Глава 7. Настройка Высокой доступности и кластера
Содержание
В этой главе мы рассмотрим такие рецепты:
-
Установка Sentinel
-
Тестирование Sentinel
-
Администрирование Sentinel
-
Настройка Кластера Redis
-
Проверка Кластера Redis
-
Администрирование Кластера Redis
Согласно требований промышленной среды один отдельный экземпляр Redis далеко не достаточен для предоставления некоторой стабильной и действенной службы данных ключ- значение с избыточностью данных и HA (high availability, Высокой доступностью). Применение репликаций и удержания (persistence) Redis могут решать имеющуюся проблему избыточности данных. Тем не менее, без вмешательства оператора служба Redis целиком не имеет возможности восстановления при останове своего экземпляра хозяина. Хотя для наличия HA в Redis и были разработаны различные виды решений, Redis Sentinel, поддерживаемый естественным образом начиная с версии 2.6 Redis является наиболее широко применяемым решением HA. Вооружившись преимуществами Sentinel, вы может запросто построить устойчивую к отказам службу Redis.
По мере быстрого роста хранимых в Redis объёмов данных имеющиеся в экземпляре Redis вычислительная мощность и ёмкость памяти при некотором большом наборе данных (как правило, свыше 16 ГБ), могут становиться узким местом в вашем приложении. И имеются всё большие и большие задержки или иные проблемы при выполнении удержания или репликаций с ростом такого размера наборов данных в Redis. При таком развитии событий немедленно требуется горизонтальное масштабирование, или иначе масштабирование с добавлением дополнительных узлов в некую службу Redis. Для такого вида проблем имеется Кластер Redis, поддерживаемый начиная с версии 3.0. Кластер Redis является предоставляемым сразу после установки решением для создания разделов имеющегося набора данных во множестве экземпляров хозяин- подчинённый (master- slave) Redis.
В данной главе мы будем придерживаться шаблона Установки, Проверки и Администрирования для обсуждения по- отдельности того как выстраивать некую готовую к промышленному применению службу Redis с использованием Sentinel и Кластера Redis.
Наконец, стоит отметить, что в качестве условного обозначения слово Кластер с заглавной буквы первого слова относится именно к технологии Кластера Redis. Вы можете обнаружить различные виды систем сторонних разработчиков для реализации кластерной функциональности Redis вплоть до версии Redis 3.0. Поэтому не путайте Кластер Redis, о котором мы ведём речь в данной главе с прочими системами кластеризации данных, применяющими Redis.
Redis Sentinel, как подразумевает его название (Стоящий на страже), действует в качестве охранника для имеющихся экземпляров хозяина и подчинённых Redis. Одного Sentinel, очевидно, не достаточно чтобы гарантировать высокую доступность, так как некий отдельный Sentinel сам по себе также выступает объектом отказа. Так как решение о восстановлении основного хозяина принимается на основании системы кворума, в качестве устойчивой распределённой системы, которая продолжает отслеживать текущее состояние своего сервера Redis хозяина данных, необходимо наличие по крайней мере трёх процессов Sentinel. Если несколько процессов Sentinel обнаруживают что из хозяин остановлен, один из имеющихся процессов Sentinel выбирается для представления подчинённого на замену старого хозяина. При надлежащей настройке весь процесс выполняется автоматически без какого бы то ни было вмешательства оператора. В данном рецепте мы продемонстрируем как установить некую простую среду из одного хозяина и двух подчинённых, которые мониторятся тремя Sentinel.
Вам требуется установить один сервер хозяина Redis и два подчинённых сервера. В качестве справочной информации вы можете воспользоваться разделом Настройка репликации Redis Главе 5, Репликации. В данном примере мы развёртываем Сервер Redis и экземпляры Sentinel в трёх различных хостах, причём значения их ролей, IP адресов и портов отображены в следующей таблице:
| Роль | IP адрес | Порт |
|---|---|---|
Master |
|
|
Slave-1 |
|
|
Slave-2 |
|
|
Sentinel-1 |
|
|
Sentinel-2 |
|
|
Sentinel-3 |
|
|
Общая архитектура может быть представлена следующей схемой:
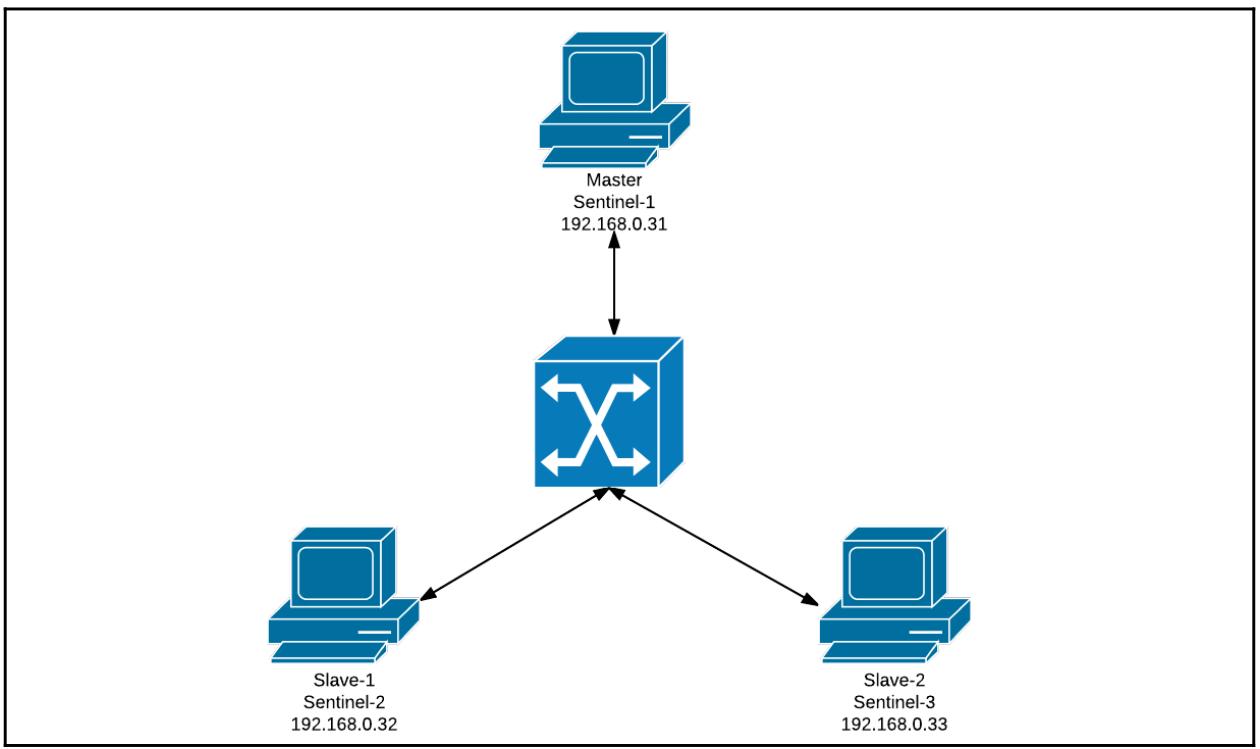
Эти три хоста должны иметь возможность взаимодействия друг с другом. Вам требуется правильно настроить привязку IP в имеющемся файле настроек
Redis чтобы позволить прочим хостам общаться с установленным экземпляром Redis. Установленным по умолчанию связываемым IP является
127.0.0.1, который делает возможным доступ только с локального хоста. Вы можете добавлять в конец необходимые
IP адреса следующим образом:
bind 127.0.0.1 192.168.0.31
Убедитесь что все серверы данных Redis подняты и запущены.
Шаги настройки Sentinel таковы:
-
В каждом из хостов подготовьте некий файл настроек,
sentinel.conf. Вы можете выполнить простое копирование с данного исходного кода. Убедитесь что данный файл настроек доступен для записи тому пользователю, который запускает необходимый процесс Sentinel:port 26379 dir /tmp sentinel monitor mymaster 192.168.0.31 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000 -
Запустите процесс Sentinel в трёх хостах:
user@192.168.0.31:~$bin/redis-server conf/sentinel.conf --sentinel user@192.168.0.32:~$bin/redis-server conf/sentinel.conf --sentinel user@192.168.0.33:~$bin/redis-server conf/sentinel.conf --sentinel -
Проверьте соответствующий журнал в
Sentinel-1:21758:X 29 Oct 22:31:51.001 # Sentinel ID is 3ef95f7fd6420bfe22e38bfded1399382a63ce5b 21758:X 29 Oct 22:31:51.001 # +monitor master mymaster 192.168.0.31 6379 quorum 2 21758:X 29 Oct 22:31:51.001 * +slave slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.31 6379 21758:X 29 Oct 22:31:51.003 * +slave slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 21758:X 29 Oct 22:31:52.021 * +sentinel sentinel d24979c27871eafa62e797d1c8e51acc99bbda72 192.168.0.32 26379 @ mymaster 192.168.0.31 6379 21758:X 29 Oct 22:32:17.241 * +sentinel sentinel a276b044b26100570bb1a4d83d5b3f9d66729f64 192.168.0.33 26379 @ mymaster 192.168.0.31 6379 -
При помощи
redis-cliподключитесь кSentinel-1и исполните командуINFO SENTINEL. Не забывайте, пожалуйста, определять соответствующий порт,26379:user@192.168.0.31:~$ bin/redis-cli -p 26379 127.0.0.1:26379> INFO SENTINEL # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=192.168.0.31:6379,slaves=2,sentinel-1 -
В
Sentinel-1проверьте содержимоеsentinel.conf:user@192.168.0.31:~$ cat conf/sentinel.conf ... # Generated by CONFIG REWRITE sentinel known-slave mymaster 192.168.0.33 6379 sentinel known-slave mymaster 192.168.0.32 6379 sentinel known-sentinel mymaster 192.168.0.33 26379 a276b044b26100570bb1a4d83d5b3f9d66729f64 sentinel known-sentinel mymaster 192.168.0.32 26379 d24979c27871eafa62e797d1c8e51acc99bbda72 sentinel current-epoch 0
На шаге 1 мы подготовили некий файл настроек для своих процессов Sentinel Redis. В исходном коде Redis имеется некий файл образца
sentinel.conf, поэтому в данном примере мы просто вносим изменения поверх него. Как уже упоминалось,
Sentinel Redis является неким охранным процессом для серверов данных Redis, тем самым он должен выполнять ожидание в портах, отличающихся от портов
серверов данных. Портом по умолчанию для Sentinel Redis является 26379. Для добавления нового сервера хозяина
для его мониторинга со стороны Sentinel мы можем прибавить некую строку в свой файл настроек в виде
sentinel monitor <master-name> <ip> <port> <quorum>.
В данном примере sentinel monitor mymaster 192.168.0.31 6379 2 означает, что наш Sentinel собирается
отслеживать имеющийся сервер хозяеина в 192.168.0.31 6379, который имеет название
mymaster. <quorum> означает значение минимального числа Sentinel,
которые подтвердят факт недоступности своего сервера хозяина прежде чем будут предприняты действия по восстановлению отказа. Необязательный параметр
down-after-milliseconds означает значение максимального времени в миллисекундах, которое допустимо для некоторого
экземпляра Redis пребывать в состоянии недоступности прежде чем Sentinel отметит его как отключённый. Sentinel будет выполнять ping указанного сервера
данных каждую секунду для проверки его доступности.
