Приложение C. Рекомендации по разработке высокопроизводительных систем RDMA
Перевод статьи Anuj Kalia, Michael Kaminsky†, David G. Andersen Design Guidelines for High Performance RDMA Systems, Carnegie Mellon University, †Intel Labs, 2016
USENIX ATC ’16, June 22–24, 2016 • Denver, CO, USA
978-1-931971-30-0
Open access to the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16) is sponsored by USENIX.
Содержание
Современный RDMA предлагает потенциал для исключительной производительности, однако значительное воздействие на наблюдаемую производительность оказывает то, какие именно операции RDMA применять и как их использовать. Данная статья предлагает руководящие правила, которые могут применяться проектировщиками системы для навигации в пространстве решения RDMA. Наше руководство придаёт особое значение деталям нижнего уровня, которые могут применяться для улучшения производительности систем на основе RDMA: мы спроектировали некий сетевой генератор последовательностей, который превосходит в производительности имеющиеся в 50 раз и улучшили эффективность предыдущего высокопроизводительного хранилища ключ- значение на 83%. Мы также представляем и делаем оценку некоторых новых оптимизационных решений и подводных камней RDMA, а также обсуждаем как они воздействуют на проектирование систем RDMA.
В последние годы сетевые среды с поддержкой RDMA (Remote Direct Memory Access - Удалённый прямой доступ к памяти) упали в цене и значительно продвинулись в центрах обработки данных. Несмотря на свою вновь приобретаемую популярность, применение их передовых возможностей для получения наилучших результатов остаётся сложным для разработчиков программного обеспечения.Эти сложности возникают по причине почти пугающего массива возможностей, которые имеются у программистов при применении NIC (в данной статье мы обсуждаем исключительно обладающие RDMA сетевые интерфейсы, поэтому мы применяем именно это более общее название, которое во всех отношениях название NIC), а также по той причине, что относительная производительность этих операций определяется сложными вопросами нижнего уровня, таким как транзакции шины PCIe и самими деталями архитектуры данных NIC (частными и зачастую конфиденциальными).
К несчастью, важным является определение действенного соответствия между возможностями RDMA и неким приложением. Как мы показываем это в Разделе 5, наилучший и наихудший выборы вариантов RDMA отличаются множителем в семьдесят раз в своей общей пропускной способности и на множитель 3.2 в количестве потребляемых ЦПУ хоста. Более того, не существует наилучшего с единым- размером- для- всех подхода. Небольшие изменения в требованиях к приложениям оказывают существенное влияние на относительные показатели производительности различных решений. К примеру, применение RPC общего назначения поверх RDMA является наилучшим решением для сетевого хранилища ключ- значение (Раздел 4), однако тот же самый выбор решения предоставляет более низкий уровень масштабирования и на 16% ниже пропускную способность, чем наилучший выбор для сетевого "генератора последовательности" (Раздел 4; такой генератор возвращает некую монотонно возрастающие целые для запросов такого клиента).
Данная статья помогает проектировщикам системы решать такие проблемы двумя способами. Во- первых, она предоставляет руководящие правила, основываясь на инструментарий измерений с открытым исходным кодом, для оценки и оптимизации наиболее важных показателей системы, которые оказывают воздействие на всеобщую полосу пропускания при использовании NIC RDMA. Для каждого руководящего правила (такого как "Исключение промахов кэширования") данная статья предоставляет полное понимание как того как определять является ли это правило существенным (например, за счёт применения замеров счётчиков PCIe для определения чрезмерности обмена между этими NIC и ЦПУ), так и обсуждения того какие режимы использования данных NIC скорее всего смягчат данную проблему.
Во- вторых, мы оцениваем значение силы воздействия утих руководящих правил за счёт из применения как микротестирований, так и реальных систем на протяжении трёх поколений оборудования RDMA. Раздел 4.2 предоставляет новейший дизайн для некоторого сетевого генератора последовательностей, который превосходит в производительности в 50 раз имеющиеся. Наше решение наилучшего генератора последовательностей обрабатывает 122 миллиона операций в секунду с применением некоторого отдельного NIC и хорошего масштабирования. Раздел 4.3 применяет соответствующее руководство для улучшения значения эффективности ЦПУ и пропускной способности кэширования ключ- значение нашего HERD [20] на 83% и 35% соответственно. Наконец, мы показываем сто современные NIC RDMA обрабатывают состязательность атомарных операций исключительно медленно, исполнение проектов которые их применяют [27, 30, 11] чрезвычайно неторопливо.
Неким уроком нашей работы является то, что детали нижнего уровня являются существенно важными для архитектуры системы RDMA. Лежащая у нас в основе цель состоит в предоставлении исследователям и разработчикам некоторой дорожной карты сквозь эти подробности без необходимости становиться гуру RDMA. Мы предоставляем простые модели операций RDMA и связанные с ними стоимости ЦПУ и PCIe, плюс программное обеспечение с открытым исходным кодом для их измерения и анализа (https://github.com/efficient/rdma_bench).
Мы начинаем своё путешествие в системы с высокой производительностью на основе RDMA с некоторого обзора существенных возможностей NIC RDMA и шины PCIe, которые часто выступают в роли узких мест.
Рисунок 1 показывает существенные аппаратные компоненты некоторой машины в каком- то кластере RDMA. Некий NIC с одним или более портами соединений с контроллером PCIe со множеством ядер ЦПУ. Этот контроллер PCIe считывает/ записывает свой кэш L3 для обслуживания соответствующих запросов PCIe NIC; в современных серверах Intel [4] такой кэш L3 предоставляет счётчики событий PCIe.
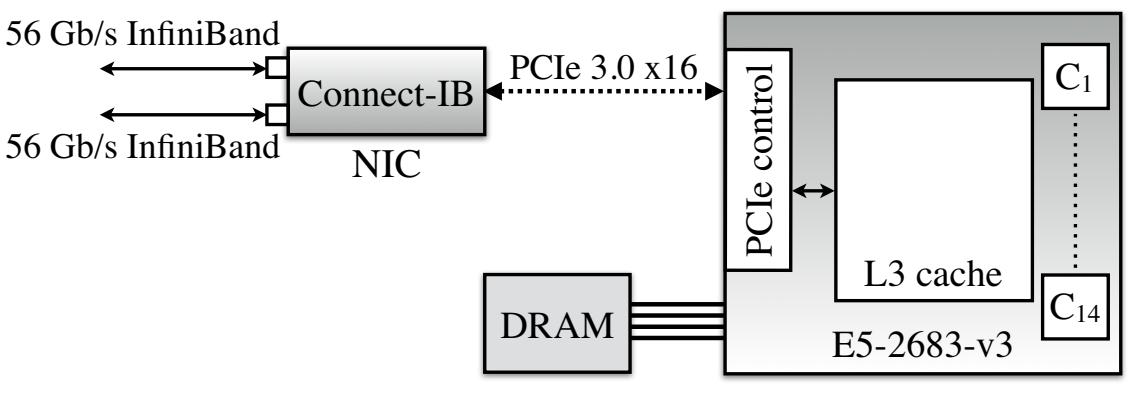
Имеющееся в настоящее время самое быстрое соединение PCIe это PCIe "3.0 x16", 3е поколение протокола PCIe с применением 16 лейнов (lane). Значение пропускной способности соединения PCIe является полосой пропускания каждого лейна, помноженной на общее число имеющихся лейнов. PCIe является протоколом с уровнями и соответствующие заголовки уровня добавляют накладные расходы, которые важно осознавать с точки зрения эффективности. Операции RDMA вырабатывают три вида уровней транзакций пакетов (TLP - transaction layer packets) PCIe: запросы на чтение, запросы на запись и завершения чтения (не существует никакого отклика уровня транзакции для записи). Рисунок 2a перечисляет значения полос пропускания и накладных расходов заголовка для имеющихся в наших кластерах поколений PCIe. Отметим, что значение накладных расходов заголовка в 20- 26 байт сопоставимо с общим размером элементов данных, применяемых в таких службах как memcached [25] и RPC [15].
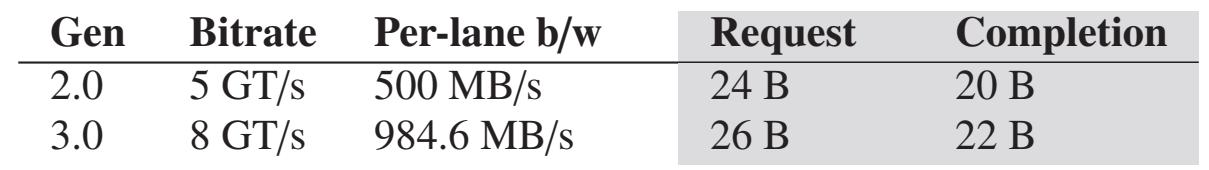
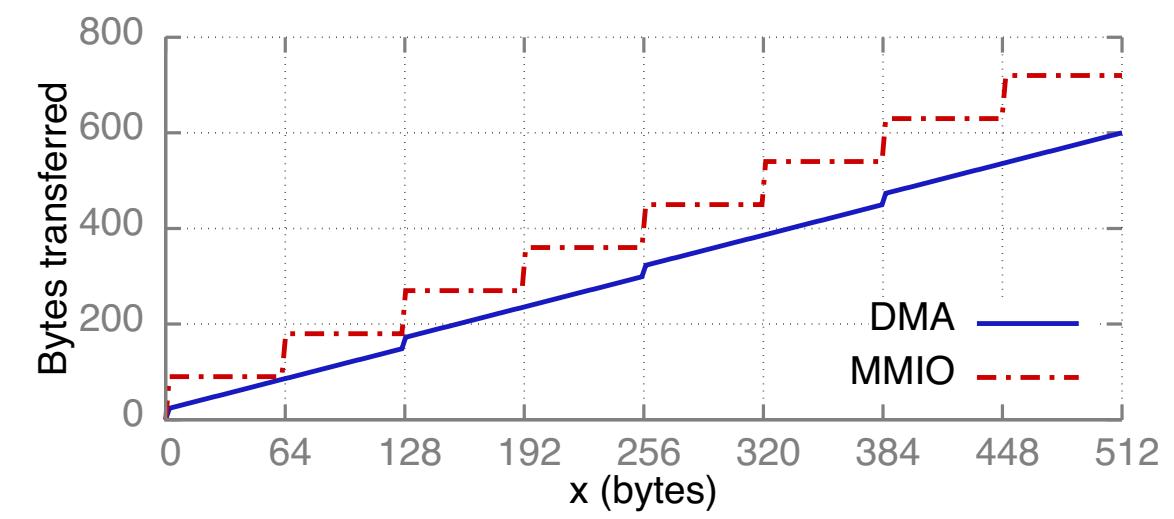
Сопоставление записей MMIO и чтений RDMA Существует важное отличие этих двух метеодов передачи данных из ЦПУ в некое устройство PCIe. ЦПУ осуществляет запись в соответствующую память устройств (MMIO - Memory-mapped I/O) для инициализации записей. Во избежание генерации некоторой операции записи PCIe для каждой инструкции сохранения ЦПУ применяет некую оптимизацию, именуемую "комбинированием записи" (write combining), которая объединяет сохранения для выработки транзакций PCIe с размером строк кэширования. Устройства PCIe имеют механизмы DMA и могут считывать из ОЗУ (DRAM) при помощи DMA. Считывания DMA не ограничиваются строками кэша, но отклики считывания длиннее чем значение размера комбинированного завершения считывания ЦПУ (Crc) разбиваемого на множество завершений. Составляющий в ЦПУ Intel 128 байт Crc) используется в наших измерениях (Таблице 2); для значения ЦПУ AMD мы предполагаем 128 байт [4, 3]. Некое считывание DMA всегда использует меньшую полосу пропускания PCIe от- хоста- к- устройству, нежели MMIO с тем же самым размером; Рисунок 2b отображает некое аналитическое сравнение. Это некий важный показатель и мы покажем как он воздействует на производительность протоколов более высокого уровня в последующих разделах.
Счётчики PCIe Наши достижения полагаются на понимание числа взаимодействий PCIe между
NIC и ЦПУ. Хотя точный анализ PCIe требует дорогостоящих анализаторов PCIe или частных/ конфиденциальных руководств NIC, доступные в современных ЦПУ счётчики PCIe
могут предоставлять некоторую полезную внутреннюю информацию (Имеющийся ЦПУ перехватывает действия строки кэширования между контроллером PCIe и его кэшем L3,
поэтому его счётчики могут пропускать некую критически важную информацию. Например, его счётчики указывают 2 считывания PCIe когда имеющийся NIC считал
фрагмент из 4 байт, охватывающие 2 строки кэширования.)
Для каждого счётчика получаемое значение перехваченных событий в секунду является его скоростью счётчика
(counter rate). Наш анализ в первую очередь использует счётчики для считываний DMA (PCIeRdCur) и записей DMA
(PCIeItoM).
