Глава 2. Язык ассемблера
Содержание
Существуют различные типы языков программирования и в данной главе мы сосредоточимся на их варианте нижнего уровня, который зачастую именуется языком ассемблера. Такой язык ассемблера обладает тесной взаимосвязью с инструкциями кода своей архитектуры машины и уникален для данной машины. В результате, многие машины пользуются отличающимися языками ассемблера. В данной форме языка программирования для представления операции или команды используются символы. Таким образом он также именуется символьным машинным языком.
По причине того, что он полагается на машинный код, язык ассемблера связан с отдельными вычислительными архитектурами. Вы обнаружите язык ассемблера для таких архитектур как x86, x64 и ARM.
В данной главе мы обсудим следующие вопросы:
-
Снятие мистики с языка ассемблера
-
Типы языка ассемблера
-
Идентификацию элементов языка ассемблера
В данной главе вы скомпилируете простой сценарий для представления языка ассемблера. Если вы пожелаете воспроизвести это в своей собственной среде, вам потребуется следующее:
-
Некий текстовый редактор (Nano, Vim и тому подобный)
-
Компилятор GCC
-
Применяемая операционная система: Debian Linux
Язык ассемблера (часто сокращаемый до asm) делает возможным напрямую взаимодействовать с процессором компьютера. Поскольку язык ассемблера это язык программирования очень нижнего уровня, обычно он применяется для особых вариантов применения, например, написания драйверов и шеллкода. Попытка написания полноценной программы на языке ассемблера практически невозможна, поэтому они пишутся на языках верхнего уровня.
Понимание языка ассемблера способствует вашей осведомлённости о массе вещей, в частности, относящихся к самому шеллкоду. Например, вы будете способны разбираться со следующим:
-
Взаимодействие между различными компонентами внутри компьютера
-
Представление данных в хранилище, в памяти и во множестве устройств
-
Как процессор выполняет доступ к инструкциям и исполняет их
-
Как инструкции осуществляют доступ к данным и обрабатывают их
-
Тот способ, которым программа взаимодействует с внешними устройствами
Язык ассемблера составляется из:
-
Наборов исполняемых инструкций
-
Команд ассемблера или псевдо- операций
-
Макросов
Имеющиеся инструкции сообщают своему процессору что делать. В каждой инструкции содержится некий код операции (opcode). Для всякой исполняемой инструкции вырабатывается одна инструкция машинного языка.
Директивы ассемблера, также именуемые как псевдо- операции, предоставляют самому ассемблеру сведения что производится внутри различных шагов в соответствующих процедурах ассемблера. Эти процедуры не являются исполняемыми и не вырабатывают команд машинного языка.
Макросы это некий вид техники замены текста.
Операторы языка ассемблера вводятся построчно. В следующем формате: [label] mnemonic [operands]
[;comment]. Вот образец такого оператора:
mov RX, 13 ; Перемещает значение 13 в регистр RX
В языке ассемблера всякая машинная инструкция нижнего уровня или код операции, а также каждый регистр архитектуры, флаг и тому подобное представляется в мнемоническом виде. Всякий оператор в языке ассемблера разбивается на некий код операции и операнды. Собственно код операции это та инструкция, которую исполняет центральный процессор, а его операнды это данные или местоположение в памяти, с которыми осуществляет действия эта инструкция.
Например, давайте рассмотрим следующую строку ассемблера:
mov ecx, msgЗдесь кодом операции выступает mov, ecx (регистр) и
msg. Это все операнды, и данная инструкция ассемблера перемещает некое сообщение в
регистр ecx.
Язык ассемблера пользуется инструкциями, которые работают непосредственно с процессором. Основная цель этих инструкций в том, чтобы сообщить своему процессору как работать с его компонентами. Например, они предоставляют некую инструкцию для перемещения конкретных данных из какого- то регистра в стек программы или перемещать некое значение в регистр и тому подобное.
В своей предыдущей главе те примеры, которые вы наблюдали, были написаны на языке программирования верхнего уровня. При
использовании языка программирования верхнего уровня вы определяете необходимые переменные, а ваш компилятор заботится обо всех
внутренностях. Давайте рассмотрим пример написанного на C Hello World:
#include <stdio.h>
char s[] = "Hello World";
int main ()
{
int x = 2000, z =21;
printf("%s %d /n", s, x+z);
}
Вы можете исполнить это в своей собственной среде Kali, добавив приведённый выше текст в некий файл.
Затем вы сохраняете этот файл в hello.c. Далее вы пользуетесь компилятором с
названием GCC для компиляции этого в язык ассемблера при помощи такой команды:
gcc –S hello.c
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Когда вы применяете компилятор GCC, ваш обычный поток подвергнется компиляции и выполнит компоновку полученного кода
для создания некого исполняемого файла. Применение команды |
давайте изучим файл hello.s чтобы просмотреть собственно язык ассемблера для того
сценария, который мы только что создали. Наш код ассемблера содержит различные инструкции как это показано в следующем
примере:
.file "hello.c"
.text
.globl s
.data
.align 8
.type s, @object
.size s, 13
s:
.string "Hello World"
.section .rodata
.LC0:
.string "%s %d \n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
Pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
Movq %rsp, %rbp
.cfi_def_cfa_register 6
Subq $16, %rsp
Movl $2000, -4(%rbp)
Movl $21, -8(%rbp)
Movl -4(%rbp), %edx
Movl -8(%rbp), %eax
Addl %edx, %eax
Movl %eax, %edx
Leaq s(%rip), %rsi
Leaq .LC0(%rip), %rdi
Movl $0, %eax
Call printf@PLT
Movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
Как вы можете наблюдать, если вы целиком скомпилируете этот фрагмент кода и исполните его, его результатом будет представленный вам на экране текст Hello World 2021
В нашем предыдущем коде ассемблера каждая строка ассемблера соотносится с некой машинной инструкцией. Вы заметили
применение соответствующих мнемонических кодов операций, регистров и операндов. Например, вы можете наблюдать применённый
нами movl, поскольку мы воспользовались в этом коде неким целым. Вы заметили вызванными
различные регистры (edx, eax и тому подобные),
а также системный вызов printf. Данный вывод имеет целью представить вам в сам язык
ассемблера и как он изображается. По мере работы с данной главой вы разберётесь с различными имеющимися регистрами, инструкциями
и их применением.
