Глава 2. Компоненты и службы Ceph
Содержание
Данная глава обсудит компоненты, службы Ceph и то как они совместно работают:
-
Демоны и компоненты, которые создают серверы Ceph:
-
RADOS
-
Мониторы (MON)
-
OSD
-
Диспетчер Ceph
-
RGW
-
-
Предоставляемые пользователю службы:
-
Блоки
-
Объекты
-
Файлы
-
Мы обсудим всё это по очереди и то, что они означают для администраторов и пользователей Ceph. Это установит почву для обсуждаемых в последующих главах тем.
Одним из преимуществ Ceph над прочими решениями хранения является имеющееся широкое разнообразие служб, которые могут предлагаться для управления в отдельном сервере.
Фундаментом Ceph является хранилище нижнего уровня, именуемое RADOS (Reliable Autonomic Distributed Object Store, Надёжное автономное распределённое хранилище объектов), которое предоставляет общую основу для множества потребляемых пользователями служб.
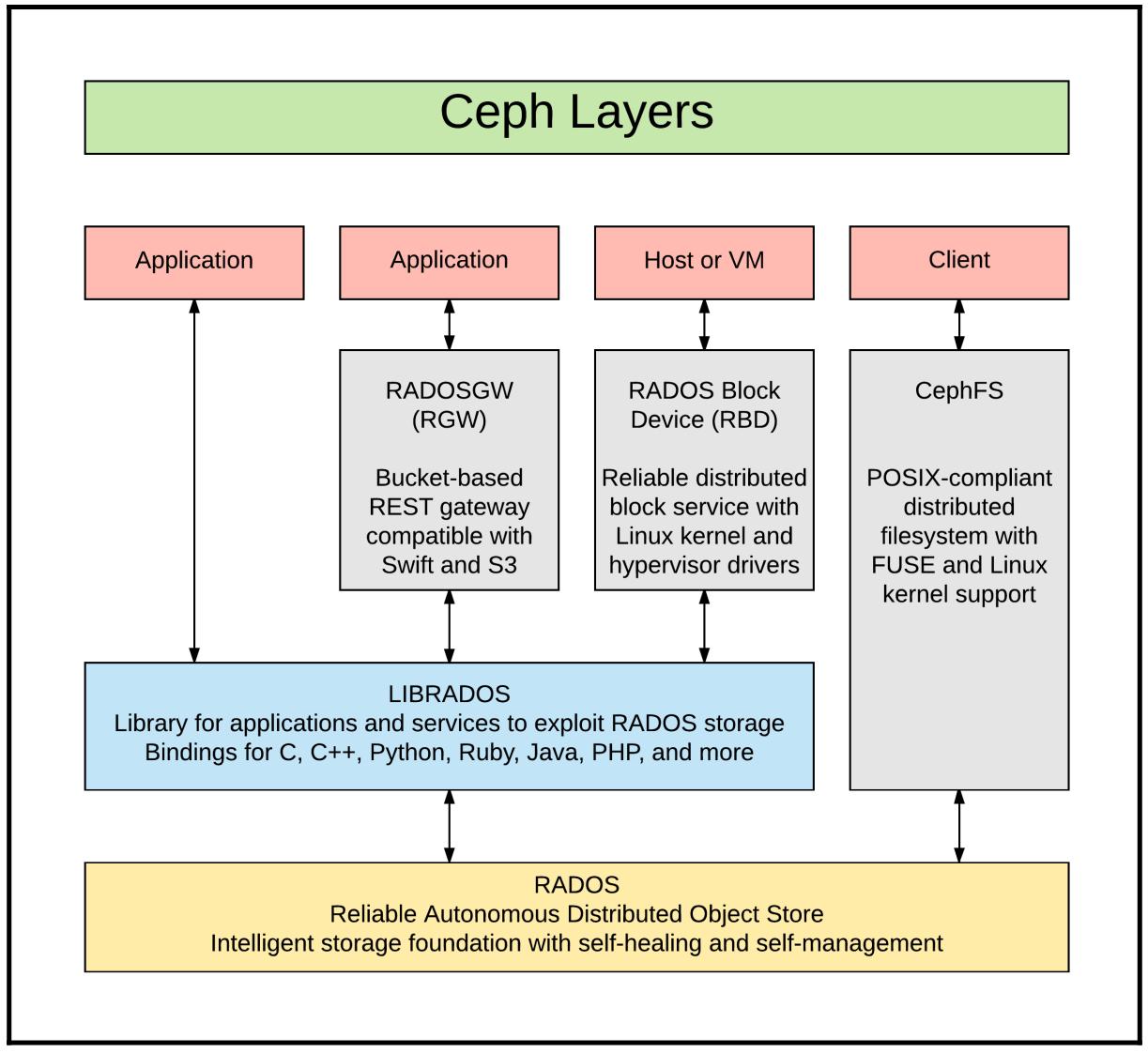
RADOS является неким системным уровнем хранения, который предоставляет инфраструктуру долговечности и доступности данных, поверх которой укладываются взаимодействующие с пользователем службы Ceph. RADOS это:
-
Высокая доступность при отсутствии единой точки отказа SPoF single point of failure
-
Надёжность и эластичность
-
Самовосстановление
-
Самоуправляемость
-
Приспособляемость
-
Масштабирование
-
То чего невозможно отыскать в Галактике
RADOS управляет всеми распределёнными данными внутри Ceph. Долговечность и доступность данных адаптивно сопровождается инициализацией операций, необходимых для восстановления в случае отказов компонентов и для балансировки самого кластера при добавлении ёмкости или её извлечении. Основополагающим для этого является алгоритм CRUSH (Controlled Replication Under Scalable Hashing, Управляемых масштабируемым хешированием репликаций), который будет подробнее обсуждён позже. RADOS обеспечивает то, что множество копий данных постоянно сопровождаются по всем определённым зонам отказа с тем, чтобы в случае если диски, хосты или даже стойки с оборудованием целиком отказывают, целостность данных и службы клиентов были в сохранности.
Из всей номенклатуры и всего жаргона внутри экосистемы Ceph, MON Ceph возможно являются наиболее дезориентирующим
названием. Хотя MON и осуществляют мониторинг состояния кластера, они также
являются чем-то гораздо большим. Они выступют в роли арбитра, гаишника на шоссе и врача- терапевта для всего
кластера целиком. Как и OSD, MON Ceph является, строго говоря, неким процессом демона
(ceph-mon), который одноранговым образом (peer) взаимодействует с MON,
