Глава 5. Не получайте сообщения, потребляйте их
Содержание
Данная глава рассматривает
-
Потребление сообщений
-
Регулировку пропускной способности потребления
-
Когда потребители и очереди взаимоисключающие
-
Определение качества обслуживания для ваших потребителей
После глубокого погружения в мир публикации сообщений самое время обсудить потребление сообщений, отправляемых вашими издателями. Потребляющие приложения могут быть выделенными приложениями с единственной целью получения сообщений и выполнения с ними действий, либо же получение сообщений может быть лишь очень маленькой частью приложения гораздо большего размера. Например, если вы реализуете некий шаблон RPC в RabbitMQ, соответствующее приложение публикации также потребляет и соответствующий отклик RPC (Рисунок 5-1).
Рисунок 5-1
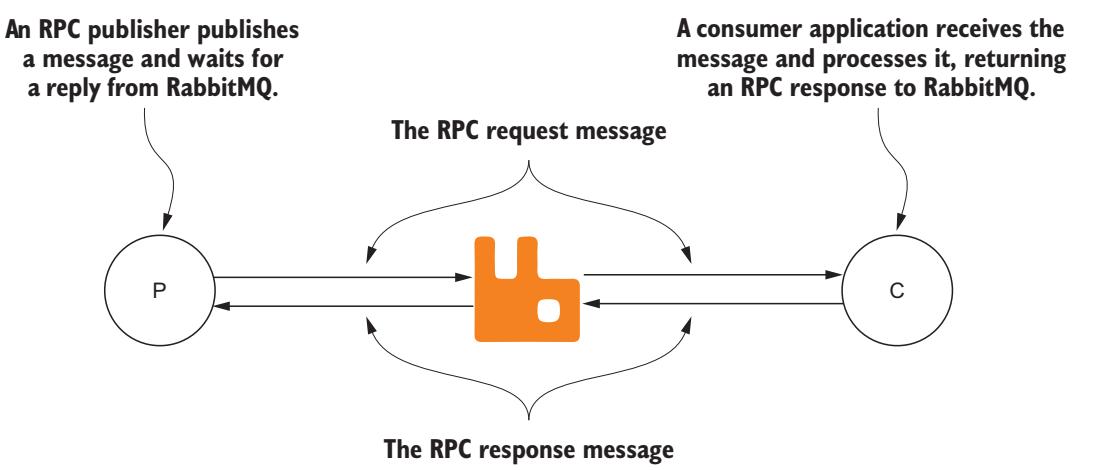
Некий издатель RPC, который публикует сообщение в RabbitMQ и ожидает отклика RPC в качестве потребителя от потребителя своего RPC.
При наличии столь большого числа доступных для реализации сообщений доступных шаблонов в вашем приложении, достаточно всего лишь чтобы RabbitMQ имел разнообразные установки для нахождения правильного баланса между производительностью и надёжностью обмена сообщениями. Принятие решения о том как ваше приложение будет потреблять сообщения является самым первым шагом при нахождении такого баланса и он стартует с одного простого выбора: Должны ли вы получать (get) сообщения, или же вы должны потреблять (consume) сообщения. В этой главе мы изучим
-
Почему вам следует избегать получение сообщений в пользу их потребления
-
Как поддерживать баланс гарантии доставки сообщения с производительностью доставки
-
Как применять установки каждой очереди RabbitMQ для автоматического удаления очередей, ограничения возраста сообщение и тому подобного
RabbitMQ реализует две различные команды AMQP RPC для выборки сообщений из очереди: Basic.Get и
Basic.Consume. Как подразумевает заголовок данного раздела,
Basic.Get не является идеальным способом для выборки сообщений с сервера. Для упрощения терминологии,
Basic.Get является моделью опроса (polling), в то время как
Basic.Consume представляет собой модель с активным источником данных (активная доставка, push).
Когда ваше приложение применяет для выборки сообщений запрос Basic.Get, оно должно отправлять запрос
всякий раз когда желает получить некое сообщение, даже если в его очереди имеется множество сообщений. Если данная очередь, из которой вы осуществляете
выборку сообщений, имеет при вызове Basic.Get ожидающие выборки сообщения, RabbitMQ ответит RPC откликом
Basic.GetOk
(Рисунок 5-2).
Рисунок 5-2
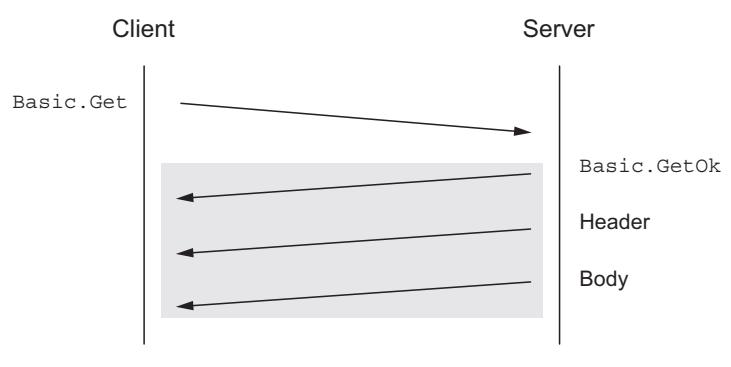
Если при вызове RPC запроса
Basic.Get имеются доступными какие- то сообщения, RabbitMQ ответит откликом Basic.GetOk
и соответствующим сообщением.
Если в данной очереди нет никаких ожидающих сообщений, она ответит с помощью Basic.GetOk, указывая
что в данной очереди нет никаких сообщений (Рисунок 5-3).
Рисунок 5-3
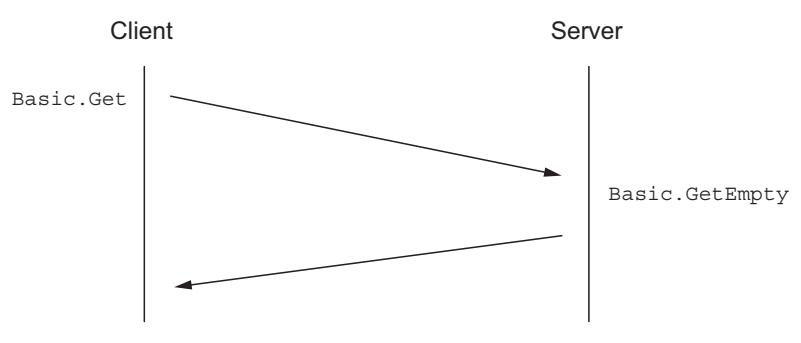
Если при вызове RPC запроса
Basic.Get нет доступных сообщений, RabbitMQ ответит Basic.GetEmpty
и соответствующим сообщением.
при использовании Basic.Get ваше приложение должно оценивать полученный от RabbitMQ отклик RPC чтобы определить
было ли получено сообщение. Для большинства получающих сообщения от RabbitMQ длительных процессов, это не самый эффективный способ получения и обработки
сообщений.
Рассмотрим код из записной книжки "5.1.1 Basic.Get Example". После соединения с RabbitMQ и открытия необходимого канала он пребывает в бесконечном цикле опрашивая сообщения из RabbitMQ.
import rabbitpy
with rabbitpy.Connection() as conn: # Соединяемся с RabbitMQ
with conn.channel() as channel: # Открываем канал для взаимодействия
queue = rabbitpy.Queue(channel, 'test-messages') # Создаём новый экземпляр объекта Queue для взаимодействия с RabbitMQ
queue.declare() # Объявляем очередь сервера RabbitMQ
while True: # Бесконечный цикл с попыткой получения сообщений
message = queue.get() # Получаем сообщение из RabbitMQ
if message: # Оцениваем было ли отправлено сообщение
message.pprint()
message.ack() # Выдаём подтверждение приёма сообщения
if message.body == 'stop': # Покидаем данный цикл если телом сообщения является “stop”
break
Хотя это самый простой способ взаимодействия с RabbitMQ для выборки ваших сообщений, во многих случаях его производительность будет в лучшем случае
не приводящей в восторг. При простейших проверках скорости использование Basic.Consume по крайней мере вдвое
быстрее чем использование Basic.Get. Наиболее очевидной причиной в таком различии скоростей является то, что при
Basic.Get всякое доставляемое сообщение переносит с собой дополнительные накладные расходы осуществления
синхронного взаимодействия с RabbitMQ, состоящего из отправки самим клиентским приложением некторого кадра запроса, а также отправки отклика RabbitMQ.
