Глава 12. Восстановление после сбоев
Содержание
- Глава 12. Восстановление после сбоев
- Что из себя представляет катастрофа?
- Как избежать потери данных
- Что может повлечь вывод из строя или утрату данных?
- Зеркалирование RBD
- Восстановление RBD
- RGW со множеством площадок
- Восстановление CephFS
- Утраченные объекты и неактивные PG
- Восстановление при полном отказе монитора
- Применение инструмента object-store Ceph
- Внесение утверждений
- Выводы
- Вопросы
В предыдущей главе вы изучили как осуществлять поиск неисправностей для основных проблем Ceph, которые, хотя и могут оказывать воздействие на саму работу данного кластера, скорее всего не будут причиной его полного выхода из строя или потери данных. Данная глава рассмотрит более серьёзные ситуации, когда весь кластер Ceph упал или не отвечает. Она также обсудит различные подходы к к восстановлению в случае утраты данных. Следует понимать, что эти методы имеют ещё большие возможности утраты данных сами по себе и их необходимо применять только в случае крайне меры. Если у вас имеется контакт поддержки вашего поставщика Ceph или вы имете взаимоотношения с Red Hat, настоятельно рекомендуем вначале проконсультироваться с ними прежде чем выполнять некие приёмы восстановления перечисленные в данной главе.
В данной главе мы изучим следующее:
-
Как избежать утраты данных
-
Как применять зеркалирование RBD для предоставления высокой доступности блочного хранилища
-
Как исследовать декларации
-
Как перестроить монитор баз данных из OSD
-
Как выделять PG из мёртвого OSD
-
Как проводить восстановление из потерянных объектов или неактивных PG
-
Как проводить восстановление отказавшей файловой системы CephFS
-
Как перестроить RBD из умершего OSD
Чтобы быть способным восстанавливаться в случае чрезвычайной ситуации, вы для начала должны понимать и распознавать её саму. Для целей данной главы мы будем работать в предположении, что нечто, что приводит к устойчивому периоду простоя классифицируется как катастрофа. Это не будет охватывать те сценарии, в которых произошёл некий сбой, над восстановлением которого активно работает Ceph, или когда предполагается, что данное воздействие, скорее всего, будет кратковременным. Другой тип бедствий - это тот, который приводит к постоянной утрате данных если только не станет возможным восстановление такого кластера Ceph. Потеря данных, вероятно, наиболее серьёзная проблема, так как данные могут быть незаменимыми или могут нанести серьёзный ущерб делам в будущем.
Прежде чем начать обсуждать некие методики восстановления, важно рассмотреть некие моменты, обсуждавшиеся в Главе 1, Планирование Ceph. Восстановление после чрезвычайной ситуации следует рассматривать как самый крайний вариант; руководства по восстановлению в данной главе не должно рассматриваться как замена для приводимого далее наилучшего практического опыта.
Прежде всего, убедитесь что вы работали с резервным копированием своих данных и проверяли его; при возникновении ситуации полного выхода из строя вы будете ощущать себя в миллион раз спокойнее, если вы знаете, что в самых плохих ситуациях вы сможете упасть до резервных копий. Хотя некий полный выход из строя может вызвать затруднение для ваших пользователей и потребителей, информирование их о том, что их данные, которые они передоверили вам, теперь потеряны - это намного хуже. Кроме того, просто потому что у вас имеется резервная копия на месте, не доверяйте ей вслепую. Проверка операций восстановления на постоянной основе будет означать, что вы будете в состоянии полагаться на неё когда это понадобится.
Убедитесь что вы следуете некоторым основным принципам, также упоминавшимся в
Главе 1, Планирование Ceph. Не применяйте опции настроек
подобные nobarrier и строго рассматривайте тот уровень репликаций,
который вы применяете в Ceph для защиты своих данных. Ваши шансы на потерю данных сильно увязаны с тем уровнем
избыточности, который вы настроили в Ceph, поэтому здесь предлагается тщательное планирование.
Основная часть выхода из строя и случаев утраты данных будет напрямую вызвана потерей некоторого числа OSD, которые превысили имеющийся уровень репликаций в некий короткий промежуток времени. Если эти OSD не возвращаются обратно в рабочее состояние, будь то из- за программного или аппаратного сбоя и Ceph не в состоянии восстановить объекты в промежутках между отказами OSD, тогда эти объекты теперь утрачены.
Если некий OSD отказал из- за неработающего диска, тогда маловероятно что восстановление будет возможным, только если не будет применена дорогостоящая служба восстановления, кроме того, нет никакой гарантии, что какие- либо восстановленные данные будут в согласованном состоянии. Данная глава не рассматривает восстановление физического диска после отказа и мы будем просто предполагать, что должен применяться имеющийся по умолчанию 3 уровня репликаций для защиты против множественных отказов дисков.
Если некий OSD отказал из- за некоторой ошибки программного обеспечения, результат, возможно, более положительный, однако данный процесс сложный и занимающий продолжительное время. Обычно если некий OSD, не смотря на то, что его физический диск находится в хорошем состоянии, не способен запускаться, тогда это, как правило, связано либо с программной ошибкой, либо некоторым видом разрушения. Некая программная ошибка может быть вызвана необработанной исключительной ситуацией, которая оставляет данный OSD в состоянии, из которого он не может восстановиться. Разрушение может произойти после неожиданной потери электропитания, когда данное оборудование и программное обеспечение не настроены надлежащим образом для поддержания согласованности данных. В обоих случаях извне данный OSD сам по себе, скорее всего, будет как терминальный и, если данный кластер управляет восстановлением потерянных OSD, лучше всего просто удалить этот OSD и ввести повторно как некий пустой диск.
Если общее число отключённых OSD означает что все копии некоторого объекта отключены, тогда процедура восстановления должна попытаться и выделить данные объекты из таких отказавших OSD, а затем вставить их обратно в данный кластер.
Как уже отмечалось ранее, работа с резервными копиями является некоторой ключевой стратегией гарантии что некий отказ не приведёт в конечном итоге к полной потере данных. Начиная с версии Jewel, Ceph ввёл зеркалирование RBD, которое делает возможным вам асинхронно поддерживать зеркало с одного кластера на другой. Обратите внимание на разницу между естественными репликациями Ceph, которые синхронны, и зеркалированием RBD. При синхронных репликациях низкая латентность между узлами однораговой сети существенна, а асинхронная репликация делает возможной двум определённым кластерам Ceph находиться географически раздельно, так как задержка больше не играет роли.
При наличии некоторой реплицированной копии ваших образов RBD в некотором отдельном кластере вы можете впечатляюще снизить как RTO (Recovery Time Objective, Целевое время восстановления), так и RPO (Recovery Point Objective, Директивный срок восстановления). RTO является показателем того, сколько времени пройдёт с момента начала восстановления до того момента, когда данный станут доступными. RPO это наихудший вариант измерения времени между каждой точкой данных и описывает ожидаемую потерю данных. Ежедневное резервное копирование имело бы некий RPO в 24 часа; например, потенциально любые данные, записанные до 24 часов с момента последнего резервного копирования будут потеряны если вам придётся их восстанавливать из резервной копии.
При зеркалировании RBD данные асинхронно реплицируются на свой целевой RBD и, таким образом, в большинстве случаев RPO должен быть в пределах минуты. Поскольку целевой RBD также является репликой, а не резервной копией, которая потребует вначале восстановления, значение RTO также вероятно будет чрезвычайно низким. Кроме того, поскольку целевой RBD хранится в некотором отдельном кластере Ceph, он предоставляет дополнительную защиту для моментальных снимков, что также может оказывать влияне и в случае если данный кластер Ceph сам по себе испытывает проблемы. На первый взгляд это делает зеркалирование RBD очень полезным инструментом для защиты от потери данных, и в большинстве случаев оно является очень полезным инструментом. Зеркалирование RBD не является заменой для надлежащей процедуры резервного копирования, однако. В тех случаях, когда утрата данных связана с внешними по отношению к RBD действиями, такими как разрушение файловой системы, или ошибка пользователя, эти изменения будут реплицированы в имеющийся целевой RBD. Некая отдельная изолированная копия ваших данных жизненно необходима.
После всего сказанного, давайте взглянем ближе на то как работает зеркалирование RBD.
Одним из ключевых компонентов при зеркалировании RBD является сам журнал. Именно журнал зеркалирования RBD
сохраняет все записи в данный RBD и отправляет подтверждения клиенту когда они совершены. Эти записи затем
переписываются в свой первичный образ RBD. Такой журнал сам по себе хранится как объекты RADOS, аналогично
предваряя то, чем являются образы RBD. Отдельно, удалённый демон rbd-mirror
опрашивает настроенные зеркала RBD и вытаскивает самые новые записанные в журнал объекты на весь свой целевой кластер и
воспроизводит их в своём целевом RBD.
Демон rbd-mirror отвечает за воспроизведение всего содержимого
имеющегося журнала в некий целевой RBD в другом кластере Ceph. На данном целевом кластере должен исполняться только
один демон rbd-mirror, только если вы не выполняете репликацию в обе стороны,
в таком случае потребуется исполнение в обоих кластерах.
Чтобы воспользоваться функциональностью зеркалирования RBD, нам потребуются два кластера Ceph. Мы можем развернуть два идентичных кластера, которые мы использовали ранее, однако общее число вовлечённых ВМ может превысить возможности того, что может исполнить человеческая персональная машина. Таким образом, мы изменим наши файлы настройки Vagrant и Ansible чтобы развернуть два отдельных кластера Ceph, причём каждый с одним монитором и неким узлом OSD.
Требующийся Vagrantfile очень похож на тот, что мы использовали в
Главе 2, Развёртывание Ceph в контейнерах для развёртывания вашего
первоначального тестового кластера; вся части хостов в верхней части должны теперь выглядеть так:
nodes = [
{ :hostname => 'ansible', :ip => '192.168.0.40', :box => 'xenial64' },
{ :hostname => 'site1-mon1', :ip => '192.168.0.41', :box => 'xenial64' },
{ :hostname => 'site2-mon1', :ip => '192.168.0.42', :box => 'xenial64' },
{ :hostname => 'site1-osd1', :ip => '192.168.0.51', :box => 'xenial64', :ram => 1024, :osd => 'yes' },
{ :hostname => 'site2-osd1', :ip => '192.168.0.52', :box => 'xenial64', :ram => 1024, :osd => 'yes' }
]
Для настройки Ansible мы будем сопровождать два отдельных экземпляра настройки Ansible с тем, чтобы каждый
кластер мог быть развёрнут отдельно. Затем мы будем сопровождать отдельные файлы хостов для экземпляров, которые
мы определим, когда мы исполним план (playbook). Для выполнения этого мы не будем копировать свои файлы
ceph-ansible в etc/ansible,
а придержим их в соответствующем домашнем каталоге.
Склонируйте git https://github.com/ceph/ceph-ansible.git.
git clone https://github.com/ceph/ceph-ansible.git
cp -a ceph-ansible ~/ceph-ansible2
Создайте точно такие же файлы с именами all и
Ceph в своём каталоге group_vars,
как мы это делали в Главе 2, Развёртывание Ceph. Это необходимо
сделать в обеих копиях ceph-ansible:
-
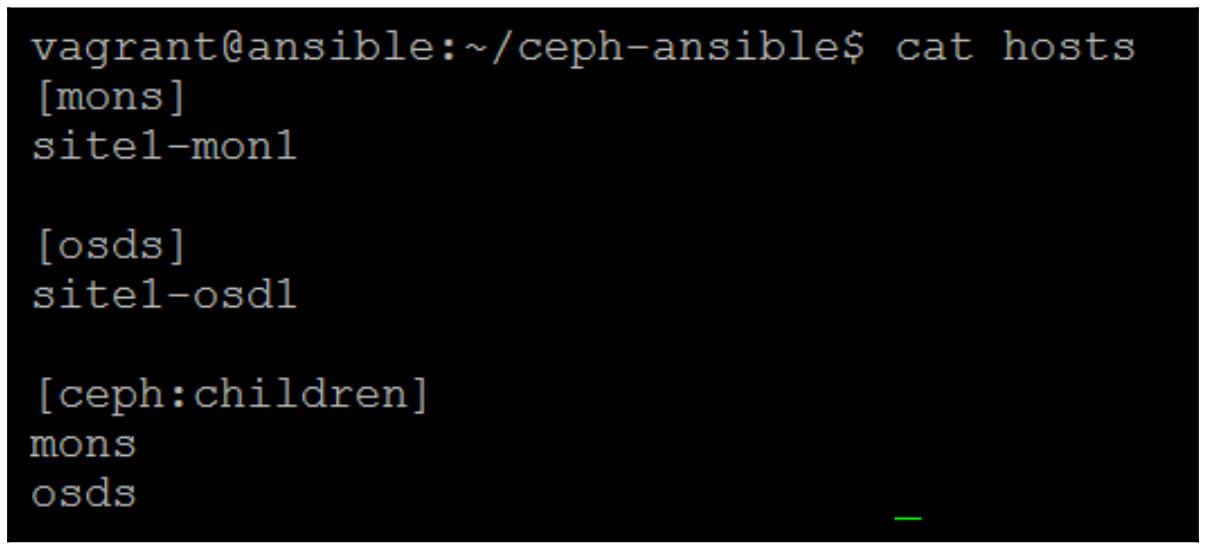
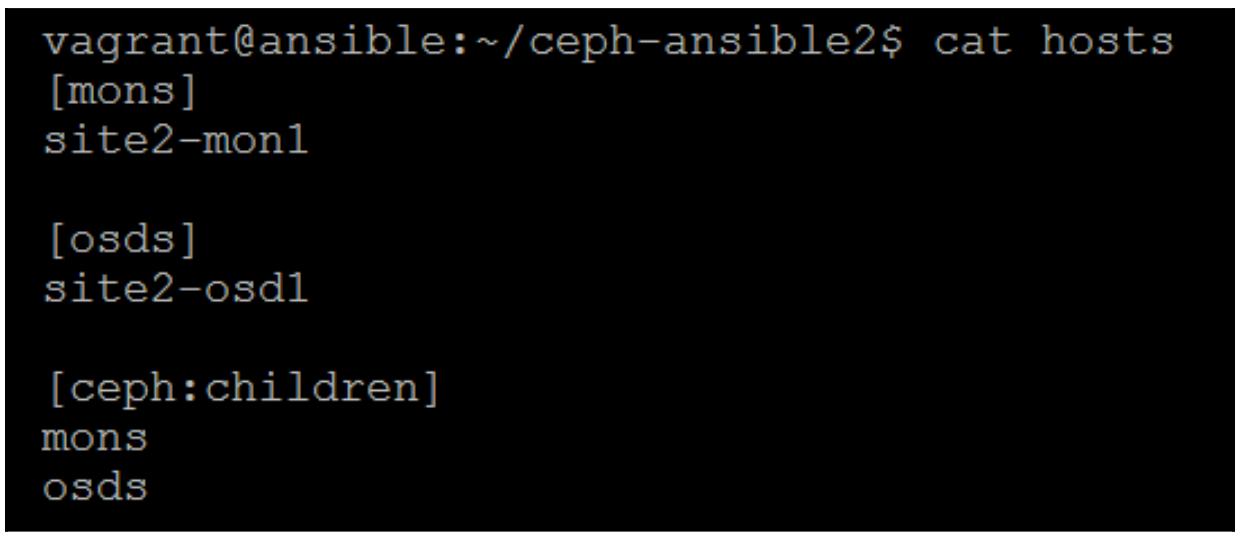
Создайте некие файлы хостов в каждом из каталогов Ansible и поместите два соответствующих хоста в каждый:
Приведённый выше снимок для первого хоста, а снимок внизу для второго необходимого хоста.