В данном примере, если некий сервер не отвечает на ping более 30 секунд, он будет рассматриваться как отключённый. При возникновении отказа некоторого
хозяина (master), один из подчинённых) slave серверов будет избран в качестве нового хозяина и прочие подчинённые серверы будут обязаны выполнять
репликации с этого нового хозяина. Необязательный параметр parallel-syncs указывает сколько подчинённых
серверов могут начинать процесс синхронизации с такого нового хозяина одновременно.
Некий процесс Sentinel может быть запущен при помощи redis-server <sentinel.conf> --sentinel.
Если вы компилируете Redis из исходного кола, вы обнаружите некий файл redis-sentinel, который является
символьной ссылкой на redis-server. Данный процесс Sentinel также может быть запущен с помощью
redis-sentinel <sentinel.conf>.
Из полученных на шаге 3 регистрационных записей Sentinel и самой последней строки в выводе INFO SENTINEL
на шаге 4 мы можем увидеть, что Sentinel-1 успешно обнаружил своих подчинённых и прочие Sentinel (вы обнаружите тот же самый результат если вы проверите
соответствующие журналы Sentinel-2 и Sentinel-3).
Вы можете удивиться как наш процесс Sentinel способен обнаружить соответствующие подчинённые серверы и прочие Sentinel, поскольку мы определили в своём
файле настроек только информацию о самом сервере хозяина. Вы можете считать, что для получения информации о своих подчинённых, соответствующий Sentinel
способен отсылать команду INFO REPLICATION своему хозяину. Если существует множество уровней подчинения, они могут
обнаруживаться таким образом рекурсивно. На самом деле, каждые 10 секунд все процессы Sentinel отправляют INFO REPLICATION
во все имеющиеся узлы данных (в том числе хозяевам и обнаруженным подчинённым), которые он отслеживает с целью активной доставки самой последней информации обо
все топологии репликаций целиком.
Для обнаружения и взаимодействия с прочими процессами Sentinel, каждые 2 секунды все Sentinel публикуют некое сообщение о своих состояниях и свое
видение о состоянии их хозяина в некий канал с названием __sentinel__:hello. Тем самым, прочая информация
Sentinel может быть обнаружена через подписку на этот канал.
Сообщения в данном канале могут просматриваться посредством подключения к любому из серверов данных и подписки на данный канал:
user@redis-master:/redis$ bin/redis-cli -h 192.168.0.31
192.168.0.31:6379> SUBSCRIBE __sentinel__:hello
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "__sentinel__:hello"
3) (integer) 1
1) "message"
2) "__sentinel__:hello"
3) "192.168.0.31,26379,3ef95f7fd6420bfe22e38bfded1399382a63ce5b,0,mymaster,192.1.68.0.31,6379,0"
1) "message"
2) "__sentinel__:hello"
...
"192.168.0.31,26379,3ef95f7fd6420bfe22e38bfded1399382a63ce5b,0,mymaster,192.1.68.0.31,6379,0"
Соответствующие файлы настроек для Sentinel Redis будут также обновлены чтобы отобразить информацию о подчинённых и прочих Sentinel. Именно поэтому такие файлы настроек должны быть доступными для записи со стороны соответствующего процесса Sentinel.
Следует отметить, что для поддержки стороны клиента необходимо применять Sentinel Redis. Когда мы представляли клиентов Java/ Python Redis в
Главе 4, Разработка с помощью Redis, мы передавали адрес своего сервера хозяина в соответствующий
API. Однако, после включения Sentinel Redis, такой адрес сервера хозяина будет изменяться в случае возникновения ситуации отработки отказа хозяина.
Для получения информации о самом последнем хозяине всем клиентам необходимо делать запрос у имеющегося Sentinel. Это можно сделать при помощи
команды sentinel get-master-addr-by-name <master-name>. Реальный процесс несколько более сложный и мы
не собираемся рассматривать его здесь. К счастью, и Jedis, и библиотеки
redis-py имеют поддержку Sentinel.
Официальная документация по Redis Sentinel.
{Прим. пер.: Для лучшего понимания технологии обмена сообщениями рекомендуем наш перевод RabbitMQ для профессионалов Гайвина Роя.}
В своём предыдущем рецепте мы продемонстрировали как устанавливать некую среду из одного хозяина и двух подчинённых Redis, которая мониторится со стороны трёх Sentinels. В данном рецепте мы проведём пару экспериментов в такой среде и убедимся, что имеющиеся Sentinels правильно выполняют сви задания. Мы также подробно объясним процесс восстановления хозяина в случае отказа.
Вам следует завершить установку из раздела Установка Sentinel в данной главе. Кроме того вы можете получить справочную информацию из показанной в предыдущем разделе Таблицы 7-1.
Для проверки выполненной в предыдущем рецепте установки Redis Sentinel выполните следующие шаги:
-
Включите вручную некое восстановление после сбоя своего хозяина:
-
Подключитесь к какому- нибудь Sentinel при помощи
redis-cli; в данном случае мы подключаемся к Sentinel-2 (192.168.0.32):192.168.0.32:26379> SENTINEL FAILOVER MYMASTER OK -
Проверьте что ваш старый хозяин
192.168.0.31отработал отказ и теперь является подчинённым:192.168.0.31:26379> INFO REPLICATION # Replication role:slave master_host:192.168.0.33 master_port:6379 master_link_status:up ... -
Проверьте журнал Sentinel-2:
2283:X 12 Nov 15:35:14.782 # Executing user requested FAILOVER of 'mymaster' 2283:X 12 Nov 15:35:14.782 # +new-epoch 1 2283:X 12 Nov 15:35:14.782 # +try-failover master mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:14.789 # +vote-for-leader d24979c27871eafa62e797d1c8e51acc99bbda72 1 2283:X 12 Nov 15:35:14.789 # +elected-leader master mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:14.789 # +failover-state-select-slave master mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:14.872 # +selected-slave slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:14.872 * +failover-state-send-slaveof-noone slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:14.949 * +failover-state-wait-promotion slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:15.799 # +promoted-slave slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:15.800 # +failover-state-reconf-slaves master mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:15.852 * +slave-reconf-sent slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:16.503 * +slave-reconf-inprog slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:16.503 * +slave-reconf-done slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:16.580 # +failover-end master mymaster 192.168.0.31 6379 2283:X 12 Nov 15:35:16.580 # +switch-master mymaster 192.168.0.31 6379 192.168.0.33 6379 2283:X 12 Nov 15:35:16.580 * +slave slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.33 6379 2283:X 12 Nov 15:35:16.581 * +slave slave 192.168.0.31:6379 192.168.0.31 6379 @ mymaster 192.168.0.33 6379 -
Опросите журнал
redis-serverв192.168.0.33(новом хозяине):2274:M 12 Nov 15:35:14.953 # Setting secondary replication ID to 8a005b14ac7166dfc913846060bee4a980f97785, valid up to offset: 92256. New replication ID is a897d63fb211d7ebf6c1269998dab1779d14f8a4 2274:M 12 Nov 15:35:14.953 # Connection with master lost. 2274:M 12 Nov 15:35:14.953 * Caching the disconnected master state. 2274:M 12 Nov 15:35:14.953 * Discarding previously cached master state. 2274:M 12 Nov 15:35:14.953 * MASTER MODE enabled (user request from 'id=3 addr=192.168.0.32:60540 fd=9 name=sentinel-d24979c2- cmd age=356 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec') 2274:M 12 Nov 15:35:14.954 # CONFIG REWRITE executed with success. 2274:M 12 Nov 15:35:16.452 * Slave 192.168.0.32:6379 asks for synchronization 2274:M 12 Nov 15:35:16.452 * Partial resynchronization not accepted: Requested offset for second ID was 92534, but I can reply up to 92256 ... 2274:M 12 Nov 15:35:16.462 * Synchronization with slave 192.168.0.32:6379 succeeded 2274:M 12 Nov 15:35:26.839 * Slave 192.168.0.31:6379 asks for synchronization ... 2274:M 12 Nov 15:35:26.936 * Background saving terminated with success 2274:M 12 Nov 15:35:26.937 * Synchronization with slave 192.168.0.31:6379 succeeded -
Проверьте содержимое
sentinel.confв Sentinel-1:user@192.168.0.31:~$ cat conf/sentinel.conf port 26379 dir "/tmp" sentinel myid d24979c27871eafa62e797d1c8e51acc99bbda72 sentinel monitor mymaster 192.168.0.33 6379 2 ...
