Часть 2. Работа и настройка
В концу данного раздела читатель будет способен получать оригинальную версию установки Ceph и её настраивать её для наилучшего обслуживания его потребностей.
В этом разделе содержатся следующие главы:
Глава 5. Пулы RADOS и доступ клиента
Содержание
Ceph предоставляет разнообразие различных типов и настроек пулов. Он также поддерживает некие различные типы хранения данных для их предложения клиентам. Данная глава рассмотрит различия между пулами с репликациями и удаляющим кодированием, предоставит примеры создания обоих и их сопровождения. Мы затем перейдём к тому как применять пулы для трёх методов хранения данных: RBD (RADOS Block Device), объектов и CephFS. Наконец, мы завершим рассмотрением того как получать моментальные снимки различными типами хранения. В этой главе будут рассмотрены такие темы:
-
Пулы
-
Типы хранения Ceph
Пулы RADOS являются центральной частью кластера Ceph. Создание пула это то что движет созданием и распределением групп размещения, которые в свою очередь сами по себе являются автономной частью Ceph. Можно создавать два типа пулов, с репликациями и с удаляющим кодированием, предлагая разные ёмкости применения, уровни надёжности и производительности. Затем рулы RADOS могут применяться для предоставления клиентам различных решений для хранения данных посредством RBS, CephFS и RGW, либо же они могут использоваться для производительности за счёт множества уровней, путём накладывания на прочие пулы RADOS.
Пулы с репликациями являются пулами по умолчанию в Ceph; данные получаются от клиента первичным OSD и затем реплицируются по остальным OSD. Сама логика, стоящая за репликациями, предельно проста и требует минимальной обработки для вычисления и реплицирования получаемых данных между OSD. Тем не менее, раз данный реплицируются целиком, имеется большой штраф записи, поскольку эти данные требуется записывать множество раз по соответствующим OSD. По умолчанию Ceph будет применять множитель репликаций равный 3x, следовательно все данные должны быть записаны три раза; это без учёта всех прочих усложнений записи, которые могут присутствовать далее вниз по имеющемуся стеку Ceph. Такие штрафы записи имеют два основных нежелательных момента: они очевидно накладывают дополнительную нагрузку ввода/ вывода на ваш кластер Ceph, так как записывается больше данных, а в случае с SSD эти дополнительные записи будут достаточно быстро протирать ячейки флеш- памяти. Тем не менее, как мы увидим в следующем разделе, Пулы удаляющего кодирования, для небольшого ввода/ вывода самые простые стратегии репликаций на самом деле всегда будут иметь результатом меньшее общее число требуемых операций - всегда имеется только фиксированное число из трёх штрафных записей, вне зависимости от размера ввода/ вывода.
Следует также отметить, что хотя все реплики некого объекта записываются в течении некой клиентской операции записи, при чтении объекта вовлекается только копия данного объекта на его первичном OSD. Клиент тоже отправляет свою операцию записи на первичный OSD, который затем уже отправляет необходимые операции в остающиеся реплики. Существует множество причин для такого поведения, но они в целом сводятся к гарантии согласованности чтения.
Как уже упоминалось, устанавливаемым по умолчанию значением реплик является 3, при том что требуемым минимумом является размер в 2 реплики для приёма ввода/ вывода клиента. Не рекомендуется уменьшать эти значения, а их увеличение скорее всего даст минимальный эффект для надёжности данных, поскольку шансы утраты трёх OSD которые все разделяют одну и ту же PG очень маловероятны. Поскольку Ceph будет предоставлять приоритет своему восстановлению для PG с меньшим числом копий, это ещё больше снижает вероятность утраты данных, тем самым увеличение общего числа копий реплик до четырёх имеет преимущество только когда речь заходит об улучшении доступности данных, когда могут быть утрачены два OSD, совместно использующие одну и ту же PG и это позволяет продолжать обслуживание ввода/ вывода клиента. Однако по причине накладных расходов хранения четырёх копий, для этой цели рекомендуется рассмотреть вариант с удаляющим кодированием. С введением NVMe, которые по причине своей более высокой производительности сокращают время восстановления, применение размера реплики 2 может обеспечить разумную устойчивость.
Для создания пула с репликациями вызовите команду подобную приводимой в примере ниже:
ceph osd pool create MyPool 128 128 replicated
Она создаст пул с репликациями со 128 группами размещений и наванием
MyPool.
Определяемый по умолчанию в Ceph уровень репликаций предоставляет исключительную защищённость данных от потерь путём хранения трёх копий ваших данных в различных OSD. Вероятность потери данных на всех трёх дисках, которые содержат одни и те же объекты в пределах того периода времени, пока Ceph перестроит отказавший диск, граничит с самой крайней степенью вероятности. Однако, хранение трёх копий данных чрезмерно увеличивает как затраты приобретения, аппаратных средств, так и связано с операционными расходами, такими как электропитание и охлаждение. Более того, сохранение копий также означает, что для любой записи клиента лежащее в основе хранилище должно выполнять запись три раза весь объём данных. В некоторых ситуациях любые из этих обратных сторон могут означать, что Ceph не является приемлемым вариантом.
Для решения такой ситуации спроектировано решение удаляющего кодирования (erasure code). Во многом также как и RAID 5 и 6 предлагает увеличение применяемого пространства хранения в сравнении с RAID 1, удаляющее кодирование позволяет Ceph предоставлять больше используемого пространства с одной и той же сырой ёмкости. Однако в точности так же как и уровни RAID на основании чётности, удаляющее кодирование привносит свои собственные недостатки.
Что такое удаляющее кодирование?
Удаляющее кодирование
(Erasure coding) позволяет Ceph достигать даже
большей используемости ёмкости хранения или увеличения устойчивости к отказам дисков при том же самом числе
дисков при сопоставлении со стандартным методом репликаций. Удаляющее кодирование достигает этого расщеплением
имеющегося объекта на некоторое число частей с последующим вычислением какого- то типа
CRC
(cyclic redundancy check, Циклического избыточного
кода), удаляющего кода (erasure code) с последующим сохранением всех результатов в одной или более
дополнительных частей. Каждая часть затем сохраняется в отдельном OSD. Эти части имеют название порций
(chunks) K и M,
где K обозначает общее число кусочков самих данных,
а M обозначает общее число кусочков удаляющего кода. Как и в
случае с RAID, это может быть выражено в формуле K+M,
например, 4+2. {Прим. пер.: в общем случае
удаляющее кодирование описывается формализмом Рида- Соломона, наглядное объяснение которого приводится в нашей
врезке слайд- шоу в переводе "Книги рецептов Ceph" Карана Сингха или в
презентации Луиса Кевина.}
В случае возникновения события отказа какого- то OSD, который содержит кусочек объекта, вычисляемый удаляющим кодом, данные считываются с остающихся OSD, которые хранят данные, не подвергшиеся воздействию. Однако, если в случае отказа OSD утрачиваются данные, содержавшие кусочки данных некоторого объекта, Ceph может воспользоваться имеющимся удаляющим кодом для восстановления путём математического вычисления данных из некоторой комбинации кусочков оставшихся данных и удаляющих кодов.
K+M
Чем больше кусочков удаляющего кода имеется у вас, тем к большему числу отказов OSD вы можете быть готовыми и всё ещё продолжать успешно считывать данные. Аналогично, имеющееся соотношение K+M кусочков расщепления каждого объекта имеет прямое отношение к процентному соотношению сырого хранилища, которое требуется для каждого объекта.
Конфигурация 3+1 даст вам 75% использования ёмкости но позволит только единственный отказ OSD и по это причине не будет рекомендована. В качестве сравнения, пул реплик с тремя копиями даёт только 33% используемого пространства.
Конфигурация 4+2 предоставит вам применение пространства на 66% и допускает два отказа OSD. Скорее всего, это достаточно хорошая настройка для применения большинством людей.
С другой стороне шкалы 18+2 позволило бы вам использование имеющейся ёмкости на 90% и всё ещё позволяло бы два отказа OSD. На поверхности это звучит как идеальный выбор, однако большее значение общего числа кусочков привносит некую стоимость. Более высокое значение общего числа разбиений имеет отрицательное воздействие на производительность, а также увеличивает потребности в ЦПУ. Один и тот же объект 4МБ, который бы хранился как некий единый объект в каком- то пуле с репликациями, теперь должен будет быть разделённым на 20 x200кБ порций, каждая из которых должна быть препровождена и записана в различные 20 OSD. Шпиндельные диски предоставят большую полосу пропускания измеряемую MBps на операциях ввода/ вывода с большими размерами, однако полоса пропускания коренным образом уменьшится для операций ввода/ вывода меньших размеров. Такие маленькие кусочки создадут большой объём операций ввода/ вывода малого размера и вызовут дополнительную нагрузку в некоторых кластерах.
Кроме того, важно не забывать, что эти кусочки необходимо распространять по различным хостам в соответствии с имеющимися правилами карты CRUSH: никакие кусочки одного и того же объекта не должны храниться на одном и том же хосте с прочими кусочками из того же самого объекта. Некоторые кластеры просто могут не иметь достаточного число хостов чтобы удовлетворить данное требование.
Обратное считывание с такого пула с большой порционностью также является проблемой. В отличии от пула с репликациями, в котором Ceph может просто считывать требуемые данные с любого смещения некоторого объекта, в каком- либо пуле удаляющего кодирования все куочки со всех OSD должны быть считаны прежде чем данный запрос на чтение будет удовлетворён. В нашем примере 18+2 это может массивно расширить общее число требующихся операций дискового чтения и средняя латентность в результате вырастет. Такое поведение является сторонним эффектом, который имеет тенденцию вызывать исключительное воздействие на пулы, использующие некоторое большое число порций. Конфигурация 4+2 во многих экземплярах предоставит потребность в производительности, сравнимую с неким пулом реплик за счёт результата разделения объекта на кусочки. Поскольку данные эффективно чередуются по некоторому числу OSD, каждый из OSD должен записывать меньше данных и при этом отсутствуют вторичные и третичные реплики, подлежащие записи.
Удаляющее кодирование также может применяться для улучшения надёжности взамен максимизации доступного пространства.
В качестве примера рассмотрим некий пул 4+4: он имеет эффективность хранения 50%,
поэтому он лучше пула с репликами 3x, но при этом может выдерживать до 4 потерь OSD сохраняя при этом данные.
Как работает удаляющее кодирование в Ceph?
Как и в случае с репликациями, Ceph имеет некое понятие первичного OSD, которое также имеется и в случае, когда мы применяем пулы с удаляющим кодированием. Такой первичный OSD несёт ответственность за взаимодействие с самим клиентом, вычисление кусочков для удаления, а также отправкой их оставшимся OSD в данном наборе групп размещения (PG). Это иллюстрируется на следующей схеме:
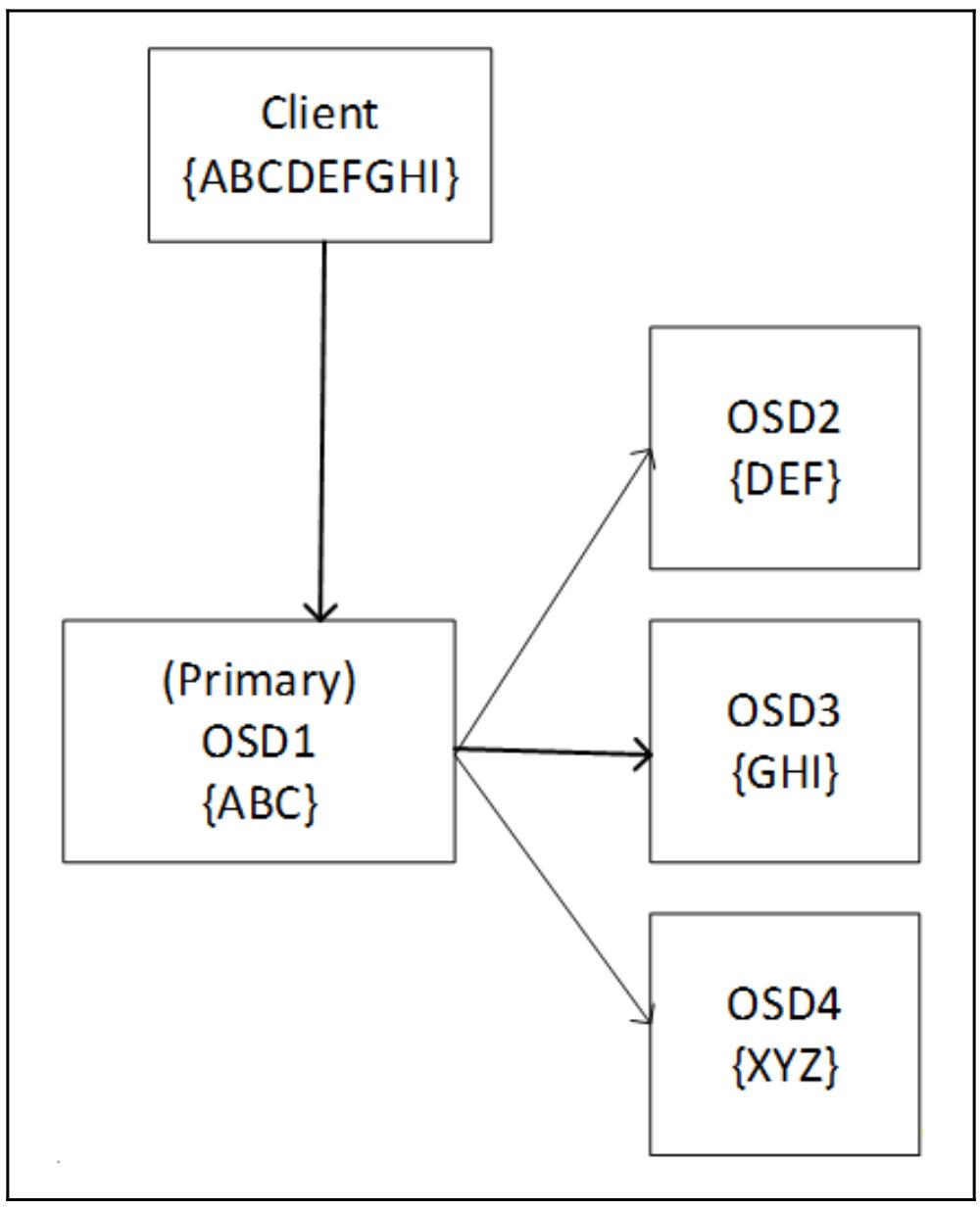
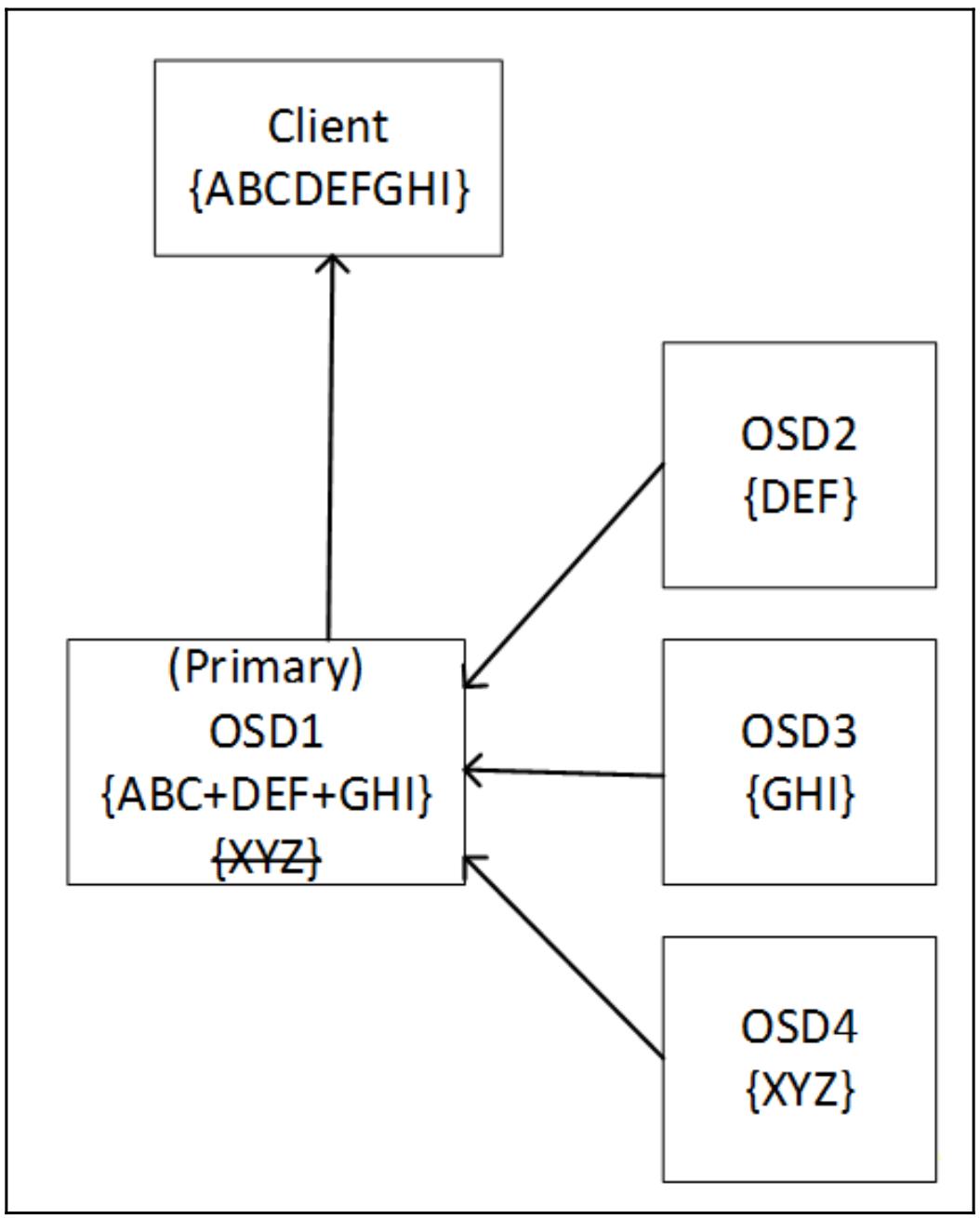
