Глава 7. Ускорение RDMA
Содержание
Данная глава представляет краткий обзор задач и вариантов выбора, связанных с проектированием подсистемы взаимодействия с поддержкой RDMA для программного обеспечения (ПО) промежуточного слоя Больших данных. Далее следует всесторонний обзор различных современных систем обработки и хранения данных с ускорением RDMA, предлагаемых в имеющейся литературе. Примеры включают стеки с ускорением для Hadoop (включая HDFS, MapReduce и RPC), Spark, Memcached, Kafka, Mizan, Wukong и прочих сред. Представлен обзор преимуществ производительности, достигаемых такими построениями с ускорением.
Современные системы HPC (высокопроизводительных вычислений) и связанное с ними ПО промежуточного уровня (например, MPI и PFS) на протяжении последнего десятилетия применяют последние достижения в области сетевых технологий, таких как RDMA (remote direct memory access - удалённый прямой доступ к памяти). С другой стороны, традиционное ПО промежуточного уровня для обработки Большими данными и управления им (например, Apache Hadoop и Apache Spark) полагалось на более медленные сетевые протоколы, такие как TCP/IP (см. Главу 4). Тем не менее, по мере сращивания Больших данных и HPC произошёл значительный сдвиг в том как для современных вычислительных систем крупного масштаба разрабатывается промежуточное ПО Больших данных. Промежуточное По Больших данных оптимизируется и перерабатывается для применение сетевой среды с поддержкой RDMA для более быстрых взаимодействия и операций ввода/ вывода. При разработке инфраструктуры взаимодействия и ввода/ вывода с поддержкой RDMA для обработки данных необходимо решить две основные задачи:
-
Как интегрировать архитектуру на основе RDMA в ПО промежуточного уровня?
-
Какие операции RDMA вовлекать в протоколы высокопроизводительного взаимодействия для применения его архитектуры?
Были изучены два различных подхода к интеграции RDMA в ПО промежуточного уровня Больших данных (Su et al., 2017). При первом подходе создаётся независимая библиотека с поддержкой RDMA, которая способна заменить традиционную подложку взаимодействия на основе TCP/ IP. Он носит название подхода "ответ сервера", поскольку при нём требуется чтобы сервер отвечал или отправлял необходимые результаты клиентам. Второй подход применяет одностороннюю семантику взаимодействия обхода RDMA своего ЦПУ при извлечении данных непосредственно из памяти сервера. Он именуется подходом "обхода сервера". Итак, хотя такой подход с обходом сервера идеально обеспечивает лучшую производительность и масштабируемость сервера, он полагается на разработчиков промежуточного ПО в разработке конкретных структур данных и алгоритмов, которые делают возможными односторонние операции RDMA. Поэтому был предпринят ряд попыток применения гибридного механизма ответа сервера/ обхода сервера для достижения приемлемого компромисса, включая сквозную задержку, масштабируемость сервера и загруженность ЦПУ (Jose et al., 2011; Kalia et al. и др., 2014; Су и др., 2017).
Несмотря на то, что современное оборудование RDMA обладает потенциалом исключительной производительности, конкретный выбор применяемых операций RDMA и их использование способны существенно влиять на фактическую производительность промежуточного ПО с ускорением RDMA. Все двусторонние операции RDMA (подробно описанные в Главе 4) могут быть "входящими" (inbound) и "исходящими" (outbound). Крайне важно различать входящие и исходящие глаголы (verbs), поскольку их рабочие характеристики существенно разнятся. Односторонние команды считывания/ записи (Read/ Write) RDMA и двусторонние отправки (Send) выступают (1) исходящими для запрашивающего процесса и (2) входящими в отвечающем процессе. Двусторонние получения (Recv) RDMA всегда рассматриваются как входящие. Для дополнительного пояснения о типичных ожидания производительности стоит сказать, что исполнение одностороннего RDMA (то есть исходящего RDMA) обладает гораздо более высокими накладными расходами чем его обслуживание (то есть входящего RDMA). Это обусловлено тем, что запрашивающая сторона для гарантии отправки и завершения своей операции должна поддерживать определённый контекст и задействовать как программное, так и аппаратное обеспечение, в то время как отвечающая сторона обрабатывается исключительно в оборудовании своей сетевой карты (NIC). По данным Kalia et al. (2016), пиковое значение операций ввода/ вывода (операций в секунду, IOPS) входящего RDMA примерно в пять раз выше чем у исходящего RDMA. Таким образом, в зависимости от схемы взаимодействия промежуточного ПО сам выбор применяемых для разработки высокопроизводительного протокола ввода/ вывода операций RDMA способен изменять правила игры. В данной главе рассматривается ПО промежуточного уровня с ускорением RDMA по семи различным направлениям:
-
Системы пакетной и потоковой обработки, которые применяют RDMA для ускорения этапов промежуточного перемешивания данных.
-
Системы обработки в графах, которые пользуются схемами с учётом RDMA для быстрого и распределённого исследования графов.
-
Библиотеки RPC, применяющие RDMA для быстрых основ однорангового взаимодействия.
-
Применяющие для высокоскоростного перемещения с целью отказоустойчивости и удалённого считывания данных RDMA файловые системы
-
Хранилища KV в памяти, которые используют RDMA для высокопроизводительного хранения и извлечения данных между клиентом и сервером
-
Применяющие RDMA для более быстрой обработки распределённых запросов системы баз данных.
-
Среды Машинного обучения и Глубинного обучения, пользующиеся RDMA для высокоскоростной сходимости параметров.
Для каждого из этих направлений наши последующие разделы обсудят их архитектуры для разнообразных проектов с высокой производительностью последних дней, которые предлагаются в имеющейся литературе, включая выбор пользующихся RDMA протоколов (в сопоставлении отклика сервера и обхода сервера), а также примитивы ускорения RDMA (в сопоставлении входящих и исходящих), задействованных для достижения высокой производительности. В Главе 10 мы изучим среды Машинного обучения и Глубинного обучения с применением RDMA.
Автономные аналитические или пакетные вычислительные среды включают в себя промежуточную фазу перетасовки данных между фазами отображения и сокращения. Точно так же применяемые в конвейере обработки потоковых данных, такие как Kafka, брокеры сообщений, выступают в качестве посредника данных для системы обработки потоковых данных. по причине интенсивного обмена данными на этих промежуточных этапах перемещения данных данные системы продемонстрировали значительные преимущества за счёт применения RDMA по сравнению с высокопроизводительными интерконнектами. В этом разделе обсуждаются доступные для популярных сред пакетной и потоковой обработки данных проекты с ускорением RDMA.
По умолчанию среда MapReduce пользуется массовым обменом данных поверх лежащего в её основе интерконнекта, а также большим числом дисковых операций на этапах перемешивания и слияния, что создаёт узкое место в современных кластерах HPС. В литературе были предложены различные усовершенствования, которые решают такие проблемы и предоставляют внутри MapReduce перетасовку на основе RDMA.
Hadoop-A
Двухэтапный протокол MapReduce в среде Hadoop становится возможным благодаря промежуточному этапу перемешивания и слияния (как это обсуждалось в Главе 2). Такие исследователи как Wang et al. (2011) и Rahman et al. (2013) обнаружили, что простая замена сетевого оборудования новейшими технологиями интерконнекта (скажем, InfiniBand и 10 GigE) с продолжением работы Hadoop поверх TCP/IP (через HTTP (Apache Software Foundation, 2020c)) не позволит Hadoop воспользоваться сильными сторонами RDMA для этапа перетасовки с интенсивным применением сетевой среды. Они выявили, что этап перетасовки, в свою очередь, может стать основным узким местом для Hadoop, в особенности когда необходимо идти в ногу с достижениями других процессорных технологий, устройств хранения и интерконнекта, которые развёртываются в различных кластерах HPC и ЦОД. Wang et al. (2011) представили новый протокол, который напрямую строит соединение на основе RDMA поверх протокола InfiniBand Verbs и полностью исключает накладные расходы стека виртуальной машины Java (JVM) для перетасовки данных Hadoop. Они предложили два новых компонента: сервер RDMA, который служит поставщиком карты выходных файлов, и клиент RDMA, который запрашивает выходные данные карты в задачах слияния/ уменьшения. Они также предложили нового клиент RDMA, который отправляет запрос вместе с информацией о доступном буфере памяти, а его сервер RDMA находит данные и записывает их в буфер клиента при помощи операции записи RDMA с нулевым копированием. Протоколы с поддержкой RDMA для поддержки TaskTrackers:
Фаза слияния при понижении, которая следует за промежуточной фазой перетасовки в протоколе Hadoop MapReduce по умолчанию, формирует "барьер сериализации", который значительно задерживает операцию понижения и сильно зависит от локального дискового хранилища. Для слияния данных без повторения и доступа к диску Wang et al. (2011) предложили альтернативный алгоритм слияния, с названием "сетевого слияния". Эти проекты продемонстрировали более чем 36-процентное увеличение пропускной способности обработки данных Hadoop при значительном снижении загруженности ЦПУ.
