Глава 4. Компромиссы с производительностью при публикации
Содержание
- Глава 4. Компромиссы с производительностью при публикации
- Балансировка между скоростью доставки и гарантией доставки
- Чего ожидать при отсутствии гарантии
- RabbitMQ не будет принимать немаршрутизируемые сообщения с обязательной установкой
- Подтверждение издателю как альтернатива с малым весом транзакциям
- Использование Альтернативного обмена для не выполнивших маршрут сообщений
- Пакетная обработка с транзакциями
- Обслуживание отказов узла с помощью очередей HA
- Очереди HA с транзакциями
- Оставление сообщений на диск посредством delivery-mode
- Когда RabbitMQ выталкивается обратно
- Выводы
Данная глава описывает
-
Гарантии доставки сообщения в RabbitMQ
-
Компромиссы между опубликованием и производительностью
Публикация сообщений является одной из самых центральных активностей в архитектуре на базе сообщений, причём имеется множество граней публикации сообщений в RabbitMQ. Многие из доступных вашим приложениям опций публикации сообщений могут оказывать большое воздействие на производительность и надёжность вашего приложения. Хотя любой брокер обмена сообщениями и меряется его производительностью и пропускной способностью, первостепенное значение имеет надёжная доставка сообщений. Представим что бы произошло, если бы не было гарантий при использовании вами некоего ATM для вклада денег на ваш банковский счёт. Допустим, вы внесли свои деньги без уверенности в том, что баланс вашего счёта должен возрасти. Это неминуемо должно стать задачей для вас и для вашего банка. Даже в приложениях не являющихся критически важными, когда сообщения публикуются для некоторой цели, их молчание легко может создать проблемы.
Хотя не каждая система имеет столь жёсткие требования относительно гарантий доставки сообщений, как это имеет место у банковских приложений, тем не менее, для программного обеспечения, аналогичного RabbitMQ важно гарантировать что те сообщения что он получил доставлены. Имеющаяся спецификация AMQP предоставляет транзакции для публикации сообщений, а также для необязательного оставления (persistence) сообщений с целью обеспечения более высокого уровня надёжной передачи сообщений чем обычная публикация сообщений, представляемая сама по себе. RabbitMQ имеет дополнительную функциональность, такую как подтверждение доставки, которая предоставляет различные уровни гарантии доставки для их выбора вами, включая очереди с высокой доступностью (HA, highly available), которые расширяются на множество серверов. В этой главе вы ознакомитесь с компромиссами производительности и гарантии публикации, связанные с применением такой функциональности, а также о том как определять что RabbitMQ втихую дросселирует публикацию ваших сообщений.
Когда дело доходит до RabbitMQ, к различным уровням гарантии при доставке сообщений применяется правило "Золотой середины". Вынесенное из "Сказки про трёх медведей", правило Золотой середины описывает где именно находится нечто Золотой середины, что приходится впору. Когда вам требуется надёжная доставка, вы должны применять это правило к тем компромиссам, которые возникают при использовании механизмов RabbitMQ с обязательствами. Некоторые из получаемых в этом случае свойств могут быть слишком медленными для вашего приложения, например возможность гарантии выживания сообщения после перезагрузки какого- то сервера RabbitMQ. С другой стороны публикация сообщений без запроса на предоставление дополнительных гарантий намного быстрее, хотя она может и не предоставлять достаточного окружения для критически важных приложений (Рисунок 4-1).
Рисунок 4-1
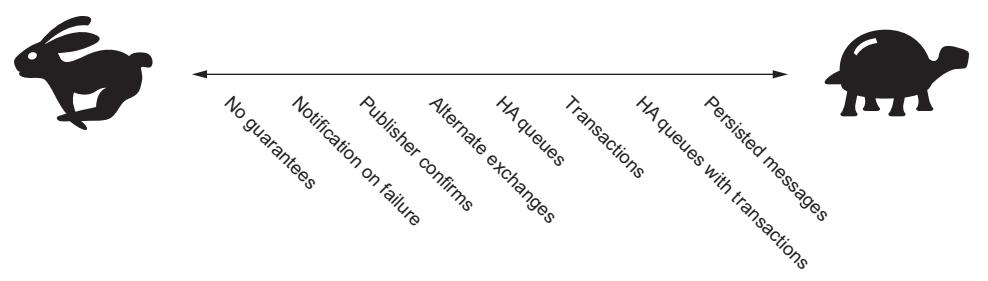
Производительность пострадает в случае применения каждого из механизмов гарантии доставки, причём в ещё большей степени когда они применяются комбинированно.
В RabbitMQ всякий спроектированный для создания гарантий доставки механизм привносит с собой воздействие на производительность. Когда они применяются сами по себе, вы можете и не заметить значительной разницы в пропускной способности, однако в случае их комбинированного использования они могут оказывать существенное влияние на пропускную способность сообщений. Только выполнив своё собственное тестирование производительности вы сможете определить приемлемый компромисс между эффективностью и гарантированной доставкой.
При создании архитектур приложений с применением RabbitMQ вы всегда должны помнить о правиле Золотой середины. Приводимые ниже вопросы могут помочь вам определить верный баланс между высокой производительностью и сохранностью сообщений для подходящего решения.
-
Насколько существенна гарантия постановки в очередь сообщения при его публикации?
-
Следует ли осуществлять возврат издателю некого сообщения если его маршрутизация на может быть выполнена?
-
Если какое- то сообщение не может выполнить перенаправление, следует ли его отправить куда- то ещё где его можно привести в соответствие позднее?
-
Допустима ли утрата сообщений в случае выхода из строя какого- то сервера RabbitMQ?
-
Должен ли RabbitMQ подтверждать что он выполнил все необходимые маршрутизации и задачи оставления (persistence) для некоего издателя после того, как он обработал сообщение?
-
Должен ли издатель иметь возможность пакетной доставки сообщений с последующим приёмом подтверждений от RabbitMQ о том, что все запрошенные маршрутизации и задачи оставления были применены ко всем имевшимся в этом пакете сообщениям?
-
Если вы помещаете необходимую публикацию сообщений в пакет, который требует подтверждения выполнения маршрутов и их оставления, есть ли потребность в истинной атомарности фиксации в очередях назначения для сообщения?
-
Имеются ли приемлемые компромиссы относительно надёжности доставки, которые ваш издатель может применять для достижения более высокой производительности и пропускной способности сообщений?
-
Какие прочие стороны публикации сообщения повлияют на пропускную способность и производительность?
В данном разделе мы рассмотрим как эти вопросы соотносятся с RabbitMQ и какие технические приёмы и функции ваши приложения могут применять для реализации подходящего уровня надёжной доставки и производительности. По ходу данной главы вам будут представлены те варианты, которые предоставляет RabbitMQ для нахождения правильного баланса между производительностью и гарантией доставки. Вы можете ткнуть и выбрать что именно является для вас наиболее существенным в имеющейся у вас среде и приложении, поскольку нет единого правильного решения. Вы можете выбрать комбинацию обязательной маршрутизации и очередей с высокой доступностью, либо вы можете придерживаться публикации с транзакцией совместно с режимом 2 доставки, оставляющим ваши сообщения на диске. Я рекомендую попробовать каждый из различных технических приёмов в вашей собственной комбинации с прочими, пока вы не отыщите некий баланс, который устроит вас - что-то подходящее вам.
В некотором исключительном мире RabbitMQ надёжным образом доставляет сообщения без каких- либо дополнительных шагов настройки. Просто публикует свои
сообщения посредством Basic.Publish в своём правильном обмене и с правильной информацией о маршрутизации, а
ваше сообщение будет приниматься и отправляться в надлежащую очередь. Нет никаких сетевых проблем, оборудование сервера надёжно и не подвержено
поломкам, а операционные системы никогда не сталкиваются с проблемами, которые могут воздействовать на состояние времени исполнения вашего брокера
RabbitMQ. Завершая вашу утопическую прикладную среду, ваши потребительские приложения никогда не сталкиваются с ограничениями на производительность при
своём взаимодействии со службами, способными замедлить их обработку. Очереди никогда не выполняют резервное копирование, а сообщения обрабатываются
сразу после их публикации. Издатели не испытывают дросселирования ни коим образом.
К сожалению, мы живём в мире, где закон Мёрфи высечен на камне, вещи, никогда не происходящие в идеальном мире случаются регулярно.
