Глава 6. Шаблоны сообщений через маршрутизацию сообщений
Содержание
- Глава 6. Шаблоны сообщений через маршрутизацию сообщений
- Простая маршрутизация сообщений при помощи прямого обмена
- Широковещательные сообщения через веерный обмен
- Выборочная маршрутизация сообщений при помощи предметного обмена
- Выборочная маршрутизация сообщений при помощи обмена заголовками
- Эталонное тестирование производительности обмена
- Мета переход: маршрутизация обмена- к- обмену
- Маршрутизация сообщений посредством обмена с согласованным хэшированием
- Выводы
Данная глава рассматривает
-
Четыре основных типа обмена, доступных через RabbitMQ плюс некий подключаемый модуль обмена
-
Какой из типов обмена находится в соответствии с архитектурой вашего приложения
-
Как использование маршрутизации обмен- к- обмену может добавлять многочисленные варианты опций маршрутизации вашим сообщениям
Скорее всего наивысшая сила RabbitMQ состоит в той гибкости, которую он предлагает для направления сообщений в различные очереди на основе предоставляемой самим издателем информации о маршрутизации. Будет ли он отправлять сообщения в единственную очередь, во множество очередей, обменов или в иной внешний источник, предоставляемый неким подключаемым модулем обмена, механизм маршрутизации RabbitMQ одновременно и чрезвычайно быстрый и обладает высокой гибкостью. Хотя ваши первоначальные приложения могут и не нуждаться в сложной логике маршрутизации, стартовав с верного типа обмена можно получить впечатляющее воздействие на архитектуру вашего приложения.
В данной главе мы рассмотрим четыре основных типа обмена и те типы архитектур, которые могут получать от них преимущества:
-
Прямой обмен
-
Расширяемый по краю обмен
-
Тематический обмен
-
Обмен заголовками
Мы начнём с некой простой маршрутизации с применением Прямого обмена (direct exchange). За ним мы воспользуемся Веерным обменом (Ветвящимся обменом, fanout exchange) для отправки образов как потребителю их распознающему, так и потребителю их хэширующему. Тематический обмен (предметный обмен, topic exchange) делает для нас возможной выборочную маршрутизацию основываясь на соответствии символьной подстановке в предлагаемом ключе маршрутизации, а обмен заголовками (headers exchange) представляет некий альтернативный подход к маршрутизации сообщений с применением самого сообщения. Я развею существующий миф относительно того, что определённые обмены не так действенны как прочие и затем я покажу вам как связывание обмена- к- обмену может открывать реальность, аналогичную Зарождению, но при этом для маршрутизации сообщений, а не для мечтаний. Наконец, мы рассмотрим согласуемый хэшерованием обмен (consistent-hashing exchange), некий тип обмена подключаемого модуля, который должен помогать когда пропускная способность вашего потребителя нуждается в росте поверх возможностей множества потребителей, совместно использующих единственную очередь.
Прямой обмен полезен когда вы собираетесь доставлять некое сообщение в определённую цели или устанавливать цели. Любая очередь, которая связывается с неким обменом с помощью того же самого ключа маршрутизации, который применяется для публикации сообщения получит это сообщение. RabbitMQ применяет эквивалентность строк при проверке имеющегося связывания и не позволяет никаких разновидностей соответствий шаблонов при использовании прямого обмена (Рисунок 6-1).
Рисунок 6-1
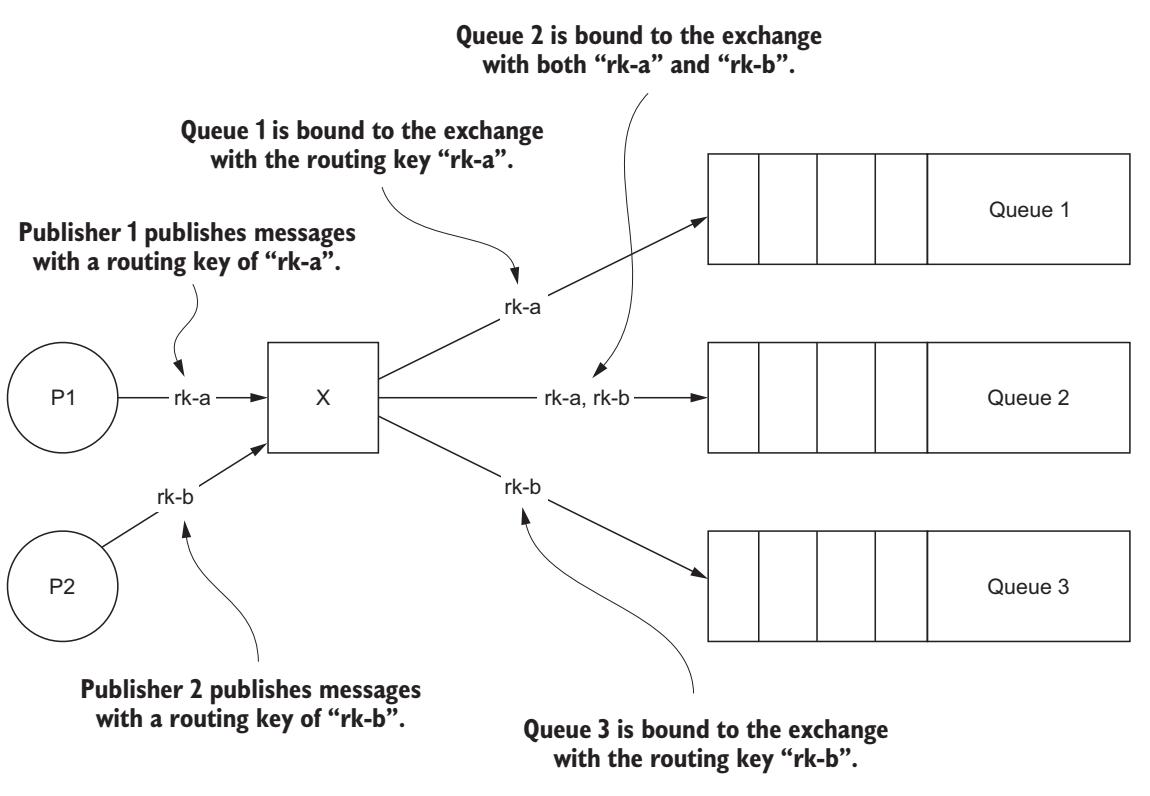
Применяя прямой обмен публикуемые издателем 1 сообщения будут направляться в очередь 1 и очередь 2, в то время как публикуемые издателем 2 сообщения будут направляться в очереди 2 и 3.
Как это иллюстрируется Рисунком 6-1, множество очередей может связываться с прямым обменом при помощи одного и того же ключа маршрутизации. Каждая связываемая одним и тем же ключом маршрутизации очередь будет получать все те сообщения, которые публикуются с таким ключом маршрутизации.
Прямой тип обмена встроен в RabbitMQ и не требует никаких дополнительных подключаемых модулей. Создание прямого обмена настолько же простое, как и объявление типа обмена как "direct", что демонстрируется фрагментом кода в записной книжке "6.1 Direct Exchange".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
exchange = rabbitpy.Exchange(channel, 'direct-example', # Создаём объект rabbitpy.Exchange
exchange_type='direct')
exchange.declare() # Объявляем соответствующий обмен
Благодаря своей простоте прямой обмен является хорошим выбором для маршрутизации отклика сообщения, применяемого в шаблонах обмена сообщениями RPC. Создание разъединённых приложений с помощью RPC является исключительным способом создания высоко масштабируемых приложений с различными компонентами, которые предоставляются в множестве серверов {Прим. пер.: а также в приложениях "&без серверов" см., например, перевод Kubernetes для приложений без сервера Русс Мак-Кендрика}.
Данная архитектура выступает в качестве основы в нашем первом примере. Вы напишите некого работника RPC, который потребляет образы для выполнения распознавания лиц с последующей публикацией их обратно в своём издательском приложении. В сложном вычислительном процессе, таком как обработка образа или видео, применение удалённых исполнителей (workers) RPC является великолепным способом масштабирования некоего приложения. Если такое приложение работало в облаке, например, то приложение, которое публикует сами запросы может обитать в виртуальных машинах малого размера, а исполнитель обработки данного образа может применять оборудование более крупного размера - либо, если этот рабочий поток поддерживает такое оборудование - на базе GPU вычислений. {Прим. пер.: или вовсе это может происходить в контейнерах, например, упакованных в поды с целью присутствия в одном и том же хосте, подробнее Глава 1, Понимание архитектуры Kubernetes перевода Полное руководство Kubernetes, 2е изд. Джиджи Сэйфан}
Чтобы начать строить соответствующий пример приложения вы напишите своего исполнителя, потребителя обработки изображения с единственной целью.
Допустим, вы хотите реализовать некую службу API на веб- основе, которая обрабатывает выкладываемые с мобильного телефона фотографии. Проиллюстрированный на Рисунке 6-1 могут быть реализованы как облегчённые, масштабируемые с высокой степенью, асинхронные веб приложения интерфейса с применением технологии подобной веб схеме Tornado или Node.js. После запуска приложения веб- интерфейса оно создаст в RabbitMQ некую очередь с применением названия, уникального для этих процессов откликов RPC.
Как показано на Рисунке 6-2, процесс запроса начинается когда приложение мобильного клиента
загружает изображение, и ваше приложение получает его содержимое. Затем приложение создаёт сообщение с уникальным идентификатором, который указывает на
удалённый запрос. При публикации этого образа в имеющемся обмене в соответствующем поле reply-to будет установлено
название очереди отклика, а идентификатор этого отклика будет помещён в поле correlation-id. Само тело
данного сообщения будет содержать только непрозрачные бинарные данные данного образа.
Рисунок 6-2
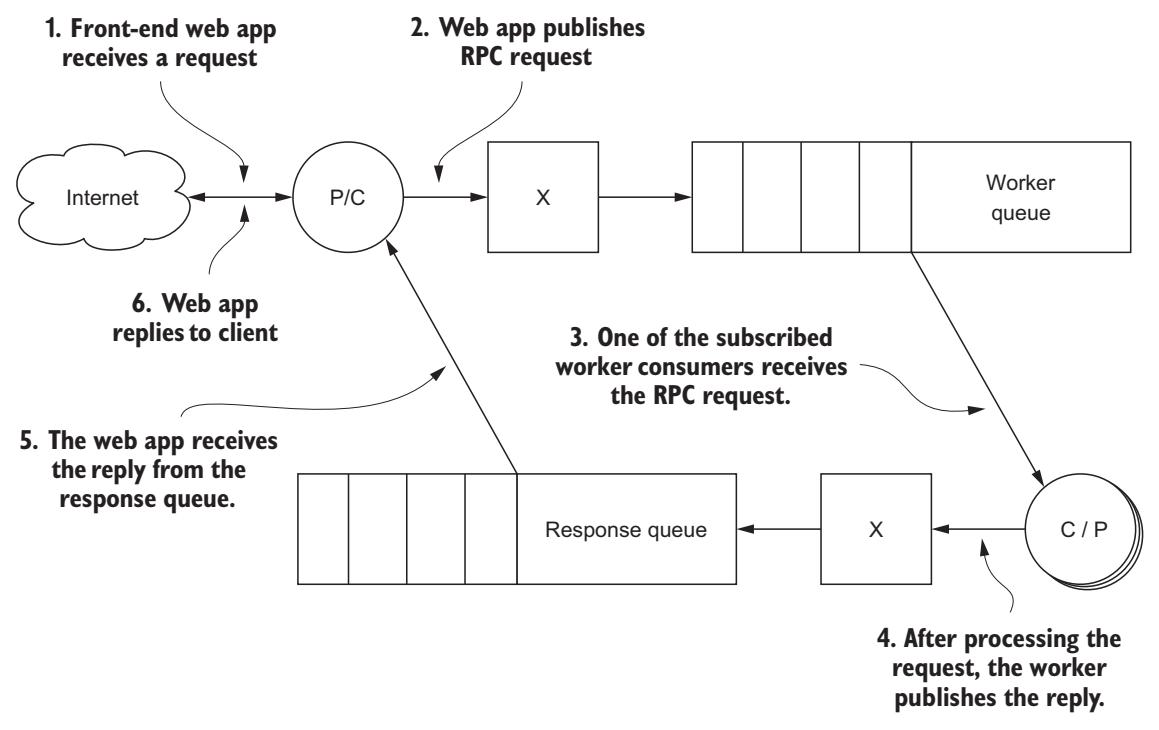
Пример шаблона RPC, в котором издатель отсылает некий запрос с помощью прямого обмена, а исполнитель потребляет это сообщение и публикует результат, который следует потребить первоначальному издателю.
Мы уже обсуждали некоторые структуры нижнего уровня кадра в Главе 2. Давайте рассмотрим те кадры, которые требуются для создания такого запроса RPC (Рисунок 6-3).
