Глава 5. Хранилище libvirt
Содержание
- Глава 5. Хранилище libvirt
- Введение в хранилище
- Пулы хранения
- Пул хранения NFS
- Хранилище iSCSI и SAN
- Избыточность хранилища и множество путей
- Gluster и Ceph в качестве основы хранения для KVM
- Виртуальные образы диска и форматы, а также базовые операции хранилища KVM
- Самые последние развёртывания в хранилище - NVMe и NVMeOF
- Выводы
- Вопросы
- Дополнительное чтение
Эта глава снабдит вас внутренними сведениями о том способе, коим KVM использует хранилище. В частности, мы рассмотрим как хранилище, которое является внутренним для самого хоста, в котором запущены виртуальные машины,так и разделяемое хранилище. Не позволяйте этой терминологии запутать вас в данном случае - в технологии виртуализации и облачных решений термин разделяемого хранилища означает пространство хранения, к котором могут осуществлять доступ множество гипервизоров. Как мы поясним чуть позднее, три наиболее распространённых способа достижения этого состоят в применении хранилищ блочного уровня, разделяемого уровня и уровня объектов. В качестве некого примера хранилища разделяемого уровня мы воспользуемся NFS, а iSCSI (Internet Small Computer System Interface) и FC (Fiber Channel) как примеры хранилища блочного уровня. С точки зрения основанного на объектах хранилища мы применим Ceph. GlusterFS также широко применяется в ниши дни, поэтому мы уделим внимание и ей. Чтобы завернуть всё это в простой для использования и лёгкий в управление блок, мы обсудим некоторые проекты с открытым исходным кодом, которые способны помочь вам при практике и создания сред тестирования.
В этой главе мы рассмотрим следующие вопросы:
-
Введение в хранилище
-
Пулы хранения
-
Хранилище NFS
-
Хранилище iSCSI и SAN
-
Избыточность хранилища и множество путей
-
Gluster и Ceph как серверное хранилище для KVM
-
Образы виртуальных дисков, а также форматы и основы операций хранилища KVM
-
Самые последние разработки в хранилищах - NVMe и NVMeOF
В отличии от построения сетевых сред, которые представляют собой нечто, о чём большинство ИТ специалистов имеют, по крайней мере, базовое представление,в отношении хранилищ тенденция достаточно отличается. Короче говоря, да, они имеют склонность быть слегка сложнее. Существует множество вовлекаемых параметров, отличающихся технологий, и ... давайте будем честны, разнообразные типы вариантов конфигураций и применяющих их людей. А также множество вопросов. Вот некоторые из них:
-
Следует ли нам настраивать одну совместную NFS на устройство хранения или две?
-
Нужно ли нам создавать одну цель iSCSI на устройство хранения или две?
-
Надлежит ли нам создавать одну цель FC или две?
-
Сколько LUN (Logical Unit Numbers) на цель?
-
Какой размер кластера следует нам применять?
-
Как нам следует позаботиться о множестве путей?
-
Следует ли еам воспользоваться хранилищем блочного уровня или разделяемого уровня?
-
Следует ли еам воспользоваться хранилищем блочного уровня или объектного уровня?
-
Какую именно технологию или решение нам надлежит выбрать?
-
Как нам стоит настроить кэширование?
-
Как нам требуется настраивать зонирование и маскирование?
-
Сколько коммутаторов надлежит применять?
-
Стоит ли нам воспользоваться неким видом кластерной технологии на уровне хранилища?
Как вы можете видеть, эти вопросы продолжают накапливаться, а мы едва лишь коснулись самой поверхности, потому как имеются также вопросы о том, какую именно файловую систему применять, какой физический контроллер мы будем применять для доступа к хранилищу, и какой тип кабеля - это просто превращается в большую смесь переменных, у которой имеется множество потенциальных ответов. А что ещё хуже, что правильными может быть множество ответов - а не один из них.
Давайте избавимся от вычислений базового уровня. В среде корпоративного уровня общее хранилище обычно является наиболее затратной частью окружения, а также способно оказывать наиболее значительное отрицательное воздействие на производительность и в то же самое время самым перегруженным ресурсом в такой среде. Давайте задумаемся об этом на мгновение - всякая включённая виртуальная машина постоянно собирается молотить наше устройство хранение операциями ввода/ вывода. Когда у нас имеется 500 виртуальных машин, запущенных в единственно устройстве хранения, не слишком ли многого мы требуем от такого устройства хранения?
В то же самое время некий вид разделяемого хранилища это ключевая опора виртуальных сред. Основной принцип прост - имеется множество современных функциональных возможностей, которые будут работать намного лучше с совместным хранилищем. Кроме того, при наличии общего хранилища многие операции выполняются намного бустрее. Более того, имеется очень много простых вариантов высокой доступности когда наши виртуальные машины не хранятся в том же самом месте, в котором им надлежит выполняться.
В качестве премии мы запросто можем избегать ситуаций со SPOF (Single Point Of Failure, Единой точкой отказа) если мы спроектируем своё совместное хранилище как подобает. На уровне корпорации исключение SPOF это один из ключевых принципов проектирования. Однако когда мы начинаем добавлять коммутаторы, а также адаптеры и контроллеры в свой перечень покупок, у наших менеджеров или клиентов как правило начинается головная боль. Мы говорим о производительности и рисках управления, в то время как они твердят о цене. Мы говорим, что их базы данных и приложения нуждаются в правильном подпитывании с точки зрения ввода, вывода и полосы пропускания, а они предполагают, что всё это вы способны соткать из воздуха. Просто взмахните волшебной палочкой и вуаля: хранилище неограниченной производительности.
Однако наилучшее и во все времена любимейшее сопоставление яблок с апельсинами, которое наверняка ваши клиенты попытаются вам навязать, звучит примерно так: "прекрасный новый NVMe SSD 1ТБ в моём ноутбуке обладает в 1 000 раз большим числом IOPS и более чем в 5 раз большей производительностью нежели ваше устройство хранения за $50 000 и в то же время стоит в 100 раз меньше! Вы не понимаете что вы делаете!"
Если вы это переживали, мы вам сочувствуем. Редко вы встретите так много дискуссий и боёв по поводу куска железа из коробки. Но это настолько важный законченный кусок железа, что им неплохо обладать. Итак, давайте поясним некоторые ключевые понятия, которые применяет libvirt с точки зрения доступа к хранилищу и работы с ним. Затем давайте воспользуемся своими знаниями для извлечения той производительности, которая только возможна в нашей системе хранения и применяется в libvirt.
В этой главе мы в целом намерены охватить почти все типы хранилищ через примеры установки и настройки. Каждый из них обладает собственным вариантом применения, но, как правило, выбор того, что вы намерены применять, остаётся за вами.
Итак, давайте пустимся в своё путешествие по этим поддерживаемым протоколам и изучим как их настраивать. После того, как мы рассмотрим пулы хранения, мы собираемся обсудить NFS, типичный протокол общего уровня доступа для хранения виртуальных машин. Затем мы намерены перейти к протоколам блочного уровня, таким как iSCSI и FC. После этого мы перейдём к избыточности и множеству путей для увеличения доступности и пропускной способности наших устройств хранения. Мы также намерены рассмотреть различные варианты применения не очень распространённых файловых систем (таких как Ceph, Gluster и GFS) для виртуализации KVM. Мы также собираемся обсудить новые разработки, которые в настоящее время являются основной тенденцией.
Когда вы впервые начинаете использовать устройства хранения - даже когда это недорогие коробки - вы сталкиваетесь с несколькими вариантами. Они попросят вас выполнить небольшую настройку - выбрать уровень RAID, настроить горячее резервирование, кэширование SSD... это всё некий процесс.Тот же самый процесс применяется и в том случае, когда вы с нуля собираете центр обработки данных или расширяете уже имеющийся. Чтобы иметь возможность применять своё хранилище, вам требуется его настроить.
Когда речь заходит о хранилищах, гипервизоры слегка привередливы, ибо имеются типы хранилищ, которые они поддерживают и типы хранилищ, которые они не поддерживают. К примеру, Hyper-V Microsoft поддерживает разделяемые ресурсы SMB как хранения виртуальных машин и в действительности не поддерживает для хранения виртуальных машин NFS. Гипервизор vSphere VMware поддерживает NFS, но не поддерживает SMB. Основная причина проста - разрабатывающая гипервизор компания выбирает и квалифицирует те технологии, которые будет сопровождать её гипервизор. Далее различные производители HBA/ контроллеров (Intel, Mellanox, QLogic и тому подобные) должны разработать под это гипервизор драйверы, а поставщик хранилища принимает решение какие типы протоколов хранения он намерен поддерживать в своём устройстве хранения.
С точки зрения CentOS имеется множество различных поддерживаемых типов пулов хранения. Вот некоторые из них:
-
Пулы хранения на основе LVM (Logical Volume Manager)
-
Пулы хранения на основе каталога
-
Пулы хранения на основе разделов
-
Пулы хранения на основе GlusterFS
-
Пулы хранения на основе iSCSI
-
Пулы хранения на основе дисков
-
Пулы хранения на основе HBS, которые применяют устройства SCSI
С точки зрения libvirt, неким пулом хранения может выступать каталог, устройство хранения или файл, которыми управляет libvirt. Это приводит нам к более чем десятку различных типов пулов хранения, с которыми вы намерены встретиться в нашем следующем разделе. С точки зрения виртуальной машины, libvirt управляет хранилищем виртуальной машины, которое виртуальная машина применяет с тем, чтобы у неё была необходимая ёмкость для хранения данных.
oVirt, с другой стороны, смотрит на вещи несколько иначе, поскольку он обладает своей собственной службой, которая работает с libvirt для предоставления централизованного управления хранилищем с точки зрения центра обработки данных (ЦОД). Точку зрения ЦОД может показаться несколько странным термином. Но задумайтесь об этом - ЦОД это своего рода объект верхнего уровня, в котором вы можете наблюдать все свои ресурсы. ЦОД применяет хранилище и гипервизоры для снабжения нас всеми теми службами, которые требуются нам при виртуализации - виртуальными машинами, виртуальными сетями, доменами хранения и тому подобным. В целом, с точки зрения ЦОД, вы способны наблюдать за всем что происходит во всех ваших хостах, которые являются участниками этого ЦОД. Тем не менее, на уровне хоста вы не имеете возможности наблюдать что происходит на другом хосте. Именно такая иерархия логична как с точки зрения управления, так и с точки зрения безопасности.
oVirt способен централизованно управлять такими типами пулов хранения (и этот список может становиться больше или меньше с годами):
-
NFS (Network File System)
-
pNFS (Parallel NFS)
-
iSCSI
-
FC
-
Локальное хранилище (напрямую подключаемое к хостам KVM)
-
Экспорты GlusterFS
-
Совместимые с POSIX файловые системы
Давайте сначала озаботимся о некоторой терминологии:
-
Brtfs это некий тип файловой системы, которая поддерживает моментальные снимки, функциональные возможности подобные RAID и LVM, сжатие, дефрагментацию, изменение размера в реальном масштабе времени и множество прочих современных свойств. Имеются возражения против неё, после того как было выявлено, что её RAID5/6 запросто может приводить к утрате данных.
-
ZFS это тип файловой системы, которая поддерживает всё, что выполняет Btrfs и плюс к этому кэширует чтение и запись (подробнее...).
В CentOS появился новый способ работы с пулами хранения. Несмотря на то, что он всё ещё пребывает в состоянии предварительного ознакомления с технологией, стоит пройти полную настройку при помощи этого нового инструментария с названием Stratis (Слоистые облака). По существу, пару лет назад Red Hat целиком отказалась от идеи продвигать Btrfs в последующих выпусках и приступила к работе над Stratis. Если вы когда- нибудь применяли ZFS, то, скорее всего, это именно то что вам требуется - простой в управлении, схожий с ZFS набор утилит управления томами, который Red Hat может поддерживать в своих последующих выпусках {Прим. пер.: в текущих версиях RHEL (8.3) Stratis не отрабатывает отказы в жёстких дисках или прочем оборудовании, в случае создания пула хранения на множестве устройств имеется возможность утраты данных в случае выхода из строя их множественного отказа}. К тому же, также как и ZFS, основанный на Stratis пул способен применять кэширование; а потому, когда вы хотите выделить под кэширование пула некий SSD, вы в самом деле также можете сделать это. Если вы ожидали что Red Hat будет поддерживать ZFS, имейте в виду что имеется основополагающая политика Red Hat, которая препятствует такому развитию. В частности, ZFS не является частью ядра Linux, в основном по причинам лицензирования. Для подобных случаев у Red Hat имеется некая политика - когда это не является частью ядра Linux (восходящего потока), они не поддерживают это и не сопровождают. В нынешнем виде этого не произойдёт в обозримом будущем. Такие же политики отражаются и в CentOS. {Прим. пер.: тем не менее, имеются Open Source решения поддержки ZFS Linux, например, см. наш перевод первых глав Введение в ZFS для Linux Дамиана Войслава.}
С другой стороны, Stratis доступен прямо сейчас. Мы намерены воспользоваться им для управления своим локальным хранилищем путём создания пулов хранения. Создание пула потребует от нас предварительно настроить разделы или диски. После того как мы создадим некий пул, мы можем создать поверх него том. Нам требуется быть осторожным лишь в одном: хотя Stratis и способен управлять файловыми системами XFS, нам не следует вносить изменения в управляемые Stratis файловые системы XFS непосредственно на уровне файловых систем. Например, не изменяйте и не форматируйте повторно файловую систему на основе Stratis непосредственно из основанных на XFS команд, ибо вы наведёте в своей системе хаос.
Stratis поддерживает разнообразные различные типы блочных устройств хранения:
-
Жесткие диски и SSD
-
iSCSI LUN
-
LVM
-
LUKS
-
MD RAID
-
Соответствие устройств со множеством путей
-
Устройства NVMe
Давайте начнём с нуля и установим Stratis с тем, чтобы вы могли воспользоваться им. Давайте применим такие команды:
# dnf -y install stratisd stratis-cli
# systemctl enable --now stratisd
Самая первая команда установит необходимую службу Stratis и соответствующие утилиты командной строки. Вторая запустит и включит саму службу Stratis.
Теперь мы собираемся пройтись по полному примеру того как применять Stratis для настройки ваших устройств хранения. Мы намерены рассмотреть некий образец такого подхода со множеством уровней. Итак, мы намерены выполнить это следующим образом:
-
При помощи MD RAID создать некий программный RAID10 + запас.
-
Из утого MD RAID устройства создать пул Stratis.
-
Добавить устройство кэширования в свой пул для того чтобы применить возможности кэширования Stratis.
-
Создать файловую систему Stratis и смонтировать её в своём локальном сервере.
Основная предпосылка здесь проста - программный RAID10 + резерв будут приближены к стандартному промышленному подходу в котором у вас будет иметься некий аппаратный RAID контроллер, представляющий отдельное блочное устройство для имеющейся системы. Мы намерены добавить в свой пул устройство кэширования, чтобы проверить функциональные возможности кэширования, ибо это именно то, что мы скорее всего бы сделали, когда мы воспользовались бы ZFS. Затем мы намерены создать поверх этого пула файловую систему и смонтировать её в локальном каталоге при помощи следующих команд:
# mdadm --create /dev/md0 --verbose --level=10 --raid-devices=4 /dev/sdb /dev/sdc /dev/sdd /dev/sde --spare-devices=1 /dev/sdf2
# stratis pool create PacktStratisPool01 /dev/md0
# stratis pool add-cache PacktStratisPool01 /dev/sdg
# stratis pool add-cache PacktStratisPool01 /dev/sdg
# stratis fs create PackStratisPool01 PacktStratisXFS01
# mkdir /mnt/packtStratisXFS01
# mount /stratis/PacktStratisPool01/PacktStratisXFS01 /mnt/packtStratisXFS01
Эта смонтированная файловая система отформатирована под XFS. Затем мы запросто можем применять эту файловую систему через экспорт NFS, что именно то, что мы намерены выполнить в своём уроке по хранилищу NFS. Однако теперь это всего лишь просто пример того как создать пул при помощи Stratis.
Мы рассмотрели некоторые основы локальных пулов хранения, которые подводят нас ближе к нашему следующему предмету, который состоит в том как применять пулы с точки зрения libvirt. Итак, это будет нашей следующей темой.
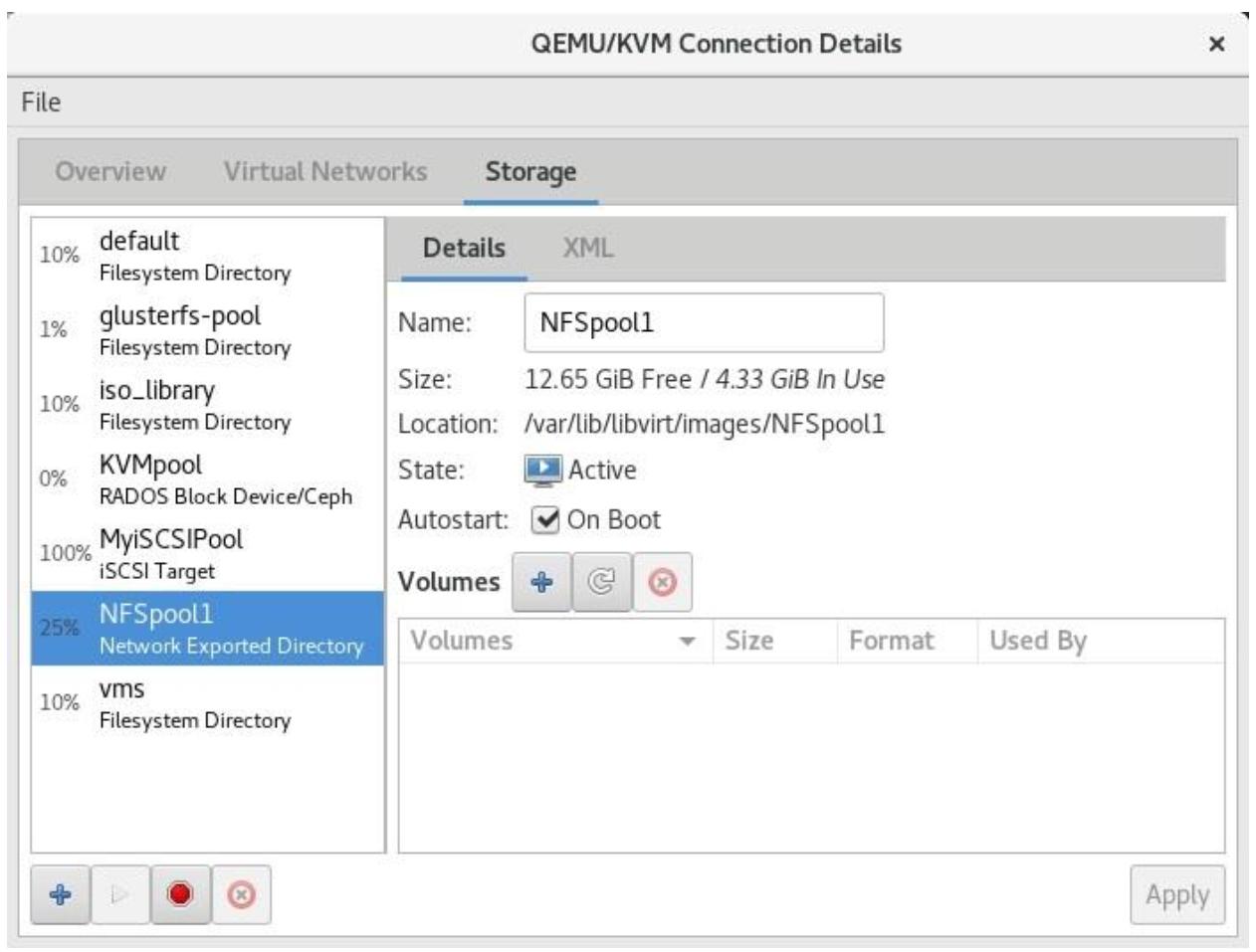
Libvirt управляет своими собственными пулами хранения, что осуществляется с единственной мыслью на уме - для предоставления различных пулов под диски виртуальных машин и связанные с ними данные. Имея в виду что libvirt применяет то, что поддерживает лежащая в его основе операционная система, не будет удивительным то, что он поддерживает загрузку различных типов пулов хранения. Картинка будет лучше тысячи слов, а потому вот некий снимок экрана создания пула хранения libvirt из virt-manager:
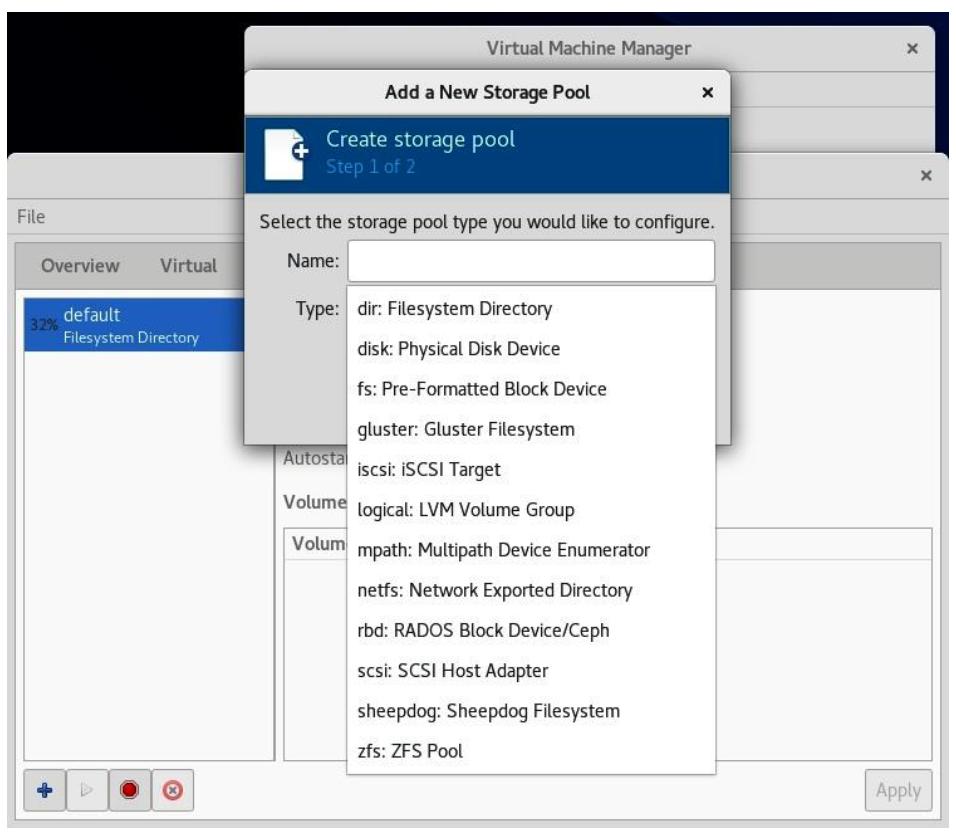
Сразу после установки libvirt уже обладает неким предопределённым по умолчанию пулом хранения, которым является каталог
пула хранения в самом локальном сервере. Этот пул по умолчанию пребывает в каталоге
/var/lib/libvirt/images. Он представляет наше установленное по умолчанию
местоположение, в котором хранятся все данные из локально установленных виртуальных машин.