В не являющихся критически важными приложениях обычная публикация сообщений не должна обрабатывать все возможные точки отказа; поиск верного баланса составит для вас основную часть пути к надёжному и предсказуемому времени работы без отказов. В среде с обратной связью, в которой вам нет нужды беспокоиться об отказах сетевой среды и оборудования и вы не тратите время на проблему того, что потребление потребителей не достаточно быстрое, архитектура и набор свойств RabbitMQ демонстрируют уровень надёжного обмена сообщениями, который достаточно хорош для большинства приложений, не являющихся критически важными. Например, Graphite, самая популярная, высоко масштабируемая графическая система, первоначально разрабатывавшаяся Orbitz, имеет некое взаимодействие AMQP для представления ваших статистических данных в Graphite. Персональные серверы исполняют службы сбора измерений, такие как collectd, получая информацию о своих состояниях времени исполнения и публикуя информацию на основе поминутного графика (Рисунок 4-2).
Рисунок 4-2
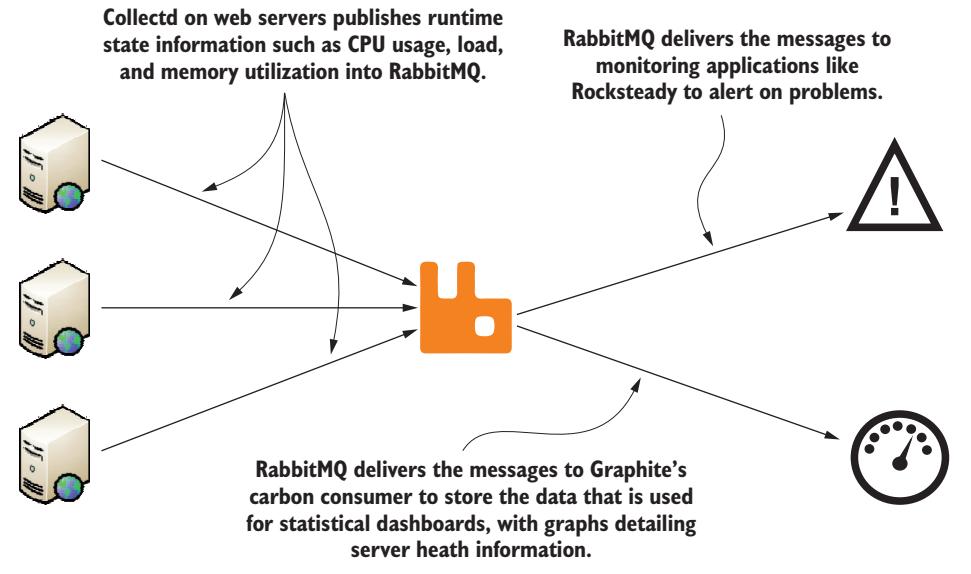
Демоны сбора информации веб сервера collectd публикуют данные мониторинга в RabbitMQ для доставки потребителям Graphite и Rocksteady.
Эти сообщения переносят такую информацию, как загруженности ЦПУ, использование оперативной памяти и сетевой среды вашего сервера. Graphite имеет службу коллектора с названием carbon, которая потребляет эти сообщения и сохраняет все данные в своём внутреннем хранилище. В большинстве сред эти данные не рассматриваются как критически важные, даже несмотря на то, что они могут быть очень существенными в общем операционном управлении вашей сетевой средой. Если данные для определённой минуты не получаются carbon и не сохраняются в Graphite, это не будет того же уровня как, скажем, в случае финансовой транзакции. Пропущенные образцы данных могут на самом деле указывать на проблему с каким- то сервером или процессом, который публикует эти данные в Graphite и могут использоваться такими системами как Rocksteady для инициации событий в Nagios или иных аналогичных приложениях для предупреждения об имеющейся проблеме.
При публикации аналогичным таким данным вам необходимо представлять себе имеющиеся компромиссы. Доставка и мониторинг данных без дополнительных гарантий публикации требует меньшего числа опций настройки, имеет меньшие накладные расходы на обработку и проще чем в случае, когда вы имеете гарантию доставки. В данном случае подходящий пример это просто установка без каких бы то ни было дополнительных гарантий доставки сообщений. имеющийся процесс collectd способен извергать сообщения и забывать о них после их отправки. Если он отключился от RabbitMQ, он попытается повторить соединение в следующий раз, когда ему понадобится отправить статистические данные. Подобным образом потребительские приложения повторят соединения когда они отключатся и вернутся обратно к потреблению из той же самой очереди, из которой они потребляли до того.
Это работает неплохо в большинстве обстоятельств, пока на сцену не выходит закон Мёрфи и что- то не начинает идти не так. Если вы желаете, чтобы ваши сообщения всегда были доставлены, RabbitMQ может изменить доставку и перейти от достаточно приемлемых к критически важным.
Если вам требуется чтобы определённый сервер выполняющий мониторинг данных всегда направлялся маршрутом к КфиишеЬЙ прежде чем collectd переместит их,
все что должны сделать collectd, так это сообщить RabbitMQ что публикация данных является mandatory.
Такой флаг mandatory является неким аргументом, который передаётся совместно с командой RPC
Basic.Publish , а также сообщать RabbitMQ, что если некое сообщение не может быть перемещено по маршруту,
то ему следует отправить данное сообщение обратно своему издателю через RPC Basic.Return
(Рисунок 4-3). Этот флаг mandatory можно
понимать как включенеи режима определение отказа; это приведёт только к тому что RabbitMQ уведомляет вас об отказах, а не об успешных доставках.
Если сообщение следует своим маршрутом должным образом, ваш издатель не уведомляется.
Рисунок 4-3
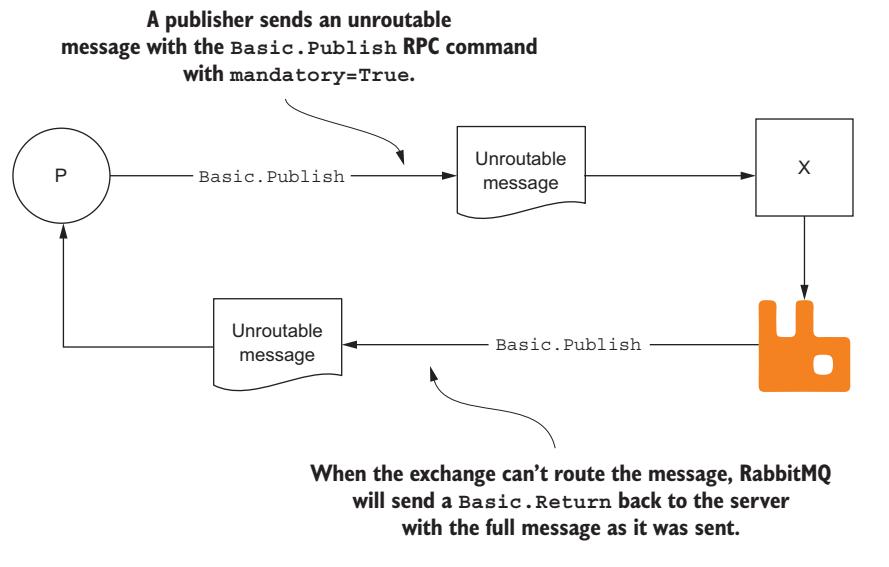
Когда не доставляемое сообщение публикуется с
mandatory=True, RabbitMQ возвращает его через RPC обратного вызова
Basic.Return отправлявшему его клиенту.
Чтобы опубликовать сообщение с флагом mandatory, вы просто передаёте его в данном аргументе после передачи
необходимого обмена, ключа маршрутизации, сообщения и свойств, как это показано в нашем следующем примере. Чтобы включить такое ожидаемое исключение
для не прошедшего маршрут сообщения, вы можете применять тот же самый обмен что и в Главе 2. Когда
данное сообщение опубликовано, не существует связанного ограничения и должно быть возбуждено некое исключение когда оно исполнено. Данный код находится
в записной книжке "4.1.2 Publish Failure"
import datetime
import rabbitpy
# Подключение к установленному по умолчанию в amqp://guest:guest@localhost:15672/%2F URL
with rabbitpy.Connection() as connection: # Подключает с RabbitMQ при помощи данного соединения в качестве некоторого диспетчера контекста
with connection.channel() as channel: # Открывает канал для для взаимодействия в качестве диспетчера контекста
# Создание сообщения для отправки
body = 'server.cpu.utilization 25.5 1350884514' # Создаёт необходимое для доставки тело сообщения
message = rabbitpy.Message(channel, # Создаёт данное приложение для его публикации, передачи канала, тела и свойств
body,
{'content_type': 'text/plain',
'timestamp': datetime.datetime.now(),
'message_type': 'graphite metric'})
# Публикация данного сообщения в имеющемся обмене с заданным ключом маршрутизации
# "server-metrics" и предоставления гарантии того что он прошёл маршрут к своему обмену
message.publish('chapter2-example', 'server-metrics', mandatory=True) # Публикация данного сообщения с включённым mandatory
Когда вы выполните данный пример, вы должны получить неое исключение аналогичное приведённому далее. RabbitMQ не может осуществить маршрутизацию данного сообщения, так как нет никакой очереди, связанной с этими обменом и ключом маршрутизации.
rabbitpy.exceptions.MessageReturnedException:
(312, 'NO_ROUTE', 'chapter2-example')
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
В нашем предыдущем примере использован некий новый способ вызова объектов |
Данный вызов Basic.Return является неким асинхронным вызовом из RabbitMQ и он может произойти в любой
момент времени после публикации данного сообщения. Например, когда collectd публикует статистические данные в RabbitMQ, он может опубликовать
множество пункутом данных прежде чем получит соответствующий вызов Basic.Return, который вызовет исчезание
публикации. Если данный код не установлен в ожидание такого вызова, он не услышит команду на исчезновение и collectd никогда не узнает, что данное
сообщение не было опубликовано надлежащим образом. Это создаст проблему если вы желаете иметь гарантию того что данное сообщение доставлено в
требуемую очередь.
