Глава 3. Выбор оборудования и сетевой среды
Содержание
Традиционные решения хранения крупного масштаба часто оснащаются дорогостоящим, проприетарным оборудованием, которое представляет собой проблемы физические, управленческие, связанные с безопасностью и даже с электричеством при их интеграции в некий центр обработки данных, наполненный привычными сетевыми и серверными устройствами. Ceph, по своей архитектуре, не требует специализированных типов или моделей аппаратных компонентов. Исключается зашоренность на производителя оборудования и конкретный проектировщик способен выбирать серверные и сетевые компоненты, которые соответствуют индивидуальным критерия стоимости, стандартов, производительности и физики. Распределённая архитектура Ceph также способна на гигантскую гибкость со временем когда изменяются и развиваются потребности и продуктовые линейки оборудования. Вы можете построить свой кластер из одного набора устройств сегодня только чтобы обнаружить, что потребности, ограничения и бюджет завтрашнего дня совершенно другой. Применяя Ceph вы можете безшовно добавлять ёмкость или обновлять состарившееся оборудование применяя очень отличающиеся модели, причём совершенно прозрачно для своих пользователей. Совершенно просто выполнить 100% замену оборудования кластера, а пользователям это даже не икнётся.
Кластеры Ceph успешно строились на всей гамме классов серверов от 90- дисковых 4RU монстров {Прим. пер.: и более того: целиком стойками} вплоть до минимальных систем, интегрированных непосредственно в саму логическую плату диска хранения (http://ceph.com/community/500-osd-ceph-cluster).
Тем не менее по- прежнему важно выбирать оборудование, которое отвечает потребностям организации, сопровождения, финансирования и производительности. В следующем разделе мы изучим ряд критериев; ваша ситуация вполне может представлять нечто иное. Ceph предназначается для систем Linux и может работать на самых разнообразных дистрибутивах. Большинство кластеров развёртывается в системах x64, но возможны и 32- битные архитектуры, а также архитектуры ARM {Прим. пер.: и Байкал}.
Сегодняшние серверные компоненты предлагают головокружительные массивы возможностей; если они кажутся ошеломительными, можно выполнить поиск в предварительно сконфигурированных для применения Ceph таких торговых марок как Quanta и Supermicro {Прим. пер.: и mdl.ru®}/
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Приводимые ниже ссылки на примеры являются информационными и не являются поддержкой какого- либо определённого поставщика: https://www.qct.io/solution/index/Storage-Virtualization/QxStor-Red-Hat-Ceph-Storage-Edition https://www.supermicro.com/solutions/storage_ceph.cfm {Прим. пер.: также см. наш перевод Ceph. Рекомендации по оборудованию} |
Тем не менее, очень важно познакомиться с идеями, изложенными в оставшейся части этой главы. Данные примеры приводятся для иллюстрации самой идеи и не должны толковаться как рекомендации для любого конкретного поставщика.
Существует головокружительное количество оборудования для серверы x64 сегодняшнего дня. В данном разделе мы изучим ряд тех вариантов, которые помогут вашей навигации в процессе выбора для ваших локальных условий и требований. Мы обсудим далеко идущие последствия каждого и предложим поразмыслить над компромиссами, ограничениями и возможностями.
Выбор оборудования может быть ограничен политикой организации. Возможно вашей компании посчастливилось стать обладателем существенной скидки от HP {Прим. пер.: HPE} или получить некий зонтик поддержки контрактов от IBM. Вы даже можете работать для некоторой компании, которая продаёт серверы и, тем самым вынуждены и обязаны оставаться в своей семье в стиле потребления своей собственной собачьей еды https://en.wikipedia.org/wiki/Eating_your_own_dog_food.
В большинстве случаев это не завербует вас к существенному ухудшению работы в стиле Ceph, хотя автор этих строк и видел три экземпяра подобных проблем:
-
Порой политика закупок настолько драконовская, что практически невозможно заказать конфигурацию персонализированного оборудования и при этом единственным выбором является лишь малая доля непригодных моделей в некоторов устаревшем меню, например, какие- то 1U шасси с поддержкой только 4 x 300 ГБ дисков LFF. К счастью, такие случаи достаточно редки, однако вы должны взвесить насколько творчески вы можете мыслить с теми вариантами, которые предоставлены вам, в сопоставлении с теми трудностями эскалациями, которыми сопровождается создание некоторой конфигурации и имеет ли всё это некий смысл. Одной из стратегий является заказ шасси с пустыми отсеками с тем, чтобы добавить необходимые диски и адаптеры в качестве дополнительных опций. {Прим. пер.: если вы при этом не желаете самостоятельно решать проблемы совместимости и сопровождения, обращайтесь к нам!}
-
Другой являлось подразделение обязанное применять только определённую торговую марку серверов без наличия возможности добавлять какие- либо выходящие за рамки подобные внутренние компоненты сторонних производителей. Это привело к некоторой начальной архитектуре совместного использования журналов (смотри Главу 2, Компоненты и службы Ceph) на шпиндельных дисках LFF (Large Form Factor). Агрегированная производительность кластера была усечена пополам прямо на старте, а шаблон интенсивного поиска поймал дефект одного производителя встроенного программного обеспечения, приводившего к частым ошибкам чтения. Стоимость процесса исправления намного выше и состоит в деградации обслуживания, времени работы инженера и замене накопителей, в сопоставлении с лоббированием соответствующих компонентов стороннего производителя в замен того, что мы имеем при поставке.
-
Главный клиент другого подразделения внутри этой компании внезапно вышел из- под обслуживания, оставив почти три тысячи серверов со значительным временем их лизинга. Прочие бизнес- подразделения были вынуждены взять под свои нужды эти устаревшие на одно или два поколения системы с маленькими и накопившими наработку на отказ жёсткими дисками, вместо того чтобы приобрести новое оборудование. {Прим. пер.: аналогичный случай: уважаемый партнёр навязал для одного топового решения HPC применение Myrinet 2000, хотя на момент развёртывания уже был доступен Infiniband, которое верой и правдой прослужило более пяти лет. Идея воспользоваться по прошествии пяти лет этим, всё ещё продолжающим работать, оборудованием для построения кластера хранения разбилась на отсутствие поддержки производителем драйверов для минимально необходимого ядра ОС. Затраты на его написание были признаны нецелесообразными. Хотя 4Gbps в полном дуплексе и при наличии настоящей CLOS связности Myrinet 2000 вполне хватило бы для того числа дисков, которое можно было бы разместить в этих серверах.}
Тщательно рассматривайте свои компромиссы в данных областях, поскольку они устанавливают прецеденты и могут быть сложными, затратными, или невозможными для восстановления при развёртывании неподходящих устройств.
В США стандартными выводами электропитания являются 110-120В, 60 Гц с розетками NEMA 5-15 {Прим. пер.: National Electrical Manufacturers Association}, выдающие приблизительно 1 875 Ватт {Прим. пер.: 15 Ампер}. В других странах мира применяются различные стандарты, но все основные идеи применимы. {Прим. пер.: Более детально с разнообразием выводов электропитания можно ознакомиться, например, на сайте Википедия, касательно принятых в России стандартов скажем лишь, что однофазное электропитание у нас применяются напряжения 220-230В (стандарт, ГОСТ 29322-2014 (IEC 60038:2009) именно последнее, 230В) и частотой 50Гц со стандартами вилок C1-b, C1-a, С6 и С5, тип 2 (ГОСТ 7396.1-89) а после распада СССР, как правило типа F (Schuko), рассчитанные, как правило, на 6-10 Ампер. Имеются модификации на 16 Ампер. Вилки и розетки на 25-32-40 Ампер и более относятся уже к профессиональному уровню и, как правило, здесь уже применяется двухфазное электропитание.} Многие (на это не означает что все) от небольших до средних, и даже крупных центров обработки данных и установки серверов, применяют имеющиеся локальные общие стандарты. Серверы сегодня зачастую совместно используют электропитание, которое может обслуживать некий диапазон входного напряжения и частот, требующих только локализованного кабеля для приспособления к соответствующему типу розетки/ разъёма.
