Глава 10. Настройка производительности Ceph и эталонное тестирование
В данной главе мы рассмотрим следующие темы:
-
Обзор производительности Ceph
-
Общий анализ производительности Ceph - уровень аппаратных средств
-
Настройка производительности Ceph - уровень программных средств
-
Кодирование удаления Ceph
-
Создание уровне кэша Ceph
-
Эталонное тестирование Ceph с применением RADOS bench
Содержание
- Общее представление о производительности Ceph
- Анализ производительности Ceph- аппаратный уровень
- Настройка производительности Ceph- уровень программного обеспечения
- Настройка производительности кластера Ceph
- Кодирование затирания Ceph
- Многоуровневое кэширование Ceph Ceph
- Эталонное тестирование Ceph с применением оснастки RADOS
- Заключение
Данные и информация всегда сохраняют тенденцию к изменению и росту. Каждая организация, вне зависимости от того маленькая она или большая, сталкивается с проблемами роста данных со временем и большую часть времени эти проблемы роста данных привносят также с собой и проблемы с производительностью. В текущую эпоху, когда мир создает огромное количество данных, организации вынуждены искать решения для хранения данных, которые являются высоко масштабируемыми, распределенными, чрезвычайно надежными, а поверх всего этого, еще и обладают хорошей производительностью для всех своих потребностей рабочих нагрузок.
Одним из самых больших преимуществ Ceph является то, что она обладает масштабируемой, распределенной архитектурой. Благодаря распределенной природе все входящие нагрузки распределяются и назначаются всему кластеру для хранения, что делает Ceph системой хранения с хорошей производительностью. Вы можете представлять себе файлы данных в традиционных системах хранения как весьма ограниченные в масштабируемости, с практически отсутствующей распределенностью и имеющие только ограниченное число узлов хранения данных и дисков. В такого рода традиционных установках могут возникать проблемы с производительностью по мере роста объемов данных и увеличением числа запросов пользователей.
В это время, когда приложения обслуживают громадные количества клиентов, они требуют в своей основе систем хранения с лучшей производительностью. Типичная установка Ceph содержит множество узлов, причем каждый узел содержит несколько OSD (устройств хранения объектов). Поскольку Ceph является распределенной, при поступлении данных для сохранения они распределяются по множеству узлов и находящихся в них OSD, обеспечивая аккумуляцию производительности множества узлов. Помимо этого, традиционные системы ограничены определенными показателями производительности когда вы добавляете к ним дополнительную емкость, т.е. вы не получите дополнительной производительности по мере роста емкости. В некоторых случаях производительность падает по мере роста емкости. В Ceph вы никогда не увидите снижения производительности при росте емкости {Прим.пер.: несколько прямолинейное утверждение (в отношении никогда): на самом деле существуют ограничения, связанные с системой интерконнекта и внутренних шин узлов, а именно: суммарной пропускной способностью каналов, их латентностью и конкуренцией за сами каналы связи. Однако, действительно, эти проблемы также можно решать путем масштабирования}. При увеличении емкости системы хранения Ceph, т.е. когда вы добавляете новые узлы, наполненные OSD, производительность всего кластера увеличивается линейно, поскольку мы получаем больше рабочих лошадок OSD, а также добавляем процессоры, оперативную память и сетевые ресурсы вместе с новыми узлами. Это то что делает Ceph уникальной и отличает ее от других систем хранения.
Когда дело доходит до производительности, важную роль играет используемое оборудование. Традиционные системы хранения работают весьма специфически на аппаратных средствах своего производителя- держателя торговой марки, причем пользователи не имеют какой бы то ни было гибкости в плане выбора базовой аппаратуры на основе своих потребностей и уникальных требований рабочих нагрузок. Для организаций, которые инвестируют средства в такие замкнутые на вендора системы, очень трудно преодолевать проблемы, создаваемые оборудованием, если оно вдруг перестало отвечать стоящим перед ним задачам.
С другой стороны Ceph абсолютно не привязан к производителю аппаратуры; организации больше не связаны с производителями технических средств и они могут свободно использовать любые аппаратные средства по своему выбору, а также требованиям бюджета и производительности. Они имеют полный контроль над своим оборудованием и лежащей в его основе инфраструктуре.
Другим преимуществом Ceph является то,что она поддерживает разнородное оборудование, т.е. Ceph может работать на кластере с аппаратурой от множества производителей. Пользователям разрешается смешивать торговые марки при создании своей инфраструктуры Ceph. Например, при покупке аппаратуры для Ceph, пользователи могут смешивать технические средства от различных производителей, таких как HP, Dell, IBM, Fujitsu, Super Micro и даже не совсем стандартное оборудование. Таким образом клиенты могут достичь огромной экономии денежных средств, получить необходимое оборудование, полный контроль и права принятия решений. {Прим.пер.: не стоит сбрасывать со счетов проблемы технического обслуживания и сопровождения системы; в крупномасштабной системе выход оборудования из строя и контакты с производителем по проблемам его замены штатная ситуация; вам стоит заранее оценить разницу в свои затратах времени и средств на контакты с одним поставщиком/ производителем и множеством таковых}.
Выбор аппаратных средств играет важную роль в общей производительности системы хранения Ceph. Поскольку клиенты имеют полное право выбирать тип аппаратных средств для Ceph, это должно быть выполнено с особой тщательностью, с проведением соответствующей оценки текущих рабочих нагрузок и их значений в будущем.
При этом следует иметь в виду, что выбор аппаратных средств полностью зависит от рабочей нагрузки, которую вы собираетесь разместить в вашем кластере, среды и всей функциональности, которую вы будете использовать. В данном разделе мы изучим некоторые общие правила при выборе оборудования для вашего кластера Ceph. {Прим.пер.: Дополнительную информацию по рекомендациям выбора аппаратуры вы можете получить на странице http://www.mdl.ru/Solutions/Put.htm?Nme=CephHW, являющейся авторским переводом Hardware Recommendations с официального сайта Ceph Documentation.}
Некоторые компоненты Ceph не являются требовательными к процессорам. Например, демоны мониторов Ceph являются легковесными, поскольку они обслуживают копии кластера и не обслуживают данные клиентов.Таким образом, в большинстве случаев процессор с одним ядром будет способен выполнять эту работу. Вы также можете рассмотреть вариант работы демона монитора на любом другом сервере в среде, имеющем свободные ресурсы. Убедитесь, что у вас есть такие системные ресурсы как оперативная память, сетевые средства и дисковое пространство в достаточном объеме для демонов монитора.
Демоны Ceph OSD могут потребовать значительные ресурсы процессоров, поскольку они обслуживают данные клиентов и, следовательно, требуют некоторой обработки данных. Для узлов OSD достаточным будет двух-ядерный процессор. С точки зрения производительности важно понимать как вы будете использовать OSD: в режиме репликаций или удаления кода. Если вы используете OSD в режиме удаления кода, вы должны рассмотреть вариант применения четырех-ядерного процессора для операций по удалению кода, требующих большого объема вычислений. В случае восстановления данных кластера потребление ресурсов процессоров демонами OSD значительно возрастает.
Демоны MDS (сервера метаданных) еще более требовательны к ресурсам процессоров по сравнению с MON и OSD. они должны динамически перераспределять свою нагрузку, что сильно загружает центральные процессоры; вы должны рассмотреть возможность применения четырех-ядерных процессоров для Ceph MDS.
Демоны монитора и метаданных должны обслуживать свои данные быстро, следовательно они должны иметь достаточно памяти для быстрой работы. С точки зрения производительности, объема в 2ГБ или более для экземпляра демона достаточно для метаданных и монитора. Как правило, OSD не являются требовательными к оперативной памяти. Для рабочей нагрузки среднего уровня должно быть достаточно 1ГБ оперативной памяти в исчислении на основе для экземпляра демона OSD; однако с точки зрения производительности лучшим выбором будет 2ГБ на демон OSD. Рекомендации предполагают, что вы используете один демон OSD для одного физического диска.Если вы используете более одного физического диска для OSD, ваши требования к оперативной памяти также должны возрасти. Обычно больший объем оперативной памяти является хорошим выбором, поскольку при операциях восстановления потребление памяти значительно возрастает.
