Глава 2. Параллельность на основе потоков
Содержание
- Глава 2. Параллельность на основе потоков
- Что такое поток?
- Модуль Python threading
- Определение потока
- Выявление значения текущего потока
- Задание подкласса потока
- Синхронизация потоков блокировкой
- Синхронизация потоков RLock
- Синхронизация потоков при помощи семафоров
- Синхронизация потоков условием
- Синхронизация потоков событием
- Синхронизация потоков барьером
- Синхронизация потоков очередью
В настоящее время, наиболее широко применяемым в программировании понятие для управления одновременностью в программных приложениях основывается на многопоточности (multithreading). В общем, некое приложение выполняется неким отдельным процессом, который делится на множество независимых потоков, которые, в свою очередь, представляют деятельность различного вида, и которые запускаются параллельно и соревнуются друг с другом.
В наши дни, современные приложения, которые применяют многопосточность, были приняты в большом масштабе. На самом деле все современные процессоры являются многоядерными, а следовательно они способны выполнять параллельные операции и эксплуатировать имеющиеся вычислительные ресурсы компьютера.
Таким образом, многопоточное программирование определённо некий хороший способ достижения одновременности в приложениях. Однако, многопоточное программирование зачастую скрывает некоторые нетривиальные сложности, которые должны управляться подобающим образом во избежание таких ошибок, как взаимная блокировка или проблемы синхронизации.
Мы вначале определим сами понятия основы потока и многопосточного программирования, а затем сделаем введение в
соответствующую библиотеку multithreading. Мы изучим основные руководства
для определения потоков, их управления и взаимодействия.
При помощи библиотеки multithreading мы рассмотрим как решать задачи различными
технологиями, такими как блокировка, RLock,
семафоры, условие,
событие, барьер и
очередь.
В этой главе мы рассмотрим такие рецепты:
-
Что такое поток?
-
Как задать поток
-
Как определить текущий поток
-
Как применять поток в неком подклассе
-
Синхронизация потоков блокировкой
-
Синхронизация потоков через RLock
-
Синхронизация потоков семафорами
-
Синхронизация потоков посредством условия
-
Синхронизация потоков событием
-
Синхронизация потоков барьером
-
Синхронизация потоков очередью
Мы также исследуем основные варианты, предлагаемые со стороны Python для программирования при помощи потоков.
Для этого мы сосредоточимся на использовании метода threading.
Некий поток (thread) это независимое течение (flow) которое может исполняться параллельно и одновременно с прочими потоками в системе.
Множество потоков могут совместно использовать данные и ресурсы, получая преимущества так называемого пространства разделяемых сведений. Сами особенности потоков и процессов зависят от той ОС, в которой вы планируете запускать своё приложение, однако, в целом, можно постулировать, что некий поток содержится внутри какого- то процесса и что различные потоки при одних и тех же условиях процесса совместно разделяют некоторые ресурсы. В противоположность этому, различные процессы не разделяют свои собственные ресурсы с прочими процессами.
Некий поток составляется из трёх элементов: программных счётчиков, регистров и стека. Совместные с прочими потоками ресурсы в том же самом процессе по существу содержат данные и ресурсы ОС. Более того, потоки обладают своим собственным состоянием исполнения, а именно, состоянием потока, а также могут выполнять синхронизацию с другими потоками.
Состоянием потока могут быть готов (ready), исполняется (running) и блокирован (blocked):
-
При создании некого потока он входит в состояние Готов.
-
Поток планируется к выполнению своей ОС (или системой сопровождения времени исполнения) и, когда появляется его включение, он начинает своё выполнение, переходя в состояние Исполняется.
-
Конкретный поток может ожидать исполнения некого условия, переходя из состояния Исполняется в состояние Блокирован. Когда такое блокирующее условие прекращается, Блокированный поток возвращается в состояние Готов.
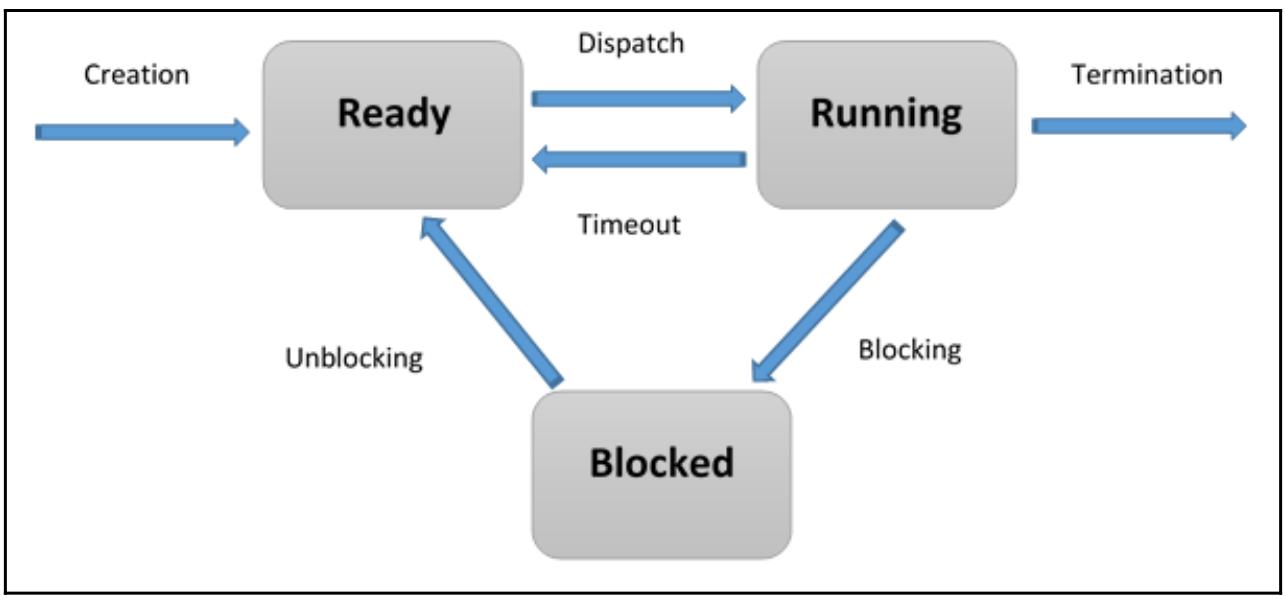
Основное преимущество многопоточного программирования состоит в производительности, поскольку контекстное переключение между процессами включается намного тяжелее чем контекстное переключение между потоками, которые относятся к одному и тому же процессу.
В наших следующих рецептах, вплоть до самого конца этой главы, мы будем изучать модуль Python
threading, делая введение в его основные функции через образцы
программирования.
Python управляет потоками при помощи модуля threading, предоставляемого
стандартной библиотекой Python. Этот модуль предоставляет некоторые очень интересные свойства, которые делают намного
более простым подход на основании потоков; фактически, сам модуль threading
предоставляет несколько механизмов синхронизации, которые очень просты в реализации.
Основными составляющими модуля threading являются:
-
Объект
thread -
Объект
lock -
Объект
RLock -
Объект
semaphore -
Объект
condition -
Объект
event
В своих последующих рецептах мы изучим основные свойства, предлагаемые самой библиотекой
threading на различных примерах приложений. Во всех идущих далее примерах мы
будем следовать дистрибутиву Python 3.5.0/
Самый простой способ применения некого потока состоит в создании его экземпляра с некой целевой функцией и последующим вызовом метода запуска чтобы позволить ему начать своё задание.