Мы собираемся создать разнообразные различные типы пулов хранения в своих последующих разделах - пут на основе NFS, пулы iSCSI и FC, а также пулы Gluster и Ceph: все до конца, без остатка.Мы также собираемся пояснить когда применять каждый из них, ибо будут рассмотрены различные варианты применения.
В качестве протокола NFS появился примерно начиная с середины 80-х. Первоначально он разрабатывался Sun Microsystems как некий протокол для совместного использования файлов, что и применяется вплоть до наших дней. В действительности он всё ещё разрабатывается, что несколько удивительно для технологии, которая настолько стара. К примеру, NFS версии 4.2 появился в 2016. В этой версии NFS получил очень большое обновление, например, следующее:
-
Копирование стороны сервера: Функциональная возможность, которая значительно улучшает значение скорости операции клонирования между серверами NFS проводя клонирование напрямую между серверами.
-
Разреженные файлы и резервирование пространства: Функциональность, которая расширяет тот способ, коим NFS работает с файлами, которые обладают не выделенными блоками, в то же время отслеживая одним глазом ёмкость с тем, чтобы обеспечивать пространство при нашей потребности в записи данных.
-
Поддержка блочных данных приложения: Свойство, которое помогает приложениям, работающим с файлами как с блочными устройствами (дисками).
-
Лучшая реализация pNFS.
Имеются и иные моменты, улучшенные в версии 4.2, но на данный момент этого более чем достаточно. Вы можете отыскать дополнительные сведения об них в документе IETF RFC 7862. Мы намерены сфокусировать ваше внимание на реализации NFS v4.2, в частности, поскольку это лучшее из того что NFS способен предложить в настоящее время. К тому же, это поддерживаемая по умолчанию версия CentOS 8.
Самый первый момент, который нам надлежит выполнить, это установить все необходимые пакеты. Мы намерены достичь этого следующими командами:
# dnf -y install nfs-utils
# systemctl enable --now nfs-server
Первая команда устанавливает все необходимые утилиты для запуска сервера NFS. Вторая предназначена для его запуска и оставления его на постоянной основе с тем, чтобы служба NFS была доступной после перезапуска.
Наша следующая задача состоит в настройке того что мы намерены совместно применять через свой сервер NFS. Для этого нам
требуется экспортировать некий каталог и превратить его в доступный для
своих клиентов по сети. NFS применяет для этой цели файл настроек, /etc/exports.
Допустим, мы желаем создать некий каталог с названием /exports и затем
разделять его для свои клиентов сетевой среде 192.168.159.0/255.255.255.0 и мы
хотим разрешить им запись данных в этом совместном ресурсе. Наш файл /etc/exports
должен выглядеть следующим образом:
/mnt/packtStratisXFS01 192.168.159.0/24(rw)
exportfs -r
Эти параметры настроек сообщают нашему серверу NFS какой каталог экспортировать
(/exports), для каких клиентов
(192.168.159.0/24) и какие параметры применять
(rw означает чтение- запись).
Некоторые прочие доступные параметры включают следующее:
-
ro: Режим только для чтения. -
sync: Синхронные операции ввода, вывода. -
root_squash: Все операции отUID 0иGID 0приводятся в соответствие анонимным UID и GID (значениям параметровanonuidиanongid). -
all_squash: Все операции от любыхUIDиGIDприводятся в соответствие анонимным UID и GID (параметрамanonuidиanongid). -
no_root_squash: Все операции отUID 0иGID 0соответствуютUID 0и иGID 0.
Коглда вам требуется применить множество параметров в экспортируемый каталог, вы добавляете их с запятой между ними следующим манером:
/mnt/packtStratisXFS01 192.168.159.0/24(rw,sync,root_squash)
Вы можете применять полные доменные имена (FQDN) или краткие названия хостов (когда они разрешимы через DNS или
любой прочий механизм). Кроме того, если вам не нравится применение префиксов (24),
вы можете применять обычные сетевые маски следующим образом:
/mnt/packtStratisXFS01 192.168.159.0/255.255.255.0(rw,root_squash)
Теперь, когда у нас имеется настроенный сервер NFS, давайте рассмотрим как мы намерены настроить libvirt на
применение этого сервера в качестве пула хранения. Кк всегда, для исполнения этого имеется пара способов. Мы можем
просто создать некий файл XML с соответствующим определением пула и импортировать его в свой хост KVM при помощи
команды virsh pool-define --file. Вот некий образец такого файла
конфигурации:
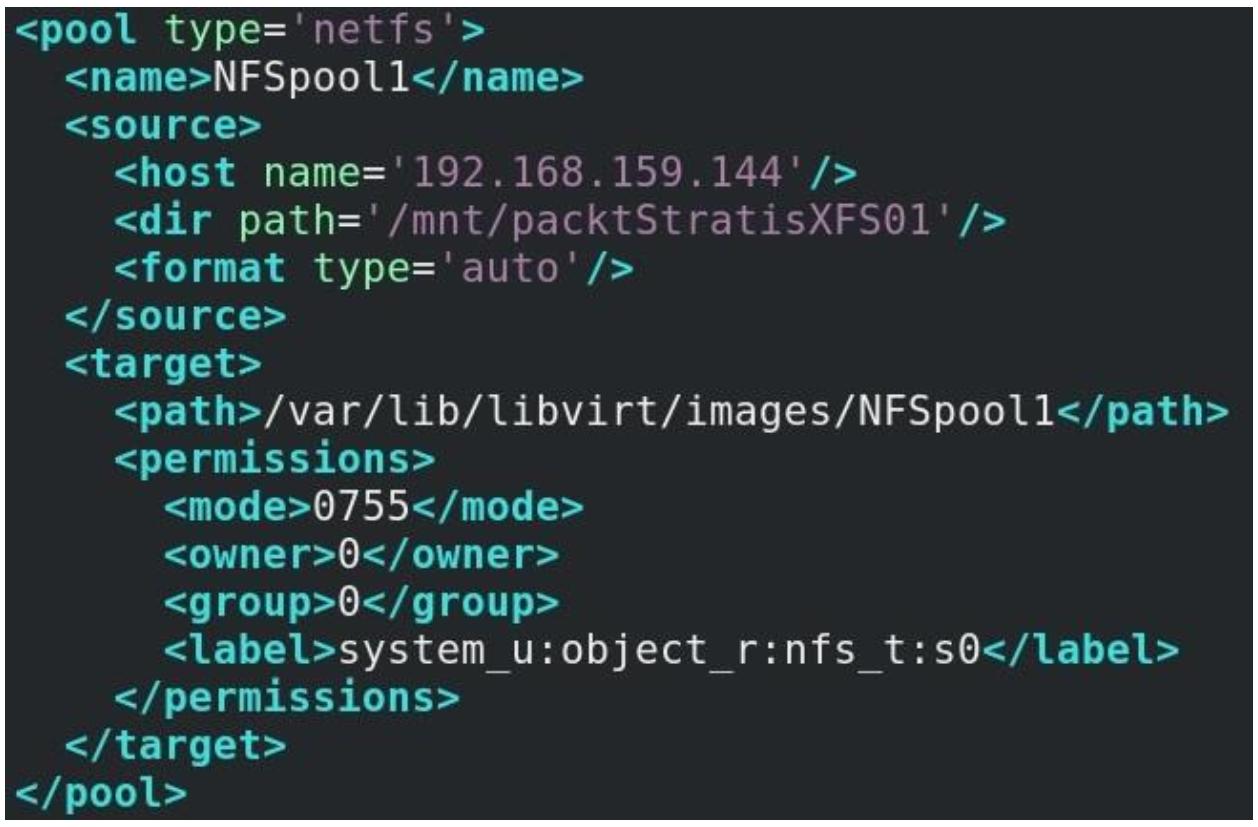
Давайте поясним эти варианты настроек:
-
pool type:netfsозначает что мы намерены применять совместный файловый ресурс NFS. -
name: Название этого пула, которое libvirt применяет для именования объектов, так же как в случае виртуальных сетей. -
host: Значение адреса того сервера NFS, к которому мы подключены. -
path: Значение локального каталога в нашем хосте KVM, в которой мы собираемся смонтировать этот совместно применяемый ресурс. -
dir path: Значение экспортируемого пути NFS, которое мы настроили в своём сервере NFS через/etc/exports. -
permissions: Значения полномочий, применяемые для монтирования этой файловой системы. -
ownerиgroup: Значения UID и GID, применяемые для целей монтирования (именно поэтому мы экспортируем данную папку ранее с параметромno_root_squash). -
.label: Значение метки SELinux для этой папки - мы намерены обсудить это в Главе 16, Руководство по поиску и устранению неисправностей KVM
Если мы пожелаем, мы запросто можем сделать то же самое через графический интерфейс Диспетчера Виртуальных машин. Прежде всего нам потребуется выбрать верный тип (пул NFS) и присвоить ему название:
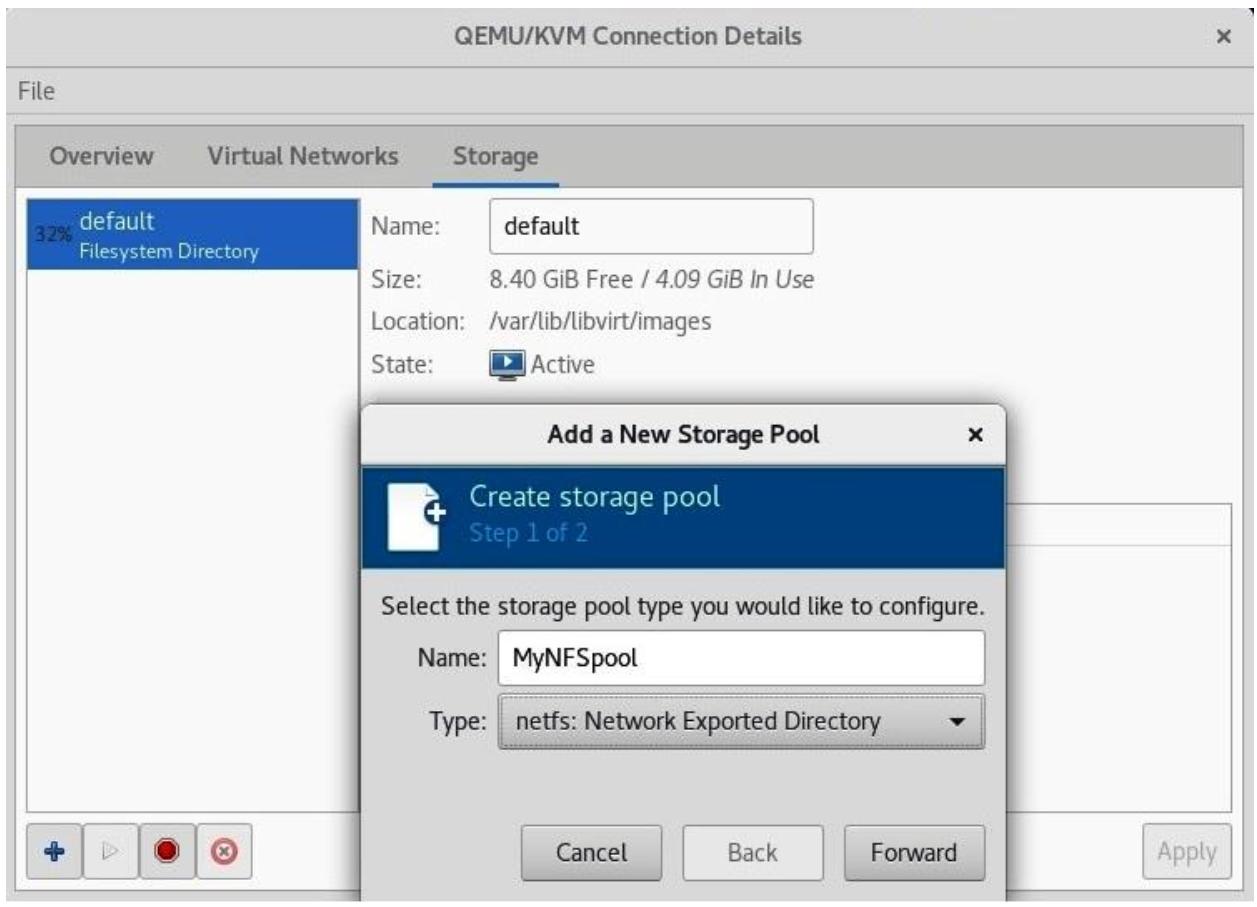
После этого мы кликаем по Forward и мы можем перейти к окончательному этапу, когда нам требуется сообщить своему мастеру с какого именно сервера мы монтируем свой совместный ресурс NFS:
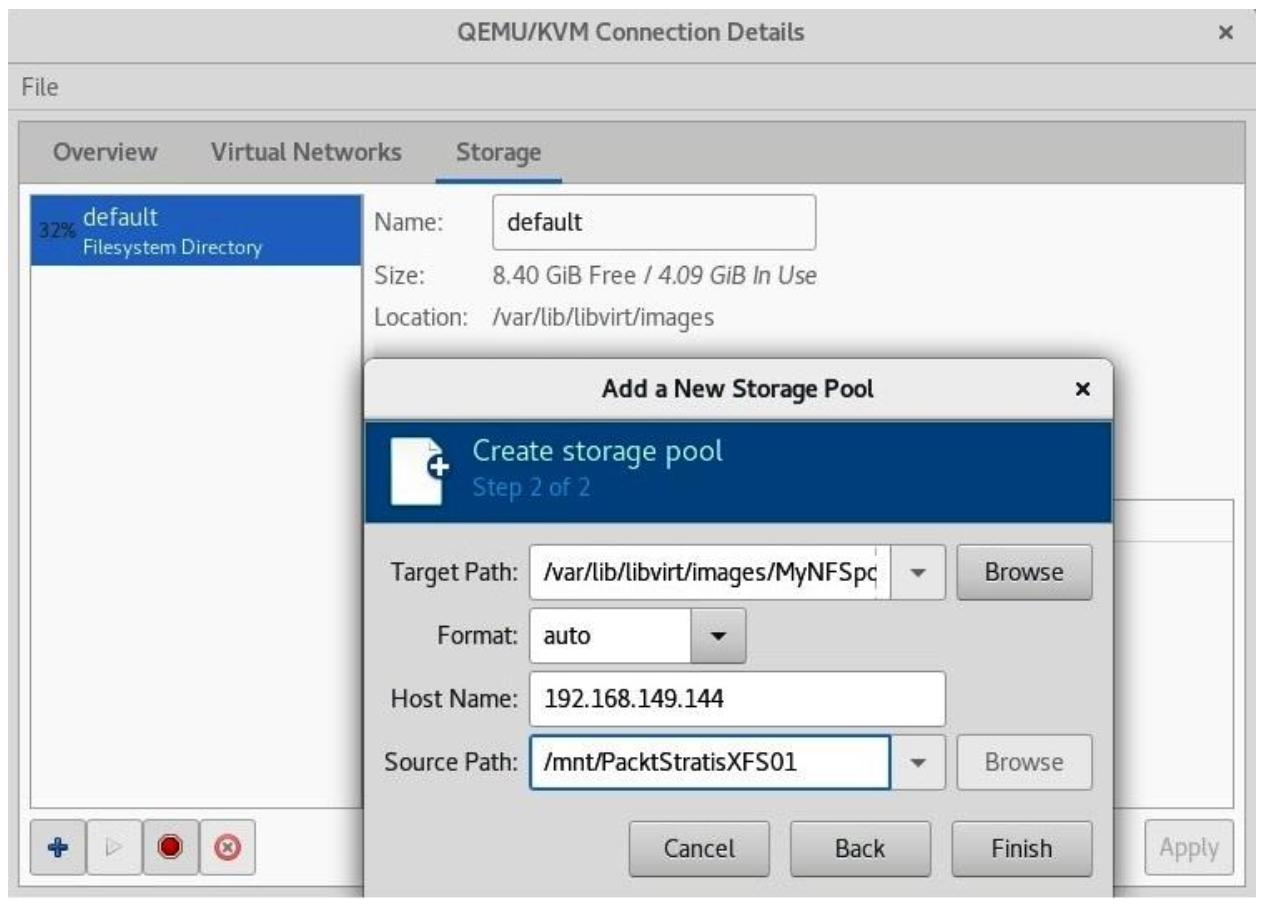
Когда мы завершим набор этих параметров настройки (Host Name и Source Path) мы можем нажать Finish, что будет означать выход из этого мастера. Кроме того, наш предыдущий экран конфигурации, который содержал лишь пул хранения default, будет обладать в перечислении также и вновь настроенным пулом:
Когда бы мы могли применять пулы хранения на основе NFS в libvirt и с какой целью В целом, мы можем прекрасно пользоваться ими для всего связанного с хранением образов установки - файлами ISO, файлами виртуальных гибких дисков, файлами виртуальных машин и тому подобного.
Помните, пожалуйста, что даже несмотря на то, что совсем недавно казалось, что NFS практически покинул корпоративные среды, NFS всё ещё имеется. На самом деле, с появлением NFS 4.1, 4.2 и pNFS, его будущее на данном рынке выглядит даже лучше чем пару лет назад. Это настолько знакомый протокол со столь длительной историей, который всё ещё достаточно конкурентоспособен во многих ситуациях. Если вы знакомы с технологией виртуализации VMware, VMware представила в ESXi 6.0 технологию с названием Virtual Volumes. Это технология объектно- ориентированного хранилища, которая способна пользоваться в качестве своей основы как протоколами на основе блоков, так и на основе NFS, что в самом деле является убедительным вариантов для применения в ряде ситуаций. Но пока мы двинемся к технологиям блочного уровня, таким как iSCSI и FC.
Применение iSCSI для хранения виртуальных машин давно стало обычным делом. Даже если принять во внимание тот факт, что iSCSI не самый действенный способ хранения данных, он всё равно настолько широко распространён, что вы найдёте его повсюду. Эффективность снижается по двум причинам:
-
iSCSI вставляет команды SCSI в обычные пакеты IP, что означает сегментацию и накладные расходы, поскольку пакеты IP обладают достаточно большим заголовком, что подразумевает меньшую эффективность.
