Глава 4. Удаляющее кодирование для лучшей эффективности хранения
{Прим. пер.: рекомендуем сразу обращаться к нашему переводу 2 издания вышедшего в феврале 2019 Полного руководства Ceph Ника Фиска}
Содержание
Определяемый по умолчанию в Ceph уровень репликаций предоставляет исключительную защищённость данных от потерь путём хранения трёх копий ваших данных в различных OSD. Вероятность потери данных на всех трёх дисках, которые содержат одни и те же объекты в пределах того периода времени, пока Ceph перестроит отказавший диск, граничит с самой крайней степенью вероятности. Однако, хранение трёх копий данных чрезмерно увеличивает как затраты приобретения, аппаратных средств, так и связано с операционными расходами, такими как электропитание и охлаждение. Более того, сохранение копий также означает, что для любой записи клиента лежащее в основе хранилище должно выполнять запись три раза весь объём данных. В некоторых ситуациях любые из этих обратных сторон могут означать, что Ceph не является приемлемым вариантом.
Для решения такой ситуации спроектировано решение удаляющего кодирования (erasure code). Во многом также как и RAID 5 и 6 предлагает увеличение применяемого пространства хранения в сравнении с RAID 1, удаляющее кодирование позволяет Ceph предоставлять больше используемого пространства с одной и той же сырой ёмкости. Однако в точности так же как и уровни RAID на основании чётности, удаляющее кодирование привносит свои собственные недостатки.
В данной главе вы изучите следующее:
-
Что такое удаляющее кодирование и как оно работает?
-
Подробности относительно реализации удаляющего кодирования в Ceph
-
Как создавать пул RADOS с удаляющим кодированием и регулировать его
-
Обзор грядущих свойств удаляющего кодирования в выпускаемой в свет редакции Ceph Kraken
Удаляющее кодирование
(Erasure coding) позволяет Ceph достигать даже
большей используемости ёмкости хранения или увеличения устойчивости к отказам дисков при том же самом числе
дисков при сопоставлении со стандартным методом репликаций. Удаляющее кодирование достигает этого расщеплением
имеющегося объекта на некоторое число частей с последующим вычислением какого- то типа
CRC
(cyclic redundancy check, Циклического избыточного
кода), удаляющего кода (erasure code) с последующим сохранением всех результатов в одной или более
дополнительных частей. Каждая часть затем сохраняется в отдельном OSD. Эти части имеют название порций
(chunks) K и M,
где K обозначает общее число кусочков самих данных,
а M обозначает общее число кусочков удаляющего кода. Как и в
случае с RAID, это может быть выражено в формуле K+M,
например, 4+2. {Прим. пер.: в общем случае
удаляющее кодирование описывается формализмом Рида- Соломона, наглядное объяснение которого приводится в нашей
врезке слайд- шоу в переводе "Книги рецептов Ceph" Карана Сингха или в
презентации Луиса Кевина.}
В случае возникновения события отказа какого- то OSD, который содержит кусочек объекта, вычисляемый удаляющим кодом, данные считываются с остающихся OSD, которые хранят данные, не подвергшиеся воздействию. Однако, если в случае отказа OSD утрачиваются данные, содержавшие кусочки данных некоторого объекта, Ceph может воспользоваться имеющимся удаляющим кодом для восстановления путём математического вычисления данных из некоторой комбинации кусочков оставшихся данных и удаляющих кодов.
Чем больше кусочков удаляющего кода имеется у вас, тем к большему числу отказов OSD вы можете быть готовыми и всё ещё продолжать успешно считывать данные. Аналогично, имеющееся соотношение K+M кусочков расщепления каждого объекта имеет прямое отношение к процентному соотношению сырого хранилища, которое требуется для каждого объекта.
Конфигурация 3+1 даст вам 75% использования ёмкости но позволит только единственный отказ OSD и по это причине не будет рекомендована. В качестве сравнения, пул реплик с тремя копиями даёт только 33% используемого пространства.
Конфигурация 4+2 предоставит вам применение пространства на 66% и допускает два отказа OSD. Скорее всего, это достаточно хорошая настройка для применения большинством людей.
С другой стороне шкалы 18+2 позволило бы вам использование имеющейся ёмкости на 90% и всё ещё позволяло бы два отказа OSD. На поверхности это звучит как идеальный выбор, однако большее значение общего числа кусочков привносит некую стоимость. Более высокое значение общего числа разбиений имеет отрицательное воздействие на производительность, а также увеличивает потребности в ЦПУ. Один и тот же объект 4МБ, который бы хранился как некий единый объект в каком- то пуле с репликациями, теперь должен будет быть разделённым на 20 x200кБ порций, каждая из которых должна быть препровождена и записана в различные 20 OSD. Шпиндельные диски предоставят большую полосу пропускания измеряемую MBps на операциях ввода/ вывода с большими размерами, однако полоса пропускания коренным образом уменьшится для операций ввода/ вывода меньших размеров. Такие маленькие кусочки создадут большой объём операций ввода/ вывода малого размера и вызовут дополнительную нагрузку в некоторых кластерах.
