Глава 3. Параллельность на основе процессов
Содержание
- Глава 3. Параллельность на основе процессов
- Основы модуля множественности процессов Python
- Порождение процесса
- Именование процесса
- Выполнение процессов в фоновом режиме
- Уничтожение процессов
- Определение процессов в неком подклассе
- Применение очереди для обмена данными
- Применение конвейеров для обмена объектами
- Синхронизация процессов
- Применение пула процессов
В своей предыдущей главе мы изучили как применять потоки для реализации одновременных приложений. Данная глава
изучит имеющийся подход на основе процессов, который был введён в Главе 1,
Приступая к параллельному программированию и Python. В особенности, в этой главе мы сосредоточимся на модуле
Python multiprocessing.
Модуль Python multiprocessing, который является частью стандартной библиотеки
самого языка, реализует парадигму программирования разделяемой памяти, то есть программирование некой системы, которая
состоит из одного или более процессоров, которые обладают доступом к некой
совместной памяти.
В этой главе мы рассмотрим следующие рецепты:
-
Основы модуля Python
multiprocessing -
Порождение некого процесса
-
Именование процесса
-
Запуск процесса в фоновом режиме
-
Уничтожение процесса
-
Определение процесса в каком- то подчинённом классе
-
Применение очереди для обмены объектами
-
Использование конвейеров для обмена объектами
-
Синхронизация процессов
-
Управление состояниыми процессов
-
Использование пула процессов
Во введении в документацию Python multiprocessing чётко указывается тот
факт, что вся имеющаяся внутри этого пакета функциональность требует того, чтобы модуль
main был доступен для импорта в его потомков (https://docs.python.org/3.3/library/multiprocessing.html).
Имеющийся в IDLE модуль __main__ не доступен для импорта в потомков, даже когда
он запускается как определённый сценарий в качестве файла в IDLE. Для получения необходимого правильного результата
мы будем запускать все свои примеры из приглашения Командной строки:
> python multiprocessing_example.py
Здесь multiprocessing_example.py является названием соотвествующего сценария.
Порождение некого процесса это собственно создание дочернего процесса из родительского процесса. Последний затем продолжает своё выполнение асинхронно или ожидает пока этот дочерний процесс не завершится.
Библиотека multiprocessing позволяет порождать процессы такой
последовательностью:
-
Определяем объект
process. -
Вызываем метод
start()того процесса, который его запускает. -
Вызываем метод
join()этого процесса. Он ожидает завершение соответствующего задания этого процесса и затем выполняем выход.
Давайте рассмотрим следующие шаги:
-
Для создания некого процесса нам требуется импортировать сам модуль
multiprocessingпри помощи такой команды:import multiprocessing -
Все процессы ассоциированы с определённой функцией
myFunc(i). Данная функция выводи числа от0доi, гдеiявляется тем идентификаторов, который ассоциирован самому номеру процесса:def myFunc(i): print ('calling myFunc from process n°: %s' %i) for j in range (0,i): print('output from myFunc is :%s' %j) -
Затем мы определяем необходимый объект
processсmyFuncв качестве функцииtarget:if __name__ == '__main__': for i in range(6): process = multiprocessing.Process(target=myFunc, args=(i,)) -
Наконец, мы вызываем необходимые методы
startиjoinв этом созданном процессе:process.start() process.join()
Без наличия такого метода join дочерний процесс не завершится и его потребуется
уничтожать вручную.
В этом разделе мы таким образом увидели как можно создавать процесс запуская некий дочерний процесс. Такая функциональность именуется порождением процесса (spawning a process).
Библиотека Python multiprocessing делает возможным простое управление следующими
тремя простыми шагами. Самый первый шаг состоит в определении самого процесса через метод класса
multiprocessing, Process:
process = multiprocessing.Process(target=myFunc, args=(i,))
Этот метод Process имеет некий параметр подлежащей порождению функции,
myFunc, а также все параметры внутри самой этой функции.
Следующие два шага необходимы для выполнения данного процесса и выхода из него:
process.start()
process.join()
Чтобы запустить необходимый процесс и отобразить его результаты, давайте откроем приглашение Командной строки,
причём предпочтительно в том же самом каталоге, который содержит наш фал примера
(spawning_processes.py) и затем наберём следующую команду:
> python spawning_processes.py
Для всех созданных процессов (их всего шесть) показывается получаемый вывод целевой функции. Помните, что это некий простейший счётчик от нуля до значения индекса установленного идентификатора процесса:
calling myFunc from process n°: 0
calling myFunc from process n°: 1
output from myFunc is :0
calling myFunc from process n°: 2
output from myFunc is :0
output from myFunc is :1
calling myFunc from process n°: 3
output from myFunc is :0
output from myFunc is :1
output from myFunc is :2
calling myFunc from process n°: 4
output from myFunc is :0
output from myFunc is :1
output from myFunc is :2
output from myFunc is :3
calling myFunc from process n°: 5
output from myFunc is :0
output from myFunc is :1
output from myFunc is :2
output from myFunc is :3
output from myFunc is :4
Это вновь напоминает нам о важности создания экземпляра необходимого объекта Process
внутри самого главного раздела: это происходит по той причине, что создаваемый дочерний процесс импортирует сам файл
сценария, который содержит необходимую функцию target. Затем, порождая
соответствующий объект process внутри этого блока, мы предотвращаем некий
бесконечный рекурсивный вызов такого порождения экземпляров.
