Глава 4. Диски, разделы и файловые системы
Содержание
В центре внимания этой книги лежит криминалистика файловых систем - как можно восстановить информацию файловой системы при помощи надёжных методов криминалистики. Чтобы проникнуться криминалистикой файловых систем, для начала необходимо разобраться в некоторых основных понятиях файловой системы. Знание общих концепций файловой системы поможет понять, как восстанавливаются файлы и метаданные в конкретных файловых системах. Прежде чем приступить к изложению этих понятий, сначала необходимо обсудить технологии хранения.
Первоначально в этой главе речь пойдёт о носителях информации, поскольку файловая система будет располагаться именно на носителе информации. Традиционно носителями информации назывались шпиндельные жёсткие диски (а также дисководы гибких дисков). С годами появились и иные формы носителей информации. К ним относятся оптические носители (CD, DVD и Blu-ray), а в последнее время и флэш-носители, которые можно найти в большинстве современных USB-устройств. В настоящее время наилучшей технологией хранения данных для домашнего рынка являются твердотельные накопители (SSD). Несмотря на то, что твердотельные накопители часто основаны на технологии flash, они обладают гораздо большей функциональностью, включая параллельный доступ, решения для кэширования и так далее, что значительно повышает скорость работы всего решения.
Затем в этой главе основное внимание будет уделено логическим сторонам носителей информации. Между физическим носителем информации и конечным пользователем имеется несколько уровней абстракции. Пользователь рассматривает диск как набор разделов, логически смежных областей, каждая из которых представляется конечному пользователю как некая единая структура. Однако на одном физическом диске может существовать несколько разделов, или даже один раздел может занимать несколько физических дисков. Существует множество методов, применяемых для описания расположения разделов на устройстве. В ходе обсуждения дисковых разделов будут представлены две наиболее распространённые схемы разбиения: главная загрузочная запись (MBR) и таблица разделов с идентификатором GUID (GPT). Анализ этих структур, как правило, является самым первым шагом при экспертизе файловой системы. Данные структуры указывают, где на физическом устройстве расположены разделы, и, в качестве таковых, информируют аналитика о потенциальных местоположениях файловой системы.
Помимо прочего, в этой главе на концептуальном уровне описывается файловая система, а также те функциональные возможности, которые файловые системы способны предоставлять пользователям. Важно отметить, что не все файловые системы предоставляют пользователям все такие функциональные возможности, поскольку некоторые файловые системы менее сложны, чем прочие. Важно, чтобы аналитик понимал, какая потенциальная информация доступна в конкретной исследуемой файловой системе.
Последняя тема в этой главе посвящена анализу файловых систем, использующих Linux. Далее мы рассмотрим:
-
Получение данных (или снятие образа): Как именно аналитик получает доступ к данным на физическом носителе таким образом, чтобы соблюдались принципы цифровой криминалистики (раздел 1.3). В этом разделе рассматриваются некоторые разнообразные формы сбора данных, включая сбор данных на логическом и физическом уровнях (раздел 4.4).
-
Криминалистика файловой системы: Как только получен образ изучаемой файловой системы, можно приступать к задаче криминалистического анализа этой файловой системы (раздел 4.5). При этом содержимое файловой системы (файлы/ каталоги) восстанавливаются совместно с соответствующими метаданными. Для автоматизации такого процесса доступны инструменты с открытым исходным кодом, например, Sleuth Kit (раздел 4.5.1).
-
Вырезка данных: Порой содержимое файла находится в образе диска, для которого недоступны сведения о файловой системе. В такой ситуации надлежит вырезать необходимые данные. Это достигается путём поиска известных сигнатур файлов (тех же самых значений, которые применяются в команде file - раздел 2.4.2). Одним из наиболее действенных инструментов при достижении вырезки данных в Linux выступает Photorec (раздел 4.5.2).
Компьютерные механизмы хранения данных подразделяются на нисходящую иерархию с четырьмя уровнями, состоящую из первичных, вторичных, третичных и автономных решений для хранения данных. Чем ниже уровень хранилища, тем больше времени требуется для доступа к хранящейся на этом устройстве информации (задержка - latency), и тем медленнее осуществляется передача информации на устройство/с устройства (пропускная способность - bandwidth). Наилучшие показатели пропускной способности/задержки имеет первичное хранилище, в то время как у автономного хранилища они наихудшие.
Первичным хранилищем обычно называется оперативная память (ОЗУ - RAM). Такое хранилище является энергозависимым; следовательно, вся хранящаяся в ОЗУ информация, теряется при отключении питания. ОЗУ, как правило, представляет собой форму памяти на полупроводниковой основе. Первичная память - это единственный вид памяти, к которому центральный процессор (ЦПУ - CPU) может обращаться напрямую. Только оперативной памяти для запуска компьютера недостаточно. Из-за её зависимости от электропитания при выключении питания компьютера инструкции по запуску будут утрачены. Перезагрузка компьютера станет невозможной. Следовательно, оперативная память объединяется с энергонезависимой областью первичной памяти, называемой памятью доступной только для чтения (ROM, read-only memory). В этой области памяти хранится необходимая для запуска компьютера информация. Обычно применяются и две другие формы первичной памяти. Это кэш процессора и регистры процессора. Обе они также являются энергозависимыми.
Первичная память не представляет интереса с точки зрения криминалистики файловой системы. Хотя структуры файловой системы и могут храниться порой в оперативной памяти (например, метаданные файлов), файловая система целиком никогда не будет храниться в оперативной памяти. Поскольку основная часть первичной памяти является энергозависимой (за исключением ПЗУ - ROM, но, как правило ПЗУ не перепрограммируется пользователями и будет содержать только сведения о загрузке системы), она не изучается в процессе криминалистики файловой системы. Вместо этого, если выясняется, что машина работает, она анализируется при помощи криминалистики данных в реальном времени (IDF), причём одним из её результатов, как правило, является получение копии энергозависимого первичного хранилища.
Следующий уровень, с которым мы встречаемся в иерархии хранения, это вторичное хранилище. Вторичное хранилище напрямую не доступно из ЦПУ, в их взаимодействии должен участвовать некий посредник. Скорость доступа ко вторичному хранилищу намного ниже чем к первичному хранилищу. (Как правило, скорости доступа первичного хранилища измеряются в наносекундах, в то время как для вторичных хранилищ это уже миллисекунды); тем не менее, вторичное хранилище всегда энергонезависимое, что подразумевает, что вторичное хранилище оставляет нетронутыми данные даже в отсутствии электропитания. Наиболее распространёнными формами вторичного хранилища в современных вычислительных системах являются жёсткие диски (шпиндельные, hdd) и твердотельные диски (ssd). Некоторые вторичные устройства хранения являются сменными, например, CD/ DVD, флеш- накопители USB, дискеты, ленты и т.п. Такие носители рассматриваются в качестве вторичных, когда они вставлены в компьютер, но при извлечении из компьютера они становятся автономными.
Третичное хранилище встречается весьма редко. Третичное хранилище включает в себя некий роботизированный механизм, который будет монтировать и демонтировать устройства архивного хранения по мере необходимости. Устройства, о которых идёт речь, обычно являются ленточными (хотя они могут использовать и иные технологии хранения). Третичное хранилище — это форма отключённого хранилища, которое может быть автоматически повторно подключено в случае необходимости.
Последняя категория — это автономные механизмы хранения. Как и в случае с третичными устройствами хранения, они не сразу доступны компьютеру. Их отличие в том, что автономные устройства хранения для перехода во включённый режим требуют вмешательства человека. Строго говоря, USB флеш-накопитель находится в отключённом режиме. Нет способа автоматически перевести его во включённое состояние; его должен вставить человек. Как было сказано ранее, многие автономные устройства хранения, когда они вставлены в компьютер, можно считать вторичными хранилищами.
В оставшейся части этого раздела кратко представлены физические виды вторичного/ отключаемого дискового хранилища. Хотя в данной книге основное внимание и уделяется скорее механизмам хранения логического уровня (то есть файловым системам), нежели физическим устройствам, важно разбираться в физике всей задачи, поскольку определённые физические устройства создают некие дополнительные задачи для цифровой криминалистики. Раздел начинается с традиционного шпиндельного жёсткого диска, а также обсуждает и иные формы вращающихся устройств хранения на основе оптической технологии, таких как CD, DVD и Blu-ray (Раздел 4.1.1.1). Подобные шпиндельные устройств работают на схожих принципах, основное отличие состоит в том, как хранится/ считывается информация: магнитно или оптически.
Современные устройства хранения, как правило, пользуются неким видом флеш- хранилища Раздел 4.1.2. Основное ключевое отличие между традиционными шпиндельными технологиями хранения и современными устройствами на основе флеш- носителей состоит в отсутствии в последних движущихся частей. {Прим. пер.: спорное утверждение, весьма существенными являются возможности одновременности множества физических очередей доступа к таким устройствам и реализация на физическом уровне CoW - copy on write, копирования записью; последнее, кстати, характерно и для шпиндельных дисков большой ёмкости последних поколений, в которых применяется черепичный метод доступа.} Технологии флеш- хранения можно обнаружить в большинстве современных устройств хранения, таких как устройства USB (часто именуемых флеш- устройствами), SD карты и SSD. SSD в этой главе рассматриваются отдельно (Раздел 4.1.3), поскольку, хотя они зачастую пользуются в качестве лежащего в основе механизма хранения флеш - памятью, они содержат гораздо больше функциональных возможностей, причём некоторые из них для цифровой криминалистики имеют особое значение.
В цифровой криминалистике всё ещё часто встречаются традиционные HDD. Для хранения данных эти устройства физически пользуются магнитной полярностью. Рисунок 4.1 показывает жёсткий диск с удалённым кожухом. Он демонстрирует внутреннее строение жёсткого диска.
Рисунок 4.1

Обычный жёсткий диск с удалённым кожухом, что показывает внутреннее строение жёсткого диска
Пластины это та область жёсткого диска, которая хранит магнитные заряды. Стек из них монтируется на шпинделе. Эти пластины непрерывно вращаются, пока на устройство подано электропитание. Данные считываются/ записываются головкой чтения/ записи. В реальности такая головка составлена множеством головок между всеми пластинами.
Каждая пластина делится на ряд областей, носящих название дорожек (треков) и секторов. Треки это цилиндрические пути, которые находятся с обеих сторон каждой пластины. Дорожки это та область пластины, которая хранит информацию. Такую дорожку можно увидеть на Рисунке 4.2. Дорожки делятся на ряд секторов. Файловая система группирует секторы в структуры с названием кластеры, которые применяются в качестве логического элемента хранения данных. Расположенные на дорожках ближе к краю пластины секторы физически больше нежели тех, что расположены ближе к центру; на самом деле каждый из них содержит одинаковый объём информации. Плотность информации на внутренних дорожках выше чем на внешних. {Прим. пер.: на современных дисках большой ёмкости дорожки составляются множествами секторов, представляющими некое "черепичное покрытие" что может иметь особое значение для цифровой криптографии.}
Как и предполагает её название, головка Чтения/ Записи применяется для доступа к сведениям на жёстком диске. Сведения записываются по сектору за раз {Прим. пер.: опять напоминаем, что на современных дисках большой ёмкости это "не совсем так"}. Для считывания конкретного сектора головка чтения/ записи выставляется на ту дорожку, на которой можно найти этот сектор. Пластина непрерывно вращается. Головка чтения/ записи дожидается поворота пластины таким образом, чтобы точно позиционироваться на необходимый сектор. Как только это происходит, можно считать/ записать данные.