RDMA является некоторой сетевой функциональностью, которая позволяет выполнять прямой доступ к имеющейся оперативной памяти какого- то удалённого компьютера. Предоставляющие RDMA сетевые среды включают в себя InfniBand, RoCE (RDMA over Converged Ethernet) и iWARP (Internet Wide Area RDMA Protocol) {Прим. пер.: а также сетевую среду Ангара, НИЦЭВТ. Также эмуляцию RDMA осуществляет OmniPath, Intel, подробнее, например, наш перевод Настройка производительности инфраструктуры Intel® Omni-Path. Руководство пользователя. v.10.0.}. Сетевые среды RDMA обычно предоставляют высокое значение полосы пропускания и низкую величину латентности: можно приобрести NIC с полосой пропускнаия 100 Gbps на порт и латентностью в оба конца ~ 2 мкс. Значение производительности и масштабирования протокола взаимодействия на основе RDMA зависит от определённых факторов, включая тип взаимодействия (глагол, verb), способа доставки, флагов оптимизации и метода инициализации операции.
Глаголы и доставка RDMA
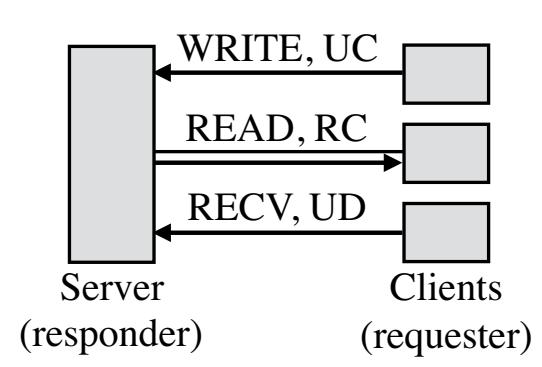
Хосты RDMA взаимодействуют с применением пар очередей (QP, queue pairs); хосты создают QP, стотящие из очереди отправки (send queue) и очереди приёма (receive queue) и выставляют (post) операции в эти очереди при помощи установленных глаголов (verb) API. Мы именуем тот хост, который инициирует некий глагол стороной запроса (requester), а хост его получателя стороной отклика (responder). Для некоторых глаголов отвечающая сторона не должна на самом деле отправлять отклик. По завершению какого- то глагола соответствующий NIC стороны отклика может (не обязательно) сигнализировать исполнение через запись завершения DMA (CQE) в некоторой очереди завершения (CQ, completion queue), связываемой с данной QP. Глаголы могут выполняться без сигнализации (unsignaled) через установку некоторого флага в конкретном запросе; эти глаголы не вырабатывают CQE и их приложение определяет завершение при помощи особенных для приложения методов.
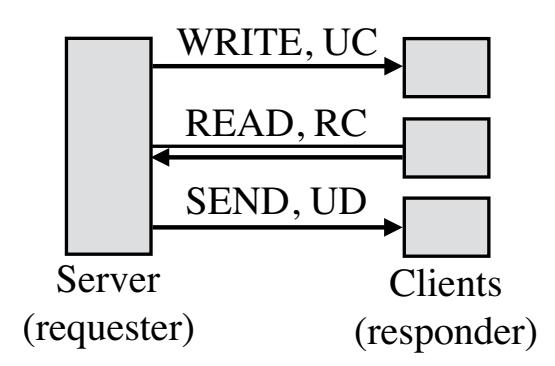
Основными двумя видами глаголов являются глаголы памяти и глаголы сообщений. Глаголы памяти включают в свой состав операции RDMA считывания, записи и атомарные. Эти глаголы определяют соответствующий удалённый адрес для действия и обходят ЦПУ соответствующей стороны отклика. Глаголы сообщений содержат глаголы отправки и приёма. Эти глаголы привлекают ЦПУ стороны отклика: полезная нагрузка отправки записывается по некоторому адресу, определяемому каким- то получателем, который предварительно был выставлен ЦПУ соответствующей стороны отклика. В данной статье мы соответственным образом именуем глаголы RDMA чтения, записи, отправки и приёма как READ, WRITE, SEND и RECV.
Доставка (transport) RDMA является либо надёжной, либо недостоверной (reliable или unreliable), и при этом с установлением соединения (connected) или без него (unconnected, что также именуется обменом дейтаграммами - datagram). При надёжной доставке соответствующий NIC применяет подтверждения для гарантии надлежащей доставки сообщений. Недостоверная доставка не предоставляет такой гарантии. Тем не менее, современные реализации RDMA, такие как InfniBand применяют канальный уровень (link layer) без потерь (loss-less), который предотвращает потери на основе заторов при помощи управления потоком на канальном уровне [1], а также потери на основе битовых ошибок с применением повторных доставок на канальном уровне [8]. Следовательно, утрата пакетов при недостоверной доставке очень маловероятна. { Прим. пер.: на момент перевода, сентябрь 2018, Mellanox предъявляет также следующие необходимые технологии в коммутаторах для использования RoCE; Priority Flow Control (PFC), Explicit Congestion Notification (ECN), DSCP-based QoS.}
Доставка с соединением требует соединений один- к- одному между QP, в то время как QP обмена дейтаграммами может взаимодействовать с множеством QP. В данной статье мы рассматриваем два типа доставки с соединением: RC (Reliable Connected) и UC (Unreliable Connected). Современное оборудование RDMA предоставляет только один вид доставки дейтаграмм: UD (Unreliable Datagram). {Прим. пер.: так в оригинале.} Различные виды доставки поддерживают различные подмножества из глаголов. UC не поддерживает чтение RDMA, а UD не поддерживает глаголы памяти. Таблица 1 суммирует эти сведения {Прим. пер.: в данном переводе таблица расширена столбцом RD и строкой с атомарными глаголами (Fetch и Add/ Cmp и Swap)}.
| Глагол | RС | UС | RD | UD |
|---|---|---|---|---|
|
V |
V |
V |
V |
|
V |
V |
V |
|
|
V |
|
V |
|
|
V |
|
V |
|
|
36 B |
36 B |
|
68 B |
UC не поддерживает READ, а UD совсем не поддерживает RDMA. {К тому же, длина кадра UD ограничена значением MTU, в то время как размер прочих кадров определяется аппаратной реализацией, например, в OmniPath это 1ГБ.} |
||||
RDMA WQE
Для инициации операций RDMA соответствующий драйвер NIC режима пользователя на стороне запроса создаёт в памяти хоста WQE (Work Queue Elements - Элементы исполнительной очереди); как правило, WQE создаются при предварительном размещении, непрерывной областью памяти, причём каждый WQE является индивидуально выравниванием под кэш. (Мы подробно обсудим методы доставки в Разделе 3.1.) Соответствующий формат WQE определяется производителем и описывается руководством соответствующего оборудования NIC.
Размер WQE зависит от определённых факторов: собственно типа операции RDMA, вида доставки,
а также будет ли содержимое полезной нагрузки указываться неким полем ссылки или встроенным
(inlined) в сам WQE (т.е. сам буфер WQE содержит такую полезную нагрузку).
Таблица 1 показывает значения заголовка WQE для NIC Mellanox в трёх видах доставки. например,
при 36 байтах заголовка WQE общий размер WQE WRITE с x- байтами вложенной полезной нагрузки составят
36 + x байт. WQE UD имеет более длинные заголовки из 68 байт для хранения дополнительной информации
маршрутизации.
Терминология и соображения по умолчанию
Мы различаем входящие (inbound) и
исходящие (outbound) глаголы, так как их производительность существенно
разнится (Раздел 5): глаголы памяти и SEND являются исходящими для стороны запроса и входящими
для стороны отклика; RECV всегда является входящим. Рисунок 3 суммирует это.
Поскольку наше изучение сосредоточено на обмене сообщениями малого размера, по умолчанию все WRITE и SEND определяются как содержащие вложения.
Мы определяем набивочную- до- выравнивания- строки- кэша функцию x' := [x/64] * 64.
Мы обозначаем для каждого лейна значения полосы пропускания, размер заголовка запроса и размер заголовка завершения, соответственно, как
Pbw, Pr и
Pc.
Теперь мы представляем свои рекомендации проектирования. Наряду с каждым руководящим правилом мы представляем новые оптимизации и кратко описываем те, которые представлены в более ранней литературе. Мы делаем два предположения о своём оборудовании NIC, которые справедливы для всех доступных в настоящее время NIC. Во- первых, мы предполагаем, что все NIC являются устройствами PCIe. Современные сетевые интерфейсы (NI) преобладающим образом являются выделенными картами PCIe; производителя начинают встраивать NI в чип [2, 5] или в пакете [6], тем не менее, эти NI всё ещё взаимодействуют с имеющимся контроллером PCIe при помощи своего протокола PCIe и являются менее мощными нежели дискретные NI. {Прим. пер.: призываем критически отнестись к данной категоричности, уже на момент написания имелись технологии Intel OPA HFI - в настоящее время Intel Scalable Xeon Processor- F (SKL-F) и Xeon Phi™ Processor- F (KNL-F), а также Tofu Fulitsu on-die, например, Tofu2 начиная с SPARC64 XIfx и A64FX с архитектурой ARM.} Во- вторых, мы предполагаем что такой NIC обладает внутренним параллелизмом с применением множества процессорных модулей (PU - processing unit) - это как правило справедливо для высокоскоростных NI [19]. Как и при обычном параллельном программировании, такой параллелизм обладает как возможностями оптимизации (Раздел 3.3), так и ловушками (Раздел 3.4).
Для обсуждения воздействия на ЦПУ и PCIe приводимых далее оптимизаций мы рассмотрим доставку N WQE с
размером D байт из определённого ЦПУ в его NIC.
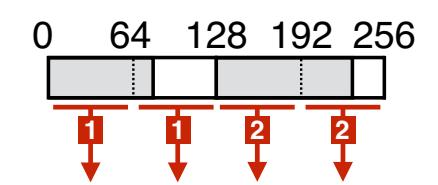
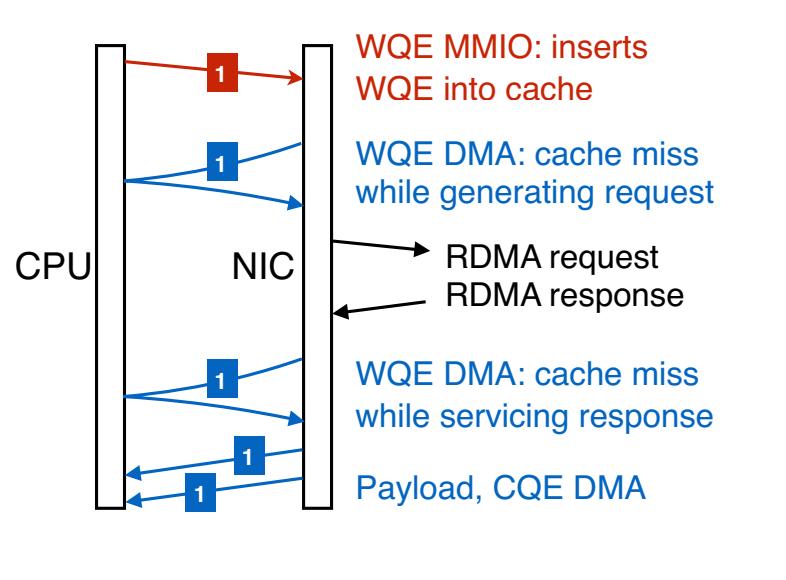
При снижении MMIO или его замене на более эффективный в отношении ЦПУ и полосы пропускания DMA могут быть улучшены как эффективность ЦПУ, так и пропускная способность RDMA. ЦПУ инициирует сетевые операции отправляя некое сообщение в свой NIC через MMIO.Такое сообщение может (1) содержать собственно новый элемент исполнительной очереди или (2) оно может ссылаться на новый WQE с применением новой информации, такой как соответствующий адрес самого последнего WQE. Во втором случае эта NIC считывает необходимые WQE с помощью одного или более DMA. (В данной статье мы предполагаем, что наши NIC считывают все новые WQE в одном DMA, как это делается в Connect-IB Mellanox и более новых NIC. Более ранние NIC Mellanox считывают по одному или более WQE на DMA в зависимости от частной логики предварительной выборки такой NIC.) Мы называем эти методы соответственно как WQE-by-MMIO и Doorbell (Различные технологии имеют разные термины для этих методов. Mellanox применяет "BlueFlame" и "Doorbell", а Intel® Omni-Path Architecture соответственно применяет "PIO send" и "SDMA".) Рисунок 4 суммирует это. Метод WQE-by-MMIO оптимизирован под низкую латентность и обычно применяется по умолчанию. Два варианта оптимизации могут улучшить производительность снижая MMIO:
Рисунок 4. Методы WQE-by-MMIO и Doorbell для доставки двух WQE (заштрихованы), охватывающих две строки кэша. Стрелки представляют транзакции PCIe. Красные (тонкие) стрелки являются записями MMIO; синие (толстые) стрелки являются чтениями RDMA. Стрелки помечены номерами WQE; ширина стрелки представляет размер транзакции.
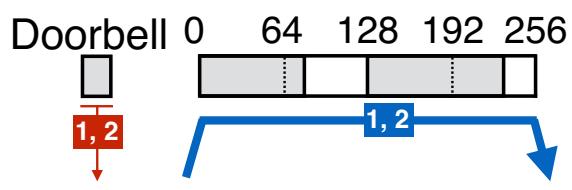
Группирование Doorbell (Doorbell batching) Если некое приложение может вызывать в некой QP
множество WQE, он может применять один MMIO Doorbell для такой группы. В ЦПУ: Число Doorbell снижает выработку ЦПУ
MMIO с N * D' / 64 при помощи WQE-by-MMIO для 1.
