Под капотом SDDC
Содержание
- Под капотом SDDC
- Аппаратные средства
- Программное обеспечение
- Технологии
- Удалённый доступ: сеансы и приложения
- Удалённое управление
- Проброс устройств
- Распределение вычислений
- Распределённое хранение данных
- Метаданные и пространства имён
- Копирование при записи
- Дедупликация данных
- Удаляющее кодирование и репликации
- Конвергенция, RDMA, QoS
- Балансировка нагрузки
- Отказоустойчивая кластеризация
Облачные решения в фокусе нашего внимания на протяжении последних десяти лет. Однако, до недавнего времени это были либо достаточно затратные проекты, либо "местечко под солнцем" в чужом облаке. Ну или практически так. Некоторые из нас даже и не задумываются о том, что обрабатывая свою почту в облаке со своего рабочего места они уже являются пользователями услуг SD DC (Software Defined Data Center, Программно определяемых Центров обработки данных). Другие уже не мыслят своей ежедневной работы без RDP - удалённой работы со своими рабочими местами. Естественно, все мы зависим в своей повседневной практике от файлов, документов, презентаций, демо- роликов хранящихся в наших корпоративных хранилищах и базах данных. На повестке дня - возможность совместной работы в крупных проектах, применяющих как мощные вычислительные ресурсы в виде кластерных системах, так и средствах подготовки данных и их обработки после вычислений в режиме реального времени. Причём, вне зависимости от вашего текущего местоположения. Без разницы сколь мощные вычислительные ресурсы вам требуются. По барабану какой объём данных вам вздумалось перешерстить, находясь на пляже под зонтиком. Это ничего, что для обработки данных расчёта кузова машины вам придётся запускать Solidworks из номера гостиницы, или там же выполнять удалённый рендеринг картинки, расчёт нового белка с заранее заданными свойствами, составить аналитический отчёт по какому- либо контрагенту, или просто распечатать презентацию на офисный принтер, потому что только вы знаете где её отыскать- и не возвращаться же вам для этого из отпуска?
Теперь всё это можно делать практически с любого терминального устройства, обладающего веб браузером. И не обязательно запускать удалённое место целиком. Можно вызвать отдельное приложение. А все ваши данные, наконец- то реплицируются и резервно копируются самостоятельно. И пусть это будет ваша библиотека с видео на 500 Терабайт и больше. Так даже интереснее. Вся работа по обработке ситуаций с выходящими из строя дисками сводится к их физической замене. Например, раз в неделю или в месяц. Забудьте про проблему бутылочного горлышка в своём центре данных, подходя к стойке бара вечером в пятницу. Теперь у нас всегда есть возможность избавиться от любого узкого места. Фантастика?
Нет, теперь, с выходом Windows Server 2016, это умеет делать даже Microsoft. И именно появление полноценных облачных решений от этого гиганта рынка программных решений можно рассматривать как наше вступление в эпоху зрелости и доступности таких решений. Да, вы могли и раньше пользоваться решениями с открытым исходным кодом. Но у всех ли из нас есть возможность постоянно практически в одиночку разбираться со всеми хитросплетениями и тонкостями решений. Да есть возможность приобрести поддержку. Но до сих пор это было достаточно затратно. Теперь мы начинаем получать "решения из коробки" привычные нам по уровню их стоимости и с уровнем поддержки, к которому мы привыкли. И потом, не обязательно сразу всё переносить в облака. Давайте двигаться постепенно.
Конечно, всё ещё много нового и непонятного здесь. И в аппаратных средствах, и в программном обеспечении. Облачные решения во многом требуют изменить образ мысли и повседневной работы. Мы готовы помогать Вам в этом!
Итак, три наших основных слагаемых в железном уравнении это: процессоры, хранилища и сети.
До недавнего времени процессоры можно было условно делить на Центральные процессоры и вспомогательные процессоры, прежде всего GPU. Конечно, и центральный процессор мог брать на себя львиную долю вычислений, однако, порой, проще выносить вычисления в специализированные вычислительные фермы. И это прекрасно. Похоже, что эти стереотипы начинают меняться. Intel уверенно заявляет о том, что он готов вам предоставлять внутри одного процессора какие угодно ядра. И это не только Xeon Phi™ x200. Уже сейчас можно знакомиться с процессорами имеющими ядра x86 наряду с FPGA и, пользуясь инструментарием производителя, создавать своё ядро под собственные нужды.
Современные процессоры давно взяли в свой руки управление памятью (включив в свой состав контроллер памяти). И мы перестали удивляться тому, что за справкой о максимальным объёмом поддерживаемой памяти мы обращаемся не к спецификации материнской платы, а к описанию её Центрального процессора. Но теперь, вслед за процессорами SPARC в исполнении Fujitsu, взявшими себе на борт ядра контроллера для обеспечения интерконнекта шестимерного тора Tofu, уже упоминавшийся Xeon Phi™ x200 может брать к себе на борт "убийцу" Infiniband OmniPath. Раз нас уже не удивляет торчащая из верхней крышки процессора связка электрических проводов, почему нас должна удивить замена в этой связке меди на оптику? Запомним это словосочетание: Silicon Photonics.
Не сбрасывая со счетов архитектуры MIPS (включая Байкал Т1) и Эльбрус, которые теоретически могут применяться в специализированных средах виртуализации, перечислим основные присутствующие на современном рынке серверных решений процессоры:
Intel® Xeon® Scalable Processor: Представляют теперь единую фамилию семейств для построения платформ различных масштабов: Платиновые для построения более мощных систем на базе 2/4/8/16/32+ Центральных процессоров, Золотые для систем с 2/4 ЦПУ, а Серебряные и Бронзовые для более экономичных решений. Рекомендуемые розничные цены (РРЦ) на них вы можете найти по ссылке xls. Со всеми новыми функциями и улучшениями можно ознакомиться в нашем переводе Технический обзор процессоров Intel® Xeon® семейства Scalable Дэйвида Маникса, с исправлениями от 22 Июня 2017.
В августе 2017 мы уже готовы принимать заказы на системы с aka E5-2600 v5 - Intel® Xeon® Scalable и всеми остальными ЦПУ, покрывающими и терминологию E7 v5.
Intel® Xeon® E5-2600 v4, v3: Без всяких сомнений, самые распространённые на сегодняшний день центральные процессоры для обсуждаемых нами платформ. Безусловно, все мы ожидаем во второй половине выхода в свет Skylake-EP Xeon E5-2600 V5 (с заменой сокета, кстати) во второй половине 2017. Существенно, например, что он должен, наконец, привнести шину PCIe v.4, которая необходима для поддержки уже имеющегося на рынке интерконнекта 200G. Но пока довольствуемся имеющимися решениями v4/v3. Рекомендуемые розничные цены (РРЦ) на них вы можете найти по ссылке (в таблице приведена выборка, более подробная информация в приводимой в указанном тексте xls-файле). Существенно, что они поддерживают Intel VT/ AMD-V и Data Execution Prevention, а также, для многих приложений, гиперпоточность.
Intel® Xeon® Processor E7 v4, v3: Служат для построения более мощных систем на базе 4/8/16/32
AMD® Opteron™ 7000 Series (EPYC) уже доступны к заказу, начиная с июля 2017. Мы приводим некоторые оценки стоимости этих процессоров как для систем с двумя ЦПУ, так и для однопроцессорных решений по состоянию на август 2017. Надеемся на скорейшее расширение разнообразия модельного ряда.
AMD® Opteron™ 6000 Series: Во многих случаях могут оказаться интересными в отношении экономики бюджета Центральных процессоров. Здесь мы также в нетерпении появления AMD Naples весной 2017 со 128 PCI Express Gen 3.0 lanes. Но и имеющиеся в продаже процессоры могут составлять достойную конкуренцию E5-2600 v4, например тем, что могут компоновать системы с числом процессоров более двух. В этих процессорах для нас актуальны технологии AMD-V и Data Execution Prevention.
Nvidia®: Вооружает нас широким диапазоном вычислительных возможностей для решения широкого разнообразия задач. Начиная с самого мощного на сегодня решения Tesla P100 (Pascal), имеющего свой собственный интерфейс NVLink™, экстремальную производительность, унифицированную работу с памятью и прочие улучшения. Продолжая разнообразие в различных решениях построения аппаратной поддержки профессиональной графики (включая технологию GRID vGPU -SR-IOV), вплоть до игровых приложений. Рекомендуем PNY конфигуратор для выбора правильного решения. Для наиболее эффективного использования аппаратной мощности рекомендуем применять PGI Accelerator™.
Intel® Xeon Phi™: Предоставляют некий композит из ядер, несомненно, предоставляющий великолепные вычислительные возможности, подкреплённые единым с x86 архитектурой компилятором Intel. Обсуждаемым на сегодня является вопрос о необходимости средств виртуализации в ядрах x86 данного процессора. В общем- то логичным кажется сказав А, и привнеся в единый кристалл архитектуру общего управления, сказать и Б, предоставив ей и возможности аппаратной поддержки гипервизоров. Подождём. Пока же, повторим, впечатляет наличие возможности кардинального снижения латентности в межпроцессорном обмене за счёт встроенного в сам процессор контроллера интерконнекта Omnipath 100G. Рекомендуемые розничные цены (РРЦ) на них вы можете найти по этой ссылке.
AMD® FirePro™ GPU: Традиционно предоставляют наивысшие в абсолютном выражении аппаратные показатели вычислительной способности, хотя эффективность её реализации в OpenCL пока ещё оставляет желать лучшего. Однако, что касается игровых приложений здесь они готовы спорить с кем угодно! В средах с виртуализацией существенна технология MxGPU (SR-IOV).
Intel® GVT-g: Технология виртуализации графических подсистем и организации совместной работы (SR-IOV), наряду с GRID vGPU и MXGPU. Доступна в ряде процессоров Intel®.
Процессоры FPGA: Сегодня позволяют достигать максимальной производительности в задачах подобных вычислениям bitcoin. Также применимы в большом разнообразии специализированных вычислений и управлений процессами (в том числе, NFV). Напомним, у нас есть предложения для данного типа решений!
SPARC процессоры: В основном, представлены двумя чередующимися (через раз, каждые год- полтора) сериями для решений Oracle/Sun и HPC. Основной производитель- Fujitsu. Отметим наличие аппаратной виртуализации Solaris, а также материалы Fujitsu: Ключевые технологии программного обеспечения для следующего поколения PRIMEHPC - Post-FX10, Fujitsu и Oracle улучшили сервера Fujitsu M10 SPARC, Tехнологии компилятора, которые демонстрируют возможности К компьютера.
OpenPower: Сегодня это открытая технология, а мы- участники программы!
ARM: На рынке имеются энтузиасты. Возможно, существуют приложения, для которых это интересно, дайте нам знать, у нас есть в запасе решения для Вас!
z/OS: Мейнфреймы с z/OS (OS/360/370/390) и прочими совместимыми ОС всё ещё эксплуатируются, а следовательно, требуют модернизации. Имеются и такие решения.
прочие x86 ЦПУ: да, современные облачные решения сегодня можно применять и дома. А экспериментировать можно начинать практически на любых процессорах. Чтобы можно было пользоваться большим объемом имеющегося на рынке ПО в процессорах необходима аппаратная поддержка виртуализации (Intel VT/ AMD-V).
Как мы уже говорили, современные процессоры, как правило, имеют встроенный контроллер памяти. От правильной организации его работы очень сильно зависит та эффективность производительности всей системы, на которую вы можете рассчитывать. Обращаем Ваше внимание на необходимость корректной настройки работы NUMA/ NUMA-CC и RDMA! Также стоит изучить вопрос с количеством каналов памяти, которое поддерживает контроллер (сейчас это, как правило, 4, хотя у процессоров x200 уже шесть каналов памяти) и заполнять планками памяти все имеющиеся каналы памяти, что существенно повышает полосу пропускания массивных операций обмена данных с оперативной памятью.
При построении обсуждаемых нами решений мы ожидаем от них надёжной работы с нужным нам числом девяток в процентном соотношении времени постоянной работы. Обычно это предполагает тщательный выбор самих аппаратных средств, их производителя, а также рассмотрения вопросов избыточности и резервирования. Парадоксальным явлением в данном классе решений является тот факт, что начиная с некоторого масштаба сами применяемые в данном виде инфраструктуры технологии и средства предоставляют необходимые способы решения проблем взаимозаменяемости, миграции решений и их эластичности, которые допускают применение недорогих унифицированных средств, которые легко могут быть извлечены из системы для ремонта и восстановительных работ в случае их выхода из строя, причём без каких- либо существенных проблем для работы системы в целом. Естественно, всякая стратегия имеет свои границы допустимости и в погоне за стоимостью необходимо знать меру.
Итак, существенным для платформы является как удобство самой её конструкции в плане манипуляции с ней (например, по выниманию из стойки и отсоединению кабелей питания и интерконнекта), а также доступности и возможности замены отдельных её компонентов без остановки всей системы (смена блока питания, вентилятора, жёсткого диска, контроллера и даже планок памяти процессоров и материнских плат - да-да: например, серверы Fujitsu PRIMEQUEST позволяют делать замену материнки по- горячему). Если заглянуть вовнутрь, рекомендуется применять дублирование сетевых контроллеров и контроллеров дисков, проверить наличие дублирующих путей для всех существенных Вам шин данных (например, возможность использования SAS вместо SATA, благо сами устройства не имеют существенной разницы в стоимости). С точки зрения "пощупать руками" и "попробовать на зуб" имеет смысл посмотреть на качество контактов в разъёмах и райзерах, а также толщину применяемых производителем проводников. Будет обидно если контакты в райзере вашего сервера выдерживают не более двух- трёх операций вставки- выемки платы контроллера. Из личного опыта: существует производитель (и мы его знаем!), который настолько уверен в качестве разводки питания и заземлений в своей платформе, что не требует дополнительных кабелей от блока питания для работы в ней самых мощных GPU! Информацию для размышления о качестве платформы могут Вам предоставить допустимые в ней температурный режимы. Например, гарантия полной работоспособности в режиме 24x7 в течение 3 лет при температуре на входе в систему 45°Ц и допустимость работы на протяжении нескольких часов при повышении этой температуры до 60°Ц говорят о многом.
Мы не будем заострять внимание на необходимости в сервере контроллера BMC и наличии интерфейса IPMI, ведь пожалуй, это одно из самых первых отличий серверного оборудования от бытового. Объём показателей и замеров, которые вы можете получать через данный интерфейс в качестве сведений о состоянии своей системы также может численно характеризовать качество Вашей платформы.
Существенным моментом при выборе платформы являются предлагаемые ею варианты начальной загрузки. В настоящее время практически все предлагающиеся на рынке сервера имеют вместо BIOS встроенное программное обеспечение (Firmware) с интерфейсом UEFI, который снимает ограничения, имевшиеся у BIOS (например, невозможность выполнения загрузки с дисков, имеющих размер более 2ТБ), а также предоставляет удобные службы загрузки, управления ею, поддержки дисковых устройств и т.п., что позволяет выполнять инициализацию платформ с применением всевозможных носителей загрузочной информации. Из имеющихся сегодня таких носителей напомним о существовании спецификации PXE - среды сетевой загрузки и устройств SATA DOM, очень удобных для предоставления образов начальной загрузки для UEFI.
При выборе подходящей платформы для вашего решения хорошей отправной точкой может быть знакомство с эталонными архитектурами, предлагаемыми производителями для облачных инфраструктур. Рекомендации по оборудованию для решений на основе Microsoft Windows Server 2016 от производителей основных торговых марок начнут появляться к окончанию весны 2017, но, в принципе, вполне подходящими могут оказаться и широко распространённые рекомендации для выбора аппаратных решений OpenStack. То же относится и к Proxmox, VMware, XenServer а также прочим решениям SD DC, поскольку по существу все эти решения основываются на одних и тех же имеющихся на рынке широко распространённых средствах и технологиях. В качестве примера можем посоветовать свой перевод Эталонной архитектуры для компактного облачного решения с применением Mirantis OpenStack 9.1 и оборудования Dell EMC, а также наш перевод официального руководства Ceph. Рекомендации по оборудованию. Неплохой обзор решений конкурентов на конец 2016г предоставила фирма Huawei с точки зрения поддержки ими NVMe. Далее, после краткого обзора современных особенностей платформ, приводится краткое перечисление платформ различных производителей, которые мы легко можем вам предложить.