OSD и пользователями, сопровождая жизненно важную информацию и распространяя её для работы кластера. На
практике этот термин также применяется для именования тех серверов, на которых исполняются эти демоны, то есть
Узлы монитора, узлы mon
или просто mon.
Как и все прочие компоненты Ceph, MON требуют распределённости, избыточности и высокой доступности и в то же время обеспечивают строгую согласованность данных на протяжении всего времени. MON осуществляют это, принимая участие в отвечающем современным требованиям кворуме, который применяет алгоритм с названием PAXOS. Рекомендуется предоставлять по крайней мере три монитора для находящегося в промышленной эксплуатации кластера, но при этом всегда нечётное число чтобы избегать проблемной ситуации, известной как раздвоение сознания, когда проблемы сетевой среды препятсвуют некоторым участникам общаться друг с другом с потенциальной возможностью когда более чем один из них полагает несущим на себе всю ответственность и, что ещё хуже, расходимость данных. Знакомые с прочими технологиями пользователями, например, Oracle Solaris Cluster ™ возможно уже сталкивались с данным понятием.
Помимо выполнения функции управления MON Ceph создают карты (maps) OSD, MON, PG (placement groups, групп размещения) и карт CRUSH, которые описывают то, где должны быть размещены и откуда необходимо получать данные. MON таким образом является распространителем таких данных: они распределяют начальное состояние и обновляют его друг для друга, OSD Ceph и пользователей Ceph. Внимательный читатель может спросить сейчас: "Эй, вы говорили что Ceph не имеет бутылочных горлышек централизованного хранения метаданных, кого вы пытаетесь обмануть?" Ответ состоит в том, что хотя эти карты и могут рассматриваться как некая разновидность метаданных, эти данные относятся к самому по себе кластеру Ceph, а не к данным пользователя. Секретным ингредиентом здесь является CRUSH, который более подробно будет рассмотрен позднее в данной главе. Алгоритм CRUSH работает с картой CRUSH и картой PG с тем, чтобы и клиенты, и сами серверы Ceph могли независимо определять где расположены определённые данные. Клиенты тем самым остаются с постоянно современными сведениями обо всём, что им необходимо для выполнения собственных вычислений которые напрямую указывают им их данные внутри всего созвездия OSD кластера. Позволяя клиентам динамически определять где располагаются их данные, Ceph делает возможным масштабирование без каких бы то ни было контрольно- пропускных пунктов или узких мест.