В PCIe: Для N = 10 и
D = 65 в PCIe 3.0 Doorbell доставляет 1534 байта, в то время как WQE-by-MMIO доставляет 1800 байт
(Добавление A).
В данной статье мы именуем группирование Doorbell как Группирование (batching) - группированные WQE передаются через WQE-by-MMIO в точности как последовательность WQE-by-MMIO, поэтому Группирование полезно только в отношении Doorbell.
Стягивание WQE (WQE shrinking) Снижение общего числа строк кэширования, применяемое WQE,
может драматическим образом улучшать пропускную способность. Например, рассмотрим снижение размера WQE всего на 1 байт, со 129 B до 128 B, и предположим,
что используется WQE-by-MMIO: В ЦПУ: Число вырабатываемых ЦПУ MMIO снизится с
3 до 2.
В PCIe: Число транзакций PCIe уменьшится с
3 до 2. Механизмы Стягивания включают в себя более компактное
представление полезной нагрузки приложения, или обременение неиспользуемых полей WQE данными приложения.
Снижение числа DMA сберегает мощность NIC и полосу пропускания PCIe, улучшая пропускную способность RDMA. Отметим, что приведённый выше вариант
оптимизации группированием добавляет некое чтение DMA, однако он избавляется от
множества MMIO, что обычно является достойным компромиссом. Известные варианты оптимизации для снижения инициируемых
NIC DMA содержат глаголы без выставления сигнала, которые избавляются от соответствующей записи DMA завершения (Раздел 2.2.1) и вложение полезной нагрузки, которое избегает считывания DMA полезной нагрузки
(Раздел 2.2.2). Два приводимых в Разделе 3.1
метода оптимизации также оказывают воздействие на DMA: Группирование при большом N требует меньшего
числа чтений DMA в отличии от варианта с меньшим числом N; Стягивание WQE и далее уменьшает число
таких чтений.
NIC должен выполнять DMA некоторого элемента очереди завершения (CQE, completion queue entry) для законченных RECV
[1]; это предоставляет некие дополнительные возможности оптимизации, которые описаны далее.
Отличие CQE от прочих глаголов состоит только в сигнале завершения и возможности его распространения, CQE RECV содержит важные метаданные, такие как
значение размера принятых данных. NIC обычно вырабатывает два отдельных DMA для полезной нагрузки и завершения, записывая их соответственно в память,
которой обладают приложение и драйвер. Похже мы покажем, что значение соответствующего штрафа производительности объясняются высеченным в граните
правилом, что глаголы сообщений медленнее глаголов памяти, а применение ниже варианта оптимизации с обходом такого DMA бросает вызов этому
высеченному на камне правилу для некоторых размеров полезной нагрузки. Мы предполагаем, что значения переносимых соответствующими SEND и RECV полезных
нагрузок составляет X байт.
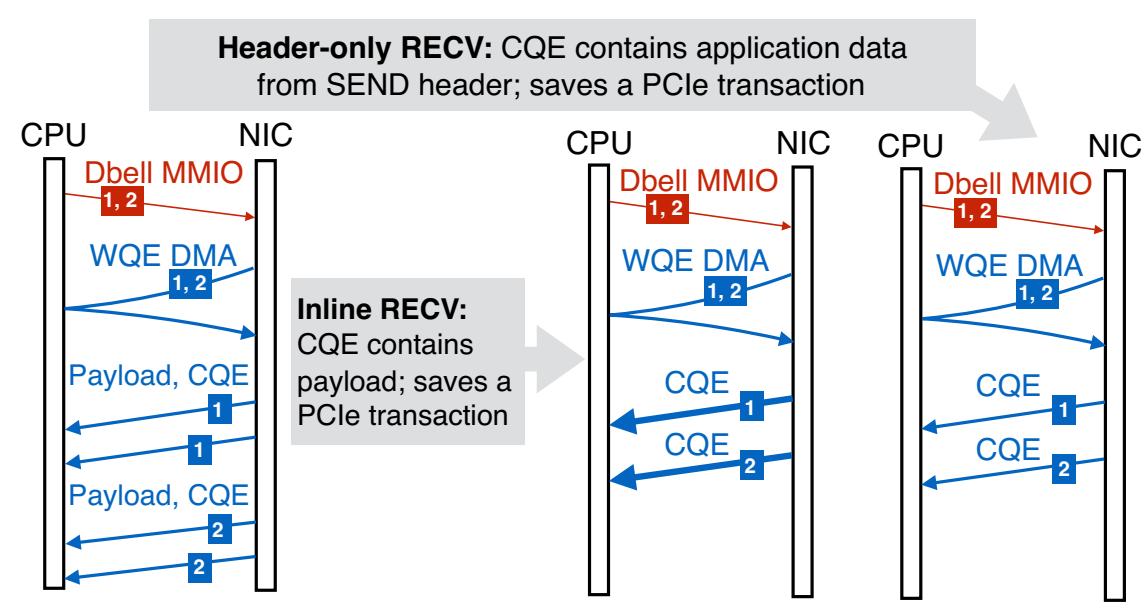
RECV с вложением (nline RECV) При малых значениях
X (Для NIC Mellanox ~ 64), сам NIC выполняет вставку имеющейся полезной нагрузки в CQE, которая
впоследствии копируется его драйвером в соответствующие адреса, относящиеся к приложению. В ЦПУ:
Незначительные накладные расходы для копирования небольшой полезной нагрузки. В PCIe:
Применение 1 DMA вместо 2.
RECV только заголовка (Header-only RECV) Если
X = 0 (т.е. пакет SEND RDMA состоит только из заголовка, а полезной нагрузки нет), на стороне
получателя не вырабатывается никакая полезная нагрузка DMA. Некоторая информация из заголовка этого пакета включается в соответствующий CQE,
передаваемый DMA, что может применяться для реализации прикладного протокола. Мы именуем SEND и RECV при
X = 0 как имеющими только заголовок (header-only) и
обычными (regular) в противном случае. В PCIe:
Применение 1 DMA вместо 2.
Рисунок 5 и Рисунок 6 подводят итог для этих двух руководящих правил, соответственно, в отношении UD SEND и RECV. Эти два глагола интенсивно применяются в наших оценках.
Рисунок 5
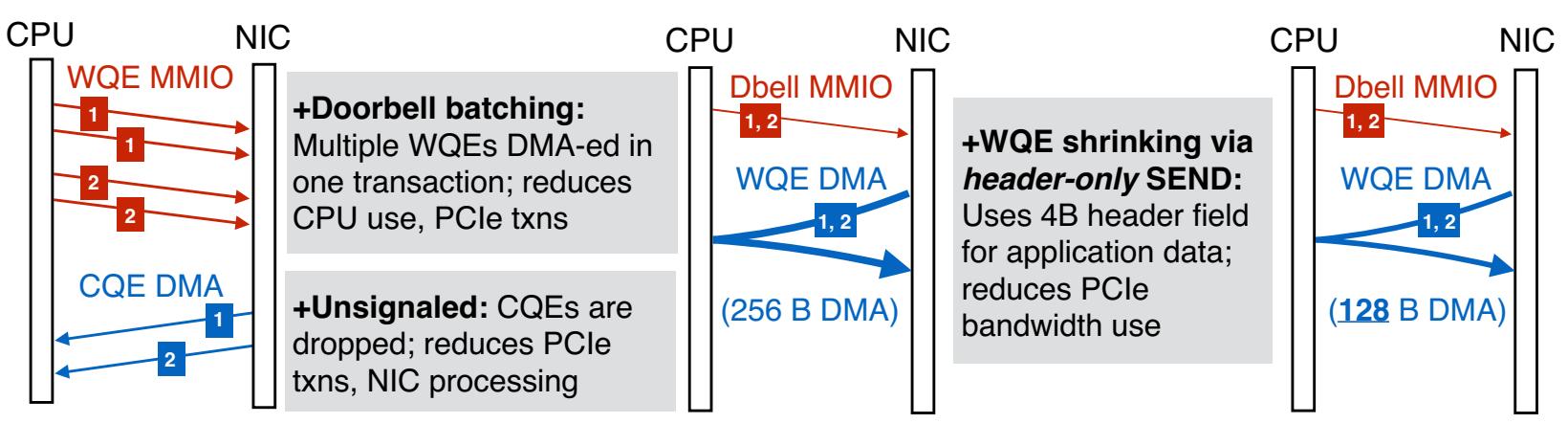
Вариант оптимизации для вызова двух 4-х байтовых UD SEND. Некий WQE UD SEND охватывает 2 строки кэша в NIC Mellanox из- за имеющегося размера заголовка 68 байт: мы стягиваем его в 1 строку кэша применяя 4-х байтовое поле заголовка для полезной нагрузки. Обозначения стрелок следуют указанным в Рисунке 4
Для достижения высокой производительности необходима эксплуатация параллелизма NIC, но это требует внимания в явном виде. Обычным решением при программировании RDMA является применение настолько небольшого числа пар очередей, насколько это возможно, однако если придерживаться этого, параллелизм NIC ограничивается на имеющееся число QP. Это происходит по той причине, что действия с одной и той же QP имеют упорядоченные зависимости и идеально обрабатываются одним и тем же процессорным элементом NIC во избежание межпроцессорной синхронизации. К примеру при взаимодействии с обменом дейтаграммами, одной QP на ядро ЦПУ достаточно для взаимодействия со всеми удалёнными ядрами. Применение одной QP потребляет наименьший объём SRAM NIC для сохранения состояния QP и при этом избегает разделение QP между ядрами ЦПУ. Однако это "привязывает" некое ядро ЦПУ к процессорному элементу и может ограничивать пропускную способность ядра пропускной способностью процессорного элемента. Именно это скорее всего произойдёт когда обработка приложением каждого сообщения мало (например, в случае генератора последовательности в Разделе 4.2) и высокоскоростное ядро ЦПУ перегружает менее мощный процессорный элемент. при таких раскладах использование множества QP на ядро увеличивает эффективность ЦПУ; для этого варианта мы применяем термин оптимизации со множеством очередей.
Требующие синхронизации между QP операции RDMA приводят к конкуренции между процессорными элементами и могут выполняться на порядок хуже, нежели операции без состязательности. Например, RDMA предоставляет атомарные операции, такие как compare-and-swap (сравнение и замена) и fetch-and-add (выборка с добавлением) в удалённой памяти. Насколько нам известно, все доступные на момент написания статьи NIC (в том числе и недавно появившийся ConnctX-4 [7]) используют для атомарности внутреннее управление параллелизмом. Процессорные элементы обзаводятся некоторой внутренней блокировкой для необходимого целевого адреса и выдают read-modify-write поверх PCIe. Обратите внимание, что атомарные операции также состязаются и с неатомарными глаголами. Последующие NIC могут использовать атомарные транзакции PCIe для более высокой производительности, причём с управлению одновременности на основе когерентности кэширования.
Таким образом, важным является имеющийся механизм внутренней блокировки NIC, такой как значение числа блокировок и установление соответствия атомарных адресов для таких блокировок; в Разделе 5.4 мы опишем эксперименты по составлению выводов об этом. Отметим,что в силу ограниченности SRAM в NIC, общее число доступных блокировок не велико, что увеличивает конкуренцию в существующих рабочих потоках.
NIC выполняют кэширование различных видов информации; критически важно поддерживать высокое соотношение попадания в кэш, так как промах транслируется в чтение поверх PCIe. Информация кэширования содержит (1) трансляцию виртуального адреса в физический для зарегистрированной в RDMA памяти, (2) состояние QP, а также (3) кэшированный элемент исполнительной очереди (WQE). В то время как первые два общеизвестны [13], третий является не документированным и был исследован в наших экспериментах. Промахи кэширования трансляции адресов могут быть снижены при поощи больших страниц (например, 2 МБ), а для снижения числа промахов в состояниях QP можно применять меньше QP [13]. В этом контексте мы сделали два новых вклада:
Определение промахов кэширования Все виды промахов кэширования NIC прозрачны для самого приложения и могут быть сложными для определения. Мы показываем как для осуществления этого могут применяться счётчики PCIe путём измерения промахов кэширования WQE (Раздел 5.3.2). В целом, вычитание значения ожидаемых приложением чтений PCIe из величины реальных считований, сообщаемых счётчиками PCIe даёт некую оценку промахов кэширования. Оценивание ожидаемого числа чтений PCIe, в свою очередь, требует моделей PCIe действий RDMA (Раздел 5.1).
Промахи кэширования WQE Самая первоначальная доставка элемента очереди исполнения от ЦПУ в NIC переключает некую вставку этого WQE в кэш WQE этого NIC. После того как данный NIC в конце концов обработает данный WQE, может произойти некий промах кэширования если он был вытеснен более новым WQE. В Раздел 5.2.2 мы показываем как измерять и снижать число таких промахов.
Теперь мы продемонстрируем как эти руководящие правила могут применяться для улучшения имеющейся архитектуры систем целиком. Мы рассмотрим две системы: сетевой генератор последовательности и хранилища ключ- значение.
