Глава 4. Планирование вашего развёртывания
Содержание
Данная глава описывает ряд архитектурных и административных решений для принятия при планировании вашего собственного решения Ceph. Глава 3, Выбор оборудования и сетевой среды выводит множество вариантов выбора аппаратных средств, которые следует осуществлять при проектировании некоторого промышленного решения хранилища Ceph. Здесь мы сосредоточимся на ряде решений, которым стоит следовать при реализации промышленных кластеров:
-
Схематические решения
-
Архитектурные решения
-
Решения операционной системы
-
Решения сетевой среды
Мы предполагаем, что вы прочтёте эту главу сейчас, а затем вернётесь к ней после углубления в Главу 8, Архитектура Ceph: под капотом, которая подробнее обсуждает многие имеющиеся идеи которые мы затрагивали ранее. Данное более глубокое понимание процессов и динамики промышленной реализации Ceph обозначит вам позицию когда вы будете принимать решения, относящиеся к вашим оснащений.
В данном разделе мы исследуем стратегии для размещения ваших серверов Ceph в пределах некоего центра обработки данных. Рассмотрим заранее каждый каждый из этих факторов, чтобы предотвратить потенциально затратное (и стеснительное) грубое освобождение от иллюзий после того как вы развернули свои промышленные кластеры.
И в печати, и в средствах массовой информации на протяжении последних лет мы постоянно слышали шумиху о Конвергентных инфраструктурах и, как если бы вы не уловили мысль окончательно, Гиперконвергентной инфраструктуре. Возможно, в следующие несколько лет мы увидим Ультраконвергентные инфраструктуры, которые также готовят мелко нарезанные яства. Имеющееся отличие между этими двумя понятиями чисто маркетинговое. Обычные архитектуры облачных платформ и ферм серверов, как правило, снабжаются серверами/ шасси для каждой роли: Вычисления, Хранения и Сетевого обслуживания. Однако конвергенция сегодня - это всё в одном - предоставление всех служб в одних и тех же серверах. Восхваление преимуществ данного подхода состоят в сбережении стоимости управления и сопровождения (читай: персонала), в постоянных эксплуатационных расходах занимаемого места в центре обработки данных, а также в начальных капитальных затратах на оборудование. Также имеется ожидание инкрементального и линейного роста по запросу.
Предположения архитектуры СуперМегаКонвергентность+ содержат в себе тот смысл, что серверы соответствуют имеющейся задаче и что все компоненты легко масштабируются горизонтально. Иногда это так. В примере оснащения OpenStack службы Nova обычно связаны с ЦПУ и оперативной памятью, но не обязательно насыщают все компоненты локального хранилища, которые могут быть предоставлены. Ceph, с другой стороны, не прожорлив в отношении таковых частот ЦПУ, когда дело касается их, а его требования к оперативной памяти достаточно ограничены во время стационарной работы. Может быть естественным рассматривать все службы как дополняющие друг друга и тем самым быть совместимыми с конвергентной архитектурой. И действительно, некоторые люди успешно делают это, например, Metacloud Cisco. Это может неплохо работать в оснащениях умеренного размера, однако, по мере роста использования можно обнаружить, что одна из частей общего уравнения= скажем, хранение - быстрее насыщается чем прочие. Следует расширять все представленные компоненты, вместо того чтобы сосредоточиться на капитальных издержках и прилагать усилия только там, где это необходимо.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Для получения дополнительной информации по OpenStack обратитесь к Главе 10, Интеграция Ceph с OpenStack. Шестьдесят процентов оснастки OpenStack или более основано на блочных и объектных хранилищах Ceph. |
Менее очевидная засада конвергентности также состоит в сложности сопровождения и наличия сплетённости областей отказа. При некоей выделенной инфраструктуре следует, как и полагается, отключить индивидуальные узлы для обновлений встроенного ПО или ядра прозрачно для пользователей, однако при наличии конвергентности такие операции также отключат ряд виртуальных машин. Миграция в реальном времени может помочь в решении данной проблемы, однако она не всегда осуществима и к тому же требует сопровождения достаточных ёмкостей для поддержки некоторого бега гипервизора по кругу при детской игре в свободный стул. Расхождение между соперничающими службами также вызывает беспокойство, которое нарастает по мере масштабирования и использования. В рамках конвергентной среды OSD Ceph использование ОЗУ может расти при конкуренции со вычислительными и прочими службами.
Всплеск голода ЦПУ со стороны Nova/QEMU или продолжительная последовательность пакетов в сетевом обмене Neutron могут значительно повлиять на службы Ceph, что приведёт снижению ранга OSD. Во время интенсивного обратного наполнения или восстановления OSD Ceph применение ОЗУ может вырасти и тогда у всех будет плохой день. Новые технологии включают контейнеры и cgroup Linux, которые обладают потенциалом смягчения такого эффекта шума соседей, однако может повлечь за собой дополнительных усилий по управлению и продолжительной настройке, поскольку каждый стремится к идеальному - или по- возможности наименее безболезненному балансу.
Это не означает что конвергентная инфраструктура по своей сути дефектна или никогда не является правильным подходом, однако необходимо взвесить все за и против совместно с вариантом применения и прогнозируемым ростом. Для более мелких реализаций PoC (Proof of Concept, проверки концепции) или для тех, у которых это является целью, она может работать хорошо, однако многие установки Ceph обнаруживают интригующие выгоды при независимом масштабировании по различным направлениям (Вычислений, Cетевой обработки, Хранения) и отделению областей отказа.
После этого, сосредоточившись на тех компонентах, которые мы изучили в Главе 2, Компоненты и службы Ceph. Необходимо выделить системы для обслуживания каждой роли:
OSD, MON, ceph-mgr, потенциально MDS Ceph, а также
RGW
(RADOS Gateway). Даже внутри такой экосистемы
Ceph естественно рассмотреть степень конвергенции для минимизации CapEx, количества серверов, RU и тому
подобного. Всё это необходимо рассматривать тщательно.
Раз уж OSD Ceph тесно спарено с подлежащим хранилищем, практически во всех системах промышленного масштаба они заслуживают выделенных серверов. Такой подход позволяет выполнять по желанию масштабирование вверх и вширь по мере степени раскрутки или узкоспециализированной гибкости сопровождения, которая заставит ваших коллег по Вычислению и Сетевому обслуживанию позеленеть от зависти.
Службы MON (Monitor, Монитора) имеют очень различающиеся потребности. Они обычно не требуют многого в отношении ЦПУ и их запросы оперативной памяти не являются ограничительными при современных стандартах. MON не требуют специального рассмотрения ёмкости локального хранилища, однако оно обязано быть долговечным. Как мы уже описывали в Главе 3, Выбор оборудования и сетевой среды, применяемые для БД MON Ceph SSD получают устойчивый обмен. БД MON в больших кластерах осуществляет запись со стабильной скоростью порядка 20 МБ/c и тем самым легко способна расходовать две DWPD (Drive Writes Per Day, Записи диска в день) при предоставленном устройстве 1 ТБ. По этой причине вам настоятельно рекомендуется предоставлять устройства с высокой износостойкостью. При применении SSD выбирайте модель с некоторым высоким показателем длительности применения, по крайней мере три DPDW или выше для приводов 1 ТБ. Пишущий эти строки автор испытывал множество почти одновременных отказов MON из- за меньшей способности высасывания из устройств; мы бы хотели избавить вас от этого мучения.
Износостойкость может быть дополнительно увеличена за счёт перезаклада (выделения заведомо большего объёма). Некий SSD в 100 ГБ может быть достаточно большим для размещения на нём БД MON, или даже впридачу и операционной системы, однако некая модель 240 ГБ с тем же самым значением DWPD будет длиться намного дольше до своего отказа. И, конечно, 480ГБ устройство предоставит обслуживание в течении ещё большего периода времени. Расположенный на борту SSD контроллер распределяет операции записи по всем ячейкам хранения по мере их утилизации, поэтому такие горячие участки интенсивной записи не исчерпают досрочно своё время жизни предоставляя циклы записи. Данная стратегия имеет название выравнивание износа (wear leveling). SSD могут опрашиваться через S.M.A.R.T. для выставления закладок оставшегося им времени жизни. Включение предупреждений счётчика долговечности в вашу систему мониторинга может предупредить вас о необходимости обновить SSD до того как он откажет.
Строго рекомендуется развёртывать некое нечётное число MON с тем, чтобы алгоритм согласования Paxosмог всегда гарантировать недвусмысленный кворум большинства. Это исключит явление раздвоения сознания при отказе в сетевой связности оставляющей два подмножества Мониторов способными взаимодействовать между собой, но при этом не с другим подмножеством. При таком развитии событий всякий может счесть себя авторитетом, а никакой OSD не может обслуживать два мастера. Хотя некий кластер и может работать какое- то время без доступных MON, это достаточно опасное состояние и, следовательно, предоставление только одного MON в промышленном оснащении неприемлемо. некий жизнеспособный кластер требует (n/2)+1 демонов Мониторов поднятыми и участвующими в том, что именуется как кворум Мониторов. Многие кластеры с размером от небольшого до среднего успешно работают с тремя, поскольку один MON может быть остановлен для сопровождения или обновления без прерывания работы Ceph.
В кластеры большего размера, такие как оснащения с 900+ OSD авторы обычно включают пять MON. Предоставление пяти делает возможным время от времени проводить работы по обслуживанию на одном и при этом быть готовым к отказу ещё одного.
Мало для каких- либо кластеров требуется семь MON. На недавнем Summit OpenStack группа опытных операторов Ceph задавала вопрос запрашивал ли кто- либо семь; общее мнение свелось к тому, что никто не нашёл оправданий для этого. Так как MON Ceph постоянно общается со всеми прочими MON, обслуживающими тот же самый кластер, необходимый объём и накладные расходы межсетевого взаимодействия между MON значительно растут при добавлении MON. Это одна из причин, по которой 7, 9 или даже ещё большие значения обычно не предлагаются.