Некоторые устройства хранения большего масштаба, дисковые массивы и даже определённые плотно нагруженные серверы, однако, могут потребовать электропитания 240В (US {, Прим. пер.: напомним, в России стандарт 230/400В}), которые могут оказаться не столь легко доступными в вашем центре обработки данных. Даже те серверы, которые получают общепринятое электропитание могут потреблять настолько большой ток, вы не сможете заполнить некую стойку ими. Скажем, у вас имеется доступным стоечное пространство 40U и выбран некий сервер 4U, который потребляет 800 Ватт. Если ваши стойки центра обработки данных выдают только 5 кВт каждая, тогда вы будете способны размещать только по шесть таких серверов на стойку и можете дорого заплатить за пространство, занимая только накладными панелями оставшиеся 26U.Прим. пер.: для предотвращения перемешивания горячего и холодного воздуха. Автор перевода данный вопрос рассмотрел бы несколько с другой стороны, а именно, начал с того момента, что вся вычислительная техника имеет к.п.д. (с точки зрения термодинамики) равный 0%. Поскольку не производит никакой механической работы: даже перемещение воздуха в конечном итоге завершается в замкнутом помещении ЦОД, тоже превращаясь в тепло. Следовательно, вся подводимая к стойке мощность должна отводиться от неё в виде тепла. Значение 5кВт на стойку не предусматривает каких- либо дополнительных затрат по персональному отводу тепла от такой стойки (разве что за исключением уже обсуждённого перекрытия передних частей незаполненных отсеков заглушками во избежания подсоса горячего воздуха передними панелями серверов). Когда стойка начинает потреблять 7, 12, 20 и более килоВатт, это подразумевает наличие специальных мероприятий теплоотвода со стойки, обычные системы общего термоконтроля всего серверного помещения не справятся с создаваемыми горячими зонами за такими стойками. В России обычным стандартом являются стойки 42U, стойки 45/48U могут сталкиваться с проблемами доставки из- за имеющихся геометрических ограничений дверных проёмов и/ или путей их доставки на место монтажа. Стойки для массивного серверного оборудования, как правило, не разборные и чувствительны к ударам при транспортировке. Ещё одной проблемой при монтаже стоек является допустимая нагрузка на межэтажное перекрытие, выражаемая в тоннах на квадратный метр и в килограммах на точку. При современном росте плотности оборудования может быть уже недостаточным показателя в 1 тонну на квадратный метр (и 250кг на точку), которыми мы оперировали ещё лет 5-7 назад. Стоит задумываться о 1.5 тоннах на квадратный метр (и, соответственно, 375- 400кг на точку).}
Некоторые центры обработки данных также предоставляют ограниченное число выводов электропитания на стойку и в случае с легковесными серверами - скажем, 1RU моделями, применяющими SSD - вы можете выйти за доступное число подводов электропитания задолго до того как используете всю имеющуюся выделенной для данной стойки мощности электроснабжения. Многие центры обработки данных, в особенности те, что предпочитают телекоммуникационное оборудование, предлагают снабжение напряжением постоянного тока 48В. Основные производители серверного оборудования обычно предлагают модели или блоки питания, совместимые с электропитанием 48В, но это может не распространяться на всю продуктовую линейку. Некоторые центры обработки данных предпочитают постоянное напряжение электропитания исходя из соображений эффективности, во избежание внутренних потерь на одном или более этапах преобразования AC-DC или DC-AC на имеющихся этапах электропитания в здании, кондиционировании, UPS (uninterruptible power supply batteries, батареях бесперебойного снабжения электропитанием) и устройств электропитания серверов. Зачастую это предложение всё- или- ничего для некоторого центра обработки данных; не предполагайте, что вы сможете разместить свои серверы без контактов с управляющим персоналом своего центра обработки данных.
На практике часто создают разнообразные балансы сильно энергопотребляющего и более скромного в своём аппетите оборудования внутри некоторой стойки для соответствия выводам и выделенным мощностям, скажем, подмешивая панели IDF/ODF и сетевые устройства для усреднения электропотребления. Разлагайте на составляющие такие схемные решения в логической топологии своего кластера Ceph во избежание поломок областей отказа.
В рамках самого сервера вы можете иметь множество опций для соответствия необходимому электропитанию. Вас следует оценивать компромиссы по следующим моментам:
-
Локальные стандарты центра обработки данных
-
Требования в Ваттах при запуске, пиковых нагрузках и стабильной работе серверов
-
Эффективность электропитания
-
Избыточность
Многие установки находят золотой серединой серверы 2RU; это может быть, а может и нет, верным для вашего варианта использования центра обработки данных. Также очень часто в установках корпоративного уровня предоставляются серверы и прочее оборудование с избыточными источниками электропитания в качестве как защиты от отказа компонентов, так и чтобы допускать снабжение электричеством без прерывания работы. Некоторые центры обработки данных даже требуют избыточного подвода электропитания.
|
| Замечание |
|---|---|
|
Пишущий эти строки автор сталкивался с глобальной аварией некоторого указателя электропитания внутри сервера Ceph, которое вызывало отказ такого сервера целиком и его останов. Система мониторинга выдала предупреждение бригаде по вызову о сбое данного узла, а сам кластер выполнил повторную балансировку, удалив его из обслуживания. Только на следующий день я узнал, что отказ также затронул половину электропитания для всего ряда из 20 стоек. Все серверы были предоставлены со сдвоенными блоками питания, что позволило им пережить такой сбой. |
Производители серверов часто предлагают выбирать из некоторого массива возможностей PSU (power supply unit, устройств блоков питания):
-
Отдельный, сдвоенный или учетверённый {а также работающий по схеме 2+1}
-
Множество уровней эффективности
-
Множество токовых диапазонов
-
Совместимость по напряжению
Ваш выбор может существенным образом повлиять на надёжность вашего кластера и стоимость инфраструктуры центра обработки данных. Сдвоенные источники электропитания также означают удвоение общего числа электрических розеток, что может стать ограничением в вашей стойке. Это также означает удвоение числа кабелей электропитания, товаром на который производители могут устанавливать значительную наценку. Всегда выполняйте проверку, что ваши кабели электропитания подходят для нужной вам силы тока {Амперы}.
Архитектура с единственным PSU (блоком питания) упрощает обвязку кабелями и зачастую стоят меньше чем сдвоенное решение. Обратной стороной является то, что в случае отказа цепи энергоснабжения электричеством такого PSU отключает весь сервер целиком или даже целую стойку/ весь ряд. Также имеется уязвимость, что такой кабель может отсоединиться из- за небрежности технического специалиста, выполняющего работы поблизости этого сервера, или даже из- за проезжающего вниз по улице самосвала. В больших кластерах с небольшими серверами, распределёнными по множеству стоек, рядов и даже помещений, это может быть приемлемым риском при надлежащих выборах топологии и установок. Пишущий это автор, однако, предполагает, что операционная стоимость отказа или длительный простой обычно перевешивают дополнительные стоимость и усложнения на 1 уровень.
При любой архитектуре PSU вы обязаны гарантировать адекватную мощность для своих серверов в потребностях настоящего и будущего времён. Например, как я уже писал, один известный производитель предлагает не менее десяти вариантов PSU со значениями в 495, 750 и 1100 Ватт. Спецификации сервера и их конфигураторы часто предлагают некие суммарные потребности тока/ Ватт для выбранных шасси и компонентов. Будьте внимательными к энергопотреблению компонентов при запуске, пиковых нагрузках и при обычном режиме - особенно в отношении шпиндельных дисков - они могут разниться очень существенно. В некоторых случаях раскрутка дисков может смещаться по времени для выравнивания всплесков. {Прим. пер.: с одновременным массовым запуском шпиндельных дисков в шасси может быть потенциально связана ещё она проблема: воздействие взаимной вибрации. Современные серверные диски, как правило, снабжены гиро-датчиками для компенсации колебаний при выставлении головок на соответствующую дорожку, но стоит также обратить внимание и на сам крепёж дисков: как правило, он должен предполагать наличие неких демпферов, прокладок и пружин.}
Также заблаговременно планируйте свои последующие обновления. Если вы заказали модель шасси под 24 диска, а сегодня у вас установлены только 12, вам необходимо располагать инфраструктурой электропитания, ккоторая примет такую дополнительную нагрузку. Через два года после вы можете пожелать заменить свои диски 4 ТБ на модели с 8 ТБ, что в свою очередь потребует дополнительной оперативной памяти. Такое действие может быть не тривиальным для ваших потребностей электропитания. Это говорит о том, что если вы предвидите добавление, скажем, 600 Ватт, сдвоенный PSU 1000 Ватт может быть перегибом, а сдвоенного PSU 750 Ватт вполне может хватить. Инкрементальный рост стоимости или экономии на каждый узел быстро суммируется в кластерах с десятками или даже сотнями серверов.
Кроме того, убедитесь, что если вы утратите один блок питания, оставшихся вам хватит по мощности для корректного запуска данного сервера. В предыдущем примере именно по этой причине сдвоенный с 495 Ватт блок был неподходящим вариантом. В наши дни применяемые для Ceph серверы предлагают только один или два варианта блоков питания, однако всё ещё имеются предлагающие три, а то и четыре варианта. Скажем, вам необходимо 900 Ватт мощности и имеется четыре отсека для PSU. Вы можете предложить один или два PSU в 1000 Ватт, три устройства по 495 Ватт или даже четыре по 300 Ватт. При таком выборе с большим числом, если утрата одного устройства не позволит вашему серверу работать, вы на самом деле снизили надёжность в сравнении с орхитектурой с единственным PSU.
Некоторые поставщики серверов предлагают различные варианты эффективности блоков питания. Блок питания с большей эффективностью может приводить к снижению общих затрат на потребляемую мощность и отвод тепла в центре обработки данных при находении компромисса с более высокой стоимостью. Рассмотрим бытовые обогреватели на природном газе: традиционная модель может работать на уровне эффективности 80%. Модель с конденсатором и повторным применением тепла вывода может сохранять вам деньги при оплате счетов за газ, однако может быть изначально дорогостоящей и быть более затратной при установке. В качестве примера, когда я пишу об одном из уже упоминавшихся производителей, он предлагает Silver PSUs с к.п.д. 90%, Gold с 92%, и Platinum с 94%. Рассмотрите свои локальные компромиссы CapEx и OpEx (капитальных и операционных затрат) помимо зелёного корпоративного руководства и зелёного стандарта центра обработки данных.
Ваша организация может быть вложена в межсистемные серверные системы управления, такие как Cisco UCS, HPE SIM или CMC Dell. Возможно, существует некая традиция дистанционного управления через последовательные консоли, что может быть проблематичным для многих типов серверов на базе x64. При выборе серверов следует учитывать совместимость в этом отношении.