Для задания самой функции target в каком- то ином сценарии применяется некий
допустимый обходной путь, а именно, myFunc.py:
def myFunc(i):
print ('calling myFunc from process n°: %s' %i)
for j in range (0,i):
print('output from myFunc is :%s' %j)
return
Сама программа main, содержащая экземпляр головного процесса определяется
в неком втором файле (target):
import multiprocessing
from myFunc import myFunc
if __name__ == '__main__':
for i in range(6):
process = multiprocessing.Process(target=myFunc, args=(i,))
process.start()
process.join()
Для запуска этого примера наберите следующую команду:
> python spawning_processes_names.py
Получаемый вывод будет тем же самым что и у нашего предыдущего примера.
Официальное руководство по этой библиотеке multiprocessing можно найти
по ссылке.
В своём предыдущем примере мы определили сам процесс и то, как передать некую переменную в целевую функцию. Однако очень полезно ассоциировать с таким процессом некое название, поскольку отладка некого приложения требует чтобы такой процесс был бы помечен и идентифицирован должным образом.
В некотором месте вашего кода может быть критически важным знать какой именно процесс исполняется в настоящий момент.
Для этой цели обсуждаемая нами библиотека multiprocessing предоставляет свой
метод current_process(), который применяет значение атрибута
name для определения того какой процесс исполняется в данный момент. В
своём следующем разделе мы рассмотрим эту тему.
Давайте выполним такие шаги:
-
Значением функции
targetдля обоих процессов выступает функцияmyFunc. Она выводит соответствующее название процесса вычисляя методmultiprocessing.current_process().name:import multiprocessing import time def myFunc(): name = multiprocessing.current_process().name print ("Starting process name = %s \n" %name) time.sleep(3) print ("Exiting process name = %s \n" %name) -
Затем мы создаём
process_with_nameпросто создавая экземпляры со значением параметраnameиprocess_with_default_name:if __name__ == '__main__': process_with_name = multiprocessing.Process\ (name='myFunc process',\ target=myFunc) process_with_default_name = multiprocessing.Process\ (target=myFunc) -
Наконец, эти процессы запускаются и затем присоединяются:
process_with_name.start() process_with_default_name.start() process_with_name.join() process_with_default_name.join()
В нашей программе main все процессы создаются с применением одной и
той же целевой функции, myFunc. Эта функция просто выводит на печать название
своего процесса.
Для запуска нашего примера откройте приглашение Командной строки и наберите такую команду:
> python naming_processes.py
Получаемый вывод будет примерно таким:
Starting process name = myFunc process
Starting process name = Process-2
Exiting process name = Process-2
Exiting process name = myFunc process
Основным процессом Python выступает multiprocessing.process._MainProcess,
в то время как дочерним процессом является multiprocessing.process.Process.
Это можно запросто проверить набрав следующее:
>>> import multiprocessing
>>> multiprocessing.current_process().name
'MainProcess'
Дополнительные сведения по этой теме можно найти по ссылке.
Запуск в фоновом режиме является состоянием исполнения, которое типично для некоторых программ, которым не требуется присутствие определённого пользователя или его вмешательство и которое может быть одновременным с выполнением прочих программ (и, тем самым, он возможен лишь в многозадачных системах), что имеет результатом тот факт, что пользователь не осведомлён о ней. Программы фонового режима обычно выполняют длинные или потребляющие много времени задачи, такие как программы однорангового совместного использования файлов или дефрагментация файловых систем. Многие процессы ОС также выполняются в фоновом режиме.
В Windows программы в таком режиме (сканирующие антивирусы или обновляющие ОС) зачастую помещают некую иконку в системном лотке (system tray, та область на рабочем столе, которая следует за системными часами) чтобы сигнализировать о своей активности и приспосабливать поведение, которое снижает потребление ресурсов с тем, чтобы не оказывать влияния ни интерактивную деятельность самого пользователя, например, замедление или вызывание прерываний. В системах Unix или Unix- подобных, работающие в фоновом режиме процессы называются демонами. Воспользовавшись диспетчера задач можно выделить все исполняющиеся программы, включая те, которые работают в фоновом режиме.
Наш модуль multiprocessing позволяет - через свой демонический вариант -
запускать процессы в фоновом режиме. В нашем следующем примере определяются два процесса:
-
background_processс его параметромdaemon, настроенным в значениеFalse. -
NO_background_processс его параметромdaemon, настроенным в значениеTrue.
