Глава 7. Эксплуатация и обслуживание Ceph
Как администратору системы хранения Ceph, вам будет очень полезно эффективно управлять вашим кластером Ceph уровня предприятия. В данной главе мы рассмотрим следующие темы:
-
Управление службой Ceph
-
Увеличение в масштабе кластера Ceph
-
Сокращение кластера Ceph
-
Замена отказавшего диска
-
Управление картой CRUSH (Управляемых масштабируемым хешированием репликаций, Controlled Replication Under Scalable Hashing)
Содержание
Поскольку у вас есть первый установленный кластер Ceph, вам необходимо управлять им. Вам, как администратору системы хранения
Ceph, необходимо иметь знания о службах Ceph и их использовании. В дистрибутивах на основе Red Hat демонами Ceph можно управлять двумя
способами, а именно: традиционным sysvinit или как службой. Теперь давайте узнаем больше
об этих методах управления службой.
sysvinit является традиционным, но все еще рекомендуемым способом управления
демонами в системах на основе Red Hat, а также в некоторых более старых дистрибутивах на основе Debian/Ubuntu.
Общий синтаксис управления демонами Ceph с использованием sysvinit выглядит
следующим образом:
/etc/init.d/ceph [options] [command] [daemons]Параметры (options) Ceph включают в себя:
-
--verbose (-v): Используется при регистрации с подробными листингами -
--allhosts (-a): Выполняется на всех узлах, отмеченных вceph.conf, в противном случае на локальном хосте. -
--conf (-c): Использовать альтернативный файл настройки
Команды Ceph содержат:
-
status: Отображает состояние демона -
start: Запускает демон -
stop: Останавливает демон -
restart: Останавливает, а затем вновь запускает демон
Демоны Ceph включают в себя:
-
mon{монитор} -
osd{устройство хранения объектов, Object Storage Device} -
mds{сервер метаданных, Metadata Server} -
ceph-radosgw{шлюз безотказного автономного распределенного хранилища объектов, Reliable Autonomic Distributed Object Store}
При выполнении задач администрирования вашего кластера, вам может понадобиться управлять службами Ceph по их типам. В данном разделе мы изучим как запускать демоны по их типам.
Для запуска демонов монитора Ceph на локальном хосте выполните Ceph с командой start:
# /etc/init.d/ceph start mon
Для запуска демонов монитора Ceph как на локальном хосте, так и на удаленных хостах выполните Ceph с командой
start и параметром -a:
# /etc/init.d/ceph -a start mon
Параметр -a выполнит запрошенную операцию на всех узлах, отмеченных в файле
ceph.conf. Давайте посмотрим на следующий снимок экрана:
[root@ceph-node1 ~]# /etc/init.d/ceph -a start mon === mon.ceph-node1 === Starting Ceph mon.ceph-node1 on ceph-node1... Starting ceph-create-keys on ceph-node1... === mon.ceph-node2 === Starting Ceph mon.ceph-node2 on ceph-node2... Starting ceph-create-keys on ceph-node2... === mon.ceph-node3 === Starting Ceph mon.ceph-node3 on ceph-node3... Starting ceph-create-keys on ceph-node3... [root@ceph-node1 ~]#
Аналогично вы можете запускать демоны других типов, например, osd и
mds:
# /etc/init.d/ceph start osd # /etc/init.d/ceph start mds
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Перед использованием параметра |
В данном разделе мы ознакомимся с остановом демонов по их типам.
Для останова демонов монитора Ceph на локальном хосте выполните Ceph с командой
stop:
# /etc/init.d/ceph stop mon
Для останова демонов монитора Ceph на всех хостах выполните Ceph с командой
stop и параметром -a:
# /etc/init.d/ceph -a stop mon
Параметр -a выполнит запрошенную операцию на всех узлах, отмеченных в файле
ceph.conf. Давайте посмотрим на следующий снимок экрана:
[root@ceph-node1 ~]# /etc/init.d/ceph -a stop mon === mon.ceph-node3 === Stopping Ceph mon.ceph-node3 on ceph-node3...kill 9679...done === mon.ceph-node2 === Stopping Ceph mon.ceph-node2 on ceph-node2...kill 12758...done === mon.ceph-node1 === Stopping Ceph mon.ceph-node1 on ceph-node1...kill 12331...done [root@ceph-node1 ~]#
Аналогично вы можете запускать демоны других типов, например, osd и
mds:
# /etc/init.d/ceph stop osd # /etc/init.d/ceph stop mds
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Перед использованием параметра |
Для запуска вашего кластера Ceph, выполните Ceph с командой start. Данная команда
запустит все службы Ceph которые вы развернули для всех хостов, перечисленных в файле ceph.conf:
# /etc/init.d/ceph -a start
Для останова вашего кластера Ceph, выполните Ceph с командойstop. Данная команда
остановит все службы Ceph которые вы развернули для всех хостов, перечисленных в файле ceph.conf:
# /etc/init.d/ceph -a stop
Для запуска определенного демона в вашем кластере Ceph, выполните Ceph с командой start и
идентификатором (ID) демона:
# /etc/init.d/ceph start osd.0
Для проверки состояния определенного демона в вашем кластере Ceph выполните Ceph с командой status и
идентификатором (ID) демона:
# /etc/init.d/ceph status osd.0
Для останова определенного демона в вашем кластере Ceph выполните Ceph с командой stop и
идентификатором (ID) демона:
# /etc/init.d/ceph stop osd.0
Данный снимок экрана отображает вывод всех предыдущих команд:
[root@ceph-node1 -]# /etc/init.d/ceph start osd.0
=== osd.0 ===
create-or-move updated item name 'osd.0' weight 0.01 at location {host=ceph-node1,root=default} to crush map
Starting Ceph osd.0 on ceph-node1...
starting osd.0 at :/0 osd_data /var/lib/ceph/osd/ceph-0 /var/lib/ceph/osd/ceph-0/journal
[root@ceph-node1 ~]#
[root@ceph-node1 ~]# /etc/init.d/ceph status osd.0
=== osd.0 ===
osd.0: running {"version":"0.80.1"}
[root@ceph-node1 -]#
[root@ceph-node1 ~]# /etc/init.d/ceph stop osd.0
=== osd.O ===
Stopping Ceph osd.0 on ceph-node1...kill 20792...done
[root@ceph-node1 ~]#
Аналогично вы можете управлять определенными демонами osd и
mds в вашем кластере Ceph.
