Глава 3. BlueStore
{Прим. пер.: рекомендуем сразу обращаться к нашему переводу 2 издания вышедшего в феврале 2019 Полного руководства Ceph Ника Фиска}
Содержание
В этой главе мы изучим BlueStore, совершенно новое хранилище объектов в Ceph, разработанное для замены имеющегося файлового хранилища. Оно увеличивает производительность и расширяет набор свойств, разработанных с целью позволить Ceph продолжить рост и предоставлять некую надёжную высокопроизводительную систему хранения на будущее.
Мы изучим следующие темы:
-
Что такое BlueStore?
-
Имеющиеся ограничения при файловом хранении
-
Какие проблемы преодолевает BlueStore
-
Все компоненты BlueStore и как они работают
-
Как развёртывать OSD BlueStore
BlueStore является неким хранилищем объектов Ceph, которое в первую очередь разработано для решения имеющихся ограничений файлового хранения, которое, что касается имеющейся редакции Kraken, является основным текущим хранилищем объектов, неким новым хранилищем объектов, которое было разработано для замены файлового хранения с весьма оригинальным названием Новое хранилище (NewStore). NewStore было некоторой комбинацией RockDB, некоторого хранилища ключей для запоминания метаданных и какой- то стандартной файловой системы POSIX (portable operating system interface) для самих реальных объектов. Однако, быстро стало очевидным, что применением файловой системы POSIX приводит к высоким накладным расходам, что было одной их ключевых причин для попытки уйти прочь от файлового хранения.
Таким образом, родилось BlueStore; применение сырых блочных устройств в комбинации с RockDB дало решение ряда проблем, угнетавших NewStore. Само название BlueStore было неким отображением такого объединения применения слов Block и NewStore:
Block+NewStore=BlewStore=BlueStore
BlueStore разработано для удаления штрафов двойной записи, вызываемых файловым хранением и для увеличения производительности. Помимо этого, благодаря наличию теперь большего контроля над тем путём, которым объекты сохраняются на диск, могут быть реализованы дополнительные свойства, такие как контрольные суммы и сжатие.
Имеющееся на сегодняшний день в Ceph хранилище объектов имеет некоторые пределов, которые начали ограничивать требующееся масштабирование с которым может работать Ceph и свойства, которые оно может предоставлять. Далее приводятся некоторые из основных причин зачем необходимо BlueStore.
Некий объект в Ceph, совместно со своими данными, также располагает связанными с ними метаданными, причём решающее значение имеет тот факт, что и данные, и метаданные обновляются автоматически. Если либо такие метаданные, либо данные обновляются как одно без другого, рискует вся непротиворечивость модели Ceph. Чтобы гарантировать, что такие обновления произошли автоматически, они должны обслуживаться в некоторой единой транзакции.
Ограничения файлового хранения
Файловое хранилище первоначально проектировалось как некое хранилище объектов чтобы позволить разработчикам протестировать Ceph на их локальных машинах. Благодаря его стабильности оно быстро стало необходимым хранилищем объектов и обнаружило себя применяемым в промышленных кластерах по всему миру.
Первоначально идея относительно файлового хранилища предполагала, что приходящая на вооружение btrfs (B-tree file system), которая предлагает поддержку транзакций, позволит Ceph выгрузить требования атомарности в btrfs. Транзакции позволяют некоторому приложению отправлять какую- то последовательность запросов в btrfs и всего лишь получать один раз подтверждение, когда всё будет зафиксировано для стабильного хранения. Без некоторой поддержки транзакций, в случае если на полпути какой бы то ни было операции записи Ceph возникает любое прерывание, либо сами данные, либо метаданные могут быть утрачены, или же одно из них потеряет синхронность с другим.
К сожалению, зависимость от btrfs для решения этих проблем оказалась ложной надеждой, к тому же, был обнаружен ряд ограничений. Btrfs все ещё можно применять для файлового хранения, но имеется целый ряд известных проблем, которые могут повлиять на стабильность Ceph.