-
-
Смоделируем отключение хозяина:
В настоящий момент нашим хозяином является
192.168.0.33. Давайте выполним останов его Сервера Redis в данном хосте и посмотрим что сделает наш Sentinels:-
Подключитесь к Серверу Redis в
192.168.0.33черезredis-cliи остановите это сервер:192.168.0.33:6379> SHUTDOWN not connected> -
Проверьте текущее состояние в
192.168.0.31и192.168.0.32:192.168.0.31:6379> INFO REPLICATION # Replication role:master connected_slaves:1 slave0:ip=192.168.0.32,port=6379,state=online,offset=349140,lag=1 192.168.0.32:6379> INFO REPLICATION # Replication role:slave master_host:192.168.0.31 master_port:6379 master_link_status:upВы можете увидеть, что
192.168.0.31был выставлен новым хозяином. -
Опросите журналы трёх Sentinel:
Sentinel-1 (3ef95f7fd6420bfe22e38bfded1399382a63ce5b): 2931:X 12 Nov 17:05:02.446 # +sdown master mymaster 192.168.0.33 6379 2931:X 12 Nov 17:05:03.570 # +odown master mymaster 192.168.0.33 6379 #quorum 2/2 2931:X 12 Nov 17:05:03.570 # +new-epoch 2 2931:X 12 Nov 17:05:03.570 # +try-failover master mymaster 192.168.0.33 6379 2931:X 12 Nov 17:05:03.573 # +vote-for-leader 3ef95f7fd6420bfe22e38bfded1399382a63ce5b 2 2931:X 12 Nov 17:05:03.573 # a276b044b26100570bb1a4d83d5b3f9d66729f64 voted for d24979c27871eafa62e797d1c8e51acc99bbda72 2 2931:X 12 Nov 17:05:04.224 # +config-update-from sentinel d24979c27871eafa62e797d1c8e51acc99bbda72 192.168.0.32 26379 @ mymaster 192.168.0.33 6379 2931:X 12 Nov 17:05:04.224 # +switch-master mymaster 192.168.0.33 6379 192.168.0.31 6379 ... 2931:X 12 Nov 17:05:34.283 # +sdown slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 Sentinel-2 (d24979c27871eafa62e797d1c8e51acc99bbda72): 3055:X 12 Nov 17:05:02.394 # +sdown master mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:03.505 # +odown master mymaster 192.168.0.33 6379 #quorum 2/2 3055:X 12 Nov 17:05:03.505 # +new-epoch 2 3055:X 12 Nov 17:05:03.505 # +try-failover master mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:03.507 # +vote-for-leader d24979c27871eafa62e797d1c8e51acc99bbda72 2 3055:X 12 Nov 17:05:03.516 # a276b044b26100570bb1a4d83d5b3f9d66729f64 voted for d24979c27871eafa62e797d1c8e51acc99bbda72 2 3055:X 12 Nov 17:05:03.584 # +elected-leader master mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:03.584 # +failover-state-select-slave master mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:03.668 # +selected-slave slave 192.168.0.31:6379 192.168.0.31 6379 @ mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:03.668 * +failover-state-send-slaveof-noone slave 192.168.0.31:6379 192.168.0.31 6379 @ mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:03.758 * +failover-state-wait-promotion slave 192.168.0.31:6379 192.168.0.31 6379 @ mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:04.135 # +promoted-slave slave 192.168.0.31:6379 192.168.0.31 6379 @ mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:04.135 # +failover-state-reconf-slaves master mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:04.224 * +slave-reconf-sent slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:04.609 # -odown master mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:05.147 * +slave-reconf-inprog slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:05.147 * +slave-reconf-done slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:05.201 # +failover-end master mymaster 192.168.0.33 6379 3055:X 12 Nov 17:05:05.201 # +switch-master mymaster 192.168.0.33 6379 192.168.0.31 6379 3055:X 12 Nov 17:05:05.201 * +slave slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.31 6379 3055:X 12 Nov 17:05:05.201 * +slave slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 3055:X 12 Nov 17:05:35.282 # +sdown slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 Sentinel-3 (a276b044b26100570bb1a4d83d5b3f9d66729f64): 2810:X 12 Nov 17:05:02.519 # +sdown master mymaster 192.168.0.33 6379 2810:X 12 Nov 17:05:03.512 # +new-epoch 2 2810:X 12 Nov 17:05:03.517 # +vote-for-leader d24979c27871eafa62e797d1c8e51acc99bbda72 2 2810:X 12 Nov 17:05:04.225 # +config-update-from sentinel d24979c27871eafa62e797d1c8e51acc99bbda72 192.168.0.32 26379 @ mymaster 192.168.0.33 6379 2810:X 12 Nov 17:05:04.225 # +switch-master mymaster 192.168.0.33 6379 192.168.0.31 6379 2810:X 12 Nov 17:05:04.225 * +slave slave 192.168.0.32:6379 192.168.0.32 6379 @ mymaster 192.168.0.31 6379 2810:X 12 Nov 17:05:04.225 * +slave slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379 2810:X 12 Nov 17:05:34.277 # +sdown slave 192.168.0.33:6379 192.168.0.33 6379 @ mymaster 192.168.0.31 6379
-
-
Проведём моделирование останова двух подчинённых:
Так как мы остановили свой Сервер Redis в
192.168.0.33, в настоящий момент у нас имеются запущенными один хозяин (192.168.0.31) и один подчинённый (192.168.0.32):-
В своём хозяине установите
min-slaves-to-writeв1:192.168.0.31:6379> CONFIG SET MIN-SLAVES-TO-WRITE 1 OK -
Остановите
192.168.0.32:192.168.0.32:6379> SHUTDOWN -
Попробуйте выполнить запись в своего хозяина:
127.0.0.1:6379> SET test_key 12345 (error) NOREPLICAS Not enough good slaves to write.
-
-
Выполним имитацию останова одного Sentinel:
-
Перед выполнением данного эксперимента давайте вернём в жизнь Серверы Redis в
92.168.0.32и92.168.0.33:user@192.168.0.32:/redis$ bin/redis-server conf/redis.conf user@192.168.0.33:/redis$ bin/redis-server conf/redis.conf -
Остановим Sentinel-1:
192.168.0.31:26379> SHUTDOWN -
Остановим своего хозяина в
192.168.0.31и проверим произошло ди восстановление после сбоя:192.168.0.31:6379> SHUTDOWN 192.168.0.32:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=192.168.0.33,port=6379,state=online,offset=782227,lag=0 192.168.0.33:6379> info replication # Replication role:slave master_host:192.168.0.32 master_port:6379 master_link_status:up
-
-
Смоделируем отказ двух Sentinels:
-
Вернём в строй Сервер Redis на
192.168.0.31. Нашим текущим хозяином является192.168.0.32:user@192.168.0.31:/redis$ bin/redis-server conf/redis.conf -
Остановим Sentinel-2 и погасим своего хозяина,
192.168.0.32:192.168.0.32:6379> SHUTDOWN -
Выполним проверку Sentinel-3:
... 2810:X 12 Nov 18:22:41.171 # +sdown master mymaster 192.168.0.32 6379Восстановление хозяина после сбоя не произошло.
-
Мы объясним всё что произошло в предыдущем разделе шаг за шагом.
Ручное переключение мастера для восстановления при сбое
В данном эксперименте мы вручную заставили Sentinel отработать отказ хозяина Redis и предложить некоего подчинённого. Это выполняется вызовом
команды sentinel failover <master-name> в Sentinel-2. Как мы могли заметить, в качестве нового хозяина
был предложен 192.168.0.33, а старый хозяин стал подчинённым.
Теперь давайте рассмотрим этот процесс подробнее из журнала регистраций в Sentinel-2; имеется множество событий Sentinel (+vote-for-leader, +elected-leader, +selected-slave и так далее). Большинство из них объясняют себя самостоятельно, но вы можете отыскать их в таблице всех событий Sentinel, указанной в разделе Также ознакомьтесь....
-
Так как данная отработка отказа была включена вручную, вашему Sentinel не требуется выполнять поиск согласий от прочих Sentinel перед выполнением необходимых действий восстановления. Он был выбран ведущим напрямую, без проведения каких- бы то ни было выборов.
-
Затем этот Sentinel прихватывает какого- то подчинённого, которым в данном эксперименте является
192.168.0.33. -
Наш Sentinel отправляет необходимую команду
slaveof no oneв192.168.0.33, с тем чтобы он стал хозяином. Если мы проверим журнал этого сервера,192.168.0.33, мы обнаружим, что он получил соответствующую команду от Sentinel-2, остановил выполнение репликаций со старого хозяина192.168.0.31и был сам представлен в качестве хозяина. -
Наш Sentinel выполнил перенастройку старого хозяина
192.168.0.31и другого подчинённого192.168.0.32чтобы позволить им выполнять репликации с их нового хозяина. -
На самом последнем шаге наш Sentinel обновил всю информацию о новом хозяине и предоставил эту информацию прочим Sentinel через установленный канал
__sentinel__:helloс тем, чтобы клюиенты получали информацию о новом хозяине.
Имеющиеся файлы настроек, redis.conf и sentinel.conf, также были
обновлены соответствующим образом чтобы соответствовать новым ролям хостов.
Имитация падения мастера
В данном эксперименте мы выполнили имитацию оказа в своём Сервере Redis хозяина 192.168.0.33 остановив
его вручную. Наши Sentinel предложили 192.168.0.31 в качестве нового хозяина и завершили отработку восстановления
после отказа.
Давайте посмотрим как прошёл весь этот процесс:
-
На Sentinel-1, в
17:05:02.446, было обнаружено, что его сервер хозяина стал недоступным. Как уже упоминалось в предыдущем рецепте, каждый Sentinel будет выполнять ping к своему хозяину Redis, его подчинённым и прочим Sentinel на постоянной основе. Если некий ping завершается по тайм- ауту, такой сервер будет расценен Sentinel как остановленный. Однако это только некий субъективное видение одного из Sentinel, а именно индивидуальный останов (+sdownв событиях Sentinel). В данном примере Sentinel-1 помечает нашего хозяина как+sdown. -
Для предотвращения неверных предупреждений тот Sentinel, который отметил своего хозяина как
+sdownзапросы прочим Sentinel на предмет их видения ситуации с имеющимся хозяином. Действия будут предприняты только если более чем указанное в<quorum>Sentinel будут наблюдать своего хозяина остановленным, что именуется объективным остановом (+оdown). В данном примере Sentinel-1 получает отклик от оставшихся Sentinel в17:05:03.570и помечает текущего хозяина как+оdown. -
Затем Sentinel-1 пытается выполнить отработку отказа но не выбирается в качестве ведущего.
-
Почти в то же самое время Sentinel-2 также помечает своего хозяина как
+sdownи+odownи он был выбран в качестве ведущего для выполнения восстановления после отказа. Весь оставшийся процесс в точности тот же, что и для предыдущего этапа переключения на нового хозяина вручную.
Как выбирается лидер? Само голосование начинается после +down в одном из Sentinel; этот Sentinel начнёт
просить для себя голоса у прочих Sentinel. Каждый Sentinel имеет тоько один голос. После того как некий иной Sentinel получает такую просьбу,
если он ещё не принимал участие в голосовании, он примет полученную просьбу и ответит запросившему об этой просьбе. В противном случае он отвергнет
данную просьбу и своему другому лидеру, за которого он только что проголосовал. Если некий Sentinel получает больше или равно от половины максимального
значения (кворум, общее число Sentinel/ 2 + 1) голосов (включая его самого; сам Sentinel выставляет голос за себя перед тем как просить голоса у прочих),
он станет лидером. Если некий лидер не выбран, данный процесс повторяется.
Вернёмся обратно к своим журналам регистраций Sentinel. Sentinel-1 отправляет свою просьбу в 17:05:03.573,
однако не получает отклика от Sentinel-3 (идентификатор: a276b044b26100570bb1a4d83d5b3f9d66729f64), который отдал
голос за Sentinel-2 (идентификатор: d24979c27871eafa62e797d1c8e51acc99bbda72). Sentinel-2 отправил свой голос ранее
в 17:05:03.507 и получил отклик от Sentinel-3, который согласился отдать голос за Sentinel-2. Таким образом
Sentinel-2 получает 2 голоса и становится лидером.
Имитация падения двух подчинённых
В данном эксперименте мы установили значение min-slaves-to-write в 1
и остановили 2 подчинённых, оставив запущенным только своего хозяина. Величина параметра min-slaves-to-write
имеет значение минимального числа подчинённых, требующихся для принятия соответствующего запроса на запись.
Так как нет никаких подчинённых, данный запрос на запись отвергается нашим хозяином.
Имитация падения одного Sentinel
Останов одного Sentinel не оказывает воздействия на весь процесс отработки отказа в данном эксперименте, так как значение кворума всё ещё может соответствовать объективному останову и выбору своего лидера.
Имитация падения двух Sentinel
Оставление единственного запущенного Sentinel не может переключать объективный останов и делать выбор своего
лидера, таким образом, Sentinel только отметит +sdown для своего хозяина, а собственно отработка отказа так
никогда и не произойдёт.
В Redis Sentinel имеетс множество видов событий. В силу ограничений в пространстве у нас нет возможности рассмотреть их все. За дополнительными подробностями вы можете обратиться к имеющейся документации Redis Sentinel: https://redis.io/topics/sentinel.