В зависимости от вашего стиля работы в Linux вы можете выбирать управление вашими службами Ceph либо через
sysvinit, либо с применением команды Linux service.
Начиная с Ceph Argonaut и Bobtail вы можете управлять демонами Ceph с применением команды Linux
service:
service ceph [options] [command] [daemons]Параметры (options) Ceph включают в себя:
-
--verbose (-v): Используется при регистрации с подробными листингами -
--allhosts (-a): Выполняется на всех узлах, отмеченных вceph.conf, в противном случае на локальном хосте. -
--conf (-c): Использовать альтернативные файлы настройки
Команды Ceph содержат:
-
status: Отображает состояние демона -
start: Запускает демон -
stop: Останавливает демон -
restart: Останавливает, а затем вновь запускает демон -
forcestop: Принудительно останавливает демон; это аналогичноkill -9
Демоны Ceph включают в себя:
-
mon{монитор} -
osd{устройство хранения объектов, Object Storage Device} -
mds{сервер метаданных, Metadata Server} -
ceph-radosgw{шлюз безотказного автономного распределенного хранилища объектов, Reliable Autonomic Distributed Object Store}
Для запуска вашего кластера Ceph, выполните Ceph с командой start. Данная команда
запустит все службы Ceph которые вы развернули для всех хостов, перечисленных в файле ceph.conf:
# service ceph -a start
Для останова вашего кластера Ceph, выполните Ceph с командойstop. Данная команда
остановит все службы Ceph которые вы развернули для всех хостов, перечисленных в файле ceph.conf:
# service ceph -a stop
Для запуска определенного демона в вашем кластере Ceph, выполните Ceph с командой start и
идентификатором (ID) демона:
# service ceph start osd.0
Для проверки состояния определенного демона в вашем кластере Ceph выполните Ceph с командой status и
идентификатором (ID) демона:
# service ceph status osd.0
Для останова определенного демона в вашем кластере Ceph выполните Ceph с командой stop и
идентификатором (ID) демона:
# service ceph stop osd.0
Данный снимок экрана отображает вывод всех предыдущих команд:
[root@ceph-node1 ~]# service ceph start osd.0
=== osd.0 ===
create-or-move updated item name 'osd.0' weight 0.01 at location {host=ceph-node1,root=default} to crush map
Starting ceph osd.0 on ceph-node1...
starting osd.O at :/0 osd_data /var/lib/ceph/osd/ceph-0 /var/lib/ceph/osd/ceph-0/journal
[root@ceph-node1 ~]#
[root@ceph-node1 ~]# service ceph status osd.0
=== osd.0 ===
osd.0: running {"version":"0.80.1"}
[root@ceph-node1 ~]#
[root@ceph-node1 ~]# service ceph stop osd.0
=== osd.0 ===
Stopping Ceph osd.0 on ceph-node1...kill 22435...done
[root@ceph-node1 ~]#
При построении решения для системы хранения масштабируемость является одним из наиболее важных аспектов проекта. Ваше решение системы хранения данных должно быть масштабируемыми, чтобы удовлетворить Ваши будущим потребностям в данных. Как правило, система хранения данных начинается с размеров от малого и среднего и постепенно растет в течение некоторого периода времени. Традиционные системы хранения основываются на решениях с расширением масштаба и ограничены некоторой емкостью. Если вы попытаетесь расширить вашу систему хранения данных за определенные рамки, вам придется идти на компромисс между производительностью и надежностью. Методы решений расширения (scale-up) для систем хранения включают в себя добавление дисковых ресурсов в существующее устройство, которое становится узким местом в производительности, емкости и управляемости при достижении определенного предела.
С другой стороны, увеличиваемые в масштабе (scale-out) проекты сосредотачиваются на добавлении нового узла целиком, содержащего диски, процессоры и память, в существующий кластер. При таком типе проекта вы не будете в конечном итоге ограничены в объеме хранения; более того, вы получите дополнительный рост производительности и надежности. Давайте взглянем на следующую архитектуру:
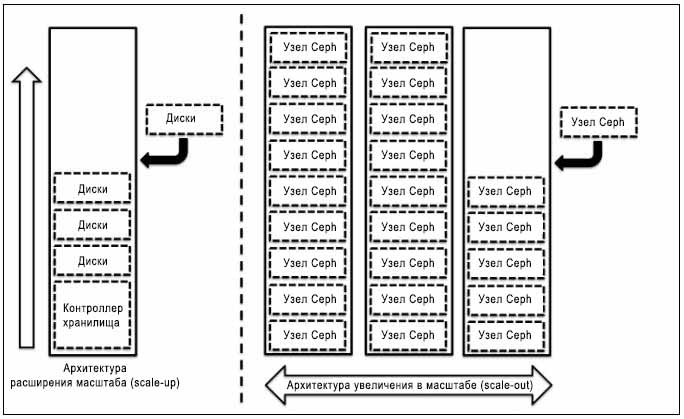
Ceph является бесшовно масштабируемой системой хранения на основе увеличивающегося в масштабе решения, при котором вы можете добавить любой готовый к использованию узел сервера в кластер Ceph и расширить вашу систему хранения далеко за пределы традиционной системы. Ceph позволяет добавлять на лету узлы мониторов и OSD (устройств хранения объектов) в существующий кластер Ceph. Теперь, давайте узнаем как добавлять узлы в кластер Ceph.
Добавление узлов OSD (устройств хранения объектов) в кластер Ceph является процессом реального времени. Чтобы продемонстрировать
это нам понадобится новая виртуальная машина с именем ceph-node4 с тремя дисками; мы
добавим этот узел в наш существующий кластер Ceph.