-
Затем выполните плейбук
site.ymlпод каждым экземпляромceph-ansible, чтобы развернуть наши два кластера Ceph:ansible-playbook -K -i hosts site.yml -
Прежде чем мы продолжим настройку зеркалирования данного RBD, нам необходимо установить имеющиеся уровни репликации имеющихся пулов по умолчанию в значение
1, так как наши кластеры имеют только по одному OSD. Исполните эти команды в обоих кластерах:
-
Теперь установите необходимый демон зеркалирования RBD в обоих имеющихся кластерах:
sudo apt-get install rbd-mirrorНиже приводится снимок экрана вывода предыдущей команды:
-
Чтобы демон
rbd-mirrorимел возможность взаимодействовать с обоими кластерами, нам необходимо скопироватьceph.confиkeyringиз обоих кластеров друг в друга:Копируем
ceph.confсsite1-mon1вsite2-mon1и называем егоremote.conf; -
Копируем
ceph.client.admin.keyringсsite1-mon1вsite2-mon1и называем егоremote.client.admin.keyring; -
Повторяем эти два шага, но в этот раз копируем с
site2-mon1вsite1-mon1; -
Не забываем убедиться, что кольцами ключей владеет
ceph:ceph:sudo chown ceph:ceph /etc/ceph/remote.client.admin.keyring -
Теперь нам необходимо сообщить Ceph что пул с названием
rbdдолжен иметь включённой функцию зеркалирования:sudo rbd --cluster ceph mirror pool enable rbd image -
Повторите это для нашего целевого кластера:
sudo rbd --cluster remote mirror pool enable rbd image -
Добавьте данный целевой кластер в качестве однораногового участника настройки зеркалирования пула:
sudo rbd --cluster ceph mirror pool peer add rbd client.admin@remote -
Выполните также такую же команду локально в своём втором кластере Ceph:
sudo rbd --cluster ceph mirror pool peer add rbd client.admin@remote -
Вернитесь обратно в свой первый кластер, давайте создадим некий тестовый RBD для его использования в нашей лаборатории зеркалирования:
sudo rbd create mirror_test --size=1G -
Включите необходимое свойство журналирования в данном образе RBD:
sudo rbd feature enable rbd/mirror_test journaling -
Наконец, включите зеркалирование для данного RBD:
sudo rbd mirror image enable rbd/mirror_test


Важно отметить, что зеркалирование RBD работает через систему извлечения (pull). Имеющийся демон
rbd-mirror необходим для исполнения на том кластере, на который вы
желаете зеркально отобразить свой RBD; он затем соединится со своим кластером источником и извлечёт все RBD.
Если вы намереваетесь реализовать двустороннюю репликацию при которой каждый кластер Ceph реплицируется друг
на друга, тогда вам необходимо исполнять такой демон rbd-mirror в
обоих кластерах. Имея это в виду, давайте разрешим и запустим имеющуюся службу systemd для
rbd-mirror на вашем целевом хосте:
udo systemctl enable ceph-rbd-mirror@admin
sudo systemctl start ceph-rbd-mirror@admin
Данный демон rbd-mirror теперь начнёт обрабатывать все имеющиеся
образы RBD настроенные на зеркалирование в вашем первичном кластере.
Мы можем убедиться, что всё работает как и ожидалось, исполнив в целевом кластере следующую команду:
sudo rbd --cluster remote mirror pool status rbd –verbose
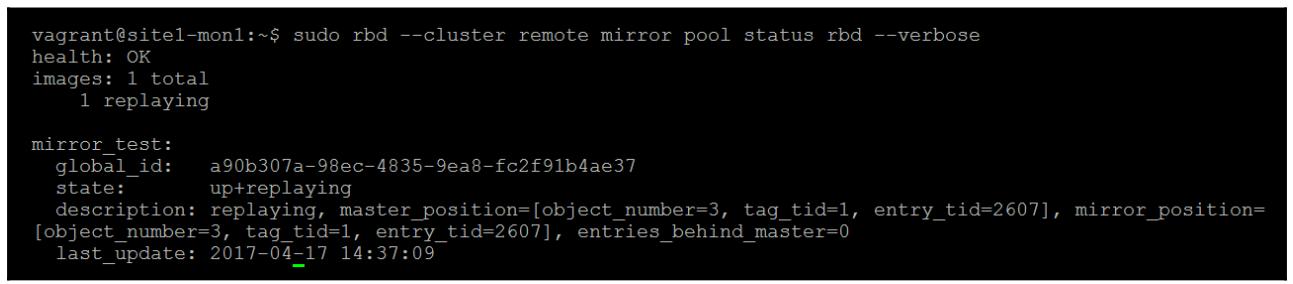
Из предыдущего снимка экрана мы можем увидеть, что наш RBD mirror_test
находится в состоянии up+replaying, это означает, что зеркалирование
работает и мы можем видеть через entries_behind_master что он
в настоящее время новейший.
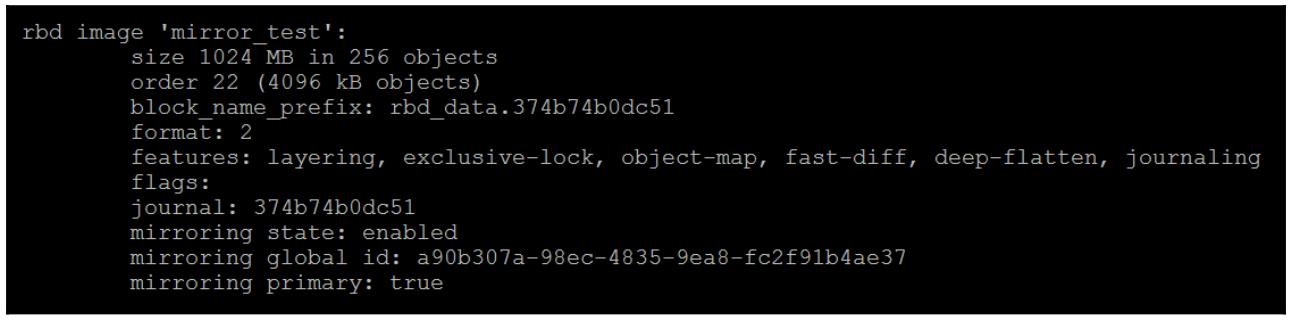
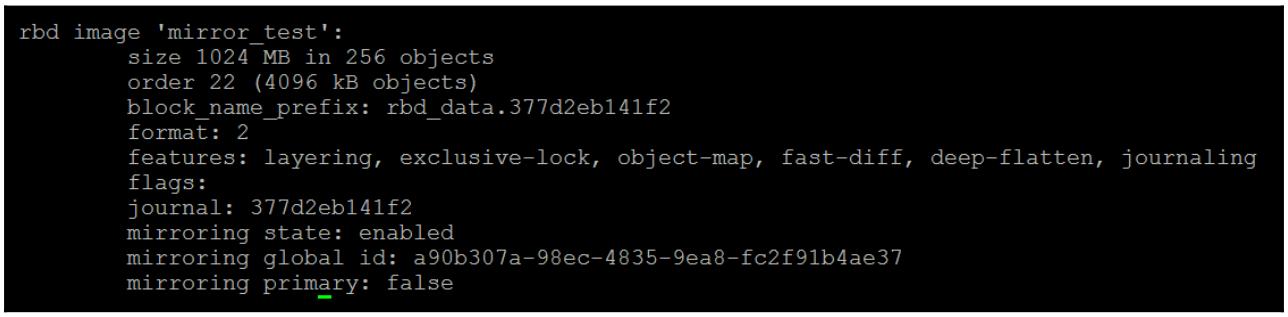
Также отметим разницу в имеющемся выводе команд info нашего RBD
в каждом из кластеров. В кластере источнике состояние первичного истинно, что позволяет нам определить у какого
кластера его RBD имеет состояние хозяина (master) и он может использоваться клиентами. Это также
подтверждает, что хотя мы только создали данный RBD в своём первичном кластере, он был реплицирован во
второй.
Наш кластер источник показан здесь:
А вот и целевой кластер:
Прежде чем мы отработаем отказ своего RBD на имеющийся у нас второй кластер, давайте установим его
соответствие, создадим некую файловую систему и поместим в него какой- нибудь файл, таким образом мы
сможем подтвердить, что наше зеркалирование работает правильно. Так как в ядре Linux 4.11 имеющийся
драйвер ядра RBD не поддерживает необходимую для зеркалирования RBD функцию журналирования имеющегося
RBD, это означает, что вы не можете поставить в соответствие (map) данный RBD воспользовавшись имеющимся
клиентом RBD ядра. Раз так, нам необходимо воспользоваться утилитой rbd-nbd,
которая применяет драйвер librbd в комбинации с устройствами Linux
nbd чтобы поставить в соответствие RBD через пространство пользователя.
Хотя имеется множество вещей, которые могут заставить Ceph испытывать низкую производительность, вот один из
самых вероятных вариантов:
sudo rbd-nbd map mirror_test

sudo mkfs.ext4 /dev/nbd0
sudo mount /dev/nbd0 /mnt
echo This is a test | sudo tee /mnt/test.txt
sudo umount /mnt
sudo rbd-nbd unmap /dev/nbd0
Now lets demote the RBD on the primary cluster and promote it on the
secondary
sudo rbd --cluster ceph mirror image demote rbd/mirror_test
sudo rbd --cluster remote mirror image promote rbd/mirror_test
Теперь поставим в соответствие и смонтируем свой RBD в нашем втором кластере, и мы должны иметь возможность прочитать свой проверочный текстовый файл, который вы создали в своём первичном кластере:
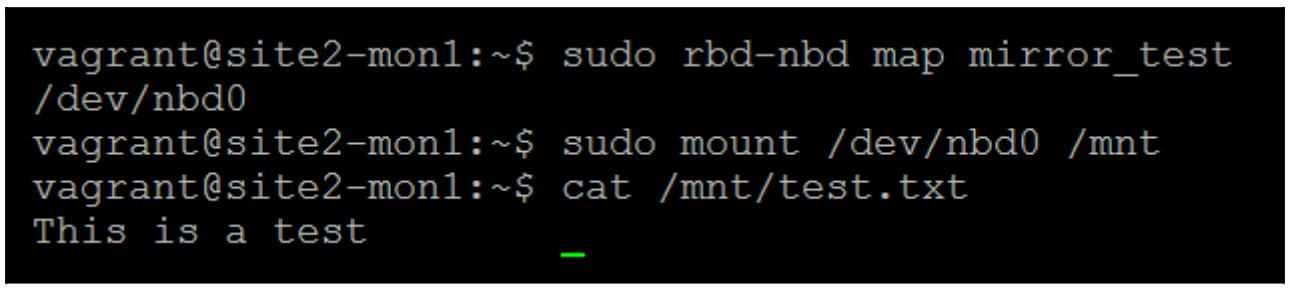
Мы можем отчётливо видеть, что данный RBD был успешно зеркалирован в наш второй кластер и всё содержимое файловой системы в точности такое же как мы оставили её в своём первичном кластере.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Если вы попытаетесь и сделаете соответствие, а потом смонтируете свой RBD в тот кластер, где данный RBD не находится в своём первичном состоянии, все операции будут просто повисшими, так как Ceph не позволит операции ввода/ вывода в некий образ RBD в состоянии не хозяин (non-master). |
При возникновении события, когда ряд OSD отказал, а вы не способны восстановить их с применением инструмента
ceph-object-store, ваш кластер скорее всего будет в состоянии при котором
большая часть, если не все, образов RBD являются недоступными. Однако всё ещё имеется вероятность что у вас
будет возможность восстановить данные RBD с имеющихся в вашем кластере Ceph дисков. Существуют инструменты,
которые могут осуществлять поиск по всей структуре данных OSD, выявлять файлы объектов, относящиеся к RBD, а
затем собирать эти объекты обратно в некий образ диска, похожий на имевшийся первоначальный образ RBD.