Предоставление множества MON на самом деле помогает разделять сетевой обмен и имеющуюся рабочую нагрузку транзакций, однако наша первичная мотивация состоит в устойчивости. Масштабируемость MON была впечатляюще улучшена в последних выпусках LTS Ceph, причём каждый соответственным образом вооружённый демон может адекватно обслуживать очень большое количество клиентов. Обратитесь к приводимому далее разделу Стоечная стратегия для получения дополнительной информации относительно масштабируемости.
Итак, для вашего оснащения целью должно быть три или пять MON.
Принимая во внимание их относительно скромные требования, обычно высказывается пожелание прикреплять прицепом службу MON к узлам OSD. Это работает для оснащения dev или PoC, как будет изучено в нашей следующей главе, однако не поддавайтесь этому соблазну в промышленном решении:
-
Поскольку нет нужды развёртывать более пригоршни MON, некоторые узлы OSD будут размещать MON, а какие- то нет. Такая асимметричность может вводить в заблуждение и усложнять управление системой.
-
MON Ceph создают некий эластичный кластер для их собственного применения алгоритма согласования Paxos, однако частые разрывы могут быть проблематичными. Например, достаточно просто временно отключить некий отдельный узел OSD для обслуживания или даже просто чтобы перезагрузиться. Если MON расположен на том же самом сервере, время простоя означает нечто большее, чем просто жизнеспособность OSD, поскольку оно затрагивает и службу OSD, и службу MON отключаемыми в одно и то же время.
-
OSD легки в накатывании на них сопровождения, однако для MON требуется больше времени для урегулирования и восстановления. Накатываемые обновления, которые выделенные OSD переживают просто великолепно, могут приводить к существенной деградации производительности MON если следующий сервер MON OSD рухнет до того как кворум полностью восстановится после предыдущего простоя. Пишущй эти строки автор лично испытывал перебои из- за слишком частого зацикливания MON.
-
Интенсивное использование OSD может оставлять на голодном пайке в отношении ресурсов MON, существенно замедляя их, что может каскадным образом перекинуться на OSD.
Разумное применение cgroup может смягчит это последнее соображение, однако для большинства промышленных оснащений наличие рисков конвергенции MON с OSD в одном и том же шасси превосходит потенциал инкрементального сбережения CapEx. По этой причине всех читателей мы настоятельно призываем выделять серверы для применения MON. Они не обязаны быть слишком большими, узлами энтузиастов; скромная, относительно экономная система 1U с базовым ЦПУ в одном сокете будет вполне достаточной. На самом деле, сокеты с ЦПУ имеющим большой запас частоты и ядер для MON может иметь результатом проблемы сетевой среды и производительности из- за охоты c-state. Тем не менее, они должны быть стоящими отдельно чтобы минимизировать площадь области отказа, например, блейд- сервер может не быть наилучшим решением, в особенности если в одном и том же шасси расположено более одного лезвия MON, поскольку обслуживание шкасси может вызвать непредусмотренную деградацию обслуживания. Пишущий данные строки автор наблюдал достаточно горя, вызываемого сложностями и частыми поломками шасси блейд- сервера чтобы полностью их избегать; ваш пробег, как говорится, может быть другим.
Так как производительность VM (ВМ, virtual machine) может быть чем- то непредсказуемым, они также не рекомендуются для обслуживания MON Ceph. Если к тому же ВМ полагается на Ceph для собственного хранения, циклическая зависимость может стать реальной проблемой так как MON являются критически важной частью всего серверного обеспечения Ceph.
Службы RGW Ceph, тем не менее, являются клиентами Ceph, а не частью основного ядра серверной основы. Они имеют меньшие запросы к латентности и производительности чем компоненты серверной основы и легко масштабируются горизонтально при абстрагировании за неким балансировщиком нагрузки. Если ваш вариант применения включает службу объектов, предоставление некоторых или всех серверов RGW в виде виртуальных машин может иметь под собой основания.
Поскольку служба Диспетчера Ceph (ceph-mgr) является новой
(и обязательной) в последнем выпуске Luminous, а наилучшие варианты её применения всё ещё развиваются,
кажущееся наилучшей сегодня стратегией видится её совместное размещение на узлах MON.
Некоторые оснастки и документы Ceph ссылаются на один или более узлов администратора, которые не предоставляют никаких служб сами по себе , но предназначены исключительно как место для исполнения команд администрирования и мониторинга. Раз так, они являются исключительными кандидатами для виртуализации, предоставляемой такие ВМ использующими для загрузки локальное по отношению к их гипервизору хранилище (также именуемое эфемерным) и, тем самым, они не полагаются на кластер Ceph для своих жизнеобеспечения и работы. Когда дела становятся плохи, самая последняя вещь, которая вам нужна это циклическая зависимость, которая не даёт вам отыскать или разрешить возникшую проблему.
Один или более выделенных узлов администратора не являются необходимыми и, на самом деле, просто узлы MON могут применяться в качестве узлов администратора. Пишущий эти строки автор применял оба подхода. Применение MON даёт дополнительную степень инкрементального уменьшения сложности, однако разделение узлов администрирования и MON популярно во многих организациях. Вы даже можете применять имеющийся узел jump или хост bastion в качестве узла администратора Ceph, хотя имеются специальные соображения доступности и взаимной зависимости. Один или более узлов администрирования также избавляют от потребности для NOC (network operating center, центра управления сетью), поддержки, биллинга или прочей персонализации для регистрации в реальных узлах серверов промышленного кластера, что приветствуется и рекомендуется вашим подразделением Информационной безопасности с целью ограничения информированности сотрудников в рамках их служебных обязанностей (compartmentalization).
Стратегии и политики стоек и монтажа варьируются от организации к организации и даже между центрами обработки данных внутри определённой организации. В данном разделе мы исследуем вопросы размещения ваших серверов Ceph, в особенности касательно областей отказа (failure domain), темы, которая более подробно обсуждается в Главе 8, Архитектура Ceph: под капотом.
Кластеры Ceph с размером от малого до умеренного могут не составлять достаточного для заполнения множества стоек центра обработки данных количества серверов, в особенности учитывая сегодняшние плотности шасси 1U и 2U. Для них имеется две стратегии расположения:
-
Разместить всё в одной стойке
-
Разбросать все серверы по множеству стоек
Размещение в одной стойке предлагает простоту: сетевые соединения могут быть заполнены меньшим числом коммутаторов и вам никогда не придётся задумываться к какой стойке должны быть направлены удалённые руки. Однако, при размещении всех упомянутых OSD в одной корзине, возникновение отказа в некотором коммутаторе или на уровне PDU могут стать катастрофическими. При таком оснащении мы настраиваем Ceph рассматривать каждый хост в качестве некоторой области отказа и при этом гарантировать, что никакой отдельный хост не имеет более одной копии реплицированных данных. Что в особенности важно при размещениях в единственной стойке, так это усилить избыточность сетевой среды и бесперебойного электропитания, как это раскрывается ниже и в наших предыдущих главах.
Оснащение во множестве стоек добавляет сильную степень устойчивости к отказам даже в небольшие кластеры, так как при тщательном планировании отказ целой стойки не ставит под угрозу имеющийся кластер в целом. Это может однако означать некую более сложную сетевую стратегию и запросы того, чтобы логическая топология была близка к имеющейся физической топологии, что мы также рассмотрим в Главе 8, Архитектура Ceph: под капотом. При устанавливаемом по умолчанию в пулах кластера множителе репликаций равным трём, крайне желательно распределить все узлы по крайней мере по трём стойкам с тем, чтобы область отказа CRUSH могла быть усилена тем, чтобы в каждой из них было не более одной копии. Для пулов с удаляющим кодированием (EC, Erasure Coded), может быть лучшим большее число стоек для гарантии того, что кластер целиком может переживать утрату одной из них без простоя обслуживания или утраты данных.
При размещении во множестве стоек оснащения с размером от малого до среднего серверы Ceph не заполняют целиком каждую стойку. Обычные стойки центра обработки данных предлагают пространство из 42U, причём часть его зачастую занимает сетевое оборудование. В таком случае кластер скромного размера может заполнять всего лишь треть свободного места для установки, что зачастую имеет существенные финансовые особенности. Парни из вашего центра обработки данных может таким образом оказывать на вас давление с тем, чтобы вы целиком сосредоточили всё в оснащении одной стойки, либо совместно использовали свои стойки с другими службами. Совместное применение часто вполне реально, хотя при такой схеме вы должны на самом деле рассмотреть и спланировать на будущее ряд моментов:
-
Место для роста, поскольку ваш наиболее исключительный кластер Ceph потребует дополнительных серверов для увеличения ёмкости для того чтобы гасить никогда не угасающую жажду пользователей в хранении данных. Это включает в себя как пространство стоек, сокращённо RU, так и доступных Ампер мощности и сокетов, что мы обсуждали в своей предыдущей главе. {Прим. пер.: а также мощностей по отводу дополнительного тепла!}
-
Места для всех прочих служб на вырост, которые могут стать потенциальным препятствием расширению вашего кластера Ceph, или даже вытесняться в прочие стойки.
-
Если сетевое оборудование используется совместно, настаивайте на выделенных коммутаторах по крайней мере для репликации Ceph, сокращённо именуемой частной - или на крайний случай неком выделенном VLAN. Разногласия по поводу полосы пропускания с прочими службами могут приводит к деградации обслуживания или отказам, то есть шумные соседи - это преисподняя.
Для более крупных оснащений мы часто имеем выделенные стойки, которые могут устранять фактор назойливых соседей и делают возможной для нас желательные сетевую среду и топологию областей отказа.
Вот некий пример размещения, которым управлял автор этих строк. Мы обсудим далее некоторые важные моменты, относящиеся к целям данного проекта, его преимуществам и темам для беспокойства.
| Стойка 1 | Стойка 2 | Стойка 3 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В этом кластере у нас имеется множество пулов с репликациями, причём каждый имеет по три копии. Таким образом, каждая стойка размещает только одну копию данных. Для MON были предоставлены серверы 1U; все серверы OSD имели 2U. При наличии накладных расходов на сетевую среду и патч панели это заполняло всё доступное пространство стоек до нуля не используемого пространства. При наличии сдвоенных коммутаторов ToR (Top of Rack) все системы Ceph были удовлетворительно снабжены сетевой избыточностью, которую мы более подробно обсудим чуть позже в данной главе. Все узлы OSD обслуживали по 10 устройств каждый, что давало для кластера в целом общее значение 450.