Создадим новый узел ceph-node4 стремя дисками (OSD). Вы можете повторить процесс
создания новой виртуальной машины с дисками, настройки операционной системы и установки Ceph как это описано в
Главе 2. Моментальное развертывание Ceph
и в Главе 5.
Развертывание Ceph - дорога, которую вы обязаны знать.
Когда у вас появится новый узел, готовый к добавлению в кластер Ceph, проверьте подробности Ceph OSD на текущий момент:
# ceph osd tree
Вот что вы должны получить в результате выполнения данной команды:
[root@ceph-node1 ceph]# ceph osd tree # id weight type name up/down reweight -1 0.08995 root default -2 0.02998 host ceph-node1 0 0.009995 osd.O up 1 1 0.009995 osd.l up 1 2 0.009995 osd.2 up 1 -3 0.02998 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.02998 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 [root@ceph-node1 ceph]#
Расширение кластера Ceph является интерактивным процессом и, чтобы продемонстрировать этот факт, мы выполним некоторые действия
в нашем кластере Ceph; параллельно мы будем расширять кластер. В Главе 5. Развертывание Ceph - дорога, которую вы обязаны знать,
мы развернули блочное устройство RADOS (Безотказное автономное распределенное хранилище объектов - Reliable Autonomic Distributed
Object Store) на машине ceph-client1. Мы будем использовать эту же машину для создания
операций обмена в нашем кластере Ceph. Убедимся, что ceph-client1 смонтировал RBD (блочное
устройсто RADOS):
# df -h /mnt/ceph-vol1
[root@ceph-client1 ~]# df -h /mnt/ceph-vol1 Filesystem Size Used Avail Use% Mounted on /dev/rbdO 10G 33M 10G 1% /mnt/ceph-vol1 [root@ceph-client1 ~]#
Зарегистрируемся на ceph-client1 с отдельного терминала cli
и выведем список дисков, доступных для добавления в качестве OSD для ceph-node4.
Машина ceph-node4 должна иметь установленный Ceph, а также скопированный на нее файл
ceph.conf. Вы увидите три диска sdb,
sdc и sdd в списке, выводимым в результате выполнения
следующей команды:
# ceph-deploy disk list ceph-node4
Как уже отмечалось ранее, увеличение масштаба кластера Ceph является безшовным и интерактивным процессом. Чтобы показать это, мы создадим некоторую нагрузку на кластер и одновременно выполним операцию увеличения масштаба. Заметим, что это является необязательным шагом.
Убедимся что хост с работающей на нем средой VirtualBox имеет соответствующее дисковое пространство, поскольку мы будем записывать данные в кластер Ceph. Как только вы запустите создание трафика в наш кластер, запустите его расширение путем выполнения последующих шагов.
# dd if=/dev/zero of=/mnt/ceph-vol1/file1 count=10240 bs=1M
Переключитесь на терминал cli ceph-node1 и расширьте кластер путем добавления
дисков ceph-node4 в качестве новых OSD Ceph:
# ceph-deploy disk zap ceph-node4:sdb ceph-node4:sdc ceph-node4:sdd # ceph-deploy osd create ceph-node4:sdb c eph-node4:sdc ceph-node4:sdd
Во время выполнения добавления OSD вам следует отслеживать состояние вашего кластера Ceph из отдельного терминального окна. Вы заметите, что кластер Ceph выполняет операцию записи при одновременном увеличении масштаба свое емкости:
# watch ceph status
Наконец, когда добавление дисков ceph-node4 завершено, вы сможете проверить состояние
своего кластера Ceph с применением предыдущей команды. Ниже приводится то, что вы увидите после выполнения этой команды:
[root@ceph-node1 /]# ceph status
cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97
health HEALTH_OK
monmap e3: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.57.102:6789/0,
ceph-node3=192.168.57.103:6789/0}, election epoch 938, quorum 0,1,2 ceph-node1,ceph-node2,cep
h-node3
mdsmap e61: 1/1/1 up {0=ceph-node2=up:active}
osdmap e807: 12 osds: 12 up, 12 in
pgmap v3998: 1472 pgs, 13 pools, 78568 kB data, 2687 objects
828 MB used, 107 GB / 107 GB avail
1472 active+clean
[root@ceph-node1 /]#
В данной точке если вы выведите список всех OSD, он даст вам лучшее понимание:
# ceph osd tree
Данная команды выводит некоторую ценную информацию, связанную с OSD, такую как вес OSD, а также какой узел Ceph содержит их. OSD, состояние OSD (рабочее/выключенное, up/down), а также состояние IN/OUT OSD представляются 1 или 0. Обратим внимание на следующий снимок экрана:
[root@ceph-node1 tmp]# ceph osd tree # id weight type name up/down reweight -1 0.12 root default -2 0.009995 host ceph-node1 0 0.009995 osd.0 up 1 1 0.009995 osd.l up 1 2 0.009995 osd.2 up 1 -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 -5 0.04999 host ceph-node4 9 0.009995 osd.9 up 1 10 0.009995 osd.10 up 1 11 0.009995 osd.11 up 1 [root@ceph-node1 tmp]#
Решения для хранения данных оцениваются на основе их гибкости; хорошее решение для хранения должно быть достаточно гибким чтобы поддерживать его расширение и уменьшение, не вызывая при этом каких-либо простоев в обслуживании. Традиционные системы хранения очень ограничены, когда дело касается гибкости; они поддерживают добавление емкости хранения, но в очень малой степени, а также не существует никакой поддержки для интерактивного уменьшения емкости. Вы блокированы емкостью хранения и не можете выполнять изменения в соответствии с вашими потребностями.
Ceph является абсолютно гибкой системой хранения, обеспечивающей интерактивное изменение и изменение на лету емкости как
в отношении ее увеличения, так и в отношении ее уменьшения. В последнем разделе мы увидели как легко выполнять увеличение
масштаба Ceph. Мы добавили новый узел ceph-node4 с тремя OSD в кластер Ceph. Теперь
мы покажем операцию уменьшения масштаба кластера Ceph, без какого-либо влияния на его доступность, путем удаления
ceph-node4 из кластера Ceph.
