Глава 19. Тестирование, отладка и планирование параллельных приложений
Содержание
В этой главе мы обсудим сам процесс применения программ Python совместной обработки на некотором верхнем уровне. Для начала вы изучите планирование программ Python для их совместного исполнения в последующем - либо единожды, либо периодически. Мы проанализируем APScheduler, некую библиотеку Python, которая позволит нам делать это не обращая внимание на платформу. Более того, мы пройдём сквозь тестирование и отладку, которые являются весьма существенными, но не до конца распознанными компонентами в программировании. Принимая во внимание сложность программирования совместной обработки, проверка и отладка являются даже ещё более сложными чем это имеет место при обычном программировании. Данная глава охватит ряд стратегий для действенного тестирования и отладки параллельных программ.
В этой главе будут рассмотрены следующие темы:
-
Библиотека APScheduler и её применение в планировании приложений Python для совместной обработки
-
Различные технологии проверок для программ Python
-
Практические приёмы отладки в программировании Python, а также особенные для совместной обработки технологии отладки
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Убедитесь что в вашем дистрибутиве Python имеются установленными библиотеки
apschedulerиconcurrencytest -
Вам следует иметь установленными OpenCV и NumPy для вашего дистрибутива Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter19 -
Ознакомьтесь со следующими видеоматериалами Code in Action
APScheduler (сокращение от Advanced Python Scheduler) является некоторой внешней библиотекой, которая поддерживает код планирования на Python для исполнения в последующем либо один раз, либо периодически. Эта библиотека снабжает нас вариантами верхнего уровня для динамического добавления/ удаления заданий в/ их имеющегося списка заданий с тем, чтобы они могли планироваться и исполняться, а также для принятия решения как распределять эти задания по различным потокам и процессам.
Некоторые могут задуматься о Celery в качестве инструмента для следования планированию в Python. Однако Celery является некоторой распределённой очередью задач с основными возможностями планирования, APScheduler совершенно противоположен: это некий планировщик с возможностями базовых очередей задач и расширенными функциями планирования. Кроме того, пользователи обоих инструментов сообщают, что APScheduler проще при установке и реализации.
Как и большинство распространённых внешних библиотек Python, APScheduler может быть установлен через диспетчер пакетов
pip, выполнив следующую команду в своём терминале:
pip install apscheduler
Другим способом установить эту библиотеку, если команда pip не работает, это
вручную выгрузить весь исходный код из PyPI, который можно отыскать в pypi.org/project/APScheduler/.
Этот выгруженный файл может быть затем извлечён и установлен путём исполнения следующей команды:
python setup.py install
Как и всегда, для проверки того был ли ваш дистрибутив правильно установлен, откройте свой интерпретатор Python и попробуйте импортировать эту библиотеку следующим образом:
>>> import apscheduler
Если не будет получено никаких ошибок, это означает что данная библиотека была полностью установлена и готова к применению.
Хотя сам термин планирования и может быть достаточно вводящим в заблуждение определённую группу разработчиков, давайте проясним те функции, которые предоставляет APScheduler, а также то что он не предоставляет. Прежде всего, и это самое главное, данная библиотека может применяться как кроссплатформенный планировщик, который к тому же специфичен для приложений в противоположность более распространённым планировщикам, которые специфичны к платформам, например, как демон cron (для систем Linux) или планировщик задач Windows.
Важно отметить, что APScheduler сам по себе не является какой- то службой планирования, который имеет предварительно встроенный GUI или интерфейс командной строки. Он всё ещё некая библиотека Python, которую приходится импортировать и применять внутри имеющихся приложений (именно по этой причине он является специфичен для приложений). Тем не менее, как вы изучите, APScheduler приходит с массой свойств, которые могут применяться для построения некоей реальной службы планирования.
Например, возможность планирования заданий (в частности, для работающих в фоновом режиме) существенна для современных веб- приложений. так как они могут содержать различные но важные свойства, такие как отправка электронной почты или резервное копирование синхронизируемых данных. В этом контексте APScheduler обоснованно наиболее распространённый инструмент для планирования приложений, которые вовлекают инструкции Python, такие как Heroku и PythonAnywhere.
Давайте исследуем некие наиболее распространённые функции, предоставляемые рассматриваемой библиотекой APScheduler. В качестве широко применяемых при исполнении он предлагает три различных механизма планирования с тем, чтобы была возможность выбрать именно тот механизм, который является наиболее подходящим для чьего- то приложения (эти механизмы также иногда именуются триггерами событий):
-
Планирование в стиле Cron: Этот механизм позволяет заданиям иметь предварительно заданные времена запуска и окончания
-
Исполнение на основе интервалов: данный механизм исполняет задания в однородных интервалах времени (например, каждые две минуты, каждый день) с необязательными временами запуска и окончания
-
Задерживаемое исполнение: Механизм позволяет данному приложению выполнять ожидание предписанный промежуток времени перед исполнением элементов в соответствующем перечне заданий
Более того, APScheduler позволяет нам сохранять задания для исполнения в различных серверных системах, таких как обычная память, MongoDB, Redis, SPLAlchemy или ZooKeeper. Будь это некая программа рабочего стола, некое веб- приложение или просто сценарий Python, APSheduler скорее всего способен работать с тем как сохранены спланированные задания.
Помимо этого, данная библиотека бесшовно работает с распространёнными инфраструктурами Python совместной обработки, такими как AsyncIO, Gevent, Tornado и Twisted. Это означает, что сам включённый в библиотеку APScheduler код нижнего уровня содержит инструкции, которые способны сплочённо планировать и исполнять функции и программы, реализуемые в таких инфраструктурах, делая данную библиотеку ещё более динамичной.
