Глава 4. Базы данных и их система памяти
Содержание
- Глава 4. Базы данных и их система памяти
- Система управления базой данных
- Базы данных в памяти
- Типы баз данных
- Реляционная модель
- Управление хранением базы данных
- Структуры индекса данных
- Хранение данных: диски и файлы
- Структурированные деревом индексы
- Индексы на основе хэша
В наши дни базы данных занимают важное место в любом деле. Всякий раз когда вы посещаете выбранный веб сайт, такой как Google, Ebay, Amazon.com или тысячу прочих предоставляющих сведения площадок, имеется некая база данных, обслуживающая запрашиваемую информацию. Кроме того, Базы данных пребывают в самом ядре многих научных исследований. Они представляют данные, собираемые астрономами, исследователями человеческого генома и биохимиками, изучающими белки, помимо многих прочих научных интересов.
Некая Система управления базой данных в памяти (In-Memory Database Management System) это система управления базой данных, которая в первую очередь при хранении, управлении и манипуляции данными полагается на основную память. Это исключает существенные задержку и накладные расходы хранения на жёстком диске и снижает тот набор инструкций, который требуется для доступа к данным. Для разрешения более действенного хранения и доступа сами данные могут храниться в сжатом формате.
Традиционные Системы управления базами данных при доступе перемещают данные с диска в память в кэш или в буферный пул. Перемещение этих данных в память превращает данные с повторным доступом в более действенные, однако сама постоянная потребность перемещения данных способна вызывать проблемы с производительностью. Производительность приложения и запроса может быть значительно улучшена по причине того, что данные в Системах управления базами данных в памяти расположены в оперативной памяти.
В данной главе мы обсудим методы хранения Базы данных, в основном применяемые в Системах управления базами данных отношений (реляциями) в памяти и файлов.
База данных это коллекция сведений, которые существуют длительное время, часто на протяжении многих лет. Сам термин базы данных относится к некому собранию данных, которые управляются Системой управления базой данных (DBMS, Data Base Management System). От DBMS ожидается:
-
Разрешать пользователям создавать новые базы данных и определять их схемы (логические структуры их данных) при помощи специализированного языка определения данных (DDL, data-defnition language).
-
Предоставлять пользователям возможность выполнения запросов самих данных (запрос это вопрос к базе данных относительно имеющихся данных) и изменять эти данные, применяя некий подходящий язык, часто именуемый языком запросов или языком манипуляции данными.
-
Сопровождать собственно хранилище с очень большим числом данных (со множеством терабайт или более) на протяжении длительного времени, допуская действенный доступ к своим данным на запросы и изменения базы данных.
-
Обеспечивать надёжность, восстановление базы данных в случае сбоев, ошибок множества видов или преднамеренного неправильного применения.
-
Управлять одновременным доступом к данным множества пользователей, причём не позволяя не ожидаемое взаимодействие между пользователями (что носит название изоляции) и без действий над данными, над которыми производятся пока не завершённые действия (что именуется атомарностью).
На Рисунке 4.1 мы наблюдаем схему завершённой DBMS [16].
В самом верху Рисунка имеются два различных источника команд к этой DBMS:
-
Обычные пользователи и прикладные программы, которые запрашивают данные или изменяют их.
-
Администратор базы данных: персона или персонал, отвечающие за установленную структуру или схему самой базы данных.

Команду второго типа проще обрабатывать и мы отображаем её след, начинающийся в правом верхнем углу Рисунка 4.1. Например, администратор базы данных, иначе DBA (database administrator), может принять решение для базы данных регистратора университета [16], что должна быть таблица или отношение со столбцами студентов, пройденным ими курсом и оценкой данного студента по этому курсу. Этот DBA также может решить что единственными доступными оценками выступают A, B, C, D и F.
Данная структура и сведения ограничения это всё часть общей схемы имеющейся базы данных. На Рисунке 4.1 показано как это вводится таким DBA, которому требуется особая авторизация на исполнение команд видоизменения, ибо они способны иметь серьёзные последствия для всей базы данных. Такие команды изменения схемы языком определения данных (DDL, data-defnition language) синтаксически разбираются процессором DDL и передаются в механизм исполнения, который затем следует через диспетчер индексации/ файлов/ записей для изменения соответствующих метаданных, то есть сведений о самой схеме этой базы данных.
Преобладающее большинство взаимодействий с DBMS следует путём из левой стороны Рисунка 4.1. Некие пользователь либо прикладная программа инициализируют какое- то действие при помощи Языка манипуляции данными (DML, data-manipulation language). Такая команда не влияет на установленную схему самой базы данных, но может обрабатываться двумя обособленными подсистемами следующим образом.
-
Ответ на Запрос: Для получаемого запроса компилятором запросов выполняются синтаксический разбор и оптимизация. Получаемый в результате план запроса, или последовательность действий самой DBMS выполнит ответ на данный запрос, передаваемый в механизм исполнения. Этот механизм исполнения активирует некую последовательность запросов к меньшим частям данных, обычно к записям или кортежам отношения (relation), к диспетчеру ресурсов, которому известно относительно файлов данных (содержащих отношения), установленного формата и размера записей таких файлов, а также к индексным файлам, которые способствуют быстрому поиску элементов файлов данных.
Такие запросы на данные передаются в диспетчер буфера. Основная задача этого диспетчера буфера состоит в привнесении частей необходимых данных из вторичного хранилища (диска), в котором они хранятся постоянно, в имеющиеся буферы основной памяти. Обычно, элементом обмена между буферами и диском выступает страница или блок диска. Для получения необходимых данных с диска данный диспетчер буфера взаимодействует с диспетчером хранения. Соответствующий диспетчер хранения может вовлекать в процесс команды операционной системы, однако более типично, когда сама DBMS активирует команды непосредственно соответствующему контроллеру дисков.
-
Обработка транзакций: Запросы и прочие действия DML группируются в транзакции, которые представляют собой подлежащие атомарному и изолированному друг от друга исполнению элементы. Любой запрос или действие изменения обязаны сами по себе представлять некую транзакцию. Кроме того, само исполнение транзакция обязано быть надёжным, что означает, что всякая исполненная транзакция обязана сохраняться даже в случае отказа системы неким образом сразу после выполнения такой транзакции. Мы делим сам процессор транзакций на две основные части:
-
Диспетчер управления одновременностью, или планировщик, ответственный за гарантию атомарности и изоляции транзакций и
-
Диспетчер ведения журнала и восстановления, отвечающий за долговечность транзакций.
-
Собственно данные базы данных обычно располагаются во вторичном хранилище. В современных вычислительных системах вторичное хранилище обычно подразумевает магнитный диск. Тем не менее, для осуществления любых полезных действий с данными такие данные обязаны пребывать в основной памяти. Контроль за помещением данных на диск и их перемещение между диском и основной памятью именно и составляет задание диспетчера хранения.
В простой системе управления базой данных имеющийся диспетчер хранения может быть ничем иным как своей файловой системой лежащей в его основе операционной системы. Тем не менее, для целей эффективности, DBMS обычно управляет хранилищем на диске напрямую, по крайней мере в определённых ситуациях. Такой диспетчер хранения отслеживает местоположение файлов на соответствующем диске и получает необходимый блок или блоки, содержащиеся в запрашиваемом от своего диспетчера буфера файле.
Соответствующий диспетчер буфера отвечает за разбиение на разделы всей доступной основной памяти на буферы, которые представляют собой области со страничным размером в которые могут передаваться блоки дисков. Тем самым, все компоненты DBMS, которым требуются сведения со своего диска будут взаимодействовать с буферами и своим диспетчером буферов, причём либо напрямую, либо через механизм исполнения. Основные виды сведений, которые могут требоваться различным компонентам содержат:
-
Данные: содержимое самой базы данных.
-
Метаданные: схему этой базы данных, которая описывает её структуру, а также ограничения в этой базе данных.
-
Записи журнала: сведения о самых последних изменениях для этой базы данных; они поддерживают долговечность такой базы данных.
-
Статистические сведения: информация получаемая и сохраняемая самой DBMS относительно таких свойств данных как размеры и значения различных отношений или прочих компонентов своей базы данных.
-
Индексы: струкутры данных, которые поддерживают эффективность доступа к имеющимся данным.
