Раздел 1. Знакомство с Rust
В этом разделе мы ухватим понимание Rust. Вместо того чтобы знакомить с основами Rust, такими как циклы и функции, мы рассмотрим специфичный для Rust синтаксис. После этого мы рассмотрим вводимые языком программирования Rust ухищрения, в первую очередь связанные с управлением памятью. Далее мы рассмотрим как управлять зависимостями и выполнять структуризацию нашего кода по множеству файлов. После этого мы поэкспериментируем с многопоточностью и многопроцессностью в Rust и Python.
Данный раздел содержит следующие главы:
Глава 1. Введение в Rust с точки зрения Python
Содержание
- Глава 1. Введение в Rust с точки зрения Python
По причине его скорости и безопасности, неудивительно что Rust стал новым языком программирования, набирающим популярность. Однако за успехом поспевает и критика. Несмотря на популярность Rust в качестве впечатляющего языка, он также обрёл ярлык сложного для изучения, понятие, которое не совсем соответствует действительности.
В этой главе мы рассмотрим все особенности Rust, которые будут внове разработчикам Python. Если Python является вашим основным языком программирования, такие понятия как управление памятью и типизация могут сначала замедлять вашу способность быстро писать производительный код на Rust по той причине, что компилятор отказывает в компиляции кода. Однако это можно быстро преодолеть, изучив правила, касающиеся функций Rust, таких как владение переменными, время жизни и т.п.,поскольку Rust является языком программирования безопасной памяти. Таким образом, мы обязаны следить за своими переменными, так как они обычно мгновенно удаляются при выходе за пределы области видимости. Если сказанное для вас пока не имеет смысла, не волнуйтесь; мы рассмотрим эту концепцию в соответствующем разделе Отслеживание областей действия и времени жизни.
В данной главе мы также рассмотрим необходимые основы синтаксиса, в то время как в нашей следующей главе вы будете настраивать в своём компьютере среду Rust. Не беспокойтесь, однако, вы сможете кодировать все имеющиеся в этой главе примеры на бесплатной интернет площадке воспроизведения Rust.
В частности, в этой главе мы рассмотрим следующие вопросы:
-
Понимание отличий между Python и Rust
-
Основы владения переменными
-
Отслеживание сферы действия и времени жизни
-
Построение структур в противоположность объектам
-
Метапрограммирование при помощи макросов вместо декораторов
Поскольку это только введение, все приводимые примеры Python из этой главы могут реализовываться при помощи бесплатного интернет интерпретатора Python, например, https://replit.com/languages/python3.
То же самое и относительно всех примеров Rust. Они могут быть реализованы в бесплатной интернет площадке воспроизмедения Rust в https://play.rust-lang.org/.
Весь обсуждаемый в этой главе код можно отыскать в https://github.com/PacktPublishing/Speed-up-your-Python-with-Rust/tree/main/chapter_one.
Порой Rust может описываться как яязык системного программирования. В результате он может помечаться инженерами программного обеспечения неким аналогичным C++ образом: быстрый, сложный для изучения, опасный и трудоёмкий для написания кода. В итоге, большинство из вас в основном работающих с динамическими языками программирования, такими как Python, могут отталкивать от себя эту идею. Тем не менее, Rust является безопасным для памяти, действенен и производителен. Как только мы преодолеем некоторые вводимые Rust причуды, ничто не удержит вас от применения преимуществ Rust для написания быстрого, безопасного и эффективного кода. Поскольку у Rust столь много преимуществ, мы исследуем их в своём следующем разделе.
Когда речь заходит о выборе языка программирования, как правило, существует некий компромисс между ресурсами, скоростью и временем разработки. Подобные Python динамические языки программирования становятся популярными по мере роста вычислительной мощности. Мы смогли применять имевшиеся у нас дополнительные ресурсы для управления своей памятью при помощи сборщиков мусора. В результате разработка программного обеспечения упростилась, стала быстрее и безопаснее. Как мы позднее рассмотрим в своём разделе Отслеживание областей действия и времени жизни, плохое управление памятью может приводить к некоторым недостаткам в отношении безопасности. Экспоненциальный рост вычислительной мощности с годами известен как закон Мура. Однако он не продолжается и в 2019 году генеральный директор nVidia Дженсен Хуанг предположил, что по мере того, как компоненты микросхем приближаются к размеру отдельных атомов, становится всё тяжелее угоняться за темпами закона Мура, тем самым заявляя о его кончине (https://github.com/PacktPublishing/Speed-up-your-Python-with-Rust/tree/main/chapter_one).
Тем не менее, с появлением Больших данных для удовлетворения наших потребностей растёт и потребность в более быстрых языках программирования. Именно это приводит к появлению таких языков программирования как Golang и Rust. Эти языки безопасны для памяти, но они компилируют и обладают значительным увеличением в скорости. Что делает Rust ещё более уникальным, так это то, что ему удалось обеспечить безопасность памяти без сборки мусора. Чтобы быстрее с этим разобраться, давайте кратко опишем сборку мусора: именно при ней ваша программа временно приостанавливается, проверяет все свои переменные на предмет обнаружения какие из них более не применяются и удаляет те, которые не используются. Учитывая что Rust не должен осуществлять такого, это выступает значительным преимуществом, поскольку Rust не нуждается в продолжении остановок для очистки своих переменных. Это было продемонстрировано в блог посте Discord в 2000 году Почему Discord переходит с Go на Rust. Из этого сообщения мы можем увидеть, что Golang просто не поспевает за Rust, как это демонстрирует приводимый ниже график:
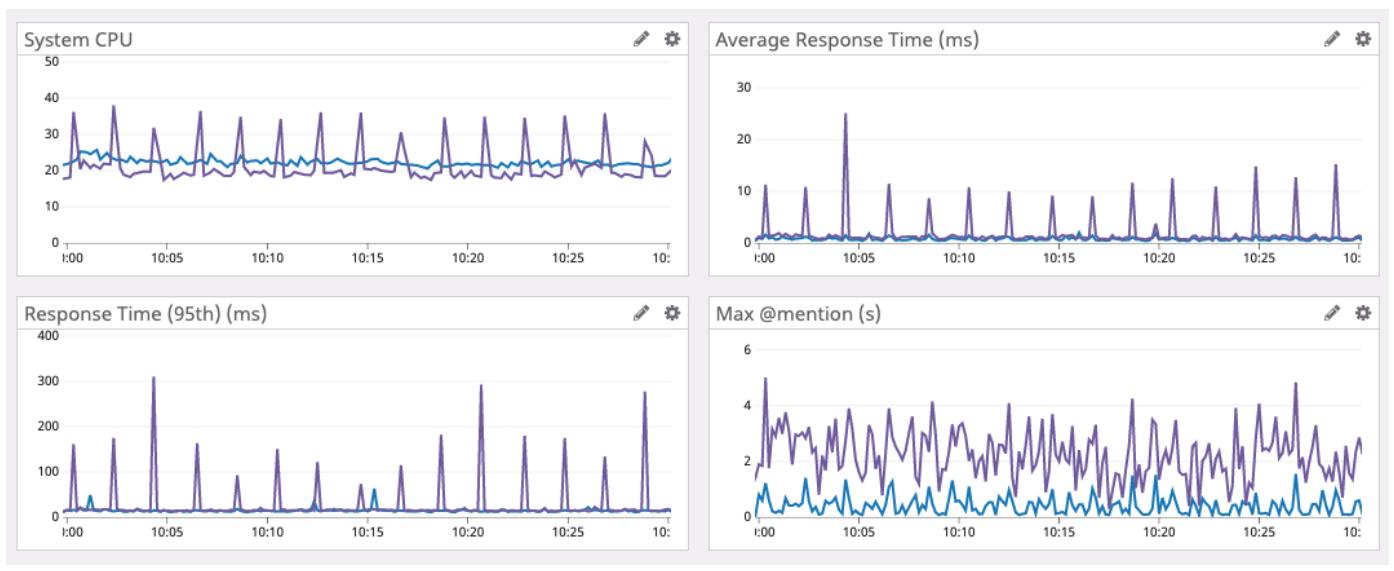
В комментариях к этому посту было полно народу, который выражал недовольство тем, что Discord применял устаревшую версию Golang. Discord ответил на это, что они пробовали разные версии Golang и все они дали одинаковые результаты. При этом имеет смысл получать лучшее из обоих миров без каких бы то ни было компромиссов. Мы можем применять Python для прототипирования и сложной логики. Широкий спектр сторонних библиотек, которые Python сочетает с поддерживаемым им гибким объектно- ориентированным программированием, делает его идеальным языком для решения практических задач. Однако это является медленным и не эффективным в отношении использования ресурсов. И именно тут мы тянемся к Rust.
Rust слегка более ограничен в том как мы можем размещать и структурировать свой код; однако он быстрый, безопасный и
действенный при организации многопоточности. Сочетание этих двух языков позволяет разработчику Python обладать мощным
инструментом, который можно в случае необходимости применять в коде Python. Временные затраты на необходимость изучение и
сплавление с Rust невелико. Всё что нам требуется, это упаковать Rust и установить его в нашей системе Python при помощи
pip и разобраться с некоторыми особенностями Rust, которые отличаются от Python.