В конце концов, всё вернулось к тому, что XFS была наилучшим выбором для использования в качестве хранения файлов, однако XFS имела самое главное ограничение, что она не поддерживала транзакций, что означало тот факт, что для Ceph не имелось возможности гарантии атомарности её записей. Единственным решением для этого было в применении журнала с упреждающей записью. Все записи, включая данные и метаданные должны были вначале быть записанными в некий журнал, располагающийся на некотором сыром блочном устройстве. Когда данная файловая система содержит содержит подтверждение того, что все данные и метаданные были успешно сброшены на диск, такие записи журнала могут быть освобождены. Благоприятным побочным эффектом этого является то, что при использовании SSD для хранения журнала шпиндельного диска, он действует как кеш обратной записи, что уменьшает латентность записи до скоростей самого SSD. Однако, если такой журнал файлового хранилища располагается на том же самом устройстве хранения, что и сам раздел данных, тогда пропускная способность, по крайней мере, делится пополам. В случае OSD шпиндельного диска этого может приводить к очень плохой производительности, так как имеющиеся дисковые головки непрерывно перемещаются между двумя областями дисков, причём даже при последовательных операциях. Хотя файловое хранилище на основе SSD OSD не страдает примерно такими же штрафами в отношении производительности, их пропускная способность по- прежнему в действительности сокращается вдвое за счёт удвоения подлежащих записи данных. В любом случае, такая потеря производительности крайне нежелательна, а в случае флеш- устройств также влечёт вдвое более быстрый износ самого устройства, что требует более дорогостоящих устройств с увеличенным числом циклов перезаписи. Приводимая ниже схема отображает как Файловое хранилище и его журнал взаимодействуют с неким блочным устройством, причём вы можете увидеть, что вся обработка данных должна проходить сквозь имеющийся журнал Файлового хранилища и его журнал файловой системы.
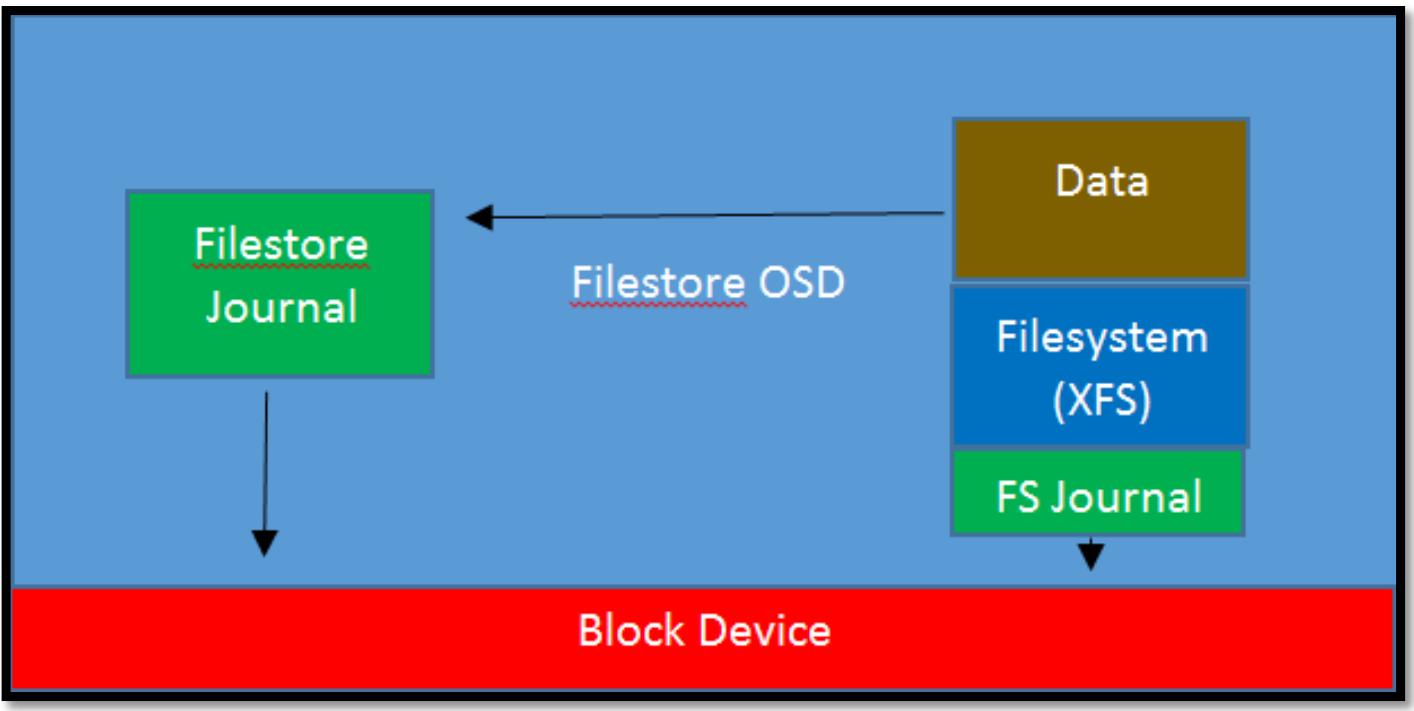
Дополнительные проблемы с файловым хранилищем состояли в попытке контролировать все действия лежащей в его основе файловой системы POSIX для того, чтобы она выполняла работу и вела себя так, как это требуется Ceph. На протяжении многих лет разработчики файловой системы выполняли большой объём работы в попытках сделать файловые системы интеллектуальными и предсказывать как некое приложение может представлять свой ввод/ вывод. В случае с Ceph, целый ряд таких оптимизаций переплетаются с тем, как она пытается инструктировать поведение имеющейся файловой системы, что требует дополнительной работы и усложняет весь процесс.
