Глава 1. Приступая к параллельному программированию и Python
Содержание
- Глава 1. Приступая к параллельному программированию и Python
- Зачем нам требуется параллельное программирование?
- Систематика Флинна
- Организация памяти
- Модели параллельного программирования
- Оценка значения производительности параллельной программы
- Введение в Python
Модели параллельных или распределённых вычислений основываются на одновременном использовании различных вычислительных единиц для исполнения програмы. Хотя само отличие между параллельным и распределённым вычислением и чрезвычайно тонкое, одно из возможных определений связывает модель параллельных вычислений с моделью вычислений совместно используемой памяти, а распределённые вычисления с моделью передачи сообщений.
С этого момента мы будем применять термин параллельные вычисления для обозначения как параллельной, так и распределённой модели вычислений.
Наши следующие разделы предоставляют некий обзор архитектур параллельного программирования и моделей параллельного программирования. Эти понятия полезны для неискушённых программистов, которые впервые встречаются с технологиями параллельного программирования. Более того,это может послужить некой основой для опытных программистов. Также представлена дуальность характеристик параллельных систем. Первый словесный портрет основывается на самой архитектуре системы, в то время как второе описание базируется на парадигмах параллельного программирования.
Эта глава завершается кратким введением в язык программирования Python. Сами характеристики языка, простота изучения и применения, а также расширяемость и богатство программных библиотек и приложений делают Python неким ценным инструментом для любого приложения, а также и для параллельных вычислений. Основные понятия потоков (threads) и процессов вводятся в отношении их использования в самом языке.
В этой главе мы рассматриваем следующие темы:
-
К чему вам параллельное прграммирвоание?
-
Систематика Флинна
-
Организация памяти
-
Модели параллельного программирования
-
Оценка производительности
-
Введение в Python
-
Python и параллельное прграммирование
-
Введенеи в процессы и потоки
Происходящий рост вычислительной мощности ставший доступным в современных компьютерах в результате привёл нас к столкновению с вычислительными проблемами возрастающей сложности в отношении коротких временных кадров. Вплоть до ранних 2000-х, сложность имела отношение к возрастающему числу транзисторов, а также временной частоте систем с единственным процессором, которые достигли пика в 3.5- 4ГГц. Однако рост числа транзисторов вызвал экспоненциальное увеличение рассеиваемой мощности на самих процессорах. На практике, следовательно, существует некое физическое ограничение, которое препятствует дальнейшему улучшению систем с единственным процессором.
По этой причине в последние годы производители микропроцессоров сосредоточили своё внимание на системах с множеством ядер. Они основываются на неком ядре определённых физических процессоров, которые совместно используют (разделяют) одну и ту же память, тем самым обходя основную описанную выше проблему рассеивания мощности. В последние годы системы с четырьмя ядрами и восемью ядрами также стали стандартом для обычных настольных и ноутбучных конфигураций.
С другой стороны, столь значительное изменение в оборудовании также имело результатом и некую эволюцию структуры программного обеспечения, которое всегда разрабатывалось для последовательного исполнения в неком отдельном процессоре. Для получения преимуществ имеющихся больших вычислительных ресурсов предоставляемого доступным ростом числа процессоров, требуется по- новому проектировать имеющееся программное обеспечение в неком виде подхода к имеющейся параллельной структуре установленных ЦПУ с тем, чтобы получать более высокую эффективность посредством одновременного исполнения во всех отдельных устройствах частей одной и той же программы.
Систематика Флинна выступает в качестве некой системы для классификации архитектур компьютеров. Она основывается на двух главных понятиях:
-
Потоке инструкций: некая система с n ЦПУ имеет n программных счётчиков и, таким образом, n потоков инструкций. Это относится к некому программному счётчику.
-
Поток данных: Какя- то программа, которая вычисляет некую функцию на списке данных обладает потоком данных. Та программа, которая вычисляет одни и те же функции на различных списках данных имеет больше потоков данных. Это составляет некий набор операндов.
Так как имеющиеся инструкции и потоки данных независимы, существует четыре категории параллельных машин: Один поток команд, один поток данных (SISD - Single Instruction Single Data), Много потоков команд, один поток данных (MISD - Single Instruction Multiple Data), Один поток команд, много потоков данных (SIMD - Multiple Instruction Single Data), Много потоков команд, много потоков данных (MIMD - Multiple Instruction Multiple Data):
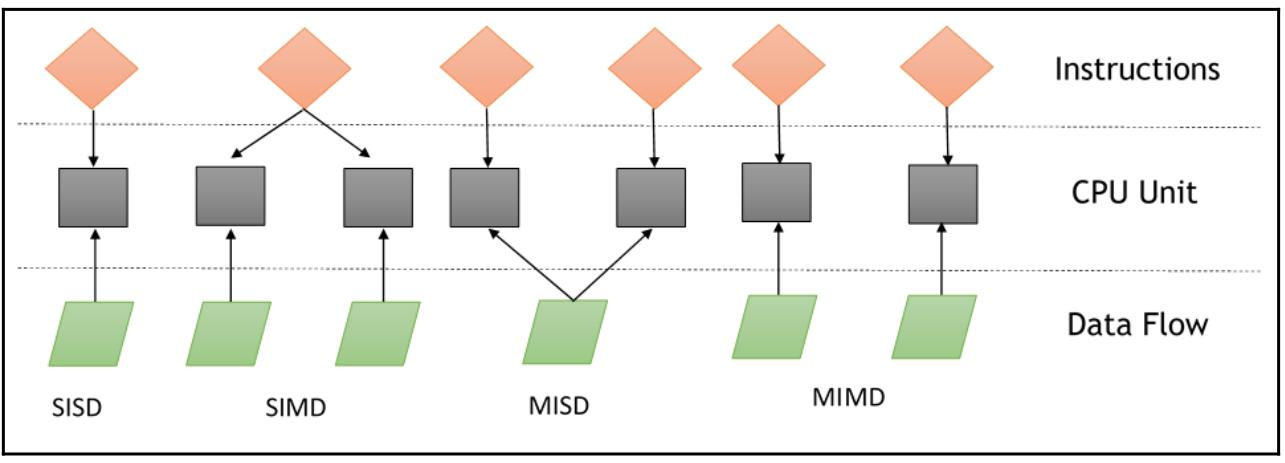
Вычислительная система SISD подобна машине фон Неймана, которая является машиной с единственным процессором. Как вы могли видеть на схеме систематики Флинна, она исполняет отдельную команду (инструкцию), которая обрабатывает отдельный поток (strem) данных. В SISD машинные команды обрабатываются последовательно.
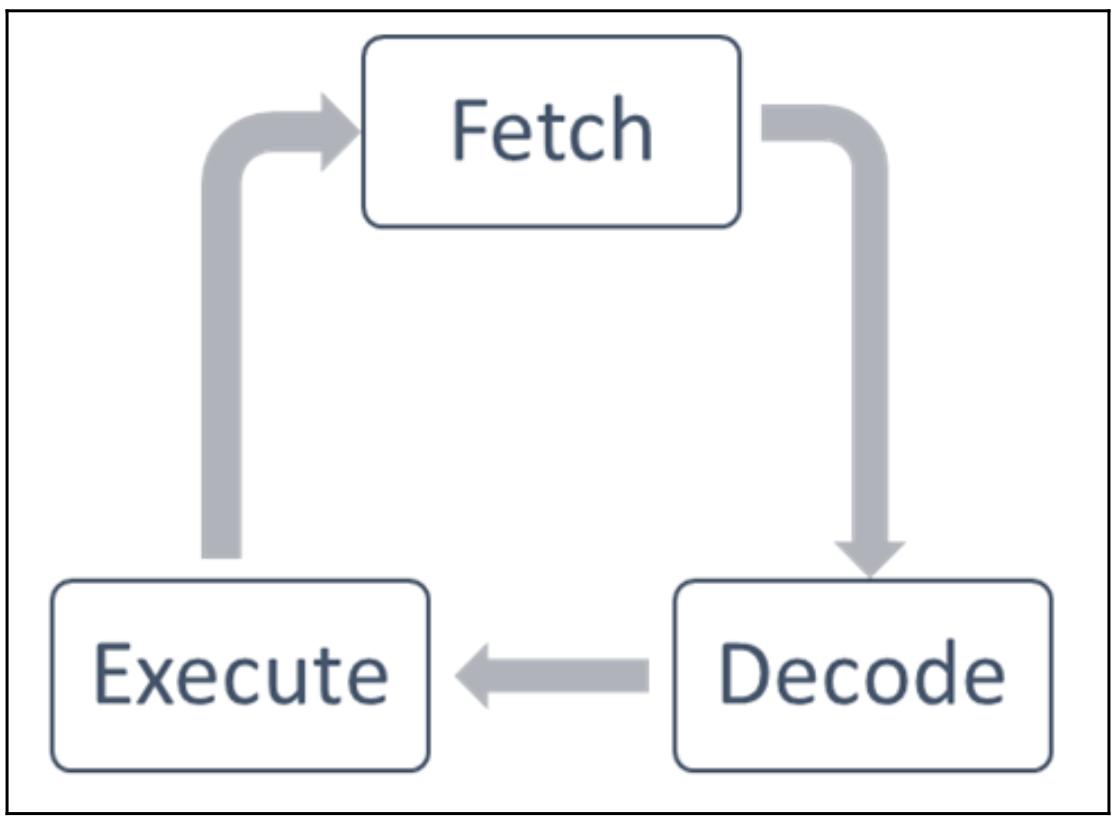
Во временном цикле её ЦПУ исполняет следующие операции:
-
Fetch (выборка): Данный ЦПУ выполняет выборку данных и инструкций из некой области памяти, которая именуется регистром.
-
Decode (декодирование): Рассматриваемый нами ЦПУ декодирует полученную команду (инструкцию).
-
Execute (исполнение): Декодированная команда выполняется для полученных данных. Получаемый результат данной операции сохраняется в другом регистре.
После завершения исполнения этапа исполнения, данный ЦПУ устанавливает себя в начало другого цикла ЦПУ:
Те алгоритмы, которые выполняются в этом типе компьютера являются последовательными (или серийными), так как они не содержат никакого параллелизма. Неким образцом компьютера SISD выступает система оборудования с единственным ЦПУ.
