Глава 3. Одновременность, параллельность и асинхронная обработка
Содержание
- Глава 3. Одновременность, параллельность и асинхронная обработка
Данная глава рассматривает
-
Применение асинхронной обработки для проектирования приложений с пониженным временем ожидания
-
Построение потоков в Python и его ограничения при написании параллельных приложений
-
Создание приложений со множеством процессов для полного получения преимуществ многоядерных компьютеров
Современные архитектуры ЦПУ допускают одновременное исполнение более чем одной последовательной программы, позволяя добиваться впечатляющего прироста скорости обработки. На самом деле скорость может увеличиваться вплоть до значения числа доступных параллельных процессорных устройств (например, ядер ЦПУ). Плохая новость заключается в том, что применения преимуществ всей такой скорости параллельной обработки для своих программ нам требуется превратить свой код поддерживающим параллельную обработку, а Python плохо подходит для написания параллельных решений. Бо́льшая часть кода Python является последовательным, поэтому он не способен применять все доступные ресурсы ЦПУ. Кроме того, реализация имеющегося интерпретатора Python, как мы обнаружим, не настраивается под параллельную обработку. Иными словами, наш обычный код Python не может пользоваться современными возможностями оборудования и всегда будет работать с намного более низкой скоростью, нежели позволяют аппаратные средства. Таким образом, нам требуется разрабатывать методы, которые поспособствуют Python пользоваться всей доступной мощностью ЦПУ.
В данной главе мы узнаем как сделать это в точности, начиная с некоторых подходов, с которыми вы, вероятно, знакомы в целом, но которые обладают некоторыми уникальными заворотами Python. Мы обсудим одновременность, многопоточность т параллельность стиля Python, включая некоторые серьёзные ограничения, связанные с многопоточным программированием.
Мы также ознакомимся с методами асинхронного программирования, которые позволяют нам действенно обслуживать большое число одновременных запросов без необходимости параллельных решений. Асинхронное программирование существует уже довольно давно и популярно в мире JavaScript/ Node.JS, но только недавно оно обрело стандартизацию в Python при помощи добавления новых модулей для облегчения асинхронного программирования.
Для целей этой главы давайте предположим, что мы работающий в большой компании программного обеспечения разработчик. У вас задача разработки инфраструктуры MapReduce, которая ожидается очень быстрой. Все необходимые данные будут в оперативной памяти и нам требуется всё делать в отдельном компьютере. Более того, ваша служба будет способна обрабатывать одновременно запросы нескольких клиентов, причём большинство из них автоматизированные боты ИИ. Для оснастки данного проекта вы воспользуетесь методиками одновременного и параллельного программирования, включая многопоточность и работу со множеством процессов для ускорения обработки запросов MapReduce. Кроме того, вы воспользуетесь асинхронным программированием для действенной обработки большого числа одновременных запросов от пользователей.
Мы разделим данную задачу на две части. В первом разделе этой главы мы построим некий сервер, который способен одновременно обрабатывать большое число запросов. Затем нам потребуется создать собственно инфраструктуру MapReduce и это займёт бо́льшую часть данной главы после раздела 3.1. Мы рассмотрим три различных способа построения необходимой инфраструктуры: последовательный, многопоточный и со множеством процессов. Это даст нам возможность увидеть различные подходы к работе, причём совместно с их преимуществами, компромиссами и ограничениями. В заключительном разделе мы совместим две части воедино и соединим свой сервер с инфраструктурой MapReduce, что позволит нам разобраться с тем, как проектировать решение, которое эффективно интегрирует все части.
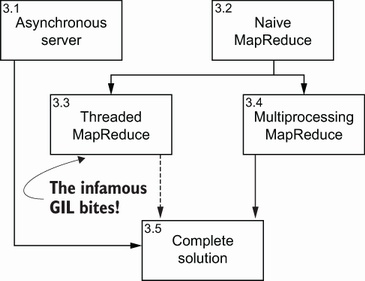
Для прояснения имеющихся в главе тем и собственно её организации, Рисунок 3.1 предоставляет визуализацию дорожной карты данной главы. Он отображает развиваемые нами подходы, а также как они соединяются друг с другом и/ или применяются совместно. В левой верхней части каждого из блоков вы обнаружите номер того раздела, в котором мы изучаем каждую из методик.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Мы не рассматриваем базовые функциональные возможности многопоточности и многозадачности Python. если вам требуется освежить их, много вводных руководств способны заполнить этот пробел вам, включая Python Concurrency with Asyncio, Matthew Fowler; Manning, 2022. {Прим. пер.: рекомендуем также наши переводы Полное руководство параллельного программирования на Python Куан Нгуен, Packt Publishing, 2018; Книга рецептов параллельного программирования Python. 2е изд Джанкарло Закконе, Packt Publishing, 2019; Asyncio в Python 3 Цалеб Хаттингх, O’Reilly Media, Inc, 2018; Внутреннее устройство CPython Энтони Шоу, Real Python, 2012 - 2021; Ускоряем ваш Python при помощи Rust Максвелл Флиттон, Packt Publishing, 2021}. |
Хотя наше основное задание состоит в применении инфраструктуры MapReduce для обработки запросов, мы начнём с построения той части своего сервера, которая получает соответствующие запросы (то есть предоставляет интерфейс клиентам). Надлежащая обработка этих запросов станет предметом для всей остающейся части данной главы. В данном разделе мы напишем сервер, который будет принимать подключения от всех клиентов и получать запросы MapRequest (и данные, и код). Выполняя это, мы увидим как асинхронное программирование способно помогать в создании действенных серверов, причём даже не применяя одновременность.
|
| Появление асинхронного программирования |
|---|---|
|
Асинхронное программирование стало популярным в мире JavaScript, в частности, в серверах NodeJS. Это особенно хорошая модель когда у нас имеется большое число медленных потоков ввода/ вывода, которые необходимо отслеживать. Наиболее очевидным примером выступает веб сервер, в котором обмен данными в большинстве вариантов применения ограничен в размере, а собственно степень обработки быстрая, обычно порядка миллисекунд. Но такая асинхронная модель также может способствовать нам в написании ясных параллельных и одновременных программ. Кроме того как мы обнаружим в оставшейся части данной главы, асинхронный подход также полезен для более традиционных сценариев данных. В качестве уточнения, асинхронность ортогональна работе в один поток, многопоточности или многопроцессности. Вы можете обладать асинхронностью поверх любой из них. |
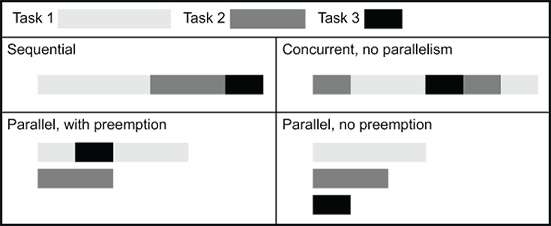
Прежде всего давайте взглянем на те основные проблема, которые создаёт синхронная обработка, итак, мы можем сравнить свои синхронные решения с асинхронными. Синхронное программирование это наиболее распространённый подход в мире Python и, скорее всего, будет самым первым пристанищем для большинства программистов Python. Однако синхронная (и с единственным процессом) версия сервера будет блокирована в процессе ожидания ввода пользователя. Поскольку пользователю может потребоваться от 1 миллисекунды до 1 часа на реальное написание запроса после открытия своего подключения, в синхронном мире это бы означало, что все прочие клиенты были бы подвешены на протяжении данного времени. Здесь существуют три решения (Рисунок 3.2):
Рисунок 3.2

Различные архитектуры, рассматривающие единственный синхронный процесс/ поток, синхронная множественная обработка и асинхронная обработка одним процессом для сервера
-
Мы просто выполняем блокирование (метка 1 на Рисунке 3.2). Это означает, что пока данное соединение обрабатывается, что бы то ни было ещё (то есть забота о прочих пользователях) такое блокирование всех соединений недопустимо.
-
У нас имеется решение со множеством потоков или процессов в котором для обслуживания запроса запускается отдельный поток или процесс (метка 2 Рисунка 3.2). Это означает, что основной процесс высвобождается для заботы о прочих входящих запросов. Для вариантов, при которых у нас имеется гигантское число производящих небольшой объём сведений каналов ввода/ вывода возможным является однопоточное решение, которое ещё и обладает меньшим весом.
-
Наконец, когда происходит блокирующий вызов, альтернативой выступает код, неким образом высвобождающий управление исполнением чтобы могли выполняться прочие фрагменты кода, пока поступают данные (метка 3 Рисунка 3.3). Именно это решение мы и будем здесь изучать: асинхронная обработка с единственным потоком.
Этим трём вариантам имеется множество альтернатив. Например, наше решение в самом конце главы будет сочетанием решений 2 и 3. Другой очень распространённой альтернативой решению 2 является наличие пула предварительно запущенных процессов для ускорения отклика. Для решения 3 мы предполагаем, что его вычислительные задачи могут прерываться (предположение, которое мы позднее в этой главе ослабим). Наконец, как возможно вам известно, многопоточный код в Python обычно (хотя и не всегда) не одновременный, этим мы займёмся позднее. По мере рассмотрения своего проекта MapReduce мы обсудим все эти решения, а также связанные с ними задачи. Мы будем следовать изображённому на Рисунке 3.1 процессу. Во- первых, мы попробует естественное решение без одновременности. (Хотя самое первое реализуемое нами решение с асинхронным взаимодействием слишком простое для нашего случая, оно очень хорошо подходит для прочих ситуаций. Например, оно вполне разумно для большинства веб серверов, как это демонстрирует NodeJS. Как и всегда, что слишком просто, а что лучше, зависит от вашей конкретной задачи.)
