Глава 4. Системы хранения
Содержание
Система хранения является носителем, который хранит данные для одновременного доступа множеством устройств или узлов в сетевой среде. По мере того как виртуализация серверов и рабочих мест становится нормой жизни, сегодня стабильная система хранения является наиболее критически важной для виртуальной среды. В терминах Proxmox система хранения является тем местом, где хранятся образы виртуальных дисков.
Хотя кластер Proxmox может быть полностью функциональным с DAS (Direct Attached Storage) или локальной системой хранения на том же самом узле Proxmox, совместно используемая система хранения имеет большое число преимуществ в промышленных средах, таких как возрастающая управляемость, плавное расширение хранилища, а также избыточность, это только некоторые из тех, что можно перечислять. В данной главе мы охватим следующие темы:
-
Сопоставление локальных и совместно используемых хранилищ
-
Типы образов виртуальных дисков
-
Поддерживаемые Proxmox типы систем хранения
-
Коммерческие и бесплатные опции совместно используемых хранилищ
-
FreeNAS как вариант совместно используемого хранилища с низкой стоимостью
-
Ceph в качестве совместно применяемого хранилища корпоративного уровня
Будь то локальная или совместно применяемая, система хранения является жизненно важной компонентой кластера Proxmox. Система хранилища это то место, где располагаются наши виртуальные машины. По этой причине более глубокое понимание различных систем хранения позволит системному администратору надлежащим образом планировать требования к хранилищам для любой кластерной среды.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
{Прим. пер.: Это может показаться забавным, однако с некоторых пор стало возможным построение бесплатной среды виртуализации на основе гипервизора Hyper-V с бесплатной же системой хранения Storage Spaces, обладающей современными функциональностью и мощностью сопоставимыми, например, с Ceph. Хотя она и ограничена в масштабировании применением аппаратных технологий SAS/ FC. Остаётся дождаться смещения Storage Spaces Direct (S2D) в сферу халявного применения, чтобы имеющаяся в Непосредственно подключаемых пространствах хранения Программно определяемая шина хранения (Software Storage Bus), заменяющая собой SAS/FC, смогла составить конкуренцию системам хранения уровня Ceph!} |
В кластерной среде Proxmox совместно используемое хранилище не является обязательным, однако, без всяких сомнений, оно делает управление хранением более простой задачей. В небольших бизнес- средах может быть достаточным не иметь время работы 24/7 и 100% надёжность, поэтому локальная система хранения будет достаточной. Когда данные выходят за пределы нескольких Терабайт, совместно используемое хранилище может быть оправданным или не очень. Вопрос заключается в том, насколько важны бюджет, надёжность, устойчивость и доступность. В большинстве корпоративных виртуальных сред с критически важными данными совместно используемые хранилища являются единственным логичным выбором из-за привносимых ими для всего кластера операций преимуществ. Далее мы рассмотрим преимущества использования совместно применяемого хранилища:
-
Миграция виртуальных машин в реальном масштабе времени
-
Плавное расширение пространства хранения с множеством узлов
-
Централизованное резервное копирование
-
Многоуровневое кэширование данных
-
Централизованное управление хранением
Скорее всего, это одна из самых важных по популярности причин для совместно используемых систем хранения. Миграция в реальном времени (live migration) это когда виртуальная машина может быть перемещена на другой узел без её выключения перед этим. Миграция в выключенном состоянии (offline migration) это случай, когда виртуальная машина выключается перед выполнением перемещения. Оборудование и операционная система узлов Proxmox нуждаются в обновлениях, исправлениях, и происходящих заменах. Некоторые обновления требуют немедленной перезагрузки, в то время как некоторые не требуют её совсем. первичная функция узлов Proxmox в кластере состоит в работе виртуальных машин. Когда узел нуждается в перезагрузке, все выполняющиеся ВМ должны быть остановлены или перемещены на другие узлы. Затем их миграция назад на первоначальный узел после цикла перезагрузки завершает процесс. В Proxmox включённая ВМ не может переместиться с применением миграции в реальном времени без её выключения перед этим если эта ВМ расположена на локальном диске запрашиваемого узла. Если вдруг по какой- либо причине происходит общий отказ узла Proxmox, все хранящиеся на этом узле ВМ будут полностью недоступны пока этот узел не будет исправлен или заменён. Это происходит из- за того, что ВМ не могут быть доступны для перемещения на другой узел пока проблемный узел включён.
В большинстве случаев выключение всех ВМ только для перезагрузки узла хоста не является вариантом.
Это вызывает слишком большие простои в зависимости от общего числа ВМ обрабатываемых данным узлом.
Чтобы выполнить миграцию хранимых локально ВМ, они должны быть остановлены, после чего должна быть
инициирована миграция из GUI Proxmox. Миграция из локального хранилища на другое локальное хранилище
занимает много времени в зависимости от размера переносимой ВМ, так как Proxmox переносит весь файл образа
с использованием rsync для размещения этой ВМ на другом узле.
Давайте взглянем на следующую схему кластера с 40 хранимыми локально виртуальными машинами по 10 на каждом из четырёх узлов Proxmox:
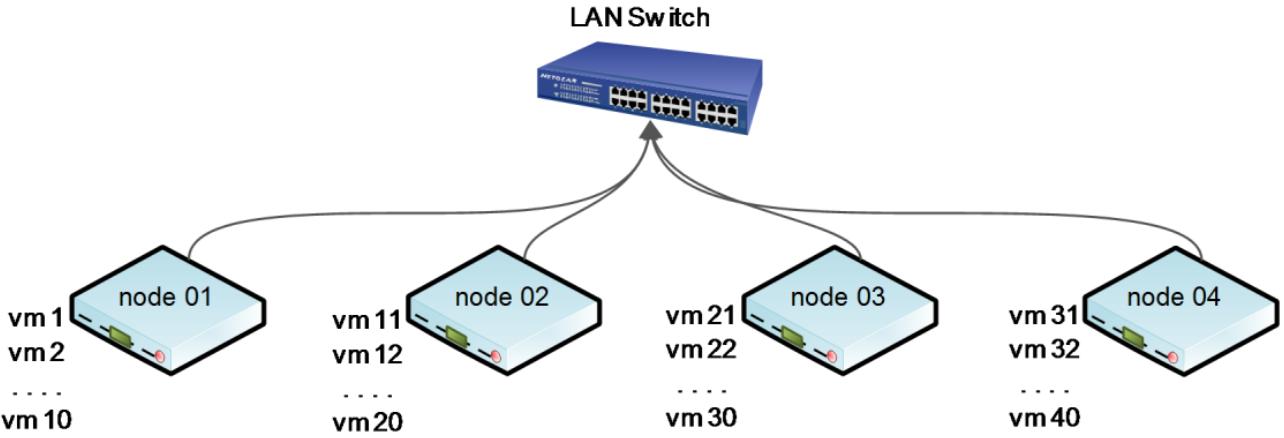
В предыдущей небрежно упрощённой схеме присутствуют четыре узла Proxmox с 10 виртуальными машинами на
каждом. Если узлу 01 требуется перезагрузка, все 10 виртуальных машин
должны быть остановлены, узел должен быть перезагружен, а затем все эти виртуальные машины должны быть
включены. Если узел 01 должен быть выведен из строя для обновления
оборудования, тогда все виртуальные машины должны быть остановлены и вручную перемещены на другие узлы.
Если узел 01 полностью отказал, тогда все 10 виртуальных машин будут
недоступны пока узел 01 не вернётся вновь.
Таким образом ясно, что настройка кластера с локальным хранилищем для виртуальных машин может вызывать нежелательные простои в случаях, когда необходима миграция. Теперь давайте взглянем на следующую схему где четыре узла Proxmox с 40 виртуальными машинами хранятся в совместно используемом хранилище:
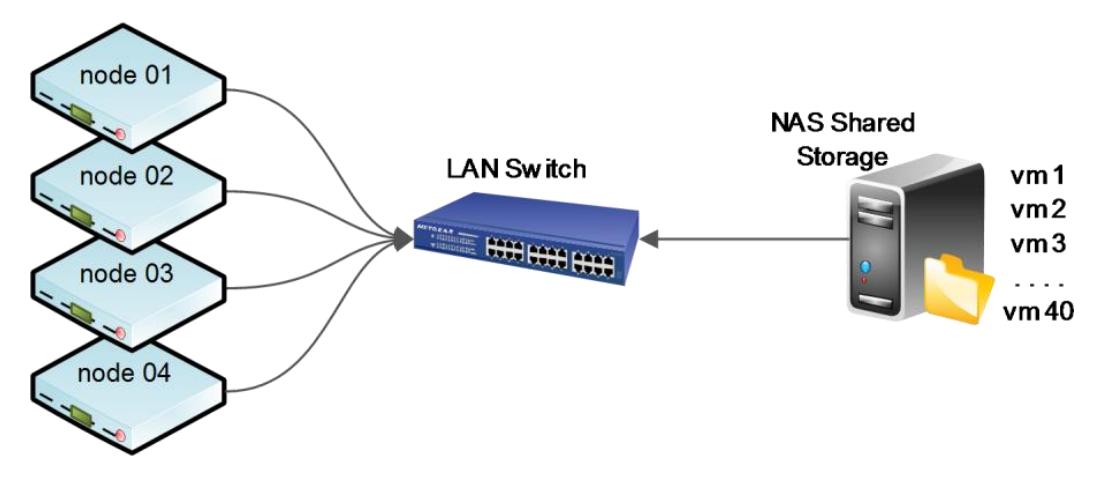
На предыдущей схеме все 40 виртуальных машин хранятся в совместно используемой системе хранения. Узел
Proxmox всего лишь хранит файлы настройки для каждой виртуальной машины. В этом сценарии если узлу
01 требуется перезагрузка из- за исправления безопасности или
обновления, все виртуальные машины могут быть просто перемещены на другой узел без выключения отдельной
виртуальной машины. Пользователь виртуальной машины никогда не заметит что его машина в действительности
переместилась на другой узел. Если произошёл общий отказ узла Proxmox, файл настройки такой виртуальной
машины может быть просто вручную перенесён из /etc/pve/nodes/node01/qemu-server/<vmid>.conf
в /etc/pve/nodes/node02/qemu-server/<vmid>.conf
|
| Замечание |
|---|---|
|
Мы также можем усилиться другой функцией Proxmox, называемой высокой доступностью (HA, high availability) для автоматизации перемещения файла настройки такой ВМ в случае отказа узла. Для изучения данной функциональности обратитесь к Главе 9, Высокая доступность Proxmox. |
Поскольку все файлы настроек виртуальных машин находятся в кластеризованной файловой системе Proxmox, они
могут быть доступны с любого узла. Отсылаем к Главе 3, Под капотом Proxmox за подробностями о кластеризованной файловой системе Proxmox, или
pmxcfs. При наличии файлов образов виртуальной машины на совместно используемом хранилище, миграция Proxmox
не должна перемещать все такие файлы образов c применением rsync с одного
узла на другой, что делает возможной гораздо более быструю миграцию виртуальной машины.
|
| Замечание |
|---|---|
|
|
При выполнении миграции ВМ в реальном времени имейте в виду, что чем больше оперативной памяти (ОЗУ) выделено этой ВМ, тем больше времени займёт такое перемещение в реальном времени включённой ВМ.
Следует отметить, что совместно используемое хранилище может стать единой точкой отказа в случае, если установлено совместное хранилище на основе одного узла, такого как FreeNAS или NAS4Free без настроенной высокой доступности. Применение распределённых совместно используемых хранилищ или систем со множеством узлов, например, Ceph, Gluster или DRBD, исключает единую точку отказа. {Прим. пер.: механизм Репликаций также позволяет решать эту задачу для систем на основе ZFS. Особенно стоит отметить появившуюся в свободно распространяемых версиях в 2016г Возобновляемой отсылки, дополняющий механизм инкрементальных репликаций до законченного решения при работе на плохих каналах связи.} В случае использования разделяемого хранилища с одним узлом все виртуальные машины хранятся на одном узле. Если происходит отказ узла, хранилище становится недоступным со стороны кластера Proxmox, тем самым предоставляя все работающие виртуальные машины недоступными.
|
| Замечание |
|---|---|
|
В Proxmox VE 4.1 контейнеры LXC не могут выполнять миграцию в реальном времени. Они должны быть выключены для выполнения миграции в режиме офлайн. ВМ KVM могут выполнять миграцию в реальном времени без выключения этих ВМ. |
Цифровые данные растут быстрее чем когда- либо прежде в нашем современном 24/7 численно объединяемым мире. С момента появления виртуализации рост был экспоненциальным. Так как гораздо проще установить виртуальный сервер немедленно, администратор может просто клонировать шаблон виртуального сервера и, при использовании пространства хранения, в пределах нескольких минут будет запущен и заработает новый виртуальный сервер. Если его оставить неконтролируемым, такое создание и изымание виртуальных машин на постоянной основе может заставить компанию выйти за пределы доступного пространства хранения. Распределённая совместно используемая система хранения разработана с учётом таких очень специфичных требований.
В корпоративных средах пространство хранения должно увеличиваться по запросу без отключения или прерывания критически важных узлов или виртуальных машин. Используя распределённые совместно используемые системы хранения или системы со множеством узлов, виртуальные машины могут теперь выходить за пределы нескольких узлов локальных кластеров до разрозненных множественных узлов распределённых по географическим областям. Например, Ceph или Glaster могут распространяться на несколько стоек и удовлетворительно поддерживать несколько Петабайт используемого пространства хранения. Просто добавьте новый узел полностью набитый дисками, затем сообщите кластеру о необходимости распознавать новый узел для увеличения пространства хранения сего кластера. Поскольку совместно используемое хранилище отделяется от ваших узлов хостов виртуальных машин, хранилище может увеличиваться или уменьшаться без воздействия на какие- либо работающие виртуальные машины. Позже в этой главе мы увидим как интегрировать Ceph в Proxmox.
Совместно используемое хранилище делает возможным централизованное резервное копирование, позволяя каждому узлу виртуальных машин создавать резервную копию в одном центральном местоположении. Это помогает менеджеру резервного копирования или администратору реализовывать цельный план резервного копирования и управлять всеми существующими резервными копиями. Так как отказ узла Proxmox не приводит к падению совместно используемой системы хранения, виртуальные машины могут быть легко восстановлены на новом узле для уменьшения времени простоя.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Всегда применяйте отдельный узел для целей резервного копирования. Плохой практикой будет хранение и виртуальной машины и её резервных копий на одном и том же узле. |
Многоуровневые данные являются концепцией при которой различные файлы могут храниться в различных пулах хранения на основе их требований к производительности. Например, виртуальный файловый сервер может предоставлять очень быструю службу если данная ВМ хранится в пуле хранения на SSD {NVMe}, в то время как виртуальный сервер резервных копий может храниться на более медленных хранилищах HDD, так как файлы резервных копий не часто востребованы и, таким образом, не требую очень быстрого ввода/ вывода. Многоуровневость (tiering) может быть установлена с применением различных совместно используемых узлов хранения с различными уровнями производительности. Она также может быть установлена на одном и том же узле путём назначения томов или пулов на определённые наборы дисков.
