Введение RabbitMQ на самом начальном этапе разработки некоего приложения является реальным форсирование для вашего прикладного решения. Однако код больше не сваливается командами "за оградой" где- то в инфраструктуре производства; выступая в роли разработчиков мы несём ответственность за хорошее понимание его установки в нашей инфраструктуре.
Эта часть данной книги имеет дело с применением RabbitMQ в кластерах: установка кластера, изучение его поведения, а также управление им. Мы также рассмотрим распределение сообщений и репликации по всему веб интерфейсу: имеющему дело с федеративными обменами и очередями, которые делают возможным физическое разделение на два или более кластера, а также выполнение репликаций между этими кластерами.
Глава 7. Масштабирование RabbitMQ в кластерах
Содержание
Эта глава обсуждает
-
Управление кластером
-
Как местоположение очереди влияет на производительность
-
Все шаги, входящие в состав установки кластера
-
Что делать когда падает узел
Являясь брокером сообщений, RabbitMQ является исключительным для автономных приложений. Однако поддержка вашего приложения нуждается в дополнительных гарантиях доставки, которой удовлетворяет лишь высокая доступность. Или может быть вы желаете применять RabbitMQ в качестве центрального хаба обмена сообщениями для множества приложений. Встроенный в RabbitMQ возможности кластеризации предоставляют надёжную, образующую единое целое среду, которая может занимать множество серверов.
Я начну с описания самих свойств и поведения кластеров RabbitMQ, а затем мы установим кластер RabbitMQ из двух серверов в среде виртуальных машин (ВМ) Vagrant. Кроме того вы изучите насколько важно размещение очередей для производительности кластера и как настраивать очереди с высокой доступностью. Вы также изучите то, как работает кластеризация RabbitMQ на нижнем уровне и какие ресурсы серверов являются наиболее важными для гарантии производительности и стабильности. Под занавес этой главы вы ознакомитесь с тем как восстанавливаться после крушений и отказов узла.
Кластер RabbitMQ создаёт бесшовный обзор RabbitMQ для двух или более серверов. В кластере RabbitMQ состояние времени исполнения содержит обмены, очереди, связывания, пользователей, виртуальные хосты и политики, доступные во всех узлах. Благодаря такому разделению состояния времени исполнения каждый узел в кластере может выполнять связывание, публикацию или удаление обмена, который был создан при подключении на своём первом узле. (Рисунок 7-1).
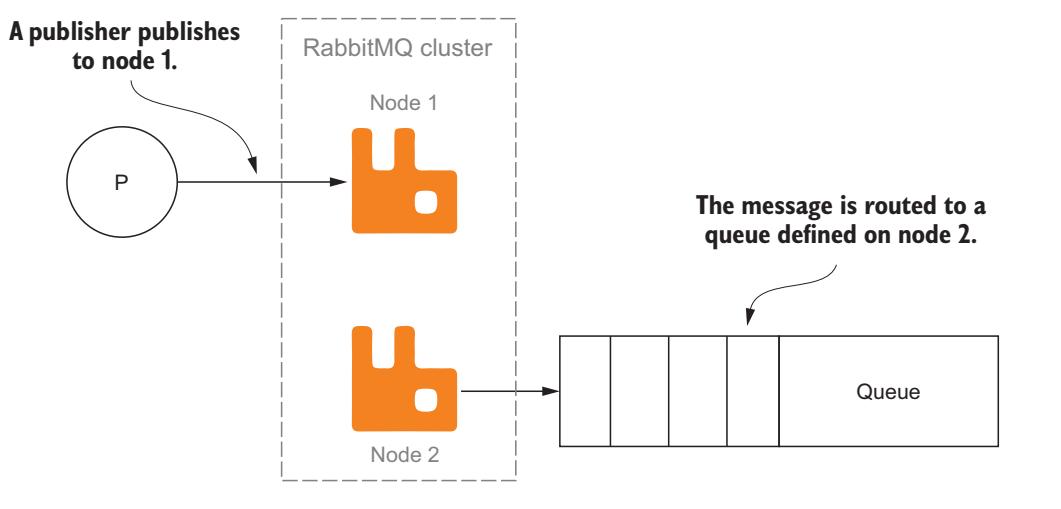
Образующие единое целое кластеры RabbitMQ создают интригующий способ масштабирования RabbitMQ. Помимо этого кластеры предоставляют механизм, который позволяет вам создавать некое структурированное решение для ваших издателей и потребителей. В больших кластерных средах нет ничего необычного в наличии узлов, полностью посвящающих себя определённым задачам или очередям. Например, у вас могут присутствовать узлы кластера, которые действуют исключительно как публикующие интерфейсы и прочие которые применяются исключительно для очередей и потребителей. Если вы собираетесь создать в своей среде RabbitMQ устойчивость к отказам, кластер предоставляет исключительный способ создания очередей с высокой доступностью (HA). Очереди с высокой доступностью распространяются на множество узлов кластера и совместно используют синхронное состояние очереди, включая данные сообщения. Если вдруг какой- то из узлов очереди упадёт, остающиеся в этом кластере узлы всё ещё продолжат свой обмен сообщениями и поддержку состояния очереди. Когда отказавший узел воссоединится снова с очередью, такой повторно подключившийся узел стане полностью синхронным только тогда, когда добавленные во время его простоя сообщения будут потреблены.
