Часть 2. Стандартизация ваших серверов Linux
Данная часть представляет некий практический взгляд на то, как обеспечивать чтобы согласованность и повторяемость оставались основными аспектами вашей среды серверов Linux, продвигая такие наилучшие практические приёмы как масштабируемость, воспроизводимость и эффективность.
Данная часть состоит из следующих глав:
Глава 4. Методологии развёртывания
Содержание
До сих пор в этой книге нам приходилось настраивать фундамент для некого стабильного основания вашего корпоративного окружения Linux. Мы обсудили подробности того как гарантировать вашей среде Linux придания самой себе автоматизации через стандартизацию и как использовать Ansible и AWX для сопровождения вашего путешествия по автоматизации. Прежде чем мы начнём реальную техническую работу в данной главе, нам следует рассмотреть одну финальную часть подробностей - вашу методологию развёртывания.
Мы уже установили потребность в небольшом числе согласованных сборок Linux для вашей среды. Теперь имеется некий процесс принятия решения вами - как развёртывать эти сборки в вашем предприятии. Большинство предприятий имеют особые выбранные ими предпочтения в диапазоне от простейших - выгрузки общедоступных шаблонов образов - через сборку собственных шаблонов, до возможно наиболее сложных - сборку с нуля с применением некой среды предварительной загрузки. В качестве альтернативы наилучшим подходом может оказаться некий гибрид из этих подходов. В данной главе мы изучим эти варианты и разберёмся как обеспечивать вам наилучший выбор для своего предприятия, который поддержит вас в вашем путешествии по автоматизации и является действенным и простым в его реализации. В последующих главах мы также углубимся в технические подробности каждого из подходов.
В данной главе будут охвачены следующие темы:
-
Знакомство с вашим окружением
-
Поддержка действенности сборок
-
Обеспечение согласованности образов Linux
Данная глава предполагает, что у вас имеется доступ к некой среде с возможностями виртуализации, запущенной под Ubuntu 18.04 LTS. Часть примеров также будет выполнена в CentOS 7. В любом из этих вариантов наши примеры могут запускаться как на физической машине (или ноутбуке) под управлением одной из вышеуказанных операционных систем, так с процессом, который обладает включённой расширенной виртуализаций или в некой виртуальной машине с включённой встроенной виртуализацией.
Позднее в этой главе также используется Ansible 2.8 и предполагается что вы уже имеете его установленным в том хосте Linux, который вы применяли ранее.
Все обсуждаемые в этой книге примеры доступны в GitHub.
Никакие две среды предприятия не являются одинаковыми. Некоторые компании всё ещё полагаются на тяжёлые серверы голого железа, в то время как прочие теперь основываются на мириадах поставщиков виртуализации или облачных решений (причём как частных, так и общедоступных). Знание того какая именно среда доступна вам это ключевой момент в вашем процессе принятия решения.
Давайте изучим различные среды и относящиеся к ним стратегии сборки для каждой.
Несомненно, что дедушкой всех окружений предприятий являются среды голого железа. До революции в виртуализации и последовавших затем облачных технологий на протяжении нашего 21го века, единственным способом сборки некой среды являлось голое железо.
В наши дни не обычно отыскать некую среду целиком которая работает на голом железе, хотя всё ещё можно отыскать отдельные компоненты, которые всё ещё запускаются на голом железе, в особенности базы данных или вычислительные задачи, требующие определённого содействия со стороны аппаратных средств (например, ускорителей GPU или аппаратной выработки случайных чисел).
При сборке серверов на голом железе для большинства сред подходят два основополагающих подхода. Первый состоит в сборке серверов вручную при помощи оптических носителей или, что сейчас более распространено, устройств USB {Прим. пер.: также стоит относить к этому подходу и удалённую сборку через IPMI}. Это медленно, причём с интерактивным процессом, который масштабно повторяется, а следовательно не рекомендуется для любых сред, за исключением тех, в которых содержится лишь несколько физических серверов и где требования по созданию новых машин редкие и минимальные.
Другой более жизнеспособный вариант масштабной сборки, причём согласованным образом, который мы отстаивали в данной книге до сих пор, применяет PXE (Pre-eXecution Environment, среду предварительного исполнения). Он содержит в себе загрузку крошечной среды начальной загрузки с некого сетевого сервера с последующим её применением для загрузки необходимого ядра Linux и связанных с ним данных. Таким образом становится возможным привнесение среды установки без необходимости какого бы то ни было физического носителя. После того как такая среда поднята, мы можем применять метод установки без вмешательства персонала чтобы позволить выполнение этой установки без какого бы то ни было вмешательства со стороны пользователя.
Мы рассмотрим подробнее эти методы позднее в данной книге, также как и техники повтора для настройки тех серверов, на которых они собираются. Однако, пока будет достаточным просто указать, что для построения физических серверов на предприятии именно тем путём, которым проще всего автоматизировать и воспроизводить наиболее повторяемые результаты является загрузка PXE напару с установкой без вмешательства персонала.
Традиционные виртуальные среды предшествовали тому, что нам известно сегодня в качестве облачных сред - то есть они представляют собой простые гипервизоры, в которых запускаются операционные системы. Распространены такие коммерческие среды как VMware, а также их аналоги с открытым исходным кодом, такие как Xen и KVM (а также построенные на их основе платформы, таке как oVirt).