Десятилетия назад компьютеры были большими, а стандартов было мало; всякий мог потребовать выделенное помещение с уникальными физическими требованиями. В наши дни мы пользуемся преимуществами стандартов и конвергентных (совместно работающих) архитектур, но всё ещё можем сталкиваться с некоторыми сюрпризами. Всего лишь за последние пять лет автор столкнулся со следующим:
-
Консоли последовательного доступа по умолчанию применяют 9600 бит в секунду, однако для оборудования установки по умолчанию составляют 19200 бит в секунду
-
Нетипичная распиновка DTE/DCE не совместима с обычным RJ45 адаптерами
-
Оборудование всё ещё применяет соединения в стиле DB9 1990=х или даже некие круглые разъёмы 3.5 мм аудио- типа для доступа к управлению
-
Одну модель сервера из более крупной продуктовой линейки с необычным встроенным сетевым интерфейсом, код PXE которого для загрузки через сетевую среду необъяснимо переключал консоль с последовательным доступом к системе на 115 200 бит в секунду
-
Производителя серверов, монтажное оборудование которого предназначено для 19" стоек с квадратными отверстиями крепления. Теоретически, такие рельсы не были приспособлены для обычных круглых отверстий в стойке, так что их пришлось рассверливать дрелью из- за различий в размерах отверстий и винтов. {Прим. пер.: ладно хоть не цветные, как новая Казахстанская монета!}
Скорее всего, вы хорошо разбираетесь в своей практике работы с локальными серверами, но всё это относятся к числу засад, которые могут появляться при знакомстве с новыми торговыми марками или поколениями продуктов.
Позаботьтесь о том, чтобы ваш выбор сервера соответствовал вашим стойкам центра обработки данных! Некоторые черезчур нагруженные серверы, например, 90- дисковые 4U зверюги, могут быть настолько глубокими, что они не соответствуют стойкам и могут блокировать проходы или создавать препятствия закрытию дверей стоек. Заблаговременно соберите все свои габаритные ограничения и тщательно изучите таблицы спецификаций. {Прим. пер.: А также путей прохода и выхода! На автора перевода в своё время произвела сильное впечатление одинокая 45U стойка в нише сильно петляющего коридора в подвальном помещении купеческого дома 19 века, ведущего к серверному помещению. Сопровождающие поснили, что до этого места она дошла, а дальше её невозможно протащить ни вперёд, ни назад. Воистину: входя в ситему, знайте как из неё выходить!}
Корпоративные закупки, скажем так, могут быть корпоративными. Ваша организация может дать вам разрешение выбирать только из некого набора мню предварительно настроенных систем, которые к тому же могут быть устаревшими. Может так случиться, что персонал закупки заключает сделку по определённой товарной линейке и будет сопротивляться заказу всего прочего, что может лучше походить вашим предпочтениям Ceph. Скажем, предлагается только сервер с 12 LFF отсеками, в то время как для вашего IOPS требуется сервер с 25 LFF. Или предлагаются только конфигурации с единственным 300 ГБ диском в качестве наследия стратегии SAN или NAS. Может так оказаться, что ваш склад забит сверх ваших потребностей высокоскоростными серверами с 24 ядрами с всего лишь 4 дисковыми отсеками, либо хилыми 4-х ядерными 1.2ГГц серверами. Или вы переплачиваете за оптический дисковод, который вам совершенно не нужен. {Прим. пер.: Нам всем ещё памятен анекдот про то, что Билл Гейтс владеет фабриками по производству дисководов 3.5" дискет и по этой причине упорно предлагает загрузку по умолчанию именно с них. Всё развивается по спирали.}
В некоторых случаях вы имеете возможность заказать базовую конфигурацию и дополнительные позиции, чтобы увеличивать по мере необходимости, но будьте готовы к значительным компромиссам, которые могут помешать успешности, ёмкости и стабильности ваших кластеров Ceph.
В прошлом Оперативная память с произвольным доступом (RAM, Random Access Memory) была очень дорогостоящей и администраторы были тесно зажаты рамками бюджета и числом слотов сервера при закупке своей инфраструктуры. Технологии сегодняшнего дня, однако, снабжают нас очень ёмкими модулями оперативной памяти и достаточным числом слотов с тем, чтобы зачастую предлагать для каждого сервера по terabyte (TB, ТБ) или даже более. {Прим. пер.: Справедливости ради отметим, что стоимость 1 ГБ с конца лета 2016 почти удвоилась к концу лета 2017 на рынке общедоступных комплектующих. А прямо в момент перевода, например, скакнула на 25% стоимость LR памяти (позволяющей в те же самые слоты устанавливать, скажем, 2ТБ вместо 1ТБ в сравнении с её не так сильно дорожающим аналогом). Интересующихся спекуляциями на рынке памяти отсылаем на сайт биржи.}
Компоненты Ceph разнятся в своих потребностях к оперативной памяти; в данном разделе мы поможем вам выбрать верный размер для ваших серверов чтобы соответствовать и целям работы и размеру выделенных финансов.
Рассмотрим общую ёмкость ОЗУ ваших серверов. Это не является затруднительным моментом, но его всё же очень важно тщательно планировать. Если ваша модель сервера принимает не более 16 модулей памяти и ваши первоначальные вычисления состоят в том, что 64 ГБ ОЗУ это то, что вам нужно, воспротивьтесь желанию сэкономить несколько долларов на 4 ГБ DIMM. Любые последующие обновления потребуют выбрасывания уже установленных модулей чтобы освободить место для новых и более ёмких DIMM. Ситуации, которые могут увеличит ваши потребности в ОЗУ включают в себя:
-
Добавление дополнительных устройств хранения в каждый сервер
-
Замена большими устройствами менее ёмких
-
Расширение кластера посредством дополнительных серверов может увеличивать требования для отдельного процесса
-
Последующее применение программного обеспечения кэширования
-
Тонкие настройки установок операционной системы или Ceph
-
Переход на некую когерентную архитектуру хранения/ вычислений
Часто так происходит, что доступные модули самой большой ёмкости обладают и самой высокой стоимостью за каждый ГБ, поэтому один шаг вниз в уровне ёмкости на модуль может стать приятным местом для сохранения CapEx и расширяемости.
Сегодня серверы могут применять оперативную память с различными скоростями, хотя смешение модулей обычно делает шаг вниз к самому нижнему общему знаменателю. Ваш производитель сервера может предлагать память с различными скоростями, технологиями и ценовыми позициями, а ваш выбор размера модуля, их количества и расположения могут повлиять на скорость, с которой вся система оперативной памяти способна работать. Некоторые варианты выбора ЦПУ также могут иметь различия в оперативной памяти или QPI каналах {Прим. пер.: см. UPI, Ultra Path Interconnect для семейства Scalable Intel® Xeon®}, которые влияют на параметры конфигурации, общий объём настраиваемой памяти и её скорость. Такие проблемы могут увеличиваться при более крупных конфигурациях систем, например, для некоторой системы с четырьмя сокетами ЦПУ и 72 слотами памяти, в которой может потребоваться тщательная настройка для извлечения самых последних 20% производительности.
На требования к ОЗУ влияет множество правил. Когда- то предлагалась база в 16 ГБ плюс не менее 2 ГБ для каждого демона Ceph (MON, RGW, MDS) и по крайней мере по 2 ГБ на каждый OSD. При доступности сегодня модулей DIMM с объёмом 16 ГБ мы предлагаем чтобы для каждой роли сервера Ceph вы могли предоставить как минимум 64 ГБ, причём для плотно заполненных узлов OSD добавляли бы по 2 ГБ для каждого OSD после первой десятки. Опять же, при выборе размеров модулей памяти убедитесь, что вы пересчитали доступные слоты и предоставляете DIMM таким образом, чтобы это позволило вам в будущем выполнять расширение не выбрасывая уже сделанные инвестиции. Тем не менее, в любой момент времени самый последний и самый ёмкий модуль зачастую непропорционально дорого, что делает модули предыдущего уровня плотности более приемлемыми. В многопроцессорных системах позаботьтесь о том, чтобы каждый процессорный разъём имел свои собственные слоты памяти, которые сбалансированы идеальным образом. {Прим. пер.: Помните, что процессоры Intel® Xeon® семейства Scalable имеют теперь шесть каналов памяти в отличие от четырёх для предыдущих двух поколений E5/E7, а процессоры Amd Epyc восемь каналов памяти. Заполнение всех слотов каналов памяти может давать вам выигрыш в скорости обмена между ЦПУ и ОЗУ.}
Всякий кластер Ceph состоит из большого числа индивидуальных дисковых устройств которые размещают как внутренние метаданные Ceph, так и доверяемые нам пользователями данные внавал. По привычке многие ресурсы ссылаются на них как на диски (disks), артефакты того времени, когда SSD не обладали достаточной ёмкостью или доступностью м даже ещё не существовали. По этой причине в данной книге мы применяем более расширенный термин устройств (drives, приводов) чтобы включать в него прочие технологии. На практике и в имеющемся сообществе вы столкнётесь с тем, что эти термины применяются взаимозаменяемо, хотя это и неточно.
Модели устройств меньшей ёмкости часто более привлекательны с точки зрения стоимости/ ГБ (или стоимости/ ТБ), чем самые плотные монстры в этом же поколении {Прим. пер.: точнее, всё же представлять колоколообразную зависимость}, однако имеются и прочие стороны. Каждое устройство требует некого отсека для своего размещения и в некотором контроллере/ HBA/ расширителе канала. Менее дорогостоящие устройства не являются выгодной покупкой если вам необходимо владеть, управлять, размещать в стойке, запитывать и охлаждать удвоенным числом серверов для их расмещения.