Потенциально менее очевидная причина избегать Basic.Get состоит в ещё большем воздействии на пропускную способность,
которая обусловлена самой особенной природой Basic.Get, не позволяющей RabbitMQ оптимизировать данный процесс
доставки ни коим образом, так как он никогда не знает когда некое приложение собирается запросить сообщение.
В противовес этому, потребляя сообщения при помощи команды Basic.Consume вы регистрируете своё приложение в
RabbitMQ и сообщаете ему о необходимости отправлять сообщения асинхронно вашему потребителю по мере того как они становятся доступными. Обычно это именуется
как шаблон подписки на публикацию (publish-subscribe pattern) или pub-sub. Вместо ведения синхронного общения с RabbitMQ, которое происходит при
Basic.Get, потребление сообщений с помощью Basic.Consume означает,
что ваше приложение автоматически получает сообщения от RabbitMQ по мере того как они становятся доступными пока клиент не вызовет
Basic.Cancel
(Рисунок 5-4).
Рисунок 5-4
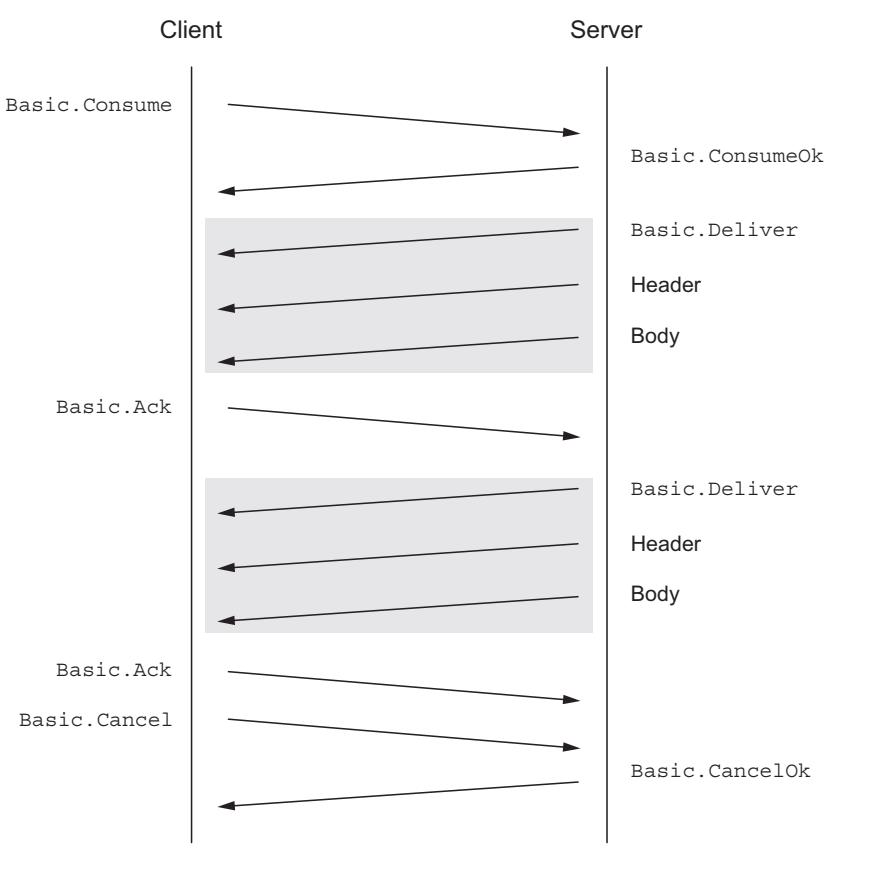
Когда клиент вызывает
Basic.Consume, RabbitMQ отправляет ему сообщения пока они остаются доступными или пока этот клиент
сам не вызовет Basic.GetEmpty.
Потребление сообщений из RabbitMQ также требует на один шаг меньше в вашем коде когда вы получаете сообщение. Как это иллюстрирует приводимый
далее пример, когда ваше приложение получает некое сообщение из RabbitMQ в качестве потребителя, ему не требуется оценивать это сообщение чтобы
определить имеется ли полученное значение сообщением или неким пустым откликом (Basic.GetEmpty). Однако,
как и в случае с Basic.Get, вашему приложению всё ещё требуется выдавать подтверждения приёма такого сообщения
чтобы давать знать RabbitMQ что его сообщение было обработано. Этот код содержится в записной книжке
"5.1.2 Basic.Consume Example".
import rabbitpy
with rabbitpy.consume('amqp://guest:guest@localhost:5672/%2f', # Выполняем итерации по всем сообщениям в очереди test-messages
'test-messages') as consume:
for message in consume.next_message():
message.pprint()
message.ack() # Выдаём подтверждение приёма данного сообщения
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Вы должны заметить, что показанный в нашем предыдущем примере код намного короче чем код из предшествовавших ему примеров. Это происходит из- за того, что rabbitpy имеет ссылки на методы, которые внедряют в себя большую часть той логики, которая требуется для соединения с RabbitMQ и использования каналов. |
Тег потребителя
Когда ваше приложение вызывает Basic.Consume, создаётся уникальная строка, которая указывает на необходимое
приложение в соответствующем открытым канале в RabbitMQ. Эта строка, именуемая Тегом потребителя (consumer tag), отправляется в ваше приложение при
отправке каждого сообщения из RabbitMQ.
Твакой Тег потребителя может применяться для прекращения всех последующих квитанций сообщений от RabbitMQпосредством вызова команды
Basic.Cancel. Это в особенности полезно если ваше приложение выполняет одновременное потребление из
множества очередей, так как каждое содержащее такой Тег потребителя принятое сообщение подлежит доставке в своём собственном кадре метода.
Если ваше приложение должно выполнять разные действия для получаемых из разных очередей сообщений, оно может применять используемый в запросе
Basic.Consume Тег потребителя чтобы определить как оно должно обрабатывать сообщение. Однако в большинстве
случаев Тег потребителя обрабатывается под покровом клиентской библиотеки, и вам не нужно беспокоиться об этой процедуре.
В записной книжке "5.1.2 Consumer with Stop" приводимый ниже код потребителя будет ожидать сообщения до тех пор, пока не получит некого сообщения с телом сообщения, содержащим единственное слово "stop".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
for message message in rabbitpy.Queue(channel, 'test-messages'): # Выполняем итерации по всем сообщениям в очереди test-messages
message.pprint() # Структурированный вывод (pretty-print) атрибутов данного сообщения
message.ack # Выдаём подтверждение приёма данного сообщения
if message.body == 'stop': # Оцениваем тело полученного сообщения, выполняя прерывание в случае получения “stop”
break
После того как вы запустили своего потребителя, вы можете публиковать сообщения для него применяя соответствующий код из записной книжки "5.1.2 Message Publisher" в каой-то новой закладке браузера:
import rabbitpy
for iteration in range(10): # Выполнить в цикле 10 раз
rabbitpy.publish('amqp://guest:guest@localhost:5672/%2f', '', 'test-messages', 'go') # Опубликовать одно и то же сообщение в RabbitMQ
rabbitpy.publish('amqp://guest:guest@localhost:5672/%2f', '', 'test-messages', 'stop') # Останов издания сообщения в RabbitMQ
Когда вы запустили своего издателя, исполнение кода записной книжки "5.1.2 Consumer with Stop" выполнит останов как только он получит
такое сообщение останова осуществи выход из итератора Queue.consume_messages.
Под покровом библиотеки rabbitpy при вашем выходе из данного итератора произойдёт несколько вещей. Во- первых, сама библиотека отправит команду
Basic.Cancel в RabbitMQ. После получения RPC отклика Basic.CancelOk,
если RabbitMQ отправил какое- то сообщение вашему клиенту, которое не было обработано, rabbitpy отправит команду отрицательного подтверждения
(Basic.Nack) и проинструктирует RabbitMQ выполнить возврат в очередь этих сообщений.
Выбор между синхронным Basic.Get и асинхронным Basic.Consume
является самым первым выбором, который вам требуется выполнить при написании своего потребительского приложения. Как и компромиссы, связанные с
публикацией сообщений, данный выбор, который вы делаете для своего приложения, может напрямую влиять на гарантии доставки и производительность
доставки сообщений.
Как и при публикации сообщений, в потреблении сообщений имеются компромиссы в балансе пропускной способности с гарантией доставки. Как указано на Рисунке 5-5, существуют различные опции, которые могут быть применены для ускорения доставки сообщений от RabbitMQ в ваше приложение. К тому же, когда при публикации сообщений RabbitMQ предлагает меньшие гарантии для доставки сообщений при опциях более быстрой пропускной способности доставки.