Кроме того, важно не забывать, что эти кусочки необходимо распространять по различным хостам в соответствии с имеющимися правилами карты CRUSH: никакие кусочки одного и того же объекта не должны храниться на одном и том же хосте с прочими кусочками из того же самого объекта. Некоторые кластеры просто могут не иметь достаточного число хостов чтобы удовлетворить данное требование.
Обратное считывание с такого пула с большой порционностью также является проблемой. В отличии от пула с репликациями, в котором Ceph может просто считывать требуемые данные с любого смещения некоторого объекта, в каком- либо пуле удаляющего кодирования все куочки со всех OSD должны быть считаны прежде чем данный запрос на чтение будет удовлетворён. В нашем примере 18+2 это может массивно расширить общее число требующихся операций дискового чтения и средняя латентность в результате вырастет. Такое поведение является сторонним эффектом, который имеет тенденцию вызывать исключительное воздействие на пулы, использующие некоторое большое число порций. Конфигурация 4+2 во многих экземплярах предоставит потребность в производительности, сравнимую с неким пулом реплик за счёт результата разделения объекта на кусочки. Поскольку данные эффективно чередуются по некоторому числу OSD, каждый из OSD должен записывать меньше данных и при этом отсутствуют вторичные и третичные реплики, подлежащие записи.
Как и в случае с репликациями, Ceph имеет некое понятие первичного OSD, которое также имеется и в случае, когда мы применяем пулы с удаляющим кодированием. Такой первичный OSD несёт ответственность за взаимодействие с самим клиентом, вычисление кусочков для удаления, а также отправкой их оставшимся OSD в данном наборе групп размещения (PG). Это иллюстрируется на следующей схеме:
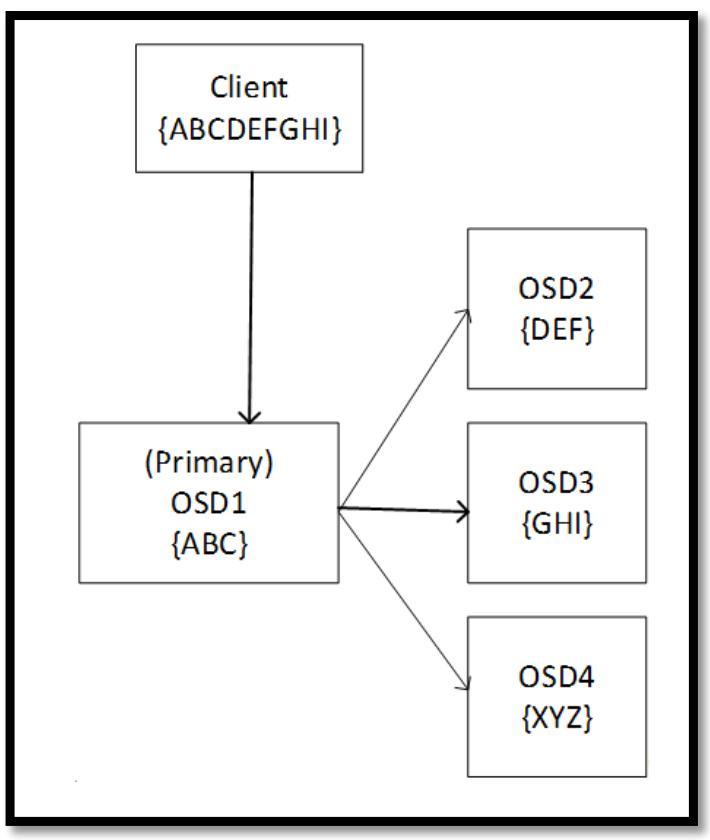
