Глава 1. Введение в систему хранения Ceph
Содержание
Ceph является неким проектом с открытым исходным кодом, который предоставляет какое- то решение для программно определяемого, доступного через сетевую среду хранилища с высокой производительностью и без какой бы то ни было единой точки отказа. Он разработан для того чтобы являть собой высокую масштабируемость вплоть до уровня экзабайт и выше при работе на общедоступном оборудовании для обычных целей.
В данной главе мы охватим следующие темы:
-
Историю и развитие Ceph
-
Что нового с момента публикации первого издания Изучаем Ceph
-
Будущее систем хрванения
-
Сопоставление Ceph с прочими решениями хранения
Ceph значительно увеличивает шум в отрасли систем хранения благодаря своей внутренне присущей открытости, масштабируемости и распределённости. Сегодня общедоступные, частные и гибридные модели являются доминирующими стратегиями для масштабируемыз и горизонтально масштабируемых инфраструктур. Архитектура и свойства Ceph, включая поддержку множества арендаторов, естественным образом соответствуют облачным развёртываниям IaaS (Infrastructure as a Service, Инфраструктуры в виде службы) и PaaS (Platform as a Service, Платвормы как службы): по крайней мере 60% применений OpenStack усилены с помощью Ceph.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Для получения дополнительных подробностей по применению Ceph в рамках проектов OpenStack посетите https://keithtenzer.com/2017/03/30/openstack-swift-integration-with-ceph. |
Ceph умышленно спроектирован для предоставления служб корпоративного уровня на разнообразных общедоступных аппаратных средствах. Философия архитектуры Ceph включает в себя следующее:
-
Все компоненты обязаны масштабироваться
-
Никакой индивидуальный процесс, сервер или другой компонент не может представлять собой единую точку отказа
-
Данное решение должно основываться на программном обеспечении, причём с открытым исходным кодом и при этом быть приспосабливаемым
-
Программное обеспечение Ceph должно работать на легко доступном обычном оборудовании без завязывания на производителя
-
Всё должно быть самоуправляемым там, где это возможно
Ceph предоставляет великолепную производительность, безграничное масштабирование, корпоративные мощность и гибкость, что помогает компаниям выполнить переход с затратных проприетарных бункеров хранения. Универсальная система хранения Ceph предоставляет хранилище блоков, файлов и объектов из некоей единой, унифицированной основы, что позволяет пользователям осуществлять доступ к хранилищу по мере развития и роста своих потребностей.
Основой Ceph являются объекты, строительные блоки, из которых собираются сложные службы. Все разновидности данных, будь то блоки, объекты или файлы, представляются объектами внутри серверов самого Ceph. Объектное хранилище является определённым гибким решением для потребностей неструктурированных данных сегодня и в нашем будущем. Некая система хранения на основе объектов предлагает преимущества в сопоставлении с обычными, основывающимися на файлах, хранилищами, которые включают в себя независимость от платформы и оборудования. Ceph тщательно управляет данными, реплицируя их по устройствам хранения, серверам, стойкам центра обработки данных для гарантии надёжности, доступности и износостойкости. В рамках объектов Ceph отсутствует привязка к некоторому физическому пути, что делает объекты гибкими и не зависящими от своего местоположения. Это делает возможным линейную масштабируемость Ceph с уровня петабайт до уровня экзабайт.
Ceph был разработан в Университете Калифорнии, Санта Круз, Сейджем Вейлем в 2003 как часть его проекта докторской диссертации. Самая первая реализация представляла CephFS (Ceph Filesystem) с приблизительно 40 000 строками кода C++. Он был открытым исходным кодом в 2006 под LGPL (Lesser GNU Public License) для обслуживания справочных реализаций и исследовательских платформ. Национальная лаборатория Lawrence Livermore осуществляла поддержку раннего выполнения работ Сейджа с 2003 по 2007.
С Сейджем Вейлем также сотрудничала компания предоставления веб хостинга и доменной регистрации DreamHost, базирующаяся в Лос Анжелесе, поддерживавшая разработку Ceph с 2007 по 2011. На протяжении этого периода времени Ceph приобрёл свои известные нам очертания: его центральные составляющие приобрели стабильность и надёжность, были реализованы новые свойства, а также была прочерчена дорожная карта на его будущее. В течение этого времни приступили к сотрудничеству ключевые разработчики, в том числе Йехуда Садех- Вайнрауб, Грегори Фарнум, Джош Даргин, Самуэл Джаст, Видо ден Холандер и Лойк Дачари.
В 2012 Сейдж Вейль основал Inktank чтобы включить повсеместную адаптацию Ceph. Их экспернтые заключения, процессы, инструменты и поддержка позволили потребителям корпоративной подписки действенные реализацию и упралвение системами хранения Ceph. В 2014 Red Hat, Inc., мировой лидер производства решений с открытым исходным кодом, согласился приобрести Inktank.
|
| Замечание |
|---|---|
|
Для получения дополнительной информации посетите https://www.redhat.com/en/technologies/storage/ceph. |
Термин Ceph является распространённым прозвищем, даваемым домашним осьминогам; Ceph также является сокращением от cephalopod, морского обитателя, относящегося к классу моллюсков Cephalopoda. Талисманом Ceph является осьминожек, что является напоминанием высоко распараллеленного поведения осьминогов и был выбран для соединения файловой системы с талисманом UCSC, бананового слизняка с именем Sammy. Банановые слизняки являются брюхоногими моллюсками (gastropods), которые также входят в класс моллюсков. Поскольку Ceph не является сокращением, его не следует писать заглавными буквами CEPH.
|
| Замечание |
|---|---|
|
Для получения дополнительной общей информации о Ceph посетите, пожалуйста, https://en.wikipedia.org/wiki/Ceph_(software). |
Каждый выпуск Ceph имеет некий номер версии. Основные редакции также получают сефлапоидное кодовое именование в алфавитном порядке. Благодаря выпуску Luminous сообщество Ceph пометило новую основную версию приблизительно дважды в год, чередуя их долговременной поддержкой (LTS, Long Term Support) и стабильными редакциями. При этом официально выполнялась поддержка двух редакций LTS, но только одной самой последней стабильной версии.
