Глава 12. Мониторинг кластера Proxmox
Содержание
Мониторинг сетевой среды любого размера обязателен для гарантирования жизнеспособности операций и своевременного отклика на любые проблемы. В данной главе мы рассмотрим как осуществлять наблюдение и настраивать уведомления с тем, чтобы если что- то пойдёт не так в вашем кластере, мы могли узнать об этом немедленно и предпринять необходимые действия. В данной главе мы охватим следующие темы:
-
Введение в мониторинг
-
Zabbix в качестве решения мониторинга
-
Встроенный в Proxmox мониторинг
-
Настройку уведомлений о состоянии дисков
-
Настройку SNMP в Proxmox
- Мониторинг кластера Proxmox при помощи Zabbix
-
Мониторинг кластера Ceph при помощи инструментальной панели Ceph
В сетевой среде любого размера возникновение проблемы вследствие умышленных или непреднамеренных обстоятельств всего лишь вопрос времени. Основной причиной для проблемы могут быть аппаратные сбои, проблемы программного обеспечения, человеческие ошибки или просто почти любой фактор окружающей среды, который приводит к потере сети или данных. Мониторинг сетевой среды является практикой, при которой администратор может проверять пульсацию сетевых компонентов в сетевой среде.
Не существует системы для мониторинга всего. Хорошая система мониторинга обычно собирает вместе различные инструменты и некоторые типы вариантов уведомления для автоматической отправки сигналов тревоги. Кластер Proxmox является суммой коммутаторов, сетевых кабелей, физических узлов, выступающих в роли хостов, а также виртуальных машин. Система мониторинга должна быть в состоянии наблюдать за всеми этими компонентами и автоматически отсылать уведомления через среды, такие как электронная почта или SMS для важных частей. Существует широкий диапазон инструментов сетевого мониторинга доступных сегодня, таких как Icinga, Zabbix, Nagios, OpenNMS, Pandora FMS, Zenoss и тому подобные. Существует много вариантов, как оплачиваемых, так и бесплатных в виде решений с открытым исходным кодом. В данной главе мы рассмотрим как применять Zabbix для наблюдения за кластером Proxmox. Zabbix имеет дружественный пользователю графический интерфейс, возможности графиков, а также многие дополнительные свойства в основной поставке. Он очень прост для изучения новичками, также профессионалами сетевых сред. Когда Zabbix установлен, все настройки и весь мониторинг могут выполняться с применением GUI.
Узел мониторинга должен быть отдельно стоящей надёжной машиной. Для целей обучения и тестирования он может быть установлен на виртуальной машине. Однако, для мониторинга кластера промышленного уровня идеальным решением будет отдельный узел за пределами вашего главного кластера. Это будет гарантировать вам, что даже в случае отказа внутренней сетевой среды система мониторинга всё ещё будет в состоянии отправлять уведомления. {Прим. пер.: см. также наш перевод отдельных глав 2го издания Полного руководства Zabbix.}
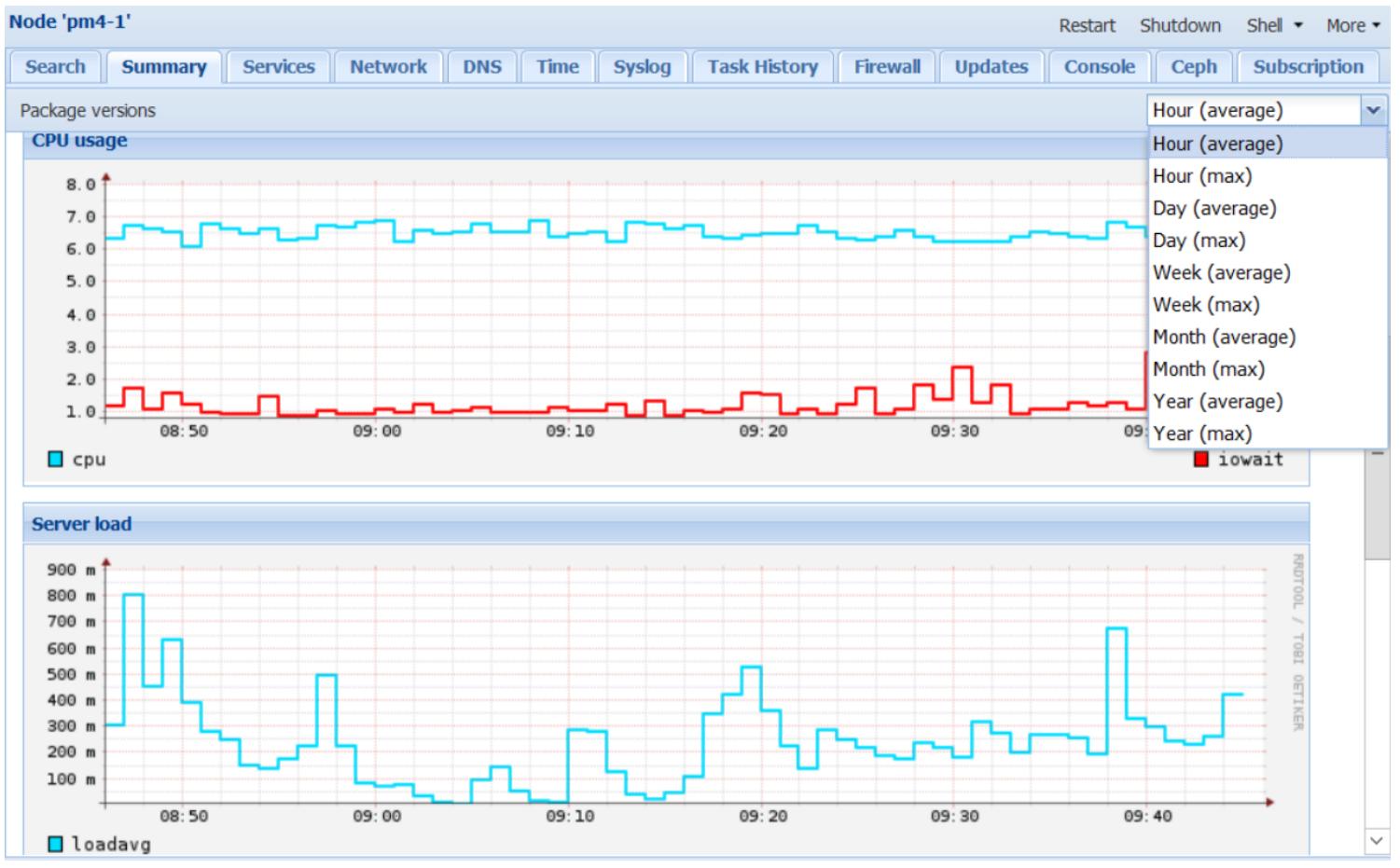
Proxmox имеет ограниченные возможности мониторинга, встроенные в GUI; однако, он действительно испытывает недостаток в обширном и надёжном мониторинге, который обычно присутствует в законченном решении мониторинга. Proxmox поставляется со встроенными графиками на основании RRD для отображения истории применения ресурсов и производительности данных сроком до 1 года. Применяя этот инструмент, мы можем анализировать тенденции производительности ресурса за некий период времени. Все данные о потреблении и производительности находятся в меню с закладками Summary как для узлов Proxmox, так и для виртуальных машин. Мы можем просматривать данные на основе почасового, ежедневного, еженедельного или за год периодов.
Следующий снимок экрана отображает страницу Summary узлаpm4-1 с ниспадающим списком для выбора периода данных:
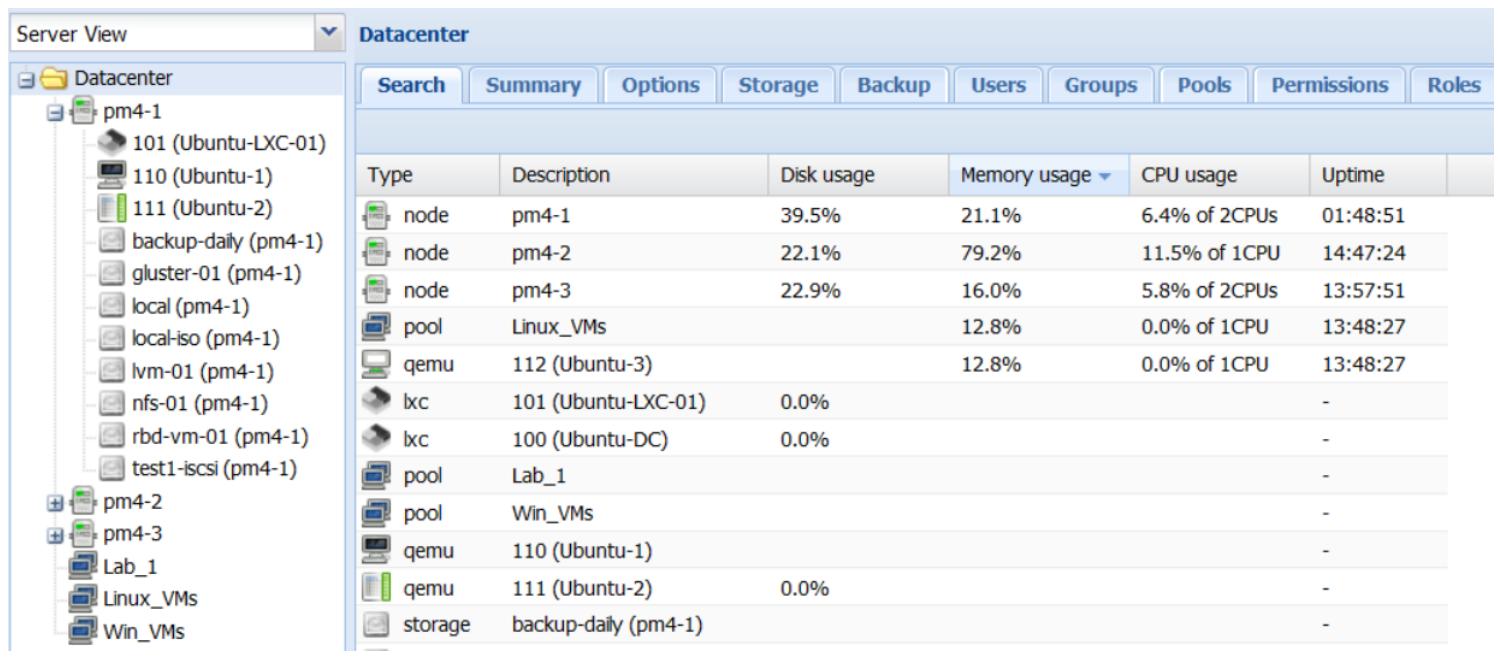
Существует также способ отображения списка всех ваших узлов и виртуальных машин в кластере и отсортировать их по потреблению для получения быстрой информации по элементам с самыми высокими и низкими потреблениями ресурсов. Мы можем просмотреть такой список переместившись в Datacenter | Search. Следующий снимок экрана отображает перечень узлов Proxmox и виртуальных машин отсортированных по элементам, с наивысшим потреблением оперативной памяти:
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Мы можем сортировать этот список по Type, Description, Disk usage, Memory usage, CPU usage и Uptime, кликнув по заголовку соответствующей колонки. В этом списке отсутствуют исторические данные. Он отображает потребление ресурсов только в реальном масштабе времени. |
Мы можем усилиться данными S.M.A.R.T. для дисковых устройств, чтобы получать автоматические электронные сообщения от вашего узла Proxmox, когда присутствуют существенные проблемы, происходящие на любом дисковом устройстве в этом узле. Для этого нам необходимо установить инструментарий мониторинга Smart при помощи следующей команды:
# apt-get install smartmontools
|
| Совет |
|---|---|
|
Убедитесь что вы установили этот инструментарий на все ваши узлы Proxmox в своём кластере. Не существует никакой другой необходимой настройки необходимой для получения сообщений электронной почты, за исключением уверенности в том, что для пользователя root в Proxmox был введён правильный адрес электронной почты. |
Мы можем проверить правильность такого адреса электронной почты из блока диалога подробностей пользователя, как это показано на снимке экрана ниже:
В случае, если возникла существенная проблема с любым дисковым устройством в вашем узле Proxmox,
будет отослано автоматическое электронное сообщение с именем того узла, где возникла проблема и
природой данного отказа или проблемой для данного дискового устройства. Электронное почтовое сообщение
также отобразит детализацию самого данного устройства, такую как серийный номер и идентификатор
дискового устройства. Следующий снимок экрана отображает пример некоего электронного почтового
сообщения, полученного от узла pm4-1 с ошибкой сектора
для устройства /dev/sda с серийным номером
V1FA516P:
This message was generated by the smartd daemon running on:
host name: pm4-1
DNS domain: domain.com
The following warning/error was logged by the smartd daemon:
Device: /dev/sda [SAT], 8 Offline uncorrectable sectors
Device info:
ST2000DM001-1CH164, S/N:V1FA516P, WWN:5-000c50-06040e51c, FW:CC26, 2.00 TB
For details see host's SYSLOG.