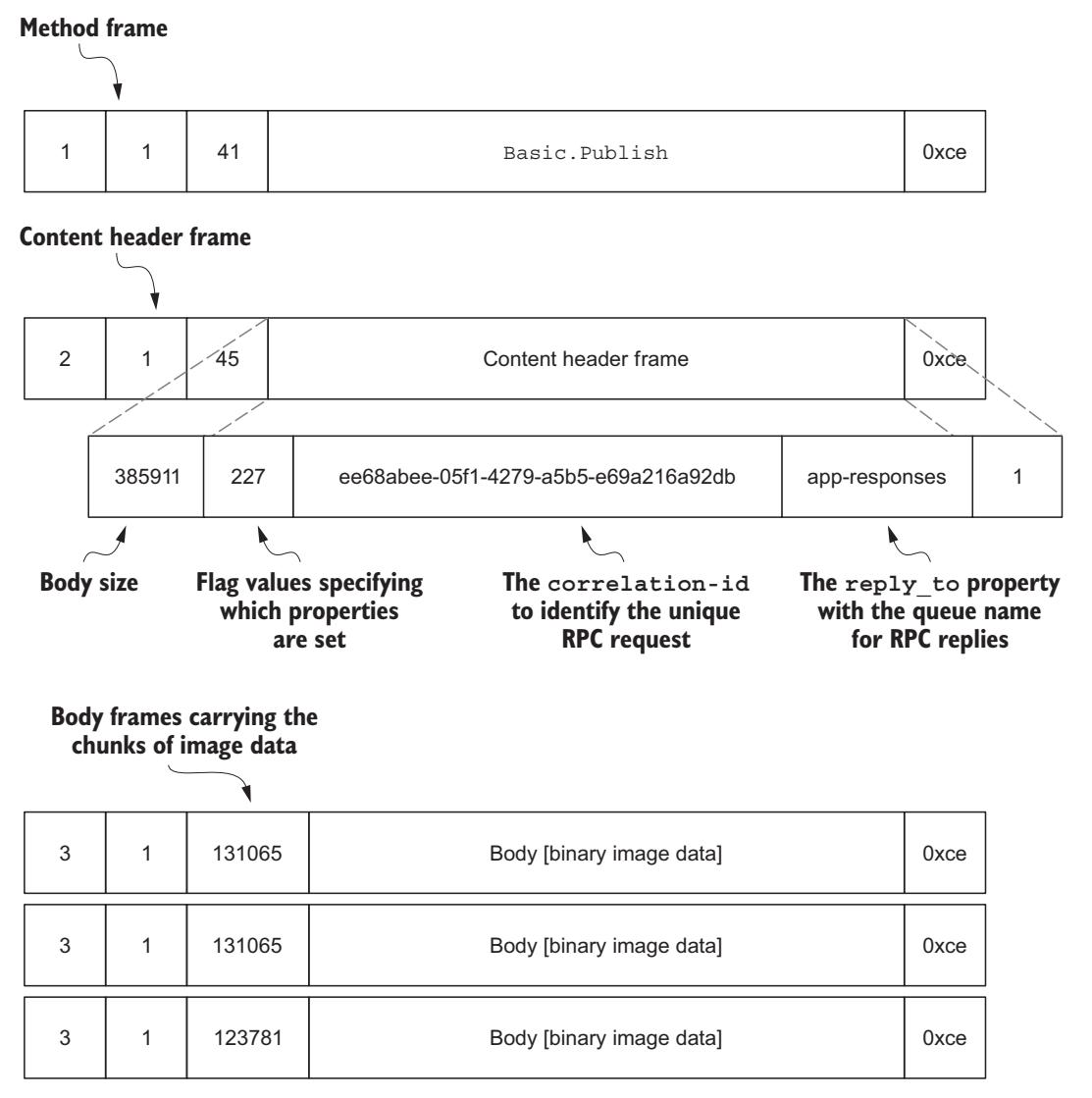
На Рисунке 6-3 значения полей reply-to и
correlation-id переносятся в полезной нагрузке свойства Content-Headers.
Тот образ, который подлежит отправке в качестве тела данного сообщения разделяется на три фрагмента, отправляемых в кадры тела AMQP. Максимальный размер
кадра RAbbitMQ составляет 131 072 байт, что означает, что любое сообщение, которое превосходит этот размер должно делиться на фрагменты на уровне
протокола AMQP. Так как имеются 7 байт накладных расходов, которые также следует учитывать, кадр каждого тела может переносить только 131 065 байт таких
непрозрачных двоичных данных образа.
Когда данное сообщение опубликовано и отправлено по маршруту, подписанный для такой обработки очереди потребляет его как вы это изучали в Главе 5. Данный потребитель может тяжёлый подъём и осуществлять необходимые блокирование, затратные вычисления или интенсивные операции ввода/ вывода, которые само веб приложение интерфейса не могло бы осуществлять не заблокировав прочих клиентов. Вместо этого, выгружая интенсивные задачи вычисления или ввода/ вывода в какого- то потребителя, асинхронно работающий интерфейс волен обрабатывать другие клиентские запросы пока он ожидает отклика от своего исполнителя RPC. После того как исполнитель завершит свою обработку полученного образа, конечный результат такого начального запроса RPC отправляется обратно в основной веб интерфейс, позволяя ему отправить отклик своему удалённому мобильному клиенту изначального запроса.
Мы не хотим в своём последующем листинге описывать полномасштабное веб приложение, однако мы создадим некоего простого потребителя, который попытается определять лица в изображениях, которые публикуются для него и затем возвращать тот же самый образ своему издателю с обведёнными вокруг распознанных лиц рамками. Чтобы продемонстрировать как работает такая сторона издателя, мы создадим какого- то издателя, который будет отгружать рабочие запросы для каждого размещаемого в предварительно определённом каталоге изображения. Как вы можете увидеть из Рисунка 6-4, такой сокращённый рабочий поток, который вы реализуете, составляет основную часть данного приложения; он всего лишь опускает само веб приложение.
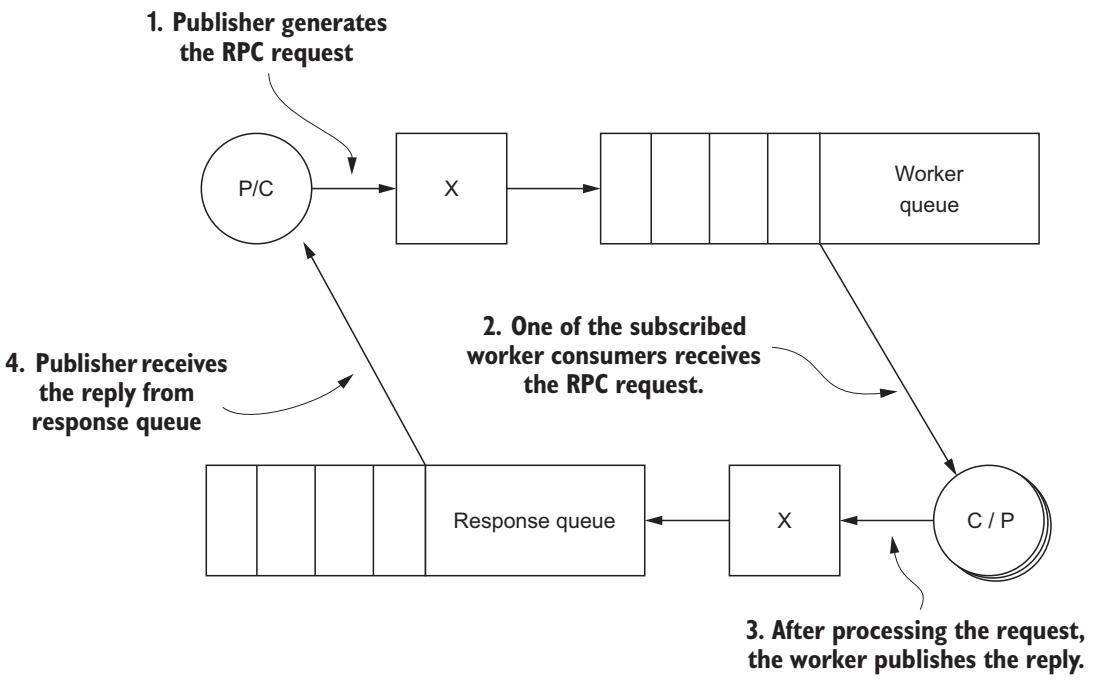
При помощи обозначенной структуры нам теперь понадобится выполнить небольшую подготовку, прежде чем мы приступим к самому коду.
Объявление создаваемого обмена
Прежде чем создавать своих потребителя и издателя, вам понадобится объявить несколько обменов. В нашем следующем коде установленный для соединения URL не определён, поэтому данное приложение будет подключаться к RabbitMQ при помощи определённого по умолчанию URL, amqp://guest:guest@localhost:5672/%2F. Выполнив соединение, наш код затем объявит некий обмен для направления через него запросов RPC и обмен для маршрутизации через него откликов RPC. Следующий код объявления прямого обмена находится в записной книжке "6.1 RPC Exchange Declaration".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
for exchange_name in ['rpc-replies', 'direct-rpc-requests']: # Выполняем итерации по всем подлежащим созданию именам обменов
exchange = rabbitpy.Exchange(channel, exchange_name,
exchange_type='direct')
exchange.declare() # Объявляем необходимый обмен
В отличие от предыдущих примеров для объявления какого- то обмена данный код объявляет множество обменов вместо всего лишь одного. Для ограничения
объёма кода для итераций по нему вводится некий list или array Python
с именами обменов. В каждой итерации данного цикла создаётся объект Exchange rabbitpy, а затем в RabbitMQ
объявляется сам обмен.
После того как вы объявили необходимые обмены RPC для нашего рабочего потока RPC, пройдём далее и приступим к созданию своего исполнителя RPC.
Мы создадим своего исполнителя (worker) RPC как некое приложение потребителя, которое будет получать сообщения, содержащие файлы образа и осуществлять распознавание образа в нём при помощи выдающегося OpenCV, обводя рамки вокруг каждого лица на полученной фотографии. После завершения обработки полученная новая картинка публикуется обратно через RabbitMQ при помощи информации, предоставляемой в свойствах полученного первоначально сообщения (Рисунок 6-5).

Данный потребитель RPC является более сложным примером, чем рассматриваемые нами ранее, поэтому он заслуживает чего- то слегка большего чем простое
перечисление только кода. Чтобы удержаться от отвлечения на подробности распознавания лиц, весь тот код, который выполняет собственно распознавание
лиц импортируется как модуль detect из соответствующего пакета Python ch6.
Помимо этого, модуль ch6.utils предоставляет функциональность управления файлами на диске для целей нашего потребителя.
Весь код потребителя представлен в соответствующей записной книжке "6.1.2 RPC Worker".
import os
import rabbitpy
import time
from ch6 import detect
from ch6 import utils
# Открываем необходимые соединение и канал
connection = rabbitpy.Connection()
channel = connection.channel()
# Создаём очередь исполнителя
queue_name = 'rpc-worker-%s' % os.getpid()
queue = rabbitpy.Queue(channel, queue_name,
auto_delete=True,
durable=False,
exclusive=True)
# Объявляем очередь исполнителя
if queue.declare():
print('Worker queue declared')
# Выполняем привязку очереди исполнителя
if queue.bind('fanout-rpc-requests'):
print('Worker queue bound')
# Потребляем сообщения из RabbitMQ
for message in queue.consume_messages():
# Отображаем сколько времени заняло получение сообщения
duration = time.time() - int(message.properties['timestamp'].strftime('%s'))
print('Received RPC request published %.2f seconds ago' % duration)
# Записываем полученное тело сообщения во временный файл для процесса обработки лиц
temp_file = utils.write_temp_file(message.body,
message.properties['content_type'])
# Определяем лица
result_file = detect.faces(temp_file)
# Строим свойства отклика, включая полученный из первичной публикации временной штамп
properties = {'app_id': 'Chapter 6 Listing 2 Consumer',
'content_type': message.properties['content_type'],
'correlation_id': message.properties['correlation_id'],
'headers': {
'first_publish': message.properties['timestamp']}}
# Если ничего не обнаружено, результирующий файл будет всего лишь самим оригинальным файлом
body = utils.read_image(result_file)
# Удаляем временный файл
os.unlink(temp_file)
# Удаляем файл результата
os.unlink(result_file)
# Публикуем выработанный отклик
response = rabbitpy.Message(channel, body, properties)
response.publish('rpc-replies', message.properties['reply_to'])
# Выдаём подтверждение доставки сообщения первичного запроса RPC
message.ack()
Импорт надлежащих библиотек
Чтобы начать построение потребителя распознавания лиц вы вначале должны импортировать все необходимые для данного приложения пакеты или модули
Python. Они включают соответствующие модули из упомянутого ранее пакета ch6, rabbitpy,
os и time.
import os
import rabbitpy
import time
from ch6 import detect
from ch6 import utils
Пакет os применяется для удаления файлов с диска и получения идентификатора текущего процесса, в то время как
пакет time поддерживает информацию о времени при предоставлении в нашу системную консоль информации об
обработке.
Подключение, объявление и привязка очереди
Покончив с импортом, вы можете применить rabbitpy для подключения к RabbitMQ и открытию канала:
connection = rabbitpy.Connection()
channel = connection.channel()
Как и в предыдущих примерах потребления, необходимо объявить некий объект rabbitpy.Queue, связать и
выполнить потребление из соответствующей очереди RabbitMQ, которая будет получать необходимые сообщения. В отличие от предыдущих примеров
эта очередь является временной и исключительной для отдельного экземпляра нашего потребляющего приложения. Чтобы дать знать RabbitMQ что данная
очередь должна пропасть как только это сделает потребляющее приложение, её флаг auto_delete устанавливается
в значение True, а значение флага durable устанавливается равным
False. Чтобы позволить RabbitMQ знать что никакие иные потребители не должны иметь возможности доступа к
этому сообщению в рассматриваемой очереди, значение флага exclusive устанавливается равным
True. Если иной потребитель попробует потреблять из этой очереди, RabbitMQ не даст этому потребителю
такой возможности и отправит ему кадр AMQP Channel.Close.
Для создания содержательного имени данной очереди создаётся простое идентификационное строковое имя, содержащее идентификатор процесса операционной системы для данного потребительского приложения Python.
queue_name = 'rpc-worker-%s' % os.getpid()
queue = rabbitpy.Queue(channel, queue_name,
auto_delete=True,
durable=False,
exclusive=True)
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Если вы опустите имя очереди при её создании, RabbitMQ автоматически создаст название очереди за вас. Вы должны узнавать такие
очереди в интерфейсе управления RabbitMQ, так как они следуют некому шаблону, похожему на
|
После того как объект Queue был создан, вызывается запрос AMQP
Queue.Declare для RabbitMQ. За ним следует запрос RPC AMQP
Queue.Bind для привязки данной очереди к надлежащему обмену с применением ключа маршрутизации
detect-faces, поэтому вы будете получать только сообщения, отправляемые как запросы на распознавание лиц
от того издателя, который мы создадим в нашем следующем разделе.
if queue.declare():
print('Worker queue declared')
if queue.bind('direct-rpc-requests', 'detect-faces'):
print('Worker queue bound')
Потребление необходимых запросов RPC
Имея созданную и связанную очередь, наше приложение готово потреблять сообщения. Для потребления сообщений из RabbitMQ наш потребитель будет применять
соответсвующий метод итератора rabbitpy.Queue.consume_messages, который также действует как некий
диспетчер контекста Python. Диспетчер контекста Python является некоей конструкцией, которая вызывается оператором
with. Для того чтобы некий объект предоставил поддержку диспетчера контекста, он определяет магические меоды
(__enter__ и __exit__), которые выполняются при осуществлении
входа в блок кода и выхода из него при помощи оператора with.