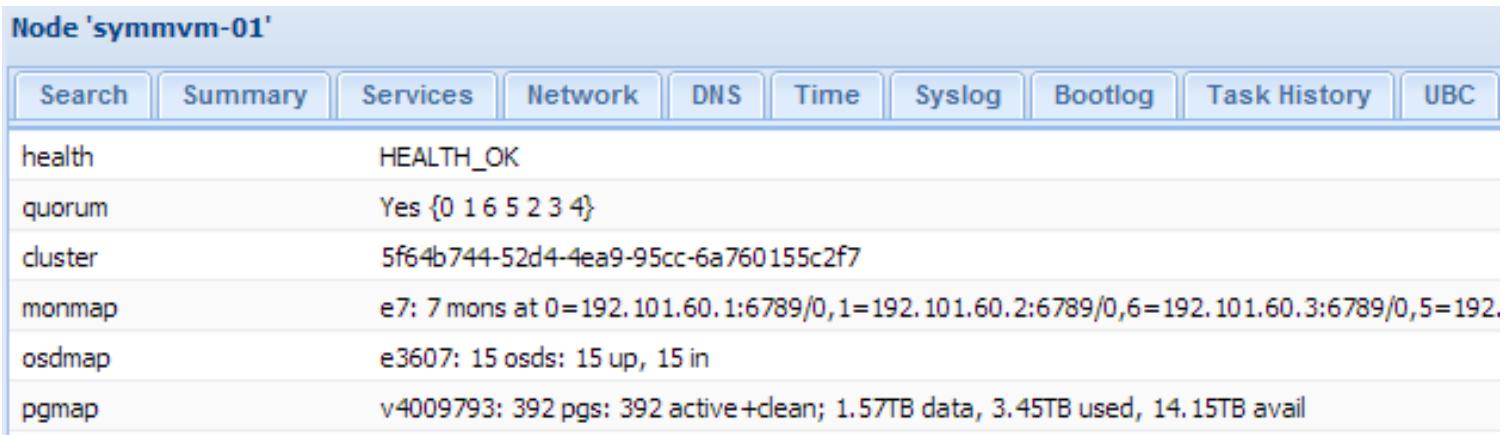
Выделяя совместно используемое хранилище из первичных кластеров Proxmox, мы можем управлять двумя кластерами без их взаимодействия друг на друга. Так как совместно используемая система хранения может быть установлена на отдельные узлы и физические коммутаторы, управление ими на на основе различных авторизаций и полномочий становится более простой задачей. NAS, SAN и другие типы совместно используемых решений хранения поступают вместе с их собственными программными средствами управления в которых администратор или оператор могут проверять работоспособность кластера, состояние диска, свободное пространство и тому подобное. Хранилище Ceph настраивается через CLI, однако Proxmox интегрировал бОльшую часть опций управления Ceph в рамках GUI Proxmox, что делает управление кластером Proxmox более простым. {Прим. пер.: бурное развитие добавляет много высококачественных продуктов управления Ceph с графическим интерфейсом, например, в 2015г Intel внесла в сообщество Ceph свой продукт Менеджер виртуального хранения Ceph (VSM).} Применяя API Proxmox может теперь собирать данные кластера Ceph и отображать их с использованием GUI Proxmox, как это показано на следующем экранном снимке:
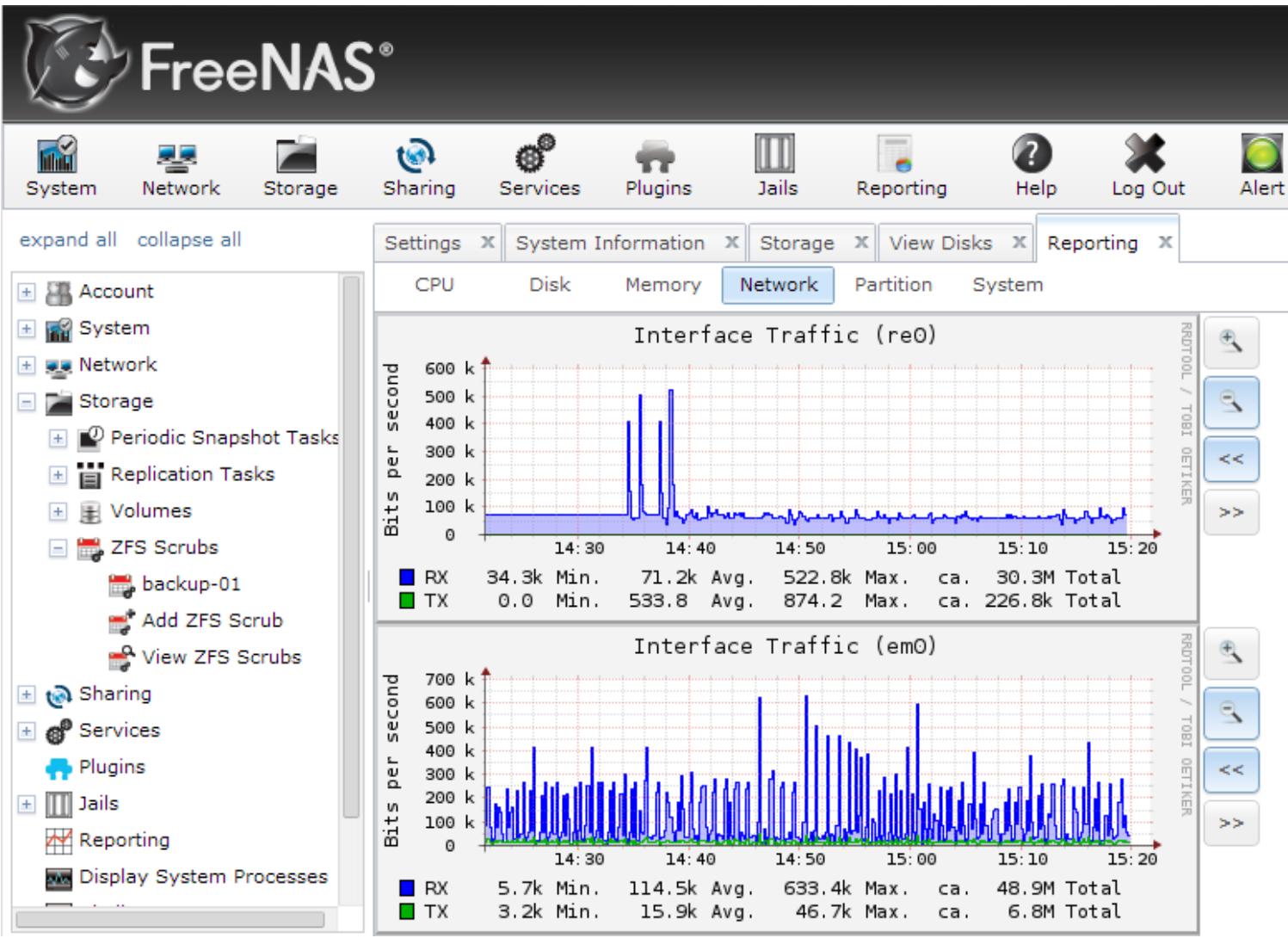
Другие решения NAS, например, FreeNAS, OpenMediaVault и NAS4Free также имеют GUI, который упрощает управление. Следующий снимок экрана является примером состояния жёсткого диска в окне GUI FreeNAS:
Ниже для быстрой ссылки приводится таблица сравнения и локальных, и совместно используемых хранилищ
| Локальное хранилище | Совместно используемое хранилище | |
|---|---|---|
Миграция ВМ в реальном времени |
Нет |
Да |
Высокая доступность |
Нет |
Да, если применяется совместно используемое хранилище со множеством узлов |
Стоимость |
Низкая |
Значительно выше |
Производительность ввода/ вывода {Прим. пер.: без учёта распределённого хранения} |
Естественная скорость дисков |
Медленнее чем естественная скорость дисков {Прим. пер.: может масштабироваться за счёт хранения данных по частям на большом числе дисков множества узлов.} |
Требования к навыкам |
Не требуются специальные знания по хранению |
Необходим опыт использования совместно применяемых хранилищ |
Наращиваемость |
Ограничена доступным местом для дисковых устройств в узле |
Расширяется по множеству узлов при использовании множества узлов или распределённой СХД |
Сложность сопровождения |
Бесплатное виртуальное сопровождение |
Узлы хранения или кластеры требуют постоянного мониторинга |
Образ виртуального диска является файлом или группой файлов, в которых виртуальная машина хранит свои данные. В Proxmox файл настройки ВМ может создаваться повторно и использоваться для подключения образа диска. Однако, если образ сам по себе утрачен, он может быть восстановлен только из резервной копии. Существуют различные типы форматов образов виртуальных дисков доступные для применения виртуальными машинами. Стоит знать эти различные типы образов для получения оптимальной производительности ВМ. Знание дисковых образов также поможет предотвращать преждевременную нехватку пространства при поставке виртуальных дисков.
Proxmox поддерживает форматы виртуальных дисков .raw,
.qcow2 и .vmdk. Каждый формат
имеет свои собственные преимущества и недостатки. Формат образа обычно выбирается на основании функции
виртуальной машины, используемой системы хранения, требующейся производительности и доступного бюджета.
Следующий экранный снимок показывает меню, в котором мы можем выбрать тип образа в процессе создания
виртуального диска при помощи GUI:
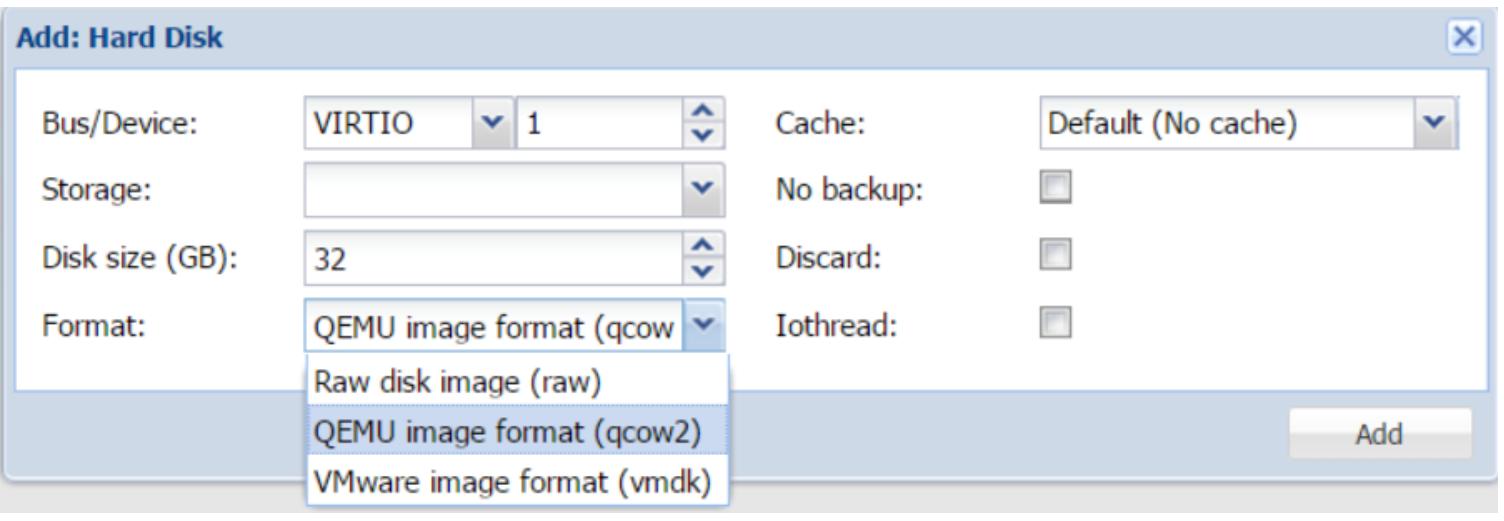
Приводимая ниже таблица вкратце подытоживает различные форматы образов и их возможное применение:
| Тип образа | Поддерживаемые хранилища | Сильные стороны | Слабые стороны |
|---|---|---|---|
|
NFS и каталог |
Делает возможными динамичные виртуальные фалы хранимых образов. Стабильный и безопасный. Большинство функций обогащаются типами образов. |
Сложный формат файлов с дополнительными программными уровнями. Высокие накладные расходы ввода/ вывода. |
|
LVM, RBD, iSCSI и каталог |
Отсутствует дополнительный программный уровень. Прямой доступ к файловым образам. Стабильный, безопасный и самый быстрый. |
Только фиксированные виртуальные образы. Не может быть использован для хранения динамичных образов. ВМ требуется больше времени для резервного копирования из- за размера файлов образа. |
|
NFS и каталог |
Исключительно хорошо работает с инфраструктурой VMware. Делает возможными динамичные виртуальные фалы хранимых образов. |
Дополнительный программный уровень, следовательно меньшая производительность. Не полностью протестирован с Proxmox. |
|
| Совет |
|---|---|
|
Настройка виртуальной машины с неверным форматом образа очень снисходительна. Вы всегда можете преобразовать такие типы образов из одного формата в другой. Преобразование может быть выполнено как в CLI, так и при помощи GUI. Преобразование образа виртуального диска объясняется позже в этой главе. |
Тип образа .qcow2
Тип образа .qcow2 является очень стабильным форматом образа ВМ.
Proxmox полностью поддерживает этот формат файла. Диск ВМ создаваемый с использованием
.qcow2 намного меньше так как по умолчанию создаётся как образ
диска с динамичным выделением (thin-provisioning). Например, ВМ Ubuntu, создаваемый с пространством
хранения 50ГБ может иметь файл образа с размером около 1ГБ. По мере сохранения пользователем данных в
этой ВМ, такой образ будет постепенно увеличиваться в размере. Формат образа .qcow2
позволяет администратору превышать обеспечение ВМ файлом образа диска .qcow2.
Если не мониторить постоянно состояние, то совместно используемое хранилище выйдет за пределы размещающие
все растущие файлы виртуальных образов. В таких средах необходимо постоянно наблюдать за доступным
пространством хранения. Хорошей практикой является добавлять дополнительное пространство хранения когда
общее потребление пространства хранения достигает примерно 80%.
|
| Замечание |
|---|---|
|
Динамичное выделение (thin-provisioning) происходит когда образ виртуального диска не выполняет предварительное выделение всех необходимых блоков, таким образом придерживая размер файла только в тех размерах, в каких мы хотим. По мере сохранения данных в такой виртуальной машине, файл динамично выделяемого образа растёт, пока не достигает максимального заявленного размера. С другой стороны, при полном выделении (thick-provisioning) файл вашего образа виртуального диска предварительно выделяет все необходимые блоки, тем самым создавая файл образа который в точности соответствует установленному размеру для вашего создаваемого файла образа виртуального диска. {Прим. пер.: Современные системы хранения умеют нивелировать это разницу, беря динамичное выделение на свой уровень управления.} . |
Файлы .qcow2 также имеют очень большие накладные расходы из- за
дополнительного программного уровня. Таким образом, это плохой выбор формата образа для таких ВМ, как
сервер базы данных. Все данные чтения или записи в формате образа проходят сквозь программный уровень
.qcow2, что увеличивает операции ввода/ вывода, делая их медленнее.
Создаваемые из образа .qcow2 резервные копии могут восстанавливаться
только в NFS или локальный каталог.
Когда бюджет является основным критерием и пространство хранения очень ограничено,
.qcow2 является исключительным выбором. Этот тип образа поддерживает
снимки KVM в реальном времени для сохранения состояний виртуальных машин.
Тип образа .raw
Тип образа .raw также является очень стабильным и зрелым форматом
образа ВМ. Его первичное преимущество состоит в производительности. Нет никакого дополнительного
программного уровня который необходимо преодолевать данным. ВМ имеет прямой сквозной доступ в файл
.raw, что делает его намного более быстрым. К тому же отсутствуют
присоединяемые к нему программные компоненты, поэтому он гораздо менее предрасположен к проблемам.
Формат .raw может создавать только файлы образов ВМ фиксированного
азмерас предварительным выделением (thick-provisioned). Например, создаваемая ВМ Ubuntu с пространством
хранения 50ГБ будет иметь файл образа 50ГБ. Это помогает администратору точно знать сколько пространства
используется, поэтому отсутствует возможность неуправляемого выхода за пределы хранения.
{Прим. пер.: Как уже отмечалось, большинство современных систем хранения
могут самостоятельно предоставлять динамичное выделение пространства. Что также требует применения
специализированного инструментария наблюдения за остающимся свободным пространством.}
Тип .raw является предпочитаемым файловым форматом для всех ВМ
Proxmox. Формат образа .raw может восстанавливаться практически
на любой тип системы хранения. В виртуальной среде дополнительные файлы образа виртуального диска могут
добавляться к виртуальной машине в любой момент. Поэтому нет необходимости изначально выделять больший размер
файла образа виртуального диска .raw подразумевая необходимость
дальнейшего роста в будущем. ВМ может начать с небольшого файла образа .raw
и добавить по мере необходимости ещё образов дисков. Например, ВМ с 50ГБ данных начинает с файлом образа
.raw с 80ГБ. Затем увеличивает размер образа диска или добавляет
ещё образы виртуальных дисков по мере роста потребностей. Proxmox позволяет добавлять порядочное число
дополнительных виртуальных устройств к ВМ.
Следующая таблица отображает максимальное число разрешённых дисковых устройств на ВМ в Proxmox:
| Тип шины/ устройства | Разрешённый максимум |
|---|---|
IDE |
3 |
SATA |
5 |
VirtIO |
15 |
SCSI |
13 |
Поскольку файлы образов диска .raw размещаются предварительно,
отсутствует риск превышения выделения сверх общего доступного пространства хранения. Снимки в
реальном времени KVM также поддерживаются форматом образов .raw.
Существуют некоторые совместно используемые хранилища которые поддерживают исключительно образы
дисков .raw. Ceph RBD является таким хранилищем. В Proxmox 4.1
мы можем хранить в блочных устройствах Ceph только образы виртуальных дисков .raw.
Однако файловая система Ceph, или CephFS, поддерживает все типы образов дисков. CephFS является одним из
трёх типов хранения, поддерживаемых платформой Ceph. В настоящее время в Proxmox отсутствует прямой
подключаемый модуль хранения для CephFS, только для RBD. Однако мы можем присоединять CephFS к Proxmox как
совместный ресурс NFS.
Тип образа .vmdk
Формат образа .vmdk очень распространён в инфраструктуре VMware.
Основное преимущество поддержки Proxmox .vmdk состоит в более простой
миграции с кластера VMware на Proxmox. Создаваемые в VMware в формате .vmdk
ВМ могут быть легко настроены для применения в кластере Proxmox и преобразованы. Нет преимуществ для
хранения файла образа виртуального диска в формате .vmdk за
исключением их использования на протяжении переходного периода, такого как преобразование виртуальных
машин из инфраструктуры VMware.
Файл виртуального образа Proxmox может управляться как через WebGUI, так и при помощи CLI. WebGUI позволяет администратору использовать опции добавления, изменения размера (только увеличение), перемещения, дросселирования и удаления, как это показано на следующем снимке экрана:
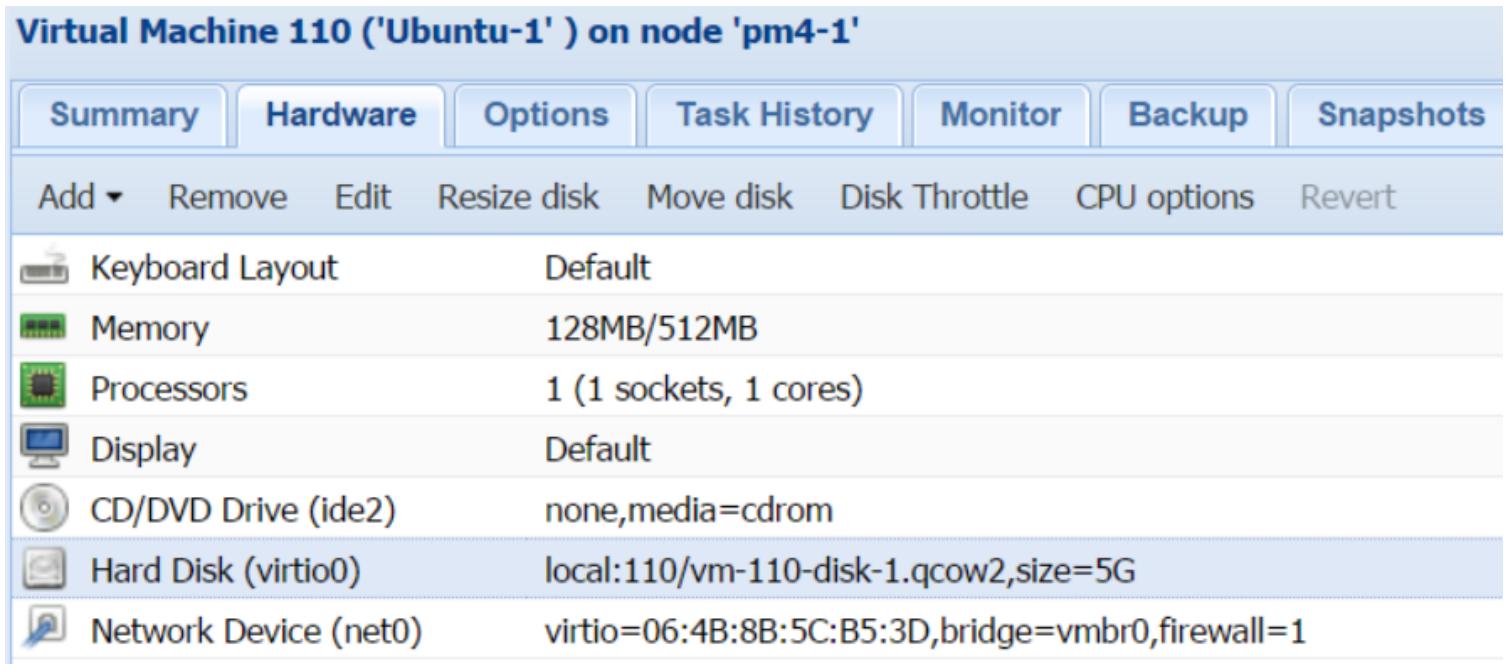
Чтобы сделать какое- либо изменение с файлом образа виртуального диска вначале необходимо выбрать образ в закладке Hardware как показано в предыдущем экранном снимке. Файлами образов виртуальной машины можно также манипулировать при помощи команд CLI. Следующая таблица показывает некоторые примеры наиболее общих команд, применяемых для удаления, преобразования и изменения размера файла образа:
| Команда | Функция |
|---|---|
|
Создаёт образ файла |
|
Преобразует образ файла |
|
Изменяет размер образа файла |
Изменение размера виртуального диска
Опция изменения размера диска поддерживает только увеличение размера файла образа виртуального
диска. Она не имеет функциональности отсечения. Опция изменения размера Proxmox только регулирует
размер файла образа виртуального диска. После каждого изменения размера этот раздел должен быть
отрегулирован изнутри самой ВМ. Самый безопасный способ изменения размера разделов состоит в
загрузке виртуальной машины на основе Linux с образом ISO разбиения, например,
gparted
(http://gparted.org/download.php), а затем изменить размеры разделов с использованием
графического интерфейса gparted.