You can also use the smartctl utility for further investigation.
The original message about this issue was sent at Sat Feb 13 09:01:14 2016 MST
Another message will be sent in 24 hours if the problem persists.
Если та же самая ошибка продолжит возникать, данный узел Proxmox будет отсылать данное электронное сообщение каждые 24 часа. Основываясь на содержащейся в данном электронном сообщении информации мы можем установить данное устройство и заменить его в случае такой необходимости.
Как мы можем видеть, Proxmox действительно не имеет надёжной системы мониторинга и очень вероятно, не будет иметь её когда- либо. Его мощность заключается в том, что он является великолепным гипервизором, а не системой мониторинга. Тем не менее, мы легко можем заполнить этот пробел при помощи системы мониторинга стороннего производителя, например, Zabbix.
Zabbix, выпущенный впервые в 2004г, является надёжным средством сетевого мониторинга на основе веб- интерфейса, обладающий способностью мониторинга многих сотен хостов и обработки тысяч проверок на хост в любой момент времени. Zabbix является продуктом с полностью открытым исходным кодом и не имеет корпоративных или платных версий. Установка Zabbix занимает всего несколько минут, причём даже для новичков, и к тому же он может быть настроен целиком с применением веб- интерфейса. {Прим. пер.: см. также наш перевод отдельных глав 2го издания Полного руководства Zabbix.} Ниже приводится экранный снимок инструментальной панели Zabbix 3.0 после регистрации в нем при помощи интерфейса GUI:
Zabbix имеет очень активное сообщество и много шаблонов для загрузки, используемых для мониторинга различных устройств и оборудования. Также относительно просто создавать ваши собственные персонально настроенные шаблоны для нестандартных устройств. Дополнительные подробности по Zabbix можно найти на официальном сайте Zabbix http://www.zabbix.com/. {Прим. пер.: следите за ссылкой Zabbix, Полное руководство, 2е изд. по которой в скором времени (мы надеемся) появится перевод новой книги Mastering Zabbix, 2ed, вышедшей в сентябре 2015}
Достаточно легко аргументировать отдание предпочтения Zabbix в сравнении с находящимися в основном потоке системами, такими как Nagios или Icinga, или любое другое доступное сегодня решение. Причина заключается в простоте без принесения в жертву каких- либо функций, которые выполняют основные системы мониторинга. Будь то небольшая сетевая среда, или большая, распространяющаяся по регионам, Zabbix с лёгкостью отвечает на все вызовы.
В данном раздела мы рассмотрим как устанавливать Zabbix и настраивать его для наблюдения за вашим кластером Proxmox и сетевыми устройствами. Мы собираемся установить Zabbix версии 3.0 на CentOS 7. Zabbix может быть легко установлен и на другие дистрибутивы, такие как Debian или Ubuntu.
|
| Совет |
|---|---|
|
Для достижения стабильности и производительности при мониторинге больших промышленных сред настоятельно рекомендуется применять CentOS в качестве базовой операционной системы. Всегда проверяйте, что вы настроили отдельный узел или виртуальную машину для получения максимальной производительности. Полностью настроенный Zabbix с тысячами элементов будет выполнять частые проверки, что тяжело для ресурсов. Применение Zabbix на узле или ВМ, которые имеют ещё и другие роли, будет иметь значительное воздействие на производительность. |
Zabbix также представляет предварительно установленные и настроенные скачиваемые инструменты для целей оценки. Они полезны для целей изучения и тестирования, однако не рекомендуются для промышленного применения. Инструменты Zabbix могут быть загружены с http://www.zabbix.com/download.php.
Zabbix всё ещё будет работать без установленного агента Zabbix на подлежащем наблюдении хосте, однако агент может собирать намного больше данных с вашего хоста. Существуют агенты, доступные для всех основных операционных систем, включающих Linux, Windows, FreeBSD, AIX, Solaris и HP-UX. Для устройств, на которые установка агента невозможна, такие как управляемые коммутаторы или прочее сетевое оборудование, Zabbix способен осуществлять мониторинг ри помощи SNMP. После того, как установка сервера Zabbix завершена, установите агенты Zabbix на подлежащие мониторингу хосты.
Агент Zabbix способен захватывать гораздо больше данных, чем даёт SNMP. Используйте агента всякий раз когда это возможно, вместо SNMP. Это уменьшит сложности с настройкой SNMP при создании гораздо большего количества настраиваемых пользователем проверок. Отсылаем вас к документации для получения инструкций по установке вашего сервера Zabbix 3.0 и агента по ссылке https://www.zabbix.com/documentation/3.0/manual/installation/install_from_packages. {Прим. пер.: следите за ссылкой Zabbix, Полное руководство, 2е изд. по которой в скором времени (мы надеемся) появится перевод новой книги Mastering Zabbix, 2ed, вышедшей в сентябре 2015}
После завершения установки сервера, сам сервер Zabbix может быть доступен по ссылке, доступной в
виде формата: http://<node_ip>/zabbix.
По умолчанию логин и пароль для регистрации в веб GUI Zabbix это Admin:Zabbix,
причём имя пользователя является чувствительным к регистру. Рекомендуется изменять этот пароль сразу
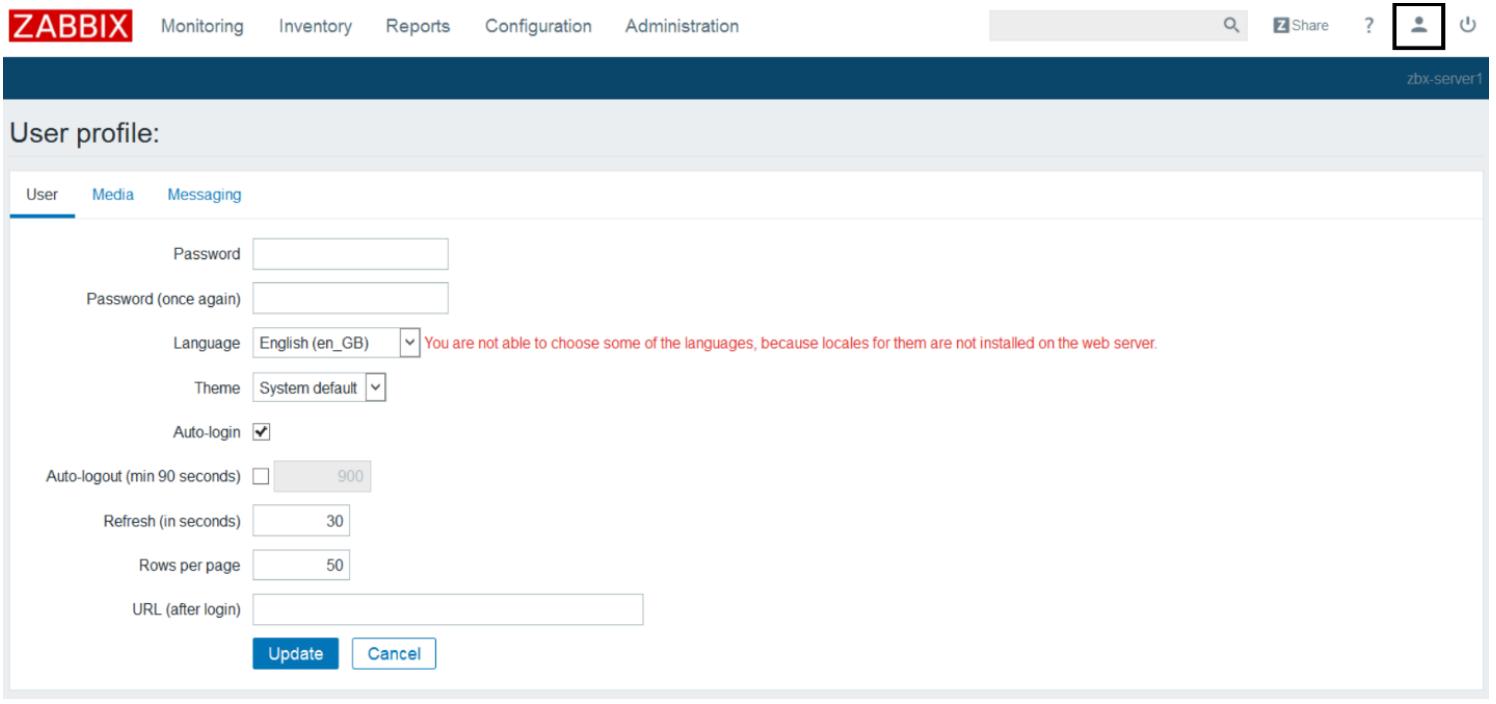
после первой регистрации. Перейдите в Administration |
Users, затем кликните на вашего участника Adnin (администратор Zabbix), или кликните по иконке
User Profile в правом верхнем углу вашего GUI
для изменения пароля администратора, как это показано на снимке экрана ниже:
Если вы используете для сервера Zabbiz CentOS 7, тогда после доступа к своему графическому интерфейсу Zabbix вы можете заметить что состояние информирует, что сервер Zabbix не работает, как это показано на следующем экранном снимке, даже когда сервер на самом деле работает:
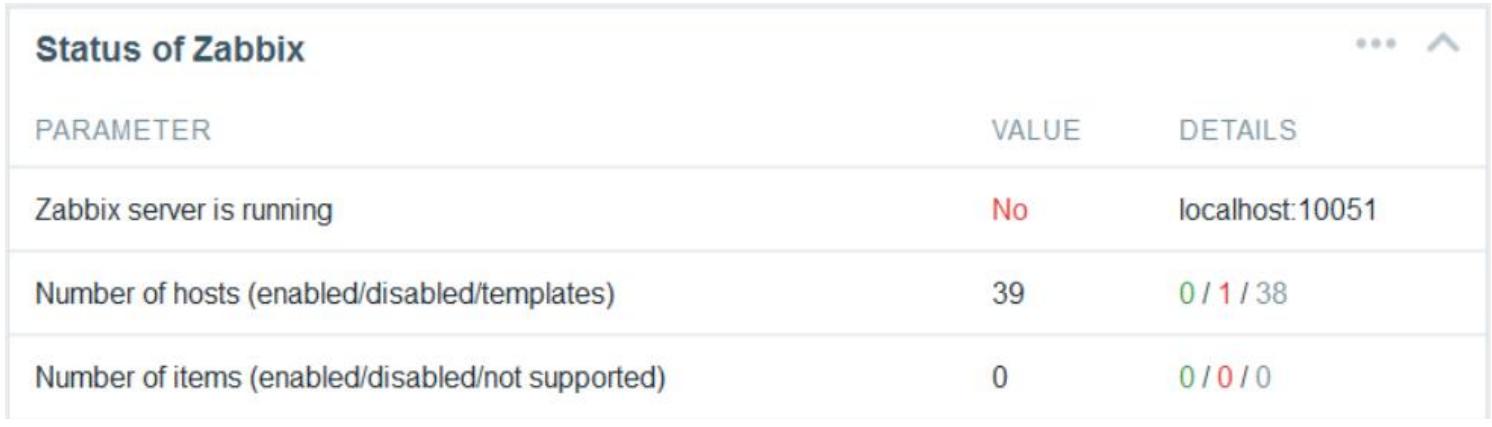
Это происходит из- за аргумента httpd_can_connect_network
в настройке межсетевого экрана SELinux. Данный аргумент должен быть включён для того чтобы сделать
возможным доступ Zabbix к сетевой среде. Чтобы проверить что он выключен или запрещён, выполните следующую
команду:
# getsebool httpd_can_network_connect
Если результат показывает рабочее состояние {межсетевого экрана}, тогда разрешите его выполнив следующую команду:
# setsebool httpd_can_network_connect on
Теперь GUI Zabbix показывает, что сервер находится в рабочем состоянии.