Мы можем приступить к данному путешествию с рассмотрения в своём следующем разделе того, как Rust обрабатывает строки.
Однако, прежде чем мы приступим к изучению строк, нам для начала надо разобраться с тем как работает Rust по сравнению с
Python.
Если вы собирали веб- приложение на Python при помощи Flask, вы наблюдали во множестве руководств забавы со следующим кодом:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def home():
return "Hello, World!"
if __name__ == "__main__":
app.run(debug=True)
На что нам следует обратить внимание здесь, так это самые последние две строки этого кода. Всё что выше, определяет базовые прикладное веб- приложение и маршрут Flask. Однако запуск данного прикладного приложения в последних двух строках исполняется лишь тогда, когда наш интерпретатор Python напрямую запускает это файл. Это означает, что прочие файлы Python могут импортировать это прикладное приложение Flask из данного файла без его исполнения. Многими это именуется как некая точка входа.
Вы импортируете в этот файл всё что вам требуется, а для запуска данного приложения мы заставляем свой интерпретатор
исполнять этот сценарий. В свою строку кода if __name__ == "__main__":
мы можем вкладывать любой код. Он не будет исполнен до тех пор, пока этот файл напрямую не попадает в свой интерпретатор Python.
Rust обладает аналогичной концепцией. Тем не менее, именно это более существенно в нём, по сравнению с Python, где это просто
полезная функциональная особенность. На площадке воспроизведения Rust (см. наш раздел
Технические требования), мы можем набрать приводимый ниже код, если его там
ещё нет:
fn main() {
println!("hello world");
}
Это наша точка входа. Наша программа Rust компилируется и затем выполняет свою функцию main.
Если что бы вы не закодировали не доступно из вашей функции main, это никогда не будет
исполнено. Здесь мы уже приобрели некое ощущение той безопасности, к которой принуждает Rust. На протяжении данной книги мы
обнаружим много чего подобного этому.
Теперь, когда мы заставили свою программу исполняться, мы можем перейти к осознанию тех отличий, которые имеются между Rust и Python, когда речь заходит о строках.
В Pyton строки (strings) являются гибкими. Мы можем делать с
ними всё что пожелаем. Хотя технически говоря, под капотом, строки Python не могут изменяться, в синтаксисе Python мы способны
кромсать и изменять их, передавать их куда угодно и преобразовывать их в целые или плавающие числа (когда это допустимо), не
особенно об этом задумываясь. Всё это мы можем делать также и в Rust. Тем не менее, мы обязаны заранее запланировать что мы
намерены делать. Чтобы продемонстрировать это, мы можем непосредственно погрузиться, создав свою собственную функцию
print и вызвать её как это видно в нашем следующем коде:
fn print(input: str) {
println!("{}", input);
}
fn main() {
print("hello world");
}
В Python аналогичная программа сработала бы. Однако когда мы запускаем её с площадки воспроизведения Rust, мы получаем такую ошибку:
error[E0277]: the size for values of type 'str' cannot be known at compilation time
Это происходит по той причине, что мы не определили значение максимального размера. У нас нет такого в Python; следовательно,
мы должны вернуться на шаг назад и разобраться с тем как переменные назначаются в памяти. При компиляции вашего кода, для различных
переменных в имеющемся стеке выделяется память. Когда код исполняется, он сохраняет данные в своей куче. Строки могут быть
различной длины, поэтому мы не можем быть уверены на момент компиляции сколько памяти мы можем выделить для своего параметра
input нашей функции при компиляции. То что мы передаём вовнутрь, это срез строки
(string slice). Мы можем исправить это, передав строку и
преобразовав свой строковый литерал, прежде чем передавать его в нашу функцию, как это показано здесь:
fn print(input: String) {
println!("{}", input);
}
fn main() {
let string_literal = "hello world";
print(string_literal.to_string());
}
Здесь мы можем наблюдать, что мы воспользовались функцией to_string() для
преобразования своего строкового литерала в строку. Чтобы разобраться почему принимается
String, нам потребуется понимать чем является строка.
Строка это некий тип обёртки, реализуемый как вектор байт. Такой вектор содержит ссылку на срез строки в памяти своей кучи. Далее он содержит значение количества данных, доступных для его указателя и длину своего строкового литерала. Например, когда у нас имеется значение строкового литерала one, это можно пояснить следующей схемой:
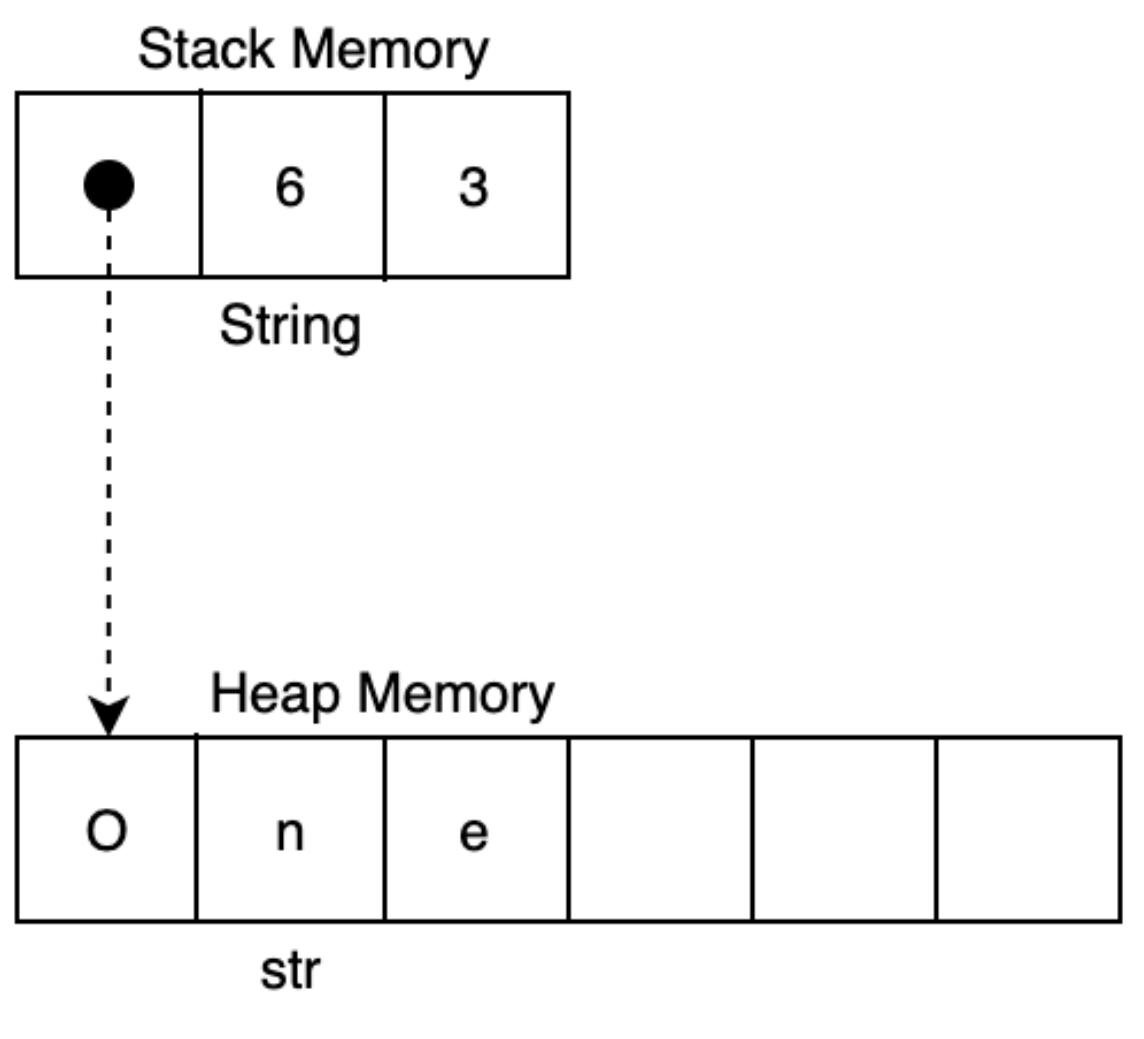
Рассмотрев это мы можем понять почему мы способны гарантировать значение размера String
при её передаче в нашу функцию. Это всегда будет указатель на сам строковый литерал с некоторыми метасведениями о самом
строковом литерале. Когда мы просто выполняем ссылку на такой строковый литерал, мы можем передать его в свою функцию как
если бы это просто ссылка и тем самым можем обеспечить что значение размера нашей ссылки всегда будет оставаться одним и тем
же. Это можно сделать путём заимствования при помощи оператора &, как это показано в нашем следующем коде:
fn print(input_string: &str) {
println!("{}", input_string);
}
fn main() {
let test_string = &"Hello, World!";
print(test_string);
}
Мы рассмотрим это понятие заимствования позднее в данной главе, однако, на данный момент, мы понимаем, что в отличии от Python
мы обязаны гарантировать значение размера той переменной, которая подлежит передаче в функцию. Для обработки этого мы можем
пользоваться заимствованием и обёртками, подобными String. Возможно, это не станет
неожиданностью, но это касается не только строк. Учитывая это, мы можем перейти к своему следующему разделу для понимания
различий между Python и Rust, когда речь заходит о числах с плавающей запятой и целых.