Затем мы испробуем решение на основе потоков, которое недостаточно для наших потребностей. После этого мы разработаем решение со множеством процессов, которое наконец повысит производительность. В своём последнем разделе, когда мы свяжем свой разработанный в этом разделе интерфейс с решением множества процессов, мы обнаружим место,в котором всё ещё может быть полезным многопоточный код, хотя и не для одновременности.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Представленное здесь решение это некое решение. Существует достаточно альтернативных подходов. Даже если бы это было наилучшее из возможных решений (а это не так), в нём ради пояснений были осуществлены определённые уступки: то что определяется как наилучшее зависит от ваших критериев. К тому же разные задачи потребуют совершенно различных подходов. Что вы должны отсюда вынести, так это не набор чётких правил, а множество методов и идей, которые помогут вам разрабатывать наилучшее решение для вашей собственной задачи и ваших собственных критериев. |
Теперь же, давайте вернёмся к своему асинхронному, однопоточному серверу с единственным процессом.
Наш сервер будет основываться на протоколе TCP и отвечать по порту 1936. Он доступен в нашем репозитории из
03-concurrency/sec1-async/server.py. Вот самый верхний уровень каркаса, который обрабатывает запросы клиентов:
import asyncio (1)
import pickle
results = {}
async def submit_job(reader, writer): (2)
job_id = max(list(results.keys()) + [0]) + 1
writer.write(job_id.to_bytes(4, 'little')) (3)
results[job_id] = job_id * 3
async def get_results(reader, writer):
job_id = int.from_bytes(await reader.read(4), 'little') (3)
pickle.dump(results.get(job_id, None), writer)
async def accept_requests(reader, writer):
op = await reader.read(1) (3)
if op[0] == 0:
await submit_job(reader, writer)
elif op[0] == 1:
await get_results(reader, writer)
async def main():
server = await asyncio.start_server(
accept_requests, '127.0.0.1', 1936) (4)
async with server: (5)
await server.serve_forever() (6)
asyncio.run(main()) (7)
(1) Мы пользуемся библиотекой asyncio Python.
(2) Все наши функции определяются asyncio.
(3) Эти строки способны заблокировать и поставить на паузу весь окружающий код.
(4) Мы применяем start_server из
asyncioс целью вызова accept_requests для каждого подключения. Наш сервер будет выполнять
ожидание по порту 1936 локального интерфейса 127.0.0.1.
(5) Ключевое слово async может применяться
ключевым словом with для превращения в не блокируемый код.
(6) Мы указываем себе обслуживать запросы постоянно.
(7) Это точка входа для нашего кода: запускается функция
main.
На данный момент это лишь каркас кода; мы закончим данный код в самом последнем разделе данной главы, когда свяжем всё воедино. Тем не менее, здесь есть много чего раскрыть. Основной вопрос: зачем вообще это предпринимать? Почему бы просто не сделать "обычную" синхронную версию?
Основная причина состоит в том, что относящиеся к аннотации (3) функции - в нашем случае считывание из сети и запись в неё - способны тратить неопределённое количество времени. Кроме того, скорость сетевой среды на несколько порядков ниже скорости центрального процессора. Если бы мы выполнили там блокировку, мы бы работали значительно ниже потенциальных возможностей и к тому же заставляли бы прочих пользователей ожидать без необходимости на то.
Вся та инфраструктура Python, которую вы только что наблюдали - async, await
и сам модуль asyncio - присутствуют для препятствия блокированию вызовов чтобы останавливать прочие части данного кода,
которые не зависят от него в приложении с единственным потоком.
Асинхронные функции, подобные созданным в нашем предыдущем разделе (то есть те, которые создаются при помощи
async def) носят название сопрограмм (coroutines). Сопрограммы это функции, которые
добровольно оставляют контроль исполнения. Существует ещё одна часть общей системы, executor (исполнитель), который управляет
всеми сопрограммами и запускает их в соответствии с некой политикой.
Когда вы вызываете некую сопрограмму изнутри другой сопрограммы при помощи await, на самом деле вы сообщаете Python
что на этом этапе контроль может быть отведён куда- то ещё. Именно это носит название кооперативного планирования
(cooperative scheduling), поскольку высвобождение контроля добровольное и требует исполнения в явном виде со стороны соответствующего кода сопрограммы.
Сравните систему сопрограмм с системами потоков большинства операционных систем: там потоки принудительно вытесняются и не обладают контроля над тем когда им
выполняться. Это носит название планированием с приоритетами (preemptive scheduling, планирования с вытеснением). В типичном
многопоточном коде нет необходимости указывать в явном виде где его можно прервать, потому как он будет прерван принудительно. В каком- то смысле, потоки Python
работают подобно системным потокам ОС. Только для кода async используется добровольное вытеснение.
Типичным образцом могла бы быть программа, выполняющая ожидание каких- то сетевых данных и выполняющая запись на диск (обычно это задача ввода/ вывода). Это могло бы работать следующим образом - обратите внимание что здесь приводится последовательная работа, а потому нет необходимости в потоках:
-
Программа main планирует асинхронному исполнителю две сопрограммы: одну для ожидания соединения по сети, а другую для записи на диск.
-
Исполнитель выбирает - возможно случайным образом - запуск сетевой сопрограммы.
-
Эта сетевая сопрограмма настраивает прослушивание сети. Затем она ожидает подключений. На данный момент нет соединений, поэтому она добровольно сообщает исполнителю делать что- то ещё кроме неё.
-
Исполнитель запускает дисковую сопрограмму.
-
Дисковая сопрограмма начинает выполнять запись на диск. По сравнению со скоростью ЦПУ запись идёт медленно, поэтому данная сопрограмма просит исполнителя выполнять нечто иное.
-
Исполнитель продолжает с сетевой сопрограммой.
-
Запросов на подключение нет по- прежнему; сетевая программа уступает своё место.
-
Исполнитель планирует дисковую сопрограмму.
-
Дисковая сопрограмма завершает выполнение записи и прекращает свою работу.
-
Исполнитель позволяет сетевой сопрограмме исполняться постоянно, поскольку ему больше нечем заниматься. Если сетевая сопрограмма уступает, исполнитель просто возвращает её обратно.
-
Сетевая сопрограмма в конечном итоге отвечает соединением или может выполнять выход по таймауту.
-
Исполнитель завершает свою работу и передаёт контроль обратно программе main.
В этом разделе, наряду с последним разделом главы, представлены образцы сопрограмм - помните, что все async def это
сопрограммы. Но давайте проведём небольшой (схематичный) тест со следующим подмножеством нашего предыдущего кода:
import asyncio
async def accept_requests(reader, writer):
op = await reader.read(1)
# ...
result = accept_requests(None, None)
print(type(result))
Давайте посмотрим что нам здесь предлагает async. Если бы приведённый выше код не имел бы ключевого слова
async, мы бы ожидали, что он возбудит некую исключительную ситуацию (в reader.read())
ибо reader был бы None. Тем не менее, подобный данному вызов
accept_requests не выполняет функцию, а вместо этого возвращает сопрограмму, и именно это в действительности создаёт
async def.
Вызов await в нашем коде сообщает Python что accept_requests может быть отложена
в данный момент и что нечто ещё можно исполнять вместо неё. Таким образом, пока мы ждём отправки данных со стороны reader,
Python может заниматься другими делами пока не поступят данные. Если сопрограммы слегка выглядят для вас как генераторы (которые обсуждались в Главе 2), в том плане,
что выполнение откладывается и может быть приостановлено, то вы на верном пути.
Для взаимодействия со своим сервером мы теперь напишем простого синхронного клиента. Это служит образцом более синхронного кода, который значительно распространённый в мире Python и вполне достаточный для потребностей нашего клиента. Но что ещё более важно, мы также воспользуемся возможностью показать как осуществлять обмен данными и кодом между процессами. Хотя позднее сервер будет дорабатываться, на самом деле это завершённая версия клиента.
Наш клиент предоставит как наш код (этот код можно обнаружить в 03-concurrency/sec1-async/client.py) так и данные и затем
будет проверять сервер пока не будет возвращён ответ:
import marshal (1)
import pickle (2)
import socket
from time import sleep
def my_funs(): (3)
def mapper(v):
return v, 1
def reducer(my_args):
v, obs = my_args
return v, sum(obs)
return mapper, reducer
def do_request(my_funs, data):
conn = socket.create_connection(('127.0.0.1', 1936)) (4)
conn.send(b'\x00')
my_code = marshal.dumps(my_funs.__code__) (5)
conn.send(len(my_code).to_bytes(4, 'little'))
conn.send(my_code)
my_data = pickle.dumps(data)
conn.send(len(my_data).to_bytes(4, 'little'))
conn.send(my_data)
job_id = int.from_bytes(conn.recv(4), 'little') (6)
conn.close()
print(f'Getting data from job_id {job_id}')
result = None
while result is None: (7)
conn = socket.create_connection(('127.0.0.1', 1936))
conn.send(b'\x01')
conn.send(job_id.to_bytes(4, 'little'))
result_size = int.from_bytes(conn.recv(4), 'little')
result = pickle.loads(conn.recv(result_size))
conn.close()
sleep(1)
print(f'Result is {result}')
if __name__ == '__main__':
do_request(my_funs, 'Python rocks. Python is great'.split(' '))
(1) marshal применяется для представления кода.