Микропроцессор выполняет различные функции. Эти функции охватывают арифметические вычисления, логические операции и функции управления. Всякое семейство процессоров обладает своими собственными наборами инструкций, которые применяются для решения различных задач. Эти задачи находятся в диапазоне от ввода с клавиатуры, до отображения сведений на экране и много иного. Помните, что инструкции машинного языка, представляющие собой двоичные строки из единиц и нулей, - это всё что понимает процессор. Машинный язык чересчур непрозрачен и сложен чтобы его можно было бы применять в повседневной разработке программного обеспечения. В результате, конкретный язык ассемблера нижнего уровня подогнан под определённое поколение процессоров и кодирует различные инструкции в символьном коде более доступным способом.
Архитектура языка ассемблера охватывает сборки (ассемблеры) x86, x64, ARM и много иное.
По мере того как вы начнёте работать с шеллкодом и начнёте наблюдать его визуализацию на языке ассемблера, вы заметите, что программу на ассемблере можно подразделить на три раздела:
-
Раздел data объявляет инициализированные данные. Во время исполнения эти данные остаются неизменными. В данной области вы обнаружите различные значения констант, названия файлов, размеры буферов и тому подобное. Этот раздел начинается с объявления
section.data. -
Раздел bss применяется для объявления переменных; он отображается через
section.bss -
Раздел text это то, где хранится собственно реальный код или инструкции. Он отображается как
section.textи начинается с объявленияglobal_start, которое информирует об ядре точки исполнения данной программы. Последовательность кода для этого раздела выглядит так:section.text global _start _start:
Когда вы работаете с языком ассемблера, важно разбираться в различных элементах, которые вы можете находить в нём. Вспомните
пример в начале данной главы. После компиляции файла hello.c получаемый в результате
код ассемблера содержал ряд кодов операций, регистров и операндов. В данном разделе мы рассмотрим эти разнообразные компоненты.
Мы поощряем вас к дальнейшему изучению языка ассемблера, поскольку охват всех разнообразных регистров, инструкций и тому
подобного далеко выходит за рамки этой книги.
В вычислительной архитектуре устройство центрального процессора (central processing unit, CPU, ЦПУ) отвечает за обработку данных. Поэтому давайте сделаем шаг назад и визуализируем компьютер простыми блоками построения. Приводимая ниже схема сосредоточена на трёх основных компонентах вычислительной системы:

Тремя простейшими компонентами выступают ЦПУ, память и ввод/ вывод. Будучи основным мозгом всего, ЦПУ нуждается в данных. Итак, давайте взглянем на те компоненты, которые конкретно относятся к самому ЦПУ и тому как они применяются.
Мы начнём с управляющего блока (control unit). Такое управляющее устройство отвечает за направление памяти компьютера, арифметическо- логического блока и различных устройств ввода/ вывода в отношении того, как реагировать на инструкции, полученные ЦПУ. Оно также будет получать инструкции из различных мест, таких как память и регистры, а в конечном итоге контролировать их исполнение.
Следующий компонент это исполнительный блок (execution unit). Это именно тот компонент, в котором происходит выполнение инструкций.
Следующие два компонента это регистры и флаги. Глубже мы сосредоточимся на регистрах и флагах позднее в этой главе.
Теперь, когда у нас имеется обзор на верхнем уровне архитектуры ЦПУ, давайте сосредоточимся на том как хранятся и выполняются данные. Эти данные могут храниться либо в регистрах, либо в местоположениях памяти. Одним из основных отличий между регистрами и местоположениями в памяти является время доступа. Поскольку регистры ближе к самому процессору, их время доступа очень быстрое. Для иллюстрации разницы в скорости, рассмотрим действительно быстрые микросхемы оперативной памяти. Они будут обладать временем доступа около 10- 50 наносекунд, в то время как доступ к регистру происходит в районе 1 наносекунды.
Приводимая ниже таблица иллюстрирует значения скорости регистров в сопоставлении с прочими видами хранения.
