Глава 3. Параллельные и распределённые системы хранения
Содержание
В этой главе представлен обзор программного обеспечения (ПО) промежуточного уровня хранения данных, применяемого для ускорения рабочих нагрузок с интенсивным использованием данных в средах высокопроизводительных вычислений и центров обработки данных (ЦОД). В ней перечислены и обсуждаются примеры различных типов ПО промежуточного слоя хранения данных, предназначенных для различных рабочих нагрузок, связанных с Большими данными. В данной главе также представлен обзор различных интерфейсов приложений, которые применяются для хранения массивных объёмов данных аналитики Больших данных и управления ими.
Гигантский рост данных в современном мире потребовал разработки программного обеспечения (ПО) промежуточного уровня Больших данных (таких как Hadoop MapReduce и Apache Spark), способного предоставлять высокую производительность. С архитектурной точки зрения хранение и управление массивными объёмами данных это серьёзный вызов. Поскольку Большие данные требуют хранения гигантских количеств данных с размерами порядка Эксабайт или Петабайт, был разработан ряд решений промежуточного ПО, позволяющих масштабировать инфраструктуру хранения на множестве серверов. Дополнительно к размещению массивных объёмов данных, существует и потребность в промежуточном ПО хранения, которое способно удовлетворять соответствующие требования приложений в достоверности и разнообразии (veracity and variety) данных. Развитие ПО промежуточного уровня хранения данных была обусловлена не только меняющимися потребностями приложений, но и появлением новых аппаратных средств хранения данных. Например, переход на твердотельные накопители (SSD) NVMe and Peripheral Component Interconnect Express (PCIe) способствовал улучшению производительности для случайных и последовательных операций по сравнению с традиционными жёсткими дисками (HDD, hard disk drives).
Мы классифицируем различное ПО промежуточного уровня для хранения применяемого в облачных решениях и кластерных средах Больших данных по четырём основным категориям: файловой хранилище, блочное хранилище, объектное хранилище и ориентированное на оперативную память хранилище (Рисунок 3.1). Файл и блок - это методы доступа к хранилищу на основе файловой системы. Оба эти метода традиционно применялись для для предоставления приложениям доступа к данным на блочных устройствах хранения, таких как твердотельные накопители и жёсткие диски. Основное различие между ними состоит в том как само приложение способно взаимодействовать с блоками данных на своём устройстве хранения; файловая система обеспечивает доступ через API интерфейсы на основе файлов, таких как POSIX, то есть Portable Operating System Interface - интерфейс переносимой операционной системы (The Open Group, 2011), а блочное хранилище предоставляет прямой доступ к блокам необработанных (сырых, raw) данных. С наступлением бума Больших данных было сделано наблюдение, что бо́льшая часть производимых данных является "неструктурированной", неизменной и масштабируется на многие Петабайты в географически распределённых кластерах. Это потребовало разработки новых подходов, которые лучше бы подходили к работе с хранилищем как с обособленными элементами, а также с настраиваемыми метаданными для каждого из таких обособленных элементов вместо файлов или блоков. С другой стороны, по причине снижения с каждым годом стоимости микросхем оперативной памяти большое внимание уделяется "обработке в оперативной памяти" (in-memory), которая сосредотачивается на максимально возможном применении "активной памяти". Для дополнения этим, как научные исследования, так и аналитика центров обработки данных (ЦОД) обратились к сосредоточенным на оперативной памяти системам хранения, включая хранилищ ключ- значение в оперативной памяти (KV, key- value), а также базы данных и файловые системы в оперативной памяти. На Рисунке 3.1 также продемонстрированы различные интерфейсы приложений (такие как файловый, блочный, службы REST/ RESTfull (Fielding, 2000), KV, SQL (ISO/IEC, 2016), NoSQL (NoSQL Database.org, 2021)), которые обрабатывают рабочие нагрузки Больших данных для доступа к таким различным решениям хранения.
Рисунок 3.1
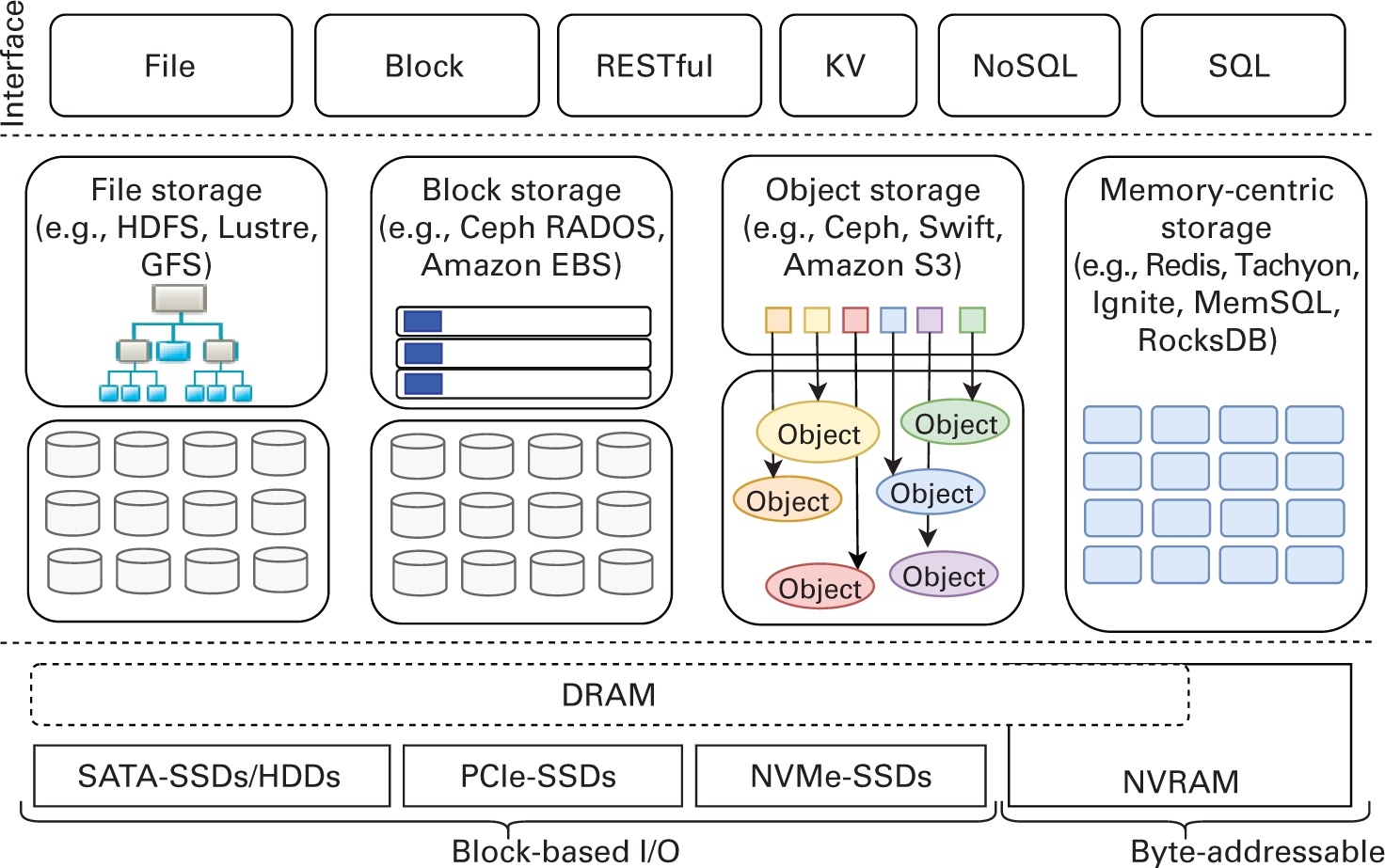
Различные типы параллельных и распределённых систем хранения. PCIe, Peripheral Component Interconnect Express; RADOS, Reliable, Autonomic Distributed Object Store; SATA, Serial AT Attachment.
В данной главе мы изучим необходимые основы для этих четырёх систем хранения промежуточного уровня и обсудим образцы из реального мира с соответствующими интерфейсами, применяемыми для разработки приложений Больших данных крупного масштаба.
Большие данные предъявляют требования хранения огромного количества данных. Это делает необходимым иметь передовую инфраструктуру хранения: высокопроизводительную файловую систему, которая способна обрабатывать результаты такого роста Больших данных за счёт масштабирования по большому числу серверов.