(2) pickle применяется для представления структур
данных Python более высокого уровня.
(3) наши функции определяются в отдельной функции, которая возвращает функции.
(4) Здесь мы создаём сетевое соединение.
(5) Мы создаём байтовое представление нашего кода.
(6) Мы получаем значение job_id и сами заботимся
о декодировании.
(7) Мы удерживаем соединение до тех пор пока не готов результат.
Здесь также есть много чего раскрыть. Начнём с сетевого кода: мы создаём TCP соединение с интерфейсом сокетов Python и применяем этот API для отправки и получения данных. Все вызовы потенциально блокирующие, что нормально для данного клиента.
Вероятно, наиболее важная для запоминания часть этого кода это имеющиеся различными варианты обмена данными. В Python наиболее распространённым способом сериализации
данных, которыми можно обмениваться между процессами выступает модуль pickle. Но это не всеобъемлющее решение; к примеру, им
нельзя пользоваться для обмена кодом. Для кода мы применяем модуль marshal. Мы также используем функцию
to_bytes объекта int, служащей в качестве напоминания того, мы сами способны заботиться о
кодировании при более крайних обстоятельствах. Чаще всего это происходит когда нам требуется одновременно компактное и быстрое решение - те два момента, которые не
присущи pickle. Естественно, в подобном случае мы сами будем обременены кодированием/ декодированием. Когда мы будем иметь дело
с вводам/ выводом, мы вернёмся к этому.
Своим кодом мы обмениваемся внутри функции my_funs, которая возвращает функции. Альтернативной версией программирования
было бы применение объектов. Для применения данного кода откройте терминал и запустите свой сервер при помощи:
python server.py
Затем следующим запустите его клиента:
python client.py
Мы получим вывод:
Getting data from job_id 1
Result is [Number between 1 and 4]
Более распространённым подходом к взаимодействию клиент/ сервер было бы применение интерфейса REST поверх HTTPS, однако REST в действительности не столь полезен, когда мы пытаемся разобраться с лежащими в основе понятиями. В Главе 6 мы повторно вернёмся к воздействию на производительность альтернативных стратегий сетевого взаимодействия. В любом случае, реальная реализация несомненно требует, по крайней мере, некого вида кодирования.
Асинхронное программирование может быть действенным при обработке гигантского числа одновременных запросов пользователей. Для улучшения времени отклика
async должны присутствовать два условия. Прежде всего, взаимодействие с внешними процессами должно быть ограниченным.
Во- вторых, объем процессорной обработки также должен быть не большим. Поскольку оба эти условия имеют тенденцию выполнения для веб серверов, программирование
async в целом может быть полезным для большинства веб приложений.
Более того, хотя в данном разделе мы сосредоточены на основных моментах программирования async, о базовых функциональных
возможностях асинхронности в Python можно сказать гораздо больше. Я рекомендую вам ознакомиться с такими функциональными возможностями языка как асинхронные
итераторы (async for) и диспетчеры контекста (async with). Существует также растущая
область асинхронных библиотек как aiohttp для взаимодействия HTTP в качестве альтернативы хорошо известным библиотекам
синхронных запросов.
Теперь давайте приступим к основной цели этой главы, а именно, к реализации инфраструктуры MapReduce. В своём первом разделе мы позаботились об архитектуре взаимодействия этой инфраструктуры. В данном разделе мы приступим к реализации ядра своего решения. В этом разделе будет установлено базовое решение, из которого позднее в этой главе мы получим более действенные с вычислительной точки зрения версии.
Давайте начнём с разбора инфраструктуры MapReduce чтобы увидеть какие компоненты входят в её состав. С точки зрения теории, вычисления MapReduce по крайней мере
разделяются на две половины: части map (соответствия) и reduce (сокращения). Давайте рассмотрим это в действии на типовом примере приложения MapReduce: подсчёт слов.
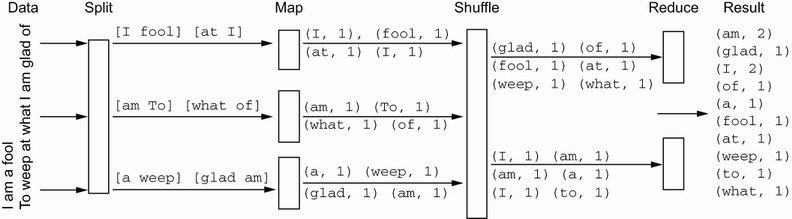
В данном случае мы воспользуемся двумя строками из Бури Шекспира: "I am a fool. To weep at what I am glad of." {Как я
глупа: я слезы лью от счастья!}. На Рисунке 3.3 вы можете наблюдать эти входные данные в MapReduce. На практике, помимо map и reduce необходимо присутствие прочих
компонентов. К примеру, перед отправкой в процессы reduce получаемые из map результаты необходимо перетасовать: когда два экземпляра слова am
были отправлены в различные процессы reduce, значение числа слов было бы не верным:
Рисунок 3.3
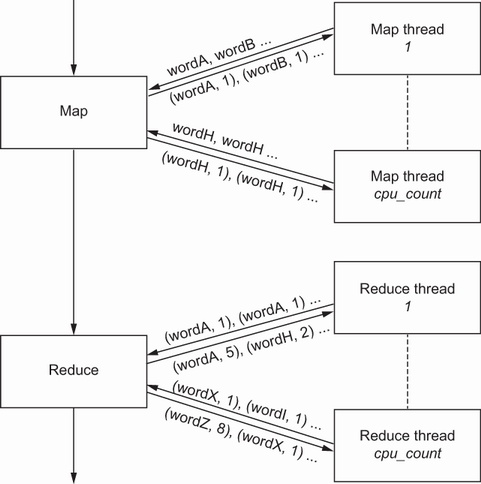
Основы инфраструктуры
map_reduce, применяемые в качестве образца подсчёта слов. Традиционные инфраструктуры
MapReduce обладают несколькими процессами или потоками реализации его этапов map и reduce. Во многих случаях они могут быть распределены по нескольким
компьютерам
Подсчёт слов может быть реализован функцией map, которая испускала бы некую запись для каждого найденного слова со счётчиком 1, а функция reduce суммировала бы все такие записи map для одного и того же слова. Итак, map испускает:
I, 1
am, 1
a, 1
fool, 1
To, 1
weep, 1
at, 1
what, 1
I, 1
am, 1
glad, 1
of, 1
А reduce затем производит:
I, 2
a, 1
fool, 1
To, 1
weep, 1
at, 1
what, 1
am, 2
glad, 1
of, 1
Где- то в промежутке, нам необходимо перетасовать полученные результаты с тем, чтобы каждое уникальное слово наблюдалось бы отдельной функцией reduce.
Например, если бы am наблюдалось двумя различными функциями reduce, в конечном счёте это приводило бы к двум
счётчикам 1, в то время как мы бы желали наблюдать один счётчик 2. В нашем сервере такая функция shuffle является встроенной; пользователю нет нужды
предоставлять её.
Помните что мы выполняем реализацию инфраструктуры mapReduce самостоятельно. Хотя мы и не являемся пользователями, нам потребуется проверить свою инфраструктуру mapReduce. Для этого мы вернёмся к наиболее распространённому образцу для mapReduce: подсчёту слов в тексте. Затем наша инфраструктура будет применена со множеством прочих задач, но для базовой проверки этой инфраструктуры достаточно подсчёта слов.
Код пользователя для реализации этого будет столь же прост, как приводимый ниже. Помните, что это вовсе не то что нам было поручено делать, это просто пример, которым мы воспользовались для проверки:
(1) Мы намеренно будем пользоваться функциональной нотацией, ибо MapReduce обладает
функциональным происхождением. Если вы пользуетесь PEP8, ваше средство синтаксического анализа всегда будет выражать недовольство, поскольку PEP8 утверждает:
"Всегда пользуйтесь оператором def вместо оператора присваивания, который привязывает выражение лямбда непосредственно
к идентификатору." Тот способ, о котором вы получаете это сообщение зависит от вашего линтера. Вам решать, предпочитаете ли вы пользоваться такой нотацией,
или применять нотацию PEP8, которая будет обладать формой def emitter(word). Для проверки выстраиваемой в данной главе
инфраструктуры мы будем пользоваться этим кодом.