Вы также можете обнаружить что благоговейность вашего кластера Ceph привлекает пользователей и приложения из столярной мастерской и та ёмкость, которую вы изначально полагали адекватной, может оказаться сильно истощена в следующем финансовом году, или даже квартале. Кластеры могут быть расширены за счёт добавления дополнительных серверов или замены более крупными дисками дисков меньшего размера. Первое может потребовать рассмотрения с финансовой и логистических сторон, если даже вы сможете вернуться в центр обработки данных за дополнительными стойками в удобном расположении. Последнее можно выполнять по частям но, скорее всего, потребует значительных инженерных и логистических ресурсов. Также необходимо соблюдать аккуратность чтобы не прерывать текущие операции клиентов в процессе повторной балансировки вашего кластера.
В этом случае можно было бы определиться с тем как сделать доступными самые большие диски. Это может быть действенной стратегией, однако имеется ряд оговорок:
Как мы уже писали, все шпиндельные диски с большой ёмкостью часто применяют технологию, называемую SMR (Shingled Magnetic Recording, Черепичной магнитной записи) для получения ошеломительных плотностей. К сожалению, SMR предоставляет значительные взыскания операций записи, которые зачастую означают что они не подходят для реализаций Ceph, в особенности для чувствительных к латентности приложениям блочного хранения. Замысловатое кэширование может каким- то образом смягчить этот недостаток, однако автор этих строк утверждает, что это не те устройства, которые вы ищите.
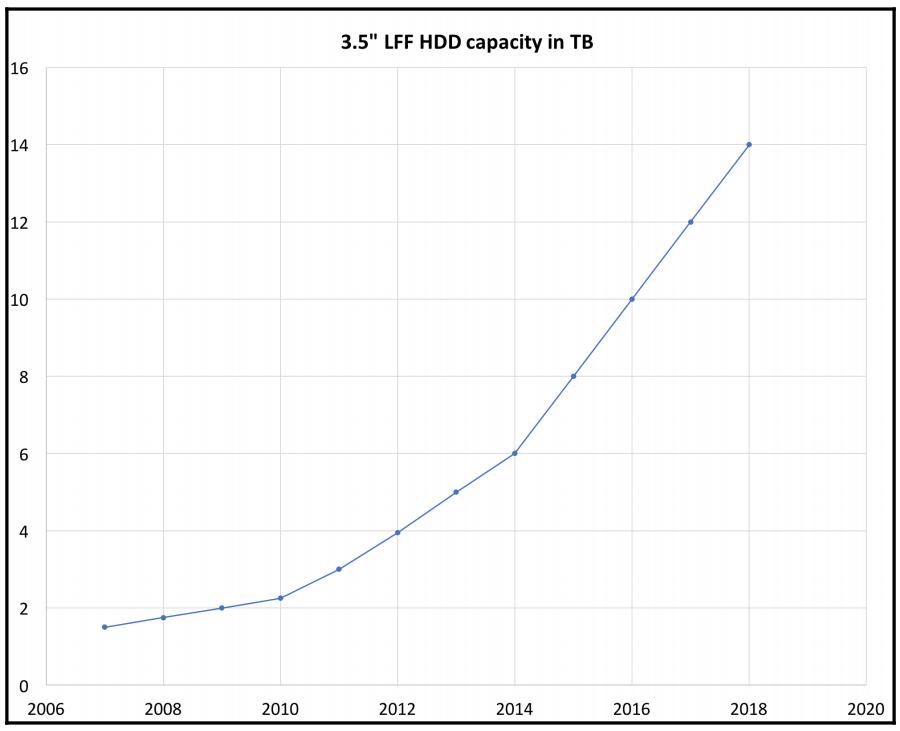
Меньшее число более ёмких устройств также предоставляет некий компромисс в сопоставлении с менее ёмкими дисками, в классической терминологии, чем больше шпинделей, тем быстрее. Для обычных вращающихся дисков (также называемых обычными шпиндельными) устройствами пропускная способность имеет тенденцию оставаться примерно той же с ростом ёмкости. Таким образом, некий кластер, построенный на 300-х 8 ТБ устройствах может предоставлять намного меньшую агрегированную скорость (IOPS), чем некий кластер с той же самой сырой ёмкостью, построенный на 600-х устройствах с 4ТБ каждое.
Более современные технологии, наоборот, могут представлять обратное: часто модели большей ёмкости устройств SAS SATA или NVMe являются намного более быстрыми чем модели меньшей ёмкости благодаря встроенному параллелизму: внутри них операции распределяются по множеству электронных компонентов меньшей ёмкости.
Таким образом, критически важно планировать наперёд ту ёмкость, которая понадобится вам в следующем месяце, в следующем году и на протяжении трёх лет с настоящего момента. Имеется множество путей роста, однако вы убережётесь от многих печалей если подготовите некий план на будущее. Вы даже можете выбрать не полное наполнение своих дисковых отсеков в ваших серверах OSD Ceph. Допустим, вы остановились на шасси с 12-ю отсеками и первоначально заполнили только восемь из имеющихся отсеков устройствами в 6 ТБ. На следующий год, когда вам потребуется дополнительная ёмкость, вы сможете заполнить эти оставшиеся в сервере отсеки устройствами с ёмкостью 8 или 10 ТБ по ой же самой стоимости за единицу сегодняшних устройств меньшего объёма. Развёртывание не будет требовать неуклонного удаления таких дисков меньшего объёма, хотя это всё ещё можно делать попутно.
|
| Замечание |
|---|---|
|
При вычислении и сравнении ёмкостей, которые сообщаются Ceph или такими инструментами как
https://www.gbmb.org/tb-to-tib
является полезным калькулятором для преобразования между этими показателями. Он показывает нам, например,
что некое устройство с номинальными 8 ТБ на самом деле является неким устройством с 7.28 TiB. Когда начинает
строиться некая файловая система, например XFS, её структурные накладные расходы и небольшое процентное
соотношение зарезервированного для необходимого пользователя root пространства дополнительно уменьшают общую
ёмкость, в особенности сообщаемую тем не менее, мы в первую очередь пишем именно ТБ и ПБ на протяжении данной книги, как по той причине что они более знакомы читателям, в также и потому, что отображают метки Ceph и прочих инструментов. |
Хотя и имеется возможность смешивать варианты применения, стратегии серверов и технологи хранения в некотором отдельном кластере, для ясности здесь мы будем сосредоточены на единообразных решениях.
Наиболее распространёнными размерами устройств хранения, применяемых в настоящем являются 3.5" LFF и 2.5" SFF. Вы можете также время от времени натыкаться на имеющийся формфактор 1.8", который никогда не имел широкого распространения. Последние и развивающиеся технологии включают NVMe твердотельные устройства PCI-e и заменяемые в горячем режиме U.2.
Основные производители серверов обычно предлагают и модели шасси и с LFF, и с SFF. Модели LFF и шпиндельные диски часто предлагают больше ТБ/RU (Rack Unit, единицу монтируемого в стойку устройства, высотой 4.4см = 1.73 дюйма) и стоимостью ТБ/ единицы. Модели SFF и шпиндельные диски обычно предлагают больше устройств, но с намного меньшей ёмкостью, а большее число шпинделей представляет возрастающее распараллеливание и агрегированную производительность за счёт (как правило) меньшей плотности на стойку и стоимости единичного устройства. Выбор формфактора, таким образом, является частью вашего процесса принятия решения. Предназначенные для чувствительного к латентности блочного хранения могут предпочитать устройства SFF, в то время как те, которые оптимизируются под стоимость, большую ёмкость и/ или хранение объектов склонны к устройства м LFF.
Твердотельные устройства (SSD, Solid State Disk) редко доступны в естественном конструктивном исполнении LFF; обычно они представлены в виде LFF. Хотя SFF могут быть вставлены во многие отсеки и направляющие LFF через недороги адаптеры и наполнители, более распространённым является выбор натуральных моделей SFF. Тем не менее, покупатели серверов сегодня сталкиваются с затруднительным положением; одним популярным подходом является шасси сервера, которое представляет 12 или даже до 72 LFF устройств для высокой плотности TB/RU и в то же время выделять пару внутренних или расположенных на задней панели SFF отсеков для применения в качестве загрузки/ операционной системы. Это позволяет избегать уменьшения ёмкости вашего кластера из- за необходимости отвлекать драгоценные отсеки LFF передней панели от общего объёма массово обслуживаемых данных.
В свои ранние годы хранилища SSD в основном применялись для специализированных случаев из- за очень высокой стоимости относительно шпиндельных дисков, например, для кэширования, интенсивно применяемых баз данных, а также вариант для ноутбуков, в которых мощность батарей стоила высоко и при этом часто встречались физические сотрясения.
Долговечность некоторой определённой модели устройства обычно не рассматривается для традиционных шпиндельных устройств, несмотря на претензии корпоративных дисков относительно потребительских. Устройства флэш/ SSD, однако очень разнятся и требуют особого рассмотрения. Раньше традиционная мудрость состояла в том, что флэш устройства SLC (Single-Level Cell, Одноуровневые ячейки памяти) будут служить намного дольше чем более плотные и менее затратные модели MLC (Multi-Level Cell, Могоуровнеые ячейки памяти), хотя в последнее время это было поставлено под сомнение.До тех пор пока вы не начнёте рассматривать самый нижний уровень устройств SATA потребительского/ настольного сегмента SATA это отличие не стоит серьёзного рассмотрения.
