Глава 10. Выбор лидера
Содержание
Синхронизация может стоить достаточно дорого: когда каждый шаг алгоритма вовлечён в контакт с каждым иным участником, мы можем завершить значительными накладными расходами взаимодействия. Это в особенности справедливо для крупных и географически распределённых сетевых сред. Для снижения накладных расходов синхронизации и общего числа путешествующих из конца в конец сообщений для достижения некого решения, некоторые алгоритмы полагаются на наличии некого процесса лидера (порой именуемого координатором), ответственного за исполнение или координацию этапов некого распределённого алгоритма.
Как правило, процессы в распределённой системе единообразны и любой процесс может взять на себя роль такого лидера. Процессы предполагают лидерство на протяжении длительного времени, но это не постоянная роль. Как правило, такой процесс остаётся лидером до своего крушения. После такого крушения любой иной процесс способен запустить новый раунд выборов, предложить лидерство и, если он будет избран, продолжить работу отказавшего лидера.
Сама жизнеспособность такого алгоритма гарантирует, что в большинстве случаев будет иметься некий лидер, а также такие выборы в конечном счёте будут завершены (то есть данная система никогда не будет пребывать в подобном состоянии выборов неопределённо долго).
В идеале мы также предполагаем безопасность, и гарантируем что в некий определённый момент времени может быть не более одного лидера, и целиком исключаем возможность ситуации расщепления сознания (когда выбраны два лидера обслуживающими одну и ту же цель, но не знают друг о друге). Тем не менее, на практике, многие алгоритмы выбора нарушают данное соглашение.
Процессы выбора лидера, к примеру, могут применяться для достижения общего порядка сообщений при их широковещательной раздаче. Такой лидер собирает и удерживает своё глобальное состояние, получает сообщения и распространяет их по всем имеющимся процессам. Он также может использоваться для координации реорганизации системы после её отказа, в процессе инициализации или когда происходят важные изменения состояния.
Выборы включаются когда инициализируется данная система и лидер выбирается в самый первый раз, или же когда такой предыдущий лидер претерпевает крушение или отказывает во взаимодействии. Выборы должны быть детерминистскими: по результатам этого процесса должен появиться лишь один лидер. Такое решение должно быть действенным для всех участников.
Хотя выборы лидера и распределённая блокировка (т.е. исключительное обладание неким совместно используемым ресурсом) и выглядят с теоретической точки зрения схоже, они слегка отличаются. Когда один процесс удерживает некую блокировку для исполнения какого- то критического раздела, для прочих процессов не важно знать кто в точности удерживает блокировку прямо сейчас до тех пор, пока удовлетворяется сам процесс жизнеспособности (то есть такая блокировка в конечном итоге высвобождается, позволяя прочим овладевать ею). В противоположность этому, процесс выборов обладает некими особыми свойствами и обязан быть известен всем прочим участниками, следовательно его новый лидер обязан уведомить своих одноранговых партнёров о своей роли.
Когда некий алгоритм распределённой блокировки имеет некий вид предпочтения для какого- то процесса или группы процессов, он в конечном итоге будет морить голодом процессы без предпочтений в отношении этого разделяемого ресурса, что противоречит необходимому свойству живучести. В противоположность этому, выбранный лидер может оставаться в своей роли до тех пор пока не претерпит крушения и более предпочтительными являются долгоживущие лидеры.
Наличие некого стабильного лидера в рассматриваемой системе помогает избегать состояние синхронизации между удалёнными участниками, снижает общее число обмена сообщениями и направление исполнения с какого- то отдельного процесса вместо требования координации одноранговой сети. Одна из основных потенциальных проблем в системах с представлением о лидерстве состоит в том, что такой лидер способен становиться узким местом. Для преодоления этого многие системы разделяют данные на разделы в не пересекающиеся независимые наборы реплик (см. раздел Создание разделов баз данных). Вместо наличия отдельного лидера по всей системе, каждый набор реплик обладает своего собственного лидера. Одна из тех систем, которые применяют такой подход, является Spinner (см. раздел Распределённые транзакции при помощи Spanner).
По причине того, что каждый лидирующий процесс в конечном итоге отказывает, отказ должен быть обнаружен, о нём должно быть выдано сообщение, а также на него должна быть реакция: система обязана выбрать иного лидера для замены вышедшего из строя.
