Глава 1. Планирование Ceph
{Прим. пер.: рекомендуем сразу обращаться к нашему переводу 2 издания вышедшего в феврале 2019 Полного руководства Ceph Ника Фиска}
Содержание
- Глава 1. Планирование Ceph
- Что такое Ceph?
- Как работает Ceph?
- Варианты применения Ceph
- Особые случаи применения
- Проектирование инфраструктуры
- Проектирование сетевой среды
- Размеры узла OSD
- Как спланировать успешную реализацию Ceph
- Осознание ваших требований и того как они относятся к Ceph
- Определение целей с тем, чтобы вы могли калибровать его как успешный проект
- Выбор вашего оборудования
- Подготовка себя и своей команды к применению Ceph
- Исполнение PoC для определения того, отвечает ли Ceph поставленным целям
- Применение практического опыта для развёртывания вашего кластера
- Определение процесса изменения управления
- Создания плана резервного копирования и восстановления
- Выводы
Самая первая глава данной книги охватывает все области, которые вы должны учитывать при рассмотрении развёртывания какого бы то ни было кластера Ceph, начиная с начальных этапов планирования, вплоть до выбора аппаратных решений. В данной главе мы рассматриваем следующие темы:
-
Что такое Ceph и как он работает
-
Хорошие варианты использования Ceph и важные соображения
-
Рекомендации и наилучшие практические приёмы проектирования инфраструктуры
-
Идеи в отношении планирования какого- либо проекта Ceph
Ceph является системой с открытым исходным кодом, распределённого, горизонтально масштабируемого, определяемого программным обеспечением хранения данных (SDS, software-defined storage). Благодаря применению алгоритма CRUSH (Controlled Replication Under Scalable Hashing, Управляемых масштабируемым хешированием репликаций), Ceph исключает необходимость в централизованных метаданных и может распределять имеющуюся нагрузку по всем присутствующим в кластере узлам. Так как CRUSH является алгоритмом, размещение данных вычисляется вместо того, чтобы полагаться на табличные поиски и может масштабироваться до сотен петабайт без риска бутылочных горлышек и наличия сопутствующих одиночных точек отказа. Клиенты также создают прямые соединения с теми серверами, которые хранят требуемые данные и поэтому во всех путях данных отсутствуют узкие места.
Ceph предоставляет три основных типа хранения, которыми явдяются блоки через RBD (RADOS Block Devices), файлы посредством CephFS (Ceph Filesystem) и объекты при помощи шлюза RADOS (Reliable Autonomous Distributed Object Store, Безотказного автономного распределённого хранилища объектов), который предоставляет совместимое с S3 (Simple Storage Service) и Swift хранилище.
Ceph является чистым решением SDS (программно определяемого хранилища) и это означает, что вы вольны работать с ним на общедоступных аппаратных средствах, если только они предоставляют достаточные гарантии для согласованности данных. Дополнительная информация о рекомендуемых типах оборудования может быть найдена далее в этой главе. Именно это является главным разработке для отрасли хранения, которая обычно страдает от прямой привязки к производителю. Несмотря на то, что имелось множество проектов с открытым исходным кодом для предоставления услуг хранения. Очень немногие из них смогли предоставить такие как у Сузр масштабируемость и высокую надёжность не требуя при этом специализированных аппаратных средств.
Следует отметить, что Ceph предпочитает согласованность в отношении Теоремы CAP и будет стараться изо всех сил ставить главным приоритетом защиту ваших данные нежели их доступность при происшествиях в некотором разделе.
Центральным уровнем хранения в Ceph является RADOS, который предоставляет, как об этом заявляет само название, некоторое хранение объектов на которых строятся и распространяются протоколы хранения более высокого уровня. Данный уровень RADOS в Ceph включает в себя большое число OSD. Каждое OSD полностью независимо и образует одноранговое (peer-to-peer) взаимодействие для формирования некоторого кластера. Каждый OSD обычно ставится для ОС в соответствие (mapped) некому отдельному физическому диску через базисный HBA (host bus adapter, адаптер основной шины) в противоположность с обычным подходом представления некоторого числа дисков через контроллер RAID (Redundant Array of Independent Disks, Массива независимых дисков с избыточностью).
Другим ключевым компонентом в каком бы то ни было кластере Ceph являются мониторы; именно они отвечают за формирование кворума кластера с использованием Paxos. Благодаря создания кворума все мониторы могут быть уверены в некотором состоянии, которое позволяет им принимать авторитетные решения для данного кластера и избегать сценариев разделённого мозга (split brain, {Прим. пер.: ситуации, при которой из- за разрыва множества соединений не способный корректно обрабатывать данную ситуацию узел начинает вести себя так, как будто все остальные узлы кластера вышли из строя, запуская дубликаты уже работающих в кластере служб}). Данные мониторы не напрямую вовлекаются в имеющийся путь данных и не имеют тех же самых требований к производительности, что и OSD. Они в основном используются для предоставления известным состояния кластера, включая членство, настройки и статистические данные через применение различных карт (maps) кластера. Такие карты кластера используются как компонентами кластера Ceph, так и клиентами, для описания всей топологии кластера и делают возможным безопасное сохранение данных в конкретном правильном местоположении.
Благодаря тем масштабам, с которыми намеревается работать Ceph, можно понять, что отслеживание состояния и размещение каждого отдельного объекта в данном кластере могло бы стать с точки зрения вычислений очень затратным. Ceph решает эту проблему применяя CRUSH для размещения объектов в группы объектов, именуемые PG (placement groups, группами размещения). Это снижает потребность в отслеживании миллионов объектов до намного более управляемого числа в диапазоне тысяч.
Librados является библиотекой Ceph, которая может применяться для построения приложений, которые напрямую взаимодействуют с самим кластером RADOS для сохранения и получения объектов.
Для получения дополнительной информации о том, как работают все внутренности Ceph, настоятельно рекомендуется прочесть официальную документацию, а также все тезисы, написанные Сейджем Вейлем (Sage Weil), создателем и первоначальным архитектором Ceph. {Прим. пер.: см. Приложение B}.
Прежде чем мы перескочим к особым вариантам применения, давайте рассмотрим некоторые ключевые моменты, которые стоит понимать прежде чем замыслить развёртывание некоего кластера Ceph.
Ceph не следует сравнивать с обычными масштабируемыми массивами хранения. Они имеют принципиальные отличия и попытка втиснуть Ceph в эту роль с применением имеющихся знаний, инфраструктуры и ожиданий приведёт к разочарованию. Ceph является SDS (Software Defined Storage, программно управляемой системой хранения), чьи внутренние перемещения данных выполняются поверх сетевой среды TCP/IP. Это вводит некоторые дополнительные уровни технологии и сложности при сопоставлении с некой обвязкой кабелями SAS позади обычного массива хранения. {Прим. пер.: см. RDMA ещё вносит добавку во всё это, стек протоколов как бы растёт вверх несмотря на очевидное углубление в аппаратные средства}.
Благодаря распределённому подходу Ceph, он может предложить необузданную производительность в сравнении с масштабируемыми массивами хранения, которые обычно должны направлять все операции ввода/ вывода через какую- то пару голов контроллеров. Хотя технология непрерывно предоставляет новые более быстрые ЦПУ и более высокие скорости сетевой среды, всё ещё имеется некий предел общей производительности, которую вы могли бы ожидать достигаемой всего лишь парой контроллеров. При наличии последних достижений в технологии флеш- памяти в комбинации с новыми интерфейсами, подобными NVMe (Non-volatile Memory Express), имеющаяся природа горизонтального масштабирования Ceph предоставляет некий линейный рост в ресурсах ЦПУ и сетевой среды при добавлении каждого нового узла OSD.