Установка оценочного стенда Мы выполняем свои оценки в трёх кластерах, описанных в Таблице 2. Мы именуем эти кластеры по первичным буквам их NIC, которые являются основными компонентами обслуживания производительности. CX3 и CIB запускают Ubuntu 14.04 с Mellanox OFED 2.4; CX запускает Ubuntu 12.04 с Mellanox OFED 2.3. На протяжении данной статьи мы применяем WQE-by-MMIO для операций без группирования и Doorbell для операций с группировкой. Тем не менее, когда включено группирование, но доступный размер группирования равен единице, применяется WQE-by-MMIO. (Doorbell предоставляет маленькое сохранение ЦПУ при доставке одного небольшого WQE и применяет некую дополнительную транзакцию PCIe.) Для краткости мы вначале пользуемся в данном разделе современным кластером CIB; Раздел 5 оценивает наши варианты оптимизации во всех кластерах.
| Название | Оборудование |
|---|---|
|
ConnectX (1x 20 Gb/s InfniBand ports), PCIe 2.0 x8, AMD Opteron 8354 (4 ядра, 2.2 GHz) |
|
ConnectX-3 (1x 56 Gb/s InfniBand портов), PCIe 3.0 x8, Intel® Xeon® E5-2450 CPU (8 ядер, 2.1 GHz) |
|
Connect-IB (2x 56 Gb/s InfniBand портов), PCIe 3.0 x16, Intel® Xeon® E5-2683-v3 CPU (14 ядер, 2 GHz) |
Для взаимодействия между клиентами и своим генератором последовательности/ сервером ключ- значение мы применяем протокол RPC HERD. RPC HERD имеет низкие накладные расходы со стороны своего сервера и высокое значение масштабируемости числа клиентов. Протокол клиентов применяет недостоверные WRITE для записи запросов в область памяти запроса в своём сервере. Перед выполнением этого они выставляют RECV в некую QP недостоверной доставки дейтаграмм для отклика своего сервера. Некий поток сервера (исполнитель - worker) определяет какой- то новый запрос путём опроса в своей области памяти запросов. Затем он выполняет прикладную обработку и делает отклик при помощи UD SEND, выставляемого через WQE-by-MMIO.
Для RPC HERD мы в целом применяем два приводимых ниже метода оптимизации; для каждой из систем мы используем поздее специфические варианты оптимизации.
-
Группирование Вместо того чтобы выставлять отклик после определения одного запроса, наш исполнитель проверяет по одному запросу от каждого из всех
Cклиентов, собираяN ≤ Cзапросов. Затем он SENDNприменяя некий сгруппированный Doorbell. -
Множество очередей Все исполнители чередуются между настраиваемым числом UD парами очередей по всем группированным SEND.
Заметим, что Группирование не добавляет значительной латентности, так как мы выполняем его в удачное время [23, 21]; мы не дожидаемся накопления некоторого числа запросов. Кратко мы обсудим значение латентности, добавляемое Группированием в Раздел 4.2.2.
Централизованные генераторы последовательности являются полезными строительными блоками для разнообразных сетевых приложений, таких как упорядоченные операции в распределённых системах через логические или реальные временные штампы [11], или предоставления возрастающих смещений в линейно увеличивающихся областях памяти [10]. Некий централизованный генератор последовательности может быть существенным узким местом в высокопроизводительных вычислительных системах, поэтому построение какого- то быстрого генератора является важным шагом при улучшении общей производительности системы.
Наш сервер Генератора последовательности запускается на отдельной машине и предоставляет некие возрастающие 8- байтовые целые процессм клиентов, запущенным
на удалённых машинах. Наша архитектура базового уровня использует RPC HERD. Имеющиеся потоки исполнителей в данном сервере совместно используют некий
8- байтовый счётчик; каждый клиент может отправлять некий запрос генератора последовательности любому исполнителю. Существующее приложение исполнителя
обрабатывает построение атомарного инкрементального возрастания имеющегося разделяемого счётчика по одному. При включённом Группировании Doorbell мы применяем
некую дополнительную оптимизацию уровня приложения для снижения конкуренции относительно имеющегося совместно используемого счётчика: после сбора
N запросов, какой- то исполнитель атомарно инкрементально увеличивает значение
разделяемого счётчика на N, те самым заявляя право пользования некоторой
последовательностью N следующих друг за другом целых. Затем он отправляет эти
N целых своим клиентам при помощи Группированных Doorbell (по одному целому каждому
клиенту).
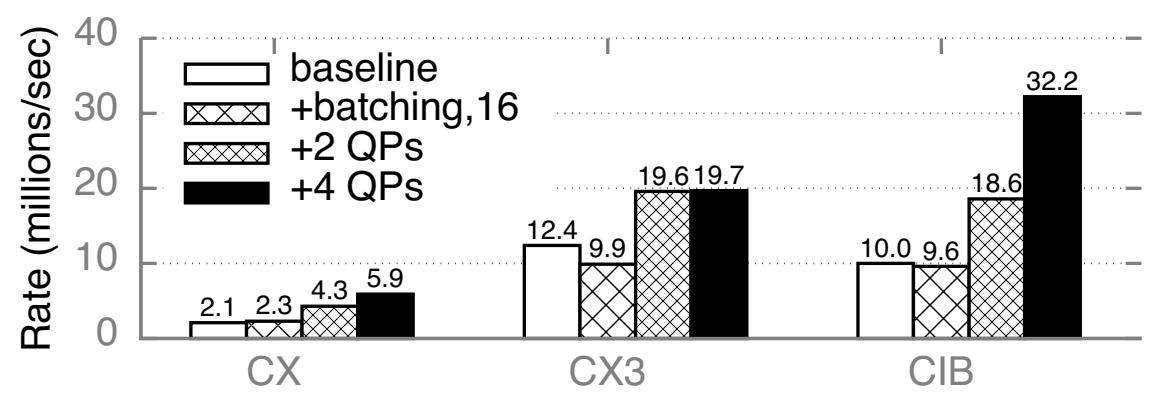
Рисунок 7 отображает воздействие Группирования и Множества очередей на пропускную способность генератора последовательностей на основе RPC HERD при возрастании числа ядер ЦПУ. Мы запускаем 1 поток исполнителя на ядро и используем 70 процессов клиентов в 5 машинах клиентов. Группирование увеличивает пропускную способность единственного ядра с 7 миллионов запросов в секунду (Mrps) до 16.6 Mrps. В данном режиме каждое ядро всё ещё применяет 2 UD пары очередей откликов - по одной для каждого порта NIC - и являются узким местом для со сторону обрабатывающих элементов NIC, обслуживающих QP; привлечение дополнительных PU (процессорных элементов) при Множестве очередей (3 на порт QP для ядра) увеличивает пропускную способность ядра до 27.4 Mrps. При 6 ядрах и обоих методах оптимизации пропускная способность возрастает до 97.2 Mrps и бутылочным горлышком становится полоса пропускания DMA. Значение предела полосы пропускания DMA для получаемых Группированных UD SEND, применяемых нашим генератором последовательности составляет 101.6 миллионов операций в секунду (Раздел 5.2.1). При 97.2 Mrps наш генератор последовательности достигает 5% от этого предела; мы приписываем этот зазор накладным расходам канала PCIe и физического уровня в доставляемых DMA запросах, которые отсутствуют в нашем эталонном тестировании с применением только SEND. При использовании более 6 ядер пропускная способность падает, так как значение размера группирования меньше: при 6 ядрах (97.2 Mrps) имеется 15.9 откликов на пакет; при 10 ядрах (84 Mrps) присутствует 4.4. отклика на группирование.
Рисунок 7
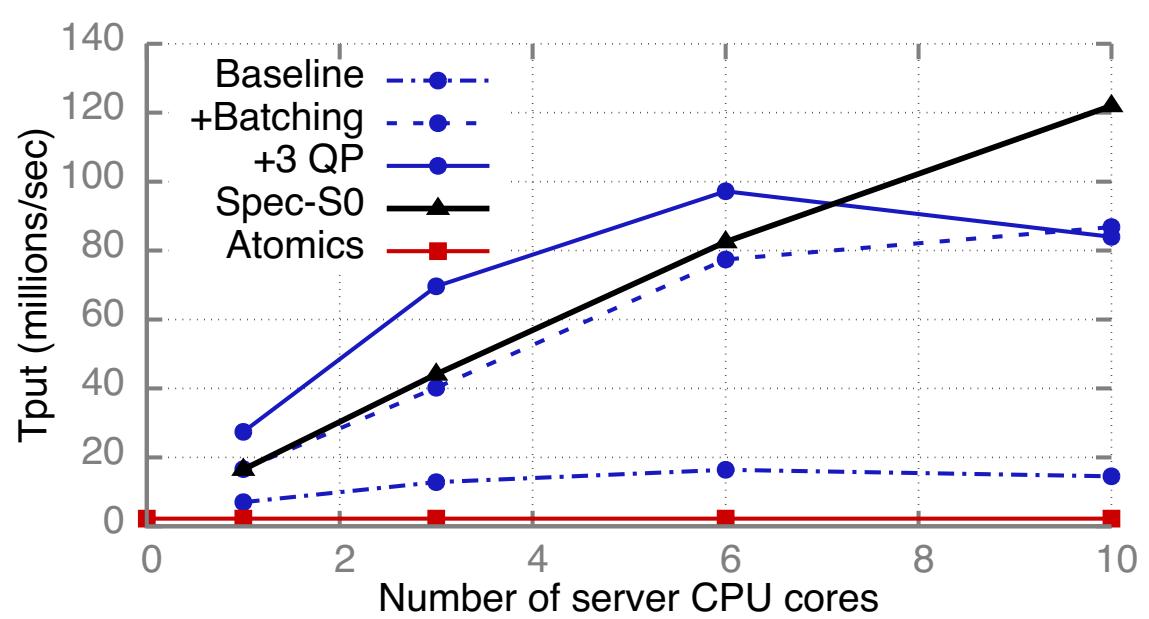
Воздействие методов оптимизации на генератор последовательностей RPC HERD (синие линии с круглыми точками) и пропускную способность
Spec-S0, а также атомарный генератор последовательности
Особенные для генератора последовательности оптимизации
Приведённая выше архитектура является прямолинейной адаптацией общего RPC для некоторого генератора последовательности и наследует все ограничения такого протокола RPC. Во- первых такие соединённые QP применяются для записи запросов необходимого состояния в имеющийся NIC сервера и ограничивают масштабирование до нескольких сотен клиентов RPC [20]. Более крупное масштабирование делает необходимым исключительное применение доставки дейтаграммами, которые поддерживают только глаголы SEND/ RECV. Основной вызов затем состоит в применении SEND/ RECV вместо WRITE для запросов Генератора последовательности без принесения в жертву производительности. Во- вторых, он не эффективно использует PCIe: элементы исполнительной очереди UD SEND в NIC Mellanox охватывают ≥ 2 строк кэширования из- за своего 68- байтного заголовка (Таблица 1); отправка 8 байт полезных данных Генератора последовательности требует DMA доставки 128 байт (2 строки кэширования) в соответствующий NIC.
Для победы над этими ограничениями мы эксплуатируем особые требования своего Генератора последовательности. Мы применяем запрос SEND только с заголовком и для запроса, и для отклика для решения обеих проблем:
-
Наш запрос клиента SEND без заголовка вырабатывает только заголовок, причём единственный RECV DMA на своём сервере (Рисунок 6), который такой же быстрый, как и тот WRITE, который применялся ранее.
-
WQE отклик WRITE без заголовка нашего сервера использует поле заголовка для полезной нагрузки приложения и заполняет его 1 строкой кэша (Рисунок 5), снижая размер доставляемых DMA данных для каждого отклика на 50% до 64 байт.
Применение запросов SEND только из заголовка кодирует прикладную информацию в самом заголовке пакета SEND; мы используем4-х байтовое поле
immediate integer пакетов RDMA [1]. Наш 8-ми байтовый Генератор последовательности
обрабатывает предел в 4 байта следующим образом: Клиенты самостоятельно дополняют 4 верхних байта своего счётчика и отправляют его в некотором SEND,
содержащим только заголовок или они отправляют все 8 байт значения целиком обычным SEND, не ограниченным только заголовком, который позднее переключается
на обновление с присутствием догадки клиента. Обычными SEND является только тонкая часть (при C
клиентах ≤ C/232). Мы обсудим данную технологию доосмысления позднее в
Разделе 5.
Мы именуем такой Генератор последовательности с доставкой только дейтаграммами Spec-S0
(speculation with header-only SENDs). Рисунок 7 отображает его пропускную способность при
росте числа ядер сервера. Предел полосы пропускания DMA для Spec-S0 выше значения для RPC HERD из- за меньших WQE
отклика; она достигает 122 Mrps и ограничивается величиной мощности процессора NIC вместо полосы пропускания PCIe.
Spec-S0 имеет более низкую пропускную способность единственного ядра чем Генератор последовательности на основе
RPC HERD по причине величины дополнительных накладных расходов ЦПУ выставления RECV.