Как и строками, Python легко и просто управляет числами с плавающей запятой и целыми. Мы можем делать с ними всё что
заблагорассудится. Например, следующий код в результате выдаёт 6.5:
result = 1 + 2.2
result = result + 3.3
Однако, возникает проблема когда мы просто попытаемся просто вычислить свою первую строчку в Rust со следующим кодом Rust:
let result = 1 + 2.2;
Она имеет результатом ошибку, сообщающую нам что число с плавающей запятой не может прибавляться к целому. Эта ошибка высвечивает один из моментов с головной болью, через который проходят разработчики Python при изучении Rust, поскольку Rust агрессивно принуждает к типизации отвергая компиляцию когда типизация отсутствует и не согласована. Тем не менее, хотя это и вызывает головную боль, агрессивная типизация на самом деле помогает при длительных работах, поскольку поддерживает безопасность.
Аннотация типов в Python становится популярной. Именно здесь, когда объявляется значение типа переменной для параметров функций, это позволяет некоторым авторам кода подчёркивать когда типы не согласованы. То же самое происходит в JavaScript с TypeScript. Мы можем реплицировать свой код из начала этого раздела следующим кодом в Rust:
let mut result = 1.0 + 2.2;
result = result + 3.3;
Обратите внимание на то, что наша переменная result должна быть объявлена как
изменяемая (mutable) при помощи нотации
mut. Изменяемость означает, что значение переменной можно заменять. Это обусловлено
тем, что автоматически Rust назначает все значения переменных неизменными, если не применяется нотация
mut.
Теперь, когда мы рассмотрели воздействие типов и изменяемости, нам следует на практике изучить
integers и floats.
Rust обладает двумя типами целых: signed integers (целые со знаком),
которые обозначаются через i и unsigned
integers (целые без знака), обозначаемые посредством u. Целые без знака
размещают исключительно положительные числа, в то время как целые со знаком содержат и положительные, и отрицательные целые.
На этом всё не заканчивается. В Rust мы можем также обозначать значения размера дозволенного целого. Оно может вычисляться с
применением двоичных чисел. Теперь усвойте то простое правило, при помощи которого может вычисляться значение
размера через возведение в степень двойки для значения числа бит, что может дать нам понимание того, насколько большим допустимо
некое целое число. Мы можем вычислять все размеры целых чисел, которые можно использовать в Rust при помощи следующей таблицы:
| Биты | Вычисление | Размер |
|---|---|---|
8 |
2^8 |
256 |
16 |
2^16 |
65 536 |
32 |
2^32 |
4 294 967 296 |
64 |
2^64 |
1.8446744e+19 |
128 |
2^128 |
3.4028237e+38 |
Как вы можете видеть, мы способны получать здесь очень большие числа. Тем не менее, не будет самой лучшей идеей назначать
все переменные и параметры как целые числа u128. Это обусловлено тем, что ваш
компилятор будет предназначать такое количество памяти при каждой компиляции. Это не очень эффективно с учётом того, что
маловероятно что мы будем пользоваться столь большими числами. Следует обратить внимание, что изменения при каждом скачке
настолько велики, что их бессмысленно наносить на график. Каждый скачок в битах полностью затмевает все остальные, что
приводит к ровной линии вдоль оси и огромному пику на последнем отображаемом на графике количестве битов. Однако мы должны
быть уверены, что наше назначение не слишком мало. Мы можем продемонстрировать это при помощи кода на Rust следующим образом:
let number: u8 = 255;
let breaking_number: u8 = 256;
Наш компилятор будет в норме для переменной number, однако он возбудит показанную
ниже ошибку при присваивании переменной breaking_number:
literal '256' does not fit into the type 'u8' whose range
is '0..=255'
Это происходит по той причине, что между 0 -> 255 имеется 256 целых. Мы можем изменить своё целое без знака на целое со знаком при помощи такого кода Rust:
let number: i8 = 255;
Это выдаст нам следующую ошибку:
literal '255' does not fit into the type 'i8' whose range
is '-128..=127'
При этой ошибке нам напоминают, что в пространстве памяти выделено указанное число бит. Следовательно, целое число
i8 должно содержать и положительные, и отрицательные числа в пределах того же самого
числа битов. В результате мы можем поддерживать только величину, которая составляет половину целого числа без знака.
Когда речь заходит о числах с плавающей запятой, наш выбор более ограничен. Здесь Rust размещает как
f32, так и f64 с плавающей запятой. Для объявления
переменных с плавающей запятой требуется тот же самый синтаксис, что и для целых чисел:
let float: f32 = 20.6;
Следует отметить, что мы также можем давать аннотацию чисел при помощи суффиксов, как это показано в нашем следующем коде:
let x = 1u8;
Здесь x имеет значение 1 с типом
u8. Теперь, когда мы рассмотрели числа с плавающей запятой и целые, мы можем применять
для их хранения векторы и массивы.
В Python у нас имеются списки (list). Такие списки мы можем набивать чем нам угодно при помощи функции
append и такие списки, по умолчанию, изменяемые. Кортежи (tuple) Python, технически
говоря, не списки, однако мы можем рассматривать их как неизменные массивы. В Rust у нас имеются массивы
(array) и векторы
(vector). Массивы наиболее базовые из этих двух. Определение
массивов и выполнение по ним циклов достаточно простое в Rust, что мы можем видеть в своём следующем коде:
let array: [i32; 3] = [1, 2, 3];
println!("array has {} elements", array.len());
for i in array.iter() {
println!("{}", i);
}
Если мы попробуем добавить другое целое число в наш массив при помощи функции push,
мы не сможем этого сделать, даже когда наш массив изменяемый. Когда мы добавляем в определение своего массива четвёртый элемент,
который не является целым числом, нашей программе будет отказано в компиляции, поскольку все элементы в нашем массиве обязаны
быть одинаковыми. Однако это не целиком так.
Позднее в этой главе мы рассмотрим struct (структуры). В Python ближайшим сопоставлением объектам выступают структуры, поскольку они обладают собственными атрибутами и функциями. Структуры также способны обладать trait (признаками), которые мы также обсудим позднее. В терминах Python, ближайшим сопоставлением для trait являются mixin {подмес, набор свойств и методов, которые могут применяться в различных классах, но не поставляются их базовым классом}. Таким образом, некий диапазон структур может быть размещён в массиве, когда все они обладают одним и тем же признаком (trait). При переборе такого массива ваш компилятор позволит вам выполнять функции только для этого признака, поскольку это всё что мы можем гарантировать согласованным для данного массива.
Те же самые правила с точки зрения типа или согласованности признака (trait) также применимы и к векторам
(vector). Однако, векторы помещают свою память в имеющейся
куче и расширяемы. Как и всё прочее в Rust, они, по умолчанию, неизменны. Тем не менее, применение тега
mut позволит нам выполнять добавления и манипулировать таким вектором. В своём
следующем коде мы определяем некий вектор, выводим на печать значение длины этого вектора, добавляем в конец этого вектора
другой элемент и затем выполняем цикл по такому вектору, выводя на печать все элементы:
let mut str_vector: Vec<&str> = vec!["one", "two", \
"three"];
println!("{}", str_vector.len());
str_vector.push("four");
for i in str_vector.iter() {
println!("{}", i);
}
Это предоставляет нам следующий вывод:
3
one
two
three
four
Как мы можем видеть, наше добавление в конец сработало.
Для разработчиков Python рассмотрение правил относительно согласованности, векторов и массивов может казаться слегка ограничивающим. Однако, если это так, расслабьтесь и спросите зачем? Почему вы желаете поместить в некий диапазон элементы, которые не обладают никакой согласованностью? Хотя Python и позволяет вам это делать, как бы вы могли пройтись по списку с несовместимыми элементами и уверенно выполнять над ними операции, не вызывая сбоя своей программы?
Принимая это во внимание, мы начинаем видеть те преимущества и безопасность, которая стоит за такой системой ограничительной типизации. Существуют некоторые способы, которыми мы имеем возможность помещать различные элементы которые не являются структурами, связываемыми одним и тем же признаком (trait). Учитывая это, в своём следующем разделе мы рассмотрим как мы можем хранить различные элементы данных и получать к ним доступ в Rust при помощи хэш-карт.
Хэш-карты (hashmap) в Rust это, по- существу, словари из Python. Однако, в отличии от своих предыдущих векторов и массивов мы бы хотели обладать помещаемыми в хэш-картах неким диапазоном различных типов данных (хотя мы можем также это выполнить при помощи векторов и массивов). Для достижения этого мы можем воспользоваться Enum (перечислением). Enum это, ну да, перечисление и у нас имеется точно то же понятие в Python. Однако вместо того чтобы представлять собой некий Enum, у нас просто имеется некий объект Python, который наследует соответствующий объект Enum, как это показано в нашем следующем коде:
from enum import Enum
class Animal(Enum):
STRING = "string"
INT = "int"
Здесь мы применяем Enum чтобы уберечь нас от использования сырых строк в нашем коде Python когда мы цепляемся к определённой категории. Для редактора кода, называемого IDE, это очень полезно, но совершенно ясно, если разработчик Python никогда не применял это, поскольку это нигде не применяется. Отсутствие его применения превращает код в более подверженный ошибкам и его труднее сопровождать при изменении категорий и тому подобному, однако в Python ничто не мешает разработчику просто пользоваться сырой строкой для описания некого варианта. В Rust мы хотим, чтобы наша хэш-карта принимала строки и целые. Для этого нам придётся выполнить следующие шаги:
-
Для обработки множества типов данных создать некий Enum.