В своих предыдущих рецептах мы изучали как установить и проверить Redis Sentinel. Помимо отслеживания текущего состояния хозяина и подчинённых Redis, Redis Sentinel также предоставляет такие удобные функции, как исполнение сценариев при возникновении событий Sentinel или в случае восстановления после отказа. В данном рецепте мы вначале представим несколько наиболее часто применяемых команд Sentinel, а затем мы рассмотрим как применять имеющуюся функциональность исполнения сценариев для автоматизации некоторых наиболее общих операций.
Вам следует завершить установку из раздела Установка Sentinel в данной главе и серверы данных и Sentinel Redis поднятыми и запущенными.
Основные действия для администрирования Redis Sentinel таковы:
-
Рассмотрим команды Sentinel:
-
Подключение к одному из Sentinel при помощи
redis-cli:user@192.168.0.33:~$bin/redis-cli -h 192.168.0.33 -p 26379 192.168.0.33:26379> -
Для получения текущей информации сервера хозяина данных, воспользуйтесь
SENTINEL GET-MASTER-ADDR-BY-NAME <master-name>192.168.0.33:26379> SENTINEL GET-MASTER-ADDR-BY-NAME mymaster 1) "192.168.0.31" 2) "6379" -
Для получения значения состояния всех отслеживавшихся хозяев примените
SENTINEL MASTERS:192.168.0.33:26379> SENTINEL MASTERS 1) 1) "name" 2) "mymaster" 3) "ip" 4) "192.168.0.31" 5) "port" ... 17) "last-ok-ping-reply" 18) "364" ... -
Аналогично, для получения информации о подчинённых на предмет мониторинга узла хозяина, воспользуйтесь
SENTINEL SLAVES <master-name>:192.168.0.33:26379> SENTINEL SLAVES mymaster 1) 1) "name" 2) "192.168.0.33:6379" 3) "ip" 4) "192.168.0.33" 5) "port" 6) "6379" 7) "runid" 8) "23b3730d1b32fde674c5ea07b9440c08cee9fabe" ... -
Для обновления настроек Sentinel примените
SENTINEL SET:192.168.0.33:26379> SENTINEL SET MYMASTER DOWN-AFTER-MILLISECONDS 1000 OK
-
-
Исполнение сценариев при возникновении событий Sentinel:
-
Мы бы желали получать электронные письма при каждом возникновении события Sentinel (скажем, в случае
+sdown,+odown). В данном случае мы применяем сценарий Python. Это всего лишь некий пример; вам следует установить правильный сервер SMTPи полномочия регистрации в реальной среде. Данный сценарий Python можно обнаружить среди пакета исходного кода к данной книге. -
Обновите иекущие настройки данного сценария уведомлений в одном из своих Sentinels при помощи команды
SENTINEL SET. Для данного примера мы включим эту функциональность в Sentinel-3 (192.168.0.33):192.168.0.33:26379> SENTINEL SET mymaster notification-script mymaster /redis/scripts/sentinel_events_notify.py OKНаш сценарий
/redis/scripts/sentinel_events_notify.pyдолжен включаться при всех событиях Sentinel.
-
-
Исполнение сценариев в случает отработки после отказа:
Redis Sentinel может быть настроен на автоматический запуск некоторого сценария в случае отработки отказа. Такая функциональность очень полезна в случае различия настроек между серверами Redis хозяина и подчинённых. При возникновении отработки отказа хозяина, один из подчинённых собирается быть представленным в качестве хозяина, но его настройка не будет обновлена Sentinel, таким образом параметр удержания RDB будет всё ещё включён в таком новом хозяине, пока мы не отключим его вручную. При наличии обсуждаемой функциональности мы можем установить некий сценария для обновления в автоматическом режиме необходимых настроек в случае изменения текущей роли данного экземпляра.
-
Отключите удержание RDB в данном хозяине (
192.168.0.31):127.0.0.1:6379> CONFIG SET SAVE "" OK -
Подготовьте некий сценарий, который обновляет текущие настройки RDB при отработке отказа согласно текущей установленной роли. Данный сценарий оболочки Bash вы можете обнаружить в пакете исходного кода к данной книге.
-
Обновите текущие настройки во всех Sentinels:
192.168.0.31:26379> sentinel set mymaster client-reconfig-script /redis/scripts/rdb_control.bash OK 192.168.0.32:26379> sentinel set mymaster client-reconfig-script /redis/scripts/rdb_control.bash OK 192.168.0.33:26379> sentinel set mymaster client-reconfig-script /redis/scripts/rdb_control.bash OK -
Включите отработку после отказа:
192.168.0.32:26379> SENTINEL FAILOVER mymaster OK -
Убедитесь что текущее значение параметра удержания RDB отключено в вашем новом хозяине (
192.168.0.33) и включено в старом хозяине (192.168.0.31):192.168.0.33:6379> INFO REPLICATION # Replication role:master connected_slaves:2 ... 192.168.0.33:6379> CONFIG GET save 1) "save" 2) "" 192.168.0.31:6379> CONFIG GET save 1) "save" 2) "900 1 300 10 60 10000"
-
В данном примере исполнения сценариев при событиях Sentinel мы настраиваем некий сценарий Python для автоматической отправки уведомительных
электронных писем всякий раз когда появляется новое событие Sentinel. В настройке Sentinel он именуется как
notification-script. Его аргументами, которые передаются в данный сценарий являются
<event_type> и <event_description>. Данная функциональность
часто применяется для уведомления имеющегося администратора операторов системы при любых критически важных событиях. Вы можете пожелать добавить некую
фильтрацию или установить уровни оповещения в данном сценарии с тем чтобы получать уведомления только об определённых событиях.
В данном примере исполнения сценариев при отработке оказа мы устанавливаем некий сценарий оболочки для автоматического обновления настройки
удержания RDB при каждом возникновении отработки отказа. В настройке Sentinel он именутеся как
client-reconfig-script.
Теми аргументами, которые передаются в данный сценарий, являются <master-name> <role> <state>
<from-ip> <from-port> <to-ip> <to-port>, причём <state> всегда
failover, <role> это значение роли текущего Sentinel
(leader или observer),
<from-ip> и <from-port> являются значениями IP адреса и порта
вашего старого хозяина, а <to-ip> и <to-port> это значения
IP адреса и порта вашего нового хозяина.
В данном сценарии мы вначале проверяем значение роли своего текущего экземпляра по его IP адресу. Заметьте, пожалуйста, что это значение новой
роли после отработки отказа. Затем, согласно полученному значению роли, мы обновляем текущие настройки вызывая
redis-cli либо для включения (если значением роли является подчинённый) или для отключения (если установлена
роль хозяина) в параметре удержания RDB.
Оба сценария, и notification-script, и client-config-script,
будут исполняться во всех Sentinels, которые имеют включёнными данные параметры в своих настройках. Для нашего варианта применения уведомления
нам всего- лишь требуется включить notification-script в одном из своих Sentinels, так как обычно те события,
которые вам интересны, появляются во всех Sentinels и следует отправлять всего лишь одно электронное письмо.
Данный сценарий должен возвращать 0 в случае успешного исполнения. Он буде пытаться повторять себя до 10 раз
если его возвращаемым значением является 1. Если некий сценарий не завершается в пределах 60 секунд, он будет
прекращён с помощью SIGKILL и будет повторяться до 10 раз. Данный сценарий не будет повторно исполняться если
возвращаемое значение превышает 1.
В своих предыдущих рецептах мы изучили как настраивать, проверять и сопровождать некое решение Высокой доступности с Redis Sentinel. Как мы уже описали во введении данной главы, все данные Redis следует разбивать на разделы, как только они начинают расти впечатляющим образом. Для такого развития событий, без всяких сомнений, на сцену выходит Кластер Redis, поддерживаемый начиная с версии 3.0. Начиная с данного рецепта мы следуем шаблону установка- проверка- администрирование с тем, чтобы показать вам использование кластера Redis для достижения автоматического разделения данных и Высокой доступности в Redis. В данном рецепте мы вначале изучим как установить некий Кластер Redis и обсудим как работает Кластер Redis.
Вам следует завершить установку своего сервера Redis, как это было описано в рецепте Загрузка и установка Redis из Главы 1, Приступая к Redis.
Для лучшего понимания того как работает ваш Кластер Redis, потребуются базовые знания о репликации Redis, которые являлись предметом обсуждения в Главе 5, Репликации.
Для подготовки необходимой среды вам также следует скопировать сценарий redis-trib.rb из соответствующего
каталога src/ вашего исходного кода в папку script.