Также допустимо выполнять изменение раздела в реальном времени при включённой виртуальной машине.
Изменение размера файла образа виртуального диска включает в себя следующие этапы:
-
Измените размер файла образа виртуального диска в Proxmox:
-
При помощи GUI: выберите нужный виртуальный диск, а затем кликните на Resize disk.
-
В CLI: Выполните следующую команду:
# qm resize <vm_id> <virtual_disk> +<size>G
-
-
Измените размер раздела файла образа виртуального диска изнутри данной ВМ:
-
Для ВМ Windows: Измените размер текущего диска перейдя в управление компьютером (Computer Management) в инструментах администрирования (Administrative Tools)
-
Для ВМ Linux с разделом RAW выполните следующую команду:
# cfdisk <disk_image> -
Для ВМ Linux с разделом LVM выполните следующую команду:
# cfdisk </dev/XXX/disk_image> -
Для ВМ Linux с разделом QCOW2 выполните следующую команду:
# apt-get install nbd-client # qemu-ndb –connect /dev/nbd0 <disk_image> # cfdisk /dev/nbd0 # qemu-nbd –d /dev/nbd0
-
-
Измените размер файловой системы в разделе файла образа виртуального диска:
-
Для клиента Linux с LVM:
# pvscan (find PV name) # pvresize /dev/xxx (/dev/xxx found from pvscan) # lvscan (find LVname) # lvresize –L+G /dev/xxx/lv_<disk> -
Для использования 100% свободного пространства:
# lvresize –l +100%FREE /dev/xxx/lv_<disk> # resize2fs /dev/xxx/lv_<disk> (resize filesystem)
-
|
| Замечание |
|---|---|
|
Шаги 2 и 3 необходимы только при изменении размера в реальном времени без выключения ВМ.
Если используется |
Перемещение виртуального диска
Перемещение диска позволяет перемещать этот файл образа в другое хранилище или преобразовывать различные типы образов:
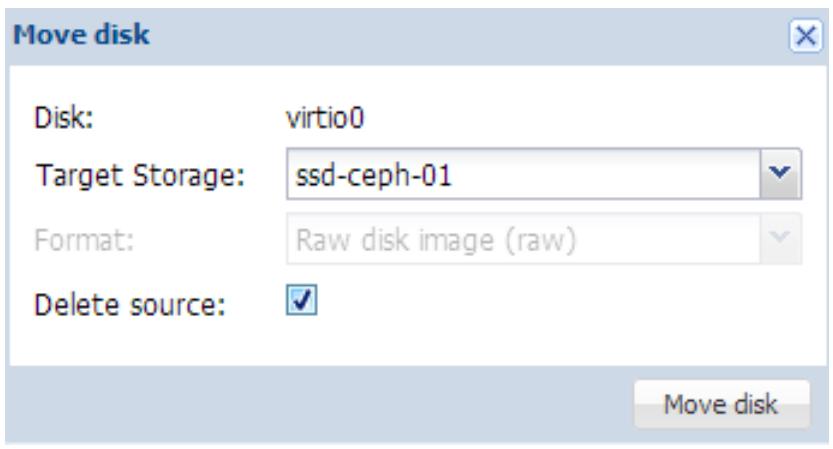
В опции меню Move disk просто выберите Target Storage и Format type, а затем кликните Move disk для перемещения выбранного файла образа. Перемещение может выполняться в реальном времени без выключения этой ВМ.
|
| Совет |
|---|---|
|
В опции перемещения диска тип формата будет отображаться серым цветом если хранилище получатель
поддерживает только один тип формата образа. В предыдущем снимке экрана
|
Кликнув на Delete source мы удалим файл источника образа после завершения перемещения.
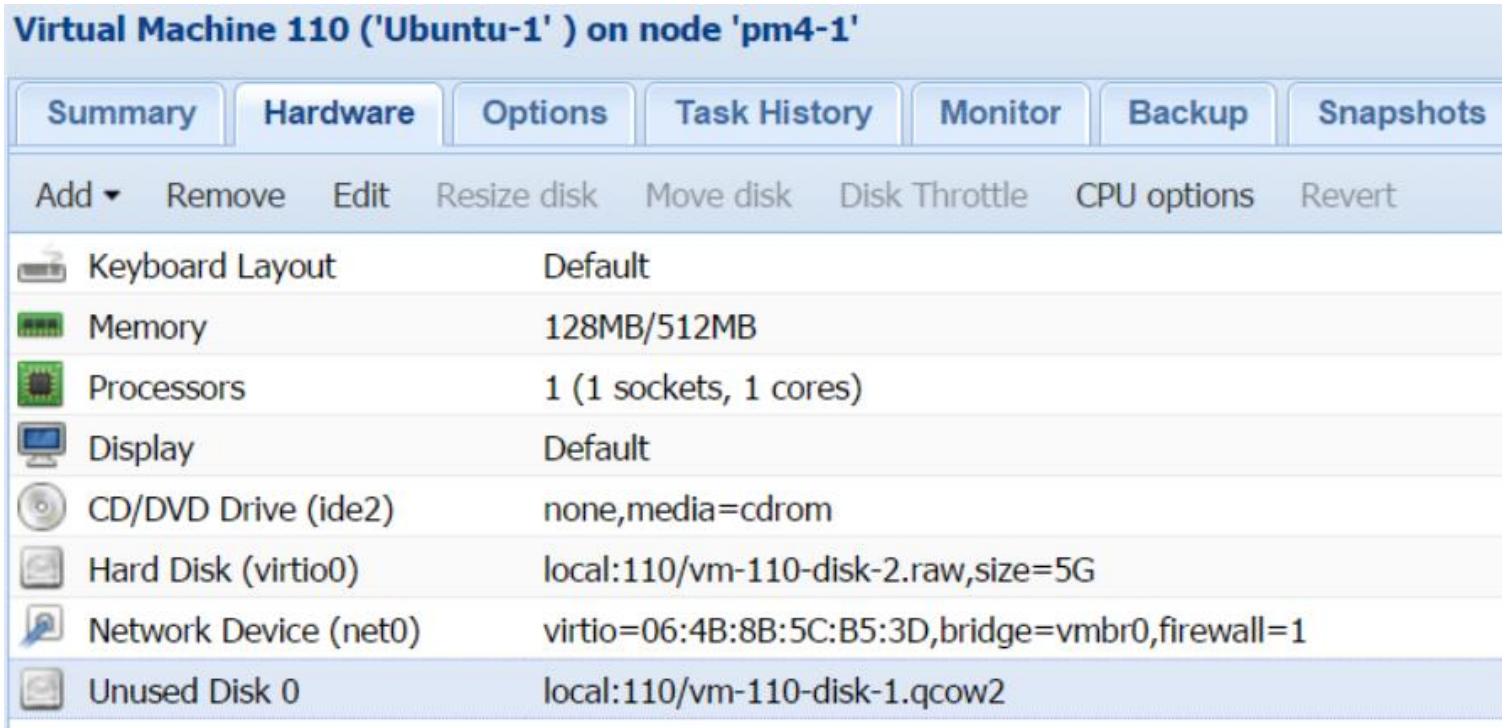
Отметим, что если виртуальная машина имеет какие- нибудь снимки, Proxmox не будет способен удалить
такой файл источника автоматически. В подобном случае образ будет перечисляться как Unused
disk, как это показано на следующем снимке экрана после выполнения перемещения образа
диска со снимками:
Дросселирование виртуального диска
Proxmox делает возможным дросселирование или установку предела на скорость чтения/ записи или IOPS (Input Output Per Second или операций в секунду) для каждого образа виртуального диска. По умолчанию нет установленных пределов. Каждый образ диска будет пытаться читать или записывать с максимальной скоростью, получаемой в хранилище в котором хранится этот образ диска. Например, если образ диска хранится в локальном хранилище, оно будет пытаться выполнять операции чтения и записи примерно со скоростью 110МБ/c так как это теоретический предел диска SATA. {Прим. пер.: в настоящее время на рынке присутствуют шпиндельные диски с заявленной пропускной способностью потокового чтения до 250МБ/c, подробнее см. Таблицу Топовых характеристик устройств хранения, март 2016.} Эта производительность будет меняться для различных вариантов хранения. Для хранилищ со множеством владельцев или в больших средах в случае, когда все образы дисков не дросселированы никакими пределами, это может оказывать давление на сетевую среду и/ или пропускную способность хранилища. Применяя дросселирование, мы можем управлять пропускной способностью, которую может использовать каждый образ диска. Опция Disk Throttle доступна в закладке ВМ Hardware. Следующий снимок экрана показывает диалоговый блок Disk Throttle с опциями для установки пределов:
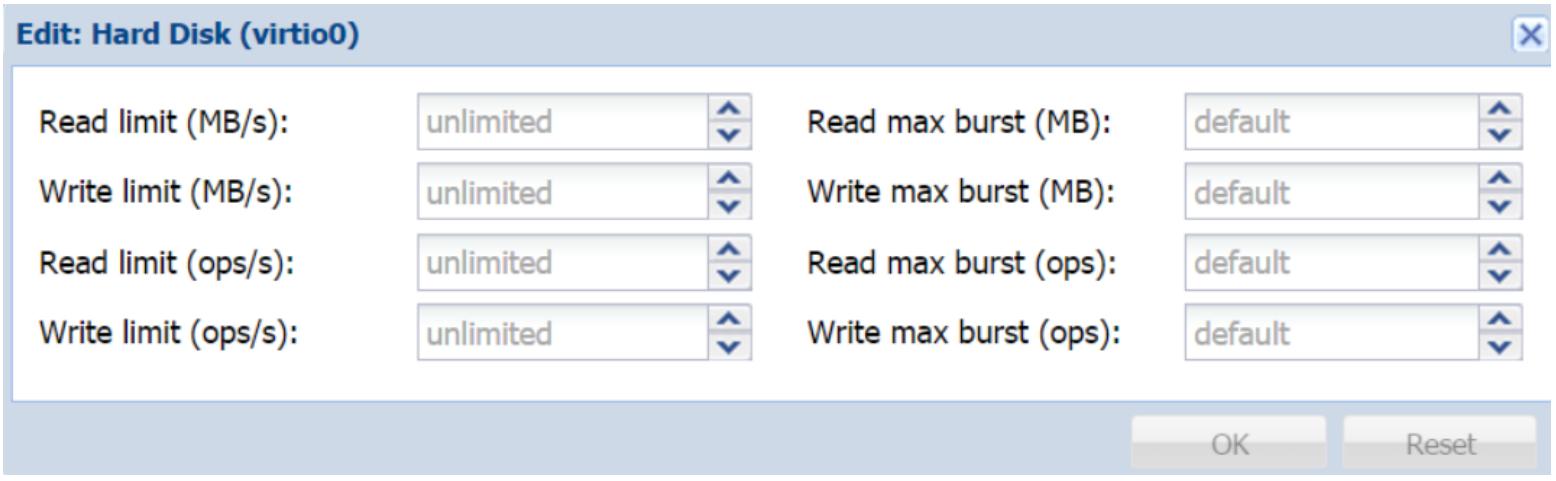
Когда дело доходит до дросселирования, не существует единого предела для всех случаев жизни. Настройки пределов сильно разнятся для различных хранилищ применяемых в кластерных средах и для объёмов нагрузок выполняемых каждой ВМ. В зависимости от типа применяемого хранилища может оказаться необходимым просто установить пределы для записи, чтения или и того и другого. Например, кластер хранения Ceph с журналом SSD может иметь намного более высокую скорость записи в сравнении со скоростью чтения. Таким образом, дросселирование ВМ пределом наивысшей скорости чтения при установке предела записи может оказаться жизнеспособным вариантом.
Как упоминалось ранее, мы можем устанавливать предел на основе МБ/с или операций/с. Установка предела в МБ/с намного проще, так как нам может оказаться легче определять скорость чтения/ записи дискового устройства или сети в мегабайтах. Например, стандартный SATA диск может достигать теоретической скорости в 115МБ/с, в то время, как гигабитная сетевая среда может достигать примерно 100МБ/с. Знание производительности в IOPS или в операциях/с требует некоторых дополнительных шагов. В некоторых системах ранения мы можем интегрировать определённые формы мониторинга, которые могут представлять нам данные IOPS в реальном времени. Для прочих нам необходимо вычислять данные IOPS чтобы знать матрицу производительности используемой системы хранения. Полное изложение вычисления данных IOPS выходит за пределы данной книги. Однако последующее руководство должно послужить отправной точкой для вычисления операций/с для различных устройств хранения:
Для вычисления операций/с отдельного 7200 RPM SATA диска может быть применена такая формула:
IOPS = 1 / (средняя латентность в секундах + среднее время позиционирования в секундах)
Отталкиваясь от предыдущей формулы, мы можем вычислить IOPS для стандартного SSD устройства.
Для получения средних времён латентности и позиционирования некоего устройства мы можем
воспользоваться инструментом Linux, ioping.
Он не установлен в Proxmox по умолчанию. Поэтому мы можем установить его с использованием следующей
команды:
# apt-get install ioping
Ioping аналогична команде iperf,
однако применяется для дисковых устройств. Следующая команда покажет значение латентности ввода/вывода
для используемого нами в примере диска SSD:
# ioping /dev/sda
Следующий снимок экрана показывает, что результат ioping
для средней латентности 1.79 милисекунд, или 0.00179 секунды:
--- /dev/sdh (block device 111.8 GiB) Toping statistics
5 requests completed in 4.01 s, 558 fops, 2.18 MiB/s
mln/avg/max/mdev = 1.52 ms / 1.79 ms / 2.40 ms / 312 us
Для получения среднего времени позиционирования нам нужно выполнить следующую команду
ioping:
# ioping –R /dev/sda
Следующий снимок экрана показывает что результат ioping
для среднего времени позиционирования составляет 133 микросекунды, или 0.000133 секунды:
--- /dev/sdh (block device 111.8 GiB) ioping statistics ---
21.9 k requests completed in 3.00 s, 7.50 k iops, 29.3 MiB/s
min/avg/max/mdev = 27 us / 133 us / 3.02 ms / 128 us
Применяя полученные результаты, мы можем вычислить IOPS или операции/c устройства SSD следующим образом:
IOPS = 1 / (0.00179 + 0.000133) = 520
Если мы знаем максимальное значение, которое может предоставлять хранилище, мы можем корректировать каждую ВМ с дросселированием операций/с для предотвращения проблем ввода/ вывода в нашем кластере. В Proxmox VE 4.1 мы не можем устанавливать предел дросселирования на весь кластер. Каждый образ диска требует ручного дросселирования по отдельности.
Кэширование виртуального диска
Кэширование образа виртуального диска предоставляет производительность и некую защиту экземпляра от
неаккуратного выключения ВМ. Не любое кэширование является безопасным для применения. Для
оптимальности производительности ВМ важно быть осведомлённым о различных предлагаемых в
Proxmox режимах кэширования. Эта опция доступна в закладке ВМ Hardware в диалоговом блоке создания или изменений текущего образа
диска. Следующий снимок экрана отображает блок диалога создания образа диска с ниспадающим меню
кэширования для образа диска .raw нашего примера ВМ:
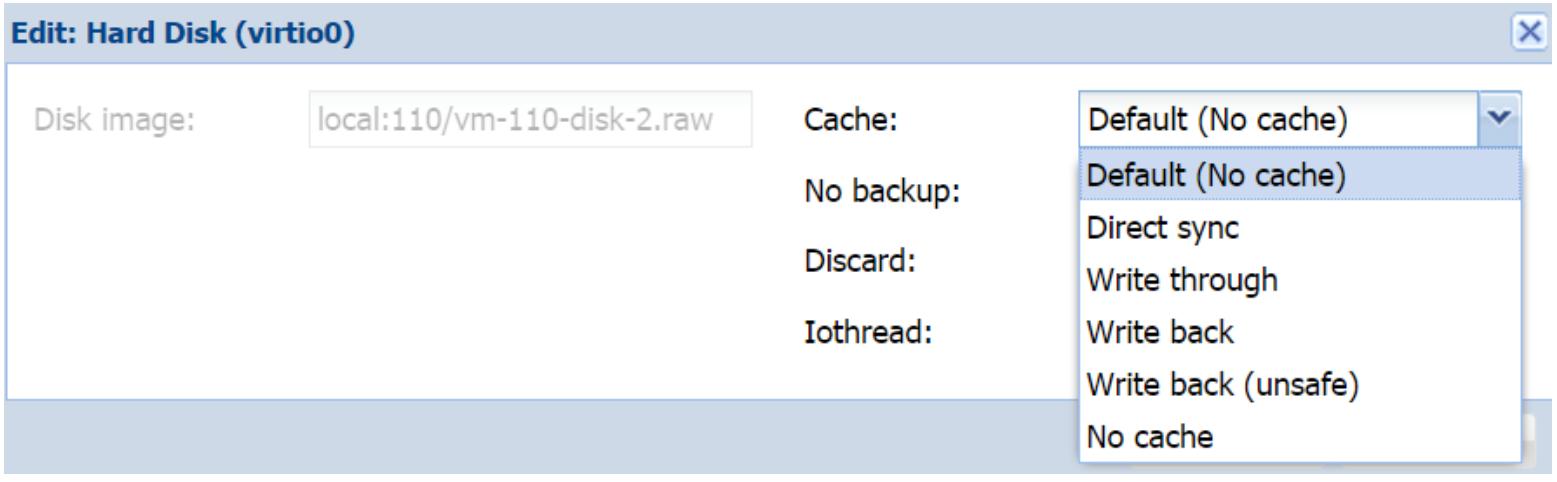
В Proxmox VE 4.1 доступны следующие параметры кэширования:
| Параметр кэширования | Описание |
|---|---|
(Прямая синхронизация) |
При этом параметре кэширования хост Proxmox не делает никакого кэширования, однако образ диска ВМ использует кэш сквозной записи (write through). При этом кэше подтверждение на запись выдаётся только когда данные зафиксированы на устройстве хранения. Прямая синхронизация рекомендуется для ВМ, которые не отправляют запросы на сброс при их необходимости. Это наиболее безопасный кэш, так как данные не будут утрачены при отказа питания, однако он также и медленнее. |
(Отложенная запись) |
При этом параметре кэширования хост выполняет и кэширование чтения и кэширование записи. Подтверждение на запись диском ВМ выполняется как только данные зафиксированы в кэше хоста вне зависимости от того были они зафиксированы в хранилище или нет. В таком кэше могут происходить потери данных. |
(Ненадёжная отложенная запись) |
Этот кэш аналогичен отложенной записи за исключением того, что все сбросы полностью игнорируются со стороны гостевой ВМ. Это самый быстрый кэш, хотя при этом он самый опасный. Этот кэш никогда не должен применяться в промышленных кластерах. Обычно этот кэш используется для ускорения установки ОС в ВМ. После установки ОС этот кэш должен быть отключён и возвращён в другую более безопасную опцию. |
(Без кэширования) |
Это опция кэширования Proxmox по умолчанию. При этой опции никакого кэширования не происходит на уровне хоста, однако гостевые ВМ выполняют кэширование отложенной записи. Диск такой ВМ напрямую получает подтверждение от устройства хранения при такой опции кэширования. Данные могут быть утрачены при внезапном выключении хоста в случае отказа питания. |
Proxmox имеет исключительные встраиваемые модули для вариантов широко распространённых систем хранения. В данном разделе мы собираемся рассмотреть какие встраиваемые модули хранения интегрированы в Proxmox, а также понять как применять их для соединения с различными типами хранилищ в Proxmox. Ниже перечислены все типы хранилищ, которые естественным образом поддерживаются в Proxmox VE 4.1:
-
Каталог
-
LVM
-
NFS
-
ZFS
-
Ceph RBD
-
GlusterFS
-
{Прим. пер.: экспериментально: Sheepdog}
Хранилищем каталога является монтируемый каталог вашего локального узла Proxmox. В основном он используется
как локальное хранилище. Но мы также можем смонтировать удалённый каталог на другом узле и использовать эту
точку монтирования для создания нового хранилища Directory.