В данном разделе мы сосредоточимся на инструменте Леннара Бэйдера (Lennart Bader) для восстановления некоторого тестового образа RBD из своего проверочного кластера. Данный инструмент позволяет восстанавливать образы RBD из имеющегося содержимого OSD Ceph без какого либо требования чтобы этот OSD был в рабочем и используемом состоянии. Следует отметить, что если данный OSD был разрушен вследствие разрушения лежащей в его основе файловой системы, имеющееся содержимое данного образа RBD может всё ещё быть разрушенным. Данный инструмент восстановления можно найти по адресу в следующем репозитории github: https://gitlab.lbader.de/kryptur/ceph-recovery.
Прежде чем мы приступим, убедитесь что у вас имеется небольшой тестовый RBD с действующей файловой системой, созданной в вашем кластере Ceph. Из- за того размера дисков в тестовой среде, которую мы создали в Главе 2, Развёртывание Ceph в контейнерах, рекомендуется чтобы ваш RBD был размеров всего в один гигабайт.
Мы выполним данное восстановление с одного из имеющихся узлов монитора, однако на практике данная процедура может быть выполнена с любого узла, который имеет доступ к необходимым дискам OSD Ceph. Для доступа к данным дискам мы должны быть уверены, что наш сервер восстановления имеет достаточное пространство для восстанавливаемых данных.
В данном примере мы смонтируем необходимое содержимое удалённого OSD через sshfs,
который позволит вам удалённо монтировать каталоги через ssh. Однако
в реальной жизни ничто не останавливает вас от физического монтирования дисков в другой сервер или какого- либо
другого метода, если он потребуется. Данному инструменту всего лишь необходимо видеть все каталоги данных этого
OSD:
-
Вначале нам необходимо клонировать данный инструмент восстановления Ceph из его репозитория Git:
git clone https://gitlab.lbader.de/kryptur/ceph-recoveryСледующий рисунок отображает вывод предыдущей команды:
-
Кроме того, убедитесь что у вас установлен
sshfs:sudo apt-get install sshfsСледующий снимок экрана отображает вывод предыдущей команды:
-
Переместитесь в каталог только что клонированного инструмента и создайте необходимые пустые каталоги для каждого из имеющихся OSD:
cd ceph-recovery sudo mkdir osds sudo mkdir osds/ceph-0 sudo mkdir osds/ceph-1 sudo mkdir osds/ceph-2

Для файлового хранилища мы можем просто смонтировать все удалённые OSD в те каталоги, которые мы только что создали. Отметим, что вам необходимо убедится, что ваши каталоги OSD соответствуют вашему реальному тестовому кластеру:
sudo sshfs vagrant@osd1:/var/lib/ceph/osd/ceph-0 osds/ceph-0
sudo sshfs vagrant@osd2:/var/lib/ceph/osd/ceph-2 osds/ceph-2
sudo sshfs vagrant@osd3:/var/lib/ceph/osd/ceph-1 osds/ceph-1
Так как BlueStore не хранит свои объекты в некой естественной файловой системе Linux, мы не сможем просто смонтировать
его файловые системы. Тем не менее, инструмент ceph-object-store позволяет вам
монтировать содержимое его OSD BlueStore как некую файловую систему fuse.
В каждом узле OSD создайте в папке /mnt некий каталог для монтирования всех
OSD в данном узле:
mkdir /mnt/osd-0
Теперь в таком новом каталоге смонтируйте соответствующий OSD BlueStore:
ceph-objectstore-tool --op fuse --data-path /var/lib/ceph/osd/ceph-0 --mountpoint /mnt/osd-0
Следующий снимок экрана отображает вывод предыдущей команды:
Наш OSD BlueStore теперь смонтирован как некая файловая система fuse в
соответствующем каталоге /mnt/osd-0. Тем не менее, он остаётся смонтированным
только пока исполняется наша команда ceph-object-store. Следовательно если вы желаете
смонтировать множество OSD или вручную просматривать имеющееся дерево каталога, откройте дополнительные сеансы SSH
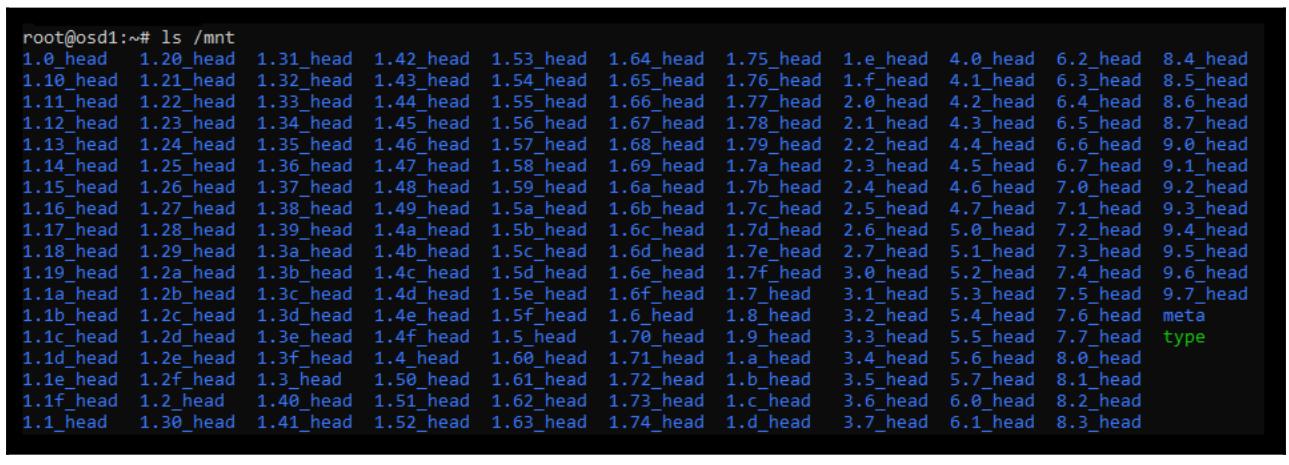
для соответствующего узла Ceph. Ниже приводится снимок экрана, отображающий содержимое каталога
/mnt/osd-0 из нового сеанса SSH:
Когда вы завершите со своими OSD, просто в текущем сеансе SSH, исполняющем команду
ceph-objectstore-tool , для размонтирования
воспользуйтесь Ctrl + C.
Теперь мы можем монтировать свои fuse- монтируемые OSD для своего сервера управления также как мы это делали для своего файлового хранилища:
sudo sshfs vagrant@osd1:/mnt/osd-0 osds/ceph-0
sudo sshfs vagrant@osd2:/mnt/osd-1 osds/ceph-1
sudo sshfs vagrant@osd3:/mnt/osd-2 osds/ceph-2
Теперь мы можем применить имеющийся инструмент для сканирования всех каталогов и скомпилировать некий список
обнаруженных RBD, которые являются недоступными. Единственный параметр, который необходим данной команде, это то
местоположение, в котором смонтированы все рассматриваемые OSD. В данном случае они находятся в каталоге
osds. Все результаты будут перечислены в каталоге нашей ВМ:
sudo ./collect_files.sh osds
Следующий снимок экрана отображает вывод предыдущей команды:
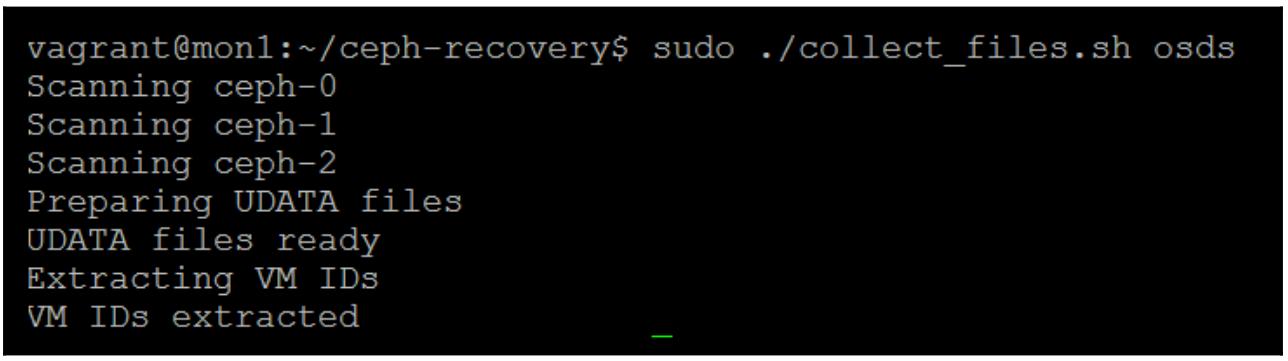
Если мы заглянем вовнутрь своего каталога ВМ, мы сможем обнаружить, что наш инструмент нашёл тестовый образ RBD. Теперь, когда мы локализовали этот образ, следующий шаг состоит в сборке различных расположенных в этих OSD объектов. Тремя параметрами для данной команды являются название того RBD, который был обнаружен на предыдущем этапе, общий размер этого образа и определение назначения для самого файла восстанавливаемого образа. Размер данного образа определяется в байтах и важно что он должен быть по крайней мере настолько же большим, как и сам первоначальный образ; он может быть больше, однако данный RBD не будет восстановлен, если данный размер меньше.
sudo ./assemble.sh vms/test.id 1073741824
Следующий снимок экрана отображает вывод предыдущей команды:
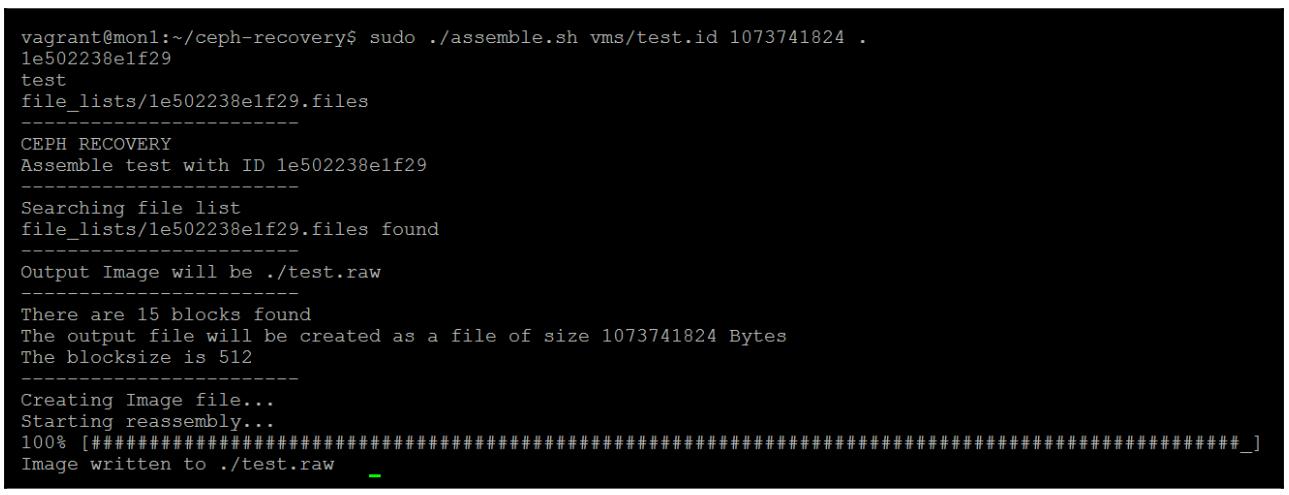
Данный RBD теперь будет восстановлен из смонтированного содержимого OSD в определённый нами файл образа. В зависимости от размера данного образа, это может потребовать некоторого времени и ползунок исполнения будет отображать его состояние.
Наш сценарий сборки RBD не будет работать с OSD BlueStore, так как BlueStore хранит свои объекты RBD в соответствии со слегка иным соглашением об именовании. Нам поможет с восстановлением RBD некий обновлённый сценарий предоставляемый на следующих этапах.
Выгрузите надлежащий сценарий для содействия в восстановлении RBD с OSD BlueStore:
wget https://raw.githubusercontent.com/fiskn/assemble_bluestore_rbd/master/assemble_bluestore.sh
chmod +x ./assemble_bluestore.sh
Выполните этот сценарий восстановления с параметрами дерева, где первым идёт хэш имя соответствующего образа RBD, вторым является размер RBD в байтах, а третьим название файла вывода.
Ниже приводим образец для некого проверочного RBD с 10 ГБ:
./assemble_bluestore.sh 7d8ad6b8b4567 1073741824 text.img
Следующий снимок экрана отображает вывод предыдущей команды:

Теперь необходимый образ RBD должен быть восстановлен.