несмотря на огромные преимущества использования встроенной кластеризации RabbitMQ, важно осознавать имеющиеся в кластеризации RabbitMQ ограничения и недостатки. Во- превых, кластеры предназначены для сред с низкой латентностью. Вам никогда не следует создавать кластеры RabbitMQ поверх WAN или Интернет соединений. Синхронизация состояний и передача сообщений между узлами требует взаимодействия с низкой латентностью, которая может достигаться только в локальных сетевых средах. Вы можете исполнять RabbitMQ в облачных средах подобных Amazon EC2, однако не поверх различных зон. Для синхронизации сообщений в средах с высокой латентностью вам понадобиться рассмотреть имеющийся инструментарий Shovel и Federation, обозначаемый в нашей следующей главе.
Другой важной проблемой при рассмотрении кластеров RabbitMQ является размер кластера. Общие работа и накладные расходы сопровождения совместно используемого состояния кластера находятся в прямо пропорциональной зависимости к общему числу узлов в имеющемся кластере. К примеру, использование API управления для сбора статистических данных в большом кластере может происходить значительно длиннее чем в отдельно взятом узле. Такие действия могут быть лишь настолько быстрыми, как это допускает самый медленный узел {Прим. пер.: 1-ый закон Амдала}. В сообществе RabbitMQ общепринято называть верхней границей в кластере значение в 32 или 64 узла. Помните, что при добавлении всякого нового узла в кластер вы добавляете и сложность синхронизации данного кластера. Каждый узел в кластере должен знать обо всех прочих узлах в этом же кластере. такое нелинейное поведение усложнения может замедлять доставку сообщений между узлами и управление кластером. К счастью, даже при наличии такой сложности UI (User Interface, интерфейс пользователя) управления кластера может обрабатывать большие кластеры.
UI (интерфейс пользователя) управления RabbitMQ построен для выполнения всех тех же самых действий в кластере, которые он выполняет в каком- то отдельном узле и он является великолепнейшим инструментом для понимания ваших кластеров RabbitMQ после их создания. Обзорная страница UI управления содержит информацию верхнего уровня о кластере RabbitMQ и его узлах (Рисунок 7-2).

В выделенной области на Рисунке 7-2 узлы кластера перечисляются в колонках, которые описывают их общие жизнеспособность и состояние. По мере того как вы добавляете в кластер узлы, они будут добавляться в эту таблицу. В больших кластерах данная таблица может требовать большего времени для обновления, причём всякий раз вызывается API для получения этой информации, опрашиваются все узлы в вашем кластере для обновления информации перед возвратом отклика.
Тем не менее, прежде чем погружаться глубже в UI управления относительно кластеров, важно понимать все типы узлов в кластере RabbitMQ.
В кластере RabbitMQ имеется множество видов узлов с различным поведением. Когда в кластер добавляется некий узел, он поступает с одним из двух первичных обозначений: дисковый узед или узел с оперативной памятью.
Дисковые узлы сохраняют имеющееся состояние времени исполнения кластера и в оперативной памяти и на диске. В RabbitMQ состояние времени исполнения содержит текущие определения обменов, очередей, связываний, виртуальных хостов, пользователей и политик. По этой причине в кластерах с большими объёмами состояния реального времени операции дискового ввода/ вывода могут быть более проблематичными в дисковых узлах, нежели работа с узлами оперативной памяти.
Узлы с оперативной памятью хранят такую информацию состояния времени исполнения только в базе данных оперативной памяти (in- memory).
Типы узлов и оставление сообщений
Назначение дисковому узлу или узлу оперативной памяти не управляет поведением оставляемого сообщения. Когда некое сообщение помечается как
оставляемое (persistent) в своём свойстве сообщения delivery-mode, это сообщение будет записано на диск в любом
случае, вне зависимости от типа используемого узла. По причине этого следует обращать внимание на то воздействие, которое имеют дисковые операции
ввода/ вывода на ваши узлы кластера RabbitMQ. Если вам требуются оставляемые сообщения, вам следует предоставлять дисковую подсистему, которая
способна обрабатывать скорость записи, требуемую тем очередям, которые обитают в ваших узлах кластера.
Типы узлов и поведение при крушении
Если некий узел или кластер падают, для восстановления текущего состояния времени исполнения вашего кластера будут применяться дисковые узлы как только они повторно присоединятся к своему кластеру. Узлы оперативной памяти, с другой стороны, не будут содержать никаких данных состояния времени исполнения при их присоединении к кластеру. В процессе повторного присоединения к кластеру прочие узлы будут отправлять ему свою информацию, такую как определения очередей.