HOMR
хотя перетасовка с поддержкой RDMA и способна обеспечивать более высокую производительность, ряд исследований показывают, что она не может извлечь полный потенциал производительности из современных кластеров HPC без действенного конвейера исполнения между различными фазами заданий в MapReduce. Для решения этой задачи Rahman et al. (2014) предложили высокопроизводительную архитектуру MapReduce с названием Hybrid Overlapping in MapReduce (HOMR, гибридного перекрытия в MapReduce). HOMR отличается от применяемой по умолчанию платформы MapReduce следующими вариантами:
-
По умолчанию среда MapReduce выполняет перетасовку при помощи HTTP для обмена картой данных на выходе. В HOMR этот этап перетасовки данных реализуется поверх RDMA. Копиры (Copiers) RDMA отправляют запросы в свои TaskTrackers, или изначально ReduceTasks. HOMR не только привносит в свою среду обмен данными на основе RDMA, но к тому же монтирует расширенные функциональные возможности.
-
В HOMR вся операция слияния целиком может иметь место в оперативной памяти, что значительно снижает число дисковых операций в его ReduceTask. Как и в архитектуре Wang et al. (2011) на основе RDMA данные могут изыматься намного быстрее. Это создаёт возможность передачи одного файла карты вывода во множество шагов взаимодействия вместо одного. Осуществляя это, данный этап слияния может запускаться как только некоторые пары KV из всех файлов карты вывода достигают стороны понижения. Дополнительно к этому, HOMR реализует эффективную технику кэширования для промежуточного помещения данных в файлах карты вывода при использовании RDMA.
-
В отличии от изначальных архитектур на основе RDMA, предложенных Wang et al. (2011) и Rahman et al. (2013), HOMR на этапе перетасовки пользуется массовым обменом данных. Тем самым, HOMR способен запускать операцию понижения как только первый процесс слияния вырабатывает отсортированный вывод. Таким образом он способен перекрывать операции перетасовки, слияния и понижения на протяжении действенной конвейеризации совместно с этими этапами, что позволяет приложениям Hadoop MapReduce выполняться в современных кластерах HPC намного быстрее чем в среде MapReduce по умолчанию.
Такая расширенная архитектура HOMR была включена в выпуск ПО RDMA–Hadoop 2.x как часть его проекта программного стека HiBD. Подробнее данный проект рассматривается в разделе 7 этой главы.
Как уже упоминалось в Главе 2, Apache Spark определяет два типа зависимостей между распределёнными наборами данных (RDD, remote distributed datasets), которые специфичны для задач map/ reduce: узкие зависимости и широкие зависимости. Когда между RDD имеются широкие зависимости, они вызовут в Spark глобальный процесс перетасовки данных "многие- ко- многим", который является процессом с интенсивным обменом данными. Стандартная архитектура Apache Spark предлагает два подхода к перемещению данных. Первый - это перетасовка данных на основе Java NIO, а второй основан на коммуникационной подложке Netty (The Netty Project, 2021). В последней версии Apache Spark (Zaharia et al., 2010) перетасовка на основе Netty является подходом по умолчанию. И Java NIO, и Netty по-прежнему полагаются на модель двустороннего взаимодействия на базе сокетов для отправки и получения, которая не может в полной мере применять обеспечиваемые высокопроизводительным интерконнектом преимущества производительности (Lu et al., 2014). Это стало основным узким местом производительности Apache Spark в кластерах HPC.
Для решения такой проблемы был предложена высокопроизводительная архитектура перетасовки на основе RDMA (Lu et al., 2014). Однако без эффективного буфера и управления соединениями, а также оптимизации связи в Spark схема перетасовки на основе RDMA не способна полностью раскрыть потенциал производительности современных HPC. предложенный Lu et al. (2014) и Lu et al. (2016) высокопроизводительный дизайн Apache Spark на основе RDMA, включает следующие расширенные свойства.
Архитектура перемешивания данных на основе SEDA: При разработке систем перетасовки данных высокая пропускная способность является одной из основных целей. Поэтапная управляемая событиями архитектура (SEDA, Staged Event-Driven Architecture) (Welsh et al., 2001) широко применяется для достижения высокой пропускной способности. Основной принцип SEDA состоит в декомпозиции сложной логики обработки на связанный очередями набор этапов. Выделенный пул потоков по-прежнему отвечает за обработку событий в соответствующей очереди для каждого этапа. Вся система достигает высокой пропускной способности за счёт максимального перекрытия различных этапов обработки, при этом выполняя контроль доступа в таких очередях событий. Усилия по улучшению компонентов Hadoop (например, HDFS, RPC) (Islam et al., 2014; Lu et al., 2013) также показали, что подход SEDA применим для систем обработки данных на основе RDMA. С помощью SEDA весь процесс перетасовки можно разделить на несколько этапов, причём каждый этап может перекрываться с другими при помощи событий и пулов потоков. Таким образом, проект может обеспечить одновременность на уровне задач по умолчанию в Apache Spark, а также перекрытие обработки блоков с механизмом перемешивания SEDA. В механизме перетасовки данных на основе RDMA пул буферов применяется как для отправки, так и для получения данных в любой конечной точке. Пул буферов создаётся из буферов JVM вне кучи, что также отображаются на уровень Java/Scala в качестве теневых буферов.
Действенное управление соединениями RDMA и их совместное использование: Как показано в проектах Hadoop с применением RDMA (Islam et al., 2012; Rahman et al., 2013), накладные расходы на установление соединения RDMA немного выше, чем на установление соединения при помощи сокетов. Для уменьшения этих накладных расходов необходима усовершенствованная схема управления соединениями с целью уменьшения числа соединений. Apache Spark по умолчанию для поддержки многозадачного выполнения в одной JVM применяет многопоточный подход, что предоставляет хорошую возможность для совместного использования ресурсов. Это наводит на интересную идею совместного использования соединения RDMA между различными задачами, которые желают передавать данные в одно и то же место назначения. Этот механизм совместного применения соединений значительно сокращает общее число соединений, что, в свою очередь, позволяет сократить общую загруженность ресурсов. Благодаря не блокируемому обмену данных на основе фрагментов, данная архитектура Lu et al. (2016) способна действенно работать с механизмом совместного применения соединений. Это также способствует хорошему компромиссу между загруженностью ресурсов и производительностью.
Неблокируемый обмен данными: При совместном применении соединения каждое подключение может использоваться несколькими задачами (потоками) для одновременной передачи данных. В этом случае пакеты по одной и той же линии связи будут направляться к разным объектам как на стороне сервера, так и на стороне клиента. Для достижения высокой пропускной способности большой блок данных может быть разделен на последовательность фрагментов и отправлен без блокирования. Это может улучшать применение пропускной способности сети за счёт пересылки большего количества пакетов в сетевой карте, как указано Lu et al. (2014).
За последнее десятилетие организации стали в значительной степени полагаться на близкое к мгновенному предоставление конечному пользователю сведений на основе огромных объёмов данных, собираемых из различных источников в режиме реального времени. Для выполнения такой задачи создаётся конвейер потоковой обработки, который в своём самом базовом виде состоит из механизма потоковой обработки (SPE, Stream Processing Engine) и брокера сообщений (MB, Message Broker). SPE отвечает за выполнение реальных вычислений данных и предоставление их сведений. MB, с другой стороны, выступает как промежуточная очередь, в которую данные записываются эфемерными источниками, а затем извлекаются SPE для осуществления вычислений. Из-за присущего такому конвейеру характера работы в реальном времени для него весьма желательно иметь низкую задержку. Таким образом, ряд имеющихся в сообществе исследовательских работ сосредоточен на улучшении латентности и пропускной способности такого потокового конвейера. Однако существует недостаток исследований по оптимизации хвостовых задержек таких конвейеров. Более того, основная причина такой высокой задержки хвоста все ещё находится в стадии расследования.
Javed et al. (2018) представили Frieda, которая являет основанный на некой модели подход для углублённого анализа причин высокой задержки хвоста в таких потоковых системах как Apache Kafka. Обнаружив, что основным источником сообщений с высокой задержкой хвоста в потоковом конвейере выступает MB, ими была разработана и реализован высокопроизводительный MB с расширенным RDMA, названный Frieda, причём с более высокой целью ускорения любого произвольного конвейера потоковой обработки независимо от применяемого SPE. Экспериментальные оценки показывают сокращение до 98 процентов задержки 99,9-го процентиля для микротестов и до 31 процента для полноценного конвейера потоковой обработки, построенного с применением YSB.
Исследование графов крупного масштаба в распределённом на основе графов хранилище в памяти содержит большое число одновременных и чувствительных к задержкам запросов и способно действенно применять RDMA для запросов с высокой степенью одновременности и низкой задержкой поверх Больших данных на графе. Данный раздел обсуждает два образца из литературы, в которых применяются такие высокопроизводительные архитектуры для обработки в графах поверх современного интерконнекта HPC.