Давайте также рассмотрим где Ceph не очень хорошо соответствует производительности, и это в основном варианты применения, когда необходима чрезвычайно низкая латентность. По той же самой причине, по которой Ceph получает возможность стать неким горизонтально масштабируемым решением, это же означает, что задержки будут иметь тенденцию практически удваиваться в сопоставлении с обычными массивами хранения и быть примерно в 10 раз выше имеющихся у локальных хранилищ. Следует задуматься о выборе более лучшей технологии для данного требования к производительности. Тем не менее, хорошо разработанный и настроенный кластер Ceph должен быть способен соответствовать требованиям производительности почти для всех вариантов, за исключением разве что наиболее экстремальных. {Прим. пер.: частично может решить проблему высокой латентности подход, формулируемый в притче о горе и Магомеде, а именно, перенос вычислений на узлы OSD, обсуждаемый в Главе 6, Распределённые вычисления при помощи классов RADOS Ceph.}
Ceph разработан для предоставления системы хранения с высокой устойчивостью к отказам благодаря горизонтально масштабируемой природе составляющих его компонентов. Хотя никакой индивидуальный компонент не обладает высокой доступностью, когда они все собраны в единый кластер, любой из этих компонентов может испытать отказ без вызова невозможности обслуживания запросов клиента. В действительности, по мере роста вашего кластера Ceph, отказы индивидуальных компонентов должны становиться ожидаемыми и превращаются в обычные условия работы. Тем не менее, способность Ceph предоставлять надёжный кластер не должна быть приглашением к компромиссу по выбору оборудования или архитектуры. Такой подход с большой вероятностью приведёт к неудаче. Имеется целый ряд моментов, которым, как предполагает Ceph, соответствует ваше оборудование и они будут рассмотрены далее в этой главе.
В отличие от RAID, в котором перестроение диска с дисками большого размера может теперь растянуться на период времени, измеряемый неделями, Ceph часто производит восстановление отказа отдельного диска в пределах часов. С возрастанием тенденции к увеличению ёмкости дисков, Ceph предлагает различные преимущества как в отношении надёжности, так и для деградации производительности в случае его сопоставления с обычными массивами хранения.
Ceph разработан для работы на общедоступном оборудовании, которое предоставляет возможность способности проектирования и построения некоего кластера без дополнительных запросов стоимости традиционных производителей систем хранения первого уровня и серверов. Это может быть и благословением и проклятием. Иметь возможность выбора ваших собственных аппаратных средств, которые позволят вам построить вашу инфраструктуру Ceph в точности соответствующей вашим потребностям. Тем не менее, одна из вещей, которую предполагает фирменное оборудование, это тестирование совместимости {Прим. пер.: см. пример}; именно это избавляет вас от наличия странных экзотических ошибок встроенного программного обеспечения, которые могут приводить к очень непонятному поведению. Следует задуматься о том, имеете ли вы и ваша ИТ команда соответствующие время и навыки чтобы справиться со всеми непонятными проблемами, которые могут возникнуть в оборудовании, не прошедшем соответствующей проверки.
Использование общедоступного оборудования также защищает от традиционной модели обновления вилочным погрузчиком, при которой обновление одного компонента зачастую требует полной замены всего массива хранения. Применяя Ceph вы можете заменять индивидуальные компоненты достаточно гранулярным образом, причём с наличием автоматической балансировки данных и исключением длительных периодов миграции данных. Распределённая природа Ceph означает, что замена и обновление оборудования Ceph могут выполняться в рабочее время без воздействия на доступность служб.
Теперь мы рассмотрим некоторые наиболее распространённые варианты применения Ceph и обсудим некоторые из тех причин, которые лежат в основе такого выбора.
Ceph исключительно соответствует предоставлению хранилища некоторой среде OpenStack. На самом деле, Ceph в настоящее время является наиболее популярным вариантом. Блочное устройство OpenStack Cinder применяет RBD Ceph для предоставления ВМ блочных томов, а OpenStack Manila, служба совместного использования файловой системы (Faas), интегрирована с CephFS. Имеется целый ряд причин почему Ceph настолько хорошее решение для OpenStack:
-
Оба являются проектами с открытым исходным кодом при наличии предложений коммерческой поддержки
-
Оба имеют достоверные записи истории крупномасштабных реализаций
-
Ceph может предоставлять хранение блоков, CephFS и объектов, всего что может использовать OpenStack
-
Имеется возможность развёртывания гиперконвергентного {Прим. пер.: выполняющего широкий спектр служб} кластера с тщательным планированием
Если вы не используете OpenStack или не планируете применять его, Ceph также очень хорошо интегрирован с виртуализацией KVM. {Прим. пер.: всё сказанное, например, верно и для Proxmox, и для контейнеризации LXC подробнее....}
Благодаря возможности проектировать и строить эффективные в стоимостном отношении узлы OSD, Ceph делает возможным для вас построение больших высокопроизводительных кластеров хранения, которые очень выгодны с точки зрения цены при их сопоставлении с альтернативными вариантами. Однако, из- за рекомендуемой трёхкратной репликации, эффективность хранения не может соответствовать традиционным RAID JBOD (сокращение от Just a Bunch of Disks, простого массива независимых дисков) по стоимости или потребляемой мощности. Однако, масса относящихся к доступности и производительности преимуществ может всё ещё делать привлекательным такой вариант использования. Поддержка удаляющего кодирования применительно к RBD, которая должна стать доступной в редакции Luninious, великолепно закроет этот пробел. Если ваши архивные требования позволяют вам хранить данные в виде объектов, тогда пулы с удаляющим кодированием позволят вам соответствовать RAID по стоимости и являются очень привлекательным решением.
Объектное хранилище
Тот факт, что основной центральный сердцевинный уровень RADOS является хранилищем объектов, означает что Ceph превосходен при предоставлении хранения через протоколы S3 и Swift. Если стоимость, латентность или безопасность данных рассматриваются при использовании решений хранения объектов в общедоступном облаке, работа с вашим собственным кластером Ceph для предоставления хранилища объектов может быть идеальным вариантом применения.
Объектное хранилище применяемое для индивидуальных приложений
Применяя librados вы можете получить своё собственное домашнее приложение для прямого общения с лежащим в основе уровнем RADOS Ceph. Это может великолепно упростить саму разработку вашего приложения и снабдит вас прямым доступом к высокопроизводительному надёжному хранилищу. Некоторые более продвинутые свойства librados, которые позволяют вам собирать ряд операций в единую атомарную операцию также очень тяжело выполнять в имеющихся решениях хранения.
Распределённые файловые системы - веб ферма
Некая фабрика веб серверов, каждому из которых необходим доступ к одним и тем же файлам с тем, чтобы все они могли обслуживать одно и то же содержимое, в не зависимости от того к кому из них подключается определённый клиент. Обычно для предоставления распределённого файлового доступа предоставлялось бы решение NFS с HA (high-availability, высокой доступностью), однако оно может начинать сталкиваться с определёнными ограничениями при масштабировании. CephFS может предоставить некую распределённую файловую систему для хранения такого веб содержимого и позволять его монтирование по всем имеющимся в данной ферме веб серверам.
Распределённые файловые системы - замена файлового сервера SMB
Имеются определённые взаимодействия между CephFS и Samba, которые не стали изысканными, что означает, что окончательное решение не будет работать настолько хорошо, как это ожидалось. Samba может успешно применяться для представления некоторой файловой системы CephFS, однако отсутствие HA и стабильных моментальных снимков означает что это часто будет некой недостаточной заменой. На момент публикации данной книги {май 2017}, это не является рекомендуемым в настоящий момент вариантом использования для Ceph.