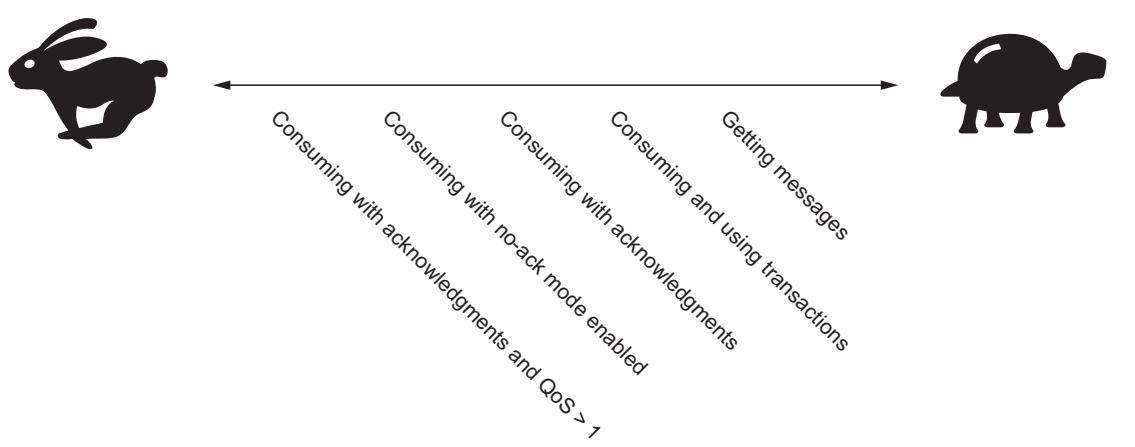
В этом разделе вы изучите как регулировать пропускную способность доставки сообщений RabbitMQ к потребителям через переключение соответствующих требований для подтверждений на приём сообщений, как модифицировать предварительно установленные пороговые значения сообщений RabbitMQ и как выполнять доступ к воздействию транзакций, происходящему при их использовании в потребителях.
При потреблении сообщений ваши приложения регистрируют себя в RabbitMQ и запрашивают доставку сообщений по мере того как они становятся доступными.
Ваши приложения отправляют RPC запрос Basic.Consume, а в нём имеется некий флаг
no-ack. Когда он включён, это флаг сообщает RabbitMQ что ваш потребитель не нуждается в подтверждающих квитанциях
сообщений и RabbitMQ должен всего лишь отправлять их настолько быстро, насколько это возможно.
Следующий пример в записной книжке "5.2.1 No-Ack Consumer" демонстрирует как потреблять сообщения без получения уведомления о получении от
них. Передавая True в качестве аргумента в метод Queue.consumer, rabbitpy
отправляет запрос RPC Basic.Consume c no_ack=True.
import rabbitpy
with rabbitpy.Connection() as connection: # Подключаемся к RabbitMQ
with connection.channel() as channel: # Открываем необходимый канал в установленном соединении
queue = rabbitpy.Queue(channel, 'test-messages') # Создаём новый объект для потребления им
for message in queue.consume_messages(no_ack=True): # Потребляем сообщения с no_ack=True
message.pprint() # Структурированный вывод атрибутов полученного сообщения
Потребление сообщений с no_ack=True является самым быстрым способом получения доставки сообщений RabbitMQ
вашему потребителю, но это к тому же и самый ненадёжный способ переправки сообщений. Для понимания того почему это происходит, рассмотрим каждый шаг,
который сообщение должно пройти прежде чем оно будет получено вашим потребляющим приложением
(Рисунок 5-6).
Рисунок 5-6
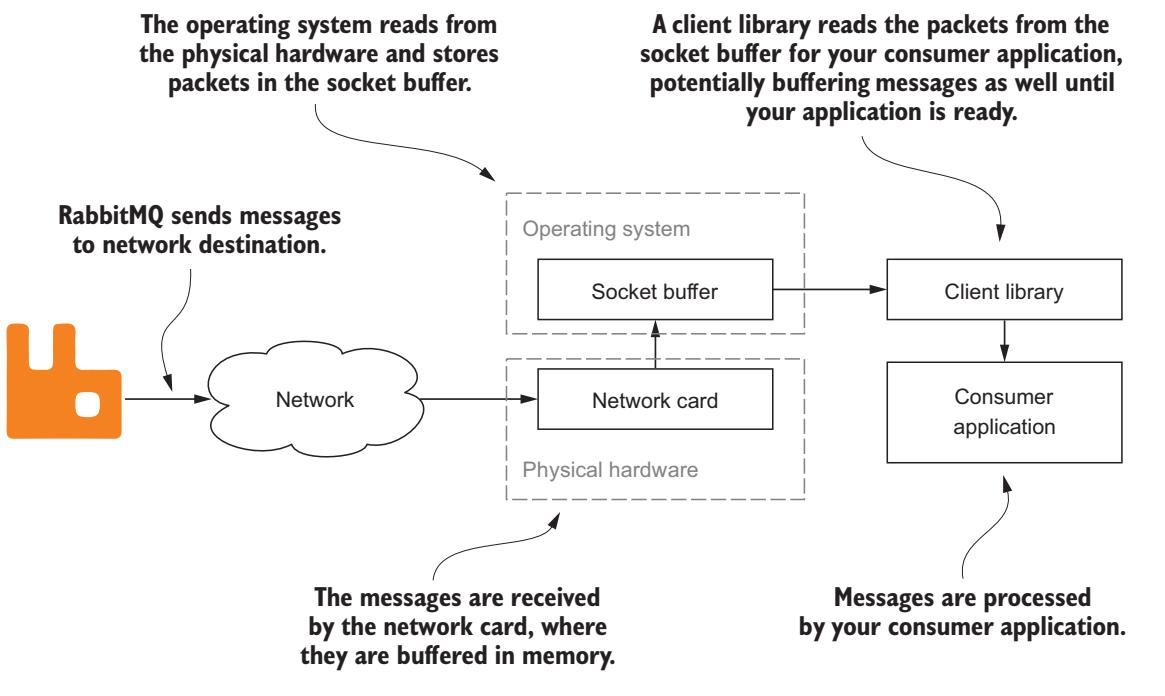
Имеется множество буферов данных, которые получают данные сообщения прежде вашего потребительского приложения.
Когда RabbitMQ отправляет какое- то сообщение в открытое соединение, оно взаимодействует с клиентом через некое соединение сокета TCP. Если это
соединение открыто и в него допустима запись, RabbitMQ предполагает, что всё в нём работает как положено и что соответствующее сообщение было доставлено.
В случае возникновения некоей сетевой проблемы в тот момент, когда RabbitMQ пытается выполнить запись в соответствующий сокет чтобы доставить текущее
сообщение, ваша операционная система возбудит ошибку сокета, что позволит RabbitMQ узнать о произошедшей проблеме. Если не возникло никакой ошибочной
ситуации RabbitMQ полагает, что данное сообщение было доставлено. Подтверждение получения сообщения, отправленное через отклик RPC
Basic.Ack, является одним из способов для клиента дать знать RabbitMQ что оно было успешно получено и, в
большинстве случаев, обработка сообщения выполнена. Однако, если вы отключает отправку уведомлений о получении, RabbitMQ отправляет без ожидания следующее
сообщение, в случае его доступности. На самом деле RabbitMQ продолжает отправлять вашему потребителю сообщения в случае их доступности пока не заполнит все
буферы имеющегося сокета.
|
| Увеличение буферов сокета приёма в Linux |
|---|---|
|
Чтобы увеличить общее число буферов принимающего сокета в операционных системах Linux, следует увеличить значения настроек
|
именно по причине того, что RabbitMQ не ожидает подтверждения, данный метод потребления сообщений может зачастую предоставлять наивысшую пропускную способность. Для являющихся одноразовыми сообщений это идеальный способ создания наивысшей возможной скорости, но он не лишён серьёзных рисков. Подумайте что произойдёт если некое потребляющее приложение завершилось падением при сотне 1кБ сообщений в буфере принимающего сокета его операционной системы. RabbitMQ полагает, что он уже отправил эти сообщения и он не получил никаких указаний о том сколько сообщений необходимо прочесть из имеющейся операционной системы после крушения вашего приложения и закрытия его сокета. Выставление интерфейсов вашего приложения зависит от размера и количества сообщений в сочетании с установленным размером буфера принимающего сокета в вашей операционной системе.
