Глава 4. Ceph и инородные протоколы
Содержание
Годы разработок позволили Ceph отстроить обильный набор функциональных возможностей, привнося в Linux хранилища с высокими качеством и производительностью. Тем не менее, те клиенты, которые не работают в Linux (и которые тем самым не способны общаться естественным образом с Ceph) имеют ограниченную область развёртывания Ceph. Для того чтобы начать общаться с некоторыми из подобных клиентов не на основе Linux, таких как iSCSI ( Internet Small Computer Systems Interface ) и NFS (Network File System), в последнее время был разработан рад новых расширений. Данная глава рассмотрит подробности различных методов, посредством которых хранилища Ceph могут быть экспортированы клиентам, а также достоинства и недостатки каждого. Во всех методах некий сервер Linux применяется в качестве посредника (прокси) для трансляции соответствующих запросов ввода/ вывода от таких клиентов в естественные операции ввода/ вывода Ceph, а раз так, преимуществом будут некие рабочие знания того как применять эти протоколы в Linux. В данной главе также будет рассмотрено придание таким сререам посредников высокой доступности наряду с трудностями этого.
Двумя основными типами хранения которые будут рассматриваться в данной главе будут файловые и блочные хранилища, поскольку это наиболее популярные типы хранения в наследуемых корпоративных рабочих потоках.
Если кратко, в данной главе мы рассмотрим такие вопросы:
-
Блоки
-
Файлы
-
Примеры:
-
Экспорт Ceph RBDs через iSCSI
-
Экспорт CephFS через Samba
-
Экспорт CephFS через NFS
-
-
Гипервизор ESXi
-
Построение кластера
Хранилище на уровне блочных устройств имитирует тот тип хранилищ, которые первоначально предоставлялся жёсткими дисками, а позднее массивами хранения. Обычно блочное хранилище экспортируется через массивы хранения поверх fiber channel или iSCSI в хосты, где затем форматируется некая файловая система в данном блочном устройстве. В некоторых случаях такая файловая система может быть представлена неким типом кластера и может допускать представление такого блочного устройства в одно и то же время множеству хостов. Важно отметить, что хотя хранилище на основе блочных устройств и позволяет вам представлять его множеству хостов, это может быть осуществлено только если сама файловая система поддерживает это; в противном случае достаточно вероятно разрушение такой файловой системы.
Одно из применений блочных хранилищ, которые наблюдают массовую экспансию в последние годы, было обусловлено виртуализацией. Блочное хранилище достаточно часто предоставляется некому гипервизору который форматирует некую файловую систему. Одна или более виртуальных машин затем сохраняются в этой файловой системе. Это целиком отличается от естественного подхода при использовании в качестве гипервизора KVM; поскольку KVM напрямую поддерживает RBD (RADOS Block Devices) Ceph, он сохраняет каждый диск ВМ напрямую как некий RBD, устраняя возникающие сложности и накладные расходы, вызываемые файловой системой гипервизора.
RBD Ceph, который является неким типом блочного хранилища, может экспортироваться через iSCSI чтобы позволить клиентам, которые поддерживают iSCSI употреблять хранение Ceph. Начиная с выпуска Mimic Ceph поддерживает базовый уровень поддержки для настройки iSCSI экспорта образов RBD. Настройка поддержки iSCSI целиком управляется через Ansible, который устанавливает всё требуемое программное обеспечение и экспортирует имеющиеся устройства iSCSI.
На момент написания книги всё ещё имеется ряд ограничений в настоящем, о которых стоит знать читающим, причём в основном они относятся к возможностям HA (Highly Available, высокой доступности). Эти проблемы в основном касаются решений ESXi и кластеров, в которых множество хостов одновременно пытаются осуществить доступ и выполняют его к конкретному блочному устройству. На момент написания книги вам не рекомендуется применять поддержку iSCSI Ceph для каждого из данных вариантов использования. Для тех пользователей, которые интересуются в дальнейшем изучении современного состояния дел рекомендуются консультации с восходящим потоком документации Ceph и списками рассылки.
Как и указывает их название, файловые хранилища поддерживают некий вид файловой системы ,которая сохраняет файлы и каталоги. В традиционном сценарии хранения файловая система обычно предоставляется через серверы, выступающие в качестве файловых серверов, либо через применение NAS (network-attached storage, подключаемых к сети хранилищ). Хранилища на файловой основе могут предоставляться поверх различных протоколов и могут располагаться в некоторых различных видах файловых систем.
Двумя наиболее распространёнными протоколами доступа к файлам являются SMB и NFS, которые широко поддерживаются множеством клиентов. SMB обычно рассматривается как некий протокол Microsoft, выступая в качестве естественного протокола в Windows, в то время как NFS рассматривается в качестве протокола, применяемого в инфраструктурах на основе Unix.
Как мы обнаружим впоследствии, и RBD Ceph, и его собственная файловая система CephFS могут применяться в качестве основы для экспорта клиентам хранилища на основе файлов. RBD может быть смонтирован в некотором сервере посредника (прокси), в котором затем поверх него помещается некая файловая система. Исходя из этого сам экспорт как NFS, так и SMB очень похож на любой прочий сервер с локальным хранилищем. При использовании CephFS, которая сама по себе является некоторой файловой системой, существуют непосредственные интерфейсы как для программного обеспечения сервера NFS, так и для сервера SMB, для минимизации общего числа уровней во всём стеке.
Имеется ряд преимуществ экспорта CephFS вместо размещения файловой системы поверх некого RBD. Они в основном сосредоточены вокруг упрощения общего числа уровней, которое приходится проходить операциям ввода/ вывода и общего количества компонентов в некоторой настройке HA. Как мы уже обсуждали ранее, большинство локальных файловых систем может монтироваться за раз только в одном сервере, в противном случае может происходить их повреждение. Таким образом, при разработке некоторого решения с высокой доступностью, вовлекающем RBD и локальные файловые системы, следует позаботиться о том, чтобы гарантировать что ваше кластерное решение не попытается смонтировать и не выполнит это для конкретных RBD и файловой системы по множеству хостов. Это обсуждается более подробно в данной главе позднее в разделе разработки кластера.
Тем не менее, существует одна вероятная причина для пожелания экспорта RBD форматированного локальной файловой системой: имеющиеся компоненты RBD Ceph намного проще чем CephFS в своей работе и отмечены в качестве стабильных намного дольше чем CephFS. Хотя CephFS подтвердила высокую стабильность, следует подумать об эксплуатационной стороне вашего решения, и при этом вы должны быть уверены что ваш оператор доволен управлением CephFS.
Для экспорта CephFS через NFS существует два возможных решения. Одно заключается в применении самого клиента ядра CepFS и монтирования вашей файловой системы в саму операционную систему, а затем в применении сервера NFS на основе ядра для его экспорта клиентам. Хотя эта конфигурация должна работать достаточно хорошо, как сам сервер NFS на основе ядра, так и конкретный клиент CephFS обычно будут полагаться на то что сам оператор исполняет достаточно современное ядро для поддержки всех самых последних свойств.
Намного лучшей предоставлялась бы идея применения nfs-ganesha, который имеет
поддержку для прямого взаимодействия с файловыми системами CephFS. Посколку Ganesha исполняется целиком в пространстве
пользователя, не существует никаких особых требований к версиям ядра и вся поддерживаемая функциональность клиента CephFS
может отслеживать имеющееся состояние самого проекта Ceph. Существуют также некоторые расширения в Ganesha, которые сам
сервер NFS на основе ядра не поддерживает. Кроме того, HA NFS гораздо проще получить при помощи Ganesha чем в случае
использования соответствующего сервера ядра.
Samba может применяться для экспорта CephFS в качестве некого совместного ресурса, совместимого с Windows. Как и NFS, Samba также поддерживает возможность прямого взаимодействия с CephFS, а следовательно в большинстве случаев, не должно быть никаких требований получать вначале монтирование соответствующей файловой системы CephFS в саму ОС. Для предоставления HA совместных ресурсов Samba на основе CephFS можно применять некий отдельный проект CTDB.
Наконец, стоит отметить, что хотя клиенты Linux могут монтировать CephFS напрямую, может оказаться более предпочтительным экспортировать в них CephFS через NFS или SMB. Нам следует это делать по той причине что, принимая во внимание тот способ, которым работает CephFS, клиенты напрямую взаимодействуют с самим кластером Ceph, а во многих случаях это может быть нежелательным по причинам вопросов безопасности. Посредством повторного экспорта CephFS через NFS, клиенты могут употреблять это хранилище без непосредственного выставления самого кластера Ceph.
Приводимые ниже примеры продемонстрируют как экспортировать RBD в качестве устройств iSCSI, а также как экспортировать CephFS через NFS и Samba. Все эти примеры предполагают что вы уже имеете некую работающую файловую систему CephFS готовую к экспорту; если это не так в вашем случае, тогда, будьте любезны, обратитесь к Главе 5, Пулы RADOS и доступ клиента относительно инструкций по её развёртыванию.
Они также предполагают что у вас имеется доступной ВМ для действия в качестве некого сервера посредника (прокси). Это может быть невая ВМ монитора Ceph для целей проверки, но подобное не рекомендуется при промышленных нагрузках.
iSCSI является технологией, которая позволяет вам экспортировать блочные устройства через сетевые среды IP. Поскольку сетевые среды 10G нашли широкое распространение, iSCSI стал чрезвычайно популярным и в настоящее время выступает в виде доминирующей технологии на сцене блочных хранилищ.
То устройство, которое экспортирует имеющееся блочное хранилище именуется целью (target) iSCSI, а его клиент имеет нащвание инициатора iSCSI, причём оба они идентифицируются неким именем IQN.