Если некий OSD в наборе падает, такой первичный OSD может воспользоваться оставшимися данными и удаляющим кодом для восстановления всех данных прежде чем отправит их обратно запросившему клиенту. В процессе операций чтения такой первичный OSD запрашивает все OSD в данном наборе группы размещения (PG) на отправку их кусочков. Данный первичный OSD использует данные всех порций для построения запрошенных данных, а удаляющие кусочки отвергаются. Существует опция быстрого чтения, которая может быть включена в пулах удаляющего кодирования, которая позволяет имеющемуся первичному OSD строить эти данные из удаляющих кусочков если они возвращаются быстрее чем кусочки данных. Это может помочь снизить общую задержку за счёт стоимости слегка более высокого использования ЦПУ. Следующая схема показывает как Ceph считывает с некоторого пула с удаляющим кодированием:
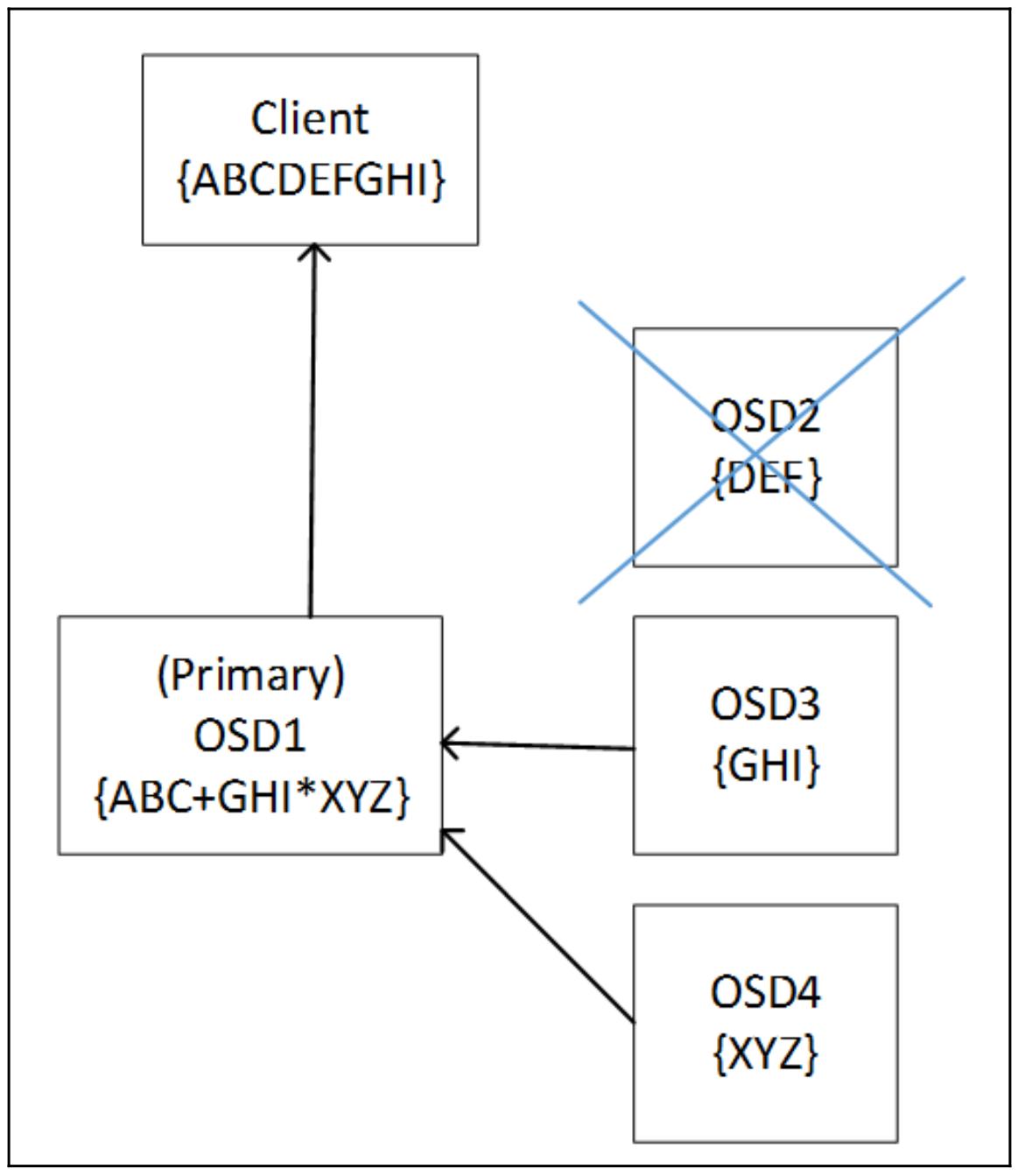
Приводимая далее схема отображает как Ceph читает некий пул удаляющего кодирования когда один из кусочков получаемых данных недоступен. Данные восстанавливаются изменяя направление алгоритма удаления с использованием оставшихся данных и удаляющих кусочков:
Алгоритмы и профили
Имеется ряд различных встраиваемых модулей удаляющего кодирования, которые вы можете применять при создании своего пула удаляющего кодирования.
Jerasure
Встраиваемым модулем удаляющего кодирования по умолчанию в Ceph является Jerasure, который представляет высоко оптимизированную библиотеку удаляющего кодирования с открытым исходным кодом. Эта библиотека имеет целый ряд разнообразных техник, которые могут применяться для вычисления удаляющего кодирования. По умолчанию это Reed-Solomon и он предоставляет хорошую производительность на современных процессорах которые могут ускорять все операторы, применяемые данным методом. Другим методом в данной библиотеке является Cauchy, это хорошая альтернатива Риду- Соломону и имеет тенденцию выполняться слегка лучше. Как и всегда, прежде чем приступить к хранению любых промышленных данных в некотором пуле удаляющего кодирования, необходимо провести эталонное тестирование чтобы определить какая из методик лучше соответствует вашим рабочим нагрузкам.
Также имеется целый ряд прочих методов, которые могут быть применены, причём все они имеют фиксированное число кусочков M. Если вы собираетесь иметь только две порции M, они являются хорошими претендентами, так как их фиксированный размер означает, что возможна оптимизация ведущая к росту производительности. Всякая техника оптимизации, помимо поддержки только двух кусочков удаляющего кодирования, также имеет тенденцию иметь определённые требования относительно общего числа кусочков. Вот краткое описание каждой из техник оптимизации:
-
reed_sol_van: Это устанавливаемая по умолчанию технология, полная гибкость на кусочкахk+m, но при этом самая медленная. -
reed_sol_r6_op: Оптимизированная версия устанавливаемой по умолчанию техники для тех случаев применения, когдаm=2. Хотя она намного быстрее версии без оптимизации, она не настолько быстрая как прочие варианты. Тем не менее, общее число кусочков,k, всё ещё остаётся гибким. -
cauchy_orig: Лучше устанавливаемой по умолчанию, ноcauchy_goodбудет ещё лучше. -
cauchy_good: Даёт производительность среднего уровня, но при этом всё ещё поддерживая полную гибкость настройки числа фрагментов. -
liberation: Общее число кусочков должно быть простым числом и хорошими претендентами будут3+2,5+2и7+2, исключительная производительность. -
liber8tion: Общее число кусочков должно быть равно8, аm=2, доступен только вариант6+2, но при этом исключительная производительность. -
blaum_roth: Общее число должно быть на один меньше простого числа иm=2, поэтому идеален для4+2и при этом даёт исключительную производительность.
Как всегда, необходимо проводить эталонное тестирование перед тем как приступать к хранению данных в промышленном применении для некого пула с удаляющим кодированием для выявления того какая именно технология лучше всего удовлетворяет вашим рабочим нагрузкам.
В общем случае данный профиль Jerasure следует предпочесть в большем числе вариантов, если только другой профиль не имеет некоторого основного преимущества, так как он предлагает хорошо сбалансированную производительность и богатую историю тестирования.
ISA
Данная библиотека ISA разработана для работы с процессорами Intel и предлагает расширенную производительность. Она также предлагает поддержку как методов Рида- Соломона, так и Коши.
LRC
Одним из недостатков применения удаляющего кодирования в любой распределённой системе хранения является то, что восстановление может очень интенсивно применять сетевой обмен между хостами. Поскольку все порции хранятся на отдельных хостах, операция восстановления требует участия в данном процессе множества хостов. Когда топология CRUSH занимает множество стоек, тогда могут интенсивно применяться сетевые связи между стойками. Встраиваемый модуль удаляющего кодирования LRC (Locally Repairable erasure Code, удаляющее кодирование Локального восстановления) добавляет некий дополнительный кусочек избыточных данных (parity), причём локально на каждый узел OSD. Это позволяет операциям восстановления оставаться локальными по отношению к узлу, в котором отказал некий OSD и удаляет необходимость узлам получать данные со всех остальных остающихся держателями порций узлов.
Однако добавление таких локальных кодов восстановления на самом деле влияет на объём используемого хранилища для заданного числа дисков. В случае множественных сбоев подключаемый модуль LRC должен прибегать к глобальному восстановлению, как это происходит и в случае подключаемого модуля Jerasure.
SHEC
Профиль SHEC (Shingled Erasure Coding, Черепичного/ Драночного удаляющего кодирования) разработан с той же целью, что и подключаемый модуль LRC, в отношении того, чтобы снизить требования сетевого обмена в процессе восстановления. Однако, вместо создания дополнительных кусочков паритетности на каждом узле, SHEC опоясывает всеми порциями все OSD перекрывающим образом Такая драночная/ черепичная часть в данном имени подключаемого модуля заявляет о самом способе распространения данных, который повторяет покрытие плитками кровли крышу здания. Путём перекрытия порций избыточного кода по OSD, данный встраиваемый модуль SHEC снижает требования к ресурсам восстановления как в случае одиночного, так и при множественных отказах диска. {Прим. пер.: подробнее см. наш перевод работ авторов метода Shingled Erasure Code. Также отметим ещё одну работу, произведённую в тот же временной период, направленную на снижение нагрузки в сетевой среде при использовании операций восстановления, а именно Интеллектуальные отложенные средства, результаты которой позволяют относить по времени восстановительные работы на наименее загруженные периоды суток и дни недели. Обратим ваше внимание и на уже доступные аппаратные решения разгрузки удаляющего кодирования на ASIC сетевых интерфейсов - см. наш перевод Понимание разгрузки удаляющего кодирования, которая в совокупности со Стеком системы асинхронных сообщений Ceph позволяют снять нагрузку вычисления избыточных кодов с ЦПУ.}
Поддержка наложенной записи в пулах с удаляющим кодированием
Хотя поддержка пулов удаляющего кодирования существует уже на протяжении некоторого числа выпусков Ceph, до появления BlueStore в выпуске Luminous, она не поддерживала частичных записей. Это ограничение означает, что пулы с удаляющим кодированием не могли непосредственно применяться в рабочих нагрузках RBD и CephFS. С введением BlueStore в Luminous, именно BlueStore предоставил рабочую основу для реализации поддержки частичной записи. Имея поддержку частичной записи, всё поддерживаемое пулами удаляющего кодирования число типов ввода/ вывода может поддерживать почти полное соответствие пулам с репликациями, что делает возможным применение пулов с удаляющим кодированием для рабочих нагрузок RBD и CephFS. Это впечатляюще снижает стоимость хранения для таких вариантов применения.
При записях с полным чередованием, которые появляются для новых объектов или когда имеющийся объект переписывается целиком, общие
штрафы записи снижаются гигантским образом. Некому клиенту, записывающему объект в 4 МБ в пуле удаляющего кодирования 4+2 придётся
записать всего 6 МБ кусочков данных и 2 МБ кусочков удаляющего кодирования. Это по сравнению с 12 МБ данных, записываемых в некий
пул с репликациями. Тем не менее, следует отметить, что каждый кусочек полосы удаляющего кода будет записан в неком отличном OSD.
Для небольших профилей удаляющего кодирования, таких как 4+2, это будет иметь тенденцию
предложения взрывных больших производительностей как для шпиндельных дисков, так и для SSD, поскольку каждому OSD приходится
записывать меньше данных. Однако, для больших полос удаляющего кодирования, получаемые накладные расходы необходимости записи во
всё увеличивающееся число OSD нчинает перевешивать преимущества от снижения подлежащих записи объёмов данных, в особенности для
шпиндельных дисков, задержки которых не имеют линейной зависимости от размера текущего ввода/ вывода.
Такие клиенты пространства пользователей как librbd и libcephfs
обладают достаточной интеллектуальностью чтобы попытаться объединять операции ввода/ вывода меньшего размера и по возможности
предоставлять полную запись с чередованием; это может помогать когда предварительно размещённое приложение передаёт последовательный ввод/ вывод
без выравнивания по границам объектов в 4 МБ.
Частичная запись позволяет для некоторых объектов выполнять перезаписи; это дополнительно вводит ряд осложнений, поскольку, как только
выполнена частичная запись, также требуется обновлять и кусочки удаляющего кодирования, чтобы они соответствовали новому содержимому
объекта. Это очень схоже с теми вызовами, с которыми сталкиваются RAID 5 и 6, хотя необходимость координации данного процесса по различным
OSD неким согласованным образом увеличивает имеющуюся сложность. После завершения частичной записи Ceph вначале считывает весь имеющийся объект
с диска, а затем должен слить воедино в памяти необходимые новые записи, вычисляя новые фрагменты удаляющего кодирования и записывая всё это
обратно на диск. Таким образом, присутствуют вовлечёнными в общий процесс и операции чтения, и операции записи. Как вы можете видеть,
отдельный ввод/ вывод может завершиться необходимостью штрафных записей в несколько раз больше чем при пуле с репликациями. Для пула с
удаляющим кодированием 4+2, некая небольшая запись 4 кБ может в конце концов приводить к
12 операциям ввода/ вывода на диски в кластере, не принимая во внимание некие дополнительные накладные расходы Ceph.
Создание пула удаляющего кодирования
Давайте проведём своё тестирование кластера вновь и переключимся в режим
суперпользователя в Linux с тем, чтобы нам не
приходилось всё время начинать свои команды с префикса sudo.
Пулы удаляющего кодирования управляются при помощи применения профилей удаляющего кодирования; они управляют тем на сколько порций разбивается каждый объект, включая разбиение между порциями данных и избыточного кода. Данные профили также содержат настройки для определения того какой встраиваемый модуль удаляющего кодирования используется для вычисления необходимых хэшей.
К применению доступны следующие встраиваемые модули:
-
Jerasure
-
ISA
-
LRC
-
SHEC (Shingled Erasure Coding)
Чтобы просмотреть список имеющихся профилей удаляющего кодирования, выполните следующую команду:
ceph osd erasure-code-profile ls
Вы можете увидеть, что имеется некий профиль default в только что
выполненной установке Ceph:

Давайте посмотрим какие варианты настроек он содержит воспользовавшись такой командой:
# ceph osd erasure-code-profile get default
Данный профиль default предписывает, что он будет применять
встраиваемый модуль Jerasure с кодированием посредством коррекции ошибок Рида- Соломона и будет расщеплять
объекты на 2 порции данных и 1
порцию избыточного кода:

Это почти идеально для целей нашего тестового кластера, однако для целей данного упражнения мы создадим некий новый профиль воспользовавшись следующей командой:
# ceph osd erasure-code-profile set example_profile k=2 m=1 plugin=jerasure technique=reed_sol_van
# ceph osd erasure-code-profile ls
Как вы можете отметить, был создан наш новый example_profile:

Теперь давайте создадим с этим профилем свой пул удаляющего кодирования:
# ceph osd pool create ecpool 128 128 erasure example_profile
Предыдущая команда предоставит вам следующий вывод:

Предыдущая команда проинструктировала Ceph создать некий новый пул с названием
ecpool with и со
128 группами размещений (PG). Он должен быть пулом удаляющего
кодирования и должен применять тот example_profile, который мы
создали ранее.
Давайте создадим некий объект с небольшой тестовой строкой внутри него и затем докажем что эти данные были сохранены, считав их обратно:
# echo "I am test data for a test object" | rados --pool
ecpool put Test1 –
# rados --pool ecpool get Test1 -
Это докажет что данный пул удаляющего кодирования работает, но вряд ли у вас перехватило дух от этого открытия:

Давайте обратим внимание на то, можем ли мы посмотреть что произошло на некотором нижнем уровне.
Вначале отыщем какая PG содержит тот объект, который мы только что создали:
# ceph osd map ecpool Test1
Результат предыдущей команды сообщает нам что данный объект сохранён в PG
3.40 в OSD 1,
2 и 0 в данном примере кластера
Ceph. Это достаточно очевидно, поскольку у нас имеется всего три OSD, однако в кластерах большего размера
это может быть очень полезной составной частью информации:

![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Ваши PG скорее всего будут отличаться в вашем тестовом кластере, поэтому убедитесь что структура
папок PG соответствует выводу предыдущей команды Если вы применяете BlueStore, файловая структура вашего OSD более по умолчанию не видна для просмотра. Тем не менее, вы можете воспользоваться приводимой ниже командой на остановленном OSD для монтирования OSD BlueStore в файловой системе Linux. |
Следующие примеры показаны с применением файлового хранения; при использовании BlueStore замените путь к OSD надлежащим содержимым
точки монтирования /mnt из команды предыдущего Совета:
ls -l /var/lib/ceph/osd/ceph-2/current/1.40s0_head/
Предыдущая команда предоставит вам следующий вывод:

ls -l /var/lib/ceph/osd/ceph-1/current/1.40s1_head/
Предыдущая команда предоставит вам следующий вывод:

# ls -l /var/lib/ceph/osd/ceph-0/current/1.40s2_head/
total 4
Предыдущая команда предоставит вам следующий вывод:

Заметим, что все имена каталогов PG были дополнены соответствующими номерами порций и реплицируемого пула просто чтобы иметь необходимый номер PG в своём имени каталога. Если вы проверите всё содержимое данных файлов объекта, вы обнаружить нашу текстовую строка, которую мы ввели в данный объект при его создании. Однако, из- за малого размера данной текстовой строки Ceph заполнил вторую порцию символами null, а избыточная порция здесь будет содержать то же самое, что и первая порция. Вы можете повторить данный пример с неким новым объектом, содержащим больший объём текста и увидеть как Ceph расщепляет такой текст на необходимые порции и вычисляет свой удаляющий код.
Поиск неисправностей для ошибки 2147483647
Данный небольшой раздел включён вовнутрь данной главы удаляющего кодирования вместо того чтобы быть
размещённым в Глава 11. Поиск неисправностей
данной книги так как обычно встречается в пулах с удаляющим
кодированием и поэтому очень связан с данной главой. В качестве примера данной ошибки продемонстрируем
следующий снимок экрана при выполнении команды ceph health detail:

Если вы наблюдаете 2147483647 перечисленным в качестве одного из
присутствующих OSD для некоторого пула удаляющего кодирования, обычно это означает, что CRUSH не может
найти достаточное число OSD для выполнения необходимого процесса однораногового обмена (peering) PG. Обычно
это обусловлено тем, что общее число порций K+M
будет больше чем общее число хостов в топологии CRUSH. Однако, в некоторых случаях эта ошибка может всё ещё
происходить даже когда общее число хостов равно или больше чем общее число порций. В таком случае важно понимать
как CRUSH указывает OSD в качесте претендентов для размещения данных. Когда CRUSH применяется для нахождения
OSD в качестве кандидата для некоторой PG, он применяет имеющуюся карту CRUSH для поиска соответствующего
местоположения в имеющейся топологии CRUSH. В случае когда возвращается тот же самый результат, что и выбранный
перед этим OSD, Ceph попытается повторно создать другое соответствие, передавая слегка отличные значения в свой
алгоритм CRUSH. В некоторых случаях, если имеется аналогичное общему числу порций избыточных кодов число хостов,
CRUSH может завершить работу до того как он надлежащим образом обнаружит правильный OSD, соответствующий всем
имющимся порциям. Более новые версии Ceph имеют более исправленной данную проблему за счёт увеличения подстройки
choose_total_tries в своём CRUSH.
Воспроизводство данной проблемы
С целью более подробного понимания данной проблемы, последующие шаги продемонстрируют как создать некий профиль удаляющего кодирования, который запросит больше порций, чем может поддерживать наш кластер из трёх узлов.
Вначале, как и ранее в этой главе, создайте некий новый профиль удаляющего кодирования, однако измените
параметры K/M чтобы они равнялись k=3 и
m=1.
$ ceph osd erasure-code-profile set broken_profile k=3 m=1 plugin=jerasure technique=reed_sol_van
Теперь создайте при помощи него некий пул:
$ ceph osd pool create broken_ecpool 128 128 erasure broken_profile
Если мы посмотрим на вывод от ceph -s, мы обнаружим, что все PG
для данного нового пула застряли в состоянии создания:
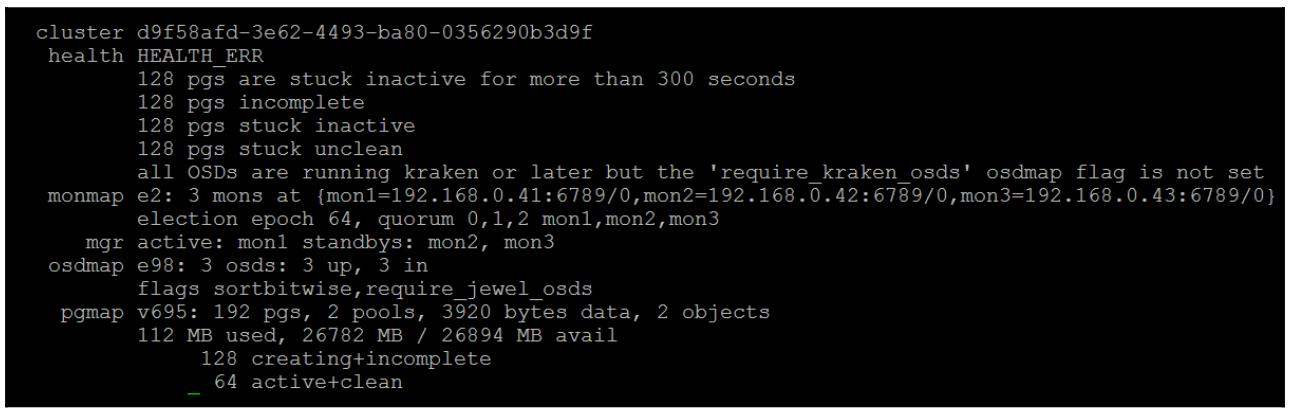
Вывод ceph health detail демонстрирует причину почему это так, и мы
обнаруживаем ошибку 2147483647:

Если вы столкнулись с этой ошибкой и она является неким результатом того, что ваш профиль удаляющего кодирования больше чем имеющееся у вас число хостов или стоек, в зависимости от того как вы спроектировали свою карту CRUSH, тогда единственным практическим решением будет или снижение общего числа порций, или увеличение общего числа хостов.
Создание пула удаляющего кодирования
Для создания некого пула с удаляющим кодированием вызовите команду, как это показано в следующем примере:
ceph osd pool create MyECPool 128 128 erasure MyECProfile
Она создаст пул удаляющего кодирования со 128 группами размещения и с названием MyECPool,
применив профиль удаляющего кодирования MyECProfile.
Хотя частичные записи и приводят к тому, что пулы удаляющего кодирования почти полностью совпадают с пулами репликаций с точки зрения поддерживаемых функций, они всё ещё не способны хранить все необходимые данные для RBD. Поэтому при создании RBD вы вначале поместить объект заголовка в некий пул RADOS с репликациями, а затем определить что все объекты данных для этого RBD следует хранить в пуле с удаляющим кодированием.
Для защиты от деградации битов Ceph периодически выполняет процесс, именуемый очисткой (scrubbing) для проверки всех данных, хранимых по всем своим OSD. Данный процесс очистки работает на уровне PG и сравнивает содержимое каждой PG по всем участвующим в них OSD для проверки того что во всех OSD имеется идентичное содержимое. Если обнаружен некий OSD имеющим некие копии объекта, которые отличаются друг от друга или даже пропускают этот объект, данная PG помечается как несогласованная. Несогласованная PG может быть восстановлена инструктированием Ceph для восстановления этой PG; это объясняется в Главе 11. Поиск неисправностей.
Имеется два вида очистки: обычная и глубокая. Обычная очистка просто проверяет существование самого объекта и того что его метаданные правильные; глубокая очистка это когда выполняется сравнение самих реальных данных. Глубокая очистка требует гораздо более интенсивного ввода/ вывода нежели обычная очистка.
Хотя BlueStore теперь и поддерживает контрольные суммы, потребность в очистке не является целиком избыточной. BlueStore только выполняет сравнение значений контрольных сумм с теми данными, которые считаны активным образом, и поэтому для холодных данных, которые очень редко записываются, утрата или разрушение данных могут выявляться только когда их обнаруживает такой процесс очистки.
Существует ряд параметров настройки очистки, которые обсуждаются позднее в Главе 9. Тонкая настройка Ceph; они оказывают воздействие на составление расписания того когда происходит очистка и влияют на ввод/ вывод клиента.
Хотя Ceph предоставляет базовые объекты хранения через уровень RADOS, само по себе это не очень удобно, так как область приложений, которые напрямую могут применять хранилище RADOS чрезвычайно ограничена. Поэтому Ceph основывается на базовых возможностях RADOS и предоставляет типы хранения верхнего уровня, которые уже могут запросто использоваться пользователем.
Для краткости, RBD это то как хранилище Ceph может представляться в виде стандартных блочных устройств Linux. RBD составляется из некоторого числа объектов, по умолчанию по 4 МБ, которые составляются воедино. RBD в 4 ГБ по умолчанию будет содержать 1 000 объектов.
Динамичное предоставление
Благодаря тому способу, которым работает RADOS, RBD предоставляют динамичное выделение (thin provisioning); это означает, что лежащие в его основе объекты выделяются только когда данные записываются по имеющимся адресам логического блока, который соответствуют данному объекту. Не существует никаких гарантий для этого; Ceph с радостью выделит вам устройство 1 ПБ на неком диске в 1 ТБ, и если вы на нём никогда не размещаете больше 1 ТБ, всё будет работать как ожидалось. При правильном применении динамичное выделение может значительно увеличивать полезную ёмкость кластера Ceph, поскольку ВМ, которые обычно являются одним из самых основных вариантов применения RBD, скорее всего имеют большой объём содержащегося в них незаполненного пространства. Тем не менее, надлежит отслеживать рост данных в самом кластере Ceph; если лежащая в основе полезная ёмкость заполняется, такой кластер Ceph в действительности отключается пока не высвободится пространство.
Моментальные снимки и клоны
RBD поддерживает внутри себя получение моментальных снимков. Моментальные снимки являются доступными только на чтение копиями некоторого образа RBD, которые продолжают сохранять своё состояние на тот момент времени когда они осуществлены. Если есть такое желание, для поддержания истории данного RBD можно удерживать множество снимков. Сам процесс получения моментального снимка некого RBD чрезвычайно быстрый и нет никаких штрафов для производительности для чтений, которые вы намерены осуществлять из самого исходного RBD. Тем не менее, когда некая запись производится в этом исходном RBD, само имеющееся содержимое данного объекта будет для нас клонировано необходимым моментальным снимком, причём последующие операции ввода/ вывода не будут оказывать воздействия. Такой процесс именуется копированием записью (copy- on- write) и является стандартным способом выполнения моментальных снимков в продуктах хранения данных. Следует отметить, что данный процесс значительно ускорен в BlueStore, так как не требуется полная копия объекта, как это было в случае с файловым хранением, хотя всё ещё стоит заботиться о том, чтобы испытывающие интенсивное операции ввода/ вывода записи RBD не оставались с открытыми моментальными снимками на продолжительное время.Помимо того что моментальные снимки требуют дополнительных операций ввода/ вывода в процессе записи - дополнительное пространство кластера потребляется поскольку процесс копирования записью создаёт клоны имеющихся объектов - следует позаботиться об отслеживании потребляемого пространства при применении моментальных снимков. {Прим. пер.: пожалуй, стоит уточнить фразу автора относительно "процесс копирования записью создаёт клоны имеющихся объектов". Если быть более точным, процесс копирования данных не изменяет уже имеющийся объект в случае необходимости внесения в него изменений. Просто в свободном пространстве сохраняется новый объект, ссылки на который и будут соответствовать в новой версии RBD, в то время как в клоне сохраняются ссылки на остающийся на старом месте подвергшийся изменению объект.}
В процессе удаления некого моментального снимка те PG, которые содержат объекты моментального снимка переходят в состояние подрезки снимка (snaptrim). В этом состоянии удаляются те объекты, которые подверглись клонированию как часть процесса копирования записью. {Прим. пер.: и опять же, точнее было бы сказать, что удаляются те объекты, которые подверглись изменению после клонирования этого RBD.} Стоит отметить, что и в данном случае при использовании BlueStore этот процесс оказывает меньшее воздействие на общую нагрузку в кластере.
RBD также поддерживает множество уровней моментальных снимков: а именно, такой процесс, при котором для какого- то моментального снимка делается допускающий запись клон, который сам по себе является моментальным снимком имеющегося RBD. Данный процесс обычно применяется для создания клонируемых образов образов хозяина ВМ; для какой- то ВМ создаётся некий первоначальный RBD, в котором устанавливается ОС. На протяжении жизненного цикла данного образа хозяина затем осуществляются моментальные снимки для фиксации происходящих изменений. Эти снимки в дальнейшем применяются в качестве основы для клонирования новых ВМ.Когда первоначально клонируется некий моментальный снимок, не требуется дублировать никакие объекты из расположенных в RBD объектов, так как они идентичны своему исходному образу, на них может продолжать ссылаться полученный клон. После того как клонированный RBD начинает получать записываемые в него данные, каждый подвергающийся изменению объект затем записывается в некий новый объект, который и относится уже к этому клону.
Такой процесс работы со ссылками на объекты означает, что большое число ВМ, которые совместно используют один и тот же шаблон ОС будут скорее всего потреблять меньшее пространство чем в том случае, когда каждая ВМ индивидуально бы развёртывала некий RBD заново. В некоторых случаях может быть желательным принудительное клонирование при котором все имеющиеся объекты RBD дублируются; такой процесс именуется в Ceph как выравнивание (flattening) клона.
Для начала создадим некий моментальный снимок с названием snap1 для некого RBD, именуемого
test, в установленном по умолчанию пуле RBD:
rbd snap create rbd/test@snap1
Убедитесь что этот моментальный снимок был создан просмотрев все моментальные снимки данного RBD:
rbd snap ls rbd/test