Параллельные файловые системы это категория файловых систем, в которых блоки данных параллельно чередуются по множеству устройств хранения в обособленном кластере узлов хранения. Это первейший уровень хранения данных в кластерах HPC. Параллельная файловая система позволяет каждому исполняемому приложению получать доступ к данным и из него через обычное сетевое подключение. Имеющийся подход к проектированию позволяет всем узлам одновременно обращаться к одному и тому же файлу, тем самым, предоставляя одновременные возможности считывания и записи.
В последнее время был предложен ряд файловых систем, которые применяются и в наши дни. Большинство из них составляются из двух специализированных серверов: серверов собственно данных и серверов их метаданных. Сервер данных состоит из кластера устройств хранения, например, устройств хранения объектов или подключаемых через сетевую среду дисков. Сервер метаданных отвечает за метаданные, которые составляют такие сведения, как размеры данных, права доступа, а также расположение среди множества серверов данных.
Рисунок 3.2a представляет показательную архитектуру параллельных файловых систем. Ключевым понятием проектирования такой
архитектуры выступает разделение путей метаданных и данных. Для всех операций с пространствами имён клиенты взаимодействуют
с сервером метаданных, таких как open(), а с сервером данных общаются на предмет всех
операций файлового ввода/ вывода, таких как read() и write().
По причине изолированности уровня данных, когда речь заходит об уровне доступа к хранилищу, не существует никакой
"локальности". В данном контексте мы опишем две основные архитектуры параллельных файловых систем.
Рисунок 3.2
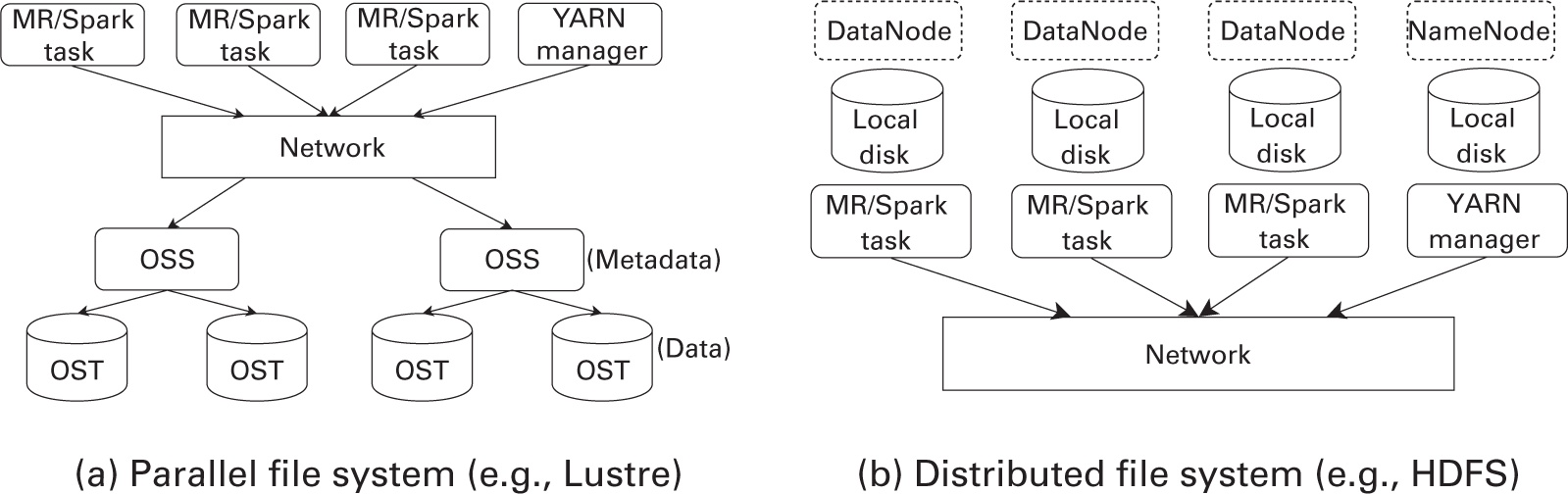
Архитектура файловой системы. MR, MapReduce; OSS, Object Storage Server; OST, Object Storage Target.
Lustre
Предложенная (Braam and Zahir, 2002), Lustre (OpenSFS and EOFS, 2021) это высокопроизводительная параллельная файловая система, которая предоставляет согласованное, совместимое с POSIX глобальное пространство имён для платформ HPC очень крупного масштаба. Она способна поддерживать сотни Петабайт хранимых данных и сотни гигабайт в секунду при одновременной, агрегированной пропускной способности. Для того чтобы сохранять правление собой простым, она не распределяет метаданные. Именуемая расщеплением данных технология делит каждый файл на порции фиксированного размера, которые носят название полос(stripes). Такие полосы сохраняются по большому числу серверов данных карусельным образом. Данный выбор архитектуры позволяет параллельным файловым системам доставлять оптимальную пропускную способность приложениям верхнего уровня. Значение размера полосы в различных параллельных файловых системах зависит от целевых приложений системы. К примеру, Lustre обладает размером полосы в диапазоне от 64кБ до 1Мб. Lustre предлагает схему блокирования полосы, которая не позволяет нескольким клиентам одновременно обращаться к одной и той же полосе для обеспечения согласованности данных. Она отслеживает зависимости для каждого объекта и позволяет применять изменения только тогда, когда его предыдущая версия соответствует текущей версии данного объекта. Это делает возможным восстановление Lustre даже когда из строя выходят несколько клиентов одновременно с соответствующим сервером. {Прим. пер.: подробнее в нашем переводе Часть I. Введение в файловую систему Lustre. Глава 1. Понимание архитектуры Lustre Intel, 2014, Введение в файловую систему Lustre Глава 2. Понимание сети Lustre (LNET) Intel, 2014.}
IBM GPFS
Предложенная Schmuck and Haskin (2002), IBM General Parallel File System (GPFS) (IBM, 2021), это кластерная файловая система, которая способна поддерживать одновременный доступ к единственной файловой системе (системе с разделяемым диском) или множеству файловых систем из множества узлов (ничего не разделяющих систем). Аналогично Lustre, это масштабируемое вширь решение предоставляет глобальное пространство имён, совместный файловый доступ по кластерам на основе GPFS, а также одновременный файловый доступ со множества вычислительных узлов. Тем не менее, в отличии от Lustre, она предлагает высокую степень восстановления м доступности данных посредством репликаций. {Прим. пер.: подробнее в нашем переводе GPFS 4.1: Концепции, планирование и руководство по установке IBM, 2014, Часто задаваемые вопросы и ответы по GPFS IBM, 2014, а также Программно определяемые системы хранения для чайников Лоуренс К. Миллер,Скотт Фадден, IBM, 2014.}
API файловой системы POSIX
POSIX (The Open Group, 2011) это определяемое вычислительным сообществом IEEE (Institute of Electrical and Electronics Engineers)
семейство стандартов для обеспечения совместимости между вариантами Linux и прочих операционных систем. Оно определяет свой API,
который делает для нас возможным получать доступ к твердотельным накопителям (SSD), жёстким дискам (HDD) или любым прочим блочным
устройствам хранения. Оно предоставляет богатый набор API стандарта (таких как open(),
read(), write(),
ioctl()) для доступа к файлам через драйвер периферийного устройства хранения. Типичные
файловые системы, такие как IBM GPFS и Lustre употребляют API такой файловой системы для доступа к лежащей в их основе системе
хранения.
В коде Листинга 3.1 представлен образец копирования данных из одного файла в другой при помощи API C POSIX в соответствующей файловой системе. Как видно из данного примера, создаётся некий файловый дескриптор с режимом по выбору, а данные могут считываться или записываться из любой позиции его файла. Такой файловый дескриптор может быть повторно позиционирован по любому смещению внутри своего файла (Linux, 2021b).
Листинг 3.1. Образец API POSIX файловой системы
int copy_file (char* input_file, char* output_file, long copy_offset)
{
/* Create input file descriptor */
input_fd = open (input_file, O_RIDONLY);
if (input_fd == —1) {
perror ("open");
return 2;
}
/* Create output file descriptor */
output_fd = open(output_file, O_WRONLY O_CREAT, 0644);
if (output_fd == —1){
perror ("open");
return 3;
}
/* Re—position within the output file */
file_posn = lseek(output_fd, copy_offset, SEEK CUR);
/* Copy process */
while((ret_in = read (input_fd, &buffer, BUF_SIZE)) > 0){
ret_out = write (output_fd, &buffer, (ssize_t) ret_in );
if (ret_out != ret_in){
/* Write error */
perror("write");
return 4;
}
}
/* Close file descriptors */
close (input_fd);
close (output_fd);
return 0;
}
Распределённая файловая система обычно работает в среде, в которой имеющиеся данные могут быть распределены по множеству узлов в высокопроизводительной сетевой среде. Они были разработаны для обеспечения действенного и надёжного доступа к данным с применением больших кластеров из общедоступных серверов. В наши дни они играют жизненно важную роль в обеспечении бесперебойной работы интенсивно использующих данных приложений для анализа данных в автономном режиме. В дополнение к задачам автономной обработки, эти распределённые системы хранения облегчают складирование данных промежуточного уровня, такое как Apache Hive (Apache Software Foundation, 2021h) для управления и обработки больших наборов данных с применением SQL. Мы обсудим два видных примера применяемых в настоящее время распределённых файловых систем.
