Глава 3. Основы одновременности
Содержание
Ускорение нашего кода при помощи Rust это полезно. Однако понимание одновременности и применения потоков и процессов может способствовать нашей возможности ускорения кода на следующем уровне. В этой главе мы пройдёмся по тому что представляют собой процессы и потоки. Затем мы пройдёмся по практическим этапам раскрутки потоков и процессов в Python и Rust. Тем не менее, хотя это может и быть увлекательным, мы также должны признать, что обращение к п потокам и процессам без того чтобы не задумываться о нашем подходе может окончательно сбить нас с толку. Чтобы избежать этого, мы также изучим сложность алгоритма и того, как это влияет на время нашего вычисления.
В данной главе мы рассмотрим следующие вопросы:
-
Введение в одновременность
-
Основы асинхронного программирования при помощи потоков
-
Запуск множества процессов
-
Безопасная персонализация потоков и процессов
К коду для данной главы можно получить доступ по следующей ссылке GitHub.
Как мы уже изучали во введении в Главу 1, Введение в Rust с точки зрения Python, закон Мура больше не работает, а следовательно нам приходится рассматривать иные способы, которыми мы способны ускорять свою обработку. Именно тут вступает в дело одновременность. Одновременность это по существу исполнение множества вычислений в одно и то же время. Одновременность повсеместна и чтобы отдать должное этому понятию, нам бы пришлось написать целую книгу о ней.
Однако, для целей данной книги понимание основ одновременности (и того когда его применять) может добавить на наш пояс дополнительные инструменты, которые позволят нам ускорять вычисления. Кроме того, потоки и процессы это то, как мы можем разбивать свою программу на вычисления, которые способны исполняться в одно и то же время. Чтобы приступить к нашему туру по одновременности мы рассмотрим потоки. {Прим. пер.: в данной книге мы будем стараться отличать понятия одновременности (concurrency) и параллелизма (параллельности, parallelism), следуя традиции наших переводов книг по параллельности в Python Полное руководство параллельного программирования на Python, Куан Нгуен, Packt, 2018; Asyncio в Python 3, Цалеб Хаттингх, O`Reilly, 2018; второго издания Книги рецептов параллельного программирования Python, Джанкарло Закконе, Packt, 2019 и прочих, которые применяют термин concurrency в более широком смысле нежели parallelism. При этом parallelism, как правило, подчёркивает тот факт, что исполнение осуществляется именно в одно и то же, как правило, реальное время, в то время как concurrency обычно подразумевает лишь наличие синхронизации своих вычислений. Да, в переводе на русский это может звучать странно, но мы придерживаемся именно такого разделения из англоязычной литературы. Пояснения автора ниже.}
Потоки (threads) это наименьший элемент вычислений, который мы можем обрабатывать и которым мы можем управлять независимо. Потоки применяются для разбиения программы на вычислительные части, которые мы можем выполнять одновременно. Также необходимо отметить, что потоки могут исполняться в последовательности. Это выдвигает важное различие между одновременностью и параллелизмом. Одновременность (concurrency) это задача одновременного выполнения множества вычислений и управления ими, в то время как параллельность (parallelism) это задача выполнения множества вычислений в одно и то же время. Одновременность обладает не детерминированным потоком управления, в то время как параллельность имеет детерминированный поток управления. Потоки совместно используют ресурсы, такие как память и вычислительная мощность; тем не менее, они блокируют друг друга. Например, если мы выделим некий поток, которому требуется постоянная вычислительная мощность, мы просто заблокируем свой другой поток, как это показано в приводимой ниже схеме:
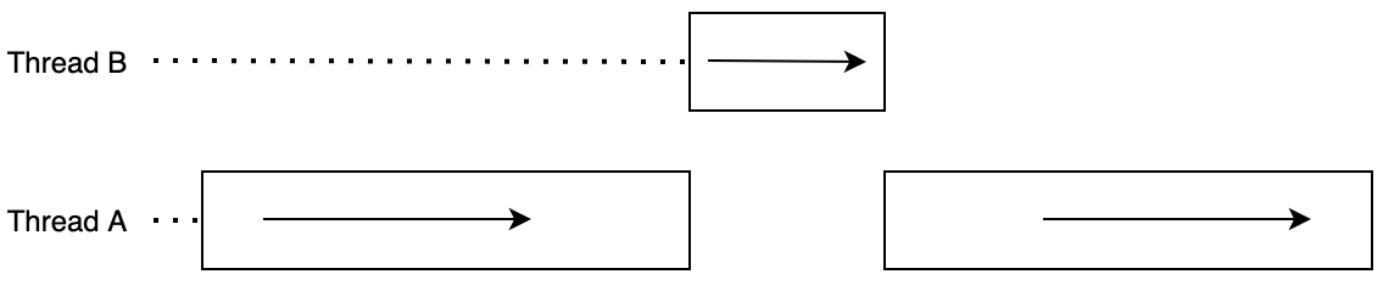
Здесь мы наблюдаем, что поток A останавливает выполнение при запуске потока B. Именно это демонстрируется в статье Ву Пана 2019 года для понимания многопоточности при имитациях, в которых измеряются времена выполнения различных типов задач. Основные результаты этой статьи суммируются в нашей следующей схеме:
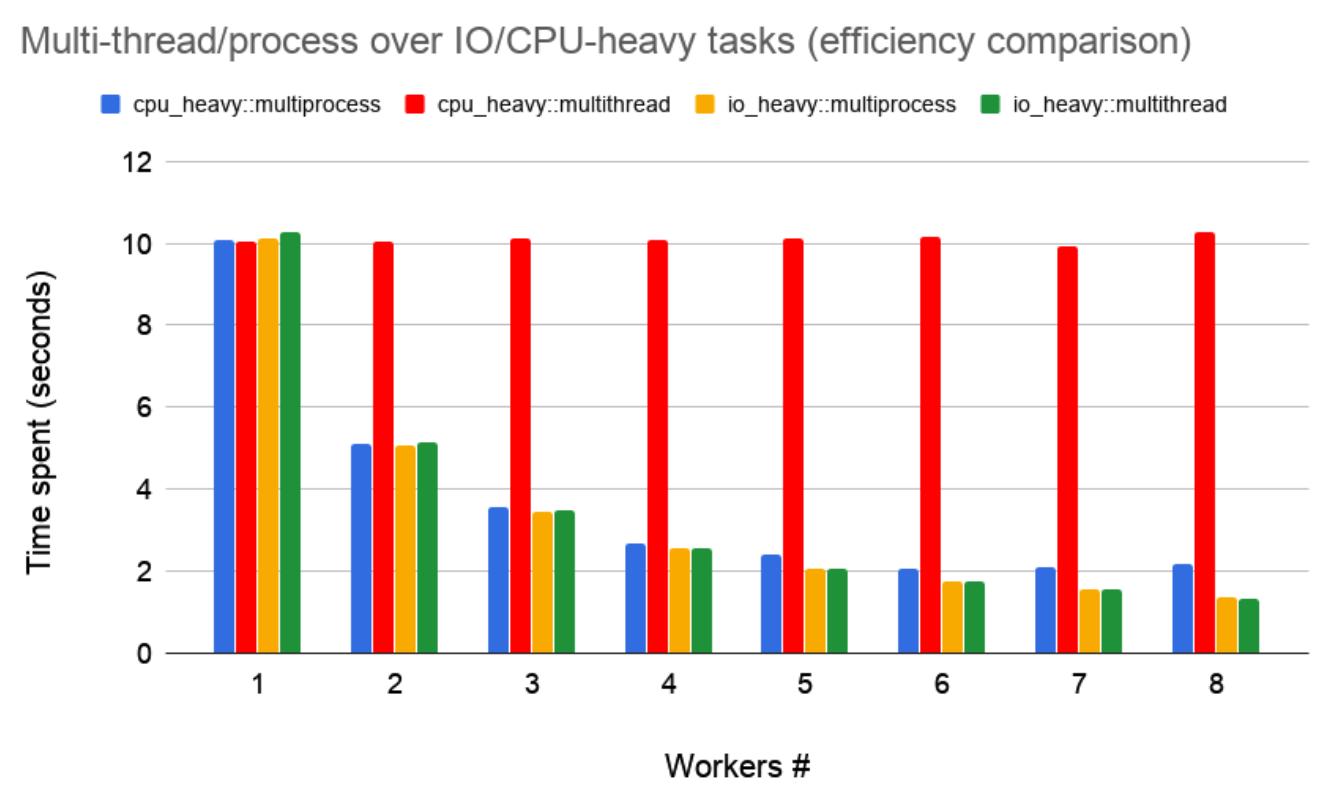
Здесь мы можем видеть, что затраты времени уменьшаются по мере уменьшения числа исполнителей за исключением многопоточных задач с загруженным ЦПУ (CPU, central processing unit). Это обусловлено тем, что, как это показано на Рисунке 3-1, потоки с загруженностью ЦПУ выполняют блокировку, а потому только один исполнитель может выполняться за раз. Это не зависит от того, сколько исполнителей вы добавляете. Следует отметить, что это обусловлено global interpreter lock (GIL), которая рассматривается в Главе 6, Работа с объектами Python в Rust {Прим. пер.: подробнее в наших переводах Полного руководства параллельного программирования на Python Куан Нгуен, Packt, 2018 и Внутреннее устройство CPython Энтони Шоу, Real Python, 2021}. При прочих обстоятельствах, например в Rust, они могут исполняться в различных ядрах ЦПУ и обычно не будут блокировать друг друга.
Также из Рисунка 3-2 мы наблюдаем, что наши задачи с интенсивным вводом/ выводом (I/O, input/output) на самом деле уменьшаются в отношении времени при росте числа исполнителей. Это обусловлено тем, что в задачах с интенсивным вводом/ выводом имеется время простоя. Именно тут мы реально можем применять потоки. Допустим, наша задача выполняет вызов к серверу. Существует некое время простоя при ожидании отклика, таким образом применение потоков для выполнения множества вызовов к серверам ускоряет время выполнения. К тому же мы должны отметить, что для задач с интенсивным применением ЦПУ и ввода/ вывода срабатывают процессы. Поэтому нам полезно изучить что представляют собой процессы.
