Глава 8. Архитектура Ceph: под капотом
Содержание
В этой главе мы обсудим внутреннее устройство Ceph. Изучаемые нами компоненты будут следующими:
-
Объекты Ceph
-
Группы размещения
-
Алгоритм CRUSH и персональная настройка
-
Пулы Ceph
-
Управление данными Ceph
Предоставляемые клиентам Ceph данные хранятся в объектах. На самом деле, даже большинство связанных с ними метаданных, которые Ceph хранит для создаваемых клиентом данных полезной нагрузки также хранятся либо как отдельные Объекты Ceph, либо внутри имеющихся объектов совместно с данными полезной нагрузки. Каждый объект идентифицируется своим уникальным именем. Когда некое имя выделено какому- то вновь создаваемому объекту, никакой другой объект не может быть создан в точности с этим же именем в том же самом пространстве имён внутри некоторого кластера.
Объектами в Ceph именуются объекты RADOS
(Reliable, Autonomic, Distributed Object Store,
Надёжного автономного распределённого хранилища объектов) и действия с ними могут выполняться с применением
инструментов командной строки rados. Это облегчает сбалансированное
распределение данных и рабочих нагрузок в некотором гетерогенном кластере, который может динамически расти или
сокращаться в размерах. Он предоставляет всем своим клиентским приложениям (в том числе RBD и RGW) определённую
иллюзию единого хранилища логических объектов с безопасной семантикой и надёжными гарантиями согласованности.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Важно помнить об отличии между теми объектами RADOS, которыми управляет Ceph за сценой и теми видимыми пользователю объектами, к которым осуществляется доступ через RGW. |
Объекты RADOS в определённой степени аналогичны основной концепции файла; обе они действуют как некая абстракция хранения данных, однако внутренне они совершенно различны в терминах функциональности. Хранилища на основании файла ограничены теми структурами и семантикой, которыми снабжает лежащая в основе файловая система. Блоки в некоторой файловой системе обычно фиксированы в размере. Определённое добавление информации пользовательских метаданных в некую обычную файловую систему может быть ограниченным или восе невозможным. В Ceph каждый хранящий данные объект способен хранить вместе с ними богатые метаданные. Каждый объект может иметь произвольный размер и его внутренние характеристики не зависят от прочих объектов в данном кластере. Метаданные объекта позволяют пользователям управлять неструктурированным содержимым или данными внутри и осуществлять к ним доступ.
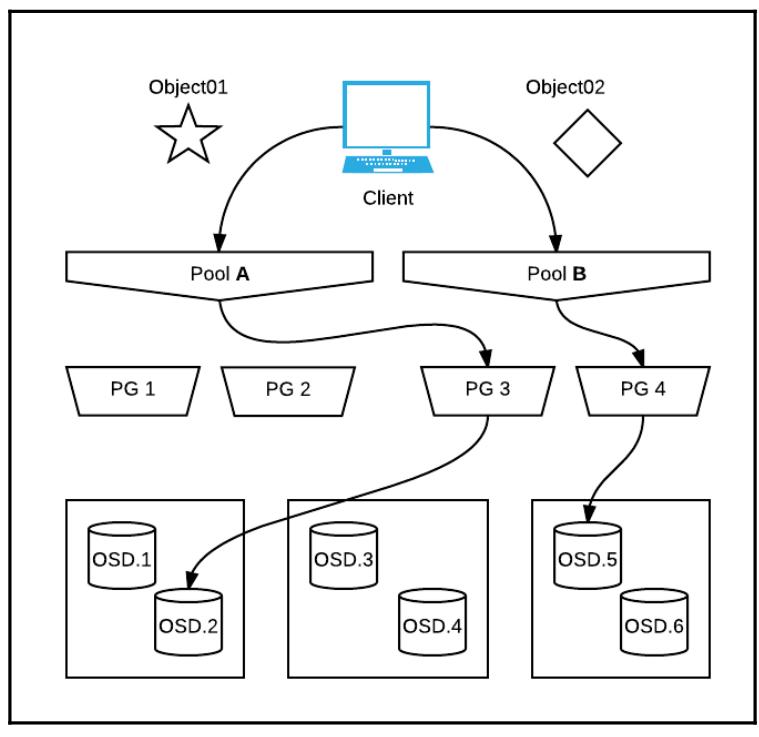
Ceph не навязывает некую концептуальную иерархию подобно тому как это делает файловая система для файлов и каталогов. Все объекты внутри некоторого пространства имён находятся на одном и том же уровне. Исключение иерархических пространств имён позволяет Ceph горизонтальное масштабирование по тысячам машин и десяткам тысяч устройств. Ceph хранит объекты в OSD (Object-based Storage Devices, Устройствах хранения на основе объектов). Эти объекты группируются воедино и ставятся в соответствие OSD с применением алгоритма CRUSH. Объекты логически собираются в некие наборы большего размера, имеющие название Групп размещения, которые предоставляют некий способ управления их распределением с тем, чтобы данные хранились некоторым надёжным, высоко- доступным и устойчивым к отказам образом. Мы изучим эти концепции более подробно позднее в этой главе.
Данные в рамках Ceph хранятся в неких неделимых элементов, называемых Объектами. Все Объекты располагаются внутри определяемого пользователем пространства имён, называемого пулом. Некий пул Ceph является логическим разделом всех Объектов внутри его пространства хранения. Объекты могут реплицироваться внутри некоего пула, однако не могут реплицироваться между множествами пулов в автоматическом режиме. Если требуется такой вид реплицирования, пользователям понадобится копирование некоторого объекта вручную, однако это не является существенной частью обычного рабочего процесса. Мы рассмотрим пулы более целостно позже в данной главе.
При оснащении нового кластера Ceph для хранения данных требуются пулы. Пулы по умолчанию могут создаваться
в зависимости от текущего выпуска Ceph и типа развёртываемой службы. Оснастка некого MDS для CephFS
автоматически создаст два пула с названиями cephfs_data и
cephfs_metadata. Аналогично, развёртывание некоей новой службы RGW
создаст дополнительные данные, метаданные и пулы пользователя для обслуживания операций API S3 или Swift.
В выпусках Ceph, предшествовавших Luminous (включая тот кластер Jewel, который мы создали в
Главе 5, Развёртывание виртуального кластера песочницы)
некий пул с названием rbd всегда создавался по умолчанию. Также имеется
возможность создавать новый индивидуальный пул вручную и переименовывать или удалять имеющиеся пулы.
Чтобы понимать как создаются объекты и как осуществляется доступ к ним, мы начнём вначале с создания некоторого пула. Для этого практического упражнения мы воспользуемся тем кластером, который мы создали в Главе 5, Развёртывание виртуального кластера песочницы. Если у вас нет какого- нибудь работающего кластера в вашем распоряжении для исполнения команд данного упражнения, настоятельно рекомендуем вам вначале пройти Главу 5, Развёртывание виртуального кластера песочницы чтобы иметь в своей песочнице некий рабочий кластер.
Зарегистрируйтесь в нашей виртуальной машине клиента чтобы исполнять наши операции в данном кластере:
$ vagrant ssh client0
vagrant@ceph-client0:~$sudo -i
root@ceph-client0:~#
Убедитесь что кластер находится в жизнеспособном состоянии:
root@ceph-client0:~# ceph health
HEALTH_OK
Всё выглядит неплохо! Давайте начнём создавать объекты. Прежде чем создать некий объект, давайте вначале создадим некий новый пул Ceph. Мы будем применять этот пул для хранения наших новых объектов.
root@ceph-client0:~# ceph osd pool create my_pool 64
pool 'my_pool' created
Предыдущая команда создаст некий пул с названием my_pool в
нашем кластере. Мы можем именовать свой пул как нам заблагорассудится. Значением параметра командной строки
после самого названия пула является некое число, именуемое pg_num.
Это значение применяется для определения общего числа Групп
размещения (PG, подлежащих
созданию внутри нашего нового пула. Мы обсудим PG более подробно в нашем следующем разделе, но на текущий
момент отметим, что каждый пул содержит выделенное множество Групп размещения.
Вы можете вывести перечень пулов, которыми владеет ваш кластер исполнив
ceph osd pool ls:
root@ceph-client0:~# ceph osd pool ls
rbd
my_pool
Вы можете также получить детализированный обзор всех имеющихся атрибутов некоторого пула добавив параметр
detail в конец предыдущей команды:
oot@ceph-client0:~# ceph osd pool ls detail
pool 2 'my_pool' replicated size 3 min_size 2 crush_ruleset 0
object_hashrjenkinspg_num 64 pgp_num 64 last_change 12409 flags
hashpspoolstripe_width 0
Данный вывод представлен в виде пар ключ- значение, однако без каких- либо определённых ограничителей вокруг
каждого, что делает прочтение данных значений слегка умудрённым. Мы можем видеть, что то пул, который мы только
что создали имеет некий идентификатор 2. Это какой- то пул с репликациями
с установленным по умолчанию множителем репликаций X, неким минимальным множителем репликаций для обслуживания
ввода/ вывода равным 2, и что он является частью набора правил CRUSH с идентификатором
0. Не беспокойтесь, если предыдущий вывод выглядит зашифрованным на данном
этапе, все ключи и их применение станет намного более понятным по мере того как мы будем продвигаться по
этой главе.
Теперь, когда у нас имеется готовым некий пул, давайте перейдём к сохранению самих объектов:
root@ceph-client0:~# echo "somedata" > data.txt
root@ceph-client0:~# rados -p my_pool put my_data data.txt
Команда rados сохранит все данные из нашего файла- пустышки с
названием data.txt в соответствующий пул Ceph с названием
my_pool, который мы создали с применением флага
-p. Общий синтаксис для создания какого- то нового объекта в Ceph
выгляди так: rados -p <poolname> put <object-name><file-path>.
Мы также можем организовывать конвейер данных в radosput из
stdin в случае необходимости, однако выгрузка из некоторого файла
является обычной практикой.
Поздравляем! Вы только что создали совершенно новый пул и сохранили свой самый первый сиятельный объект в нём. Если мы выведем перечень всех объектов в нашем пуле, мы должны иметь возможность отыскать своё в этом списке. Мы также способны отображать прочие атрибуты нашего объекта, включая то, когда он изменялся последний раз и его текущий размер:
root@ceph-client0:~# rados -p my_pool ls
my_data
root@ceph-client0:~# rados -p my_pool stat my_data
my_pool/my_datamtime 2017-08-30 01:49:27.000000, size 9
Должно быть понятно, что данная подкоманда rados ls отображает
перечень всех объектов в данном пуле. Подкоманда stat показывает
определённые ключевые свойства данного объекта, включая то, когда он изменялся последний раз
(mtime) и его реальный размер
(size).
Мы ввели много новых терминов в своём предыдущем примере и попытаемся осудить большую их часть в оставшейся части данной главы.
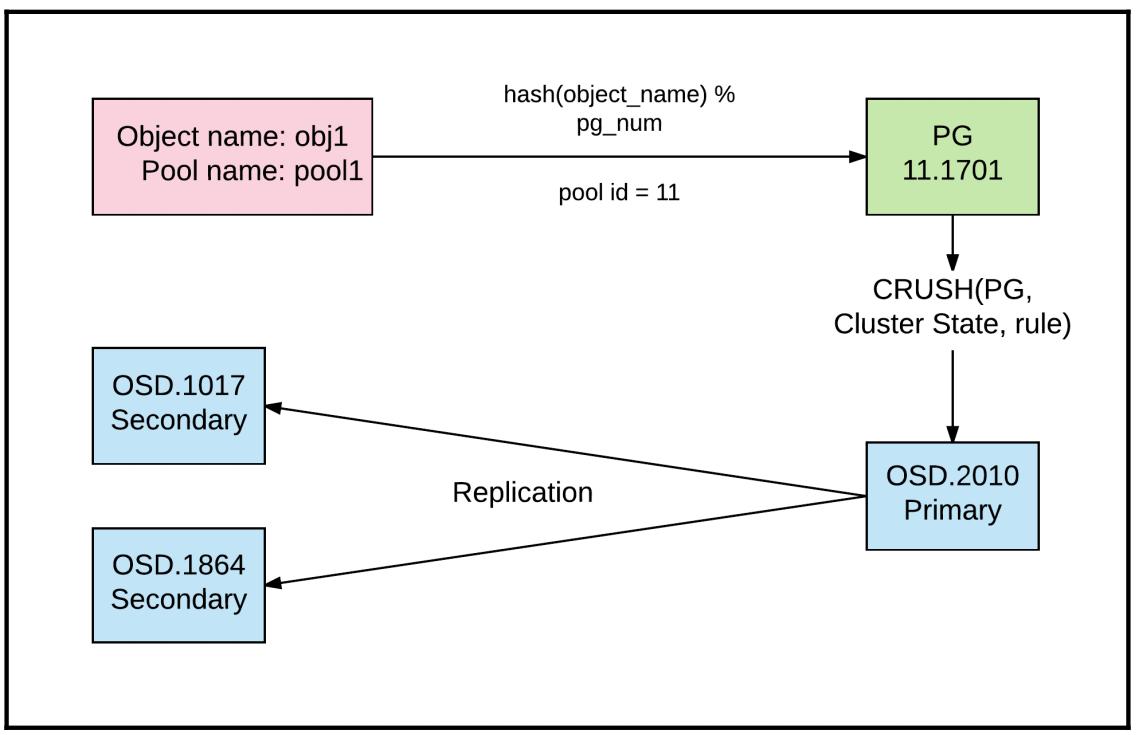
В своём предыдущем разделе мы объяснили что такое объекты в Ceph и как мы можем осуществлять к ним доступ. Ceph распределяет объекты псевдо- случайно по устройствам хранения основываясь на предварительно определённых политиках назначения данных. такая политика назначения применяет новый алгоритм размещения, имеющий название CRUSH, для выбора некоторого вероятностно сбалансированного распределения объектов по всему кластеру. Это гарантирует, что устройства представляют почти единообразное распределение хранения и рабочей нагрузки для большинства вариантов применения. Когда некий кластер расширяется за счёт добавления нового хранилища или удаляются старые/ отказавшие устройства, необходимо восстанавливать баланс путём миграции данных для восстановления имеющихся настроенных политик репликации. Так как такие перемещения данных сохраняются на минимальном уровне, пополнение некоторого существующего кластера значительно менее громоздко в сравнении с использованием другого, менее изощрённого алгоритма размещения. CRUSH будет рассмотрен в деталях в нашем следующем разделе.