Для клонирования данного моментального снимка его требуется защитить. Поскольку имеются клоны, зависящие от данного моментального снимка, любые изменения этого моментального снимка могли бы вызывать разрушение таких клонов:
rbd snap protect rbd/test@snap1
Представим информацию относительно данного моментального снимка; как можно увидеть, этот моментальный снимок теперь защищён:
rbd info rbd/test@snap1
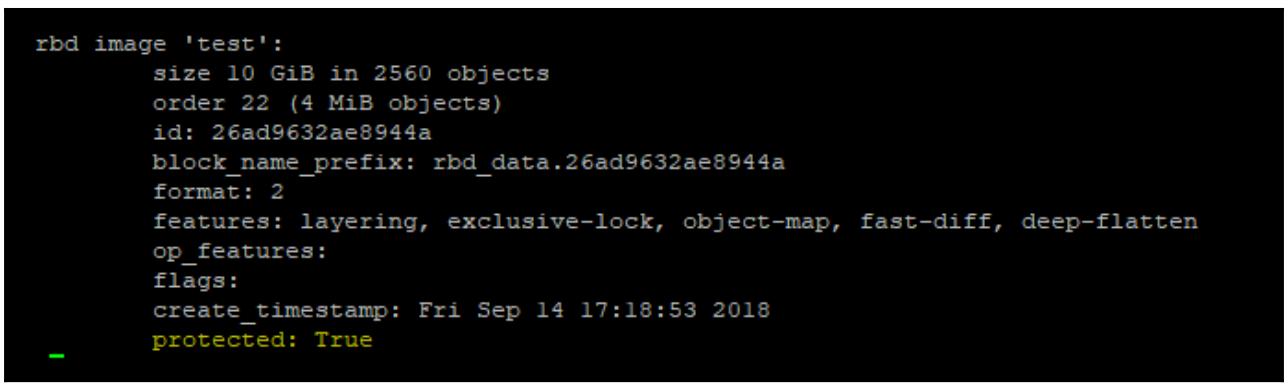
Теперь можно сделать некий клон данного снимка:
rbd clone rbd/test@snap1 rbd/CloneOfTestSnap1
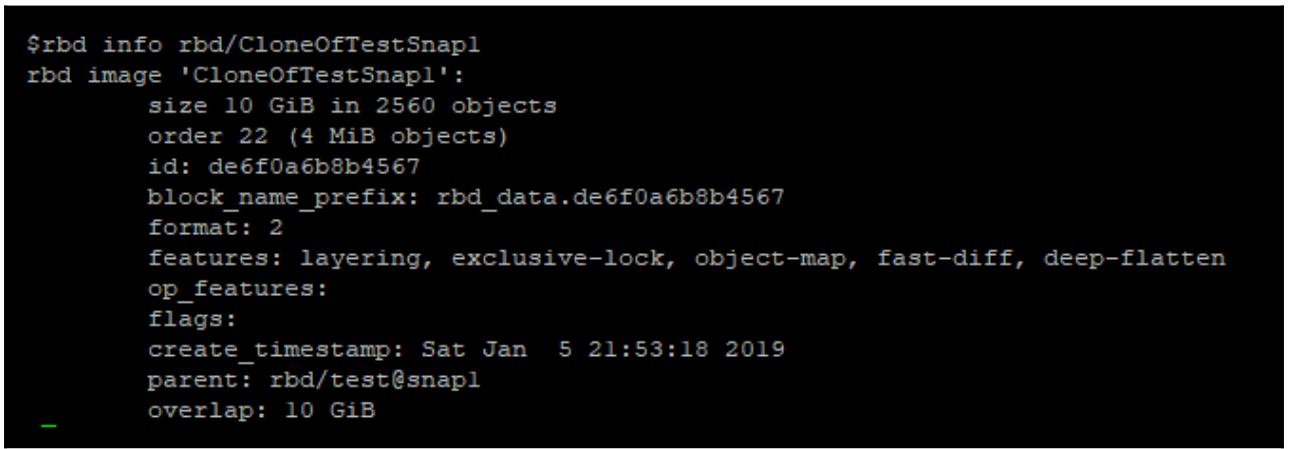
Вы можете подтвердить взаимосвязь вашего клона его моментальному снимку представив rbd info
данного клона:
rbd info rbd/CloneOfTestSnap1
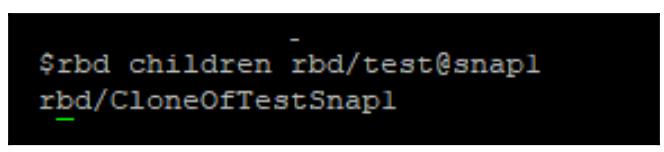
Либо вы можете выполнить это просмотрев список потомков для своего моментального снимка:
rbd children rbd/test@snap1
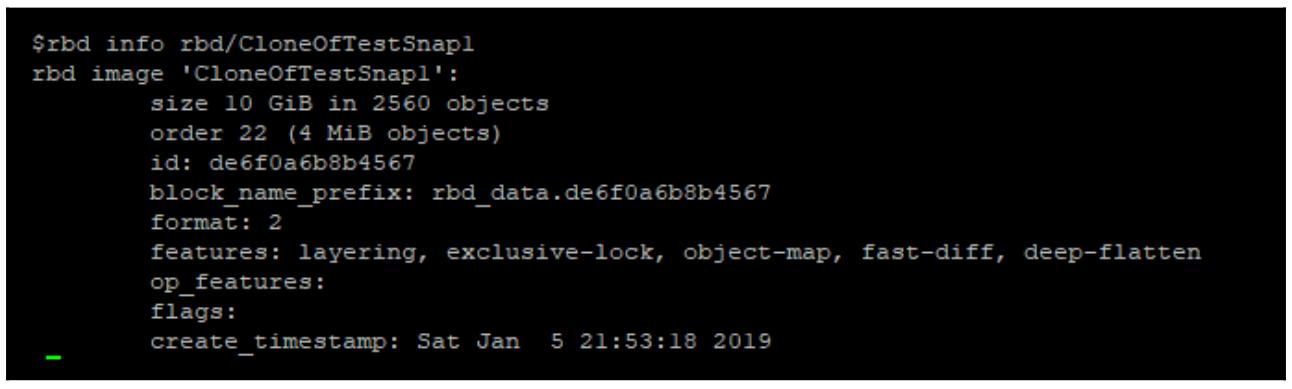
Теперь выполним выравнивание данного клона; это создаст совершенно независимый образ RBD более не зависящий от первоначального моментального снимка:
rbd flatten rbd/CloneOfTestSnap1

Убедимся что наш клон больше не подключён к первоначальному моментальному снимку; обратите внимание, что поле родителя теперь опущено:
rbd info rbd/CloneOfTestSnap1
Уберём защиту с первоначального моментального снимка:
rbd snap unprotect rbd/test@snap1
И наконец удалим его:
rbd snap rm rbd/test@snap1
Соответствия объектов
Так как RBD поддерживает динамичное выделение и составляется из большого числа объектов по 4 МБ, задачи подобные определению потребляемого данным RBD пространства или клонирования RBD будут вовлекать в себя большое число запросов на чтение на предмет определения того, существует ли некий определённый объект как часть данного RBD. Для решения данной задачи RBD сопровождает карты соответствия объектов; эти карты указывают какие логические блоки некого RBD были выделены и тем самым существенно увеличивают скорость данного процесса вычисления существующих объектов. Данная карта объекта в свою очередь хранится как некий объект в этом пуле RADOS и ею нельзя управлять напрямую.
Блокировка ограничения доступа
Чтобы попытаться избежать разрушений записями двух клиентов в одно и то же RBD одновременно, блокировка ограничения доступа (exclusive locking) позволяет определённому клиенту обзавестись некой блокировкой для запрета всем прочим клиентам выполнять запись в данном RBD. Важно отметить, что клиенты всегда могут запросить передачу этой блокировки себе, а потому блокировка предназначена исключительно для защиты самого устройства RBD; скорее всего, не кластерная файловая система всё ещё будет получать повреждения когда два клиента попытаются смонтировать её не обращая внимание на блокировку ограничения доступа.
CephFS является некой POSIX- совместимой файловой системой, которая располагается поверх пулов RADOS. То что она является POSIX- совместимой, означает что она должна быть способна работать как вклинивающаяся подмена для любой иной файловой системы Linux и всё ещё работать надлежащим образом. Существуют как клиенты ядра, так и клиенты пространства пользователя для монтирования этой файловой системы в некой исполняемой системе Linux. Предлагаемый клиент ядра, хотя он обычно и быстрее, имеет склонность отставать от клиента пространства пользователя в плане предоставляемых функциональных возможностей и зачастую требует чтобы вы применяли самое новое ядро чтобы применять преимущества конкретных функций и иметь исправленными последние выявленные ошибки. Файловую систему CephFS также можно экспортировать через NFS или Samba в клиентов не на основе Linux. Обе разновидности программного обеспечения имеют непосредственную поддержку для общения с CephFS. Эта тема обсуждается в Главе 4, Ceph и инородные протоколы.
CephFS хранит все файлы в одном или более объектов RADOS. Если некий объект превышает 4 МБ, он будет разделён на множество объектов. Таким поведением чередования можно управлять при помощи XATTR, которые могут быть связаны как с файлами, так и с каталогами и способны управлять размеров объектов, шириной полос чередования и числом таких полос. Установленная по умолчанию политика чередования на практике объединяет множество объектов по 4 МБ воедино, но изменяя общее число полос и их ширину можно получать разновидность чередования RAID 0.
MDS и их состояния
Для координации доступа клиентов и {собственных} метаданных CephFS требуются некий дополнительный компонент; такой компонент именуется Metadata Server или для краткости MDS. Хотя этот MDS и применяется для обслуживания запросов к метаданным со стороны клиента и к нему, сами реальные считывания и записи данных всё ещё напрямую выполняются через имеющиеся OSD. Данный подход минимизирует воздействие самого MDS на производительность файловой системы для больших продолжительных обменов данными, хотя операции меньшего размера с интенсивными вводам/ выводом могут начинать ограничиваться имеющейся производительностью MDS. В настоящее время MDS запускаются как некий обособленный в потоке процесс и поэтому рекомендуется запускать MDS на оборудовании с максимально доступной по возможности тактовой частоте.
Сам MDS обладает неким локальным кэшем для хранения горячих порций метеданных CephFS чтобы уменьшать количество операций ввода/ вывода для обращения к пулу этих метаданных; такой кэш хранится в оперативной памяти с целью достижения высокоу производительности и может управляться посредством регулировок параметров настройки пределов памяти кэширования данного MDS с установленным по умолчанию значением 1 ГБ.
CephFS применяет журнал, в целом по причине согласованности хранящийся в RADOS. Этот журнал хранит сам поток обновлений метаданных от клиентов и затем сбрасывается в хранилище метаданных CephFS. Если некий MDS прекращает свою работу, тот MDS, который берёт на себя роль активного может затем воспроизвести эти сохранённые в журнале события метаданных. Данный процесс воспроизведения журнала является неотъемлемой частью активации соответствующего MDS и тем самым будет блокирован вплоть до завершения данного процесса. Данный процесс может быть ускорен благодаря присутствию MDS в режиме ожидания, который непрерывно воспроизводит имеющийся журнал и готов принять на себя роль активного в намного более короткий промежуток времени. Если у вас имеется множество активных MDS в то время как некий истинный резервный MDS может пребывать в состоянии ожидания для перехода в активное состояние, необходимо выполнять такие ожидающие MDS для определённого диапазона MDS.
Помимо активного состояния и состояния воспроизведения некий MDS также может пребывать в неких прочих состояниях; те состояния Ceph, с которыми вы можете скорее всего сталкиваться перечисляются в виде справочных материалов для работы с кластером Ceph при помощи файловой системы CephFS. Эти состояния разделяются на две части: часть с левой стороны двоеточия показывает является ли данный MDS поднятым или отключённым. Часть справа от двоеточия представляет текущее рабочее состояние:
-
up:active: Это обычное желательное состояние, пока хотя бы один из MDS пребывает в данном состоянии, клиенты имеют возможность доступа к общей файловой системе CephFS. -
up:standby: Данной состояние может быть нормальным пока по крайней мере один MDS пребывает вup:active. В этом состоянии MDS доступен, но не играет никакой активной роли в имеющейся инфраструктуре CephFS. Он переходит в рабочее состояние и воспроизводит соответствующий журнал CephFS в случае отключения соответствующего ему активного MDS. -
up:standby_replay: Как и при состоянииup:standby, некий MDS в данном состоянии доступен для того чтобы стать активным в случае отключения некого активного MDS. Тем не менее, некий MDS сstandby_replayпродолжает воспроизводить содержимое журнала MDS который ему необходимо настраивать для отслеживания, что означает значительное снижение времени отработки отказа. Следует отметить, что в то время как MDSstandbyможет заменять любой активный MDS, MDSstandby_replayможет заменять только тот активный MDS, журнал которого он отслеживает. -
up:replay: В этом состоянии некий MDS начинает брать на себя роль активного и прямо сейчас воспроизводит те метаданные, которые хранятся в его журнале CephFS. -
up:reconnect: Если имелись активные сеансы активных клиентов когда данный активный MDS перешёл в рабочий режим, такой восстановившийся MDS в данном состоянии попробует повторно устанавливать подключения клиентов вплоть до истечения времени ожидания самого клиента.
Хотя имеются и некие прочие состояния, в которых может пребывать MDS, скорее всего при обычной работе они не будут видны вам, поэтому мы их не включаем в приводимые здесь. Для дополнительных сведений относительно всех возможных состояний просим вас обращаться к официальной документации Ceph.
Создание файловой системы CephFS
Для создания файловой системы CephFS требуется два пула RADOS: один для хранения метаданных и другой для хранения объектов реальных данных. Хотя технически говоря можно применять любые имеющиеся пулы RADOS, настоятельно рекомендуется создавать специально посвящённые этому пулы. Требуемый для метаданных пул обычно содержит лишь небольшой процент данных по сравнению с самим пулом данных, следовательно значение числа PG необходимое при предоставлении данного пула может обычно назначаться в диапазоне 64 - 128. Этот пул данных следует предоставлять во многом аналогично тому как это делается для некого пула RBD и значение числа PG вычисляется так, чтобы соответствовать общему числу OSD в имеющемся кластере и разделять данные, которые будет хранить файловая система CephFS.
Для развёртывания потребуется по крайней мере один MDS, но рекомендуется чтобы во всех промышленных реализациях были развёрнуты
по крайней мере один активный и один в режиме ожидания (standby) или ожидания с воспроизведением
(standby_replay).
Измените имеющийся файл /etc/ansible/hosts и добавьте тот сервер, который будет выполнять
роль MDS. В следующем примере мы применяем ВМ mon2 из тестовой лаборатории в
Главе 2, Развёртывание Ceph в контейнерах:
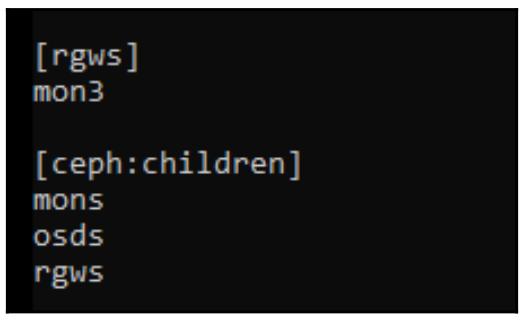
Теперь вновт исполните плейбук Ansible и он развернёт необходимый mds:

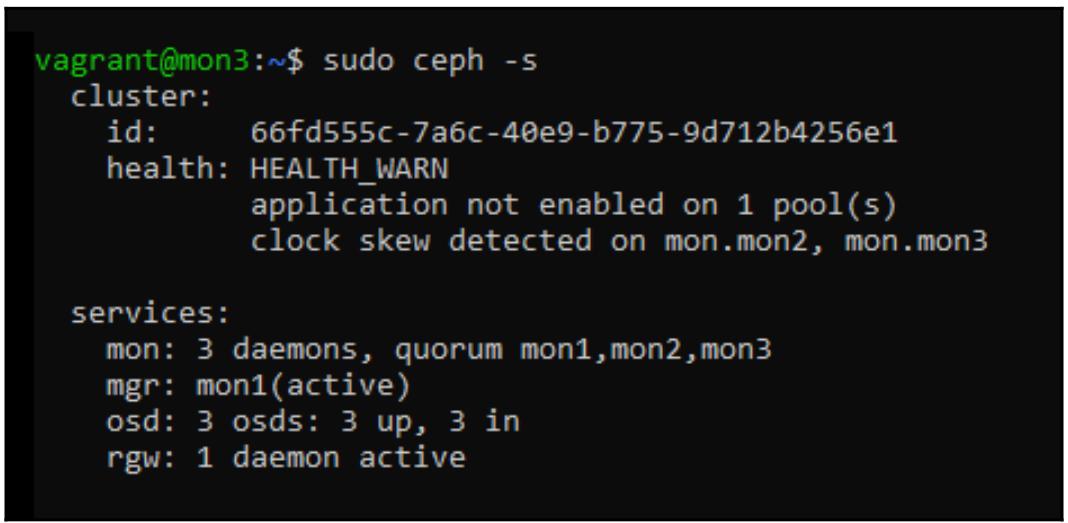
Когда этот плейбук завершит своё исполнение, убедитесь что ваш mds поднялся и запустился;
это можно представить через вывод ceph -s:
Ansible должен предоставить пулы данных и пулы метаданных как часть своего процесса развёртывания; в этом можно убедиться исполнив следующую команду в узле одного из имеющихся мониторов:
sudo ceph osd lspools
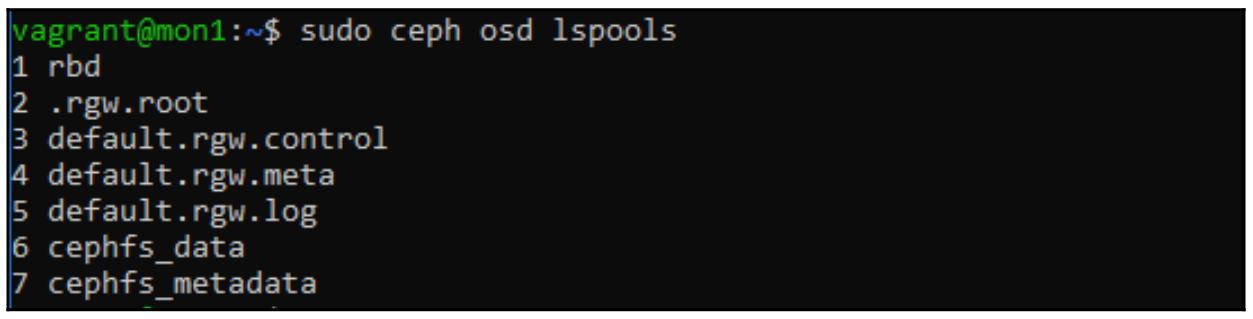
В предыдущем снимке экрана мы можем увидеть, что для CephFS были созданы пулы 6 и 7. Если эти пулы не были созданы, повторите те шаги из самого начала данной главы, при помощи которых мы создавали пулы RADOS. В то время как сам пул данных может быть создан в виде пула с удаляющим кодированием, его пул метаданных следует создавать с типом реплицируемого.
Окончательный этап создания файловой системы CephFS состоит в том чтобы указать Ceph на необходимость применения этих созданных пулов RADOS для построения самой файловой системы. Однако как и все прочие предыдущие этапы, для нас это должен был выполнить Ansible. Мы можем убедиться в этом, вызвав такую команду:
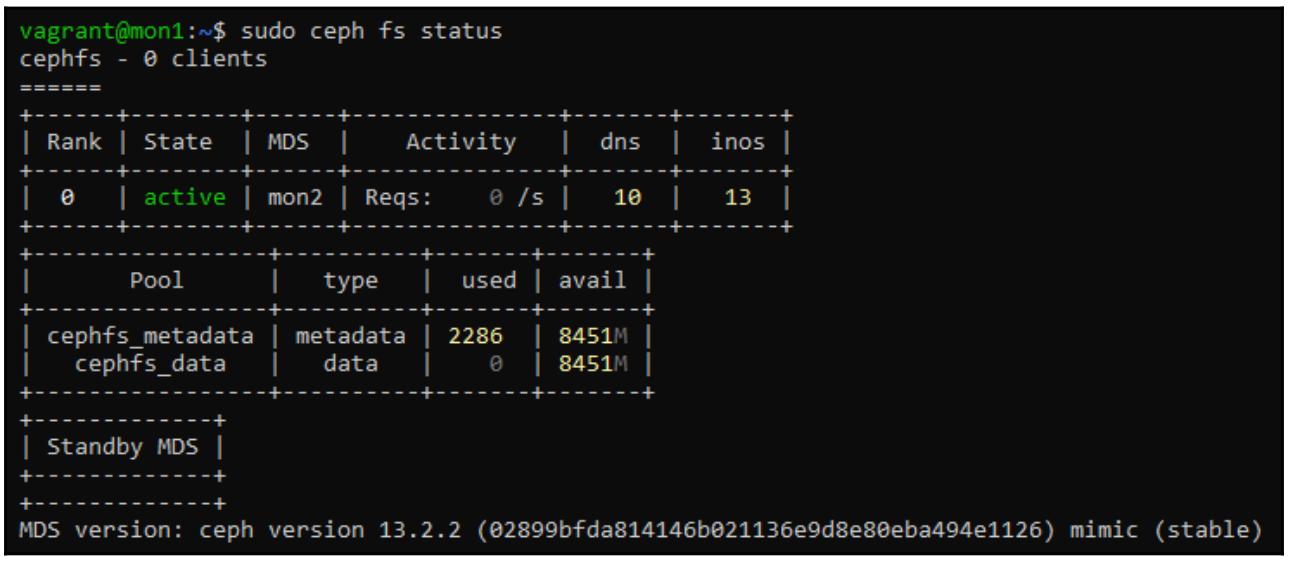
sudo ceph fs status
Если требуемая файловая система CephFS была создана и готова к обслуживанию, она отобразит следующее:
Если же необходимая файловая система CeрhFS не была создана, воспользуйтесь для её создания такой командой:
sudo ceph fs create <Filesystem Name> <Metadata Pool> <Data Pool>
Теперь, когда наша файловая система CephFS активна, мы можем смонтировать ей некому клиенту и применять как и прочие файловые
системы Linux. При монтировании файловой системы CephFS через соответствующую команду монтирования следует передать необходимый
ключ пользователя cephx. Этого можно добиться путём кольца ключей, хранимых в каталоге
/etc/ceph/. В нашем следующем примере мы применили кольцо ключей admin; в промышленных
сценариях рекомендуется создавать некое особое кольцо ключей пользователя cephx:
cat /etc/ceph/ceph.client.admin.keyring
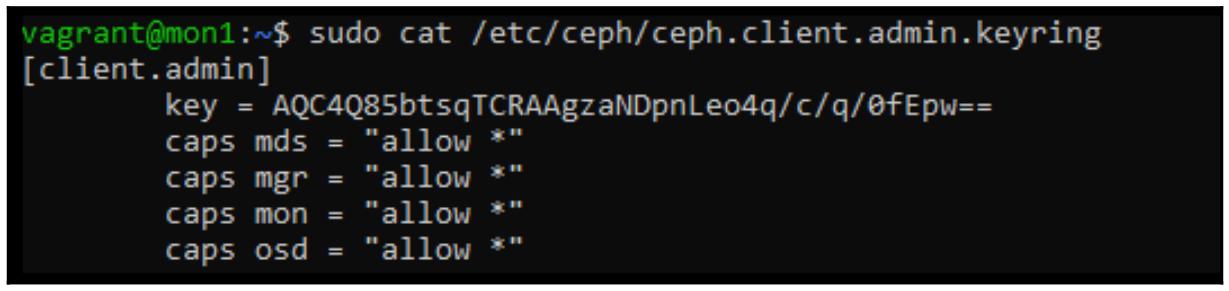
Для монтирования данной файловой системы CephFS всё что требуется, это значение хэширования ключа:
sudo mount -t ceph 192.168.0.41:6789:/ /mnt -o name=admin,secret=AQC4Q85btsqTCRAAgzaNDpnLeo4q/c/q/0fEpw==
|
| Совет |
|---|---|
|
В данном примере был задан только один монитор; в промышленных установках рекомендуется поддерживать все три адреса монитора в формате с разделением запятыми для гарантии отработки отказов. |
Вот подтверждение того что файловая система смонтирована:
Как данные хранятся в CephFS?
для лучшего понимания того CephFS устанавливает соответствие некой POSIX- совместимой файловой системе поверх хранилища объектов, мы можем более пристально рассмотреть как Ceph устанавливает соответствие inode файлов объектам.
Прежде всего давайте рассмотрим некий файл с названием test, который хранится в файловой
системе CephFS, монтируемой в /mnt/tmp. Следующая команда применяет хорошо известную команду
ls, но с некоторыми дополнительными параметрами для отображения дополнительных подробностей,
включая значение номера inode файла:
ls -lhi /mnt/tmp/test
Далее представлен снимок экрана вывода предыдущей команды:
Этот вывод показывает, что что наш файл имеет размер в 1 ГБ а также длинное число значения номера inode слева в самом начале.
Далее, перечисляя все хранимые в CephFS объекты и выполнив поиск указанного номера мы можем обнаружить именно тот объект, который содержит все подробности файловой системы для данного файла. Прежде чем мы продолжим, тем не менее, нам понадобится преобразовать значение номера inode, хранящегося в десятичном значении в его шестнадцатеричное представлении, ибо именно так CephFS хранит соответствующие номера inode в качестве названий объекта.
printf "%x\n" 1099511784612
Следующий снимок экрана является выводом предыдущей команды:
Теперь мы можем отыскать свой объект в просматриваемом пуде; заметим, что это может потребовать значительного времени в неком пуле CephFS, наполненном данными, поскольку будут перебираться все объекты в фоновом режиме:
rados -p cephfs_data ls | grep 100000264a4 | wc -l
Обратите внимание, что было обнаружено 256 объектов. По умолчанию CephFS разбивает файлы большого размера на объекты по 4 МБ, и именно 256 составляют размер файла в 1 ГБ.
Сами реальные объекты хранят в точности те самые данные, оторые представлены в самой файловой системе CephFS. Если в файловой системе
CephFS сохранён некий текстовый файл, его содержимое можно считать, устанавливая соответствие лежащих в основе объектов их номерам
inode и применяя команду rados для выгрузки самого данного объекта.
Наш пул cephfs_metadata хранит все метаданные для тех файлов, которые хранятся в нашей файловой
системе CephFS; они содержат, к примеру, значение времени изменения, названий файла, а также местоположения файла в основном дереве
каталога. Без таких метаданных наши хранимые в пуле данных объекты данных попросту говоря всего лишь случайным образом именованные объекты;
все данные всё ещё присутствуют, но крайне бессмысленны для оператора человека. Утрата метаданных CephFS, тем самым, не приводит к
реальной утрате данных, но всё ещё делает их более или менее не доступными для считывания. Таким образом, следует предпринимать меры
предосторожности для защиты пула метаданных в точности как и и для всех остальных пулов RADOS в вашем кластере Ceph. Существует ряд
продвинутых этапов восстановления, которые могут оказать вам содействие при утрате метаданных, которые обсуждаются в
Главе 12, Восстановление после сбоев.
Схемы файлов
CephFS позволяет вам изменять тот способ, которым файлы сохраняются промеж лежащих в их основе объектов применяя настройки, которые имеют название схем файлов (file layouts).Схемы файлов позволяют вам контролировать значением размера полос чередования и шириной, а также тем как пул RADOS будет размещать эти объекты данных. Такие схемы файлов хранятся в виде расширенных атрибутов в файлах и каталогах. Некий новый файл или каталог наследует установки схем файла своих предков, последующие изменения в некой схеме родительского каталога не оказывают воздействия на уже существующие файлы.
Регулировки значениями чередования файла обычно выполняются по причинам производительности для увеличения значения распараллеливания считывания больших файлов, поскольку некий раздел данных в конце концов разбрасывается по большему числу OSD. По умолчанию чередование не установлено и хранящиеся в CephFS большие файлы просто перекрываются множеством объектов по 4 МБ в их размере.
Схемы файлов также можно применять для изменения того в каком именно пуле данных будут сохраняться конкретные объекты некоторого
файла. Это может быть полезным чтобы допускать применение различных каталогов для горячих и холодных данных, когда горячие данные
могут помещаться в неком пуде 3x SSD, а для холодных файлов выполняется резервное копирование в неком пуле удаляющего кодирования на
шпиндельных дисках. Хорошим примером может быть возможный вариант наличия некого подкаталога с названием
Archive/, в который пользователи могут копировать файлы, котрые не предназначены для
повседневного использования. Все копируемые в этот каталог файлы сохранялись бы в пуле удаляющего кодирования.
Схемы файлов можно просматривать и изменять при помощи соответствующих инструментов setfattr
и getfattr:
getfattr -n ceph.file.layout /mnt/test

