Глава 8. Распространение межкластерных сообщений
Содержание
Данная глава рассматривает
-
Федеративные обмены и очереди
-
Как установить множество федеративных узлов RabbitMQ в еб службах Amazon
-
Различные шаблоны, применяемые при федерализации RabbitMQ
Намереваетесь ли вы реализовать обмен данными между Центрами обработки данных, обновление RabbitMQ или предоставлять прозрачный доступ к обмену сообщениями различных кластеров RabbitMQ, вы пожелаете рассмотреть подключаемые модули федерализации. Распространяемый совместно с RabbitMQ в качестве подключаемого модуля для фондовых рынков, подключаемый модуль федерализации предоставляет два различных способа получения сообщений из одного кластера в другой. Применяя федеративный обмен, публикуемые в каком- то обмене в другом сервере или кластере сообщения направляются в связанные обмены или очереди в подлежащие хосты. В качестве альтернативы, если вам необходимы большая специфичность, федеративные очереди предоставляют некий способ целеуказания вашим сообщениям в отдельной очереди вместо обмена. В любом из вариантов применения конечная цель состоит в прозрачной трансляции сообщений из находящегося в восходящем потоке узла, в котором они первоначально и были опубликованы, в определённый узел вниз по потоку (Рисунок 8-1).
Рисунок 8-1
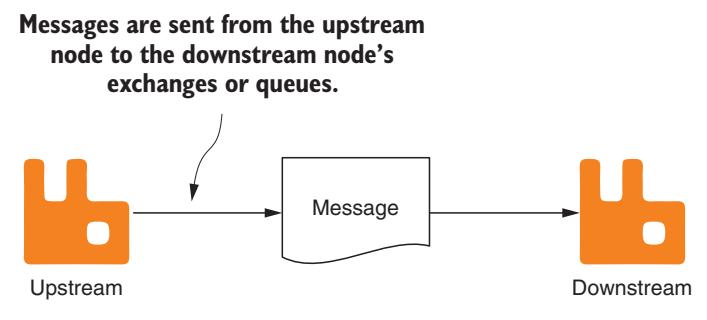
Сообщения отправляются в обмены и очереди узла нисходящего потока из своего узла восходящего потока
Для выяснения того имеет ли место федерализация в вашей топологии обмена сообщениями, может помочь именно понимание того как работает федерализация и что вы можете ожидать когда применяете имеющийся в распоряжении подключаемый модуль федерализации. Предоставляемый как часть основного ядра дистрибутива RabbitMQ, данный подключаемый модуль федерализации обеспечивает гибкие способы прозрачной транспортировки сообщений между узлами и кластерами. Общая функциональность данного подключаемого модуля подразделяется на два основных компонента: федеративные обмены и федеративные очереди.
Федеративные обмены позволяют публикацию сообщений в некотором узле восходящего потока для его прозрачной публикации в каком- то обмене с тем же самым наименованием в определённом узле нисходящего потока. Федеративные очереди, с другой стороны, позволяют узлам нисходящего потока действовать как потребителям совместных очередей в узлах восходящего потока, предоставляя возможность карусельного (round- robin) обмена сообщениями по множеству узлов нисходящего потока.
Позднее в этой главе вы настроите тестовую среду в которой вы сможете поэкспериментировать с обоими типами федерализации, но вначале я хочу объяснить как работает каждый из них.
Допустим, вы решаете задачу добавления возможности выполнения крупномасштабной обработки данных поведения пользователей, связанного с вашим существовавшим ранее веб приложением, запущенном в конкретном облачном решении. Данное приложение имеет крупный масштаб, новые продвигаемые пользователями сайты, такие как Reddit или Slashdot, а к тому же данное приложение уже применяет топологию на основе обмена сообщениями, в которой возникают события когда имеющиеся пользователи предпринимают некие действия на вашей площадке. При регистрации пользователя, отправке им статей или оставлении комментариев, вместо непосредственной записи в базу данных самого содержимого, сообщения публикуются в RabbitMQ, а уже потребители выполняют сами записи в базу данных (Рисунок 8-2).
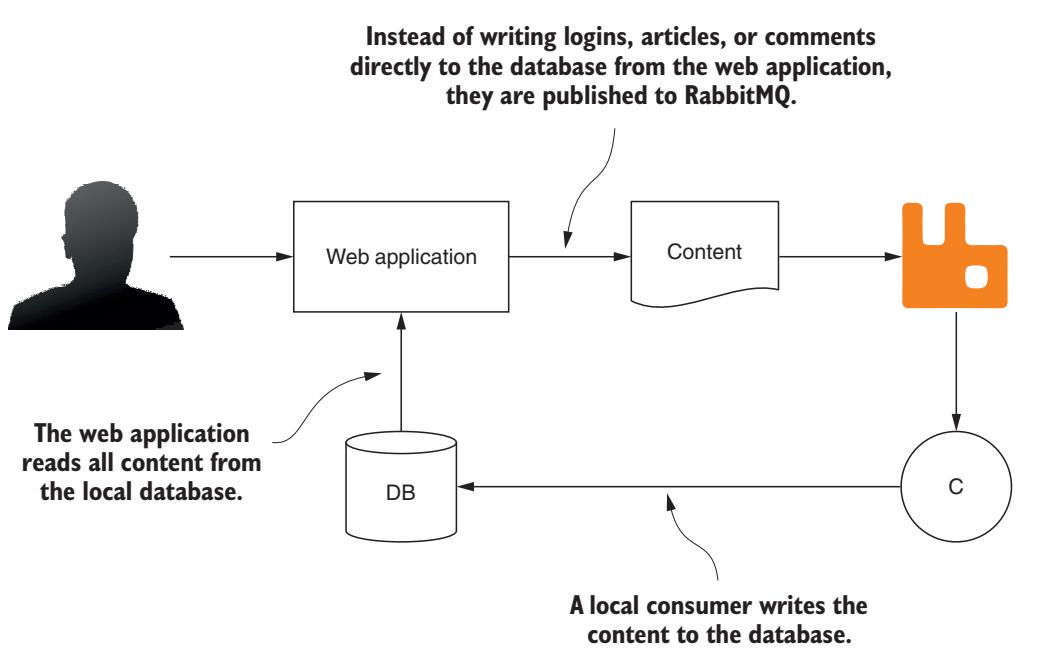
Так как применяя RabbitMQ в качестве промежуточного программного обеспечения между приложением и потребителем, вы отвязываете от самого приложения операции записи в базу данных, вы легко можете разветвить поток сообщений для записи всех данных в некое хранилище данных для выполнения его анализа помимо всего прочего. Дин из способов, с помощью которого вы бы могли сделать это - добавить локального пользователя к тому веб приложению, которое выполняет записи в имеющееся хранилище данных. Однако что вам делать, если ваши инфраструктура и накопители для вашего хранилища данных размещены где- то ещё?
Как мы уже обсуждали это в нашей последней главе, встроенные в RabbitMQ возможности кластеризации требуют сетевых сред с низкой латентностью, в которых сетевое подразделение является редкостью. Данный термин разделения сети на фрагменты (network partition) ссылается на невозможность некоторых узлов взаимодействовать друг с другом, пребывая в сетевой среде.
Когда вы выполняете подключение по сетевому соединению с высокой латентностью, например через Интернет, сетевая фрагментация не является чем- то необычным и её следует принимать во внимание. К счастью, RabbitMQ был укомплектован подключаемым модулем для федеральных узлов, который может применяться именно в таких ситуациях. Данный подключаемый модуль федерализации делает возможным для некого сервера RabbitMQ нисходящий поток, который и осуществляет федерализацию сообщений от имевшегося до этого сервера RabbitMQ (Рисунок 8-3).
Рисунок 8-3
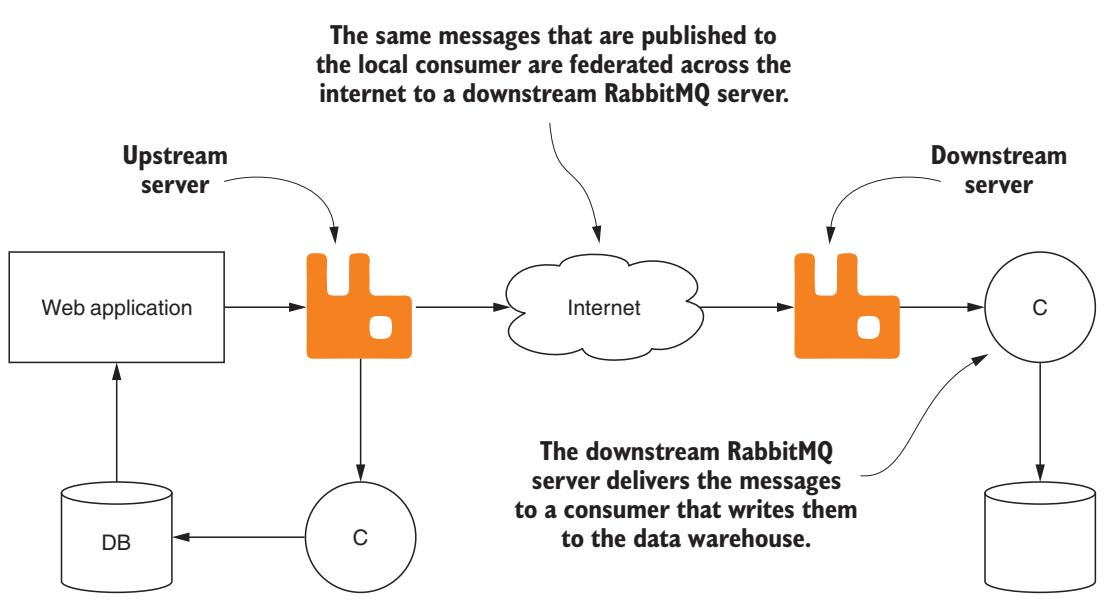
То же самое веб приложение с федеративным сервером RabbitMQ нисходящего потока, сохраняющим сообщения в определённом хранилище данных
После того как федеративный сервер настроен, всё что вам требуется сделать, так это создать политики, которые будут применяться к обменам,
которые вам необходимо осуществлять. Если сервер RabbitMQ восходящего потока имеет обмен с названием events,
в который публикуются все регистрации, статьи и сообщения комментариев, ваш сервер RabbitMQ нисходящего потока должен создать некую федеративную политику
соответствующую данному имени обмена. Когда вы создаёте определённый обмен в своём RabbitMQ нисходящего потока и связываете его с какой- то очередью,
вы сообщаете RabbitMQ о необходимости выполнять подключение к имеющемуся серверу восходящего потока и начать публикацию сообщений в данной
очереди нисходящего потока.