После того, как сервер Zabbix установлен и работает, мы должны настроить адрес электронной почты с тем, чтобы мы автоматически получали сообщения в электронном виде всякий раз, когда возникают проблемы. Zabbix 3.0 имеет возможность отправлять электронную почту через SMTP. Мы можем настроить его переместившись в меню Administation | Media types и изменив свою информацию SMTP в Bold. После того как настройка электронной почты завершена, самое время добавить какие- нибудь хосты или устройства для нчала мониторинга.
В данном разделе мы рассмотрим как добавить хост, будь это узел Proxmox или виртуальная машина, в
сервер мониторинга Zabbix. Данная процедура одна и та же для любого хоста с установленным агентом
Zabbix. По умолчанию, к наблюдаемому хосту добавляется сервер Zabbix.
{Прим. пер.: также можно применять прокси сервера Zabbix, подробнее можно узнать
в : следите за ссылкой Zabbix,
Полное руководство, 2е изд. по которой в скором времени (мы надеемся) появится перевод новой книги
Mastering Zabbix, 2ed, вышедшей в сентябре 2015}
Сейчас мы собираемся добавить наш пример узла Proxmox, pm4-2,
в Zabbix для его мониторинга. Приведённые ниже шаги показывают как добавить ваш хост в Zabbix:
-
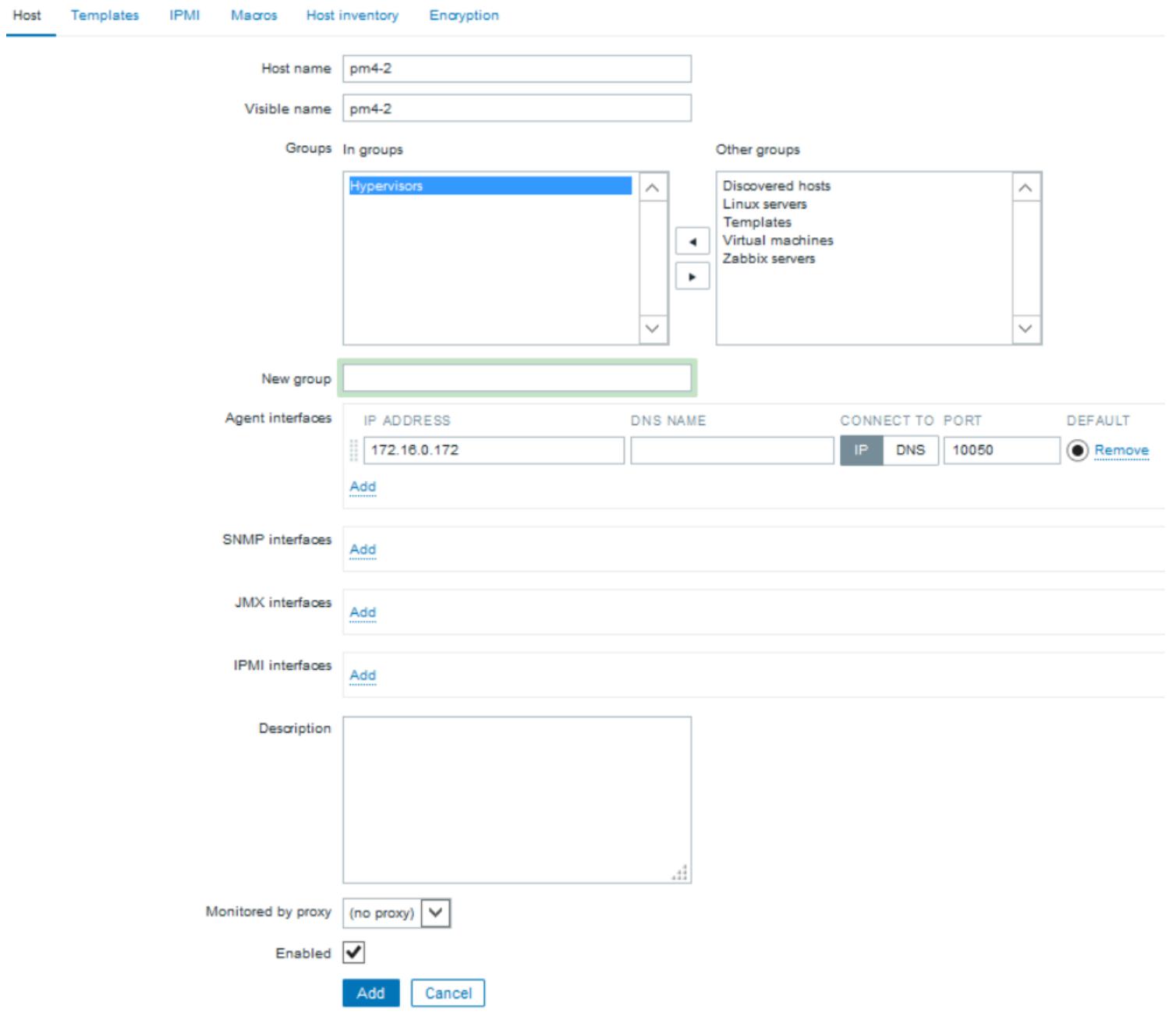
Перейдите в Configuration | Hosts и кликните по Create Host.
-
Наберите в Hostname и Visible имя. Имя хоста должно соответствовать имени хоста, введённому в файле настройки агента Zabbix данного хоста. Отображаемое (Visible) имя может быть любым.
-
Выберите соответствующую Group. Так как мы добавляем узел хоста Proxmox, нам нужно выбрать Hypervisors as Group.
-
Если мы добавляем хост с установленным агентом, наберите IP адрес этого хоста в блоке Agent interfaces. По умолчанию агент прослушивает порт
10050. Если мы используем другой порт, наберите этот порт здесь. Убедитесь, что вы открыли этот порт в своём межсетевом экране если этот хост находится под защитой какого- либо межсетевого экрана. Следующий снимок экрана отображает страницу настройки host после добавления необходимой информации:
-
Кликните на закладку Templates для добавления шаблона в наш хост. В Zabbix шаблоны являются предварительно настроенными группами проверок.
-
Наберите имя шаблона в текстовом блоке Link new templates или выберите его кликнув по кнопке Select. Данный текстовый блок является блоком со встроенным автоматическим поиском, поэтому имя не обязательно должно быть точным именем искомого шаблона. Для примера мы ввели Linux, что предлагает нам два возможных шаблона. Мы собираемся выбрать
Template OS Linux, что отображено на снимке экрана ниже:
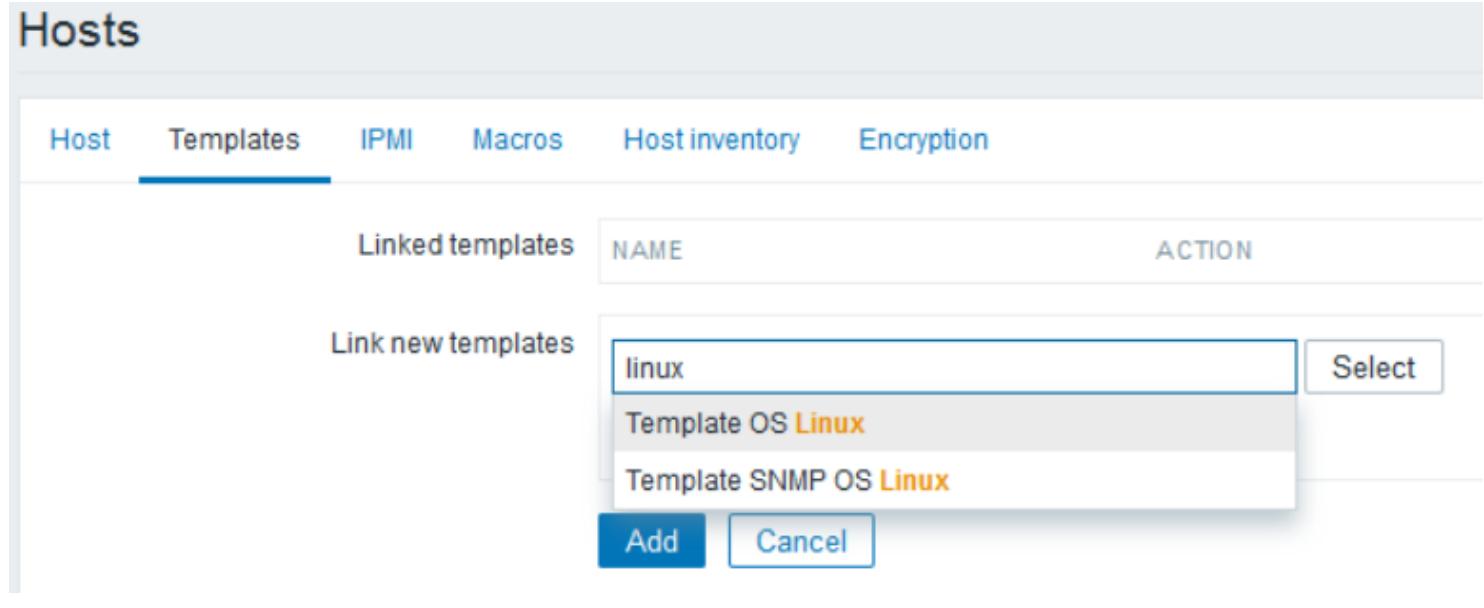
Мы также можем назначить устройство SNMP при помощи той же самой страницы шаблонов. Отсылаем вас к разделу Настройка SNMP в Zabbix ниже в данной главе по вопросу того, как установить и настроить SNMP на узлах Proxmox, а затем выполните следующие шаги для добавления хоста с применением шаблонов SNMP:
-
Кликните на Add для назначения нужного шаблона данному хосту.
-
Кликните на Host inventory, а затем выберите Automatic чтобы агент Zabbix мог поместить соответствующую информацию о данном хосте, такую как производитель хоста, серийный номер, установленная ОС и тому подобное. Мы также можем ввести данные вручную, такие как Долгота, Широта, Оборудование и Программные средства, установленные на данном узле. Это полезно для построения инвентарного списка.
-
Кликните на Save для завершения добавления данного хоста.
Следующие шаги необходимо выполнить для настройки вашего агента Zabbix на хосте:
-
Откройте файл настройки вашего агента Zabbix в
/etc/zabbix/zabbix_agentd.confхоста. -
Сделайте изменения в следующих строках параметров:
Server=172.16.0.172 //IP сервера Zabbix ServerActive=172.16.0.171:10051 //IP_Server:Server_Port Hostname=pm4-2 //должен быть тем же, что и Hostname набранный в Zabbix Server для данного хостаСохраните изменения и выйдите из редактора.