Когда Ceph получает запросы на сохранение данных, ему необходимо определить то множество назначаемых объектов, на которые должны быть отправлены эти запросы, а также их расположения. Каждый объект может быть поставлен в соответствие только одной Группе размещения в некий момент. Такое соответствие между неким объектом и его Группой размещения остаётся постоянным пока мы не изменим общее число PG внутри пула. Соответствие PG вычисляется с применением алгоритма хэщирования CRUSH. Внешними данными для имеющейся функции хэширования являются идентификатор пула и название объекта. Применяя данный идентификатор пула он выделяет имеющийся профиль пула, который указывает текущую политику реплицирования или удаляющего кодирования пула и то сколько копий или полос некоторого Объекта данный пул должен сохранять. Данные идентификатор пула и название объекта в комбинации также помогают определить необходимый pgid (Placement Group ID, Идентификатор Группы размещения).
Вот та формула, которая применяется для вычисления некоторой Группы размещения Объекта:
pgid = func(hash(o) & m,r) [pgid]
pgid является некоторой функцией названия объекта
(o), битовой маски для текущего
пространства ключей (m) и
множителя репликаций (r).
Вначале мы определяем хэш эначение некоторого объекта используя его имя
o и выполняем побитовую операцию
двоичного AND с имеющейся маской бит
(m). Эта битовая маска проистекает
изнутри общего числа PG, которое мы настроили для наличия в нашем пуле. Это ограничивает весь диапазон
(вывод) имеющейся функции хэширования попаданием только вовнутрь того множества Групп размещения, которое
существует в настоящее время. Значение переменной r
является множитель числа репликаций данного пула и он применяется для определения общего числа OSD,
которому должна соответствовать данная Группа размещения, так как Ceph будет в общем случае хранить данные
в разъединённых OSD.
Устройства или OSD выбираются на основе общего числа полос, которые требует иметь некая политика реплицирования
или удаляющего кодирования Объекта и которая связана с данным pgid и,
таким образом, с некоей уникальной PG. Сама PG ответственна за то, что объекты снабжены надёжными доступом и
хранением. Допустим, мы установили значение множителя репликаций некоторого пула равным
3 (определяемого ключом с названием
size), все Группы размещения внутри такого пула должны гарантировать,
что некий объект, при своём жизнеспопосбном состоянии, реплицирован в точности три раза по множеству
отдельных устройств или OSD. Группы размещения разработаны для усиления строгой согласованности по всем
копиям некоторого объекта.
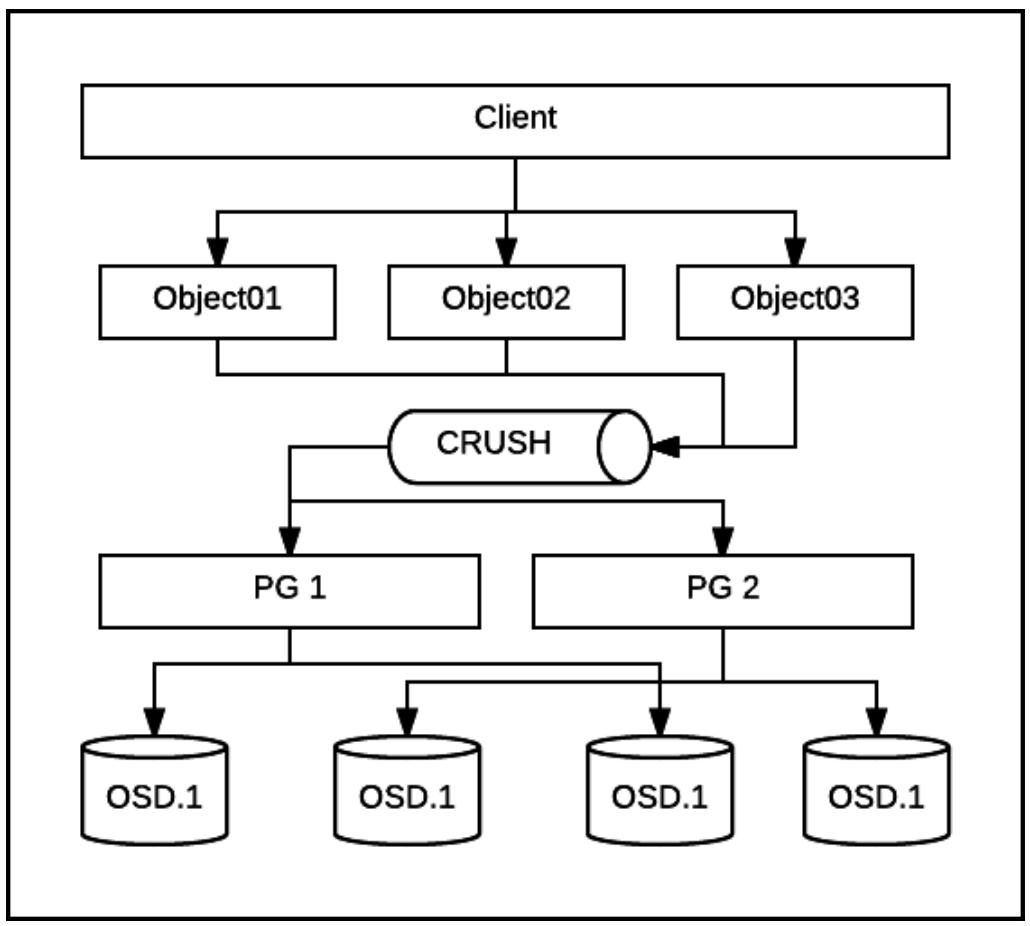
Некоторой важной характеристикой Группы размещения является то, что она устанавливает соответствие между её
pgid, который является уникальным идентификатором для какой- то
Группы размещения, и именем объекта, которые не хранятся постоянно ни у клиентов, ни в OSD или MON.
На самом деле, это соответствие в явном виде не хранится нигде. Оно
динамически и независимо вычисляется при его появлении всякий раз когда некий запрос данных на основании объекта
или управления отправляется с какого- то клиента Ceph. Уполномочив клиентов самостоятельно вычислять
размещение объектов на лету, мы устраняем необходимость в распределении большого централизованного
индекса метаданных, который содержит запись для каждого создаваемого Объекта. Избегая такой единой потенциальной
точки отказа, Ceph может быстро масштабироваться по большому числу клиентов и Объектов в средах с высокой
динамикой.
Объекты внутри каждого пула собираются в Группы размещения, а этим Группам размещения назначаются множество OSD в соответствии с имеющейся стратегией и политикой пула. Каждая Группа размещения хранит от тысяч до миллионов Объектов и каждый OSD хранит от десятков до сотен Групп размещения. Установленные пределы более строго продиктованы на уровне OSD размером раздела, ограничениями пропускной способности и латентности лежащего в основе устройства и самими размерами этих Объектов. Для обычного шпиндельного магнитного диска типично хранить от 50 до 100 Групп размещения, в то время как для OSD, работающих на твердотельных устройствах ( SSD) с управлением AHCI нет ничего необычного в том, что счётчик PG находится в диапазоне между 100 и 500. Значение счётчика может быть ещё выше для SSD на основе PCIe или устройств NVMe. Большее число Групп размещения на некотором диске имеет результатом увеличение операций ввода/ вывода на таком устройстве. Каждые тип или модель устройства имеют уникальные характеристики и вам следует выполнять эталонное тестирование своей установки прежде чем установить некое оптимальное соотношение PG к OSD. Настройка более одного пула в вашем кластере может усложнить такое вычисление, но пока общее число PG в каждом OSD (на уровне всего кластера) будет оставаться в рамках рекомендуемых пределов, сами поведение и производительность кластера не должны испытывать серьёзного воздействия.
Тем не менее, Ceph имеет устанавливаемый по умолчанию, но настраиваемый порог соотношения PG к OSD. При работе с Luminous и последующими редакциями, действия могут иметь результатом к отказу пересечения такого порогового значения. Мы изучили особенности и последствия данного соотношения в Главе 4, Планирование вашего развёртывания.
В Главе 4, Планирование вашего развёртывания мы обсуждали важность надлежащего числа Групп размещения на пул.
Для каждого пула необходима установка значения pg_num Групп размещения
и его создание прежде чем вы сможете записывать в него данные. Ceph снабжает нас двумя настройками для подсчёта
значения PG. Одно управляет общим числом представленных в данном пуле Групп размещения, в то время как второе
управляет общим числом Групп размещения, реально применяемых для размещения Объектов в данном пуле. Ими
являются, соответственно, pg_num и
pgp_num.
Давайте рассмотрим pg_num и
pgp_num более подробно. Префикс pg
в pg_num является сокращением Групп размещения, в то время как
префикс pgp из pgp_num является
сокращением Групп размещения для их помещения (PGs for placement). Когда мы увеличиваем установленное значение
pg_num, некоторые или все имеющиеся PG разбиваются на множество
Групп размещение, и этот процесс мы называем расщеплением
(splitting). Некое меньшее инкрементальное увеличение в
pg_num будет иметь результатом то, что меньшее число имеющихся Групп
размещения подлежит расщеплению на множество новых PG. Если мы в точности удваиваем текущее значение
pg_num пула - помните, что мы строго предпочитаем степени 2 - все
имеющиеся Группы размещения расщепляются. Расщепление очень затратный процесс в FileStore OSD на основе XFS или
EXT4, поскольку оно требует от Ceph создания дополнительных каталогов во всех устройствах OSD для каждой
Группы размещения с последующим одновременным обновлением всех записей каталога
(dentries,
directory entries) обеих - существующей и новой -
Групп размещения во всём кластере.
Это может приводить в результате к некоторому отставанию занятых OSD при обработке обычного обмена пользователя,
что в свою очередь замедляет запросы. В большинстве случаев мы таким образом мы таким образом поэтапно увеличиваем
pg_num небольшими шагами со временем с тем, чтобы рассеять воздействие на свой
кластер и тем самым операции пользователя. Скажем, у нас есть некий кластер с единственным пулом
rbd, содержащим 4096 Групп размещения. Если при расширении или по
какой- то другой причине нам требуется увеличить общее число до 8192, мы можем выбрать поэтапное увеличение
pg_num и pgp_num шагами всего
лишь по 128 за раз, давая возможность своему кластеру выполнять выравнивание прежде чем переходить к следующему
этапу. Вы можете заметить, что это означает, что на какое- то время общее число групп размещения в данном
рассматриваемом пуле будет суб- оптимальным и не составлять степень 2, однако поскольку это временная ситуация,
мы можем допускать наличие несбалансированности пока мы не достигнем окончательного значения степени
2.
Для серверной основы с BlueStore, которая является устанавливаемой по умолчанию в выпуске Ceph Luminous, влияние расщепления большого числа Групп размещения в некотором пуле почти не будет составлять проблему. BlueStore хранит всё, включая данные и метаданные в некоторой базе данных ключ- значение, что позволяет избегать ограничений и накладных расходов некоторой файловой системы XFS. Все метаданные разбиваются на разделы во множество пространств имён базы данных, что эквивалентно некоторой таблице при хранении данных на основе SQL. Это включает метаданные Объекта, собрание метаданных, состояния, карту Объекта (omap, Object Map) и томк подобное. Группы размещения соответствуют коллекциям и, как следствие, расщепление некоторой Группы размещения будет относительно быстрой операцией, которая будет воздействовать только на части имеющейся коллекции пространства имён без воздействия на все прочие пространства имён метаданных или реальные данные объекта. Таким образом, оно становится относительно лёгкой операцией с минимальными накладными расходами, в отличии от имеющегося в настоящее время достаточно затратного процесса при использовании FileStore.
Установленное значение pg_num управляет тем сколько Групп размещения
из общего числа должно быть целью CRUSH для хранения данных; естественно,
pg_num на протяжении всего времени должно быть меньше чем или равно
pgp_num. Увеличение pgp_num
в результате приводит к нарушению баланса в распределении Групп размещения в данном пуле и данные будут
перемещаться в данном кластере. Чем больше данных данные Группы размещения содержат, тем больше потребуется
перемещать. По данной причине может оказаться лучшим оставаться в верхних значениях этих величин, отрегулировав
их как можно раньше для минимизации разрушений. Обычно, когда мы увеличиваем
pg_num, мы увеличиваем и pg_num
на то же самое значение в строгом соответствии. Важно помнить, что прежде чем изменять эти значения для некоторого
пула, что мы можем только увеличивать значение pg_num (и, тем самым,
pgp_num); мы не можем уменьшать их значения. Другими словами, мы можем
расщеплять Группы размещения, но мы не можем их сливать. FileStore Ceph является экспертом по расщеплению PG,
однако пока еще не имеется никакого механизма их слияния.