Когда RabbitMQ публикует сообщения из своего сервера восходящего потока в созданной очереди нисходящего потока, вам не следует беспокоиться о том что произойдёт если между ними будет разорвано интернет соединение. Когда связь возобновится, RabbitMQ с покорностью возобновит подключение к своему главному кластеру RabbitMQ начнёт локальную публикацию всех тех сообщений, которые были опубликованы на его веь сайте пока соединение отсутствовало. По истечению некоторого времени потребитель нисходящего потока должен догнать, а вам даже не придётся и пальцем шевельнуть. Это звучит как волшебство? Возможно, однако под покровом в этом нет никакого чуда.
Некий обмен с федеративной политикой в определённом хосте получает свой собственный специализированный процесс в RabbitMQ. Когда некий обмен имеет какую- то применяемую к нему политику, он подключается ко всем определённым в такой политике восходящим узлам и создаёт исполнительную очередь в которую он может получать сообщения. Сам процесс для данного обмена затем регистрируется как некий потребитель данной очереди исполнителя и выполняет ожидание сообщений чтобы начать прибытие. Привязка обмена к такому узлу восходящего потока применяется автоматически к данному обмену и очереди исполнителя в его узле восходящего потока, что вызывает публикацию сообщений узлом RabbitMQ восходящего потока в своём потребителе нисходящего потока. Когда этот потребитель получает некое сообщение, он публикует его в своём локальном обмене в точности также как это происходило бы со всеми прочими сообщениями. Данный сообщения, совместно с некоторыми добавочными подключёнными заголовками направляются их соответствующему получателю (Рисунок 8-4).
Рисунок 8-4
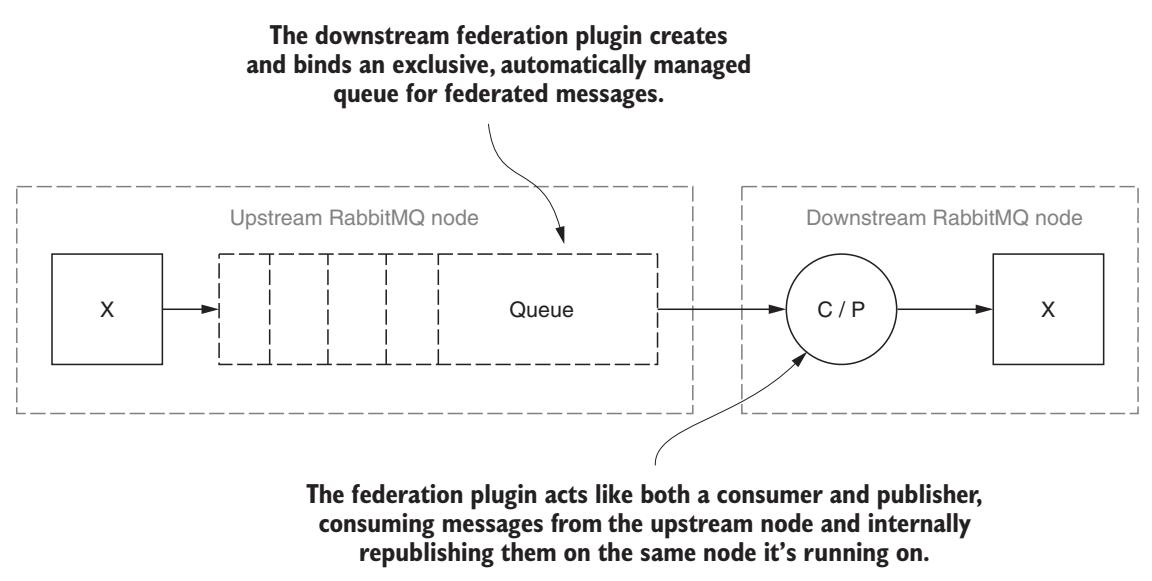
Подключаемый модуль федерализации создаёт некую очередь исполнителя в имеющемся узле RabbitMQ восходящего потока.
Как вы можете видеть, федеративный обмен предоставляет простой, надёжный и устойчивый способ расширения вашей инфраструктуры RabbitMQ в сетевых средах с латентностью, которую не допускает кластеризация RabbitMQ. Кроме того, он позволяет вам соединение мостами логически разделённых кластеров RabbitMQ, например, двух кластеров в одном и том же Центре обработки данных, запущенных с разными версиями RabbitMQ.
Федеративный обмен является мощным инструментом, который может быть мощным инструментом, который может применяться повсеместно в сети для вашей инфраструктуры обмена сообщениями, но что если ваши потребности более специфичны? Федеративные очереди могут обеспечить также и более целенаправленный способ распространения сообщений по кластерам RabbitMQ чем то, которое предоставляет карусельное поведение по множеству узлов нисходящих потоков и потребителей RabbitMQ.
Более новое добавление к имеющемуся подключаемому модуль федерализации - федерализация на основе очередей (queue-based federation) - предоставляет некий способ масштабирования ёмкости очереди. Это в особенности полезно для рабочих нагрузок обмена сообщениями (Рисунок 8-5).
Рисунок 8-5
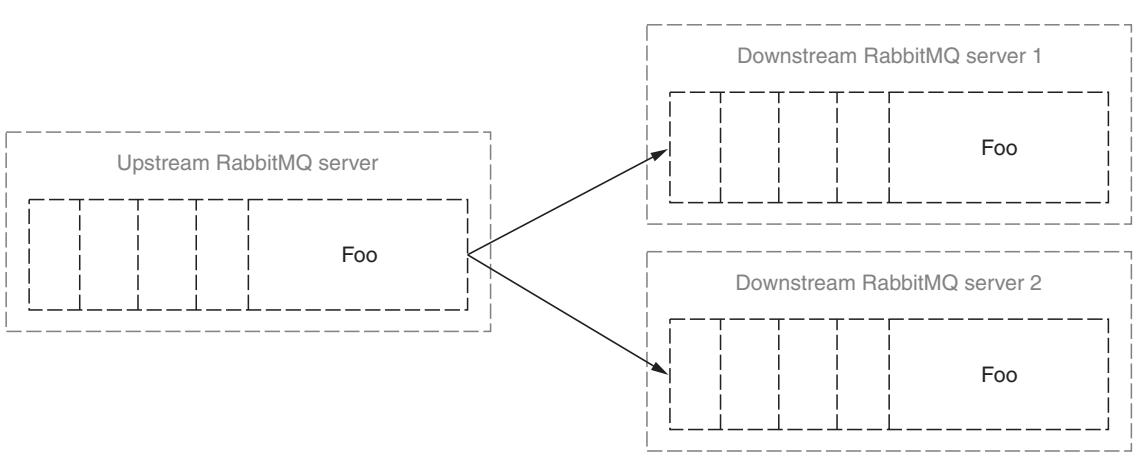
Очередь восходящего потока "foo" имеет балансировку нагрузки для своих сообщений между двумя серверами RabbitMQ при применении подключаемого модуля федерализации.
Как и сама очередь восходящего потока, очереди нисходящих потоков могут присутствовать в каком- то отдельном узле или как часть некоторой очереди с высокой доступностью в кластере. Имеющийся подключаемый модуль федерализации гарантирует что очереди нисходящих потоков будут получать сообщения только когда эти очереди имеют доступными потребителей для обработки сообщений. Выполнив проверку общего числа потребителей для каждой очереди и выполнив привязку к соответствующему узлу восходящего потока только при наличии потребителей, она предотвращает от накопления в очередях без потребителей простаивающих сообщений.
По мере прохождения вами относящихся к настройке примеров позднее в данной главе, вы обнаружите, что имеется весьма малое отличие между настройкой федеративных очередей и обменов. На самом деле имеющаяся по умолчанию настройка для федерализации имеет целью как обмены, так и очереди.
В оставшейся части данной главы мы будем применять бесплатные экземпляры Amazon EC2 для установки множества серверов RabbitMQ, которые будут применять федерализацию для прозрачного распространения сообщений без кластеризации. Если вы вместо этого применяете своего собственного поставщика облачного решения или имевшуюся ранее сетевую среду и серверы, сама концепция остаётся прежней. Когда вы отказываетесь от использования веб служб Amazon (AWS, Amazon Web Services) для работы с примерами их данной главы, просто создайте свои собственные серверы и попробуйте выполнить соответствующую настройку собственной среды настолько близкой к нашей, насколько это возможно. В любом из подходов вам необходимо настроить два сервера RabbitMQ для работы с нашими примерами.
Для настройки ВМ в Amazon EC2 вы создадите свой первый экземпляр, установите и настроите RabbitMQ, а затем создадите некий образ данного экземпляра, что позволит вам создать одну или более копий данного сервера для экспериментов. Если вы не предоставляете свои собственные виртуальные серверы, вам понадобится некая учётная запись AWS. Если у вас её пока нет, вы можете создать её бесплатно.
Чтобы начать зарегистрируйтесь в своей консоли AWS и кликните Create Instance. Вам будет представлен перечень шаблонов для создания ВМ. Выберите из этого списка Ubuntu Server (Рисунок 8-6).
После выполнения выбора вам будет предложен следующий шаг, выбор типа экземпляра. Выберите экземпляр с общей целью t2.micro, который должен быть помечен как Free Tier Eligible.
После выбора необходимого типа экземпляра вы получаете экран настроек своего экземпляра. Вы можете оставить в этом экране выбранные по умолчанию значения и кликнуть кнопку Next: Add Storage. Оставьте и здесь установленные по умолчанию значения, кликнув по кнопке Next: Tag Instance. Здесь на этом экране вам также нечего делать. Кликните Next: Configure Security Group и вам будут представлены настройки Security Group. Вы пожелаете изменить данные установки с тем, чтобы вы могли взаимодействовать с RabbitMQ. Так как это всего лишь пример, вы можете открыть порты 5672 и 15672 для интернета без каких бы то ни было ограничений на источник. Кликните кнопку Add Rule чтобы разрешить определение нового правила межсетевого экрана и создайте записи для каждого из портов в настройках источника, установив их в Anywhere, как это показано на Рисунке 8-7.