Механическая природа доступа к данным на жёстком диске означает, что это относительно медленный вид технологии. Надлежит принимать во внимание два значения промежутков времени: время позиционирования (seek) и время задержки (latency). Время позиционирования это та продолжительность, которая необходима для правильного позиционирования головки чтения/ записи по отношению к требуемой дорожке. Задержка (часто именуемая латентностью вращения) это время, которое занимает поворот необходимого сектора до головки чтения/ записи. Это одна из причин, по которой в технологии жёстких дисков очень важна скорость вращения (RPM, revolutions per minute). Чем быстрее вращаются пластины, тем ниже величина латентности, а следовательно тем быстрее в целом может выполняться доступ к данным.
Оптические носители
Оптические диски это другой вид технологии хранения данных со шпинделем. Они включают CD, DVD и Blu-ray. Традиционно они применялись для хранения в отключённом состоянии, но в последние годы заменены устройствами USB.
Все оптические диски обладают пластинами, аналогично шпиндельным жёстким дискам. В отличии от жёстких дисков они пользуются оптической технологией вместо магнитной. Данный кодируются в виде последовательности ямок (pits, не отражающих участков) и площадок (lands, отражающих элементов) на пластине. Ямки гравируются на отражающей поверхности пластины, а площадки - это плоские участки между углублениями. Переход от ямки к площадке (или наоборот) означает изменение в битах, равное 1, в то время как отсутствие изменений, вне зависимости будь то углубление или площадка, означает равное нулю значение в битах. Как правило, для запоминания данных и доступа к ним используются лазеры.
Флеш память это разновидность энергонезависимого хранения которое, вместо основанного на механических устройствах, базируется на электронных средствах хранения. Флеш память это некая разновидность EEPROM (Electronically Erasable Programmable Read-Only Memory, ПЗУ с электрическим стиранием). Традиционные EEPROM требовали стирания во всём устройстве для повторной записи информации. Это не приемлемо для жёстких дисков. Когда для изменения одного байта требуется стирания со всего жёсткого диска, это было бы не эффективным процессом. (Не говоря уж задаче по хранению всех сведений до того как они будут записаны обратно на это устройство.)
Флеш память допускает удаление с устройства данных на уровне заданного блока (или даже байта). Это означает, что обновление отдельного байта требует удаления или перезаписи отдельного блока (или байта) данных, вместо перезаписи всего диска. {Прим. пер.: что аналогично ситуации с современными дисками большой ёмкости с "черепичным покрытием".}
Широкое употребление получили два типа флеш памяти: NOR и NAND. Основное отличие основано на типе применяемой для хранения данных логической схемы. При расследованиях наиболее распространённой является флеш память на основе NAND. Она применяется в смартфонах, накопителях USB и в прочих небольших устройствах. (Она также встречается совместно с более совершенными контроллерами в SSD.) Флеш память на основе NOR, как правило, более дорогая и применяется в небольших устройствах, таких как контроллеры устройств, например в микросхемах BIOS.
Одним из ключевых преимуществ флеш памяти над традиционными технологиями хранения является то, что она является электрической системой, а не механической. Основанные на пластинах технологии, такие как шпиндельные жёсткие и оптические диски для считывания/ записи данных требуют движущихся частей. Отсутствие движущихся частей также означает, что они работают намного тише, чем традиционные механические накопители.
SSD (solid-state disk, полупроводниковый твердотельный диск) это ещё один вид энергонезависимого хранения. Как правило, они основаны на подключённой в них флэш-памяти. Твердотельные накопители работают намного быстрее традиционных жёстких дисков, поскольку в них отсутствуют движущиеся части. Это означает, что для запуска устройства не требуется много времени и что при выполнении операций позиционирования (seek, поиска) задержка очень мала. Кроме того, в дальнейшем шпиндельные жёсткие диски, как правило, ещё больше замедляют работу, поскольку всё больше файлов сильно фрагментируются. Это означает, что операции чтения/ записи занимают ещё больше времени. У твердотельных накопителей нет проблем с фрагментацией.
Сама природа хранилища SSD приводит к определённым проблемам для цифровой криминалистики. На компоненты SSD запись можно выполнять только определённое число раз прежде чем они утратят такую способность. Следовательно, когда в одну и ту же область диска запись производится слишком много раз, это приводит к износу диска. Для борьбы с этим в контроллере SSD реализована технология, носящая название выравнивания износа (wear levelling). Это обеспечивает аналогичное число перезаписей в разные области диска. Порой это приводит к тому, что контроллер перемещает информацию независимо от своей операционной системы.
Такой контроллер SSD к тому же реализует сборку мусора. Когда его операционная система помечает сведения как высвобожденные (unallocated), функция TRIM SSD удалит эти данные. Это допускает последующую запись обратно в эту область устройства, но при этом не удаляет содержимое удалённых файлов. Это подразумевает меньшую вероятность присутствия на SSD удалённых файлов, нежели это имеет место в традиционных жёстких дисках.
Твердотельные накопители также нарушают один из основных принципов цифровой криминалистики, согласно которому в вещественные доказательства не должны вноситься изменения! Как и в случае с жёсткими дисками, для получения достоверной копии твердотельного накопителя на него должно быть подано питание. Однако, как только оно подаётся, контроллером твердотельного накопителя запускаются процедуры сбора мусора. Это означает, что данные на его устройстве могут измениться. При анализе твердотельных накопителей необходимо принимать во внимание подобные проблемы.
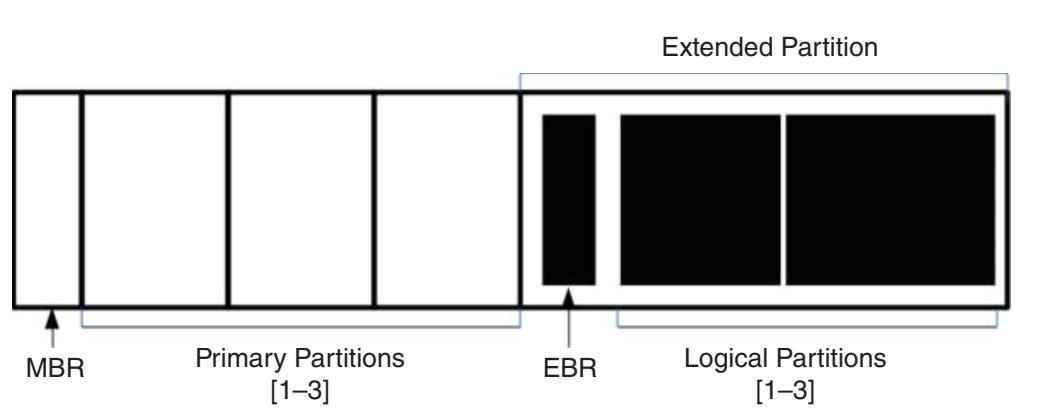
Раздел (partition? также именуемый томом - volume) это последовательность подряд идущих секторов на устройстве. Каждый раздел может обрабатываться по отдельности, даже когда все они присутствуют на одном и том же физическом устройстве. Разделы создаются перед установкой любой файловой системы. Конкретная файловая система будет создана внутри некого раздела.
Для применения разделов имеется множество причин. Прежде всего, они позволяют делить отдельный физический диск на множество логических областей, причём каждая из них способна содержать определённую файловую систему. Разделы применяются по целому ряду причин, прежде всего, современные вычислительные системы обладают множеством разделов. Как правило, системы Windows обладают первичным разделом (который монтируется по умолчанию как C:), а также разделом восстановления системы, которая содержит сведения, необходимые на случай крушения всей системы. Обычный пользователь никогда не взаимодействует с этим разделом. ОС Linux зачастую обладает множеством разделов. Именно это выполняется для отделения данных от специфичных для операционной системы областей. Такая ОС может обновляться или даже полностью заменяться без риска утраты данных. Во- вторых, некоторые пользователи обладают множеством загружаемых систем, например, имеют в одном и том же компьютере и Windows, и Linux. Каждая из этих операционных систем требует отдельного раздела. Для правильной загрузки системы Windows требуют NTFS, в то время как системам Linux необходима одна из файловых систем Linux (например, ext, BtrFS или XFS).
Для создания работающей файловой системы имеются два этапа, которые вам необходимо выполнить. Самый первый состоит в создании некого раздела,
который будет содержать соответствующую файловую систему. В Linux это можно сделать при помощи команд
fdisk и
gdisk (или же также можно воспользоваться графическими инструментами).
Второй этап состоит в создании необходимой файловой системы. Обратим ваше внимание на то, что данный процесс в два этапа происходит во всех
операционных системах. Их часто называют форматированием и инициализацией. Большинство современных операционных систем скрывают от своего
пользователя подробности данного процесса. Пользователь лишь выбирает тип файловой системы, которой необходимо отформатировать его устройство, а
уже сам инструмент изначально разбивает своё устройство (если это необходимо) и затем создаёт требующуюся файловую систему.
Остающаяся часть данного раздела покажет как в системе Linux можно разбить на разделы некое USB и создать две файловые системы. Для целей такой демонстрации будут созданы файловые системы ExFAT и ext2. Самый первый шаг после вставки USB состоит в идентификации такого вновь вставленного устройства.
Всякое устройство Linux обладает файлом в каталоге /dev/. Жёсткие
диски (как и USB) обладают идентификатором sdX, где X это a, b, c и т.д.
Самым первым (primary) жёстким диском будет /dev/sda. В системе с
единственным жёстким диском, когда вставляется USB, это скорее всего, придаст такому устройству идентификатор
/dev/sdb. Тем не менее, подобное поведение не гарантировано.
Чтобы быть уверенным в значении идентификатора, в нём необходимо убедиться вручную. Для выявления значения идентификатора существует ряд способов.
Два из них включают команды dmesg и
lsblk.
При вставке нового устройства USB такие действия регистрируются самим ядром. Доступ к ней позволяет выполнить команда
dmesg. Сразу после вставки USB выполните
dmesg и изучите несколько последних строк. Листинг 4.1 показывает вывод
dmesg после вставки устройства USB. Подчёркиванием выделены значение
идентификатора устройства и перечень его разделов. Отсюда понятно, что идентификатором данного устройства является
/dev/sdb.
Листинг 4.1. Вывод dmesg
после вставки нового устройства USB
[ 3256.841603] usb 3-1: new high-speed USB device number 6 ...
[ 3257.080876] usb 3-1: New USB device found, idVendor=058...
[ 3257.080881] usb 3-1: New USB device strings: Mfr=1, Produc...
[ 3257.080884] usb 3-1: Product: Mass Storage
[ 3257.080886] usb 3-1: Manufacturer: Generic
[ 3257.080888] usb 3-1: SerialNumber: E8B07B49
[ 3257.081721] usb-storage 3-1:1.0: USB Mass Storage device ...
[ 3257.082005] scsi host6: usb-storage 3-1:1.0
[ 3258.103720] scsi 6:0:0:0: Direct-Access Generic Flash ...
[ 3258.104410] sd 6:0:0:0: Attached scsi generic sg2 type 0
[ 3258.105270] sd 6:0:0:0: [sdb] 31129600 512-byte logica ...
[ 3258.106061] sd 6:0:0:0: [sdb] Write Protect is off
[ 3258.106066] sd 6:0:0:0: [sdb] Mode Sense: 23 00 00 00
[ 3258.106888] sd 6:0:0:0: [sdb] Write cache: disabled, rea ...
[ 3259.129337] sdb: sdb1 sdb2 sdb3 sdb4 < sdb5 sdb6 >
[ 3259.159832] sd 6:0:0:0: [sdb] Attached SCSI removable disk
Другой метод определения значения идентификатора устройства состоит в применении команды
lsblk. Она перечислит все имеющиеся в системе юлочные устройства
(то есть дисковые устройства). Он будет содержать все такие устройства в данной системе. Листинг 4.2 показывает вывод в машине команды
lsblk. В ней имеются три устройства
(/dev/sda - первичный жёсткий диск;
/dev/sdb вставленный ключ USB и
/dev/sr0 - диск DVD).