Если данный метод потребления сообщений не удовлетворяет архитектуре вашего приложения и вы желаете ещё более быструю пропускную способность, чем имеющуюся при доставке одиночных сообщений и предоставлением последующего подтверждения, вы возможно захотите рассмотреть управление предварительно установленными настройками качества обслуживания в вашем потребляющем канале.
Спецификация AMQP требует настройки качества обслуживания (QoS) каналов чтобы потребитель мог запросить заранее установленное количество сообщений, которые следует получать прежде чем это потребитель выдаст квитанцию подтверждения приёма. Такие установки QoS позволяют RabbitMQ более эффективно отправлять сообщения, указывая сколько сообщений предназначено для данного потребителя.
В отличии от потребителя с отключённым уведомлением получения (no_ack=True), если ваше потребляющее приложение
рушится после того как оно может подтвердить получение этих сообщений, все предварительно выбранные сообщения будут возвращены в установленную
очередь при закрытии соответствующего сокета.
На самом уровне протокола отправка запроса RPC Basic.QoS в канал определяет значение качества обслуживания.
В качестве части этого запроса RPC вы можете определять, будет ли это значение QoS установлено для того канала, который он отправлен, или же для всех
каналов в данном открытом соединении. Запрос RPC Basic.QoS может быть отправлен в любой момент времени, однако
как это показано в следующем коде из записной книжки "5.2.2 Specifying QoS", он обычно выполняется перед тем как потребитель запускает свой запрос
RPC Basic.Consume.
import rabbitpy
with rabbitpy.Connection() as connection: # Подключаемся к RabbitMQ
with connection.channel() as channel: # Открываем канал для соединения
channel.prefetch_count(10) # Задаём значение количества предварительной выборки равным 10 сообщениям
for message in rabbitpy.Queue(channel, 'test-messages'): # Выполняем итерации по всем сообщениям в соответствующей очереди в качестве потребителя
message.pprint() # Структурированный вывод атрибутов полученного сообщения
message.ack() # Подтверждение приёма сообщения
|
| Замечание |
|---|---|
|
Хотя спецификация AMQP требует и количества предварительно выбираемых сообщений и их размера для своего метода
|
Калибровка ваших значений предварительной выборки в некое оптимальное значение
Также важно осознавать, что чрезмерное выделение числа значений предварительной выборки может оказывать отрицательное воздействие на пропускную способность сообщений. Множество потребителей в одной и той же очереди будут получать сообщения карусельным образом (round-robin) от RabbitMQ, однако важно производить эталонное тестирование производительности числа значений предварительной выборки высокоскорстных приложениях потребителей. Преимущество определённых установок может варьироваться на основе построения конкретного сообщения, поведения потребителя и прочих факторов, например таких, как операционная система и язык.
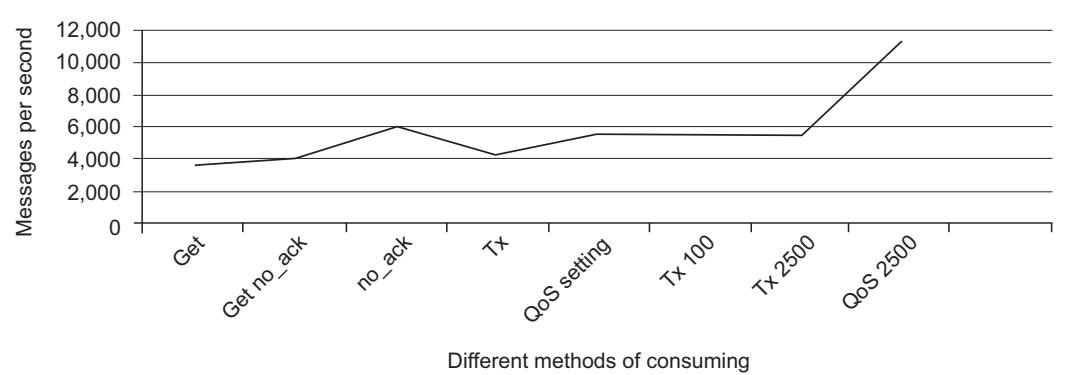
На Рисунке 5-7 приводится сравнение простого сообщения в эталонном тестировании с отдельным потребителем, показывающее что в этих обстоятельствах наилучшей установкой для получения максимальной скорости сообщения было значение предварительной выборки, равное 2 500.
Рисунок 5-7
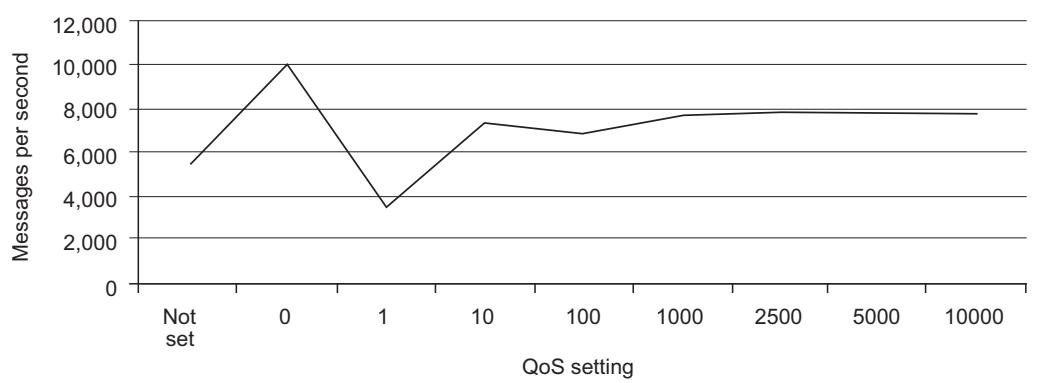
Простой эталонный тест, выдающий результаты потребления с установленным QoS и различными значениями количества предварительных выборок.
Подтверждение множества сообщений за один раз
Одной из полезных вещей применения соответствующих установок QoS является то, что вам не требуется выдавать подтверждение приёма для каждого
сообщения, получаемого с RPC откликом Basic.Ack. Вместо этого ваш отклик RPC
Basic.Ack имеет некий атрибут с названием multiple и когда он
установлен в значение True, он позволяет RabbitMQ знать что ваше приложение хотело бы заверить получение всех
предыдущих не получивших подтверждения в получении сообщений. Это демонстрируется в следующем примере из записной книжки
"5.2.2 Multi-Ack Consumer"ю
import rabbitpy
with rabbitpy.Connection() as connection: # Подключаемся к RabbitMQ
with connection.channel() as channel: # Открываем канал для соединения
channel.prefetch_count (10) # Задаём значение количества предварительной выборки равным 10 сообщениям
unacknowledged = 0 # Инициализируем счётчик не получивших подтверждения приёма сообщений
for message in rabbitpy.Queue(channel, 'test-messages') # Потребляем сообщения из rabbitMQ
message.pprint() # Структурированный вывод атрибутов полученного сообщения
unacknowledged += 1 # Увеличиваем счётчик значений не получивших подтверждения приёма сообщений
if unacknowledged == 10: # Выполняем проверку того, что число сообщений без подтверждения соответствует значению prefetch_count
message.ack(all_previous=True) # Подтверждаем получение всех предыдущих сообщений без подтверждения
unacknowledged = 0 # Сброс значения счётчика не получивших подтверждения приёма сообщений
Выдача подтверждения на приём множества сообщений за один раз позволяет минимизировать общий объём сетевого взаимодействия, необходимого для обработки ваших сообщений, что улучшает пропускную способность (Рисунок 5-8). Не лишим будет заметить, что такой тип выдачи подтверждений приёма несёт с собой определённый уровень риска. Если вы успешно обработали какое- то число сообщений, а ваше приложение упало прежде чем подтвердить это, все неподтверждённые сообщения возвратятся в свою очередь для обработки другим потребляющим их процессом.