При обычных репликациях Ceph размещение одной копии данных в каждой стойке имеет результатом эквивалент ёмкости одной стойки. Если бы, скажем, все серверы в Стойке 3 размещали бы устройства OSD большего размера чем первые две Стойки, их дополнительное приращение ёмкости было бы потрачена впустую. Стойки 1 и 2 вначале бы заполнились, а имеющиеся требования для репликаций запретили бы нашему кластеру использовать имеющийся баланс Стойки 3. По этой причине настоятельно рекомендуется предоставлять начальное заполнение стоек (серверов) эквивалентной ёмкостью.
Если обстоятельства (доступность, срочная распродажа, горячо полюбившееся оборудование и тому подобное) оставляет вас один на один с замесом серверов или объёмов устройств, будет лучше распределить компоненты таким образом, чтобы компоненты каждой стойки примерно составляли равные значения итого. Это в особенности важно при применении стойки в качестве области отказа, как это описано в Главе 8, Архитектура Ceph: под капотом, что является обычным в больших оснащениях со множеством стоек. При суммировании объёмов устройств или серверов убедитесь что применяете реальные размеры, предоставляемые каждым устройством, например, 3.84 ТБ вместо обозначенного маркетингового номинала навроде 4ТБ. Любое округление и (хм!) преувеличение подразумевает впоследствии результатом затруднительные ошибки.
Наличие предоставленных ToR (Top of Rack) коммутаторов в каждой стойке означает, что некий отказ не повлияет на прочие стойки и не вынудит раскладки кабелей между стойками. Пять узлов MON являются очень типичным для кластера такого размера. Они аккуратно распределены по стойкам с тем, чтобы весь кластер мог выжить в случае катастрофического отказа любой из одной отдельной стойки (допусти, если в одну из них въедет вилочный погрузчик).
Финансовые, операционные и организационные соображения установили, что при необходимости расширения предоставляются одна или более стоек серверов OSD со связанными с ими сетевыми средами. Как мы уже обсуждали ранее, общее число MON Ceph не должно масштабироваться линейно по мере роста фермы OSD, поэтому такие стойки расширения не содержат дополнительных узлов MON. Внимательный читатель может отметить, что это может заметить, что данное решение может позволить предоставление какого- то шестнадцатого узла OSD в имеющемся пространстве или для осуществления MON с целью их распространения для повышения эластичности. Нам точно нужно было сделать то или это.
|
| Замечание |
|---|---|
|
Для увлекательной дискуссии о реальном тестировании, которые нагружают полностью упакованные Ceph при их масштабировании настоятельно рекомендуется данная статья CERN. Она является исключительным примером того, что сообщество Ceph является бесценным ресурсом для администраторов Ceph. |
При любой схематике стоек, будь она сосредоточена в одной стойке или распределена по множеству, предлагается спланировать дальнейшее расширение. Это может означать предварительное выделение дополнительного пространства в стойках чтобы гарантировать что оно будет доступно при необходимости, либо может снабжать информацией о выборе сетевого устройства или топологии для обеспечения роста в виде шасси коммутатора или количестве портов. Конкретное добавление четвёртой стойки в кластер с репликациями неким образом ослабит строгий баланс ёмкости (или весов) каждой стойки. Поскольку Ceph требует всего три стойки для наличия реплик каждой Группы размещения (PG, Главе 8, Архитектура Ceph: под капотом), скромные отклонения в агрегированном объёме теперь будут задействованы целиком. В приведённой выше схеме три стойки с номинальными устройствами по 3 ТБ были дополнены двумя стойками расширения с устройствами по 4ТБ. Ceph разместил больше данных на предоставленные устройства большего масштаба, сделав предоставленные новые серверы менее загруженными чем серверы в первоначальных трёх стойках, однако имея возможность выбирать только две из оставшихся трёх стоек для прочих копий таких данных Ceph был способен использовать всё имеющееся новое пространство. Если бы приводы расширения имели бы значительно большую ёмкость чем имеющиеся в настоящий момент, допустим, 8 ТБ, имело бы смысл поменять некоторые из них местами с расположенными в первоначальных стойках чтобы добиться более ровного баланса. При сильно не сбалансированных стойках остаётся потенциал, что имеющийся кластер будет заполнен прежде чем это сделают самые большие стойки.
Это может показаться тривиальным, однако соглашения по именованию серверов могут быть внезапно
противоречивыми. Многие реализации Ceph будут использовать имена, аналогичные
ceph-osd-01 и ceph-mon-03.
Другие имеют организационные соглашения именования систем после их последовательной нумерации или по местоположению,
кодируя некоторое помещение центра обработки данных, ряд, стойку и RU в рамках название, например,
h3a1r3ru42.example.com. В то время, как имена хостов по их местоположению
могут казаться неудобными для применения, их привлекательность возрастает после повторения вызывающих
головную боль ошибок, полученных в результате именования хостов на основании их ролей:
-
Самоклеящиеся метки с именами хостов могут утрачиваться или превращаться в не читаемые со временем
-
Что ещё хуже, они могут прикрепляться и помечать не тот сервер
-
Серверы с изменённым предназначением могут также в лёгкую оставаться с метками на основании роли из прошлой жизни
-
Различные подразделения, совместно использующие один и тот же центр обработки данных, может так случиться, будут применять очень похожие названия
Пишущий это автор на своём опыте встречал всё вышеперечисленное. В лучшем случае это затрудняло поиск
необходимого сервера. В худшем случае это имело результатом, что вы - или кто-то ещё - выключал серверы или
вынимал их из стойки совершенно неожиданным образом. Народонаселение вашего центра обработки данных и платформ
может разделять, а может и нет вашу гибкость именования хостов, однако если вы на самом деле используете
имена хостов на основании ролей, я полагаю вы планируете расширение. Чтобы сострить: если вы начнёте с
ceph-osd-1, ceph-osd-2 и
ceph-osd-3, имена могут стать неудобными для применения когда вы
обнаружите у себя десятки или сотни систем, а потенциально и множество кластеров. Имена подобные
ceph-osd-001.cluster1.example.com и
ceph-cluster3-mon-042.example.com, таким образом, предполагают последующий
рост и удобный порядок для сортировки. В площадках со множеством кластеров может иметь преимущества следование
последней форме с обозначением кластера в коротком имени хоста. Могут иметься части общей экосистемы, в которых
само название домена может быть не видимым, и такая практика поможет внести ясность в отношении конкретного
названия кластера и ссылочных данных.
В данном разделе мы изучим ряд вариантов, которые предстоит выбирать в зависимости от того, какими ресурсами оснащается ваш кластер Ceph. Некоторые из них подлежат уточнению после обнаружения факта с отличающимися степенями сложности, однако ваше пристальное внимание к своим текущим и последующим потребностям убережёт вас от многих печалей впоследствии.
Как мы изучим это в Главе 8, Архитектура Ceph: под капотом, кластеры Ceph снабжены одним или более пулами в которые организованы данные, например, один для блочного хранения и другой для хранения объектов. Такие пулы могут иметь различную архитектуру на основании различных вариантов применения; они даже могут располагаться на различных аппаратных средствах. Перед предоставлением каждого пула необходимо принять ряд важных решений.
Репликации
Основой Ceph является сохранение избыточных копий данных, а способ, которым это осуществляется, является фундаментальной характеристикой каждого пула. Никому не запрещено предоставлять некий пул без избыточности, однако редко кто имеет основания делать это. На сегодняшний день Ceph предоставляет две стратегии избыточности для обеспечения их живучести и доступности: репликации (replication) и удаляющее кодирование (erasure coding, EC).
Репликации знакомы всякому, кто работал с зеркалированными дисками, сокращённо RAID 1 ил RAID 10: множество
копий данных сохраняются на множестве устройств. Ceph реализует пулы с репликациями на протяжении многих лет и
предлагает чрезвычайно зрелые и стабильные реализации. Утрата одного или потенциально большего числа устройств
не имеют результатом утрату или недоступность данных пользователя. Стоимость репликаций заключается в том, что
используемая ёмкость пространства данного кластера является частью всего
сырого (raw) пространства, например, некий кластер с 1000GiB индивидуального
дискового пространства использует для некоторого пула с устанавливаемым по умолчанию значением репликаций,
равным 3, будет способен сохранять 333GiB (1000/3) данных пользователя.
Такая стоимость может быть непопулярной для вашей команды бюджета или для кого- то приученного к старой
школе зеркалировния, которое зачастую сопровождается только двумя копиями данных. Репликации доступны для всех
типов пулов данных в любой версии Ceph.
Удаляющее кодирование
Удаляющее кодирование (EC, Erasure Coding) является стратегией, при которой можно реализовать более предпочтительное соотношение сырых данных к используемой ёмкости хранения, а также потенциально с большей устойчивостью к ошибкам. Обратной стороной является большая сложность, дополнительные вычисления и потенциально растущее время восстановления при отказах. В зависимости от выбираемых параметров EC, оборудования и рабочей нагрузки может также иметься существенное воздействие на производительность.
Какое- то время Ceph поддерживал EC для объектов RGW; новой в редакции Kraken и ставшая зрелой начиная с Luminous LTS является поддержка также и для пулов блочного хранения RBD теперь, когда частичная перезапись была улучшена для определённых выгод производительности записи. Поскольку последнее относится к относительно новой и в промышленном применении пока находится в стадии экспериментов, консервативные администраторы хранилищ сегодня могут выбирать продолжение предоставление пулов с репликациями для служб RBD, хотя менее стеснённые запросами латентности потребности служб объектного хранения делают EC чрезвычайно привлекательными для пулов массового хранения RGW.
