Часть 3. Устранение неисправностей и восстановление
Данный раздел этой книги рассматривает чёрные моменты в жизни администратора Ceph. К концу даанного раздела читатель окажется более осведомлённым в восстановлении кластера и исправлении проблем, если уж они возникнут.
В этом разделе содержатся следующие главы:
Глава 11. Поиск неисправностей
Содержание
Ceph во многом автономен в заботе о себе и при восстановлении в случае отказов, однако в некоторых вариантах требуется вмешательство человека. Данная глава рассмотрит такие общие ошибки и варианты отказов, а также как переносить Ceph обратно в рабочее состояние находя неисправности в нём. Вы изучите следующие вопросы:
-
Как правильно восстанавливать несогласованные объекты
-
Как решать проблемы при помощи однорангового обмена
-
Как обрабатывать OSD с
near_fullиtoo_full -
Как исследовать ошибки при помощи журналов Ceph
-
Как изучать плохую производительность
-
Как обследовать PG в состоянии
down
При использовании BlueStore все данные по умолчанию снабжены контрольными суммами, поэтому в данном разделе более не применяются шаги безопасного выявления верной копии самого объекта.
Сейчас мы рассмотрим как мы можем правильно восстанавливать несогласованные объекты.
-
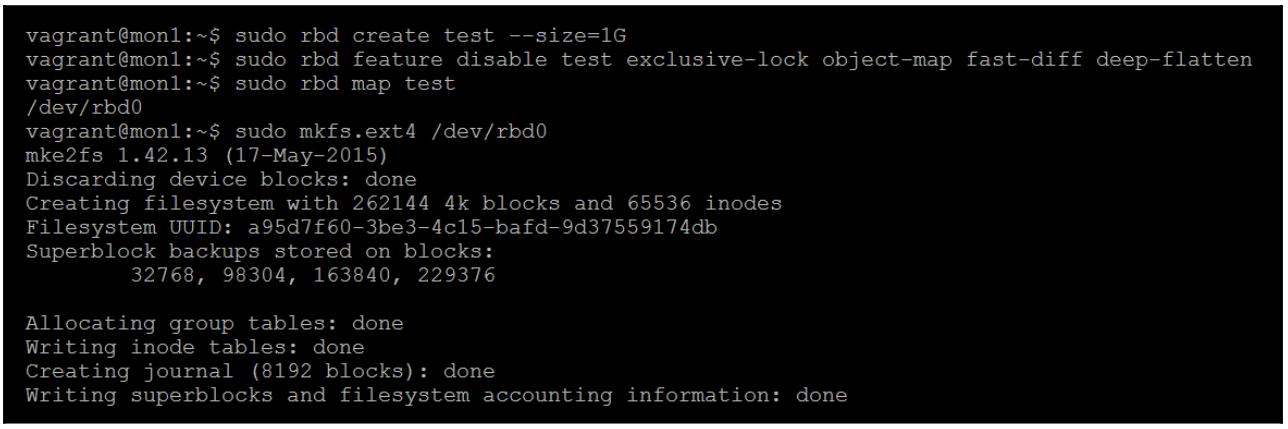
Чтобы иметь возможность восстановления несогласованного сценария создайте некий RBD и далее мы сделаем в нём некую файловую систему:
-
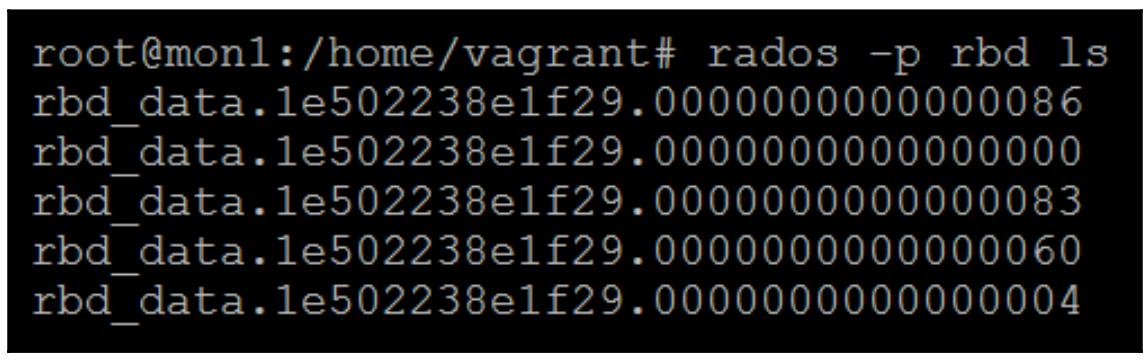
Теперь проверьте просмотром какие объекты были созданы путём форматирования данного RBD некоторой файловой системой:
-
Возьмите произвольный объект и воспользуйтесь командой
osd mapдля поиска того, в каких PG сохранён данный объект:
-
Найдите этот объект на конкретном диске на одном из узлов OSD; в данном случае это
osd.0наosd1:
-
Разрушьте его скопировав на него командой
echoмусорную запись:
-
Теперь запросите Ceph выполнить в той PG, которая содержит разрушенный нами объект, чистку:
-
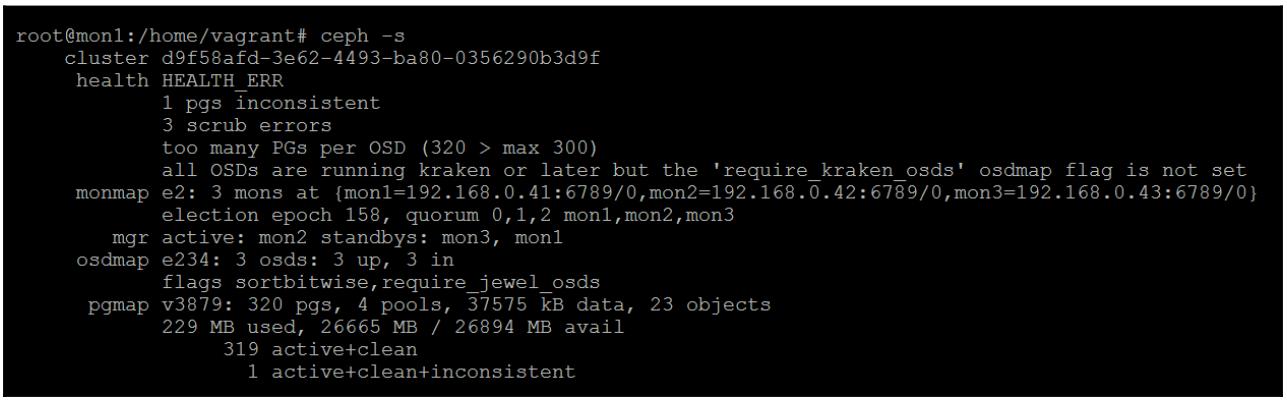
Если вы проверите состояние Ceph, вы увидите, что Ceph обнаружил испорченный объект и пометил его PG несогласованной. Начиная с этого момента и далее забудем что мы разрушили данный объект вручную и отработаем весь процесс так, как если бы это произошло в реальности:
Рассматривая более внимательно сообщение о работоспособности, мы можем обнаружить ту PG, которая содержит испорченный объект. Мы можем теперь просто запросить у Ceph восстановление данной PG; однако, если именно первичный OSD содержит испорченный объект, это перепишет оставшиеся хорошие копии. Это будет не хорошо; таким образом, чтобы убедиться, что этого не произойдёт, перед тем как исполнить команду восстановления мы убедимся в том какой именно OSD содержит испорченный объект.
Просмотрев полученный отчёт о работоспособности мы можем увидеть все три OSD которые содержат некие копии данного объекта, причём самый первый OSD является первичным.
-
Зарегистрируемся на своём узле первичного OSD и откроем файл журнала для искомого первичного OSD. Вы должны иметь возможность отыскать ту запись журнала, которая отображает тот факт, что объект был помечен операцией чистки PG.
-
Теперь, перемещаясь по соответствующей структуре PG и открывая соответствующий файл журнала отыщите необходимые объекты, упомянутые в соответствующем файле журнала и вычислите
md5sumкаждой копии.
md5sumобъекта в osd первого узла
md5sumобъекта в osd второго узла
md5sumобъекта в osd третьего узлаМы можем обнаружить, что объект в
osd.0имеет отличное значениеmd5sumи поэтому мы знаем что именно он является разрушенным объектом.OSD.0 = \0d599f0ec05c3bda8c3b8a68c32a1b47 OSD.2 = \b5cfa9d6c8febd618f91ac2843d50a1c OSD.3 = \b5cfa9d6c8febd618f91ac2843d50a1c







Хотя мы уже знаем какая копия объекта была разрушена, поскольку мы вручную изувечили объект в
OSD.0, давайте притворимся что мы не делали этого и такое разрушение
могло быть вызвано случайными космическими лучами. Теперь у нас имеется md5sum
трёх реплицированных копий и можно ясно понять что копия в OSD.0
неверная. Это очевидный факт для того почему схема с двумя репликациями плоха; если некая PG становится
несогласованной, вы можете определить какая из них плохая. Поскольку первичным OSD для этой PG является 2, как
мы могли убедиться и в подробностях о работоспособности Ceph, и в выводе команды Ceph
OSD map, мы можем безопасно выполнить имеющуюся команду
ceph pg repair без опасений что скопируем плохой объект поверх
оставшихся неиспорченными копий:

Мы можем отметить, что наша несогласованная PG восстановила себя:
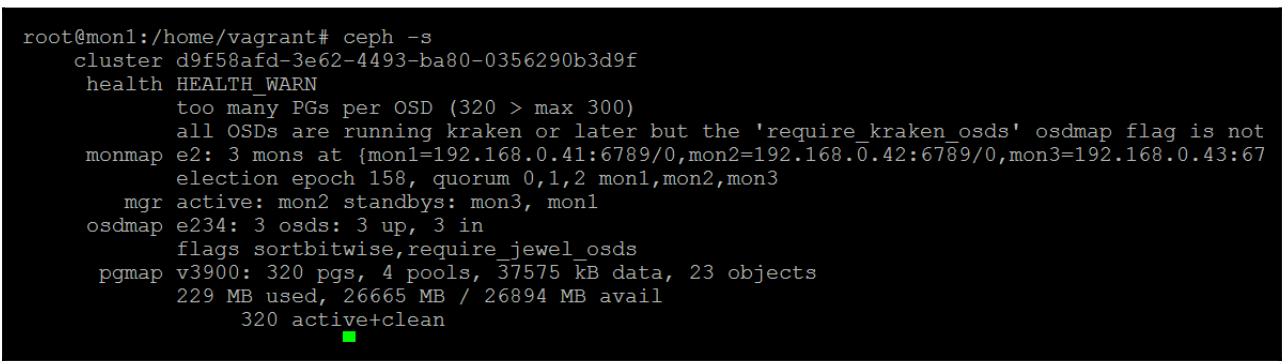
При возникновении ситуации, когда разрушена копия на самом первичном OSD, тогда необходимо предпринять следующие шаги:
-
Остановить первичный OSD.
