Глава 6. Распределённый Python
Содержание
Данная глава предоставит введение в некоторые важные модули Python для распределённых вычислений. В частности,
мы опишем модуль socket, который позволяет вам реализовывать простые приложения,
распределяемые посредством модели клиент- сервер.
Затем мы сделаем введение в модуль Celery, который является мощной
инфраструктурой Python, которая используется для управления распределёнными задачами. Наконец, мы опишем модуль
Pyro4, позволяющий вам вызывать методы, которые используются в различных процессах, причём
потенциально в различных машинах.
В этой главе мы рассмотрим такие рецепты:
-
Введение в распределённое программирование
-
Применение модуля Python
socket -
Управление распределённой задачей при помощи
Celery -
Вызов удалённого метода (RMI) с применением
Pyro4
Параллельное и распределённое вычисления являются схожими технологиями, разработанными для увеличения общей вычислительной мощности, доступной для определённой задачи. Обычно эти методы используются для решения задач, которым требуются большие вычислительные возможности.
Когда ваша задача разделяется на множество частей меньшего размера, индивидуальные разделы этой задачи могут одновременно вычисляться большим числом процессоров. Это даёт возможность задействовать больше процессорной мощности над задачей, которая может быть предоставлена какому- то отдельному процессору.
Основное отличие между параллельной и распределённой обработкой состоит в том, что параллельные конфигурации множество процессоров внутри некой отдельной системы, в то время как распределённые конфигурации эксплуатируют одновременно процессорную мощность многих компьютеров.
Давайте посмотрим на имеющиеся другие различия:
| Параллельная обработка | Распределённая обработка |
|---|---|
Параллельная обработка имеет то преимущество, что предоставляет надёжную вычислительную мощность с очень низкой степенью латентности. |
Распределённая обработка не является чрезвычайно действенной на основе взаимодействия процессор- процессор, поскольку их данные должны путешествовать по имеющейся сетевой среде вместо того чтобы проходить по внутренним подключениям в некой отдельной системе. |
Сосредотачивая всю вычислительную мощность в одной системе, сводятся к минимуму обусловленные передачей данных потери в скорости. |
Каждый процессор будет вносить намного меньше вычислительной мощности чем любой процессор в параллельной системе, поскольку обмен данными создаёт узкие места, ограничивающие вычислительную мощность. |
Единственным реальным ограничением выступает общее число процессоров, содержащихся в такой системе. |
Система почти неограниченно масштабируется так как нет практического верхнего ограничения на общее число процессоров для некой распределённой системы. |
Однако, в контексте вычислительных приложений, обычно различают локальные и распределённые архитектуры:
| Локальные архитектуры | Распределённые архитектуры |
|---|---|
Все необходимые компоненты находятся в одной и той же машине. |
Приложения и компоненты могут располагаться в различных узлах, которые соединены некой сетевой средой. |
Основные преимущества использования распределённых вычислений состоят в основном из возможности одновременного исполнения необходимых программ, имеющейся централизации их данных, а также распределения вычислительной нагрузки, причём всё это происходить за счёт большей сложности, в частности в отношении взаимодействия между различными компонентами.
Распределённые приложения можно классифицировать согласно степени распределения:
-
Клиент- серверные приложения
-
Приложения со множеством уровней
Существует всего лишь два уровня тех операций, которые целиком обслуживаются в вашем сервере. В качестве примера мы можем упомянуть классические статические и динамические вебсайты. Основными инструментами для реализации таких видов приложений являются именно сетевые сокеты, программирование которых возможно на различных языках, включая C, C ++, Java и, конечно же, Python.
Терминология клиент- серверной системы относится к некой сетевой архитектуре, в которой компьютер или терминал клиента подключается к некому серверу для использования определённой службы; например, совместно с прочими клиентами использовать определённый аппаратный/ программного ресурса, или полагаться на лежащую в основе архитектуру протокола.
Клиент- серверная архитектура
Клиент- серверная архитектура это система, которая реализует распределение как обработки, так и самих данных. Основным центральным элементом выступает сервер. Понятие сервера можно рассматривать как с логической, так и с физической точки зрения. С физической точки зрения - аппаратных средств - сервер выступает как машина, посвящённая исполнению серверного программного обеспечения.
С логической точки зрения сервер это программное обеспечение. Сам сервер, в качестве некого логического процесса, предоставляет услуги прочим процессам, которые выступают в роли запрашивающей стороны или клиента. Обычно сам сервер не отправляет свои результаты запрашивающей стороне пока эти результаты не будут затребованы его клиентом.
Некое свойство, которое достигается клиентом от его сервера состоит в том, что этот клиент способен инициировать некую транзакцию со своим сервером, в то время как сам сервер может никогда не инициировать транзакции со своими клиентами по собственно инициативе:
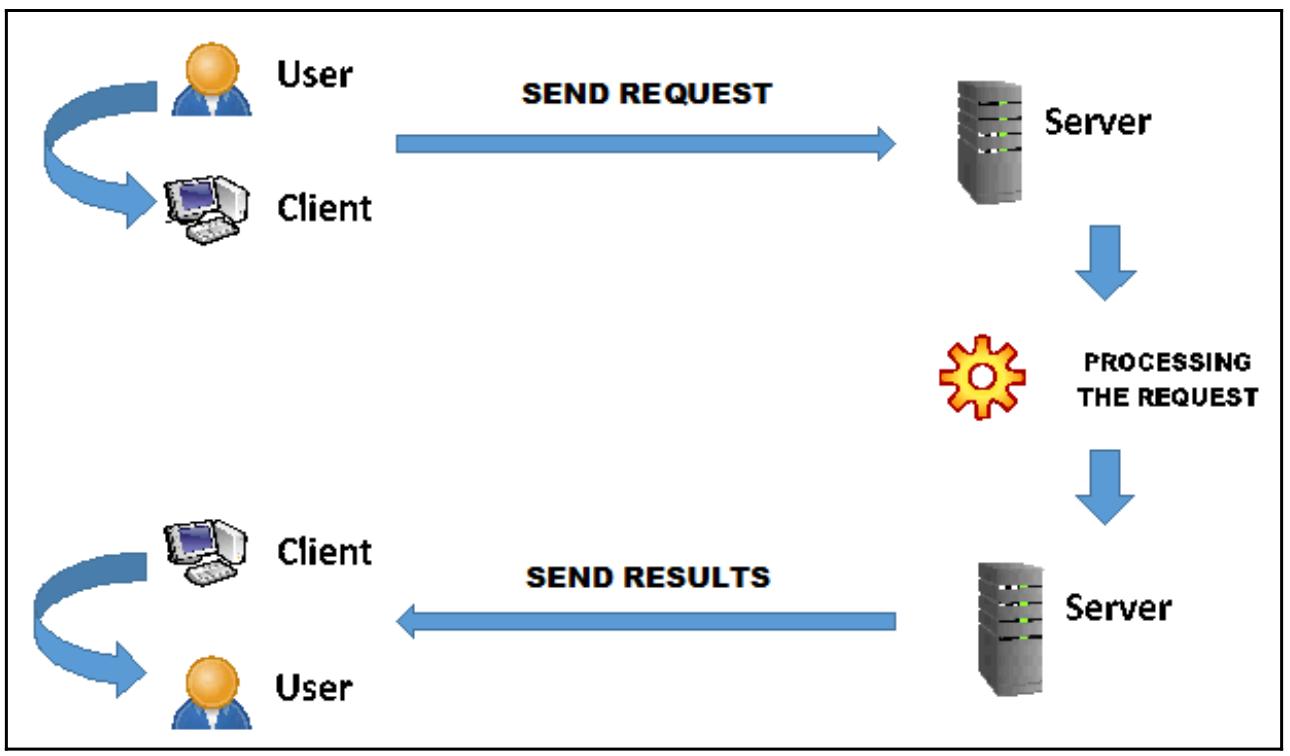
Фактически, основными специфическими задачами самого клиента являются запуск транзакций, запрос конкретной услуги, получение уведомления о завершении запрошенной услуги и получении результатов от своего сервера, как это показано на предыдущей схеме.