Наконец, APScheduler предоставляет различные возможности реального исполнения самого кода планирования определяя соответствующий необходимый исполнитель (исполнители). В частности, можно просто исполнять задания обычным образом, неким блокируемым манером или в фоновом режиме. У нас также имеются варианты применения некоторого пула потоков или процессов для распределения работ неким манером совместной обработки. Позднее мы рассмотрим некий пример в котором мы воспользуемся каким- то пулом для исполнения спланированных заданий.
Следующая схема отображает связи всех основных классов и содержащиеся в APScheduler свойства:
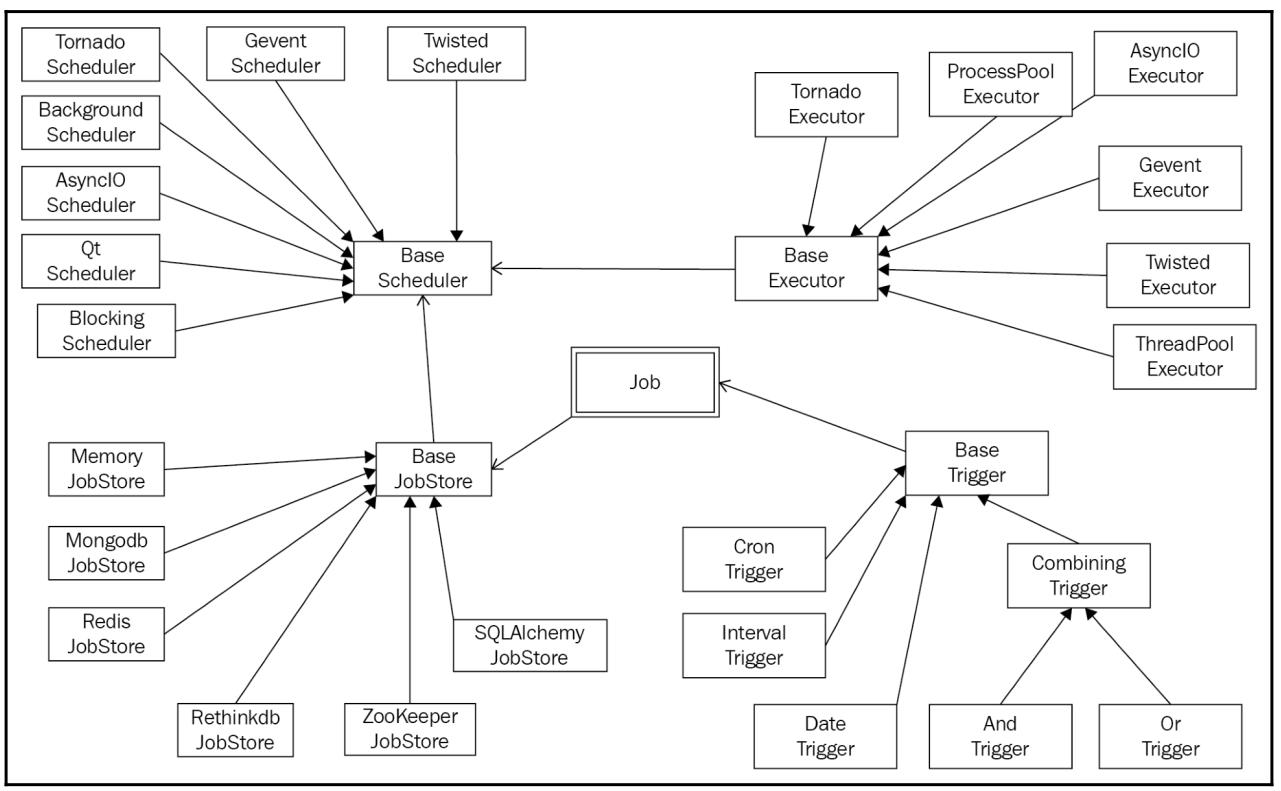
В этом разделе мы рассмотрим как в реальности интегрировать APScheduler в имеющиеся программы Python путём анализа различных предоставляемых этой библиотекой классов и методов. Мы также рассмотрим как задания распределяются по различным потокам и процессам когда мы применяем исполнитель совместной обработки для запуска спланированных заданий.
Классы планировщика
Для начала давайте рассмотрим те опции, которые доступны нашему основному планировщику, являющемуся наиболее важным компонентом в самом процессе планирования задач для их исполнения в дальнейшем:
-
BlockingScheduler: Этот класс может применяться когда сам планировщик предназначен выступать единственной задачей запускаемой в данном процессе. Как и предполагает само название, некий экземпляр данного класса будет блокировать все прочие инструкции в том же самом процессе. -
BackgroundScheduler: В противоположностьBlockingSchedulerэтот класс позволяет планировать задания к исполнению в фоновом режиме внутри некоего имеющегося приложения.
Помимо этого, также имеются классы планирования для применения если ваше приложение использует особые инфраструктуры
совместного программирования: AsyncIOScheduler для модуля
asyncio; GeventScheduler для Gevent;
TornadoScheduler для приложений Tornado;
TwistedScheduler для приложений Twisted и так далее.
Классы исполнителя
Другим важным выбором, который предстоит осуществить в самом процессе планирования заданий для их исполнения в дальнейшем
это: Какой исполнитель (исполнители) должен запускать эти задания? Обычно таким исполнителем по умолчанию рекомендуется
исполнитель ThreadPoolExecutor, который распределяет всю работу по различным
потокам внутри одного и того же процесса. Однако, как вы уже изучали, если некие планируемые задания содержат инструкции,
которые применяют интенсивные операции ЦПУ, тогда эта рабочая нагрузка должна распределяться по множеству ядер ЦПУ и следует
применять ProcessPoolExecutor.