Модуль Python threading предоставляет некий класс
Thread, который используется для запуска процессов и функций в различных
потоках:
class threading.Thread(group=None,
target=None,
name=None,
args=(),
kwargs={})
Вот значения параметров самого класса Thread:
-
group: Это именно то значениеgroup, которое должно быть установлено вNone; оно зарезервировано для последующих реализаций. -
target: Это значение той функции, котороая должна быть выполнена при запуске вами некого действия потока. -
name: Является названием данного потока; по умолчанию ему назначается некое уникальное имя в видеThread-N. -
args: Это определённый кортеж аргументов, которые должны быть переданы вtarget. -
kwargs: Это заданный словарь аргументов с ключевыми словами, который должен применяться к установленной функцииtarget.
В своём следующем разделе мы изучим как задавать некий поток.
Мы зададим некий поток передав его номер, который представляет номер этого потока и, наконец, полученный результат будет выведен на печать:
-
Импортируем модуль
threadingпри помощи следующей команды Python:import threading -
В нашей программе
mainсоздаётся некий экземпляр объектаThreadс функциейtargetпод названиемmy_func. Далее будет включён некий аргумент для этой функции, передаваемый в получаемом сообщении вывода:t = threading.Thread(target=my_func, args=(i,)) -
Данный поток не приступит к исполнению, пока не будет вызван метод
start, а методjoinсоздаст вызывающий поток и будет ожидать пока этот поток не завершит своё исполнение следующим образом:import threading def my_func(thread_number): return print('my_func called by thread N°\ {}'.format(thread_number)) def main(): threads = [] for i in range(10): t = threading.Thread(target=my_func, args=(i,)) threads.append(t) t.start() t.join() if __name__ == "__main__": main()
В своей программе main мы инициализируем необходимый список потоков, в
который мы добавляем соответствующий экземпляр каждого создаваемого потока. Общее число созданных потоков равно 10,
в то время как значения индекса i для
iго потока передаётся в качестве некого
аргумента в сам iй поток:
my_func called by thread N°0
my_func called by thread N°1
my_func called by thread N°2
my_func called by thread N°3
my_func called by thread N°4
my_func called by thread N°5
my_func called by thread N°6
my_func called by thread N°7
my_func called by thread N°8
my_func called by thread N°9
Все имеющиеся в настоящее время процессоры многоядерные, это предлагает отличную возможность исполнения множества параллельных операций и задействования большей части вычислительных ресурсов. Хотя это и так, многопоточное программирование скрывает целый ряд нетривиальных сложностей, которые должны управляться надлежащим образом во избежание таких ошибок как взаимная блокировка или проблемы с синхронизацией.
Использование аргументов для выявления или именования созданного потока является громоздким и ненужным. Всякий
экземпляр Thread обладает неким названием
с устанавливаемым по умолчанию значением, которое можно изменять как тлько этот поток создан.
Именованные потоки полезны в серверных процессах со множеством обслуживающих потоков, которые обрабатывают различные операции.
Данный модуль threading предоставляет метод
currentThread().getName(), который возвращает значение названия данного
текущего потока.
Наш последующий раздел показывает нам как применять эту функцию для определения какой поток запущен.
Давайте взглянем на следующие этапы:
-
Для определения того, какой именно поток исполняются, мы создадим три функции
targetи импортируем необходимый модульtimeчтобы ввести некое подвешивание исполнения на две секунды:import threading import time def function_A(): print (threading.currentThread().getName()+str('-->\ starting \n')) time.sleep(2) print (threading.currentThread().getName()+str( '-->\ exiting \n')) def function_B(): print (threading.currentThread().getName()+str('-->\ starting \n')) time.sleep(2) print (threading.currentThread().getName()+str( '-->\ exiting \n')) def function_C(): print (threading.currentThread().getName()+str('-->\ starting \n')) time.sleep(2) print (threading.currentThread().getName()+str( '-->\ exiting \n')) -
Экземпляры трёх потоков создаются при помощи функции
target. Затем мы передаём то название которое следует вывести на печать и, если оно не определено, тогда будет использоваться установленное по умолчанию название. Далее вызываются методыstart()иjoin()для каждого потока:if __name__ == "__main__": t1 = threading.Thread(name='function_A', target=function_A) t2 = threading.Thread(name='function_B', target=function_B) t3 = threading.Thread(name='function_C',target=function_C) t1.start() t2.start() t3.start() t1.join() t2.join() t3.join()
Мы намерены установить три потока, причём каждый из них назначается функцией target.
Когда эта функция target выполнена и завершена, само название функции выводится на
печать надлежащим образом.
Для данного примера вывод будет выглядеть как- то так (даже хотя сам показанный порядок может быть не в точности тем же):
function_A--> starting
function_B--> starting
function_C--> starting
function_A--> exiting
function_B--> exiting
function_C--> exiting
Создание некого потока может потребовать определения какого- то подкласса, который наследуется из самого
класса Thread. Последний, как пояснялось в разделе
Определение потока, входит в состав модуля
threading, который следует импортировать.
Определяемый в нашем следующем разделе класс, который мы представим в своём следующем разделе, представит наш
поток, учитывающий некое точное построение: вначале мы должны определить необходимый метод
__init__, но, помимо всего прочего, нам следует переопределить имеющийся метод
run.
Необходимые шаги содержат следующее:
-
Мы определяем необходимый класс
MyThreadClass, который мы можем применять для создания всех желаемых нами потоков. Каждый поток с этим типом будет характеризоваться теми операциями, которые определены в методеrun, который, в данном простом примере, ограничивает себя выводом на печать какой-то строки в самом начале и по завершению своего выполнения:import time import os from random import randint from threading import Thread class MyThreadClass (Thread): -
Более того, в сомом методе
__init__нам необходимо задать два параметра инициализации, соответственно,nameиduration, которые будут использованы в методеrun:def __init__(self, name, duration): Thread.__init__(self) self.name = name self.duration = duration def run(self): print ("---> " + self.name +\ " running, belonging to process ID "\ + str(os.getpid()) + "\n") time.sleep(self.duration) print ("---> " + self.name + " over\n") -
Эти параметры далее будут настроены в процессе самого создания данного потока. В частности, значение параметра
durationвычисляется на основании функцииrandint, которая выводит некое случайное целое от1до10. Начиная с собственно определенияMyThreadClass, давайте рассмотрим как создать экземпляры дополнительных потоков следующим образом:def main(): start_time = time.time() # Создание потока thread1 = MyThreadClass("Thread#1 ", randint(1,10)) thread2 = MyThreadClass("Thread#2 ", randint(1,10)) thread3 = MyThreadClass("Thread#3 ", randint(1,10)) thread4 = MyThreadClass("Thread#4 ", randint(1,10)) thread5 = MyThreadClass("Thread#5 ", randint(1,10)) thread6 = MyThreadClass("Thread#6 ", randint(1,10)) thread7 = MyThreadClass("Thread#7 ", randint(1,10)) thread8 = MyThreadClass("Thread#8 ", randint(1,10)) thread9 = MyThreadClass("Thread#9 ", randint(1,10)) # Запуск потока thread1.start() thread2.start() thread3.start() thread4.start() thread5.start() thread6.start() thread7.start() thread8.start() thread9.start() # Присоединение потока thread1.join() thread2.join() thread3.join() thread4.join() thread5.join() thread6.join() thread7.join() thread8.join() thread9.join() # Кнец print("End") #Время исполнения print("--- %s seconds ---" % (time.time() - start_time)) if __name__ == "__main__": main()
В этом примере мы создали девять потоков, причём каждый со своим собственным name
свойством duration, в соответствии со сделанным определением в его методе
__init__.
Далее мы запустили из при помощи метода start, который ограничен исполнением
самого содержимого ранее заданного метода run. Обратите внимание, что идентификатор
процесса для каждого потока тот же самый, что означает, что мы пребываем в неком процессе со множеством потоков.