Процессы более затратны при работе по сравнению с потоками. По существу, процесс может размещать множество потоков. Обычно это отображается следующей классической схемой со множеством потоков, на которую можно наткнуться где угодно (включая страницу многопроцессности Wikipedia):
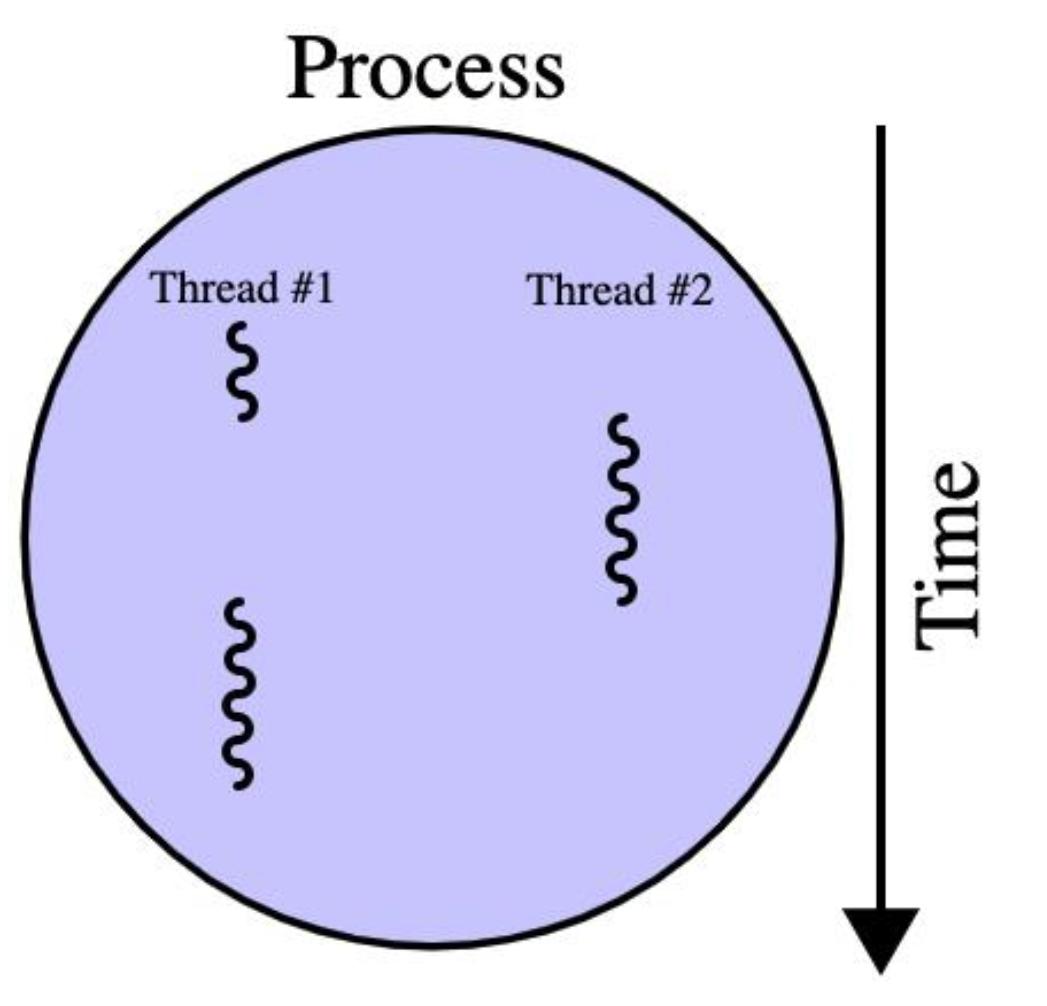
Это классическая схема, поскольку она очень хорошо заключает в себе имеющиеся взаимоотношения между процессами и потоками. Из неё мы можем видеть, что потоки это подмножество процесса. Также мы можем понять почему потоки разделяют оперативную память и, в результате, мы должны отметить, что процессы обычно независимы и не используют совместно оперативную память. Также следует обратить внимание на то, что переключения контекста более затратно при переключении процессов. Под переключением процесса мы понимаем то, что состояние процесса (или потока) сохраняется с тем, чтобы он имел возможность восстановления и возобновления в более позднем состоянии. Примером этого может служить ожидание отклика API (application programming interface, программного интерфейса приложения). Такое состояние может быть сохранено, а другой процесс/ поток может выполняться пока мы дожидаемся отклика соответствующего API.
Теперь, когда мы разобрались с основными понятиями, стоящими за потоками и процессами, нам требуется изучить как на практике применять потоки в своих программах.
Для применения потоков нам требуется способность запускать процессы, позволять им исполняться и затем присоединяться к ним. На приводимой ниже схеме мы можем видеть эти стадии практического управления своими потоками:
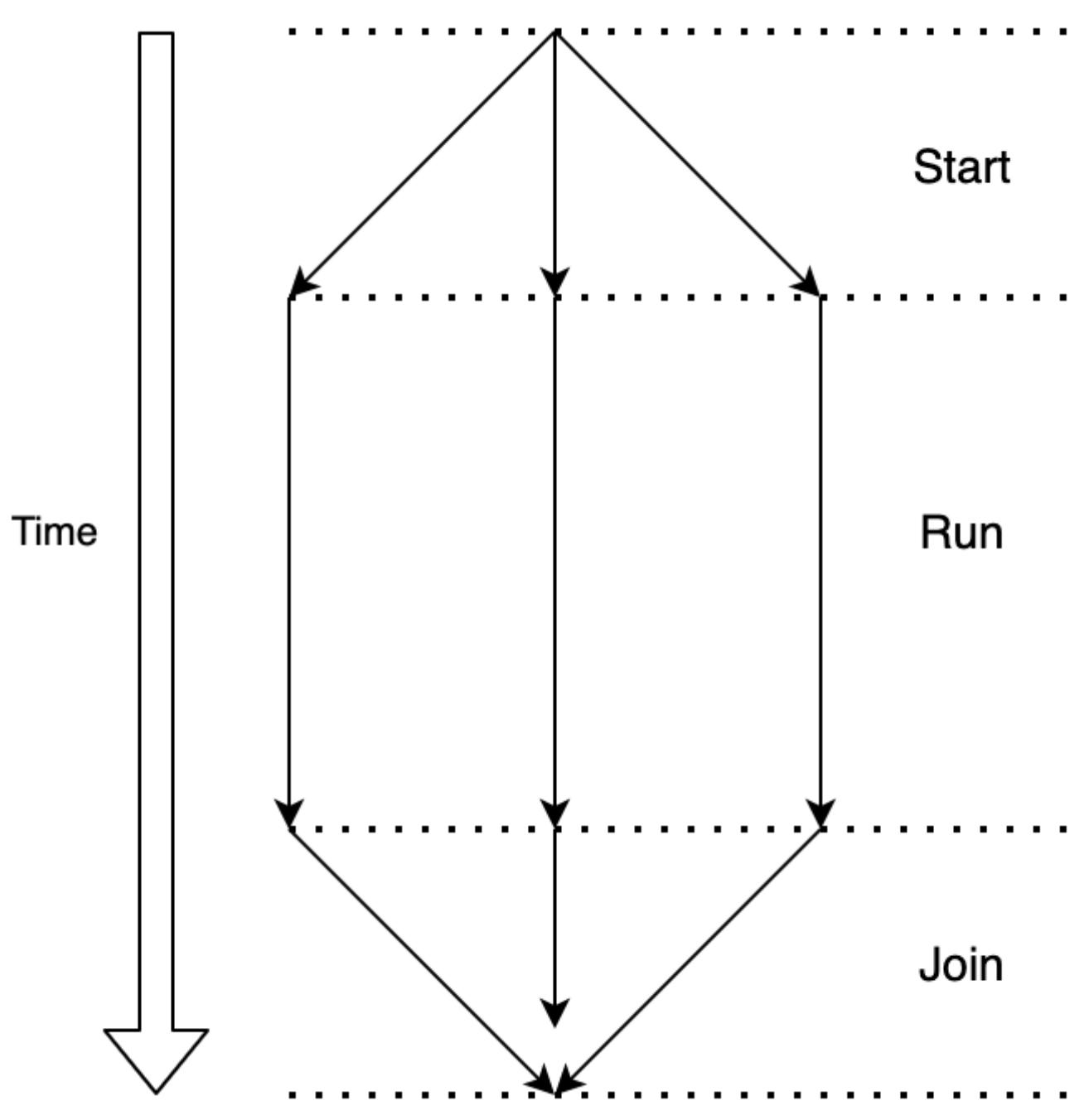
Мы стартуем свои потоки, далее мы позволяем им выполняться и, после того как они исполнились, мы присоединяемся к ним. Если
бы мы не присоединились к ним, наша программа продолжала бы работать до завершения потоков. В Python мы создаём поток, наследуя
объект Thread следующим образом:
from threading import Thread
from time import sleep
from typing import Optional
class ExampleThread(Thread):
def __init__(self, seconds: int, name: str) -> None:
super().__init__()
self.seconds: int = seconds
self.name: str = name
self._return: Optional[int] = None
def run(self) -> None:
print(f"thread {self.name} is running")
sleep(self.seconds)
print(f"thread {self.name} has finished")
self._return = self.seconds
def join(self) -> int:
Thread.join(self)
return self._return
Здесь мы можем видеть, что мы перекрыли свою функцию run в классе
Thread. Эта функция выполняется при работе нашего потока. Затем мы перекрываем свой
метод join. Однако, мы должны обратить внимание на то, что в нашей функции
join имеется поступающая под капотом дополнительная функциональность;
по этой причине нам необходимо вызвать метод join класса
Thread и затем в самом конце возвращаем всё то что пожелаем. Мы не обязаны возвращать
что бы то ни было, если пожелаем. Если имеется именно этот случай,нет никакого смысла переписывать имеющуюся функцию
join. Затем мы можем реализовать соответствующие потоки выполняя следующий код:
one: ExampleThread = ExampleThread(seconds=5, name="one")
two: ExampleThread = ExampleThread(seconds=5, name="two")
three: ExampleThread = ExampleThread(seconds=5,
name="three")
Затем мы должны измерить время старта, исполнения и присоединения к полученному итогу, например, так:
import time
start = time.time()
one.start()
two.start()
three.start()
print("we have started all of our threads")
one_result = one.join()
two_result = two.join()
three_result = three.join()
finish = time.time()
print(f"{finish - start} has elapsed")
print(one_result)
print(two_result)
print(three_result)
Когда мы исполним этот код, мы получим следующий вывод на печать консоли:
thread one is running
thread two is running
thread three is running
we have started all of our threads
thread one has finished
thread three has finished
thread two has finished
5.005641937255859 has elapsed
5
5
5
Сразу видно, что наше выполнение заняло чуть больше 5 секунд для всего процесса целиком. Если бы мы исполняли свою программу последовательно, это отняло бы у нас 15 секунд. Это показывает нам, что наши потоки работают!