-
Ещё хуже, они основываются на TCP, что означает что имеются последовательные номера и переповторы, что приводит к выстраиванию очередей и задержкам, причём чем больше среда, тем больше ваши виртуальные машины обычно ощущают такие воздействия.
При этом тот факт, что он основан на стеке Ethernet, упрощает развёртывание стека на основе iSCSI, но в то же самое время создаёт некоторые уникальные проблемы. Например, иногда сложно объяснить заказчику, что применение одного и того же сетевого коммутатора (коммутаторов) для обмена виртуальных машин и обмена iSCSI - не лучшая идея. Что ещё хуже, так это то, что клиенты порой настолько ослеплены своим желанием сэкономить, что не понимают, что действуют против своих собственных интересов. Особенно когда речь идёт о пропускной способности сетевой среды. Большинство из нас попадало в такую ситуацию, пытаясь ответить на такой вопрос наших клиентов, как "но у нас уже имеется коммутатор Gigabit Ethernet, зачем вам что- то более быстрое?"
Всё дело в том, что при всей сложности iSCSI больше - это значит больше. Чем выше у вас скорость на стороне диска/ кэша/ контроллера и чем больше у вас пропускная способность на стороне сетевой среды, тем больше у вас шансов создать более быструю систему хранения. Всё это может сильно повлиять на производительность вашей виртуальной машины. Как вы обнаружите в разделе Избыточность хранилища и множество путей, вы и в самом деле самостоятельно можете создать очень хорошую систему хранения - как на iSCSI, так и на FC. Это может оказаться очень кстати, когда вы попытаетесь создать некий вид тестовой лаборатории/ среды чтобы поиграться по мере развития собственных навыков виртуализации KVM. Вы также можете применить эти знания и к прочим виртуальным средам.
Архитектуры iSCSI и FC очень похожи - они обе нуждаются в цели (цель iSCSI и цель FC) и неком инициаторе (инициатор iSCSI и инициатор FC). В данной терминологии такая цель является серверным компонентом, а его инициатор это компонент клиента. Проще говоря, инициатор подключается к цели для получения доступа к блочному хранилищу, представленному этой целью. Далее мы можем применять идентификатор инициатора чтобы ограничить то, что иницитор способен наблюдать в этой цели. Именно тут наша терминология начинает слегка различаться при сопоставлении iSCSI и FC.
В iSCSI идентичность его инициатора может определяться четырьмя различными свойствами:
-
iSCSI Qualifed Name (IQN): это уникальное название, которым обладают все инициаторы и цели при взаимодействии iSCSI. Мы можем сопоставить это с MAC или IP адресом в обычных сетевых средах на основе Ethernet. Вы можете представлять себе это следующим образом - ISN для iSCSI это то, чем служат MAC или IP адрес для сетевых сред на основе Ethernet.
-
IP address: все инициаторы будут обладать различными IP адресами, которые они применяют для подключения к своим целям.
-
MAC address: каждый инициатор обладает отличающимся MAC адресом на Уровне 2.
-
Fully Qualifed Domain Name (FQDN): представляет название самого сервера в том виде, который разрешим службой DNS.
С точки зрения iSCSI - в зависимости от его реализации - вы можете пользоваться любым их этих свойств для создания некой конфигурации, которая намерена сообщать соответствующей цели iSCSI какие именно IQN, IP адреса, MAC адреса или FQDN могут применяться для подключения. Именно это носит название маскирования, ибо мы способны маскировать какой инициатор способен наблюдать соответствующую цель iSCSI при помощи этих индивидуальных свойств и парных им в LUN. LUNы это просто сырые блочные ёмкости, которые мы экспортируем через некую цель iSCSI в сторону инициаторов. LUNы индексируются, или нумеруются, обычно с нуля и далее. Всякий номер LUN представляет собой некую отличаемую ёмкость хранения, к которой способен подключиться какой- то инициатор.
К примеру, у нас может иметься некая цель iSCSI с тремя различными LUN - LUN0
с 20ГБ, LUN1 с 40ГБ и LUN2 с 60ГБ.
Все они будут размещаться в одной и той же цели системы хранения iSCSI. Мы можем настроить эту цель iSCSI принимать
некий IQN для обозревания всех таких LUN, другой IQN для обнаружения лишь LUN1
и ещё один IQN чтобы видеть лишь LUN1 и
LUN2. И это именно то, что мы собираемся настроить прямо сейчас.
Давайте приступим к настройке своей службы цели iSCSI. Для этого нам потребуется установить соответствующий пакет
targetcli и настроить соответствующую службу (с названием
target) для её запуска:
# dnf -y install targetcli
# systemctl enable --now target
Позаботьтесь о настройке своего межсетевого экрана; вам может понадобиться настроить его на допуск подключения по
порту 3260/tcp, который выступает тем портом, который применяет портал ваших
целей iSCSI. Итак, если запущен межсетевой экран, наберите такую команду:
# firewall-cmd --permanent --add-port=3260/tcp ; firewall-cmd --reload
В терминах применяемой нами основы хранения имеются три возможности для iSCSI в Linux. Мы можем пользоваться обычной файловой системой (например, XFS), блочным устройством (жёстким диском), или LVM. Итак, именно это мы и намерены сделать. Наш сценарий состоит в следующем:
-
LUN0(20ГБ): файловая система на основе устройства/dev/sdb -
LUN1(40ГБ): жёсткий диск, устройство/dev/sdc -
LUN2(60ГБ): LVM, устройство/dev/sdd
Итак, после того как мы установили все необходимые пакеты и настроили свою целевую службу и межсетевой экран,
мы должны запустить свою настроенную цель iSCSI. Мы просто стартуем командой targetcli
и проверяем состояние, которое должно быть чистым состоянием, поскольку мы только что начали этот процесс:
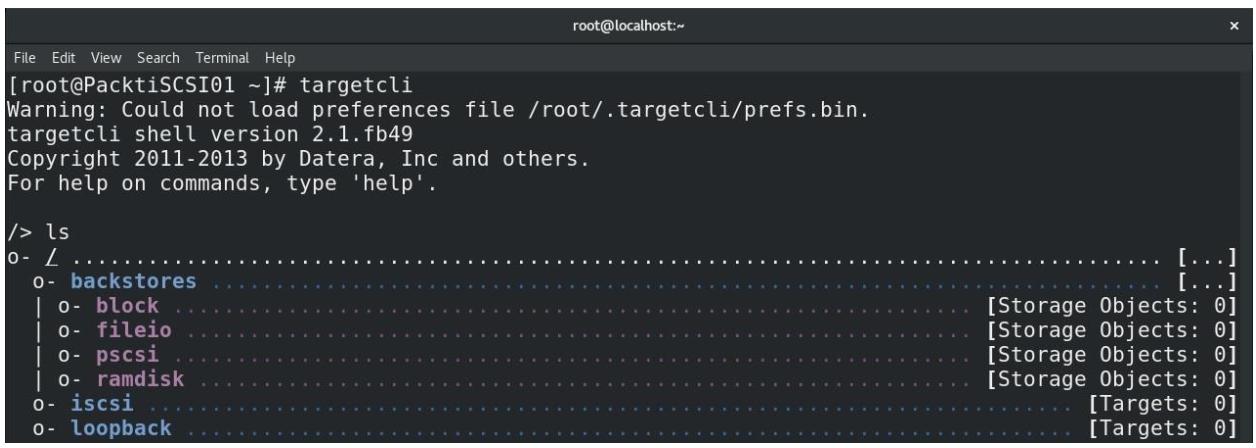
Давайте начнём с этой пошаговой процедуры:
-
Итак, давайте настроим файловую систему на основе XFS и сконфигурируем файл образа
LUN0, подлежащий хранению здесь. Прежде всего нам требуется разбить этот диск на части (в данном случае,/dev/sdb):
-
Наш следующий шаг состоит в форматировании этого раздела, создание каталога с названием
/LUN0и его применение для монтирования данной файловой системы и обслуживания нашего образаLUN0, который мы намерены настраивать на последующих шагах:Рисунок 5-8
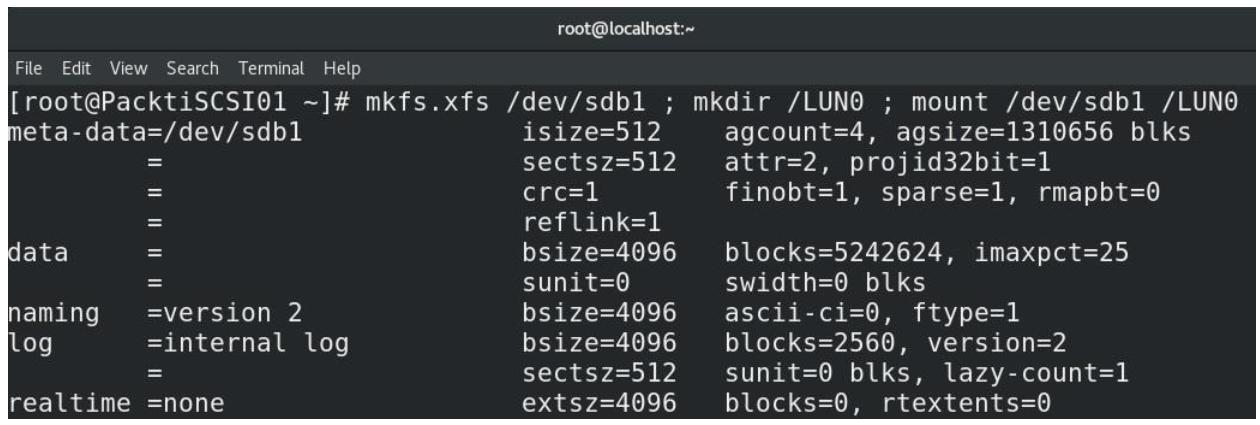
Форматирование файловой системы XFS, создание каталога и его монтирование в этом каталоге
-
Наш очередной шаг заключается в настройке
targetcliс тем, чтобы он создалLUN0и назначил дляLUN0некий файл образа, который будет храниться в каталоге/LUN0. Прежде всего нам необходимо запустить командуtargetcli:
-
Затем давайте настроем некую основу LUN на основе блочного устройства -
LUN1- которое собирается применять устройство/dev/sdc1(создайте этот раздел при помощи нашего предыдущего примера) и проверим его текущее состояние:
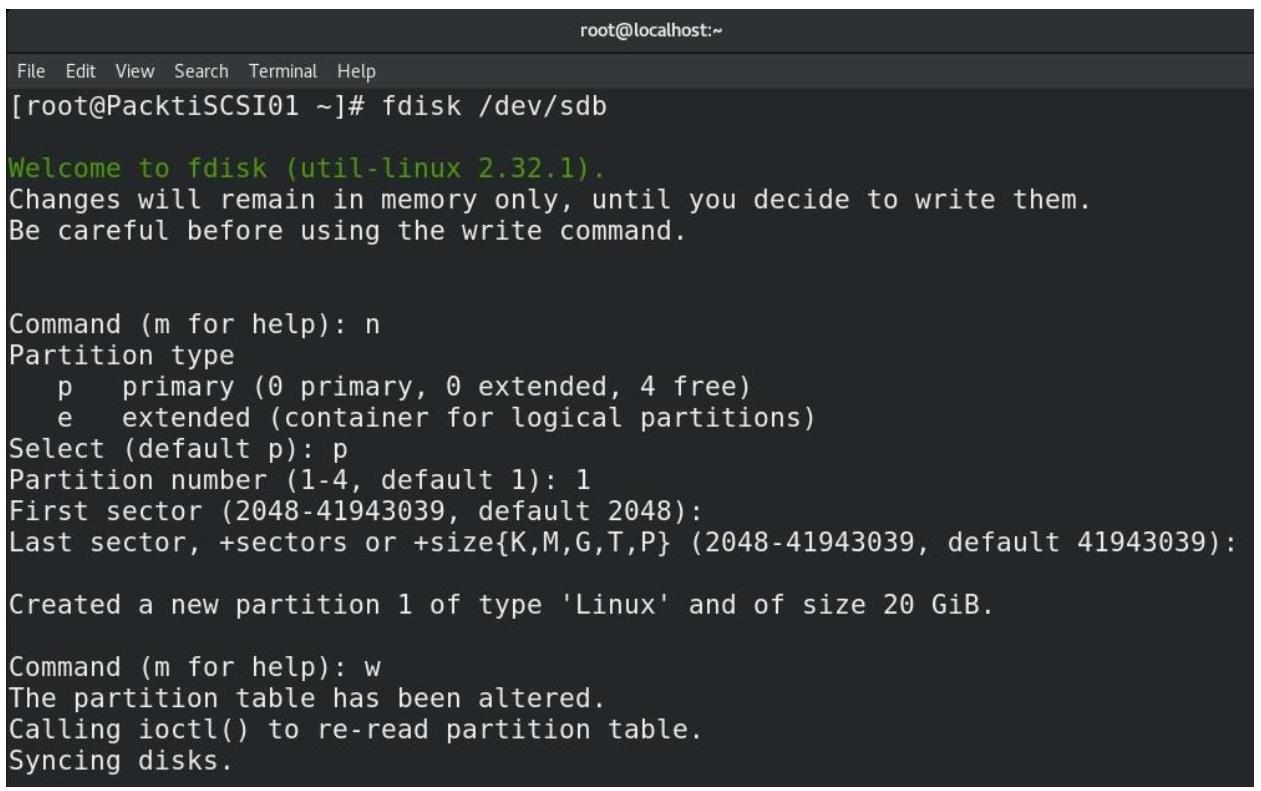
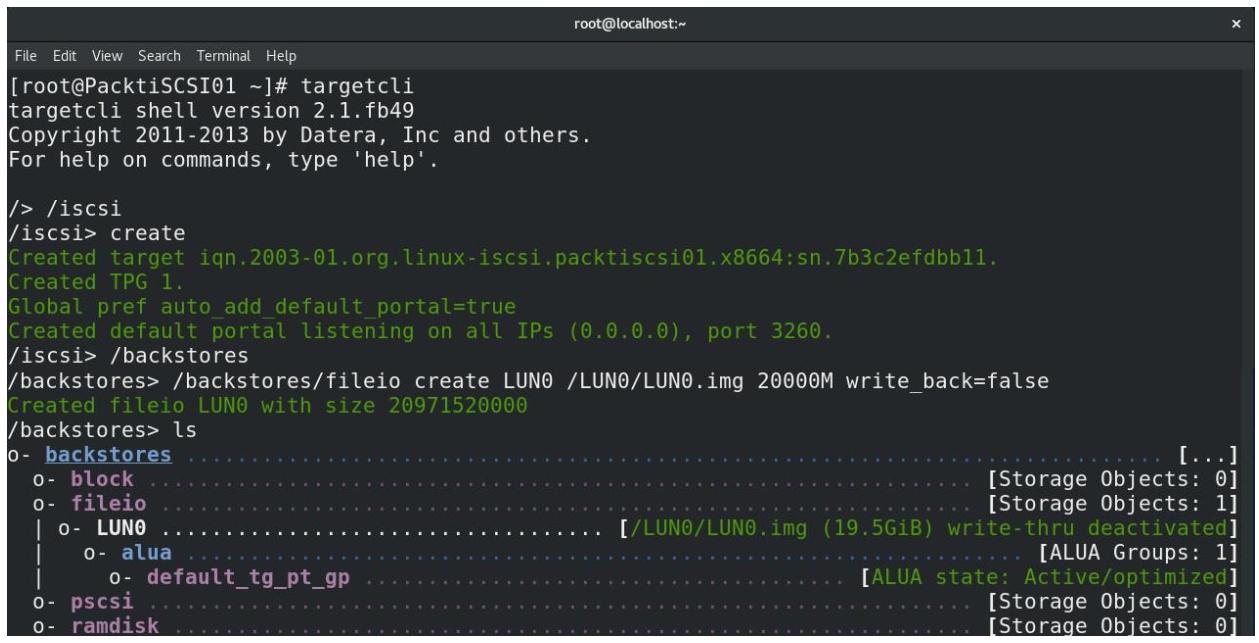
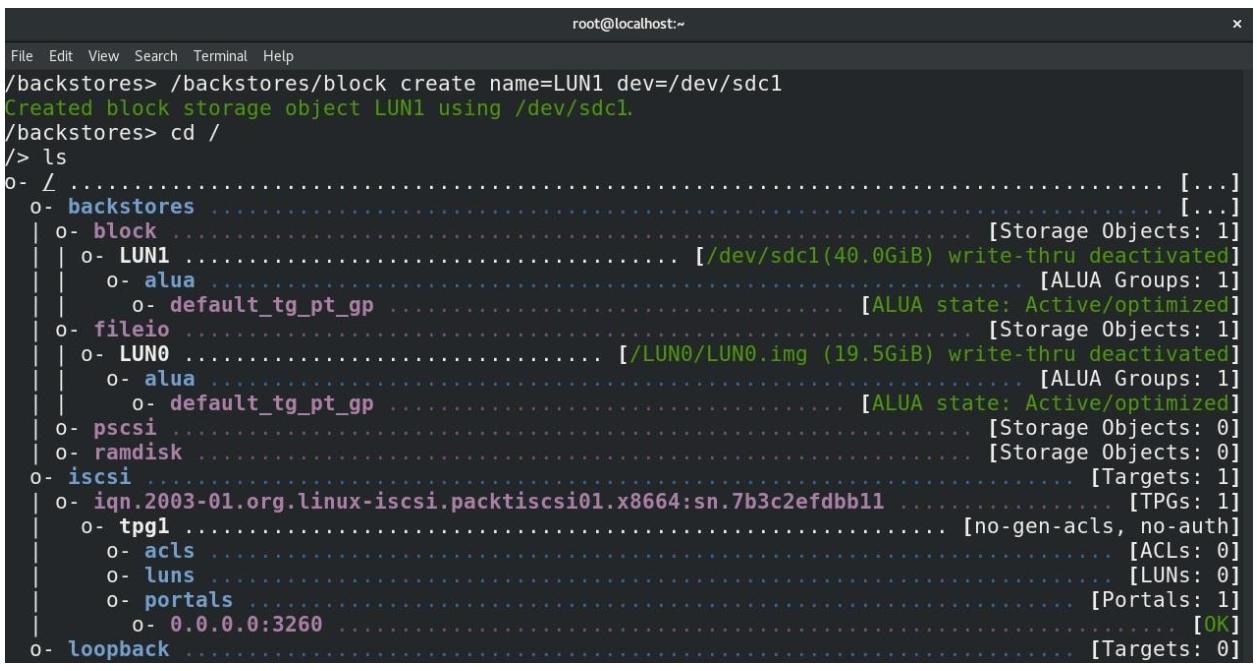
Итак, LUN0 и LUN1, а также
соответствующие им основы теперь настроены. Давайте покончим с этим, настроив LVM:
-
Прежде всего мы намерены подготовить необходимый физический том для LVM, создать из этого тома группу тома и отобразить все сведения об этой группе тома с тем, чтобы мы могли увидеть сколько пространства мы имеем для
LUN2:Рисунок 5-11
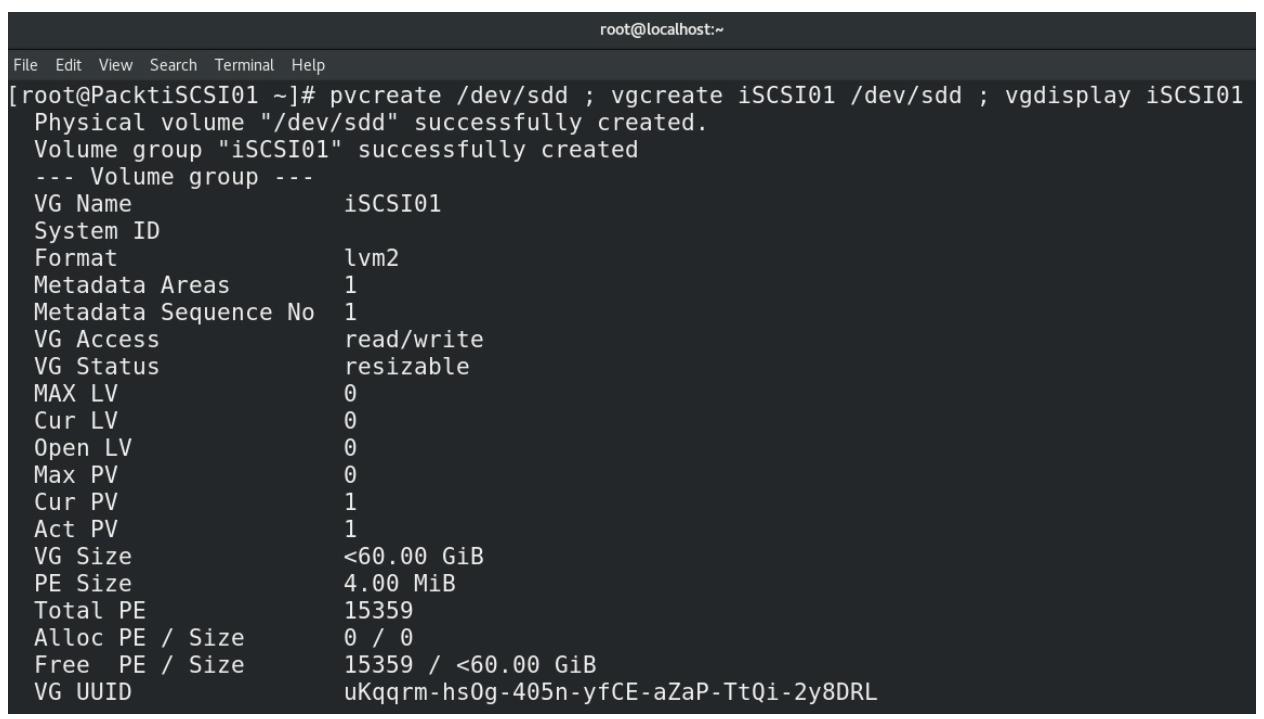
Настройка физического тома для LVM, построение группы тома и отображение сведений относительно группы тома
-
Наш следующий шаг состоит в реальном создании необходимого логического тома, который мы рассматриваем как основу своего устройства блочного хранения для
LUN2в нашей цели iSCSI. Из выводаvgdisplayмы можем видеть что у нас имеются доступными 15 359 4M блоков, а потому давайте применим их для создания своего логического тома с названиемLUN2. Пройдём вtargetcliи настроим все необходимые установки дляLUN2:
-
Давайте притормозим тут на секундочку и переключимся на настройку своего хоста KVM (нашего инициатора iSCSI). Прежде всего нам необходимо установить сам инициатор iSCSI, который является частью пакета с названием
iscsi-initiator-utils. Итак, давайте воспользуемся программойdnfдля его установки:# dnf -y install iscsi-initiator-utils -
Дальше нам требуется настроить значение IQN своего инициатора. Обычно мы желаем чтобы это название напоминало имя хоста, поэтому, смотрим, что значение FQDN нашего хоста это
PacktStratis01, мы воспользуемся им для установки значения IQN. Для этого нам потребуется изменить файл/etc/iscsi/initiatorname.iscsiи настроить параметрInitiatorName. К примеру, давайте установим его в значениеiqn.2019-12.com.packt:PacktStratis01. Содержание нашего файла/etc/iscsi/initiatorname.iscsiдолжно быть следующим:InitiatorName=iqn.2019-12.com.packt:PacktStratis01 -
Теперь, когда всё это настроено, давайте вернёCмся обратно к своей цели iSCSI и создадим некий ACL (Access Control List, Список контроля доступа). Этот ACL предназначен для того чтобы позволять нашему инициатору хоста KVM подключаться к своему целевому порталу iSCSI:
Рисунок 5-13
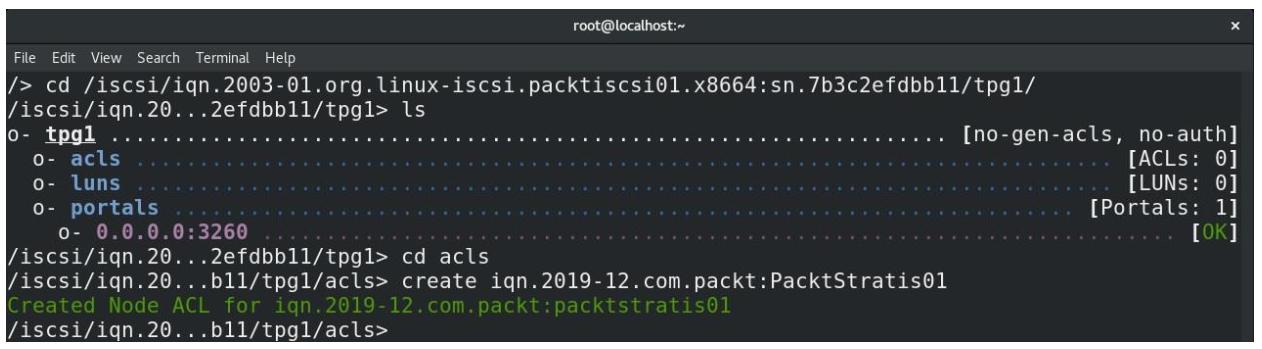
Создание ACL с тем, чтобы инициатор хоста данного KVM был способен соединяться со своей целью iSCSI
-
Далее нам требуется опубликовать свои предварительно созданные устройства на основе файла и блоков для своих целевых LUN iSCSI. Поэтому нам требуется сделать это:
Рисунок 5-14
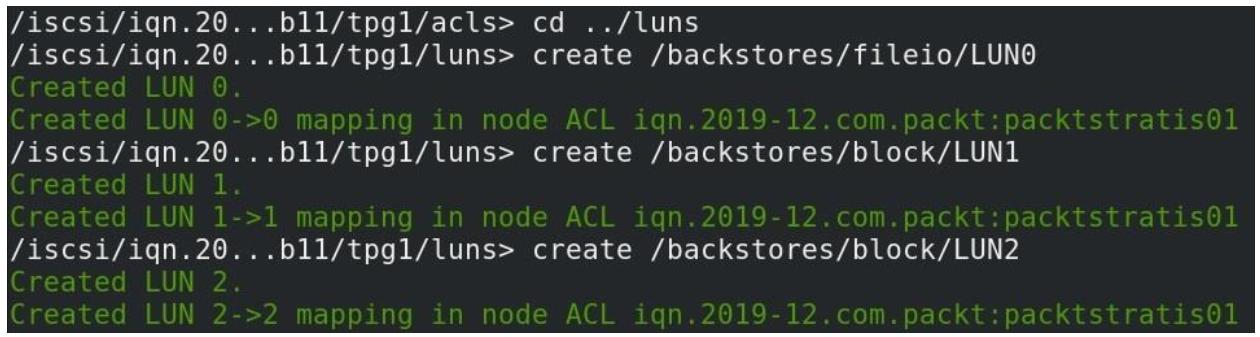
Добавление наших устройств на основе файлов и блочного доступа в соответствующие цели iSCSI LUN0, 1 и 2
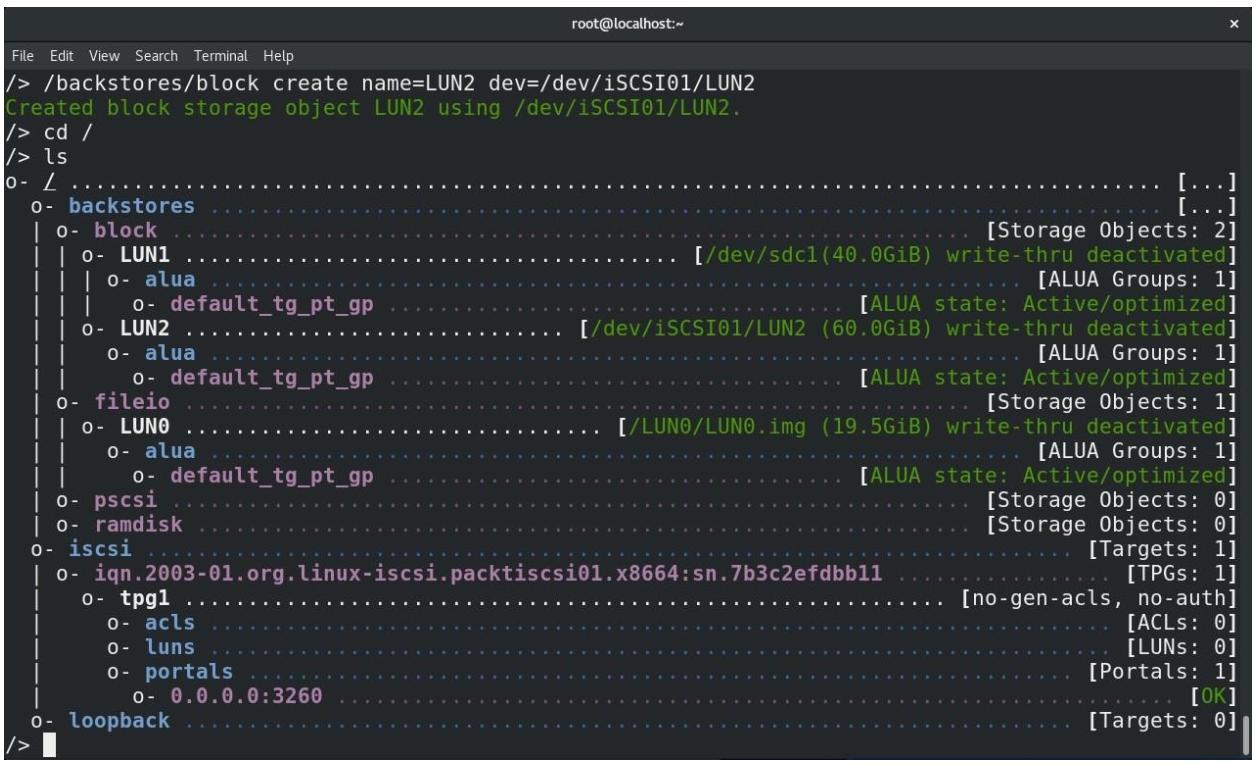
Окончательный результат должен выглядеть как-то так:
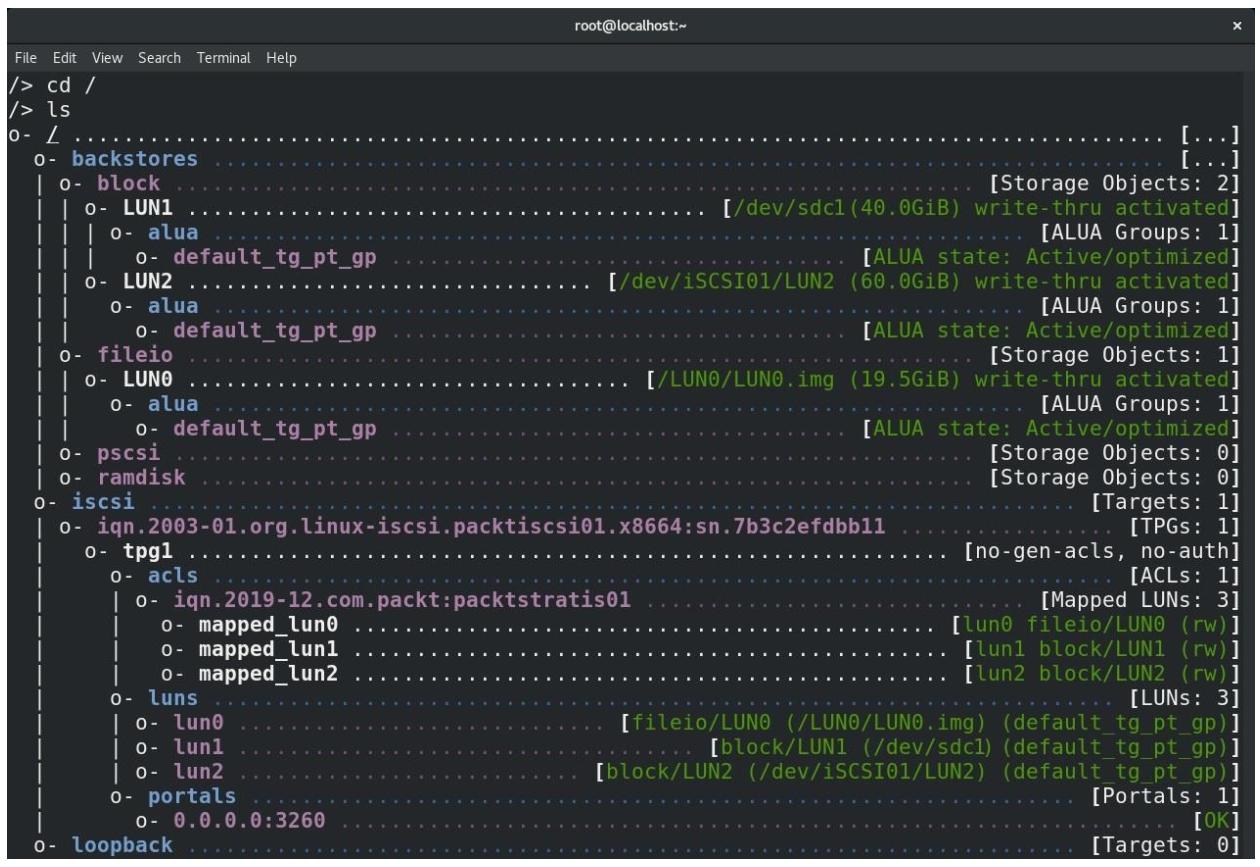
На данный момент всё настроено. Нам необходимо вернуться обратно в свой хост KVM и определить некий пул хранения,
который воспользуется этими LUN. Самый простой способ для осуществления этого состоит в в применении для этого пула
XML файла настроек. Итак, вот наш образец файла настроек; мы назовём его
iSCSIPool.xml:
<pool type='iscsi'>
<name>MyiSCSIPool</name>
<source>
<host name='192.168.159.145'/>
<device path='iqn.2003-01.org.linux-iscsi.packtiscsi01.x8664:sn.7b3c2efdbb11'/>
</source>
<initiator>
<iqn name='iqn.2019-12.com.packt:PacktStratis01' />
</initiator>
<target>
<path>/dev/disk/by-path</path>
</target>
</pool>
Давайте дадим пошаговые пояснения этого файла:
-
pool type= 'iscsi': Мы сообщаем libvirt что это некий пул iSCSI. -
name: Название этого пула. -
host name: Значение IP адреса нашей цели iSCSI. -
device path: Значение IQN этой цели iSCSI. -
Значение имени
IQNв разделе самого инициатора: Значение IQN этого инициатора. -
target path: Значение местоположения, по которому будут смонтированы LUN целевого iSCSI.
Теперь, всё что нам осталось сделать, это определить, запустить и выполнить автоматический старт нашего нового пула хранения KVM на основе iSCSI:
# virsh pool-define --file iSCSIPool.xml
# virsh pool-start --pool MyiSCSIPool
# virsh pool-autostart --pool MyiSCSIPool
Значение части настроек пути цели запросто можно проверить при помощи virsh.
Если мы наберём в своём хосте KVM следующую команду мы получим весь перечень доступных LUN из своего пула
MyiSCSIPool, который мы только что настроили:
# virsh vol-list --pool MyiSCSIPool
Для этой команды мы получили следующий результат:
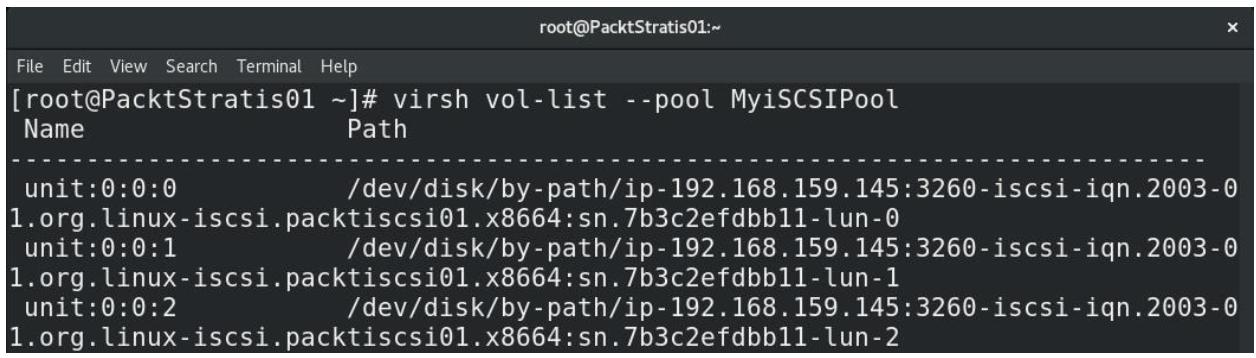
Если этот вывод слегка напоминает вам имена времени исполнения хранилища гипервизора VMware vSphere, вы несомненно идёте верным путём. Мы воспользуемся этими пулами хранения в Главе 7, Виртуальные машины: Установка, настройка и управление жизненным циклом, когда мы приступим к развёртыванию своих виртуальных машин.
Избыточность это одно из основных ключевых слов ИТ, когда отказ любого отдельного компонента может означать большие проблемы для компании или её потребителей. Самый основной принцип проектирования в избежании SPOF (единой точки отказа) это нечто, чего нам всегда следует придерживаться. В конце концов, никакие сетевые адаптеры, кабели, коммутаторы или контроллеры хранения не собираются работать вечно. Итак, вычисление избыточности в нашем проекте поспособствует нашей ИТ среде на протяжении её обычного жизненного цикла.
В то же самое время избыточность может комбинироваться со множеством путей чтобы к тому же обеспечивать наивысшую пропускную способность. Например, когда вы подключаете наш физический хост к хранилищу FC с двумя контроллерами, причём каждый с четырьмя портами, мы можем воспользоваться четырьмя путями (когда наше хранилище активно- пассивное) и восемью путями (если оно активно- активное) к тем же самым LUN, эксплуатируемым из этого устройства хранения в хост. Это снабжает нас дополнительными вариантами множества путей для доступа к LUN, причём поверх того факта, что это предоставляет нам дополнительную доступность, даже в случае некого отказа.
Обращаясь к тому что выполняет обычный хост KVM, к примеру, множественность путей iSCSI, значительно сложнее. Существует множество проблем настройки и белых пятен в терминологии документации, а сопровождение такой конфигурации пользуется плохой репутацией. Тем не менее, имеются применяющие KVM продукты, которые поддерживают это сразу после установки, например, oVirt (который мы обсуждали ранее), а также RHEV-H (Red Hat Enterprise Virtualization Hypervisor). Итак, давайте применим oVirt для такого примера на iSCSI.
Прежде чем мы выполним это, убедитесь что вы сделали следующее:
-
Ваш хост Гипервизора добавлен в опись этого oVirt.
-
Ваш хост Гипервизора обладает двумя дополнительными сетевыми картами, причём не зависящими от его сетевой среды управления.
-
Ваше хранилище iSCSI обладает двумя дополнительными сетевыми картами в тех же самых сетях Уровня 2, что и две дополнительные сетевые карты гипервизора.
-
Ваше хранилище iSCSI настроено так, чтобы оно обладало по крайней мере уже настроенными неким образом целью и LUN с тем, чтобы иметь возможность вашему хосту гипервизора подключаться к нему.