Многие общедоступные базы знаний представляются и хранятся в виде графов RDF, в которых пользователи могут запрашивать базы данных графов при помощи SQL, например SPARQL. Например, несколько больших наборов графических данных, таких как Google Knowledge Graph (Singhal, 2012), PubChemRDF (NLM, 2020) и другие, представлены в формате RDF, который представляет набор данных как набор триплетов субъект-предикат-объект, которые образуют ориентированный и помеченный граф. Ранние хранилища графов, предназначенные для обслуживания таких сред обработки графов на основе RDF, включают RDF-3X (Neumann and Weikum, 2008), SW-Store (Abadi et al., 2009) и т.д., а также более поздний TriAD (Gurajada et al., 2014), Trinity.RDF (Semiodesk, 2021) и SHARD (Rohloff and Schantz, 2010). При массовых запросах к большим и постоянно растущим данным RDF хранилище графов RDF должно обеспечивать низкую задержку и высокую пропускную способность для одновременной обработки запросов. Таким образом, проектирование распределённого хранилища RDF на основе графов, в котором используется исследование графов с применением RDMA, имеет большой потенциал для повышения производительности по сравнению с существующими современными хранилищами RDF.
В этом направлении Shi et al. (2016) представили Wukong, распределённое хранилище RDF в памяти, которое обеспечивает одновременные запросы с малой задержкой к большим наборам данных RDF. В отличие от своих предшественников, Wukong хранит триплеты RDF в виде собственного графа и позволяет выполнять быстрые и одновременные запросы на исследование графа. Его ключевые методы основаны на применении одностороннего RDMA для исследования графов следующими способами.
-
Модель графа и его хранение: Для облегчения действенного применения RDMA Wukong построен на дружественной RDMA распределённой хэш- таблице, полученной из DrTM-KV (Wei, Shi, et al., 2015). Она упрощает архитектуру хранения необходимых ключей/ значений с адаптацией из DrTM-KV для удаления ненужных метаданных проверки согласованности поддержки транзакций, однако Wukong применяет отличные функциональные возможности DrTM-KV, например, хэширование кластера с поддержкой RDMA и кэширование на основе местоположения.
-
Подрезка полной истории: Wukong обладает полной историей на протяжении исследования графа, которая передаётся на каждом шаге внутри и по всем машинам (либо CN) через Write RDMA. Благодаря такой полной истории исследования может устраняться окончательное соединение для фильтрации не совпадающих результатов, что способно значительно повышать общую производительность обработки транзакций.
-
Распределение запросов: Wukong разбивает запрос на последовательность подзапросов. Он одновременно обрабатывает множество независимых подзапросов и для каждого из них применяет механизм взаимодействия с использованием RDMA. В частности, для небольших запросов выборки он применяет исполнение на месте, которое пользуется считыванием (Read) RDMA для выборки необходимых данных, а потому нет необходимости в перемещении промежуточных данных. Точно так же, для больших сложных запросов без выбора он пользуется односторонней записью (Write) RDMA для распределения обработки запросов на все относящиеся к делй машины. Он также предоставляет схему перехвата работы (work-stealing) с ориентированностью на задержку для балансировки нагрузки обработки подзапросов по своим узлам.
Wukong значительно превосходит современные системы и способен обрабатывать как небольшие, так и крупные запросы в кластере InfiniBand из шести узлов с интерконнектом Fourteen Data Rate (FDR) 56 Гбит/с и десятиядерными процессорами Intel Haswell при 269 000 запросах в секунду.
Mizan это расширенная версия системы обработки графов Google Pregel (Malewicz et al., 2010), которая пользуется миграцией в реальном времени вершин графа для динамической оптимизации выполнения алгоритмов графа. Для обеспечения связи между исполнителями модуль обмена сообщениями применяет библиотеку MPI. Платформа обработки графов Mizan применяет двустороннюю модель программирования MPI. С другой стороны, MPI предлагает модель удалённого доступа к памяти (RMA), которая отделяет синхронизацию от перемещения данных. Поскольку многие современные высокопроизводительные интерконнекты предлагают функции RDMA, модель программирования RMA может быть непосредственно реализована в такой сетевой среде для обеспечения наилучшее перекрытие вычислений/коммуникаций, чем двусторонние операции MPI Send/Recv. Односторонняя связь считается выгодной для приложений с нерегулярными схемами взаимодействия. Несколько исследований показали преимущества односторонней модели программирования для обработки графов (например, Graph500 (2021) с MPI RMA (Li, Lu, et al., 2014)). Расширяя эту концепцию, Li, Lu et al. (2016) представили Mizan-RMA, в которой применяется односторонняя модель программирования MPI. Mizan-RMA использует возможности RDMA обхода ЦПУ, применяя подпрограммы MPI RMA в оптимизированной для RDMA библиотеке MPI MVAPICH2 (Network Based Computing (NOWLAB), 2021b) для достижения наилучшего перекрытия вычислений/коммуникаций и балансировки нагрузки исполнителей для общего прироста производительности в 2.8 раза по сравнению с Mizan.
По определению, RPC это взаимодействие между процессами, напоминающее обычный вызов процедуры. Хотя это и напоминает обмен сообщениями между двумя процессами, RPC представляет собой механизм взаимодействия клиент/ сервер, при котором "вызываемая процедура" берёт на себя роль сервера, а вызывающая сторона получает роль клиента. По причине свей природы интенсивного взаимодействия, библиотеки RPC совершенствуются для применения высокопроизводительных технологий интерконнекта, такие как RDMA.
Hadoop RPC это основной механизм взаимодействия в экосистеме Hadoop. В реальных ЦОД, таких как Facebook и Yahoo!, он используется совместно с прочими компонентами Hadoop, например MapReduce, HDFS и HBase. Однако текущая архитектура Hadoop RPC построена на интерфейсе сокетов Java, что ограничивает его потенциальную производительность. Lu et al. (2013) выявили определили, что узкие места в конструкции Hadoop RPC по умолчанию не чувствительны к взаимодействию на основе сокетов по TCP/IP в сети 1-GigE, поскольку узким местом является передача данных по сети.
Они также предложили взаимодействие данными и соответствующее управление буфером Hadoop RPC при работе в оснащённом InfiniBand кластере с поддержкой RDMA, носящем название RPCoIB. RPCoIB пользуется естественным интерконнектом InfiniBand, управление буфером с обходом JVM и локальность размера сообщения во избежание накладных расходов на выделение буфера и копирование памяти при сериализации и восстановлении данных. Оно вводит классы RDMAInputStream и RDMAOutputStream и изменяет стандартные применяемые клиентом/сервером потоки Hadoop RPC IOStream на основе Java для предоставления потоков ввода/ вывода на основе RDMA. RPCoIB демонстрирует автономный прирост производительности до 50 процентов по задержкам и в 82 процента по пропускной способности RPC. При интеграции с компонентами Apache Hadoop HDFS и HBase RPCoIB демонстрирует повышение общей производительности на 10-24%. RPCoIB интегрирован как часть пакета RDMA–Hadoop 2.x, который входит в состав проекта HiBD (подробнее см. в разделе 7.7).
gRPC (gRPC Authors, 2021) это наиболее фундаментальный механизм взаимодействия в распределённых средах Машинного обучения, таких как TensorFlow (Abadi, Agarwal, et al., 2016). Он поддерживает различные каналы для действенного обмена тензорами, например, gRPC поверх TCP/IP, gRPC InfiniBand Verbs и gRPC + MPI. Точно также была предложена оптимизированная библиотека gRPC, которая заменяет встроенный по умолчанию канал взаимодействия на основе TCP/IP двусторонними операциями отправки/ получения (Send/Receive) RDMA (CGCL-codes, 2017). К тому же, Biswas et al. (2018) предложил унифицированный подход к применению единой среды выполнения gRPC, носящей название AR-gRPC для TensorFlow с адаптивными и действенными протоколами RDMA. Он включает такие функциональные возможности, как гибридные протоколы взаимодействия, конвейерная обработка и слияние сообщений, передача с нулевым копированием, помимо прочего для соответствия среды исполнения различным размерам сообщений в распределённых рабочих нагрузках Глубинного обучения.
Для разрешения дилеммы того, что способно предоставлять наилучшую производительность - ответ сервера или обход сервера (как это обсуждалось в разделе Обзор этой Главы), Su et al. (2017) предложили новую парадигму RPC на основе RDMA с названием Remote Fetching Paradigm (RFP, парадигмы удалённого извлечения). При RFP сам сервер обрабатывает запросы клиентов, отправляемые ими, и сопровождает применение ЦПУ, аналогично традиционным интерфейсам RPC. RFP пользуется гибридным механизмом, который адаптивно переключается между повторяемым обходом сервера (удалённое извлечение) и ответом сервера для достижения наиболее высокой производительности на основании таких двух наблюдений:
-
Поскольку исполнение односторонней операции RDMA (то есть исходящего RDMA) сопряжено с гораздо большими накладными расходами нежели его обслуживание (то есть входящего RDMA), ответ сервера является не оптимальным для масштабирования сервера. Следовательно, применение исходящего RDMA в самом клиенте может быть более выгодным.
-
Применение исключительно односторонних операций считывания RDMA способно приводить к необходимости координации множества клиентов во избежание конфликтов доступа к данным. Полагаясь на сам сервер для вычисления необходимых результатов можно избегать соответствующей деградации производительности.
Su et al. (2017) продемонстрировали, что в таких схемах RFP повышает значение пропускной способности в 1.6- 4 раза при различных рабочих нагрузках по сравнению со схемами, основанными исключительно на обходе сервера или отклике сервера (например, Pilaf (Mitchell et al., 2013)).