-
Удалить этот объект из каталога данной PG.
-
Повторно запустить этот OSD.
-
Проинструктировать Ceph восстановить эту PG.
По умолчанию Ceph предостерегает когда использование OSD достигает 85% и остановит операции ввода/ вывода на запись в данный OSD когда будет достигнуто 95%. Если по какой- либо причине данный OSD полностью заполнится до 100%, тогда данный OSD скорее всего разрушится и откажется вернуться назад в рабочее состояние. Некий OSD который превысил уровень предупреждения в 85% также отвергает участие в наполнении, поэтому восстановление данного кластера может получить удар в случае если OSD находятся около заполненного состояния.
Прежде чем рассмотреть все шаги поиска неисправностей в ситуации заполненных OSD настоятельно рекомендуется
чтобы вы наблюдали за использованием ёмкости ваших OSD, как это описывалось в
Главе 8, Монторинг Ceph. Это снабдит вас заблаговременным
уведомлением таким как подход к OSD с пороговым предупреждением near_full.
Если вы обнаружили что находитесь в ситуации когда ваш кластер переступил через состояние предупреждение близости к заполнению у вас имеются два основных варианта:
-
Добавить немного дополнительных OSD.
-
Удалить некоторые данные
Однако в реальном мире они оба или невозможны, либо потребуют времени и в таком случае ситуация может
ухудшиться. Если данный OSD только в пороговом значении near_full,
тогда вы скорее всего вероятно можете вернуть всё в правильное русло проверкой сбалансировано ли использование
вашего OSD, с возможной последующей балансировкой, если её нет. Это было подробно рассмотрено в предыдущей
Главе 9, Тонкая настройка Ceph. То же самое применимо и к ситуации
когда OSD too_full; хотя вы вряд ли вернёте его обратно ниже 85%, вы
по крайней мере можете отвергать операции записи.
Если ваши OSD заполнились полностью, тогда они все в состоянии отключённых и будут отвергать запуск. Теперь вы имеете некоторую дополнительную проблему. Если данные OSD не запустятся, тогда вне зависимости от того что вы выполните - ребалансировку или удаление данных, они не отразятся на всех заполненных OSD, так как они отключены. Единственный способ восстановиться из данной ситуации - это вручную удалить некоторые PG из файловой системы данных дисков чтобы сделать возможным запуск такого OSD.
Вот шаги, которые необходимо для этого предпринять:
-
Убедитесь что данный процесс OSD не исполняется.
-
Установите в данном кластере
nobackfillчтобы остановить все восстановления от их наступления после возврата в работу данного OSD. -
Найдите некую PG, которая находится в активном, чистом и переназначенном состоянии и присутствует в данном отключённом OSD.
-
Удалите эту PG из данного отключённого OSD.
-
Будем надеяться, что вы теперь сможете перезапустить данный OSD.
-
Удалите данные из данного кластера Ceph или выполните повторную балансировку PG.
-
Удалите
nobackfill. -
Выполните очистку и восстановление той PG, которую вы только что удалили.