Итак, поскольку мы выполняем это в oVirt, имеется пара моментов, которые нам придётся сделать. Прежде всего, с
точки зрения построения сети, было бы неплохо создать некие сетевые среды хранения. В нашем случае мы намерены
выделить под iSCSI две сетевые среды, и мы назовём их iSCSI01 и
iSCSI02. Нам нужно открыть панель администрирования oVirt, встать над
Network и выбрать из этого меню
Networks. Это откроет вплывающее окно для нашего мастера
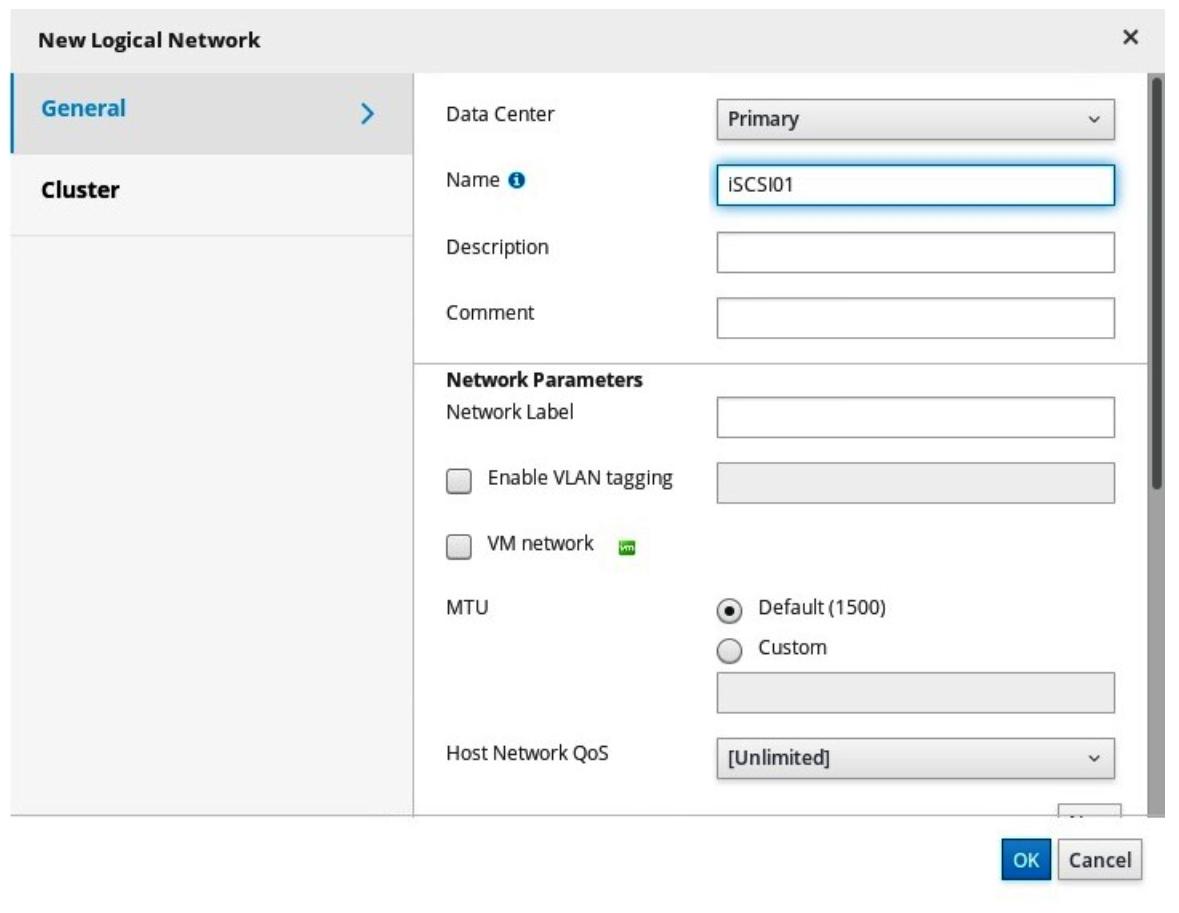
New Logical Network. Итак, нам просто требуется назвать
свою сеть iSCSI01 (для первой), убрать пометку в флаговой кнопке
VM network (поскольку она не является сетевой средой
виртуальных машин) и перейти к закладке Cluster, где
мы отменим выбор флаговой кнопки Require all. Полностью
повторите этот процесс снова для своей сетевой среды iSCSI02:
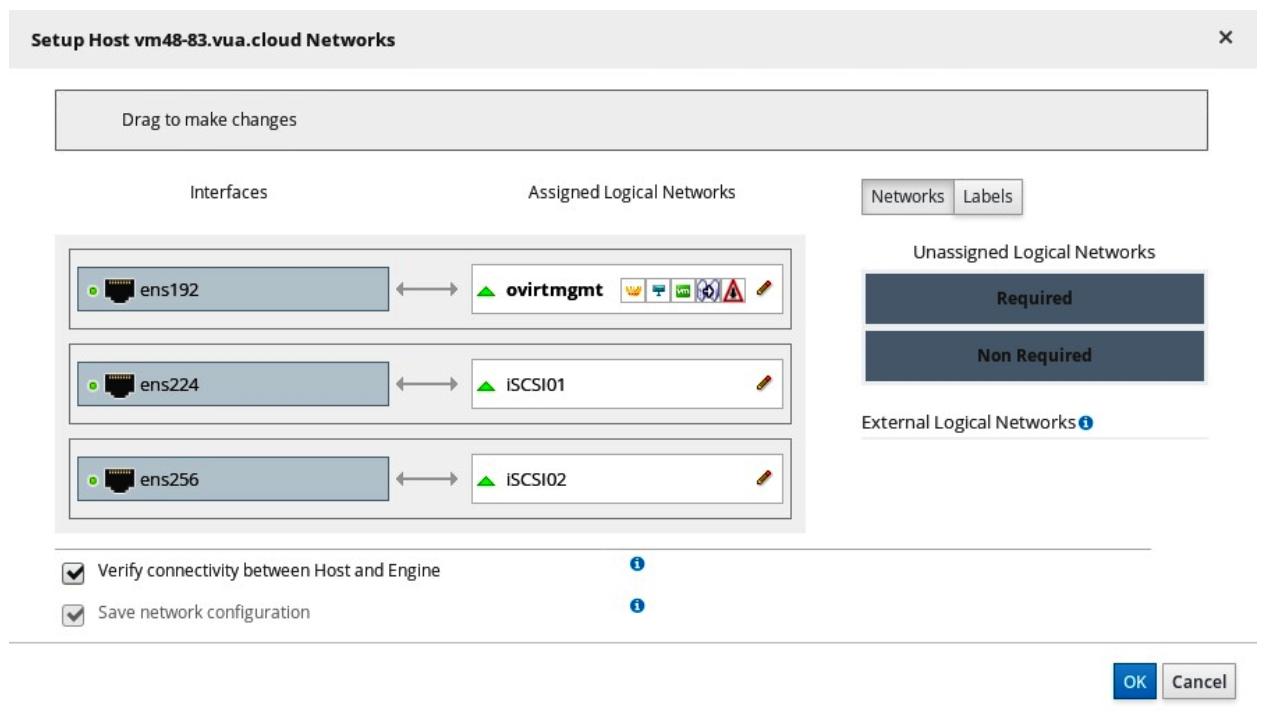
Наш следующий шаг состоит в назначении этих сетевых сред сетевым адаптерам хоста. Пройдите в
compute/hosts, дважды кликните по тому хосту, который вы добавили в опись oVirt,
выберите закладку Network interfaces , и кликните по
иконке Setup Host Networks в правом верхнем углу. В этом
UI перетащите и бросьте iSCSI01 во втором сетевом интерфейсе и
iSCSI02 в третьем. Самый первый интерфейс уже был взят сетевой средой управления
oVirt. Это должно выглядеть как- то так:
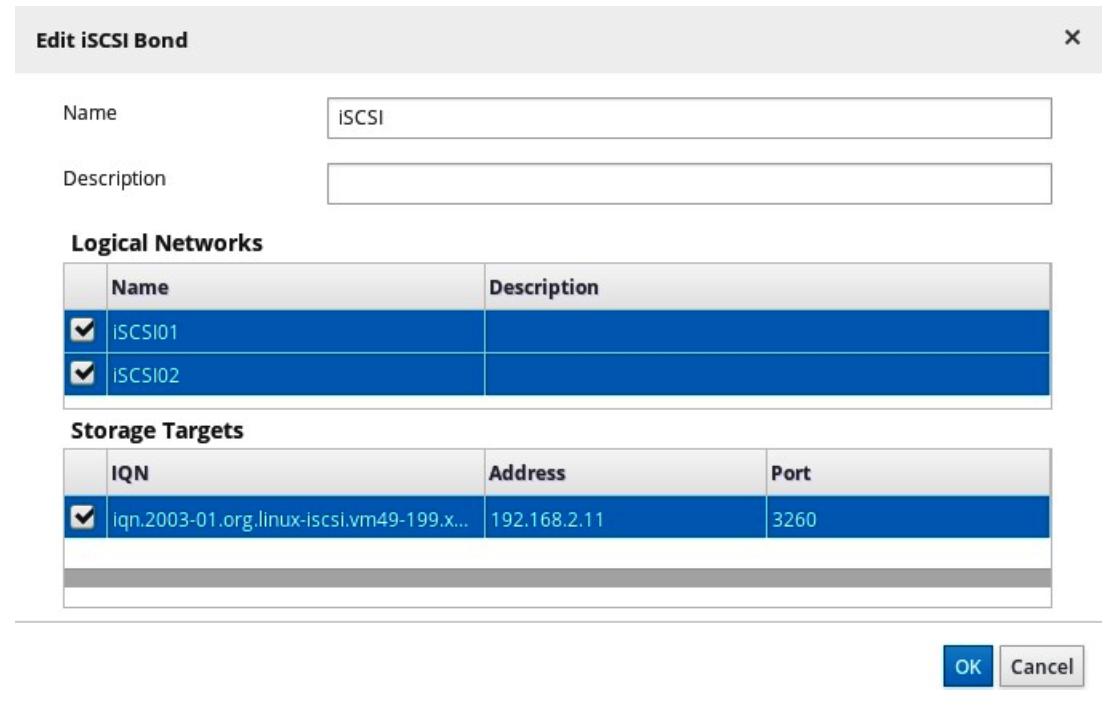
Прежде чем мы закроем это окно, убедитесь что вы кликнули по подписи pencil
в обеих iSCSI01 и iSCSI02 для настройки
IP адресов для этих обеих двух виртуальных сетей. Назначьте сетевые настройки который способны соединяться с вашим
iSCSI хранилищем в той же самой или в различных подсетях:
Вы только что настроили сращивание iSCSI. Самая последняя часть нашей настройки включила его. И снова, в GUI oVirt пройдите в Compute | Data Centers, выберите свой ЦОД и дважды кликните и проследуйте в его закладку iSCSI Multipathing:
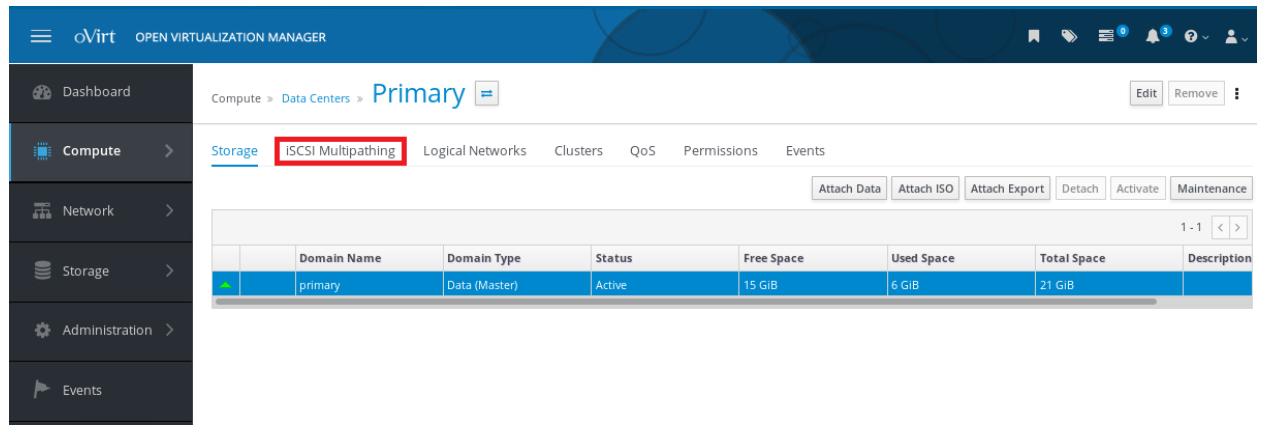
Кликните по кнопке Add в правой верхней стороне и
пройдите этот мастер. В частности, выберите обе сети iSCSI01 и
iSCSI02 в верхней части всплывающего окна и соответствующую цель
iSCSI в нижней стороне.
Теперь, когда вы рассмотрели имеющиеся основы пулов хранения, NFS и iSCSI, мы можем перейти к стандартному способу с открытым исходным кодом развёртывания инфраструктуры хранения, который будет состоять в применении Gluster и/ или Ceph.
Существуют и более современные типы файловых систем, которые можно применять в качестве основы хранилища libvirt. Итак, давайте теперь рассмотрим две из них - Gluster и Ceph. Позднее мы также проверим как libvirt работает с GFS2.
Gluster это распределённая файловая система, которая часто используется в ситуациях с высокой доступностью. Её основные преимущества над прочими файловыми системами состоят в том факте что она масштабируется, она может применять репликации и моментальные снимки, она способна работать на любом сервере и она пригодна к применению как основа для совместного хранилища - например, через NFS и SMB. Она была разработана компанией с названием Gluster Inc., которая была приобретена RedHat в 2011. Тем не менее, в отличии от Ceph, это служба файлового хранилища, в то время как Ceph предлагает блочное хранилище и основано на объектах. Основанное на объектах хранилище для базирующихся на блоках устройствах подразумевает непосредственное, двоичное хранилище непосредственно в LUN. Не существует вовлечённых файловых систем, что в теории означает меньшие накладные расходы, ибо нет никакой файловой системы, таблиц файловой системы и прочих построений, которые способны замедлять общий процесс ввода/ вывода.
Давайте сначала настроим Gluster чтобы показать её вариант привнесенения с libvirt. В промышленном решении это означает установку по крайней мере трёх серверов Gluster с тем, чтобы мы имели возможность создать высокую доступность. Настройка Gluster в самом деле проста и, в нашем примере, мы собираемся создать три машины CentOS 7, которые мы будем применять для размещения своей файловой системы Gluster. Затем мы монтируем эту файловую систему в хосте своего гипервизора и воспользуемся ею как локальным каталогом. Мы имеем возможность применять GlusterFS напрямую из libvirt, однако такая реализация не настолько совершенна как её использование через соответствующую службу клиента gluster, его монтирования в качестве локального каталога и его применения напрямую в libvirt как пула каталога.
Наша конфигурация будет следующей:

Итак, давайте пустим это в дело. Нам придётся вызвать большую последовательность команд для всех своих серверов
прежде чем мы настроим Gluster и выставим его в свой хост KVM. Давайте начнём с gluster1.
Прежде всего, мы намерены выполнить обновление всей системы и перезапустить её для подготовки её ядра операционной системы
под установку Gluster. Во всех трёх серверах CentOS 7 наберите следующие команды:
# yum -y install epel-release*
# yum -y install centos-release-gluster7.noarch
# yum -y update
# yum -y install glusterfs-server
# systemctl reboot
Далее мы можем запустить развёртывание всех необходимых репозиториев и пакетов, форматирование дисков, настройку соответствующего межсетевого экрана и тому подобное. Во всех своих серверах наберите такие команды:
# mkfs.xfs /dev/sdb
mkdir /gluster/bricks/1 -p
echo '/dev/sdb /gluster/bricks/1 xfs defaults 0 0' gt;gt; /etc/fstab
mount -a
mkdir /gluster/bricks/1/brick
systemctl disable firewalld
systemctl stop firewalld
systemctl start glusterd
systemctl enable glusterd
Также нам требуется слегка настроить сетевую среду. Было бы неплохо, чтобы эти три сервера были способны
разрешать друг друга, что подразумевает либо настройку некого сервера DNS,
либо добавления пары строк в наш файл /etc/hosts. Давайте придерживаться
последнего. В свой файл /etc/hosts добавьте такие строки:
192.168.159.147 gluster1
192.168.159.148 gluster2
192.168.159.149 gluster3
Для своей следующей части настройки мы можем просто зарегистрироваться в своём первом сервере и воспользоваться им как фактически сервером управления своей инфраструктуры Gluster. Наберите следующие команды:
# gluster peer probe gluster1
# gluster peer probe gluster2
# gluster peer probe gluster3
# gluster peer status
Первые три команды должны выдать вам состояние peer probe: success. Четвёртая
же должна выдавать нечто подобное приводимому ниже:
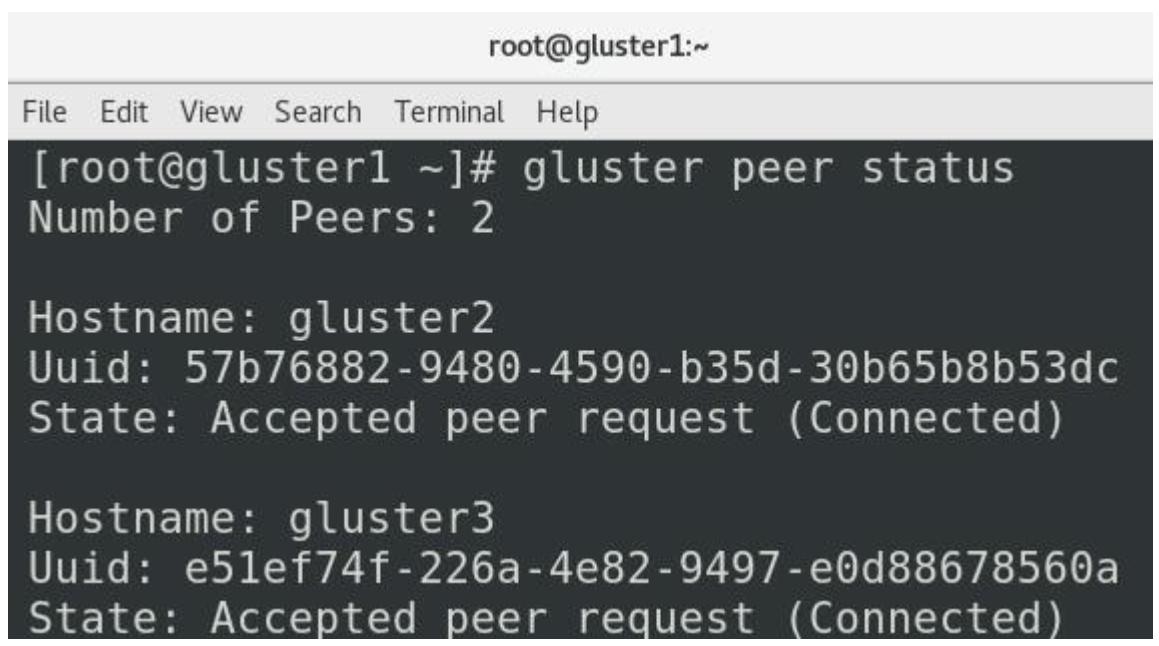
Теперь, когда выполнена эта часть настройки, мы имеем возможность создать распределённую Gluster файловую систему. Сделать это мы можем набрав такие команды:
# gluster volume create kvmgluster replica 3 \ gluster1:/gluster/ bricks/1/brick gluster2:/gluster/bricks/1/brick \ gluster3:/ gluster/bricks/1/brick
# gluster volume start kvmgluster
# gluster volume set kvmgluster auth.allow 192.168.159.0/24
# gluster volume set kvmgluster allow-insecure on
# gluster volume set kvmgluster storage.owner-uid 107
# gluster volume set kvmgluster storage.owner-gid 107
Затем мы можем смонтировать Gluster как некий каталог NFS для целей проверки. Например, мы способны создать
распределённое пространство имён с названием kvmgluster для всех участвующих
хостов (gluster1, gluster2 и
gluster3). Мы можем выполнить это приводимыми далее командами:
# echo 'localhost:/kvmgluster /mnt glusterfs \ defaults,_ netdev,backupvolfile-server=localhost 0 0' >> /etc/fstab
# mount.glusterfs localhost:/kvmgluster /mnt
Наша часть Gluster теперь готова, поэтому нам необходимо вернуться обратно в свой хост KVM и смонтировать для него файловую систему Gluster набрав такие команды:
# wget \ https://download.gluster.org/pub/gluster/glusterfs/6/LATEST/CentOS/gl\ usterfs-rhel8.repo -P /etc/yum.repos.d
# yum install glusterfs glusterfs-fuse attr -y
# mount -t glusterfs -o context="system_u:object_r:virt_image_t:s0" \ gluster1:/kvmgluster /var/lib/libvirt/images/GlusterFS
Нам следует уделять пристальное внимание выпускам Gluster для своего сервера и клиента, именно поэтому мы выгрузили соответствующие сведения репозитория Gluster для CentOS 8 (мы используем его в своём сервере KVM) и установили надлежащие пакеты клиента Gluster. Это позволяет нам монтировать данную файловую систему самой последней командой.
Теперь, когда мы покончили со своей настройкой, нам всего лишь требуется добавить этот каталог в качестве пула хранения libvirt. Давайте выполним это воспользовавшись файлом XML с определением соответствующего пула хранения, который содержит следующие записи:
<pool type='dir'>
<name>glusterfs-pool</name>
<target>
<path>/var/lib/libvirt/images/GlusterFS</path>
<permissions>
<mode>0755</mode>
<owner>107</owner>
<group>107</group>
<label>system_u:object_r:virt_image_t:s0</label>
</permissions>
</target>
</pool>
Допустим, что мы сохранили этот файл в своём текущем каталоге и что этот файл носит название
gluster.xml. Мы можем импортировать его и запустить в libvirt воспользовавшись
такими командами virsh:
# virsh pool-define --file gluster.xml
# virsh pool-start --pool glusterfs-pool
# virsh pool-autostart --pool glusterfs-pool
Нам также надлежит монтировать этот пул автоматически при запуске с тем, чтобы libvirt был способен пользоваться им.
Следовательно, нам необходимо добавить в /etc/fstab такие строки:
gluster1:/kvmgluster /var/lib/libvirt/images/GlusterFS \ glusterfs defaults,_netdev 0 0
Применение основанного на каталоге подхода позволяет нам избежать две проблемы, которые имеет libvirt (и его интерфейс
GUI, virt-manager) для пулов хранения Gluster:
-
Мы можем применять возможность восстановления Gluster при отказах, которая будет управляться автоматически утилитами Gluster, которые устанавливаются напрямую, ибо libvirt их ещё пока не поддерживает.