Перед выполнением процесса сокращения размера кластера или уменьшения его масштаба необходимо удостовериться, что кластер имеет достаточно свободного пространства для размещения всех данных, расположенных на узле, который вы собираетесь удалить. Кластер не должен быть близок состоянию почти заполненного.
На узле ceph-node1 создайте некую нагрузку на кластер Ceph. Это необязательный шаг,
призванный продемонстрировать выполнимость на лету операции уменьшения масштаба кластера Ceph. Убедитесь, что хост, поддерживающий
среду VirtualBox имеет соответствующее дисковое пространство, поскольку мы будем записывать данные в кластер Ceph.
# dd if=/dev/zero of=/mnt/ceph-vol1/file1 count=3000 bs=1M
Поскольку нам необходимо уменьшить масштаб кластера, мы удалим ceph-node4 и все
связанные с ним OSD (устройства хранения объектов) из нашего кластера. OSD Ceph должны быть настроены таким образом, чтобы
Ceph мог выполнять восстановление данных. С любого из узлов Ceph выведите OSD из состава кластера:
# ceph osd out osd.9 # ceph osd out osd.10 # ceph osd out osd.11
[root@ceph-node1 /]# ceph osd out osd.9 marked out osd.9. [root@ceph-node1 /]# ceph osd out osd.10 marked out osd.10. [root@ceph-node1 /]# ceph osd out osd.11 marked out osd.11.
Как только вы отметите OSD находящимися вне кластера, Ceph запустит ребалансировку нашего кластера путем миграции групп размещения с OSD, которые мы вывели из состава кластера на другие OSD в пределах кластера. Состояние вашего кластера на какое- то время станет неисправным, однако он останется в состоянии обслуживать данные клиентов. В зависимости от числа удаленных OSD может возникнуть некий провал в производительности кластера пока не завершится время восстановления. Как только кластер станет вновь работоспособным, он долже заработать как прежде. Давайте взглянем на следующий снимок экрана:
[root@ceph-node1 /]# ceph -s
cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97
health HEALTH_WARN 517 pgs peering; 16 pgs recovering; 4 pgs recovery_wait; 363 pgs stuck
inactive; 379 pgs stuck unclean; 43 requests are blocked > 32 sec; recovery 1401/5290 objects
degraded (26.484%)
monmap e3: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.57.102:6789/0,c
eph-node3=192.168.57.103:6789/0}, election epoch 938, quorum 0,1,2 ceph-node1,ceph-node2,ceph-
node3
mdsmap e61: 1/1/1 up {0=ceph-node2=up:active}
osdmap e824: 12 osds: 12 up, 9 in
pgmap v4077: 1472 pgs, 13 pools, 161 MB data, 2618 objects
748 MB used, 82095 MB / 82844 MB avail
1401/5290 objects degraded (26.484%)
437 inactive
10 active
511 peering
4 active+recovery_wait
487 active+clean
16 active+recovering
1 remapped
6 remapped+peering
recovery io 0 B/s, 52 objects/s
client io 517 B/s rd, 78962 kB/s wr, 398 op/s
[root@ceph-node1 /]#
В предыдущем скриншоте вы можете увидеть что кластер находится в режиме восстановления, хотя в то же время он продолжает обслуживать данные клиентов. Вы можете наблюдать за процессом восстановления при помощи следующей команды:
# ceph -w
Поскольку мы отметили для вывода из состава кластера osd.9,
osd.10 и osd.11, они не являются участниками
кластера, однако их службы все еще работают. Наконец, зарегистрируйтесь на машине ceph-node4
и остановите службы OSD:
# service ceph stop osd.9 # service ceph stop osd.10 # service ceph stop osd.11
После выключения OSD проверьте дерево OSD, как это показано на следующем снимке экрана. Вы увидите, что соответствующие OSD выключены и выведены:
[root@ceph-node4 ~]# ceph osd tree # id weight type name up/down reweight -1 0.12 root default -2 0.009995 host ceph-node1 0 0.009995 osd.O up 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 -5 0.04999 host ceph-node4 9 0.009995 osd.9 down 0 10 0.009995 osd.10 down 0 11 0.009995 osd.11 down 0 [root@ceph-node4 ~]#
Процесс удаления OSD (устройства хранения объектов) из кластера Ceph затрагивает удаление всех записей этих OSD из карт кластера.
Удалите OSD из карты CRUSH (Управляемых масштабируемым хешированием репликаций, Controlled Replication Under Scalable Hashing). Для этого зарегистрируйтесь на любом узле кластера и выполните следующие команды:
# ceph osd crush remove osd.9 # ceph osd crush remove osd.10 # ceph osd crush remove osd.11
[root@ceph-node1 ~]# ceph osd crush remove osd.9 removed item id 9 name 'osd.9' from crush map [root@ceph-node1 ~]# ceph osd crush remove osd.10 removed item id 10 name 'osd.10' from crush map [root@ceph-node1 ~]# ceph osd crush remove osd.11 removed item id 11 name 'osd.11' from crush map [root@ceph-node1 ~]#
Как только OSD удалены из карты CRUSH, кластер Ceph становится работоспособным. Вам следует просмотреть карту OSD;
поскольку мы не удалили OSD, она покажет 12 OSD, 9 UP, 9 IN:
[root@ceph-node1 /]# ceph status
cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97
health HEALTH_OK
monmap e3: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.57.102:
6789/0,ceph-node3=192.168.57.103:6789/0}, election epoch 938, quorum 0,1,2 ceph-node1,
ceph-node2,ceph-node3
mdsmap e61: 1/1/1 up {0=ceph-node2=up:active}
osdmap e898: 12 osds: 9 up, 9 in
pgmap v4400: 1472 pgs, 13 pools, 683 MB data, 2838 objects
1876 MB used, 80968 MB / 82844 MB avail
1472 active+clean
[root@ceph-node1 /]#
Удалите ключ аутентификации OSD:
# ceph auth del osd.9 # ceph auth del osd.10 # ceph auth del osd.11
Наконец, удалите OSD и проверьте состояние вашего кластера. Вы должны увидеть 9 OSD, 9 UP,
9 IN и работоспособность (health) кластера должна быть OK:
[root@ceph-node1 /]# ceph osd rm osd.9
removed osd.9
[root@ceph-node1 /]# ceph osd rm osd.10
removed osd.10
[root@ceph-node1 /]# ceph osd rm osd.11
removed osd.11
[root@ceph-node1 /]# ceph status
cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97
health HEALTH_OK
monmap e3: 3 mons at {ceph-node1=192.168.57.101:6789/0fceph-node2=192.168.57.102:
6789/0,ceph-node3=192.168.57.103:6789/0}, election epoch 938, quorum 0,1,2 ceph-node1,
ceph-node2,ceph-node3
mdsmap e61: 1/1/1 up {0=ceph-node2=up:active}
osdmap e901: 9 osds: 9 up, 9 in
pgmap v4413: 1472 pgs, 13 pools, 683 MB data, 2838 objects
1879 MB used, 80965 MB / 82844 MB avail
1472 active+clean
[root@ceph-node1 /]#
Чтобы оставить кластер в чистом состояни, выполите некоторую работу по хозяйству. Поскольку мы удалили все OSD из
карты CRUSH, ceph-node4 больше не имеет никаких элементов. Удалите
ceph-node4 из карты CRUSH, чтобы удалить все следы этого узла из кластера Ceph:
# ceph osd crush remove ceph-node4
Если вы администратор системы хранения Ceph, вам нужно будет управлять кластером Ceph с множеством физических дисков.