|
| Замечание |
|---|---|
|
Для получения дополнительной информации по выпускам Ceph посетите, пожалуйста, https://ceph.com/category/releases. |
Схема нумерации редакций (выпусков) была изменена с момента публикации первой редакции Изучаем Ceph. Более ранние выпуски помечались изначально неким номером версии (0.87) и за ним следовали многочисленные выпуски после точки (0.87.1, 0.87.2, ...). Начиная с Infernalis, однако, нумерация выпусков производится как отображено ниже:
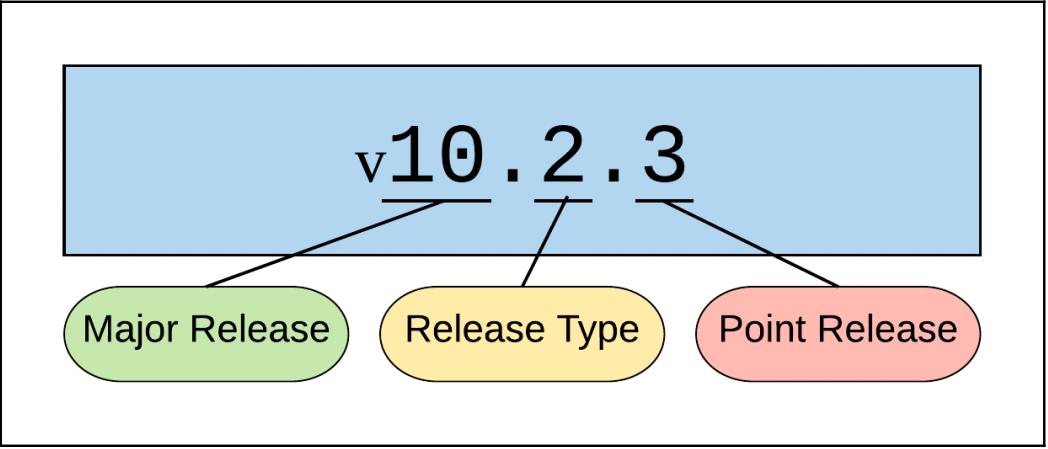
Самый основной номер выпуска, соответствует букве в его алфавитном кодировании (например, I является девятой буквой в Английском алфавите, поэтому 9.2.1 имеет название Infernalis). Как мы уже писали, имелось четыре выпуска, следующих данному соглашению нумерации: Infernalis, Jewel, Kraken и Luminous.
Все ранние версии каждого основного выпуска имеют некий тип 0 в своём втором поле, что указывает на активное состояние предварительного выпуска для более ранних тестирующих мужественных сердец. Более поздние кандидаты на выпуск имеют тип 1 и предназначаются для проверочных кластеров и мужественных пользователей. Тип 2 представляет общую доступность, готовый к промышленной эксплуатации выпуск. Точечные версии в основном содержат исправления безопасности и ошибок, но порой также предлагают улучшения функциональности.
| Название выпуска Ceph | Версия пакета Ceph | Дата выпуска |
|---|---|---|
|
|
Июль 2012 |
|
|
Январь 2013 |
|
|
Май 2013 |
|
|
Август 2013 |
|
|
Ноябрь 2013 |
|
|
Май 2014 |
|
|
Октябрь 2014 |
|
|
Апрель 2015 |
|
|
Ноябрь 2015 |
|
|
Апрель 2016 |
|
|
Январь 2017 |
|
|
Август 2017 |
|
|
2018 |
|
|
2019 |
|
| Замечание |
|---|---|
|
Отметим, что поскольку данная книга читается после опубликования в октябре 2017, Сейдж анонсированл, что все циклы выпусков изменены. Начиная с Mimic более не будет выбора между LTS и стабильной редакцией. Все выпуски впредь будут LTS с приблизительной цикличностью в 9 месяцев. Для получения подробностей посетите https://github.com/ceph/ceph/pull/18117/files. |
Выпуск Jewel LTS привнёс ряд значительных изменений:
-
Унифицированы очереди для ввода/ вывода клиентов, восстановление, очистка и обрезка моментальных снимков
-
Демоны не работают как определённый пользователь ceph, что может вызвывать проблемы при обновлениях
-
Улучшения многоуровневого кэширования
-
Удаляющее кодирование SHEC более не является экспериментальным
-
API SWIFT теперь поддерживает срок истечения действия объекта
-
Улучшения RBD (теперб поддерживаются суффиксы)
-
rbd duотображает дейтвующее и предоставляемое использование через свойстваobject-mapиfast-diff -
Новая команда
rbd status -
deep-flattenтеперь обрабатывает моментальные снимки -
Моментальные снимки CephFS темерь можно переименовывать
-
CephFS рассматривается как стабильная!
-
Улучшения вычистки
-
Улучшения TCMalloc
-
Значительно улучшена работа множества сайтов в RGW
-
Поддержка OpenStack Keystone v3
-
Индивидуальная поддержка пространств имён Swift для арендаторов
-
Асинхронное зеркалирование RBD
-
Новый поиск для
ceph status
|
| Замечание |
|---|---|
|
Дополнительные подробности версии Jewel можно найти на http://ceph.com/releases/v10-2-0-jewel-released. |
Как мы уже писали, основная редакция Luminous LTS только что поличила общую доступность. Ранний опыт является положительным и это наилучший выбор для развёртывания. Наиболее ожидаемые свойства Luminous включают в себя:
-
Поддержку в своей основе BlueStore
-
Сжатие и контрольные суммы в реальном времени
-
Удаляющее кодирование для томов RBD
-
Лучший инструментарий для единоообразия использования OSD
-
Улучшенные средства для жизненого цикла OSD
-
Расширение CLI
-
Поддирживается множество активных серверов MDS CephFS
|
| Замечание |
|---|---|
|
Замечания по выпуску Luminous 12.2.0 можно найти на https://ceph.com/releases/v12-2-0-luminous-released/. |
Требования корпортативного хранилища последнее десятилетие росли взрывообразно. Исследования показали, что данные в крупных компаниях ежегодно росли со скоростью от 40 до 60 процентов, а большое число компаний удваивали отпечаток своих данных каждый год. Аналитики IDC оценивали, что общие цифровые данные по состоянию на 2000 год составляли 54.4 экзабайт. К 2007 они достигли 295 экзабайт, к 2012 2 596 экзабайт, а к 2020 ожидается что они достигнут 40 000 экзабайт по всему миру.
|
| Замечание |
|---|---|
|
Источник: https://www.emc.com/leadership/digital-universe/2012iview/executive-summary-a-universe-of.htm. |
Обычные и проприетарные решения хранения часто страдают от умопомрачительных стоимостей, ограничений в масштабировании и функциональности, а также зашоренности на производителе. Каждый из этих показателей ставить в тупик бесшовный рост и обновление в отношении скорости и ёмкости.
Закрытое программное обеспечение и проприетарное оборудование оставляют всякого между молотом и наковальней при достижения предела продуктовой линейки, которое зачастую требует продолжительной, затратной и разрушительной тотальной замены EOL (закончившего свой жизненный цикл) оборудования в стиле выброса на свалку.
Современное хранение требует некую систему, которая является универсальной, надёжной, высокопроизводительной и, что наиболее важно, массивно масштабируемой до уровня экзабайт и выше. Ceph является реальным решением для взрывообразного всемирного роста данных. Ключевым фактором роста и освоения Ceph с молниеносной скоростью является яркое сообщество действительно верящих в мощность Ceph пользователей. Генерация данных - это бесконечный процесс, и нам необходимо развивать хранилище для удовлетворения своего растущего объема.
Ceph является идеальным решением для современного, растущего хранилища: он универсален, распределён, эффективен в отношении стоимости, а также масштабируется естественным образом в конкретном решении сегоднящнего дня и под потребности хранения данных в будущем. Сообщество программного обеспечения с открытым исходным кодом Linux увидело потенциал Ceph в 2008 и добавило поддержку Ceph в основное направление ядра Linux.