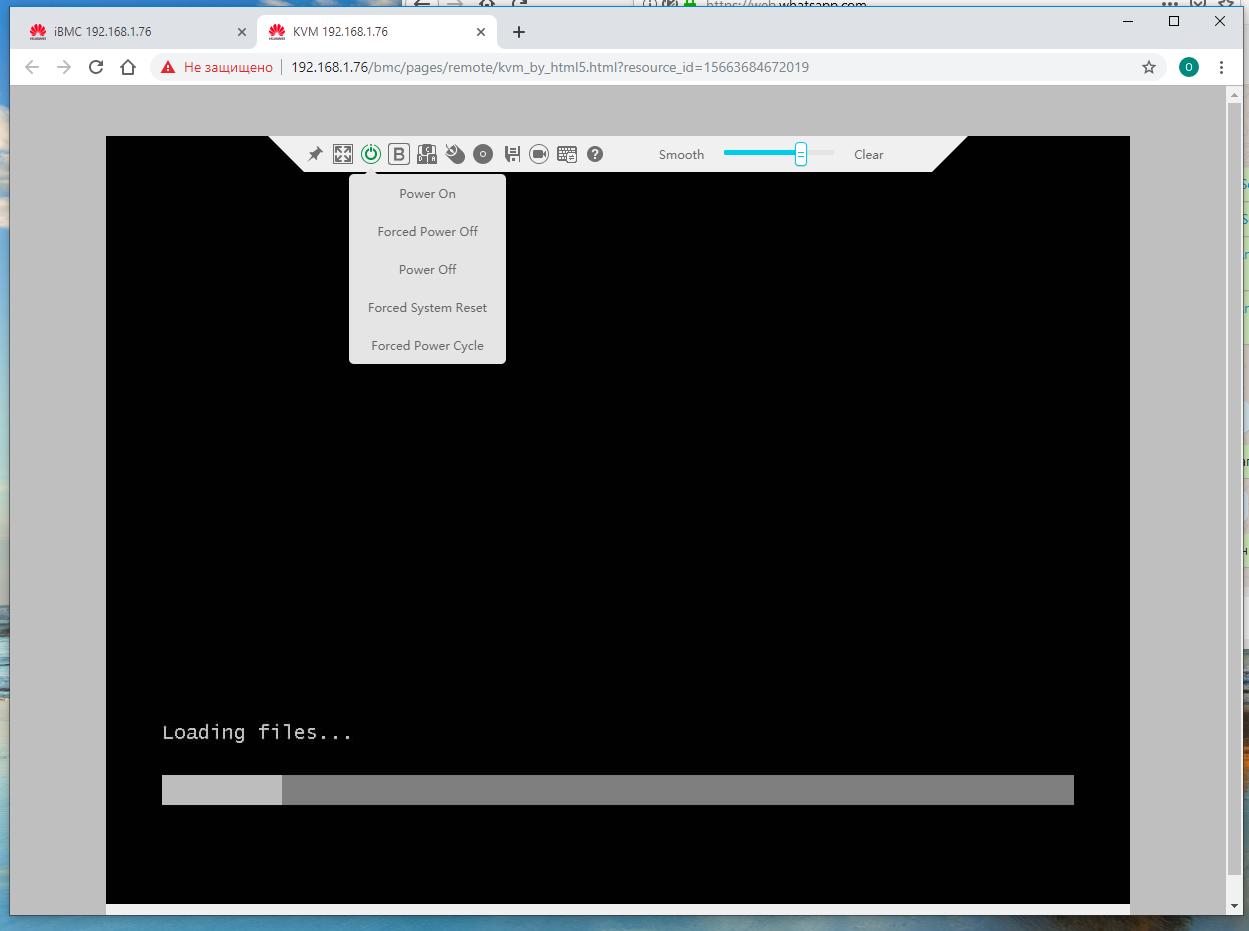
Практически все современные серверные системы предоставляют возможности установки Операционной Системы при помощи средств iBMC (через протокол IPMI). Причём, практически все они поддерживают теперь HTML5, работать в котором несравненно удобнее, нежели через Java интерфейс. У каждого производителя могут быть свои нюансы, но основная последовательность действий в целом одна и та же (мы рассматриваем ввариант с интерфейсом HTML5):
-
Настраиваем сетевые праметры контроллера iBMC под Вашу локальную сеть с тем, чтобы к нему имелся доступ.
-
На своём рабочем месте открываем в браузере IP адрес iBMC сервера, установленный на предыдущем шаге.
Поскольку операции работы с iBMC проходят в целом через HTTPS, ваш браузер может пожаловаться на не зарегистрированный в открытом доступе сертификат. Мы доверяекм своему производителю, поэтому игнорируем такую жалобу и продолжаем.
-
Переходим к Удалённой консоли iBMC в браузере. Как правило, это сопровождается открытием нового окна браузера. Убедитесь что в браузере отключён VPN и вы свободно можете осуществлять доступ к узлам своей локальной сети.
-
В настройках виртуального DVD устройства устанавливаем ссылку на ISO образ операционной системы. Желательно чтобы он был расположен или в самой вашей рабочей машине, или в ресурсе сетевой среды с хорошей полосой пропускания.
-
Настраиваем загрузку системы на режим загрузки с DVD и перезагружаем сервер через средства Удалённой консоли iBMC.
-
Дожидаемся приглашения ОС из образа ISO на инициацию загрузки и действуем согласно инструкциям установки.
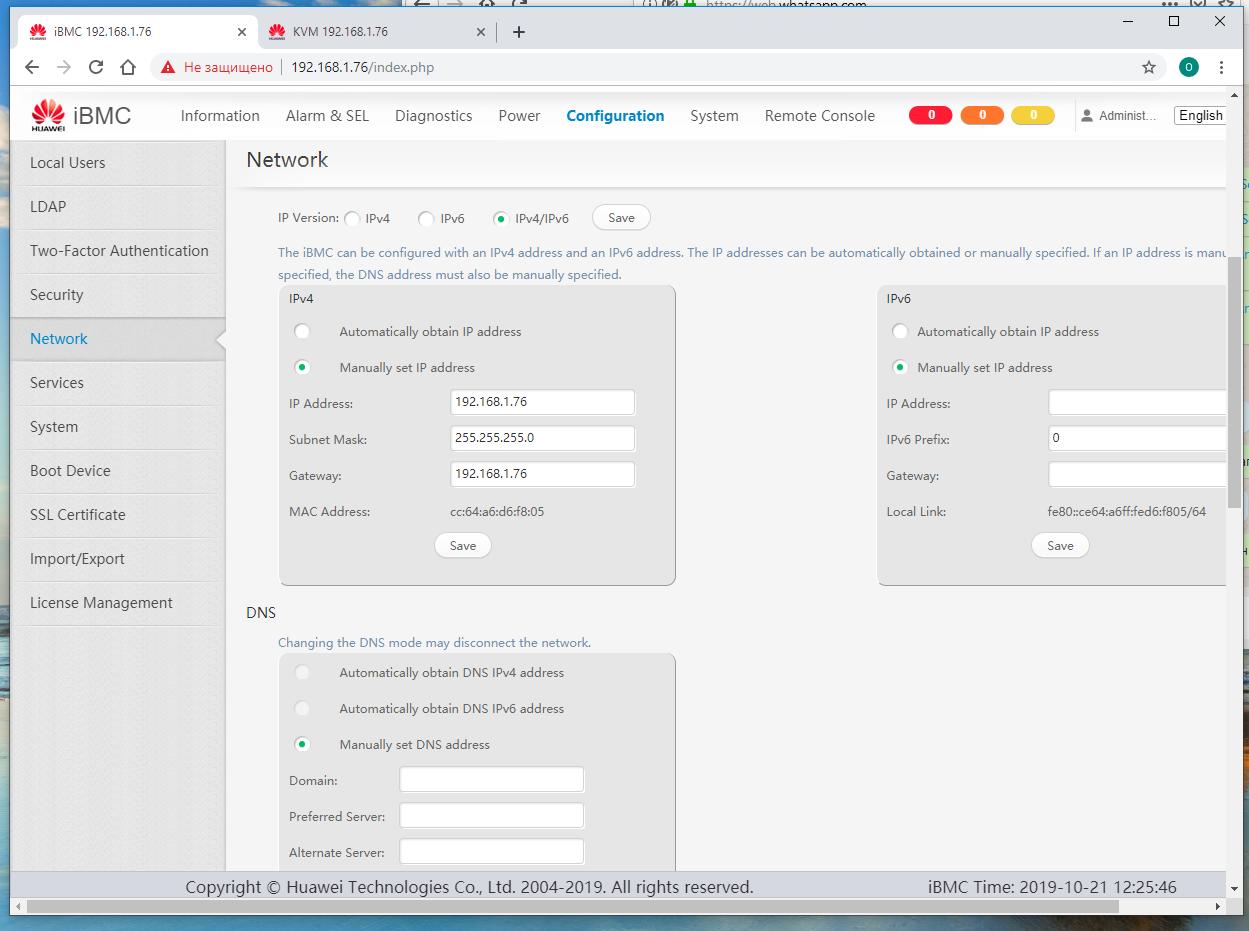
Пример установки сервера Huawei
-
Устанавливаем IP адрес своего iBMC равным
192.168.1.76и остальные некобходимые сетевые настройки. Это лучше сделать непосредственно в самом сервере. По умолчанию серверы Huawei v5 приходят с предустановленным IP адресом192.168.2.100, который можно заменить на подходящий вам.
-
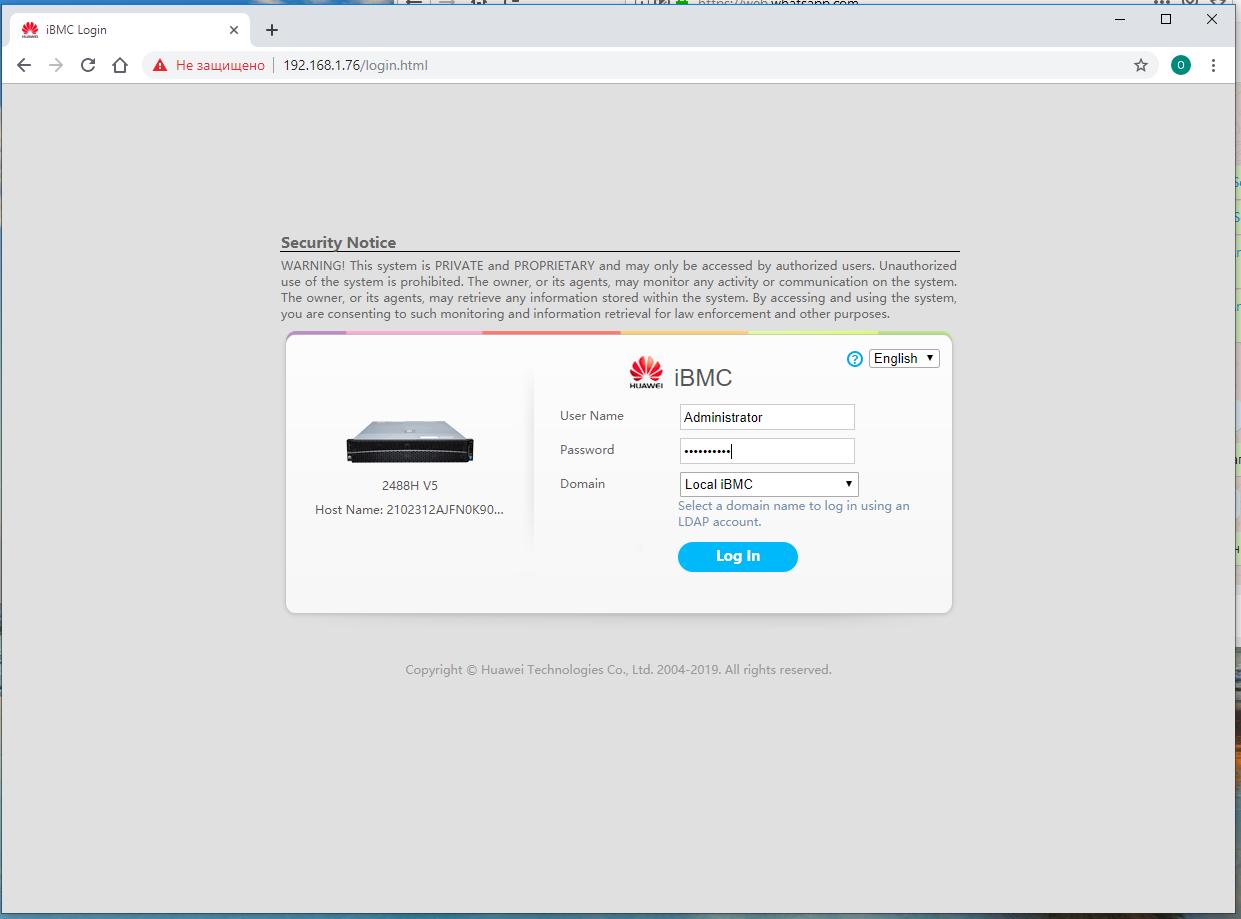
На своём рабочем месте открываем в браузере установленный на предыдущем шаге IP адрес, причём скорее всего вам придётся проигнорировать жалобы браузера на недоступность подтверждения ключа для протокола HTTPS.
В самом первом окне вам предлагается зарегистрироваться в качестве администратора. Регистрационные сведения по умолчанию, как и значение предустановленного IP адреса iBMC указаны на наклейке самого сервера. Для серверов Huawei v5 логин -
Administrator, пароль -Admin@9000.
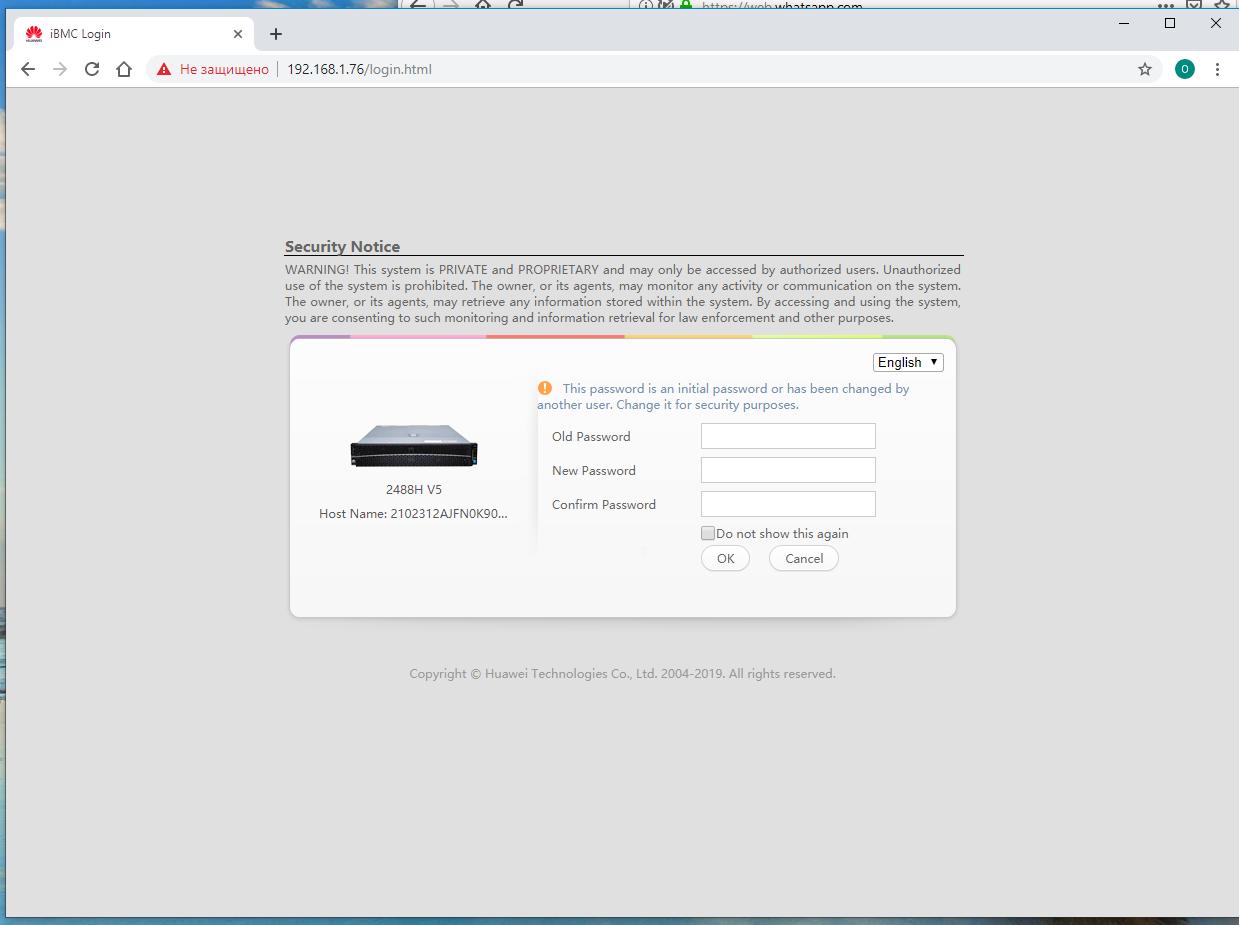
Система будет усиленно принуждать вас к изменению начения пароля по умолчанию. Если вы не конечный владелец системы, можете проигнорировать это, нажав Cancel.