На момент написания книги поддержка iSCSI работала только в производных от Red Hat дистрибутивах. Хотя все лежащие в основе компоненты должны полностью работать по всем имеющимся дистрибутивам Linux, те связующие субстанции, которые связывают их воедино всё ещё требуют некоторого количества обновлений для улучшения совместимости. Следовательно данный пример потребует некой ВМ под управлением CentOS для устанавливаемых компонентов iSCSI. Если вы проверяете функциональность в соответствующих лабораториях Vagrant и Ansible, созданных в Главе 2, Развёртывание Ceph в контейнерах, тогда вам придётся изменить свой файл Vagrant для предоставления некоторой дополнительной ВМ под управлением CentOS.
Официальный репозиторий для необходимых компонентов iSCSI доступен исключительно через полную подписку RHEL. Для получения необходимых для данного примера пакетов их следует выгрузить из соответствующего проекта Ceph сборки сервера.
Приводимые здесь ссылки снабдят вас самыми последними сборками каждого из пакетов:
В каждой из указанных страниц вам следует обратиться к колонке arch, как это отображено на приводимом ниже снимке экрана. Именно это тот каталог, который вам следует искать для своих пакетов впоследствии:
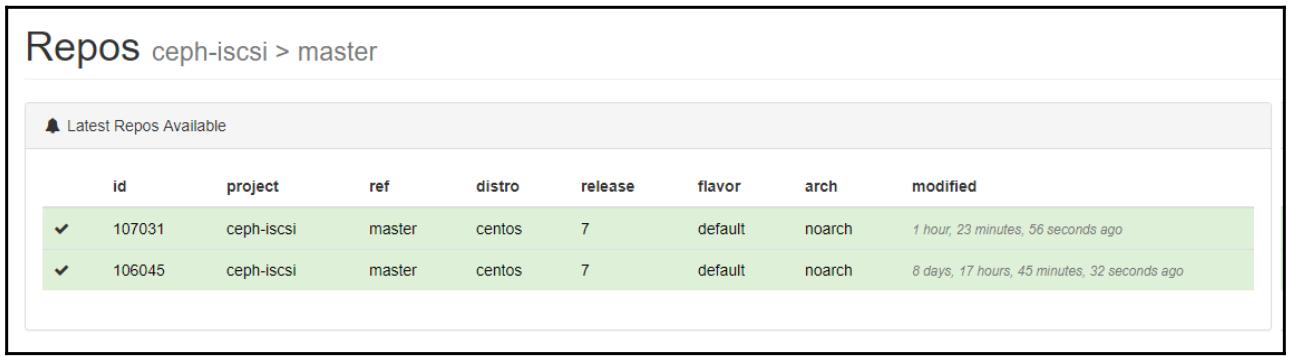
Кликните по самому последнему (либо по требующейся вам версии) номеру сборки слева, что приведёт вас на следующую страницу:
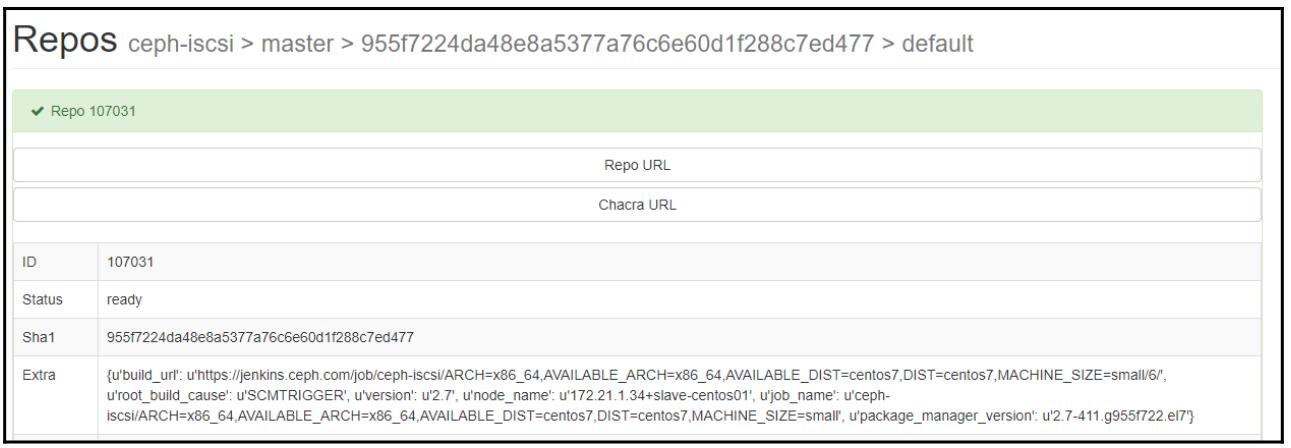
Кликните по ссылке Repo URL, которая перенесёт вас в дерево необходимого репозитория. Переместитесь к правильному типу архива, который вы видели в соответствующей колонке ранее и вам будет представлен необходимый для выгрузки RPM, как это показано на следующем снимке экрана:

Скопируйте предоставленный URL, а затем воспользуйтесь wget для
выгрузки требуемого пакета, как это показано на снимке экрана ниже:

Повторите это для всех перечисленных ранее URL. Когда вы завершите, вы должны получить такие пакеты:

Теперь установите все полученные RPM исполнив:
yum install *.rpm

Теперь после установки основной поддержки iSCSI вам также потребуется установка надлежащих пакетов Ceph при помощи такого кода:
rpm --import 'https://download.ceph.com/keys/release.asc'
Создайте новый файл репозитория и добавьте соответствующие репозитории RPM Ceph при помощи приводимого ниже кода:
nano /etc/yum.repos.d/ceph.repo
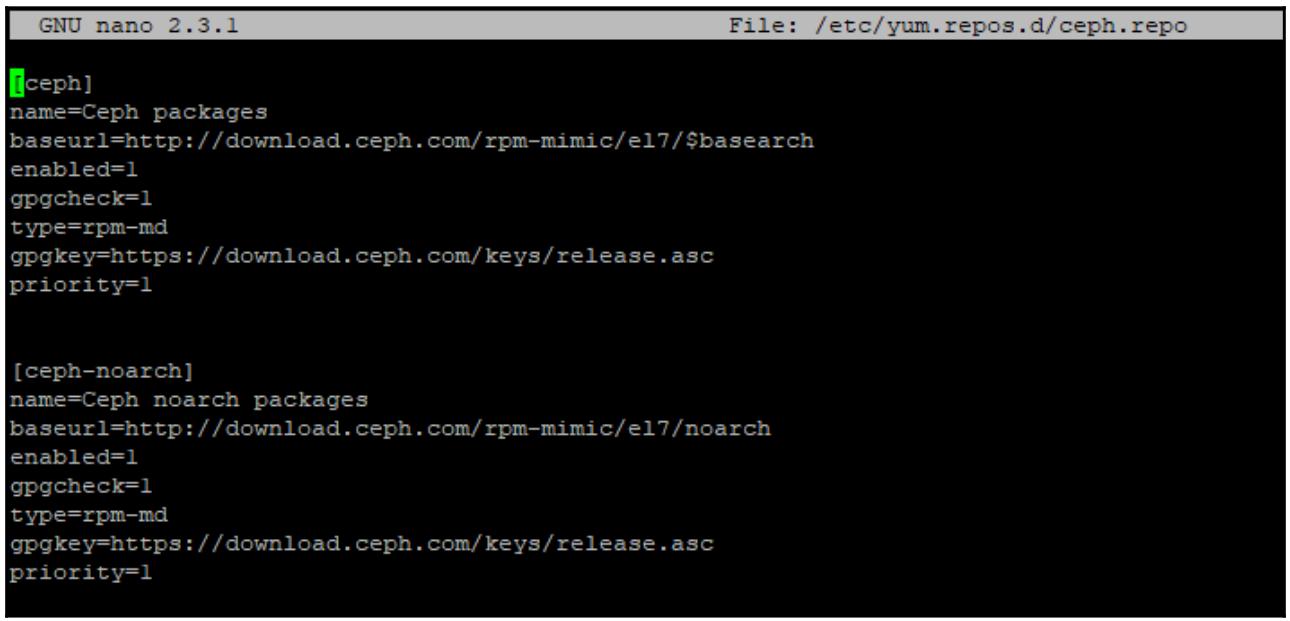
Теперь лобавьте репозиторий Fedora EPEL и установите с обновлением Ceph при помощи такого кода:
yum install -y
https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
yum update
yum install ceph
Создайте необходимый каталог настроек Ceph, если его ещё нет, воспользовавшись таким кодом:
mkdir /etc/ceph
Скопируйте повсеместно ceph.confс узла монитора Ceph при помощи:
scp mon1:/etc/ceph/ceph.conf /etc/ceph/ceph.conf
Выполните массовое копирование keyring так:
scp mon1:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring
Измените свой файл настроек шлюза iSCSI Ceph воспользовавшись приводимым далее кодом:
nano /etc/ceph/iscsi-gateway.cfg
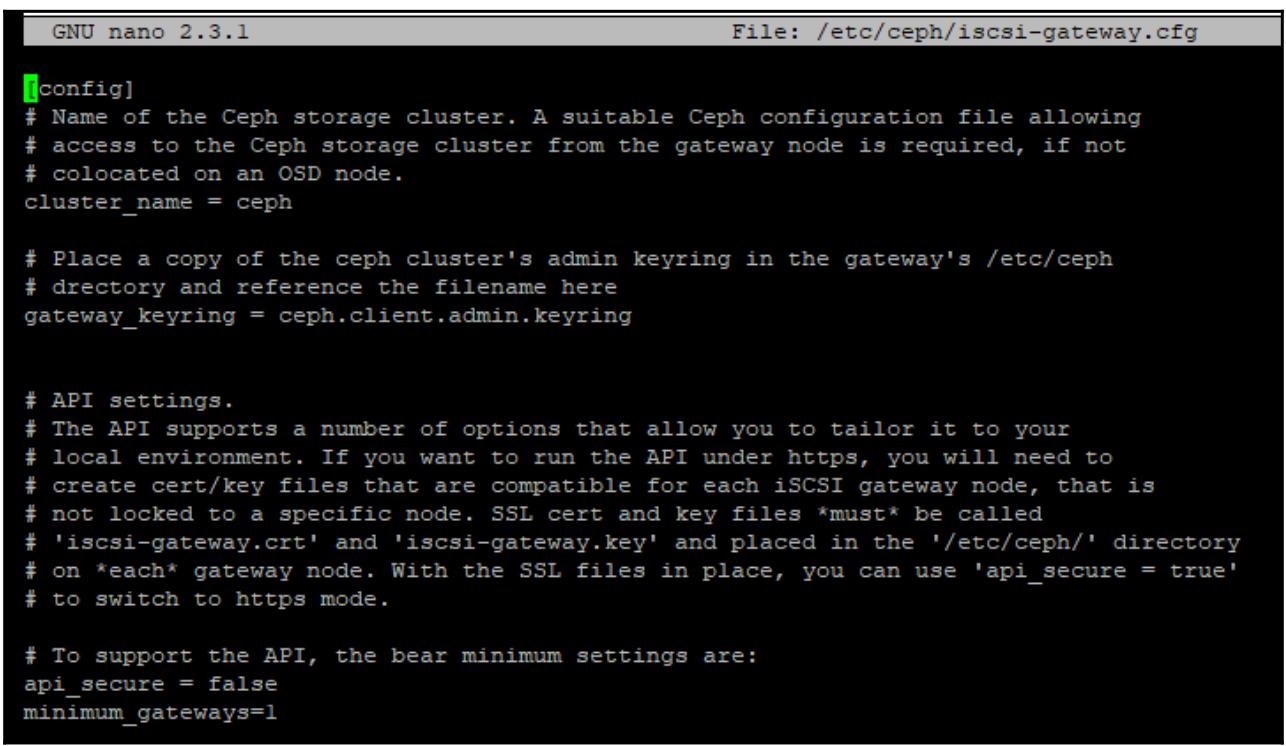
Убедитесь что всё выглядит как на приводимом выше снимке экрана. Обратите внимание на добавление в самой нижней строчке
для разрешения проверок ceph-iscsi только для отдельного сервера. В установказ
для промышленного использования эта строка не требуется, поскольку вы скорее всего будете иметь избыточные шлюзы iSCSI.