OSD предоставляют резервуар хранения всех пользовательских данных в рамках Ceph. Говоря в точности, некий
OSD является определённым процессом операционной системы (ceph-osd),
исполняемом в некотором хосте хранения, который управляет чтением, записью и целостностью данных. На практике,
однако OSD также применяется для обозначения всего лежащего в его основе собрания данных, самого устройства
хранения объектов, которым управляет данный OSD. Поскольку они оба тесно взаимосвязаны, также достаточно
обоснованно считать, что некий OSD является конкретной логической комбинацией самого процесса и лежащего в его
основе хранилища. Порой также можно обнаружить, что OSD применяется для обозначения целиком всего сервера/ хоста,
который размещает такие процессы и данные, хотя более правильно обозначать такой сервер/ хост как некий
узел OSD, который размещает многие десятки индивидуальных OSD.
Каждый OSD внутри некоего кластера Ceph хранит какое- то подмножество данных. Как это объяснялось в Главе 1, Введение в систему хранения Ceph, Ceph является распределённой системой без какого бы то ни было центрального узкого места. Многие традиционные решения хранения имеют одно или два головных устройства, которые являются всего лишь компонентами, с которыми взаимодействуют пользователи, некий контрольно- пропускной пункт и уровня управления и уровня данных, что приводит к наличию бутылочного горлышка и ограничений масштабирования. Клиенты Ceph, однако - виртуальные машины, приложения и тому подобное - взаимодействуют напрямую с самими OSD кластера. Операции Создания, Чтения, Обновления и Удаления (CRUD, Create, Read, Update, Delete) отправляются клиентами и выполняются самими процессами OSD, которые управляют лежащим в основе хранилищем.
Устройство хранения объектов (object storage device), которым управляет данный OSD, обычно некий отдельный HDD (Hard Disk Drive, жёсткий диск) или SSD (Solid State Device, твердотельный диск). Экзотические построения для такого основания хранения отдельного OSD не распространены, но и не являются не известными, и находятся в диапазоне от простого программного тома или тома RAID некоего HBA, вплоть до LUN или таргетов iSCSI во внешних массивах хранения, InfiniFlash SanDisk или даже ZFS ZVOL.
Ceph организует данные в единицах, именуемых PG (Placement Groups, Группами размещения). Некая PG обслуживается как определённая степень детализации с которой работают различные определения и операции в рамках данного кластера. Хорошо используемый кластер будет содержать миллионы объектов нижнего уровня, некое наполнение, которое является тяжеловесным для действий верхнего уровня. Группы размещения (PG) являются коллекциями объектов, которые группируются вместе и обычно исчисляются тысячами или десятками тысяч. Каждая Группа размещения сопровождает множество копий на разъединённых OSD, узлах, стойках или даже центроах обработки данных как ключевой части страсти Ceph к высоким доступности и живучести данных. Группы размещения распределяются согласно определяемым ограничениям во избежание создания горячих пятен и минимизации воздействия отказов серверов и инфраструктуры. По умолчанию Ceph сопровождает три реплики данных, реализуемые помещением некоторой копии каждой Группы размещения в трёх различных OSD, расположенных в трёх различных серверах. Для дополнительной независимости от отказов могут быть добавлены настройки, гарантирующие что эти серверы располагаются внутри трёх отдельных стоек центра обработки данных.
В каждый определённый момент времени одна копия OSD какой- то Группы размещения определена как первичная (primary), а остальные как вторичные (secondary); одним из важнейших отличий является то, что в этот момент все операции чтения и записи клиента направляются на такой первичный OSD. Все вторичные OSD, содержащие копии некоторой Группы размещения, могут трактоваться как резервные или вторичные; причём наиболее часто применяется именно последний термин. Последние редакции Ceph содержат некую альтернативу, называемую удаляющим кодированием (erasure coding); мы изучим её в последующих главах.
Созвездие OSD Ceph поддерживает периодическое взаимодействие друг с другом как для гарантии согласованности, так и для предприятия шагов в случае, если некий данный OSD становится недоступным. Когда некий определённый процесс OSD или хост рушится, оборудование или сетевая среда испытывают проблемы или по иной причине становятся недоступными, другие OSD в этом кластере выдадут сообщение о его отключении и начнут восстановление для поддержки адекватных копий данных.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Некий полный словарь терминов Ceph можно найти здесь. |
Редакция Kraken привнесла дебют демона Диспетчера Ceph (ceph-mgr),
который работает бок о бок с MON для обеспечения служб всего кластера посредством архитектуры подключаемых
модулей (plugins). Хотя эксплуатация ceph-mgr
всё ещё в стадии зародыша, он имеет большой потенциал:
-
Управление LED состояния/ местоположения диска и шасси
-
Создание и управление некоей карты клиентов, например,
rbd-mirrorи шлюза RADOS, которые ранее имели меньшую степень интеграции -
Целостное управление выскребанием (scrub) Ceph
-
Обогащение управления повторными операциями выставления весов и балансировки
-
Интеграция с внешними системами учёта, такими как RackTables, NetBox, HP SIM и Cisco UCS Manager {Прим. пер.: или Ansibe}
-
Взаимодействие с системами мониторинга/ измерения, такими как Nagios, Icinga, Graphite и Prometheus {Прим. пер.: или Zabbix и разнообразные средства мониторинга Python.}
|
| Замечание |
|---|---|
|
Дополнительные сведения можно найти здесь. |
Серверы RGW Ceph предлагают интерфейс в стиле API с высокой степенью масштабирования к данным, содержащимся в виде объектов внутри сегментов ("корзин" - buckets). Могут быть включены службы RESTful, совместимые как с S3 Amazon, так и со Swift OpenStack, включая непосредственную интеграцию с Keystone для множественности арендаторов.