-
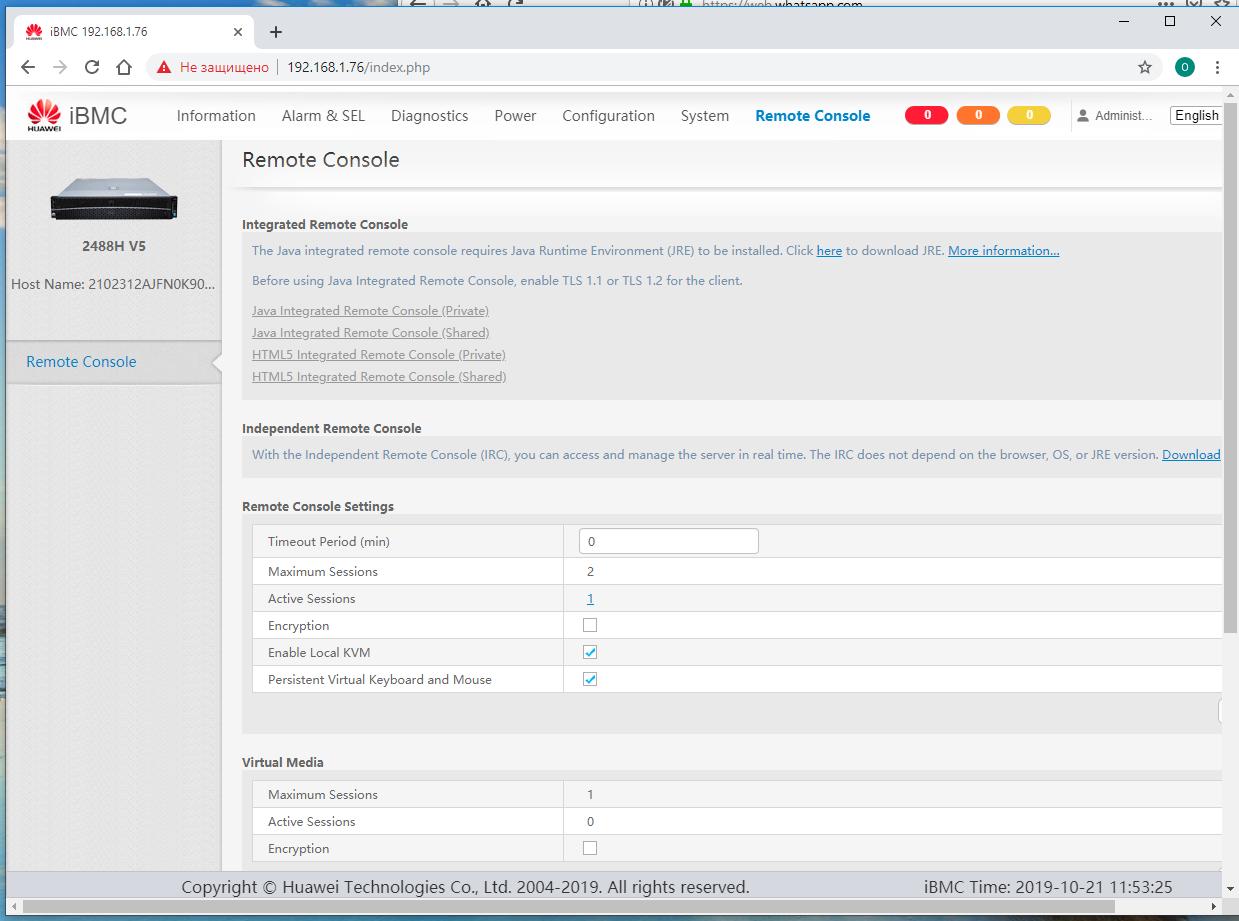
Перейдите к закладке Удалённой консоли.
Если вдруг у вас на каком- то ещё рабочем месте открыта эта консоль, тогда в поле управления вам окажутся недоступными опции открытия консоли iBMC, как на предыдущем снимке экрана. Закройте ненужное вам окно браузера и перезагрузите окно в своём браузере. Теперь Вам доступна опция доступа к HTML5 консоли. Я предпочитаю приватную, это придаёт уверенности что никто больше не занимается тем же самым на данном сервере.
-
В рабочей области отображается экран консоли, а сверху видна планка управления. Мы не будем останавливаться на всех её подробностях, предоставив это Вам.
Ваша система пребывает в собственной жизни. Вне зависимости от контроллера iBMC, который автономен.
-
В планке управления проходим к настройкам виртуального CD/DVD и устанавливаем в них значение образа своей ОС и нажимаем на кнопку соединения.
Дожидаемся подтверждения того, что наш образ подцепился: кнопка
Connectменяет своё действие наDisconnect.
-
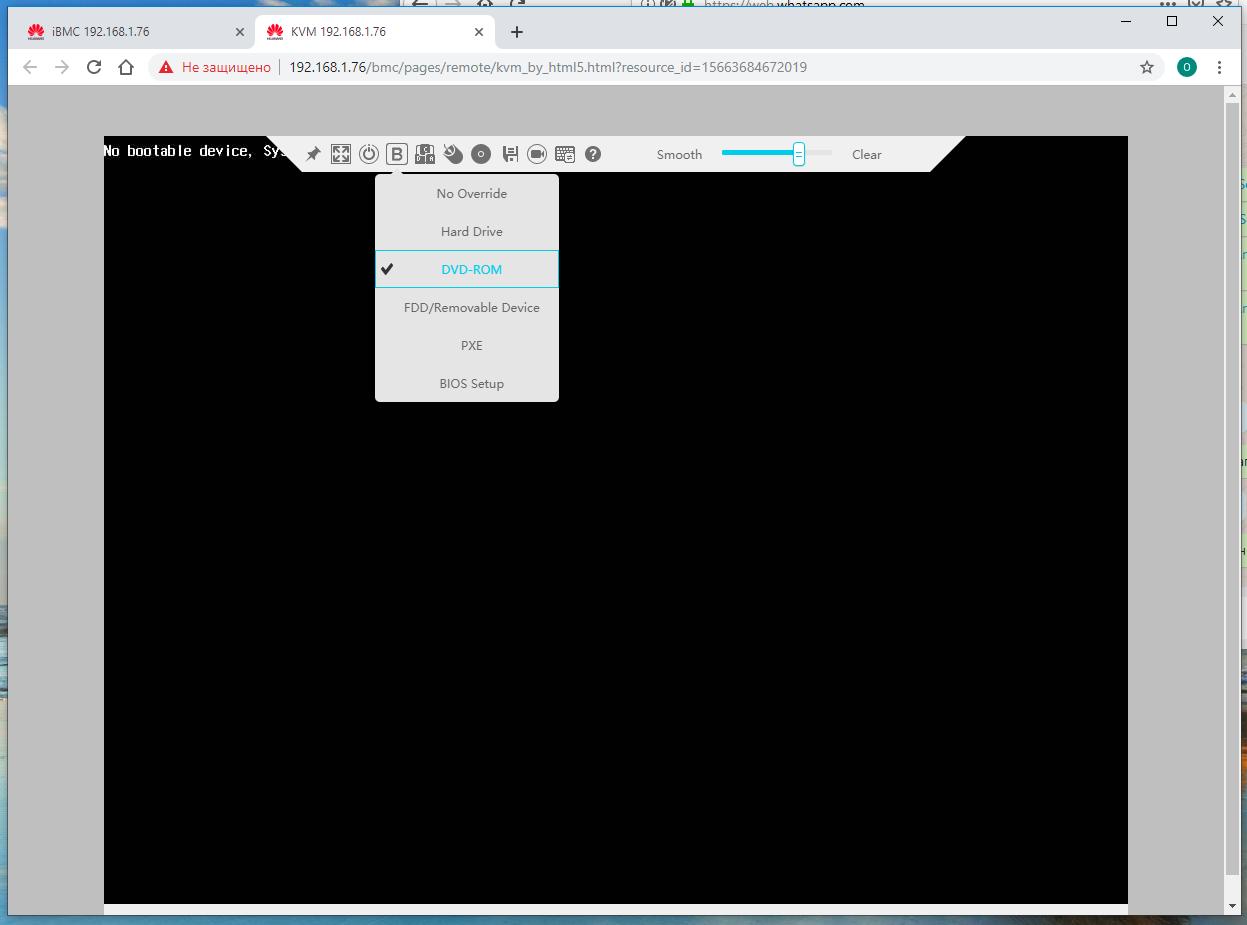
Следуем к установке параметров устройства загрузки в планке управления iBMC. Устанавливаем DVD.
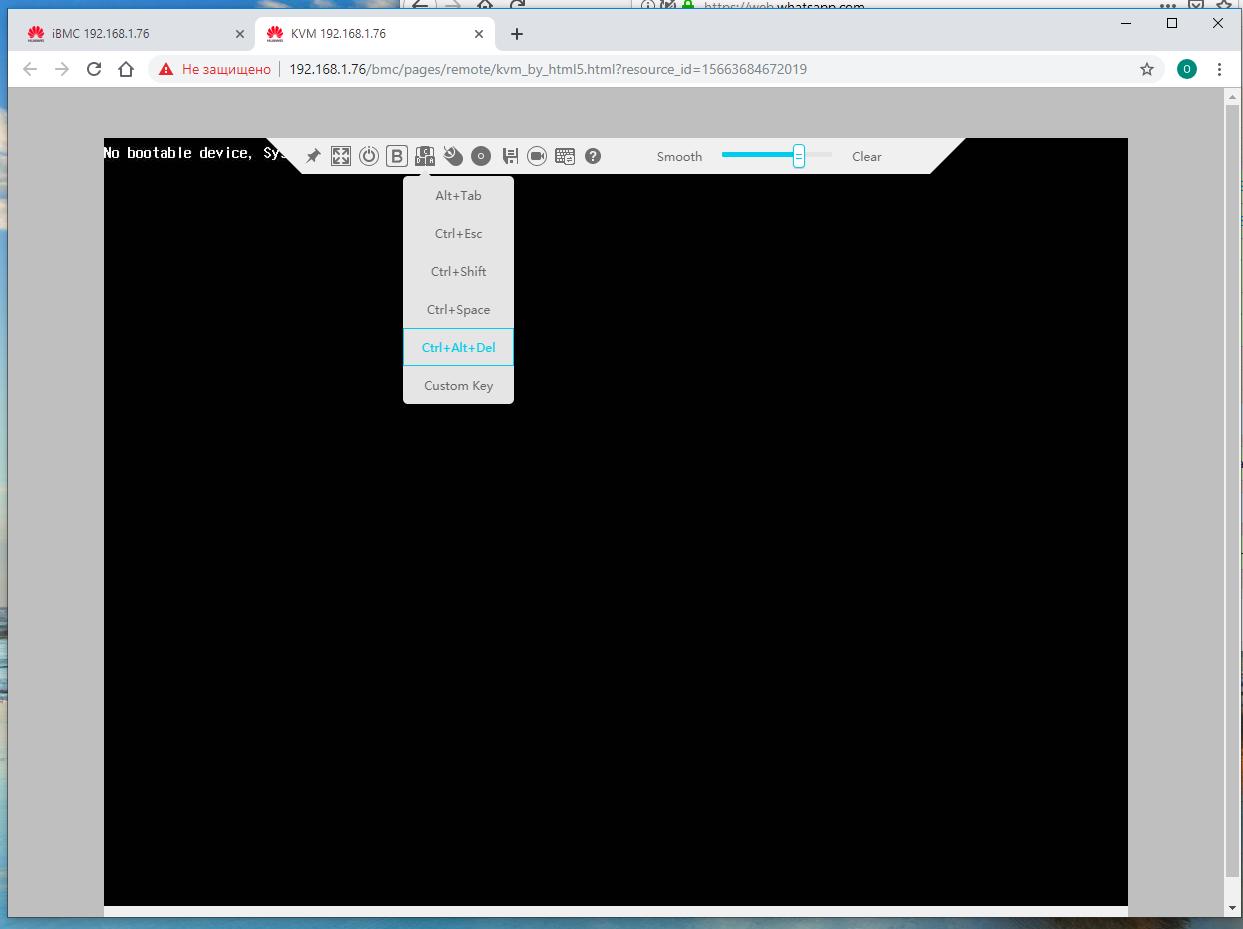
Перезагружаем свою серверную систему, например, через эмуляцию нажатия
Ctrl-Alt-Delв планке управления iBMC.
-
В окне терминала дожидаемся предложения от установленного ранее образа на его активацию. Жмём пробел, естественно.
Процесс загрузки пошёл. Следуем инструкциям производителя ОС.
-
Чтобы скрасить время в ожидании продолжения банкета, можно изучить планку управления. Например, функции удалённого включения - выключения - перезагрузки.