После завершения мы можем исполнить вызов файловой системы fsck
для данного образа, чтобы убедиться что он был восстановлен корректно. В данном случае наш RBD был
отформатирован с помощью ext4, поэтому нам придётся воспользоваться
для проверки данного образа инструментом e2fsck:
sudo e2fsck test.raw
Следующий снимок экрана отображает вывод предыдущей команды:

Замечательно, данный файл образа чистый, что означает, что теперь имеется очень высокая вероятность, что все наши данные были успешно восстановлены.
Теперь мы можем окончательно смонтировать данный образ в виде некоторого закольцованного устройства для доступа к его данным. Если данная команда не вернёт никакого вывода, это означает что мы успешно смонтировали его:
sudo mount -o loop test.raw /mnt
Теперь вы можете видеть что данный образ успешно смонтирован в качестве закольцованного устройства:
Ceph также поддерживает возможность исполнения двух или более Зон шлюза RADOS (RADOS Gateway Zones) для предоставления высокой доступности совместимых с S3 хранилищ, что означает достаточно низкую вероятность того что какой- то аппаратный или программный сбой сможет полностью отключить данную службу. При использовании RGW со множеством площадок важно отметить, что данные становятся согласованными в конечном счёте, по прошествию какого- то времени, поэтому нет гарантии того что данные будут пребывать в одном и том же состоянии во всех зонах сразу после их записи.
Для получения дополнительных сведений относительно конфигураций RGW со множеством площадок проконсультируйтесь, пожалуйста, с официальной документацией Ceph.
В отличии от RBD, который просто объединяет объекты, CephFS требует согласованности данных в обоих пулах, и для данных, и для метаданных. Это также потребует некого жизнеспособного журнала CephFS; в случае когда любой из этих источников данных испытывает проблемы, CephFS отключится и не может быть восстановлен. Данный раздел нашей главы рассмотрит восстановление CephFS до активного состояния, а затем последующие шаги восстановления при том сценарии, когда разрушен или не состоятелен его пул метаданных.
Существует множество условий при которых CephFS может отключаться, но при этом не приводит к окончательной утрате данных№ зачастую это вызывается проходящими событиями в вашем кластере Ceph, но это не должно приводить к окончательной утрате данных, причём в большинстве случаев Ceph должен осуществлять автоматическое восстановление.
Поскольку CephFS располагается поверх RADOS, за исключением каких- то программных ошибок в CephFS, все прочие потери или повреждения данных должны происходить только в том случае, когда произошла некая утрата данных на самом уровне RADOS, скорее всего по причине множественных отказов OSD, приводящих к утрате некой PG.
Собственно утрата объектов или PG из имеющегося пула данных не приводит к отключению самой CephFS, но в результате может приводить к запросам на доступ, приводящим к файлам, возвращающим нули. Скорее всего это приведёт к тому что откажут приложения более высокого уровня в имеющемся стеке, а из- за частично хаотичной природы файлов или частей файлов, отображаемых в PG, такой результат может означать что данная файловая система CephFS в целом пригодна для применения. В таком случае лучше всего попытаться восстановить сами PG пула RADOS, как это будет показано далее в этой главе.
Утрата объектов или PG из пула метаданных переведёт файловую систему CephFS в автономный режим и не будет восстановлена без ручного вмешательства. Важно отметить, что фактическое содержимое данных не зависит от утраты метаданных, но хранящие эти данные объекты без метаданных были бы в значительной степени бессмысленными. В Ceph имеется ряд инструментов которые можно применять для восстановления и повторного построения метаданных, что может позволить нам выполнить восстановление после утраты метаданных. Однако, как уже несколько раз упоминалось в данной книге, профилактика лучше лечения, а потому эти инструменты не следует рассматривать как некий стандартный механизм восстановления, а следует применять исключительно в качестве крайней меры, когда не удалось восстановление резервных копий.
Для создания некого сценария, при котором файловая система CephFS имеет утраты или разрушения в своём пуле метаданных, мы просто удалим все объекты в этом пуле метаданных. Данный пример будет использовать ту файловую систему, которую мы развернули в Главе 5, Пулы RADOS и доступ клиента, но сама процедура должна быть идентичной для любой развёрнутой файловой системы CephFS.
Прежде всего, давайте переключимся на учётную запись root и смонтируем свою файловую систему CephFS:
sudo -i
mount -t ceph 192.168.0.41:/ /mnt/cephfs -o
name=admin,secret=AQC4Q85btsqTCRAAgzaNDpnLeo4q/c/q/0fEpw==
Поместим несколько файлов для проверки в этой файловой системе CephFS, которые мы позднее и попытаемся восстановить:
echo "doh" > /mnt/cephfs/doh
echo "ray" > /mnt/cephfs/ray
echo "me" > /mnt/cephfs/me
Теперь, когда у нас на своём месте проверочные файлы, давайте удалим все свои объекты в нашем пуле метаданных для имитации утраты этого пула метаданных:
rados purge cephfs_metadata --yes-i-really-really-mean-it
Следующий снимок экрана отображает вывод предыдущей команды:

Давайте перезапустим свой демон mds; тем самым мы включаем сбой:
systemctl restart ceph-mds@*
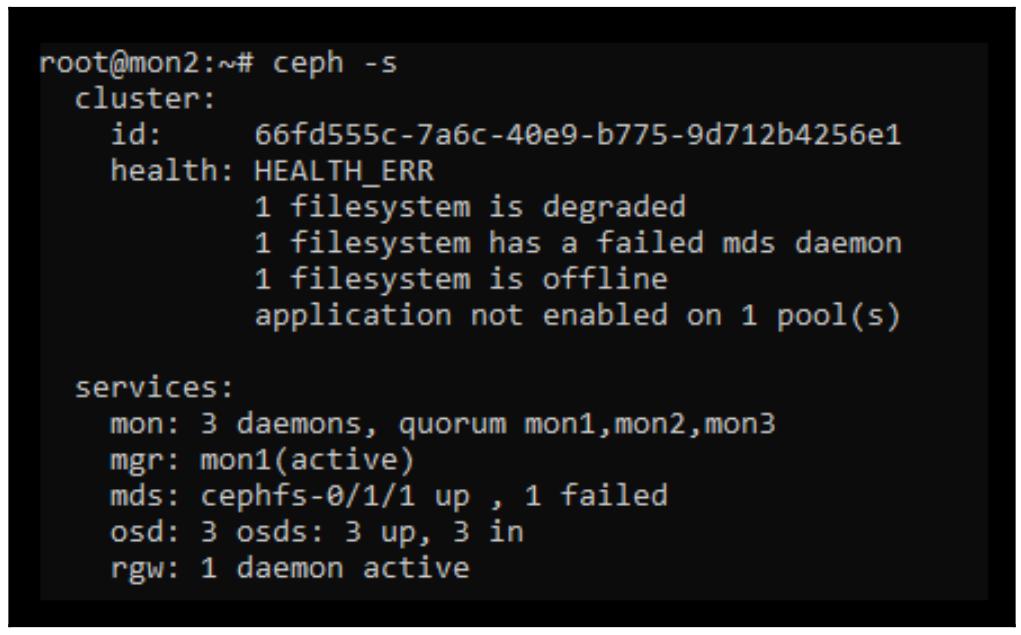
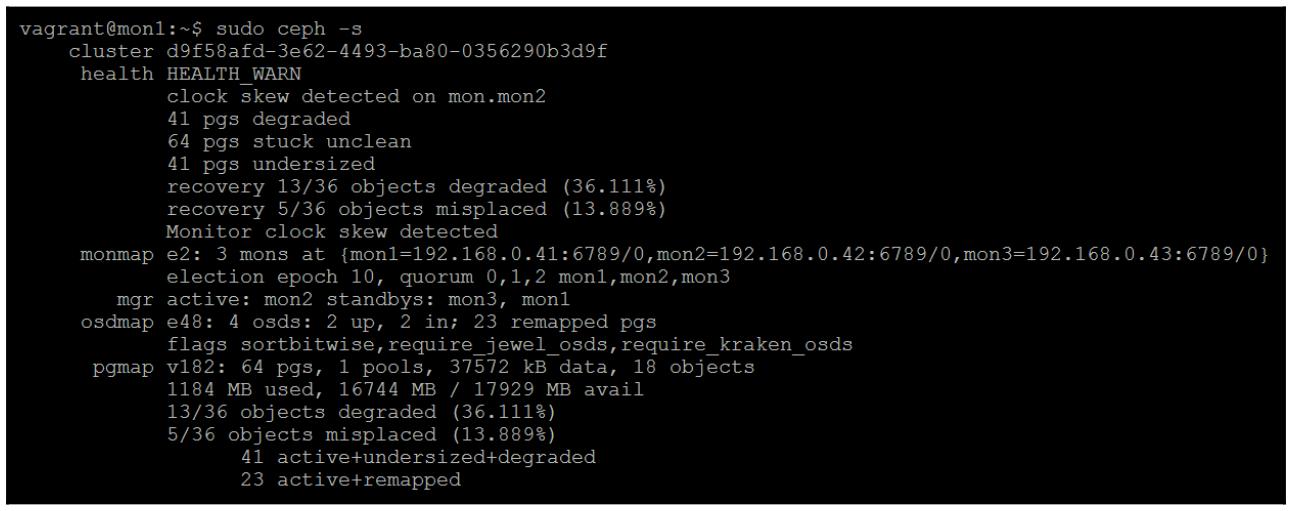
Если мы проверим состояние CephFS при помощи команды ceph -s, мы обнаружим
что mds имеет нарушение удаления метаданных и это приводит к отключению самой
файловой системы:
Для получения дополнительных сведений относительно разрушений мы можем вызвать приводимую ниже команду. Проверим журнал CephFS:
cephfs-journal-tool journal inspect
Следующий снимок экрана отображает вывод предыдущей команды:
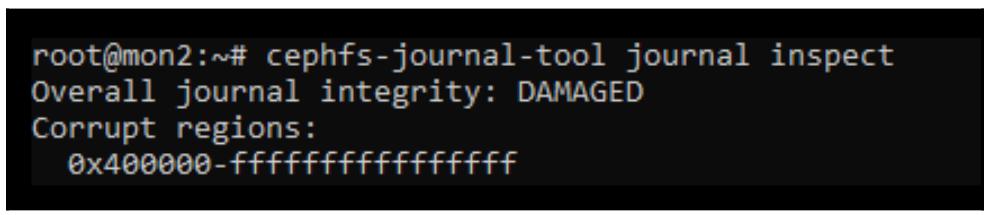
Да уж, как и ожидалось, это серьёзное повреждение.