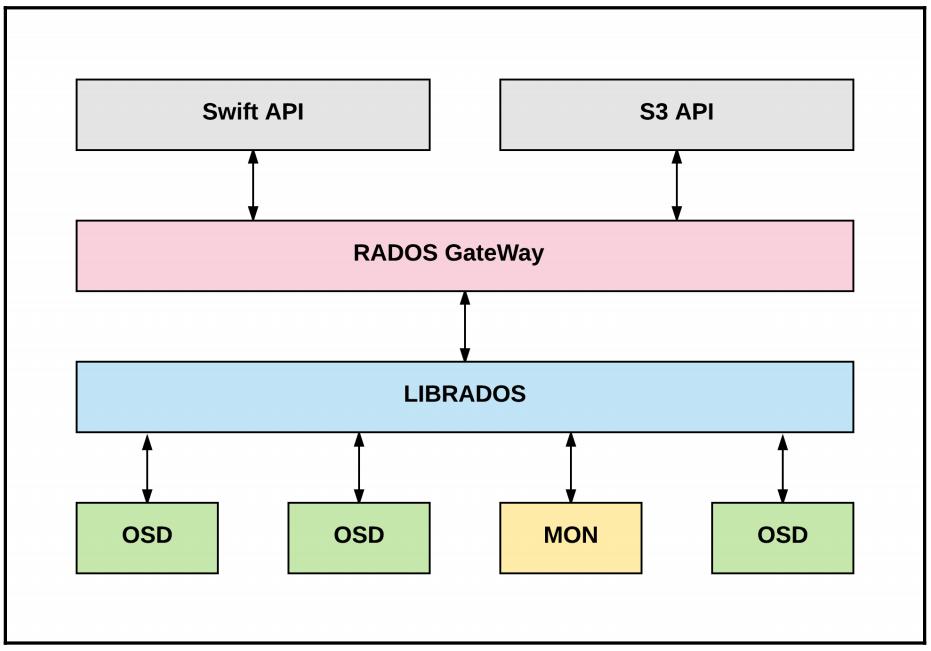
Как и в случае с MDS, компоненты RGW Ceph являются не обязательными; у вас нет необходимости предоставлять их в кластеры, котрые предназначены исключительно для предоставления блочных и файловых служб.
Управление кластером Ceph обычно осуществляется через некий набор инструментов командной строки (CLI, command-line interface). Хотя некотрые диспетчеры Ceph выполняют эти действия с одного или более хостов MON, прочие выбирают предоставление одного или более выделенных, отдельно располагающихся серверов для данной цели. Такие хосты администрирования требуют крайне мало ресурсов и легко реализуются как VM (Virtual Machines, Виртуальные машины) или даже цепляются прицепом к бастиону, переходу, шлюзу или прочим службам инфраструктуры. Одним из вариантов может быть совместное использование некоего имеющегося главного хоста Puppet или Ansibe, который вероятно установлен неким подходящим образом. Однако, будьте внимательны относительно предоставления предоставления хостов Администратора с циклическими зависимостями и избегайте их. Если вы применяете некий экземпляр OpenStack с каким- то загрузочным диском, который располагается в кластере Ceph, рано или поздно вы обнаружите что проблемы кластера, которые требуют воздействия не дают самому хосту администратора работать надлежащим образом!
Другой подлежащей рассмотрению стороной при работе в прицепе с необходимой вам ролью хоста администратора на одном или более узлов MON Ceph является то, что в процессе обновления программного обеспечения кластера и сопроводительных работ с оборудованием серверов, каждый из них может в свою очередь выполнять перезагрузку или испытывать прочие прерывания отсутствием доступа. Хотя это и не воздействует на операции кластера, это не предоставляет той непрерывности, которая необходима хосту администратора. По этой причине, как правило, предлагается предоставлять один или более хостов администратора, которые не размещаются на каком- либо из компонентов Ceph или зависят от них.