Кроме того, обратите внимание, что сам метод запуска не блокируется: при
его выполнении, само управление немедленно переходит к следующей строке, в то время как сам поток стартует в фоновом
режиме. На самом деле, как вы можете видеть, собственно создание потоков не происходит
в том порядке, который определён в этом коде. Подобным образом, прекращение потока вынуждается тем значением, которое
определено значением параметра duration, вычисляемым на основании функции
randint, а также передаваемым в качестве соответствующего параметра для каждого
из создаваемых экземпляров потока. Для того чтобы дождаться завершения некого потока, следует выполнить операцию
join.
Получаемый вывод выглядит подобным образом:
---> Thread#1 running, belonging to process ID 13084
---> Thread#5 running, belonging to process ID 13084
---> Thread#2 running, belonging to process ID 13084
---> Thread#6 running, belonging to process ID 13084
---> Thread#7 running, belonging to process ID 13084
---> Thread#3 running, belonging to process ID 13084
---> Thread#4 running, belonging to process ID 13084
---> Thread#8 running, belonging to process ID 13084
---> Thread#9 running, belonging to process ID 13084
---> Thread#6 over
---> Thread#9 over
---> Thread#5 over
---> Thread#2 over
---> Thread#7 over
---> Thread#4 over
---> Thread#3 over
---> Thread#8 over
---> Thread#1 over
End
--- 9.117518663406372 seconds ---
Тем свойством, которое наиболее часто ассоциируется с ООП является наследование, что является способностью определять некий новый класс, как изменённую версию уже имеющегося класса. Самое основное преимущество наследования состоит в том, что вы можете добавлять в какой- то класс новые методы без необходимости изменения самого первоначального определения.
Такой первоначальный класс обычно называется родительским (parent) классом, а порождаемый класс подклассом. Наследование является мощным свойством и многие программы могут писаться гораздо проще и выразительнее, предоставляя собой возможность индивидуализации собственно поведения некого класса без изменения самого первоначального класса. Тот факт, что сама структура наследования может отражать то что может сама задача, в некоторых случаях, делает такую программу более простой для понимания.
Однако (исключительно чтобы насторожит читателя!), наследование способно сделать более сложным прочтение такой программы. эТо обусловлено тем, что при вызове некого метода не всегда отчётливо понятно где это было определено внутри самого кода, что требуется отслеживать внутри множества методов, вместо того, чтобы размещаться в едином чётко определённом месте.
Много моментов, которые могут выполняться при помощи наследования, обычно могут элегантно управляться даже без него, поэтому уместно применять наследование только когда того требует сама структура данной задачи. При неверном применении наследования ущерб способен перевешивать те преимущества, которые сулит его применение.
Модуль threading также содержит некий простейший механизм блокировки, который
позволяет нам реализовывать синхронизацию между потоками.
Некая блокировка ничто иное, как какой- то объект, который обычно доступен
множеству потоков и которым эти потоки обязаны располагать прежде чем они смогут продолжить исполнение некого защищённого
раздела некой программы. Такие блокировки создаются посредством исполнения имеющегося метода Lock(),
который определяется в самом деле threading.
После того, как необходимая блокировка создана, мы можем применять два метода, которые делают возможной
синхронизацию самого выполнения двух (или более) потоков: метод acquire() для
овладения управления этой блокировкой и метод release() для её высвобождения.
Метод acquire() получает некий необязательный параметр , который, когда он
не задан ил установлен в значение True, принуждает данный поток подвешивать своё
исполнение пока данная блокировка на высвободится и появится возможность овладения ею. Когда, в противном случае, такой
метод acquire() исполняется с неким аргументом, равным False,
тогда он немедленно возвращает Булев результат, который установлен в True, если
эта блокировка захвачена или False в противном случае.
В своём следующем примере мы показываем этот механизм блокирования через видоизменение того кода, который был введён в нашем предыдущем рецепте Задание подкласса потока.
Необходимые шаги таковы:
-
Как это отображено в последующем блоке кода, наш класс
MyThreadClassбыл видоизменён введением методовacquire()иrelease()внутри уже имевшегося методаrun, в о время как определениеLock()находится вне самого определения данного класса:import threading import time import os from threading import Thread from random import randint # Определение блокировки threadLock = threading.Lock() class MyThreadClass (Thread): def __init__(self, name, duration): Thread.__init__(self) self.name = name self.duration = duration def run(self): #Запрос на блокировку threadLock.acquire() print ("---> " + self.name + \ " running, belonging to process ID "\ + str(os.getpid()) + "\n") time.sleep(self.duration) print ("---> " + self.name + " over\n") #Высвобождение установленной блокировки threadLock.release() -
Наша функция
main()не изменилась по соотношению к предыдущему образцу кода:def main(): start_time = time.time() # Thread Creation thread1 = MyThreadClass("Thread#1 ", randint(1,10)) thread2 = MyThreadClass("Thread#2 ", randint(1,10)) thread3 = MyThreadClass("Thread#3 ", randint(1,10)) thread4 = MyThreadClass("Thread#4 ", randint(1,10)) thread5 = MyThreadClass("Thread#5 ", randint(1,10)) thread6 = MyThreadClass("Thread#6 ", randint(1,10)) thread7 = MyThreadClass("Thread#7 ", randint(1,10)) thread8 = MyThreadClass("Thread#8 ", randint(1,10)) thread9 = MyThreadClass("Thread#9 ", randint(1,10)) # Запуск потоков thread1.start() thread2.start() thread3.start() thread4.start() thread5.start() thread6.start() thread7.start() thread8.start() thread9.start() # Присоединение потоков thread1.join() thread2.join() thread3.join() thread4.join() thread5.join() thread6.join() thread7.join() thread8.join() thread9.join() # Конец print("End") #Execution Time print("--- %s seconds ---" % (time.time() - start_time)) if __name__ == "__main__": main()
Мы изменили свой код из нашего предыдущего раздела применив блокировку с тем, чтобы наши потоки выполнялись последовательно.
Самый первый поток овладевает этой блокировкой и выполняет свои задачи, в то время как прочие восемь
отложены (on hold). В самом конце исполнения первого потока, то есть когда выполнен
метод release(), наш второй поток получает эту блокировку, а потоки с третьего по
восьмой всё ещё дожидаются окончания исполнения (то есть, опять же, только вплоть до выполнения соответствующего метода
release()).
Такие выполнения овладения- блокировкой и высвобождения- блокировки требуются вплоть до девятого потока, с окончательным результатом, как следствием данного механизма блокирования, причём это выполнение имеет место в неком последовательном режиме, что можно видеть из следующего вывода:
---> Thread#1 running, belonging to process ID 10632
---> Thread#1 over
---> Thread#2 running, belonging to process ID 10632
---> Thread#2 over
---> Thread#3 running, belonging to process ID 10632
---> Thread#3 over
---> Thread#4 running, belonging to process ID 10632
---> Thread#4 over
---> Thread#5 running, belonging to process ID 10632
---> Thread#5 over
---> Thread#6 running, belonging to process ID 10632
---> Thread#6 over
---> Thread#7 running, belonging to process ID 10632
---> Thread#7 over
---> Thread#8 running, belonging to process ID 10632
---> Thread#8 over
---> Thread#9 running, belonging to process ID 10632
---> Thread#9 over
End
--- 47.3672661781311 seconds ---
Сами точки вставки соответствующих методов acquire() и
release() определяют всё исполнение данного кода целиком. По этой причине, очень
важно чтобы вы потратили время на анализ того, какой именно поток вы желаете применять и как вы бы хотели его
синхронизировать.