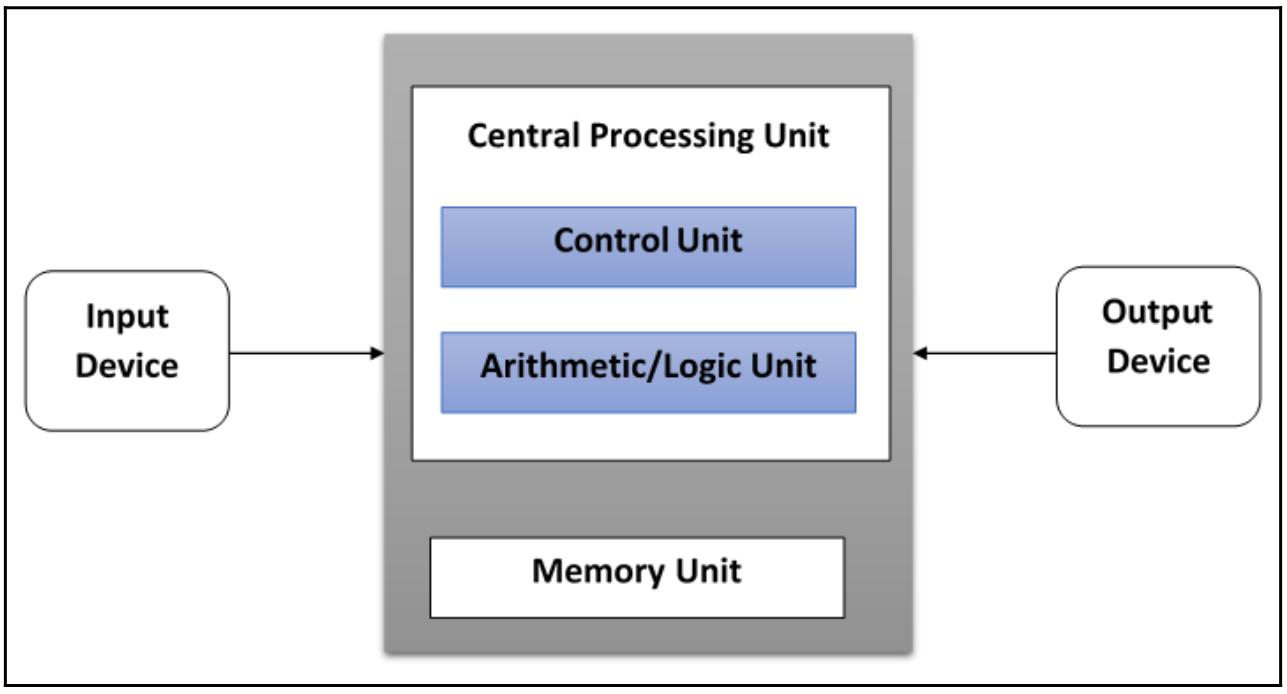
Основными элементами таких архитектур (а именно, архитектур фон Неймана) являются такие:
-
Центральное устройство памяти: Оно применяется для хранения как инструкций, так и данных программы.
-
ЦПУ: Используется для получения инструкций и/ или данных из своего устройства памяти, причём декодирует получаемые команды и последовательно реализует их.
-
Система ввода/ вывода: Обозначает собственно ввод и выод данных для данной программы.
Обычные однопроцессорные компьютеры классифицируются как системы SSD:
Наша следующая схема в частности отображает какие области применяются на стадиях выборки, декодирования и выполнения:
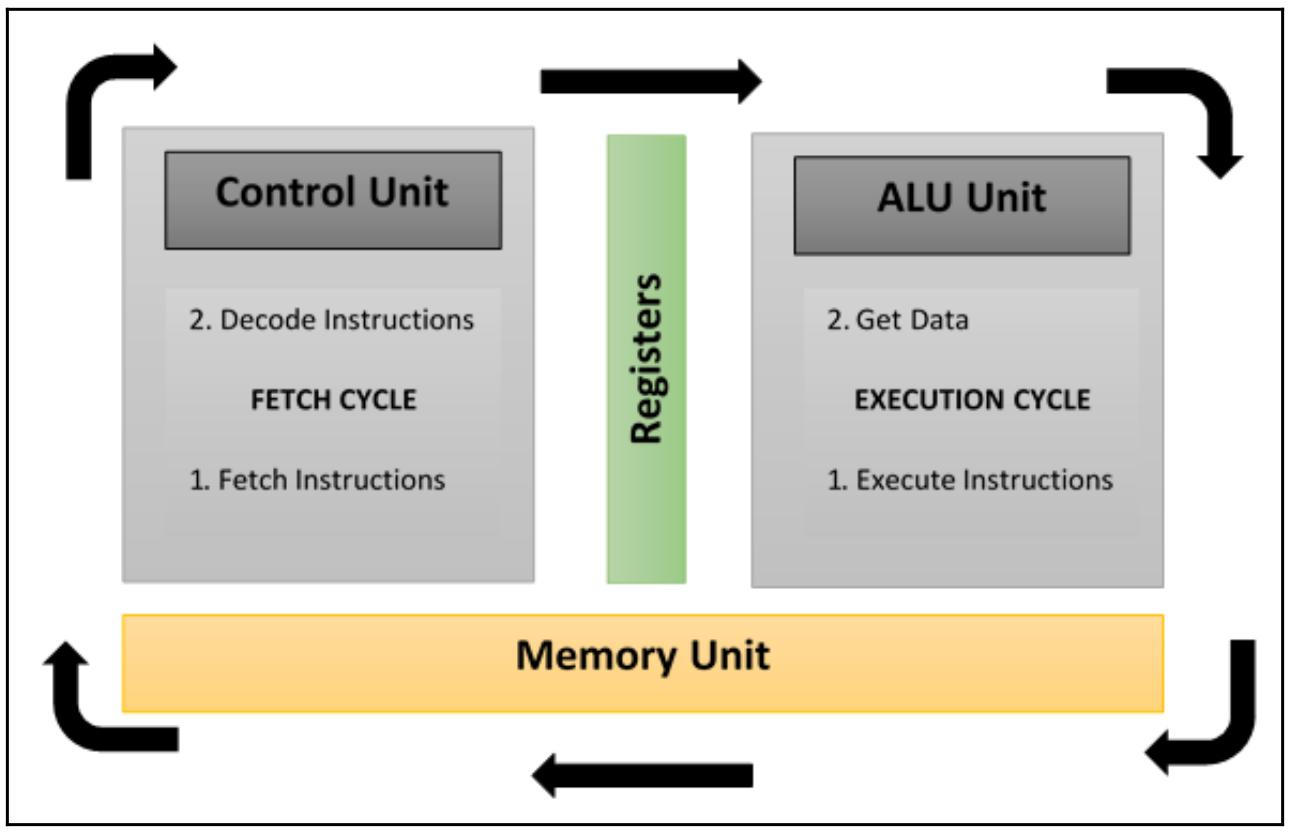
В этой модели n процессоров, причём каждый из них имеет своё собственное устройство управления, совместно используют единственное устройство памяти. В каждом временном цикле все получаемые из общей памяти данные обрабатываются всеми процессорами одновременно, причём каждым в соответствии с теми командами, которые получены его управляющим устройством.
В этом случае присутствующий параллелизм (параллелизм уровня инструкций) достигается за счёт выполнения нескольких операций с одними и теми же данными. Те типы задач, которые могут действенно решаться в подобных архитектурах достаточно специфичны, к примеру, шифрование данных. По этой причине подобные компьютеры MISD невозможно отыскать в имеющемся коммерческом секторе. Компьютеры больше относятся к умственному примеру, нежели к какой- то практической конфигурации.
Компьютер SIMD состоит из n идентичных процессоров, каждый из которых обладает своей собственной локальной памятью, в которой он способен хранить данные. Все процессоры работают под управлением единственного потока (stream) команд. Помимо этого, имеются n потоков данных, по одному для каждого процессора. Эти процессоры работают одновременно на каждом шаге и выполняют одни и те же инструкции, но для различных элементов данных. Это некий пример параллелизма данных.
Подобные архитектуры SIMD являются более многосторонними, нежели архитектуры MISD. Параллельные алгоритмы на компьютерах SIMD способны решать множество задач, охватывающих широкий диапазон приложений. Другим интересным свойством является то, что подобные алгоритмы для таких компьютеров относительно просты для проектирования, анализа и реализации. Единственным ограничением является то, что компьютерами SIMD могут решаться только те задачи, которые могут делиться на некое число подзадач (которые все идентичны, причём каждая из них будет решаться одновременно тем же самым набором инструкций).
В отношении суперкомпьютеров, разработанных в соответствии с этой парадигмой, нам следует упомянуть Connection Machine (Thinking Machine, 1985) и MPP (NASA, 1983).
Как мы обнаружим в Главе 6, Распределённый Python и Главе 7, Облачные вычисления, появление современных видеокарт (GPU), построенных на множестве встроенных SIMD устройств, привело к более широкому применению данной вычислительной парадигмы.
Этот класс параллельных компьютеров является наиболее распространённым и наиболее мощным классом, в соответствии с классификацией Флинна. Он содержит n процессоров, n потоков инструкций и n потоков данных. Каждый процессор имеет своё собственное управляющее устройство и локальную память, что превращает архитектуры MIMD в более мощные вычислительно, нежели архитектуры SIMD.
Каждый процессор работает под управлением некого потока инструкций, вызываемых его собственным устройством управления. Следовательно, такие процессоры способны потенциально выполнять различные программы с различными данными, что позволяет им решать подзадачи, которые являются различными и могут быть частью одной задачи большего размера. В MIMD данная архитектура достигается при помощи такого уровня параллелизма за счёт потоков (threads) и/ или процессов. Это также означает, что данные процессоры обычно работают асинхронно.
В наши дни данная архитектура применяется во множестве ПК, суперкомпьютеров и компьютерных сетей. Однако имеется некая фишка, которую стоит учитывать: асинхронные алгоритмы сложны в разработке, анализе и реализации:
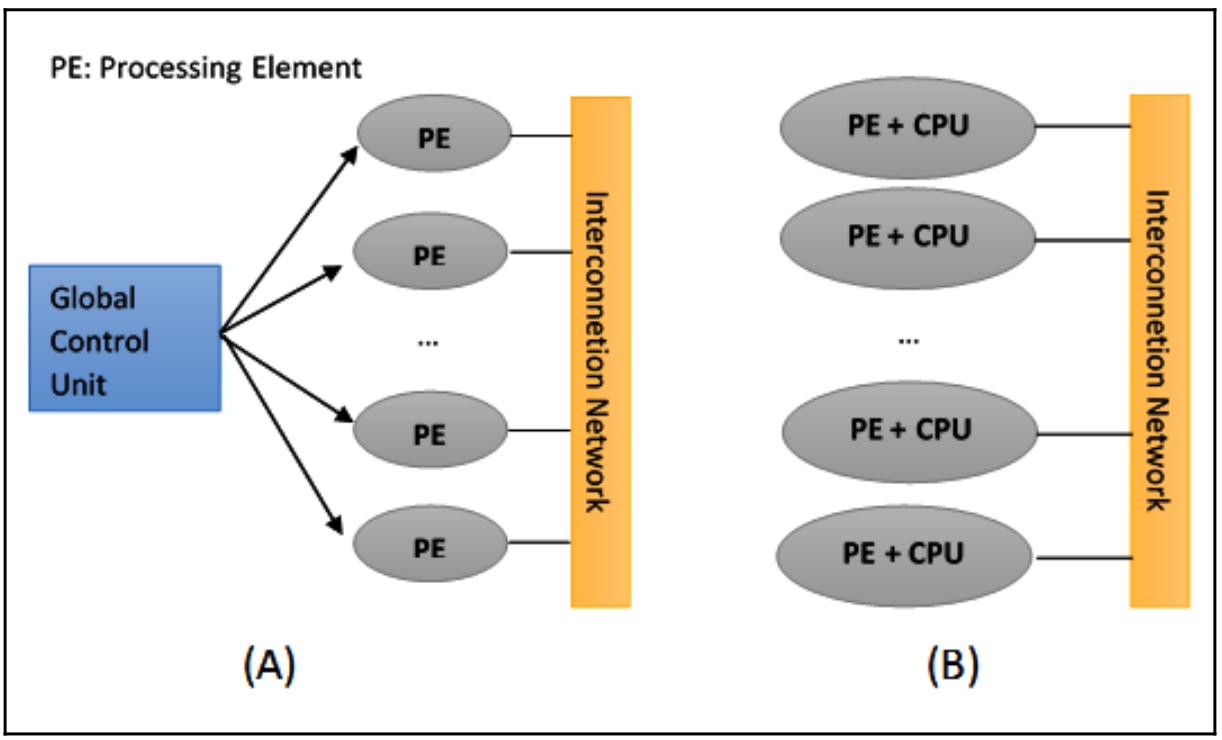
Систематику Флинна можно расширить с учётом того, что машины SIMD можно подразделить на две подгруппы:
-
Вычислительные суперкомпьютеры
-
Векторные машины
С другой стороны, MIMD можно подразделять на машины обладающие совместно используемой памятью и те, которые имеют распределённую память.