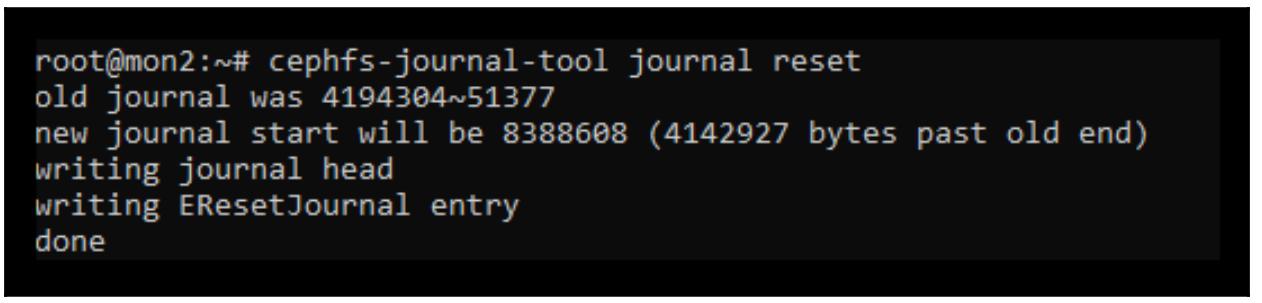
Обычно для сохранности предлагается экспортировать имеющийся журнал, чтобы минимизировать утрату данных, но в данном случае, как мы знаем, мы уже можем просто отбросить его сразу:
cephfs-journal-tool journal reset
Следующий снимок экрана отображает вывод предыдущей команды:
Наша следующая команда выполняет сброс состояния RADOS нашей файловой системы чтобы сделать возможным процесс восстановления для повторной сборки из некого согласованного состояния:
ceph fs reset cephfs --yes-i-really-mean-it
Затем сбрасываются все таблицы MDS чтобы позволить им выработаться с самого начала. Эти таблицы хранятся в виде объектов в нашем пуле метаданных. Приводимые ниже команды создадут новые объекты:
cephfs-table-tool all reset session
cephfs-table-tool all reset snap
cephfs-table-tool all reset inode
Следующий снимок экрана отображает вывод предыдущей команды:
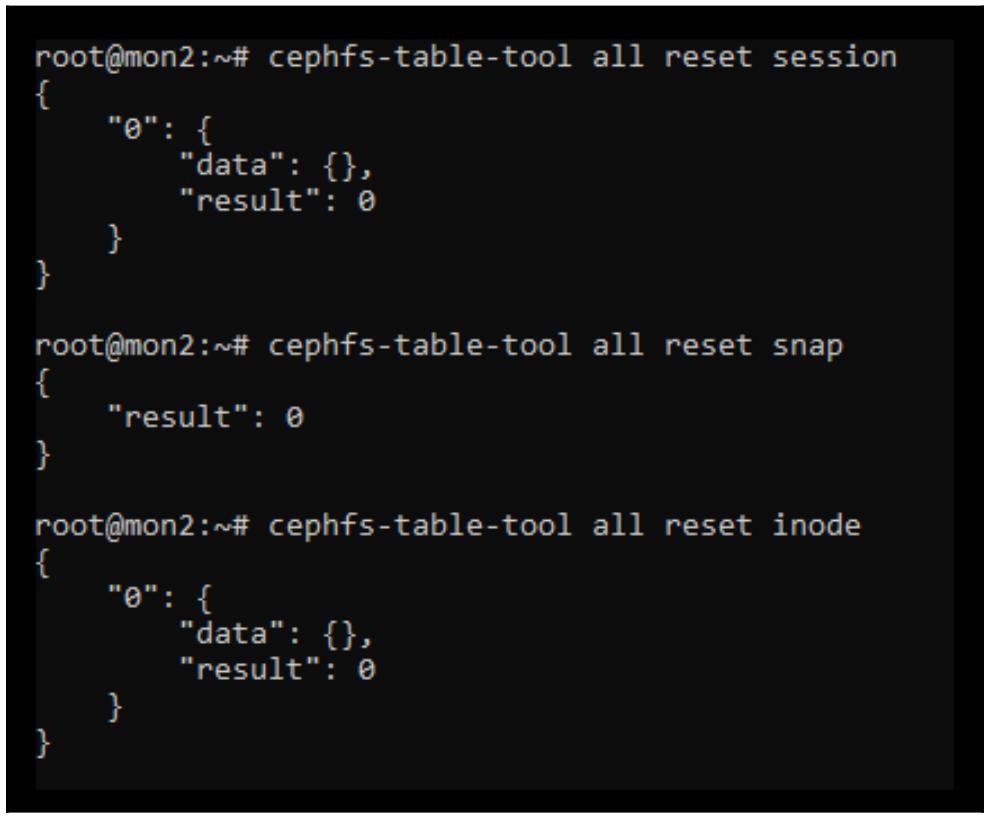
Сбросим имеющийся журнал CephFS:
cephfs-journal-tool --rank=0 journal reset
Наконец, создадим основные inode корня и выполним подготовку для обнаружения объектов:
cephfs-data-scan init
Теперь, когда было полностью сброшено текущее состояние CephFS, может быть предпринято сканирование для восстановления метаданных из доступных объектов данных. Это трёхэтапный процесс с применением приводимых ниже трёх команд. Первая команда просматривает предложенный пул данных, находит все экстенты, из которых составлен каждый файл и сохраняет их как временные данные. Также рассчитывается и сохраняется такая информация как время создания и размер файла. Далее второй этап просматривает полученные временные данные и перестраивает inode в самом пуле метаданных. Наконец, выполняется связывание inode:
cephfs-data-scan scan_extents cephfs_data
cephfs-data-scan scan_inodes cephfs_data
cephfs-data-scan scan_links
|
| Замечание |
|---|---|
|
Подобные команды сканирования inode и экстентов может занимать чрезвычайно продолжительное время в больших файловых системах. Данные операции могут выполняться параллельно для ускорения этого процесса; для получения дополнительных сведений ознакомьтесь с официальной документацией Ceph. |
После завершения данного процесса убедитесь что ваша файловая система CephFS теперь пребывает в жизнеспособном состоянии:
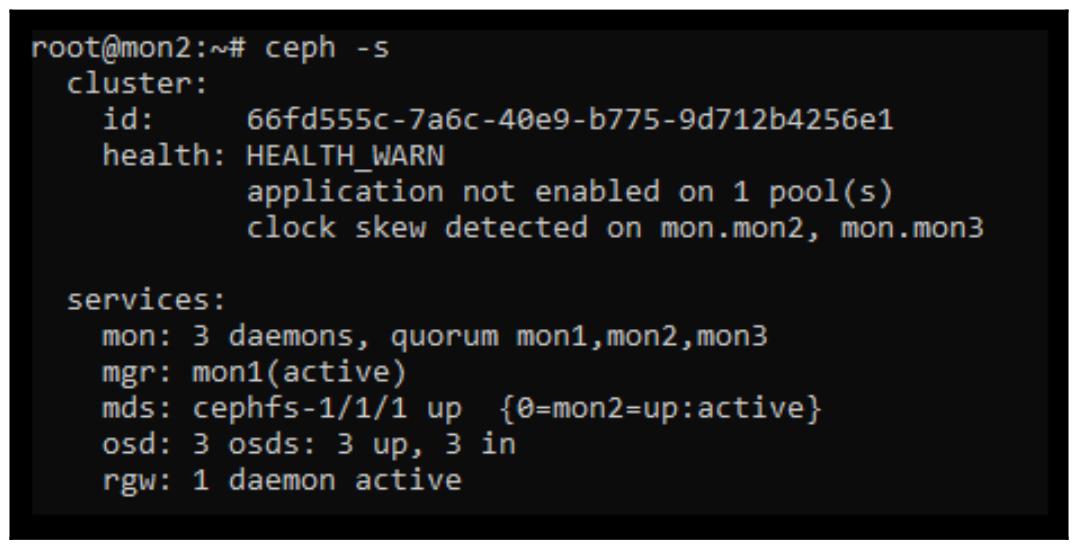
Теперь мы также имеем возможность пройтись по своей файловой системе начиная с той точки монтирования, в которй мы её смонтировали в самом начале данного раздела:
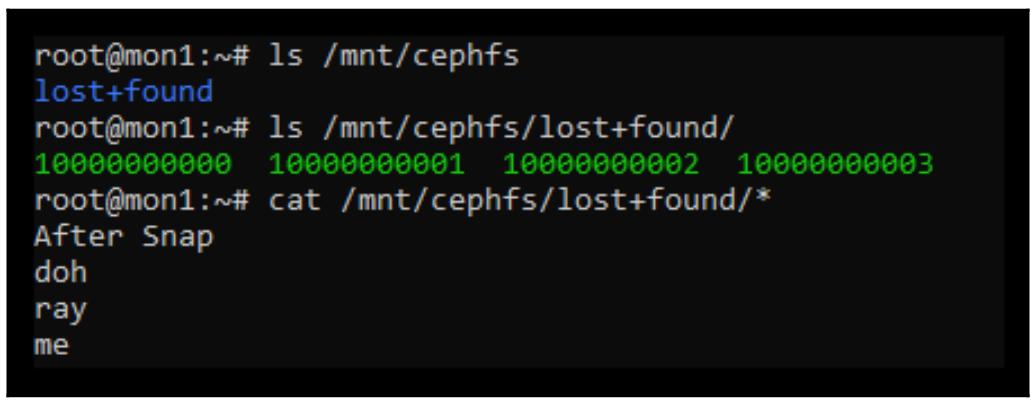
Обратите внимание, что хотя нашим инструментам восстановления и удалось обнаружить файлы и восстановить некоторые из их
метаданных, такие сведения как название файла были утрачены, а следовательно они помещены в каталог
lost+found. Изучив содержимое самих файлов мы можем определить какой файл
чем является и переименовать их в первоначальные названия.
На практике, несмотря на то, что мы восстановили файловую систему CephFS, тот факт, что нам не хватает оригинальных имён файлов и расположения в каталоге, скорее всего, означает, что восстановление успешно лишь частично. Следует также отметить, что восстановленная файловая система может быть нестабильной, и настоятельно рекомендуется, чтобы все восстановленные файлы были восстановлены до того, как сама файловая система будет очищена и восстановлена. Это процесс аварийного восстановления, который следует использовать только после исключения возможности восстановления из резервных копий.
В данном разделе текущей главы мы рассмотрим сценарий, в котором некоторое число OSD может отключиться на некий
непродолжительный промежуток времени, оставив некоторые объекты без достаточного числа копий репликаций. Важно
заметить, что существует некая разница между неким объектом у которого совсем не осталось копий и объектом, который
имеет остающуюся копию, однако он информирован, что другая копия должна иметь более поздние записи. Последний
случай обычно наблюдается, когда мы исполняем свой кластер с установленным в 1
значением min_size.
Чтобы продемонстрировать как восстанавливать некий объект, который имеет просроченную копию данных, давайте выполним некую последовательность шагов для разрушения своего кластера:
-
Вначале давайте установим
min_sizeв значение1; надеемся, к концу данного примера вы поймёте почему не стоит даже желать этого в реальной жизни:sudo ceph osd pool set rbd min_size 1
-
Создайте некий тестовый объект, который мы позже превратим в то, что заставит Ceph поверить в его утрату:
sudo rados -p rbd put lost_object logo.png sudo ceph osd set norecover sudo ceph osd set nobackfillЭти два флага обеспечат, что даже в случае если данные OSD вернутся обратно в рабочее состояние после выполнения записи в некий отдельный OSD, все изменения не будут восстановлены. Так как мы всего лишь тестируем с единственной копией, эти флаги нам необходимы для имитации такого условия в реальной жизни в случае, когда только одна копия отключена по какой либо причине, имеется вероятность, что не все объекты подлежат восстановлению за достаточное время для прежнего OSD.
-
Завершим работу двух из имеющихся OSD, следовательно останется только одно OSD. Так как мы установили
min_sizeв значение1, мы всё ещё имеем возможность записывать данные в свой кластер. Как вы можете видеть, текущее состояние Ceph показывает, что два OSD в настоящее времяdown:
-
Теперь мы вновь выполняем запись в данный объект, причём эта запись пройдёт во все оставшиеся OSD:
sudo rados -p rbd put lost_object logo.png -
Остановим все оставшиеся OSD; когда они отключатся, вновь запитаем первые два оставшихся OSD:
Как вы можете увидеть, Ceph известно что он уже имел не найденные объекты даже до того как начался данный процесс восстановления. Это обусловлено тем, что в процессе фазы однораногового обмена, те PG, которые содержали изменённые объекты знали, что единственная действующая копия расположена на
osd.0, который сейчас отключён. -
Удалите установленные ранее флаги
nobackfillиnorecoverи позвольте своему кластеру попробуете и выполнить восстановление. Вы обнаружите, что даже после запуска восстановления будет иметься одна PG в некотором деградировавшем состоянии, а также всё ещё будет присутствовать предупреждение об одном не обнаруженном объекте. Это хороший момент, поскольку Ceph защищает ваши данные от разрушения. Представим себе что бы произошло, если бы некая порция в 4МБ некоторого содержащего базу данных RBD внезапно вернулась обратно со временем!
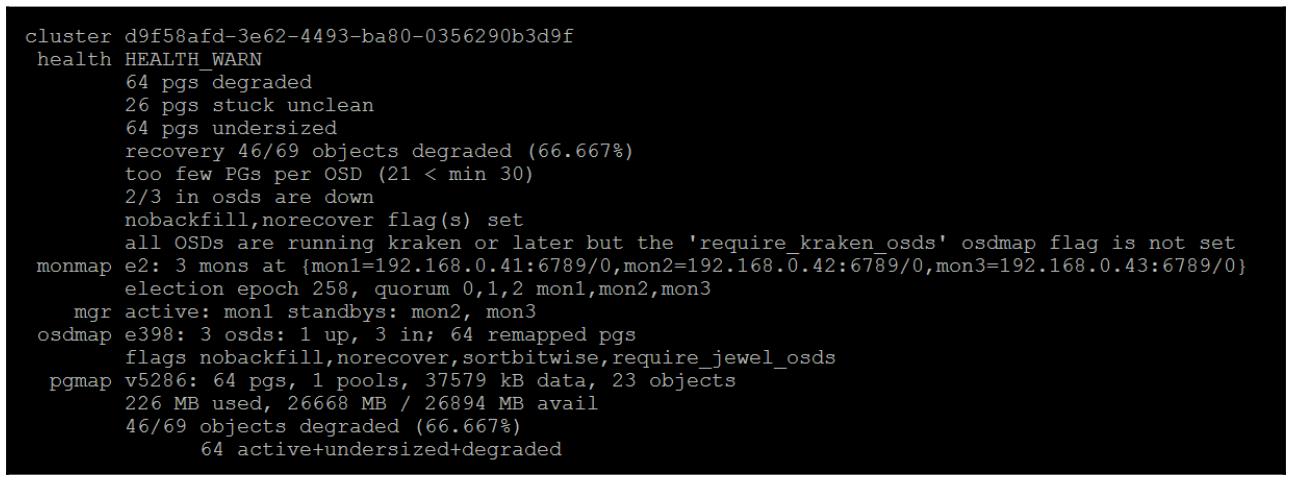
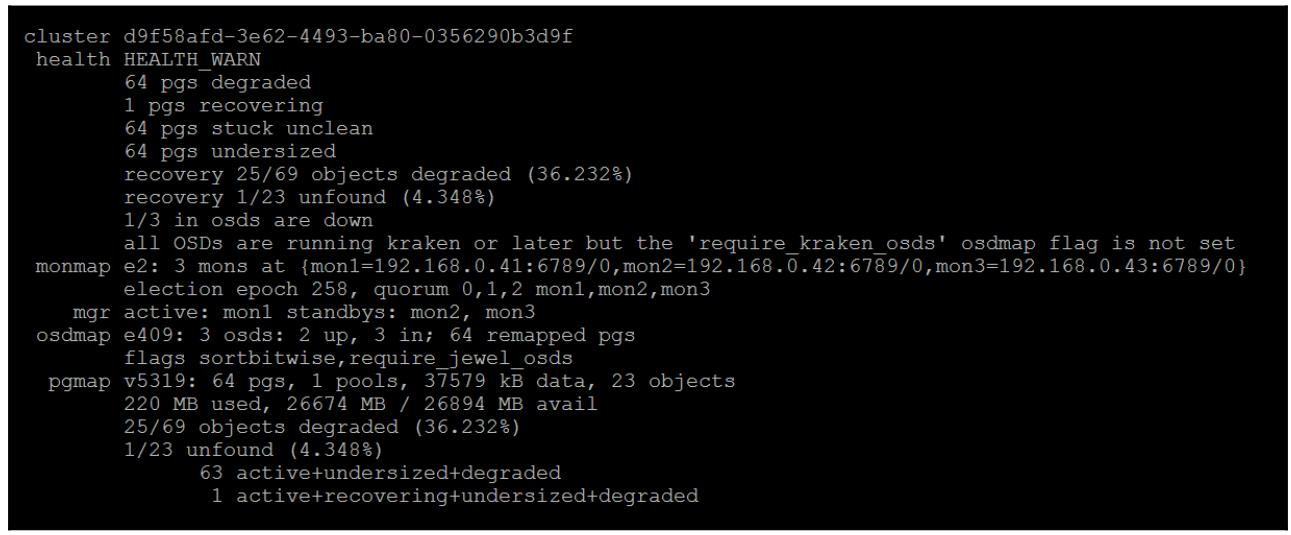
Если вы попробуете и прочтёте или запишите в наш тестовый обект, вы заметите, что данный запрос просто
повиснет; именно так Ceph вновь защищает ваши данные. Существует три способа решения данной проблемы.