Современные приводы корпоративного класса содержат большое избыточное сопровождение, а это означает, что часть ячеек памяти зарезервирована с тем, чтобы встроенный контроллер накопителя мог более эффективно балансировать запись равномерно по ячейкам памяти и, по мере необходимости, извлекать запасные блоки для обслуживания со временем для замены состарившихся блоков. Например, вы можете обнаружить недорогой потребительский диск с заявленной ёмкостью 480ГБ и корпоративную модель того же самого производителя имеющего только 400 ГБ.
|
| Замечание |
|---|---|
|
Определённые характеристики устройств также влияют на то, насколько хорошо данная модель может обслуживать журналы OSD. Вот исключительная статья по их оценке для этой цели: https://www.sebastien-han.fr/blog/2014/10/10/ceph-how-to-test-if-your-ssd-is-suitable-as-a-journal-device/. |
Даже среди корпоративных SSD значение долговечности - общее число записей данных всей ёмкости данного устройства в отношении его времени жизни - может значительно разниться. Оно часто измеряется как DWPD (Drive Writes Per Day, Число записей диска за день) - в зависимости от срока службы накопителя, который часто составляет пять лет, но иногда бывает равным трём годам. Скажем, устройство 1 ТБ имеет пятилетнюю гарантию и рассчитано на запись 3.56 ПБ на протяжении своего срока службы. Это приводит к оценке ~ 2 DWPD.
Рассмотрим этот пример некоторой продуктовой линейки с тремя уровнями кэширования.
| Ёмкость | Случайные 4кБ IOPS 70/30 чтения/ записи | DWPD |
|---|---|---|
|
65 000 |
|
|
65 000 |
|
|
80 000 |
|
| Ёмкость | Случайные 4кБ IOPS 70/30 чтения/ записи | DWPD |
|---|---|---|
|
80 000 |
|
|
110 000 |
|
|
130 000 |
|
|
160 000 |
|
|
160 000 |
|
| Ёмкость | Случайные 4кБ IOPS 70/30 чтения/ записи | DWPD |
|---|---|---|
|
150 000 |
|
|
200 000 |
|
|
240 000 |
|
|
265 000 |
|
Вы можете видеть, что долговечность даже в одной линейке продуктов может меняться более чем в 30 раз и при этом также значительно меняется и скорость. Внимательно относитесь к обоим рейтингам, особенно для дисков, которые предназначены для применения в журналах, поскольку они будут определять сколько разделов журналов может принимать каждый из них прежде чем стать узким местом. В качестве высеченного на камне правила примите частное от скорости записи устройства журналирования на скорость записи самого устройства OSD. Например, если журнальное устройство работает со скоростью записи 1 ГБ/c, а ваше OSD записывает со скоростью 100МБ/с, вы можете составить пакет из не более чем 10 журналов на каждом устройстве ведения журналов.
Выбор целевой долговечности для журнала вашего кластера и OSD устройств может быть сложным и опираться на трудно прогнозируемый последующий обмен. Личная философия автора этих строк состоит в том, что душевное спокойствие, полученное в результате надёжности на верхнем уровне имеет тенденцию перевешивать дополнительные затраты на переход со среднего уровня, но ваши ограничения могут быть иными. Многие кластеры прекрасно справляются с приводами, имеющими класс 3 DWPD, однако автор этих строк не стал бы рекомендовать снижение по кривой стоимость/ долговечность. Обратите внимание, что SSD, применяемые для БД Монитора Ceph легко могут получать 2 DPWD или более в кластере с сотнями OSD. По этой причине вам настоятельно рекомендуется предоставлять MON SSD с отношением 3 DWPD, а ещё лучше 10 DWPD. Авторы сталкивались со множественными почти одновременными отказами MON из- за маленького показателя износостойкости устройств; мы не хотим чтобы вы испытали нечто подобное.
Обстоятельства порой заставляют нас развёртывать решение на своих горячо любимых серверах. В прошлом
использованные жёсткие диски могли стать постоянной головной болью, но сегодняшние диски обладают значительно
лучшей долговечностью. Повторно применяемые SSD, однако, могут стать постоянно тикающей (втихую) бомбой
замедленного действия. По крайней мере, вам необходимо будет проверять счётчик остающегося времени жизни таким
инструментом, как smartctl или isdct
чтобы избежать (в буквальном смысле слова) грубого ночного пробуждения.
|
| Замечание |
|---|---|
|
Инструментарий Утилита {Прим. пер.: рекомендуем автоматизировать этот процесс с помощью Ansible или Zabbix. } |
Устройства Fibre channel (FC), хотя когда- то и были популярны в корпоративных центрах обработки данных, всё более и более выходят из употребления в новых развёртываниях и в большинстве случаев не являются хорошо приспособленными для архитектуры Ceph, работающей на общедоступном оборудовании. Большинство кластеров в наши дни построено с интерфейсами SAS или SATA. Относительно достоинств SAS перед SATA мнения различаются; при современных технологиях HBA, устройствах и драйверов ОС зазор между ними двумя может быть меньше чем ранее. Успешные кластеры были построены на устройствах SATA, однако многие администраторы полагают, что устройства SAS имеют тенденцию работать лучше, в особенности при интенсивных нагрузках. Ни один из вариантов не может иметь катастрофических последствий, поскольку Ceph строится с тем, чтобы гарантировать избыточность и доступность данных. {Прим. пер.: во многих линейках продуктов единственной существенной разницей является возможность построения Множества путей SAS.}
Более существенен выбор между обычными устройствами с вращающимися магнитными пластинами, обычно именуемыми шпинделями и SSD. Скорость и ёмкость современных SSD неуклонно растут, а их стоимость стремительно падает неуклонно год за годом. Развитие магнитных дисков менее впечатляюще: ёмкость со скрипом поступательно растёт вверх, однако скорости/ пропускные способности во многом ограничены физикой. В прошлом стоимость га ГБ некоторого SSD была впечатляюще выше чем стоимость для дагнитного диска, что ограничивало их применение определёнными критически важными и другими приложениями, однако по мере того, как их цена непрерывно падала, они становятся всё более конкурентными по стоимости. С учётом TCO, а не просто CapEx, тот факт, что вращающиеся диски потребляют большую мощность и таким образом требуют большего дополнительного охлаждения, дополнительно выравнивает имеющийся финансовый зазор. Сегодняшние корпоративные SSD к тому же более надёжны чем магнитные диски, что также следует рассматривать.
Ваши ограничения могут разниться, но для многих теперь выбор между SSD и магнитными дисками теперь основывается на варианте применения. Если роль вашего кластера состоит в том, чтобы предоставлять блочное хранилище для тысяч виртуальных машин, работающих с различными приложениями, ваши пользователи могут не удовлетвориться имеющимися ограничениями производительности магнитных дисков и у вас есть шанс забить IOPS задолго до того, как кластер заполнится. Если, однако, вашим вариантом использования является истинная служба объектов для работы в стиле REST с применением шлюза RADOS или долговременного архива, плотность и ёмкость могут иметь большее предпочтение в отношении больших по размеру, но более медленных вращающихся дисков для службы OSD.
Устройства NVMe совершенно новая технология, которая быстро получает распространение в качестве альтернативы устройствам на основе SSD SAS/ SATA. Большинство доступных сегодня устройств NVMe имеют вид обычных карт PCIe, хотя имеется интересные развивающиеся архитектуры для заменяемых в горячем режиме в традиционном стиле вращающихся устройств в отсеках передней панели. За последние годы цены на диски NVMe значительно снизились, что при их потрясающей скорости делает их всё более популярным выбором для обслуживания журналов Ceph. {Прим. пер.: ещё более впечатляющим численным показателем является не столько само значение скорости обмена с отдельным процессом, сколько общее число одновременно поддерживаемых таких процессов, что делает возможным практичеки линейный рост общей пропускной способности подробнее....} Традиционные интерфейсы SAS и SATA были разработаны в некую эру намного более медленных носителей в сравнении с шиной PCIe со множеством lane.
NVMe был разработан для современных, быстрых носителей без ограничений физического поиска вращающихся дисков и предлагает более эффективный протокол. Огромная скорость, достигаемая при этом благодаря дискам NVMe всё чаще находит их выбранными для обслуживания журнала Ceph {Прим. пер.: базы данных BlueStore}: вы зачастую можете упаковывать десять или более журналов OSD на одно устройство NVMe. Несмотря на то, что сегодня они стоят дороже из расчёта на 1 ГБ чем обычный SSD, резко возрастает производительность, и мы должны ожидать, что NVMe станет обычным местом для журналов{Прим. пер.: BlueStore}. Большинство серверов предлагает несколько доступных обычных слотов PCIe, которыми сегодня оычно ограничено применение NVMe для хранения данных вместо объёмного хранилища OSD, но по мере развития архитектуры серверов и шасси мы начинаем видеть продукты, предлагающие устройства NVMe с горячей заменой, применяющие новейшие типы соединения PCIe и в ближайшие годы целые горизонтально масштабируемые кластеры смогут получать преимущество скоростей NVMe. {Прим. пер.: Современные системы 2017 года на базе процессоров Intel® Xeon® семейства Scalable и процессоров Amd Epyc уже оснащаются такими устройствами на базе разъёма SFF-8639, физически (но не на уровне протоколов!) совместимого с применяемыми для подключения устройств SAS/ SATA для вывода до 4 lane PCIe.}
Независимо от типа устройства вы можете рассматривать предоставляемые устройства от по крайней мере двух производителей для того, чтобы свести к минимуму проблемы с питанием, разницу в частоте отказов и потенциальные недостатки конструкции или встроенного ПО, которые могут повлиять на ваши кластеры. некоторые следуют далее, до исходных дисков с различными VAR или выпущенными в разное время, основная идея состоит в наличии дисков от множества производств во избежание феномена плохой партии.