Распределённая файловая система Hadoop
HDFS (Shvachko et al., 2010) это распределённая файловая система, которая работает в качестве первичного хранилища для большинства сред обработки Больших данных. Рисунок 3.2b иллюстрирует основу архитектуры HDFS.
Архитектура: Кластер HDFS составляется из двух типов узлов: NameNode и DataNode. NameNode это диспетчер имеющихся метаданных для соответствующих кластеров распределённого хранения, который отвечает за поддержание пространства имён своей файловой системы и структур дерева каталога и опирается на вторичный NameNode. Файлы делятся на блоки размеров в 64МБ (настраиваемый параметр) и хранятся или предоставляют доступ напрямую с DataNode. Для включения отказоустойчивости HDFS обычно реплицирует каждый блок в три или более DataNode. Дополнительно к этому последние выпуски Hadoop (начиная с 3.x) реализована отказоустойчивость с действенным хранением за счёт распределённой отказоустойчивости через кодирование удаления (Apache Software Foundation, 2020a).
При осуществлении любых операций файловой системы клиент устанавливает контакты с NameNode. Для записи клиент получает идентификаторы блоков и перечень соответствующих адресов DataNode из NameNode. Каждый блок разбивается на более мелкие пакеты и отправляется своему первому DataNode в имеющемся конвейере, а этот первый DataNode реплицирует каждый пакет в последующие DataNode. Тем не менее, HDFS допускает только операции записи добавлением в конец, иными словами, имеющиеся файлы неизменны. Любые обновления требуют записи новых файлов вместо имеющихся. Точно так же соответствующий клиент считывает данные из ближайшего DataNode. HDFS делает возможным для таких сред обработки как Hadoop MapReduce и Spark применять "локальность данных", упрощая перемещение вычислений поблизости от необходимых данных вместо перемещения массивных данных для вычислений над ними. Например, типичный кластер Hadoop развёртывается таким образом, чтобы диспетчеры задач (например, YARN), планирующие вычисления для своих вычислительных ядер, выполняются локально в DataNode. Тем самым, задачи "map" (сопоставления) можно планировать так, чтобы выделенные блоки данных располагались в DataNode, запущенном на соответствующем узле кластера Hadoop.
API HDFS: API HDFS в настоящее время не совместим с POSIX, поскольку API предлагает некое подмножество общего поведения файловой подсистемы POSIX. Тем не менее, интерфейс LocalFileSystem в Hadoop предоставляет доступ к лежащей в основе файловой системе своей платформы с которой она работает и способна применять для исполнения поверх совместимых с POSIX файловых систем, таких как Lustre (что подробнее описывается в Главах 7 и 9) что способно давать чрезвычайные преимущества в частных кластерах. В Листинге 3.2 иллюстрируется простой образец, который копирует файл из своей локальной файловой системы в кластер HDFS. Как показано в данном примере, для считывания такого файла из своей локальной файловой системы создаётся некий входной поток с применением BufferedInputStream, в то время как поток вывода создаётся для местоположения файла в HDFS.
Листинг 3.2. Образец применения API HDFS
public void addFile (String source, String dest, Configuration conf)
throws IOException
{
FileSystem fileSystem = FileSystem.get (conf);
/* Check if the file already exists */
Path path = new Path(dest);
if (fileSystem.exists (path)) {
System.out.println("File" + dest + "already exists");
return;
}
/* Create a new file and write data to it */
FSDataOutputStream out = fileSystem.create(path);
InputStream in = new BufferedlnputStream (
new FileInputStream(new File(source)));
byte[] b = new byte[1024];
int numBytes = 0;
while ((numBytes = in.read(b)) > 0) {
out.write (b, 0, numBytes);
}
/* Close all the file descriptors */
in.close();
out.close();
fileSystem.close();
}
Файловая система Google и Colossus
Предложенная Ghemawat et al. (2003) Google File System (GFS) является предшественницей HDFS, основанной на архитектуре, аналогичной Рисунку 3.2b. Она реализована для быстро растущих потребностей Google в обработке данных. Она опирается на большое число общедоступных серверов для определения распределённого кластера, который способен охватывать вплоть до тысяч машин. Кластер GFS состоит из единственного сервера хозяина (master) и множества серверов фрагментов (chunk). Аналогично NameNode HDFS, сервер Master управляет имеющимся пространством имён, соответствием файлов - блокам и значением текущего местоположения их блоков. Они поддерживаются узлами Shadow Master.
В отличие от HDFS GFS обладает возможностью по конкретному смещению в имеющийся файл дополнительно к атомарным операциям добавления в конец. Однако одновременная запись в одну и ту же область не подвержена сериализации {Прим. пер.: подробнее в нашем переводе Внутреннее устройство баз данных Алекса Петрова (с), 2019, O’Reilly.}. Такие записи могут содержать фрагменты данных от большого числа клиентов, а следовательно, получаемое состояние файла в GFS при непротиворечивости может оказываться недетерминированным. Кроме того, во время операций записи, клиент GFS одновременно отправляет данные в все свои реплики в нескольких серверах фрагментов для обеспечения действенного применения пропускной способности сетевой среды. Это контрастирует с механизмом отказоустойчивости HDFS, который делегирует репликацию первичному серверу (или DataNode).
В 2010 году Google представила следующее поколение GFS с названием Google Colossus (Fikes, 2010). В отличие от GFS,которая намеренно разрабатывалась для пакетной обработки, Colossus создан для обработки данных в реальном масштабе времени. Наряду с новой системой веб индексирования, Caffeine (Google, 2010), которая заменяет MapReduce для создания обновляемых индексов поиска в реальном масштабе времени, Google применяет эту новую инфраструктуру для поддержки своих веб- служб и облачного хранилища.
Системы хранения объектов представляют собой архитектуру хранения данных, которая запоминает данные и управляет ими в виде объектов. В отличие от файловых и блочных систем хранения, хранилища объектов заключают данные, метаданные и глобально уникальный идентификатор внутри своего объекта. Они интенсивно применяются такими поставщиками служб больших облачных решений, как Amazon, Google и Microsoft для хранения гигантских объёмов неструктурированных данных. Растущая популярность простых облачных служб непреднамеренно повысила важность систем хранения объектов в наши дни.
Основная цель таких систем - предоставление простых интерфейсов приложений, разделение аппаратного и программного обеспечения, а также возможности управления данными, такими как репликация и удаляющее кодирование (erasure coding). Имеющаяся семантика объектов широко варьируется в зависимости от реализации. Однако большинство реализаций предоставляют доступ к объектам при помощи передачи состояния представления. Это делает возможным получение доступа к объектам поверх соединений HTTP/ HTTPS (hypertext transfer protocol/hypertext transfer protocol secure)с применением простых методов GET/PUT. Хранилища объектов отлично подходят для абстрагирования от нижних уровней хранения, причём включая аппаратные средства. Имеется возможность применения большого числа дисков по множеству серверов (возможно, распределённых географически). С точки зрения приложения физическое расположение данных не имеет значения. Наконец, хранилища объектов также обеспечивают отказоустойчивость в виде репликации и удаляющего кодирования (erasure coding) на уровне детализации объекта. Такие функции превращают хранилища объектов в отличную основу для создания современных приложений центров обработки данных (ЦОД), требующих высоких степеней масштабируемости и доступности.
Благодаря своей неограниченной структуре плоской масштабируемости, хранилища объектов всё чаще применяются для задач, которые традиционно требуют систем файлов таких, как аналитика данных, потоковая передача мультимедиа, архивирование, веб- сервер и так далее. Такм образом, они превратились в недорогую альтернативу распределённым файловым системам, в особенности когда задания анализа Больших данных были перенесены в облачное решение.
В последующих разделах описываются некоторые популярные хранилища объектов.
Amazon S3 (Amazon-Web-Services, 2019) это разработанное Amazon промышленное хранилище объектов. Основными преимуществами S3 выступают надёжность и доступность, при этом Amazon заявляет, что надёжность данных составляет 99.999999999%. Данные хранятся в виде объектов внутри сегментов, которые служат эквивалентом каталогов в хранилище объектов. Архитектура S3 не публиковалась, но считается, что она похожа на DynamoDB от Amazon.