Важно отметить, что эти два класса исполнителей взаимодействуют с модулем concurrent.futures,
который мы обсуждали в более ранних главах для содействия исполнению совместной обработки. Установленным по умолчанию максимальным
числом работников для обоих классов исполнителей является 10 и оно может быть
изменено при инициализации.
Ключевые слова триггера
Самое последнее решение в нашем процессе построения планировщика состоит в том как спланированные задания должны исполняться впоследствии; это касается уже упомянутых ранее триггеров событий. APScheduler предоставляет три различных механизма триггеров; приводимые далее ключевые слова следует передавать в качестве аргументов в соответствующий инициализатор планировщика чтобы определить необходимый тип триггера события:
-
'date': Это ключевое слово применяется когда планируемое задание должно быть исполнено один раз в определённый момент в будущем. -
'interval': Данное ключевое слово применяется когда планируемое задание должно исполняться в некие фиксированные интервалы времени. -
'cron': Это ключевое слово применяется когда планируемое задание должно периодически запускаться в заданное время дня.
Кроме того, имеется возможность смешивать и устанавливать соответствие множества типов триггеров. У нас также имеется возможность иметь спланированные задания исполняемыми либо когда срабатывают все зарегистрированные триггеры, либо по крайней один из них.
Общие методы планирования
Наконец, давайте рассмотрим те методы, которые обычно применяются при определении некоторого планировщика в
дополнение ко всем предыдущим классам и ключевым словам. В частности, объектами scheduler
вызываются такие методы:
-
add_executor(): Этот метод вызывается для регистрации некоторого исполнителя для запуска заданий в будущем. В частности, мы обычно передаём строку'processpool'в этот метод чтобы получить все задания распределёнными по множеству процессов. В противном случае, как уже упоминалось, в качестве установленного по умолчанию будет применяться пул потоков. Данный метод также возвращает некий объект исполнителя, которым можно в последующем манипулировать. -
remove_executor(): Этот метод применяется в качестве некоторого объекта исполнителя для удаления его из планировщика. -
add_job(): Данный метод может быть применён для добавления некоторого дополнительного задания в общий список заданий для его исполнения впоследствии. Этот метод вначале получает нечто пригодное для вызова, что является неким новым заданием в имеющемся списке заданий, а также различные прочие аргументы, которые применяются для определения того как это задание следует спланировать и исполнить. Аналогичноadd_executor(), данный метод может возвращать некий объектjob, которым можно манипулировать вне данного метода. -
remove_job(): Аналогичным образом, этот метод может применяться в некотором объектеjobдля его удаления из запланированных. -
start(): Метод запускает запланированное задание совместно с реализованными исполнителями и начинает обрабатыввать свой список заданий. -
shutdown(): Данный метод останавливает свой вызываемый объект планировщика помимо его списка заданий и реализованных исполнителей. Если нн вызывается когда имеются запущенными текущие задания, эти задания не будут прерваны.
В этом подразделе мы рассмотрим как применяются некоторые из обсуждённых нами API в простых программах Python.
Выгрузите соответствующий код для данной книги с её страницы GitHub, затем пройдите далее и переместитесь в папку
Chapter19.
Планировщик с блокировкой
Для начала давайте взглянем на некий пример планирования с блокировкой в следующем файле
Chapter19/example1.py:
# Chapter19/example1.py
from datetime import datetime
from apscheduler.schedulers.background import BlockingScheduler
def tick():
print(f'Tick! The time is: {datetime.now()}')
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(tick, 'interval', seconds=3)
try:
scheduler.start()
print('Printing in the main thread.')
except KeyboardInterrupt:
pass
scheduler.shutdown()
В этом примере мы реализовали некий планировщик для своей функции tick(),
определённой в предыдущем коде, которая просто выводит на печать значение текущего времени в которое она исполнена.
В нашей основной функции мы пользуемся неким экземпляром из соответствующего класса
BlockingScheduler, который импортируется из APScheduler в качестве нашего
планировщика для данной программы. Дополнительно к этому применяется также уже упомянутый метод
add_job() для регистрации tick()
в качестве некоторого задания для его последующего исполнения. А именно, его следует исполнять периодически, через
равные промежутки времени (задаваемые в соответствующей передаваемой строке 'interval')
- в частности, каждые три секунды (что предписано соответствующим аргументом
seconds=3).
Напомним, что некий блокирующий планировщик заблокирует все прочие инструкции в том же самом процессе, в котором исполняется
и он сам. Для проверки этого факта мы также вставляем некий оператор print, причём
сразу после запуска самого планировщика, чтобы увидеть будет ли он также исполнен. После запуска данного сценария ваш
вывод должен выглядеть аналогично приводимому ниже (за исключением конкретных значений времени, выведенных на печать):
> python3 example1.py
Tick! The time is: 2018-10-31 17:25:01.758714
Tick! The time is: 2018-10-31 17:25:04.760088
Tick! The time is: 2018-10-31 17:25:07.762981
Заметим, что этот планировщик будет исполняться бесконечно долго до тех пор пока он не будет остановлен неким
событием KeyboardInterrupt или иной потенциальной исключительной ситуацией, причём
будет выведен на печать тот оператор, что мы поместили рядом с окончанием своей основной программы, который никогда не
исполнялся. Именно по этой причине такой класс BlockingScheduler следует применять
только когда вы намерены исполнить только одну задачу в своём процессе.
