Copyright © 2016 J. Prades, C. Reano, F.Silla
Первая публикация на английском языке: PPoPP’16 March 12-16, 2016, Barcelona, Spain
Многие центры обработки данных в настоящее время применяют виртуальные машины (ВМ) для достижения более эффективного использования аппаратных ресурсов. Однако, современные решения виртуализации, например, Xen, не предоставляют приложениям графические ускорители вычислений (GPU) простым способом для работающих в виртуальном домене приложений с обычно необходимой в центрах обработки данных гибкостью (т.е. управление экземплярами виртуальных GPU и одновременное их применение для различных ВМ). СТруктуры удалённой виртуализации GPU подобные решению rCUDA могут предназначаться для решения данной проблемы.
В данной работе мы анализируем применение подобной структуры rCUDA для ускорения научных приложений, работающих внутри виртуальных машин Xen. Результаты показывают, что применение структуры rCUDA является допустимым подходом, характеризующийся очень низкими затратами в случае, когда в вашем кластере уже присутствует структура коммутации Infiniband.
Виртуальные машины (ВМ) предоставляют центрам обработки данных множество преимуществ, так как они одновременно работают в одном узле кластера, тем самым совместно применяя аппаратные ресурсы и таким образом уменьшая стоимости комплектования и сопровождения, а также общее потребление электроэнергии
Однако ВМ всё ещё не поддерживают эффективно современный тренд использования устройств графических вычислений (GPU) в качестве ускорителей. В связи с этим были получены некоторые последние достижения, например, новая GRID K1 GPU производства NVIDIA[1] или технология KVMGT Intel[2], хотя они в основном и предназначены для виртуализации рабочих мест. К сожалению, отсутствие эффективной поддержки для CUDA GPU в решениях виртуализации в настоящее время имеет результатом то, что подобные приложения, выполняющиеся в вашем виртуальном домене не могут простым способом получить такие ускорители.
В данной работе мы изучаем другой подход для предоставления ускорений CUDA в ВМ: применение структуры rCUDA. Данная структура отсоединяет GPU от узлов, тем самым позволяя приложениям осуществлять доступ к виртуальным GPU вне зависимости от того, на каком именно компьютере они работают. Цель данной работы состоит в оценке накладных расходов, испытываемых данным приложением при доступе к GPU вне ВМ Xen через сетевую среду кластера с применением решения rCUDA. Структура rCUDA была выбрана благодаря её очень хорошей производительности[6]. В данном исследовании предполагается, что в вашем кластере уже имеется сетевая среда Infiniband.
Обычная настройка Xen помещает тонкий уровень программного обеспечения (гипервизор Xen) поверх оборудования
компьютера. Выше этого гипервизора можно обнаружить ваши виртуальные машины (Dom0
и DomUi). В случае, когда компьютер таже содержит GPU, может
также быть назначен эксклюзивный способ для одной из ВМ при помощи механизма пробрасывания (passthrough) PCI.
Однако к данному GPU будет способна осуществлять доступ только эта ВМ. Такое исключительное назначение данного
GPU единственной ВМ препятствует широкому применению в виртуальных доменах приложений с GPU ускорителями.
В данной работе мы рассмотрим использование структуры rCUDA в кластере с сетевой инфраструктурой InfiniBand делающей возможным таким ВМ осуществлять доступ к установленным в других узлах кластера GPU удобным образом. Рисунок 1 изображает подобный сценарий. Принимая во внимание, что адаптеры Infiniband поддерживают виртуальные экземпляры, взаимодействие между клиентами rCUDA в ваших ВМ и удалённым сервером rCUDA будет выполняться с применением таких виртуальных функций. Данная конфигурация предоставляет высокую производительность (используется API InfiniBand Verbs), а также гибкость совместного использования ускорителей CUDA с учётом того, что rCUDA делает возможным один или несколько виртуальных экземпляров удалённого GPU на каждой ВМ.
Рисунок 1

Используемый для экспериментов в данной работе испытательный стенд. Для доступа к удалённым GPU в данном кластере используется среда коммутации InfiniBand.