Если некий OSD в наборе падает, такой первичный OSD может воспользоваться оставшимися данными и удаляющим кодом для восстановления всех данных прежде чем отправит их обратно запросившему клиенту. В процессе операций чтения такой первичный OSD запрашивает все OSD в данном наборе группы размещения (PG) на отправку их кусочков. Данный первичный OSD использует данные всех порций для построения запрошенных данных, а удаляющие кусочки отвергаются. Существует опция быстрого чтения, которая может быть включена в пулах удаляющего кодирования, которая позволяет имеющемуся первичному OSD строить эти данные из удаляющих кусочков если они возвращаются быстрее чем кусочки данных. Это может помочь снизить общую задержку за счёт стоимости слегка более высокого использования ЦПУ. Следующая схема показывает как Ceph считывает с некоторого пула с удаляющим кодированием:
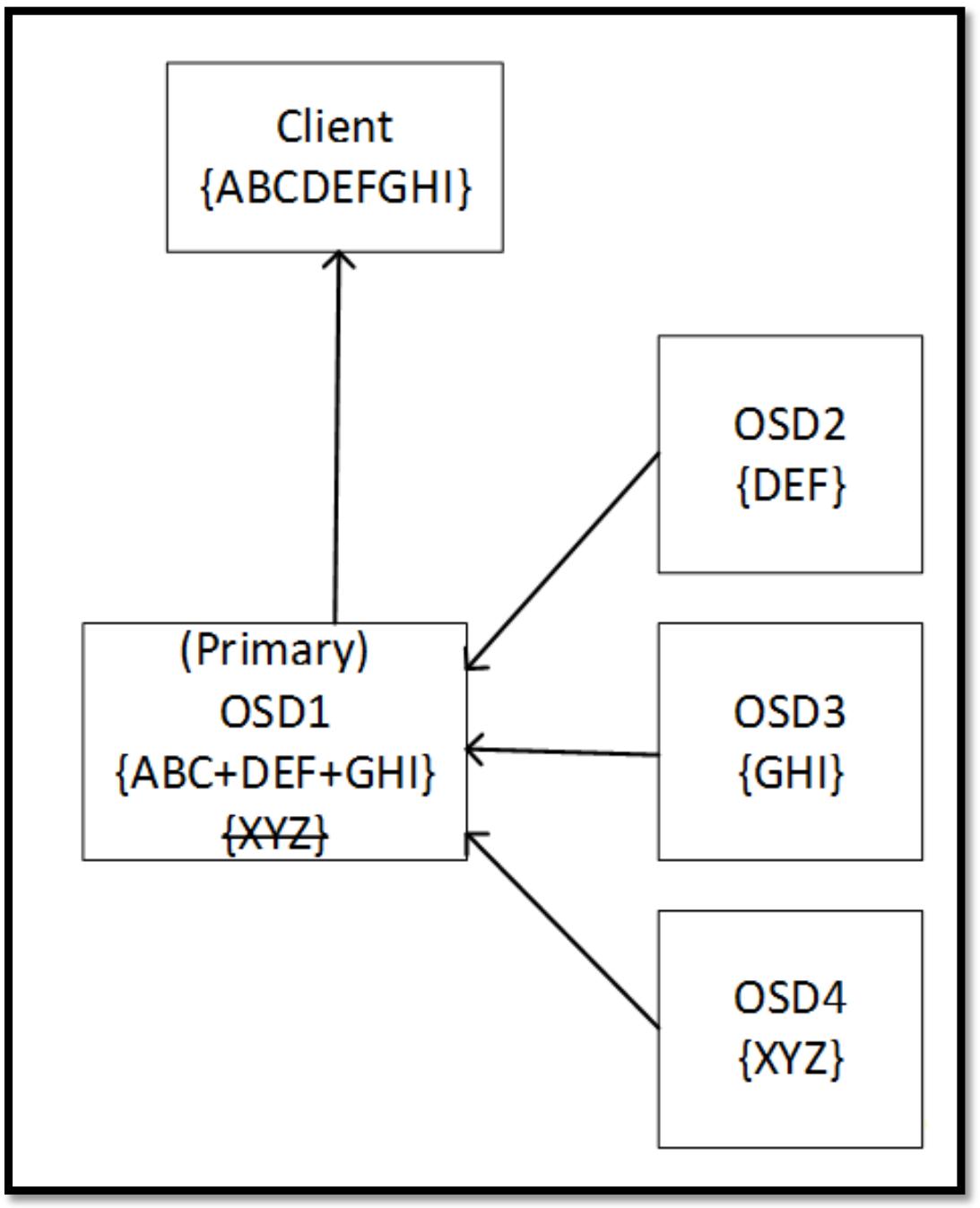
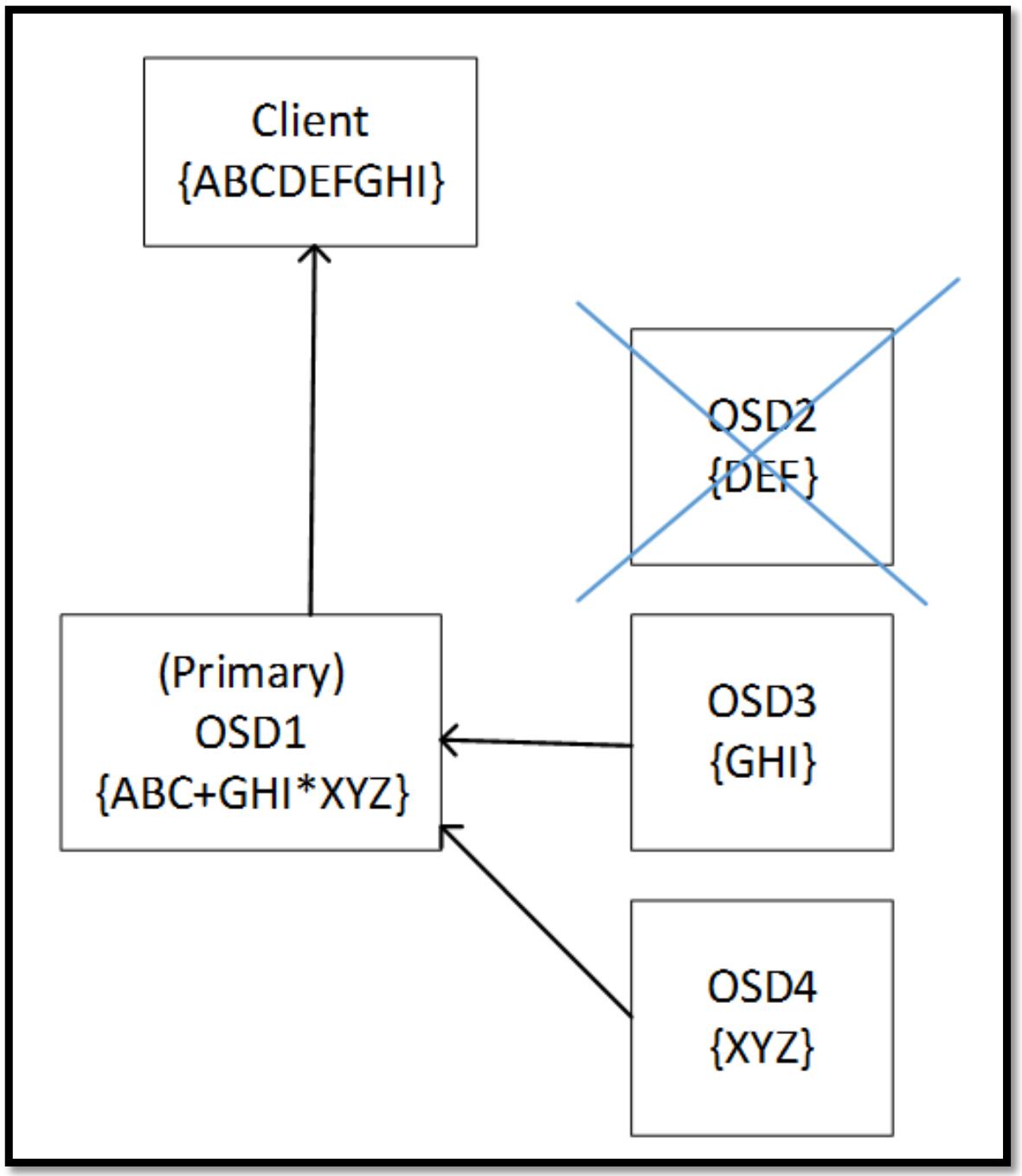
Приводимая далее схема отображает как Ceph читает некий пул удаляющего кодирования когда один из кусочков получаемых данных недоступен. Данные восстанавливаются изменяя направление алгоритма удаления с использованием оставшихся данных и удаляющих кусочков:
Имеется ряд различных встраиваемых модулей удаляющего кодирования, которые вы можете применять при создании своего пула удаляющего кодирования.
Встраиваемым модулем удаляющего кодирования по умолчанию в Ceph является Jerasure, который представляет высоко оптимизированную библиотеку удаляющего кодирования с открытым исходным кодом. Эта библиотека имеет целый ряд разнообразных техник, которые могут применяться для вычисления удаляющего кодирования. По умолчанию это Reed-Solomon и он предоставляет хорошую производительность на современных процессорах которые могут ускорять все операторы, применяемые данным методом. Другим методом в данной библиотеке является Cauchy, это хорошая альтернатива Риду- Соломону и имеет тенденцию выполняться слегка лучше. Как и всегда, прежде чем приступить к хранению любых промышленных данных в некотором пуле удаляющего кодирования, необходимо провести эталонное тестирование чтобы определить какая из методик лучше соответствует вашим рабочим нагрузкам.