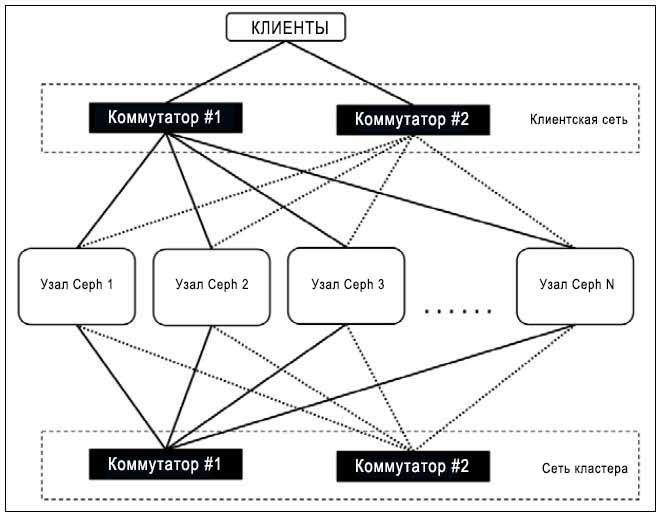
Все узлы кластера должны иметь двойные интерфейсы сети для двух различных сетей, а именно: для сети кластера и для сети клиентов. Для кластера среднего размера, в несколько сотен терабайт, должно быть достаточно сетевых соединений 1G. Однако, если размер вашего кластера большой и он обслуживает множество клиентов, вы должны подумать об использовании сети с пропускной способностью 10G или более. Во время восстановления сеть играет важную роль. Если у вас есть хорошее сетевое соединение 10G или более, ваш кластер будет восстанавливаться быстрее, в противном случае это может потребовать некоторого времени. Следовательно, с точки зрения производительности, 10G или более дублированная сеть будет хорошим выбором. Хорошо спроектированный кластер использует две физически разделенные сети, одну для сети кластера (внутренняя сеть), и вторую для сети клиентов (внешняя сеть); обе эти сети должны быть физически разделены на сетевом коммутаторе; настройка точки доступности требует резервированной двойной сети, как это показано на рисунке ниже:
Выбор дискового устройства для кластера хранения Ceph имеет большое значения в отношении общей производительности и общей стоимости кластера. Прежде чем принимать окончательное решение по выбору диска вы должны понимать вашу общую нагрузку и возможные требования к производительности. OSD (устройство хранения объектов) Ceph состоит из двух различных частей: журнальной части OSD и части данных OSD. Каждая операция записи представляет собой двухэтапный процесс.
Когда какое-то OSD получает запросы клиента на сохранение объекта, оно сначала записывает объект в журнальной части, а затем из журнала пишет тот же объект в часть данных до отправки подтверждающего уведомления клиенту. Таким образом, вся производительность кластера вращается вокруг журнала OSD и раздела данных. Для журналов рекомендуется использование SSD с точки зрения производительности. При использовании SSD вы можете добиться значительного улучшения пропускной способности за счет сокращения времени записи и латентности при чтении. В большинстве сред, в которых вы не озадачены экстремальной производительностью. вы можете выбрать настройку журнала и раздела данных на одном и том же диске. Однако, если вы в поиске значительного улучшения производительности вашего кластера Ceph, стоит вложиться в SSD для журналов.
Чтобы использовать SSD в качестве журналов мы создадим логические разделы на каждом физическом SSD, который будет использоваться для ведения журнала, таким образом, чтобы каждый раздел журнала соответствовал одному разделу данных OSD. При таком типе установки вы должны держать в уме пределы SSD, чтобы не выйти за их пределы перегрузкой множества журналов. Выполняя это вы будете влиять на общую производительность. Чтобы получить хорошую производительность ваших SSD вам следует хранить не более четырех OSD на каждом SSD диске.
Темной стороной использования одного SSD для нескольких журналов является то, что потеря вашего SSD, поддерживающего множество журналов, откажут все OSD, связанные с этим SSD, и вы можете потерять свои данные. Тем не менее вы можете побороть эту ситуацию, воспользовавшись RAID 1 для журналов, что, однако, приведет к увеличению стоимости хранения. Кроме того стоимость одного SSD примерно в 10 раз выше стоимости HDD. Следовательно если вы строите кластер с SSD, это приведет к увеличению стоимости гигабайта для вашего кластера Ceph.
Выбор файловой системы также является одним из аспектов производительности кластера. Btrfs является более современной файловой системой, способной записывать объект одной операцией по сравнению с XFS и EXT4, которым необходимо два этапа для записи объекта. Btrfs является файловой системой с копированием при записи (copy-on-write), т.е. при записи объекта в журнал она может одновременно записывать тот же объект в раздел данных, обеспечивая значительное увеличение производительности {Прим. пер.: при изменении новых данных эти данные вначале копируются в новую область}. Тем не менее, в момент написания данного руководства Btrfs не была готова к промышленному применению. Вы можете столкнуться с проблемами несогласованности данных в Btrfs.
Производительность любой системы измеряется тестированием нагрузки и производительности. Результаты таких тестов помогут нам принять решение о том, требуют ли текущая установка настройки или нет. Настройка производительности является процессом исправления узких мест производительности, выявленных в результате тестов производительности. Настройка производительности это очень обширная тема, которая требует глубокого изучения, всех без исключения компонентов, вне зависимости от того являются ли они внутренними или внешними по отношению к Ceph.
Рекомендуемый подход для тонкой настройки кластера Ceph заключается в начале обследования с одной стороны мельчайших элементов вверх до уровня конечных пользователей, которые используют данные службы хранения. В данном разделе мы обсудим некоторые параметры настройки производительности с точки зрения кластера Ceph. Мы будем определять эти параметры настройки в файле настройки кластера Ceph, следовательно, при каждом запуске любого демона Ceph он должен придерживаться этих установок настроек. Вначале мы ознакомимся с файлами настройки Ceph и их различными разделами, а затем мы сосредоточимся на установках настройки производительности.
Большинство установок настройки всего кластера определены в файле настройки кластера Ceph. Если вы не изменяли имя вашего
кластера и местоположения файла настройки для вашего кластера, то именем по умолчанию будет
ceph.conf, а путем к нему /etc/ceph/ceph.conf. Этот
файл настройки имеет общий раздел а также несколько разделов для каждого типа служб. Всякий раз при запуске каждого типа служб
Ceph, т.е. MON (мониторов), OSD (устройств хранения объектов) и MDS (серверов метаданных), они считывают настройки, определенные
в общем разделе, а также в специфичном для них разделе.
Файл настройки Ceph имеет множество разделов; сейчас мы обсудим роль каждого из них.
Общим разделом является раздел, определенный [global]; все установки данного раздела
воздействуют на все демоны кластера Ceph. Здесь определяются все установки, которые должны быть применены ко всему кластеру.
Ниже приводится пример установок в данном разделе:
public network = 192.168.0.0/24
Установки указанные в разделе [MON] применяются ко всем демонам ceph-mon в данном
кластере Ceph. Установки, определенные в данном разделе, переопределяют установки, определенные в разделе
[global]. Ниже приводится пример установок в данном разделе:
mon initial members = ceph-mon1
Установки указанные в разделе [OSD] применяются ко всем демонам ceph-osd в данном
кластере Ceph. Установки, определенные в данном разделе, переопределяют установки, определенные в разделе
[global]. Ниже приводится пример установок в данном разделе:
osd mkfs type = xfs
Установки указанные в разделе [MDS] применяются ко всем демонам ceph-mds в данном
кластере Ceph. Установки, определенные в данном разделе, переопределяют установки, определенные в разделе
[global]. Ниже приводится пример установок в данном разделе:
mds cache size = 250000
Как уже упоминалось ранее, настройка производительности очень специфична к окружению. Среда вашей организации и инфраструктура аппаратуры для кластера Ceph сильно отличается от других организаций. Вещи, которые вы настраиваете в вашем кластере могут работать, а могут и не работать таким же образом в других средах. В данном разделе мы обсудим некоторые общие параметры настройки производительности, которые вы можете настроить более конкретно для вашего окружения.
Указанные в данном разделе параметры должны быть определены в секции [global]
вашего файла настройки Ceph.