Листинг 4.2. Применение lsblk
для вывода списка всех подключённых к системе блочных устройств и, таким образом, выработки идентификатора устройства.
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 931.5G 0 disk
|-sda1 8:1 0 100M 0 part
|-sda2 8:2 0 278.5G 0 part
|-sda3 8:3 0 563M 0 part
|-sda4 8:4 0 1K 0 part
|-sda5 8:5 0 14.9G 0 part
|-sda6 8:6 0 512M 0 part /boot/efi
|-sda7 8:7 0 637G 0 part /
sdb 8:16 1 14.9G 0 disk
|-sdb1 8:17 1 1G 0 part
|-sdb2 8:18 1 1G 0 part
|-sdb3 8:19 1 1G 0 part
|-sdb4 8:20 1 1K 0 part
|-sdb5 8:21 1 1G 0 part
|-sdb6 8:22 1 1G 0 part
sr0 11:0 1 1024M 0 rom
После определения идентификатора устройства мы получаем возможность повторного разбиения этого устройства на разделы. Как это отражено в
Листингах 4.1 и 4.2, наше устройство было идентифицировано как /dev/sdb.
Именно этот идентификатор будет применяться в остающейся части данного раздела. Будьте любезны убедиться в своей системе что вы пользуетесь
верным идентификатором!
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Наши последующие шаги уничтожат в указанном устройстве все данные. Убедитесь, пожалуйста, также в том, что вы пользуетесь верным идентификатором устройство, которое вы отыскали именно в своей собственной машине. Не пользуйтесь простым копированием команд, когда у вас отличающееся от нашего устройство! |
Обычно новые устройства будут поставляться с единственным разделом в своём устройстве. Исполнение команды
sudo fdisk -l /dev/sdb перечислит все присутствующие в этом устройстве
разделы. (Для перечисления всех разделов в устройстве также можно воспользоваться командой
gdisk. Строго говоря, команда
fdisk служит для применения со схемами разбиения на разделы MBR, в то
время как gdisk предназначена для схем с разбиением GPT. Позднее в
этой главе мы поясним эти схемы.) Листинг 4.3 отображает вывод данной команды, показывающей единственный раздел.
Листинг 4.3. Вывод команды fdisk
в новом устройстве устройстве. Он отображает единственный раздел
Disk /dev/sdb: 3.96 GiB, 4226809856 bytes, 8255488 sectors
Disk model:
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x0bf1620a
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 8255487 8253440 4G 7 HPFS/NTFS/exFAT
Для создания новой схемы разбиения на разделы также применяется команда fdisk.
Запуск fdisk без параметра -l введёт нас в некую интерактивную
оболочку, которой можно пользоваться для разбиения устройства на разделы. Существует ряд представляющих интерес команд, вот они:
-
d: удалить раздел
-
p: распечатать текущую таблицу разделов
-
n: создать новый раздел
-
t: изменить тип раздела. Обратите внимание, что ввод L выдаст список всех доступных типов разделов
-
w: записать на диск новую таблицу разделов
-
q: выйти из
fdiskбез записи каких бы то ни было изменений в само устройство -
m: отобразить страницу подсказки
Путём удаления имеющегося раздела и создания двух новых разделов становится возможным создать отображаемую в Листинге 4.4 структуру.
Листинг 4.4. Вновь созданная таблица разделов показывает в нашем устройстве два раздела.
Disk /dev/sdb: 3.96 GiB, 4226809856 bytes, 8255488 sectors
Disk model:
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x0bf1620a
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 4196351 4194304 2G 7 HPFS/NTFS/exFAT
/dev/sdb2 4196352 8255487 4059136 2G 83 Linux
На данном этапе были созданы разделы, но в них не представлены никакие файловые системы. Linux по умолчанию предоставляет поддержку
множества файловых систем. Для создания файловой системы можно воспользоваться одной из команд семейства
mkfs. Листинг 4.5 отображает созданную в первом разделе
(/dev/sdb1) файловую систему ExFAT и файловую систему EXT, созданную
во втором разделе (/dev/sdb2).
Листинг 4.5. Применение семейства команд mkfs
для создания файловых систем.
$ sudo mkfs.exfat /dev/sdb1
mkexfatfs 1.3.0
Creating... done.
Flushing... done.
File system created successfully.
$ sudo mkfs.ext2 /dev/sdb2
mke2fs 1.45.5 (07-Jan-2020)
Creating filesystem with 507392 4k blocks and 126976 inodes
Filesystem UUID: 74b1ba39-5a2b-4913-8f3e-d94017345e91
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
Чтобы воспользоваться этими файловыми системами после их создания, необходимо смонтировать эти файловые системы.
Монтирование файловых систем в Linux
Linux предоставляет команду mkfs, которую можно применять для
монтирования файловой системы. Чтобы она сработала, для начала необходимо создать точку монтирования такой файловой системы. Это просто
некий каталог в текущей файловой системе. Перед выполнением этого вы можете ознакомиться со смонтированными в настоящее время файловыми
системами, воспользовавшись командой df. Вы можете удивиться тому их
числу, которое присутствует в системе Linux!
Предположим, что каталоги с названием fs1 и
fs2 были уже созданы командой монтирования двух созданных
ранее файловых систем, что отражено в Листинге 4.6. Как только файловые системы были смонтированы, становится возможным применять их для сохранения/
выборки файлов. Остаток данного раздела более подробно изучит стандартные схемы разбиения на разделы.
Листинг 4.6. Монтирование двух созданных ранее файловых систем.
Выжимка из df показывает две смонтированные файловые системы.
$ sudo mount /dev/sdb1 fs1/
FUSE exfat 1.3.0
$ sudo mount /dev/sdb2 fs2/
$ df
Filesystem 1K-blocks Used Available Use% Mounted on
...[[snip]]...
/dev/sdb1 2097152 416 2096736 1% /home/fergus/data/fs1
/dev/sdb2 1997648 2976 1893196 1% /home/fergus/data/fs2
Одним из часто встречающихся методов описания схем разбиения выступает MBR. MBR располагается в секторе 0 устройства хранения. Он содержит ряд областей. MBR содержит некий код начальной загрузки, подпись диска, таблицу разделов и подпись MBR. Код начальной загрузки занимает первые 0x1B8 (440d). За ними следуют 4d байта подписи диска. Эта подпись обязана быть уникальной для той системы, к которой он подключён. Далее следуют два байта заполнителя, вслед за которыми идут 64d байт таблицы разделов. Эта таблица разделов сама по себе составлена четырьмя записями разделов по 16d байт. Наконец, в заключительных двух байтах находится подпись MBR 0xAA55. Листинг 4.7 отображает последние 80d байт нулевого сектора в отформатированном MBR диске.
Листинг 4.7. Извлечение из примера MBR, показывающее последние 80d байт данных. Выделены альтернативные записи таблицы разделов.
001b0: 0000 0000 0000 0000 bc50 c882 0000 003c .........P.....<
001c0: 0900 8379 463c 0008 0000 0000 2000 005c ...yF<...... ..\
001d0: c533 8357 8664 0008 2000 0000 2000 0000 .3.W.d.. ... ...
001e0: 0101 833f 2000 0008 4000 0000 2000 0000 ...? ...@... ...
001f0: 0000 0000 0000 0000 0000 0000 0000 55aa ..............U.
Таблица 4.1 показывает структуру записи таблицы разделов MBR, в то время как Таблица 4.2 отображает обрабатываемые из Листинга 4.7 значения.
| Смещение | Размер | Название | Описание |
|---|---|---|---|
|
|
Загружаемый |
Значение 0x80 указывает на возможность загрузки из этого раздела; в противном случае загрузка невозможна. |
|
|
Начальный сектор (CHS) |
Адрес цилиндра, головки, сектора для самого первого сектора в данном разделе. Данная форма адресации больше не применяется. |
|
|
Тип раздела |
Идентификатор типа раздела. Некоторые из наиболее часто встречающихся идентификаторы типов разделов перечислены в Таблице 4.3. |
|
|
Конечный сектор (CHS) |
Адрес цилиндра, головки, сектора для самого последнего сектора в данном разделе. Данная форма адресации больше не применяется. |
|
|
Начальный сектор (LBA) |
Адрес логического блока для самого первого сектора в данном разделе. |
|
|
Число секторов |
Значение числа секторов в данном разделе. |
| Смещение | Размер | Название | Запись 1 | Запись 2 | Запись 3 |
|---|---|---|---|---|---|
|
|
Загружаемый |
|
|
|
|
|
Начальный сектор (CHS) |
|
|
|
|
|
Тип раздела |
|
|
|
|
|
Конечный сектор (CHS) |
|
|
|
|
|
Начальный сектор (LBA) |
|
|
|
|
|
Число секторов |
|
|
|
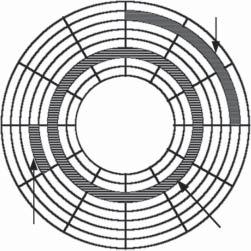
Таблица 4.3 предоставляет небольшой пример часто встречающихся типов разделов MBR. Приводимые в этой таблице значения охватывают основные файловые системы данной книги. Один из них следует отметить особо - это расширенный раздел (0x05, extended partition). Основная таблица разделов способна содержать лишь четыре раздела; тем не менее, имеется специальный тип расширенного раздела, который также может применяться. Рисунок 4.3 показывает разбитый MBR диск с пятью разделами, причём первые три раздела первичные, а один расширенный раздел содержит два логических раздела.
| Значение | Файловая система |
|---|---|
|
Расширенный раздел |
|
ExFAT/NTFS/HPFS |
|
FAT32 |
|
Файловая система Linux |
Рисунок 4.3
Диск с пятью разделами, созданный при помощи первичной MBR и расширенной записи загрузки (EBR, extended boot record).
Таблица 4.2 показывает обработанные значения таблицы разделов из Листинга 4.7. Как и ожидалось, здесь имеются перечисленными в ней три раздела. Все три раздела имеют флаг возможности загрузки установленным в 0x00, что означает, что с этих разделов невозможно загружаться. Аналогично, все три обладают типом раздела Linux (0x83). Одним из ключевых моментов при разбиении на разделы по схеме с MBR состоит в том, что они могут выполнять адресацию двумя способами. В одном случае они пользуются адресацией CHS (Цилиндр, Головка, Сектор). Данный физический адрес основывается на реальной геометрии диска (отсюда и отсылка к цилиндрам, головкам и секторам). В другом случае применяется логическая адресация. В современных вычислительных системах наиболее часто применяется именно логическая адресация (а также во всех инструментах цифровой криминалистики).
Значение местоположения раздела можно найти воспользовавшись адресом логического блока (LBA, logical block address) начального сектора данного раздела совместно со значением числа секторов в этом разделе. Во всех случаях в Таблице 4.2 соответствующие разделы занимают 2 097 152d с начальными адресами 2048d, 2099200d и 4196352d, соответственно.
Листинг 4.8 отображает вывод команды mmls при её запуске на
содержащем таблицу разделов из Листинга 4.7 диске. Сравните его с обработанными значениями из Таблицы 4.2, чтобы убедиться в верности информации.
Обратите внимание, что инструмент mmls не перечисляет значения
адресов CHS.
Листинг 4.8. Вывод из команды mmls
Sleuthkit для некого диска. Этот диск содержит значения таблицы разделов из Листинга 4.7.