Вам всегда следует иметь по крайней мере один дисковый узел при создании кластера, а в некоторых случаях и больше. Наличие более одного дискового узла в кластере может предоставлять большую надёжность в случае возникновения множественных отказов. Однако наличие множества дисковых узлов может быть обоюдоострым мечом при некоторых сценариях отказов. Если у вас имеется множество отказавших узлов в кластере с двумя дисковыми узлами, которые не достигли соглашения о своих разделяемых состояниях данного кластера, вы будете иметь проблемы при попытке восстановления данного кластера в его предыдущее состояние. В случае возникновения такой ситуации может помочь останов всего кластера и перезапуск имеющихся узлов в ином порядке. Запустите свой дисковый узел с более правильными данными состояния, а затем добавляйте прочие узлы. Позднее в этой главе мы обсудим дополнительные стратегии поиска неисправностей и восстановления кластеров.
Состояния узлов
Если вы применяете подключаемый модуль rabbitmq-management , существует ещё один тип узла, который работает только в объединении с дисковыми узлами: узел статистики. Такие узлы статистики отвечают за выборку всех статистических данных и данных состояния со всех узлов в кластере. Только один узел в кластере может быть таким узлом статистики в любой конкретный момент времени. Хорошей стратегией для крупных установок кластера является наличие выделенного узла управления, который является вашим первичным дисковым узлом и определённого узла статистики, а также иметь ещё один дисковый узел для предоставления возможностей отказоустойчивости (Рисунок 7-3).
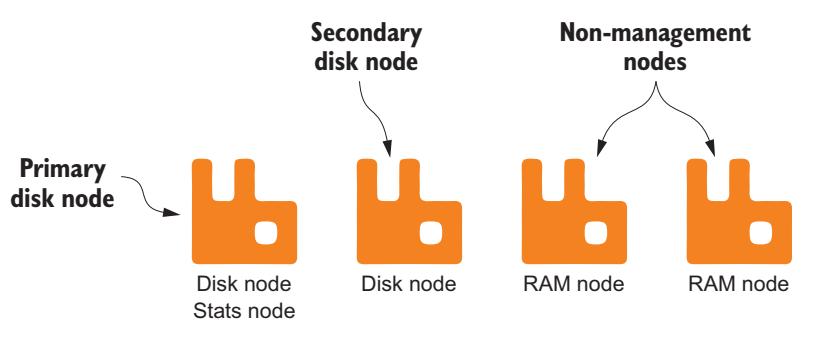
В зависимости от частоты и использования API управления, а также объёма применяемых в RabbitMQ ресурсов, для управления API-интерфейсом может потребоваться ЦПУ c высокой стоимостью. Запуск выделенного узла управления гарантирует что доставка сообщений не замедляет сбор статистики, а сбор статистики не влияет на скорость доставки сообщений.
при топологии кластера с двумя дисковыми узлами, в случае отказа первичного узла назначение вашего узла статистики будет передано второму дисковому узлу. Если этот первичный дисковый узел вернётся обратно, он не подключится повторно к узлу статистики пока вторичный дисковый узел с назначенным ему статистическим узлом не будет остановлен или не покинет данный кластер.
Наличие узла статистики играет важную часть в управлении вашими кластерами RabbitMQ. Без присутствия подключаемого модуля rabbitmq-management и узла статистики может быть сложно получать широкое видение производительности, соединений, глубины очередей и проблем в работе.
Опубликованное в любом узле кластера сообщение будет должным образом направляться в некую очередь вне зависимости от того где эта очередь присутствует в данном
кластере. Когда некая очередь объявлена, она создаётся в том узле кластера, куда был отправлен RPC запрос Queue.Declare.
В каком именно узле определена очередь, может иметь воздействие на пропускную способность и производительность сообщений. некий узел с очень большим числом
очередей, издателей и потребителей может оказаться медленнее чем если бы эти очереди, издатели и потребители были сбалансированы по узлам в кластере.
В добавление к неравномерному распределению использования ресурсов, невнимательность к местоположению очереди в кластере может влиять как на публикацию,
так и на потребление.
Вопросы публикации
Вы можете узнать Рисунок 7-4, который слегка изменён в сравнении с рисунком из Главы 4. При издании в кластер данная шкала становится ещё более важной чем в случае с отдельным сервером RabbitMQ.