Настоятельно рекомендуется, чтобы вы использовали две физически раздельные сети для своего кластера Ceph. Каждая из этих сетей имеет свое собственное предназначение. В соответствии с принятой в Ceph терминологии эти сети называются общедоступной (public) сетью и сетью кластера (cluster):
-
Общедоступная сеть также называется сетевой средой стороны клиентов, которая позволяет клиентам взаимодействовать с кластерами Ceph и осуществлять доступ к кластеру за своими хранящимися там данными. Эта сеть выделена только клиентам, следовательно никакие внутренние взаимодействия кластера не осуществляются в данной сети. Вам следует определить общедоступную сеть для конфигурации вашего кластера Ceph следующим образом:
public network = {public network / netmask}Пример такого определения приводится ниже:
public network = 192.168.100.0/24
-
Сеть кластера также называется внутренней сетью, которая является выделенной сетью для всех внутренних операций кластера между узлами Ceph. С точки зрения производительности эта сеть должна иметь приличную производительность в 10Gb или 40Gb, поскольку эта сеть отвечает за операции кластера с высокой пропускной способностью, например, репликацию данных, восстановление, ребалансировку, а также за проверку тактовых импульсов. Вы можете определить сеть кластера следующим образом:
cluster network = {cluster network / netmask}Пример такого определения приводится ниже:
cluster network = 192.168.1.0/24
Если этот параметр находится на своем месте и кластер Ceph запущен, он устанавливает определение максимального числа
открытых файлов на уровне операционной системы. Это помогает демону OSD (устройства хранения объектов) не выходить за пределы
дескрипторов файлов. Значением по умолчанию является 0; вы можете установить его в значение
любого 64-разрядного целого.
Давайте взглянем на пример:
max open files = 131072
Параметры, перечисленные в данном разделе, должны быть определены в секции [OSD]
файла настройка вашего кластера Ceph.
-
Расширенные атрибуты: Они также известны как XATTR, которые очень полезны для хранения метаданных файлов. Некоторые файловые системы предоставляют ограниченное множество байт для хранения XATTR. В некоторых случаях файловой системе могут помочь хорошо определенные расширенные атрибуты. Параметры XATTR необходимо использовать с файловой системой EXT4 для достижения хорошей производительности. Ниже приводится пример:
filestore xattr use omap = true
-
Интервал синхронизации файловой системы: Чтобы создать непротиворечивую точку завершения, файловой системе необходимо блокировать операции записи, а также выполнять syncfs, которая синхронизацию данных журнала с разделом данных, и, таким образом, освобождает журнал. Более частое выполнение операций синхронизации уменьшает количество данных, хранимых в журнале. В таком случае журнал становится недозагруженным. Настройка более редких синхронизаций позволяет файловой системе лучше объединять малые записи и мы можем получить увеличение производительности. Следующие параметры определяют минимальный и максимальный промежутки времени между двумя синхронизациями:
filestore min sync interval = 10 filestore max sync interval = 15
![[Замечание]](/common/images/admon/note.png)
Замечание Вы можете установить любое другое сдвоенное значение, которое больше соответствует вашей среде для
filestore minиfilestore max. -
Очередь файловой системы: Следующие установки предоставляют пределы размеров очереди файловой системы. Эти установки могут иметь минимальное воздействие на производительность:
-
filestore queue max ops: Это максимальное число операций, которое файловая система может принять перед блокированием новых операций для присоединения их в очередь. Давайте взглянем на следующий пример:filestore queue max ops = 25000
-
filestore queue max bytes: Это максимальное число байт операций. Ниже приводится пример:filestore queue max bytes = 10485760
-
filestore queue committing max ops: Это максимальное значение операций, которое может фиксировать (commit) файловая система. Пример для этого следующий:filestore queue committing max ops = 5000
-
filestore queue committing max bytes: Это максимальное количество байт, которое может фиксировать файловая система. Взгляните на следующий пример:filestore queue committing max bytes = 10485760000
-
filestore op threads: Это число потоков (thread) операций файловой системы, которые могут выполняться одновременно. Ниже приводится пример:filestore op threads = 32
-
-
Настройка журнала OSD: Демоны OSD Ceph поддерживают следующие настройки журналов:
-
journal max write bytes: Это максимальное количество байт, которое журнал может записать за один раз. Далее следует пример:journal max write bytes = 1073714824
-
journal max write entries: Это максимальное значение элементов, которое журнал может записать за один раз. Вот пример:journal max write entries = 10000
-
journal queue max ops: Это максимальное значение операций, разрешенных в очереди журнала в определенный момент времени. Его пример такой:journal queue max ops = 50000
-
journal queue max bytes: Это максимальное число байт, разрешенное очереди журнала в определенный момент времени. Взгляните на следующий пример:journal queue max bytes = 10485760000
-
-
Настройка конфигурации OSD: Демоны OSD Ceph поддерживают следующие установки конфигурации OSD:
-
osd max write size: Это максимальный размер в мегабайтах, которое OSD может записывать за один раз. Ниже приводится пример:osd max write size = 512
-
osd client message size cap: Это максимальный размер данных клиента в мегабайтах, который допустим в оперативной памяти. Пример такой:osd client message size cap = 2048
-
osd deep scrub stride: Это размер в байтах, который читается OSD при выполнении глубокой очистки. Взгляните на следующий пример:osd deep scrub stride = 131072
-
osd op threads: Это число потоков операций, используемое демоном OSD Ceph. Например:osd op threads = 16
-
osd disk threads: Это число дисковых потоков для выполнения интенсивных OSD операций, подобных восстановлению (recovery) и очистке (scrubbing). Ниже приводится пример:osd disk threads = 4
-
osd map cache size: Это размер кэша карты OSD в мегабайтах. Ниже приводится пример:osd map cache size = 1024
-
osd map cache bl size: Это размер хранимого в памяти кэша карты OSD в мегабайтах. Пример такой:osd map cache bl size = 128
-
osd mount options xfs: Он позволяет нам поддерживать опции монтирования файловой системы xfs. Во время монтирования OSD он произведет монтирование с предложенными параметрами монтирования. Взглянем на следующий пример:osd mount options xfs = "rw,noatime,inode64,logbsize=256k,delaylog,allocsize=4M"
-
-
Настройка восстановления OSD: Эти установки должны быть использованы когда вы предпочитаете производительность над восстановлением или наоборот. Если ваш кластер Ceph неисправен и находится в состоянии восстановления, вы можете не получить его обычной производительности, поскольку OSD будут заняты восстановлением. Если вы все- таки предпочитаете производительность над восстановлением, вы можете уменьшить приоритет восстановления, чтобы OSD были меньше заняты восстановлением. Вы также можете установить эти значения, если вы хотите быстрого восстановления вашего кластера, чтобы помочь OSD выполнять восстановление быстрее.
-
osd recovery op priority: Это установка приоритета доя операций восстановления. Чем ниже значение тем выше приоритет восстановления. Высшие значения приоритета восстановления могут вызвать проблемы деградации производительности пока не будет завершено восстановление. Ниже приведен пример:osd recovery op priority = 4
-
osd recovery max active: Это максимальное число активных запросов восстановления. Чем выше значение, тем быстрее восстановление, что может воздействовать на общую производительность кластера до завершения восстановления. Ниже приведен пример:osd recovery max active = 10
-
osd max backfills: Это максимальное количество операций заполнения разрешенных OSD. Чем выше значение, тем быстрее восстановление, что может воздействовать на общую производительность кластера до завершения восстановления. Ниже приведен пример:osd max backfills = 4
-
Реализация пространства пользователя блочных устройств Ceph не может применять преимущества кэширования страниц Linux,
поэтому в версии Ceph 0.46 был введен новый механизм кэширования в оперативной памяти, который называется кэшированием RDB (RADOS
block device, блочных устройств безотказного автономного распределенного хранилища объектов). По умолчанию Ceph не разрешает
кэширование RBD; чтобы разрешить эту возможность вам следует обновить раздел [client] в вашем
файле настройки кластера Ceph на следующие параметры:
-
rbd cache = true: Это разрешает кэширование RBD. -
rbd cache size = 268435456: Это задает размер кэша RBD в байтах. -
rbd cache max dirty = 134217728: Это предел измененных данных в байтах; после такого описания предела данные будут сбрасываться на сервер хранения. Если это значение установлено в0, Ceph использует метод сквозного кэширования (write-through caching). Если это параметр не используется, механизмом кэширования по умолчанию является сквозное кэширование. -
rbd cache max dirty age = 5: Это число секунд, на протяжении которых измененные данные будут храниться в кэше до того, как они будут скинуты на сервер хранения.