-
Мы избежим создания дисков виртуальных машин вручную, что выступает другим ограничением реализации libvirt поддержки Gluster, в то время как основанные на каталоге пулы хранения сопровождают их без каких бы то ни было проблем.
Кажется странным, что мы упоминаем отработку отказа, ибо мы не настраивали
её как некую часть ни на каком из своих предыдущих шагов. В действительности она имеется. Когда мы вызвали две
самые последние команды монтирования, мы воспользовались встроенными модулями Gluster для установления подключения
к своему первому серверу Gluster. Это, в свою очередь, означает, что после
такого подключения, мы получили все необходимые сведения относительно пула Gluster целиком, которые мы настроили с
тем, чтобы он размещался в трёх серверах. Когда происходит какой- то отказ - который просто сымитировать - такое
подключение продолжит работать. Мы можем смоделировать такую ситуацию выключив любой из серверов Gluster, например -
gluster1. Вы обнаружите, что наш локальный каталог, в котором мы смонтировали
каталог Gluster всё ещё работает, даже несмотря на то, что gluster1 упал. Давайте
посмотрим на это в действии (значение таймаута по умолчанию составляет 42 секунды):
Рисунок 5-23
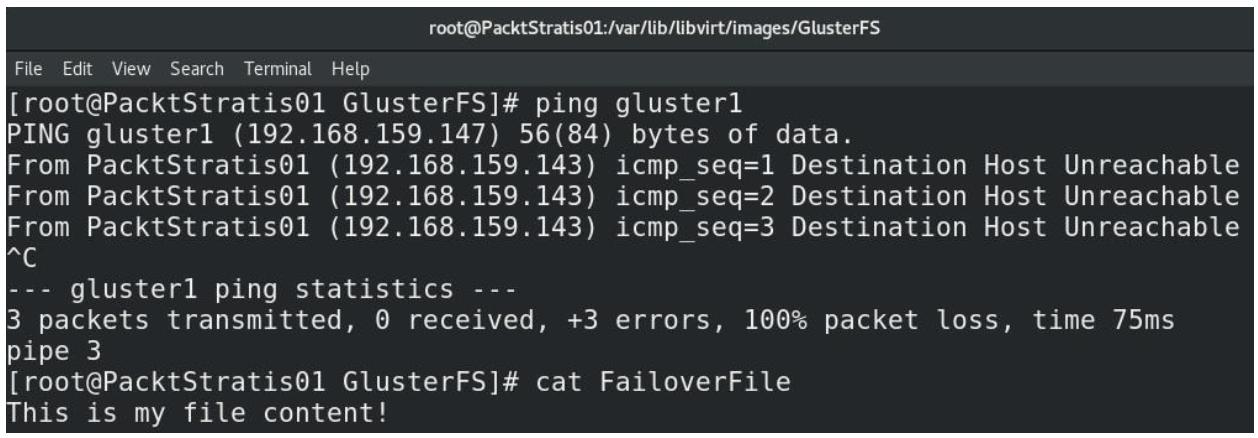
Отработка отказа со стороны Gluster: падает первый узел, тем не менее мы всё ещё способны получать свои файлы
Если вы желаете быть более энергичными мы можем укоротить этот промежуток таймаута - например - до 2 секунд вызвав приводимую далее команду в любом из своих серверов Gluster:
# gluster volume set kvmgluster network.ping-timeout number
Значение части number задаётся в секундах и назначается наинизшее
число, тем самым мы можем непосредственно влиять на то, насколько энергичен процесс отработки отказа.
Итак, теперь, когда всё настроено, мы можем приступить к применению пула Gluster под развёртывание виртуальных машин, которое мы обсудим далее в Главе 7, Виртуальные машины: Установка, настройка и управление жизненным циклом.
Поскольку Gluster основан на файловых серверах, которые можно применять для libvirt, вполне естественно описать как применять более современную основу хранилища на базе блочного уровня и основанного на объектах хранилища. Вот тут- то и сгодится Ceph, давайте поработаем над этим сейчас.
Ceph способно выступать в качестве основанного на файлах, блоках и объектах хранилища. Однако по большей части мы обычно применять его в качестве блочного хранилища или хранилища объектов. И снова, это фрагмент программного обеспечения с открытым исходным кодом, который разработан под работу на любом сервере (или виртуальной машине {Прим. пер.: или даже в контейнере}). В своей сердцевине Ceph исполняет алгоритм с названием CRUSH (Controlled Replication Under Scalable Hashing, Управляемых репликаций при масштабируемом хэшировании). Этот алгоритм пытается распределять данные по устройствам объектов псевдо случайным образом и в Ceph это управляется картой кластера (картой CRUSH). Мы запросто можем масштабировать Ceph вширь добавляя дополнительные узлы, что перераспределяет данные минимальным образом для обеспечения настолько наименьшего числа репликаций, насколько это возможно.
Для моментальных снимков, репликаций и динамичного выделения (thin provisioning) применяется внутренний компонент Ceph с названием RADOS (Reliable Autonomic Distributed Object Store, Надёжное автономное распределённое хранилище объектов). Это проект с открытым исходным кодом, разработанный в Университете Калифорнии.
По всей своей архитектуре Ceph обладает тремя основными службами:
-
ceph-mon: применяется для мониторинга кластера, карт CRUSH и карт OSD (Object Storage Daemon, демона хранения объектов).
-
ceph-osd: Здесь обрабатываются реальные сохранения, репликации и восстановления данных. Она требует по крайней мере двух узлов; мы будем применять три по причинам кластеризации.
-
ceph-mds: Сервер метаданных, применяется когда Ceph нуждается в файловом доступе.
Руководствуясь рекомендациями, убедитесь что вы всегда проектируете свои среды Ceph подразумевая основные ключевые принципы - все узлы данных обязаны обладать одной и той же конфигурацией. Это означает один и тот же объём памяти, те же самые контроллеры хранения (не применяйте контроллеры RAID, всего лишь простые HBA без встроенного программного обеспечения RAID, по возможности), одни и те же диски и так далее. Именно это является единственным способом обеспечения постоянного уровня производительности Ceph в ваших средах.
Одной из очень важных сторон Ceph выступают размещение данных и то как работают группы размещения (placement groups, PG). Группы размещения предоставляют нам возможность расщеплять создаваемые нами объекты и помещать их в OSD неким оптимальным образом. Переведём: чем большее число групп размещения мы настроим, тем лучшую балансировку мы намерены получить.
Итак, давайте настроим Ceph с нуля. Мы снова намерены следовать рекомендациям и развернуть Ceph применяя пять серверов - один для администрирования, один для мониторинга и три OSD.
Наша конфигурация будет выглядеть как- то так:

Проверьте что все эти хосты способны разрешать друг друга через DNS или в /etc/hosts
и что вы настроили их на использование одного и того же источника NTP. Убедитесь что вы обновили все свои хосты
следующим образом:
# yum -y update; reboot
Кроме того проверьте что вы набрали приводимые ниже команды во всех хостах от имени пользователя
root. Давайте приступим к развёртыванию пакетов, созданию
пользователя администратора и предоставления ему прав для sudo:
# rpm -Uhv http://download.ceph.com/rpm-jewel/el7/noarch/ceph-release-1-1.el7.noarch.rpm
# yum -y install ceph-deploy ceph ceph-radosgw
# useradd cephadmin
# echo "cephadmin:ceph123" | chpasswd
# echo "cephadmin ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephadmin
# chmod 0440 /etc/sudoers.d/cephadmin
Отключение SELinux упростит нашу жизнь для данной демонстрации, поскольку избавит нас от его межсетевого экрана:
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
# systemctl stop firewalld
# systemctl disable firewalld
# systemctl mask firewalld
Давайте добавим названия хостов в /etc/hosts для упрощения своего
администрирования:
# echo "192.168.159.150 ceph-admin" >> /etc/hosts
# echo "192.168.159.151 ceph-monitor" >> /etc/hosts
# echo "192.168.159.152 ceph-osd1" >> /etc/hosts
# echo "192.168.159.153 ceph-osd2" >> /etc/hosts
# echo "192.168.159.154 ceph-osd3" >> /etc/hosts
Для соответствия своей среде измените все последние echo - названиями
хостов и IP адресами. Наш следующий шаг состоит в проверке того что мы способны применять свой хост администратора
для подключения ко всем необходимым хостам. Самый простой способ состоит в использовании ключей SSH. Итак в
ceph-admin зарегистрируйтесь в качестве root и наберите команду
ssh-keygen, после чего нажимайте на клавишу
Enter на протяжении всего пути.
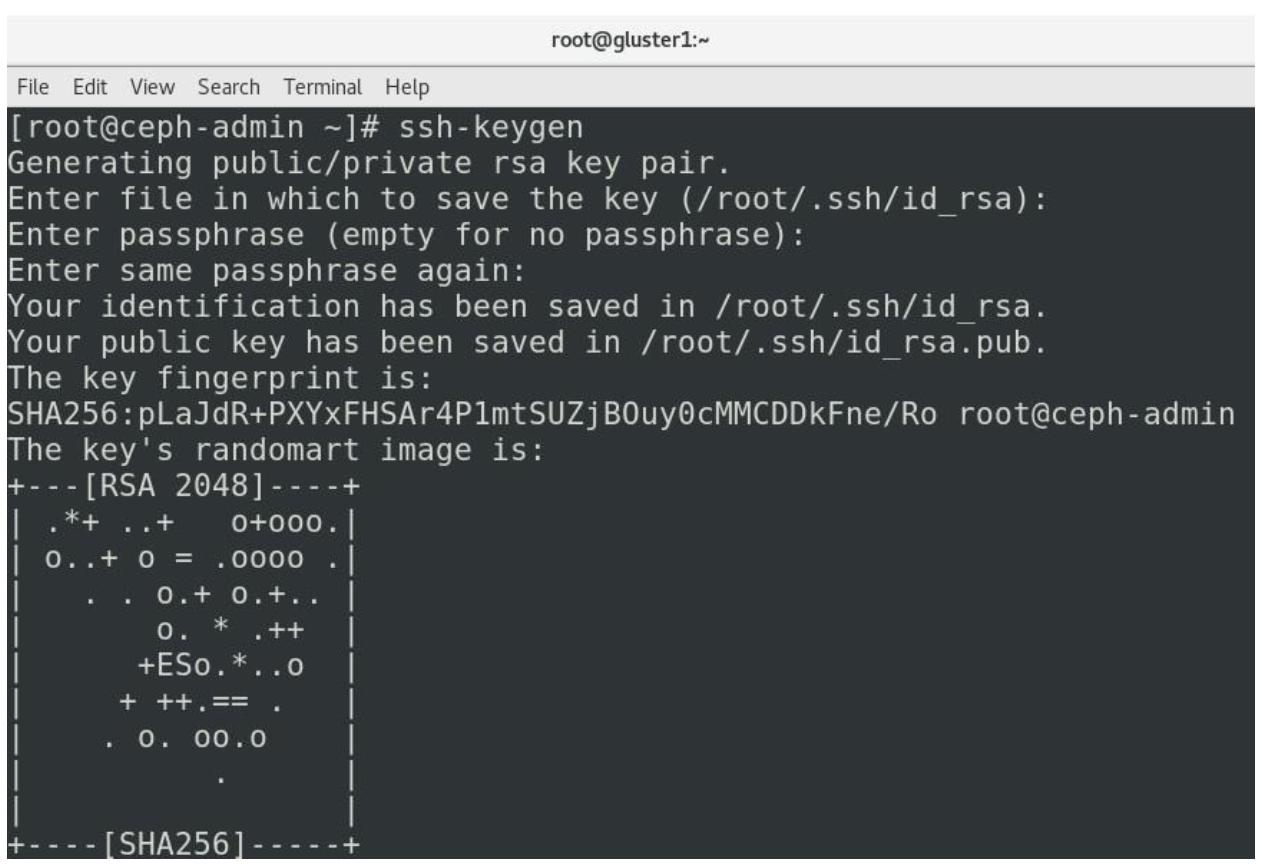
Вам также необходимо скопировать этот ключ во все имеющиеся хосты. Итак, снова, в
ceph-admin воспользуйтесь ssh-copy-id
для копирования своих ключей во все необходимые хосты:
# ssh-copy-id cephadmin@ceph-admin
# ssh-copy-id cephadmin@ceph-monitor
# ssh-copy-id cephadmin@ceph-osd1
# ssh-copy-id cephadmin@ceph-osd2
# ssh-copy-id cephadmin@ceph-osd3
Примите все эти ключи когда SSH запросит вас об этом, а в качестве пароля воспользуйтесь
ceph123, который мы выбрали на своём предыдущем шагу. После того как всё это
выполнено, имеется ещё один последний шаг, который нам требуется сделать на
ceph-admin прежде чем мы приступим к развёртыванию Ceph - нам придётся
настроить SSH на применение пользователя cephadmin в качестве пользователя
по умолчанию для регистрации во всех имеющихся хостах. Мы выполним это проследовав в каталог
.ssh в качестве root в ceph-admin и
создав файл с названием config со следующим содержимым:
Host ceph-admin
Hostname ceph-admin
User cephadmin
Host ceph-monitor
Hostname ceph-monitor
User cephadmin
Host ceph-osd1
Hostname ceph-osd1
User cephadmin
Host ceph-osd2
Hostname ceph-osd2
User cephadmin
Host ceph-osd3
Hostname ceph-osd3
User cephadmin
Это была длительная предварительная настройка, не так ли? Теперь пришло время к реальному развёртыванию Ceph.
Наш первый шаг состоит в настройке ceph-monitor, итак, в
ceph-admin наберите следующие команды:
# cd /root
# mkdir cluster
# cd cluster
# ceph-deploy new ceph-monitor
По причине того факта, что мы выбрали конфигурацию при которой у нас имеются три OSD, нам требуется настроить
Ceph с тем, чтобы он применял эти два дополнительных хоста. Итак, в каталоге
cluster измените файл с названием ceph.conf
и добавьте в него в самом конце две такие строки:
public network = 192.168.159.0/24
osd pool default size = 2
Это обеспечит что мы можем применять для Ceph только сетевую среду нашего примера (192.168.159.0/24)
и что у нас имеются два дополнительных OSD поверх первоначального.
Теперь, когда всё готово, нам придётся вызвать последовательность команд настройки Ceph. Иакт, снова из
ceph-admin наберите следующие команды:
# ceph-deploy install ceph-admin ceph-monitor ceph-osd1 ceph-osd2 ceph-osd3
# ceph-deploy mon create-initial
# ceph-deploy gatherkeys ceph-monitor
# ceph-deploy disk list ceph-osd1 ceph-osd2 ceph-osd3
# ceph-deploy disk zap ceph-osd1:/dev/sdb ceph-osd2:/dev/sdb ceph-osd3:/dev/sdb
# ceph-deploy osd prepare ceph-osd1:/dev/sdb ceph-osd2:/dev/sdb ceph-osd3:/dev/sdb
# ceph-deploy osd activate ceph-osd1:/dev/sdb1 ceph-osd2:/dev/sdb1 ceph-osd3:/dev/sdb1
Давайте поясним эти команды одну за другой:
-
Самая первая команда запускает реальный процесс развёртывания - для наших узлов администрирования, монитора и OSD, причём с установкой всех необходимых пакетов.
-
Вторая и третья команды настраивают наш хост монитора с тем, чтобы он был готов принимать внешние подключения.
-
Следующие две команды посвящены подготовке диска - Ceph очистит все назначенные ему диски (для хостов OSD
/dev/sdb) и создаст в них по два раздела, один для данных Ceph и один для журнала Ceph. -
Последние две команды подготавливают эти файловые системы под использование и активацию Ceph. Если в любой момент времени остановится ваш сценарий
ceph-deploy, проверьте свой DNS, а также настройки/etc/hostsиfirewalld, поскольку именно в них могут заключаться проблемы.
Нам требуется выставить Ceph своему хосту KVM, что означает, что нам придётся выполнить немного дополнительных
настроек. Мы намерены выставить для своего хоста KVM Ceph в качестве некого пула объектов, а потому нам требуется
создать пул. Давайте назовём его KVMpool. Подключитесь к
ceph-admin и вызовите следующую команду:
# ceph osd pool create KVMpool 128 128
Эта команда создаст пул с названием KVMpool, причём со 128 группами
размещений.
Наш следующий шаг вовлекает приём Ceph с точки зрения безопасности. Мы не желаем чтобы к этому пулу подключался кто бы то ни было, поэтому мы собираемся создать некий ключ для аутентификации Ceph, который мы намерены применять в хосте KVM для целей аутентификации. Мы осуществим это набрав такую команду:
# ceph auth get-or-create client.KVMpool mon 'allow r' osd 'allow rwx pool=KVMpool'
Она собирается выдать нам сообщение о состоянии, подобное чему- то такому:
key = AQB9p8RdqS09CBAA1DHsiZJbehb7ZBffhfmFJQ==
Далее мы можем переключиться в хост KVM, в котором нам необходимо выполнить два момента:
-
Задать секрет - некий объект, который собирается связывать libvirt с пользователем Ceph - и, сделав это, мы намерены содать объект секрета с его UUID (Universally Unique Identifer).
-
Применить этот UUID для его привязки к имеющемуся ключу Ceph при определении создаваемого пула Ceph.
Самый простой способ осуществления этих двух шагов состоял бы в использовании двух файлов настройки XML для
libvirt. Итак, давайте создадим эти два файла. Давайте назовём первый secret.xml,
и вот его содержимое:
<secret ephemeral='no' private='no'>
<usage type='ceph'>
<name>client.KVMpool secret</name>
</usage>
</secret>
Убедитесь что вы сохранили и импортировали этот файл, набрав такую команду:
# virsh secret-define --file secret.xml
После того как вы нажмёте клавишу Enter, эта команда намерена
выбросить UUID. Пожалуйста, скопируйте и вставьте этот UUID в какое- то безопасное место, поскольку он понадобится
нам для файла XML пула. В нашей среде эта первая команда virsh выбросила
нам следующий вывод:
Secret 95b1ed29-16aa-4e95-9917-c2cd4f3b2791 created
Нам требуется назначить это значение данному секрету с тем, чтобы когда libvirt попытается воспользоваться этим
секретом, он знал бы какой пароль применять. Это в действительности именно
тот пароль, который мы создали на уровне Ceph, когда воспользовались ceph auth
get-create и который выбросится нам данным ключом. Итак, теперь, когда мы обладаем и UUID секрета,
и значением ключа Ceph, мы можем скомбинировать их для создания полного объекта аутентификации. В своём хосте
KVM нам потребуется набрать следующую команду:
# virsh secret-set-value 95b1ed29-16aa-4e95-9917-c2cd4f3b2791AQB9p8RdqS09CBAA1DHsiZJbehb7ZBffhfmFJQ==
Теперь мы можем создать необходимый файл пула Ceph. Давайте вызовем файл настроек
ceph.xml и вот что он содержит:
<pool type="rbd">
<source>
<name>KVMpool</name>
<host name='192.168.159.151' port='6789'/>
<auth username='KVMpool' type='ceph'>
<secret uuid='95b1ed29-16aa-4e95-9917-c2cd4f3b2791'/>
</auth>
</source>
</pool>
Итак, значение UUID с нашего предыдущего шага было использовано в данном файле для ссылки на то, какой именно секрет (идентичность) мы намерены применять для доступа к пулу Ceph. Теперь нам требуется выполнить стандартную процедуру - импортировать необходимый пул, запустить его и сделать его запускаемым автоматически - когда мы хотим применять его на постоянной основе (после перезапуска хоста KVM). Итак, давайте осуществим это такой последовательностью команд в своём хосте KVM:
# virsh pool-define --file ceph.xml
# virsh pool-start KVMpool
# virsh pool-autostart KVMpool
# virsh pool-list --details
Самая последняя команда должна выдать вывод, подобный следующему:
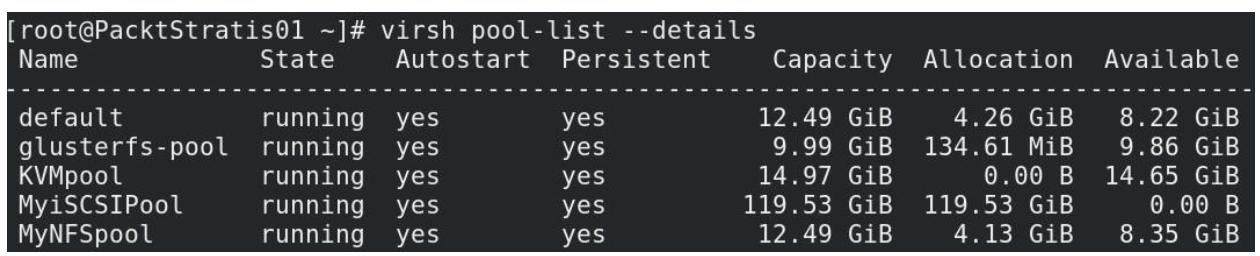
Теперь, когда пул объектов Ceph доступен для нашего хоста KVM, мы можем устанавливать в нём виртуальную машину. Мы намерены поработать с этим - опять же - в Главе 7, Виртуальные машины: Установка, настройка и управление жизненным циклом.