$ sudo mmls /dev/sdb
[sudo] password for fergus:
DOS Partition Table
Offset Sector: 0
Units are in 512-byte sectors
Slot Start End Length Description
000: Meta 0000000000 0000000000 0000000001 Primary Table (#0)
001: ------- 0000000000 0000002047 0000002048 Unallocated
002: 000:000 0000002048 0002099199 0002097152 Linux (0x83)
003: 000:001 0002099200 0004196351 0002097152 Linux (0x83)
004: 000:002 0004196352 0006293503 0002097152 Linux (0x83)
005: ------- 0006293504 0031129599 0024836096 Unallocated
Схема MBR плохо масштабируется для современных устройств. Величина логического адреса в MBR ограничена четырьмя байтами. Поскольку всякий логический адрес это обычно сектор с 512d байтами, это эквивалентно ограничению файловой системе в размере на 2TiB. В наши дни имеются устройства, способные хранить объёмы данных намного больше 2TiB, а раз так, MBR более не достаточна. Заменяющая её структура носит название GPT и она обнаруживается в большинстве современных устройств (хотя MBR всё ещё достаточно часто встречается). При стандартном размере сектора (512d байт), когда необходимо иметь раздел с размером более 2TiB, следует пользоваться GPT.
Рисунок 4.4 отображает структуру устройства, которое было разбито на разделы при помощи схемы GPT. Самый первый сектор содержит защитную MBR. Обычно она содержит единственный раздел, который велик настолько, насколько возможно (вплоть до размера данного устройства или предела в размере раздела MBR). Такая защитная MBR предохранит более старые операционные системы, не поддерживающие GPT, от определения того, что на данном диске нет вообще никакой операционной системы и повторно инициализирует его.

Структура GPT сама по себе дублируется. Непосредственно на защитным MBR следует первичная структура GPT. Это структура из 33 секторов. Самая первая структура содержит заголовок Первичной GPT, которая предоставляет информацию о своём устройстве в целом. Её строение отражено в Таблице 4.4. За ней следуют 32d сектора, каждый из которых содержит четыре записи таблицы разделов по 128d байт. Сопоставление GPT с MBR показывает, что в ней имеется намного больше доступного пространства для хранения сведений о каждом разделе (128d байт по сравнению с 16d байт), а также что для их применения присутствует существенно больше разделов (128d в противоположность 4d). Строение каждой записи таблицы разделов GPT отражена в Таблице 4.5.
| Смещение | Размер | Название | Описание |
|---|---|---|---|
|
|
Подпись |
Подпись со значением EFI PART. |
|
|
Модификация |
Номер Модификации обычно 0x100. |
|
|
Зарезервировано |
Должны быть нули. |
|
|
Текущий LBA |
Местоположение этого сектора заголовка. |
|
|
Резервная копия LBA |
Местоположение другого сектора заголовка. |
|
|
Первый применяемый LBA |
Местоположение самого первого доступного для разделов сектора. |
|
|
Последний применяемый LBA |
Местоположение самого последнего доступного для разделов сектора. |
|
|
GUID диска |
GUID диска со смешанным порядком следования. |
|
|
LBA самой первой записи |
Местоположение самой перовой записи таблицы разделов (0x02 в первичной структуре GPT). |
|
|
Число записей |
Общее число записей таблицы разделов. |
|
|
Размер записи |
Размер записи таблицы разделов в байтах (обычно 0x80). |
|
|
CRC32 (записей) |
Контрольная сумма CRC32 значений для записей всей таблицы разделов. |
|
|
Зарезервировано |
Остаток этого сектора должен быть заполнен нулями. |
| Смещение | Размер | Название | Описание |
|---|---|---|---|
|
|
GUID типа раздела |
Представляющий тип файловой системы GUID со смешанным порядком следования. |
|
|
GUID раздела |
Уникальный GUID со смешанным порядком следования, представляющий саму эту таблицу. |
|
|
Первый LBA |
Стартовый сектор для этого раздела. |
|
|
Последний LBA |
Завершающий сектор в этом разделе. Обращаем внимание, что этот сектор включён в данный раздел. |
|
|
Атрибуты |
Атрибуты раздела. См. Таблицу 4.7. |
|
|
Имя |
36 символов UTF-16 для названия этого раздела. |
Преимущество GPT над MBR сразу становится очевидным при изучении Таблицы 4.5, которое показывает размер адресуемого пространства. Для хранения адресов GPT пользуется структурой из 8d байт. Это означает, что можно адресовать 2d64 секторов. По сравнение с этим MBR пользуется 4d байтами поля адреса (что допускает 2d32 секторов). В предположении что размер сектора по умолчанию 512d байт, это подразумевает что MBR способна применять диски размером до 241 байт (то есть 2 TiB), в то время как GPT может использовать диски с размером вплоть до 273 байт (то есть 8 ZiB).
Схема GPT также предоставляет некие сведения идентификации, которые не представлены в MBR. Они включают Globally Unique Identifier (GUID, глобально уникальный идентификатор) для маркировки своего раздела. Такой GUID (более распространённый термин для GUID UUID - Universally Unique Identifier, системы Microsoft пользуются термином GUID вместо UUID) это идентификатор из 128d бит, которые почти обеспечивают его уникальность (уникальность не гарантируется; однако вероятность того, что значение не является уникальным, настолько мала, что мы можем объявить их уникальными). UUIDs обычно отображаются при помощи формата 8-4-4-4-12, как это показано в Листинге 4.9.
Листинг 4.9. Структура UUID показывает полубайт номера версии (M) и полубайт номера варианта (N).
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
В этой структуре значение бит M представляет номер версии UUID. На момент написания этих строк существует пять допустимых версий (1 - 5). Различие версий относится к тому как вырабатывается их UUID. Она может включать текущее время и MAC адрес (Версия 1), некий идентификатор, время и MAC адрес (Версия 2), имя и идентификатор пространства имён (Версии 3 и 5), а также случайные числа (Версия 4). Значение варианта представлено 1 - 3 наиболее значимыми битами в N из Листинга 4.9. Вот все возможные значения:
-
Вариант 0 (0xxxd)
-
Вариант 0 (10xxd)
-
Вариант 0 (110xd)
Вариант 0 теперь считается устаревшим. Хотя в текстовом представлении Варианты 1 и 2 идентичны (за исключением содержимого для байта самого варианта) их хранение отличается. Вариант 1 UUID основывается на обратном порядке следования байт для всех полей, в то время как Вариант 2 UUID пользуется прямым порядком следования байт для первых трёх полей (8-4-4) и обратным порядком следования для остающихся полей (4-12).
Дополнительно к GUID раздела также существует GUID для представления типа файловой системы. Это именно та же структура что и применяемая для GUID раздела, однако допускается лишь определённое число значений. Эти значения суммируют значение типа файловой системы в соответствующем разделе. Некоторые из наиболее распространённых значений для этих GUID приводятся в Таблице 4.6. (За полным списком этих значений типов файловых систем обратитесь к странице 8).
| ОС | Тип раздела | GUID - обратный порядок следования байт |
|---|---|---|
Windows |
Зарезервировано Microsoft |
|
|
Раздел основных данных |
|
Linux |
Файловая система Linux |
|
|
Раздел подкачки (swap) |
|
MacOS |
HFS+ |
|
|
Контейнер APFS |
|
Заключительные дополнительные функциональные возможности, предоставляемые схемой разделов GPT это допустимость 64d бит для хранения атрибутов. 48d бит общие, в то время как остающиеся 16d бит могут применяться индивидуальными файловыми системами. Таблица 4.7 отражает общие значения атрибутов, в то время как Таблица 4ю8 показывает специфичные для Microsoft Basic Data Partition значения бит.
| Бит | Значение |
|---|---|
|
Требуется платформа – утилиты разбиения диска должны сохранить этот раздел. |
|
Встроенное ПО EFI обязано игнорировать этот раздел. |
|
Наследуемая загрузка BIOS. |
|
Зарезервированы. |
|
Определяются индивидуальными типами разделов. |
| Бит | Значение |
|---|---|
|
Только для чтения |
|
Дубликат (Shadow copy) |
|
Скрытый |
|
Без выделенной буквы (не монтируется автоматически) |
Технопедиа определяет файловую систему как "некий процесс, который управляет тем как и где данные сохраняются на диске, причём обычно для хранения, доступа и управления применяется жёсткий диск". Брайан Карриер утверждает что "компьютерам требуется некий метод для долговременного хранения и для выборки данных", который и достигается посредством файловой системы. Собственно файловая система это некий набор структур, который управляет тем как содержимое файла хранится в электронном носителе хранения. Они предоставляют средства, посредством коих пользователь имеет возможность организовывать данные в какой- то иерархии файлов и каталогов.
Данный раздел представляет все основные понятия, которые являются общими для множества файловых систем. Чтобы действенно анализировать файловые системы существенно разбираться в этих понятиях. Эти понятия включают:
-
Сектор: Сектор это базовый элемент диска хранения. В большинстве устройств секторы составляют в размере 512d байт, однако имеются определённые устройства, обладающие большим размером. Операции чтения/ записи обычно проводятся на уровне сектора. В плане криминалистики файловой системы значение номера сектора или LBA (Logical Block Address, Адрес логического блока) применяются для определения местоположения структур на диске.
-
Кластер/ Блок: Некий кластер (порой именуемый блоком) это коллекция секторов. Именно он выступает основным элементом хранения в файловой системе. Файлы занимают кластеры (или их части). Рассмотрим вариант, в котором файловая система в каждом кластере пользуется восемью секторами. В результате это кластер с размером 4096d байт. Файл размером в один байт будет занимать единственный кластер. Такой файл с единственным байтом будет размером в 1d байт, но под него выделяется размер в 4096d байт; иными словами, он занимает один кластер.
-
Файл: Файлы это контейнеры для хранения в компьютере/ файловой системе информации. В своей файловой системе файлы занимают некое число кластеров/ блоков. Файловые системы также содержат о каждом файле метаданные.
-
Каталог: Каталоги применяются для организации файлов/ каталогов в иерархическую структуру. Файловые системы зачастую рассматривают каталоги в качестве особенных файлов, в которых их содержимое это список файлов/ каталогов, которые содержатся в таком каталоге.
-
Метаданные: Метаданные это данные о данных. Это сведения, которые файловые системы поддерживают о каждых представленных в этой файловой системе файлах/ каталогах. Зачастую в процессе криминалистического анализа метаданные настолько же важны как и содержимое файла.
-
Механизмы хранения: В большинстве файловых систем именно метаданные делают возможным определять местоположение его содержимого. Это может достигаться рядом способов. В более старых файловых системах, таких как FAT и ext, в самой файловой системе перечислены все кластеры/ блоки. Более современные файловые системы обычно допускают хранение на основе экстентов (extent). Для них значение местоположения содержимого файла описывается структурами с названием экстентов. Такая структура содержит значение стартового кластера для содержимого своего файла совместно с числом кластеров в данном экстенте. Именно такой способ является более действенным способом хранения о множестве последовательно идущих кластерах, нежели перечисление всех кластеров. В ряде файловых систем собственно содержимое небольших файлов может храниться в самой структуре его метаданных. Это носит название внутреннего хранения (inline storage).
-
Удаление файла: При использовании стандартной операционной системы для просмотра файловой системы, удалённые файлы не появляются, тем не менее, содержимое и метаданные таких файлов зачастую всё ещё присутствуют в этой файловой системе. Многие файловые системы в действительности не удаляют файл; вместо этого они помечают его структуру метаданных как удалённую. Такая ОС не отражает эти удалённые файлы, однако инструменты криминалистики файловой системы покажут их. В конечном счёте эти удалённые файлы будут перезаписаны, поскольку все занимаемые таким файлом кластеры (и структуры метаданных) помечены как доступные и в будущем могут использоваться для чего- то ещё.
-
Фрагментация файла: Фрагментация файла происходит когда в файловой системе нет достаточно большой единой области для хранения содержимого файла целиком. Такой файл далее расщепляется на ряд частей и каждая из них хранится индивидуальною Такие части носят название фрагментов.