К примеру, мы можем изменить место вставки своего метода release() в нашем
классе MyThreadClass следующим образом:
import threading
import time
import os
from threading import Thread
from random import randint
# Lock Definition
threadLock = threading.Lock()
class MyThreadClass (Thread):
def __init__(self, name, duration):
Thread.__init__(self)
self.name = name
self.duration = duration
def run(self):
#Acquire the Lock
threadLock.acquire()
print ("---> " + self.name + \
" running, belonging to process ID "\
+ str(os.getpid()) + "\n")
#Release the Lock in this new point
threadLock.release()
time.sleep(self.duration)
print ("---> " + self.name + " over\n")
В этом случае получаемый вывод слегка изменится:
---> Thread#1 running, belonging to process ID 11228
---> Thread#2 running, belonging to process ID 11228
---> Thread#3 running, belonging to process ID 11228
---> Thread#4 running, belonging to process ID 11228
---> Thread#5 running, belonging to process ID 11228
---> Thread#6 running, belonging to process ID 11228
---> Thread#7 running, belonging to process ID 11228
---> Thread#8 running, belonging to process ID 11228
---> Thread#9 running, belonging to process ID 11228
---> Thread#2 over
---> Thread#4 over
---> Thread#6 over
---> Thread#5 over
---> Thread#1 over
---> Thread#3 over
---> Thread#9 over
---> Thread#7 over
---> Thread#8 over
End
--- 6.11468243598938 seconds ---
Как вы можете видеть, только само создание потока происходит последовательно. После того как создание потока выполнено, такой новый поток овладевает данной блокировкой, в то время как все предыдущие потоки продолжают вычисляться в фоновом режиме.
Некая реентерабельная блокировка (блокировка с повторной входимостью), или просто RLock является примитивом синхронизации, которым можно овладевать множество раз из одного и того же потока.
Она использует концепцию собственнического потока. Это означает, что в установленном блокированном состоянии этой блокировкой владеют некие потоки, в то время как в состоянии без блокирования этой блокировкой не владеет ни один поток.
Наш следующий пример демеонстрирует как управлять потоками через механизм
RLock().
RLock реализуется посредством класса threading.RLock(). Он предоставляет
методы acquire() и release(), которые
имеют тот же синтаксис что и в классе threading.RLock().
Блокировкой RLock можно овладевать множество раз из одного и того же
самого потока. Прочие потоки не будут иметь возможности овладеть этой блокировкой RLock
до тех пор, пока владеющий ею поток не выполнит вызов release() для всех
предыдущих вызовов acquire(), такая блокировка RLock
должна высвобождаться, но только тем потоком, который овладел ею.
Необходимые шаги содержат:
-
Мы введём некий класс
Box, который предоставляет свои методыadd()иremove(), которые осуществляют доступ к методуexecute()для выполнения необходимого действия, соответственно, по добавлению или удалению некого элемента. Дотсуп к такому методуexecute()регулируетсяRLock():import threading import time import random class Box: def __init__(self): self.lock = threading.RLock() self.total_items = 0 def execute(self, value): with self.lock: self.total_items += value def add(self): with self.lock: self.execute(1) def remove(self): with self.lock: self.execute(-1) -
Наши следующие функции вызываются двумя имеющимися потоками. У них имеются в качестве параметров необходимый класс
boxи общее значение числаitemsна добавление или на удаление:def adder(box, items): print("N° {} items to ADD \n".format(items)) while items: box.add() time.sleep(1) items -= 1 print("ADDED one item -->{} item to ADD \n".format(items)) def remover(box, items): print("N° {} items to REMOVE\n".format(items)) while items: box.remove() time.sleep(1) items -= 1 print("REMOVED one item -->{} item to REMOVE\ \n".format(items)) -
Здесь устанавливается значение общего числа элементов на добавление или удаление из имеющегося набора
box. Как вы можете видеть, эти два числа будут различными. Само исполнение завершается обоими методамиadderиremover, совершающими свои задачи:def main(): items = 10 box = Box() t1 = threading.Thread(target=adder, \ args=(box, random.randint(10,20))) t2 = threading.Thread(target=remover, \ args=(box, random.randint(1,10))) t1.start() t2.start() t1.join() t2.join() if __name__ == "__main__": main()
В нашей программе main два имеющихся потока t1
и t2 были ассоциированы с соответствующими функциями
adder() и remover(). Эти функции
активируются когда значение числа элементов больше нуля.
Собственно вызов RLock() обслуживается внутри самого метода
__init__ из созданного класса Box:
class Box:
def __init__(self):
self.lock = threading.RLock()
self.total_items = 0
Две имеющиеся функции adder() и
remover() взаимодействуют со всеми элементами установленного класса
Box соответственным образом и вызывают методы класса
Box add() и
remove().
При каждом вызове метода ресурс захватывается, а затем высвобождается при помощи того праметра
lock, который установлен в соответствующем методе
__init__.
Вот получаемый вывод:
N° 16 items to ADD
N° 1 items to REMOVE
ADDED one item -->15 item to ADD
REMOVED one item -->0 item to REMOVE
ADDED one item -->14 item to ADD
ADDED one item -->13 item to ADD
ADDED one item -->12 item to ADD
ADDED one item -->11 item to ADD
ADDED one item -->10 item to ADD
ADDED one item -->9 item to ADD
ADDED one item -->8 item to ADD
ADDED one item -->7 item to ADD
ADDED one item -->6 item to ADD
ADDED one item -->5 item to ADD
ADDED one item -->4 item to ADD
ADDED one item -->3 item to ADD
ADDED one item -->2 item to ADD
ADDED one item -->1 item to ADD
ADDED one item -->0 item to ADD
>>>
Отличия между lock и RLock следующие:
-
Блокировкой
lockможно овладевать лишь единожды до того как она должна быть высвобождена. Однако блокировкойRLockможно овладевать множество раз из одного и того же потока; она должна высвобождаться в точности то же самое число раз для своего высвобождения. -
Другое отличие состоит в том, что некая захваченная блокировка
lockможет высвобождаться любым потоком, в то время как выполненная блокировкаRLockможет быть высвобожден лишь овладевшим ею потоком.
Некий семафор является каким- то абстрактным типом данных, который отправляется своей ОС для синхронизации доступа со стороны множества потоков к совместным ресурсам и данным. Он состоит из некой внутренней переменной, которая указывает значение числа одновременных доступов к некому ресурсу, с которым она ассоциирована.
Все действия с семафорами основываются на двух функциях: acquire() и
release(), как это поясняется здесь:
-
Всякий раз когда некий поток желает получить доступ к некому ассоциированному с каким- то семафором данному или ресурсу, он обязан вызвать его операцию
acquire(), которая уменьшает значение внутренней переменной этого семафора и разрешает доступ к данному ресурсу, когда получаемое значение этой переменной оказывается не отрицательным. Когда это значение отрицательно, данный поток подвешен, а высвобождение данного ресурса другим потоком будет приостановлено. -
По завершению использования совместных ресурсов, выполнявший работу с ними поток высвобождает ресурсы посредством инструкции
release(). Тем самым, значение внутренней переменной этого семафора увеличивается, допуская некому ожидающему потоку (когд такой имеется) его возможность выполнения доступа к такому вновь высвобожденному ресурсу.
Понятие семафор является одним из старейших примитивов в истории информатики, введённым ранним голландским научным сотрудником- компьютерщиком Эдсгером Вибе Дейкстрой.
Наш следующий пример показывает как осуществлять синхронизацию потоков при помощи семафора.