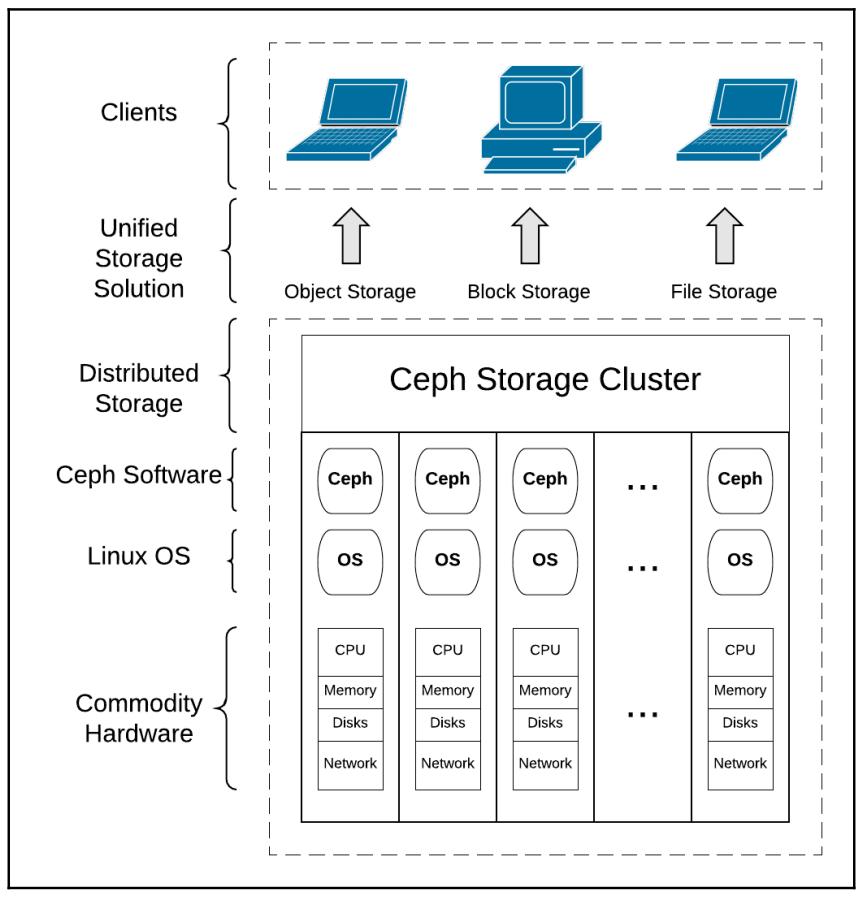
Одним из наиболее проблемных, но всё ещё критически важных компонентов реализации облачной инфраструктуры является система хранения. Облачной среде требуется хранилище, которое может может масштабироваться вверх и вширь при низкой стоимости и при этом хорошо интегрируется с прочими компонентами. Такая система хранения является ключевой составляющей в совокупной стоимости владения (TCO, total cost of ownership) всей облачной платформы. имеются традиционные производители систем хранения, которые притязают на предоставление интегрированных облачных инфраструктур, однако нам необходимы дополнительные свойства помимо простой поддержки интеграции. Обычные решения хранения, возможно, доказали свою адекватность в прошлом, но сегодня они являются идеальными кандидатами на унификацию решения облачного хранения. Традиционные системы хранения затратны при развёртывании и поддержке при их рассмотрении в долгосрочной перспективе а вертикальное и горизонтальное масштабирование является не изученной территорией. Нам требуется некое решение хранения разработанное для удовлетворения текущих и грядущих потребностей, какой- то системы, построенной на основе программного обеспечения с открытым исходным кодом и общедоступном оборудовании, которые могут предоставить такую необходимую масштабируемость эффективным в стоимостном отношении варианте.
Ceph быстро был вовлечён в это пространство чтобы заполнить имеющуюся потребность в реальной основе облачного хранения. Он является предпочтительным в основных облачных платформах с открытым исходным кодом, включающими в себя OpenStack, CloudStack и OpenNebula {Прим. пер.: в также любимый нами Proxmox}. Ceph выстроил партнёрство с Canonical, Red Hat и SUSE, основными столпами в пространстве Linux, которые предпочитают распределённые, надёжные и масштабируемые кластеры хранения Ceph для своих дистрибутивов программного обеспечения Linux и облачных платформ. Сообщество Ceph тесно сотрудничает с этими гигантами Linux для предоставления надёжной основы хранения со множеством функций в своих облачных платформах.
Общедоступные и частные облака набрали импульс поступательного движения с помощью платформы OpenStack. OpenStack проявил себя как сквозное облачное решение. Он содержит два компонента ядра хранения: Swift, который предоставляет хранилище на основе объектов и Cinder, который снабжает томами блочного хранения экземпляры. Ceph отличается как единая основа и для хранения объектов, и для блочного хранения в решениях OpenStack.
Swift ограничен хранением объектов. Ceph является унифицированным решением хранения для блоков, файлов объектов и предоставляет решениям OpenStack преимущество обслуживания множества способов хранения в едином кластере серверной части. Сообщества OpenStack и Ceph совместно работают на протяжении многих лет над разработкой полной поддержки со стороны Ceph основы хранения для облака OpenStack. Начиная с редакции OpenStack Folsom OpenStack Ceph был полностью интегрирован. разработчики Ceph предоставляют гарантии надлежащей роботы Ceph во всех новых изданиях OpenStack, привнося новые свойства и исправляя ошибки. Компоненты Cinder и Glance OpenStack используют ключевую службу RBD (RADOS Block Device). RBD Ceph позволяет решениям OpenStack быстро предоставлять сотни виртуальных машин обеспечивая динамично выделяемые (thin-provision) моментальные снимки и клонированные тома, которые создаются быстро и эффективно.
Облачные платформы с Ceph в качестве серверной основы хранения предоставляют большую часть необходимой гибкости поставщикам услуг, которые строят решения SaaS (Storage as a Service) и IaaS (Infrastructure-as-a-Service) и которые не могут быть реализованы обычными решениями корпоративных хранилищ. Получая мощность Ceph в качестве основы хранения для облачных платформ, поставщики услуг могут предлагать своим потребителям облачные службы с низкой стоимостью. Ceph позволяет им предлагать относительно низкие стоимости хранения при функциональности корпоративного уровня в сравнении с прочими решениями хранения.