Поскольку эти технологии изначально строились в качестве дополнения к обычным физическим средам, они представляют ряд возможных вариантов для сборки вашего собственного корпоративного штата Linux. Например, большинство таких платформ поддерживает схожие с их аналогами на голом железе возможностей сетевой загрузки, а следовательно мы можем на самом деле представлять их себе как голое железо и продолжать методологию сетевой загрузки.
Тем не менее, виртуальные среды вводят нечто, чего трудно достигать в физических средах по причине отличий в оборудовании между устройствами голого железа на котором они запущены - шаблоны. Некая шаблонная виртуальная машина это достаточно просто развёртываемый моментальный снимок предварительно настроенной виртуальной машины. Следовательно, вы можете собрать исключительный образ CentOS 7 для своего предприятия, интегрировать его со своей платформой мониторинга, выполнить всё требуемое усиление безопасности, а затем применить инструменты сборки собственно в соответствующей виртуальной платформе, превращая его в некий шаблон. Приводимый ниже снимок экрана отражает шаблоны CentOS 7 в лабораторной среде автора:
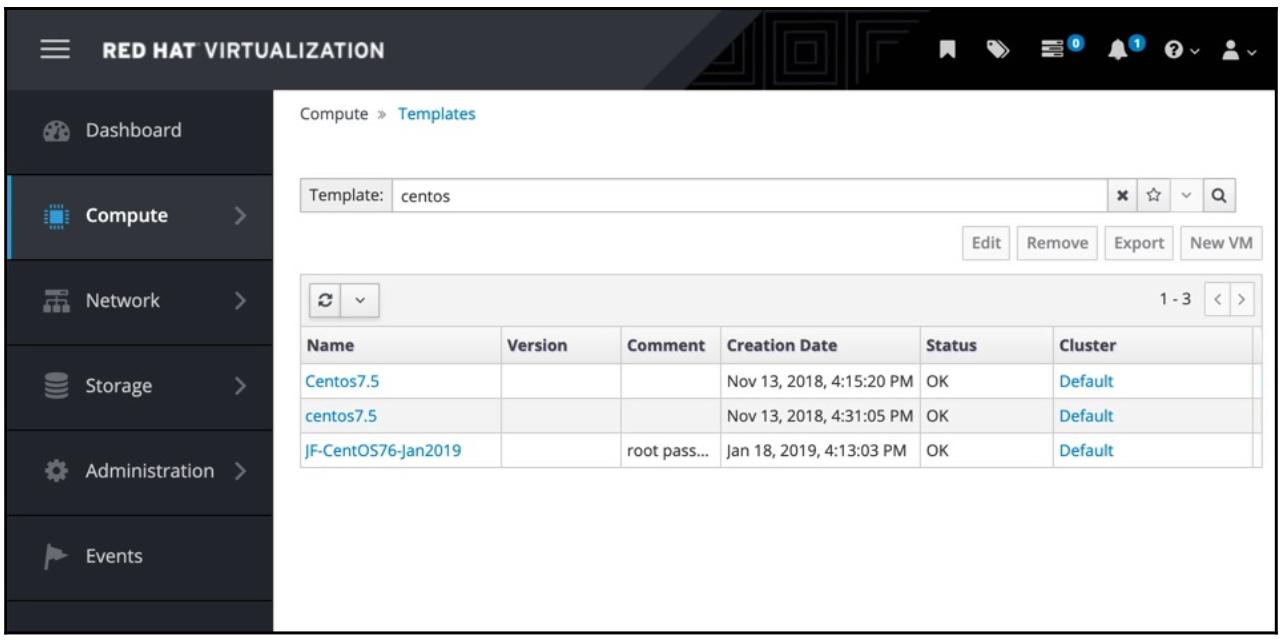
Каждый из этих шаблонов это полностью настроенный базовый образ CentOS 7, готовый к развёртыванию, причём со всей выполненной до конца предварительной работой, такой как удаление ключей SSH хоста. В результате некий администратор должен выбрать подходящий шаблон и кликнуть по кнопке New VM - этот процесс будет аналогичен и в прочих отличающихся от RHV платформах, поскольку большинство решений виртуализации основного течения производят такую функциональность с аналогичным внешним видом.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Обратите внимание, что для обеспечения доступности своих примеров в качестве основного процесса создания некой новой ВМ я применяю графический интерфейс. Почти все виртуальные и облачные платформы обладают взаимодействием API, командной строки и даже модулями Ansible, которые могут применяться для развёртывания виртуальных машин и в условиях предприятия они будут масштабироваться намного лучше нежели данный графический интерфейс сам по себе. Учитывая широкое разнообразие доступных сред это оставлено в качестве упражнения для самостоятельного изучения. |
Сам по себе это процесс достаточно незатейлив, но требует небольшой заботы и внимания. К примеру, почти все серверы Linux в наши дни обладают включённым SSH, а демон SSH в каждом из серверов обладает уникальным ключом идентификации, который применяется для предотвращения (помимо всех прочих моментов) атак с человеком в середине. Когда вы выполняете некий шаблон предварительно настроенной операционной системы, вв также переносите и эти ключи, что означает явную возможность дубликатов в вашей среде. Это существенно снижает безопасность. Поэтому очень важно выполнить ряд шагов для подготовки виртуальной машины прежде чем превратить её в некий шаблон и одним из таких распространённых шагов является удаление ключей хоста SSH.