Теперь включите и запустите необходимые демоны ceph-iscsi воспользовавшись таким
кодом:
systemctl daemon-reload
systemctl enable rbd-target-api
systemctl start rbd-target-api
systemctl enable rbd-target-gw
systemctl start rbd-target-gw
Отметим, что те настройки, которые хранятся в iscsi-gateway.conf позволяют
соответствующим службам ceph-iscsi только запускаться и выполнять подключение к
вашему кластеру Ceph. Все реальные настройки iSCSI централизованно хранятся в объектах RADOS.
Теперь, когда запущены демоны iSCSI, наш инструмент gwcli может быть применён
администратором данной конфигурации iSCSI для представления RBD в качестве устройств iSCSI.
После успешного запуска gwcli мы можем выполнить команду
ls для просмотра имеющейся структуры конфигурации
ceph-iscsi, как это отображено на следующем снимке экрана:
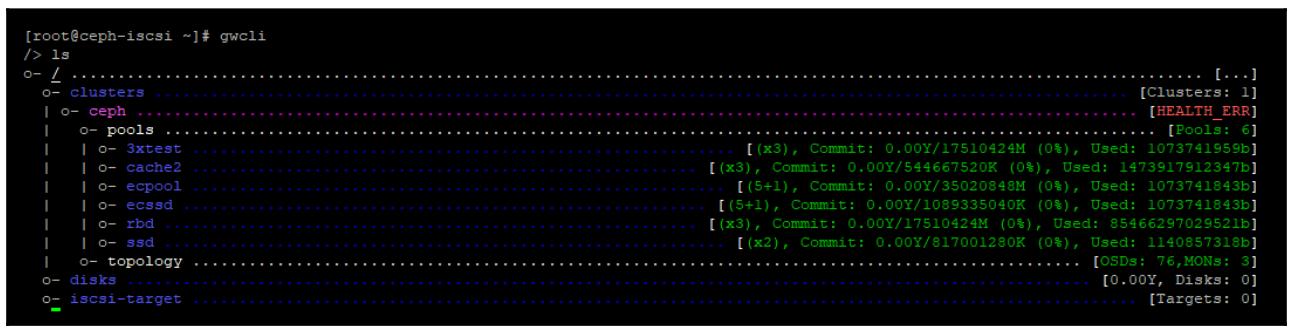
наш инструмент gwcli подключился к имеющемуся кластеру Ceph и осуществил
выборку его перечня пулов и прочих настроек. Теперь мы способны настроить необходимый iSCSI.
Самым первым элементом подлежащим настройке является наш шлюз iSCSI с применением такого кода:
cd iscsi-target
create iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw

Теперь, вводя созданные iqn, при помощи приводимого далее кода можно добавить
соответствующие IP для всех необходимых шлюзов:
cd iscsi-target
create iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw
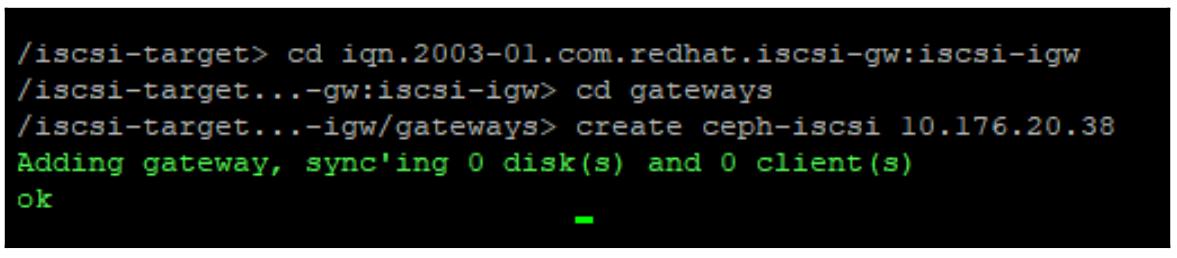
Теперь мы можем создать или добавить необходимые RBD. Если эти RBD уже существуют на момент исполнения данной команды
create, тогда ceph-iscsi просто добавит
такой имеющийся RBD; если никаго RBD с заданным именем не существует, тогда будет создан новый RBD. Неким хорошим примером
того когда может потребоваться уже имеющийся RBD является случай когда этот RBD уже содержит данные, либо когда вам требуется
разместить соответствующие данные RBD в некотором пуле с удаляющим кодированием.
В данном примере в нашем пуле RBD будет создан некий RBD 100 ГБ с названием iscsi-test,
что демонстрируется таким кодом:
cd /disks
create pool=rbd image=iscsi-test size=100G

Теперь следует добавить наш инициатор iqn и назначить проверку подлинности,
как это демонстрируется в приводимом далее коде:
cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw
cd hosts
create iqn.2018-11.com.test:my-test-client
auth chap=chapuser/chappassword

Наконец, добавьте соответствующие диски к своему хосту в качестве LUN при помощи приводимого далее кода. Надлежащим
форматом для вашей цели будет <rados pool>.<RBD name>:
disk add rbd.iscsi-test

Настройка получателя iSCSI теперь выполнена и доступна для добавления в перечень целей любого инициатора iSCSI. После добавления и посторного сканирования соответствующий RBD будет отображён в качестве LUN и затем может рассматриваться в качестве обычного блочного устройства и форматироваться любой требующейся файловой системой.
Проект Samba изначально был спроектирован для того чтобы позволить клиентам и серверам общаться с протоколом SMB Microsoft. С тех пор он превратился в способный действовать в качестве полноценного контроллера домена Windows. Раз Samba может выступать в качетсве некого файлового сервера для клиентов, применяющих для общения такой протокол SMB, его можно применять для экспорта CephFS в клиенты Windows.
Существует также отдельный проект под названием CTDB, который применяется в сочетании с Samba для создания некого отказоустойчивого кластера с целью предоставления совместных ресурсов SMB с высокой доступностью. CTDB применяет свою концепцию блокировки восстановления для выявления и обработки сценариев расщепления сознания (split-brain). Обычно CTDB применялся как некая область кластерной файловой системы для хранения соответствующего файла блокировки восстановления; однако этот подход не работает достаточно хорошо с CephFS по причине того факта, что имеющиеся временные интервалы последовательности восстановления вступают в конфликт с временными значениями восстановления после отказов OSD и MDS CephFS. По этой причине была разработана блокировка восстановления специфичная для RADOS, которая позволила CTDB сохранять информацию о блокировке восстановления непосредственно в объекте RADOS, что избегает упомянутых выше проблем.
В данном примере для экспорта некоторого каталога в CepFS в качестве какого- то совместного ресурса SMB, к которому можно осуществлять доступ из клиентов Windows, будет применяться некий кластер из дух узлов посредников. CTDB будет применяться для предоставления функциональности отработки отказа. Этот совместный ресурс также будет применять моментальные снимки CepFS для разрешения функциональности предыдущих версий Проводника файлов Windows.
Для данного примера нам потребуются две ВМ с рабочей сетевой средой и способностью достигать ваш кластер Ceph. Эти ВМ могут быть либо созданы вручную, через развёртывание Ansible в вашей лаборатории, либо имеющихся мониторах Ceph для проверки возможности программного обеспечения Samba.