Dell, SUSE, Redhat и Canonical предлагают и поддерживают инструментарий развёртывания и настройки, такой как Crowbar Dell, Ansible Red Hat и Juju для автоматизации и упрощения развёртывания хранилища Ceph для их облачных решений OpenStack. Для автоматизации развёртывания Ceph популярны и прочие инструменты управления настройкой, такие как Puppet, Chef и SaltStack. Каждый из этих инструментов имеет открытый исходный код, готовые модули для Ceph в доступности, которые могут быть легко применены для воздействия на развёртывание Ceph. При поддержке Red Hat их комплект ceph-ansible с открытым исходным кодом становится предпочтительным инструментом развёртывания и управления. В средах распределённых облачных решений (и прочих) должен масштабироваться каждый компонент. Такие средства управления настройкой являются существенными для быстрого масштабирования вашей инфраструктуры. Ceph полностью совместим с данными инструментами, позволяя пользователям развёртывать и расширять некий кластер Ceph незамедлительно.
|
| Замечание |
|---|---|
|
Дополнительные сведения об Ansible и ceph-ansible можно найти по ссылкам https://www.redhat.com/en/about/blog/why-red-hat-acquired-ansible и https://github.com/ceph/ceph-ansible/wiki. {Прим. пер.: обращаем ваше внимание на наши переводы второго издания "Полного руководства Ansible" и раздела Ansible в увидевшем свет в мае 2017 "Полном руководстве Ceph". Если вы впервые сталкиваетесь с Ansible и вам сложно понять его внутреннюю логику, советуем прочесть пару глав из перевода "Полного руководства работы с сетями на Python" в качестве примера применения Ansible при автоматизации работ с сетевыми устройствами.} |
Архитекторы инфраструктуры хранения всё больше начинают предпочитать Программно определяемые решения хранения (SDS, Software-defined Storage). SDS предлагает некое притягательное решение для организаций с крупными инвестициями в наследуемые хранилища, которые не получили гибкости и масштабируемости своих потребностей для развивающихся запросов. Ceph является реальным решением SDS:
-
Программное обеспечение с открытым исходным кодом
-
Работает но общедоступных аппаратных средствах
-
Отсутствует привязка к производителю
-
Низкая стоимость за ГБ
SDS решение предоставляет столь необходимую гибкость в отношении выбора оборудования. Потребители могут выбрать общедоступные аппаратные средства любого производителя и вольны проектировать гетерогенные аппаратные решения, которые развиваются со временем для удовлетворения их специфических потребностей и ограничений. Программно определяемое хранилище Ceph выстраивается из общедоступного оборудования гибко предоставляя динамичные свойства корпоративного хранилища на уровне программного обеспечения.
В Главе 3, Выбор оборудования и сетевой среды мы изучим разнообразные стороны, которые воздействуют на выбор аппаратных средств, который вы осуществляете для своего решения Ceph.
Единообразная система хранения с точки зрения производителя хранилища определяется как доступ к NAS (Network-Attached Storage) на основе файлов и к SAN (Storage Area Network) на основе блоков в одной платформе. Технологии NAS и SAN стали популярными в конце 1990-х и в ранние 2000-е, однако когда мы смотрим в будущее, уверены ли мы что обычные проприетарные технологии NAS и SAN могут управлять потребностями хранения на протяжении последующих 50 лет? Будут ли они способны обрабатывать экзабайты данных?
Применительно к Ceph термин унифицированности (единообразия) хранения означает намного больше чем только то, что заявляют к продаже производители обычных хранилищ. Ceph изначально разрабатывается чтобы быть готовым к грядущему; его строительные блоки масштабируются для того чтобы обрабатывать бесчисленное количество данных, а его модель открытого исходного кода гарантирует, что мы не ограничены наличием причуд или успеха отдельного производителя. Ceph является реально единообразным решением, которое предоставляет блочные, файловые и объектные службы из единой унифицированной программно определяемой серверной основы. Объектное хранение наилучшим образом соответствует сегодняшнему смешению стратегий неструктурированных данных в сравнении с блоками и файлами. Доступ осуществляется через хорошо специфицированный сетевой интерфейс RESTful, освобождая проектировщиков приложений и инженеров программного обеспечения от нюансов и капризов ядер операционной системы и файловых систем. Более того, основанные на объектах приложения охотно масштабируются, полностью удаляя пользователей от управления имеющимися пределами дискретного размера блочных томов. Порой блочные тома могут расширяться на своём месте, однкако это редко бывает простой, быстрой или бесперебойной операцией. Приложения могут быть написаны с доступом ко множеству томов, причём либо естественным путём, либо через уровни, такие как Linux LVM (Logical Volume Manager), однако это также может быть трудновыполнимым для управления, а масштабирование может всё ещё быть головной болью. С точки зрения клиента объектное хранилище не требует управления томами или устройствами с фиксированным размером. {Прим. пер.: забегая вперёд, скажем что и здесь имеются подводные камни, связанные с практической реализацией хранения объектов, но это отдельная тема для обсуждения.}
Вместо того чтобы управлять сложностью блоков и файлов за сценой, Ceph управляет объектами RADOS на нижнем уровне и определяет хранение блоков и файлов поверх них. Если вы мыслите в парадигме обычной системы хранения на файловой основе, адресация к файлам осуществляется через некий каталог и путь к файлу и, аналогично, объекты в Ceph адресуются неким уникальным указателем и хранятся в каком- то плоском пространстве имён.
|
| Замечание |
|---|---|
|
Важно делать разницу между объектами RADOS, которыми Ceph управляет на внутреннем уровне и видимыми пользователю объектами, доступными через службы Ceph S3/ Swift RGW. В большинстве случаев термин объект относится к последним. |
традиционные системы хранения не обладают эффективными способами управления метаданными. Метаданные являются информацией (данными) о реальной полезной нагрузке самих данных, включая то где эти данные будут записаны и откуда считаны. Обычные системы хранения сопровождают некую центральную таблицу поиска для отслеживания своих метаданных. Всякий раз когда клиент отправляет некий запрос для операции чтения или записи, система хранения вначале выполняет поиск в гигантской таблице метаданных. После получения необходимых результатов она осуществляет саму операцию клиента. Для систем хранения небольшого размера вы можете не замечать воздействия на производительность бутылочного горлышка такой централизации, однако когда хранилище достигает большого размера, имеющиеся ограничения производительности и масштабируемости данного подхода становятся всё более и более возрастающей проблемой.
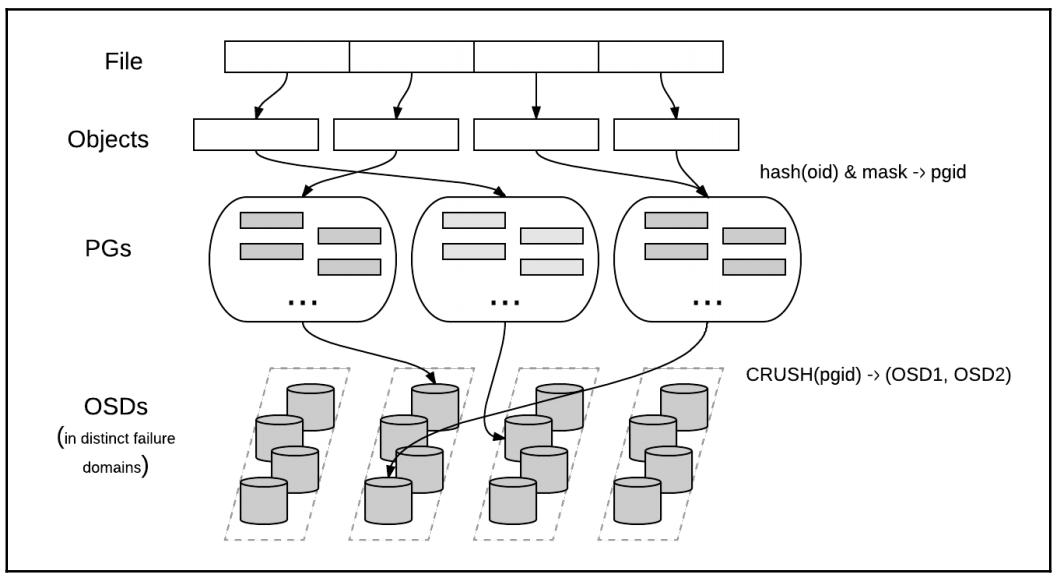
Ceph не следует традиционной архитектуре хранения; он был полностью переделан для следующего поколения. Вместо того чтобы централизованным образом хранить, манипулировать и осуществлять доступ к метаданным, Ceph внедрил новый подход, алгоритм CRUSH (Controlled Replication Under Scalable Hashing, Управляемых масштабируемым хешированием репликаций).