Наш следующий код описывает некую задачу, в которой у нас имеются два потока, producer()
и consumer(), которые разделяют какой- то общий ресурс, коим является
соответствующий элемент. Основное задание producer() состоит в выработке такого
элемента, в то время как задание потока consumer() заключается в применении
того элемента, который был произведён.
Когда необходимый элемент ещё не произведён для потока consumer(), тому
приходится ожидать. Как только этот элемент произведён, поток producer()
уведомляет consumer(), что этим ресурсом следует воспользоваться:
-
Выполнив инициализацию некого семафора в значение
0, мы получаем так называемое событие семафора, единственная цель которого состоит в синхронизации вычислений двух или более потоков. В нашем случае некий поток обязан одновременно использовать данные или общие ресурсы:semaphore = threading.Semaphore(0) -
Это действие очень похоже на то, которое описан в механизме блокирования надлежащей блокировкой. Имеющийся поток
producer()создаёт необходимый элемент и, после этого, он высвобождает данный ресурс, вызывая методrelease():New-VM -Name VM01 -Generation 2emaphore.release() -
Аналогично, поток
consumer()овладевает необходимыми данными посредством методаacquire(). Когда значение счётчика семафора равно0, тогда это блокирует условия методаacquire()до тех пор, пока он не получит уведомление от другого потока. Когда значение семафора больше0, он уменьшает это значение. После того как производитель создаёт некий элемент, он высвобождает этот семафор, а затем соответствующий потребитель овладевает им и потребляет этот совместный ресурс:semaphore.acquire() -
Весь процесс синхронизации, который осуществляется через описанные семафоры показан в следующем блоке кода:
import logging import threading import time import random LOG_FORMAT = '%(asctime)s %(threadName)-17s %(levelname)-8s %\ (message)s' logging.basicConfig(level=logging.INFO, format=LOG_FORMAT) semaphore = threading.Semaphore(0) item = 0 def consumer(): logging.info('Consumer is waiting') semaphore.acquire() logging.info('Consumer notify: item number {}'.format(item)) def producer(): global item time.sleep(3) item = random.randint(0, 1000) logging.info('Producer notify: item number {}'.format(item)) semaphore.release() #Main program def main(): for i in range(10): t1 = threading.Thread(target=consumer) t2 = threading.Thread(target=producer) t1.start() t2.start() t1.join() t2.join() if __name__ == "__main__": main()
Захваченные данные затем выводятся на печать в стандартный вывод:
print ("Consumer notify : consumed item number %s " %item)
Вот результат, полученный после 10 запусков:
2019-01-27 19:21:19,354 Thread-1 INFO Consumer is waiting
2019-01-27 19:21:22,360 Thread-2 INFO Producer notify: item number 388
2019-01-27 19:21:22,385 Thread-1 INFO Consumer notify: item number 388
2019-01-27 19:21:22,395 Thread-3 INFO Consumer is waiting
2019-01-27 19:21:25,398 Thread-4 INFO Producer notify: item number 939
2019-01-27 19:21:25,450 Thread-3 INFO Consumer notify: item number 939
2019-01-27 19:21:25,453 Thread-5 INFO Consumer is waiting
2019-01-27 19:21:28,459 Thread-6 INFO Producer notify: item number 388
2019-01-27 19:21:28,468 Thread-5 INFO Consumer notify: item number 388
2019-01-27 19:21:28,476 Thread-7 INFO Consumer is waiting
2019-01-27 19:21:31,478 Thread-8 INFO Producer notify: item number 700
2019-01-27 19:21:31,529 Thread-7 INFO Consumer notify: item number 700
2019-01-27 19:21:31,538 Thread-9 INFO Consumer is waiting
2019-01-27 19:21:34,539 Thread-10 INFO Producer notify: item number 685
2019-01-27 19:21:34,593 Thread-9 INFO Consumer notify: item number 685
2019-01-27 19:21:34,603 Thread-11 INFO Consumer is waiting
2019-01-27 19:21:37,604 Thread-12 INFO Producer notify: item number 503
2019-01-27 19:21:37,658 Thread-11 INFO Consumer notify: item number 503
2019-01-27 19:21:37,668 Thread-13 INFO Consumer is waiting
2019-01-27 19:21:40,670 Thread-14 INFO Producer notify: item number 690
2019-01-27 19:21:40,719 Thread-13 INFO Consumer notify: item number 690
2019-01-27 19:21:40,729 Thread-15 INFO Consumer is waiting
2019-01-27 19:21:43,731 Thread-16 INFO Producer notify: item number 873
2019-01-27 19:21:43,788 Thread-15 INFO Consumer notify: item number 873
2019-01-27 19:21:43,802 Thread-17 INFO Consumer is waiting
2019-01-27 19:21:46,807 Thread-18 INFO Producer notify: item number 691
2019-01-27 19:21:46,861 Thread-17 INFO Consumer notify: item number 691
2019-01-27 19:21:46,874 Thread-19 INFO Consumer is waiting
2019-01-27 19:21:49,876 Thread-20 INFO Producer notify: item number 138
2019-01-27 19:21:49,924 Thread-19 INFO Consumer notify: item number 138
>>>
Неким особым видом применения семафора является взаимное исключение
(mutex). Взаимное исключение это ничто иное, как семафор с некой внутренней переменной, значение которой
инициализировано 1, что делает возможным взаимное исключение в доступе к
данным и ресурсам.
Семафоры всё ещё широко применяются в языках программирования с множеством потоков; тем не менее, они обладают двумя основными проблемами,которые мы должны обсудить, и они таковы:
-
Они не препятствуют вероятности выполннения неким потоком слишком долгого ожидания операций в одном и том же семафоре. Очень просто забыть сделать все необходимые сигналы в отношении числа значений выполненных ожиданий.
-
Вы можете попасть в ситуацию взаимной блокировки (deadlock). Например, ситуация взаимной блокировки возникает когда наш поток
t1выполняет ожидание на семафореs1, в то время как наш потокt2ожидает что потокt1выполняет ожидание вs2иt2, а затем выполнфет ожидание вs1.
Некое условие устанавливает какое- то изменение состояния в данном приложении. Именно оно является тем механизмом синхронизации, при котором поток ожидает какое- то конкретное условие, а другой поток уведомляет что это условие произошло.
Когда ожидаемое условие произошло, соответствующий поток овладевает необходимой блокировкой для получения исключительного доступа к требующемуся совместному ресурсу.
Хорошим способом иллюстрации данного механизма является повторное рассмотрение задачи производитель/ потребитель. Имеющийся класс производителей выполняет записи в некий буфер, если он не заполнен, а другой класс потребителей получает данные из этого буфера (исключая их из последнего), когда буфер заполнен. Класс производителей будет уведомлять своих потребителей что общий буфер не пуст, в то время как потребители будут отчитываться перед своими производителями что этот буфер не заполнен.