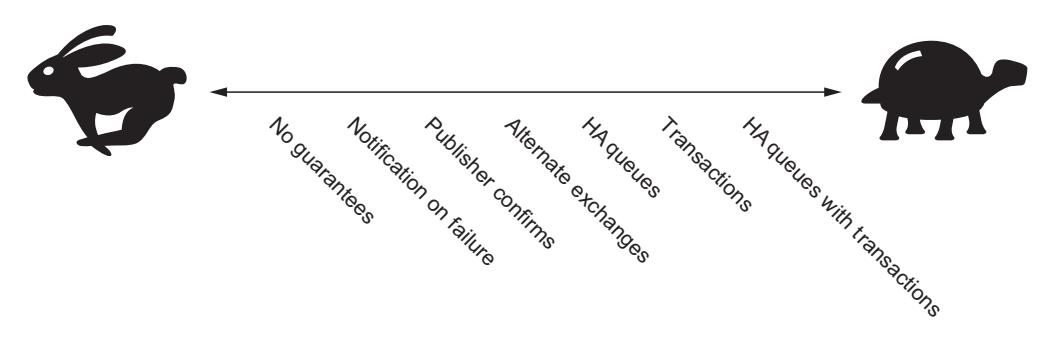
По мере вашего перемещения слева направо по указанной шкале усиливается объём взаимодействия между узлами в кластере. Если вы публикуете сообщения в одном узле, которые направляются в очередь на другом, эти двум узлам приходится выполнять координацию в методах для обеспечения доставки.
В качестве примера рассмотрим Рисунок 7-5, который иллюстрирует логические шаги публикации сообщений среди узлов с применением подтверждений издателю.
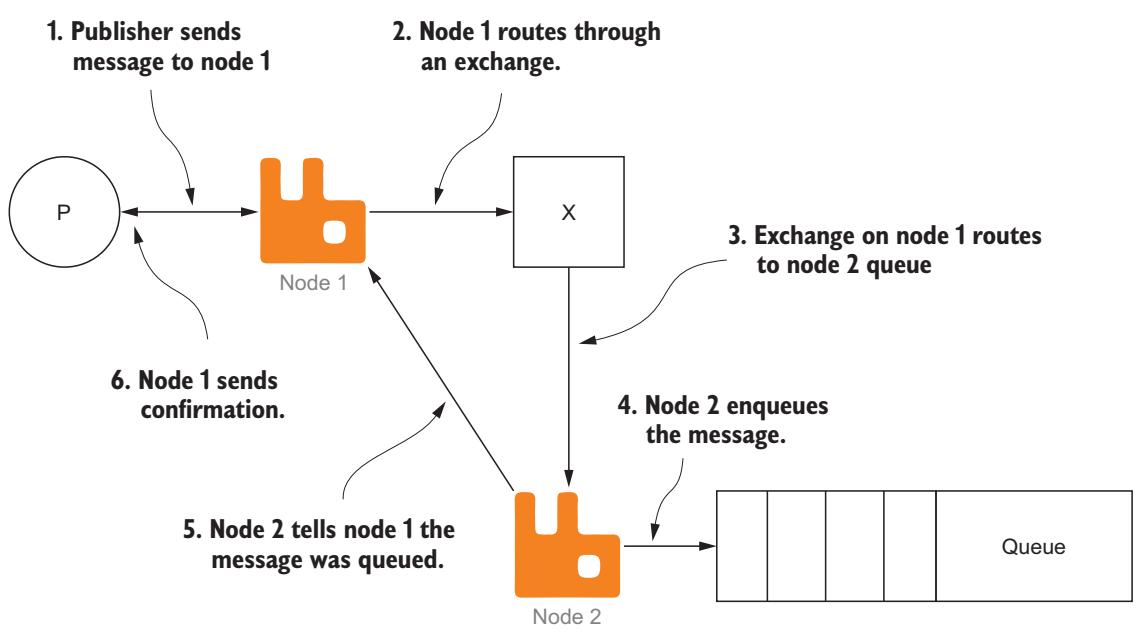
Хотя приводимые на Рисунке 7-5 шаги и не будут значительно снижать пропускную способность сообщений, вам следует учитывать сложность поведения подтверждения при создании решения с высокой доступностью. Осуществляйте эталонное тестирование различных методов с издателями и потребителями в различных узлах и отслеживайте как лучше организовать работу в вашем случае. Пропускная способность может не быть наилучшим указателем успешности реализации решения обмена сообщениями; плохая производительность определённо окажет отрицательное воздействие.
Как и в случае с отдельным узлом, публикация это всего лишь одна сторона монеты когда дело касается пропускной способности сообщения. Кластеры также могут оказывать также и воздействие на пропускную способность потребителей.
Специфичные к узлу потребители
Для улучшения пропускной способности в кластере RabbitMQ пытается по возможности направлять вновь публикуемые сообщения ранее существовавшим потребителям. Однако в очередях с обратной регистрацией сообщений новые сообщения публикуются по всему кластеру в тех узлах, в которых определены их очереди. При подобном развитии событий может страдать производительность когда вы подключаете некоего потребителя к узлу, который отличается от узла, в котором определена его очередь (Рисунок 7-6).