Помните, что наш предыдущий код был тем, что написал ваш пользователь. Теперь мы реализуем механизм MapReduce, который и
является нашей реальной целью, и который будет подсчитывать слова и делать много чего ещё. Мы начнём с того, что работает, но не более того и на протяжении оставшейся
части главы разработаем действенный механизм, который пользуется потоками, одновременностью и асинхронными интерфейсами (первая версия доступна в
03-concurrency/sec2-naive/naive_server.py):
from collections import defaultdict
def map_reduce_ultra_naive(my_input, mapper, reducer):
map_results = map(mapper, my_input)
shuffler = defaultdict(list)
for key, value in map_results:
shuffler[key].append(value)
return map(reducer, shuffler.items())
Вы можете воспользоваться ею так:
words = 'Python is great Python rocks'.split(' ')
list(map_reduce_ultra_naive(words, emiter, counter))
list приводит к фактическому исполнению отложенного вызова map (если у вас оесть непонимание относительно семантики
отложенности, отсылаем вас к Главе 2), а потому вы получите следующий вывод:
[('Python', 2), ('is', 1), ('great', 1), ('rocks', 1)]
Хотя наша предыдущая реализация и достаточно ясна с точки зрения концептуального представления, с точки зрения работы она не способна уловить самое важное операционное ожидание от инфраструктуры MapReduce, а именно, что её функции выполняются одновременно. В своих последующих разделах мы позаботимся о том, чтобы создать действенную реализацию одновременности в Python.
Давайте предпримем вторую попытку и сделаем параллельную инфраструктуру, причём на этот раз воспользуемся многопоточностью. Для своих заданий MapReduce мы будем
применять исполнителем потоков из модуля concurrent.futures. Мы проделаем это чтобы обладать решением, которое не только
параллельное, но и одновременное (то есть позволяет нам применять всю имеющуюся вычислительную мощность) - по крайней мере, мы надеемся на это.
Мы начинаем с concurrent.futures, потому как он намного описательнее и более высокого уровня нежели наиболее часто
применяемые модули threading и multiprocessing. Это основополагающие модули в данной
области и в своём следующем разделе мы воспользуемся модулем multiprocessing, так как его интерфейс нижнего уровня позволит
нам более точно распределять ресурсы ЦПУ.
Вот эта новая версия (полный код доступен в 03-concurrency/sec3-thread/threaded_mapreduce_sync.py):
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor as Executor (1)
def map_reduce_still_naive(my_input, mapper, reducer):
with Executor() as executor: (2)
map_results = executor.map(mapper, my_input) (3)
distributor = defaultdict(list) (4)
for key, value in map_results:
distributor[key].append(value)
results = executor.map(reducer, distributor.items()) (3)
return results
(1) мы пользуемся исполнителем потоков из модуля
concurrent.futures.
(2) исполнитель может работать в качестве диспетчера контекста.
(3) исполнители обладают функцией map с блокирующим поведением.
(4) мы пользуемся очень простой функцией перетасовки.
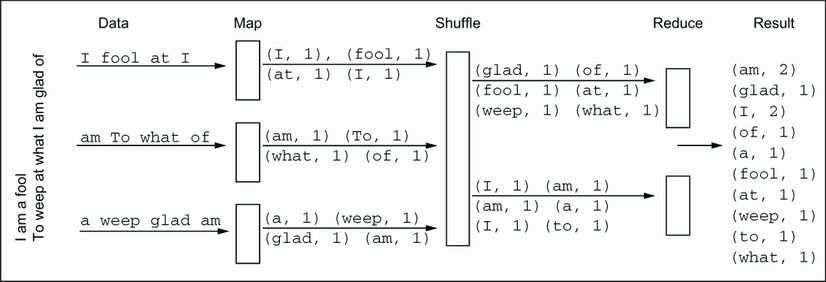
При помощи функций mapper и reducer наша функция снова получают некоторые входные
данные. Наш исполнитель из concurrent.futures отвечает за управление потоками, хотя мы и способны определить желаемое нами значение
числа потоков. Если это не так, значение по умолчанию ссылается на os.cpu_count; действительное число потоков изменяется по
версиям Python. Всё это суммирует Рисунок 3.4.
Помните, что нам необходимо быть уверенными, что наши получаемые для одного и того же объекта результаты (в нашем примере, для слова) отправляются в правильную
функцию понижения (reduce). В нашей ситуации мы реализовали очень простую версию в словаре по умолчанию distributor, который
создаёт по записи для слова.
Наш предыдущий код может обладать весьма большим отпечатком в памяти, в частности, по той причине, что наш перетасовщик будет хранить все результаты в оперативной памяти, хотя и в компактной версии. Однако с целью упрощения мы оставим всё как есть.
Точное число управляемых обработчиков это более или менее чёрный ящик в concurrent.futures. А раз так, нам не известно подо
что он оптимизирована. В конечном счёте, если мы желаем быть уверенным в извлечении максимального значения производительности, мы должны обладать полным контролем над
тем как выполняется исполнение. Если вы желаете управлять тонкой настройкой обработчиков, вам потребуется воспользоваться модулем
threading напрямую. (Другой альтернативой является реализация исполнителя concurrent.futures
самостоятельно, однако в таком случае вам придётся в любом случае разбираться в лежащих в его основе модулях threading и
multiprocessing.) Как осуществлять это, мы рассмотрим в своём следующем разделе.
Вы можете испробовать данное решение при помощи
words = 'Python is great Python rocks'.split(' ')
print(list(map_reduce_still_naive(words, emiter, counter)))
и получаемый вывод будет тем же самым что и в нашем предыдущем разделе.
Однако наше предыдущее решение обладает проблемой: оно не допускает никакого вида взаимодействия с происходящим вне рамок программы. То есть, когда вы
делаете executor.map, вам придётся дожидаться пока не завершатся все вычисления полностью. Это не имеет значения для
образца из пяти слов, однако вы можете захотеть получить обратную связь с очень большими текстами. Скажем, вы желаете иметь возможность сообщать о проценте
прогресса времени выполнения данного кода. Это требует несколько иного решения.
Прежде всего давайте закодируем часть map чтобы разобраться что происходит (весь код доступен в
03-concurrency/sec3-thread/threaded_mapreduce.py):
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor as Executor
def async_map(executor, mapper, data):
futures = []
for datum in data:
futures.append(executor.submit(mapper, datum)) (1)
return futures
def map_less_naive(executor, my_input, mapper):
map_results = async_map(executor, mapper, my_input)
return map_results
(1) при вызове исполнителя мы применяем submit
вместо map.
В то время как функция map исполнителя ждёт результаты, submit этого не делает.
Вскоре мы обнаружим что это означает, когда всё запустим.
Мы изменим свой emitter чтобы иметь возможность отслеживать что происходит:
from time import sleep
def emitter(word):
sleep(10)
return word, 1
Вызов sleep присутствует здесь для приостановки нашего кода, что позволяет нам отслеживать что происходит даже в простом
примере. Давайте воспользуемся своей функцией map в том виде как она присутствует:
with Executor(max_workers=4) as executor:
maps = map_less_naive(executor, words, emitter)
print(maps[-1])
Если вы выведете на печать самый последний элемент из имеющегося списка, вы можете получить нечто неожиданное:
<Future at 0x7fca334e0e50 state=pending>
Вы не получаете ('rocks', 1), а вместо этого у вас future (фьючерс). Фьючерс
представляет некий потенциальный результат, который может быть предметом для await и проверки его состояния. Теперь мы
можем позволить пользователю отслеживать прогресс как- то так:
03-concurrency/sec3-thread/threaded_mapreduce.py):
with Executor(max_workers=4) as executor: (1)
maps = map_less_naive(executor, words, emitter)
not_done = 1
while not_done > 0: (2)
not_done = 0
for fut in maps:
not_done += 1 if not fut.done() else 0 (3)
sleep(1) (4)
print(f'Still not finalized: {not_done}')
(1) мы размещаем только четыре исполнителя чтобы позволить нам отслеживать прогресс раз у нас имеется пять задач.
(2) пока имеются задачи для выполнения вы выводим на печать состояние.
(3) проверяем выполнен ли фьючерс.
(4) слегка засыпаем чтобы не преграждать текст.
Если вы выполните наш предыдущий код, вы получите несколько строк с Still not finalized…. Обычно на протяжении первых 10
секунд вы наблюдаете пять, а затем может начаться одна из завершающих. Поскольку имеется пять рабочих элементов, для исполнения первых четырёх требуется 10 секунд,
а затем может стартовать завершающий. Представляя что это параллельный код, это может слегка меняться от запуска к запуску, а потому тот способ, которым происходит
вытеснение потоков может меняться при каждом запуске этого кода: он не предопределён.
Имеется один окончательный фрагмент нашей мозаики, который остаётся сделать, который будет состоять в самой последней версии исполнителя потоков: нам требуется некий способ для вызывающей стороны иметь возможность получать сведения о ходе исполнения. Такой вызывающей стороне потребуется передать функцию обратного вызова, которая будет вызываться когда происходит важное событие. В нашей ситуации таким важным событием будет отслеживание завершение заданий map и reduce. Это реализовано в нашем следующем коде:
def report_progress(futures, tag, callback): (1)
done = 0
num_jobs = len(map_returns)
while num_jobs > done:
done = 0
for fut in futures:
if fut.done():
done +=1
sleep(0.5)
if callback:
callback(tag, done, num_jobs - done)
def map_reduce_less_naive(my_input, mapper, reducer, callback=None):
with Executor(max_workers=2) as executor:
futures = async_map(executor, mapper, my_input)
report_progress(futures, 'map', callback) (2)
map_results = map(lambda f: f.result(), futures) (3)
distributor = defaultdict(list)
for key, value in map_results:
distributor[key].append(value)
futures = async_map(executor, reducer, distributor.items())
report_progress(futures, 'reduce', callback) (4)
results = map(lambda f: f.result(), futures) (5)
return results
(1) report_progress потребует
функции обратного вызова, которая будет вызываться каждые полсекунды со статистическими сведениями о сделанных заданиях.