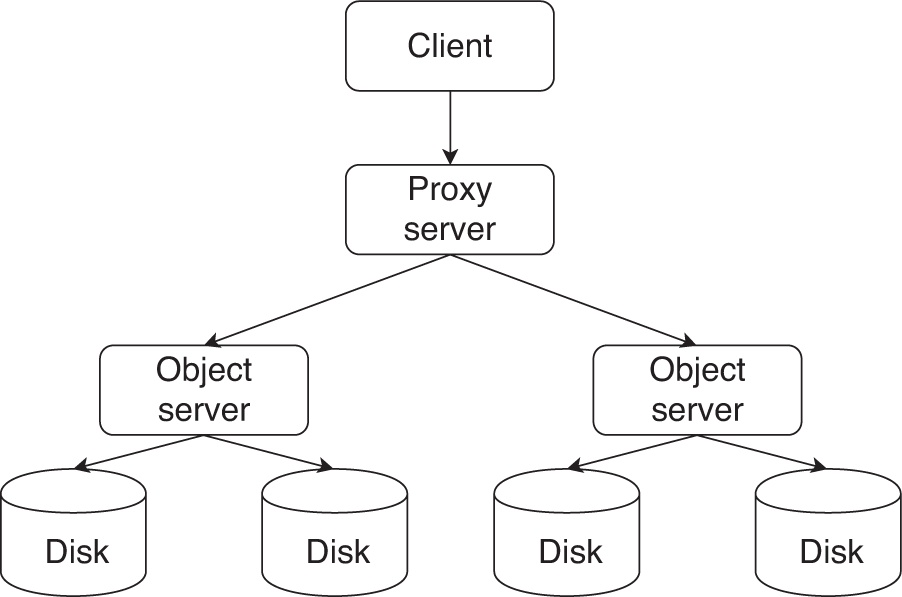
OpenStack Swift (OpenStack, 2021b) это хранилище объектов с открытым исходным кодом, разработанное как часть программного комплекта OpenStack. Swift предоставляет те же API и семантику, что и S3. Однако, скорее всего, внутренняя архитектура отличается. Swift хранит все данные в серверах объектов, применяя в качестве шлюза для всех запросов серверы посредников (прокси). Данные распределяются между серверами объектов при помощи механизма согласованного кэширования. Swift обеспечивает согласованность в конечном счёте {Прим. пер.: подробнее в нашем переводе Внутреннее устройство баз данных Алекса Петрова (с), 2019, O’Reilly} терминальным приложениям в качестве способа поддержки высокой доступности не взирая на высокую частоту сбоев в облачных средах. На рисунке 3.3 показана общая архитектура Swift. {Прим. пер.: подробнее в нашем переводе Реализация облачного хранилища с OpenStack Swift Кападиа Амара, Вармы Средхара, Раджана Криса, (с) Packt Publishing, 2014, Руководство по эксплуатации OpenStack Фонд OpenStack, 2014, а также Справочник рецептов по облакам OpenStack, 2е изд. Кевин Джексон и Коди Банч, Packt Publishing, 2013.}
Ceph (Ceph, 2021) это ещё одно популярное хранилище объектов, которое также выступает составной частью программного комплекта OpenStack. Ceph архитектурно схож как с S3, так и со Swift. Основное отличие Ceph от прочих хранилищ состоит в его модели согласованности данных и API. Ceph предоставляет строгую согласованность {Прим. пер.: подробнее в нашем переводе Внутреннее устройство баз данных Алекса Петрова (с), 2019, O’Reilly}, в отличие от согласованности в конечном счёте {Прим. пер.: подробнее в нашем переводе Внутреннее устройство баз данных Алекса Петрова (с), 2019, O’Reilly}, предоставляемой прочими решениями. Более того, Ceph предоставляет некоторое число удобных интерфейсов для доступа к данным, включая файловую систему POSIX, блочные устройства и iSCSI (Internet Small Computer Systems Interface). {Прим. пер.: подробнее в нашем переводе Полное руководство Ceph, 2е изд Ника Фиска, (с) Packt Publishing, 2019, Изучаем Ceph, 2е изд, Энтони Д'Атри, Вайбхав Бхембре, Каран Сингх, (с) Packt Publishing 2019, а также Книга рецептов Ceph, Каран Сингха, Packt Publishing, 2016.}
Клиент обладает возможностью создавать, изменять и получать объекты и метаданные при помощи API хранилища объектов, запуска
индивидуальных команд в специфичных для хранилища интерфейсах командной строки (например, AWS CLI for S3 (Amazon, 2021e)), и
собственном REST API (Fielding, 2000). Для иллюстрации управления объектами и доступа к ним в хранилище объектов мы воспользуемся
в качестве образца Amazon S3. В Листинге 3.3 представлен пример приложения, применяющего API Python boto3 (Amazon, 2021c) для
сохранения (put_object()) и извлечения (get_object())
объекта из Amazon S3.
Листинг 3.3. Образец API Python Amazon S3
import boto3
from botocore.exceptions import ClientError
KEY = os.urandom(32)
BUCKET = 'your—bucket—name'
s3_client = boto3.client ('s3')
s3_client.create_bucket(Bucket=BUCKET)
# Put object into object store
s3.put_object(Body='HappyFace.jpg',
Bucket =BUCKET,
Key= 'HappyFace.jpg',
ServerSideEncryption='AES256',
StorageClass='STANDARD_IA')
# Getting the object
response = client.get_object(
Bucket=BUCKET,
Key= 'HappyFace.jpg',
)
print (response)
Блочное хранилище это промежуточный уровень программного обеспечения (ПО), обычно применяемого в облачных средах. Файлы разбиваются на блоки данных одинакового размера, причём каждый обладает своим собственным адресом. Оно более абстрактно нежели файловая система хранения, поскольку не предоставляет никаких дополнительных сведений о метаданных для снабжения дополнительным контекстом относительно того как и для чего применяются эти блоки данных. Блочное хранилище применяется для ускорения большого числа корпоративных рабочих нагрузок, в особенности в SAN (storage-area network, сетевых средах хранения данных), которые напрямую обращаются к блокам данных при помощи протокола SCSI. Например, несколько блоков (скажем в системе SAN) создают некий файл. Блок состоит из адреса, а приложение SAN получает такой блок, когда оно отправляет для этого адреса команду SCSI-Request. Приложение этого хранилища принимает решение где внутри его системы хранятся такие блоки данных и как получать к ним доступ. Блоки в SAN не обладают связанных с его системой хранения или приложением метаданных. Иначе говоря, блоки - это сегменты данных без описания, отношения и без владельца его решения хранения. Всё обрабатывается и управляется ПО SAN. В следствие этого, SAN и блочное хранилище зачастую применяются для требовательных к производительности приложений, таких как базы данных или транзакции, поскольку к его данным можно получать доступ, изменять их и сохранять. В наших последующих разделах описаны некоторые популярные хранилища объектов.
Amazon EBS (Elastic Block Store) (Amazon, 2021a) это служба хранения, которая предоставляет постоянные тома хранения для экземпляров Amazon EC2 (Elastic Compute Cloud). EBS прозрачно обрабатывает хранение данных для приложений, создавая иллюзию безграничного хранилища. Обосабливая лежащие в основе носители хранения от своего пользователя, EBS обеспечивает быстрое увеличение или уменьшение масштаба. Общие варианты применения EBS включают механизмы анализа Больших данных, системы баз данных и приложения потоковой обработки.
Cinder
Cinder (OpenStack, 2021a) это служба блочного хранения для OpenStack, которая в основном применяется компонентом nova. Как и EBS, Cinder создаёт виртуальную среду управления блочными устройствами хранения, позволяя пользователям потреблять ресурсы не отдавая себе отчёта где и на каких именно устройствах данных они развёрнуты. Предлагаемые Cinder базовые ресурсы включают Тома (Volumes), Моментальные снимки (Snapshots) и Резервные копии (Backups), которые отвечают различным требованиям пользователей. Главным образом Cinder отличается от EBS с точки зрения совместного применения ресурсов. В отличие от EBS за раз блочное устройство Cinder может быть подключено только к одному экземпляру.
Blizzard
Blizzard (Mickens et al., 2014) это новое облачное блочное хранилище, предлагаемое Microsoft Research. Blizzard совместимо с POSIX, а это означает, что такое выставленное блочное хранилище может применяться приложениями, не обращающими внимание на облачное решение. Blizzard применяет новую схему чередования для реализации одновременного доступа к дискам и допускает неупорядоченную фиксацию записи для обеспечения низкой задержки и гарантии согласованности при сбоях. Получаемая в результате служба хранения демонстрирует значительное улучшение по отношению к EBS для различных рабочих нагрузок SQL.