Когда мы рассматриваем архитектуру инфраструктуры, нам необходимо принимать во внимание определённые компоненты Сейчас мы вкратце взглянем на эти составляющие.
SSD великолепны. За последние 10 лет они значительно упали в стоимости, причём все данные свидетельствуют о том, что они продолжат это. Они имеют возможность предоставления времени доступа с на порядки меньшими значениями по сравнению со шпиндельными дисками и потреблять меньшую мощность.
Одним важным понятием, которое надо уяснить об SSD, является тот факт, что хотя их задержки при чтении и записи обычно измеряются в десятках микросекунд, для того чтобы перезаписать некие имеющиеся данные в каком бы то ни было блоке флеш- памяти, это потребует удаление целиком всего данного блока, прежде чем такая запись осуществится. Обычно размер блока флеш- памяти в SSD может составлять 128кБ и даже некие операции ввода/ вывода по 4кБ потребуют прочтения всего блока целиком, удаления и последующей окончательной записи всех существующих данных и новой операции ввода/ вывода. Данная операция удаления может потребовать нескольких миллисекунд и без наличия интеллектуальных процедур во встроенном программном обеспечение SSD может делать запись мучительно медленной. Для обхода данного ограничения SSD снабжаются неким буфером оперативной памяти, тем самым он может немедленно подтвердить запись, в то время как встроенное программное обеспечение внутренне ещё перемещает данные по блокам фэш- памяти для оптимизации всего процесса перезаписи и уровня износа. Однако, такой буфер оперативной памяти является энергозависимой памятью и может в нормальных условиях приводить в результате к возможности утраты данных в случае внезапного пропадания электропитания. Во избежание этого, SSD могут иметь защиту от потери электропитания, которое выполняется наличием большей некоторой ёмкости на борту, для сохранения мощности под сброс всех отложенных записей во флеш- память.
Одной из самых значительных тенденций последнего времени являются различные уровни SSD, которые становятся доступными. Вообще говоря, они могут быть разбиты на перечисляемые ниже категории.
Бытовые
Это самые экономичные устройства из тех, что вы можете приобрести и установить для обычного пользователя ПК. Они предоставляют массу ёмкости очень дёшево и предлагают достаточно достойную производительность. Они скорее всего не будут предоставлять защиту от потери энергоснабжения и даже будут демонстрировать очень плохую производительность, когда будет запрошена синхронная запись или будут врать о целостности хранимых данных. Они также вероятно будут иметь очень плохую выносливость на количество записей, но её всё ещё будет более чем достаточно для стандартного применения.
Для продвинутых
Это некий шаг вверх от обычных бытовых моделей и обычно они будут предоставлять лучшую производительность и иметь более высокое значение перезаписей, хотя всё ещё далеки от того, что предоставляют SSD корпоративного уровня.
Прежде чем перейти к имеющимся корпоративным моделям, стоит просто напомнить почему вам не следует ни при каких условиях применять упомянутые ранее модели SSD для Ceph:
-
Отсутствие надлежащей защиты от потери энергоснабжения либо приведёт к чрезвычайно плохой производительности, либо не будет обеспечивать надлежащую согласованность данных
-
Встроенное программное обеспечение не было протестировано в столь же тяжёлых условиях, что и SSD корпоративного уровня, что зачастую разоблачается ошибками порчи данных
-
Низкое количество доступных перезаписей будет означать, что они будут быстро вырабатывать ресурс, причём часто это будет происходить внезапно
-
Из- за высоких частот износа и отказов, их преимущество низкой стоимости быстро улетучивается
Применение бытовых SSD в Ceph будет иметь результатом плохую производительность и увеличенную вероятность катастрофической потери данных.
SSD корпоративного уровня
Наибольшая разница между бытовыми и корпоративными SSD состоит в том, что некий корпоративный SSD должен предоставлять гарантию что когда он отвечает системе хоста о том, что данные были безопасно сохранены, это действительно так. Именно это означает что ели, скажем, внезапно в некоторой системе пропадает электропитание, все те данные, которые данная операционная система считает зафиксированными на диске, будут на самом деле сохранены в флеш- памяти. Более того, следует также ожидать, что для ускорения скорости записи, но при этом с сохранением безопасности состояния данных, данные SSD будут содержать суперконденсаторы для предоставления достаточной мощности на сброс всего буфера SSD в флеш- память в случае возникновения условия утраты электроснабжения.
SSD корпоративного уровня обычно предоставляются в некотором числе различных предпочтений для предоставления широкие стоимостные варианты за ГБ и сбалансированное количество допустимых перезаписей.
Корпоративные - для интенсивного чтения
SSD для интенсивного чтения - своего рода маркетинговый термин. Все SSD будут запросто обрабатывать операции чтения, однако это название ссылается на более низкое значение возможных перезаписей. Тем не менее, они будут предлагать наилучшую стоимость за ГБ. Эти SSD часто будут иметь износостойкость 0.3-1 на протяжении 5-ти летнего периода DWPD (drive writes per day, записей диска в день). Это означает, скажем, что у вас будет иметься возможность записи 400ГБ в день на некий SSD объёмом 400ГБ и ожидать при этом что он будет работать на протяжении 5 лет. Если вы пишите на него по 800ГБ в день, это будет гарантировать по крайней мере 2.5 года. Как правило, для большинства нагрузок Ceph, такие диапазоны SSD обычно считаются недостаточными для устойчивости к количеству перезаписей.
Корпоративные - для обычного применения
SSD обычного применения будут нормально предоставлять 3-5 DWPD и являются хорошим балансом стоимости и устойчивости к количеству перезаписей. Что касается Ceph, они, как правило, будут хорошим выбором для некоторого OSD на основе SSD в предположении, что рабочая нагрузка такого кластера Ceph не планирует интенсивной перегруженности записями.
Корпоративные - для интенсивной записи
Предназначенные для интенсивной записи SSD являются наиболее затратным типом SSD; они часто предлагают устойчивость к общему числу перезаписей до 10 DWPD и более. Они должны применяться для журналов шпиндельных дисков в кластерах Ceph или также для OSD с применением только SSD в случае, если планируются очень интенсивные рабочие нагрузки операций записи.
В настоящее время Ceph применяет в качестве метода хранения объектов на дисках файловые хранилища. Детали того как и зачем осуществляют свою работу файловые хранилища обсуждаются в Главе 3, BlueStore. На данный момент важно понимать, что из за ограничений в обычных файловых системах POSIX на их способность предоставлять атомарные транзакции для определённых порций данных, Ceph применяется вынужденная запись в журнал. Если для такого журнала не используется никакой отдельный диск, для него отводится отдельный раздел. Всякая обрабатываемая этим OSD запись будет вначале записана в такой журнал, а затем сброшена в свою основную область хранения на данном диске. Это является основной причиной, по которой предлагается применять SSD в качестве некоторого журнала для шпиндельных дисков. Такая двойная запись сурово воздействует на производительность шпиндельных дисков, что в основном вызывается самой природой случайного перемещения всех дисковых головок между областями журнала и данных.
Точно так же OSD SSD всё ещё требуют некоего журнала и поэтому они будут испытывать примерно удвоение общего числа записей и тем самым предоставлять половину ожидаемой клиентом производительности.
Как мы смогли увидеть, не все модели SSD равны, причём требования Ceph могут сделать выбор правильного достаточно сложным процессом. К счастью, можно провести быструю проверку, чтобы установить потенциал SSD для использования в качестве журнала Ceph.