(2) мы сообщаем прогресс для всех задач map.
(3) Поскольку получаемые результаты в действительности фьючерсы, нам требуется получать их из своих объектов фьючерсов.
(4) мы сообщаем значение прогресса для всех задач reduce.
(5) поскольку все результаты в действительности фьючерсы, нам требуется получать их из имеющихся объектов фьючерсов.
Итак, в процессе выполнения map и reduce, каждые 0.5 секунды будет исполняться поддерживаемая пользователем функция обратного вызова. Обратный вызов может быть как простым, так и сложным насколько пожелаете, хотя он обязан быть быстрым, поскольку все вокруг дожидаются его. Для применяемого нами тестового примера подсчёта слов у нас имеется очень простой:
def reporter(tag, done, not_done):
print(f'Operation {tag}: {done}/{done+not_done}')
Обратите внимание на то, что отличительные признаки нашей функции обратного вызова не произвольны: она обязана следовать выставляемому
report_progress протоколу, который требует в качестве аргументов соответствующий тег и установленное число выполненных и
незавершённых задач.
Если вы выполните
words = 'Python is great Python rocks'.split(' ')
results = map_reduce_less_naive(words, emitter, counter, reporter)
вы получите несколько выведенных на печать строк состояния выполнения данной операции, за которыми следуют полученные результаты:
Operation map: 3/5
Operation reduce: 0/4
('is', 1)
('great', 1)
('rocks', 1)
('Python', 2)
Было бы не слишком сложно, скажем, пользоваться возвращаемым значением в качестве индикатора под инфраструктуру MapReduce для отмены выполнения. Это позволило бы нам изменить семантику функции обратного вызова чтобы прервать её процесс.
К сожалению, это решение является параллельным, но не одновременным. Это обусловлено тем, что Python (или скорее CPython) за раз исполняет только один поток по причине печально известного GIL CPython, Global Interpreter Lock (глобальная блокировка интерпретатора). Давайте в своём следующем разделе взглянем поближе на GIL и то, как он обрабатывает потоки.
Хотя CPython применяет потоки Операционной Системы, а потому они являются вытесняемыми (preemptive, "обладающие повторным вхождением") имеющийся механизм GIL выставляет ограничение, а потому за раз может выполняться только один поток. Таким образом, вы можете обладать многопоточной программой, исполняемой в компьютере со множеством ядер, но в конечном счёте без одновременности. В действительности есть нечто более плохое чем это: значение производительности переключения потоков в многоядерных компьютерах может быть плохой по причине трения между самой GIL, механизм которой не допускает запускать более одного потока за раз, а также ЦПУ и ОС, которые как раз оптимизированы на выполнение противоположного.
Данная книга содержит раздел по многопоточности потому как любая связанная с производительностью книга была бы без него неполной. Однако, по правде говоря, если вы желаете производительности, потоки Python редко бывают наилучшим решением.
Проблемы GIL переоценены. Дело в том, что когда вам требуется создавать высокопроизводительный код на уровне потоков, скорее всего, Python всё равно слишком медленный. По крайней мере, его реализация CPython, а, возможно, и динамические функциональные возможности Python также. Существенно более действенный код вы пожелаете реализовывать на языке программирования более низкого уровня, таком как C или Rust, или же при помощи системы, подобной Cython или Numba, которые мы изучим позднее.
Для реализуемого на языках программирования низкого уровня кода GIL предоставляет несколько обходных путей: по мере ввода своего решения нижнего уровня вы, по существу, можете высвобождать GIL пользоваться одновременностью сколько вашей душе угодно. Именно это предоставляют такие библиотеки, как mPy, SciPy и scikit-learn. У них имеется написанный на C или Fortran многопоточный код, который отпускает GIL и на самом деле одновременный. Тем самым, ваш код всё ещё может быть одновременным в мире многопоточности. Просто такая одновременная часть будет написана на на Python.
Но мы всё ещё способны писать действенный одновременный код на чистом Python и осуществлять его на уровне подробностей вычислений, имеющей смысл в Python. Просто вы делаете это не при помощи многопоточности, а применяя множество процессов.
|
| PyPy |
|---|---|
|
В то время как CPython это стандартная для Python реализация, существуют и прочие, такие как IronPython и Jython для .NET и для JVM, соответственно. Другой реализацией, которую стоит упомянуть, является PyPy, которая не является интерпретатором, а вместо этого компилятором just-in-time (JIT, оперативный компилятор, преобразующий псевдокод в исполняемый код в процессе исполнения программы). PyPy не является заменой CPython, поскольку многие библиотеки CPython не работают с ним напрямую. Однако если вам требуются более быстрые библиотеки сопровождения, он может оказаться более быстрой реализацией. Хотя PyPy во многих ситуация быстрее CPython, у него всё- таки имеется GIL, поэтому и он не решает данную проблему. В данной книге мы будем придерживаться CPython, но для разумного подмножества действенных вариантов PyPy может выступать в качестве потенциальной альтернативы. И напоследок: если вы путаете PyPy, соответствующую реализацию Python с PyPl, репозиторием пакетов, знайте что вы не одиноки. |
По причине GIL наш многопоточный код в действительности не одновременный. Для решения данной задачи мы можем пойти двумя путями: мы можем повторно реализовать свой код Python на языке программирования более низкого уровня, таком как C или Rust, или же, как в случае с наши решением в данном разделе, для обладания одновременностью и применением всей доступной мощности ЦПУ, мы можем обратиться ко множеству процессов. Решения более низкого уровня будут рассмотрены в последующих главах.
Теоретически, основанное на concurrent.futures решение достаточно простое. Оно
разработано с целью упрощения замены того модуля, который осуществляет импорт из ThreadPoolExecutor на
ProcessPoolExecutor (данный код доступен в 03-concurrency/sec4-multiprocess/futures_mapreduce.py):
from concurrent.futures import ProcessPoolExecutor as Executor
Если вы замените эту строку на асинхронную версию из нашего предыдущего раздела, вы заметите, что что- то не так, поскольку ваш код кажется подвисающим в части
reduce. Нам необходимо копнуть глубже; поэтому мы создадим более информативную функцию report_progress из своего
последнего раздела:
def report_progress(futures, tag, callback):
done = 0
while num_jobs > done:
done = 0
for fut in futures:
if fut.done():
done +=1
print(fut)
print(fut.exception())
sleep(0.5)
if callback:
callback(tag, done, not_done)
Мы всего лишь добавили два вывода на печать. Если мы снова запустим этот код, мы получим:
<Future at 0x7f1ffff104c0 state=finished raised PicklingError>
Can't pickle at 0x7f2000131ca0>: attribute lookup
<lambda> on __main__ failed
Оказывается, лямбды (помните, наша функция counter была написана как лямбда) не могут быть реализованы через
pickle. Тем не менее, взаимодействие множества процессов осуществляется через pickle.
Поэтому нашу функцию counter нельзя передавать подчинённому процессу как есть. Мы можем просто переопределить её как
функцию def:
def counter(emitted):
return emitted[0], sum(emitted[1])
Это решает конкретно наш тестовый пример, но ещё более важный момент состоит в том, что вы не можете просто подменить исполнителя потоков на него же на основе процессов. Какие ещё функциональные возможности могут отличаться? Чтобы ознакомиться с этим, перейдите к нашему следующему разделу.
|
| Проблемы с совместным использованием данных и кода при применении модуля множества процессов |
|---|---|
|
Мы только что заметили что обмен лямбдами между процессами не возможен при помощи конфигурации по умолчанию Как правило, раз Указатели файлов, соединения с базой данных и сокеты либо невозможно передавать, либо это требует особого внимания. При использовании потоков все эти типы объектов
могут применяться совместно, хотя нам и следует проверять являются ли они безопасными (сохраняющимися) для потоков (thread-safe). Другая проблема с
Использование примитивов взаимодействия Python идеально годится для вариантов с низким уровнем взаимодействия. Но в ситуациях с большими накладными расходами на взаимодействие следует быть особенно осторожными, ибо получаемая за счёт многопроцессной обработки скорость может быть растрачена во время взаимодействия. |
concurrent.futures предоставляет нам очень простой интерфейс для осуществления параллельного программирования. Для наиболее
очевидных задач он может быть достаточно эффективным в плане как продуктивности программиста, так и производительности вычислений. Однако простота программирования
имеет свою стоимость: мы утрачиваем контроль над тем как исполняется код. Каков порядок выполнения фьючерсов? Хотя мы и задаём максимальное число работников, сколько
из них доступно в определённый момент времени? Применяются ли процессы повторно или заново создаются с нуля для каждой задачи? При использовании
concurrent.futures это определяется исполнителем, а мы не обладаем никаким контролем над ним.
В нашей ситуации мы действительно пожелали бы принуждать к определённым политикам для достижения высокой производительности . Например, мы бы хотели создавать все процессы прежде чем появляется работа для поддержки процессов в активности, даже хотя нет никаких задач. Это обусловлено тем, что создание и уничтожение процессов при возникновении запросов обладают некими накладными расходами, которые мы предпочли бы уплатить когда мы не имеем дело с обработкой таких запросов. Мы начнём с собственно ручного создания пула процессов.