По мере увеличения количества физических диске в вашем кластере Ceph частота отказов дисков также может увеличиваться. Таким образом,
замена отказавших дисков может стать повторяющейся задачей для администратора системы хранения Ceph. Rак правило, нет нужды
беспокоиться, если в кластере Ceph вышел из строя один или несколько дисков, поскольку Ceph будет заботиться о данных,
их репликации и функции высокой доступности. Процесс удаления OSD из кластера Ceph основан на репликации данных Ceph и
удалении всех записей об отказавших OSD из карт CRUSH кластера. Теперь мы рассмотрим процесс замены отказавшего диска
в ceph-node1 и osd.0.
Вначале проверим состояние вашего кластера Ceph. Покольку в кластере нет оказавших дисков, его состояние
будет HEALTH_OK:
# ceph status
Поскольку мы демонстрируем это упражнение на виртуальных машинах, нам нужно принудительно вывести из строя диск путем вывода
из рабочего состояния ceph-node1, отсоединения диска и последующего включения виртуальной
машины:
# VBoxManage controlvm ceph-node1 poweroff # VBoxManage storageattach ceph-node1 --storagectl "SATA Controller" --port 1 --device 0 --type hdd --medium none # VBoxManage startvm ceph-node1
На следующем снимке экрана вы увидите, что ceph-node1 содержит отказавший
osd.0, подлежащий замене:
[root@ceph-node1 ~]# ceph osd tree # id weight type name up/down reweight -1 0.06999 root default -2 0.009995 host ceph-node1 0 0.009995 osd.0 down 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 [root@ceph-node1 ~]#
Поскольку данный OSD не работает, Ceph помечает этот OSD вышедшим из кластера в некоторый момент времени; по умолчанию, через 300 секунд. Если нет, мы можем сделать это вручную:
# ceph osd out osd.0
Удалим отказавший OSD из карты CRUSH:
# ceph osd crush rm osd.0
Уничтожим ключ аутентификации Ceph для этого OSD:
# ceph auth del osd.0
Наконец, удалим этот OSD из кластера Ceph:
# ceph osd rm osd.0
[root@ceph-node1 ~]# ceph osd out osd.0 marked out osd.0. [root@ceph-node1 ~]# ceph osd crush rm osd.0 removed item id 0 name 'osd.0' from crush map [root@ceph-node1 ~]# ceph auth del osd.0 updated [root@ceph-node1 ~]# ceph osd rm osd.0 removed osd.0 [root@ceph-node1 ~]#
Поскольку одно из ваших OSD недоступно, состояние работоспособности кластера не будет OK,
и он выполнит восстановление; не стоит беспокоиться об этом, это обычная операция Ceph
Теперь мы должны физически заменить отказавший диск овым в вашем узле Ceph. На сегодняшний день практически все серверное оборудование и все операционные системы поддерживают горячую замену дисков, следовательно у вас нет нужды в каком бы то ни было простое для замены диска. Так как мы используем виртуальную машину, нам нужно выключить эту виртуальную машину, добавить новый диск и перезапустить эту виртуальную машину. Поскольку данный диск вставлен, сделаем замечание о его идентификаторе устройства операционной системы:
# VBoxManage controlvm ceph-node1 poweroff # VBoxManage storageattach ceph-node1 --storagectl "SATA Controller" --port 1 --device 0 --type hdd --medium ceph-node1-osd1.vdi # VBoxManage startvm ceph-node1
Выполним следующие команды для вывода списка дисков; новый диск в общем случае не имеет никакого раздела:
# ceph-deploy disk list ceph-node1
Перед добавлением диска в кластер Ceph, выполним полное стирание (zap) диска:
# ceph-deploy disk zap ceph-node1:sdb
Наконец, создадим на этом диске OSD и Ceph добавит его как osd.0:
# ceph-deploy --overwrite-conf osd create ceph-node1:sdb
Поскольку OSD создан, Ceph выполнит операцию восстановления и запустит перемещение групп размещения со вторичных
OSD на новый OSD. Операция восстановления может занять некоторое время, по истечению которого кластер Ceph придет опять
в состояние HEALTHY_OK:
[root@ceph-node1 /]# ceph status
cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97
health HEALTH_OK
monmap e3: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.57.102:
6789/0,ceph-node3=192.168.57.103:6789/0}, election epoch 938, quorum 0,1,2 ceph-node1,
ceph-node2,ceph-node3
mdsmap e61: 1/1/1 up {0=ceph-node2=up:active}
osdmap e901: 9 osds: 9 up, 9 in
pgmap v4413: 1472 pgs, 13 pools, 683 MB data, 2838 objects
1879 MB used, 80965 MB / 82844 MB avail
1472 active+clean
[root@ceph-node1 /]#
Мы уже рассматривали карты CRUSH (Управляемых масштабируемым хешированием репликаций, Controlled Replication Under Scalable Hashing) в Главе 4. Ceph изнутри. В данном разделе мы погрузимся в детали карт CRUSH, включающие их макеты, а также определение пользовательских карт CRUSH. При развертывании кластера Ceph с помощью процедуры, описанной в данном руководстве, для вашего кластера Ceph создаются карты CRUSH по умолчанию. Такие карты по умолчанию хорошо подходят для окружений песочницы и тестирования. Однако если вы запускаете кластеры Ceph в промышленности или в большом масштабе, рассмотрите возможность разработки пользовательской карты CRUSH для вашей среды, чтобы обеспечить более высокую производительность, надежность и безопасность данных.