Официально рекомендуется иметь 1ГБ оперативной памяти для каждого 1ТБ хранения. Положа руку на сердце, имеется целый ряд переменных, из которых выводится данная рекомендация, но достаточно напомнить, что вы никогда не пожелаете обнаружить себя в ситуации, когда ваш OSD работает с недостаточной оперативной памятью и любая дополнительная память будет применена для повышения производительности.
Помимо основного значения использования OSD оперативной памяти, главной переменной эффективного применения оперативной памяти является общее число исполняемых на OSD групп размещения (PG). Хотя общий размер данных и влияет на использование оперативной памяти, он остаётся в тени от воздействия общего число PG. Некий работающий в пределах рекомендаций в 200 PG на OSD жизнеспособный кластер скорее всего будет использовать менее 2ГБ оперативной памяти на OSD. Однако в некотором кластере, в котором общее число групп размещения было установлено выше значения из практики применения, использование оперативной памяти будет выше. Также стоит отметить, что когда OSD удаляется из кластера, дополнительные PG будут помещены в остающиеся OSD для перебалансировки данного кластера; это также увеличивает потребление памяти помимо самих по себе операций восстановления. Такие всплески потребления оперативной памяти могут порой вызывать каскадные отказы если было предоставлено недостаточно оперативной памяти. Для снижения риска случайного уничтожения процессов OSD поглотителем Linux OOM (out-of-memory, нехватки памяти) в случае возникновения ситуации недостаточной памяти, всегда следует предоставлять некий большой раздел подкачки страниц (swap) на SSD.
В зависимости от вашей рабочей нагрузки и подлежащих применению в OSD Ceph размеров шпиндельных дисков для гарантии того, что сама операционная система имеет возможность достаточного кэширования всех записей узлов каталогов и файлов из файловой системы, применяемой для хранения всех объектов Ceph. Всё это может повлиять на размер оперативной памяти, который вы собираетесь настроить в своих узлах и более подробно описывается в разделе данной книги, посвящённом тонкой настройке.
Вне зависимости от размера настраиваемой памяти всегда следует применять паять с ECC.
Ceph официально рекомендует использовать мощность ЦПУ в 1 ГГц для каждого OSD. К сожалению, в действительности всё не так просто как представляет эта рекомендация. В официальных рекомендациях не указывается, что ввод/ вывод также требуют мощности ЦПУ и это не просто фигура речи статистики. Имеет смысл задуматься об этом; сам ЦПУ применяется тогда, когда есть какая- либо работа. Нет ввода/ вывода, никакой ЦПУ не требуется. Однако масштабируется это иначе, чем больше операций ввода/ вывода, тем больше потребность в ЦПУ. Официальная рекомендация является хорошей выигрышной ставкой для OSD на основе шпиндельных дисков. Когда некий узел OSD снабжён быстрыми OSD, часто можно обнаружить что мы потребляем в несколько раз больше этой рекомендации. Что ещё больше всё усложняет, так это то, что текущие потребности в ЦПУ разнятся в зависимости от размеров операций ввода/ вывода, кроме того, операции большего размера требуют больше ЦПУ. {Прим. пер.: разгрузить ЦПУ позволяет применение RDMA, обсуждаемое в Приложении A.}
Если узел OSD начинает бороться за ресурсы ЦПУ, это может привести к тому, что OSD начнёт завершаться по тайм- ауту и выходить из состава данного кластера, причём зачастую повторно присоединяться через несколько секунд позже. Такие непрерывные потери и восстановления ведут к размещению дополнительного напряжения в и без того уже ограниченные ресурсы ЦПУ, вызывая каскадные отказы.
Хорошим целевым значением было бы приблизительно 1- 10 МГц на операцию ввода/ вывода, относительно соответствующего ввода/ вывода 4кБ- 4МБ. Как и обычно, для выхода в жизнь следует провести тестирование чтобы убедиться, что требования ЦПУ соответствуют и обычным, и стрессовым нагрузкам ввода/ вывода.
Другим аспектом выбора ЦПУ, который является ключевым при определении производительности в Ceph, является тактовая частота имеющихся ядер. Большая часть пути ввода/ вывода в Ceph является однопоточной и, следовательно, чем больше частота ядра, тем быстрее исполнится этот код, что приведёт к меньшей латентности. Из за ограничений теплового дизайна большинства ЦПУ, зачастую имеется некий компромисс между ростом значения тактовой частоты и общего числа ядер. Более высокое число ядер ЦПУ и более высокие частоты также имеют тенденцию размещаться в самых верхних позициях имеющейся структуры стоимости. Таким образом, было бы полезно понимать ваши требования к операциям ввода/ вывода и латентности при выборе наилучшего ЦПУ.
Был проведён небольшой эксперимент для нахождения самой подходящей тактовой частоты ЦПУ в сопоставлении с задержкой записи. Некая исполняющая Ceph рабочая станция имела выравниваемой вручную тактовую частоту своего ЦПУ с использованием регулятора пространства пользователя. Приводимые ниже результаты с очевидностью демонстрируют преимущество ЦПУ с высокими значениями таковых частот:
| ЦПУ, МГц | Операций записи 4кБ | Средняя летентность (микросекунды) |
|---|---|---|
1600 |
797 |
1250 |
2000 |
815 |
1222 |
2400 |
1161 |
857 |
2800 |
1227 |
812 |
3300 |
1320 |
755 |
4300 |
1548 |
644 |
Если важна низкая латентность и в особенности низкая латентность на запись, тогда двигайтесь в сторону наиболее высоких тактовых частот ЦПУ, которые вам доступны, в идеале, по крайней мере, 3ГГц.
Может потребоваться некий компромисс в имеющих только SSD узлах в том, сколько ядер доступно и сколько SSD может поддерживать каждый узел. Для узлов с 12 шпиндельными дисками и журналами SSD четырёхядерные процессоры в одном разъёме могут быть исключительным выбором, поскольку они часто доступны с очень высокими тактовыми частотами и очень агрессивными стоимостями.
Когда латентность не очень важна, например, при объектных рабочих нагрузках, обратите внимание на процессоры начального уровня с хорошо сбалансированным числом ядер и тактовой частотой. {Прим. пер.: см. краткую таблицу рекомендованных к продаже цен Intel при заказе от 1000 штук для процессоров E5-2600 v4/v3 от 1 апреля 2016 в нашем переводе Книги рецептов Ceph Карана Сингха и более полную таблицу xls с выделенными жёлтым фоном ЦПУ, имеющими наилучшие поназатели стоимости исходя из требования 1ГГц на OSD.}
Другим подлежащим рассмотрению моментом относительно ЦПУ и материнской платы должен быть вопрос общего числа разъёмов ЦПУ. В архитектуре с двумя сокетами {Прим. пер.: а также 4/8/16/32} все оперативная память, контроллеры дисков, а также контроллеры сетевых интерфейсов (NIC, network interface controllers), совместно используются всеми разъёмами. Когда данные, требующиеся одному ЦПУ запрашиваются неким ресурсом, расположенным в другом сокете ЦПУ, они могут передаваться через шину взаимосвязи между такими двумя ЦПУ. Современные ЦПУ имеют высокоскоростное взаимодействие, однако они вносят некие штрафы в производительность и следует поразмыслить не стоит ли остановиться на архитектуре с одним сокетом. Имеется ряд вариантов, приводимых в разделе тонкой настройки по поводу того, как обойти некоторые из таких возможных штрафов производительности.