Метаданные объекта хранятся в виде комбинации атрибутов файловой системы с названием XATTR (Extended Attributes, Расширенных атрибутов) и в некотором хранилище значений ключей LevelDB, которое также располагается на самом диске OSD. LevelDB была выбрана в момент создания файлового хранилища вместо RockDB, так как RockDB не была доступна, а LevelDB удовлетворяла целому ряду требований Ceph.
Ceph разрабатывалось для масштабирования до петабайт данных и хранения миллиардов объектов. Однако, из- за ограничений вокруг общего числа файлов, которые вы можете объективно сохранять в некотором каталоге, вводились дальнейшие обходные ухищрения чтобы помочь с такими ограничениями. Объекты хранятся в некоторой иерархии хэшированных имён каталогов; когда общее число файлов в одной из таких папок достигает установленного предела, такой каталог расщепляется на некий последующий уровень и все объекты перемещаются. Тем не менее, имеется некий компромисс для улучшения общей скорости нумерации объектов, так как при возникновении расщепления такого каталога они влияют на производительность, поскольку все объекты перемещаются в надлежащие каталоги. На дисках большего размера такое увеличивающееся число каталогов приводит к дополнительной нагрузке на имеющийся кэш VFS и может повлечь дополнительные штрафы производительности для объектов с нечастым использованием.
Как данная книга рассмотрит в соответствующей главе настройки производительности, основное узкое место
производительности в файловом хранилище состоит в том, когда XFS начинает поиск
inode и записей каталога, а они
в настоящий момент не кэшированы в оперативной памяти. В случаях, когда имеется некое большое число объектов,
хранимое в расчёте на один OSD, в настоящее время нет реального решения для данной проблемы и достаточно
распространённым является наблюдение, что определённый кластер Ceph постепенно начинает замедляться по мере
своего заполнения.
Уход прочь от хранения объектов в некоторой файловой системе POSIX в действительности единственный способ для решения большей части этих проблем.
BlueStore было разработано для решения этих ограничений. Начиная с разработки NewStore, было очевидно, что попытка использования какой либо файловой системы POSIX в качестве лежащей в основополагающем уровне хранилища при любом подходе повлекло бы целый ряд задач, которые также имелись бы и в файловом хранилище. Чтобы Ceph было способным получить необходимые гарантии, ему необходимо не только само хранилище, но также и отсутствие общих накладных расходов некоторой файловой системы, следовательно Ceph требует наличия прямого доступа блочного уровня к имеющимся устройствам хранения. Сохраняя метаданные в RocksDB, а все реальные данные объекта напрямую в блочных устройствах, Ceph может намного усилить контроль над лежащим в его основе хранилищем и в то же самое время также и предоставить лучшую производительность.
Следующая схема показывает как BlueStore взаимодействует с неким блочным устройством. В отличие от файлового хранилища, данные напрямую записываются в имеющееся блочное устройство, а операции с метаданными обрабатываются RocksDB.