Преимущества эффективности использования пространства и устойчивости к отказам некоторого пула EC перед
пулами репликаций зависят от выбираемых параметров k
и m, однако обычные стратегии реализуют соотношение вплоть
до 1.4:1 или 1.5:1 в сопоставлении с пропорцией 3:1 для обычных репликаций Ceph. Тем самым приведённый выше
пример кластера с сырым пространством 1000GiB может дать вплоть до 666GiB используемого пространства - вдвое
больше чем репликации на тех же самых устройствах.
Одно из соображений EC состоит в том, что для реализации его магии необходим некий кластер, по крайней мере, среднего размера: данные разбразываются порциями меньшего размера по большему числу устройств. Пулы EC также требуют тщательного планирования центра обработки данных если некто пожелает убедиться, что полная потеря какой- то стойки целиком не выведет из строя пул полностью; именно это является существенной стороной при выборе некоторого профиля EC. Мы обсудим и репликации, и удаляющее кодирование более подробно в Главе 8, Архитектура Ceph: под капотом.
Вычисление Групп размещения
Выбор верного значения PG для каждого пула является одним из наиболее важных решений при планировании некоторого кластера Ceph. Некоторое значение, которое является слишком высоким или слишком низким может значительно повлиять на производительность. Слишком малое число PG будет иметь результатом неравномерное распределение и избыточные перемещения в процессе заполнения/ восстановления. Слишком большое число увеличивает накладные расходы самого кластера, претерпеваемые при обеспечении доступности данных, включая использование памяти демонами OSD.
Мы можем иметь целью общее число групп размещения для некоторого пула с применением следующей формулы:
Общее число PG = (Общее число OSD x PGPerOSD)/ множитель реплик [TotalPG]
Другими словами, соотношение может быть вычислено так:
PGPerOSD = (Общее число PG)(Общее число OSD / множитель реплик) [PGPerOSD]
Выбор правильного числа Групп размещения для каждого пула является одним из самых важных решений при планировании некоторого кластера Ceph. Слишком высокое значение или слишком низкое значение могут существенно влиять на производительность. Слишком низкое число будет иметь результатом неравномерное распределение и избыточную миграцию в процессе заполнения / восстановления. Слишком много PG увеличит применение памяти демонами OSD и добавит существенные накладные расходы вашему кластеру, которые он испытывает при обеспечении доступности данных.
Мы знаем общее число OSD, предоставляемых в некотором кластере; во многих случаях каждый пул применяет их все. Очень важно в кластерах со сложной топологией учесть все OSD, которые не являются частью нашего рассматриваемого пула в предыдущем вычислении. Значение множителя реплик данного пула определяется имеющимся ключом, именуемым размером (size); оно определено по умолчанию и обычно оставляется равным трём для пула с репликациями.
В предыдущем уравнении PGPerOSD является отношением PG к OSD: общее число Групп размещения, которое будет выделяться каждому OSD, размещающему данный пул. Когда все устройства OSD внутри некоторого пула однородны, такое вычисление просто выполнить.
Допустим, у нас имеются SSD 2 ТБ и мы желаем нацелить 200 Групп размещения на каждый OSD: мы подставляем
200 для PGPerOSD в приведённые выше уравнения. Наш пул применяет установленный по умолчанию множитель репликаций
(атрибут размера) равный 3 и состоит из 50 OSD. Вычисленное общее число PG (pg_num)
для нашего пула составляет:
(Общее число OSD x PGPerOSD)/ множитель реплик => pg_num
(50 x 200) / 3 = 3333
Основываясь на приведённом вычислении нашим решением будет установить размером данного 3333 Групп размещения.
Однако, когда Ceph распределяет данные по Группам размещения некоторого пула, он назначает байты данных для
Групп размещения степенями 2. Это означает, что если мы не установим pg_num
в точности в значение 2 в некоторой степени, наше распределение по Группам размещения будет неравномерным.
Все Группы размещения должны идеально обслуживаться неким идентичным размером фрагмента пространства. В приведённом
выше примере, однако, 3333 не является степенью 2. Так как Ceph выделяет ёмкость для некоторого числа степеней 2
Групп размещения как множества, самые первые 2048 PG получат выделенными им примерно 20 ГБ, следующие 1024
также получат примерно по 20 ГБ выделения каждой, однако выделения для оставшихся быстро расходятся. Остающиеся
261 PG каждая в среднем получат примерно по 80 ГБ ёмкости кластера. Это приблизительно в 4 раза больше использует
всех таких отбившихся от стада, чем для большинства OSD. Достаточно плохо что устройства, в которых их размещают,
будут видеть их больше, чем они совместно размещают в общей рабочей нагрузке, однако ещё хуже что те устройства,
которые размещают их заполнятся раньше чем прочие OSD, которые имеют ещё пространство для роста.
Чтобы избежать данной роблемы лучше выбирать некую степень 2 для каждого
pg_num пула. Обычной практикой является округление вверх вычисленного
значения до следующей степени двух. В приводимом выше примере следующей степенью двух, большей 3333, является 4096,
поэтому нашим идеальным значением для определения pg_num данного
пула будет
вверх_к_степени_2(3333) => 4096 # Значение pg_num для данного пула
Если наши кластеры состоят из множественных ёмкостей, типов или скоростей устройств, их вычисление становится хитроумным. Если мы указываем необходимое соотношение на основании самого большого или самого быстрого типа устройства, тогда более медленные устройства получат больше Групп размещения чем они смогут обработать. Аналогично и для другой крайности, если мы выберем соотношение на основании самого маленького или самого медленного типа устройства, тогда более быстрые носители окажутся недозагруженными. Наилучшим подходом для данной ситуации является выбор некоторого усреднённого значения по всем типам представленных для применения в таком пуле устройств. Если придерживаться однородной топологии кластера, по крайней мере для всех OSD внутри отдельного пула, это позволит целиком избежать данной проблемы.
Общее соотношение кластера, вычисляемое как сумма всех значений
pg_num, также является предметом рассмотрения при добавлении новых пулов
в работающий кластер. Всякий новый создаваемый пул добавляет свой собственный набор Групп размещения. Поскольку
все они являются частью одного и того же кластера, мы должны гарантировать, что общее агрегированное собрание
Групп размещения не переполнит все OSD, в особенности если, как это обычно бывает, такие пулы совместно используют
одни и те же перекрывающиеся наборы OSD. Если наше отношение PG к OSD уже имеет высокое значение, тогда
наложение дополнительных пулов (и запрашиваемых ими новых PG) может воздействовать на текущий ввод/ вывод
в имеющихся пулах, а также на рабочие нагрузки, предназначенные для таких новых пулов. Таким образом,
существенно планировать рост кластера на перспективу. Если мы знаем, что некоторый кластер потребует дополнительные
пулы в недалёком будущем, нам следует устанавливать целью более низкое соотношение Групп размещения к OSD для
создаваемого изначально пула (пулов) с тем, чтобы мы могли комфортно размещать PG создаваемым впоследствии
пулами.
|
| Замечание |
|---|---|
|
Один из авторов на своей практике испытал некий кластер, в котором повторное добавление пулов Glance и Cinder OpenStack привело в конечном итоге к некоторому соотношению 9000 : 1. Когда тот центр обработки данных, который размещал такой кластер пережил полное отключение электричества, данный кластер стал не восстанавливаемым из- за бесчеловечного объёма памяти, которое эти процессы OSD попытались выделить при запуске. Всё пришлось стереть и начать с нуля. К счастью, данный кластер использовался для лабораторно - проектных работ, а не для промышленной эксплуатации, однако является объектом для урока (это не каламбур, право!), став недоступным. |
И наоборот, когда промышленные кластеры выполняют заполнение, будучи жертвой собственного успеха, обычным является добавление дополнительных узлов OSD и устройств OSD для увеличения ёмкости. По мере того, как имеющиеся Группы размещения перераспределяются по такой добавляемой ёмкости, имеющееся соотношение PG к OSD в пуле и в самом кластере в целом будет уменьшаться. Таким образом важно рассматривать потенциальное дальнейшее расширение при планировании своих пулов. По этой причине может быть более преимущественным иметь целью самую высокую сторону соотношения PG к OSD для каждого пула с тем, чтобы такое расширение не уменьшало эффективное соотношение ниже предлагаемого минимума в 100 : 1 . Это явление несколько расходится с постулированным в предыдущем параграфе при добавлении пулов. Тщательное предварительное планирование крайне разумно, хотя, как мы увидим в Главе 8, Архитектура Ceph: под капотом, мы имеем возможность улучшать слишком низкое соотношение шаг за шагом добавляя PG до следующей степени 2, однако мы не можем удалять их чтобы исправить слишком высокое соотношение.
|
| Замечание |
|---|---|
|
Полезный калькулятор для планирования |
Что касается данной книги, она публикуется примерно в момент анонса выпуска Luminous 12.2.2. Стоящее особой
отметки является замечание, что ceph status и прочие операции теперь
выдают жалобы в случае, когда соотношение PG : OSD превосходит 200 : 1. Редакции начиная с Hammer вплоть до
Luminous 12.2.0 выдавали предупредительное сообщение при превышении порогового значения 300 : 1. Более ранние
версии тихо стояли в стороне, о чём автор текста вспоминает с мучениями.
|
| Замечание |
|---|---|
|
Вот великолепный шанс посетить базу кода Ceph. Чтобы посмотреть все сообщения, которые оказали воздействие на данные изменения посетите: https://github.com/ceph/ceph/pull/17814. |
Все ресурсы, включая http://ceph.com/pgcalc, ранее предполагали целеуказанием соотношение 200 : 1, зачастую плюс округление. По мере всё большего роста кластеров Ceph, последствия более высоких соотношений PG : OSD включают в себя значительное увеличение использования оперативной памяти со стороны процессов OSD и замедление однорангового обмена (peering) Групп размещения при возникновении событий топологии кластера и состояний. Если вы предвкушаете в своём кластере расширение количества OSD на множитель 2 или более в срок от короткого до среднего, вы можете принять обоснованное решение по- прежнему стремиться к высокому показателю.