-
Выполните следующую команду для перезапуска данного агента Zabbix на вашем хосте:
# service zabbix-agent restart
В пределах минуты или около того после добавления вашего хоста, настроенный сервер Zabbix начнёт выполнять автоматические проверки и обнаружит, что ваш хост теперь имеет внутри себя работающего агента. Следующий экранный снимок показывает список хостов в настроенном сервере Zabbix после добавления нашего хоста и настройки его агента:

Из данного списка мы также можем обнаружить, что наш шаблон добавил 32 элемента, 15 триггеров и 5 графиков к нашему хосту. Элементами (Items) является то, что будет проверяться Zabbix, а триггеры (Triggers) это то, что инициирует определённые действия такие, как отсылка автоматических оповещений для любого события. Каждый шаблон имеет два элемента обнаружения, которые автоматически собирают информацию установленных и настроенных дисковых устройств и разделов в данном узле. Следующий снимок экрана отображает страницу Triggers для нашего хоста pm4-2:
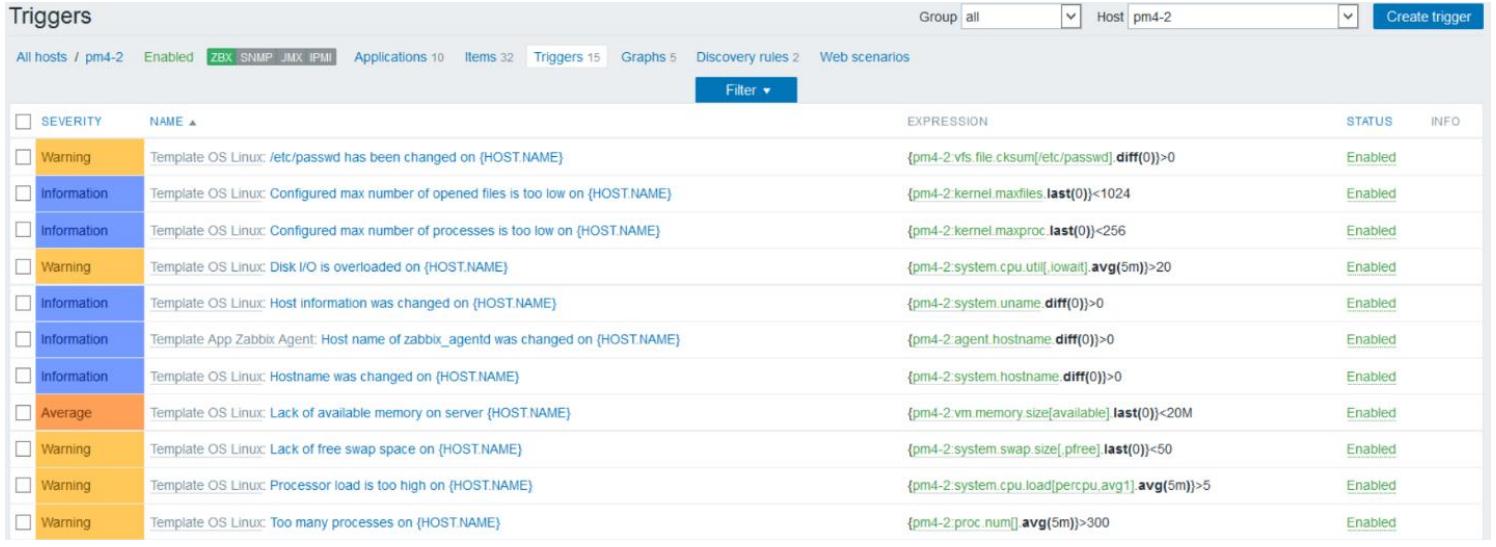
Колонка выражений на странице Triggers
отображает когда событие включилось. Например, выражение {pm4-2:system.cpu.util[,iowait].avg(5m)}>20 для дискового ввода/ вывода
включит предупреждение, когда число ожиданий ввода/ вывода превысит 20 для 5 минут на данном хосте. Другой пример
триггера {pm4-2:proc.num[].avg(5m)}>300 для процессов может
включиться, когда общее число процессов превысит 300 для 5 минут. Современные серверы могут выполнять
множество процессов за раз. Поэтому, для некоего узла или хоста, который размещает множество
виртуальных машин, такое ограничение числа процессов в 300 может оказаться не достаточным и будет включать
предостережения слишком часто. Мы можем изменить этот триггер, например, на 900 для увеличения
вашего предела. Дополнительные подробности по триггерам можно получить на странице
https://www.zabbix.com/documentation/2.2/manual/config/triggers/expression.
{Прим. пер.: также следите за ссылкой Zabbix,
Полное руководство, 2е изд. по которой в скором времени (мы надеемся) появится перевод новой книги
Mastering Zabbix, 2ed, вышедшей в сентябре 2015}
Также мы можем добавить в качестве хоста каждую виртуальную машину и затем наблюдать за ней при
помощи Zabbix. Для этого нам необходимо установить агента Zabbix внутри такой виртуальной
машины и добавить его в качестве хоста в Zabbix. Чтобы сгруппировать все виртуальные машины, нам
необходимо создать группу с именем Virtual Machine в Zabbix и
назначить для отслеживания все ВМ в эту группу.
Zabbix приходит вместе с исключительными графическими возможностями в самой поставке без всякой установки
вручную. Как только данные поступают из ресурса, утилиты построения графиков начинают построение графиков
применяя исходные данные. Практически все ваши встроенные шаблоны в Zabbix имеют некоторые предварительно
определённые элементы построения графиков. Мы можем получить графики наблюдаемых элементов переместившись
в Monitoring | Graphs в GUI Zabbix.
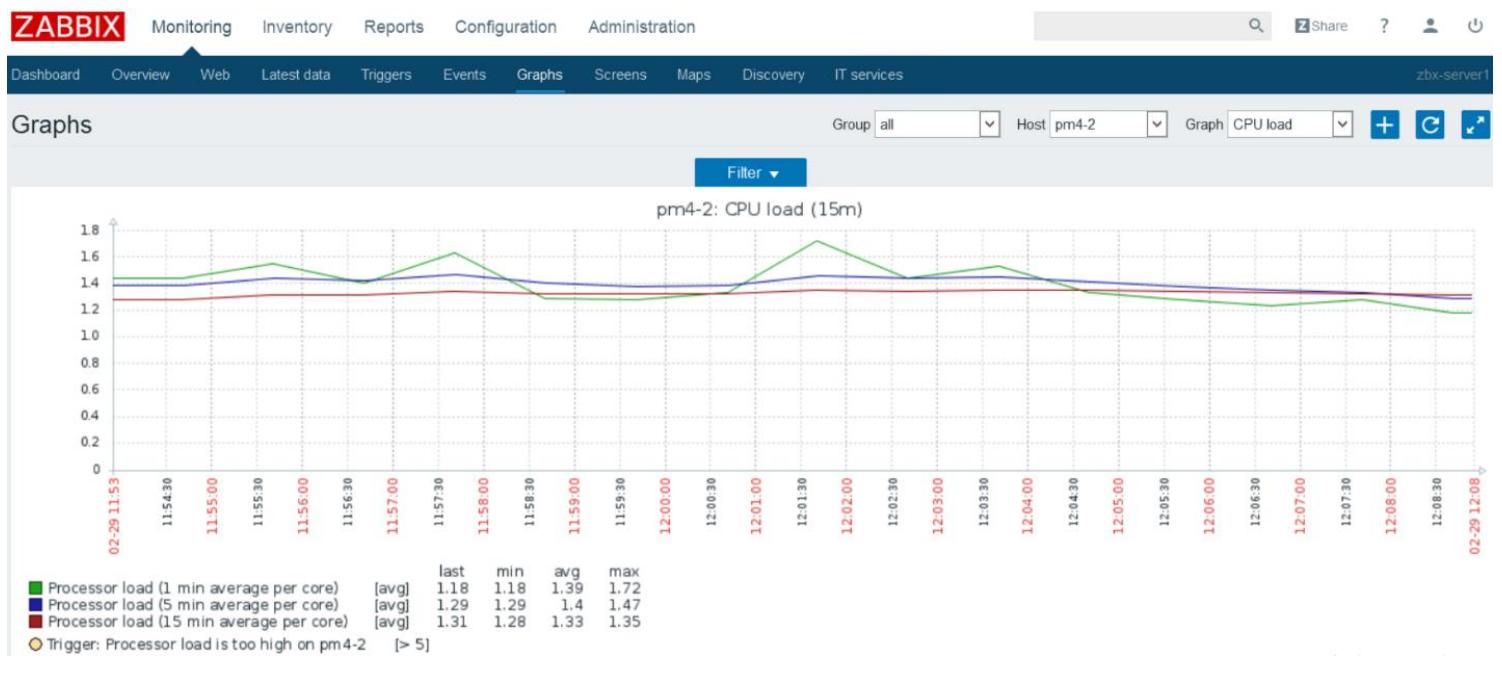
Следующий снимок показывает график CPU load
в промежутке 15 минут для выбранного хоста pm4-2 в нашем
примере кластера.
Мы также можем создать наш собственный график элементов в несколько кликов для любого наблюдаемого
хоста или устройства. Например, давайте создадим график для визуализации iowait
сверх нормальной работы CPU. Для этого нам нужно перейти в Configuration |
Hosts, а затем кликнуть на выбранный node.
Находясь внутри выбранного узла, кликните на меню Graphs
для открытия страницы редактирования графиков, как это показано на снимке экрана ниже.
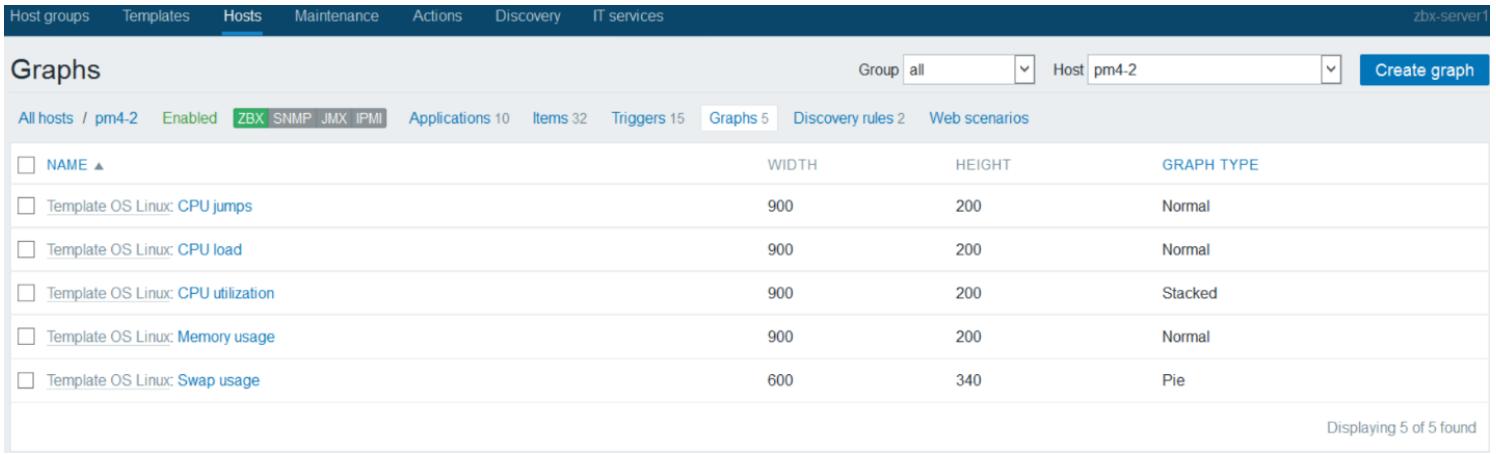
На предыдущем снимке экрана мы можем увидеть, что существует пять уже созданных графиков элементов. Мы
собираемся добавить новый элемент в CPU iowait time. Кликните по
кнопке Create Graph для открытия новой страницы
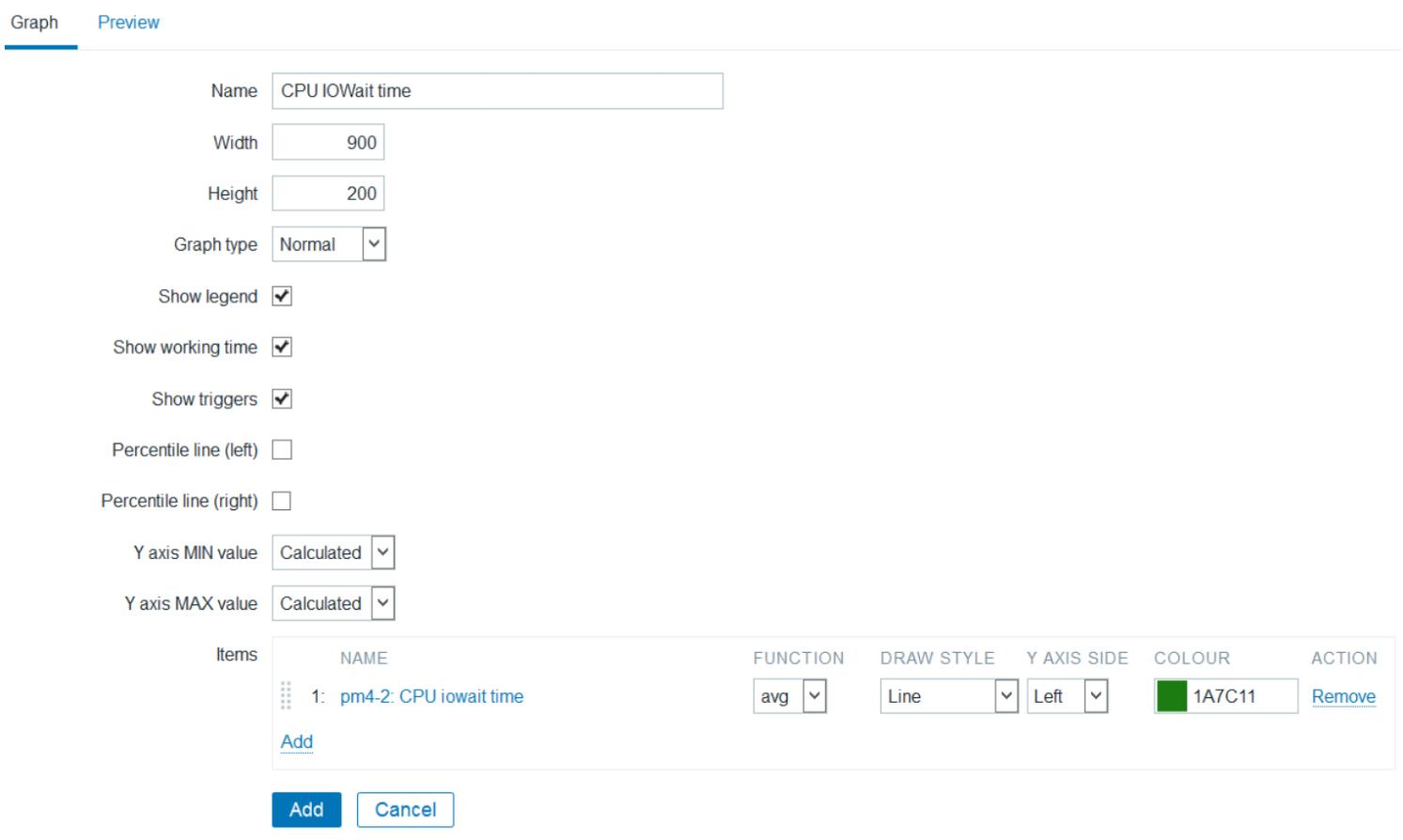
графика элемента. Введите легко понимаемое имя для создаваемого графика элемента. Мы собираемся назвать его
CPU IOWait Time. В расположенном блоке Items кликните на Add
для открытия перечня доступных элементов для выбора из него. Для данного примера мы собираемся выбрать
CPU iowait time. Мы можем настроить цвет и тип настраиваемого
графика. Кликните по кнопке Add, когда вы
удовлетворены своими настройками. Следующий снимок экрана отображает вашу страницу создания графика для
нашего примера CPU iowait time:
Чтобы увидеть вновь созданный график элемента нам нужно перейти в Monitoring | Graphs и выбрать созданный элемент для нашего узла.