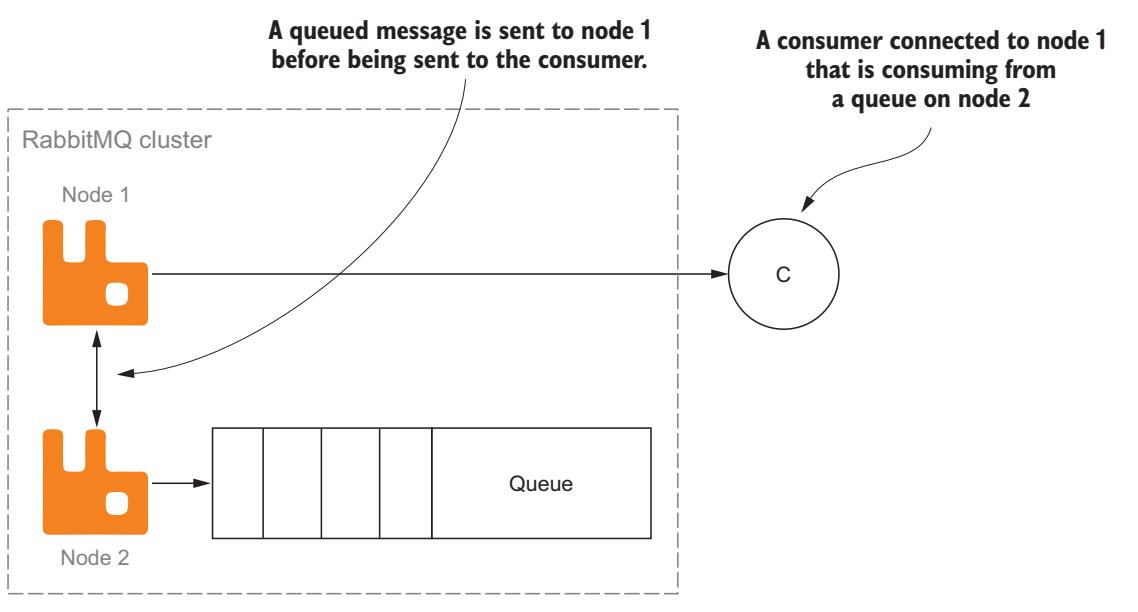
В рассматриваемом сценарии сообщения публикуются в некую очередь, размещаемую на узле 2, а потребитель подключён к узлу 1. Когда сообщения выбираются из соответствующей очереди для того потребителя , который подключён к узлу 1, им следует вначале переместиться по кластеру к узлу 1 прежде чем быть доставленными своему потребителю. Если вы учтёте где обитает ваша очередь при подключении потребителя, вы можете снизить общие накладные расходы, требуемые для отправки такого сообщения его потребителю. Вместо необходимости перемещения сообщений через весь кластер к вашему потребителю, сам узел в котором обитает данная очередь может напрямую доставлять сообщения потребителям, подключаемым непосредственно в нём (Рисунок 7-7).
Рисунок 7-7
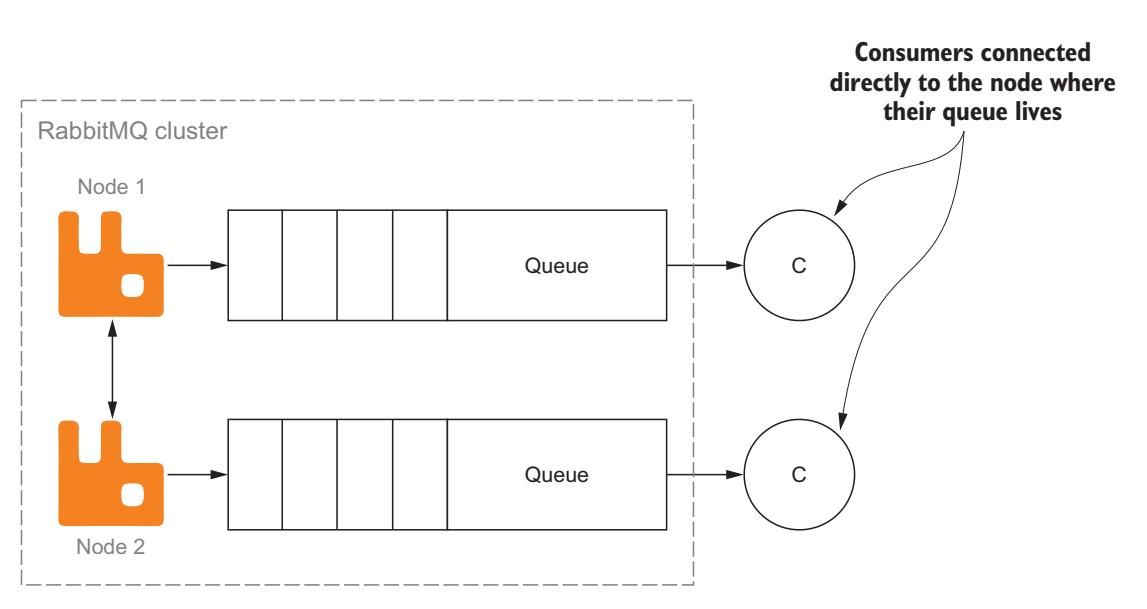
Подключаясь к тем же самым узлам, в которых обитает очередь, потребители могут наблюдать улучшение пропускной способности.
