Tesla P100: Революционные производительность и функциональность для GPU вычислений
Содержание
- Tesla P100: Революционные производительность и функциональность для GPU вычислений
- Экстремальная производительность для высокопроизводительных вычислений и глубинного обучения
- NVLink: Экстраординарная пропускная способность для связности множества GPU и GPU-ЦПУ
- Высокоскоростная архитектура памяти HBM2
- Упрощённое программирование для разработчиков с унифицированной памятью и вычислением вытеснения
Обладая 15.3 миллиардами транзисторов в GPU, новым высокопроизводительным интерконнектом, который очень сильно ускоряет одноранговый обмен и взаимодействие GPU-с-ЦПУ, новыми технологиями упрощающими программирование GPU, а также исключительной энергоэффективностью, Tesla P100 не просто наиболее мощная, но также и наиболее сложная архитектура ускорителя GPU из созданных сегодня.
Основные свойства Tesla P100 включают в себя:
-
Экстремальная производительность
Возводимые в степень HPC, Глубинное обучение, а также многие прочие области GPU вычислений
-
NVLink™
Новый высокоскоростной, с большой пропускной способностью интерконнект NVIDIA для максимальной масштабируемости приложений
-
HBM2
Быстрая, обладающая большой ёмкостью, чрезвычайно эффективная CoWoS (Chip-on-Wafer-on-Substrate) архитектура памяти в стеке
-
Унифицированная память, Вычисляемое вытеснение и Новые Алгоритмы ИИ
Значительно улучшенная модель программирования и расширенные оптимизации программного обеспечения ИИ для архитектуры Pascal
-
16нм FinFET
Предоставляет большую функциональность, наивысшую производительность и улучшает энергоэффективность

Tesla P100 была разработана чтобы предоставлять исключительную производительность для большинства требующих вычислений приложений, предоставляя:
-
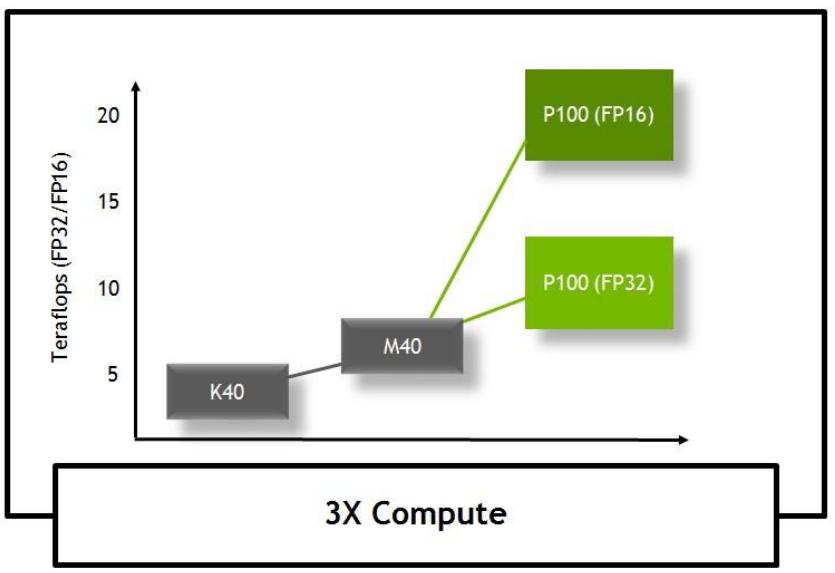
производительность 5.3 TFLOPS двойной точности с плавающей запятой (FP64)
-
производительность 10.6 TFLOPS одинарной точности с плавающей запятой (FP32)
-
производительность 21.2 TFLOPS половинной точности с плавающей запятой (FP16)
В дополнение к большому числу областей высокопроизводительных вычислений, которые GPU NVIDIA ускоряют на протяжении многих лет, самые последние достижения Глубинного обучения (Deep Learning) становятся очень важной областью сосредоточения для ускорения GPU. NVIDIA GPU в настоящее время находятся на переднем краю Глубинных нейронных сетей (DNN, deep neural networks) и искусственного интеллекта (ИИ, AI- artificial intelligence). Они ускоряют DNN в различных приложения со множителем от 10x до 20x в сравнении с ЦПУ и уменьшают время обучения от недель до дней. За последние три года вычислительные платформы на основе GPU NVIDIA помогли ускорить Сети Глубинного Обучения (DNN) в разы со множителем пятьдесят. За последние два года число компаний, сотрудничающих с NVIDIA в Глубинном Обучении подскочило в 35 раз до более чем 3`400 компаний.