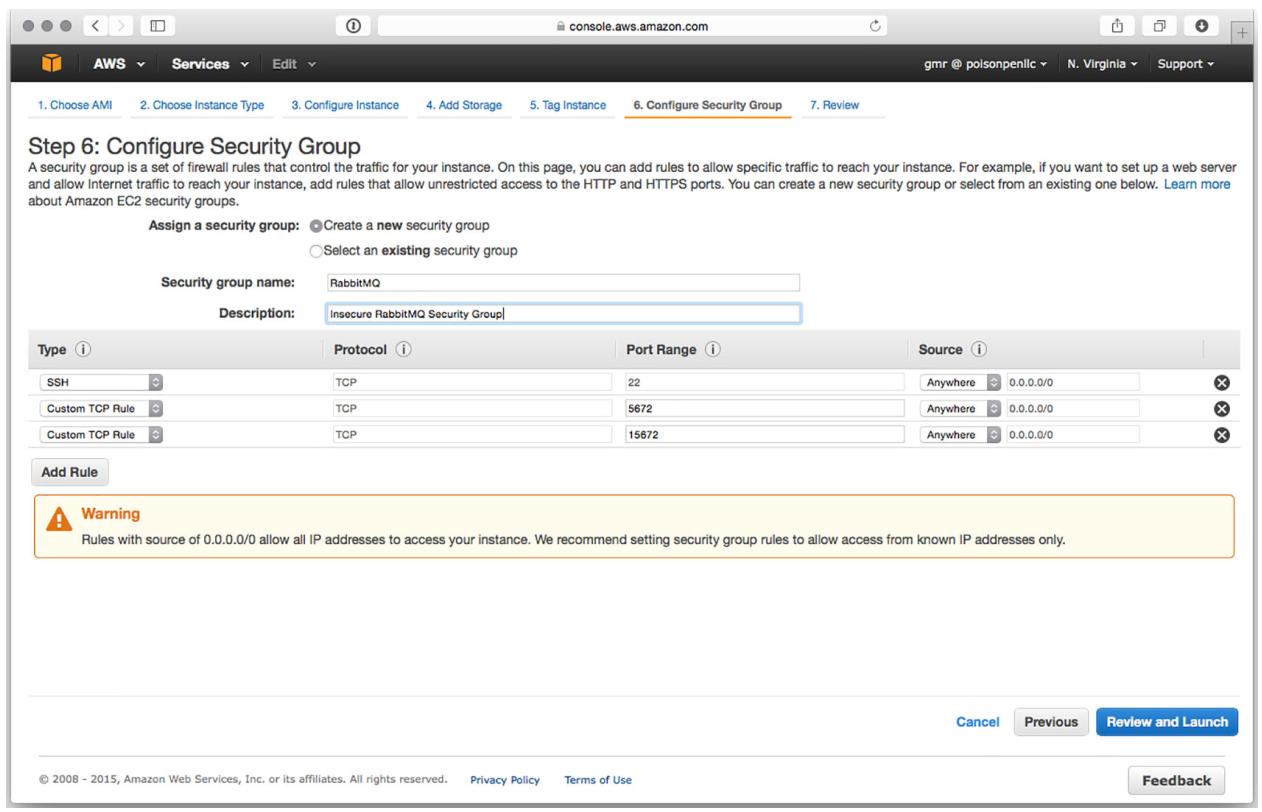
После того как вы добавили два созданных правила кликните по кнопке Review and Launch. Когда вы окажетесь в экране просмотра кликните Launch. Вам будет представлен блок диалога, позволяющий вам выбрать некую пару ключей SSH или создать новую. Из первого ниспадающего блока выберите Select Create a New Key Pair и выберите для этой пары название, а затем кликните Download Key Pair (Рисунок 8-8). Вы пожелаете сохранить эту пару ключей в некотором предпочитаемым вами местоположении в вашем компьютере, так как вы будете применять SSH в своём экземпляре EC2.
Когда вы выгрузите эту пару ключей, кликните кнопку Launch Instance. Затем AWS приступит к процессу создания и запустит ваш новый экземпляр ВМ. Перейдите обратно к своей инструментальной панели EC2 и вы должны обнаружить там только что созданный новый экземпляр запускающимся или уже исполняемым (Рисунок 8-9).
После того как новый экземпляр EC2 был запущен, он получит некий общедоступный IP адрес и имя DNS. Запишите себе этот IP адрес, так как вы будете применять его при подключении в своей ВМ при настройке RabbitMQ.
Подключение к экземпляру EC2
Имея на руках IP адрес своего экземпляра EC2 и путь к соответствующей паре ключей SSH, вы можете теперь выполнить SSH подключение к своей ВМ и
приступить к процессу установки RabbitMQ. Подключившись от имени пользователя ubuntu, вам понадобится
определить соответствующий путь к своей паре ключей SSH. Приводимая далее команда ссылается на файл в папке Downloads из моего каталога home.
ssh -i ~/Downloads/rabbitmq-in-depth.pem.txt ubuntu@[Public IP]
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Если вы находитесь в среде Windows, имеется ряд хороших приложений для подключения через SSH к удалённым системам, в том числе PuTTY (бесплатно) и SecureCRT (коммерческая). {Прим. пер.: с января 2018 Windows 10 и Server 2016 располагают встроенным OpenSSH, который не включён по умолчанию. Для включения клиента/ сервера OpenSSH вам следует пройти в Пуск > Приложения и возможности > Управление дополнительными возможностями > Клиент OpenSSH/ Сервер OpenSSH}. |
Выполнив подключение, вы будете зарегистрированы под пользователем ubuntu и вы должны увидеть баннер
MOTD аналогичный следующему:
Welcome to Ubuntu 14.04.1 LTS (GNU/Linux 3.13.0-36-generic x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Sun Jan 4 23:36:53 UTC 2015
System load: 0.0 Memory usage: 5% Processes: 82
Usage of /: 9.7% of 7.74GB Swap usage: 0% Users logged in: 0
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
ubuntu@ip-172-31-63-231:~$
Так как имеется ряд команд, которые вам следует исполнять от имени пользователя root, пройдите далее
и переключите пользователей чтобы вы могли не набирать всякий раз команду sudo:
sudo su –
Так как вы обладаете правами root, вы можете теперь установить оболочку времени исполнения Erlang и RabbitMQ в своём первом экземпляре EC2.
Установка Erlang и RabbitMQ
Для установки RabbitMQ и Erlang вы можете воспользоваться официальными репозиториями RabbitMQ и Erlang Solutions. Хотя основной репозиторий пакетов Ubuntu имеет поддержку как для RabbitMQ, так и для Erlang, более предпочтительным будет получить самую последнюю версию обоих, а установленные в дистрибутиве репозитории часто могут иметь существенно устаревшие версии. Для того чтобы воспользоваться внешними репозиториями, вам понадобится добавить ключи подписей необходимых пакетов и настроить эти внешние репозитории.
Вначале добавим общедоступный ключ RabbitMQ, который позволит Ubuntu выполнять проверку соответствующего файла подписи подлежащего установке пакета:
apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 \
--recv 6B73A36E6026DFCA
Вы можете видеть вывод приложения apt-key, постулирующего что он импортировал “RabbitMQ Release Signing Key
<info@rabbitmq.com>.”
Имея импортированный ключ соответствующей базы доверительных ключей пакетов, вы можете теперь добавить официальный репозиторий пакета RabbitMQ для Ubuntu. Приводимая ниже команда добавит новый файл в надлежащее местоположение, дополняя для использования репозиторий RabbitMQ:
echo "deb http://www.rabbitmq.com/debian/ testing main" \
> /etc/apt/sources.list.d/rabbitmq.list
Теперь, после настройки репозитория RabbitMQ вам нужно добавить ключ Erlang Solutionsв свою базу данных доверенных ключей:
apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv \
D208507CA14F4FCA
После завершения apt-key вы увидите что он импортировал ключ “Erlang Solutions Ltd.
<packages@erlang-solutions.com>”
Теперь добавим соответствующую настройку Erlang Solutions Ltd.:
echo "deb http://packages.erlang-solutions.com/debian precise contrib" \
> /etc/apt/sources.list.d/erlang-solutions.list
Разместив на своих местах конфигурации и ключи, для синхронизации локальной базы пакетов и чтобы разрешить вам установку RabbitMQ выполните следующую команду
apt-get update
Теперь вы можете установить Erlang и RabbitMQ. Пакет rabbitmq-server автоматически разрешит
зависимости Erlang и установит надлежащие пакеты.
apt-get install –y rabbitmq-server
По завершению данной команды вы получите поднятым и запущенным RabbitMQ, но вам требуется выполнить ещё несколько команд чтобы включить соответствующий подключаемый модуль и разрешить ему подключаться как к порту AMQP, так и к интерфейсу управления.
Настройка RabbitMQ
RabbitMQ содержит всю необходимую функциональность как для управления самим сервером, так и применением федерализации, однако по умолчанию они
не включены. Самым первым шагом в настройке нашего экземпляра RabbitMQ состоит во включении того подключаемого модуля, который входит в поставку
RabbitMQ, который и позволит установить и воспользоваться его возможностями федерализации. Для того чтобы сделать это примените команду
rabbitmq-plugins:
rabbitmq-plugins enable rabbitmq_management rabbitmq_federation \
rabbitmq_federation_management
Начиная с RabbitMQ 3.4.0 это автоматически загружает необходимые подключаемые модули без необходимости перезапуска нашего брокера. Однако вы
пожелаете разрешить своему пользователю по умолчанию guest позволять регистрацию с IP адресов, относящихся
к localhost. Для того чтобы сделать это, вам следует создать файл настроек RabbitMQ в
/etc/rabbitmq/rabbitmq.config со следующим содержимым:
[{rabbit, [{loopback_users, []}]}].
loopback_users
service rabbitmq-server restart
Чтобы предотвратить путаницу впоследствии, когда вы будете использовать обе ВМ, вы можете обновить название своего кластера при помощи
команды rabbitmqctl. Когда вы используете имеющийся интерфейс управления, установленное название кластера
отображается в верхнем правом углу. Для установки этого названия через командную строку выполните такую команду:
rabbitmqctl set_cluster_name cluster-a
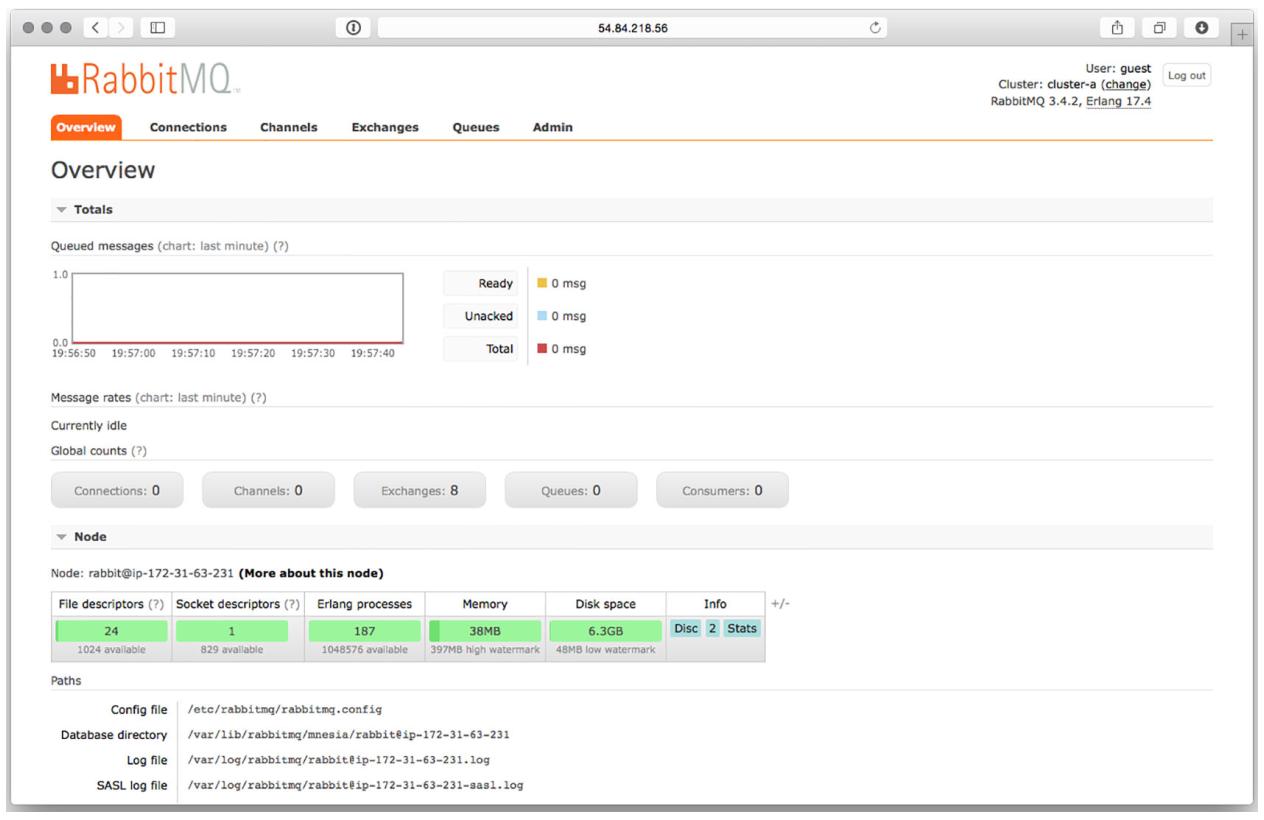
Теперь вы можете проверить то, что данные установка и настройки работают. Откройте интерфейс управления в своём браузере применив IP адрес
нашего экземпляра EC2 с портом 15672 в таком формате URL: http://[Public IP]:15672. После того как вы
зарегистрировались в качестве пользователя guest с паролем
"guest", вы должны увидеть экран общего обзора
(Рисунок 8-10).