В последнем разделе мы обсудим различные параметры настройки, которые вы можете определять в файле конфигурации вашего кластера. Это были советы по тюнингу полностью на основе Ceph. В данном разделе мы обучимся ряду общих приемов регулировки, которые будут настроены на уровне операционной системы и сетевом уровне для вашей инфраструктуры.
-
Kernel pid max: Это параметр ядра Linux, который отвечает за максимальное число идентификаторов потоков и процессов. Основная часть ядер Linux имеет относительно небольшое значение
kernel.pid_max. Настройка этого параметра с бОльшим значением на узлах Ceph предоставляет в распоряжение бОльшее число OSD (устройств хранения объектов), например,OSD > 20может помочь в порождении бОльшего числа потоков для более быстрого восстановления и ребалансировки. Для применения этого параметра выполните следующую команду с правами пользователя root:# echo 4194303 > /proc/sys/kernel/pid_max
-
Кадры Jumbo: Кадры Ethernet, которые имеют длину более 1500 байт называются кадрами jumbo. Разрешение кадров jumbo для всех ваших сетевых интерфейсов вашего узла кластера Ceph должно обеспечить лучшую пропускную способность сети и общее улучшение производительности. Кадры jumbo настраиваются на уровне операционной системы, однако сетевой интерфейс и базовый коммутатор сети должны поддерживать кадры jumbo. Чтобы разрешить кадры jumbo вы должны настроить ваши интерфейсы стороны коммутатора на их прием, а затем приступить к настройке на уровне операционной системы. Например, со стороны операционной системы для разрешения кадров jumbo на интерфейсе eth0 выполните следующую команду:
# ifconfig eth0 mtu 9000
9000 байт полезной информации является пределом сетевого интерфейса MTU; чтобы изменения носили необратимый характер, вам также следует обновить ваш файл настройки сетевого интерфейса,
/etc/sysconfig/network-script/ifcfg-eth0, to MTU=9000. -
read_ahead диска: Параметр
read_aheadускоряет операции дискового чтения путем предварительной выборки и их загрузки в оперативную память. Установка относительно высоких значенийread_aheadдаст преимущества клиентам при выполнении операций последовательного чтения. Вы можете проверить установленное в настоящий момент значениеread_aheadс применением следующей команды:# cat /sys/block/vda/queue/read_ahead_kb
Чтобы установить для
read_aheadбОльшее значение воспользуйтесь командой:# echo "8192">/sys/block/vda/queue/read_ahead_kb
Обычно установка пользователем
read_aheadиспользуется клиентами Ceph, которые используют RBD. Вы должны изменитьread_aheadдля всех RBD, помеченных для данного хоста; также убедитесь, что вы используете правильное имя пути устройства.
Технологии сохранения данных и их резервирования существовали в течение многих десятилетий. Один из самых популярных методов для предоставления надежности данным является репликация. Метод репликации включает в себя хранение одних и тех же данных в нескольких экземплярах в разных физических местах. Этот метод оказывается хорошим, когда речь заходит о производительности и надежности данных, однако он увеличивает общую стоимость системы хранения. Совокупная стоимость владения (TOC) с применением метода репликаций является достаточно дорогостоящим способом.
Этот метод требует в два раза больше пространства хранения для обеспечения избыточности. Например, если вы планируете решение для хранения 1PB данных с фактором репликаций один. вам потребуется 2PB физического пространства хранения для запоминания 1PB реплицируемых данных. Таким образом, стоимость за гигабайт реплицируемых данных системы хранения значительно увеличивается. Вы можете игнорировать стоимость хранения в небольших кластерах хранения, однако представьте как ударит стоимость, если вы строите гипер- масштабируемое решение хранения данных на основе реплицируемых серверов хранения.
В таких ситуация метод кодирования затирания (erasure coding) {Прим.пер.: прямой коррекции ошибок}, приходит как подарок. Это механизм, используемый при хранении как для защиты данных, так и для их надежности, который абсолютно отличается от метода репликаций. Он гарантирует сохранность данных путем разделения каждого объекта хранения на меньшие части называемые порциями (chunk), их расширение и кодирование с частями шифра и, в конечном итоге, сохранении всех таких порций в различных зонах отказов кластера Ceph.
Функциональность кодирования затирания была введена в редакции Ceph Firefly и была основана на математической функции для достижения защищенности данных. {Прим.пер.: В редакции Hammer введен драночный код затирания, SHEC, еще больше увеличивший эффективность восстановления, занятия пространства, варьируемости допустимого числа отказов и их настраиваемости.}, Общая концепция вращается вокруг следующего уравнения:
n = k + mСледующие пункты объясняют эти термины и их назначение:
-
k: Это число порций, подлежащих разделению, также называемое частями данных (data chunks).
-
m: Это дополнительный код, добавляемый к данным для обеспечения их защищенности, также называемый частью кодирования (coding chunk). Для более легкого восприятия вы можете рассматривать его как уровень надежности.
-
n: Это общее число частей, создаваемое после процесса кодирования затирания.
На основании предыдущего уравнения каждый объект в пуле кодирования затирания Ceph будет сохраняться как k+m порций, причем каждая порция сохраняется в OSD в действующем наборе. Таким образом все порции объекта распределяются по всему кластеру Ceph обеспечивая более высокую степень надежности. Теперь давайте поясним некоторые полезные в отношении кодирования затирания термины:
-
Восстановление: Во время восстановления Ceph нам требуются любыеk порций из имеющихся n порций для восстановления данных
-
Уровень надежности: При кодировании затирания Ceph может допускать потерю до m порций
-
Порядок кодирования (r): Может быть вычислен по формуле r = k/n, где r < 1
-
Необходимое пространство хранения: Вычисляется как 1/r
Например, рассмотрим пул Ceph с пятью OSD, который создан с применением правила кодирования затирания (3,2). Каждый объект, сохраняемый в этом пуле, будет разделен на следующие порции данных и кода:
n = k + m
по аналогии, 5 = 3 + 2
следовательно n = 5 , k = 3 и m = 2Таким образом, каждый объект будет разделен на 3 порции данных и к нему будут добавлены две порции кодирования затирания, давая в итоге пять порций, которые будут сохранены и распределены по пяти OSD пула кодирования затиранием в кластере Ceph. В случае отказа для построения оригинального файла нам потребуются любые три порции из любых пяти порций для его восстановления. Таким образом, мы можем перенести утрату любых двух OSD, поскольку данные могут быть восстановлены с использованием трех OSD.
Порядок кодирования (r) = 3 / 5 = 0.6 < 1
Необходимое пространство хранения = 1/r = 1 / 0.6 = 1.6 умноженное на размер оригинала.Предположим, что у нас имеется файл размером 1GB. Для сохранения этого файла в кластере Ceph в пуле кодирования затирания (3,5) вам понадобится 1.6GB пространства хранения, что обеспечит вашему файлу хранение, устойчивое по отношению к отказам двух OSD.
В противоположность методу репликаций, если тот же файл хранится в реплицируемом пуле, то для устойчивости к отказу двух OSD Ceph потребует репликации с размером 3, что в конечном счете потребует пространства хранения объемом 3GB для надежного хранения файла размером 1GB. Таким образом, при использовании функциональности Ceph кодирования затирания вы сохраняете примерно 40 процентов стоимости хранения с получением той же надежности, что и при реплицировании.
Пулы с кодированием затирания требуют меньше мета для хранения по сравнению с реплицируемыми пулами; однако, такая экономия в объеме хранения достигается за счет стоимости производительности, поскольку каждый процесс кодирования затирания делит каждый объект на несколько порций меньшего размера и несколько новых кодированных порций смешиваются с этими порциями данных. Наконец, все эти порции сохраняются в разных зонах отказов кластера Ceph. Весь этот механизм требует несколько больше вычислительной мощности от узлов OSD. Кроме того, в момент восстановления декодирование порций также требует значительных вычислений. Таким образом, вы можете ожидать, что механизм кодирования затирания будет несколько медленнее механизма репликаций. Метод кодирования затирания в основном зависит от варианта использования и вы можете получить максимальную отдачу от кодирования затирания на основании требований ваших данных.