Планировщик фонового режима
В этом примере мы рассмотрим поможет ли применение нашего класса BackgroundScheduler
если мы желаем исполнять свой планировщик в фоновом режиме, причём совместно с прочими задачами. Необходимый код для данного
примера содержится в следующем файле Chapter19/example2.py:
# Chapter19/example2.py
from datetime import datetime
import time
from apscheduler.schedulers.background import BackgroundScheduler
def tick():
print(f'Tick! The time is: {datetime.now()}')
if __name__ == '__main__':
scheduler = BackgroundScheduler()
scheduler.add_job(tick, 'interval', seconds=3)
scheduler.start()
try:
while True:
time.sleep(2)
print('Printing in the main thread.')
except KeyboardInterrupt:
pass
scheduler.shutdown()
сам код в данном примере почти идентичен тому что мы уже видели ранее. Однако здесь мы применяем свой класс для планировщиков
в фоновом режиме, а также мы выводим на печать сообщения из своей основной программы каждые две секунды в некотором
бесконечном цикле while. Теоретически, если рассматриваемый объект
scheduler может быть на самом деле быть запущенным в спланированном задании
в фоновом режиме, наш вывод будет составлен из некоторой комбинации операторов вывода на печать, как из нашей основной
программы, так и из соответствующей функции tick().
Ниже приведён мой вывод после исполнения этого сценария:
> python3 example2.py
Printing in the main thread.
Tick! The time is: 2018-10-31 17:36:35.231531
Printing in the main thread.
Tick! The time is: 2018-10-31 17:36:38.231900
Printing in the main thread.
Printing in the main thread.
Tick! The time is: 2018-10-31 17:36:41.231846
Printing in the main thread.
И снова, данный планировщик будет исполняться бесконечно, пока не будет выдано некое прерывание от клавиатуры. В данном случае мы можем наблюдать то что мы и ожидали увидеть: операторы печати из нашей основной программы и из спланированного задания производятся совместно, что указывает на то, что этот планировщик на самом деле запущен в фоновом режиме.
Пул исполнителя
Одной дополнительной функциональностью, предлагаемой APScheduler, является возможность распределять запланированные
задания для их исполнения по множеству ядер ЦПУ (или процессов). В данном примере вы изучите как делать это с неким
планировщиком в фоновом режиме. Перейдите к файлу Chapter19/example3.py и
проверьте следующий вложенный код:
# Chapter19/example3.py
from datetime import datetime
import time
import os
from apscheduler.schedulers.background import BackgroundScheduler
def task():
print(f'From process {os.getpid()}: The time is {datetime.now()}')
print(f'Starting job inside {os.getpid()}')
time.sleep(4)
print(f'Ending job inside {os.getpid()}')
if __name__ == '__main__':
scheduler = BackgroundScheduler()
scheduler.add_executor('processpool')
scheduler.add_job(task, 'interval', seconds=3, max_instances=3)
scheduler.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
pass
scheduler.shutdown()
В этой программе то задание, которое мы желаем спланировать (свою функцию task())
выводит на печать соответствующий идентификатор того процесса, в котором она запущена при каждом вызове (получаемого
с помощью метода os.getpid()) и спроектирована на завершение примерно через четыре
секунды. В нашей основной программе мы используем тот же самый планировщик фонового режима, который мы применяли в своём
последнем примере, но мы определяем, что планируемые задания должны исполняться в некотром пуле процессов:
scheduler.add_executor('processpool')
Напомним, что установленным по умолчанию значением числа процессов в этом пуле является 10, и мы можем изменять его на другое значение. Далее, так как мы добавили соответствующее задание в свой планировщик, нам также придётся определить что это задание может исполняться в более чем одном экземпляре процесса (в данном случае, в трёх экземплярах); это позволяет нашему исполнителю пула процессов использоваться полностью и действенным образом:
scheduler.add_job(task, 'interval', seconds=3, max_instances=3)
Самые первые несколько строк из моего вывода после исполнения этой программы таковы:
> python3 example3.py
From process 1213: The time is 2018-11-01 10:18:00.559319
Starting job inside 1213
From process 1214: The time is 2018-11-01 10:18:03.563195
Starting job inside 1214
Ending job inside 1213
From process 1215: The time is 2018-11-01 10:18:06.531825
Starting job inside 1215
Ending job inside 1214
From process 1216: The time is 2018-11-01 10:18:09.531439
Starting job inside 1216
Ending job inside 1215
From process 1217: The time is 2018-11-01 10:18:12.531940
Starting job inside 1217
Ending job inside 1216
From process 1218: The time is 2018-11-01 10:18:15.533720
Starting job inside 1218
Ending job inside 1217
From process 1219: The time is 2018-11-01 10:18:18.532843
Starting job inside 1219
Ending job inside 1218
From process 1220: The time is 2018-11-01 10:18:21.533668
Starting job inside 1220
Ending job inside 1219
From process 1221: The time is 2018-11-01 10:18:24.535861
Starting job inside 1221
Ending job inside 1220
From process 1222: The time is 2018-11-01 10:18:27.531543
Starting job inside 1222
Ending job inside 1221
From process 1213: The time is 2018-11-01 10:18:30.532626
Starting job inside 1213
Ending job inside 1222
From process 1214: The time is 2018-11-01 10:18:33.534703
Starting job inside 1214
Ending job inside 1213
Как вы можете видеть из выведенных нами на печать идентификаторов процессов, наше спланированное задание исполнялось в
различных процессах. Вы также можете отметить, что соответствующим идентификатором самого первого процесса был
1213, а в скорости наш планировщик запустил в применение процесс с идентификатором
1222, затем он переключился обратно к своему процессу
1213 (обратите внимание на самые последние несколько строк в нашем предыдущем выводе).
Это происходит потому, что наш пул процессов содержит 10 работников, а наш процесс
1222 был самым последним элементом в этом пуле.