В блочном хранилище каждый том хранения действует как некий отдельный жёсткий диск, а данные сохраняются в виде фрагментов фиксированного размера, носящих название блоков. Копии тома на заданный момент времени носят название "моментальных снимков" (snapshot) и могут применяться для хранения и извлечения данных из своего блочного хранилища. Как правило, для управления блочным хранилищем применяется REST API. Для сохранения блока применяется метод HTTPS POST, а для выборки блока моментального снимка используется метод GET. Кроме того, для различных систем блочных хранилищ также предоставляются и непосредственные API.
Подобно хранилищам объектов, мы иллюстрируем доступ к данным в блочном хранилище на образце Amazon EBS. Листинг 3.4
представляет пример приложения, использующего API Python boto3 (Amazon, 2021c) для
сохранения (put) и выборки (get) блока
моментального снимка из Amazon EBS.
Листинг 3.4. Образец API Python Amazon EBS
import boto3
from botocore.exceptions import ClientError
client = boto3.client('ebs')
response = client.put_snapshot_block (
Snapshotld='string',
BlockIndex=123,
BlockData=b 'bytes'|file ,
DataLength=123,
Progress=123,
Checksum='string',
ChecksumAlgorithm= 'SHA256'
)
response = client.get_snapshot_block (
Snapshotld='string',
Blocklndex=123,
BlockToken='string'
)
Вдохновляемые предлагаемыми вычислениями в оперативной памяти производительностью и масштабируемостью, ориентированные на оперативную память хранилища, или хранилища в памяти (in-memory) стали важным шагом на пути к альтернативы узким местам дискового вода/ вывода. Ранние ориентированные на память решения предлагали сочетание мощности распределённого хранилища в памяти с надёжностью традиционных баз данных и файловых систем без необходимости переделывать имеющиеся решения для хранения. Ярким примером этого выступает такое решение распределённого хранения в памяти как Memcached (Dormando, 2021). На протяжении многих лет ориентированные на память системы хранения разрабатывались с нуля чтобы наилучшим образом применять доступную оперативную память (DRAM) совместно с долговременным хранением на диске в единой системе, удовлетворяя при этом потребности в согласованности различных приложений (например, Redis (Redis Labs, 2021d), SingleStore [formerly MemSQL (SingleStore Inc., 2021)] и Apache Cassandra (Apache Software Foundation, 2021c)).
Традиционные базы данных SQL, которые представляют собой базы данных на основе таблиц отношений по управлению наборами данных с базированием на предопределённой структуре или схеме, уже давно применяются для предоставления служб данных для обработки транзакций в реальном времени (OLTP, online transactional processing), а также рабочих нагрузок аналитической обработки в реальном времени (например, MySQL, PostgreSQL). Подобные надёжные и реляционные базы данных развивались и создали поколение систем, носящих название баз данных NoSQL, которые способны обрабатывать массивные объёмы неструктурированных данных, имеющих требования масштабируемости, надёжности и доступности, которые предъявляют современные приложения для работы с Большими данными. С другой стороны, с ростом объёма обработки данных в оперативной памяти, сосредоточенные на оперативной памяти базы данных не превращаются в узкие места по причине блочной системы и структуры страниц памяти и управления буферизацией, а ориентированные на оперативную память базы данных развились в прямой доступ и управление данными с байтовой адресацией в памяти. Такие высокопроизводительные системы управления базами данных, как HyPer (Kemper, 2021) и MemSQL (SingleStore Inc., 2021) демонстрируют производительность на уровне систем NoSQL, отвечая требованиям атомарности, согласованности, изоляции и надёжности систем управления реляционными базами данных. {Прим. пер.: подробнее в нашем переводе Внутреннее устройство баз данных Алекса Петрова (с), 2019, O’Reilly}.
Такие базы данных SQL и NoSQL строятся на сложных системах обработки транзакций и аналитики с применением лежащих в основе устройствах ранения и их обсуждению посвящено большое число книг. Здесь мы обсудим два рельефных примера ориентированной на оперативную память архитектур.
Cassandra
По существу, Cassandra (Apache Software Foundation, 2021c) применяет гибридную модель хранилища ключ- значение для определения представляемого столбцами (то есть табличного) хранилища данных NoSQL. Данные делятся на строки с регулируемой согласованностью и такие строки организованы в таблицы. Механизм хранения Cassandra позволяет определять семейства столбцов с составными первичными ключами. Первый столбец в составном ключе применяется для идентификации необходимого раздела таблицы (то есть служит в качестве ключа раздела). Все совместно использующие этот ключ строки сортируются по оставшимся компонентам своего первичного ключа для облегчения автоматической кластеризации внутри раздела. Cassandra дополнительно к своей системе без схемы применяет механизм разрежённых столбцов. Поскольку пространство используется только присутствующими в некой строке столбцами, определение таблицы с тысячами столбцов не приводит к не оптимальному хранению, которое в противном случае характерно для разрежённых данных.
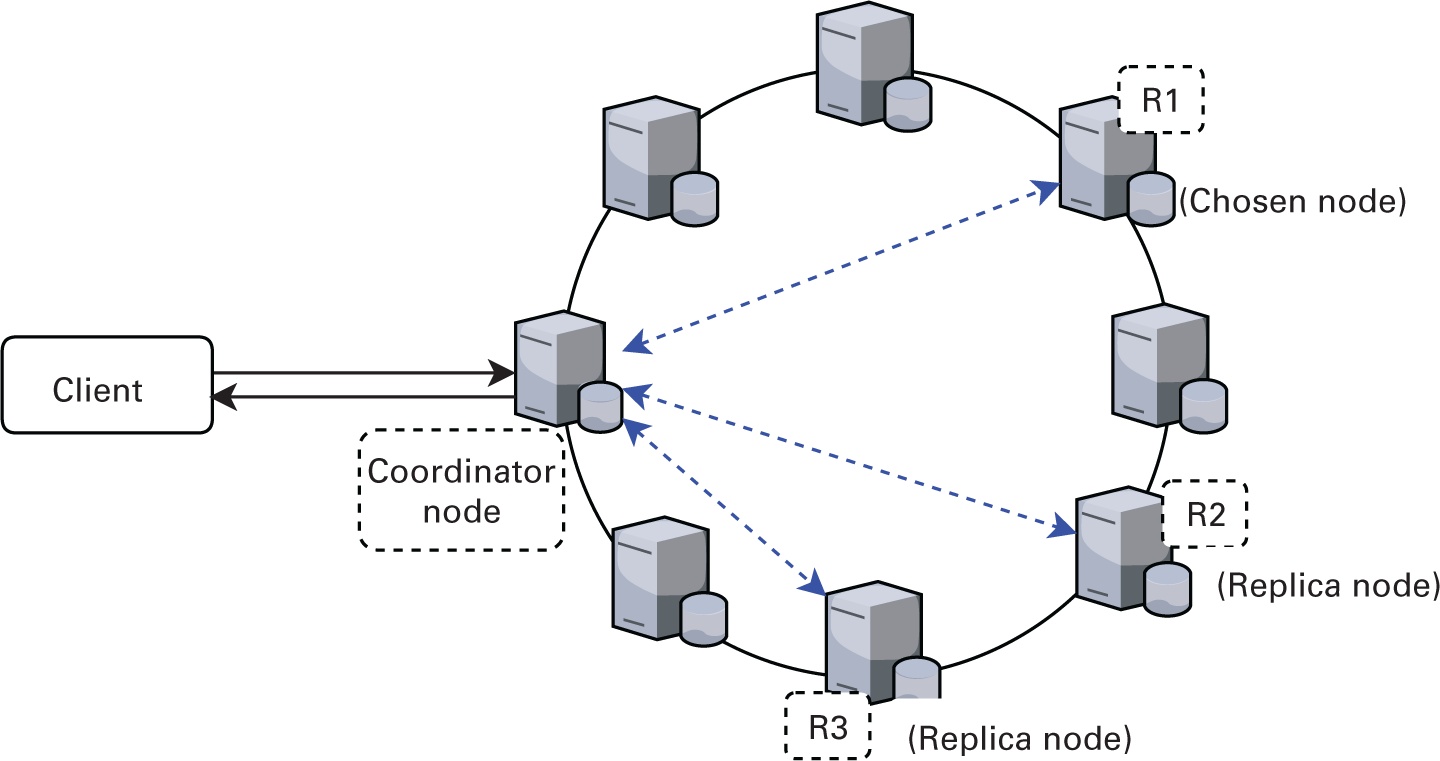
Cassandra применяет распределённую базу данных без общего доступа, которая работает в однородном кластере, как это показано на Рисунке 3.4. Она разработана с нуля для обработки больших объёмов данных и обеспечения высокой пропускной способности при записи и считывании. Кластер Cassandra со своей архитектурой без общего доступа не обладает хозяевами, подчинёнными или избираемыми лидерами. {Прим. пер.: подробнее в нашем переводе Внутреннее устройство баз данных Алекса Петрова (с), 2019, O’Reilly}. Такой одноранговый дизайн без централизации управления данными обеспечивает высокую доступность, исключая при этом возможность единственной точки отказа.