С применением кодирования затирания вы можете хранить больше за меньшие деньги. Холодильное хранение может быть хорошим вариантом использования кодирования затирания, поскольку при нем операции чтения и записи менее часты; например, большие наборы данных, в которых данные образов и генома хранятся длительное время без их чтения и записи, или некоторые виды архивных систем, в которых данные архивируются и к ним не осуществляется частый доступ.
Обычно такие пулы хранилищ с кодированием затирания и низкой стоимостью выстраиваются в ярус с более быстрыми пулами с репликациями и, если данные не используются определенное время (несколько недель), они могут быть перемещены в пул с кодированием затирания с более низкой стоимостью, в которых производительность не является главным критерием.
Кодирование затирания реализуется путем создания пулов Ceph с типом затирания; каждый такой пул основывается на файле параметров кодирования затирания, который определяет характеристики кодирования затирания. Сейчас мы создадим файл параметров кодирования затирания и пул кодирования затирания на его основе:
-
Обсуждающаяся в данном разделе команда создаст файл параметров кодирования затирания с именем
EC-profileс характеристикамиk=3иm=2, которые, соответственно, являются числом порций данных и кодирования. Таким образом, каждый подлежащий сохранению объект будет разделен на 3 (k) порции данных и к ним будут добавлены 2 (m) дополнительные порции кодирования, имея результатом 5 (k+m) порций. Наконец,эти 5 (k+m) порций распределяются по различным OSD зон отказа.-
Создайте файл параметров кодирования затирания:
# ceph osd erasure-code-profile set EC-profile rulesetfailure-domain=osd k=3 m=2
-
Составьте список файла параметров:
# ceph osd erasure-code-profile ls
-
Выведите содержание вашего файла параметров кодирования затирания:
# ceph osd erasure-code-profile get EC-profile
[root@ceph-node1 /]# ceph osd erasure-code-profile set EC-profile ruleset-failure-domain=osd k=3 m=2 [root@ceph-node1 /]# ceph osd erasure-code-profile ls EC-profile [root@ceph-node1 /]# ceph osd erasure-code-profile get EC-profile directory=/usr/lib64/ceph/erasure-code k=3 m=2 plugin=jerasure ruleset-fai1ure-domain=osd technique=reed_sol_van [root@ceph-node1 /]#
-
-
Создайте пулс типом затирания, который будет базироваться на файле параметров кодирования затирания, который вы создали на 1 шаге:
# ceph osd pool create EC-pool 16 16 erasure EC-profile
Проверьте состояние вашего вновь созданного пула; вы должны обнаружить, что размер вашего пула 5 (
k+m), т.е. размер затирания 5. Следовательно, данные будут записываться в пять различных OSD:# ceph osd dump | grep -i EC-pool
[root@ceph-node1 /]# ceph osd pool create EC-pool 16 16 erasure EC-profile pool 'EC-pool' created [root@ceph-node1 /]# [root@ceph-node1 /]# ceph osd dump | grep -i EC-pool pool 15 'EC-pool' erasure size 5 min_size 1 crush_ruleset 3 object_hash rjenkins pg_num 16 pgp_num 16 last_change 975 owner 0 flags hashpspool stripe_width 4128 [root@ceph-node1 /]#
Замечание Используйте относительно хорошие значения или
PG_NUMиPGP_NUMдля вашего пула Ceph, которые больше подходят для вашей установки. -
Теперь у нас есть новый пул Ceph, который имеет тип затирания. Теперь мы должны поместить некоторые данные в этот пул путем создания файл примера с некоторым случайным содержимым и поместите его во вновь созданный пул кодирования затирания Ceph:
[root@ceph-node1 /]# echo "Mona is now testing Ceph Erasure Coding" > filel.txt [root@ceph-node1 /]# cat filel.txt Mona is now testing Ceph Erasure Coding [root@ceph-node1 /]# rados -p EC-pool ls [root@ceph-node1 /]# rados put -p EC-pool object1 file1.txt [root@ceph-node1 /]# rados -p EC-pool ls object1 [root@ceph-node1 /]#
-
Проверьте карту OSD для EC-pool и object1. Вывод этой команды сделает детали понятными отображая идентификаторы OSD, в которых хранятся порции объектов. Как объяснялось на 1 шаге, object1 разделяется на
3 (m)порции данных и дополняется2 (k)кодируемыми порциями; следовательно, совместно пять порций были сохранены в различных OSD по всему кластеру Ceph. В данной демонстрации object1 был сохранен в пяти OSD, а именно osd.7, osd.6, osd.4, osd.8 и osd.5.[root@ceph-node1 /]# ceph osd map EC-pool object1 osdmap e976 pool 'EC-pool' (15) object 'object1' -> pg 15.bac5debc (15.c) -> up ([7,6,4,8,5], p7) acting ([7.6.4.8.5], p7) [root@ceph-node1 /]#
На данный момент мы выполнили установку пула затирания в кластере Ceph. Теперь мы намеренно попытаемся разрушить OSD, чтобы посмотреть как пул затирания будет себя вести когда OSD являются недоступными.
-
Как упоминалось на предыдущем шаге, некоторыми OSD для пула затирания являются osd.4 и osd.5; теперь мы протестируем надежность пула затирания разрушением этих OSD одного за другим.
Замечание Это некоторые необязательные шаги и они не должны выполняться на кластерах Ceph, обслуживающих критические данные. Кроме того, число OSD может изменяться в вашем кластере; замена необходима везде.
Выведите из строя osd.4 и проверьте карту OSD для EC-pool и object1. Вы должны заметить, что osd.4 замещается случайным числом
2147483647, что означает, что osd.4 больше не доступно для данного пула:# ssh ceph-node2 service ceph stop osd.5 # ceph osd map EC-pool object1
[root@ceph-node1 /]# ssh ceph-node2 service ceph stop osd.4 === osd.4 === Stopping Ceph osd.4 on ceph-node2...kill 4542...done [root@ceph-node1 /]# ceph osd map EC-pool object1 osdmap e980 poo1 ’EC-pool' (15) object 'object1' -> pg 15.bac5debc (15.c) -> up ([7,6,2147483647,8,5], p7) acting ([7,6,2147483647,8,5], p7) [root@ceph-node1 /]#
-
Аналогично, выведите из строя еще одно OSD, т.е. osd.5, и обратите внимание на карту OSD для EC-pool и object1. Вы должны заметить, что osd.5 замещается случайным числом
2147483647, что означает, что osd.5 больше не доступен для этого пула:[root@ceph-node1 /]# ssh ceph-node2 service ceph stop osd.5 === osd.5 === Stopping Ceph osd.5 on ceph-node2...kill 5437...done [root@ceph-node1 /]# [root@ceph-node1 /]# [root@ceph-node1 /]# ceph osd map EC-pool object1 osdmap e982 pool 'EC-pool' (15) object 'object1' -> pg 15.bac5debc (15.c) -> up ([7,6,2147483647,8,2147483647], p7; acting ([7,6,2147483647,8,2147483647], p7) [root@ceph-node1 /]#
-
Теперь пул Ceph работает на трех OSD, что является минимумом, необходимым для данной установки пула затирания. Как уже обсуждалось ранее, для EC-pool будет необходимо любые три порции из пяти для для обслуживания данных. Теперь у нас осталось только три порции, а именно, osd.7, osd.6 и osd.8, а мы все еще имеем доступные данные.
[root@ceph-node1 /]# rados -p EC-pool ls object1 [root@ceph-node1 /]# rados get -p EC-pool object1 /tmp/file1 [root@ceph-node1 /]# cat /tmp/file1 Mona is not testing Ceph Erasure Coding
Таким образом, кодирование затирания предоставляет пулам Ceph надежность и, в то же время, меньшее пространство хранения требуется для обеспечения надежности.
Функциональность Кодирования затирания дает значительные преимущества надежности архитектуры Ceph. Когда Ceph определяет недоступность любой из зон отказа, он запускает базовую операцию восстановления. На протяжении операции восстановления пулы затирания перестраивают себя путем декодирования отказавших порций на новых OSD, и, после всего они делают все порции доступными автоматически.
В последних двух шагах, обсуждавшихся ранее, мы преднамеренно вывели из строя osd.4 и osd.5. Через некоторое время запускает Ceph восстановление и обновление потерянных порций на различные OSD. Когда операции восстановления завершаются, вы должны проверить для EC-pool и object1; вы будете удивлены увидеть новые идентификаторы, такие как osd.1, osd.2 и osd.3 и, таким образом, пул затирания становится жизнеспособным без вмешательства администратора.