Запуск в облаке
Ранее мы упоминали, что службы облачного решения, которые размещают код Python, такие как Heroku и PythonAnywhere
являются одним из наиболее используемых мест применения свойств APScheduler. В этом подразделе мы рассмотрим один пример
соответствующего руководства пользователя с веб-сайта Heroku, который можно отыскать в файле
Chapter19/example4.py:
# ch19/example4.py
# Copied from: http://devcenter.heroku.com/articles/clock-processes-python
from apscheduler.schedulers.blocking import BlockingScheduler
scheduler = BlockingScheduler()
@scheduler.scheduled_job('interval', minutes=3)
def timed_job():
print('This job is run every three minutes.')
@scheduler.scheduled_job('cron', day_of_week='mon-fri', hour=17)
def scheduled_job():
print('This job is run every weekday at 5pm.')
scheduler.start()
Вы можете видеть, что эта программа применяет декораторы для регистрации планируемых заданий в своём планировщике.
В частности, когда неким объектом scheduler вызывается соответствующий метод
scheduled_job(), эта инструкция может применяться целиком как некий декоратор функции
для преобразования её в некое спланированное задание для такого планировщика. Вы также можете видеть некий пример
спланированного задания cron в нашем предыдущем коде, который может исполняться в
предписанное время дня (в данном случае в 5:00 вечера в каждый выходной день).
В качестве окончательного замечания относительно APScheduler, мы можем видеть, что те инструкции, которые используют API данной библиотеки, также являются кодом на Python, а не отдельной службой самой по себе. тем не менее, принимая во внимание насколько гибкой является данная библиотека в предоставлении различных вариантов планирования и насколько она подключаема со своими программами в смысле работы с внешними службами (например, с базирующимися в облачных решениях), APScheduler является ценным инструментом для планирования приложений Python.
Как уже упоминалось ранее, проверка является существенным компонентом (пока часто недооцениваемым) разработки программного обеспечения в частности и программирования в целом. Основной целью проверки является продуцирование ошибок, которые указывали бы на присутствие ошибок в ваших программах. Это отличается от процесса от того процесса отладки, который применяется для выявления самих таких ошибок; мы обсудим основные вопросы отладки в своём следующем разделе.
В наиболее общем случае проверка это то, что определяет будут ли конкретные функции и методы способны исполняться и производить результаты как мы и ожидали от них; это обычно выполняется путём сопоставления тех результатов, что они производят. Иными словами, проверка это сбор доказательств правильности наших программ.
Тем не менее, проверка не может гарантировать что были выявлены все потенциальные дефекты и ошибки в вашей находящейся в рассмотрении программе. Кроме того, сами результаты проверки хороши только как тесты сами по себе и если эти тесты не охватили неких особенных потенциальных ошибок, тогда такие ошибки скорее всего не будут выявлены в процессе данного процесса проверок.
В данной главе мы будем рассматривать две различные темы проверок относительно совместной обработки: проверка программ совместной обработки и совместная проверка программ. Когда наступает время проверки программ совместной обработки, имеется общее мнение что она чрезвычайно требовательная и сложная для правильного применения. Как вы уже наблюдали это в наших предыдущих главах, такие ошибки как взаимные блокировки и условия состязательности могут быть достаточно скрытыми в программе совместной обработки могут проявлять себя многими способами.
Более того, одними из отличительных свойств параллельности является её недетерминизм, что означает что имеется возможность выявления ошибки совместной обработки при одном прогоне вашей проверки и того что она становится невидимой в следующий раз. Это происходит по той причине, что неким основным компонентом параллельного программирования выступает само планирование задач, и, как и сам порядок, в котором различные задачи исполняются в программе совместной обработки, ошибки совместной обработки могут проявляться или скрываться неким непредсказуемым манером. Мы называем такие проверки не имеющими повторяемости (не репродуцируемыми), чтобы указать на то, что мы не способны надёжно подтвердить прохождение или отказ некоей программой своих проверок каким- то последовательным образом.
Имея это ввиду, существуют некоторые общие стратегии, которые способны помочь нам в продвижении в процессе проверки параллельных программ. В нашем следующем разделе мы изучим те различные инструменты, которые могут способствовать нам в определённых стратегиях при проверке параллельных программ.
Тестирование элемента
Самой первой рассматриваемой нами стратегий является проверка элемента. Этот термин указывает на то, что мы выполняем проверку индивидуальных элементов своей программы, при которой некий элемент является самой наименьшей частью нашей программы. По этой причине проверка элемента не является средством проверки всей системы совместной обработки. В частности, вам не рекомендуется некую программу совместной обработки как нечто целое, а вместо этого разбивать эту программу на меньшие компоненты и проверять их по отдельности.
Как обычно, Python предоставляет библиотеки, которые предлагают интуитивно ясный API для решения наиболее распространённых
проблем в программировании; в данном случае это модуль unittest. Данный модуль
изначально был вдохновлён инфраструктурой проверки элемента для языка программирования Java JUnit; он также предоставляет
общие функции проверки элемента в других языках. Давайте рассмотрим некий быстрый пример того как мы можем воспользоваться
unittest для проверки некоторой функции Python в следующем файле
Chapter19/example5.py:
# Chapter19/example5.py
import unittest
def fib(i):
if i in [0, 1]:
return i
return fib(i - 1) + fib(i - 2)
class FibTest(unittest.TestCase):
def test_start_values(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
def test_other_values(self):
self.assertEqual(fib(10), 55)
if __name__ == '__main__':
unittest.main()
В данном примере мы бы хотели проверить свою функцию fib(), которая выабатывает
определённые элементы в последовательности Фибоначчи (в которой некий элемент является суммой двух своих предшествующих
элементов), причём её стартовыми значениями являются соответственно 0 и
1.