Локализация CRUSH является метоположением OSD в карте CRUSH. Например, организация с названием
mona-labs.com имеет кластер с местоположением osd.156,
которое располагается в хосте ceph-node15. Этот хост физически представляет
chassis-3, которое установлено в rack-16,
являющемся частью room-2 и datacentre-1-north-FI
Такой osd.156 будет частью карты CRUSH, как это показано на следующем рисунке:
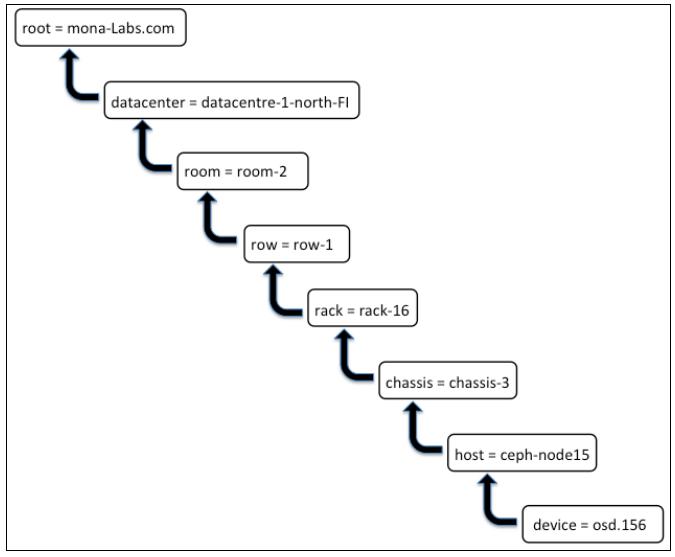
На предыдущем рисунке ключи показаны с левой стороны от =; они также называются типами CRUSH. Карта по умолчанию содержит
root, datacentre,
room, row,
pod, pdu,
rack, chassis и
host. Не обязательно использовать все типы CRUSH при определении карты CRUSH, однако
используемые типы CRUSH должны быть допустимыми, иначе вы можете получить ошибки компиляции. CRUSH является достаточно гибким;
вы даже можете определять ваши собственные типы и использовать их в картах CRUSH по-своему.
Чтобы понять что находится внутри карты CRUSH, мы должны извлечь ее и декомпилировать в человеко- читаемую форму для легкого редактирования. На этом этапе мы можем выполнить все необходимые изменения в карте CRUSH и, чтобы изменения вступили в силу, мы должны скомпилировать и внедрить ее назад в кластер Ceph. Изменения в кластере Ceph, выполняемые такой новой картой CRUSH, т.е. как только новая карта CRUSH внедрена в кластер Ceph, изменения имеют эффект немедленно, на лету. Теперь мы взглянем на карту CRUSH нашего кластера Ceph который мы развернули в данном руководстве.
Извлечем карту CRUSH из любого нашего узла монитора:
# ceph osd getcrushmap -o crushmap_compiled_file
Когда мы получим карту CRUSH, декомпилируем ее чтобы сделать ее человечески читаемой и редактируемой:
# crushtool -d crushmap_compiled_file -o crushmap_decompiled_file
Начиная с этого момента файл выдачи, crushmap_decompiled_file, может
просматриваться/ редактироваться в предпочитаемом вами редакторе.
В следующем разделе мы изучим как выполнять изменения в карте CRUSH.
После внесения необходимых изменений вам следует скомпилировать изменения с параметром команды -c
# crushtool -c crushmap_decompiled_file -o newcrushmap
Наконец, внедрим заново скомпилированную карту CRUSH в кластер Ceph с параметром команды
# ceph osd setcrushmap -i newcrushmap
Файл карты CRUSH содержит четыре раздела; они следующие:
-
Устройства карты CRUSH: Раздел устройств содержит список всех OSD представленных в кластере Ceph. Как только любое новое OSD добавляется в кластер Ceph или удаляется из него, раздел устройств карт CRUSH обновляется автоматически. Обычно у вас нет нужды вносить изменения в данный раздел; Ceph заботится об этом. Однако, если вам нужно добавить новое устройство, добавьте новую строку в конце раздела устройств уникальным номером устройства, идущим за OSD. Приводимый далее снимок экрана показывает раздел устройств карты CRUSH из нашего кластера песочницы:
# devices device 0 osd.O device 1 osd.1 device 2 osd.2 device 3 osd.3 device 4 osd.4 device 5 osd.5 device 6 osd.6 device 7 osd.7 device 8 osd.8
-
Типы сегментов карты CRUSH: Этот раздел определяет типы сегментов (bucket), которые могут использоваться в карте CRUSH. Карта CRUSH по умолчанию содержит определенные типы сегментов, которых обычно достаточно для большинства кластеров Ceph. Однако, основываясь на ваших требованиях, вы можете добавлять или удалять типы сегментов в данном разделе. Чтобы добавить тип сегмента добавьте новую строку в разделе типов сегментов файла карты CRUSH, введите type и идентификатор (ID) типа (следующее численное значение) с последующим именем сегмента. Список сегментов по умолчанию из нашего кластера песочницы выглядит следующим образом:
# types type 0 osd type 1 host type 2 rack type 3 row type 4 room type 5 datacenter type 6 root
-
Определение сегмента карты CRUSH: Поскольку тип сегмента (bucket) объявлен, он должен быть определен для хостов и других доменов отказа. В данном разделе вы можете иерархически изменять архитектуру вашего кластера Ceph, например, определять хосты, ряды, стойки, шасси, комнаты и центры обработки данных. Вы также может определять какие типы алгоритмов сегментов необходимо использовать. Определение сегмента содержит определенные параметры; вы можете использовать следующий синтаксис для создания определения сегмента:
[bucket-type] [bucket-name] { id [a unique negative numeric ID] weight [the relative capacity/capability of the item(s)] alg [the bucket type: uniform | list | tree | straw ] hash [the hash type: 0 by default] item [item-name] weight [weight] }Далее приводится определение раздела сегмента из нашего кластера Ceph песочницы:
# buckets host ceph-node1 { id -2 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkins1 item osd.1 weight 0.010 item osd.2 weight 0.010 item osd.0 weight 0.010 } host ceph-node2 { id -3 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkins1 item osd.3 weight 0.010 item osd.5 weight 0.010 item osd.4 weight 0.010 } host ceph-node3 { id -4 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkins1 item osd.6 weight 0.010 item osd.7 weight 0.010 item osd.8 weight 0.010 > root default { id -1 # do not change unnecessarily # weight 0.090 alg straw hash 0 # rjenkins1 item ceph-node1 weight 0.030 item ceph-node2 weight 0.030 item ceph-node3 weight 0.030 } -
Правила карты CRUSH: Они определяют способ для выбора соответствующего сегмента (bucket) для размещения данных в пуле. Для большого кластера Ceph должно быть много пулов, причем каждый пул должен иметь собственный набор правил CRUSH. Правилам карты CRUSH необходим ряд параметров; вы можете использовать следующий синтаксис для создания набора правил CRUSH:
rule <rulename> {
ruleset <ruleset>
type [ replicated | raid4 ]
min_size <<min-size>
max_size <max-size>
step take <bucket-type>
step [choose|chooseleaf] [firstn|indep] <N>
<bucket-type>
step emit
}
# rules
rule data {
ruleset 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule metadata {
ruleset 1
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule rbd {
ruleset 2
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush mapCeph легко работает на разнородной общедоступной вычислительной технике. Существуют возможности чтобы вы могли использовать ваши существующие аппаратные системы для Ceph и разработать кластер хранения с различными типами оборудования. Для вас, как администратора хранилища Ceph, ваш вариант использования может потребовать создание множества пулов Ceph на множестве типов устройств. Наиболее распространенный вариант использования заключается в предоставлении пула быстрого хранилища на основе дисков типа SSD, с которыми вы можете получить высокую производительность для вашего кластера хранения. Данные, которые не требуют навысшего уровня ввода/вывода, как правило, хранятся в пулах на более медленных магнитных устройствах.
Наша следующая практическая демонстрация будет направлена на создание двух пулов Ceph, а именно SSD-пулов с более быстрыми дисками SSD и SATA-пулов, хранящих данные на более медленных дисках SATA. Чтобы сделать это мы отредактируем карты CRUSH и выполним необходимые настройки.
Кластер Ceph песочницы, который мы развернули в предыдущих главах, размещается на виртуальных машинах и не имеет реальных дисков SSD в своем распоряжении. Следовательно мы будем рассматривать несколько дисков как SSD диски для целей обучения. Если вы выполняете это упражнение в кластерах Ceph с реальными дисками SSD в их основе, не потребуется никаких изменений в последовательности, которую мы будем выполнять.
В следующей демонстрации мы предполагаем, что ceph-node1 является нашим узлом SSD
с размещенными на нем тремя SSD. ceph-node2 и ceph-node3
содержат диски SATA. Основная копия пула SSD привязана к ceph-node1, в то время как
вторичная и третичная копии будут находиться на других узлах. Аналогично, первичная копия пула SATA будет находиться либо на
ceph-node2, либо на ceph-node3, поскольку у нас
есть два узла для поддержки SATA пула. На любом шаге данной демонстрации вы можете обратиться к скорректированному файлу карты CRUSH,
поддерживаемому данным руководством на веб- сайте Packt Publishing.
Извлеките карту CRUSH из любого узла монитора и декомпилируйте ее:
# ceph osd getcrushmap -o crushmap-extract # crushtool -d crushmap-extract -o crushmap-decompiled
[root@ceph-node1 tmp]# ceph osd getcrushmap -o crushmap-extract got crush map from osdmap epoch 1045 [root@ceph-node1 tmp]# crushtool -d crushmap-extract -o crushmap-decompiled [root@ceph-nodel tmp]# ls -l crushmap-decompiled -rw-r-— r—-. 1 root root 1591 Jul 25 00:18 crushmap-decompiled [root@ceph-node1 tmp]#
Воспользуйтесь предпочитаемым вами редактором и внесите изменения в карту CRUSH по умолчанию:
# vi crushmap-decompiled
Замените сегмент (bucket) по умолчанию root на root ssd
и root sata. В нашем случае root ssd содержит
один элемент, а сегмент root sata имеет два описанных хоста. Взглянем на следующий
моментальный снимок:
root ssd {
id -1
alg straw
hash 0
item ceph-node1 weight 0.030
}
root sata {
id -5
alg straw
hash 0
item ceph-node2 weight 0.030
item ceph-node3 weight 0.030
}
Отрегулируйте существующие правила для работы с новыми сегментами. Для этого измените step take
default на step take sata для правил данных, метаданных и RBD. Это даст
команду данным правилам использовать сегмент root sata вместо используемого по умолчанию
сегмента root, поскольку мы его удалили на предыдущем шаге.