Взаимодействие клиент- сервер
Взаимодействие между клиентами и серверами может иметь место с применением различных механизмов - начиная с географически распределённых и локальных сетевых сред, вплоть до услуг коммуникации - между приложениями на уровне своей ОС. Более того, некая клиент- серверная архитектура должна быть независимой от того метода физического подключения, которое существует между рассматриваемым им клиентом и сервером.
Также следует отметить, что для процесса клиент- сервер нет необходимости располагаться в физически разрозненных системах. На самом деле, рассматриваемые процессы сервера и клиента могут располагаться в одной и той же вычислительной платформе.
Основным предметом в рассматриваемой архитектуре клиент- сервера, в плане управления данными, является предоставление приложениям клиента возможности доступа к управляемым его сервером сведениям. Такой сервер (понимаемый в неком логическом смысле как программное обеспечение) часто работает в некой удалённой системе (например, в другом городе или не в локальной сети).
Таким образом, клиент- серверные приложения часто ассоциируются с распределённой обработкой.
Архитектура TCP/IP клиент- сервер
Соединение TCP/IP устанавливает подключение точка- точка между двумя приложениями. Окончания этого соединения помечены неким IP адресом, который указывает необходимую рабочую станцию по номеру порта, который делает возможным наличие некоторого числа подключений, которые соединяются с различными приложениями в одной и той же рабочей станции.
После того как такое подключение установлено и имеющийся протокол может выполнять через него обмен данными, лежащий в его основе протокол TCP/IP заботится об отправке таких данных, разделяя их на пакеты, с одной стороны соединения к другой. В частности, протокол TCP имеет дело со сборкой и разборкой таких пакетов, а также с управлением взаимодействием (handshaking), которое обеспечивает надёжность самого соединения, в то время как протокол IP заботится о транспортировке всех индивидуальных пакетов и необходимом выборе наилучшего маршрута своих пакетов внутри имеющейся сетевой среды.
Такой механизм, составляет основу надёжности данного протокола TCP/IP, что, в свою очередь, представляет собой одну из причин развития самого этого протокола в военной сфере (ARPANET).
В различных имеющихся стандартных приложениях (таких как веб- просмотр, файловый обмен и обмен электронной почтой) применяют стандартизованные протоколы, например, HTTP, FTP, POP3, IMAP и SMTP.
Каждое клиент- серверное приложение должно вместо этого определять и применять свой собственный частный протокол приложения. Он может включать в себя необходимый обмен данными в блоках с фиксированным размером (что является самым простым решением)
{Прим. пер.: В современных системах, требующих максимально возможной скорости обмена, предоставляемой каналом связи, всё чаще вместо протокола IP в сетевых средах применяются другие протоколы, обладающие более высокой пропускной способностью, например UDP или RDMA. По большому счёту, всё излагаемое здесь применимо и к ним. Например.}
Существует большое число уровней, которые делают возможной облегчение обработки нагрузки на свои серверы. Они на практике подразделяют необходимую функциональность стороны сервера, не трогая характеристики своей части клиента, которая имеет свою задачу размещения интерфейса приложения в основном неизменной. Неким примером такого вида архитектуры является приводимая трёхуровневая модель, обладающая структурой, подразделяющейся на три слоя уровней:
-
Лицевая сторона или уровень представления, или интерфейс
-
Средний уровень или логика приложения
-
Часть основы или уровень данных, или управление постоянными данными
Такой перечень является обычным для веб приложений. В более общем виде можно ссылаться на разделение на три уровня, которые применимы к любому программному приложению и которые таковы:
-
Presentation Layer (PL, уровень представления): Это часть визуализации самих данных (например, модели и управление выводом) необходимые для устанавливаемого интерфейса пользователя.
-
Business Logic Layer (BLL, уровень запроса бизнес логики): Это основная часть рассматриваемого приложения, которая определяет различные логические составляющие и их взаимоотношения независимо от доступных пользователю методов представления и сохраняемого в архивах.
-
Data Access Layer (DAL, уровень доступа к данным): Содержит всё что требуется для необходимого управления постоянными данными (естественно, системы управления базой данных {Прим. пер.: так в тексте, на практике это могут быть и системы управления метаданными файловой системы, например, или основанных на API S3/ Swift системах хранения объектов}.)
Эта глава будет представлять некоторые предлагаемые Python решения для реализации распределённых архитектур.
Мы начнём с описания модуля socket, при помощи которого мы сможем реализовать некие
образцы основополагающих моделей клиент- сервер.
Сокет представляет собой некий программный объект, который позволяет отправлять и получать данные между удалёнными хостами (через некую сетевую среду) или между локальными процессами, например, IPC (Inter-Process Communication, межпроцессное взаимодействие).
Сокеты были предложены в Беркли как чассть проекта BSD Unix. Они в точности базируются на основной модели управления ввода и вывода файлов Unix. На самом деле все операции открытия, чтения, записи и закрытия сокета происходят в точности так же как управление файлами Unix, с единственной разницей в том, что необходимо рассматривать параметры, пригодные для взаимодействия, такие как адреса, номера портов и протоколы.
Основной успех распространения технологии сокетов идёт в ногу с развитием Интернета. На самом деле, именно сочетание сокетов с Интернетом создало взаимодействие между машинами любого типа и/ или разбросанных по всему миру, невообразимо простым (по крайней мере по сравнению с прочими системами).
Модуль socket Python выставляет API C нижнего уровня для взаимодействия поверх
сетевой среды при помощи интерфейса сокета BSD
(сокращение от Berkeley Software Distribution).
Этот модуль содержит класс Socket, который содержит самые основные методы
для управления следующими задачами:
-
socket ([family [, type [, protocol]]]): строит сокеты при помощи таких аргументов:-
Значения адреса
family, которым может быть:AF_INET(значение по умолчанию),AF_INET6илиAF_UNIX -
Значение
typeсокета, которыми могут бытьSOCK_STREAM(значение по умолчанию),SOCK_DGRAMили возможно одна из прочих констант"AF_UNIX" -
Значение номера
protocol(которым обычно является нуль)
-
-
gethostname(): Возвращает текущее значение IP адреса этой машины. -
accept(): Возвращает такую пару значений (connиaddress), в которойconnвыступает объектом типа сокета (для отправки, получения данных в этом соединении), в то время какaddressэто значение адреса подключения к этому сокету с другой стороны данного соединения. -
bind(address): Ассоциирует данный сокет со значениемaddressсервера.![[Замечание]](/common/images/admon/note.png)
Замечание Этот метод исторически принимал пару параметров для значения адресов
AF_INETвместо отдельного кортежа. -
close(): Предоставляет возможность очистки данного соединения после того как взаимодействие с данным клиентом завершено. Такие сокеты закрываются и собираются сборщиком мусора. -
connect(address): Подключает некий удалённый сокет с каим- то адресом. Представление форматаaddressзависит от применяемого семейства адреса.