Мы стартуем с простого решения, которое не позволяет нам отслеживать развитие в реальном масштабе времени (этот код доступен в
03-concurrency/sec4-multiprocess/mp_mapreduce_0.py):
from collections import defaultdict
import multiprocessing as mp (1)
def map_reduce(my_input, mapper, reducer):
with mp.Pool(2) as pool: (2)
map_results = pool.map(mapper, my_input) (3)
distributor = defaultdict(list)
for key, value in map_results:
distributor[key].append(value)
results = pool.map(reducer, distributor.items()) (3)
return results
(1) мы импортируем модуль multiprocessing.
(2) мы создаём пул с двумя процессами.
(3) этот пул предоставляет синхронную функцию
map.
Данный код прост настолько, насколько это возможно. Единственная новая строка- создание Pool. Этот пул создаётся всякий
раз когда запрашивается работа mapReduce, а потому он отсутствует при множестве инициаций: мы платим стоимость создания пула для каждого исполнения.
|
| Сопоставление CPU_count и
sched_getaffinity при определении размера пула |
|---|---|
|
Наш предыдущий код определяет для создания в нашем пуле два процесса. В большинстве ситуаций вы пожелаете чтобы данное число было некой функцией от мощности
вашего компьютера. Значением по умолчанию для размера пула выступает Слегка более строгой альтернативой было бы применение |
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Семантика функции |
map(fun, data)
Pool.map(fun, data)
Первый выполняет возврат немедленно и не выполняет fun.list(map(fun, data), что было бы точным эквивалентом. Типичным
шаблоном разработки является замена Pool.map на map, так как отладка кода упрощается при
её выполнении в том же процессе. Однако это не совсем верно. Со стороны multiprocessing у вас также имеется
imap, который выступает отложенной версией, и асинхронная версия map_async.
На данный момент, map_async не поддерживает отслеживание развития. Обратите внимание, что она обладает поддержкой обратного
вызова, но она вызывает соответствующую функцию callback только когда становятся готовыми все результаты. Мы бы хотели
чего- то более подробного: возможности обладания вызовом всякий раз, когда готов его итератор. Именно это требуется нам для отслеживания развития.
Для поддержки этого мы изменяем свой код. В то время как имеется функция Pool.map_async, которая может быть полезной
в большом числе случаев, она выполняет обратный вызов системы только с отчётом в самом конце исполнения, а этого не достаточно. Нам необходимо решение со слегка более
низким уровнем (данный код доступен в 03-concurrency/sec4-multiprocess/mp_mapreduce.py):
def async_map(pool, mapper, data):
async_returns = []
for datum in data:
async_returns.append(pool.apply_async( (1)
mapper, (datum, ))) (2)
return async_returns
def map_reduce(pool, my_input, mapper, reducer, callback=None):
map_returns = async_map(pool, mapper, my_input)
report_progress(map_returns, 'map', callback)
map_results = [ret.get() for ret in map_returns] (3)
distributor = defaultdict(list)
for key, value in map_results:
distributor[key].append(value)
returns = async_map(pool, reducer, distributor.items())
results = [ret.get() for ret in returns]
return results
(1) для запуска индивидуальных заданий мы пользуемся
Pool.apply_async.
(2) Обратите внимание на то, что параметры для данной функции определяются как кортеж.
(3) получение результатов асинхронных объектов при помощи их метода
get.
Этот код не слишком отличается от решения concurrent.futures - до той степени, что мы могли бы задаться вопросом,
для дополнительного упрощения стоит ли того отсутствие гибкости в concurrent.futures.
Наша функция map_reduce теперь применяет некий предоставляемый своим пользователем пул, причём допуская повторное
использование пула. В целом это более эффективно нежели запуск нового процесса при каждом новом выполнении операции. В нашем примере практически нет накладных
расходов, однако в в более сложных образцах инициализация каждого процесса может оказаться более временеёмкой и потребляющей больше ресурсов.
Для вызова данного кода нам придётся заблаговременно создать необходимый пул. Например, так:
pool = mp.Pool()
results = map_reduce(pool, words, emitter, counter, reporter)
pool.close() (1)
pool.join() (2)
(1) мы закрываем этот пул.
(2) мы дожидаемся завершения всех процессов.
Здесь мы можем воспользоваться пулом из диспетчера контекста, однако это позволяет нам обнаружить, что очистка пула не просто закрывает все процессы; она к тому
же дожидается выхода из них - соответствующим вызовом join. Более убедительной альтернативой для
close послужил бы terminate, который заставил бы завершиться имеющимся процессам, даже
не завершая никакую текущую работу.
|
| Чрезмерное или недостаточное выделение ресурсов ЦПУ |
|---|---|
|
Когда мы создаём свой пул, мы пользуемся установленным по умолчанию размером, Наиболее распространённой причиной не полного выделения обусловлены ограничениями ввода/ вывода: слишком интенсивный ввод/ вывод запросто способен забить вашу машину, ибо большое число процессов может вызывать большую загрузку ввода/ вывода, нежели способна обрабатывать эта машина. В особенности это справедливо для дискового ввода/ вывода. Когда процессы потребляют большой объём памяти, тогда вам также потребуется уменьшать масштаб, так как вы можете получить понижение производительности по причине загруженности кэша памяти. В наихудшем случае ваша ОС может приступить к уничтожению процессов в случае когда компьютер израсходует память.. Типичным вариантом выделения сверх размера выступает ожидание сетевого отклика. Это означает, что развитие может впустую тратить большую часть времени, а потому доступны ресурсы ЦПУ. Это парадоксально, но чрезмерная загрузка ЦПУ может оказываться полезной для некоторых ограниченный в вычислительных ресурсах процессах - к примеру, когда загруженность ЦПУ не является непрерывной, а происходит в режиме наличия пиков, или же когда перед фактическим началом вычислений необходимо значительное время настройки. |
Функция report_progress почти такая же: когда некое задание завершается, она выполняет обратный вызов. Соответствующий
вызов Future.done заменяется на AsyncReturn.ready:
def report_progress(map_returns, tag, callback):
done = 0
num_jobs = len(map_returns)
while num_jobs > done:
done = 0
for ret in map_returns:
if ret.ready():
done += 1
sleep(0.5)
if callback:
callback(tag, done, num_jobs - done)
Теперь вы можете запустить этот код и это всё работает. Однако является ли данное решение достаточно быстрым?
Для ответа на вопрос является ли соответствующее решение достаточно быстрым или нет, нам потребуется сопоставить его с чем- то ещё. Как мы уже видели в своей предыдущей главе, а также вернёмся к этому позднее, разбиение для записи на диск на фрагменты способно значительно ускорять операции записи на диск. Настолько ли хорош этот метод для затрат ЦПУ и взаимодействия между процессами?
Для ответа на этот вопрос мы выполняем незначительное изменение в своей архитектуре MapReduce. Мы добавим этап расщепления в самом начале, который будет отправлять необходимые данные не как единый элемент, а как фрагменты. Рисунок 3.5 представляет новый этап для Рисунка 3.3, который отвечает за расщепление.
Наше расщепление и на самом деле достаточно простое, однако более искушённые инфраструктуры MapReduce способны здесь выполнять существенно более совершенные
оптимизации. Мы начнём с рассмотрения кода, который представляет задания разбиения на фрагменты и собирает эти фрагменты в процессах имеющегося пула (этот код
находится в 03-concurrency/sec4-multiprocess/chunk_mp_mapreduce.py):
def chunk(my_iter, chunk_size): (1)
chunk_list = []
for elem in my_iter:
chunk_list.append(elem)
if len(chunk_list) == chunk_size:
yield chunk_list
chunk_list = []
if len(chunk_list) > 0:
yield chunk_list
def chunk_runner(fun, data): (2)
ret = []
for datum in data:
ret.append(fun(datum))
return ret
def chunked_async_map(pool, mapper, data, chunk_size): (3)
async_returns = []
for data_part in chunk(data, chunk_size): (4)
async_returns.append(pool.apply_async( (5)
chunk_runner, (mapper, data_part)))
return async_returns
(1) теперь у нас имеется генератор фрагментов, который будет расщеплять итератор в списке
с размером chunk_size.
(2) для распаковки списка фрагментов привод фрагмента выполняется в имеющемся пуле процессов .
(3) нам требуется приспособить свою функцию для представления заданий имеющемуся пулу через наличие некого промежуточного уровня для распаковки списков.
(4) здесь мы вызываем функцию фрагмента.
(5) теперь мы вместо непосредственного окончательного вызова функции вызываем промежуточный уровень.
chunked_async_map это тот код, который будет распределять всю работу по установленному пулу. Он вызывает генератор
chunk для расщепления имеющихся на входе данных на фрагменты с chunk_size. Обратите
внимание, что он более вовсе не вызывает напрямую заданную функцию: тем первым моментом, который исполняется в установленном пуле процессов выступает
chunk_runner, который итерациями проходит по всем элементам соответствующего фрагмента и вызывает реальную рабочую
функцию fun.
Вам может показаться, что проще реализовать необходимый генератор chunk подобно следующему:
def chunk0(my_list, chunk_size):
for i in range(0, len(my_list), chunk_size):
yield my_list[i:i + chunk_size]
Основная проблема такой реализации состоит в том, что она требует len(my_list), тем самым ограничивая наш ввод списком.
Итератор может быть отложенным и, следовательно, занимать меньше памяти и, вероятно, требовать на обработку меньше процессорного времени.