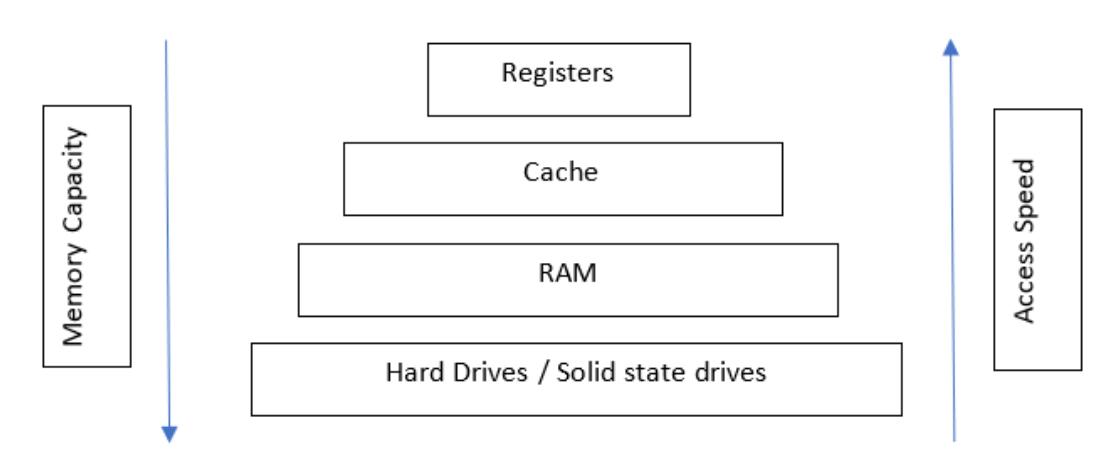
Регистры формируют самые мелкие компоненты памяти и, хотя они и наименьшие, они самые быстрые. Хранимые в регистрах данные не стойкие. Далее следует кэш ЦПУ, который способен содержать больше чем регистр и применяется ЦПУ для снижения среднего времени доступа, которое требуется для доступа к данным. Регистры и кэш обладают высокой скоростью и они помещаются между самим ЦПУ и оперативной памятью для увеличения скорости и производительности. Оперативная память обладает намного более высокой ёмкостью и, по мере увеличения скорости оперативной памяти, она всё ещё не столь быстра как кэш или регистр. Наконец, у вас имеются самые большие, самые медленные и самые экономичные жёсткие диски или твердотельные накопители. Они предлагают большой объём памяти и относительно быстрое время чтения и записи, но не столь быстрое как у оперативной памяти, кэша или регистров.
Давайте рассмотрим различные типы регистров.
Регистры общего назначенияМы начинаем с регистров общего назначения (GPR, general-purpose registers). Они применяются для временного хранения данных в самом ЦПУ. Имеется 16 GPR, причём каждый длиной в 64 бита. GPR приведены на Рисунке 2.3. Доступ к GPR может выполняться по всем 64 битам или по их подмножеству.
|
| Замечание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
64- битные регистры начинаются с
|
В приводимой таблице вы обнаружите быструю ссылку на номер регистра, который распространяется на различные архитектуры. Давайте сосредоточимся на 16- битных регистрах и разберём их применение:
-
AX: Аккумулятор, обозначаемый как AX. Этот регистр состоит из 16 бит, которые далее расщепляются на такие регистры как AH и AL, каждый из которых составлен из 8 бит. Такое расщепление также позволяет регистру AX обрабатывать и 8- битные инструкции. Вы обнаружите этот регистр вовлекаемым в арифметические и логические операции.
-
BX: Этот базовый регистр обозначается как BX. Данный 16- битный регистр также расщепляется на два 8- битных регистра, которыми выступают BH и BL. Этот регистр BX применяется для отслеживания значения смещения.
-
CX: Данный регистр счётчика обозначается как CX. CX расщепляется на CH и CL, каждый из которых по 8 бит. Этот регистр вовлекается в циклы и вращение данных.
-
DX: Этот регистр данных обозначается как DX. Данный регистр также содержит 8- битные регистры, а именно DH и DL. Основная функция этого регистра состоит в адресации функций ввода и вывода.
При применении элементов данных с размером менее 64 бит (32- бита, 16- бит или 8- бит), доступ к нижней части регистра можно
получать применяя иное имя регистра, как это показано на Рисунке 2.3.
Для иллюстрации давайте взглянем на регистр rax
Рисунок 2.4 отображает подробности схемы доступа к нижним частям
регистра rax:
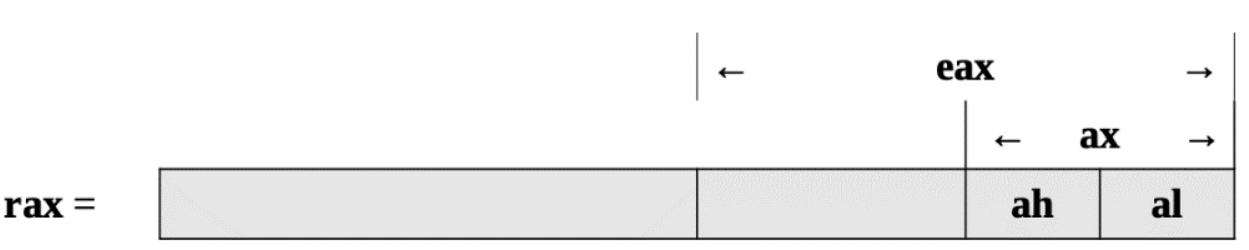
Самые первые четыре регистра, rax, rbx,
rcx и rdx предоставляют доступ к битам 8-15
при помощи имён регистров ah, bh,
ch и dh, как это указано на
Рисунке 2.3 и
Рисунке 2.4. Это предоставляется для сопровождения преемственности,
причём с исключением для ah.