Следует также отметить, что поток three завершился до потока
two, даже хотя поток two стартовал раньше. Не
волнуйтесь если вы получили завершили последовательность one,
two, three; это обусловлено тем, что потоки
завершаются не детерминированным образом. Даже хотя ваше расписание и детерминировано, при исполнении вашей программы имеется
тысячи событий и работающих под капотом ЦПУ процессов. В результате, точное значение временных срезов каждого из процессов
никогда не оказывается тем же самым. Такие крошечные изменения накладываются со временем и, как результат, мы не можем
гарантировать что наши потоки завершатся предопределённым образом когда исполнения близки и их продолжительность примерно
одна и та же.
Теперь, когда у нас имеется понимание потоков Python, мы можем перейти к раскрутке потоков в Rust. Однако, прежде чем мы
приступим к этому, нам необходимо усвоить понятие замыканий
(closures), которое по своей сути является способом анонимного хранения функций вместе с их окружением, частью которого они
и являются. С учётом этого мы можем определять функции внутри области действия функции main
или внутри прочих областей действия, содержащихся в прочих функциях. Простым образцом построения замыкания выступает вывод
на печать входных данных, например так:
fn main() {
let example_closure: fn(&str) = |string_input: &str| {
println!("{}", string_input);
};
example_closure("this is a closure");
}
Используя такой подход мы можем эксплуатировать области действия. Также следует отметить, что поскольку замыкания чувствительны к области действия, мы также можем применять по всему замыканию все имеющиеся переменные. Для демонстрации этого мы можем создать некое замыкание, которое вычисляет размер процентов, которое нам надлежит выплатить по кредиту из- за внешней базовой ставки. Это мы также определяем во внутренней области действия, как это показано ниже:
fn main() {
let base_rate: f32 = 0.03;
let calculate_interest = |loan_amount: &f32| {
return loan_amount * &base_rate
};
println!("the total interest to be paid is: {}",
calculate_interest(&32567.6));
} Исполнение этого кода снабдит нас следующим выводом на печать консоли:
the total interest to be paid is: 977.02795
Здесь мы можем обнаружить, что замыкания способны возвращать значения, однако мы не определили значение типа для своего
замыкания. Это именно так, даже хотя мы и возвращаем число с плавающей запятой. На самом деле, если мы установим
calculate_interest в f32, наш компилятор
пожалуется что значения типов не совпадают. Это происходит по той причине, что наше замыкание является уникальным анонимным
типом, который нельзя выставлять. Замыкание является структурой, которая генерируется самим компилятором, которая содержит
перехваченные переменные. Когда мы попробуем вызвать своё замыкание извне своей внутренне области действия, наше приложение
получит отказ в компиляции, поскольку доступ к замыканию запрещён вне области действия.
Теперь, когда мы рассмотрели замыкания Rust, мы можем реплицировать образец потоков Python, который рассматривали в ранней части этого раздела. Сначала нам надлежит импортировать необходимые корзины (crates) своего стандартного модуля выполнив такой код:
use std::{thread, time};
use std::thread::JoinHandle;
Для порождения потоков мы пользуемся thread,
time для отслеживания продолжительности своего процесса и структурой
JoinHandle для присоединения к необходимому потоку. При помощи данного импорта мы можем
собрать свой собственный поток выполнив приводимый ниже код:
fn simple_thread(seconds: i8, name: &str) -> i8 {
println!("thread {} is running", name);
let total_seconds = time::Duration::new(seconds as \
u64, 0);
thread::sleep(total_seconds);
println!("thread {} has finished", name);
return seconds
}
Здесь мы можем наблюдать что мы создали структуру Duration, обозначаемую как
total_seconds. Затем мы можем воспользоваться этим потоком и
total_seconds чтобы поместить свою функцию в спящее состояние, возвращая значение
числа секунд по завершению всего процесса целиком. Прямо сейчас это всего лишь некая функция и исполнение её самой не раскрутит
различные потоки. Внутри своей функции main мы запускаем наш таймер и порождаем три
потока выполняя следующий код:
let now = time::Instant::now();
let thread_one: JoinHandle<i8> = thread::spawn(|| {
simple_thread(5, "one")});
let thread_two: JoinHandle<i8> = thread::spawn(|| {
simple_thread(5, "two")});
let thread_three: JoinHandle<i8> = thread::spawn(|| {
simple_thread(5, "three")});
Здесь мы породили потоки и передаём свою функцию с верными параметрами в своём замыкании. Ничто не мешает нам разместить
в своём замыкании любой код. Самой последней строкой нашего замыкания будет то, что возвращается в соответствующую структуру
JoinHandle для развёртывания. После выполнения этого мы присоединяемся ко всем потокам
чтобы удерживать свою программу пока не завершатся все потоки, прежде чем двигаться далее при помощи следующего кода:
let result_one = thread_one.join();
let result_two = thread_two.join();
let result_three = thread_three.join();
Наша функция join возвращает результат при помощи типа
Result<i8, Box<dyn Any + Send>>.
Здесь имеется несколько новых понятий, но мы можем разбить их по частям следующим образом:
-
Мы помним, что структура
Resultв Rust возвращает либоOK, либо некий откликErr. Если наш поток выполнится без проблем, тогда мы, как и ожидалось, вернём полученное значениеi8. Если нет, тогда мы получим этот достаточно безобразный выводResult<i8, Box<dyn Any + Send>>в качестве ошибки. -
Первое что нам следует здесь рассмотреть, это структура
Box. Это одна из самых основных форм указателя, которая позволяет нам хранить данные в куче, а не в стеке. Мы пользуемся ею, поскольку не знаем насколько велики данные по выходу из потока. -
Следующим подлежащим объяснению выражением является
dyn. Это ключевое слово применяется для указания того что данный тип является признаком (trait) объекта. Например, мы можем пожелать сохранить в массиве некий диапазон структурBox. Эти структурыBoxмогут указывать на различные структуры. Тем не менее, мы всё ещё можем гарантировать что они могут быть сгруппированными воедино когда у нас имеется общим некий определённый признак. Скажем, когда все структуры должны иметь реализованным некийTraitA, мы бы обозначили это какBox<dyn Any + TraitA>. -
Ключевое слово
Anyэто признак (trait) для динамической типизации. Это означает, что таким типом данных может быть что угодно. ПризнакAnyсочетается сSendпри помощи выраженияAny + Send. Это означает что обязаны быть реализованными оба признака. -
Признак (trait)
Sendслужит для типов, которые могут передаваться через границы потоков.Sendреализуется автоматически самим компилятором, если он полагает это целесообразным. При всём этом мы можем с уверенностью сказать, что присоединение потока в Rust возвращает результат, который может быть целым числом, которое нам требуется, либо указателем на нечто ещё, что может быть передано между потоками.
Для обработки полученных из соответствующего потока результатов, мы можем просто напрямую развернуть их. Однако, это было бы
не очень полезно когда возрастают общие запросы наших многопоточных программ. Мы должны обладать возможностью обрабатывать то,
что потенциально выходит из потока, а сделав это нам придётся понизить приведение типа (downcast) полученного результата.
Понижение приведения типа (downcasting) это метод преобразования Rust некого признака (trait) в конкретный тип. В данном контексте
мы будем преобразовывать структуры PyO3, которые обозначают типы Python, в конкретные типы
данных Rust, такие как строки или целые числа. Чтобы продемонстрировать это, давайте создадим функцию, которая обрабатывает результат
нашего потока следующим образом:
-
Прежде всего, нам придётся импортировать всё что требуется, как это видно во фрагменте кода ниже:
use std::any::Any; use std::marker::Send; -
При помощи этого импорта мы создаём функцию, которая распаковывает полученный результат и выводит его а печать при помощи такого кода:
fn process_thread(thread_result: Result<i8, Box<dyn \ Any + Send>>, name: &str) { match thread_result { Ok(result) => { println!("the result for {} is {}", \ result, name); } Err(result) => { if let Some(string) = result.downcast \ _ref::<String>() { println!("the error for {} is: {}", \ name, string); } else { println!("there error for {} does \ not have a message", name); } } } } -
Здесь в основном мы выводим полученный результат, когда он успешен. Однако, если имеется некая ошибка, как указывалось ранее, мы не знаем какой тип данных у этой ошибки. Тем не менее, мы бы всё ещё хотели обработать это. Именно тут мы выполняем понижение приведения типа. Наше понижение приведения типа возвращает некий параметр, и именно поэтому мы имеем условие
if let Some(string) = result.downcast _ref::<String>(). Если понижение приведения типа успешно, мы можем переместить полученную строку в свою область действия и распечатать строку этой ошибки. В случае неудачи мы можем двигаться дальше и заявить, что хотя ошибка и была, строка ошибки не была предоставлена. Если пожелаем, мы можем применять несколько условных операторов для учёта диапазона типов данных. Мы можем написать большой код на Rust, если мы не полагаемся на понижающее приведение, поскольку Rust обладает разделом строгой типизации. Тем не менее, при взаимодействии с Python это может быть полезным, поскольку, как мы знаем, объекты Python являются динамическими и могут быть чем угодно. -
Теперь мы можем обработать свои потоки по их завершению, мы можем остановить свои часы и обработать полученные итоги выполнив такой код:
println!("time elapsed {:?}", now.elapsed()); process_thread(result_one, "one"); process_thread(result_two, "two"); process_thread(result_three, "three"); -
Это снабжает нам следующим выводом на печать:
thread one is running thread three is running thread two is running thread one has finished thread three has finished thread two has finished time elapsed 5.00525725s the result for 5 is one the result for 5 is two the result for 5 is three
И вот оно: мы можем запускать и обрабатывать потоки в Python и Rust. Однако помните, что если мы попытаемся запускать ресурсоёмкие задачи с написанным нами кодом, мы не получим увеличения скорости. Тем не менее, следует отметить, что в плане кода Rust может иметься ускорение, в зависимости от окружения. Например, когда доступно большое число ядер ЦПУ, планировщик операционной системы (ОС) может помещать эти потоки в те ядра, которые могут исполнять его параллельно. Для написания кода, который ускорит наш код именно в этом плане, нам придётся на практике научиться запускать несколько процессов, что мы и рассмотрим в своём следующем разделе.