В своём следующем примере мы реализуем некую целевую функцию, с названием foo,
которая отображает цифры от 0 до 4,
когда её дочерний процесс пребывает в
фоновом режиме; в противном случае, она выводит на
печать цифры от 5 до 9:
-
Давайте импортируем относящиеся к делу библиотеки:
import multiprocessing import time -
Затем мы определяем свою функцию
foo(). Как это описано ранее, выводимые на печать цифры зависят от значения параметраname:def foo(): name = multiprocessing.current_process().name print ("Starting %s \n" %name) if name == 'background_process': for i in range(0,5): print('---> %d \n' %i) time.sleep(1) else: for i in range(5,10): print('---> %d \n' %i) time.sleep(1) print ("Exiting %s \n" %name) -
Наконец, мы определяем такие процессы:
background_processиNO_background_process. Обратите внимание, что значение параметраdaemonустанавливается для обоих этих процессов:if __name__ == '__main__': background_process = multiprocessing.Process\ (name='background_process',\ target=foo) background_process.daemon = True NO_background_process = multiprocessing.Process\ (name='NO_background_process',\ target=foo) NO_background_process.daemon = False background_process.start() NO_background_process.start()
Заметим, что значение параметра daemon самого процесса определяет должен ли
этот процесс запускаться в фоновом режиме или нет. Для исполнения данного примера наберите такую команду:
> python run_background_processes.py
Наш вывод очевидно выдаёт отчёт только о выводе NO_background_process:
Starting NO_background_process
---> 5
---> 6
---> 7
---> 8
---> 9
Exiting NO_background_process
Сам вывод изменяет соответствующую настройку значения параметра daemon для
background_process на False:
background_process.daemon = False
Для исполнения этого примера наберите следующее:
C:\> python run_background_processes_no_daemons.py
Получаемый вывод выдаёт отчёт о выполнении обоих процессов, и background_process,
и NO_background_process:
Starting NO_background_process
Starting background_process
---> 5
---> 0
---> 6
---> 1
---> 7
---> 2
---> 8
---> 3
---> 9
---> 4
Exiting NO_background_process
Exiting background_process
Некий фрагмент кода для того как запускать некий сценарий Python в фоновом режиме в Linux можно найти по ссылке.
Не существует безупречного программного обеспечения и даже в самое наилучшее приложение вы можете вложить некую ошибку, которая приводит к блокировке данного приложения и именно по этой причине современные ОС имеют разработанными различные методы прекращения таких процессов приложений чтобы высвобождать системные ресурсы и позволять своему пользователю применять их для других операций настолько быстро, как только это возможно. Данный раздел покажет вам как уничтожать (kill) некий процесс в вашем приложении со множеством процессов.
Имеется возможность немедленного уничтожения процесса при помощи метода terminate.
Кроме того мы воспользуемся методом is_alive для отслеживания того жив ли
конкретный процесс или нет.
Для осуществления данного рецепта следуйте приводимым ниже шагам:
-
Давайте импортируем относящиеся к делу библиотеки:
import multiprocessing import time -
Затем реализуется некая простейшая функция
target. В этом примере наша функцияtarget,foo()выводит на печать первые10цифр:def foo(): print ('Starting function') for i in range(0,10): print('-->%d\n' %i) time.sleep(1) print ('Finished function') -
В своей программе
mainмы создаём некий процесс отслеживания её времени жизни посредством методаis_alive; далее мы завершаем её при помощи вызоваterminate;if __name__ == '__main__': p = multiprocessing.Process(target=foo) print ('Process before execution:', p, p.is_alive()) p.start() print ('Process running:', p, p.is_alive()) p.terminate() print ('Process terminated:', p, p.is_alive()) p.join() print ('Process joined:', p, p.is_alive()) -
После этого мы проверяем значение кода состояния когда наш процесс завершён и считываем значение атрибута значения
ExitCodeсвоего процесса:print ('Process exit code:', p.exitcode) -
Возможными значениями
ExitCodeявляются такие:-
== 0: Не воспроизведена никакая ошибка -
> 0: Наш процесс имел некую ошибку и вышел с данным кодом -
< 0: Наш процесс был уничтожен сигналом-1 * ExitCode.
New-VM -Name VM01 -Generation 2 -
Наш образец кода состоит из некой целевой функции, foo(), задача которой
состоит в выводе на экран печати самых первых 10 целых чисел. В нашей программе
main этот процесс исполняется, а затем уничтожается инструкцией
terminate. Этот процесс затем присоединяется и определяется
ExitCode.
Для выполнения данного кода наберите такую команду:
> python killing_processes.py
После этого мы получаем следующий вывод:
Process before execution: <Process(Process-1, initial)> False
Process running: <Process(Process-1, started)> True
Process terminated: <Process(Process-1, started)> True
Process joined: <Process(Process-1, stopped[SIGTERM])> False
Process exit code: -15
Обратите внимание, что величина выводимого значения ExitCode равна
-15. Отрицательность значения -15
указывает на то, что наш потомок был уничтожен сигналом прерывания, который определяется его числовым значением
15.
В машине Linux некий процесс Python может быть идентифицирован, а затем уничтожен просто следуя такому руководству.
Модуль multiprocessing предоставляет доступ к функциям управления процессом.
В данном разделе мы изучим как определять некий процесс в каком- то подклассе имеющегося класса
multiprocessing.Process.