В нашем следующем примере применяемый сервер прослушивает установленный по умолчанию порт, а через соединение TCP/IP наш клиент отправляет в этот сервер данные и время установления подключения.
Вот реализация для server.py:
-
Импортируем относящиеся к делу модули Python:
import socket import time -
Создаём новый сокет применяя заданные адрес, тип сокета и номер протокола:
serversocket=socket.socket(socket.AF_INET,socket.SOCK_STREAM) -
Получаем название локальной машины (
host):host=socket.gethostname() -
Устанавливаем значение номера
port:port=9999 -
Подключаем (привязываем) свой сокет к
hostиport:serversocket.bind((host,port)) -
Ожидаем осуществления подключения по данному порту. Значение нашего параметра
5определяет максимальное число подключений в данной очереди. Это максимальное значение зависит от самой системы (обычно это5), а минимальное значение всегда0:serversocket.listen(5) -
Устанавливаем соединение:
while True: -
Затем принимается установленное соединение. Возвращаемым значением является некая пара (
conn,address), гдеconnэто новый объектsocket, который применяется для отправки и получения данных, аaddressэто адрес подключёния к данному сокету. После принятия создан некий новый сокет и он будет обладать собственным идентификатором. Этот новый сокет применяется только для определённого клиента:clientsocket,addr=serversocket.accept() -
На печать выводятся значения подключённых адреса и порта:
print ("Connected with[addr],[port]%s"%str(addr)) -
Выполняется оценка
currentTime:currentTime=time.ctime(time.time())+"\r\n" -
Наш следующий оператор отправляет данные в созданный сокет, возвращая общее число отправленных байт:
clientsocket.send(currentTime.encode('ascii')) -
Наш следующий оператор указывает на закрытие сокета (то есть канала взаимодействия); все последующие операции с этим сокетом будут завершаться отказом. Все сокеты автоматически закрываются после того как они отвергнуты, но всегда рекомендуется закрывать их такой операцией
close():clientsocket.close()
Следующий код служит для нашего клиента (client.py):
-
Импортируем библиотеку
socket:import socket -
Далее создаётся объект
socket:s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) -
Получаем название своей локальной машины (
host):host=socket.gethostname() -
Настраиваем значение номера
port:port=9999 -
Устанавливаем соединение с
hostиport:s.connect((host,port))Замечание Максимальное значение байт, которые могут быть приняты не может превышать 1 024 байт (
tm=s.recv(1024)). -
Теперь закрываем своё соединение и в самом конце выводим на печать время данного подключения к серверу:
s.close() print ("Time connection server:%s"%tm.decode('ascii'))
Клиенты и серверы создают свои собственные соответствующие сокеты и наш сервер выполняет в нём ожидание для некого порта. Наш клиент выполняет запрос на подключение к своему серверу. Следует отметить, что мы можем иметь два различных номера порта, так как один может быть выделен только для исходящего обмена, а другой может быть выделен только на вход. Это зависит от настроек самого хоста.
Естественно, значение локального порта клиента не должно совпадать со значением удалённого порта его сервера. Наш сервер получает соответствующий запрос и, если он принимается, создаётся новое соединение. Теперь наши клиент и сервер взаимодействуют через некий виртуальный канал между этим сокетом и его сервером, который создан специально для потока данных подключённого сокета.
В соответствии с тем, что мы упоминали на самом первом этапе, наш сервер создаёт свой сокет данных, так как он применяется исключительно для запросов управления. Таким образом, имеется возможность того, чтобы имелось множество клиентов, взаимодействующих с этим сервером при помощи созданного для них сокета сервера. Протокол TCP является ориентированным на соединение, что означает что когда больше не требуется взаимодействие, сам клиент сообщает об этом своему серверу и установленное подключение закрывается.
Для запуска нашего примера стартуем свой сервер:
C:\> python server.py
Затем запускаем своего клиента (в другом терминале Windows):
C:\> python client.py
Получаемый на стороне клиента результат должен выдавать отчёт о подключаемых значениях адреса
(addr) и порта (port):
Connected with[addr],[port]('192.168.178.11', 58753)
Однако на стороне сервера результат должен выглядеть как- то так:
Time connection server:Sun Mar 31 20:59:38 2019
С небольшими изменениями в своём предыдущем коде мы можем создать простое приложение клиент- сервер для файлового обмена. Наш сервер создаёт экземпляр сокета и ожидает подключения в этом экземпляре со стороны клиента. Подключившись к этому серверу, наш клиент начинает необходимый обмен данными.
Подлежащие передаче данные, которые содержатся в файле mytext.txt,
побайтно копируются и отправляются в свой сервер через вызов функции conn.send.
Этот сервер затем получает все данные и записывает их во второй файл, received.txt.
Исходный код для client2.py такой:
import socket
s =socket.socket()
host=socket.gethostname()
port=60000
s.connect((host,port))
s.send('HelloServer!'.encode())
with open('received.txt','wb') as f:
print ('file opened')
while True :
print ('receiving data...')
data=s.recv(1024)
if not data:
break
print ('Data=>',data.decode())
f.write(data)
f.close()
print ('Successfully get the file')
s.close()
print ('connection closed')
А это исходный код server2.py:
import socket
port=60000
s =socket.socket()
host=socket.gethostname()
s.bind((host,port))
s.listen(15)
print('Server listening....')
while True :
conn,addr=s.accept()
print ('Got connection from',addr)
data=conn.recv(1024)
print ('Server received',repr(data.decode()))
filename='mytext.txt'
f =open(filename,'rb')
l =f.read(1024)
while True:
conn.send(l)
print ('Sent',repr(l.decode()))
l =f.read(1024)
f.close()
print ('Done sending')
conn.send('->Thank you for connecting'.encode())
conn.close()
Типы сокетов
Мы можем различать следующие три типа сокетов, которые задаются режимом соединения:
-
Сокеты Stream: это ориентированные на соединение сокеты и они основываются на протоколах надёжного подключения, таких как TCP или SCTP.
-
Сокеты Datagram: Это не ориентированные на установление соединения сокеты и они основываются на быстром, но не дающим гарантии протоколе UDP.
-
Сырые сокеты (raw IP): Он обходит транспортный уровень и значение заголовка доступно на неком уровне самого приложения.
Сокеты потоков
Мы более подробно остановимся только на этом типе сокета. Будучи основанном на транспортном уровне такого протокола как TCP, он гарантирует надёжное, полнодуплексное и ориентированное на установление соединения взаимодействие с неким потоком байт переменной длины.