Применение диспетчера контекста помогает rabbitpy иметь дело с отправкой запросов RPC AMP
Basic.Consume и Basic.Cancel, поэтому мы можем сосредоточиться на
вашем собственном коде:
for message in queue.consume_messages():
Так как вы выполняете итерации по всем сообщениям, которые доставляются RabbitMQ, вы получите некий обзор соответствующего свойства
timestamp в сообщении чтобы отобразить сколько времени данное сообщение находилось в своей очереди прежде чем
потребитель получил его. Соответствующий код издателя автоматически будет устанавливать это значение в каждом сообщении, предоставляя источник
информации за пределами RabbitM, который содержит подробности того когда именно данное сообщение было впервые создано и опубликовано.
Так как rabbitpy автоматически преобразовывает свойство timestamp в объект Pyhon
datetime, ваш потребитель вынужден преобразовывать это значение обратно в эпоху UNIX для вычисления общего числа
секунд с момента публикации данного сообщения:
duration = (time.time() –
int(message.properties['timestamp'].strftime('%s')))
print('Received RPC request published %.2f seconds ago' %
duration)
Обработка сообщения с образом
Далее, для осуществления распознавания лиц, файл изображения, содержащегося в теле вашего сообщения должен быть записан на диск. Так как этот файл
необходим лишь на протяжении короткого времени, данное изображение будет записано виде временного файла. Значение
content-type также передаётся, поэтому при именовании данного файла можно применять соответствующее
расширение файла.
temp_file = utils.write_temp_file(message.body,
message.properties['content_type'])
Имея данный файл записанным в своей файловой системе, наш потребитель может теперь выполнить распознавание лиц с применением метода
ch6.detect.faces. Данный метод возвращает соответствующий путь к некому новому файлу на диске,
который содержит само первоначальное изображение с определёнными лицами в перекрывающих их рамках:
result_file = detect.faces(temp_file)
Отправка результата обратно
Теперь, после того как вся тяжёлая работа выполнена, настало время опубликовать полученный результат в соответствующем запросе RPC обратно
нашему первоначальному издателю. Для этого мы должны вначале построить необходимые свойства ответного сообщения, которые будут содержать
correlation-id нашего первичного сообщения с тем, чтобы его издатель знал какому изображению соответствует
данный отклик. Кроме того, свойство headers используется для установки значения временного штампа с тем,
чтобы указать когда данное сообщение было впервые опубликовано. Это позволяет его издателю замерить общее время от запроса до отклика, что можно
применять для целей мониторинга.
properties = {'app_id': 'Chapter 6 Listing 2 Consumer',
'content_type': message.properties['content_type'],
'correlation_id':
message.properties['correlation_id'],
'headers': {
'first_publish':
message.properties['timestamp']}}
Имея определёнными необходимые свойства отклика, с диска считывается сам результирующий файл с полученным изображением и оба файла, первонаяальный и результирующий, стираются из вашей файловой системы:
body = utils.read_image(result_file)
os.unlink(temp_file)
os.unlink(result_file)
Наконец, наступило время для создания и публикации итогового сообщения отклика и после этого уведомления в получении первоначального сообщения запроса RPC с тем, чтобы RabbitMQ смог удалить его из своей очереди:
response = rabbitpy.Message(channel, body, properties)
response.publish('rpc-replies', message.properties['reply_to'])
message.ack()
Обработка сообщения с образом
После создания кода потребителя пора уже и запустить данное приложение потребителя. Как и со всеми предыдущими примерами, вы можете выбрать Cell > Run All to bypass чтобы запускать каждый элемент индивидуально.Заметим, что самый последний элемент данного приложения в нашей записной книжке IPython отсанется в работе пока вы не остановите его. Вы знаете о его работе, поскольку отображается индикатор Kernel Busy (Рисунок 6-6), Вы можете оставить данную закладку браузера открытой и вернуться обратно в панель управления IPython для нашего следующего раздела.
Теперь у вас есть запущенное приложение потребления RPC, которое будет потреблять сообщения, выполнять распознавание лиц и возвращать полученный результат. Пришло время написать некое приложение, которое будет публиковать для него сообщения. В нашем простом случае применения наша цель состоит в перемещении блокирующих и медленных процессов к внешним потребителям с тем, чтобы данное высокопроизводительное веб приложение могло принимать запросы и обрабатывать их без блокировки прочих запросов пока выполняется его обработка.
Поскольку создание полномасштабного асинхронного веб приложения выходит за рамки данной книги, наш код издателя просто будет публиковать определённый запрос RPC и отображать соответствующее сообщение отклика RPC когда оно будет получено. Кроме того, все применяемые в данном примере изображения уже находятся в нашей виртуальной машине Vagrant и все расположены в нашей общедоступной области.
Определение импортируемых библиотек библиотек
Чтобы стартовать, вы вначале должны импортировать все необходимые пакеты и модули Python для выполнения находящихся в ваших руках задач. В нашем
случае разработки издателя применяются все те же самые пакеты и модули кроме модуля ch6.detect.
import os
import rabbitpy
import time
from ch6 import utils
Аналогично применению потребителем пакета os, издатель применяет метод os.getpid()
для создания некой имеющей уникальное имя очереди, из которой данный издатель будет выполнять выборку обрабатываемых изображений. Как и в случае с
очередью запросов потребителя, данная очередь откликов издателя будет иметь установленными в значение True
auto_delete и exclusive, а
durable устанавливается в False.
queue_name = 'response-queue-%s' % os.getpid()
response_queue = rabbitpy.Queue(channel,
queue_name,
auto_delete=True,
durable=False,
exclusive=True)
Объявление и привязка необходимого обмена
После создания объекта rabbitpy.Queue нашей очереди откликов нам также потребуются его объявление и
привязка, но в этот раз к обмену rpc-replies, применяя это имя для устанавливаемого ключа маршрутизации:
if response_queue.declare():
print('Response queue declared')
if response_queue.bind('rpc-replies', queue_name):
print('Response queue bound')
Получив объявленную и привязанную очередь подходит время выполнить итерации по всем доступным образам.
Выполнение итераций по всем доступным образам
Для выполнения итераций по изображениям наш модуль ch6.utils предоставляет функцию с названием
get_images(), которая возвращает перечень подлежащих публикации изображений на диске. Этот метод обёрнут в
функцию Python итератора enumerate, которая будет возвращать кортеж текущей величины индекса в данном перечне
и связанного с ним значения. Кортеж является обычной структурой данных. В Python это неизменяемая последовательность объектов.
for img_id, filename in enumerate(utils.get_images()):
Внутри данного управляющего блока вы конструируете необходимое сообщение и публикуете его в RabbitMQ. Однако прежде чем ваш издатель создаст данное сообщение, давайте выведем информацию, которая сообщит вам о самом подлежащем публикации для обработки изображения:
print('Sending request for image #%s: %s' % (img_id, filename))
Построение сообщения самого запроса
Создание данного сообщения достаточно простое и укладывается в одну строку. Конструируется необходимы объект
rabbitpy.Message, причём в качестве его первого аргумента передаётся необходимый канал,а затем он
применяет метод ch6.utils.read_image() для чтения сырых данных с диска и передачи их в качестве соответствующего
аргумента тела сообщения.
Наконец, создаются необходимые свойства сообщения. Значение content-type для данного сообщения
устанавливается с применением метода ch6.utils.mime_time(), который возвращает соответствующий тип mime для
текущего изображения. Значение свойства correlation-id устанавливается с помощью значения
img_id, предоставляемого нашей функцией перечисляющего итератора. В некотором асинхронном веб приложении
это может быть идентификатор соединения для вашего клиента или значения файлового дескриптора сокета. Наконец, свойство сообщения
reply_to устанавливается в значение названия очереди отклика вашего издателя. Наша библиотека rabbitpy
автоматически устанавливает свойство timestamp, если оно опускается путём установки значения флага
opinionated в True.
message = rabbitpy.Message(channel,
utils.read_image(filename),
{'content_type':
utils.mime_type(filename),
'correlation_id': str(img_id),
'reply_to': queue_name},
opinionated=True)
Имея созданным сам объект сообщения, пора приступить к его публикации в соответствующем обмене
direct-rpc-requests с применением ключа маршрутизации detect-faces:
message.publish('direct-rpc-requests', 'detect-faces')
Как только эта строка исполниться, наше сообщение отправляется и должно быть вскорости получено приложением потребления RPC.
Ожидание отклика
В асинхронном веб приложении наше приложение должно обрабатывать другой клиентский запрос при ожидании отклика от своего потребителя RPC. Для
цели данного примера мы создадим некое приложение с блокировкой вместо асинхронного сервера. Вместо потребления соответствующей очереди наш издатель
применит RPC AMQP метод Basic.Get проверки для проверки наличия какого- нибудь сообщения в данной очереди и
его приёма следующим образом:
message = None
while not message:
time.sleep(0.5)
message = response_queue.get()
Выдача подтверждения приёма
После того как некое сообщение получено, ваш издатель обязан выдать подтверждение получения чтобы RabbitMQ мог удалить его из своей очереди:
message.ack()
Обработка отклика
Если вы похожи на меня, вы захотите знать сколько времени заняло распознавание лиц и маршрутизация сообщения, поэтому добавьте эту печать общей продолжительности с первоначальной публикации вплоть до приёма его отклика. В сложных приложениях для переноса метаданных подобных этим могут применяться свойства сообщения, они применяются для всего начиная с отладки информации вплоть до применения этого с целью мониторинга, отслеживания тенденций и аналитики.
duration = (time.time() -
time.mktime(message.properties['headers']['first_publish']))
print('Facial detection RPC call for image %s duration %.2f sec' %
(message.properties['correlation_id'], duration))
Этот выводящий искомую продолжительность код применяет значение штампа времени first_publish в
таблице заголовка свойств данного сообщения, который был установлен его потребителем. Таким образом вы узнаёте полное время прохождения в оба конца
от первоначальной публикации запроса RPC до приёма квитанции в RPC отклика.