Некоторые алгоритмы, например, ZAB (см. раздел ZAB), Multi-Paxos (Multi-Paxos) или (Raft) применяют временных лидеров для снижения общего числа сообщений необходимых для достижения некого согласия между имеющимися участниками. Тем не менее, эти алгоритмы применяют свои собственные особенные для алгоритма средства для выбора лидера, выявления отказа и разрешения конфликтов между соперничающими за лидерство процессами.
Один из алгоритмов выбора лидера, именуемый как алгоритм задиры (bully algorithm), ипользует ранги процессов для выявления своего нового лидера. Каждый процесс получает некий уникальный назначаемый ему ранг. В процессе проведения выборов процесс с наивысшим значением ранга становится лидером [MOLINA82].
Этот алгоритм стал известным благодаря своей простоте. Данный алгоритм носит название задиры по той причине, что узел с наивысшим значением ранга "быкует" прочие узлы чтобы они приняли его в качестве лидера. Он также известен под названием монархического выбора лидера: монархом становится собрат с наивысшим рейтингом после того как прежний перестаёт существовать.
Выборы запускаются когда один из имеющихся процессов замечает что в его системе отсутствует лидер (он не был инициализирован) или предыдущий лидер перестал отвечать на запросы и выполняется в три этапа (данные шаги описывают видоизменённый алгоритм выборов задиры [KORDAFSHARI05], поскольку он более компактный и ясный):
-
Этот процесс отправляет сообщение о выборах процессам с более высокими идентификаторами.
-
Данный процесс выполняет ожидание, позволяя откликнуться процессам с более высоким рангом. Если ни один из процессов с более высоким рангом не отвечает, он продолжает с шага 3. В противном случае этот процесс отмечает ответивший ему процесс с наивысшим рангом и позволяет этому процессу выполнять шаг 3.
-
Процесс этого шага полагает, что больше нет активных процессов с более высоким рангом и уведомляет все процессы с более низким рангом о своём лидерстве.
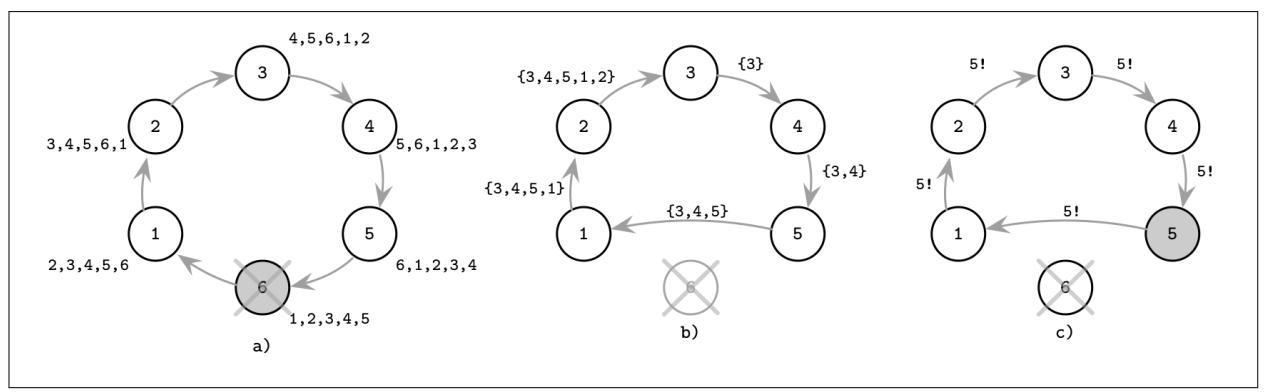
Рисунок 10-1 иллюстрирует обсуждённый алгоритм задиры выборов лидера:
-
Процесс 3 замечает, что его предыдущий лидер 6 претерпел крушение и запустил новые выборы отправив сообщение
Election(выборы) процессам с более высокими значениями идентификаторов. -
4 и 5 отвечают
Alive(живём), поскольку у них более высокий ранг чем у 3. -
3 обнаруживает, что в процессе этого раунда откликнулся процесс 5 с наивысшим рангом.
-
5 выбирается в качестве нового лидера. Он широковещательно рассылает сообщения
Elected(избран), уведомляя процессы с более низким рангом о результатах этих выборов.