Для реализации некого индивидуального подкласса многопроцессности нам требуется выполнить следующие моменты:
-
Задать некий подкласс класса
multiprocessing.Process, переопределив его методrun(). -
Перекрыть метод
_init__(self [,args])для добавления дополнительных параметров, если это требуется. -
Перекрыть метод
run(self [,args])для реализации того чтоProcessдолжен выполнять при своём запуске.
После того как мы создали нужный нам новый подкласс Process, мы можем
создать некий его экземпляр и затем запустить, вызвав соответствующий метод start,
который, в свою очередь, вызывает установленный метод run.
Просто рассмотрим очень простой пример:
-
Импортируем относящуюся к делу библиотеку:
import multiprocessing > -
Далее определяем некий подкласс,
MyProcess, перекрывая лишь его методrun, который возвращает название своего процесса:class MyProcess(multiprocessing.Process): def run(self): print ('called run method by %s' %self.name) return -
В своей программе
mainмы определим некий подкласс из10процессов:if __name__ == '__main__': for i in range(10): process = MyProcess() process.start() process.join()
Каждый процесс подкласса представлен неким классом, который расширяет установленный класс
Process и перекрывает его метод run().
Данный метод является отправной точкой Process:
class MyProcess (multiprocessing.Process):
def run(self):
print ('called run method in process: %s' %self.name)
return
В своей программе main мы создаём некоторые объекты с типом
Process(). Исполнение данного потока начинается после вызова метода
start():
p = MyProcess()
p.start()
Наша команда join() просто обрабатывает сам процесс останова. Для выполнения
этого сценария из приглашения Командной строки наберите такую команду:
> python process_in_subclass.py
Её вывод будет следующим:
called run method by MyProcess-1
called run method by MyProcess-2
called run method by MyProcess-3
called run method by MyProcess-4
called run method by MyProcess-5
called run method by MyProcess-6
called run method by MyProcess-7
called run method by MyProcess-8
called run method by MyProcess-9
called run method by MyProcess-10
В объектно ориентированном программировании некий подкласс является классом, который наследует все свойства из некого суперкласса, которыми выступают объекты и методы. Неким альтернативным названием подкласса является порождаемый класс (derived class). Наследование (inheritance) является специфическим термином, который указывает на тот процесс, коим его потомок или порождаемые классы наследуют свои свойства из родительского класса или суперклассов.
Вы можете представлять себе подкласс как определённую разновидность его суперкласса; на самом деле он может применять методы и/ или атрибуты, а также переопределять их путём перекрытия (overriding).
Дополнительные сведения по технологиям определения классов можно найти по ссылке.
Некая очередь является структурой данных с типом FIFO (First-In, First-Out, первый пришедший обслуживается первым). Неким примером из практики являются очереди на получение обслуживание, как производится оплата в супермаркете или ваша стрижка в парикмахерской. В идеале вы обслуживаетесь точно в том порядке, в котором вы были представлены. Именно так и работает очередь FIFO.
В данном разделе мы покажем вам как применять очередь для задачи производитель- потребитель, которая является классическим примером синхронизации процессов.
Задача производитель- потребитель описывает два процесса: один выступаетпроизводителем, а другой является потребителем, и они совместно используют общий буфер с неким фиксированным размером.
Основная задача производителя состоит в выработке данных для их непрерывного депонирования в имеющемся буфере. В то же самое время, существующий потребитель будет использовать произведённые данные, удаляя время от времени их из этого буфера. Основная задача состоит в гарантии того, что имеющийся производитель не вырабатывает новые данные когда буфер заполнен и что его потребитель не ищет данные когда буфер пуст. Основное решение состоит в том, что имеющийся производитель приостанавливает своё выполнение когда буфер заполнен.
Как только его потребитель возьмёт некий элемент из имеющегося буфера, наш производитель проснётся и начнёт снова наполнять этот буфер. Аналогично, наш потребитель приостановится когда буфер пуст. Как только его производитель выгрузит необходимые данные в имеющийся буфер, этот потребитель просыпается.
Это решение может быть реализовано посредством стратегий взаимодействия между процессами, совместной памятью или обменом сообщениями. Неверное решение может приводить к взаимной блокировке (deadlock), при которой оба процесса ожидают пробуждения.