В библиотеке rabbitpy вызовы Basic.Return автоматически принимаются имеющейся библиотекой клиента и будут
возбуждать некое MessageReturnedException после получения в области действия данного канала. В нашем
следующем примере то же самое сообщение будет отослано тому же самому обмену при помощи того же самого ключа маршрутизации. Этот код для публикации
данного сообщения был слегка перестроен для обёртки области действия данного канала в блок try/except.
При возбуждении данной исключительной ситуации, новый код напечатает соответствующий идентификатор сообщения и возвратит причину, выделенную из
соответствующего атрибута reply-text нашего кадра Basic.Return.
Вы всё ещё будете выполнять публикацию в своём обмене chapter2-example, однако вы теперь не будете остановлены
препятствием данного возбуждения исключительной ситуации. Данный пример расположен в записной книжке "4.1.2 Handling Basic.Return".
import datetime
import rabbitpy
import time
# Соединение с установленным по умолчанию в amqp://guest:guest@localhost:15672/%2F URL
connection = rabbitpy.Connection() # Подключение к RabbitMQ по порту 5672 локального хоста в качестве guest
try:
with connection.channel() as channel: # Открывает канал для взаимодействия
properties = {'content_type': 'text/plain', # Создаёт свойства сообщения
'timestamp': datetime.datetime.now(),
'message_type': 'graphite metric'}
body = 'server.cpu.utilization 25.5 1350884514' # Создаёт тело сообщения
message = rabbitpy.Message(channel, body, properties) # Создаёт некий объект сообщения в комбинации с каналом, телом и свойствами
message.publish('chapter2-example', # Публикация сообщения
'server-metrics',
mandatory=True)
except rabbitpy.exceptions.MessageReturnedException as error: # Отлавливает соответствующую исключительную ситуацию как некую переменную c названием error
print('Publish failure: %s' % error)
Когда вы исполните данный пример, вместо соответствующей исключительной ситуации из предыдущего примера вы должны увидеть дружественное сообщение, подобное такому:
Message was returned by RabbitMQ: (312) NO_ROUTE for exchange chapter2-example
В прочих библиотеках вам может понадобиться регистрировать некий метод обратного вызова, который будет запускаться если получен соответствующий
вызов RPC Basic.Return из RabbitMQ когда опубликовано ваше сообщение. В модели асинхронного программирования
когда вы на самом деле обрабатываете само сообщение Basic.Return, вы получите некий кадр метода
Basic.Return, его кадр заголовка содержимого, а также соответствующий кадр тела, в точности как если бы вы
были потребителем сообщений. Если это кажется слишком сложным, не беспокойтесь. Существуют и иные способы упрощения данного процесса и ведения дел
с отказами маршрутизации сообщений. Один из них состоит в применении Publisher Confirms
(подтверждении публикаций) в RabbitMQ.
|
| Замечание |
|---|---|
|
Рассматриваемая нами библиотека rabbitpy и наши примеры в данном разделе применяют только до трёх аргументов при отправке команды
|
Свойство Подтверждения издателю (Publisher Confirms) в RabbitMQ является расширением имеющейся спецификации AMQP и поддерживается только библиотеками
клиента, которые поддерживают специфичные лоя RabbitMQ расширений. Хотя сохранения записей на диске и является неким важным шагом в предотвращении
утраты сообщений, его выполнение не создаёт некоего контракта между имеющимися издателем и сервером RabbitMQ, который заверяет этого издателя что некое сообщение
было доставлено. Прежде чем публиковать любое сообщение, издатель сообщения должен выпустить запрос RPC Confirm.Select
в сторону RabbitMQ и ожидать отклика Confirm.SelectOkчтобы быть уверенным что подтверждения доставки включены.
С этого момента для каждого сообщения, которое некий издатель отправит к RabbitMQ, его сервер будет отвечать подтверждающим откликом
(Basic.Ack) или отрицанием его (Basic.Nack), или же включать целое значение,
определяющее величину смещения того сообщения, которое подтверждается
(Рисунок 4-4).
Получаемый номер подтверждения указывает на конкретное сообщение по порядковому номеру, который оно получает после выполнения RPC запроса
Confirm.Select.
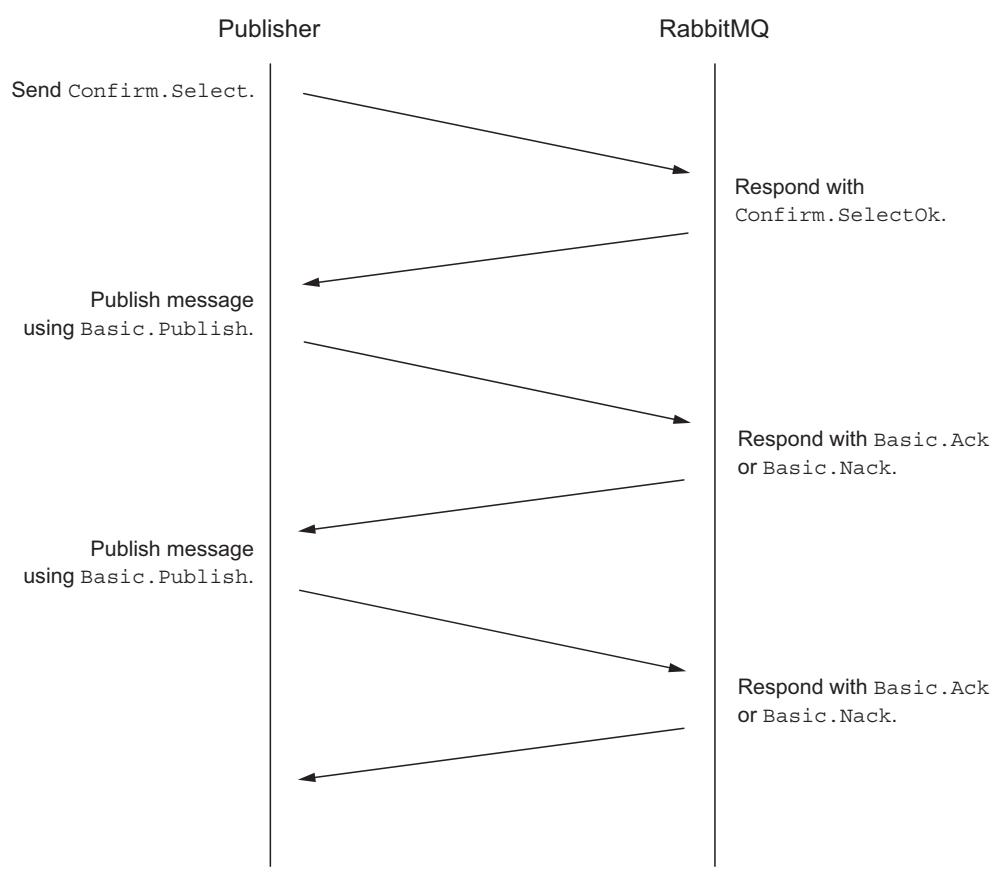
Запрос Basic.Ack отправляется издателю когда опубликованное сообщение было непосредственно потреблено
приложениями во всех очередях, в которые выполняется его маршрутизация, либо когда это сообщение было поставлено в очередь и оставлено (persisted),
как это запрашивалось. Если некое сообщение не может быть доставлено, имеющийся брокер отправит некий запрос
Basic.Nack, содержащий определённый отказ. А затем вверх к издателю чтобы принять решение что делать с этим
сообщением.