Также имеется целый ряд прочих методов, которые могут быть применены, причём все они имеют фиксированное число кусочков M. Если вы собираетесь иметь только две порции M, они являются хорошими претендентами, так как их фиксированный размер означает, что возможна оптимизация ведущая к росту производительности.
В общем случае данный профиль Jerasure следует предпочесть в большем числе вариантов, если только другой профиль не имеет некоторого основного преимущества, так как он предлагает хорошо сбалансированную производительность и богатую историю тестирования.
Данная библиотека ISA разработана для работы с процессорами Intel и предлагает расширенную производительность. Она также предлагает поддержку как методов Рида- Соломона, так и Коши.
Одним из недостатков применения удаляющего кодирования в любой распределённой системе хранения является то, что восстановление может очень интенсивно применять сетевой обмен между хостами. Поскольку все порции хранятся на отдельных хостах, операция восстановления требует участия в данном процессе множества хостов. Когда топология CRUSH занимает множество стоек, тогда могут интенсивно применяться сетевые связи между стойками. Встраиваемый модуль удаляющего кодирования LRC (Locally Repairable erasure Code, удаляющее кодирование Локального восстановления) добавляет некий дополнительный кусочек избыточных данных (parity), причём локально на каждый узел OSD. Это позволяет операциям восстановления оставаться локальными по отношению к узлу, в котором отказал некий OSD и удаляет необходимость узлам получать данные со всех остальных остающихся держателями порций узлов.