И действительно, наш следующий раздел посвящён этому последнему аспекту организации самой памяти машин MIMD.
Другой стороной, которую нам следует рассмотреть при оценке параллельных архитектур является организация памяти, или даже тот способ, которым осуществляется доступ к данным. Не имеет значения насколько быстрым является наше вычислительное устройство, когда память не способна сопровождать и поддерживать инструкции и данные на некой достаточной скорости, тогда не будет никакого улучшения в производительности.
Основная подлежащая решению задача состоит в том, чтобы время цикла памяти было сопоставимо со скоростью имеющегося процессора, который определяется как то время, которое проходит между двумя последовательными операциями. Такое время цикла рассматриваемого процессора обычно намного меньше чем значение времени цикла памяти.
Когда некий процессор инициирует какой- то обмен в или из памяти, имеющиеся ресурсы процессора будут оставаться занятыми на протяжении всего цикла памяти; следовательно, в этот период времени никакие устройства (например, контроллер ввода/ вывода, процессор или даже тот процессор, который сделал данный запрос) не будут в состоянии применять эту память из- за выполнения данного обмена:
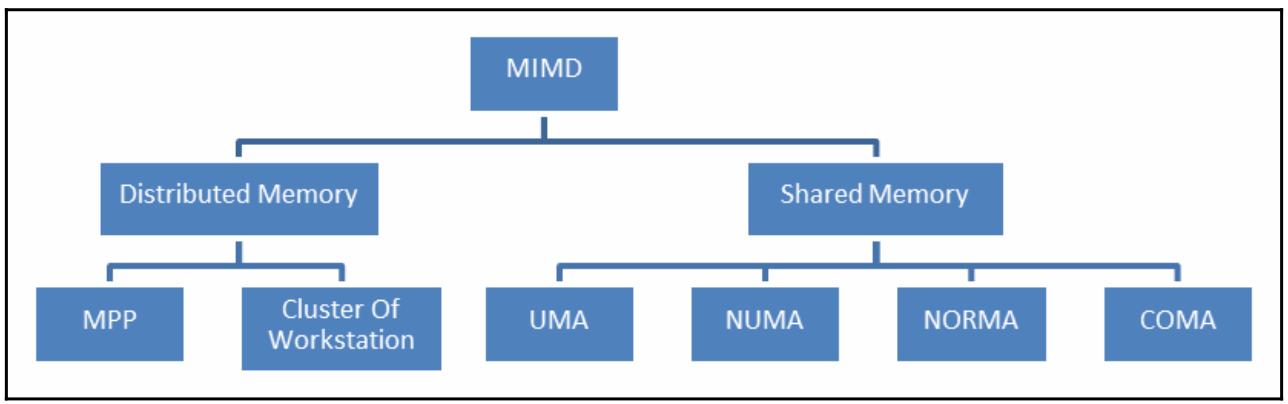
Решением данной проблемы доступа к памяти привели в результате к разветвлению архитектур MIMD. Самый первый тип систем, называемый системой с разделяемой памятью, обладает роскошной виртуальной памятью, а все процессоры имеют эквивалентный доступ к данным и инструкциям из этой памяти. Другим типом системы является модель с распределённой памятью, в которой каждый процессор имеет локальную память, которая не доступна прочим процессорам.
Что отличает разделяемую память от распределённой памяти, так это управление доступом к памяти, которое осуществляется самим процессорным устройством; это отличие очень существенно для программистов, так как оно определяет как должны взаимодействовать различные части некой параллельной программы.
В частности, некая машина с распределённой памятью обязана делать копии совместной памяти в каждой локальной памяти. Такие копии создаются отправкой сообщений, содержащих те данные, которые должны разделяться (совместно использоваться) между одним и другим процессорами. Чёрной стороной такой организации памяти является то, что порой такие сообщения могут быть очень большими и требовать относительно продолжительного времени для передачи, в то время как в некой системе с разделяемой памятью обмен сообщениями отсутствует, а основная проблема состоит в синхронизации доступа к совместно используемым ресурсам.
На приводимой ниже диаграмме показана схема совместно используемой памяти. Все физические связи здесь достаточно просты:
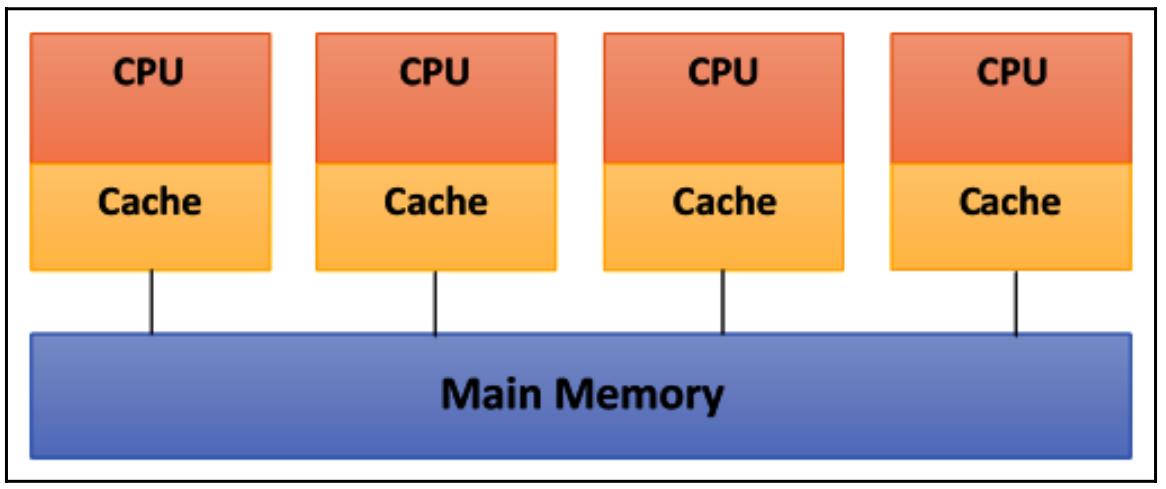
В данном случае имеющаяся структура шины позволяет некому произвольному числу устройств (ЦПУ + Кэш на предыдущей схеме), которые разделяют один и тот же канал (Главная память, как это отображено на схеме выше). Такие протоколы шины изначально проектировались чтобы позволить некому отдельному процессору и одному или более дискам или ленточным контроллерам взаимодействовать здесь через совместно используемую память.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
С каждым процессором была связана кэш- память, так как предполагается, что вероятность того, что процессору потребуется иметь присутствующими в локальной памяти очень высока. |
Основная проблема возникает когда некий процессор изменяет данные, хранящиеся в той памяти системы, которая одновременно используется другими процессорами. Такое новое значение будет передано из кэша того процессора, который произвёл изменения, в общую разделяемую память. Позднее, однако, оно должно быть передано во все прочие процессоры с тем, чтобы они не работали с устаревшими данными. Эта проблема именуется задачей когерентности кэша - некий особый случай согласованности памяти, которая требует аппаратной реализации, способной обрабатывать проблемы одновременности и синхронизации и аналогичны программированию потоков (thread).
Основными свойствами систем с разделяемой памятью являются следующие:
-
Сама память является одной и той же для всех процессоров. например, все те процессоры, которые связаны с одной и той же структурой данных, будут работать с одними и теми же логическими адресами памяти, а следовательно выполнять доступ к одним и тем же местоположениям в памяти.
-
необходимая синхронизация достигается за счёт чтения самих задач различных процессоров и предоставления разделяемой памяти. На самом деле эти процессоры за раз могут получить доступ только к одной области памяти.
-
Некая совместно используемая память не может изменяться из какой- то задачи пока другая задача имеет к ней доступ.
-
Разделение данных между задачами является быстрым. То время, которое требуется для взаимодействия состоит в значении времени, которое требуется одной из задач для считавания отдельного местоположения (и зависит от самой скорости доступа к памяти).
Сам доступ к совместно используемой памяти в системах бывает следующим:
-
UMA (Uniform Memory Access, Единообразный доступ к памяти): Основной характеристикой таких систем является то, что время доступа к имеющейся памяти является постоянным значением для всех процессоров и для любых областей памяти. По этой причине такие системы также называются SMP (Symmetric Multiprocessors). Они достаточно просты в реализации, однако не очень масштабируемы. Сам составитель кода отвечает за управление синхронизацией, вставляя надлежащий контроль, семафоры, блокировки и прочее в свои программы, которые управляют ресурсами.
-
NUMA (Non-Uniform Memory Access, Неоднородный доступ к памяти): Эти архитектуры подразделяют имеющуюся память на области с выской скоростью доступа, которые выделяются каждому процессору, а также некой общей области собственно для обмена данными, причём с более медленным доступом. Такие системы также именуются системами DSM ( Distributed Shared Memory, с распределённой общей памятью). Они чрезвычайно масштабируемы, но сложны в разработке.
![[Замечание]](/common/images/admon/note.png)
Замечание {Прим. пер.: Следует отметить, что неоднородность доступа к памяти также зависит и от уровня программного обеспечения. К примеру, современные ЦПУ имеют встроенный контроллер памяти и в то же время обладают общим адресным пространством. Это, например, позволяет на уровне операционной системы выделять одному и тому же процессу и/ или потоку области памяти, управляемые физически различными ЦПУ. В результате, с точки зрения приложения выделенная ему память будет иметь тип UMA, хотя при этом могут иметься различия во временах доступа к различным адресам в общем адресном пространстве. Эти различия могут быть ещё более существенными для приложений, работающих в архитектурах NUMA, имеющих более глубокие связи интерконнекта и располагающиеся в физически обособленных системах.}
-
NoRMA (No Remote Memory Access, доступ к памяти без удалённого доступа): Всякая локальная память предоставляется для частного использования и может иметь доступ только с локального процессора. Необходимое взаимодействие между процессорами состоит в неком протоколе взаимодействия, применяемом для обмена сообщениями, который именуется протоколом передачи сообщений (message-passing protocol).
-
COMA (Cache-Only Memory Architecture, архитектура исключительно с кэшируемой памятью): Такие архитектуры снабжаются исключительно памятью кэширования. При анализе архитектур NUMA было отмечено, что такая архитектура удерживает локальные копии данных в кэше и что эти данные сохранялись в виде дубликатов в своей главной памяти. Данная же архитектура избавляется от дублирования и оставляет лишь свои кэш области памяти; вся память физически распределяется между имеющимися процессорами (локальная память). Все локальные области памяти являются частными и к ним могут выполнять доступ лишь их локальные процессоры. Необходимое взаимодействие между процессорами также происходит через протокол передачи сообщений.