В данном разделе мы настроим некий Кластер Redis с тремя узлами хозяем Redis, причём каждый с единственным узлом экземпляра подчинённого Redis. Топология данного Кластера показана здесь:
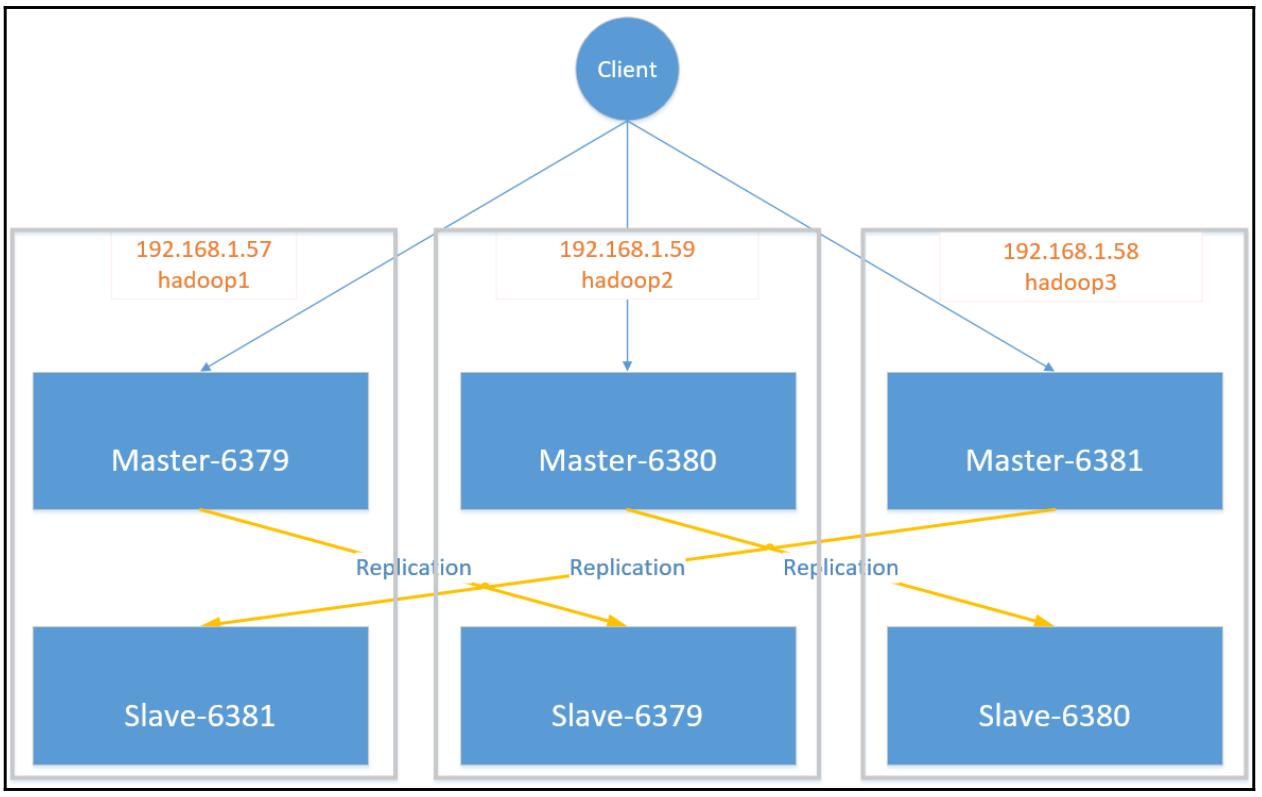
-
Каждый экземпляр Redis имеет свой собственный файл настроек (
redis.conf). Для включения требуемой функциональности Кластера, подготовим некий файл настроек для каждого экземпляра redis и затем изменим его IP, порт ожидания и путь к файлуlogнадлежащим образом (в силу ограниченности в пространстве данной книги мы покажем файл настроек одного экземпляра на самом первом хосте; вы можете выгрузить все файлы настроек из исходного кода, предоставленного для данной книги):redis@192.168.1.57:~> cat conf/redis-6379.conf daemonize yes pidfile "/redis/run/redis-6379.pid" port 6379 bind 192.168.1.57 logfile "/redis/log/redis-6379.log" dbfilename "dump-6379.rdb" dir "/redis/data" ... cluster-enabled yes cluster-config-file nodes-6379.conf cluster-node-timeout 10000![[Замечание]](/common/images/admon/note.png)
Замечание Когда Кластер Redis запущен, каждый узел имеет открытыми два сокета TCP. Самый первый является стандартным протоколом Redis для подключения клиента. Значение второго порта вычисляется из значения суммы вашего первого порта плюс 10 000 и используется как некая шина взаимодействия для обмена информации между узлами. Это значение 10 000 является зашитым аппаратно. Таким образом, вы не сможете запустить некий узел Кластера Redis с ожиданием по порту со значением более
55536. -
Прежде чем мы двинемся далее, давайте убедимся что все файлы настроек были подготовлены как следует во всех хостах:
redis@192.168.1.57:~> ls conf/ redis-6379.conf redis-6381.conf ... redis@192.168.1.58:~> ls conf/ redis-6380.conf redis-6381.conf -
Очистим каталог
dataи запустим все экземпляры Redis в каждом из хостов:redis@192.168.1.57:~> rm -rf data/* redis@192.168.1.57:~> bin/redis-server conf/redis-6379.conf redis@192.168.1.57:~> bin/redis-server conf/redis-6381.conf ... redis@192.168.1.58:~> rm -rf data/* redis@192.168.1.58:~> bin/redis-server conf/redis-6380.conf redis@192.168.1.58:~> bin/redis-server conf/redis-6381.conf -
После запуска соответствующего экземпляра Redis будут выработаны файлы настройки для каждого узла. Их можно обнаружить в соответствующем каталоге
data. Проверим один из них, чтобы посмотреть что он содержит:redis@192.168.1.57:~> cat data/nodes-6379.conf 58285fa03c19f6e6f633fb5c58c6a314bf25503f :0@0 myself,master - 0 0 0 connected vars currentEpoch 0 lastVoteEpoch 0 -
Прежде чем мы настроим свой Кластер, мы выполним выборку информации об исполняемом Кластере Redis вызвав команду
INFO CLUSTERи выводя перечень всех процессов Redis при помощи команды ОСps(с целью краткости отображается только информация для хоста192.168.1.57):redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6379 INFO CLUSTER # Cluster cluster_enabled:1 redis@192.168.1.57:~> ps -ef |grep redis-server redis 119911 1 0 16:22 ? 00:00:00 bin/redis-server 192.168.1.57:6379 [cluster] redis 119942 1 0 16:22 ? 00:00:00 bin/redis-server 192.168.1.57:6381 [cluster] -
Проверим соответствующий журнал экземпляра:
redis@192.168.1.57:~> vim log/redis-6379.log ... 26569:C 05 Nov 16:50:33.832 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 26569:C 05 Nov 16:50:33.832 # Redis version=4.0.1, bits=64, commit=00000000, modified=0, pid=26569, just started 26569:C 05 Nov 16:50:33.832 # Configuration loaded 26570:M 05 Nov 16:50:33.835 * No cluster configuration found, I'm 58285fa03c19f6e6f633fb5c58c6a314bf25503f 26570:M 05 Nov 16:50:33.839 * Running mode=cluster, port=6379. -
Давайте позволим каждому экземпляру Redis встретиться со всеми остальными посредством вызова команды
CLUSTER MEETчерезredis-cli. Вы можете сделать это только на одном хосте (в данном примере э то хост192.168.1.57):redis@192.168.1.58:~> bin/redis-cli -h 192.168.1.57 -p 6379 CLUSTER MEET 192.168.1.57 6379 OK ... redis@192.168.1.58:~> bin/redis-cli -h 192.168.1.57 -p 6379 CLUSTER MEET 192.168.1.58 6380 OK redis@192.168.1.58:~> bin/redis-cli -h 192.168.1.57 -p 6379 CLUSTER MEET 192.168.1.58 6381 OKЗамечание Если в качестве адреса соответствующего узла в вашем Кластере вы применяете имя хоста, даже если может быть установлено правильное соответствие IP имени вашего хоста, возникнет следующая ошибка:
redis@192.168.1.58:~> bin/redis-cli -h 192.168.1.57 -p 6379 CLUSTER MEET 192.168.1.58 6381 (error) ERR Invalid node address specified: 192.168.1.58:6381 -
Далее, выполните выделение слотов своих данных. Вы можете выполнить данный шаг при помощи
redis-cliв единственном хосте, определяя необходимые значения хоста и порта:redis@192.168.1.57:~> for i in {0..5400}; do redis-cli -h 192.168.1.57 -p 6379 CLUSTER ADDSLOTS $i; done OK ... OK redis@192.168.1.57:~> for i in {5401..11000}; do redis-cli -h 192.168.1.59 -p 6380 CLUSTER ADDSLOTS $i; done OK ... OK redis@192.168.1.57:~> for i in {11001..16383}; do redis-cli -h 192.168.1.58 -p 6381 CLUSTER ADDSLOTS $i; done OK ... OKЗамечание Если вы выделяете некий слот, который уже применялся ранее, вы получите такую ошибку:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.58 -p 6381 CLUSTER ADDSLOTS 11111 (error) ERR Slot 11111 is already busyЕсли значение идентификатора того слота, который вы определили выходит за рамки
0- 16383, вы получите следующую ошибку:redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.58 -p 6381 CLUSTER ADDSLOTS 22222 (error) ERR Invalid or out of range slot -
Итак, мы добавили все необходимые узлы в некий Кластер и выделили все
16384слотов хэширования. Мы можем вывести список всех узлов отправив соответствующую командуCLUSTER NODESв один из имеющихся в нашем кластере узлов:redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6379 CLUSTER NODES eeeabcab810d500db1d190c592fecbe89036f24f 192.168.1.58:6381@16381 master - 0 1509885956764 0 connected 11001-16383 549b5b261c765a97b74a374fec49f2ccf30f2acd 192.168.1.58:6380@16380 master - 0 1509885957000 3 connected 58285fa03c19f6e6f633fb5c58c6a314bf25503f 192.168.1.57:6379@16379 myself,master - 0 1509885955000 2 connected 0-5400 2ff47eb511f0d251eff1d5621e9285191a83ce9f 192.168.1.59:6380@16380 master - 0 1509885957767 1 connected 5401-11000 bc7b4a0c4596759058291f1b8f8de10966b5a1d1 192.168.1.59:6379@16379 master - 0 1509885957000 4 connected 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a 192.168.1.57:6381@16381 master - 0 1509885957066 0 connected -
Для реализации репликации данных установите некий узел в качестве подчинённого одного из узлов хозяина. Мы прицепим три узла в качестве подчинённых, так как мы хотим иметь в данном кластере три узла хозяев:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.59 -p 6379 CLUSTER REPLICATE 58285fa03c19f6e6f633fb5c58c6a314bf25503f OK redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.58 -p 6380 CLUSTER REPLICATE 2ff47eb511f0d251eff1d5621e9285191a83ce9f OK redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6381 CLUSTER REPLICATE eeeabcab810d500db1d190c592fecbe89036f24f OK -
Проверьте установленные репликации, вновь применив команду
CLUSTER NODES, а вслед за ней вызываяCLUSTER INFOдля получения дополнительной информации о вашем Кластере:192.168.1.57:6379> CLUSTER NODES eeeabcab810d500db1d190c592fecbe89036f24f 192.168.1.58:6381@16381 master - 0 1510536168000 0 connected 11001-16383 549b5b261c765a97b74a374fec49f2ccf30f2acd 192.168.1.58:6380@16380 slave 2ff47eb511f0d251eff1d5621e9285191a83ce9f 0 1510536170545 3 connected 58285fa03c19f6e6f633fb5c58c6a314bf25503f 192.168.1.57:6379@16379 myself,master - 0 1510536168000 2 connected 0-5400 2ff47eb511f0d251eff1d5621e9285191a83ce9f 192.168.1.59:6380@16380 master - 0 1510536169541 1 connected 5401-11000 bc7b4a0c4596759058291f1b8f8de10966b5a1d1 192.168.1.59:6379@16379 slave 58285fa03c19f6e6f633fb5c58c6a314bf25503f 0 1510536167000 4 connected 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a 192.168.1.57:6381@16381 slave eeeabcab810d500db1d190c592fecbe89036f24f 0 1510536169000 5 connected 192.168.1.57:6379> CLUSTER INFO cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 ... cluster_stats_messages_meet_received:2 cluster_stats_messages_received:1483481 -
Теперь у нас имеется успешно установленный Кластер Redis. Мы можем проверить его устанавливая и получая простую пару строковых ключ- значение:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6379 -c 192.168.1.57:6379> set foo bar -> Redirected to slot [12182] located at 192.168.1.58:6381 OK 192.168.1.58:6381> get foo "bar"
В своём предыдущем примере мы пошагово провели вас по процессу установки Кластера Redis. Самый первый предпринятый нами шаг состит в подготовке необходимого файла настроек для каждого экземпляра Redis
cluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 10000
После определения различных портов ожидания и путей к данным для каждого экземпляра по отдельности, мы включили функциональность Кластера
установив значение параметра cluster-enabled в yes. Более того,
для каждого экземпляра Redis имеется некий файл настроек узла, который будет выработан в процессе настройки Кластера Redis и может изменяться
всякий раз, когда требуется удержание (persist) некоторой информации кластера. Название такого файла настроек устанавливается набором параметров
cluster-config-file.
Файл настроек узла вашего Кластера не следует изменять вручную.
Короче говоря, значение таймаута узла означает: если такой определённый временной промежуток истёк, будет активирована некая отработка отказа для предложения какого- то подчинённого в качестве хозяина. В своём следующем рецепте мы подробно обсудим как этот параметр влияет на поведение всего Кластера.