В приводимом далее примере, содержащемся в записной книжке "4.1.3 Publisher Confirms",
издатель включает Подтверждение издателю и затем вычисляет значение отклика на вызов
Message.publish.
import rabbitpy
with rabbitpy.Connection() as connection: # Подключаемся к RabbitMQ
with connection.channel() as channel: # Открываем необходимый канал для взаимодействия
exchange = rabbitpy.Exchange(channel, 'chapter4-example') # Создаём некий объект для объявления соответствующего обмена
exchange.declare() # Объявляем обмен
channel.enable_publisher_confirms() # Включаем подтверждение публикации в RabbitMQ
message = rabbitpy.Message(channel, # Создаём объект rabbitpy для его публикации
'This is an important message',
{'content_type': 'text/plain',
'message_type': 'very important'})
if message.publish('chapter4-example', 'important.message'): # Публикуем своё сообщение, вычисляем его отклик для подтверждения
print('The message was confirmed')
Как вы можете видеть, в rabbitpy достаточно просто применять Подтверждение издателю. В прочих библиотеках вам скорее всего понадобится какой- то
обработчик обратного вызова, который будет асинхронно отвечать на запросы Basic.Ack или
Basic.Nack. Для каждого из этих стилей имеются свои преимущества: реализация rabbitpy проще, но она всё же медленнее,
так как она выполняет блокировку до тех пор пока не примет необходимое подтверждение.
|
| Замечание |
|---|---|
|
Вне зависимости от того, будете ли вы применять Подтверждение издателю или нет, если вы выполняете публикацию в некотором обмене, которое не
существует, тот канал, в котором вы выполняете публикацию будет закрыт RabbitMQ. В rabbitpy это вызывает возбуждение некоей исключительной ситуации
|
Подтверждение издателю не работает совместно с транзакциями и рассматривается как легковесная и более производительная альтернативы процессу
TX AMQP (котроый обсуждается в разделе 4.1.5). Кроме того, выступая в роли некоего асинхронного
отклика на RPC запрос Basic.Publish, оно не даёт никаких гарантий тому когда данные подтверждения будут получены.
Поэтому, всякое включившее Подтверждение издателю должно иметь возможность получать подтверждение в любой момент после отправки своего сообщения.
Альтернативные обмены являются ещё одним расширением имеющейся модели AMQ, созданным командой RabbitMQ как некий способ обработки не выполнивших маршрутизацию сообщений. Некий альтернативный обмен определяется при самом первом объявлении некоторого обмена и он декларирует некий предварительно имеющийся обмен в RabbitMQ, в который определяемый новый обмен будет выполнять маршрутизацию сообщений в случае когда определяемый обмен не будет способен осуществлять их маршрутизацию. (Рисунок 4-5).
Рисунок 4-5
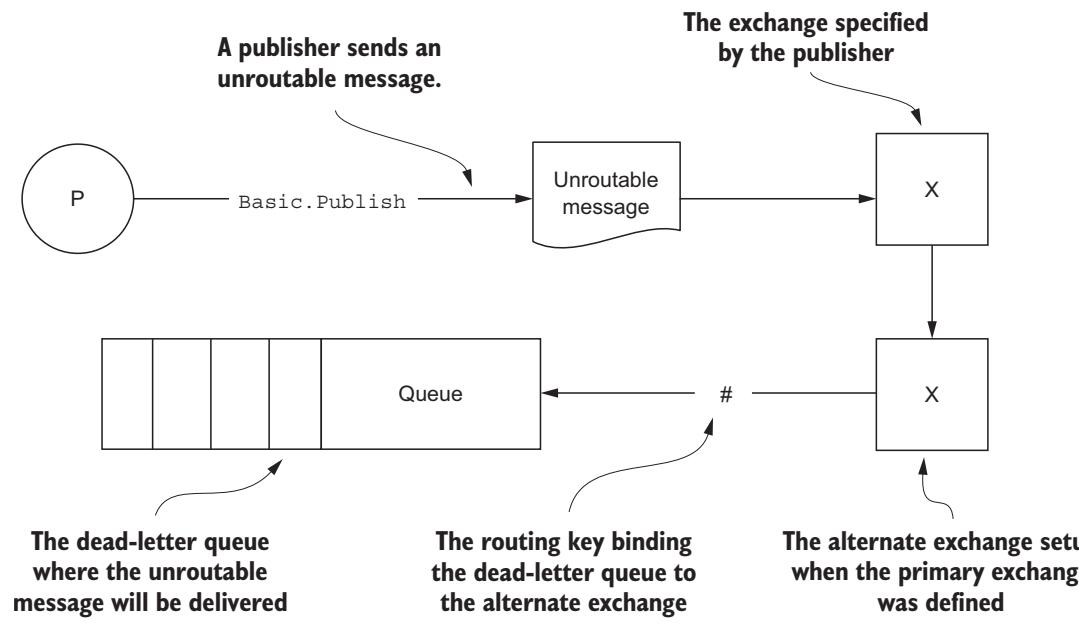
Когда не выполнившее маршрутизацию сообщение опубликовано в каком- то обмене, который имеет определённым некий альтернативный обмен, оно затем будет отправлено по маршруту через такой альтернативный обмен.
|
| Замечание |
|---|---|
|
Если для какого- то сообщения вы установили флаг |
Для того чтобы воспользоваться Альтернативным обменом вам вначале нужно настроить соответствующий обмен, в который будут отправляться не выполнившие
маршрутизацию сообщения. Затем, находясь в своём первичном обмене где вы будете публиковать сообщения, добавьте аргумент
alternate-exchange в своей команде Exchange.Declare.
Данный процесс демонстрируется в следующем примере, который проходит на один шаг далее в создании очереди сообщения, которая будет хранить любые не
выполнившие маршрут сообщения. Данный пример находится в записной книжке "4.1.4 Alternate-Exchange Example".
import rabbitpy
with rabbitpy.Connection() as connection: # Подключаемся к RabbitMQ
with connection.channel() as channel: # Открываем необходимый канал для взаимодействия
my_ae = rabbitpy.Exchange(channel, 'my-ae', # Создаём некий объект rabbitpy для необходимого нам Альтернативного обмена
exchange_type='fanout')
my_ae.declare() # Объявляем обмен в своём сервере RabbitMQ
args = {'alternate-exchange': my_ae.name} # Определяем соответствующий словарь, который задаёт необходимый Альтернативный обмен для нашего обмена graphite
exchange = rabbitpy.Exchange(channel, # Создаём объект Exchange rabbitpy для своего обмена graphite, передавая в аргументах словарь
'graphite',
exchange_type='topic',
arguments=args)
exchange.declare() # Объявляем обмен graphite
queue = rabbitpy.Queue(channel, 'unroutable-messages') # Создаём объект rabbitpy Queue
queue.declare() # Объявляем необходимую очередь в имеющемся сервере RabbitMQ
if queue.bind(my_ae, '#'): # Связываем созданную очередь со своим Альтернативным обменом
print('Queue bound to alternate-exchange')
При объявлении нашего Альтернативного обмена был выбран тип обмена fanout (раскрытие веером), в то время как
обмен graphite использует обмен topic (тема). Обмен
fanout доставляет сообщения во все очереди о которых ему известно; обмен
topic может осуществлять выборочную маршрутизацию сообщений на основании частей некоторого ключа маршрутизации.
Эти два типа обмена подробно обсуждаются в Главе 5. Когда эти два обмена определены, к нашему
Альтернативному обмену привязывается очередь unroutable-messages. Все те сообщения, которые последоваельно
публикуются в обмене graphite и не могут выполнить маршрутизацию в конечном итоге попадают в очередь
unroutable-messages.
Прежде чем появились подтверждения доставки, единственным путём, который мог бы гарантировать доставку пролегал через транзакции. Транзакция AMQP,
или TX, класс, предоставляющий некий механизм, посредством которого может выполняться публикация RabbitMQ в
пакетах и затем фиксироваться в какой- то очереди или откатывать назад. Приводимый далее пример, содержащийся в записной книжке “4.1.5 Transactional
Publishing”, показывает что создание кода, который пользуется преимуществами транзакции достаточно тривиально.
import rabbitpy
with rabbitpy.Connection() as connection: # Подключаемся к RabbitMQ
with connection.channel() as channel: # Открываем необходимый канал для взаимодействия
tx = rabbitpy.Tx(channel) # Создаём новый экземпляр своего объекта rabbitpy.Tx
tx.select() # Начинаем транзакцию
message = rabbitpy.Message(channel, # Создаём сообщение для публикации
'This is an important message',
{'content_type': 'text/plain',
'delivery_mode': 2,
'message_type': 'important'})
message.publish('chapter4-example', 'important.message') # Публикуем сообщение
try:
if tx.commit(): # Фиксируем транзакцию
print('Transaction committed')
except rabbitpy.exceptions.NoActiveTransactionError: # Перехватываем исключительную ситуацию TX в случае её возникновения
print('Tried to commit without active transaction')
Данный механизм транзакции предоставляет некий метод, посредством которого издатель может уведомляться об успешной доставке сообщения в
какую- то очередь в имеющемся брокере RabbitMQ. Чтобы начать некую транзакцию, такой издатель отправляет в RabbitMQ запрос RPC
TX.Select, а RabbitMQ ответит откликом TX.SelectOk. Когда данная
транзакция открыта, её издатель может оправить в RabbitMQ одно или более сообщений
(Рисунок 4-6).