Профиль SHEC (Shingled Erasure Coding, Черепичного/ Драночного удаляющего кодирования) разработан с той же целью, что и подключаемый модуль LRC, в отношении того, чтобы снизить требования сетевого обмена в процессе восстановления. Однако, вместо создания дополнительных кусочков паритетности на каждом узле, SHEC опоясывает всеми порциями все OSD перекрывающим образом Такая драночная/ черепичная часть в данном имени подключаемого модуля заявляет о самом способе распространения данных, который повторяет покрытие плитками кровли крышу здания. Путём перекрытия порций избыточного кода по OSD, данный встраиваемый модуль SHEC снижает требования к ресурсам восстановления как в случае одиночного, так и при множественных отказах диска. {Прим. пер.: подробнее см. наш перевод работ авторов метода Shingled Erasure Code. Также отметим ещё одну работу, произведённую в тот же временной период, направленную на снижение нагрузки в сетевой среде при использовании операций восстановления, а именно Интеллектуальные отложенные средства, результаты которой позволяют относить по времени восстановительные работы на наименее загруженные периоды суток и дни недели. Обратим ваше внимание и на уже доступные аппаратные решения разгрузки удаляющего кодирования на ASIC сетевых интерфейсов - см. наш перевод Понимание разгрузки удаляющего кодирования, которая в совокупности со Стеком системы асинхронных сообщений Ceph позволяют снять нагрузку вычисления избыточных кодов с ЦПУ.}
Начиная с редакции Ceph 2014 FireFly появилась возможность создания некоторого пула RADOS с применением удаляющего кодирования. Имеется один важный момент, о котором вы должны быть осведомлены: сама поддержка удаляющего кодирования в RADOS не допускает частичного обновления некоторого объекта. Вы можете делать записи в некий объект в пуле удаляющего кодирования, считывать это обратно и даже переписывать его целиком, но вы не можете обновлять отдельно взятую секцию в нём. Это означает, что пулы с удаляющим кодированием не могут применяться для рабочих нагрузок RBD и CephFS и ограничены предоставлением чистого хранения объектов либо через шлюз RADOS, либо через написанные с применением librados приложениями.
Конкретным решением на данный момент было использование имеющейся возможности многоуровневого кэширования, которое было реализовано примерно в то же время, чтобы действовать поверх некоторого пула с удаляющим кодированием так, чтобы можно было применять RBD. В теории это выглядит великолепной идеей; на практике производительность чрезвычайно низка. Всякий раз, когда некий объект получает запрос на запись, весь объект вначале должен быть Представлен в имеющийся уровень кэширования. Такое действие Представления Представления также вероятно означает, что другой объект где- то в этом пуле кэша был Вытеснен. Наконец, данный объект теперь в самом уровне кэширования может выполнить операцию записи. Весь этот процесс постоянного считывания и записывания данных между двумя пулами означает неприемлемую производительность, если только очень высокий процент таких данных не чвляется простаивающим.
В процессе цикла разработки выпуска Kraken была предложена некая начальная реализация для поддержки прямой перезаписи в каком- либо пуле удаляющего кодирования. Что касается окончательной версии выпуска Kraken, поддержка помечена как экспериментальная и ожидающая отметки стабильная в следующем выпуске. Проверка этой функциональности будет рассмотрена в данной главе позднее.
Давайте проведём своё тестирование кластера вновь и переключимся в режим
суперпользователя в Linux с тем, чтобы нам не
приходилось всё время начинать свои команды с префикса sudo.
Пулы удаляющего кодирования управляются при помощи применения профилей удаляющего кодирования; они управляют тем на сколько порций разбивается каждый объект, включая разбиение между порциями данных и избыточного кода. Данные профили также содержат настройки для определения того какой встраиваемый модуль удаляющего кодирования используется для вычисления необходимых хэшей.
К применению доступны следующие встраиваемые модули:
-
Jerasure
-
ISA
-
LRC
-
SHEC
Чтобы просмотреть список имеющихся профилей удаляющего кодирования, выполните следующую команду:
ceph osd erasure-code-profile ls
Вы можете увидеть, что имеется некий профиль default в только что
выполненной установке Ceph:

Давайте посмотрим какие варианты настроек он содержит воспользовавшись такой командой:
# ceph osd erasure-code-profile get default
Данный профиль default предписывает, что он будет применять
встраиваемый модуль Jerasure с кодированием посредством коррекции ошибок Рида- Соломона и будет расщеплять
объекты на 2 порции данных и 1
порцию избыточного кода:

Это почти идеально для целей нашего тестового кластера, однако для целей данного упражнения мы создадим некий новый профиль воспользовавшись следующей командой:
# ceph osd erasure-code-profile set example_profile k=2 m=1 plugin=jerasure technique=reed_sol_van
# ceph osd erasure-code-profile ls
Как вы можете отметить, был создан наш новый example_profile:

Теперь давайте создадим с этим профилем свой пул удаляющего кодирования:
# ceph osd pool create ecpool 128 128 erasure example_profile
Предыдущая команда предоставит вам следующий вывод:
Предыдущая команда проинструктировала Ceph создать некий новый пул с названием
ecpool with и со
128 группами размещений (PG). Он должен быть пулом удаляющего
кодирования и должен применять тот example_profile, который мы
создали ранее.
Давайте создадим некий объект с небольшой тестовой строкой внутри него и затем докажем что эти данные были сохранены, считав их обратно:
# echo "I am test data for a test object" | rados --pool
ecpool put Test1 –
# rados --pool ecpool get Test1 -
Это докажет что данный пул удаляющего кодирования работает, но вряд ли у вас перехватило дух от этого открытия:
Давайте обратим внимание на то, можем ли мы посмотреть что произошло на некотором нижнем уровне.