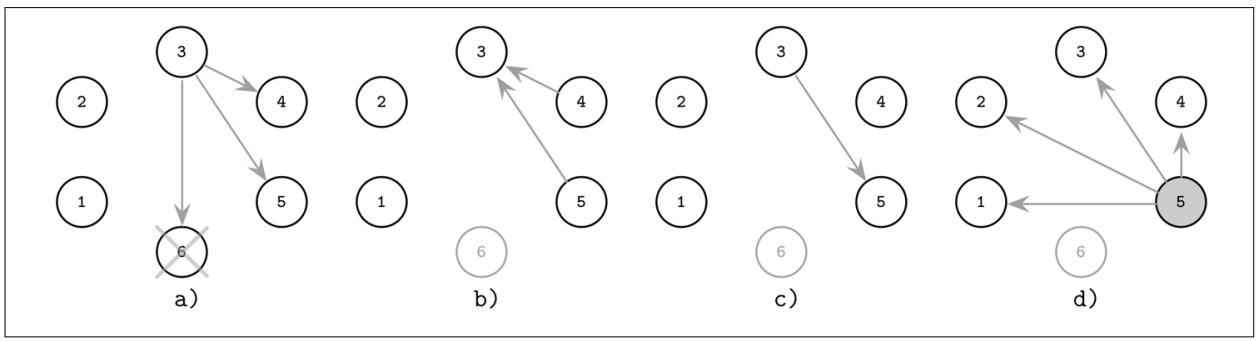
Одной из очевидных проблем для данного алгоритма является то, что он нарушает необходимые гарантии безопасности (относительно того, что за раз может быть выбран лишь один лидер) пр наличии разбиения сетевой среды на разделы. Это развитие событий может запросто завершиться ситуацией, при которой узлы разбиваются на два или более независимо работающих подмножества и каждый из наборов выбирает своего собственного лидера. Такое положение дел носит название расщепления сознания.
Другой проблемой для данного алгоритма является строгое предпочтение для узлов с самыми высокими рангами, что становится трудным случаем когда они нестабильны и способны вызывать непрерывную череду перевыборов. Некий нестабильный узел с наивысшим рангом, предлагающий себя в качестве лидера вскоре после этого откажет, выборы будут запущены, опять последует отказ и весь этот процесс повторится целиком. Эту задачу можно разрешить распространяя замеры качества и принимая их в рассмотрении при самих выборах.
Существует множество вариаций обсуждённого алгоритма задиры, которые улучшают его различные свойства. К примеру, мы можем воспользоваться альтернативными следующими- в- строю процессами в качестве отказоустойчивости для скорейших повторных выборов [GHOLIPOUR09].
Всякий избранный лидер производит некий перечень отказоустойчивых узлов. Когда один из имеющихся процессов определяет отказ лидера, он запускает новые выборы, отправляя сообщение альтернативе наивысшим рангом из списка, произведённого отказавшим лидером. Когда одна из предлагаемых альтернатив поднята, она становится новым лидером без какой бы то ни было необходимости проходить полный раунд выборов.
Если тот процесс, который был определил отказ лидера сам по себе обладает наивысшим рангом из данного перечня, он может уведомлять прочие процессы о новом лидере прямо сразу.
Рисунок 10-2 показывает данный процесс с данной оптимизацией на своём месте:
-
6 является лидером с обозначенными альтернативами {5,4}, претерпевает крушение, 3 отмечает этот отказ и контактирует с 5, альтернативой из имеющегося списка с наивысшим рангом.
-
5 отвечает 3 что он работает, чтобы предотвратить тому контакты с прочими узлами из имеющегося перечня альтернатив.
-
5 уведомляет все прочие узлы что он новый лидер.
Рисунок 10-2
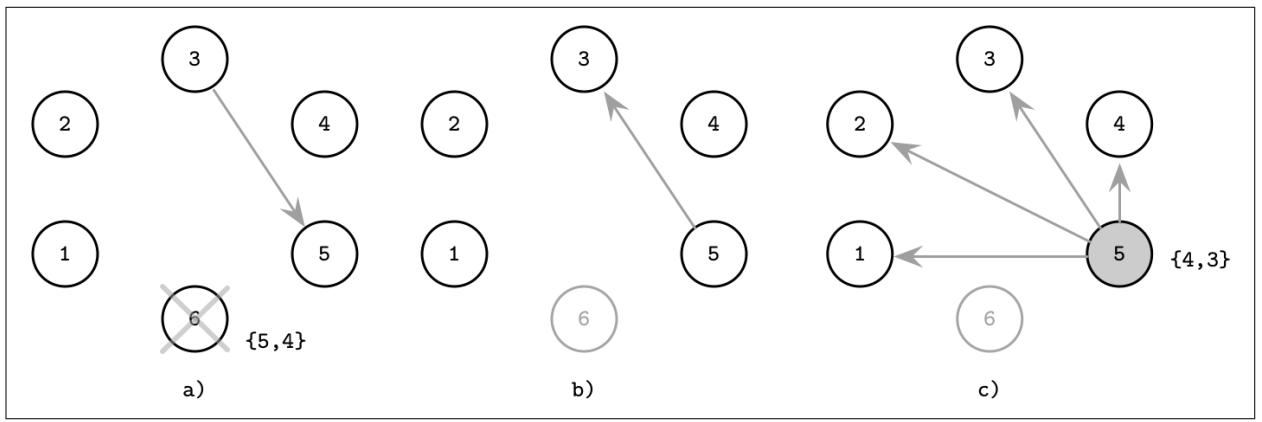
Алгоритм задиры с предпочтением: предыдущий лидер (6) отказал и процесс 3 запустил новые выборы, контактируя с имеющейся альтернативой наивысшего ранга
В результате нам требуется меньше шагов в процессе таких выборов в случае, когда следующий в строю жив.