Теперь давайте сосредоточим своё внимание на нашем классе FibTest, который расширяет
соответствующий класс TestCase из модуля unittest.
Этот класс содержит различные методы, которые проверяют различные варианты получения результатов, возвращаемых нашей
функцией fib(). В частности, у нас есть некий метод, который просматривает
граничные варианты данной функции, коими выступают два самых первых элемента в этой последовательности и другой метод,
который проверяет некое произвольное значение в данной последовательности.
После исполнения предыдущего сценария ваш вывод должен быть похож на следующее:
> python3 unit_test.py
..
----------------------------------------------------------------------
Ran 2 tests in 0.000s
OK
Этот вывод указывает, что наши проверки прошли без каких бы то ни было ошибок. Дополнительно, как и подразумевало название самого класса, этот класс является неким индивидуальным вариантом проверки, который является проверкой элемента. Вы можете расширить различные варианты проверок в некий комплект проверок (test suite), который определяется как некая коллекция вариантов проверок, комплект проверок, или и то, и другое. Такие комплекты обычно применяются для сочетания проверок которые вы бы желали запускать совместно.
Анализ статического кода
Другим допустимым методом выявления потенциальных ошибок и неточностей в ваших программах совместной обработки является выполнение анализа статического кода. Это метод просматривает сами шаблоны имеющегося кода вместо того чтобы исполнять некоторые (или все) части данного кода. Иными словами, анализ статического кода инспектирует некую программу визуально просматривая её структуру, само использование переменных и инструкций и того как различные части данной программы взаимодействуют друг с другом.
Основным преимуществом статического анализа кода является то, что мы не полагаемся только на исполнение своей программы и те результаты, которые воспроизводит такой процесс (иначе говоря, динамическое тестирование) для определения того насколько правильно спроектированы данные программы. Этот метод способен выявлять ошибки и недочёты которые не проявляют себя самостоятельно (простым образом, или вовсе) при воспроизведении проверок. По этой причине анализ статического кода следует сочетать с прочими методами проверок, например, проверкой элементов, для создания всестороннего процесса проверки.
Анализ статического кода часто применяется для выявления скрытых ошибок или недочётов, таких как неиспользуемые переменные, пустые блоки ловушек, или даже недостаточное создание объекта. В смысле программирования совместной обработки этот метод может быть использован для анализа технологий синхронизации, применяемых в некоторой программе. В частности, анализ статического кода может отыскивать атомарность совместных ресурсов в некоторой программе, затем выявлять некие не скоординированные случаи использования не являющихся атомарными ресурсов, которые могут вызывать причиняющие ущерб условия состязательности.
Для сопутствия анализу статического кода программ Python доступны различные инструменты, причём один из наиболее часто применяемых является PMD (https://github.com/pmd/pmd). Указав это, особые случаи применения данного инструментария выходят за рамки нашей книги и мы не будем далее обращаться к этой теме.
Другой стороной совместного тестирования и параллельного программирования является осуществление проверок неким
одновременным способом. та сторона тестирования более прямолинейна и интуитивно понятна нежели проверка программ
совместной обработки сама по себе. В данном подразделе мы исследуем некую библиотеку, которая способна помочь нам в
содействии такому процессу, concurrencytest, который способен бесшовно работать с
теми вариантами проверок, которые были реализованы в предыдущем модуле unittest.
concurrencytest разработан как некое расширение
testtools, которое реализует совместную обработку в запущенных тестовых комплектах.
Он может быть установлен при помощи PyPI с применением pip таким образом:
pip install concurrencytest
Кроме того, concurrencytest зависит от testtools
библиотек (pypi.org/project/testtools/)
и python-subunit
(pypi.org/project/python-subunit/),
которые являются, соответственно, неким проверочными расширениями инфраструктуры и потокового протокола для проверки
результатов. Эти библиотеки также могут быть установлены через pip
так:
pip install testtools
pip install python-subunit
Как всегда, для проверки вашей установки попробуйте импортировать соответствующую библиотеку в интерпретаторе Python:
>>> import concurrencytest
Отсутствие получения ошибок в выводе на печать означает что эта библиотека и её зависимости были успешно установлены.
Теперь давайте рассмотрим как эта библиотека поможет нам достичь лучшей скорости при наших проверках. Перейдите к
файлу Chapter19/example6.py и рассмотрите следующий код:
# Chapter19/example6.py
import unittest
def fib(i):
if i in [0, 1]:
return i
a, b = 0, 1
n = 1
while n < i:
a, b = b, a + b
n += 1
return b
class FibTest(unittest.TestCase):
def __init__(self, *args, **kwargs):
super(FibTest, self).__init__(*args, **kwargs)
self.mod = 10 ** 10
def test_start_values(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
def test_big_value_v1(self):
self.assertEqual(fib(499990) % self.mod, 9998843695)
def test_big_value_v2(self):
self.assertEqual(fib(499995) % self.mod, 1798328130)
def test_big_value_v3(self):
self.assertEqual(fib(500000) % self.mod, 9780453125)
if __name__ == '__main__':
unittest.main()
Основная цель приведённых в данном разделе примеров состоит в проверке тех функций, которые производят числа в последовательности
Фибоначчи, в частности, числа с большими индексами. Та функция fib(), которая
имеется у нас, аналогична приведённой в нашем предыдущем примере, хотя она и выполняет свои вычисления итеративно,
не пользуясь рекурсией.
В случае нашей проверки, помимо двух стартовых значений мы теперь проверяем числа с индексами 499 990, 488 995 и 500 000.
Так как получаемые в результате числа существенно больше, мы проверяем только самые последние десять цифр для каждого числа
(это осуществляется через атрибут mod в данном классе проверки, определяемом в самом
инициализируемом методе). Такой процесс проверки бедет исполнен в одном процессе, причём неким последовательным образом.