Рассматривая расположение очереди и подключая её к надлежащему узлу как потребителей, так и издателей, вы можете снижать межкластерное взаимодействие и улучшать общую пропускную способность сообщения. Издатели и потребители с высокой скоростью обнаружат громадное воздействие непосредственного взаимодействия в подходящих своим очередям узлах. Это, конечно, работает пока вы не применяете очереди с высокой доступностью.
Очереди с высокой доступностью
не должно стать сюрпризом то, что использование очередей с высокой доступностью может приводить к наказаниям в производительности. При помещении сообщения в некую очередь или при потреблении сообщения из очереди RabbitMQ должен выполнять координацию по всем узлам, в которых обитают данные очереди с высокой доступностью. Чем в большем числе узлов размещаются очереди с высокой доступностью, тем больше координации между узлами понадобится.
В больших кластерах вам следует рассмотреть сколько узлов следует применять вашей очереди прежде чем объявлять её. Если вы запросите все узлы в кластере из 24 узлов, вы скорее всего создадите колоссальную работу для RabbitMQ с очень слабым выхлопом. Поскольку очереди высокой доступности имеют некую копию всех сообщений в каждом узле, вам следует спросить себя следует ли вам применять более двух или трёх узлов для обеспечения того, чтобы никакие сообщения не терялись.
Для кластера RabbitMQ требуется два или более узлов. В данном разделе вы установите кластер при помощи ВМ Vagrant. Настройку Vagrant вы выгрузили в Дополнении A (при выполнении установки для Главы 2) имеет конфигурации лоя обеих ВМ, применяемых в последующих примерах. Наша первичная ВМ, которую вы применяли до сих пор, будет применяться в качестве самого первого сервера в создаваемом кластере и вы также будете применять и определение вторичной ВМ в Vagrnt для целей данной главы.
Чтобы начать процесс установки кластера вам придётся загрузить вторичную ВМ и зарегистрироваться в ней через безопасную оболочку.
Перейдите в то местоположение, в которое вы разархивировали файл rmqid-vagrant.zip когда устанавливали
рабочую среду этой книги. Запустите вторую ВМ, сообщив Vagrant о необходимости старта этой ВМ:
vagrant up secondary
Это запустит вторую ВМ, которую вы примените для установки и экспериментов с кластеризацией RabbitMQ. Когда завершится установка данной ВМ, вы должны обнаружить вывод, подобный приводимому на Рисунке 7-8.
Имея данную Вм запущенной, вы теперь можете открыть безопасную оболочку исполнив следующую команду Vagrant в том же самом каталоге:
vagrant ssh secondary
Теперь вы должны быть подключены к своей второй ВМ в качестве пользователя vagrant. Вам понадобится запускать
свои команды от имени пользователя root, поэтому переключитесь на пользователя root с помощью следующей команды:
sudo su –
После исполнения данной команды, то приглашение, которое вы будете наблюдать в своей безопасной оболочке изменится с
vagrant@secondary:~$ на root@secondary:~#, указывая на то, что теперь вы
зарегистрированы в качестве пользователя root в данной ВМ. Будучи пользователем root вы получаете полномочия для исполнения сценария
rabbitmqctl для взаимодействия со своим только что установленным локальным экземпляром сервера RabbitMQ.
Пора установить сам кластер.
Существует два способа добавлять узлы в кластер с помощью RabbitMQ.
Первый состоит в изменении файла настроек rabbitmq.config и определении каждого узла в кластере.
Этот метод предпочтителен если вы применяете некий инструмент автоматизации настройки, с такой как
Chef или
Puppet
{Прим. пер.: или же Ansible} и у вас имеется чётко определённый кластер с самого начала. Прежде чем вы создадите некий кластер через
rabbitmq.config, будет полезно создать его вручную.
В качестве альтернативы вы можете добавлять или удалять узлы из кластера в манере применения для конкретного случая применяя инструмент командной
строки rabbitmqctl. Этот метод предоставляет менее жёсткую структуру для изучения поведения кластера RabbitMQ и
его хорошо знать при поиске неисправностей деградировавших кластеров. Вы воспользуетесь rabbitmqctl для создания
кластера среди ВМ в данном разделе, но прежде чем сделать это, вам следует узнать кое- что о куках Erlang и об их воздействии на построение кластера
RabbitMQ.
Куки Erlang
Для взаимодействия между узлами RabbitMQ применяет встроенный механизм взаимодействия для множества узлов в Erlang. Для безопасного использования
такого взаимодействия множества узлов процессы Erlang и RabbitMQ имеют совместно применяемый файлы безопасности, именуемые куками
(cookie). Файл куки Erlang для RabbitMQ содержится в самом каталоге данных RabbitMQ.
В платформах *NIX он обычно находится в /var/lib/rabbitmq/.erlang.cookie, хотя это может меняться в зависимости
от дистрибутива и пакета. Данный файл куки содержит короткую строку и должен быть одним и тем же во всех узлах вашего кластера. Если данный файл
куки отличается на каком- то из узлов кластера, такой узел не будет способен взаимодействовать со всеми прочими.