Необходимые для этого шаги таковы:
-
Наш класс потребителей овладевает имеющимся совместным ресурсом , который моделируется посредством списка
items[]:condition.acquire() -
Когда значение длины этого списка равно
0, тогда наш потребитель помещается в состояние ожидания:if len(items) == 0: condition.wait() -
Далее он выполняет некую операцию
popиз общего списка элементов:items.pop() -
Итак, состояние потребителя уведомляет его производителя, а совместный ресурс высвобождается:
condition.notify() -
Имеющийся класс производителя овладевает общим совместным ресурсом и затем он проверяет не является ли этот список полностью заполненным(в нашем примере мы разместили значение максимального числа элементов,
10, с тем, чтобы они могли содержаться в данном списке элементов). Когда наш список заполнен, тогда наш производитель помещается в состояние ожидания до тех пор, пока не произойдёт потребление списка:condition.acquire() if len(items) == 10: condition.wait() -
Когда список не заполнен, добавляется ещё один элемент. Происходит уведомление об этом состоянии и данный ресурс высвобождается:
condition.notify() condition.release() -
Для отображения механизма условия мы снова применим модель потребитель/ производитель:
import logging import threading import time LOG_FORMAT = '%(asctime)s %(threadName)-17s %(levelname)-8s %\ (message)s' logging.basicConfig(level=logging.INFO, format=LOG_FORMAT) items = [] condition = threading.Condition() class Consumer(threading.Thread): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) def consume(self): with condition: if len(items) == 0: logging.info('no items to consume') condition.wait() items.pop() logging.info('consumed 1 item') condition.notify() def run(self): for i in range(20): time.sleep(2) self.consume() class Producer(threading.Thread): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) def produce(self): with condition: if len(items) == 10: logging.info('items produced {}.\ Stopped'.format(len(items))) condition.wait() items.append(1) logging.info('total items {}'.format(len(items))) condition.notify() def run(self): for i in range(20): time.sleep(0.5) self.produce()
producer постоянно производит необходимый элемент и сохраняет его в
имеющемся буфере. В то же самое время, consumer время от времени использует
произведённые данные, удаляя их из общего буфера.
Как только некий consumer прихватывает какой- то объект из общего
буфера, он пробуждает producer, который начнёт снова заполнять общий
буфер.
Аналогично, consumer будет приостанавливаться если общий буфер пуст.
Как только producer выгрузил необходимые данные в имеющийся буфер,
consumer будет пробуждён.
Как вы можете видеть, и в этом случае также, надлежащее использование имеющейся директивы
condition делает возможной должную синхронизацию существующих потоков.
Вот результат, который мы получили после отдельного исполнения:
2019-08-05 14:33:44,285 Producer INFO total items 1
2019-08-05 14:33:44,786 Producer INFO total items 2
2019-08-05 14:33:45,286 Producer INFO total items 3
2019-08-05 14:33:45,786 Consumer INFO consumed 1 item
2019-08-05 14:33:45,787 Producer INFO total items 3
2019-08-05 14:33:46,287 Producer INFO total items 4
2019-08-05 14:33:46,788 Producer INFO total items 5
2019-08-05 14:33:47,289 Producer INFO total items 6
2019-08-05 14:33:47,787 Consumer INFO consumed 1 item
2019-08-05 14:33:47,790 Producer INFO total items 6
2019-08-05 14:33:48,291 Producer INFO total items 7
2019-08-05 14:33:48,792 Producer INFO total items 8
2019-08-05 14:33:49,293 Producer INFO total items 9
2019-08-05 14:33:49,788 Consumer INFO consumed 1 item
2019-08-05 14:33:49,794 Producer INFO total items 9
2019-08-05 14:33:50,294 Producer INFO total items 10
2019-08-05 14:33:50,795 Producer INFO items produced 10. Stopped
2019-08-05 14:33:51,789 Consumer INFO consumed 1 item
2019-08-05 14:33:51,790 Producer INFO total items 10
2019-08-05 14:33:52,290 Producer INFO items produced 10. Stopped
2019-08-05 14:33:53,790 Consumer INFO consumed 1 item
2019-08-05 14:33:53,790 Producer INFO total items 10
2019-08-05 14:33:54,291 Producer INFO items produced 10. Stopped
2019-08-05 14:33:55,790 Consumer INFO consumed 1 item
2019-08-05 14:33:55,791 Producer INFO total items 10
2019-08-05 14:33:56,291 Producer INFO items produced 10. Stopped
2019-08-05 14:33:57,791 Consumer INFO consumed 1 item
2019-08-05 14:33:57,791 Producer INFO total items 10
2019-08-05 14:33:58,292 Producer INFO items produced 10. Stopped
2019-08-05 14:33:59,791 Consumer INFO consumed 1 item
2019-08-05 14:33:59,791 Producer INFO total items 10
2019-08-05 14:34:00,292 Producer INFO items produced 10. Stopped
2019-08-05 14:34:01,791 Consumer INFO consumed 1 item
2019-08-05 14:34:01,791 Producer INFO total items 10
2019-08-05 14:34:02,291 Producer INFO items produced 10. Stopped
2019-08-05 14:34:03,791 Consumer INFO consumed 1 item
2019-08-05 14:34:03,792 Producer INFO total items 10
2019-08-05 14:34:05,792 Consumer INFO consumed 1 item
2019-08-05 14:34:07,793 Consumer INFO consumed 1 item
2019-08-05 14:34:09,794 Consumer INFO consumed 1 item
2019-08-05 14:34:11,795 Consumer INFO consumed 1 item
2019-08-05 14:34:13,795 Consumer INFO consumed 1 item
2019-08-05 14:34:15,833 Consumer INFO consumed 1 item
2019-08-05 14:34:17,833 Consumer INFO consumed 1 item
2019-08-05 14:34:19,833 Consumer INFO consumed 1 item
2019-08-05 14:34:21,834 Consumer INFO consumed 1 item
2019-08-05 14:34:23,835 Consumer INFO consumed 1 item
Интересно рассмотреть внутренний механизм Python для данного механизма синхронизации условием. Имеющийся
class _Condition создаёт некий объект RLock()
если конструктору этого класса не передана никакая имеющаяся блокировка. Кроме того, эта управление блокировкой будет
осуществляться при вызовах acquire() и
released():
class _Condition(_Verbose):
def __init__(self, lock=None, verbose=None):
_Verbose.__init__(self, verbose)
if lock is None:
lock = RLock()
self.__lock = lock
Некое событие является объектом, который применяется для взаимодействия между потоками. Поток может ожидать
сигнал, в то время как другой поток выдаёт его. По существу, объект event
управляет внутренним флагом, который может устанавливаться в false через
clear() и устанавливаться в true
при помощи set(), а также выполнять проверку посредством
is_set().
Некий поток может фиксировать сигнал посредством метода wait(), который
отправляет вызов через метод set().
Чтобы уяснить синхронизацию потоков через объект event, давайте снова
рассмотрим задачу производитель/ потребитель.
И снова,чтобы пояснить как синхронизировать потоки при помощи событий, мы будем ссылаться на известную нам задачу производитель/ потребитель. Эта задача описывает два процесса, производителя и потребителя, которые совместно используют некий буфер фиксированного размера. Задача производителя состоит в выработке элементов и в непрерывном депонировании их в буфер. В то же самое время, потребитель будет время от времени использовать выработанные элементы из этого буфера.
Основная проблема состоит в том, чтобы гарантировать что наш производитель не вырабатывает новые данные когда общий буфер заполнен и что его потребитель не ищет данные когда этот буфер пустой.