Технически говоря, в Python мы можем просто переключить наследование своих потоков с Thread
на Process исполняя следующий код:
from multiprocessing import Process
from typing import Optional
class ExampleProcess(Process):
def __init__(self, seconds: int, name: str) -> None:
super().__init__()
self.seconds: int = seconds
self.name: str = name
self._return: Optional[int] = None
def run(self) -> None:
# do something demanding of the CPU
pass
def join(self) -> int:
Process.join(self)
return self._return
Тем не менее, имеются некие составления. Если мы обратимся к Рисунку 3-3, мы можем обнаружить, что процессы обладают своей собственной памятью. Именно тут вещи начинают усложняться.
Например, нет ничего плохого в том, что наш определённый ранее процесс ничего не возвращает напрямую, кроме записи в базу
данных или файл. С другой стороны, функция join не возвращает ничего напрямую и вместо
этого будет иметься лишь None. Это обусловлено тем, что
Process не разделяет то же самое пространство памяти, что и процесс main. Нам также
следует помнить, что раскрутка процессов более затратна, а потому мы должны быть с ними более аккуратны.
Поскольку мы получаем дополнительные сложности со своей памятью, а наши ресурсы становятся более затратными, имеет смысл обуздать их и сохранить простоту. Именно тут мы применяем пул. Пул это то место, где несколько рабочих процессов одновременно обрабатывающих входные данные и затем упаковывают их в качестве некого массива, что можно видеть здесь:
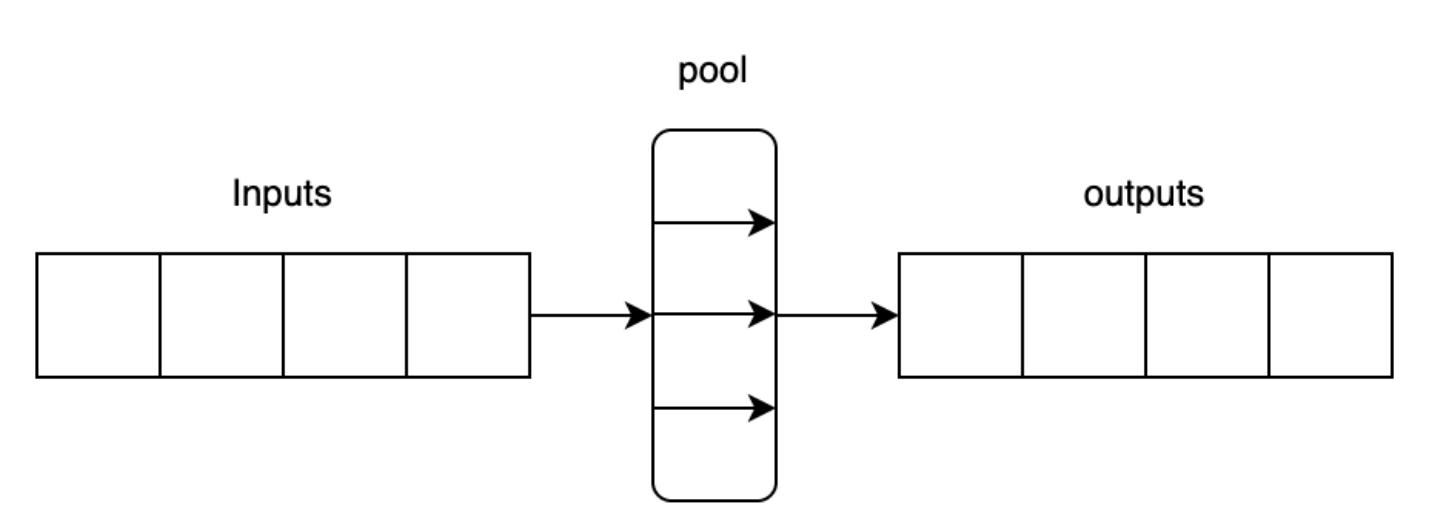
Основное преимущество здесь состоит в том что мы сохраняем затратный контекст множества процессов для небольшой части своей программы. Также мы можем просто контролировать значение числа исполнителей, которые мы бы желали поддерживать. Для Python это означает что мы сохраняем необходимое взаимодействие настолько легковесным, насколько это возможно. Как видно из следующей схемы, мы упаковываем некую индивидуальную изолированную функцию в кортеж с массивом входных данных. Этот кортеж обрабатывается в таком пуле исполнителем, а затем полученный результат полученного итога возвращается из нашего пула:
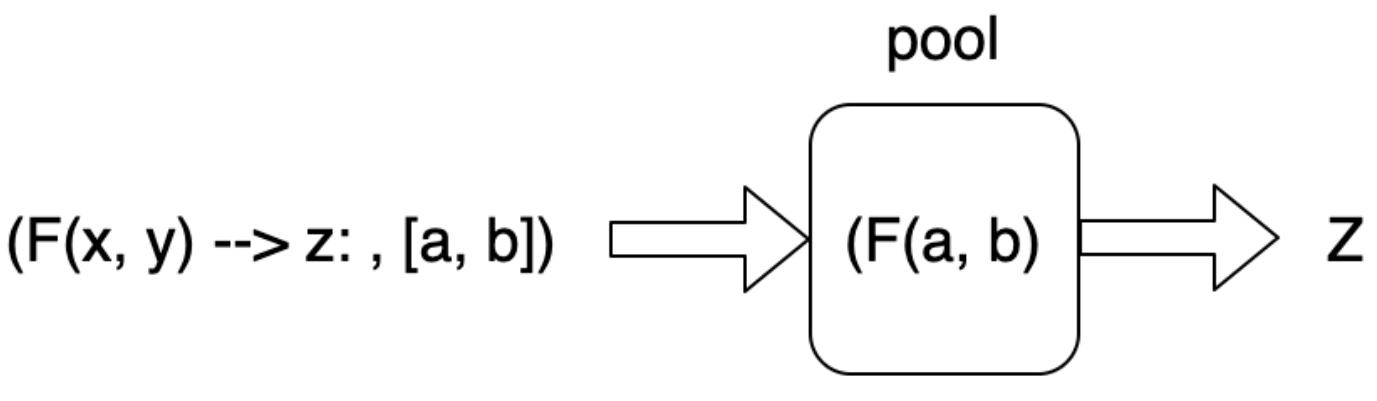
Для демонстрации множественности процессов через пул мы можем воспользоваться последовательностью Фибоначчи. Именно здесь наше следующее число в последовательности это значение суммы предыдущего числа в этой последовательности и значения перед ним, что иллюстрируется здесь:
Fn = Fn-1 + Fn-2
Для вычисления числа из этой последовательности нам приходится воспользоваться
рекурсией. Существует закрытая форма последовательности Фибоначчи;
однако, она не позволяет нам применять множество процессов, поскольку такая закрытая последовательность по самой
своей природе не масштабируется в вычислениях при росте n. Для вычисления числа
Фибоначчи на Python мы можем написать изолированную функцию, что видно в следующем фрагменте кода:
def recur_fibo(n: int) -> int:
if n <= 1:
return n
else:
return (recur_fibo(n-1) + recur_fibo(n-2))
Данная функция продолжает возвращаться обратно пока не достигнет нижней части дерева либо в 1, либо в 0. Эта функция ужасно масштабируется. Чтобы продемонстрировать это, давайте взглянем на её дерево рекурсии, показанное ниже:
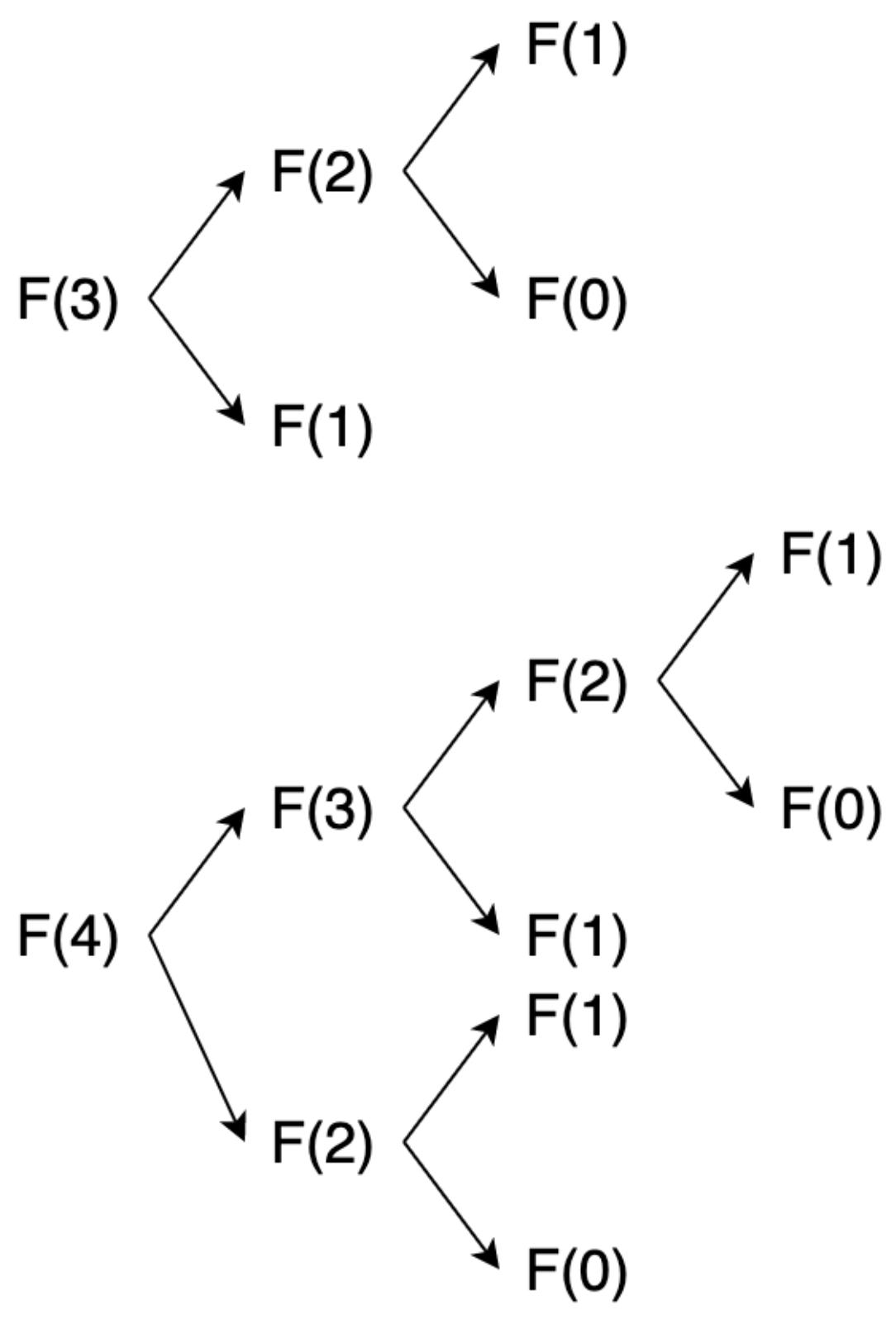
Мы видим, что это далеко не идеальное дерево, а если вы зайдёте в Интернет и поищите нотацию
большого О последовательности Фибоначчи (big O notation of the Fibonacci sequence), возникнут споры, и некоторые
уравнения приравняют значение множителя масштабирования к золотому сечению. Хотя это и интересно само по себе, это выходит за
рамки этой книги, поскольку мы сосредоточены на вычислительной сложности. В результате мы упростим математику будем
рассматривать его как идеально симметричное дерево. Деревья рекурсии масштабируются со скоростью
2n, где n значение
глубины дерева. Обращаясь к Рисунку 3-7, мы можем видеть, что мы
рассматриваем это дерево как идеально симметричное дерево, значение n равное 3
обладает глубиной 3, а значение n равное 4 обладает глубиной 4. По мере роста
n наши вычисления экспоненциально растут.