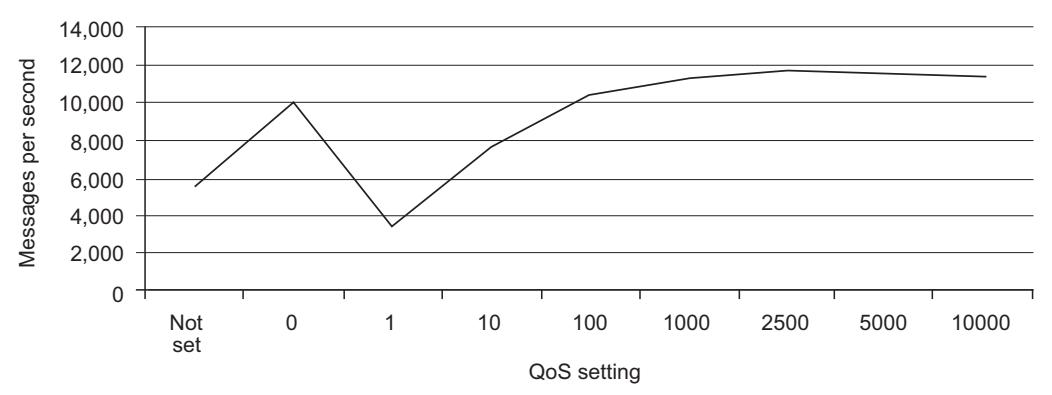
Как и в случае с публикацией сообщений к потребляющим сообщения приложениям применяется принцип Золотой середины - вам необходимо найти привлекательное место между приемлемым риском и максимальной производительностью. Помимо QoS вам следует также рассмотреть и транзакции в качестве способа улучшения гарантии доставки сообщений в ваше приложение. Исходный код для такого эталонного тестирования доступен на вебсайте этой книги.
Как и в случае с публикацией сообщений в RabbitMQ, транзакции позволяют вашим потребляющим приложениям выполнять фиксацию или откат пакетов операций.
Транзакции (класс TX AMQP) могут иметь некое отрицательное воздействие на пропускную способность за единственным
исключением. Если вы не применяете установки QoS, вы можете на самом деле видеть лёгкое улучшение при использовании транзакций при пакетной обработке
подтверждений приёма сообщений
(Рисунок 5-9).
Рисунок 5-9
Скорости сообщений при использовании транзакций в сопоставлении со скоростями сообщений без применения транзакций.
Как и в случае с определёнными установками QoS, вам следует проводить эталонное тестирование производительности своего потребляющего приложения как части своей оценки в определении того будут ли в вашем потребляющем приложении играть какую- то роль транзакции. Независимо от того, используете ли вы их для подтверждения приёма пакета сообщений или для того, чтобы вы могли откатывать отклики RPC при потреблении сообщений, знание значения истинного влияния транзакций на производительность поможет вам найти правильный баланс между гарантиями доставки сообщений и пропускной способностью сообщений.
|
| Замечание |
|---|---|
|
Транзакции не работают для потребителей с отключёнными подтверждениями получения. |
Выдача подтверждений в получении является великолепным способом гарантировать что RabbitMQ знает что его потребитель получил и обработал сообщение
перед его уничтожением, но что происходит когда возникает некая проблема либо с самим сообщением, либо в процессе обработки этого сообщения? Для развития
таких событий RabbitMQ предоставляет два механизма откидывания сообщения обратно его брокеру: Basic.Reject и
Basic.Nack
(Рисунок 5-10).
В данном разделе мы рассмотрим различия обоих, а также обмены пропавшими письмами, особого расширения RabbitMQ к имеющейся спецификации AMQP, которое
может помогать в указании систематических проблем с пакетами отвергаемых сообщений.
Рисунок 5-10
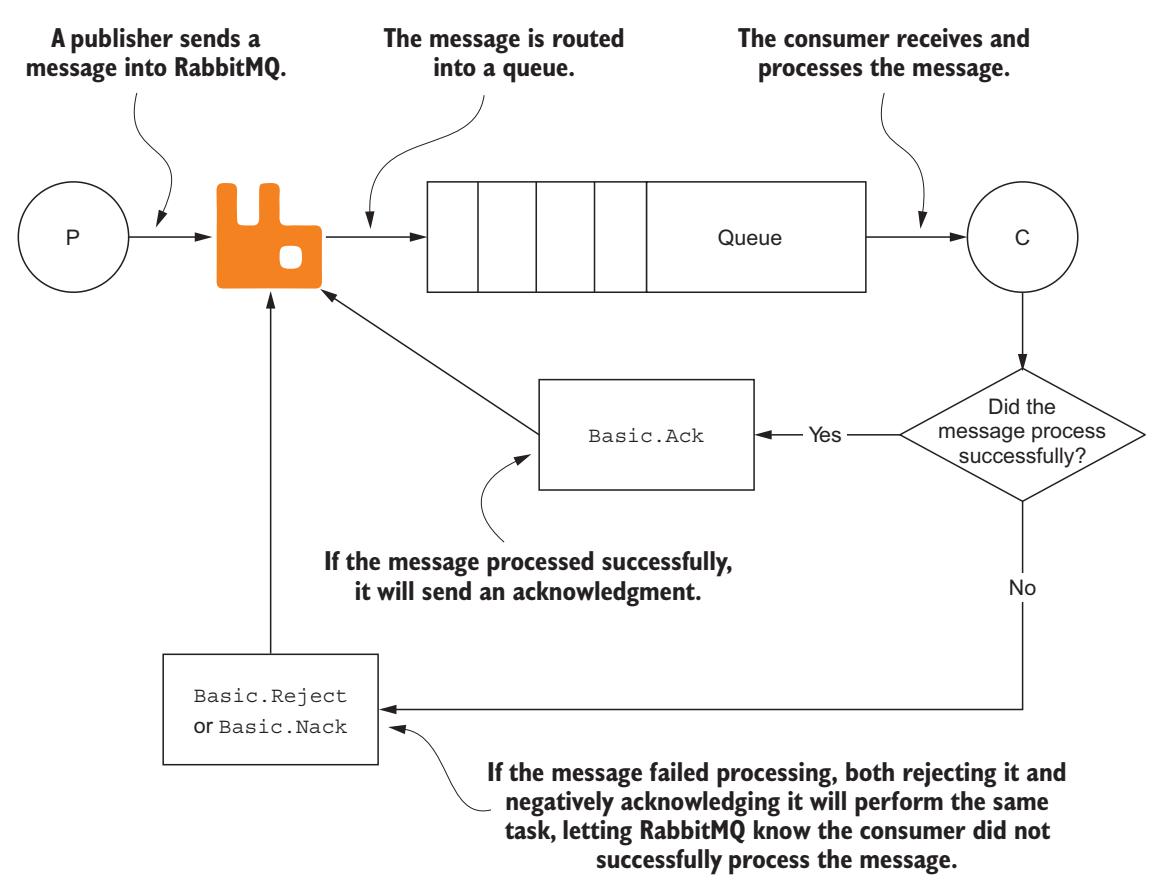
Потребитель может выдать подтверждение приёма, его отклонение или отрицательный результат подтверждения приёма сообщения.
Basic.Nack делает возможным отвержения множества сообщений за раз, в то время как
Basic.Reject позволяет отвергать за раз только одно сообщение.
Basic.Reject является неким специфичным для AMQP откликом RPC на доставку сообщения, который информирует
имеющегося брокера что полученное сообщение не может быть обработано. Как и Basic.Ack, он переносит с собой
создаваемый RabbitMQ тег доставки для персонального указания на то сообщение в канале, относительно которого ваш потребитель обращается к RabbitMQ.
Когда некий потребитель отвергает сообщение, вы можете указать RabbitMQ либо уничтожить это сообщение, либо повторно поставить в очередь данное
сообщение с соответствующим флагом requeue. При включённом значении флага
requeue, RabbitMQ поместит данное сообщение в соответствующую очередь для повторной обработки.
Я часто применяю эту функциональность при написании приложений потребителей, которые взаимодействуют с прочими службами, такими как базы данных
или удалённые API. Вместо того чтобы создавать логику в моё м потребителе для последующих повторов в случае отказа, вызванного удалённой исключительной ситуацией,
такой как отключение курсора базы данных или отказ в контакте с каким- то удалённым API, я просто отлавливаю такую исключительную ситуацию и отвергаю
своё сообщение с установкой значения requeue в True. Это позволяет мне
упрощать путь моего кода к потребителю и при использовании в объединении с программами сбора статистики, такими как Graphite, я могу наблюдать
тенденции в поведении исключительных ситуаций отслеживая скорость повторного прохождения очереди.