Рисунок 4-6
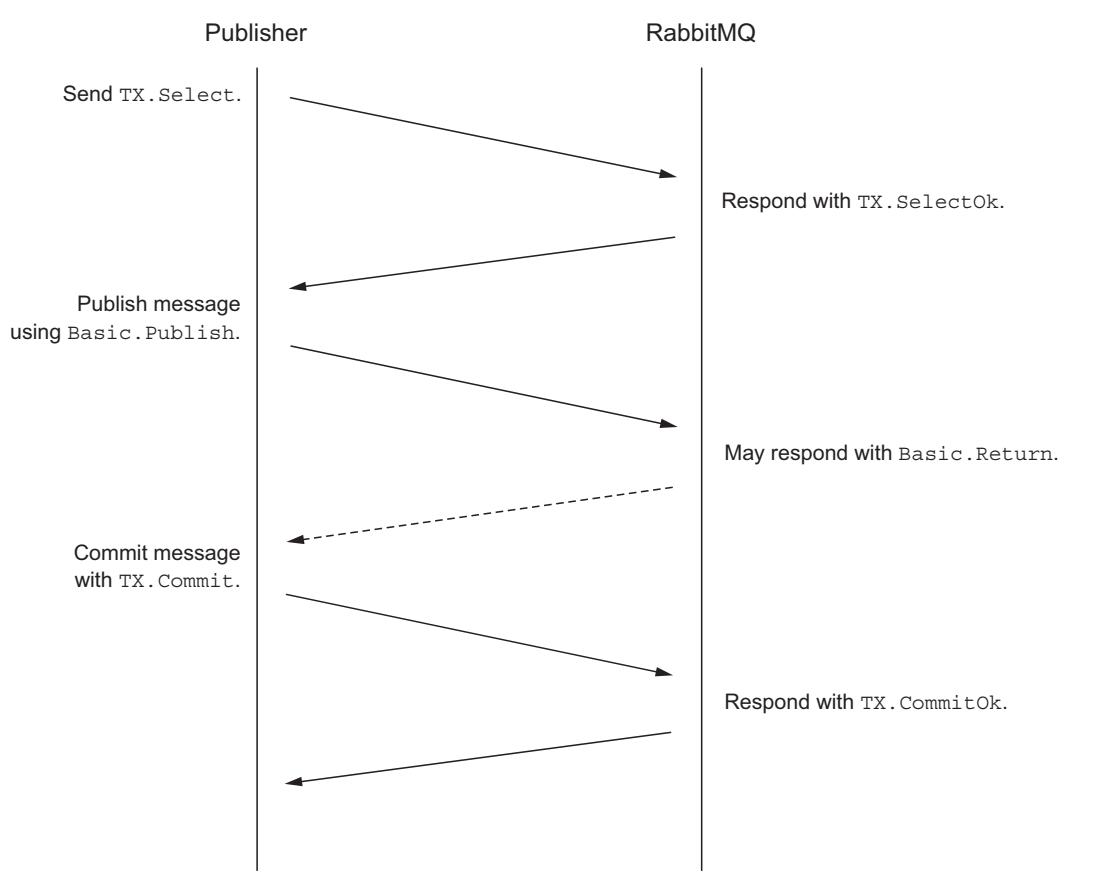
Издатель начинает некую транзакцию отправкой команды
TX.Select, публикует сообщения и фиксирует данные сообщения с помощью команды
TX.Commit.
Если RabbitMQ не может осуществить маршрутизацию некоторого сообщения по причине ошибки, например, в случае не существующего обмена, он возвратит
это сообщение в отклике Basic.Return прежде чем отправить отклик
TX.SelectOk. Те издатели, которые пожелают прервать транзакцию, должны отправить запрос RPC
TX.Rollback и ожидать отклика TX.RollbackOk от своего
брокера, прежде чем продолжить.
|
| RabbitMQ и атомарные транзакции |
|---|---|
|
Атомарность гарантирует что все действия в некоторой транзакции выполняются как часть данной фиксируемой транзакции. В AMQP это означает, что
ваш клиент не может принять кадр отклика Хотя RabbitMQ и выполнит атомарные транзакции если все команды в транзакции влияют только на одну и ту же очередь, издатели обычно не имеют большого контроля над тем будет ли данное сообщение доставлено более чем в одну очередь. В расширенных методах маршрутизации RabbitMQ легко представить себе что некое приложение стартует с атомарной фиксации при публикации в единственной очереди, однако затем кто- то может добавить некую дополнительную очередь, связанную с тем же самым ключом маршрутизации. Все публикуемые транзакции при таком ключе маршрутизации более не будут атомарными. Не лишним будет также отметить, что истинные атомарные транзакции с оставляемыми сообщениями, применяющими
|
Будучи реализованными, транзакции в RabbitMQ делают возможными подобные пакетной обработке операции в доставке подтверждения с помощью RabbitMQ. Если вы рассматриваете транзакции как некий метод подтверждения доставки, рассмотрите применение Подтверждения издателю в качестве альтернативы с меньшим весом - оно быстрее и может предоставлять как положительные, так и отрицательные подтверждения.
Во многих случаях, тем не менее, это не выполняет публикации требующегося подтверждения, а вместо него лишь гарантию того, что сообщения не будут утрачены пока они сидят в какой- то очереди. Именно здесь вступает в игру Высокая доступность (HA, high availability).
Если вы в поиске усиления своего контракта между издателем и RabbitMQ с целью гарантии доставки сообщения, не упустите ту важную роль, которую могут сыграть очереди с высокой доступностью (HA queues) в архитектурах с критически важными сообщениями. Очереди HA - некое расширение созданное командой RabbitMQ, которое не является частью имеющейся спецификации AMQP - являются функциональностью, которая позволяет очередям иметь избыточные копии по множеству серверов.
Очереди HA требуют кластерной среды RabbitMQ и могут устанавливаться одним из двух способов: при помощи AMQP или с применением взаимодействия управления на основе веб интерфейса. В Главе 8 мы повторно ознакомимся с очередями HA и воспользуемся таким интерфейсом управления для определения политик очередям HA, однако на данный момент мы сосредоточимся на применении AMQP.
В своём следующем примере мы установим некую новую очередь, которая распространится на все узлы в каком- то кластере RabbitMQ с помощью аргументов,
передаваемых в команде AMQP Queue.Declare . Этот код находится в записной книжке
"4.1.6 HA-Queue Declaration".
import rabbitpy
connection = rabbitpy.Connection() # Подключаемся к RabbitMQ в локальном хосте от имени guest
try:
with connection.channel() as channel: # Открываем необходимый канал для взаимодействия
queue = rabbitpy.Queue(channel, # Создаём новый экземпляр своего объекта Queue, передаваемого в устанавливаемой политике HA
'my-ha-queue',
arguments={'x-ha-policy': 'all'})
if queue.declare(): # Объявляем очередь
print('Queue declared')
except rabbitpy.exceptions.RemoteClosedChannelException as error: # Перехватываем исключительную ситуацию в случае возникновения ошибки
print('Queue declare failed: %s' % error)
Когда сообщение публикуется в какую- то очередь, которая установлена как очередь HA (с высокой доступностью), она отправляется в каждый сервер в имеющемся кластере, который ответственен за такую очередь HA (Рисунок 4-7). После того как сообщение употребится с любого из узлов в данном кластере, все копии данного сообщения будут немедленно удалены со всех прочих узлов.