Образы диска это стандартные файлы, хранящиеся в файловой системе соответствующего хоста. Они обладают большим
размером и выступают для гостей в качестве виртуальных жёстких дисков. Вы можете создать такой файл с посощью
команды dd, следующим образом:
# dd if=/dev/zero of=/vms/dbvm_disk2.img bs=1G count=10
Вот перевод данной команды для вас:
Дублировать данные dd (duplicate data) из входного файла
if (input file) /vms/dbvm_disk2.img
(виртуальная неограниченная поставка нулей) при помощи блоков с размером в 1 ГБ (bs = block size) и повторить это
(count) 10 раз.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
|
Результатом нашей предыдущей команды будет /vms/dbvm_disk2.img. Наш образ теперь
обладает предварительно выделенными 10 ГБ и готов к использованию гостем либо как загрузочный диск, либо как
вторичный диск. Аналогично, вы также можете создавать образы диска с динамическим выделением. Предварительное
выделение и динамическое выделение (разбросанное) это методы выделения диска, или вы также можете называть их
значением формата:
-
Предварительно выделяемый (Preallocated): Виртуальный диск с предварительным выделением забирает всё пространство сразу в момент своего создания. Обычно это означает более быстрые скорости записи, нежели у виртуальных дисков с динамическим выделением.
-
Динамически выделяемый (Tin-provisioned): При данном методе пространство будет выделяться для данного тома по мере необходимости - например, когда вы создаёте некий виртуальный диск в 10 ГБ (образ диска) с разбросанным выделением. Первоначально он бы занял пару МБ пространства в вашем хранилище и продолжал бы рост по мере получения записей от своей виртуальной машины вплоть до размера в 10 ГБ. Это делает возможным принятие чрезмерных обязательств хранилищем, что означает обман со значением доступной ёмкости с точки зрения хранилища. Более того, позднее это может приводить к проблемам, когда пространство хранения будет заполнено. Для создания диска с динамическим выделением пользуйтесь параметром
seekв командеddкак это показано в следующей команде:# dd if=/dev/zero of=/vms/dbvm_disk2_seek.imgbs=1G seek=10 count=0
У каждого из форматов имеются собственные преимущества и недостатки. Когда вы ищите производительность ввода/ вывода, принимайте формат предварительного выделения, но если у вас отсутствует интенсивная нагрузка ввода/ вывода, выбирайте формат динамичного выделения.
Теперь вам может оказаться любопытным, каким образом вы можете определить какой именно метод выделения
применяет некий конкретный диск. Имеется добрая утилита для поиска этого:
qemu-img. Она также поддерживает создание нового диска и выполнение
преобразования формата нижнего уровня.
Параметр info команды qemu-img
отображает сведения относительно образа диска, включая определение абсолютного пути этого образа, значение
формата файла, а также виртуальный и дисковый размеры. Отыскав значение размера виртуального диска с точки зрения
QEMU и сопоставив его со значением размера файла образа на родительском диске, вы запросто можете определить
какая политика выделения диска применяется. В качестве образца давайте рассмотрим два созданных нами образа
дисков:
# qemu-img info /vms/dbvm_disk2.img
image: /vms/dbvm_disk2.img
file format: raw
virtual size: 10G (10737418240 bytes)
disk size: 10G
# qemu-img info /vms/dbvm_disk2_seek.img
image: /vms/dbvm_disk2_seek.img
file format: raw
virtual size: 10G (10737418240 bytes)
disk size: 10M
Взгляните на строку disk size обоих дисков. Она отображает
10G для /vms/dbvm_disk2.img, в
то время как для /vms/dbvm_disk2_seek.img, показывается
10M MiB. Это отличие обусловлено тем, что второй диск применяет формат
динамического выделения. Значение виртуального размера это то, что наблюдает гость, а размер диска это то пространство,
которое зарезервировано этим диском в его хосте. Когда оба размера одни и те же, это означает, что данный диск
предварительно выделен. Теперь давайте подключим этот образ диска к виртуальной машине; вы можете подключать его
при помощи virt-manager или его альтернативой CLI,
virsh.
Из среды с графическим рабочим столом системы хоста запустите virt-manager. Его также можно запустить удалённо при помощи SSH, как это показывается следующими командами:
# ssh -X host's address
[remotehost]# virt-manager
Итак, давайте воспользуемся Диспетчером виртуальных машин для присоединения своего диска к нашей виртуальной машине.
-
Из главного окна Диспетчера виртуального менеджера выберите ту виртуальную машину, к которой вы хотите добавить этот вторичный диск.
-
Пройдите в окно подробностей имеющегося виртуального оборудования и кликните по кнопке Add Hardware, расположенной в нижней левой стороне появившегося блока диалога.
-
В Add New Virtual Hardware выберите Storage и воспользуйтесь кнопкой Create a disk image for the virtual machine и размером виртуального диска, как это отображено на снимке экрана ниже:
-
Если вы желаете подключить предварительно созданный образ
dbvm_disk2.img, выберите Select или создайте индивидуальное хранилище, кликните по Manage и, либо пройдите к своему файлуdbvm_disk2.imgиз каталога/vms, либо отыщите его в пуле своего локального хранилища, затем выберите его и кликните Finish.Замечание Здесь мы пользуемся неким образом диска, но вы вольны применять любое устройство хранения, которое присутствует системе его хоста, например,
LUN, некий физический диск целиком (/dev/sdb) или раздел диска (/dev/sdb1), либо логический том LVM. Мы могли бы применять любой из ранее настроенных пулов хранения для складирования этого образа либо в виде файла, либо как объект, либо непосредственно в блочном устройстве. -
Клик по кнопке Finish подключит выбранный образ диска (файл) в качестве второго диска к своей виртуальной машине при помощи настроек по умолчанию. Те же самые действия можно быстро выполнить с применением команды
virsh.
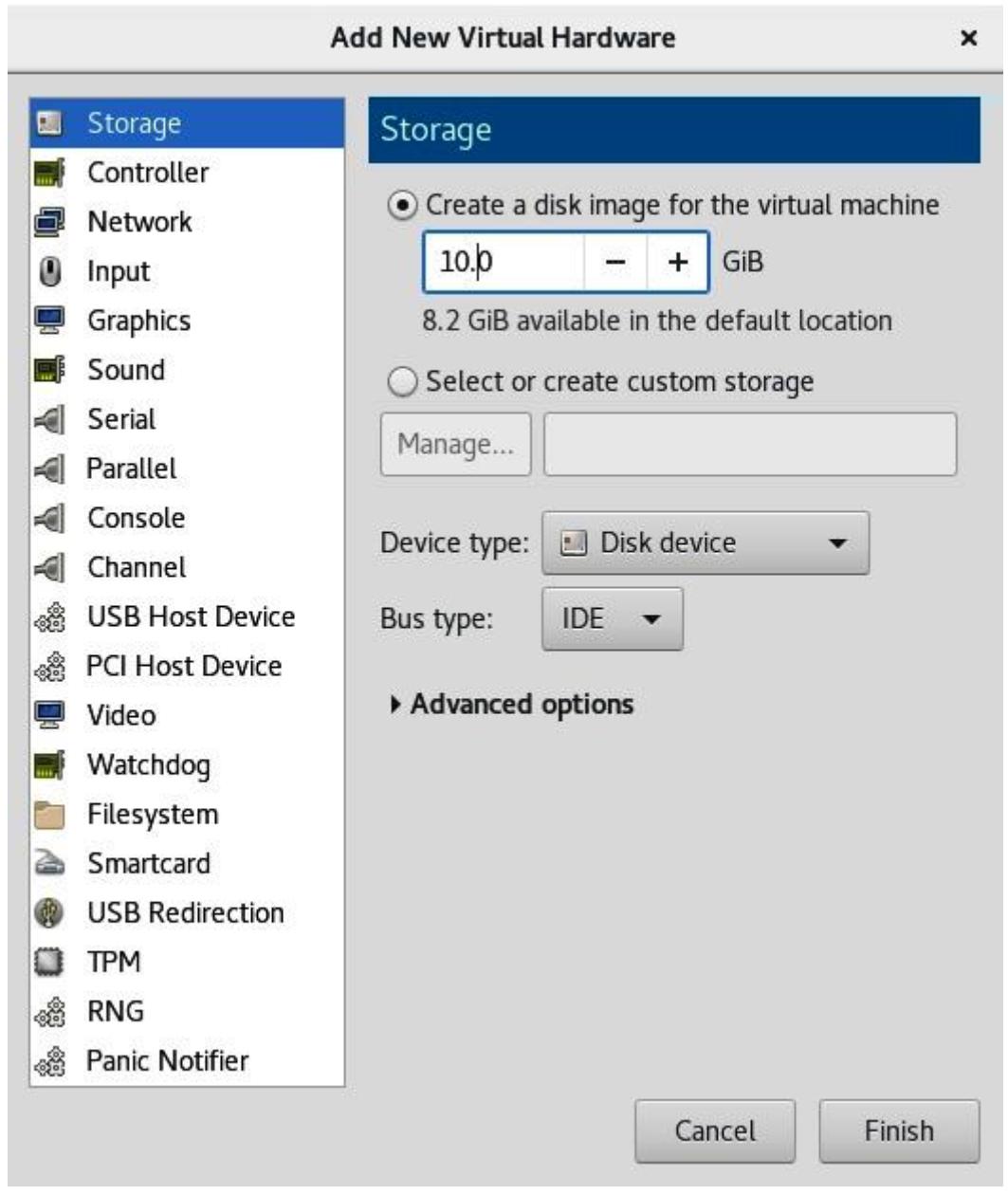
Использование virt-manager для создания некого виртуального диска было достаточно простым - всего пара кликов
мышкой и небольшой набор текста. Теперь давайте рассмотрим как мы можем выполнять это из командной строки, а именно,
при помощи virsh.
virsh это очень мощная альтернатива для virt-manager. Вы можете выполнить
за секунду то, что отняло бы минуту для исполнения через графический интерфейс, такой как virt-manager. Она выполняет
параметр attach-disk для подключения некого нового диска к виртуальной
машине. Имеется великое множество переключателей, предоставляемых с
attach-disk:
attach-disk domain source target [[[--live] [--config] | [--current]] | [--persistent]] [--targetbusbus] [--driver driver] [--subdriversubdriver] [--iothreadiothread] [--cache cache] [--type type] [--mode mode] [--sourcetypesourcetype] [--serial serial] [--wwnwwn] [--rawio] [--address address] [--multifunction] [--print-xml]
Тем не менее, в обычной ситуации для осуществления подключения к виртуальной машине в горячем режиме диска следующего будет достаточно:
# virsh attach-disk CentOS8 /vms/dbvm_disk2.img vdb --live --config
Здесь CentOS8 это та виртуальная машина, к которой выполняется подключение
диска. Затем имеется значение пути данного образа диска. vdb это название
целевого диска, которое должно быть видимым внутри соответствующей гостевой операционной системы.
--live означает осуществление этого действия в то время как эта виртуальная машина
запущена, а --config подразумевает его подключение на постоянной основе при
перезапусках. В случае когда переключатель --config не добавлен, этот диск
будет оставаться подключенным только до перезапуска.
|
| Замечание |
|---|---|
|
Поддержка подключения в горячем режиме: В гостевой операционной системе Linux должен быть загружен модуль
|
Для быстрого определения того, сколько vDisk подключено к некой виртуальной машине, вы можете использовать
команду virsh domblklist <vm_name>. Вот некий пример:
# virsh domblklist CentOS8 --details
Type Device Target Source
------------------------------------------------
file disk vda /var/lib/libvirt/images/fedora21.qcow2
file disk vdb /vms/dbvm_disk2_seek.img
Это ясно указывает, что к нашей виртуальной машине подключены два vDisk, которые являются обоими файлами образов.
Они видны для гостевой операционной системы, соответственно, как vda и
vdb, а в самом последнем столбце путь из системы хоста соответствующих
дисковых образов.
Далее мы собираемся рассмотреть как создавать некую библиотеку ISO.
Хотя гостевая операционная система в вашей виртуальной машине может быть установлена с физического носителя, через выполнение проброса имеющегося в хосте устройства CD/DVD в вашу виртуальную машину, это не самый эффективный способ. Считывание с DVD медленнее по сравнению со считыванием с жёсткого диска, а потому наилучший способ состоит в хранении применяемых для установки операционных систем и приложений в ваших виртуальных машин ISO файлов (или логических CD) в пуле хранения на основе файлов и создание некой библиотеки ISO.
Для создания ISO библиотеки образов вы можете воспользоваться командой
virsh virt-manager. Давайте рассмотрим как создавать некую библиотеку ISO
при помощи команды virsh:
-
Прежде всего, создайте аталог в системе своего хоста для хранения обрзов
.iso:# mkdir /iso -
Установите верные полномочия. Его владельцем должен быть пользователь root с правами , установленными в значение
700, когда установлен принудительный режим SELinux, требуется установить такой контекст:# chmod 700 /iso # semanage fcontext -a -t virt_image_t "/iso(/.*)?" -
Задайте библиотеку ISO при помощи команды
virsh, как это отображено в следующем кодовом блоке:# virsh pool-define-as iso_library dir - - - - "/iso" # virsh pool-build iso_library # virsh pool-start iso_libraryВ своём предыдущем примере мы воспользовались значением названия
iso_libraryчтобы продемонстрировать как создавать пул хранения, который будет содержать образы ISO, но вы вольны применять любое название по своему усмотрению. -
Убедимся что этот пул (библиотека образов ISO) был создан:
# virsh pool-info iso_library Name: iso_library UUID: 959309c8-846d-41dd-80db-7a6e204f320e State: running Persistent: yes Autostart: no Capacity: 49.09 GiB Allocation: 8.45 GiB Available: 40.64 GiB -
Теперь вы можете скопировать или переместить свои образы
.isoв каталог/iso_lib. -
По окончанию копирования своих файлов
.isoв каталог/iso_libобновите свой пул, а затем проверьте его содержимое:# virsh pool-refresh iso_library Pool iso_library refreshed # virsh vol-list iso_library Name Path ------------------------------------------------------------------------------ CentOS8-Everything.iso /iso/CentOS8-Everything.iso CentOS7-EVerything.iso /iso/CentOS7-Everything.iso RHEL8.iso /iso/RHEL8.iso Win8.iso /iso/Win8.iso -
Это выдаст список всех сохранённых в вашем каталоге файлов ISO, причём вместе с их путями. Данные образы ISO теперь можно теперь напрямую использовать с виртуальной машиной для установки гостевой операционной системы, установки программного обеспечения или для обновлений.
Создание библиотеки образов фактически обыденно в корпорациях наших дней. Лучше обладать централизованным
местом, в которое вы помещаете все свои образы ISO и это упростит реализацию некого типа метода синхронизации
(к примеру, rsync), когда вам требуется выполнять синхронизацию по
различным местоположениям.
Удалить пул хранения достаточно просто. Обратите, пожалуйста, внимание на то, что удаление некой области хранения не уничтожает никакие файловые/ блочные устройства. Оно всего лишь отсоединяет данное хранилище от virt-manager. Само файловое/ блочное устройство надлежит удалить вручную.
У нас имеется возможность удалить пул хранения через virt-manager или применяя команду
virsh. Давайте сначала проверим как это сделать при помощи virt-manager:
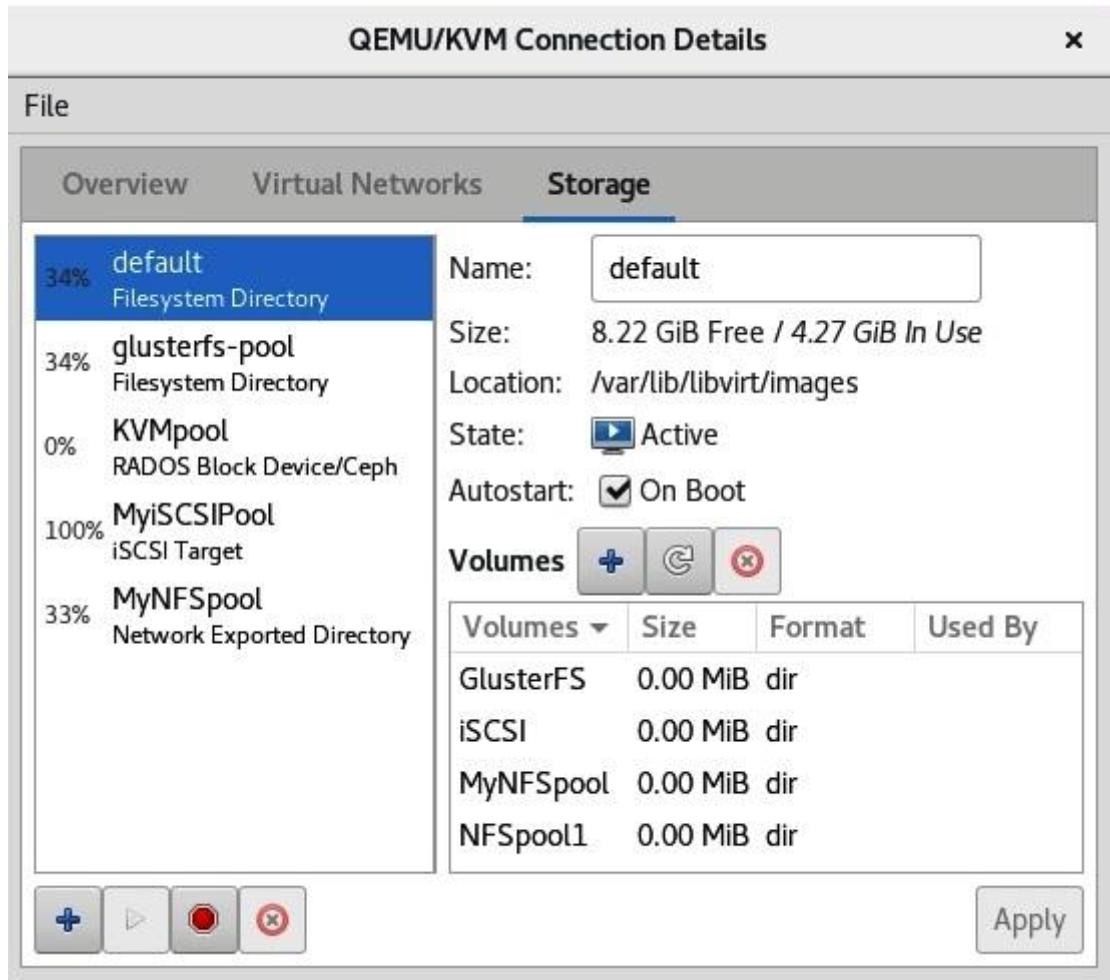
Прежде всего, выберите красную кнопку останова чтобы остановить пул, а затем кликните по красной окружности с X для удаления этого пула.
Если вы желаете воспользоваться virsh, то всё ещё проще. Допустим, вы
желаете удалить пул с названием MyNFSpool из нашего предыдущего снимка
экрана. Всего лишь наберите следующие команды:
# virsh pool-destroy MyNFSpool
# virsh pool-undefine MyNFSpool
Наш следующий этап после создания пула состоит в создании тома хранения. С логической точки зрения, такие тома хранения расщепляют пул хранения на меньшие части. Давайте изучим как это делать.