import multiprocessing
import random
import time
Давайте выполним следующее:
-
Наш класс
producerотвечает за ввод10элементов в имеющуюся очередь при помощи своего методаput:class producer(multiprocessing.Process): def __init__(self, queue): multiprocessing.Process.__init__(self) self.queue = queue def run(self) : for i in range(10): item = random.randint(0, 256) self.queue.put(item) print ("Process Producer : item %d appended \ to queue %s"\ % (item,self.name)) time.sleep(1) print ("The size of queue is %s"\ % self.queue.qsize()) -
Класс
consumerимеет задачу удаления элементов из общей очереди (с помощью методаget) и проверки того что эта очередь не пуста. Когда это происходит, тогда установленный внутри его циклаwhileпоток останавливается операторомbreak:class consumer(multiprocessing.Process): def __init__(self, queue): multiprocessing.Process.__init__(self) self.queue = queue def run(self): while True: if (self.queue.empty()): print("the queue is empty") break else : time.sleep(2) item = self.queue.get() print ('Process Consumer : item %d popped \ from by %s \n'\ % (item, self.name)) time.sleep(1) -
Наш класс
multiprocessingимеет свой объектqueue, устанавливаемый в основной программеmain:if __name__ == '__main__': queue = multiprocessing.Queue() process_producer = producer(queue) process_consumer = consumer(queue) process_producer.start() process_consumer.start() process_producer.join() process_consumer.join()
Внутри своей программы main мы определяем необходимую очередь с помощью
объекта multiprocessing.Queue. Затем он передаётся в качестве некого аргумента
в процессы producer и consumer:
queue = multiprocessing.Queue()
process_producer = producer(queue)
process_consumer = consumer(queue)
В нашем классе producer метод queue.put
применяется для добавления в конец общей очереди новых элементов:
self.queue.put(item)
В то же время в классе consumer его метод
queue.get применяется для вытаскивания имеющихся элементов:
self.queue.get()
Выполните полученный код набрав следующую команду:
> python communicating_with_queue.py
Приводимый ниже вывод является отчётом о взаимодействии между нашими производителем и потребителем:
Process Producer : item 79 appended to queue producer-1
The size of queue is 1
Process Producer : item 50 appended to queue producer-1
The size of queue is 2
Process Consumer : item 79 popped from by consumer-2
Process Producer : item 33 appended to queue producer-1
The size of queue is 2
Process Producer : item 57 appended to queue producer-1
The size of queue is 3
Process Producer : item 227 appended to queue producer-1
Process Consumer : item 50 popped from by consumer-2
The size of queue is 3
Process Producer : item 98 appended to queue producer-1
The size of queue is 4
Process Producer : item 64 appended to queue producer-1
The size of queue is 5
Process Producer : item 182 appended to queue producer-1
Process Consumer : item 33 popped from by consumer-2
The size of queue is 5
Process Producer : item 206 appended to queue producer-1
The size of queue is 6
Process Producer : item 214 appended to queue producer-1
The size of queue is 7
Process Consumer : item 57 popped from by consumer-2
Process Consumer : item 227 popped from by consumer-2
Process Consumer : item 98 popped from by consumer-2
Process Consumer : item 64 popped from by consumer-2
Process Consumer : item 182 popped from by consumer-2
Process Consumer : item 206 popped from by consumer-2
Process Consumer : item 214 popped from by consumer-2
the queue is empty
Очередь обладает неким подклассом JoinableQueue. Он предоставляет такие
методы:
-
task_done(): Данный метод указывает что некая задача завершена, например, после применения методаget()для выборки элементов из этой очереди. По этой причинеtask_done()можно применять потребителям очереди. -
join(): Данный метод блокирует все процессы до тех пор, пока все имеющиеся в этой очереди элементы не будут завершены и обработаны.
Хорошее руководство относительно того как применять очереди доступно по ссылке.
Некий конвейер (pipe) выполняет следующее:
-
Возвращает пару соединённых объектов, объединяемых неким конвейером.
-
Каждый из присоединённых объектов обладает методами отправки/ получения для взаимодействия между процессами.
Рассматриваемая нами библиотека multiprocessing позволяет вам реализацию
некой структуры данных конвейера при помощи своей функции
multiprocessing.Pipe(duplex). Она возвращает некую
пару объектов (conn1, conn2), которые представляют концы этого конвейера.
Значение параметра duplex будет ли данный конвейер для нашего последнего
случая двунаправленным (то есть, duplex = True), или однонаправленным
(то есть, duplex = False), когда conn1
может применяться лишь для получения сообщений, а conn1 только для
отправки сообщений.
Теперь давайте рассмотрим как выполнять обмен сообшениями при помощи конвейеров.
Здесь приводится некий образец конвейеров. У нас имеется один процесс конвейера, который выводит числа от
0 до 9, а второй процесс конвейера
получает числа и возводит их в квадрат:
-
Давайте импортируем библиотеку
multiprocessing:import multiprocessing -
Наша функция
pipeвозвращает пару соединённых объектов, объединяемых двусторонним конвейером. В этом примереout_pipeсодержит числа от0до9, которые были выработаны функциейtargetизcreate_items:def create_items(pipe): output_pipe, _ = pipe for item in range(10): output_pipe.send(item) output_pipe.close() -
Следующая функция
multiply_itemsоснована на двух конвейерах,pipe_1иpipe_2:def multiply_items(pipe_1, pipe_2): close, input_pipe = pipe_1 close.close() output_pipe, _ = pipe_2 try: while True: item = input_pipe.recv() -
Эта функция возвращает произведение всех поступающих из конвейера элементов:
output_pipe.send(item * item) except EOFError: output_pipe.close() -
В нашей программе
mainопределяютсяpipe_1иpipe_2:if __name__== '__main__': -
Первым процесс
pipe_1с числами от0до9:pipe_1 = multiprocessing.Pipe(True) process_pipe_1 = \ multiprocessing.Process\ (target=create_items, args=(pipe_1,)) process_pipe_1.start() -
Затем процесс
pipe_2, который выхватывает поступающие изpipe_1числа и возводит их в квадрат:pipe_2 = multiprocessing.Pipe(True) process_pipe_2 = \ multiprocessing.Process\ (target=multiply_items, args=(pipe_1, pipe_2,)) process_pipe_2.start() -
Закрываем свои процессы:
pipe_1[0].close() pipe_2[0].close() -
Выводим на печать полученные результаты:
try: while True: print (pipe_2[1].recv()) except EOFError: print("End")
По существу, наши два конвейера, pipe_1 и
pipe_2, создаются операторами
multiprocessing.Pipe(True):
pipe_1 = multiprocessing.Pipe(True)
pipe_2 = multiprocessing.Pipe(True)
Самый первый конвейер, pipe_1 просто создаёт некий список целых с
0 до 9, в то время как наш второй
конвейер, pipe_2, обрабатывает каждый элемент из этого списка, создаваемого
pipe_1, вычисляя значение квадрата для каждого из элементов:
pipe_1 = multiprocessing.Pipe(True)
pipe_2 = multiprocessing.Pipe(True)
Следовательно, оба процесса закрываются:
pipe_1[0].close()
pipe_2[0].close()
И на печать выводится окончательный результат:
print (pipe_2[1].recv())
Выполним созданный код набрав такую команду:
> python communicating_with_pipe.py
Ниже приводится результат, отображающий квадраты первых 9 цифр:
0
1
4
9
16
25
36
49
64
81
Когда вам требуется для взаимодействия иметь более двух точек, пользуйтесь методом
Queue(). Однако если вам необходима максимальная производительность, тогда имейте
в виду, что метод Pipe() намного быстрее, потому что
Queue() строится поверх Pipe().