[root@ceph-node1 /]# ceph osd stat osdmap e1025: 9 osds: 7 up, 7 in [root@ceph-node1 /]# [root@ceph-node1 /]# ceph osd map EC-pool object1 osdmap e1025 pool 'EC-pool' (15) object 'object1' -> pg 15.bac5debc (15.c) -> up ([7,6,1.8,3], p7) acting ([7,6,1,8,3], P7) [root@ceph-node1 /]#
Это то, как Ceph и кодирование затирания делают значительную комбинацию. Функциональность кодирования затирания для систем хранения таких как Ceph, которые являются масштабируемыми до уровня петабайтов и выше, будет неограниченно давать эффективный в стоимостном отношении, надежный способ хранения данных.
Как и кодирование затирания, функциональность многоуровневого кэширования также была введена в редакции Ceph Firefly и это была одна из самых обсуждаемых особенностей Ceph Firefly. Многоуровневое кэширование создает пул Ceph, который будет построен поверх самых быстрых дисков, обычно SSD. Такой пул кэширования должен быть размещен перед обычным, реплицируемым пулом или пулом с затиранием таким образом, чтобы все операции ввода/ вывода клиентов вначале обрабатывались пулом кэширования; после этого данные сбрасываются в существующие пулы данных.
Клиенты пользуются высокой производительностью пула кэширования, в то время как данные прозрачно записываются в обычные пулы.
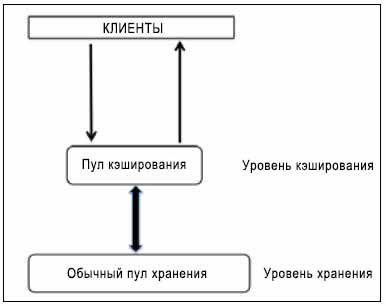
Как правило, кэш строится поверх более дорогостоящих/ более быстрых SSD дисков, таким образом он предоставляет клиентам более высокую производительность ввода/ вывода. Пул кэширования имеет под собой уровень хранения, который выполняется на шпиндельных дисках с типом реплицирования или затирания. При таком типе установки клиенты предоставляют запросы ввода/ вывода пулу кэширования и получают мгновенные ответы на свои запросы, будь то чтение или запись; быстрейший уровень кэша обслуживает запросы клиента. Через некоторое время уровень кэша сбрасывает все свои данные на основной уровень хранения, таким образом он может кэшировать новые запросы от клиентов. Все перемещения данных между уровнями кэша и хранения осуществляются автоматически и прозрачно для клиентов. Многоуровневое кэширование можно настроить в двух режимах.
Когда уровень кэширования Ceph настроен в режим с обратной записью, клиенты Ceph записывают данные в пул кэширования, то есть в самый быстрый пул, и, следовательно, мгновенно получаю подтверждение. На основании политики сбрасывания/ отселения, которую вы установили для своего многоуровневого кэширования, данные перемещаются с уровня кэша агентом многоуровневого кэширования. Во время операций чтения клиента данные перемещаются с уровня хранения на уровень кэширования агентом многоуровневого кэширования и после этого предоставляются клиенту. Данные остаются на уровне кэша пока не становятся неактивными или пока не теряют актуальность.
Когда уровень кэширования Ceph настроен в режим только для чтения, он работает только для операций чтения клиентов. Операции записи клиентов не предполагают многоуровневое кэширование, наоборот, все записи клиентов выполняются на уровне хранения. Во время операций чтения клиента агент многоуровневого кэширования копирует запрашиваемые данные с уровня хранения на уровень кэширования. На основании политики, которую вы настроили для своего многоуровневого кэширования, просроченные объекты удаляются из него. Такой подход идеален, когда множеству клиентов требуется чтение больших объемов схожих данных.
Уровень кэша реализуется на самых быстрых физических дисках, обычно SSD, что дает быстрый уровень кэша поверх более медленных традиционных пулов, выполненных на шпиндельных дисках. В данном разделе мы создадим два отдельных пула, пул кэша и обычный пул, которые будут соответственно использоваться как уровень кэширования и уровень хранения.
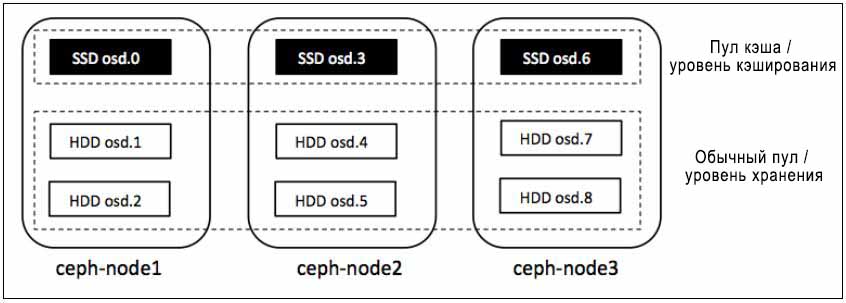
В Главе 7. Эксплуатация и обслуживание Ceph мы обсуждали процесс создания пулов Ceph поверх определенных OSD (устройств хранения объектов) путем изменения карт CRUSH (Управляемых масштабируемым хешированием репликаций, Controlled Replication Under Scalable Hashing). Аналогично мы создадим пул кэша который будет базироваться на osd.0, osd.3 и osd.6. Поскольку у нас нет настоящих SSD для такой установки, мы сделаем предположение, что эти OSD являются SSD и создадим пул кэширования поверх них. Ниже приводится инструкция для создания пула кэширования на osd.0, osd.3 и osd.6.
-
Получите текущую катру CRUSH и декомпилируйте ее:
# ceph osd getcrushmap -o crushmapdump # crushtool -d crushmapdump -o crushmapdump-decompiled
-
Измените файл декомпилированной карты CRUSH и добавьте следующий раздел после раздела root default:
# vim crushmapdump-decompiled root cache { id -5 alg straw hash 0 item osd.0 weight 0.010 item osd.3 weight 0.010 item osd.6 weight 0.010 }![[Предостережение]](/common/images/admon/warning.png)
Предостережение Вам следует изменять карту размещения CRUSH на основании вашей среды.
-
Создайте правило CRUSH добавлением следующего раздела после раздела rules, обычно располагающегося в конце файла. Наконец, сохраните файл карты CRUSH и покиньте редактор:
rule cache-pool { ruleset 4 type replicated min_size 1 max_size 10 step take cache step chooseleaf firstn 0 type osd step emit } -
Скомпилируйте и внедрите новую карту CRUSH в кластер Ceph:
# crushtool -c crushmapdump-decompiled -o crushmapdump-compiled # ceph osd setcrushmap -i crushmapdump-compiled
-
Поскольку к кластеру Ceph была применена новая карта CRUSH, вам следует проверить состояние OSD, чтобы увидеть новое расположение OSD. Вы найдете новый сегмент root cache:
# ceph osd tree
[root@ceph-node1 tmp]# ceph osd tree # id weight type name up/down reweight -5 0.02998 root cache 0 0.009995 osd.0 up 1 3 0.009995 osd.3 up 1 6 0.009995 osd.6 up 1 -1 0.09 root default -2 0.03 host ceph-node1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 0 0.009995 osd.O up 1 -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 [root@ceph-nodel tmp]#
-
Создайте новый пул и установите значение crush_ruleset равным 4, следовательно новый пул будет создаваться на дисках SSD:
# ceph osd pool create cache-pool 32 32 # ceph osd pool set cache-pool crush_ruleset 4
[root@ceph-node1 ~]# ceph osd pool set cache-pool crush_ruleset 4 set pool 16 crush_ruleset to 4 [root@ceph-node1 ~]# ceph osd dump | grep -i cache-pool pool 16 'cache-pool' replicated size 3 min_size 1 crush_ruleset 4 object_hash rjenkins pg_num 32 pgp_num 32 last_change 1142 owner 0 flags hashpspool stripe_width 0 [root@ceph-node1 ~]#
Предостережение У нас в действительности нет SSD; мы предполагаем таковыми osd.0, osd.3 и osd.6 для данной демонстрации.