Мы предприняли небольшой тур в сложность для выделения важности учёта этого перед тем как приступим к многопроцессности. Основная причина о которой вы приобрели эту книгу вместо того чтобы искать в Интернете фрагменты многопроцессного кода для его копирования и вставки в свой код, состоит в том, что вы хотите ориентироваться в этих понятиях с указаниями на последующее чтение и понимания их контекста. В отношении этой последовательности, обращение к закрытой форме или кэширование значительно сократит время вычислений. Когда у нас имеется некий упорядоченный список чисел, получение наибольшего числа из перечня и последующее создание последовательности до самого наивысшего числа оказалось бы намного быстрым, нежели повторяющееся вычисление этой последовательности снова и снова для каждого числа, которое мы бы хотели вычислить. Избежание рекурсии полностью это лучший вариант, нежели необходимость прибегать к многопроцессности.
Для реализации и тестирования пула множества процессов, нам вначале требуется определить сколько времени для последовательного вычисления некого диапазона чисел. Это может быть сделано как- то так:
import time
start = time.time()
recur_fibo(n=8)
recur_fibo(n=12)
recur_fibo(n=12)
recur_fibo(n=20)
recur_fibo(n=20)
recur_fibo(n=20)
recur_fibo(n=20)
recur_fibo(n=28)
recur_fibo(n=28)
recur_fibo(n=28)
recur_fibo(n=28)
recur_fibo(n=36)
finish = time.time()
print(f"{finish - start} has elapsed")
Мы представили достаточно длинный список; однако именно в этом существенное отличие. Когда нам требовалось бы вычислить только два числа Фибоначчи, стоимость раскрутки процессов могла бы превысить выигрыш от многопроцессности.
Свой пул множества процессов мы можем реализовать так:
if __name__ == '__main__':
from multiprocessing import Pool
start = time.time()
with Pool(4) as p:
print(p.starmap(recur_fibo, [(8,), (12,), (12,), \
(20,), (20,), (20,), (20,), (28,), (28,), (28,), \
(28,),(36,)]))
finish = time.time()
print(f"{finish - start} has elapsed")
Обратите внимание на то, что нам приходится встраивать этот код под if __name__ ==
"__main__":. Это обусловлено тем, что весь этот сценарий запускается снова при раскрутке другого
процесса, что в результате может привести к бесконечным циклам. Когда наш код встроен под
if __name__ == "__main__":, тогда он не будет запущен снова когда имеется
лишь один процесс main. Также стоит отметить, что мы определили пул из четырёх исполнителей. Это можно изменить на то, что мы
посчитаем нужным, но при увеличении этого значения мы уменьшим отдачу, как мы поясним позднее. Имеющиеся кортежи в нашем
списке параметров для каждого вычисления. Исполнение этого сценария снабжает нас следующим выводом:
3.2531330585479736 has elapsed
[21, 144, 144, 6765, 6765, 6765, 6765, 317811,
317811, 317811, 317811, 14930352]
3.100019931793213 has elapsed
Мы видим, что значение скорости не составляет и четверти наших последовательных вычислений. Тем не менее, наш пул множества процессов слегка быстрее. Если вы выполните его множество раз, вы получите некие вариации в разнице времён. Тем не менее, подход со множеством процессов всегда будет быстрее. Теперь когда мы запустили инструмент множества процессов на Python, мы можем реализовать свою многопоточность Фибоначчи в различных контекстах пула множества процессов на Rust. Вот как мы это сделаем:
-
В своём новом проекте Cargo, мы можем закодировать такую функцию в своём файле
main.rs:pub fn fibonacci_recursive(n: i32) -> u64 { if n < 0 { panic!("{} is negative!", n); } match n { 0 => panic!( "zero is not a right argument to fibonacci_reccursive()!"), 1 | 2 => 1, _ => fibonacci_reccursive(n - 1) + fibonacci_reccursive(n - 2) } }Мы можем видеть, что наша функция Rust не более сложная чем наша версия Python. Дополнительные строки кода служат только учёту неожиданных входных данных.
-
Для исполнения этого и замера времени нам следует импортировать корзину (crate) time в самом верху файла
main.rsвыполняя такой код:use std::time; -
Затем нам надлежит вычислить в точности те же числа Фибоначчи, как мы это делали в своей реализации Python следующим образом:
fn main() { let now = time::Instant::now(); fibonacci_reccursive(8); fibonacci_reccursive(12); fibonacci_reccursive(12); fibonacci_reccursive(20); fibonacci_reccursive(20); fibonacci_reccursive(20); fibonacci_reccursive(20); fibonacci_reccursive(28); fibonacci_reccursive(28); fibonacci_reccursive(28); fibonacci_reccursive(28); fibonacci_reccursive(36); println!("time elapsed {:?}", now.elapsed()); } -
Для выполнения этого мы намерены воспользоваться такой командой:
cargo run –release -
Мы намерены воспользоваться версией выпуска (release), поскольку это именно то, что мы будем применять в промышленном решении. Исполнение её представит нам следующий вывод:
time elapsed 40.754875ms
Выполнение этого несколько раз снабжает нас средним округлением около 40 миллисекунд. Учитывая то, что наш код Python со множеством процессов исполняется примерно 3.1 секунды, наша однопоточная реализация работает в 77 раз быстрее чем наш код Python со множеством процессов. Только попробуйте себе это представить! Наш код был не более сложным, и при этом безопасен в отношении памяти. Поэтому сплав Rust с Python это настолько быстрый выигрыш! Сочетание агрессивной типизации и его компилятором принуждает нас учитывать все входные и выдаваемые данные, и мы пребываем на пути турбонаддува своих систем Python при помощи более безопасного, более быстрого кода.
Теперь мы собираемся рассмотреть что произойдёт со значением скорости когда мы запускаем свои числа через многопоточный пул. Вот как мы обойдёмся с этим:
-
Для этого мы намерены воспользоваться корзиной
rayon. Мы определим эту зависимость в своём файлеCargo.tomlвыполняя такой код:[dependencies] rayon="1.5.0" -
После выполнения этого мы импортируем её в свой файл
main.rsследующим манером:use rayon::prelude::*; -
Затем в своей функции
mainмы можем запустить многопоточный пул ниже наших последовательных вычислений выполняя такой код:rayon::ThreadPoolBuilder::new().num_threads(4) \ .build_global().unwrap(); let now = time::Instant::now(); let numbers: Vec<i32> = vec![8, 12, 12, 20, 20, 20, \ 20, 28, 28, 28, 28, 36]; let outcomes: Vec<u64> = numbers.into_par_iter() \ .map(|n| fibonacci_reccursive(n)).collect(); println!("{:?}", outcomes); println!("time elapsed {:?}", now.elapsed()); -
Здесь мы определяем значение числа потоков своего собираемого тут же пула. Далее мы выполняем свою функцию
into_par_iterна соответствующем векторе. Это достигается реализацией признака (trait)IntoParallelIteratorв этом векторе, что осуществляется при импорте корзиныrayon. Если бы она не была импортирована, тогда наш компилятор пожаловался бы, постулируя что вектор не обладает ассоциированной с ним функциейinto_par_iter. -
Затем мы ставим в соответствие свои функции Фибоначчи имеющимся в нашем векторе целым числа, применяя замыкание и собирая их. Все вычисленные числа Фибоначчи связываются с переменной
outcomes. -
Затем мы выводим их на печать и печатаем затраченное время. Исполнение этого через выпуск снабжает нас в консоли следующей печатью:
time elapsed 38.993791ms [21, 144, 144, 6765, 6765, 6765, 6765, 317811, 317811, 317811, 317811, 14930352] time elapsed 31.493291msВыполнение этого несколько раз предоставит нам примерное значение времён, указанное в нашем предыдущем консольном выводе. Вычисление этого снабжает нас 20% ускорением в скорости. Принимая во внимание, что многопроцессность Python выдаёт лишь 5% увеличения, мы можем заключить, что Rust к тому же более эффективен в многопоточности при применении верного контекста.