-
Создать новую хэш-карту и вставить значения, относящиеся к тому Enum, что мы создали на Шаге 1.
-
Проверить согласованность имеющихся данных через последовательность этой хеш-карты и отметки всех возможных результатов.
-
Сборку функции, которая обрабатывает выделенные из этой хэш-карты данные.
-
Применить эту функцию для обработки результатов для полученных из нашей хеш-карты значений.
Таким образом, мы намерены создать Enum, который размещает это при помощи следующего кода:
enum Value {
Str(&'static str),
Int(i32),
}
Здесь мы можем наблюдать что нам пришлось ввести соответствующий оператор 'static. Это
обозначает некое время жизни и в целом постулирует, что эта
ссылка остаётся до самого конца времени жизни этой программы. Времена жизни мы поясняем в своём разделе Отслеживание областей действия и времени жизни.
Теперь, когда мы определили свой Enum, мы можем собрать свою собственную изменяемую хеш-карту и вставить некое целое число и строку туда при помощи следующего кода:
use std::collections::HashMap;
let mut map = HashMap::new();
map.insert("one", Value::Str("1"));
map.insert("two", Value::Int(2));
Теперь, когда наша хеш-карта содержит один тип, содержащий два определённых нами типа, нам следует их обработать.
Помните, что Rust обладает строгой типизацией. В отличие от Python, Rust не позволяет нам компилировать лишённый
безопасности код (Rust имеет возможность компиляции в небезопасном контексте, но это не установленное по умолчанию
поведение). Мы обязаны обрабатывать все возможные результаты, иначе наш компилятор откажет при компиляции. Мы можем выполнить
это при помощи оператора match, как это показано в следующем коде:
for (_key, value) in &map {
match value {
Value::Str(inside_value) => {
println!("the following value is an str: {}", \
inside_value);
}
Value::Int(inside_value) => {
println!("the following value is an int: {}", \
inside_value);
}
}
}
В этом образце кода мы обошли последовательность по заимствованной ссылке на соответствующую хэш-карту при помощи &.
И снова, мы рассмотрим заимствование позднее в нашем разделе Основы владения
переменной. Мы предваряем префиксом _ свой key.
Это сообщает нашему компилятору что мы не намерены применять этот ключ. Нам нет нужды делать это, так как наш компилятор всё
равно скомпилирует необходимый код тем не менее, он будет выражать недовольство, выдавая предупреждение. То значение, которое
мы извлекаем из своей хэш-карты, является нашим значением Enum. В данном операторе match
мы можем устанавливать соответствие тому полю своего Enum, развернуть внутреннее значение, которое мы обозначаем как
inside_value, выводя его на свою консоль, и получить к нему доступ.
Исполнение данного кода предоставляет нам вывод в наш терминал следующим образом:
the following value is an int: 2
the following value is an str: 1
Следует отметить, что Rust ничего не упустит для своего компилятора. Когда мы удаляем соответствие для своего поля
int нашего Enum, тогда наш компилятор возбудит ту ошибку, которую мы наблюдаем тут:
18 | match value {
| ^^^^^ pattern '&Int(_)' not covered
|
= help: ensure that all possible cases are being
handled,
possibly by adding wildcards or more match arms
= note: the matched value is of type '&Value'
Это происходит по той причине, что нам приходится обрабатывать все возможные по отдельности результаты. Поскольку мы
указываем в явном виде, что в в нашу хэш-карту могут вставляться только значения, которые способны размещаться в нашем Enum,
мы знаем, что имеются лишь два возможных типа, которые можно извлекать из нашей хэш-карты. Мы почти всё необходимое рассказали
про хэш-карты, чтобы действенно применять их в программах Rust. Последнее понятие, которое нам надлежит рассмотреть, это Enum
с названием Option.
Учитывая то, что у нас имеются массивы и векторы, мы не будем применять свои хэш-карты в первую очередь для циклического
перебора результатов. Вместо этого мы будем извлекать их значения по мере необходимости в них. Как и в Python, хэш-карта
обладает функцией get. В Python, когда соответствующий найденный ключ не имеется в
нашем словаре, тогда наша функция get возвратит None.
Затем это отдаётся на откуп самому разработчику что с этим предпринимать. Тем не менее, в Rust наша хэш-карта будет возвращать
Some или None. Для демонстрации этого давайте
попробуем получить значение для ключа, о котором нам известно, что его нет:
-
Начинаем исполнять следующий код:
let outcome: Option<&Value> = map.get("test"); println!("outcome passed"); let another_outcome: &Value = \ map.get("test").unwrap(); println!("another_outcome passed");Здесь мы можем наблюдать, что наша ссылка на соответствующее
ValueEnum обёртывается вOptionпри помощи нашей функцииget. Затем мы напрямую выполняем доступ по самой ссылке к томуValueEnum, которое применяется функциейunwrap. -
Однако мы знаем, что этого ключа
testнет в нашей хэш-карте. По этой причине соответствующая функцияunwrapвызывает крушение нашей программы, что видно из вывода нашего предыдущего кода:thread 'main' panicked at 'called 'Option::unwrap()' on a 'None' value', src/main.rs:32:51Мы можем видеть, что наша простая функция
getне рушит нашу программу. Тем не менее, мы не управляем получением соответствующей строки"another_outcome passed"при выводе на печать в нашей консоли. Мы имеем возможность обрабатывать это при помощи оператораmatch.Тем не менее, это будет оператор
matchвнутри оператораmatch. -
Для снижения сложности нам следует изучить функции Rust для обработки своего
valueEnum. Это можно выполнить при помощи такого кода:fn process_enum(value: &Value) -> () { match value { Value::Str(inside_value) => { println!("the following value is an str: \ {}", inside_value); } Value::Int(inside_value) => { println!("the following value is an int: \ {}", inside_value); } } }Данная функция на практике не снабжает нас никакой новой логикой для изучения. Выражение
-> ()просто постулирует что эта функция не возвращает ничего. -
Когда мы намерены возвращать некую строку, например, таким выражением должно быть
-> String. У нас нет нужды в выражении-> (); однако это может быть полезно разработчикам чтобы быстро разобраться что происходит с этой функцией. Затем мы можем применять эту функцию для обработки получаемого из нашей функцииgetвывода при помощи такого кода:match map.get("test") { Some(inside_value) => { process_enum(inside_value); } None => { println!("there is no value"); } }
Теперь мы достаточно информированы про применение хэш-карт в своих программах. Однако, нам следует отметить, что что мы на
самом деле не обрабатывали ошибки; мы просто выводили на печать что ничего не было найдено или что наша функция
unwrap просто возвращает некую ошибку. Принимая это во внимание, мы переходим в своём
следующем разделе к обработке ошибок в Rust.
Обработка ошибок в Python простая. У нас имеется блок try, который размещает под
собой блок except. В Rust у нас имеется обёртка Result.
Она работает точно так же как Option. Однако вместо
Some или None у нас есть
Ok или Err.
Для того чтобы продемонстрировать это мы можем построить такую хэш-карту, которая была определена в нашем предыдущем
примере. Мы принимаем Option из функции get,
применяемой к значению хэш-карты. Наша функция проверит чтобы убедиться чт значение целого числа из её хэш-карты выше
порогового значения. Когда оно выше значения порога, мы возвращаем true. Если это не
так, возвращается false.
Основная проблема возникает когда в Option может отсутствовать значение. К тому же нам
известно, что Enum Value может быть не целым. В любом из таких случаев нам надлежит
вернуть ошибку. Если это не так, мы возвращаем Булево значение. Здесь можно увидеть такую функцию:
fn check_int_above_threshold(threshold: i32,
get_result: Option<&Value>) -> Result<bool, &'static \
str> {
match get_result {
Some(inside_value) => {
match inside_value {
Value::Str(_) => return Err(
"str value was supplied as opposed to \
an int which is needed"),
Value::Int(int_value) => {
if int_value > &threshold {
return Ok(true)
}
return Ok(false)
}
}
}
None => return Err("no value was supplied to be \
checked")
}
}
Здесь мы можем видеть что результат None из Option
немедленно возвращает ошибку с полезным сообщением относительно того почему мы возвращаем ошибку. При значении
Some мы пользуемся другим оператором match
для возврата ошибки с полезным сообщением, что мы не способны поддерживать строку для проверки своего порогового значения
в случае строкового Value. Следует обратить внимание на то, что
Value::Str(_) имеет внутри _. Это означает, что
мы не заботимся о том каково само значение, поскольку мы не намерены применять его. В своей заключительной части мы проверяем
будет ли наше целое выше порогового значения, возвращая значения OK, которыми
являются либо true, либо false. Мы реализуем эту
функцию при помощи такого кода:
let result: Option<&Value> = map.get("two");
let above_threshold: bool = check_int_above_threshold(1, \
result).unwrap();
println!("it is {} that the threshold is breached", \
above_threshold);
Это выдаёт в нашем терминале такой вывод:
it is true that the threshold is breached
Если мы установим свой первый параметр в функции check_int_above_threshold в
3, мы получаем следующий вывод:
it is false that the threshold is breached
Если мы изменим значение ключа в map.get на three,
мы получаем такой терминальный вывод:
thread 'main' panicked at 'called 'Result::unwrap()'
on an 'Err' value: "no value was supplied to be checked"'
Когда мы заменяем значение ключа в map.get на one,
мы получаем такой терминальный вывод:
thread 'main' panicked at 'called 'Result::unwrap()' on
an 'Err' value: "str value was supplied as opposed to an
int
К своему развёртыванию мы можем добавить дополнительные указатели при помощи функции expect.