Одним из ключевых факторов при выборе вашей модели сервера является общее число устройств, которое может быть предоставлено внутри каждого. В недавнем прошлом серверы зачастую могли предоставить только два диска, требуя внешних JBOD или массивов RAID для массового хранения, однако сегодня вся передняя панель и в некоторых случаях большая часть задней панели доступна для хранения.
Серверы MON, RGW и MDS Ceph не требуют большого объёма локального хранилища и часто реализуются в виде базовых 1U серверов, лезвий или тонких моделей, предоставляющих два серверных модуля в отдельном 1U шасси {Прим. пер.: четырёх модулей в 2U шасси и т.п., вплоть до 24 двухпроцессорных модулей в 8U исполнении.} Два или четыре привода, скорее всего, всё что вам понадобится. Позаботьтесь, тем не менее о наличии области отказа (failure domain): при сдвоенных или бейд системах вы должны принять меры к тому, что утрата или временный простой одного из шасси не принесёт больших потерь вашему кластеру. По этой причине проектировщики Ceph применяют самые современные, но отдельно располагающиеся 1U серверы для таких приложений.
Для серверов OSD Ceph отсеки приводов зачастую основной ограничивающий показатель. Поскольку оптические носители становятся всё менее актуальными, их применяемость на сервере в значительной степени исчезла, а занимаемое ими когда- то пространство лучше использовть для большего количества отсеков для дисков. Например, некий 1U сервер с расположенным в нём оптическим дисководом может предлагать 8 SFF, однако он же без него обычно предлагает 10, на 25% вспучивая плотность. Для 2U серверов привычно обнаруживать модели для 24 или 25 SFF или 12 LFF с фронтально загружаемыми отсеками. Также у некоторых производителей доступны модели с отсеками под приводы на задней панели, размещающие 24 или 32 устройства в 2U или 3U шасси. {Прим. пер.: к тому же, доступны выдвигаемые на рельсах в рабочем состоянии шасси с вертикальной горячей заменой дисков, причём не только в известном всем 4RU исполнении, но и в 1RU реализации}. Рассматривайте построение охлаждения и монтажа при обдумывании таких моделей. Некий центр обработки данных с горячими и холодными коридорами, к примеру, может не быть идеальной средой для расположенных на задней панели устройств.
Распространённым является зеркалирование операционной системы/ загрузочного устройства и в некоторых серверных моделях пара отсеков на задней панели или внутри для такого применения, высвобождая дорогостоящие отсеки передней панели для устройств массового хранения данных. Соблюдайте осторожность при использовании внутренних отсеков, которые требуют, чтобы сервер был отключён для замены привода. {Прим. пер.: если выходят из строя загрузочные устройства, высока ли верятность, что вы пожелаете обслуживать его во включённом состоянии? Обратите внимание на устройства SATA DOM, также, как правило, обладающие функцией зеркалирования.}
Поскольку пространство центров обработки данных часто ограничено, либо начисляет плату аренды исходя из числа стоек или RU, более востребованными являются серверы, предлагающие больше слотов на стойку с точки зрения плотности, относимой к RU и стоимости 1 RU. Они могут также давать финансовый выигрыш ещё и в том, что необходимо предусмотреть меньшее общее число ЦПУ портов коммутатора. Таким образом, за исключением очень маленьких или лабораторных/ тестовых кластеров, серверы с 1U с ограниченным количеством отсеков для приводов изредка - но не всегда - являются предпочтительными для систем OSD. {Прим. пер.: ещё раз напомним о своём 1U решении с 14 приводами!}
Возможно, возникает соблазн создания кластера поверх плотных серверов, обеспечивающих 36, 72, или даже 90 отсеков, но для такого подхода имеются существенные опасности, в частности, наличие размера областей отказа. Область отказа (failure domain) является неким набором ресурсов, которые могут испытать совместный отказ или прочий вид недоступности. Для Ceph здесь имеются два важных фактора. Во- первых, вы должны гарантировать что никакая область отказа не остановит основную часть ваших узлов MON или более обной копии данных в узлах OSD. Тем самым, MON лучше располагать не более чем по одному в каждой физической стойке. Во- вторых, для узлов OSD, рассмотрите процентное соотношение от общего содержащегося в кластере для расположения в одной стойке или, что более критично, в одном шасси.
Имеются некие слвоенные/ учетверённые системы, предоставляющие скрытую угрозу: если они совместно применяют источники питания, один отказ может выводить из строй множество серверов. Любой вид серверного шасси периодически обслуживается на предмет замены сбойных или отказавших компонентов, для вставки дополнительного ОЗУ, для обновления встроенного ПО, либо для проведения прочих встроенных или архитектурных изменений. Поскольу Ceph строится с избыточностью для гарантии того, что ничто не будет утрачено, некая крупная область отказа может временно, но при этом значительно, снизить агрегированную производительность вашего кластера на время данного отказа, работ сопровождения илидаже простой перезагрузки для обновления вашего ядра. Даже ещё более опасны катастрофические отказы оборудования: чем крупнее часть вашего кластера в отдельном шасси - или даже в отдельной стойке - тем больше воздействие на службу, в особенности если ваш кластер как сумасшедший выполняет повторную балансировку данных для гарантирования безопасности. Такая повторная балансировка может в значительной степени оказать воздействие на нармальную работу пользователей или даже иметь результатом что что все оставшися устройства заняты заполнением, поскольку они быстро принимают дополнительные данные.
Рассмотрим пример для некоторого кластера с 450 OSD, распределёнными по трём физическим и логическим стойкам:
| Общее число OSD на сервер/ шасси | Занимаемое место сервером в одной стойке | Доля сервера во всём кластере |
|---|---|---|
|
6.66% |
2.22% |
|
16.66% |
5.55% |
|
33.33% |
11.11% |
|
50% |
16.66% |
В случае выхода из строя всего одного сервера с 75-ю отсеками это будет означать что для поддержания сохранности данных ваш кластер будет вынужден переместить половину данных на этом томе для хранения на остающихся в этой стойке серверах. Если такой сервер заполнен уже на 40%, они теперь будут заниматься планированием восстановления записи, оставляя в состоянии жуткого голода работу пользователей. Когда данные будут залиты, многие OSD также пересекут порог наполнения и кластер будет доведён до останова. Ваши пользователи получат очень плохой день, а у вас и того хуже, поскольку все они штурмуют ваше рабочее место с факелами и вилами. Даже если этот OSD менее заполнен, производительность службы объектов деградирует, а блочная служба замедлится до того уровня, когда сотни и тысячи ВМ могут рухнуть.
На другой экстремальной стороне находятся сдвоенные, учетверённые или прочие влейд- системы. Они обладают свойством отдельного шасси, которое размещает два, четыре и более компактных серверных лезвий/ поддонов. Некоторые организации предпочитают их с точки зрения плотности или по прочим причинам, хотя порой такие преимущества остаются за гранью в лучшем случае. Такие системы обычно не являются лучшим выбором для OSD Ceph:
-
Они зачастую не спроектированы для размещения более чем два или три устройства хранения, что ставит в тупик плотность и стоимость за ТБ.
-
Они препятствуют удобному соотношению OSD для ведения журналов с целью эффективного применения быстрых, но дорогостоящих устройств.
-
Шасси выступает в роли области отказа: отказ или работы по сопровождению отключат все содержащиеся в нём серверы. Некоторые модели имеют ограниченную избыточность, либо вовсе не имеют её, либо даже совместно используют сетевые соединения, что увеличивает площадь подверженную мощным проблемам.
Поскольку узлы MON, RGW и MDS Ceph не требуют больших локальных хранилищ, такие системы, однако, имеют определённую популярность для данных приложений в сравнении при наличии дополнительных стеснённых требований к оборудованию. Это однако может оказаться некоей ловушкой, опять же возвращаясь к обсуждению наличия области отказа. Если ваш кластер имеет пять MON, причём четыре из них находятся в счетверённом шасси, всего один отказ может прекратить всю работу.
Плотность серверов таким образом представляет собой компромисс множества обстоятельств, однако вы обязаны рассмотреть имеющиеся области отказа. Для блочного хранения применение вариантов с шасси с 24- 25 отсеками часто рассматривается как золотая середина. Для хранения объектов, при котором латентность менее критична, более плотные системы могут быть допустимыми с целью максимизации ГБ на RU и минимизации стоимости RU.