Базы данных пользуются RDMA в качестве быстрого механизма обмена данными из хранилища в серверы баз данных. Это дополнительно расширяет вовлекаемые в обработку распределённых соединений транзакции для более быстрой сходимости посредством более быстрого обмена между серверами баз данных. Данный раздел обсуждает некоторые основные относящиеся к делу исследовательские работы.
память выступает жизненно важным ресурсом в реляционных базах данных или системах управления реляционными базами данных (реляционные СУБД, RDBM - relational database management systems). Ситуации с нехваткой памяти в СУБД способны заставлять её полагаться на более медленные устройства хранения, такие как жёсткие диски или твердотельные накопители. Это способно не столько снижать производительность рабочей нагрузки, но и приводить к не оптимальному применению высокоскоростных сетевых ресурсов, таких как сетевые адаптеры с поддержкой RDMA, которые в наши дни доступны в большинстве ЦОД. В частности, реляционные СУБД с симметричной многопроцессорной обработкой (SMP, symmetric multi-processing), такие как Amazon Relational Database Service, Microsoft Azure SQL Database и т.п., обладают требованиями к памяти, которые обычно превышают доступную локально память. Реляционные СУБД потенциально способны пользоваться RDMA для применения неиспользуемой удалённой памяти для значительного повышения общей производительности запросов.
Li, Das, et al. (2016) представили Реляционную СУБД SMP, которая применяет удалённую память для ускорения интенсивно пользующихся памятью рабочих нагрузок без существенного переписывания. Их Реляционная СУБД SMP абстрагирует доступ к удалённой памяти через RDMA и представляет соответствующие файловые API с малым весом. Li, Das, et al. (2016) предлагают ряд сценариев, которые способны пользоваться абстракциями удалённой памяти:
-
Реляционная СУБД SMP полагается кэширование процедур и буферных пулов и вырабатывает множество временных данных. Вместо вытеснения записей при нехватки памяти такие записи кэшируются в удалённой памяти. При необходимости, если есть такая необходимость, вместо их извлечения с SSD/ HDD можно снова получать доступ к таким вытесненным записям. Аналогично, временные данные могут пользоваться удалённой памятью для увеличения ёмкости вместо более медленных устройств хранения чем оперативная память.
-
Семантические кэши уровня приложений Реляционных СУБД способны создавать специализированные избыточные структуры, сохранять их закреплёнными в удалённой памяти и получать к ним доступ с применением RDMA при выполнении запросов, которые и извлекают из этого выгоду.
-
Быстрый доступ к удалённой памяти при помощи RDMA способен значительно снижать влияние подкачки пула буферов из первичной памяти во вторичную на рабочие нагрузки приложений.
По сравнению с использованием твердотельных/ жёстких дисков при нехватке памяти, такие абстракции с поддержкой RDMA демонстрируют улучшения в три-десять раз для рабочих нагрузок TPC-H и от двух до ста раз для рабочих нагрузок TPC-DS.
Для достижения прироста производительности в сетях с малой задержкой и высокой пропускной способностью, таких как InfiniBand и в алгоритмах одновременной обработки транзакций, которые жизненно важны для проектирования высокопроизводительных систем баз данных, в ряде работ основное внимание уделялось применению примитивов RDMA для ускорения перемещения данных между имеющимися машинами. С появлением многоядерных алгоритмов выполнения соединения в основной памяти (например, см., Kim et al. 2009; Albutiu et al. 2012), расширились возможности использования обмена данными с поддержкой RDMA для снижения общей загруженности ЦПу и, тем самым, улучшения общей производительности.
Barthels et al. (2015) представили распределённую схему позиционного соединения (join), продемонстрировавшую, что её этап разбиения на разделы может перекрываться с перераспределением имеющихся данных в сетевой среде с применением RDMA. Некое отношение разделяется либо в локальном буфере, когда такой раздел будет обрабатываться локально, либо в посвящённый этому буфер RDMA, когда он назначается удалённому узлу. Операции записи (Write) RDMA выполняются через регулярные промежутки времени для чередования необходимых вычислений и взаимодействий. Аналогично, Barthels et al. (2017) воспользовались операциями RDMA для реализации алгоритмов хэшированного позиционного соединения и алгоритмов соединения сортировки-слияния при помощи односторонних операций MPI RMA. Кроме того, в ней также представлено исследование поведения расширенных распределённых соединений (join) большого масштаба и демонстрируется пропускная способность 48.7 миллиардов кортежей на входе в секунду в 4096 ядрах.
Обработка транзакций в памяти является важнейшим компонентом многих систем баз данных реального времени, применяемых для веб- служб и электронной коммерции. После введения транзакционной памяти с аппаратной поддержкой (HTM, hardware transactional memory) при помощи таких возможностей, как транзакционная память с ограничением Intel (Intel, 2021i), несколько исследователей изучали применение её функциональных возможностей атомарности, согласованности и изоляции для транзакций базы данных. Wei, Shi, et al. (2015) представили DrTM, быструю систему обработки транзакций в памяти, которая для повышения общей производительности более чем на порядок по сравнению с современным распределённым программным обеспечением систем транзакций применяет такие расширенные аппаратные свойства, как RDMA и HTM.
DrTM пользуется строгой согласованностью между RDMA и HTM для обеспечения сериализации одновременных транзакций на разных машинах, позволяя при этом разгружать управление одновременностью внутри локальной машины в HTM. Она состоит из двух независимых компонентов: уровня транзакций и хранилища памяти. Хранилище в памяти создаёт эффективную хэш-таблицу для DrTM, применяя HTM и RDMA для упрощения общей архитектуры и повышения производительности. Удалённый доступ выполняется с применением односторонних операций RDMA для повышения эффективности. На уровне транзакций для блокировки удалённых записей применяется одностороннее сравнение-и-подкачка (CAS, compare-and-swap) RDMA, которая работает в пользу реализации протокола двухфазной блокировки. Считывание (Read) RDMA извлекает данные в локальную память и повторяет попытку RDMA CAS, если истёк срок аренды. Оценки DrTM с использованием типичных рабочих нагрузок обработки транзакций в реальном времени, таких как TPC-C, демонстрируют примерно 17.9-кратное улучшение по сравнению с такими современными системами как Calvin (Thomson et al., 2012; Ren et al., 2014).
В отличие от предыдущих работ, которые основаны на улучшении конкретных компонентов с помощью архитектур с поддержкой RDMA, Rödiger et al. (2015) представили разработку и реализацию комплексного механизма распределённых запросов на основе RDMA, способную обрабатывать сложные аналитические рабочие нагрузки, такие как эталонный тест TPC-H. Применяя в качестве основы современную систему баз данных в памяти HyPer (Kemper and Neumann, 2011; Hyper, 2021), они воспользовались гибридный подходом, в котором для одновременности внутри рабочего узла применяется локальная обработка NUMA. Для распределённой обработки разработана новая схема перераспределения данных между серверами, которая сочетает в себе несвязанные операторы обмена и мультиплексор взаимодействия на основе RDMA. Этот мультиплексор представляет собой выделенный сетевой поток (thread) для каждого сервера, который выполняет обмен данными между локальными и удалёнными операторами обмена. Он выполняет такой обмен данными, отправляя сообщения с применением глобального карусельного расписания, в котором используются двусторонние операции отправки/получения (Send/Receive) RDMA (т.е. семантику канала).
Применяя RDMA для снижения накладных расходов обработки TCP и отсутствия гибкости модели классического оператора обмена, предлагаемое Rödiger et al. (2015) планирование сетевого обмена с малыми задержками делает возможной высокую производительность одного сервера по сравнению с работающей поверх подложки взаимодействия на основе TCP/IP с настройками по умолчанию базой данных в памяти HyPer, причём с числом узлов до шести в кластере.
Производительность хранилищ KV в памяти по-прежнему обладает первостепенным значением, поскольку они выходят за рамки традиционной рабочей нагрузки кэширования объектов. Они превратились в ключевой компонент распределённых вычислений в основной памяти в ЦОД. Внедрение высокоскоростных соединений, таких как InfiniBand (IBTA, 2021a), позволил значительно повысить производительность такого промежуточного ПО за счёт адаптации к архитектуре с применением RDMA.
Memcached это популярная архитектура хранения KV для ускорения обслуживающих данные приложений (подробнее см. обсуждение в Главе 3). Ряд работ (см. Atikoglu et al., 2012; Xu et al., 2014 и прочие) продемонстрировали, что рабочие нагрузки хранилища KV являются доминирующими по считыванию и чувствительности к задержкам, а следовательно, выступают идеальными претендентами на получение преимуществ от основы взаимодействия с низкой задержкой. Рисунок 7.1 отображает предложенную Jose et al. (2011) архитектуру Memcached RDMA.