Обычным делом является группирование одной или более операций базы данных в некую транзакцию, которая представляет собой некий элемент обработки, который обязан исполняться атомарно и в явной изоляции от прочих транзакций. Кроме того, DBMS предлагает определённую гарантию долговечности: а именно, что выполненная транзакцией работа никогда не будет утрачена. Имеющийся диспетчер транзакций, таким образом, принимает команды транзакции от некого приложения, которые сообщают этому диспетчеру транзакций когда начинает и завершается транзакция, а также сведения относительно имеющихся ожиданий этого приложения (некоторые, к примеру, могут не желать атомарности). Такой процессор транзакций осуществляет следующие задачи:
-
Ведение журнала: Для гарантии долговечности, всякое изменение в самой базе данных отдельно регистрируется на диске. Установленный диспетчер регистрации (журнала) следует одной из нескольких политик, спроектированных для гарантии того, что ни прикаких обстоятельствах отказа системы или в случае возникновения "крушения", диспетчер восстановления будет обладать возможностью изучить имеющийся журнал изменений и восстановить свою базу данных до некоторого согласованного состояния. Диспетчер журнала изначально записывает некую регистрацию в буферы и договаривается со своим диспетчером буферов о гарантии того, что эти буферы записаны на диск (где данные способны пережить крушение) в надлежащее время.
-
Управление одновременностью: Транзакции обязаны появляться исполняемыми изолированно. Однако в большинстве систем будет иметься большое число исполняемых транзакций, суммарный эффект которых точно такой же, как если бы такие транзакции фактически исполнялись совместно, по одной за раз. Обычный планировщик выполняет свою работу поддерживая блокировку определённых частей данных своей базы данных. Такие блокировки препятствуют доступу двум транзакциям к одному и тому же фрагменту данных с плохим взаимодействием. Обычно блокировки сохраняются в таблице блокировок основной памяти, как это представлено на Рисунке 4.1. Имеющийся планировщик воздействует на необходимое исполнение запросов и прочие действия базы данных запрещая механизму исполнения доступа к заблокированным фрагментам базы данных.
-
Разрешение взаимных блокировок: Поскольку транзакции конкурируют за ресурсы посредством предоставляемых их планировщиком блокировок, они способны попадать в ситуацию, при которой ни одна из них не способна продолжаться по причине того, что каждой из них требуется нечто, имеющееся у другой транзакции. За вмешательство и прекращение (откат или прерывание) одной или более транзакций для того чтобы позволить им выполняться далее несёт ответственность диспетчер транзакций.
Та часть DBMS, которая более всего ответственна за производительность, наблюдаемую пользователем, является процессором запросов. На Рисунке 4.1 такой процессор запросов представлен двумя компонентами:
-
Компилятор запроса, который транслирует сам запрос во внутренний вид, носящий название плана запроса. Последний это последовательность подлежащих исполнению операций над соответствующими данными. Часто такие операции в плане запроса представляются операциями реляционной алгебры. Сам компилятор запросов составлен из трёх основных элементов:
-
Синтаксический анализатор запроса, который строит структуру дерева полученного запроса в текстовом виде.
-
Препроцессор запроса, который осуществляет семантическую проверку полученного запроса (т.е. убеждается что все упомянутые в данном запросе отношения действительно существуют) и выполняет некоторые преобразования в дереве превращая дерево разбора в дерево алгебраических действий, представляющих первоначальный план запроса.
-
Оптимизатор запроса, который преобразует свой первоначальный план запроса в наилучшую из доступных последовательностей операций со своими реальными данными.
Данный компилятор запросов пользуется метаданными и статистическими сведениями относительно имеющихся данных для принятия решения о той последовательности операций, которая скорее всего должна быть самой быстрой. Например, наличие индекса, который представляет специальную структуру данных, снабжающую доступ к данным, представленный для значений по одной или более компонент этих данных, способен превратить один план в намного более быстрый нежели иной.
-
-
Механизм исполнения:, который отвечает за исполнение всех шагов избранного плана запроса. Этот механизм исполнения взаимодействует с большинством прочих компонентов своей DBMS, либо непосредственно, либо через имеющиеся буферы. Он обязан получать необходимые данные от своей базы данных в буферы для манипуляции с этими данными. Для избежания доступа к блокируемым данным ему требуется взаимодействие со своим планировщиком, а также с диспетчером журнала чтобы гарантировать надлежащую регистрацию всех изменений базы данных.
В системе баз данных в основной памяти (MMDB, main memory database system) данные располагаются в основной физической памяти; в то время как в обычной системе баз данных (DRDB) резидентом выступает именно диск [64].В DRDB данные диска данные для доступа могут кэшироваться в память; в MMDB обитающие в памяти данные могут обладать резервной копией на диске. Тем самым, в обоих случаях, определённый объект способен обладать копиями как в памяти, так и на диске. Основополагающим отличием выступает то, что в MMDB первичная копия обитает именно в памяти, а это обладает важными реализациями (подлежащими обсуждению), как в отношении их структурной организации, так и в в отношении доступа.
По мере того как полупроводниковая память становится более экономичной, а плотность микросхем растёт, становится осуществимым хранить в памяти базы данных всё большего и большего размера, превращая MMFDB в реальность. Поскольку к данным становится возможным осуществлять доступ непосредственно в памяти, MMDB способны предоставлять намного лучшие отклики по времени и пропускную способность транзакций по сравнению с DRDB. Это в особенности важно для приложений реального времени, когда транзакции должны осуществляться в определённые им сроки окончания.
Очевидно что основная память компьютера обладает отличными от магнитных дисков свойствами и эти различия оказывают чрезвычайное воздействие на проектирование и производительность самой системы баз данных. Хотя такие отличия и хорошо известны, будет неплохо их вкратце пролистать [64].
-
Значение времени доступа для основной памяти на порядки величин меньше чем у дисковых хранилищ.
-
Основная память обычно энергозависима, в то время как дисковое хранилище нет. Тем не менее, имеется возможность (за некую цену) построить энергонезависимую основную память.
-
Диски обладают высокой, фиксированной стоимостью доступа, которая не зависит от величины выбираемых в процессе такого доступа данных. По этой причине диски являются ориентированными на блочное хранение устройствами. Основная память не ориентирована на блочное хранение.
-
Устанавливаемая схема расположения данных на диске намного более критична нежели схема расположения данных в основной памяти, поскольку последовательный доступ к диску быстрее произвольного доступа. Для основной памяти последовательный доступ не столь существенен.
-
Основная память обычно обладает прямым доступом из своего процессора (процессоров), в то время как диски нет. Это может превращать данные в основной памяти в более уязвимые к программным ошибкам, чем обитающие на диске данные.
Эти отличия оказывают воздействие практически на все стороны управления базами данных, от управления одновременностью до взаимодействия с приложением [64].
На протяжении последних пятидесяти лет управление базами данных с применением вычислительных систем предпринимало множество подходов, таких как:
-
Небольшие системы на момент времени, которые пользуются для хранения данных единственным файлом.
-
Системы обработки файлов, которые хранят данные в большом числе файлов.
-
Реляционные базы данных.
-
Базы данных объектов.
-
Базы данных NoSQL.
Начиная с семидесятых (1970) именно реляционные базы данных стали преобладающими на поле систем баз данных. Тем не менее, в последние годы для заполнения имеющегося зазора реляционных систем стали применяться базы данных объектов и NoSQL. [12].
В данной главе мы обсуждаем исключительно реляционные базы данных.
В модели объекта для представления сведений в виде объектов система баз данных пользуется парадигмой объектной ориентации. Такой подход отличается от реляционной модели, которая ориентирована на таблицы. Системы управления объектно- ориентированными базами данных пытаются сочетать системы баз данных с с объектно ориентированными языками программирования. По этой причине программисты обладают возможностью последовательного сопровождения в одной среде. ОО подход к проектированию и реализации баз данных предпочтителен для сложных приложений, в которых уровень отношения между объектами низок, например, в [12]:
-
Проектировании вычислительных средств
-
Географических информационных системах
-
Системах искусственного интеллекта и в экспертных системах
NoSQL это сокращение для Not Only SQL (не только SQL) и база данных NoSQL для хранения и выборки данных предоставляет отличающиеся от реляционной базы данных механизмы. Обычно данные в базе данных NoSQL структурированы в виде некого дерева, графа или ключа- значения вместо табличного отношения, а язык запросов обычно также не SQL. База данных NoSQL мотивирована своей простотой, горизонтальным масштабированием и более тонким контролем доступности, а также обычно компромиссом в пользу доступности и частичной отклоняемости [51].
При наличии тенденции "Память это наш новый диск" базы данных NoSQL в памяти преуспевают в последние годы. Имеются такие хранилища ключ- значение как Redis [52], RAMCloud [53], MemepiC [54], Masstree [55] и MICA [64]. К тому же существуют такие хранилища документов как MongoDB [56], Couchbase[57], графовые базы данных наподобие Trinity [58], Bitsy [59], базы данных RDF (Resource Description Framework), например, OWLIM [60] и WhiteDB [61].
Существуют некоторые системы, которые являются частично размещаемые в памяти, например MongoDB [56], MonetDB [62], MDB [63], поскольку они применяют файлы соответствия памяти для хранения данных, доступ к данным в которых может осуществляться так, как если бы они пребывали в памяти.