Чтобы управлять некоторой иерархией данных и выдавать её как представляемую в определённом контексте некотрой знакомой файловой древовидной организации, для Ceph требуется хранить дополнительные метаданные, задаваемые ожидаемой семантикой:
-
Полномочия
-
Иерархия
-
Имена
-
Временные штампы
-
Владельцы
-
Основная совместимость с POSIX, в целом
В отличии от наследуемых систем, MDS CephFS разработан чтобы удовлетворять масштабированию. Важно отметить, что реальные ланные файла не протекают через сам MDS Ceph: как и в случае с томами RBD, клиенты CephFS применяют саму систему RADOS для выполнения основных операций с данными напрямую совместо с немим масштабируемым числом распределённых демонов хранения OSD. Упрощённо говоря, сам MDS реализует некую уровень управления, в то время как RADOS реализует уровень собственно данных; на самом деле, все управляемые MDS Ceph метаданные в свою очередь размещаются на таких же OSD с применением полезной нагрузки содержимого данных/ файла в RADOS:
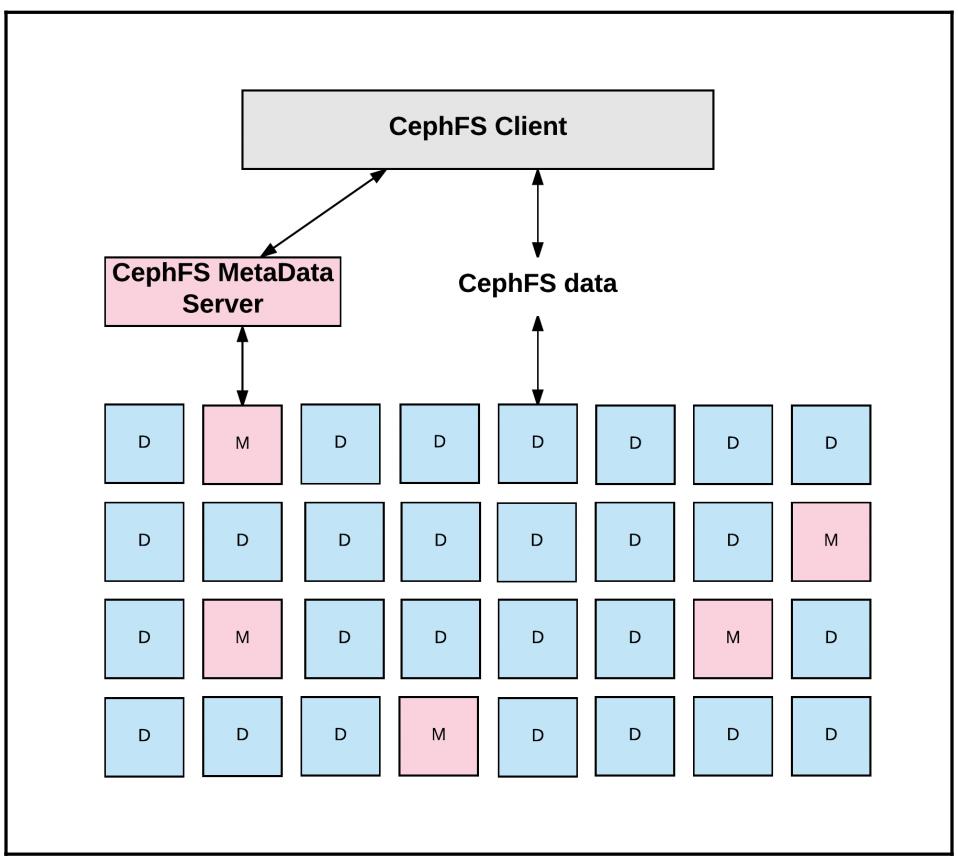
Следует отметить, что серверы MDS необходимы только если вы собираетесь применять интерфейс на основе файлов CephFS; большая часть кластеров, которая предоставляет только блочные и/ или объектные службы взаимодейтсвия с пользователем вовсе не нуждаются в его предоставлении. Также важно отметить, что CephFS лучше применять для серверов - неких служб B2B, если желаете - в отличие от B2C. Некоторые операторы Ceph экспериментировали с работой через NFS или Sambs (SMB/ CIFS) для предоставления служб напрямую клиентам рабочих станций, однако это следует рассматривать как перспективу.