Создаваемые при помощи метода PXE серверы не подвержены этой проблеме, поскольку все они устанавливаются с нуля, а следовательно не имеется никаких историй записей в журналах для их очистки и никаких дублированных ключей SSH.
В Главе 5, Применение Ansible для создания шаблонов виртуальных машин развёртывания мы углубимся в эти детали при создании шаблонов виртуальных машин, подходящих для разработки шаблонов пр и помощи Ansible. Хотя и методология загрузки PXE и развёртывания из шаблона в равной степени допустимы для виртуальных сред, большинство людей находят путь с шаблонами более действенным и более простым для управления, а по этой причине я также выступаю в его защиту (к примеру, большинству сред с загрузкой через PXE необходимо знать MAC адреса используемого сетевого интерфейса в подлежащему развёртыванию физическом или виртуальном сервере - при развёртывании из шаблона данный шаг не требуется).
Самым последним возложением в архитектуры корпоративного Linux (исключая, конечно, контейнеры, которые также подлежат нашему обсуждению) являются среды, предоставляемые в облачных решениях. Это может быть сделано через некое общедоступное облачное решение, такое как Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP) или один из мириадов поставщиков меньшего размера, которые появились в последние годы. В равной степени это может выполнено и через локальное решение, такое как один из вариантов OpenStack или некая частная платформа.
Такие облачные окружения радикальным образом изменили весь жизненный цикл машин Linux на предприятии. В то время как архитектуры машин Linux голого железа или традиционной виртуализации обслуживались, создавались и ремонтировались в случае их отказа, облачные архитектуры собираются в изначальном предположении что все машины в той или иной степени расходный материал и, в случае их отказа, просто на их месте развёртываются новые.
Как результат, методологии развёртывания PXE даже не возможны в таких средах, а вместо этого они полагаются на предварительно созданные образы операционной системы. По сути, это всего лишь некий созданный сторонним производителем или подготовленный для данного предприятия шаблон.