По умолчанию такое местоположение монтируется в /var/lib/vz
{Прим. пер.: см. сноску Thin-LVM ниже по тексту для версии Proxmox VE 4.2 и выше}.
Никакая сохранённая в подобном хранилище Directory
ВМ не допускает миграцию в реальном времени. ВМ должна быть остановлена перед выполнением миграции на другой
узел. Все типы файлов образов виртуальных дисков могут храниться в таком хранилище
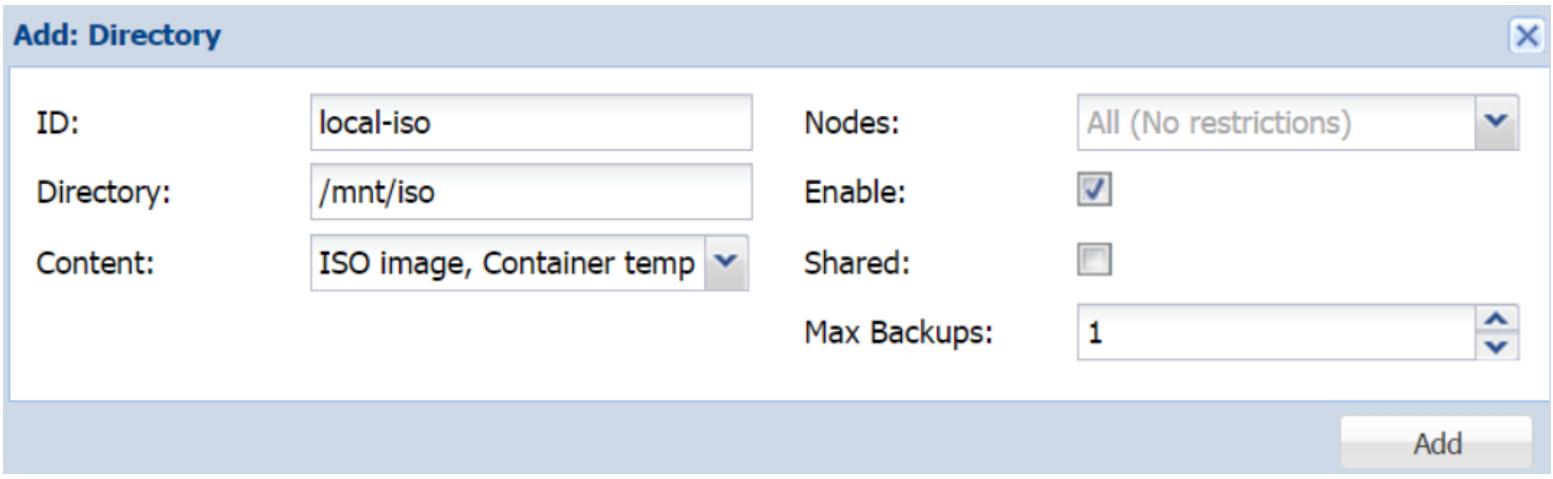
Directory. Для создания нового хранилища с точкой
монтирования перейдите в Datacenter |
Storage и кликните
Add для выбора встраиваемого модуля
Directory. Следующий снимок экрана показывает блок
диалога хранилища Directory в котором мы можем
добавить хранилище с именем local-iso, которое будет смонтировано в
/mnt/iso для хранения ISO и шаблонов контейнеров:
Для монтируемых локально хранилищ выбор флаговой пометки Shared не является обязательным. Эта опция имеет отношение только к совместно используемым системам хранения, таким как NFS, RBD и тому подобные.
|
| Замечание |
|---|---|
|
{Прим. пер.: Если вы используете Proxmox VE 4.2 и последующие версии, вы столкнётесь
с неким изменением местоположения данных. Более не существует никаких смонтированных в
Источник: Optional: Reverting Thin-LVM to "old" Behavior of /var/lib/vz (Proxmox 4.2 and later).} |
iSCSI, который является аббревиатурой для Internet Small Computer System Interface, основывается на IP (Internet Protocol), который позволяет обмениваться командами SCSI поверх стандартных сетевых сред на основе IP. Устройства iSCSI могут устанавливаться локально или на значительных расстояниях для предоставления возможностей хранения. Мы не можем сохранять образы виртуальных дисков напрямую в устройствах iSCSI, однако мы можем настроить хранилище LVM поверх такого устройства iSCSI, а затем сохранять образы диска. Подключённое устройство iSCSI появляется так, как если бы оно было физически присоединено, даже если это устройство хранится на другом удалённом узле. Для дополнительных подробностей по iSCSI отсылаем вас к http://en.wikipedia.org/wiki/ISCSI. {Прим. пер.: пожалуй, самую простую и достаточно эффективную реализациею предоставляет ZFS, подробнее см. раздел iSCSI в "ZFS для профессионалов".}
Мы предполагаем, что у вас уже имеется устройство iSCSI
созданное на удалённом узле при помощи FreeNAS или любого другого дистрибутива Linux. Чтобы добавить
такое устройство в Proxmox мы собираемся применить встраиваемый модуль iSCSI, который может быть найден путём навигации в меню
Datacenter |
Storage |
Add. Как показано на снимке экрана ниже, мы
добавляем таргет iSCSI с именем
test1-iSCSI, который настроен на удалённом узле,
172.16.0.170:
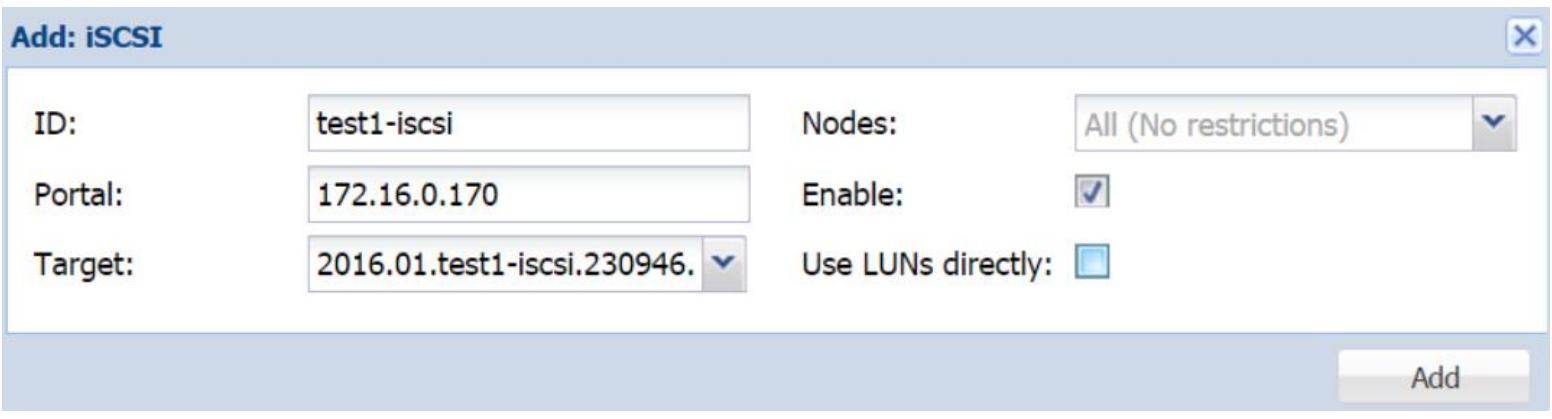
Отметим, что не рекомендуется использовать LUN напрямую, хотя и существует опция для его разрешения. Документированы случаи вызывающие ошибку устройства iSCSI при прямом дуступе к нему.
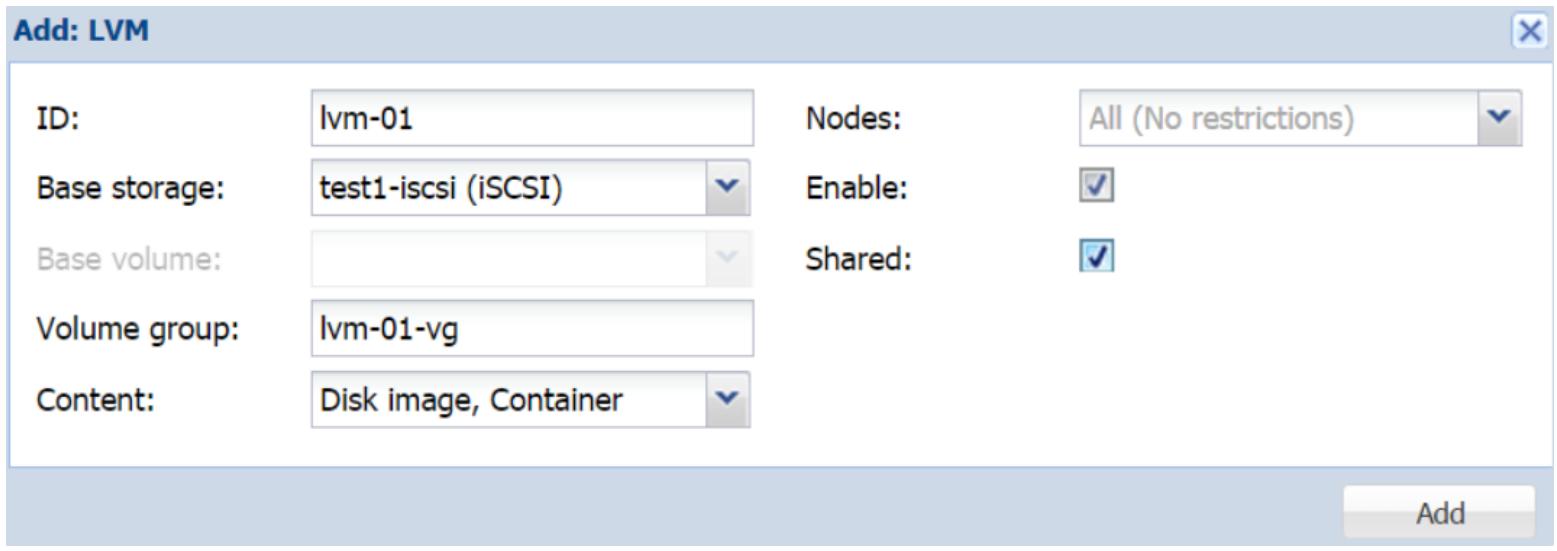
LVM (Logical Volume Management) предоставляет метод выделения пространства хранения с использованием одного или более разделов дисков или устройств лежащих в основе хранилища. Хранилище LVM требует надлежащей работы и функционирования базового хранилища. Мы можем создать хранилище LVM с локальными устройствами в качестве основы или положить в основу сетевую среду с устройствами iSCSI. LVM позволяет масштабировать пространство хранения, так как лежащие в основе хранилища могут быть на том же самом узле или на каком- нибудь другом. Хранилище LVM может поддерживать только формат образа виртуальных дисков RAW. В хранилище LVM мы можем хранить только образы виртуальных дисков или контейнеры. Для получения дополнительных подробностей по LVM отсылаем вас к http://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux). {Прим. пер.: с примерами работы с LVM можно ознакомиться, например, в разделе Администрирование хранилища LVM нашего перевода книги "Полная виртуализация (4 в 1)". Также рекомендуем прочитать Повесть о Linux и LVM И.Лесина и И.Чубина.}
Если дисковый массив LVM настроен на использование локальных подключённых напрямую к данному узлу дисков, сохраняемые на таком хранилище ВМ не смогут выполнять миграцию в реальном времени без выключения. Однако, присоединив устройства iSCSI с удалённого узла с последующим созданием хранилища LVM поверх такого тома iSCSI, мы сможем выполнять возможность миграции в реальном времени, так как это хранилище теперь рассматривается как совместно используемое. FreeNAS является исключительно хорошим вариантом для создания LVM плюс iSCSI совместно используемого хранилища без какой либо платы за лицензию. Она поставляется с прекрасным графическим интерфейсом пользователя и многими функциями, которые выходят за пределы просто LVM или iSCSI. Подробнее о FreeNAS и опциях загрузки вы можете узнать на freenas.org. {Прим. пер.: также напоминаем о наших переводах книг Майкла В. Лукаса и Аллана Джуда ZFS и ZFS для профессионалов, а также атласа Ли Сюрбера Полная виртуализация, 4-в-1.}
Чтобы добавить хранилище LVM, перейдите в
Datacenter |
Storage |
Add и выберите встраиваемый модуль хранилища
LVM. Следующий снимок экрана показывает блок
диалога в котором используется устройство iSCSI,
test1-iscsi, которое мы добавили в предыдущем разделе для создания
хранилища LVM:
NFS (Network
File System) является вполне зрелым протоколом файловой системы, первоначально разработанным
Sun Microsystems в 1984. В настоящее время применяется 4 версия этого протокола NFS.
Однако он не был принят повсеместно как в случае версии 3 из- за ряда проблем с совместимостью. Однако зазор
между версиями 3 и 4 быстро покрывается. По умолчанию Proxmox применяет версию 3 протокола
NFS, хотя администраторы могут изменить это на
версию 4 применив параметры настройки в storage.cfg. Хранилище
NFS может хранить форматы образов
.qcow2, .raw и
.vmdk, предоставляя универсальность и гибкость в кластерной среде.
NFS также прост в настройке и требует самую
скромную авансовую стоимость аппаратных средств, что делает доступным его для бюджета малого бизнеса или
домашнего использования для предоставления в их руки стабильной системы совместного хранения для кластера
Proxmox.
|
| Совет |
|---|---|
|
Следует применять NFS версии 4 вместо версии 3 с предосторожностью. Всё ещё присутствуют ошибки в NFSv4, такие как тревога ядра в процессе запуска системы при монтировании совместного ресурса NFSv4. |
Сервер NFS может быть настроен почти в любом дистрибутиве Linux с последующим подключением к кластеру Proxmox. Совместные ресурсы NFS ничто иное, как точка монтирования на сервере NFS, которая читается встраиваемым модулем NFS Proxmox. Мы также можем применять FreeNAS для обслуживания сервера NFS и тем самым предоставить преимущества функциональности FreeNAS и его GUI для простого мониторинга совместно используемого хранилища. Благодаря простоте настройки NFS, скорее всего, это наиболее широко применяемый вариант хранилища в мире виртуализации. Почти все сетевые администраторы использовали сервер NFS по крайней мере один раз за свою карьеру.
На следующем снимке экрана мы присоединяем хранилище NFS
с именем nfs-01 с удалённого сервера 172.16.0.170:
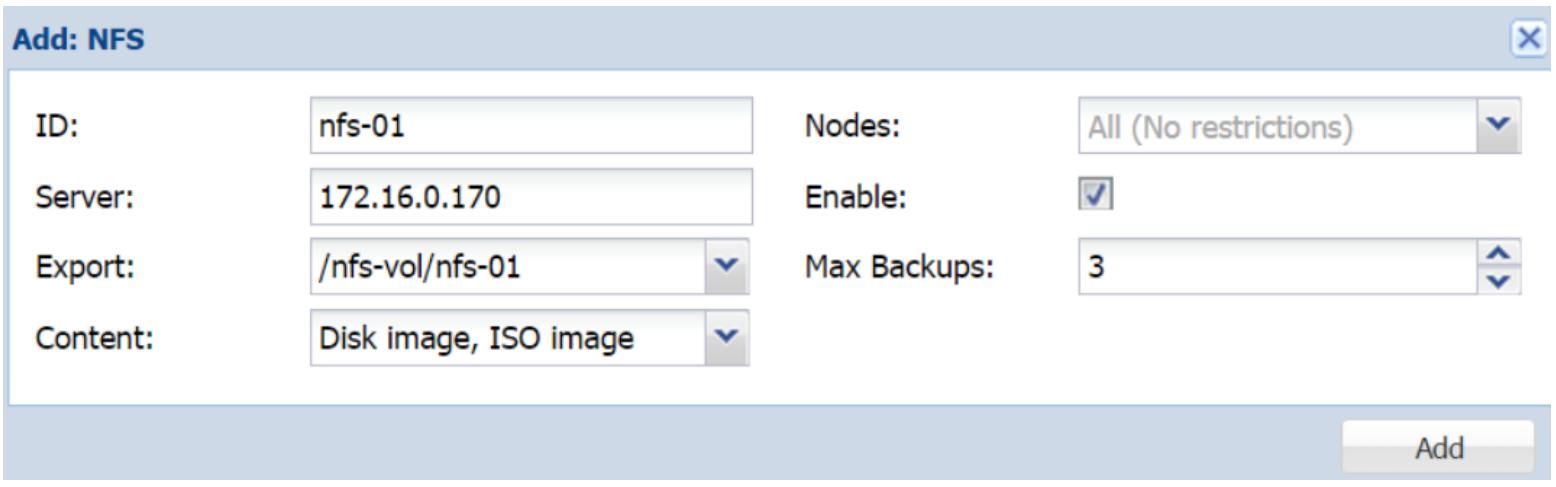
После ввода IP адреса удалённого сервера, ниспадающее меню Export
просканирует удалённый сервер на предмет всех совместных ресурсов NFS
и отобразит их в списке. В нашем примере обнаруженная в блоке диалога точка монтирования это
/nfs-vol/nfs-01.