В некой системе с распределённой памятью сама память ассоциирована с каждым процессором и некий процессор имеет возможность адресации только к своей собственной памяти. Некоторые авторы называют данный вид систем мультикомпьютером, отражая тот факт, что все элементы такой системы, фактически, являются маленькими и законченными системами из неких процессора и памяти, как вы это можете наблюдать на следующей схеме:
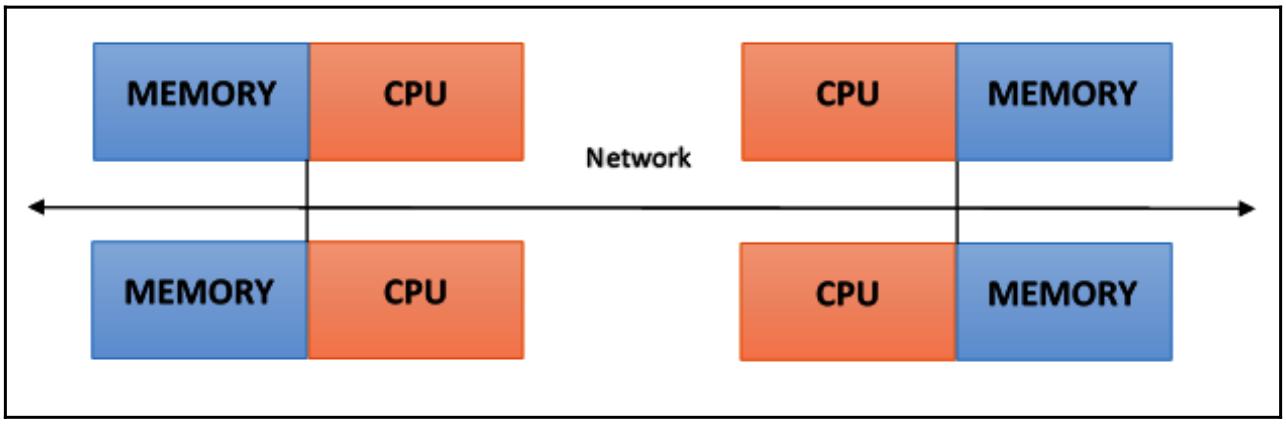
Такой вид организации обладает рядом преимуществ:
-
Нет никаких конфликтов на самом уровне имеющихся шины или коммутатора взаимодействия. Всякий процессор может применять полную полосу пропускания своей собственной локальной памяти без каких либо помех со стороны прочих процессоров.
-
Сам факт отсутствия общей шины означает что нет никакого ограничения на общее число процессоров. Общий размер такой системы ограничен только самой сетевой средой, применяемой для соединения имеющихся процессоров.
-
Нет никаких проблем с когерентностью кэшей. Каждый процессор отвечает за свои собственные данные и не беспокоится относительно обновления каких бы то ни было копий.
Основным недостатком является то, что взаимодействие между процессорами более сложное для реализации. Когда процессору требуются данные из памяти другого процессора, тогда таким двум процессорам обязательно нужно обмениваться сообщениями через протокол передачи сообщений. Это приводит к двум источникам замедления: для построения и отправки сообщений от одного процессора к другому требуется время, и к тому же все процессоры должны останавливаться для управления получением сообщений от прочих процессоров. Некая программа, спроектированная для работы в какой- то машине с распределённой памятью должна быть организована в виде набора независимых задач, которые взаимодействуют через сообщения:
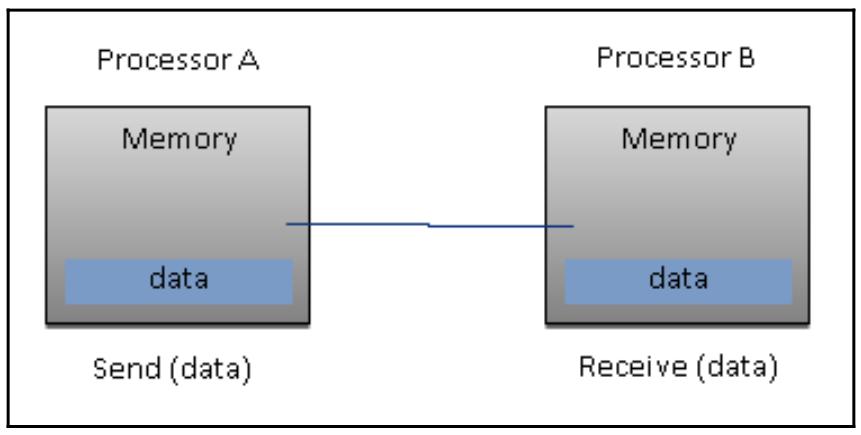
Основные свойства систем с распределённой памятью следующие:
-
Память физически распределена между процессорами; всякая локальная память напрямую доступна только из своего процессора.
-
Синхронизация достигается перемещением данных (даже если это всего лишь само по себе сообщение) между процессорами (взаимодействие).
-
Само подразделение данных в имеющихся локальных областях памяти воздействует на производительность такой машины - существенно выполнять деление аккуратно, с тем, чтобы свести к минимуму взаимодействие между имеющимися ЦПУ. Дополнительно к этому, тот процессор, который осуществляет координацию таких операций по разбиению и составлению должен эффективно взаимодействовать со всеми процессорами, которые работают как самостоятельные части структур данных.
-
Для взаимодействия ЦПУ друг с другом посредством обмена пакетами применяется протокол передачи сообщений. Такие сообщения являются дискретными элементами информации в том смысле, что они обладают чётко заданной идентичностью, а потому их всегда можно отличать друг от друга.
Машины MPP составляются из сотен процессоров (и может достигать сотен и тысяч процессоров в некоторых машинах), которые соединяются некой сетевой средой взаимодействия. На таких архитектурах основаны самые быстрые в мире компьютеры; некими представителями таких архитектур являются Earth Simulator, Blue Gene, ASCI White, ASCI Red, а также ASCI Purple и Red Storm.
Такие системы обработки основаны на классических компьютерах, которые соединены сетевыми средами взаимодействия. В этот класс также подпадают и вычислительные кластеры.
В некой кластерной архитектуре мы определяем некий узел (node) как отдельный вычислительный элемент, который выступает частью в общем кластере. Для самого пользователя подобный кластер полностью прозрачен - все имеющиеся сложности оборудования и программного обеспечения маскируются, а данные и приложения делаются доступными, как если бы все они были доступны из некого отдельного узла.
Здесь мы выделим три вида кластеров:
-
Отказоустойчивый кластер: В нём непрерывно отслеживается активность определённого узла и если один из них прекращает работу, другая машина перехватывает на себя все его действия. Основная цель состоит в гарантии непрерывного обслуживания благодаря избыточности имеющейся архитектуры.
-
Кластер балансировки нагрузки: В такой системе некий запрос задания отправляется в тот узел, который имеет меньшую активность. Это обеспечивает меньшее время на обработку данного задания.
-
Кластер высокопроизводительных вычислений: В нём все узлы настроены на воспроизводство чрезвычайно высокой производительности. Сам процесс также делится на множество заданий во множестве узлов. Эти задания распараллеливаются и будут распределяться по различным машинам.
Введение ускорителей GPU в имеющийся однородный мир суперкомпьютеров изменило саму природу того, как суперкомпьютеры и применяются, и программируются в настоящее время. несмотря на предлагаемую GPU высокую производительность, их нельзя рассматривать в качестве автономных процессоров, так как они всегда должны сопровождаться сочетанием с ЦПУ. Тем самым сама парадигма программирования очень проста: имеющийся ЦПУ берёт на себя управление и последовательно выполняемые вычисления, назначая те задачи, которые очень затратны в вычислительном отношении и обладают высокой степенью параллелизма, своему графическому ускорителю.
Необходимое взаимодействие между ЦПУ и GPU может происходить не только посредством использования высокоскоростной шины, но также и путём совместного использования отдельной области памяти как для физической, так и для виртуальной памяти. Фактически, в том случае, когда оба устройства не оснащены собственными областями памяти, можно ссылаться на общую область памяти применяя имеющиеся библиотеки программного обеспечения, предоставляемые различными моделями программирования, такими как CUDA и OpenCL.
Эти архитектуры именуются гетерогенными (неоднородными), в то время как приложения могут создавать структуры в неком отдельном адресном пространстве и отсылать некое задание в соответствующее оборудование устройства, которое подходит для решения такой задачи. Различные задачи обработки могут безопасно работать в тех де самых областях во избежание проблем согласованности данных благодаря атомарным операциям.
Таким образом, несмотря на то, что ЦПУ и GPU не кажутся работающими действенно совместно, благодаря применению такой новой архитектуры мы можем оптимизировать их взаимодействие, также как и показатели производительности, для параллельных приложений:
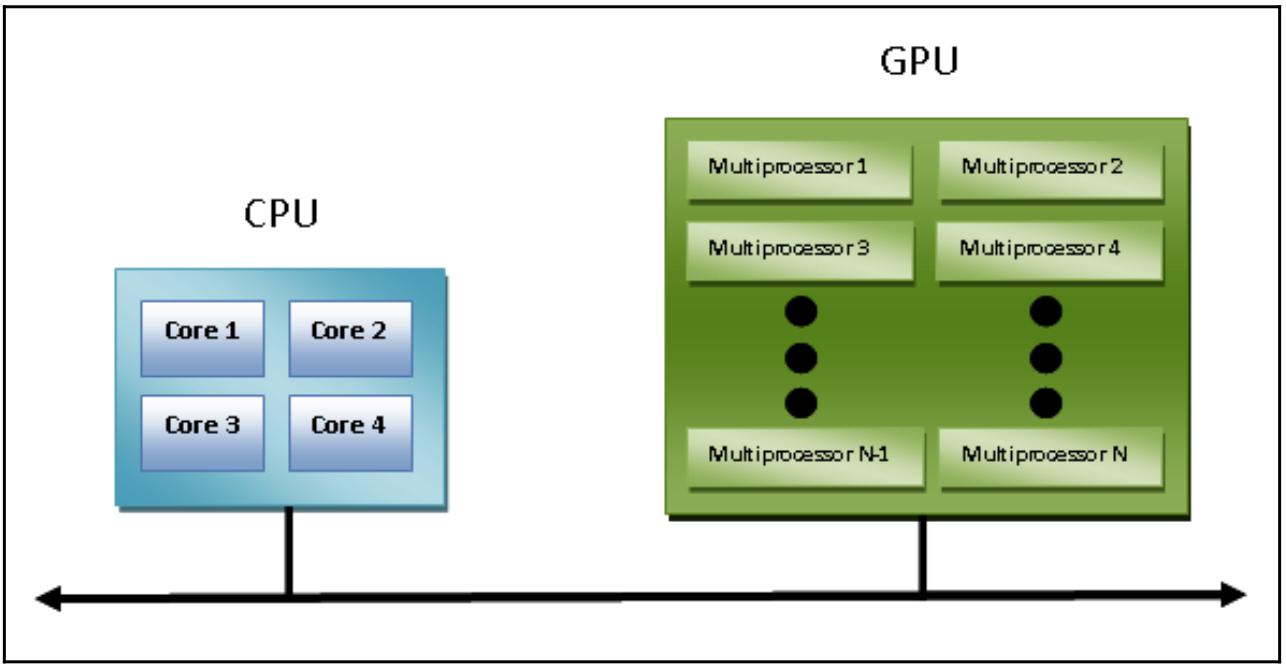
В своём следующем разделе мы сделаем введение в основные модели параллельного программирования.