Взаимодействие через этот сокет состоит из следующих фаз:
-
Создание сокета: Клиенты и серверы создают свои соответствующие сокеты и сервер выполняет ожидание по некому порту. Так как такой сервер способен создавать множество подключений с различными клиентами (а также и с тем же самым), ему требуется некая очередь для обработки различных запросов.
-
Запрос на подключение: Имеющиеся клиенты отправляют запросы на соединение со своим сервером. Обратите внимание на то, что у нас могут быть различными номера портов, так как один может назначаться лишь для исходящего обмена, а другой на вход. Это зависит от установленных настроек самого хоста. Естественно, значение локального порта клиента не обязательно должно совпадать со значением порта его удалённого сервера. Установленный сервер получает соответствующий запрос и, если он принимается, создаётся некое новое соединение. На приводимой схеме значением порта сокета клиента выступает
8080, в то время как значением порта сервера является80. -
Взаимодействие: Теперь наши клиент и сервер взаимодействуют через некий виртуальный канал между созданным сокетом клиента и новым сокетом (со стороны сервера), созданным специально для необходимого потока данных: сокета данных. Как уже было упомянуто на самой первой фазе, наш сервер создаёт такой сокет данных, так как его первый сокет данных применяется исключительно для запросов управления. Таким образом становится возможным для работы с этим сервером множества клиентов, причём каждый с соответствующим сокетом данных, намеренно создаваемым для него сервером.
-
Закрытие соединения: Поскольку TCP является протоколом с установлением соединения, когда больше нет необходимости во взаимодействии, наш клиент сообщает об этом своему серверу, который открепляет его сокет данных.
Основные фазы взаимодействия через сокет потока сведены в следующую схему:
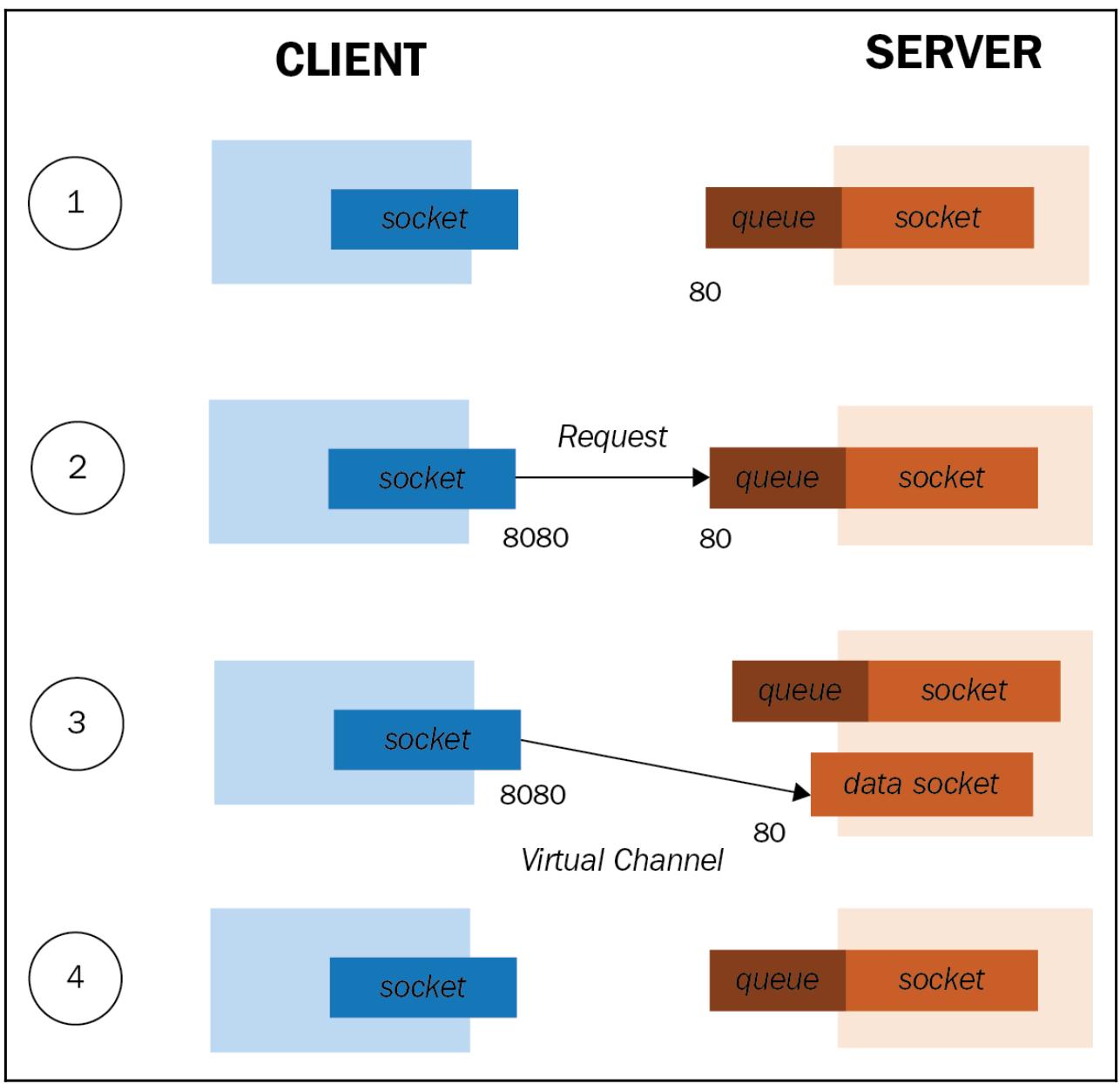
Дополнительные сведения о сокетах Python можно найти по следующей ссылке.
Celery является инфраструктурой Python, которая управляет распределёнными задачами
приводимым ниже объектно- ориентированным подходом программного обеспечения (ПО) среднего уровня. Его главная функциональность
состоит в обработке большого числа небольших задач и их распределения по многим вычислительным узлам. В конце концов,
получаемые каждой задачей результаты будут затем переработаны чтобы составить общее решение.
Для применения Celery требуется брокер сообщений. Это некий независимый (от Celery) программный компонент, который обладает функциональностью программного обеспечения промежуточного уровня и который используется для отправки и получения сообщений для распределения задач по исполнителям (workers).
На самом деле брокер сообщений - также именуемый промежуточным ПО сообщений - имеет дело с обменом сообщениями в некой сетевой среде взаимодействия: устанавливаемая для данного вида промежуточного ПО схема адресации больше не принадлежит к типу соединений точка- точка, а является ориентированной на сообщения.