Хотя CephFS является старейшим интерфейсом стороны клиента Ceph, он не получил такого числа клиентов, какое внимание уделяют пользователи и разработчики наличию блочных служб RBD и самого общего ядра RADOS. CephFS на самом деле не рассматривался как готовый к промышленному применению вплоть до выпуска Jewel в начале 2016 и, как я уже писал, всё ещё имеет определённые ограничения, в особенности одновременная работа множества MDS для предоставления масштабирования и высокой доступности всё ещё имеет проблемы. Хотя можно и нужно запускать множество MDS, для выпуска Kraken только один может быть активным безопасно в любое время. Дополнительные экземпляры MDS предлагаются для работы в роли ожидания для отработки отказа в случае падения имеющегося первичного. В редакции Luminous поддерживается множество активных экземпляров MDS. Ожидается, что последующие выпуски продолжат улучшать доступность и масштабируемость имеющихся служб MDS.
|
| Замечание |
|---|---|
|
Дополнительные сведения и обновления можно найти по ссылкам вариантов практического применения и обсуждения реализации POSIX. {Прим. пер.: основополагающей проблемой являются ноправданные ожидания на работу с метаданными через btrfs, в том числе с поддержкой транзакций (изменения по принципу всё или ничего). С переходом в Luminous на BlueStore в качестве применяемого по умолчанию средства хранения метаданных ситуация меняется кардинальным образом.} |
Сообщество Ceph является активной, растущей и жизненной частью всей экосистемы Ceph. Вклад кода, практики и неоценимого опыта работы Ceph на разнообразном оборудовании и в различном сетевом контексте для мириадов целей постоянно помогают рафинировать и улучшать опыт применения Ceph для всех и каждого.
Тем, кто заинтересован в разработке или изучении Ceph, в особенности рекомендуется проверять списки
рассылки ceph-announce и
ceph-users .
|
| Замечание |
|---|---|
|
Списки рассылки и прочие ресурсы сообщества можно найти на следующих сайтах: http://ceph.com/irc/#mailing-lists http://ceph.com/ceph-tech-talks И, конечно, справочная документация по Ceph доступна здесь: http://docs.ceph.com. |
Ceph предоставляет четыре различных интерфейса для своей общей основы хранения, причём кадлый из них разработан для особого варианта применения. В данном разделе мы опишем каждый из них и предложим пример из реального мира для того как его применять.
Служба RBD, вероятно, наиболее известная и на многих площадках она является основным или даже единственным приложением Ceph. Она предоставляет блокчное хранилище (также именуемое томом) тем же манером, которым приложения могут потреблять обычные HDD/ SSD с небольшой настройкой или без неё. Таким образом, это нечто аналогичное граням (facetes) VxVM™, Solaris Disk Suite (SVM™), системе Linux MD/LVM, устройствам iSCSI или Fibre Channel™, или даже ZFS™ ZVOL. Тома RBD, однако, естественным образом доступны множеству серверов в рамках имеющейся сетевой среды.
Можно построить некую файловую систему поверх кого- либо тома RBD, причём зачастую как определённое загружаемое
устройство некоторой виртуальной машины и в этом случае сам гипервизор является определённым клиентом данной службы
RBD и представляет такой том для конкретной гостевой операционной системы через имеющийся
virtio или драйвер эмуляции. Другие варианты применения включают прямое
сырое использование базами данных, напрямую подключая его к некоторой
физической или виртуальной машине через драйвер ядра. Некоторые пользователи находят том в построении логических
томов внутри своих экземпляров операционной системы поверх множества томов RBD для достижения производительности или
осуществления целей расширения. Блочное хранене подходит когда желателен ресурс подобный диску и при этом
предоставляет непротиворечивые производительность и латентность. Ёмкость предоставляется дискретными, разъединёнными
порциями, поэтому масштабирование вверх или вниз может быть затруднительным и сложным. Такие инструменты как
ZFS или некий диспетчер томов, такой как Linux LVM могут выполнять миграцию этого каким- то
образом, однако приложение с часто меняющимися томами данных - подумайте об изменениях на порядок - могут лучше
соответствовать некоторой модели хранения объектов.
Операции томов RBD включают считывание и запись обычных данных, а также создание и удаление. Возможно управление моментальными снимками для архивирования, работы с контрольными точками и извлечения связанных томов. Службы OpenStack Nova, Cinder и Glance (Глава 11, Настройка производительности и надёжности) применяют соответственно моментальные снимки RBD для экземпляров, абстрактных томов и образов гостевых ОС. Имеется средство реплицирования/ зеркалирования томов RBD между кластерами или даже площадками для высокой доступности и восстановления при чрезвычайных ситуациях.