Испытательный стенд состоит из трёх узлов Supermicro 1027GR-TRF. Одна из них будет размещать ВМ Xen, в то время как оставшиеся два узла не применяют ВМ. На одном из них выполняется сервер rCUDA, как это отображено на Рисунке 1. Другой узел будет применяться для целей сравнения. Каждый из этих серверов содержит два процессора Intel Xeon E5-2620 v2 (6 ядер с архитектурой Ivy Bridge), работающими с частотой 2.1 ГГц и с 32 ГБ DDR3 SDRAM с 1600 МГц. Они также имеют по адаптеру Mellanox InfiniBand FDR и GPU NVIDIA Tesla K20. Что касается настройки программного обеспечения, на всех трёх серверах был использован SUSE Linux Enterprise Server 11 SP3 (x86 64). Кроме того, на сервере, размещающем наши ВМ был использован Xen version 4.2.2 {Прим. пер.: более корректно XenServer, см. Глава 1. Что такое XenServer?.} Кроме того был использован Mellanox OFED 2.3-1.0.1 совместно с CUDA 6.5 и драйвер NVIDIA 340.29. Наконец, ВМ были настроены на использование 4 ядер и 12 ГБ оперативной памяти.
В этом разделе мы исследуем применение структуры rCUDA для обеспечения приложениям ускорения CUDA при их работе внутри ВМ Xen. Рисунок 2 отображает производительность приложений LAMMPS[3], CUDA-MEME[4], CUDASW++[5] и GPU-BLAST[7] при различных сценариях: использование CUDA с локальым GPU в обычном домене ("CUDA non-VM") и внутри ВМ Xen, осуществляющей доступ к GPU в хосте с применением проброса (passthrough) PCI ("CUDA VM PT"). В случае с rCUDA, метка "rCUDA non-VM" относится к производительности со структурой rCUDA применяемой в обычном домене (не вовлечённом в ВМ Xen), делая доступным применение сетевой среды Infiniband. Когда тест включает в себя ВМ Xen, метка "rCUDA VM IB" относится к значениям производительности с rCUDA в случае применения сценария показанного на Рисунке 1. Кроме того, диаграммы на рисунке содержат разбиение по времени исполнения, которое распадается на три компоненты: (1) время, необходимое для передачи данных к/от GPU ("GPU Data Transfer"), (2) время, затрачиваемое на вычисления в GPU ("GPU Computation") и (3) время, расходуемое на задачи, в которых не участвует GPU, например, вычисления ЦПУ и операции ввода/ вывода ("Other").
Рисунок 2
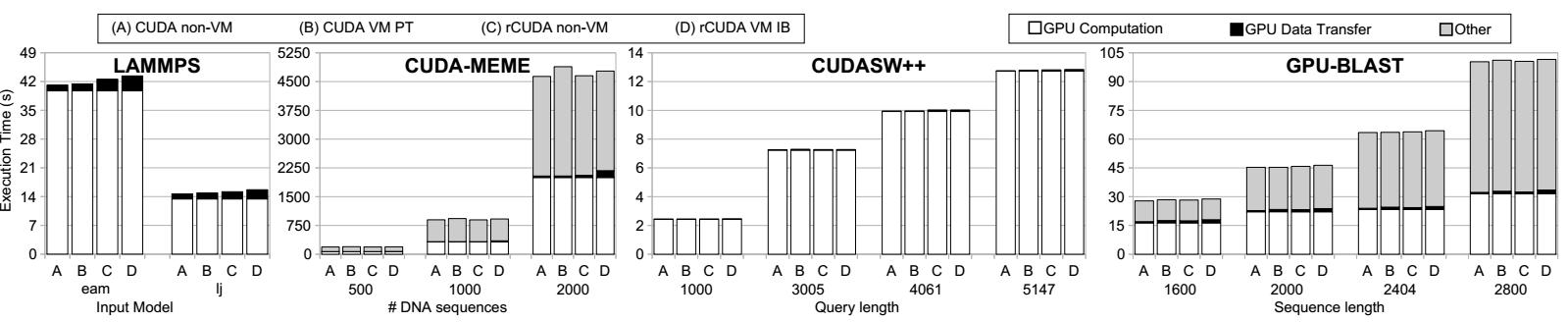
Время исполнения различных приложений при работе в различных локальных и удалённых сценариях. Время исполнения подразбивается на три компоненты: вычисления GPU, обмен данными GPU и прочее (Other).