-
Не выделенное пространство: Не выделенное пространство это пространство в файловой системе, которое в настоящее время не используется. В карте выделения оно помечается как не выделенное (unallocated). Когда удаляется некий файл, все содержащие содержимое этого файла кластеры помечаются не выделенными в побитовой карте выделений, что означает, что они превращаются в не распределённое пространство; тем не менее, содержимое удалённого файла всё ещё присутствует. Копирование файла мз файловой системы не содержит не выделенного пространства; следовательно, чтобы обеспечить также и анализ не распределённого пространства, при цифровой криминалистике создаётся побитовый образ такого устройства.
-
Неактивное пространство: (Slack Space) Хотя именно кластер выступает базовым элементом хранения в файловой системе, файлы не обязаны занимать кластеры целиком. Рассмотрим упоминавшуюся ранее ситуацию, при которой файл в один байт занимает кластер в 4096d байт. Остающиеся 4095d байт в этом кластере это и есть неактивное пространство. Оно может содержать данные предыдущих файлов, которые занимали этот кластер ранее.
Рисунок 4.5 показывает такой пример. Рисунок 4.5(A) отражает последовательность из трёх кластеров с содержимым одного файла. Когда это файл удалён, а другой файл занимает чуть больше чем два кластера записанным на его место, мы видим, что третий кластер всё ещё содержит некие данные из своего первого файла (Рисунок 4.5(B)). Именно это и является неактивным пространством.
Рисунок 4.5
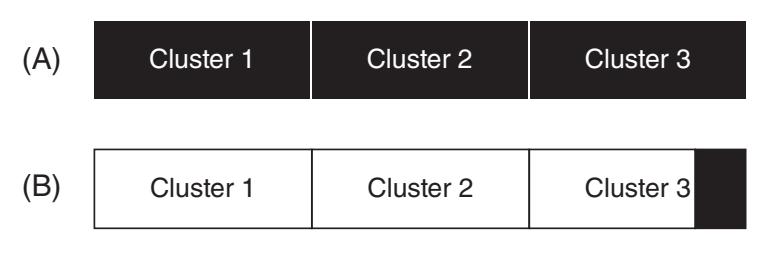
Демонстрирует не активное пространство. (A) Занимающий в файловой системе три кластера файл. (B) Эта область после того как первоначальный файл удалён а новый, более короткий, записан вместо него. Очевидно, что всё ещё присутствует часть первоначального файла.
-
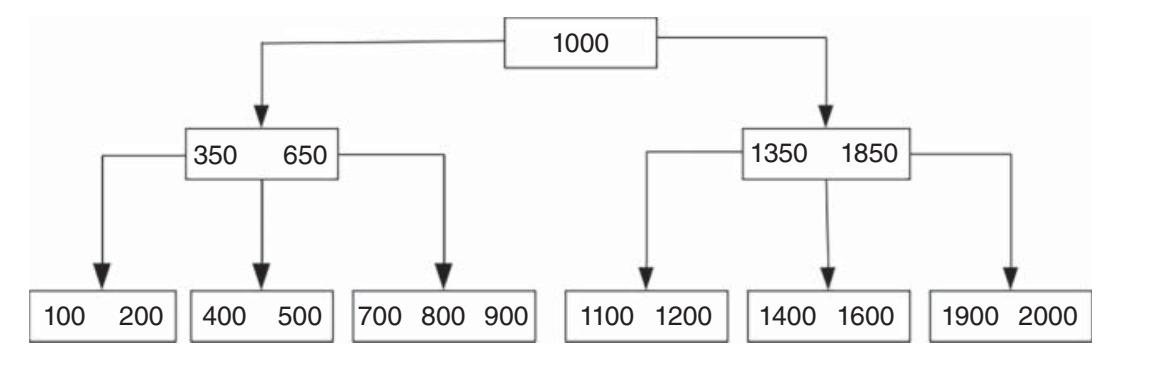
Деревья: Большинство современных файловых систем в качестве базового механизма хранения применяют Деревья. Обычно это деревья с самостоятельной балансировкой, которые допускают быстрые поиски. Деревья составляются из узлов трёх типов: Узел корня, внутренние (или индексные) узлы и узлы листьев. Существует множество типов встречающихся в файловых системах деревьев. Некоторые пользуются B- деревьями, в которых все узлы листьев пребывают на одном и том же уровне, но также данные можно отыскать только во внутренних узлах. Иные применяют B+ деревья, в которых данные находятся только в узлах листьев. Рисунок 4.6 показывает образец дерева B+ для структуры каталога. Этот каталог содержит 13d файлов, причём все они с названиями из номеров. Они появляются в узлах листьев.
Деревья это быстрые структуры для поиска по причине своей организации. Рассмотрим вариант поиска файла с названием 1200d в структуре каталога с Рисунка 4.6. Значением корневого узла является 1000d., искомое значение файла 1200d больше величины корневого узла; следовательно, искомый файл должен быть потомком справа. Правый потомок это внутренний узел. Он содержит указатели на три узла листьев, один со значением менее 1350d, один, значения которого это 1350d - 1849d и один, значения которого больше 1850d. Искомый узел, 1200d меньше 1350d и, таким образом, мы следуем по левому потомку. Это приводит нас к узлу листа в котором находится искомый файл.
-
Копирование записью: CoW (Copy-on-write) это применяемая многими современными файловыми системами политика, при которой при изменении оригинала создаётся копия ресурса. Это означает, что оригинал всё ещё присутствует в своей файловой системе. CoW применяется для обеспечения целостности в своей файловой системе, но к тому же оно предоставляет потенциал для обнаружения артефактов более ранних версий.
-
Загрузочная запись тома: Большинство файловых систем обладают структурой VBR (Volume Boot Record, порой она именуется Boot Sector, Superblock и т.п.). Данная структура предоставляет сведения о своей файловой системе в целом. Она может содержать метки (то есть имена), размеры сектора/ кластера, размер файловой системы и местоположения важных структур файловой системы.
-
Карты размещения: Файловая система отслеживает все контролируемые ею структуры. Этими структурами могут быть кластеры, структуры метаданных и т.п. Для осуществления этого большинство файловых систем пользуются картой размещения (allocation maps, также носящей название побитовыми картами). Эти структуры, как правило, для представления единичного элемента применяют единственный бит. Значение 1b по что она оказывает на то, что данная структура в данный момент применяется, в то время как значение 0b указывает она не используется.
-
Журнал: Большое число современных систем поддерживают структуру журнала. Перед фиксацией на самом диске именно журнал записывает изменения в своей файловой системе. В случае крушения файловой системы можно воспользоваться этим журналом для её быстрого восстановления.Большинство записей журнала изменяют лишь метаданные, а не реальное содержимое. С точки зрения криминалистики журналы предоставляют определённый потенциал для просмотра изменений в файловой системе со временем.
-
Моментальный снимок: Моментальный снимок это некое представление файловой системы на конкретный момент времени. Многие современные файловые системы допускают создание моментальных снимков (snapshots). Как правило, это достигается копированием записью (CoW). Такие моментальные снимки применяются в качестве механизма резервного копирования и, таким образом, показывают исследователю более старые версии изучаемой файловой системы.
-
RAID: Redundant Array of Independent (изначально Inexpensive, однако более поздние статьи предпочитают Independent) Disks - Избыточный массив независимых дисков - делает возможность сочетание множества дисков в виде единой файловой системы. Такая новая файловая система может просто применяться для создания одной единой большой файловой системы (сочетая все устройства в общем массиве) или же она может применяться для целей избыточности. Многие современные файловые системы реализуют RAID на уровне самой файловой системы. (Существуют также аппаратные решения RAID, но они не являются предметом рассмотрения данной книги. В случае аппаратного RAID файловая система, по-видимому, присутствует на традиционном диске, а всеми вопросами RAID управляет аппаратный контроллер. В файловой системе с RAID именно файловая система управляет системой RAID. И именно этому посвящена данная книга.) Существует целый ряд различных уровней RAID. Некоторые из наиболее часто встречающихся это: RAID 0, который применяется для сочетания последовательности дисков в один большой диск. Нет никакой избыточности (хотя имеется выигрыш в производительности). RAID 1 это зеркалирование в чистом виде. Данные записываются на один или более дисков, предоставляя исключительные решения для восстановления.RAID 5 делает возможность полную избыточность. В RAID 5 устройство может отказать, а его содержимое всё ещё восстанавливается с прочих дисков. RAID 5 требует по крайней мере три диска. {Прим. пер.: RAID 6 допускает выход из строя двух дисков, что особенно актуально в случае восстановления первого вышедшего из строя диска, создающего продолжительную нагрузку на остающиеся в рабочем состоянии диски, способную вызывать дополнительные отказы.}
Эти понятия присутствуют во многих файловых системах. Более простые файловые системы, такие как FAT не будут обладать многими из этих современных концепций. К примеру, файловая система FAT не поддерживает RAID, также она не имеет журнала, она не пользуется B- деревьями и тому подобным. Тем не менее, современные файловые системы, скорее всего поддерживают все (или большую часть) этих концепций.
Имеется большое число применяемых в наши дни файловых систем, от традиционных, ориентированных на диск, файловых систем, таких как FAT и EXT, до устойчивых к отказам систем, подобных BtrFS и ReFS. Также существуют распределённые файловые системы, файловые системы для устройств определённого типа и тому подобных, но лишь небольшое число таких файловых систем часто встречаются в цифровой криминалистике.
Представляющие наибольший интерес для анализа файловые системы, это те, с которыми мы сталкиваемся в основных операционных системах (Windows, MacOS и Linux – который включает Android). Основная часть встречающихся файловых систем будут традиционными файловыми системами на основе дисков, которые в общем виде поддерживаются этими основными операционными системами.
По данной причине эта книга сосредоточится на таких файловых системах Windows: FAT (имеется множество версий файловой системы FAT: FAT12; FAT16 и FAT32), ExFAT и NTFS; для Linux: Ext (существует ряд систем Ext: 2, 3 и 4), XFS и BtrFS; а также для MacOS: HFS+ и APFS. В данном разделе обсуждаются и сопоставляются основные возможности каждой из этих файловых систем.
Из Таблицы 4.9 становится ясно, что по мере движения времени, росла ёмкость файловых систем. В основном, это обусловлено ростом ёмкости жёстких дисков. Самая ранняя файловая система FAT 12 была способна обрабатывать лишь объёмы 32MiB, крошечные по современным стандартам. Самые новые файловые системы измеряют свои ёмкости в йобибайтах (280 байт).