Эта функция развёртывает полученный результат и добавляет некое дополнительное сообщение для вывода на печать когда имеется
какая- то ошибка. К такому сообщению об ошибке пр помощи следующей реализации будет добавлено сообщение
"an error happened":
let second_result: Option<&Value> = map.get("one");
let second_threshold: bool = check_int_above_threshold(1, \
second_result).expect("an error happened");
К тому же мы можем непосредственно возбудить ошибку при помощи такого кода:
panic!("throwing some error");
При помощи функции is_err мы можем проверить будет ли наш результат некой ошибкой,
как это показано здесь:
result.is_err()
Это возвращает bool, позволяя нам изменять направление своей программы когда мы
пересекаем какую- то ошибку. Как мы можем видеть, Rust снабжает нас неким диапазоном способов, которым мы способны
возбуждать ошибки и управлять ими.
Теперь мы способны справляться с некими причудами Rust, что достаточно для написания базовых сценариев. Однако, когда программа становится несколько сложнее, мы попадаем в другие ловушки, такие как владение переменными и их времена жизни. В своём следующем разделе мы рассмотрим базовые принципы владения переменными с тем, чтобы мы были способны продолжать применять свои переменные в различных функциях и структурах.
Как мы указали в своём обсуждении во введении, то, почему нам следует пользоваться Rust, так это потому что Rust не обладает сборкой мусора; тем не менее, он всё ещё безопасен для памяти. Мы осуществляем это удерживая ресурсы низкими, а скорость высокой. Однако, как мы достигаем безопасности памяти без сборки мусора? Rust добивается этого принуждая к некоторым сильным правилам относительно владения переменными.
Как и при наборе текста, эти правила действуют и при компиляции вашего кода. Любое нарушение таких правил останавливает ваш процесс компиляции. Это может приводить разработчиков Python к большому разочарованию, поскольку разработчики Python любят пользоваться своими переменными всякий раз как пожелают. Когда они передают некую переменную в функцию, они также ожидают что если они пожелают, эта переменная по- прежнему может быть изменена вне такой функции. Это может приводить к проблемам при реализации одновременного исполнения. Python к тому же делает это возможным, запуская под своим капотом дорогостоящие процессы чтобы включать множество ссылок с механизмами очистки, когда на такую переменную больше нет ссылок {Прим. пер.: подробнее в нашем переводе Внутреннего устройства CPython Энтони Шоу.}
Как результат, такое несоответствие в стилях кодирования снабжает Rust фальшивым ярлыком как обладающим крутой траекторией обучения. Если мы изучим установленные правила, нам потребуется лишь слегка переосмыслить свой код, так как наш полезный компилятор позволит нам запросто их соблюдать Также вы будете удивлены тем, что данный подход не столь изобилует ограничениями, как это кажется. Проверка Rust времени компиляции выполняется для защиты от таких ошибок памяти:
-
Применение после освобождения: Это та ситуация, когда доступ к памяти осуществляется после её высвобождения, что может приводить к крушениям. Это также делает возможным для хакеров выполнять код через такие адреса памяти.
-
Висячие указатели: Это тот случай, когда указатель указывает на адрес памяти, который более не размещает тех данных, на который ссылался такой указатель. По сути, такой указатель теперь указывает null или на случайные данные.
-
Двойное освобождение: В подобной ситуации выделенная память уже высвобождена и затем освобождается снова. Это способно приводить к краху вашей программы и увеличивает риск разоблачения чувствительных данных. Это также позволяет хакерам выполнять произвольный код.
-
Отказы в сегментации: Это происходит при попытках выполнения доступа к памяти, к которой запрещён доступ.
-
Переполнение буфера: Примером этого является чтение за пределами конца массива. Это может приводить к крушений вашей программы.
Rust управляет защитой от таких ошибок, принуждая к соблюдению следующих правил:
-
Значения находятся во владении тех переменных, которым они присвоены.
-
Как только определённая переменная выходит за область своего действия, она освобождает занимаемую ею память.
-
Значения могут применяться другими переменными когда мы придерживаемся соглашений о копировании, перемещении, заимствовании без изменений и заимствовании с изменениями.
Чтобы на практике чувствовать себя уверенно при навигации по этим правилам в коде, мы более подробно изучим копирование, перемещение, заимствование без изменений и заимствование с изменениями.
В этом случае значение величины копируется. После копирования этим значением владеет ваша новая переменная, а сама имеющаяся переменная также владеет своим собственным значением:
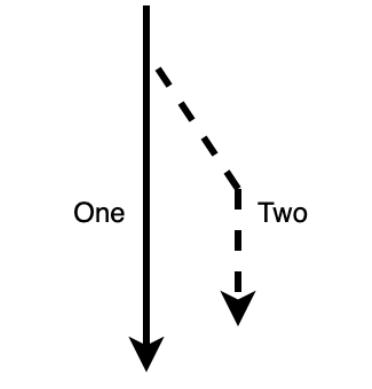
Как мы можем наблюдать при помощи схемы пути следования на Рисунке 1.3, мы можем продолжать пользоваться обеими переменными. Когда ваша переменная обладает признаком
(trait) Copy, такая переменная автоматически копирует соответствующее значение. Этого
также можно достигать следующим кодом:
let one: i8 = 10;
let two: i8 = one + 5;
println!("{}", one);
println!("{}", two);
Тот факт, что мы способны выводить на печать обе переменные, one и
two, означает, что мы знаем, что one была
скопирована и само значение этой копии применяется в two.
Copy это простейшая операция ссылки; однако, если ваша подлежащая копированию переменная
не обладает признаком Copy, тогда эта переменная должна быть перемещена. Для того чтобы
разобраться с этим, мы теперь изучим в качестве понятия перемещения.
Здесь именно само значение перемещается из одной переменной в другую. Тем не менее, в отличии от
Copy, первоначальная переменная больше не владеет этим значением:
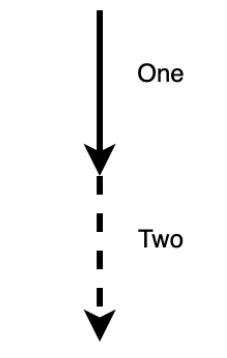
Взглянув на схему пути следования на Рисунке 1.4, мы можем
видеть, что one не может более использоваться, поскольку она подлежит перемещению в
two. В своём разделе Копирование
мы упоминали, что если наша переменная не обладает признаком (trait) Copy, тогда эта
переменная перемещается. В нашем следующем коде мы показываем это выполняя то, что мы сделали в своём разделе
Копирование, но применяя String,
поскольку она не обладает признаком Copy:
let one: String = String::from("one");
let two: String = one + " two";
println!("{}", two);
println!("{}", one);
Выполнение этого предоставляет нам такую ошибку:
let one: String = String::from("one");
--- move occurs because 'one' has type
'String', which does not implement the
'Copy' trait
let two: String = one + " two";
------------ 'one' moved due to usage in operator
println!("{}", two);
println!("{}", one);
^^^ value borrowed here after move
Именно тут во всём своём сиянии выступает наш компилятор. Он сообщает нам, что наша строка не реализует признак
Copy. Затем он показывает нам где произошло перемещение. Не удивительно, что многие
разработчики восхваляют свой компилятор Rust. Мы можем обойти это, воспользовавшись функцией
to_owned при помощи такого кода:
let two: String = one.to_owned() + " two";
Понятно почему строки не обладают признаком Copy. Это связано с тем, что строка является
указателем на срез строки. Копирование в действительности означает копирование битов. Принимая это во внимание, если бы были
способны копировать строки, у нас бы имелось множество несогласованных указателей на одну и ту же строку литеральных данных, что
было бы опасным. Когда речь идёт о перемещении данных, также играет некую роль и область действия. Чтобы изучить как область
действия оказывает влияние на перемещение, нам требуется изучить заимствования без изменений.