При выявлении ошибок очень удобно иметь возможность просматривать все файлы журналов Ceph чтобы
получать лучшие идеи по поводу того что происходит. По умолчанию имеющиеся уровни ведения журнала установлены
так, чтобы регистрировались только все важные события. В процессе поиска неисправностей может возникнуть
потребность повысить эти уровни ведения журналов чтобы обнаружить вызывающую данную ошибку причину. Для
увеличения уровня ведения журнала вы можете либо изменить ceph.conf,
добавив новый уровень журнала, а затем перезапустить этот компонент, либо, если вы не желаете перезапускать
сам демон Ceph, вы можете внедрить необходимый новый параметр настройки в свой работающий в реальном времени
демон. Для внедрения параметров применяйте команду ceph tell:
ceph tell osd.0 injectargs --debug-osd 0/5
Здесь мы устанавливаем уровень ведения журнала для журнала OSD на osd.0
в значение 0/5. Число 0
является уровнем журнала на диске, а число 5 уровень журнала в
оперативной памяти.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
На уровне ведения журнала |
Низкая производительность определяется в том случае, когда сам кластер активно обрабатывает запросы операций ввода/ вывода, однако они кажутся работающими на более низком уровне производительности чем это ожидается. Обычно малая производительность вызывается неким компонентом в вашем кластере Ceph, который достиг насыщения и становится узким местом. Это может быть обусловлено увеличением числа запросов клиентов или неким отказом компонента, который заставляет Ceph выполнять восстановление.
Хотя имеется множество вещей, которые могут заставить Ceph испытывать низкую производительность, вот некоторые из наиболее общих, которые могут происходить:
Возросшая рабочая нагрузка клиентов
Порой низкая производительность может быть обусловлена не лежащими в её основе отказами; это может быть просто результатом того, что общее число и тип запросов клиентов могут превосходить возможности имеющегося оборудования. Будь то последствия некоторого числа рабочих нагрузок, которые все исполняются в одно и то же время, или всего лишь некое медленное общее увеличение на некий период времени, если вы отслеживаете общее число запросов клиентов по всему своему кластеру, это должно быть простым для отслеживания. Если увеличившаяся рабочая нагрузка выглядит как нечто постоянное, тогда единственным решением будет добавить некоторое дополнительное оборудование.
Останов OSD
Если в некотором кластере значительное число OSD помечены как down,
возможно из- за того, что остановлен целый узел, хотя восстановление не начнётся пока эти OSD не будут
помечены как out, это повлияет на общую производительность, поскольку
общее число IOP, доступное для обслуживания всех операций ввода/ вывода клиентов теперь будет ниже. Ваше
решение мониторинга должно уведомить вас если это произойдёт и позволит вам предпринять действия.
Восстановление и наполнение
Когда некий OSD помечен как out, попавшие под воздействие этого PG
переустановят одноранговые соединения на новые OSD и начнут свой процесс восстановления и наполнения данными
по всему кластеру. Этот процесс может разместить на все диски в некотором кластере Ceph дополнительную
нагрузку и повлечь большие задержки для запросов клиентов. Имеется ряд параметров регулировки, которые
могут снизить воздействие заполнения уменьшением его скорости и приоритета. Это следует оценить в
противовес воздействию снижения восстановления отказавших дисков, что могло бы уменьшить уровень живучести
всего кластера.
Очистка
Когда Ceph выполняет глубокую очистку для проверки того, находятся ли ваши данные в какой- либо несогласованности, ему приходится считывать все объекты с данного OSD; это может быть очень интенсивной задачей в отношении операций ввода/ вывода, а на больших дисках этот процесс может отнимать много времени. Очистка жизненно важна для защиты от утраты данных и, следовательно, её нельзя отключать. Различные варианты настроек обсуждались в Главе 9, Тонкая настройка Ceph, относящиеся к установкам окон для очистки и её приоритету. Регулируя эти установки можно избежать большую часть воздействия на рабочую нагрузку клиента от очистки.
Подрезка снимков
Когда вы удаляете некий моментальный снимок, Ceph должен удалить все имеющиеся объекты, которые были созданы
благодаря природе копирования при записи данного процесса получения снимка. Начиная с Ceph 10.2.8 и далее имеется
некоторое улучшенная установка OSD с названием osd_snap_trim_sleep,
которая заставляет Ceph ожидать предписанного установкой значения между подрезкой каждого объекта моментального
снимка. Это гарантирует, что все лежащие в основе хранения объекты не станут перегруженными.
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Хотя эти установки были доступны в предыдущих редакциях Jewel, их поведение было не тем же самым и их не следует применять. |
Проблемы с оборудованием или драйверами
Если вы только что добавили новое оборудование в свой кластер Ceph и, после того как заполнение повторно
сбалансировало ваши данные, вы начинаете испытывать медленную производительность, проверьте своё
встроенное программное обеспечение или драйверы связанные с вашим оборудованием, поскольку новые драйверы
могут требовать более нового ядра. Если вы добавили только небольшой объём аппаратных средств, тогда вы можете
временно пометить эти OSD как out не выходя ниже установленного для ваших
пулов значения min_size; это может быть хорошим способом исключения
проблем с оборудованием.
Именно здесь приходит на пользу тот мониторинг, который вы настроили в Главе 7, Мониторинг Ceph, так как он позволит вам сравнивать долговременные тенденции с чтением текущих измерений и увидеть некоторые ясные аномалии, если они имеются.