После проверки соответствующего файла настроек каждого экземпляра и выполнения некоторой необходимой читки, мы запускаем все имеющиеся экземпляры.
Для проверки того что данный узел запущен в режиме Кластера, мы можем вызвать команду CLUSTER INFO из
redis-cli или отыскать Running mode в журнале соответствующего
экземпляра Redisю Хначение идентификатора узла Кластера, которое является неким идентификатором для некоторого экземпляра Redis в Кластере Redis,
записывается в необходимом журнале. Вы также назвать его если некий экземпляр Redis запущен в режиме Кластера, воспользовавшись командой ОС
ps.
Тепрь, после того как мы настроили и запустили все необходимые узлы своего Кластера, самое время создать некий Кластер Redis. Узлы в этом Кластере
Redis применяют имеющийся протокол Кластера Redis (RDP) для общения друг с другом в виде сетевой топологии ячеек. Поэтому, самый первый шаг,
который мы предпринимаем, состоит в том, чтобы позволить каждому узлу встречать всякий иной с тем, чтобы они могли работать надлежащим образом а
некотором Кластере. Для этой уели применяется команда CLUSTER MEET.
Хотя необходимо чтобы все узлы в некотором Кластере Redis знали друг друга, нет необходимости отправлять эту команду в каждый узел. Это обусловлено тем, что один узел будет распространять всю информацию об известных ему узлах как только он повстречает иной узел (именно это означает соответствующая информация exchange-of-gossip в пакетах сердцебиения, о которой упоминается в документации Кластера Redis). Во избежаие конфликтов мы можем позволить одному узлу повстречаться со всеми остальными узлами. Таким образом все имеющиеся в некотором Кластер узлы смогут взаимодействовать друг с другом.
В Кластере Redis данные распространяются в 16384 слотов хэширования по показанному далее алгоритму:
HASH_SLOT = CRC16(key) mod 16384
Всякий узел хозяина назначается некому поддиапазону слотов хэширования для хранения некоторой порции всего имеющегося набора данных. Таким образом,
наш второй шаг, который мы предпринимаем, состоит в выделении необходимых слотов среди всех узлов хозяев с помощью команды
CLUSTER ADDSLOTS. По завершению выделения слотов, мы проверяем свой кластер, отправляя соответствующую
команду CLUSTER NODES. Вывод данной команды отображается следующим образом:
eeeabcab810d500db1d190c592fecbe89036f24f 192.168.1.58:6381@16381 master - 0 1510536168000 0 connected 11001-16383
Все строки в нём представлены следующим форматом:
[Node-ID] [Instance-IP:Client-Port@Cluster-Bus-Port][Master\Slave\Myself] [-\Node-ID] [Ping-Sent timestamp] [Pong-Recv timestamp] [Config-epoch] [Connection status] [Slots allocated]
Для предоставления избыточности данных мы назначаем некого подчинённого для каждого хозяина в отдельности, отправляя
CLUSTER REPLICATE node-id в тот узел, который мы бы желали получит в качестве подчинённого. После настройки
необходимых репликаций мы можем выполнять взаимодействие хозяин- подчинённый (master- salve) путём просмотра соответствующего вывода команды
CLUSTER NODES. Для данного примера мы запросто можем сказать, что тот экземпляр, который запущен в
192.168.1.59:6379, и чьим идентификатором является
bc7b4a0c4596759058291f1b8f8de10966b5a1d1, является подчинённым для экземпляра с узлом, у которого идентификатор
58285fa03c19f6e6f633fb5c58c6a314bf25503f, и который является тем экземпляром, который запущен в
192.168.1.57:6379.
На данный момент у нас имеется успешно созданный Кластер Redis. Отправив команду CLUSTER INFO вы можете
получить значения состояния и измерения всего вашего Кластера.
Для проверки того что наш Кластер рабоатает как ожидалось, мы подключаемся к своему кластеру при помощи redis-cli
с параметром -c для описания необходимого режима Кластера. Для проверки мы устанавливаем, а затем извлекаем некий
образец строковой пары ключ- значение. Тот узел, к кторому мы подключились, способен перенаправлять наш инструментарий
redis-cli к правильному кзлу в нашем Кластере.
Вам может показаться, что имеется слишком много этапов при создании Кластера Redis. Намного проще воспользоваться имеющимся сценарием
redis-trib.rb, поставляемым совместно с общим исходным кодом Redis для выполнения такого создания
и администрирования Кластера Redis. Для поиска дополнительных подробностей вы можете обратиться к руководству по Кластеру Redis.
Например, мы можем проверить значение состояния Кластера применив следующую команду:
redis@192.168.1.57:~> ./script/redis-trib.rb check 192.168.1.57:6379
>>> Performing Cluster Check (using node 192.168.1.57:6379)
M: 58285fa03c19f6e6f633fb5c58c6a314bf25503f 192.168.1.57:6379
slots:0-5400 (5401 slots) master
...
slots: (0 slots) slave
replicates 58285fa03c19f6e6f633fb5c58c6a314bf25503f
S: 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a 192.168.1.57:6381
slots: (0 slots) slave
replicates eeeabcab810d500db1d190c592fecbe89036f24f
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
|
| Замечание |
|---|---|
|
Для быстрой проверки концепции вы можете получить некий Кластер Redis из 6 узлов с тремя хозяевами и тремя подчинёнными в одном хосте
воспользовавшись сценарием |
Что касается документации о том как создавать некий Кластер Redis, для вас имеется официальное руководство: https://redis.io/topics/cluster-tutorial.
Подробности о команде CLUSTER NODES вы можете отыскать на
https://redis.io/commands/cluster-nodes.
Ознакомится с деталями команды CLUSTER INFO можно по ссылке
https://redis.io/commands/cluster-info.
После настройка Кластера Redis необходимо имитировать различные варианты отказов чтобы посмотреть как поведёт себя наш Кластер в случае неожиданных происшествий или запланированного администрирования. В данном рецепте мы проверим свой построенный в нашем предыдущем рецепте Кластер Redis посредством некоторого числа вариантов отказов. Вслед за этим мы также обсудим подробности отработки восстановления после отказов.
Вам следует завершить рецепт Настройка кластера Redis из
этой Главы, а также вам понадобится некий хост с установленным в данном Кластере в виде клиента Redis
redis-cli. Подводя итог предыдущего рецепта, представим в приводимой ниже Таблице полную информацию о
своём Кластере:
| Название экземпляра | IP адрес | Порт | Идентификатор | Слоты |
|---|---|---|---|---|
I_A |
|
|
|
|
I_A1 |
|
|
|
|
I_B |
|
|
|
|
I_B1 |
|
|
|
|
I_С |
|
|
|
|
I_C1 |
|
|
|
|
Кроме того, для целей проверки мы введём некий тестовый комплект, который был предложен самим автором Redis, Antirez. Для его установке вы можете следовать приводимыми далее шагами:
-
Установите соответствующий модуль Ruby Redis:
~$ gem install redis ~$ su - redis ~$ cd coding/ -
Выгрузите необходимый тестовый комплект:
~$ mkdir coding ~$ cd coding ~/coding$ git clone https://github.com/antirez/redis-rb-cluster.git ~/coding$ cd redis-rb-cluster/
Для проверки нашего Кластера Redis из предыдущего рецепта мы вначале запустим свою тестовую программу в качестве некоторого клиента Redis с помощью такой команды:
~$ ruby coding/redis-rb-cluster/consistency-test.rb 192.168.1.59 6380
1441 R (0 err) | 1441 W (0 err) |
4104 R (0 err) | 4104 W (0 err) |
25727 R (0 err) | 25727 W (0 err) |
...
-
Симулируем падение хозяина:
-
При помощи команды
DEBUG SEGFAULTзаставим упасть свой экземплярI_A:redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6379 -c DEBUG SEGFAULT Error: Server closed the connection -
Проверим журнал своего экземпляра
I_A:96013:M 15 Nov 14:49:40.224 # Redis 4.0.1 crashed by signal: 11 -
Проверим вывод нашей программы тестирования:
190927 R (0 err) | 190927 W (0 err) | 201012 R (0 err) | 201012 W (0 err) | Reading: Connection lost (ECONNRESET) Writing: Too many Cluster redirections? (last error: MOVED 183 192.168.1.57:6379) 235022 R (2 err) | 235022 W (2 err) | Reading: Too many Cluster redirections? (last error: MOVED 994 192.168.1.57:6379) Writing: Too many Cluster redirections? (last error: MOVED 994 192.168.1.57:6379) .... 261178 R (1310 err) | 261179 W (1309 err) | -
Проверим журнал своего экземпляра
I_A1:35623:S 15 Nov 14:49:40.355 # Connection with master lost. 35623:S 15 Nov 14:49:40.356 * Caching the disconnected master state. 35623:S 15 Nov 14:49:40.410 * Connecting to MASTER 192.168.1.57:6379 35623:S 15 Nov 14:49:40.410 * MASTER <-> SLAVE sync started 35623:S 15 Nov 14:49:40.410 # Error condition on socket for SYNC: Connection refused ... 35623:S 15 Nov 14:49:50.452 * Connecting to MASTER 192.168.1.57:6379 35623:S 15 Nov 14:49:50.452 * MASTER <-> SLAVE sync started 35623:S 15 Nov 14:49:50.452 # Error condition on socket for SYNC: Connection refused 35623:S 15 Nov 14:49:50.970 * FAIL message received from 2ff47eb511f0d251eff1d5621e9285191a83ce9f about 58285fa03c19f6e6f633fb5c58c6a314bf25503f 35623:S 15 Nov 14:49:50.970 # Cluster state changed: fail 35623:S 15 Nov 14:49:51.053 # Start of election delayed for 888 milliseconds (rank #0, offset 5084834). 35623:S 15 Nov 14:49:51.455 * Connecting to MASTER 192.168.1.57:6379 35623:S 15 Nov 14:49:51.455 * MASTER <-> SLAVE sync started 35623:S 15 Nov 14:49:51.455 # Error condition on socket for SYNC: Connection refused 35623:S 15 Nov 14:49:51.957 # Starting a failover election for epoch 8. 35623:S 15 Nov 14:49:51.959 # Failover election won: I'm the new master. 35623:S 15 Nov 14:49:51.959 # configEpoch set to 8 after successful failover 35623:M 15 Nov 14:49:51.959 # Setting secondary replication ID to 744a9fb2c14c245888b8e91edd212ae533dd33e3, valid up to offset: 5084835. New replication ID is b8fc14c9af26e00c40e964e8c70a8b6001602be1 35623:M 15 Nov 14:49:51.959 * Discarding previously cached master state. 35623:M 15 Nov 14:49:51.960 # Cluster state changed: ok -
Проверим соответствующие журналы всех прочих узлов:
=========I_B======== 35634:M 15 Nov 14:49:50.969 * Marking node 58285fa03c19f6e6f633fb5c58c6a314bf25503f as failing (quorum reached). 35634:M 15 Nov 14:49:50.969 # Cluster state changed: fail 35634:M 15 Nov 14:49:51.959 # Failover auth granted to bc7b4a0c4596759058291f1b8f8de10966b5a1d1 for epoch 8 35634:M 15 Nov 14:49:51.999 # Cluster state changed: ok =========I_C======== 41354:M 15 Nov 14:50:49.154 * Marking node 58285fa03c19f6e6f633fb5c58c6a314bf25503f as failing (quorum reached). 41354:M 15 Nov 14:50:49.154 # Cluster state changed: fail 41354:M 15 Nov 14:50:50.143 # Failover auth granted to bc7b4a0c4596759058291f1b8f8de10966b5a1d1 for epoch 8 41354:M 15 Nov 14:50:50.145 # Cluster state changed: ok =========I_B1========== 41646:S 15 Nov 14:50:49.154 * FAIL message received from 2ff47eb511f0d251eff1d5621e9285191a83ce9f about 58285fa03c19f6e6f633fb5c58c6a314bf25503f 41646:S 15 Nov 14:50:49.154 # Cluster state changed: fail 41646:S 15 Nov 14:50:50.146 # Cluster state changed: ok =========I_C1========== 27576:S 15 Nov 14:49:50.968 * FAIL message received from 2ff47eb511f0d251eff1d5621e9285191a83ce9f about 58285fa03c19f6e6f633fb5c58c6a314bf25503f 27576:S 15 Nov 14:49:50.968 # Cluster state changed: fail 27576:S 15 Nov 14:49:51.959 # Cluster state changed: ok -
Получим значение текущего состояния нашего Кластера:
redis@192.168.1.57:~> ./script/redis-trib.rb check 192.168.1.57:6381 >>> Performing Cluster Check (using node 192.168.1.57:6381) ... M: bc7b4a0c4596759058291f1b8f8de10966b5a1d1 192.168.1.59:6379 slots:0-5400 (5401 slots) master 0 additional replica(s) ... [OK] All 16384 slots covered.