При выборе дисков для построения некоторого кластера Ceph, всегда имеется соблазн пойти с самыми большими дисками,которые только возможны, поскольку на бумаге они выглядят наилучшим образом. К сожалению, на практике, это зачастую не самый лучший выбор. Хотя диски и впечатляюще увеличились за последние 20 лет, их производительность выросла не так стремительно. Во первых, не обращайте внимания на значения MBps последовательного обмена, так как вы никогда не обнаружите их в корпоративных рабочих нагрузках. {Прим. пер.: с оговоркой случая восстановления и, частично, задач выполнения повторной балансировки}. Всегда имеется нечто, делающее все модели ввода/ вывода достаточно непоследовательными и даже достаточными для того чтобы они могли выглядеть случайными. Во вторых, запомните эти значения:
диски 7.2k = 70-80 4k IOPS
диски 10k = 120-150 4k IOPS
диски 15k = вам следует применять SSD
В качестве основного правила, если вы проектируете некий кластер, тогда предлагайте активные рабочие нагрузки вместо того чтобы выступать грудой неактивных/ архивных хранилищ. Выполняйте проект для необходимого значения IOPS (Input/Output Operations Per Second , числа операций ввода/ вывода в секунду), а не ёмкость. Если ваш кластер будет содержать шпиндельные диски большего размера при предназначении предоставлять хранение для некоторой активной рабочей нагрузки, увеличенное число дисков с меньшей ёмкостью обычно более предпочтительно чем применение дисков большего размера. С уменьшением стоимости SSD серьёзно задумайтесь о необходимости их применения в вашем кластере, либо в виде некоторого уровня кэширования, либо даже для всего кластера SSD.
Стоит также подумать об использовании SSD либо для журнала вместе с файловым хранением Ceph, либо для хранения DB и WAL (write-ahead log, журнала отложенной записи) при применении BlueStore. Производительность файлового хранения впечатляюще улучшается при применении журналов SSD и не рекомендуется к использованию, если только данный кластер не спроектирован для применения с очень замороженными данными.
Кроме того, обратите внимание на то, что установленный по умолчанию уровень репликаций 3 будет означать, что любая запись операции ввода/ вывода клиента будет создавать по крайней мере троекратное увеличение ввода/ вывода на всех лежащих в основе дисках. В действительности, из за имеющихся в Ceph внутренних механизмов, это значение может при некоторых обстоятельствах составлять около шестикратного увеличения записей. Если в кластере не применяются никакие журналы SSD, тогда это значение может быть около 12 кратного увеличения записей в случае наихудших сценариев.
Поймите, что хотя Сeph делает возможным намного более быстрое восстановление с отказавшего диска, поскольку в таком процессе восстановления примут участие все диски в данном кластере, однако, диски большего размера всё ещё чинят препятствие, в особенности, когда сталкиваемся с необходимостью восстановления отказа некоторого узла. В некотором кластере, состоящем из 10 дисков по 1ТБ, причём каждый из них заполнен на 50%, в случае выхода из строя некоторого диска, всем оставшимся дискам пришлось бы восстанавливать 500ГБ данных между всеми, или, приблизительно по 55ГБ каждому. При средней скорости 20 Mbps, восстановление потребовало бы примерно 45 минут. Некий кластер с сотней 1ТБ дисков всё ещё потребует восстановления 500ГБ данных, однако это время, поскольку диск разделяется между 99 дисками, в теории для кластера с большим размером для восстановления в случае единичного отказа это потребовало бы примерно четырёх минут. В действительности, такое время восстановления будет выше, поскольку имеются задействованные в работе дополнительные механизмы, которые увеличивают время восстановления. В кластерах меньшего размера времена восстановления должны быть неким ключевым фактором при выборе ёмкости диска.
Сетевая среда является ключевым и зачастую не до конца осознанным компонентом в кластере Ceph; плохо спроектированная сетевая среда зачастую ведёт к целому ряду проблем, которые заявляют о себе своеобразным манером и делают крайне запутанным сеанс поиска неисправностей.
Для построения кластера Ceph настоятельно рекомендуется сетевая среда 10G, хотя сетевые среды 1G будут работать, однако задержки будут подталкивать к пределам неприемлемости и ограничат вас в общем числе узлов, которое вы способны развернуть. Следует также обдумать восстановление; в случае отказа некоторого диска или узла, требуется перемещение больших объёмов данных по всему кластеру. Мало того, что некая сеть 1G не будет способна предоставить достаточной производительности для этого, однако это повлияет на обычные операции ввода/ вывода. В наихудших случаях это может привести к выходу по тайм- ауту OSD, что вызовет нестабильность кластера.
Как уже упоминалось, одним из основных преимуществ сетевой среды 10G является более низкая латентность. Достаточно часто некий кластер никогда не производит достаточного обмена чтобы целиком использовать всю пропускную способность 10G, однако, реализуется улучшение латентности, вне зависимости от общей загруженности в данном кластере. Среднее время пути для некоторого пакета 4K по сети 10G может занять примерно 90 микросекунд, а тот же самый 4K пакет по сетевой среде 1G потребует более 1 миллисекунды. В соответствующем разделе по тонкой настройке в данной книге мы изучим как задержки напрямую воздействуют на общую производительность некоторой системы хранения, в особенности при выполнении прямых или синхронных операций ввода/ вывода.
Если ваш узел OSD будет снабжён дуальным NIC, тщательно изучите сетевую архитектуру, которая позволит вам применять его в качестве активный/ активный как для передачи, так и для приёма. Будет расточительным оставить некое соединение 10G в каком бы то ни было пассивном состоянии и это поможет понизить задержки при загруженности.
Хороший проект сетевой среды является важным шагом по выводу некоторого кластера Ceph в рабочий режим. Если ваша сетевая среда обрабатывается другой командой, убедитесь что они вовлечены во все этапы данного проекта, поскольку зачастую некоторая имеющаяся сетевая среда не спроектирована для соответствия требованиям Ceph, что ведёт и к плохой производительности Ceph, и к воздействию на существующие системы.
Рекомендуется чтобы каждый узел Ceph был подключён через соединения с резервироанием к двум различным коммутаторам с тем, чтобы в случае отказа одного из коммутаторов, все узлы Ceph всё ещё были бы доступны. Собранные в стек коммутаторы следует по возможности избегать, поскольку они могут стать единой точкой отказа и в некоторых ситуациях оба требуют вывода для обслуживания обновления нового встроенного программного обеспечения.
Если ваш кластер Ceph будет целиком содержаться в одном наборе коммутаторов, вы вольны пропустить этот следующий раздел.
Обычные сетевые среды в основном разрабатывались вдоль пути доступа Север- Юг, когда расположенные на Севере клиенты получают доступ к данным через имеющуюся сетевую среду к расположенным на Юге серверам. Если некому подключённому к к какому- то коммутатору доступа серверу требется взаимодействие с другим серевром, который в свою очередь подключён к другому коммутатору доступа, весь обмен должен будет направляться через имеющийся центральный коммутатор ядра. Благодаря такой схеме взаимодействия, все входящие в имеющийся уровень ядра уровни доступа и агрегации не были спроектированы для обработки массивного обмена внутри серверов, что великолепно для той среды, которую они предназначены поддерживать. Обмен сервера- с- сервером именуется обменов Восток- Запад и он становится преобладающим в большей части современных центров обработки данных, поскольку приложения становятся менее изолированными и требуют данных от множества прочих серверов.
Ceph создаёт большой обмен Восток- Запад, причём состоящий не только из внутреннего обмена кластера репликациями, но также и со стороны прочих серверов, потребляющих хранилище Ceph. В больших средах традиционная архитектура ядра, а также уровни агрегации и доступа может не справиться, так как большие объёмы обмена будут ожидаться подлежащими маршрутизации через имеющийся коммутатор ядра. Могут быть получены более быстрые коммутаторы, а также добавлены более быстрые или большее число восходящих связей, однако лежащая в основе проблема состоит в том, что вы попытаетесь исполнить горизонтальное масштабирование системы хранения в вертикально масштабируемой сетевой архитектуре. Приводимая ниже схема демонстрирует типичную сетевую архитектуру с уровнями Ядра, Агрегации и Доступа. Обычно было бы активным только одно соединение от уровня доступа к уровню агрегации.