В Листинге 3.5 показан образец клиентского приложения Cassandra, которое считывает и записывает данные из кластера
Cassandra. Первоначально устанавливается соединение с одним (или несколькими) узлами серверов Cassandra, выступающими в
роли драйвера. Этот драйвер автоматически обнаруживает прочие узлы в своём кластере. После подключения по мере необходимости
создаётся "пространство ключей" или можно пользоваться уже имеющимся. Пространства ключей служат самым внешним
объектом, определяющим как на узлы реплицируются данные и состоят из семейства столбцов (то есть из таблицы), индексов и
тому подобного. Таблицу можно создать в указанном Пространстве ключей, а данные вставлять при помощи подобной SQL команды
INSERT. Аналогично, считывать из этого кластера Cassandra данные можно применяя
запросами типа SQL SELECT.
Листинг 3.5. Образец API клиента Java Cassandra
import corn.datastax.driver.core.Cluster;
import corn.datastax.driver.core.ResultSet;
import corn.datastax.driver.core.Session;
public class Create_Table {
public static void main( String args[]){
/* create Cluster and Session objects */
Cluster cluster = Cluster.builder().addContactPoint ("serverl").build ();
Session session = cluster.connect();
/* create keyspace with replication factor 1*/
String ks_query = "CREATE KEYSPACE my_keyspace WITH replication
" + "= {'class':'SimpleStrategy', 'replication_factor':1}; "
session. execute (ks_query);
/* create table in `my_keyspace */
session.execute ("USE my_keyspace");
String create_table_query = "CREATE TABLE my_table (id int
PRIMARY KEY, " + "my_data text );";
session.execute (create_table_query);
/* insert data */
String insert_query = "INSERT INTO id (my_data)" + " VALUES(1, 'some_data_here'); ";
session.execute( insert_query );
/* read data from table */
String select_query = "SELECT * from my_table" ;
ResultSet result = session.execute(query);
System.out.println (result.all());
}
}
Apache Ignite
Apache Ignite (Apache Software Foundation, 2021p) это ориентированная на оперативную память система хранения, которая содержит сетку данных в памяти, возможности базы данных в оперативной памяти и поддержку потоковой аналитики, обработку в реальном масштабе времени и развивающихся рабочих нагрузок Машинного обучения. Хотя её можно интегрировать с уже имеющимися базами данных, такими как Cassandra, она также обеспечивает надёжную архитектуру памяти. Ткой настраиваемый компонент долговечной памяти рассматривает оперативную память не только как уровень кэширования, но и как всеобъемлющий и функциональный уровень хранения. Когда не установлена долговечность, то она способна работать в качестве распределённой базы данных в оперативной памяти или как сетка данных в оперативной памяти в зависимости от того какой именно интерфейс необходим: API SQL или NoSQL. Когда применяется долговременная память, тогда она способна функционировать как распределённая, горизонтально масштабируемая база данных, которая гарантирует полную согласованность данных {Прим. пер.: подробнее в нашем переводе Внутреннее устройство баз данных Алекса Петрова (с), 2019, O’Reilly} и устойчива к любым сбоям кластера. Подобные ориентированные на оперативную память конструкции позволяют применять единое промежуточное ПО хранилища для обслуживания различных приложений транзакций в реальном времени и автономных аналитических приложений для работы с Большими данными.
Для моделирования данных и доступа к ним Ignite поддерживает как кэширование ключ- значение, так и SQL. Пример клиента
Ignite на основе Java, который сохраняет и извлекает данные из кэша ключ- значение в Ignite показан в Листинге 3.6. Этот
клиент при инициализации подключается к своему кластеру серверов Ignite через setAddresses().
Указатель на его удалённый кэш может создаваться назначением имени посредством getOrCreateCache.
Кэш Ignite можно разделять на разделы, реплицировать или локализовать, а сопоставление ключа значению определяется при помощи
функции родства (affinity) (Apache Software Foundation, 2021a). Применяемая по умолчанию схема представляет собой хеширование
рандеву (Thaler and Ravishankar, 1996). Дополнительные сведения о модели SQL в Ignite можно найти в Apache Software Foundation
(2021u).
Листинг 3.6. Образец API клиента Java Ignite
import org.apache.ignite.client.ClientException;
import org.apache.ignite.client.IgniteClient;
import org.apache.ignite.IgniteCache;
import org.apache.ignite.IgniteException;
import org.apache.ignite.configuration.ClientConfiguration;
public class IgniteExample {
public static void main(String[] args) {
try (IgniteClient client = Ignition.startClient (new
ClientConfiguration().setAddresses ("serverl:1234"))
{
final String CACHE NAME = "put—get —example";
IgniteCache <String, String> cache = client.getOrCreateCache (
CACHE NAME)
cache.put("key" ,"value");
cachedVal = cache.get(key);
assertEquals(cachedVal, "value ");
System.out.format ("Loaded [%s] from the cache.\n", cachedVal);
}
catch (ClientException e) {
System.err.println (e.getMessage());
}
catch (IgniteException e) {
System.err.println (e.getMessage());
}
catch (Exception e) {
System.err.format ("Unexpected failure : %s\n", e);
}
}
} Хранилище ключ- значение это парадигма хранения, предназначенная для управления данными как набором пар ключ- значение (key- value), в которой ключ применяется как уникальный идентификатор для хранения или извлечения объекта данных, называемого значением. И ключи, и значения являются абстрактными объектами данных, иначе говоря, они могут состоять из чего угодно от простых строк до сложных структур данных. Типичное развёртывание хранилища ключ- значение позволяет объединять память с малой задержкой (например, DRAM - оперативную память) и быстрое постоянное хранилище (скажем, SSD) во множестве распределённых узлов. В эпоху Больших данных хранилище ключей и значений составляет основу для множества интенсивно применяющих данные приложений крупного масштаба.
Типичное развёртывание хранилища ключ- значение делает возможной агрегацию памяти с малой задержкой (например, DRAM -
оперативной памяти) с быстрым постоянным хранилищем (например, SSD) по большому числу распределённых узлов. Обычно хранилище
ключ- значение поддерживает API для хранения и извлечения данных из распределённого кластеров ключ- значение следующим образом:
(1) Put(K, V): операция Put (также именуемая как Set) вставляет и обновляет ключ- значение
пары (K,V) и (2) Get(K): операция Get извлекает соответствующие ключу K данные значения V.
Также доступны API для разрешения множественной пакетной вставки (Multi-Put) и пакетного извлечения (Multi-Get).
Хранилища ключ-значение применяются для ускорения работы приложений с интенсивным использованием данных, охватывающих различные области приложений, включая обработку данных в реальном времени, автономную аналитику, работу на графах и рабочие нагрузки Машинного обучения. Для представления некой перспективы мы обсудим ситуации из реального мира, в которых применяются хранилища ключ- значение и рассмотрим три ярких представителя хранилищ ключ- значение.
Memcached
Memcached (Dormando, 2021) это универсальная система кэширования с распределённой памятью. Она часто применяется для ускорения управляемых базами данных динамических веб- сайтов через кэширование данных и объектов в оперативной памяти, собранной в распределённых узлах для снижения нагрузки на серверную базу данных. Memcached реализует распределённую хэш- таблицу, в которой применяется согласованный механизм хэширования для поиска назначенного сервера всякой пары ключ- значение.
На Рисунке 3.5 представлен обзор архитектуры Memcached. Как видно из этого рисунка, Memcached повышает производительность имеющихся систем и сложных систем баз данных, выступая в качестве внешнего высокопроизводительного уровня. Такой уровень кэширования обычно поддерживается серверами приложений, что делает возможной работу наследуемыми серверами баз данных обеспечивая при этом более высокую производительность.