Все выпуски от Hammer до Kraken выдают предупреждение если действующее соотношение эффективности выше имеющегося по умолчанию или настроенного значения. Начиная с редакции Luminous определённые действия с кластером теперь запрещены если установленное по умолчанию или настроенное значение превышено. В Luminous определённые действия в кластере теперь запрещены, если изменение привело бы к превышению предела действующего соотношения для:
-
Расщепление Групп размещения за счёт увеличения
pg_num(см. Главе 8, Архитектура Ceph: под капотом) -
Изменения множителя репликаций пула (это может травмировать)
-
Добавления новых пулов
Названия этих установок были тем самым изменены, чтобы отобразить тот факт, что это не просто идея, это - закон.
Каак и сотни прочих установок, эти пороговые значения могут регулироваться. Мы рекомендуем вам выполнять это
со всеми мерами предосторожности, чтобы предотвратить состояние жизнеспособности
EALTH_WARN для наследуемых кластеров, которые вы не можете вернуть к
жизни. Было бы слишком просто пропустить дополнительные события кластера, которые установили бы
EALTH_WARN , если бы ваш кластер пребывал в этом состоянии продолжительное
время. Если вы на самом деле понимаете что вы делаете, скажите что вы
знаете что вы в скором времени пожелаете увеличить размер кластера, вы всё ещё будете иметь возможность
достичь цели и изменить имеющееся пороговое значение.
Когда некоторое число устройств OSD (или хосты OSD целиком) отказывают и удаляются из имеющегося кластера, получаемое в результате уменьшение значения OSD соответственным образом увеличивает действующее соотношение PG : OSD. Такое увеличение соотношения может проскользнуть выше установленного нового жёсткого порогового значения. Имейте в виду такую возможность с тем, чтобы при последующих изменениях кластера вы могляи выполнить выравнивание для восстановления отвечающего требованиям значения.
Как мы изучим это далее, мы можем увеличивать действующее соотношение расщепляя Группы размещения внутри заданного пула чтобы увеличить их наполненность (и тем самым значение знаменателя в соответствующем вычислении соотношения), однако не существует обратной возможности. Превышающее оптимальное значение соотношения может быть однако понижено путём добавления дополнительных OSD в имеющийся кластер, что распространяет дейтсвие имеющихся Групп размещения по большему числу OSD.
Для Luminous 12.2.1 и последующих версий можно устанавливать жёсткое пороговое значение:
[mon]
mon_max_pg_per_osd = 300
Более ранние версии устанавливали предупреждающее пороговое значение:
[mon]
mon_pg_warn_max_per_osd = 300
В данном разделе мы обсудим ряд решений, которые воздействуют на то как вы развёртываете то большое число OSD, которые размещают данные внутри ваших кластеров Ceph.
Что в основе: FileStore или BlueStore
Вплоть да самого последнего выпуска Luminious Ceph официально поддерживалась только серверная основа FileStore. С применением FileStore данные OSD сохраняются в некоторой структурированной иерархии внутри файловой системы XFS, EXT4 или даже Btrfs. Оно пользовалось годами вызревавшей в своей основе кода такой файловой системы, а разработчики Ceph имели возможность сосредоточиться на прочих частях всей своей системы. Со временем, однако, а также поскольку оснащения Ceph становились всё крупнее, более занятыми и обширными, наличие ограничений обычных файловых систем - в особенности EXT4 - становилось всё возрастающей занозой в заднице разработчиков и администраторов Ceph.
Блестящая новая серверная основа BlueStore прозрачна для пользователей Ceph и во многом для самого Ceph.
При развёртывании Ceph, к примеру, с помощью популярной утилиты ceph-deploy
просто добавляется определённый переключатель -bluestore в саму командную
строку. Как мы будем обсуждать в Главе 6, Работа и сопровождение
и в Главе 8, Архитектура Ceph: под капотом, BlueStore
предлагает существенные улучшения производительности в сопоставлении со зрелой серверной основой FileStore.
Однако BlueStore достаточно нова и хотя и поддерживается официальной редакцией Luminous и далее, многие
администраторы Ceph дают ей возможность дозреть и доказать себя по крайней мере в редакции Nautilus прежде чем
сделать ставку своей [серверной] фермы на неё. Хотя все мы и любим лучше,
быстрее и дешевле, когда некий
отдельный кластер может обслуживать тысячи виртуальных машин или прочих клиентов
стабильность имеет неоспоримое преимущество.
Некоторые читатели данной книги будут исполнять кластеры Jewel или даже Hammer ещё какое- то время, поэтому пока её авторы страдают головокружением по поводу BlueStore, даже мы работаем с осторожностью. FileStore всё ещё поддерживается в Luminous и будет предсказуемо и в дальнейшем. При планировании развёртывания с нуля, мы предлагаем вам ознакомиться со статьями, блогами и списками рассылки, упомянутыми в Главе 2, Компоненты и службы Ceph для получения опыта работы с BlueStore на текущий момент времени для определённой версии точки Luminous (или Mimic, или Nautilus).
|
| Замечание |
|---|---|
|
Богатые данные о стимулах и архитектуре BlueStore можно найти в этой презентации Сэеджа Вейля, отца и проектировщика Ceph. Эти слайды настоятельно рекомендуются всем управляющим или рассматривающим некое оснащение BlueStore http://events.linuxfoundation.org/sites/events/files/slides/20170323%20bluestore.pdf. |
Мы также чрезвычайно рекомендуем вам попробовать его сначала в лабораторном или ToC кластерах, прежде чем принимать в промышленной реализации, или даже на вашем промышленном оборудовании прежде чем сделать General Availability (GA, Общую доступность) редакции для пользователей. Вы всегда сможете мигрировать с FileStore на BlueStore позже без разрушений для пользователей, если у вас не будет иметься сомнений относительно её безопасности. Выпуск Ceph Luminous также привнёс нам новые инструменты, которые делают пошаговое модернизации OSD (также имеющее название переукладки, repaving) даже ещё более простым:
-
ceph osd crush swap-bucket <src> <dest> -
ceph osd destroy
В Luminous или последующих выпусках имеется возможность подготовить замену OSD на некотором не используемом устройстве с последующим удалением имеющегося, либо частично переместить имеющиеся OSD для Переукладки в месте залегания. Каждый из подходов минимизирует перемещения данных и тем самым своё воздействие на пользователей. Представляйте себе первое как пересадку сердца, а второе как операцию на открытом сердце. {Прим. пер.: подробнее см. раздел Обновление OSD в вашем кластере в нашем переводе увидевшего свет в мае 2017 Полного руководства Ceph.}
Стратегия устройств OSD
При любой серверной основе, будь то FileStore или BlueStore, настоятельно рекомендуется в промышленном оснащении применять только один OSD на физическое устройство, будь то HDD или SSD. Инструменты и код Ceph разработаны исходя из этого подхода на уме; игнорирование этого может стоить вам непомерных накладных расходов поиска, износа устройства или проблем при работе, в том числе смешения правил репликаций CRUSH.
Аналогично вам предлагается развёртывать OSD непосредственно на подлежащие физические устройства, что противопоставляется томам оборудования, аппаратным или программным RAID. Когда- то имел смысл лежащий в основе RAID как некое средство сбережения оперативной памяти за счёт ограничения числа OSD, либо для специализированных областей отказа. Однако благодаря современному оборудованию и существенным усовершенствованиям и улучшениям в результате последовательных выпусков Ceph, привлекательность подобных стратегий имеет очень большую избирательность для необычных вариантов использования. К тому же, поскольку Ceph гарантирует собственную репликацию данных, наличие избыточности, предлагаемое лежащими в основе RAID была бы, ну ладно, избыточной, а зависящие от топологии скорости записи могли бы быть слишком ограниченными. Для большей части реализаций сложность управления и имеющийся потенциал для неожиданного или квазиоптимального поведения отдаёт сильное предпочтение правилу одно устройство == один OSD.
Журналы
Как это уже затрагивалось в Главе 3, Выбор оборудования и сетевой среды, при выборе FileStore каждого OSD необходим некий журнал. В оставшейся части этого раздела мы обсуждаем журналы, предполагая что применяется серверная основа FileStore, поскольку BlueStore не предполагает журналов как таковых. {Прим. пер.: маленькая, но существенная, неточность. Пусть она и не является журналом целиком, однако база данных метаданных BlueStore - RocksDB - благосклонно относится к расположению некоторой своей части на быстрых носителях и во многом (если не сказать почти во всём) уход за ней аналогичен обхождению с журналами. Точнее, механизм метаданных BlueStore предполагает наличие собственного журнала упреждающего чтения (WAL, write-ahead log) и самой БД метаданных. Так вот, журнал - он и в Африке журнал. Подробнее.... Впрочем, автор в последнем параграфе данного раздела допускает возможность такого применения быстрых устройсв при Переукладке OSD с FileStore на BlueStore, но всё равно это не оправдывает данную неточность: При установке с нуля BlueStore на медленных HDD стоит сразу задуматься о размещении WAL на более быстрых устройствах.} FileStore Ceph применяет журналы по двум причинам: производительность и целостность данных. Производительность записи случайных запросов небольшого размера улучшается путём их комбинирования в меньшее число более эффективных последовательных записей журнала. Ceph возвращает записи клиентам после требуемого числа копий записанных в журналы OSD, которые зачастую быстрее чем имеющаяся соответствующая файловая система OSD. Если аппаратный отказ возникает до того, как данные перенесены в некую файловую систему OSD, они могут быть восстановлены из имеющегося журнала. Важно не путать журналы OSD Ceph с внутренними журналами, которые современные файловые системы с протоколирвоанием или регистрацией применяют по соответствующим причинам.
Для каждого журнала OSD должен быть установлен определённый размер с тем, чтобы он не переполнялся между интервалами сброса; для вычисления этого значения можно было бы позволить по крайней мере удвоить ожидаемую скорость имеющегося устройства журнала помноженную на интервал сброса, который по умолчанию установлен в значение пяти секунд. Многие администраторы Ceph, однако, выбирают для удобства некий заведомо достаточный размер одного- размера- соответствующего- всем, составляющий 10GiB.