В реляционной модели системы баз данных это коллекция отличающихся по времени отношений с желательными ограничениями и свойствами, что увеличивают эффективность и действенность управления самой базой данных. Вот некоторые характеристики отношений:
-
Сами отношения осмысливаются и реализуются в виде файлов. Всякое отношение содержит один тип записи. Каждое отношение обладает первичным ключом, выбираемым из некого множества кандидатов на ключи.
-
Всякий тип отношения составлен из атомарных атрибутов. Тем самым, каждый атрибут определяется в неком домене (или типе данных) и может обладать лишь допустимыми из этой области значениями.
-
Отношения организованы в множествах, которые содержат один и тот же тип отношений.
Сама модель отношений по большей части основывается на теории множеств, а она определяет все возможные операции, которые могут выполняться над его множествами, например [12]:
-
Проекция
-
Соединение
-
Произведение
-
Объединение
-
Пересечение
-
Вычитание
Реляционные базы данных реализуют те операции, которые определены в их модели отношений.
Таблицы
В системе реляционной базы данных таблицы применяются для реализации экземпляров реляционных множеств. Таким образом, таблицы являются не сортированными коллекциями записей (или отношений) одного и того же типа [13]. Для таблиц система \ предлагает такие свойства управления как:
-
Создание таблицы
-
Удаление таблицы
-
Вставка кортежа
-
Удаление кортежа
-
Выборка кортежа
Индексы
Индексы это структуры, которые производятся из таблиц баз данных. Они выступают ответом на необходимость оптимизации доступа к записям таблицы. Таблицы содержат не сортированные записи. Тем не менее, индексы организуют записи таблицы в соответствии с потребностями доступа своего приложения. Имеются два семейства индексов [13]:
-
Диапазон индексов, приспособленный для оптимизации выбора диапазона записей.
-
Индексы соответствия, подходящие для оптимизации необходимого соответствия выборки записей.
Индексация это лучший вариант нежели хранение записей в некой сортированной таблице так как они обладают лучшими характеристиками производительности при вставке, удалении или проходу по ним.
Система управления базой данных определяет для работы с данными подмножества язык манипулирования данными (DSL, data sub-language), например, SQL или Structured Query Language (язык структурированных запросов) это отраслевой стандарт для определения таблиц и доступа к данным. DSL это типичный метод, применяемый в качестве некого внешнего интерфейса пользователя; он имеет отношение именно к объектам данных и операциям базы данных. Эти характеристики составляют четвёртое поколение языка (4GL) [14].
Подмножество языка манипуляций данными может быть подразделено на следующие категории [12]:
-
DDL или язык определения данных (data defnition language) применяется для определения всех объектов базы данных, который составляет необходимую концептуальную схему, то есть оператор создания таблицы.
-
DML или язык манипулирования данными (data manipulation language) используется для содействия манипуляции данными. DML обычно содержит язык запросов, то есть оператор вставки в таблицу.
-
DCL или язык управления данными (data control language) служит для настройки среды контроля управления данными самим конечным пользователем, то есть оператор установки переменной.
Рабочая нагрузка в системе баз данных определяется как полный набор запросов, которые система базы данных получает за определённый период времени. Не имеет значения, оцениваются ли эти заявления или исполняются. Тип заявления, получаемых системой баз данных, полностью зависит от работающего поверх базы данных приложения. Однако рабочую нагрузку можно определять для оптимизации шаблонов доступа к базе данных и обеспечению наилучших характеристик производительности приложения. Такая характеристика рабочих нагрузок баз данных также применяется администраторами баз данных для сопоставления всех имеющихся в продаже различных систем управления базами данных, поскольку их количественное описание выступает основополагающей частью всех исследований оценки производительности [15]. Вот некоторые обычные типы рабочих нагрузок базы данных:
-
OLTP: Online transaction processing - Обработка транзакций в реальном времени. Приложения карт покупок в основном применяют рабочие нагрузки OLTP.
-
Аналитика. Это системы с доступом только на чтение, которые хранят исторические данные ведения дел для получения отчётов.
-
Поддержка решений на основе данных. Эти системы интегрируют взаимодействующие возможности, предоставляемые системой управления или пользуются агрегирующей функцией в самой базе данных.
-
Batch/ELF: ELF это сокращение для Efcient, lightweight, fast - действенных, обладающих малым весом, быстрых транзакций. Этот тип приложений для обычно гигантского набора данных применяет небольшие транзакции.
Хранимые в системе управления базами данных (DBMS) должны сохраняться на протяжении исполнения программы, перезапуска машины и перезагрузки баз данных. Таким образом, они должны храниться во внешних устройствах хранения. Тем не менее, чтобы DBMS обладала способностью работать с данными, они должны иметься в памяти.
Основной базовой абстракцией данных в DBMS выступает некое собрание записей или файл, причём всякий файл составлен из одной или более страниц. Эти файлы и методы доступа тщательно организовывают данные для поддержки быстрого доступа к желаемым подмножествам записей. Для действенного применения систем баз данных существенно понимание того как организованы записи.
Минимальным элементом сведений на диске выступает страница, причём все обмены между основной памятью и вторичным устройством хранения должны осуществляться элементами в одну страницу. Обычно стоимость ввода/ вывода страницы доминирует в общей стоимости всех операций базы данных. Таким образом, системы баз данных аккуратно оптимизируются с целью минимизации этой стоимости [13].
Когда у нас имеется доступ к собранным множеством способов записей, помимо эффективной поддержки различных видов выбора содействие может оказывать техника с названием индексирования. В этом разделе мы сделаем введение в индексацию, важную сторону организации файла в DBMS.
DBMS хранит обширные количества данных и эти данные должны быть сохранными в процессе исполнения программ. Таким образом, данные хранятся во внешних устройствах хранения, таких как диски и ленты и подлежат выборке в основную память по мере необходимости их обработки. Основным элементом считываемым с диска или записываемым на него сведений выступает страница. Значение размера страницы это некий параметр DBMS и его обычные величины это 4кБ или 8 кБ.
Значение стоимости страничного ввода/ вывода (ввод с диска в оперативную память и вывод из памяти на диск) преобладает в общей стоимости типичных операций базы данных и системы баз данных тщательно оптимизируются для минимизации этой стоимости. Тем временем, ниже в этой главе рассматриваются основные подробности того как сохраняются физически файлы записей на диске и как применяется основная память.
Разработку базы данных направляли следующие постулаты:
-
Диски выступают наиболее важными устройствами хранения.
-
Ленты являются устройствами последовательного доступа и побуждают вашу систему считывать одну страницу за другой {Прим. пер.: во многом это относится теперь и к современным дискам большой ёмкости, использующим черепичный метод записи множества блоков за одну операцию записи, подробнее, в наших переводах Что представляют собой Зонированные хранилища и Инициатива Зонированных хранилищ?}.
-
Всякая запись в неком файле обладает уникальным идентификатором, носящим название id записи (rid, record id).
-
Данные только считываются в память для обработки и записываются на диск для сохранности. {Данное утверждение не верно для баз данных В памяти, в которых все данные располагаются в памяти на протяжении всего времени, а ко вторичным хранилищам доступ выполняется только для целей восстановления после сбоев.}
-
Управление буферами привносит соответствующую страницу с диска когда она уже не в памяти.
Данные считываются в память для обработки и записываются на диск для постоянного хранения неким уровнем программного обеспечения, носящим название управления буферами. Когда имеющимся файлам и уровню методов доступа (которые зачастую именуются просто файловым уровнем) требуется обработать некую страницу, они запрашивают своего диспетчера буферов выбрать необходимую страницу, задаваемую значением rid страницы. Если эта страница ещё не в памяти, имеющийся диспетчер буферов выполняет выборку такой страницы с диска.
Пространство на диске , в соответствии с архитектурой DBMS, управляется диспетчером дискового пространства. Когда соответствующим файлам и уровню методов доступа необходимо дополнительное пространство для сохранения в файле новых записей, они запрашивают у своего диспетчера пространства диска выделения некой дополнительной страницы диска для такого файла. Они также информируют своего диспетчера дискового пространства когда они больше не нуждаются в своих страницах на диске. Именно диспетчер диска отслеживает используемые страницы на файловом уровне. Когда страница высвобождается на своём файловом уровне, диспетчер пространства отслеживает это и если его файловый уровень и повторно пользуется данным пространством если такой файловый уровень позднее запрашивает новую страницу.
Подобный файл записей это важная абстракция в DBMS и он реализуется соответствующим уровнем файлов и методов доступа в своём коде.