Модели параллельного программирования существуют в виде некой абстракции архитектур оборудования и памяти. На самом деле, эти модели не являются чем- то особенным и не относятся к каким- то конкретным видам архитектур машин или памяти. Они могут быть реализованы (по крайней мере теоретически) на любом виде машин. По сравнению с нашими предыдущими подразделениями, такие модели программирования выполняются на более высоком уровне и представляют собой тот способ, которым может быть реализовано необходимое программное обеспечение для выполнения параллельных вычислений. Каждая модель обладает своим собственным способом разделения информации с прочими процессорами для доступа к памяти и разделения выполняемой работы.
Говоря точно, ни одна из моделей не имеет абсолютных преимуществ перед прочими. По этой причине, самое лучшее решение, котрое будет использовано, будет во многом зависеть от той задачи, которую обязан рассмотреть и решить программист. Наиболее распространённые модели для параллельного программирования таковы:
-
Модель с совместно используемой памятью
-
Модель со множеством потоков
-
Модель с распределённой памятью/ передачей сообщений
-
Модель параллельных данных
В этом рецепте мы дадим вам некий обзор таких моделей.
В этой модели задачи совместно используют некую отдельную область памяти в которой мы можем выполнять асинхронно чтения и записи. Существуют механизмы, которые позволяют пишущему код контролировать сам доступ к такой разделяемой памяти; например, блокировки или семафоры. Такая модель предлагает то преимущество, что пишущему её код не требуется выяснять взаимодействие между задчами. Важным недостатком, в отношении производительности, является то, что более сложно уяснять и управлять локализацией данных. Это относится к локальному хранению данных по отношению к тому процессору, который работает сохраняя доступ к памяти, обновлениям кэша и обмену в шине, который возникает в случае, когда множество процессоров используют одни и те же самые данные.
В этой модели некий процесс может иметь множество потоков (flows) вычислений. Например, создаётся какая- то последовательная часть, а вслед за этим, создаётся некая последовательность задач, которые могут исполняться параллельно. Обычно такой тип модели используется в архитектурах с разделяемой памятью. Поэтому для нас будет очень важно управлять синхронизацией между потоками (threads), так как они работают с общей памятью и самому программисту требуется предотвращать обновления множеством потоков одной и той же области в одно и то же самое время {Прим. пер.: см. Ресторан Серийных ботов Цалеба Хаттингха}.
ЦПУ текущего поколения многопоточны как в отношении программного обеспечения, так и с аппаратной точки зрения. Потоки POSIX (сокращение для Portable Operating System Interface, интерфейса переносимой операционной системы) являются классическими примерами такой реализации многопоточности в программном обеспечении. Технология Hyper-Threading Intel реализует многопоточность на аппаратном уровне путём переключения между двумя потоками (threads), когда один из них приостанавливается или ожидает ввода/ вывода. За счёт этой модели можно достигать параллелизма даже когда расположение данных нелинейно.
Модель передачи сообщений обычно применяется в тех случаях, когда каждый процессор имеет свою собственную память (система с распределённой памятью). Множество зада могут располагаться в одной и той же физической машине, или в неком произвольном числе машин. Сам выполняющий кодирование отвечает за определение собственно параллелизма и обмена данными, который происходит посредством необходимых сообщений и внутри его кода требуются запросы и вызовы неких библиотечных функций.
Некоторые образцы имелись начиная с 1980-х, но только в середине 1990-х была создана некая стандартизованная модель, которая привела к фактическому стандарту с названием MPI (Message Passing Interface, Интревейс передачи сообщений).
Данная модель MPI очевидно разрабатывалась для распределённой памяти, однако, будучи моделью параллельного программирования, некая модель со множеством платформ также может применяться и в машинах с разделяемой памятью:
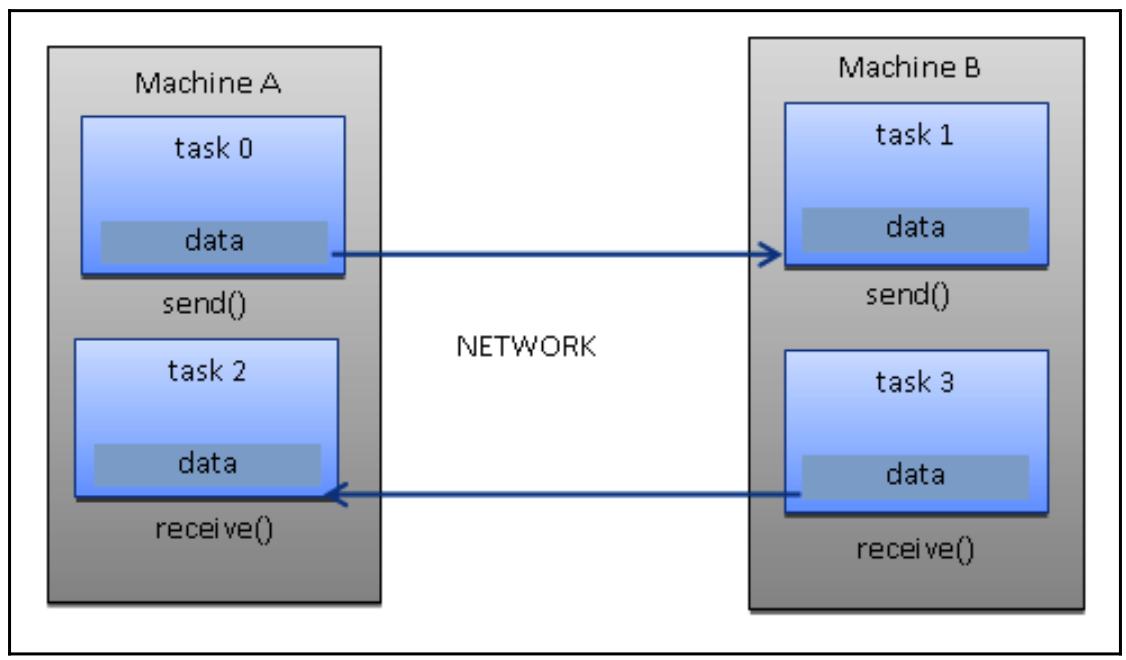
В этой модели у нас имеется множество задач, которые работают с одной и той же структурой данных, но каждая из задач работает с различными частями данных. В архитектуре с разделяемой памятью все задачи имеют доступ к данным через совместно применяемую память, а в архитекутрах с распределённой памятью имеющаяся структура данных делится на части и располагается в локальной памяти каждой из задач.
Для реализации данной модели пишущий код должен разработать некую программу, которая определяет распределение и группировку данных; например, GPU современного поколения обладают высокой производительностью только когда данные (Task 1, Task 2 и Task 3) сгруппированы так, как это показано на следующей схеме:
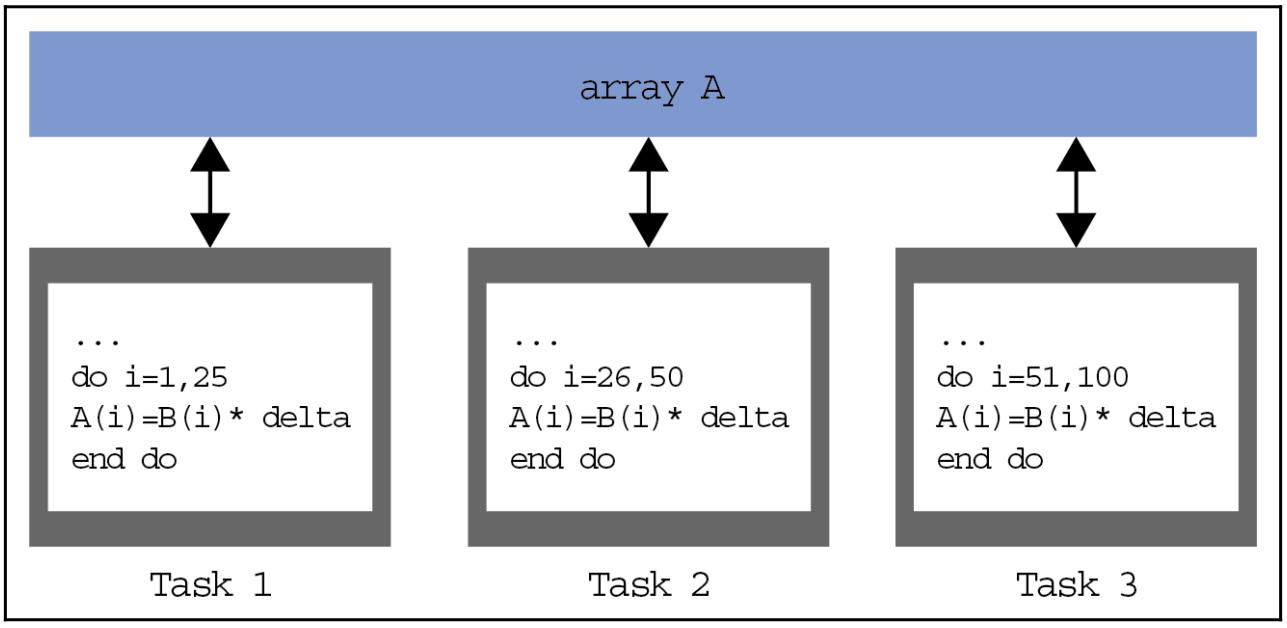
Разработка параллельной программы
разработка эксплуатирующих параллелизм алгоритмов основывается на некой последовательности действий, которые следует выполнять для данной программы чтобы правильно осуществлять само задание бкз воспроизводства частичных или ошибочных результатов. Для верного распараллеливания алгоритма следует выполнять такие макро- операции:
-
Декомпозиция задачи
-
Назначение задачи
-
Агломерация
-
Установление соответствия
Декомпозиция задачи
На этом этапе сама создаваемая программа расщепляется на задачи или множество инструкций, которые могут исполняться в различных процессорах для реализации параллельности. Для осуществления такого деления применяются два метода:
-
Декомпозиция по областям: В этом случае делятся сами данные этих задач. Собственно приложение является общим для всех тех процессоров, которые работают с различными порциями данных. Эта методология применяется когда у нас имеются большие объёмы данных, подлежащие обработке.
-
Функциональная декомпозиция: При этом основная проблема расщепляется на задачи, причём каждая задача будет выполнять некую определённую операцию на всех доступных данных.
Назначение задачи
На данной фазе определяется тот механизм, посредством которого все задачи будут распределяться по различным процессам. Эта фаза очень важна, так как она устанавливает само распределение рабочей нагрузки по различным имеющимся процессорам. Здесь критически важна балансировка нагрузки; на практике все процессоры должны работать непрерывно, избегая каких бы то ни было простоев на длительный промежуток времени.
Для выполнения этого, пишущий код принимает во внимание всю имеющуюся неоднородность своей системы с попыткой назначить больше задач процессорам с лучшей производительностью. Наконец, для большей эффективности распараллеливания, необходимо ограничивать взаимодействие между процессорами насколько это возможно, так как именно оно часто выступает основным источником замедления и потребления ресурсов.