Следующий снимок экрана показывает график для сбора данных CPU iowait time
за период в 15 минут:
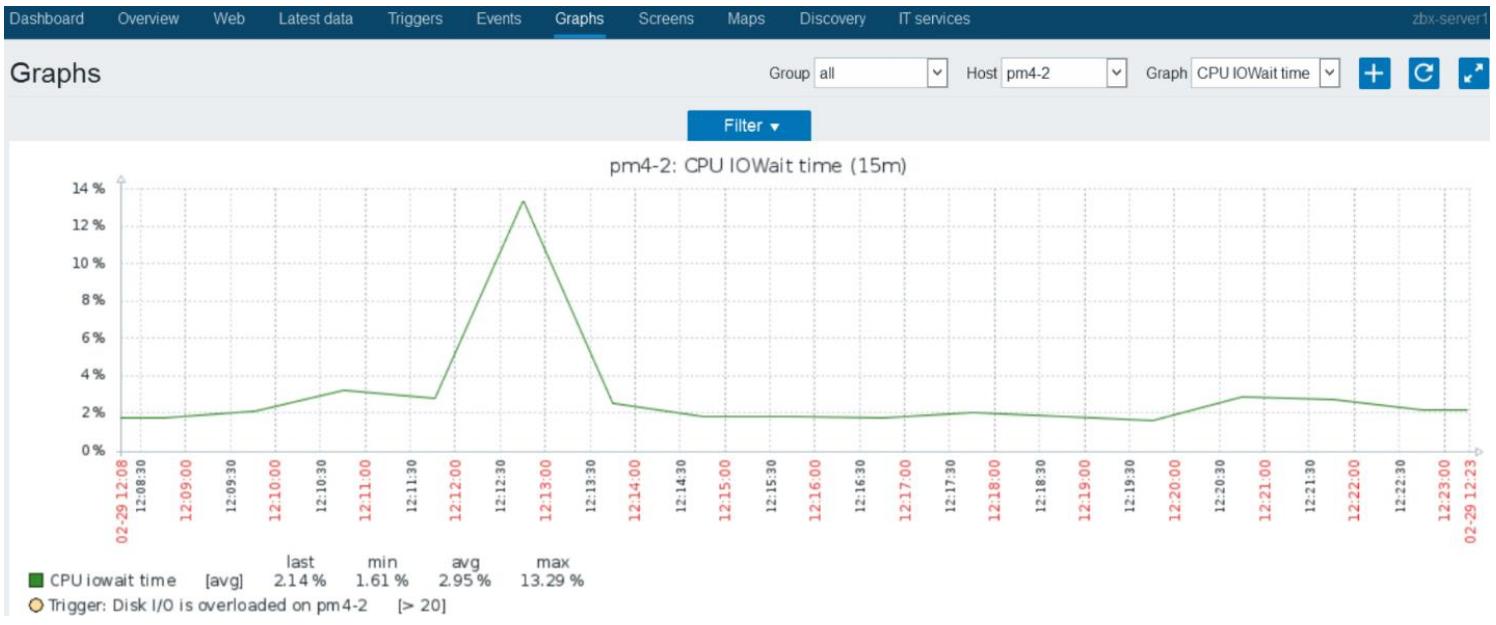
На предыдущем снимке экрана мы можем увидеть, что время IOtime отображается зелёным цветом, а если присутствует некий триггер событий в котором отслеживается превышение времени IOwait на 20%, то оно будет отображаться жёлтым цветом.
В разделе Встроенный мониторинг Proxmox, который обсуждался ранее в данной главе, мы увидели, что можем усилить S.M.A.R.T. автоматическим получением электронных сообщений в случае, когда возникают какие- либо проблемы с дисковыми устройствами. В этом разделе мы собираемся выполнить то же самое, но средствами Zabbix с расширенной функциональностью, например, графиками. Великолепным применением графика для дисковых устройств является мониторинг данных по температуре. Высокая температура является плохим признаком для шпиндельных дисков. Применяя график Zabbix, мы можем наблюдать за точной тенденцией температурного режима в кластере хранения вплоть до отдельного диска и предпринимать соответствующие действия. Zabbix также может отправлять автоматические электронные сообщения при возникновении какой- либо проблемы с любым из наблюдаемых дисков, например, обусловленные плохим сектором ошибки чтения или записи или любые другие события S.M.A.R.T.
На сегодняшний день почти все HDD или SDD имеют возможности S.M.A.R.T., которая может собирать различные существенные для жизнеспособности вашего дискового устройства данные. Используя инструменты мониторинга S.M.A.R.T. мы можем избегать предварительного отказа диска путём определения потенциальных проблем на ранней стадии. Мы можем настроить все узлы Proxmox на отправку сообщений электронной почты при обнаружении любой проблемы на любом из подключённых устройств.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Отметим, что если устройства подсоединяются через RAID контроллеры и настраиваются в виде какого- либо массива RAID, тогда ваши инструменты S.M.A.R.T. не будут способны получать данные о состоянии жизнеспособности данных устройств. |
Установка средств мониторинга SMART
Нам необходимо установить smartmontools в нашем хранилище
с помощью следующей команды:
#apt-get install smartmontools
Запросите список всех подключённых дисков при помощи такой команды:
#apt-get install smartmontools# fdisk -l
Убедитесь, что все подключённые диски имеют функцию S.M.A.R.T. и она включена выполнив приведённую ниже команду:
#smartctl –a /dev/sdX
Если диск имеет функцию S.M.A.R.T. и она разрешена, появится нечто подобное показанному на снимке экрана ниже:
smartctl 6.4 2014-10-07 r4002 [x86_64-linux-4.2.8-1-pve] (local build)
Copyright (C) 2002-2014, Bruce Allen, Christian Franke, www.smartmontools.org
ATA device successfully opened
Use 'smartctl -a' (or '-x') to print SMART (and more) information
Если же данная функция, но по какой- либо причине запрещена, мы можем включить её при помощи следующей команды:
#smartctl –s on –a /dev/sdX
Настройка агента Zabbix
Добавление мониторинга дискового устройства в Zabbix является двухступенчатым процессом. На первом шаге нам нужно добавить аргументы в файл настройки нашего агента Zabbix, а уже после этого добавлять элементы устройств в наш сервер Zabbix для каждого хоста. Такие специальные аргументы называются параметрами пользователя. Они работают аналогично сценариям (script) в которых мы можем определять команды, предназначенные для выполнения на хосте, после чего агент Zabbix возвращает данные на ваш сервер Zabbix.
В данном примере мы собираемся добавить пользовательские параметры для отсылки данных о серийном
номере и температуре устройства. Следующие две строки необходимо добавить в конец файла настройки
агента в /etc/zabbix/zabbix_agentd.conf:
UserParameter=hdd.temp[*],smartctl -A /dev/$1 | grep -E -i '^[ ]*($2)[]' | cut -c88-98
UserParameter=hdd.serial[*],smartctl -i /dev/$1 | grep 'Serial Number' | cut -c19-
После добавления этих строк нам необходимо осуществить перезапуск агента Zubbix при помощи следующей команды:
# service zabbix_agentd restart
Создание элемента Zabbix в GUI
После того как добавлены параметры пользователя, нам нужно создать в сервере Zabbix новые элементы для нашего хоста. Для начала мы добавим элемент для сбора данных температуры для наших устройств. Перейдите в Configuration | Hosts | Items, а затем кликните на Create item для открытия новой страницы элемента. Следующий снимок экрана показывает эту страницу с необходимыми настройками:
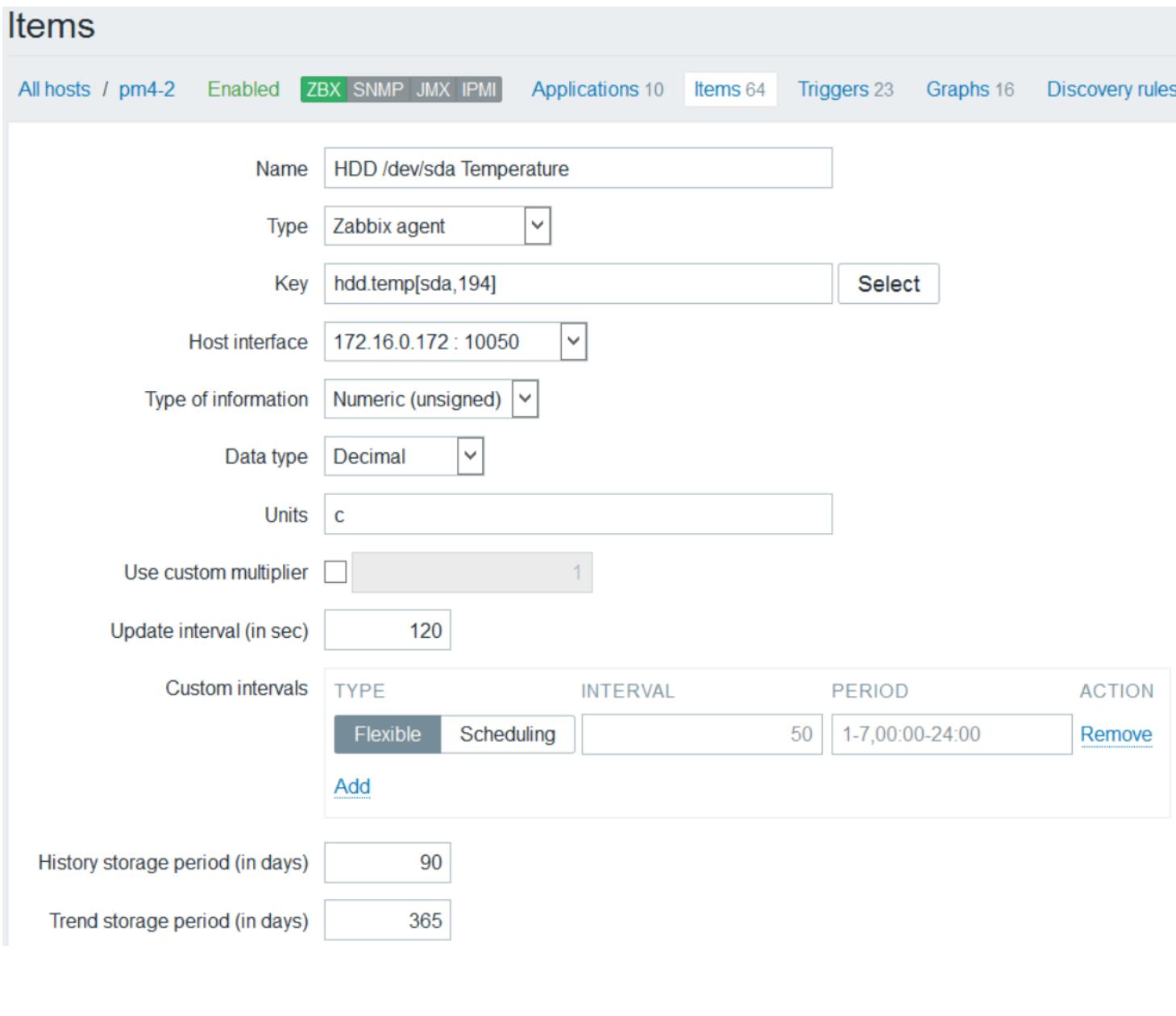
Имя элемента может быть любой текстовой строкой. Поскольку мы извлекаем данные через параметры пользователя
своего агента Zabbix, нам необходимо выбрать тип нашего агента. Блок Key
является здесь наиболее важным, поскольку это то место, в котором определяется какие данные мы извлекаем.