Вначале рекомендуется взглянуть на производительность дисков так как, в большинстве случаев плохой производительности, именно лежащие в основе диски обычно становятся теми компонентами, которые становятся бутылочным горлышком.
Если у вас нет настроенного мониторинга или вы желаете вручную углубиться в пучину имеющихся параметров производительности, тогда имеется целый ряд инструментов, который вы можете применить для этого.
iostat
iostat может быть применён для получения обзора работы в отношении
имеющихся производительности и латентности всех дисков, функционирующих в ваших узлах OSD. Исполните
span class="term">iostat посредством следующей команды:
iostat -d 1 -x
Вы получите отображение подобное следующему, которое обновляется раз в секунду:
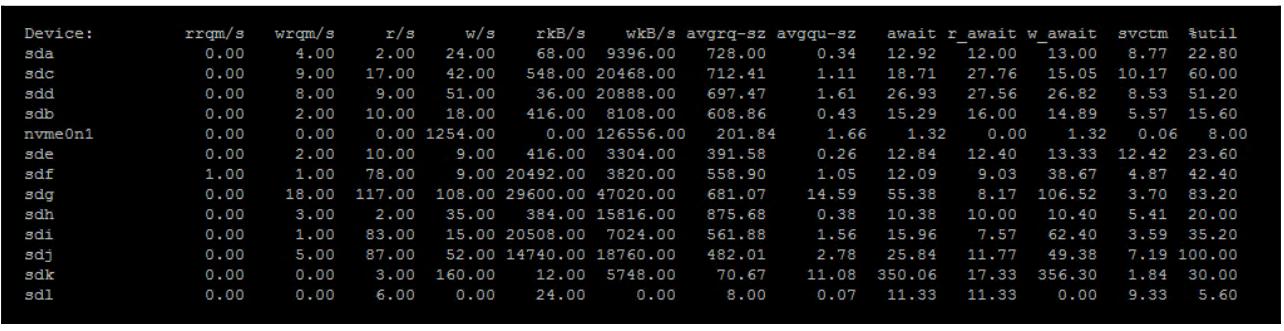
В качестве высеченного в граните правила, если достаточно большое число ваших дисков показывают высокий
процент util на протяжении длительного времени, скорее всего ваши диски перенасыщены запросами. Может быть
неплохо взглянуть на время r_await чтобы проверить что запросы на
чтение не занимают больше времени, чем это следует ожидать для данного типа диска в ваших узлах OSD. Как уже
упоминалось ранее, если вы обнаружите что интенсивное использование дисков является причиной низкой
производительности и тем переключающим фактором, который вряд ли рассосётся скоро, тогда дополнительные
диски являются единственным решением.
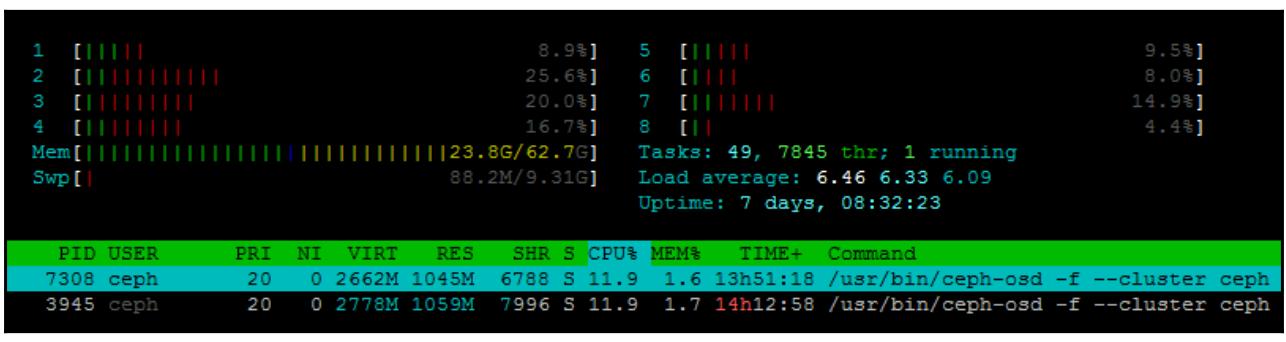
htop
Как и стандартная утилита top, htop предоставляет в реальном
времени просмотр потребления имеющихся ЦПУ и оперативной памяти данного хоста. Однако, она также предоставляет
более интуитивное отображение, которое может сделать оценку использования всех ресурсов системы проще, в
особенности для быстро меняющегося использования ресурсов Ceph.
atop
Другим полезным инструментом является atop; он улавливает параметры
производительности для ЦПУ, оперативной памяти, дисков, сетевой среды и может представлять всё это в одном
просмотре, что делает его очень простым для получения полного обзора всех применяемых ресурсов системы.