Скорее всего, у вас имеется на примете некое значение ёмкости для вашего кластера, тщательно экстраполированная из существующих данных, потребностей пользователей и прогнозов. Вы запросто можете выполнить вычисления и спланировать сколько отсеков устройств и OSD вам может понадобиться для предоставления такой ёмкости. Учитывайте, однако, что отказы являются непредсказуемыми; вы можете заслужить значительную признательность, спланировав наперёд дополнительную ёмкость отсеков приводов, которые изначально не заполнены, для размещения впоследствии пошагового расширения без необходимости изыскивать бюджет или пространство в стойках для новых серверов. Это также обеспечит органичную миграцию на более ёмкие устройства хранения без необходимости предварительного сжатия всего кластера на меньшее число имеющихся устройств или списания некоторых для освобождения отсеков.
Серверы сегодняшнего дня применяют контроллеры для подключения устройств хранения, сетевых сред, и прочих технологий, которые мы применяем для вызова периферийных устройств. Зачастую это обычно отдельная дополнительная карта, применяющая PCI-e или прочие стандарты, хотя некоторые материнские платы серверов или шасси могут предлагать также встроенные варианты. Встроенные контроллеры удобны, однако могут предлагать скромные ёмкости и производительности. Они также меньше приспособлены для обновления чтобы применять улучшения технологий.
В данном разделе мы изучим ряд вариантов для ваших серверных контроллеров Ceph.
HBA (Host Bus Adapter) является синонимом для контроллера, описывает компонент сервера, который подключает устройства хранения к оставшейся части сервера. Если такая функциональность встроена в вашу материнскую плату, вместо того чтобы быть представленной дискретной картой, она всё ещё представлена неким HBA {Прим. пер.: более того, она может содержаться и внутри самого процессора, как это реализовано, например, в процессорах Байкал.} Тщательно рассматривайте вопрос применения встроенных контроллеров HBA для данных Ceph; их производительность может в лучшем случае тусклой.
Существует два основных типа HBA: базовые контроллеры и те которые предлагают встроенную функциональность RAID. Некоторые аппелируют к прошлому, когда имелись карты JBOD и позже стали HBA, хотя это не точно и ошибочно.
Имеющие возможности RAID HBA обычно содержат SoC (System on Chip) совместно с ГБ или более памяти кэширования. Поскольку память является энергозависимой, она персонально запитывается BBU (battery backup unit, устройством резервной батареи) для сохранения содержимого при перезагрузках или событиях с электропитанием с тем, чтобы его можно было сбросить на устройства когда система восстановиться. Такие карты могут применяться для организации зеркалирования устройств, их чередования, или прочих томов, которые могут затем предоставляться операционной системе как некое отдельное устройство. Это может уменьшать сложность на стороне программного обеспечения за счёт расширения накладных расходов значительного управления и обратных сторон при работе:
-
Увеличение стоимости
-
Увеличение сложности и возможностей для ошибок встроенного ПО, приводящего в конечном счёте к снижению надёжности
-
Увеличение сложности развёртывания
-
В некотрых случаях увеличение латентности
-
Рост сопровождения: обычные батареи как правило ограничены для применения всего лишь в течении года; альтернативой являются суперёмкости, вероятно, на три года. Когда они отказывают, становятся нестабильными или выпускаются декларации встроенного ПО, производительность падает, и их необходимо заменять или обновлять.
-
Снижается способность мониторинга: отдельным дискам, представленным как OSD может понадобиться проброс напрямую или обёрнутого в отдельное устройство тома RAID0; это создаёт сложности или делает невозможным применение таких инструментов как
iostatиsmartctl.
Пишущий эти строки автор считает, что RAID HBA является самым хлопотным отдельным компонентом его кластеров Ceph и с неистовством рекомендует применять простые модели HBA без RAID. Высвобождаемые стоимости покупки и сопровождения могут поддержать улучшения где- то ещё в вашей системе. Такой подход, однако, означает, что вам может быть придётся выбрать уязвимость некоторого загрузочного тома без зеркалирования или сложности создания зеркала программным путём. Некоторые администраторы исполняют системы Ceph с загрузочными томами без зеркала, однако отказ в этом месте может оказаться головной болью при восстановлении, поэтому автор настоятельно рекомендует создавать зеркало.
Улучшение сетевой среды возможно отдельное из наиболее эффективных мест применения денег внутри вашего кластера Ceph, а порой и наиболее легко обнаруживаемое среди пропущенных. Это наихудшая часть вашей архитектуры для мелочной экономии и хуже всего поддающаяся исправлениям впоследствии. Не делайте этого. Просто никогда.
Большинство кластеров Ceph реализуется с сетевой средой Ethernet, хотя Infiniband и прочие технологии {Прим. пер.: например, Omni-Path и Ангара} не являются неизвестными. Поскольку кластер Ceph применяет TCP/IP, он может применять большинство типов сетевых инфраструктур. {Прим. пер.: строго говоря, при использовании RDMA Ceph выходит за рамки TCP/IP, но это не столь важно в данный момент.} Лаборатории, PoC (Proof of Concept, проверки концепций) и очень небольшие кластеры могут начинать с соединением 1Gb/s, однако большая часть промышленных кластеров требует по крайней мере 10Gb/s. Установки большего размера и основанные на SSD возрастающе применяют развивающиеся сетевые среды 25Gb/s, 40Gb/s и 100Gb/s.
Хотя Ceph и не требует LACP или прочей стратегии связывания/ транков/ агрегации, их применение является стандартной практикой. Поскольку Ceph обычно используется большим числом клиентов, обращающихся к каждому из серверов, это на самом деле увеличивает доступность полосы пропускания пользователей. Возможность благополучно выйти из шторма отказов NIC / коммутатора и сопровождения сетевой среды однако более важны и сама по себе стоит затраченных средств. Автор этих строк рекомендует связывание LACP активный/ активный.
Привычным для Ceph является предоставление двух сетевых сред:
-
Общедоступной (public) сетевой среды по которой клиенты получают доступ к данным. Узлы MON и OSD также взаимодействуют в такой общедоступной сетевой среде.
-
Частная (private) сетевая среда применяется исключительно для репликаций и восстановления между узлами OSD и также имеет названия сетевой среды
кластера,серверов(backend) ирепликации. Рекомендуется для этой сети не применять какой бы то ни было шлюз.
Имеется возможность настроить Ceph для применения только одно сетевой среды, однако для развёртываемых в промышленном масштабе кластеров это выступает препятствием для помощи в гарантировании того, что обмен репликациями и клиентский обмен не завершат друг друга или не приведёт к DoS (отказу в обслуживании). Расщеплённая архитектура также упрощает анализ тенденций использования полосы пропускания и снабжает функциональностью дальнейшего повышения скорости и расширения ёмкости по мере необходимости.
Общедоступная и частная сетевые среды могут реализовываться с помощью отдельных сетевых коммутаторов, либо они могут применять VLAN или прочие стратегии разбиения на разделы. Проконсультируйтесь со своей сетевой командой по поводу предпочтительных подходов, однако получите гарантии, что ваша архитектура сетевой среды может предоставить полную пропускную способность и допускает дальнейшее расширение добавлением дополнительных хостов OSD, RGW или MDS.
Если ваши бюджет, инфраструктура или серверные компоненты не позволяют быстрой реализации обеих сетевых сред, и общедоступной, и частной для репликаций, ваше предпочтение должно быть отдано частной сетевой среде репликаций, например, связанных соединений 40Gb/s для репликаций и связанных соединений 10Gb/s для вашей общедоступной сетевой среды. В периоды наполнения/ восстановления ваша сеть репликаций легко может насытиться и стать узким местом.
Одним из общих подходов является предоставление каждого сервера с двумя идентичными двухпортовыми NIC, при связывании по одному из портов с каждой из карт для вашей сети репликаций и по одному из каждой карты для общедоступной сетевой среды. Таким образом, отказ отдельного NIC хорошо переносится как и отказ одного из коммутаторов восходящего сетевого потока.
Раньше серверы обычно управлялись через последовательные консоли с CLI или интерфейсом меню. В наши дни даже недорогие общедоступные серверы в бежевом шасси предлагают некий сетевой интерфейс управления, как правило, с UI SSH или HTTPS. Примерами являются ILOM Oracle, iDRAC Dell и iLO HPE.