Дополнительные сведения относительно Python и конвейеров можно найти по ссылке.
Множество процессов могут совместно работать для выполнения поставленной задачи. Обычно они совместно используют данные. Важно чтобы доступ к разделяемым данным со стороны различных процессов не производил несогласованных данных. Таким образом, процессы, которые вступают в кооперацию разделяя данные, обязаны действовать неким упорядоченным образом для доступа к этим данным. Примитивы синхронизации достаточно схожи с теми что мы перечисляли для библиотек с потоками.
Примитивы синхронизации таковы:
-
Lock: Этот объект может быть либо в заблокированном, либо в разблокированном состоянии. Некий заблокированный объект обладает двумя методами,
acquire()иrelease()для управления доступом к некому совместному ресурсу. -
Event: Данный объект реализует простое взаимодействие между процессами; один процесс выставляет сигналом некое событие, а другой ожидает его. Объект события имеет два метода,
set()иclear()для управления своим собственным внутренним флагом. -
Condition: Такой объект используется для синхронизации частей некого рабочего потока, причём как в последовательных, так и в параллельных процессах. Он имеет два основных метода:
wait()применяется для ожидания некого условия, аnotify_all()применяется для взаимодействия с тем условием, которое было применено. -
Semaphore: Используется для разделения некого ресурса, например, для поддержки фиксированного числа одновременных подключений.
Code -
RLock: Задаёт объект рекурсивной блокировки. Все методы и функциональность RLock те же самые что и в обсуждавшемся уже модуле
threading. -
Barrier: Делит программу на фазы, которые требуют достижения всеми процессами установленного барьера прежде чем они могут быть продолжены. Исполняемый после барьера код не может быть одновременным с тем кодом, который исполнялся перед этим барьером.
Объекты Barrier Python используются для ожидания завершения
исполнения фиксированного числа потоков прежде чем эти потоки смогут продолжить своё выполнение общей программы.
Наш следующий пример показывает как выполнять синхронизацию одновременных задач при помощи объекта
barrier().
Давайте рассмотрим четыре процесса, причём процессы p1 и
p2 управляются неким оператором барьера, в то время как процессы
p3 и p4 не обладают
директивами синхронизации.
Для выполнения этого осуществите такие шаги:
-
Импортируем нужные нам библиотеки:
import multiprocessing from multiprocessing import Barrier, Lock, Process from time import time from datetime import datetime -
Наша функция
test_with_barrierвыполняет метод барьераwait():def test_with_barrier(synchronizer, serializer): name = multiprocessing.current_process().name synchronizer.wait() now = time() -
Когда наши два процесса вызвали метод
wait(), они высвобождаются одновременно:with serializer: print("process %s ----> %s" \ %(name,datetime.fromtimestamp(now))) def test_without_barrier(): name = multiprocessing.current_process().name now = time() print("process %s ----> %s" \ %(name ,datetime.fromtimestamp(now))) -
В своей программе
mainмы создаём четыре процесса. Однако нам также требуются некие примитивы барьера и блокировки. Значение параметра2в оператореBarrierустанавливается для общего числа управляемых процессов:if __name__ == '__main__': synchronizer = Barrier(2) serializer = Lock() Process(name='p1 - test_with_barrier'\ ,target=test_with_barrier,\ args=(synchronizer,serializer)).start() Process(name='p2 - test_with_barrier'\ ,target=test_with_barrier,\ args=(synchronizer,serializer)).start() Process(name='p3 - test_without_barrier'\ ,target=test_without_barrier).start() Process(name='p4 - test_without_barrier'\ ,target=test_without_barrier).start()
Обсуждаемый объект Barrier предоставляет одну из технологий Python при
которой один или множество потоков будут дожидаться в определённом месте в множестве действий и осуществлять
развитие совместно.