Мы можем пройти чуть дальше чтобы на самом деле увидеть преимущества таких пулов. Вспомните что наша последовательность растёт экспоненциально. В своей программе Rust мы можем добавить дерево вычислений для
nравного 46 для своих последовательных вычислений и вычислений в пуле и получить такой вывод:time elapsed 12.5856675s [21, 144, 144, 6765, 6765, 6765, 6765, 317811, 317811, 317811, 317811, 14930352, 1836311903, 1836311903, 1836311903] time elapsed 4.0485755sПрежде всего, мы должны осознать, что значение времени перешло от миллисекунд к двузначным секундам. Экспоненциально масштабируемые алгоритмы это сплошная головная боль, и всего лишь добавляя 10 к вашим вычислениям, приводят к стремительному росту. К тому же мы можем обнаружить, что наши сбережения возросли. Наши вычисления в пуле теперь в 3.11 раз быстрее в противоположность ускорению в 1.2 раза при предыдущем тесте!
-
Когда мы добавим дерево дополнительных вычислений для
nравного 46 в своей реализации Python, мы получим такой консольный вывод:1105.5351197719574 has elapsed [21, 144, 144, 6765, 6765, 6765, 6765, 317811, 317811, 317811, 317811, 14930352, 1836311903, 1836311903, 1836311903] 387.0687129497528 has elapsed
Здесь мы можем наблюдать, что наша обработка в пуле Python в 2.85 раз быстрее наших последовательных вычислений Python. Также мы должны отметить тут, что наши последовательные вычисления Rust примерно в 95 раз быстрее чем наши последовательные вычисления Python, а наш пул многопоточности Rust примерно в 96 раз быстрее нашей обработки пула Python. По мере увеличения требующих обработки пунктов будет расти и значение разницы. Это подчёркивает ещё большую мотивацию подключения Rust к Python.
Следует отметить, что мы получили рост своей скорости в нашей программе Rust посредством многопоточности, в противоположность
многопроцессности. Многопроцессность в Rust не столь проста как в Python - в целом это связано с тем, что Rust более новый
язык программирования. К примеру, имеется корзина (crate) с названием mitosis,
которая сделает возможной для нас запуск функций в неком обособленном процессе; однако у этой корзины имеется лишь четыре
разработчика, причём последний разработчик на момент написания этих строк книги делал свой вклад около 13 месяцев назад.
Принимая это во внимание, нам надлежит подойти к множеству процессов в Rust без каких бы то ни было корзин сторонних
разработчиков. Для этого нам требуется закодировать программу вычисления Фибоначчи и многопроцессную программу, которая будет
вызывать её в различных процессах, как это показано на приводимой ниже схеме:
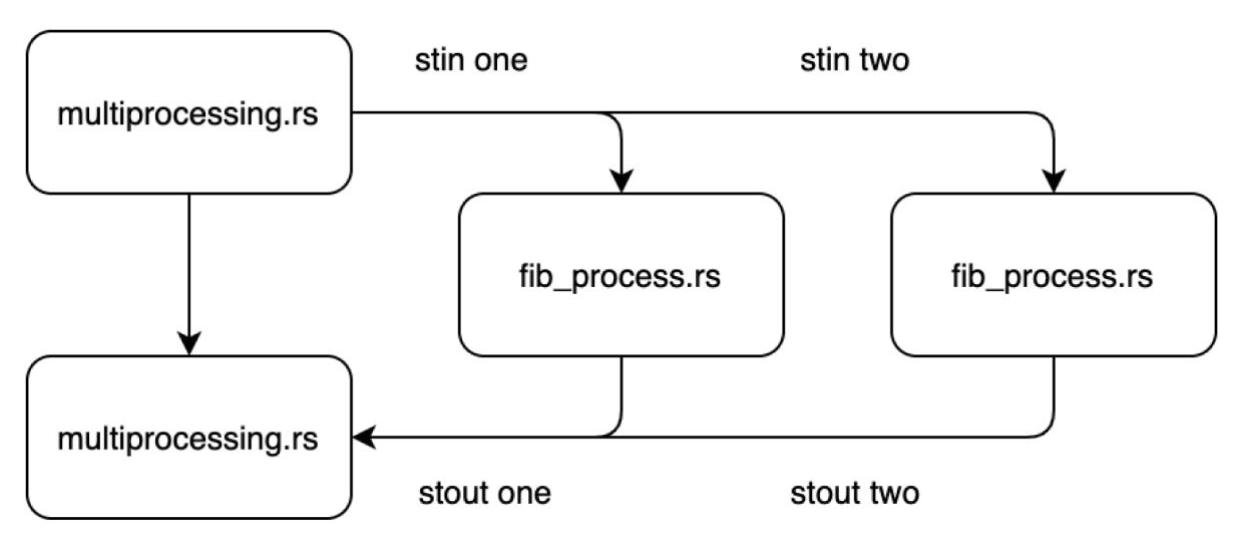
Мы намерены передавать свои данные в эти процессы и выполнять синтаксический разбор получаемого вывода обрабатывая их в
своём файле multiprocessing.rs. Для осуществления этого простейшим способом мы кодируем
оба файла в одном и том же каталоге. Сначала мы соберём свой файл fib_process.rs.
Нам необходимо импортировать то, что мы собираемся делать выполнив такой код:
use std::env;
use std::vec::Vec;
Мы хотим чтобы наши процессы принимали список целых для вычисления, поэтому мы определяем функции
fibonacci_number и
fibonacci_numbers следующим образом:
use std::env;
pub fn fibonacci_number(n: i32) -> u64 {
if n < 0 {
panic!("{} is negative!", n);
}
match n {
0 => panic!("zero is not a right argument \
to fibonacci_number!"),
1 | 2 => 1,
_ => fibonacci_number(n - 1) +
fibonacci_number(n - 2)
}
}
pub fn fibonacci_numbers(numbers: Vec<i32>) -> Vec>u64> {
let mut vec: Vec<u64> = Vec::new();
for n in numbers.iter() {
vec.push(fibonacci_number(*n));
}
return vec
}
Мы видели эти функции ранее, поскольку в этой книге они стали стандартным способом вычисления чисел Фибоначчи. Теперь нам следует взять список целых числе из параметров, выполнить их синтаксический разбор в целые числа и передать их в свою функцию вычисления, а также вернуть получаемые результаты следующим образом:
fn main() {
let mut inputs: Vec<i32> = Vec::new();
let args: Vec<String> = env::args().collect();
for i in args {
match i.parse::<i32>() {
Ok(result) => inputs.push(result),
Err(_) => (),
}
}
let results = fibonacci_numbers(inputs);
for i in results {
println!("{}", i);
}
}
Отсюда мы можем видеть, что мы собираем необходимые входные данные из своего окружения. После синтаксического разбора целых
в целые числа i32 и применения вычисления чисел Фибоначчи, мы просто выводим их на
печать. Вывод на печать в консоль обычно действует как stdout. Наш файл процесса
полностью закодирован, поэтому мы можем скомпилировать его следующей командой:
rustc fib_process.rs
Это создаёт из нашего файла некий двоичный файл. Теперь, когда это сделано, мы можем перейти к своему файлу
multiprocessing.rs, который породит множество процессов. Мы импортируем всё что нам
требуется выполняя такой код:
use std::process::{Command, Stdio, Child};
use std::io::{BufReader, BufRead};
Наша структура Command намерена применяться для порождения нового процесса, структура
Stdio намерена использоваться для задания организации конвейера данных обратно из
полученного процесса, а структура Child возвращается когда наш процесс порождён.
Мы воспользуемся ею для доступа к выводимым данным и получения своего процесса для ожидания окончания. Структура
BufReader применяется для считывания получаемых от нашего дочернего процесса данных.
Теперь, когда мы импортировали всё что нам требуется, мы можем определить функцию, которая получает некий массив целых в
строковом представлении и раскручивает необходимые процессы, возвращая соответствующую структуру
Child как это показано ниже:
fn spawn_process(inputs: &[&str]) -> Child {
return Command::new("./fib_process").args(inputs)
.stdout(Stdio::piped())
.spawn().expect("failed to execute process")
}
Здесь мы можем наблюдать, что нам просто требуется вызвать свой двоичный файл и передать свой массив строк в соответствующей
функции args. Затем мы определяем stdout и
порождаем необходимый процесс, возвращая его структуру Child. Теперь, когда это сделано,
мы можем включить три процесса в своей функции main и дождаться их выполнения, запуская
такой код:
fn main() {
let mut one = spawn_process(&["5", "6", "7", "8"]);
let mut two = spawn_process(&["9", "10", "11", "12"]);
let mut three = spawn_process(&["13", "14", "15", \
"16"]);
one.wait();
two.wait();
three.wait();
}
Теперь мы можем начать выделять получаемые из этих процессов данные внутри своей функции main,
выполняя следующий код:
let one_stdout = one.stdout.as_mut().expect(
"unable to open stdout of child");
let two_stdout = two.stdout.as_mut().expect(
"unable to open stdout of child");
let three_stdout = three.stdout.as_mut().expect
("unable to open stdout of child");
let one_data = BufReader::new(one_stdout);
let two_data = BufReader::new(two_stdout);
let three_data = BufReader::new(three_stdout);
Здесь мы можем обнаружить, что мы осуществили доступ к необходимым данным при помощи поля
stdout, а затем обработали их воспользовавшись своей структурой
BufReader. Мы можем далее обойти в цикле свои выделенные данные, добавляя их
в конец к некому пустому вектору выполняя приводимый ниже код:
let mut results = Vec::new();
for i in three_data.lines() {
results.push(i.unwrap().parse::<i32>().unwrap());
}
for i in one_data.lines() {
results.push(i.unwrap().parse::<i32>().unwrap());
}
for i in two_data.lines() {
results.push(i.unwrap().parse::<i32>().unwrap());
}
println!("{:?}", results);
Данный код слегка повторяющийся, однако он иллюстрирует как порождать в Rust множество процессов и управлять ими. После этого мы компилируем этот файл при помощи такой команды:
rustc fib_multiprocessing.rs
Далее мы можем выполнить свой код со множеством процессов при помощи такой команды:
./multiprocessing
Потом мы получаем свой вывод подобно такому:
[233, 377, 610, 987, 5, 8, 13, 21, 34, 55, 89, 144] we have
it, our multiprocessing code in Rust works.