Наконец, вы можете отобразить полученное изображение в своей записной книжке IPython, воспользовавшись соответствующей функцией
ch6.utils.display_image():
utils.display_image(message.body,
message.properties['content_type'])
Закрытие
После выполнения основного блока кода издателя следующие строки закрывают его канал соединение и больше не должны отмечаться отступом в четыре пробела:
channel.close()
connection.close()
Проверка всего приложения
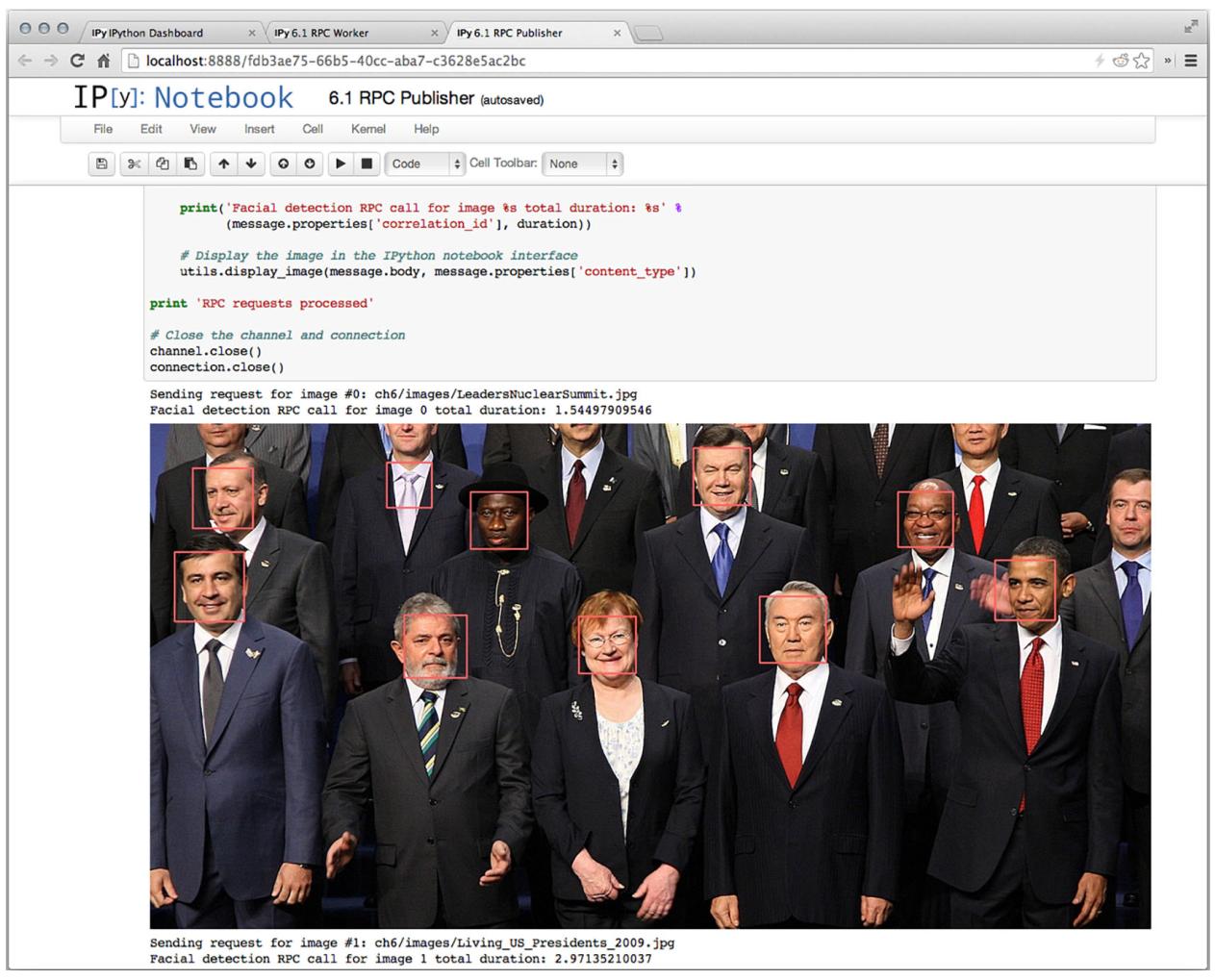
Пора приступить к проверке. Откройте в своей записной книжке "6.1.3 RPC Publisher" и кликните кнопку воспроизведения Run Code, чтобы запустить свои сообщения и увидеть результаты (Рисунок 6-7),
import os
import rabbitpy
import time
from ch6 import utils
# Откываем необходимые канал и соединение
connection = rabbitpy.Connection()
channel = connection.channel()
exchange = rabbitpy.DirectExchange(channel, 'rpc-replies')
exchange.declare()
# Создаём очередь отклика, которая будет удалена автоматически, она не является долговременной
# и исключительной для данного издателя
queue_name = 'response-queue-%s' % os.getpid()
response_queue = rabbitpy.Queue(channel,
queue_name,
auto_delete=True,
durable=False,
exclusive=True)
# Объявляем соответствующую очередь отклика
if response_queue.declare():
print('Response queue declared')
# Выполняем связывание этой очереди отклика
if response_queue.bind('rpc-replies', queue_name):
print('Response queue bound')
# Осуществляем итерации по всем изображениям для отправки запросов RPC
for img_id, filename in enumerate(utils.get_images()):
print('Sending request for image #%s: %s' % (img_id, filename))
# Создаём текущее сообщение
message = rabbitpy.Message(channel,
utils.read_image(filename),
{'content_type': utils.mime_type(filename),
'correlation_id': str(img_id),
'reply_to': queue_name},
opinionated=True)
# Публикуем это сообщение
message.publish('direct-rpc-requests', 'detect-faces')
# Выполняем цикл пока нет сообщения отклика
message = None
while not message:
time.sleep(0.5)
message = response_queue.get()
# Выдаём подтверждение получения сообщения отклика
message.ack()
# Вычисляем сколько времени прошло от момента публикации до окончательного отклика
duration = (time.time() -
time.mktime(message.properties['headers']['first_publish']))
print('Facial detection RPC call for image %s total duration: %s' %
(message.properties['correlation_id'], duration))
# Отображаем результирующее изображение в интерфейсе своей записной книжки
Display the image in the IPython notebook interface
utils.display_image(message.body, message.properties['content_type'])
print('RPC requests processed')
# Закрываем применявшиеся канал и соединение
channel.close()
connection.close()
Как вы могли заметить, код распознавания лиц не является совершенным, однако он работает достаточно неплохо для виртуальной машины с небольшой мощностью. Для улучшения качества распознавания лиц могут применять дополнительные алгоритмы для поиска какого- то кворума результатов всех алгоритмов. Такая работа слишком медленная для веб приложения реального времени, но не для армии потребительских приложений RPC со специальным оборудованием. В нашем следующем разделе мы выполним ответвление в линии отправки своего сообщения созданного издателя RPC без воздействия на уже установленный рабочий поток. Для этого вы будем применять Веерный (fanout) обмен вместо прямого обмена для запросов RPC.
В то время как прямой обмен позволяет очередям получать предназначенный им сообщения, веерный обмен не делает различий. Все публикуемые через веерный обмен сообщения доставляются во все очереди в таком веерном обмене. Это предоставляет значительные преимущества в производительности так как RabitMQ не требуется вычислять ключ маршрутизации для доставки сообщений, однако утрата селективности означает, что все потребляющие приложения из связанных с веерным обменом очередей должны иметь возможность потреблять доставляемые им сообщения.
Допустим, что помимо определения лиц вы желаете создавать инструменты с тем, чтобы ваши мобильные приложения могли идентифицировать спаммеров в реальном масштабе времени. Применяя веерный обмен который ваше веб приложение публикует когда выполняется запрос RPC распознавания лиц, вы можете связать такие потребляющие очереди и все прочие потребительские приложения, какие пожелаете, для выполнения действий с этими сообщениями. Потребитель распознавания лиц будет всего лишь потребителем для предоставления откликов RPC в ваше веб приложение, но ваши прочие приложения могут выполнять иные типы анализа в этих публикуемых изображениях исключительно во внутренних целях Рисунке 6-8.
Рисунок 6-8
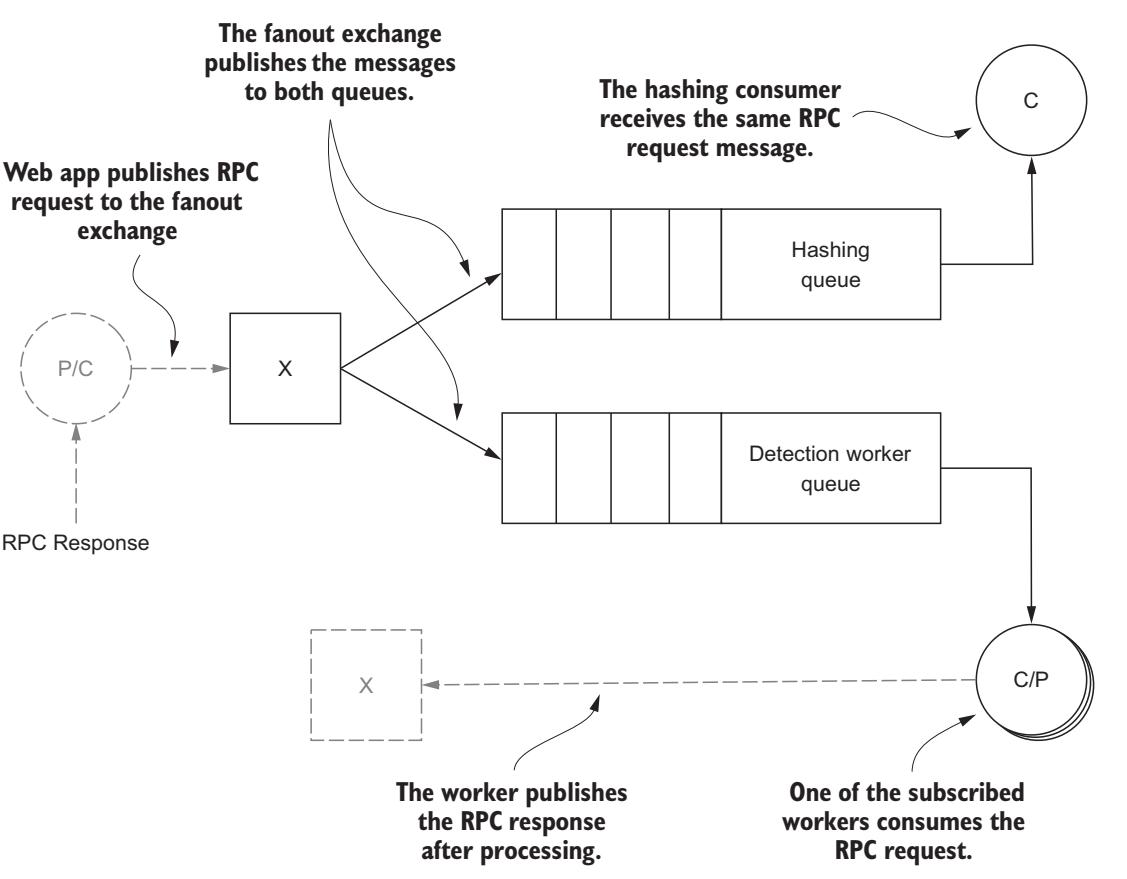
Добавление другого потребителя, который получает те же самые сообщения, что и потребитель RPC при помощи веерный обмена
По моему собственному опыту, спаммеры часто применяют одни и те же изображения при регистрации в сервисе или при представлении содержимого в вашей службе. Один из способов ослабления атак состоит в снятии "отпечатков пальцев" для идентификации в качестве спама, выполняя некое действие при выгрузке нового изображения с тем же самым идентификационным следом. В нашем следующем примере кода вы применим сообщение запроса RPC, которое включает потребителя распознавания лиц для снятия идентификаторов.
В том примере, коим мы следуем, а мы выполняем построение поверх примеров из раздела 6.1, сделаем ряд небольших изменений и добавим нового потребителя хэширования изображений, который будет создавать эеш некоторого изображения при выполнении очередного запроса RPC.
Для начала нам требуется создать свой веерный обмен. Следующий фрагмент кода взят из записной книжки "6.2.1 Fanout Exchange Declaration".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
exchange = rabbitpy.Exchange(channel, # Создаём объект веерного обмена
'fanout-rpc-requests',
exchange_type='fanout')
exchange.declare() # Объявляем необходимый обмен
Кроме того, первоначальный код из раздела 6.1 должен быть слегка изменён в отношении того как
ограничивается его очередь. Вместо связывания с обменом direct-rpc-requests, имеющим ключ маршрутизации,
наш потребитель должен быть связан с fanout-rpc-requests, не имеющим ключа маршрутизации. Это изменение уже
выполнено в нашей записной книжке "6.2.1 RPC Worker" и оно изменило такую строку:
if queue.bind('direct-rpc-requests', 'detect-faces'):
с тем чтобы она применяла новый веерный обмен:
if queue.bind('fanout-rpc-requests'):
Единственное изменение, которое вам следует сделать в коде вашего издателя состоит в замене того обмена, который надлежит публиковать. И вновь этот код уже заменён в записной книжке IPython "6.2.1 RPC Worker" и он поменял эту строку:
message.publish('direct-rpc-requests', 'detect-faces')
для применения нашего нового обмена следующим образом:
message.publish('fanout-rpc-requests')
Перед тем как вы опубликуете и потребите своё сообщение, давайте создадим потребителя хэширования изображения или иначе, идентификационного отпечатка.
С целью упрощения наш потребитель будет применять стандартный алгоритм двоичного хэширования, MD5. Имеются намного более изощрённые алгоритмы, которые проделывают работу создания хэшей изображений намного лучше, допуская разновидности обрезки рисунка, разрешающей способности и глубины бит, однако цель данного примера состоит в том чтобы проиллюстрировать обмены RabbitMQ, а не сами крутые алгоритмы распознавания изображений.
Импорт базовых библиотек и подключение к RabbitMQ
Для начала наш потребитель в записной книжке "6.2.2 Hashing Consumer" разделяет большую часть того же самого кода, что и потребитель RPC.
В первую очередь, однако, вместо импорта ch6.detect, данный потребитель импортирует пакет Python
hashlib:
import os
import hashlib
import rabbitpy
Аналогично ранее обсуждавшимся издателю и исполнителю RPC, потребитель хэширования изображения должен подключится к RabbitMQ и создать канал:
connection = rabbitpy.Connection()
channel = connection.channel()
Создание и привязка очереди отработанного
После открытия необходимого каналавы можете создать очередь, которая будет автоматически удаляться когда её потребитель покидает её и которая является исключительной для данной потребителя:
queue_name = 'hashing-worker-%s' % os.getpid()
queue = rabbitpy.Queue(channel, queue_name,
auto_delete=True,
durable=False,
exclusive=True)
if queue.declare():
print('Worker queue declared')
if queue.bind('fanout-rpc-requests'):
print('Worker queue bound')
Хэширование изображения
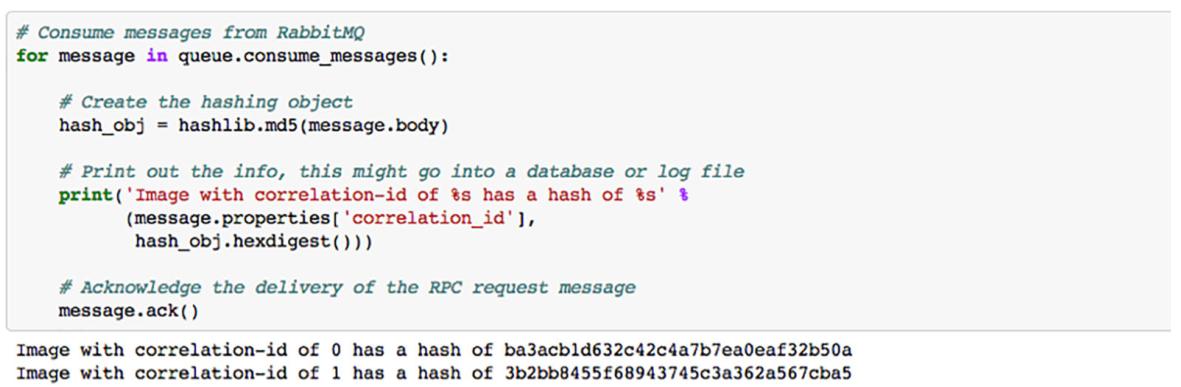
Наш потребитель достаточно прямолинеен. Он будет выполнять итерации по всем принимаемым сообщениям и создавать некий объект
hashlib.md5, пропуская в двоичном виде данные сообщения. Затем он выводит строку со значением хэша.