В своей предыдущей главе мы обсуждали выбор устройств для их назначения журналом. При развёртывании OSD FileStore с журналами у нас имеются два варианта:
-
Совместного размещения (colo, colocated)
-
Дискретизации
Совместно размещаемый журнал предоставляется в виде некоторого выделенного раздела в логическом окончании каждого устройства OSD. Таким образом, при журналах colo, ма журнал и главная файловая система расположены в двух разделах одного и того же устройства. Это эффективно с точки зрения оборудования: 10 ГБ является простейшим фрагментом для выделения из современных устройств со многими ТБ. Когда OSD предоставляется с журналами colo, на шпиндельных HDD, однако, производительность может пострадать. Даже при совмещении запросов каждой записи в некий заданный OSD усилением в отдельном журнале и записью в файловой системе, требуются дополнительные операции позиционирования (seek), выполняемые головками устройства. Такие операции seek относительно медленны и, таким образом, общая пропускная способность (IOPS) каждого OSD значительно снижается. Агрегированная пропускная способность всего кластера как целого может в конце концов значительно снизиться.
Журналы colo на устройствах HDD также имеют результатом намного более дальнее позиционирование, поскольку блок головок устройства челночно мотается между разделом журнала, который в любом случае располагается в самом конце устройства и самой файловой системой, которая разбросана по всей поверхности этого устройства. Такой шаблон позиционирований может также снизить агрегированную производительность. При применении SSD устройств для OSD, однако, будет естественным не выполнять перемещения и, тем самым, совместно расположенные журналы значительно менее проблематичны на SSD чем они же на HDD {Прим. пер.: ещё дальше идёт интерфейс NVMe, устраняющий ограничения AHCI на работу с очередями запросов, восходящие в своей основе к природе цилиндр- головка- сектор шпиндельных устройств.}
Некий дискретный журнал является располагающимся на устройстве, отличном от того, где находится сама файловая система OSD. Такая стратегия, при надлежащей реализации, имеет результатом значительный прирост производительности, поскольку накладные расходы записи (или усложнений) значительно снижаются, в особенности на устройствах HDD. Когда отдельные устройства HDD порой применяются как журналы, более распространённым является использование устройств хранения с наивысшей скоростью чтобы увеличить производительность. Так как журналам FileStore требуется всего несколько GiB в своём размере, вполне хватает устройств журнала с умеренным размером, что помогает минимизировать стоимость. Некое отдельное быстрое устройство журнала может также обслуживать множество устройств OSD, причём каждое настраивается на применение определённого раздела.
Предоставление SSD в качестве журналов для OSD вбирает в себя всплеск в вашей рабочей нагрузке. Однако, если журналы не быстрее вашего лежащего в основании файлового хранилища, они будут неким ограничительным фактором в производительности записи вашего кластера. При обычных SAS или SATA SSD, выступающих в роли журналов для OSD шпиндельных HDD, рекомендуется не превосходить соотношение 4 или 5 OSD на одно журнальное устройство. При использовании вместо них всё более доступных и популярных SSD PCI-e NVMe, можно обоснованно разделять журналы отдельного устройства вплоть до 10 или 12 OSD. Превышение этих соотношений будет иметь в результате бутылочные горлышки производительности, именно те, которые мы собирались обойти поставив на своё первое место быстрые журналы. Менее очевидным, но всё ещё важным является наличие области отказа: чем больше OSD обслуживает некое отдельное устройство журнала, тем больше будут наши потери в случае падения этого устройства. Таким образом, отказ некоторого отдельного устройства журнала может привести к выходу из строя множество OSD в одно и то же время; чем больше соотношение OSD : устройство журнала, тем большая часть всего кластера утрачивается. Поскольку мы всегда настраиваем свои промышленные кластеры Ceph не хранить более одной копии реплицированной копии данных на каждом хосте, мы не должны утратить какие- бы то ни было данные при отказах некоторого устройства журналов, однако, совместно с наличием узкого места, это является дополнительным основанием для ограничения данного соотношения.
|
| Замечание |
|---|---|
|
Неким дополнительным преимуществом быстрых PCI-e NVMe журналов является то, что они высвобождают отсеки устройств, которые могут применяться для дополнительных устройств OSD. Такое увеличение плотности OSD помогает смещаться в значении стоимости к более быстрым, выделенным устройствам журналов. {Прим. пер.: напомним ещё раз, что решения 2017 года уже предлагают NVMe устройства с горячей заменой, например, в компактном исполнении формфактора U2, которые также высвобождают место для OSD устройств.} |
Мы отметили, что OSD Ceph, построенные на своей новой серверной основе BlueStore не требуют журналов. Можно было бы предположить, что дополнительную экономию средств можно получать не имея потребности развёртывать устройства журналов и это может быть сущей правдой. Однако, BlueStore всё ещё получают выгоду от предоставления определённым компонентам более быстрого устройства хранения, в особенности, когда OSD развёртывается на относительно медленных HDD. Инвестиции сегодняшнего дня на быстрые устройства журналов FileStore для HDD OSD не будут потрачены впустую при миграции на BlueStore. при Переукладе OSD в качестве устройств BlueStore, имевшиеся ранее устройства журналов могут быть с лёгкостью применены для целей RockDB и данных WAL (write-ahead log). При использовании OSD на основе SSD такие сообщники данных BlueStore обоснованно могут размещаться совместно с хранилищем данных OSD. Для ещё большей производительности они могут улучшаться ещё более быстрыми NVMe или прочими технологиями для WAL и RockDB. Такой подход не является чем- то неизвестным также и для обычных журналов FileStore, хотя его и нельзя назвать не затратным. Кластеры Ceph, которым посчастливилось эксплуатировать SSD в качестве своих первичных устройств OSD, обычно не требуют дискретных устройств журналов, хотя варианты применения, требующие очень быстрых бит производительности могут оправдывать журналы NVMe. Кластеры SSD с журналами NVMe являются пока редкостью из- за своей дороговизны, однако они всё же имеются.
Файловые системы
Мы уже отмечали, что когда мы применяем для OSD Ceph серверную основу FileStore, имеется выбор лежащей в основе файловой системы. Хотя официально на протяжении определённого времени поддерживаются EXT4, XFS и Btrfs, EXT4 испытывает определённые неприятности изъянов, включая ограниченные возможности хранения необходимых XATTR метаданных, которые требуются Ceph. Начиная с редакции Luminous от выбора EXT4 в качестве файловой системы для FileStore вас настоятельно отговаривают и на самом деле её необходимо разрешать в явном виде, если она требуется, совместно с ограничениями обслуживания в возможностях OSD Ceph. Btrfs одновременно имеет и фанатов и хулителей. Какими бы ни были чьи- то чувства относительно неё, она не нашла широкого применения среди оснащений Ceph и тем самым информация внутри сообщества ограничена.
Это оставляет XFS как единственную файловую систему для выбора FileStore. Ceph строит файловые системы XFS
под FileStore применяя определённые параметры по умолчанию; регулируйте их только если вы в точности знаете
что вы делаете. Автор этих строк в своё время унаследовал некую архитектуру, которая была построена на тысячах
OSD файловых систем XFS с определённым дополнительным параметром n size=65536.
Это передписывало минимизировать применение ЦПУ кодом файловой системы, хотя Ceph даже близко не подступается к
тем вариантам использования где это вступает в игру. Плохой обратной стороной этого было то, что имеющийся
код ядра Linux не был оптимизирован для такой не устанавливаемой по умолчанию настройки, что в результате
приводило к отказам в выделении оперативной памяти, что в свою очередь вызывало замедление работы демонов OSD
и даже крахам системы.
Единственным возможным исправлением было очистить и повторно развернуть каждый OSD с параметрами XFS, устанавливаемыми по умолчанию, что было бы массивно затратным (хотя Luminous оснастил бы такой процесс достаточно быстро). В качестве неохотного обходного пути был выбран хак периодического сброса кэша ядра для дефрагментации оперативной памяти, что было уродливо, смущающе и как- то не естественно. Мораль этой истории состоит в том, что отклонение от устанавливаемых по умолчанию параметров XFS подвергает вас смертельной опасности.
Очень небольшое число ищущих приключений администраторов Ceph с необычными вариантами применения и малым объёмом определённости экспериментировали с FileStore поверх ZFS, хотя они были предоставлены сами себе при такой новейшей и пока не поддерживаемой стратегии.
Шифрование
Кластеры Ceph обычно обслуживают сотни и тысячи клиентов, а данные каждого из них нарезаются и разбрасываются по многим сотням устройств OSD. Такое смешение и рассеивание данных представляет нечто навроде барьера для потенциальных злоумышленников, которые могут получить физический доступ к вашим серверам и даже физически скрывать их. Однако когда данные на самом деле являются чувствительными, требования пользователя или организации должны требовать более сильной защиты в виде шифрования.
Имеются устройства хранения, которые реализуют шифрование данных на месте, что означает, что фактические данных сохраняются непосредственно в них. Self Encrypting Drive (SED, Самошифруемые устройства {Прим. пер.: ограничены для применения на территории РФ}) являются наиболее популярными из подобных подходов и широкое разнообразие моделей доступно для их реализации, хотя и с увеличением их стоимости по сравнению с обычными моделями. Устройства SED могут применяться Ceph прозрачно для пользователя, хотя управление необходимыми ключами может быть неудобным и громоздким.
Относительно новой альтернативой является программно определяемое шифрование, применяющее
dmcrypt. Просто добавляя ключ --dmcrypt
в командную строку ceph-deploy при создании OSD вы можете напрямую
указать Ceph создавать безопасные и зашифрованные разделы как для журнала, так и для данных OSD. Все ключи
шифрования сохраняются в базе данных MON. Некий третий, не зашифрованный раздел создаётся для некоего
ключа начальной загрузки OSD в обычном текстовом виде; он необходим для идентификации каждого OSD в имеющемся в
MON накопителе. Прежде чем некий OSD с разделом зашифрованных данных может быть активирован, он должен выполнить
некий вызов к имеющемуся накопителю MON, предоставляя свой код начальной загрузки для собственной аутентификации
в этом MON. Если такая попытка аутентификации успешна, этому OSD разрешается выгружать тот код шифрования,
который необходим для дешифрации и доступа к разделам журнала и OSD.