Агломерация
Агломерация является процессом сочетания задач меньшего размера в более крупные для улучшения производительности. Если наши два предыдущих этапа процесса проектирования разбили общую проблему на некое число задач, которые намного превосходят общее число доступных процессоров и когда наш компьютер не разработан специально для обработки гигантского числа маленьких задач (некоторые архитектуры, например, GPU, справляются с этим, и на самом деле выигрывают от выполнения миллионов или даже миллиардов задач), тогда наш проект может стать очень неэффективным.
Обычно это происходит по причине того, что задачам приходится взаимодействовать с самим процессором или потоком с тем, чтобы они вычисляли оговоренную задачу. Большинство взаимодействий имеют стоимость, которая не пропорциональна необходимому количеству передаваемых данных, но также следует из фиксированной стоимости для каждой операции взаимодействия (таких как задержки, которые наследуются при установлении некого TCP подключения). Когда такие задачи слишком малы, тогда такие фиксированные стоимости легко способны превратить данную разработку в неэффективную.
Установление соответствия
На данном этапе установления соответствия процесса разработки параллельного алгоритма мы определяем где каждая из задач должна выполняться. Основная цель состоит в минимизации общего времени исполнения. Здесь вам зачастую приходится идти на компромиссы, поскольку две имеющихся основных стратегий часто вступают в конфликт друг с другом:
-
Часто взаимодействующие между собой задачи следует помещать в одном и том же процессоре для увеличения локализации.
-
Все задачи, которые могут исполняться одновременно, следует помещать а различные процессоры для увеличения одновременности.
Это имеет название проблемы соответствия, причём она известна как NP-полная задача. А раз так, в общем случае не может существовать никакого решения с полиномиальным временем для этой проблемы. Для задач с одним размером и задач с просто выявляемыми шаблонами взаимодействия, такое соответствие является простым (здесь мы также можем выполнять агломерацию для объединения задач, отображаемых в один и тот же процессор). Однако, когда задачи обладают шаблонами взаимодействия, которые трудно предсказуемы, либо объёмы работы разнятся от задачи к задаче, тогда сложно разработать действенную схему установления соответствия и агломерации.
Для такого типа задач можно применять алгоритмы балансировки нагрузки чтобы выявлять стратегии агломерации и установления соответствия в процессе времени исполнения. Самыми сложными задачами являются те, в которых объём взаимодействия или общее число задач изменяется в процессе исполнения данной программы. Для такого вида задач можно применять алгоритмы динамичной балансировки нагрузки, которые периодически запускаются на протяжении времени исполнения.
Динамическое соответствие
Для некого разнообразия задач имеется ряд алгоритмов балансировки нагрузки:
-
Глобальные алгоритмы: Они требуют глобального знания о выполняемых вычисления, что зачастую добавляет множество накладных расходов.
-
Локальные алгоритмы: Они полагаются только на сведения которые локальны для задач в запросе, что уменьшает накладные расходы по сравнению с глобальными алгоритмами, однако они обычно более плохи в поиске оптимальных агломерации и установления соответствия.
Однако сокращение накладных расходов способно сократить общее время исполнения, даже когда установление соответствия само по себе хуже. Когда задачи редко обмениваются данными, помимо обмена в самом начале и по завершению выполнения, тогда часто применяется некий алгоритм планирования задач, который просто устанавливает соответствие тем процессорам, которые простаивают. В неком алгоритме планирования задач поддерживается какой- то пул задач. Задачи помещаются в этот пул и изымаются обработчиками (workers).
При такой модели имеются три распространённых подхода:
-
Диспетчер/ обработчик: Это базовая схема динамического соответствия в которой все имеющиеся обработчики соединены с центральным диспетчером. Имеющийся диспетчер часто отправляет задачи обработчикам и собирает полученные результаты. Эта стратегия скорее всего наилучшая для некого относительно небольшого числа процессоров. Основа стратегии может улучшаться в последующем задачами опроса с тем, чтобы перекрывались друг с другом взаимодействия и вычисления.
-
Иерархический диспетчер/ обработчик: Это определённый вариант диспетчер/ обработчика, который имеет частично распределённую схему. Обработчики разделяются на группы, причём каждая со своим собственным диспетчером. Такие диспетчеры групп взаимодействуют со своим центральным диспетчером (и возможно также и промеж собой), в то время как обработчики запрашивают задачи от своего диспетчера группы. Это расделяет общую нагрузку по различным диспетчерам и способно, тем самым, обрабатывать большее число процессоров чем если бы обработчики запрашивали задачи у одного и того же самого диспетчера.
-
Децентрализация: В этой схеме всё децентрализовано. Каждый процессор сопровождает свой собственный пул задач и взаимодействует с прочими процессорами чтобы запрашивать задачи. То, как эти процессоры выбирают прочие процессоры для запроса задач варьируется и определяется на основе самой общей задачи.
Сама разработка параллельных программ создаёт потребность замеров производительности для принятия решения относительно того будет ли это подходящим применением или нет. В самом деле, основной фокус параллельных вычислений направлен на решение больших задач в некий относительно короткий период времени. Те факторы, которые вносят в клад в этот предмет это, например, тип применяемого оборудования, степень распараллеливания самой задачи, а также применяемый метод параллельного программирования. Для обеспечения этого был введён анализ базовых понятий, который сопоставляет предлагаемые параллельные алгоритмы, получаемые из соответствующей первоначальной последовательности.
Значение производительности достигается путём анализа и количественной оценки применяемых общего числа потоков и/ или общего числа процессов. Для такого анализа давайте введём несколько индексов производительности:
-
Ускорение
-
Эффективность
-
Масштабируемость
Показатели ограничений параллельных вычислений вводятся законом Амдала. Для оценки степени эффективности величины распараллеливания некого последовательного алгоритма у нас имеется закон Густафсона.
Величина ускорения это та мера, которая отображает значение преимущества параллельного решения некой задачи. Она определяется как значение соотношения времени, требуемого на решение задачи отдельным обрабатывающим элементом (Ts) к величине времени на решение той же самой задачи p идентичными обрабатывающими элементами (Tp).
Мы выражаем ускорение следующим образом:
S = Ts / Tp
Когда у нас имеется линейная зависимость ускорения, S=p, это означает, что значение скорости выполнения растёт вместе с числом процессоров. Конечно, это некий идеальный случай. В то время как значение ускорения будет абсолютным когда Ts равняется времени исполнения самого наилучшего последовательного алгоритма, величина ускорения является относительной когда Ts равняется времени исполнения рассматриваемого параллельного алгоритма для некого отдельного процессора.
Давайте переобуем эти условия:
-
S = p является линейным, или идеальным ускорением.
-
S < p является реальным ускорением.
-
S > p является превышающим линейное, супер ускорением.
В неком идеальном мире, какая- то параллельная система с p обрабатывающими элементами может предоставить нам ускорение, которое равняется p. Тем не менее, это крайне редко достигается. Как правило, какое- то время тратится на простои или взаимодействие. Эффективность является мерой того, сколько времени исполнения некого обрабатывающего элемента идёт на выполнение полезной работы, а какая часть времени теряется.
Мы обозначим её как E и определим следующим образом:
E = S / p = Ts / (pTp)
Те алгоритмы, у которых ускорение линейное, будут иметь значение E = 1. Во всех прочих случаях они будут иметь значение E меньшим чем 1. Три существенных варианта указывают нам следующее:
-
Когда E = 1, это случай линейного ускорения.
-
Когда E < 1, это некий реальный случай.
-
Когда E << 1, это некая задача, которая распараллеливается крайне неэффективно.
Масштабирование определяется как наличие возможности быть эффективным в некой параллельной машине. Она указывается значением вычислительной мощности (скоросьтю выполнения) пропорционально общему числу процссоров. При увеличении самого размера задачи и в то же самое время общего числа процессоров, не должно быть потерь в смысле производительности.
В зависимости от различных факторов, конкретная масштабируемая система при её росте может сохранять ту же самую эффективность или улучшать её.
Закон Амдала является широко применяемым законом, который используется при проектировании процессоров и параллельных алгоритмов. Он постулирует, что максимальное ускорение, которого можно достигнуть, ограничивается величиной последовательной составляющей в рассматриваемой программе:
S = 1 / (1 - p)
|
| Совет |
|---|---|
|
1 - p показывает величину последовательной составляющей (не подлежащей распараллеливанию) в некой программе. |
Это означает, к примеру, что когда некая программа, в которой 90% кода может выполняться параллельно, а 10% должно оставаться последовательным, тогда максимальным значением ускорения является 9, причём даже при неком бесконечном числе процессоров.
|
| Замечание |
|---|---|
|
{Прим. пер.: Ещё одним известным следствием Закона Амдала является тот факт, что максимальное ускорение системы из некого числа обрабатывающих элементов определяется производительностью самого медленного из них.}. |
Закон Густафсона постулирует следующее:
S(P) = P - α(1 - p)
Здесь мы определяем указанные в уравнении величины следующим образом:
-
P это значение числа процессоров
-
S это величина фактора ускорения
-
α это не поддающаяся распараллеливанию часть любого параллельного процесса.
Закон Густафсона отличен от закона Амдала, который, как мы уже описывали, предполагает, что общая рабочая нагрузка не изменяется по отношению к имеющемуся числу процессоров.
Фактически, закон Густафсона предполагает, что программисты вначале устанавливают значение времени, отводимое на решение некой задачи параллельно, а затем на основании этого (то есть времени) оценивают данную задачу. Таким образом, чем быстрее данная параллельная система, тем больше задач можно решить в то же самое время.
Действие закона Густафсона состоит в том, чтобы направить стремления исследования вычислений на отбор или повторную постановку задач таким образом, чтобы за то же самое время можно было бы решить большее число задач. Кроме того, этот закон переопределяет само понятие эффективности как некую потребность сокращения, по крайней мере, значения последовательной части некой программы, вне зависимости от роста рабочей нагрузки.
Python это мощный, динамичный и интерпретируемый язык программирования, который применяется в широком разнообразии приложений. Вот некоторые из его свойств:
-
Ясниый и доступный для чтения синтаксис
-
Очень всесторонняя стандартная библиотека в еоторой, помимо дополнительных программных модулей мы способны добавлять типы данных, функции и объекты.
-
Простые для обучения быстрые разработка и отладка. Разработка Python кода на Python может быть до 10 раз быстрее чем в коде C/ C++. Этот код может работать в качестве прототипа и затем преобразовываться в C/ C++.
-
Обработка ошибок на основе исключительных ситуаций.
-
Функциональность строгого самоанализа.
-
Богатство документации и сообщества программирования.
Python можно рассматривать в качестве некого склеивающего языка. При помощи Python можно разрабатывать лучшие приложения, так как различные виды разработчиков кода могут совместно работать над неким проектом. Например, при построении некого научного приложения, программисты C/ C++ могут реализовывать эффективные численные алгоритмы, в то время как научные сотрудники в том же самом проекте могут писать программы Python, которые проверяют и применяют эти алгоритмы. Научным сотрудникам нет нужды изучать язык программирования нижнего уровня, а программистам C/ C++ не требуется понимать то, во что вовлечены эти научные сотрудники.
|
| Замечание |
|---|---|
|
Вы можете прочесть об этом дополнительно в https://www.python.org/doc/essays/omg-darpa-mcc-position. |
Давайте рассмотрим некоторые образцы очень базового кода для получения некой основы свойтв Python.
|
| Замечание |
|---|---|
|
Наш последующий раздел служит для того чтобы обновить сведения для большинства из вас. Мы будем применять эти техники на практике в Главе 2, Параллельность на основе потоков и Главе 3, Параллельность на основе процессов. |
Сам интерпретатор Python уже предоставляет некую действенную систему подсказок. Если вы пожелаете узнать как
применять некий объект, тогда просто наберите help(object).