В этом случае переменная имеет возможность ссылаться на конкретное значение другой переменной. Когда та переменная, которая заимствует определённое значение покидает область действия, само значение не освобождает память, поскольку она не владеет самим значением такой заимствуемой переменной:
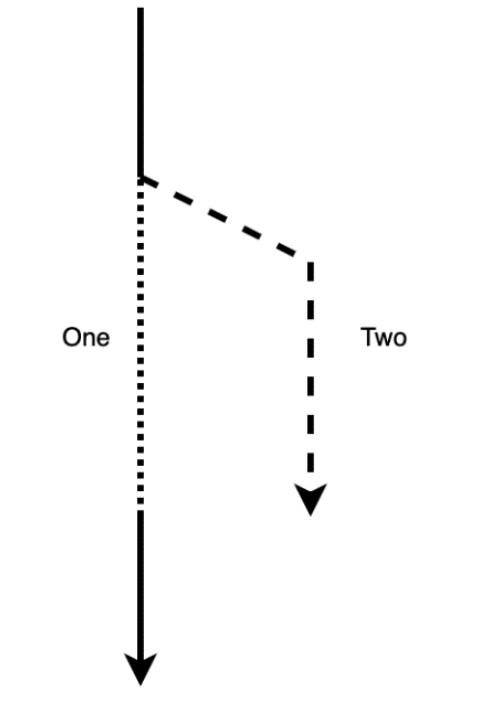
На схеме пути на Рисунке 1.5, мы можем видеть, что
two заимствует величину значения из one.
Когда это происходит, one являет вид блокировки. Мы всё ещё способны копировать и
заимствовать one, однако мы не можем заимствовать с изменением или перемещать пока
two всё ещё заимствует это значение. Это обусловлено тем, что когда мы обладаем
заимствованием с возможностью изменения и неизменное для одной и той же переменной, сами данные тапкой переменной могут
изменяться на протяжении своего заимствования с возможностью изменения, вызывая несогласованность. Принимая это во внимание,
мы можем видеть, что у нас имеется возможность одновременно обладать множеством неизменных заимствований, в то время как
за раз мы можем иметь единственным заимствованием с возможностью изменения. После завершения
two, мы снова можем делать что угодно с one. Для
демонстрации этого мы можем отыграть назад и создать свою собственную функцию print со
следующим кодом:
fn print(input_string: String) -> () {
println!("{}", input_string);
}
При помощи этого мы создаём строку и передаём её через свою функцию print. Затем мы
предпринимаем попытку и выводим на печать эту строку снова, что видно из следующего кода:
let one: String = String::from("one");
print(one);
println!("{}", one);
Если мы попробуем выполнить это, сы получим ошибку, постулирующую что one была
перемещена в нашу функцию print и, следовательно, не может использоваться в
println!. Мы можем решить это единственно принимая заимствование строки при помощи
& в нашей функции, что обозначается в нашем следующем коде:
fn print(input_string: &String) ->() {
println!("{}", input_string);
}
Теперь мы можем передать заимствованную ссылку в нашу функцию print. После этого
мы всё ещё можем выполнять доступ к своей переменной one, что видно из следующего
кода:
let one: String = String::from("one");
print(&one);
let two: String = one + " two";
println!("{}", two);
Заимствования являются безопасными и полезными. По мере роста нашей программы неизменные заимствования это безопасные способы передачи переменных через прочие функции в иные файлы. Мы дошли почти до конца своего понимания имеющихся правил. Осталось одно понятие, которое нам надлежит изучить, и это изменяемое заимствование.
В этом случае другая переменная способна ссылаться на значение иной переменной и производить в неё запись. Когда такая переменная, которая выполнила заимствование покидает область действия, для этого значение не выполняется освобождение памяти, поскольку та переменная, которая заимствовала это значение не является владельцем. В сущности, изменяемое заимствование обладает те же самым путём что и заимствование без изменения. Единственное отличие состоит в том, что на время заимствование значения его первоначальная переменная совсем не способна им пользоваться. Оно будет полностью заблокировано, поскольку это значение может быть изменено в процессе его заимствования. Такое заимствование с изменением может перемещаться в иную область действия, такую как функцию, однако не может копироваться, поскольку мы не можем обладать множеством изменяемых ссылок, как это постулировалось в нашем предыдущем разделе.
Принимая во внимание всё то, что мы обсудили для заимствования, мы обнаруживаем определённую тему. Мы можем видеть, что области действия играют большую роль в реализации самих обсуждаемых нами правил. Если не ясно понятие областей действия, поясним, передача переменной в функцию изменяет область действия, поскольку функция это своя собственная область действия. Чтобы в полной мере оценить это, нам необходимо перейти к изучению области действия и времён жизни.
В Python у нас в действительности имеется понятие области действия. Обычно она принудительно применяется в функциях.Например, мы можем вызывать определённую здесь функцию:
def add_and_square(one: int, two: int) -> int:
total: int = one + two
return total * total
В данном случае мы можем выполнять доступ к возвращаемой переменной. Однако, мы не будем способны выполнять доступ к
переменной total. Помимо этого, большинство переменных доступно по всей программе. В
Rust всё по- другому. Как и при наборе кода, Rust агрессивен с областями действия. Как только некая переменная передаётся в
какую- то область действия, она удаляется по завершению этой области действия. Rust удаётся поддерживать безопасность памяти
без выполнения сборки мусора при помощи правил заимствования. Rust удаляет все свои переменные без сборки мусора стирая все
переменные области видимости. Он также способен определять область действия при помощи фигурных скобок. Классический способ
демонстрации областей действия можно реализовать при помощи такого кода:
fn main() {
let one: String = String::from("one");
// начало внутренней области действия
{
println!("{}", &one);
let two: String = String::from("two");
}
// конец внутренней области действия
println!("{}", one);
println!("{}", two);
}
Когда мы попытаемся выполнить этот код, мы получим значение кода ошибки определяемого тут:
println!("{}", two);
^^^ not found in this scope
Мы можем видеть, что к нашей переменной one можно выполнять доступ во внутренней
области действия. Однако наша переменная two определена в нашей внутренней области
действия. Как только наша внутренняя область действия заканчивается, через выдаваемую ошибку мы можем наблюдать, что
наша переменная two пребывает вне рамок нашей внутренней области действия. Нам следует
помнить, что определяемая для функции область действия несколько строже. Из обзора правил заимствования мы знаем, что когда
мы перемещаем переменную в область действия функции, к ней нельзя выполнять доступ извне области действия такой функции когда
эта переменная не заимствована по причине её перемещения. Тем не менее, мы всё ещё изменяем переменную внутри иной области
действия, такой как функция, а затем всё ещё способны выполнять доступ к такой изменённой переменной. Для этого нам надлежит
выполнять заимствование с возможностью изменения, а затем следует разыменовать (при помощи *)
такую заимствованную с возможностью изменения переменную, изменять такую переменную, а затем выполнять доступ к этой изменённой
переменной извне данной функции, что мы можем наблюдать в своём следующем коде:
fn alter_number(number: &mut i8) {
*number += 1
}
fn print_number(number: i8) {
println!("print function scope: {}", number);
}
fn main() {
let mut one: i8 = 1;
print_number(one);
alter_number(&mut one);
println!("main scope: {}", one);
}
Это снабжает нас следующим выводом:
print function scope: 1
main scope: 2
Отсюда мы можем видеть, что когда мы не будем чувствовать проблем с заимствованием, мы можем быть гибкими и безопасными со своими переменными. Теперь, когда мы изучили понятие областей действия, это естественным образом подводит нас к временам жизни, поскольку времена жизни могут определяться областями действия. Помните, что заимствование это не только владение. По этой причине имеется риск что мы можем ссылаться на удалённую переменную. Это можно продемонстрировать следующей классической демонстрацией времени жизни:
fn main() {
let one;
{
let two: i8 = 2;
one = &two;
} // -----------------------> two lifetime stops here
println!("r: {}", one);
}
Выполнение этого кода снабжает нас такой ошибкой:
one = &two;
^^^^ borrowed value does not live long enough
} // -----------------------> two lifetime stops here
- 'two' dropped here while still borrowed
println!("r: {}", one);
--- borrow later used here
Что здесь произошло, так это то, что что мы постулируем что имеется переменная с названием
one. Затем мы определяем некое целое число two.
После этого мы назначаем one в качестве ссылки на
two. Когда мы пытаемся вывести на печать one
вне области действия, мы не можем сделать этого, поскольку та переменную, на которую была установлена ссылка удалена.
Таким образом, мы более не сталкиваемся с той проблемой, что наша переменная выходит за пределы области действия, а
проблема состоит в том, что время жизни значения, на которое указывает эта переменная более не доступно, так как это значение
удалено. Время жизни two короче времени жизни one.