Для доступа к данным в обычном текстовом виде создаётся некий новый логический том в
оперативной памяти для каждого из разделов данных и журнала. Все записи в эти логических томах
шифруются перед своим размещением в соответствующих устройствах OSD и журнала, что обеспечивает что постоянно
хранимые данные сохраняются в безопасности постоянно. Сам код шифрования, получаемый из имеющегося накопителя
MON сохраняется только в оперативной памяти и уничтожается после того, как такие соответствующие логические
тома смонтированы и успешно открыты для доступа. Сочетание локальных зашифрованных разделов OSD с ключами
шифрования, хранимыми в основном MON делает очень низкой вероятность того, что злоумышленник будет способен
выполнить дешифрацию чувствительных данных. Применение dmcrypt на самом
деле требует дополнительного времени ЦПУ, однако для современных процессоров с большим числом ядер это редко
является проблемой.
|
| Замечание |
|---|---|
|
Дополнительную информацию по |
Существует ряд подлежащих рассмотрению моментов при принятии решения по развёртыванию операционной системы ваших кластеров Ceph. Некоторые, такие как совместимость подлежащих установке пакетов могут быть отрегулированы позже. Другие, в особенности определение размера и местоположения раздела загрузочного диска и файловых систем потребуют значительных усилий для изменения после своего свершения. Будет лучше тщательно спланировать заблаговременно начальную загрузку ваших систем.
Хотя некоторые ищущие приключений администраторы Ceph отработали развёртывание Ceph в прочих операционных
системах, таких как Solaris или FreeBSD, Ceph разработан для развёртывания в современных системах Linux.
Определённые разработчики могут строить Ceph из исходного кода, однако большинство площадок развёртывается
из предварительно построенных пакетов. Ceph доступен в виде как пакетов .deb,
для происходящих от Debian дистрибутивов, включая Ubuntu, так и в виде пакетов
.yum для семейства Red Hat, включающих RHEL и CentOS. SUSE также демонстрирует
значительное участие в Ceph и также предлагает пакеты.
Хотя лежащие в основе серверы Ceph работают целиком в пользовательском пространстве, зачастую имеются преимущества исполнения на практике самого последнего ядра Linux. Имеющиеся в накопитялях ядра последние дистрибутивы содержать достаточных для многих RHEL 7.4 и Ubuntu 16.04, хотя не является чем- то необычным для площадки отбирать самое лучшее или строить новое ядро чтобы получать преимущества самых последних драйверов, исправлений ошибок и улучшений производительности. {Прим. пер.: в качестве предостережения для энтузиастов сообщим, что Ceph применяет некие существенные особенности, присущие Linux, например, механизм epoll для однорангового обмена. Нельзя сказать что он не имеет схожих по действию движков в других операционных системах, однако это существенно осложняет процесс переноса.}
Пакеты Ceph
Некоторые дистрибутивы Linux предлагают скомпонованные пакеты Ceph для упрощения установки, которые невозможно разбивать для удобства. Однако это не всегда удобно в наши дни. Большинство администраторов Ceph выгружают предварительно построенные, готовые к употреблению установочные пакеты из имеющегося центрального репозитория https://download.ceph.com, хотя их также возможно построить из исходного кода, в особенности если имеется желание внести свой вклад в разработку или добавление индивидуальных свойств или тонких настроек.
Некоторые эталоны и инструменты программного обеспечения будут настраивать
download.ceph.com напрямую как репозиторий пакетов
apt или yum.
Это говорит о том, что он потребует минимальных усилий локально и гарантирует, что всегда доступны самые
последние пакеты выпусков точки. Проблемы данного подхода включают потенциал атак
MITM
(Man In The Middle, Злоумышленника в виде
посредника) если применяется URL HTTP вместо URL HTTPS, помимо некоторой зависимости от потенциально
медленного или часто отказывающего соединения Интернет. Существуют также промежутки времени, когда
имеющиеся центральные серверы отключаются по различным причинам и, что также не редкость, по причине
локальной политики безопасности, запрещающей системам промышленной эксплуатации прямое соединение с
внешним Интернетом.
По этой причине предлагается сопровождать некий локальный репозиторий пакетов Ceph, зеркалируемый с
официального сайта восходящего потока, причём в идеале вручную. Такие инструменты, как
createrepo, Pulp
и aptly облегчают управление локальными настраиваемыми пакетами
репозиториев. Можно также кататься следуя старой школе, копируя
.rpm и .deb
scp, Ansible или прочим инструментарием.
Развёртывания операционной системы
Здесь мы обсудим ряд моментов при определении самой установки базовой операционной системы на ваших серверах, а также варианты уровня платформы, которые облегчают управление системами Ceph.
В первую очередь зеркалируйте свои загрузочные устройства. Хотя хорошо спроектированная инфраструктура Ceph может быть легко скопирована при потере всего сервера целиком при отказе некоторого загрузочного устройства без зеркала, намного лучше избежать этого вида значимого внезапного события. Зеркалирование загрузочного устройства может быть осуществлено через HBA или программным образом при помощи системы Linux MD. Многие продуктовые линейки последнего времени предлагают сдвоенные отсеки устройств на задней панели или даже внутри для установки операционной системы. Ещё одна надёжная, но всё ещё доступная по цене стратегия - это пара SSD 100 - 200 GB корпоративного уровня, которые не съедают отсеки устройств на вашей передней панели, которые вы желаете заполнить OSD и потенциально устройствами журналов. Любая стратегия зеркалирования, конечно, является спорным вопросом если не отслеживается должным образом с тем, чтобы падающее / отказавшее устройство могло быть заменено прежде чем упадёт его партнёр.
Другим пунктом обсуждения при планировании установки вашей операционной системы является разбиение на разделы вашего загрузочного тома. Для современных систем и объёмов оперативной памяти обычная область подкачки (swap) на диске редко когда либо имеет существенное значение и лучше её не предоставлять. Кроме того, имеется ряд стратегий, которые изменяются в зависимости от локального вкуса и целей проекта.
Некоторые администраторы предпочитают предоставлять всё доступное пространство на имеющемся загрузочном
томе в виде единой корневой (/) файловой системы. Это имеет обоснованное
значение с точки зрения простоты и эффективности применения - вы никогда не обнаружите стопку своего
свободного пространства в некотором отличающемся от того, который вам необходим, разделе.
Прочие предпочитают расщеплять разделы своего дерева файловой системы ОС по множеству разделов. Такая
стратегия помогает ограждать части вашей системы друг от друга, ограничивая потенциал выхода из под
контроля для постановки под угрозу всей системы целиком. Например, на сервере OSD можно выделить в качестве
примера 50 GiB для вашей корневой операционной системы, 200 GiB для /var/log
и остаток под /home. В размещённых таким образом системах
непредсказуемое хранение файлов пользователями ограничено и ошибки не поставят под угрозу саму операционную
систему. Аналогично, если кто- то пойдёт неверной дорогой и rsyslogd
имеет повышенный объём сообщений, /var/log может заполниться, однако
вся прочая операционная система будет изолирована., что обеспечит непрерывность обслуживания. Можно также пожелать
предоставить /tmp в виде ramdisk или как некий выделенный раздел чтобы
и то что это пространство всегда будет доступным, когда оно потребуется, и что некий пользователь по недоразумению
не заполнит его и это не поставит под угрозу прочие части вашей системы.
В серверах Монитора Ceph /var/lib/ceph содержит часто изменяемые
файлы базы данных, которые содержат разнообразную информацию, которую сопровождают эти демоны. Мы действительно,
на самом деле, не хотим, чтобы изжоги вашего демона
ceph-mon, не имеющего рабочего пространства, поэтому может быть весьма
желательным выделить в отдельный раздел /var/lib/ceph чтобы
обеспечить, что ничего подобного не произойдёт. В процессе размеренной работы MON Ceph требуется всего лишь
небольшой объём GiB для хранения БД, некоторой функции от степени всего размера самого кластера. Однако
при расширении кластера, замене компонентов, сопровождении сервера, обновлении кода и прочих неустановившихся
изменений топологии БД MON может взвинчиваться временами до десятков GiB. Чтобы гарантировать, что такого рода
всплески не переполнят файловую систему и таким образом вызовут массовую печаль всех демонов, предлагается
выделять по крайней мере 100 ГБ для /var/lib/ceph на узлах MON.
Также настоятельно рекомендуется чтобы узлы MON применяли SSD вместо HDD. Автор текста присутствовал при
распростаняющемуся по всему кластеру каскадному выходу из строя из- за медленного хранилища MON. Наличие
гибкости разделов означает, что можно даже развёртывать отдельные устройства для
/var/log, /var/lib/ceph и
самой операционной системы с раздичными размерами и скоростями.
Обычным является централизованны сбор всех файлов журналов, либо механизмами
syslog, или инструментами, подобными имеющимся в стеке
ELK
(Elasticsearch, Logstash, and Kibana).
Имеется значительная польза от централизованного протоколирования., однако также может иметь смысл получать
журналы локально в каждой системе Ceph. По умолчанию компоненты /etc/logrotate.d
устанавливаются Ceph для удержания журналов локально только на протяжении семи дней; я рекомендую увеличивать
срок хранения, по крайней мере, до 30 дней. Даже при сжатии журналы MON и OSD Ceph могут быть достаточно
большими, в особенности когда что- то идёт не так, поэтому рекомендуем выделять по крайней мере несколько
сотен MiB для /var/log.
Синхронизация времени
Ceph требует, чтобы лежащие в основе серверы, в особенности его MON имели точно синхронизованные часы.