Рисунок 7.1
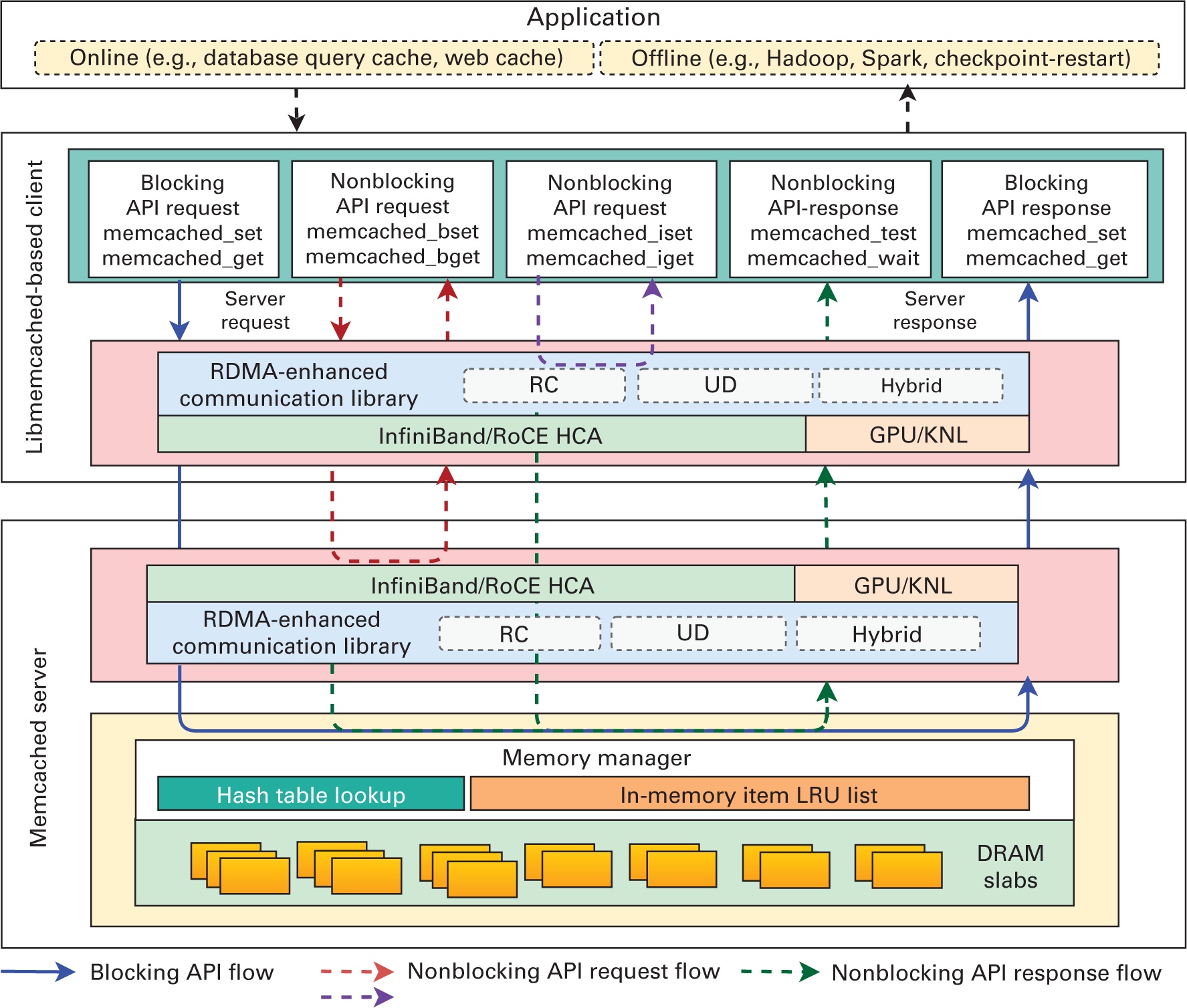
Обзор архитектуры Memcached на основе RDMA (Shankar, Lu, Islam, et al., 2016; Jose et al., 2011). KNL, kernel - ядро; LRU, least recently used - только что применённый.
Данная архитектура Memcached RDMA способна поддерживать все существующие приложения Memcached без каких бы то ни было изменений. Shankar, Lu, Islam, et al. (2016) также предложили не блокирующий API для ускорения автономной аналитики данных с целью облегчения выходящей за рамки традиционных рабочих нагрузок баз данных реального времени работы приложений для получения преимуществ от хранилищ данных в памяти, оптимизированных под RDMA. Подложка взаимодействия на основе RDMA для сервера Memcached и Libmemcached включает в себя:
Основа взаимодействия на базе RDMA: Библиотека Memcached текущего поколения разработана с применением традиционного интерфейса сокетов Berkeley. Хотя интерфейс сокетов (Sockets) обеспечивает высокую степень переносимости, модель потока байтов в интерфейсе сокетов не соответствует объектной модели памяти Memcached. Кроме того, реализации на основе сокетов должны внутри себя копировать сообщения, что приводит к дальнейшему снижению производительности. Высокопроизводительной интерконнект и его программный API, такой как OpenFabrics Verbs (linux rdma, 2021), обеспечивают возможности RDMA с семантикой на основе памяти, что очень хорошо согласуется с моделью Memcached. Вдохновлённые библиотекой обмена сообщениями MVAPICH2 (Network Based Computing (NOWLAB), 2021b) (выделена в разделе 4.3 Главы 4), которая применяется в научных приложениях для параллельных вычислений, Jose et al. (2011) предложили подложку взаимодействия на основе RDMA для Memcached.
Такая основа взаимодействия предоставляет простые в применении API на базе активных сообщений (Active Message), которые могут применяться в Memcached без повторной реализации критически важной логики (например, управления буфером, контроля потока) и оптимизирована как для небольших, так и для сообщений большой длины. Когда объём передаваемых данных не умещается в одном сетевом буфере (допустим, ≤8кБ), он упаковывается в одну транзакцию и имеющийся механизм взаимодействия выполнит для них единую активную отправку. Благодаря этому имеется возможность снижения накладных расходов на квитирование, требуемое для операций RDMA. В больших сообщениях мы пользуемся подходом на основе считывания (Read) RDMA для обмена данных с большим перекрытием. Такая архитектура способна работать непосредственно с сетевыми средами InfiniBand и RoCE. Подробные сопоставления производительности архитектуры Memcached RDMA с Memcached без изменений с применением сокетов в сети RDMA, 10-GigE с аппаратным ускорением протоколов TCP/IP и IPoIB на HCA InfiniBand различных поколений показывают, что задержки Memcached RDMA лучше, чем у прочих схем до 20 раз. Кроме того, пропускная способность небольших операций Get(K) может быть улучшена в шесть раз по сравнению с Sockets в сети 10-GigE и SDP.
Поддержка множественного транспорта (RC/UD/гибридный): Вышеупомянутая базовая архитектура с RDMA показала, что применение RDMA способно значительно повышать производительность Memcached. Эта архитектура основана на InfiniBand как на ориентированном на соединение транспорте RC. Однако исключительное применение транспорта RC препятствует масштабируемости по причине высокого потребления памяти. С другой стороны, UD-транспорт InfiniBand решает такую проблему масштабируемости, поскольку UD — это транспорт без установления соединения, и один UD QP способен выполнять обмен данными с любым количеством прочих UD QP. Это может значительно снижать потребление памяти и обеспечивать лучшую масштабируемость. Однако он не предлагает RDMA, надёжность или какое- либо упорядочение сообщений, а основанный исключительно на UD архитектура, может не обеспечивать такой же производительности, как и Memcached с RC. Такие сценарии привели к внедрению гибридной транспортной модели (Jose et al., 2012), в которой с целью обеспечения высокой производительности и масштабируемости Memcached применяются наилучшие функциональные возможности RC и UD . Основная идея состоит в том, что для достижения масштабируемости максимальное количество RC-соединений может быть ограничено заданным пороговым значением.
Две хорошо известные архитектуры хранения KV с поддержкой RDMA, которые пользуются односторонними операциями считывания или записи (Reads или Writes) RDMA содержат Pilaf и HERD.
Pilaf: Будучи одной из самых ранних предложенных в данном направлении работ, Pilaf (Mitchell et al., 2013), это архитектура распределённого хранилища KV в памяти, пользующееся преимуществами RDMA для достижения высокой производительности при низкой нагрузке на ЦПУ. Она обрабатывает операции записи на сервере (ответ сервера) и пользуется RDMA для ограниченных считыванием операций (обход сервера). Её общая архитектура содержит следующие протоколы с поддержкой RDMA для операций KV:
-
Операции Get(K) исполняются независимо в своём сервере. Клиенты этого хранилища KV выполняют считывание RDMA на протяжении множества карусельных обходов для непосредственного извлечения данных из памяти своего сервера. Для решения проблемы состязательности считывания/ записи между самим сервером и клиентом, вводится понятие "структуры данных с самостоятельной проверкой" за счёт добавления контрольной суммы к каждому объекту KV, которая проверяется всякий раз при считывании пары KV с применением RDMA.
-
Протокол Put(K, V) вовлекает двусторонний обмен сообщениями Глаголов (Verbs) Send/Receive InfiniBand для отправки в свой сервер необходимого запроса, обрабатывающего локальные обновления KV для своих структур данных.
Эксперименты Mitchell et al. (2013) показали, что Pilaf потенциально способен обеспечивать низкую задержку и высокую пропускную способность с приблизительно 1.3 миллионами операций в секунду (при 90 процентах операций получения) пользуясь одним ядром ЦПУ по сравнению в 55 000 для Memcached и 59 000 для Redis.