|
| Замечание |
|---|---|
|
За богатсвом официальных технических описаний (whitepaper) и прочей документации обращайтесь к http://ceph.com/resources/publications. {Прим. пер.: CRUSH не единственный имеющийся сегодня алгоритм хэшированного доступа к данным, в качестве примера можно сослаться на FusionStorage Huawei, который применяет архитектуру распределённой хэш- таблицы (http://www.mdl.ru/Solutions/Put.htm?Nme=FusionStorage).} |
Вместо выполнения какого- то поиска в таблице метаданных для каждого запроса клиента, наш алгоритм CRUSH позволяет определённому клиенту вычислять где должны быть записаны данные или откуда их необходимо считывать. При динамическом извлечении таких метаданных нет необходимости в управлении централизованной таблицей. Современные компьютеры могут осуществлять поиск CRUSH очень быстро; более того, меньшая вычислительная нагрузка может быть распределена по узлам кластера, получая усиление от мощности распределённого хранения.
CRUSH осуществляет это благодаря информированности об инфраструктуре. Он понимает имеющуюся иерархию и ёмкости различных компонентов вашей логической и физической инфраструктуры: диски, узлы, шасси, стойки центра обработки данных, пулы, домены сетевых коммутаторов, ряды центра обработки данных и даже помещения центра обработки данных и злания как диктующие требования местоположения. Это области отказа (failure domain) для любой инфраструктуры. CRUSH хранит данные безопасно реплицируя их таким образом, чтобы эти данные были защищены (надёжность) и достижимы (доступность) даже в случае, если множество компонентов выходят из строя внутри одной или по всем областям отказа. Диспетчеры Ceph определяют такие области отказа для своей инфраструктуры в рамках имеющейся топологии карты CRUSH Ceph. Серверная основа Ceph и клиенты совместно используют некую копию имеющейся карты CRUSH, причём клиенты таким образом способны извлекать необходимые местоположение, диск, сервер, центро обработки данных и тому подобное для желаемых данных и лсуществлять к ним непосредственный доступ без наличия централизованного узкого места поиска.
CRUSH делает возможными самоуправляемость Ceph и самовосстановление. В случае отказа компонента, имеющаяся карта CRUSH обновляется чтобы отразить такой упавший компонент. Прозрачность серверной основы определяет воздействие такого отказа на сам кластер в соответствии с определённым размещением и правилами репликации. Без вмешательства администратора, сами платформы серверов Ceph за сценой восстанавливают гарантированные надёжность и доступность данных. Сами серверы создают реплики данных из выживших копий на прочих, не подвергшихся воздействию компонентах для восстановления желаемой степени безопасности. Надлежащим образом спроектированные карта CRUSH и правила CRUSH гарантируют, что данный кластер будет сопровождать более одной копии данных распределённым образом по всему кластеру на разнообразных компонентах, избегая утраты данных в случае отказа одного или множества компонентов.
Массив независимых накопителей с избыточностью (RAID, Redundant Array of Independent Disks) служил основополагающей технологией хранения на протяжении последних 30 лет. Однако, по мере того, как тома данных и ёмкости компонентов впечатляюще меняются, системы хранения, базирующиеся на RAID всё возрастающе демонстрируют свои ограничения и терпят неудачу в потребностях хранения сегодняшнего дня и дня грядущего.
Технологии дисков взрослеют со временем. Производители выпускают в настоящее время магнитные диски корпоративного уровня с гигантской ёмкостью по всё уменьшающейся цене. Мы больше не говорим о дисках 450ГБ, 600ГБ или даже 1ТБ по мере роста ёмкости и производительности дисков. На момент написания, современные диски корпоративного уровня предлагают до 12ТБ хранения; на тот момент, когда вы будете читать эти слова, ёмкости в 14 или более ТБ могут быть уже доступными. SSD ( Solid State Drives, твердотельные диски) изначально были затратным решением для высокопроизводительных сегментов с малой ёмкостью или нишами, требующими ударостойкости или минимального энергопотребления или охлаждения. В последние годы ёмкости SSD впечатляюще выросли при резком падении стоимости. С момента публикации первого издания Изучаем Ceph становятся всё возрастающе доступными также и для массового хранения.
Рассмотрим некую корпоративную сисему хранения на основе RAID, построенную из большого числа дисковых устройств 4 или 8 ТБ; в случае отказа диска RAID потратит множество часов или даже дней для восстановления с некоторого отдельного отказавшего диска. Если в процессе восстановления отказывает другой диск, хаос гарантирован и данные могут быть утрачены. Восстановление с отказавшго диска или замена множества дисков большого объёма с применением RAID является обременительным процессом, который может приводить к значительной деградации производительности клиента.
Обычные технологии RAID включают в себя RAID 1 (зеркалирование), RAID 10 (зеркалирование плюс чередование) и RAID 5 (контрольные суммы - parity).
Действенные реализации RAID требуют выделения дисков целиком для предоставления их в качестве запсной части в горячем режиме. Это оказывает воздействие на TCO (издержки совокупного владения) и окончание резерва запасных дисков может быть фатальным. Большинство стратегий RAID предполагают некое множество дисков идентичного размера, пэтому на практике вы будете испытывать недостачу эффективности и скорости или даже сбои при восстановлении если вы смешиваете диски различных скоростей или размеров. Зачастую RAID системы будут не способны применить некий запасной или заменяемый диск, который всего чуть- чуть меньше первоначального, а если замещающий диск имеет больший размер, вся дополнительная ёмкость обычно теряется впустую.
Другим изъяном обычных систем хранения на основе RAID является то, что они редко предлагают какие бы то ни было обнаружение или исправление латентных ошибок или ошибок сброса бита (bit-flip) также имеющих название битовой деградации (bit-rot). Микроскопический отпечаток данных на современном носителе означает, что рано или поздно то что вы прочтёте со своего устройства хранения не будет сосответствовать тому, что вы туда записали, и у вас может не быть способа узнать что это произошло. Ceph периодически выполняет выскребания (scrub), которые сравнивают контрольные суммы и удаляют изменившиеся копии данных из обслуживания. Начиная с версии Luminous Ceph также получил аналогичную ZFS возможность контрольной суммы данных для каждого считывания, что дополнительно улучшает надёжность ваших критических данных.
