озабочен своими кадрами в секунду.
Простой текстовый формат делает элементарным выставление измерений в Prometeus. Прочие системы мониторинга, причём как с открытым исходным кодом, так и коммерческие, имеют дополнительную поддержку для данного формата. Это позволяет всем этим системам мониторинга для сосредоточения на более существенных свойствах, вместо того чтобы каждый из них тратил своё время на дублирование своих усилий для поддержки всех отдельных частей программного обеспечения, которые пользователи подобные вам желают мониторить.
Имеющаяся модель данных идентифицирует все временные последовательности не только по имени, но также и неупорядоченным набором пар ключ- значение, которое именуется метками. Её язык запросов PromQL делает возможным агрегирование по любой из таких меток, поэтому вы можете выполнять анализ не просто по процессам, но также и по центрам обработки данных и по служба, или по любым прочим определённым вами меткам. Это может быть представлено графически в таких системах инструментальных панелей, как Grafana.
При помощи того же самого языка запросов, который вы применяете для построения графиков, могут определяться оповещения. Если вы это можете отобразить это графически, вы можете и оповестить об этом. Метку упрощают поддержку оповещений, так как вы можете создавать некое единое оповещение, которое охватывает все возможные значения меток. В каких-то иных системах мониторинга вам приходится персонально создавать некое оповещение для каждой машины/ каждого предложения. Родственная с этим служба обнаружения может автоматически определять какие приложения и машины следует выискивать (scraped) из источников, подобных Kubernetes, Consul, Amazon Elastic Compute Cloud (EC2), Azure, Google Compute Engine (GCE) и OpenStack.
Для всех этих свойств и преимуществ Prometheus является отлаженным и простым для исполнения. Один сервер Prometheus может поглощать миллионы выборок в секунду. Это отельный статически связываемый с каким- то файлом настроек исполняемый модуль. Все компоненты Prometheus могут запускаться в контейнерах, причём они избегают выполнения чего- то интригующего, что может стать на пути инструментов управления настройкой. Он предназначен для интеграции в инфраструктуру, которая уже имеется у вас и строится поверх неё, а не собственно для того чтобы выступать в качестве некоторой платформы управления.
Теперь, после того как вы получили некий обзор того чем является Prometheus, давайте на минутку отступим на шаг назад, чтобы рассмотреть что мы подразумеваем под термином "мониторинг" чтобы снабдить вас неким контекстом. Вслед за этим я рассмотрю что является основными компонентами Prometheus, а что не является Prometheus.
В средней школе один из моих учителей сказал нам, что если спросить десять экономистов что означает экономика, вы получите одиннадцать ответов. Мониторинг обладает аналогичным недостатком в консенсусе того что именно он в точности означает. Когда я рассказываю кому- либо чем я занимаюсь, люди представляют себе, что моя работа влечёт за собой всё от отслеживания одним глазом температуры на фабриках, вплоть до отслеживания персонала на предмет того где они шляются, чтобы определять кто пользуется Facebook-ом в рабочее время и даже определять злоумышленников в сетевых средах.
Prometheus не проектировался ни для одной из этих целей2. Он был построен в помощь разработчикам программного обеспечения и администраторов при работе с промышленными вычислительными системами, такими как приложения, инструменты, базы данных и сетевые среды, которые поддерживают популярные вебсайты.
Итак, что же такое мониторинг в данном контексте? Я бы хотел сузить данный вид операционного мониторинга вычислительных систем до четырёх положений:
-
ОповещениеЗнание того, что нечто происходит не так как нужно, как правило, наиболее важная сущность того что вы желаете отслеживать. Вы хотите чтобы ваша система мониторинга привлекала внимание персонала чтобы обратить на это внимание.
-
ОтладкаТеперь, после того как вы вызвали персонал, ему следует провести расследование чтобы определить вызвавшую происшествие причину и в конечном счёте определить что является проблемой.
-
ТенденцииОповещение и отладка обычно производятся во временной шкале в порядке от минут да часов. Когда это не так срочно, наличие возможности просмотреть то, как ваша система использовалась и изменялась со временем также очень полезно. Тенденции могут соответствовать проектным решениям и процессам, например, планированию мощности.
-
ТрубопроводыКогда у вас имеется молоток, всё становится похожим на гвоздь. В конечном итоге все системы мониторинга являются трубопроводами обработки данных. Иногда удобнее применять часть вашей системы мониторинга для иной цели, вместо тог, чтобы строить некое индивидуальное решение. Это не обязательно в точности относится к мониторингу, но это распространено на практике, поэтому я бы хотел включить и это.