Будете ли вы обращаться к некому поставщику коммерческого решения или собирать локальную архитектуру OpenStack, вы обнаружите некий каталог доступных образов операционных систем для своего выбора. Как правило, те, что предоставляются самим поставщиком облачных услуг, вполне заслуживают доверия, хотя в зависимости от ваших требований безопасности вы можете находить подходящими и те, которые предоставляются сторонними организациями.
К примеру, вот некий снимок экрана доступных для OpenStack образов операционных систем:
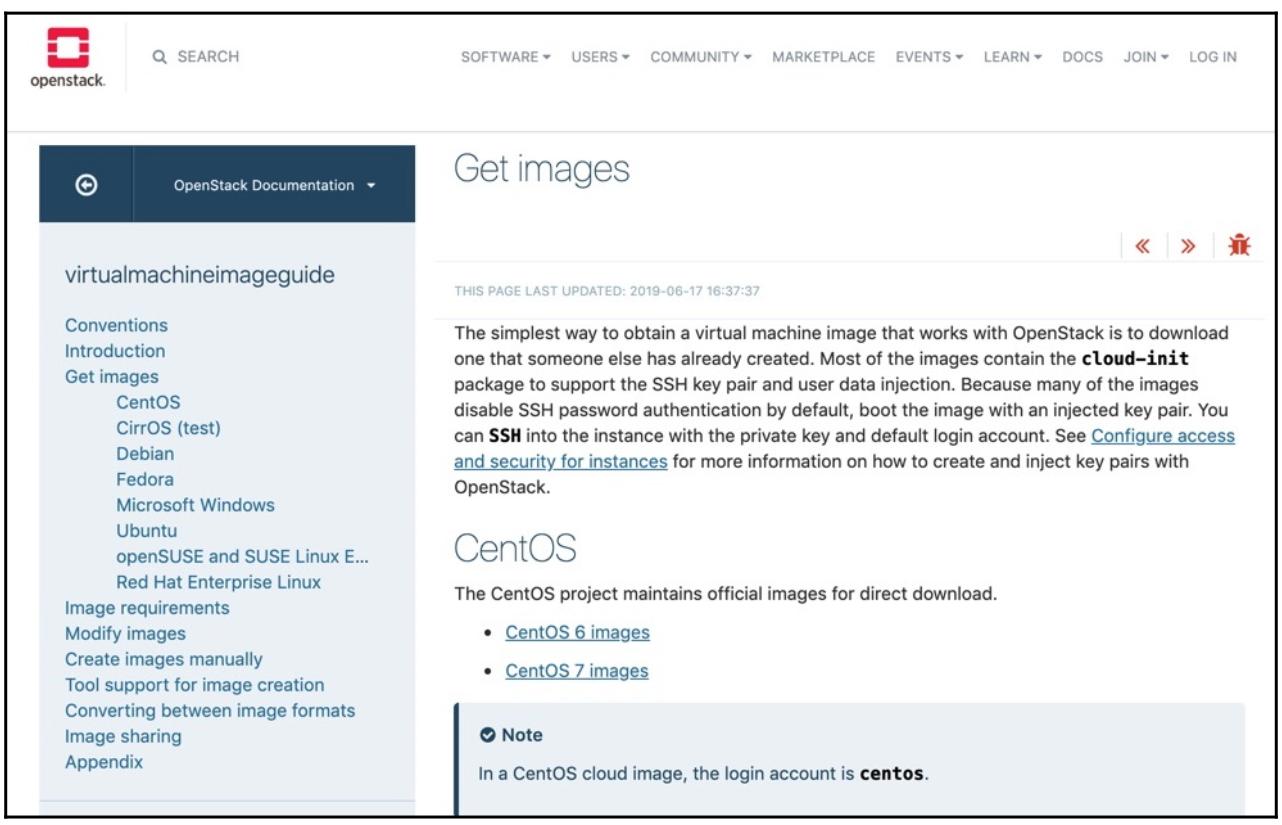
Как вы можете видеть из содержимого приводимой таблицы, здесь представлено большинство основных дистрибутивов Linux, что немедленно сберегает для вас от задач сборки базовой операционной системы самой по себе. То же самое справедливо и для AWS:
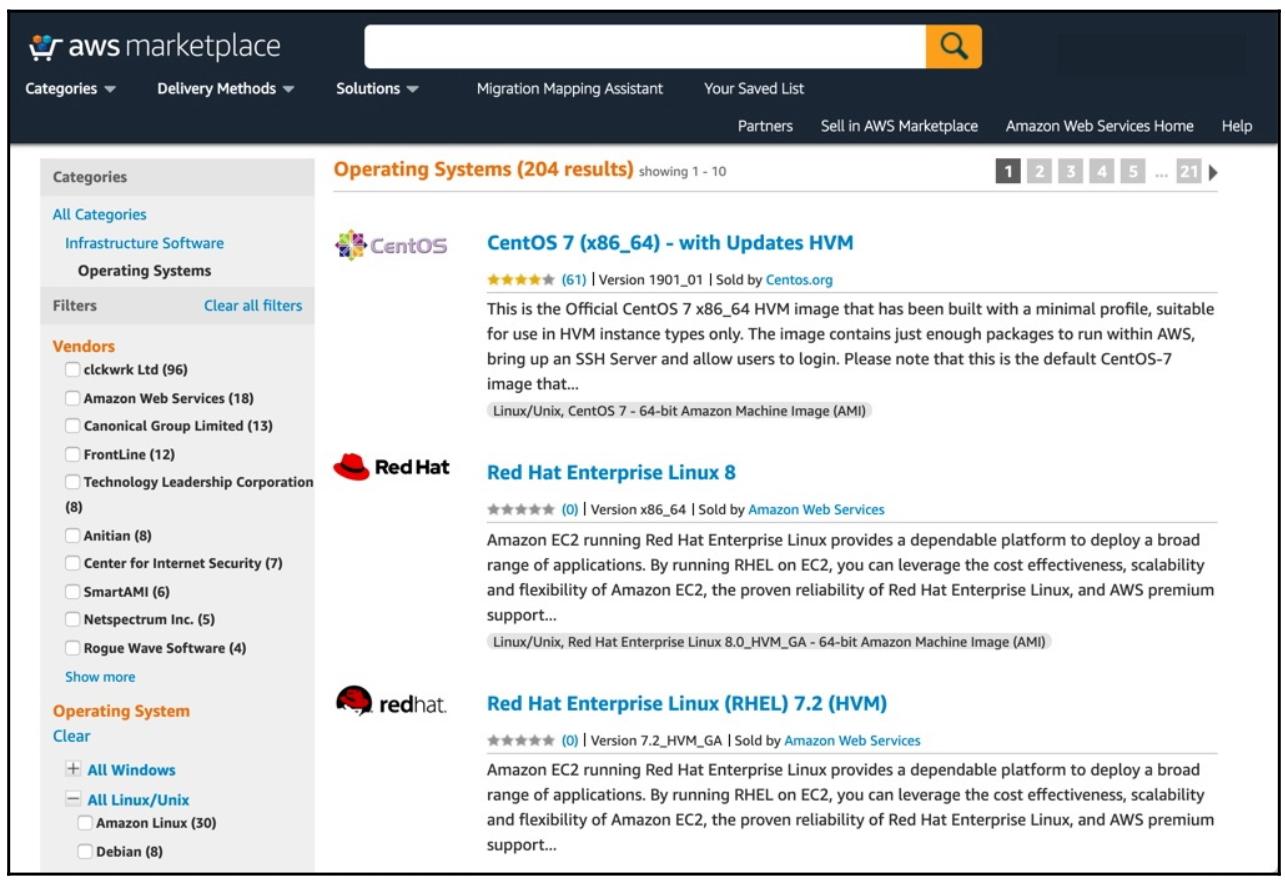
Короче говоря, когда вы применяете некую облачную среду, вы будете избалованы выбором из образов для базовой операционной системы с которых можно начинать. Несмотря на это, вряд ли такой выбор будет достаточным для всех предприятий. Например, применение предварительно созданного, готового к работе в облаке образа не отменяет требований для таких моментов как стандарты безопасности предприятия, мониторинг или интеграция с агентом пересылки журналов, а также множество прочих вещей, которые настолько важны для конкретного предприятия. Прежде чем мы продолжим, стоит отметить, что вы, конечно же, можете создавать свои собственные образы для выбранных вами облачных платформ. Однако в целях эффективности зачем заново изобретать колесо?Если кто- то уже осуществил этот шаг для вас, это именно то что вы можете действенно представлять где- то ещё.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Хотя большинство готовых образов операционной системы и заслуживают доверия, при выборе чего- то нового всегда следцует соблюдать осторожность, в особенности когда они созданы незнакомым вам автором. Невозмжно в точности знать что сожержит в себе образ и вы всегда должны проявлять должную осмотрительность при выборе образа для работы с ним. |
В предположении что вы решили продолжить с предварительно изготовленным образом, готовым для облачного использования, вся работа по настройке после установки может быть тщательно выполняться со стороны Ansible. Фактически, все необходимые шаги будут практически идентичны тем, которые требуются и для сборки из щаблонов обычных виртуальных платформ и, опять же, мы подробно рассмотри этот процесс позднее в своей книге.