Давайте поупражняемся в регулировке этих значений в нашем кластере песочницы. Мы воспользуемся индивидуальным
пулом с названием my_pool, который мы создали в самом начале данной
главы:
root@ceph-client0:~# ceph osd pool get my_poolpg_num
pg_num: 64
root@ceph-client0:~# ceph osd pool get my_poolpgp_num
pgp_num: 64
Давайте сделаем оценку этих значений чтобы посмотреть являются ли подходящими. Мы будем применять ту же самую формулу, которую мы применяли ранее в своём разделе Вычисление Групп размещения ранее. Нам понадобится следующая информация:
-
Общее число OSD, применяемое для данного пула
-
Множитель репликаций в данном пуле
-
Гипотетическое значение соотношения PG : OSD
Мы можем увидеть общее число OSD в данном кластере равным 6, исполнив
следующую команду:
root@ceph-client0:~# ceph osd stat
osdmap e12577: 6 osds: 6 up, 6 in
flags sortbitwise,require_jewel_osds
У нас имеется итого шесть OSD (и, к счастью, все они являются in и
up). Так как это пример кластера PoC мы не должны разделять OSD между
различными пулами. Таким образом, мы можем рассматривать общее значение итогового числа OSD в своём кластере,
которое мы получаем из ceph osd stat, как применяемое исключительно для
своего пула. Это может не иметь место в вашем промышленном кластере в зависимости от того как вы его настроили.
Давайте определим какой множитель репликаций у нас установлен для данного пула.
root@ceph-client0:~# ceph osd pool get my_pool size
size: 3
Мы будем применять 3 в качестве множителя репликаций. Единственный оставшийся нам параметр это гипотетическое значение, которое нам необходимо определить для соотношения PG к OSD. Поскольку эти OSD исполняются на виртуальных машинах в эмулированных дисках, а это не особенно высокая скорость, мы выберем некое значение, равное 100, на данный момент. Итак, наш окончательный набор значений таков:
Число используемых этим пулом OSD |
|
Множитель репликаций данного пула |
|
Гипотетическое соотношение PG к OSD |
|
Подставляя формулу вычисления PG мы получаем:
(Общее число OSD * PGPperOSD)/ Множитель репликаций => Общее число PG
(6 * 100) /3 => 200
окгугл_вверх_до_степени2(200) => 256
Желательное нам число PG для данного пула, таким образом, равняется 256. Мы выбрали это значение не проверяя имеются ли другие пулы и, таким образом, не зная общего текущего значения соотношения PG к OSD. В нашем окружении песочницы, в котором мы проверяем манекены, это не имеет значения аналогичного тому, что имеется при промышленном использовании. На практике настоятельно рекомендуется исследовать все имеющиеся пулы и рассчитывать соотношение PG к OSD пержде чем принимать решение о наилучшем значении для какого- то нового пула. Однако теперь давайте настроим наш пул PoC:
root@ceph-client0:~# ceph osd pool set my_poolpg_num 256
set pool 1 pg_num to 256
root@ceph-client0:~# ceph osd pool set my_poolpgp_num 256
set pool 1 pgp_num to 256
Это всё! Ваш счётчик в вашем пуле (а следовательно и в вашем кластере) должен теперь увеличиться. Мы увеличили
значение счётчика Групп размещения непосредственно в его окончательное значение за один шаг так как эти операции
выполняются в кластере песочницы с очень малым объёмом данных и не существенным воздействием на пользователей.
В промышленной среде, однако, вам понадобится пройти к окончательному значению большим числом шагов, поступательно
увеличивая устанавливаемое значение на каждом шаге. Увеличение pg_num и
pgp_num сразу большим значением до их окончательных величин может
опрометчиво привести к интенсивным изменениям, что на время приведёт к деградации жизнеспособности и действий
клиентов пока все OSD не закрепятся. Выполните наблюдение жизнеспособности своего кластера прежде чем вы увеличите
pgp_num, а также следите чтобы pg_num
медленно и пошагово увеличивался в строгом соответствии до своего окончательного значения. Как и со всеми
прочими операциями сопровождения Ceph, в процессе расщепления Групп размещения предполагается выполнение
ceph -w или watch ceph status
в некотором выделенном окне для того, чтобы одним глазом следить за жизнеспособностью вашего кластера на
протяжении данного процесса. Если каждый этап сопровождается массивными перемещениями данных, или в особенности
медленными/ блокирующими запросами, это верный признак снизить значение такого шага.
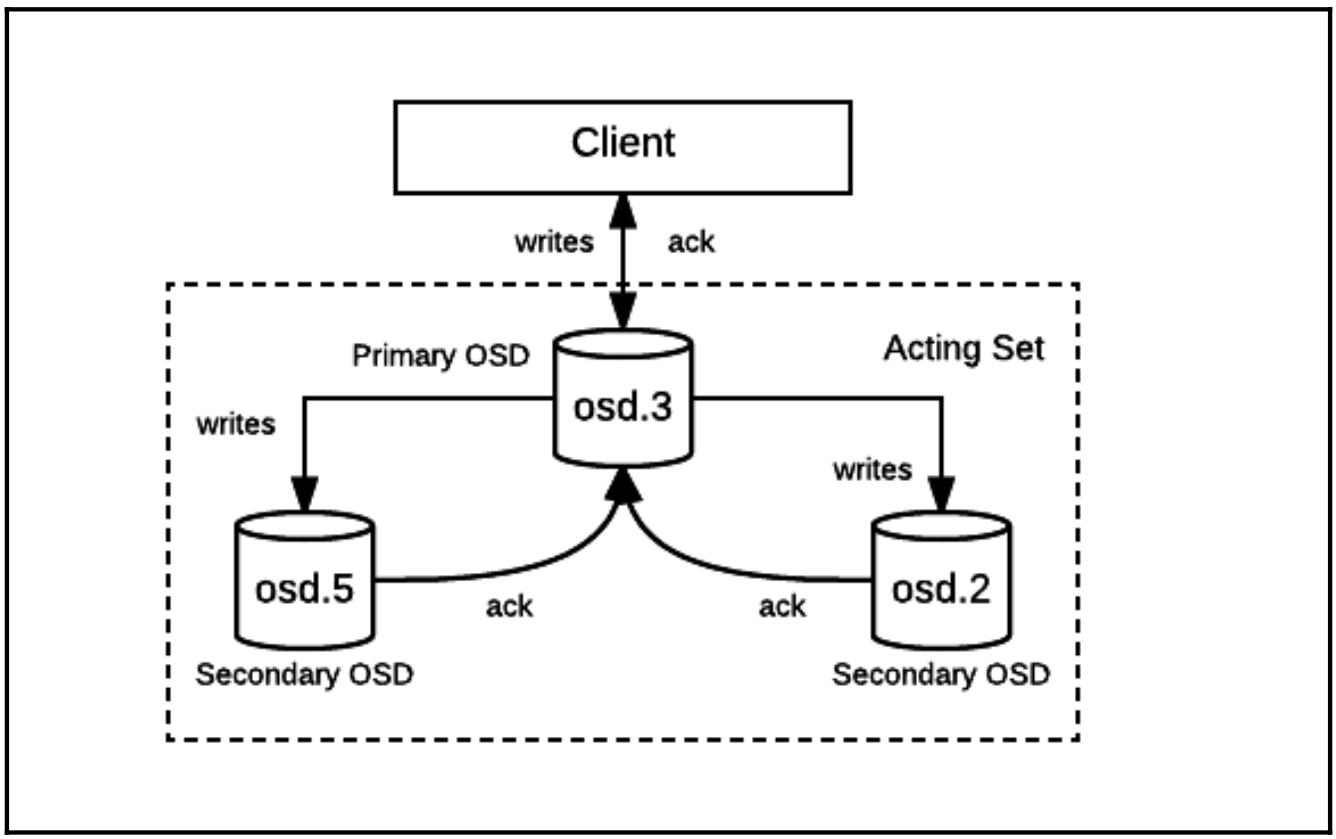
Запросы записи и чтения клиента выполняемые в отношении объектов RADOS со стороны клиента отправляются к
необходимой Группе размещения, к которой относится данный объект прежде чем остановится в OSD. Если установленный
множитель репликаций (обозначенный атрибутом size)
данного пула превышает 1, тогда записи должны продолжиться на множество OSD. Например,
при значении size пула равным 3 мы тогда должны иметь три копии каждого Объекта присутствующего в нашем пуле,
расщепляемых по 3 разъединённым OSD. Любая задача записи клиента таким образом должна быть завершена на всех трёх
OSD до того как этот клиент получит некое подтверждение. Каждая Группа размещения подразумевает один OSD
назначенный как свой первичный
(primary) или ведущий OSD. Все
дополнительные OSD, которые хранятся в данной Группе размещения называются
вторичными (secondary) в
контексте данной Группы размещения. Определённый первичным, этот OSD отвечает за обслуживание запросов клиента для
некоторой определённой Группы размещения и гарантирует успешное завершение записей на всех вторичных OSD прежде чем
ответит соответствующему клиенту. такой первичный OSDтакже ответственен за обслуживание всех чтений Объектов, которые
относятся к той Группе размещения, в которой он является первичным. Некий отдельный OSD может быть первичным для
множества Групп размещения и в то же время вторичным для прочих. Однако, в любой определённый момент времени,
каждой Группе размещения будет установлен только один первичный OSD. Тот OSD, который назначен в качестве первичного
для некоторой определённой Группы размещения, скорее всего, однако, не будет оставаться первичным для этой PG на
протяжении всего времени жизни. Событя, которые могут изменить некий первичный OSD Группы размещения таковы:
-
Добавление или удаление OSD на продолжительное время
-
Крушение OSD или хоста
-
Обновления или прочие сопроводительные работы Ceph
-
Расщепление Групп размещения
Первичный OSD для каждой Группы размещения отвечает за периодическое проведение операций проверки состояния, некого процесса, который мы именуем одноранговым обменом (peering). Одноранговый обмен является существенным при сопровождении необходимой согласованности содержимого каждой Группы размещения по всем его OSD. основная цель состоит в проверке того, что все нет ли в этой Группе размещения реплики, которая утратила необходимые данные или не полностью была охвачена изменениями. Одноранговый обмен упрощает восстановление от происшествий и изменений в кластере, позволяя данной системе надёжно выявлять несоответствия и помогает одноранговой Группе размещения отлавливать их и возвращаться в согласованное состояние. При некотором изменении топологии кластера, когда устройства или даже серверы целиком удаляются или добавляются, все OSD получают некую обновляемую карту кластера (также называемую картой CRUSH). Имеющийся алгоритм CRUSH способствует минимизации изменений в данной карте CRUSH, однако всякая Группа размещения, чьи соответствия OSD изменены потребует повторения одноранговых операций.
Если некий OSD удаляется и впоследствии добавляется в данный кластер - или даже оно остановлен на какое- то время - операции клиента могут за этот промежуток изменить содержимое той Группы размещения, которая его содержит. Имеющийся первичный OSD каждой Группы размещения в различное время опрашивает всю одноранговую сеть своей Группа размещения, отправляя в неё самую последнюю информацию, включающую самые последние обновления, границы регистрации Группы размещения и имеющуюся карту Эпох Группы размещения по которой они проводили последний одноранговый обмен. Некая Эпоха (epoch) является уникальным идентификатором для каждой версии карт Ceph, если пожелаете, некий логический временной штамп. Самое последнее значение некоторой Эпохи обычно обозначается каким- то префиксом, зависящим от различных типов карт кластера (имеются отдельные Эпохи для карты Групп размещения, карты Монитора, карты OSD, карты CRUSH и так далее) с целым значением на конце. При каждом изменении некоторой карты, значение его Эпохи инкрементально увеличивается. Применяя эту информацию о состоянии, каждый OSD создаёт некий перечень пропущенных фрагментов журнала для каждой реплики, самая последняя информация которой не соответствует имеющейся у первичного OSD. Затем он отправляет эти фрагменты OSD в одноранговой сети чтобы помочь каждой реплике приподняться, выполнив в фоновом режиме операции восстановления и при этом всё ещё обслуживать клиентов. Если все реплики некоторой Группы размещения уже подняты до необходимого уровня, тогда это помечается как некая новая Эпоха для данного успешного завершения однорангового обмена и следует далее.
Каждая Группа размещения имеет некий атрибут с названием
Acting Set (Набор действующих),
включающий в себя свой текущий первичный OSD и активные в настоящее время реплики. Этот набор OSD отвечает за
деятельное (actively) обслуживание ввода/ вывода в некий данный момент времени. При изменениях топологии
данного кластера некая Группа размещения может обновиться и занять другой набор OSD. Такой новый набор OSD
может перекрывать, а может и нет предыдущий набор, называемый определённым
Up Set (Набором поднятых) для
каждой Группы размещения. Такие OSD в Наборе поднятых отвечают за перенос данных со своего текущего OSD Набора
действующих, так как они теперь являются ответственными за то, чтобы данная Группа была отрегулирована. Когда
все данные становятся текущими {Прим. пер.: соответствующими Эпохе},
данный Набор действующих будет тем же самым что и Набор поднятых и сама Группа размещения должна пребывать
в некотором активном состоянии.
Тем самым эти наборы являются стабильными и идентичными большую часть времени пока класетр управляется с делами в своей обычной манере.
Каждой Группе размещения назначается некий набор состояний в любой определённый момент времени. При повседневных
операциях некая жизнеспособность Группы размещения отображается как active+clean.
Значение состояния active указывает, что эта Группа размещения не имеет проблем
с обслуживанием ввода/ вывода клиента, а clean подразумевает, что
она полностью соответствует прочим требованиям, включая распределение своих копий по достаточному числу устройств,
которое определено значением атрибута size для данного пула.
Некая неполадка или деградация Группы размещения обозначается каким- то изменением в её состояниях; например, она прекратила обслуживать ввод/ вывод, потеряла взаимодействие в своей одноранговой сети или имеет меньше требующихся копий своих объектов. Каждое состояние Групп размещения может содержать одно или более из описываемых здесь. Ceph предпринимает все зависящие от него усилия чтобы вернуть не жизнеспособную Группу размещения обратно к её состояниям жизнеспособности и повторной балансировки чтобы отвечать тем ограничениям, которые применяют к ней правила CRUSH.