Другой алгоритм пытается снизить требования в общем числе сообщений расщепляя все узлы на два подмножества: соискателей и обычные. в которых лишь один из имеющихся узлов кандидатов может в конечном итоге становиться лидером [MURSHED12].
Ординарный процесс инициирует выборы контактами с узлами кандидатов, собирая от них отклики, указывая рабочего кандидата с наивысшим рангом в качестве нового лидера, а затем оповещая все оставшиеся узлы о полученных результатов выборов.
Для решения проблемы с множеством одновременных выборов данный алгоритм предлагает пользоваться переменной δ схемы разрешения конфликтов, некой конкретной для процесса задержкой, значительно меняющейся между имеющимися узлами, которая позволяет одному из существующих узлов инициировать необходимые выборы до того как этим займутся прочие. Значение времени схемы разрешения конфликтов обычно больше времени прохода сообщения в оба конца. Узлы с большими приоритетами обладают более низкими δ, и наоборот.
Рисунок 10-3 отображает установленные этапы данного процесса выборов:
-
Процесс 4 из множества обычных отмечает отказ процесса лидера 6. Он запускает новый раунд выборов контактируя с остающимися в своём наборе кандидатами.
-
Процессы кандидатов откликаются 4 указывая что они в рабочем состоянии.
-
4 уведомляет все процессы о новом лидере: 2.
Рисунок 10-3
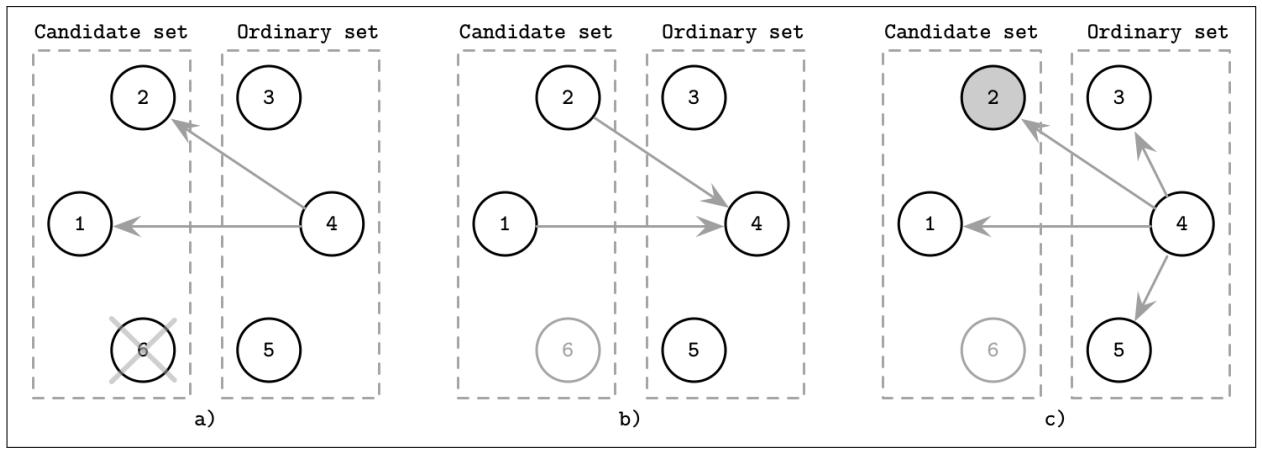
Модификация кандидат/ обычный алгоритм задиры: предыдущий лидер (6) отказал и процесс 4 запустил новые выборы
Некий алгоритм приглашения позволяет процессам "зазывать" прочие процессы соединяться с ними в группы вместо того чтобы выставлять более высокий ранг им. Этот алгоритм допускает множество лидеров, по определению, поскольку всякая группа обладает своим собственным лидером.