В нашей программе main определяется необходимый объект
Barrier (то есть synchronizer)
следующим оператором:
synchronizer = Barrier(2)
Обратите вниме=ание, что значение числа 2 внутри скобок представляет
общее число процессов, которого должен дожидаться этот барьер.
Затем мы реализуем некое множество из четырёх процессов, однако лишь p1
и p2 имеют барьер. Обратите внимание, что
synchronizer передаётся в виде некого параметра:
Process(name='p1 - test_with_barrier'\
,target=test_with_barrier,\
args=(synchronizer,serializer)).start()
Process(name='p2 - test_with_barrier'\
,target=test_with_barrier,\
args=(synchronizer,serializer)).start()
Действительно, в самом теле функции test_with_barrier, метод
wait() барьера применяется для синхронизации этих процессов:
synchronizer.wait()
Выполнив данный сценарий, мы можем видеть, что наши процессы p1 и
p2 выводят, как и ожидалось, одно и то же значение временного штампа:
> python processes_barrier.py
process p4 - test_without_barrier ----> 2019-03-03 08:58:06.159882
process p3 - test_without_barrier ----> 2019-03-03 08:58:06.144257
process p1 - test_with_barrier ----> 2019-03-03 08:58:06.175505
process p2 - test_with_barrier ----> 2019-03-03 08:58:06.175505
Наша следующая схема показывает вам как работает барьер с двумя процессами:
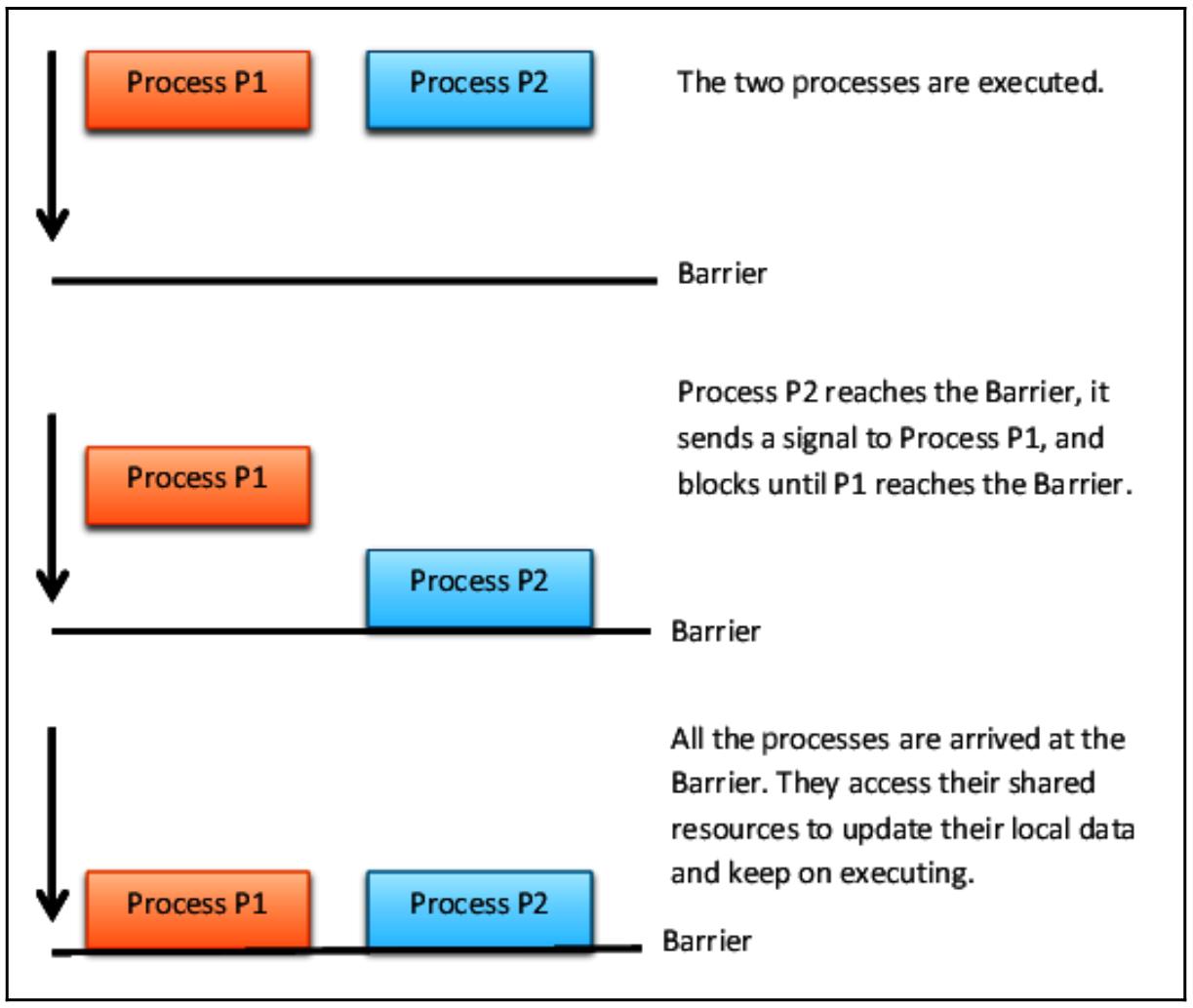
Для знакомства с дополнительными примерами синхронизациями обратитесь к этому блогу.