Легко можно увидеть, что применяемая по умолчанию схема файла сохраняет все объекты данных для данного проверочного файла в
пуле cephfs_data. Также можно обнаружить, что этот файл расщепляется на объекты по 4 МБ, а,
благодаря тому что значение stripe_unit также установлено в 4 МБ и
stripe_count равен 1, не применяется никакое чередование.
Моментальные снимки
CephFS также поддерживает на уровне вниз по каталогу моментальные снимки; нет необходимости включать такие моментальные снимки в
файловую систему CephFS целиком. Каждый каталог в файловой системе CephFS содержит некий скрытый каталог .snap;
когда внутри создаётся некий новый подкаталог, на практике выполняется моментальный снимок и представление внутри такого нового
подкаталога будет отображать значение состояния первоначального каталога на момент производства данного моментального снимка.
Множество моментальных снимков может осуществляться и просматриваться независимо друг от друга, что делает возможным применять такие моментальные снимки как часть краткосрочной схемы архивирования. Одним из таких вариантов применения является случай, когда экспорт CephFS через Samba должен применяться для выставления функциональности моментального снимка через соответствующие закладки Windows Explorer предыдущих версий.
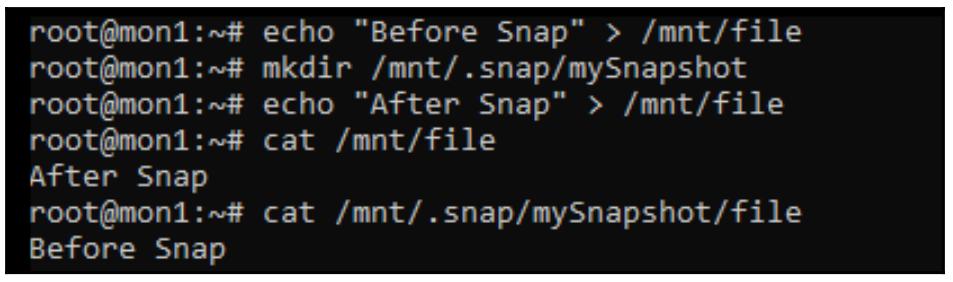
В приводимом ниже примере создан некий проверочный файл, взят некий моментальный снимок, а затем этот файл изменён. Опрашивая значение содержимого своего файла в реальном времени и значения этого файла в его моментальном снимке мы можем видеть как представляют себя моментальные снимки CephFS:
Множественные MDS
неким новым свойством CephFS является поддержка для множества активных MDS. Первоначально было рекомендовано иметь всего один активный MDS с одним или более ожидающих, чего для развёртываний CephFS было более чем достаточно. Тем не менее, в крупных реализациях некий обособленный MDS может начинать становиться ограничением, в особенности благодаря существующему пределу на MDS в единственном потоке. Следует отметить, что такое множество активных MDS целиком служит увеличению производительности и не предоставляет совсем никакой отказоустойчивости или высокой доступности самих по себе; более того, всегда надлежит предоставлять достаточное число ожидающих MDS.
При наличии множества активных MDS общая файловая система CephFS расщепляется по всем имеющимся MDS с тем, чтобы, как мы надеемся, запросы к метаданным не обрабатывались более все целиком в отдельном MDS. Такой процесс расщепления выполняется на уровне подкаталогов и динамически выравнивается на основании имеющейся нагрузки запросов к метаданным. Данный процесс расщепления вовлекает создание новых рангов CephFS; каждый ранг требует чтобы был доступен некий рабочий MDS чтобы он стал активным.
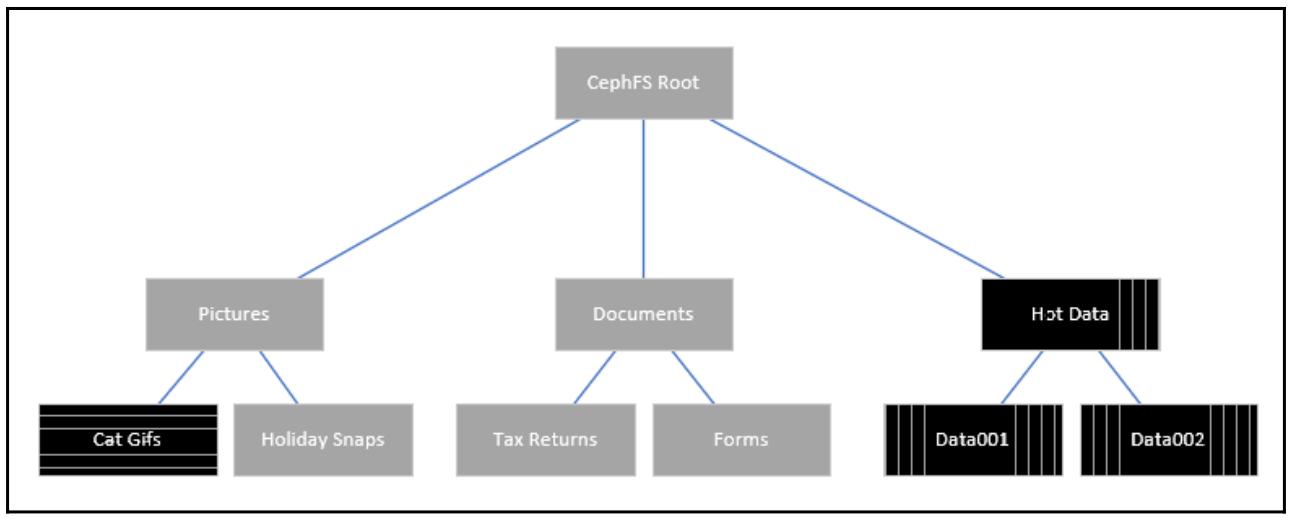
В приводимом ниже примере в нашем кластере Ceph применяются три активных сервера MDS. Самый первичный MDS, исполняемый с рангом 0 всегда размещает основной корень CephFS. Второй MDS обслуживает метаданные для вертикально заштрихованные шаблоны каталогов, поскольку нагрузка на их метаданные достаточно велика. Все прочие каталоги всё ещё получают свои метаданные, обслуживаемые имеющимся первичным MDS, поскольку они имеют активность от малой- до- отсутствующей, за исключением каталогов, содержащего Cat Gifs; именно этот каталог испытывает чрезвычайно высокую нагрузку запросов к метаданным и тем самым имеет отдельный ранг и выделенный ему самому MDS, что отображается горизонтально заштрихованным шаблоном.
RADOS Gateway (RGW) представляет в Ceph естественное хранилище объектов через S3- или Swift- совместимый интерфейс, которые оба являются наиболее популярными API объектов для доступа к хранилищу объектов, причём с преобладанием S3 благодаря большому успеху Amazon AWS S3. Данный разде нашей книги в основном сосредоточен на S3.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
RGW недавно был переименован в Ceph Object Gateway, хотя наряду с этим названием всё ещё широко применяется и предыдущие названия. |
Компонент Ceph radosgw отвечают за настройку запросов API S3 и Swift в запросы RADOS. Хотя он и может устанавливаться совместно с прочими компонентами, по причинам производительности рекомендуется устанавливать его на отдельном сервере. Все компоненты radosgw полностью освобождены от отслеживания состояний (stateless), а следовательно отлично помещаются за балансировщиком нагрузки допуская горизонтальное масштабирование.
Помимо хранения данных пользователя сам RGW также требует ряда дополнительных пулов RADOS для хранения вспомогательных метаданных. За исключением существенного пула индексации, большинство этих пулов имеют очень малую загруженность, следовательно могут создаваться с небольшим числом PG, обычно вполне достаточно порядка 64. Имеющиеся пулы индексации помогают с перечислением содержимого корзин и поэтому настоятельно рекомендуется помещение таких пулов индексации на SSD. Сами пулы данных могут располагаться либо на шпиндельных дисках, либо на SSD в зависимости от подлежащего хранению типа объектов, хотя в целом вполне хорошими для хранилища объектов являются шпиндельные диски. Достаточно часто клиенты являются удалёнными и задержки подключений к глобальной сети покрывают те преимущества, которые можно получать от SSD. Следует отметить, что в пулах удаляющего кодирования следует размещать только сами пулы данных.
Для удобства RGW будет создавать все требующиеся пулы при первой же попытке обращений к нему, что несколько снижает сложность установки. Однако пулы создаются с устанавливаемыми по умолчанию значениями, а может случиться так что вы желаете создать для хранения объектов данных пул удаляющего кодирования. До тех пор, пока не было выполнено запросов к службе RGW, после её создания не должно существовать пула данных, а следовательно его можно создать вручную. Поскольку получаемое им название будет соответствовать тому названию пула, которое предназначено для использования в зоне RGW, RGW воспользуется таким пулом при первом же доступе вместо того чтобы пытаться создавать новый.
Развёртывание RGW
Для развёртывания RGW мы будем применять ту лабораторию Ansible, которую мы оснастили в Главе 2, Развёртывание Ceph в контейнерах.
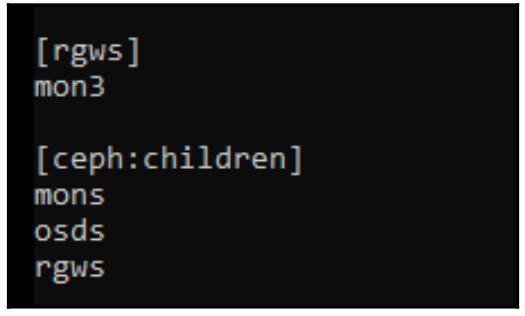
Для начала измените свой файл /etc/ansible/hosts и добавьте роль rgws
для своей ВМ mon3:
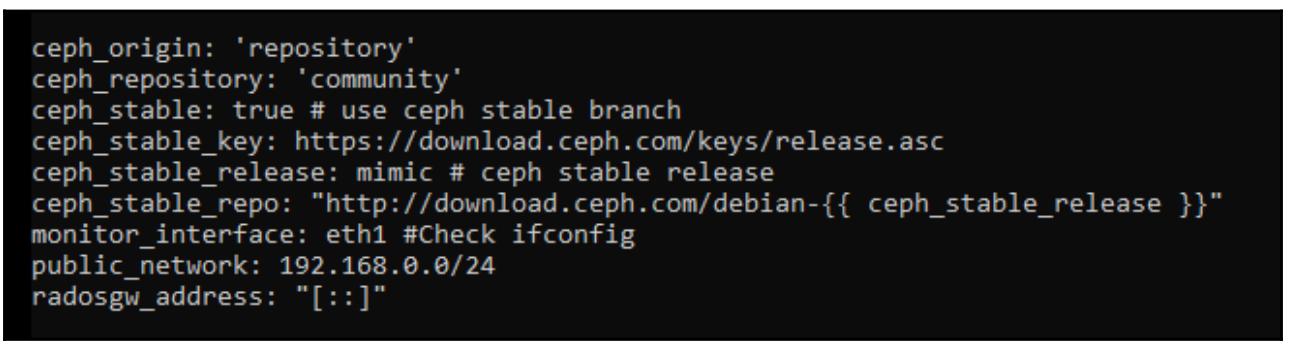
Нам также потребуется обновить свой файл /etc/ansible/group_vars/ceph и добавить в нём
переменную radosgw_address; она будет установлена в
[::], что означает привязку ко всем интерфейсам IPv4 и IPv6:
Теперь вновь запустите свой плейбук Ansible:
ansible-playbook -K site.yml
После его исполнения вы должны обнаружить успешно развёрнутые компоненты своего RGW:

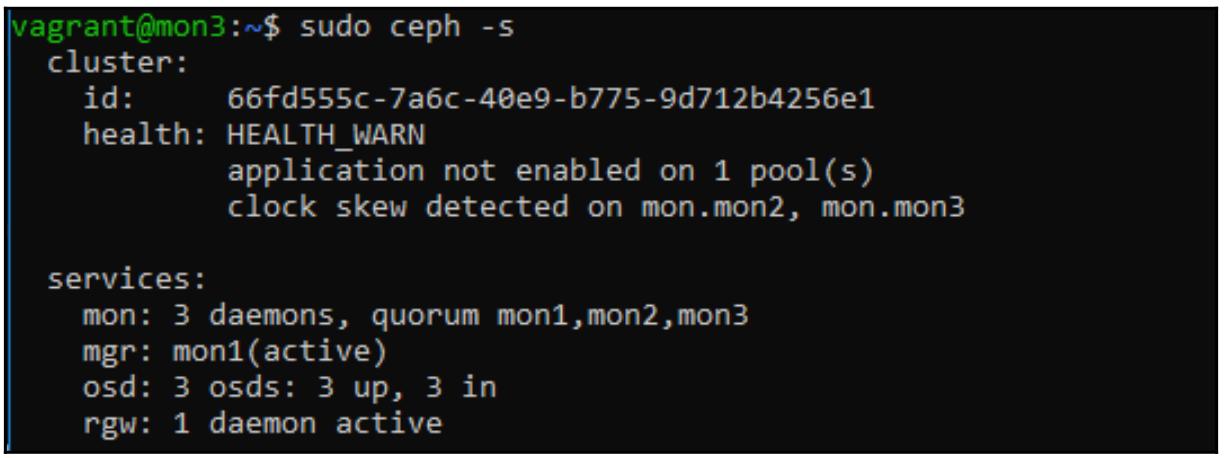
Представляя значение состояния Ceph с узла монитора мы можем убедится что наша служба
RGW зарегистрирована в имеющемся кластере Ceph и находится в рабочем состоянии:
Теперь, когда RGW активен, для взаимодействия с API S3 требуется некая учётная запись пользователя и её можно создать с помощью
инструмента radosgw-admin как это показано далее:
sudo radosgw-admin user create --uid=johnsmith --display-name="John Smith" --email=john@smith.com
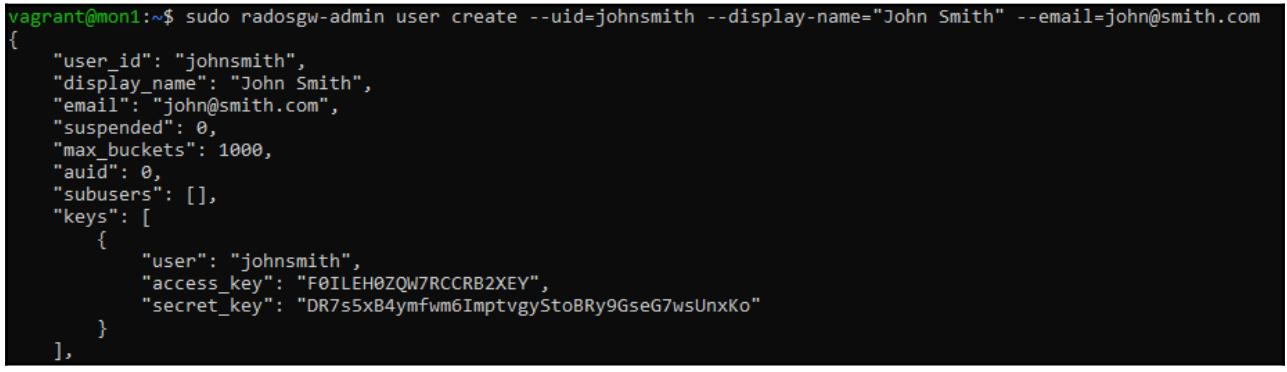
Обратите внимание на вывод данной команды, в частности на значения access_key и
secret_key, они будут применяться для клиентов S3 с целью аутентификации в нашем RGW.
Для выгрузки объектов из нашего кластера Ceph с возможностями S3, нам для начала требуется создать некую корзину
(bucket) S3. Для того чтобы выполнять это, мы воспользуемся инструментом s3cmd, который
предоставляется следующим образом:
sudo apt-get install s3cmd
Теперь, когда s3cmd установлен, его следует настроить с тем чтобы он указывал на наш
сервер RGW; он имеет встроенный инструмент настройки, который можно применять для выработки первоначально конфигурации. В процессе
работы с мастером настройки вы получите приглашение для ввода ключа доступа и секретного кода, которые были выработаны при создании
учётной записи соответствующего пользователя, что выглядит так:
s3cmd --configure
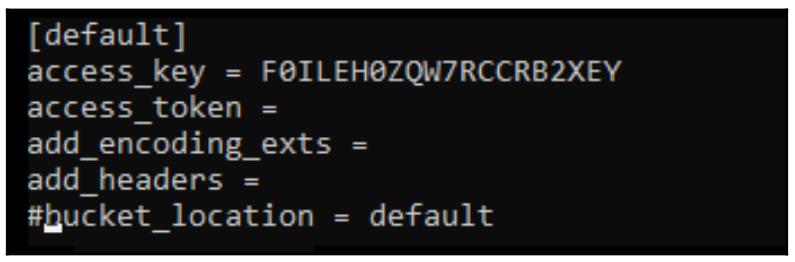
Выработанная нами конфигурация будет указывать на службу S3 Amazon; этот выработанный файл следует отредактировать для внесения
изменений в несколько параметров. Отредактируйте этот файл .s3cfg из домашнего каталога
своего пользователя и сделайте такие изменения:
nano .s3cfg
Скройте комментарием свою переменную bucket_location:
Измените значения host_base и host_buckets с тем, чтобы
они соответствовали надлежащему адресу нашего RGW:
Сохраните этот файл и вернитесь обратно в оболочку своей командной строки; теперь для манипуляций с s3
можно применять s3cmd. Ниже приведён пример создания нами корзины
test, в которую можно выгружать объекты:
s3cmd mb s3://test
Теперь у вас имеется полностью функционирующая совместимая с S3 платформа хранения, готовая для изучения мира хранения объектов.
В этой главе мы изучили различия между пулами с репликациями и пулами удаляющего кодирования, а также их сильные стороны и недостатки. Вооружившись этой информацией вы теперь должны быть способны предпринимать наилучшие решения когда дело доходит до выбора между реплицируемыми пулами и пулами удаляющего кодирования. Вы также теперь обладаете более глубоким пониманием того как работают пулы удаляющего кодирования, что поможет при планировании и работе.
Теперь вы должны уверенно себя ощущать при развёртывании кластеров Ceph с тем, чтобы обеспечивать хранение блоков, файлов и объектов и быть способными демонстрировать обычные административные задачи.
В своей следующей главе мы изучим librados и как её применять для создания индивидуальных приложений, которые будут общаться с Ceph напрямую.
-
Приведите названия двух различных техник удаляющего кодирования.
-
Как называется тот процесс, когда пул удаляющего кодирования выполняет частичную запись в некий объект?
-
Зачем вы можете выбирать пул удаляющего кодирования с двумя фрагментами удаляющих кодов?
-
Как именуется процесс преобразования некоторого клонированного снимка в полностью наполненный образ RBD?
-
Какой демон Ceph требуется для запуска файловой системы CephFS?
-
Зачем вам может потребоваться запуск множества активных серверов метаданных поверх отдельной обособленной файловой системы CephFS?
-
Какой демон Ceph требуется для запуска RGW?
-
Какие два API способен поддерживать RGW Ceph?