Хоть и здорово что это помечается при компиляции, Rust на этом не останавливается. Это понятие также транслирует
функции. Допустим, мы создаём функцию, которая ссылается на два целых числа, сравнивает их и возвращает ссылку на наибольшее
из этих двух целых чисел. В такой функции мы можем обозначить значение времени жизни таких двух целых чисел. Это делается
при помощи префикса, который выступает нотацией времени жизни. Значения имён такого обозначения может быть любым, каким
вы только пожелаете, однако принято применять a,
b, c и так далее. Давайте рассмотрим пример:
fn get_highest<'a>(first_number: &'a i8, second_number: &'\
a i8) -> &'a i8 {
if first_number > second_number {
return first_number
} else {
return second_number
}
}
fn main() {
let one: i8 = 1;
{
let two: i8 = 2;
let outcome: &i8 = get_highest(&one, &two);
println!("{}", outcome);
}
}
Как вы можете видеть, переменные first_number и
second_number обладают одной и той же нотацией времени жизни
a. Это означает, что они обладают одним и тем же временем жизни. Так жем нам следует
обратить внимание на то, что наша функция get_highest возвращает
i8 со временем жизни a. В результате, могут
быть возвращены обе переменные first_number и
second_number , что означает что мы не можем применять переменную
outcome вне пределов внутренней области действия. Однако мы знаем, что наши времена
жизни для наших переменных one и two
отличаются. Если мы хотим воспользоваться значением переменной outcome вне своей
внутренней области действия, мы обязаны сообщить своей функции что имеются два различных времени жизни. Здесь мы можем
наблюдать такие определение и реализацию:
fn get_highest<'a, 'b>(first_number: &'a i8, second_ \
number: &'b i8) -> &'a i8 {
if first_number > second_number {
return first_number
} else {
return &0
}
}
fn main() {
let one: i8 = 1;
let outcome: &i8;
{
let two: i8 = 2;
outcome = get_highest(&one, &two);
}
println!("{}", outcome);
}
И снова, возвращается значение времени жизни a. Таким образом, значение параметра
для нашего времени жизни b может быть определено во внутренней области действия,
поскольку в данной функции мы его не возвращаем. Принимая это во внимание, мы можем наблюдать, что время жизни не существенно,
строго говоря. Мы можем писать выразительные программы не затрагивая время жизни. Однако оно выступает неким дополнительным
инструментом. Мы не должны позволять областям действия целиком ограничивать нас временем жизни.
Теперь мы пребываем на заключительной стадии того чтобы в достаточной степени быть знакомым с Rust для производительной разработки на нём. Всё с чем нам осталось разобраться теперь, так это с построением структур и управления ими при помощи макросов. После того как мы сделаем это, мы сможем перейти к своей следующей главе структурного программирования Rust. В своём следующем разделе мы и рассмотрим такое построение структур.
В Python мы пользуемся множеством объектов. На практике, всё с чем вы работаете в Python, это объект. В Rust самым ближайшим к объекту выступает структура. Для демонстрации этого давайте соберём некий объект в Python, а затем реплицируем его поведение в Rust. Например, мы построим базовую акцию, как это можно видеть в нашем следующем примере:
class Stock:
def __init__(self, name: str, open_price: float,\
stop_loss: float = 0.0, take_profit: float = 0.0) \
-> None:
self.name: str = name
self.open_price: float = open_price
self.stop_loss: float = stop_loss
self.take_profit: float = take_profit
self.current_price: float = open_price
def update_price(self, new_price: float) -> None:
self.current_price = new_price
Здесь мы можем видеть, что у нас имеются два обязательных поля, которыми выступают само название и цена данной акции. Также мы можем обладать необязательным остановом потерь (stop loss) и необязательным получением прибыли (take profit). Это означает, что когда рыночная стоимость пересекает одно из данных пороговых значений, будет форсирована продажа, а потому мы не продолжим терять деньги или позволять стоимости акции расти до того момента, в котором произойдёт её обвал. Далее у нас имеется функция, которая всего лишь обновляет текущую рыночную стоимость. В случае необходимости мы можем добавлять дополнительную логику в свои пороговые значения для возврата булева значения относительно того следует или нет продавать эту акцию. Для Rust мы определяем эти поля при помощи такого кода:
struct Stock {
name: String,
open_price: f32,
stop_loss: f32,
take_profit: f32,
current_price: f32
}
Теперь, когда у нас имеются свои поля для этой структуры, нам требуется построить соответствующий конструктор. Мы можем
собирать функции, которые относятся к нашей структуре с применением блока impl. При
помощи приводимого ниже кода мы собираем свой конструктор
impl Stock {
fn new(stock_name: &str, price: f32) -> Stock {
return Stock{
name: String::from(stock_name),
open_price: price,
stop_loss: 0.0,
take_profit: 0.0,
current_price: price
}
}
}
Здесь мы можем видеть, что мы задали некоторые значения по умолчанию для каких- то атрибутов. Для построения какого- то экземпляра мы воспользуемся таким кодом:
let stock: Stock = Stock::new("MonolithAi", 95.0);
Однако мы реплицировали свой объект Python не полностью. В Python имеется неким дополнительным параметром объект
__init__. Мы можем выполнит это путём добавления в свой блок
impl следующих функций:
fn with_stop_loss(mut self, value: f32) -> Stock {
self.stop_loss = value;
return self
}
fn with_take_profit(mut self, value: f32) -> Stock {
self.take_profit = value;
return self
}
Что мы здесь осуществляем, так это получаем свою структуру, видоизменяем поле, а затем возвращаем его. Создание новой
акции с остановом потерь включает в себя вызов нашего конструктора, за которым следует функция
with_stop_loss, как мы это можем видеть здесь:
let stock_two: Stock = Stock::new("RIMES",\
150.4).with_stop_loss(55.0);
При помощи этого наша акция RIMES будет обладать стоимостью открытия 150.4, текущей
стоимостью 150.4 и остановом потерь в 55.0. Мы
можем связывать в цепочку несколько функций, поскольку они возвращают нашу структуру акции. Затем при помощи приводимого далее
кода мы можем создать структуру акций с остановом потерь и получением прибыли:
let stock_three: Stock = Stock::new("BUMPER (former known \
as ASF)", 120.0).with_take_profit(100.0).\
with_stop_loss(50.0);
Мы можем продолжить собирать цепочку с таким множеством нужного нам числа необязательных переменных, которое нам требуется.
Это также делает для нас возможным встраивание вовнутрь логики, стоящей за такими атрибутами. Теперь, когда когда мы отсортировали
всё что требуется для нашего конструктора, нам требуется изменить свой атрибут update_price.
Это можно выполнить посредством реализации нашей приводимой ниже функции в соответствующем блоке
impl:
fn update_price(&mut self, value: f32) {
self.current_price = value;
}
Это можно реализовать таким кодом:
let mut stock: Stock = Stock::new("MonolithAi", 95.0);
stock.update_price(128.4);
println!("here is the stock: {}", stock.current_price);
Следует обратить внимание на то, что наша акция (stock) должна быть изменяемой. Наш предыдущий код предоставляет нам следующий вывод на печать:
here is the stock: 128.4
Имеется лишь одно понятие, которое следует изучить для структур и им выступают признаки. Как мы уже указывали на это ранее,
признаки аналогичны подмесам (mixin) Python. Однако trait
(признаки) могут также выступать в качестве типа данных, ибо мы знаем, что структура, обладающая определённым признаком
обладает теми функциями, которые размещаются в этом признаке. Для демонстрации этого мы можем создать признак
CanTransfer в подобном коде:
trait CanTransfer {
fn transfer_stock(&self) -> ();
fn print(&self) -> () {
println!("a transfer is happening");
}
}
Когда мы реализуем такой признак для структуры, соответствующий экземпляр такой структуры может пользоваться
функцией print. Однако наша функция transfer_stock
не обладает телом. Это означает, что нам следует определять свою собственную функцию когда та имеет то же самое возвращаемое
значение. Мы можем реализовать такой признак для своей структуры при помощи следующего кода:
impl CanTransfer for Stock {
fn transfer_stock(&self) -> () {
println!("the stock {} is being transferred for \
£{}", self.name, self.current_price);
}
}
Теперь мы можем воспользоваться своим признаком при помощи такого кода:
let stock: Stock = Stock::new("MonolithAi", 95.0);
stock.print();
stock.transfer_stock();
Это предоставит нам приводимый ниже вывод:
a transfer is happening
the stock MonolithAi is being transferred for £95
Мы можем сделать свою собственную функцию, которая будет выводить на печать и передавать нашу акцию. Она примет все структуры,
которые реализовывает наш признак CanTransfer и мы можем применять в ней все функции
этого признака, как это видно тут:
fn process_transfer(stock: impl CanTransfer) -> () {
stock.print();
stock.transfer_stock();
}
Мы можем видеть, что признаки выступают мощной альтернативой наследованию объектов; они снижают объём повторяющегося кода для структур, который помещается в одной и той же группе. Не существует предела для значения числа признаков, которые способна реализовать структура. Это делает для нас возможным подключать и отключать признаки, добавляя в наши структуры большую гибкость при сопровождении кода.
Признаки это не единственный способ коим мы способны управлять тем как взаимодействуют с остальной нашей программой структура; мы можем добиваться метапрограммирования при помощи макросов, которые мы и обсудим в своём следующем разделе.
Метапрограммирование в целом можно описать как некий способ, которым сама программа способна манипулировать собой на основании определённых инструкций. Принимая во внимание строгую типизацию Rust, одним из самых простых способов метапрограммирования выступает применение обобщений (generic). Классический пример демонстрации обобщения проводится через координаты:
struct Coordinate <T> {
x: T,
y: T
}
fn main() {
let one = Coordinate{x: 50, y: 50};
let two = Coordinate{x: 500, y: 500};
let three = Coordinate{x: 5.6, y: 5.6};
}
Что здесь происходит, так это то,что наш компилятор просматривает все применения нашей структуры на протяжении всей программы. Затем он создаёт структуры, которые обладают такими типами. Обобщения хороший способ сбережения времени и получения от компилятора написания повторяющегося кода. В то время как это самая простая форма метапрограммирования, другим видом метапрограммирования в Rust выступают макросы.