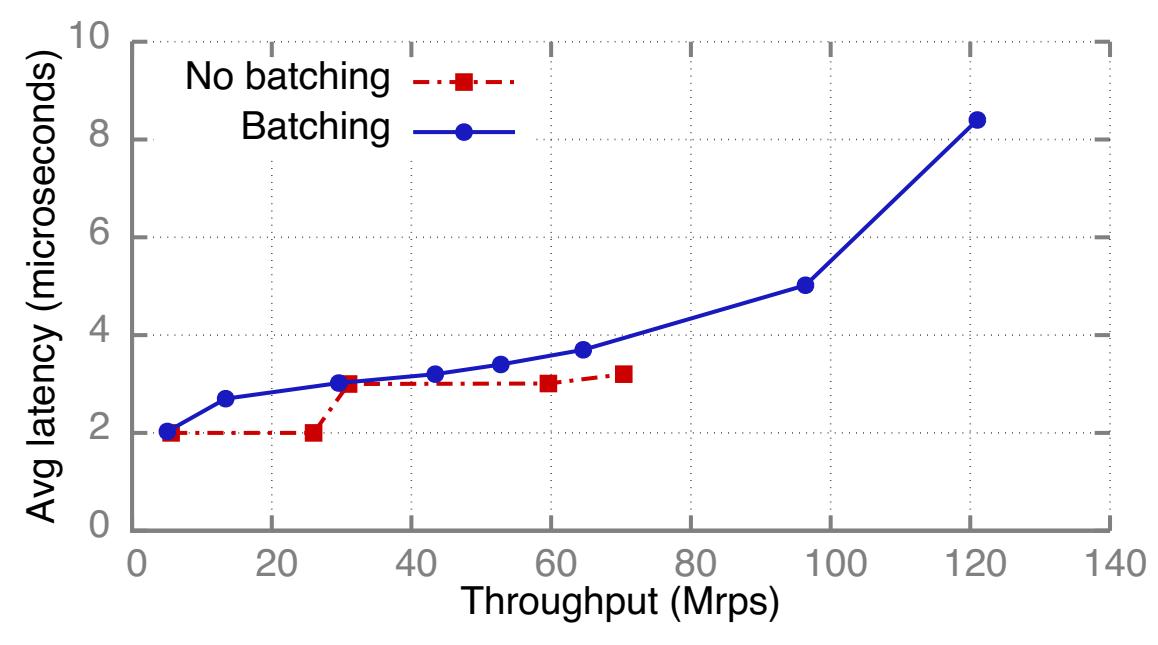
Латентность
Рисунок 8 показывает среднее значение латентности из конца в конец
Spec-S0 с Группированием и без него. Оба режима принимают некую группу запросов из своего NIC; эти два режима
различаются только методом отправки откликов одного- к- одному при помощи WQE-by-MMIO , в то время как групповой режим применяет Doorbell в случае,
когда доступны к отправке многие отклики. Мы группируем атомарные инкрементальные увеличения для своего совместно используемого счётчика в обоих режимах.
Мы применяем 10 ядер ЦПУ сервера, что составляет минимум для достижения пиковой пропускной способности. Мы измеряем пропускную способность при
росте нагрузки клиента добавляя ещё клиентов, а также увеличивая величину числа исходящих запросов для каждого клиента. Группирование добавляет до 1 мкс
латентности, так как при методе Doorbell требуется одно дополнительное чтение DMA. Мы полагаем, что такая небольшая дополнительная задержка является
допустимой благодаря большому значению пропускной способности и эффективности ЦПУ, достигаемых при Группировании.
Генераторы основанных на атомарности последовательностей
Атомарное fetch-and-add поверх RDMA является притягательным методом для реализации Генератора последовательности: Binnig и пр. [11] применяли такую архитектуру для своего сервера временных штампов в их протоколе распределённых транзакций. Однако, блокировка содержимого для самого счётчика между имеющимися процессорными элементами NIC приводит в результате к более бедной производительности. Получаемые эффекты состязательности усиливаются значением продолжительности действия такой блокировки - несколько сотен наносекунд для прохода в обе стороны PCIe. Наш Генератор последовательности на основе RPC имеет меньшую состязательность и более короткую длительность блокировки: имеющиеся возможности программирования ЦПУ общего назначения делают для нас возможным группировать обновления в своём счётчике, которое снижает конкуренцию на строки кэширования, а также обеспечивает близость к самому хранилищу счётчика (т.е. применяет кэширование ядер ЦПУ), что делает такие обновления быстрыми. Рисунок 7 отображает значения пропускной способности нашего Генератора последовательности на базе атомарности: он достигает только 2.24 Mrp, что примерно в 50x раз хуже чем в случае нашей оптимизированной архитектуры и в 12.2x раза хуже чем пропускная способность нашего варианта с единственным ядром. Таблица 3 суммирует значения производительности для наших Генераторов последовательности.
| Baseline | +RPC opts | Spec-S0 | Atomics | |
|---|---|---|---|---|
|
26 |
97.2 |
122 |
2.24 |
|
ЦПУ |
полоса DMA |
NIC |
PCI RTT |
Для хранилищ ключ- значение на основе RDMA были предложены различные решения. Наше кэширование ключ- значение HERD применяет для всех запросов RPC HERD и не минует свой удалённый ЦПУ; прочие архитектуры ключ- значение обходят имеющийся ЦПУ для GET ключ- значение (Pilaf [24] и FaRMKV [13]) или для обеих, и GET, и PUT (DrTM-KV [30] и Nessie [27]). Наша цель здесь заключается в демонстрации того, как наши руководящие правила могут применяться для оптимизации или для поиска упущений в системных решениях RDMA в целом; мы не проводим сравнение по различным системам ключ- значение. Вначале мы представляем улучшения производительности для HERD. Затем мы показываем как получаемая производительность хранилищ ключ- значение на атомарной основе подвергается неблагоприятному воздействию со стороны конкуренции с блокировками внутри NIC.
Улучшение производительности HERD
Мы применяем в HERD Группирование следующим образом. После сбора N ≤ C запросов наш исполнитель стороны
сервера осуществляет операции GET и PUT в основополагающем хранилище данных. Он применяет предварительную выборку для скрытия латентности памяти доступа
к соответствующим структурам данных [32, 23]. Затем соответствующий
исполнитель отправляет необходимый отклик либо посредством один- к- одному при помощи WQE-by-MMIO, либо как единую группу, используя Doorbell.
Для выполнения оценок мы запускаем сервер HERD c переменным числом исполнителей в машине CIB; мы применяем 128 потоков клиентов в восьми машинах клиентов для вызова запросов. Мы предварительно наполняем соответствующий раздел пространства ключей, которым владеет каждый исполнитель, 8 миллионами пар ключ- значение, которые выполняют соответствие 16- байтовых ключей 32- байтовым значениям. Общая рабочая нагрузка состоит из операций 95% GET и 5% PUT, причём ключи выбираются единообразно случайным образом из имеющихся вставленных ключей.
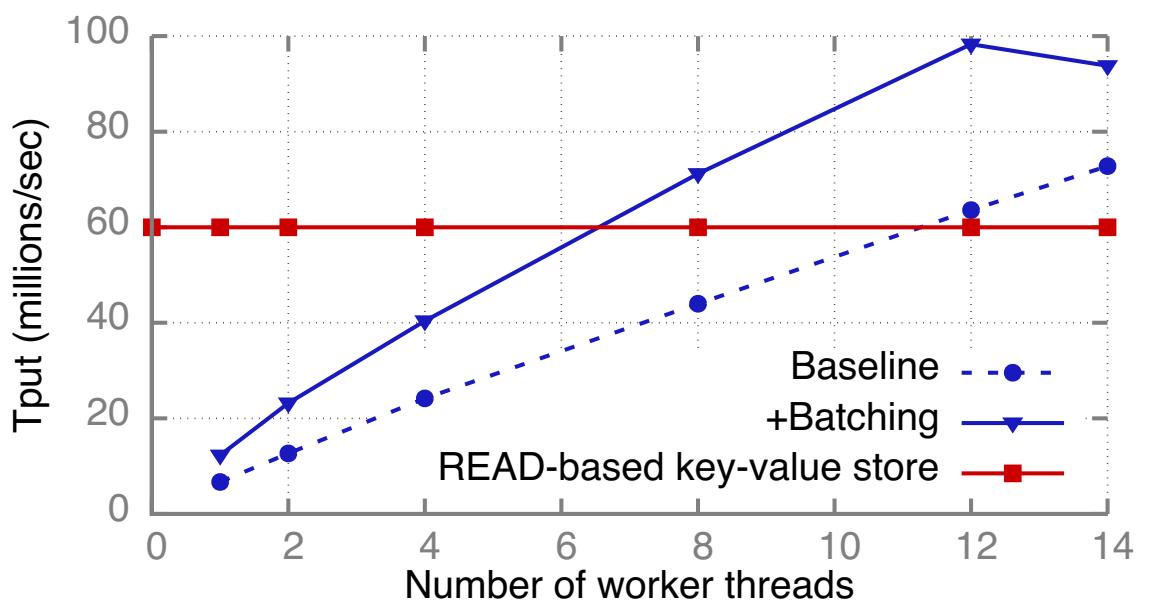
Рисунок 9 отображает значения пропускной способности, которые мы достигаем в указанных
выше экспериментах. Также мы включили такие значения максимальной пропускной способности, как Pilaf или FaRM-KV, которые применяют
≥ 2 небольших READ на каждый GET (один READ для выборки самого индекса записи и один для выборки её
значения). Мы вычислили их аналитически поделив пополам пиковое значение пропускной способности входящих READ для CIB (Разделе
5.3.1). Мы сделали три наблюдения:
-
Группирование улучшает пропускную способность HERD для каждого ядра на 83% с 6.7 Mrps до 12.3 Mrps. Это улучшение меньше нежели для нашего Генератора последовательности, так как значение сберегаемого времени обработки ЦПУ при избегании MMIO относительно меньше для обработки каждого запроса в HERD, чем в нашем Генераторе последовательности.
-
Группирование улучшает пиковое значение пропускной способности на 35% с 72.8 Mrps до 98.3 Mrps. Для Группированной пропускной способности узким местом является полоса пропускания DMA PCIe.
-
При Группировании пропускная способность HERD выше вплоть до 63% чем в случае с хранилищем ключ- значение на основе READ. В то время как первоначальный HERD с архитектурой без группирования требует 12 ядер чтобы превосходить в производительности решение на основе READ, при Группировании требуется только 7 ядер. Это высвечивает важность включения факторов нижнего уровня, таких как группирование при сопоставлении системных решений RDMA.
Атомарные хранилища и хранилища ключ- значение
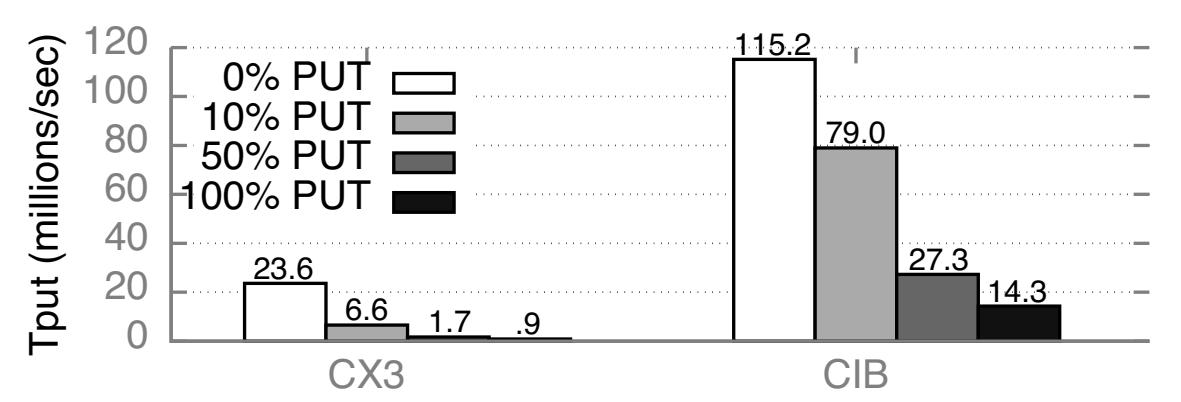
DrTM-KV [30] и Nessie [27, 28] применяют атомарный RDMA для обхода ЦПУ и при GET, и при PUT. Однако, эти проекты не принимают во внимание воздействие соответствующего одновременного управления на производительность для нагрузок с только GET (DrTM-KV) или с преимущественным GET (Nessie). Сейчас мы покажем как блокирование внутри имеющихся NIC приводит в результате к низкой пропускной способности PUT и деградации пропускной способности даже когда лишь малая доля операций ключ- значения являются операциями PUT.
Здесь мы обсуждаем DrTM-KV по причине его простоты, однако аналогичное наблюдение можно применить и к Nessie. DrTM-KV кэширует некоторые поля своего индекса ключ- значение для всех клиентов; для кэшированных ключей GET применяет только READ. Операции PUT блокируют, обновляют и снимают блокировку с элементов ключ- значение; блокировка и её снятие выполняются атомарно. Запуск базового кода DrTM-KV в CIB требует существенного изменения, так как NIC CIB с двумя портами соединяются неким способом, который не допускает взаимодействия между портами. Чтобы победить это, мы написали некую упрощённую версию эмуляции DrTM-KV: мы эмулируем GET при помощи 1 READ и 2 PUT с применением атомарности и предполагаем соотношение попадания а кэш равным 100%.