Система базы данных способна выполнять в неком файле пять следующих основных операций:
-
Создание
-
Уничтожение
-
Вставка
-
Удаление
-
Сканирование
Операция сканирования это особенная операция, которая позволяет пользователю шагать по всем записям в некой таблице, по одной за раз. Такая операция сканирования критически важна, поскольку именно она составляет основу более сложных операций реляционной алгебры, например, проекций.
Наиболее непосредственной структурой таблицы выступает некий неупорядоченный файл или куча. В подобной схеме основанная на куче таблица хранит свои запис произвольным образом по имеющемся в такой куче страницам. Сама база данных способна создавать различные структуры данных поверх таблицы, такие как индексы, которые выступают той структурой, которая организует записи данных на диске для оптимизации определённых видов операций выборки [13]. Отдельное собрание записей способно обладать множеством индексом с применением различных ключей поиска для оптимизации различных наборов операций выборки. Некий индекс, который содержит свой первичный ключ носит название первичного индекса и именно он обеспечивает отсутствие дублирований; прочие индексы именуются вторичными индексами.
Индекс это структура данных, которая организует записи данных надиске для оптимизации определённых видов операций выборки. Некий индекс позволяет нам действенно выполнять выемку всех записей, которые удовлетворяют условиям поиска по значению полей ключа поиска в установленном индексе. Также мы имеем возможность создания дополнительных индексов на заданном собрании записей данных, причём каждая с иным ключом поиска, для ускорения операций поиска, которые не поддерживаются действенным образом установленной организацией файла, применяемого для хранения своих записей данных.
Сам термин записи данных применяется для обозначения тех записей, которые хранятся в неком индексном файле. Некая запись данных со значением k ключа поиска обозначается как k<sup>*</sup> и содержит достаточно сведений для определения места (одной или более) записей данных со значением k ключа поиска. Мы можем эффективно выполнять поиск некого индекса для нахождения необходимых желательных записей данных и затем применять его для получения записей данных (когда они отличаются от записей данных).
Для того чтобы хранить записи данных в виде некого индекса существуют три основных альтернативы:
-
Запись данных h это некая реальная запись данных (со значением k ключа поиска).
-
Запись данных это какая- то пара (k, rid), где rid это идентификатор соответствующей записи в записи данных со значением k ключа поиска.
-
Запись данных это пара (k, rid- list), где rid-list это список идентификаторов соответствующей записей тех записей данных, которые имеют значение k ключа поиска.
Обратите внимание, что если индекс применяется для хранения реальных записей данных, вариант (1), всякая запись b это запись данных со значением k ключа поиска. Мы можем представлять себе такой индекс как некий особый случай организации файла. Такая организация индексированного файла, например, может применяться вместо сортированного или неупорядоченного файла записей.
Варианты (2) и (3), которые содержат записи данных, указывающие на записи данных, не зависят от установленной организации файла, который применяется для их индексируемого файла (то есть того файла, который содержит сами записи данных). Вариант (3) предлагает лучшую загруженность нежели вариант (2), однако записи данных отличаются по длине в зависимости от значения числа записей данных с определённым значением ключа поиска.
Если мы хотим построить более одного индекса на неком собрании записей данных - скажем, мы желаем выстроить индексацию для собрания записей о сотрудниках как по возрасту, так и по порядку - нам надлежит пользоваться максимум одним из индексов варианта (1), потому как нам следует избегать многократного хранения записей данных.
Кластерная организация индекса
Некий кластерный индекс это организация файла для лежащих в его основе записей данных. Записи данных могут быть любого размера; следовательно их репликация не желательна. Кластерная индексация менее затратна нежели сопровождение полностью сортированного файла. Тем не менее, она всё ещё затратна в плане поддержки. К кластеризации следует подходить ответственно и лишь тогда, когда от неё напрямую выигрывают разнообразные запросы [13].
Кластеризация может оказываться полезной в следующих ситуациях:
-
Самих сведений в соответствующем индексе ключа поиска достаточно для разрешения необходимого запроса.
-
Определённые записи данных могут обладать одним и тем же значением ключа.
Составной ключ поиска
Установленный ключ поиска по некому индексу может содержать несколько полей; такие ключи поиска носят название составных или соединённых ключей. Составные ключи полезны при следующих обстоятельствах:
-
Запросы на эквивалентность, в которых каждое поле в ключе поиска ограничено константой.
-
Некий индекс соответствует критерию выбора когда сам индекс может применяться для выборки только тех кортежей, которые удовлетворяют такому условию.
-
Составные запросы, в которых значение подобного индекса способно их разрешать.
Индексация составных ключей поиска поддерживает широкий диапазон запросов, поскольку они соответствуют большему числу условий чем индексация с единственным ключом поиска. Такая возможность увеличивает имеющиеся возможности для оценок исключительно по индексу. К сожалению, составные индексы нуждаются в сопровождении в ответ на любые операции, которые изменяют любое поле в их ключе поиска. Кроме того, составные индексы, вероятно, будут иметь больший размер [13].
Имеются два основных способа организации записей данных:
-
Индексация на основе хэша: При данной схеме для быстрого поиска записей, которые обладают заданным ключом поиска, записи организованы с применением хэша. Имеющаяся структура индекса внутренним образом содержит некое множество сегментов. Каждый сегмент состоит по крайней мере из одной первичной страницы и, возможно, дополнительных вторичных страниц. Эти страницы хранят соответствующие идентификаторы записей (id) от своего файла. Для значения ключа поиска необходимого сегмента, к которому относится запись, сама система применяет функцию хэширования. Отметим, что значением ключа поиска может быть любая последовательность полей и нет необходимости указывать записи уникальным образом. Если же это имеет место, такой индекс носит название уникального индекса [16].
-
Индексация на основе дерева: записи данных, упорядочиваемые сортируемым образом деревом индексов определяются значением ключа поиска и некой иерархической структурой, которая поддерживается для поддержания соответствия поиску необходимых записей данных. В такой структуре дерева в качестве точки входа для любого поиска имеется узел корня. Имеющиеся указатели узлов листьев этого дерева отделяются значениями ключа поиска. Данная структура наилучший способ для определения места всех точек данных при помощи значения ключа поиска в указанном диапазоне желаемых [16].
Как мы видели в предыдущих главах, память имеет ранг в некой иерархии: в самой вершине у нас имеются регистры процессора, затем основная память, после этого вторичная память, которая составлена дисками и, наконец, третьесортнные устройства хранения, такие как ленты.
Более медленные устройства хранения, такие как ленты и диски играют в системах баз данных значительную роль по той причине, что имеющиеся количества данных обычно массивны и лишь подобные устройства способны содержать их полностью. Тем не менее, чтобы система работала с любыми данными; эти данные должны присутствовать в памяти.
Диски поддерживают прямой доступ к любому требуемому месту. Приложения баз данных широко применяют диски. В них всё хранится в блоках, поскольку такие блоки это наименьший элемент данных. Контроллер диска осуществляет взаимодействие устройства диска с компьютером. Он реализует команды считывания и записи сектора.
Тот элемент, которым данные обмениваются между диском и памятью выступает блок. Для работы DBMS с данными, им требуется обмен с диска в память и наоборот. К сожалению, даже когда требуется единичный байт, выполняется обмен для целого блока. Значение времени для считывания сохранённого на диске блока разнится в зависимости от физического местоположения самих таких данных. Это наблюдение подразумевает, что занимаемое операциями базы данных время существенно подвержено влиянию самой организации данных на дисках.
По существу, две часто применяемые совместно записи также должны обитать поблизости друг от друга. Для снижения значения общего времени ввода/ вывода соответствующей системы баз данных очень важно пользоваться организацией записей на диске с тем, чтобы предпочтительно выполнять считывания и сохранение записей последовательно [13].
Потенциально диски выступают узким местом в отношении производительности и надёжности систем хранения, поскольку они содержат механические элементы {Прим. пер.: или обладают ограничение на общее число перезаписей для SSD}. Диски обладают намного более высокой частотой отказов чем любые иные электронные части вычислительной системы. Дисковый массив это некая компоновка нескольких дисков, организуемая для увеличения производительности или улучшения надёжности получаемой в результате системы хранения.
Дисковые массивы делают возможным:
-
Увеличение производительности чередованием данных
-
Увеличение надёжности посредством избыточности
RAID или избыточные массивы (redundant arrays) независимых дисков это массивы дисков, которые реализуют некое сочетание чередования и избыточности данных [13].
Чередование данных
Чередование данных это метод, при котором данные разбрасываются по множеству дисков. Сегменты данных системы в разделах равного размера распределены по множеству дисков. Собственно элементом чередования выступает значение размера раздела, а сами разделы обычно распределяются при помощи простого карусельного алгоритма.
Получаемое в результате чередование улучшает производительность считывания и записи, поскольку доступ к разным дискам может осуществляться одновременно [18].