Теперь я полностью понимаю, что чтение всего этого может отнимать много времени, а потому давайте рассмотрим это при
помощи примера. Я воспользуюсь программой отладчика проекта GNU в своей машине Kali Linux для отладки
/bin/bash в своём компьютере:
|
| Замечание |
|---|---|
|
Если у вас не установлен отладчик GNU, вы можете сделать это воспользовавшись такой командой:
|
-
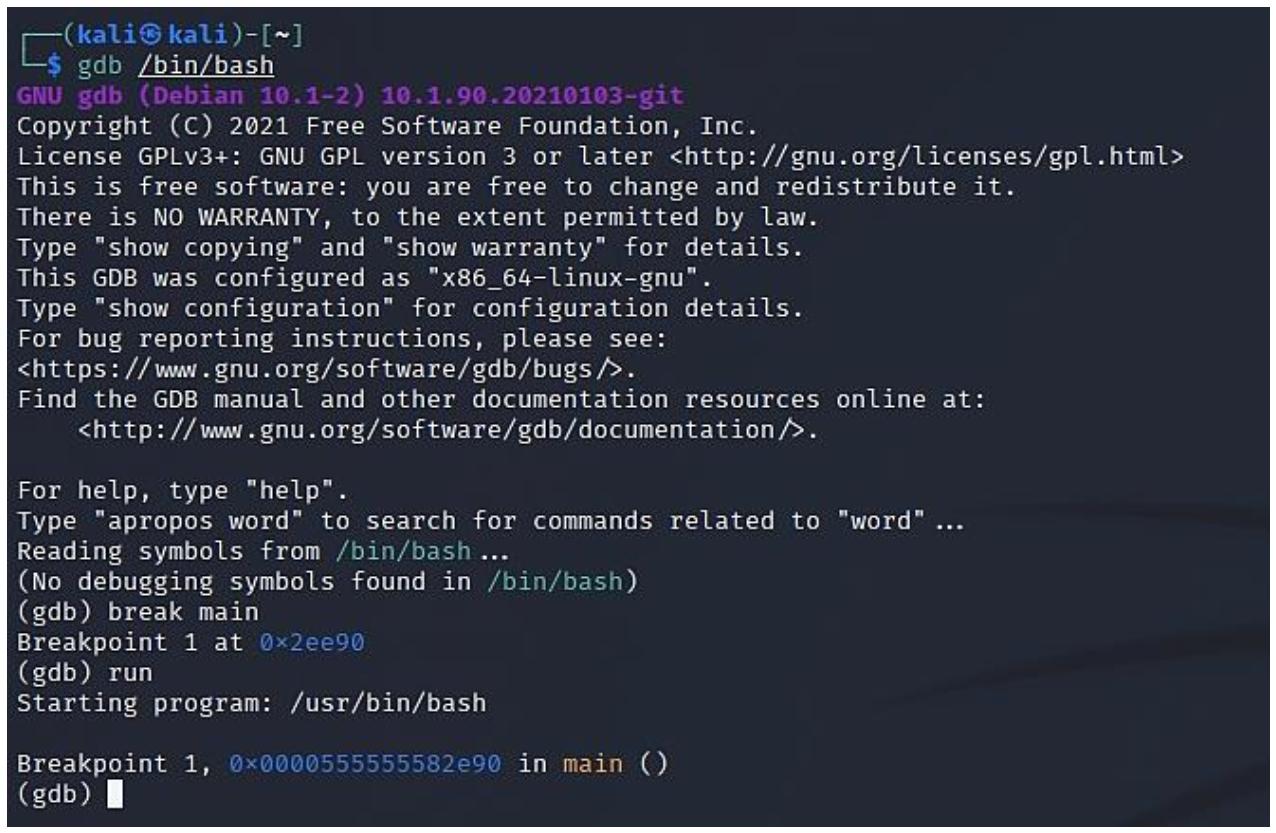
Поскольку моя машина Kali Linux это x64, мы будем рассматривать 64- битные регистры и также будем способны просматривать и его 32- битные компоненты. Для запуска своего отладчика я активирую его такой командой:
gdb /bin/bash -
Затем я определю некую точку прерывания с тем, чтобы данная программа остановилась на функции
main. Это делается путём активации следующей команды:break main -
Затем я запускаю эту программу при помощи такой команды:
runТеперь наш отладчик остановится в установленной точке прерывания в разделе
main. Это отображено на приводимом ниже снимке экрана:
-
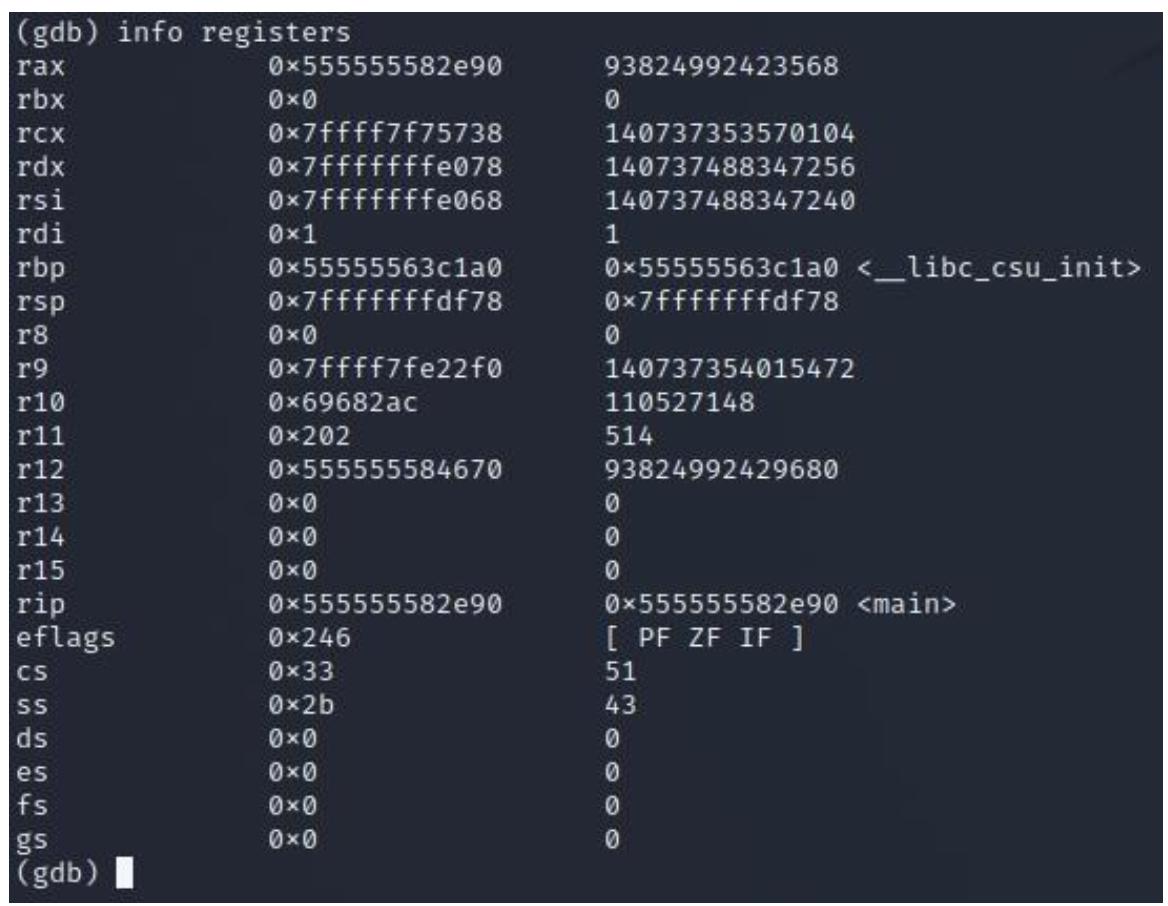
Теперь, когда мы достигли точки прерывания, давайте взглянем на свои регистры воспользовавшись такой командой:
info registersТеперь вы способны просмотреть значения регистров, как это отображено на приводимом далее снимке экрана. Обратите, пожалуйста, внимание что получаемые значения адреса могут быть иными в вашей системе.
Давайте сосредоточимся на регистре RAX. Если вы вернётесь к Рисунку 2.3 и Рисунку 2.4, вы увидите что наш 64- битный регистр RAX содержит 32- битный регистр EAX. Внутри этого регистра EAX вы обнаружите регистр AX, который состоит из 16 бит и, наконец, вы обнаружите регистры AH и AL, который содержат по 8 бит.
-
Вы можете просмотреть это в gdb. Давайте взглянем на значение EAX исполнив такую команду:
display /x $eaxВ моей системе возвращаемым значением является 1: /x $eax = 0x55582e90. Это значение 32- бит моего регистра RAX, как мы это можем видеть из Рисунка 2.6.
-
Для представления значения регистра AX вы можете исполнить и предыдущую команду, но на этот раз мы воспользуемся значением
axследующим образом:display /x $axЭто предоставит нам значение соответствующего 16- битного регистра. Вы можете воспользоваться той же самой командой для проникновения вовнутрь своего регистра AL. Идущий далее снимок экрана показывает их значения в моей системе:
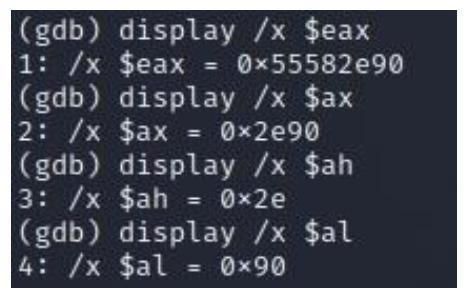
Данное упражнение можно также выполнить на всех прочих регистрах чтобы помочь вам визуально представить как эти регистры разбиваются на части. Теперь, давайте двинемся далее к своему следующему разделу, в котором мы сосредоточимся на регистрах указателей.
Регистры указателяРегистр указателя это регистр, применяемый для хранения адреса памяти в вашей архитектуре процессора. Мы можете быть способны применять их также и для прочих нужд, но обычно они в инструкциях, которые интерпретируют их как адреса в памяти и выполняют выборку по хранимому в них адресу. Давайте рассмотрим некоторые регистры указателей и их функции:
-
SP: Это сокращение от stack pointer (указателя стека). Он обладает размером в 16 бит. Он указывает на самый верхний элемент в имеющемся стеке. Если ваш стек пустой, данный указатель стека будет (FFFEH). Это адрес относительного смещения на ваш раздел стека.
-
BP: Наш base pointer (базовый указатель) обозначается буквами BP. Он обладает размеров в 16 бит. Обычно он применяется для доступа к передаваемым в стеке параметрам. Это относительный адрес смещения для вашего раздела стека.
-
IP: Определяет значение адреса следующей подлежащей исполнению инструкции. Полное значение адреса текущей инструкции в сегменте кода задаётся через IP в сочетании с регистром кодового сегмента (CS, code segment) в виде (CS:IP)
Замечание Значение регистра CS применяется при адресации к вашему сегменту кода или для того места, в котором хранится соответствующий код. Значение смещения внутри такого раздела памяти кода хранится в нашем IP (instruction pointer, указателе инструкции).
Значение текущего смещения местоположения в памяти хранится в индексном регистре, а значение его базового адреса запоминается в другом регистре, что имеет результатом законченный адрес памяти. Например, на Рисунке 2.8 вы обнаружите что значения 32- битных индексных регистров, включающих в свой состав ESI и EDI, а также их 16- битные двойники, SI и DI, применяются для индексной адресации. Эти регистры порой применяются в таких арифметических функциях как сложение и вычитание.