В зависимости от того с кем вы ведёте беседу и от их рода занятий, эти люди могут рассматривать только часть из того что следует подвергать мониторингу. Это приводит к многочисленным обсуждениям относительно мониторинга и вокруг него, оставляя всех разочарованными. Чтобы помочь вам понять откуда происходит всё прочее, я собираюсь слегка окунуться в историю мониторинга.
В то время как в последние годы мониторинг сдвигается в сторону инструментов, включающих в свой состав Prometheus, доминирующими решениями остаются некие сочетания Nagios и Graphite или их вариации.
Когда я произношу Nagios, я включаю включаю в него любое программное обеспечение из одного и того широкого семейства, такое как Icinga, Zmon и Sensu. Они работают в первую очередь за чёт регулярного исполнения сценариев, именуемых проверками (check). Если какая- то проверка отказывает, возвращая ненулевой код выхода, вырабатывается некое оповещение. Nagios первоначально запустил Итан Гальстад в 1996 в качестве некоего приложения MS DOS, применяемого для выполнения пингов. Вначале в 1999 он был выпущен с названием NetSaint, а поздее переименован в 2002 в Nagios.
Чтобы обсудить общую историю Graphite, мне требуется вернуться в 1994. Тобиас Отайкер создал сценарий Perl, который стал в 1995 Multi Router Traffic Grapher, или MRTG 1.0. Как указывает его название, он в основном был создан для сетевого мониторинга через Simple Network Management Protocol (SNMP). Он также способен получать измерения выполняя сценарии3. 1997 год привнёс большие изменения с переносом части кода на C и созданием карусельной базы данных (RRD, Round Robin Database), которая применялась для хранения данных измерений. Это придало заметные улучшения производительности, а RRD послужила основой и для прочих инструментов, таких как Smokeping и Graphite.
Начиная с 2006, для хранения измерений Graphite использует Whisper, который имеет аналогичную с RRD архитектуру. Graphite сам по себе не собирает данные, вместо этого они отправляются инструментами сбора, например, collectd и Statsd, которые были созданы в 2005 и 2010, соответственно.
Основным ключевым моментом здесь является то, что графическое отображение и оповещение в былые времена были целиком обособленными проблемами, которые осуществлялись различными инструментами. Вы можете написать некий сценарий проверки для оценки запроса и вырабатывать на этой основе предупреждения, однако большая часть проверок имело тенденцию находиться в неопределённых состояниях, например, процесс не запущен.
Ещё одним пережитком той эпохи является в подходе с достаточной степенью ручной обработкой вычислительных служб администрирования. Службы развёртывались на индивидуальных машинах и любовно обслуживались системными администраторами. Те оповещения, которые потенциально указывали на некую проблему, перебрасывались выделенным на то инженерам. По мере того как приобретали известность облачные и естественно облачные технологии, такие как EC2, Docker и Kubernetes, трактовка индивидуальных машин и служб в качестве домашних питомцев , каждый из которых получает персональное внимание, плохо поддаётся масштабированию. Скорее, их следует рассматривать больше как стадных животных и администрировать и мониторить в качестве групп. В точности так же, как сама отрасль перешла от управления вручную к инструментарию подобному Chef или Ansible, а в настоящее время начинает использовать такие технологии как Kubernetes, мониторинг также нуждается в в необходимости перехода с проверок или персональных обработок на индивидуальных машинах к мониторингу, основывающемуся на жизнеспособности в целом.
Вы могли заметить, что я не упоминал ведение журналов регистрации. исторически журнали применялись как нечто, для чего вы применяли tail, grep и awk вручную. Возможно, у вас имелся подобный AWStats инструментарий для производства отчётов каждый час или ежедневно. На протяжении последних лет также применялись в качестве значительной части мониторинга такой стек, как Elasticsearch, Logstash и Kibana (ELK).
Теперь, когда мы слегка взглянули на графическое отображение и оповещения, давайте рассмотрим как вступают в действие измерения и журналы. Имеются ли ещё некие категории помимо этих двух?