Избыточность
В то время как наличие большего числа применяемых дисков для чередования данных повышает производительность системы, это также снижает общую надёжность системы хранения (значение среднего времени отказа), поскольку независимо друг от друга способны испытывать отказ большее число дисков. Система увеличивает надёжность дисков через сохранение избыточных сведений. В случае отказа диска такая исзбыточная информация применяется для повторного построения данных, содержавшихся на отказавшем диске. Подобные избыточные сведения либо хранятся на меньшем числе проверенных дисков, либо единообразно распределяются по всем дискам. Для сбережения места на дисках большинство избыточных дисковых систем хранят в качестве избыточных сведений бит чётности. В подобно схеме с чётностью может применяться дополнительный проверочный диск для восстановления отказа на любом из дисков в общей системе.
Такая RAID система разбивает имеющийся дисковый массив на группы надёжности. Группа надёжности это множество дисков и множество дисков проверки [18].
Уровни избыточности
Всякая система обладает собственными требованиями для избыточности и производительности. Тем самым, системы RAID могут настраиваться с применением одного из следующих пяти определений, предлагающих различные компромиссы между производительностью и избыточностью данных [18]. {Прим. пер.: на самом деле таких определений существует бесконечное счётное множество, причём и на практике применимо намного больше пяти. Механистическое соединение в уровень 6 разных вариантов избыточности, например, которые к тому же способны сочетаться с чередованием, на наш взгляд делают туманным представление о реально применяемых технологиях построения массивов с избыточностью и чередованием. На практике практически не наблюдаются приводимые ниже уровни 2-4, в то время как весьма распространён уровень 60, а в больших системах хранения весьма существенны различия в тех массивах, которые здесь объединены в Уровень 6, подробнее в наших переводах книг о Ceph и ZFS, скажем, Удаляющее кодирование в Изучаем Ceph, 2е издание, Энтони Д'Атри, Вайбхав Бхембре, Каран Сингх, 2017 Packt Publishing}:
-
Уровень 0: Система RAID без избыточности. Применяет лишь чередование данных для увеличения максимально доступной полосы пропускания.
-
Уровень 1: Зеркалирование. Вместо наличия одной копии данных два различных диска хранят идентичные копии данных.
-
Уровень 0+1: Чередование и зеркалирование. Иногда также именуемый RAID уровня 10, он сочетает чередование и зеракалирование.
-
Уровень 2: Коды исправления ошибок. Элемент чередования представляет собой один бит. Применяемая схема избыточности представляет собой код Хэмминга. По причине элемента чередования все диски всякий раз требуют операции считывания; по этой причине Уровень 2 показывает хорошую производительность для рабочих нагрузок с большим числом больших запросов.
-
Уровень 3: Побитовая чередующаяся чётность. Единственный диск проверки со сведениями чётности и одним битом в качестве элемента чередования. Этот Уровень обладает наименее возможными накладными расходами, единственным диском.
-
Уровень 4: Чётность с чередованием блоков: Единственный проверочный диск со сведениями о чётности и блоком в качестве элемента чередования.
-
Уровень 5: Распределённая чётность с чередованием блоков. На данном уровне сведения о чётности равномерно распределяются по дискам, а единицей данных выступает блок. Данный уровень устраняет узкое место четвёртого уровня, вызываемое единственным диском. Данный уровень показывает наилучшую производительность для системы RAID {Прим. пер.: Весьма сомнительное утверждение, Уровень 0+1, например, обладает намного лучшей производительностью}.
-
Уровень 6: Избыточность P+Q. Основным мотивом для этого уровня выступает его способность к восстановлению отказа более чем одного диска. Такой уровень 6 обладает специальной возможностью, в особенности важной для гигантских дисковых массивов. Уровень 6 RAID применяет коды Реда- Соломона для восстановления при отказах дисков. {Прим. пер.: На наш взгляд здесь упущена важная для практики подробность того факта, что при выходе из строя одного диска и после его замены система приступает к восстановлению, при котором интенсивность работы дисков резко возрастает, а следовательно растёт и риск выхода из строя ещё одного диска, следовательно второй избыточный диск тут будет весьма кстати. Уровень 60, к тому же, обладает весьма высокими показателями производительности.}
Выбор уровня RAID
Различные конфигурации RAID полезны в различных ситуациях. В зависимости от требований системы её системный администратор может выбирать один уровень вместо другого. Ниже приводятся суммарные сведения о том как проектировщик может выбирать один уровень вместо другого:
-
Уровень 0: Когда потеря данных не проблема, он улучшает производительность системы.
Уровень 0+1: Полезен для небольших подсистем хранения и предоставляет наилучшую производительность записи.
-
Уровень 3: Подходит для рабочих нагрузок, составленных в основном запросами большого обмена непрерывных блоков.
-
Уровень 5: Приемлем для любых рабочих нагрузок с небольшими или большими запросами.
-
Уровень 6: Хорош когда требуются более высокие уровни надёжности.
Диспетчер дискового пространства систем баз данных поддерживает основное понятие страницы в качестве элемента данных и предоставляет команды для выделения или изъятия страниц или записи страниц. Он часто применяется для выделения последовательных страниц блоков для хранения данных, к которым часто осуществляется доступ последовательным образом. Такой диспетчер дискового пространства скрывает все подробности лежащего в его основе оборудования и позволяет более верхнему уровню оборудования представлять данные как собрание страниц [13]. Тем не менее, диспетчер дискового пространства отслеживает на своём диске используемые блоки, а также какие страницы в каких блоках. Весьма вероятно, что последовательно подчинённые выделения и высвобождения создают внешнюю фрагментацию, однако такие пробелы в самом диске могут добавляться в списки свободных для последующего применения [13] без каких- либо действий пользователя.
Как правило, ОС поддерживает диск в качестве некого файла с последовательными байтами, который в дальнейшем преобразуется в операции считывания и записи в блок на диске. Диспетчер дискового пространства отвечает за управление пространством в таких файлах ОС, когда он строится с применением самой операционной системы.
Диспетчер буфера это тот уровень программного обеспечения, который отвечает за привнесение страниц с диска в основную память по мере их необходимости. Для осуществления этого диспетчер буфера разбивает всю доступную память на собрание страниц. Названием этой коллекции выступает пул буфера. Дополнительно к такому пулу буфера наш диспетчер буфера также хранит сведения относительно каждой страницы, такие как изменённые данные (dirty byte) и число контактов (pin count). Бит изменённых данных информируют диспетчер буфера о том, что данная страница подверглась изменению. Число контактов содержит значение счётчика того, сколько процессов в данный момент пользуются этой страницей. Изначально, для всякой страницы бит изменённых данных отключён, а число контактов равно нулю. Когда система запрашивает страницу, её диспетчер буфера выполняет следующее:
-
Проверяет свой пул буфера содержит ли какой- то кадр эту запрашиваемую страницу и, если это так, увеличивает на единицу значение счётчика контактов этого кадра. Когда данная страница отсутствует в данном пуле, диспетчер буфера привносит её следующим образом:
-
Выбирает кадр под замену, применяя установленную политику замены и увеличивает на единицу её счётчик контактов.
-
Если бит для данного заменяемого кадра включён, записывает содержащуюся в нём страницу на диск (то есть имеющаяся на диске копия этой страницы переписывается содержимым данного кадра).
-
Считывает запрашиваемую страницу в данный заменяемый кадр.
-
Возвращает значение адреса (основной памяти) данного кадра, содержащего запрашиваемую страницу выполнившей запрос стороне.
Увеличение на единицу значения счётчика контактов носит название закрепления (pinning), а его уменьшение откреплением (unpinning). Сам диспетчер буфера никогда не выполнит считывание в кадр иной страницы пока её счётчик контактов не равен нулю [13].
Политики замены буфера
В мире операционных систем наиболее известной политикой выступает LRU (least recently used, наиболее долго не применявшегося). Тем не менее, LRU и обсуждавшиеся ранее алгоритмы приближения к ней не всегда наилучшая стратегия для систем баз данных; это в особенности верно когда большое число пользователей запрашивает последовательное сканирование одних и тех же данных [16].
Допустим, что некое сканирование требует по крайней мере ещё одну страницу дополнительно по сравнению с доступными в его пуле буфера. В данных обстоятельствах всякое сканирование будет считывать каждую страницу с диска. На самом деле, для подобного случая LRU является наихудшей из возможных стратегий. Данная проблема носит названия последовательного лавинообразования (sequential fooding).
Прочими политиками замены являются: FIFO (first in frst out, первый пришедший обслуживается первым) и MRU (most recently used, последний по времени использования). Для сканирования наиболее идеальной политикой выступает MRU [13].