Новые инновации в нашей архитектуре Pascal, включая обычные 16-битные вычисления с плавающей запятой (FP) позволяют GP100 предоставить великолепное ускорение для многих алгоритмов Глубинного Обучения. Эти алгоритмы не требуют высокого уровня точности с плавающей запятой, однако они достигают больших преимуществ от предоставления дополнительной вычислительной мощности FP16 и понижают требования к хранению 16-битных типов данных.
По мере роста популярности ускоряемых GPU вычислений всё больше систем со множеством GPU разворачиваются на всех уровнях, от рабочих станций к серверам и дальше к суперкомпьютерам. В настоящее время для решения более крупных и сложных задач применяется множество конфигураций систем с 4- и 8- GPU. Множество групп систем с большим числом GPU соединяются с применением Infiniband® и 100Gb Ethernet для создания более крупных и более мощных систем. Соотношение GPU к ЦПУ также возрастает. Самый быстрый суперкомпьютер 2012, Titan, размещённый в Oak Ridge National Labs, разворачивал одно GPU GK110 на ЦПУ. Сегодня два и более GPU обычно используются совместно на один ЦПУ, так как разработчики в своих приложениях всё чаще раскрывают возможности и применяют как рычаг возможности параллелизма предоставляемые GPU. Посколку эта тенденция сохраняется, пропускная способность PCIe в системах уровня со множеством GPU становится узким местом.
Для решения этой проблемы Tesla P100 предоставляет функциональность нового высокоскоростного интерфейса NVIDIA, NVLink, который предоставляет обмен данными для GPU-с-GPU до 160 Гигабайт в секунду - пятикратную пропускную способность PCIe Gen 3 x16. Рисунок 4 показывает соединение при помощи NVLink восьми ускорителей Tesla P100 в топологию сетки гибридного куба (Hybrid Cube Mesh).
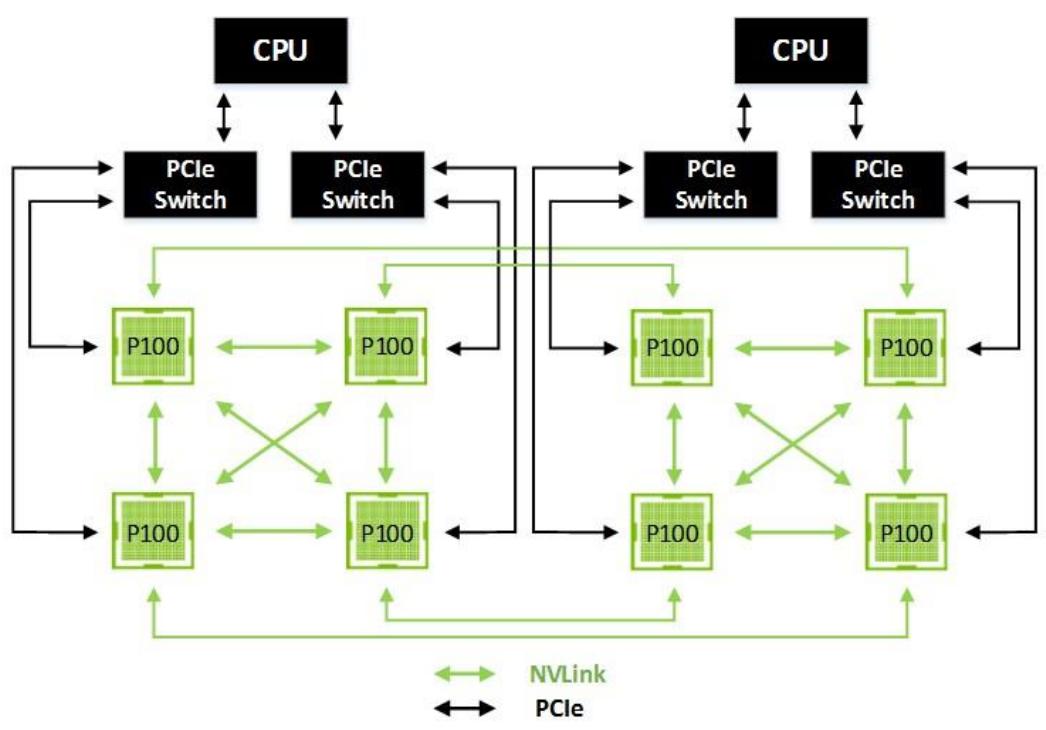
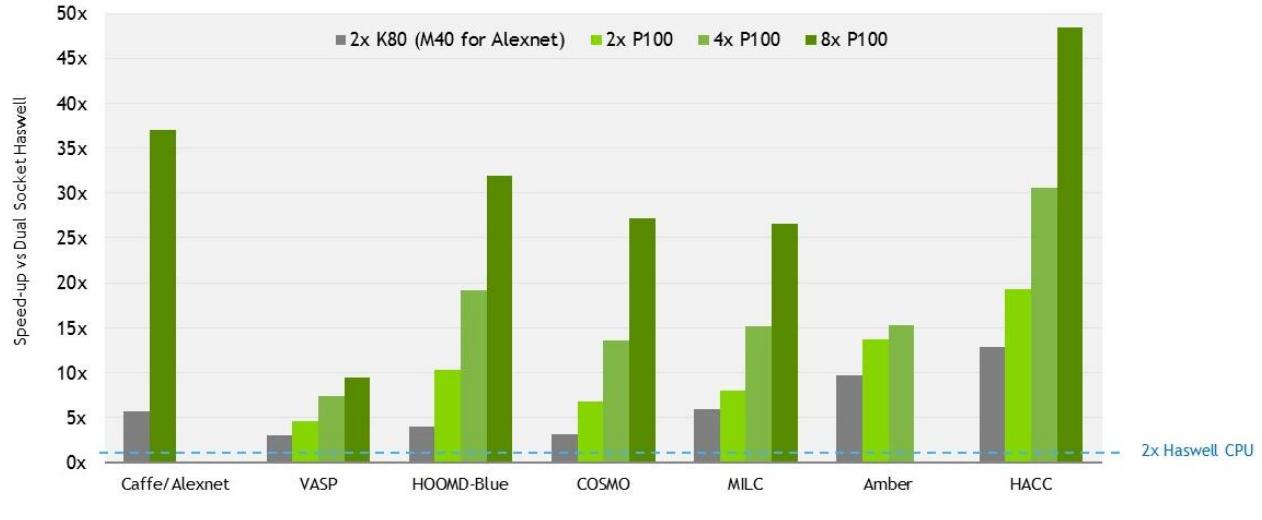
Рисунок 5 отображает производительность для различных рабочих нагрузок, демонстрируя масштабируемость сервера, которую можно достичь с GPU GP100 общим числом до восьми с применением NVLink (Замечание: Данные значения были замерены при предпродаже GP100 GPU.)