Строкой вывода также запросто может быть оператор insert базы данных или некий запрос RPC для сравнения значений полученного хэша и имеющихся в
базе данных. Наконец, данное сообщение подтверждает приём и наш потребитель будет ожидать доставки следующего сообщения.
for message in queue.consume_messages():
hash_obj = hashlib.md5(message.body)
print('Image with correlation-id of %s has a hash of %s' %
(message.properties['correlation_id'],
hash_obj.hexdigest()))
message.ack()
|
| Замечание |
|---|---|
|
Для хранения материализованных наборов хэшей исключительным выбором базы данных является Redis. Она предоставляет быстрые, размещаемые в оперативной памяти структуры данных для просмотра хэшей и может предоставлять очень быстрые отклики относительно наведения справок относительно такого типа данных. |
Проверка вновь созданного рабочего потока
Имея нового только что созданного потребителя и все прочие приложения изменёнными, пора проверить всё это. Откройте записные книжки "6.2.2 Hashing Consumer", "6.2.1 RPC Worker" и "6.2.1 RPC Publisher" в их собственных закладках в вашем веб браузере. начните с исполнения всех элементов в записной книжке "6.2.2 Hashing Consumer", затем всех элементов из записной книжки "6.2.1 RPC Worker" и наконец всех элементов в записной книжке "6.2.1 RPC Publisher", а по завершению всего введите мяч в игру запустив все элементы в записной книжке "6.2.1 RPC Publisher". Вы должны увидеть все те же самые отклики на свои приложения издателя и потребителя RPC, как если бы вы исполнили примеры из предыдущего раздла. Кроме того, вы должны теперь иметь вывод аналогичному на Рисунке 6-9 в вашем выводе приложения "6.2.2 Hashing Consumer"
import os
import hashlib
import rabbitpy
# Создаём очередь исполнителя
queue_name = 'hashing-worker-%s' % os.getpid()
queue = rabbitpy.Queue(channel, queue_name,
auto_delete=True,
durable=False,
exclusive=True)
# Объявляем очередь исполнителя
if queue.declare():
print('Worker queue declared')
# Выполняем привязку очереди исполнителя
if queue.bind('fanout-rpc-requests'):
print('Worker queue bound')
# Потребляем сообщения из RabbitMQ
for message in queue.consume_messages():
# Создаём необходимый объект хэша
hash_obj = hashlib.md5(message.body)
# Выводим полученную информацию, это же можно сделать в базу данных или файл протокола
print('Image with correlation-id of %s has a hash of %s' %
(message.properties['correlation_id'],
hash_obj.hexdigest()))
# Подтверждаем доставку первичного сообщения запроса RPC
message.ack()
Веерный обмен предоставляет великолепный способ, который позволяет всем потребителям выполнять доступ к основному брандспойту данных. Однако, это может стать обоюдоострым мечом, так как потребители не могут выборочно получать принимаемые сообщения. Например, допустим, вы желаете чтобы отдельный обмен допускал различные направляемые ему типы запросов RPC и при этом он выполняет обычные задачи, такие как аудит каждого запроса RPC безотносительно его типа. В таком случае предметный (topic) обмен позволил бы вам связать ваших потребляющих исполнителей RPC с ключами маршрутизации, особенными для их задач, а также связать потребителей запросов аудита с сопоставлением групповыми символами всех сообщений или их подмножества.
Как и в случае прямого обмена, предметный обмен будет направлять сообщения в любую связанную с ключом маршрутизации очередь. Применяя формат с
разграничением точкой, очереди могут привязываться ключами маршрутизации при помощи шаблонов подстановки. Применяя символы звёздочки
(*) и решётки (#) вы можете помечать особую часть своих ключей
маршрутизации или даже множество частей одновременно. Звёздочка будет соответствовать всем символам до точки в ключе маршрутизации, а символ решётки
соответствует всем последующим символам, в том числе и точкам.
Рисунок 6-10 показывает некий ключ маршрутизации предметного обмена с тремя частями, которые вы можете применять для нового профиля изображений, подлежащих выгрузке. Самая первая часть указывает то сообщение, которое следует перенаправить потребителям, которые знают как поступать с относящимся к изображениям сообщениям. Вторая часть указывает что сообщение содержит новое изображение, а третья содержит дополнительные данные, которые могут применяться для направления такого сообщения в очереди потребителей, которые являются особенными для связанной с профилем функциональностью.
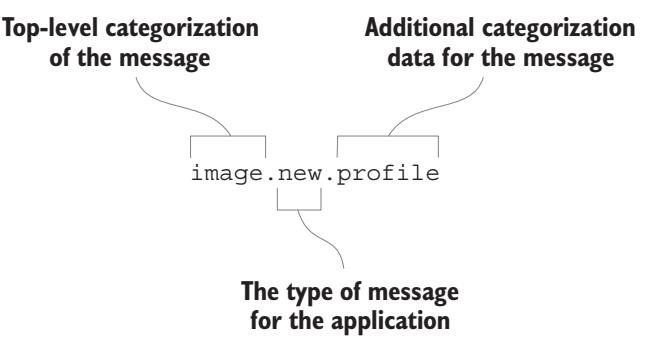
Если бы нам пришлось строить процесс загрузки изображений, создавая архитектуру на основе обмена сообщениями для управления всеми задачами, связанными с изображением на веб-сайте, следующие ключи маршрутизации могли бы описывать несколько сообщений, которые будут опубликованы.
-
image.new.profile: для сообщений, содержащих новый профиль изображения -
image.new.gallery: для сообщений, содержащих новое изображение галерей фотографий -
image.delete.profile: для сообщений, с подлежащими удалению метаданными профиля изображения -
image.delete.gallery: для сообщений, с подлежащими удалению метаданными изображениями галереи -
image.resize: для сообщений, запрашивающих изменение изображения
В нашем предыдущем примере ключей маршрутизации семантическая важность самих ключей маршрутизации становится совершенно очевидной, описывая намерение или содержание данного сообщения. Применяя семантическое именование ключей для сообщений, направляемых через данный предметный обмен, отдельное сообщение может направляться подразделом данного ключа маршрутизации, доставляя это сообщение в очереди, специфичные для выполняемых задач. На Рисунке 6-11 такой предметный обмен определяет какие очереди потребляющих приложений будут получать сообщение на основе того как они ограничивают данный обмен.
Рисунок 6-11
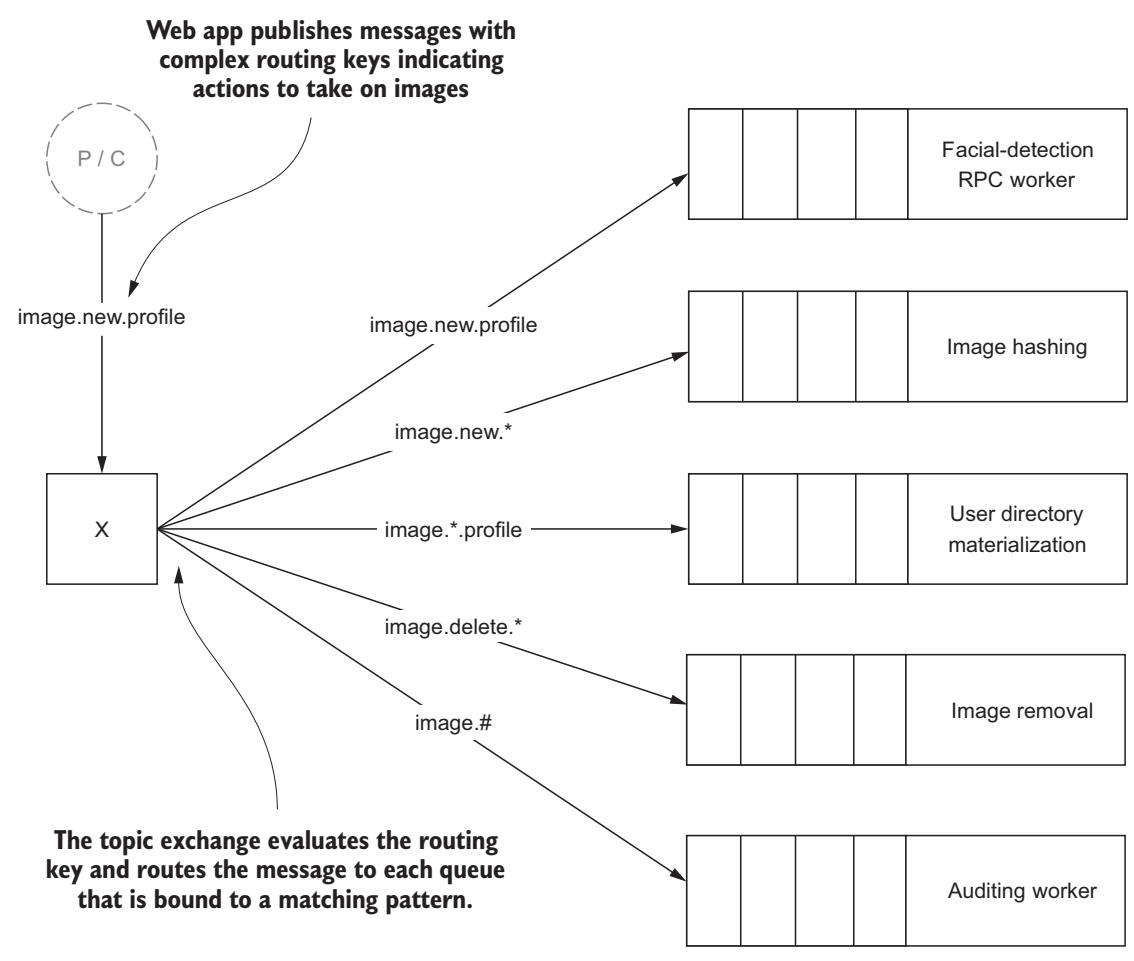
Сообщения выборочно направляются в различные очереди на основе объединения их ключей маршрутизации
Предметный обмен исключительно подходит для направления сообщений в очереди, поэтому потребители с единственной целью могут выполнять с ним
различные действия. На
Рисунке 6-11
наша очередь для исполнителя RPC распознавания лиц ограничена image.new.profile, ведя себя таким образом, как
если бы она была ограничена прямым обменом, принимая исключительно новые запросы профиля изображения. Наша очередь для потребителей хэширования
изображений удерживается image.new.# и получает все новые сообщения сообщения вне зависимости от их происхождения.
Сопровождающий материализуемый каталог пользователя потребитель может потреблять из очереди, замыкаемой на #.profile
и получает все сообщения, завершающиеся на .profile для выполнения своих задач претворения в жизнь.
Удаляющие изображения сообщения будут публиковаться в очередт ограничиваемую image.delete.*, что делает возможность
для отдельного пользователя удалять все выгруженные на сайт изображения. Наконец, замкнутый на image.#
потребитель аудита получает все связанные с изображениями сообщения с тем, чтобы он мог регистрировать информацию в помощь поиску неисправностей и
анализу поведения.
Применяющие архитектуры подобную данной потребители с единственной целью могут одновременно выполнять более простым способом как сопровождение, так и масштабирование в сравнении с монолитными приложениями, которые выполняют те же самые действия по доставке сообщений в единственную очередь. Монолитное приложение увеличивает сложность исполнения и кода. Подумайте насколько модульный подход к написанию потребляющего кода упрощает то, что в противном случае было бы сложным действием, таким как перемещение оборудования, увеличение пропускной способности путём добавления новых потребителей или даже простого добавления или удаления функций приложения. При модульном подходе с единственной целью с применением предметного обмена соответствующая новая функциональность может составляться из каких- то новых потребителя и очереди без воздействия на имеющиеся рабочие потоки и обработку прочих потребляющих приложений.
|
| Замечание |
|---|---|
|
Может оказаться полезным создавать ключи маршрутизации, которые семантически относятся к данному приложению, описывая его намерение или содержимое. Вместо того чтобы размышлять о самом сообщении и его ключе маршрутизации, как о некоторой детали относящейся к приложению, некий обобщающий, основанный на событии подход к обмену сообщениями поощряет повторное применение сообщений. Снижение сложности кода и уменьшение пропускной способности сообщения являются ключевыми преимуществами в том случае, когда разработчики имеют возможность повторно применять существующие сообщения в своих приложениях. Одновременно с виртуальными хостами и обменами ключи маршрутизации должны иметь возможность предоставлять достаточные семантические данные о сообщениях для любого приложений чтобы использовать их без каких- либо проблем загромождения пространства имён. |
Применение предметного обмена вместо прямого обмена демонстрируется в записных книжках "6.3 Topic Exchange Declaration", "6.3 RPC Publisher" и "6.3 RPC Worker". Единственная существенная разница в этих записных книжках в сравнении с записными книжками из раздела 6.1 состоит в объявлении значения типа обмена и применяемых ключах маршрутизации. Запуск этих примеров должен продемонстрировать что имеется лишь небольшое отличие между использованием предметных и прямых обменов когда вы выполняете соответствие всего ключа маршрутизации. Тем не менее, применяя предметные обмены у вас появляется возможность выполнять частичное обозначение шаблоном ключа маршрутизации для любой иной цели в дальнейшем без необходимости изменять архитектуру своих сообщений.
Применение предметного обмена с ключами маршрутизации в пространствах имён является хорошим выбором для будущего развития ваших приложений.
Даже если имеющиеся шаблоны соответствия при маршрутизации являются излишеством для ваших потребностей на старте, некий предметный обмен
(применяемый с верным связыванием очереди) может имитировать необходимое поведение как прямого, так и веерного обменов. Для эмуляции поведения прямого
обмена свяжите очереди с самым полным ключам маршрутизации вместо применения соответствия шаблону. Поведение веерного обмена даже ещё проще
смоделировать, так как связываемые с # в качестве ключа маршрутизации очереди будут получать все сообщения,
публикуемые в предметном обмене. При такой гибкости легко понять почему предметный обмен может стать мощным инструментом в вашей архитектуре на
основе обмена сообщениями.