Рисунок 10 отображает значения пропускной способности нашего сервера эмуляции DrTM-KV с различными долями операций PUT внутри рабочего потока. Наш сервер размещает 16 миллионов элементов с 16-ти байтовыми ключами и значениями в 32 байта. Клиенты случайным образом выбирают ключи и применяют столько клиентов, сколько требуется для достижения максимальной пропускной способности. Хотя пропускная способность для рабочего потока со 100% GET является высокой, добавление всего 10% PUT деградирует её на 72% для CX3 и на 31% в CIB. Пропускная способность со 100% PUT является тоненькой долей от пропускной способности с исключительными GET: 4% в CX3 и 12% для CIB. Отметим, что значение деградации для CIB является более постепенной, так как CIB имеет лучший механизм блокировки, что показывается в Разделе 5.
Наши руководящие правила и системные решения основываются на некотором улучшенном понимании факторов нижнего уровня, которые влияют на производительность RDMA, в том числе механизм инициации ввода/ вывода, PCIe и архитектуру NIC. Эти факторы являются сложными и имеется мало опубликованных сведений, описывающих их или изучающих их значимость для сетевых систем. Мы пытаемся заполнить эту пустоту предоставляя проясняющие измерения производительности, эксперименты и модели. Таблица 4 отображает частичные итоговые значения для CIB. Кроме того, мы обсуждаем важность этих факторов на общее построение систем RDMAвне рамок обсуждавшихся в Разделе 4 систем.
| Исходящие глаголы | Входящие глаголы | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| UD SEND | UD RECV | READ | Атомарные | ||||||
| без группи-рования | Группи-рованные | Группи-рованные + HO | Группи-рованные | Группи-рованные + HO | ≤ 64 B | 128 B | Z = 1 | Z ≥ 4096 | |
Скорость (Mops) |
80 |
101.6 |
157 |
82 |
122 |
121.6 |
76.2 |
2.24 |
52 |
Узкое место |
bw MMIO |
bw DMA |
NIC |
NIC |
NIC |
NIC |
bw IB |
RTT PCIe |
NIC |
Мы делим своё обсуждение на три общих варианта применения, которые высвечивают различные стороны нижнего уровня: (1) Группирование операций, (2) операции без группирования, а также (3) атомарные операции. Для каждого варианта применения мы предоставляем анализ производительности, сосредоточенный вокруг узких мест аппаратных средств и способов оптимизации, а также обсуждаем их последствия на проектирование систем RDMA.
Мы уже продемонстрировали, что понимание поведения PCIe критически важно для улучшения производительности RDMA. Однако, вывод аналитических моделей поведения PCIe без доступа к частным/ конфиденциальным руководствам NIC, а также наши ограниченные ресурсы - счётчики PCIe строк кэширования и недокументированное программное обеспечение драйвера - требуют интенсивных экспериментов и анализа. Выведенные нами модели представляются в слегка упрощённом виде в различных местах данной статьи (Рисунки 5, 6, 13). Точные аналитические модели являются сложными и зависят от различных факторов, таких как NIC, их возможности PCIe, используемые глаголы и способы доставки, значение уровня группирования Doorbell и т.п.. Чтобы сделать нашу модель более простой для доступа, мы оборудовали имеющиеся пути данных двух драйверов Mellanox (ConnectX-3 и Connect-IB) таким образом, чтобы они предоставляли статистические данные об используемой полосе пропускания PCIe (https://github.com/efficient/rdma_bench). Наши модели и драйверы ограничены поведением на запрашивающей стороне PCIe. Мы опускаем поведение на стороне отклика PCIe, так как он в точности такое же, как уже описанное нами в предыдущей работе [20 {Прим. пер.: см. также наш перевод} этой статьи]: входящие READ и WRITE вырабатывают соответственно одно чтение и запись PCIe; входящие SEND включают некое завершение RECV - мы обсуждаем соответствующие транзакции PCIe для такого RECV.
Ограниченность Группирования в имеющихся в настоящее время аппаратных средствах делает их полезными в основном для доставки дейтаграмм: все операции в некоторой группе должны использовать одну и ту же пару очередей, так как Doorbell имеются для каждой QP. Это ограничение выглядит фундаментальным для имеющейся параллельной архитектуры NIC: В некоторой гипотетической архитектуре NIC, в которой Doorbell содержат существенную информацию для множества пар очередей (например, некоторое компактное кодирование "2 и 1 новых WQE соответственно для QP 1 и QP 2"), отправка соответствующего Doorbell в надлежащий процессорный элемент NIC, обрабатывающий эти QP потребует дорогостоящей выборочной полосы пропускания внутри такого NIC. Эти процессорные элементы (PU) должны затем вызывать отдельные DMA для WQE, теряя преимущества объединения при Группировании. Такое ограничение делает Группирование менее полезным для QP с соединением, что предоставляет исключительно соединения один- к- одному между двумя машинами: значение вероятности того, что некий процесс имеет множество сообщений для одной и той же удалённой машины является низким при больших средах. По этой причине мы обсуждаем Группирование только для транзакций UD.
SEND UD
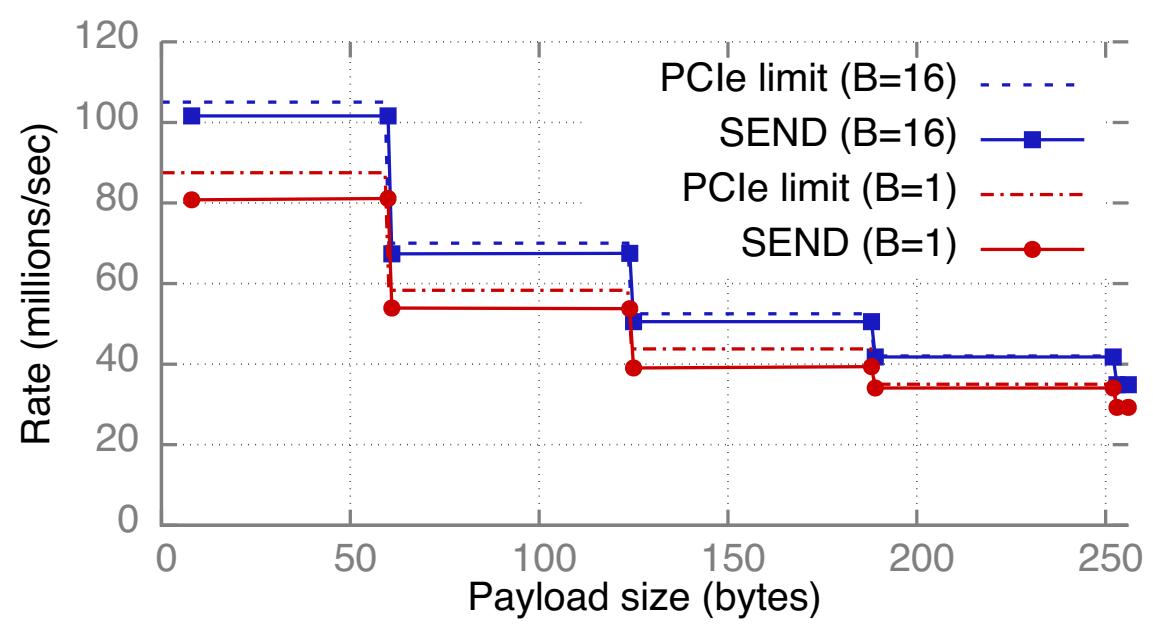
Рисунок 11 отображает значения пропускной способности и предел полосы пропускания PCIe US DEND в CIB с Группированием и без него. Мы используем один сервер для вызова SEND ко множеству машин клиентов. При группировании мы применяем размер группирования равный 16 (т.е. DMA данной NIC доставляет 16 элементов исполнительной очереди на каждый Doorbell). В противном случае наш ЦПУ записывает WQE при помощи метода WQE-by-MMIO. Мы применяем столько ядер сколько необходимо для достижения максимальной пропускной способности. Группирование улучшает пиковое значение пропускной способности SEND на 27% с 80 миллионов операций в секунду (Mops) до 101.6 Mops.
Рисунок 11: (a) Пиковые пропускные способности UD SEND с группированием и без него в CIB, при размере группирования
B; точечные линии отображают соответствующие пределы PCIe.
(b) Эффект оптимизации в пропускной способности UD SEND с единственным ядром при полезной нагрузке в 60 байт (WQE 128 байт)
Узкие места Группированная пропускная способность ограничивается полосой пропускания DMA.
Для каждого завершения DMA с размером Crc байт имеются накладные расходы заголовка в
Pc байт Раздел 2.1,
что приводит к полезной полосе пропускания чтения DMA в CIB, составляющей 13443 MB/s. Так как UD WQE охватывает по крайней мере 2 строки кэширования, максимальное
значение скорости доставки составляет 13443/ 128 = 105 миллионов/ с, что находится в пределах 5% от достигаемой нами пропускной способности; мы приписываем
получаемую разницу накладным расходам PCIe канального и физического уровней.
Пропускная способность без группирования ограничивается полосой пропускания MMIO. Значение скорости MMIO комбинированной записи в CIB составляет
(16 * Pbw)/ (64 + Pr = 175 миллионов строк кэширования в секунду. WQE
UD SEND с ненулевой полезной нагрузкой захватывают по крайней мере 2 строки кэширования
(Таблица 1) и достигают до 80 Mops. Это находится в пределах 10% от значения предела полосы
пропускания в 87.5 Mops.
Оптимизация со множеством очередей Рисунок 11b показывает пропускную способность с вариантом с единственным ядром для UD SEND с Группированием и без него 60 байт - самого большого значения, для которого WQE умещается в 2 строки кэширования. Что интересно, Группирование уменьшает пропускную способность ядра при использовании только одной QP: при одной QP некое ядро спаривается с процессорным элементом NIC (Раздел 3.3), поэтому пропускная способность зависит от того, как имеющийся процессорный элемент обрабатывает операции с Группированием и без него. Группирование имеет ожидаемый эффект когда мы прекращаем это спаривание применяя множество QP. Пропускная способность с Группированием возрастает примерно в 2 раза во всех кластерах при 2 QP и примерно в 2- 3.2 раза при 4 QP. Полоса пропускания без группирования (WQE-by-MMIO) не возрастает при множестве QP (не отображено на графике), что показывает тот факт, что она ограничивается ЦПУ.
Последствия решения Системы на основе RDMA часто могут оказываться перед выбором решения обхода ЦПУ или его вовлечения. Например, клиенты могут осуществлять доступ к некому хранилищу ключ- значение либо напрямую через READ из оперативной памяти соответствующего сервера [24, 13, 30, 28], или через RPC, как это сделано в HERD [20 {Прим. пер.: см. также наш перевод} этой статьи]. Наши результаты показывают, что достижение пиковой пропускной способности даже на более мощных NIC не требует введения запретов на объёмы мощности ЦПУ: всего лишь 4 ядра требуется для насыщения самых быстрых соединений PCIe. Тем самым, решения с привлечением ЦПУ не будут ограничиваться мощностью обработки ЦПУ, в случае когда это допускает их обработка на уровне приложений.
RECV UD
Таблица 5 сравнивает значения пропускной способности обычных RECV только из заголовка и несущих полезную нагрузку (Рисунок 6). В нашем эксперименте множество машин клиентов вызывают SEND в сторону единственной машины сервера, которая выставляет RECV. В CIB исключение полезной нагрузки DMA в случае применения RECV только с заголовком увеличивает пропускную способность на 49% с 82 Mops до 122 Mops и делает их настолько же быстрыми, как и в случае со входящими WRITE (Рисунок 12, Приём с вложением улучшает пропускную способность обычных RECV с 22 Mops до 26 Mops в CX3, но ещё пока не поддерживается для UD в CIB). Таблица 5 также сопоставляет SEND только с заголовком и обычные SEND (Рисунок 5). SEND, ограниченные заголовком настолько же быстрые как и входящие WRITE, если мы избавляемся от них.
| RECV 0 | RECV ≥ 1 | SEND 0 | SEND ≥ 1 | |
|---|---|---|---|---|
CIB |
122.0 |
82.0 |
157.0 |
101.6 |
CX3 |
34.0 |
21.8 |
32.1 |
26.0 |
CX |
15.3 |
9.6 |
11.9 |
11.9 |
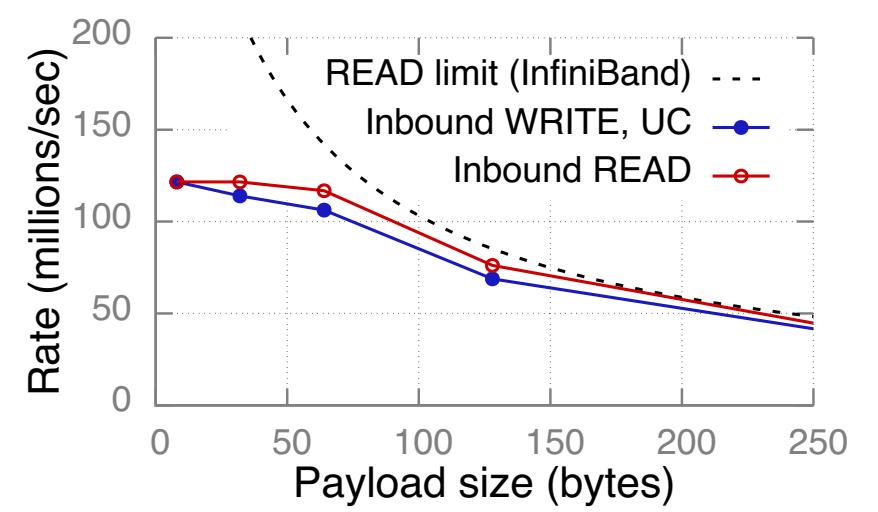
Рисунок 12 Пропускные способности входящих READ и UC WRITE, а также предел InfiniBand для READ. Отметим различный масштаб по оси Y.