Эталонная архитектура, в которой имеющийся брокер сообщений управляет их обменом, основана на так называемой концепции публикации, подписки, которая выглядит следующим образом:
Рисунок 6-3
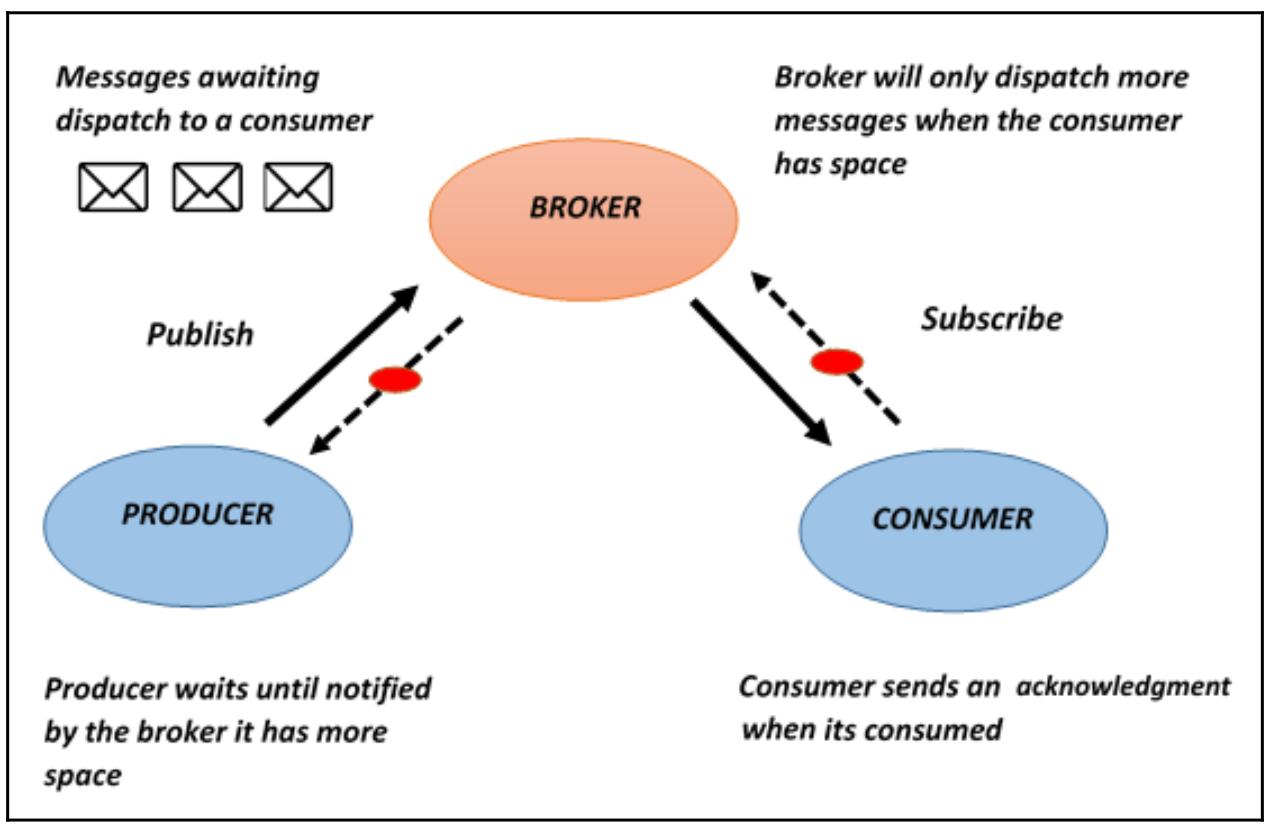
Архитектура брокера сообщений
Производитель дожидается от брокера уведомления, что у того имеется дополнительное свободное место
Сообщения дожидаются диспетчеризации для потребителя
Брокер отправляет дополнительные сообщения только когда у потребителя имеется свободное место
Потребитель отправляет подтверждения после поглощения сообщений
Celery поддерживает множество видов брокеров. Однако наиболее совершенными являются RabbitMQ и Redis.
Для инсталляции Celery воспользуйтесь установщиком pip следующим образом:
C:\> pip install celery
Затем необходимо установить брокера сообщений. Имеются доступными несколько возможностей, однако для нашего примера мы рекомендуем установить RabbitMQ со следующей ссылки.
|
| Замечание |
|---|---|
|
RabbitMQ является ПО промежуточного уровня для обмена сообщениями, который реализует протокол AMQP (Advanced Message Queuing Protocol). Сам сервер RabbitMQ написан на языке программирования Erlang, поэтому для его установки вам потребуется установить и Erlang, выгрузив его со ссылки. |
Необходимые шаги таковы:
-
Для проверки правильности установки
celeryвначале запустите необходимый брокер сообщений (например, RabbitMQ). А затем наберите следующее:C:\> celery --version -
Приводимый ниже вывод указывает какая именно версия
celeryустановлена:4.2.2 (Windowlicker)
Далее мы изучим как создавать некую задачу при помощи модуля celery.
celery предоставляет для вызова задачи два таких метода:
-
apply_async(args[, kwargs[, ...]]): Он отправляет некое сообщение с задачей. -
delay(*args, **kwargs): Это сокращение для отправки некого сообщения с задачей, однако оно само по себе не сопровождает вариант исполнения.Замечание Метод
delayпроще применять, так как он вызывается как обычная функция:task.delay(arg1, arg2, kwarg1='x', kwarg2='y'). В то время как дляapply_asyncсинтаксис таков:task.apply_async(args=[arg1,arg2] kwargs={'kwarg1':'x','kwarg2': 'y'}).
Установка Windows
Для использования Celery в среде Windows, вы должны выполнить такие процедуры:
-
Проследовать в System Properties | Environment Variables | User or System variables | New.
-
Установить следующие значения:
-
Имя переменной:
FORKED_BY_MULTIPROCESSING -
Значение переменной:
1
-
Основной причиной для данной установки выступает зависимость Celery от пакета billiard, который
пользуется переменной FORKED_BY_MULTIPROCESSING.
Для дополнительных сведений относительно установки Celery в Windows ознакомьтесь со следующими материалами.
Наша задача состоит в суммировании двух чисел. Для осуществления этой простой задачи нам придётся скомпоновать
файлы сценариев addTask.py и addTask_main.py.
-
Для
addTask.pyмы начинаем с импорта инфраструктуры Celery:from celery import Celery -
Далее определяем саму задачу. В нашем примере это сумма двух чисел:
app = Celery('tasks', broker='amqp://guest@localhost//') @app.task def add(x, y): return x + y -
Теперь импортируем файл
addTask.py, который был определён ранее вaddtask_main.py:import addTask -
После этого вызываем
addTask.pyдля нахождения суммы двух чисел:if __name__ == '__main__': result = addTask.add.delay(5,5)
Чтобы применять Celery, прежде всего требуется запустить службу RabbitMQ, а затем запустить сервер исполнения
Celery (то есть наш файл сценария addTask.py), набрав следующее:
C:\> celery -A addTask worker --loglevel=info
Вывод будет примерно таким:
Microsoft Windows [Versione 10.0.17134.648]
(c) 2018 Microsoft Corporation. Tutti i diritti sono riservati.
C:\Users\Giancarlo>cd C:\Users\Giancarlo\Desktop\Python Parallel Programming CookBook 2nd edition\Python Parallel Programming NEW BOOK\chapter_6 - Distributed Python\esempi
C:\Users\Giancarlo\Desktop\Python Parallel Programming CookBook 2nd edition\Python Parallel Programming NEW BOOK\chapter_6 - Distributed Python\esempi>celery -A addTask worker --loglevel=info
-------------- celery@pc-giancarlo v4.2.2 (windowlicker)
---- **** -----
--- * *** * -- Windows-10.0.17134 2019-04-01 21:32:37
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x1deb8f46940
- ** ---------- .> transport: amqp://guest:**@localhost:5672//
- ** ---------- .> results: disabled://
- *** --- * --- .> concurrency: 4 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. addTask.add
[2019-04-01 21:32:37,650: INFO/MainProcess] Connected to amqp://guest:**@127.0.0.1:5672//
[2019-04-01 21:32:37,745: INFO/MainProcess] mingle: searching for neighbors
[2019-04-01 21:32:39,353: INFO/MainProcess] mingle: all alone
[2019-04-01 21:32:39,479: INFO/SpawnPoolWorker-2] child process 10712 calling self.run()
[2019-04-01 21:32:39,512: INFO/SpawnPoolWorker-3] child process 10696 calling self.run()
[2019-04-01 21:32:39,536: INFO/MainProcess] celery@pc-giancarlo ready.