Теперь нам необходимо изменить свою функцию MapReduce верхнего уровня:
def map_reduce(
pool, my_input, mapper, reducer, chunk_size, callback=None): (1)
map_returns = chunked_async_map(pool, mapper, my_input, chunk_size) (1)
report_progress(map_returns, 'map', callback)
map_results = []
for ret in map_returns:
map_results.extend(ret.get()) (2)
distributor = defaultdict(list)
for key, value in map_results:
distributor[key].append(value)
returns = chunked_async_map(
pool, reducer, distributor.items(), chunk_size) (1)
report_progress(returns, 'reduce', callback)
results = []
for ret in returns:
results.extend(ret.get())
return results
(1) в качестве параметра мы добавляем chunk_size.
(2) вместо append мы пользуемся
extend.
Единственная необходимая оговорка состоит в том, что результатом каждого выполнения выступает уже не единственный элемент, а список элементов. Поэтому нам и требуется расширять получаемый список, а не выполнять добавление в конец.
Для получения лучшего теста скорости мы воспользуемся Анной Карениной Толстого, доступной в проекте Гутенберг. Вот соответствующий код вызова:
words = [word (1)
for word in map(lambda x: x.strip().rstrip(),
' '.join(open(
'text.txt', 'rt', encoding='utf-8').readlines()).split(' '))
if word != '' ]
chunk_size = int(sys.argv[1]) (2)
pool = mp.Pool()
counts = map_reduce(pool, words, emitter, counter, chunk_size, reporter)
pool.close()
pool.join()
for count in sorted(counts, key=lambda x: x[1]): (3)
print(count)
(1) здесь в список считывается весь текст.
(2) chunk_size это параметр командной строки.
(3) мы выводим на печать все счётчики слов в порядке возрастания.
Я выполнил свой предыдущий код с размером фрагментов 1, 10, 100, 1 000 и 10 000. В Таблице 3.1 приводятся значения времени в каждом из этих случаев:
| Размер фрагмента | Время (сек) |
|---|---|
|
114.2 |
|
12.3 |
|
4.3 |
|
3.31 |
|
3.31 |
Численные значения Таблицы 3.1 говорят сами за себя: фрагментация существенно увеличивает производительность нашей инфраструктуры. Фрагментация настолько важное понятие, что мы будем к ней обращаться повторно в своих последующих главах.
|
| Совет |
|---|---|
|
Если вы пользуетесь |
|
| Разделяемая память |
|---|---|
|
Альтернативой представленному здесь (неявному) решению передачи сообщений могло бы быть применение служб совместной памяти. Как известно, естественные модели совместно используемой памяти, такие как доступные во встроенных библиотеках Python, сильно подвержены ошибкам, а потому мы не будем их рассматривать здесь. Если вам требуется совместно применять оперативную память, скорее всего, вы пребываете в той ситуации, когда вам всё равно придётся реализовывать собственный код в решении более низкого уровня. Мы обсудим разделяемую память позднее, когда будем применять подходы нижнего уровня, относящиеся к нашему коду Python для осуществления обработки. |
В данной главе мы протестировали различные подходя и сочетания подходов с применением одновременности, параллельности, многопоточности, а также синхронного и асинхронного программирования. Теперь мы отберём наиболее действенные из этих стратегий и соединим их, вернувшись к своему примеру задачи разработки чрезвычайно быстрой среды MapReduce. Восстановим все параметры своей задачи: все данные пребывают в оперативной памяти, вся обработка будет производиться в одном компьютере, а наша система будет обрабатывать запросы от нескольких клиентов, в том числе от автоматизированных ботов ИИ. В данном заключительном разделе мы, в конце концов, разработаем завершённое решение, которое в конце концов придёт к реализации MapReduce множеством процессов позади асинхронного TCP сервера, отвечающего на запросы множества клиентов.
Мы уже собрали две необходимые части: реализацию MapReduce с фрагментацией из своего предыдущего раздела и того клиента, которого мы сделали когда-то в разделе 3.1. Мы можем воспользоваться этими двумя частями как есть. Обо всём прочем в этом решении читайте далее.
Мы спроектируем свою архитектуру согласно Рисунка 3.6. Интерфейс переднего плана со всеми клиентами будет асинхронным. Обработка будет отправляться в другой поток через некую очередь. Этот поток будет отвечать за управление пулом процессов, который и будет выполнять работу MapReduce.
Наш передний план сервера TCP будет реализован внутри некого асинхронного цикла. Будет также иметься второй поток, который будет отвечать лишь за управление пулом обработки MapReduce множеством процессов.
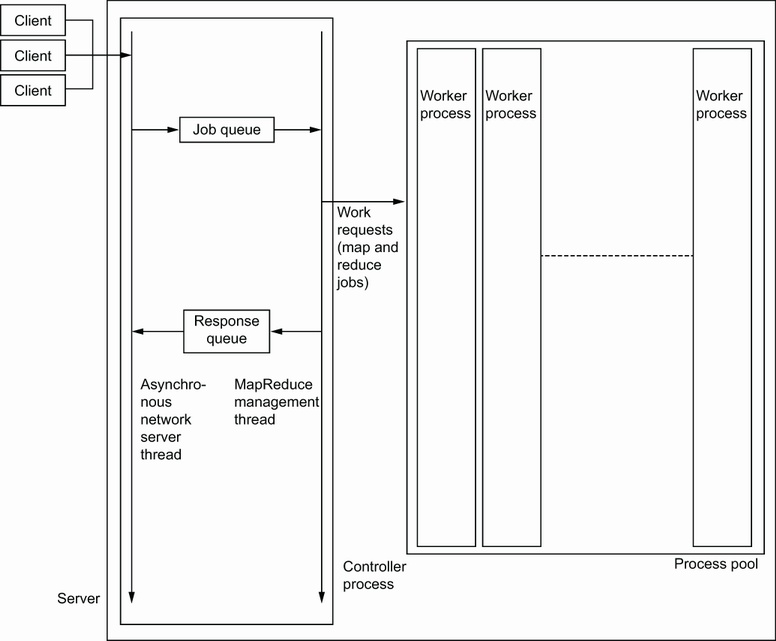
Взаимодействие между этими двумя потоками будет применять Queue из модуля queue.
Код входа настроит необходимый асинхронный сервер и тот поток, который управляет пулом MapReduce (весь код расположен в
03-concurrency/sec5-all/server.py):
import asyncio
from queue import Queue, Empty
import multiprocessing as mp
import types
work_queue = Queue()
results_queue = Queue()
results = {}
def worker(): (1)
pool = mp.Pool() (2)
while True:
job_id, code, data = work_queue.get() (3)
func = types.FunctionType(code, globals(), 'mapper_and_reducer')
mapper, reducer = func()
counts = mr.map_reduce(pool, data, mapper, reducer, 100, mr.reporter)
results_queue.put((job_id, counts)) (4)
pool.close()
pool.join()
async def main():
server = await asyncio.start_server(accept_requests, '127.0.0.1', 1936)
worker_thread = threading.Thread(target=worker) (5)
worker_thread.start() (6)
async with server:
await server.serve_forever()
asyncio.run(main())
(1) эта функция вызывается в новом потоке.
(2) этот пул создаётся в нашем потоке worker.
(3) поток worker ожидает какую- нибудь работу для исполнения.
(4) результаты помещаются в очередь отклика.
(5) подготавливается поток, указывающий на работника в качестве начальной точки.
(6) запускается соответствующий поток.
Наша главная точка входа, main, прежде всего подготавливает соответствующую асинхронную инфраструктуру, а также создаёт и
запускает тот поток, который будет управлять пулом MapReduce, который реализуется в нашей функции worker.
worker создаёт пул обработки множеством процессов и имеет дело с запросами от своего асинхронного сервера. Взаимодействие
осуществляется через очереди FIFO (first-in, first-out - первый вошедший первым обрабатывается). Соответствующий модуль queue
гарантирует что наши очереди синхронные (то есть в них применяется механизм блокировки для обеспечения того, что потоки не будут не согласованными). Имеется
queue для получения работы и другая для возврата полученных результатов. Все используемые в worker
функции являются блокирующими, поскольку при инициализации нет ничего для обработки: сами клиенты организуются асинхронной частью.
|
| Замечание |
|---|---|
|
Очереди к тому же великолепный способ взаимодействия когда вы пользуетесь множеством процессов вместо многопоточности. Наш модуль
|
Давайте начнём с подачи задания. Наша асинхронная часть теперь закодирована так:
async def submit_job(job_id, reader, writer):
writer.write(job_id.to_bytes(4, 'little'))
writer.close()
code_size = int.from_bytes(await reader.read(4), 'little')
my_code = marshal.loads(await reader.read(code_size))
data_size = int.from_bytes(await reader.read(4), 'little')
data = pickle.loads(await reader.read(data_size))
work_queue.put_nowait((job_id, my_code, data)) (1)
(1) мы записываем данные в work_queue,
причём без блокировки.
Наша функция submit_job теперь, наконец, делает нечто полезное: она подставляет соответствующее задание в
work_queue, которое будет подхватываться соответствующим потоком, исполняющим функцию worker.