Рисунок 4-7
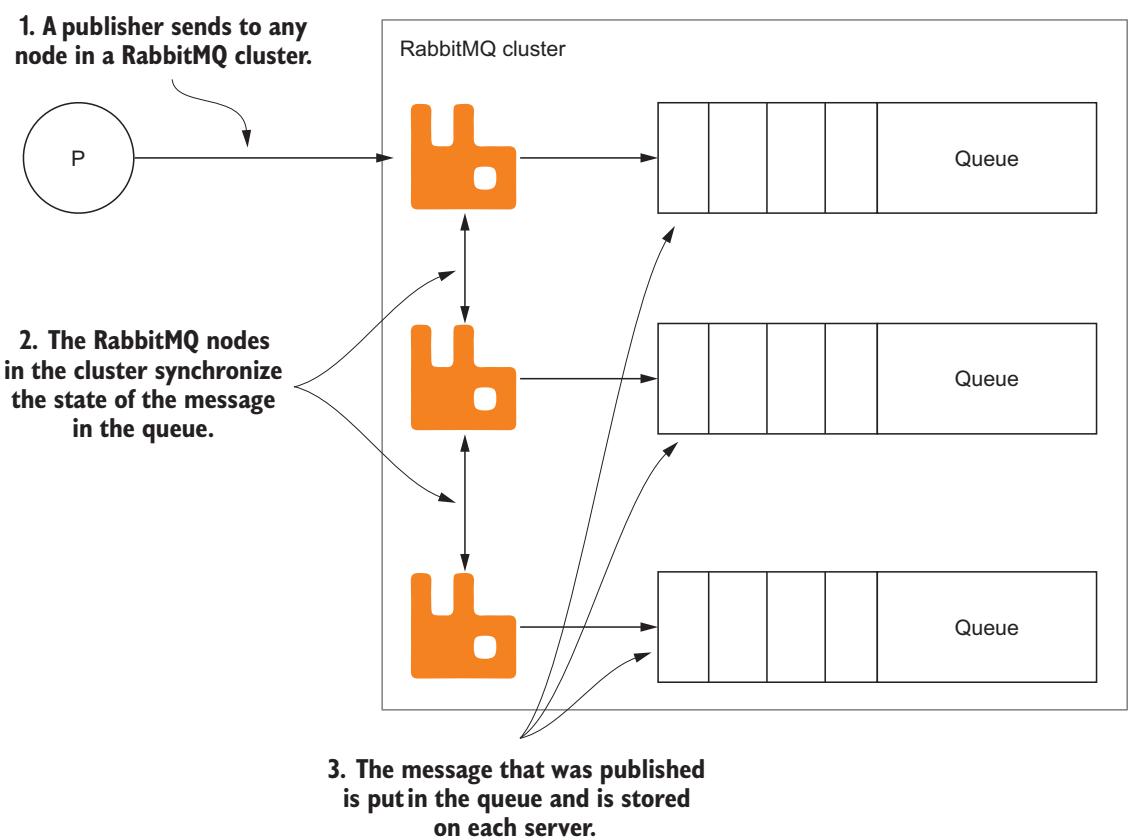
Публикуемое в очереди HA сообщение сохраняется в каждом сервере, который настроен под это.
Очереди HA могут распространяться на все серверы в некотором кластере или только на индивидуальные узлы. Для определения индивидуальных узлов вместо
передачи в аргументе x-ha-policy: all, передайте в аргументе
x-ha-policy of nodes, а затем другой аргумент, x-ha-nodes,
содержащий перечень всех узлов, для которых следует настроить данную очередь. Следующий пример содержится в записной книжке
"4.1.6 Selective HA Queue Declaration"
import rabbitpy
connection = rabbitpy.Connection() # Подключаемся к RabbitMQ
try:
with connection.channel() as channel: # Открываем канал для взаимодействия
arguments = {'x-ha-policy': 'nodes', # Определяем необходимую политику HA, которую следует применять вашей очереди
'x-ha-nodes': ['rabbit@node1',
'rabbit@node2',
'rabbit@node3']}
queue = rabbitpy.Queue(channel, # Создаём новый экземпляр своего объекта Queue, передаваемого в устанавливаемой политике HA
'my-2nd-ha-queue',
arguments=arguments)
if queue.declare(): # Объявляем очередь
print('Queue declared')
except rabbitpy.exceptions.RemoteClosedChannelException as error: # Перехватываем исключительную ситуацию в случае если RabbitMQ закрыл данный канал
print('Queue declare failed: %s' % error)
|
| Замечание |
|---|---|
|
Даже если у вас нет определённого |
Очереди HA имеют отдельный первичный узел сервера, а все прочие узлы являются вторичными. В случае падения имеющегося первичного узла, один из вторичных узлов возьмёт на себя такую роль первичного узла. Если один из вторичных узлов будет утрачен в некоторой конфигурации очереди HA, все прочие узлы продолжат свою работу, совместно применяя состояние операций которые происходят по всем настроенным узлам. Когда утраченный узел восстанавливается обратно, либо же в кластер добавляется некий новый узел, он не будет содержать каких -либо сообщений, которые уже находятся в данной очереди по присутствовавшим до того узлам. Вместо этого он получает все новые сообщения и войдёт в состояние синхронизации только после того, как все ранее опубликованные сообщения будут потреблены.
Очереди HA работают так же точно как и любая иная очередь в том, что касается семантики. Если вы применяет транзакции или подтверждения доставки, RabbitMQ не отправит отклик об успехе пока будет подтверждено на всех активных узлах, определённых для данной очереди HA.
Вы уже ознакомились ранее с тем как применять Альтернативные обмены для сообщений, которые не имели возможности быть перенаправленными. Теперь пришло время добавить им иной уровень гарантии доставки. Если броке RabbitMQ погибает по какой бы то ни было причине прежде чем ваши сообщения потреблены, они будут утрачены навсегда, только если вы не сообщите RabbitMQ при публикации такого сообщения что вы желаете оставлять (persist) это сообщение на диск пока оно находится в его попечении.
Как мы уже изучали в Главе 3, delivery-mode является одним
из свойств вашего сообщения, описываемого как часть определения Basic.Properties AMQP. Если какое- то сообщение
имеет delivery-mode установленным в 1, что определено по умолчанию,
это указывает на то, что RabbitMQ нет нужды сохранять такое сообщение на диск и что оно может пребывать в оперативной памяти на протяжении всего
времени. Таким образом, когда RabbitMQ запускается повторно, такие не оставленные сообщения не будут доступны после возврата RabbitMQ и его запуска.
С другой стороны, если delivery-mode установлен в значение 2,
RabbitMQ обеспечит что все сообщения сохраняются на диск. Имея название оставления сообщений (message
persistence), сохранение такого сообщения на диск гарантирует что если броке RabbitMQ будет повторно запущен по любой причине, это сообщение
всё ещё будет пребывать в данной очереди как только RabbitMQ возобновит свою работу опять.
|
| Замечание |
|---|---|
|
Помимо значения |
Для серверов, не имеющих достаточной производительности ввода/ вывода, оставление сообщений может вызвать впечатляющие проблемы с производительностью. Аналогично высокопроизводительному серверу баз данных веб приложения, высокоскоростной экземпляр RabbitMQ должен достаточно часто выполнять обращения к диску с оставляемыми сообщениями.
Для большинства динамичных веб приложений соотношение чтения- к- записи для баз данных OLTP в большей степени зависит от чтения (Рисунок 4-8). Это в особенности справедливо для содержимого таких сайтов как Wikipedia. В этом случае имеются миллионы статей, многие из которых остаются в активных созданиях и обновлениях, однако подавляющее большинство пользователей пребывают в чтении имеющегося содержимого и не осуществляют запись.
Рисунок 4-8
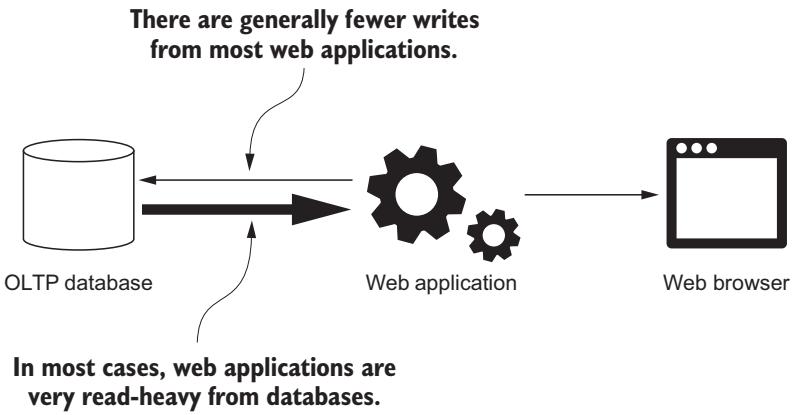
Хотя это и не всегда имеет место, большинство веб приложений считывают из базы данных намного больше чем записывают при создании веб страниц.
при оставлении (persisting) сообщений в RabbitMQ, вы можете ожидать довольно сильного уклона в сторону записи (Рисунок 4-9). В среде с высокой пропускной способностью сообщений RabbitMQ записывает оставляемые сообщения на диск и отслеживает ссылки на них пока они не исчезнут из всех очередей. Когда все ссылки на некое сообщение завершаются, RabbitMQ вслед за этим удаляет такое сообщение с диска. при выполнении высокоскоростных записей нередко возникают проблемы с производительностью по причине недостаточно подготовленного оборудования, поскольку в большинстве случаев кэш записи на диске намного меньше, чем кэш чтения. В большинстве операционных систем ядро будет использовать свободную оперативную память для буферизации считывания страниц с диска, тогда как единственным компонентом кэширования записей на диск - это контроллер диска и сами диски. По этой причине важно устанавливать правильный размер своего необходимого оборудования при использовании оставляемых сообщений. Миниатюрный сервер, которому поручена крупная рабочая нагрузка записи может привести весь сервер RabbitMQ целиком к пробуксовке.