В конце концов, большая часть мониторинга сосредотачивается на одном и том же понятии: событиях. События могут быть практически любыми, в том числе:p>
-
Получение запроса HTTP
-
Отправка запроса HTTP 400
-
Вход в некую функцию
-
Достижение определённого оператора
elseилиif -
Выход из функции
-
Регистрация пользователя
-
Запись данных на диск
-
Получение данных из сети
-
Запрос дополнительной памяти из основного ядра
Все события к тому же имеют контекст. Запрос HTTP будет иметь IP адрес, с которого он получен, подставленный в этот запрос URL, куки, которые необходимо установить, а также того пользователя, который сделал данный запрос. Отклик HTTP будет иметь продолжительность получения данного отклика, значение кода состояния HTTP, а также длину тела сообщения. Вовлечённые в функции события имеют стек вызова функций, стоящих перед данной, причём вне зависимости от того, что именно послужило переключением в данную часть стека, к примеру, некий запрос HTTP.
Наличие всех наборов контекста для всех существующих событий было бы замечательно для отладки и понимания того как ваша система исполняется и с технической точки зрения, и с точки зрения ведения дел, однако такой объём данных является непрактичным для обработки и хранения. Таким образом, существует то, что я примерно сформулировал бы четырьмя видами подходов к сокращению объёма данных до некоторого работоспособного состояния, а именно, профилирование, отслеживание, ведение журналов и проведение измерений.
Профилирование
Профилирование применяет такую стратегию, при которой вы не можете иметь контекст для всех имеющихся событий на протяжении всего времени наблюдения, но вы располагаете неким контекстом на ограниченные промежутки времени.
Одним из примеров инструментария профилирования является tcpdump. Он позволяет вам осуществлять запись сетевого обмена на основе некоего заданного фильтра. Это некий весомый инструмент отладки, однако на самом деле вы не можете держать его включённым всё время, поскольку вы заполните всё дисковое пространство.
Отладочное построение исполняемых модулей, которые отслеживают профилируемые данные является другим примером. Они предоставляют изобилие отладочной информации, однако воздействие на окончательную производительность от получения такой информации, например, временные задержки для каждого вызова функции, означают, что это будет непрактично для запуска в промышленном варианте на постоянной основе.
В текущем ядре Linux, расширенные фильтры пакетов Беркли (eBPF, enhanced Berkeley Packet Filters) делают возможным подробное профилирование событий ядра начиная с операций файловой системы вплоть до странностей сетевой среды. Они предоставляют доступ к внутреннему уровню, который не был в общем случае доступен изначально и я рекомендую по этому вопросу ознакомиться с текстами Брендана Грегга.
Профилирование как правило предназначается для тактической отладки. Если оно применяется на более долгосрочной основе, то необходимо сократить общий объём данных чтобы вписаться в одну из прочих категорий мониторинга.
Отслеживание
Отслеживание (tracing) не наблюдает за всеми событиями, а вместо этого берёт на себя некую пропорцию событий, например, одно из сотни, для тех, которые происходят в представляющих интерес функциях. Отслеживание будет отмечать определённые функции в имеющемся стеке трассировки представляющих интерес моментов, а также зачастую и значение продолжительности этих функций. Исходя из этого вы можете получить некое представление о том, на что затрачивает время ваша программа и какие именно пути кода вносят основной вклад во временные задержки.
Вместо того, чтобы выполнять моментальные снимки отслеживания стека в представляющих интерес моментах, некоторые системы трассировки отслеживают и записывает значения времён исполнения всех вызовов функций, начиная с представляющий интерес функции. К примеру, в качестве образца может браться каждый сотый HTTP запрос пользователя, причём для этого запроса вы можете отслеживать какое время было затрачено на общение с такими серверами как базы данных и кэши. Это позволяет вам обнаружить насколько отличаются временные затраты на основании таких факторов как попадание или промах в кэше.
Распределённое отслеживание продвигает этот этап на шаг вперёд. Оно выполняет работу отслеживания по процессам, присоединяя уникальные идентификаторы к запросам, передаваемым от одного процесса к другому при использовании вызовов удалённых процедур (RPC, remote procedure calls) дополнительно к тому является ли данный запрос тем, что надлежит отслеживать. Такие трассировки от различных процессов и машин могут сшиваться обратно на основании заданного идентификатора запроса. Это жизненно важный инструмент для отладки распределённых архитектур микрослужб. Технологии из этого пространства представлены OpenZipkin и Jaeger.
При использовании отслеживания, именно выборка сдерживает в разумных пределах объёмы данных и воздействие на производительность инструментария.