В следующем примере из записной книжки "5.3.1 Message Rejection" демонстрируется как устанавливается флаг
redelivered в соответствующем сообщении когда некое сообщение было повторно помещено в очередь с тем, чтобы
проинформировать следующего потребителя сообщения что оно изначально не было доставлено. Я пользуюсь этой функциональностью для реализации политики
"два попадания и ты уходишь". Некорректное сообщение может вызывать у потребителя хаос, но если у вас нет уверенности в том, связана ли эта
проблема с самим сообщением, либо с чем- то ещё уже у потребителя, проверка значения флага redelivered
является хорошим способом определения того следует ли отклонять сообщение, запрашивающее повторную постановку в очередь или уничтожить его при
возникновении ошибки.
import rabbitpy
for message in rabbitpy.consume('amqp://guest:guest@localhost:5672/%2f', # Выполняем итерации в качестве потребителя
'test-messages'):
message.pprint() # Структурированный вывод атрибутов данного сообщения
print('Redelivered: %s' % message.redelivered) # Вывод атрибута redelivered данного сообщения
message.reject(True) # Отклонение данного сообщения и его повторная постановка в очередь для нового потребления
Как и в случае с Basic.Ack, применение Basic.Reject
высвобождает удержание сообщения после того как оно доставляется без включённого no-ack. Хотя вы можете
подтверждать соответствующие приём или обработку множества сообщений за раз с Basic.Ack, вы
можете в то же самое время отвергать множество сообщений при помощи Basic.Reject - и именно здесь
выходит на сцену Basic.Nack.
Basic.Reject делает возможным отклонение отдельного сообщения, однако, если вы применяете рабочий поток,
использующий Basic.Ack во множественном режиме, вы можете пожелать тот же самый тип функциональности и для
отвержения сообщений. К сожалений, спецификация AMQP не предоставляет такой функциональности. Команда RabbitMQ рассматривает это как недостаток в
имеющейся спецификации и реализовала новый метод отклика RPC с названием Basic.Nack. Будучи сокращением для
"negative acknowledgment", сходство методов отклика Basic.Nack и
Basic.Reject может объяснимо сбивать с толку при первом взгляде на них. Чтобы подвести итог, метод
Basic.Nack реализует то же самое поведение что и метод отклика
Basic.Reject, но при этом он добавляет несколько отсутствующих аргументов к множественному поведению
Basic.Ack.
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Выступая в качестве частного дополнения RabbitMQ для протокола AMQP, |
Свойство обмена пропавшими сообщениями (DLX, dead-letter exchange) RabbitMQ является неким расширением имеющейся спецификации AMQP и выступает в роли не обязательного поведения, которое может осуществлять попытку отвергать не доставленные сообщения. Это свойство полезно при попытке диагностирования того, почему имеются проблемы при потреблении определённых сообщений.
Например, один из написанных мной типов приложения брал сообщения на основе XML и превращал их в файлы PDF с применением стандартного языка разметки с названием XSL:FO. За счёт сочетания такого документа XSL:FO и содержимого XML из получаемого сообщения я мог применять приложение Apache для генерации файла PDF и его последующей передачи в электронном виде. Этот процесс работал достаточно неплохо, но время от времени он падал. Воспользовавшись обменом пропавшими письмами в данной очереди, я получил возможность инспектировать упавшие документы XML и вручную запускать их снова сопоставляя с соответствующим документом XSL:FO для поиска неисправностей. Не имея обмена пропавшими письмами, мне бы пришлось добавить код в своего потребителя, который выставлял бы данный документ XML в какое- то место, в котором я бы мог вручную обрабатывать его из командной строки. Вместо этого я смог запускать своего потребителя в интерактивном режиме, указывая его в другой очереди и я получил возможность выяснять что данная проблема связана с тем как обрабатывались символы Unicode при генерации этого документа его издателем сообщения.
Хотя это может на слух восприниматься как некий особый тип обмена в RabbitMQ, обмен пропавшими письмами является обычным обменом. При его создании не
требуется и не выполняется ничего особенного. Единственное что делает его собственно обменов пропавшими письмами это объявление использования данного
обмена для отклонённых сообщений при создании очереди. При отказе от сообщения, в котором отпала необходимость, RabbitMQ выполнит маршрутизацию данного
сообщения в соответствующий обмен, определяемый в данной очереди как аргумент x-dead-letter
(Рисунок 5-11).
Рисунок 5-11
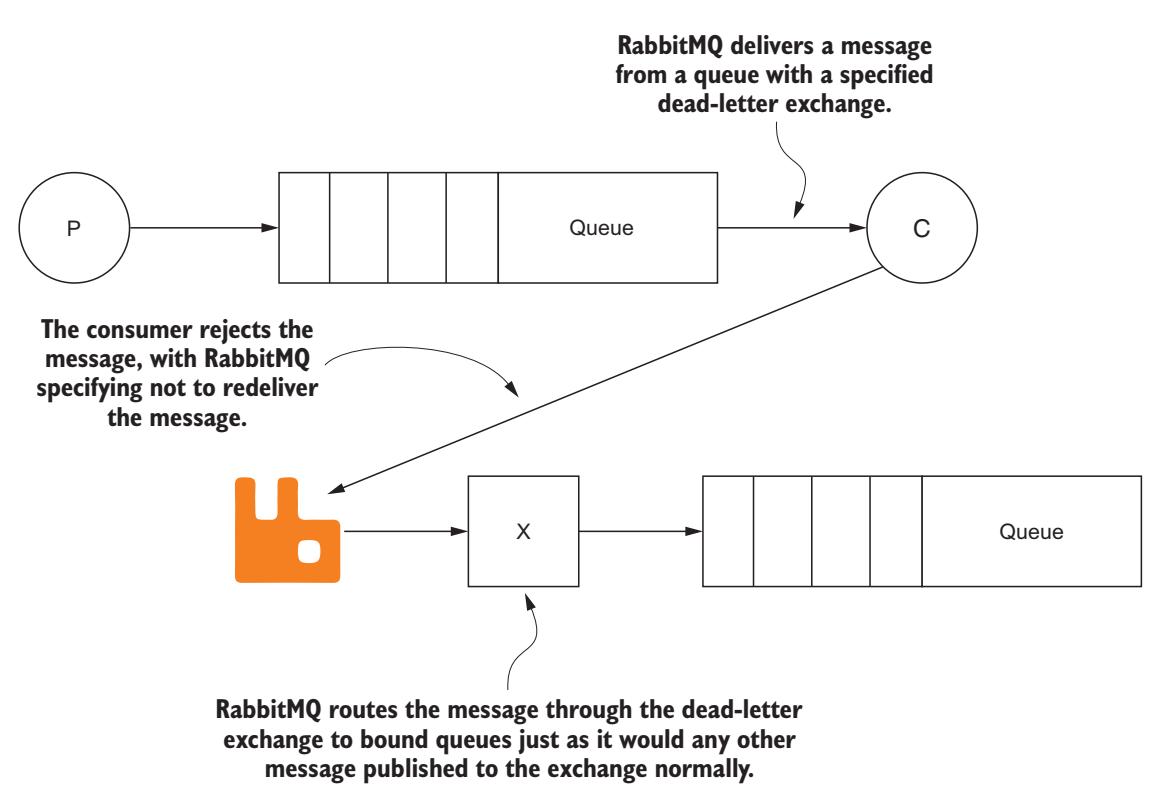
Отклонённое сообщение может маршрутизироваться как сообщение письма смерти через иной обмен.
|
| Замечание |
|---|---|
|
Обмен пропавшими письмами не то же самое что и Альтернативный обмен, описанный нами в Главе 4. Письмо с истекшим сроком или отклонённое письмо доставляется через обмен пропавших писем, в то время как Альтернативный обмен направляет сообщения, которые в противном случае не выполнили бы маршрутизацию RabbitMQ. |
Определение обмена пропавшими сообщениями при объявлении очереди является достаточно тривиальным. Просто передайте соответствующее название обмена
в качестве аргумента dead_letter_exchange при создании объекта rabbitpy
Queue или как аргумент x-dead-letter-exchange при вызове соответствующего
RPC запроса Queue.Declare. персональные аргументы позволяют вам определять произвольные пары ключ/ значение, которые
сохраняются в соответствующем определении очереди. Дополнительно вы изучите их в разделе 5.4.6.
Следующий пример находится в записной книжке "5.3.3 Specifying a Dead Letter Exchange".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
rabbitpy.Exchange(channel, 'rejected-messages').declare() # Объявляем обмен пропавшими сообщениями
queue = rabbitpy.Queue(channel, 'dlx-example', # Создаём объект очереди rappitpy
dead_letter_exchange='rejected-messages')
queue.declare() # Объявляем очередь своего примера с обменом потерянных писем “rejected-messages”
Помимо собственно обмена, данная функциональность потерянных писем позволяет вам переписывать имеющийся ключ маршрутизации с предопределённым значением.