Развёртывания Docker это особый случай в нашем обсуждении сред Linux. С практической точки зрения они совместно используют много общего с облачными средами - образы Docker собираются но основе предварительно имеющихся минимальных образов ОС и часто собираются при помощи естественных инструментальных цепочек Docker, хотя также целиком возможна и автоматизация с помощью Ansible.
Раз Docker является особым случаем, мы не будем сосредотачиваться на нём в этой книге, хотя и важно отметить, что Docker, не так давно занявший своё место присутствия в корпоративном Linux на самом деле строится на основании многих уже рассмотренных нами в этой книге принципов. Давайте коротко рассмотрим Dockerfile, применяемого для создания официального контейнера Linux.
|
| Совет |
|---|---|
|
Для тех, кто не знаком с Docker, Dockerfile это простой текстовый файл, который содержит все те директивы и команды, которые требуются для сборки некого образа контейнера под его развёртывание. |
На момент написания этих строк он содержал следующее:
#
# Nginx Dockerfile
#
# https://github.com/dockerfile/nginx
#
# Pull base image.
FROM ubuntu:bionic
# Install Nginx.
RUN \
add-apt-repository -y ppa:nginx/stable &:&: \
apt-get update &:&: \
apt-get install -y nginx &:&: \
rm -rf /var/lib/apt/lists/* &:&: \
echo -e "\ndaemon off;" >> /etc/nginx/nginx.conf &:&: \
chown -R www-data:www-data /var/lib/nginx
Хотя он и не основывается на Ansible, мы можем обнаружить в предыдущем коде следующее:
-
Строка
FROMближе к верхней части определяет минимальный базовый образ Ubuntu, в котором осуществлять все прочие настройки - о ней можно говорить как о вашем образе SOE Linux, который мы обсуждали для прочих платформ. -
Затем команда
RUNвыполняет те шаги, которые требуются для установки пакетаnginxи выполнения некой уборки чтобы оставлять этот образ сжатым и минимальным (снижение минимального необходимого пространства и беспорядка).
Далее код содержит следующее:
# Define mountable directories.
VOLUME ["/etc/nginx/sites-enabled", "/etc/nginx/certs", "/etc/nginx/conf.d", "/var/log/nginx", "/var/www/html"]
# Define working directory.
WORKDIR /etc/nginx
# Define default command.
CMD ["nginx"]
# Expose ports.
EXPOSE 80
EXPOSE 443
Продолжая свой анализ этого файла мы можем обнаружить:
-
Строка
VOLUMEопределяет какие каталоги из файловой системы имеющегося хоста могут быть смонтированы внутри данного контейнера. -
Директива
WORKDIRсообщает Docker о необходимости запуска следующего за неюCMD- представляйте себе это как настройку времени загрузки.Строка
CMDопределяет ту команду, которая запускается при старте данного контейнера - микрокосмос определений самого процесса относительно тех служб, которые запускаются в момент загрузки в полном образе системы Linux.Наконец, строки
EXPOSEопределяют какие порты данного контейнера следует выставлять в имеющуюся сетевую среду - возможно, слегка похоже на некий межсетевой экран, который может включать проход определённых портов.
Короче говоря, естественный процесс сборки контейнера Docker во многом следует в ногу с нашим определением процесса сборки некой корпоративной среды Linux - а следовательно, мы можем продолжать доверять такому процессу. Имея это в виду, мы теперь рассмотрим собственно процесс обеспечения максимально возможных опрятности и действенности сборок.
Знание основ своей среды Linux, как мы уже обсуждали в своём последнем разделе, жизненно важно для разработки вашей методологии развёртывания. Хотя существуют некоторые сходства между самими процессами сборки (в особенности между традиционными гипервизорами и облачными окружениями), знание таких отличий позволяет вам принимать обоснованные решения относительно того как развернуть Linux в вашем предприятии.
После того как вы выбрали ту методологию, которая наиболее подходит вашей среде, важно рассмотреть некоторые принципы, обеспечивающие вашему процессу рациональность и действенность (и опять же, под лозунгом развёртывания корпоративного Linux). Мы рассмотрим здесь это чтобы перейти к реальной углублённой практической работе в остающейся части данной книги. Давайте начнём с рассмотрения простоты в своих сборках.