ZFS изначально была разработана Sun
Microsystems. Хранилище ZFS является
комбинацией файловой системы и LVM, предоставляя хранилище с высокой ёмкостью с важными функциями, такими как
защита данных, их сжатие, самовосстановление, а также снимки. ZFS
имеет встроенный определяемый программным обеспечением RAID, который удаляет необходимость использования
RAID на аппаратной основе. Дисковый массив с RAID ZFS
может мигрировать на совершенно другой узел и затем полностью импортироваться без перестроения всего
массива. В хранилище ZFS мы можем хранить
только образы виртуального диска в формате .raw. За дополнительными
подробностями по ZFS отправляем вас к ссылке
http://en.wikipedia.org/wiki/ZFS.
{Прим. пер.: позволим себе ещё раз напомнить о наших переводах книг Майкла В. Лукаса и Аллана Джуда
ZFS
и ZFS для
профессионалов, а также атласа Ли Сюрбера Полная
виртуализация, 4-в-1.}
В Proxmox VE 4.1 уже включён встраиваемый модуль хранилища ZFS, что усиливает естественное применение ZFS в узлах кластера Proxmox. Пул ZFS поддерживает следующие типы RAID:
-
Пул RAID-0: требует минимально один диск
-
Пул RAID-1: минимально требует два диска
-
Пул RAID-10: минимально требует четыре диска
-
Пул RAIDZ-1: минимально требует три диска
-
Пул RAIDZ-2: минимально требует четыре диска
Для определения хранилища ZFS применяет
пулы. Пулы могут быть созданы только через CLI. В Proxmox VE 4.1 отсутствуют возможности управления
ZFS при помощи GUI. Все операции создания и
управления ZFS должны выполняться из CLI.
После создания пулов они может быть присоединены к Proxmox через GUI Proxmox. В нашем примере мы собираемся
создать зеркалированный пул RAID1 с именем zfspool1 и
присоединить его к Proxmox. Используемая для создания пула ZFS
имеет следующий формат:
# zpool create <pool_name> <raid_type> >dev1_name> <dev2_name> ...
Поэтому для пула нашего примера мы воспользуемся следующей командой:
# zpool create zfspool1 mirror /dev/vdd /dev/vde
Для различных типов RAID можно применять следующие параметры:
| Тип RAID | Используемое значение параметра |
|---|---|
RAID0 |
нет строки |
RAID1 |
|
RAIDZ-1 |
|
RAIDZ-2 |
|
Для проверки того, что пул создан выполним следующую команду:
# zpool list
Следующий снимок экрана показывает список пулов ZFS в том виде, как он отобразился в нашем примере узла ZFS:
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
zfspool1 9.94G 64K 9.94G - 0% 0% 1.00x ONLINE -
Мы можем применять пул напрямую или мы можем создать набор данных внутри этого пула и присоединить
такой набор данных отдельно к Proxmox в качестве индивидуального хранилища. Преимущество последнего
состоит в изолировании различных типов хранимых данных в каждом наборе данных. Например, если мы
создаём набор данных для хранения образов ВМ и другой набор данных для хранения файлов резервных
копий, мы можем включить сжатие для набора данных образов наших ВМ чтобы сжимать свои файлы образов
дисков и при этом оставить сжатие в выключенном состоянии для хранения набора данных резервных
копий, так как файлы резервных копий уже сжаты, тем самым сохраняя значительные ресурсы. Каждый
набор данных ZFS
может настраиваться индивидуально со своими собственными параметрами настройки. Если мы сравним
zpool с каталогом, наборы данных похожи на подкаталоги внутри
главного каталога. Для создания набора данных внутри пула ZFS
используется следующая команда:
#zfs create <zpool_name>/<zfs_dataset_name>
Перед тем как станет доступным применение набора данных, он должен быть смонтирован в каталоге. По
умолчанию, новый пул zfs или набор данных монтируются в корневом
каталоге. Приведённая ниже команда установит новую точку монтирования для набора данных:
## zfs set mountpoint=/mnt/zfs-vm zfspool1/zfs-vm
Чтобы разрешить сжатие для этого набора данных мы можем выполнить следующую команду:
# zfs set compression=on zfspool1/zfs-vm
Пул ZFS будет работать только локально для узла, на котором он создан. Другие узлы в кластере Proxmox не будут способны к коллективному использованию его для хранения. Смонтировав ZFS локально и создав совместный ресурс NFS, станет возможным совместно использовать пул ZFS для всех узлов Proxmox в качестве сервера NFS.
Процесс монтирования и создания совместного ресурса должен выполняться только через CLI. В GUI Proxmox мы можем только осуществлять подключение совместного ресурса NFS с лежащим в его основе пулом ZFS. Чтобы обслуживать совместные ресурсы NFS, нам потребуется установить сервер NFS в узле Proxmox при помощи следующей команды:
# apt-get install nfs-kernel-server
Добавьте в /etc/exports следующую строку кода:
/mnt/zfs/ 172.16.0.71/24(rw,nohide,async,no_root_squash)
Запустите службу NFS при помощи приведённой ниже команды:
# service nfs-kernel-server start
Чтобы совместно применять пул ZFS с
разрешённым NFS через GUI Proxmox мы можем
просто следовать шагам описанным в предыдущем разделе для нашего хранилища
NFS. Чтобы добавить пул
ZFS или набор данных в кластер Proxmox с
применением GUI нам нужно зарегистрироваться в GUI того узла, где создан пул
ZFS. В нашем примере кластера
с двумя узлами у нас есть пулы ZFS в узле
#1, поэтому мы получим доступ к GUI на этом узле. С другой стороны,
такие пулы или наборы данных ZFS не могут быть
добавлены из GUI другого узла. Мы можем найти опцию встраиваемого модуля хранения
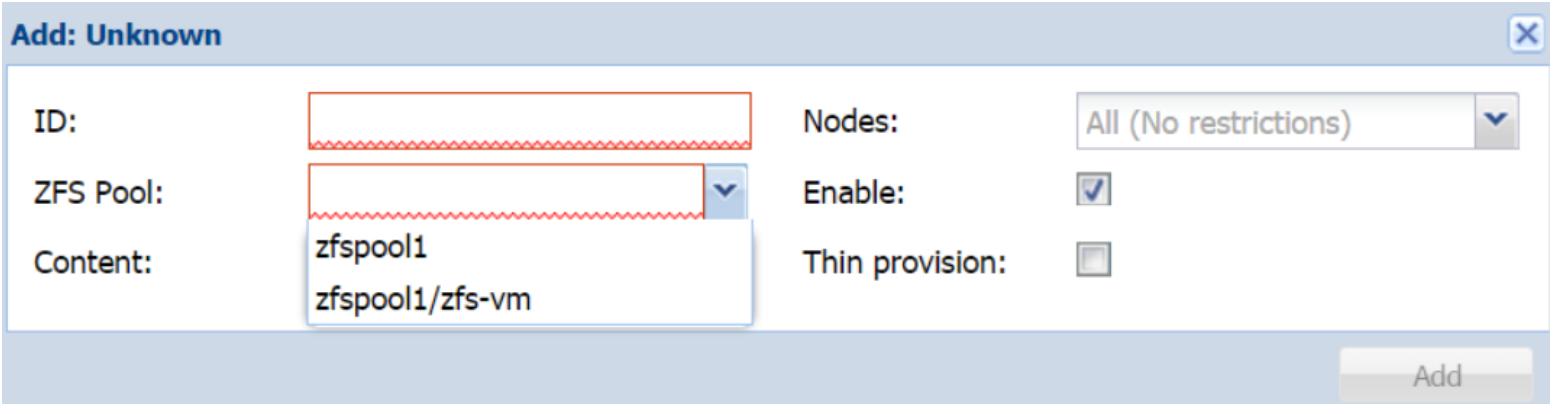
ZFS путём навигации в своём меню
Datacenter |
Storage |
Add. Кликните на встраиваемый модуль
ZFS для открытия блока диалога. Экранный снимок ниже
по тексту отображает блок диалога ZFS с примером
пула zfs и набором данных в ниспадающем меню:
Объединяя пул ZFS с разделяемым ресурсом NFS мы можем создавать совместно используемое хранилище с полной функциональностью ZFS, тем самым создавая гибкое совместно применяемое хранилище для использования на всех узлах Proxmox в нашем кластере. Воспользовавшись этой техникой, мы можем создать узел хранения резервных копий, который также управляется из GUI Proxmox. таким образом, при возникновении кризисных ситуаций в узлах мы также сможем выполнить временную миграцию ВМ на наши узлы резервного копирования. Предыдущие шаги применимы для любых дистрибутивов Linux, а не только для узла Proxmox. Например, мы можем установить ZFS плюс сервер NFS с использованием Linux Ubuntu или CentOS для хранения образов виртуальных дисков или шаблонов. Если вы используете FreeNAS или аналогичную систему хранения, тогда шаги для ZFS, представленные в этом разделе не обязательны. Весь процесс создания ZFS полностью полагается на GUI FreeNAS.
Хранилище RBD
(Rados Block Device) предоставляется
распределённой системой хранения Ceph. Это наиболее сложная система хранения, которой требуется
множество установленных узлов. По своей архитектуре Ceph является распределённой системой хранения и может
она распространяться на десятки узлов. Хранилище RBD
может содержать только форматы образов .raw. Чтобы расширить
кластер Ceph просто добавьте диск или узел и позвольте Ceph узнать об этом новом приобретении. Ceph
автоматически выполнит ребалансировку данных для приспособления этого нового жёсткого диска или узла.
Ceph может масштабироваться до нескольких Петабайт и более. Ceph также поддерживает создание множества пулов
для различных дисковых устройств. Например, мы можем хранить образы ВМ серверов баз данных в пуле с SSD
дисками, а образы сервера резервных копий в пуле медленных шпиндельных дисков. Ceph является системой
хранения, рекомендуемой для сред от средних до больших кластеров благодаря её эластичности в отношении
потери данных и простоте расширения хранилища.
В версии 4.1 Proxmox VE сервер Ceph был интегрирован в Proxmox для совместного существования на одном и том же узле. также была добавлена возможность управления кластерами Ceph через GUI Proxmox. Ceph является истинным решением хранения корпоративного уровня с кривой накопления технического опыта. Когда механика Ceph осознана, Ceph становится одной из простейших в обслуживании. Для более глубокого изучения хранилища Ceph отсылаем вас к http://ceph.com/docs/master/start/intro/. {Прим. пер.: полный перечень русскоязычных материалов по Ceph представлен на нашей веб- странице CloudComputing#Ceph. Особенно отмечаем переводы книг Карана Сингха Книга рецептов Ceph (март 2016) и Изучаем Ceph (январь 2015).}
Компоненты Ceph
перед углублением в Ceph давайте взглянем на некоторые ключевые компоненты которые формируют кластер Ceph.
Физический узел
Физический узел является реальным серверным оборудованием, которое размещает OSD, мониторы и MDS.
Карты
Карты в Ceph содержат информацию, такую как список участвующих в кластере узлов и их местоположение, пути данных, а также перечень OSD с определёнными порциями данных. В кластере Ceph существуют различные карты, такие как карта кластера (cluster), карта OSD (Object Storage Daemon) для перечня OSD, карта монитора для знания об узлах монитора monitor, карта групп размещения (PG, Placement Group) для определения местоположения объектов или порций данных, а также карта CRUSH для как сохранять и получать данные путём вычисления местоположения хранения данных.
Карта кластера
Карта кластера является картой устройств и ёмкостей (bucket), которые представляют кластер Ceph. Ceph применяет иерархию ёмкостей (bucket) для определения местоположения узла, такие как помещение (room), стойка (rack), полка (shelf), хост (host) и тому подобное. Например, давайте обсудим четыре дисковых устройства используемых в качестве четырёх OSD в следующей иерархии ёмкостей:
Bucket datacenter = dc01
|
Bucket room = 101
|
Bucket rack = 22
|
Bucket host = ceph-node-1
|
Bucket osd = osd.1, osd.2, osd.3, osd.4
В предыдущем примере мы можем увидеть что osd.1 до
osd.4 находятся в узле ceph-node-1,
который находится в стойке 22, расположенной в
помещении номер 101, которое находится в центре обработки
данных dc01. Если osd.3
отказывает, а на площадке присутствует технический специалист, то администратор быстро сообщает
этому специалисту предыдущую иерархию ёмкостей для идентификации точного местоположения диска для
его замены. В кластере может присутствовать несколько сотен OSD. Карта кластера помогает указывать
на отдельный хост или дисковое устройство применяя иерархию ёмкостей.
Карта CRUSH
CRUSH (Controlled Replication Under Scalable Hashing, Управляемых масштабируемым хешированием репликаций) является используемым Ceph алгоритмом для сохранения и получения данных путём вычисления местоположения хранения внутри кластера. Он выполняет это на основе значений веса каждого устройства для распределения объектов данных по устройствам хранения. Значение веса автоматически назначается на основании реального размера используемого диска. Например, диск с 2ТБ может иметь приблизительный вес 1.81. Диск будет сохранять записываемые данные пока не достигнет значения этого веса. Согласно своей архитектуре, CRUSH равномерно распределяет данные по снабжённым весами устройствам для обеспечения сбалансированного использования ресурсов хранения и пропускной способности устройств. Карта CRUSH может настраиваться пользователем для приспособления любой кластерной среды с любым размером. Для более подробного изучения карт CRUSH отсылаем вас к http://ceph.com/docs/master/rados/operations/crush-map/. {Прим. пер.: хорошее изложение механизма CRUSH приводится в разделе Понимание механизма CRUSH второй книги Карана Сингха по Ceph.}
Монитор
Монитор Ceph (MON) является узлом демона монитора кластера, который поддерживает карту OSD, карту размещения групп (PG), карту CRUSH и карту мониторов. Мониторы могут быть установлены как на тех же узлах серверов с OSD, так и на полностью самостоятельных машинах. Настоятельно рекомендуется для стабильности кластера Ceph устанавливать отдельные узлы с Мониторами. Поскольку мониторы всего лишь отслеживают всё, что происходит в кластере и не выполняют реальных операций чтения/ записи данных кластера, узел монитора может быть не очень производительным и, таким образом, не сильно затратным. Для достижения состояния жизнеспособности кластера Ceph необходимо установить как минимум три монитора. Состояние жизнеспособно (healthy) когда все состояния кластера находятся в состоянии OK, без наличия каких- либо предупреждений или ошибок. Отметим, что имея в виду интеграцию Ceph с Proxmox последнего времени, тот же узел Proxmox может применяться в качестве Монитора. Начиная с версии 3.2 Proxmox стало возможным устанавливать Мониторы на те же самые узлы, которые используются узлами Proxmox, тем самым исключая необходимость использовать отдельный узел для Монитора. Мониторы также могут управляться из GUI Proxmox. Подробнее о Мониторах Ceph можно ознакомиться на http://ceph.com/docs/master/man/8/ceph-mon/. {Прим. пер.: также рекомендуем раздел Наблюдение за мониторами Ceph второй книги Карана Сингха по Ceph.}
OSD
OSD (Object Storage Daemon) является реальным носителем хранения или
разделом в пределах носителя, например HDD или SSD который хранит актуальные данные кластера. OSD
является ответственным за все репликации данных, их восстановление, а также ребалансировку. Каждый
OSD предоставляет информацию наблюдения для Мониторов Ceph чтобы проверять их жизнеспособность. Кластер
Ceph требует минимально два Демона хранения объектов чтобы быть в состоянии
active + clean. Кластер Ceph предоставляет обратную связь для
состояния кластера на постоянной основе. Состояние active + clean
отображает отсутствие предупреждений и ошибок в кластере. Отсылаем вас к разделу Групп размещения для
получения информации о других состояниях которые может достигать кластер Ceph. Начиная с версии 3.2 Proxmox
OSD могут управляться при помощи GUI Proxmox.
Журнал OSD
В Ceph любая запись ввода/ вывода сначала осуществляется в Журнал (Journal) перед тем как эти данные будут перенесены на действительный OSD. Журналы это просто разделы меньшего размера, которые принимают меньшие данный в то время, как лежащие в основе OSD навёрстывают основную запись. Помещая Журналы на дисковые устройства с более быстрым доступом, например, SSD, мы можем значительно увеличить скорость работы Ceph, так как данные пользователя записываются в Журнал с более высокой скоростью тогда как такой Журнал отправляет короткие всплески данных в OSD, давая им время для того чтобы догнать поток. Журналы для нескольких OSD могут храниться на одном SSD в узле. Или OSD может быть разделён между множеством SSD. Для небольшого кластера с общим числом до восьми OSD на узел применение SSD улучшает производительность. Однако при работе с большими кластерами с более высокими значениями OSD на узел совмещение журнала с тем же самым OSD увеличивает производительность вместо применения SSD. Объединение скорости записи всех OSD вместе превосходит скорость одного или двух SSD в качестве журнала. {Прим. пер.: можно согласиться с автором что каждый раз следует тщательно производить расчёты производительности, причём как в терминах пропускной способности в МБ/с, так и в IOPS, для определения потенциальных узких мест. До недавнего времени именно IOPS создавали основные бутылочные горлышки. Появление нового интерфейса NVMe позволяет существенно снизить латентность SSD и существенно увеличить количество одновременно обслуживаемых очередей одним устройством, подробнее в обсуждении NVMe при выборе аппаратных средств Ceph на основе обзора в книге М. Лукаса и А.Джуда ZFS для профессионалов.}
Важный момент, который следует помнить о Журналах, состоит в том, что утрата раздела Журнала приводит к потере данных OSD. По этой причине настоятельно рекомендуется чтобы вы применяли SSD корпоративного уровня {Прим. пер.: eMLC}. Хорошо известно, что SSD Intel DC3700 прекрасно работает в качестве SSD устройства Журнала Ceph.
MDS
MDS (Meta Data Server) хранит информацию метаданных для файловой системы Ceph или CephFS. Блочное хранилище и хранилище объектов Ceph не используют MDS. Поэтому если в кластере будут использоваться только Блоки и Объекты, нет необходимости устанавливать сервер MDS. Как и Мониторы, MDS должны быть установлены на собственные отдельные машины для достижения высокой производительности. В Proxmox версии 3.2 MDS не могут управляться или создаваться из GUI Proxmox.