Это делает для вас возможным применять тот же самый обмен для ваших сообщений о пропавших письмах, что и для сообщений с не пропавшими письмами, но при этом
гарантировать что такие сообщения пропавших писем не доставляются в ту же самую очередь. Для установки предварительно заданного ключа маршрутизации
требуется определять при объявлении такой очереди некий дополнительный аргумент, x-dead-letter-routing-key.
|
| Замечание |
|---|---|
|
Согласно стандарта AMQP, все настройки очереди в RabbitMQ являются неизменными, что означает, что их нельзя изменять после объявления какой бы то ни было очереди. Для внесения изменения обмена пропавшими письмами в какой- то очереди вам следует удалить её и повторно объявить её. |
Имеется множество путей применения в вашей архитектуре приложений обменов пропавших писем с целью их усиления. Начиная с предоставления места хранения некорректных сообщений вплоть до более прямой интеграции концепций рабочих потоков, таких как обработка отклонённых разрешений на кредитную карту, причём не смотря на то, что функциональность пропавших сообщений очень мощная, её часто упускают из виду из- за её вторичного размещения в качестве некоторого пользовательского аргумента в очереди.
Имеется множество различных вариантов применения для потребляющих приложений. Для некоторых приложений допустимо чтобы множество потребителей выполняли ожидание в одной и той же очереди, а в прочих очередь должна иметь только одного потребителя. Приложение чата может создавать некоторую очередь для каждой комнаты или каждого пользователя, причём эти очереди могут рассматриваться как временные, в то время как приложение обработки кредитной карты может создавать одну долговременную очередь, которая присутствует всегда. При наличии такого широкого набора вариантов применения трудно предоставлять каждую опцию как желаемую при работе с очередями. Удивительно, но RabbitMQ предоставляет достаточную гибкость практически для любых вариантов применения очередей.
При определении очереди имеется множество установок, которые определяют поведение какой- то очереди. Очередь может выполнять перечисленное далее и ещё много чего:
-
Автоматически удалять себя
-
Разрешать для себя только одного потребителя
-
Автоматически завершать срок действия сообщения
-
Придерживаться ограниченного числа очередей
-
Выпихивать старые сообщения из стека
Важно понимать, что согласно имеющейся спецификации AMQP установки очереди неизменные. После того как вы объявили некую очередь, вы не можете изменять никакие имеющиеся установки, которые вы применили при её создании. Для изменения установок очереди вы обязаны удалить такую очередь и создать её заново.
Для исследования различных доступных при создании очереди установок давайте вначале изучим параметры для временных очередей, начав с уничтожающих себя самостоятельно очередей.
Автоматическое удаление очередей
Аналогично портфелю из Миссия невыполнима, RabbitMQ предоставляет для очередей возможность самостоятельного самоуничтожения после того, как в ней нет потребности. Как и падение мёртвого в шпионском фильме, автоматически уничтожающие себя очереди могут создаваться и наполняться сообщениями. После того как некий потребитель соединился, выбрал все сообщения и отсоединился, данная очередь может быть удалена.
Создание автоматически удаляющейся очереди выполняется так же просто как установить флаг auto_delete в значение
True в RPC соответствующем запросе Queue.Declare, как в приводимом
примере "5.4.1 Auto-Delete Queue" из записной книжки IPython.
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
queue = rabbitpy.Queue(channel, 'ad-example', # Создаём объект очереди rappitpy
auto_delete=True)
queue.declare() # Объявляем очередь примера “ad-example” с установкой auto_delete в значение Истина
Важно отметить, что из автоматически удаляемой очереди выполнять потребление может любое число потребителей; такая очередь удалит себя только тогда, когда больше нет потребителей, выполняющих её ожидание. Забавный вариант применения для автоматического удаления это её представление себе как некой разновидности шпионского снаряжения, но это не единственный вариант её использования.
Одним из вариантов использования является приложение в стиле чата, в котором каждая очередь представляет собой входящий буфер пользователя. Если соединение пользователя прерывается, для такого приложения имеются все основания ожидать, что данная очередь и любые непрочитанные сообщения должны быть удалены.
Другой пример применения это приложения в стиле RPC. Для приложения отправляющего запросы RPC потребителям и ожидающего доставленные ответы RabbitMQ, создание удаляющей себя очереди после завершения или отключения данного приложение, позволяет RabbitMQ автоматически очищаться после выполнения приложения. В этом случае важно, чтобы очередь ответов RPC была потребляемой только тем приложением, которое публикует исходный запрос RPC.
Доступность только одному потребителю
При отсутствии включённой установки exclusive в некоторой очереди RabbitMQ допускает очень беспорядочное
поведение потребителей. Он не устанавливает ограничений на общее число потребителей, которые могут соединяться с какой- то очередью и выполнять
потребление из неё. На самом деле это поощряет для варианта со множеством потребителей реализовывать карусельный метод поведения доставки для всех
потребителей, которые способны получать сообщения из данной очереди.
Имеются определённые сценарии, как например очередь откликов RPC в некотором рабочем потоке RPC, при которых вы пожелаете иметь гарантию что
только единственный потребитель имеет возможность потреблять все сообщения в некоторой очереди. Включение исключительного использования некоторой очереди
включает передачу аргумента в процессе создания очереди и, как и в случае аргумента auto_delete,
разрешение exclusive очередей автоматически удаляет данную очередь после отсоединения её потребителя. Это
демонстрируется следующим примером из записной книжки "5.4.1 Exclusive Queue" .
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
queue = rabbitpy.Queue(channel, 'exclusive-example', # Создаём объект очереди rappitpy
exclusive=True)
queue.declare() # Объявляем очередь примера “exclusiveexample” с установкой exclusive в значение Истина
Очередь, объявленная как exclusive, может потребляться только в том же самом соединении и в том же самом
канале в котором она была объявлена, в отличии от очередей, которые объявлены с установкой auto_delete в
значение True, которая может иметь любое число потребителей из любого числа соединений. Некая исключительная
очередь также буде автоматически удалена после закрытия канала, для которого была создана данная очередь, что аналогично случаю с очередью, которая
имеет установку auto-delete и которая будет удалена после того как больше нет подписанных на неё потребителей.
В отличии от очереди auto_delete для очереди exclusive вы можете
выполнять потребление и удалять её потребителя столько сколько пожелаете, пока не будет закрыт сам канал. Важно также отметить, что такое автоматическое
удаление некоторой очереди exclusive происходит вне зависимости от того был ли вызван запрос
Basic.Consume, в отличии от очереди auto-delete.
Автоматическое истечение срока действия очередей
В то время, пока мы рассматриваем тему автоматически удаляющих себя очередей, RabbitMQ позволяет и некие дополнительные необязательные аргументы
при объявлении очереди, которые обратятся к RabbitMQ за удалением такой очереди если она становится не используемой на протяжении определённого
промежутка времени. Как и в случае с очередями exclusive, которые самостоятельно удаляют себя, очереди с
автоматическим истечением срока действия просто представлять себе в виде очередей откликов RPC.
Допустим, у вас имеется чувствительная ко времени операция и вы не желаете ожидать неопределённое время какого- то отклика RPC. Вы можете создать некую очередь откликов RPC которая имеет значение срока истечения действия, причём когда этот срок истекает, данная очередь уничтожается. Применяя некое пассивное объявление очереди, вы можете опрашивать присутствие данной очереди и действовать либо когда вы видите наличие ожидающих сообщений, или когда данная очередь больше не существует.