Давайте приступим к помещению неких практических приложений в свой более раннее обсуждение значения важности SOE в нашем процессе сборки Linux. Какой бы маршрут вы не избрали, и какой бы не нравилась вам среда, один из ключевых аспектов состоит в том чтобы сохранять ваш стандарт сборки простым и кратким насколько это возможно.
Никакие две корпоративные среды не являются одинаковыми, а следовательно сами требования сборки для каждого из предприятий несомненно будут различными. Тем не менее, некий общий набор примеров требований приводится здесь чтобы продемонстрировать такие виды вещей, которые потребуются в конкретном процессе построения.
-
Агенты мониторинга
-
Настройка передачи журналов
-
Упрочнение безопасности
-
Центральные требования к программному обеспечению предприятия
-
Настройка NTP для синхронизации времени
Этот список всего лишь для начала и у каждого предприятия будет отличаться, но он снабдит вас основной идеей тех видов вещей, которые будут проходить при сборке. Тем не менее, давайте начнём рассматривать некоторые граничные случаи вашего процесса сборки. Справедливо сказать что всякий сервер Linux будет собираться с определённой целью на уме, а раз так, мы будем работать с неким стеком приложений.
И снова, такой стек приложений определённо будет разниться между предприятиями, но примеры тех видов приложений, которые могут быть общими из требуемых таковы:
-
Некий подобный Apache или nginx веб сервер
-
Среда OpenJDK для рабочих нагрузок Java
-
Сервер базы данных MariaDB
-
Сервер базы данных PostgreSQL
-
Инструменты совместного применения файлов NFS и расширения ядра
Теперь, в вашем процессе стандартизации, когда вы первоначально определили свою SOE, вы возможно даже пошли на то, что уже указали использование (просто в качестве примера) OpenJDK 8 и MariaDB 10.1. Означает ли это что вы обязаны включать их в свой процесс сборки?
Почти всегда ответ нет. Достаточно просто добавка этих приложений прибавляет сложность к самой сборке, а также настройке и отладке после установки. Это также снизит безопасность - но дополнительно об этом вскорости.
Давайте допустим что мы выбрали в качестве стандарта MariaDB 10.1 и включили её в свой базовый образ операционной системы (а следовательно её содержат все разворачиваемые отдельные машины Linux), при этом известно что лишь некое подмножество машин в реальности будут её применять.
Существует ряд причин для того чтобы не включать MariaDB в создаваемый базовый образ:
-
Установка лишь компонентов самого сервера MariaDB 10.1потребует около 120 МБ, в зависимости от вашей операционной системы и пакетов - также будут иметься пакеты зависимостей, но давайте начнём только с этого. Хотя в наши дни хранение недорого и в изобилии, когда вы развернёте в своём предприятии 100 серверов (действительно небольшое число для большинства корпораций), это составит примерно 11.7 ГБ пространства, выделяемого под установку таких пакетов и тому подобного.
-
Это также может иметь лобовое воздействие на резервные копии и требуемое для этого хранилище, а также в действительности на любые моментальные снимки виртуальных машин если вы применяете в своём предприятии.
-
Когда появляется какое- то приложение, которое потребует MariaDB 10.3 (или в конечном итоге ваш бизнес решит обновить её до 10.3), тогда все образы необходимо обновить или даже возможно выполнить деинсталляцию версии 10.1, прежде чем устанавливать версию 10.3. Это некий ненужный уровень сложности когда некий минимальный образ Linux может запросто получать некую обновлённую рабочую нагрузку MariaDB.
-
Вам потребуется обеспечить что MariaDB отключена и закрыта межсетевым экраном когда в ней нет необходимости - это для того чтобы предотвращать дополнительные требования аудита и принудительного применения, которое опять- таки не требуется на многих серверах, в которых MariaDB не применяется.
Существуют и прочие соображения относительно безопасности, но самое ключевое сообщение здесь состоит в том, что всё это пустая трата ресурсов и времени. Естественно это не применимо лишь для MariaDB 10.1 - она взята лишь в качестве примера, но он служит для того чтобы показать, что в качестве некого правила, рабочие нагрузки приложений не следует включать в определение базовой операционной системы. Давайте теперь слегка более подробно рассмотрим сами требования безопасности для сборки.
Мы уже касались безопасности и не устанавливали и не запускали ненужные пакеты. Всякая запускаемая служба предоставляет некий потенциал для направления атак для злоумышленника и хотя, надеюсь, у вас никогда и не будет такого внутри вашей корпоративной сетевой среды, всё же рекомендуется создавать свою среду таким образом, чтобы она была безопасной настолько, насколько это возможно. Это в особенности справедливо для служб, настраиваемых с устанавливаемыми по умолчанию паролями (а в некоторых случаях и вовсе настраиваемыми без паролей - хотя сейчас, к счастью, это становится редким).
Эти принципы также применяются и для самой сборки также. Не создавайте сборку со слабыми статическими паролями,
к примеру. В идеале каждая сборка должна настраиваться на получение даже первоначальных учётных записей из некого
внешнего источника и хотя и существуют мириады способов для достижения этого, мы призываем вас обратить внимание на
cloud-init, если это новое понятие для вас. Существуют варианты, в особенности
для наследуемых сред, когда ввам могут потребоваться некие первоначальные учётные сведения чтобы позволить доступ для
вновь создаваемого сервера, но повторное использование слабых паролей опасно и открывает возможность перехвата только
что собранного сервера перед его настройкой и установки в нём вредоносного программного обеспечения.