Ниже мы обсудим некоторые важные состояния Групп размещения:
-
Active (Активная)
Данная Группа размещения помечена как активная когда завершены все необходимые одноранговые операции. Когда некая Группа размещения находится в активном состоянии, ввод/ вывод клиента должен происходить без проблем на её первичном и вторичных OSD.
-
Clean (Чистая)
Первичный и вторичные OSD успешно завершили одноранговый обмен и все Объекты реплицированы правильное число раз. Группа размещения также указывает на своё первоначальное местоположение и не пребывает ни в каком перемещении.
-
Peering (Одноранговый обмен)
Все OSD, которые размещают некую Группу размещения должны оставаться в некотором согласии текущего состояния всех своих Объектов. Одноранговый обмен является определённым процессом, приведения каждой Группы размещения в такое соответствие. Когда Одноранговый обмен завершён, соответствующий OSD помечает свои Группы размещения как
cleanили иными состояниями, сообщая если требуется восстанволение/ заполнение. -
Degraded (Деградировавшая)
Когда некий OSD помечается как отключённый, все назначенные на него Группы размещения помечаются как Деградировавшие. Когда этот OSD перезапускается, он обязан осуществить повторный одноранговый обмен чтобы вернуть деградировавшие Группы размещения в их Чистое состояние. Если такой OSD остаётся помеченным как остановленный на протяжении более 5 минут (установленное по умолчанию значение в Jewel), тогда он помечается как Отсоединён (out) и Ceph запускает восстановление всех Деградировавших Групп размещения. На некоторой Деградировавшей Группе размещения ввод/ вывод клиента может выполняться на протяжении всего времени пока она Активна. Группа размещения также может быть помечена как Деградировавшая когда Объекты внутри неё становятся недоступными или обнаружено в некоторой реплике разрушение втихую. Ceph инициирует восстановление из имеющейся авторитетной копии для таких объектов чтобы обеспечить их безопасность репликациями надлежащим количеством раз прежде чем пометит её как Чистую.
-
Stale (Несвежая)
Каждый OSD отвечает за периодические сообщения своим Мониторам самых последних данных статистик всех Групп размещения для которых он является первичным. Если по некоторой причине какой- то первичный OSD получил отказ в отправке такого отчёта Мониторам или если прочие OSD сообщают, что хи первичный OSD для некоторой Группы размещения Остановлен (down), такая Группа размещения немедленно будет помечена как Несвежая.
-
Undersized (Неполномерная)
Группы размещения, которая имеет меньше реплик, чем это определено атрибутом репликаций size пула помечаются как Неполномерные. Для Неполномерных Групп размещения инициируются восстановление и заполнение чтобы вернуть соответствующее число копий.
-
Scrubbing (Выскребание)
OSD отвечают за периодические проверки того, что их реплики не изменены в своём хранимом содержимом. Такой процесс Выскребания (scrubbing) гарантирует что контрольные суммы хранимых данных согласованы в одноранговых сетях. Состояние Выскребания применяется к Группам размещения когда они осуществляют такие проверки, которые именуются Лёгким выскребанием (light scrubs), Мелким выскребанием (shallow scrubs), или просто Выскребанием (scrubs). Группы размещения также подвергаются менее редкому Глубокому выскребанию (deep scrubs), которое сканирует все биты данных и проверяет соответствие всех реплик. Соответствующее множество состояний в Группах размещения на протяжении Глубокого выскребания устанавливается как
scrubbing+deep. -
Recovering (Восстановление)
При добавлении некоторого нового OSD в ваш кластер или когда некий имеющийся OSD становится Выключенным (down), Группы размещения завершаются с неким подмножеством OSD одноранговых сетей, которые имеют свой новый контекст пока оставшиеся не поднимутся до нужного уровня. Некая Группа размещения входит в состояние Восстановления чтобы приподнять все свои реплики с их OSD чтобы они имели самое последнее содержимое.
-
Backfilling (Наполнение)
Ceph уведомляется о необходимости повторной балансировки при добавлении новых OSD в имеющийся кластер. Он осуществляет такую операцию повторной балансировки перемещая некоторые Группы размещения с остальных OSD на вновь обретённые OSD в фоновом режиме. данная операция имеет название Наполнения (backfill). Когда повторная балансировка завершается на некотором OSD, он может принимать участие в операциях ввода/ вывода.
|
| Замечание |
|---|---|
|
Некий полный перечень состояний Групп размещения может быть найден по ссылке: http://docs.ceph.com/docs/master/rados/operations/pg-states/. |
Ceph является высоко распределённой системой хранения данных, разработанной не только для хранения массивных объёмов данных, но также и для гарантии надёжности, масштабируемости и производительности. Вместо построения ввода/ вывода, подлежащего исполнению исключительно блоками фиксированного размера, как обычные файловые системы, он предоставляет некий простой интерфейс для чтения и записи данных в элементах переменного размера, называемых объектами. Эти объекты затем реплицируются и распределяются по всему кластеру для предоставления действенного, переносящего отказы и одновременного доступа.
Распределение объектов по всему имеющемуся кластеру произвольным образом улучшает агрегированную производительность записи, но усложняет операции чтения. Как нам следует размещать объекты в кластере? Что нам даёт нам единообразное распределение невзирая на изменения в топологии? Что нам следует делать при умирании устройств или отказах хостов? Если мы передислоцируем данные в некое новое местоположение как клиенты будут узнавать об этом новом местоположении? В прошлом эти задачи решались посредством хранения некоего списка расположения всех Объектов, который обновляется при восстановлении объектов или их перемещении на какой- то новый сервер. Последующие чтения затем подкреплялись доступом к такому списку.
При таком подходе имеются определённые засады, в особенности список расположения, который одновременно выступает и в роли узкого места, и в качестве некоторой единой точки отказа. Более того, также сохраняются требования некоего алгоритма распределения, который оптимизирует глобальную балансировку местоположения при добавлении некоторого нового хранилища.
Перейдём к CRUSH! CRUSH ( Controlled Replication Under Scalable Hashing, Управляемые масштабируемым хешированием репликации) является алгоритмом псевдослучайного распределения данных, который оптимизирует размещение данных в гетерогенном кластере и обрабатывает намеренные (и не предумышленные) их изменения на протяжении времени жизни. Он не полагается ни на какую внешнюю индексацию метаданных для каждого Объекта или каталоги для построения маршрута чтения или записи. Вместо этого он усиливает иерархическое определение топологии всего кластера и детерминированную функцию, которая приводит соответствие значений на входе (название Объекта и множитель репликаций) для вычисления некоторого списка устройств, по которым будут сохранены объекты. Такое вычисление для определения местоположения каждого Объекта делает возможным повышение масштабирования и производительности Ceph за счёт децентрализации сведений о размещении, поскольку все клиенты могут независимо и самостоятельно вычислять местоположение каждого Объекта. Вся необходимая для вычисления местоположения Объекта информация извлекается из Ceph не часто (как правило, только когда изменяется топология кластера и эти изменения оказывают воздействие на Группы размещения для нашего Объекта), что минимизирует накладные расходы у клиентов.
Узлы Монитора (MON) Ceph хранят имеющееся состояние кластера в виде некоторого карты (map). Эта карта представлена устройствами и сегментами (buckets, корзинами). Каждому устройству и сегменту назначаются некие уникальный идентификатор и вес. Собранное множество устройств и сегментов называется определённой картой кластера или картой CRUSH. Сегменты являются иерархическими. Они содержат устройства или прочие сегменты, позволяя им взаимодействовать в качестве внутренних узлов в имеющейся иерархии хранения, причём устройства всегда выступают в роли листьев, а самый верхний сегмент во всей иерархии именуется корнем (root). По мере оснащения OSD, Ceph выделяет каждому OSD некий начальный вес, обычно основывающийся на значении ёмкости того устройства, в котором он располагается. Вес сегмента вычисляется как общая сумма всех весов всех внутренних сегментов или устройств, содержащихся в нём. Впоследствии администраторы могут выравнивать относительные веса устройств или сегментов по мере необходимости.
Имеющаяся карта CRUSH является известной топологией и настраивается пользователем. некий сегмент может быть ассоциирован с каким- то хостом, стойкой, коммутатором, PDU, помещением, центром обработки данных или любым типом компонентов. Типичным и полезным для конкретной топологии CRUSH представлять само физическое расположение компонентов кластера настолько точно, насколько это возможно, так как это позволяет Ceph оптимально выделять Группы размещения в имеющемся кластере для достижения RAS (Reliability, Availability, Serviceability - Надёжности, Доступности и Обслуживаемости). Поскольку сегменты все го лишь коллекции устройств и/ или прочих сегментов, имеется возможность построения некоторой карты CRUSH, которая не соответствует какой- то физической топологии, однако это не рекомендуется делать, только если вы на самом деле не знаете что вы делаете и несколько администраторов Ceph будут иметь какую- то причину для этого.
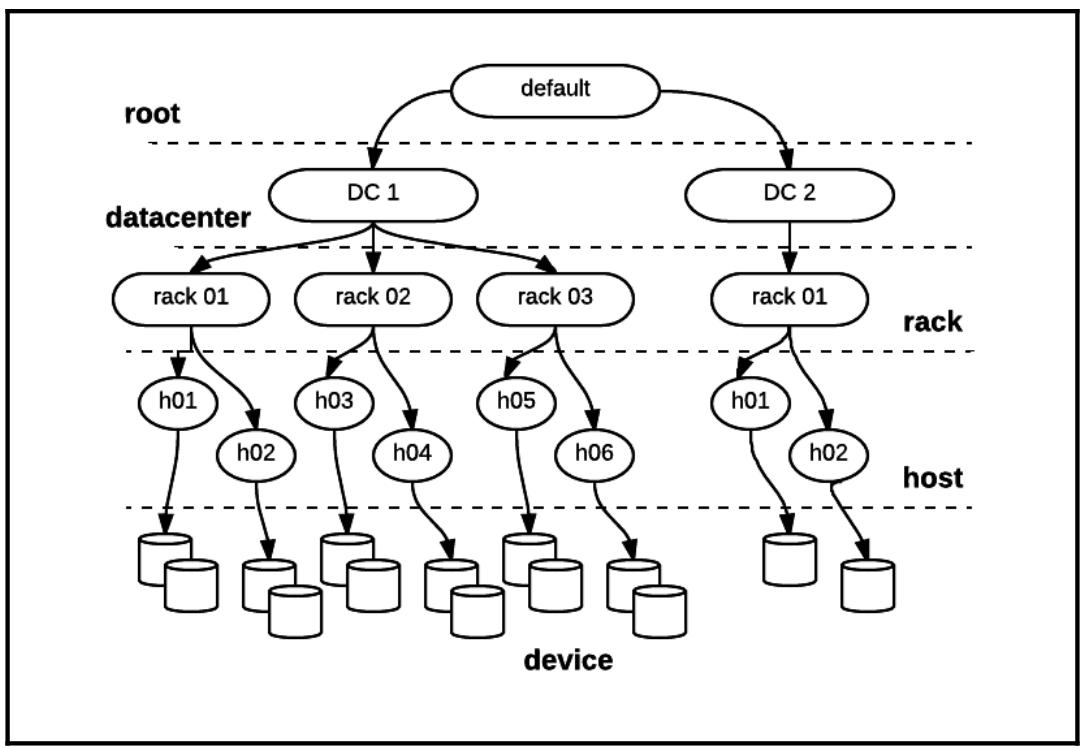
Такая карта CRUSH также содержит некий перечень правил, определяющие политики, которые обеспечат размещение реплик Объектов в их пуле чтобы обеспечить требуемые уровни долговечности и доступности данных. Администраторы могут определять эти правила для распространения реплик по множеству областей отказа (failure domains) или для принудительного применения прочих ограничений. Некая область отказа может быть чем- то, что вы полагаете уязвимым в вашей установке. Области отказов чаще всего являются предметом рассмотрения при планировании кластеров Ceph, причём они представляют целые узлы OSD или каждую логическую стойку. Если ваши стойки центра обработки данных являются предметом отказов электропитания (либо имеют некий единый коммутатор ToR, который может вызывать недоступность такой стойки целиком при останове) тогда вы должны также рассмотреть вопрос об исполнении некоторой области отказа для стойки.
Ваша установка может иметь множество областей отказа и вам следует планировать свои размещения реплик таким образом, чтобы вы никогда не помещали две копии в некую отдельную область отказа. Это означает, что если у вас имеется некий пул с множителем репликаций равным 3, вам придётся иметь по крайней мере 3 стойки (с множеством хостов в каждой), вам следует распределять свои данные таким образом, чтобы каждая копия находилась в различной стойке. Если у вас имеется менее 3 стоек, однако более 3 хостов, вам следует распределять свои копии по различным хостам. CRUSH попытается распределить Объекты по всему кластеру некоторым сбалансированным образом, причём все устройства делятся в пропорции, соответствующей их весам.
Каждый клиент, который намерен исполнять чтения или записи в имеющемся кластере, должен выполнять операцию просмотра с тем, чтобы знать где расположен такой объект запроса.