HERD, Kalia et al. (2014), представил собой систему хранения KV, предназначенную для наилучшего применения сетевой среды RDMA. В отличие от предыдущих хранилищ KV на основе RDMA, HERD сосредотачивается на снижении карусельных обходов сетевой среды пр одновременном действенном использовании примитивов RDMA. В отличие от Pilaf и Memcached RDMA, которые пользуются преимуществами одностороннего обхода ЦПУ считываниями (Reads) RDMA, HERD пытается существенно снижать задержку и насыщает значение пропускной способности на современном оборудовании RDMA. Его архитектура пользуется сочетанием глаголов записи (Write) RDMA и двустороннего обмена сообщениями, что позволяет применять один и тот же карусельный обход для всех запросов Get(K) и Set(K, V), как показано ниже:
-
Для этапа запроса клиент хранилища KV HERD записывает необходимые запросы в память своего сервера, применяя Writes RDMA без сигналов. Его сервер опрашивает свою память вместо сетевого оборудования и вычисляет соответствующие отклики.
-
На этапе отклика имеющийся сервер отправляет отклик своему клиенту посредством двусторонних сообщений UD. Поскольку рабочие нагрузки хранилища KV имеют дело с сообщениями длиной менее 4Б, HERB способен умещаться в одном пакете дейтаграммы, тем самым оставаясь нетронутым получением неупорядоченного подтверждающего сообщения через UD.
HERD демонстрирует значительно более низкое обеспечение задержки при насыщении пропускной способности на современном общедоступном оборудовании RDMA. Точнее, за счёт применения единого карусельного обхода для всех запросов эта архитектура поддерживает до двадцати шести миллионов операций KV в секунду со средней задержкой 5 мкс на интерконнекте InfiniBand FDR 56 Гбит/с. {Прим. пер.: подробнее в нашем переводе статьи Эффективное применение RDMA для служб ключ- значение Anuj Kalia, Michael Kaminsky†, David G. Andersen, Carnegie Mellon University, †Intel Labs, 2014.}
Хранилища данных в памяти играют жизненно важную роль в высокоскоростных аналитических системах. Среди таких систем имеются два заслуживающих внимания и представленных в литературе хранилища KV с поддержкой RDMA.
FaRM: Fast Remote Memory (FaRM) (Dragojević et al., 2014) это распределённая вычислительная платформа с основной памятью, которая для достижения улучшения значений скорости передачи сообщений и задержки на порядок по сравнению с применением TCP/IP в сети Ethernet использует RDMA. Она предоставляет память всех машин в распределённом кластере как общее адресное пространство. Благодаря этому FaRM позволяет потокам сервера применять транзакции атомарности, согласованности, изоляции и устойчивости со строгой сериализуемостью для поддержки совместного размещения объектов и доставки функций, что позволяет действенно применять транзакции на одной машине. Транзакции используют оптимистичный контроль одновременности с оптимизированным протоколом двухфазной фиксации, который использует преимущества RDMA следующим образом:
FaRM достигает доступности и сохранности применяя реплицируемое журналирование на SSD, но она также способна развёртываться и как кэш. Имея это в основе, FaRM демонстрирует что предлагаемые ею технологии способны достигать улучшение производительности на порядок по сравнению с реализацией на основе TCP/IP путём построения применяющих RDMA KV и графовых систем хранения. {Прим. пер.: подробнее в нашем переводе статьи Эффективное применение RDMA для служб ключ- значение Anuj Kalia, Michael Kaminsky†, David G. Andersen, Carnegie Mellon University, †Intel Labs, 2014.}
HydraDB: HydraDB это промежуточное ПО KV общего назначения в памяти, предназначенное для всестороннего применения протокола RDMA с целью оптимизации различных сторон хранилища KV общего назначения, включая, среди прочего критичные к задержками операции, улучшение чтения и репликацию данных для службы высокой доступности. В частности, с точки зрения архитектуры HydraDB применяет RDMA следующим образом:
-
Управляемый Write RDMA интерфейс передачи сообщений, который действенно применяется для репликации данных и способен снижать накладные расходы за счёт высокой доступности. HydraDB к тому же представляет механизм постоянного опроса как в клиентах, так и в серверах, для опроса выдаваемых RDMA запросов и откликов. {Прим. пер.: пример мультиплексирования веб сервера с помощью select.epoll в нашем переводе второго издания Книги рецептов сетевого программирования Python Прейдибэн Катхирейвелу и др. М.О. Фарук Саркер, Copyright © 2017 Packt Publishing.}
-
Для непосредственного извлечения клиентами данных из памяти за один цикл HydraDB применяет Read RDMA. При самом первом доступе к паре KV запрос отправляется соответствующему серверу с применением передачи сообщений на основе Write RDMA и такие удалённые записи кэшируются. Для пар KV, к которым Read RDMA обращается впоследствии, выдаётся значение кэшированного указателя выборки данных с применением одной односторонней операции.
Дополнительно к RDMA, HydraDB применяет набор современных технологий, включая непрерывную отказоустойчивость, осведомлённость о множестве ядер и т.п., что обеспечивает надёжную высокую производительность приложениям кластерных вычислений. HydraDB применяется для ускорения сред кластерных вычислений, включая Hadoop, Spark, смысловой аналитики и обработки записей вызовов. Кроме того, Y. Wang et al. (2014) представили несколько оптимизаций для эффективного и надёжного управления кэшем, включая управление KV на основе аренды, которое интегрировано в HydraDB.
Проект HiBD выполняется Лабораторией сетевых вычислений Университета штата Огайо. Основная цель проекта HiBD состоит в разработке высокопроизводительного промежуточного ПО для работы с Большими данными, которое способно применять технологии высокопроизводительных вычислений. Он предлагает несколько типов промежуточного ПО для распределённой обработки данных, оптимизированного для высокопроизводительных вычислений. По состоянию на март 2022 года для ускорения работы приложений с Большими данными пакеты HiBD применяются более чем 340 организаций по всему миру в 38 странах. С сайта этого проекта было выполнено более сорока четырёх тысяч загрузок. В настоящее время проект HiBD содержит следующие типы промежуточного ПО для работы с Большими данными и связанные с ним пакеты:
-
Apache Spark на основе RDMA: RDMA-Spark это высокопроизводительная архитектура с естественной поддержкой InfiniBand и RoCE на уровне Глаголов для Apache Spark, базирующемся на работах Lu et al. (2014) and Lu et al. (2016), которые были представлены в разделе 2.2 этой Главы. Она поддерживает большое число современных функциональных возможностей, например, перетасовку данных на основе RDMA, архитектуру на основе SEDA, эффективное управление соединениями, не блокируемого обмена данными на основе фрагментов данных, а также управление буфером JVM вне кучи.
-
Apache Hadoop 2.x на основе RDMA: RDMA–Hadoop 2.x это высокопроизводительная архитектура с натуральной поддержкой InfiniBand и RoCE на уровне глаголов для Apache Hadoop 2.x, основывающаяся на представленных в разделе 2.1 этой Главы работах Rahman et al. (2013), Rahman et al. (2014), Rahman et al. (2015). Это ПО производное от Apache Hadoop 2.x и совместимо с API и приложениями Apache Hadoop 2.x и Hortonworks Data Platform. На Рисунке 7.2 представлена архитектура верхнего уровня RDMA для Apache Hadoop.
Рисунок 7.2
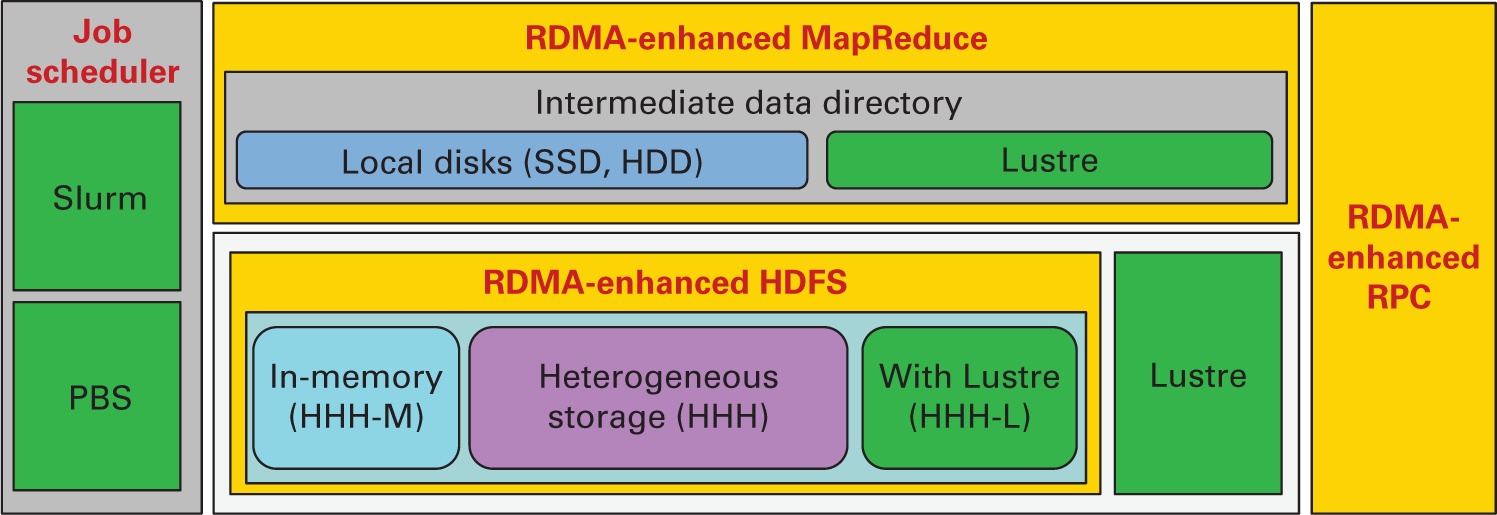
Основанная на RDMA архитектура Hadoop и её различные режимы. PBS, Portable Batch System.