Каждый процесс запускается как некий лидер какой- то новой группы, в которой только этот процесс и является участником группы. Лидеры групп контактируют одноранговым образом с не относящимися к их группам участникам, приглашая их к объединению. Если такой одноранговый процесс сам по себе является лидером, две группы сливаются. В противном случае находящийся в контакте процесс отвечает идентификатором лидера группы, позволяя двум лидерам групп наладить контакт и слить группы меньшим числом шагов.
Рисунок 10-4 отображает шаги, исполняемые этим алгоритмом приглашения:
-
Четыре процесса начинают как лидеры групп, каждая из которых содержит единственного участника. 1 приглашает 2 соединиться в группу, а 3 зазывает в объединённую группу 4.
-
2 соединяется в группу с процессом 1, а 4 объединяется в группу с процессом 3. 1, лидер своей первой группы, выходит на контакт с 3, лидером другой группы. Остающиеся участники группы (в данном случае 4) уведомляются о новом лидере группы.
-
Две группы сливаются и 1 становится лидером некой расширенной группы.
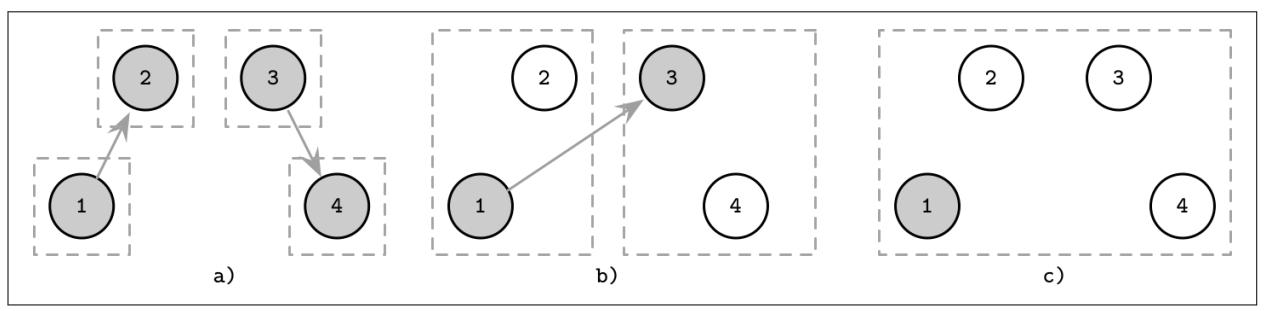
Поскольку группы сливаются, не имеет значения будет ли приглашённый процесс становиться лидером сливаемой группы, или другой им станет лидер. Чтобы удерживать минимальным общее число сообщений для слияния групп, лидером для новой группы может становиться лидер большей группы. Тем самым, уведомляться о смене лидера будут лишь члены меньшей группы.
Аналогично прочим обсуждавшимся алгоритмам, этот алгоритм позволяет улаживать с множеством групп и иметь множество лидеров. Данный алгоритм приглашений допускает создание групп процессов и их слияние без необходимости включения новых выборов с нуля, снижая общее число сообщений, требующихся для завершения необходимых выборов.
В данном алгоритме кольца [CHANG79] все узлы рассматриваемой системы формируют некое кольцо и осведомлены об установленной топологии кольца (то есть о своих предшественниках и последователях в этом кольце). Когда определённый процесс замечает отказ имевшегося лидера, он запускает соответствующие новые выборы. Такое сообщение о выборах пускается далее по этому кольцу: каждый процесс вступает в контакт со своим последователем (следующим ближайшим к нему в кольце узлом). Когда такой узел недоступен, процесс пропускает недостижимый узел и пытается вступить в контакт со следующим после него узлом в кольце, до тех пор пока один из них не ответит.
Узлы контактируют со своими собратьями, следуя по кругу и собирая набор рабочих узлов, добавляя себя в это множество перед тем как передать его следующему узлу, аналогично алгоритму выявления отказов, описанному в разделе Свободный от таймаутов определитель отказа, в котором узлы добавляют себя в конец пути перед его передачей следующему узлу.
Данный алгоритм продолжается до полного обхода своего кольца. Когда данной сообщение приходит обратно к тому узлу, который запустил эти выборы, в качетсве лидера выбирается узел с самым высоким рангом в данном наборе работающих. На Рисунке 10-5 вы можиете видеть пример такого обхода.