Имея созданным свой первый экземпляр, вы можете применить инструментальную панель Amazon EC2 для создания некоторого образа из исполняемого экземпляра, который вы только что создали, и примените этот образ для запуска некоего дубликата ВМ. Этот новый образ сделает простым раскрутку новых, предварительно настроенных, обособленных серверов RabbitMQ для проверки федеративных возможностей RabbitMQ.
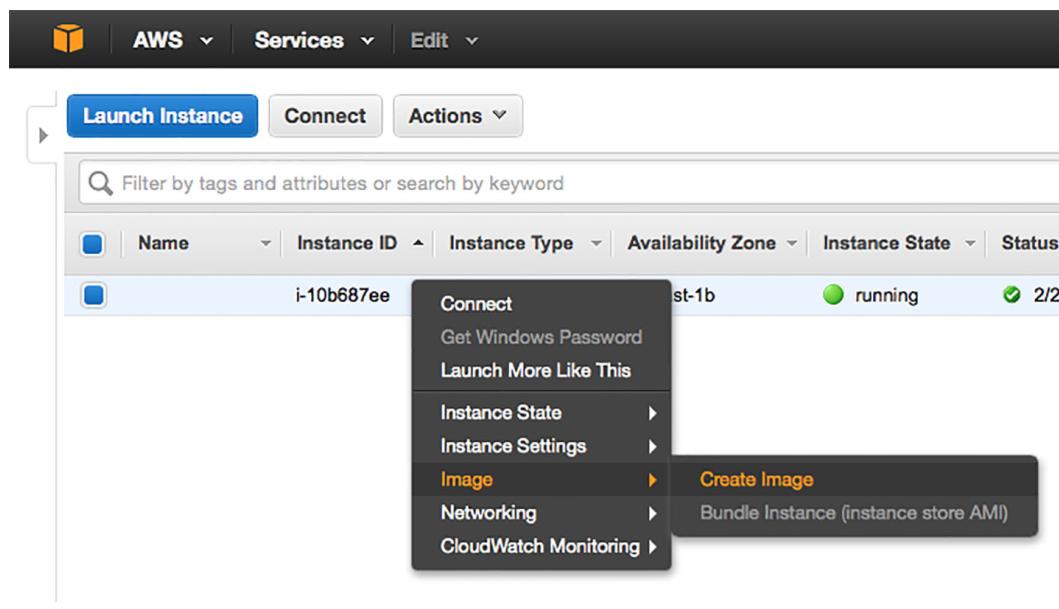
Вместо того чтобы дублировать все предыдущие шаги по созданию отдельного экземпляра RabbitMQ, давайте заставим Amazon проделать эту работу. Для выполнения этого вам требуется сообщить EC2 о необходимости создать некий новый образ или AMI из нашего запущенного экземпляра, который вы только что создали.
Перейдите в инструментальную панель EC2 Instances в своём веб браузере, и кликните по этому запущенному экземпляру. При этом всплывёт контекстное меню, позволяющее вам исполнять команды с этим экземпляром. В этом меню перейдите в Image > Create Image (Рисунок 8-11).
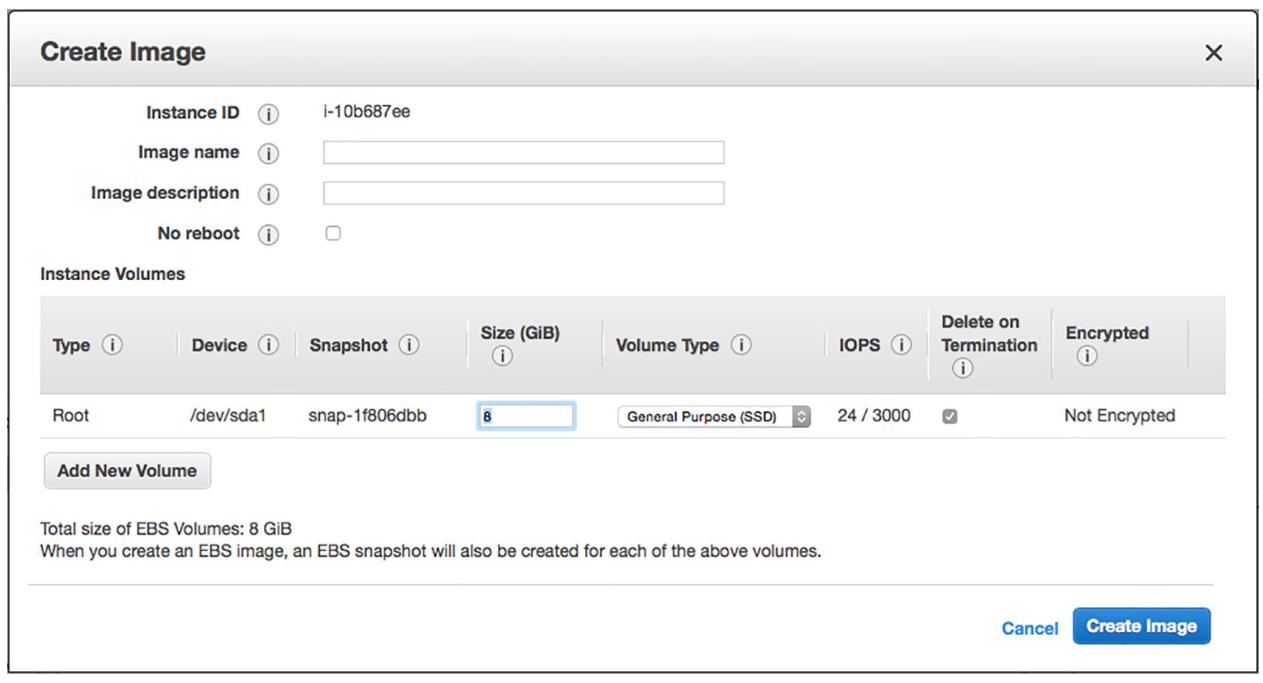
После того как вы выберите Create Image возникает всплывающий блок диалога, который позволит вам установить опции для создания необходимого образа. Задайте название образа и оставьте прочие опции как есть. Когда вы кликните по кнопке Create Image, имеющаяся ВМ будет остановлена и соответствующий дисковый образ для данной ВМ будет применён для создания нового AMI (Рисунок 8-12).
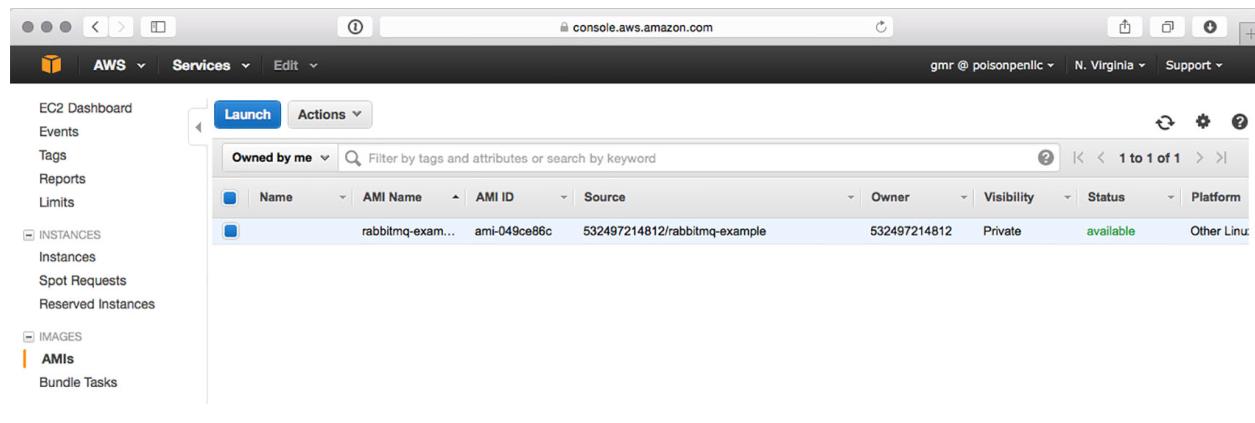
Когда ваша система создаст необходимый моментальный снимок файловой системы вашей оригинальной ВМ, она автоматически будет запущена, а задача создания нового AMI будет поставлена в очередь в системе Amazon. чтобы данный AMI стал доступен для применения потребуется несколько минут. Вы можете проверить полученное состояние кликнув опцию Images > AMIs в боковом поле навигации (Рисунок 8-13).
После того как AMI стал доступным, выберите его в своей инструментальной панели AMI и затем кликните по кнопке Launch в его верхней полосе кнопок. Это запустит для вас второй шаг создания необходимой ВМ. Вы пройдёте все те шаги, которые вы проходили при создании своей первоначальной ВМ, но вместо создания новых политики безопасности и пары ключей SSH выберите те, которые вы уже создали для своей первой ВМ.