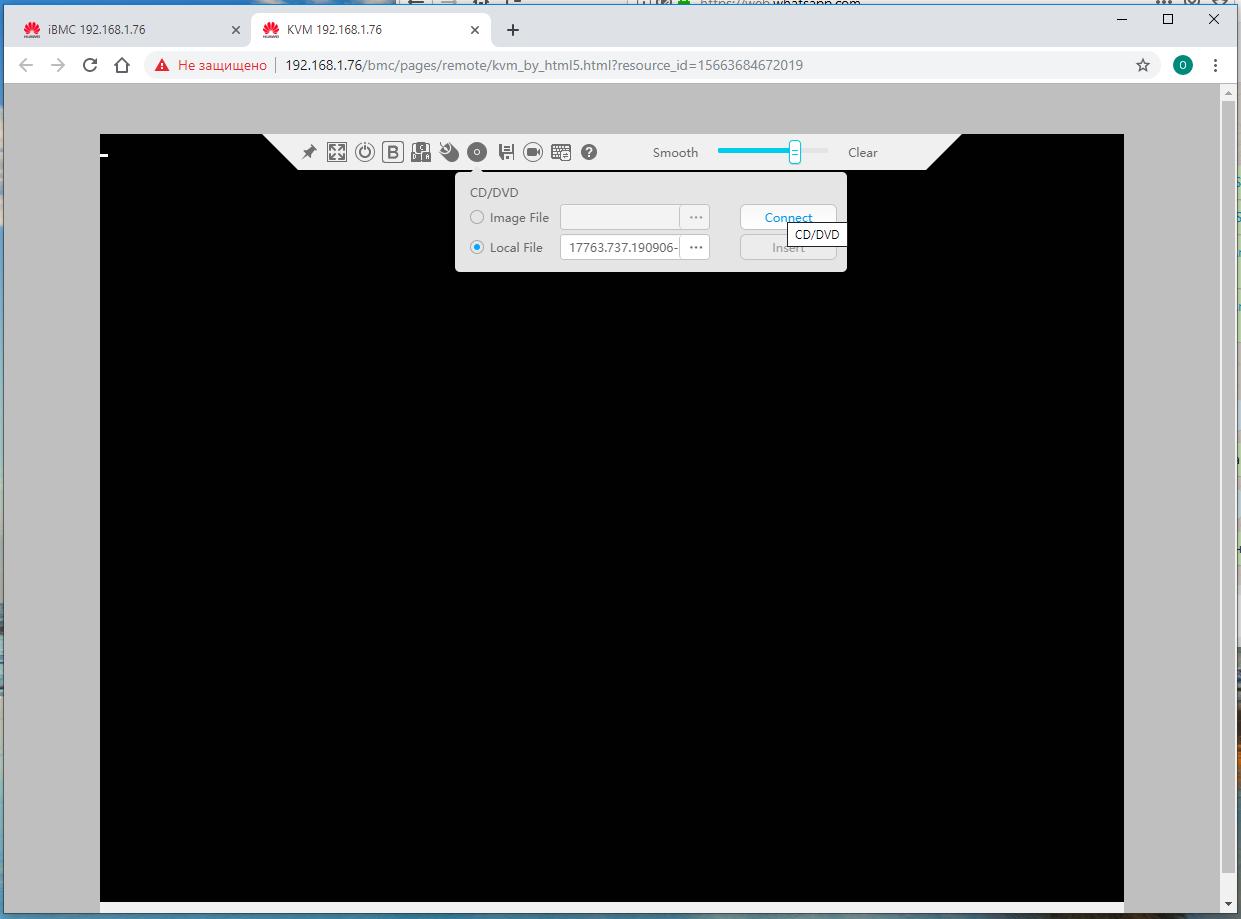
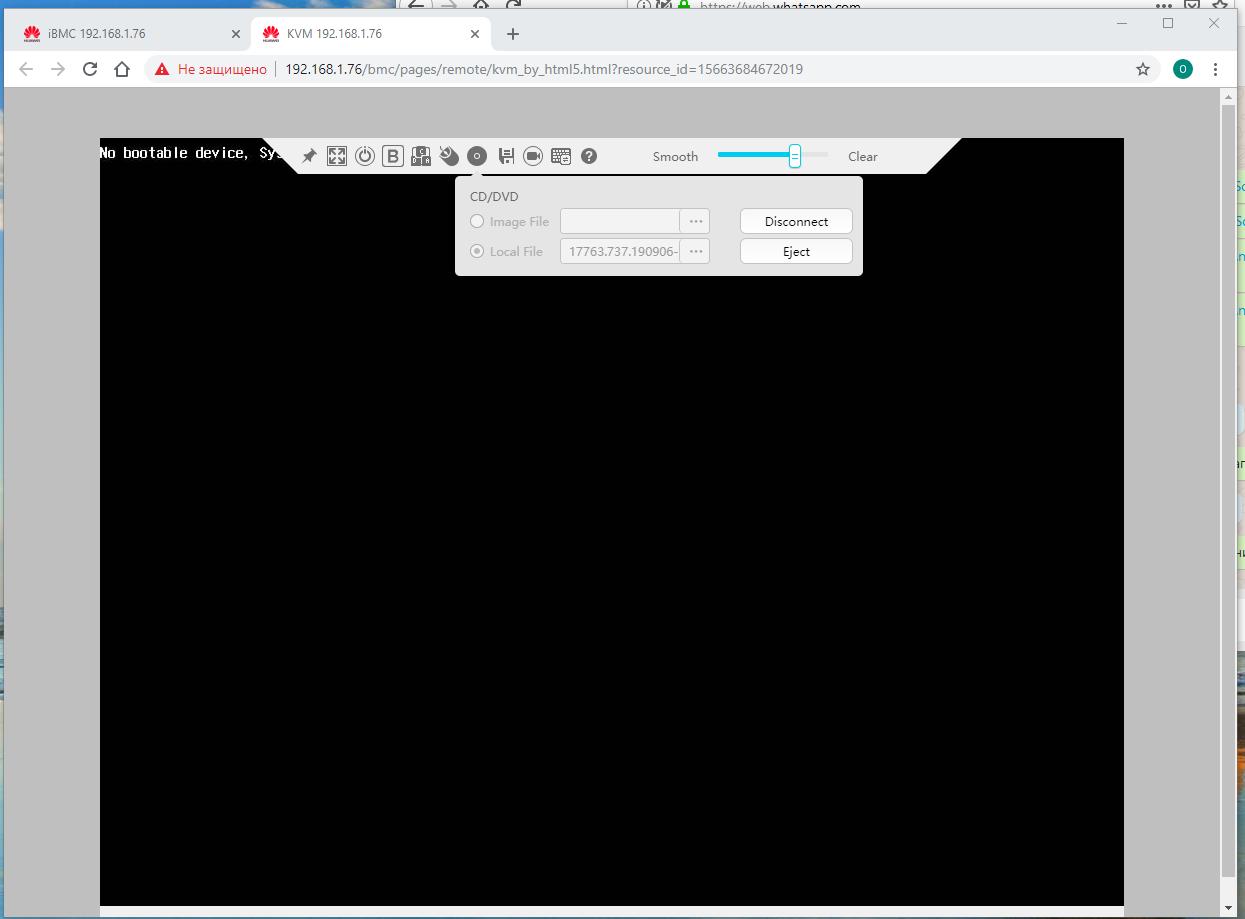
Пример установки сервера Supermicro
-
По умолчанию серверы Supermicro X11 приходят с предустановленной настройкой на получение данных от
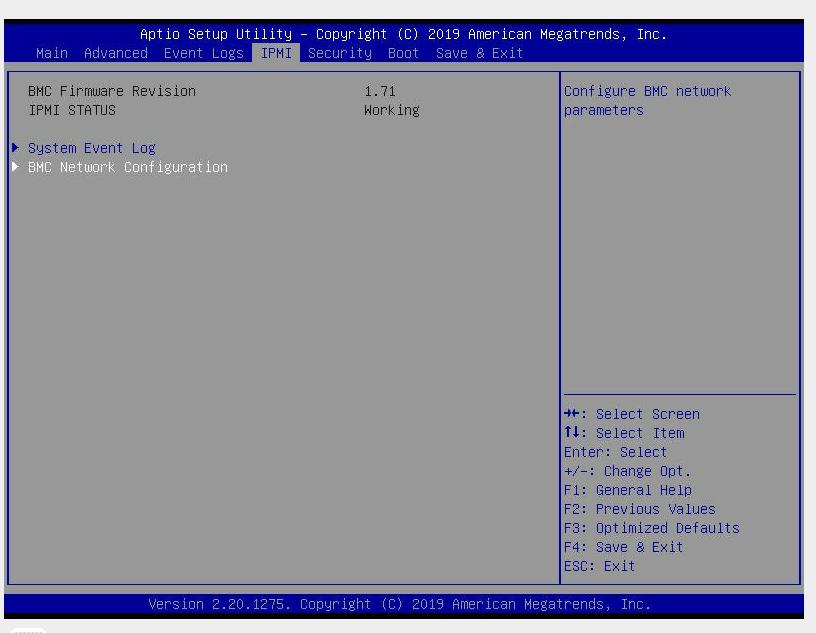
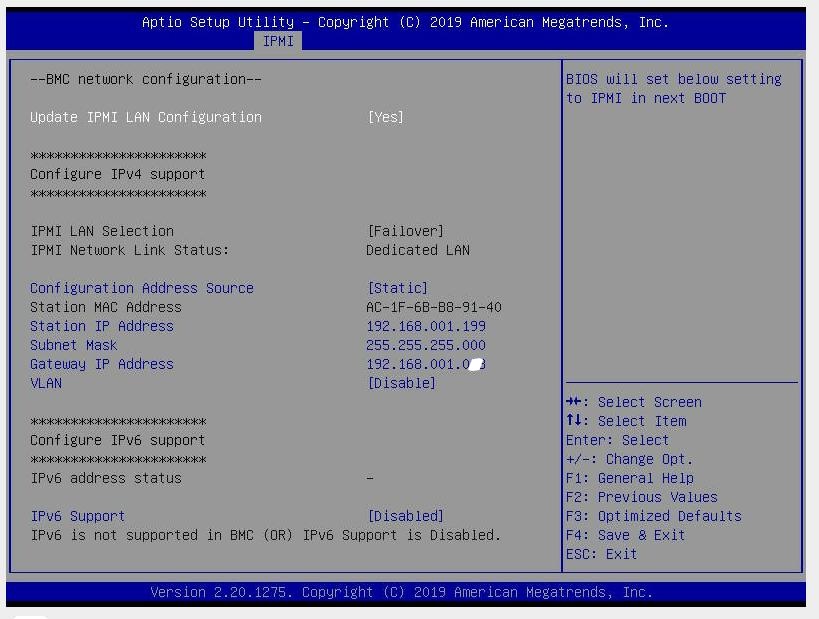
DHCP, если вас это не устраивает, можете заменить эту установку на подходящую вам статическую. Например, устанавливаем IP адрес своего iBMC равным192.168.1.199и остальные необходимые сетевые настройки. Это лучше сделать непосредственно в самом сервере.Для этого при загрузке сервера нажмите и удерживайте клавишу
DEL, когда появится экран настройки, пройдите в закладкуIPMI
-
и далее в
сетевые настройки BMC.
-
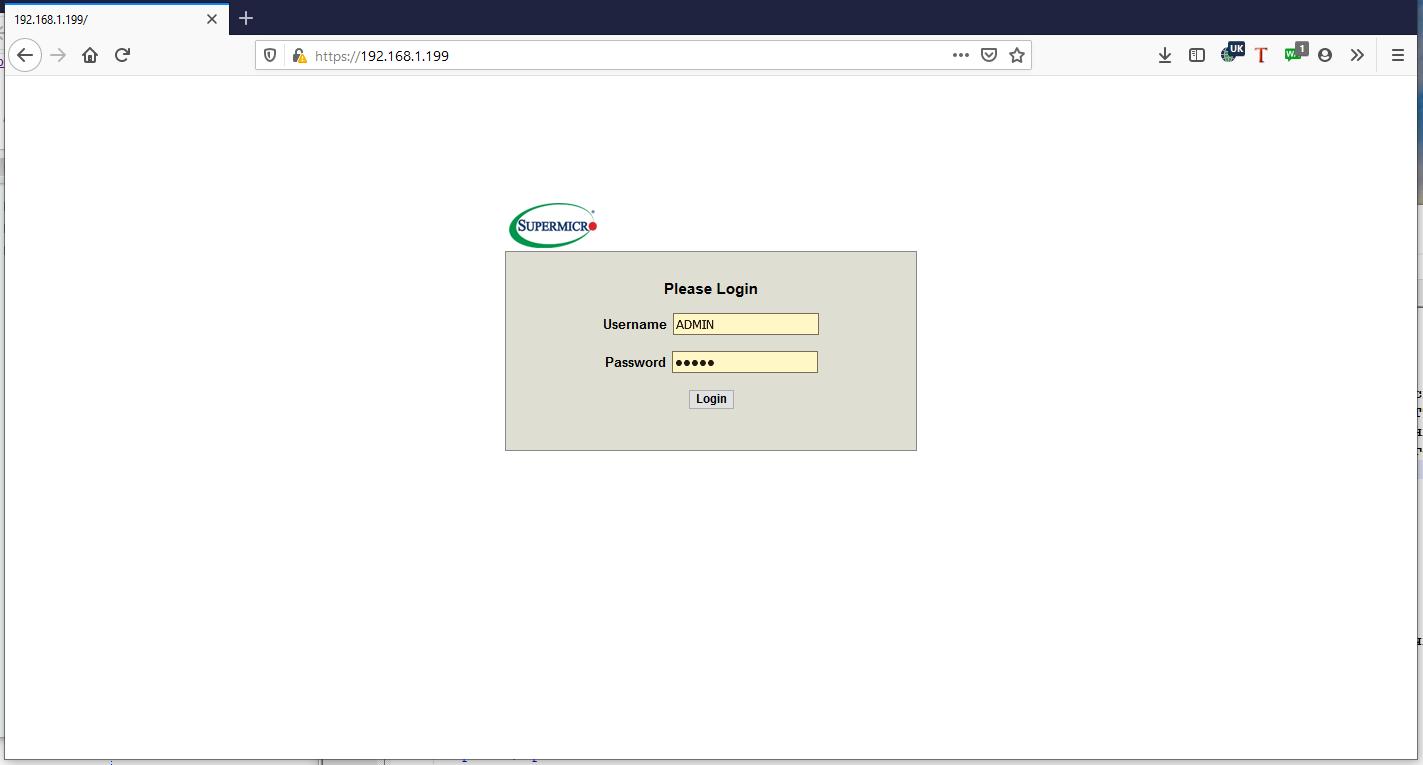
На своём рабочем месте открываем в браузере установленный на предыдущем шаге IP адрес, причём скорее всего вам придётся проигнорировать жалобы браузера на недоступность подтверждения ключа для протокола HTTPS.
В самом первом окне вам предлагается зарегистрироваться в качестве администратора. Регистрационные сведения по умолчанию, как и значение предустановленного IP адреса iBMC вы можете узнать у поставщика своего оборудования. Для серверов Supermicro X11 -
ADMIN, пароль -ADMIN.
Если вы конечный владелец системы, рекомендуем заменить установленный пароль и надёжно его запомнить.
-
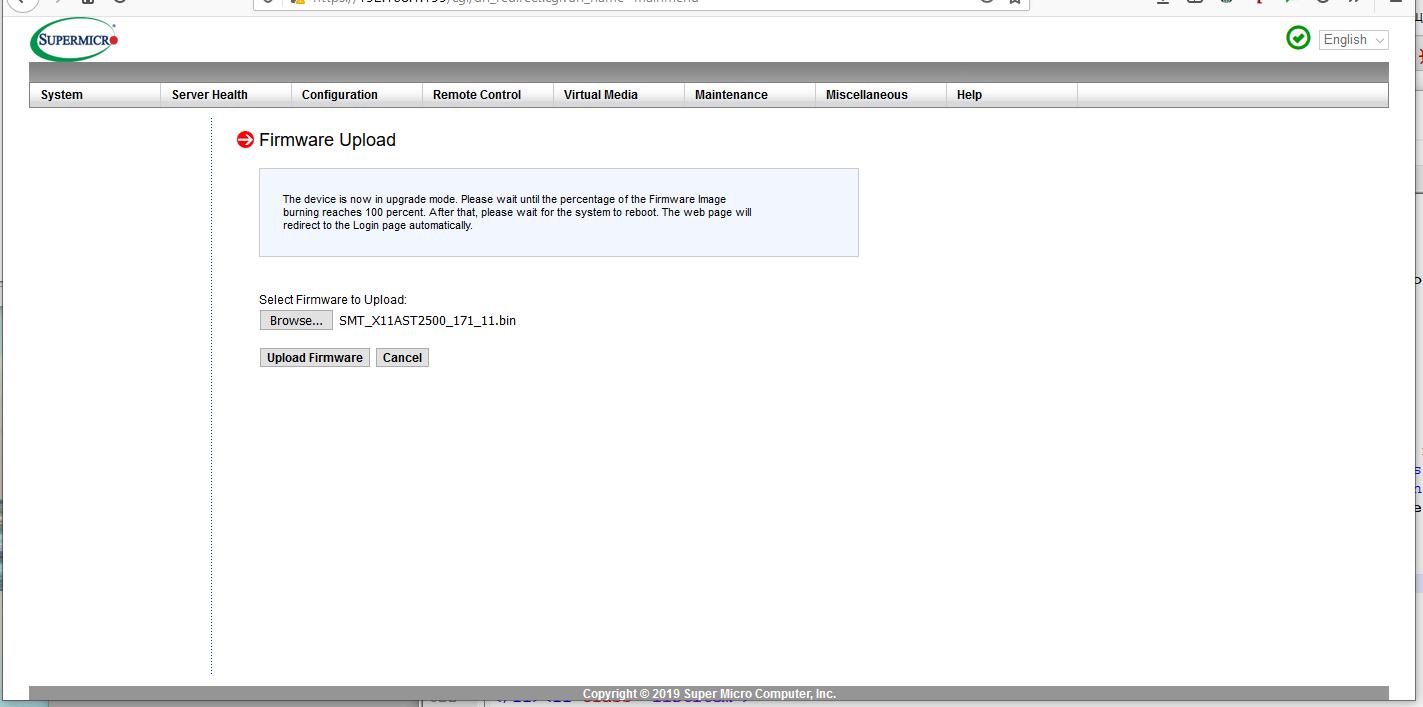
Настоятельно рекомендуем выгрузить с вебсайта производителя последнюю версию Firmware для вашей системы и обновить его в
Firmware UpdateзакладкиMaintenance. Для этого необходимо войти в режим обновленияEnter Update Mode, ответив согласием на подтверждение, выбрав черезBrouse...распакованный из выгруженного ранее архива двоичный образ Firmware и выполнить загрузку этого образа (Upload Firmware).