Сопоставление управления буфером в DBMS и в ОС
Между задачами выставления раздела в виртуальной памяти и теми, с которыми сталкивается система управления буфером базы данных имеется много чего похожего. DBMS зачастую способна предсказывать шаблоны ссылок потому как большинство ссылок вырабатывается операциями более верхнего уровня, таких как сканирования и прочие операции реляционной алгебры. Такая возможность предсказания необходимого шаблона доступа делает возможным лучший выбор страниц для замены и превращает в более привлекательную саму идею особых политик замены в буфере. Поскольку диспетчер буфера способен предугадывать последующие запрашиваемые страницы, весьма существенной становится предварительная выборка. При верной предварительной выборке они окажутся доступными в своём пуле буфера при их запросе системой. Такое поведение порой весьма затруднено на уровне виртуальной памяти, но тривиально на уровне DBMS.
Другой доступной стратегией с предсказанием отказов выступает считывание непрерывных блоков памяти в пул буфера, что намного быстрее их независимого считывания.
DBMS к тому же требует возможности принудительного помещения страницы на диск в явном виде, поскольку это необходимо для гарантии того, что имеющаяся на диске копия актуальна по отношению копии в памяти. На самом деле, для адекватной обработки аварийного восстановления системы, протокол WAL (Write-ahead logging, упреждающей записи в журнал) требует возможности упорядочивания того, как конкретные страницы пула буфера будут сохраняться на диске перед прочими страницами.
Сейчас мы обсудим способы хранения страниц на диске и их переноса в основную память, а также тот способ, которым страницы используются для хранения записей и организуются в логические собрания или файлы. Более верхние уровни кода DBMS рассматривают страницу как набор записей, игнорируя подробности представления и хранения. В действительности понятие набора записей не ограничивается содержимым одной страницы, поскольку некий набор данных способен занимать несколько страниц. В данном разделе мы рассмотрим как может быть организовано в виде файла некое собрание страниц.
Реализация файла кучи
Данные в страницах файла кучи не имеют определённого порядка, а вместо этого лишь гарантируют что некто способен выполнять выборку всех записей в данном файле повторяя запросы для последующей записи. Всякая запись обладает уникальным идентификатором записи (rid), а всякая страница в файле имеет один и тот же размер. Поддерживаемые в файле кучи операции включают в свой состав:
-
Создание кучи
-
Уничтожение кучи
-
Вставку записи
-
Удаление записи с заданным номером записи
-
Получение записи сзаданным номером записи
-
Сканирование всех записей в данном файле кучи
Самой DBMS необходимо отслеживать какие записи в каком файле кучи реализовывать для действенного сканирования. Также требуется отслеживание имеющегося в данной куче свободного пространства для эффективной вставки [13].
Куча может быть организована с применением двусвязного списка страниц. Важной используемой им задачей выступает поддержка сведений относительно всех имеющихся пустых слотов или создание и удаление записей в соответствующем файле кучи.
Вот две задачи, которые необходимо решить:
-
Отслеживание свободного пространства в странице
-
Отслеживание страниц со свободным пространством
Когда требуется новая страница, выполняются такие шаги:
-
У диспетчера дискового пространства запрашивается блок.
-
Этот блок форматируется в качестве страницы кучи.
-
Данная страница добавляется в соответствующий связный список страниц в этом файле кучи.
Когда система удаляет из файла кучи страницу, исполняются такие этапы:
-
Данная страница удаляется из своего списка связных страниц.
-
Диспетчер дискового пространства запрашивает высвобождение того блока, в котором располагалась данная страница кучи.
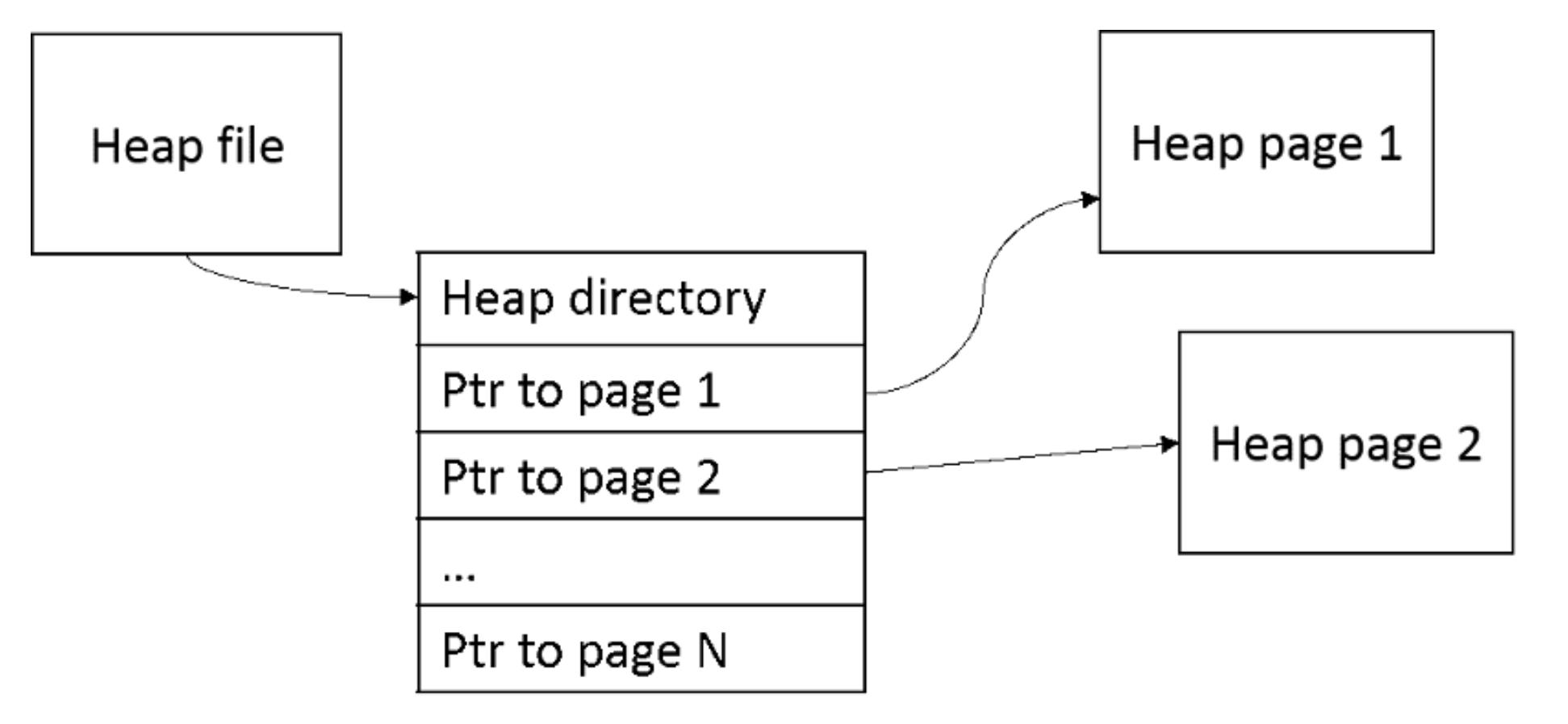
Некий каталог это собрание страниц. Самой DBMS затем всего лишь требуется помнить где находится самая первая страница каталога в каждом из файлов кучи. Один из способов реализации каталога выступает массив указателей на страницы кучи, в котором всякая запись каталога указывает страницу или последовательность страниц в своём файле кучи (Рисунок 4.2). По мере роста кучи также растёт и значение числа страниц в этом каталоге. Свободным пространством может управлять сама система сопровождая бит не занятости для страницы и счётчик, указывающий величину свободного пространства в этой странице.
В целом, страница это некое собрание слотов и каждый слот содержит запись. Пара идентифицирующая запись:
-
Идентификатор страницы
-
Номер записи
Основная цель имеющегося идентификатора записи состоит в уникальной идентификации записи среди всей базы данных целиком. Значение идентификатора само по себе может обладать большим числом полей в соответствии с потребностями базы данных для осуществления этой необходимой цели.
При использовании данной схемы все записи на странице гарантированно обладают одной и той же длиной. Таким образом, записи могут последовательно помещаться на странице аналогично массиву. В любом из экземпляров записи могут быть занятыми или свободными [13]. Имеется возможность найти любой пустой слот и поместить в нём запись. Вот основные задачи:
-
как отслеживать пустые записи?
-
как определять местоположение всех записей на странице?
Для решения этих задач существует две распространённые стратегии:
-
Для отслеживания того, используется запись или доступна ли она для вставки, важно удерживать некую карту бит.
-
Первые N записей всегда должны быть занятыми. Поэтому слоты от N и до самого последнего доступного в странице свободны.