-
-
Восстановим свой рухнувший узел:
-
Вернём обратно свой экзепляр Redis
I_A:redis@192.168.1.57:~> bin/redis-server conf/redis-6379.conf -
Проверим журнал своего экземпляра
I_A1:35623:M 15 Nov 15:00:40.610 * Clear FAIL state for node 58285fa03c19f6e6f633fb5c58c6a314bf25503f: master without slots is reachable again. 35623:M 15 Nov 15:00:41.552 * Slave 192.168.1.57:6379 asks for synchronization 35623:M 15 Nov 15:00:41.552 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for '9d2a374586d38080595d4ced9720eeef1c72e1d7', my replication IDs are 'b8fc14c9af26e00c40e964e8c70a8b6001602be1' and '744a9fb2c14c245888b8e91edd212ae533dd33e3') 35623:M 15 Nov 15:00:41.553 * Starting BGSAVE for SYNC with target: disk 35623:M 15 Nov 15:00:41.553 * Background saving started by pid 113122 113122:C 15 Nov 15:00:41.572 * DB saved on disk 113122:C 15 Nov 15:00:41.572 * RDB: 6 MB of memory used by copyon-write 35623:M 15 Nov 15:00:41.611 * Background saving terminated with success 35623:M 15 Nov 15:00:41.614 * Synchronization with slave 192.168.1.57:6379 succeeded -
Проверим общее состояние своего Кластера:
redis@192.168.1.57:~/script> ./redis-trib.rb check 192.168.1.57:6381 >>> Performing Cluster Check (using node 192.168.1.57:6381) S: 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a 192.168.1.57:6381 slots: (0 slots) slave replicates eeeabcab810d500db1d190c592fecbe89036f24f M: eeeabcab810d500db1d190c592fecbe89036f24f 192.168.1.58:6381 slots:11001-16383 (5383 slots) master 1 additional replica(s) M: 2ff47eb511f0d251eff1d5621e9285191a83ce9f 192.168.1.59:6380 slots:5401-11000 (5600 slots) master 1 additional replica(s) M: bc7b4a0c4596759058291f1b8f8de10966b5a1d1 192.168.1.59:6379 slots:0-5400 (5401 slots) master 1 additional replica(s) S: 58285fa03c19f6e6f633fb5c58c6a314bf25503f 192.168.1.57:6379 slots: (0 slots) slave replicates bc7b4a0c4596759058291f1b8f8de10966b5a1d1 S: 549b5b261c765a97b74a374fec49f2ccf30f2acd 192.168.1.58:6380 slots: (0 slots) slave replicates 2ff47eb511f0d251eff1d5621e9285191a83ce9f [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
-
-
Имитируем падение подчинённого:
-
С помощью команды Redis
DEBUG SEGFAULTзаставим упастьI_C1:redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6381 -c DEBUG SEGFAULT Error: Server closed the connection -
Проверим журнал
I_C:41354:M 15 Nov 15:13:03.564 # Connection with slave 192.168.1.57:6381 lost. 41354:M 15 Nov 15:13:13.750 * FAIL message received from bc7b4a0c4596759058291f1b8f8de10966b5a1d1 about 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a -
Проверим журнал
I_A:112615:S 15 Nov 15:12:15.528 * FAIL message received from bc7b4a0c4596759058291f1b8f8de10966b5a1d1 about 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a -
Посмотрим на текущее состояние своего Кластера:
redis@192.168.1.57:~> ./script/redis-trib.rb check 192.168.1.57:6379 >>> Performing Cluster Check (using node 192.168.1.57:6379) ... M: eeeabcab810d500db1d190c592fecbe89036f24f 192.168.1.58:6381 slots:11001-16383 (5383 slots) master 0 additional replica(s) ... [OK] All 16384 slots covered.
-
-
Смоделируем падение и хозяина и подчинённого одного куска (shard):
-
Так как мы уже уронили
I_C1, теперь нам осталось также положить иI_C:redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.58 -p 6381 -c DEBUG SEGFAULT Error: Server closed the connection -
Проверим журнал
I_A1:35623:M 15 Nov 15:47:29.855 # Cluster state changed: fail -
Посмотрим на состояние своего Кластера:
redis@192.168.1.57:~> ./script/redis-trib.rb check 192.168.1.57:6379 >>> Performing Cluster Check (using node 192.168.1.57:6379) S: 58285fa03c19f6e6f633fb5c58c6a314bf25503f 192.168.1.57:6379 slots: (0 slots) slave replicates bc7b4a0c4596759058291f1b8f8de10966b5a1d1 M: 2ff47eb511f0d251eff1d5621e9285191a83ce9f 192.168.1.59:6380 slots:5401-11000 (5600 slots) master 1 additional replica(s) M: bc7b4a0c4596759058291f1b8f8de10966b5a1d1 192.168.1.59:6379 slots:0-5400 (5401 slots) master 1 additional replica(s) S: 549b5b261c765a97b74a374fec49f2ccf30f2acd 192.168.1.58:6380 slots: (0 slots) slave replicates 2ff47eb511f0d251eff1d5621e9285191a83ce9f [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [ERR] Not all 16384 slots are covered by nodes. -
Проверим вывод своей тестовой программы:
~$ ruby coding/redis-rb-cluster/consistency-test.rb 192.168.1.57 6379 0 R (6261 err) | 0 W (6261 err) | ... Reading: CLUSTERDOWN The cluster is down Writing: CLUSTERDOWN The cluster is down 0 R (7727 err) | 0 W (7727 err) |
-
Запуская свой тестовый сценарий, consistency-test.rb, мы можем периодически выполнять запись и чтение в
своём Кластере Redis. Общее число записей, чтений, а также ошибок регистрируется в журнали при исполнении данного сценария. Все несогласованности
данных также могут перехватываться.
В своей самой первой выполняемой проверке мы переводим свой экземпляр хозяина в выключенное состояние. Для опрокидывания своего экземпляра
I_A мы применяем команду DEBUG SEGFAULT с идентификатором узла
58285fa03c19f6e6f633fb5c58c6a314bf25503f. Эта команда имеет результатом некий отказ сегмента экземпляра Redis.
В итоге это экземпляр уходит, как это отображено в журнале I_A. Из получаемого вывода тестовой программы
можно также ясно увидеть, что на какое- то время получают отказ некоторые запросы на запись и чтение. Позднее наш кластер возобновляет обработку всех
запросов. На самом деле, значение того периода времени пока наш Кластер не работает, зависит от времени процесса отработки отказа
I_A1. Для получения большей информации об этом отказе давайте углубимся в журнал
I_A1.
Во- первых, наш подчинённый экземпляр обнаружил, что текущее подключение к его хозяину было утрачено в 14:49:40.
Он на протяжении 10 секунд пытался возобновить подключение к своему экземпляру хозяина, что является тем промежутком времени, которое определяется в
параметре cluster-node-timeout. Затем, в 14:49:50, отказ нашего
экземпляра I_A был подтверждён соответствующим получением сообщения FAIL,
а текущее состояние нашего Кластера рассматривалось как состояние отказа. I_A1 получил голоса двух выживших
хозяев и после этого он был включён как новый хозяин в 14:49:51. Наконец, результирующее состояние нашего
Кластера было снова изменено на OK. Из наблюдаемой временной линии в журналах прочих хозяев и подчинённых можно
сказать, что I_B с идентификатором 2ff47eb511f0d251eff1d5621e9285191a83ce9f
вначале пометил наш I_A как FAIL и широковещательно отправил это сообщение
всем имеющимся подчинённым.
Хотя вес наши слоты были покрыты и состояние нашего Кластера перешло в OK, проверив свой Кластер мы обнаружили, что
наш новый хозяин, обслуживающий слоты 0- 5400 не имеет никакой реплики.
Второй выполненный нами тест заключался в восстановлении упавшего в нашем предыдущем тесте узла. Вновь запустив наш экземпляр
I_A, мы обнаружили, что он стал подчинённым имеющегося экземпляра I_A1,
который теперь выступает в качестве узла хозяина после отработки отказа. Значение состояния FAIL
I_A было удалено и была запущена повторная синхронизация. Наконец, наш новый экземпляр хозяина
I_A1, обслуживающий слоты 0- 5400 получил одну реплику, предоставляемую
I_A.
Выполняемый нами третий тест заключался в опрокидывании какого- то подчинённого. Мы прицепились к узлу
I_C1. После останова I_C1 мы обнаружили, что состояние нашего Кластера
не изменилось, так как тот экземпляр, который мы уронили, был подчинённым который не обслуживал имеющиеся слоты.
Самый последний выполняемый нами тест состоял в том, что мы поломали и хозяина и подчинённого одного куска (shard). Поскольку не все слоты покрываются,
текущее состояние нашего Кластера переключается в FAIL. Поэтому, наша тестовая программа получает сообщение об
ошибке CLUSTERDOWN The cluster is down.
На самом деле, перед получением сообщения FAIL имеется некое состояние
PFAIL (possible failure - возможен отказ), распространяемое по всем узлам в вашем кластере. Такое состояние
PFAIL означает, что некий узел, вне зависимости от того является ли он хозяином или подчинённым, может пометить
иной узел как PFAIL если другой узел не доступен. Затем он распространяет эту информацию через свои сердцебиения.