Создать очередь с автоматическим сроком истечения действия так же просто, как объявить очередь с неким аргументом
x-expires со значением времени жизни очереди (TTL, time to live), задаваемым в миллисекундах, как это показано
в данном примере из записной книжки "5.4.1 Expiring Queue".
import rabbitpy
import time
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
queue = rabbitpy.Queue(channel, 'expiring-queue', # Создаём объект для взаимодействия с очередью
arguments={'x-expires': 1000})
queue.declare() # Объявляем очередь “expiring-queue” время жизни которой будет завершаться по истечению 1 секунды простоя
messages, consumers = queue.declare(passive=True) # Применяем объявление пассивной очереди для получения сообщений и подсчёта потребителей в этой очереди
time.sleep(2) # Засыпаем на 2 секунды
try:
messages, consumers = queue.declare(passive=True) # Применяем объявление пассивной очереди для получения сообщений и подсчёта потребителей в этой очереди
except rabbitpy.exceptions.AMQPNotFound:
print('The queue no longer exists') # Отлавливаем исключительную ситуацию AMQPNotFound для очереди с истекшим временем жизни
Для очередей с истекающим временем жизни имеется ряд строгих правил:
-
Данная очередь может израсходовать своё время существования только если она не имеет никаких потребителей. Если у вас есть некая очередь с подключёнными потребителями, она будет автоматически удаляться только когда они вызовут
Basic.Cancelили отсоединятся. -
Срок жизни данной очереди может завершиться только в случае если не было запроса
Basic.Getдля значения продолжительности TTL. Как только для очереди был выполнен хотя бы один запросBasic.Getс неким значением срока годности, текущее значение установки времени жизни обнуляется и эта очередь больше не будет автоматически удаляться. -
Как и в любой другой очереди, параметры и аргументы, объявленные с аргументом
x-expiresне могут быть переопределены или изменены. Если бы вы могли переопределить такую очередь, продлив срок действия на значение аргументаx-expires, вы бы нарушили правило жёсткой установки из текущей спецификации AMQP, запрещающее клиенту любые попытки повторного использования очереди с различными настройками. -
RabbitMQ не предоставляет гарантий того, насколько быстро он удалит такую очередь после истечения её срока жизни.
Длительность присутствия очереди
При объявлении некоторой очереди, которая должна выдерживать перезапуски сервера необходимо настроить значение флага
durable равным True. Часто постоянство (durability) очереди путают с
оставлением (persistence) сообщений. Как мы обсуждали уже это в предыдущей главе, сообщения
сохраняются на диск в случае, когда некое сообщение публикуется со свойством delivery-mode установленным в
значение 2. Значение флага durable, напротив, указывает RabbitMQ что
вы желаете иметь данную очередь настроенной пока не будет вызван запрос Queue.Delete.
В то время как приложениям в стиле RPC обычно требуются очереди которые приходят к потребителям и покидают их, длительные очереди очень подходят тем рабочим потокам приложений, в которых множество потребителей подключаются к одной и той же очереди и выполняют маршрутизацию и поток сообщений, которые не изменяются динамически. Записная книжка "5.4.2 Durable Queue" демонстрирует как объявляется долговременная очередь.
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
queue = rabbitpy.Queue(channel, 'durable-queue', # Создаём объект взаимодействия с очередью
durable=True)
if queue.declare(): # Объявляем эту очередь долговременной
print('Queue declared')
Автоматическое истечение срока действия сообщений в очереди
Для не являющихся критически важными сообщений зачастую лучше чтобы они автоматически исчезали прочь если они слишком долго висят не будучи употреблёнными. Независимо от того, рассматриваете ли вы случай с устаревающими данными, которые следует удалять по истечению их срока полезности, или же вы желаете быть уверенным что вы сможете просто восстановиться в случае падения потребляющего сообщения с высокоскоростной очередью, установки TTL для сообщений делают возможными ограничения для серверной стороны в максимальном возрасте сообщения. Очереди с объявленными одновременно и обменом потерянных писем (DLX), и со значением TTL, повлекут к тому, что сообщения пропавших писем в данной очереди будут иметь срок жизни.
В отличие от свойства истечения срока сообщения, значение которого может меняться от сообщения к сообщению, установки очереди
x-message-ttl задают максимальный возраст для всех сообщений в данной очереди. Это демонстрируется следующим
примером из записной книжки "5.4.2 Queue with Message TTL".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
queue = rabbitpy.Queue(channel, 'expiring-msg-queue', # Создаём объект взаимодействия с очередью
arguments={'x-message-ttl': 1000})
queue.declare() # Объявляем эту очередь
Применение TTL для каждого сообщения в очереди предоставляет неотъемлемое значение для сообщений, которые могут иметь различные значения для различных потребителей. Для некоторых потребителей сообщение может содержать значение транзакции, которое имеет стоимостную оценку и оно должно применяться к учётной записи клиента. Создание очереди с автоматическим сроком истечения действия предотвратит получение устаревшей информации для очереди ожидания инструментальной панели в реальном режиме времени.
Максимальная длина очередей
Начиная с RabbitMQ 3.1.0, очереди могут объявляться как имеющие некий максимальный размер. Если вы установите значение аргумента
x-max-length для какой- то очереди, когда она достигнет своего максимального размера, RabbitMQ будет удалять
сообщения из передней части этой очереди по мере добавления новых сообщений. В чат- помещении с буфером прокрутки объявляемая с
x-max-length очередь будет гарантировать, что опрашивающий n
самых последних сообщений клиент всегда имеет их доступными.
Как и для установок сообщений со сроком истечения, а также для сообщений с потерянными письмами, установка значения максимальной длины настраивается как некий аргумент очереди и не может изменяться после его объявления. Удаляемые из передней части очереди сообщения могут относиться к потерянным сообщениям если данная очередь объявляется с обменом потерянными сообщениями. Приводимый ниже пример показывает некую очередь с предварительно определённой максимальной длиной. Вы можете отыскать его в записной книжке "5.4.2 Queue with a Maximum Length".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
queue = rabbitpy.Queue(channel, 'max-length-queue', # Создаём объект взаимодействия с очередью
arguments={'x-max-length': 1000})
queue.declare() # Объявляем эту очередь с максимальной длиной в 1000 сообщений
Поскольку команда RabbitMQ реализует новые функции, расширяющие спецификацию AMQP в отношении очередей, для переноса настроек для каждого набора функций используются аргументы очереди. Аргументы очереди используются для очередей с высокой доступностью, обмена потерянными письмами, с истечения срока действия сообщения, истечения времени жизни очереди и для очередей с максимальной длиной.
Спецификация AMQP определяет аргументы очереди как некую таблицу, в которой сами синтаксис и семантика её значений должна быть определена основным сервером. RabbitMQ имеет зарезервированные аргументы, перечисляемые в Таблице 5-1, и игнорирует все прочие передаваемые ему аргументы. Аргументы могут иметь только допустимые типы данныхAMQP и могут применяться для любых нужных вам целей. Что касается лично меня, я нахожу эти аргументы очень полезным способом установки набора мониторинга для каждой очереди, а также для поиска неисправностей.
| Название аргумента | Назначение |
|---|---|
|
Некий обмен, в который направляются отвергнутые сообщения, которые не поставлены повторно в очередь |
|
Не обязательный ключ маршрутизации для сообщений потерянных писем |
|
Очередь удаляется после заданного числа миллисекунд |
|
При создании очередей с высокой доступностью определяет режим принудительной HA по узлам |
|
Те узлы, на которые распространяется некая очередm HA (см. раздел 4.1.6) |
|
Максимальное число сообщений в очереди |
|
Время истечения срока жизни сообщения в миллисекундах, применяемое ко всему уровню очереди |
|
Разрешает сортировку по приоритетам в очереди с максимальным значением приоритета 255 (RabbitMQ версий 3.5.0 и выше) |
Настройка производительности ваших потребительских приложений RabbitMQ требует эталонного тестирования и рассмотрения компромиссов между быстрой пропускной способностью и гарантированной доставкой (так же, как и настройка для публикации сообщений). При настройке создаваемых потребительских приложений для нахождения комфортного места вашего приложения рассмотрите следующие вопросы:
-
Требуется ли вам гарантия получения всех сообщений, или они могут отбрасываться?
-
Можете ли вы получать сообщения и после этого выдавать подтверждение приёма или отклонять их как некую пакетную операцию?
-
Если нет, можете ли вы применять транзакцию для улучшения производительности путём автоматического помещения в пакет ваших индивидуальных операций?
-
На самом ли деле вам требуется функциональность фиксации транзакций и отката для ваших потребителей?
-
Требуется ли вашему потребителю исключительный доступ к своим сообщениям в той очереди, из которой он выполняет потребление?
-
Что должно произойти если потребитель столкнётся с какой- то ошибкой? Должно ли это сообщение быть удалено? повторно поставлено в очередь? снабжено письмом потери?
Эти вопросы предоставляют стартовые моменты для создания некоторой прочной архитектуры обмена сообщениями, которая поможет усилить контракт между вашими приложениями публикации и потребления.
Теперь, когда вы располагаете за поясом основами публикации и потребления, мы изучим в следующей главе как вы можете применять их на практике с некоторыми различными шаблонами сообщений и варианты применения.