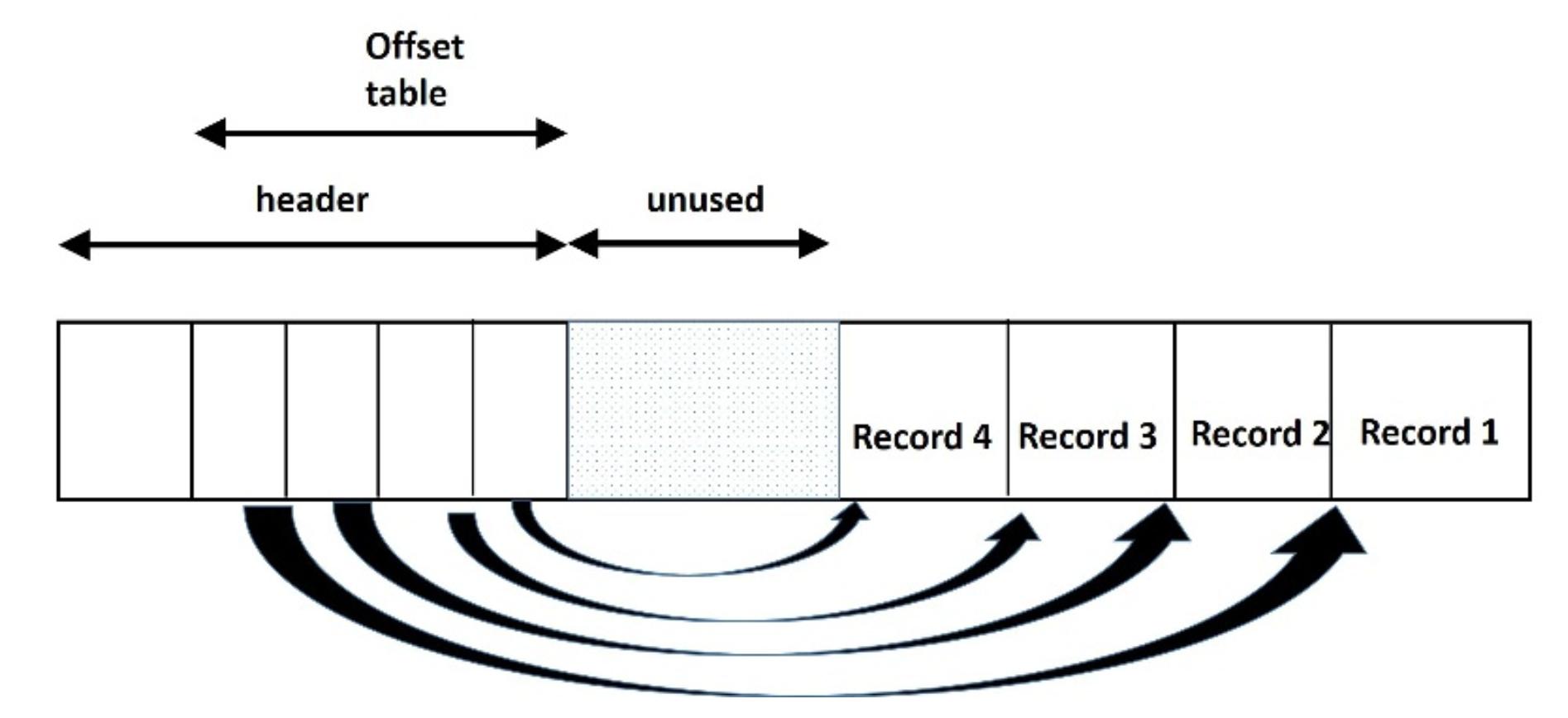
Наиболее удобной организацией для записей переменной длины является поддержка каталога для каждой страницы со следующей парой для слота:

Необходимо тщательно относиться к управлению свободным доступным пространством для новых записей, потому как предварительное форматирование страниц в слотах не единообразно. Один из способов решения данной проблемы состоит в отслеживании указателя на самое начало остающегося свободным сегмента данной страницы [13]. Когда какая- то запись слишком велика для того чтобы помещаться в данной странице по причине фрагментации, сама система способна выполнить возврат пространства для того, чтобы все имеющиеся записи на данной странице могли помещаться непрерывно. Такая организация также применяется для записей фиксированной длины когда они подлежат частому повсеместному перемещению.
В данном разделе мы обсудим как организовывать поля внутри записи. При выборе некого способа организации таких полей записи нам следует учитывать обладают ли эти поля фиксированной или переменной длиной и рассматривать величину стоимость различных операций с такой записью, включая выборку и изменение данных полей.
Записи фиксированной длины
При данной схеме система обладает фиксированной длиной для каждого поля и имеется фиксированное число полей (Рисунок 4.4). Такие поля всякой записи всегда непрерывны и значение адреса таких полей может вычисляться при помощи значений длин полей, которые поступают заранее [16].

Стратегия записей фиксированной длины аналогична описанному ранее Выделению плит/
Записи переменной длины
Некая запись способна обладать переменной длиной когда одно из её полей обладает переменным размером или может меняться число полей в такой записи. Последнее, однако, не допускается в реляционной алгебре.
Одна из возможных организаций файла состоит в согласованном хранении таких полей и применении определённого символа в качестве разделителя (Рисунок 4.5). В качестве альтернативы, в самом начале каждого блока может быть зарезервировано некое пространство для хранения значения смещения самого начала соответствующих полей, таким образом, значение i-го целого это значение смещения на начало i-го поля данной записи [16].
Индексация на основе дерева также предоставляет поддержку выбора по равенству, хотя и не столь хорошо как индексы на основе хэшей. Данный тип индексов великолепен при выборах диапазона. B+ дерево это динамическая структура, которая изящно приспособлена к изменениям в своём файле. Это наиболее широко применяемая структура индекса, поскольку она хорошо регулируется под изменения.
Структура дерева ISAM хранит записи данных следующим образом:
-
Необходимые записи соответствующего индекса ISAM пребывают в предварительно выделенных страницах листьев своего дерева.
-
По мере необходимости к страницам листьев могут добавляться составляемые в цепочку дополнительные страницы переполнения.
Базы данных тщательно организуют свою схему страниц с тем, чтобы они соответствовали физическим характеристикам применяемого диска или лежащего в основе устройства хранения. Собственно структура ISAM статическая. Когда система создаёт необходимый файл, все страницы листьев выделяются последовательно и сохраняются значениями своего ключа поиска.
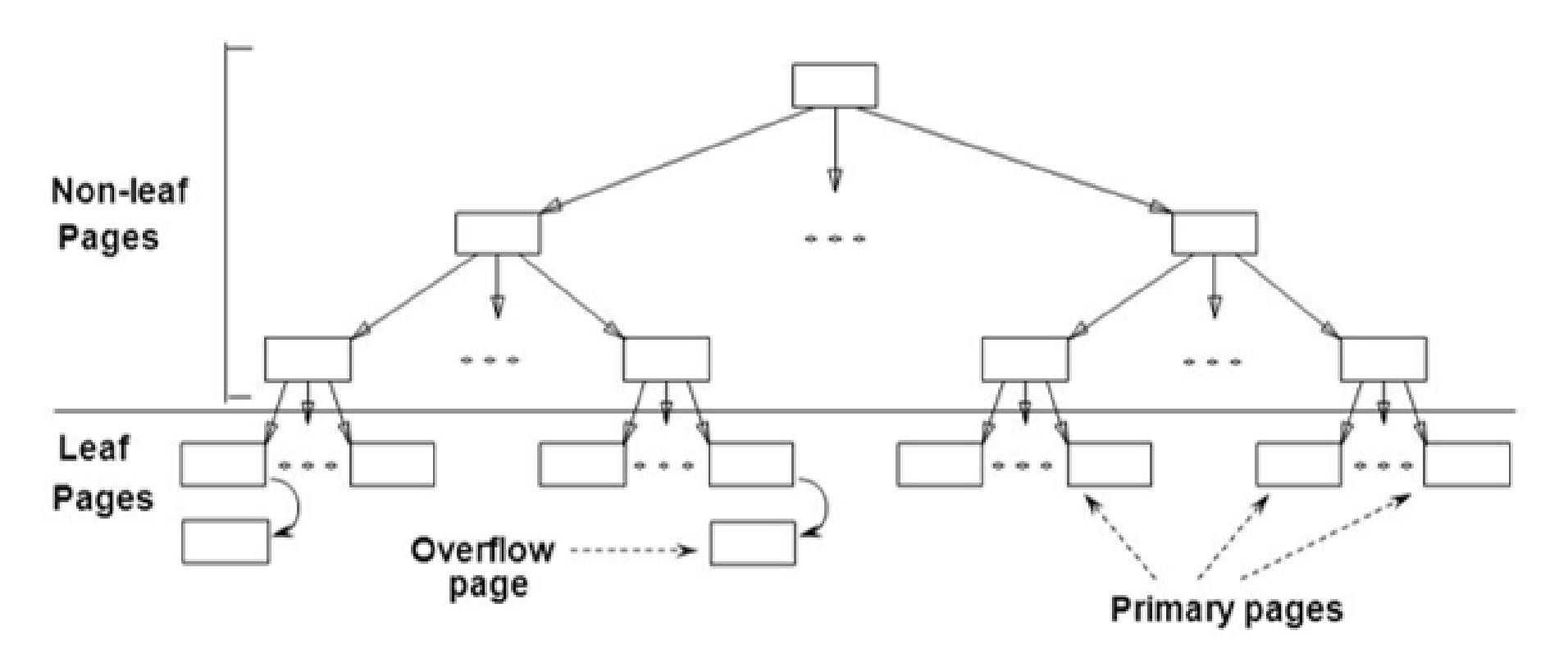
Далее сама система выделяет не-листьевые страницы и, когда существуют последующие вставки в этот файл такие, что пространство этой страницы исчерпывается, для выделения последующих страниц имеется именно область переполнения.