Когда вы завершите свои шаги по созданию своей ВМ, переместитесь обратно в инструментальную панель экземпляров EC2. Дождитесь когда созданный
экземпляр станет доступным, выпишите его общедоступный адрес IP. Когда он запустится, вы должны получить возможность подключиться к нему через
свой веб браузер по порту 15672 при помощи URL в формате http://[Public IP]:15672. Зарегистрируйтесь в его
интерфейсе управления и замените название кластера на "cluster-b", кликнув по ссылке Change в верхнем правом углу и следуйте за
инструкциями на той странице, к которой вы будете отосланы
(Рисунок 8-14).
Такое изменение названия сделает простым различение того на каком из серверов вы зарегистрированы при использовании вашего интерфейса управления.
Имея оба экземпляра EC2 поднятыми и запущенными вы готовы к установке федерализации между этими двумя узлами. Хотя мы применяем в данном примере Amazon EC2 в одной и той же зоне для обоих узлов, федерализация разработана для надлежащей работы в средах, в которых может возникать сетевая фрагментация, позволяя RabbitMQ совместно применять сообщения по центрам обработки данных, располагающихся на значительном географическом удалении.
Для того чтобы с чего- то начать, давайте применим федерализацию для копирования сообщений с одного узла на другой.
Будете ли вы рассматривать применение федерализации для доставки сообщений по Центрам обработки данных, или вы применяете федерализацию для бесшовной миграции ваших потребителей и издателей в новый кластер RabbitMQ, вы начинаете вс одного и того же места: настройки восходящего потока. Хотя сам узел восходящего потока отвечает за доставку получаемых сообщений в соответствующий узел нисходящего потока, именно в этом узле нисходящего потока и происходит сама настройка.
Настройка федерализации имеет две части: настройку самого восходящего потока и политики федерализации. Во- первых, сам узел нисходящего потока настраивается при помощи информации, требуемой для того чтобы этот узел выполнил соединение AMQP с соответствующим узлом восходящего потока. Затем создаются политики, которые применяются к подключениям к восходящему потоку и опциям настройки обменов и очередей нисходящего потока. Отдельный сервер RabbitMQ может иметь множество восходящих потоков и множество политик федерализации.
Чтобы начать получать сообщения с соответствующего узла восходящего потока, cluster-a, в узле
нисходящего потока, cluster-b, вы вначале должны определить сам восходящий поток в имеющемся интерфейсе
управления RabbitMQ.
По завершению установки подключаемый модуль федерализации добавляет две новые закладки Администрирования в имеющемся интерфейсе управления RabbitMQ Federation Status и Federation Upstreams. Хотя экран состояния будет пустым пока вы не создадите политик, которые настраивают обмены или очереди для применения федерализации, закладка же Federation Upstreams (Рисунок 8-15) является самым первым местом, в котором вам следует запускать весь процесс настройки.
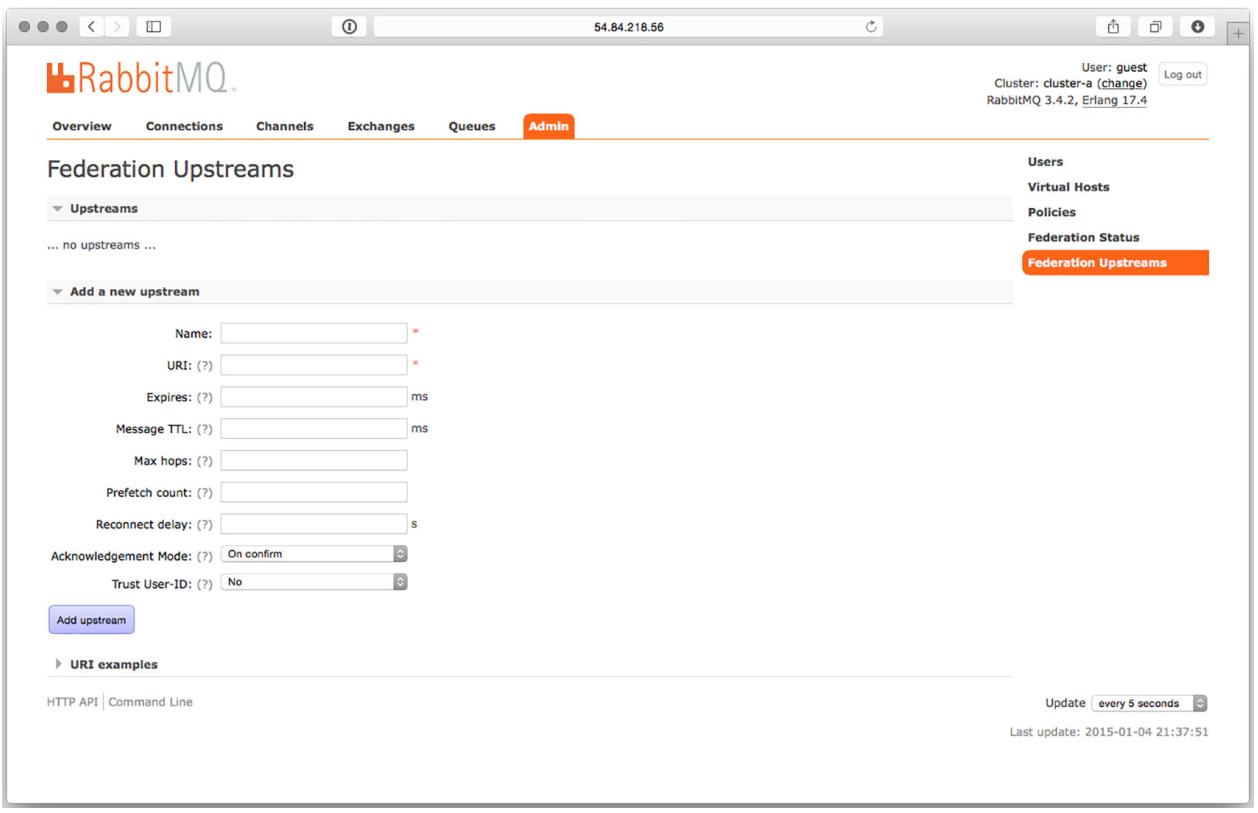
Имеется множество опций для добавления нового соединения с восходящим потоком, однако необходимым для такого соединения является лишь его название и URI AMQP. В промышленной среде вы скорее всего пожелаете настроить также и прочие опции. Если эти опции кажутся вам знакомыми, так это потому что они представляют комбинацию опций, которые доступны при определении очереди и для потребления сообщений. Для своего первого соединения с восходящим потоком оставьте их незаполненными и позвольте RabbitMQ применять установки по умолчанию.
Чтобы определить информацию соединения для конкретного узла восходящего потока, введите соответствующий URI AMQP для его удалённого сервера. Такое определение URI AMQP делает возможной гибкую настройку данного соединения, в том числе возможность подстройки интервала сердцебиений, максимальный размер кадра, порт подключения, имя пользователя и пароль, а также многое другое. Полная спецификация для установленного синтаксиса URI AMQP, включая все доступные параметры запроса, доступны на вебсайте RabbitMQ. Так как применяемая нами среда тестирования настолько упрощена, насколько это возможно, вы можете применять имеющиеся по умолчанию установки для всего за исключением названия хоста и его URL.
В вашей тестовой среде тот узел, который представляет cluster-b будет действовать как узел нисходящего
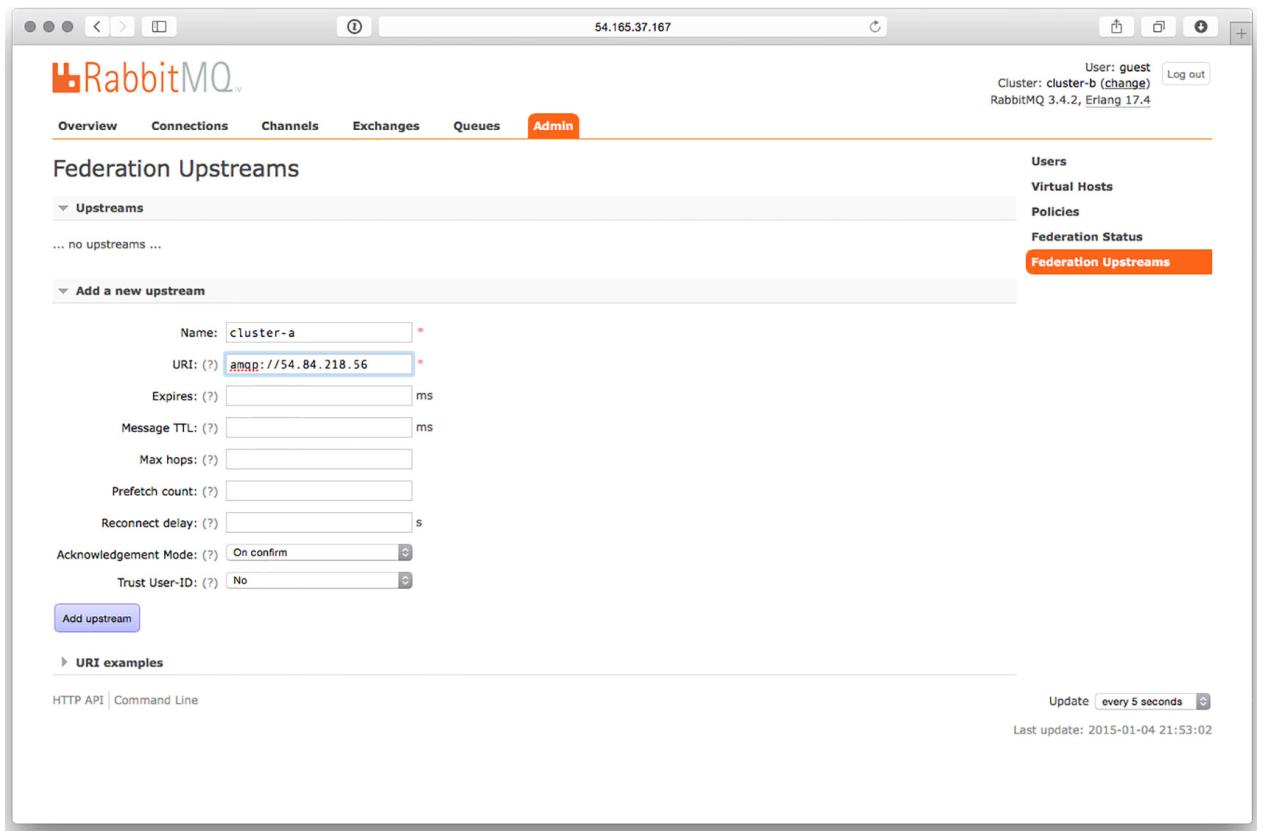
потока и он подключается к соответствующему узлу, который представляет cluster-a. Откройте в своём веб
браузере интерфейс управления и перейдите в закладку Federation Upstreams в соответствующем разделе Admin. Раскройте раздел Add a New Upstream и
введите в качестве имени своего восходящего потока cluster-a. В качестве его URI введите
amqp://[Public IP], заменив [Public IP] IP адресом своего
первого узла, который вы установили в данной главе
(Рисунок 8-16).