Теперь мы рассмотрели всё что нам требуется знать относительно запуска процессов и потоков для ускорения своих вычислений. Тем не менее, нам надлежит быть внимательными и исследовать как безопасно настраивать свои потоки и процессы во избежание ловушек.
В данном разделе мы рассмотрим некоторые существующие ловушки, которые нам надлежит избегать при создании своих потоков и процессов. Мы не будем глубоко вникать в эти понятия, поскольку современные многопроцессность и одновременность это большая тема и существуют книги, целиком посвящённые им. Тем не менее, важно понимать что следует рассматривать и какие темы прочесть если вы желаете увеличить свои знания многопроцессности/ многопоточности.
Оглядываясь назад к нашим последовательностям Фибоначчи, может показаться заманчивым раскрутить дополнительные потоки внутри наших потоков для ускорения имеющихся индивидуальных вычислений внутри имеющегося пула потоков. Однако для полного понимания будет ли это хорошей мыслью, нам необходимо разобраться с законом Амдала.
Закон Амдала позволяет нам описать компромисс добавления дополнительных потоков. Когда мы раскручиваем потоки внутри потоков, мы получаем экспоненциальный рост потоков. Вас можно простить за то, что вы бы могли счесть это хорошей мыслью; однако закон Амдала гласит, что при увеличении числа ядер имеется уменьшение полезной отдачи. Взгляните на следующую формулу:
Speedlatency(s) = 1 / ((1-p) + p/s)
Здесь мы полагаем следующее:
-
Speed: Это величина теоретического ускорения вычисления всей задачи. -
s: Это ускорение той части задачи, которое выигрывает от улучшения ресурсов системы. -
p: Это доля времени исполнения той части, которая выигрывает от улучшения ресурсов.
В целом, увеличение числа ядер оказывает воздействие; однако убывающую отдачу можно увидеть на следующем снимке экрана:
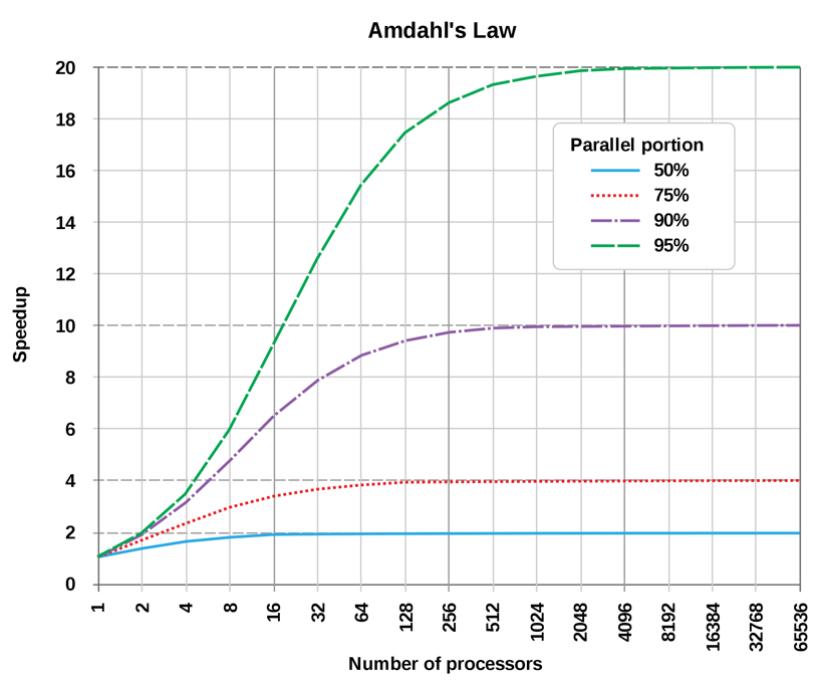
Принимая это во внимание, мы могли бы пожелать исследование применения посредника для управления своей многопроцессностью. Однако, может повлечь закупорку посредника, в результате приводящую к взаимной блокировке (deadlock). Чтобы понять всю тяжесть этой ситуации, в своём следующем разделе мы изучим взаимные блокировки.
Взаимные блокировки могут возникать когда дело доходит до приложений большего размера, в котором обычно управление выполняется через посредника (брокера) задач. Обычно это управление выполняется через базу данных или механизм кэширования, такой как Redis. Оно состоит из очереди, в которую добавляются задачи, как это проиллюстрировано ниже:
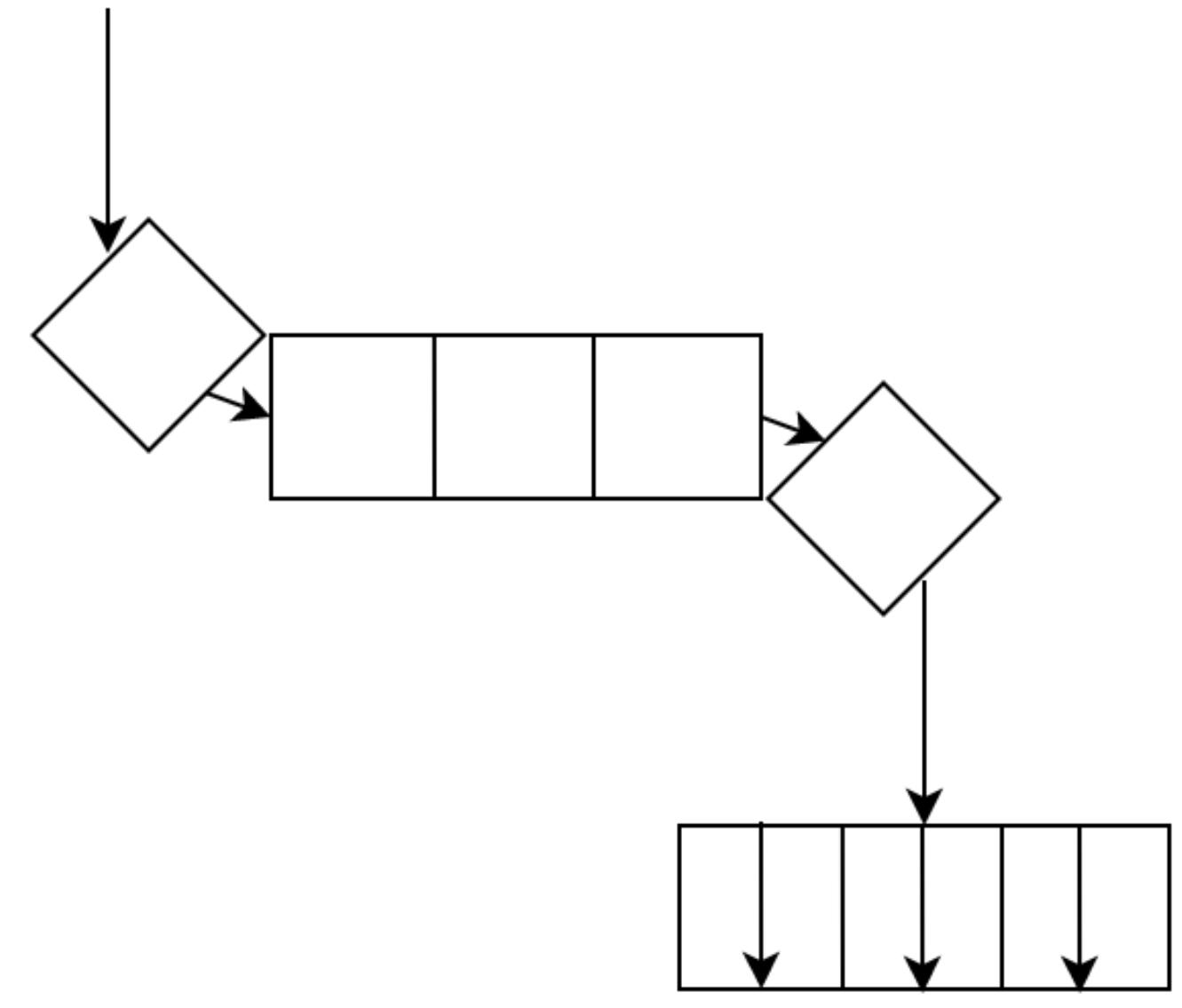
Здесь мы можем видеть, что новые задачи можно добавлять в нашу очередь. Со временем самые старые задачи снимаются из этой очереди и передаются в свой пул. Во всём приложении наш код способен отправлять функции и параметры в очередь в любом месте этого приложения.