Ведение журналов
Ведение журналов (logging) отслеживает некий ограниченный набор событий и записывает часть общего контекста для каждого из таких событий. Например, оно может просматривать все входящие запросы HTTP или же все исходящие вызовы базы данных. Во избежание потребления слишком большого числа ресурсов, в качестве столбового правила вам следует следует ограничиваться примерно сотней полей на регистрационную запись. Выше этого предела следует принимать во внимание влияние полосы пропускания и пространства хранения.
Например, для сервера, обрабатывающего тысячи запросов в секунду, некая регистрационная запись с сотней полей, причём каждое занимает десять байт, выливается в мегабайт в секунду. Это будет нетривиальным для 100 мегабитной сетевой карты и потребует сохранения 84 ГБ в день только под ведение журнала.
Большим преимуществом ведения журналов является то, что (как правило) отсутствует выборка событий, поэтому, не смотря на то, что имеется некое ограничение на общее число полей, будет практичным определять насколько медленные запросы влияют на одного определённого пользователя, общающегося с одной конкретной оконечной точкой.
Также как мониторинг означает разные вещи для разных людей, ведение журналов также означает различные вещи в зависимости от того, к кому вы обращаетесь с вопросом, что может вызывать путаницу. Различные виды ведения журнала имеют различные требования применения, продолжительности и сроков хранения. Как мне видится, имеется четыре кое- где перекрывающихся категории:
-
Журналы транзакцийЭто критически важные для ведения дел записи, которые вы обязаны сберегать за любую цену, скорее всего, навсегда. К данной категории, как правило, относится всё, касающееся денежных средств или применяется для критически важных функций.
-
Журналы запросовЕсли вы отслеживаете все запросы HTTP, или все вызовы базы данных, это именно журнал запросов. Они могут обрабатываться для реализации пользовательских функций представления или просто для внутренних оптимизаций. Как правило, вы не желаете их терять, но это не будет концом света, если некоторые из них бесследно исчезнут.
-
Журналы приложенийНе все журналы относятся к запросам; некоторые относятся к самим процессам. Здесь обычны стартовые сообщения, задачи сопровождения оснастки, а также прочие строки регистрации уровня процесса. Эти регистрационные записи обычно считываются напрямую персоналом, поэтому вам следует попытаться избегать наличия более нескольких в минуту при нормальной работе.
-
Журналы отладкиОтладочные журналы имеют склонность быть очень подробными и таким образом затратны при создании и сохранении. Они часто применяются в крайне узких ситуациях отладки и имеют склонность приближаться к профилированию благодаря своим объёмам данных. Требования надёжности и продолжительности сохранения как правило очень низкие, причём журналы отладки могут даже не покидать той машины, на которой они вырабатываются.
Смешение всех различных видов журналов в одну кучу может привести вас к худшему из всех миров, когда у вас в наличии значительные объёмы данных отладочных записей в комбинации с требованиями высокой надёжности для журналов транзакции. Таким образом, по мере роста вашей системы вам придётся спланировать отделение журналов отладки с тем, чтобы их можно было обрабатывать отдельно.
Примеры систем ведения журналов включают в свой состав стек ELK и Graylog.
Измерения
Измерения по большей части игнорируют контекст, вместо этого отслеживая вырабатываемые со временем различные типы событий. Для сбережения применяемых ресурсов в чистоте следует ограничивать количество подлежащих отслеживанию различных чисел; десять тысяч на процесс является обоснованным верхним пределом, которого следует придерживаться.
Примерами различных видов измерений, которые могут иметься у вас, может быть общее число раз, которое вы получаете запросы HTTP, сколько времени было затрачено на обработку запросов и сколько запросов выполняется в настоящий момент. Посредством исключения любой информации о контексте, вы оставляете в разумных пределах необходимые объёмы данных и обработки.
Тем не менее, это не означает, что контекст всегда игнорируется. Для запросов HTTP вы можете определить наличие замеров по каждому из путей URL. Однако правило десяти тысяч измерений всегда должно быть на уме, так как всякий отличающийся путь теперь считается измерением. Применение такого контекста как адрес электронной почты пользователя бедет не разумным, поскольку он имеет неограниченное кардинальное число (мощность)4.
Вы можете применять измерения для отслеживания значений латентности и объёмов данных, обрабатываемых каждой из имеющихся подсистем в ваших приложениях, что делает более простым определение того, что именно вызывает замедление. Журналы не могут записывать такое большое число полей, но если вы знаете какая система ответственна за это, журналы могут помочь вам выявить какие именно запросы пользователей вовлечены в это.