Основанные на RAID системы копроративного уровня часто требуют затратных, сложных и требовательных плат HBA с возможностями RAID, которые увеличивают накладные расходы управления, сложность мониторинга и приводят к общему увеличению стоимости. RAID может ударяться в стенку при достижении предела размера. Сам автор необнократно сталкивался с с системами, которые не способны расширить некий пул хранения выше 64 ТБ. Реализации контрольных сумм RAID, включающие в себя RAID 5 и RAID 6, также страдают от штрафных затрат пропускной способности при записи и требуют сложных и привередливых стратегий кэширования чтобы выдерживать производительность большинства приложений. Зачастую наибольшим ограниченивающим недостатком обычных RAID является то, что они защищают только от отказа диска; они не могут защищать при сбое коммутатора и сетевой среды, а также от поломок серверного оборудования или операционных систем или даже региональных чрезвычайных происшествий. В зависимости от выбранной стратегии, та максимальная защита, которую вы можете реализовать применяя RAID состоит в обслуживании одного или в крайнем случае двух отказов дисков. Такие стратегии как RAID 60 могут каким- то образом уменьшать этот риск, хотя они не являются повсеместно доступными, при этом не эффективны, могут требовать дополнительные лицензии и всё ещё предоставлять не полную защищённость от определённых шаблонов отказов.
Для современных потребностей ёмкостей, производительностей и надёжности нам необходима некая система, которая может обойти все такие ограничения в отношении эффективности производительности или стоимости. В прошлые дни неким общим решением для отказа компонентов служила какая- то система резервного копирования, которая сама по себе могла быть медленной, затратной, ограниченной в ёмкости и предметом зашоривания на определённом производителе. Современные тома данных являются такими, что обычные стратегии резервного копирования часто неосуществимы в силу масштаба или изменчивости.
Система хранения Ceph является наилучшим доступным сегодня решением для решения этих проблем. В отношении надёжности данных Ceph применяет репликацию данных (включая удаляющее кодирование - erasure coding). Он не использует традиционные RAID, и благодаря этому свободен от ограничений и уязвимостей обычных основанных на RAID систем хранения корпоративного уровня. Так как Ceph является программно определяемым и применяет общедоступные компоненты, нам не требуется специализированное оборудование для репликации данных. {Прим. пер.: если не рассматривать возможности применения чего- то подобного RDMA}. Более того, имеющийся уровень репликации имеет богатые возможности настройки диспетчерами Ceph, которые могут запросто управлять стратегиями защиты данных в соответствии с локальными потребностями и лежащей в основе инфраструктуре. Гибкость Ceph даже позволяет диспетчерам определять множества типов и уровней защищённости чтобы решать потребности различных видов и наполнений в рамках одних и тех же серверов.
|
| Замечание |
|---|---|
|
Под реплицированием мы понимаем что Ceph хранит завершённые, независимые копии всех данных на множестве не связанных между собой дисков и серверов. По умолчанию Ceph будет сохранять три копии, давая в результате использование 1/3 ёмкости общего сырого дискового пространства, однако возможны и прочие настройки и некий отдельный кластер может разрешать множество стратегий для различных потребностей. |
Репликации Ceph превосходят традиционные RAID в случае отказа компонентов. В отличии от RAID когда некий диск (или сервер!) отказывает, все данные, которые хранились на этом диске восстанавливаются с большого числа выживших дисков. Так как Ceph является распределённой системой, ведомой имеющейся картой CRUSH, необходимые копии репликаций данных разбрасываются по многим дискам. Согласно проектированию нет первичных и реплицированных копий, располагающихся на одном и том же диске или сервере; они размещены внутри различных областей отказа. В восстановлении данных принимает участие большое число дисков кластера, позволяя распределять общую рабочую нагрузку и минимизировать конкуренцию и воздействие на текущии операции клиента. Это делает операции восстановления удивительно быстрыми и не имеющими узких мест.
Более того, восстановление не требует запасных дисков; данные реплицируются в невыделенное пространство на прочих устройствах внутри данного кластера. Ceph реализует некий механизм весов для дисков и сортирует данные независимо от некоторой гранулярности, меньшей чем ёмкость любого отдельного диска. Это позволяет избегать ограничений и плохой эффективности, которым подвержены RAID при отсутствии единообразия размеров дисков. Ceph хранит данные основываясь на весе каждого диска и каждого сервера, что адаптивно управляется через карту CEPH. Замена некоторого отказавшего диска диском меньшего размера имеет результатом небольшое понижение общей ёмкости кластера, однако в отличии от обычных RAID он всё ещё работает. Если некий заменяемый диск больше первоначального, причём даже если во много раз больше, общий объем кластера возрастёт соответствующим ожидаемым образом. Ceph делает верные вещи, что бы вы не выбрали.
Дополнительно к репликациям Ceph также поддерживает другой современные метод гарантирования надёжности данных: удаляющее кодирование (erasure coding), которое является некоторой разновидностью Упреждающей коррекции ошибок (FEC, Forward Error Correction). Пулам с удаляющим кодированием требуется меньшее пространство хранения в сравнении с пулами репликаций, что имеет результатом большее соотношение использования сырого пространства. В данном процессе данные отказавших компонентов восстанавливаются в соответствии с алгоритмом. Вы можете применять в различных пулах как репликации, так и удаляющее кодирование внутри одного и того же кластера Ceph. Мы изучим все преимущества и изъяны удаляющего кодирования в сопоставлении с репликациями в последующих главах.
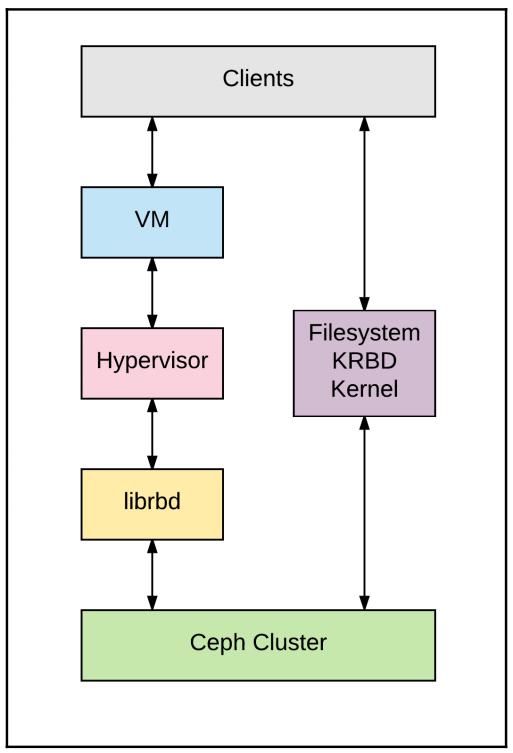
Блочные хранилища будут знакомы тем, кто работал с традиционными технологиями SAN (Storage Area Network). Выделение требуемого пространства предоставляется по запросу и представляется как непрерывные тома со статическим размером (иногда также называемые образами). RBD Ceph поддерживают тома с размером до 16 экзабайт. Эти тома подключаются к операционной системе клиента как виртуальные дисковые устройства, которые во многом могут применяться как локальные физические устройства. В средах виртуализации такая точка подключения часто определяется на уровне гипервизора (например, QEMU/ KVM). Этот гипервизор затем представляет тома имеющимся гостевым операционным системам через драйвер virtio или в виде эмулированного диска IDE или SCSI. Обычно на таком томе далее создаётся некая файловая система для традиционного хранения файлов. Данная стратегия призывает к тому, чтобы гостевым операционным системам не требовалось знать о Ceph, что в особенности полезно для доставки программного обеспечения в виде некоторого образа. Исполняемые на голом железе операционные системы клиента также могут напрямую устанавливать соответствие томам применяя некий драйвер Ceph ядра.