Механизм пула процессов делает возможным параллельное выполнение некой функции на множестве входных значений, распределяя имеющиеся данные между процессами. Сам пул процессов, таким образом, позволяет реализовывать так называемый параллелизм данных, который основывается на распределении данных по различным процессам, которые параллельно работают с данными.
Обсуждаемая нами библиотека multiprocessing предоставляет класс
Pool для упрощения обработки параллельных задач.
Этот класс Pool обладает такими методами:
-
apply(): Блокирует до момента готовности получения результата. -
span class="term">
apply_async(): Это некий вариант методаapply(), который возвращает некий получаемый в результате объект. Это некая асинхронная операция, которая не будет блокировать свой основной поток до тех пор, пока не выполнятся все классы потомков. -
map(): Это некий параллельный вариант встроенной функцииmap(). Он осуществляет блокирование до тех пор, пока не получен конечный результат, а также он расчленяет все итеративные данные на некое число фрагментов, которые подставляются его пулу процессов как отдельные задачи. -
map_async(): Это некий вариант методаmap(), который возвращает объектresult. Когда определён некий обратный вызов, тогда он должен быть выполнен, причём с приёмом некого отдельного аргумента. После того как получаемый результат становится готовым, к нему применяется этот обратный вызов (только если такой вызов не приводит к отказу). Обратный вызов должен быть выполнен немедленно; в противном случае тот поток, который обрабатывает данный результат будет заблокирован.
Данный пример покажет вам как реализовать некий пул процессов для выполнения параллельного приложения. Мы создаём
некий пул из четырёх процессов, а затем мы применяем метод map пула для
выполнения какой- то простой функции:
-
Импортируем библиотеку
multiprocessing:import multiprocessing -
Наш метод
Poolприменяетfunction_squareдля введённого элемента чтобы выполнить некое простое вычисление:def function_square(data): result = data*data return result if __name__ == '__main__': -
Следующий параметр вводит некий список целых от
0до100:inputs = list(range(0,100)) -
Общее число параллельных процессов равняется
4:pool = multiprocessing.Pool(processes=4) -
Наш метод
pool.mapподставляется в пул процессов как отдельные задачи:pool_outputs = pool.map(function_square, inputs) pool.close() pool.join() -
Полученные результаты вычислений сохраняются в
pool_outputs:print ('Pool :', pool_outputs)
Важно отметить, что сам получаемый результат метода pool.map() эквивалентен
встроенной функции Python map(), за исключением того что в нашем случае процессы
выполняются параллельно.
Здесь, воспользовавшись приводимым ниже оператором, мы создали пул из четырёх процессов:
pool = multiprocessing.Pool(processes=4)
Каждый процесс имеет некий список целых в качестве данных на входе. Здесь, pool.map
работает точно так же как и стандартный map, но применяет множество процессов,
число которых, четыре, было ранее определено в процессе создания пула:
pool_outputs = pool.map(function_square, inputs)
Для завершения вычислений в данном пуле применяются обычные функции close
и join:
pool.close()
pool.join()
Для выполнения этого наберите такую команду:
> python process_pool.py
Вот полученные нами результаты по завершению наших вычислений:
Pool : [0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361, 400, 441, 484, 529, 576, 625, 676, 729, 784, 841, 900, 961, 1024, 1089, 1156, 1225, 1296, 1369, 1444, 1521, 1600, 1681, 1764, 1849, 1936, 2025, 2116, 2209, 2304, 2401, 2500, 2601, 2704, 2809, 2916, 3025, 3136, 3249, 3364, 3481, 3600, 3721, 3844, 3969, 4096, 4225, 4356, 4489, 4624, 4761, 4900, 5041, 5184, 5329, 5476, 5625, 5776, 5929, 6084, 6241, 6400, 6561, 6724, 6889, 7056, 7225, 7396, 7569, 7744, 7921, 8100, 8281, 8464, 8649, 8836, 9025, 9216, 9409, 9604, 9801]
В своём предыдущем примере мы увидели, что Pool также предоставляет метод
map, который позволяет нам применять некую функцию для различных наборов
данных. В частности, тот сценарий, в котором одни и те же действия выполняются параллельно над теми же самыми
данными именуется параллелизмом данных.
В нашем следующем примере, в котором мы применяем Pool и
map, мы создаём pool из
5 обработчиков и, применяя метод map,
некая функция f применяется к списку из
10 элементов:
from multiprocessing import Pool
def f(x):
return x+10
if __name__ == '__main__':
p=Pool(processes=5)
print(p.map(f, [1, 2, 3,5,6,7,8,9,10]))
Вывод получается таким:
11 12 13 14 15 16 17 18 19 20
Для знакомства с дополнительными примерами пулов процессов обратитесь к следующей ссылке.