Вначале отыщем какая PG содержит тот объект, который мы только что создали:
# ceph osd map ecpool Test1
Результат предыдущей команды сообщает нам что данный объект сохранён в PG
3.40 в OSD 1,
2 и 0 в данном примере кластера
Ceph. Это достаточно очевидно, поскольку у нас имеется всего три OSD, однако в кластерах большего размера
это может быть очень полезной составной частью информации:
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Ваши PG скорее всего будут отличаться в вашем тестовом кластере, поэтому убедитесь что структура
папок PG соответствует выводу предыдущей команды |
Теперь мы можем взглянуть на структуру данной папки текущего OSD и посмотреть как данный объект был разделён применив следующую команду:
ls -l /var/lib/ceph/osd/ceph-2/current/1.40s0_head/
Предыдущая команда предоставит вам следующий вывод:

ls -l /var/lib/ceph/osd/ceph-1/current/1.40s1_head/
Предыдущая команда предоставит вам следующий вывод:

# ls -l /var/lib/ceph/osd/ceph-0/current/1.40s2_head/
total 4
Предыдущая команда предоставит вам следующий вывод:

Заметим, что все имена каталогов PG были дополнены соответствующими номерами порций и реплицируемого пула просто чтобы иметь необходимый номер PG в своём имени каталога. Если вы проверите всё содержимое данных файлов объекта, вы обнаружить нашу текстовую строка, которую мы ввели в данный объект при его создании. Однако, из- за малого размера данной текстовой строки Ceph заполнил вторую порцию символами null, а избыточная порция здесь будет содержать то же самое, что и первая порция. Вы можете повторить данный пример с неким новым объектом, содержащим больший объём текста и увидеть как Ceph расщепляет такой текст на необходимые порции и вычисляет свой удаляющий код.
Именно впервые предложенная в последнем выпуске Ceph Kraken в качестве экспериментального свойства, новая возможность позволила частичную перезапись в пулах удаляющего кодирования. Поддержка частичной перезаписи (partial overwrite) делает возможным создание томов RBD в пулах удаляющего кодирования, что улучшает использование сырого пространства в имеющемся кластере Ceph.
RAID с избыточными данными, в которых некоторая операции записи не охватывает целиком всю полосу, требуется операция чтения- изменения- записи. Она требуется поскольку изменение порции данных будет означать, что имеющаяся порция избыточного кода теперь будет не верной. Данному контроллеру RAID приходится считывать все имеющиеся текущие порции в данной полосе, изменять и в оперативной памяти, вычислять новую порцию избыточных данных (parity) и, наконец, записывать их обратно на свой диск.
Для Ceph также требуется выполнять такую операцию чтения- изменения- записи, однако его распределённая модель увеличивает сложность данной операции. Когда имеющийся первичный OSD для некоторой группы размещения (PG) получает некий запрос на запись, который частично перезаписывает имеющийся объект, он сначала обрабатывает то, какие порции не будут полностью изменены данным запросом и взаимодействует с относящимся к ним OSD запрашивая некую копию таких порций. Этот первичный OSD затем объединяет такие полученные порции с имеющимися новыми данными и вычисляет необходимую порцию избыточного кода. Наконец, изменённые порции отправляются в соответствующие OSD для их фиксации. Вся эта операция целиком должна соответствовать всем прочим требованиям согласованности, обеспечиваемыми Ceph; это влечёт за собой применение временных объектов в данном OSD с тем, чтобы в случае возникновения некоторого условия, Ceph исполнил необходимость отката назад операции записи.
Такая операция частичной записи, как и можно было ожидать, воздействует на производительность. В общем случае, чем меньше данная операция ввода/ вывода на запись, тем более очевидно воздействие. Такое влияние на производительность является результатом того, что теперь данный путь операции ввода/ вывода будет длиннее и потребует большего числа операций ввода/ вывода диска, а также дополнительных скачков (hops) по сети. Однако, следует отметить, что благодаря эффекту чередования пула удаляющего кодирования, в том сценарии, в котором происходит запись всей полосы, производительность обычно превосходит ту, что имеется в некотором пуле на основе репликаций. Такое снижение в этом случае происходит благодаря меньшему усложнению записи, обусловленному присутствием эффекта чередования. Если данная производительность некоторого пула удаляющего кодирования не удовлетворительна, рассмотрите помещение её под неким уровнем кэширования, выполненным из какого- то пула с репликациями.