Вводимая здесь информация определяет отдельное соединение с другим узлов RabbitMQ. Это соединение не будет применяться пока не будет создана политика, которая будет ссылаться на имеющийся восходящий поток. Когда применена политика использования данного восходящего потока, ваш подключаемый модуль федерализации подключится к этому узлу восходящего потока. Если он отключится вследствие ошибки маршрутизации или по причине иного сетевого события, установленное по умолчанию поведение попытается восстанавливать соединение раз в секунду; вы можете изменить такое поведение при определении своего восходящего потока в поле Reconnect Delay. Если вы желаете изменить его уже после того как вы создали некий восходящий поток, вам следует удалить и создать этот восходящий поток повторно.
После того как вы ввели требуемые название и URI кликните Add Upstream для сохранения настройки данного восходящего потока в RabbitMQ. После добавления вашего восходящего потока вы можете определить необходимую политику и проверить федерализацию на основе обмена.
|
| Замечание |
|---|---|
|
Хотя приводимые в этой главе примеры для создания узлов восходящего потока используют имеющийся интерфейс управления, вы также можете применять
приложения HTTP API управления и CLI |
Настройка федерализации управляется с помощью системы политик RabbitMQ, которые предоставляют гибкий способ динамической настройки необходимых правил, которые сообщают самому подключаемому модулю что необходимо делать. Когда вы создаёте политику, вначале вы определяете название политики и некий шаблон. Такой шаблон может либо вычислять строку для прямого соответствия, либо он может определять некое регулярное выражение (regex) шаблона для установки соответствия объектам RabbitMQ. Данный шаблон может сравниваться с обменами, очередями или же одновременно и с обменами, и с очередями. Политики также могут определять некий приоритет, который используется для установки того какая политика должна применяться для соответствующих множеству политик очередей или обменов. Когда некая очередь или обмен соответствуют множеству политик, выигрывает политика с наивысшим уровнем приоритета. Наконец, некая политика имеет таблицу определений, которая делает возможным определение пар ключ/ значение.
В качестве первого примера вы создадите политику с названием federation-test, которая выполняет
проверку на равенство с неким обменом, имеющим название test
(Рисунок 8-17).
Чтобы сообщить своему подключаемому модулю федерализации что вы желаете федерализовать обмен из восходящего потока
cluster-a, введите некий ключ federation-upstream с соответствующим
значением cluster-a в задаваемой таблице определений. После того как вы введёте эту информацию, кликните
кнопку Add Policy для добавления её в вашей системе.
Рисунок 8-17
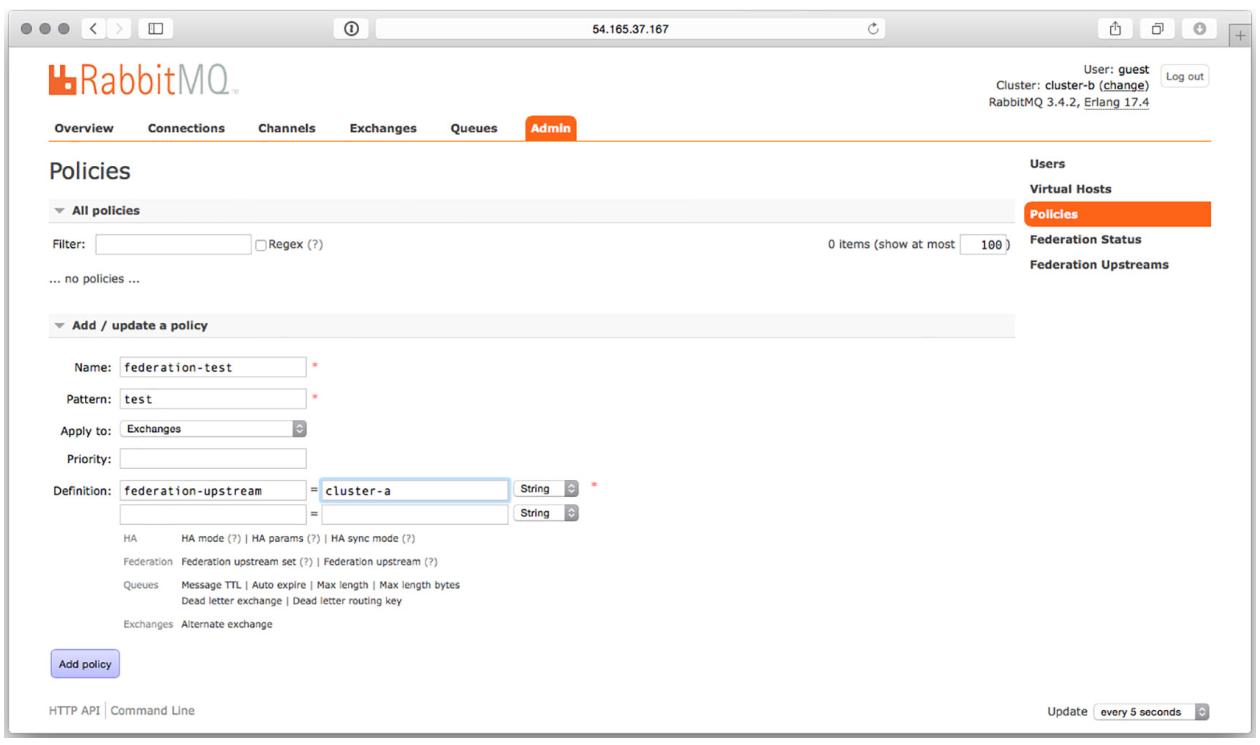
Добавление новой политики с применением узла Восходящего потока федерализации
cluster-a.
После добавления политики вам требуется добавить в обоих узлах соответствующий обмен test. Для добавления
необходимых обменов вы можете воспользоваться закладкой Exchanges в каждом из интерфейсов управления. Чтобы не допустить того чтобы узел
cluster-b пытался выполнять федерализацию не существующего обмена в узле cluster-a,
вначале объявите необходимый обмен в кзлеcluster-a. Вы можете применить любой из встроенных типов обмена, но
я рекомендую воспользоваться предметным обменом для гибкости при проведении экспериментов. Какой бы вы тип не выбрали, вам следует придерживаться
согласованности и применять тот же самый тип обмена для создаваемых обменов test и в
cluster-a, и в cluster-b.
Когда вы добавили обмены в обоих узлах, вы можете заметить закладке Exchanges интерфейса управления в узле cluster-b
что его обмен test имеет метку, соответствующую установленной политике федерализации в колонке Features
(Рисунок 8-18).
Эта пометка указывает что вы успешно установили соответствие данной политики своему обмену.
Рисунок 8-18
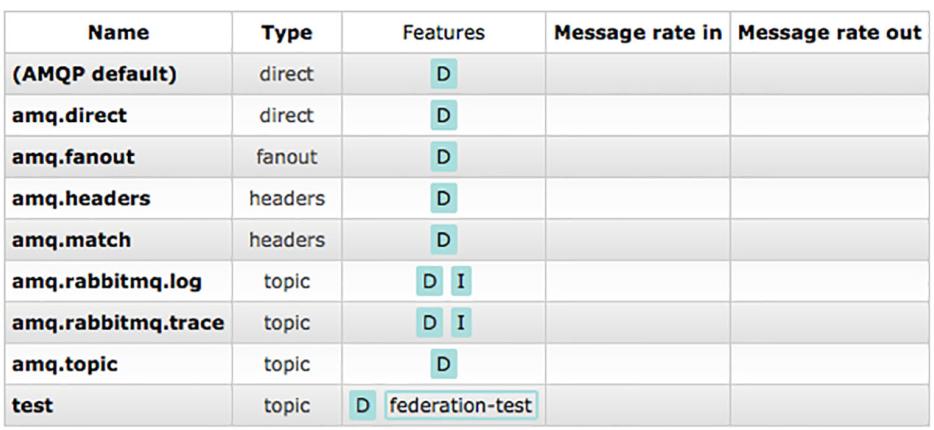
Таблица Обменов, показывающая что ваш обмен
test имеет применённой к нему политику
federation-test.
После того как вы убедились что ваша политика применена корректно, проверьте установленное состояние федерализации чтобы проверить что ваш узел
cluster-b смог подключиться к своему восходящему потоку, cluster-a.
Кликните по закладке Admin, а затем элемент справа в меню Federation Status чтобы просмотреть всё ли настроено должным образом. Если всё работает,
вы должны обнаружить таблицу с единственной записью, а именно с cluster-a в колонке Upstream. Колонка
State должна указывать что ваш восходящий поток исполняется
(Рисунок 8-19).
Рисунок 8-19
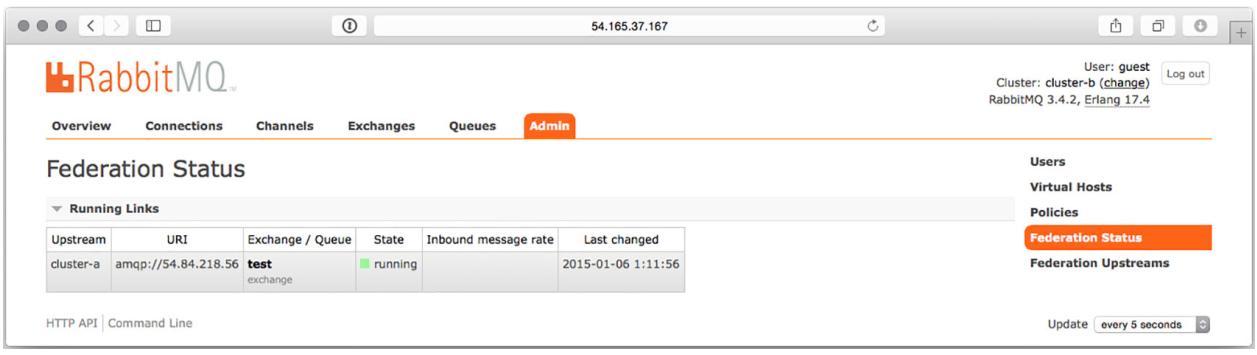
Страница Состояния федерализации, указывающая что что ваш Восходящий поток
cluster-a запущен для обмена
test.
Теперь, когда вы проверили что RabbitMQ полагает что всё настроено и запущено как требуется, вы можете проверить публикацию сообщений в
cluster-a и получить их установленными в очередь в cluster-b.
Чтобы сделать это, создайте некую очередь для проверки в cluster-b и свяжите её с установленным обменом
test при помощи ключа связывания demo. Это настроит привязку и
локально в cluster-b, и для самой федерализации сообщений чтобы проверить обмен в
cluster-a.
Переключитесь в интерфейс управления для cluster-a и выберите обмен test
в соответствующей закладке Exchanges. В соответствующей странице обмена test раскройте раздел
Publish Message. Введите ключ маршрутизации demo и какое- либо по вашему желанию содержимое в поле Payload.
Когда вы кликните по кнопке Publish Message, это сообщение будет опубликовано в своём обмене test и в
cluster-a, и в cluster-b, и оно должно быть установлено в очереди в
вашей очереди проверки в cluster-a.