Данный пакет может быть настроен для запуска заданийMapReduce поверх HDFS и таких PFS как Lustre. Что ещё более важно, данный пакет предоставляет различные режимы, разработанные для оптимизации производительности под различные виды приложений и сред Hadoop. Например, для некой среды HPC с ограниченным локальным хранилищем и файловой системой Lustre, предоставляется механизм MapReduce с применением архитектуры Beowulf (Rahman et al., 2015). Аналогично, неоднородные оптимизированные под RDMA хранилища с применением HDFS доступны в различных режимах развёртывания (HHH [Triple-H]. HHH-M [Triple-H In-Memory Mode]. HHH-L [Triple-H with Lustre]). Различные неоднородные режимы хранения для HDFS в пакете RDMA–Hadoop 2.x более подробно обсуждаются в Главе 9. Он также предоставляет встроенные сценарии для поддержки развёртывания RDMA под пакет Apache Hadoop 2.x для таких планировщиков заданий HPC как Slurm (SchedMD, 2020a).
-
Apache Apache Hadoop 1.x на основе RDMA RDMA–Hadoop 1.x это высокопроизводительная архитектура с естественной поддержкой InfiniBand и RoCE на уровне Глаголов для Apache Apache Hadoop 1.x. Данное ПО производно от Apache Hadoop 1.x и совместимо с API и приложениями Apache Apache Hadoop 1.x. Оно поддерживает современные такие функциональные возможности как запись HDFS на основе RDMA, репликация HDFS на основе RDMA, поддержка одновременной репликации в HDFS, перетасовка на основании RDMA MapReduce, слияние в памяти, расширенная оптимизация при перекрытии по различным этапам, RPC Hadoop на основе RDMA и прочее. Благодаря таким современным архитектурным решениям, значение производительности Apache Hadoop 1.x значительно улучшено по сравнению с базовой версией Apache Hadoop.
-
Memcached на основе RDMA: RDMA-Memcached это высокопроизводительная архитектура с натуральной поддержкой InfiniBand и RoCE на уровне глаголов для Memcached и Libmemcached со стороны Shankar, Lu, Islam, et al. (2016), а также Jose et al. (2011), которая обсуждалась в разделе 6.1 этой Главы. Данное ПО производно от Memcached и Libmemcached и совместимо с API и приложениями Libmemcached. Она поддерживает большое число современных функциональных возможностей, например, операции с парами KV на основе RDMA, поддерживаемая SSD гибридная память и тому подобными. Благодаря основанной на RDMA архитектуре, значительно улучшается значение производительности пар KV при том, что поддерживаемая SSD гибридная память предоставляет увеличенную ёмкость кэширования.
-
Эталонные тесты Memcached: Обычно для оценки новых проектов экосистемы Hadoop исследователи используют традиционные тесты, такие как Sort, TeraSort и т.д. Однако все эти тесты требуют участия нескольких компонентов, таких как HDFS, RPC, среды MapReduce и прочих, что затрудняет изолирование задач и оценку производительности отдельных жизненно важных для функционирования всей системы компонентов. Для удовлетворения подобной потребности при разработке эффективных микротестов и оценке производительности промежуточного ПО для Больших данных, проект HiBD предложил микротесты OHB поддержки автономных оценок HDFS (Islam, Sharmin, et al., 2012), MapReduce (Shankar et al., 2012). al., 2014), Hadoop RPC (Lu, Rahman, Islamic, Panda, 2014), Spark и Memcached. Этот набор микротестов подробно описан в разделе 5 данной Главы.
В подтверждение того, что стек взаимодействия традиционных платформ Больших данных требует повторного проектирования под современное оборудование высокой производительности, данный раздел предоставляет набор примеров из различных поддерживающих RDMA проектов.
Как уже обсуждалось в разделе 2 этой Главы, RDMA может применяться для улучшения значения производительности этапа перетасовки в средах map- reduce. В данном разделе мы обсудим основные преимущества применения RDMA для Apache Spark и Apache Hadoop MapReduce 2.x.
RDMA для Spark
Предлагаемый Lu et al. (2014) подход на основе подключаемого модуля с архитектурой поддержки SEDA- / на основе RDMA, предоставляет как высокую производительность, так и высокую продуктивность. Как показано на Рисунке 7.3a, основанная на RDMA архитектура для Apache Spark (обозначаемая как RDMA-IB) улучшает значение времени среднего исполнения задания HiBench (Intel, 2020a) PageRank в шестидесяти четырёх рабочих узлах SDSC Comet (SDSC, 2021a) на 40-60 процентов по сравнению со временем выполнения IPoIB (56 Gb/s). Данные эксперименты были выполнены с полным задействованием всех ядер с тем, чтобы шестьдесят четыре узла исполнителей выполняли в общей сложности 1 536 map и 1 536 reduce. Spark запускался в автономном режиме. Для локальных и рабочих данных использовались SSD. Дополнительные подробности конфигурации и численных значений можно найти на веб сайте HiBD (Network Based Computing Lab, 2022).
Рисунок 7.3

Улучшение производительности с применяющей RDMA архитектурой для Apache Spark и Hadoop в кластере SDSC Comet. (a) PageRank с RDMA-Spark. (b) Sort с RDMA–Hadoop 2.x
RDMA для Hadoop 2.x
Производительность Apache Hadoop 2.x значительно улучшается и его также становится проще запускать в кластерах HPC. Как показано на Рисунке 7.3b, основанная на RDMA архитектура для Apache Hadoop 2.x (обозначаемая как RDMA-IB) улучшает время исполнения задания Sort в шестнадцать узлах SDSC Comet вплоть до 49 процентов по сравнению со значением времени исполнения в IPoIB (56 Gb/s). Данные эксперименты производились при общем числе шестидесяти четырёх map и двадцать восьми reduce. Размер блока HDFS оставлялся равным 26 МБ. Запускавшийся в различных узлах данного кластера Hadoop NameNode, а сам эталонный тест запускался в NameNode. Хранилище данных HHH использовало 70 процентов своего диска RAM.
Как уже обсуждалось в разделах 5 и 6 этой Главы, RDMA способен улучшать производительность значительно снижая накладные расходы взаимодействия клиент- сервер, а также взаимодействия по всем составляющим свой кластер распределённых серверов узлам. В этом разделе мы представим примеры использования RDMA для хранилищ данных в памяти, таких как Memcached. Затем мы обсудим примеры, демонстрирующие преимущества RDMA для систем баз данных.
RDMA поверх Memcached
Для интенсивно применяющих данные масштабируемых приложений неоценимым оказывается использование распределённого уровня кэширования на основе хранилища KV. Для иллюстрации преимуществ производительности мы предоставим два варианта применения, которые иллюстрируют (1) кэширование в реальном времени и (2) автономную аналитику.
Кэширование в реальном времени: Для иллюстрации преимуществ применения Memcached RDMA под ускорение подобных MySQL нагрузок Shankar et al. (2015) представили гибридные микротесты, использованные в кластере Intel Westmere. Каждый узел оснащён 12ГБ оперативной памяти, жёстким диском 160ГБ и интерконнектом MT26428 InfiniBand QDR ConnectX (со скоростью 32 Гбит/с) с интерфейсом PCIe Gen-2 , запущенным под Red Hat Enterprise Linux 6.1. Для эмуляции клиентов применялся набор (от восьми до шестнадцати) CN, работающих как для реализации на базе сокетов BSD (Libmemcached v1.0.18), так и для реализации с расширенным RDMA (RDMA-Libmemcached 0.9.3). Эти эксперименты проводились с шестьюдесятью четырьмя клиентами, стопроцентным считыванием, совокупным размером рабочей нагрузки 5 ГБ, размером KV 32кБ и оценочным средним штрафом за промах в 95 мс.
Мы сравнили различные реализации Memcached, включая Memcached по умолчанию (Dormando, 2021 г.), Twemcache (Twitter, 2019 г.), Fatcache (Twitter, 2017 г.) и RDMA-Memcached (Network Based Computing Lab, 2022). Из Рисунка 7.4a для шаблона единого доступа, в котором каждая хранящаяся в кластере серверов Memcached пара KV будет запрошена с одинаковой вероятностью, можно отметить, что конструкции с поддержкой SSD, такие как Fatcache и RDMA-Memcached, обеспечивают наилучшую производительность благодаря их высокой способности удержания данных. В частности, RDMA-Memcached может повысить производительность до 94% по сравнению с используемыми по умолчанию Memcached в памяти (включая Twemcache). Производительность изучается с применением двух асимметричных шаблонов доступа, а именно Zipf-Latest (последний из популярных) и Zipf-Earliest (самый ранний популярный), которые моделируют популярность пары KV на основе самых старых и совсем недавно обновлённых пар KV соответственно. По сравнению с прочими решениями на Рисунке 7.4a можно отметить, что RDMA-Memcached способен повышать производительность примерно на 68–93%.