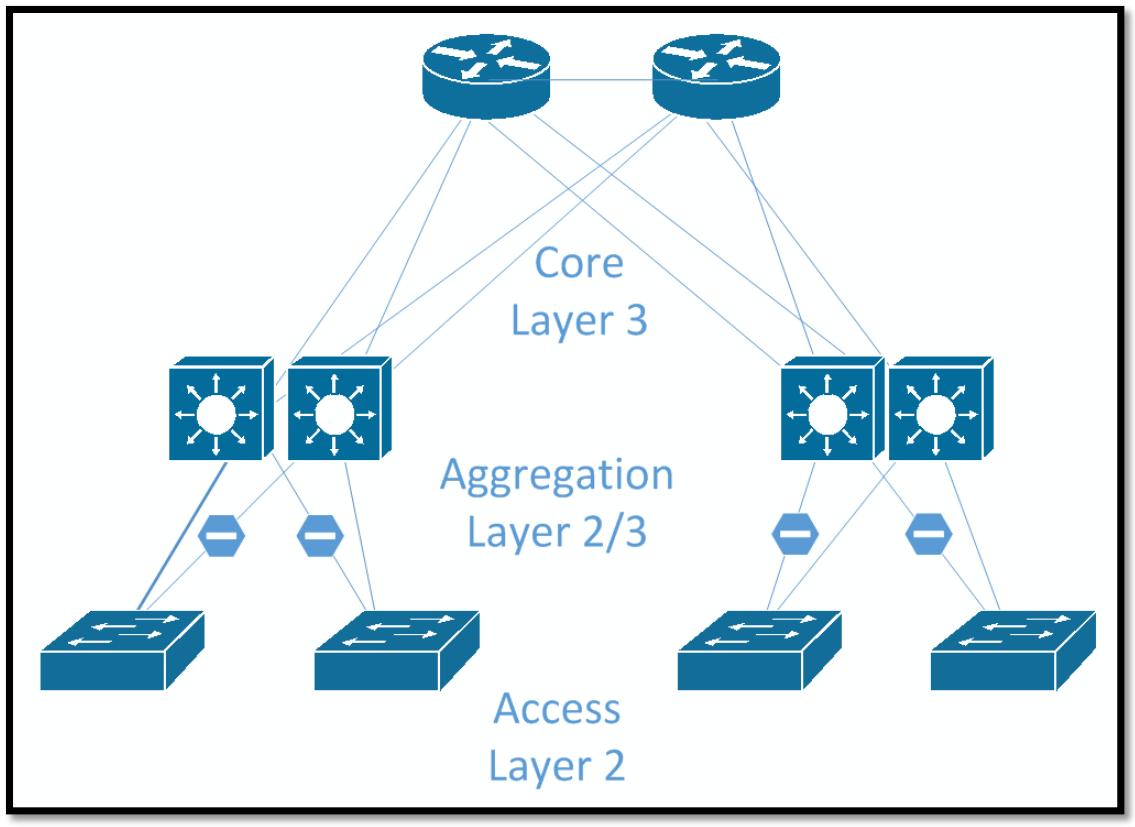
Очень популярной в центрах обработки данных становится архитектура листья- ствол (leaf-spine). Этот подход полностью избавляется от традиционной модели и вместо этого заменяет её двумя уровнями коммутаторов: стволового уровня и уровня листьев. Имеющаяся концепция ядра состоит в том, что кажый коммутатор листа соединён с каждым из коммутаторов ствола с тем, чтобы каждый коммутатор листа имел только один прыжок (hop) к любому другому коммутатору листа. Это предоставляет согласованные латентность прыжков и пропускной способности. Ниже приведён пример некоторой топологии листьев и ствола. В зависимости от областей отказа вы можете пожелать наличие одного или множества коммутаторов листа на стойку для резервирования.
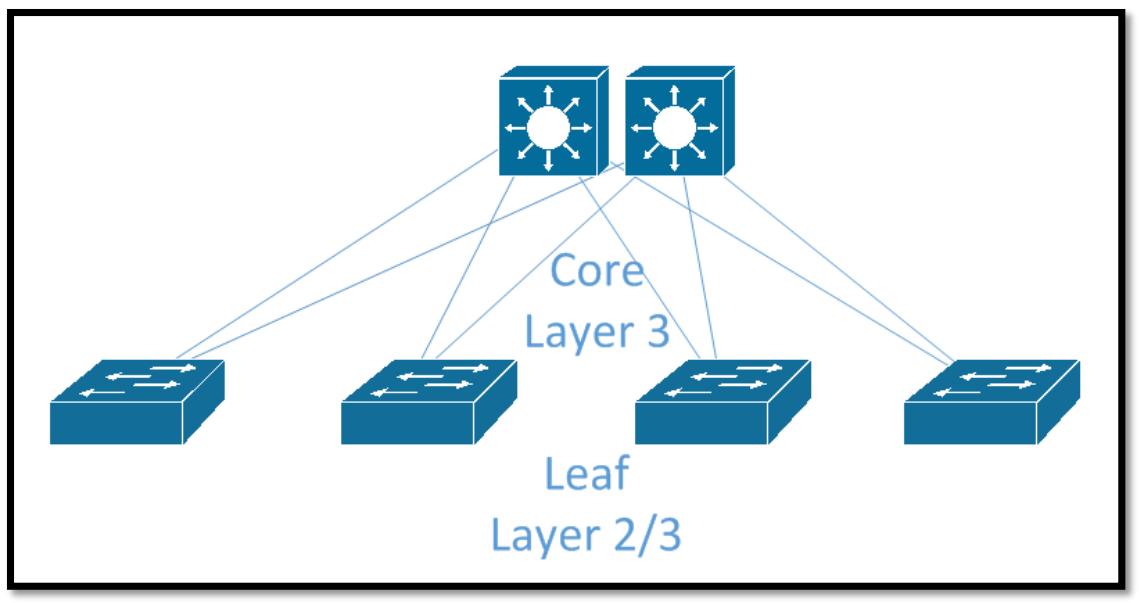
Именно на уровне листа подключаются все серверы и обычно он раздаёт большое число портов 10G и некое небольшое число 40G или более быстрых восходящих портов для соединения с имеющимся уровнем ствола.
Сам уровень ствола обычно не соединяется напрямую с серверами, только если нет неких особых требований, и будет просто выступать службой некоторого пункта агрегации для всех имеющихся листовых коммутаторов. Такой коммутатор ствола обычно имеет более высокие скорости портов для уменьшения всех возможных соединений входящего со стороны всех листовых коммутаторов обмена.
Сетевые среды листьев и ствола обычно отступают от чистой топологии 2 уровня, при которой область 2 уровня завершается на таких коммутаторах листьев , а маршрутизация 3 уровня выполняется между всеми уровнями листев и ствола. Это рекомендуется осуществлять при помощи протоколов динамической маршрутизации, таких как BGP (Border Gateway Protocol, Протокола пограничного шлюза) или OSPF (Open Shortest Path First, Открытия первым кратчайшего маршрута) для установления полной маршрутизации по всей имеющейся инфраструктуре. Это привносит целый ряд преимуществ в сравнении с сетевыми средами 2 уровня. Стволовое дерево, которое обычно применяется в сетевых средах 2 уровня для предотвращения зацикливаний коммутаторов, выполняет работу блокируя некое восходящее соединение при использовании восходящих соединений 40G; это пустая трата огромных полос пропускания. При применении протоколов динамической маршрутизации с некоторой архитектурой 3 уровня можно применять маршрутизацию ECMP (Equal-cost multi-path, Множественных маршрутов с равной стоимостью) для справедливого распределения данных по всем восходящим связям для максимизации применения всей доступной полосы пропускания. В данном примере листовых коммутаторов, подключаемых к двум коммутаторам ствола через некие восходящие соединения 40G будет доступна полоса пропускания 80G любому коммутатору листа, причём вне зависимости от того где он расположен.