[2019-04-01 21:32:39,551: INFO/SpawnPoolWorker-1] child process 6084 calling self.run()
[2019-04-01 21:32:39,615: INFO/SpawnPoolWorker-4] child process 2080 calling self.run()
Затем при помощи Python запускается второй сценарий:
C:\> python addTask_main.py
Наконец, в своём первом приглашении Командной строки мы получаем следующий результат:
[2019-04-01 21:33:00,451: INFO/MainProcess] Received task: addTask.add[6fc350a9-e925-486c-bc41-c239ebd96041]
[2019-04-01 21:33:00,452: INFO/SpawnPoolWorker-2] Task addTask.add[6fc350a9-e925-486c-bc41-c239ebd96041] succeeded in 0.0s: 10
Как вы можете видеть, полученным результатом является 10. Давайте
сосредоточимся на своём первом сценарии, addTask.py: в первых двух строках
кода мы создали некий экземпляр приложения Celery, который использует
установленную службу брокера RabbitMQ:
from celery import Celery
app = Celery('addTask', broker='amqp://guest@localhost//')
Самым первым параметром в нашей функции Celery является название текущего
модуля (addTask.py), а вторым параметром выступает аргумент распределительного
щита брокера; он указывает значение URL, которое применяется для соединения с установленным брокером (RabbitMQ).
Теперь давайте введём подлежащую исполнению задачу.
Всякую задачу следует добавлять с помощью аннотации @app.task
(а именно, применяя декоратор); такой декоратор помогает Celery
определять какую именно функцию следует планировать в его очереди задач.
После такого декоратора мы создаём необходимую задачу, которую способны выполнять исполнители: это будет некая простая функция, которая вычисляет сумму двух чисел:
app.task
def add(x, y):
return x + y
В своём втором сценарии, addTask_main.py, мы вызываем нашу задачу с помощью
метода delay():
if __name__ == '__main__':
result = addTask.add.delay(5,5)
Напоминаем вам, что этот метод является закладкой для имеющегося метода apply_async(),
что предоставляет нам дополнительный контроль над исполнением нашей задачи.
Применение Celery очень простое. Для этого можно пользоваться такими командами:
Usage: celery <command> [options]
Вот её параметры:
positional arguments:
args
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
Global Options:
-A APP, --app APP
-b BROKER, --broker BROKER
--result-backend RESULT_BACKEND
--loader LOADER
--config CONFIG
--workdir WORKDIR
--no-color, -C
--quiet, -q
Основные команды следующие:
+ Main:
| celery worker
| celery events
| celery beat
| celery shell
| celery multi
| celery amqp
+ Remote Control:
| celery status
| celery inspect --help
| celery inspect active
| celery inspect active_queues
| celery inspect clock
| celery inspect conf [include_defaults=False]
| celery inspect memdump [n_samples=10]
| celery inspect memsample
| celery inspect objgraph [object_type=Request] [num=200 [max_depth=10]]
| celery inspect ping
| celery inspect query_task [id1 [id2 [... [idN]]]]
| celery inspect registered [attr1 [attr2 [... [attrN]]]]
| celery inspect report
| celery inspect reserved
| celery inspect revoked
| celery inspect scheduled
| celery inspect stats
| celery control --help
| celery control add_consumer <queue> [exchange [type [routing_key]]]
| celery control autoscale [max [min]]
| celery control cancel_consumer <queue>
| celery control disable_events
| celery control election
| celery control enable_events
| celery control heartbeat
| celery control pool_grow [N=1]
| celery control pool_restart
| celery control pool_shrink [N=1]
| celery control rate_limit <task_name> <rate_limit (e.g., 5/s | 5/m |
5/h)>
| celery control revoke [id1 [id2 [... [idN]]]]
| celery control shutdown
| celery control terminate <signal> [id1 [id2 [... [idN]]]]
| celery control time_limit <task_name> <soft_secs> [hard_secs]
+ Utils:
| celery purge
| celery list
| celery call
| celery result
| celery migrate
| celery graph
| celery upgrade
+ Debugging:
| celery report
| celery logtool
+ Extensions:
| celery flower
-------------------------------------------------------------
При помощи Webhooks протокол Celery можно реализовать в любом языке программирования.
-
Дополнительные сведения по Celery можно найти на странице его проекта.
-
Рекомендуемыми брокерами сообщений являются: RabbitMQ и Redis. Кроме того имеются MongoDB, Beanstalk, Amazon SQS, CouchDB и IronMQ.
-
{Прим. пер.: рекомендуем также свои переводы RabbitMQ для профессионалов Гайвина Роя, Manning Publications Co., сентябрь 2017; большого числа глав из Книга рецептов Redis 4.x Пеньчень Хуань, Зуофей Вань, Packt Publishing, февраль 2018; а также ряда глав из Практического программирование MQTT на Python Гастона К. Хайляра, Packt Publishing, май 2018 и Копирки для программирования на Python Даниеля Фуртейдо, Маркуса Пеннингтона, Packt Publishing, февраль 2018.}
Pyro это сокращение для Python Remote Objects. Он работает в точности как Java RMI (сокращение для Remote Method Invocation), позволяя вызывать некий метод какого- то удалённого объекта (относящегося к другому процессу) в точности как если бы такой объект был бы локальным (и относился бы к тому же самому процессу, в котором вызвано это исполнение).
Само применение механизма RMI для некой объектно- ориентированной системы сулит значительные преимущества унификации и симметричности в вашем проекте; так как такой механизм позволяет возможность моделирования взаимодействия между распределёнными процессами при помощи одного и того же концептуального инструментария.