Именно тут становится наиболее очевидным компромисс между журналами и измерениями. Измерения позволяют вам собирать информацию о событиях от всех ваших процессов, но при этом обычно имеют не более одного или двух полей контекста в ограничении мощности множества измерений. Журналы допускают для вас сбор информации обо всех событиях одного типа, но могут отслеживать только сотню полей контекста с неограниченной мощностью множества. Данное замечание относительно кардинального числа (мощности множества) и установленных пределов, которые накладываются на измерения важно осознать, и я буду возвращаться к нему в последующих главах.
Будучи основанной на измерениях системой мониторинга, Prometheus спроектирована для отслеживания общесистемных жизнеспособности, поведения и производительности, а не для присмотра за индивидуальными событиями. Иными словами, Prometheus отвечает за то, что в последнюю минуту было 15 запросов, которые отняли 4 секунды на обработку, что повлекло за собой 40 обращений к базе данных, 17 попаданиям в кеш и 2 покупкам клиентами. Значения же стоимости и пути кода для каждого индивидуального вызова будет предметом внимания профилирования или журнала регистраций.
теперь, когда вы получили понимание того, где место Prometheus в общем пространстве мониторинга, давайте рассмотрим различные компоненты Prometheus.
Рисунок 1-1 отображает общую архитектуру Prometheus. Prometheus разыскивает цели для их выуживания из службы обнаружения. Это могут быть ваши собственные инструментальные приложения или приложения сторонних разработчиков, которыми вы можете выполнять выуживание через некоего экспортёра. Все выуженные данные сохраняются и вы можете применять их в инструментальных панелях при помощи PromQL или отправляя запросы в Alertmanager, который будет преобразовывать их в страницы, электронные письма или прочие уведомления.
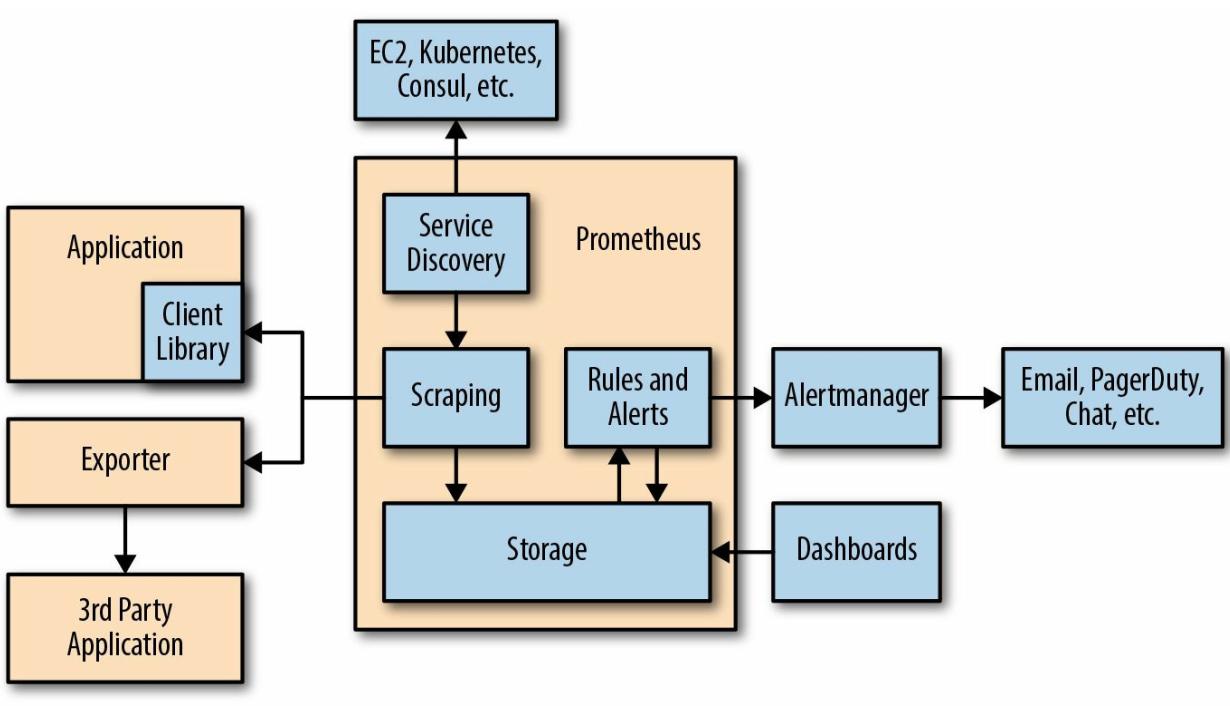
Как правило, измерения не появляются чудесным образом из приложений; кто- то должен добавить конкретный инструментарий, который их производит. Именно тут появляются библиотеки клиентов. Всего лишь в двух или трёх строках кода вы можете одновременно определить некое измерение и добавить желаемую вами инструментальную поточную обработку в код своего управления. Это именуется непосредственной инструментальной обработкой (direct instrumentation).