Давайте посмотрим, например, как применить функцию help для целого
0:
>>> help(0)
Подсказка по объекту int:
class int(object)
| int(x=0) -> integer
| int(x, base=10) -> integer
|
| Преобразовывает некое число или строку в целое, либо возвращает 0 когда
| не задан никакой аргумент. Когда x является неким числом, djpdhfoftn x.__int__(). Для
| числ с плавающей запятой, также выполняется усечение в сторону нуля.
|
| Когда x не является неким числом или когда определено основание, тогда x должно быть некой строкой,
| байтами, или экземпляр массива байт, представленный как некая целая константа по заданному
| основанию. Перед такой константой может идти '+' или '-', а также она может выравниваться
| пробельными символами. Основанием по умолчанию выступает 10. Допустимыми основаниями являются 0
| и 2-36.
| Основание 0 подразумевает интерпретацию значения основания из значения строки в качестве целой
| константы.
>>> int('0b100', base=0)
За данным описанием объекта int следует перечень методов, которые применимы
для него. Самыми первыми методами являются такие:
| Methods defined here:
|
| __abs__(self, /)
| abs(self)
|
| __add__(self, value, /)
| Возвращает self+value.
|
| __and__(self, value, /)
| Возвращает self&value.
|
| __bool__(self, /)
| self != 0
|
| __ceil__(...)
| Округление в большую сторону целого возвращает его значение.
Кроме того также полезна dir(object), которая перечислит все доступные
для объекта методы:
>>> dir(float)
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
Наконец, относящаяся к объекту документация предоставляется функцией .__doc__,
что показывает наш следующий пример:
>>> abs.__doc__
'Возвращает абсолютное значение своего аргумента.'
Python не принимает терминаторы оператора, а блоки кода определяются через отступы. Операторы, которые ожидают
некого уровня отступа должны завершаться двоеточием (:). Это приводит к тому,
что:
-
Код Python яснее и лучше читается.
-
Имеющаяся структура программы всегда в соответствии с такими имеющимися отступами.
-
Установленный стиль отступов единообразен в любом листинге.
Плохие отступы могут повлечь за собой ошибки.
Наш следующий пример показывает как применяется конструкция if:
print("first print")
if condition:
print(“second print”)
print(“third print”)
В приведённом примере мы можем наблюдать следующее:
-
Следующие операторы:
print("first print"), if condition:, print("third print")имеют один и тот же уровень отступа и всегда выполняются. -
После оператора
ifимеется некий блок кода с более высоким уровнем отступа, который содержит операторprint ("second print"). -
Когда условие
ifявляется истиной, операторprint ("second print")выполняется. -
Когда условие
ifявляется ложью, операторprint ("second print")не выполняется.
Таким образом, очень важно уделять внимание отступам, так как они всегда вычисляются в в данной программе в процессе синтаксического разбора.
Комментарий начинается с символа хэша (#) и расположен в одной строке:
# комментарий одной строкой
Для комментариев во множестве строк применяются строковые значения множественных строк:
""" первая строка комментария из множества строк
вторая строка комментария из множества строк."""
присвоение выполняется при помощи символа равенства (=). Для проверки
эквивалентности применяется значение того же самого (==). Вы можете
увеличивать или уменьшать некое значение при помощи операторов += и
-= с идущей следом разницей. Это работает со многими типами данных, включая
строки. В одной и той же строке вы можете выполнять присвоение множеству выражений.
Вот некоторые примеры:
>>> variable = 3
>>> variable += 2
>>> variable
5
>>> variable -= 1
>>> variable
4
>>> _string_ = "Hello"
>>> _string_ += " Parallel Programming CookBook Second Edition!"
>>> print (_string_)
Hello Parallel Programming CookBook Second Edition!
наиболее значимыми структурами в Python являются списки (lists), кортежи (tuples) и словари (dictionaries). Множества были интегрированы в Python начиная с версии 2.5 (для предыдущих версий они были доступны в соответствующей библиотеке sets):
-
Списки: Они аналогичны одномерным массивам, но вы также можете создавать списки, содержащие другие списки.
-
Словари: Это массивы, содержащие пару ключа и значения (хэш таблицы).
-
Кортежи: Это неизменяемые одномерные объекты.
Массивы могут иметь различные типы, поэтому вы можете смешивать переменные, такие как целые и строки в своих списках, словарях и кортежах.
Значение индекса самого первого объекта в любом виде массива всегда ноль. Допускаются отрицательные индексы и они
исчисляются с самого конца данного массива; -1 указывает на самый последний
элемент данного массива:
#давайте поиграем со списками
list_1 = [1, ["item_1", "item_1"], ("a", "tuple")]
list_2 = ["item_1", -10000, 5.01]
>>> list_1
[1, ['item_1', 'item_1'], ('a', 'tuple')]
>>> list_2
['item_1', -10000, 5.01]
>>> list_1[2]
('a', 'tuple')
>>>list_1[1][0]
['item_1', 'item_1']
>>> list_2[0]
item_1
>>> list_2[-1]
5.01
#построим некий словарь
dictionary = {"Key 1": "item A", "Key 2": "item B", 3: 1000}
>>> dictionary
{'Key 1': 'item A', 'Key 2': 'item B', 3: 1000}
>>> dictionary["Key 1"]
item A
>>> dictionary["Key 2"]
-1
>>> dictionary[3]
1000
при помощи символа двоеточия (:) вы можете задавать некий диапазон
массива:
list_3 = ["Hello", "Ruvika", "how" , "are" , "you?"]
>>> list_3[0:6]
['Hello', 'Ruvika', 'how', 'are', 'you?']
>>> list_3[0:1]
['Hello']
>>> list_3[2:6]
['how', 'are', 'you?']
Строки Python выделяются при помощи символов одинарной (') или двойной
(") кавычки, причём им дозволяется применение одной нотации внутри
строки, ограниченной другой нотацией:
>>> example = "she loves ' giancarlo"
>>> example
"she loves ' giancarlo"
Для множества строк они заключаются в тройные кавычки (или три одинарных,
'''строковое значение
из множества строк''':
>>> _string_='''I am a
multi-line
string'''
>>> _string_
'I am a \nmulti-line\nstring'
Python также поддерживает Unicode; просто применяйте синтаксис u"This is a unicode
string":
>>> ustring = u"I am unicode string"
>>> ustring
'I am unicode string
Для ввода в некой строке значений наберите значение оператора % и
некий кортеж. Далее каждый оператор % замещается элементом кортежа,
причём слева направо:
>>> print ("My name is %s !" % ('Mr. Wolf'))
My name is Mr. Wolf!
Инструкциями управления потока выступают if,
for, и while.
В своём следующем примере мы проверяем будет ли данное число положительным, отрицательным или нулём и отображаем полученный результат:
num = 1
if num > 0:
print("Positive number")
elif num == 0:
print("Zero")
else:
print("Negative number")
Наш следующий блок кода находит сумму всех хранимых в неком списке чисел при помощи цикла
for:
numbers = [6, 6, 3, 8, -3, 2, 5, 44, 12]
sum = 0
for val in numbers:
sum = sum+val
print("The sum is", sum)
Для выполнения итераций в коде пока установленное условие истинно, мы будем выполнять оператор
while. Мы будем применять такой цикл вместо цикла
for, так как мы не знаем точное число итераций, которое будет в результате
в данном коде. В своём примере мы применяем while для добавления натуральных
чисел в sum = 1+2+3+...+n:
n = 10
# инициализируем sum и счётчик
sum = 0
i = 1
while i <= n:
sum = sum + i
i = i+1 # обновляем счётчик
# выводим на печать значение sum
print("The sum is", sum)
Вот вывод для наших предыдущих трёх примеров:
Positive number
The sum is 83
The sum is 55
>>>
Функции Python объявляются при помощи ключевого слова def:
def my_function():
print("это некая функция")
Для запуска функции воспользуйтесь её названием со следующими за ним скобками:
>>> my_function()
это некая функция
Параметры должны определяться после самого названия функции, внутри скобок:
def my_function(x):
print(x * 1234)
>>> my_function(7)
8638
Множество параметров необходимо разделять запятой:
def my_function(x,y):
print(x*5+ 2*y)
>>> my_function(7,9)
53
Для определения значения по умолчанию пользуйтесь символом равенства. Когда вы вызываете такую функцию без этого параметра, будет применено установленное по умолчанию значение:
def my_function(x,y=10):
print(x*5+ 2*y)
>>> my_function(1)
25
>>> my_function(1,100)
205
Значения параметров функции могут иметь любой тип данных (например, строку, число, список и словарь). Здесь в качестве
некого параметра для my_function применяется следующий список,
lcities:
def my_function(cities):
for x in cities:
print(x)
>>> lcities=["Napoli","Mumbai","Amsterdam"]
>>> my_function(lcities)
Napoli
Mumbai
Amsterdam
Для возврата некого значения из функции пользуйтесь оператором return:
def my_function(x,y):
return x*y
>>> my_function(6,29)
174
Python поддерживает интересный синтаксис, который позволяет вам задавать небольшие функции в одну строку прямо на лету. Имеющие своё происхождение из языка программирования Lisp, такие лямбда функции могут применяться везде где требуется некая функция.
Некий пример лямбда функции, functionvar, демонстрируется следующим
образом:
# определения лямбда эквивалентно def f(x): return x + 1
functionvar = lambda x: x * 5
>>> print(functionvar(10))
50
Python поддерживает множество наследуемых классов. Условно (это не правило языка) частные переменные и методы
объявляются предшествующим двойным нижним подчёркиванием (__). Мы можем
назначать произвольные атрибуты (свойства) своим экземплярам класса, как это показано в нашем следующем примере:
class FirstClass:
common_value = 10
def __init__ (self):
self.my_value = 100
def my_func (self, arg1, arg2):
return self.my_value*arg1*arg2
# Строим некий первый экземпляр
>>> first_instance = FirstClass()
>>> first_instance.my_func(1, 2)
200
# Строим второй экземпляр FirstClass
>>> second_instance = FirstClass()
#проверяем common_value для обоих своих экземпляров
>>> first_instance.common_value
10
>>> second_instance.common_value
10
#Изменяем common_value для своего first_instance
>>> first_instance.common_value = 1500
>>> first_instance.common_value
1500
#Как вы можете отметить, значение common_value для second_instance не изменилось
>>> second_instance.common_value
10
# SecondClass наследуется из FirstClass.
# множество экземпляров объявляются следующим образом:
# class SecondClass (FirstClass1, FirstClass2, FirstClassN)
class SecondClass (FirstClass):
# The "self" argument is passed automatically
# and refers to the class's instance
def __init__ (self, arg1):
self.my_value = 764
print (arg1)
>>> first_instance = SecondClass ("hello PACKT!!!!")
hello PACKT!!!!
>>> first_instance.my_func (1, 2)
1528
Исключительные ситуации в Python управляются при помощи блоков try-except
(exception_name)
def one_function():
try:
# Деление на ноль вызывает исключительную ситуацию
10/0
except ZeroDivisionError:
print("Oops, error.")
else:
# Не было никакой исключительной ситуации, мы можем продолжить.
pass
finally:
# Этот код выполняется после того, как блок
# try..except уже был выполнен и все исключительные ситуации
# были обработаны, даже когда некая новая
# исключительная ситуация произошла в самом этом блоке.
print("We finished.")