Если данный клиент не имеет какой- то текущей карты CRUSH, например при выполнении самой первой операции при новом исполнении, он соединяется с одним из имеющихся узлов мониторов кластера для запроса самой последней карты CRUSH. Эта карта содержит необходимые состояния, топологию и настройки всего кластера. Каждый объект исполняет некую быструю функцию хэширования, затем применяется некая битовая маска для обеспечения того, что диапазон данной функции сопоставления совпадает с ключевым пространством, определяемым имеющимся числом Групп размещения, в которые следует записывать данный Объект.
|
| Замечание |
|---|---|
|
Имена или идентификаторы (ID) Групп размещения таким образом всегда начинаются с определённого номера того пула, к которому они относятся. Это удобно при перемещении по состоянию, журналу и расследованиям Ceph и добавляет значимое содержимое, в особенности когда некий кластер содержит много пулов, например, для оснащения OpenStack и RGW. |
CRUSH снабжает нас неким определённым набором OSD на котором выстраивается соответствие каждой Группы размещения, включая назначение определённого первичного OSD, которому клиент и отправляет операции. Так как вычисление осуществляется целиком на самой стороне клиента, имеющийся кластер Ceph не требует своего вклада в них и не испытывает какого- либо воздействия на производительность, проистекающего из такого просмотра. Такой механизм децентрализации помогает правильному распараллеливанию и масштабированию кластеров Ceph для очень большого числа клиентов.
Когда какой- то компонент внутри некоторого кластера отказывает, будь то отдельное устройство OSD или некий
полный OSD хост, или даже ещё больший сегмент, например, стойка, Ceph ожидает некую небольшую отсрочку периода
прежде чем он пометит эти отказавшие OSD как Отсоединённое
(out). Данное состояние затем обновляется в имеющейся карте CRUSH.
Как только некий OSD помечен как Отсоединённый, Ceph инициирует действия восстановления. Такой период отсрочки
устанавливается имеющимся необязательным mon_osd_down_out_interval.conf,
настраиваемом в ceph.conf, значением по умолчанию которого является 300
секунд (5 минут). В процессе восстановления Ceph перемещает или копирует все данные, которые были на тех
устройствах OSD, которые отказали.
Поскольку CRUSH реплицирует данные на множество OSD, реплицированные копии выживают и считываются в процессе восстановления. По мере того, как CRUSH разрабатывает новое требуемое соответствие PG для OSD для заполнения имеющейся карты CRUSH, он минимизирует общий объём данных, которые должны быть перемещены в другие, всё ещё работающие хосты и устройства OSD для полного восстановления. Это помогает Деградировавшим Объектам (тем, которые утратили свои копии в результате отказа) и тем самым данный кластер как целое становится жизнеспособным вновь по мере того, как все запрошенные политикой правил CRUSH настройки восстановлены.
Как только добавляется новый диск в некий кластер Ceph, CRUSH запустит обновление состояния этого кластера, указав как получаемые новый местоположения Группы размещения должны произойти для всех имеющихся Групп размещения и перемещает такой новый диск в Набор поднятых (Up Set, а затем в Набор активных - Active Set) таких новых дисков. Когда некий диск добавляется заново в имеющийся Набор поднятых, Ceph запустит повторную балансировку данных на этом новом диске для тех Групп размещения, которым он предложен. Необходимые данные перемещаются с более старых хостов или дисков на наш новый диск. Операция повторной балансировки необходима для поддержания всех дисков в примерно равном использовании и тем самым в однородности размещения и рабочей нагрузки. Например, если некий кластер Ceph содержит 2000 OSD и в него добавляется какой- то новый сервер с 20 OSD, CRUSH попытается изменить местоположение только 1% всех Групп размещения. Для выдёргивания актуальных данных в свои собственные Группы размещения можно применять множество OSD, но при этом они будут работать одновременно чтобы быстрее переместить необходимые данные.
Для кластеров Ceph работающих с интенсивными нагрузками является первостепенно важным принять меры предосторожности перед добавлением новых дисков. Тот объём перемещения данных, который может вызвать новый диск или новый сервер находится в прямо пропорциональной зависимости от имеющегося процентного соотношения его веса CRUSH к имеющемуся первоначальному весу CRUSH остальной части всего кластера. Обычно для больших кластеров предпочтительной методологией добавления новых дисков или серверов является добавление их с весом CRUS равным нулю в имеющуюся карту CRUSH с постепенным увеличением их весов. Это позволит вам управлять текущей скоростью перемещения данных и проводить её ускорение или замедление в зависимости от вашего варианта применения и рабочих нагрузок. Другая методика, которой вы можете воспользоваться при добавлении новых серверов, заключается в том, что вы можете добавлять их в некий отдельный, макетный корень CRUSH когда вы оснащаете OSD в нём с тем, чтобы они не испытывали какого- либо ввода/ вывода даже несмотря на то, что в данном хосте выполняются процессы Ceph. А затем перемещаете эти серверы один за другим в соответствующие сегменты внутри того корня CRUSH, который применяют правила CRUSH вашего пула.
В данном разделе мы обсудим этапы настройки некоторой карты CRUSH для отражения локальных топологии и требований.
Ceph предоставляет нам два способа для обновления некоторой карты кластера CRUSH. Один состоит в выделении
текущей карты CRUSH в её двоичном виде, её декомпиляции в текст, изменения
полученного файла как и любого обычного, затем его компиляции и повторного внедрения. Во многих случаях, однако,
в имеющихся сегодня версиях Ceph мы можем применять подкоманды уже известной нам утилиты
ceph содержащей ceph osd crush
чтобы сделать изменения безопасным и намного более обычным образом. В данном разделе мы продемонстрируем оба
этих способа.
Для данного упражнения мы снова попрактикуемся в своём кластере песочницы, применяемом нами и ранее в этой главе. Если у вас нет некоторого рабочего кластера песочницы Ceph, пожалуйста, вернитесь к Главе 5, Развёртывание виртуального кластера песочницы для того чтобы настроить такой.
Давайте зарегистрируемся в нашей виртуальной машине, как мы это делали раньше.
$ vagrant ssh client0
vagrant@ceph-client0:~$sudo -i
root@ceph-client0:~#
Убедимся, что этот кластер жизнеспопосбен.
root@ceph-client0:~# ceph health
HEALTH_OK
Настройка карты CRUSH является необходимым этапом для построения некоторого устойчивого и надёжного кластера хранения Ceph. Установленные по умолчанию значения Ceph не осведомлены о вашей физической топологии и, следовательно, также не имеет информации о специфичных для вас областях отказа. Применяя данную методику в данном разделе мы снабдим Ceph информацией о вашей конфигурации, которая улучшит эластичность и поможет нам достичь оптимальной невосприимчивости к отказам.
Прежде чем изменять имеющуюся карту CRUSH, давайте исследуем текущую топологию.
root@ceph-client0:~# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.06235 root default
-2 0.02078 host ceph-osd1
6 0.01039 osd.6 up 1.00000 1.00000
10 0.01039 osd.10 up 1.00000 1.00000
-3 0.02078 host ceph-osd0
7 0.01039 osd.7 up 1.00000 1.00000
11 0.01039 osd.11 up 1.00000 1.00000
-4 0.02078 host ceph-osd2
8 0.01039 osd.8 up 1.00000 1.00000
9 0.01039 osd.9 up 1.00000 1.00000
По мере исполнения ceph osd tree мы видим, что наш кластер имеет шесть
OSD, три хоста и один корень. Эти шесть OSD именуются osd.6, osd.7, osd.8, osd.9, osd.10 и osd.11.
Ваш кластер песочницы может иметь другие номера или идентификаторы для OSD, что всего лишь Смурфами - помните,
что Ceph назначает вновь создаваемым OSD самый первый неиспользуемый номер, что может изменяться со временем,
так как OSD и хосты проходят свои жизненные циклы. Мы видим, что наши три хоста имеют названия
ceph-osd0, ceph-osd1 и
ceph-osd2. Наш корневой сегмент, который охватывает все три хоста
умно именуется как default.
Теперь давайте добавим три виртуальных стойки в своей карте CRUSH. Представим что каждый наши хосты расположены в некоторой собственной стойке., что мы хотим отразить в своей логической топологии CRUSH. Поскольку наш кластер песочницы (и следовательно в нашем центре обработки данных) исполняется в единой машине хоста, мы обладаем возможностью растягивать границы своего воображения когда дело доходит до проектирования нашего макета. При работе с промышленной оснасткой настоятельно рекомендуется располагать карту CRUSH таким образом, чтобы она максимально точно моделировала ваши физические аппаратные средства.
root@ceph-client0:~# ceph osd crush add-bucket rack01 rack
added bucket rack01 type rack to crush map
root@ceph-client0:~# ceph osd crush add-bucket rack02 rack
added bucket rack02 type rack to crush map
root@ceph-client0:~# ceph osd crush add-bucket rack03 rack
added bucket rack03 type rack to crush map
Три приведённые выше команды создадут три новых сегмента с типом
rack. Важно отметить, что эти стойки изначально не будут в самом корне
default, а вместо этого плавают в темноте и одиночестве забвения
эфира CRUSH. Они не будут размещать какие- либо данные, пока они не будут перемещены в установленный по
умолчанию корень.
Мы увидим вновь полученную топологию выполнив снова ceph osd tree.
root@ceph-client0:~# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-7 0 rack rack03
-6 0 rack rack02
-5 0 rack rack01
-1 0.06235 root default
-2 0.02078 host ceph-osd1
6 0.01039 osd.6 up 1.00000 1.00000
10 0.01039 osd.10 up 1.00000 1.00000
-3 0.02078 host ceph-osd0
7 0.01039 osd.7 up 1.00000 1.00000
11 0.01039 osd.11 up 1.00000 1.00000
-4 0.02078 host ceph-osd2
8 0.01039 osd.8 up 1.00000 1.00000
9 0.01039 osd.9 up 1.00000 1.00000
Мы можем видеть свои новые логические стойки собранными в кластер в самой вершине, как и ожидалось, за
пределами имеющегося корня. Теперб давайте переместим их из небытия в свой имеющийся корень
default. Однако, прежде чем мы переместим их, мы проверим, что их
вес CRUSH изменён на значение 0. Если их вес CRUSH окажется не нулевым, тогда Ceph попытается расположить
в них Группы размещения, что не будет работать, так как они пока ещё не содержат никакие устройства OSD, а
состояние нашего кластера будет Деградировано. В отслеживании приведённых выше команд мы легко можем
обнаружить в своей второй колонке (именуемой WIEGHT) что их вес CRUSH, тем не менее 0. Воспользуйтесь
приводимой далее командой чтобы теперь переместить их в их верное местоположение в имеющейся иерархии
CRUSH.
root@ceph-client0:~# ceph osd crush move rack01 root=default
moved item id -5 name 'rack01' to location {root=default} in crush
map
root@ceph-client0:~# ceph osd crush move rack02 root=default
moved item id -6 name 'rack02' to location {root=default} in crush
map
root@ceph-client0:~# ceph osd crush move rack03 root=default
moved item id -7 name 'rack03' to location {root=default} in crush
map
Если наш кластер находился в жизнеспособном состоянии когда мы начинали этот процесс, то он должен оставаться в нём также и сейчас. Это происходит по той причине, что мы пока не сделали ничего, что может вызвать какое бы то ни было перемещение данных. В качестве окончательного шага давайте перейдём к перемещению своих новых хостов в их соответствующие стойки.
Это потенциально приведёт к перемещению данных, поэтому в промышленном исполнении эти шаги должны исполняться последовательно и тщательно. Однако, поскольку мы всё это делаем в слабо нагруженном окружении песочницы, вы можем безопасно выполнить их все за один раз.
root@ceph-client0:~# ceph osd crush move ceph-osd0 rack=rack01
moved item id -3 name 'ceph-osd0' to location {rack=rack01} in
crush map
root@ceph-client0:~# ceph osd crush move ceph-osd1 rack=rack02
moved item id -2 name 'ceph-osd1' to location {rack=rack02} in
crush map
root@ceph-client0:~# ceph osd crush move ceph-osd2 rack=rack03
moved item id -4 name 'ceph-osd2' to location {rack=rack03} in
crush map
Данное действие на время Деградирует ваш кластер, поскольку имеющаяся карта CRUSH обновляется и выполняется выравнивание распределения Групп размещения. Данные в определённых Группах размещения могут на очень короткое время стать недоступными, но не должно произойти никакой утраты данных, а общая обычная работа восстановится достаточно быстро, так что пользователи даже и не заметят. Тем не менее, данные операции очень редкие в случае находящегося в промышленном применении кластера. После того, как все необходимые перемещения копий Объектов сместят их в их новые местоположения, данный кластер обязан вернуться в своё жизнеспособное состояние.
Критически важно отметить здесь, что мы не должны исполнять в обратном порядке самые последние два этапа. Если мы мы должны переместить эти хосты в свои первичные стойки, прежде чем эти стойки разместятся в том же самом корне, все наши Группы размещения были должны стать неактивными. Это привело бы не только к тому что все имеющиеся данные кластера стали бы недоступными клиентам, однако это потенциально могло бы ввергнуть утрату данных если бы наш кластер оставался в таком неудачном состоянии длительное время. Крайне важно, чтобы всякое перемещение, которое мы исполняем в некотором промышленном кластере непустых хостов или стоек всегда осуществлялось в их текущем корневом каталоге CRUSH.
Теперь мы переместили все хосты в наши новые виртуальные стойки, давайте проверим свой новый расклад:
root@ceph-client0:~# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.06235 root default
-5 0.02078 rack rack01
-3 0.02078 host ceph-osd0
7 0.01039 osd.7 up 1.00000 1.00000
11 0.01039 osd.11 up 1.00000 1.00000
-6 0.02078 rack rack02
-2 0.02078 host ceph-osd1
6 0.01039 osd.6 up 1.00000 1.00000
10 0.01039 osd.10 up 1.00000 1.00000
-7 0.02078 rack rack03
-4 0.02078 host ceph-osd2
8 0.01039 osd.8 up 1.00000 1.00000
9 0.01039 osd.9 up 1.00000 1.00000
Устройства внутри хостов, находящихся в стойках, которые в нашем корне. Отлично!