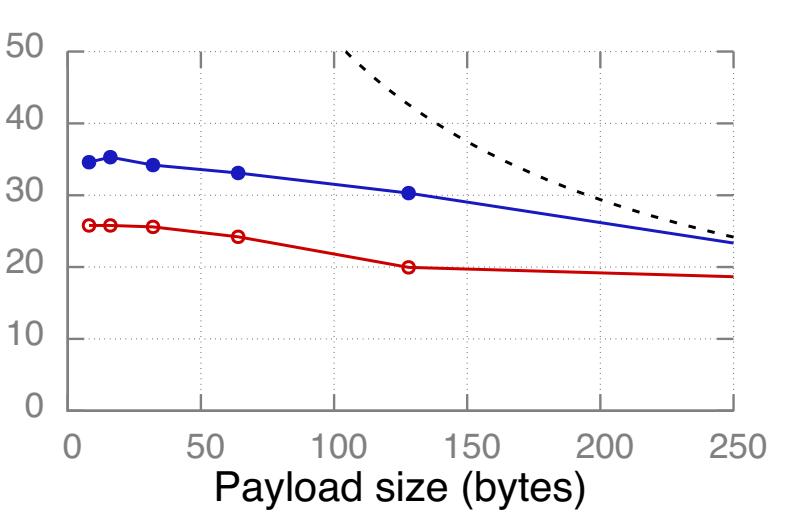
Последствия решения Разработчики избегают применять RECV на критически важных машинах следуя высеченным в граните правилам, предпочитая постулируемыми как более быстрые глаголам READ/ WRITE [24, 20]. Наша работа определяет точную причину: RECV медленные из- за CQE DMA; если его обойти, они будут настолько же быстрыми, как и входящие WRITE.
Упреждающая выборка Имеющиеся в настоящее время {июнь 2016} реализации RDMA допускают 4 байта данных приложения в самом заголовке пакета при использовании SEND только с заголовком. Для приложений, которым требуется более длинные сообщения, SEND/ RECV могут применяться в случае, когда имеется возможность предварительной выборки; мы продемонстрировали такое решение в Разделе 4.2 для некоторого 8-ми байтового Генератора последовательности. В общем случае исполнители предварительной выборки работают так: клиенты передают свои ожидаемый отклик вместе с запросами и получают небольшой подтверждающий отклик в общем случае. Например, для хранилища ключ- значение с кэшированием на стороне клиента, клиенты могут оправлять запросы GET с определённым ключом и е номером версии его кэширования (применяя WRITE или обычный SEND). Имеющийся сервер выполняет оклик SEND "OK", ограниченный только заголовком если полученная версия правильная.
Имеются приложения, для которых достаточно 4 байт данных в каждом сообщении. К примеру, некоторые таблицы баз данных для эталонного тестирования TPC-C [29] имеют размер первичного ключа от 2 до 3 байт. Некий запрос доступа к таблице может быть отправлен при помощи SEND, ограниченного только заголовком (используя остающийся 1 байт для определения идентификатора таблицы), в то время как его отклик может потребовать более длинный SEND.
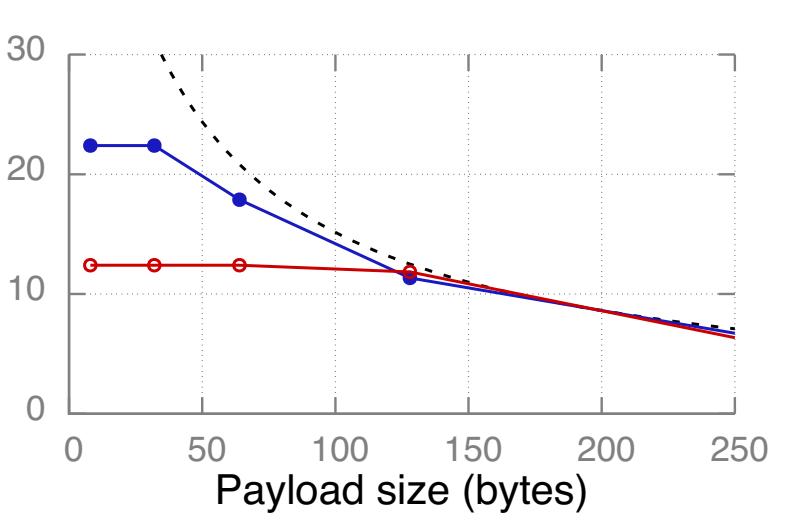
Входящие READ и WRITE
Рисунок 12 показывает значения измеренной пропускной способности входящих READ и UC WRITE, а также предел полосы пропускания нашего InfiniBand входящих READ. Мы не показываем значение предела Infiniband для WRITE и пределов PCIe, поскольку они выше.
Узкие места В нашем кластере входящие READ и WRITE изначально ограничены бутылочным горлышком со стороны вычислительной мощности своего NIC, а вслед за этим полосой пропускания InfiniBand. Значение полезной нагрузки, при котором полоса пропускания становится узким местом зависит от соотношения вычислительной мощности NIC к полосе пропускания. Для READ точкой перехода являются примерно 128 байт, 256 байт и 64 байт, соответственно для CX, CX3 и CIB. NIC CIB достаточно мощный чтобы насыщать 112 Gbps при помощи 64-х байтных READ, в то время как NIC CX3 требуются 256-ти байтные READ для насыщения 56 Gbps.
Последствия Значение точки перехода является важным фактором для системы, которая осуществляет компромисс между установленным размером и числом READ: Для выборки ключ- значение небольших элементов (~ 32 байта), хранилище ключ- значение FaRM [13] может применять одну большую (~ 256- байт) операцию READ. В некоторым решении клиент- сервер, в котором производительность GET определяют входящие READ, такая архитектура хорошо исполняется в CX3, поскольку 32-х и 256-ти байтные READ имеют аналогичные пропускные способности; прочие решения, такие ккак DrTM-KV [30] и Pilaf [24], которые вместо этого применяют 2- 3 небольших READ могут предоставлять более высокие пропускные способности в CIB.
Исходящие READ и WRITE UD
В целях краткости мы предоставляем только итоговые значения производительности исходящих операций без Группирования для CIB. Исходящие UC WRITE с длиной более 28 байт, т.е. WRITE с WQE, охватывающими более одной строки кэширования (Таблица 1), достигают до 80 Mops и ограничиваются бутылочным горлышком пропускной способности MMIO PCIe, аналогично исходящим SEND без группирования (Рисунок 11a). Операции READ достигают 88 Mops и ограничиваются узким местом вычислительной мощности NIC.
Достижение высокой исходящей пропускной способности требует сопровождения множества исходящих запросов в конвейере. При инициации со стороны ЦПУ некоторой операции RDMA, соответствующий элемент исполнительной очереди (WQE) вставляется в кэш WQE NIC. Однако, если такой ЦПУ вставляет новые WQE быстрее чем скорость вычислений его NIC, такой WQE может выселяться более новыми WQE. Это может вызывать промахи кэширования когда такой NIC в конечном итоге обработает данный WQE при генерации своих пакетов запроса пока его RDMA обрабатывает отклик, или и отклик, и запрос. Рисунок 13a подытоживает данную модель.
Рисунок 13 Модель PCIe, отображающая возможные промахи WQE, а также измерения числа промахов в кэше WQE для READ и RC WRITE.
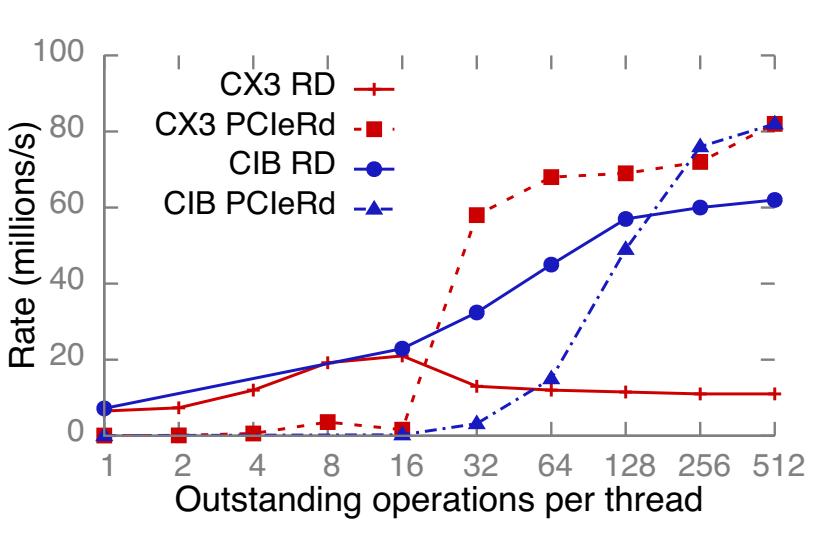
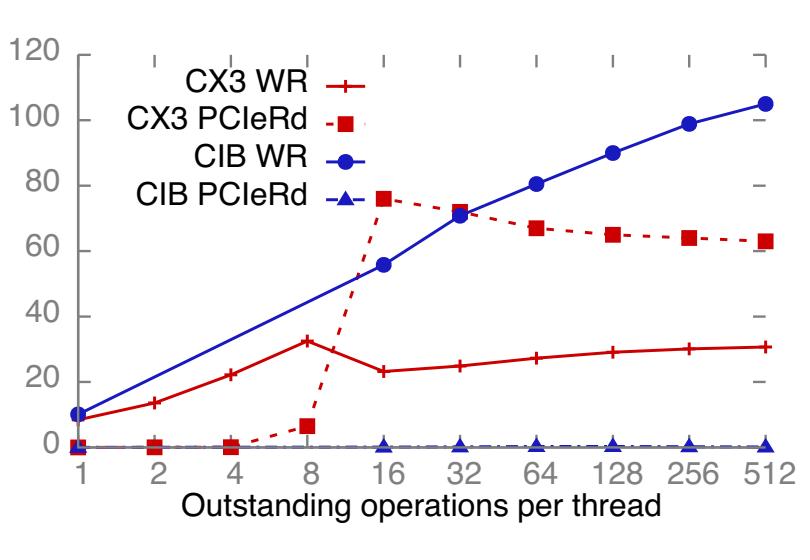
Для количественного измерения данного эффекта мы провели в CIB следующий эксперимент: 14 запрашивающих потоков в сервере вызывают окна
N 8-ми байтных READ и WRITE поверх надёжного транспорта для 14 удалённых процессов. На Рисунках
13b и 13c мы
показываем значение накапливаемой скорости запросов RDMA и степень промахов кэширования WQE с применением имеющегося счётчика скорости
PCIeRdCur. Каждый поток ожидает N запросов для завершения,
прежде чем вызывает следующее окно. Мы применяем все 14 ядер в своём сервере для выработки максимально возможной скорости запросов, а также доставку
RC для включения промахов кэширования при обработке ACK для WRITE. Мы сделали следующие наблюдения, отображающие важность значения кэширования WQE
для улучшения пропускной способности RDMA и её понимания:
-
Оптимальный размер окна для максимальной пропускной способности не является очевидным: пропускная способность не всегда растёт с ростом размера окна и находится в зависимости от соответствующего NIC. Например,
N = 16иN = 512, соответственно, достигают максимума в CX3 и CIB. -
Более высокие пропускные способности RDMA можно получать за счёт чтений PCIe. Например, в CIB, при росте
Nвозрастают и пропускная способность READ и чтение PCIe. Хотя самые высокиеNявляются оптимальными для некоторой машины, которая только вызывает исходящие READ, это может быть близким к оптимальному, когда она также обслуживает и прочие операции. -
NIC CIB имеющийся ЦПУ может обслуживать пиковую скорость вложения WQE для WRITE и никогда не испытывать промахов кэширования. Это не выполняется для READ, что указывает на то, что они требуют больше вычислений NIC чем соответствующие WRITE.
Процессорные элементы NIC вступают в единоборство при атомарных операциях (Раздел 3.4).
Значение производительности атомарных операций зависит от объёма параллельных работ в имеющейся рабочей нагрузке по отношению к самой внутренней схеме
блокировки в NIC. Для изменения объёма предоставляемого распараллеливания мы создали некий массив Z
8-ми байтных счётчиков м памяти сервера и множество удалённых клиентов, обрабатывающих вызовы атомарных операций со счётчиками, выбираемыми
случайным образом при каждой итерации. Рисунок 14 показывает общее значение пропускной
способности в данном эксперименте. Для CX3 оно остаётся равным 2.7 Mops вне зависимости от Z, для
CIB оно возрастает до 52 Mops.