Тома RBD часто применяются прозрачно виртуальными машинами и абтракициями, включающими OpenStack Cinder и
Glance, однако приложения и пользователи могут эксплуатировать их также применяя командную строку
rbd или программно через librbd.
Ниже приводится некий вариант применения:
Автору данной главы необходимо развернуть некую систему зеркал репозитория
yum внутри облоков OpenStack для использования арендаторами. Требования
ЦПУ и ОЗУ были низкими, однако требовался достаточно большой объём хранилища для зеркалирования растущих
собраний восходящих rpm и файлов метаданных для болього числа версий двух дистрибутивов Linux. Некий небольшой
предпочтительный экземпляр был выбран с 4ГБ ОЗУ и одним vCPU, но с томом виртуального диска имеющим только
50ГБ. Этот том 50ГБ, который сам по себе соответствует некоторому тому RBD быстро заполнялся по мере того, как
добавлялись новые версии пакета и новые дистрибутивы. Был применён интерфейс Cinder OpenStack к RBD для
предоставления некоторого тома с 500 ГБ, который был подключён к данному экземпляру, причём необходимы драйвер
virtio был представлен в /dev/vdb. На этом устройстве была создана файловая
система EXT4 и некая точка входа добавлена в /etc/fstab для монтирования
при каждой загрузке и при этом все данные полезной нагрузки были перемещены в их вместительный новый дом. Внимательный
читатель может предложить простое изенение размера данного первоначального тома. Это может быть возможным в
некоторых средах, однако более сложно и потребует дополнительные шаги.
Ceph естественным образом управляет объектами, однако критически важно не путать их с прочими применениями и названиями, в особенности в отношении хранимых объектов в жилах служб OpenStack Swift или Amazon S3. Служба RGW Ceph может применяться для предоставления хранения объектов, совместимого и со Swift, и с S3. Отметим, что при применении эта служба RGW Ceph использует один или более выделенных пулов (см. Главу 2, Компоненты и службы Ceph) и не могут применяться для доступа к томам RBD или прочим типам данных, которые могут располагаться внутри вашего кластера в своих собственных пулах. Данная служба представляется RESTfull со знакомым интерфейсом HTTP/HTTPS.
Служба RGW Ceph может располагаться на тех же самых серверах, что и сами OSD и их устройства в некоторой конвергентной архитектуре, однако более распространённым является выделять серверы или даже виртуальные машины для служб RGW. Среды с очень лёгкими вариантами применения могут совмещать их с демонами MON на физических серверах Ceph, однако имеется некая западня, и это следует делать аккуратно, возможно, даже применяя контейнеры или cgroup. Небольшие, слабо нагруженные или установки proof-of-concept (PoC, проверки концепции) могут выбирать некую виртуальную машину для простоты предоставления и содержания цены и пространства. Большие установки промышленного масштаба часто предоставляют серверы RGW на голом железе с целью производительности и для ограничения зависимостей и чтобы избегать каскадных отказов. Автор данной главы работал, но не рекомендует её, с комбинацией выделенных серверов RGW и ими же совместно размещающимися с MON Ceph на более современных серверах.
Обычно для достижения балансировки и высокой доступности службы по множеству экземпляров RGW применяется
haproxy или другое решение балансировки нагрузки, возможно, совместно с
keepalived. Общее число серверов RGW может масштабироваться вверх и вниз
в соотвествиии с требованиями рабочей нагрузки, причём не зависимо от прочих ресурсов Ceph, включая OSD и MON.
Такая гибкость является одной из множества проявляющихся преимуществ Ceph в сравнении с обычными решениями
хранения, включая аппаратные. Ceph может запросто применять ресурсы сервера, которыми вы уже знаете как управлять
без каких либо одиночных отличий при управлении шасси, поддержке контрактов или экономии компонентов. Обычным
будет даже миграция некоторого кластера Ceph целиком с одной операционной системы и одного производителя сервера
на другие без предупреждения пользователей. Ceph также допускает проектирование и расширение для изменения
применяемых байт, IOPS и смешения рабочих нагрузок без необходимости перегружать один компонент чтобы
масштабировать другой.
В версиях Ceph, предшествующих Hammer, служба RGW предоставлялась неким дискретным демоном для взаимодействия
с самим кластером,на пару с обычным Apache / httpd в качестве клиентского интерфейса. Это было хитроумным и сложным
для управления и, начиная с выпуска Hummer Ceph, эта служба была переработана на применение единого приложения
ceph.radowsgw со встроенным веб сервером Civetweb.