Вначале узел A помечает узел как PFAIL. Затем, когда A получает PFAIL
или FAIL относительно B от большинства хозяев в пределах NODE_TIMEOUT * 2,
он изменит PFAIL на FAIL и широковещательно отправит сообщение об этом
прочим узлам.
Таким образом, в нашем примере если мы роняем двух хозяев примерно в обно и то же самое время, наш Кластер не сможет выполнить восстановление даже если эти
два хозяина имеют своих подчинённых по- отдельности. Это происходит по причине отключения большинства хозяев. Как результат, никакой
PFAIL не будет установлен в FAIL. Тем самым, не будет наблюдаться никакой
отработки отказа. По этой причине, в качестве практического приёма при промышленном применении, вам никогда не следует развёртывать некое большинство
хозяев в одном и том же хосте.
Для поиска дополнительных подробностей о Кластере Redis вы можете обратиться к Redis Cluster Specification.
Команду DEBUG SEGFAULT вы можете изучить на
https://redis.io/commands/debug-segfault.
Также вы можете окунуться в исходный код Кластера Redis для изучения дополнительных подробностей.
Также имеется некая презентация от самого автора, Antirez, рассказывающая о Кластере Redis.
Благодаря своей полностью разбитой на ячейки топологии и механизму восстановления после отказов Кластер Redis является более сложным нежели отдельное решение Redis хозяин- подчинённый. Для тех, кому придётся решать задачи администрирования очень важно изучить как получать рабочую топологию и состояние своего Кластера. Более того, одним из величайших преимуществ использования Кластера Redis является его гибкость относительно простого добавления и удаления узлов. Эти операции достаточно распространены при применении вами Кластера Redis.
В данном рецепте мы предоставим ввам руководство для того чтобы выполнять распространённые операции в Кластере Redis.
Вам следует завершить рецепт Настройка кластера Redis из
этой Главы. Вам также вам понадобится некий хост с установленным в данном Кластере в виде клиента
Redis redis-cli. Относительно применяемой среды демонстрации вы можете обращаться к справочной информации
из Таблицы 7-2 рецепта Проверка кластера
Redis.
Операции администрирования Кластера Redis таковы:
-
Выборка значения состояния самого Кластера:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6381 -c CLUSTER INFO cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 ... cluster_stats_messages_pong_received:113 cluster_stats_messages_fail_received:2 cluster_stats_messages_auth-req_received:2 cluster_stats_messages_received:233 -
Проверка значения состояния в узлах Кластера:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6381 -c CLUSTER NODES eeeabcab810d500db1d190c592fecbe89036f24f 192.168.1.58:6381@16381 master - 0 1510818967000 0 connected 11001-16383 ... 58285fa03c19f6e6f633fb5c58c6a314bf25503f 192.168.1.57:6379@16379 slave bc7b4a0c4596759058291f1b8f8de10966b5a1d1 0 1510818968000 14 connected 2ff47eb511f0d251eff1d5621e9285191a83ce9f 192.168.1.59:6380@16380 master - 0 1510818967067 1 connected 5401-11000 -
Включение вручную отработки отказа для предложения подчинённого в качестве хозяина:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6381 -c CLUSTER FAILOVER OK -
Выборка информации об определённом подчинённом с заданного хозяина:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6381 -c CLUSTER SLAVES 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a 1) "eeeabcab810d500db1d190c592fecbe89036f24f 192.168.1.58:6381@16381 slave 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a 0 1510819599257 17 connected" -
Добавить фрагмент (shard, и сам экземпляр хозяина, и его подчинённые экземпляры) в некий запущенный кластер.
-
Подготовим файл настроек для своих хозяина и подчинённого с ожиданием по порту
6382:redis@192.168.1.57:~> cat conf/redis-6382.conf daemonize yes pidfile "/redis/run/redis-6382.pid" port 6382 bind 192.168.1.57 logfile "/redis/log/redis-6382.log" dbfilename "dump-6382.rdb" dir "/redis/data" ... cluster-enabled yes cluster-config-file nodes-6382.conf cluster-node-timeout 10000 -
Запускаем по- отдельности два экземпляра в
192.168.1.57и192.168.1.59:~> bin/redis-server conf/redis-6382.conf -
Добавляем и экземпляр хозяина, и экземпляр подчинённого:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6379 -c CLUSTER MEET 192.168.1.57 6382 OK redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6379 -c CLUSTER MEET 192.168.1.59 6382 OKЗамечание Если при добавлении узла появится приведённое ниже сообщение об ошибке, это указывает на то, что такой узел содержит некие данные или что файл настроек этого узла уже имеется:
[ERR] Node 192.168.145.128:6382 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.Вы можете предпринять следующие шаги для выполнения сброса в данном узле:
-
Войдите в определяемый параметром каталог
dirи удалите имеющийся файл настроек. -
При помощи
redis-cliподключитесь к требуемому узлу и вызовите командуFLUSHDB. -
Удалите все файлы
RDBиAOF.
-
-
Выведите перечень соответствующих идентификаторов двух узлов:
redis@192.168.1.57:~> script/redis-trib.rb check 192.168.1.57:6381 >>> Performing Cluster Check (using node 192.168.1.57:6381) M: 7e06908bd0c7c3b23aaa17f84d96ad4c18016b1a 192.168.1.57:6381 slots:11001-16383 (5383 slots) master 1 additional replica(s) M: a693372f4fee1b1cf2bd4cb1f4881d2caa0d7a7c 192.168.1.57:6382 slots: (0 slots) master 0 additional replica(s) ... M: 7abe13b549b66218990c9fc8e2d209803f03665d 192.168.1.59:6382 slots: (0 slots) master 0 additional replica(s) [OK] All 16384 slots covered.
-
-
Настройте необходимые репликацию для своих двух экземпляров:
redis@192.168.1.57:~> bin/redis-cli -h 192.168.1.57 -p 6382 -c CLUSTER REPLICATE 7abe13b549b66218990c9fc8e2d209803f03665d OK -
Проверьте взаимодействие полученной репликации:
redis@192.168.1.57:~> script/redis-trib.rb check 192.168.1.57:6381 >>> Performing Cluster Check (using node 192.168.1.57:6381) ... S: a693372f4fee1b1cf2bd4cb1f4881d2caa0d7a7c 192.168.1.57:6382 slots: (0 slots) slave replicates 7abe13b549b66218990c9fc8e2d209803f03665d M: 7abe13b549b66218990c9fc8e2d209803f03665d 192.168.1.59:6382 slots: (0 slots) master 1 additional replica(s) ... [OK] All 16384 slots covered. -
Выполните миграцию
500слотов из своего экземпляраI_Aв новый, только что добавленный экземпляр:redis@192.168.1.57:~> script/redis-trib.rb reshard --from bc7b4a0c4596759058291f1b8f8de10966b5a1d1 --to 7abe13b549b66218990c9fc8e2d209803f03665d --slots 100 --yes 192.168.1.57:6379 >>> Performing Cluster Check (using node 192.168.1.57:6379) ... M: 7abe13b549b66218990c9fc8e2d209803f03665d 192.168.1.59:6382 slots: (0 slots) master 0 additional replica(s) ... S: a693372f4fee1b1cf2bd4cb1f4881d2caa0d7a7c 192.168.1.57:6382 slots: (0 slots) slave replicates bc7b4a0c4596759058291f1b8f8de10966b5a1d1 ... [OK] All 16384 slots covered. Ready to move 100 slots. Source nodes: M: bc7b4a0c4596759058291f1b8f8de10966b5a1d1 192.168.1.59:6379 slots:0-5400 (5401 slots) master 2 additional replica(s) Destination node: M: 7abe13b549b66218990c9fc8e2d209803f03665d 192.168.1.59:6382 slots: (0 slots) master 0 additional replica(s) Resharding plan: Moving slot 0 from bc7b4a0c4596759058291f1b8f8de10966b5a1d1 Moving slot 1 from bc7b4a0c4596759058291f1b8f8de10966b5a1d1 Moving slot 2 from bc7b4a0c4596759058291f1b8f8de10966b5a1d1 ... Moving slot 0 from 192.168.1.59:6379 to 192.168.1.59:6382: .. ... Moving slot 98 from 192.168.1.59:6379 to 192.168.1.59:6382: ... Moving slot 99 from 192.168.1.59:6379 to 192.168.1.59:6382: -
Опять проверьте свой Кластер:
redis@192.168.1.57:~> script/redis-trib.rb check 192.168.1.57:6381 >>> Performing Cluster Check (using node 192.168.1.57:6381) ... S: a693372f4fee1b1cf2bd4cb1f4881d2caa0d7a7c 192.168.1.57:6382 slots: (0 slots) slave replicates bc7b4a0c4596759058291f1b8f8de10966b5a1d1 M: 7abe13b549b66218990c9fc8e2d209803f03665d 192.168.1.59:6382 slots:0-99 (100 slots) master 1 additional replica(s) ... [OK] All 16384 slots covered.
Удалите некий фрагмент (shard, и экземпляр хозяина, и экземпляр подчинённого) в исполняющемся Кластере:
-
Удалите имеющийся узел подчинённого:
redis@192.168.1.57:~> script/redis-trib.rb del-node 192.168.1.57:6379 a693372f4fee1b1cf2bd4cb1f4881d2caa0d7a7c >>> Removing node a693372f4fee1b1cf2bd4cb1f4881d2caa0d7a7c from cluster 192.168.1.57:6379 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node. -
Выполните миграцию всех слотов, размещённых в том хозяине, который вы намереваетесь удалить:
redis@192.168.1.57:~> script/redis-trib.rb reshard --to bc7b4a0c4596759058291f1b8f8de10966b5a1d1 --from 7abe13b549b66218990c9fc8e2d209803f03665d --slots 100 --yes 192.168.1.57:6379 -
Удалите этот узел хозяина:
redis@192.168.1.57:~> script/redis-trib.rb del-node 192.168.1.57:6379 7abe13b549b66218990c9fc8e2d209803f03665d >>> Removing node 7abe13b549b66218990c9fc8e2d209803f03665d from cluster 192.168.1.57:6379 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node. -
Проверяем значение состояния своего Кластера:
redis@192.168.1.57:~> script/redis-trib.rb check 192.168.1.57:6381
Показанные в предыдущем разделе команды достаточно хорошо сами себя поясняют. Один момент, о котором вам следует знать, состоит в том, что пока переписываемые слоты меняют положение фрагмента с узла на узел, запросы на запись и чтение в данном Кластере не будут выполняться.
Из- за ограниченности размеров данной книги мы не представляем такие команды как CLUSTER ADDSLOTS,
CLUSTER DELSLOTS и CLUSTER SETSLOT. На самом деле, понимание того
как работают эти команды очень полезно когда наступает время разобраться с тем как выполнять операции изменения фрагментов без воздействия на
обработку запросов.
В своём рецепте Миграция данных в Главе 9, Администрирование Redis мы покажем как выполнять миграцию данных из отдельного экземпляра Redis в некий Кластер Redis.
Относительно команд в Кластере Redis вы можете применять справочные материалы из официальной документации: https://redis.io/commands#cluster
Также вы можете получить дополнительную информацию о сценарии redis-trib.rb с помощью параметра
help.