Теперь давайте рассмотрим как реализовать эту задачу потребитель, производитель воспользовавшись синхронизацией
при помощи оператора event:
-
Сначала мы импортируем относящиеся к делу библиотеки:
import logging import threading import time import random -
Далее мы определяем необходимый формат вывода регистрационных записей. Это полезно для ясной визуализации того что происходит:
LOG_FORMAT = '%(asctime)s %(threadName)-17s %(levelname)-8s %\ (message)s' logging.basicConfig(level=logging.INFO, format=LOG_FORMAT) -
Устанавливаем необходимый список
items. Этот параметр будет применяться в классахConsumerиProducer:items = [] -
Ниже определяется параметр
event. Этот параметр будет применяться для синхронизации необходимого взаимодействия между потоками:event = threading.Event() -
Наш класс
Consumerинициализируется необходимым списком элементов и функциейEvent(). В методеrunэтот потребитель жидает потребления какого- то нового элемента. Когда такой элемент появляется, он выталкивается из общего спискаitem:class Consumer(threading.Thread): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) def run(self): while True: time.sleep(2) event.wait() item = items.pop() logging.info('Consumer notify: {} popped by {}'\ .format(item, self.name)) -
Соответствующий класс
Producerинициаизируется заданием списка элементов и функцииEvent(). В отличии от примера с объектамиcondition, данный список элементов не глобальный, а вместо этого он передаётся в качестве параметра:class Producer(threading.Thread): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) -
В методе
runдля каждого созданного элемента наш классProducerдобавляет его в конец ощего списка элементов, а затем выставляет уведомление данного события:def run(self): for i in range(5): time.sleep(2) item = random.randint(0, 100) items.append(item) logging.info('Producer notify: item {} appended by\ {}'\.format(item, self.name)) -
Имеются два шага, которые требуется предпринять для этого и наш первый шаг такой:
event.set() event.clear() -
Поток
t1добавляет в конец имеющегося списка некий элемент, а затем устанавливает событие, уведомляющее своего потребителя. Вызов потребителяwait()перестаёт блокироваться и соответствующее целое значение выбирается из общего списка:if __name__ == "__main__": t1 = Producer() t2 = Consumer() t1.start() t2.start() t1.join() t2.join()
Все операции между классами Producer и
Consumer могут быть проще резюмированы при помощи следующей схемы:
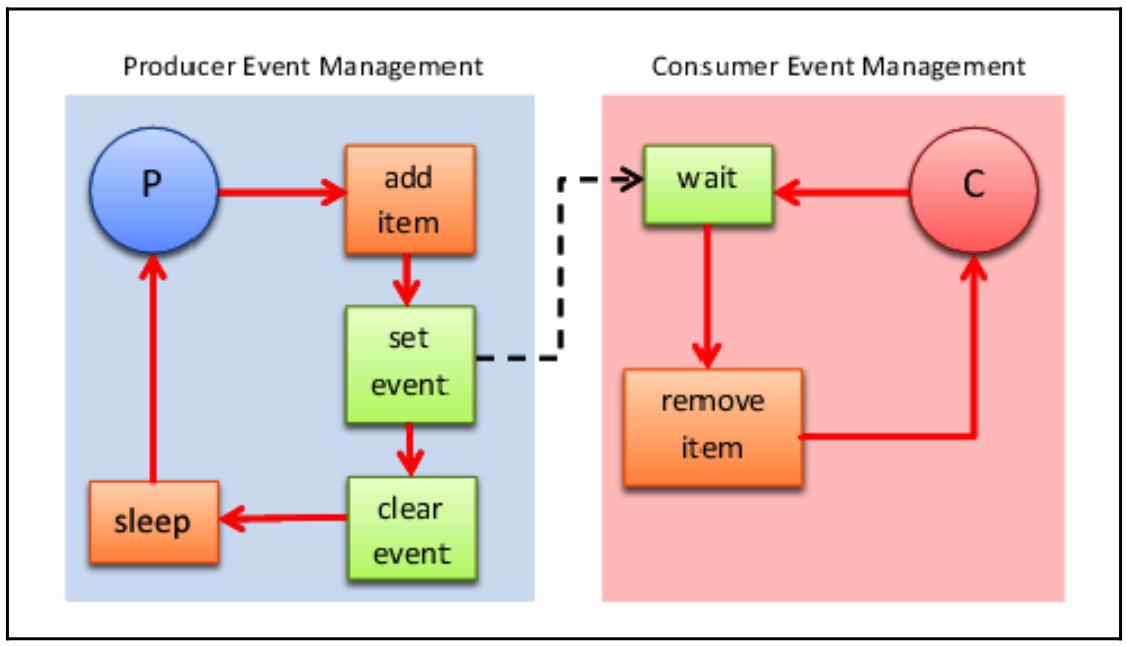
В частности, классы Producer и
Consumer обладают следующим поведением:
-
Producerовладевает некой блокировкой, добавляет элемент в имеющуюся очередь и уведомляет об этомConsumerсообщением (set event). Далее он засыпает до тех пор, пока не получит новый элемент на добалвение. -
Consumerовладевает блокировкой, а затем начинает выполнять ожидание входящих элементов в непрерывном цикле. В тот момент, когда появляется соответствующее событие, этот потребитель обрывает блокировку с тем, чтобы другой производитель/ потребитель вошёл и владел этой блокировкой. КогдаConsumerповторно активируется, он тогда повторно овладевает блокировкой, безопасно обрабатывая новый элементы из общей очереди:2019-02-02 18:23:35,125 Thread-1 INFO Producer notify: item 68 appended by Thread-1 2019-02-02 18:23:35,133 Thread-2 INFO Consumer notify: 68 popped by Thread-2 2019-02-02 18:23:37,138 Thread-1 INFO Producer notify: item 45 appended by Thread-1 2019-02-02 18:23:37,143 Thread-2 INFO Consumer notify: 45 popped by Thread-2 2019-02-02 18:23:39,148 Thread-1 INFO Producer notify: item 78 appended by Thread-1 2019-02-02 18:23:39,153 Thread-2 INFO Consumer notify: 78 popped by Thread-2 2019-02-02 18:23:41,158 Thread-1 INFO Producer notify: item 22 appended by Thread-1 2019-02-02 18:23:43,173 Thread-1 INFO Producer notify: item 48 appended by Thread-1 2019-02-02 18:23:43,178 Thread-2 INFO Consumer notify: 48 popped by Thread-2
Иногда некое приложение может быть поделено на этапы с заданным правилом, согласно которому никакой процесс не может продолжиться если вначале все потоки этого процесса не завершили свою собственную задачу. Такую концепцию реализует барьер: некий завершивший свою фазу поток вызывает какой- то примитив барьера и останавливается. Когда все вовлечённые потоки завершат свою стадию выполнения и также вызовут этот примитив барьера, сама система разблокирует их все, позволяя потокам перейти к следующему этапу.
Модуль потоков Python реализует барьеры посредством класса Barrier. В
своём следующем разделе давайте изучим как применять этот механизм синхронизации в очень простом примере.
В этом примере мы имитируем забег трёх участников, Huey,
Dewey и Louie, при котором некий
барьер уподобляется финишной линии.
Более того, эта гонка может завершиться сама собой когда все три участника пересекают установленную финишную черту.
Наш барьер реализуется классом Barrier, в котором общее число подлежащих
выполнению потоков для перехода к следующему этапу должно быть указано в качестве некого аргумента:
from random import randrange
from threading import Barrier, Thread
from time import ctime, sleep
num_runners = 3
finish_line = Barrier(num_runners)
runners = ['Huey', 'Dewey', 'Louie']
def runner():
name = runners.pop()
sleep(randrange(2, 5))
print('%s reached the barrier at: %s \n' % (name, ctime()))
finish_line.wait()
def main():
threads = []
print('START RACE!!!!')
for i in range(num_runners):
threads.append(Thread(target=runner))
threads[-1].start()
for thread in threads:
thread.join()
print('Race over!')
if __name__ == "__main__":
main()
Прежде всего мы устанавливаем значение числа бегунов в num_runners = 3
чтобы задать конечную цель на нашей первой линии через соответствующую директиву Barrier.
Наши бегуны установлены в соответствующем списке забега; каждый из них будет иметь время появления, которое определяется
значением функции runner, использующей директиву
randrange.