Как вы можете увидеть на следующей схеме, Pyro4 делает возможным распределение
объектов в неком стиле клиент, сервер; это означает что основная часть системы Pyro4
может переключаться с какого- то вызывающего клиента на некий удалённый объект, который вызывается на обслуживание
какой- то функции:
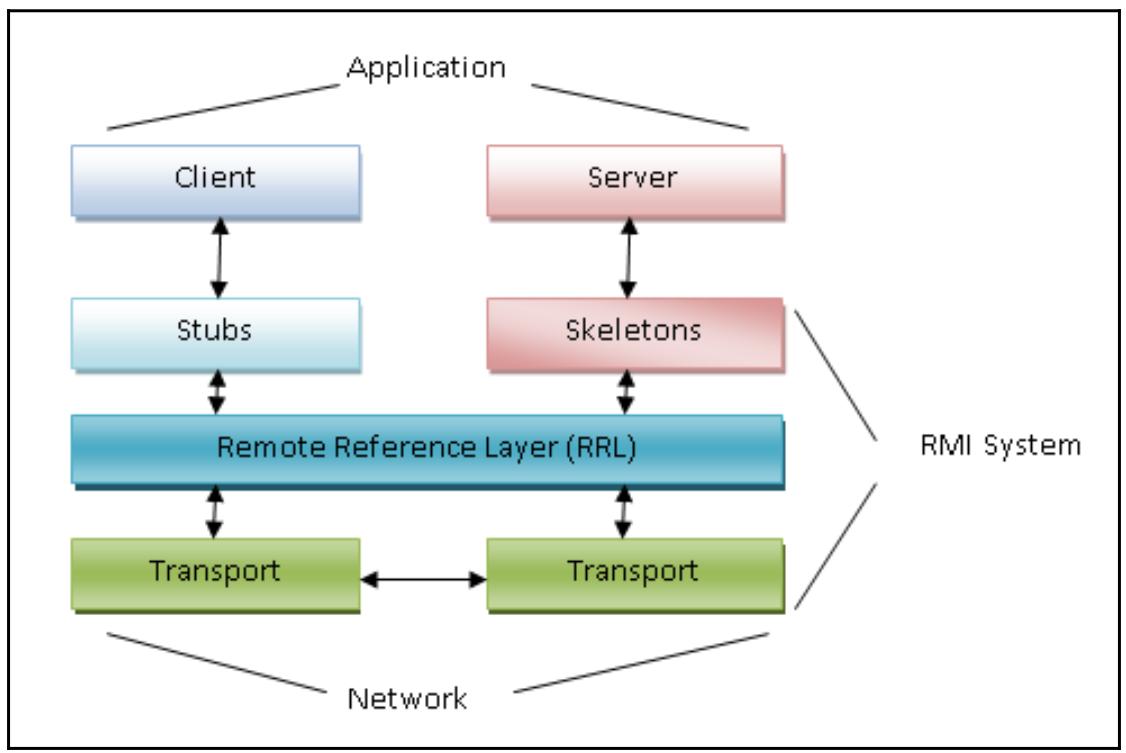
Важно отметить, что в процессе удалённого вызова существуют две различающиеся части: некий клиент и какой- то сервер, который принимает и выполняет вызов своего клиента.
Весь метод управления данным механизмом неким распределённым образом целиком предоставляется
Pyro4. Для установки самого последнего выпуска Pyro4
воспользуйтесь установщиком pip (в нашем случае применяется установка в Windows)
и добавьте такую команду:
C:\> pip install Pyro4
Для данного рецепта мы воспользуемся кодами pyro_server.py и
pyro_client.py.
В этом примере мы рассмотрим как построить и применить простейшее взаимодействие клиент- сервер с использованием
программного обеспечения (ПО) промежуточного уровня Pyro4. Вот код для
сервера pyro_server.py:
-
Импортируем библиотеку
Pyro4:import Pyro4 -
Определяем класс
Server, который содержит подлежащий выставлению методwelcomeMessage():class Server(object): @Pyro4.expose def welcomeMessage(self, name): return ("Hi welcome " + str (name))Замечание Обратите внимание на декоратор,
@Pyro4.expose, означающий что наш предыдущий метод будет доступен удалённо. -
Функция
startServerсодержит все инструкции, которые применяются для запуска необходимого сервера:def startServer(): -
Далее строим экземпляр
serverклассаServer:server = Server() -
После этого определяем демона
Pyro4:daemon = Pyro4.Daemon() -
Для выполнения данного сценария нам следует запустить некий оператор
Pyro4для определения местоположения некого сервера имён:ns = Pyro4.locateNS() -
Регистрируем свой объект сервера как
Pyro object; он будет известен только в демоне Pyro:uri = daemon.register(server) -
Теперь мы имеем возможность регистрации своего объекта сервера с неким именем в своём сервере имён:
ns.register("server", uri) -
Эта функция завершается вызовом метода
requestLoopустановленного демона. Это запускает необходимый цикл событий данного сервера и ожидания вызовов:print("Ready. Object uri =", uri) daemon.requestLoop() -
Наконец, вызываем
startServerчерез свою программуmain:if __name__ == "__main__": startServer()
Вот код для клиента pyro_client.py:
-
Импортируем библиотеку
Pyro4:import Pyro4 -
API библиотеки
Pyro4позволяет разработчику распределять объекты неким прозрачным образом. В данном примере наш сценарий клиента отправляет запросы в программу своего сервера для выполнения методаwelcomeMessage():uri = input("What is the Pyro uri of the greeting object? ").strip() name = input("What is your name? ").strip() -
Затем создаётся сам удалённый вызов:
server = Pyro4.Proxy("PYRONAME:server") -
Наконец, наш клиент вызывает свой сервер, выводя на печать сообщение:
print(server.welcomeMessage(name))
Наш предыдущий пример состоит из двух основных функций: pyro_server.py и
pyro_client.py.
В pyro_server.py объект класса Server
предоставляет свой метод welcomeMessage(), возвращающий некую строку,
идентичную значению имени, вставляемого в данном сеансе клиента:
class Server(object):
@Pyro4.expose
def welcomeMessage(self, name):
return ("Hi welcome " + str (name))
Pyro4 использует для диспетчеризации входящих вызовов по надлежащим
объектам объекты демонов. Некий сервер обязан создать лишь одного демона, который управляет всем из такого
экземпляра. Каждый сервер обладает демоном, которому известно обо всех имеющихся объектах Pyro, предоставляемых
этим сервером:
daemon = Pyro4.Daemon()
Что касается самой функции pyro_client.py, вначале выполняется необходимый
удалённый вызов и создаётся какой- то объект Proxy. В частности, клиент
Pyro4 применяет объекты посредников (прокси) для передачи вызовов методов
в необходимые удалённые объекты, а затем передаёт получаемые результаты обратно в код вызова:
server = Pyro4.Proxy("PYRONAME:server")
Для выполнения некого клиент- серверного соединения нам требуется иметь запущенным некий сервер имён
Pyro4. В приглашении командной строки наберите следующее:
C:\> python -m Pyro4.naming
После этого вы обнаружите такое сообщение:
Not starting broadcast server for localhost.
NS running on localhost:9090 (127.0.0.1)
Warning: HMAC key not set. Anyone can connect to this server!