Тома хранения создаются поверх пулов хранения и подключаются к виртуальным машинам в качестве виртуальных дисков. Для создания некого тома хранения запустите консоль Управления хранением, перейдя к virt-manager, затем кликните Edit | Connection Details | Storage и выберите тот пул хранения, в котором вы желаете создать новый том хранения. Кликните по кнопке создания нового тома (+):
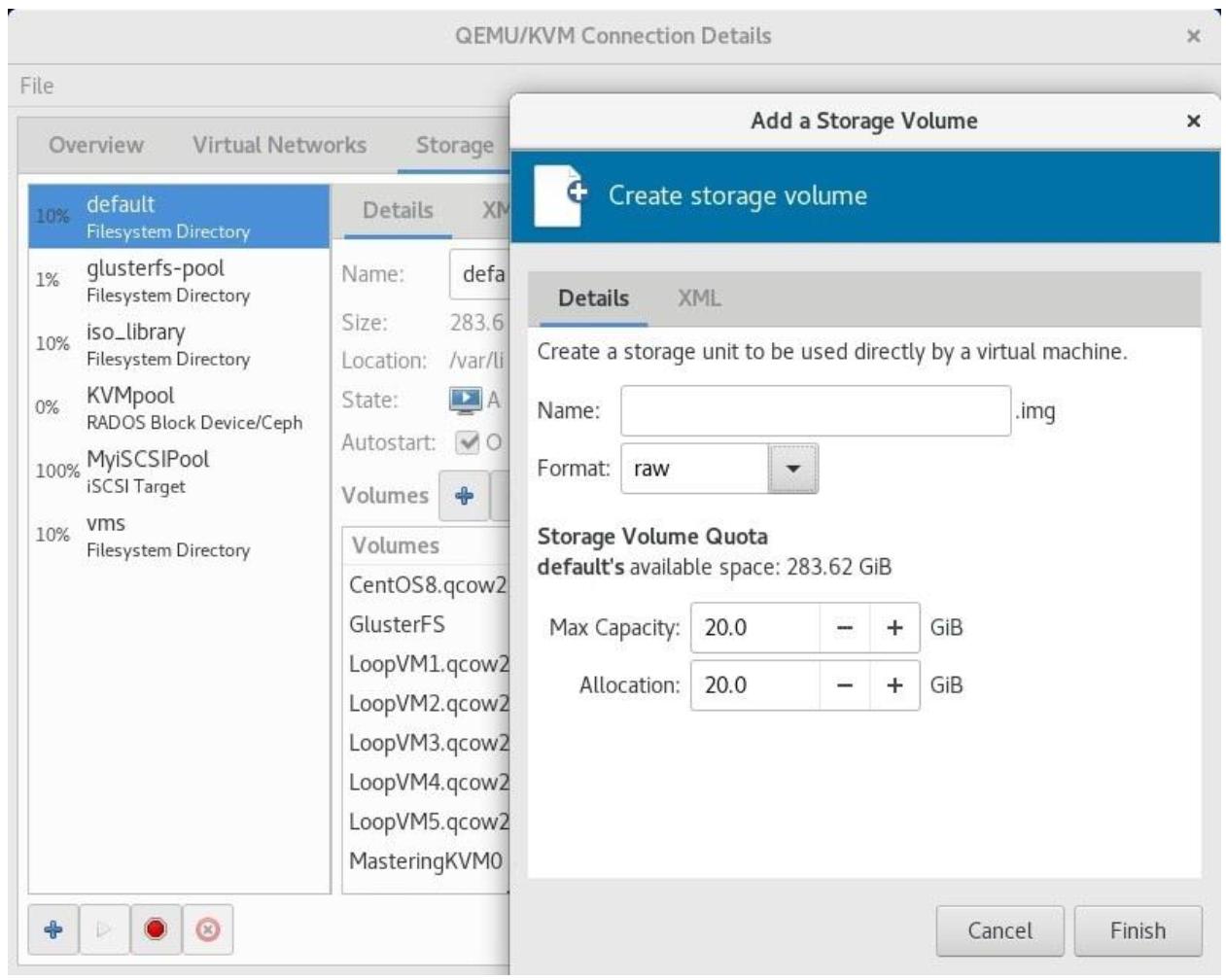
Далее предоставьте название для этого нового тома, выберите под него формат выделения диска и кликните по
кнопке Finish для построения этого тома и его подготовки
к подключению к виртуальной машине. Вы можете присоединять его при помощи обычного virt-manager или командой
virsh. Имеются различные поддерживаемые libvirt форматы дисков
(raw, cow,
qcow, qcow2,
qed и vmdk). Пользуйтесь тем
форматом, который подходит вашей среде и установите надлежащий размер в полях Max
Capacity и Allocation чтобы определиться хотите ли вы выполнить
предварительное выделение или же придерживаться динамического выделения. Если вы оставите размер диска одним и тем же
и в поле Max Capacity, и в поле
Allocation, это будет предварительное выделение вместо
динамического. Обратите внимание на то, что формат qcow2 не поддерживает
метод динамического выделения.
В Главе 8, Создание и модификация дисков ВМ, шаблонов и моментальных
снимков все эти форматы дисков будут подробно пояснены. На данный момент просто уясните, что формат
qcow2это специальным образом разработанный формат диска под виртуализацию
KVM. Он поддерживает современные свойства, требующиеся для создания внутренних моментальных снимков.
Синтаксис для создания тома при помощи команды virsh таков:
# virsh vol-create-as dedicated_storage vm_vol1 10G
Здесь dedicated_storage это наш пул хранения,
vm_vol1 это название создаваемого тома, а
10 ГБ это его размер:
# virsh vol-info --pool dedicated_storage vm_vol1
Name: vm_vol1
Type: file
Capacity: 1.00 GiB
Allocation: 1.00 GiB
Команда virsh и параметры создания тома почти одни и те же, вне зависимости
от пула хранения, в котором он создаётся. Просто введите надлежащий ввод для переключателя
--pool. Теперь давайте посмотрим как удалять том при помощи команды
virsh.
Синтаксис для удаления тома с использованием команды virsh следующий:
# virsh vol-delete dedicated_storage vm_vol2
Исполнение данной команды удалит том vm_vol2 из пкла хранения
dedicated_storage.
Наш следующий этап в путешествии по хранилищам состоит в небольшом заглядывании в будущее, поскольку все упомянутые в этой главе понятия были известны на протяжении многих лет, причём некоторые даже на протяжении десятилетий. Существующий мир хранилищ изменяется и движется в новых и увлекательных направлениях, поэтому давайте слегка обсудим это далее.
За последние 20 или около того лет самым крупным прорывом в мире хранения с точки зрения технологии стало появление SSD (Solid State Drives, Твердотельных устройств). Сейчас мы уже знаем, что многие люди привыкли, что они обладают ими в своих компьютерах - ноутбуках, рабочих станциях и в любых применяемых нами устройствах. Но опять же, мы обсуждаем хранение под виртуализацию, а также понятия корпоративного хранилища в целом, а это означает, что наши обычные твердотельные накопители с интерфейсом SATA никуда не годятся. Хотя многие и применяют их в устройствах хранения среднего уровня и/ или самодельных устройствах хранения, в которых размещаются пулы ZFS (для кэширования), некоторые из этих понятий обладают своей собственной жизнью в устройствах хранения самых последних поколений. Данные устройства коренным образом меняют сам способ, которым работают данная технология и преобразуют разделы современной истории ИТ с точки зрения того, какие именно протоколы применяются, насколько низкими задержками они обладают и как они подходят к многоуровневому хранению - многоуровневость, это то понятие, которое разделяет различные устройства хранения или их пулы хранения в зависимости от возможностей, обычно от скорости.
Давайте кратко поясним что мы здесь обсуждаем на примере того, куда направляется наш мир хранения. Наряду с этим наш мир хранения собирает с собой вселенные виртуализации, облачных решений, а также высокопроизводительных вычислений, а потому такие понятия не являются чужеземными. Они уже присутствуют в виде свободно доступных устройств хранения, которые вы способны приобрести в наши дни.
Внедрение твердотельных накопителей существенным образом изменило сам способ доступа к нашим устройствам. Всё дело в производительности и латентности, а также старые понятия, например AHCI (Advanced Host Controller Interface), которые мы всё ещё активно применяем с большим числом твердотельных накопителей на имеющемся в наши дни рынке, просто не достаточно хороши для обработки той производительности, которой обладают твердотельные накопители. AHCI - это стандартный метод, которым обычный жёсткий диск (механический диск или обычно шпиндельный) обменивается данными через программное обеспечение с устройствами SATA. Тем не менее, ключевым моментом этого выступает жёсткий диск, который подразумевает цилиндры, секторы, головки - те моменты, которыми не обладают SSD, ибо им не требуется вращаться и нет такого вида системы понятий. Это подразумевает, что для того чтобы мы были способны применять SSD более естественным образом, должен быть создан другой стандарт. Именно этому и посвящён NVMe (Non-Volatile Memory Express) - наведению мостов между тем что способны делать твердотельные устройства и что они в реальности выполняют без использования трансляции из SATA в AHCI и в PCI Express (и тому подобное).
Быстрые темпы разработки твердотельных накопителей и интеграция с NVMe сделали возможными огромные достижения в области корпоративных систем хранения данных. Это означает, что требовалось изобрести новые контроллеры, новое программное обеспечение и совершенно новую архитектуру для поддержки такого сдвига системы взглядов. по мере того, как всё больше и больше устройств хранения интегрируют NVMe для различных целей - в первую очередь для кэширования, а далее и для увеличения хранимой ёмкости - становится очевидным, что имеются и иные подлежащие решению задачи. первая из них - это тот способ, коим мы намерены подключать устройства хранения, предлагающие столь огромные возможности, к своим виртуальным, облачным или высокопроизводительным средам.
В последние 10 лет, или около того, многие люди утверждали, что FC исчезнет с рынка и многие компании сделали ставку на разные стандарты - iSCSI, iSCSI over RDMA, NFS over RDMA и тому подобные. Обоснования этого казались достаточно весомыми:
-
FC затратны - они требуют отдельных физических коммутаторов, отдельной кабельной обвязки и отдельных контроллеров, причём всё это стоит больших денег.
-
Здесь вовлекается лицензирование - когда вы приобретаете, скажем, коммутатор Brocade, который обладает 40 портами FC, это вовсе не означает, что вы вольны применять их все сразу после включения, поскольку имеются лицензии для получения дополнительных портов (8- портов, 16- портов, и так далее).
-
Устройства хранения FC дорогостоящи и часто требуют более дорогих дисков (с FC коннекторами).
-
Настройка FC требует пространных знаний и/ или навыков, поскольку вы не можете просто пойти и настроить некиц стек коммутаторов FC для компании корпоративного уровня без владения основными понятиями и того CLI от производителя такого коммутатора помимо тех знаний, которые нужны данной компании.
-
Возможность FC как протокола в отношении ускорения своих разработок для достижения новых скоростей на практике была плохой. Проще говоря, когда требовался FC для перехода с 8 Гбит/с до 32 Гбит/с, Ethernet перешёл с 1 Гбит/с на полосу пропускания в 25, 40, 50 и 100 8 Гбит/с. Уже сейчас речь идёт о 400 Гбит/с Ethernet и имеются первые устройства, которые поддерживают данный стандарт. Как правило, это беспокоит клиентов, так как большие числа означают лучшую пропускную способность, по крайней мере, в сознании большинства людей.
Однако то что в настоящий момент происходит на рынке, рассказывает нам совершенно иную историю - не только о том, что FC вернулся, но и то, что он вернулся с миссией. Компании, занимающиеся корпоративными системами хранения, приняли это и начали предлагать устройства хранения с безумным уровнем производительности (за счёт твердотельных накопителей NVMe на первой стадии). Эту производительность надлежит передать в наши виртуальные и облачные среды, среды высокопроизводительных вычислений, а для этого требуется наилучший из возможных протоколов с точки зрения наименьших задержек, его дизайна, качества и надёжности и всё это имеется у FC.
Это подводит ко второй стадии, на которой твердотельные NVMe применяются не только как устройства кэширования, но также и как устройства основной ёмкости.
Обратите внимание на тот факт, что прямо сейчас назревает большая схватка на рынке интерконнекта памяти/ хранилищ. Существует множество различных стандартов, которые пытаются конкурировать с технологией Intel QPI (Quick Path Interconnect), технологией, применяемой в ЦПУ Intrl более десятилетия. Если этот предмет вам интересен, в конце данной главы имеется ссылка, в разделе Дополнительное чтение, по которой вы можете ознакомиться с дополнительными сведениями. По существу, QPI это технология интерконнекта точка- точка с низкой латентностью и высокой полосой пропускания, которая составляет сердцевину серверов наших дней. В частности, она обрабатывает взаимодействие между ЦПУ, ЦПУ и памятью, ЦПУ и чипсетом и тому подобное. Это именно та технология, которую Intel разработала после того как избавилась от технологии FSB (Front Side Bus) и интегрированных в чипсет контроллеров памяти. FSB выступала общей шиной, которая разделялась между памятью и запросами ввода/ вывода. Этот подход обладал гораздо большей задержкой, плохо масштабировался, имел меньшую полосу пропускания и проблемы в ситуациях, когда на стороне памяти и ввода/ вывода происходило большое число операций ввода/ вывода. После переключения на архитектуру, в которой сам контроллер памяти был частью своего ЦПУ (тем самым, память напрямую подключалась к нему), для Intel стал существенным окончательные переход к такой концепции.
Если вам более знакомы ЦПУ AMD, QPI для Intel представляет то, чем выступает шина HyperTransport в ЦПУ со встроенными контроллерами памяти для ЦПУ AMD.
Поскольку твердотельные накопители SSD стали быстрее, сам стандарт PCI Express также нуждался в обновлении, что послужило основной причиной столь страстного ожидания его последней версии (PCIe 4.0 - в последнее время стали поставляться первые такие продукты {Прим. пер.: например, ЦПУ AMD, сетевые адаптеры Mellanox и NVMe устройства}). Однако теперь внимание переключилось на две другие задачи, которые необходимо решить для работы систем хранения. Кратко сформулируем их:
-
Задача номер один проста. Для обычного пользовательского компьютера ситуации с одним или двумя твердотельными накопителями будет достаточно для 99% и более случаев. В действительности, основная причина, по которой обычным пользовательским компьютерам требуется более быстрая шина PCIe это более быстрые графические карты. Но для производителей хранилищ всё иначе. Они желают производить корпоративные устройства хранения, которые будут обладать 20, 30, 50, 100, 500 твердотельными NVMe устройствами в единой системе хранения - и они хотят этого прямо сейчас, поскольку твердотельные накопители являются зрелой технологией и широко доступны.
-
Вторая проблема более сложная. Чтобы усугубить положение вещей, самое последнее поколение твердотельных накопителей (скажем, основывающихся на Intel Optane) способно предложить ещё более низкую латентность и более высокую пропускную способность. И по мере развития технологий эта ситуация (ещё более низкие латентности и более высокие пропускные способности) будет только ухудшаться. Для служб наших дней - виртуализация, облачные решения, высокопроизводительные вычисления - важно чтобы система хранения имела возможность справляться с любой нагрузкой, которую мы способны на неё возлагать. Эти технологии и в самом деле меняют правила игры с точки зрения того, насколько быстрыми могут стать устройства хранения, причём лишь тогда, когда интерконнект способен их обрабатывать (QPI, FC и многие прочие). Два из таких понятий заимствованы из Intel Optane — SCM (Storage Class Memory, Память класса хранения) и PM (Persistent Memory, Постоянная память), представляют собой новейшие технологии, которые компании и заказчики систем хранения данных желают внедрить в свои системы хранения, причём быстро.
-
Третя задача состоит в том как передавать всю эту полосу пропускания и возможности ввода/ вывода в серверы и применяющие их инфраструктуры. Именно по этой причине была создана концепция NVMe-OF (NVMe over Fabrics, NVMe поверх системы коммутации), чтобы попытаться поработать над собственно стеком инфраструктуры хранения и чтобы превратить NVMe в ещё более действенные и быстрые для потребителей.
Если вы взгляните на эти достижения с концептуальной точки зрения, на протяжении десятилетий было очевидно, что ОЗУ- подобная память является самой быстрой технологией с наименьшей задержкой, которая у нас имелась последние пару десятилетий. Также логично, что мы по возможности перемещаем рабочие нагрузки в оперативную память. Вспомните базы данных в памяти (такие как Microsof SQL, SAP Hana и Oracle). Все они были крутились вокруг этого блока много лет.
Данные технологии коренным образом изменяют сам способ, которым мы размышляем о хранении. По существу, мы более не обсуждаем многоуровневое хранение на основе технологии (SSD в сопоставлении с SAS и SATA) или полной скорости, поскольку сама скорость не вызывает сомнений. Самые последние технологии хранения обсуждают многоуровневое хранение в терминах задержек. Основная причина очень проста - допустим, вы представляете компанию хранения и вы выстраиваете систему хранения, которая использует 50 SCM SSD в качестве ёмкости. Для кэширования единственной разумной технологией была бы оперативная память, причём сотни гигабайт. Единственный способ работы с многоуровневым хранением в таком устройстве - это в целом эмуляция на уровне программного обеспечения, причём через создание дополнительных технологий, которые будут производить дополнительные технологии, порождающие службы очередей, подобные многоуровневым, обработки приоритетов в кэше (ОЗУ) и похожие понятия. Почему? Потому что когда вы применяете одни и те же твердотельные накопители SCM для общей ёмкости, а они предлагают одни и те же скорость и операции ввода/ вывода, у вас просто не будет никакого способа создания множества уровней на базе технологии или возможностей. {Прим. пер.: подробнее о методах построения распределённых и многоуровневых систем хранения, а также организации очередей в наших переводах Внутреннее устройство баз данных, Алекс Петров, O`Reilly Media, Inc., октябрь 2019 и Распределённые системы для практиков, Даймос Раптис, Learnpub, май 2020.}
Давайте дополнительно опишем это применяя для пояснения доступную систему хранения. Наилучшие устройства для выделения нашей точки зрения - это серия устройств хранения Dell/EMC PowerMax. Когда вы заполните их твердотельными NVMe и SCM, самая высшая модель (8000), способна масштабироваться до 15 миллионов IOPS (!), пропускной способности в 350 ГБ/с при задержках менее чем в 100 микросекунд и ёмкости вплоть до 4 ПБ. Задумайтесь на секунду об этих показателях. Зтем добавьте ещё одно число - во внешнем интерфейсе может иметься до 256 портов FC/FICON/iSCSI. Совсем недавно для этой серии Dell/EMC выпустила новые 32 Gbit/s модули FC. Самая нижняя модель PowerMax (2000) способна выполнять 7.5 миллионов IOPS с задержкой под 100 микросекунд и масштабированием до 1 ПБ. Она также способна выполнять все обычные операции EMC - репликацию, сжатие, дедупликацию, моментальные снимки функции NAS и т.п.. Итак, это не просто макетинговые рассуждения, эти устройства уже существуют и применяются корпоративными клиентами.

Это очень важные понятия для будущего, поскольку всё больше и больше производителей выпускают аналогичные устройства (и они уже на подходе). Мы всецело ожидаем, что основанный на KVM мир, охватит эти понятия в крупномасштабных средах, в особенности для инфраструктур с OpenStack и OpenShif.
В этой главе мы представили и настроили разнообразные концепции хранения с Открытым исходным кодом для libvirt. Мы также обсудили стандартные для отрасли подходы, такие как iSCSI и NFS, поскольку они часто применяются в инфраструктурах, которые не основаны на KVM. Например, из рассмотренного перечня рассмотренных в этой главе основанные на VMware vSphere среды могут применять FC, iSCSIи NFS, в то время как базирующиеся на Microsof среды способны пользоваться FC и iSCSI.
Наша следующая глава рассмотрит предметы, относящиеся к виртуальным устройствам отображения и их протоколам. Мы предоставим глубокое введение в протоколы VNC и SPICE. Мы также представим некое описание прочих протоколов, которые используются для подключения к виртуальным машинам. Всё это поможет нам разобраться с полным стеком основ, которые требуются нам для работы со своими виртуальными машинами, которые мы рассматривали в своих трёх последних главах.
-
Что такое пул хранения?
-
Как работает с libvirt хранилище NFS?
-
Как работает с libvirt iSCSI?
-
Как достигается избыточность подключений к хранилищу?
-
Чем ещё могут пользоваться виртуальные машины кроме NFS и iSCSI?
-
Какую основу хранения можно применять для основанного на объектах хранения с libvirt?
-
Как мы можем создавать образ виртуальной машины для его применения с виртуальной машиной KVM?
-
Как применение устройств NVMe SSDs и SCM изменило сам способ которым мы создаём множество уровней хранения??
-
В чём состоят фундаментальные проблемы доставки служб хранения 0-го уровня для сред виртуализации, облачных решений и сред высокопроизводительных вычислений?
Для получения дополнительных сведений относящихся к рассмотренному нами в этой главе воспользуйтесь, пожалуйста, следующими ссылками:
Что нового в файловых системах и хранилищах RHEL8
Руководство администрирования RHEL7
Управление устройствами хранения RHEL8
{Прим. пер.: методы построения распределённых систем хранения в наших переводах Внутреннее устройство баз данных, Алекс Петров, O`Reilly Media, Inc., октябрь 2019 и Распределённые системы для практиков, Даймос Раптис, Learnpub, май 2020.}
{Прим. пер.: работа с Caph в наших переводах Полное руководство Ceph, 2е изд, Ник Фиск, O`Reilly Media, Inc., март 2019 и Изучаем Ceph, 2е изд, Энтони Д'Атри,Вайбхав Бхембре,Каран Сингх, O`Reilly Media, Inc., октябрь 2017.}