Дождитесь окончания процесса (порядка 60 секунд) и выполнения перезагрузки системы.
-
Перейдите к закладке Удалённого управления и выберите
iKVM/HTML5. В новом окне браузера загрузится консоль управления iKVM.
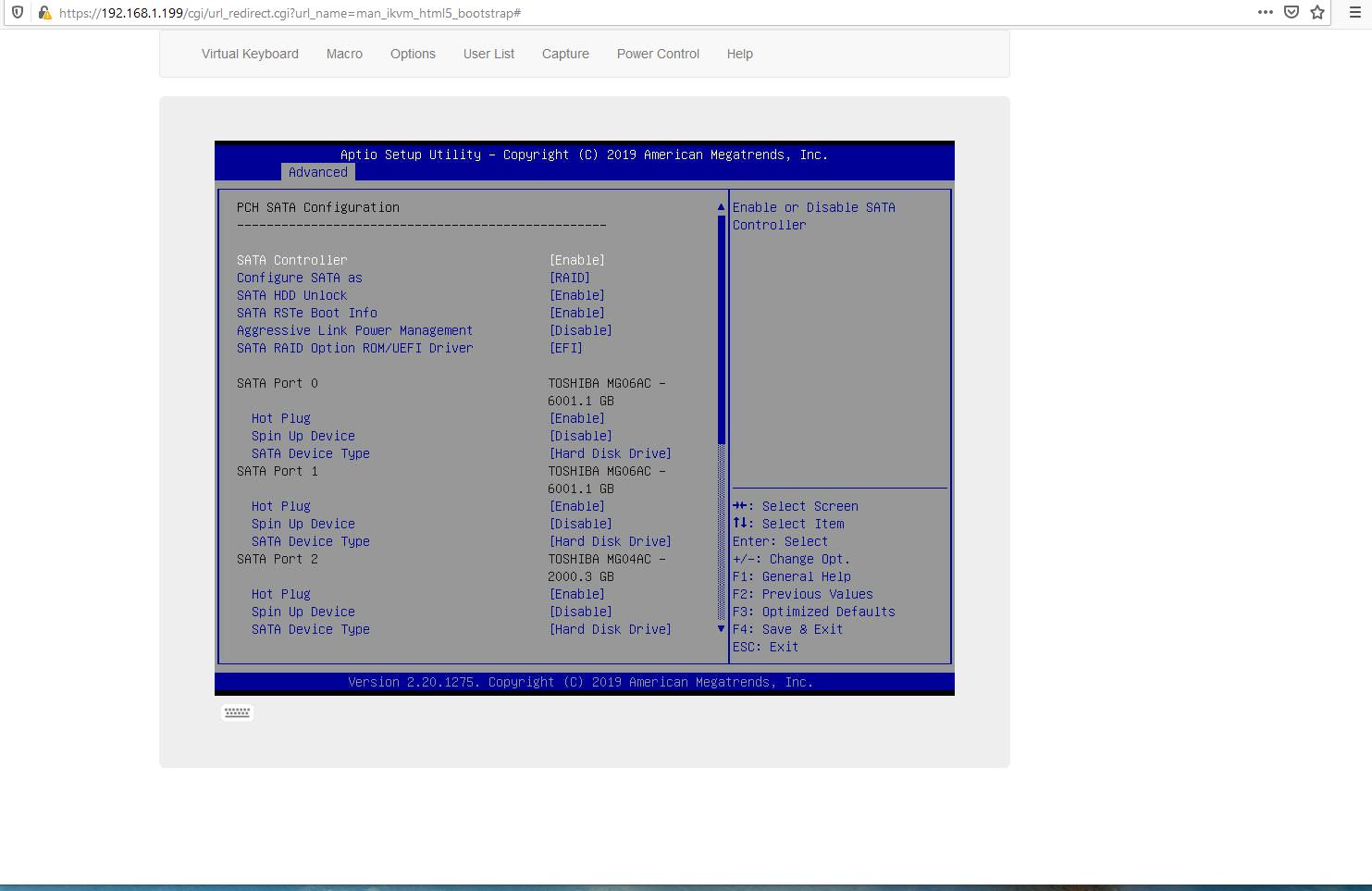
Разберитесь с дисками, если нужно, например, настройте RAID массивы. Intel VROC SATA контроллер имеет ряд не совсем очевидных особенностей. К примеру, чтобы он появился в закладке
Advancedменю BIOS, его необходимо включить через соответствующий пунктPCH SATA Configuration:
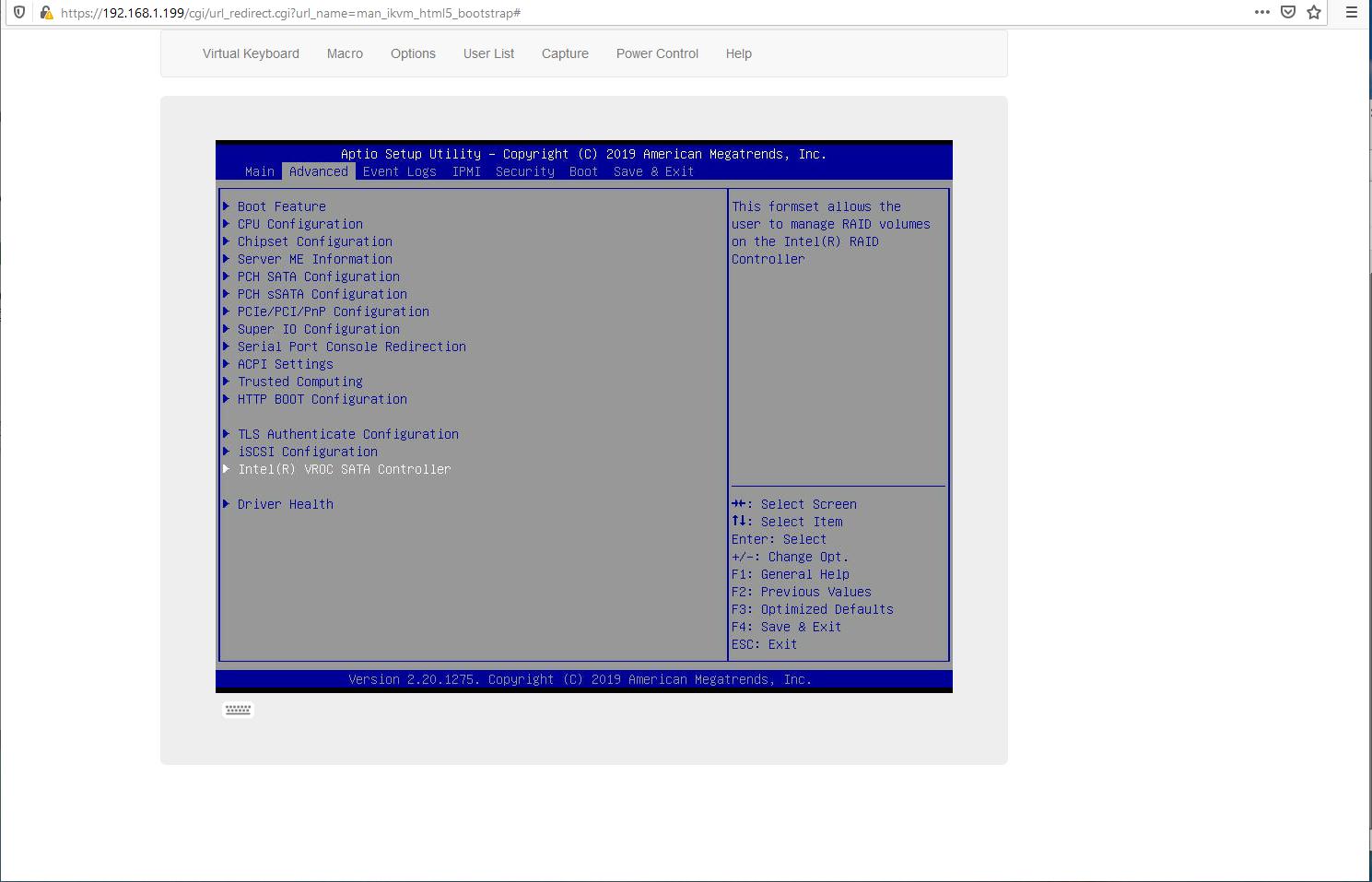
Это включит
Intel VROC SATA Controller:
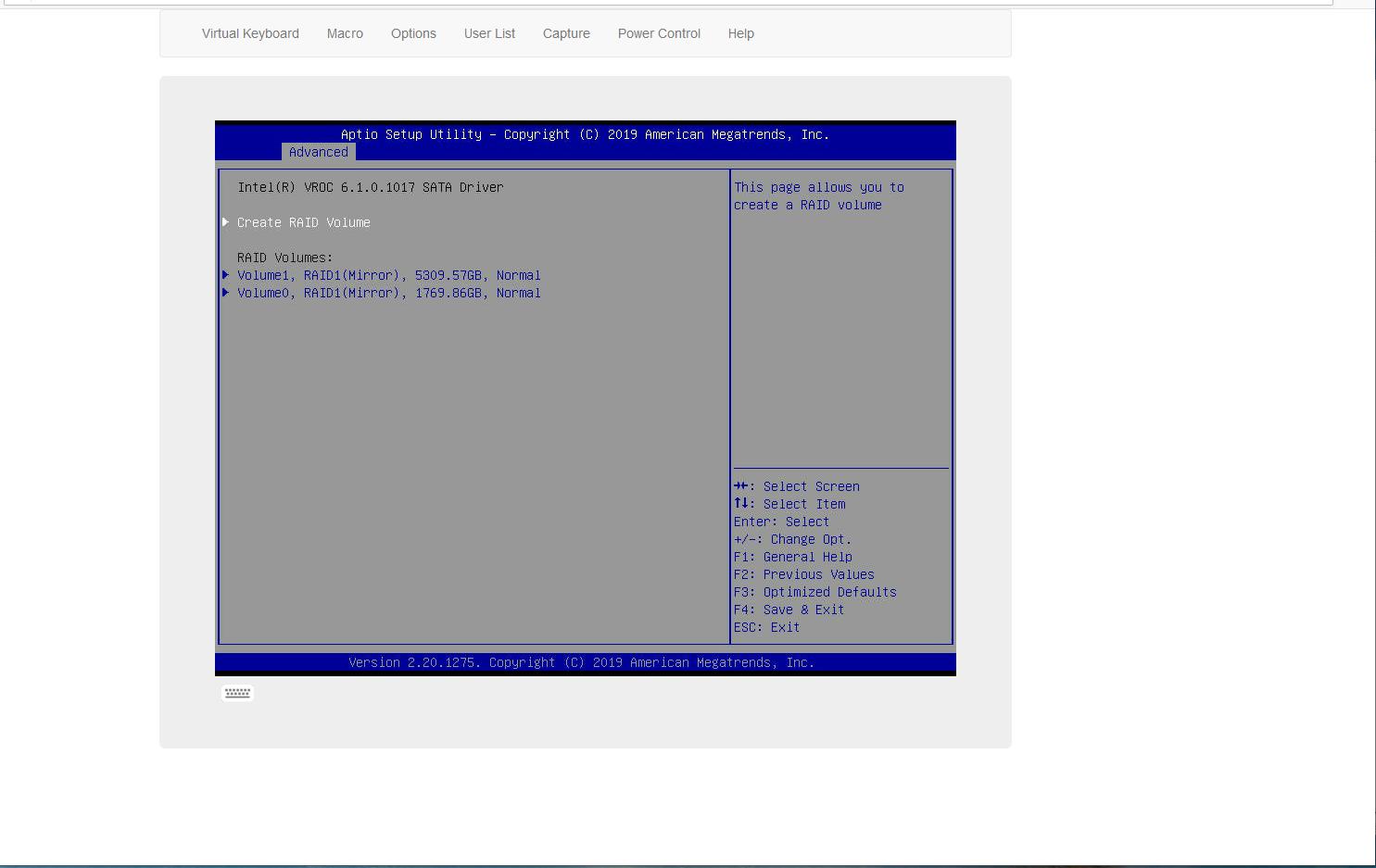
В котором вы и сможете создать нужные вам RAID тома:
-
В рабочей области отображается экран консоли, а сверху видна планка управления. Мы не будем останавливаться на всех её подробностях, предоставив это Вам.
Ваша система пребывает в собственной жизни. Вне зависимости от контроллера iBMC, который автономен.