Библиотеки клиентов доступны для всех имеющихся основных языков и сред исполнения. Проект Prometheus предоставляет официальные клиентские библиотеки для Go, Python, Java/JVM и Ruby. имеется также широкое разнообразие клиентских библиотек сторонних разработчиков, например, для C#/.Net, Node.js, Haskell, Erlang и Rust.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Сопоставление официальных и неофициальных Не отбрасывайте в сторону такие интеграционные решения как неофициальные или сторонние клиентские библиотеки. При наличии сотен приложений и систем, в которые вы можете пожелать быть интегрированными, сама команда проекта Prometheus не располагает ни временем ни опытом для создания и сопровождения их всех. Таким образом, подавляющая часть интеграций в общей экосистеме являются сотронними. Для того чтобы всё оставалось разумно согласованным и работало надлежащим образом доступны руководства как создавать интеграции. |
Клиентские библиотеки заботятся обо всех технических деталях, например, о безопасности потоков, учёте системных ресурсов и производстве самого выставляемого в отклике на запросы HTTP формата текста Prometheus. Так как мониторинг на основе измерений не отслеживает отдельные события, использование памяти клиентских библиотек не даёт роста событий более того числа, которое уже имеется у вас. Вместо этого память зависит от общего числа имеющихся у вас измерений.
Если в одной из имеющихся зависимостей библиотек для вашего приложения имеется инструментарий Prometheus, она будет автоматически прихватываться. Таким образом, применяя некую ключевую библиотеку, например вашего клиента RPC, вы можете получать для неё инструментарий во всех своих приложениях.
Некоторые измерения обычно предоставляются сразу после установки библиотек клиентов, скажем, использование ЦПУ и сбор коллекций статистик в зависимости от имеющейся библиотеки и среды времени исполнения.
Библиотеки клиента не ограничиваются выводом измерений в определённом текстовом формате Prometheus. Prometheus является открытой экосистемой и тот же самый API применяется для насыщения того формата генерации текста, который может применяться для выработки измерений в прочих форматах или для подпитки прочих инструментальных систем. Аналогично, имеется возможность брать измерения из прочих инструментальных систем и вывешивать их в некую библиотеку клиента Prometheus, если вы ещё пока не полностью преобразовали всё в инструментальные средства Prometheus.
Вы можете управлять или даже получать доступ не ко всякому запущенному вами коду. К слову, маловероятно, например, что ядра операционной системы начнут выводить измерения в формате Prometheus через HTTP в ближайшем будущем.
Такое программное обеспечение как правило имеет некий интерфейс, через который вы можете получать доступ к замерам. Это может быть некий специализированный формат, требующий индивидуальных синтаксического разбора и обработки, как это, к примеру, требуется для большей части замеров Linux или установившихся стандартов, подобных SNMP.
Экспортёр является той частью программного обеспечения, которую вы развёртываете в непосредственной близости от своего приложения, от которого вы желаете получать измерения. Он получает запросы от Prometheus, выполняет сбор всех необходимых данных от определённого приложения, преобразует их в правильный формат и в конечном счёте возвращает их в ответ на Prometheus. Вы можете представлять себе экспортёр как некий небольшой посредник (прокси) один- к- одному, выполняющий преобразование данных между интерфейсом измерений какого- то приложения и собственно форматом представления Prometheus.
В отличии от непосредственной инструментальной оснастки, которую вы могли бы применять для кодирования своего управления, экспортёры применяют некий
иной стиль инструментальной оснастки, называемый индивидуальными коллекторами или
ConstMetrics5.
Хорошим известием является то, что исходя из размера сообщества Prometheus, требующийся вам экспортёр скорее всего уже имеется и может быть использован вами с приложением минимальных усилий с вашей стороны. Если у определённого экспортёра отсутствует интересующее вас измерение, вы всегда можете отправить активный запрос на улучшение, что улучшит его для последующих применяющих этот экспортёр лиц.
