Глава 2. Структуры и операции сетевого протокола
Содержание
В Главе 1, Архитектура центров данных и корпоративной сетевой среды, а также их компоненты мы обсуждали архитектуры сетей и то как строятся сетевые среды организации. В данной главе мы бросим взгляд на те сетевые протоколы, которые работают в этих сетях и как мы будем изучать имеющиеся уязвимости и потенциальные риски каждого из них.
В этой главе мы рассмотрим сетевые протоколы и риски ненадлежащей безопасности каждого из них. Кроме того, мы изучим собственно потенциальные риск, в то время как в последующих главах протоколов мы изучим как выполнять атаки на них и как противодействовать таким атакам.
Мы начнём с OSI-RM (Open Systems Interconnection Reference Model, Справочной модели Взаимодействия открытых систем) и потока данных через вашу сетевую среду. Затем мы пройдёмся по каждому из уровней с Уровня 2 до прикладных уровней, изучим структуры протоколов и потенциальные риски для каждого из уровней протоколов.
В этой главе мы намерены сосредоточиться на следующих основных вопросах:
-
Протоколы сети передачи данных и структуры данных
-
Протоколы 2 Уровня - STP, VLAN и методы безопасности
-
Протоколы 3 Уровня - IP и ARP
-
Маршрутизаторы и протоколы маршрутизации
-
Протоколы 4 Уровня - UDP, TCP, а также QUIC/ GQUIC
-
Протоколы и методы инкапсуляции
Цель сети передачи данных состоит в продвижении информационных пакетов из конца в конец, причём настолько быстро, насколько это возможно. В 1970е появился ряд архитектур взаимодействия, которые описывали требования к коммуникационной сетевой среде. Среди них имелись OSI-RM от ISO (International Standards Organization, Международной организации по стандартизации) и TCP/IP от DoD (Department of Defense, Министерства обороны) США. В то время как первая - OSI RM - превратилась в теоретическую архитектуру, в основном, применяемую в учебных целях, за последние 25 лет или около того модель TCP/IP стала той единственной архитектурой, которая применяется для сетевых сред передачи данных.
Взгляните на эти две архитектуры на приводимой ниже схеме. Обратите внимание, что на практике они относительно схожи. В то время как OSI-RM описывает требования к сетевой среде передачи данных на семи уровнях, архитектура TCP/IP описывает их на четырёх. Однако устанавливаемые требования те же самые. Давайте взглянем поближе:

В OSI-RM Уровни 1 и 2, в точности как Уровень интерфейса в модели TCP/IP это уровни, которые выполняют соединение между непосредственно подключаемыми NE (Network Elements, Сетевыми элементами). Например, это может быть ПК, который напрямую подключается к маршрутизаторам, или маршрутизатор, который напрямую подключается к другому маршрутизатору, как мы это наблюдаем на Рисунке 2.2.
Уровни 3 и 4, ровно так же как соответствующие уровни модели TCP/IP отвечают за доставку сведений из конца в конец. Здесь у нас имеется IP на Уровне 3 и далее мы имеем TCP/UDP, которые выступают наиболее распространёнными протоколами для Уровня 4.
Уровни 5, 6 и 7, точно так же как Уровень Процесса модели TCP/IP это приложения взаимодействия, например, HTTP, протоколы электронной почты, SIP (Session Initiation Protocol, Протокол инициации сеанса), DNS (Domain Name Service, Служба доменных имён) и многие иные.
На нашей следующей схеме вы можете наблюдать цели для каждого из имеющихся уровней совместно с типичными для всех протоколами:
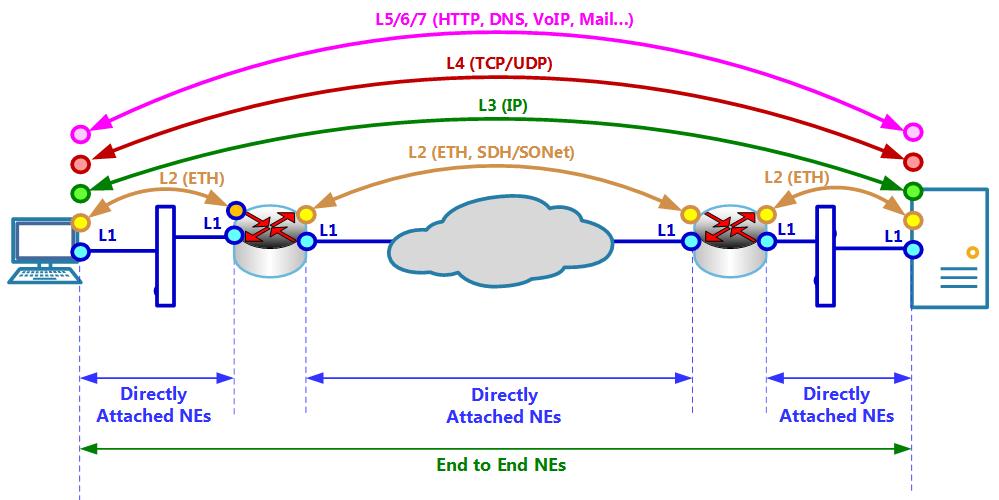
Уровень 1, Физический уровень отвечает за физическое подключение; он содержит кабели, коннекторы, частоты, техники модуляции и многое иное. Здесь мы имеем медные провода или оптические волокна, различные методы модуляции в сотовой и беспроводной связи, а также оптическую передачу по воздуху.
Уровень 2, Канальный уровень, отвечает за связь между непосредственно подключаемыми сетевыми элементами (NE). Уровень 2 определяет структуру кадра и способ отправки кадра в канал. В нашем предыдущем примере он находится между ПК слева и маршрутизатором, между маршрутизаторами и между правым маршрутизатором и сервером. Здесь основным применяемым в последние десятилетия протоколом выступал Ethernet, причём как для корпоративных Центров обработки данных (ЦОД), так и для сетей операторов. Прочие распространённые протоколы включают SDH (Synchronous Digital Hierarchy, Синхронную цифровую иерархию) в её Европейской версии, SONet (Synchronous Optical Network, Синхронную оптическую сеть) в Североамериканской версии и OTN (Optical Transport Network, Оптическую транспортную сеть), которая применяется в сетевых средах поставщиков крупного масштаба.
Уровень 3, Сетевой уровень, ответственен за доставку пакетов от сквозных сетевых элементов по сетевой среде, скажем, от ПК к серверу. Здесь у нас имеется IP (Internet Protocol, Протокол межсетевого взаимодействия), который определяет структуру самого пакета и метод адресации, причём совместно с протоколами маршрутизации, которые отвечают за изучение имеющейся сетевой архитектуры и того пути, через который передаются пакеты.
Уровень 4, Транспортный уровень, отвечает за доставку сегментов из приложения источника или процесса источника в приложение назначения или прикладной процесс. Здесь мы обладаем кодами приложений или номерами портов, которые, совместно с адресами 3 Уровня устанавливают некий сокет, который выступает оконечной точкой соответствующего приложения. В то время как пакеты 3 Уровня принимают пакеты из IP источника в соответствующем IP назначения, Уровень 4 принимает сведения из соответствующего пакета и передаёт их в своё конечное приложение.
Уровни с 5 по 7, соответственно, уровни Сеанса, Представлений и Приложений в OSI-RM или уровень Процесса в архитектуре TCP/IP составляют собственно приложение, например, HTTP, DNS и тысячи прочих хорошо известных либо частных приложений.
На приводимой далее схеме вы можете наблюдать как данные доставляются между процессами в соответствующий конечный узел и как они отправляются в свою сетевую среду:

На нашей предыдущей схеме вы можете наблюдать что происходит когда клиент открывает некий сеанс со своим сервером HTTP. Слева у нас имеется клиент, который просматривает веб сервер на находящемся справа сервере.
Когда пользователь клиента слева открывает веб браузер (обозначен цифрой 1 на Рисунке 2.3), его клиент HTTP инициирует запрос к серверу и отправляет его процессу TCP (2) в этом клиенте. Данный процесс TCP добавляет в HTTP необходимые сведения TCP, иначе говоря код своего процесса (номер порта) и номер порта назначения, которые для сервера HTTP являются кодом 80 и перенаправляет их процессу IP (3). Этот процесс IP добавляет необходимые IP адрес самого клиента и IP адрес своего сервера. Затем он пересылает этот пакет в NIC (Network Interface Card, Сетевую карту интерфейса), то есть в сетевой адаптер (4). Эта Сетевая карта добавляет значение адреса MAC (Media Access Control управления доступа к среде) и отправляет полученный кадр к Сетевой карте получателя (5). Внутри соответствующего пункта назначения, в качестве которого выступает сервер, эта Сетевая карта замечает в прибывшем кадре что он содержит сведения IP и перенаправляет их своему процессу IP (6). Этот процесс IP просматривает внутренность пакета и обнаруживает что протоколом более верхнего уровня выступает TCP и переправляет его в TCP (7). TCP просматривает заголовок и выявляет код 80, который указывает на то, что протоколом более верхнего уровня является HTTP и перенаправляет его серверному процессу HTTP (8). На следующей схеме вы можете наблюдать как сведения инкапсулируются между имеющимися Уровнями.

Соответствующий заголовок на каждом из уровней содержит разнообразные части сведений, включая MAC- адреса на Уровне 2, IP- адреса на Уровне 3
и номера портов на Уровне 4. Основной принцип состоит в том, что каждый уровень на стороне отправки добавляет необходимый код самого процесса
того уровня, с которого он исходит, а на принимающей стороне каждый уровень просматривает этот код и, в зависимости от данного кода пересылает
эти сведения на необходимый более высокий уровень. В нашем предыдущем примере HTTP- клиент добавляет идентификатор процесса (произвольное
число >1023, как это поясняется позднее в данной главе), TCP добавляет код 6 для TCP, а его IP
добавляет код 0x0800 для IP. На принимающей стороне её Сетевая карта наблюдает код
0x0800 и передаёт полученные сведения своему процессу IP. Этот процесс IP видит код
6 и пересылает информацию своему процессу TCP, а TCP наблюдает код
80 и пересылает полученные сведения в свой сервер HTTP.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Формальным названием передаваемых по сети единиц информации выступает PDU (Protocol Data Unit, единица обмена протокола). Мы называем их кадрами на Уровне 2, пакетами на Уровне 3 и сегментами на Уровне 4. Тем самым, мы, например, можем сказать, кадры Ethernet, пакеты IP, и сегменты TCP. Существует некая путаница в терминах и порой вы обнаружите термин пакет или сообщение для Уровня 4, либо применяемый для Уровня 2 термин пакет. |
На нашей следующей схеме вы можете наблюдать что происходит с сообщениями на каждом уровне когда некий запрос HTTP отправляется от соответствующего клиента в его сервер через сетевую среду. Кроме того, на идущей далее схеме вы можете видеть типичную структуру пакета, который был перехвачен Wireshark в этой сетевой среде:

Здесь обратите внимание на то, что происходит когда мы отправляем некий запрос HTTP от своего клиента слева к его серверу справа.
На стороне отправителя имеет место следующее:
-
Отправитель открывает свой веб браузер и набирает значение запрашиваемого URL.
-
Этот ПК создаёт кадр HTTP (Уровень 7), применяя параметры HTTP.
-
Данный кадр HTTP вставляется в кадр TCP своего Уровня 4. Программное обеспечение TCP этого ПК помечает порт получателя номером
80(HTTP) и произвольный порт источника (чтобы сообщить своему получателю на какой порт отправлять ответ). -
Данный кадр TCP вставляется в кадр IP Уровня 3, что добавляет IP адреса источника и получателя.
-
Этот кадр IP вставляется в кадр Ethernet Уровня 2. Здесь добавляются адреса MAC, а сами пакеты переносятся по LAN к установленному маршрутизатору по пути к своему получателю.
По пути происходит следующее:
-
Все маршрутизаторы по пути к получателю открывают поступающие пакеты до Уровня 3, просматривают значение IP адреса получателя, принимают решение маршрутизации и переправляют этот кадр данному получателю.
-
В случае различных интерфейсов маршрутизаторы к тому же извлекают этот IP пакет из кадра соответствующего исходного Уровня 2 и вставляет его в кадр получателя Уровня 2.
В получателе случается следующее:
-
Получающий сервер принимает пакет Ethernet из своей сетевой среды. Он просматривает заголовок Ethernet (значение поля Type) и видит что значением Уровня 3 протокола выступает IP.
-
Данный сервер извлекает полученный кадр IP из кадра Ethernet и отправляет его своему процессу IP, который работает с ним.
-
Этот процесс IP просматривает пакет IP и обнаруживает что протоколом Уровня 4 выступает TCP. Он выделяет из него данные Уровня 4 и переправляет их имеющемуся в данном сервере процессу TCP.
-
На Уровне 4 процесса TCP сервер отслеживает номер порта, выявляет
80, что указывает на HTTP и отправляет это своему серверу HTTP.
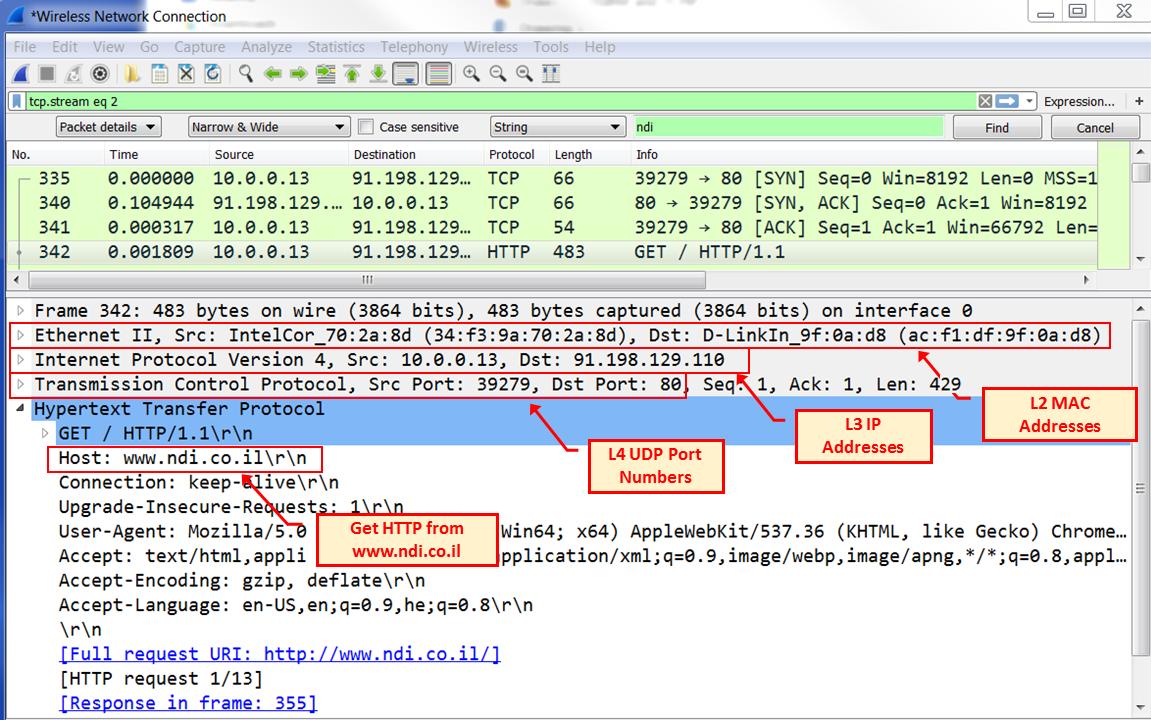
На нашем следующем снимке экрана мы можем наблюдать образец некого запроса HTTP. Обратите внимание, что кадр Ethernet был отправлен с
MAC адреса 34:f3:9a:70:2a:8d на MAC адрес ac:f1:df:9f:0a:db.
Данный кадр Ethernet переносит свой пакет IP от 10.0.0.13 к
91.198.129.110, а соответствующий IP переносит свой сегмент TCP от порта
39279 к порту 80. Данный переносимый запрос HTTP направляется
соответствующему серверу, а именно, www.ndi.co.il:
Нам важно понимать эту структуру когда мы будем обсуждать сетевые атаки и средства защиты. Атака на протоколы Уровня 2 может повлиять на имеющуюся локальную сеть, подключённую к её локальному маршрутизатору. Для сравнения, атаки на Уровне 3 могут оказывать влияние на конечные устройства или маршрутизаторы, которые будут блокировать данные или пересылать из в неверном направлении, в то время как атаки на Уровень 4 могут воздействовать на службы соответствующей конечной точки.
Уровень 2 предназначен для соединения подключённых узлов напрямую, а основной протокол, который реализует кадры, переносимые IP верхнего уровня пакеты, носит название Ethernet. Теми устройствами, которые передают кадры и Уровень 2 являются коммутаторы локальной сети. Имеются некоторые дополнительные механизмы улучшения, управления и защиты информации, например, виртуальные локальные сети (VLAN), безопасность портов и тому подобное. Теперь давайте рассмотрим как всё это работает совместно.
Протокол Ethernet был представлен в начале 1980-х и впервые был стандартизован как IEEE 802.3 для Ethernet 10 Mbps. Позднее стандарт вырос до скорости бит 100 Mbps, 1 и 10 Gbps, 25/ 40/ 100 Gbps, а позднее в 2019 они выросли до 200/ 400 Gbps. Совместно с ёмкостью соединения поступали дополнительные механизмы; те, что относятся к сведениям безопасности, будут обсуждаться в наших последующих разделах.
Структура кадра Ethernet
Кадры Ethernet бывают трёх типов: Ethernet-2, 802.3 с инкапсуляцией LLC и 802.3 с инкапсуляцией SNAP, которые применяются для передачи пакетов IP, как это показано на следующем снимке экрана:

Кадр Ethernet-2 начинается с PA
(preamble, преамбулы). В нашем предыдущем примере мы можем наблюдать отправляемый
с MAC адреса источника 00:50:56:ad:00:ea к MAC адресу получателя
00:1c:7f:89:e1:06. Кроме того, мы можем наблюдать что кодом верхнего уровня является
0x0800, который обозначает IP адрес верхнего уровня. Первая половина адресов Ethernet указывает поставщика.
В данном примере мы видим, что источником этого кадра является VMware,
гипервизор, в котором размещены серверы, а получателем выступает Checkpoint, которым является межсетевой экран
Check Point.
Чтобы разобраться с этим получше, давайте рассмотрим другой вовлечённый к канал взаимодействия пример и изучим как отправляются и получаются кадры. Мы рассмотрим три типа передачи в IPv4, которые переносятся в Ethernet-2: Unicast (индивидуальная, одноадресная), Multicast (групповая) и Broadcast (широковещательная рассылка).
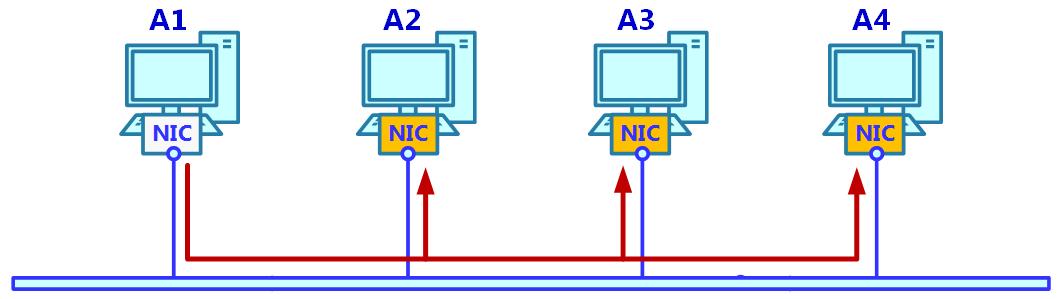
При индивидуальной передаче, как это иллюстрирует наша следующая схема, в случае ПК, A1 отправляет кадр конкретному получателю, A3. A1 заполнит значение адреса MAC своего получателя, A3, в поле адреса получателя, A3. A3 видит что это его MAC адрес и считывает данный кадр:

При Широковещательной передаче, как это иллюстрирует идущая далее схема,
A1 выполняет широковещательную отправку во всю сетевую среду. В данном случае
A1 заполняет MAC адрес получателя 1-ми,
что в шестнадцатеричном виде представлено всеми F -
ff:ff:ff:ff:ff:ff и в такой ситуации все получающие устройства, которые видят все
1, считывают это кадр:
При Групповой передаче это работает иначе. Подключённая к группе станция начинает принимать кадры с MAC адресами получателя, разрешаемых из группового адреса IP групповой рассылки, когда отправленный в эту группу MAC адрес взаимосвязан с IP адресом этой групповой рассылки, который дожидается данная станция:
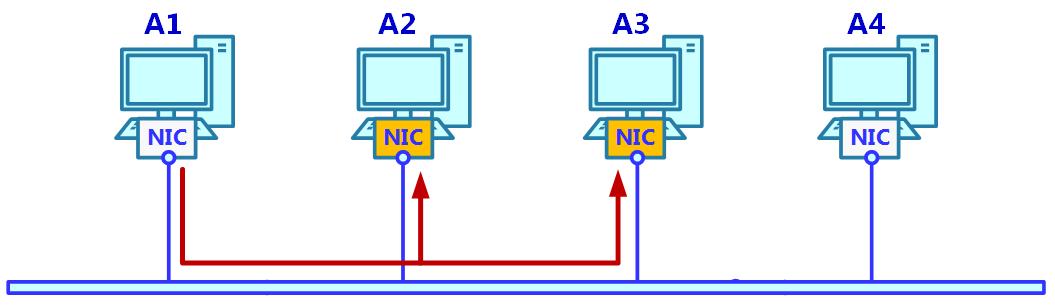
В нашем примере происходит следующее:
-
A2 и A3 желают ожидать многоадресную группу
224.1.2.3. -
224.1.2.3соответствует MAC адресу01:00:5e:01:02:03. -
Теперь A2 и A3 считывают предназначенные для
01:00:5e:01:02:03кадры.
Коммутатор локальной сети, как это иллюстрируется следующей схемой, это устройство, которое изучает значения MAC адресов подключённых к одному из его физических портов и затем предпринимает решения о передаче. Он узнаёт эти MAC адреса следующим образом: поскольку подключённое к этому коммутатору устройства отправляет что- то, как мы узнаем позднее об этом в разделе Протоколы Уровня 3 - IP и ARP, всякое устройство осуществляет в сеть некую отправку. Его коммутатор распознаёт значение исходного адреса такого устройства и сохраняет его таблицах адресов данного коммутатора. Такой процесс обучения является динамическим и продолжается до тех пор пока этот коммутатор работает.
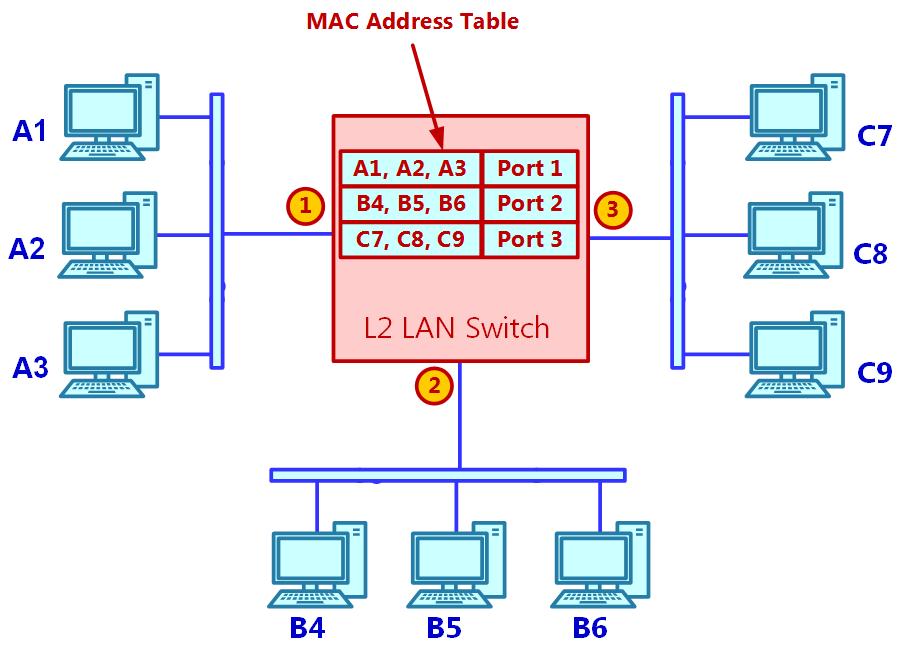
Теперь этот коммутатор предпринимает следующие решения:
-
Кадр индивидуальной передачи: Когда устройство отправляет некий кадр конкретному получателю, его коммутатор переправляет этот кадр в тот порт, в котором он узнал MAC адрес назначения. Например, когда A1 отправляет кадр в C7, этот кадр будет отправлен в порт
3. -
Кадр широковещательного обмена: Когда устройство отправляет широковещательный кадр, то есть когда значение адреса получателя заполнено всеми
F, данный кадр заполняет все порты, например, в порты2и3. В случае неизвестного получателя данный кадр также заполнит все прочие порты данного коммутатора. -
Кадр групповой передачи: Когда кадр отправляется на групповой адрес многоадресной рассылки, то есть начинающийся с
01:00:5e(для реализаций IPv4) MAC адрес, данный кадр также отправляется во все порты своего коммутатора. В нашем примере отправленный с A1 кадр многоадресной рассылки будет отправлен в порты2и3. -
Кадр с неизвестным получателем: Когда в коммутатор поступает кадр с неизвестным получателем, этот коммутатор заполняет им все свои порты.
Такая таблица MAC адресов в этом коммутаторе также носит название CAM (Context Addressable Memory, Контекстно адресуемой памяти), в которой хранятся полученные данным коммутатором MAC адреса. В зависимости от модели коммутатора данная таблица CAM обладает ограничением на число MAC адресов, которое она способна сохранять. Это может быть значение от 16 000/ 32 000 для небольших коммутаторов доступа до 8 миллионов/ 16 миллионов адресов и более для коммутаторов крупного масштаба ядра и коммутаторов ЦОД.
Обратите внимание, что для многоадресной передачи через коммутатор существует исключение, которое носит название IGMP Snooping (перехвата IGMP) или MLD Snooping (перехвата MLD). IGMP (Internet Group Management Protocol, Межсетевой протокол управления группами) и MLD (Multicast Listener Discovery, Обнаружение многоадресных ожиданий) это протоколы при помощи которых желающие присоединиться к группе устройства отправляют запросы на подключение к ней. Когда настроено отслеживание IGMP или MLD, данный коммутатор прослушивает поступающие от желающих присоединиться к группе многоадресной рассылки запросы IGMP/ MLD и перенаправляет кадры многоадресной рассылки только на эти порты.
Угрозы безопасности для коммутаторов могут исходить от перехвата пересылаемого через коммутатор обмена, от подделки MAC адресов реальных устройств и перехвата обмена, предназначенного для пересылки к ним, вплоть до атак на плоскости контроля и управления коммутатором локальной сети. Более подробно мы узнаем об этом в Главе 10, Выявление атак LAN на основе IP и TCP/ UDP.
Сетевые взломы в коммутаторах Ethernet и локальной сети могут включать следующее:
-
Поддельный MAC адрес: при нём злоумышленник подделывает MAC адрес, а потому тот обмен, который должен следовать к месту назначения, вместо этого направляется злоумышленнику.
-
Затопление сети: это простая атака, целью которой является затопление сети и прекращение её применения.
-
Переполнение таблицы CAM: это именно тот случай, который обусловлен тем, что коммутатор может содержать в своей таблице CAM ограниченное число MAC адресов. В случае заполнения таблицы CAM данный коммутатор начинает вести себя как концентратор (хаб) и станут возможными атаки подслушивания и с человеком в промежутке.
-
Атаки CDP/LLDP: CDP (Cisco Discovery Protocol, Протокол обнаружения Cisco) и более общий LLDP (Layer Discovery Protocol, Протокол обнаружения канального уровня) это протоколы, которые применяются сетевыми устройствами для объявления своих идентификационных данных, скажем, IP адресов, режимов устройств, версий и тому подобного. Применяя такие протоколы, злоумышленник способен получать сведения об имеющихся сетевых устройствах, которые будут применяться для его атаки.
Замечание До тех пор, пока в середине - конце 1990-х на рынке не появились первые коммутаторы локальных сетей, применялись концентраторы (хабы), также носящие название многопортовых повторителей. Концентратор работает как шина по которой одно устройство отправляет кадр, принимаемый всеми остальными ПК. Вопрос о том считывают ли устройства данный кадр с общей шины зависит от того, является ли этот кадр кадром индивидуальной, групповой или широковещательной передачи.
Когда имеющаяся таблица CAM забита адресами MAC, её коммутатор не может запоминать новые адреса. CAM- лавинная рассылка не позволяет коммутатору запоминать новые адреса и тогда все отправляемые в коммутатор кадры будут лавинообразно рассылаться во все порты, что соответствует поведению концентратора.
Виртуальные локальные сети, или VLAN, применяются для разделения взаимодействующих локальных сетей на локальные сети меньшего размера, которые виртуально отделены. VLAN также носят название Широковещательного домена, поскольку основной способ работы VLAN состоит в блокировании широковещательного обмена между различными VLAN.
|
| Замечание |
|---|---|
|
Блокируя широковещательный обмен между узлами в одной и той же локальной сети мы можем отключать взаимодействие между ними. Это обусловлено тем, что ARP (Address Resolution Protocol, Протокол разрешения адресов), который осуществляет разрешение значения MAC адреса из его адреса IP работает с широковещательным обменом. Таким образом, когда он блокирован, соответствующий источник не будет знать значения MAC адреса соответствующего получателя и не будет иметь возможности взаимодействия с ним. |
Когда мы настраиваем VLAN в отдельном коммутаторе, такой процесс прост: мы назначаем портам идентификатор VLAN, тогда все подключённые к портам с одним и тем же идентификатором VLAN устройства способны общаться между собой. Единственная проблема возникает когда вы желаете настроить VLAN по всей сетевой среде. При таком сценарии когда кадр отправляется из одного коммутатора в другой, мы обязаны сообщить своему коммутатору получателя из какой именно VLAN отправлен этот кадр. Давайте взглянем на следующую схему:

Когда PC1 отправляет кадры к PC2 в верхнем коммутаторе, кадры отправляются внутри VLAN 10 в этом верхнем коммутаторе. Когда кадр отправляется из PC1 в верхнем коммутаторе в PC4 из нижнего коммутатора, он проходит через Магистральный порт (Trunk port). Это добавляет тег VLAN с VLAN ID 10 и такой кадр отправляется в Магистральный порт нижнего коммутатора. Этот нижний коммутатор удаляет значение тега и переправляет его в PC4. Однако что происходит, когда два ПК из различных VLAN попробуют взаимодействовать друг с другом? Например, давайте рассмотрим ситуацию, при которой PC4 пожелает отправить кадр в PC5. Его первоначальным шагом будет отправка ARP запроса для обнаружения MAC адреса PC5. Поскольку запрос ARP широковещательный, это взаимодействие будет блокировано.
На Рисунке 2.13 вы можете наблюдать структуру Тега VLAN. Такой Тег VLAN вставляется после значения MAC адреса:
-
Код типа протокола (2 байта)
8100: Получатель данного кадра знает что это помеченный тегом кадр. Иные коды здесь доступны для прочих целей. -
Биты приоритета (3 бита) служат для приоритета:
0для самого нижнего приоритета и7для наивысшего приоритета. Получающий кадр с приоритетом коммутатор будет переправлять его в соответствии с его приоритетом. -
CFI (1 бит) всегда установлен в
0. -
Тег VLAN (12 бит) указывает идентификатор VLAN. Идентификатор VLAN
1предназначен для естественной VLAN. Пакеты из такой естественной VLAN всегда переправляются не помеченными:

Поставщики услуг применяют Double Tagging (Двойной тег,
QinQ, IEEE-802.1ad), когда применяются два тега - стандартный тег и тег, который
поставщик добавляет при поступлении данного кадра в его сетевую среду. В данной ситуации такой тег это
8a88.
Сетевые взломы в VLAN таковы:
-
Перескок VLAN: относится к атаке, при которой злоумышленник пытается получить доступ к VLAN, к которой он не подключён. Существует два типа атак с перескоком VLAN: атаки с подменой коммутатора и атаки с двойной маркировкой.
-
Подмена коммутатора: данный тип атаки заставляет коммутатор полагать, что злоумышленник выступает Магистральным портом и, следовательно, перенаправляет ему обмен из всех VLAN.
-
Атака с двойной маркировкой: это атака, при которой злоумышленник добавляет первый поддельный тег к отправляемому коммутатору кадру, а затем второй тег к той VLAN, в которую этот злоумышленник желает проникнуть. Коммутатор удаляет первый фальшивый тег, затем он обнаруживает второй и пересылает этот кадр в атакуемую VLAN.
STP (Spanning Tree Protocol, Протокол связывающего дерева) это протокол, который применяется для предотвращения возникновения зацикливаний в сетевых средах 2 Уровня. Самая первая версия STP была стандартизована в IEEE 802.1d и устарела благодаря Rapid STP (RTSP, IEEE-802.1w), а позднее расширена до Multiple STP (MST, IEEE-802.1s).
Основная цель всех версий STP состоит в предотвращении зацикливаний в локальной сети. Давайте рассмотрим что представляет собой цикл, как STP ему препятствует и что добавили в этот протокол расширения RSTP и MST. Взглянем на Рисунок 2.14:

Как вы можете видеть на предыдущей схеме, при отправке нижним компьютером широковещательной рассылки эта широковещательная передача следует к коммутатору слева (1) и к коммутатору справа (2). Оба коммутатора обнаруживают широковещательную рассылку и переправляют её. Коммутатор слева отправляет её коммутатору справа (3), а коммутатор справа отправляет её коммутатору слева (4). Затем, снова, коммутатор слева получает соответствующий кадр от правого (5) и переправляет его, а затем коммутатор справа получает соответствующий кадр от левого (6) и переправляет его. Эти кадры будут перемещаться бесконечно, пока мы не отсоединим один из кабелей и не прервём эту петлю. Именно это носит название петли (зацикливания) Уровня 2 и при её возникновении сетевая среда перестанет функционировать. Именно это пытается разрешать STP.
Основная идея STP проста; он обеспечивает множество физических путей между коммутаторами когда в сетевой среде во всякий заданный момент имеется лишь один активный путь между любыми двумя коммутаторами. В случае сбоя активируется резервный путь. Взглянем на Рисунок 2.15:
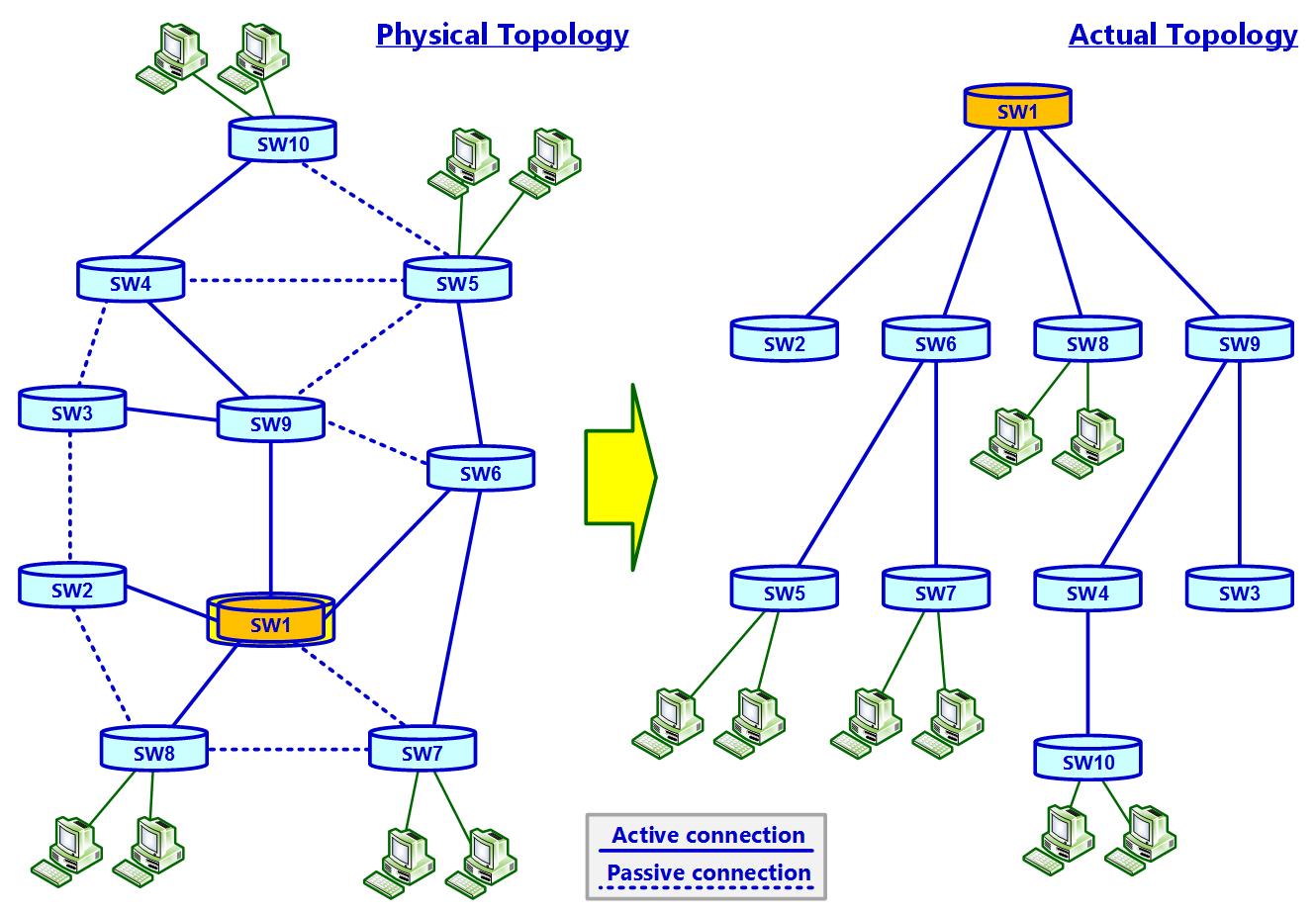
Как вы видите на Рисунке 2.15, слева у нас имеется сетевая среда коммутаторов L2 со множеством соединений между ними. Справа мы видим топологию реального дерева, в которой активные соединения показаны сплошной линией, а пассивные соединения показаны пунктирными линиями. Наш алгоритм STP принимает решение какие из них должны быть активными соединениями (сплошными линиями) и логически отсоединяет все прочие (пунктирные линии).
|
| Замечание |
|---|---|
|
Хотя слово коммутатор и стало стандартным названием для устройств 2 Уровня в сетях обмена данными, установленные стандарты именуют их мостами или мостами со множеством портов. Это наследство взаимодействия данных прошлых дней, когда широко применялись двухпортовые мосты. Хотя стандарт и применяет этот термин мост, в отрасли более распространённым стал термин коммутатор. |
Топология автоматически устанавливается следующим образом (для согласованности со стандартом мы пользуемся словом мост):
-
Самым первым шагом для мостов является выбор единственного корневого моста. Это корневой мост это тот мост, от которого определяются все остальные пути. Выбор корневого моста осуществляется в так (в указанном порядке):
-
Самый низкий приоритет моста (настраивается)
-
Самый низкий идентификатор моста (замыкается своим собственным MAC адресом)
-
-
После выбора корневого моста все прочие мосты вычисляют своё расстояние от установленного корня. Это расстояние вычисляется как сумма всех стоимостей до корня. Цена, или стоимость порта зависит от полосы пропускания этого порта. Например, рассмотрим следующее:
-
В STP: 10 Mbps/ Cost=100, 100 Mbps/ Cost=19, 1 Gbps/ Cost=4 и 10Gbps/ Cost=2
-
В RSTP: 100 Mbps/ Cost=200 000, 1Gbps/ Cost=20 000, 10Gbps/ Cost=2 000 и 100Gbps/Cost=200
-
-
Как вы можете видеть, активными станут пути с наименьшим расстоянием, то есть пути с наибольшей пропускной способностью до корня, но не обязательно самые короткие.
Обмен сведениями о протоколе между мостами осуществляется при помощи кадров, носящих название BPDU (Bridge Protocol Data Units, Блоков данных протокола моста). В BPDU каждый мост сообщает своим соседям известный ему корневой мост и на каком расстоянии он пребывает от этого корня. Всякий получающий эти обновления мост может решить какой из имеющихся путей является кратчайшим к корню и отключить все подключённые к другим портам мосты.
Другим важным сообщением в STP является TCN (Topology Change Notification, Уведомление об изменении топологии). Изменяющий топологию коммутатор уведомляет свой корень относительно своего изменения топологии. Установленный корень, при получении такого TCN сообщит всем коммутаторам в сетевой среде сократить время устаревания таблицы MAC адресов с 300 до 15 секунд. Таким образом, все коммутаторы в этой сетевой среде узнают MAC адреса в новой топологии.
На Рисунке 2.16 мы можем наблюдать что происходит при изменении топологии:

В приводимых ниже топологиях реализованы следующие улучшения:
-
Rapid STP (RSTP) путём научного обоснования сократил время, необходимое для резервирования на случай отказа моста или канала. То что в STP может занимать до минуты, теперь в RSTP сокращается до нескольких секунд.
-
Multiple STP (MST/MSTP) позволяет применять несколько экземпляров RSTP, поэтому мы можем настраивать его разными экземплярами для каждой VLAN или группы VLAN. К примеру, его можно применять как простой механизм распределения нагрузки, при котором разные VLAN обладают разными корневыми коммутаторами и обмен между ними будет происходить по- разному.
Сетевой взлом в STP сводится к следующему:
-
Атака с применением роли корня: в данном случае подключаются к сети при помощи коммутатора с низким приоритетом чтобы стать корнем этой сетевой среды. Данный тип атаки можно применять для двух целей: во- первых, просто обрушить данную сеть, а во- вторых, стать корнем, чтобы можно было пробросить через него весь обмен, например, для его прослушивания. Второй тип атаки - это тип атаки со злоумышленником в качестве посредника (man-in-the-middle, MITM).
-
Атака TCN: применяется для сокращения времени устаревания таблицы CAM с 300 секунд до 15 секунд, в результате чего коммутаторы удаляют изученные MAC адреса, а следовательно, заполняют свою сетевую среду всеми кадрами, отправляемыми к неизвестному MAC адресу.
-
Переполнение BPDU: при данном типе атаки мы просто пытаемся подвергнуть избыточной нагрузке ЦПУ коммутатора, отправляя этому коммутатору большое число BPDU, что приводит к его замедлению до такой степени, что он начинает утрачивать обмен. Это носит название атаки типа DDoS.
Основная цель Уровня 3 состоит в пересылке сведений пользователя из конца в конец. Обычно она происходит от ПК, ноутбука или смартфона к серверам организации или к серверам в Интернете, но также он имеет место в устройствах и датчиках IoT, от мобильного телефона к мобильному телефону и много где ещё.
В данном разделе мы изучим IPv4 (Internet Protocol version 4) и ARP (Address Resolution Protocol), который выполняет разрешение значения локального MAC адреса получателя по его IP адресу. Далее мы обсуждаем IPv4.
Как вы можете видеть на Рисунке 2.17, IP пакет Уровня 3 переносится внутри поля полезной нагрузки кадра Уровня 2, как правило, Ethernet, и несёт внутри себя полезную нагрузку протокола Уровня 4, которым обычно выступают UDP или TCP.
|
| Замечание |
|---|---|
|
IP может переноситься кадрами Ethernet 2 Уровня или иными кадрами. Ethernet это наиболее распространённый кадр 2 Уровня, но IP может переноситься сотовыми кадрами или иным Уровнем 2 {Прим. пер.: например, InfiniBand}. |

Заголовок IPv4 содержит следующие поля:
-
Версия (4 бита): это
4для IPv4 или6для IPv6. -
Internet Header Length (IHL:, длина межсетевого заголовка, 4 бита): Значение длины заголовка в 32- битных словах. Обычно равна 5. Поле Options применяется редко.
-
ToS/DiffServ (8 бит): Это быйт QoS (Quality of Service). Изначально он определялся как байт ToS (Type of Service, RFC 791, в сентябре 1981), однако позднее он был изменён на протокол Differentiated Services (дифференцированного обслуживания, RFC 2472, в декабре 1998).
-
Поля фрагментации(обратите внимание на описываемый далее механизм фрагментации):
-
Идентификация: это уникальный идентификатор пакета.
-
Флаги: Здесь
Rэто "Reserved", аD"Don't Fragment"; то есть, когда маршрутизатор видит IP пакет с установленным в1данным флагом, этому маршрутизатору не позволяется его фрагментировать, причём даже если маршрутизатор вынужден отбросить его, иMFдля дополнительных фрагментов (more fragments).
-
-
Смещение фрагмента: Когда происходит фрагментация, это поле указывает значение числа байт от самого начала первоначальной полезной нагрузки.
-
TTL (Time to Live): Определяет как долго данная дейтаграмма может жить в сетевой среде в терминах скачков (hops) маршрутизатора. Каждый маршрутизатор уменьшает данное значение TTL на единицу. Когда значение поля TTL падает до нуля, данный пакет отвергается.
-
Upper-Layer Protocol (Протокол верхнего уровня, 8 бит): Обычно применяется протоколами 4 Уровня, например, TCP (код
6) или UDP (код17). Это также может быть ICMP (Internet Control Message Protocol, код1) или OSPF ( Open Shortest Path First, код89). -
Контрольная сумма заголовка (8 бит): Это значение контрольной суммы заголовка.
-
Адреса источника и получателя: Это 32- битные адреса.
-
Опции (32 бита): Они применяются редко, особенно в стандартных сетях организаций.
Фрагментация происходит когда длина передающего этот пакет кадра интерфейса Уровня 2 меньше самого пакета IP. Длина стандартного кадра Ethernet обладает, например, максимальным размером кадра в 1 518 байт (без тегов), в то время как длина пакета IP может составлять до 64 килобайт:

При фрагментации первоначальный пакет делится чтобы умещаться внутри соответствующего кадра Уровня 2. На Рисунке 2.18 мы можем наблюдать некий первоначальный пакет из 4 000 байт, который делится чтобы он помещался внутри максимального размера кадра Ethernet, который составляет 1 500 байт.
В самом первом фрагменте значение смещения равно 0, что указывает на то, что это самое начало
изначального пакета. Значения флага фрагментации равно 1 чтобы указывать на то, что должны поступить
дополнительные фрагменты.
Во втором фрагменте значение смещения равно 1480, что составляет значение номера самого первого
байта данного фрагмента из первоначального пакета. Значения флага фрагментации равно 1 для указания
что должны прийти дополнительные фрагменты.
В третьем фрагменте значение смещения равно 2960, что является номером самого первого байта данного
фрагмента в изначальном пакете. Значения флага фрагментации равно 0 для указания того, что больше нет
ожидаемых фрагментов.
В протоколе IP существуют различные типы уязвимостей, в том числе:
-
Перехват IP (IP spoofing): Злоумышленник вырабатывает IP с ложными исходными данными чтобы попытаться проникнуть в атакуемую сеть.
-
DDoS: Сканирование IP или сканирование ICMP, которое загружает сетевую среду для множества источников дабы блокировать сетевые ресурсы от их применения обменом пользователей.
Основная цель ARP состоит в получении разрешения значения MAC адреса соответствующего устройства получателя. Вы можете наблюдать как это происходит на Рисунке 2.19:
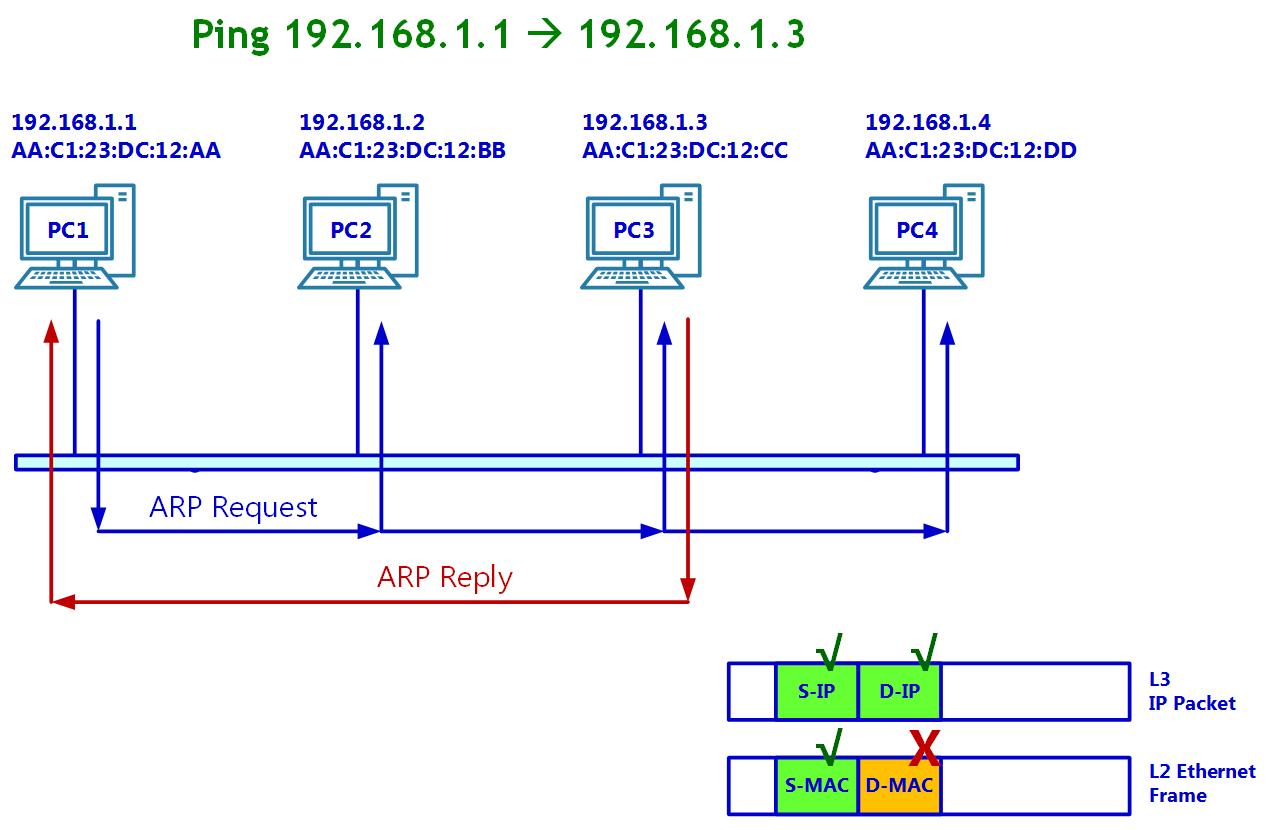
В нашем предыдущем примере PC1 отправляет пакет PING к PC3. PC1 знает свои адреса MAC и IP. Ему известен IP адрес получателя, поскольку это тот IP, который пингуется, однако ему не знаком адрес MAC получателя и именно это и составляет основную цель ARP - отыскать его.
Способ работы ARP состоит в том, что он просто отправляет вопрос, то есть запрос ARP. Такой запрос ARP является широковещательным и он отправляется в свою локальную сеть вопрос у кого данный адрес? В нашем случае это вопрос кто обладает адресом 192.168.1.3? Поскольку он широковещательный, этот запрос считывают все ПК. PC3 определяет что этот запрос предназначен ему и отвечает своим MAC адресом. Теперь PC1 хранит значение MAC адреса для PC3 в своём кэше ARP и он там будет храниться несколько минут после отправки последнего пакета к PC3.
Существует ряд уязвимостей ARP и способы, которыми ARP может применяться для взлома:
-
Отравление/ перехват ARP: Применяется для выработки ответов ARP с целью захвата сеанса пользователя.
В этом разделе мы изучим маршрутизаторы, принципы маршрутизации и дополнительные механизмы, такие как ACL (Access Control Lists, Списки контроля доступа), коммутацию 3 Уровня, NAT (Network Address Translation, Трансляцию сетевых адресов) и многое иное. В Главе 12, Атака на протоколы маршрутизации, мы погрузимся глубже в подробности протоколов маршрутизации, их уязвимости, потенциальные атаки и как им противостоять.
Маршрутизация это процесс перемещения пакетов из конца в конец через имеющуюся сетевую среду. Как вы можете наблюдать на Рисунке
2.20, ПК слева, 10.1.1.20/24, отправляет пакет в свой шлюз по умолчанию,
R1 с IP адресом 10.1.1.1/24.
R1 переправляет этот пакет в следующий маршрутизатор,
R7, который далее переправляет его в
R3, затем в R4
и потом в получателя 20.1.1.20:
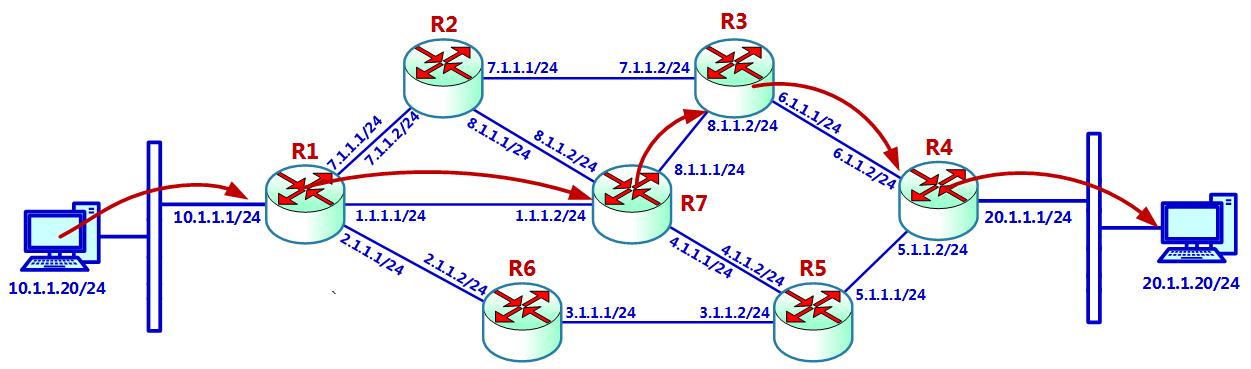
Существует несколько важных проблем, относящихся к маршрутизации:
-
То устройство, которое отправляет соответствующий пакет, ищет адрес получателя и, поскольку этого адреса нет в его сетевой среде, оно отправляет этот пакет в свой шлюз по умолчанию.
-
При отправке самого первого пакета получателю, наш ПК слева знает значение IP адреса своего шлюза по умолчанию, однако не знает его MAC адрес. По этой причине он отправляет запрос ARP чтобы узнать у своего маршрутизатора его MAC адрес, получает соответствующий отклик ARP и на его основании все пакеты будут перенаправляться в R1.
-
Маршрутизаторы отправляют пакеты в свою сеть назначения. В нашем случае пакет отправляется направо в сеть
20.1.1.0/24, а пакеты влево отправляются в10.1.1.0/24. -
Каждый маршрутизатор удерживает таблицу маршрутизации. Таблица маршрутизации это таблица, сообщающая для соответствующей сети назначения по значению маски получателя, как переправлять соответствующий пакет на следующий прыжок (hop). Давайте взглянем на Рисунок 2.21:
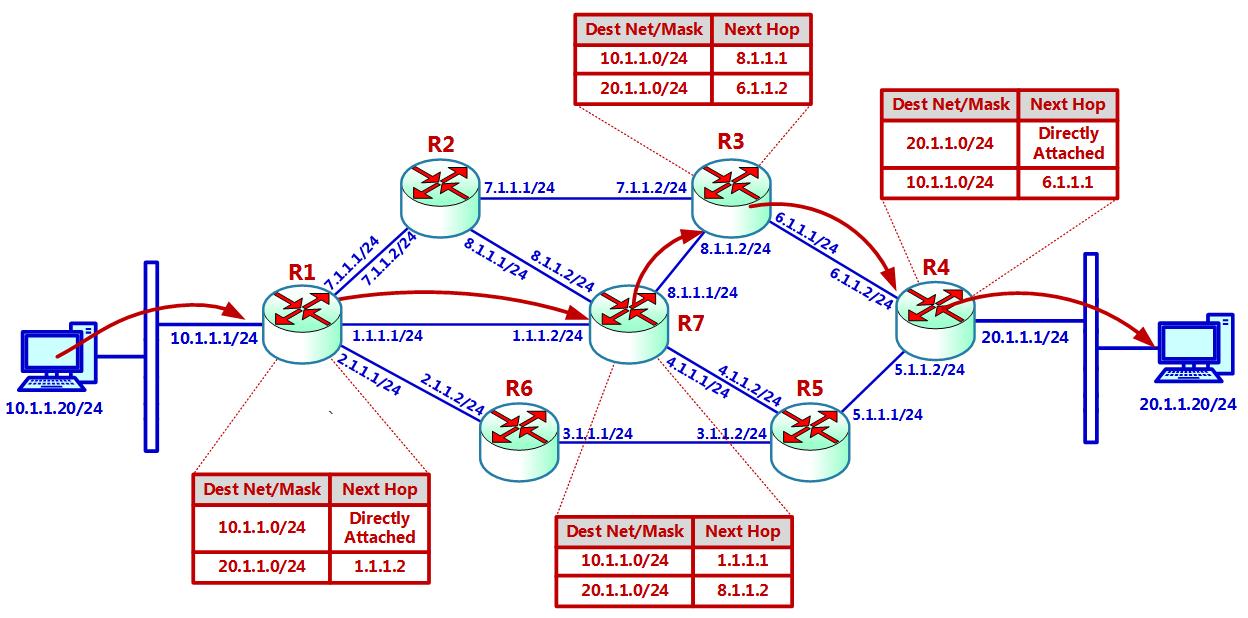
В соответствующих таблицах маршрутизации мы наблюдаем следующие маршруты:
-
Пакеты из
10.1.1.20/24слева к ПК20.1.1.20/24справа достигают маршрутизатор R1, который проверяет свои таблицы маршрутизации и отправляет эти пакеты на следующий скачок, которым выступает1.1.1.2в маршрутизаторе R7. -
В R7 следующим прыжком для сети
20.1.1.0/24является8.1.1.2, поэтому соответствующие пакеты переправляются в R3. -
В R3 ещё одним прыжком для сети
20.1.1.0/24выступает6.1.1.2, а потому пакеты отправляются в R4. -
В R4 значения сети
20.1.1.0/24напрямую присоединены к сетевой среде, а потому пакет непосредственно переправляются в ПК20.1.1.20.
Вот некоторые важные моменты относительно маршрутизаторов, которые переправляют пакеты:
-
Переправляющий пакеты маршрутизатор не знает сколько прыжков следует предпринять по пути до получателя. Единственное что он выполняет, это переправка соответствующего пакета на следующий скачок с тем, чтобы о нём смог позаботиться маршрутизатор следующего прыжка (hop).
-
Таблицы маршрутизации заполняются вручную или динамически. Когда они заполняются вручную, сам сетевой администратор набирает необходимые маршруты и далее эти маршруты носят название статических. А если они заполняются динамически, эти маршрутизаторы применяют протоколы маршрутизации, которые изучают имеющуюся топологию обмена сведениями между ними и затем они именуются динамическими маршрутами.
-
Протокол маршрутизации может быть более действенными или менее действенным, быстрым или медленным, а также интеллектуальным или простым. Самой нижней линией в каждом из сетевых маршрутизаторов выступает таблица маршрутизации. Записи такой таблицы маршрутизации могут быть результатом статических маршрутов, отдельного протокола маршрутизации или нескольких протоколов маршрутизации, которые работают одновременно. В основе всегда имеется таблица маршрутизации - одна для маршрутизатора.
-
Каждый следующий прыжок (hop) в маршрутизаторе это именно непосредственное подключение к тому маршрутизатору, который переправляет соответствующий пакет в сетевую среду между маршрутизаторами. Когда они соединены непосредственно, это может быть или физически, то есть кабелем, или непосредственно линией взаимодействия Уровня 2, либо логически, скажем, поверх туннеля, который соединяет маршрутизаторы, которые не соединены напрямую.
Как вы можете наблюдать на Рисунке 2.22, существует два типа протоколов маршрутизации:
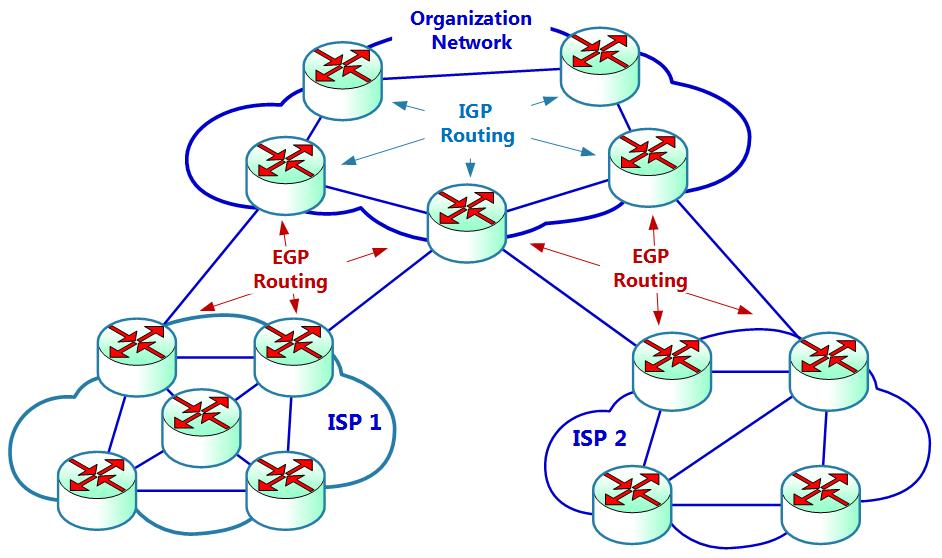
Каждый из протоколов мы можем описать следующим образом:
-
Протоколы IGP (Interior Routing Gateway): Эти протоколы, которые работают между находящимися под одним и тем же административным органом маршрутизаторами. Все маршрутизаторы настраиваются персоналом из одной организации и все они доверяют друг другу. Здесь имеется несколько протоколов от старого RIP (Routing Information Protocol, Протокола информации о маршрутизации), OSPF (Open Shortest Path First, Первыми открываются кратчайшие маршруты), ISIS (Intermediate System to Intermediate System, Взаимодействие промежуточных систем) и частных протоколов Cisco до IGRP (Interior Gateway Routing Protocol, Внутреннего протокола маршрутизации) и EIGRP (Enhanced IGRP, Усиленного IGRP).
-
Протоколы EGP (Exterior Routing Gateway, Протоколы внешнего шлюза маршрутизации): Это протоколы, которые работают между различными административными органами, обычно межу сетевыми средами организации и ISP (Internet Service Providers, Поставщиками услуг Интернета) или между поставщиками услуг Интернета. Здесь применяется единственный протокол - BGP (Border Gateway Protocol, протокол междоменной маршрутизации) версии 4, то есть BGP4, которым в версии внешнего EGP выступает eBGP. В BGP для идентификации административного домена мы применяем номера AS (Autonomous System, Автономных систем), то есть находящихся под единым администрированием маршрутизаторов.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Интересный вариант BGP возникает когда имеются обе версии: iBGP (nterior BGP) и eBGP (Exterior BGP). Эти версии применяют один и тот же механизм разными вариантами; например в том способе, коим объявляются маршруты, подсчитываются скачки т TTL, применяемые атрибуты, топология сетевой среды и многое иное. |
Давайте взглянем на основные принципы того, как заполнятся таблицы маршрутизации роутера. Основной принцип прост: они общаются друг с другом и взаимно обновляются. Как вы можете видеть на Рисунке 2.23, они просто общаются друг с другом следующим образом:
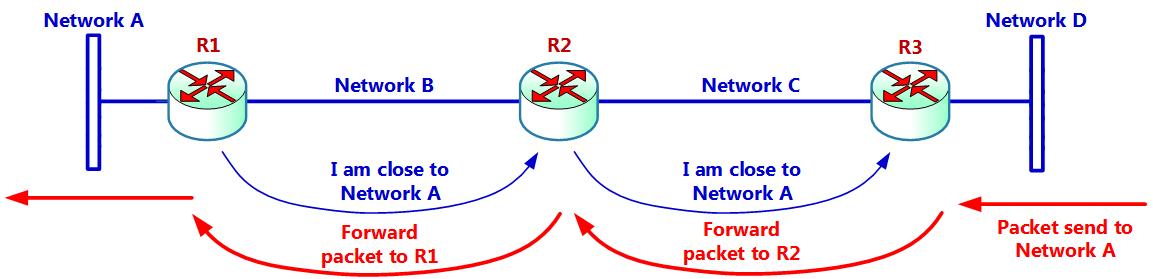
Применяя сообщение протокола маршрутизации, которые проходят между имеющимися маршрутизаторами, R1 сообщает R2 что R1 близок к Network A, а R2 сообщает то же самое R3. Теперь, когда пакет поступает справа на R3, R3 знает, что для попадания в Network A он должен переслать этот пакет R2, а R2 перешлёт его R1 , который напрямую подключён к Network A. На Рисунке 2.24 вы можете увидеть пример того как именно маршрутизаторы рассчитывают путь к месту назначения:

Величина маршрута до места назначения вычисляется метриками, которые вставляются в данное вычисление. Имеются различные типы метрик. В своём предыдущем примере мы могли наблюдать счётчик скачков (hop) и полосу пропускания интерфейса.
Эти два варианта можно пояснить следующим образом:
-
При Варианте 1, когда применяется лишь метрика скачков, этот выбор прост. R3 отправляет обновления маршрутизации со своих двух интерфейсов к R2 и R1. R2 получает данное обновление, увеличивает его на 1 и отправляет его к R1. Теперь R1 получает два обновления маршрутизации, сообщающие ему как достигать Network D, причём значение счётчика скачков высшего направления равно 2, а значение счётчиков нижнего направления равно 1. В подобном случае R1 отправляет пакеты по пути с наименьшим счётчиком переходов, то есть по нижнему пути.
-
При Варианте 2 у нас имеются две метрики: значение счётчика скачков и величина полосы пропускания интерфейса. Теперь R3 справа отправляет обновления со своим счётчиком скачков в Network D совместно со значением полосы пропускания интерфейса с которого отправляется данное обновление. То же самое обновление отправляется и в нижнее, и в верхнее соединение. R2, как и в Варианте 1, увеличивает значение счётчика скачков на 1 и переправляет это обновление в R1. Теперь R1 получает два обновления, которые содержат значение счётчика переходов и величину полосы пропускания и они служат ему для расчёта наилучшего маршрута к назначению в Network D.
Каждый маршрутизатор вычисляет наилучший маршрут к сети назначения при помощи метрик. При стандартной маршрутизации наиболее распространённой метрикой выступает метрика величины полосы пропускания. С годами наиболее употребимым протоколом в сетевых средах организаций стал OSPF с вычислением пути на основе значений суммы стоимостей соединений, которые вычисляются на основе полос пропускания соединений.
Списки контроля доступа (ACL)
По существу, ACL это перечень условий классификации пакетов. ACL можно применять для следующих целей:
-
Фильтрация пакетов: В данном случае он будет сообщать нам какие пакеты будут переправляться, а какие пакеты будут сбрасываться.
-
NAT: В такой ситуации он будет сообщать нам какие пакеты будут транслироваться, а какие нет.
-
Качество обслуживания: Здесь нам предлагается приоритет конкретным адресам, определённым приложениям и так далее.
ACL представляет собой последовательный список операторов разрешения или запрета. По своей сути операторы списка доступа это фильтры, с которыми сравниваются, классифицируются такие пакеты и осуществляются соответствующие действия.
Избыточность маршрутизации - HSRP и VRRP
HSRP (Hot Standby Routing Protocol, Протокол маршрутизации с горячим резервированием) и VRRP (Virtual Router Redundancy Protocol, Протокол резервирования виртуального маршрутизатора) это обеспечивающие резервирование маршрутизаторов протоколы. Представленный Cisco HSRP и позднее стандартизованный в RFC 2281, был реализован только Cisco. Напротив, VRRP, впервые стандартизованный в RFC 2338, получил широкое распространение на рынке, а также в Cisco. Оба протокола были созданы для одной и той же цели и схожи в работе.
Как вы можете видеть из Рисунка 2.25, два маршрутизатора, Ra и Rb соединены в группу HSRP/VRRP по принципу:

HSRP и VRRP работают, предоставляя каждому из маршрутизаторов в конкретной группе уникальный IP адрес и виртуальный IP адрес, который представляет их оба, причём как активный и пассивный маршрутизаторы, то есть VIP. В самих маршрутизаторах, тот, который настроен с более высоким приоритетом, превращается в хозяина, а второй становится резервным. Такой хозяин в VRRP отправляет подчинённому каждую секунду пакеты жизнеспособности, а в HSRP раз в три секунды (оба параметра можно настраивать). Когда резервный маршрутизатор не получает три последовательных пакетов жизнеспособности, этот резервный маршрутизатор берёт на себя управление и превращается в хозяина. Для тех серверов, которые мы наблюдаем на Рисунке 2.25, именно VIP выступает в качестве шлюза по умолчанию.
В HSRP и VRRP имеется ряд условий, при которых установленный хозяин остановит отправку пакетов жизнеспособности с тем, чтобы резервный маршрутизатор превратился в хозяина. Это може происходить при отказе этого хозяина, при отказе интерфейса, например, самый верхний интерфейс в Ra, который подключён к внешней сетевой среде, либо это может происходить при изменении в его таблице маршрутизации или когда не доступны конкретные адреса.
В то время как HSRP поддерживает аутентификацию, поддержка VRRP для подтверждения права на доступ была удалена в последних версиях (RFC 5798), а для действий по обеспечению безопасности операций VRRP должны быть предприняты иные меры безопасности. Мы обсудим это более подробно в Главе 12, Атака на протоколы маршрутизации.
|
| Замечание |
|---|---|
|
HSRP и VRRP аналогичные протоколы с одними и теми же целями и сетевыми топологиями. Существенное отличие между ними заключается в настройке. Некоторые отличия состоят в том, что для HSRP существуют лишь один маршрутизатор хозяина и один маршрутизатор резерва, в то время как в VRRP может иметься несколько маршрутизаторов резерва. Кроме того, оба пользуются групповыми адресами для обновлений пакетов жизнеспособности, но при этом с различными групповыми адресами многоадресной передачи. Оба обладают несколькими вариантами отслеживания и слегка отличающимися командами настройки. |
NAT
Существует несколько версий NAT. Далее мы обсудим Статическую NAT, Динамическую NAT и Трансляцию портов.
Статическая NAT это простейшая трансляция, когда отдельный внутренний адрес транслируется в отдельный внешний адрес, как это иллюстрируется на Рисунке 2.26:

Самый первый метод показывает Статическую NAT. Как это иллюстрируется
на Рисунке 2.26, помещайте простую, статическую NAT в случае обособленного внутреннего IP адреса, например,
10.1.1.50 транслируется в отдельный внешний IP адрес, например,
212.1.2.10.
При Динамической NAT, как это показано на Рисунке 2.26, в отдельный
внешний адрес транслируется диапазон адресов 10.1.1.0/24. Таким образом, организация целиком,
вплоть до 64 000 IP адресов, как мы это обнаружим позднее, может обладать доступом к интернету по единственному внешнему IP адресу,
который обозначен как 212.1.2.11.
В случае Трансляции портов основная цель иная. Трансляция портов
применяется для доступа ко множеству внутренних адресов через единственный внешний адрес. В нашем предыдущем примере пакет отправляется
из внешнего мира на адрес назначения 212.1.2.12 с портом получателя
1500. Наш маршрутизатор получает такой пакет и переправляет его на внутренний адрес
10.1.1.50 в порт получателя 80. Данный метод иногда
именуется как проброс порта или Трансляцию адресов портов
(PAT, Port Address Translation).
Уязвимости маршрутизации, которые могут применяться для атак обладают несколькими типами:
-
Атаки на таблицу маршрутизации (отравление таблицы маршрутизации): Она вовлекает в себя изменение таблиц маршрутизации в своей сетевой среде для останова обмена или передачи обмена в нашем направлении для подслушивания. Некоторые из наиболее знаменитых атак на BGP относятся к данной категории.
-
DoS/DDoS: Это включает переполнение имеющейся сети обменом, который благодаря маршрутизации будет повсеместно переправляться вызывая блокирование данной сетевой среды.
-
Атака ресурсов маршрутизации: Содержит атаки на ЦПУ, память и прочие аппаратные и программные ресурсы маршрутизатора для его замедления вплоть до момента при котором он не откликается.
Уровень 4, Транспортный уровень, предоставляет логическое взаимодействие между прикладными процессами, исполняющимися в различных хостах. На 4 уровне существуют различные протоколы. Наиболее широко применяемыми являются UDP (User Datagram Protocol, Протокол передачи дейтаграмм пользователя), который является ненадёжным протоколом без установления соединения и протокол TCP (Transport Control Protocol, Протокол управления передачей), который является надёжным протоколом, ориентированным на установление соединения.
Дополнительные протоколы включают QUIC (Quick UDP Internet Connections) Google, который представляет собой разработанный Google для повышения производительности сети через Интернет протокол и SCTP (Stream Control Transport Protocol), которым в основном пользуются в сотовых сетях.
В этой главе мы в основном обсудим TCP, а также кратко рассмотрим UDP (о нём особенно нечего сказать), а также QUIC.
UDP, который является протоколом ненадёжных соединений, это очень простой протокол, что вы можете наблюдать по заголовку UDP на Рисунке 2.27:
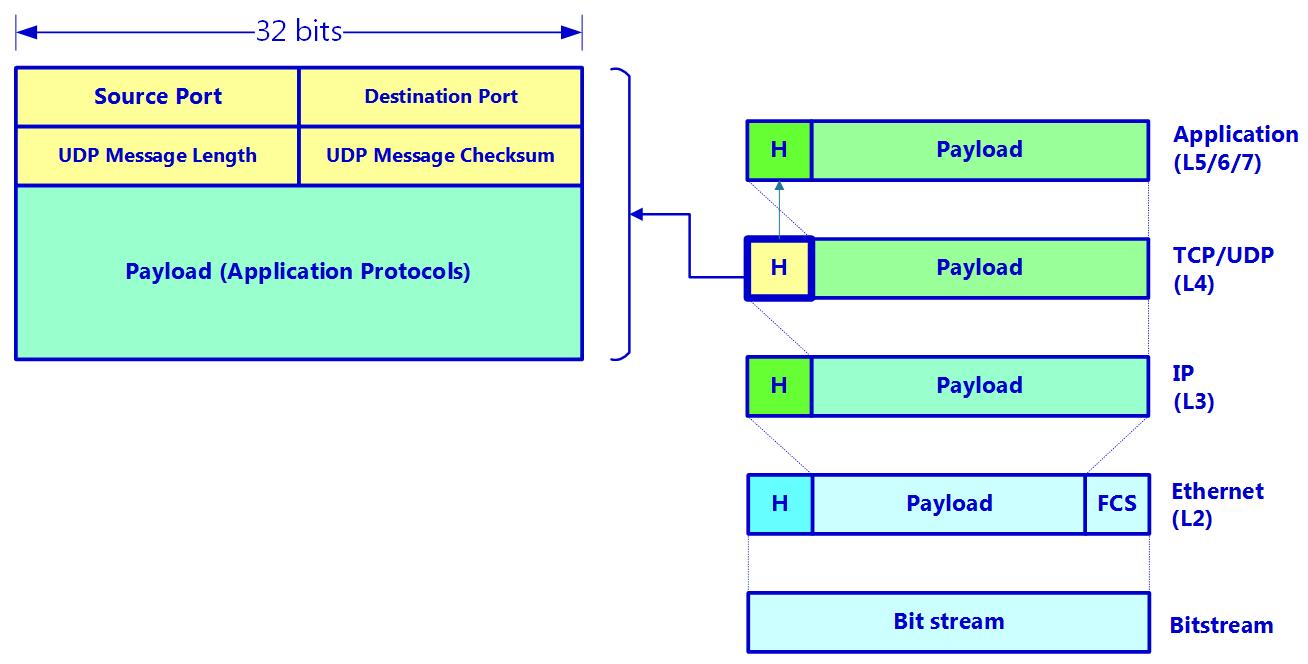
Как вы можете видеть из предыдущей схемы, у нас имеются порты источника и получателя, значение общей длины сообщения и контрольная сумма данного сообщения.
TCP это надёжный, ориентированный на установление соединения, протокол, который пользуется различными механизмами для удержания надёжных соединений. При этом в некоторых ситуациях такие механизмы обладают уязвимости, которые следует защищать, ибо сам протокол, первоначально опубликованный в RFC 791 в сентябре 1981 г, не обеспечивает безопасности ни для каких механизмов.
В данном разделе мы обсудим собственно операции протокола и структуру данных. В Главе 5, Поиск уязвимостей протокола, мы взглянем на уязвимости данного протокола и на то как защищаться против использующих их атак.
Принципы работы TCP
TCP основывается на следующих принципах: связность, надёжность, обмен данными с полным дуплексом, управление потоком и контроль перегрузок.
Связность это тот механизм, при котором, прежде чем отправлять какие бы то ни было сведения между двумя концами, они устанавливают соединение между ними обоими. Затем они отправляют и получают данные и, наконец, завершают это соединение.
Надёжность это такой механизм для всякого сегмента TCP, либо для нескольких достигающих получателя сегментов, когда такой получатель отправляет подтверждение своему отправителю, сообщающее этому отправителю что сведения были приняты.
Обмен данным с полным дуплексом это когда оба конца TCP соединения отправляют данные и подтверждают их в одном и том же соединении. Другими словами, при соединении между A и B A отправляет сведения TCP, а B подтверждает это, в то время как в тех же самых пакетах B отправляет сведения, и A подтверждает их.
Управление потоком это механизм, который применяется обеими сторонами соединения для уведомления противоположной стороны о максимальном значении байт в секунду, которое они способны принимать. Это осуществляется значением поля размера окна в самом заголовке TCP.
Контроль перегрузок относится к тому, как обе стороны реагируют на условия перегрузки сетевой среды, скажем, на потерю пакетов, задержку пакетов и т.п.
Структура пакета TCP
Как вы можете видеть на Рисунке 2.28, заголовок TCP сложнее заголовка UDP. Он начинается с порта источника и порта назначения. Далее значения поля порядкового номера и поля номера подтверждения подсчитывают отправленные байты и их подтверждения. Длина заголовка предоставляет значение длины заголовка, включая поле параметров, а величина размера окна получателя сообщает отправителю какой размер буфера выделен для соответствующего процесса в памяти получателя. Применяемые флаги включают SYN (Sync, синхронизацию) для запуска соединения, Fin (Finish, окончание) для закрытия соединения, RST (Reset, сброс) для немедленного сброса соединения, PSH (Push, активная доставка) для передачи содержимого в соответствующее приложение и ACK (Acknowledge, подтверждение) для уведомления получателя пакета о наличии допустимого значения в поле ACK. Флаги ECE, CWR и NS используются для контроля перегрузок, а Checksum (контрольная сумма) предоставляет проверку ошибок внутри данного пакета. Флаги URG (Urgent, срочно) и Urgent Pointer (Указатель срочности) не используются:

Поле Options (параметров) может применяться (и используется в последних операционных системах) для увеличения значения размера окна, для выборочного подтверждения, сообщающего отправитель какие байты были получены и для уведомления получателя об увеличении размера сегмента TCP. Применительно к безопасности TCP эти параметры будут подробно обсуждаться в Главе 10, Выявление атак LAN на основе IP и TCP/ UDP.
Механизмы связности и надёжности TCP
Как уже упоминалось ранее, перед отправкой каких бы то ни было сведений, TCP устанавливает соединение меж двух сторон. Такое соединение устанавливается тремя пакетами:
-
Сегмент клиента к серверу (Флаг
SYN= 1): Клиент отправляет запрос на открытие соединения с сервером. Такое соединение отправляется с произвольного порта на стороне клиента к хорошо известному порту в сервере. В данном пакете клиент сообщает серверу каким является первоначальный номер последовательности клиента, то есть некое число, которое данный клиент задаёт для самого первого байта в данной передаче. -
SYN- ACK сервера к клиенту (
SYN= 1,ACK= 1): Сервер отвечает обоими флагами,SYN= 1 иACK= 1 для указания того, что запрос на это соединение был принят. В данном сегменте сервер сообщает своему клиенту каков изначальный номер последовательности совместно со значением размера буфера сервера. -
ACK клиента к серверу (
ACK= 1): В этом третьем сегменте клиент подтверждает приём SYN- ACK и сообщает своему серверу какой размер буфера выделен под данное соединение у данного клиента.
Теперь, после установления данного соединения, данные начинают отправляться между обеими сторонами:

Как вы можете видеть на Рисунке 2.29, после каждых двух пакетов сторона приёма отправляет обратно отправителю подтверждение. Когда такое подтверждение не принимается в предварительно определённое время (значение RTO - Retransmission Timer Timeout, Таймаута таймера повторной передачи), данный пакет отправляется снова.
QUIC это разработанный Google протокол 4 уровня, который постепенно приобретает популярность благодаря возможности подключения по протоколу HTTP. В основном он применяется для доступа к серверам Google. Преимущества QUIC в основном проявляются при работе с многоканальными (multiplexed) соединениями HTTP/2 и он станет стандартным протоколом в HTTP/3.
В протоколах 4 уровня имеются тонны уязвимостей (одновременно с полезными способами защиты от них). Давайте изучим некоторые из них:
-
Переполнение сети: Здесь нечего сказать; существует возможность затопления сети на всех уровнях. Вы будете удивлены насколько много атак происходит здесь.
-
Сканирование TCP/UDP: Применяется для обнаружения открытых портов, что позволит нам проникать в сеть.
-
Атаки TCP SYN: В случае отсутствия мер противодействия это может приводить к выводу из строя сетевых устройств.
-
Атаки TCP RST и последовательности: Применяются для закрытия соединений пользователя или для их захвата.
-
Применение QUIC для сетевого проникновения: Это находит применение поскольку QUIC ещё не полностью распознаётся межсетевыми экранами.
Инъекция (encapsulation) это общий механизм во взаимодействии данных, при котором одна дейтаграмма протокола переносится в другой. Хотя это стандартный способ передачи пакетов одного через другой, скажем TP over IP, HTTP over TCP и прочие, бывают ситуации, когда пакеты одного уровня передаются через пакеты того же самого уровня или же пакеты внедряются для их шифрования. Применение внедрения для сокрытия внутреннего заголовка внутри внешнего заголовка также может применяться для обхода сетевой защиты, как мы увидим это в Главе 6, Поиск атак на основе сетевой среды.
На Рисунке 2.30 мы можем наблюдать простой образец инъекции. Здесь у нас имеются две локальные сети, соединённые через туннель,
который настроен между R1 и
R3. Имеющиеся с двух сторон ПК обладают адресами
172.12.1.10/24 и 172.16.2.10/24. Интерфейс туннеля в
R1 настроен с адресами 20.1.1.1/24,
а другой конец этого туннеля настроен в R3 со значением адреса
172.21.1.1/24:
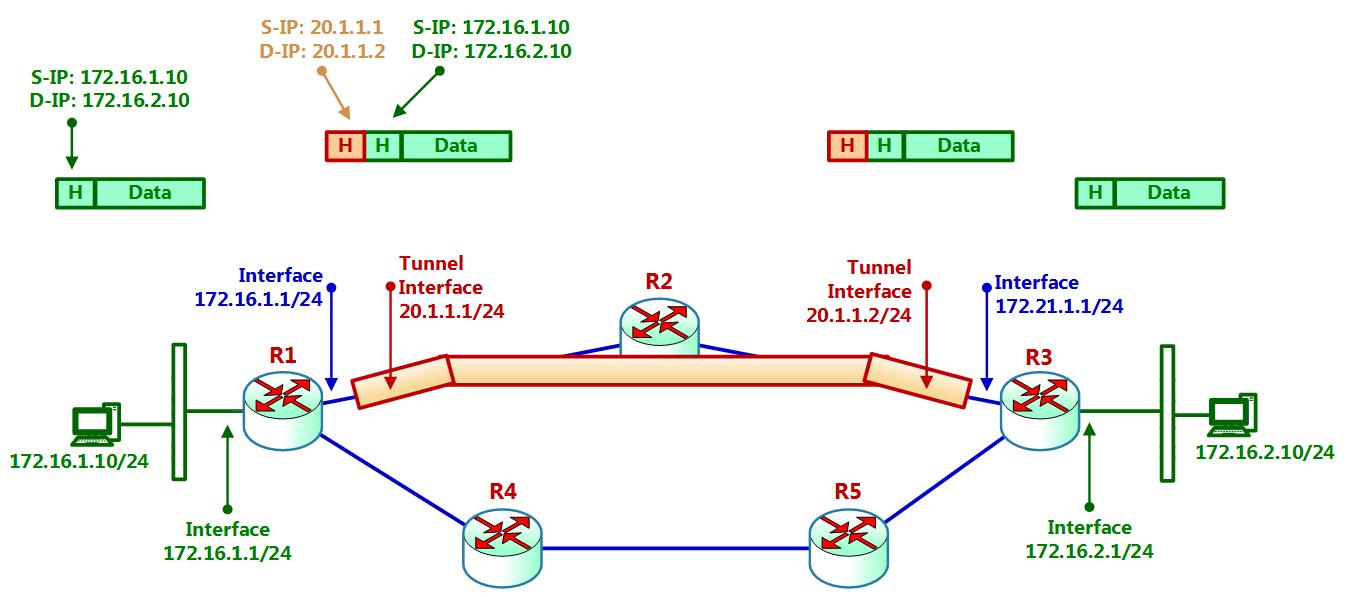
Когда пакет отправляется из ПК слева к ПК справа, этот пакет отправляется из своих адресов источника и получателя данных двух ПК.
Когда такой пакет пересекает R1, он входит в туннель и, таким образом,
получает значения IP источника и получателя туннеля из 20.1.1.1 к
20.1.1.2.
Для большого числа целей используется множество типов туннелирования. Данные внутри туннелей могут идти явным текстом или шифрованным текстом, например, между межсетевыми экранами поверх Интернета.
В данной главе мы обсудили сети данных с целью указания потенциальных рисков и уязвимостей. Мы обсудили те способы, которыми работают сетевые среды: Уровни 1 и 2 переносят информацию непосредственно между подключаемыми сетевыми элементами, Уровни 3 и 4 непосредственно переносят сведения из конца в конец, а Уровни с 5 по 7 реализуют сами сетевые приложения.
Для Уровней 1 и 2 мы обсудили протоколы Ethernet и то как работают коммутаторы локальной сети. Кроме того, мы взглянули на VLAN, которые виртуально делят всю сеть на различные локальные сети. Мы обсудили STP, который препятствует зацикливаниям в имеющихся сетях и рассмотрели методы передачи - одноадресный, групповой и широковещательный.
Для Уровня 3 мы обсудили ARP и IP. Кроме того, мы бросили взгляд на маршрутизаторы и протоколы маршрутизации, которые делают возможной передачу пакетов по сетевой среде. Для Уровня 4 мы поговорили о связности и надёжности, а также мы обсудили TCP, UDP и относительно новый протокол QUIC Google.
Наконец, мы рассмотрели туннелирование и инъекцию, а также как мы можем переносит один пакет поверх другого - метод, который широко применяется в сетях коммуникации.
В своей следующей главе мы изучим протоколы безопасности и их реализацию, включая то, как протоколы могут применяться для защиты нашей сетевой среды.
-
Пакет верхнего уровня будет вложен в поле данных пакета нижнего уровня для передачи (к примеру TCP внутри IP или IP внутри Ethernet).
-
Это всегда верно.
-
Это применимо только для локальной сети.
-
Это применимо только в рамках глобальной сети.
-
Это применимо только при перемещении из локальной сети в глобальную.
-
-
В чём заключается основная цель STP?
-
Запрещает портам коммутатора локальной сети расширение производительности
-
Создаёт циклы для включения избыточности
-
Устанавливает избыточность портов между коммутаторами
-
Препятствует зацикливаниям в локальной сети
-
-
Что лучше всего описывает различие между TCP и UDP?
-
TCP и UDP, оба, обладают упорядоченностью, однако UDP не устанавливает соединений.
-
TCP это надёжный, ориентированный на соединения протокол, в то время как UDP ненадёжный протокол без соединений.
-
И TCP, и UDP ориентированы на соединение, но только TCP пользуется окнами.
-
TCP ориентирована на соединения; UDP пользуется только подтверждениями.
-
-
Какие уровни в OSI-RM определяют повсеместную связь между процессами?
-
Физический Уровень
-
Сетевой Уровень
-
Транспортный Уровень
-
Уровень приложения
-
-
Какой именно уровень реализуют маршрутизаторы в OSI-RM?
-
Уровень сеанса
-
Сетевой уровень
-
Транспортный уровень
-
Уровень приложений
-
-
В чём состоят риски в TCP?
-
Атаки SYN, которые способны заполнить всю сеть.
-
Атаки сброса, которые могут останавливать соединения.
-
Атаки последовательностей, которые способны красть соединения.
-
Возможно всё вышеперечисленное.
-
-
Что является коммутатором Уровня 3?
-
Устройства, которые переключают пакеты очень быстрым способом.
-
Если это происходит на Уровне 3, это маршрутизация.
-
Устройства, которые применяют VLAN для включения безопасности пользователей.
-
Маршрутизаторы с функциональностью межсетевого экрана.
-
-
Что представляют собой атаки переполнения?
-
Загрузка сети или сетевых устройств
-
Отправка массивных объёмов обмена в сетевую среду или серверы
-
Отправка пакетов конкретной цели
-
Отправка групповых или широковещательных сообщений в коммутаторы сети
-