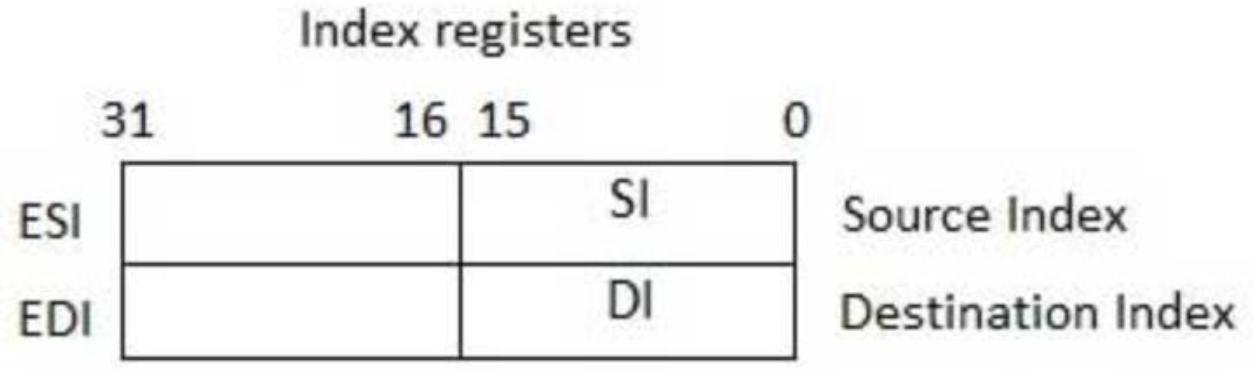
Вот эти два типа индексных регистров:
-
Source Index (SI): Этот регистр предназначен для значения индекса источника. Он обладает размером в 16 бит. Он применяется для адресации указателя данных в качестве источника для различных операций со строками. Он обладает относительным смещением на значение сегмента данных.
-
Destination Index (DI): Этот регистр предназначен для значения индекса получателя.
Теперь, когда мы рассмотрели индексные регистры, давайте перейдём к управляющим регистрам.
Управляющие регистрыУправляющие регистры (Control registers) вступают в игру когда инструкции пользуются сопоставлениями и математическими операциями для изменения значения состояния флагов, в то время как прочие применяют условные инструкции для проверки соответствующего значения таких состояний флагов перед отклонением потока исполнения в иное место. Когда вы сочетаете регистры указателей и регистры флагов, они рассматриваются как регистры управления.
Вот наиболее распространённые флаги, которые работают с управляющими регистрами:
-
Overflow Flag (OF, Флаг переполнения): После выполнения арифметической операции со знаком, он сигнализирует произошедшее переполнение бита верхнего порядка (которым будет самый левый бит) данных.
-
Direction Flag (DF, Флаг направления): Он определяет перемещаться ли по строковым данным или сопоставлять ихв направлении налево или направо. Когда значением DF является
0, ваша операция со строкой выполняется слева направо, а когда его значение1, операция со строкой осуществляется справа налево. -
Interrupt Flag (IF, Флаг прерывания): Указывает на то следует ли игнорировать, либо обрабатывать происходящие внешние прерывания, например, ввод с клавиатуры. Когда он установлен в
0, он запрещает внешние прерывания, а когда равен1, он разрешает их. -
Trap Flag (TF, Флаг ловушки): Позволяет вам устанавливать ваше ЦПУ на работу в пошаговом режиме. Значение TF устанавливается программой отладчика, что позволяет вам проходить по вашему исполнению. Такое прохождение осуществляется в соответствии с поступающими инструкциями.
-
Sign Flag (SF, Флаг знака): Отображает значение знака получаемого результата арифметической операции. Следуя за арифметической операцией, этот флаг устанавливается на основе значения знака своего элемента данных. Самый старший бит крайнего левого бита указывает значение знака. Положительный результат сбрасывает значение SF в
0, а отрицательный результат сбрасывает его в1. -
Zero Flag (ZF, Флаг нуля): Обозначает значение результата вычисления или сравнения. Когда результат не нулевой, это приводит к установке ZF в
0; и наоборот, когда результат нулевой, значение ZF устанавливается в1. -
Auxiliary Carry Flag Flag (AF, Флаг вспомогательного переноса): когда дело доходит до кодируемых двоично десятичных операций, или сокращённо BCD (binary coded decimal), в действие вступает этот вспомогательный флаг переноса. Он связан с математическими операциями и взводится при переносе от младшего бита к старшему, например, от бита 3 к биту 4.
-
Parity Flag (PF, Флаг чётности): Когда происходит арифметическая операция и получаемые в результате биты чётные, устанавливается данный флаг. Если же результат не чётный, данный флаг чётности будет установлен равным
0. -
Carry Flag (CF, Флаг переноса): По завершению арифметической операции этот флаг CF отражает значение переноса
0или1из старшего бита (самого левого). Он также сохраняет содержимое сдвига или сдвигает самый последний бит своей операции.
Далее нам потребуется разобраться с тем как в языке ассемблера обрабатываются местоположения в памяти. Именно тут вступают в действие сегментные регистры.
Сегментные регистрыВнутри своего ЦПУ сегментные регистры это в целом указатели памяти. Сегментные регистры указывают на месторасположение в памяти, в котором происходит одно из следующих событий: местоположение данных, подлежащая исполнению инструкция и тому подобное.
Когда речь заходит о сегментных регистрах, мы сосредоточимся на следующих:
-
Code Segment: Он покрывает все те направления, которые подлежат выполнению. Значение регистра CS применяется для хранения начального адреса своего сегмента кода.