Введённый нами ключ, как это показано на предыдущем снимке экрана, сообщает Zabix о необходимости
извлекать температуру устройства для нашего устройства sda. Численное
значение 194 в поле ключа используется для обозначения информации о
температуре. Каждый атрибут монитора S.M.A.R.T. имеет уникальный численный идентификатор. Например, если
мы хотим собирать данные о неверных счётчиках секторов, код должен быть 197.
Для просмотра полного списка кодов атрибутов монитора S.M.A.R.T. перейдите по ссылке
https://en.wikipedia.org/wiki/S.M.A.R.T.#Known_ATA_S.M.A.R.T._attributes.
Тип информации является ниспадающим списком, применяемым для природы собираемых данных. Поскольку температура является численным значением, мы выбираем тип Numeric. Для увеличения точности собираемой температуры нам необходимо выбрать Decimal в качестве Data type.
Интервал Update является текстовым блоком для ввода секунд, что требует особенного внимания. Именно этот интервал Zabbix будет выдерживать для проверки каждого элемента. По умолчанию Zabbix применяет интервал в 30 секунд. При добавлении проверок с большими объёмами, такими как данные дисковых устройств, чем больше дисковых устройств присутствует в некоем узле, тем больше возрастает объём данных проверок, причём экспоненциально. Для примера, если мы хотим собирать данные устройств для какого- либо узла Ceph с 12 устройствами, Zabbix будет выполнять проверку каждые 30 секунд для всех 12 устройств и это наберёт до сотен проверок за час. Для уменьшения узкого места объёма проверок мы можем установить их на больший интервал. В нашем примере мы используем 2 минуты или 120 секунд для проверки устройств. Кликните на Add для завершения создания данного элемента.
|
| Замечание |
|---|---|
|
Отметим, что нам необходимо создавать отдельные новые элементы для каждого устройства, которое
нуждается в мониторинге. Изменяйте необходимый идентификатор устройства для каждого элемента, например,
|
Создание спускового устройства в GUI
После создания элемента нам необходимо создать спусковое устройство (trigger) с тем, чтобы Zabbix мог отправлять автоматические уведомления электронной почтой если температура выходит за пороговые значения. Для создания спускового устройства перейдите в Configuration | Hosts | Trigger и кликните по кнопке Create trigger. Следующий снимок экрана отображает страницу создания нового спускового устройства с необходимой введённой информацией:
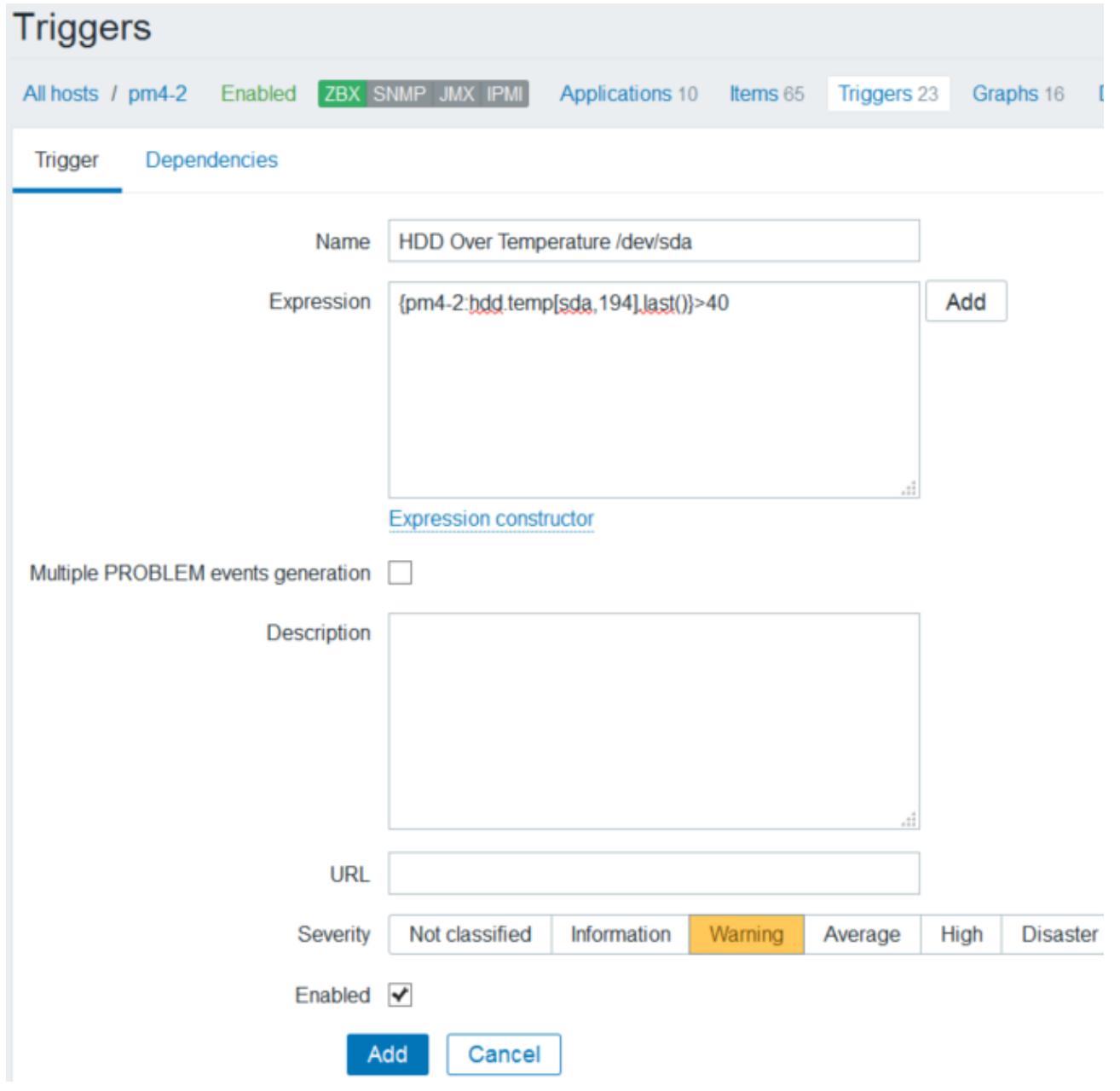
Введите имя для идентификации созданного спускового устройства и затем введите выражение для этого
спускового устройства. Данное выражение используется для установления порогового значения, выше которого
Zabbix запустит некое событие (такое как отсылка электронного почтового сообщения).
{Прим. пер.: строго говоря, само выражение содержит оператор сравнения и
выдаёт значение False в случае, когда результат не
требует срабатывания спускового механизма и True в
случае подобной необходимости. Подробнее см. наш перевод Главы 6, Управление
сигналами тревоги новой книги Mastering Zabbix, 2ed, вышедшей в сентябре 2015} В нашем примере, как это
отображено на предыдущем экранном снимке, наше выражение показывает, что если последнее полученное
значение температуры выше 40 градусов по Цельсию, Zabbix отошлёт электронной почтой сигнал тревоги.
С тем, чтобы идентифицировать важноть данного спускового устройства, нам необходимо выбрать уровень Severity (серьёзности). Например, мы выбрали в качестве уровня серьёзности Warning. Выбирайте соответствующую тяжесть в зависимости значимости спускового устройства. Это создаёт цветовое кодирование информации сквозь Zabbix для идентификации того, насколько серьёзна данная проблема. Кликните на Add для завершения создания данного спускового устройства (trigger). Подобно спусковым механизмам, каждое устройство будет нуждаться в отдельном элементе спускового механизма.
Создание графиков в GUI
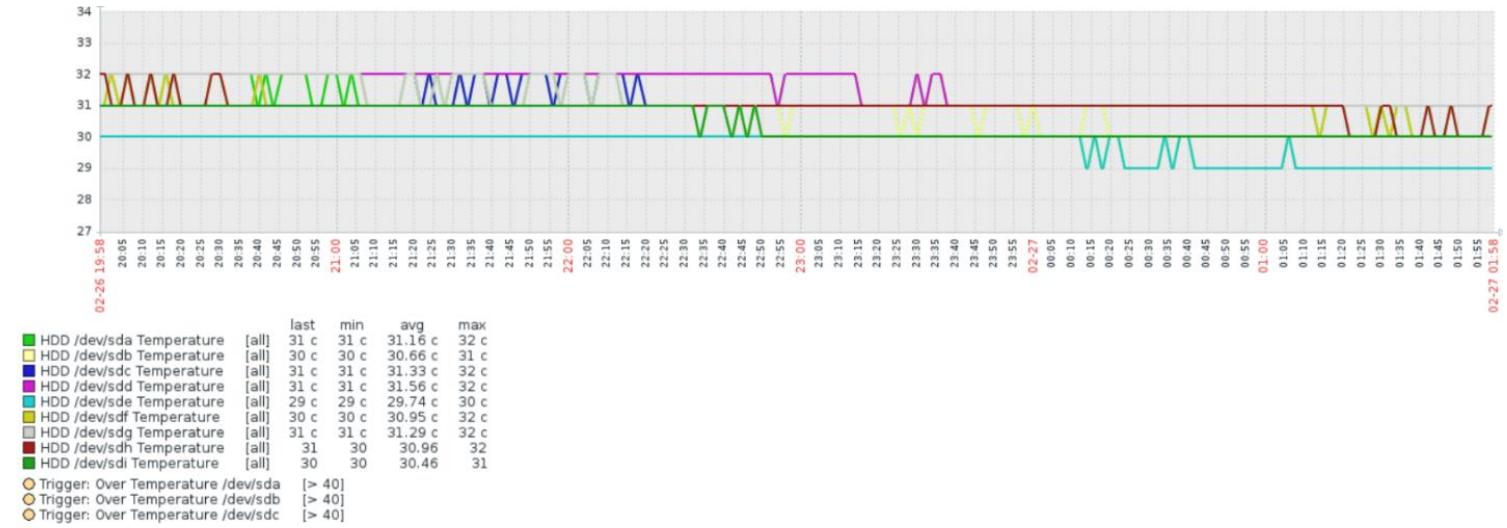
Придерживаясь наших инструкций для отображения данных с применением графиков, как это обсуждалось ранее в данной главе, теперь мы намереваемся создать новый элемент графика для визуального отображения данных о температуре устройства. В отличие от спусковых механизмов и элементов, у нас нет необходимости в создании отдельных элементов графиков. Мы можем настроить один элемент графика для отображения данных множества устройств просто добавляя свои элементы устройств в один и тот же элемент графика. Следующий экранный снимок показывает график температуры устройств для узла Ceph с семью дисковыми устройствами за период времени в 6 часов:
SNMP (Simple Network Management Protocol) является протоколом сетевого управления, применяемым для мониторинга большого разнообразия сетевых устройств. Он в особенности полезен, когда невозможна установка полного агента сетевого мониторинга, например, для коммутаторов, маршрутизаторов, принтеров, устройств на базе IP и тому подобного. Почти все программы сетевого мониторинга поддерживают некоторый уровень SNMP. Если конкретный выбранный пакет мониторинга не имеет никакого агента, тогда для мониторинга подобного устройства SNMP будет наилучшим выбором. SNMP является полностью настраиваемым в Linux, а поскольку Proxmox основан на Debian, он наследует все преимущества SNMP. Для получения более подробной информации по SNMP посетите https://en.wikipedia.org/wiki/Simple_Network_Management_Protocol. {Прим. пер.: или аналог на русском языке https://ru.wikipedia.org/wiki/SNMP.}
Существует несколько компонентов SNMP, о которых стоит упомянуть здесь, так как мы их будем применять для настройки SNMP. А именно:
-
OID; идентификатор объекта (Object Identifier)
-
MIB; ; база управляющей информации (Management Information Base)
OID (идентификаторы объекта, Object
Identifiers), являются объектами, которые ваш SNMP опрашивает для сбора информации с устройства. Объект
может быть неким состоянием сетевого интерфейса, использованием дискового хранилища, именем устройства
и тому подобным. Такие идентификаторы объектов в высшей степени структурированы древовидным иерархическим
образом. Каждый OID имеет особенную
нумерацию. Например, OID нашего объекта, который собирает имена устройств равен
1.3.6.1.2.1.1.5.0. OID всегда имеют численные значения. OID можно
сравнить с адресами IP, в которых численные значения используются для идентификации устройства в
сетевой среде.