# 6.3 Topic Exchange Declaration
import rabbitpy
with rabbitpy.Connection() as connection:
with connection.channel() as channel:
exchange = rabbitpy.Exchange(channel,
'topic-rpc-requests',
exchange_type='topic')
exchange.declare()
# 6.3 RPC Publisher
import os
import rabbitpy
import time
from ch6 import utils
# Открываем канал и соединение
connection = rabbitpy.Connection()
channel = connection.channel()
# Создаём очередь отклика которая удалится автоматически. # Создаём очередь отклика которая удалится автоматически, не является долговременной
# и исключительной для данного издателя
queue_name = 'response-queue-%s' % os.getpid()
response_queue = rabbitpy.Queue(channel,
queue_name,
auto_delete=True,
durable=False,
exclusive=True)
# Объявляем свою очередь отклика
if response_queue.declare():
print('Response queue declared')
# Привязываем очередь отклика
if response_queue.bind('rpc-replies', queue_name):
print('Response queue bound')"
# Выполняем итерации по всем изображениям для отправки запросов RPC
for img_id, filename in enumerate(utils.get_images()):
print 'Sending request for image #%s: %s' % (img_id, filename)
# Создаём сообщение
message = rabbitpy.Message(channel,
utils.read_image(filename),
{'content_type': utils.mime_type(filename),
'correlation_id': str(img_id),
'reply_to': queue_name},
opinionated=True)
# Публикуем созданное сообщение
message.publish('topic-rpc-requests', 'image.new.profile')
# Выполняем цикл пока имеется отклик
message = None
while not message:
time.sleep(0.5)
message = response_queue.get()
# Выдаём сообщение подтверждения получения
message.ack()
# Вычисляем продолжительность публикации и получения ответа
duration = (time.time() -
time.mktime(message.properties['headers']['first_publish']))
print('Facial detection RPC call for image %s total duration: %s' %
(message.properties['correlation_id'], duration))
# Отображаем полученное изображение в интерфейсе записной книжки IPython
utils.display_image(message.body, message.properties['content_type'])
print 'RPC requests processed'
# Закрываем применявшиеся канал и соединение
channel.close()
connection.close()
# 6.3 RPC Worker
import os
import rabbitpy
import time
from ch6 import detect
from ch6 import utils
# Открываем соединение и канал
connection = rabbitpy.Connection()
channel = connection.channel()"
# Создаём новую очередь исполнителя
queue_name = 'rpc-worker-%s' % os.getpid()
queue = rabbitpy.Queue(channel, queue_name,
auto_delete=True,
durable=False,
exclusive=True)
# Объявляем созданную очередь исполнителя
if queue.declare():
print('Worker queue declared')
# Связываем объявленную очередь исполнителя
if queue.bind('topic-rpc-requests', 'image.new.*'):
print('Worker queue bound')
# Потребляем сообщения из RabbitMQ
for message in queue.consume_messages():
# Отображаем сколько времени потребовалось для получения сообщения здесь
duration = time.time() - int(message.properties['timestamp'].strftime('%s'))
print('Received RPC request published %.2f seconds ago' % duration)
# Выводим содержимое тела собщения в некий временный файл для процесса распознавания лиц
temp_file = utils.write_temp_file(message.body,
message.properties['content_type'])
# Распознаём лица
result_file = detect.faces(temp_file)
# Строим свойства отклика, в том числе временной штамп первичной публикации
properties = {'app_id': 'Chapter 6 Listing 2 Consumer',
'content_type': message.properties['content_type'],
'correlation_id': message.properties['correlation_id'],
'headers': {
'first_publish': message.properties['timestamp']}}
# Получаемый в результате файл может просто быть первоначальным файлом если нет обнаруженных лиц
body = utils.read_image(result_file)
# Удаляем рабочий временный файл
os.unlink(temp_file)
# Удаляем построенный файл результата
os.unlink(result_file)
# Публикуем отклик на отклик
response = rabbitpy.Message(channel, body, properties, opinionated=True)
response.publish('rpc-replies', message.properties['reply_to'])
# Подтверждаем получение доставки первичного сообщения RPC
message.ack()
RabbitMQ имеет и другой встроенный тип обмена, который позволяет аналогичную гибкость в маршрутизации, но к тому же позволяет ещё сообщениям выполнять самостоятельное описание себя как часть такого процесса маршрутизации, устраняя потребность в структурированных ключах маршрутизации. Обмен заголовками применяет совершенно иную парадигму маршрутизации чем та, которую предлагают прямые и предметные обмены, предоставляя альтернативный взгляд на маршрутизацию сообщений.
Четвёртым типом встроенного обмена является обмен заголовками. Он делает возможной произвольную маршрутизацию с применением таблицы
headers. Привязываемые к обмену заголовками очереди применяют параметр аргументов
Queue.Bind для передачи в некотором массиве пар ключ/ значение для маршрутизации, а также аргумент
x-match. Этот аргумент x-match является строковым значением, которое
устанавливается в any или all. Если его значением является
any, сообщения будут направляться если любое из значение таблицы
headers соответствует любому имеющемуся связанному значению. Если же значением
x-match является all, все значения, передаваемые как аргументы
Queue.Bind должны совпадать. Это не препятствует наличию для данного сообщения дополнительных пар
ключ/ значение в его таблице headers.
Для темонстрации того как применяется обмен заголовками мы видоизменим примеры исполнителя и издателя RPC из
раздела 6.1, переместив свой ключ маршрутизации в значения таблицы
headers. В отличие от предметного обмена данное сообщение само по себе содержит необходимые значения,
которые составляют сами критерии маршрутизации.
Прежде чем мы изменим своих издателя и исполнителя для применения ими обмена заголовками, давайте вначале объявим сам обмен заголовками.
Приводимый ниже пример создаёт обмен заголовками с названием headers-rpc-requests; он находится в
записной книжке "6.4 Headers Exchange Declaration".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
exchange = rabbitpy.Exchange(channel, # Создаём объект обмена
'headers-rpc-requests',
exchange_type=' headers')
exchange.declare() # Объявляем необходимый обмен
При наличии объявленного обмена, давайте изучим те изменения в коде издателя RPC, которые содержатся в записной книжке
"6.4 RPC Publisher". Имеются два первичных изменения. Первое состоит в построении публикуемого сообщения. В данном примере будет опубликовано
такое свойство headers:
message = rabbitpy.Message(channel,
utils.read_image(filename),
{'content_type': utils.mime_type(filename),
'correlation_id': str(img_id),
'headers': {'source': 'profile',
'object': 'image'
'action': 'new'},
'reply_to': queue_name})
как вы можете видеть, были установлены три значения: в нашем свойстве headers назначаются значения для записей
источника, объекта и действия. Именно эти значения будут направляться при издании данного сообщения. Так как мы направим эти значения, нет никакой
потребности в каком- то ключе маршрутизации, поэтому наш вызов message.publish() заменяется только на название
обмена заголовками который будет выполнять маршрутизацию данного сообщения:
message.publish('headers-rpc-requests')
Прежде чем вы исполните свой код в данной записной книжке, давайте исследуем внесённые в исполнителя RPC изменения в записной книжке
"6.4 RPC Worker" и запустим имеющийся в ней код чтобы начать потребление. Самое первое изменение состоит в вызове
Queue.Bind. Вместо привязки к ключу маршрутизации, этот вызов Queue.Bind
определяет свой тип соответствия, необходимый для направления изображений в имеющуюся очередь и все согласуемые атрибуты:
if queue.bind('headers-rpc-requests',
arguments={'x-match': 'all',
'source': 'profile',
'object': 'image',
'action': 'new'}):
Значение аргумента x-match устанавливается равным all, что указывает,
что все имеющиеся в заголовке сообщения значения source, object и
action должны соответствовать всем значениям, определяемым в связываемых аргументах. Если вы теперь исполните
записные книжки "6.4 RPC Worker" и "6.4 RPC Publisher", вы должны обнаружить те же самые результаты, которые вы выдели в обоих
примерах прямого и предметного обменов.
Являются ли дополнительные метаданные в свойствах такого сообщения достаточной гибкостью, предлагаемой обменом заголовками? Хотя обмен заголовками
создаёт дополнительную гибкость при соответствиях возможностей any и all,
он приводит с дополнительным накладным расходам вычислений при выполнении маршрутизации. При использовании обмена заголовками все значения в свойстве
headers должны сортироваться по имени ключа перед вычислением значений маршрутизации сообщения. Общепринятое
суждение состоит в том, что обмен заголовками значительно медленнее чем прочие типы обмена из-за дополнительной вычислительной сложности. Но
в эталонном тестировании для данной главы я обнаружил, что не было существенной разницы между любыми встроенными брокерами в отношении производительности
при использовании одного и того же количества значений в свойстве headers.
|
| Замечание |
|---|---|
|
Если вам интересно внутреннее поведение потребителей RabbitMQ при сортировке данной таблицы заголовков, ознакомьтесь с модулем
|
# 6.4 Headers Exchange Declaration
import rabbitpy
with rabbitpy.Connection() as connection:
with connection.channel() as channel:
exchange = rabbitpy.Exchange(channel,
'headers-rpc-requests',
exchange_type='headers')
exchange.declare()
# 6.4 RPC Publisher
import os
import rabbitpy
import time
from ch6 import utils
# Открываем канал и соединение
connection = rabbitpy.Connection()
channel = connection.channel()
# Создаём необходимую очередь отклика, которая будет удалена автоматически, она не является долговременной
# и исключительной для данного издателя
queue_name = 'response-queue-%s' % os.getpid()
response_queue = rabbitpy.Queue(channel,
queue_name,
auto_delete=True,
durable=False,
exclusive=True)
# Объявляем созданную очередь отклика
if response_queue.declare():
print('Response queue declared')
# Связываем объявленную очередь отклика
if response_queue.bind('rpc-replies', queue_name):
print('Response queue bound')
# Выполняем итерации по всем изображениям для отправки сапросов RPC
for img_id, filename in enumerate(utils.get_images()):
print('Sending request for image #%s: %s' % (img_id, filename))
# Создаём соответствующее сообщение
message = rabbitpy.Message(channel,
utils.read_image(filename),
{'content_type': utils.mime_type(filename),
'correlation_id': str(img_id),
'headers': {'source': 'profile',
'object': 'image',
'action': 'new'},
'reply_to': queue_name},
opinionated=True)
# Публикуем созданное сообщение
message.publish('headers-rpc-requests')
# Выполняем цикл пока имеются сообщения отклика
message = None
while not message:
time.sleep(0.5)
message = response_queue.get()
# Выдаём сообщение подтверждения получения
message.ack()
# Вычисляем сколько времени заняли публикация и отклик
duration = (time.time() -
time.mktime(message.properties['headers']['first_publish']))
print('Facial detection RPC call for image %s total duration: %s' %
(message.properties['correlation_id'], duration))
# Отображаем полученное изображение в интерфейсе соответствующей записной книжки IPython
utils.display_image(message.body, message.properties['content_type'])
print('RPC requests processed')
# Закрываем применявшиеся канал и соединение
channel.close()
connection.close()
# 6.4 RPC Worker
import os
import rabbitpy
import time
from ch6 import detect
from ch6 import utils
# Открываем соединение и канал
connection = rabbitpy.Connection()
channel = connection.channel()
# Создаём необходимую очередь исполнителя
queue_name = 'rpc-worker-%s' % os.getpid()
queue = rabbitpy.Queue(channel, queue_name,
auto_delete=True,
durable=False,
exclusive=True)
# Объявляем созданную очередь исполнителя
if queue.declare():
print('Worker queue declared')
# Связываем объявленную очередь исполнителя
if queue.bind('headers-rpc-requests',
arguments={'x-match': 'all',
'source': 'profile',
'object': 'image',
'action': 'new'}):
print('Worker queue bound')
# Потребляем сообщения из RabbitMQ
for message in queue.consume_messages():
# Отображаем сколько времени потребовалось сообщению чтобы попасть сюда
duration = time.time() - int(message.properties['timestamp'].strftime('%s'))
print('Received RPC request published %.2f seconds ago' % duration)
# Записываем тело полученного сообщения во временный файл для процесса распознавания лиц
temp_file = utils.write_temp_file(message.body,
message.properties['content_type'])
# Распознаём лица
result_file = detect.faces(temp_file)
# Строим свойства отклика, включая значение временного штампа из самой первой публикации
properties = {'app_id': 'Chapter 6 Listing 2 Consumer',
'content_type': message.properties['content_type'],
'correlation_id': message.properties['correlation_id'],
'headers': {
'first_publish': message.properties['timestamp']}}
# Файл результата может быть просто самим первоначальным файлом, если ничего не было обнаружено
body = utils.read_image(result_file)
# Удаляем применявшийся временный файл
os.unlink(temp_file)
# Удаляем полученный файл результата
os.unlink(result_file)
# Публикуем созданный отклик на отклик
response = rabbitpy.Message(channel, body, properties, opinionated=True)
response.publish('rpc-replies', message.properties['reply_to'])
# Выдаём подтверждение получения доставки первичного сообщения запроса RPC
message.ack()
Не лишним будет отметить, что использование свойства headers напрямую воздействует на общую производительность
издания сообщений вне зависимости от применяемого типа обмена для публикации в него
Рисунке 6-12.