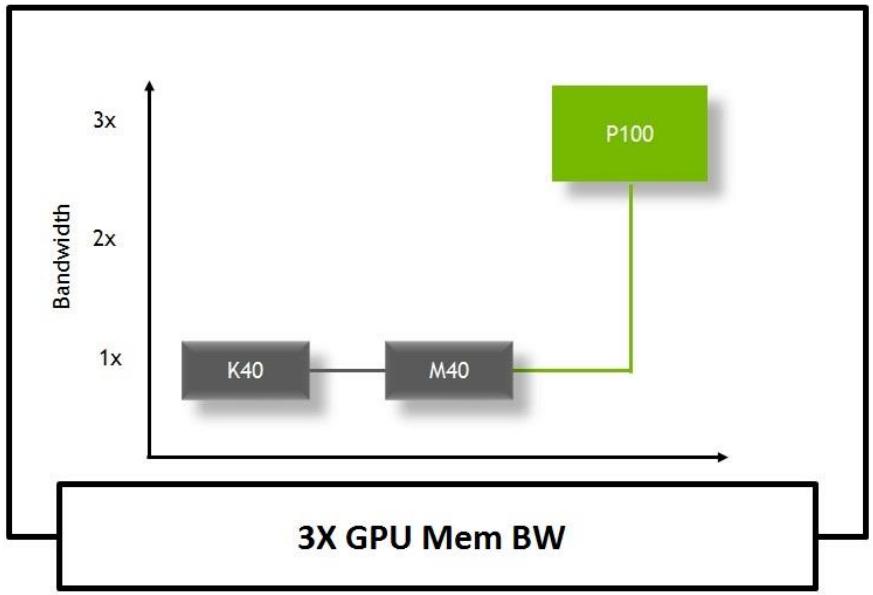
Tesla P100 является первой в мире архитектурой GPU, поддерживающей память HBM2. HBM2 предлагает тройную (3x) пропускную способность памяти в сравнении с GPU Maxwell GM200. Это позволяет P100 снаряжать более крупные наборы данных с более высокой полосой пропускания, улучшая эффективность и вычислительную пропускную способность при уменьшении числа обменов с оперативной памятью системы.
Так как HBM2 является стекируемой памятью и размещается в той же физической упаковке, что и GPU, она обеспечивает значительную экономию пространства в сравнении с традиционными GDDR5, что позволяет нам строить более просто чем когда бы то ни было более плотные серверы GPU.
Унифицированная память (Unified Memory) является значительным улучшением для GPU вычислений NVIDIA и основным новым аппаратным и программным свойством архитектуры GPU Pascal GP100. Она предоставляет единое бесшовное виртуальное адресное пространство для оперативной памяти ЦПУ и GPU. Унифицированная память значительно упрощает программирование GPU и портирование приложений в GPU, а также уменьшает искривление обучения GPU вычислениям. Программисты теперь не должны беспокоиться об управлении данными совместно используемыми двумя различными системами виртуальной памяти. GP100 является первым GPU NVIDIA для поддержки аппаратных отказов страниц, а в комбинации с новой 49-битной (512ТБ) виртуальной адресацией делает возможной прозрачную миграцию данных между полным пространством виртуальных адресов как GPU, так и ЦПУ.
Вычисляемое вытеснение (Compute Preemption) является другой важной аппаратной и программной функциональностью добавленной в GP100, которая позволяет вычислительным задачам быть вытесняемыми на степени разбиения уровня инструкций вместо степени разбиения блоков потоков в предыдущих архитектурах GPU Maxwell и Kepler. Вычисляемое вытеснение предотвращает для длительно выполняющихся приложений либо монополизацию всей системы (не позволяющим выполнение остальных приложений), либо тайм- ауты. Программистам больше не требуется изменять их длительно выполняющиеся приложения для хорошего взаимодействия с остальными приложениями GPU. Обладая вычисляемым вытеснением GP100, приложения могут работать так долго, как это требуется для обработки больших наборов данных, или ожидать возникновения различных условий при планировании находящихся поблизости других задач. Например, и задачи интерактивной графики, и интерактивные отладчики могут выполняться одновременно с длительно исполняемыми вычислительными задачами.