Когда некий бегун достигает финиша, он вызывает метод wait, который
заблокирует всех тех бегунов (имеющиеся потоки) которые сделали этот вызов. Вывод для данного случая таков:
START RACE!!!!
Dewey reached the barrier at: Sat Feb 2 21:44:48 2019
Huey reached the barrier at: Sat Feb 2 21:44:49 2019
Louie reached the barrier at: Sat Feb 2 21:44:50 2019
Race over!
В нашем варианте забег выиграл Dewey.
Многопоточность может усложняться, когда потокам требуется совместно применять данные или ресурсы. К счастью, наш модуль потоков предоставляет множество примитивов синхронизации, включая семафоры, переменные условия, события и блокировки.
Тем не менее, рекомендуется применять модуль queue. На самом деле, некая
очередь намного проще для работы и делает потоковое программирование относительно безопаснее, поскольку она
увлекает в одну воронку весь доступ к некому ресурсу отдельного потока и обеспечивает чёткий и более читаемый шаблон
разработки.
Мы просто рассмотрим эти методы очереди:
-
put(): помещает элемент в очередь -
get(): удаляет элемент из очереди и возвращает его -
task_done(): требуется вызывать всякий раз при воспроизведении некого элемента -
join(): выполняет блокировку пока не обработаны все элементы
В данном примере мы рассмотрим как применять модуль threading с
модулем queue. Кроме того, здесь у нас имеются два логических элемента,
которые пытаются разделять некий общий ресурс, очередь. Код таков:
from threading import Thread
from queue import Queue
import time
import random
class Producer(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queue
def run(self):
for i in range(5):
item = random.randint(0, 256)
self.queue.put(item)
print('Producer notify : item N°%d appended to queue by\
%s\n'\
% (item, self.name))
time.sleep(1)
class Consumer(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queue
def run(self):
while True:
item = self.queue.get()
print('Consumer notify : %d popped from queue by %s'\
% (item, self.name))
self.queue.task_done()
if __name__ == '__main__':
queue = Queue()
t1 = Producer(queue)
t2 = Consumer(queue)
t3 = Consumer(queue)
t4 = Consumer(queue)
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
Прежде всего, для нашего класса producer, нет нужды передавать список
целых значений, так как мы применяем очередь для хранения тех целых, которые вырабатываются.
Наш поток класса producer вырабатывает целые и помещает их в установленную
очередь в цикле for. Класс producer
применяет Queue.put(item[, block[, timeout]]) для вставки данных в
общую очередь. Этот метод обладает необходимой логикой овладения необходимой блокировкой перед вставкой данных в
некую очередь.
Имеются две возможности:
-
Если значениями необязательных параметров
blockвыступаетtrue, аtimeoutравенNone(это устанавливаемый по умолчанию вариант и мы именно его применяем в своём примере), тогда нам требуется выполнять блокирование пока не станет доступным некий свободный слот. Когда значением таймаута является некое положительное число, тогда блокирование осуществляется по крайней мереtimeoutсекунд и выставляется полная исключительная ситуация если за это время не стал доступным никакой свободный слот. -
Когда значением
blockявляетсяfalse, тогда если немедленно доступен какой- то свободный слот, в него помещается некий элемент, в противном случае вызывается полная исключительная ситуация (значениеtimeoutв этом случае игнорируется). Здесьputпроверяет будет ли наша очередь заполнена и затем вызываетwaitвнутренним образом, после чего соответствующий производитель начинает ожидание.
Следующим идёт класс consumer. Его поток получает значение целого из
установленной очереди и указывает что это выполнено при помощи task_done. Наш
класс consumer применяет
Queue.get([block[, timeout]]) и овладевает необходимой блокировкой перед тем как
удалять данные из этой очереди. Этот потребитель помещается в состояние ожидания в том случае, когда данная очередь пуста.
Наконец, в своей функции main мы создаём четыре потока, причём один для
класса producer и три для класса consumer
соответственно.
Получаемый вывод должен выглядеть как- то так:
Producer notify : item N°186 appended to queue by Thread-1
Consumer notify : 186 popped from queue by Thread-2
Producer notify : item N°16 appended to queue by Thread-1
Consumer notify : 16 popped from queue by Thread-3
Producer notify : item N°72 appended to queue by Thread-1
Consumer notify : 72 popped from queue by Thread-4
Producer notify : item N°178 appended to queue by Thread-1
Consumer notify : 178 popped from queue by Thread-2
Producer notify : item N°214 appended to queue by Thread-1
Consumer notify : 214 popped from queue by Thread-3
Все операции между нашими классами Producer и
Consumer запросто можно свести воедино на следующей схеме:
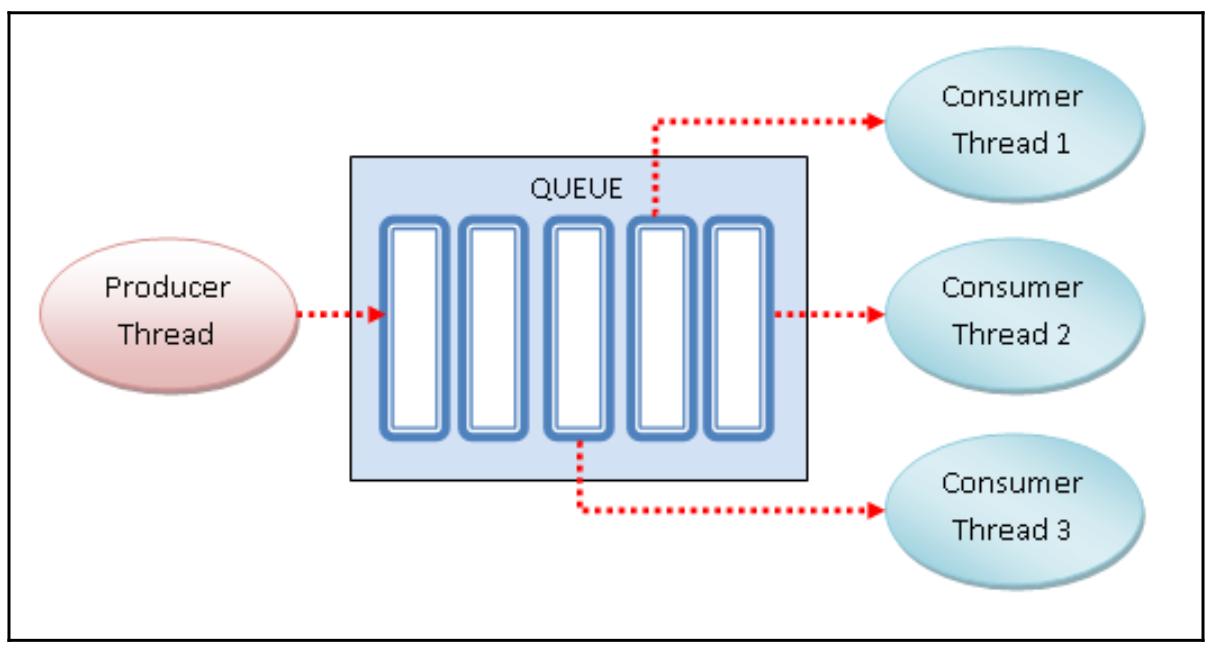
-
Наш поток
Producerовладевает необходимой блокировкой и затем вставляет данные в структуру данных QUEUE. -
Созданные потоки
Consumer: получают целые значения из общей QUEUE. Эти потоки овладевают необходимой блокировкой прежде чем удалять данные из общей QUEUE.
Когда QUEUE пуста, потоки
consumer получают состояние ожидающих.
На этом рецепте данная глава, посвящённая праллелизму на основе потоков подошла к концу.