Самое первое и наиболее идеальное решение состоит в получении действующей копии данного объекта обратно
в рабочее состояние; это можно бы даже сделать вернув osd.0
обратно в рабочее состояние или воспользовавшись инструментом objectstore
для экспорта и импорта данного объекта в рабочеспособный OSD. Однако для целей данного раздела давайте
предположим, что никакой из этих вариантов не возможен. Прежде чем мы восстановим две оставшиеся опции,
давайте поисследуем ещё и попробуем и вскроем что происходит под капотом.
Выполните подробности работоспособности Ceph чтобы обнаружить какая из PG имеет данную проблему:

В данном случае это pg 0.31, которая находится в деградированном
состоянии, так как она имеет некий не обнаруженный объект. Давайте сделаем запрос к этой PG:
ceph pg 0.31 query
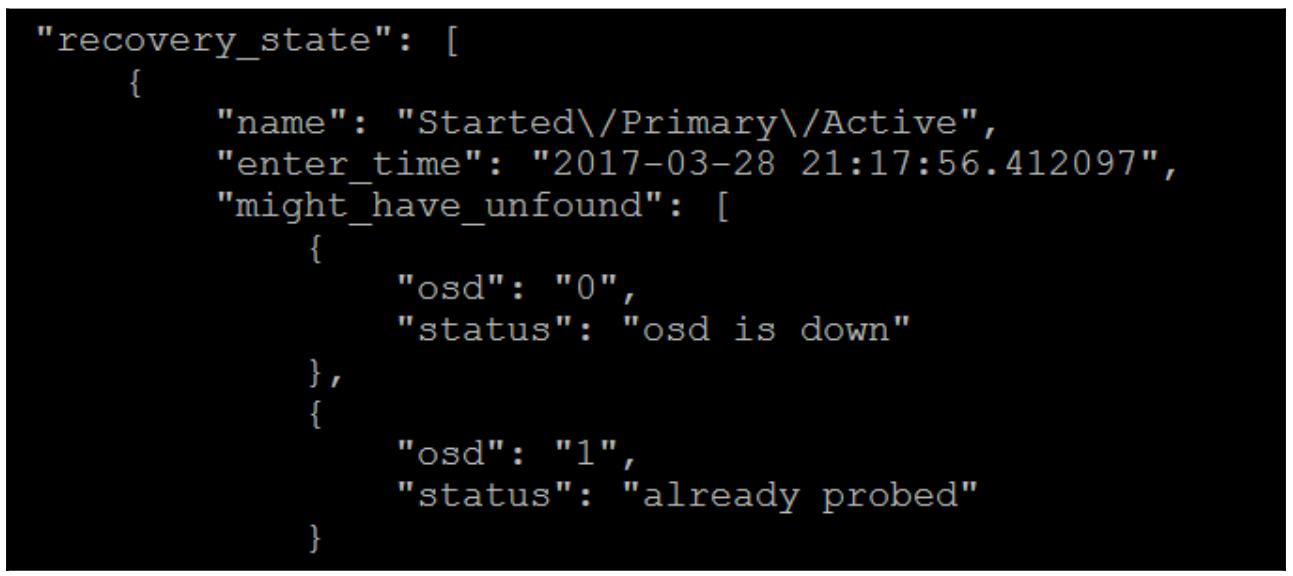
Заглянем в раздел восстановления; мы можем обнаружить, что Ceph попытался попробовать
"osd": "0" для данного объекта, однако он
down. Он попытался попробовать для этого объекта
"osd": "1", но по некоторой причине он не был
задействован, хотя мы и знаем что истинная причина состоит в устаревшей копии.
Теперь давайте взглянем некоторые дополнительные подробности утраченного объекта:
sudo ceph pg 0.31 list_missing
Следующий снимок экрана отображает вывод предыдущей команды:
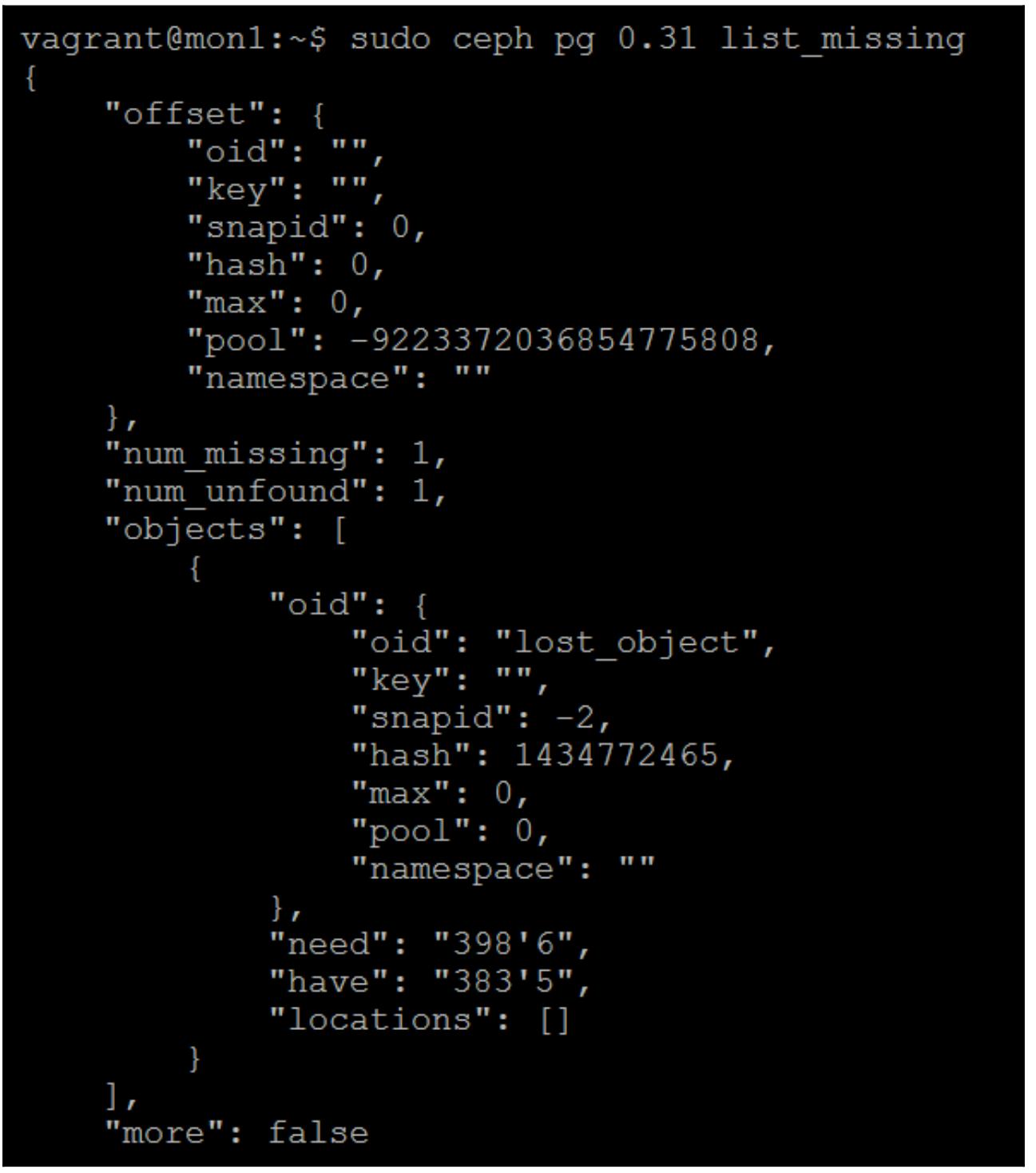
Строки need и have раскрывают причину.
У нас имеется epoch 383'5,
однако действующая копия данного объекта присутствует в 398'6; именно
поэтому min_size=1 очень плохо. Вы можете оказаться в положении, когда у вас
имеется только единственная действующая копия некоторого объекта. Если это было вызвано неким отказом диска,
вы бы имели ещё большие проблемы.
Чтобы восстановиться в данном случае у нас имеются два варианта: мы можем либо выбрать применение более старой копии своего объекта, либо просто удалить его. Следует отметить, что если этот объект новее и некая более старая копия отсутствует в оставшихся OSD, это также удалит данный объект.
Чтобы удалить данный объект выполните это:
sudo ceph pg 0.31 list_missing
Для возврата выполните следующее:
ceph pg 0.31 mark_unfound_lost revert
На этом мы заканчиваем обсуждение восстановление не обнаруженных объектов.
При возникновении невероятного события, состоящего в том что вы потеряли все мониторы, не всё ещё будет
потеряно. Вы можете перестроить всё содержимое базы данных своего монитора из самого содержимого имеющихся
OSD применив инструмент ceph-objectstore.
Чтобы установить такую ситуацию, мы предположим, что случилось некое событие при котором были разрушены все наши три монитора, что в действительности означает, что наш кластер Ceph оказался недоступным. Для восстановления такого кластера мы два из наших мониторов и оставим один единственный монитор в отказавшем состоянии работающим. Затем мы выполним повторное построение базы данных своего монитора, перезапишем разрушенную копию и после этого перезапустим данный монитор чтобы вернуть свой кластер Ceph обратно в рабочее состояние.
Чтобы иметь возможность доступа к каждому OSD в нашем кластере для перестроения базы данных нашего монитора
необходим инструментарий ceph-objectstore; в данном примере мы применим
некий сценарий, который соединяется через ssh для доступа к
нужным нам данным OSD. Так как все данные OSD не доступны любому пользователю, нам понадобится воспользоваться
пользователем root чтобы зарегистрироваться во всех хостах OSD. По умолчанию большинство дистрибутивов
Linux не допускают удалённую регистрацию root на основе пароля, поэтому убедимся что вы скопировали свой
общедоступный ключ ssh для своих пользователей root в некоторые
удалённые узлы OSD.
Приводимый ниже сценарий соединит с каждым из имеющихся узлов OSD, определённых в переменной
hosts и выделит все те данные, которые необходимы для построения
базы данных нашего монитора:
#!/bin/bash
hosts="osd1 osd2 osd3"
ms=/tmp/mon-store/
mkdir $ms
# collect the cluster map from OSDs
for host in $hosts; do
echo $host
rsync -avz $ms root@$host:$ms
rm -rf $ms
ssh root@$host <<EOF
for osd in /var/lib/ceph/osd/ceph-*; do
ceph-objectstore-tool --data-path \$osd --op update-mon-db --mon-store-path $ms
done
EOF
rsync -avz root@$host:$ms $ms
done
Этот код создаст в каталоге /tmp/mon-store следующее содержимое:

Нам также понадобится назначить новые полномочия через keyring:
sudo ceph-authtool /etc/ceph/ceph.client.admin.keyring --create-keyring --gen-key -n client.admin --cap mon 'al
Следующий снимок экрана отображает вывод предыдущей команды:
sudo ceph-authtool /etc/ceph/ceph.client.admin.keyring --gen-key -n mon. --cap mon 'allow *'
sudo cat /etc/ceph/ceph.client.admin.keyring
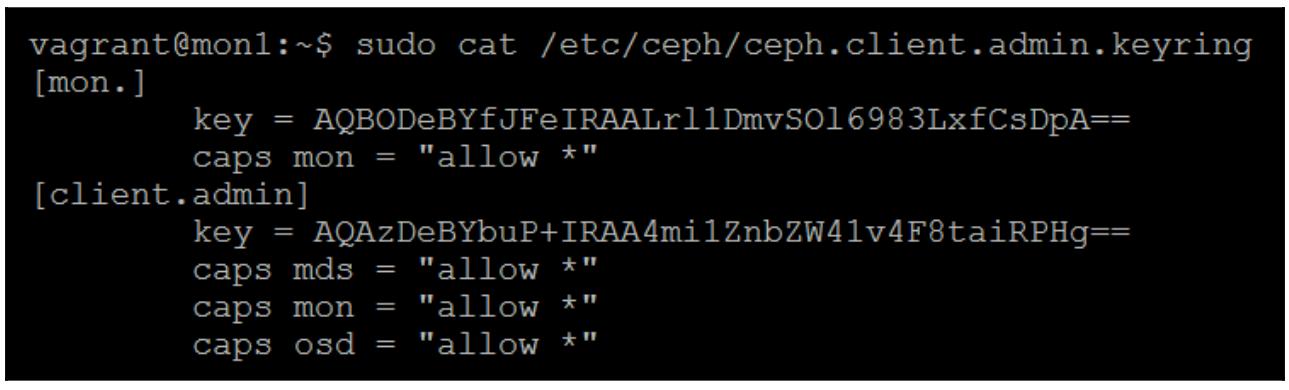
Теперь, когда база данных монитора перестроена, мы можем скопировать её в свой каталог монитора, на перед этим давайте сделаем резервную копию имеющейся базы данных:
sudo mv /var/lib/ceph/mon/ceph-mon1/store.db /var/lib/ceph/mon/ceph-mon1/store.bak
Теперь скопируем свою построенную вновь версию
sudo mv /tmp/mon-store/store.db /var/lib/ceph/mon/ceph-mon1/store.db
sudo chown -R ceph:ceph /var/lib/ceph/mon/ceph-mon1
Если вы попробуете и запустите этот монитор сейчас, он повиснет в некотором пробном состоянии , так как он
пытается испытать остальные мониторы. Именно это позволяет Ceph избежать ситуации расщепления сознания;
однако в данном случае мы хотим заставить его сформировать кворум и приступить к полномасштабной работе.