URI = PYRO:Pyro.NameServer@localhost:9090
Наше предыдущее сообщение означает, что данный сервер имён запуще в вашей сетевой среде. Наконец, мы можем запустить свой сервер и необходимые сценарии клиентов в двух отдельных консолях Windows:
-
Чтобы запустить
pyro_server.pyпросто наберите:C:\> python pyro_server.py -
Вслед за этим вы обнаружите нечто такое:
Ready. Object uri = PYRO:obj_76046e1c9d734ad5b1b4f6a61ee77425@localhost:63269 -
Затем запустите клиента набрав:
C:\> python pyro_client.py -
На печать будет выведено сообщение:
What is your name? -
Вставьте некое имя, например,
Ruvika:What is your name? Ruvika -
Будет отображено следующее сообщение:
Hi welcome Ruvika
Помимо самих функциональных возможностей Pyro4, также существует необходимость
создания топологий объектов. Например, давайте предположим что мы желаем построить некую распределённую архитектуру,
которая следует какой- то цепной топологии, как показано ниже:
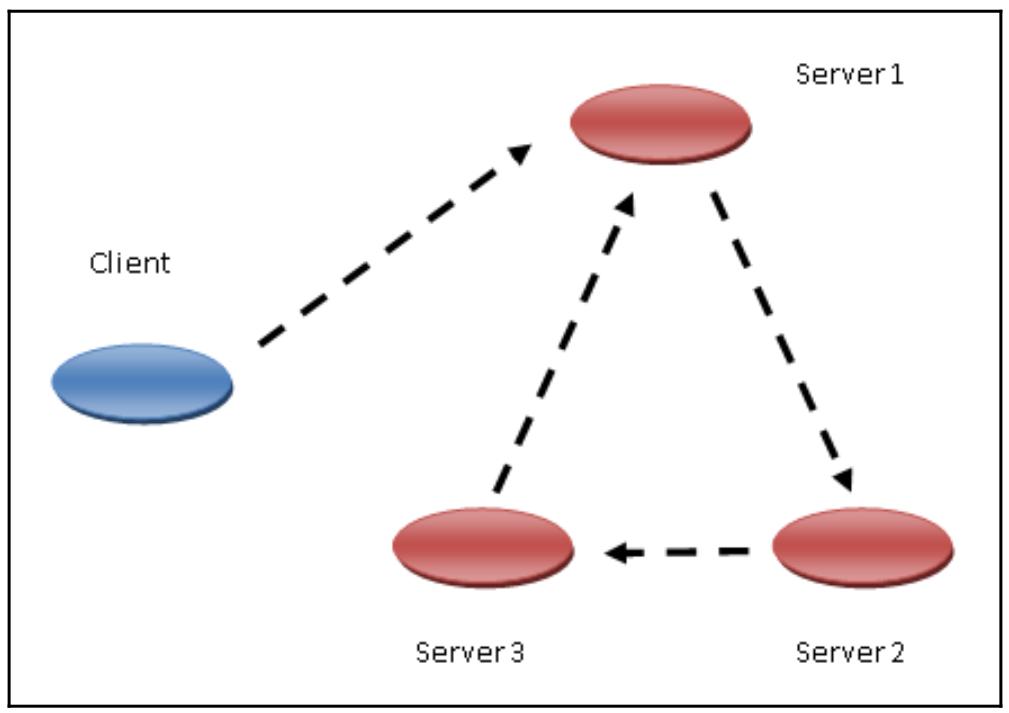
Наш клиент выполняет запрос к Server 1, а далее запрос отправляется к Server 2, который после этого вызывает Server 3. Данная цепь вызовов завершается когда Server 3 вызывает Server 1.
Реализация топологии цепочки
Для реализации некой цепной технологии с помощью Pyro4, нам требуется
реализовать какой- то объект chain, а также объекты
client и server. Класс
Chain делаем возможным перенаправление вызова к следующему серверу в
последовательности путём обработки входного сообщения и перестройки установленного адреса сервера к которому следует
адресовать данный запрос.
Также обратите внимание, что в данном случае применяется декоратор @Pyro4.expose,
который позволяет выставление всех методов данного класса (chainTopology.py):
import Pyro4
@Pyro4.expose
class Chain(object):
def __init__(self, name, next_server):
self.name = name
self.next_serverName = next_server
self.next_server = None
def process(self, message):
if self.next_server is None:
self.next_server = Pyro4.core.Proxy("PYRONAME:example.\
chainTopology." + self.next_serverName)
Когда цепочка закрывается (выполняется самый последний вызов от server_chain_3.py
к server_chain_1.py), тогда на печать выводится вызвавшее закрытие
сообщение:
if self.name in message:
print("Back at %s;the chain is closed!" % self.name)
return ["complete at " + self.name]
Переправлямое сообщение выводится на печать когда в данной цепи имеется некий следующий элемент:
else:
print("%s forwarding the message to the object %s" %\
(self.name, self.next_serverName))
message.append(self.name)
result = self.next_server.process(message)
result.insert(0, "passed on from " + self.name)
return result
Далее у нас имеется исходный код для нашего клиента (client_chain.py):
import Pyro4
obj = Pyro4.core.Proxy("PYRONAME:example.chainTopology.1")
print("Result=%s" % obj.process(["hello"]))
Вслед за этим имеется исходный код для нашего первого сервера (server_1)
в данной цепи, который вызывается из нашего клиента (server_chain_1.py). Здесь
импортируются относящиеся к делу библиотеки. Обратите внимание на файл chainTopology.py,
который был описан ранее.
import Pyro4
import chainTopology
Также отметим что наш исходный код для всех серверов отличается только в отношении самих определений текущего и следующего серверов из общей цепи:
current_server= "1"
next_server = "2"
Остальные строки кода определяют необходимое взаимодействие со следующем элементом в общей цепи:
servername = "example.chainTopology." + current_server
daemon = Pyro4.core.Daemon()
obj = chainTopology.Chain(current_server, next_server)
uri = daemon.register(obj)
ns = Pyro4.locateNS()
ns.register(servername, uri)
print("server_%s started " % current_server)
daemon.requestLoop()
Для исполнения данного примера вначале запускаем необходимый сервер имён Pyro4:
C:\> python -m Pyro4.naming
Not starting broadcast server for localhost.
NS running on localhost:9090 (127.0.0.1)
Warning: HMAC key not set. Anyone can connect to this server!
URI = PYRO:Pyro.NameServer@localhost:9090
Запускаем свои три сервера в трёх различных терминальных окнах, набирая каждый из них соответствующим образом (в нашем случае применяются терминалы Windows).
Самый первый сервер (server_chain_1.py) расположен в первом терминале:
C:\> python server_chain_1.py
Вслед за ним второй сервер (server_chain_2.py) во втором терминале:
C:\> python server_chain_2.py
И, наконец, третий сервер (server_chain_3.py) в третьем терминале:
C:\> python server_chain_3.py
После этого ещё в одном терминале запускаем сценарий client_chain.py:
C:\> python client_chain.py
Это приводит к такому выводу в приглашении его Командной строки:
Result=['passed on from 1','passed on from 2','passed on from 3','complete at 1']
Предыдущее сообщение отображается как результат передачи запроса по трё м серверам после того как они возвращают
тот факт, что задача для server_chain_1 завершена.
Кроме того мы сосредоточимся на поведении самих объектов серверов в процессе передачи ими запроса в свой следующий в цепи объект (отсчитывая со стартового сообщения):
-
Запускается
server_1и его сообщение передаётся вserver_2:server_1 started 1 forwarding the message to the object 2 -
server_2передаёт сообщение вserver_3:server_2 started 2 forwarding the message to the object 3 -
server_3передаёт сообщение вserver_1:server_3 started 3 forwarding the message to the object 1 -
Наконец, это сообщение возвращается в точку отправления (иными словами, в
server_1), закрывая данную цепочку:server_1 started 1 forwarding the message to the object 2 Back at 1; the chain is closed!
Документация Pyro4 доступна по ссылке.
Она содержит описание и некие примеры для выпуска 4.75.