Файловая система Ceph пока не полностью стандартизована и всё ещё находится на этапе разработки. Она не должна применяться для хранения критически важных данных. В основном она стабильна, однако непредвиденные ошибки всё ещё могут вызывать серьёзные проблемы, например, потерю данных. Отметим, что не было очень большого количества массовой утраты данных из- за нестабильности CephFS. Две виртуальные машины применявшиеся для написания этой книги работали на протяжении более чем 11 месяцев без каких либо проблем. {Прим. пер.: хорошие новости: с мая 2016 CephFS уже рекомендована к промышленному применению.}
Для обеспечения избыточности должны быть использованы два узла {как минимум}, поскольку потеря узла MDS может вызвать потерю данных CephFS и приведёт к их недоступности. Два узла MDS будут работать как активный- пассивный, когда отказ одного узла обрабатывается другим узлом и наоборот. Для получения дополнительной информации по CephFS посетите ceph.com/docs/master/cephfs/. {Прим. пер.: также см. Глава 4, Работа с файловой системой Ceph в переводе Книги рецептов Ceph Карана Сингха.}
Группа размещения
Основное назначение Группы размещения или PG состоит в объединении определённых объектов в группу с последующим их отображением в определённые OSD. Погрупповой механизм намного эффективнее механизма на основании объектов, так как первый использует меньше ресурсов. При выборке данных намного эффективнее обращаться к группе чем вызывать отдельный объект в группе. Следующая схема отображает как Группа размещения соотносится с OSD:
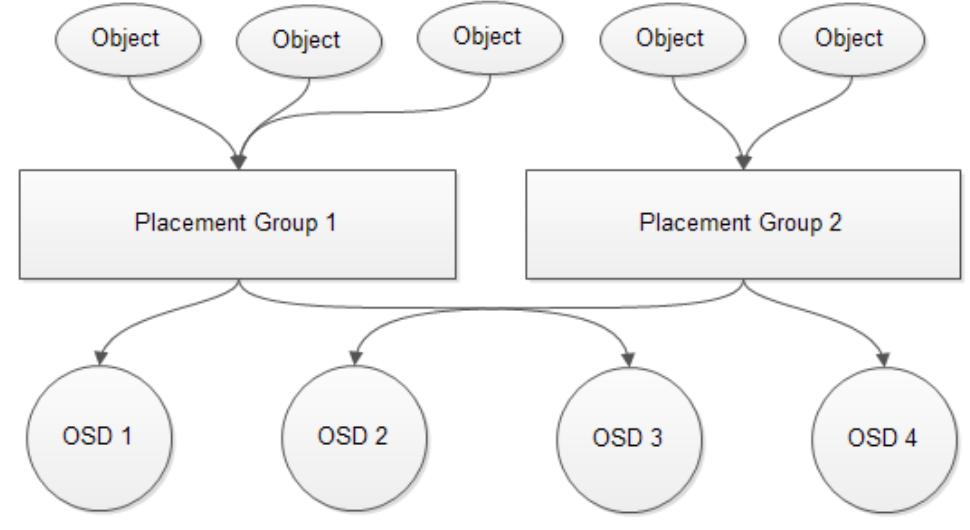
Для лучшей эффективности мы рекомендуем в общей сложности от 50 до 100 PG на OSD для всех пулов. Каждая группа размещения потребляет некоторые ресурсы конкретного узла такие как ЦПУ и оперативная память. Баланс распределения Групп размещения гарантирует, что все узлы и OSD в этих узлах не выйдут за пределы памяти или что ЦПУ не столкнутся с проблемой перегруженности. Следует применять приводимую ниже простую формулу для выделения Групп размещения в пуле:
Total PGs = (OSD x 100) / Number of Replicas
Результат общего числа PG должен быть округлён вверх до ближайшей степени двух. В кластере Ceph с тремя узлами (репликами) и 24 OSD общее число Групп размещения должно быть следующим:
Total PGs = (24 x 100) / 3 = 800
Если мы разделим 800 на 24, что является общим числом OSD, то мы получим 33.33. Это общее число PG на реплику в OSD. Так как у нас есть три реплики, мы умножаем 33.33 на 3 и получаем 99.99. Это общее число PG на OSD в предыдущем примере. Формула всегда вычисляет число Групп размещения на OSD. Для настройки с тремя репликами каждая Группа размещения записывается трижды, поэтому мы умножаем вычисленное значение PG 33.33 на 3 чтобы получить общее число PG на OSD.
Давайте рассмотрим другой пример вычисления PG. Следующая установка имеет 150 OSD, 3 узла Ceph и 2 реплики:
Total PGs = (150 x 100) / 2 = 7500
Если мы разделим 7500 на 150, то общее число OSD, которое мы получим равно 50. Поскольку у нас есть 2 реплики, мы умножим 50 на 2 и получим 100. Таким образом, каждый OSD в этом кластере должен хранить 100 PG. В обоих примерах общее число PG на OSD было в пределах рекомендуемого диапазона 50-100. Всегда округляйте значение PG для удаления всех значений после запятой.
Для балансировки доступных аппаратных ресурсов необходимо назначать верное число Групп размещения. Значение PG будет изменяться в зависимости от общего числа OSD в кластере. Следующая таблица показывает предложение PG даваемое разработчиками Ceph:
| Число OSD | Число PG |
|---|---|
меньше 5 OSD |
128 |
В пределах 5-10 OSD |
512 |
в пределах 10-50 OSD |
1024 |
Выбор надлежащего числа Групп размещения является критически важным, так как каждая PG потребляет ресурсы вашего узла. Слишком большое число PG для неверного значения OSD будет в действительности наказывать использованием ресурсов узла OSD, в то время как очень маленькое значение PG в большом кластере подвергает данные риску. Практический способ состоит в том, чтобы начать с наименьшего возможного значения PG, а затем увеличивать его по мере роста числа OSD. Для более подробных сведений по Группам размещения посетите http://ceph.com/docs/master/rados/operations/placement-groups/.
Существует великолепный калькулятор PG созданный разработчиками Ceph для вычисления рекомендуемого значения PG для различных размеров кластера Ceph по адресу: http://ceph.com/docs/master/rados/operations/placement-groups/. {Прим. пер.: также см. Раздел Группы размещения Ceph в переводе Книги рецептов Ceph Карана Сингха.}
Пулы
Пулы являются логическими разделами, в которых Ceph хранит данные. При создании кластера Ceph по умолчанию создаются три пула: данных (data), метаданных (metadata) и RBD. Пулы данных и метаданных используются самим кластером Ceph, в то время как пул RBD доступен для хранения реальных пользовательских данных. Группы размещения устанавливаются на основе пулов. Обсуждавшаяся ранее в разделе Группа размещения формула вычисляет значение PG, необходимое для одного пула. Поэтому, когда создаётся множество пулов важно слегка изменить эту формулу, чтобы общее значение PG оставалось в пределах 50-100 на OSD.
Например, для упражнения со 150 OSD, тремя узлами и 2 репликами, у нас было 7500 PG на пул. Это давало нам 50 Групп размещения на OSD. Если в данной установке у нас имеется три пула и каждый пул имеет 7500 PG, то общее число PG достигнет 150 на OSD. Чтобы поддерживать баланс Групп размещения по всему кластеру мы можем разделить 7500 на 3 для трёх пулов и установить значение PG равное 2500 для каждого пула. Это даёт нам 2500/150 OSD = 16 PG на пул для каждого OSD или 16 x 3 пула = 48 PG в сумме на OSD. Поскольку в данной установке у нас имеется 2 реплики, окончательное общее значение PG для OSD составит 48 x 2 реплики = 96 PG. Это находится в пределах рекомендуемого диапазона 50 - 100 PG для OSD.
Резюме компонентов Ceph
Если мы хотим понимать взаимосвязь между всеми компонентами Ceph, которые мы видели до сих пор, мы должны представлять себе это следующим образом: каждый Пул содержит в себе множество Групп размещения. Каждая Группа размещения содержит в себе множество OSD. Карта OSD отслеживает хранение ряда OSD в нашем кластере и в узлах из которых он состоит. Карта MON отслеживает хранение всего числа Мониторов в кластере для создания кворума и сопровождения главной копии карты всего кластера. Карта CRUSH диктует то, сколько данных необходимо записывать в OSD и то, как записывать и читать их. Это основные строительные блоки кластера Ceph.
Виртуальный Ceph для обучения
Существует возможность установки всего кластера Ceph в виртуальном окружении. Однако этот кластер должен использоваться только для целей обучения и тренировки. Если вы изучаете Ceph впервые и не хотите вкладывать средства в покупку физического оборудования, тогда несомненно можно применить виртуальную платформу Ceph. Это исключит потребность в установке физического оборудования для настройки узлов Ceph. {Прим. пер.: пошаговая инструкция установки виртуальной среды Ceph приводится в книгах Карана Сигха Настройка виртуальной инфраструктуры в более современной редакции в кратком изложении и более подробное изложение 2015г: Глава 2, Моментальное развёртывание Ceph.}
Кластер Ceph
Следующая схема является основным представлением Proxmox и кластера Ceph. Отметим, что оба кластера находятся в отдельных подсетях на различных коммутаторах:
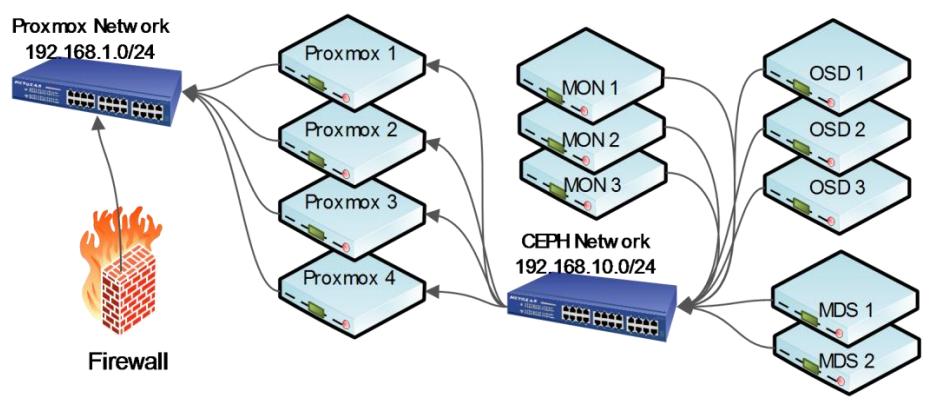
Кластер Ceph должен устанавливаться в отдельной подсети на отдельном коммутаторе для сохранения
изолированности от общедоступной подсети Proxmox. Преимущество такой практики состоит в сохранении
изолированности внутреннего обмена таким образом, что он не взаимодействует с обменом работающих
виртуальных машин. Для нормально работающего кластера с состоянием active+clean
это не является большой проблемой. Однако если кластер Ceph переходит в режим самовосстановления
из- за отказа OSD или узла, он начинает выполнение повторной балансировки перемещая PG по всему
кластеру, что вызывает очень высокое потребление полосы пропускания. В плохой день разделение
двух кластеров гарантирует что кластер не замедлит свою работу очень значительно из- за падения
пропускной способности сетевой среды. {Прим. пер.: наличие трёх и более
копий данных позволяет создавать различные методы отложенного копирования в периоды времени с
наименьшей загруженности кластера. С примерами реализации такого подхода можно, например, ознакомиться
в переводе статьи см. Интеллектуальные отложенные средства.}
Это также предоставляет дополнительную безопасность так как сетевая среда кластера Ceph полностью скрыта от открытого доступа так как использует отдельный коммутатор. В предыдущем примере у нас было три MON, два MDS и три OSD соединены выделенным коммутатором применяемым только для кластера Ceph. Кластер Proxmox соединяется с кластером Ceph путём создания соединения с хранилищем в своём GUI Proxmox.
Ceph в Proxmox
В Proxmox VE версии 4.1 теперь возможна установка Ceph на том же самом узле Proxmox, таким образом уменьшая число необходимых Ceph узлов, например, узла администрирования, узла Монитора или узла OSD. {Прим. пер.: последнее совмещение, с OSD, не рекомендуется для промышленного применения.} Proxmox также предоставляет собственную функциональность GUI которую мы можем применять для просмотра кластера Ceph и управления OSD, Мониторами, пулами и тому подобным. В данном разделе мы рассмотрим как устанавливать Ceph на узел Proxmox. В версии 4.1 управление сервером MDS и картой CRUSH не доступно из GUI Proxmox. {Прим. пер.: рекомендуем применять GUI VSM, переданный в сообщество Ceph компанией Intel, подробнее см. Главу 9. Менеджер виртуального хранения Ceph в вышедшей в 2016г новой Книге рецептов Ceph Карана Сингха.}
Подготовка узла Proxmox для Ceph
Когда мы устанавливаем Ceph на том же самом узле, на котором установлен Proxmox, мы установим
сетевые интерфейса для отдельной сетевой среды только для обмена Ceph. Мы установим три узла
Proxmox: pmxvm01, pmxvm02
и pmxvm03 c Ceph. На всех трёх узлах мы добавим следующий
раздел интерфейсов в /c/network/interfaces. Вы можете применить
любой IP адрес, который удовлетворяет вышей сетевой среде.
Выполните следующую команду в узле Proxmox pmxvm01:
# nano /etc/network/interfaces
Введите следующий раздел для добавления второй сетевой среды:
auto eth2
iface eth2 inet static
address 192.168.10.1
netmask 255.255.255.0
Выполните следующую команду чтобы сделать новый интерфейс активным:
# ifup eth2
Повторите предыдуще шаги и добавьте дополнительные сетевые интерфейсы с IP адресами
192.168.10.2 и 192.168.10.3
соответственно.
Установка Ceph
Proxmox добавляет небольшую утилиту командной строки с названием pveceph
для выполнения различных задач связанных с Ceph. В настоящее время pveceph
может выполнять следующие задачи в командной строке:
| Команда | Выполняемая задача |
|---|---|
|
Устанавливает Ceph на узле Proxmox |
|
Создаёт Монитор Ceph и должна быть выполнена на узле, который станет Монитором |
|
Создаёт новый пул. Может использоваться с любого узла. |
|
Удаляет Монитор. |
|
Удаляет пул Ceph. |
|
Создаёт начальный файл настройки Ceph на основе используемых сетевых CIDR. |
|
Запускает службы демонов Ceph, такие как MON, OSD и MDS. |
|
Останавливает службы демонов Ceph, такие как MON, OSD и MDS. |
|
Отображает состояние кластера, Монитора, сервера MDS, состояние OSD и идентификатор кластера. |
|
Создаёт демоны OSD. |
|
Удаляет демоны OSD. |
|
Удаляет Ceph и все относящиеся к Ceph данные с узла, на котором выполняется эта команда. |
Перед тем как можно будет начать управлять Ceph из GUI Proxmox с помощью командной строки должен быть установлен Ceph и создан по крайней мере один Монитор. Для установки Ceph на узле Proxmox и создании первого Монитора (MON) мы можем выполнить следующие шаги:
-
Выполните следующую команду для установки Ceph на всех узлах Proxmox которые будут частью вашего кластера Ceph:
# pveceph install –version hammerСовет Отметим, что на момент написания данной книги последней версией Ceph была редакция с кодовым именем Infernalis. Однако, для написания данной книги была использована версия Ceph Hammer, поскольку она полностью поддерживается Proxmox, по крайней мере в версии 4.1. Чтобы установить самую последнюю редакцию Ceph просто измените кодовое имя в своей команде когда эта версия станет доступной в Proxmox.
-
Для создания начального файла настроек на первом узле Proxmox выполните следующую команду. Нам нужно выполнить эту команду только один раз на одном узле:
# pveceph init --network 192.168.10.0/24 -
После выполнения этой команды Proxmox создаст файл настройки Ceph в
/etc/pve/ceph.confТакже он создаст символическую ссылку файла настройки в/etc/Ceph/ceph.conf. Таким образом, любые изменения пользователя сделанные в вашем файле настройки Ceph будут реплицироваться по всем узлам Proxmox.
После успешной начальной настройки вы увидите следующее предостерегающее сообщение:
libust[23466/23466]: Warning: Home environment variable not set. Disabling LTTng-UST user tracing. (In setup_local_apps() at lttng-ust-comm.c:375)
Это нормальное поведение из- за небольшой ошибки в Ceph. В последующих редакциях это предостережение будет исправлено. Вы также будете видеть это предостережение на протяжении своих ежедневных операций.
Для создания первого Монитора Ceph на том же узле, на котором мы только что создали файл настройки, выполните следующую команду:
# pveceph createmon
После выполнения данных шагов мы можем продолжить в GUI Proxmox работу по последующему созданию MON, OSD или Пулов. Все параметры Ceph могут быть получены при навигации по закладке Datacenter | Node | Ceph. Следующий снимок показывает то, как кластер Ceph нашего упражнения выглядит после начальной настройки в GUI Proxmox:
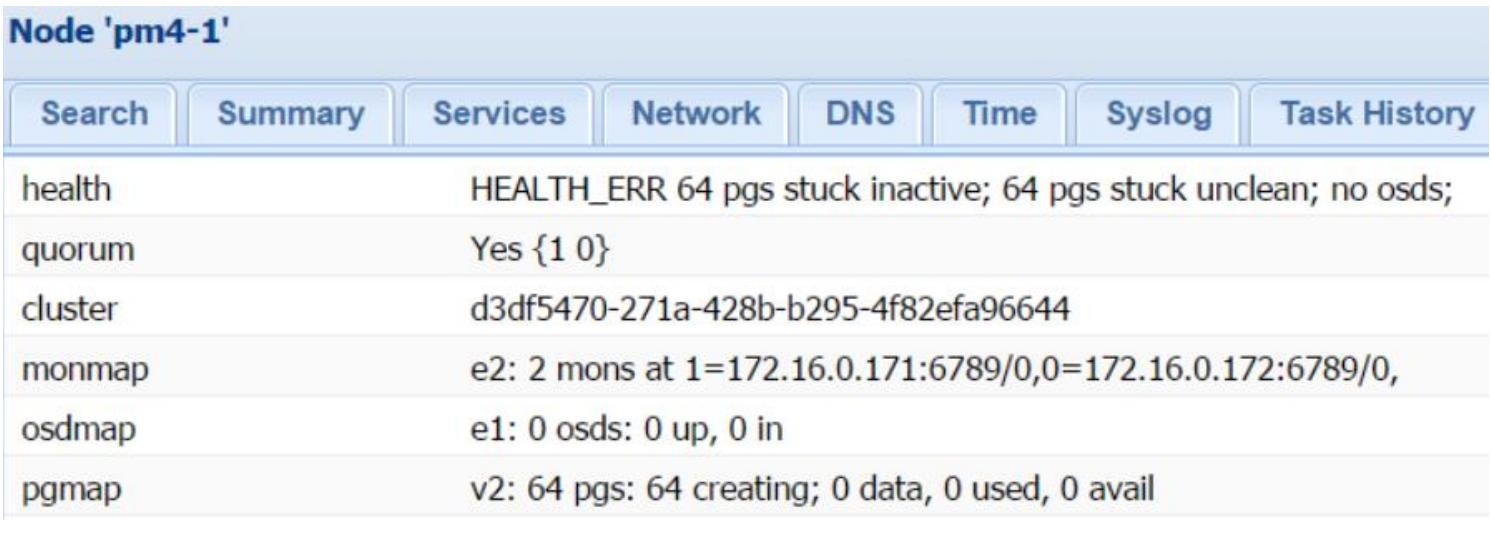
Совершенно нормально что кластер показывает pgs stuck неактивным и не очищенным (inactive и unclean), так как мы пока не добавили никаких OSD.