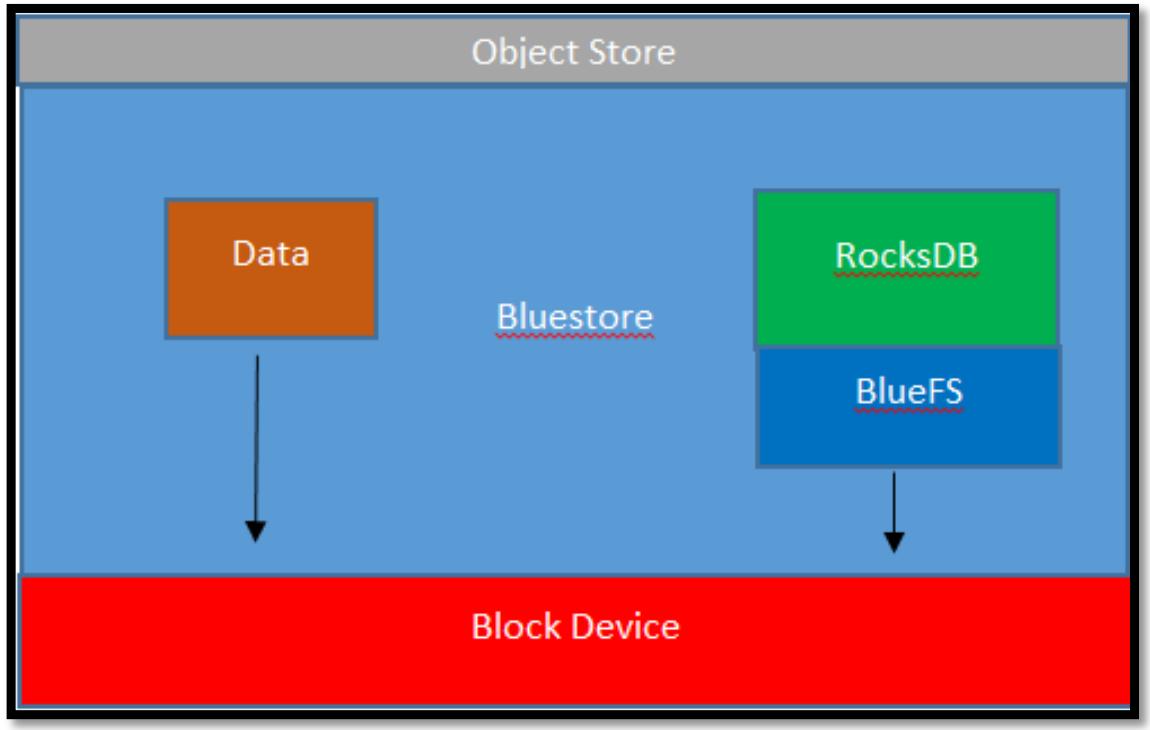
RocksDB является некоторым высокопроизводительным хранилищем значений ключей, которое первоначально ответвилось от LevelDB, однако после доработки Facebook прошёл к предложению значительных улучшений производительности приспособленных к многопроцессорным серверам с низколатентными устройствами хранения. Оно также получило большое число улучшенных свойств, некоторые из которых используются в BlueStore.
RocksDB применяется для хранения метаданных самих хранимых объектов, которые изначально обрабатывались в виде комбинации LevelDB и XATTR в файловом хранилище.