Некоторые серверы могут не предлагать ничего иного кроме какого- нибудь устройства KVM с такой торговой маркой как Lantronix или Raritan, которые могут модернизировать некую необходимую функциональность. Пишущий эти строки автор принадлежит старой школе и ему нравятся серверы, которые имеют по крайней мере основное управление питанием и возможность самораскрутки через последовательную консоль, хотя это и требует выделенной инфраструктуры. Сетевые интерфейсы управления предлагают некое разнообразие управления и функциональности мониторинга. Каким бы вы ни пошли, автор настоятельно рекомендует вам чтобы вы имели возможность подключения серверной консоли, которая работает ка до загрузки (BIOS и установки), так и после неё (операционная система). Такая возможность бесценна для поиска сетевых неисправностей и проблем с оборудованием и предохраняет кого- то от отправки в ваш центр обработки данных в 3 часа ночи чтобы отыскать что там сломалось. {Прим. пер.: автор перевода советует применять для этого в качестве стандарта IPMI (согласитесь, стандартизация имеет резон, не так ли?) и ещё раз рекомендует автоматизировать этот процесс с помощью Ansible илиZabbix.}
Современные серверы зачастую предлагают изобилие встроенных ресурсов:
-
Сетевые интерфейсы
-
Интерфейсы управления
-
Контроллеры хранения
-
Клавиатуру/ видео/ мышь (KVM)
-
Многоцелевые порты USB
Имеются шансы, что вам потребуется добавить дополнительные контроллеры сети и хранения для связывания или потому что встроенные интерфейсы могут иметь всего лишь 1Gb/s. В зависимости от вашей модели сервера они могут иметь форму:
-
Стандартных карт PCI-e
-
Индивидуальной карты мезанина (mezzanine), которая не потребляет слот PCIe {Прим. пер.: имеется в виду именно слот, не порт PCIe, который волей- неволей расходует доступные lane PCIe. Обращаем внимание на наличие открытого стандарта для такого типа конструктива: OCP - Open Compute Project - так что тут не всё так плохо!}
-
Проприетарных модулей LAN On Board (LOM)
Что касается систем Ceph - в особенности серверов OSD - обычно требуется добавить по крайней мере четыре сетевых интерфейса и по крайней мере один адаптер хранения, что легко съедает три слота PCI-e. Тщательно изучите схемы своей модели сервера и описания спецификаций, чтобы убедиться что вы сможете предоставить то, что вам необходимо. Некоторые серверы могут потребовать не обязательные райзеры PCI-e для того чтобы разместить достаточное количество слотов; изучите спецификацию модели своего сервера плотнее чтобы убедиться, что общее число и длина/ высота {Прим. пер.: а порой и ширина!} слотов достаточны. Некоторые системы также определяют некий порядок для заполнения слотов PCI-e и могут ограничивать те карты, которые поддерживаются в определённых слотах из- за ограничений охлаждения или чистоты. Скорости доступных слотов могут разниться; не является чем- то необычным для сервера поддерживать как слоты x8, так и слоты x16. Жадные карты, в том числе NIC могут стать узким местом если установлены в некий слот, который предоставляет меньше lane, чем они могут использовать. {Прим. пер.: обратим ваше внимание также на имеющуюся в стандарте PCI-e и реализованную в ряде материнских плат возможность бифуркации слота PCIe, которая позволяет разделять lane слота по различным ЦПУ, осуществляющим доступ к внешним устройствам через этот слот, тем самым снижая нагрузку на сами ЦПУ.}
Автор этих строк настоятельно рекомендует планировать наперёд по крайней мере один слот PCI-e пустым: вы можете обнаружить, что через год пожелаете добавить журналы NVMe или прочие модернизации в силу изменившихся потребностей и рабочих нагрузок. Это доставит гораздо меньше хлопот и затрат, чем замена неподходящего сервера целиком и ваша дальновидность получит восхваление.
Самым первым решением для планирования сервера часто является выбор модели CPU (ЦПУ, Central Processor Unit). Раньше у вас была всего лишь пригоршня или даже один выбор, однако в наши дни процессоры серверов x64 предлагают десятки вариантов, включающие число ядер и тактовую частоту. {Прим. пер.: а также количество каналов между процессорами, систем команд и даже наличия внешнего интерфейса, см., например, Intel® Xeon® семейства Scalable.} В данном разделе мы исследуем эти варианты и поможем вам сделать правильные выборы для вашей реализации Ceph. Именно в этой области также возможно перегнуть палку, но, как мы увидим, это возможно не самое лучшее место нанесения удара по вашему бюджету.
Большинсто серверов применяемых для Ceph сегодня являются либо архитектурой с одним, либо с двумя разъёмами под ЦПУ. Большие четырёхсокетные серверы обычно черезчур расточительны для Ceph и вноят возрастающие стоимость и сложность работы. Серверы MON и RGW часто могут обойтись только с одним заполненным сокетом с по крайней мере четырьмя ядрами ЦПУ, хотя это также ограничит и ёмкость памяти. {Прим. пер.: Задумайтесь о пользе единообразия, а значит и взаимозаменяемости материнских плат! Это может помочь вам в унифицикации сопровождения.}
Вполне естественно ощущать, что чем быстрее ядра ЦПУ, тем лучше, однако относительно Ceph это обычно не самое эффективное место для траты дополнительных средств. Самым первым и самым узким бутылочным горлышком кластера, находящегося под нагрузкой обычно являются перегруженность приводов хранения или сетевой среды репликации. Демоны Ceph являются многопоточными, поэтому решение с большим числом ядер обычно лучше чем затрата денег в соответствии с кривой зависимости стоимости от ГигаГерц. Высеченные на камне правила могут быть хитроумными и варианты здесь изменятся, в особенности с эволюцией ЦПУ, однако, как минимум, атор этих строк предлагает следующее:
-
Узлы MON: четыре ядра
-
Узлы RGW: восемь ядер
-
Узлы MDS: четыре ядра с самой высокой тактовой частотой
-
Узлы OSD: один ГГц-ядра на HDD, два на SSD, пять на NVMe. Округляйте вверх если используете dmcrypt или сжатие.
OSD системы с быстрыми устройствами хранения SSD/ NVMe нуждаются в большем числе ЦПУ на единицу хранения во избежание перегруженности ЦПУ.
В рамках некоторой продуктовой линейки ЦПУ различные модели ЦПУ могут поддерживать различное количество межсокетных соединений QPI {Прим. пер.: UPI} или различное количество каналов памяти. Это может влиять на общую ёмкость памяти или результирующую скорость. Делая выбор, останавливайтесь на той модели, которая имеет больше каналов при сравнении с аналогом с меньшим числом каналов.
Тем не менее, большое число ЦПУ может навредить производительности. Современные процессоры применяют технологию C-states чтобы замедлять или даже отключать отобранные ядра для сбережения мощности и тепла. Имеются некие факты, говорящие о том, что переход между C-states может воздействовать на прерывание обработки, в особенности когда используются высокоскоростные NIC. Таким образом, самый топовый ЦПУ с по крайней мере 18 ядрами может оказаться пагубным для узлов MON, или даже для узлов OSD со скромным числом устройств. Это может вероятно смягчится после такого факта, как запрет C-states и в BIOS, и через имеющиеся аргументы командной строки ядра {Прим. пер.: подробнее...}, однако это подчёркивает важность того факта, что не стоит заниматься гигантоманией в предоставлении тактовых частот ЦПУ.
|
| Замечание |
|---|---|
|
Пример из реального мира: Узлы OSD с дуальными процессорами Xeon E5-2680 v2 управляют 10 OSD, каждый с 3-4 ТБ вращающимися LFF. Эти 10 ядер, ЦПУ 2.8ГГц были в основном простаивающими. Выбор вместо него Xeon E5-2630 v2 мог бы сберечь примерно по $2600 на систему (согласно прайс- листу, xls) и избежать проблемы C-states. |
Долгое время было так, что внутри одного поколения ЦПУ прирост производительности давал прирост цены. Для всех серверов, кроме самых плотных, самые ьыстрые доступные модели - измеряется это числом ядер или тактовой частотой - обычно являются избыточными и не эффективными в стоимостном отношении для Ceph. Однако, разумно не слишком урезать его; вы хотите разгонять мощность в тех случаях, когда ваш кластер забит или находится под нагрузкой. Мы также никогда не знаем какая приводящая в трепет вычислительно- затратная функциональность ещё появится в следующей редакции (включая сжатие в только что ставшем доступным Luminous), поэтому в разумном запасе также имеется некая ценность. Непрерывная работа ваших ЦПУ на 90% загруженности не будет творить чудеса для вашей латентости и возможности выдерживать стресс. По мере того, как удаляющее кодирование (см. Главу 4 и Главу 8) становится всё более распространённым, ресурсы ЦПУ требуют увеличения, что является другой причиной предоставления разумного количества дополнительных частот ЦПУ в наши дни.
В наши дни в реализациях Ceph обычно применяются обычные серверы, однако интересная новая технология состоит во встраиваинии некоторой компактной системы прямо в электронную плату устройства, включая сдвоенные интерфейсы Ethernet. Можно рассматривать это как новейшую сборку дискового устройства, которое исполняет Linux на борту. Поскольку каждому требуется всего лишь вооружать единственный OSD, его скромных процессора и пропускной способности вполне достаточно. Некое шасси OSD, вместо того чтобы быть неким затратным компьютером общего назначения, становится действенным дисковым массивом со встроенным сетевым коммутатором. Такие микропроцессорные устройства пока ещё не широко доступны или реализованы, однако завтра обещают интересную, масштабируемую модульную систему.
|
| Замечание |
|---|---|
|
Прочтите дополнительно о микросерверных приводах здесь: http://ceph.com/community/500-osd-ceph-cluster. |
Другой новейшей технологией, которую можно приобрести и развернуть сегодня является InfiniFlash SanDisk, плотная технология SSD, которая может применяться как ложащееся в основу хранилище для OSD Ceph.
Дополнительные ресурсы по выбору оборудования могут быть найдены на следующих сайтах:
-
https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/1.3/html-single/hardware_guide
-
http://docs.ceph.com/docs/wip-17440/start/hardware-recommendations
-
http://tracker.ceph.com/projects/ceph/wiki/Tuning_for_All_Flash_Deployments
-
{Прим. пер.: Ceph. Рекомендации по оборудованию}
-
{Прим. пер.: Книга рецептов Ceph, Первое издание, перевод}
Существует множество факторов, которые влияют на выбор серверного оборудования для кластеров Ceph, причём каждый тип узла имеет различные требования и ограничения. Помимо всего прочего, наиболее важным является рассмотрение скорости сетевой среды и областей отказа. При планировании ёмкости Ceph; важно помнить, что неследует работать с OSD устройствами, заполненными прямо до 99%; будет благоразумным планировать кластер с тем, чтобы он не превышал использование сырого пространства OSD выше 70%.