-
Предыдущий лидер 6 отказал, и все процессы обладают неким представлением данного кольца со своей точки зрения.
-
3 запускает процесс обхода раунда выборов. На каждом этапе имеется некий набор обойдённых узлов по установленному пути к этому моменту. 5 не способен достичь 6, поэтому он пропускает его и переходит сразу к 1.
-
Поскольку именно 5 был узлом с наивысшим значением ранга, 3 инициирует следующий раунд обмена сообщениями, распространяя сведения о новом избранном лидере.
Вариации этого алгоритма содержат сбор отдельного идентификатора с наивысшим рангом вместо набора активных узлов с целью
сохранения пространства: так как функция max коммуникативна, достаточно обладать текущим
максимальным значением. Когда данный алгоритм возвращается обратно к узлу, запустившему данные выборы, значение наивысшего
известного идентификатора вновь пускается по этому кругу.
Так как данное кольцо может быть разбито на две или более части, с возможностью потенциального выбора такой частью своего собственного лидера данный подход также не сохраняет свойство безопасности.
Как вы можете видеть, для правильной работы систем с лидером нам необходимо знать состояние текущего лидера (жив он или нет), так как для продолжения поддержки организации процессов и самого исполнения такой лидер должен быть рабочим и и достижим чтобы исполнять свои обязанности. Для выявления крушения лидера мы можем применять алгоритмы выявления отказов (см. Главу 9).
Выбор лидера это важная тема распределённых систем, так как использование назначенного лидера способствует снижению накладных расходов координации и улучшает производительность применяемого алгоритма. Раунды выборов могут быть дорогостоящими, однако, поскольку они не часты, они не оказывают отрицательного воздействия на общую производительность системы. Некий отдельный лидер способен становиться узким местом, но в большинстве случаев это решается разбиением данных на части и применением лидеров для каждой части или использованием различных лидеров для отличающихся действий.
К сожалению, все обсуждавшиеся нами в этой главе алгоритмы склонны к проблеме расщепления сознания: мы можем приходить к двум лидерам в двух независимых подсетях, которые даже и не догадываются о существовании друг друга. Во избежание расщепления сознания нам приходится получать большинство голосов всего кластера.
Многие алгоритмы консенсуса, включая Multi-Paxos и Raft, полагаются на некого лидера для координации. Тем не менее, являются ли выборы лидера тем же самым что и консенсус? Для выборов некого лидера нам требуется достичь согласия о его идентичности. Если мы способны достичь консенсуса относительно идентичности лидера, мы можем применять то же самое средство для достижения согласия по чему угодно [ABRAHAM13].
Значение идентичности некого лидера может изменяться без знания этого процессами, потому будет справедлив также и вопрос о том знает ли о своём лидере локально процесс. К примеру, алгоритм стабильного выбора лидера (stable leader election) использует раунды с уникальным стабильным лидером и выявление отказов на основании таймаутов для обеспечения того, что это лидер может оставаться в своём положении пока он не испытает крушения и является доступным [AGUILERA01].
Полагающиеся на выборы лидера алгоритмы часто допускают наличие присутствия множества лидеров и пытаются разрешать конфликты между этими лидерами настолько быстро, насколько это возможно. Например, это справедливо для Multi-Paxos (см. раздел Multi-Paxos), в котором способен продолжать лишь один из двух конфликтующих лидеров (доверенное лицо, proposers), а эти конфликты разрешаются сбором некого вторичного кворума, что обеспечивает тот факт, что не будут приняты значения от двух различных доверенных лиц.
В Raft (см. раздел Raft) может обнаружить, что его звание устарело, что подразумевает присутствие в этой системе другого лидера, и ему придётся обновлять это звание на более позднее.
В обоих случаях присутствие лидера это некий способ гарантии живучести (когда отказывает текущий лидер, нам требуется новый), а процессам не требуется неопределённо длительного времени для того чтобы понять отказали ли они на самом деле. Отсутствие безопасности и допуск множества лидеров это некая оптимизация производительности: алгоритмы способны продолжать фазу репликации, а безопасность гарантируется выявлением и разрешением конфликтов.
Мы обсудим более подробно консенсус и выборы лидера в контексте консенсуса в Главе 14.
![[Замечание]](/common/images/admon/note.png) | Последующее чтение |
|---|---|
|
Если вы желаете узнать больше относительно упоминавшихся в этой главе понятий, вы можете ссылаться на следующие источники:
|