Короче говоря, приводимый ниже список предоставляет некие звучащие разумными рекомендации по обеспечению безопасности сборки:
-
Не устанавливайте те приложения или службы, которые не требуются.
-
Убедитесь что отключены общие для всех сборок службы, требующие настроек после развёртывания.
-
Не используйте повторно пароли для начального доступа и настройки когда это возможно.
-
В данном процессе применяйте свои корпоративную политику безопасности настолько рано, насколько это возможно - если это допустимо, в самом процессе сборки, но если это не так, как можно быстрее сразу после инициализации.
Эти принципы просты, но фундаментальны и важно их придерживаться. Надеемся, что никогда не возникнет ситуация когда окажется важным их применение, но если она таки возникнет, они смогут запросто остановить или в достаточной степени воспрепятствовать вторжению или атаке для вашей инфраструктуры. Конечно же, эта тема заслуживает отдельной книги, но есть надежда, что эти указания совместно с примерами из Главы 13, Применение эталонного тестирования CIS укажут вам верное направление. Давайте кратко рассмотрим как обеспечить действенность своих процессов сборки.
Эффективность процессов в существенной степени поддерживается автоматизацией, поскольку она обеспечивает минимальное вовлечение персонала и согласованные, повторяемые результаты. Стандартизация также служит этому, ибо она означает что основная часть процесса принятия решений уже завершена, а потому весь вовлечённый персонал в точности знает что ему делать и как всё следует осуществлять.
Короче говоря, придерживайтесь принципов данной книги и ваши процессы сборки по своей сути будут действенными. Некая степень ручного вмешательства неизбежна, даже если она включает в себя выбор уникального имени хоста (хотя и это можно автоматизировать) или, быть может, в процессе запроса у пользователя при размещении впервые сервера Linux. Тем не менее, начиная с этого момента вы желаете автоматизировать и стандартизировать всё что только возможно. Мы будем следовать этой мантре на протяжении всей данной книги. однако теперь рассмотрим важность согласованности в вваших процессах сборки.
В Главе 1, Построение стандартной среды работы в Linux, мы обсуждали важность единообразия в средах SOE. Теперь, когда мы на самом деле рассматривваем сам процесс построения, это выходит на первый план, ибо мы впервые рассмотрим как на самом деле реализовывать единообразие. Предполагая, что Ansible является выбранным нами инструментом, рассмотрим следующую задачу. Мы пишем плейбуки для своего процесса сборки и приняли решение, что наш стандартный образ обязан синхронизировать своё время с нашим локальным сервером времени. Допустим, что по историческим причинам, нашей базовой операционной системой выступает Ubuntu 16.04 LTS.
Давайте создадим некую простую роль чтобы обеспечить установку NTP и копировать в качестве своего корпоративного
стандарта ntp.conf, который содержит все адреса нашил серверов домашнего
времени. наконец, нам потребуется перезапустить NTP чтобы подцепить эти изменения.
|
| Замечание |
|---|---|
|
Все примеры в этой книге чисто гипотетические и приводятся для демонстрации того как мог бы выглядеть для такой цели код Ansible. Мы расширим выполняемые нами задачи (такие как развёртывание файлов настройки) более подробно в последующих главах и снабдим вас практическими примерами вам на пробу. |
Данная роль могла бы выглядеть так:
---
- name: Ensure ntpd and ntpdate is installed
apt:
name: "{{ item }}"
update_cache: yes
loop:
- ntp
- ntpdate
- name: Copy across enterprise ntpd configuration
copy:
src: files/ntp.conf
dest: /etc/ntp.conf
owner: root
group: root
mode: '0644'
- name: Restart the ntp service
service:
name: ntp
state: restarted
enabled: yes
Эта роль проста, лаконична и отвечает цели. Она всегда обеспечивает установку необходимого пакета
ntp, а также гарантирует что мы скопируем одну и ту же версию своего файла настроек
повсеместно, обеспечивая что он один и тот же на всех серверах. Мы можем ещё усилить это проверкой данного файла в системе
контроля версий, но я оставлю это на вас.
Мгновенно вы можете обнаружить всю мощь написания некой роли Ansible для данного одного простого шага - именно этим достигается согласованность при включении данной роли в некий плейбук и когда вы масштабируете данный подход на всё своё предприятие целиком, тогда все настроенные службы будут установлены и настроены согласованно.