Существует некое число внутренних инструментов Ceph, которые можно применять в помощь диагностированию низкой производительности. Большинство полезных команд для исследования медленной производительности сбрасывают текущие операции в реальном времени, что может быть сделано командой, например такой:
sudo ceph daemon osd.x dump_ops_in_flight
Она сбрасывает все текущие операции для данного определённого OSD и расчленяет все имеющиеся различные времена для каждого этапа данной операции. Вот некий пример какой- то операции ввода/ вывода на лету:
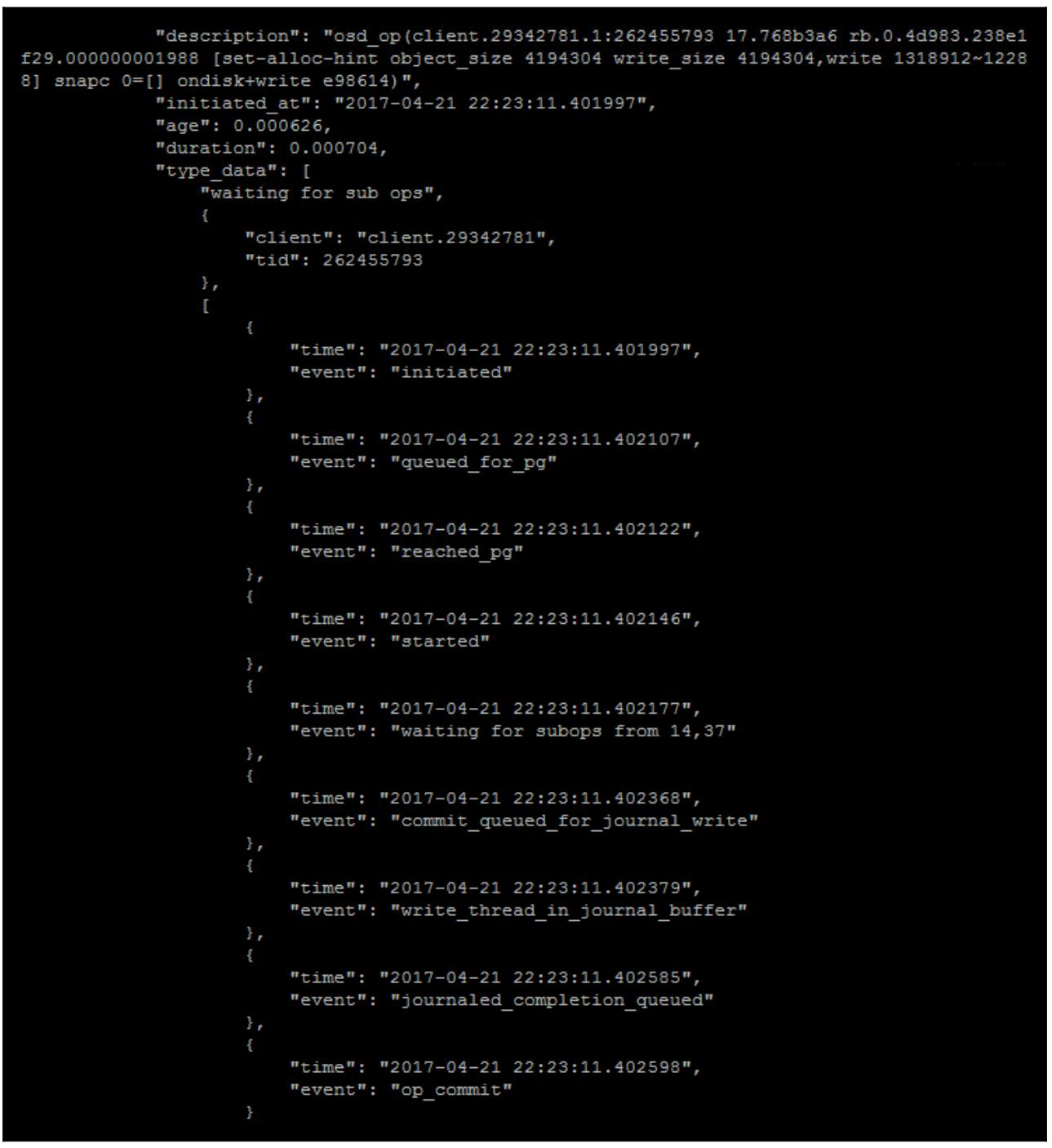
Из предыдущего примера операции ввода/ вывода мы можем увидеть все имеющиеся этапы, которые зарегистрированы для каждой операции; очевидно что данная операция исполняется без каких- либо проблем с производительностью. Однако, при возникновении низкой производительности вы можете увидеть некие большие задержки между двумя этапами и, направив свои изыскания в эту область, можете выйти на вызвавшую проблему процедуру.
Если ваш кластер работает действительно медленно, причём до такой степени что он почти не обслуживает запросы операций ввода/ вывода, тогда, скорее всего, имеются некие лежащие в основе этого отказ или проблема настройки. Такие медленные запросы будут вероятно выделены в дисплее состояния Ceph с помощью счётчика для того, насколько долго запрос был блокирован. В этом случае необходимо проверить несколько моментов.