Теперь давайте исследуем нашу новую схему чтобы спроектировать улучшенную устойчивость к отказам, доступность и долговечность для хранимых в нашем кластере данных. По умолчанию, при создании некоторого пула с репликациями (в противоположность удаляющему кодированию), Ceph усилит такое распределение имеющимися копиями по разъединённым OSD. Распределение данных по любым хостам, стойкам, рядам и т.п. не будет соблюдаться. Таким образом, если у нас имеется некий пул с множителем репликаций (size) 2, обе копии некоторого объекта будут назначены двум различным OSD, обнаруженным в одном и том же хосте. Это означает, что отках хоста или прочий простой не только предотвратит доступ ко всем объектам вмести со всеми копиями на этом хосте, но потенциально, если такой сбой серьёзный, мы можем в конечном счёте и вовсе утратить данные. Другими словами, не кладите все свои данные в одну корзину (или сегмент).
Однако мы с лёгкостью можем предотвратить данный нежелательный сценарий, подогнав свою карту CRUSH к локальным топологии и требованиям. CRUSH предлагает гибкие возможности, которые позволяют нам переписать назначенное по умолчанию распределение, определив правила для размещения копий в своём кластере. Мы можем выбрать непосредственно каждую копию в некотором отдельном хосте или даже в отдельной стойке в зависимости от своих целей надёжности и производительности. В расширенных сложных сценариях мы можем также снабжать данные определёнными хостами или стойками для определённых целей.
Далее мы изменим определённую по умолчанию стратегию размещения в своём кластере Ceph песочницы чтобы строго распределять реплики Объектов по воображаемым новым стойкам, которые мы с помощью магии вообразили себе и установили в кратчайшие сроки в своём предыдущем упражнении.
Мы начнём вначале с извлечения своей карты CRUSH из имеющихся Мониторов.
root@ceph-client0:~# ceph osd getcrushmap -o /tmp/crushmap.bin
got crush map from osdmap epoch 1234
Приведённая выше команда соединяется с имеющимися в кластере Мониторами, выгружает имеющуюся карту CRUSH
в двоичном виде и сохраняет её в каталоге /tmp.
Полученное двоичное представление карты CRUSH является естественным для кода Ceph, однако не воспринимается человеком, поэтому давайте преобразуем её в текстовый вид с тем, чтобы мы смогли посмотреть на неё в качестве примера и легко изменить.
root@ceph-client0:~# crushtool -d /tmp/crushmap.bin -o
/tmp/crushmap.txt
Данная карта CRUSH теперь представлена в некотором виде, который мы можем открывать в своём любимом
текстовом редакторе. Модифицируйте полученный файл с названием /tmp/crushmap.txt
и переместитесь в самый конец данного файла. Самые последние строки должны выглядеть примерно так, как это
показано ниже.
# rules
rule replicated_ruleset {
ruleset 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaffirstn 0 type host
step emit
}
Данный раздел содержит правила CRUSH. Некая карта CRUSH может иметь множество правил CRUSH, хотя в любой определённый момент времени только одно правило может быть применено к каждому пулу Ceph. Мы поясним все компоненты этих правил ниже:
-
Данное правило имеет название
replicated_ruleset. За названием следует далее само правило в фигурных скобках, которые ограничивают его реальное определение. -
Самым первым полем в данном правиле является идентификатор набора правил. Это конкретный номер, который сохраняется в качестве атрибута
crush_rulesetдля любого пула, к которому применяется данное правило. Мы можем видеть, что нашеreplicated_rulesetимеет идентификатор набора правил, установленный в значение 0. -
Данное правило имеет тип
replicated. В настоящее время Ceph поддерживает два типа правил:replicatedиerasure-coded. -
Установки
min_sizeиmax_sizeопределяют минимальный и максимальный множители которые могут быть установлены в пулах, к которым применяется данное правило. Это делает возможной гибкость при настройке множества пулов с различными характеристиками внутри некоторого отдельного кластера. Отметим, что значениеmin_sizeздесь отличается от значения атрибутаmin_sizeв самом пуле; данный термин, к сожалению, перегружен и его легко спутать. -
Директива
stepопределяет последовательность этапов, для следования при выборе соотвествующего сегмента (стойки, хоста, OSD и т.п.) для нашего объекта. Самые последние три строки в имеющемся по умолчанию правиле определяют следующую последовательность:-
Вначале мы выбираем свой корень
defaultи следуем вниз по его дереву топологии. Все копии объектов будут отправлены только в этот корень. -
Затем мы выбираем некий набор сегментов с типом
hostи помечаем некий узел листа, которым является устройство OSD, в имеющемся поддереве каждого из них. Общее число сегментов в данном наборе обычно является самими множителем репликации в данном пуле. -
Правило
firstnопределяет сколько копий некоторого Объекта мы можем выбирать при жадном подходе для отправления в один и тот же сегмент. Поскольку это значение установлено в 0, а мы на самом деле находимся в листовом узле, будет возможно указывать только единственный хост для копии. -
Окончательный шаг
emitзавершает данный процесс и освобождает полученный стек.
-
Чтобы распределять по одной копии на стойку, как мы предложили в качестве предпочтения в Главе 4, Планирование вашего развёртывания, нам необходимо изменить вторую из последних строк чтобы она имела вид:
step chooseleaffirstn 0 type host
А также заменим host на rack:
step chooseleaffirstn 0 type rack
Мы обеспечим, что нашим выбором в качестве листа будет стойка для распределения наших копий и соответствующие OSD внутри некотрой стойки могут указываться случайным образом (по модулю их весов) для равномерного применения в рамках данной стойки.
Давайте внесём эти изменения в свой файл с тем, чтобы наш replicated_ruleset
выглядел следующим образом:
# rules
rule replicated_ruleset {
ruleset 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaffirstn 0 type rack
step emit
}
Теперь сохраним этот файл и выйдем. Мы скомпилируем этот файл в его двоичное представление и отправим обратно, ограниченным должным образом, в свои Мониторы Ceph, откуда он был получен.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Отметим: Всё это временно деградирует наш кластер. Знайте, что всякий раз, когда вы вносите изменения в нашу карту CRUSH, всегда потенциально имеется возможность понести перемещения данных в размере от небольших до массовых и это воздействует на работу клиентов с вводом/ выводом. В идеале такие изменения следует исполнять в окнах сопровождения или в часы отключения. |
root@ceph-client0:~# crushtool -c /tmp/crushmap.txt -o
/tmp/crushmap.bin
root@ceph-client0:~# ceph osd setcrushmap -i /tmp/crushmap.bin
set crush map
Ваш кластер на короткий промежуток времени выдаст сообщение о деградации, однако в скорости вернётся в жизнеспособное состояние. Это завершает окончательный шаг изменения вручную имеющейся настройки CRUSH.
Понятие пулов не является новым в системах хранения. Корпоративные
системы хранения часто делятся на несколько пулов для удобства управления. Некий пул Ceph является логическим
разделом Групп размещения и расширений Объектов. Каждый пул в Ceph содержит ряд Групп размещения, которые в
свою очередь содержат некоторое число Объектов, которым ставятся в соответствие OSD из данного кластера. Такое
распределение по узлам кластера помогает гарантировать необходимый уровень RAS. В предшествующих Luminous
версиях, начальная оснастка Ceph создавала по умолчанию некий пул с названием
rbd; в Luminous и последующих версиях вам понадобится создавать его
своими руками, если вы планируете предоставлять блочные службы. Этого может не хватать для всех вариантов
применения и рекомендуется создавать ваши собственные когда они необходимы. Развёртывание RGW или CephFS
для вашего кластера создаст требующиеся пулы автоматически.
Некий пул обеспечивает доступность данных определяя и поддерживая желательное число копий каждого объекта. Сам тип пула (с репликациями или с удаляющим кодированием) определяет сколько копий объектов будет сопровождаться. Ceph поддерживает стратегии Удаляющего кодирования (EC, Erasure Coding), которые делают возможной эластичность и устойчивость к отказам данных, разбивая данные на участки и сохраняя их распределённым образом с уже готовой избыточностью.
На момент создания пула мы определяем множитель репликаций (или size) данного пула; значением по умолчанию является 3. Пул с репликациями очень гибок и установленный множитель репликаций может быть изменён в любой момент. Однако, увеличение множителя репликаций немедленно обновляет Группы размещения чтобы сделать новые копии всех Объектов внутри имеющегося кластера. Это может быть достаточно затратным в зависимости от текущего размера кластера и его используемости, так что планировать такое действие следует со всей тщательностью. Некий пул также может применять удаляющее кодирование. Оно предоставляет меньшую гибкость в сравнении с реплицируемыми пулами, поскольку общее число копий данных в рамках пула с удаляющим кодированием не может изменяться с такой гибкостью. Для изменения стратегии EC необходимо предоставить какой- то новый пул с желаемым профилем EC и переместить данные, вместо того чтобы проводить обновление на месте, которое можно делать в любом пуле с репликациями.
Некий пул Ceph определяется соответствующим образом наборами правил CRUSH при записи данных. Имеющийся набор правил CRUSH управляет размещением реплик Объекта внутри данного кластера. Такой набор правил делает возможным изощрённое поведение пулов Ceph. Например, имеется возможность создания некоторого быстрого пула кэширования из устройств SSD или NVMe, либо гибридых пулов, смешивающих SSD с дисковыми устройствами SAS или SATA. При аккуратном планировании можно даже создать некий пул в котором ведущие OSD размещены на устройствах SSD для быстрых чтений в то время как реплики безопасности расположены на менее затратных устройствах HDD. {Прим. пер.: но, с точки зрения сложности сопровождения рекомендуем добиваться преследуемых таким подходом целей всё- таки кэширующими пулами.}
Пулы Ceph также поддерживают функциональность моментальных снимков (snapshot). Мы можем воспользоваться
ceph osd pool mksnap чтобы выполнить некий моментальный снимок некоторого
пула целиком в одной операции. Мы также можем восстановить некий пул целиком в случае такой необходимости.
Пулы Ceph также позволяют нам устанавливать владельцев и полномочия доступа к Объектам. Некий идентификатор
пользователя может быть установлен как текущий владелец данного пула. Это очень полезно в сценариях, при которых
нам требуется ограничивать доступ к определённым пулам.
Действия c пулом Ceph являются одними из повседневных задач любого администратора Ceph. Ceph предоставляет богатый инструментарий CLI для создания пула и управления им. Мы изучим действия с пулами в своём следующем разделе.
При создании некоторого пула Ceph мы обязаны определить некоторое название, количество Групп размещения и
тип пула: либо replicated, либо
erasure-coded. Мы начнём с создания пула с репликациями. Мы не будем
определять тип, так как значение replicated установлено применяемым по
умолчанию. В данном упражнении мы опять применим свой кластер проверок песочницы.
-
Создайте некий пул с названием
web-servicesи со значениемpg_numравным 128. Значениеpgp_numпула установлено чтобы в явном виде соответствовать нашему определённомуpg_num.root@ceph-client0:~# ceph osd pool create web-services 128 pool 'web-services' created -
Вывод перечня пулов может быть осуществлён тремя способами. Первые два списка выдают только сами названия данных пулов, в то время как третий отображает больше информации, включая численное значение идентификатора пула, множитель репликации, набор правил CRUSH и счётчик Групп размещения.
root@ceph-client0:~# ceph osd lspools 1 rbd,2 my_pool,3 web-services root@ceph-client0:~# rados lspools rbd my_pool web-services root@ceph-client0:~# ceph osd pool ls detail pool 1 'rbd' replicated size 3 min_size 2 crush_ruleset 0 object_hashrjenkinspg_num 64 pgp_num 64 last_change 5205 flags hashpspoolstripe_width 0 pool 2 'my_pool' replicated size 3 min_size 2 crush_ruleset 0 object_hashrjenkinspg_num 256 pgp_num 256 last_change 12580 flags hashpspoolstripe_width 0 pool 3 'web-services' replicated size 3 min_size 2 crush_ruleset 0 object_hashrjenkinspg_num 128 pgp_num 128 last_change 12656 flags hashpspoolstripe_width 0 -
Установленный size репликаций по умолчанию равен 3 при его создании в Ceph Jewel. Это значение также является устанавливаемым по умолчанию значением для выпуска Luminous. В случае необходимости мы можем изменить установленный множитель репликаций применив приводимую ниже команду. Помните, что хотя мы можем избежать этого в данном случае с песочницей, однако в промышленной реализации это повлекло бы в результате к значительным перемещениям данных, что может противоречить действиям клиентов и перегружать их.
root@ceph-client0:~#ceph osd pool set web-services size 3 set pool 3 size to 3 -
Наш Ведущий проектировщик требует различных названий для наших пулов, поэтому мы переименуем его.
root@ceph-client0:~# ceph osd pool rename web-services frontendservices pool 'web-services' renamed to 'frontend-services' root@ceph-client0:~# rados lspools rbd my_pool frontend-services -
Пулы Ceph поддерживают моментальные снимки. Мы можем восстанавливать Объекты из некоторого моментального снимка в случае сбоев. В приводимом ниже примере мы создадим некий Объект, затем выполним моментальный снимок данного пула. Затем мы осуществим удаление данного объекта из текущего пула и после этого восстановим этот удалённый из нашего пула объект.
root@ceph-client0:~# echo "somedata" > object01.txt root@ceph-client0:~# rados -p frontend-services put object01 object01.txt root@ceph-client0:~# rados -p frontend-services ls object01 root@ceph-client0:~# rados mksnap snapshot01 -p frontend-services created pool frontend-services snap snapshot01 root@ceph-client0:~# rados lssnap -p frontend-services 1 snapshot01 2017.09.04 18:02:24 1 snaps root@ceph-client0:~# rados -p frontend-services rm object01 root@ceph-client0:~# rados -p frontend-services listsnaps object01 object01: cloneid snaps size overlap 1 1 9 [] root@ceph-client0:~# rados rollback -p frontend-services object01 snapshot01 rolled back pool frontend-services to snapshot snapshot01 root@ceph-client0:~# rados -p frontend-services ls object01 -
Удаление некоторого пула также удаляет и все его моментальные снимки. После окончательного удаления какого- то пула будет неплохо попрактиковаться с удалением любых связанных индивидуальных наборов праил CRUSH если мы не желаем повторно применять их. Если вы создадите пользователей с полномочиями исключительно для некоторого пула и ни для чего более, вы можете удалить их впоследствии.
root@ceph-client0:~# ceph osd pool delete frontend-services frontend-services —yes-i-really-really-mean-it pool 'frontend-services' removed
Управление данными по мере их прохождения в кластере Ceph включает в себя все обсуждавшиеся нами до сих пор
компоненты. Координация этих компонентов вооружает Ceph на предоставление некоторой надёжной и устойчивой
системы хранения. Управление данными начинается с записи клиентами данных в пулы. Когда клиент пишет данные в
некий пул Ceph, эти данные отправляются в свой первичный OSD. Этот первичный OSD фиксирует полученные данные
локально и немедленно отправляет подтверждение своему клиенту если множитель репликаций равен 1. Если установлено
значение репликаций более 1 (как это должно быть в любой серьёзной оснастке), данный первичный OSD выполняет
операцию записи subops во все дочерние (вторичный, третичный и так далее)
OSD и ожидает отклика. Так как у нас всегда имеется только один первичный OSD, общее число дочерних OSD равняется
множителю репликаций минус 1. Когда все отклики собраны, в зависимости от их успешности, он отправляет
подтверждение (или отказ) обратно своему клиенту.