На обе эти ВМ установите пакеты ceph, ctdb
и samba, применив такой код:
sudo apt-get install ceph samba ctdb
Скопируйте на них ceph.conf с узла монитора Ceph при помощи:
scp mon1:/etc/ceph/ceph.conf /etc/ceph/ceph.conf
Следующим кодом скопируйте на них необходимое кольцо ключей Ceph с узла монитора:
scp mon1:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring
Теперь ваши шлюзы Samba должны иметь возможность выступать в качестве клиентов для вашего кластера Ceph. В этом можно убедиться проверив что вы можете выполнить запрос значения состояния кластеров Ceph.
Как уже ранее отмечалось, CTDB имеет некий подключаемый модуль Ceph для непосредственного сохранения необходимой блокировки восстановления (recovery lock) в неком пуле RADOS. В некоторых дистрибутивах Linux этот подключаемый модуль может не распространяться совместно с пакетами Samba и CTDB; в частности, дистрибутивы на основе Debian в настоящее время его не содержат. Для аботы с ним и чтобы сохранить время, которое вам пришлось бы потратить на компиляцию вручную, мы переймём некую предварительно скомпилированную версию из другого дистрибутива.
Выгрузите соответствующий пакет samba-ceph из одного из репозиториев SUSE при
помощи следующего кода:
wget http://widehat.opensuse.org/opensuse/update/leap/42.3/oss/x86_64/samba-ceph-4.6.7+git.51.327af8d0a11-6.1.x86_64.rpm

Установите некую утилиту, которая выделит имеющееся содержимое пакетов RPM при помощи кода:
apt-get install rpm2cpio
Воспользуйтесь полученной утилитой rpm2cpio для выделения содержимого RPM,
который только что был выгружен применив:
rpm2cpio samba-ceph-4.6.7+git.51.327af8d0a11-6.1.x86_64.rpm | cpio -i --make-directories
Наконец, скопируйте вспомогательное программное обеспечение CTDB RADOS в свою папку
bin в соответствующей ВМ, воспользовавшись:
cp usr/lib64/ctdb/ctdb_mutex_ceph_rados_helper /usr/local/bin/
Убедитесь что все перечисленные шаги выполнены в обеих ВМ. Теперь, когда всё необходимое программное обеспечение установлено, мы можем продолжить настройку Samba и CTDB. Как CTDB, так и Samba поставляются с примером содержимого в своих файлах настройки. Для целей нашего примера будет отображён только самый необходимый минимум этого содержимого; он оставлен в качетсве некого упражнения для самого читателя если тот пожелает дополнительно исследовать весь доступный диапазон вариантов настройки:
nano /etc/samba/smb.conf
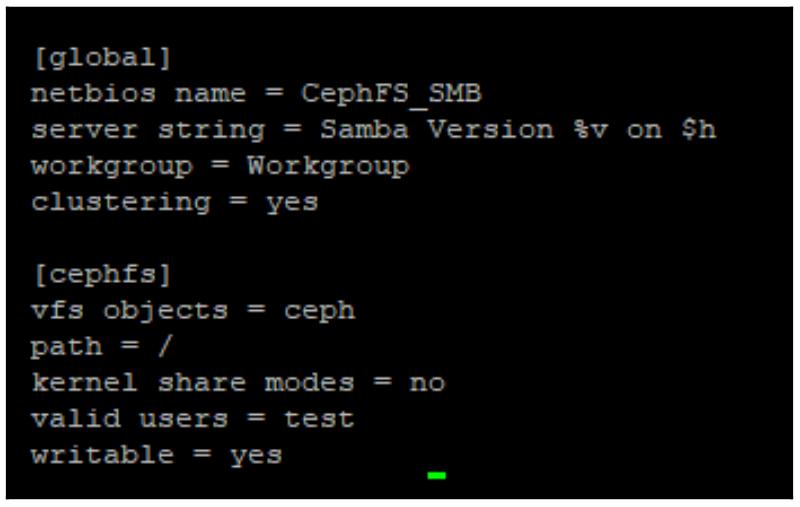
nano /etc/samba/ctdbd.conf

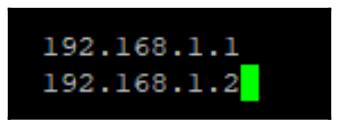
nano /etc/samba/nodes
В каждой строке введите соответствующий IP адрес всех принимающих участие в данном кластере CTDB Samba узлов, как это отражено на снимке экрана внизу:
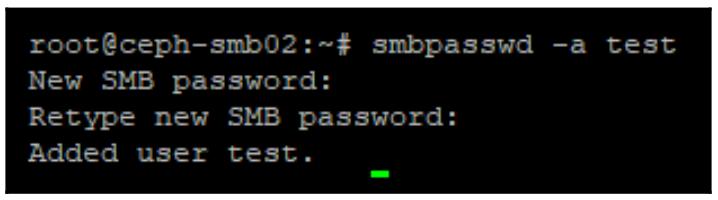
Самый последний шаг сосотоит в создании некого пользователя Samba которого можно применять для доступа к данному совместному ресурсу. Для этого исполните:
smbpasswd -a test
И снова убедитесь что данные настройки были повторены на обоих узлах Samba. После завершения соответствующая служба CTDB может быть запущена, что к счастью должно сформировать кворум, а затем запустите Samba. Запустить вашу службу CTDB можно при помощи такой команды:
systemctl restart ctdb
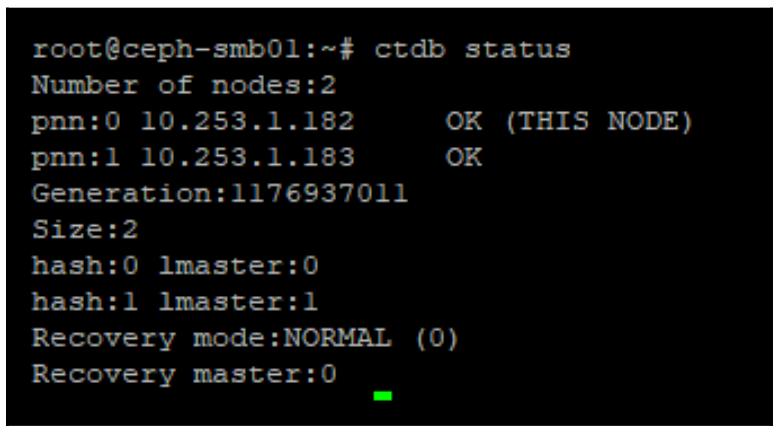
Через несколько секунд CTDB начнёт помечать эти узы как жизнеспособные, в чём можно убедиться выполнением следующего кода:
ctdb status
Следует надеяться, что она отобразит некое состояние, аналогичное приводимому на снимке экрана внизу:
На протяжении короткого промежутка сразу после запуска будет нормальным для статуса его пребывание в положении
не жизнеспособного, однако если значение состояния продолжит оставаться таким, проверьте свои записи регистрации CTDB,
располагающиеся в /var/log/ctdb на предмет возможных объяснений что там пошло
не так.
Как только CTDB войдёт в состояние жизнеспособного, вы должны получить возможность доступа к своему совместному ресурсу CephFS с любого клиента Windows.
Для предоставления реальной HA вам понадобится некий механизм наведения клиентов на имеющиеся активные IP адреса при помощи чего- то аналогичного балансировщику нагрузки. Это выходит за рамки данного примера.
NFS является протоколом совместного использования файлов, который поддерживается в операционных системах Linux, Windows и ESXi. Таким образом, наличие возможности экспорта файловых систем CephFS в качестве NFS открывает двери способности применения CephFS во множестве различных типов клиентов.
Ganesha является сервером NFS пространства пользователя, который обладает собственным подключаемым модулем CephFS, следовательно он имеет возможность напрямую взаимодействовать с файловыми системами CephFS без необходимости их монтирования вначале в данном локальном сервере. Он также обладает поддержкой для хранения своих настроек и информации о восстановлении напрямую в объектах RADOS, что способствует возможности запуска его сервера NFS в неком виде без сохранения состояния.