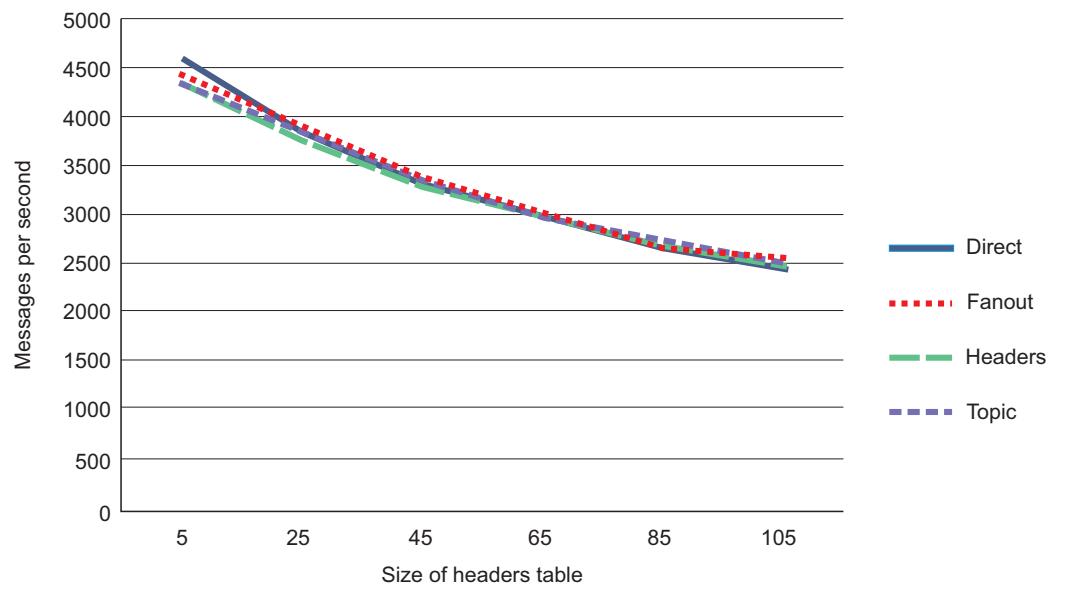
Как вы можете видеть, производительность для всех четырёх встроенных типов обмена относительно согласована. Это эталонное тестирование показывает, что при сопоставлении одного и того же сообщения с одними и теми же заголовками сообщения вы не обнаружите впечатляющих отличий в скорости публикации сообщения, вне зависимости от самого типа обмена.
А что если воспользоваться более идеальным вариантом проверки для предметного обмена и обмена заголовками?
Рисунок 6-13
сравнивает значения скорости публикации для того же самого тела сообщения с какой- то пустой таблицей headers для
соответствующего предметного обмена и при наличии значений ключей маршрутизации в свойстве headers для
обмена заголовками. В таком случае совершенно очевидно, что наш предметный обмен намного более производителен чем обмен заголовками при выполнении
сравнения только публикации в качестве вазового уровня требований маршрутизации нашего сообщения в некотором приложении- к- приложению.
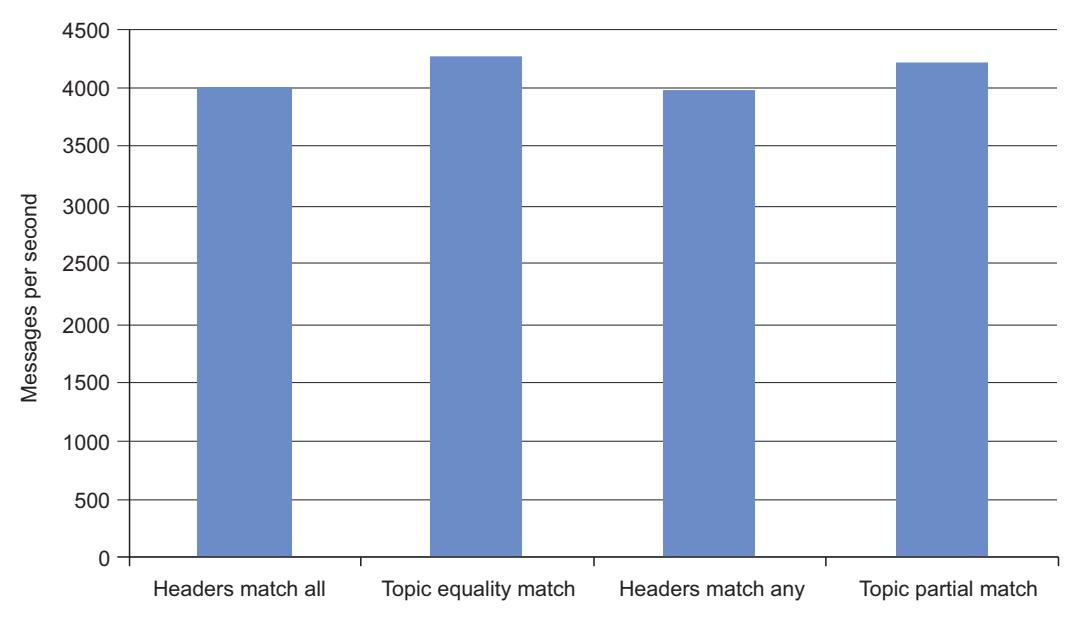
Если вы применяете свойство headers, можно полагать, что ваша общая скорость публикации сообщений не будет
сильно затронута при выборе обмена заголовками, если только вы не получаете очень большую таблицу значений в получаемом свойстве
headers. Но такой штраф в производительности применим ко всем встроенным типам обмена.
Теперь, когда у вас есть хорошее понимание возможностей встроенных типов обмена и того как они выполняются при сопоставлении друг с другом, пора изучить как вы можете применять множество типов обмена для публикации единственного сообщения в RabbitMQ.
Если вы не считаете что вам была предоставлена достаточная гибкость маршрутизации сообщений и вашему приложению требуется немного от одного типа
обмена и немного от другого для в точности одного и того же сообщения, вам повезло. Команда RabbitMQ добавила в RabbitMQ очень гибкий механизм, которого
нет в имеющейся спецификации AMQP, и и который позволяет вам выполнять маршрутизацию сообщений практически в любой комбинации обменов. Этот механизм для
связывания обмена- с- обменом очень похож на связывание с очередью, но вместо привязки какой- то очереди к обмену, вы связываете некий обмен к другому
обмену, применяя метод Exchange.Bind.
При применении связывания обмена- к- обмену сама логика маршрутизации, которая применяется к связыванию обмена, остаётся той же самой, как если бы этот прикрепляемый объект был бы очередью. Любой обмен может быть прикреплён к другому обмену, включая все типы встроенных обменов. Такая функциональность позволяет вам сцеплять обмены всеми мыслимыми способами. Вы желаете направлять сообщения при помощи ключей пространства имён через предметный обмен и затем распространять их основываясь на имеющихся свойствах в таблице заголовка? Если это так, именно связывание обмена- с- обменом послужит вам таким инструментарием Рисунке 6-14.
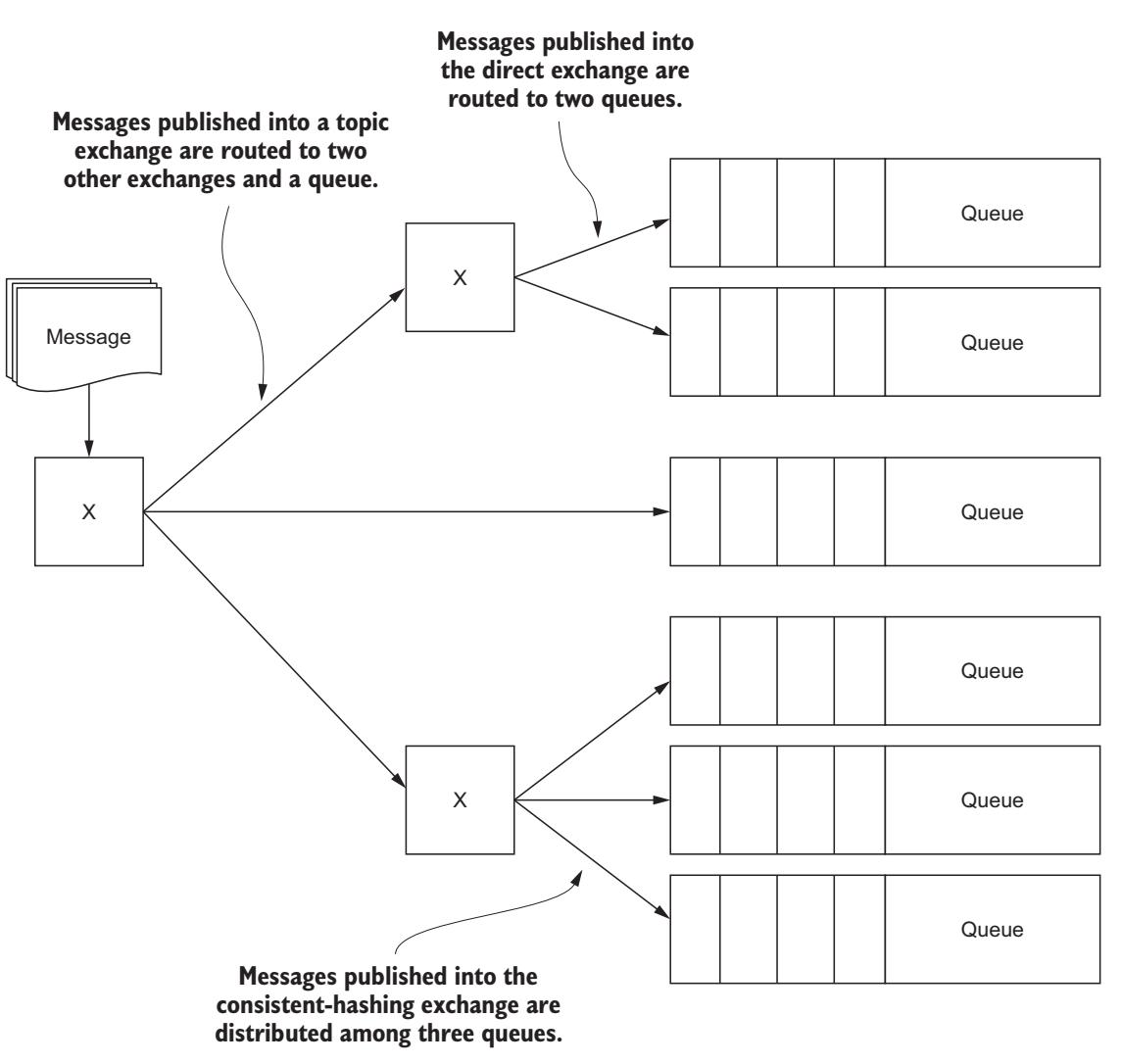
В нашем следующем примере из записной книжки "6.6 Exchange Binding" обмен согласованного хэширвания с наименованием
distributed-events связывается с предметным обменом с именем
events для распространения маршрутизации сообщений при помощи ключа маршрутизации
any по всем очередям, подключённым к нашему обмену согласованного хэширования.
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
tpc = rabbitpy.Exchange(channel, 'events', # Создаём предметный обмен
exchange_type='topic')
tpc.declare() # Объявляем предметный обмен
xch = rabbitpy.Exchange(channel, 'distributed-events', # Создаём обмен согласованного хэширования
exchange_type='x-consistent-hash')
xch.declare() # Объявляем обмен согласованного хэширования
xch.bind(foo, '#') #H # Связываем обмен согласованного хэширования с предметным обменом при помощи символа подстановки
Выступая в качестве инструмента, связывание обмена- с- обменом создаёт гигантский объём гибкости в доступных вам шаблонах обмена сообщениями. Однако вместе с такой гибкостью приходят и дополнительная сложность с отдельными накладными расходами. Прежде чем сходить с ума применяя сверхсложные привязки обмена- к- обмену, помните, что простые архитектуры легче поддерживать и диагностировать в случае, когда что-то идёт не так. Если вы планируете использовать привязки обмена- к- обмену, вы должны убедиться, что у вас есть предмет для такой функциональности, который требует дополнительных усложнений и накладных расходов.
Обмен с согласованным хэшированием, некий подключаемый модуль, распространяемый с RabbitMQ, распределяет данные по имеющимся связанным с ним очередям. Он может применяться для балансировки нагрузки подключённых очередей, которые получают публикуемые в нём сообщения. Вы можете применять его для распределения сообщений по очередям в различных физических серверах в некотором кластере или для очередей с единственными потребителями, предоставляя определённый потенциал для более быстрой пропускной способности чем если бы RabbitMQ распределял сообщения множеству потребителям в единственной очереди. При использовании баз данных или иных систем, которые могут напрямую интегрироваться с RabbitMQ в качестве потребителя, обмен с согласованным хэшированием может предоставлять некий способ раскалывать данные без необходимости создавать программное обеспечение промежуточного уровня.
|
| Замечание |
|---|---|
|
Если вы рассматриваете применение обмена с согласованным хэшированием для увеличения пропускной способности потребления, вам следует выполнить эталонное тестирование разницы между множеством потребителей в единственной очереди и отдельными потребителями на множестве очередей прежде чем принять решение что будет правильно для вашей среды. |
Обмен с согласованным хэшированием применят алгоритм согласованного хэширования для указания того какая из очередей будет получать сообщение при том условии, что все очереди являются потенциальными получателями. Вместо того чтобы очереди связывались с некими ключами маршрутизации или значениями заголовка, они связываются с весом на основе целочисленного значения, который применяется как часть общего алгоритма для определения получателя сообщения. Алгоритмы согласованного хэширования обычно применяются в клиентах для кэширования систем на основе сетевой среды, таких как memcached и в распределённых системах баз данных, таких как Riak и Cassandra, а также в PostreSQL (при применении методологии разбиения PL/ Proxy). Для наборов данных или в случае когда имеются сообщения с высоким уровнем беспорядочности (энтропии) в строковых значениях для маршрутизации, такой обмен с согласованным хэшированием предоставляет достаточно универсальный метод распределения данных. При двух подключённых к обмену с согласованным кэшированием очередях, причём каждая имеет эквивалентный вес, такое распределение сообщений будет выделять деление примерно пополам Рисунке 6-15.