В Python та библиотека, которая осуществляет это носит название Celery. Также имеется корзина (crate) Celery для Rust. Этот подход также применяется для множественной установки сервера. Принимая это во внимание, у нас мог бы возникнуть соблазн отправлять задачи в эту очередь внутри другой задачи. Однако ниже мы видим, что такой подход может вызвать блокировку нашей очереди:
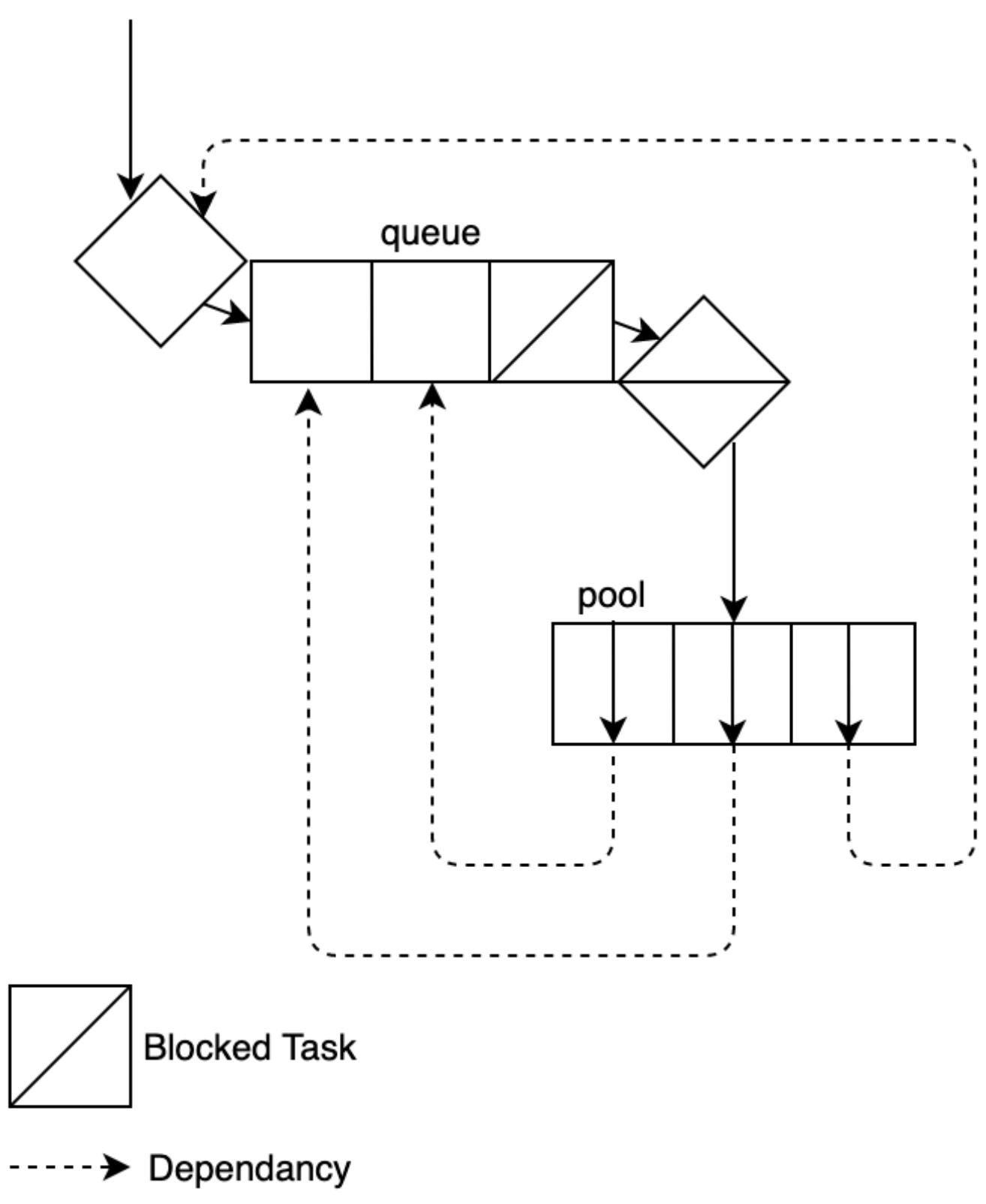
На Рисунке 3-11 мы видим, что наши задачи в пуле должны отправлять задачи в общую очередь. Однако они не могут завершиться пока не будут выполнены их зависимости. Дело в том, что они никогда не исполнятся, потому как этот пул полон задач ожидающих завершения своей зависимости, а их пул заполнен, поэтому они не могут обработаться. Основная незадача с этой проблемой состоит в том, что при этом не возникает никаких ошибок - пул просто зависнет. Взаимная блокировка не единственная проблема, которая может возникнуть без полезных предупреждений. С учётом этого нам следует рассмотреть своё последнее понятие, о котором мы обязаны знать прежде чем приступать к творчеству: состязательность.
Состязательность (race conditions) возникает когда два или более потока выполняют доступ к совместным данным, которые они оба пытаются выполнить изменения. Как мы могли заметить когда мы собирали и запускали свои потоки, они иногда нарушали порядок. Мы можем продемонстрировать это при помощи простого понятия следующим образом:
-
Если у нас имелся поток один, вычисляющий цену и записывающий в файл и поток два также вычисляет цену, считывает ту стоимость, которая вычислена из файла поток один, и складывает их вместе, есть шанс, что общая цена никогда не будет записана в соответствующий файл прежде чем поток два считает её. Что ещё хуже, так это то, что в нашем файле может остаться старая цена. Если это случилось, мы никогда не узнаем что произошла такая ошибка. Термин состязательность основывается на том факте что оба потока конкурируют за свои данные.
В качестве некого решения состязательности мы можем ввести блокировки (locks). Блокировки могут применяться для предотвращения прочих потоков от доступа к определённым вещам, таким как файл, пока ваш поток не закончит с ним. Однако, необходимо отметить, что такие блокировки работают только внутри самого процесса; таким образом, другие процессы могут осуществлять доступ к этому файлу. Решения кэширования, такие как Redis и базы данных общего применения обладают уже реализованными таких сторожевых, а блокировки не защитят против описанной в этом разделе состязательности. По моему опыту, когда мы проявляем творческий подход к таким понятиям как блокировки, это обычно знак к тому, что нам следует предпринять шаг обратно и повторно продумать нашу архитектуру.
Даже файл базы данных SQLite будет управлять нашей проблемой состязательности данных при чтении и записи в файл и когда похоже, что может произойти описанная в начале этого раздела состязательность данных, будет лучше совсем не запускать их одновременно. Последовательное программирование безопаснее и полезнее.
В этой главе мы прошлись по основе многопроцессности и многопоточности. Затем мы проследовали практическим путём применения потоков и процессов. Затем мы изучили последовательность Фибоначчи на предмет того как процессы способны ускорять наши вычисления. Через эту последовательность Фибоначчи мы также обнаружили, что то, как мы вычисляем свои задачи, это самый большой фактор по сравнению с потоками и процессами. Прежде чем переходить к многопроцессности для получения ускорения, стоит избегать алгоритмов с экспоненциальным масштабированием. Нам следует помнить, что хотя и может быть заманчивым применение более сложных подходов, это может приводить к таким проблемам как взаимная блокировка и состязательность. Если мы будем помнить об этих понятиях и будем сохранять всю свою многопроцессность в пуле, мы сведём к минимуму свои трудно диагностируемые проблемы. Это не означает, что мы никогда не должны проявлять творческий подход к многопроцессной обработке, однако рекомендуется продолжить чтение в этой области, поскольку имеются книги, целиком посвящённые одновременности (которые отмечены в разделе Дальнейшее чтение, с указанием конкретных глав на которых стоит остановиться). Это просто введение, позволяющее нам применять одновременность в своих пакетах Python, когда она потребуется. В своей следующей главе мы будем собирать свои собственные пакеты с тем, чтобы мы смогли распространять свой код Python по множеству проектов и повторно применять код.
-
В чём состоит разница между процессом и потоком?
-
Почему многопоточность не ускорит наше последовательное вычисление Python Фибоначчи?
-
Зачем мы применяем пул множества процессов?
-
Наши потоки в Rust возвращают
Result<i8, Box<dyn Any + Send>>Что это означает? -
Почему нам следует по возможности избегать дерево рекурсии?
-
Когда вам требуется более быстрое время выполнения, не следует ли нам раскрутить больше процессов?
-
Почему нам следует по возможности избегать сложной многопроцессности?
-
Что делает
joinдля нашей программы при многопоточности? -
Почему
joinничего не возвращает в процессе?
-
Потоки обладают малым весом и допускают многопоточность, при которой мы можем запускать множество задач, которые могут обладать временем простоя. Процесс более затратен, позволяя нам одновременно запускать множество задач с интенсивным применением ЦПУ. Процессы не разделяют память, в то время как потоки используют ей совместно.
-
Многопоточность не ускорит наши последовательные вычисления Фибоначчи по той причине, что вычисление чисел Фибоначчи является задачей, интенсивно использующей ЦПУ, которая вовсе не обладает временем простоя; тем самым, наши потоки будут выполняться в Python последовательно. Однако, мы продемонстрировали, что Rust способен исполнять множество пооков одновременно, получая значительный рост производительности.
-
Многопроцессность затратна и сами процессы не разделяют память, превращая свою реализацию в потенциально более сложную. Пул обработки сохраняет часть многопроцессности минимальной. Такой подход также позволяет нам простым образом контролировать значения различного числа исполнителей, которое нам требуется помещёнными в одном месте и к тому же мы можем возвращать все получаемые итоги в ту же самую последовательность, поскольку они возвращаются из этого пула со множеством процессов.
-
Наши потоки Rust могут отказывать. Когда этого не происходит, они будут возвращать некое целое число. В случае отказа они способны вернуть что угодно любого размера, и именно поэтому это располагается в общей куче. Тут также присутствует признак (trait)
Send, который подразумевает, что это может переправляться между потоками. -
Дерево рекурсии масштабируется экспоненциально. Даже когда мы применяем многопоточность, наше время вычисления будет быстро множиться, толкая наши микросекунды к секундам когда мы пересекаем некую границу.
-
Нет - как демонстрируется в законе Амдала, рост числа исполнителей снабжает нас неким ускорением, однако по мере роста числа исполнителей мы будем обладать уменьшающимся выигрышем.
-
Сложная обработка множеством процессов/ многопоточностью может представлять диапазон ошибок втихую, таких как взаимная блокировка и состязательность данных, которые трудно выявлять и решать.
-
joinблокирует нашу программу до тех пор, пока не завершится его поток. Он также способен возвращать полученный результат из этого потока если мы переписываем функцию Pythonjoin. -
Процессы не используют память совместно, таким образом она не может быть доступной. Однако, мы можем получать доступ к данным из прочих процессов сохраняя данные в файлы для доступа из своего процесса main, либо отправлять данные конвейером через
stdinиstdout, как мы это осуществляли в своём примере со множеством процессов на Rust.
-
Understanding Python Multithreading and Multiprocessing via Simulation, Pan Wu (2020)
-
Hands-On Concurrency with Rust, Brian Troutwine, Packt Publishing (2018)
-
{Прим. пер.: Advanced Python Programming - Second Edition, Quan Nguyen, Packt Publishing (March 2022)}
-
Advanced Python Programming, Dr. Gabriele Lanaro, Quan Nguyen, Sakis Kasampalis, Packt Publishing (2019): Chapter 8 (Advanced Introduction to Concurrent and Parallel Programming)
-
Hands-On Functional Programming in Rust, Andrew Johnson, Packt Publishing (2018): Chapter 8 (Implementing Concurrency)
-
Mastering Rust, 2nd.ed., Rahul Sharma and Vesa Kaihlavirta, Packt Publishing (2019): Chapter 8 (Concurrency)
-
{Прим. пер.: Полное руководство параллельного программирования на Python, перевод, Куан Нгуен, Packt Publishing (2018)}
-
{Прим. пер.: Asyncio в Python 3, перевод, Цалеб Хаттингх, O`Reilly, 2018}
-
{Прим. пер.: Книги рецептов параллельного программирования Python, перевод второго издания, Джанкарло Закконе, Packt Publishing, 2019}