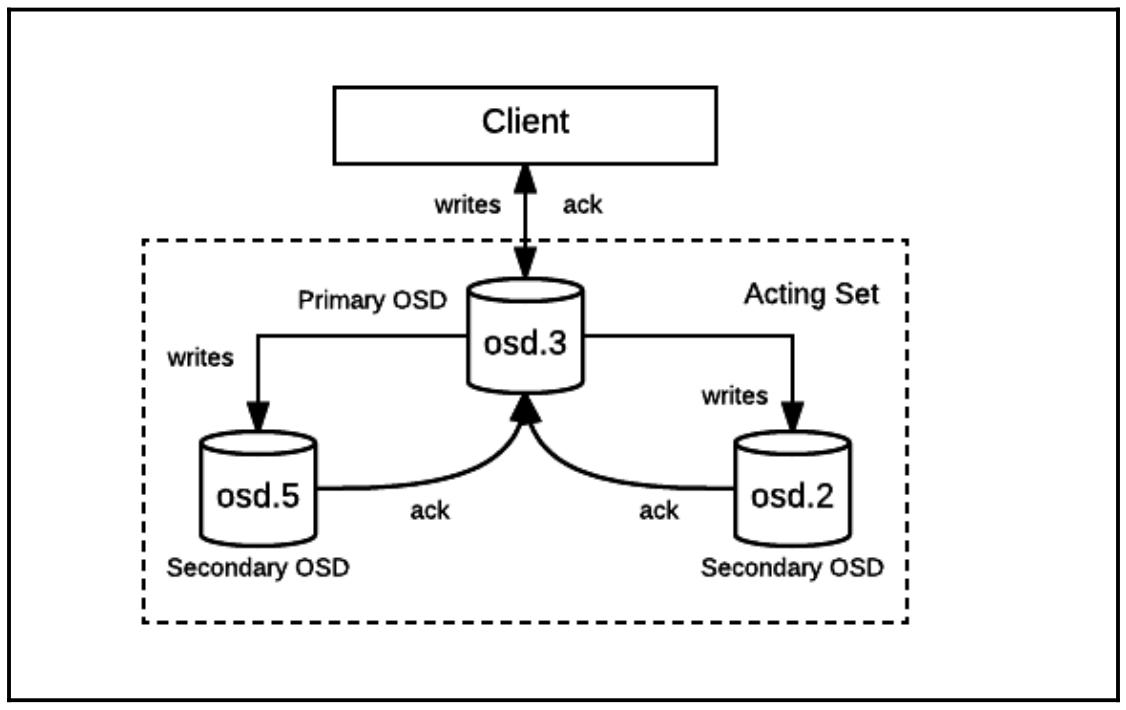
Тем самым, Ceph тщательно сохраняет все операции записи каждого клиента чтобы гарантировать строгую согласованность между репликами. Давайте рассмотри как все данные на самом деле сохраняются в некотором кластере Ceph.
-
Мы создадим некий тестовый файл, а также пул, и установим его множитель репликаций равным 3.
root@ceph-client0:~# echo "Ceph, you are awesome!" > /tmp/helloceph root@ceph-client0:~# cepho osd pool create HPC_Pool 128 128 pool 'HPC_Pool' created root@ceph-client0:~# ceph osd pool set HPC_Pool size 3 set pool 4 size to 3 -
Теперь давайте сохраним этот созданный нами в данном пуле файл тестовых данных и проверим содержимое данного пула.
root@ceph-client0:~# rados -p HPC_Pool put object1 /tmp/helloceph root@ceph-client0:~# rados -p HPC_Pool ls object1 -
Данный файл теперь сохранён в некотором пуле Ceph. Как вы уже видели, всё в Ceph сохраняется в виде объектов, причём каждый Объект относится к некоей уникальной Группе размещения, которая указывает на один или более OSD. Теперь давайте рассмотрим как в реальности данное соответствие выглядит изнутри Ceph:
root@ceph-client0:~# ceph osd map HPC_Pool object1 osdmap e12664 pool 'HPC_Pool' (4) object 'object1' -> pg4.bac5debc (4.3c) -> up ([8,7,6], p8) acting ([8,7,6], p8Давайте обсудим полученный вывод приводимой выше команды:
-
osdmap e12664: Этим определяется идентификатор версии карты данного OSD, указывающий, что мы находимся в 12664-й Эпохе. Эпохи последовательно монотонно увеличиваются при любых изменениях карты OSD. -
pool 'HPC_Pool' (4): Название пула Ceph с его идентификатором в круглых скобках. -
object 'object1': Содержит само название данного Объекта. -
pg4.bac5debc (4.3c): Содержит короткую и длинную формы идентификаторов той Группы размещения, к которой относится object1. В большинстве случаев применяется короткая форма, т.е. 4.3c . -
up ([8,7,6], p8): Отображает текущий Набор поднятых OSD, которые содержат ту Группу размещения, к которой относится данный Объект (и, тем самым, object1). При установкеsizeнашего пула равным 3, данные реплицируются в три OSD:osd.8,osd.7иosd.6. Значениеp8сообщает, что первичным, или ведущим OSD для данной Группы размещения являетсяosd.8. -
acting ([8,7,6], p8): Отображает Множество активных, совместно с имеющимся первичным, или ведущим, OSD для данной Группы размещения. Мы отмечаем, что в нашем случае Множество активных в точности совпадает со Множеством поднятых. Это может быть не всегда верным, в особенности, когда наш кластер находится в состоянии наполнения/ восстановления и некоторые Группы размещения пребывают в очереди на передислокацию.
-
-
Чтобы посмотреть как данный объект возникнет в FileStore, давайте отыщем сам физический хост нашего первичного OSD. Мы должны применить команду
ceph osd find <osd-id>чтобы получить значение родительского сегмента данного OSD:root@ceph-client0:~# ceph osd find 8 { "osd": 8, "ip": "192.168.42.102:6802\/3515", "crush_location": { "host": "ceph-osd2", "rack": "rack03", "root": "default" } }Данный OSD расположен в хосте
ceph-osd2, который обнаруживается вrack03. -
Давайте зарегистрируемся в хосте
ceph-osd2. Чтобы выполнить это, нам необходимо выйти из своей виртуальной машины клиента и зарегистрироваться опять в нашей машине хоста.root@ceph-client0:~# logout vagrant@ceph-client0:~$ exit Connection to 127.0.0.1 closed. $ vagrant ssh osd2 vagrant@ceph-osd2:~$ sudo -i root@ceph-osd2:~# -
Давайте определим где расположен наш каталог данных Ceph из полного перечня наших монтирований файловой системы. Затем мы сможем перепрыгнуть и обнаружить свой объект. Помните идентификатор Группы размещения, который мы обнаружили в своей команде
ceph osd mapранее (им был 4.3c)? Он нам сейчас понадобится. Ниже приведена та последовательность шагов, которая позволит это осуществить:root@ceph-osd2:~# df -h | grep ceph-8 /dev/sdb1 11G 84M 11G 1% /var/lib/ceph/osd/ceph-8 root@ceph-osd2:~# cd /var/lib/ceph/osd/ceph-8/current/ root@ceph-osd2:/var/lib/ceph/osd/ceph-8/current# cd 4.3c_head root@ceph-osd2:/var/lib/ceph/osd/ceph-8/current/4.3c_head# ls -l total 4 -rw-r—r— 1 cephceph 0 Sep 4 18:20 __head_0000003C__10 -rw-r—r— 1 cephceph 36 Sep 4 18:22 object1__head_BAC5DEBC__10Мы можем видеть, что нош искомый
object1сохранён в каком- то файле с префиксом из нашего объекта.
BlueStore (некое существенное расширение FileStore) поддерживается и является устанавливаемым по умолчанию в выпуске Luminous Ceph. При этом объекты BlueStore не хранятся в виде файлов в некоторой обычной файловой системе Unix/ Linux, а вместо того они сохраняются внутри встроенной базы данных, которая эксплуатирует каждое блочное устройство OSD напрямую. Это является непосредственным аналогом традиционных возможностей реляционных баз данных относительно использования сырых разделов для хранения таблиц вместо файлов в файловой системе, или тот способ, за счёт которого продукты Cyclone Highwinds и Usenet Typhoon получили существенный прирост производительности в сравнении с обычными C-news и INN. Во всех случаях такие приросты производительности получаются за счёт обхода накладных расходов уровня файловой системы. Посредством реализации лежащего в основании хранилища данных, подгоняемого под его определённые потребности - вместо деформации самого себя под соответствие пределам и семантике файловой системы, разработанных для других целей - Ceph способен управлять данными намного более эффективно. А какой {русский} не любит быстрой езды и эффективности?
Компромиссом подхода применения встроенной базы данных сырых данных BlueStore является то, что нам больше не
приходится иметь некую обычную файловую систему, по которой мы вынуждены перемещаться и применять знакомые нам
инструменты, такие как ls, cd,
cat и du. Поскольку
BlueStore является очень большим новичком на данной сцене, и её код ещё пока не был полностью проверен сам по
себе консервативными администраторами Ceph, такие оснащения пока не распространены достаточно широко.
BlueStore включает в себя внутреннее хранилище метаданных RocksDB, которое требует специализированных подходов
и инструментов для её вскрытия, которые всё ещё находились в стадии развития на момент написания данной главы.
Мы можем ожидать,однако, что как и в случае с FileStore, мы будем очень редко иметь причину проникать настолько
глубоко во внутреннее устройство OSD в промышленных реализациях.
В этой и в прочих главах мы обсуждали стратегии репликации Ceph для защиты данных. Помимо них Ceph также предлагает в качестве альтернативы удаляющее кодирование (EC). Удаляющее кодирование восходит своими корнями к передаче данных, при которой нет ничего необычного в том, что определённые части передаваемого сигнала теряются или подвергаются удалению (erasure) (отсюда и само название). В отличии от протоколов (таких как TCP), которые в основном определяют утраченные данные и выполняют переповторы, коды удаления разработаны с тем чтобы подмешивать репликации непосредственно в свою полезную нагрузку. Тем самым, пропущенные участки могут быть восстановлены путём вычислений на самой принимающей стороне, в одностороннем порядке, без потребности в общении с передающей стороной. В частности, межпланетные зонды Voyager применяли некий вид удаляющего кодирования для своих передач. На Нептуне время прохода сигнала в обе стороны к Земле, требующееся для передачи сигнала и получения отклика, составляло более пяти часов, задержка, которую достаточно успешно обходило кодирование Рида- Соломона, технологии, которая стало возможной в наши дни.
Другим, более земным примером удаляющего кодирования является кодирование Parchive (PAR), применяемое в Usenet и прочих взаимодействиях реального времени, которые делают возможной реконструкцию больших, фрагментированных файлов даже в случае если некоторое число частей не было принято. Данная реализация, возможно, более сопоставима с Ceph, в котором утрата данных из- за отказов компонентов или сетевой среды всё ещё вызывает беспокойство в то время, когда времени на передачу и подтверждение приёма (RTT) обычно нет.
Таким образом, удаляющее кодирование, как оно реализовано в Ceph, во многом сродни некоторым вариантам защиты данных, относящимся к RAID5, RAID6 или RAIDZ3. Напомним, что мы можем выбирать на уровне своего пула будем ли мы применять удаляющее кодирование или репликацию, что означает, что один и тот же кластер может реализовывать различные стратегии защиты данных в индивидуальных наборах данных в соответствии с их требованиями и экономикой.