Несмотря на поддержку частичной перезаписи, пришедшей в пулы удаляющего кодирования Ceph, не всякая операция
поддерживается. Чтобы сохранять данные RBD в некотором пуле удаляющего кодирования, для поддержки ключевых
метаданных о данном RBD всё ещё требуется некий пул с репликациями. Данная настройка включается при помощи опции
–data-pool со значением rbd
utility. Частичную перезапись также не рекомендуется применять при хранении файлов. В файловом
хранилище отсутствуют определённые свойства, которые применяют пулы с удаляющим кодированием при частичной перезаписи;
без этих свойств ожидается чрезвычайно медленная производительность. {Прим. пер.:
применяйте BlueStore только!}
Данная функциональность требует наличие редакции Ceph Kraken или более новой. Если вы развернули свой тестовый кластер при помощи Ansible и была предоставлена его конфигурация, вы будете исполнять редакцию Ceph Jewel. Последующие шаги показывают как применять Ansible для выполнения раскрутки обновления вашего кластера до выпуска Kraken. Мы также включим опции чтобы разрешить экспериментальные параметры, такие как BlueStore и поддержку частичной перезаписи в пулах удаляющего кодирования.
Отредактируйте свой файл переменных group_vars/ceph и замените
имя версии выпуска с Jewel на
Kraken.
Также добавьте следующее:
ceph_conf_overrides:
global:
enable_experimental_unrecoverable_data_corrupting_features:
"debug_white_box_testing_ec_overwrites bluestore"
А также для исправления некоторой небольшой ошибки при использовании Ansible для развёртывания Ceph Kraken, добавьте debian_ceph_packages
- ceph
- ceph-common
- ceph-fuse
В самом конце данного файла исполните следующий план (playbook) Ansible:
ansible-playbook -K infrastructure-playbooks/rolling_update.yml
Предыдущая команда даст вам следующий вывод:

Ansible выдаст вам приглашение на проверку того, уверены ли вы что желаете выполнить обновление. Когда вы
подтвердите это вводом yes, начнётся нужный вам процесс обновления.
Когда Ansible завершит свою работу, все этапы должны завершиться успехом, как это показано на снимке экрана внизу:
Ваш кластер теперь был обновлён до Kraken и это можно подтвердить, выполнив
ceph -v в одной из ваших ВМ, исполняющих Ceph:
В качестве результата того, что вы включили определённые экспериментальные опции в своём файле настроек, всякий раз, когда вы теперь будете исполнять некую команду Ceph, вам будет представляться следующее предупреждение:
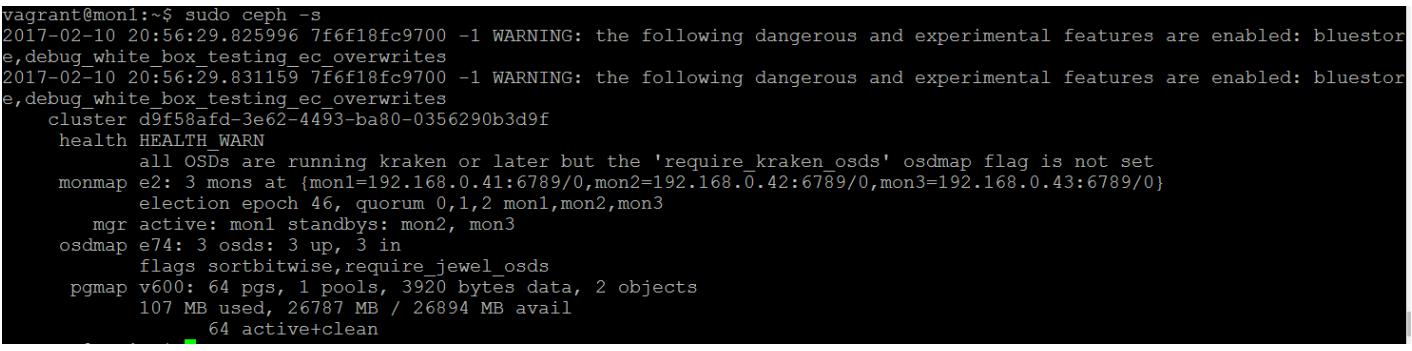
Оно разработано в целях предупреждения безопасности чтобы вы прекратили применять эти опции в реальной среде, так как они могут вызвать безвозвратную утрату данных. Поскольку мы выполняем это на проверочном кластере, ничего страшного не будет при его игнорировании, однако это должно быть суровым предупреждением для того, чтобы нигде не работать ни с какими реальными данными.
Следующая команда, которую необходимо выполнить, состоит во включении необходимого экспериментального флага, который разрешит частичную перезапись в пулах удаляющего кодирования:
ceph osd pool get ecpool debug_white_box_testing_ec_overwrites
true
|
| Совет |
|---|---|
|
Ни в коем случае не делайте этого в промышленных кластерах. |
Проверьте повторно что у вас всё ещё имеется ваш пул с удаляющим кодированием именуемый
ecpool, а также пул по умолчанию
rbd.