Рисунок 6-15
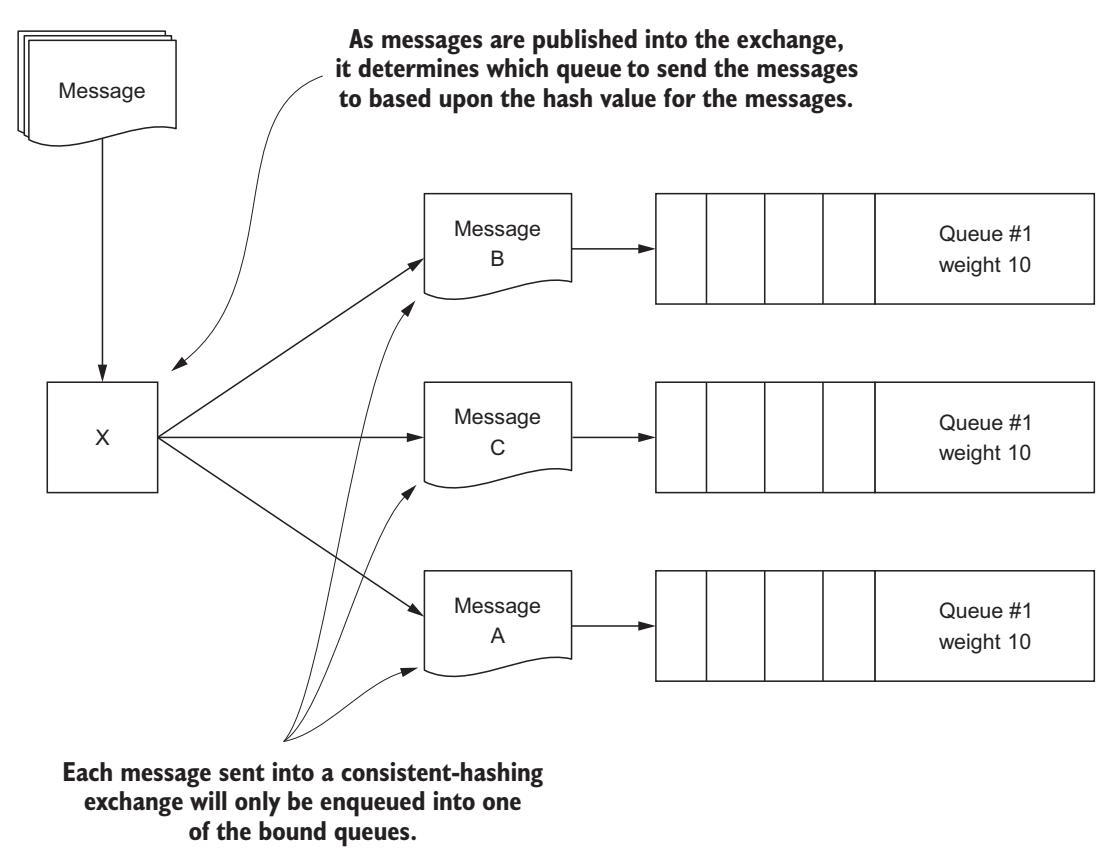
Публикуемые в обмене с согласованным хэшированием сообщения распространяются по всем связанным очередям.
При выборе получателя для какого- то сообщения, нет явных усилий по предоставлении гарантии обеспечения равномерного распределения сообщений. Обмен согласованного кэширования не выполняет карусельного (round-robin) обмена сообщениями, а вместо этого детерминировано направляет сообщения основываясь на значении хэша своего ключа маршрутизации или значения с типом свойств сообщения из заголовка. Однако некая очередь с большим весом чем прочие очереди должна получать большее процентное соотношение поступающих сообщений, публикуемых в данном обмене. Конечно, такое распределение сообщений по множеству очередей предполагает что вы публикуете сообщения с различными ключами маршрутизации или значениями таблицы заголовка. Пять сообщений, отправленных с одним и тем же значением ключа маршрутизации в конечном счёте попадут в одну и ту же очередь.
В нашей модельной системе RPC обработки изображений скорее всего что изображения должны будут сохраняться неким образом для последующего обслуживания иными клиентами HTTP. В определённый момент времени при работе с таким масштабированием запросов к хранению изображений, достаточно распространённой потребностью является использование распределённого решения хранения данных. В нашем последующих примерах мы будем применять такой обмен с согласованным хэшированием для распространения сообщений по четырём очередям, которые могут использоваться для сохранения изображений в четырёх различных серверах хранения.
По умолчанию, значение ключа маршрутизации является именно тем значением, которое выступает в роли хэша для распределения сообщений. Для некоторого изображения одним из возможных значений ключа маршрутизации является некий хэш самого изображения, аналогично тому как он вырабатывался в нашей записной книжке "6.2.2 Hashing Consumer". Если вы намереваетесь распределять сообщения через хэши значений ключа маршрутизации, ничего особенного не требуется при объявлении такого обмена. Это демонстрируется в записной книжке "6.7 A Consistent-Hashing Exchange that Routes on a Routing Key".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
exchange = rabbitpy.Exchange(channel, 'image-storage', # Создаём объект обмена с согласованным хэшированием
exchange_type='x-consistent-hash')
exchange.declare() # Объявляем свой обмен
В качестве альтернативы вы можете воспользоваться значением хэша из имеющейся таблицы свойства заголовков. Чтобы выполнить маршрутизацию таким образом,
вам следует передать значение hash-header при объявлении данного обмена. Это значение
hash-header содержит единственный ключ в общей таблице headers, который
будет содержать необходимое значение для хэширования данного сообщения. Это демонстрируется в следующем фрагменте кода из записной книжки
"6.7 A Consistent-Hashing Exchange that Routes on a Header".
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
exchange = rabbitpy.Exchange(channel, 'image-storage', # Создаём объект обмена с согласованным хэшированием,
exchange_type='x-consistent-hash', # который хэшируется для ключа значением таблицы заголовков
arguments={'hash-header':
'image-hash'})
exchange.declare() # Объявляем свой обмен
При привязке очереди к данному обмену с согласованным хэшированием, вы вводите значение веса для данной очереди с целью его применения в алгоритме
хэширования в качестве строкового значения. Например, если бы вы захотели объявить некую очередь с весом 10, вам надо было бы передать в строке значение
10 в качестве определённого ключа связывания в своём запросе RPC AMQP Queue.Bind. Применяя наш пример сохранения
изображений, допустим что ваши серверы для хранения данных изображений имеют у каждого различные ёмкости хранения. Вы можете применять эти весовые
значения для того чтобы предпочитать серверы с большим объёмом в сравнении с меньшими. Затем вы можете определить значения весов как размер ёмкости в
гигабайтах или терабайтах чтобы попытаться выполнять балансировку распределения настолько, насколько она возможна. Приводимый далее пример из
записной книжки "6.7 Creating Multiple Bound Queues" создаст четыре очереди с названиями q0,
q1, q2 и q3 и свяжет все их
эквивалентно с неким обменом, именуемым как image-storage.
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
for queue_num in range(4): # Выполняем итерацию 4 раза
queue = rabbitpy.Queue (channel, 'server%s' % queue_num) # Создаём пронумерованные номера очередей
queue.declare() # Объявляем соответствующую очередь
queue.bind('image-storage', '10') # Подвязываем к этой очереди вес 10
Важно отметить, что из- за того способа, которым работает применяемый алгоритм согласованного хэширования, если вам следует изменить применяемый
номер очередей, который связаны с данным обменом, само распределение сообщений скорее всего изменится. Если некое сообщение с определённым ключом
маршрутизации или значением таблицы заголовка всегда приходит в q0, а вы добавите какую- то новую очередь с
названием q4, это в конечном итоге приводит к пяти очередям и сообщения с тем же самым ключом маршрутизации будут
последовательно (согласовано) приходить в соответствующую очередь пока нумерация очередей не изменится вновь.
Для дальнейшей иллюстрации того как работает наше распределение данных в обмене с согласованным хэшированием, наш следующий код, взятый из записной книжки
"6.7 Simulated Image Publisheruot;, публикует 100 000 сообщений в имеющийся обмен image-storage. Нашими
ключами маршрутизации являются MD5 хэши значения текущего времени, объединяемые с номером сообщения, так как предоставление 100 000 изображений было
бы слегка накладным для такого примера. Наши результаты распределения отображены в столбиковых диаграммах на
Рисунке 6-16.
import datetime
import hashlib
import rabbitpy
with rabbitpy.Connection() as connection: # Соединяемся с RabbitMQ
with connection.channel() as channel: # Открываем канал в соединении
for iteration in range(100000): # Выполняем итерацию 100 000 раз
timestamp = datetime.datetime.now().isoformat() # Получаем строковое значение текущих даты и времени
hash_value = hashlib.md5('%s:%s' % (timestamp, iteration)) # Создаём некий объект хэша MD5
msg = rabbitpy.Message(channel, 'Image # %i' % iteration, # Создаём некий объект сообщения rabbitpy
{'headers':
{'image-hash':
str(hash_value.hexdigest()}})
msg.publish('image-storage') # Публикуем созданное сообщение с установленным хэшем MD5 в качестве ключа маршрутизации
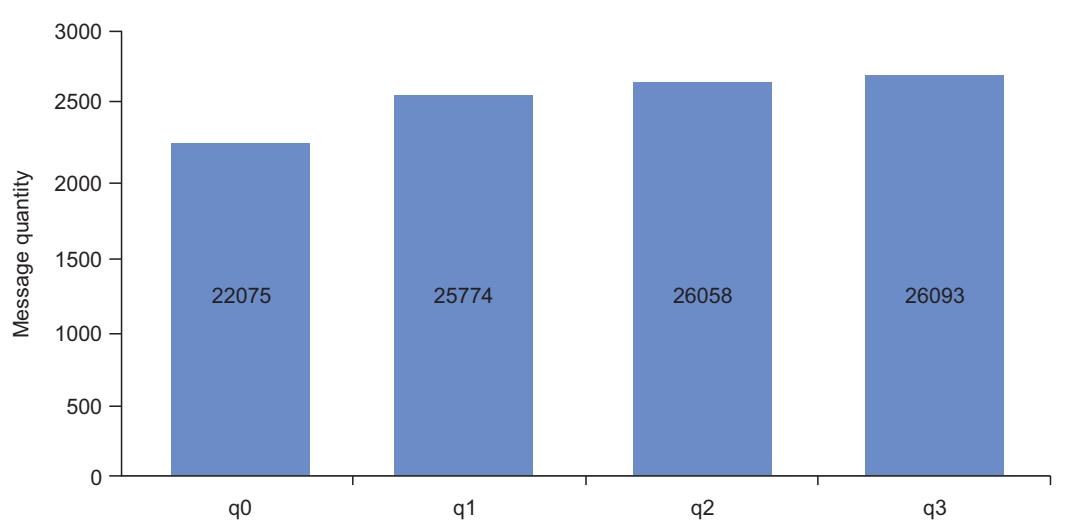
Как вы можете заметить, полученное распределение близкое, но не точное. Это происходит потому что само решение куда помещать данную очередь определяется конкретным значением, которое применяется в маршрутизации и оно не может праведно выполнять балансировку нагрузки сообщений неким карусельным образом без наличия очень специфических значений ключей маршрутизации, создаваемых для того чтобы гарантировать такое поведение. Если вы ищете балансировку нагрузки своих сообщений по множеству очередей, но при этом не желаете применять подход согласованного хэширования, рассмотрите возможности случайного обмена Джона Брисбена (John Brisbin’s random exchange). Вместо поиска соответствующего ключа маршрутизации для распределения сообщений по имеющимся очередям, он применяет генератор случайных чисел. Равняясь на гибкость подключаемого модуля RabbitMQ, не будет удивительным если в будущем на поверхность появится реальный метод карусельного обмена. Если это как- то вас интересует, возможно так случится,что кто- то из вас будет способен написать его.
Если вы рассматриваете применение обмена с согласованным кэшированием для увеличения пропускной способности, прежде чем окунуться в него с головой следует вначале рассмотреть всё, так как обычно он не требуется для увеличения производительности или пропускной способности сообщений. Однако если вам требуется выполнять такие задачи, как распределение подмножеств сообщений по центрам обработки данных или кластерам RabitMQ, обмен с согласованным кэшированием может стать подходящим инструментом.
На данный момент у вас должно иметься хорошее понимание различных встроенных в RabbitMQ механизмов маршрутизации. Если вам потребуется возврат для получения справочной информации, Таблица 6-1 содержит быстрый обзор всех обменов и их описаний. Каждый тип обмена предлагает свою собственную функциональность, которая может придать силы вашему приложению чтобы гарантировать что сообщения направляются надлежащим потребителям настолько быстро, насколько это возможно.
| Название | Подключаемый модуль | Описание |
|---|---|---|
|
Нет |
Маршрутизация связывания очередей на основе определённого значения какого- то ключа маршрутизации. Реализует только соответствия на эквивалентность. |
|
Нет |
Направляет во все связанные очереди вне зависимости от установленного ключа маршрутизации, представленного в сообщении |
|
Нет |
Направляет во все связанные очереди при помощи шаблона ключа маршрутизации и эквивалентности строк. |
|
Нет |
Направляет сообщения в связанные очереди на основе имеющихся в таблице свойства
|
|
Да |
Ведёт себя аналогично веерному обмену, однако для направления в связанные очереди распространяет сообщения основываясь на значении имеющегося хэша ключа маршрутизации или начения заголовка свойств сообщения. |
Помните, что сообщения часто могут повторно применяться способами, которые изначально и не предусматривались при разработке вашей архитектуры, поэтому я рекомендую встраивать по возможности как можно больше гибкости при создании своего решения. Применяя предметные обмены с ключами маршрутизации и семантикой пространства имён вы легко можете осушать поток сообщений, причём задача может оказаться более сложной если вы применяете в качестве своего основного механизма маршрутизации прямой обмен. Предметный обмен должен обеспечить практически такой же уровень гибкости, который делает возможным обмен заголовками, причём без блокировок протокола для получения свойств сообщения AMQP с целью выполнения маршрутизации.
В своей сердцевине обмены являются просто механизмами маршрутизации сообщений, которые проходят через RabbitMQ. Существует большое разнообразие подключаемых модулей, начиная с обменов, которые сохраняют сообщения в базах данных, таких как Riak exchange, до обменов с оперативной памятью, например, Message History exchange.
В нашей следующей главе вы изучите как объединять два или более серверов RabbitMQ в образующий единое целое кластер сообщений, предоставляя некий способ масштабирования пропускной способности ваших сообщений и добавляя более строгие гарантии сообщениям с применением очередей высокой доступности.