Каждая точка в OID представляет собой сегментацию сетевого элемента. Мы можем представлять себе OID как адрес местоположения. Давайте возьмём следующий адрес:
Wasim Ahmed
111 Server Street, 4th Floor
Calgary, AB 111-222
Canada
Если мы поместим это адрес в наш формат OID он будет выглядеть следующим образом:
WaCanada.AB.Calgary.111-222.Server Street.111.4th Floor.Wasim Ahmed
Разместив это в формулу мы увидим нечто вроде:
Country.Province.City.Postal code.Street name.Street number.Unit number.Contact name
Как и в примере с нашим адресом, OID также следует строгой иерархии следующим образом:
1 = ISO
1.3 = Organization
1.3.6 = US Department of Defense
1.3.6.1 = Internet
1.3.6.1.2 = IETF Management
1.3.6.1.2.X = Management-related OIDs
Чтобы увидеть относящиеся к управлению OID обратитесь к http://www.alvestrand.no/objectid/1.3.6.1.2.1.html
Существуют базы данных, в которых хранятся OID. MIB
выступает в качестве транслятора, который делает возможным серверу SNMP опрашивать некий объект
при помощи текстового представления вместо числового OID. Например, для извлечения имени устройства
из запросов SNMP мы можем воспользоваться OID 1.3.6.1.2.1.1.5.0 или
OID SNMPv2-MIB::sysName.0. Оба предоставят вам в точности один
и тот же результат. Однако текстовое представление OID проще в понимании, нежели числовой OID. Мы можем
сравнить MIB для OID как если бы мы сопоставляли доменные имена неким IP адресам. Некоторые производители
предоставляют свои собственные MIB, поскольку они не присутствуют в едином стандарте MIB. Очень важно
знать значение MIB при настройке не поддерживаемого устройства для средств мониторинга. Существует ряд
MIB, подготовленных для загрузки. Proxmox не устанавливает никакие MIB по умолчанию. Их необходимо
устанавливать вручную. Для получения дополнительных подробностей о MIB посетите
https://en.wikipedia.org/wiki/Management_information_base
{Прим. пер.: или аналог на русском языке https://ru.wikipedia.org/wiki/Management_Information_Base.}
В настоящее время существует три версии SNMP. Прежде чем приступать к реализации инфраструктуры SNMP, важно узнать какую версию использовать. Эти три версии таковы:
-
SNMP version 1: Это самая старая версия SNMP, которая поддерживает только 32- битные счётчики и совсем не имеет никаких средств безопасности. В данном SNMP строка сообщества отсылается как простой текст.
-
SNMP version 2: Она имеет все те же функции, что и версия 1 с добавлением функция поддержки 64- битных счётчиков. Большинство современных устройств поддерживает версию 2.
-
SNMP version 3: Она имеет всю функциональность версий 1 и 2 с добавлением преимуществ безопасности. К счётчикам добавлены и шифрование, и аутентификация. Если безопасность является наиболее значимой, необходимо использовать именно эту версию.
По умолчанию SNMP не установлена в Proxmox. Следующие шаги показывают как установить SNMP в Proxmox и как её настроить:
Выполните следующую команду для установки SNMP на узлах Proxmox:
# apt-get install snmpd snmp
Добавьте следующий репозиторий в /etc/apt/sources.list
на вашем узле Proxmox. Это используется для добавления репозитория в установку MIB SNMP:
deb http://http.us.debian.org/debian/wheezy main non-free
Выполните следующие команды для установки MIB SNMP:
# apt-get update
# apt-get install snmp-mibs-downloader
При помощи текстового редактора откройте файл настройки вашего SNMP /etc/snmp/snmpd.conf.
Убедитесь что следующая строка лишена признаков комментария. Мы можем определить адрес IP нашего
узла. SNMP прослушивает порт 161. В случае необходимости измените
его здесь:
agentAddress udp:127.0.0.1:161
Добавьте следующую строку в файл настройки вашего SNMP:
rocommunity <secret_string> <IP/CIDR>
В нашем примере мы добавили следующую строку:
rocommunity SecretSNMP 172.16.0.0/24
Сохраните этот файл и перезапустите SNMP, применив следующую команду:
#service snmpd restart
Добавление устройств SNMP в Zabbix является процессом, аналогичным добавлению хостов, за исключением того, что мы должны выбрать интерфейс SNMP вместо интерфейсов агентов, как это отображено на следующем снимке:
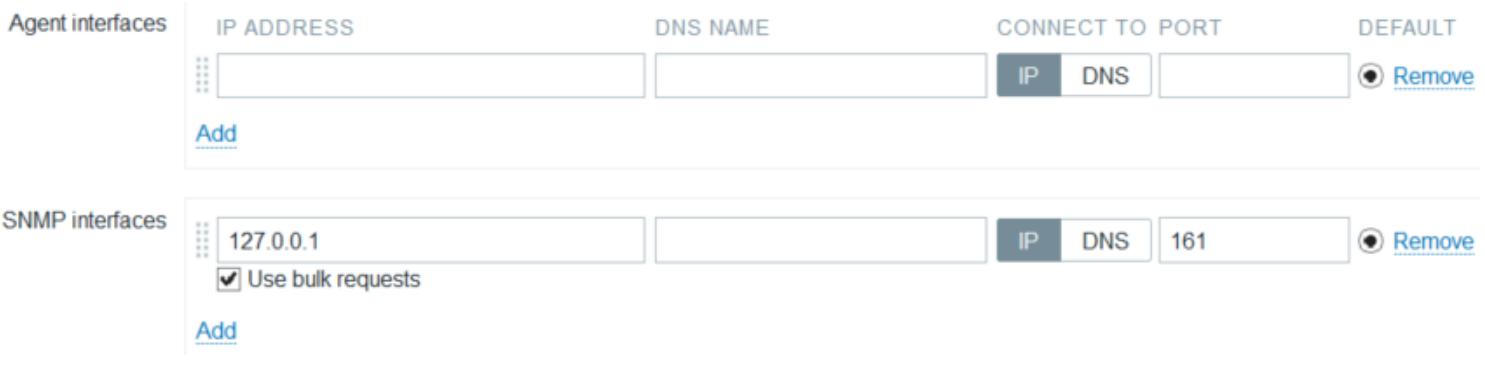
По умолчанию устройства SNMP прослушивают порт 161. Zabbix
поставляется с предварительно построенными шаблонами SNMP, которые могут собирать значительные объёмы
данных для устройств, в которых установка агента Zabbix невозможна или нежелательна. Обычным примером
подобного устройства SNMP является сетевой коммутатор. Zabbix имеет исключительную поддержку для
мониторинга коммутаторов при помощи шаблонов SNMP.
В нашем примере мы добавим 48 портовый коммутатор Netgear с применением интерфейса SNMP. Перейдите в
Configuration | Hosts и кликните по
кнопке Create host для открытия новой
страницы создания хоста. В рамках применения интерфейса SNMP на странице создания хоста, мы должны
выбрать шаблон устройства SNMP и набрать строку SNMP v2 Community
в Macros, как это показано на
следующем снимке:
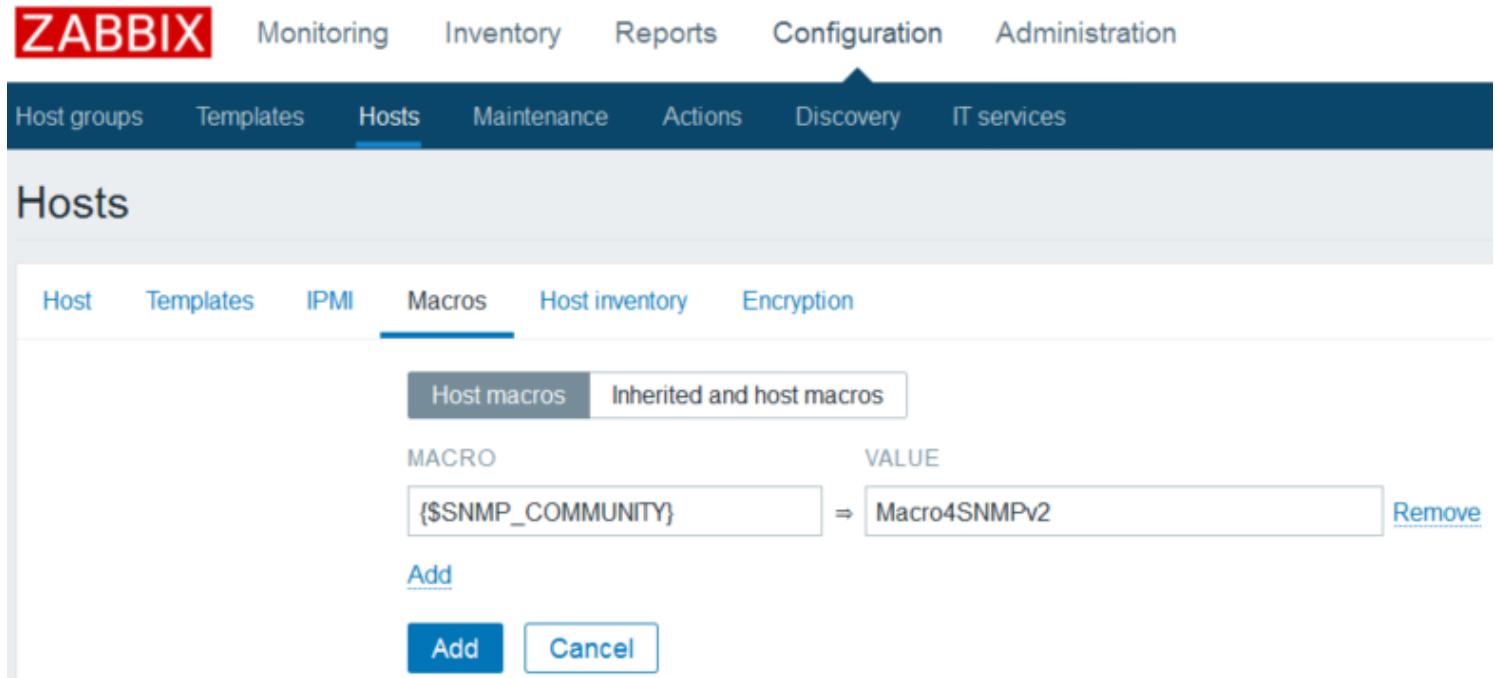
Макрос {$SNMP_COMMUNITY} применяется для передачи строки
безопасности сообщества, которая используется в SNMP версии 2. Значение данного макроса должно
соответствовать значению, введённому в самом устройстве, подлежащем мониторингу.