Наконец добавим новые правила для пулов ssd и sata
как это показано на следующем экранном снимке:
rule sata {
ruleset 3
type replicated
min_size 1
max_size 10
step take sata
step chooseleaf firstn 0 type host
step emit
>
rule ssd {
ruleset 4
type replicated
min_size 1
max_size 10
step take ssd
step chooseleaf firstn 0 type host
step emit
>
Поскольку изменения выполнены, скомпилируем файл CRUSH и внедрим его назад в кластер Ceph:
# crushtool -c crushmap-decompiled -o crushmap-compiled # ceph osd setcrushmap -i crushmap-compiled
Как только мы внедрили новую карту CRUSH в наш кластер Ceph, кластер проведет перестановку данных и их восстановление и должен
будет вскоре получить состояние HEALTH_OK. Проверьте состояние кластера следующим образом:
[root@ceph-node1 tmp]# ceph -s
cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97
health HEALTH_WARN 18 pgs recovering; 1309 pgs stuck unclean; recovery 1670/5738 objects degraded (29.104%)
monmap e3: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.57.102:6789/0,ceph-node3=192.168.57.103
:6789/0}, election epoch 1040, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
mdsmap e93: 1/1/1 up {0=ceph-node2=up:active}
osdmap el079: 9 osds: 9 up, 9 in
pgmap v4804: 1472 pgs, 13 pools, 683 MB data, 2838 objects
2106 MB used, 80738 MB / 82844 MB avail
1670/5738 objects degraded (29.104%)
11 active
1280 active+remapped
163 active+clean
18 active+recovering
recovery io 17308 kB/s, 134 objects/s
[root@ceph-node1 tmp]#
Как только ваш кластер примет рабочеспособное состояние, создайте два пула для ssd
и sata:
# ceph osd pool create sata 64 64 # ceph osd pool create ssd 64 64
Отрегулируйте crush_ruleset для правил sata
и ssd, как это определено в карте CRUSH:
# ceph osd pool set sata crush_ruleset 3 # ceph osd pool set ssd crush_ruleset 4 # ceph osd dump | egrep -i "ssd|sata"
[root@ceph-node1 /]# ceph osd pool create sata 64 64 pool 'sata' created [root@ceph-node1 /]# ceph osd pool create ssd 64 64 pool 'ssd' created [root@ceph-node1 /]# ceph osd pool set sata crush_ruleset 3 set pool 16 crush_ruleset to 3 [root@ceph-node1 /]# ceph osd pool set ssd crush_ruleset 4 set pool 17 crush_ruleset to 4 [root@ceph-node1 /]# ceph osd dump | egrep -i "ssd|sata" pool 16 'sata' replicated size 3 min_size 2 crush_ruleset 3 object_hash rjenkins pg_num 64 pgp_num 64 last^change 1093 owner 0 flags hashpspool stripe_width 0 pool 17 'ssd' replicated size 3 min_size 2 crush_ruleset 4 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1094 owner 0 flags hashpspool stripe_width 0 [root@ceph-node1 /]#
Чтобы проверить эти вновь созданные пулы мы поместим в них некоторые данные и проверим какие OSD сохранили данные. Создадим некие файлы данных:
# dd if=/dev/zero of=sata.pool bs=1M count=32 conv=fsync # dd if=/dev/zero of=ssd.pool bs=1M count=32 conv=fsync
[root@ceph-node1 /]# dd if=/dev/zero of=sata.pool bs=lM count=32 conv=fsync 32+0 records in 32+0 records out 33554432 bytes (34 MB) copied, 0.240931 s, 139 MB/s [root@ceph-nodel /]# dd if=/dev/zero of=ssd.pool bs=lM count=32 conv=fsync 32+0 records in 32+0 records out 33554432 bytes (34 MB) copied, 0.179995 s, 186 MB/s [root@ceph-node1 /]# [root@ceph-node1 /]# ls -l *.pool -rw-r-—r-—. 1 root root 33554432 Jul 25 01:00 sata.pool -rw-r—-r—-. 1 root root 33554432 Jul 25 01:01 ssd.pool [root@ceph-node1 /]#
Поместим эти данные в хранилище Ceph в соответствующие пулы:
# rados -p ssd put ssd.pool.object ssd.pool # rados -p sata put sata.pool.object sata.pool
Наконец, проверим карту OSD для пула объектов
# ceph osd map ssd ssd.pool.object # ceph osd map sata sata.pool.object
[root@ceph-node1 /]# ceph osd map ssd ssd.pool.object osdmap e1097 pool 'ssd' (17) object 'ssd.pool.object' -> pg 17.82fd0527 (17.27) -> up ([2], p2) acting ([2,5,6], p2) [root@ceph-node1 /]# [root@ceph-node1 /]# ceph osd map sata sata.pool.object osdmap e1097 pool 'sata' (16) object 'sata.pool.object' -> pg 16.f71bcbc2 (16.2) -> up ([4,8], p4) acting ([4,8], p4) [root@ceph-node1 /]#
Давайте проверим предыдущий вывод. Первый вывод результатов для пула ssd представляет
основную копию объекта, который расположен на osd.2; другие копии расположены на
osd.5 и osd.6. Это объясняется способом, которым
мы настроили нашу карту CRUSH. Мы предписали пулу ssd использовать
ceph-node1, который содержит osd.0,
osd.1 и osd.2.
Это только демонстрация основных возможностей пользовательской настройки карт CRUSH. Вы можете делать много разных вещей с помощью CRUSH. Существует масса возможностей для эффективного и результативного управления всеми данными вашего кластера Ceph с применением карт CRUSH.
В этой главе мы рассмотрели задачи эксплуатации и обслуживания, которые должны выполняться в кластере Ceph. Эта глава дает понимание служб Ceph, а также увеличение и уменьшение масштаба работающего кластера. ПОследующая часть главы посвящена процедуре замены вышедших из строя дисков в вашем кластере Ceph, которая является общим местом для кластеров среднего и крупного размера. Наконец, мы знакомимся с мощью карт CRUSH и тем, как настраивать карты CRUSH для своих нужд. Изменение и настройка карт CRUSH довольно интересная и важная часть Ceph; с ней приходит получение решения хранения уровня предприятия. Вы всегда можете получить дополнительную информацию относительно карт CRUSH Ceph на странице http://ceph.com/docs/master/rados/operations/crush-map/
В следующей главе мы изучим мониторинг Ceph, а также регистрацию в вашем кластере Ceph и его отладку с рядом советов по устранению неполадок.