Рисунок 4-9
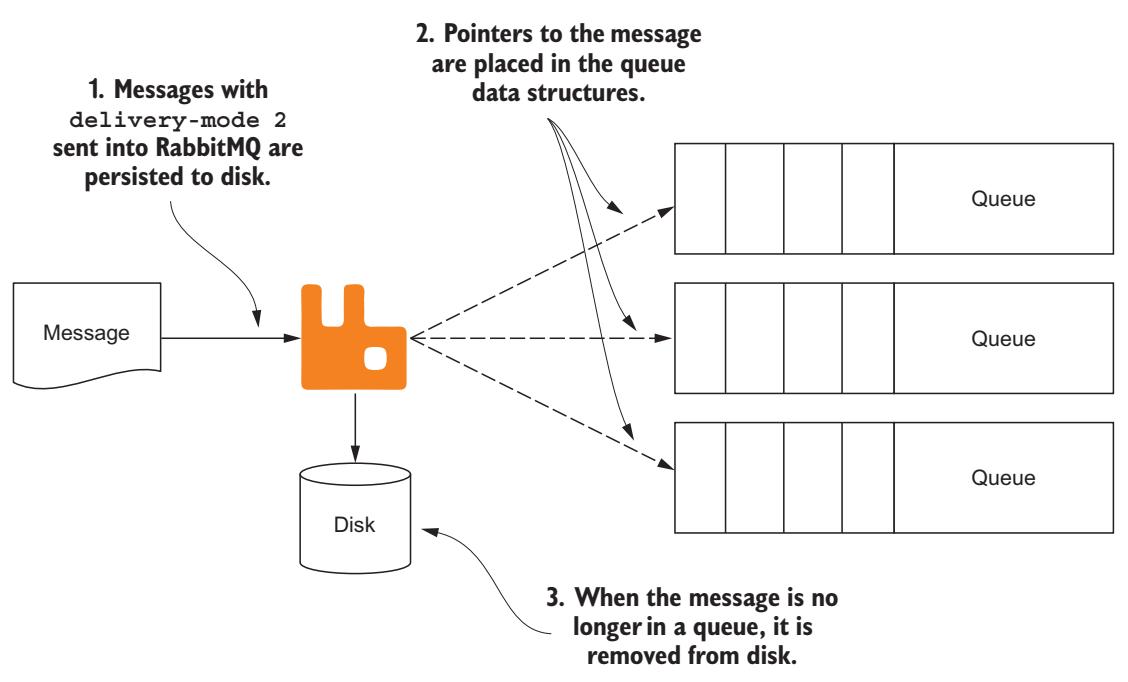
RabbitMQ сохраняет оставляемые сообщения один раз и отслеживает ссылки на них по всем очередям, в которых они хранятся. Если это возможно, считывания с диска избегаются и это сообщение будет удалены с диска однажды когда уйдут все ссылки на него.
|
| Предоставление оборудования для оставляемых сообщений в RabbitMQ |
|---|---|
|
Для надлежащего снабжения оборудованием своих сервереов RabbitMQ, которые будут оставлять сообщения, вы можете применять те же самые правила, что и для баз данных OLTP. ОЗУ это король; помимо определения размера ОЗУ на сервере для нормальной рабочей нагрузки сообщений, рассмотрите дополнительную оперативную память для операционной системы, чтобы сохранять дисковые страницы в дисковом кэше ядра. Это улучшит время отклика на чтение сообщений, которые уже были считаны с диска. Чем больше шпинделей, тем лучше; хотя SSD могут слегка изменять парадигму, основной подход применяется по- прежнему. Чем большим числом жёстких дисков вы располагаете, тем выше будет ваша пропускная способность записи. Поскольку система может распределять нагрузку записи по всем имеющимся дискам в некоторой установке RAID, это приводит к значительному уменьшению продолжительности времени блокирования каждого физического устройства. Найдите RAID-карту соответствующего размера с резервным аккумулятором и с большим объёмом кэша чтения и записи. Это сделает возможной буферизацию записи с помощью RAID-карты и будет допускать временные всплески активности записи, которые в противном случае были бы заблокированы ограничениями физических устройств. {Прим. пер.: применяйте NVMe.} |
В серверах с ограничениями на ввод/ вывод операционная система будет блокировать обработку операций ввода/ вывода пока данные передаются к устройствам хранения и от них через саму операционную систему. Когда сервер RabbitMQ пытается выполнять операции ввода/ вывода, такие как сохранение сообщений на диск, а ядро операционной системы заблокирован в ожидании отклика от устройства хранения, RabbitMQ мало что может сделать ещё кроме как подождать. Если брокер RabbitMQ слишком часто занимается ожиданием отклика операционной системы на запросы чтения и записи, пропускная способность обмена сообщениями будет сильно подавлена (Рисунок 4-10).
Рисунок 4-10
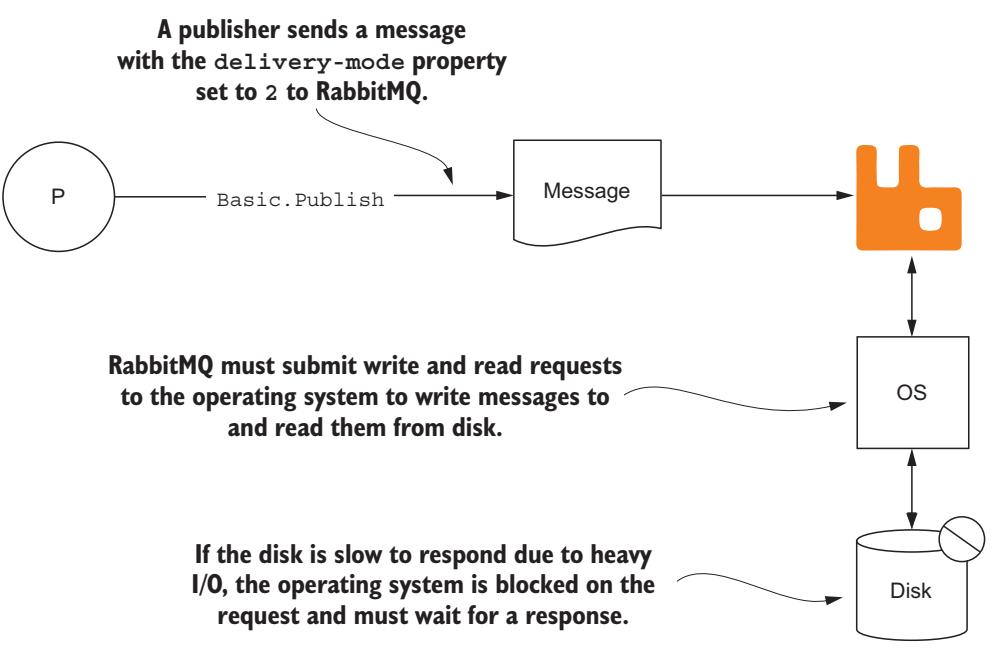
Когда какое- то сообщение получается с установленным в нём свойством
delivery-mode, установленным в значение 2,
RabbitMQ должен записать это сообщение на диск.
Хотя оставление сообщений является одним из наиболее важных путей гарантии того, что ваши сообщения в конечном счёте будут доставлены, это также и наиболее дорогостоящая операция. Плохая производительность дисков может приводить к значительной деградации скорости публикации сообщений вашим RabbitMQ. В экстремальных ситуациях задержки ввода/ вывода, вызываемые неверно подобранным оборудованием могут приводить к потере сообщений. Проще говоря, если RabbitMQ не может откликаться издателям или потребителям по причине блокировки со стороны операционной системы в отношении операций ввода/ вывода, ваши сообщения не могут быть опубликованы или доставлены.
В спецификации AMQP было принято предположение относительно издателей, которые не подходят реализации сервера. До версии 2.0 RabbitMQ если ваше
публикующее приложение начинало подавлять RabbitMQ слишком быстрым изданием сообщений, тот посылал метод RPC
Channel.Flow
(Рисунок 4-11)
чтобы проинструктировать вашего издателя о выполнения блокировки и не отсылать более сообщения пока не будет принята другая команда
Channel.Flow.