Воспользовавшись имеющимся интерфейсом управления для cluster-b переместитесь в закладку Queues и
затем выберите свою очередь проверки. Раскройте раздел Get Message и кликните по кнопке Get Message(s), после чего вы увидите своё сообщение
опубликованным в cluster-a
(Рисунок 8-20).
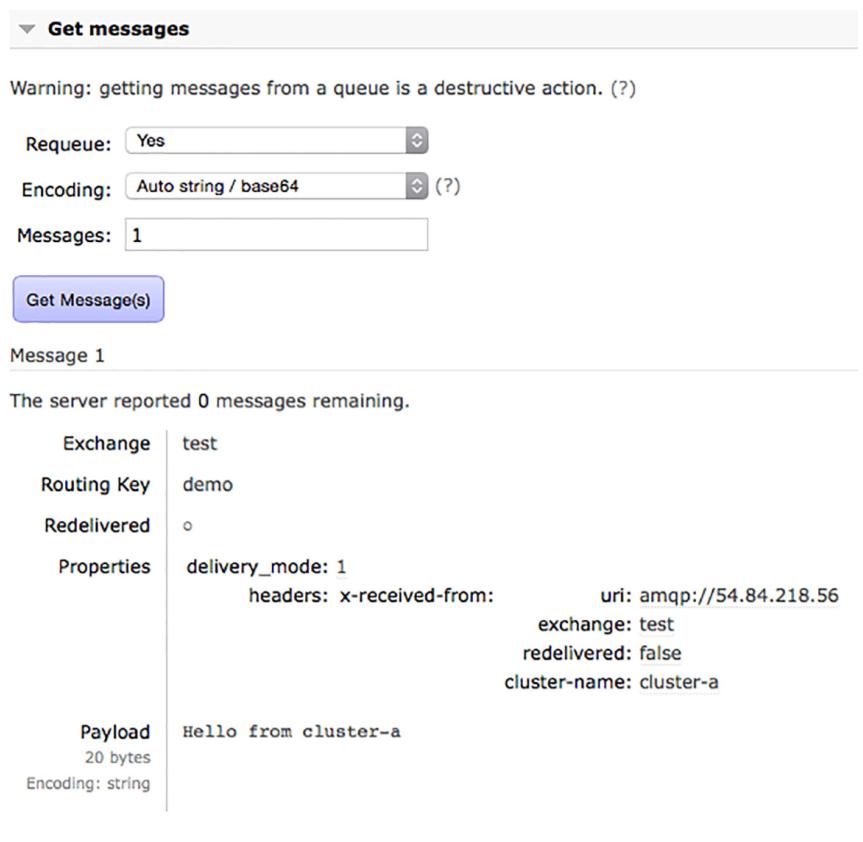
В помощь идентификации сообщений, которые распространяются посредством федерализации, ваш подключаемый модуль федерализации добавляет поле
x-received-from к значению таблицы headers в свойствах данного
сообщения. Значением этого поля является таблица ключ/ значение, которая содержит uri,
exchange, cluster-name, а также некий флаг, указывающий является ли
данное сообщение redelivered.
Помимо определения индивидуальных узлов восходящего потока подключаемый модуль федерализации предоставляет и возможность группировать множество узлов воедино для их использования в некоторой политике. Такая функциональность группирования обеспечивает достаточное снижение непостоянства относительно того как вы определяете топологию федерализации.
Предоставление избыточности
В качестве примера представим себе узел вашего восходящего потока как часть некоторого кластера. Вы можете создать некий набор восходящего потока, который определяет все узлы в данном кластере восходящего потока, предоставляя гарантию того, что если любой из узлов падает, публикуемые в этом восходящем потоке сообщения не будут потеряны в нисходящем потоке (Рисунок 8-21).
Рисунок 8-21
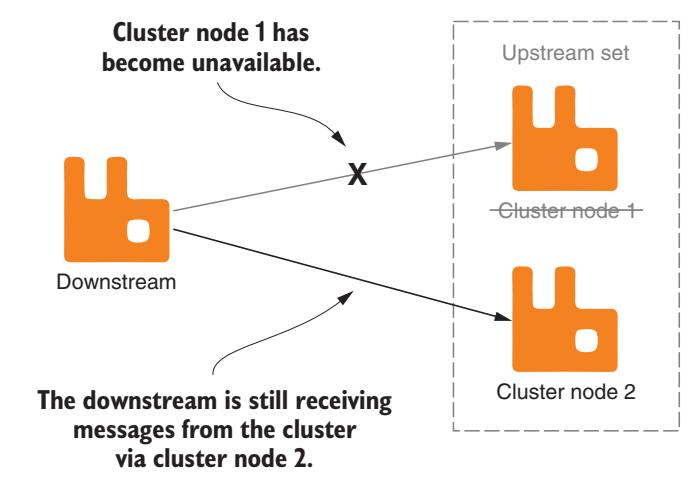
Некий набор кластера может предоставлять избыточность для взаимодействия с собранными в кластер узлами восходящего потока.
Если вы используете федеративные обмены в кластере нисходящего потока, в том случае, когда отказывает один из подключённых к вашему восходящему потоку узлов в своём кластере, другой узел автоматически примет на себя его роль, подключившись к восходящему потоку.
Географически распределённые приложения
Более сложный сценарий может включать в свой состав географически распределённый веб приложения. Допустим, что вы преследуете решение задачи разработки какой- то службы, которая записывает обзоры баннерной рекламы. Основная цель состоит в обслуживании всех баннеров так быстро, как это возможно с тем, чтобы данное приложение было развёрнуто по всему миру, а основывающаяся на DNS балансировка нагрузки применяется для распределения общего обмена по ближайшим центрам обработки данных для каждого конкретного пользователя. Когда ваш пользователь просматривает данную рекламу, сообщение публикуется в каком- то локальном узле RabbitMQ, который действует как федерализованный узел восходящего потока для централизованной системы обработки. Такой централизованный узел RabbitMQ имеет определённой некий набор федерализованного восходящего потока, который содержит необходимый сервер RabbitMQ в каждом из географически распределённых местоположений. По мере поступления сообщений в каждое из местоположений, они транслируются в свой центральный сервер RabbitMQ и обрабатываются потребляющими приложениями (Рисунок 8-22).
Рисунок 8-22
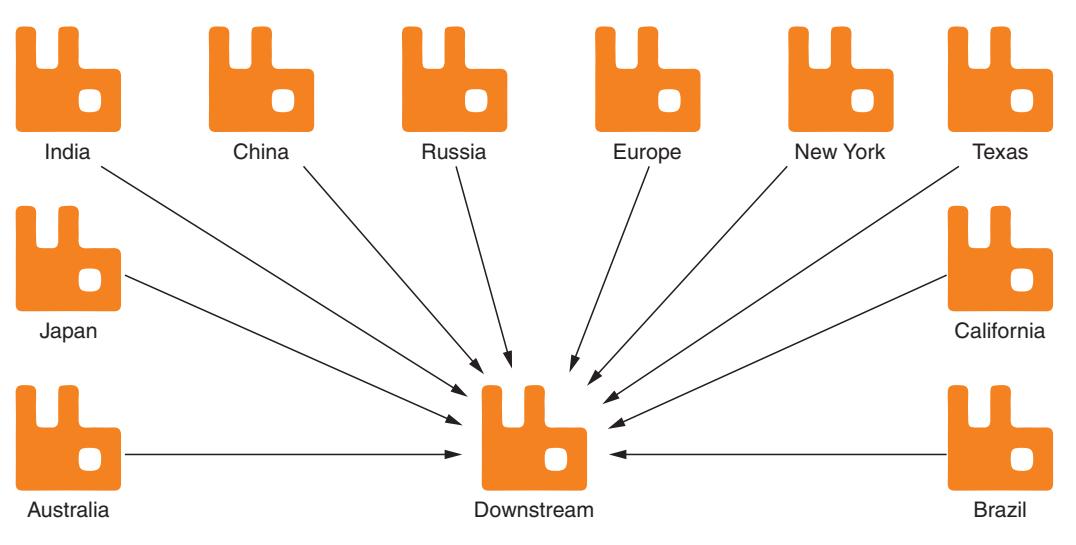
Географически распределённые восходящие потоки в некотором наборе для соответствующих узлов нисходящего потока.
Благодаря подобному клиентскому поведению федерализации подключаемый модуль делает возможными отказы соединения, причём если какой- то из географически распределённых узлов отключается, это не влияет на обработку обмена в остальной части системы. Если это проблема только региональной маршрутизации, все имеющиеся в его очереди с такого отключившегося восходящего потока будут доставлены после того как его нисходящий поток получит возможность повторно подключиться.
Создание набора восходящего потока
Для создания набора восходящего потока вначале определите все узлы восходящего потока либо через интерфейс управления, либо через
приложение CLI rabbitmqctl. Поскольку не существует никакого интерфейса для создания наборов восходящего
потока в общем интерфейсе управления федерализацией, вам придётся применять инструмент командной строки
rabbitmqctl. Как и при любом другом применении rabbitmqctl
вы обязаны исполнять его локально в том узле RabbitMQ, в котором вы желаете выполнять настройку и от имени того пользователя, который имеет
доступ к куки Erlang RabbitMQ, который мы обсудили в разделе 7.2.2.
Имея на руках список узлов восходящего потока, создайте некую строку JSON, которая содержит полный перечень всех имён, которые вы применяете
для создания данных определений восходящего потока. Например, если вы создаёте восходящие потоки с названиями
a-rabbit1 и a-rabbit2, вы создаёте следующий фрагмент JSON:
[{"upstream": " a-rabbit1"}, [{"upstream": " a-rabbit2"}]
Затем, чтобы определить некий набор восходящего потока с названием cluster-a, запустите команду
rabbitmqctl set_parameter, которая позволит вам определить
federation-upstream-set с названием cluster-a.
rabbitmqctl set_parameter federation-upstream-set cluster-a \
'[{"upstream": " a-rabbit1"}, {"upstream: " a-rabbit2"}]'
После того как необходимый восходящий поток определён, вы можете ссылаться на него по названию при создании политики федерализации при
помощи ключа federation-upstream-set для определения соответствующей политики вместо использования
ключа federation-upstream, который вы применяете для ссылки на индивидуальный узел.
Также следует отметить, что имеется также некоторое устанавливаемое по умолчанию определение набора восходящего потока с названием
all, которое не требует никаких настроек. Как вы можете ожидать, данный набор
all будет содержать все заданные федерализованные восходящие потоки.
До сих пор примеры в данной главе охватывали распространение сообщений от обмена восходящего потока к обмену нисходящего потока, однако федеративные обмены могут настраиваться и в двух направлениях.