Запустите эту программу и ваш вывод должен быть похож на следующее:
> python3 example6.py
....
----------------------------------------------------------------------
Ran 4 tests in 8.809s
OK
И опять же, определённое в нашем выводе значение времени может меняться от системы к системе. Приняв это во внимание, запомните то количество времени, которое заняла данная программа, с тем, чтобы сравнить его со скоростью другой программы, которую мы рассмотрим позднее.
Теперь давайте рассмотрим как мы можем распределить свои рабочие нагрузки проверки по множеству процессов при помощи
concurrencytest. Рассмотрим следующий файл
Chapter19/example7.py:
# Chapter19/example7.py
import unittest
from concurrencytest import ConcurrentTestSuite, fork_for_tests
def fib(i):
if i in [0, 1]:
return i
a, b = 0, 1
n = 1
while n < i:
a, b = b, a + b
n += 1
return b
class FibTest(unittest.TestCase):
def __init__(self, *args, **kwargs):
super(FibTest, self).__init__(*args, **kwargs)
self.mod = 10 ** 10
def test_start_values(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
def test_big_value_v1(self):
self.assertEqual(fib(499990) % self.mod, 9998843695)
def test_big_value_v2(self):
self.assertEqual(fib(499995) % self.mod, 1798328130)
def test_big_value_v3(self):
self.assertEqual(fib(500000) % self.mod, 9780453125)
if __name__ == '__main__':
suite = unittest.TestLoader().loadTestsFromTestCase(FibTest)
concurrent_suite = ConcurrentTestSuite(suite, fork_for_tests(4))
runner.run(concurrent_suite)
Эта версия программы проводит испытание той же самой функции fib() при помощи
того же самого варианта проверки. Тем не менее, в своей основной программе мы инициализируем некий экземпляр своего класса
ConcurrentTestSuite из нашей библиотеки concurrencytest.
Этот экземпляр получает некий комплект проверки, который был создан с помощью API TestLoader()
из модуля unittest, а также функции fork_for_tests()
с параметром 4 для определения того, что мы желаем использовать четыре отдельных процесса
для распределения своей процедуры проверки.
Теперь давайте исполним эту программу и сопоставим её скорость со скоростью наших предыдущих проверок:
> python3 example7.py
....
----------------------------------------------------------------------
Ran 4 tests in 4.363s
OK
Вы можете видеть, что таким методом со множеством процессов было достигнуто значительное улучшение в скорости. Тем не менее, это улучшение не подпадает в условия исключительной масштабируемости (обсуждавшиеся в Главе 16, Разработка параллельных структур данных, основанных на блокировании и отсутствии взаимных исключений); это происходит в следствии того, что при создании комплектов совместных проверок, которые могут исполняться по множеству процессов, имеются значительные накладные расходы.
Ещё один момент, который следует упомянуть состоит в том, что достаточно вероятно достичь той же самой установки со
множеством процессов, которую мы получили в этом случае, применяя традиционные инструменты программирования совместной
обработки, которые мы обсуждали в своих предыдущих главах, например, concurrent.futures
или multiprocessing. Имея это ввиду, наша библиотека
concurrencytest, как мы уже видели, способна избавлять от приготовления значительного
кода и тем самым снабжает неким простым и быстрым API.
В этом разделе мы обсудим различные современные стратегии отладки, которые могут применяться индивидуально или в сочетании с прочими, для выявления и пришпиливания тараканов в наших программах. В целом термин отладка применяется для обозначения того процесса, при котором программисты пытаются выявлять и разрешать проблемы или дефекты, которые в противном случае вызывали бы неверные результаты тех вычислительных приложений, которые они отправляют на постоянное проживание в промышленное применение.
Те стратегии, которые мы обсудим включают в себя общие стратегии отладки, а также особые технологии, которые применяются при отладке приложений совместной обработки. Некое системное применение этих стратегий улучшит ваш процесс отладки как в плане эффективности, так и в отношении скорости.
Прежде всего давайте вкратце рассмотрим некоторые из наиболее общих техник и инструментов, которые способствуют процессу отладки в Python.
-
Отладка выводом на печать: Возможно, это самый элементарный и интуитивно понятный метод отладки. Данный метод вовлекает вставку операторов вывода на печать определённых значений переменных или состояний функций в различные моменты исполнения рассматриваемой программы. Выполнение этого позволяет отслеживать как такие значения и состояния взаимодействуют и изменяются на протяжении всей программы, выдавая нам внутреннюю информацию об особенных ошибках или возбуждаемых исключительных ситуациях.
-
Ведение журнала: В информатике ведение журнала является определённым процессом записи различных событий, которые имеют место на протяжении исполнения некоторой определённой программы. По- существу, ведение журнала может быть достаточно похожим на отладку выводом на печать, однако оно обычно выполняет запись в некий файл журнала, который можно просмотреть позднее. Python предоставляет исключительные функции регистрации, заключённые во встроенном модуле
logging. Пользователи могут определять необходимый уровень важности для процесса ведения протокола; например, обычно можно регистрировать только важные события и операции, однако в процессе отладки можно протоколировать всё. -
Трассировка: Это ещё один вид отслеживания исполнения програмы. Трассировка следует за реальными подробностями нижнего уровня исполнения вашей программы в противовес только изменениям в переменных и функциях. Функции трассировки могут быть реализованы посредством метода Python
sys.settrace(). -
Применение отладчика: Порой самые мощные варианты отладки могут быть достигнуты через автоматические отладчики. Наиболее популярным в языке программирования Python является сам отладчик Python:
pdb. Этот модуль предоставляет интуитивно понятую среду отладки, которая реализует полезные функции, например, точки прерывания, пошаговое исполнение исходного кода или инспекцию стека.