На протяжении данной главы вы обратили внимание что некоторые применяемые нами функции, например функция
println!, имеют в самом конце !. Это обусловлено
тем, что с технической точки зрения это не функция, это макрос. Символ ! обозначает
что вызову подлежит соответствующий макрос. Определение наших собственных макросов представляет собой смесь определения нашей
собственной функции и применения нотации времени жизни в операторе match внутри
такой функции. Для демонстрации этого мы можем определить свой собственный макрос, который превращает в заглавный первый символ
в проходящей через него строке при помощи такого кода:
macro_rules! capitalize {
($a: expr) => {
let mut v: Vec<char> = $a.chars().collect();
v[0] = v[0].to_uppercase().nth(0).unwrap();
$a = v.into_iter().collect();
}
}
fn main() {
let mut x = String::from("test");
capitalize!(x);
println!("{}", x);
}
Вместо применения терма fn, который используется для определения функций, мы
воспользовались macro_rules!. Затем мы сообщили что
$a это то выражение, которое передаётся в наш макрос. После этого мы получили
соответствующее выражение, преобразовали его в вектор символов, перевели в верхний регистр самый первый символ и после
этого преобразовали это обратно в строку. Следует отметить, что такой определённый нами макрос вовсе ничего не возвращает,
на самом деле мы не назначаем никакой переменной при вызове своего макроса в своей функции main.
Тем не менее, когда мы выводим на печать значение переменной x в самом конце своей функции
main, она озаглавлена. Таким образом, мы заключаем, что наш макрос изменил значение
состояния этой переменной.
Однако нам следует помнить, что макросы - это крайняя мера. Наш пример показывает, что наш макрос изменяет значение
состояния даже когда это напрямую не продемонстрировано в нашей функции main. По мере
роста сложности программ мы можем столкнуться с большим числом хрупких, сильно связанных процессов, о которых мы не знаем.
Если мы изменим один момент, это может сломать пять прочих вещей. Для превращения в заглавную первой буквы лучше просто создать
функцию, которая и выполняет это, возвращая строковое значение.
Макросы не просто останавливаются на том, что мы рассмотрели, они также обладают в точности тем же эффектом, что и наши декораторы в Python. Для демонстрации этого давайте снова посмотрим на свои координаты. Мы можем сгенерировать свою собственные координаты и затем передать её через функцию чтобы её можно было перемещать. Затем мы попытаемся вывести на печать свои координаты извне этой функции при помощи такого кода:
struct Coordinate {
x: i8,
y: i8
}
fn print(point: Coordinate) {
println!("{} {}", point.x, point.y);
}
fn main() {
let test = Coordinate{x: 1, y:2};
print(test);
println!("{}", test.x)
}
Будет ожидаемым что Rust откажет в компиляции этого кода по причине того, что наши координаты были перемещены в
соответствующую область действия созданной нами функции print и таким образом мы
не можем применять её в своём окончательном println!. Мы могли бы заимствовать
эти координаты и передать их через эту функцию. Однако имеется и иной способ, которым мы можем это осуществить. Помните,
что целые числа могут без проблем передаваться через функции потому как они обладают признаком
Copy. Теперь мы могли бы попробовать написать признак Copy
самостоятельно, но это было бы слишком криво и потребовало бы специальных знаний. К счастью для себя, мы можем реализовать
признаки Copy и Clone воспользовавшись макросом
derive при помощи такого кода:
#[derive(Clone, Copy)]
struct Coordinate {
x: i8,
y: i8
}
При этом наш код работает, поскольку мы копируем свои координаты при их передаче через функцию. Макросы могут применяться многими пакетами от последовательного упорядочения JSON (JavaScript Object Notation) до целых веб инфраструктур. И на самом деле, вот классический пример исполнения базового сервера в инфраструктуре Rocket:
#![feature(proc_macro_hygiene, decl_macro)]
#[macro_use] extern crate rocket;
#[get("/hello/<name>/<age>")]
fn hello(name: String, age: u8) -> String {
format!("Hello, {} year old named {}!", age, name)
}
fn main() {
rocket::ignite().mount("/", routes![hello]).launch();
}
Именно это является поразительным сходством с примером приложения Flask Python в самом начале нашей главы. Этот макрос действует в точности так же как наши декораторы в Python, что и не удивительно, поскольку декораторы в Python выступают неким видом метапрограммирования, при котором обёртывается функция.
На этом мы завершаем наше краткое введение в язык Rust для разработчиков Python. Теперь мы можем перейти к другим понятиям, таким как структурирование нашего кода и создание полноценных программ на Rust.
В этой главе мы исследовали роль Rust в современном ландшафте, показав, что позиция Rust, меняющая парадигму, является результатом того, что он безопасен в отношении памяти, при этом избавившись от сборки мусора. Благодаря этому мы осознали почему он превосходит большинство языков программирования (включая Golang), когда речь заходит о скорости. Затем мы рассмотрели особенности Rust, связанные со строками, временем жизни, управлением памятью и типизацией, поэтому мы можем в качестве разработчиков Python писать действенный код на Rust. Далее мы рассмотрели структуры и признаки (trait) до такой степени, что смогли имитировать базовую функциональность объекта Python с подмешиванием (mixin), применяя его признаки (trait) в качестве типов для структуры Rust по ходу дела.
Мы рассмотрели основные понятия времени жизни и заимствования. Это позволяет нам обладать бо́льшим контролем над тем,
как мы реализуем свои структуры и функции в нашей программе, предоставляя нам множество проспектов для следования при решении
задачи. Со всем этим мы можем безопасно кодировать приложения в одну страницу с убеждённостью в понятиях, которые поставили
бы в тупик того, кто никогда не программировал на Rust. Однако мы, как опытные разработчики Python, знаем что всякая серьёзная
программа занимает множество страниц. Учитывая это, мы можем воспользоваться тем, что узнали здесь, чтобы перейти к своей
следующей главе, в которой мы настроим среду Rust в своих собственных компьютерах и узнаем как структурировать код Rust во
множестве файлов, что позволит нам на один шаг приблизиться к построению пакетов в Rust и их установке при помощи
pip.
-
Почему мы не можем просто копировать String?
-
Rust обладает сильной типизацией. Какими двумя способами мы можем позволять контейнеризацию такую как вектор и хэш-карта для содержания множества различных типов?
-
Чем схожи декораторы Python и макросы Rust?
-
Что является эквивалентом Pyton для функции
mainв Rust? -
Почему мы можем получать бо́льшие значения целых чисел при одном и том же числе байт для целого числа без знака по сравнению с целым со знаком?
-
Почему нам приходится быть точными с временами жизни и областями действия при кодировании в Rust?
-
Можем ли мы ссылаться на переменную когда она перемещена?
-
Что мы можем делать с первоначальной переменной, которая в данный момент заимствована в состоянии без возможности изменения?
-
Что мы можем делать с первоначальной переменной, которая в данный момент заимствована в состоянии с возможностью изменения?
-
Это обусловлено тем, что String, в сущности, указатель на
Vec<u8>с некоторыми метаданными. Если мы копируем её, тогда мы будем обладать множеством несогласованных указателей на один и тот же литерал строки, что приводит к ошибкам при одновременности, изменениях и временах жизни. -
Мы можем применять Enum, что означает что наш тип принимается в соответствующий контейнер, способный быть одним из тех типов, которые размещаются в Enum. При считывании таких данных, мы можем затем воспользоваться оператором
matchдля управления всеми возможными типами данных, которые могут считываться из такого контейнера. Второй способ состоит в создании признака (trait), который реализуется множеством различных структур. Однако, единственное взаимодействие, которое мы можем получать из такого контейнера, считываемого в данной ситуации, состоит в в тех функциях, которые реализует такой признак. -
Они оба обёртывают вокруг свой код и меняют саму реализацию или атрибуты такого обёртываемого ими кода без непосредственного возврата чего бы то ни было.
-
Эквивалентом Pyton выступает
if __name__ == "__main__":. -
Целые числа со знаком должны размещать как положительные, так и отрицательные значения, в то время как целые без знаком содержат только положительные значения.
-
Это обусловлено тем, что нет никакой сборки мусора; в результате переменные подвергаются удалению когда они смещаются из своей области действия, в которой они были созданы. Если бы мы не принимали во внимание времена жизни, мы бы могли ссылаться на удалённую переменную.
-
Нет, сам владелец такой переменной по- существу был перемещён и больше нет никаких ссылок на его оригинальную переменную.
-
Мы всё ещё способны копировать и заимствовать свою первоначальную переменную; однако, мы не можем осуществлять заимствование с возможностью изменения.
-
Мы совсем не можем применять свою первоначальную переменную, поскольку состояние такой переменной может быть изменено.
-
Hands-On Functional Programming in Rust (2018), Andrew Johnson, Packt Publishing
-
Mastering Rust, 2nd.ed., Rahul Sharma and Vesa Kaihlavirta, Packt Publishing (2019)