Для этого нам необходимо внести изменения в monmap, удалить все
остальные мониторы, а затем ввести их обратно в нашу базу данных мониторов:
sudo ceph-mon -i mon1 --extract-monmap /tmp/monmap
Проверьте содержимое monmap:
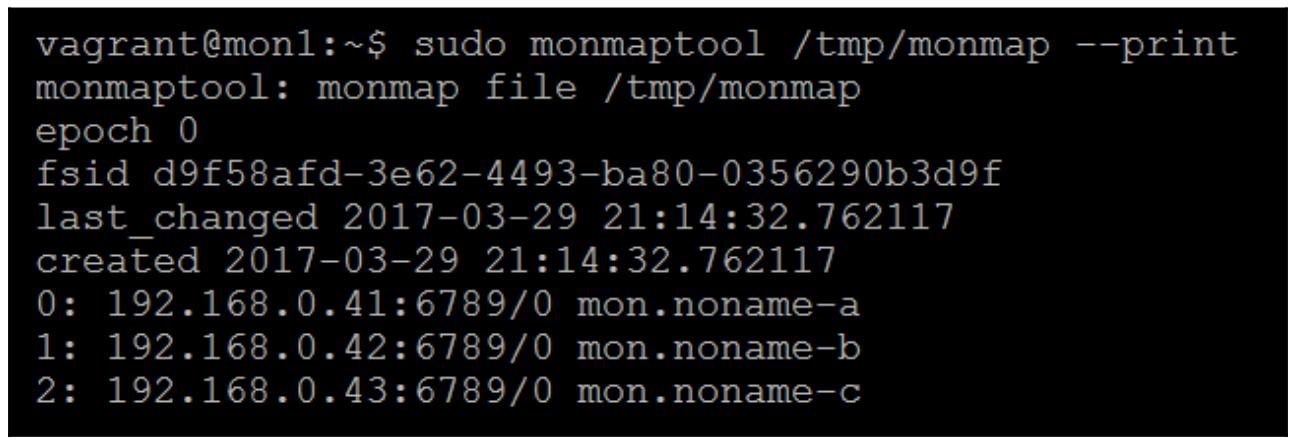
Вы можете заметить, что присутствуют все три монитора, поэтому давайте удалим два из них:
sudo monmaptool /tmp/monmap --rm noname-b
sudo monmaptool /tmp/monmap --rm noname-c
Теперь проверим вновь, чтобы удостовериться, что они ушли окончательно:
sudo monmaptool /tmp/monmap –print
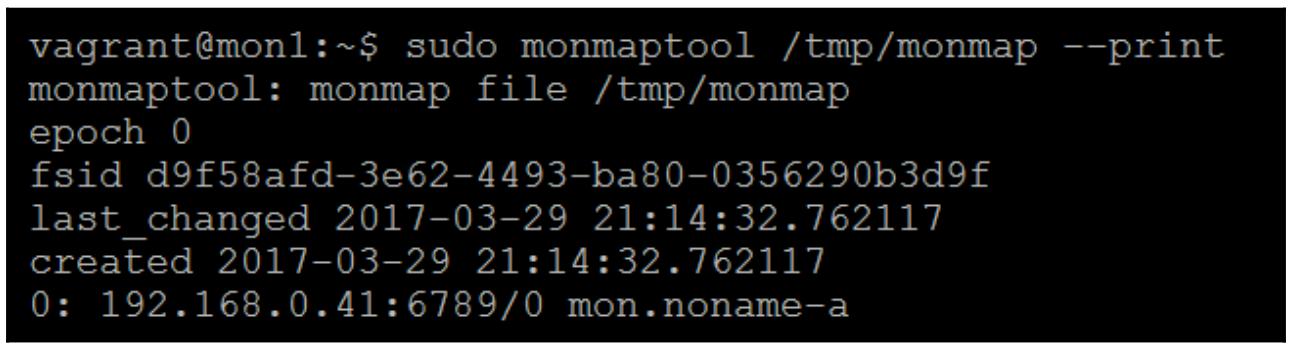
sudo monmaptool /tmp/monmap –print
Перезапустите все свои OSD, таким образом они повторно присоединятся к нашему кластеру; затем мы получим возможность успешно запрашивать состояние данного кластера и обнаружим, что ваши данные всё ещё там:
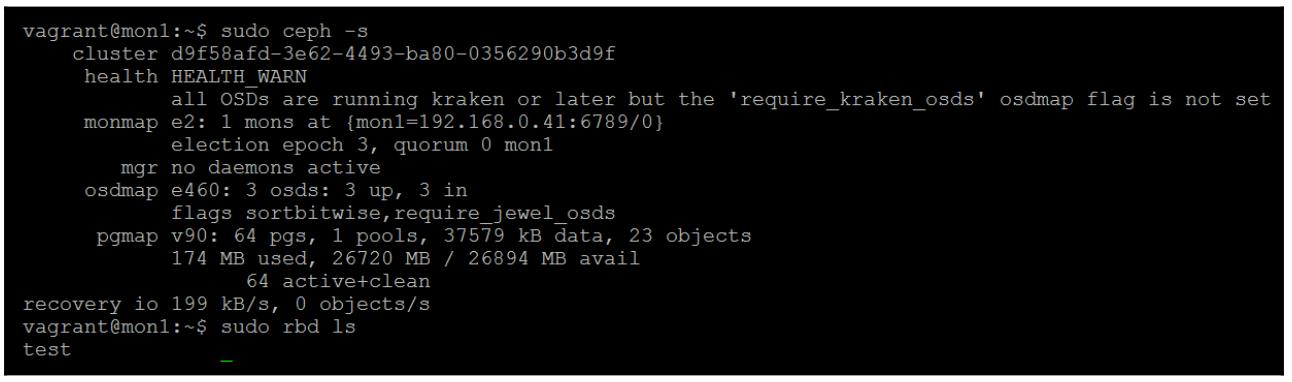
Очень надеемся, что если вы следуете рекомендуемым приёмам, ваш кластер работает с тремя репликами и не настроен с какими- то угрожающими вариантами настроек. Ceph, в большинстве случаев, должен быть способен восстанавливаться после любого отказа.
Однако, в том случае, когда некоторое число OSD отключаются, какое- то число PG и/ или объектов могут
становиться недоступными. Если у вас нет возможности повторно ввести эти OSD обратно в ваш кластер чтобы
позволить Ceph красиво восстановить их, тогда все данные в этих PG в действительности будут утрачены. Однако
имеется вероятность, что такие OSD всё ещё доступны для чтения с помощью инструмента
objectstore для восстановления содержимого подобных PG. Данный процесс
влечёт за собой экспорт таких PG из отказавших OSD и последующий импорт этих PG обратно в наш кластер.
Инструментарий objectstore не требует чтобы все внутренние метаданные OSD
всё ещё пребывали в некотором непротиворечивом состоянии, поэтому полное восстановление не гарантируется.
Чтобы продемонстрировать применение данного инструмента objectstore,
мы остановим два из своих трёх OSD тестового кластера и затем восстановим утраченные PG обратно в этот
кластер. В настоящей жизни это невероятно, чтобы вы столкнулись с ситуацией, когда все отдельные PG из отказавшего
OSD были утрачены, однако для целей демонстрации все требующиеся шаги те же самые:
-
Вначале давайте установим размер пула в значение
2, поэтому мы сможем проверить что мы утратили все копии некоторой PG когда мы остановим определённую службу OSD:
-
Теперь остановим две из своих служб OSD и мы обнаружим в своём экране состояния Ceph что общее число PG снизится до нерабочего состояния:
-
Выполнив подробности работоспособности Ceph мы также покажем какие PG находятся в дегрдированном состоянии:
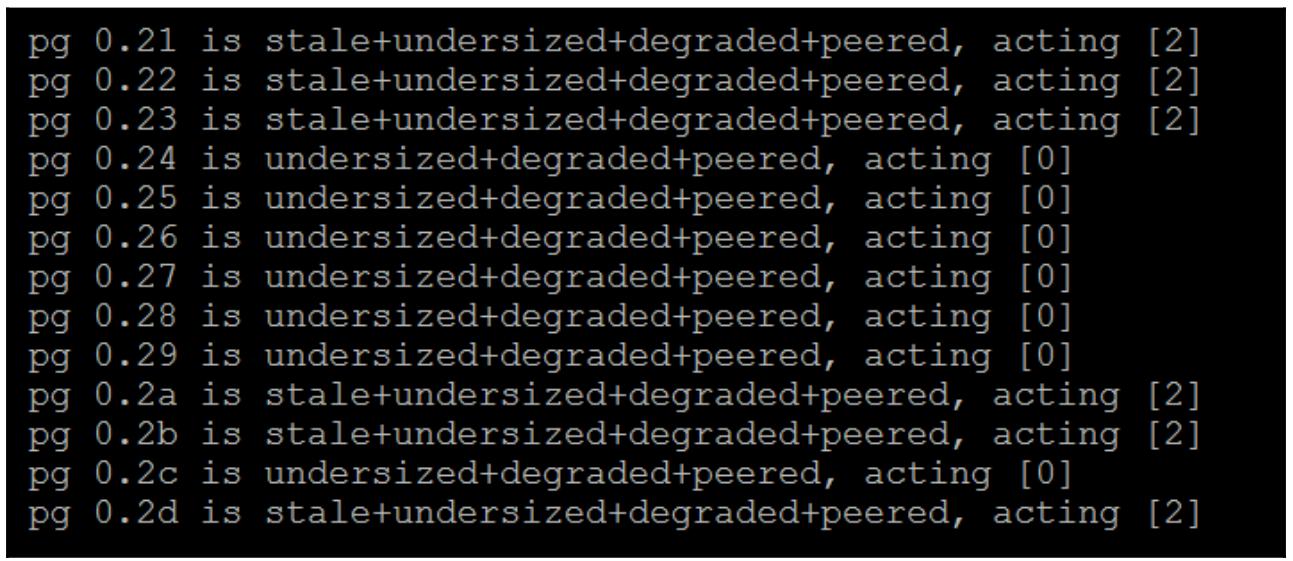
Устаревшие (stale) PG - это те, у которых больше нет сохранившейся копии, и можно видеть, что все действующее OSD - это те, который были остановлены.