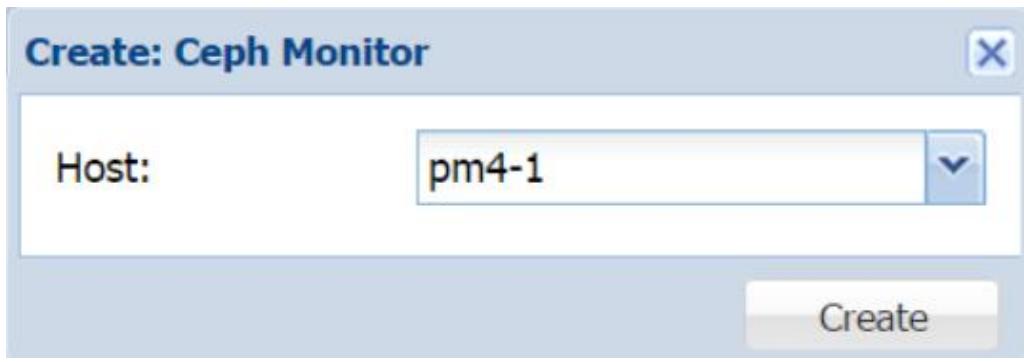
Создание MON через GUI Proxmox
Для просмотра и создания Монитора в GUI Proxmox переместитесь по меню в Datacenter | pmxvm01 | Ceph | Monitor. Кликните на Create для открытия блока диалога создания Монитора. Из ниспадающего меню со списком выберите узел Proxmox как это показано на следующем снимке экрана, а затем кликните на кнопку Create для начала процесса создания:
Следующий снимок показывает интерфейс Монитора Ceph с двумя MON созданными для нашего примера кластера Ceph:
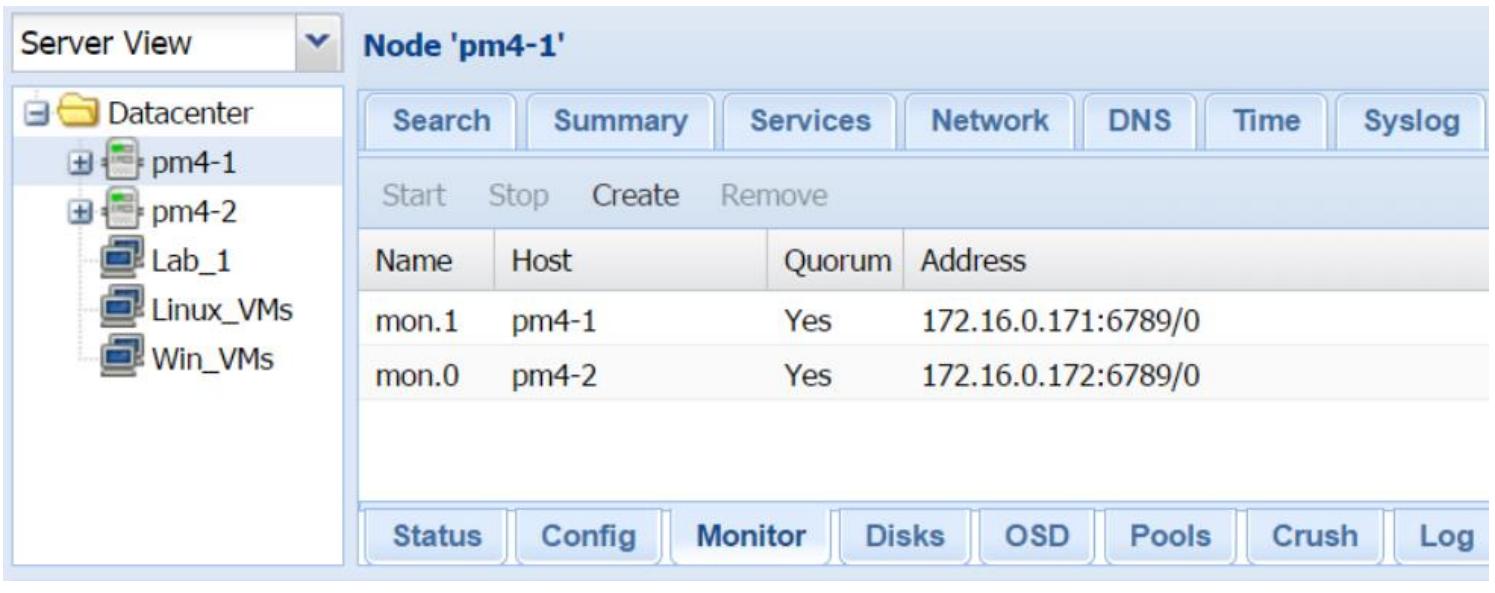
Создание OSD через GUI Proxmox
Для просмотра установленных на узле дисковых устройств и создания OSD через GUI Proxmox, переместитесь
по меню Datacenter |
pm4-1 |
Ceph |
Disk. Выберите для создания OSD доступное
дисковое устройство. Следующий экранный снимок показывает два доступных дисковых устройства,
/dev/vdb и /dev/vdc
чтобы создать OSD на одном из узлов нашего примера Proxmox.
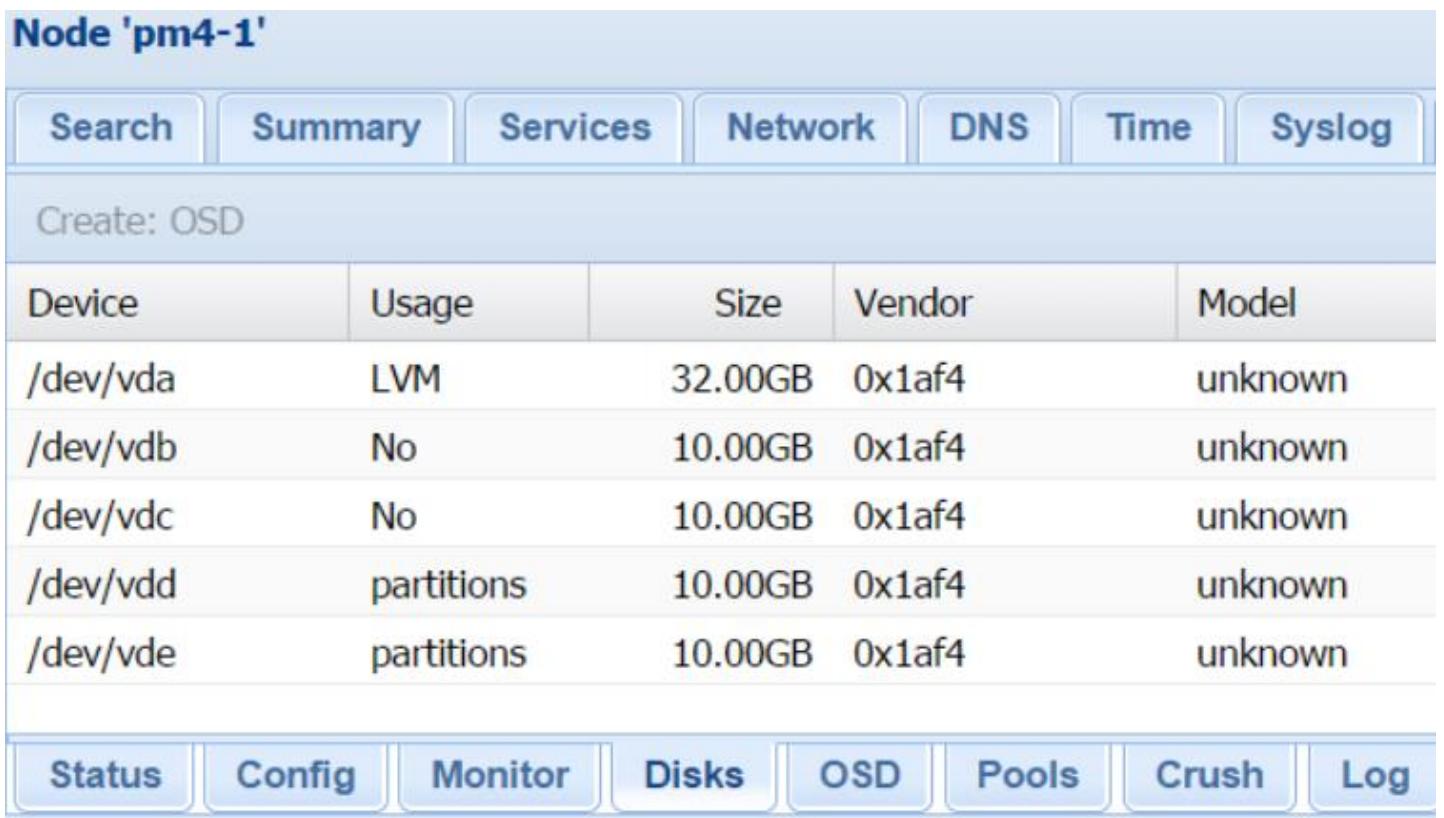
Чтобы создать OSD кликните на кнопку Create: Ceph OSD для открытия блока диалога, как это отображено на приводимом ниже снимке экрана. Выберите в ниспадающем меню доступный диск и кликните на кнопку Create:
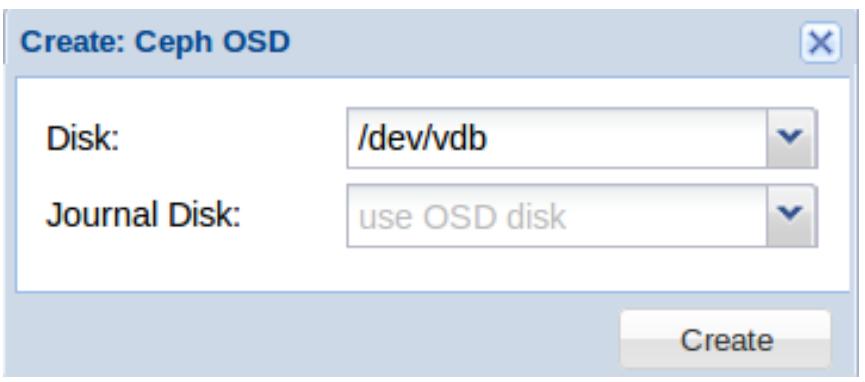
Если вы собираетесь совмещать Журнал с тем же самым диском OSD, нет необходимости в выборе Journal Disk. Для выбора другого дискового устройства для хранения журнала OSD кликните на выпавшую кнопку Journal Disk. В этом случае вначале на SSD должны быть подготовлены разделы через CLI перед созданием OSD при помощи блока диалога.
Следующий снимок экрана показывает страницу состояния Ceph после создания двух OSD на одном из ваших узлов:
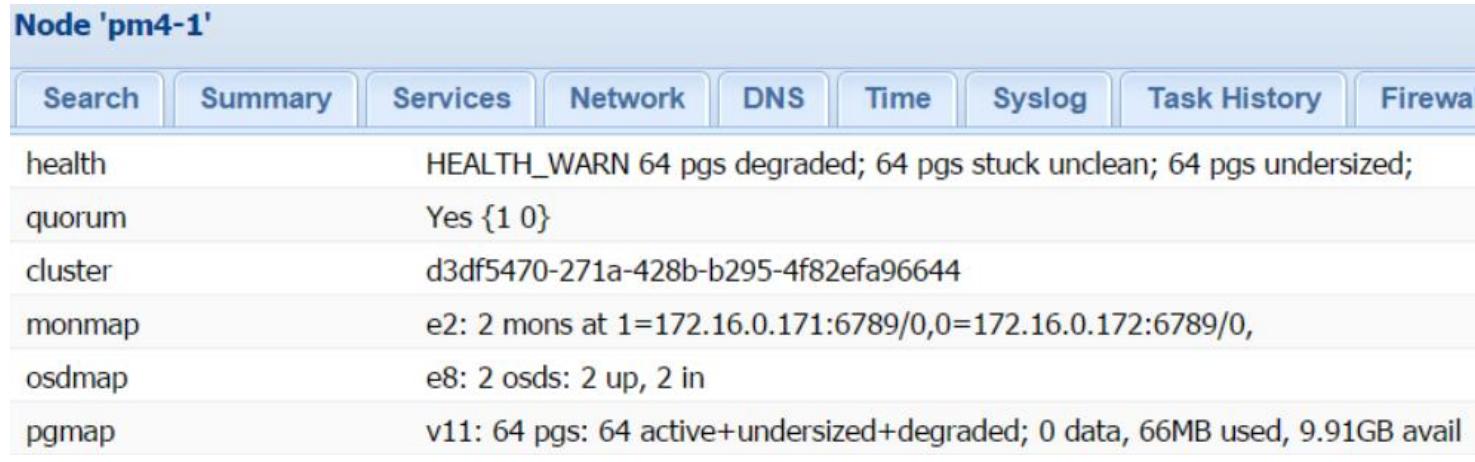
Заметим, что даже после добавления двух OSD на узле, наш кластер Ceph всё ещё остаётся в состоянии
деградировавшего и не очищенного (degraded и unclean). Это происходит по той причине, что мы создали
OSD только на одном узле. По умолчанию Ceph пытается создавать три реплики, а у нас имеется всего лишь
два узла. Поэтому мы собираемся добавить ещё два OSD на втором узле повторив предыдущие шаги и изменив
значение репликации на 2 с тем, чтобы наш кластер мог достичь
рабочеспособного состояния. Следующая команда изменит значение репликаций пула Ceph по умолчанию
rbd со значения 3
на 2:
# ceph osd pool set rbd size 2
|
| Замечание |
|---|---|
|
Хотя кластер Ceph может управляться через GUI Proxmox, чтобы выполнять расширенные задачи нам нужно применять CLI. Ceph поставляется с приличным количеством команд для различных задач. Перечисление всего перечня команд Ceph выходит за пределы данной книги. Однако краткий список команд, используемых для наиболее часто исполняемых задач включён нами позже в данную главу. |
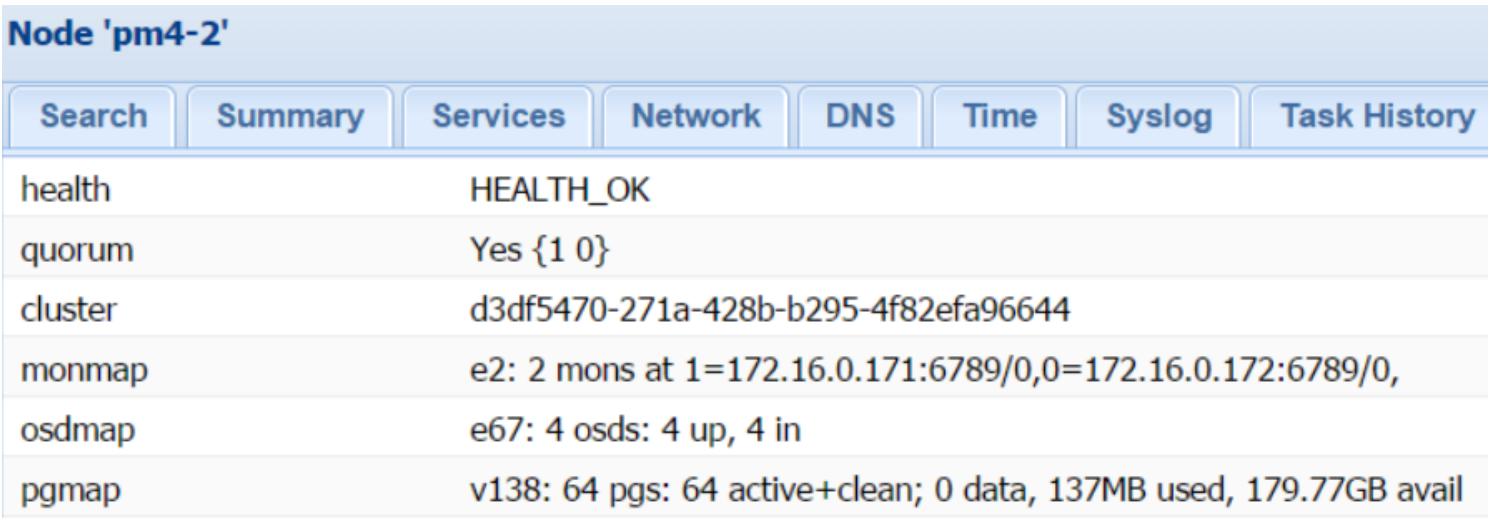
После того, как мы добавили OSD на свой второй узел и изменили значение репликаций на
2 для пула Ceph по умолчанию, кластер нашего примера достигает
рабочеспособного состояния, что отображается на следующем снимке экрана:
По умолчанию Ceph создаёт OSD с разделами xfs. Однако иногда необходимо создавать с другими типами разделов из соображений улучшения производительности. В Proxmox 4.1 мы можем отрегулировать тип раздела в процессе его создания в GUI. Для создания OSD с другим типом раздела с помощью CLI введите следующую команду:
# pveceph createosd –fstype ext4 /dev/sdX
|
| Совет |
|---|---|
|
{Прим. пер.: чтобы полностью использовать полосу пропускания SSD, они должны расщепляться примерно между 5 OSD (по опыту Mirantis), для включения такой возможности вам необходимо удалить OSD, созданные на этих SSD при установке, разделить каждый SSD на пять разделов и создать на них OSD. см., например, раздел 6.1 Эталонной архитектуры для компактного облачного решения с применением Mirantis OpenStack 9.1 и оборудования Dell EMC.} |
Создание нового пула Ceph при помощи GUI Proxmox
Чтобы создать новый пул с применением GUI Proxmox, перейдите в
Datacenter |
"node" |
Ceph |
Pools. Интерфейс Пула покажет информацию
о существующих пулах, такую как их название, число репликаций, значение числа Групп размещения, а также
процент использования по отношению к пулу. Для создания нового пула кликните на кнопку Create чтобы открыть блок диалога создания пула,
как это показано на снимке экрана ниже. Введите в поле Name его название, число реплик в поле Size, оставьте значение Min.Size равным 1 и введите
соответствующее значение pg на основе вычислений по формуле
определения значения Групп размещения, которую мы обсуждали ранее в этой главе. Кликните
OK для запуска создания пула:
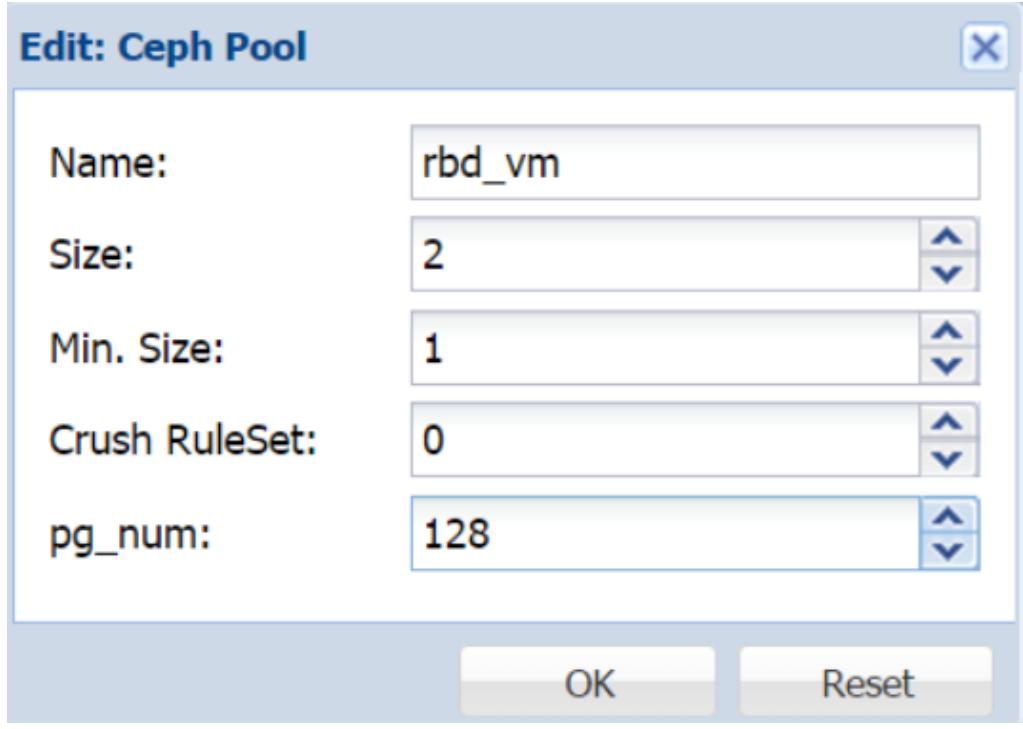
Присоединение RBD к Proxmox
Мы можем связать хранилище Ceph со своим кластером при помощи GUI Proxmox. Однако существует ещё один шаг который мы должны выполнить прежде чем Proxmox сможет успешно читать хранилище Ceph. Для своих функций Ceph применяет аутентификацию. Прохождение аутентификации производится на основании колей ключей, которые мы создали во время создания кластера Ceph. Для каждого хранилища Ceph нам необходимо присоединить его к Proxmox и нам нужно скопировать главное кольцо ключей администратора Ceph в соответствующий каталог Proxmox. Кольцо с ключами, которое нам нужно скопировать, расположено в каталоге:
/etc/pve/ceph.client.admin.keyring
Кольцо ключей должно быть скопировано в местоположение со следующим форматом:
/etc/pve/ceph/<storage_id>.keyring
Например, мы собираемся создать хранилище RBD с названием rbd-vm-01.