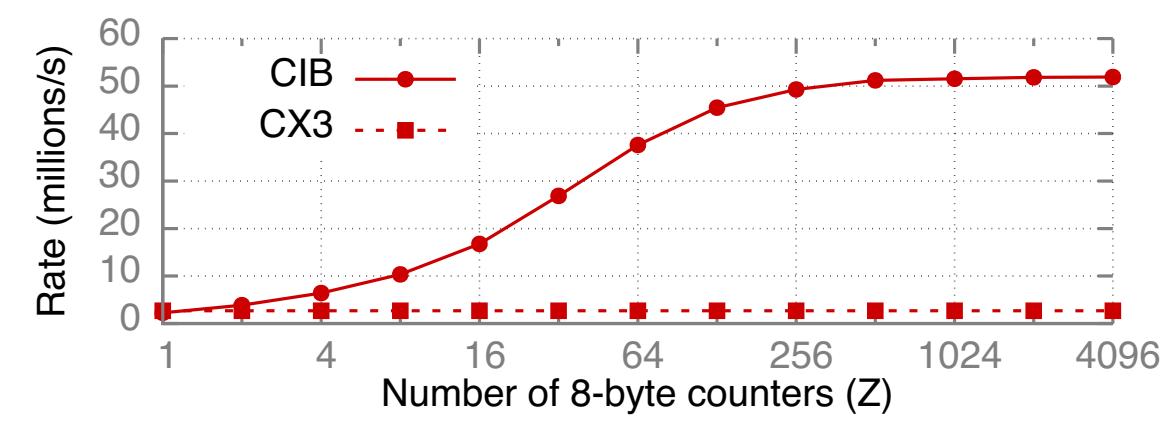
Выводы относительно механизма блокировки Монотонность графика пропускной способности CX3 указывает, что он упорядочивает все атомарные операции. Для CIB мы измерили производительность для случайно выбираемых пар адресов и наблюдали более низкую пропускную способность для пар, в которых оба адреса имеют одни и те же 12 наименьших значащих битов (LSB). Строго рекомендуется применять 4096 корзин для слотов атомарных операций для адресов в CIB - некая новая операция ожидает пока её слот пустой.
Узкие места и последствия Пропускная способность в CX3 ограничена латентностью PCIe из- за упорядоченности. Для CIB, чтобы read-modify-write PCIe сделало вычислительную мощность NIC узким местом, требуются буферизация и вычисления {ЦПУ}.
Чрезвычайная производительность для случая Z = 1 вновь подтверждает, что атомарные операции являются
плохим выбором в случае Генератора последовательности; наш оптимизированный Генератор последовательности из
Раздела 4 предоставляет производительность в 12.2x раз выше с
единственным ядром ЦПУ сервера. Служба блокировки для хранилищ данных, тем не менее, может применять более высокие
значения Z. Если такие приложения применяют CIB, атомарные операции могут выполняться неплохо, однако в
CX3 они слишком медленные, а именно она применялась в предыдущих работах [27,
30]. При использовании CIB аккуратное помещение блокировки всё ещё возможно. Например, если выравненные на
размер страницы записи данных имеют свои переменные блокированными по одному и тому же смещению в данной записи, все блокированные запросы будут иметь те же самые
12 наименьших значащих битов (LSB) и окажутся упорядоченными. Некая детерминированная схема, которая размещает необходимые блокировки по различным
смещениям в различных записях, либо схема, которая удерживает блокировки отдельно от требуемых данных будет выполняться лучше.
Системы RDMA с высокой производительностью Проектирование систем RDMA с высокой производительностью является активной областью исследований. Последние достижения содержат системы хранения ключ- значение [24, 13, 20, 30, 28] и систем с обработкой распределённых транзакций [30, 12, 14, 11]. Ключевым проектным решением в каждой из этих систем является выбор глаголов, выполняемый при помощи сопоставлений производительности на основе микротестов. Наша работа показывает что имеется больше размерностей для таких сопоставлений, чем изучают перечисленные проекты: два глагола не могут быть исчерпывающе сравнены без изучения всего пространства факторов нижнего уровня, каждый из которых может компенсировать производительность глагола определёнными факторами.
Факторы нижнего уровня при сетевом ввода/ выводе Хотя существует великое множество работ, которые измеряют значение пропускной способности и загрузку ЦПУ при сетевом взаимодействии [18, 16, 26, 13, 20], имеется намного меньше опубликованных исследований относительно понимания поведения сетевых карт на нижнем уровне. NIQ [15] представляет картину взаимодействия PCIe на верхнем уровне между неким NIC Ethernet и ЦПУ, однако не затрагивает множества скрытых взаимодействий, которые происходят при доставке с Группированием. Lee и др. [22] изучают поведение PCIe карт Ethernet при помощи анализатора протокола PCIe и подразделяют имеющийся обмен PCIe на обмен Doorbell, обмен дескриптора Ethernet и собственно обмен данными. Аналогично, при помощи анализа NIC RDMA с применением какого- то анализатора PCIe можно выявить намного больше внутренних подробностей в их поведении чем то, чего можно достичь при помощи счётчиков PCIe.
Проектирование систем RDMA с высокой производительностью требует глубокого понимания подробностей RDMA на нижнем уровне, таких как поведение PCIe и архитектура NIC: наш наилучший Генератор последовательности примерно в 50 раз быстрее чем существующее решение и при этом масштабируется исключительно хорошо, наше оптимизированное хранилище ключ- значение HERD быстрее до примерно 85% чем первоначальное, а наш самый быстрыё метод передачи вплоть до 3.2 раз превосходит обычно используемый базовый уровень. Мы полагаем, что предоставляя ясные руководящие правила и инструменты, а также эксперименты измерения на нижнем уровне на имеющихся аппаратных средствах, наша работа побудит исследователей и разработчиков отработать лучшее понимание аппаратных средств перед их применением в высокопроизводительных системах.
Благодарности Мы чрезвычайно благодарны Джозефу Муру и NetApp за предоставление доступа к их кластеру CIB. Мы выражаем признательность Хайеонтаик Лим и Солу Бушеру за предоставленную основу, а также Лиуье Шрайра за общее руководство. Для наших экспериментов применялись ресурсы Emulab [31] и PRObE [17]. PRObE выполнил частичную поддержку грантами NSF CNS-1042537 и CNS-1042543 (PRObE). Эта работа поддерживалась Национальным Научным Форумом (NSF) по грантам 1345305 и 1314721, а также со стороны Intel через Intel Science and Technology Center for Cloud Computing (ISTC-CC).
Мы обозначаем размер Doorbell через d. Общая передача данных от ЦПУ к NIC при использовании метода
WQE-by-MMIO составляет Tbf = 10 * ([65/64] * (64 + Pr)) байт. При заполнении строк
кэша 65-ти байтные WQE выкладываются в 128-ми байтные слоты в памяти хоста; полагаем Crc = 128,
Tdb = (d+Pr) + (10 * (128 + Pc)) байт. Мы игнорируем значение обмена
канального уровня PCIe, так как оно мало по сравнению с обменом на уровне транзакции: обычно предполагаются 2 пакета канального уровня (1 обновление управляющего
потока и 1 подтверждение, оба по 8 байт) на 4-5 TLP [9], что делает накладные расходы канального уровня
< 5%. Замена d = 8 даёт Tbf = 1800 и
Tdb = 1534.
[1] Infniband architecture specifcation volume 1.
[2] Intel Atom Processor C2000 Product Family for Microserver.
[3] Intel Xeon Processor E5-1600/2400/2600/4600 v3 Product Families.
[4] Intel Xeon Processor E5-1600/2400/2600/4600 (E5-Product Family) Product Families.
[5] Intel Xeon Processor D-1500 Product Family.
[6] Intel Xeon Phi Processor Knights Landing Architectural Overview..
[7] Mellanox ConnectX-4 product brief.
[8] Mellanox OFED for linux user manual.
[9] Understanding Performance of PCI Express Systems.
[10] M. Balakrishnan, D. Malkhi, V. Prabhakaran, T. Wobber, M. Wei, and J. D. Davis. CORFU: a shared log design for flash clusters. In Proc. In 9th USENIX NSDI, Apr. 2012.
[11] C. Binnig, U. Çetintemel, A. Crotty, A. Galakatos, T. Kraska, E. Zamanian, and S. B. Zdonik. The end of slow networks: It’s time for a redesign. CoRR, abs/1504.01048, 2015; URL.
[12] Y. Chen, X. Wei, J. Shi, R. Chen, and H. Chen. Fast and general distributed transactions using RDMA and HTM. In Proc. 11th ACM European Conference on Computer Systems (EuroSys), Apr. 2016. {Прим. пер.: URL to pdf}
[13] A. Dragojevic, D. Narayanan, O. Hodson, and M. Castro. FaRM: Fast remote memory. In Proc. 11th USENIX NSDI, Apr. 2014. {Прим. пер.: pdf}
[14] A. Dragojevic, D. Narayanan, E. B. Nightingale, M. Renzelmann, A. Shamis, A. Badam, and M. Castro. No compromises: Distributed transactions with consistency, availability, and performance. In Proc. 25th ACM Symposium on Operating Systems Principles (SOSP), Oct. 2015. {Прим. пер.: pdf}
[15] M. Flajslik and M. Rosenblum. Network interface design for low latency request-response protocols. In Proc. USENIX Annual Technical Conference, June 2013. {Прим. пер.: pdf}
[16] S. Gallenmüller, P. Emmerich, F. Wohlfart, D. Raumer, and G. Carle. Comparison of frameworks for high-performance packet io. In ANCS, 2015. {Прим. пер.: URL покупки pdf}
[17] G. Gibson, G. Grider, A. Jacobson, and W. Lloyd. PRObE: A Thousand-Node Experimental Cluster for Computer Systems Research. {Прим. пер.: pdf}
[18] S. Han, K. Jang, K. Park, and S. Moon. PacketShader: a GPU-accelerated software router. In Proc. ACM SIGCOMM, Aug. 2010. {Прим. пер.: pdf}
[19] S. Hauger, T. Wild, A. Mutter, A. Kirstaedter, K. Karras, R. Ohlendorf, F. Feller, and J. Scharf. Packet processing at 100 Gbps and beyond - challenges and perspectives. In Photonic Networks, 2009 ITG Symposium on, 2009. {Прим. пер.: URL to pdf}
[20] A. Kalia, M. Kaminsky, and D. G. Andersen. Using RDMA efficiently for key-value services. In Proc. ACM SIGCOMM, Aug. 2014, перевод на рус. яз..
[21] A. Kalia, D. Zhou, M. Kaminsky, and D. G. Andersen. Raising the bar for using GPUs in software packet processing. In Proc. 12th USENIX NSDI, May 2015. {Прим. пер.: pdf}
[22] S. Larsen and B. Lee. Platform io dma transaction acceleration. In CACHES. ACM, 2011. {Прим. пер.: pdf}
[23] H. Lim, D. Han, D. G. Andersen, and M. Kaminsky. MICA: A holistic approach to fast in-memory keyvalue storage. In Proc. 11th USENIX NSDI, Apr. 2014. {Прим. пер.: pdf}
[24] C. Mitchell, Y. Geng, and J. Li. Using one-sided RDMA reads to build a fast, CPU-efficient key-value store. In Cuckoo Hashing. Proc. USENIX Annual Technical Conference, June 2013. {Прим. пер.: pdf}
[25] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski, H. Lee, H. C. Li, R. McElroy, M. Paleczny, D. Peek, P. Saab, D. Stafford, T. Tung, and V. Venkataramani. Scaling Memcache at Facebook. In Proc.10th USENIX NSDI, Apr. 2013. {Прим. пер.: pdf}
[26] L. Rizzo. netmap: a novel framework for fast packet I/O. In Proceedings of the 2012 USENIX conference on Annual Technical Conference, June 2012. {Прим. пер.: pdf}
[27] T. Szepesi, B. Wong, B. Cassell, and T. Brecht. Designing a low-latency cuckoo hash table for writeintensive workloads. In WSRC, 2014. {Прим. пер.: pdf}
[28] T. Szepesi, B. Cassell, B. Wong, T. Brecht, and X. Liu. Nessie: A decoupled, client-driven, keyvalue store using RDMA. Technical Report CS- 2015-09, University of Waterloo, David R. Cheriton School of Computer Science, Waterloo, Canada, June 2015. {Прим. пер.: pdf}
[29] TPC-C. TPC benchmark C. http://www.tpc.org/tpcc/.
[30] X. Wei, J. Shi, Y. Chen, R. Chen, and H. Chen. Fast in-memory transaction processing using RDMA and HTM. In Proceedings of the 25th Symposium on Operating Systems Principles (SOSP), 2015. {Прим. пер.: pdf}
[31] B. White, J. Lepreau, L. Stoller, R. Ricci, S. Guruprasad, M. Newbold, M. Hibler, C. Barb, and A. Joglekar. An integrated experimental environment for distributed systems and networks. In Proc. 5th USENIX OSDI, pages 255–270, Dec. 2002.
[32] D. Zhou, B. Fan, H. Lim, D. G. Andersen, and M. Kaminsky. Scalable, High Performance Ethernet Forwarding with CuckooSwitch. In Proc. 9th International Conference on emerging Networking EXperiments and Technologies (CoNEXT), Dec. 2013. {Прим. пер.: pdf}