В своих мониторах проверьте ceph.log и убедитесь не выглядят ли
они как какие- то OSD бьются в up и
down. Когда некий OSD присоединяется к кластеру, его группы размещения
подлежат включению в одноранговую сеть (peering). На протяжении данного процесса установки одноранговых
соединений операции ввода/ вывода временно останавливаются, поэтому в случае некоторого число биений OSD
это может определённым образом воздействовать на операции ввода/ вывода клиента. Если с очевидностью имеются
мерцающие OSD, следующим этапом будет проход по журналам для выявления тех OSD, которые являются мерцающими
и нет ли ключей к тому что вызывает их биения. Мерцание OSD может быть сложным для отслеживания, так как
возможно вызывается различными причинами и к тому же данная проблема может широко распространяться.
Убедитесь что изменения в сетевой среде не вызвали проблем с кадрами jumbo, если они применяются. Если кадры jumbo не работают надлежащим образом, пакеты меньшего размера скорее всего могут быть успешными для прохождения к прочим OSD и MON, однако более длинные пакеты будут отбрасываться. Это будет иметь результатом то, что возникнет половинчатая функциональность, а это может быть очень трудным для обнаружения очевидным образом. Если происходит нечто странное, всегда проверяйте с применением ping тот факт, что кадры jumbo разрешены по всей вашей сети.
Так как Ceph чередует данные по всем дискам в имеющемся кластере, некий отдельный диск, который находится в процессе падения, но всё же пока ещё полностью не отказал, может начать вызывать замедление или блокировку операций ввода/ вывода по всему кластеру. Зачастую это будет вызвано неким диском, который переполнен большим числом ошибок чтения, однако всё ещё недостаточным для того, чтобы этот диск отказал полностью. Обычно некий диск будет всего лишь повторно выделять (reallocate) секторы при записи в некий плохой сектор. Наблюдение за статистиками S.M.A.R.T. со всех дисков обычно укажет на такое условие как описано только что и позволит вам предпринять действие.
Порой некий OSD может показывать очень плохую производительность без всяких заметных причин. Если нет
ничего очевидного, выявляемого вашими инструментами наблюдения, проверьте ceph.log
и подробный вывод работоспособности вашего Ceph. Вы также можете выполнить
osd perf Ceph, который выдаст перечень всех задержек фиксаций и применений
для каждого вашего OSD и также может помочь вам выявить некий проблемный OSD.
Если существует некий общий шаблон OSD, которые проявляют себя медленными в запросах, тогда есть хорошая
вероятность что именно упомянутые OSD вызывают данные проблемы. Имеется вероятность того, что перезапуск данного
OSD в состоянии разрешить данную трудность; если же данный OSD всё ещё останется проблемным, следует предложить
пометить его как out а затем заменить этот OSD.
Если ваш кластер Ceph заполнит 95% всех OSD, он прекратит принимать операции ввода/ вывода. Единственный способ
восстановления в такой ситуации состоит в удалении некоторых данных для снижения загруженности каждого OSD. Если некий
OSD не запустится или у вас нет возможности удалить данные, вы можете отрегулировать значение порога заполнения в
переменной mon_osd_full_ratio. Надеемся, это поможет вам приобрести достаточно
времени для удаления части данных и приведение кластера в состояние используемого.
Некая PG в состоянии down не будет обслуживать никакие операции
клиента и все содержащиеся в этой группе размещений будут недоступными. Это вызовет замедление построения
запросов по всему кластеру, так как клиенты пытаются получить доступ к этим объектам. Наиболее
распространённой причиной, по которой некая PG находится в состоянии down
происходит когда отключён ряд OSD, что означает, что нет имеющих силу копий данных PG на каких либо активных
OSD. Однако, чтобы определить почему некая PG находится в состоянии down
вы можете выполнить такую команду:
ceph pg x.y query
Она предоставит достаточно большое количество вывода; та секция, которая представляет для нас интерес
отображает состояние однорангового обмена. Приводимый здесь пример был взят из группы размещения, чей пул
был установлен в значение 1 для min_size и имел записанные в него
данные в то время как только OSD 0 находился в up и рабочем
состояниях. Затем OSD был остановлен, а OSD 1 и 2 были запущены.