Пройдемся по следующим шагам установки и настройки своего экспорта CephFS через Ganesha:
-
При помощи следующего кода установите Ganesha PPA (Ganesha 2.7 был самым новым выпуском на момент написания книги):
add-apt-repository ppa:nfs-ganesha/nfs-ganesha-2.7
-
Установите надлежащий PPA для
libntirpc-1.7, который требуетс для Ganesha, воспользовавшись кодом:add-apt-repository ppa:gluster/libntirpc-1.7
-
Установите Ganesha:
apt-get install ceph nfs-ganesha nfs-ganesha-ceph liburcu6
-
Скопируйте куда надо
ceph.confс узла монитора Caph воспользовавшись такой командой:scp mon1:/etc/ceph/ceph.conf /etc/ceph/ceph.conf -
Скопируйте повсеместно кольцо ключей Ceph с узла монитора следующим кодом:
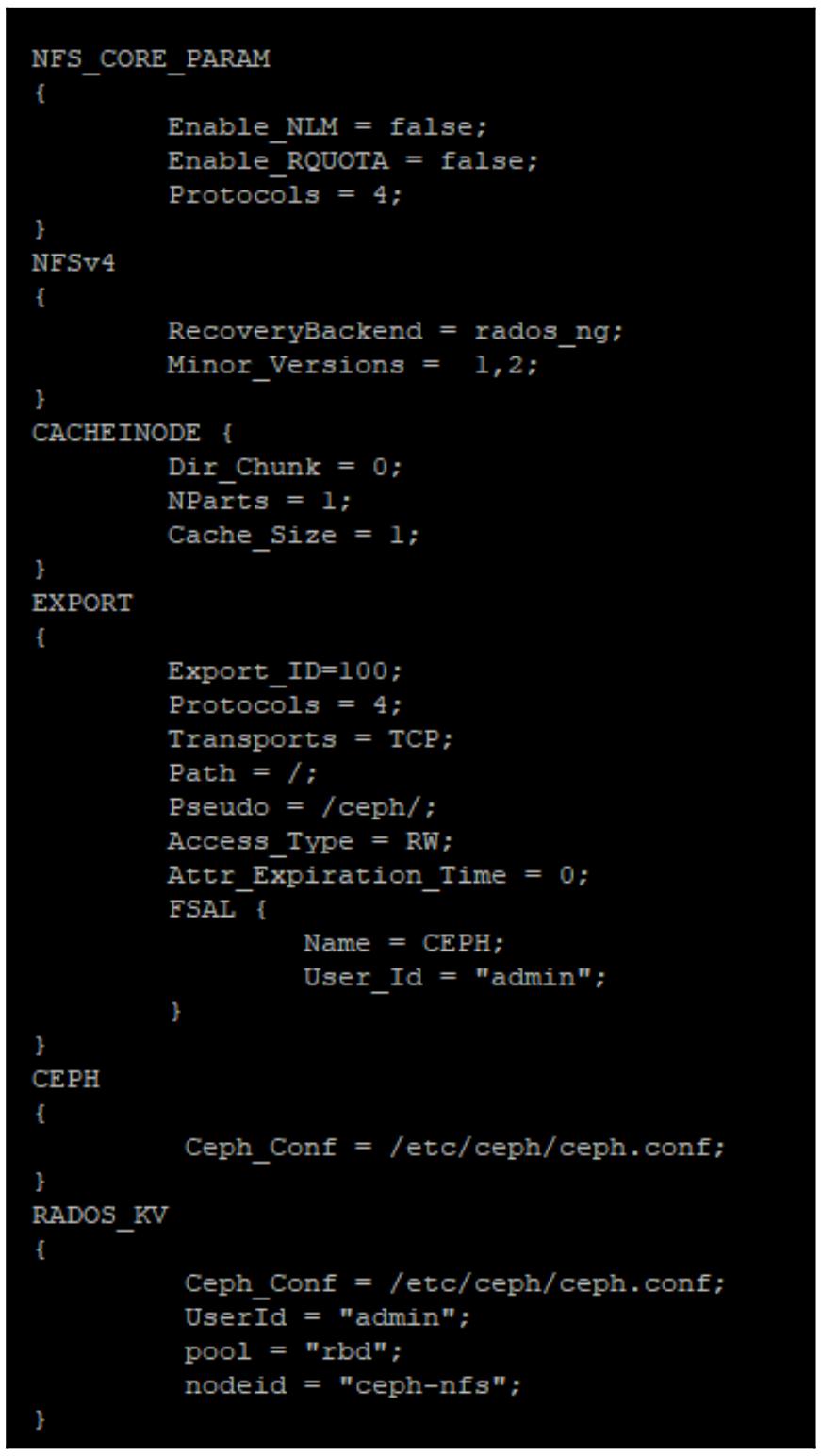
New-VM -Name VM01 -Generation 2Теперь, когда Ganesha установлен, его требуется настроить чтобы указать ему на вашу файловую систему CephFS. Некий образец файла настроек предоставляется в самих пакетах Ganesha; вы можете воспользоваться этим файлом в качестве основы для этого. Прежде всего скопируйте сам файл образца
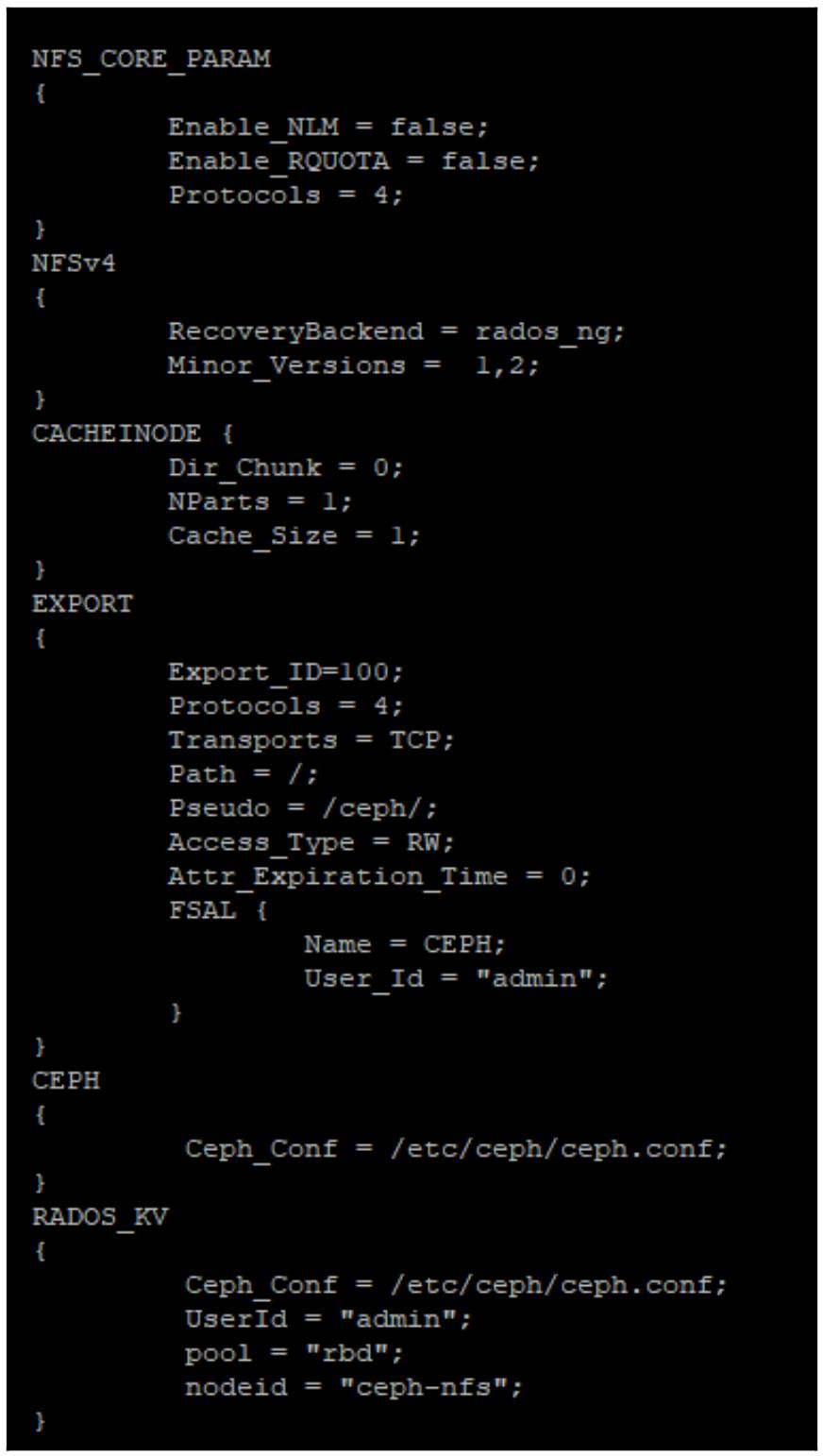
Ganesha Ceph configчтобы он стал основным файломGanesha configпри помощи такого кода:mv /etc/ganesha/ceph.conf /etc/ganesha/ganesha.confЭтот файл настроек хорошо снабжён комментариями, тем не менее следующий снимок экрана показывает версию самого существенного из того что требуется настроить. Его рекомендуется сохранить в качестве файла настроек по умолчанию и выполнить настройку параметров там, где это необходимо, вместо вставки поверх имеющегося, ибо содержащиеся в нём комментарии очень полезны для лучшего понимания всех параметров настройки:
![[Замечание]](/common/images/admon/note.png)
Замечание Требуется установить значение переменной
path configв значение корня самой файловой системы , поскольку CephFS в настоящее время не может как положено поддерживать экспорт подкаталогов через NFS. -
Теперь включите и запустите свою службу
nfs-ganeshaпри помощи:systemctl enable nfs-ganesha systemctl start nfs-ganesha
Теперь вы должны быть способны монтировать полученный совместный есурс NFS в любом поддерживающем его клиенте. Названием данного совместного ресурса NFS будет CephFs.
Обоснованно частым требованием является возможность экспортировать хранилище Ceph и употреблять его через гипервизор VMware ESXi. ESXi поддерживает блочные хранилища iSCSI, которые отформатированы его собственной кластерной файловой системой VMFS и хранилище NFS на файловой основе. И то и другое целиком работает и поддерживается, а это означает, что обычно это просто вопрос предпочтения пользователя что именно реализовывать или что дучше поддерживается его массивами хранения.
При экспорте хранилища Ceph в ESXi существует ряд дополнительных факторов, которые может потребоваться принимать к сведению при применении Ceph в качестве некого поставщика хранения и когда принимается решение между iSCSI и NFS. А раз так, данный раздел этой главы посвящён пояснению дополнительных факторов, которые стоит учитывать при представлении хранилища Ceph в ESXi.
Первым моментом для рассмотрения является то, что ESXi разрабатывался с учётом применения массивов хранения корпоративного уровня и была сделана пара соответствующих решений проектирования в процессе его разработки относительно операций таких массивов хранения. Как уже обсуждалось в открывающей главе, подключаемые напрямую массивы, а также массивы fiber channel и iSCSI будут иметь намного более низкую латентность чем распределённые сетевые хранилища. Что касается Ceph, потребуется некий дополнительный скачок в случае его действия в качестве посредника NFS или iSCSI; это зачастую приводит в результате к латентности по записи, которая в несколько раз выше чем у хорошего блочного массива хранения.