И вновь, все предыдущие стратегии применимы как в обычных, так и в параллельных программах, а сочетание более чем одной из общего числа способно помочь программистам получать драгоценную информацию на протяжении такого процесса отладки.
Аналогично рассмотренным нами задачам проверки программ совместной обработки, отладка, когда она применяется в совместной обработке, может становиться возрастающе сложной и трудной. И вновь, это происходит по причине того факта, что совместные ресурсы могут взаимодействовать с (и изменяться) многими агентами, причём одновременно. Обозначая это, тем не менее, всё же имеются стратегии, которые могут спрямлять сам процесс отладки параллельных программ. Они включают в свой состав:
-
Минимизацию: Приложения совместной обработки обычно реализуются в сложных и взаимосвязанных системах. Отладка всей системы при проявлении ошибки может быть достаточно устрашающей и не вполне осуществимой. Данная стратегия заключается в изоляции различных частей всей системы на отдельные программы меньшего размера и выявлении именно той, которая отказывает точно так же как это происходит в системе большего масштаба. Здесь мы хотим разделять большую программу на всё меньшие и меньшие части до тех пор пока их уже нельзя будет разбивать более. Первоначальная ошибка после этого может быть более просто выявлена и исправлена.
-
Сведение к единственному потоку и процессу: Этот метод аналогичен минимизации, но сосредоточен только на одной стороне программирования совместной обработки: взаимодействии между различными потоками/ процессами. Исключив самый большой аспект совместной обработки в своём параллельном программировании вы можете изолировать ошибки либо в самой логике данной программы (которая способна вызывать ошибки даже при последовательном исполнении) либо самого взаимодействия между потоками/ процессами (которые могут быть результатом общих недочётов одновременности, которые мы обсуждали в предыдущих главах)..
-
Манипуляции планированием для усиления потенциальных недочётов: В действительности мы уже наблюдали этот метод в предыдущих главах. Некие недочёты совместной обработки часто не заявляют о себя если те потоки/ процессы, которые реализованы в нашей программе, не спланированы на исполнение неким особым манером. Например, некое имеющее место условие состязательности может не воздействовать на какой- то совместный ресурс если взамодействие между ним и прочими агентами происходит настолько быстро, что они не перекрываются очень часто. Это влечёт за собой то факт, что проверка может не выявлять какое бы то ни было условие состязательности, даже хотя оно на самом деле и имеется в данной программе.
Для усиления неверных значений и операций, являющихся результатом недочётов совместной обработки в Python могут
быть реализованы различные метода. Двумя из наиболее распространённых являются распушка (fuzzing), достигаемая за счёт
вставки функция сна между командами в инструкциях потока/ процесса, и минимизация интервала переключения потока,
получаемая применением метода sys.setcheckinterval() (Обсуждённого в
Главе 17, Модели памяти и операции атомарных типов). Эти методы
нарущают обычные протоколы планирования исполнения потока или процесса в Pyhon различными способами и могут действенно
обнажать скрытые недочёты совместной обработки.
В этой главе мы предоставили анализ программ совместной обработки Python на верхнем уровне посредством планирования, проверки и отладки. Планирование в Python может осуществляться при помощи имеющегося модуля APScheduler, который предоставляет мощные и гибкие функции для определения того как планировать задания, которые следует исполнить позднее в определённом будущем. Более того, этот модуль позволяет планировать задания для распределения и исполнения по различным потокам и процессам, предлагая некое улучшение совместной обработки в проверке скорости.
Совместная обработка также вносит сложные задачи в отношении проверки и отладки, что является результатом одновременности и параллельного взаимодействия между имеющимися агентами в некоторой программе. Тем не менее, к этим задачам можно осуществлять действенный подход с помощью методических решений и соответствующих инструментов.
Этот раздел завершает наше путешествие по Полному руководству параллельного программирования на Python. На протяжении данной книги мы глубоко рассмотрели и проанализировали различные элементы программирования совместной обработки на языке Python, такие как потоки, множество процессов и асинхронное программирование. Также, дополнительно к общим проблемам, с которыми сталкиваются программисты работая с параллельностью в Python, были обсуждены мощные приложения с вовлечением совместной обработки, такие как управление контекстом, понижающие операции, обработка изображений и сетевое программирование.
В самом общем смысле данная книга служит руководством к некоторым из наиболее развитых понятий совместной обработки; я надеюсь, что прочитав данную книгу вы получите возможность хорошо разбираться в вопросах программирования совместной обработки.
-
Что представляет из себя APScheduler? Почему он не является некоторой службой планирования?
-
В чём состоят основные функциональные возможности APScheduler?
-
В чем состоят отличия между APScheduler и другим инструментом планирования в Python, Celery?
-
В чём состоит цель проверки в программировании? Как она отличается в программировании совместной обработки?
-
Какие методы проверки обсуждались в данной главе?
-
В чём состоит цель отладки в программировании? Как она отличается в программировании совместной обработки?
-
Какие методы отладки обсуждались в данной главе?
Для получения дополнительных сведений вы можете воспользоваться следующими ссылками:
-
Scheduled Jobs with Custom Clock Processes in Python with APScheduler
-
The Architecture of APScheduler, Джу Лин
-
APScheduler 3.0 released, Алекс Грёнхольм
-
Testing Your Code (The Hitchhiker's Guide to Python), Кеннет Рейц
-
Python – concurrencytest: Running Concurrent Tests, Коури Голдсберг
-
Getting Started With Testing in Python, Энтони Шоу
-
Tracing python code, Эндрю Далки