Тем не менее, становится лучше. Скажем, ваш бизнес принимает решение сменить базовую операционную систему на
Ubuntu 18.04 LTS чтобы применять более новые технологии и увеличить срок поддержки своей среды. Применённый пакет
ntp всё ещё доступен в Ubuntu 18.04, хотя по умолчанию теперь установлен пакет
chrony. Чтобы продолжать работу с NTP данной роли потребуются лишь незначительные
изменения просто для того чтобы убедиться что вначале удаляется chrony
(или же вы можете отключить её, если пожелаете) - после этого всё в точности так же, например, рассмотрите приводимый
далее код роли, который обеспечивает верное отсутствие и наличие пакетов:
---
- name: Remove chrony
apt:
name: chrony
state: absent
- name: Ensure ntpd and ntpdate is installed
apt:
name: "{{ item }}"
update_cache: yes
loop:
- ntp
- ntpdate
Затем мы могли бы продолжить этот код добавив две дальнейшие задачи, которые повсеместно копируют необходимые настройки и перезапускают данную службу чтобы обеспечить что данная новая конфигурация будет подхвачена:
- name: Copy across enterprise ntpd configuration
copy:
src: files/ntp.conf
dest: /etc/ntp.conf
owner: root
group: root
mode: '0644'
- name: Restart the ntp service
service:
name: ntp
state: restarted
enabled: yes
В качестве альтернативы мы могли бы воспользоваться этим изменением и воспользоваться
chrony в своём новом базовом образе. Следовательно, нам просто потребуется
создать некий новый chrony.conf чтобы обеспечить его общение с нашими
корпоративными серверами NTP, а затем продолжать также как и ранее:
---
- name: Ensure chrony is installed
apt:
name: chrony
update_cache: yes
- name: Copy across enterprise chrony configuration
copy:
src: files/chrony.conf
dest: /etc/chrony.conf
owner: root
group: root
mode: '0644'
- name: Restart the chrony service
service:
name: chrony
state: restarted
enabled: yes
Обратили внимание насколько похожи эти роли? Даже при поддержке изменений в самой базовой операционной системе или даже в лежащей в основе службе, требуются лишь незначительные изменения.
Хотя эти три роли и отличаются в разных местах, все они выполняют одни и те же основные задачи, а именно:
-
Обеспечивают то, что верная служба NTP установлена.
-
Повсеместно копирует стандартные настройки.
-
Обеспечивает включение и запуск данной службы в момент загрузки.
Тем самым мы получаем уверенность что применяя такой подход мы имеем согласованность.
Даже когда наша платформа меняется целиком, сам подход верхнего уровня всё ещё применим. Скажем, ваше предприятие теперь получило некое приложение, которое поддерживается лишь в CentOS 7. Это означает принятие некого отклонения от нашей SOE, тем не менее, даже наша новая сборка CentOS 7 должна обладать верным временем, а раз NTP является стандартом, она будет применять те же самые серверы времени. Следовательно, мы можем написать некую роль для поддержки CentOS 7:
---
- name: Ensure chrony is installed
yum:
name: chrony
state: latest
- name: Copy across enterprise chrony configuration
copy:
src: files/chrony.conf
dest: /etc/chrony.conf
owner: root
group: root
mode: '0644'
- name: Restart the chrony service
service:
name: chronyd
state: restarted
enabled: yes
И вновь произведённые изменения крайне незначительны. Это существенная часть основной причины для принятия нами Ansible в качестве своего инструмента автоматизации для автоматизации предприятия - мы можем запросто создавать свои стандарты и придерживаться их, а наши сборки операционных систем остаются согласованными когда мы изменяем версию или даже сам применяемый дистрибутив Linux целиком.
На данном этапе мы определили свои требования для стандартизации, установили какие инструменты применять в своём путешествии по автоматизации и теперь предприняли практическое рассмотрение фундаментальных видов сред, в которых можно ожидать развёртывание операционных систем предприятия. Это составило фундамент для нашего путешествия по автоматизации и снабдило нас контекстом на весь остаток данной книги - практическое путешествие по процессу сборки и сопровождения среды Linux в вашем предприятии.
В этой главе мы изучили различные виды сред в которых может развёртываться Linux и разнообразные доступные нам стратегии сборки. Затем мы рассмотрели некие практические примеры обеспечения того что наши сборки обладают высокой степенью стандартизации и могут выполняться действенно и повторяемо. наконец, мы начали рассматривать преимущества автоматизации и того как она обеспечивает согласованность сборок, даже когда мы изменяем лежащий в основе дистрибутив целиком.
В своей следующей главе мы начнём своё практическое путешествие в автоматизацию и развёртывание корпоративного Linux, рассматривая как можно применять Ansible для сборки шаблонов виртуальных машин, либо из образов облачной среды, либо с нуля.
-
В чём сходство между сборкой контейнера Docker и некой SOE?
-
Почему вы не включаете MariaDB в свою базовую сборку когда она требуется лишь в пригоршне серверов?
-
Как обеспечить чтобы образ вашей базовой операционной системы был настолько небольшим, насколько это возможно?
-
Почему вы должны быть аккуратными со встроенными паролями для своего образа базовой операционной системы?
-
Как бы вы могли обеспечить чтобы все образы Linux отправляли свои журналы в ваш централизованный сервер журналов?
-
Когда бы вы не применяли предоставляемый поставщиком облачного решения базовый образ и собирали бы вместо этого свой собственный?
-
Как бы вы могли обезопасить настройки своего демона SSH при помощи Ansible?
Для более глубокого понимания Ansible, включая AWX, будьте добры ознакомиться с Mastering Ansible, Third Edition — James Freeman и Jesse Keating {Прим. пер.: рекомендуем также свой перевод этого 3 издания Полного руководства Ansible Джеймса Фримана и Джесса Китинга}.
Для получения лучшего представления о коде Docker и обсуждаемого в данной главе, обратитесь, пожалуйста, к Mastering Docker, Third Edition, Russ McKendrick и Scott Gallagher {Прим. пер.: рекомендуем также свой перевод основных глав из Docker для разработчиков Rails Роба Айзенберга}.