Ceph выдаёт предупреждение если MON испытывают более чем 50 мс асимметрию времени между собой, хотя
для современных инструментов суб- миллисекундная точность вполне достижима. Наш многоуважаемый демон
времени ntpd всё ещё работает, хотя более новый, свободный от
наследований chrony предоставляет более синхронную согласованность и
лучшую точность. Можно выполнять синхронизацию относительно внутренних корпоративных источников времени,
включая устройства с источником GPS или с общедоступных серверов. Настоятельно рекомендуется предоставление
множественного, распределённого наличия источников времени; все демоны быдут опрашивать их периодически и
выбирать наилучшую синхронизацию. Чем больше источников настроено, тем более устойчивой является ваша система
к сбоям, происходящим в подключениях и внешних источниках.
Другое замечание касательно времени: настройте все свои серверы и оболочки на отображение времени в UTC. Хотя это может быт несколько необычным ментально выполнять преобразования между UTC и вашей локальной временной зоной, может быть гораздо более запутывающим то, что серверы развёрнутые по всей стране и по всему миру не выполняют протоколирование временных штампов, которое согласуется друг с другом.
|
| Замечание |
|---|---|
|
Намного больше информации о настройке NTP (Network Time Protocol) и серверах можно найти на http://www.pool.ntp.org. Серверы времени высокого качества, которые обслуживают тысячи клиентов могут быть получены в виде источника из компаний, включающих в свой состав EndRun и Symmetricom. Новейшее, крайне гибкое устройство также предлагается NetBurner: https://www.netburner.com/products/network-time-server/pk70-ex-ntp. Этот небольшой, но не дорогой сервер может быть помещён почти в любом месте, где антенна может быть направлена в небо, в том числе у окна офиса. Он может обслуживать только ограниченное число клиентов, но может быть ценным при добавлении разнообразия источников в некую конфигурацию, применяющую не надёжные общедоступные источники, или в качестве источника для внутреннего разветвления серверов. Существует масса утилит и веб сайтов чтобы помочь в преобразованиях между временными зонами, например, автору этого текста нравится https://www.worldtimebuddy.com. |
Пакеты
Также рекомендуется применять богатый набор утилит для установки вашей операционной системы.
Это можно делать при помощи шаблонов для инструментов обеспечения, таких как Ubuntu
preseed или RHEL kickstart
или посредством систем управления подобных Puppet,
Ansible и Chef. Здесь перечень пакетов, которые
предлагает автор этих строк; конечно, вы можете подровнять его под свои потребности и предпочтения.
Названия пакетов, предоставляемые вашими дистрибутивами Linux могут разниться, например, RHEL и CentOS
emacs-nox вместо
emacs24-nox, который можно выбрать в Ubuntu 14.04.
-
Управление оборудованием
-
lshw -
lspci -
lsscsi -
pciutils -
mcelog -
ipmitool -
Утилиты HBA (
perccli,storcli,hpssacli)
-
-
Состояние системы и производительность
-
atop -
htop -
iotop -
dstat -
iostat(sysstat)
-
-
Редакторы (например,
emacs24-nox, илиmg, илиjoe -
Сетевые утилиты
-
subnetcalc, также имеющий названиеsipcalc -
mtr -
iperf
-
-
Разное
-
jq -
bc -
facter -
monkeytail, также имеющий названиеmtail -
tmux -
fio -
chrony -
ntpdate
-
Текущие версии Ceph могут работать как с адресацией IPv4, так и с IPv6, однако не с обеими одновременно.
Очень распространено для Ceph частную сеть, также именуемую сетью репликаций оставлять без маршрутизации IP,
например, RFC-1918 для сохранения адресного пространства или увеличения приватности. В то время как IPv6,
вполне возможно, наилучший путь в будущее, даваемое истощённой IPv4, многие организации не торопятся
мигрировать. Достаточно распространённым является применение обширной 10.0.0.0
RFC-1918 сетевой среды внутренне для систем, которые не нуждаются в достижении Интернета по большей части.
Это один из вариантов, которым организации отключают все сложности перехода на IPv6. Данный выбор вашего
развёртывания, скорее всего, не будет в ваших руках, однако его необходимо предусмотреть.
В Главе 3, Выбор оборудования и сетевой среды мы обсуждали стратегии построения сетей для кластеров Ceph. При разработке стратегии привязки вам необходимо будет работать совместно со своей сетевой командой, но мы предложим некоторые рекомендации. В любой топологии сети настоятельно рекомендуется настраивать кадры Jumbo по всем направлениям для достижения производительности.
Ceph может применять некую отдельную сетевую среду для общедоступного (MON и клиенты) и частного (репликации между OSD) обменов, хотя достаточно распространено разделять их в две отдельные физические или виртуальные сетевые среды. Если некий кластер (частной) сетевой среды не определён, Ceph применяет имеющуюся общедоступную сетевую среду для всего обмена.
Предпочтением авторов в настоящее время являются сдвоенные соединения 40 Gbit для каждой сетевой среды, хотя многие установки находят более экономичным достаточность связанных 10 Gbit соединений. Развивающиеся стратегии 25 Gbit демонстрируют некий компромисс и для стоимости и для гибкости {Прим. пер.: и к тому же делит нацело 100 Gbit}. Для промышленного оснащения любого масштаба в любом случае сетевые среды 1 Gbit скорее всего быстро станут узким местом и не рекомендуются. Если финансовые или инфраструктурные ограничения устанавливают предел для вашей сетевой архитектуры, если полоса пропускания должна быть не равной между имеющимися двумя, обычно лучше отдать больше частной сетевой среде репликаций, чем общедоступной сети клиентов. Так как не требует и действительно не должна маршрутизироваться или иметь достижимость извне, это может оказаться менее затратным вместо предоставления восходящих связей и портов коммутатора/ маршрутизатора ядра, которые в противном случае пришлось бы выделять.
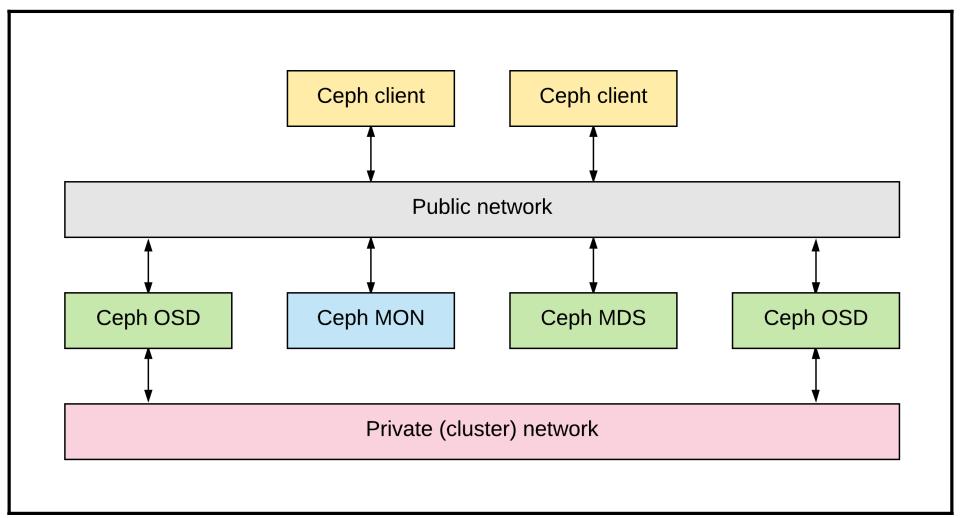
Также рекомендуется предоставлять дуальную коммутацию и пути кабелей с тем, чтобы каждая сетевая среда получала преимущества как от увеличения пропускной способности, так и устойчивость к отказам. Например, узел OSD Ceph с общедоступным и частным связываниями (bonds) разносит каждую из них с тем, чтобы даже общий отказ одного из NIC не имел результатом выход из строя тех OSD, которые зависят от данного сервера. Естественно, что связанные порты таким образом лучше всего связываются кабелями через сдвоенные параллельные коммутаторы ToR или прочую избыточную сетевую инфраструктуру.
Стратегия активный/ активный имеет преимущество над подходом активный/ пассивный. Системы могут эксплуатировать
возросшую агрегированную полосу пропускания и при этом срыв минимизируется если одно из соединений в имеющейся
паре отключается. Также предлагается настроить мониторинг соединений miimon,
скажем с частотой 100 мс.
Оснащения Ceph применяемые только для служб блочного хранения не нуждаются с сетевой балансировке нагрузки. При развёртывании имеющихся служб объектов RGW предоставление множества серверов за балансировщиком нагрузки является очень распространённой стратегией:
-
Рабочая нагрузка распределяется между серверами
-
Персональные перерывы в работе сервера прозрачны для пользователя
-
Клиенты изолированы от потенциальной динамики серверов RGW, которая получает преимущества мосштабируемости и сопровождения
-
Сетевая безопасность
Имеется множество типов сетевой балансировки нагрузки:
-
Проограммная, например,
haproxy,nginx,Envoy -
Аппаратные устройства о т таких кампаний как F5 или Cisco
-
Load Balancers as a Service (LBaaS), доступная в облачных платформах, включая OpenStack и Digital Ocean
Если вам требуются сетевые балансировщики нагрузки для пропускной способности и устойчивости к отказам, ваш выбор получит указания от имеющихся прецедента, а также практики вашей организации. Балансировка нагрузки с помощью программных средств haproxy является популярной, гибкой и простой в настройке, хотя по мере роста обмена большая пропускная способность аппаратных устройств может стать более привлекательной.
{Прим. пер.: вы можете получить существенные прирост производительности и разгрузки ЦПУ, воспользовавшись аппаратными возможностями RDMA современного сетевого оборудования}
В этой главе мы изучили длинный перечень факторов и подлежащих рассмотрению сторон при планировании ваших кластеров Ceph. Приманка для погружения непосредственно в заказы на покупку и оснащение является сильной, однако мы должны подчеркнуть преимущества тщательного планирования на будущее с тем, чтобы вы реализовали верную архитектуру для производительности, надёжности, масштабируемости и гибкости.
В нашей следующей главе мы развернём реальный работающий кластер Ceph в виртуальных машинах. Эта песочница поможет вам получить некое ощущение динамики развёртывания Ceph и даст возможность попрактиковаться с рядом операций развёртывания и сопровождения без фиксации н затратных и потребляющих временные ресурсы проектах с серверами.