В помощь QoS производителя хранилищ (пока игнорируя ускорения VAAI), ESXi будет разбивать все операции клонирования или миграции на операции ввода/ вывода меньшего размера в 64 кБ с тем обоснованием, что проще планировать дисковое время большего числа параллельных 64 кБ, чем больших операций ввода/ вывода со многими МБ, которые блокированли бы дисковые операции на продолжительное время. Ceph, однако, имеет тенденцию предпочитать операции ввода/ вывода большего размера и поэтому имеет тенденцию к худшей производительности при клонировании или миграции ВМ. Кроме того, в зависимости от метода экспорта Ceph может не предоставлять упреждающее чтение, а следовательно это может наносить вред производительности чтения.
Другой областью, о которой следует побеспокоиться, это управление имеющимся воздействием блокировки PG Ceph. При осуществлении доступа к некому хранимому в Ceph объекту, та PG, которая содержит такой объект блокируется для предоставления согласованности данных. Все прочие операции ввода/ вывода к этой PG должны выстраиваться в очередь пока не освободится данная блокировка. Для большинства сценариев это представляет минимальные проблемы; тем не менее, при экспорте Ceph в ESXi существует ряд моментов выполняемых ESXi, которые могут вызывать конфликт вокруг блокировки такой PG.
Как это уже упоминалось, ESXi выполняет миграцию подставляя свой ввод/ вывод в качестве 64 кБ. Он также пытается сопровождать некий поток из 32 подобных одновременных операций для отслеживания доступной производительности. Это приводит к проблемам при использовании Ceph в качестве лежащей в основе системы хранения, поскольку высокий процент таких операций ввода/ вывода будет попадать в тот же самый объект 4 МБ, что означает что каждый из имеющихся 32 параллельных запросов приведёт в конце концов к обработке в почти последовательном виде. Для того чтобы попробовать и убедиться что эти операции ввода/ вывода с высокой параллельностью но также и чрезвычайной локализацией распределены по некоторому числу объектов, можно воспользоваться чередованием RBD, но длины вашего пробега могут варьироваться. Для некоторых операций миграции и клонирования могут оказать помощь ускорения VAAI, однако в целом ряде случаев их не возможно применять, а в силу этого ESXI будет скатываться обратно к установленному по умолчанию методу.
В отношении миграций ВМ, если вы применяете VMFS в iSCSI поверх RBD конфигурации, вы также можете испытывать конкуренцию блокировки PG в процессе обновления соответствующих метаданных VMFS, которые хранятся только в некоторой небольшой области такого диска. Имеющиеся метаданные VMFS будут часто интенсивно обновляться при росте динамического предоставления VMDK или при записи в файлы ВМ с моментальными снимками. Спор за блокировку PG может ограничивать пропускную способность когда некоторое число ВМ в имеющейся VMFS попытаются одновременно обновить свои метаданные VMFS.
На момент написания книги имеющаяся официальная поддержка iSCSI Ceph отключала кэширование RBD. Для определённых операций такое отсутствие упреждающего чтения имеет отрицательное воздействие на производительность ввода/ вывода. Это особенно отчётливо видно когда вам приходится последовательно считывать файлы VMDK, например, когда вы осуществляете миграцию какой-то ВМ между хранилищами данных или удаляете моментальные снимки.
Что касается поддержки HA, на момент написания книги официальная поддержка iSCSI Ceph применяла только ALUA в неявном виде для управления имеющимися активными путями iSCSI. Это приводило к проблемам когда некий хост ESXi переключается на другой путь, а прочие хосты из того же самого кластера vSphere остаются в первоначальном пути. Долговременным решением будет переключение на ALUA в явном виде, что позволит имеющемуся инициатору iSCSI управлять известными активными путями для данной цели, и тем самым гарантировать что все хосты общаются в одном и том же пути. Единственный доступный в настоящий момент обходной путь для включения полного стека HA состоит в запуск только одной ВМ на каждое хранилище данных.
Настройка NFS–XFS–RBD разделяет множество проблем конкуренции блокировки PG как и соответствующая конфигурация iSCSI и страдает от конфликтов, вызываемых имеющимся журналом XFS. Имеющийся журнал XFS это небольшой циклический буфер, измеряющийся в десятках МБ и при этом покрывает только несколько лежащих в основе объектов RADOS. По мере того как ESXi отправляет запросы синхронизации через NFS, параллельные записи в XFS выстраиваются в очередь, ожидая завершения записи в журнал. Так как XFS не является распределённой файловой системой, при построении некого решения HA по управлению монтированием RBD и файловых систем XFS необходимо реализовывать некие дополнительные шаги.
Наконец, мы имеем соответствующий метод NFS {,iSCSI} и CephFS. Поскольку CephFS является файловой системой, её можно экспортировать напрямую, что означает, что имеется на один уровень меньше, чем это было бы в случае двух других методов. Кроме того, поскольку CephFS является распределённой файловой системой, она может быть смонтирована на множестве посреднических узлов одновременно, что означает что существует два меньших кластерных объекта для отслеживания и управления.
Также весьма вероятно что некая отдельная файловая система CephFS будет экспортирована через NFS, предоставляя некое отдельное большое хранилище данных ESXi, что означает что нет потребности беспокоиться о миграции ВМ между хранилищами данных как это имеет место в случае с множеством RBD. Это чрезвычайно упрощает саму операцию и позволяет обойти множество обсуждавшихся до сих пор ограничений.
Хотя CephFS всё ещё требует операций с метаданными, они обслуживаются параллельно намного лучше чем если бы это были теми операциями с метаданными, которые обрабатываются обсуждавшимся способом в XFS или VMFS и тем самым имеется только минимальное воздействие на производительность. Тот способ , которым обрабатываются метаданные также значительно снижает число возникающих блокировок PG, что означает что параллельная производительность в таком хранилище данных не ограничивается.
Как уже упоминалось ранее в нашем разделе про NFS, CephFS может быть экспортирована как напрямую через Ganesha FSAL или через монтирование в самом ядре Linux с последующим экспортом. По причинам производительности в настоящее время более предпочтительным является метод монтирования через само ядро с последующим экспортом.
Прежде чем принять решение какой из методов лучше всего подходит для вашей среды, рекомендуется чтобы вы исследовали все методы дополнительно и пришли к уверенности что вам улыбнулась удача выполнять администрирование данным решением.
Основная цель построения кластера состоит в том чтобы взять единую точку отказа и позволить ей исполняться на множестве серверов, сделав данную службу более надёжной. В теории это звучит относительно просто: если сервер A падает, запустите необходимую службу на сервере B. На практике, однако, существует ряд подлежащих рассмотрению вопросов, которые следует принимать в расчёт; в противном случае существует риск что доступность только станет хуже чем в неком отдельном сервере, или, что ещё хуже, что произойдёт разрушение данных. Высокая доступность очень сложна в своём правильном достижении и очень запросто что- то может пойти не так.
Самая первая проблема с которой приходится иметь дело при построении кластера это сценарий при котором узлы данного кластера оказываются разделёнными и перестают знать о состоянии друг друга. Такое условие именуется расщеплением сознания (split brain). При кластере из двух узлов каждый из узлов не имеет способа узнать состоит ли причина, по которой он утратил связь с другим узлом в том, что другой узел перешёл в автономный режим, или же это произошло по причине прерывания сетевого соединения. В последнем случае при неверном предположении и запуске ресурсов в обоих узлах это может приводить к разрушению данных. Основной способ обработки ситуации с расщеплением сознания состоит в наличии нечётного числа узлов; тем самым по крайней мере два узла всегда должны иметь возможность формирования кворума и прихода к согласию что именно третий узел вышел из строя.
Тем не менее, даже когда узлы сформировали кворум, всё ещё не безопасно повторно запускать ресурсы в остающихся узлах. Рассмотрим случай, когда некий узел оказывается в автономном режиме, возможно, по причине расчленения сетевой среды, либо, может статься, сам сервер пребывает под высокой загруженностью и перестаёт отвечать вовремя. Если же в остающихся узлах перезапустить службы для них самих, что произойдёт если и когда такой безответный узел вдруг вернётся в жизнь? Для отработки подобного сценария нам тербутся гарантировать что наш кластер на 100% будет уверен в значении состояния всех имеющихся узлов и ресурсов на протяжении всего времени. Это достигается выгораживанием.
Выгораживание (fencing) это процесс ограничения всех исполняющихся ресурсов до тех пор пока состояние данного кластера представляется согласованным. Оно также играет важную роль в попытке вернуть данный кластер в известное состояние через управление текущим состоянием питания узлов кластера или иными методами. Как уже упоминалось, если данный кластер не моежет быть уверенным в значении текущего состояния некоторого узла, службы не могут быть просто повторно запущенными на других узлах, так как нет способа узнать является ли подвергшийся воздействию узел на самом деле уничтоженным, либо он всё ещё исполняет данные ресурсы. Если кластер не настроен на риск утраты целостности данных, такой кластер просто будет ждать неопределённое время пока не получит полной уверенности в значении состояния и пока подвергшийся воздействию узел не вернётся самостоятельно, данные ресурсы кластера останутся отключёнными.
Решение состоит в том, чтобы воспользоваться выгораживанием при помощи метода подобного STONITH (Shoot The Other Node In The Head, Пристрелите другой узел в глову), который разработан с целью возможности вернуть данный кластер в некое нормальное состояние через управление неким внешним механизмом контроля. Наиболее распространённый подход состоит в применении встроенной в сервер функциональности IPMI для выполнения цикла перезапуска питания в данном узле. Так как IPMI данного сервера оказывается внешним для этой операционной системы обычно подключён к иной сетевой среде нежели сама LAN сервера, маловероятно что на него оказало воздействие то, что повлекло к переходу в автономный режим сам сервер. Выполнив перезапуск цикла питания самого сервера и получив подтверждение от IPMI что это произошло, наш кластер на 100% может быть уверенным что имеющиеся в данном узле ресурсы кластера больше не работают. Кластер тогда получает ДОБРО на перезапуск ресурсов в других узлах без риска возникновения конфликтов или разрушения.