-
Убедитесь что пул создан правильно, т.е. он должен всегда сохранять все свои объекты на osd.0, osd.3 и osd.6:
-
Выведите перечень cache-pool для содержания; поскольку это новый пул, он не должен иметь никакого содержания:
# rados -p cache-pool ls
-
Добавьте произвольный объект в cache-pool чтобы убедиться, что он сохраняет объекты в правильных OSD:
# rados -p cache-pool put object1 /etc/hosts
-
Выведите содержание cache-pool:
# rados -p cache-pool ls
-
Проверьте карту OSD для cache-pool и object1. Если вы настроили катру CRUSH правильно, object1 должен сохраняться в osd.0, osd.3 и osd.6, поскольку его размер репликации равен 3:
# ceph osd map cache-pool object1
-
Удалите объект:
# rados -p cache-pool rm object1
[root@ceph-node1 ~]# rados -p cache-pool ls [root@ceph-node1 ~]# rados -p cache-pool put object1 /etc/hosts [root@ceph-node1 ~]# rados -p cache-pool ls object1 [root@ceph-node1 ~]# ceph osd map cache-pool object1 osdmap e1143 pool 'cache-pool' (16) object 'object1' -> pg 16.bac5debc (16.1c) -> up ([3,6,0], p3) acting ([3,6,0], p3) [root@ceph-node1 ~]#
-
В предыдущем разделе мы создали пул на базе SSD; теперь мы воспользуемся этим пулом как многоуровневым кэшированием для пула с кодированием затирания с именем EC-pool, который мы создали раньше в этой главе.
Следующие инструкции дадут вам руководство по созданию многоуровневого кэша с режимом обратной записи и установкой наложения на EC-pool:
-
Установите многоуровневого кэширования чтобы связать пулы хранения с пулами кэша. Синтаксис этой команды:
ceph osd tier add <storage_pool> <cache_pool># ceph osd tier add EC-pool cache-pool
-
Установите режим кэширования в значение writeback или read-only. В данной демонстрации мы используем writeback и синтаксис для этого будет таким
ceph osd tier cachemode <cache_pool> writeback:# ceph osd tier cache-mode cache-pool writeback
-
Чтобы направлять все запросы клиентов из стандартного пула в пул кэширования, установите наложение (overlay) и синтаксис для этого будет следующим
ceph osd tier set-overlay <storage_pool> <cache_pool>:# ceph osd tier set-overlay EC-pool cache-pool
[root@ceph-node1 ~]# ceph osd tier add EC-pool cache-pool pool 'cache-pool' is now (or already was) a tier of 'EC-pool' [root@ceph-node1 ~]# ceph osd tier cache-mode cache-pool writeback set cache-mode for pool 'cache-pool' to writeback [root@ceph-node1 ~]# ceph osd tier set-overlay EC-pool cache-pool overlay for 'EC-pool' is now (or already was) 'cache-pool' [root@ceph-node1 ~]#
-
При проверке подробностей пула вы отметите, что EC-pool имеет
tier,read_tierиwrite_tierустановленными в значение16, которое является идентификатором пула для cache-pool.Аналогично для cache-pool установки будут следующими:
tier_ofустановлен в значение15, аcache_modeв значениеwriteback; все эти установки подразумевают, что пул кэширования настроен правильно:# ceph osd dump | egrep -i "EC-pool|cache-pool"
[root@ceph-node1 ~]# ceph osd dump | egrep -i "EC-pool|cache-pool" pool 15 'EC-pool' erasure size 5 min_size 1 crush_ruleset 3 object_hash rjenkins pg_num 16 pgp_num 16 last_change 1181 owner 0 flags hashpspool tiers 16 read_tier 16 write_tier 16 stripe_width 4128 pool 16 'cache-pool' replicated size 3 min_size 1 crush_ruleset 4 object_hash rjenkins pg_num 32 pg p_num 32 last_change 1181 owner 0 flags hashpspool tier_of 15 cache_mode writeback stripe_width 0 [root@ceph-node1 ~]#
Многоуровневое кэширование имеет ряд параметров настройки; вам следует настроить ваше многоуровневое кэширование чтобы установить для него политики. В данном разделе мы настроим политики многоуровневого кэширования:
-
Включить использование отслеживания попаданий в множество для пула кэширования; многоуровневый кэш производственного уровня использует фильтрации расплываний (bloom):
# ceph osd pool set cache-pool hit_set_type bloom
-
Сделайте доступным
hit_set_count, который является числом попаданий в множество для сохранения в кэшируемом пуле:# ceph osd pool set cache-pool hit_set_count 1
-
Сделайте доступным
hit_set_period, который является продолжительностью периода попаданий в множество в секундах для кэшируемого пула:# ceph osd pool set cache-pool hit_set_period 300
-
Сделайте доступным
target_max_bytes, который является максимальным числом байт, по достижению которого агент многоуровневого кэширования начинает сбрасывать/ выселять объекты из пула кэша:# ceph osd pool set cache-pool target_max_bytes 1000000
[root@ceph-node1 ~]# ceph osd pool set cache-pool hit_set_type bloom set pool 16 hit_set_type to bloom [root@ceph-node1 ~]# ceph osd pool set cache-pool hit_set_count 1 set pool 16 hit_set_count to 1 [root@ceph-node1 ~]# ceph osd pool set cache-pool hit_set_period 300 set pool 16 hit_set_period to 300 [root@ceph-node1 ~]# ceph osd pool set cache-pool targetLjnax_bytes 10000000 set pool 16 target_max_bytes to 10000000 [root@ceph-node1 ~]#
-
Сделайте доступными
cache_min_flush_ageиcache_min_evict_age, которые являются временем в секундах, по прошествии которого агент многоуровневого кэширования начинает сбрасывать устаревшие объекты из пула кэша в уровень хранения:# ceph osd pool set cache-pool target_max_objects 10000
-
Сделайте доступным
target_max_objects, который является максимальным числом объектов, по достижению которого агент многоуровневого кэширования начинает сбрасывать/ выселять объекты из пула кэша:# ceph osd pool set cache-pool cache_min_flush_age 300 # ceph osd pool set cache-pool cache_min_evict_age 300
[root@ceph-node1 ~]# ceph osd pool set cache-pool target_max_objects 10000 set pool 16 target_max_objects to 10000 [root@ceph-node1 ~]# ceph osd pool set cache-pool cache_min_flush_age 300 set pool 16 cache_min_flush_age to 300 [root@ceph-node1 ~]# ceph osd pool set cache-pool cache_min_evict_age 300 set pool 16 cache_min_evict_age to 300 [root@ceph-node1 ~]#
-
Сделайте доступным
cache_target_dirty_ratio, который является процентом "запачканных" (модифицированных) объектов пула кэша содежащего по достижению которого агент многоуровневого кэширования начинает сбрасывает их на уровень хранения:# ceph osd pool set cache-pool cache_target_dirty_ratio .01
-
Сделайте доступным
cache_target_full_ratio, который является процентом не измененных объектов пула кэша содежащего по достижению которого агент многоуровневого кэширования начинает сбрасывает их на уровень хранения:# ceph osd pool set cache-pool cache_target_full_ratio .02
-
Создайте временный файл размером в 500МБ, который мы используем для записи в EC-pool, и который в конечном итоге будет записан в cache-pool:
# dd if=/dev/zero of=/tmp/file1 bs=1M count=500
|
| Предостережение |
|---|---|
|
Это необязательный этап; вы можете использовать любой другой файл для тестирования функциональности пула кэша. |
Следующий снимок экрана отображает предыдущие команды в разделе:
[root@ceph-node1 ~]# ceph osd pool set cache-pool cache_target_dirty_ratio .01 set pool 16 cache_target_dirty_ratio to .01 [root@ceph-node1 ~]# ceph osd pool set cache-pool cache_targetL_full_ratio .02 set pool 16 cache_target_full_ratio to .02 [root@ceph-node1 ~]# [root@ceph-node1 ~]# dd if=/dev/zero of=/tmp/file1 bs=1M count=500 500+0 records in 500+0 records out 524288000 bytes (524 MB) copied, 1.66712 s, 314 MB/s [root@ceph-node1 ~]#
На текущий момент времени мы создали и настроили многоуровневое кэширование. Далее мы протестируем его. Как объяснялось ранее, на протяжении операции записи клиента данные кажутся записываемыми в обычный пул, однако на самом деле они вначале пишутся в пул кэша, вследствие чего клиенты получают преимущество от быстрого ввода/ вывода. Основываясь на политиках многоуровневого кэширования, данные прозрачно перемещаются из пула кэша в пул хранения. В данном разделе мы протестируем установки нашего многоуровневого кэширования посредством записи и наблюдения объектов в уровнях кэша и хранения:
-
В предыдущем разделе мы создали тестовый файл размером в 500МБ с именем
/tmp/file1; теперь мы поместим этот файл в EC-pool:# rados -p EC-pool put object1 /tmp/file1
-
Поскольку EC-pool кэшируется cache-pool,
file1не должен быть записан в EC-pool в первом состоянии. Он должен быть записан в cache-pool. Просмотрим каждый пул для получения имен объектов. Используйте команду date для отслеживания времени и изменений:# rados -p EC-pool ls # rados -p cache-pool ls # date
[root@ceph-node1 -]# rados -p EC-pool put object1 /tmp/file1 [root@ceph-node1 ~]# rados -p EC-pool ls [root@ceph-node1 ~]# rados -p cache-pool ls object1 [root@ceph-node1 -]# [root@ceph-node1 ~]# date Sun Sep 14 02:14:58 EEST 2014 [root@ceph-node1 -]#
-
По истечению 300 секунд (мы настроили
cache_min_evict_ageна 300 секунд), агент многоуровневого кэширования переместит object1 из cache-pool в EC-pool; object1 будет удален из cache-pool:# rados -p EC-pool ls # rados -p cache-pool ls # date
[root@ceph-node1 ~]# date Sun Sep 14 02:27:41 EEST 2014 [root@ceph-node1 ~]# rados -p EC-pool ls object1 [root@ceph-node1 ~]# rados -p cache-pool Is [root@ceph-node1 ~]#
Как объяснялось в предыдущей выдаче, данные перемещаются из cache-pool в EC-pool через определенное время.