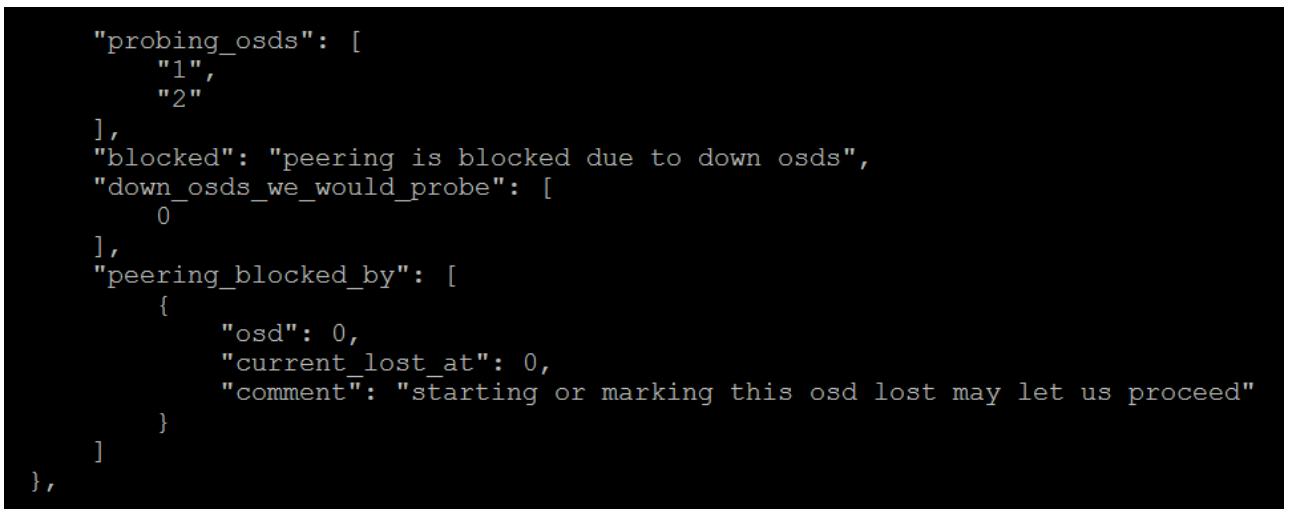
Мы можем увидеть, что был блокирован весь процесс однорангового обмена, так как Ceph знает что данная PG
имеет более новые данные, записанные в OSD 0. Он опросил OSD 1 и 2 на предмет этих данных, что означает что он
не обнаружил ничего из того что ему требовалось. Он бы хотел попробовать и опросить OSD 0, что однако не возможно,
поскольку этот OSD down, следовательно то сообщение, которое начинается с
этого osd или помечает его позволит нам продолжить.
Мониторы Ceph применяют leveldb для хранения всех требующихся
монитору данных для вашего кластера. Они содержат такие вещи как карту монитора, карту OSD и карту PG, которые
OSD и клиенты получают из этих мониторов чтобы иметь возможность определять местоположение объектов во всём
кластере RADOS. Одно особенное свойство, о котором должны быть осведомлены все состоит в том, что в тот период,
когда работоспособность всего кластера не равна HEALTH_OK, все мониторы
не отвергают никакие имеющиеся более старые карты кластера из своих баз данных. Если данный кластер находится в
деградированном состоянии на протяжении достаточно длительного периода времени и/ или данный кластер имеет
достаточно большое число OSD, данная база данных монитора может вырасти очень значительно.
При нормальных условиях работы все мониторы имеют очень малый вес в отношении потребления ресурсов; благодаря этому достаточно распространено применять диски меньшего размера для всех мониторов. При той ситуации, когда деградированное состояние происходит продолжительное время, может статься для того диска, который размещает базу данных монитора, что он заполнится, что, если это произойдёт со всеми узлами мониторов, приведёт к падению всего кластера.
Чтобы уберечься от такого поведения, может оказаться разумным развернуть ваши узлы монитора с использованием
LVM с тем, чтобы при возникновения потребности в расширении данных дисков это можно было бы сделать более простым
способом. Когда вы попадаете в данную ситуацию, добавление дискового пространства является единственным решением
пока вы не получите весь остаток своего кластера в состояние HEALTH_OK.
Если ваш кластер находится в состоянии HEALTH_OK, однако база данных
монитора всё ещё велика, вы можете уменьшить её выполнив следующую команду:
sudo ceph tell mon.{id} compact
Однако, это работает только в случае когда ваш кластер находится в состоянии HEALTH_OK;
данный кластер не сможет отбросить старые карты кластера, которые могут быть плотно упакованы, пока он не
находится в состоянии HEALTH_OK.
В этой главе мы изучили как обрабатывать те проблемы, с которыми Ceph не в состоянии справиться самостоятельно. Теперь вы понимаете все необходимые этапы поиска неисправностей при возникновении различных проблем которые, если их оставить нерешёнными, могут вырасти в ещё большие проблемы. Более того, вы также имеете хорошие идеи о том что является ключевыми областями для поиска в ситуации, когда ваш кластер Ceph не работает так как ожидалось. Вы должны получить уверенность, что вы теперь в намного лучшем положении для обработки относящихся к Ceph проблем как только они появятся.
В нашей следующей главе мы продолжим рассматривать процесс устранения неполадок и исследуем ситуации когда уже произошла утрата данных.
-
Какая команда служит для восстановления несогласованных PG?
-
Какую команду вы можете применить для изменения на лету уровня регистрации?
-
Почему со временем могут вырастать до очень больших размеров базы данных монитора?
-
Какой командой можно опрашивать PG?
-
Почему очистка может оказывать воздействие на производительность кластера Ceph?