При двунаправленной настройке сообщения могут публиковаться в любом из узлов и с применением установленной по умолчанию конфигурации они
будут направляться на каждый узел. Такая установка может регулироваться настройкой max-hops
в соответствующих установках восходящего потока. Установленное по умолчанию значение 1 для
max-hops предотвращает зацикливания сообщения при котором получаемые из некоторого узла восходящего потока
сообщения по циклу отправляются обратно в тот же самый узел. Когда вы применяете некий федерализованный обмен в котором все узлы выступают друг
для друга и как узел восходящего потока, и как узел нисходящего потока, публикуемые в каждом из узлов сообщения будут направляться во все узлы,
аналогично тому как маршрутизация сообщения ведёт себя в кластере
(Рисунок 8-23).
Рисунок 8-23
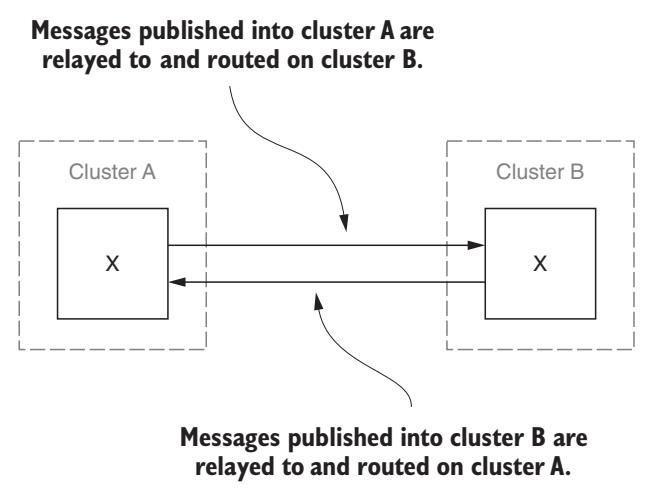
Публикуемые в одном из узлов двунаправленного федеративного обмена будут отправляться во все узлы
Такой тип поведения федерализации работает как положено при создании устойчивой к отказам структуры приложений со множеством центров обработки данных. Вместо того чтобы разделять данные между центрами обработки данных или местоположениями, такой тип федерализации делает возможным для каждого местоположения принимать одни и те же сообщения для обработки данных.
Хотя это очень мощный способ предоставления службы с высокой доступностью, он также и создаёт дополнительную сложность. При попытке сохранять
согласованным просмотр данных по различным положениям при применении федерализации, необходимо рассматривать все сложности и проблемы,
связанные с базами данных со множеством хозяев (multi-master databases). Становится очень важным управление согласованностью для гарантии того,
чтобы при воздействии на данные оно осуществлялось бы согласованно во всех местоположениях. К счастью, федерализованные обмены могкт предоставить
некий простой способ достижения согласованности сообщений в разных местах. Не лишним будет отметить, что это поведение не ограничивается двумя
узлами и может быть настроено в некотором графе, в котором все узлы соединены со всеми остальными узлами
(Рисунок 8-24).
Как и при установке с двумя узлами, настройка max-hops в 1 для
некоторого восходящего потока предотвратит от зацикливания публикации сообщений в рассматриваемом графе.
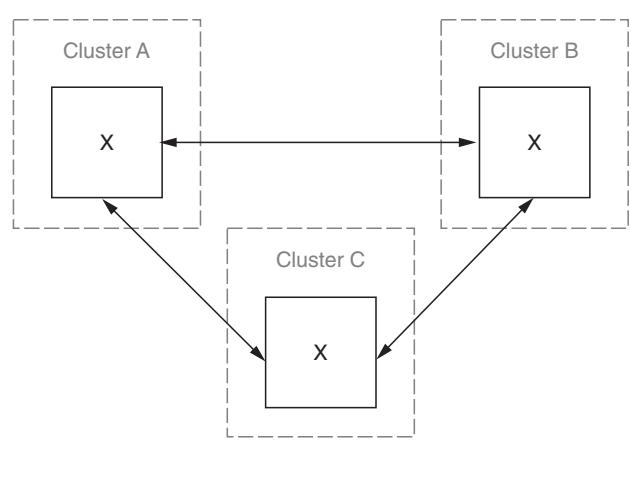
Важно понимать, что как и в любой иной структуре с графами, чем больше узлов вы добавляете, тем более сложным становится положение вещей. Как и во всех аспектах реализации ориентированной на сообщения архитектуры, вы должны проводить эталонное тестирование производительности своего решения перед его размещением в производство. К счастью, облачные поставщики услуг, такие как Amazon, имеют разные зоны доступности, поэтому строить и тестировать сложные среды федерации с помощью RabbitMQ не так сложно.
Одной из наиболее сложных проблем работы при рассмотрении управления кластером RabbitMQ состоит в обработке обновлений в промышленной среде, в которой простои являются нежелательными. Существует множество стратегий для обслуживания такого сценария.
Если ваш кластер достаточно крупный, вы можете перенести обмен с одного из узлов, удаляя его из своего кластера и обновить его. Затем вы можете вывести в оффлайн другой узел, удалить его из этого кластера, обновить его и добавить его в новый кластер, состоящий из того узла, который был удалён первым. Вы продолжаете тасовку по всему кластеру подобным образом, выводя злы один за другим, пока они не будут все удалены, обновлены и повторно добавлены в обратном порядке. Если ваши издатели и потребители хорошо выносят повторные подключения, такой подход может сработать, но он трудоёмкий. В качестве альтернативы, при условии что у вас имеются ресурсы для настройки зеркала установки данного кластера с новой версией своего кластера, федерализация может предоставить бесшовный способ миграции вашего обмена сообщениями с одного кластера на другой.
При применении федерализации как средства обновления RabbitMQ, вы начинаете с раскрутки своего нового кластера, создания той же самой конфигурации времени исполнения в вашем новом кластере, включая виртуальные хосты, пользователей, обмены и очереди. После того как вы установили и настроили свой новый кластер, добавьте необходимую конфигурацию федерализации, включающую установление соответствия символами подстановки для всех обменов всем восходящим потокам и политикам. Затем вы можете начать миграцию своих приложений потребления, заменяя их подключения со старого кластера на новый (Рисунок 8-25).
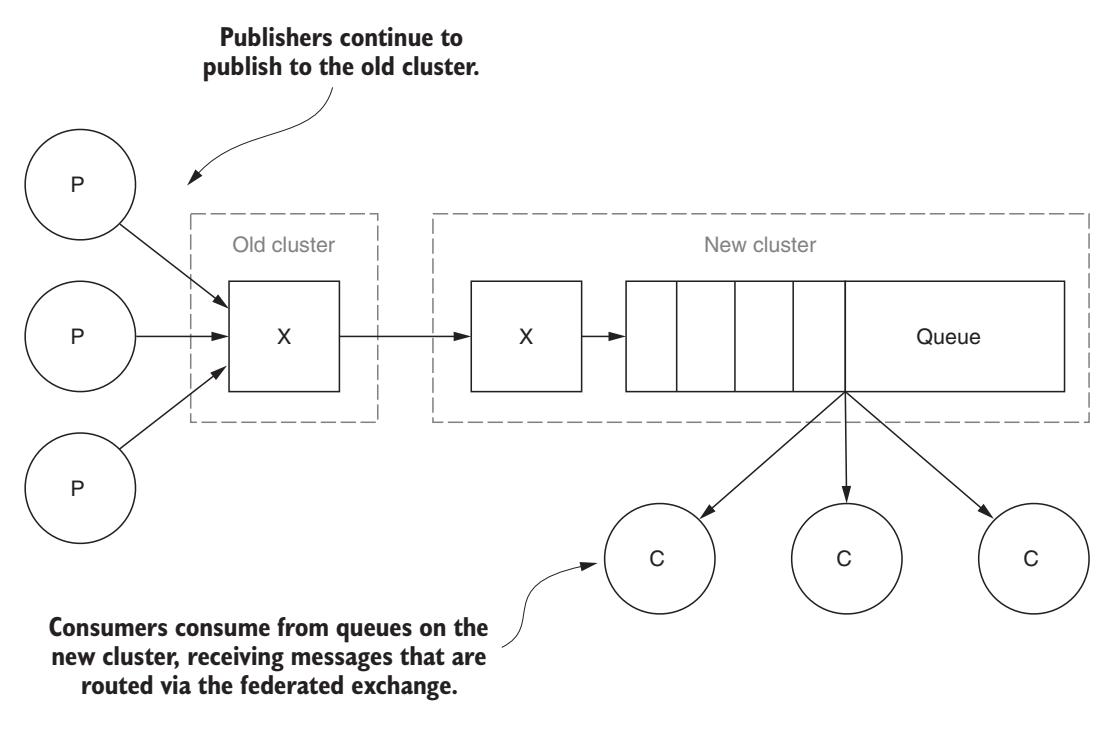
Так как вы выполняете миграцию всех потребителей из очереди, вам надлежит отвязать эту очередь от своего старого кластера, но при этом не удаляйте её. Вместо этого вы можете создать некую временную политику в своём новом кластере для федерализации этой очереди, переместив все сообщения из старого кластера в новый. Целесообразно автоматизировать данный процесс как только это возможно, потому что вы хотите свести к минимуму вероятность дублирования сообщений при их добавлении в очереди своего нового кластера из- за применения как федерализованного обмена, так и федерализованной очереди.
После того как вы завершите перемещение всех потребителей и вы отвяжете все очереди от своего старого кластера, вы можете выполнить миграцию издателей. Когда все ваши издатели были перемещены, вам следует выполнить полную миграцию на свой обновлённый кластер RabbitMQ. Конечно, вы можете пожелать оставить данную федерализацию включённой чтобы убедиться что что никакие беглые издатели не подключатся к старому кластеру в то время когда они не должны этого делать. Это позволит вам сохранять своё приложение в правильно работающем состоянии и вы можете воспользоваться журналами регистрации RabbitMQ в узлах своего старого кластера чтобы отследить соединения и отключения. Несмотря на то, что подключаемый модуль федерализации изначально и не был предназначен для этой цели, он доказал себя в качестве идеального инструмента для обновлений с нулевым временм простоя.
Предоставляемые подключаемым модулем федерализации гибкость и мощность ограничиваются только важим воображением. Если вы ищите прозрачную миграцию обмена с одного кластера RabbitMQ на другой, или вы желаете создать приложение со множеством Центров обработки данных, которое разделяет сообщения между узлами, данный подключаемый модуль федерализации является надёжным и действенным решением. Будучи горизонтально масштабируемым инструментом, федерализуемые очереди предоставляют некий способ гигантского увеличения общей ёмкости отдельной очереди путём определения её в некотором узле восходящего потока и в любом числе узлов нисходящих потоков. Объединяясь с кластеризацией и очередями высокой доступности, федерализация не только позволяет сосуществование сетевых фрагментов между кластерами, но также предоставляет и устойчивость к отказам в случае, если возникают отказы либо в наборе восходящего потока, либо в кластерах нисходящего потока.
А отказы на самом деле происходят. В нашей следующей главе вы изучите множество стратегий для мониторинга и выдачи предупреждений когда что- то пошло не так.