Наиболее распространённым решением построения кластеров в Linux являются pacemaker и corosync. Corosync отвечает за обмен сообщениями между узлами и предоставления гарантий согласованного состояния кластера, а pacemaker отвечает за управление имеющимися ресурсами поверх такого состояния кластера. Существует множество агентов ресурсов доступных для pacemaker, которые делают возможным построение кластера с широким диапазоном служб, в том числе и ряда агентов STONITH для IMPI распространённых серверов.
Они обе могут управляться целым рядом различных инструментов клиентов, причём наиболее распространёнными являются
pcs и crmsh. Последующее руководство
сосредоточится на наборе инструментов crmsh.
В данном примере для формирования необходимых узлов кластера требуются три ВМ. Пройдите все перечисленные шаги по всем трйм ВМ:
-
Установите наборы инструментов
corosync,pacemakerиcmrshвоспользовавшись следующим кодом:apt-get install corosync pacemaker crmsh
-
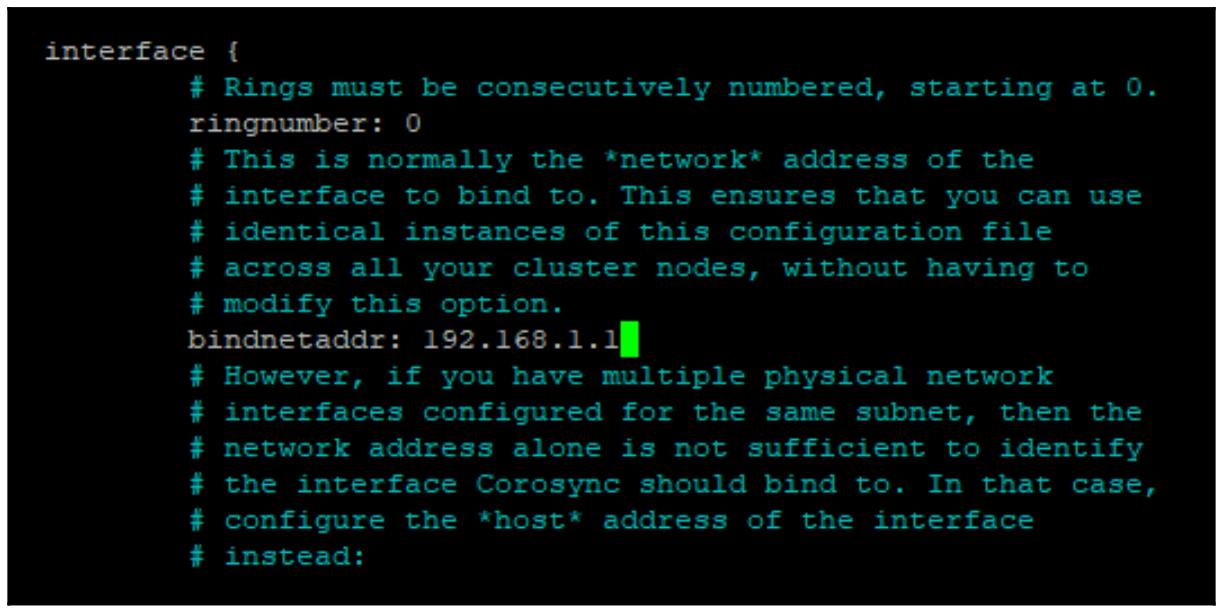
Отредактируйте файл настроек
corosyncи измените установленный адрес привязки (bindnetaddr) чтобы он соответствовал IP настроенному для данной машины:nano /etc/corosync/corosync.conf
-
Включите и запустите службу
corosyncс применением кода, показанного на следующем снимке экранаsystemctl enable corosync systemctl start corosync
-
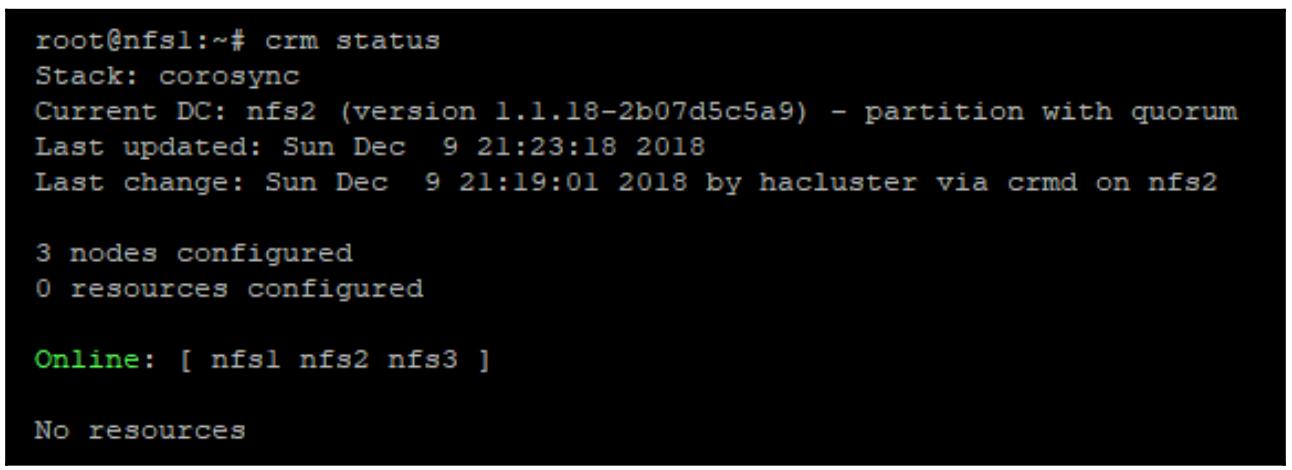
После этих выполнения данных шагов на всех уздах проверьте значение состояния данного кластера. Вы должны увидеть что все три узла объединились в создаваемый кластер, как это отображено на снимке ниже:
crm status
Отметим, что он сообщает
No resources. Жто происходит по причине того, что наш кластер запущен и узлы стали его участниками, но ресурсы пока не настроены. Потребуются некие ресурсы виртуального IP, которые будут тем, к чеиу будут подключаться клиенты NFS. Также потребуется некий ресурс для контроля за Ganesha. Ресурсы управляются агентами ресурсов. Обычно это сценарии, которые содержат некий набор стандартных функций , которые вызывают запуск, останов pacemaker, а также мониторинг его ресурсов. Существует большое число агентов ресурсов, которые содержатся в стандартной установке pacemaker, но и написание индивидуальных не слишком сложная задача, если это понадобится. -
Как уже пояснялось в самом начале данного раздела, выгораживание и STONITH являются существенными частями некого кластера HA; тем не менее, при построении среды проверки реализация STONITH может оказаться сложной. По умолчанию, если не была выполнена некая настройка STONITH, pacemaker не позволит запускать никакие ресурсы, поэтому для целей нашего примера STONITH должен быть отключён при помощи такой команды:
crm configure property stonith-enabled=false
-
Теперь, когда наш кластер готов к получению создаваемых ресурсов, давайте создадим необходимый виртуальный IP ресурса:
crm configure primitive p_VIP-NFS ocf:heartbeat:IPaddr params ip=192.168.1.1 op monitor interval=10s


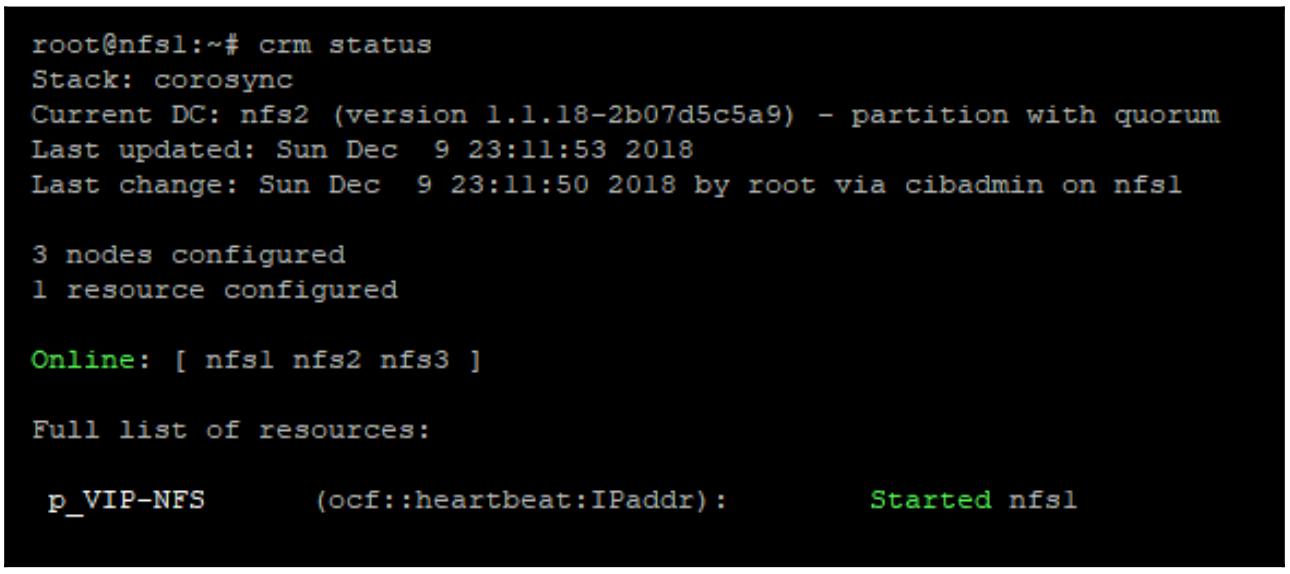
Из предыдущего снимка экрана вы можете увидеть, что наш виртуальный IP был запущен и теперь исполняется в узле
nfs1. Если данный узел nfs1 становится
недоступным, тогда наш кластер попытается сохранить данный ресурс запущенным переместив его на другой узел.