Рисунок 7.4
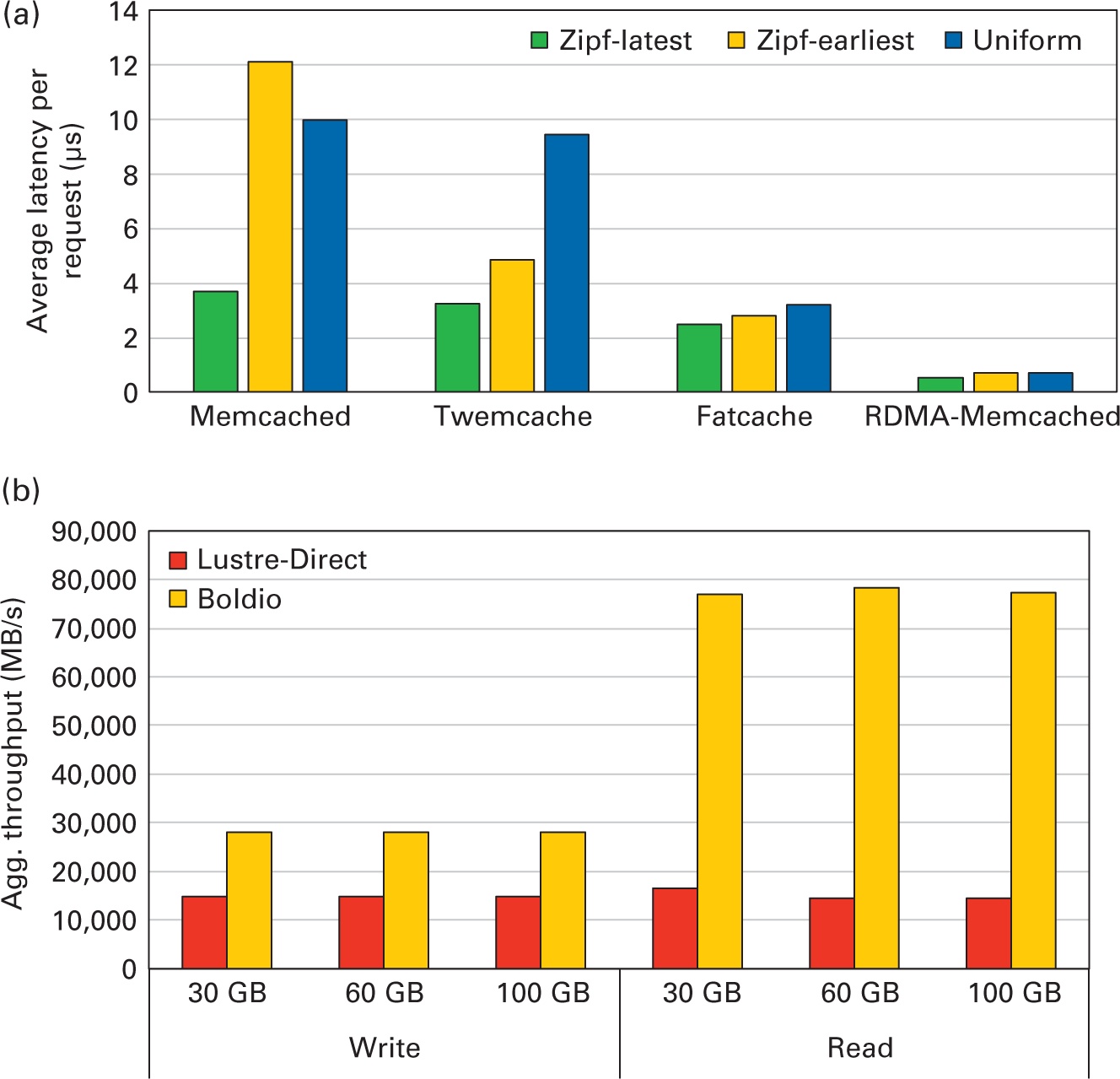
Преимущества производительности для рабочих нагрузок на основе RDMA-Memcached. (a) Memcached Set/Get поверх имитаций MySQL. (b) Пропускная способность Hadoop TestDFSIO с применением Boldio.
Автономная аналитика: Для лучшего понимания преимуществ применения RDMA для ускорения хранения данных в памяти мы проиллюстрируем как можно пользоваться Memcached для ускорения автономных аналитических приложений, например, для рабочих нагрузок на основе Hadoop MapReduce. Важнейшей частью работы Hadoop является извлечение данных из HDFS для обработки и записи результатов по завершению. Эта фаза ввода/ вывода является потенциальным узким местом производительности кластеров HPC, поскольку она связана с доступом к одной общей параллельной файловой системе, например Lustre. Несколько недавних исследований были сосредоточены на расширении возможностей подсистемы ввода/ вывода для запуска Hadoop в кластерах HPC с помощью хранилищ данных в оперативной памяти (Shankar, Lu, Islam, et al., 2016; Wang et al., 2014c). Одна из таких систем пакетной буферизации на основе Memcached с ускорением RDMA для Hadoop, именуемая Boldio (Shankar, Lu, и Panda, 2016), и она способна улучшать пропускную способность записи в 3 раза и пропускную способность чтения в 7 раз по сравнению со значением по умолчанию. Непосредственно работающий над Lustre Hadoop подробно обсуждается в главе разделе 5.2 Главы 9.
RDMA для баз данных
Современные системы баз данных могут пользоваться RDMA для взаимодействия запросов/ откликов клиент- сервер и обмена данными между серверами в распределённых базах данных с низкими задержками и широкой полосой пропускания .
Взаимодействие сервер- к- серверу: Серверы в параллельной базе данных интенсивно применяют сетевые протоколы для разнообразных распределённых операций, например, для перемешивания, репликаций и распределённой координации исполнения транзакций (то есть согласованных алгоритмов).
Например, Liu et al. (2019) подтвердили, что имеется возможность улучшения аналитической производительности системы параллельной базы данных по сравнению с простым высокопроизводительным интерконнектом за счёт применения оператора перетасовки на основе RDMA. Они продемонстрировали, что запросы TPC-H могут быть ускорены до двух раз за счёт совершенствования оператора перемешивания при прямом применении двусторонних операций Send/ Receive RDMA через транспортную службу UD по сравнению с применением такой библиотеки внешнего взаимодействия как MPI с возможностями RDMA в кластере Broadwell из шестнадцати узлов с интерконнектом InfiniBand EDR 100 Гбит/с. С другой стороны, Zamanian et al. (2019) демонстрируют, что односторонняя семантика RDMA лучше подходит для обеспечения высокой доступности посредством репликации. Они предлагают протокол репликации на основе отмены регистрации, известный как Active Memory, который применяет одностороннюю запись (Write) RDMA, которая превосходит протоколы репликации, такие как H-Store (Kallman et al., 2008) и Calvin (Thomson et al., 2012). ), применяющие двусторонние Send/ Receive RDMA.
Аналогично, Wang et al. (2017) демонстрируют, как можно использовать RDMA для ускорения связи между распределёнными серверами для алгоритмов согласия, которые играют жизненно важную роль в повышении производительности диспетчеров координации, например ZooKeeper (Apache Software Foundation, 2021o), путём представления протокола Paxos на основе RDMA, известного как APUS (Cheng, 2019). Wang et al. (2017) показывают, что производительность системы на основе репликации конечного автомата, такой как Calvin (Thomson et al., 2012), может быть улучшена до 8.2 раз за счёт применения односторонних Write RDMA по сравнению с ZooKeeper, который предполагает накладные расходы в размере только 10.6 процента в реализации Calvin при осуществлении репликации.
Взаимодействие клиент- к- серверу: Подобно архитектуре Memcached на основе RDMA, описанной в разделе 8.2.1 этой Главы, Fent et al. (2020) предложили высокопроизводительный уровень взаимодействия, с названием L5, который перепроектирует сетевой стек системы баз данных для оптимального применения функциональных возможностей прямого доступа к памяти и методов внутримашинного взаимодействия, такого как общая память. Они демонстрируют, что L5 способен повысить производительность рабочей нагрузки YCSB-C примерно на 42 процента для RPC по сравнению с eRPC (Kalia et al., 2019) и производительность базы данных в памяти Silo (Tu et al., 2013). до 1.8–15 раз по сравнению с MySQL (MySQL, 2020) и SQLite (Allen and Owens, 2010).
В данной главе представлен обзор поддерживающих RDMA протоколов для перемещения данных и взаимодействия между процессами. Приводится подробный обзор различных архитектур с поддержкой RDMA, которые были предложены для различного высокопроизводительного промежуточного ПО. Для демонстрации преимуществ производительности представлены примеры тематических исследований, которые можно применять к новыми построениям. Многие из этих проектов в настоящее время применяются в промышленных системах и дают представление о том, как эти проекты могут быть ускорены с использованием технологий и систем HPC текущего и последующих поколений.