После того, как хост или устройство добавлены, Zabbix запустит проверку на данном коммутаторе через несколько минут и начнёт накапливать данные. Шаблон устройства SNMP имеет настроенное автоматическое обнаружение, которое автоматически просканирует данный коммутатор на число портов и отобразит данные как для входящего, так и для исходящего обмена по каждому из портов. Шаблон также имеет настроенный элемент графика для отображения вам информации по каждому из портов.
Следующий снимок экрана показывает график входящего и исходящего обмена используемый для порта
1 нашего 48 портового коммутатора Netgear на протяжении
промежутка времени в 1 час:
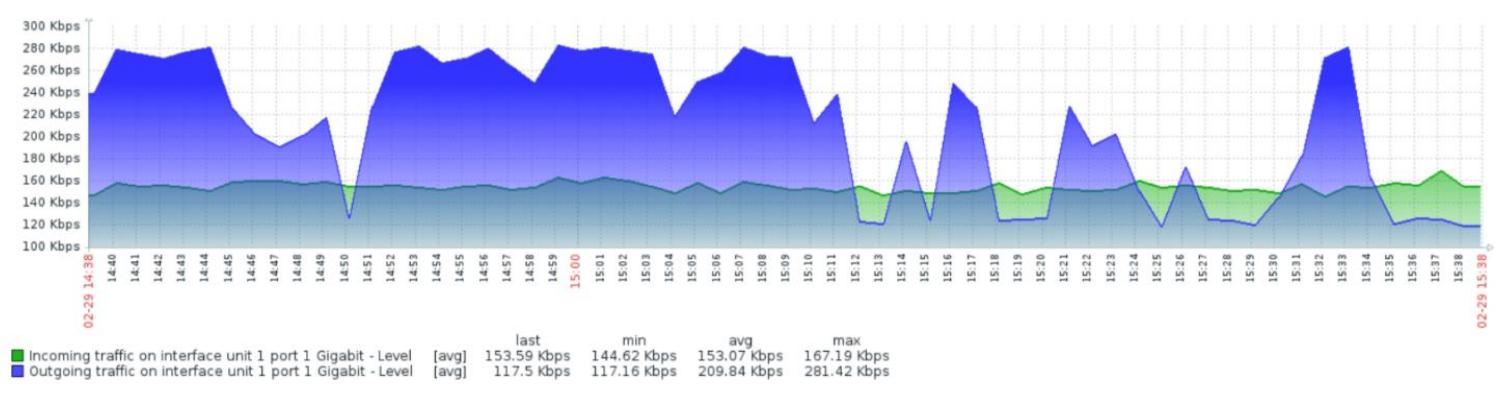
Подобно данному коммутатору мы можем добавить почти любое сетевое устройство с имеющимися возможностями SNMP для мониторинга Zabbix на протяжении всего времени. {Прим. пер.: Подробнее о построении собственных шаблонов см. наш перевод Главы 7, Управление шаблонами новой книги Mastering Zabbix, 2ed, вышедшей в сентябре 2015}
В Proxmox VE 4.1 мы можем осуществлять мониторинг и управление кластером хранения через GUI Proxmox. {Прим. пер.: хотя на наш вкус более продвинутой является VSM, предоставленная в Open Source сообщество Ceph разработчиками Intel, подробнее см. Главу 9, Менеджер виртуального хранения Ceph в нашем переводе второй книги Карана Сингха Ceph Cookbook, вышедшей в конце февраля 2016г. Вернёмся к средствам Proxmox:} в меню с закладками Ceph каждого узла вы можете увидеть большое количество данных, таких как состояние жизнеспособности вашего кластера Ceph, общее число OSD, число мониторов, пулов, настройки вашего Ceph и тому подобное. Отсылаем вас к Главе 4, Системы хранения за информацией об управлении Ceph при помощи графического интерфейса Proxmox. В данной главе мы рассмотрим как реализовывать решения сторонних производителей для мониторинга вашего кластера Ceph. Существуют различные варианты, применяемые для графического мониторинга кластера Ceph, например, следующие:
-
Calamari: https://ceph.com/category/calamari/. {Прим. пер.: также рекомендуем наш перевод Главы 5, Мониторинг кластеров Ceph с применением Calamari второй книги Карана Сингха.}
-
Kraken Dash: https://github.com/krakendash/krakendash/a>. {Прим. пер.: также рекомендуем наш перевод раздела Наблюдение за Ceph с использованием инструментальной панели на основе открытого кода первой книги Карана Сингха.}
-
Инструментальная панель самого Ceph: https://github.com/Crapworks/ceph-dash
-
{Прим. пер.: уже упомянутый нами VSM}
Все варианты являются жизнеспособными опциями, используемыми для мониторинга кластера Ceph. Однако, связанные обязательствами простоты и эффективности, определёнными для данной главы, мы собираемся рассмотреть как устанавливать инструментальную панель Ceph. Это единственная из доступных в свободном доступе, которая является доступной только для чтения, без каких- либо возможностей управления {Прим. пер.: так в оригинале}. Это к тому же безопаснее, поскольку не авторизованные пользователи не могут вносить изменения в Ceph. И Ceph Calamari, и Kraken Dashboard {Прим. пер.: а также VSM} в равной степени оспаривают право на установку и настройку.
Инструментальная панель Ceph может быть установлена на любой из узлов Ceph или узел
Proxmox+Ceph в вашем кластере. До тех пор, пока она может читать файл ceph.conf,
она будет работать просто прекрасно. Ваша инструментальная панель Ceph для своей работы не требует
никакого веб- сервера или дополнительных служб. Мы можем загрузить пакет инструментальной панели Ceph с
Git. По умолчанию, в ваших узлах Proxmox git не установлен.
Мы можем установить его при помощи следующей команды:
# apt-get install git
Далее нам необходимо клонировать репозиторий github инструментальной панели Ceph воспользовавшись следующей командой:
# git clone https://github.com/Crapworks/ceph-dash
По окончанию загрузки нам необходимо добавить IP адреса тех узлов, на которых будут запускаться
наша инструментальная панель. Нам нужно внести изменения в следующую строку в файле
ceph-dash.py:
app.run(host='ip_address',debug=True)
Для запуска нашей инструментальной панели после внесения изменений, просто выполните следующую команду:
# <dashboard_directory>/ceph_dash.py
Мы можем осуществить доступ к этой инструментальной панели указав на её узел следующим
образом: http://ip_address:5000.
Следующий снимок экрана отобразит состояние нашего кластера примера с использованием вашей инструментальной панели Ceph:
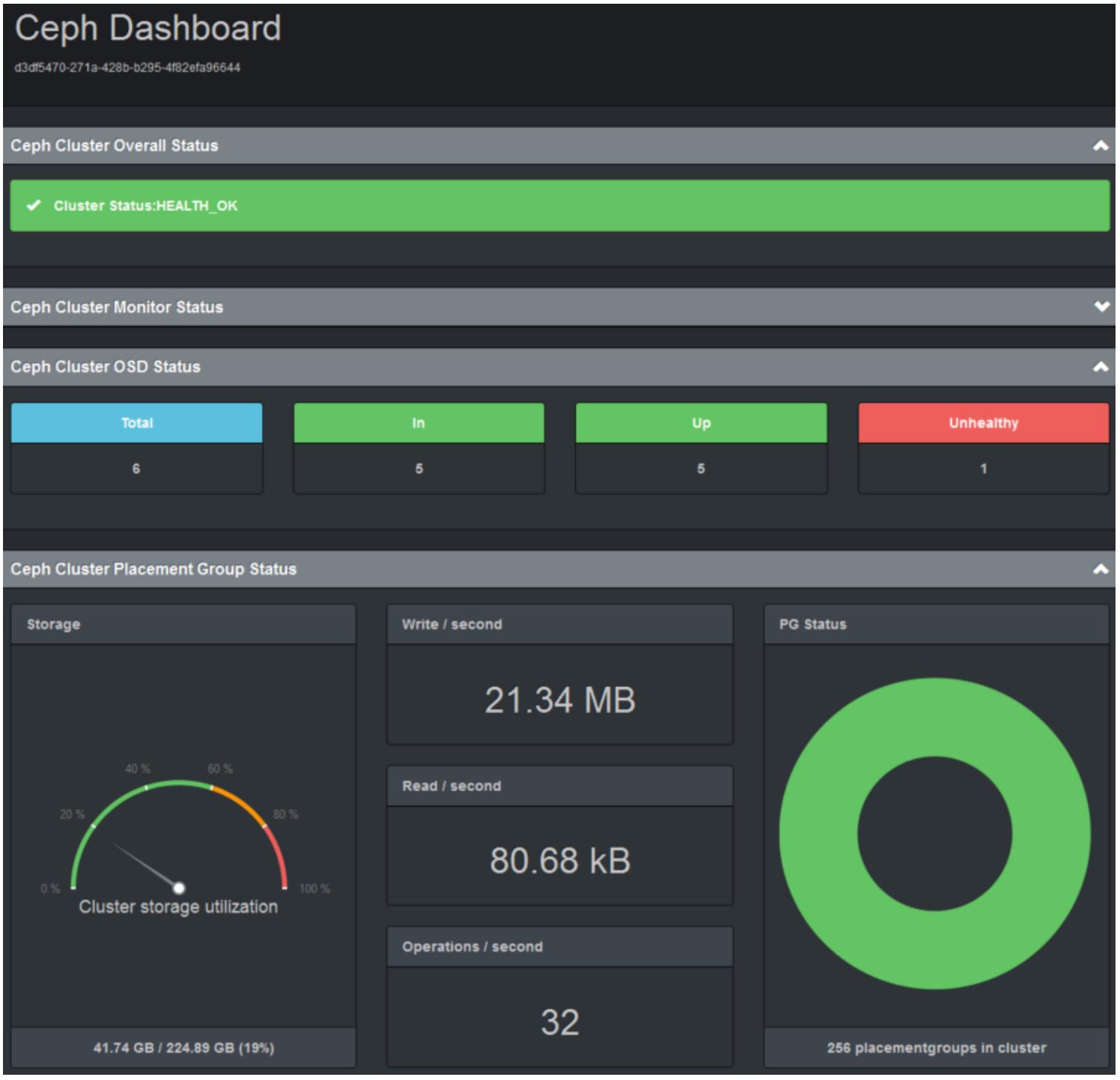
Инструментальная панель Ceph отображает следующую информацию о кластере Ceph:
-
Ключ кластера Ceph
-
Общее состояние жизнеспособности
-
Состояние монитора
-
Состояние OSD
-
Состояние групп размещения (PG)
-
Процентное соотношение использования хранилища
-
Общий объём доступного и используемого пространств
-
Скорость чтения/ записи в секунду
-
Количество операций в секунду
Для получения информации о компонентах Ceph, таких как MON, OSD, PG и тому подобные, ознакомьтесь с Главой 4, Системы хранения. Все эти данные обновляются в автоматическом режиме через равные интервалы времени. В процессе любых отказов в рамках кластера, ваша инструментальная панель отобразит связанную с этим отказом информацию в кодированном цветом формате. Применяя проброс порта через межсетевой экран мы также можем осуществлять удалённый мониторинг кластера.
В данной главе мы рассмотрели как мы можем осуществлять мониторинг сетевой среды кластера Proxmox с использованием мощных систем мониторинга, таких как Zabbix. Ни в коем случае Zabbix не является единственным вариантом мониторинга, доступным для выбора из основного русла. Однако она имеет массу преимуществ перед другими решениями. Предоставляемые в основной поставки функции, такие как графики, шаблоны, SNMP, автоматическое уведомление и тому подобное, являются только вершиной айсберга из того, что предлагает Zabbix. Будь то небольшая среда или большая облачная служба поставщика, распространённая на множество регионов, Zabbix может осуществлять мониторинг любой из них. Хороший системный администратор опробует несколько решений и найдёт то, которое отвечает его среде наилучшим образом. {Прим. пер.: также следите за ссылкой Zabbix, Полное руководство, 2е изд. по которой в скором времени (мы надеемся) появится перевод новой книги Mastering Zabbix, 2ed, вышедшей в сентябре 2015.}
В следующей главе мы рассмотрим некоторые сложности виртуальных сред промышленного уровня, усиленных гипервизором Proxmox. Мы рассмотрим сетевые диаграммы на основе сценариев для получения знаний о том, что может делать Proxmox.