-
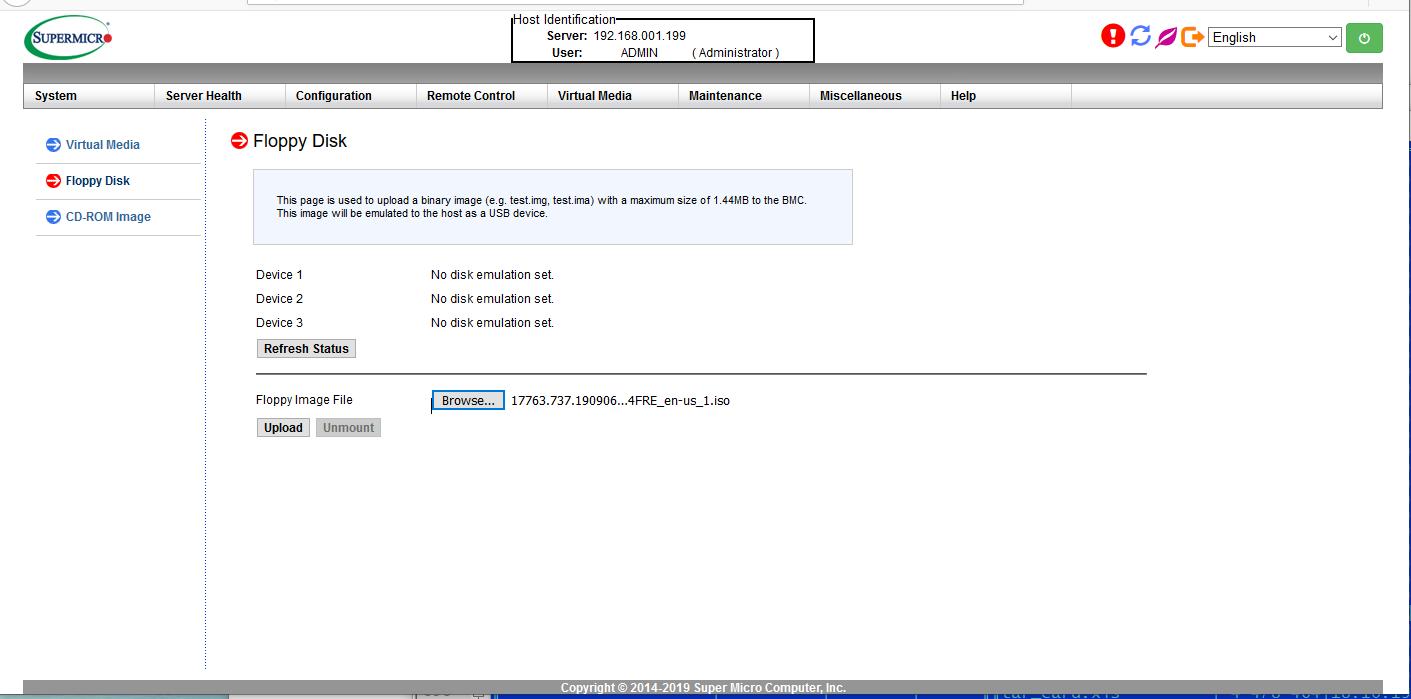
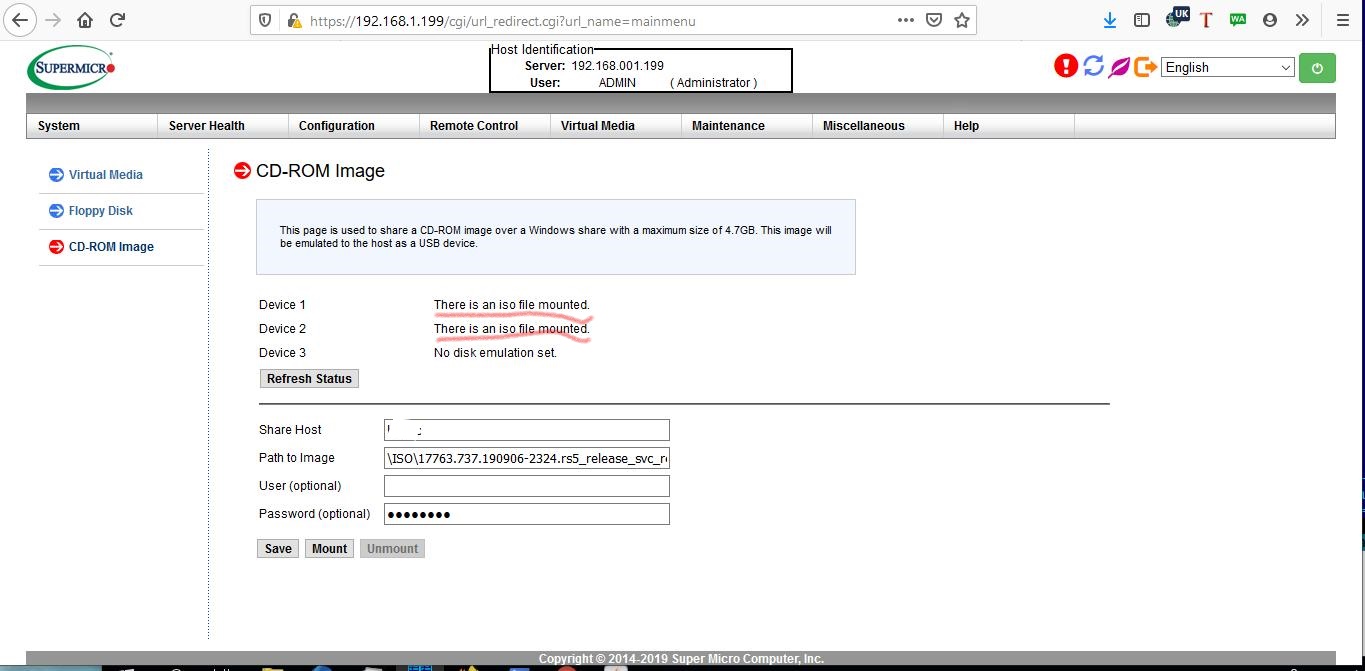
Возвращаемся в окно браузера с отображаемым управлением iBMC и в планке управления проходим к настройкам виртуального носителя через закладку
Virtual Media, в которой выбираем образ ISO для загрузки, например, локально черезCD-ROM Images, который должен видеться из iBMC как локальное USB устройство. В интернете имеются свидетельства того, что кому- то удалось добиться подключения виртуальных дисков с образами ISO через HTML5 (пример 1, пример 2 "видевших Ленина"):
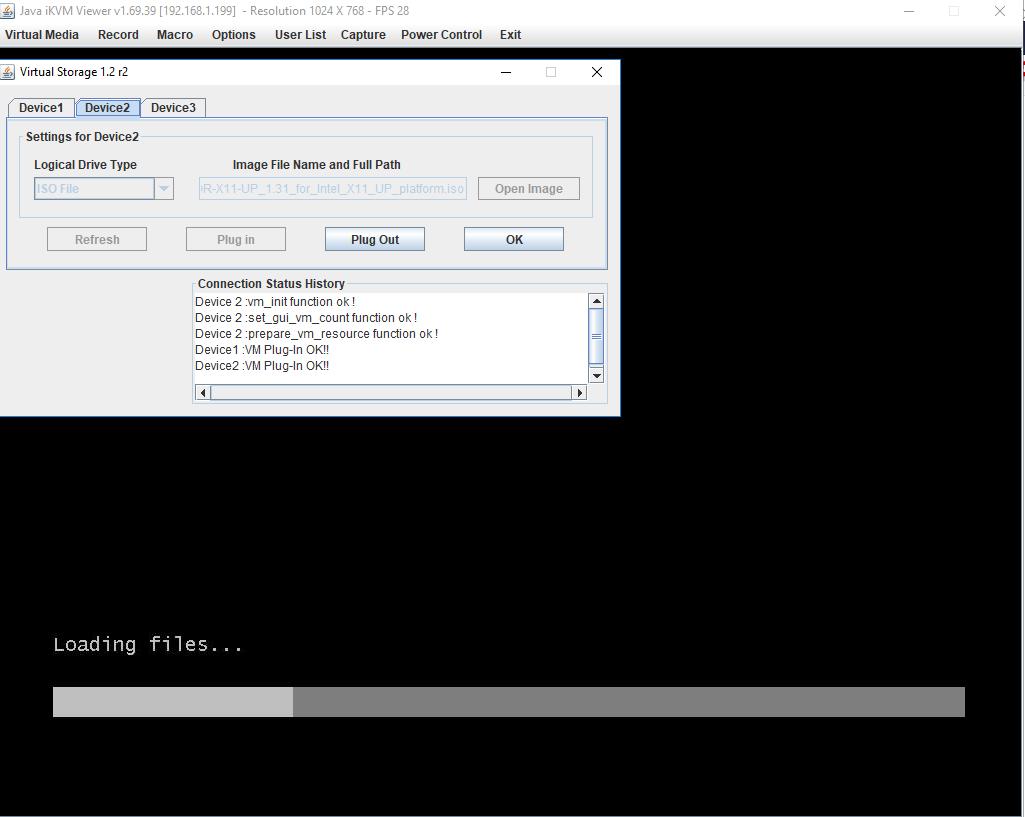
Однако, существует мнение, что это сказки и что Super Micro не умеет работать с виртуальным хранилищем iBMC через HTML5. Поэтому рекомедуется подключать образы к виртуальным дискам через консоль Java. И сразу, заодно с загрузочным образом рекомендуется вторым виртуальным диском цеплять диск с драйверами, чтобы можно было прихватывать всегда недостающие экземпляры.
-
Если вас раздражают моргания обилия окон Java, после монтирования через консоль Java образов в виртуальные диски iBMC/ iKVM, можно вернуться к более гладкому интерфейсу HTML5, убедившись в их подключении:
и продолжить работу через консоль
iKVM/HTML5.

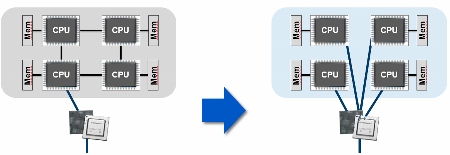 |
Бифуркация PCIe, при наличии соответствующей поддержки со стороны адаптера и его драйвера, делает возможным избежания "бутылочного горлышка" при использовании для обмена с таким адаптером шин PCIe только в одном адаптере. Её наличие в платформе помогает оптимизировать транспортные потоки данных и снижать уровень латентности. Например, слот PCIe, обладающий свойством бифуркации с 16ю lane PCIe может быть разделён на четыре части, по четыре lane каждому из четырёх имеющихся ЦПУ, в отличие от ситуации при которой все 16 lane, допустим, поступают в управление первому ЦПУ и весь обмен между вторым, третьим и четвёртым ЦПУ с таким адаптером должен осуществляться через первый ЦПУ, что увеличивает задержки и конфликты, а также отвлекает ресурсы первого ЦПУ. Пример использования: контроллеры PCIe в одном слоте, поддерживающие несколько NVMe устройств. |
Bull®
Bull Atos Technologies выпускает широкий спектр решений для применения в области высокопроизводительных и облачных приложениях от обычных монтируемых в стойку систем до блейд систем bullx b700 range с прямым жидкостным охлаждением и суперплотных решений bullx S6000 supernode.
Диапазон bullx R4xx снабжает вас семейством монтируемых в стойку эффективных в стоимостном выражении высокопроизводительных вычислительных модулей, поддерживающих непрерывную работу с с процессорами Intel® Xeon® И GPU NVIDIA® Tesla™ ИЛИ Intel® Xeon Phi™ самых последних моделей.
bullion™ состоит из диапазона 4 взаимодополняющих модулей на основе процессоров Intel® Xeon® E7 v4. Они совместно используют одни и те же инновационные технологии от 2 до 16 ЦПУ с максимальной ёмкостью ОЗУ до 24ТБ. Простым добавлением 3U модулей вы получаете доступ к конфигурациям, имеющим от 8 до 384 ядер для кластеров ВМ, критически важных баз данных или In-Memory приложений. Помимо этого, для большей динамичности, серверы bullion™ предлагают инновационную разработку подключаемых "по- горячему" лезвий памяти и ввода/ вывода. В довершение всего, bullion™ предоставляют блоки хранилищ, принимающие диски SAS/SSD или NL-SAS с ёмкостью до 2 ПБ на отдельный сервер. Такая среда хранения идеальна для приложений Hadoop или интенсивных аналитических расчётов. |
 |
Dell®
В качестве основных моделей платформ, рекомендуемых данным производителем под облачные решения выступают серверы Dell EMC PowerEdge R630 и R730xd.
Dell EMC PowerEdge R630 представляет собой монтируемый в стойку двухсокетный сервер PowerEdge R630 предоставляет бескомпромиссные плотность и производительность в 1U. Часть серверов PowerEdge 13го поколения, а именно R630, являются идеальными для виртуализации. Процессор и плотность памяти заполняющая до 24 DIMM DDR4 ОЗУ предоставляют великолепную пропускную способность оперативной памяти.
Dell EMC PowerEdge R730xd - Невероятная универсальность сервера PowerEdge R730xd обеспечивает выдающуюся функциональность всего в 2U стоечного пространства. При помощи семейства процессоров Intel® Xeon® E5-2600 v4 и до 24 DIMM DDR4 ОЗУ, R730xd имеет необходимые тактовые частоты и треды обработки для предоставления большего, крупнейшего и высоко- производительного хранилища для виртуальных машин. Широко масштабируемое хранилище, поддерживающее до шестнадцати 12Gb SAS дисков и высокопроизводительный RAID контроллер Dell PowerEdge H730, могут великолепно ускорить доступ к данным для вашей виртуальной среды.
Fujitsu®
Компания Fujitsu является традиционным игроком на рынке высокопроизводителных и облачных вычислений, являясь производителем широкого вида продукции, начиная с процессоров SPARC для серверов Sun/ Oracle и HPC систем, а также собственной системы интерконнекта Tofu, заканчивая мэйнфреймами BS2000 и широким диапазоном серверов с архитектурой x86 от простейших однопроцессорных серверов вплоть до отказоустойчивых систем с высочайшей в отрасли доступности линейки PRIMEQUEST. Особым образом стоит отметить проприетарную систему Ceph FUJITSU ETERNUS CD10000 S2, оставляющую, тем не менее, пользователю возможность отказа от сопровождения компанией и перехода к редакции сообщества.
Fujitsu PRIMERGY RX2530 M2 — это двухпроцессорный стоечный сервер, обеспечивающий высокую производительность благодаря новым процессорам Intel® Xeon® семейства E5-2600 v4, возможностям расширения до 1536 ГБ памяти DDR4 и подключения до 10 устройств хранения данных размером 2,5 дюйма. И все это в компактном корпусе высотой 1U. Таким образом, PRIMERGY RX2530 M2 является оптимальной системой для виртуализации и горизонтального масштабирования, небольших баз данных, а также для высокопроизводительных вычислений.
Fujitsu PRIMERGY RX2540 M2 — новый двухпроцессорный стоечный сервер высотой 2U, обеспечивающий высокие стандарты удобства использования, масштабируемости и экономической эффективности. Процессоры Intel® Xeon® семейства E5-2600 v4 в сочетании с технологией памяти DDR4 объёмом до 1,5 ТБ гарантируют увеличение производительности и удовлетворение требований к обработке данных в ЦОД, корпоративных приложениях, а также решениях для совместной работы. Модульная конструкция обеспечивает превосходную расширяемость – до 24 дисковых накопителей, до 8 разъёмов расширения PCIe Gen 3, а также, благодаря двум блокам питания с возможностью горячей замены, лучшую в своём классе энергоэффективность до 96%, обеспечивая возможность справляться с ростом объёмов данных в будущем. И наконец, технология DynamicLoM позволяет гибко конфигурировать сетевую инфраструктуру, обеспечивая возможность внесения необходимых изменений в будущем. Технология Cool-safe® Advanced Thermal Design обеспечивает работу сервера в условиях повышенной температуры окружающей среды, уменьшая текущие расходы.
Fujitsu PRIMERGY CX400 M1 помогает решить трудные проблемы, с которыми сейчас сталкиваются компании, исследовательские институты и институты развития. Система высотой всего 2U содержит до 4 серверных узлов, 8 процессоров Intel® Xeon® и 64 DDR4 памяти DIMM, обеспечивая самую высокую производительность и энергоэффективность. Расширением данного класса являются серверы Fujitsu PRIMERGY CX600 M1, являющиеся идеальным выбором для приложений, интенсивно использующих параллельные вычисления. Решение CX600 предназначено для высокопроизводительных вычислений в сфере научных исследований, разработки и бизнес-аналитики. Благодаря процессорам Intel® Xeon Phi™, поддерживающим до 72 ядер, этот модульный сервер предоставляет собой идеальное решение для рабочих нагрузок, при обработке которых требуется высокая степень параллелизма потоков, большие векторы и дополнительная пропускная способность памяти.
Inspur®
Inspur является одним из лидирующих поставщиков комплексных решений для центров обработки данных и облачных вычислений. Технологические возможности компании позволяют предоставлять полный стек услуг Cloud от IaaS и PaaS до SaaS. Мы получили широкое признание в качестве лидера в области вычислительной техники, а так же проектирования и производства серверного оборудования.
Inspur SmartRack может гибко настраиваться с разнообразными узлами, источниками питания с различным числом вентиляторов в соответствии с требованиями серверных помещений пользователя и свободно расширяет число узлов для соответствия различным требованиям приложений пользователя; Централизованное электроснабжение даёт преимущество, заключающееся в том, что совместное использование большим числом узлов привносит более высокую эффективность преобразования энергии и, следовательно, общие преимущества совокупного владения. Доставка стойки в сборе и централизованных функций удалённого управления, мониторинга и надзора могут существенно расширить эффективность внедрения оборудования: Традиционные серверы имеют эффективность ввода в эксплуатацию порядка 300узлов в день; SmartRack имеет эффективность 60~105 стоек в день, или до 4000 узлов в день. Эффективность такого развёртывания даёт в результате 10 кратное увеличение!
Huawei®
Тремя стандартными надёжными лошадками у этого производителя являются сервера RH1288/ 2288/ 5288, но помимо них рекомендуем обратить внимание на блейд- решение Huawei E9000v3, которое зачастую может оказаться более экономичным. Например, см. вариант реализации облачных вычислений в МФТИ (ГУ) в материалах презентации Национального Суперкомпьютерного Форума (НСКФ-2015), Переяславль- Залесский, 2015-11-25. А также представление решения 2016 года для кластера высокопроизводительных вычислений. Все серверы этого производителя поддерживают SATA DOM.
Huawei FusionServer RH1288 V3 - Стоечные серверы RH1288 V3 Huawei позволяют строить рентабельные, энергоэффективные, компактные и высокопроизводительные сети с упрощённым управлением и обслуживанием в 1U пространства.