Некоторые сетевые архитектуры продвигают это даже ещё дальше, и вытесняют имеющиеся границы 3 уровня вниз до всех серверов, фактически исполняя такие протоколы маршрутизации на серверах с тем, чтобы ECMP можно было бы применять для упрощения использования обоих NIC в режиме активный/ активный. Такой подход именуется Маршрутизацией в самом хосте (Routing on the Host).
Обычным подходом при проектировании узлов для применения в Ceph состоит в комплектации сервера большой ёмкости, который содержит большое число дисковых отсеков. В определённых проектах это может оказаться хорошим вариантом, однако для большей части сценариев с Ceph более предпочтительными являются узлы с меньшими размерами. Для принятия решения об общем числе дисков, которое должен содержать каждый узел в вашем кластере имеется целый ряд подлежащих рассмотрению вопросов, перечислим далее некоторые из основных соображений.
Если в вашем кластере менее 10 узлов, скорее всего это не самый важный момент для вас.
При наследовании вертикально масштабированного хранилища всё оборудование ожидается имеющим 100% надёжность. Все компоненты являются резервированными и наличие отказа некоторого целого компонента, такого как системная плата или JBOD диск могут с большой вероятностью привести к выходу из строя. Вследствие этого не существует никакого реального понимания сколько таких отказов может выдержать работа данной системы, просто есть надежда что это не случится! В случае с Ceph основное предположение в том, что полный отказ некоторого отдела вашей инфраструктуры, будь то некий диск, узел, или даже стойка, должны рассматриваться как нечто обычное и не должно приводить кластер в нерабочее состояние.
Давайте возьмём два кластера, каждый из которых наполнен 240 дисками. Кластер A представлен дисками узлов 20x12; Кластер B состоит из дисков узлов 4x60. Теперь допустим сценарий, при котором по какой- либо причине некий узел OSD Ceph отключается. Это может быть из за запланированного обслуживания или в случае неожиданного отказа, однако этот узел сейчас отключён и никакие данные на нём недоступны. Ceph разработан для маскирования подобной ситуации и даже проведёт восстановление пока не настроит полный доступ к данным.
В данном случае, кластер A имеет утраченными 5% наших дисков и при событии некоторой постоянной потери должен будет восстановить 72ТБ данных. Кластер B потерял 25% своих дисков и должен будет перестроить 360ТБ. В последнем случае это сильно повлияло бы на общую производительность всего кластера и при варианте применения перестроения данных такой период деградации производительности мог бы продолжаться на протяжении многих дней.
Ясно что в кластера меньшего размера такие узлы с очень высокой плотностью не очень хорошая мысль. Некий кластер Ceph из 10 узлов, скорее всего, самый минимальный размер в случае, когда вы желаете уменьшить воздействие отказа узла и поэтому в случае с JBOD из 60 дисков вам нужен некий кластер, который, как минимум, измеряется петабайтами.
Часто упоминаемой причиной желания работать с большими плотными узлами является попытка снизить общую стоимость всего покупаемого оборудования. Зачастую это обманчивая экономия, так как плотные узлы имеют тенденцию нуждаться в комплектующих премиального класса, что обычно заканчивается большими стоимостями ГБ в сравнении с вариантом менее плотных узлов.
Например, узел с 12 дисками может потребовать всего одного четырёх ядерного процессора для предоставления достаточного ресурса ЦПУ для всех OSD. Некое шасси с 60 отсеками может требовать двойных 10 ядерных процессоров, или даже более, которые стоят намного дороже за предоставляемый ГГц. Вам может даже понадобиться больше DIMM (Dual In-line Memory Modules, Модулей памяти с двухрядным расположением микросхем), которые потребуют NIC 10G премиум уровня, причём возможно с большим числом, или даже 40G.
Большую часть общей стоимости от всего оборудования будут составлять стоимости ЦПУ, оперативной памяти, сетевого оборудования и дисков. Как мы уже видели, Все эт ресурсы оборудования требуют линейной масштабирования в соответствии с общим числом и размером дисков. Единственная область в которой узлы большего размера могут иметь некоторое преимущество состоит в требовании меньшего числа материнских плат и источников питания, которые не составляют некую большую часть общей стоимости. {Прим. пер.: следует отметить, что автор упускает такие моменты, как стоимость аренды 1U в стойке, или возможность удалённого управления через ВМС, что уже давно является неотъемлемой частью оборудования, гордо носящего название серверного.}
Серверы могут быть настроены на работу с единственным или двойным, обладающим резервов, источником питания. Обычно традиционные рабочие нагрузки требуют двойных источников питания для защиты от времени простоя в случае выхода из строя источника питания или запитывающего кабеля. Если кластер Ceph достаточно велик, тогда вы будете иметь возможность рассмотреть вариант возможности работы с единственными PSU в своих узлах OSD и позволить Ceph предоставлять свои возможности в случае отказа питания. Следует уделить внимание преимуществам работы с неким отдельным источником питания в сопоставлении с наихудшим вариантом, при котором обезточивается подача электричества на весь ЦОД.
Чтобы иметь полную уверенность что ваша реализация Ceph будет успешной, имеется ряд правил, которым вы должны следовать:
-
Как минимум, применяйте сетевые среды 10G
-
Исследуйте и тестируйте правильный подбор по размеру того оборудования, которое вы собираетесь применять
-
Не применяйте опции монтирования
nobarrier -
Не настраивайте пулы с
size=2илиminsize=1 -
Не используйте SSD бытового уровня
-
Не применяйте контроллеры RAID в режиме отложенной записи без их защиты батареей
-
Не пользуйтесь теми параметрами настройки которые вы не понимаете
-
Реализуйте некие виды изменения управления
-
Выполняйте проверку отключения электропитания
-
На самом деле имейте согласованные резервные копии и план восстановления
Как мы уже обсуждали, Ceph не всегда является правильным выбором для всех требований хранения. Будем надеяться, данная глава снабдила вас достаточными знаниями чтобы иметь возможность помочь вам определить свои требования и их соответствие возможностям Ceph. Надеюсь также, что Ceph хорошо подходит для вашего варианта использования и вы можете продолжить данный проект.
Необходимо принять во внимание все требования вашего проекта, включая следующие:
-
Именно тот, кто является заинтересованной стороной данного проекта, скорее всего, должен быть тем самым человеком, который будет иметь возможность детализировать то как будет применяться Ceph.
-
Соберите все подробности о тех системах, с которыми придётся взаимодействовать Ceph. Если, например, станет очевидным, что ожидается применение не поддерживаемых операционных систем, это должно быть обозначено на самой ранней стадии.
Всякий проект должен иметь некие последовательности целей, которые могут помочь определить что проект оказался успешным. Примерами целей могут быть:
-
Стоимость менее Х
-
Предоставьте производительность Х IOPS или MBps
-
Обеспечьте определённые сценарии отказоустойчивости
-
Снизьте стоимости владения хранилища до Х
Эти цели следует пересматривать на протяжении всего жизненного цикла данного проекта чтобы убедиться что они отслеживаются.