Некоторой особенностью RocksDB, из которой получает преимущество BlueStore, состоит в возможности хранения WAL (write-ahead log, журнале упреждающей записи) в некотором более быстром устройстве хранения, что может помочь в снижении латентности работы RocksDB. Это также обнадёживающе улучшает производительность Ceph, в особенности для меньших операций ввода/ вывода. Это предоставляет целый ряд возможных настроек схем хранения, при которых WAL, DB и данные могут помещаться на различные устройства хранения. Приведём здесь три примера:
-
WAL, DB и данные - все находятся на шпиндельных дисках
-
WAL и DB на SSD, а данные на шпиндельных дисках
-
WAL на NVMe, DB на SSD, а данные на шпиндельных дисках
В отличии от файлового хранилища, в котором каждая запись целиком сохраняется и в сам журнал, и, в конечном итоге, на диск, в BlueStore вся часть данных данной записи в большинстве случаев записывается напрямую в имеющееся блочное устройство. Это удаляет необходимость штрафов дублирования, а на чистых шпиндельных дисках впечатляюще увеличивает производительность. Однако, как уже упоминалось ранее, такая двойная запись имела обратное воздействие уменьшения латентности записи в случае, когда шпиндельные диски комбинируются с журналами SSD. BlueStore также может применять устройства дискового хранения на основе флеш- памяти для снижения латентности путём отложенных (deferred) записей, вначале записывая данные в имеющиеся WAL RocksDB, а затем позже сбрасывая эти записи на диск. В отличие от файлового хранилища в имеющийся WAL записываются не все записи, параметры настройки определяют установленный размера отсечения ввода/ вывода до которого запись откладывается. Здесь продемонстрирован соответствующий параметр настройки:
bluestore_prefer_deferred_size
Он управляет тем размером ввода/ вывода, который будет записан вначале в WAL. Для шпинделных дисков это по умолчанию 32кБ, в то время как для SSD по умолчанию нет отложенных записей. Если латентность записи важна и ваши SSD достаточно быстрые, тогда увеличив это значение вы можете увеличить тот размер ввода/ вывода, который вы желаете придерживать в WAL.
Хотя основным побудителем BlueStore был отказ от лежащей в основе файловой системы, BlueStore всё же нуждается в некотором методе сохранения RockDB и самих данных в имеющийся в OSD диск. Именно с этой целью была разработана BlueFS, которая является чрезвычайно усечённой файловой системой, предоставляющей всего лишь определённый минимальный набор свойств для имеющегося тонкого набора операций, передаваемых Ceph. Она также удаляет накладные расходы являющиеся результатом необходимости двойной журнальной записи, которые присутствовали бы при использовании некой стандартной POSIX файловой системы.
Для создания некоторого OSD BlueStore вы можете воспользоваться ceph-disk,
которая полностью поддерживает создание OSD BlueStore либо с совмещением самих данных RocksDB и WAL, либо
их сохранения на раздельных дисках. Данная операция аналогична той, когда мы создавали некое файловое хранилище
OSD, за исключением того, что вместо определения некоторого устройства для его применения в качестве имеющегося
журнала файлового хранилища вы описываете устройства для всех данных RocksDB. Как уже упоминалось ранее,
вы можете разделить саму DB и части WAL RocksDB, если пожелаете:
ceph-disk prepare --bluestore /dev/sda --block.wal /dev/sdb --block.db /dev/sdb
Предыдущие код предполагает, что вашим диском данных является /dev/sda.
Для данного примера, допустим, некий шпиндельный диск, а также вы имеете некое более быстрое устройство SSD,
например, /dev/sdb. Ceph-disk
создаст два раздела на имеющемся диске данных: один для хранения реальных объектов Ceph и другой маленький раздел
XFS для хранения подробностей о самом OSD. Она также создаст два раздела на SSD для самой DB и WAL. Вы можете
создать множество OSD, совместно используя одно и то же SSD для DB и WAL не боясь перекрыть предыдущие OSD;
сeph-disk достаточно интеллектуальна для создания новых разделов без
необходимости их описания.
Однако, как мы уже обсуждали в Главе 2, Развёртывание Ceph,
применение соответствующего инструмента развёртывания для вашего кластера помогает уменьшению времени развёртывания и
обеспечивает согласованность по всему кластеру. Хотя имеющиеся модули Ansible Ceph также поддерживают
развёртывание OSD BlueStore, на момент публикации данной книги (май 2017, {Прим. пер.: равно как
и на момент выхода в феврале 2019 второго издания автоматического создания множества DB и WAL на одном диске,
но в любом случае теперь вместо сeph-disk рекомендуется применять
ceph-volume}), они не поддерживают сейчас
раздельное развёртывание разделов DB и WAL. Для демонстрации основ BlueStore мы будем применять
сeph-disk для неразрушающего обновления вручную нашего тестового
кластера OSD с файлового хранилища на BlueStore.
Убедитесь в том, что ваш кластер находится в полностью рабочем состоянии, выполнив проверку при помощи
ceph -s. Мы будем обновлять OSD первоначально удалив его из имеющегося
кластера, а затем позволив Ceph восстановить все данные в новом OSD BlueStore. Воспользовавшись преимуществом
такой возможности сопровождения, вы можете повторить эту процедуру по всем OSD в своём кластере.