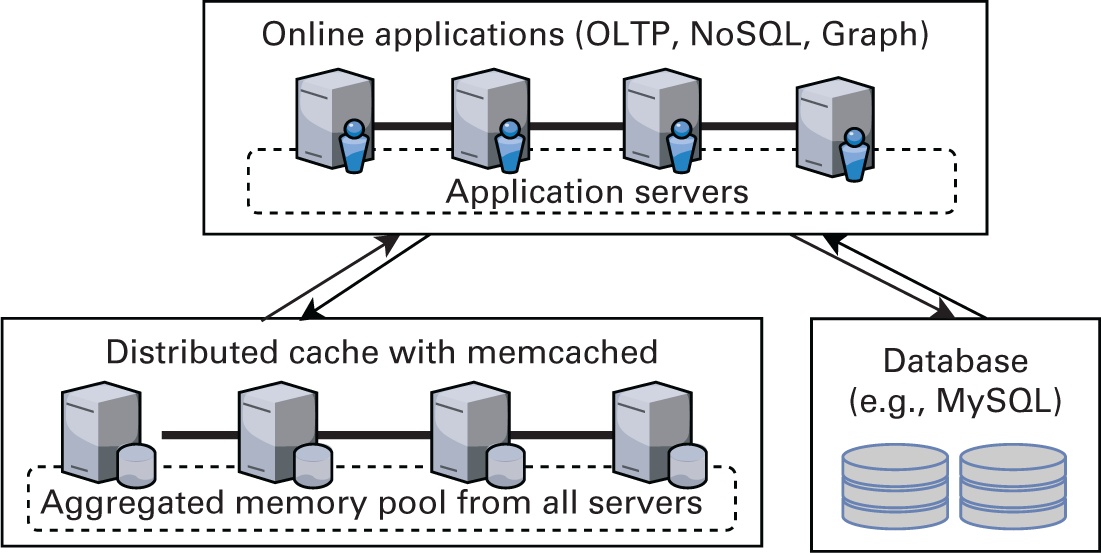
В Листинге 3.7 приводится образец клиента с библиотекой C++ Libmemcached (Aker, 2011), который сохраняет и извлекает пару
ключ- значение из кластера Memcached. Клиент подключается к имеющемуся кластеру Memcached, указав список серверов при создании
объекта memcached_st или через такой API как memcached_server_add.
После подключения в распределённом кластере могут сохраняться пары ключ- значение при помощи
memcached_set(), а извлекаться посредством memcached_get().
Более подробные сведения о таких API и их вариациях можно почерпнуть в Aker (2011).
Листинг 3.7. Образец API клиента Libmemcached
int main(int argc , char **argv)
{
const char *config_string =
"—SERVER=hostl0.example.com -SERVER=host 11.example.com"
memcached_st *memc= memcached(config_string, strlen(
config_string));
if (!memc) {
fprintf (stderr, "Couldn't add server : %s\n", memcached_strerror
(memc, rc));
exit(1);
}
char *key= "foo";
char *value= "value";
memcached_return_t rc = memcached_set ( memc
, key
, strlen(key)
, value
, strlen (value)
, (time_t)0
, (uint32_t)0
);
if (rc != MEMCACHED_SUCCESS) {
fprintf (stderr, "Couldn't store key: %s\n", memcached_strerror(
memc, rc));
}
retrieved_value = memcached_get(memc, key, strlen (key) , &
value_length , &flags , &rc);
if (rc == MEMCACHED_SUCCESS) {
fprintf(stderr, "Key retrieved successfully\n");
printf ("The key '%s' returned value '%s\n", key,
retrieved_value);
free(retrieved_value);
}
else {
fprintf(stderr, "Couldn't retrieve key: %s\n",
memcached_strerror (memc, rc));
}
memcached_free (memc) ;
}
Redis
В то время как подобные Memcached конструкции очень полезны для ускорения значения времени отклика за счёт снижения нагрузки на внутренние серверы, их уровень кэширования не стабилен и обладает ограниченным применением в качестве автономного решения. Тем не менее, архитектура Memcached заложила основу и привела к росту современных хранилищ ключ- значение в памяти, которые способны функционировать в качестве автономных объектов с производительностью оперативной памяти и всеми возможностями надёжных хранилищ данных. Ярким образцом этого выступает Redis (Redis Labs, 2021d), универсальное хранилище структур данных в памяти. Оно обеспечивает ориентированное на оперативную память с поддержкой сохранения и высокой доступности хранилище ключей и значений при более слабой чем базы данных SQL согласованностью данных. В отличие от Memcached Redis для создания отказоустойчивой системы применяет архитектуру хозяин- подчинённый (master- slave). На Рисунке 3.6 представлен обзор архитектуры Redis.
Рисунок 3.6
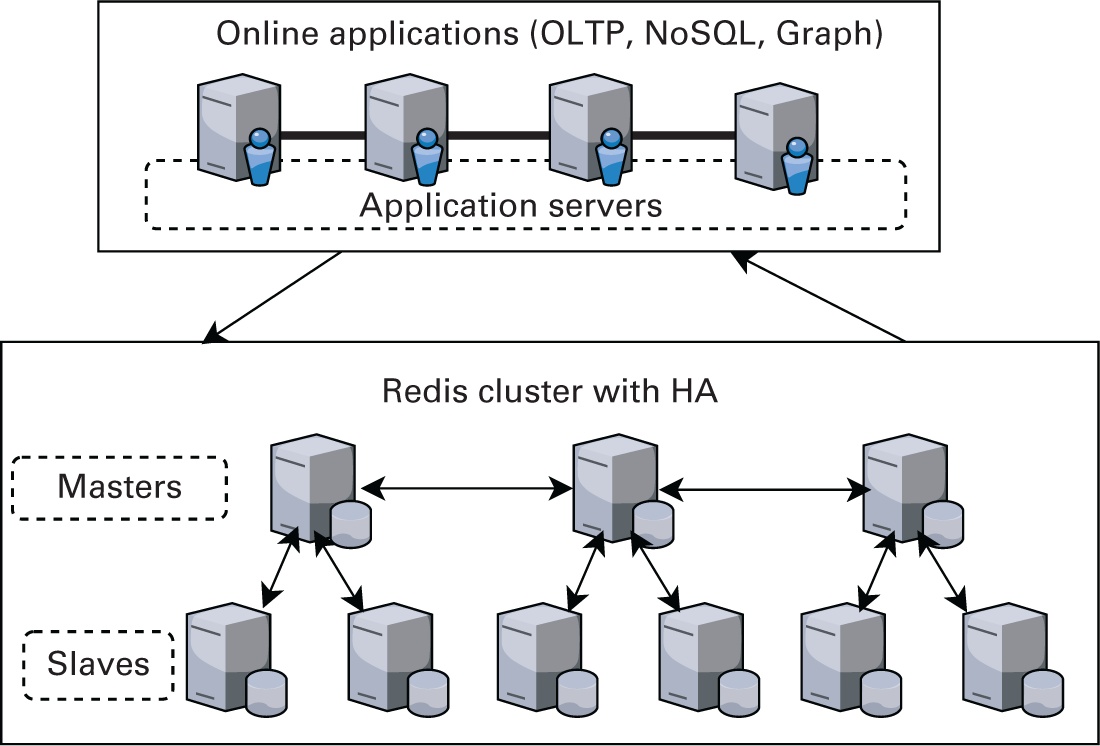
Redis (распределённое хранилище в оперативной памяти). HA, High Availability - высокая доступность.
Redis обладает гибкой моделью данных в памяти, причём встроенной в своей архитектуре, у него имеются сценарии применения, выходящие за рамки распределённого кэша. Он применяется в качестве хранилища данных для управления метаданными, брокера сообщений или первичной базы данных NoSQL для критичных к производительности данных. Такие как Redis хранилища данных в оперативной памяти применяются для повышения производительности автономных аналитических заданий Hadoop и Spark. Хотя по своей сути сервер Redis представляет экземпляр сервера с единственным потоком, для высокой доступности он обеспечивает режим предохранения (sentinel mode) (Redis Labs, 2021c) избыточность и режима кластера (Redis Labs, 2021b) для автоматического управления данными во множестве экземпляров серверов Redis.