Рисунок 4-11
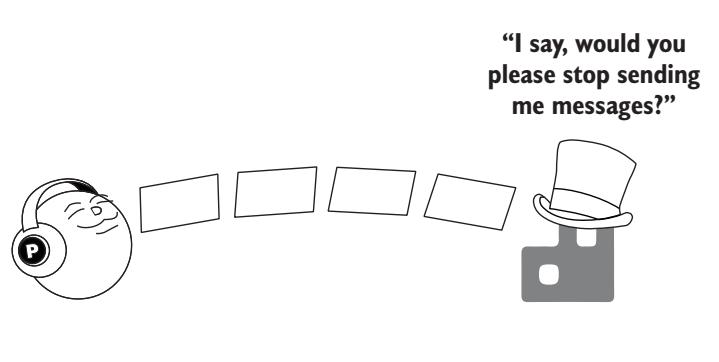
Когда RabbitMQ запрашивает
Channel.Flow, нет никакой гарантии что издатель его услышит.
Была подтверждена полная недейственность метода замедления для дурно ведущих себя или "неучтивых" издателей, которым не требовалось признавать данную
команду Channel.Flow . Если издатель продолжал публиковать сообщения, RabitMQ мог в конечном итоге перенасытиться,
что приводило к проблемам производительности и пропускной способности, а возможно даже и приводило к краху такого брокера. Перед RabbitMQ 3.2 команда
RabbitMQ признала устаревшим применение Channel.Flow, заменив его механизмом с названием TCP Backpressure для
решения данной проблемы. Вместо любезной просьбы издателю остановиться RabbitMQ останавливал бы приём данных на нижнем уровне в своём сокете TCP
(Рисунок 4-12).
Этот метод хорошо работает для защиты RabbitMQ от перенасыщения единичным издателем.
Рисунок 4-12
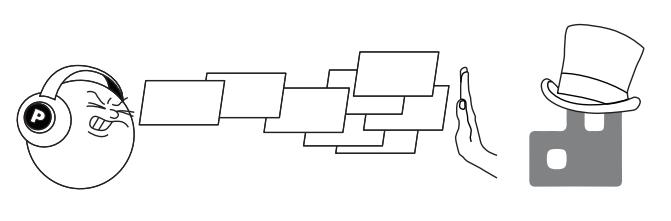
RabbitMQ применяет TCP Backpressure чтобы остановить неучтивых издателей перенасыщать себя.
Внутри RabbitMQ использует понятие кредитов для управления, когда он собирается отпихнуть издателя. Когда выполняется новое соединение, на это соединение выделяется предопределённое количество кредитов, которое он может использовать. Затем, по мере приёма каждой команды RPC со стороны RabbitMQ, кредит уменьшается. После того, как запрос RPC был обработан внутри, соединение получает кредит обратно. Кредитный баланс соединения оценивается RabbitMQ чтобы определить, следует ли выполнять считывание из его сокета соединения. Если соединение вышло за предел кредитования, оно просто пропускается, пока у него не станет достаточно кредитов.
Начиная с RabbitMQ 3.2, команда RabbitMQ расширила имеющуюся спецификацию AMQP, добавив уведомления, которые отправляются при достижении пороговых
значения для соединения, сообщая клиенту о том, что его соединение было заблокировано. Connection.Blocked и
Connection.Unblocked являются асинхронными методами, которые могут отправляться в любой момент времени для
уведомления о том, когда RabbitMQ заблокировал публикующего клиента и когда эта блокировка была удалена. Такую функциональность выполняет большинство
клиентских библиотек; вам следует проверить свою конкретную применяемую вами клиентскую библиотеку чтобы определить как ваше приложение должно вычислять
состояние своего соединения. В нашем следующем разделе вы увидите как выполнять такую проверку с помощью rabbitpy и как само API управления может применяться
для версий, предшествующих 3.2 для проверки того не блокировано ли соеднение канала.
|
| Замечание |
|---|---|
|
В конечном счете, TCP Backpressure и блокировка соединений не являются проблемами, которые вы должны исполнять каждый день, причём они могут быть признаком того, что аппаратное обеспечение того сервера на котором установлен RabbitMQ, не имеет требуемого размера. Если вы обнаружите, что это становится проблемой, настало время оценить вашу стратегию масштабирования и, возможно, реализовать некоторые из концепций, описанных в Главе 8. |
Применяете ли вы версию RabbitMQ, которая поддерживает уведомления Connection.Blocked или нет, rubbitpy
обёртывает эту функциональность в некий простой в применении API. При подключении к версии RabbitMQ, которая поддерживает уведомления
Connection.Blocked, rabbitpy будет получать это уведомление и будет устанавливать некий внутренний флаг,
постулирующий что данное соединение блокировано.
Когда вы воспользуетесь следующим примером из своей записной книжки "4.2.1 Connection Blocked", его вывод долеж выдать отчёт о том, что данное соединение не блокировано.
import rabbitpy
connection = rabbitpy.Connection() # Соединяемся с RabbitMQ
print('Channel is Blocked? %s' % connection.blocked) # Выполняем проверку чтобы определиться блокирован ли клиент
Если вы применяете более раннюю версию RabbitMQ чем 3.2, ваше приложение может опрашивать значение состояния своего соединения при помощи API управления на основе веб интерфейса. Выполнение этого достаточно прямолинейно, однако если оно применяется слишком часто, это может вызвать нежелательную нагрузку на ваш сервер RabitMQ. В зависимости от имеющегося размера вашего кластера и общего числа имеющихся у вас очередей, запросы данного API могут отнимать для возврата множество секунд.
Это API предоставляет RESTfull URL конечных точек для запроса текущего состояния некоторого соединения, канала, очереди или всего лишь о любом ином
выставляемом вовне объекте в RabbitMQ. В данном API управления, само состояние блокировки применяется к некому каналу в соединении, а не к самому соединению.
Имеется множество полей доступных при опросе состояния канала:
name, node, connection_details,
consumer_count и client_flow_blocked чтобы перечислить только несколько.
Флаг client_flow_blocked указывает применяет ли RabbitMQ TCP Backpressure для данного канала.
Чтобы получить состояние некоторого канала, вы вначале должны построить необходимое подходящее для него название. Название канала основывается на самом имени соединения и идентификаторе его канала. Для построения соответствующего названия соединения вам потребуется следующее:
-
IP адрес локального хоста и исходящий порт TCP
-
IP адрес удалённого хоста и порт TCP
Формат таков: "LOCAL_ADDR: PORT -> REMOTE_ADDDR: PORT". Расширяя его, формат для подходящего
названия канала выглядит так: "LOCAL_ADDR: PORT -> REMOTE_ADDDR: PORT (CHANNEL_ID)".
Сама конечная точка для запроса API управления RabbitMQ относительно состояния канала таков:
http://host:port/api/channels/[CHANNEL_NAME]. Будучи опрошенным, API управления возвратит свой результат
в виде упорядоченного JSON объекта. Ниже приводится сокращённый пример того что возвращает такой API для запроса состояния канала:
{
"connection_details": {…},
"publishes": […],
"message_stats": {…},
"consumer_details": [],
"transactional": false,
"confirm": false,
"consumer_count": 0,
"messages_unacknowledged": 0,
"messages_unconfirmed": 0,
"messages_uncommitted": 0,
"acks_uncommitted": 0,
"prefetch_count": 0,
"client_flow_blocked": false,
"node": "rabbit@localhost",
"name": "127.0.0.1:45250 -> 127.0.0.1:5672 (1)",
"number": 1,
"user": "guest",
"vhost": "guest"
}
Помимо поля channel_flow_blocked такой API управления возвращает информацию о скорости и состоянии самого
канала.
Одним из важнейших шагов в создании вашей архитектуры приложения является определение основной роли и поведения издателя. Вопросы, на которые вам следует ответить включают в свой состав следующее:
-
Должны издатели запрашивать эти сообщения быть оставляемыми (persisted) на диске?
-
Какие гарантии необходимы различным компонентам моего приложения, чтобы изданное сообщение было получено?
-
Что произойдёт в моей среде если мое приложение блокируется TCP Backpressure или когда это соединение блокировано при публикации сообщений в RabbitMQ?
-
Насколько важны мои сообщения? Могу ли я пожертвовать гарантиями доставки для более высокой пропускной способности сообщений?
Задав себе эти вопросы, вы окажетесь на пути к созданию архитектуры приложения которая будет в порядке. RabbitMQ обеспечивает большую гибкость - возможно, слишком большую в ряде случаев. Но, используя преимущества своих возможностей настройки, вы можете находить компромисс между производительностью и высокой надёжностью и принимать решение какой уровень метаданных назначать своим сообщениям. Какие свойства вы используете и какие механизмы вы применяете, для надёжной доставки, лучше всего определять вам чем кому- либо иному, при этом RabbitMQ станет прочной основой для того, что вы выберете в конечном итоге.