Во избежание блокировки при помещении полученного результата мы пользуемся put_nowait. В нашем случае этого не должно происходить,
поскольку данная очередь инициализируется с ограничениями по размеру, что вам необходимо предусмотреть и реализовать при создании вызова данной очереди, в то время
как в этой очереди может присутствовать множество сообщений.
Вот остальная часть нашего асинхронного кода:
def get_results_queue():
while results_queue.qsize() > 0: (1)
try:
job_id, data = results_queue.get_nowait() (2)
results[job_id] = data
except Empty: (3)
return
async def get_results(reader, writer):
get_results_queue()
job_id = int.from_bytes(await reader.read(4), 'little')
data = pickle.dumps(None)
if job_id in results:
data = pickle.dumps(results[job_id])
del results[job_id]
writer.write(len(data).to_bytes(4, 'little'))
writer.write(data)
async def accept_requests(reader, writer, job_id=[0]):
op = await reader.read(1)
if op[0] == 0:
await submit_job(job_id[0], reader, writer)
job_id[0] += 1
elif op[0] == 1:
await get_results(reader, writer)
(1) мы получаем значение размера этой очереди чтобы увидеть произошло ли что- то.
(2) из results_queue мы считываем полученный
отклик, причём без блокировки.
(3) мы предоставляем пустую очередь.
accept_requests в точности тот же что и в самом первом разделе отражается здесь исключительно из соображений законченности.
get_results обладает только одной новой строкой в самом начале: вызова get_results_queue,
который отвечает за проверку того закончился ли MapReduce и переданы ли полученные результаты в словарь results. Неплохо
отметить, что значение размера очереди определяется через qsize только приблизительно, а потому нам придётся рассматривать
пустую очередь и избегать блокирования пока мы дожидаемся возникновения сообщения.
|
| Блокирование и синхронизация нижнего уровня при использовании многопоточности и множества процессов |
|---|---|
|
Избегайте большинства примитивов нижнего уровня для блокировок! Существует множество стандартных примитивов синхронизации, которые поддерживаются как многопоточностью, так и многопроцессностью., включая блокировки и семафоры, а также ряд прочего. Тем не менее, наша точка зрения сводится к тому, что если уж вам необходимо применять такие конструкции нижнего уровня, вам, скорее всего, всё равно придётся реализовывать код на языке более низкого уровня. Итак, мы будем иметь дело с подобными механизмами в данной книге позднее, когда будем решать вопросы производительности путём повторной реализации частей кода вне рамок стандартного Python. Хотя это и не относится напрямую к производительности, широко применяемым при многопроцессной обработке примитивом является
|
До сих пор мы мало внимания уделяли ошибкам и не ожидаемым входным данным. На данном этапе мы превратим свой код в слегка более надёжный. Это существенно увеличит размер нашей реализации. Мы получим гарантию того, что даже в случае останова сервера наш асинхронный сервер прекращает работу аккуратно: потоки работников завершаются, а их пул закрывается надлежащим образом.
Нашей функции main придётся слегка располнеть:
-
Нам потребуется перехватывать запрос пользователя на прерывание (обычно Control-C) и на этом этапе выполнять очистку.
-
Поскольку наш асинхронный сервер не может быть прекращён в данный момент, нам надлежит перехватывать это также.
-
Нам придётся обладать неким способом выдачи сигнала своему работающему потоку что он тоже обязан выполнить очистку.
Вот эта реализация (полный код находится в 03-concurrency/sec5-all/server_robust.py):
import signal
from time import sleep as sync_sleep
def handle_interrupt_signal(server): (1)
server.close() (2)
while server.is_serving(): (3)
sync_sleep(0.1)
def init_worker():
signal.signal(signal.SIGINT, signal.SIG_IGN) (4)
async def main():
server = await asyncio.start_server(accept_requests, '127.0.0.1', 1936)
mp_pool = mp.Pool(initializer=init_worker) (5)
loop = asyncio.get_running_loop()
loop.add_signal_handler(signal.SIGINT, partial(
handle_interrupt_signal, server=server)) (6)
worker_thread = threading.Thread(target=partial(worker, pool=mp_pool))
worker_thread.start()
async with server:
try:
await server.serve_forever()
except asyncio.exceptions.CancelledError: (7)
print('Server cancelled')
work_queue.put((-1, -1, -1)) (8)
worker_thread.join() (9)
mp_pool.close()
mp_pool.join()
print('Bye Bye!')
(1) мы определяем обработчик сигнала для прерывания.
(2) мы запрашиваем останов сервера.
(3) мы ожидаем пока сервер выполняет этот запрос.
(4) мы игнорируем сигнал прерывания чтобы убедиться что он не распространился на пул.
(5) мы убеждаемся что наш пул обработки множеством процессов инициализирован (то есть игнорирует игнорирующий сигнал пул).
(6) мы добавляем обработку сигнала в свой асинхронный процессор.
(7) мы перехватываем прекращение для информирования своего пользователя.
(8) мы отправляем -1, что нашими работниками интерпретируется как команда ухода.
(9) мы дожидаемся завершения всех потоков.
Если вы взглянете на main, вы обратите внимание что соответствующий пул создаётся здесь просто для эффективности, а теперь
каждый процесс обладает функцией инициализации с названием init_worker. Это обусловлено тем, что когда мы нажимаем
Control-C, мы не хотим чтобы наш пул прерывался, поскольку этот сигнал распространяется по всему пулу. Раз так, мы пользуемся библиотекой
signal и оповещаем каждый процесс пула (signal.SIG_IGN) игнорировать данный
сигнал прерывания (signal.SIG_SIGINT).
Мы желаем чтобы наш основной поток перехватывал бы данный сигнал прерывания и обрабатывал бы его как положено. Поскольку мы хотим обладать возможностью управлять
асинхронным кодом по получению данного сигнала, нам необходим иной способ его отлавливания: для организации цикла мы вызываем
add_signal_handler. Нам требуется передать собственно объект сервера и мы выполняем это при помощи приложения частичной
функции. Наш обработчик handle_interrupt_signal прекращает свой сервер и дожидается окончания обслуживания им, так как
такое прекращение не может быть немедленным.
Когда мы запускаем свой асинхронный сервер, нам теперь необходимо знать о прекращения, а потому мы перехватываем такие завершения. Наконец, нам необходимо
запросить очистку у потока отслеживания. Поскольку данный сигнал передаётся только в наш основной поток, нам требуется делать это при помощи некоторого механизма
взаимодействия: мы просто отправляем work с job_id равным -1.
|
| Управление ошибками и исключительными ситуациями в многопоточном и многопроцессном коде |
|---|---|
|
Отладка кода со множеством потоков и процессов может быть чрезвычайно обескураживающей даже при применении простых моделей взаимодействия между процессами.
Мы только прикоснулись к его поверхности и слегка не реалистично предположили, что наш проект ведёт себя хорошо. Когда в своём коде вы осуществляете параллельную
обработку, вам следует задуматься о надлежащем ведении регистраций в помощь обнаружению проблем. Когда имеется такая возможность, вам необходимо попытаться
убедиться что проблема не вызвана параллельностью (например, попыткой запуска некого кода задачи не в пуле или в обособленном потоке, а одном потоке единственного
процесса). К примеру, вы можете временно заменить |
Поскольку для нашего потока работника необходима очистка в явном виде, нам требуется её реализовать
def worker(pool):
while True:
job_id, code, data = work_queue.get()
if job_id == -1:
break (1)
func = types.FunctionType(code, globals(), 'mapper_and_reducer')
mapper, reducer = func()
counts = mr.map_reduce(pool, data, mapper, reducer, 100, mr.reporter)
results_queue.put((job_id, counts))
print('Worker thread terminating')
(1) если job_id равно -1, мы покидаем
данный цикл.
-
Асинхронное программирование может быть действенным подходом в эффективной обработке множества одновременных запросов когда требуется взаимодействие, а объём требуемой обработки не велик; именно это является наиболее распространённым шаблоном для веб серверов.
-
Python медленный язык программирования в том плане, что его флагманская реализация не быстрая. Это делает ещё более важной возможность одновременного запуска кода.
-
Многопоточность Python не образец в плане улучшения производительности. Его GIL (Global Interpreter Lock, глобальная блокировка интерпретатора) требует выполнения за раз только одного потока. При этом некоторые прочие реализации Python (например, IronPython) не обладают GIL и поточный код может быть одновременным.
-
Многопоточность всё ещё может быть достаточно полезной для целей проектирования архитектуры. Хотя это и не самая лучшая трасса приближения к производительности, не отказывайтесь от неё сразу. Имеются и прочие выходящие за рамки данной книги перспективы, где она всё ещё может быть актуальной.
-
При использовании Python с множеством процессов существует возможность применения всех ядер ЦПУ компьютера даже в чистом коде Python.
-
Как правило, лучше придерживаться грубой степени детализации вычислений, а слишком большой объём взаимодействий, скорее всего, замедлит ваше решение. При выполнении взаимодействия между процессами убедитесь что накладные расходы взаимодействия не выступают существенным узким местом для производительности.
-
При разработке одновременного кода старайтесь избегать совместно используемой памяти и блокировок нижнего уровня. Если вы полагаете что они вам необходимы, реализуйте некое последовательное решение на языке программирования нижнего уровня. Отладка одновременных решений со сложными шаблонами взаимодействия чрезвычайно сложное, поскольку взаимодействие в системах с одновременностью в целом не детерминировано.