Времена выполнения, представленные на Рисунке 2 показывают, что все четыре приложения имеют примерно одинаковое поведение, затрачивая очень малую часть времени на обмен данными с GPU и тратя оставшееся время на вычисления либо в ЦПУ, либо в GPU. В случаях приложений GPU-BLAST и CUDA-MEME, в особенности, они представляют промежутки времени, когда GPU не используется. И наоборот, и LAMMPS и CUDASW++ оставляют GPU занятым почти всё время исполнения.
Рисунок 3 отображает средние накладные расходы по отношению к исполнению с применением CUDA в обычном домене для всех четырёх приложений. Этот рисунок показывает, что накладные расходы rCUDA для приложений LAMMPS, CUDASW++ и GPU-BLAST в основном обусловлены обменом данными между основной оперативной памятью и оперативной памятью GPU. Дополнительно к накладным расходам на обмен, приложение CUDA-MEME также демонстрирует уменьшение производительности при использовании ВМ, которое является результатом применения техники проброса (passthrough) PCI. Как мы можем увидеть, эти дополнительные накладные расходы не обусловлены увеличением времени обмена с GPU, а проистекают из-за времени, затрачиваемого прочими задачами на технику проброса PCI (отображаемого на данном рисунке как "Other"), объяснение чего выходит за рамки данной статьи.
Рисунок 3
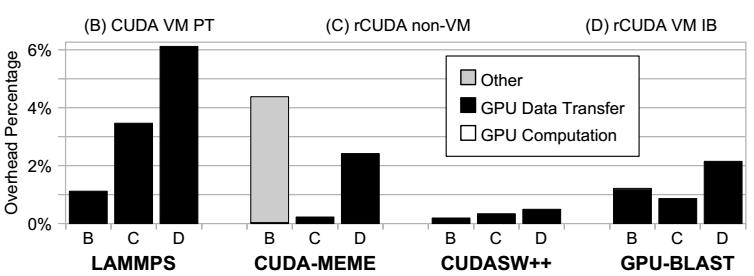
Накладные расходы относительно исполнения с CUDA в обычном домене для четырёх приложений, отображённых на Рисунке 2.
В общем случае накладные расходы rCUDA в основном вызваны обменом данных между оперативной памятью ЦПУ и памятью GPU. Это было ожидаемо, поскольку когда данные находятся в памяти удалённого GPU, вычисления GPU потребуют того же самого времени, которое необходимо для вычислений в случае обычной среды. В среднем, в нашем эксперименте накладные расходы исполнения приложений с GPU ускорением в ВМ Xen по отношению к обычному домену составляют 1.7% при использовании проброса PCI и 2.8% при использовании rCUDA из ВМ Xen.
В данной работе мы проанализировали применение структуры виртуализации удалённого GPU rCUDA для предоставления более гибкого доступа к службам ускорения CUDA из ВМ Xen. Главный вывод состоит в том, что данный подход является возможным вариантом ускорения служб для ВМ Xen. Результаты показывают, что накладные расходы исполнения приложений с ускорением в пределах ВМ Xen по отношению к существующим в настоящее время решениям (например, пробросу PCI) сильно зависят от внутренних свойств каждого приложения. В случае проанализированных в данной работе приложений эти расходы были очень низкими, в среднем около 1%.
Данная работа была спонсирована Generalitat Valenciana по Гранту PROMETEOII/2013/009 программы PROMETEO, II фаза. Авторы также благодарны за предоставленное оборудование Mellanox Technologies и NVIDIA Corporation.
1 NVIDIA GRID Technology. www.nvidia.com/object/grid-technology.html, 2015.
2 J. Song et al. KVMGT: a full GPU virtualization solution, 2014.
3 S. N. Laboratories. Lammps molecular dynamics simulator. lammps.sandia.gov/, 2013.
4 Y. Liu et al. CUDA-MEME: Accelerating motif discovery in biological sequences using GPUs., Pattern Recognition Letters, 3(14), 2010.
5 Y. Liu et al. CUDASWw++ 3.0: accelerating smith-waterman protein database search by GPUs, BMC Bioinformatics, 2013.
6 C. Reano et al. Local and Remote GPUs Perform Similar with EDR 100G InfiniBand, Middleware Conference, 2015.
7 P. D. Vouzis el at. GPU-BLAST: Using graphics processors to accelerate protein sequence alignment, Bioinformatics, 2010.