Вопросы производительности индексов ISAM
После того как система создала ISAM, все последующие вставки и удаления оказывают воздействуют только на содержимое своих страниц листьев. Таким образом, могут создаваться длинные страницы переполнения и существенно влиять на значение производительности всех операций со своим индексом.
Тот факт что изменяются лишь страницы листьев это некое преимущество длЯ одновременного доступа, поскольку это гарантирует что имеющаяся структура индекса не будет изменена при прохождении по самому индексу. Это также означает, что данная структура обязана блокироваться на короткие периоды, причём только при доступе к узлу листа. Если имеющиеся распределённые данные и размер относительно статичны настолько, что цепочки переполнения редкие, дерево ISAM хороший вариант [13]. Системы бваз данных в современных архитектурах более не пользуюмя индексами ISAM по причине этого ограничения.
Деревья B+ это широко используемые структуры деревьев поиска. Это именно то дерево, в котором его внутренние узлы направляют сам поиск, а его листья содержат все элементы данных или ключей. Ниже приводятся основные характеристики такого дерева B+:
-
Структура такого дерева растёт динамическим образом. Невозможно выделять страницы последовательно.
-
Страницы листьев привязываются при помощи страниц указателей для эффективности операций сканирования.
-
Вставки и удаления сохраняют его сбалансированным.
-
Все алгоритмы обеспечивают минимальную занятость в 50% для каждого узла за исключением корневого, таким образом, это плотная структура.
-
Поиск некой записи требует лишь прохода от корня до одного из листьев.
-
B+ деревья, скорее всего, выполняются лучше чем деревья ISAM.
В B+ деревьях каждый узел содержит m элементов, где d <= m <= 2d и это значение носит название величины порядка данного дерева и измеряет значение плотности узла. Такое понятие упорядочения B+ дерева на практике обычно необходимо смягчить для соответствия критериям физического пространства, относящимся к лежащим в основе устройствам хранения [13].
Собственно форматирование узла такое же как для ISAM: не листьевые узлы содержат m элементов индекса и содержат m+1 указателей на потомков. Помимо этого узлы листьев содержат элементы данных [13].
Вот основные операции B+ деревьев:
-
Поиск ключа: Допустим, у нас имеется индекс B дерева и мы хотим найти запись со значением ключа поиска в этом индексе. Для выполнения этого нам требуется рекурсивно вызывать функцию поиска узла в соответствующем дочернем узле до тех пор, пока не будет достигнут искомый узел листа. Для данной операции в справочных материалах [13] приводится надлежащий псевдокод.
-
Вставка ключа: Основная идея состоит в рекурсивном вызове функции вставки в соответствующий дочерний узел до тех пор, пока не будет достигнут надлежащий узел листа. Для вставки в дерево B+ системе необходимо отыскать тот узел листа, к которому она относится. Если требуемый для хранения данного элемента узел оказывается заполненным, требуется расщепление этого узла. Когда узел расщепляется, метаданные его родительского узла получают некую запись, указывающую на такой новый узел. Узел B+ дерева заполнен когда мы пытаемся вставить в этот узел элемент 2d+1. Такой узел затем расщепляется пополам и его средний ключ переходит в его родительский узел вверх по дереву. Справочный материал [13] показывает необходимый псевдокод для данной операции.
-
Удаление ключа: Основная идея заключается в рекурсивном вызове соответствующей функции удаления в надлежащем дочернем узле до тех пор, пока не пудет достигнут подходящий узел листа. Для операции удаления из дерева системе требуется отыскать тот узел листа, который содержит указанную запись. Когда содержащий такую запись узел не соответствует згачению минимальной занятости, необходимо слияние двух узлов. Когда сливаются два узла, требуется обновление их предка. Справочный материал [13] показывает необходимый для данной операции псевдокод.
Для сопоставления значений из поля поиска с диапазоном чисел из сегмента (bucket) для поиска той страницы, к которой относится нужная запись. Имеются различные схемы индексации хэшей, например:
-
Статическое хэширование. Аналогично индексации на основе дерева ISAM.
-
Расширяемое хэширование. Применяется для поддержки действенных вставок и удалений без страниц переполнения.
-
Линейное хэширование. Использует некую политику для создания сегмента (bucket), который поддерживает эффективно поддерживает вставки и удаления без применения каталога.
Индексы с хэшем не поддерживают сканирования для диапазона. Тем не менее, их действенность была доказана в реализации прочих операций реляционной алгебры, например соединения. Метод соединения индекса вложенным циклом пользуется большим числом запросов выбора по равенству и стоимостное отличие между индексацией хэшем и древовидной индексацией может быть существенным [13].
Страницы содержат данные в виде коллекций сегментов (bucket). Существует лишь одна первоначальная страница, а также может иметься большое число дополнительных страниц переполнения для каждого сегмента.
Такая система применяет функцию хэширования h для поиска элементов данных. Данная функция хэширования позволяет подобной системе выявлять тот сегмент, к которому он относится и затем выполнять поиск в этом сегменте. Эта система способна хранить все элементы данных сортированными для ускорения своего поиска. Её функция хэширования также используется для выявления верного сегмента под помещаемые данные при вставке элементов данных. Когда такая страница заполнена, под вставляемый элемент для выделения и выстраивания в цепочку к своей первичной странице требуется страница переполнения. Функция хэширования также применяется для выявления правильного сегмента при удалении элементов данных. Система отыскивает необходимый сегмент для удаляемого элемента и, когда он обнаружен, его запись в конечном счёте удаляется. Если так случится что этот элемент последний в некой странице переполнения, система удаляет также и эту страницу переполнения. Список свободных страниц может удерживаться для последующего применения или для возврата.
Поскольку такой системе известно значение номера сегмента при создании своего индекса хэша, ей первичные страницы могут храниться на диске непрерывным образом. К сожалению, это также ограничивает общее число сегментов.
Когда файл сжимается существенно, имеющееся в таком файле пространство тратится впустую, а если этот файл увеличивается, его страницы переполнения могут расти неограниченно, что приводит к ухудшению производительности.
Расширенное хэширование пытается решать саму потребность добавления страниц переполнения статического хэширования. Для этого ему требуется реорганизовывать свой файл дублируя имеющееся число сегментов. Для дублирования имеющегося размера этого файла без необходимости считывания каждого сегмента и записи получаемого дубля каждого из них используется каталог указателей. Наконец, здесь требуется лишь расщепить переполненный сегмент. Применения такого метода для дублирования своего файла вызывает выделение новой страницы сегмента и запись нового и старого сегментов. Получаемый каталог намного меньше чем полный файл сам по себе, поскольку каждый элемент в нём это идентификатор страницы и его можно удвоить только скопировав.
Основной применяемый в расширенном хэшировании метод состоит в трактовке получаемого результата применения функции хэширования как некого числа и интерпретации самых последних d бит (где d зависит от размера каталога) как некое смещение от этого каталога, причём его требуется хранить и увеличивать на единицу при каждом дублировании каталога.
В конечном итоге, элементы данных могут обнаруживаться вычислением их значения хэша, затем получения последних d бит для просмотра в найденном сегменте указанном данным элементом каталога.
При удалении система определяет местоположение и удаляет соответствующие элементы данных. Когда сегмент пуст, он может сливаться. Тем не менее, данный шаг зачастую пропускается [13].
Линейное хэширование ещё один метод динамического хэширования; тем не менее, он не нуждается в каталоге. Он применяет некое семейство функций хэширования h1, h2, h3 ... с тем свойством, что диапазон каждой функции удваивает диапазон своей предшественницы [13].