Данный файл куки будет выработан при самом первом запуске вами RabbitMQ на любом из заданных серверов или в случае если этот файл отсутствует.
При установке своего кластера RabbitMQ вам следует убедиться что RabbitMQ не запущен и вы перезапишете свой файл куки необходимым для совместного
применения файлом куки прежде чем запустите RabbitMQ снова. Кукбуки Chef, которые устанавливают ВИ Vagrant для данной книги уже имеют установленными
необходимые куки Erlang для их соответствия на обеих машинах. Это означает, что вы можете запустить создание кластера с помощью
rabbitmqctl.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Применение |
Создание кластера для данного случая
Имея запущенным RabbitMQ на данном узле и когда вы зарегистрированы от имени пользователя root, вы теперь способны добавить необходимую ВМ второго узла, создавая некий кластер совместно с ВМ первичного узла.
Для этого вам вначале следует сообщить RabbitMQ на своём втором узле о необходимости остановиться при помощи rabbitmqctl
Вы не остановите сам по себе процесс сервера RabbitMQ, однако примените rabbitmqctl для указания
RabbitMQ прекратить внутренние процессы в Erlang чтобы позволить ему осуществить подключения. В своём терминале выполните такую команду:
rabbitmqctl stop_app
Вы должны обнаружить вывод, аналогичный такому:
Stopping node rabbit@secondary ...
...done.
Теперь, когда данный процесс остановлен, вам требуется удалить текущее состояние в данном узле RabbitMQ, заставив его забыть все данные конфигурации времени исполнения или состояние, которые он имеет. Для этого вы проинструктируете о необходимости выполнить сброс внутренней базы данных:
rabbitmqctl reset
Вы должны увидеть в качестве отклика нечто вроде:
Resetting node rabbit@secondary ...
...done.
Теперь вы можете присоединить его к своему первичному узлу и сформировать необходимый кластер:
rabbitmqctl join_cluster rabbit@primary
Это должно повлечь за собой следующий вывод:
Clustering node rabbit@secondary with rabbit@primary ...
...done.
Наконец, запустите свой сервер снова воспользовавшись следующей командой:
rabbitmqctl start_app
Вы должны обнаружить в выводе следующее:
Starting node rabbit@secondary ...
...done.
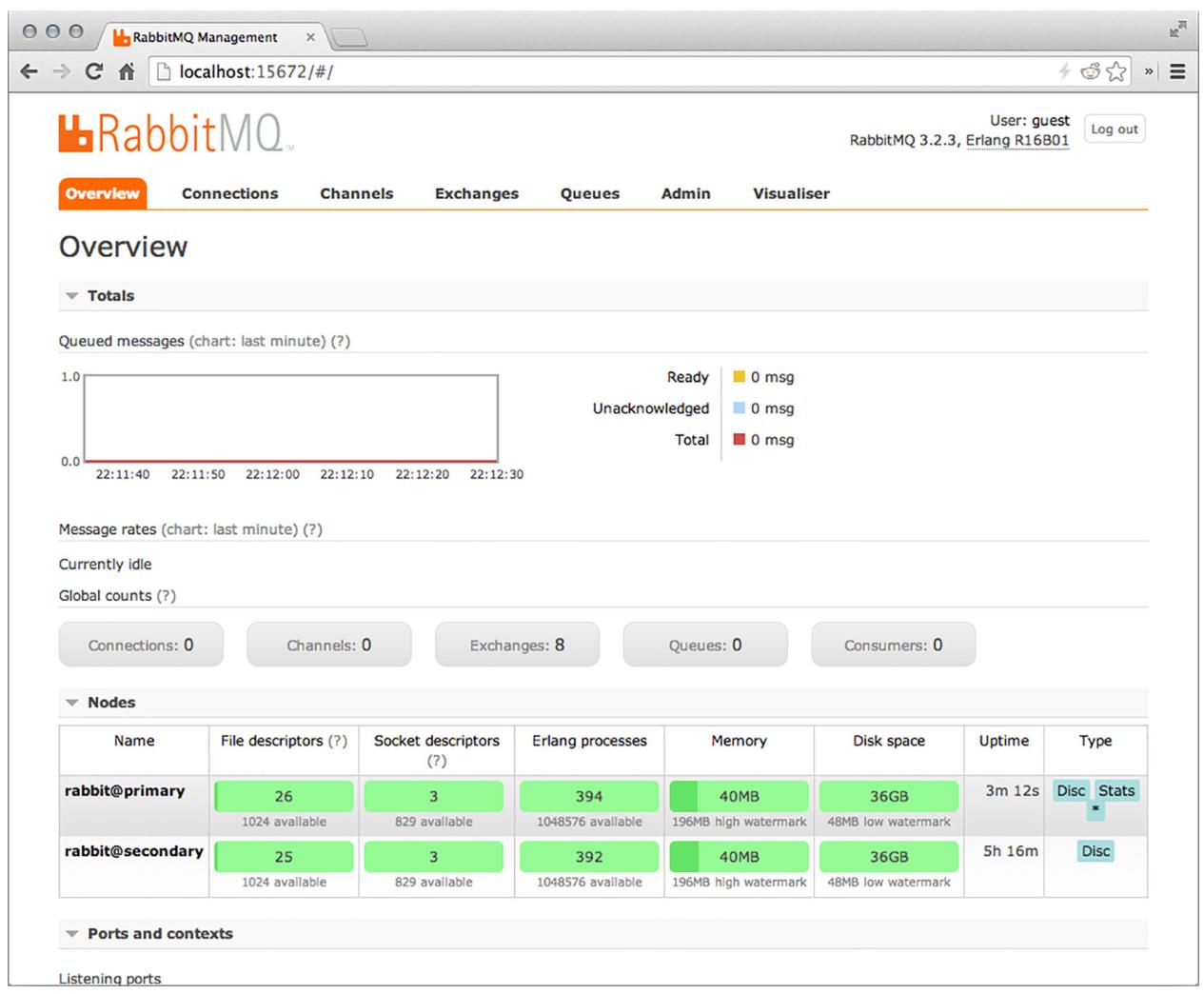
Наши поздравления! У вас теперь имеется запущенный кластер RabbitMQ из двух узлов. Если вы откроете UI управления в своём браузере с адресом http://localhost:15672, вы должны увидеть страницу Обзора, аналогичную приводиммой на Рисунке 7-9.
Кластеры на базе настроек
Создание кластера при помощи файла настроек может оказаться слегка хитроумнее. При настройке кластера с помощью
rabbitmqctl вы применили команду reset в своём сервере, сообщив ему
о необходимости забыть все его состояния и внутренние данные. При настройке кластера на основе файла настроек вы можете не делать этого, так как
RabbitMQ попытается присоединить узел к имеющемуся кластеру при запуске данного сервера. Если вы установили RabbitMQ, а сервер запущен до того