После того, как запущены ваши инструментальные приложения и ваши экспортёры, Prometheus должен узнать где они расположены. Именно таким образом Prometheus будет знать что подлежит мониторингу и будет в состоянии заметить что нечто, предназначенное для мониторинга, не отвечает. В динамических средах вы не можете просто предоставлять некий перечень приложений и экпортёров единожды, поскольку он устаревает. именно тут на сцены выходит обнаружение служб (service discovery).
Возможно, у вас уже имеется некая база данных ваших машин, приложений и того, что они делают. Она может быть внутри базы данных Chef, какого- то файла инвентаризации для Ansible, основываться на тегах вашего экземпляра EC2, в метках и аннотациях Kubernetes, либо, быть может, просто располагаться в wiki вашей документации.
У Prometheus имеется интеграция со многими распространёнными механизмами обнаружения служб, например, Kubernetes, EC2 и Consul. также существует
некая универсальная интеграция для тех, кто слегка отстаёт от имеющегося проторённого пути (см. раздел
Файл).тем не менее всё ещё остаётся некая проблема. Просто из- за того, что у Prometheus имеется некий
перечень машин и служб, это вовсе не означает, что мы понимаем как они вписываются в вашу архитектуру. Например, Вы можете применять
Name tag6 EC2 для указания
какое приложение запущено на машине, в то время как остальные могут пользоваться тегом с названием app.
Так как все организации на самом деле слегка отличаются, Prometheus делает для вас возможной настройку того как метаданные из обнаружения служб ставятся в соответствие целям мониторинга и его метки применяют Повторную пометку relabelling.
Обнаружение служб и Повторная пометка дают нам некий подлежащий мониторингу перечень целей. Теперь Prometheus нуждается в опросе самих замеров.
Prometheus осуществляет это посредством некоего запроса HTTP, именуемого Выуживанием
(scrape). Полученный на такое Выуживание отклик подлежит синтаксическому анализу и поглощению хранилищем.
Также добавляется ряд полезных показателей, таких как то, что Выуживание было успешным и сколько времени на него понадобилось. Процесс Выуживания
выполняется регулярно; обычно вы настраиваете его на то что он происходит каждый промежуток времени от 10 до 60 секунд для каждой цели.
|
| Замечание |
|---|---|
|
Сопоставление активной и пассивной доставки Prometheus является системой с активной доставкой (pull). Он принимает решение что и когда Выуживать на основе своих настроек. Также существуют и системы на основе пассивной доставки (push), в которых сами цели мониторинга принимают решение собираются ли они подлежать мониторингу и насколько часто. В настоящее время в интернете идёт энергичное обсуждение об этих двух подходах, которое зачастую имеет сходство с дебатами относительно сопоставления Vim и EMACS. Достаточно остановиться на том, что каждый из них имеет свои плюсы и минусы, но по- существу это не имеет большого значения. Будучи пользователем Prometheus вам следует понимать, что активная доставка встроена в само ядро Prometheus и попытка выполнения пассивной доставки в лучшем случае являются неразумными. |
Prometheus сохраняет данные локально в некоторой индивидуальной базе данных. Для распределённых систем надёжность является вызовом, поэтому Prometheus не предпринимает попытки выполнять какую бы то ни было форму кластеризации. Помимо надёжности это делает более простым запуск Prometheus.
на протяжении многих лет хранилища претерпели ряд изменений архитектуры, причём, причём имеющаяся в Prometheus 2.0 система хранения стала третьей итерацией. данная система хранения способна обрабатывать миллионы выборок в секунду, причём на единственном сервере Prometheus. Применяемый алгоритм сжатия может достигать 1.3 байта на выборку данных из реального мира. Рекомендуется применение SSD, но это не обязательное требование.
Prometheus имеет множество API HTTP, которые делают возможным для вас как запрос сырых данных, так и вычисление запросов PromQL. Они могут применяться для производства графических представлений и инструментальных панелей. Сразу после установки Prometheus предоставляет свой Браузер выражений (expression browser). Он использует эти API и удобен для специализированных запросов и зондирования данных, но не является общеупотребимой системой инструментальной панели.
Вам рекомендуется в качестве инструментальных панелей применять Grafana. Она имеет широкое разнообразие свойств, в том числе официальную поддержку для Prometheus в качестве источника данных. Она может производить широкое разнообразие инструментальных панелей, таких как представленная на Рисунке 1-2. Grafana поддерживает общение со множеством серверов Prometheus, даже в рамках единственной инструментальной панели.