>>> one_function()
Oops, error.
We finished
Внешние библиотеки импортируются при помощи import [library name].
В качестве альтернативы вы можете воспользоваться синтаксисом
from [library name] import [function name]
для импорта некой определённой функции. Вот некий образец:
import random
randomint = random.randint(1, 101)
>>> print(randomint)
65
from random import randint
randomint = random.randint(1, 102)
>>> print(randomint)
46
Чтобы позволить нам взаимодействовать с имеющейся файловой системой, Python предоставляет нам свою встроенную
функцию open. Данная функция вызывает открытие некого файла и возврат
файлового объекта. Последний делает для нас возможным выполнение различных операций с таким файлом, например,
чтение и запись. После того как мы заканчиваем взаимодействие с этим файлом, мы обязаны не забыть закрыть его при
помощи соответствующего метода file.close:
>>> f = open ('test.txt', 'w') # открываем необходимый файл для записи
>>> f.write ('first line of file \ n') # записываем в файл строку
>>> f.write ('second line of file \ n') # записываем в файл ещё однй строку
>>> f.close () # мы закрываем этот файл
>>> f = open ('test.txt') # повторно открываем этот файл на чтение
>>> content = f.read () # считываем всё содержимое из этого файла
>>> print (content)
first line of the file
second line of the file
>>> f.close () # закрываем этот файл
Охватывающий список является мощным инструментом для создания списков и манипуляций с ними. Они составляются из
некого выражения, за которым следует некий оператор for с последующими
нулём или более операторов if. Необходимый для охватывающего списка
синтаксис прост и выглядит так:
[expression for item in list]
Далее выполним следующее:
#Применяющий строки охватывающий список
>>> list_comprehension_1 = [ x for x in 'python parallel programming cookbook!' ]
>>> print( list_comprehension_1)
['p', 'y', 't', 'h', 'o', 'n', ' ', 'p', 'a', 'r', 'a', 'l', 'l', 'e', 'l', ' ', 'p', 'r', 'o', 'g', 'r', 'a', 'm', 'm', 'i', 'n', 'g', ' ', 'c', 'o', 'o', 'k', 'b', 'o', 'o', 'k', '!']
#Применяющий числа охватывающий список
>>> l1 = [1,2,3,4,5,6,7,8,9,10]
>>> list_comprehension_2 = [ x*10 for x in l1 ]
>>> print( list_comprehension_2)
[10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
Для выполнения некого сценария Python просто вызовите свой интерпретатор Pyton с последующим названием этого
сценария, в нашем случае Codeю Или, когда мы в другом рабочем каталоге,
тогда воспользуйтесь его полным адресом {Прим. пер.: или относительным}:
> python my_pythonscript.py
|
| Замечание |
|---|---|
|
Начиная с данного момента и далее, для каждого вызова некого сценария Python мы будем применять предыдущую
нотацию; то есть |
pip это инструмент, позволяющий нам выполнять поиск, выгрузку и установку пакетов
Python, поиск которых выполняется в установленном Python Package Index, который, в свою очередь, является неким
репозиторием, содержащим десятки тысяч написанных на Python пакетов. Это делает для нас возможным управление пакетами,
которые мы уже выгрузили, что позволяет нам обновлять и удалять их.
Установка pip
pip уже содержится в версиях Python ≥ 3.4 и ≥ 2.7.9. Чтобы проверить,
установлен ли уже этот инструмент, мы можем запустить такую команду:
C:\>pip
Когда pip уже установлен, эта команда отобразит нам значение установленной
версии.
Обновление pip
Также рекомендуется проверять что применяемая вами версия pip всегда
современна. Для её обновления мы можем воспользоваться такой командой:
C:\>pip install -U pip
Применение pip
pip поддерживает некую последовательность команд, которые позволяют нам, помимо
прочего, выполнять поиск(search), выгрузку (download),
установку (install), обновление (update) и
удаление (remove) пакетов.
Для установки PACKAGE, всего лишь вызовите такую команду:
C:\>pip install PACKAGE
Python предоставляет множество библиотек и инфраструктур, которые служат для удобства высоко производительных вычислений. Однако, выполнение параллельного программирования при помощи Python может быть достаточно коварным по причине GIL (Global Interpreter Lock, Глобальной блокировке интерпретатора).
На практике, большинство распространённых и наиболее широко применяемых интерпретаторов используют интерпретатор Python, CPython, разработанный на языке программирования C. Для интерпретатора CPython требуется GIL для сохраняющих поток (thread- safe) операций. Такое использование GIL подразумевает что вы подсчитываете глобальные блокировки всякий раз когда пытаетесь выполнить доступ к любому объекту Python, содержащемуся внутри потоков. Причём лишь один поток за раз способен выдать запрос на блокировку некого объекта Python или API C.
К счастью, дела не так плохи, потому что вне пределов этого царства GIL мы свободно можем использовать параллелизм. Эта категория содержит все те темы, которые мы обсудим с своих последующих главах, включая многопроцессность, распределённые вычисления и вычисления GPU.
Итак, Python в действительности не многопоточен. Однако что такое поток (thread)? Что такое процесс? В своём последующем разделе мы сделаем введение в эти два основополагающих понятия и то как они решаются в самом языке программирования Python. {Прим. пер.: с подробным обсуждением GIL можно ознакомиться в нашем переводе Полного руководства параллельного программирования на Python Куана Нгуена, вышедшей в ноябре 2018.}
Потоки (threads) можно сопоставлять с облегчёнными процессами, в отношении того, что они предлагают подобные процессам преимущества, однако не требуя обычных технологий взаимодействия процессов. Потоки позволяют вам делить основной поток исполнения программы на множество одновременно исполняющихся управлений течений (stream). В отличие от них процессы обладают своим собственным адресным пространством и своими собственными ресурсами. Они следуют тому, что взаимодействие между частями кода, исполняющимся в различных процессах, может иметь место только через надлежащие механизмы управления, включая конвейеры, код FIFO, обмен почтовыми сообщениями, разделяемые области памяти и передачу сообщений. Потоки (threads), с другой стороны, делают возможным создание одновременно выполняющихся частей своей программы, в которых каждая из частей может осуществлять доступ к тем же самым адресному пространству, переменным и константам.
Ниже приводится таблица, суммирующая основные отличия между потоками и процессами:
| Потоки | Процессы |
|---|---|
Совместно используют память |
Не разделяют память |
Запуск/ изменение менее затратны с точки зрения вычислений |
Запуск/ изменение затратны с точки зрения вычислений |
Требуют меньше ресурсов (облегчённые процессы) |
Требуют больше вычислительных ресурсов |
Нуждаются в механизмах синхронизации для корректной обработки данных |
Не требуется синхронизация памяти |
После краткого введения, мы, наконец, покажем как работают процессы и потоки.
В частности, мы бы желали сравнить значения времени последовательного, многопоточного и многопроцессного
исполнения нашей следующей функции, do_something, которая выполняет какие- то
базовые вычисления, содержащих построение списка выбираемых случайным образом целых (файл
do_something.py):
import random
def do_something(count, out_list):
for i in range(count):
out_list.append(random.random())
Далее имеется некая последовательная реализация (serial_test.py). Давайте
начнём с соответствующего импорта:
from do_something import *
import time
Обратите внимание, что мы импортировали модуль time, который будет применяться для оценки времени исполнения,
причём именно в этом экземпляре, а также последовательную реализацию нашей функции
do_something. size списка для построения
равен 10000000, в то время как сама функция
do_something будет исполнена 10 раз:
if __name__ == "__main__":
start_time = time.time()
size = 10000000
n_exec = 10
for i in range(0, exec):
out_list = list()
do_something(size, out_list)
print ("List processing complete.")
end_time = time.time()
print("serial time=", end_time - start_time)
Далее у нас имеется надлежащая многопоточная реализация (multithreading_test.py).
Импортируем соответствующие библиотеки:
from do_something import *
import time
import threading
Обратите внимание на импортируемый модуль threading для работы с многопоточными
возможностями в Python.
Здесь у нас присутствует многопоточное исполнение нашей функции do_something.
Мы не более более глубоко комментировать все инструкции из своего следующего кода, так как они более подробно
обсуждаются в Главе 2, Параллельность на основе потоков.
Однако, следует заметить, что в данном случае, также, длина получаемого списка очевидно та же самая, что и в
нашем последовательном варианте, size = 10000000, в то время как число потоков
задаётся равным 10, threads = 10, что
также является числом исполнений нашей функции do_something:
if __name__ == "__main__":
start_time = time.time()
size = 10000000
threads = 10
jobs = []
for i in range(0, threads):
Также обратите внимание на построение нашего отдельного потока через вызов метода
threading.Thread:
out_list = list()
thread = threading.Thread(target=list_append(size,out_list))
jobs.append(thread)
Та последовательность циклов, в которой мы запускаем выполнение потоков, а затем останавливаем их сразу впоследствии, выглядит так:
from do_something import *
import time
import threading
Наконец, присутствует реализация множества процессов (multiprocessing_test.py).
Мы стартуем с импорта необходимых модулей, в частности, multiprocessing,
свойства которого мы глубоко обсуждаем в Главе 3, Параллельность на основе
процессов:
from do_something import *
import time
import multiprocessing
Как и в предыдущих случаях, общая длина списка построения, значение size,
а также число выполнений функции do_something остаются теми же самыми
(procs = 10):
if __name__ == "__main__":
start_time = time.time()
size = 10000000
procs = 10
jobs = []
for i in range(0, procs):
out_list = list()
В этом случае реализация некого отдельного процесса через вызов метода
multiprocessing.Process задействована так:
process = multiprocessing.Process\
(target=do_something,args=(size,out_list))
jobs.append(process)
Далее та последовательность циклов, в которых мы запускаем исполнение процессов и затем сразу после этого останавливаем их выполнение выглядит следующим образом:
for j in jobs:
j.start()
for j in jobs:
j.join()
print ("List processing complete.")
end_time = time.time()
print("multiprocesses time=", end_time - start_time)
После этого мы открываем свою командную оболочку и запускаем все три описанные ранее функции.
Перейдём в ту папку, куда мы скопировали эти функции и затем наберём следующее:
> python serial_test.py
Тот результат, который мы получили в машине со следующими характеристиками - ЦПУ Intel i7/8 ГБ ОЗУ, выглядит так:
List processing complete.
serial time= 25.428767204284668
В случае реализации multithreading мы имеем следующее:
> python multithreading_test.py
С последующим выводом:
List processing complete.
multithreading time= 26.168917179107666
Наконец, имеется реализация multiprocessing:
> python multiprocessing_test.py
Её результат таков:
List processing complete.
multiprocesses time= 18.929869890213013
Как мы можем видеть, полученные результаты нашей последовательной реализации (то есть,
применения serial_test.py) аналогичны результатам, полученным в
реализации со множеством потоков (при помощи multithreading_test.py), в которой
на самом деле потоки запускаются один вслед за другим, отдавая приоритет одному над другим до конца, в то время как у
нас имеется преимущество в терминах времени исполнения при применении возможностей множества потоков
(через multiprocessing_test.py).