Huawei FusionServer RH2288H V3 - Стоечный сервер высотой 2U оснащён двумя процессорами Intel® Xeon® E5-2600 V3/V4. Максимальное число модулей памяти DIMM DDR4 — 16, в одно шасси можно установить 16 жёстких дисков 3,5-дюйма или 28 жёстких дисков 2,5-дюйма. В каждый слот PCIe 3.0 (максимально 6) можно установить двухслотовую плату GPU. Использование твердотельных накопителей с интерфейсами PCIe и NVMe производства Huawei позволяет повысить скорость операций ввода-вывода по сравнению с жёсткими дисками. Сервер RH2288 V3 отличается оптимальным соотношением производительности и плотности размещения при высоте всего 2U.
Huawei FusionServer RH5288 V3 - Стоечный сервер высотой 2U оснащён двумя процессорами Intel® Xeon® E5-2600 V3/V4. Максимальное число модулей памяти DIMM DDR4 — 16, в одно шасси можно установить до 40 жёстких дисков 3,5-дюйма. Также применяет твердотельные накопителей с интерфейсами PCIe и NVMe производства Huawei. Сервер RH5288 V3 отличается оптимальным соотношением производительности и плотности размещения при высоте 4U.
Hewlett Packard Enterprise®
HPE предоставляет широкий диапазон современных решений для организации Программно управляемых решений Центров обработки данных. В качестве примера можно привести HPE OneView, которая является интегрированной конвергентной платформой, которая автоматизирует задачи и организует доставку обработки всего управления жизненным циклом имеющейся инфраструктуры по ресурсам вычисления, хранения и архитектуры связности. ИТ персонал может программно управлять ресурсами посредством унифицированного API, что делает простой интеграцию с рабочими потоками и применяемыми сегодня инструментами управления. В качестве типового аппаратного решения предлагается HPE ConvergedSystem 700, строящаяся на основе HPE ProLiant BL460 и/ или HPE ProLiant DL360/DL380. Подробнее см., например, Официальное техническое описание Эталонной конфигурации HPE для облачного решения SUSE OpenStack Cloud с HPE OneView.
В качестве промышленно законченного решения для построения облачных систем HPE предлагает систему Helion CloudSystem, предоставляющую автоматизацию, координацию и управление для множества облачных решений. Helion CloudSystem предоставляется в двух редакциях: корпоративной и редакции сообщества. Подробности в Официальном техническом описании ПО-как-служба с Корпоративной безопасностью HPE Helion CloudSystem, Интеграция службы Защитника безопасности приложений HPE с технологией OpenStack.
HPE ProLiant DL360 Gen9 Сервер HPE ProLiant DL360 9-го поколения поставляется с одним или двумя процессорами в корпусе высотой 1U. Это оптимальное решение, отличающееся высокой производительностью, низким уровнем энергопотребления, увеличенным временем бесперебойной работы и повышенной компактностью. В сервере используются новейшие процессоры Intel E5-2600 v4, повышающие производительность на 21%, а также новейшие модули памяти HPE SmartMemory DDR4 (2400 МГц) ёмкостью до 3 ТБайт, быстродействие которых выросло на 23%. Автоматизация наиболее важных задач управления жизненным циклом сервера DL360 9-го поколения при помощи ПО OneView и iLO упрощает развёртывание, обновление, мониторинг и обслуживание серверов в любой ИТ-инфраструктуре.
HPE ProLiant DL380 Gen9 Самый популярный в мире сервер стал ещё лучше. Сервер HPE ProLiant DL380 9-го поколения обеспечивает лучшие на сегодня производительность и масштабируемость. Надёжность, удобство обслуживания и практически постоянная доступность в сочетании с комплексным гарантийным обслуживанием делают его идеальным серверным решением в любой ИТ-среде. Поддерживаются устройства SAS 12 Гбит/с, сетевые адаптеры 40 Гбит/c и широкий набор вычислительных средств. HPE Persistent Memory является первой в мире энергонезависимой памятью DIMM (NVDIMM), оптимизированной для серверов ProLiant. Она обеспечивает исключительный уровень производительности для баз данных и рабочих нагрузок аналитических приложений. Сервер прост в развёртывании и подходит для работы как базовых, так и критически важных приложений.
HPE ProLiant BL460 Gen9 Блейд-серверы HPE ProLiant BL460c Gen9 поддерживают множество вариантов конфигурации и развёртывания. Они помогают оптимизировать работу основных приложений и обеспечивают необходимую ёмкость хранения для соответствующих нагрузок при низкой общей стоимости владения. Помимо всего прочего, поддерживаются различные варианты реализации многоуровневой системы хранения, в том числе накопители SAS 12 Гбит/с и NVMe M.2, сетевые адаптеры FlexibleLOM 20 Гбит/с и энергонезависимая память HPE ProLiant.
Lenovo®
Оборудование платформ Lenovo предоставляет идеальные решения для облачных размещений. Эти серверы предоставляют широкий диапазон формфакторов, свойств и функциональности, которые необходимы для соответствия потребностям малого бизнеса всех вариантов вплоть до больших корпораций. Lenovo также применяет корпоративные стандарты в управлении системами на всех этих платформах, которые делают возможной бесшовную интеграцию с инструментами управления облаками, например, такими как OpenStack, Proxmox, VMware, XenServer, Windows Server 2016. В качестве примера рекомендуем Эталонную архитектуру для платформы Red Hat OpenStack.
Lenovo System X3550 M5 - Универсальный монтируемый в стойку двухсокетный сервер высотой 1U годится для решения практически любой задачи — от поддержки инфраструктуры до обработки больших данных — с высочайшей степенью надёжности. Сервер укомплектован двумя процессорами Intel® Xeon® серии E5-2600 v4 (в максимальной комплектации, 44 ядра на систему), высокопроизводительной энергоэффективной памятью TruDDR4 и поддерживает подключение до 12 накопителей. На 22 % больше ядер, чем у предшественника и оперативная память частотой до 2400 МГц. Сервер x3550 M5 не просто работает — он летает.
Lenovo System X3650 M5 Этому мощному универсальному монтируемому в стойку серверу в форм-факторе 2U с двумя сокетами можно доверить ещё больше круглосуточных бизнес-задач и быстрее получить качественные результаты. Благодаря двум процессорам серии Intel® Xeon® E5-2600 v4 (до 44 ядер на систему), высокопроизводительной памяти TruDDR4 2400 МГц и большому объёму хранилища сервер x3650 M5 исключительно силен в работе. На выбор предлагается впечатляющий набор конфигураций хранения (до 28 отсеков для дисков) для решения самых разнообразных задач — от облачных вычислений до обработки больших данных.
Mdl®
Если одним из ваших основных критериев является экономия стоимости, либо вам необходимы конфигурации, обладающие специфическими требованиями, мы готовы прийти вам на помощь. Самые разнообразные платформы по вашему выбору доступны из наших собственных производственных мощностей с предоставлением сервиса по всей территории РФ и ряда зарубежных стран. Полный диапазон решений от 1U до полнофункционального ЦОДа, включая решения для домашнего пользования.
Если Вам нужно уложиться в некий ограниченный бюджет, например, в 100-150 тыр. за монтируемый в стойку сервер, Вы не ошиблись адресом!
Если коротко, то в отношении дисковых устройств в настоящее время надо:
-
отказаться от RAID- контроллеров;
-
заменять 15rpm жёсткие диски на SSD;
-
применять SAS вместо SATA;
-
оценить возможность использования NVMe;
-
использовать RDMA и прочие прелести современной сетевой среды;
-
не забываем про SATA-DOM.
Давайте по порядку. RAID контроллер является существенно интеллектуальным устройством. По этой причине он вносит значительную латентность в сохранение данных, что уже не очень хорошо, а также связанные с этим проблемы: энергонезависимость, согласованность данных и т.п. Помимо этого, RAID контроллеры, как правило, маскируют внутренние данные самих устройств (например, S.M.A.R.T.), что никак не способствует их централизованному мониторингу и попыткам предсказания необходимости замены. Да, диски- расходный материал. К этому надо привыкать и современные системы хранения работают именно исходя из этого. Эпоха RAID контроллеров была обусловлена неспособностью процессоров и каналов памяти справляться с задачами, сопровождающими процесс сохранения данных. Сегодня это уже не так. Все возможные массивы хранения данных можно строить поверх самих устройств хранения. При этом даже самые сложные задачи вычисления избыточных контрольных сумм прекрасно выполняют имеющиеся в изобилии ядра ЦПУ. Помимо этого, на арену выходят технологии ASIC по разгрузке ЦПУ от вычисления подобных контрольных сумм. Так что, по возможности, воздерживаемся от применения RAID контроллеров и переходим на HBA контроллеры. Что, кстати, может оказаться существенной экономией. Общая идея: хранилища нам нужны чтобы как можно быстрее выполнять с ними необходимые операции ввода/ вывода, причём со 100% надёжностью. Всё лишнее на этом пути надо удалять.
Некоторые производители жёстких дисков (а их и так не сильно больше трёх!) уже прекратили выпуск дисков с 15 тысячами оборотов шпинделя в минуту. Они всё равно медленнее и при этом дороже чем SSD. Так что, до свидания, 15k! Наверное, эта тенденция сохранится (10k 2.5", например).
Современные шпиндельные NL- диски, наконец- таки, имеют разницу в стоимости моделей SAS и SATA всего в несколько долларов США. Это при том, что когда вы создаёте серьёзное промышленное решение, вы, скорее всего, применяете именно SAS контроллеры, рассчитывая подключать в одном шасси достаточное число дисковых устройств и при этом предоставить им широкую полосу пропускания при избавлении конкуренции за канал доступа к шинам более верхнего уровня (PCIe, например). Так что, не лишайте себя возможности организации множества путей! Не забываем суммировать пропускные способности всех дисковых устройств и сопоставлять их с имеющимися каналами: помним, что самая напряжённая работа ожидает ваши диски именно после выхода из строя одного из своих собратьев: им необходимо восстановить всю имевшуюся на умершем информацию (см. таблицу). Кстати, именно по этой причине в качестве стандарта хранения в настоящее время, как правило, принято иметь две копии (три экземпляра данных, аналог RAID6) - при восстановлении данных увеличивается вероятность выхода из строя ещё одного устройства хранения!
В то время, как SATA/ SAS диски (как шпиндельные, так и SSD) ограничены единственной очередью команд AHCI, новый интерфейс NVMe допускает 64k очередей, причём по 64k команд в каждой. Во многом это обусловлено отказом от традиции адресации цилиндр- головка- сектор. Лежащие в основе твердотельных устройств хранения микросхемы, как и оперативная память, имеют прямую адресацию! Итак, интерфейс NVMe освобождён от необходимости большей части блокировок, сопровождающих наши шпиндельные устройства, которые вынуждены оптимизировать доступ головок к цилиндрам вращающихся пластин диска. И всех сложных алгоритмов их сопровождающих, часть из которых незаслуженно перекочевала в имеющиеся сегодня SSD диски. Осталось дождаться снижения уровня жадности производителей контроллеров NVMe. Для оценки рынка имеющихся решений советуем ознакомиться с обзором Huawei, делая скидку на право автора быть первым. По крайней мере в помыслах. Считаем бюджет и сопоставляем со своими потребностями.
SMB3 может работать поверх RDMA и при этом применять несколько соединений в одном канале (многоканальность), а также выполнять шифрование AES 128 CCM и проверку целостности предварительной аутентификации с применением хеширования SHA-512, что существенно увеличивает производительность данного метода доступа. В настоящее время со стороны SMB3 применяются две реализации RDMA: RoCE (RDMA over Converged Ethernet) и iWARP (internet Wide Area RDMA). Разгрузкой ЦПУ от обработки сетевых пакетов при соответствующей настройке драйвера сетевого интерфейса (или микрокода/ firmware соответствующего устройства) и наличии такой аппаратной поддержки, призван заниматься TOE (TCP Offload Engine, механизм разгрузки TCP. Помимо этого, существенный вклад в производительность привносят DCB (DataCenter Bridging) и PFC (Priority Flow Control). DCB представляет собой последовательность стандартов, которые определяют механизмы контроля потока данных и управления полосой пропускания в сетевой среде, что, в конечном итоге, способно обеспечить требующиеся вам уровни качества обслуживания. Отсутствие DCB, например, потворствует созданию мифа о том, что FC имеет в разы большую пропускную способность в сравнении с FCoE при сопоставимых пропускных способностях каналов. Если вы собираетесь применять iSCSI- вам определённо необходим DCB. В конечном итоге, всё что мы здесь обсуждаем относится к понятию гиперконвергентности. И, по всей видимости, не далёк тот день, когда мы сможем подключать дисковые устройства напрямую в среду Ethernet. Если оно нам потребуется.
О пользе таблеток SATA- DOM мы уже говорили, обсуждая процесс загрузки платформ. Нельзя не упомянуть их здесь, поскольку они освобождают нас от выделения полноценных "карманов" 1.8/2.5/3.5 дюйма под операционную систему на сервере, основная цель которого быть хранилищем данных! Достаточно одной таблэтки. А две ещё лучше!
Мы собираемся раскрыть Вам страшную тайну. Великую тайну. Большой секрет чёрного ящика, под названием система хранения данных. Если Вы ещё не являетесь обладателем этого сокровенного знания. А вдруг? Конечно, мы, как системный интегратор, абсолютно ничего не имеем против выпускаемых ведущими мировыми производителями хранилищ. Мы готовы порассуждать о громадном количестве преимуществ VxWorks в качестве бортовой операционной системы и неустанно повторять вслед за вендорами истории разработки микрокодов, алгоритмов и ухищрений, которые позволяют Вам спокойно спать по ночам, а порой даже покидать свой Центр обработки данных на более длительный срок и отправляться в отпуск, где Вы лишь изредка следите за парой ключевых параметров. Ну, парой десятков, да. Ленивые ждут звонка с сообщением об отключении электропитания. Ещё более ценное в этих системах то, что если с ними что- то и происходит, то все вопросы идут в центр тех поддержки. Да. Пока вы её оплачиваете. Но стоимость этой поддержки растёт вместе с возрастом системы. Хорошо, когда, как в случае с уже упоминавшейся FUJITSU ETERNUS CD10000 S2 вы можете осуществлять самостоятельно осуществлять поддержку при помощи открытого сообщества по окончанию платежей за сопровождение производителю. Да мы верим в это. Или очень хотим верить. Ведь иногда дающая деньги рука вдруг пропадает. А системе хранения уже немало лет. И падают сразу оба контроллера с супернадёжными x86 процессорами сразу оба. И кэш пропадает. Так, например, недавно было у наших коллег на одной системе хранения очень известного производителя. Постойте, x86? А что ещё знакомого? Заглянем- ка вовнутрь! Наши коллеги смогли вытащить данные, так как внутри оказался ZFS. Внезапно вдруг.
Самая большая тайна состоит в её отсутствии. Да, большинство систем хранения в своей основе применяют программные средства с открытым исходным кодом. Да, производитель дотачивает её. Но современные программные средства позволяют Вам строить мощные системы хранения своими руками. Страшно? Но ведь Вы же использовали Novell NetWare, а потом и Windows Server в качестве своего файлового сервера? Да, теперь и системы хранения с открытым исходным кодом умеют копировать- при- записи (CoW), дедуплицировать данные, моментально выполнять репликации и разделять золотой виртуальный диск между тысячами пользователей. Маленькая "площадь для атак" злоумышленников в системах типа VxWorks? Наносервер Windows server 2016 готов поспорить крошечностью своих размеров! Но мы забегаем вперёд. Чтобы научиться плавать надо зайти в воду. И вы поплывёте. Не сразу и не баттерфляем. Но уж Пространства хранения Microsoft вам точно построит. А может вы и утонете без инструктора по плаванию рядом. В общем, если вы хотите строить свои облачные решения на проприетарном железе мы не будем возражать! И готовы подобрать Вам самое лучшее. Тем более, что системы хранения нижнего уровня сегодня уже научились выполнять большую часть функционала, который совсем недавно умело делать только самое дорогостоящее оборудование.