Хотя PromQL и механизм хранения являются мощными и эффективными, агрегирование показателей из тысяч машин всякий раз "на лету" при визуализации диаграмм может слегка запаздывать. Правила записи позволяют оценивать выражения PromQL на регулярной основе, а их результаты попадают в имеющийся механизм хранения.
Правила оповещений являются иным видом правил записи. Они также регулярно оценивают выражения PromQL и все результаты этих выражений становятся предупреждениями. Предупреждения отправляются в Alertmanager.
Alertmanager получает ghtleght;ltybz от серверов Prometheus и преобразует их в уведомления. Уведомления могут включать электронную почту, приложения чата, например, Slack, а также такие службы как PagerDuty.
Alertmanager выполняет намного больше чем слепое превращение предупреждений в уведомления на основе один- к- одному. Взаимосвязанные оповещения могут объединяться в единое уведомление, с которым выполняется дросселирование для снижения страничных штормов7, а различные маршутизации и выводы уведомления могут быть настроены под все ваши различные команды. оповещения также могут быть приостановлены, возможно, чтобы отложить некую проблему, о которой вы уже осведомлены, когда вы знаете, что обслуживание уже запланировано.
основная роль Alertmanager останавливается на отправке уведомлений; для управления откликами от персонала на происшествия вам следует применять такие службы как PagerDuty и систем маркеров.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Оповещения и их пороговые значения настраиваются в Prometheus, а не в самом Alertmanager. |
Так как Prometheus сохраняет данные только на своей локальной машине, вы ограничены тем, какой объём дискового пространства может умещаться в этой машине8. Хотя обычно вы заботитесь только о самых последних днях или около того, для планирования ёмкости долговременного сбережения желательными являются более длительные периоды хранения.
Prometheus не предлагает кластерного решения хранения для запоминания данных по множеству машин, однако имеются API удалённого чтения и записи, которые позволяют цеплять прочие системы и применять их в этой роли. Это делает возможным для запросов PromQL прозрачно исполняться как с локальными, так и с удалёнными данными.
Теперь, когда у вас имеется некое понимание каковы границы применения Prometheus в расширенном ландшафте мониторинга и что составляют его основные компоненты, давайте рассмотрим некоторые из тех вариантов применения, для которых Prometheus не является наилучшим выбором.
Будучи системой на основе измерений, Prometheus не подходит для хранения журналов событий или индивидуальных событий. К тому же он не является лучшим выбором для данных с большими значениями кардинального числа (данных с высокой мощностью), например, для адресов электронной почты или имён пользователей.
Prometheus спроектирован для оперативного мониторинга, при котором небольшие неточности и условия состязания, обусловленные такими факторами, как планирование ядра и отказы Выуживания являются фактом жизни. Prometheus делает компромиссы и предпочитает предоставление вам на 99.9% корректных данных вместо того чтобы прерывать мониторинг в ожидании прихода точных данных. Таким образом, в приложениях, в которые вовлечены деньги или биллинг, Prometheus должен использоваться с предосторожностями.
В своей следующей главе я покажу как запускать Prometheus и осуществлять некий базовый мониторинг.
1 Номером 1 был Kubernetes.
2 Тем не менее мониторинг температуры машин и центров обработки данных на самом деле не редкость. имеется даже ряд пользователей, которые применяют Prometheus для отслеживания погоды в своё удовольствие.
3 У меня сохранились приятные воспоминания об установке MRTG в начале 2000х годов, написании сценариев отчётов о температуре и загрузке сетевой среды.
4 Кроме того, адреса электронной почты , помимо всего прочего, также представляют собой персональную информацию (PII, personally identifiable information), которая привносит с собой проблемы соблюдения конфиденциальности, которые лучше избегать в мониторинге.
5 Термин ConstMetric является разговорным и происходит от функции MustNewConstMetric из клиентской библиотеки Go, применяемой для создания измерений экспортерами, написанными на Go.
6 Name tag EC2 является тем отображаемым названием
некоторого экземпляра EC2, которое отображается в основной веб консоли EC2.
7 Некая страница является уведомлением для обслуживающего инженера, который, как ожидается выполнит проверку и обслуживание. Хотя вы можете получать некую страницу через обычный радио пейджер, в наши дни она больше соответствует вашему мобильному телефону в виде какого- то SMS, уведомления или телефонного вызова. Страничный шторм, это когда вы получаете некую серию страниц в быстрой последовательности.
8 тем не менее, современные машины могут содержать локально огромные объёмы данных, поэтому отдельная кластерная система может вам и не потребоваться.