Относительно Таблицы 4.9 имеется ряд предостережений, к примеру, величина длины имени файла для всех файловых систем FAT задаётся как 8.3. Это подразумевает выделение под имя 11 байт, 8 из которых используются под собственно имя файла, а 3 для расширения файла. Однако, большинство вариантов FAT сейчас поддерживают Длинные имена файлов, которые предоставляют до 255 символов в кодировке UTF-16. Также следует отметить, что приведённые заключения основываются на максимальных размерах кластера, на практике пределы могут оказаться меньшими.
| Файловая система | Год | Макс. размер тома | Макс. размер файла | Макс. длина имени файла | Кодировка имени файла |
|---|---|---|---|---|---|
NTFS |
1993 |
8d PiB |
8d PiB |
255d |
UTF-16 |
EXT2 |
1993 |
32d TiB |
2d TiB |
255d |
ASCII |
XFS |
1994 |
8d EiB |
8d EiB |
255d |
ASCII |
FAT 32 |
1996 |
2d TiB |
4d GB |
255d |
UCS-2 |
HFS+ |
1998 |
8d EiB |
8d EiB |
255d |
UTF-16 |
EXT3 |
2001 |
32d TiB |
2d TiB |
255d |
ASCII |
ExFAT |
2006 |
128d PiB |
128d PiB |
255d |
UTF-16 |
EXT4 |
2008 |
1d EiB |
16d TiB |
255d |
ASCII |
Btrfs |
2009 |
16d EiB |
16d EiB |
255d |
Unicode/ ASCII |
APFS |
2017 |
263 блоков В предположении размера блока по умолчанию 212байт, максимальный размер тома 32d ZiB |
8d PiB |
255d |
UTF-8 |
Одной из наиболее важных сторон при криминальном расследовании выступает время. Время может применяться для поддержки или отклонения алиби подозреваемого.Следовательно, важно понимать те значения времени, которые присутствуют в каждой из файловых систем. Таблица 4.10 отражает значения временных отметок, которые имеются в каждой из рассматриваемых файловых систем.
| Детализация | Modified | Accessed | Change | Creation | Прочее | |
|---|---|---|---|---|---|---|
NTFSa) |
10-7c |
Да |
Да |
Да |
Да |
Нет |
EXT2b) |
1c |
Да |
Да |
Да |
Нет |
Deletion |
XFS |
10-9c |
Да |
Да |
Да |
Да |
Нет |
FAT 32 |
2c |
Да |
Даc) |
Нет |
Да |
Нет |
HFS+d) |
1c |
Да |
Да |
Да |
Да |
Backup |
EXT3b) |
1c |
Да |
Да |
Да |
Нет |
Deletion |
ExFAT |
10-2c |
Да |
Да |
Нет |
Да |
Deletion |
EXT4b) |
10-9c |
Да |
Да |
Да |
Да |
Нет |
Btrfs |
10-9c |
Да |
Да |
Да |
Да |
Нет |
APFSe) |
10-9c |
Да |
Да |
Да |
Да |
Нет |
a) NTFS хранит времена, относящиеся как к содержимому файла, так и к его имени. b) суперблок ext2, 3 и 4 содержит времена последнего монтирования, последней записи и последней проверки. c) FAT32 хранит только дату доступа, но не время. d) HFS+ хранит в заголовке своего тома временные метки создания, изменения, резервного копирования и проверки своей файловой системы. e) APFS хранит в суперблоке своего тома времена последнего изменения и последнего размонтирования. |
||||||
Что касается временных меток, то тенденции также очевидны. Современные файловые системы записывают временные метки с гораздо большей степенью детализации. Как правило, она происходит на уровне наносекунд. Старые файловые системы, предназначенные для более древних и медленных компьютеров, не требовали такого уровня точности.
Прежде чем мы сможем приступить к криминалистическому анализу файловой системы, требуется образ диска. Несмотря на физическую возможность запуска всех инструментов анализа файловой системы на реальном диске, любое непреднамеренное изменение содержимого может привести к аннулированию всех результатов. Следовательно, мы получаем образ устройства. В данном разделе описаны типы образов. Далее в разделе проводится различие между логическим и физическим получением данных. Позднее в этом разделе описывается, как можно настроить рабочую станцию Linux для получения данных, гарантируя, что файловые системы не будут автоматически подключены перед выполнением сбора данных. Наконец, представлены некоторые доступные для выполнения сбора данных инструменты Linux.
Получение данных может выполняться либо на логическом, либо на физическом уровне. При физическом получении захватывается каждый бит самого устройства. Это включает в себя не только используемые файлы, но также и свободное пространство, удалённые файлы, не распределённое пространство и тому подобное. Именно этот тип сбора данных является предпочтительным методом получения данных во всех случаях, ибо при этом не утрачиваются потенциальные доказательства. Однако получение данных на физическом уровне возможно не всегда. ПАорой нет иного выбора, кроме как выполнить сбор данных на логическом уровне.
При получении данных на логическом уровне извлекаются используемые файлы, другими словами, именно те, к которым обращаются при помощи структур метаданных и которые не помечены как удалённые. На некоторых типах устройств (например, в некоторых смартфонах) это единственная возможная форма получения данных. При получении данных из LDF {файла журнала} это также может быть единственной возможной формой получения. Рассмотрим сценарий, при котором работающий компьютер содержит открытый зашифрованный контейнер. Если компьютер выключается для получения устройства на физическом уровне, тогда такая зашифрованная информация будет потеряна, если только у вас нет ключа. Следовательно, на месте происшествия будет произведён сбор данных на логическом уровне с копированием всех файлов из зашифрованного контейнера. Это, естественно, приведёт к получению только имеющихся файлов. Поскольку данная книга посвящена анализу файловой системы, необходимо применять физический сбор данных. Логическое получение сведений не привело бы к сбору структур файловой системы. Следовательно, в оставшейся части этого раздела предполагается, что читателя интересует только получение на физическом уровне.
Многие читатели, возможно, уже обладают доступом к рабочей станции криминалиста, которая применяется для получения образов дисков. Для тех же, у кого нет рабочей станции, данный раздел предоставит краткий обзор всех шагов по настройке рабочей станции с применением Linux.
Основным ключевым моментом при получении данных является соблюдение самого первого принципа ACPO, а именно, что выполняемые расследователем действия не могут изменять лежащие в основе сведения. Рассмотрим вставку ключа USB в стандартный компьютер. Такой компьютер постарается помочь и смонтирует данное устройство с отображением его содержимого. Такой процесс способен (а зачастую и поступает так) изменять собственно содержимое вставляемого устройства. Теперь представим себе, что такое устройство USB было фрагментом потенциального доказательства. Наше простое действие его вставки в свою рабочую станцию потенциально изменяет его содержимое.
Для борьбы с этим рекомендуется применять блокиратор операций записи. Как правило, это аппаратные устройства, которые останавливают отправку любых сигналов записи на устройство. Если такой аппаратный блокиратор записи не доступен, в Linux имеется возможность отключения автоматического монтирования. В Linux Mint это достигается через приложение диспетчера файлов. (Такой метод запрета автоматического монтирования может быть различным в разных дистрибутивах и даже в различных версиях Linux Mint. Прежде чем вставлять какие бы то ни было материалы доказательств в рабочую станцию очень важно провести тестирование, дабы убедиться в успешном отключении автоматического монтирования.) В диспетчере файлов Nemo выберите Edit | Preferences. В закладке поведения отыщите обработку носителя и убедитесь что все галочки во всех блоках сняты. Это отражено на Рисунке 4.7.
Рисунок 4.7

Предпочтения обработки носителя в диспетчере файлов nemo при запрете автоматического монтирования.
Для получения образа физического устройства необходимо установить идентификатор этого устройства. Это может быть выполнено аналогично тому, как это показано в Разделе 4.2 либо применяя, dmesg, либо lsblk.
Семейство dd
dd это утилита командной строки Linux позволяет создавать некий файл образа. После того как в вашу рабочую станцию было вставлено исследуемое устройство и был выявлен идентификатор имеется простой процесс создания образа устройства при помощи команды dd. Например, Листинги 4.1 и 4.2 отражают идентификатор устройства /dev/sdb. Команда sudo dd if=/dev/sdb of=device.dd получит входным файлом /dev/sdb и создаст образ в локальном файле device.dd. Команда dd может также применяться для создания образа раздела, как это показано в Листинге 4.10, в котором создаётся образ /dev/sdb1.
Листинг 4.10. Создание образа раздела (/dev/sdb1) при помощи dd.
$ sudo dd if=/dev/sdb1 of=partition1.dd
2097152+0 records in
2097152+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 64.4124 s, 16.7 MB/s
$
Как следует из Листинга 4.10, существует несоответствие между числом записей и количеством байт. При выполнении простого вычисления каждая запись должна состоять из 512d байт. Именно это значение выступает размером блока по умолчанию, с которым работает dd. Значение размера блока команды dd можно изменить при помощи bs=. Обычно увеличение размера блока достигает того же самого результата, что и в Листинге 4.10, однако в результате имеет меньшее число операций чтения/ записи, а следовательно более быструю выборку данных.
Дополнительно к размеру блока можно определять значение начальной позиции и число байт для выделения. Представим себе, что аналитик желает выделить запись MBR из /dev/sdb. MBR занимает самый первый сектор в соответствующем устройстве. Следовательно, размер блока должен быть установлен в 512d байт (чтобы соответствовать размеру сектора), выделение должно начаться с самого начала устройства (запись MBR появляется в самом начале каждого устройства) и для выборки следует взять единственный сектор. В этом случае значения и размера блока, и стартового пункта будут установленными по умолчанию (принимаются 512d и 0d, соответственно); однако, следует определить значение числа блоков для выделения. Листинг 4.11 показывает как этого достичь.
Листинг 4.11. Выделение записи MBR при помощи параметра count= для dd.
$ sudo dd if=/dev/sdb of=mbr.dd count=1
1+0 records in
1+0 records out
512 bytes copied, 0.0017935 s, 285 kB/s
$
В листинге 4.11 выбирается только один блок. Это достигается через параметр count= count=1 означает что выделяется только один блок. Что если нам потребовалась таблица разделов? Эта таблица начинается в байте со смещением 446d и имеет в размере 64d байт. В данном случае невозможно применить блок с размером 512d байт (он слишком велик для необходимого объёма сведений). Вместо этого размер блока устанавливается в 1d байт, а количество в 64d байт (поскольку мы желаем выделить 64d байт), и, наконец, параметру с названием пропуск даётся значение 446d. Это начнёт вашу выборку с байта по смещению 446d, считывая 64d блоков из единственного байта. Это отражено в Листинге 4.12.
Листинг 4.12. Выделение таблицы разделов при помощи bs=., skip=. и count= для определения в точности нужных нам данных.
$ sudo dd if=/dev/sdb of=pt.dd bs=1 count=64 skip=446
64+0 records in
64+0 records out
64 bytes copied, 0.00377727 s, 16.9 kB/s
$
Несмотря на то, что инструмент dd и позволяет получать криминалистические данные, он не является криминалистическим инструментом. Например, он не позволяет проверять полученные данные. Как правило, аналитику необходимо создать образ устройства, а затем вычислить хэш для самого устройства и его образа чтобы убедиться, что процесс создания образа работает верно. Этот процесс отражён в Листинге 4.13.
Листинг 4.13. Проверка процесса выборки dd..
$ sudo dd if=/dev/sdb1 of=partition1.dd bs=4096
262144+0 records in
262144+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 62.4354 s, 17.2 MB/s
$ sudo md5sum /dev/sdb1
7ec0ec57cb850548b7fe93e0ee13cdf1 /dev/sdb1
$ md5sum partition1.dd
7ec0ec57cb850548b7fe93e0ee13cdf1 partition1.dd
$
Имеются два распространённых варианта dd, которые применяются в криминалистике. Оба основываются на первоначальном dd, а раз так, поддерживают большинство параметров, которые мы исследовали ранее. А именно, это dc3dd и dcfldd. Оба допускают хэширование, ведение журнала, а также расщепление образов и тому подобное. Оба этих инструмента могут быть установлены из стандартных репозиториев.
EWF
Базовая команда dd создаёт образ сырых данных, побитовую копию поданного на вход устройства. Следовательно, когда снимается образ жёсткого диска в 1 TiB, получаемый в результате файл тоже будет иметь размер 1TiB. Это может быстро приводить к проблемам хранения. Expert Witness Format (EWF, формат свидетеля- эксперта) это формат образа, применяемый в таких инструментах как EnCase и он доступен для всех основных операционных систем. В Linux Mint его можно установить, воспользовавшись sudo apt install ewf-tools. Этот пакет предоставляет ряд команд, относящихся к формату EWF, включая:
-
ewfacquire: Данная команда применяется для создания образа устройства и создаёт образ EWF.
-
ewfinfo: Формат EWF хранит сведения о файле образа в самом файле образа. Эта команда применяется для просмотра таких сведений.