-
Data Segment: Включает данные, константы и рабочие области. Значение регистра SS применяется для хранения начального адреса сегмента данных.
-
Stack Segment: Содержит сведения о процедурах и подпрограммах, а также о возвращаемых ими адресах. Соответствующая реализация этого в виде структуры данных носит название стека. Значение начального адреса стека хранится в регистре сегмента стека, или в регистре SS.
Значение начального адреса хранится в соответствующем регистре сегмента. Для обнаружения значения точного местоположения данных или инструкций в сегменте требуется значение смещения (или смещение). Сам процессор ссылается на конкретное место в памяти соответствующего сегмента связывая значение адреса этого сегмента в соответствующем регистре сегмента со значением смещения этого местоположения.
Инструкции перемещения данных переносят сведения из одной области в другую, которые носят названия операндов источника и получателя. Загрузки, сохранения, перемещения и непосредственные загрузки, всё это различные виды инструкций перемещения.
Инструкции перемещения данных могут быть подразделены на следующие категории:
-
Инструкции, которые применяются для общих целей
-
Инструкции, связанные с манипуляциями в стеке
-
Инструкции, относящиеся к преобразованиям типа
Инструкции перемещения для общих целей
Во время выполнения программы требуется перемещение данных. Например, вам может потребоваться переместить регистр или переместить данные между местоположениями в памяти и тому подобное. Именно тут применяются инструкции перемещения для общих целей. Давайте рассмотрим следующие инструкции общего назначения: MOV, MOVS и XCHG:
-
MOV: Это та команда, которая перемещает данные из одного операнда в другой. Эти данные могут быть представлены в виде байта, слова или даже слова двойной длины. Для передачи данных при помощи инструкции MOV могут применяться все такие способы. Также существуют вариации MOV, которые работают с сегментными регистрами.
Данная инструкция не предоставляет возможности перемещения из одного местоположения в памяти в иное и из одного сегментного регистра в другой. Инструкции перемещения строк, MOVS, с другой стороны, могут передавать перемещения из памяти в память.
-
MOVS: Поскольку инструкция MOV не способна предоставлять возможность перемещения данных из одного места памяти в другое, или из одного сегментного регистра в иной, этой цели соответствует инструкция MOVS, поскольку она может применяться для перемещения строк по одному байту за раз.
Вот некие образцы инструкций MOV:
mov eax, 0xaaabbbcc: перемещает данные в регистр EAX mov rbp, rax: перемещает данные между регистрами -
XCHG: Производит обмен содержимого двух операндов. Этой инструкцией заменяются три инструкции MOV. Нет необходимости в сохранении значения содержимого одного из операндов в то время как другой загружается во временное место. XCHG в частности, удобна для реализации семафоров или иных структур синхронизации данных.
Данная инструкция обмена может применяться для обмена операндов; например, она может применяться для обмена адреса памяти с регистром AX. XCHG автоматически активирует сигнал LOCK при применении с операндами памяти.
Далее мы рассмотрим те инструкции, которые могут применяться для манипуляции стеком.
Инструкции манипуляции со стеком
Для непосредственного изменения стека применяются инструкции манипуляции стеком.
-
POP: Передаёт значение, которое в настоящий момент в верху стека в операнд назначения. После выполнения этого, значение регистра ESP увеличивается для указания на новое значение стека. POP также применяется с сегментными регистрами.
-
POPA: Означает передачу всех (all) регистров. Данная инструкция применяется для восстановления значений всех регистров общего назначения. POPA сама по себе это работа с 16- битными регистрами. Это означает, что первым извлекается регистр DI, за которым следуют SI, BP, BX, DX, CX и AX. С другой стороны, POPAD это работа с 32- битными регистрами. Естественно, POPAD ссылается на слово двойной длины, поэтому, в данном случае самым первым доставляемым регистром будет EDI, за которым следуют ESI, EBP, EBX, EDX, ECX и EAX.
-
PUSHA: означает доставку всех регистров, сохраняет значение содержимого всех регистров стека. Инструкция POP применяется в сочетании с PUSHA и то же самое применимо в PUSHAD по отношению к POPAD.
-
PUSH: В целом применяется для сохранения параметров в стеке; это также первейший метод сохранения в стеке временных переменных. Действию инструкции PUSH подвержены операнды памяти, непосредственные операнды и операнды регистров (включая сегментные регистры).
По мере того как мы завершаем этот раздел, может показаться, что нужно ещё много с чем разобраться. Однако, как только мы начнём работать с шеллкодом и просматривать программы в дизассемблере, все эти инструкции станут более понятными. Теперь перейдём к арифметическим инструкциям.
Внутри ЦПУ вы можете обнаружить компонент, который носит название Arithmetic Logical Unit (ALU, арифметического логического блока). Этот компонент отвечает за выполнение арифметических операций, таких как сложение, вычитание и умножение.