# ceph osd lspools
0 rbd,1 ecpool,
Теперь создайте rbd. Отметим, что его реальный заголовок всё
ещё необходимо помещать в некий пул с репликациями, однако предоставив некий дополнительный параметр,
мы можем сообщить Ceph сохранять данные для этого RBD в каком- то пуле с удаляющим кодированием:
rbd create Test_On_EC --data-pool=ecpool --size=1G
Данная команда должна исполниться без ошибок и вы теперь имеете некий снабжённый удаляющим кодированием образ RBD. Вы должны теперь иметь возможность применять этот образ с применением любого приложения librbd.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Частичная перезапись в пулах удаляющего кодирования требует действительной работы BlueStore. Пока работает файловое хранилище, производительность будет безумно плохой. |
Данный небольшой раздел включён вовнутрь данной главы удаляющего кодирования вместо того чтобы быть
размещённым в разделе поиска неисправностей данной книги так как обычно встречается в пулах с удаляющим
кодированием и поэтому очень связан с данной главой. В качестве примера данной ошибки продемонстрируем
следующий снимок экрана при выполнении команды ceph health detail:

Если вы наблюдаете 2147483647 перечисленным в качестве одного из
присутствующих OSD для некоторого пула удаляющего кодирования, обычно это означает, что CRUSH не может
найти достаточное число OSD для выполнения необходимого процесса однораногового обмена (peering) PG. Обычно
это обусловлено тем, что общее число порций K+M
будет больше чем общее число хостов в топологии CRUSH. Однако, в некоторых случаях эта ошибка может всё ещё
происходить даже когда общее число хостов равно или больше чем общее число порций. В таком случае важно понимать
как CRUSH указывает OSD в качесте претендентов для размещения данных. Когда CRUSH применяется для нахождения
OSD в качестве кандидата для некоторой PG, он применяет имеющуюся карту CRUSH для поиска соответствующего
местоположения в имеющейся топологии CRUSH. В случае когда возвращается тот же самый результат, что и выбранный
перед этим OSD, Ceph попытается повторно создать другое соответствие, передавая слегка отличные значения в свой
алгоритм CRUSH. В некоторых случаях, если имеется аналогичное общему числу порций избыточных кодов число хостов,
CRUSH может завершить работу до того как он надлежащим образом обнаружит правильный OSD, соответствующий всем
имющимся порциям. Более новые версии Ceph имеют более исправленной данную проблему за счёт увеличения подстройки
choose_total_tries в своём CRUSH.
Воспроизводство данной проблемы
С целью более подробного понимания данной проблемы, последующие шаги продемонстрируют как создать некий профиль удаляющего кодирования, который запросит больше порций, чем может поддерживать наш кластер из трёх узлов.
Вначале, как и ранее в этой главе, создайте некий новый профиль удаляющего кодирования, однако измените
параметры K/M чтобы они равнялись k=3 и
m=1.
$ ceph osd erasure-code-profile set broken_profile k=3 m=1 plugin=jerasure technique=reed_sol_van
Теперь создайте при помощи него некий пул:
$ ceph osd pool create broken_ecpool 128 128 erasure broken_profile
Предыдущая команда даст вам следующий вывод:

Если мы посмотрим на вывод от ceph -s, мы обнаружим, что все PG
для данного нового пула застряли в состоянии создания:
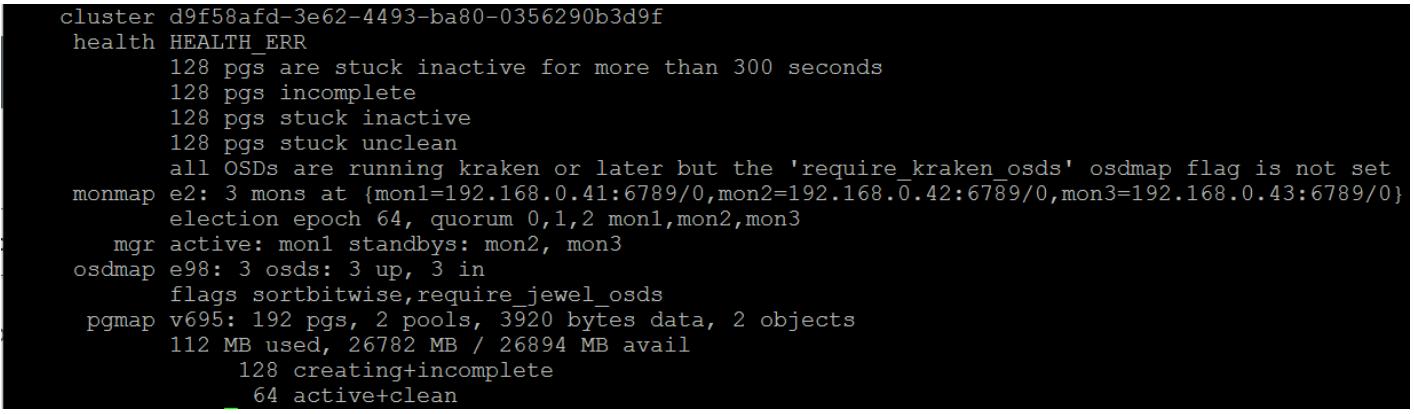
Вывод ceph health detail демонстрирует причину почему это так, и мы
обнаруживаем ошибку 2147483647:

Если вы столкнулись с этой ошибкой и она является неким результатом того, что ваш профиль удаляющего кодирования больше чем имеющееся у вас число хостов или стоек, в зависимости от того как вы спроектировали свою карту CRUSH, тогда единственным практическим решением будет или снижение общего числа порций, или увеличение общего числа хостов.