Поэтому нам нужно скопировать кольцо так, как это показывает следующий пример:
# cp /etc/pve/priv/ceph.client.admin.keyring /etc/pve/priv/ceph/rbdvm-01.keyring
Переместившись в меню Datacenter | Storage | Add, мы сможем отыскать подключаемый модуль хранилища Ceph. Кликните на подключаемый модуль RBD для открытия блока диалога и добавьте требующуюся информацию, как это отображено на следующем снимке экрана:
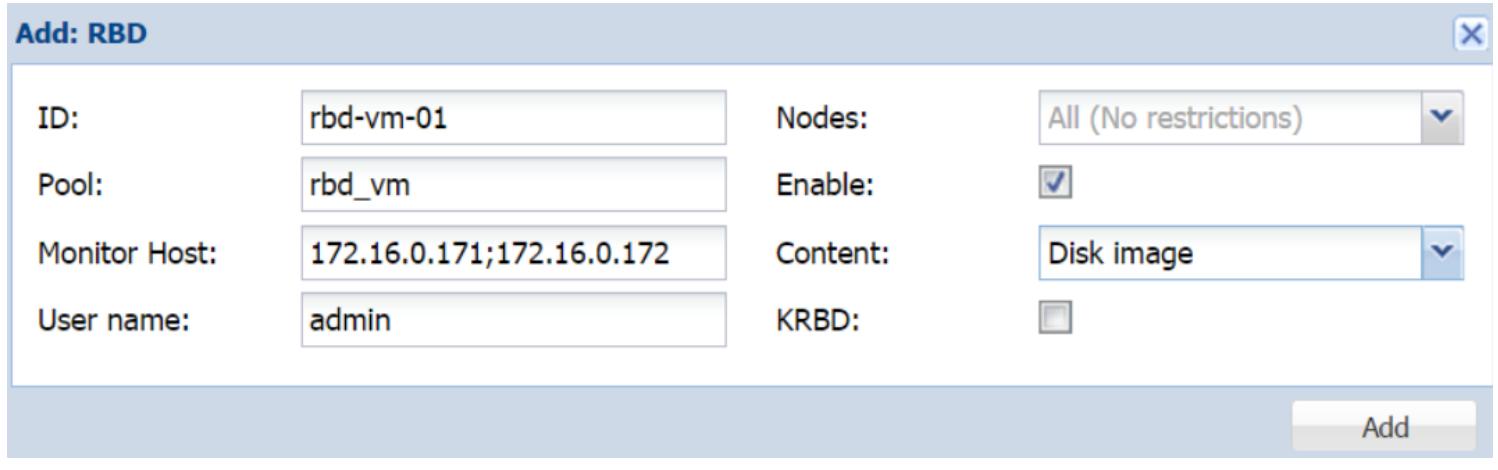
На предыдущем снимке мы добавили хранилище с названием rbd-vm-01,
которе будет хранить образы виртуальных дисков в пуле с именем rbd-vm,
созданный нами в предыдущем разделе. В текстовом блоке Monitor
Host введите IP адрес узлов MON нашего Ceph разделённые точкой с запятой. Нет необходимости
изменять имя пользователя, поскольку admin является пользователем по
умолчанию для работы с Ceph. В Proxmox VE 4.1 мы можем теперь использовать хранилище RBD Ceph для хранения
контейнеров LXC. Однако это будет работать только если мы выберем параметр KRBD в блоке диалога. Можно хранить вместе и образы LVM, и образы LXC в
едином хранилище RBD с включённым KRBD; однако для достижения максимальной производительности и
изолированности вам настоятельно рекомендуется применять два различных пула для образов дисков виртуальных
машин KVM и LXC, причём для пула контейнеров LXC включите опцию KRBD.
Следующий снимок экрана показывает состояние хранилища RBD в GUI Proxmox:
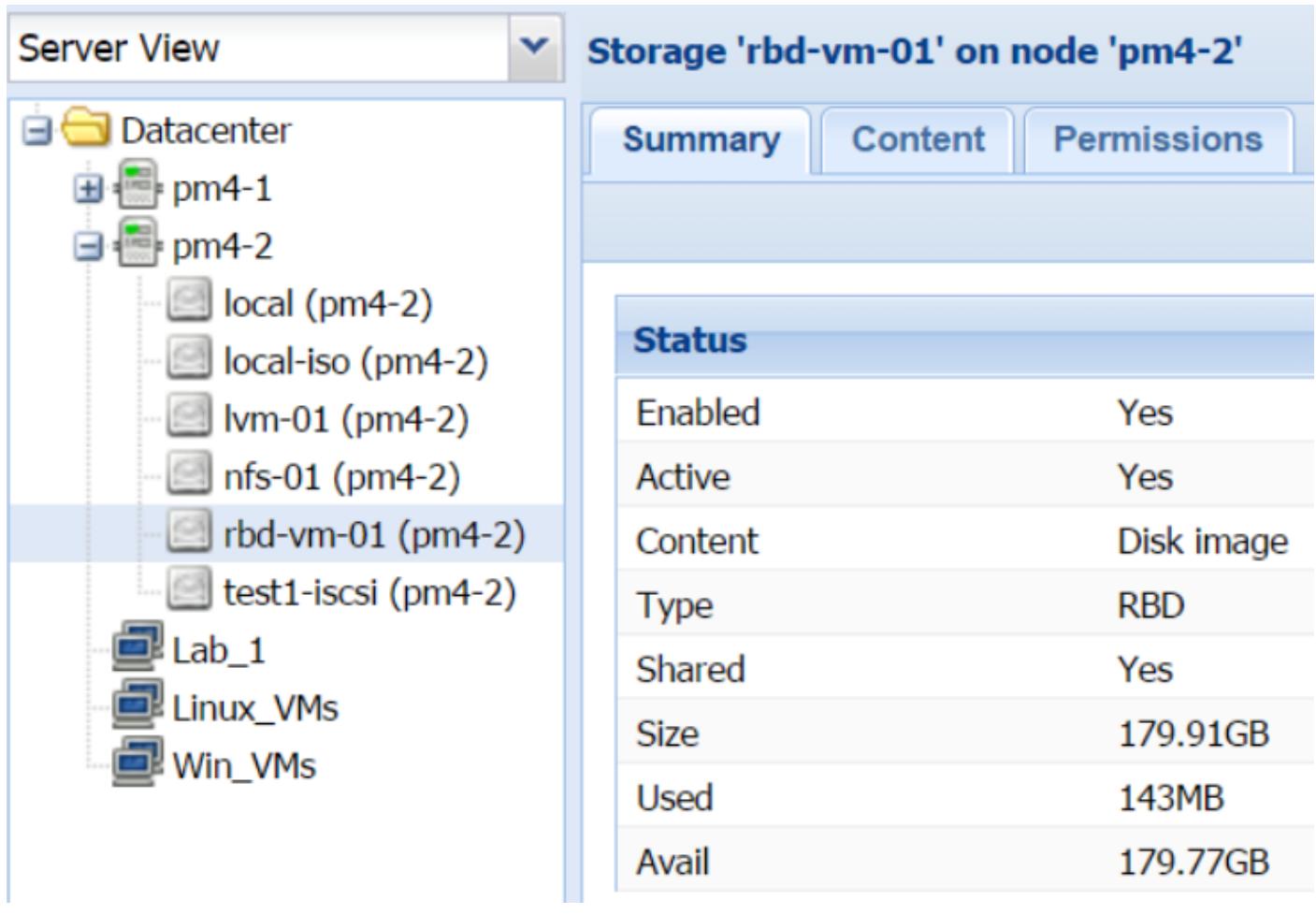
Список команд Ceph
Следующая таблица отображает некоторые наиболее употребляемые команды Ceph используемые в кластере:
| Команда | Выполняемая задача |
|---|---|
|
Отображает состояние кластера Ceph. |
|
Отображает записи журнала работающего кластера Ceph. |
|
Отображает детализацию ошибок при их наличии. |
|
Должны выполняться по окончанию обслуживания для восстановления нормальной работы. |
Пример:
|
Отображает значения времени работы Ceph. Например, мы можем выполнить эту команду для отображения всех относящихся к thread элементов в кластере Ceph. |
Пример:
|
Внедряет значения в элементы в процессе исполнения без перезапуска каких- либо демонов. Это
полезно для игры с различными значениями для нахождения оптимальных значений. Когда достигнут успех,
можно внести изменения в |
|
Перечень Пулов. |
|
Создаёт Пул. |
|
Удаляет Пул. |
|
Получает общее число PG пула. |
|
Изменяет значение числа репликаций для пула. |
GlusterFS является мощной распределённой файловой
системой, которая может масштабироваться до нескольких Петабайт под одной точкой монтирования. Gluster
является довольно новым добавлением в Proxmox, которое позволяет пользователям GlusterFS использовать все преимущества кластера Proxmox.
GlusterFS сохранения файлов использует режимы
Stripe, Replicate или
Distribute. Хотя режим Distribute
предлагает возможности масштабирования, отметим, что в режиме Stripe при
отключении некоего узла GlusterFS все файлы в этом
сервере становятся недоступными. Это означает, что если определённый файл сохраняется транслятором
GlusterFS на этот сервер, только этот
узел хранит все данные о таком файле. Даже когда все остальные узлы в рабочем состоянии, этот
определённый файл больше не будет доступен. GlusterFS может быть масштабирован до Петабайт в пределах одного
монтирования. Хранилище GlusterFS может быть
настроено на работу только на двух узлах и поддерживает NFS, тем самым позволяя хранить файлы образов
любого формата. Для получения дополнительной информации по GlusterFS посетите
http://www.gluster.org/community/documentation/index.php/GlusterFS_Concepts.
Мы можем устанавливать Gluster на тот же узел, на котором работает Proxmox или на удалённый узел с применением любого дистрибутива Linux для создания совместно используемого хранилища. Glaster является прекрасным вариантом для двух узлов, надёжной системы хранения такой как DRBD. Самая большая разница состоит в том, что он может масштабироваться для увеличения общего пространства хранения. Для виртуальных сред с требованиями избыточности при низком бюджете Gluster может быть наилучшим решением. При настройке Gluster с двумя узлами оба узла выполняют синхронизацию друг с другом, а если один из узлов становится недоступным, второй просто берёт всё на себя. Установка Gluster достаточно сложна. Для получения дополнительной информации об установке GlusterFS отсылаем вас к http://gluster.readthedocs.org/en/latest/Quick-Start-Guide/Quickstart/.
В данном разделе мы рассмотрим как соединять кластер GlusterFS с Proxmxox применяя подключаемый модуль Gluster. Мы сможем найти опции этого подключаемого модуля переместившись по меню Datacenter | Storage | Add. Кликните на подключаемый модуль GlusterFS для открытия блока диалога создания вашего хранилища как это показано на следующем экранном снимке:
Следующая таблица отображает необходимые типы информации и используемые значения для нашего примера подключения GlusterFS:
| Элементы | Тип значения | Пример значений |
|---|---|---|
|
Новое имя хранилища. |
|
|
IP адрес первого узла gluster. |
|
|
IP адрес второго узла gluster. |
|
|
Ниспадающее меню для выбора доступных томов на узле Gluster. |
|
|
Выберите тип сохраняемых файлов. |
|
|
Выберите узлы, которые могут иметь доступ к данному хранилищу. |
|
|
Разрешает или запрещает это хранилище. |
|
|
Максимальное число последних файлов резервных копий, которое можно хранить. Более старые резервные копии будут удаляться автоматически в процессе выполнения резервного копирования. |
|
Так как Gluster не имеет встроенных параметров RAID управляемых программным обеспечением, каждый узел Gluster будет требовать некий вид RAID для избыточности дисков в узле. Как и при подходе NFS поверх ZFS, который мы изучили ранее в данной главе, мы также можем поместить Gluster поверх ZFS и предоставить таким образом избыточность дисков. Отметим, что это создаст некоторые накладные расходы, так как ZFS будет потреблять ресурсы.
Мы уже обсудили какие форматы образов виртуальных машин и типы хранилищ поддерживаются Proxmox. чтобы нам получить больше информации для тестирования или практических занятий, мы сейчас собираемся взглянуть на имеющиеся бесплатные и коммерческие опции для установки системы хранения под среду с кластеризацией Proxmox. Под бесплатными (некоммерческими) я подразумеваю, что они свободны без каких- либо изъятий основных функций и без каких либо ограничений на срок использования (trial).
Такие некоммерческие варианты позволяют вам устанавливать полностью функционирующую совместно применяемую систему хранения с приложением серьёзных трудозатрат. Коммерческие версии обычно поставляются с полной поддержкой от компании- поставщика и в некоторых случаях с постоянным контрактом SLA (Service Level Agreement, соглашением об уровне обслуживания). Приводимый список ни в коей мере не претендует на полноту и публикуется исключительно в качестве отправки вас в нужном направлении когда вам нужно спланировать и реализовать кластерную среду Proxmox. Каждый из этих продуктов может предоставить вам всё что вам нужно для настройки совместно используемого хранилища:
| Не коммерческие | Коммерческие | Пример значений | ||
|---|---|---|---|---|
Solaris plus napp-IT |
Nexenta |
|||
FreeNAS |
FalconStor |
|||
GlusterFS |
EMC2 |
|||
CEPH |
Yottabyte |
|||
{Прим. пер.: Sheepdog} |
Open-E DSS |
|||
|
|
NetApp |
||
Вопрос, который очень часто задают, звучит так могу ли я устанавливать среду промышленного применения с использованием только некоммерческих решений? Короткий ответ такой: ДА!
На самом деле действительно можно создать законченный кластерный комплекс Proxmox с использованием только некоммерческих решений хранения. Однако, вы должны быть готовы к неожиданностям и тратить значительное время на изучение вашей системы. С другой стороны для коммерческих решений, простое изучение системы даст администратору преимущество при возникновении непредвиденной проблемы. Основная разница между этими некоммерческими и коммерческими решениями состоит в стоящей за ними поддержке компанией. Обычно некоммерческие решения имеют только движимую сообществом поддержку посредством форумов и рассылок сообщений. Коммерческие предложения приходят с технической поддержкой при времени отклика меняющемся от чего- то близкого к непосредственной реакции до 24 часов.
|
| Совет |
|---|---|
|
Компромисс между некоммерческими решениями с открытым исходным кодом выражается в деньгах, которые будут сохранены и которые обычно обмениваются на время, затрачиваемое на исследования и ошибки. |
В этой главе мы рассмотрели варианты хранилищ которые поддерживаются Proxmox, а также их преимущества и недостатки. Мы также увидели различные типы файлов виртуальных образов которые могут применяться в Proxmox и когда их использовать. Мы изучили как настраивать различные варианты хранения с применениями NFS, ZFS, RBD и Gluster, а также лежащих в основе хранилищ. Системы хранения являются важной составляющей кластеризации Proxmox, так как это то место, где создаются виртуальные машины и откуда они выполняют свою работу. Реализованная надлежащим образом система хранения является чрезвычайно критически важной для того чтобы сделать любой кластер успешным. При надлежащем планировании различных требований хранилищ и выборе правильных форматов и параметров большой объём хлопот и разочарований может быть сведён к минимуму.
В следующей главе мы рассмотрим как создавать виртуальные машины на основе KVM и управлять ими. Мы также исследуем файлы настройки виртуальных машин и изучим некоторые продвинутые параметры настройки.