Хотя пулы с репликациями Ceph почти всегда предоставляются с неким size (множителем репликаций), равным 3, удаляющее кодирование представляет десятки комбинаций параметров, которые изменчивы в своих накладных расходах и растяжимости. При устанавливаемом в качестве имеющегося по умолчанию алгоритме удаляющего кодирования (jerasure) мы обязаны рассматривать два параметра, K и M. На уровне RADOS Ceph будет расщеплять каждый объект на K отделюных фрагментов, из которых M дополнительных фрагментов являются вычисляемыми функциями от данных самого Объекта на входе. Такие первоначальные фрагменты данных совместно с полученными путём вычисления (также именуемыми encoded или parity) фрагментами называются черепками (shards, дранкой) и которые независимо записываются в лежащие в основе объекты RADOS. Они распространяются в соответствии с установленными правилами CRUSH для обеспечения того, что они разбросаны по хостам, стойкам и прочим областям отказа. Каждый дополнительный черепок данных, который мы вычисляем позволяет нам реконструировать весь Объект целиком если отдельный дополнительный черепок из общего набора данных стал недоступным или утрачен без ущерба для доступности данных. В то время, как jerasure является гораздо более гибким, его динамика конгруэнтна чётности RAID. RAID5, к примеру, может переносить утрату любого одного из устройств и, тем самым, он аналогичен удаляющему кодированию с M = 1. Аналогично, RAID6 сопоставим с удаляющим кодированием при M = 2, так как любые два устройства из каждой группы чётности могут быть утрачены без потери данных.
Определённый выбор конкретной стратегии защиты данных всегда является компромиссом между эластичностью и накладными расходами, в особенности самой стоимости покупки и работы устройств хранения. По мере того, как оснащённость хранения растёт всё больше, до сотен и тысяч индивидуальных устройств, мы всё возрастающе вынуждены эксплуатировать стратегии защиты данных, которые невосприимчивы к утрате всё большего числа компонентов и/ или предлагать лучшую грануляцию таких компромиссов эффективности.
Именно здесь вступает в игру выбор K и M кодирования jerasure.
Мы выбираем необходимые значения для заданного пула EC на основании тех факторов, которые включают в себя
общее число отказов к которым мы обязаны быть невосприимчивы, имеющиеся накладные издержки кодирования, которые
мы могли бы пожелать испытывать, а также логистические факторы, содержащие общее число хостов, стоек и
прочих областей отказа по которым мы выполняем оснащение. Этот выбор должен быть осуществлён тщательно, поскольку
в отличии от пулов с репликациями мы не можем осуществлять регулировку некоторого пула EC в том случае если мы
передумаем - единственным вариантом будет создание некоторого нового пула и перемещение данных, что всё же
возможно, но медленно, сложно и подвержено разрушениям.
Мы определяем значения накладных расходов некоторого пула с заданным множителем репликаций или удаляющим кодированием (K, M) как определённое соотношение общих сырых данных к используемой ёмкости. Например, устанавливаемый по умолчанию пул Ceph с репликациями, имеющий size = 3 приводит в результате к соотношению 3 : 1, или просто множителю накладных расходов 3. Некий обычный том RAID0 с чередованием не имеет избыточности и, таким образом, представляет соотношение 1 : 1, или множитель накладных расходов, равный 1. Расширение данного понятия на кодирование jerasure Ceph приводит к вычислению множителя накладных расходов как
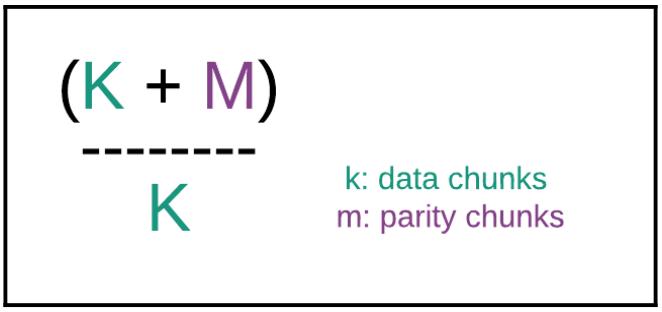
Например, некий пул EC с K=4 и M=2 достигает соотношения накладных расходов 4 : 2, или 1.5. Он идеально распределяется по 6 областям отказа, любые 2 из которых могут упасть без воздействия на доступность данных. Хотя некий пул с K=8 и M=4 может казаться убедительным доказательством идентичности приведённому выше пулу (4, 2), он отличается тем, что можно утратить любые 4 из имеющихся 12 областей отказов, что покроет несколько большее число собрания отказов.
На практике очень большие значения K и M становятся громоздкими, поэтому давайте вычислим профили для всех сочетаний.
| K | M | ||||
|---|---|---|---|---|---|
|
1 |
2 |
3 |
4 |
5 |
1 |
|
|
|
|
|
2 |
|
|
|
|
|
3 |
|
|
|
|
|
4 |
|
|
|
|
|
5 |
|
|
|
|
|
6 |
|
|
|
|
|
7 |
|
|
|
|
|
8 |
|
|
|
|
|
9 |
|
|
|
|
|
10 |
|
|
|
|
|
На практике вырожденный выбор K = 1 редко имеет смысл, поскольку он аппроксимирует простую репликацию (зеркалирование), без применения преимуществ соотношения лучших профилей EC. Такие профили не эффективны в том плане, что они потребуют больше ресурсов ЦПУ для реконструкции утраченных данных или фрагментов чётности. Сетевой обмен становится более интенсивным, так как нет черепков данных. Другим словами, даже частичные удаления требуют того, чтобы данная система действовала так, как если бы был утрачен фрагмент данных целиком, что находится в противопоставлении с более лучшими профилями при которых меньшие стирания воздействуют только на один из множества черепков и, тем самым должна восстанавливаться лишь часть данных. Можно представлять себе что конкретный выбор (K, M) обусловлен желательным соотношением эффективности, но это намного сложнее приведённого представления.
Профили EC, в которых K является неким большим числом, а M = 1 также не идеальны. Получаемый эффективность покрытия черепками ограничена и вся система может быть устойчива к единственному отказу устройства без потери данных.
EC, при которых K < M не привлекательны. Дополнительные черепки чётности порождают плохие соотношения эффективности и вычислительных накладных расходов без дополнительных преимуществ.
Применяя эти ограничения к приведённой выше таблице, мы можем сузить свои решения на имеющие теневой фон профили. Столбцы для больших значений M допустимы для соответствующим образом и больших значений K со следующими двумя оговорками:
-
При большем числе черепков соответствующее выравнивание в стойках Центра обработки данных для устойчивости к отказам становится более сложной.
-
Это может сделать таблицу действительно широкой для читатетелй электронной книги.
|
| Замечание |
|---|---|
|
Имеется и другой пример подходящих значений во всеобщем сообществе Ceph. Это информационный список электронной рассылки потоков обсуждения выбора профиля EC для определённых вариантов применения: https://www.mail-archive.com/ceph-users@lists.ceph.com/msg40452.html . |
Давайте теперь рассмотрим некий пример пула удаляющего кодирования Ceph с (K=3, M=2) и изучим что происходит при считывании и записи данных.
При заданных параметрах каждый Объект будет расщепляться на 3 черепка, из которых вычисляются два дополнительных черепка с избыточной информацией для общего количества 5 фрагментов. Все эти черепки должны быть в точности одинакового размера, поэтому дополняются пустым местов в случае необходимости. Каждый черепок записывается в отдельный OSD, который идеально подходит нашей схеме стоек и правилам CRUSH помещающим в отдельные стойки, или, по крайней мере, в некий отдельный сервер.
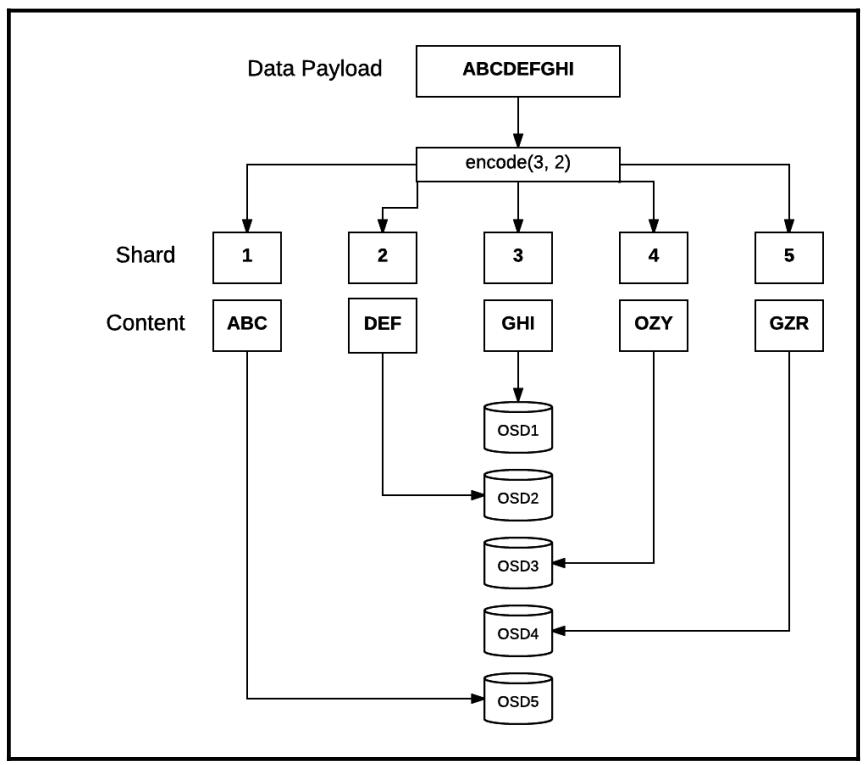
Когда наступает время считывания данного Объекта, исполняется чтение всех черепков с 1 по 5. Для иллюстрации существенности пользы удаляющего кодирования для защиты данных, допустим, что OSD2 стал медленным, а OSD4 был поражён молнией и загорелся. Поскольку наш пул и, тем самым, удаляющее кодирование определили K = 2, мы всё ещё имеем достаточно информации для реконструкции всех данных каждого Объекта. Все черепки запитывают функцию дешифрации нашего удаляющего кодирования, которая выплёвывает наши неповреждённые данные, отправляемые далее клиенту.
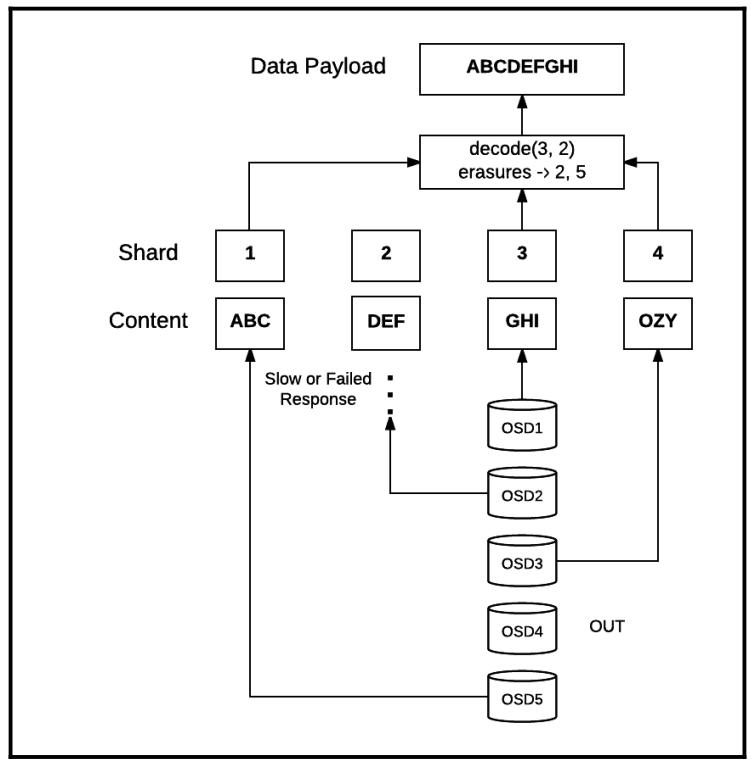
Как мы уже подробнее говорили где- то в этой книге, Ceph предлагал удаляющее кодирование пулов шлюза RADOS на протяжении многих лет, однако поддержка для пулов RBD пришла только в редакции Luminous. EC имеет значительную привлекательность в отношении эффективного использования сырой ёмкости хранения. В зависимости от выбранных параметров, устойчивость к отказам может даже превосходить аналогичные показатели для репликаций при определённых сценариях. Компромиссом, однако, является снижение производительности и более высокая латентность. Стратегия, именуемая Многоуровневым кэшированием описывается в некоторых справочных материалах как смягчающая воздействие на производительность со стороны EC, в особенности при реализации на дисках HDD, хотя на практике это оказывается достаточно хитроумной задачей. Добавляемые сложность управления и стоимость дополнительного оборудования а также быстрых устройств, предоставляемых для уровня кэширования также сокращают финансовый разрыв при сопоставлении с репликациями.
При любой стратегии, будь то репликации или удаляющее кодирование, Ceph сохраняет все Объекты данных неким реплицируемым образом по множеству областей отказа. Данная интеллектуальность является основной сердцевиной управления данными Ceph.
В данной главе мы изучили внутренние компоненты Ceph, включая Объекты, основной алгоритм CRUSH, Группы размещения и пулы, а также как они взаимодействуют друг с другом для предоставления высокой надёжности и масштабирования кластера распределённого хранения. Мы также снарядили свой кластер песочницы для получения опыта во взаимодействии с данными компонентами. Мы также изучили как данные сохраняются внутри такого кластера прямо с того момента, как они поступают в виде запросов на запись пока не достигнут верного OSD и не запишутся в некое устройство хранения в виде некоего файла Объекта {Прим. пер.: или просто объекта в случае BlueStore}. Мы рекомендуем вам попробовать повторить эти упражнения в своём тестовом кластере чтобы получить лучшее понимание того, как Ceph реплицирует и хранит данные высоко доступным образом. Если вы системный администратор, вам следует больше сосредоточиться на понимании того, как пулы Ceph и CRUSH работают в соответствии с описанием данной главы. В своей следующей главе мы изучим как предоставлять некую рабочую систему хранения Ceph.