В данном примере мы удалим osd.2, который расположен на диске
dev/sdb в нашем узле OSD выполнив следующие шаги:
-
Примените следующую команду:
sudo ceph osd out 2Предыдущая команда предоставит вам следующий вывод:
-
Зарегистрируйтесь в необходимом узле OSD, который содержит тот демон, который вы хотите пересоздать. Мы остановим его службу и размонтируем раздел XFS:
systemctl stop ceph-osd@2 umount /dev/sdb1 -
Вернитесь назад в один из своих мониторов и теперь удалите этот OSD, применив следующие команды:
sudo ceph auth del osd.2Предудущая команда выведет следующее:
sudo ceph auth del osd.2Предыдущая команда выведет следующее:
sudo ceph osd rm osd.2Предудущая команда выведет следующее:
-
Проверьте текущее состояние своего кластера Ceph при помощи команды
ceph -s, вы должны теперь увидеть, что данный OSD был удалён. Когда восстановление завершится, вы теперь сможете воссоздать данный диск как BlueStore OSD. -
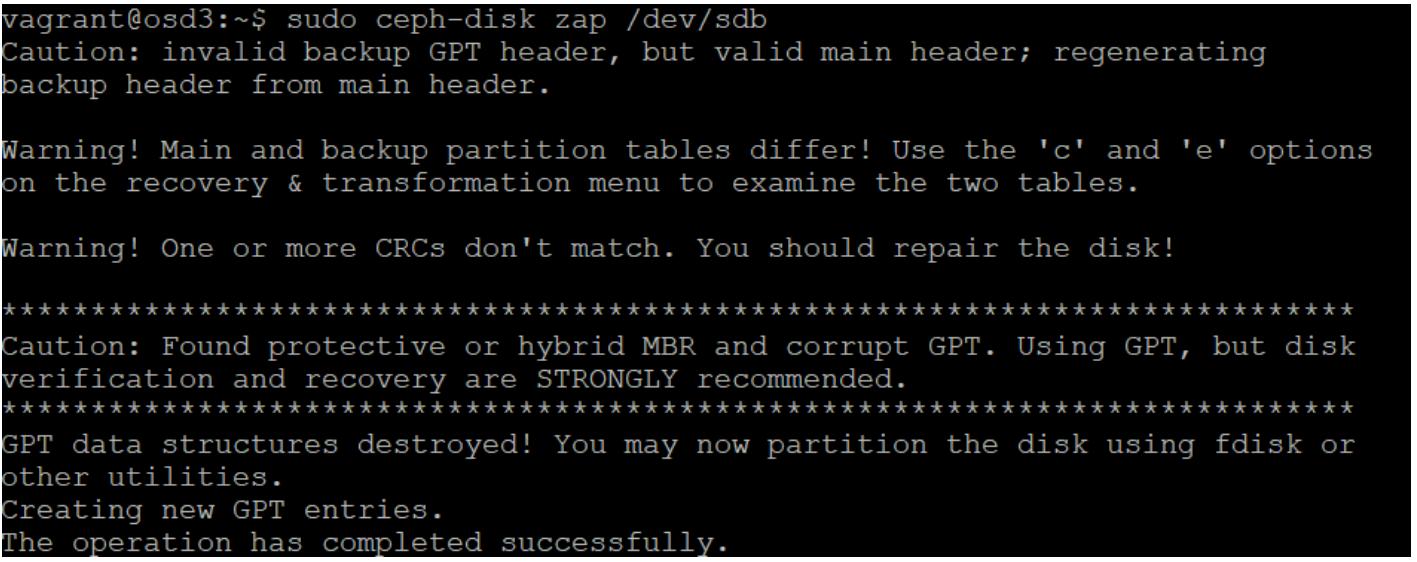
Вернитесь опять на свой узел OSD и выполните следующую команду