В Листинге 3.8 показан образец клиента с библиотекой Jedis на основе Java (Leibiusky, 2021), который сохраняет и извлекает
пару ключ- значение из кластера Redis (то есть в режиме кластера). Один или несколько экземпляров Redis, составляющих свой кластер
серверов, указываются как набор HostAndPort в процессе инициализации своего объекта
JedisCluster. После подключения пары ключ- значение можно сохранять в распределённом
кластере при помощи JedisCluster.set() и выполнять их выборку с применением
JedisCluster.get(). Более полные сведения об этих API и их вариантах можно почерпнуть в
Leibiusky (2021). {Прим. пер.: также отсылаем вас к нашему переводу Книга рецептов Redis 4.x Пеньчень Хуань, Зуофей
Вань, (с) Packt Publishing, 2018.}
Листинг 3.8. Образец API Java Redis (Jedis)
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
public class JedisClusterExample {
public static void main(String[] args) {
/* create Java Redis instance to connect to
remote Redis cluster */
Set<HostAndPort> connectionPoints =
new HashSet<HostAndPort>();
connectionPoints.add(new HostAndPort("server1", 7379));
connectionPoints.add(new HostAndPort("serverl", 7380));
connectionPoints.add(new HostAndPort("server2", 7379));
JedisCluster cluster = new JedisCluster (connectionPoints);
/* write key—value pair into table in Redis */
cluster. set ("key" , "value ");
/* read value for a key from Redis table */
String value_from_remote_store = cluster. get ("key" );
assertEquals (value_from_remote_store , "value") ;
cluster. close();
}
}
RAMCloud
RAMCloud (Ousterhout et al., 2015) это система хранения в памяти, которая предоставляет доступ с низкой задержкой к наборам данных крупного масштаба, но хранит все данные исключительно в оперативной памяти. Для поддержи рабочих нагрузок с масштабом в Петабайтах она агрегирует оперативную память тысяч серверов единое целостное хранилище ключ- значение. Оно обеспечивает надёжность базирующихся в оперативной памяти данных храня резервные копии во вторичном хранилище и поддерживая в сетевой среде лишь единственную копию данных. С целью включения высокой производительности для управления данными в динамической оперативной памяти и в резервных копиях вторичного уровня применяется экономичный в отношении памяти механизм со структурой журнала. RAMCloud также применяет механизм аварийного восстановления, который для одновременной работы использует возможности всего кластера, обеспечивая возможность масштабирования производительности восстановления в зависимости от имеющегося размера кластера.
Всякий сервер хранения в кластере RAMCloud содержит два модуля: (1) хозяина (master), который управляет объектами в
своей оперативной памяти и (2) резервный (backup), который хранит реплики сегментов в постоянном хранилище. Центральный
координатор управляет имеющимся кластером хозяев и резервных копий. Клиентское приложение RAMCloud получает доступ к данным
с применением RPC. В Листинге 3.9 представлен образец с клиентом на основе Java, который сохраняет и производит выборку
пары ключ- значение из кластера RAMCloud. Клиент подключается к имеющемуся кластеру RAMCloud через его координатора. После
подключения может быть создана таблица и при помощи RAMCloud.write() может сохраняться
пара ключ- значение. Выборку данных можно осуществлять в качестве RAMCloudObject, а
значение получается при помощи вызова API RAMCloudObject.get_value(). Дополнительные
сведения об этих API и их вариациях можно получить из PlatformLab (2021).
Листинг 3.9. Образец API Java RAMCloud
import edu.stanford.ramcloud.RAMCloud;
import edu.stanford.ramcloud.RAMCloudObject;
public class RAMCloudExample {
public static void main( String [] args) {
/* create RAMCloud instance and connect to coordinator */
String COORDINATOR LOCATOR = "tcp : host =4.3.2.1 , port =12345" ;
RAMCloud ramcloud = new RAMCloud (COORDINATOR LOCATOR);
/* create table */
long tableId = ramcloud.createTable (tableName)
/* write key—value pair into table in RAMCloud */
long version = ramcloud.write (tableld , "key" , "value") ;
/* read value for a key from RAMCloud table */
RAMCloudObject obj = ramcloud.read ( tableld , "key");
String value_from_remote_store = obj getValue();
assertEquals (value_from_remote_store , "value");
assertEquals (version, obj.getVersion()) ;
}
}
Масштабируемость распределённых файловых систем, таких как HDFS, ограничивается производительностью медленных систем постоянного хранения, на которые они полагаются в отношении отказоустойчивости и долговечности. Было показано, что медленная запись существенно снижает значение производительности задания, в особенности для итеративных заданий, когда текущее задание зависит от результатов предыдущего задания. Хотя одним из подходов к решению данной проблемы был переход к средам обработки в памяти, например, Apache Spark, был введён новый тип файловых систем, носящих название файловых систем в памяти. Файловые системы в памяти это распределённые файловые системы, которые обеспечивают надёжный обмен данными со скоростью оперативной памяти между средами кластерных вычислений через свой интерфейс файловой системы. Они обеспечивают высокую пропускную способность для операций записи и чтения за счёт агрегирования памяти с байтовой адресацией по распределённым узлам без ущерба для отказоустойчивости.
MemHDFS (Apache Software Foundation, 2020b) это разновидность HDFS, в которой все данные хранятся в оперативной памяти, а необходимая отказоустойчивость достигается за счёт репликации в памяти. Хотя это и устранило узкое место для значения производительности ввода вывода, хранение в оперативной памяти нескольких копий с точки зрения использования ресурсов обходится дорого. В этом направлении были введены такие конструкции как Tachyon (в настоящее время известной как Alluxio) (Li, Ghodsi, et al., 2014), которые обходят ограничения репликации. Такие усовершенствованные виртуальные файловые системы в памяти применяют понятие с названием "родословная" (sentinel), которое основано на повторном выполнении операций для воссоздания любых утраченных данных с целью их восстановления после любых потенциальных сбоев.
Нововведения последнего времени в конструкции аппаратных средств работы в памяти (in-memory) привели к технологиям PMEM, которые обещают аналогичную оперативной памяти производительность, устойчивость и высокую плотность. Они аналогично оперативной памяти способны подключаться непосредственно к центральным процессорам и предоставляют возможность переосмысления имеющихся конструкций постоянного хранения. Надежда создания надёжных и долговечных систем хранения данных с очень низкой задержкой привело к ряду исследовательских работ по разработке совместно используемых и распределённых файловых систем поверх PMEM, включая Linux PMFS (Intel, 2015a), NVFS (NVM- and RDMA-aware HDFS) представленной Islam et al. (2016b) и NOVA (Xu and Swanson, 2016).
Поскольку данные составляют сердцевину всего в аналитике данных, важно следить за текущей работоспособностью слоёв хранения данных. Большинство хранилищ данных и файловых систем, которые обсуждаются в данной главе, предоставляют встроенные команды и графические пользовательские интерфейсы, которые позволяют запрашивать метрики сервера для анализа его производительности.
Во многих системах анализа данных, доступны инструменты с открытым исходным кодом, такие как Ganglia (Massie, 2018), Prometheus (Prometheus, 2021), Riemann (Kingsbury et al., 2021). В имеющемся облачном решении для отслеживания серверов и баз данных в реальном масштабе времени можно применять их частные инструменты мониторинга, например, Datadog (Datadog, 2021). Они предоставляю возможности мониторинга HDFS (Mouzakitis, 2016), Cassandra (Datadog, 2015), Redis (Redis Labs, 2021d) и тому подобного. Кроме того, иные частные инструменты, такие как RapidLoop OpsDash (RapidLoop, 2021) и SolarWinds AppOptics (Harzog, 2019) позволяют отслеживать коммерческие развёртывания систем хранения, таких как MySQL, MongoDB, Memcached и прочих. {Прим. пер.: для некоторых подробностей подобных систем отсылаем вас к нашим переводам Prometheus: запуск и исполнение Брайан Брайзил, (с) Robust Perception Ltd., O’Reilly, 2018, Изучение безопасности Kubernetes Кайчжэ Хуанг, Пранджал Джумде, (с) Packt Publishing, 2020.}
В данной главе представлен обзор четырёх различных типов систем промежуточного программного обеспечения хранения: файлового хранилища, блочного хранилища, хранилища объектов и ориентированного на оперативную память хранилища. Все четыре типа систем хранения широко применяются в большом числе высокопроизводительных вычислений, центров обработки данных и облачных сред. Они играют решающую роль в приложениях ежедневного анализе данных и обработки по всему миру. Чтобы лучше разобраться с этими системами, в данной главе также рассматривались некоторые представительные образцы из реальной практики с соответствующими интерфейсами, применяемыми для разработки приложений крупного масштаба работы с Большими данными.
Принимая во внимание доступность и производительность энергонезависимых запоминающих устройств, таких как PMEM и NVMe-SSD, необходимо ускорять внедрение новых программных примитивов ввода/ вывода. Мы полагаем, что это уже открыло и ещё откроет большое число возможностей для исследований в области высокопроизводительных систем хранения данных. В данной главе представлен общий обзор высокопроизводительных и распределённых систем хранения. Ранние и продолжающиеся работы по совершенствованию проектов высокопроизводительных и распределённых хранилищ данных, которые применяют ткое новое развитие устройств хранения более подробно обсуждаются в Главе 9.