Ceph поставляется со встроенной программой эталонного тестирования, называемой
RADOS bench, которая используется для измерения производительности
хранения объектов Ceph. В данном разделе мы будем использовать RADOS bench для получения
метрик производительности нашего кластера Ceph. Поскольку мы использовали для Ceph виртуальные узлы с низкой настройкой,
мы не должны рассчитывать на результаты с хорошими значениями производительности в RADOS bench
для данной демонстрации. Однако можно получить хорошие значения производительности при использовании рекомендуемого оборудования
при развертывании Ceph с настроеной производительностью.
Синтаксис использования этого инструментария такой:
rados bench -p <pool_name> <seconds> <write|seq|rand>
Допустимыми параметрами для rados bench являются следующие:
-
-pили--pool: Имя пула -
<Seconds>: Это продолжительность в секундах работы теста -
<write|seq|rand>: Это тип тестирования; он должен быть одним из: запись, последовательное чтение или случайное чтение. -
-t: Это число одновременных операций; значение по умолчанию 16 -
--no-cleanup: Временные данные, записанные в пул данныхRADOS benchне должны очищаться. Эти данные будут использоваться для операций чтения при использовании с последовательных или случайных чтений. По умолчанию применяется очистка.
С применением приведенного выше синтаксиса мв теперь выполним некоторые тесты RADOS bench:
-
10- секундный тест записи на пуле данных создаст последующий вывод. Важно заметить, что пропускная способность вывода (МБ/с)
RADOS bench, которая для нашей установки составляет13.412, что является очень низким показателем, поскольку мы имеем виртуальный кластер Ceph. Другие детали, которые мы отслеживаем, это общее число выполненных записей, записанный объем, средняя латентность и т.п. Поскольку мы использовали флаг--no-cleanup, данные записанныеRADOS benchне будут удаляться и они будут использованы в операциях последовательного и случайного чтенияRADOS bench:# rados bench -p data 10 write --no-cleanup
[root@ceph-node1 /]# rados bench -p data 10 write --no-cleanup Maintaining 16 concurrent writes of 4194304 bytes for up to 10 seconds or 0 objects Object prefix: benchmark_data_ceph-node1_26928 sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 16 16 0 0 0 - 0 1 16 16 0 0 0 - 0 2 15 18 3 4.88541 6 2.4189 2.12187 3 16 24 8 9.21183 20 3.31423 2.59351 4 16 25 9 8.04351 4 1.90747 2.51728 5 16 29 13 9.48749 16 5.37976 3.26326 6 16 29 13 8.02065 0 - 3.26326 7 16 33 17 9.07075 8 5.23925 3.3801 8 16 35 19 8.9441 8 3.31397 3.59352 9 15 39 24 10.0899 20 2.52773 3.98084 10 16 40 24 9.12944 0 - 3.98084 11 15 41 26 9.03055 4 4.05948 4.23526 Total time run: 12.227935 Total writes made: 41 Write size: 4194304 Bandwidth (MB/sec): 13.412 Stddev Bandwidth: 7.60183 Max bandwidth (MB/sec): 20 Min bandwidth (MB/sec): 0 Average Latency: 4.61251 Stddev Latency: 2.54733 Max latency: 11.7108 Min latency: 1.17417 [root@ceph-node1 /]# -
Выполните тест последовательного чтения эталонного тестирования пула данных:
# rados bench -p data 10 seq
[root@ceph-node1 /]# rados bench -p data 10 seq sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 12 12 0 0 0 - 0 1 15 21 6 23.7445 24 0.365323 0.517866 2 15 25 10 19.889 16 1.91165 0.947636 3 16 31 15 19.9216 20 0.832548 1.1234 4 16 36 20 19.8804 20 3.81842 1.623 5 16 41 25 19.9027 20 2.4696 1.94785 6 15 41 26 17.2372 4 1.4177 1.92746 Total time run: 6.807863 Total reads made: 41 Read size: 4194304 Bandwidth (MB/sec): 24.090 Average Latency: 2.48104 Max latency: 6.38046 Min latency: 0.365323 [root@ceph-node1 /]# -
Выполните тест случайного чтения эталонного тестирования пула данных:
# rados bench -p data 10 rand
[root@ceph-node1 /]# rados bench -p data 10 rand sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 12 12 0 0 0 - 0 1 15 22 7 27.8596 28 0.300826 0.468331 2 16 27 11 21.8062 16 0.237253 0.635548 3 16 34 18 23.6913 28 1.52991 1.18525 4 15 36 21 20.7954 12 3.79887 1.53081 5 16 41 25 19.784 16 2.73283 1.91815 6 15 48 33 21.6187 32 1.68679 2.20121 7 16 58 42 23.6049 36 1.84635 2.31201 8 16 63 47 23.0549 20 4.173 2.33454 9 16 69 53 23.1574 24 2.31493 2.294 10 16 73 57 22.4116 16 2.45812 2.32087 11 4 73 69 24.7012 48 3.27041 2.3137 Total time run: 11.206381 Total reads made: 73 Read size: 4194304 Bandwidth (MB/sec): 26.057 Average Latency: 2.38341 Max latency: 5.19721 Min latency: 0.188254 [root@ceph-node1 /]#
Таким образом вы можете творчески разрабатывать тестовые варианты на основе операций записи, чтения и случайного чтения для
вашего пула Ceph. RADOS bench является быстрой и легкой утилитой эталонного тестирования
и хорошая часть заключается в том, что она поставляется в комплекте Ceph.
Настройка производительности и эталонное тестирование сделают ваш кластер Ceph кластером промышленного уровня. Вам всегда следует выполнять тонкую настройку вашего кластера Ceph перед запуском его в производство с применением предпроизводстенной подготовки, разработки или тестирования. Настройка производительности обширная тема и всегда есть пространство для тюнинга в каждой среде. Вы должны применять инструментарий производительности для измерения производительности вашего кластера Ceph и, основываясь на этих результатах, вы можете выполнять необходимые действия.
В данной главе мы рассмотрели большинство параметров настройки для вашего кластера. Вы узнали сложные темы, такие как
настройка производительности с точек зрения как аппаратуры, так и программного обеспечения. Данная глава также содержит
детальное объяснение функциональностей кодирования затирания и многоуровневого кэширования Ceph с последующим обсуждением
встроенного инструментария Ceph для эталонного тестирования, RADOS bench