ceph-diskчтобы стереть все подробности раздела с данного диска:sudo ceph-disk zap /dev/sdbПредудущая команда выведет следующее:
-
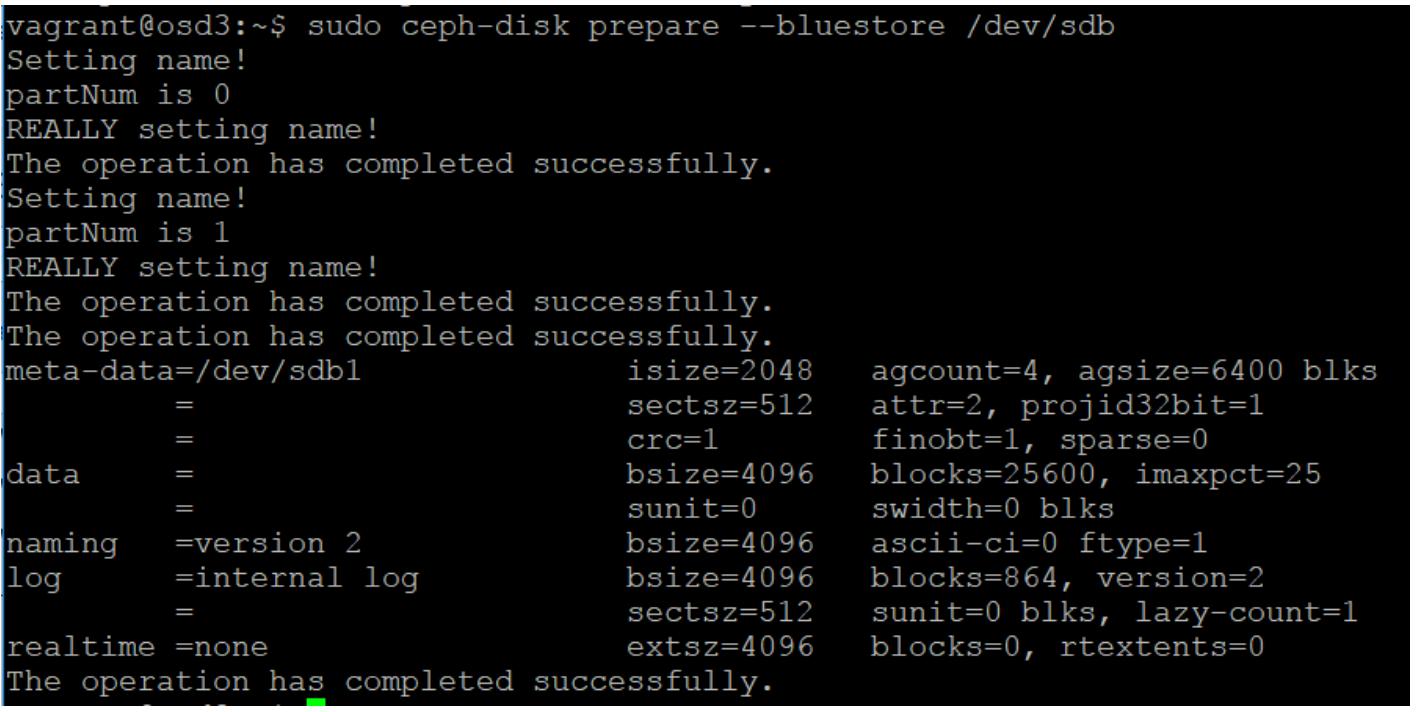
Теперь выполните команду
ceph-diskдля создания BlueStore OSD. В данном примере мы не будем сохранять WAL и DB на отдельных дисках, поэтому нам не нужно определять эти параметры:ceph-disk prepare --bluestore /dev/sdbПредудущая команда выведет следующее:
-
И, нконец, активируем OSD:
ceph-disk activate /dev/sdb1




Вернувшись в свой узел монитора мы можем теперь выполнить другую
ceph -s и увидеть, чтобыл создан новый OSD и на нём начали заполняться
данные.
Как вы можете видеть, вся процедура очень проста и является идентичной для тех шагов, которые необходимо выполнять при замене некоторого отказавшего диска.
В данной главе мы изучили имеющееся у нас в Ceph новое хранилище объектов с названием BlueStore. Надеемся, что вы лучше стали понимать зачем оно было необходимо и сами пределы в имеющейся архитектуре файлового хранилища. Вы также должны получить основы понимания внутренней работы BlueStore и наполниться уверенностью в том, как обнровлять ваши OSD до BlueStore.