-
ewfverify: Формат EWF хранит сведения о значениях хэша первоначальных данных и самого образа. Данная команда может быть исполнена для проверки того, что содержимое файла образа всё ещё не нарушено.
-
ewfexport: Эта команда применяется для преобразования формата EWF в иной формат (например, в сырые данные).
-
ewfmount: Используется для монтирования образа EWF. Такой процесс монтирования создаёт в памяти образ сырых данных, который затем монтируется как обычно.
Все приведённые выше команды в целом поясняют себя сами. Например, когда создаётся образ устройства при помощи ewfacquire, пользователю будет задан ряд вопросов, относящихся к данному случаю и создаваемому образу. Как правило, применимы значения по умолчанию (для снижения размера файла образа пользователь может пожелать определить наилучшее сжатие).
Одна команда потребует слегка больших пояснений и это ewfmount. Все поддерживаемые с вебсайта данной книги файлы представлены в формате EWF. Для просмотра шестнадцатеричных значений таких сырых данных имеются два варианта. Необходимый для просмотра образ можно экспортировать в формат сырых данных при помощи ewfexport или же его можно смонтировать, что создаст формат сырых данных в памяти. Листинг 4.14 отображает команду для монтирования файла образа с именем FAT32_V1.E01 в каталоге с названием mnt.
Листинг 4.14. Применение ewfmount для монтирования образа EWF.
$ ewfmount FAT32_V1.E01 mnt/
ewfmount 20140807
$ ls mnt/
ewf1
После монтирования файла образа содержимое каталога точки монтирования будет включать собственно файл ewf1. Именно он является образом сырых данных, которые впоследствии и анализируются.
guymager
guymager это графический инструмент образов дисков, который способен поддерживать множество форматов. В Linux Mint его можно установить, воспользовавшись sudo apt install guymager. Данный инструмент можно запустить из командной строки при помощи sudo guymager. Доступ с правами root необходим, ибо данный инструмент для получения образа служит доступу к к физическим дискам. Рисунок 4.8 демонстрирует снимок экрана для приложения guymager.
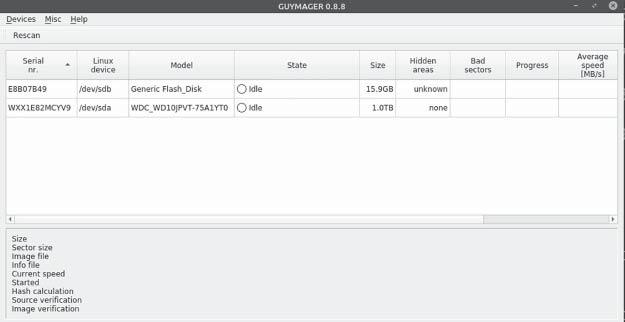
Кликнув правой кнопкой по любому из устройств в guymager вы получите доступ к выбранному устройству для получения образа либо в сыром виде (аналогично dd) или в формате EWF (как и для ewfacquire). К тому же guymager также создаёт документацию для формата EWF. Графический интерфейс допускает для пользователя вводить такие сведения, как номер дела и номер вещественного доказательства.
Криминалистика файловой системы обычно содержит пять этапов, и это:
-
Определение схемы разбиения на разделы;
-
определение типа файловой системы;
-
список файлов в файловой системе;
-
восстановление файла метаданных; и
-
восстановление содержимого файла.
Все инструменты цифровой криминалистики выполняют эти действия. В большинстве коммерческих средств элемент доказательства (как правило, образ диска) загружается в саму систему и начинается процесс. Очень быстро аналитик увидит различные представленные в образе разделы, а также типы файловых систем, которые содержатся внутри этих разделов.
Следующий выполняемый этими инструментами этап предоставляет перечень всех файлов (а также связанных с ними структур каталогов), которые представлены в данных файловых системах. Такие средства криминалистики файловой системы предоставляют не только имеющиеся файлы, иными словами, те, которые вы могли бы наблюдать, если бы данная файловая система была смонтирована, они также, где это возможно, предоставляют удалённые файлы.
После того как инструмент цифровой криминалистики перечисли всё содержимое файловой системы, он начинает обработку каждого файла (порой соответствующий инструмент будет делать это только по запросу своего клиента в явном виде). Это выдаст все метаданные для определённого файла, а также собственно содержимое файла.
Приведённый метод применяется всеми средствами криминалистики файловой системы в процессе их выполнения. В следующем разделе представляется Sleuth Kit, набор инструментов командной строки, который способен выполнять приведённые выше задачи. По мере анализа индивидуальные файловых систем в оставшейся части данной книги, будет показано вручную как средства криминалистики выполняют перечисленные ранее пять задач.
The Sleuth Kit (TSK) предоставляет набор утилит командной строки для выполнения всех необходимых этапов цифрового криминалистического анализа. Кроме того, Sleuth Kit предоставляет прочие вспомогательные (helper) команды. Данный раздел представляет основные команды Sleuth Kit. Sleuth Kit был создан Брайаном Карриером и превратился в один из наиболее широко применяемых в академической отрасли набора средств криминалистического анализа файловых систем. Для этого имеется целый ряд причин. Первая и наиболее важная в том, что это программное обеспечение бесплатное! Нет никаких стоимостей лицензий, относящихся к Sleuth Kit. С точки зрения обучения применение командной строки лучше нежели использование коммерческих, графических инструментов. Работа на более низком уровне командной строки позволит исследователям лучше разобраться в индивидуальных этапах, предпринимаемых коммерческими криминалистическими инструментами. Тем самым, Sleuth Kit является отличным введением в те методы, которые используются всеми коммерческими средствами.
Остающаяся часть данного раздела демонстрирует использование Sleuth Kit применительно к одной из доступных с вебсайта книги файловых систем. В данном случае используется файл FAT32_V2.E01 .
Поскольку это файл образа EWF, прежде чем его анализировать, данный файл следует смонтировать. В предположении, что в нашем текущем каталоге имеется каталог с названием mnt, это достигается с применением команды из Листинга 4.15.
Листинг 4.15. Применение ewfmount для монтирования образа E01. Получаемый в результате файл mnt/ewf1 это образ сырых данных.
$ ewfmount FAT32_V2.E01 mnt/
ewfmount 20140807
$ ls mnt/
ewf1
Определение компоновки раздела
Для показа имеющейся схемы разбиения на разделы в устройстве ранее была представлена команда Sleuth Kit mmls. Хотя в инструментарии Linux имеется ряд таких средств как fdisk и gdisk, которыми можно воспользоваться для отражения имеющейся файловой системы, mmls специально разработан для применения в криминалистике файловой системы. Это означает, что в отличии от средств ОС, наша команда mmls не только отразит действующие разделы, но также снабдит нас сведениями о не распределённом пространстве, которое присутствует в данном устройстве. Листинг 4.8 отображает вывод из команды mmls. Обратите внимание, что mmls не работает с образом диска, содержащемся в FAT32_V2.E01, поскольку это образ раздела, а не реальный диск. Это означает, что данный образ не содержит никакой таблицы разделов. Если читатель пожелает увидеть mmls в действии, он может запустить её на локальном жёстком диске, воспользовавшись sudo mmls /dev/sda.
Определение типа файловой системы
Средство fsstat Sleuth Kit считывает содержимое соответствующего раздела и
проверяет следует ли его формат любой из известных файловых систем. Поскольку fsstat
(и многие прочие средства Sleuth Kit) работают с файловой системой, многие из таких инструментов нуждаются в неком смещении от начала своего
раздела, который следует определить при помощи параметра -O. В случае с
FAT32_V2.E01 в этом нет нужды, ибо это образ только раздела. Листинг 4.16
отображает вывод fsstat для
FAT32_V2.E01.
Листинг 4.16. Применение fsstat для определения типа файловой системы mnt/ewf1 (вывод усечён).
$ fsstat mnt/ewf1
FILE SYSTEM INFORMATION
--------------------------------------------
File System Type: FAT32
OEM Name: mkfs.fat
Volume ID: 0x2232cfe0
Volume Label (Boot Sector): FAT_FS
Volume Label (Root Directory): FAT_FS
File System Type Label: FAT32
...[snip]...
Как можно заметить, это файловая система FAT32. Если вы продолжите просматривать вывод команды fsstat, вы обнаружите, что об этой файловой системе предоставлено намного больше сведений. Они включают схему различных структур (то есть, Загрузочный сектор - Boot Sector, FAT1 и FAT2, Область данных - Data Area, а также Корневой каталог - Root Directory), сведения об устройстве (размер сектора/ кластера и т.п.) и к тому же, когда присутствуют файлы, число секторов/ кластеров, занимаемое файлами. Весь смысл данного вывода станет понятнее в Главе 5.
Список файлов
Основной командой для перечисления файлов в файловой системе выступает fls. Точно так же как fsstat это средство файловой системы, fls также инструмент файловой системы, а раз так, ему надлежит предоставить смещение, по которому начинается его раздел. Команда для перечисления всех файлов из файла FAT32_V2.E01 представлена в Листинге 4.17. Запомните, что это конкретный случай, при котором нет нужды во предоставлении смещения.
Листинг 4.17. Базовый перечень файлов, получаемый при помощи fls.
$ fls mnt/ewf1
r/r 3: FAT_FS (Volume Label Entry)
d/d 5: Files
r/r 7: info.txt
r/r 9: cliffs.jpg
r/r 12: thelongbridge.jpg
v/v 16743939: $MBR
v/v 16743940: $FAT1
v/v 16743941: $FAT2
V/V 16743942: $OrphanFiles
Средства Sleuth Kit отличаются от обычных инструментов файловой системы в том, что они не только перечисляют имеющиеся файлы, но также приводят список доступных удалённых файлов, и даже перечень всех структур файловой системы. Самые последние четыре элемента в приводимом в Листинге 4.17 выводе являются структурами файловой системы: $MBR, $FAT1 и $FAT2. Каталог $OrphanFiles это место, используемое Sleuth Kit для списка удалённых файлов в этой файловой системе, для которых не могут быть обнаружен родительский каталог. Такие файлы не могут быть размещены в имеющейся иерархии файловой системы, поэтому вместо этого они помещены в данном каталоге.
По умолчанию команда fls перечисляет только файлы из корневого каталога. Для вывода списка всех файлов данная команда должна быть исполнена рекурсивно. Это достигается при помощи -r, действие которого показано в Листинге 4.18.
Листинг 4.18. Применение fls для рекурсивного перечисления всего содержимого из FAT32_V2.E01.
$ fls -r mnt/ewf1
r/r 3: FAT_FS (Volume Label Entry)
d/d 5: Files
+ r/r * 134: delete.txt
r/r 7: info.txt
r/r 9: cliffs.jpg
r/r 12: thelongbridge.jpg
v/v 16743939: $MBR
v/v 16743940: $FAT1
v/v 16743941: $FAT2
V/V 16743942: $OrphanFiles
Изучим подчёркнутые элементы из Листинга 4.18. Files представляет собой каталог (обозначенный как d/d), в то время как delete.txt представляет файл (с обозначением r/r). Элемент delete.txt расположен внутри каталога Files (что обозначено символом +). Файл delete.txt к тому же удалён (показано через *). Каждый из этих элементов обладает связанным с ним уникальным идентификационным номером (для Files это 5, а для delete.txt 134). Теперь эти номера определяются в запросе как зависящие от самой файловой системы.
По умолчанию, когда запускается Sleuth Kit, он перечисляет всё содержимое имеющегося корневого каталога. Тем не менее, при запуске команды следующим образом: fls mnt/ewf1 5, будет приведён список каталога Files. Имеется большое число дополнительных параметров для fls, которые рассматриваются на страницах man.
Восстановление метаданных файла
Метаданные можно восстанавливать при помощи команды Sleuth Kit istat. Такая команда istat нуждается для запроса в значении смещения своей файловой системы, а также адреса метаданных исследуемого элемента. Форма вывода istat зависит от конкретной файловой системы в запросе.