Если мы применим для фильтрации
grep, чтобы выделить только устаревшие PG, мы сможем воспользоваться таким полученным списком чтобы решить какие PG нам необходимо восстановить. Если эти OSD на самом деле были удалены из данного кластера, тогда все PG будут перечислены как несовершенные (incomplete), а не как устаревшие (stale). -
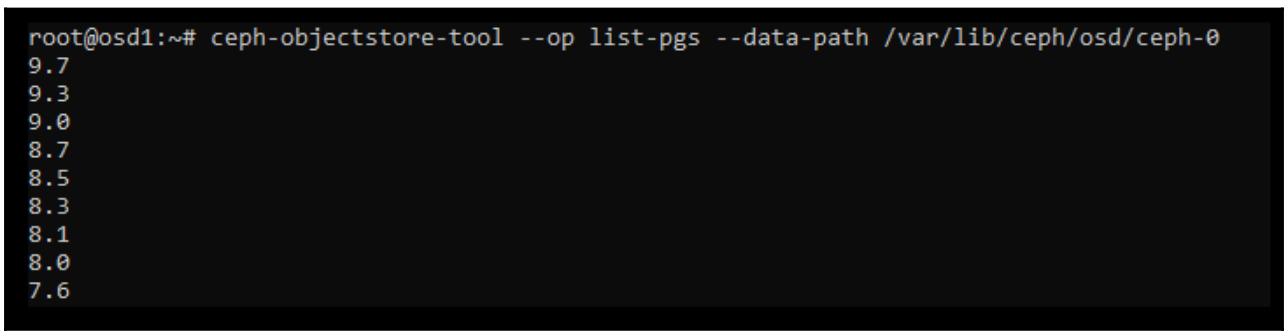
Проверьте такой OSD, чтобы убедиться что в нём имеется PG:
-
Теперь мы применим демонстрируемый инструмент
objectstoreчтобы экспортировать все PG в некий файл. Так как объём данных в нашем кластере мал, мы можем просто экспортировать эти данные на диск самой ОС. На практике вам возможно захочется рассмотреть подключение дополнительного хранилища к такому серверу. Для этого идеальны USB диски, поскольку их можно легко перемещать между серверами в качестве части всего процесса восстановления {Прим. пер.: желательно с USB 3}:sudo ceph-objectstore-tool --op export --pgid 0.2a --data-path /var/lib/ceph/osd/ceph-2 --file 0.2a
Если в процессе работы вы получите некие декларации, вы можете попробовать исполнить это с флагом
--skip-journal-replay, который пропустит воспроизведение всего журнала в ваш OSD. Если в этом журнале имелись какие- либо незавершённые данные, они будут потеряны. Однако это может позволить вам восстановить большую часть из всех утраченных PG, что в противном случае было бы невозможно. Повторяйте это пока вы не выполните экспорт всех утраченных PG. -
Теперь мы можем импортировать свои утраченные PG обратно в некий работающий OSD; Хотя мы можем импортировать все PG в некий имеющийся OSD, намного безопаснее выполнять такой импорт в какой- то новый OSD, так мы не будем рисковать терять данные и далее. Для данной демонстрации мы создадим некий OSD на базе каталога на том диске, который используется нашим отказавшим OSD. Настоятельно рекомендуется при реальной отработке ситуации восстановления после катастрофы чтобы все данные вставлялись в некий OSD, работающий на некотором отдельном диске, вместо того чтобы применять какой- то существующий OSD. Это следует делать с той целью, чтобы не было последующего риска утраты каких- либо данных в данном кластере Ceph.
Кроме того, не имеет значения чтобы все подлежащие импорту PG целиком вставлялись в один и тот же временный OSD. Как только Ceph обнаружит данные объекты, он восстановит их в правильное местоположение в данном кластере.
-
Создайте новую пустую папку для данного OSD:
sudo mkdir /var/lib/ceph/osd/ceph-2/tmposd/ -
Воспользуйтесь
ceph-diskчтобы подготовить этот каталог под Ceph:sudo ceph-disk prepare /var/lib/ceph/osd/ceph-2/tmposd/ -
Измените владельца этой папки на пользователя
cephи его группу:sudo chown -R ceph:ceph /var/lib/ceph/osd/ceph-2/tmposd/ -
Активируйте этот OSD чтобы вернуть его в рабочий режим:
sudo ceph-disk activate /var/lib/ceph/osd/ceph-2/tmposd/ -
Установите вес данного OSD чтобы остановить его заполнение какими- либо объектами:
sudo ceph osd crush reweight osd.3 0 -
Теперь мы можем продолжить импорт требующихся PG, определив местоположение временного OSD и те файлы PG, которые экспортировали ранее:
sudo ceph-objectstore-tool --op import --data-path /var/lib/ceph/osd/ceph-3 --file 0.2a_export
-
Повторите это для каждой PG, которые вы экспортировали ранее. Когда завершите, сбросьте владение файлом и перезапустите этот новый временный OSD:
sudo chown -R ceph:ceph /var/lib/ceph/osd/ceph-2/tmposd/ sudo systemctl start ceph-osd@3 -
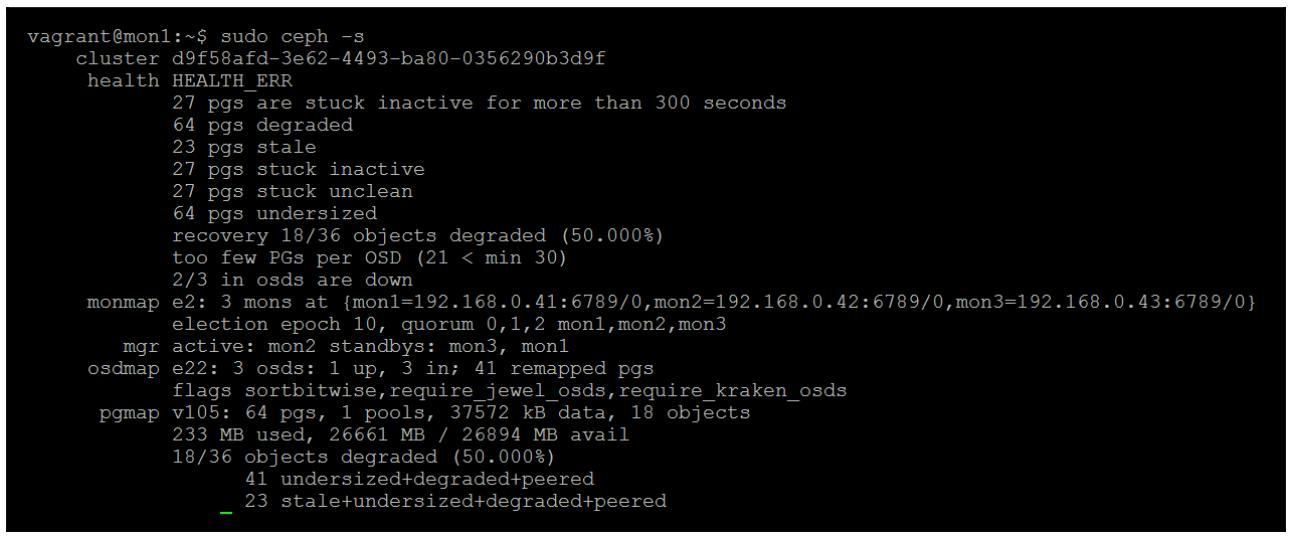
После проверки вывода состояния всего Ceph вы обнаружите, что ваши PG теперь активны, однако пребывают в деградированном состоянии. Для случая нашего тестового кластера недостаточно OSD чтобы позволить всем объектам восстановиться до правильного количества копий. Если бы в нашем кластере имелось больше OSD, эти объекты затем заполнили бы OSD по всему кластеру и восстановились бы до полностью рабочеспособного состояния с правильным числом копий.



Утверждения (assertions) применяются в Ceph чтобы гарантировать, что в процессе исполнения данного кода все предположения, которые были сделаны относительно его среды работы остаются верными. Такие декларации разбросаны по всему коду Ceph и разработаны с целью обнаружения любых условий которые могут вызвать дальнейшие проблемы если данный код не остановить.
Если вы приводите в действие некое утверждение в Ceph, вероятно некоторая форма данных имеет какое- то значение, которое является неожиданным. Это может быть вызвано некоторым видом разрушения или не обрабатываемой ошибки.
Если некий OSD вызвал какое- то утверждение и отвергает какой- либо запуск, обычно рекомендуемым подходом было бы удалить этот OSD, повторно создать его, а затем позволить Ceph заполнить его обратно объектами. Если у вас имеется воспроизводимая ситуация отказа, тогда вероятно также неплохо заполнить уведомление об ошибке в системе отслеживания ошибок Ceph.
Как уже неоднократно упоминалось в данной главе, OSD могут отказывать либо из- за аппаратных сбоев, либо из- за программных либо в самих хранимых данных, либо в коде OSD. Программные сбои скорее всего вероятно воздействуют на множество OSD за раз; если вы претерпели разрушения обусловленные потерей электропитания, тогда высока вероятность что это это оказало воздействие более чем на один OSD за раз. В случае, когда множество OSD отказывает с утверждениями и они вызывают отключение одной или более PG в вашем кластере, простое повторное создание OSD не является неким вариантом. Те OSD, которые отключены, все содержат три копии таких PG и поэтому повторное создание OSD сделает невозможным любой вид восстановления и будет иметь результатом постоянную потерю данных.
Во-первых, прежде чем приступать к методам восстановления из этой главы, например, экспортировать и импортировать PG, следует провести исследование утверждений. В зависимости от ваших технических возможностей и длительности простоя, на которое вы способны прежде чем вам необходимо начать сосредоточиваться на прочих этапах восстановления, исследование утверждений может не привести к успеху. Исследуя утверждение и просматривая исходный код Ceph, на который ссылается данное утверждение, может оказаться возможным определение причины данного утверждения. Если это возможно, тогда в коде Ceph может быть реализовано исправление, чтобы избежать данного утверждения OSD. Не бойтесь обращаться к сообществу за помощью в решении этих вопросов.
В некоторых случаях разрушение вашего OSD может оказаться настолько серьёзным, что даже инструмент
objectstore может сам по себе выдавать утверждение при попытке чтения с
этого OSD. Это ограничит шаги восстановления, описанные в данной главе и попытка исправить причину утверждения
может оказаться единственным вариантом. Хотя к этому моменту, вероятно, OSD перенёс тяжёлые разрушения и
восстановление может оказаться невозможным.
Следующее утверждение было взято из списка писем пользователе Ceph:
2017-03-02 22:41:32.338290 7f8bfd6d7700 -1 osd/ReplicatedPG.cc: In function 'void ReplicatedPG::hit_set_trim(ReplicatedPG::RepGather*, unsigned int)' thread 7f8bfd6d7700 time 2017-03-02 22:41:32.335020
osd/ReplicatedPG.cc: 10514: FAILED assert(obc)
ceph version 0.94.7 (d56bdf93ced6b80b07397d57e3fa68fe68304432)
1: (ceph::__ceph_assert_fail(char const*, char const*, int, char const*)+0x85) [0xbddac5]
2: (ReplicatedPG::hit_set_trim(ReplicatedPG::RepGather*, unsigned int)+0x75f) [0x87e48f]
3: (ReplicatedPG::hit_set_persist()+0xedb) [0x87f4ab]
4: (ReplicatedPG::do_op(std::tr1::shared_ptr<OpRequest>&)+0xe3a) [0x8a0d1a]
5: (ReplicatedPG::do_request(std::tr1::shared_ptr<OpRequest>&, ThreadPool::TPHandle&)+0x68a) [0x83be4a]
6: (OSD::dequeue_op(boost::intrusive_ptr<PG>, std::tr1::shared_ptr<OpRequest>, ThreadPool::TPHandle&)+0x405) [0x69a5c5]
7: (OSD::ShardedOpWQ::_process(unsigned int, ceph::heartbeat_handle_d*)+0x333) [0x69ab33]
8: (ShardedThreadPool::shardedthreadpool_worker(unsigned int)+0x86f) [0xbcd1cf]
9: (ShardedThreadPool::WorkThreadSharded::entry()+0x10) [0xbcf300]
10: (()+0x7dc5) [0x7f8c1c209dc5]
11: (clone()+0x6d) [0x7f8c1aceaced]
Верхняя часть утверждения отображает ту функцию, из которой данное утверждение было эскалировано, а также
сам номер строки и файл, где было обнаружено данное утверждение. В данном примере наша функция
hit_set_trim предположительно вызвала данное утверждение. Мы можем
заглянуть в файл ReplicatePG.cc вокруг строки 10514 чтобы попытаться
понять что могло произойти. Отметим версию выпуска Ceph (0.94.7), так как номер строки в GitHub будет
соответствовать искомому только если вы просматривате ту же самую версию.
Из просмотра кода становится очевидно, что данное возвращаемое значение из вызова функции
get_object_context напрямую передаётся в другую функцию
assert. Если это значение являются нулём, это указывает на то, что
данный объект, содержащий подлежащий подрезке hitset, не может быть обнаружен, в этом сучае данный OSD выставляет
утверждение. Основываясь на данной информации, имеется вероятность, что можно провести расследование почему
данный объект утрачен и восстановить его. Или же данная команда assert
может быть скрыта комментарием с целью посмотреть позволит ли это данному OSD продолжить работу. В данном примере
разрешение такому OSD продолжить работу, скорее всего, не вызовет некую проблему, однако в другом случае
некое утверждение может быть единственной вещью, останавливающей от возникновения более серьёзного разрушения.
Если вы не понимаете на 100% почему нечто вызывает некое утверждение, а также воздействие любого потенциального
изменения, которое вы можете сделать, обратитесь за помощью прежде чем продолжить.
В данной главе вы изучили как обнаруживать неисправности Ceph когда все выглядит потерянным. В случае когда Ceph не способен самостоятельно восстановить PG вы теперь понимаете как вручную перестроить PG в отказавших OSD. Вы можете также повторно построить базу данных своих мониторов в случае если вы потеряли все свои узлы мониторов, но всё ещё имеете доступ к вашим OSD. В случае полного отказа кластера из которого вы не способны восстановиться, вы также должны уметь пройти процесс воссоздания RBD из имеющихся сырых данных, всё ещё остающихся на ваших OSD. Наконец, вы настроили два раздельных кластера и устроили между ними репликацию, применив зеркалирование RBD для предоставления некоторого варианта отработки отказа, с которым вы можете столкнуться при полном отказе кластера.
-
Какой демон Ceph позволяет реплицировать RBD в другой кластер Ceph?
-
Истина или ложь: RBD по умолчанию всего лишь объединяет строки объектов.
-
Какой инструмент может применяться для экспорта или импорта PG в- из- OSD?
-
Истина или ложь: Некое состояние невозможности отыскать объект означает что данные утрачены навсегдаю
-
В чём основной недостаток того что вы утрачиваете после восстановления метаданных CephFS?