Теперь, как мы это делали в своём предыдущем разделе NFS, давайте установим самую последнюю версию Ganesha пройдя по приводимым ниже шагам:
-
Установите Ganesha PPA при помощи такого кода (
ganesha 2.7был самой последней версией на момент написания книги):add-apt-repository ppa:nfs-ganesha/nfs-ganesha-2.7
-
Припомощи приведённого ниже кода установите
libntirpc-1.7, которая требуется для Ganesha:add-apt-repository ppa:gluster/libntirpc-1.7
-
Установите Ganesha:
apt-get install ceph nfs-ganesha nfs-ganesha-ceph liburcu6
-
Повсеместно скопируйте
ceph.confс узла монитора при помощи кода:scp mon1:/etc/ceph/ceph.conf /etc/ceph/ceph.conf -
Скопируйте на все узлы кольцо ключей Ceph с узла монитора воспользовавшись:
scp mon1:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring -
Теперь, когда Ganesha установлен, могут быть применены настройки. Можно воспользоваться теми же самыми установками, что и для обособленного раздела Ganrsha, как это показано на следующем снимке экрана:
![[Совет]](/common/images/admon/tip.png)
Совет В отличии от примера с обособленным сервером, мы должны обеспечить что Ganesha не установлен на самостоятельный запуск, его может запускать только pacemaker.
Теперь, когда вся работа по настройке завершена, для управления за исполнением Ganesha может быть добавлен следующий код:
crm configure primitive p_ganesha systemd:nfs-ganesha op monitor interval=10s
Наконец, нам требуется удостовериться что наша служба Ganesha запущена в том же самом узле, в котором находится наш виртуальный IP. Мы можем осуществить это создав некую группу ресурсов при помощи приводимого далее кода. Некая группа ресурсов будет гарантировать что все ресурсы запускаются совместно в том же самом узле и что они стартуют именно в том порядке как он задан:
crm configure group g_NFS p_VIP-NFS p_ganesha
Теперь, если мы проверим состояние своего кластера, мы сможем увидеть что наша служба Ganesha в данный момент запущена и, благодаря группированию, она исполняется в том же самом узде что и наш виртуальный IP, как это отображено на следующем снимке экрана:
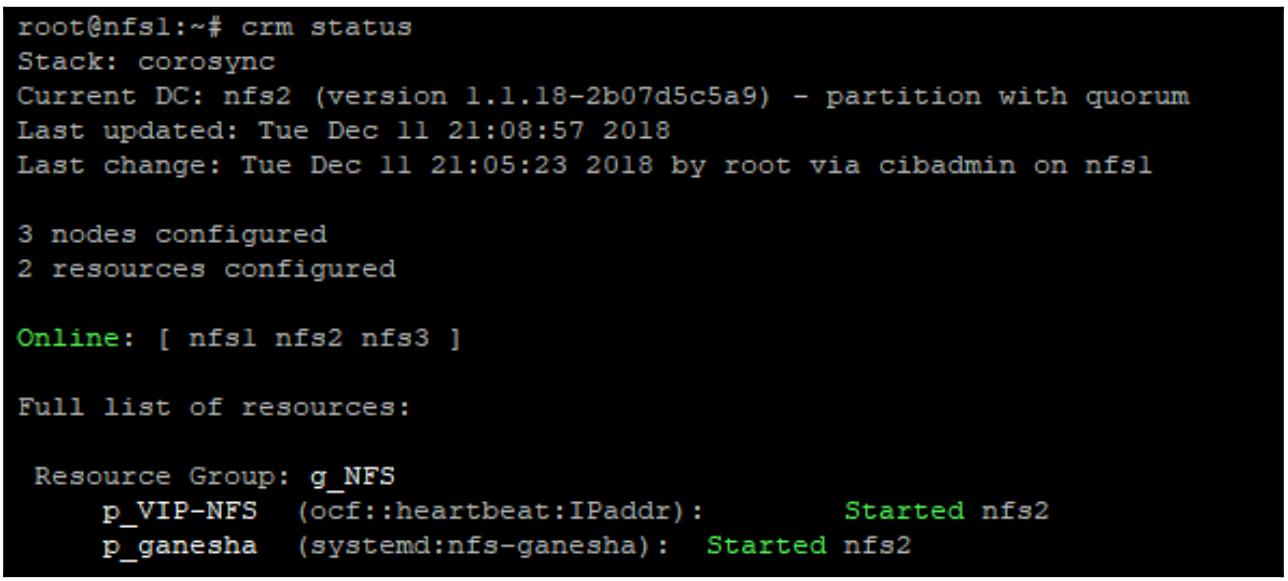
Клиенты NFS теперь имеют возможность подключаться к заданному виртуальному IP и устанавливать соответствие с данным совместным ресурсом NFS. Если некий узел кластера отказывает, наши виртуальный IP и служба Ganesha выполнят миграцию на другой узел кластера и клиенты смогут заметить лишь краткое прерывание в обслуживании.
Для проверки такой возможности отработки случая отказа вы можете поместить свой работающий узел кластера в состояние
standby для принуждения pacemaker запустить данные ресурсы на другом узле.
В нашем текущем примере все ресурсы запускаются на узле nfs2, поэтому
необходимая команда такова:
crm node standby nfs2
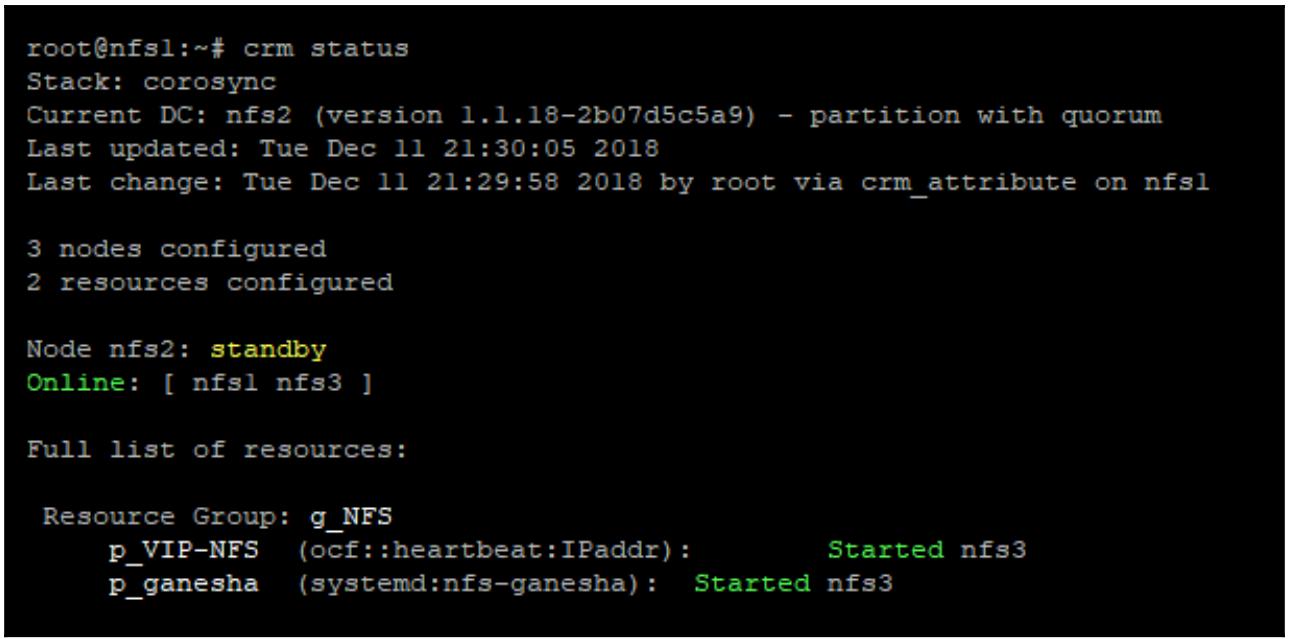
Мы можем обнаружить, что узел nfs2 теперь в режиме
standby и все ресурсы переместились для работы на узел
nfs3.
В этой главе мы изучили различные имеющиеся протоколы систем хранения и как они соответствуют возможностям Ceph. Вы также изучили те протоколы, которые лучшим образом подходят для определённых ролей и должны быть способны принимать осмысленные решения при их выборе.
Поработав с приведёнными примерами вы также должны оформит понимание того как экспортировать хранилище Ceph через iSCSI, NFS и SMB с тем чтобы позволить инородным клиентам Ceph употреблять хранилище Ceph.
Наконец, вы также должны понимать все требования для того чтобы иметь возможность спроектировать и построить некий устойчивый кластер с восстановлением в случае отказов, который может применяться для доставки хранилища Ceph с высокой доступностью для инородных клиентов Ceph.
В своей следующей главе мы рассмотрим различные виды типов пула RADOS, а также различные типы хранилищ Ceph, которые могут предоставляться.
-
Приведите названия трйх протоколов, обсуждавшихся в данной главе.
-
Какой протокол хранения обычно применяется для предоставления блочного хранилища поверх сетевой среды IP?
-
Какой из протоколов хранения в первую очередь применяется клиентами Windows?
-
Какое название носит сервер NFS пространства пользователей?
-
Какие два фрагмента программного обеспечения применяются для построения некого отказоустойчивого кластера?
-
Зачем вы можете пожелать экспортировать CephFS через NFS в клиенты Linux?