Некоторые крупные установки Ceph работают как чистые службы RGW, без каких - либо RBD или прочих клиентов. Гибкость Ceph является одной из её сильных сторон.
Объектное хранилище не предлагает низкой латентности операций и предсказуемой производительности, чем похваляется блочное хранение, однако масштабирование вверх или вниз может выполняться без каких либо усилий.
Потенциальным вариантом применения может быть некое собрание веб серверов, использующих Content Management System (CMS, Систему управления содержимым) для хранения неструктурированной смеси HTML, JavaScript, образов и прочего содержимого которое может значительно расти со временем.
CephFS, файловая система Ceph, имелась на протяжении достаточного времени и, фактически, самым первым вариантом применения сервера хранения Ceph. Хотя некоторые установки с применением CephFS и были успешными в промышленности на протяжении лет, только начиная с выпуска в 2016 версии Jewel была предоставлена официальная поддержка в противовес более раннему состоянию технического ознакомления (tech preview), а также завершённый набор инструментария управления/ сопровождения.
CephFS является чем- то схожим с NFS™, однако не является прямым аналогом. На самом деле, можно работать с NFS поверх CephFS! CephFS разработана для применения схорошо себя зарекомендовавшими серверами и не предназначается для повсеместного монтирования на рабочих станциях пользователей. Вы можете применять некий драйвер ядра операционной системы для монтирования какой- то файловой системы CephFS как это имеет место с локальным устройством или сетевой файловой системой Gluster. Существует также вариант драйвера пользовательского пространства FUSE. Всякая установка обязана взвесить два имеющихся метода монтирования: FUSE проще в обновлении, однако естественный драйвер ядра может предоставлять в какой- то степени лучшую производительность.
Монтирования клиента напрямую направляются к серверам MON кластера Ceph, однако CephFS требует одного или более экземпляров MDS для хранения имён файлов, каталогов и прочих обычных метаданных помимо управления доступом к OSD Ceph. Как и в случае с серверами RGW, небольшие и не перегруженные установки могут избирать исполнение демонов MDS в виртуальных машинах, хотя большинство выбирает производительность, стабильность и более простое управление зависимостями выделенных физических серверов.
Потенциальным вариантом применения является некая установленная архивная система построенная вокруг состарившегося файлового сервера, который требует полномочий и поведения файловой системы POSIX. Унаследованные файловые серверы могут быть заменены монтирование CephFS с небольшими настройками или без них.
Librados является общей опорой фундамента, при помощи которого прочие
службы Ceph работают за сценой. Также имеется возможность для приложений взаимодействовать напрямую с RADOS в
тех случаях, которые не идеально подходят для имеющегося верхнего уровня взаимодействия с RBD, RGW или CephFS,
однако имеется желание эксплуатировать присутствующие масштабируемость, сетевые возможности и защищённость
данных, которые предлагает Ceph вместо того чтобы повторно изобретать колесо. Имеются встроенные API RADOS для
множества языком программирования, включая C, C++, Ruby, PHP, Java, Erlang, Go, Haskell и Python.
{Прим. пер.: более того, обратим внимание на возможность локальной обработки данных
в самих узлах хранения как с применением встроенного интерпертатора Lua, так и выполняя построение
самостоятельного класса RADOS.}
Неким потенциальным вариантом применения является Vaultaire Time Series Database (TSDB). Vaultaire представляется как некая массивно масштабируемая база данных измерений с жилами RRDtool и Whisper (часть Graphite): http://www.anchor.com.au/blog/2014/06/vaultaire-ceph-based-immutable-tsdb/. {Прим. пер.: также обращаем Ваше внимание на воможность ознакомиться с данной темой на русском языке в нашем переводе Python для Cacti.}
Также имеется некий подключаемый модуль для популярной почтовой системы Dovecot, которая сохраняет сообщения электронной почты в виде объектов RADOS: https://github.com/ceph-dovecot/dovecot-ceph-plugin и https://www.mail-archive.com/ceph-users@lists.ceph.com/msg40429.html.
{Прим. пер.: лично нам представляется очень перспективным направление разработки приложений с асинхронной распределйнной обработкой данных, которую сделал возможной новый AsyncMessenger Ceph. Подробнее в нашем эссе Распределённые вычисления поверх Ceph RADOS и AsyncMessenger.}
В данной главе мы затронули необходимые и не являющиеся обязательными компоненты вашего кластера Ceph, а также те службы, которые он предоставляет. В последующих главах мы поможем вам выбрать правильное оборудование для вашего собственного решения, изучим ряд критически важных решений и зависимостей, а также пройдём виртуальное развёртывание и задачи общего сопровождения и мониторинга.