Сетевая среда является "кровеносной системой" всякого центра обработки данных, в том числе и программно- управляемого. Как правило, она распадается на ряд независимых сетей, которые имеет смысл разделять. По целому ряду причин: безопасность, гарантирование пропускной способности, различные требования к функционированию и тому подобным. По своей архитектуре они тоже могут различаться. Наиболее распространёнными в настоящее время являются: EthernetInfiniBand, OmniPath, FibreChannel, а также целый ряд проприетарных разработок, из которых, в качестве примера, мы остановимся на самой интересной для отечественного потребителя - Ангаре. Более подробно каждую из этих сред мы рассмотрим далее по тексту, пока же перечислим ряд наиболее распространённых сетевых сред, напрашивающихся на обособление:
-
Внешняя сеть: Естественным предназначением всякого Центра обработки данных является обслуживание запросов и услуг для внешнего мира. Даже Высокопроизводительный вычислительный кластер должен принимать некие входные данные и выдавать наружу результаты расчётов, в том числе и при работе в сугубо пакетном режиме. Хотя при современном уровне развития VDI, как мы увидим позже, уже существует возможность работы с Высокопроизводительными вычислениями в реальном масштабе времени. В любом случае, нашему вычислительному ресурсу требуется связь с внешним миром. Именно для решения этой задачи и предназначается данная сетевая среда. В силу её универсальности априори, как правило, она строится на базе архитектур Ethernet.
-
Сеть управления: Центр обработки данных, по своей природе, состоит из целого ряда отдельных устройств. Это серверы, системы хранения, коммутаторы и тому подобные устройства, составляющие ядро. Как правило, все эти коробки имеют собственный порт управления. Обычно он отвечает стандарту IPMI. Помимо них в процесс сопровождения может быть вовлечена целая масса датчиков контроля окружающей среды, управления инженерными системами, видеонаблюдения и тому подобного. Очевидно, что к циркулирующей здесь информации должен быть допущен строго ограниченный контингент. И здесь также основной средой является Ethernet. Даже если некоторые приборы и датчики применяют разнообразные специфические интерфейсы типа RS232/ 485, датчиков сухих контактов и т.п., для их сбора зачастую применяются некие концентраторы, которые в последующем передают эти данные в Ethernet среду управления.
-
Сеть авторизации: Вполне допустимо выделение задач аутентификации и авторизации как персонала, так и устройств в отдельную сетевую среду, например, для решения вопросов безопасности.
-
Сеть начальной загрузки: По своему функциональному назначению, а также предъявляемым к ней требованиям, зачастую близка к сети управления. Однако, в отличие от неё может требовать более существенных значений для полосы пропускания. Понятно, что в ней необходима поддержка PXE или чего- то аналогичного.
-
Сеть хранения: Может включать в свой состав и приведённую выше сеть начальной загрузки, так как также должна обладать значительной полосой пропускания. Помимо этого, решает задачи сохранения контрольных точек и результатов расчётов, миграции приложений и виртуальных машин в реальном времени, предоставления разнообразных реплицированных данных, в том числе баз данных. Специально для этих целей и разрабатывалась архитектура Fibre Channel, однако в настоящее время и Ethernet, и Infiniband, а также подобные ему решения, способны предоставлять конвергентные решения, успешно решающие все задачи среды передачи данных и при этом при существенно более низких стоимостных затратах. Для данного класса сетевых инфраструктур существенной является ширина полосы пропускания, а также предоставление некоторого заранее определённого минимума уровня качества обслуживания (QoS) для всех участников, гарантии доставки данных и т.п.. Порой важное значение имеет и латентность (временные задержки на выделение канала доступа).
-
Сеть резервного копирования, репликаций и восстановления: По своей природе близка к Сети хранения, однако решает отличные задачи, для решения которых рекомендуется обособлять данную среду от той сети хранения, которая осуществляет все рабочие процессы в сети хранения. Если, скажем, задачи резервного копирования ещё могут быть отнесены по времени суток и дня недели на те периоды, когда в Сети хранения отсутствуют пиковые рабочие нагрузки, задачи репликации данных, как правило, решаются в реальном масштабе времени или близком к нему режиме и могут совмещаться с наличием пиковых нагрузок в Сети хранения. Задачи восстановления, например, могут возникать в случае выхода из строя отдельных накопительных устройств. Причём, в силу значительной ёмкости таких устройств (уже сейчас измеряемых терабайтами с предпосылкой всё более широкого освоения двузначного диапазона в терабайтах для отдельных устройств), эти задачи способны потреблять на часы и сутки всю имеющуюся полосу пропускания, что подводит к неизбежности обособления данного вида обмена. Что важно отметить, так это то, что выход из строя накопителей имеет слабо предсказуемый характер и может происходить в самые напряжённые часы работы. Кстати, именно этим во многом объясняется почти повсеместный переход на тройной стандарт хранения данных (как в виде репликаций, так и в виде контрольных сумм). Именно в моменты восстановления устройства хранения могут испытывать наивысшие уровни нагрузок, тем самым повышая вероятность отказа из строя резервной копии, с которой и осуществляется процесс восстановления.
-
Низколатентная сеть с высокой пропускной способностью: Требования низкой латентности (малых значений времени предоставления канала связи между устройствами) характерно, например, для взаимодействия между собой процессоров, занимающихся обработкой данных. На сегодняшний день показатели латентности для отдельно взятых чипов коммутации (ASIC) составляют значения, исчисляемые десятками наносекунд.
До недавнего времени пальму первенства здесь держали ASIC InfiniBand, однако выпущенные в 2015г и поступившие в продажу ASIC OmniPath (или Intel OPA), обладают преимуществом, достигающим согласно некоторых отчётов 56%. Для данного класса коммутаторов важно понятие отсутствия блокировки, другими словами, возможности предоставления каждому участнику данного сетевого окружения всегда иметь доступ к любому свободному для контакта другому участнику среды. Верхнее решение для такой среды предоставляют Clos - сети (Чарли Клос, 1952), позволяющие реализовывать полностью неблокируемый доступ. Однако, на практике зачастую осуществляется построение так называемых "толстых деревьев", дающих приемлемые решения (см. например, наше решение 2016г или более общее обсуждение в статье Fujitsu Laboratories разработала технологию уменьшения на 40% числа сетевых коммутаторов в кластере суперкомпьютеров). Здесь важным фактором при борьбе за понижение значений латентности в среде коммутации становится значение числа портов в ASIC. На сегодняшний день оно составляет 36 для InfiniBand Mellanox и 48 для Intel OmniPath. Стоит отметить, однако, что Intel OmniPath при этом пока уступает в вопросах разгрузки центрального процессора (в том числе, отсутствие RDMA).
Такого рода сетевые среды, как правило, накладывают достаточно жёсткие условия на радиус их действия. Причём определяется это не столько ограничением технологий (оптические соединения допускают значительное удаление устройств), сколько ограничениями скорости света (3 метра для 10 наносекунд).
-
Сеть с гарантированным временем доставки: представляет собой некий уровень абстракции, отвечающий решению задач сбора данных и организации процессов автоматизации. Данные сети могут быть очень протяжёнными, но при этом (помимо собственно гарантий доставки данных) должны обеспечивать их транспортировку в определённом временном интервале, что также накладывает ограничения как на значения латентности канала, так и особые условия построения маршрута. Важныммоментом здесь может быть предоставляемый уровень безопасности данных.
-
Сеть с гарантированной полосой пропускания: в отличие от предыдущей может, например, применять протокол UTP. Её основная цель - предоставление пропускной способности достаточной для работы терминальных служб (прежде всего приложений и удалённых рабочих мест) с приемлемым качеством отображения информации и уровнем реакции в системе. Конечный результат - работа, максимально приближенная к реальному масштабу времени. Поскольку данные окружения подразумевают удалённый доступ, в данных сетях должны быть предоставлены все необходимые средства шифрования данных и соответствующих уровней авторизации.
Как следует из приведённого выше перечисления различных применяемых в Центрах обработки данных сетевых средах, наиболее универсальной и, к тому же, позволяющей построить практически любые решения при относительно невысокой стоимости, является архитектура Ethernet. В настоящее время она представлена сетевыми адаптерами с пропускной способностью 1GbE, 10GbE, 40GbE, 100GbE, а также недавно добавленными 25GbE (и, вербально, 50GbE) и 2.5GbE. Появление значения 25 объясняется его кратностью 100GbE, а вот происхождение 2.5 относится к сфере построения WiFi решений, для которых 1GbE мало, а 10GbE дорого. Также фактически готовы к запуску ASIC с 200GbE, единственным что сдерживает их появление - не очень широкое распространение PCIe v4 (пока только Power9, ждём новых процессоров Intel ближе к концу 2017). Отметим, что начиная с 10GbE рекомендуется использовать разъёмы QSFP вместо RJ-45. Основным набором сетевых протоколов здесь является TCP/IP. Как правило, в подключаемом в такую сетевую среду хосте имеется более одного сетевого адаптера Ethernet, и самым важным первым шагом является их правильная настройка.
В начале рекомендуется включить в Firmware вашего хоста поддержку Согласованного именования сетевых устройств (Consistent Network Device Naming). Она позволит устранять неоднозначности в именовании имеющихся у вас нескольких физических сетевых адаптеров. Вот её основные моменты:
-
em[1-N]: совпадает с номером на корпусе встроенных в материнскую плату сетевых адаптеров, причём нумерация начинается с1, а не с0, как для eth. Например:em4новое именование дляeth3, -
p<slot_number>p<port_number>: соответствует номеру слота PCI (нумерация начинается с 1, а не с 0) и номеру порта в контроллере, Например:p3p4 -
_<vf>: суффикс от 0 до N для NPAR и SR-IOV устройств, в зависимости от номера раздела (partition) или Виртуальной функции (Virtual Functions) выставляемых для каждого порта. Например:p3p4_1.
Для дальнейшего обсуждения построения типового решения сделаем некое допущение об ограничении на маршрутизацию. А именно, предположим, что присутствующая в рассматриваемом решении внешняя сеть имеет только одно соединение со Всемирным Интернетом. Или, то же самое относительно совокупности всех имеющихся сетей, требующих построения неограниченного числа маршрутов сетевого уровня - Level 3. Другими словами, мы выносим за скобки рассмотрения нашими сетевыми окружениями всех задач построения маршрутов к заранее не определённым нами адресатам. Например, при наличии двух поставщиков Интернет услуг, мы считаем для себя внешней задачу построения альтернативных маршрутов. Тем самым, мы можем не рассматривать решения Policy-based routing (PBR, например, см. habrahabr или Cisco PBR). Данное допущение позволяет нам достаточно просто решать задачу построения сетевой среды в хостах со множеством сетевых адаптеров (multi- homing, групповых серверах).
Следуя "Книге рецептов Windows Server 2016" Джордана Краузе его же "Полного руководства Windows Server 2016", отметим ключевой момент (применимый к любой операционной системе, Linux, FreeBSD, MacOS, Windows), а именно: наличие в данном хосте только одного шлюза по умолчанию (Default gateway). Во всех сетевых адаптерах с данной сетевой архитектурой только один сетевой адаптер имеет назначенным шлюз по умолчанию. Шлюз по умолчанию является тем местом, в котором наш хост пытается получить маршрут к адресату в том случае, когда испробовал все имеющиеся в его локальной таблице маршрутизации возможности. Это самое последнее средство, и оно обязано быть единственным. По определению: Иначе какое же оно последнее? Все остальные сетевые адаптеры должны иметь не заполненным (пустым) данное поле в своих свойствах. Это позволяет нам избегать построения PBR или чего- то аналогичного.
Далее. Если в оставшихся подключённых к прочим сетевым адаптерам сетям имеются некие подсети, необходимо вручную прописать соответствующие статические правила маршрутизации. Например, в соответствии с руководствами Джордана Краузе для Windows Server 2016 в его "Книге рецептов" или "Полном руководстве", либо в руководстве "Администрирование Linux систем для профессионалов.
Существенным является статичность прописанных IP адресов, она достигается либо прямым определением статических адресов для имеющихся сетевых интерфейсов, либо привязкой IP адресов в соответствующем DHCP сервере к MAC адресам этих физических адаптеров. В последнем случае также может помочь настройка DHCP Guard (Защитника DHCP), позволяющего блокировать нежелательную раздачу IP адресов с имеющихся в аппаратных маршрутизаторах серверов DHCP.
Для повышения производительности также рекомендуется ограничивать число DNS серверов в свойствах настраиваемых сетевых адаптеров и назначение приоритетов им.
Помимо описанной в предыдущем разделе настройки группового сервера, которая не означает ничего иного, кроме как одновременной работы в одном сервере различных сетевых адаптеров, причём каждого со своей собственной сетью, надлежит рассмотреть ещё одну возможность группирования. А именно, создание группового сетевого адаптера. Помимо группирования (teaming), данная процедура имеет названия связывания (bonding), балансировки нагрузки и устойчивости к отказам (LBFO, Load Balance and Failover), а также объединения в транки (trunk). Как это и следует из перечисленных названий, данная процедура служит целям высокой доступности и повышения отказоустойчивости, а также осуществлению балансировки нагрузки.
Вначале бросим взгляд на историю вопроса. Первоначально группирование сетевых адаптеров осуществлялось в хосте на уровне драйвера. Такой подход не предоставлял достаточной гибкости для настройки, поэтому, как правило, данная функциональность переносится на более высокий уровень внутри операционной системы. Например, в Windows Server 2012 (R2) создаётся дополнительная сущность - групповой NIC, который экранирует лежащие в его основе сетевые адаптеры. В настоящее время более распространённым является подход, при котором группирование физических устройств осуществляется на уровне виртуального коммутатора (моста) операционной системы хоста. Такой подход позволяет осуществлять более гибкую настройку всей необходимой встроенной функциональности сетевых адаптеров и реализовывать конвергентные среды коммутации.
Группирование сетевых адаптеров может получать поддержку со стороны имеющихся физических коммутаторов. Например, посредством LACP (Link Aggregation Control Protocol, Управляющего протокола агрегации связей). Для некоторых вариантов применения это предоставляет определённые преимущества. Таким образом, процедура настройки группирования, как правило, содержит различные режимы для подхода, осведомлённого о поддержке группирования физическими коммутаторами и без неё. Помимо этого, дополнительную степень разнообразия при настройке может создавать метод применения рассматриваемого физического адаптера. Во первых: активный, или находящийся в состоянии ожидания. Последнее предполагает наличие некоторого механизма перевода такого адаптера в активное состояние в случае отказа активного устройства. Однако, такой подход не позволяет эффективно использовать всю имеющуюся полосу пропускания, поэтому более распространены методы с применением балансировки нагрузки по всем имеющимся физическим сетевым адаптерам. Поддерживаемые методы балансировки создают дополнительную свободу выбора. Как правило это карусельный метод, метод хэширования адресов или другие, поддерживаемые данным уровнем операционной системы методы. Интересной особенностью, появившейся в последних версиях операционных систем, является возможность динамического подключения и отключения физических сетевых адаптеров в группу без необходимости перезагрузки самой операционной системы.
При настройке группирования NIC требуется принятие во внимание функциональности SR-IOV (Single Root Input/Output Virtualization, виртуализации ввода-вывода с единым корнем) - технологии, позволяющей осуществлять виртуализацию физических ресурсов (функций) на аппаратном уровне в виде виртуальных функций с предоставлением прямого доступа к данному ресурсу.
Несмотря на то, что современные операционные системы имеют возможность реализации группирования сетевых адаптеров различных производителей (и даже с различными пропускными способностями), вряд ли стоит всерьёз рассматривать такую возможность за исключением случаев крайней необходимости, например предоставления соответствующего уровня отказоустойчивости. Гораздо проще предусмотреть данную потребность на уровне проектирования и установить необходимое оборудование с идентичными характеристиками. Это позволит реализовать максимальную эффективность использования всех имеющихся аппаратных средств с минимальными издержками.
-
Hyper-V 2016: Книга рецептов Windows Server 2016 Hyper-V
. -
Windows Server 2016: Книга рецептов Windows Server 2016
-
Windows Server 2016: Полное руководство Windows Server 2016
-
VMware ESXi: Полное руководство Windows Server 2016
-
Proxmox: Полное руководство Proxmox
Примеры реализаций:
Альтернативы, например, RDMA с Ангарой