В языке ассемблера эти операции отображаются так:
-
Addition (
add, сложение) -
Subtraction (
sub, вычитание) -
Division (
div, деление) -
Multiplication (
mul, умножение)
Арифметические операции следуют тому же самому синтаксису, который мы наблюдали ранее:
operation destination, source
Вот пояснение этого синтаксиса:
-
operationссылается на применяемую арифметическую операцию (add,sub,div,mul). -
destinationссылается на значение места в памяти или регистр, в котором будет сохранён окончательный результат по завершению данной операции. -
sourceссылается на значение места в памяти или регистр, которое содержит первоначальное значение, с которым действует эта операция.
|
| Замечание |
|---|---|
|
Существуют отличия в том способе, которым написаны языки ассемблера AT"T и Intel. Вы можете посмотреть описание этого по следующей ссылке. |
Например, давайте ознакомимся со следующим фрагментом кода, который выполняет различные арифметические инструкции
с определёнными в a и b значениями:
#!/bin/sh
a=100
b=50
val='expr $a + $b' #Line 1
echo "a + b : $val" #Line 2
val='expr $a - $b' #Line 4
echo "a - b : $val" #Line 5
val='expr $a \* $b' #Line 7
echo "a * b : $val" #Line 8
val='expr $a / $b' #Line 10
echo "b / a : $val" #Line 11
В строке 1 у нас имеется операция сложения, выполняющаяся с двумя объявленными в a и
b значениями. Его результат здесь произведёт 150.
Строка 4 выполняет операцию вычитания тех же значений, возвращающей значением результата
50. Строка выполняет умножение тех же значений и возвращает получаемым результатом
5000. И последняя, строка 10, осуществляет деление тех же значений, имея результатом
2.
Арифметические операции часто используются в шеллкоде. По мере того как мы пройдём по относящимся к шеллкоду Linux и Windows главам, вы обнаружите арифметические операции в различных примерах шеллкода.
Условные инструкции внутри языка ассемблера могут применяться для изменения того способа, коим выполняется программа. Такие изменения направления вашей программы обычно осуществляется при её времени исполнения через создание ветвлений (переходов) или выполнения определённых инструкций только в случае удовлетворения некому условию.
Самыми распространёнными условными инструкциями, с которыми вам придётся сталкиваться, это условные и безусловные переходы. Давайте взглянем на то, к чему влекут эти инструкции.
Условный переход
Условные переходы используются для принятия решения на основе значений состояний соответствующих флагов или некого
условия. Когда в Ассемблере должны применяться такие понятия как операторы if или
loop, обычно используются условные переходы. Условные переходы применяются для
определения того, следует ли осуществлять переход, поскольку язык ассемблера не поддерживает такие слова как операторы
if.
В зависимости от значения условия и данных, существует некое разнообразие инструкций условного перехода. Например, приводимая ниже таблица отображает те инструкции условного перехода, которые применяются для данных со знаком, используемые для арифметических операций.
| Инструкция | Описание | Флаги |
|---|---|---|
|
Jump Equal или Jump Zero |
|
|
Jump Not Equal или Jump Not Zero |
|
|
Jump Greater Equal или Jump Not Less/ Equal |
|
|
Jump Greater/Equal или Jump Not Less/ Equal |
|
|
Jump Less или Jump Not Greater/ Equal |
|
|
Jump Less/ Equal или Jump Not Greater |
|
|
| Замечание |
|---|---|
|
Представленные здесь флаги обозначают Zero Flag (ZF, Флаг нуля), Overflow Flag (OF, Флаг переполнения) и Sign Flag (SF, Флаг знака). Эти флаги часть архитектуры x86. |
Имеются условные инструкции, которые относятся к логическим операциям и некоторые из них обладают особым вариантом применения. Их подробное описание далеко выходит за рамки этой книги, но вы можете найти сведения о них в руководстве по архитектуре Intel, которое можно найти в разделе Дальнейшее чтение данной главы.
Безусловный переход
Безусловный переход срабатывает когда программа переходит к метке, определённой в соответствующей инструкции. Такие безусловные переходы по существу делятся на три типа - короткий безусловный переход, ближний безусловный переход и дальний безусловный переход.
-
Short (короткий) безусловный переход делает возможным доступ или переход к месту в памяти, которое определяется внутри памяти с диапазоном в байт. Такой диапазон памяти в байт это 12 байт вперёд для безусловного перехода или 128 байт позади данной инструкции безусловного перехода.
-
Near (ближний) безусловный переход это переход в 3 байта, который делает возможным доступ к +/- 32k байт из данной инструкции безусловного перехода.
-
Far (дальний) безусловный переход работает с предписанным сегментом кода. В случае дальнего безусловного перехода его значение абсолютно, что означает что данная инструкция выполнит безусловный переход к заданной инструкции.
Условные инструкции, в особенности разнообразные безусловные переходы, могут применяться когда вы желаете выполнить безусловный переход к своему шеллкоду. Если вы обладаете управлением над указателем инструкций и ваш шеллкод расположен где-то там, для ссылки на этот указатель может применяться безусловный переход. Когда вы берёте пример с простым переполнением буфера, включая в эксплойт либо безусловный, либо условный переход, вы, по сути, будете переходить к различным разделам буфера чтобы достичь свой шеллкод.
В данной главе мы рассмотрели как работает ваш компьютер на уровне кода ниже чем C; он выполняет последовательность инструкций ассемблера, которые просто действия, преобразуемые в циклические операции процессора. Ассемблер сложен для написания на нём, однако способность понимать его на интуитивном уровне полезна. Итак, мы рассмотрели множество относящихся к языку ассемблера материалов и приветствуем дальнейшее изучение, поскольку язык ассемблера очень большая тема.
Мы узнали, что в ассемблере имеются инструкции для вычислений, перемещения данных и управления потоком, а также что компилятор для ускорения вырабатывает неожиданные последовательности инструкций. Это одна из причин, по которой мы применяем компиляторы: они хороши в сжатии наших программ в максимально короткую последовательность команд.
в своей следующей главе мы слегка больше сосредоточимся на языке ассемблера и затем перейдём к компиляторам, инструментам для шеллкода и прочему.