Листинг 4.19 отражает команду istat, необходимую для просмотра метаданных файла delete.txt из FAT32_V2.E01. Для целей представления вывод был усечён.
Листинг 4.19. Вывод команды Sleuthkit istat при исполнении для метаданных с адресом 134 (delete.txt) из FAT32_V2.E01.
$ istat mnt/ewf1 134
Directory Entry: 134
Not Allocated
File Attributes: File, Archive
Size: 44
Name: _ELETE.TXT
Directory Entry Times:
Written: 2023-10-27 11:45:16 (IST)
Accessed: 2023-10-27 00:00:00 (IST)
Created: 2023-10-27 11:45:16 (IST)
Sectors:
2608 0 0 0 0 0 0 0
Восстановление содержимого файла
Окончательной требующейся нам задачей выступает восстановление содержимого файла. Для достижения этого Sleuth Kit предоставляет команду icat. Её синтаксис идентичен istat, определяется смещение (если оно требуется), совместно с адресом метаданных. Листинг 4.20 показывает восстановление файла delete.txt. Отметим, что получаемый вывод перенаправляется в локальный файл.
Листинг 4.20. Применение icat для восстановления содержимого delete.txt (с алремом метаданных 134) из FAT32_V2.E01.
$ icat mnt/ewf1 134 > delete.txt
$ file delete.txt
delete.txt: ASCII text
$ cat delete.txt
This file will be deleted in FAT32_V2.E01.
Прочие команды TSK
Sleuth Kit предоставляет и прочие полезные команды для криминалистики файловой системы. Они включают в свой состав способность выработки временных линий, выделения не распределённого пространства и автоматизацию ряда задач восстановления.
Временные линии порой жизненно важны для криминалистики файловой системы. Sleuth Kit предоставляет команду mactime, применяемую для создания временной линии, которую уже можно представлять в любом приложении электронной таблицы. это достигается путём применения fls -m ’/’ mnt/ewf1 | mactime -b - -d > timeline.csv. Параметр -m для fls принуждает Sleuth Kit создавать файл тела, причём всякое имя файла каталога предваряются /. Он затем считывается командой mactime с применением -b для определения того, что файл тела надлежит получать через STDIN (-). Использование -d вызывает mactime производить вывод в формате, при котором данные могут применяться непосредственно в некой электронной таблице, тем самым улучшая потенциал анализа.
Команда blkls применяется для выделения всех секторов образа, которые не были выделены. Эти секторы не являются никакой структурой файловой системы; тем не менее, они способны содержать старые файлы/ структуры метаданных, которые могут представлять интерес.
Наконец, Sleuth Kit предоставляет команду для автоматизации восстановления файла. Применение команды icat для всех файлов может быть крайне не эффективным. TSK предоставляет команду tsk_recover, которая, по умолчанию, восстановит все удалённые файлы в изучаемой файловой системе. Листинг 4.21 отражает эту команду, применяемую в первом случае для восстановления удалённых файлов (и для сохранения их в каталоге с названием recovered), а второй раз с использованием параметра -e для восстановления всех файлов.
Листинг 4.21. Применение tsk_recover для восстановления удалённых файлов и всех файлов.
$ tsk_recover mnt/ewf1 recovered/
Files Recovered: 1
$
$ tsk_recover -e mnt/ewf1 recovered/
Files Recovered: 4
На протяжении всей остающейся части книги TSK будет применяться для подтверждения результатов анализа вручную для тех файловых систем, которые поддерживаются этим средством. Sleuth Kit в настоящее время поддерживает FAT (Глава 5), ExFAT (Глава 6), NTFS (Глава 7), EXT (Глава 8 и Глава 9), а также HFS+ (Глава 12). Sleuth Kit версии 4.11 (текущая версия на момент написания книги) не поддерживает прочие файловые системы из данной книги. {Прим. пер.: на момент перевода выпущены версии 4.12, 4.13, 4.14, в частности, с экспериментальной поддержкой XFS и BtrFS в 4.13 и с обещанием её реализации в 5-й версии с мультипоточностью.}.
Криминалистика файловой системы это самое действенно средство восстановления данных на электронных устройствах хранения. Основная причина этого кроется в том, что она восстанавливает как содержимое файлов, так и их метаданные. Тем не менее, в определённых ситуациях необходимые метаданные файла были перекрыты новой записью, а реальное содержимое всё ещё присутствует в устройстве. Утрата метаданных означает, что содержимое такого файла больше не может быть определено при помощи средств криминалистики файловой системы. Тем не менее, всё ещё может работать технология с названием вырезание данных (data carving, процесс повторной сборки файла из фрагментов в отсутствии метаданных).
Вырезание пользуется собственно структурой определённых файлов, выполняя поиск по всему диску на предмет конкретных отличительных признаков каждого типа файлов. Рассмотрим файл JPEG, самые первые и самые последние байты которого показаны в Листинге 4.22.
Листинг 4.22. Представление сырых данных в шестнадцатеричном виде файла JPEG, отражающее начальную и конечную подписи этого файла.
[[First Line]]
00000: ffd8 ffe0 0010 4a46 4946 0001 0100 0001 ......JFIF......
[[Final Line]]
09e40: 47b7 6163 ffd9 G.ac..
Значение подписи файлов JPEG состоит из двух полей. Всякий JPEG начинается с шестнадцатеричных значений 0xFFD8 и завершается шестнадцатеричными значениями 0xFFD9 (в действительности эта подпись более сложная, последующие байты обозначают значение применяемой версии JPEG в точности, тем не менее все подписи JPEG начинаются с 0xFFD8). Алгоритмы вырезания данных работают посредством сканирования всего диска в поиске такой стартовой подписи. После того как подобная 0xFFD8 подпись найдена, система вырезания будет проводить чтение с этой точки пока не встретит значение 0xFFD9, потенциально обозначающее конец содержимого искомого файла.
Вырезание данных не является целиком надёжной технологией, поскольку она в результате получает определённое число ложноположительных сведений. К примеру, есть вероятность того, что определены шестнадцатеричные значения 0xFFD8, которые не начинают допустимый файл JPEG, а просто являются случайными данными.
Вместо поиска начальных подписей во всех отдельных байтах на диске, как правило, алгоритмы вырезания обращают внимание на границы секторов. Все файловые системы в качестве основных единиц хранения применяют кластер (или блок). Начало файла всегда появляется в самом начале кластера. Хотя может оказаться невозможным определить размер кластера на том устройстве, на котором выполняется преобразование, во всех файловых системах кластеры формируются из нескольких секторов. Следовательно, предпочтительным методом обычно является проверка границ каждого сектора на наличие подписей. Это значительно повышает действенность алгоритмов вырезания и ограничивает количество ложных срабатываний.
Часть средств вырезания будут принимать во внимание определённые знания о файловой системе. Например, файловые системы семейства с экстентами далее разбиты на группы блоков, каждая из которых действует как мини-файловая система (Глава 8). Некоторые инструменты вырезания (например, photorec) могут применять подобное структурирование, а раз так, будут пытаться определить, может ли лежащая в основе файловая система обладать экстентами.
Распространённые средства вырезания с открытым исходным кодом включают в свой состав photorec, scalpel и foremost. Все они могут быть установлены из стандартных репозиториев Linux (обратим внимание на то, что photorec является частью пакета testdisk в системах Linux). Как правило, комплексы цифровой криминалистики обладают возможностью выполнения вырезания данных.
Эта глава изучила некоторые основополагающие понятия, которые необходимы для криминалистики файловых систем. Для обработки файловой системы необходимо знать как данные упорядочены на диске. Эта организация осуществляется как на физическом, так и на логическом уровнях. Физически сведения могут храниться при помощи магнитных зарядов, поверхностных выемок или электрических зарядов. Доступ к информации может осуществляться посредством магнитных или оптических считывателей с вовлечением в процесс вращающихся пластин или электрическим образом в случае современных устройств хранения.
Тем не менее, для криминалистики файловой системы более важна организация на логическом уровне. Она включает структуры разбиения диска на разделы, а также саму по себе файловую систему. Это руководит тем как именно сведения размещены на диске и устанавливает соответствие логических и физических адресов, что делает возможным для средств криминалистики восстанавливать сведения.
Последующие разделы данной книги более подробно изучат реальные файловые системы. Оставшаяся часть книги поделена на три основные части, покрывающих файловые системы Windows, Linux и Apple.
-
И mmls, и fdisk/ gdisk отображают содержимое таблицы разделов. Как по вашему, что из них является наилучшим средством для цифровой криминалистики? Обоснуйте своё мнение.
-
Какие проблемы повлечёт за собой более широкое применение твердотельных накопителей (SSD) для цифровой криминалистики?
-
Физическое выявление данных считается наилучшей практикой в цифровой криминалистике. В каких ситуациях можно было бы рассматривать возможности логического обнаружения?
A digital forensics approach for lost secondary partition analysis using master boot record structured hard disk drives. Akbal, E., Yakut, Ö.F., Dogan, S. et al. (2021). Sakarya University Journal of Computer and Information Sciences 4 (3): 326–346.
Analyzing master boot record for forensic investigations. Al, S.G. (2016). International Journal of Applied Information Systems 10: 22–26.
A survey on data carving in digital forensic. Alherbawi, N., Shukur, Z., and Sulaiman, R. (2016). Asian Journal of Information Technology 15 (24): 5137–5144.
Operating Systems: Three Easy Pieces. Arpaci-Dusseau, R.H. (2018). Scott’s Valley, CA: Createspace.
File System Forensic Analysis. Carrier, B. (2005). Boston, MA; London: Addison-Wesley.
Next4: Snapshots in Ext4 File System. Dani, A., Mangade, S., Nimbalkar, P., and Shirwadkar, H. (2024). arXiv preprint arXiv:2403.06790.
RFC 9562: Universally Unique IDentifiers (UUIDs). Davis, K., Peabody, B., and Leach, P. (2024).
Forensic signature for tracking storage devices: analysis of UEFI firmware image, disk signature and windows artifacts. Jeong, D. and Lee, S. (2019). Digital Investigation 29: 21–27.
Copy on write based file systems performance analysis and implementation. M.Sc Dissertation. Kasampalis, S. (2010). Technical University of Denmark, 94p.
A What’s the difference between flash and SSD storage? Nelius, J. (2020). PC Gamer. по состоянию на 09.05.2025.
Forensic analysis of GPT disks and GUID partition tables. Nikkel, B.J. (2009). Digital Investigation 6 (1–2): 39–47.
Practical Forensic Imaging: Securing Digital Evidence with Linux Tools. Nikkel, B. (2016). San Francisco, CA: No Starch Press. {dokumen.pub}.
BTRFS: The Linux B-tree filesystem. Rodeh, O., Bacik, J., and Mason, C. (2013). ACM Transactions on Storage 9 (3): 1–32.
High performance solid state storage under Linux. Seppanen, E., O’Keefe, M.T., and Lilja, D.J. (2010). In: IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), 1–12. Lake Tahoe, Nevada: IEEE.
What is a File System? - Definition from Techopedia. Techopedia.com (2019). [Internet]. Techopedia.com . по состоянию на 09.05.2025.
Solid state drive forensics: where do we stand? Vieyra, J., Scanlon, M., and Le-Khac, N.A. (2018). In: Digital Forensics and Cyber Crime: 10th International EAI Conference, ICDF2C 2018 (10–12 September 2018) Proceedings 10 2019, 149–164. New Orleans, LA, USA: Springer International Publishing.
Programming for I/O and storage (Chapter 23). Yang, X.X. (2013). In: Software Engineering for Embedded Systems, 817–877. Elsevier B.V. {2nd ed., 2019}.