Раздел об инфраструктуре в данной главе снабдит вас хорошими мыслями о требованиях Ceph к оборудованию и саму теорию выбора правильного оборудования для вашего проекта. Второй по важности причиной сбоев в кластере Ceph является не правильный выбор оборудования, что делает критически важным такой верный выбор на ранней стадии проектирования.
Если это возможно, обратитесь к своему поставщику и узнайте имеется ли у него некие эталонные архитектуры, которые часто сертифицируются Red Hat и это снимет с ваших плеч основную работу в попытке определить действительно ли пригодны ваши аппаратные средства. Вы также можете обратиться к Red Hat или доверенному поставщику с тем, чтобы он проверил ваше оборудование, они получили определённый опыт и смогут руководить вами по всем возникающим у вас вопросам.
Наконец, если вы планируете развёртывание и работу своего кластера целиком у себя без какого бы то ни было привлечения сторонних участников или поддержки, рассмотрите возможность обогатиться поддержкой сообщества Ceph. В списке рассылки пользователей Ceph участвуют люди из совершенно различных сфер, простирающихся прямо по всему миру. Имеется высокая вероятность того, что кто-то где-то будет делать что-то похожее на то, что делаете вы и сможет дать вам совет по выбору оборудования.
Как и со всеми прочими технологиями, существенно чтобы администраторы Ceph получали некий вид подготовки. Когда кластер Ceph начинает работать и начинает оказывать влияние на дело, неподготовленные администраторы представляют риск для стабильности. Сообразуясь с вашей зависимостью от поддержки сторонними организациями могут потребоваться различные уровни обучения и вы сможете также определить ищите ли вы курсы обучения или самостоятельной подготовки.
Для проверки выбранной архитектуры следует развернуть некий кластер PoC (proof of concept, Подтверждения концепции) и определить любые проблемы ранее чем начнётся процесс полномасштабного приобретения оборудования. Это должно рассматриваться в качестве момента принятия решения в данном проекте; не бойтесь пересматривать цели или начинать проект с чистого листа еслт сталкиваетесь с серьёзными проблемами. Если у вас имеется оборудование аналогичной спецификации, будет прекрасно воспользоваться им для проверки концепции, однако основная цель должна состоять в том, чтоб вы попытались проверить то оборудование, которое по возможности максимально похоже на то, которое вы намереваетесь применять при построении промышленного кластера с тем, чтобы иметь возможность полностью проверить всю архитектуру.
Помимо проверки на устойчивость, данный кластер PoC также должен применяться для прогноза того, что все поставленные вами цели будут им выполнены.
Этап проверки концепции также правильное время для того, чтобы вы укрепили свои навыки Ceph, освоили повседневную практику работы и проверили все свойства. Это будет полезно в дальнейшем. Вам также следует воспользоваться возможностью быть в особенности жестоким, насколько это возможно, по отношению к своему кластеру PoC. Произвольно вынимайте диски, отключайте узлы и разъединяйте сетевые кабели. Если он спроектирован правильно, Ceph должен быть способен перенести все эти издевательства. Выполнение таких проверок сейчас придаст вам уверенности в последующей работоспособности Ceph в большем масштабе если такие события в нём будут случаться, а также поможет вам понять как их устранять в случае возникновения.
При развёртывании вашего кластера внимание должно быть сосредоточено на понимании самого процесса вместо простого следования за примерами. Это снабдит вас лучшим пониманием различных составных частей, которые выстраивают Ceph, а если вы столкнётесь в процессе развёртывания и работы с какими- либо ошибками, вы будете лучше находить их разрешение. Следующая глава данной книги снабдит вас более подробными сведениями по развёртыванию Ceph, включая применение инструментария координации (orchestration).
Первоначально рекомендуется применять все параметры, установленные по умолчанию, причём как для самой операционной системы, та и для Ceph. Лучше начинать с известного состояния если при развёртывании первоначальной проверки возникнут какие- либо проблемы.
Уровень репликаций пула RADOS должен быть оставлен со значением, определённым по умолчанию равным 3, а
минимальный уровень репликаций должен равняться 2. Это соответствует имеющимся в пуле переменным
size и min_size
соответственно. Пока вы не получите и лучшего представления о них самих, и причин воздействия на них в
сторону уменьшения, будет неразумным изменять их. Размер репликаций определяет сколько копий данных будет
храниться в данном кластере и все последствия его снижения должны быть очевидны в смысле защиты от утраты
данных. Менее понятно воздействие от min_size в отношении утраты данных
и наличием причины для такового.
Сама переменная min_size управляет тем, сколько копий в данном кластере
должно быть записано для получения подтверждения от отложенной записи клиентом. Значение
2 в min_size означает, что данный
кластер должен иметь возможность записать две копии данных; это может означать в случае сценария требовательного
в отношении к деградации, что операции записи блокируются если данная группа размещений (PG) имеет только одну
остающуюся копию и не продолжит работу пока данная PG не восстановится чтобы иметь две копии данного объекта.
Именно это является причиной того, то может иметься желание понижения значения
min_size до 1 , чтобы в данном случае
операции кластера всё ещё могли продолжаться и если доступность более важна чем согласованность, тогда это
может стать решением. Однако при min_size установленным в
1 , данные могут быть записаны только если имеется один OSD и нет никакой
гарантии, что общее число желаемых копий будет восстановлено когда либо вскорости. На протяжении этого времени
любые отказы компонентов скорее всего будут иметь результатом утрату данных, записанных в таком состоянии
деградации. В случае когда суммарное время простоя является нежелательным, утрата данных обычно хуже и именно
эти два параметра, скорее всего, будут иметь одно из самых основных последствий для утраты данных.
Самая главная причина утраты данных и сбоев кластера Ceph это обычная ошибка человека, будь то непреднамеренный запуск неверной команды, либо случайное изменение параметров настроек., которые могут непреднамеренные последствия. Скорее всего, такие инциденты станут более вероятными по мере роста общего число людей в команде, управляющей Ceph. Хорошим способом снижения наличия риска человеческих ошибок, вызывающих прерывания служб или утрату данных состоит в реализации некоторого вида управления изменениями. Более подробно это описывается в следующей главе.
Ceph является высоко надёжным, и при надлежащем проектировании не должен иметь единственной точки отказа и быть устойчивым ко многим типам аппаратных сбоев. Однако в одном из миллиона случаев может так случиться, что, как мы и обсуждали это, человеческий фактор может быть черезчур непредсказуемым. В обеих ситуациях имеется возможность что данный кластер Ceph может войти в состояние когда он не доступен или возникла утрата данных. Во многих случаях имеется возможность восстановления части или всех данных и возврата всего кластера к полной работоспособности.
Однако, в любом случае, должен быть обсуждён план полного резервного копирования и восстановления, прежде чем размещать какие- либо рабочие данные в некий кластер Ceph. Многие компании ушли от дел или утратили доверие пользователей когда те обнаружили что не только простаивали значительное время, но и утратили критически важные для них данные. Может так случится, что в результате обсуждения было принято решение, что план резервного копирования не требуется, отлично. Пока обсуждаются риски и возможные последствия, это будет важной частью.
В данной главе вы изучили все необходимые этапы, которые позволят вам успешно спланировать и реализовать некий проект Ceph. Вы изучили все возможные варианты оборудования, как они соотносятся с требованиями Ceph, и как они могут воздействовать и на производительность Ceph, и на его надёжность.
Наконец, мы ознакомили вас о той важности всех процессов и процедур, которые должны быть рассмотрены в своё время чтобы гарантировать жизнеспособность рабочей среды для вашего кластера Ceph.