Компонентом блочного хранения Ceph является RBD, RADOS Block Device. В наших дальнейших главах мы обсудим более детально RADOS, однако на текущий момент сообщим, что RADOS является технологией, лежащей в основе построения RBD. RBD предоставляют клиентам надёжные, распределённые и высокопроизводительные тома блочных устройств. Тома RBD эффективно разделяются на множество объектов, разбрасываемых по всему кластеру Ceph, применяя стратегию, которая является ключевой в предоставлении клиентам доступности, надёжности и производительности. Само ядро Linux имеет встроенный естественным образом драйвер RBD; таким образом клиентам нет нужды устанавливать многоуровневое программное обеспечение для получения блочных служб Ceph. RBD также предоставляет функциональность корпоративного уровня, включающую инкрементальные (diff) моментальные снимки и моментальные снимки тома целиком, динамическое выделение (thin provisioning), клонирование копированием записи (COW, copy-on-write), многоуровневостью и тому подобным. Клиенты RBD также поддерживают кэширование в оперативной памяти, которое может впечатляюще улучшать производительность.
|
| Замечание |
|---|---|
|
Экзабайт является одним триллионом байт (1018), или миллиард (109) гигабайт (GB, ГБ). {Прим. пер.: Экзабайт это тысяча, т.е. 1k, в шестой степени, в США и Канаде имеет название квинтиллиона (так в тексте авторов), что вносит путаницу, поскольку в Европе квинтиллионом называется 1030, в то время как 1030 в США и Канаде имеет наименование нониллион, который (нониллион), в свою очередь, в Европе и в математике обозначает 1018. Давайте следовать термину экзабайт. Аналогично с применяемым авторами, как англоговорящими, числительным биллион, под которым они понимают привычное нам понятие миллиарда (109, тысячу миллионов), а не устаревшее значение миллиона миллионов (1012).} |
Служба RBD Ceph эксплуатируется облачными платформами, такими как OpenStack и CloudStack для предоставления как первичных/ загрузочных устройств, так и в качестве дополнительных томов. В рамках OpenStack служба RBD Ceph настраивается в качестве основы для абстрагирования компонентов Cinder (блоки) и Glance (основные образы). Функциональность копирования записью (CoW) RBD позволяет каждому из них быстро раскручивать сотни и даже тысячи динамически выделяемых (thin-provisioned) экземпляров (виртуальных машин).
Рынок хранилищ корпоративного уровня переживает фундаментальное перегруппирование. Традиционные проприетарные системы хранения неспособны отвечать грядущим потребностям хранения данных, в особенности в рамках разумного бюджета. Хранилища на основе устройств даже сокращаются по мере того как применение данных растёт не по дням, а по часам.
Высокие значения TCO проприетарных систем не завершаются после приобретения оборудования: сквалыжничание последующего лицензирования, ежегодные сопровождение и управление добавляют добавляются к захватывающему воображение затратному базовому уровню. Вы вначале должны купить доставляемое на палетах оборудование, заплатить за несколько лет поддержки, затем обнаружить, что ваше начальное решение достигло окончания срока обслуживания (EOL, End-of-Line) и тем самым не можетрасширяться или даже сопровождаться. Это приводит к вечному двигателю нескончаемых циклов последовательных раундов массового приобретения оборудования. Сопутсвующие контракты поддержки получения исправления ошибок и обновлений безопасности зачастую приводят в спиралевидному росту стоимости. Спустя несколько лет (или даже ранее) ваше некогда шикарное решение превращается в неподдерживаемую гору металолома и весь цикл повторяется. Платите, полощите горло, выпивайте и повторяйте вновь. Когда приходит время повторного развёртывания, та же самая линейка продуктов может уже быть недоступной, чтоы понуждает вас внедрять, документировать и поддерживать всё растущее число несовместимых одноразовых решений. Я полагаю, что деньги вашей организации было бы лучше потратить на нечто иное, например, предоставить вам заслуженный рост.
В отношении Ceph новые выпуски программного обеспечения всегда доступны, никакие лицензии не имеют срока давности (не истекают) и вас приглашают читать его код самостоятельно и вносить свой посильный вклад в его совершенствование. Вы также можете расширять своё решение по множеству направлений, совместимостей и без каких- либо дезорганизаций. В отличие от проприетарных решений на один раз вы в точности можете выбирать необходимый масштаб, скорость и компоненты, которые имеют смысл сегодня, в то время как без существенных усилий вырастут затра и при этом с наивысшим уровнем управляемости и персонализации.
Тем не менее, технологии хранения с открытым исходным кодом доказали производительность, надёжность, масштабируемость и низкую TCO (Total Cost of Ownership, Совокупную стоимость владения) без опаски завершения времени жизни продукта или прекращения производства модели, либо привязки к определённому производителю. Многие корпорации, помимо государственных учреждений, университетов, исследовательских организаций, департаментов здравоохранения и комплексов HPC (High Performance Computing, Высокопроизводительных вычислений) уже успешно эксплуатируют решения хранения с открытым исходным кодом.
Ceph имеет огромный интерес и набирает популярность и при этом всё больше выигрывает в соревновании с прочими открытыми проектами и проприетарными решениями хранения. В оставшейся части данной главы мы проведём сравнение Ceph с прочими решениями хранения с открытым исходным кодом. {Прим. пер.: так по тексту оригинала, несмотря на наличие далее проприетарных технологий.}
GPFS (General Parallel File System {Прим. пер.: также см. Часто задаваемые вопросы и ответы по GPFS и наш перевод руководства Программно определяемые системы хранения для чайников}) является распределённой файловой системой, разработанной и принадлежащей IBM. Это проприетарная система с закрытым исходным кодом, которая ограничивает этим свою популярность и приспосабливаемость. Стоимость лицензий и поддержки добавляют к такому оборудованию хранения нечто, что делает его достаточно затратным решением. Более того, оно очень ограничено набором интерфейсов систем хранения: оно не представляет никакого доступа блочного хранения (навроде RBD) и никакого доступа RESTfull (подобного RGW) к своей системе хранения, ограничивая варианты применения которые может обслуживать отдельное решение.
В 2015 GPFS получил новую торговую марку IBM Spectrum Scale {Прим. пер.: за некоторое время до этого IBM предпринимал эксперименты с примением термина эластичности в названии. Что мне кажется симптоматичным. Официальные лица IBM в личных беседах воздерживались от комментариев. Ну что же: дожать последнюю каплю - тоже стратегия в сравнении с выкладыванием исходных кодов на всеобщую доработку: безопасность доминирует!}
iRODS яляется абривеатурой Integrated Rule-Oriented Data System, некоторой системой управления данными с открытым исходным кодом, выпускаемой в соответствии с 3-м параграфом лицензии BSD. iRODS не обладает высокой доступностью и может иметь бутылочные горлышки. Её сервер метаданных iCAT является представителем единой точки отказа (SPoF, single point of failure), что делает невозмодными высокю доступность (HA, high availability) или масштабируемость. Более того, она организует очень ограниченноый набор интерфейсов хранения, предоставляя либо блочное хранение, либо возможности доступа RESTful. iRODS является наиболее действенной для относительно небольшого числа больших файлов при сопоставлении со смесью большого числа как не больших файлов так и файлов со значительным размером. iRODS реализует традиционную архитектуру метаданных, поддерживая индексацию имеющегося физического местоположения каждого имени файла.