как вы создали необходимый файл настроек, в котором имеются определения для данного кластера, такой узел завершит неудачей присоединение к имеющемуся
кластеру.
Если вы применяете инструментарий управления настройками, один из способов этого состоит в создании файла
/etc/rabbitmq.config перед установкой RabitMQ. Такая новая установка не должна перезаписать предварительно
имеющийся файл настроек. В течении такой же фазы настройки хорошей мыслью является создать необходимый файл куки Erlang, который будет разделяться по
всем узлам в данном кластере.
Определение кластера в файле настроек достаточно прямолинейное. В файле /etc/rabbitmq.config имеется
строфа с названием cluster_nodes, которая несёт в себе перечень узлов в данном кластере и указывает являются ли
эти узлы дисковыми или узлами оперативной памяти. Следующий файл мог бы быть применён для определения ваших ВМ кластера, который вы создали только что:
[{rabbit,
[{cluster_nodes, {['rabbit@primary', 'rabbit@secondary'], disc}}]
}].
Если вы прмиенили эту конфигурацию в обоих узлах, они оба настроены в виде дискового узла в вашем кластере. Если вы желаете сделать свой вторичный узел
узлом оперативной памяти, вы можете заменить свои настройки, заменив ключевое слово disc на
ram:
[{rabbit,
[{cluster_nodes, {['rabbit@primary', 'rabbit@secondary'], ram}}]
}].
Недостатком настройки кластера на основе конфигурации является то, что поскольку вы делаете определения в своём файле настроек, добавление и удаление узлов потребует обновления имеющихся конфигураций на всех узлах в вашем кластере прежде чем такой узел будет добавлен или удалён. Следует также отметить, что информация кластера в конечном счёте сохраняется в виде данных состояния в определённых дисковых узлах в кластере. Определение вашего кластера в создаваемом вами файле настроек сообщает узлам RabbitMQ о необходимости присоединения к кластеру при их самом первом запуске. Это означает, что если вы измените свою топологию или настройки, это не окажет никакого влияния на членство данного узла в кластере.
Кластеризация в RabbitMQ является мощным способом масштабирования ваших решений обмена сообщениями и создания избыточности в ваших конечных точках издания и потребления. Хотя составляющая единое целое топология кластера RabbitMQ допускает публикацию и поглощение в любом из узлов в кластере, издатели и потребители должны принимать во внимание текущее местоположение имеющихся очередей с которыми они работают для достижения наивысшей пропускной способности.
В средах локальных сетей кластеры предоставляют основательную платформу для существенного роста вашей платформы обмена сообщениями, однако кластеры не предназначены для сетевых сред с высокой латентностью, таких как WAN и всемирный Интернет. Для подключения RabbitMQ узлов поверх WAN или Интернет RabbitMQ поставляется с двумя подключаемыми модулями, которые мы обсудим в нашей следующей главе.