HDFS является распределённой масштабируемой файловой системой, написанной на Java для инфраструктур обработки Hadoop. HDFS является не полностью совместимой с POSIX файловой системой, а также не поддерживает блочный интерфейс. Надёжность HDFS является предметом беспокойства в оношении высокой доступности. Единый NameNode в HDFS является единой точкой отказа (SPoF) и узким местом в отношении производительности. HDFS, опять же, приспособлена в первую очередь для хранения неьольшого числа больших файлов вместо того чтобы масштабно замешивать маленькие и большие файлы, чего требуют современные реализации систем.
Lustre является параллельной распределённой файловой системой, движимой сообществом открытого исходного кода и она доступна согласно лицензии GNU GPL (General Public License). Lustre полагается на отдельный сервер хранящий и управляющий метаданными. Таким образом, запросы ввода/ вывода от определённого клиента всецело зависят от вычислительной мощности некоего отдельного сервера, что может быть бутылочным горлышком при примененни на корпоративном уровне. Как и iRODS и HDFS, Lustre лучше приспособлена для небольшого количества файлов со значительным размером в сравнении с более типичной смесью из общего числа файлов различного размера. Как и iRODS, Lustre управляет неким индексом файлов, который соответствует именам фалов в физическом адресном пространтсве, что делает её традиционной архитектурой, расположенной к наличию узких мест. Lustre не обладает механизмом для определения отказов и их исправления: кога некоторый узел отказывает, клиент должен подключиться к другому.
GlusterFS первоначально была разработана Gluster Inc., которая была приобретена Red Hat в 2011. GlusterFS является горизонтально масштабируемой подключаемой к сетевой среде файловой системой, в которой администраторы должны определять стратегию размещения для использования реплик хранимых данных в географически распределённых стойках. Gluster не предоставляет блочного доступа, файловой системы или удалённой репликации в виде встроенных функций, он предоставляет их в виде втраиваемых модулей.
Ceph выделяется из всей толпы решений хранения в силу своей функциональности. Он был разработан для обхода ограничений существующих систем хранения и эффективной замены состарившихся и затратных проприетарных решений. Ceph эконимчен благодаря открытому исходному коду и подходу программной определяемости и к тому же раотает на большей части общедоступных аппаратных средств. Его пользователи получают удовольствие от разннобразия возможностей доступа клиентов Ceph при наличии единой серверной основы.
Все компоненты Ceph являются надёжными и поддерживают высокую доступность и масштабируемость. Надлежащим образом настроенный кластер Ceph не имеет единой точки отказа и доступен для произвольного замеса типов файлов и их размеров без какого либо ущерба в отношении производительности.
За счёт своей распределённости Ceph не следует традиционным подходам централизации размещения метаданных и доступа к ним. Вместо этого он привносит новую парадигму при которой клиенты независимо вычисляют требуемое местоположение своих данных, а затем осуществляют к ним прямой доступ {Прим. пер.: в том числе асинхронный, подробнее см. Приложение A нашего перевода Полного руководства Ceph.} Это является существенным выигрышем в производительности для клиентов, поскольку у них нет необходимости выстраиваться в очередь за получением данных о местоположении и полезной нагрузкой на некотором центральном сервере метаданных. Кроме того, размещение данных внутри кластера Ceph является прозрачным и автоматическим; никакому клиенту или администратору нет нужды вручную последовательно разрасывать данные по отказоустойчивым доменам.
Ceph самостоятельно обеспечивает жизнеспособность и управляемость. В случаях происшествий при которых прочие системы хранения не могут обслуживать множестенные отказы, Ceph остаётся надёжным как скала. Ceph определяет и исправляет отказы на всех уровнях, автоматически управляя утратой компонентов и восстанавливая свою жизнеспособность без воздействия на доступность и живучесть данных. Прочие решения хранения могут предоставлять только надёжность на уровне гранулированности диска или узла.
Ceph может легко масштабироваться от размера в один сервер до тысяч и, в отличие от многих проприетарных решений ваши первоначальные инвестиции при ограниченном масштабировании не будут утрачены когда вам потребуется расширение. Основное преимущество Ceph над проприетарными решениями состоит в том, что вы выполните обновление своего последнего привезённого вилочными погрузчиками оборудования. Избыточная и распределённая архитектура Ceph делает возможной замену индивидуальных компонентов карусельным методом. При этом нет никакой необходимости наличия ни компонентов, ни хостов целиком выполненными единым производителем.
Вот примеры обновлений, выполенных авторами целиком на размещённых в промышленной эксплуатации кластерах масштабов петабайт без какого бы то ни было удара по клиентам:
-
Миграция с одного дистрибутива Linux на другой
-
Обновление в рамках одного дистрибутива Linux, например, RHEL 7.1 на RHEL 7.3
-
Замена всех дисков полезной нагрузки
-
Обновление встроенного програмного обеспечения
-
Миграция между стратегиями и устройствами журналирования
-
Восстановление оборудования, в том числе шасси целиком
-
Расширение ёмкости заменой дисков малой ёмкости на новые
-
Расширение ёмкости путём добавления новых серверов
В отличие от многих основанных на RAID и прочих традиционных решений хранения, Ceph является высоко доступным и не требует идентичности устройств хранения или хостов. Некий кластер, начинавший свою жизнь с дисками 4 ТБ легко может расширяться дисками в 6 и 8 ТБ, либо даже заменой на диски меньшего размера или путём инкрементального добавления серверов. Отдельный кластер Ceph также может содержать смесь различных типов дисков, с разным размером и разными скоростями, и при этом различать рабочие нагрузки или реализовывать многоуровневость для усиления как эффективными в стоимостном отношении, но более медленными дисками для хранения внавал, так и более быстрыми для чтения или кэширования.
При наличии определённых удобств для единообразного набора серверов и дисков, в то же время вполне реально смешивать и сопоставлять модели серверов, поколения и таже торговые марки внутри некоторого кластера.
Ceph является программно определяемым решением хранения, которое работает на общедоступном оборудовании, освобождая организацию от затратных, ограничительных, проприетарных систем. Он предоставляет единообразное, распределённое, высоко масштабируемое и надёжное решение хранения объектов, имеющее решающее значение для потребностей неструктурировнных данных сегодняшнего и завтрашнего дня. Запросы мира для хранения расширяются, поэтому нам требуются системы хранения, которые масштабируются до уровня экзабайт без ущерба надёжности и производительности. Ввиду того, что он обладает открытым исходным кодом, расширяемым, адаптивным и строящимся поверх общеупотребимых аппаратных средств, Ceph вряд ли устареет. Вы легко можете заменить целиком всё оборудование вашего кластера, его операционную систему, а также версию Ceph и при этом пользователи не заметят этого.
В нашей следующей главе мы рассмотрим центральные компоненты и те службы, которые они предоставляют.